【大数据系列】大数据前置
前置课程-入门
讲师师资
李锋涛,计算机硕士,曾任职央企和知名互联网公司,历任大数据高级研发工程师,大数据算法工程师,研发主管等职务,曾参与移动公司RFID智能资产管理系统,中石油智能化数据分析系统,亿车联大数据平台管理系统等项目。
对C/C++,Java,MySQL,Hadoop,Hive,Spark,Flink等技术有深入研究。
学习方法
- 以视频为主,抓住重点
- 学习以阶段为单位,强加练习
- 对于自己比较熟悉或者简单的内容,建议1.5倍速播放

重点划定
大数据主要侧重数据处理和分析,我们只是使用Java来调用相关大数据框架的API
大数据中的数据分析,大部分都是通过SQL完成的,SQL需要重点掌握
大数据前置课程中需要掌握的知识点: Java基础语法,面向对象,字符串,异常,集合,IO,线程、数据库、JDBC,Maven
需要先学习Java的基础阶段。
程序员需要突破的瓶颈
选择比努力更重要
1.选择瓶颈

2.技术瓶颈
向前/钱看

3.薪资瓶颈

狂野大数据里面有的同学可以达到很NB,比如53K,当然是基于上一份工资(翻一倍左右)
4.学习瓶颈

5.职业发展瓶颈

机器学习、人工智能(对学历要求高些,考研?)
大数据与其他技术的关系
Java和大数据关系
- Java语言是目前最为广泛使用的编程语言,功能强大而且简单易用。
- Hadoop 的创始人 Doug Cutting 曾说过:“ Java 在开发者的生产率和运行效率之间取得很好的权衡。开发者可以使用广泛存在的高质量类库,切身受益于这种简洁、功能强大、类型安全的语言。
- 没有 Hadoop 就不存在大数据,没有 Java 就没有 Hadoop。
- 大数据的很多框架都是用Java语言编写的
- 很多大数据框架都提供了Java相关的API
云计算
云计算初心
云计算最初的目标是对资源的管理,管理的主要是计算资源、网络资源、存储资源三个。
云计算本质
资源到架构的全面弹性
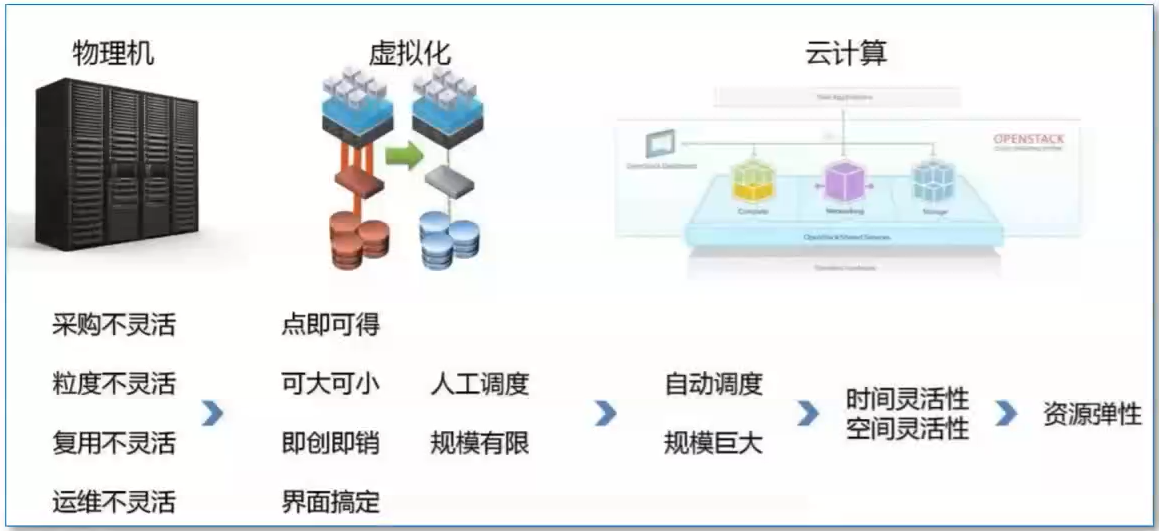
- 可以把云计算当作一种商业计算模型,它是将计算的任务发布在大量的计算机的资源池里,让用户可以根据所需求来获取计算力、存储的空间以及信息上的服务。
- “云”是可以进行自我维护和管理的虚拟化的计算资源,一般都是大型的服务器集群一起,包括计算服务器、存储服务和其他的宽带资源。
- 所谓云计算就是将资源池里的数据集中起来,并通过自动管理实现了无人参与,让用户在使用的时候可以自动调用资源,支持各种各样的程序进行运转,不再为细节而烦恼,可以专心于自己的业务。云计算的核心理念就是在资源池里进行运算。
可以简单的理解对服务器的租赁,参见阿里云厂商。
一种商业计算模块,让计算任务分布再大量的计算机资源池里。用户根据需求获取相应的服务。对用户来说不会造成浪费。
云平台分类
公有云:公有云是现在最主流也就是最受欢迎的云计算模式。公有云由云供应商运行,云供应商负责从应用程序、软件运行环境到物理基础设施等IT资源的管理、部署和维护。在使用IT资源时,用户只需为其所使用的资源付费,无需任何前期投入,所以非常经济。
私有云:私有云主要为企业内部提供云服务,不对公众开放,并且企业IT人员能对其数据、安全性和服务质量进行有效地控制。与传统的企业数据中心相比,私有云可以支持动态灵活的基础设施,降低IT架构的复杂度,使各种IT资源得以整合。
混合云:混合云是把公有云和私有云结合到一起的方式,即它是让用户在私有云的私密性和公有云灵活的低廉之间做一定权衡的模式。比如,企业可以将非关键的应用部署到公有云上来降低成本,而将安全性要求很高、非常关键的核心应用部署到完全私密的私有云上。
云平台国外排行
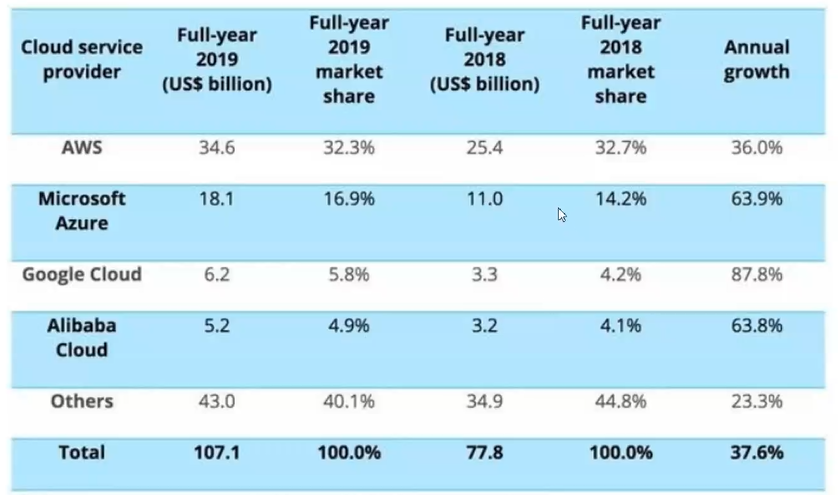
AWS 全称Amazon web service(亚马逊网络服务),是亚马逊公司旗下云计算服务平台,为全世界各个国家和地区的客户提供一整套基础设施和云解决方案。作为称雄全球云服务市场的亚马逊来说,长期以来在云服务市场独领风骚,是全球规模最大的云厂商。AWS云服务营收规模继2020年第一季度突破百亿美元大关后,第二季度继续保持稳健增长。2020年第二季度来自AWS营收规模达到108亿美元(约745亿元人民币)。
Microsoft Azure是微软基于云计算的操作系统,原名“Windows Azure”,和Azure Services Platform一样,是微软“软件和服务”技术的名称。Microsoft Azure的主要目标是为开发者提供一个平台,帮助开发可运行在云服务器、数据中心、Web和PC上的应用程序。云计算的开发者能使用微软全球数据中心的储存、计算能力和网络基础服务
2019年2月12日,在旧金山举行的高盛技术与互联网大会上,Google Cloud CEO Thomas Kurian 首次公开露面,表示Google Cloud正在追赶行业领导者AWS和微软,将招聘更多行业优秀人才加入团队中。报告认为,从2019年到2022年,Google Cloud的收入将以每年55%的速度增长,达到2022年170亿美元的收入,届时将为Google贡献约7%的税前收入。
VMware(Virtual Machine ware)是“虚拟PC”软件公司,提供服务器、桌面虚拟化解决方案。VMware(威睿) 是全球桌面到数据中心虚拟化解决方案的领导厂商。全球不同规模的客户依靠VMware来降低成本和运营费用、确保业务持续性、加强安全性并走向绿色。VMware使企业可以采用能够解决其独有业务难题的云计算模式。
Salesforce这家靠做中小企业SaaS CRM起家的公司在这20年间业务获得了陡峭的增长,其市值从2004年上市时11亿美元跃增至1300亿美元,在全球企业服务级软件公司中最快实现了百亿美元年营收,超过了前辈甲骨文创造的23年记录。截止2018年,Salesforce在全球CRM市场份额中占据第一,市场份额为20%以上,遥遥领先于第二名的SAP(8.3%)和第三名甲骨文(5.5%)
IBM 云计算提供了最开放、最安全的企业公有云,它作为下一代混合多云平台,具备诸多先进的数据和 AI 功能以及 20 个行业的深厚企业专业知识。
云平台国内排行
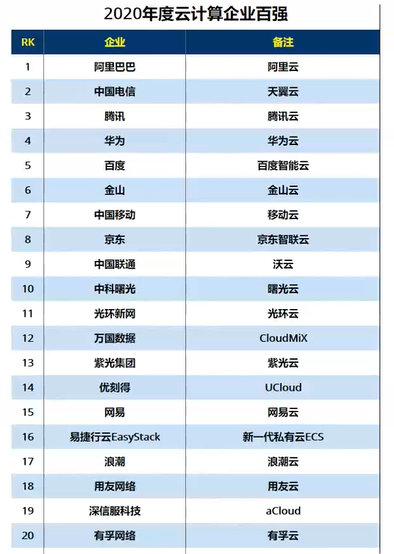
阿里云创立于2009年,是亚洲最大的云计算平台和云计算服务提供商,和亚马逊AWS、微软Azure共同构成了全球云计算市场第一阵营。阿里云在全球21个区域部署了上百个数据中心,管理的服务器规模在百万台。阿里云凭借着自主研发的飞天云操作系统,占据了国内50%左右的云计算市场份额,是国内云计算市场公认的领头羊和行业巨头。阿里云的服务群体中,活跃着淘宝、支付宝、12306、中石化、中国银行、中科院、中国联通、微博、知乎、锤子科技等一大批明星产品和公司。在天猫双11全球狂欢节、12306春运购票等极富挑战的应用场景中,阿里云保持着良好的运行纪录。
腾讯云于2013年9月正式对外全面开放,腾讯云经过QQ、QQ 空间、微信、腾讯游戏等业务的技术锤炼,从基础架构到精细化运营,从平台实力到生态能力建设,腾讯云得到了全面的发展,使之能够为企业和创业者提供集云计算、云数据、云运营于一体的云端服务体验。腾讯云在国内市场占据18%的市场份额,紧随阿里云之后。腾讯云业务主要包括:云计算基础服务、存储与网络、安全、数据库服务、人工智能、行业解决方案等。腾讯云凭借着在“社交、游戏”两大领域的庞大客户群和生态系统构建,腾讯云具备了与阿里云一较高下的实力。
华为云成立于2011年,专注于云计算中“公有云”领域的技术研究与生态拓展,致力于为用户提供一站式的云计算基础设施服务,是目前国内大型的公有云服务与解决方案提供商之一。华为云在国内市场占据8%左右的市场份额。华为云,立足于互联网领域,依托华为公司雄厚的资本和强大的云计算研发实力,面向互联网增值服务运营商、大中小型企业、政府机构、科研院所等广大企业、事业单位的用户,提供各种解决方案。
百度云于2015年正式开放运营,相对于其他厂商,百度对“人工智能”和“边缘计算”这两块的投入相对较大,目前百度云提供的主要业务,包括“云计算,云存储、AI人工智能、智能互联网、智能大数据”等四大类。
金山云,创立于2012年,是金山集团旗下的云计算企业,金山云已推出云服务器、云物理主机、关系型数据库、缓存、表格数据库、对象存储、负载均衡、虚拟私有网络、CDN、托管Hadoop、云安全、云解析等在内的完整云产品,以及适用于游戏、视频、政务、医疗、教育等垂直行业的云服务解决方案。
