【大数据系列】CDH
CDH环境搭建
确实好用,有一个管理控制台,有点all in one 的感觉。
cloudera manager基本介绍
大数据的发行版本, 主要有三个发行版本: Apache 官方社区版本, cloudera 推出CDH商业版本, Hortworks推出的HDP商业免费版本, 目前HDP版本已经被cloudera 收购了
大数据平台搭建方式
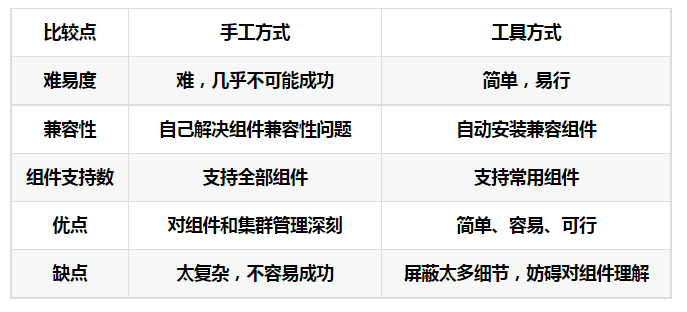
手动部署
1
2
3
4
5
6
7优点
灵活性和安全性、自定义的程度最高
缺点
如果集群的机器比较多,安装和管理就比较麻烦
如果有一台的配置改变了,其他的都要手动同步
版本之间的兼容性问题考虑十分棘手 木桶短板效应
要求运维人员精通计算机底层和大数据应用集群管理工具部署
1
2
3
4
5
6
7
8优点
由管理工具来实现批量化的同步操作:安装、配置 可以通过鼠标直接点击操作就可以完成配置
有监控管理:进程监控、资源监控
可以所有程序管理:不需要命令行,通过可视化界面来管理所有服务
缺点
Cloudera Manager:对很多非Cloudera公司的产品不兼容 大规模商业部署收费,本课程使用的就是CM
Ambari:Bug比较多,兼容性较差
Apache版本Hadoop生态圈组件的优点和弊端
Hadoop的原始版本为Apache的开源版本,在国内的使用非常多。
优点:
完全开源,更新速度很快
大数据组件在部署过程中可以深刻了解其底层原理
可以了解各个组件的依赖关系
缺点
部署过程极其复杂,超过20个节点的时候,手动部署已经超级累
各个组件部署完成后,各个为政,没有统一化管理界面
组件和组件之间的依赖关系很复杂,一环扣一环,部署过程心累
各个组件之间没有统一的metric可视化界面,比如说hdfs总共占用的磁盘空间、IO、运行状况等
优化等需要用户自己根据业务场景进行调整(需要手工的对每个节点添加更改配置,效率极低,我们希望的是一个配置能够自动的分发到所有的节点上)
CDH版本大数据组件
为了解决上述apache原生版本产生的各种问题, 出现了一些商业化大数据组件, 其中以 cloudera 公司推出 CDH版本 为主要代表
CDH是Apache Hadoop和相关项目中最完整、最稳定的、经过测试和最流行的发行版。 CDH出现帮助解决了各个软件之间的兼容问题, 同时内置大量的常规企业优化方案, 为了提供用户体验, 专门推出一款用于监控管理自家产品的大数据软件: cloudera manager
