Hadoop-数据存储
hadoop可以存储和计算,底下有三剑客:hdfs(存储)+MapReduce(计算)+yarn+(资源调度)
广义上讲Hadoop一般是指Hadoop生态,不过路要一步一步走,饭要一口一口吃,我们先从狭义的概念熟系Hadoop,即Hadoop三剑客:HDFS(存储)+MapReduce(计算)+yarn+(资源调度)
hadoop入门介绍 Hadoop介绍 Hadoop 是Apache下的开源软件,用Java实现,是一个开发和运行处理大规模数据的平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
Doug Cutting 在爬虫时遇到问题:如何解决数十亿网页的存储和索引问题。
2003年Google发表论文介绍《谷歌分布式文件系统(GFS)》 ,解决了超大文件存储需求。
2004年Google发表论文介绍《谷歌版的MapReduce系统》 ,Nutch团队研发了HDFS和MapReduce,成为独立框架Hadoop。
2006年Google发表论文《关于BigTable》 ,促使了后来的Hbase的发展。
2008年Hadoop成为Apache顶级项目。
狭义上hadoop指的是包含hdfs、mapreduce、yarn三剑客的一款软件。
广义上hadoop值得是围绕hadoop打造的大数据生态圈。
HDFS作为分布式文件存储系统(解决海量数据存储),处于生态圈底层与核心 地位
Yarn作为分布式通用的集群资源管理系统和任务调度系统(解决资源任务调度),支撑各种计算引擎运行,保证了hadoop的地位 。
MapReduce(MR)作为生态圈第一代分布式计算引擎(解决海量数据计算),由于自身设计的模型存在弊端,导致企业几乎不再直接使用 MapReduce进行编程处理,但是很多软件底层仍然使用它。(地位稍微有点尴尬 )
Hadoop特点
扩容能力:不需要停机,小规模可以方便扩到大规模
成本低:由一堆廉价计算机组成,看集群整体能力
效率高:多台计算机并行计算,相比单机肯定快
可靠性:如果数据存储不安全,计算不稳定,就没人用了。存储的时候做了副本机制,计算的时候做了重试机制等,都是为了尽量避免非人为因素导致的失败。
高容错性:能够自动将失败的任务重新分配
hadoop成功在通用性(只管储存和计算,技术和业务解耦,各行各业都可以用),简单性(个人从0写分布式计算非常复杂)
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
Hadoop谁在用 Yahoo Yahoo是Hadoop的最大支持者,Yahoo的Hadoop机器总节点数目已经超过42000个,有超过10万的核心CPU在运行Hadoop。最大的一个单Master节点集群有4500个节点(每个节点双路4核心CPUboxesw,4×1TB磁盘,16GBRAM)。总的集群存储容量大于350PB,每月提交的作业数目超过1000万个,在Pig中超过60%的Hadoop作业是使用Pig编写提交的。
Yahoo的Hadoop应用主要包括以下几个方面:
支持广告系统
用户行为分析
支持Web搜索
反垃圾邮件系统
个性化推荐
FaceBook 主要用于存储内部日志的拷贝,作为一个源用于处理数据挖掘和日志统计。 主要使用了2个集群:一个由1100台节点组成的集群,包括8800核CPU(即每台机器8核),和12000TB的原始存储(即每台机器12T硬盘) 一个有300台节点组成的集群,包括2400核CPU(即每台机器8核),和3000TB的原始存储(即每台机器12T硬盘) 由此基础上开发了基于SQL语法的项目:HIVE 。
Facebook使用Hadoop集群的机器节点超过1400台,共计11200个核心CPU,超过15PB原始存储容量,每个商用机器节点配置了8核CPU,12TB数据存储,主要使用StreamingAPI和JavaAPI编程接口。Facebook同时在Hadoop基础上建立了一个名为Hive的高级数据仓库框架,Hive 已经正式成为基于Hadoop的Apache一级项目。
IBM IBM蓝云也利用Hadoop来构建云基础设施。IBM蓝云使用的技术包括:Xen和PowerVM虚拟化的Linux操作系统映像及Hadoop并行工作量调度,并发布了自己的Hadoop发行版及大数据解决方案。
百度 Hadoop集群规模达到近10个,单集群超过2800台机器节点,Hadoop机器总数有上万台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目有数千个之多,每天的输入数据量已经超过7500TB,输出超过1700TB。
百度的Hadoop集群为整个公司的数据团队、大搜索团队、社区产品团队、广告团队,以及LBS团体提供统一的计算和存储服务,主要应用包括:
数据挖掘与分析
日志分析平台
数据仓库系统
推荐引擎系统
用户行为分析系统
用户搜索表征的需求数据、
阿拉丁爬虫数据存储
竞价排名
阿里巴巴 阿里巴巴的Hadoop集群大约有3200台服务器,大约30000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150000个,每天hivequery查询大于6000个,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大约为80%,CPU利用率平均为65%,峰值可以达到80%。
数据平台系统
搜索支撑
电子商务数据
推荐引擎系统
搜索排行榜
交易数据、信用数据
华为 华为对Hadoop做出贡献的公司之一,排在Google和Cisco的前面,华为对Hadoop的HA方案 ,以及HBase领域有深入研究,并已经向业界推出了自己的基于Hadoop的大数据解决方案。
腾讯 TDW (Tencent distributed Data Warehouse,腾讯分布式数据仓库)基于开源软件Hadoop和Hive进行构建,打破了传统数据仓库不能线性扩展、可控性差的局限,并且根据腾讯数据量大、计算复杂等特定情况进行了大量优化和改造。
TDW服务覆盖了腾讯绝大部分业务产品,单集群规模达到4400台,CPU总核数达到10万左右,存储容量达到100PB;每日作业数100多万,每日计算量4PB,作业并发数2000左右;实际存储数据量80PB,文件数和块数达到6亿多;存储利用率83%左右,CPU利用率85%左右。经过四年多的持续投入和建设,TDW已经成为腾讯最大的离线数据处理平台。TDW的功能模块主要包括:Hive、MapReduce、HDFS、TDBank、Lhotse等
Hadoop版本 Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera内部集成了很多大数据框架,对应产品CDH。2008
Hortonworks文档较好,对应产品HDP。2011
