【大数据系列】Flume
Flume 数据采集
一、Flume简介
Flume目前是Apache旗下的一款顶级开源项目, 最初是由cloudera公司开发的, 后期贡献给了Apache, Flume是一款专门用于数据采集的工具, 主要的目的将数据从一端传输到另一端的操作
Flume也是使用Java语言编写的, Flume一般部署在数据采集节点
在Flume中提供多种数据源的组件 和 多种目的地组件, 主要的目的是为了能够适应更多的数据采集场景
Flume老版本(Flume 0.8x)版本之前,称为Flume OG, 在0.8版本以后, 更改为Flume NG, 同时整个架构也发生变化, 整体操作也是不同的, 目前主要采用Flume NG版本, OG版本一般见不到
Apache Flume 是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以 NG 为基础。
使用Flume核心就是学习如何配置Flume的采集脚本
二、Flume架构和基本概念
下图为 Flume 的基本架构图:
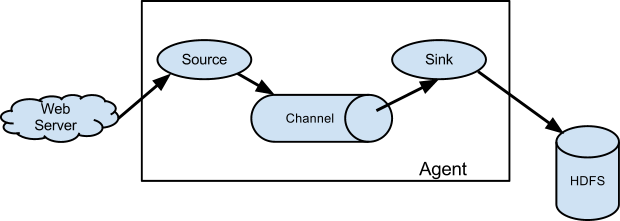
2.1 基本架构
整个Flume启动后, 就是一个agent实例对象, 而一个Agent实例对象一般由三大组件组成:
- 1- Source 组件: 数据源 主要用于对接数据源, 从数据源中采集数据, Flume提供多种source组件
- 2- Sink组件: 下沉地(目的地) 主要用于将数据源采集过来数据通过Sink下沉具体的目的地中, Flume提供多种Sink组件
- 3- channel组件: 管道 主要是用于起到缓存的作用, 从Source将数据写入到channel, sink从channel中获取数据, 然后进行下沉操作, Flume也提供多种channel组件
在agent实例内部, 数据传递是一个个event对象方式来传输的, event对象就是数据内容, 默认只是对数据本身包裹, event除了可以保存本身数据以外, 还可以附带一些其他信息
外部数据源以特定格式向 Flume 发送 events (事件),当 source 接收到 events 时,它将其存储到一个或多个 channel,channe 会一直保存 events 直到它被 sink 所消费。sink 的主要功能从 channel 中读取 events,并将其存入外部存储系统或转发到下一个 source,成功后再从 channel 中移除 events。
2.2 基本概念
1. Event
Event 是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个 Event 由标题和正文组成:前者是键/值映射,后者是任意字节数组。
2. Source
数据收集组件,从外部数据源收集数据,并存储到 Channel 中。

3. Channel
Channel 是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
Memory Channel: 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机);File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
4. Sink
Sink 的主要功能从 Channel 中读取 Event,并将其存入外部存储系统或将其转发到下一个 Source,成功后再从 Channel 中移除 Event。

5. Agent
是一个独立的 (JVM) 进程,包含 Source、 Channel、 Sink 等组件。
2.3 组件种类
Flume 中的每一个组件都提供了丰富的类型,适用于不同场景:
Source 类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source;Sink 类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等;Channel 类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
对于 Flume 的使用,除非有特别的需求,否则通过组合内置的各种类型的 Source,Sink 和 Channel 就能满足大多数的需求。在 Flume 官网 上对所有类型组件的配置参数均以表格的方式做了详尽的介绍,并附有配置样例;同时不同版本的参数可能略有所不同,所以使用时建议选取官网对应版本的 User Guide 作为主要参考资料。
三、Flume架构模式
Flume 支持多种架构模式,分别介绍如下
3.1 multi-agent flow