Cloudera Manager是用于管理CDH群集的B/S应用程序
使用Cloudera Manager,可以轻松部署和集中操作完整的CDH堆栈和其他托管服务(Hadoop、Hive、Spark、Kudu)。
其特点:应用程序的安装过程自动化,将部署时间从几周缩短到几分钟; 并提供运行主机和服务的集群范围的实时监控视图; 提供单个中央控制台,以在整个群集中实施配置更改; 并集成了全套的报告和诊断工具,可帮助优化性能和利用率。
优点:
- 统一化的可视化界面 自动部署和配置,大数据各类组件(hadoop、hive、hue、kudu、impala、zookeeper等)安装、调优极其便捷 零停机维护(免费版本不具有弹性升级)
- 多用户管理(权限控制)
- 稳定性极好(部分优化措施都已经调整好)
缺点:
- server和agent需要占用额外的内存和cpu(server占用内存为2G,agent占用内存1G,总共cpu为0.5核)
- 对linux常用命令需要了解颇深
- 对hadoop的apache版本有一定的安装经验和调优经验
CDH应用场景
- 适用于节点在5个以上的集群,小公司用到的服务较少时,为了节省服务器等资源,不需要部署cm。
- 适用于所有的专业大数据公司,这类企业的硬件资源一般都比较充足。
- 适用于运维工作较频繁的场景,使用apache版本的运维人员,对某一个组件进行调优配置,需要消耗半天的时间进行调整,效率极低;该平台安装好以后,维护工作相对来将就轻松许多。
- 补充:
- cm在国内用户量很大,戴尔、一号店等知名公司都在使用
- cm在主流的大数据平台框架中,用户量比例很高
- cm的免费版本不支持弹性升级。
ClouderaManager架构
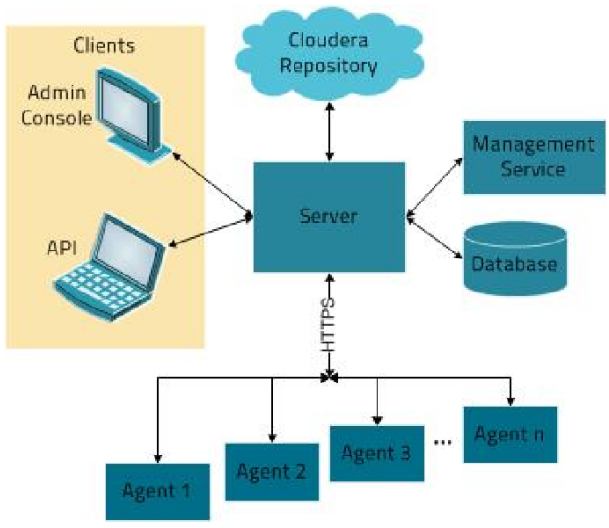
1.Server:Cloudera Manager的核心是Cloudera Manager Server。提供了统一的UI和API方便用户和集群上的CDH以及其它服务进行交互,能够安装配置CDH和其相关的服务软件,启动停止服务,维护集群中各个节点服务器以及上面运行的进程。
2.Agent:安装在每台主机上的代理服务。它负责启动和停止进程,解压缩配置,触发安装和监控主机
3.Management Service:执行各种监控、报警和报告功能的一组角色的服务
4.Database:CM自身使用的数据库,存储配置和监控信息