UCloud云成立于2012年3月,是上海优刻得科技股份有限公司的云产品,UCloud核心团队来自腾讯、阿里、百度、盛大、华为、微软等国内外互联网和IT企业。UCloud长期专注于移动互联网领域,深度了解移动互联网业务场景和用户需求。针对特定场景,UCloud通过自主研发提供一系列专业解决方案,已为上万家企业级客户在全球的业务提供云服务支持,行业涉及制造、零售、金融、游戏、直播等。
京东智联云是京东集团旗下的云计算综合服务提供商,拥有全球领先的云计算技术和完整的服务平台。依托京东集团在云计算、大数据、物联网和移动互联应用等多方面的长期业务实践和技术积淀,致力于打造社会化的云服务平台,向全社会提供安全、专业、稳定、便捷的云服务。
H3Cloud云隶属于杭州的新华三技术有限公司,该公司归属于紫光集团。H3Cloud云计算解决方案涵盖了网络、云软件、计算、存储四大类产品。目标是为用户在以太网和云计算相关技术基础上,实现数据中心资源高效利用、虚拟化环境下云网融合、基于混合云理念的资源动态扩展以及针对用户具体业务交付的行业应用交付。结合本地强大研发、服务实施能力带给用户”一站式”的”交钥匙”交付体验。
网易云是网易集团旗下云计算和大数据品牌,致力于提供开放、稳定、安全、高性能的基础技术平台和完善的云生态体系,帮助客户实现数字化转型与创新,促进其商业蜕变与持续发展,推动产业数字化升级。依托20余年技术积淀,网易云打造了轻舟微服务、瀚海私有云、大数据基础平台(猛犸)、可视化分析平台(有数)、专属云、云计算基础服务、通信与视频(云信)、云安全(易盾)、服务营销一体化方案(七鱼)、云邮箱(网易邮箱)等多类型产品,以及工业、电商、金融、教育、医疗、游戏等行业解决方案,并拥有完善的知识服务。
浪潮云,创立于2015年,面向政府机构和企业组织提供覆盖“云计算基础产品、云安全、政府政务、企业应用、工业互联网、行业场景解决方案”等在内的多种服务,致力于以云服务的方式,输出安全、可信的计算能力和数据处理能力。近年来,浪潮云的优势在于政府政务的“政务云”,根据 IDC 报告,浪潮云多年稳居中国“政务云”服务运营商的市场占有率第一。
大数据和云计算的关系
- 大数据拥抱云计算
大数据通俗的来讲就是一台机器的资源不够,需要很多台机器一块做,想什么时候要计算资源就什么时候要,想要多少台就要多少台。
只有云计算,可以为大数据的运算提供资源层的灵活性。而云计算也会部署大数据放到它的平台上,作为一个非常非常重要的通用应用。因为大数据平台能够使得多台机器一起干一个事儿。
一个小公司需要大数据平台的时候,不需要采购一千台机器,只要到公有云上一点,这一千台机器都出来了,并且上面已经部署好了的大数据平台,只要把数据放进去算就可以了。
云计算需要大数据,大数据需要云计算,二者就这样结合了。
大数据是基于云计算的,如果没有大量的机房,带宽,怎么做大数据的计算。
人工智能AI
学历、数学(高等数学)要求高!
人工智能就是通过人工开发,使得机器拥有人类的智慧,就是让机器模仿人类,达到可以像人一样思考
主要应用在三个方面:
机器视觉:机器视觉即让机器能够“看”,如人脸识别,图片搜索等等。
语音处理:语音处理即让机器能够听,还能够发音。比如讯飞的语音智能输入法、高德的语音导航等等。
自然语言处理
自然语言处理即通过计算机技术让机器理解并运用自然语言的学科,比如聊天机器人,文本纠错,文本分类等等。
AI已经在各行业均有了较大的应用,比如汽车行业的自动驾驶,广告业的智能广告推荐,电商的商品推荐,金融行业的异常转账监测,快递物流行业的路径智能规划,公告交通的智慧交通,零售行业的无人超市等等。
人工智能和大数据的关系是非常紧密的,实际上大数据的发展在很大程度上推动了人工智能技术的发展,因为数据是人工智能技术的基础之一。
一方面人工智能需要大量的数据作为”思考”和”决策”的基础;另一方面大数据也需要人工智能技术进行数据价值化操作,为智能体(人工智能产品)提供的数据量越大,智能体运行的效果就会越好,因为智能体通常需要大量的数据进行训练和验证,从而保障运行的可靠性和稳定性;
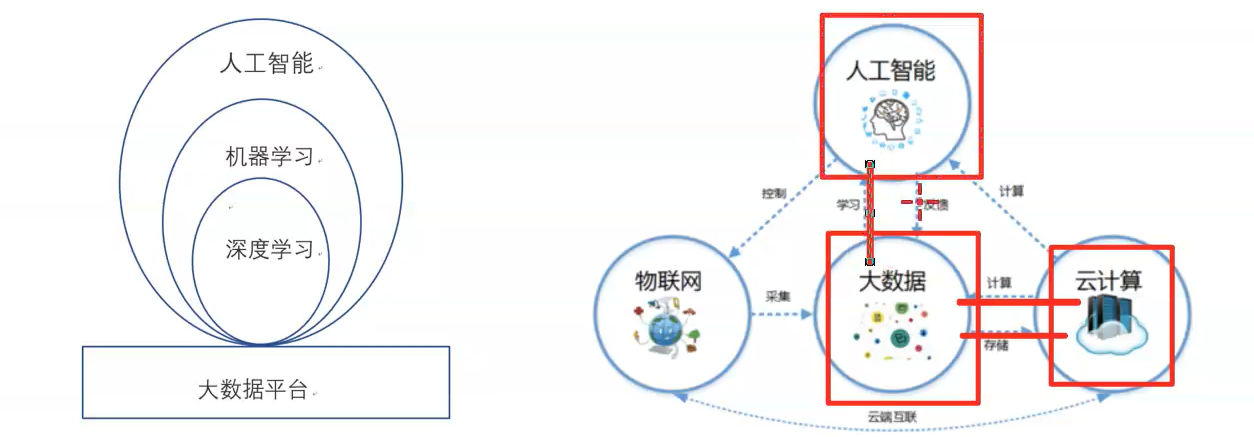
大数据为深度学习提供数据支持,深度学习是机器学习的有效方式,机器学习让人工智能更智能。
人工智能、机器学习、深度学习
人工智能、机器学习、深度学习是我们经常听到的三个热词。关于三者的关系,简单来说,机器学习是实现人工智能的一种方法,深度学习是实现机器学习的一种技术。机器学习使计算机能够自动解析数据、从中学习,然后对真实世界中的事件做出决策和预测;深度学习是利用一系列“深层次”的神经网络模型来解决更复杂问题的技术。
传统业务处理和大数据分析处理
场景1:在线购物,用户需要什么体验?
- 极致流畅的交互
- 低延迟的数据处理
- 处理过程的安全性
- 状态的最终一致性
传统开发
场景2:支付宝年度账单,用户需要什么体验?
- 多维度组织细分
- 数据的对比呈现
- 视觉效果诱人
大数据开发
传统开发和大数据开发有什么区别?
传统开发:对应OLTP数据系统(On-Line Transaction Processing,联机事务处理)
- 面向业务、支撑业务
- 捕捉业务状态的改变
- 事务的保证
- 单次操作数据量小
- 很少设计历史数据处理
- 需要很高的并发处理能力
大数据开发:对应OLAP数据系统(On-Line Analytical Processing,联机分析处理)
- 面向分析、支撑分析
- 挖掘历史数据种的价值
- 单次操作数据规模大
- 大量的读取分析操作
- 处理时效性一般要求不高
这里指的是从岗位性质,和”传统行业跟互联网行业差别”的概念不太一样。
大数据开发后期可以继续学机器学习、人工智能
OLTP 和 OLAP 的区别
| 参数 | OLTP | OLAP |
|---|---|---|
| 目的 | 捕获和存储交易数据以支持日常业务运营 | 获取业务见解、解决问题、支持决策 |
| 数据管理 | 传统关系数据库管理系统(RDBMS) 比如:Oracle、MySQL、sqlserver、postgresql、sybase、db2等 |
数据仓库(DW:data warehouse 比如:HDFS+hive、HDFS+Spark、Kudu、doris、Hbase等) |
| 数据源 | 日常业务交易 | 整合来自多个来源的数据,包括OLTP和外部来源 |
| 焦点 | 当下 | 过去、现在、未来(使用历史数据来计划和预测未来事件) |
| 任务 | 插入、更新、删除、排序、过滤 | 汇总和分析数据以支持决策 |
| 查询 | 简单 | 复杂 |
| 响应时间 | 毫秒 | 秒、分钟、小时、天、具体取决于数据量,擦汗寻的复杂性以及EDW的功能 |
以前一般是离线分析,现在比较倾向实时分析
这里就需要公司比较大,数据量大,公司大(比如:小鹏汽车、美团点评、中国平安、中通/德邦、玖富科技、花旗银行等),才会考虑怎么用大数据活得更好。而小公司一般考虑的是怎么活下去的问题。
OLTP 和 OLAP 的关系
大数据比如1PB(=1024T),OLTP传统开发,存RDBMS数据库再怎么优化都有瓶颈。
所以买机器(对大公司来说机器现在很便宜),分布式切片存储到OLAP做分布式计算。
一般公司都数据库和数据仓库都会存在,通过ETL手段将OLTP数据处理采集到OLAP
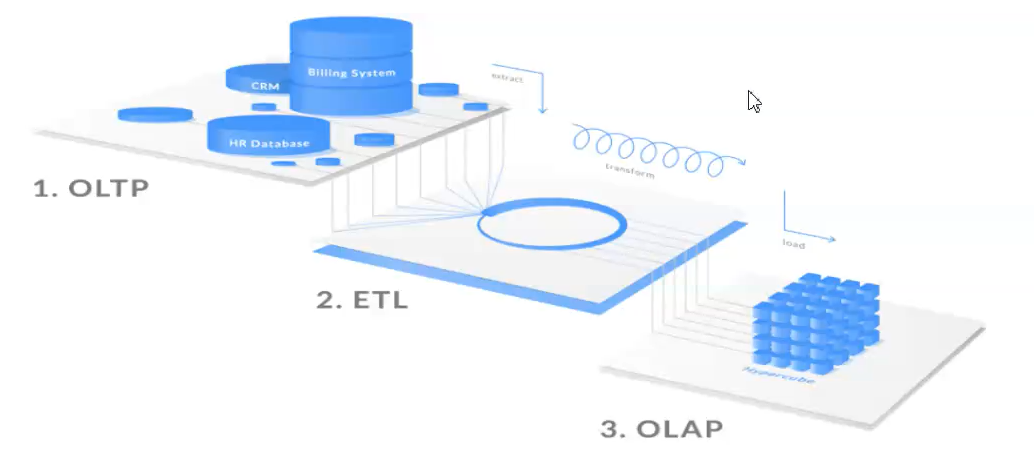
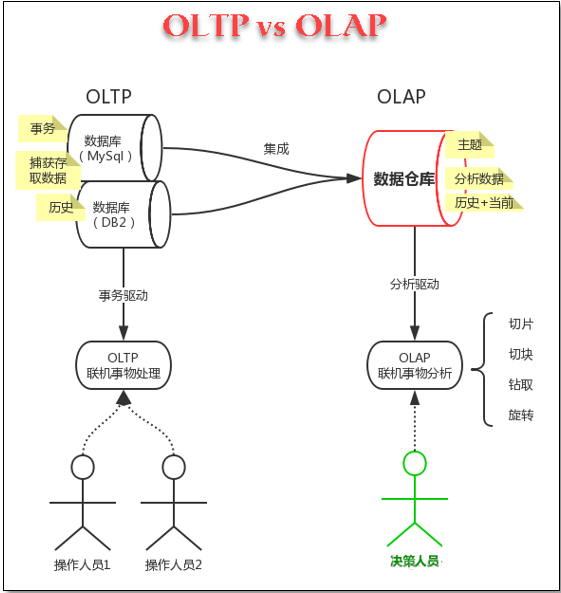
OLTP可以做直接数据分析吗?
业务数据是存储在OLTP系统中,直接开展数据分析可以吗?
OLTP环境可以开展分析,但是没有必要。
OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作。一般来说读的压力明显大于写的压力。
数据分析也是对数据进行读取操作,会让读取压力倍增。
OLTP仅储存周数据或者月数据。
数据分散在不同系统不同表中,字段类型属性不统一。
集成统一的数据分析平台
当数据规模小,在业务低峰期时可以在OLTP系统上开展直接分析。为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。
该平台目的:面向分析,支持分析,并且和OLTP系统解耦,这就是数据仓库的雏形。
大数据时代中的数据计算
计算引擎
大数据的计算模式主要分为:
批量计算(batch computing)
流式计算(stream computing) –实时计算
图计算(graph computing) —pregel
其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。
第一代计算引擎