Flume 支持跨越多个 Agent 的数据传递,这要求前一个 Agent 的 Sink 和下一个 Agent 的 Source 都必须是 Avro 类型,Sink 指向 Source 所在主机名 (或 IP 地址) 和端口(详细配置见下文案例三)。
3.2 Consolidation
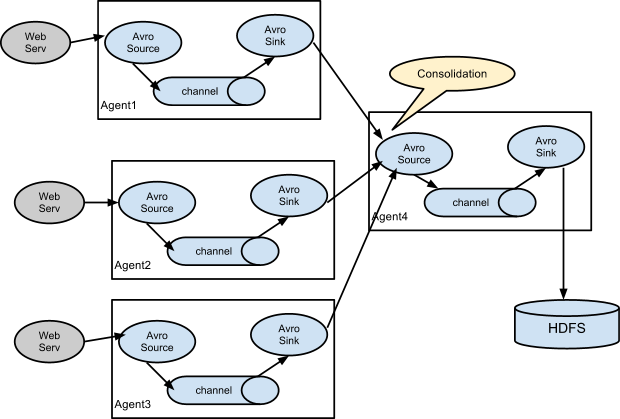
日志收集中常常存在大量的客户端(比如分布式 web 服务),Flume 支持使用多个 Agent 分别收集日志,然后通过一个或者多个 Agent 聚合后再存储到文件系统中。
3.3 Multiplexing the flow
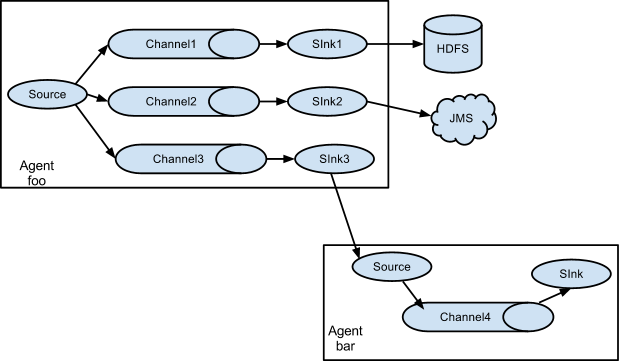
Flume 支持从一个 Source 向多个 Channel,也就是向多个 Sink 传递事件,这个操作称之为 Fan Out(扇出)。默认情况下 Fan Out 是向所有的 Channel 复制 Event,即所有 Channel 收到的数据都是相同的。同时 Flume 也支持在 Source 上自定义一个复用选择器 (multiplexing selector) 来实现自定义的路由规则。
四、Flume配置格式
Flume 配置通常需要以下两个步骤:
- 分别定义好 Agent 的 Sources,Sinks,Channels,然后将 Sources 和 Sinks 与通道进行绑定。需要注意的是一个 Source 可以配置多个 Channel,但一个 Sink 只能配置一个 Channel。基本格式如下:
1 | <Agent>.sources = <Source> |
- 分别定义 Source,Sink,Channel 的具体属性。基本格式如下:
1 | <Agent>.sources.<Source>.<someProperty> = <someValue> |
五、Flume的安装部署
为方便大家后期查阅,本仓库中所有软件的安装均单独成篇,Flume 的安装见:
1 | 步骤: 下载安装包 --> 上传 --> 解压(为解压后的目录配置软连接) --> 修改配置文件(仅需要改flume-env.sh 中java home地址) |
六、Flume使用案例
介绍几个 Flume 的使用案例:
- 案例一:使用 Flume 监听文件内容变动,将新增加的内容输出到控制台。
- 案例二:使用 Flume 监听指定目录,将目录下新增加的文件存储到 HDFS。
- 案例三:使用 Avro 将本服务器收集到的日志数据发送到另外一台服务器。
6.1 案例一
需求: 监听文件内容变动,将新增加的内容输出到控制台。
实现: 主要使用 Exec Source 配合 tail 命令实现。
1. 配置
新建配置文件 exec-memory-logger.properties,其内容如下:
1 | #指定agent的sources,sinks,channels |
2. 启动
1 | flume-ng agent \ |
3. 测试
向文件中追加数据:

控制台的显示:

6.2 案例二
需求: 监听指定目录,将目录下新增加的文件存储到 HDFS。
实现:使用 Spooling Directory Source 和 HDFS Sink。
1. 配置
1 | #指定agent的sources,sinks,channels |
2. 启动
1 | flume-ng agent \ |
3. 测试
拷贝任意文件到监听目录下,可以从日志看到文件上传到 HDFS 的路径:
1 | cp log.txt logs/ |
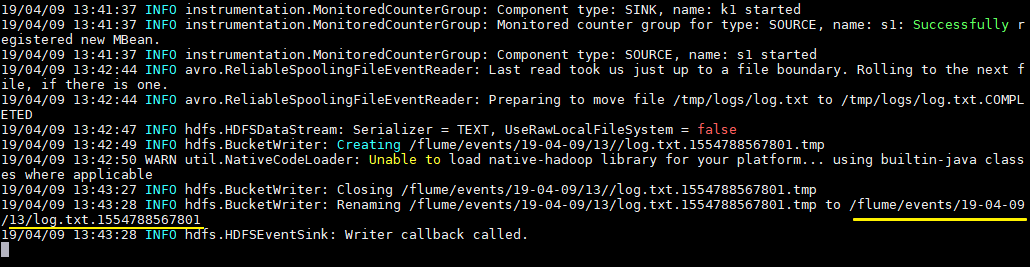
查看上传到 HDFS 上的文件内容与本地是否一致:
1 | hdfs dfs -cat /flume/events/19-04-09/13/log.txt.1554788567801 |