5.Cloudera Repository:云端存储库,提供可供Cloudera Manager分配的软件
6.Client:用于与服务器进行交互的接口,包含Admin Console和API
(1)Admin Console:管理员可视化控制台
(2)API:开发人员使用API可以创建自定义的Cloudera Manager应用程序
ClouderaManager功能
信号检测
默认情况下,Agent 每隔 15 秒向 Cloudera Manager Server 发送一次检测信号。但是,为了减少用户延迟,在状态变化时会提高频率。
状态管理
模型状态捕获什么进程应在何处运行以及具有什么配置。
运行时状态是哪些进程正在何处运行以及正在执行哪些命令(例如:重新平衡HDFS或执行备份/灾难恢复计划或集群升级、停止)。
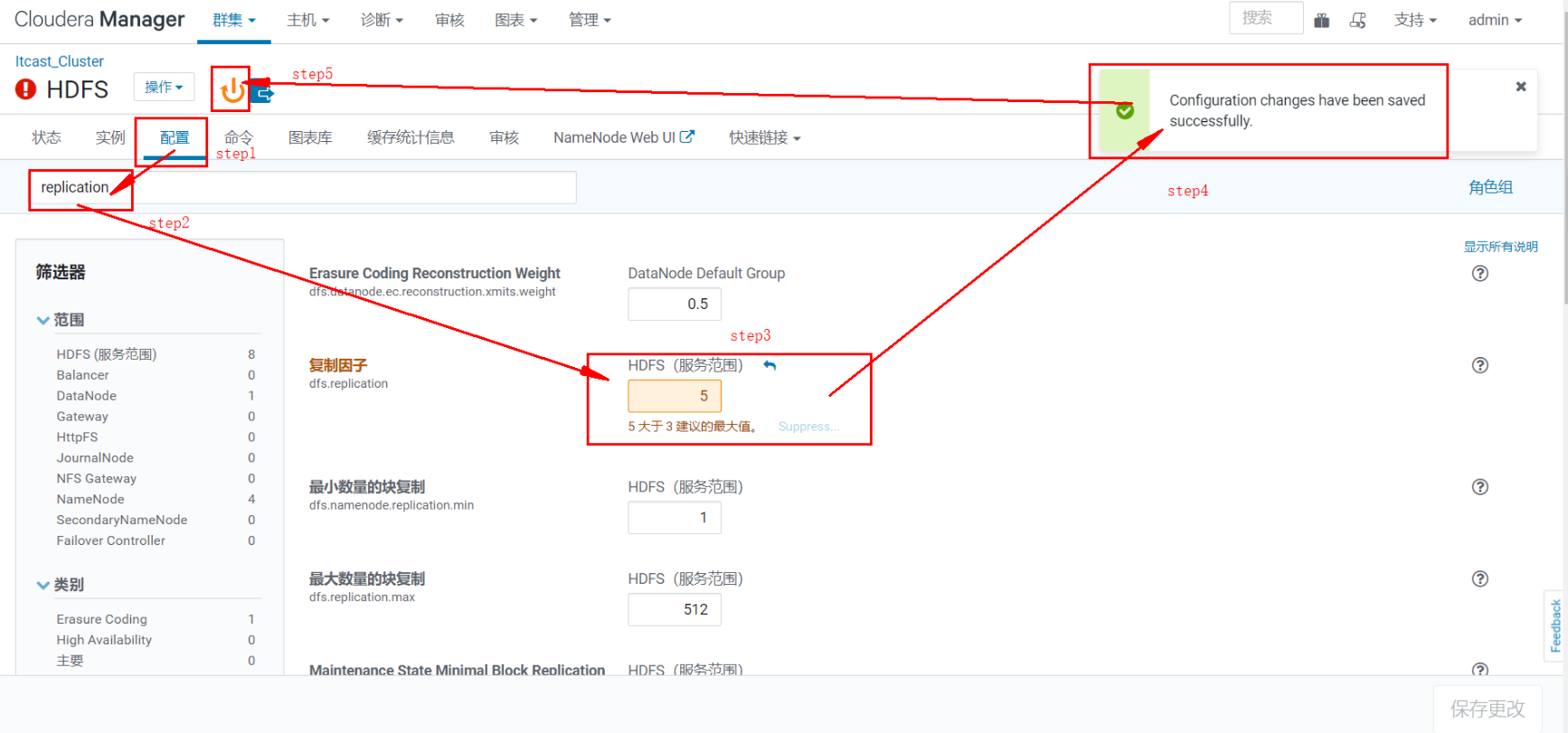
当更新配置(例如Hue Server Web 端口)时,相当于更新了模型状态。但是,如果 Hue 在更新时正在运行,则它仍将使用旧端口。当出现这种不匹配情况时,角色服务会标记为“过时的配置”。要重新同步,需重启角色服务(这会触发重新生成配置和重启进程)。
主机管理
Cloudera Manager 作为群集中的托管主机身份,可对JDK、Cloudera Manager Agent、CDH、Impala、Solr等所有软件角色的主机进行管理。
Cloudera Manager 提供添加和删除主机的操作。
Cloudera Management Service Host Monitor 角色执行状况检查并收集主机度量,可以监控主机的运行状况和性能。

进程启停
在Cloudera Manager管理的群集中,只能通过 Cloudera Manager 启动或停止服务。Cloudera Manager 支持自动重启崩溃进程。如果一个角色实例在启动后反复失败,Cloudera Manager 还会用不良状态标记该实例。
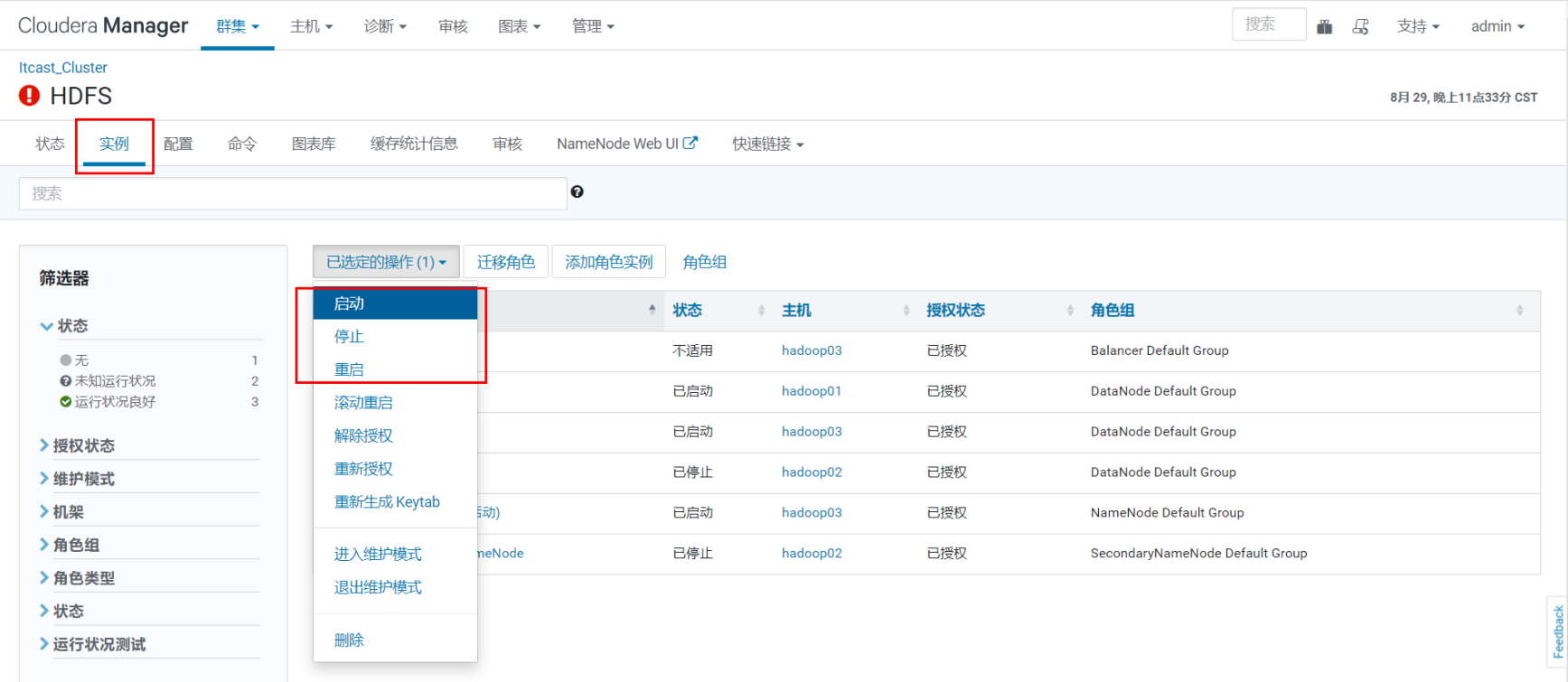
特别需要注意的是,停止 Cloudera Manager 和 Cloudera Manager Agent 不会停止群集;所有正在运行的实例都将保持运行
监控管理
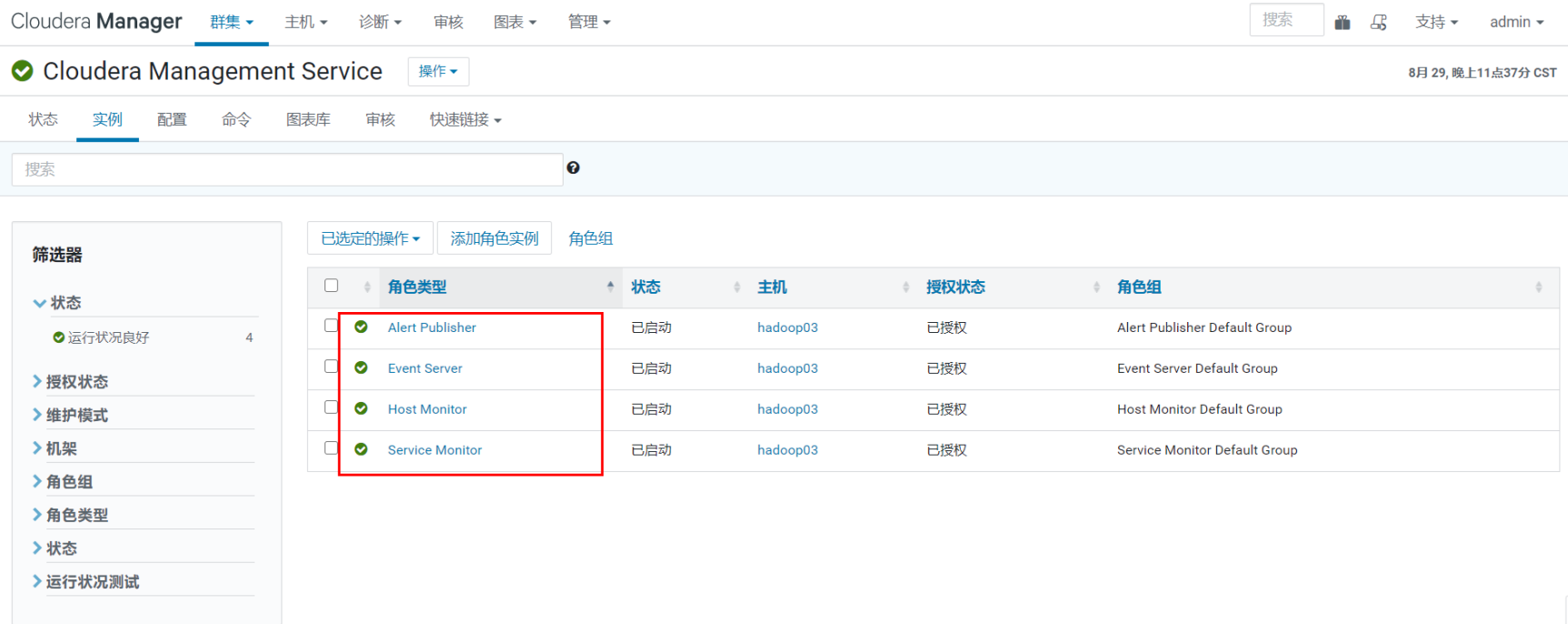
- Activity Monitor:收集关于MapReduce服务运行的活动的信息。默认情况下不添加此角色。