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP
1)Apache Hadoop
**开源版本 **(社区版,Apache官方版):
1.x版本系列:已淘汰
2.x版本系列:架构升级,加入yarn等(主流)
3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
2)Cloudera Hadoop
(1)2008 年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
3)Hortonworks Hadoop
(1)2011 年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)2018年Hortonworks目前已经被Cloudera公司收购。
商业版 (商业公司对开源版Hadoop二次调优和封装):
开源和商业优缺点 :
开源版官方更新版本块,兼容稳定性稍差,可以参数完全定制,了解配置文件的配置和组件的依赖关系。
商业版可靠性好(BUG修复/底层优化),版本更新慢。
基础框架学习用Apache开源版(3.3.0),项目部分用商业版CDH(3.1.4),工作取决于公司用什么版本。
左耳有话说:比如我司使用的是 FusionInsight HD(华为大数据平台)
Hadoop架构
Hadoop 1.0 (没人用)
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)
Hadoop 2.0 (高版本还有人用)
HDFS(分布式文件存储)
MapReduce(分布式数据处理)
YARN (集群资源管理、任务调度)
Hadoop3.x
3.0着重于性能优化
由于Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,即hadoop 3.0。且引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
Apache hadoop 项目组最新消息:hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。改变最大的是hdfs,hdfs 通过最近block块计算,根据最近计算原则,本地block块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果。
精简内核、类路径隔离、shell脚本重构
EC纠删码、多NameNode支持
任务本地化优化、内存参数自动推断
Timeline Service V2、队列配置
在hadoop3.x之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着用户的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。
现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-12811。
1 2 3 4 Namenode 端口: 50470 --> 9871 , 50070 --> 9870 , 8020 --> 9820 Secondary NN 端口: 50091 --> 9869 , 50090 --> 9868 Datanode 端口: 50020 --> 9867 , 50010 --> 9866 , 50475 --> 9865 , 50075 --> 9864 Kms server 端口: 16000 --> 9600 (原先的16000 与HMaster端口冲突)
Hadoop集群 Hadoop集群内包括HDFS集群和YARN集群 ,逻辑分离,物理在一起。两个集群都是标准的主从架构集群 。
需要搭建HDFS集群组件(海量存储),主要角色:NameNode、DataNode、SecondaryNameNode
需要搭建Yarn集群组件(海量计算资源调度):ResourceManager、NodeManager
不需要搭建MapReduce组件(分布式运算编程框架,应用程序开发包),它是一个代码库(程序),我们只需要写代码就行 。
部署方式
本地/独立/单机模式(用于调试):1台机器,1个java进程
伪分布模式(用于调试):1台机器,NameNode、DataNode、SecondaryNameNode分别启动java进程
集群模式(生产部署):n台机器,主从分布式
本地运行模式(官方WordCount) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1)创建在hadoop-3.1.3文件下面创建一个wcinput文件夹 [zuoer@hadoop02 hadoop-3.1.3]$ mkdir wcinput 2)在wcinput文件下创建一个word.txt文件 [zuoer@hadoop02 hadoop-3.1.3]$ cd wcinput 3)编辑word.txt文件 [zuoer@hadoop02 wcinput]$ vim word.txt 在文件中输入如下内容 hadoop yarn hadoop mapreduce atguigu atguigu 保存退出::wq 4)回到Hadoop目录/opt/module/hadoop-3.1.3 5)执行程序 [zuoer@hadoop02 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput 6)查看结果 [zuoer@hadoop02 hadoop-3.1.3]$ cat wcoutput/part-r-00000 看到如下结果: atguigu 2 hadoop 2 mapreduce 1 yarn 1
Hadoop集群架构模型 NN单节点和RM单节点
文件系统核心模块:
NameNode(NN):集群当中的主节点,主要用于管理集群当中的各种数据secondaryNameNode(SNN):主要能用于hadoop当中元数据信息的辅助管理DataNode(DN):集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
NN高可用和RM单节点
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中NameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode(JN):文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
NN单节点和RM高可用
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
NN高可用与RM高可用
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