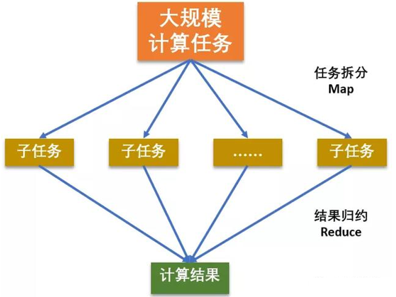
它将计算分为两个阶段,分别为 Map 和 Reduce。对于应用来说,需要想方设法将应用拆分成多个map、reduce的作业,以完成一个完整的算法。
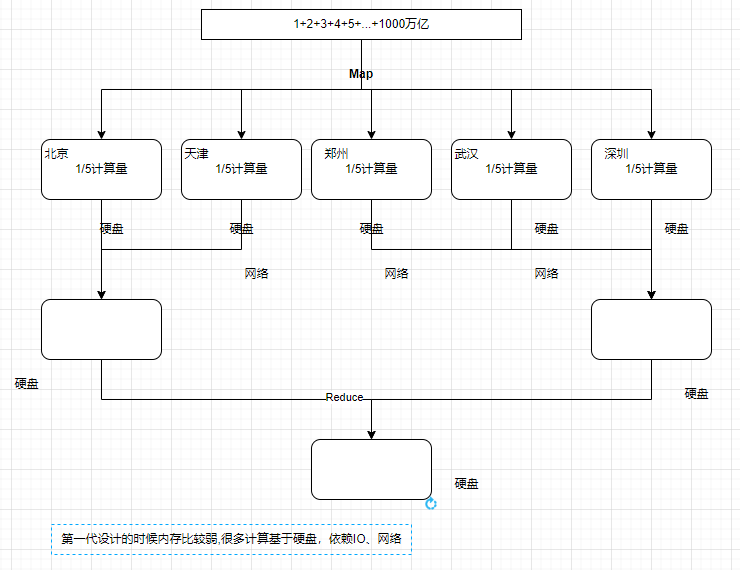
硬盘和网络开销大,这就是MapReduce为什么没落了
但是还是要学,因为后面的很多就基于它的思想。
第二代计算引擎
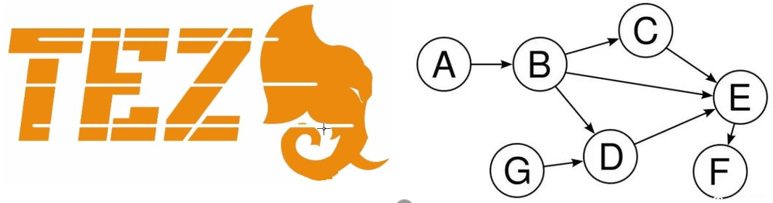
Tez把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。
它在发展史中一闪而过,就是一朵小浪花被后浪覆盖。可能不经意的人都不会发现它,就想你没听过win9一样。
第三代计算引擎

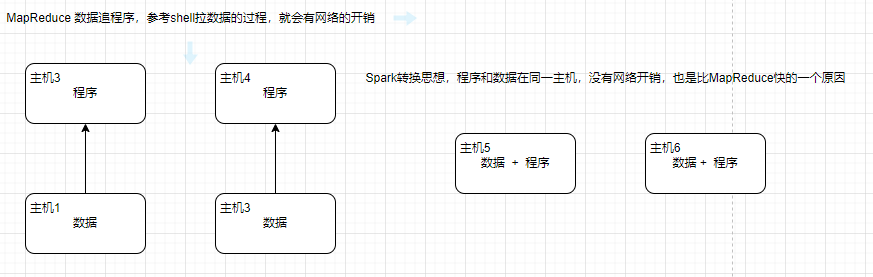
Spark 使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度比MapReduce快上百倍,基于磁盘的执行速度也能快十倍。
第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
第四代计算引擎

Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更进一步的实时性提升。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
在Flink之前,不乏流式处理引擎,比较著名的有Storm、Spark Streaming,但某些特性远不如Flink。
流式计算
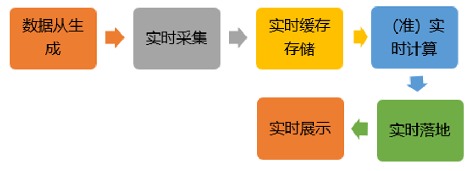
流式计算处理数据的速度在秒级甚至毫秒级。
应用场景
物联网
- 设备故障告警:极其迅速感知到故障的发生,并及时进行告警。
- 实时监控:实时分析设备的监控数据,实现对设备各项指标的实时监控。
- 动态跟踪:实时跟踪并显示设备(比如汽车)的位置。
金融行业
- 欺诈探测:实时分析用户行为,并及时辨识到可疑欺诈行为。
视频直播
- 个性化推荐:根据视频用户的访问内容,实时为视频用户推荐个性化内容。
- 实时统计:实时统计当前直播间运营情况,包括热门视频、用户走势等等。
电商行业
- 个性化精准推荐:实时掌握用户的需求和喜好,进行个性化精准推荐。
- 实时报表:多维度实时了解PV\UV、销量、销售额、地域分布等。
- 实时感知变化趋势:对商品整体的热度和关注量进行动态监测,感知商品关注度变化趋势。
发展
Spark Streaming 现在已经被Structed Streaming代替了
sparkstreaming

Spark Streaming 是构建在Spark Core基础之上的实时计算框架(或流计算框架),它扩展了Spark 处理大规模流式数据的能力。Sparking Streaming 可以整合多种输入数据源,如Kafka、Flume、HDFS、TCP socket等等,经过处理的数据可以存储到HDFS、数据库和Dashboard等等。
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经过Spark Engine以类似批处理的方式处理每个时间片数据,执行流程如下图示。

在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,以时间为单位将数据流切分成离散的数据单位;
和其他的实时计算技术(比如Storm)不太一样,我们可以将Spark Streaming理解为micro-batch模式的实时计算,也就是说Spark Streaming本质是批处理,就是这个批处理之间的时间间隔是非常的小
storm