- Host Monitor:收集有关主机的运行状况和指标信息。
- Service Monitor:从YARN服务中收集关于服务和活动信息的健康和度量信息。
- Event Server:聚合组件的事件并将其用于警报和搜索。
- Alert Publisher :为特定类型的事件生成和提供警报。
- Reports Manager:生成图表报告
教育项目的环境搭建(废弃)
资源分配
虚拟机账户密码:==root 123456==
设置VMware虚拟机网络
1
2
3提供的2台项目虚拟机采用的是vmnet8 NAT模式搭建
网段: 192.168.88.0/24
网关: 192.168.88.2设置windows本机虚拟网络配置(可选)
保证windows上的vmnet8虚拟网卡也是出于88网段。否则笔记本访问不了虚拟机。
- 虚拟机CPU、内存分配
如果两台虚拟机的CPU和内存总配置,已经超出了windows硬件的上限,要进行适当的调低,以避免windows蓝屏。
- CPU
1 | CPU的分配,至少需要给windows留下1~2个逻辑处理器。 |
- 内存
1 | windows一共8G: 第一台4.5G(4608m),第二台1.5G(1536m),win10预留2G即可。 |
基础环境
- CentOS 7
- jdhk 1.8
- mysql 5.7
- CDH 6.2.1
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.88.165 | cdh01 | Cm、nn |
| 192.168.88.166 | cdh02 | datanode |
| 192.168.88.167 | cdh03 | datanode |
CM管理界面: 192.168.88.165:7180
安装包目录:/opt/setup/cloudera
安装目录: /usr/local/apps/cloudera
系统环境
准备3台基础虚拟机,参照Linux汇总的3台虚拟机搭建过程。
CDH下载:https://archive.cloudera.com/cdh6/6.2.1/parcels/
搭建CM本地YUM仓库
这里cdh01搭建本地YUM源作为离线安装CM的仓库,让其他主机也使用该源下载CM相关的软件
1 | 安装httpd和createrepo |
配置本地的YUM仓库
1 | cat > /etc/yum.repos.d/manager-repos.repo <<EOF |