常用端口号说明
端口名称
Hadoop2.x
Hadoop3.x
NameNode内部通信端口
8020 / 9000
8020 / 9000/9820
NameNode HTTP UI
50070
9870
MapReduce查看执行任务端口
8088
8088
历史服务器通信端口
19888
19888
Hadoop集群安装 环境搭建见Linux-大数据篇
Hadoop 单机伪集群环境搭建
Hadoop 集群环境搭建
基于 Zookeeper 搭建 Hadoop 高可用集群
Hadoop集群规划
给你1000台服务器,你怎么安装规划?
角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上?
角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
HDFS集群守护进程
YARN集群守护进程
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
HistoryServer
node1
✅
❌
✅
✅
✅
✅
node2
❌
✅
✅
❌
✅
❌
node3
❌
❌
✅
❌
✅
❌
目录约定(个人向):
软件安装目录:/usr/local/apps
数据存放目录:/opt/data
软件安装包存放目录:/opt/setup
如果需要本地库需要编译(未成功) 想要使用本地库先编译
由于appache给出的hadoop的安装包没有提供带C程序访问的接口,在使用本地库时会有问题。所以从官网下载 的源码包需要重新编译。
匹配不同操作系统本地库环境 ,Hadoop某些操作比如压缩、IO需要调用系统本地库(*.so|*.dll),需要编译
如果觉得源码写的不好,想要修改源码、重构源码,需要编译。
为了让hadoop更好的兼容你的服务器环境,最好重新编译。
编译步骤在源码包里也有:根目录下文件:BUILDING.txt
准备Linux环境 准备一台linux环境,内存4G或以上,硬盘40G或以上,我这里使用的是Centos7.7 64位的操作系统(注意:一定要使用64位的操作系统),需要虚拟机联网,关闭防火墙,关闭selinux,安装好JDK8。
根据以上需求,只需要将node1再克隆一台即可,命名为node4,专门用来进行Hadoop编译。
安装依赖 1 2 yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -y yum install -y doxygen cyrus-sasl* saslwrapper-devel*
安装maven maven 3.5.4下载
然后解压maven的安装包到/usr/local/apps
1 2 cd /opt/setup/tar -zxvf apache-maven-3.5.4-bin.tar.gz -C /usr/local/apps
配置maven的环境变量
填写以下内容
1 2 3 export MAVEN_HOME=/usr/local/apps/apache-maven-3.5.4export MAVEN_OPTS="-Xms4096m -Xmx4096m" export PATH=:$MAVEN_HOME /bin:$PATH
让修改立即生效
解压maven的仓库(无,跳过)
1 tar -zxvf mvnrepository.tar.gz -C /usr/local/apps/
修改maven的配置文件
1 2 cd /usr/local/apps/apache-maven-3.5.4/confvim settings.xml
指定我们本地仓库存放的路径
1 <localRepository > /opt/data/mavenrepo</localRepository >
添加一个我们阿里云的镜像地址,会让我们下载jar包更快
1 2 3 4 5 6 <mirror > <id > alimaven</id > <name > aliyun maven</name > <url > http://maven.aliyun.com/nexus/content/groups/public/</url > <mirrorOf > central</mirrorOf > </mirror >
安装findbugs 下载
解压findbugs
1 tar -zxvf findbugs-1.3.9.tar.gz -C /usr/local/apps
配置findbugs的环境变量
添加以下内容:
1 2 3 4 5 export MAVEN_HOME=/usr/local/apps/apache-maven-3.0.5export PATH=:$MAVEN_HOME /bin:$PATH export FINDBUGS_HOME=/usr/local/apps/findbugs-1.3.9export PATH=:$FINDBUGS_HOME /bin:$PATH
让修改立即生效
安装cmake 下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # yum卸载已安装cmake 版本低 yum erase cmake # 解压 tar zxvf CMake-3.19.4.tar.gz -C /usr/local/apps/ # 编译安装 cd /usr/local/apps/CMake-3.19.4 ./configure make && make install # 验证 [root@node4 ~]# cmake -version cmake version 3.19.4 # 如果没有正确显示版本 请断开SSH连接 重写登录
安装protobuf protobuf 2.5.0
protobuf 3.7.1
解压protobuf并进行编译
1 2 3 4 5 6 7 8 9 cd /opt/setuptar -zxvf protobuf-3.7.1.tar.gz -C /usr/local/apps/ cd /usr/local/apps/protobuf-3.7.1./autogen.sh ./configure make && make install protoc --version