Storm是一个分布式计算框架,最初是由Nathan Marz带领Backtype公司团队创建,在Backtype公司被Twitter公司收购后进行开源。最初的版本是在2011年9月17日发行,版本号0.5.0。
2013年9月,Apache基金会开始接管并孵化Storm项目,2014年9月,Storm项目成为Apache的顶级项目。
Storm是一个免费开源的分布式实时计算系统。Storm能轻松可靠地处理无界的数据流,就像Hadoop对数据进行批处理;
美团点评基于Storm
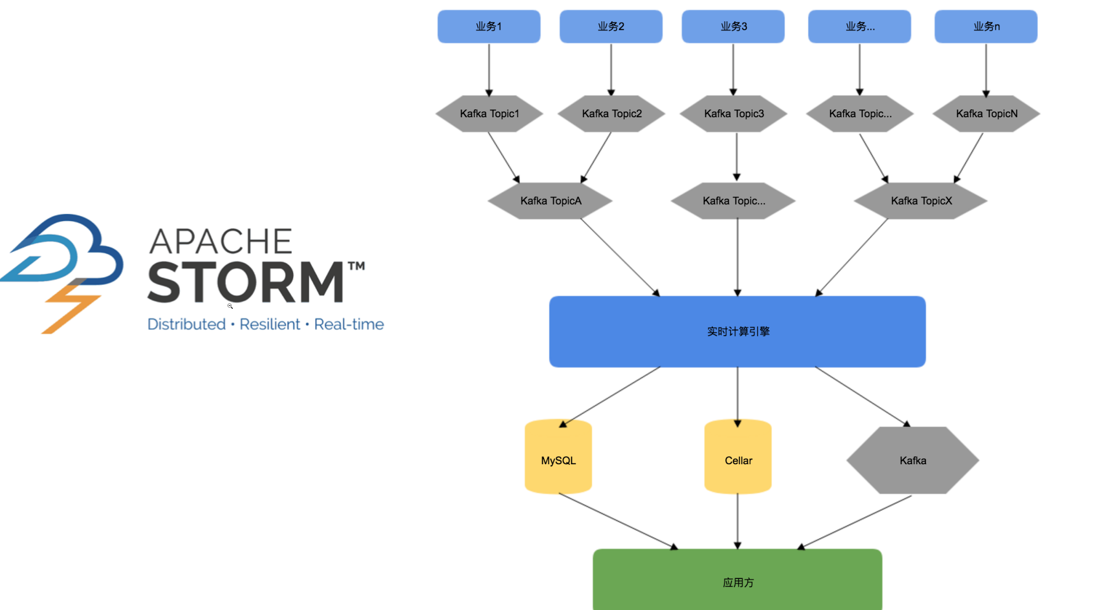
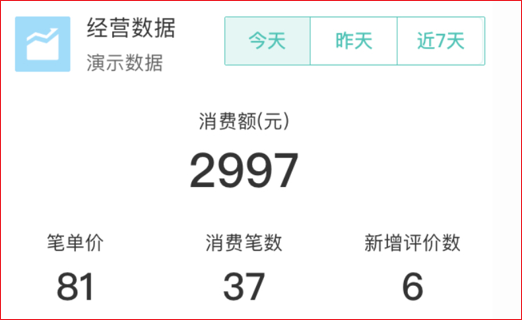
1.美团开店宝的实时经营数据卡片。
2.美团点评金融合作门店的实时热度标签。
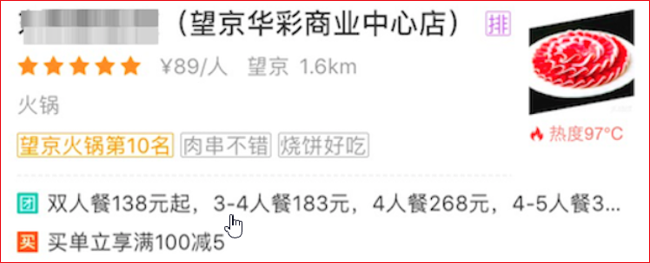
美团外卖是依托美团整体的基础数据体系建设,从技术成熟度来讲,前几年用的是 Storm,Storm 当时在性能稳定性、可靠性以及扩展性上是无可替代的。
随着 Flink 越来越成熟,从技术性能上以及框架设计优势上已经超越Storm,从趋势来讲就像 Spark 替代 MR 一样,Storm 也会慢慢被 Flink 替代,当然从 Storm 迁移到 Flink 会有一个过程,美团有一些老的任务仍然在 Storm 上,也在不断推进任务迁移。
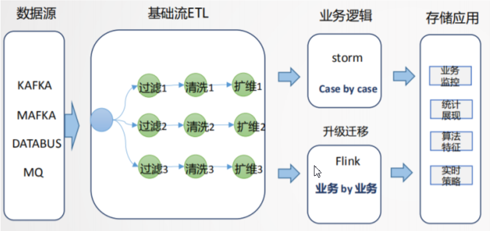
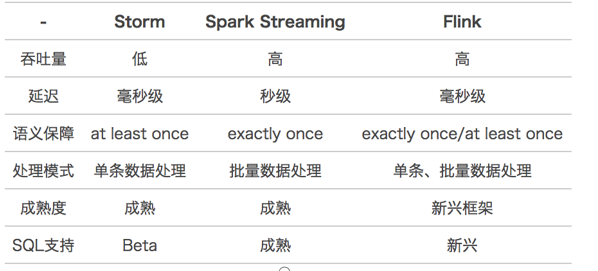
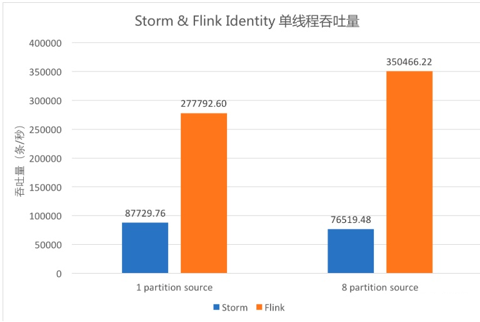
Storm VS Flink
Flink

Flink是一款分布式的计算引擎,它可以用来做批处理,即处理静态的数据集、历史的数据集;
Flink也可以用来做流处理,即实时地处理一些实时数据流,实时地产生数据的结果;
Flink还可以用来做一些基于事件的应用,比如说滴滴通过Flink CEP实现实时监测用户及司机的行为流来判断用户或司机的行为是否正当。
Flink在快手的应用
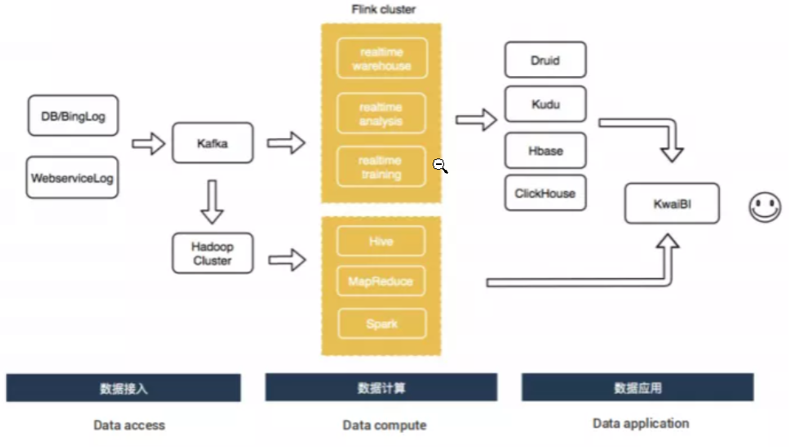
快手计算链路是从 DB/Binlog 以及 WebService Log 实时入到 Kafka 中,然后接入 Flink 做实时计算,其中包括实时数仓、实时分析以及实时训练,最后的结果存到 Druid、Kudu、HBase 或者 ClickHouse 里面;
同时 Kafka 数据实时 Dump 一份到 Hadoop 集群,然后通过 Hive、MapReduce 或者 Spark 来做离线计算;最终实时计算和离线计算的结果数据会用内部自研 BI 工具 KwaiBI 来展现出来。



快手目前集群规模有 1500 台左右,日处理条目数总共有3万亿,峰值处理条目数大约是 3亿/s 左右。集群部署都是 On Yarn 模式,实时集群和离线集群混合部署,通过 Yarn 标签进行物理隔离,实时集群是 Flink 专用集群,针对隔离性、稳定性要求极高的业务部署。