安装CM
创建数据库
1 | create database amon DEFAULT CHARACTER SET utf8; |
1 | yum install -y cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server |
配置CM数据库
官方提供了一个脚本用于初始化 CM 数据(配置/etc/cloudera-scm-server/db.properties),执行如下命令:
1 | /opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm -h localhost scm 'root密码' |
最后提示:”All done, your SCM database is configured correctly!”代表配置成功,忽略可能的WARN信息
启动CM服务
1 | systemctl start cloudera-scm-server |
观察日志输出,当看到Started Jetty server.时表示服务已经启动成功了(大约需要等待3~5分钟左右)。
1 | tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log |
访问CM控制台
浏览器访问http://master.bigdata:7180/cmf/login或者http://192.168.122.101:7180/cmf/login,账号密码统一为admin。
知行教育项目-直接使用安装好的环境(可行)
搭建失败,直接使用安装好的环境
使用步骤:
电脑必须是联网状态
要求:32G内存及以上使用三台环境,解压到一个没有中文和空格的目录下
双击.vmx文件,将虚拟机挂载到VMware上

点击每台虚拟机启动,注意: 如果弹出以下界面, 一定一定一定要选择 我以移动此虚拟机
查看每一台虚拟机的IP地址及其网关地址:
1 | Ip查看: ifconfig |
修改VMware的虚拟网卡配置: 虚拟网络编辑器
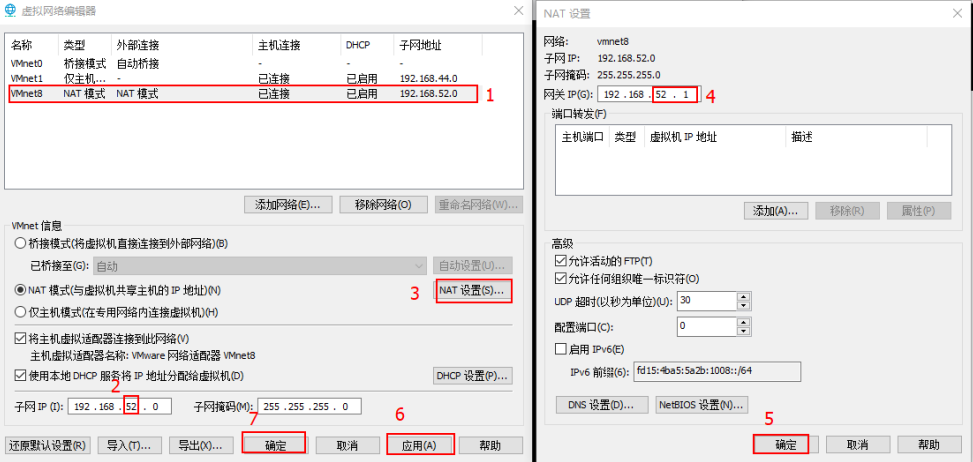
修改windows的VMware8的网卡信息:
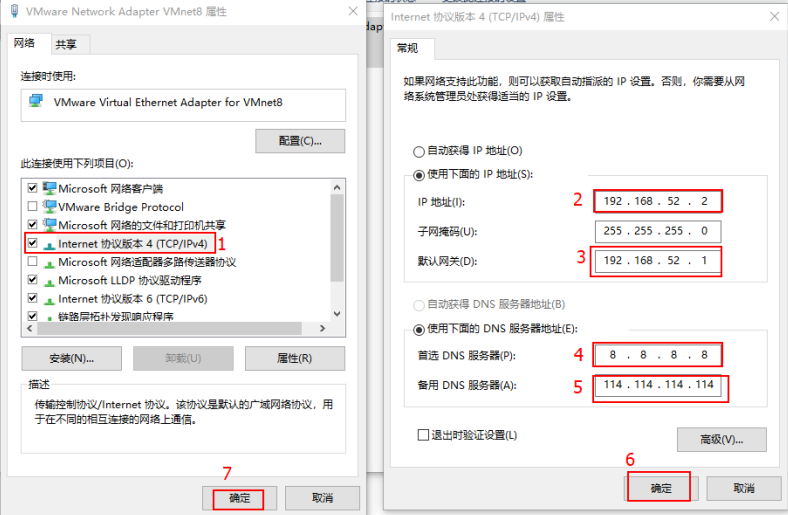
这里的IP地址:
192.168.52.1、192.168.52.150、192.168.52.151、192.168.52.152不能设置,其他的随便