安装snappy 下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 rm -rf /usr/local/lib/libsnappy*rm -rf /lib64/libsnappy*cd /opt/setuptar -zxvf snappy-1.1.3.tar.gz -C /usr/local/apps/ cd /usr/local/apps/snappy-1.1.3/./configure make && make install ls -lh /usr/local/lib |grep snappy-rw-r--r--. 1 root root 511K 1月 14 13:58 libsnappy.a -rwxr-xr-x. 1 root root 955 1月 14 13:58 libsnappy.la lrwxrwxrwx. 1 root root 18 1月 14 13:58 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 root root 18 1月 14 13:58 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 root root 253K 1月 14 13:58 libsnappy.so.1.3.0
linux fuse version 2.6 or above 1 2 3 4 5 6 7 8 9 10 11 12 13 cd /opt/setup/ wget https://github.com/libfuse/libfuse/releases/download/fuse_2_9_4/fuse-2.9.2.tar.gz tar -zxvf fuse-2.9.2.tar.gz -C /usr/local/apps/ cd /usr/local/apps/fuse-2.9.2/ ./configure make make install cd /usr/local/apps/ cp fuse-2.9.2/fuse.pc /usr/share/pkgconfig modprobe fuse lsmod | grep "fuse"
python 1 2 3 4 5 6 7 8 9 10 11 12 13 cd /opt/setup/ wget https://www.python.org/ftp/python/3.6.4/Python-3.6.4.tgz tar -xvf Python-3.6.4.tgz -C /usr/local/apps/ cd /usr/local/apps/Python-3.6.4/ ./configure --prefix=/usr/local/python3 make make install ln -s /usr/local/python3/bin/python3.6 /usr/bin/python3 ln -s /usr/local/python3/bin/pip3.6 /usr/bin/pip3 python3 -V
Node.js / bower / Ember-cli 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cd /opt/setup/ wget https://nodejs.org/dist/v12.16.3/node-v12.16.3-linux-x64.tar.gz tar -zxvf node-v12.16.3-linux-x64.tar.gz -C /usr/local/apps/ cd /usr/local/apps/ mv node-v12.16.3-linux-x64 /usr/local/apps/nodejs vim /etc/profile export NODE_HOME=/usr/local/apps/nodejs export PATH=$NODE_HOME/bin:$PATH export NODE_PATH=$NODE_HOME/lib/node_modules:$PATH source /etc/profile node -v npm -v
编译hadoop源码 下载 ,注意选择src源码包
对源码进行编译
1 2 3 cd /opt/setup tar -zxvf hadoop-3.3.0-src.tar.gz -C /usr/local/apps/ cd /usr/local/apps/hadoop-3.3.0-src
修改node版本
1 2 3 4 cd /usr/local/apps/hadoop-3.3.0-src/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-applications/hadoop-yarn-applications-catalog/hadoop-yarn-applications-catalog-webapp vim pom.xml 将<nodeVersion>v8.11.3</nodeVersion> 改为<nodeVersion>v12.16.3</nodeVersion>
编译支持snappy压缩:
1 2 3 4 5 6 7 mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib Pdist,native :把重新编译生成的hadoop动态库; DskipTests :跳过测试 Dtar :最后把文件以tar打包 Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】 Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
编译完成之后我们需要的压缩包就在下面这个路径里面,生成的文件名为hadoop-3.3.0.tar.gz
1 cd /usr/local/apps/hadoop-3.3.0/hadoop-dist/target
Hadoop安装包目录结构 将编译后的Hadoop安装包导出即可。
解压hadoop-3.3.0-Centos7-64-with-snappy.tar.gz,目录结构如下:
bin:Hadoop最基本的管理脚本和使用脚本的目录 ,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。etc:Hadoop配置文件所在的目录 ,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。lib:该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。libexec:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。sbin:Hadoop管理脚本所在的目录 ,主要包含HDFS和YARN中各类服务的启动/关闭脚本 。(比较接地气的脚本)share:Hadoop各个模块编译后的jar包所在的目录,官方自带示例 。
安装最重要的其实就是etc目录,把目录下的配置整明白了,Hadoop就安装成功了。
Hadoop配置文件修改说明
配置文件的名称 作用
hadoop-env.sh
主要配置我们的java路径
core-site.xml
核心配置文件,主要定义了我们文件访问的格式 hdfs://
hdfs-site.xml
主要定义配置我们的hdfs的相关配置