大数据时代对数据存储的挑战
当前数据存储新要求
- 1.高并发读写要求
对于实时性、动态性要求较高的社交网站,比如论坛微博等,往往需要达到每秒上万次的读写请求,这种很高的并发性数据库的并发负载相当大,特别是对于传统关系数据库的硬盘/IO是个很大的负担。
- 2.海量非结构话数据存储要求
非结构话数据,指的是数据结构不规则活不完整,没有任务预定的数据模块,不方便用二维逻辑表来表现的数据,比如办公文档(word),文本,图片,HTML,各类报表。
- 3.搞扩展性
对于传统数据库来讲,可以通过纵向扩展来提供数据存储能力,当数据量增加到一定程度时就会遇到瓶颈。
基于上面的新要求,我们大数据库开发会用到NoSQL数据库。
NoSQL数据库
NoSQL(Not Only SQL),非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQLy用于超大规模数据的存储,这类数据存储不需要固定的模式,无需多余操作就可以横向扩展。
- 灵活存储结构
- 容量水平扩张
- 高可用特性
- 可以大数据框架集成
NoSQL数据库类型
- 键值数据库:Redis
相关产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached
应用:内容缓存,适用于数据变化块切数据库大小可预见的应用程序
优点:扩展性好、灵活性好、大量写操作时性能高
缺点:无法存储结构化信息、条件查询效率低
使用者:百度云(Redis)、Github(Riak)、BestBuy(Riak)、Twitter(Redis和Memcached)
- 列族数据库:HBase
相关产品:BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS
应用:分布式数据存储和管理,并且对于大数据进行随机、实时访问的场合
优点:查找速度块、可扩展性强、容易进行分布式扩展、复杂性低
使用者:Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Facebook(HBase)
- 文档数据库:mongoDB
相关产品:MongoDB、CouchDB、ThruDB、CloudKit
应用:存储、索引并管理面向文档的数据或者类似的半结构化数据
优点:性能好、灵活性高、复杂性低、数据结构灵活
缺点:缺乏统一的查询语言
使用者:百度云数据库(MongoDB)、SAP(MongoDB)
- 图形数据库:neo4j
相关产品:Neo4j、OrientDB、InfoGrid、GraphDB
应用:使用图作为数据模块来存储数据,大量复杂、互连接、低结构化的图结构场合、比如社交网络、推荐系统等,社会关系、公共交通网络、地图及网络拓扑
优点:灵活性高、支持复杂的图形算法、可用于构建复杂的关系图谱
缺点:复杂性高,只能支持一定的数据规模
使用者:Adobe(Neo4j)、Cisco(Neo4j)、T-Mobile(Neo4j)
NoSQL和RDBMS的区别
| NoSQL | RDBMS |
|---|---|
| 代表这不仅仅是SQL | 高度组织化结构化数据 |
| 没有声明性查询语言 | 结构化查询语言(SQL) |
| 没有预定义的模式 | 数据和关系都存储再单独的表中 |
| 键值对存储,列存储,文档存储,图形数据库 | 数据操纵语言、数据定义语言 |
| 最终一致性,而非ACID属性 | 严格的一直性 |
| 非结构化和不可预知的数据 | 基础事务 |
| CAP定理 | |
| 高性能、高可用性和可伸缩性 |
大数据计算引擎的发展现状
MapReduce引擎为何没落?
Spark引擎的优势在哪里?
Flink凭啥在实时领域一枝独秀
分布式系统
1.单机服务器常见问题
- 服务器宕机
- 网络异常
- 磁盘故障
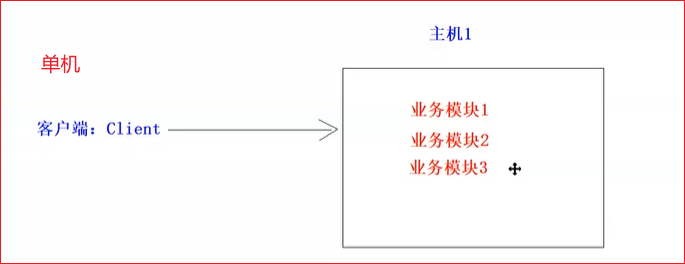
所有模块都放一台机器
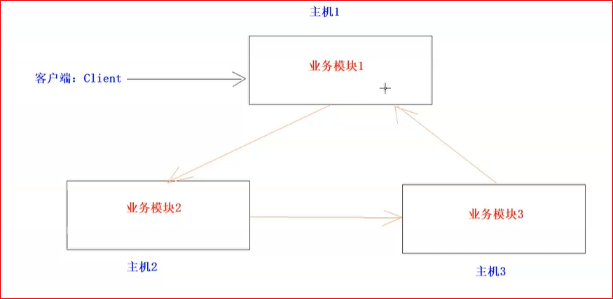
不同模块放不同机器
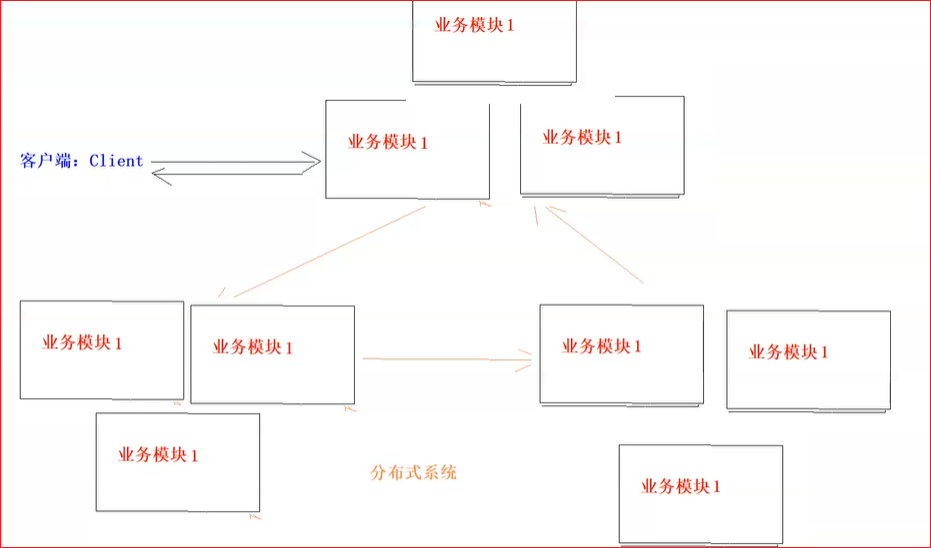
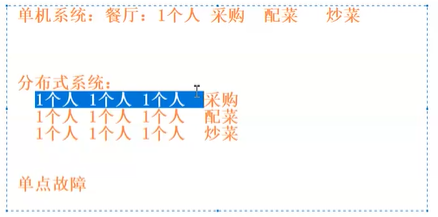
通过现实现象理解分布式:

再比如大数据中的存储就是分布式存储的
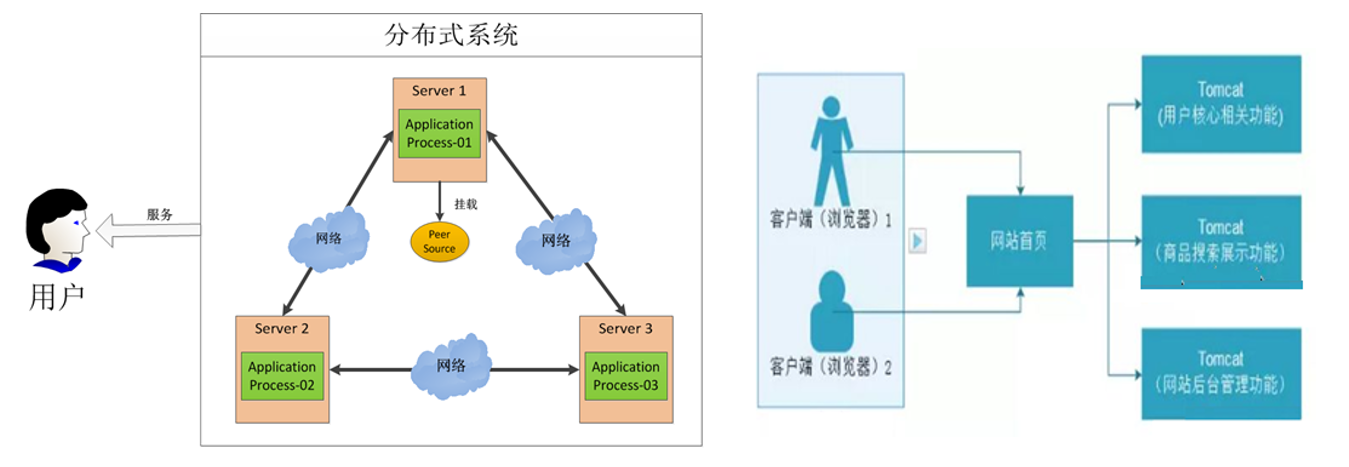
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。