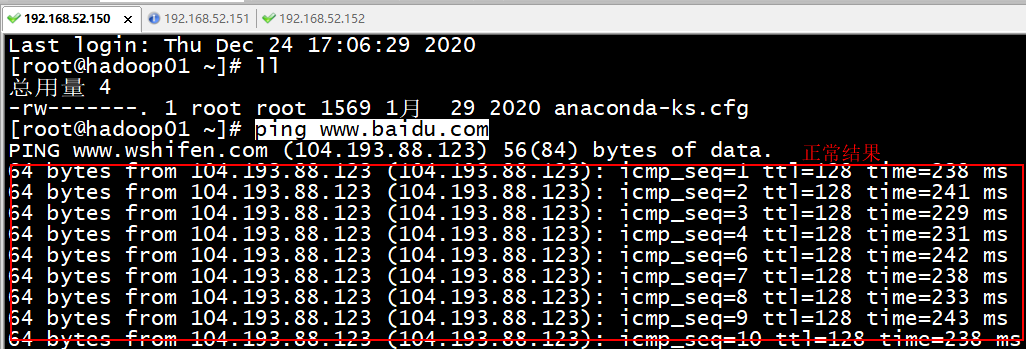
xshell连接,测试三台机子是否可以联网:
注意: 三台都需要测试 ,如果无法连接, 多测试几次
修改windows的hosts文件:
1 | 192.168.52.150 hadoop01 hadoop01.itcast.cn |
root用户:root/123456
浏览器访问的界面:
用户名和密码都是 admin
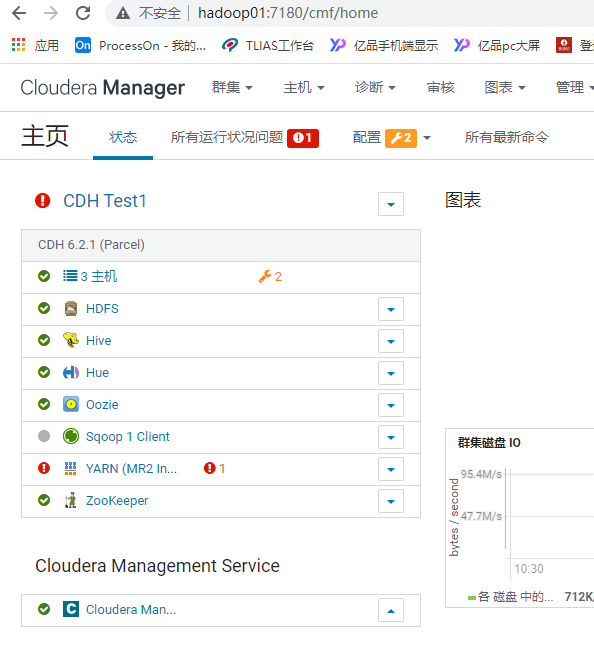
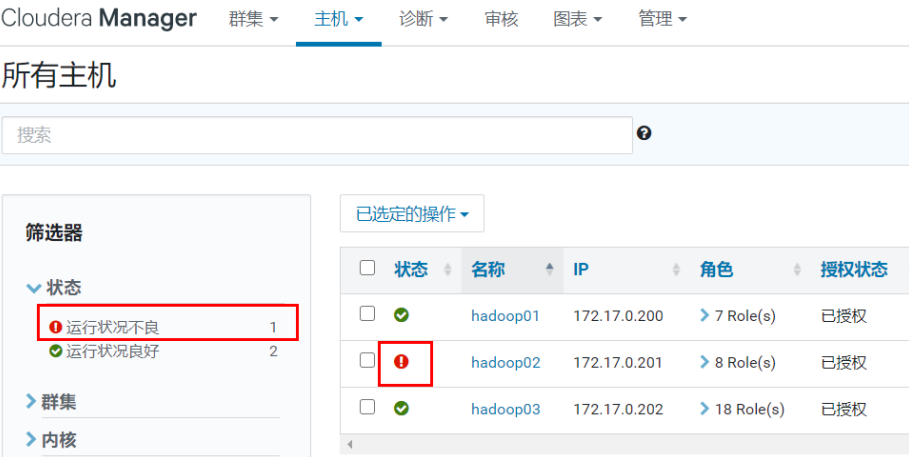
打开后, 可能会出现上述 yarn中存在问题, 点击yarn进行解决接口, 如果都是对勾,那么就OK了
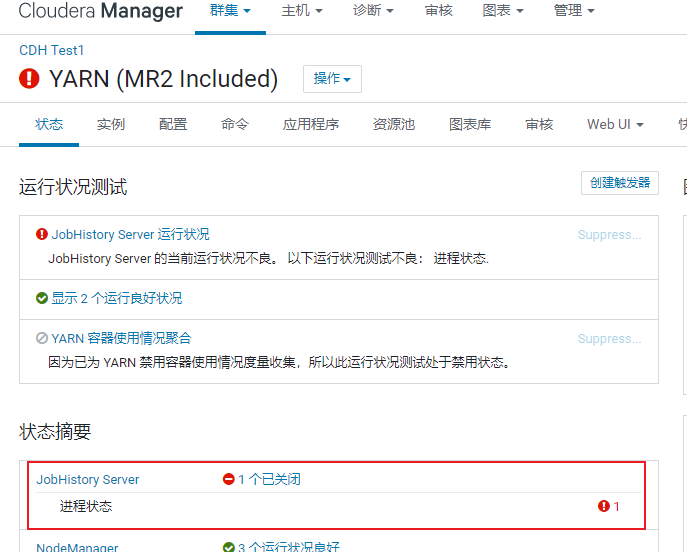
点击 jobhistory server. 进去后, 点击启动即可
最终效果:
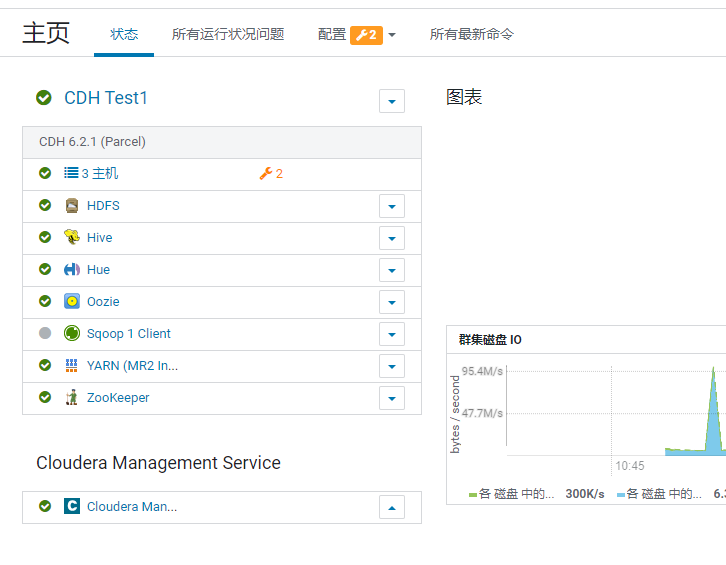
后续如何关机的问题:
教育项目中虚拟机, 坚决不允许挂起, 以及强制关闭操作, 如果做了, 非常大的概率导致服务器出现内存以及磁盘问题, 需要重新解压
- 关机必须在CRT上直接关机命令:
shutdown -h now(每一个节点都要执行) - 重启服务器: 执行
reboot(每一个节点都要执行)
需要注意: 如果将虚拟机放置在机械磁盘的, 如果长时间不使用这几个虚拟机, 建议将其关闭, 固态盘一般没啥问题, 但是依然建议关闭
服务器内存资源调整:
16GB:
- hadoop01: 默认占用12GB内存, 可以调整到 10.5GB
- hadoop02: 默认占用3.5GB, 可以调整到 3GB
不调整也没什么太大问题, 只不过刚刚启动后, 等待20分钟之后, 在操作电脑就好了
注意: CDH软件开机后, 整个所有服务恢复正常, 大约需要耗时10~20分钟左右, 所以如果一开机就访问hadoop01:7180 可能是无法访问
如果等到 10~20分钟以后, 依然有大量的都是红色感叹号, 建议重启试一下, 如果依然不行, 老找我
如果只有偶尔一两个, 建议点进去, 重启一下即可
如果是12GB内存:
建议调整为
- hadoop01: 默认占用12GB内存, 可以调整到 7.5GB
- hadoop02: 默认占用3.5GB, 可以调整到 3GB
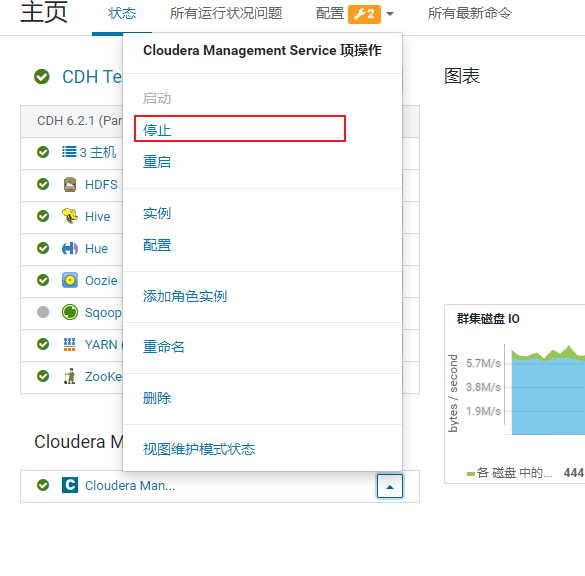