6.3 案例三
需求: 将本服务器收集到的数据发送到另外一台服务器。
实现:使用 avro sources 和 avro Sink 实现。
1. 配置日志收集Flume
新建配置 netcat-memory-avro.properties,监听文件内容变化,然后将新的文件内容通过 avro sink 发送到 hadoop001 这台服务器的 8888 端口:
1 | #指定agent的sources,sinks,channels |
2. 配置日志聚合Flume
使用 avro source 监听 hadoop001 服务器的 8888 端口,将获取到内容输出到控制台:
1 | #指定agent的sources,sinks,channels |
3. 启动
启动日志聚集 Flume:
1 | flume-ng agent \ |
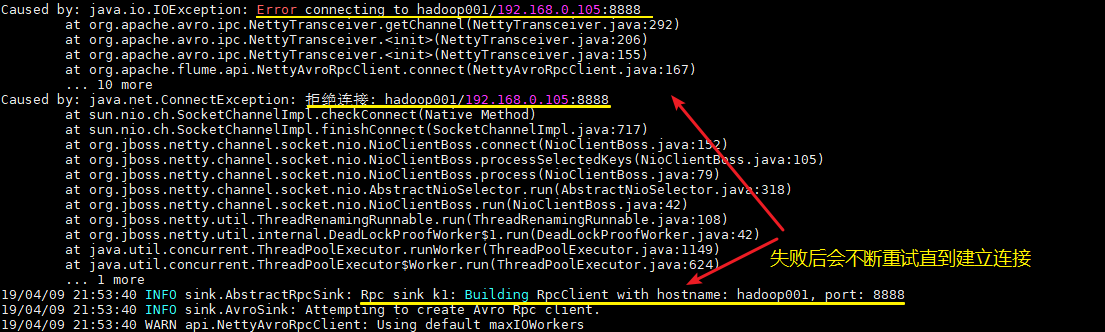
在启动日志收集 Flume:
1 | flume-ng agent \ |
这里建议按以上顺序启动,原因是 avro.source 会先与端口进行绑定,这样 avro sink 连接时才不会报无法连接的异常。但是即使不按顺序启动也是没关系的,sink 会一直重试,直至建立好连接。
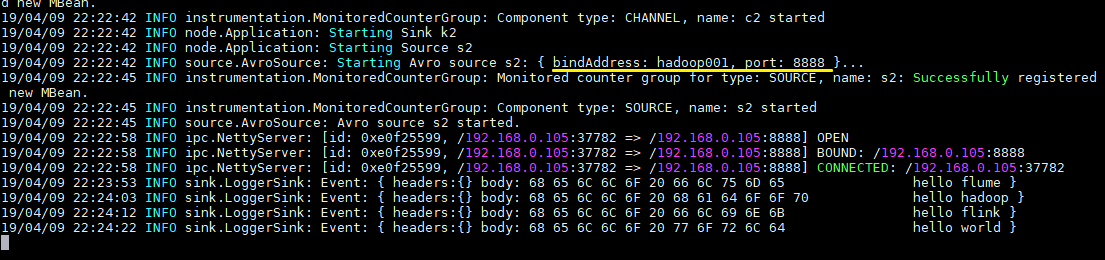
4.测试
向文件 tmp/log.txt 中追加内容:

可以看到已经从 8888 端口监听到内容,并成功输出到控制台:
Linux下Flume的安装
一、前置条件
Flume 需要依赖 JDK 1.8+,JDK 安装方式见本仓库:
二 、安装步骤
2.1 下载并解压
下载所需版本的 Flume,这里我下载的是 CDH 版本的 Flume。下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 | 下载后进行解压 |
2.2 配置环境变量
1 | vim /etc/profile |
添加环境变量:
1 | export FLUME_HOME=/usr/app/apache-flume-1.6.0-cdh5.15.2-bin |
使得配置的环境变量立即生效:
1 | source /etc/profile |
2.3 修改配置
进入安装目录下的 conf/ 目录,拷贝 Flume 的环境配置模板 flume-env.sh.template:
1 | cp flume-env.sh.template flume-env.sh |
修改 flume-env.sh,指定 JDK 的安装路径:
1 | Enviroment variables can be set here. |
2.4 验证
由于已经将 Flume 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
1 | flume-ng version |
出现对应的版本信息则代表配置成功。