- 分布式的优点是细化了应用程序的功能模块,同时也减轻了一个完整的应用程序部署在一台服务器上的负担,用了分布式拆分后,就相当于把一个应用程序的多个功能分配到多台服务器上去处理了。
- 分布式系统容易产生单点故障。
集群系统
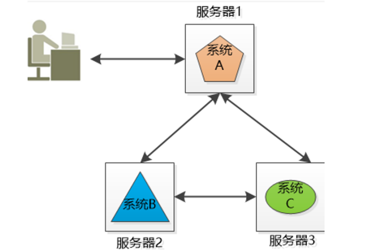
但是,虽然解决了单机问题,分布式还是解决不了单点故障问题。(某个模块出问题了,整体功能收影响)
解决办法也很理所当然,多找几个人。
这样可靠性就大大提高了,解决了单点故障问题。
也就是分布式中的集群。
所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
如果来了多个客户端请求,模块的3个节点都做事,那就是并行集群,
如果一个节点做(主节点),两外两个节点做备用(备用节点),主节点挂了,备用节点顶上去,这就是主备切换集群。
也就是分布式中集群的分类
集群的分类
(1)高可靠性(HA)
利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。
(2)高性能计算(HP)
即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析、化学分析等
虽然分布式和集群2个有差异,但是一般我们都合着叫,分布式集群
针对并行集群,由于每个节点都可以做事,为了防止每个节点做事不均匀,效率低。
所以一般要有一个主备的负载均衡集群,负责分发请求给并行集群。(类比疫情社区保安给分群分流引向不同的大白桌子提高效率)
综合上面,可以有下面比较完美的服务器架构
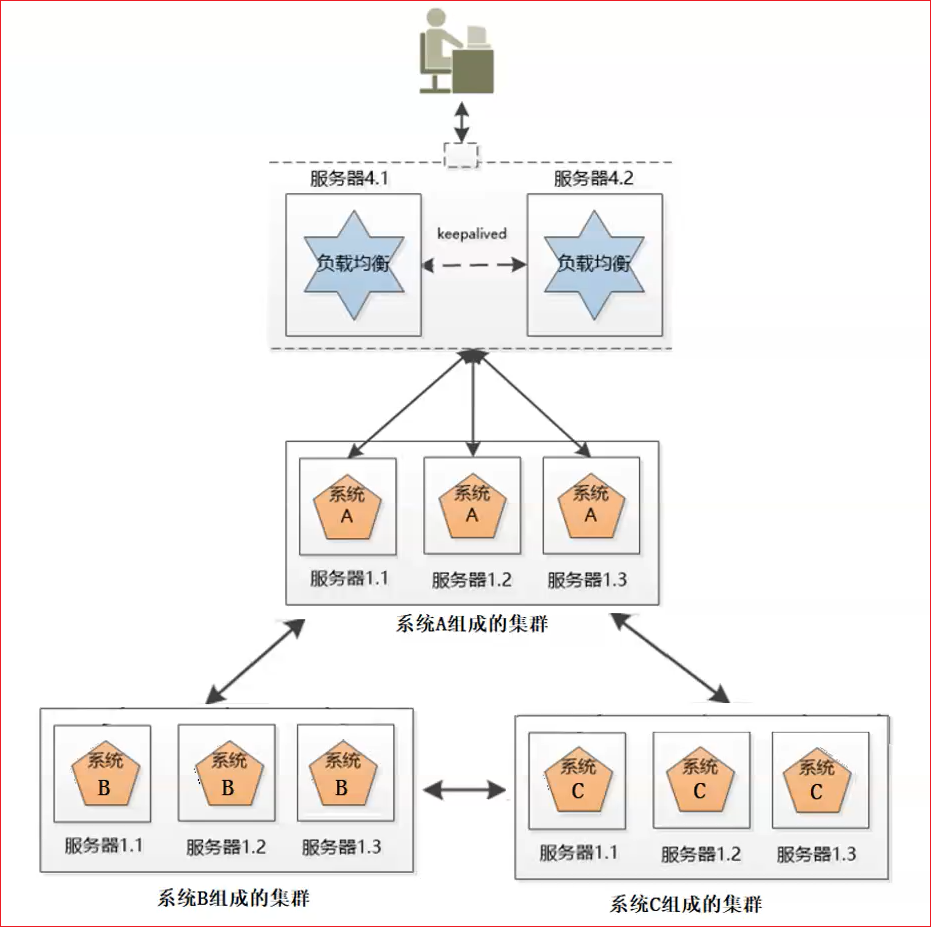
分布式集群中的过半机制
比如100台服务器,就至少要有51台存活才能正常工作。
3台要有2台,5台要有3台。
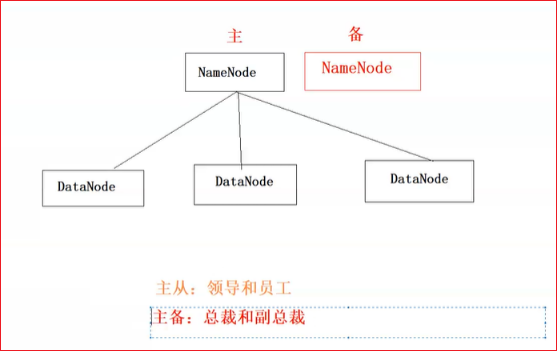
主从和主备的区别
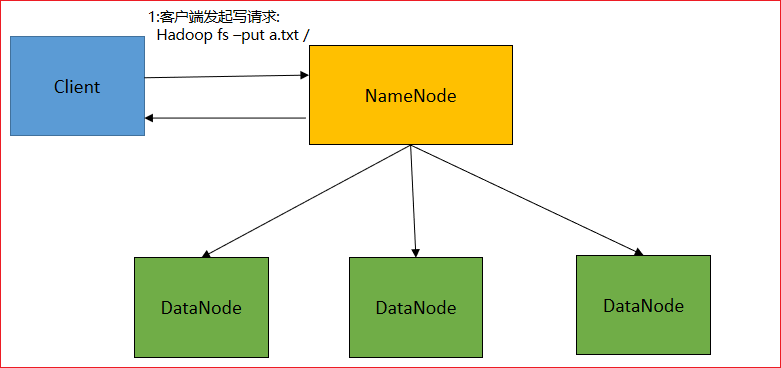
分布式存储系统一般用主从架构,NameNode(管理节点,分配任务),DataNode(数据节点,干具体的活),
而主备是备用节点盯着主节点看它什么时候挂掉的。
存储的时候,比如按字节做物理切割,比如300M切成128M+128M+44M。每个切片发给不同的节点。
为了防止每个切片丢失,将服务器上的数据切片多备份几份,比如3份。就是副本。副本也放到不同的节点。
每个切片可能存不同的机房(北京,上海,深圳等…),需要一个主节点管理每个文件的档案,每个数据切成多少份,存在哪些节点。也就是主从架构。
集群和分布式的区别
分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
大数据系统
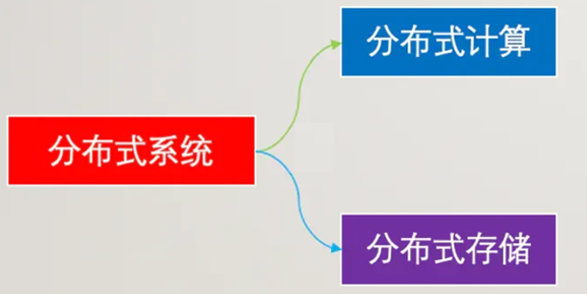
分布式系统分为分布式计算和分布式存储
分布式计算和分布式存储合起来就是大数据
分布式存储
分布式存储系统面向海量数据的存储访问与共享需求,提供基于多存储节点的高性能,高可靠和可伸缩性的数据存储和访问能力,实现分布式存储节点上多用户的访问共享。
常见的分布式文件系统:HDFS、OpenStack Swift、Ceph、GlusterFS、Lustre、AFS、OSS等。
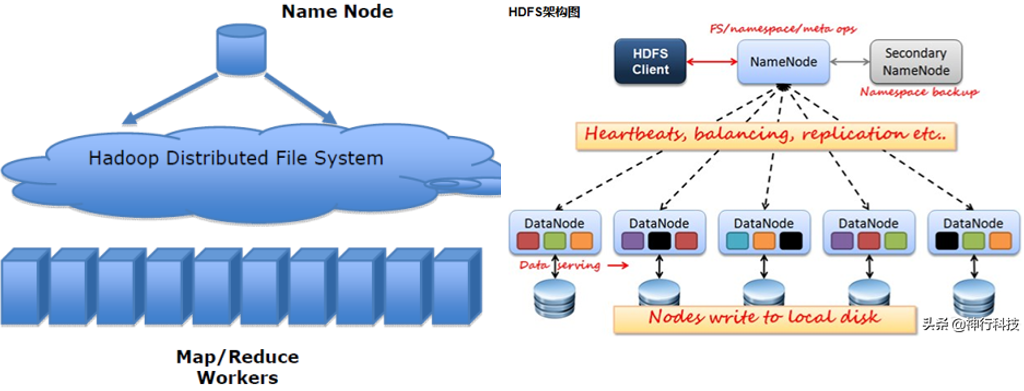
分布式计算
大数据数据可视化
什么是BI
BI——就是分析利用企业已有的各种商用数据来了解企业的经营状况和外部环境,从而为企业的经营决策提供数据支撑。
大数据应用的瓶颈(缺乏数据工具)
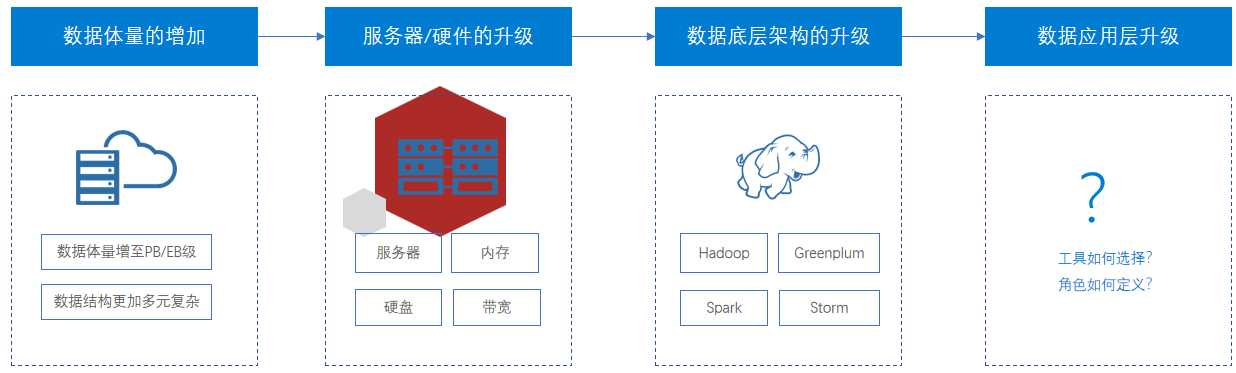
为应对大数据的快速增长时,硬件不断升级,架构不断扩展,但没有最后一公里的充分应用就无法产生价值大数据倒逼企业不断地去升级软硬件,但存储的数据越来越多,如何真正让数据发挥价值?做好数据建设的最后一公里至关重要。这就要考虑数据应用层,怎么借助有效工具让数据发挥作用。指引业务。
常见的BI系统
fineBI,永洪BI,echarts、whale、powerbi 等
ChartBlocks
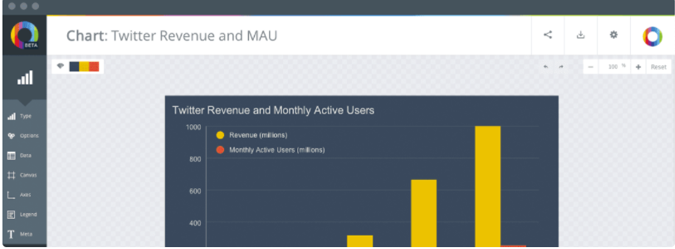
ChartBlocks是一款网页版的可视化图表生成工具,在线使用,通过导入电子表格或者数据库来构建可视化图表。整个过程可以再图表的向导指示下完成。它的图标在HTML5的框架下,使用强大的JavaScript库D3.js来创建图表。图表是响应式的,可以和任何的屏幕尺寸及设备兼容。还可以将图表嵌入任何网页中。
D3.js