同时关闭掉CM所有监控服务项(占了2G内存左右): 看下图
弊端:
- 缺失了cm的监控服务, CM无法感知各个是否都启动了…
- 只能通过手动方式检测: 进入各个软件的管理界面
新零售项目-CM环境搭建(虚拟机导入)
详细图文步骤可以参考项目讲义。
虚拟机账户密码:==root 123456==
设置VMware虚拟机网络
1 | 课程提供的2台项目虚拟机采用的是vmnet8 NAT模式搭建 |
设置windows本机虚拟网络配置(可选)
保证windows上的vmnet8虚拟网卡也是出于88网段。否则笔记本访问不了虚拟机。
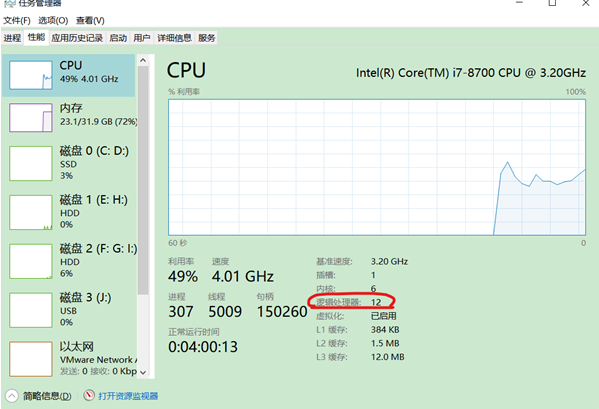
虚拟机CPU、内存分配
如果两台虚拟机的CPU和内存总配置,已经超出了windows硬件的上限,要进行适当的调低,以避免windows蓝屏。
- CPU
1 | CPU的分配,至少需要给windows留下1~2个逻辑处理器。 |
内存
1
2
3
4
5
6
7
8
9
10
11windows一共8G: 第一台4.5G(4608m),第二台1.5G(1536m),win10预留2G即可。
windows一共12G: 第一台6.5G(6656m),第二台3.5G(3584m),win10预留2G即可。
windows一共16G: 第一台7G(10752m),第二台5G(5120m),win10预留4G即可。
windows一共24G: 第一台10G,第二台8G,win10预留6G即可。
windows一共32G: 第一台16G,第二台10G,win10预留6G即可。
用方案:
hadoop01: 内存:5632M(5.5G) CPU:2*2
hadoop02: 内存:4608M(4.5G) CPU:1*2
注意:如果资源分配感觉不满意,可以在正确关闭虚拟机之后,重新分配。
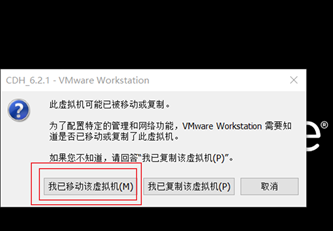
打开虚拟机
注意,一定要选择 ==我已移动该虚拟机==
windows平台添加hosts映射信息
1 | C:\Windows\System32\drivers\etc\hosts |
修改Linux虚拟内存
虚拟内存swap介绍
1
2
3如果你的服务器的总是报告内存不足,并且时常因为内存不足而引发服务被强制kill的话,在不增加物理内存的情况下,启用swap交换区作为虚拟内存是一个不错的选择。