Flume 整合 Kafka
一、背景
先说一下,为什么要使用 Flume + Kafka?
以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合后的数据输入到 Storm 等分布式计算框架中,可能就会超过集群的处理能力,这时采用 Kafka 就可以起到削峰的作用。Kafka 天生为大数据场景而设计,具有高吞吐的特性,能很好地抗住峰值数据的冲击。
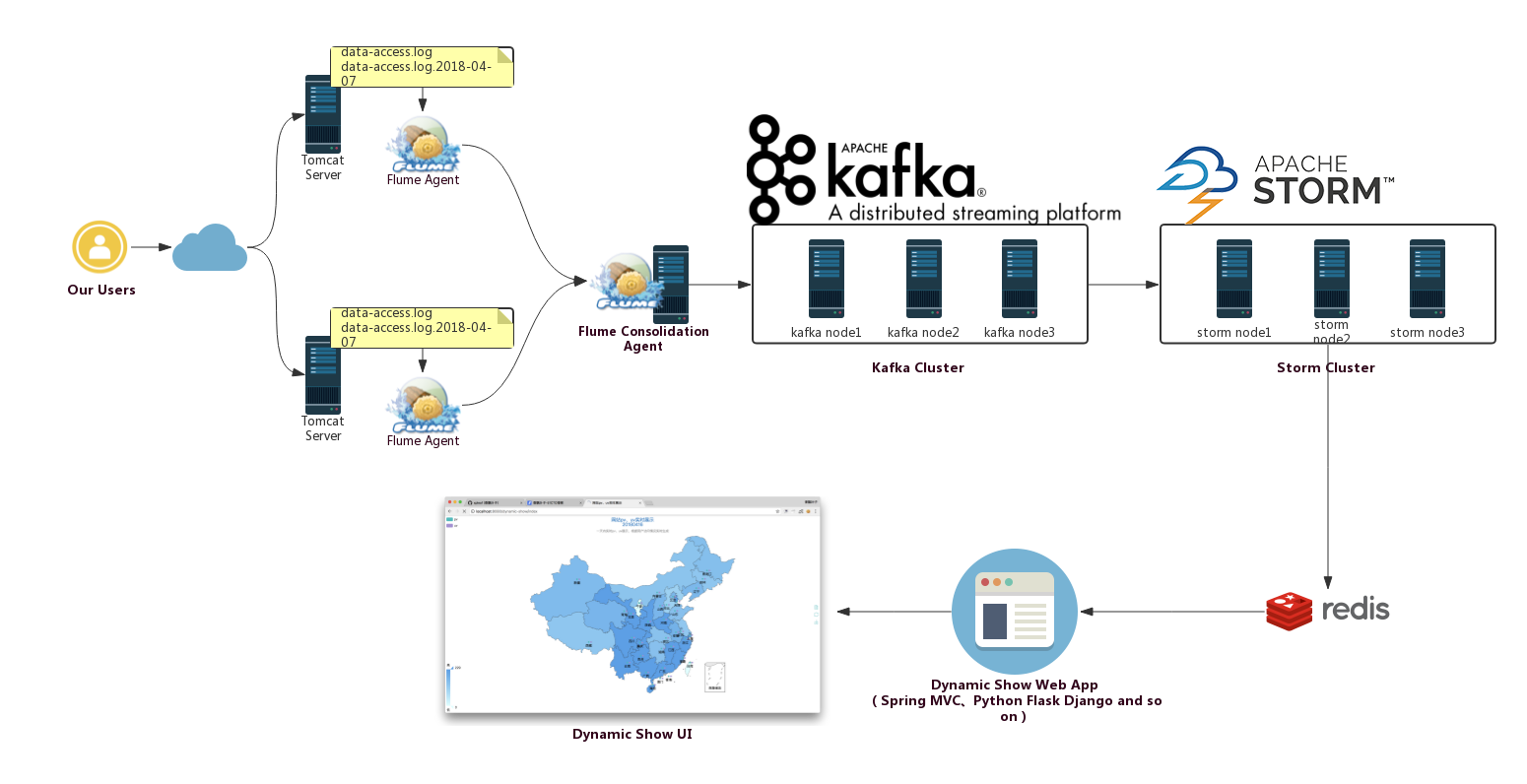
二、整合流程
Flume 发送数据到 Kafka 上主要是通过 KafkaSink 来实现的,主要步骤如下:
1. 启动Zookeeper和Kafka
这里启动一个单节点的 Kafka 作为测试:
1 | 启动Zookeeper |
2. 创建主题
创建一个主题 flume-kafka,之后 Flume 收集到的数据都会发到这个主题上:
1 | 创建主题 |
3. 启动kafka消费者
启动一个消费者,监听我们刚才创建的 flume-kafka 主题:
1 | bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic flume-kafka |
4. 配置Flume
新建配置文件 exec-memory-kafka.properties,文件内容如下。这里我们监听一个名为 kafka.log 的文件,当文件内容有变化时,将新增加的内容发送到 Kafka 的 flume-kafka 主题上。
1 | a1.sources = s1 |
5. 启动Flume
1 | flume-ng agent \ |
6. 测试
向监听的 /tmp/kafka.log 文件中追加内容,查看 Kafka 消费者的输出:

可以看到 flume-kafka 主题的消费端已经收到了对应的消息:

 微信
微信 支付宝
支付宝