D3是个图表库,对于前端工程师来说,D3.js称得上是最好的数据可视化工具库。
D3厉害的地方在于它建立了一套数据到SVG属性的计算框架,常用Data Visualization模型,大多都可以再d3.layout里面找到。D3.js运行再JavaScript上,并使用HTML,css,svg。
D3.js是开源工具,使用数据驱动的方式创建漂亮的网页,D3.js可实现实时交互,这个库非常强大和前沿。
Tableau
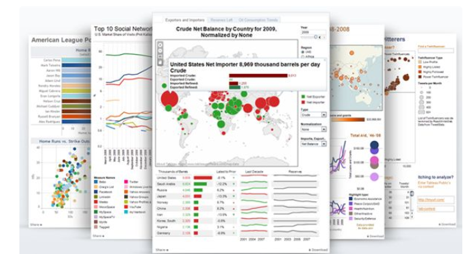
Tableau公司将数据运算与美观的图标完美地嫁接在一起。它的程序很容易上手,各公司可以用它将大量数据拖放到数字”画布”上。转眼间就能创建
好各种图表。这一款软件的理念是,界面上的数据月容易操控,公司对自己所在业务领域里的所作所为到底是正确还是错误的,就能了解得越透彻。其两种不同的变体是基于云计算的Tableau Online和Tableau Server.
它们都是与大数据有关的组织设计的,企业使用这个工具非常方便,而且提供了闪电般的速度。还有一件事对这个工具是肯定的,tableau具有用户友好的特性,并与拖放功能兼容。但是在大数据方便的性能有所缺陷,每次都是实时查询数据,如果数据量大,会卡顿。
Echarts
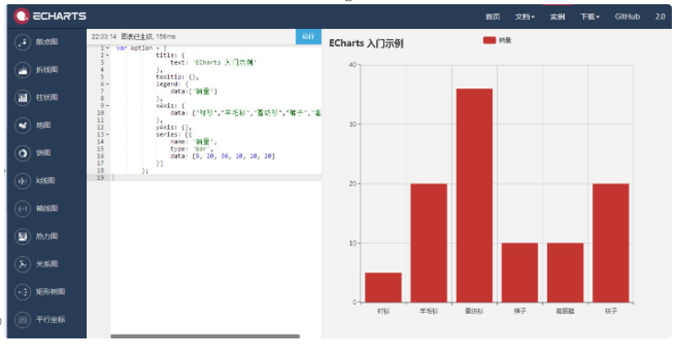
国产货有语言优势和区域优势,毕竟是made in China,亲和力思维杠杠的。对于城市的地理坐标,城市代码等都已经配置好了。需要的时候直接使用非常方便。
免费,各类图,各种形式,只能你想不到的,没有洒家做不到的。开源且免费,你还在等什么。是兄弟就来用我。
支付宝AntV
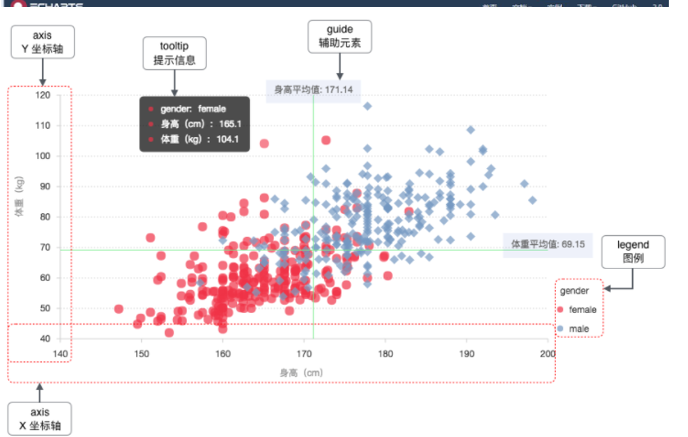
AntV是蚂蚁金服的数据可视化解决方案,主要包含[数据驱动的高交互可视化图形语法]G2、专注解决流程与关系分析的图表库G6,适于对性能、体积、扩展性要求严苛场景下使用的启动端图表库F2以及一套完整的图表使用指引和可视化设计规范。已为阿里集团内外2000+个业务系统提供数据可视化能力,其中不乏日均千万UV级的产品。
FineBI
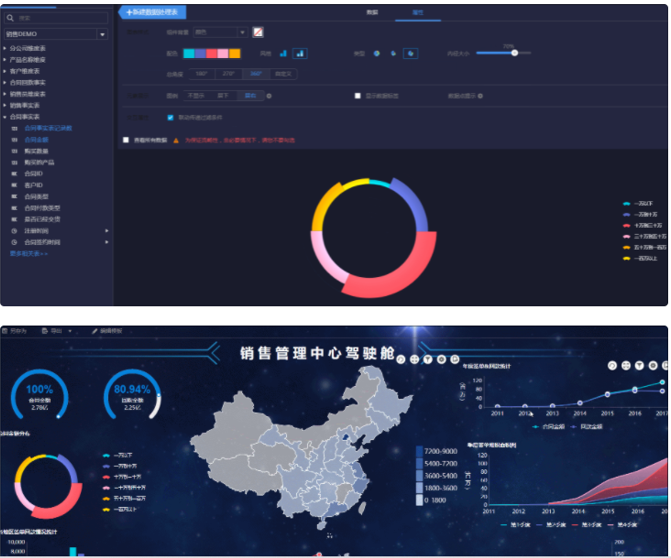
FineBI,帆软BI,是一款商业智能BI工具,做数据分析和可视化数据展现,以分析为主,提供多种数据接入方式,可视化功能强大,平台更适合掌握分析方法了解分析的思路的用户,其他用户的使用则依赖于分析师的结果输出。FineBI也是找了很久感觉不错的一款数据可视化工具。其中还有对数据处理的公式和方法,图表也比较全面。相对于百度的echarts,FineBI还是一款比较容易入手的数据分析工具。最后,FineBI提供了免费的版本,功能齐全。更加适合个人对数据分析的学习和使用。
报表是以表格、图表的形式来动态展示数据,企业通过报表进行数据分析,进而用于辅助经营管理决策。FineReport 就是一款用于报表制作,分析和展示的工具。
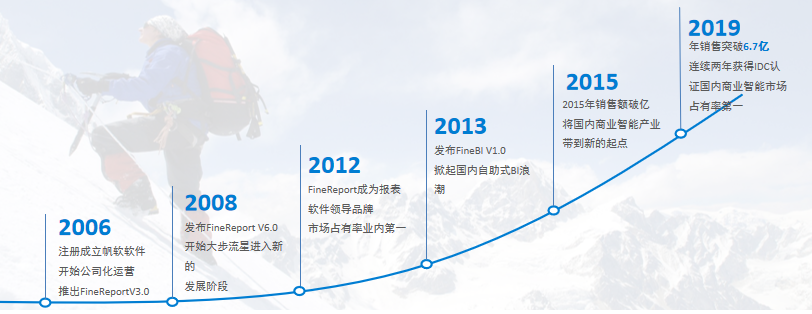
产品定位
- 多数据源关联,支持多样的数据来源,从不同的数据库、表取数,通过产品关联,可以整合不同来源的业务系统数据于一张报表中,让更多数据应用于经营分析和业务管控。
- 零编码设计器,提升开发效率,快速响应不断变化的需求,轻松搞定中国式复杂报表、参数查询、图表分析、数据钻取、dashboard等。提供统一的报表访问和管理平台,实现精细的权限控制。
- 强大的数据录入,借助设计器可迅速实现填报报表,通过 PC 或移动设备进行高效的数据补录、删除或修改,帮助企业完善数据资产;同时支持excel历史数据导入,支持数据校验,保障数据的规范和有效。
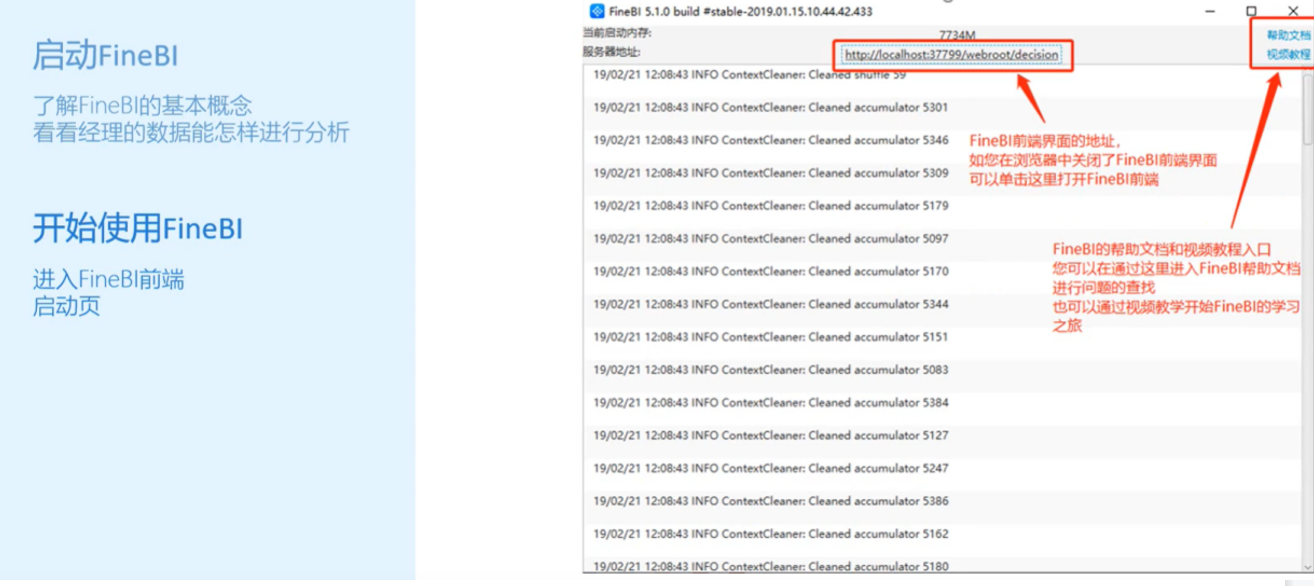
FineBI的安装部署
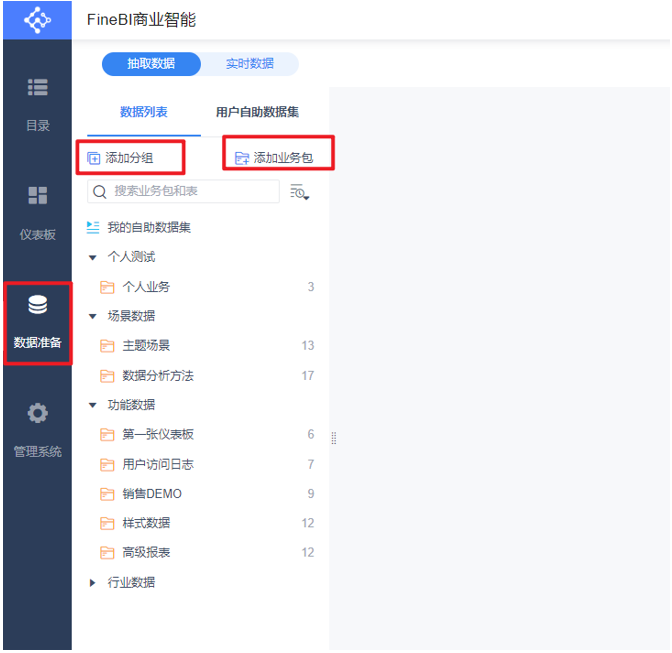
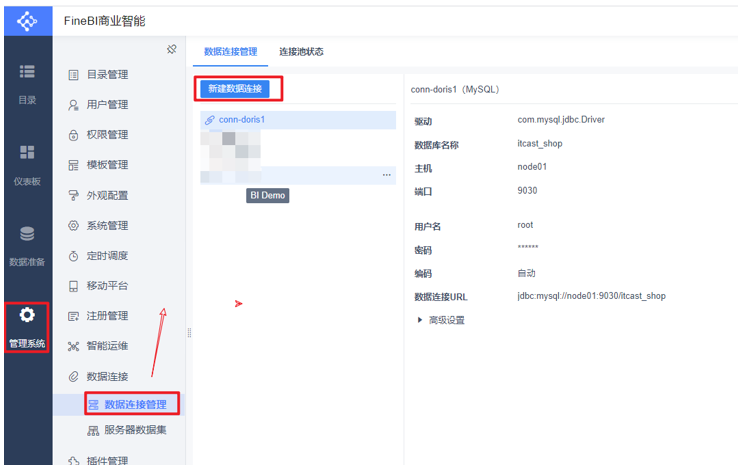