swap是Linux中的虚拟内存,用于扩充物理内存不足而用来存储临时数据存在的。它类似于Windows中的虚拟内存。hadoop01配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
161、创建一个swap文件,文件越大耗时越长,注意确保磁盘有足够的可用空间。
dd if=/dev/zero of=/home/swap bs=1024 count=5120000
2、将文件格式转换为swap格式的
mkswap /home/swap
3、文件分区挂载swap分区
swapon /home/swap
4、防止重启后swap分区变成0
vi /etc/fstab
/home/swap swap swap default 0 0
5、虚拟内存使用阈值
sysctl -w vm.swappiness=0
echo "vm.swappiness=0" >> /etc/sysctl.confhadoop02配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
161、创建一个swap文件,文件越大耗时越长,注意确保磁盘有足够的可用空间。
dd if=/dev/zero of=/home/swap bs=1024 count=3072000
2、将文件格式转换为swap格式的
mkswap /home/swap
3、文件分区挂载swap分区
swapon /home/swap
4、防止重启后swap分区变成0
vi /etc/fstab
/home/swap swap swap default 0 0
5、虚拟内存使用阈值
sysctl -w vm.swappiness=0
echo "vm.swappiness=0" >> /etc/sysctl.conf
CM Web UI页面
1 | 账号 admin |
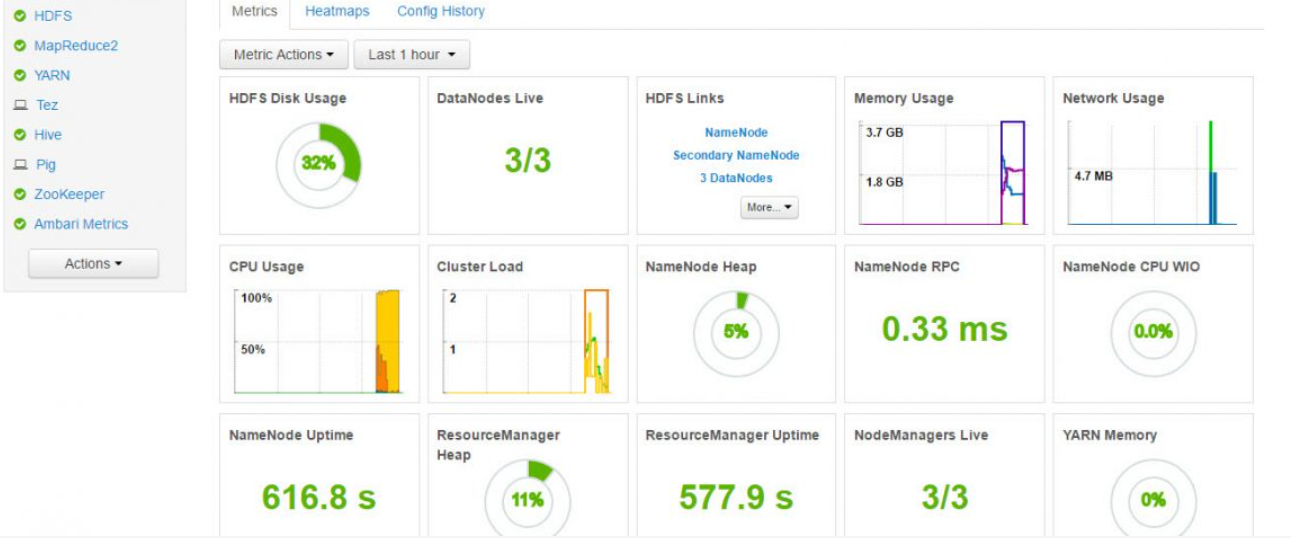
CM 服务监控
这个服务比较吃内存,如果检测无误之后,可以关系该服务,不影响CDH的使用。
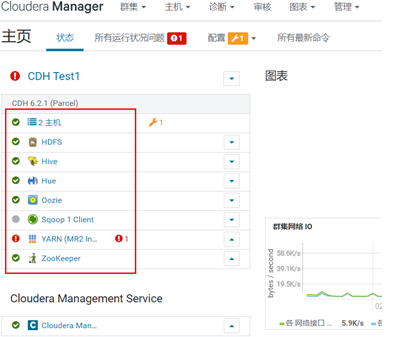
CDH服务启动状态
注意==启动后要等待一段时间,服务才会慢慢正常==。
如果遇到个别服务长时间Error(红色叹号),可以手动重启单个服务:
虚拟机的正确关闭
使用完毕后,通过==[shutdown -h now]==命令来关闭服务器,不要挂起或强行断电。
 微信
微信 支付宝
支付宝