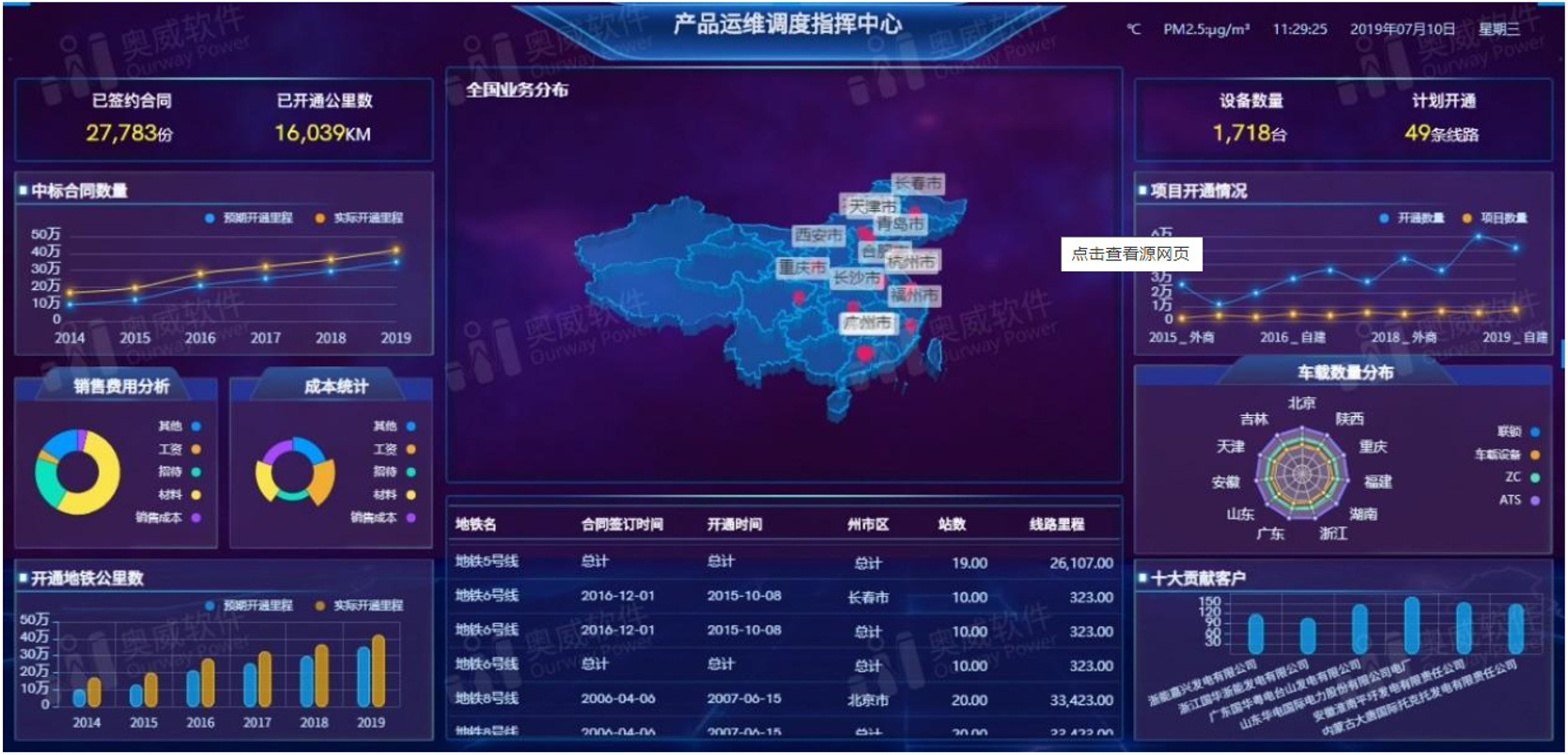
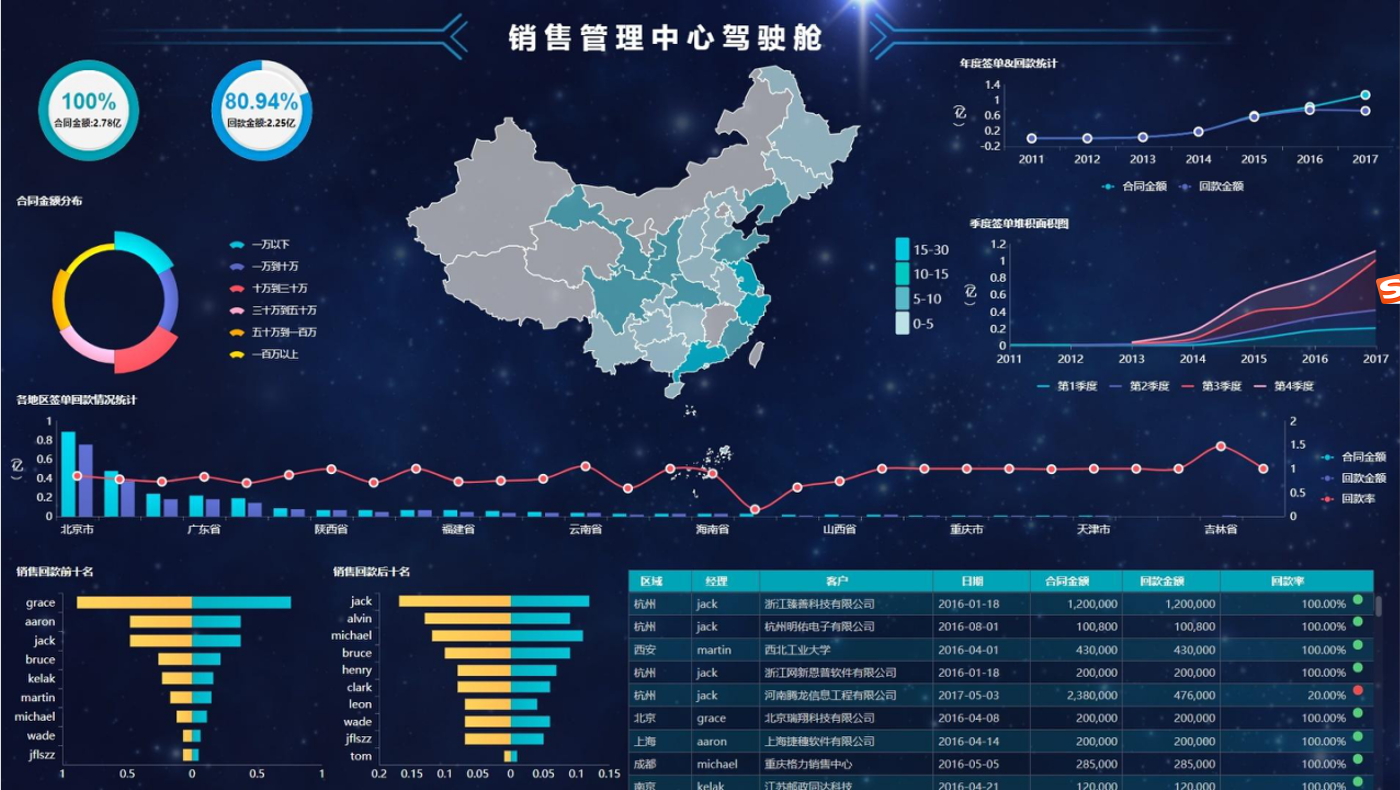
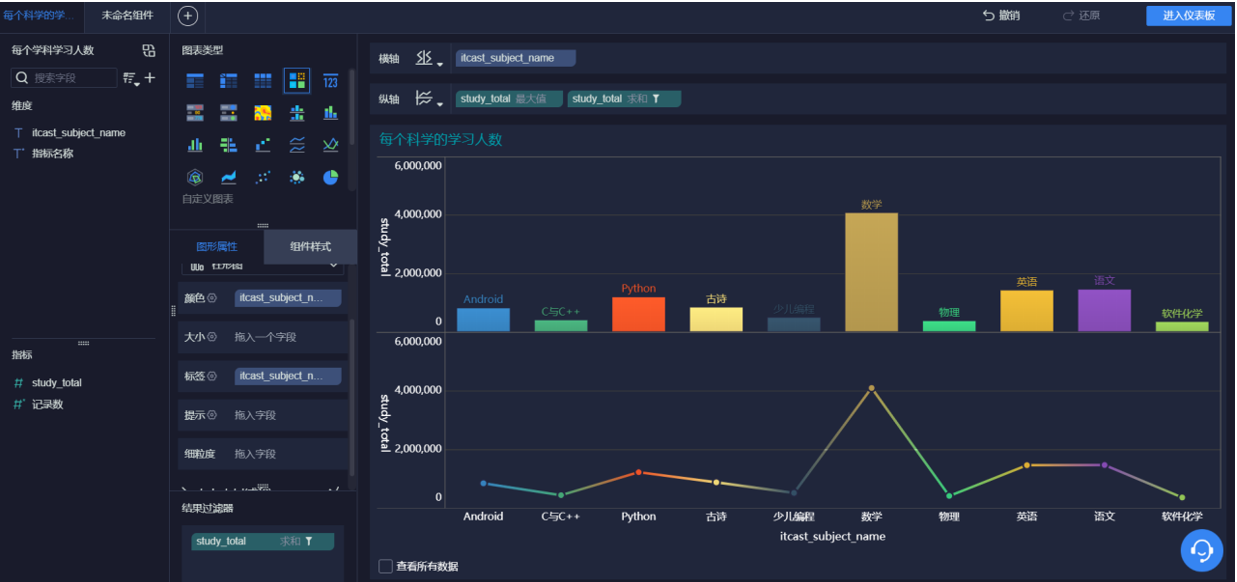
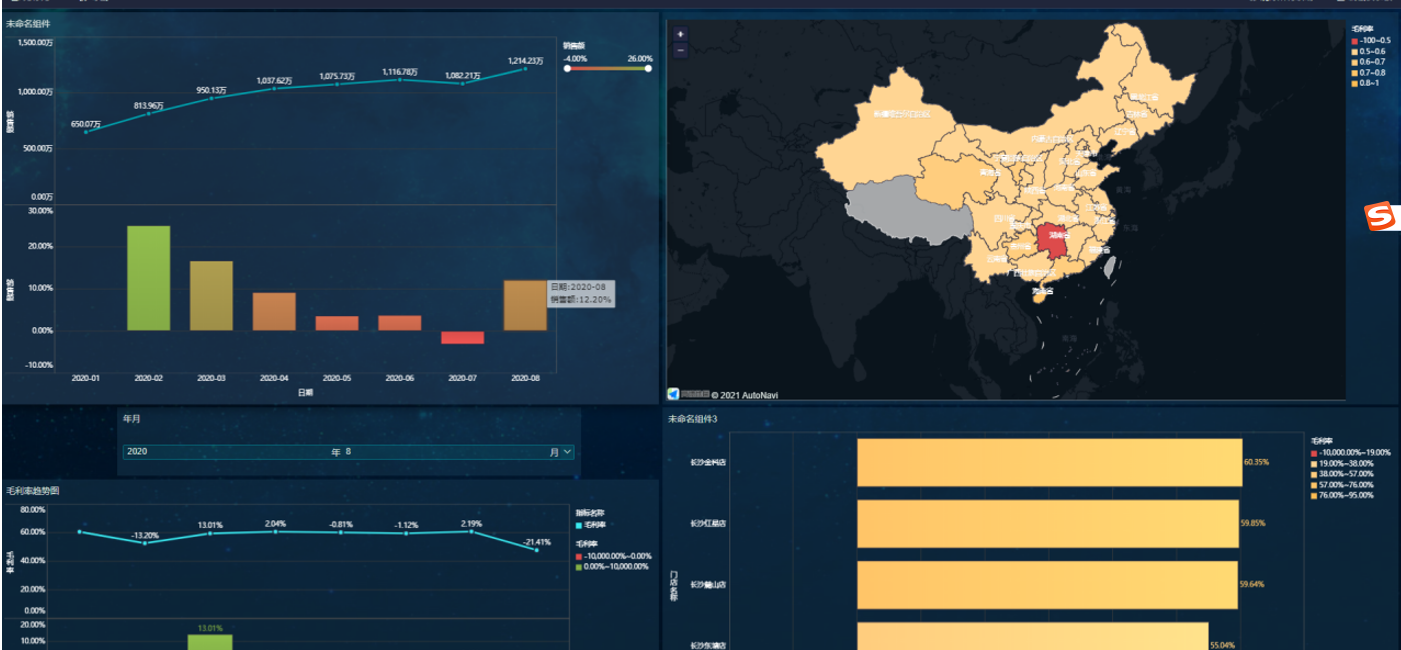
FineBI图表展示
 微信
微信 支付宝
支付宝