mapred-site.xml
主要定义我们的mapreduce相关的一些配置
slaves
控制我们的从节点在哪里 datanode nodemanager在哪些机器上
yarm-site.xml
配置我们的resourcemanager资源调度
hadoop-env.sh 文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
远程访问的时候,配置的环境变量无法读取,所以需要单独配置。
1 2 3 4 5 6 7 8 export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_321export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_SECONDARYNAMENODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=root
core-site.xml hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <property > <name > fs.defaultFS</name > <value > hdfs://node1:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/data/hadoop-3.3.0</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > root</value > </property > <property > <name > hadoop.proxyuser.root.hosts</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.root.groups</name > <value > *</value > </property > <property > <name > fs.trash.interval</name > <value > 1440</value > </property >
回收站开启配置
曾经有一份珍贵的数据摆在我面前,可我不懂得珍惜,等到失去了才后悔莫及,如果上天能给我重来一次的机会,我一个对她说三个字:回收你。
频繁删除的时候开一下,会让你笑的。
1 2 3 4 5 6 7 8 9 10 11 12 13 需求:配置,一个文件放在回收站时间60分钟,每10分钟检测一次,当超过60分钟后,文件就会被彻底删除 <property > <name > fs.trash.interval</name > <value > 60</value > </property > <property > <name > fs.trash.checkpoint.interval</name > <value > 10</value > </property >
hdfs-site.xml HDFS的核心配置文件,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 <property > <name > dfs.namenode.secondary.http-address</name > <value > node2:9868</value > </property > <property > <name > dfs.hosts.exclude</name > <value > /usr/local/apps/hadoop-3.3.0/etc/hadoop/excludes</value > </property >
mapred-site.xml MapReduce的核心配置文件,有默认的配置项mapred-default.xml。
mapred-default.xml与mapred-site.xml的功能是一样的,如果在mapred-site.xml里没有配置的属性,则会自动会获取mapred-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > yarn.app.mapreduce.am.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.map.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.reduce.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > node1:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > node1:19888</value > </property >
yarn-site.xml YARN的核心配置文件,有默认的配置项yarn-default.xml。
yarn-default.xml与yarn-site.xml的功能是一样的,如果在yarn-site.xml里没有配置的属性,则会自动会获取yarn-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 <property > <name > yarn.resourcemanager.hostname</name > <value > node1</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://node1:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property >
works workers文件里面记录的是集群主机名。主要作用是配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色(DataNode和NodeManager)所在的机器 。
1 2 3 4 5 vi workers node1.hadoop.com node2.hadoop.com node3.hadoop.com
scp同步安装包 在node1上进行了配置文件的修改,使用scp命令将修改好之后的安装包同步给集群中的其他节点。
1 2 3 4 cd /usr/local/apps scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
Hadoop环境变量 3台机器都需要配置环境变量文件
1 2 3 4 5 6 7 8 9 10 vim /etc/profile export HADOOP_HOME=/usr/local/apps/hadoop-3.3.0export PATH=$PATH :$HADOOP_HOME /bin:$HADOOP_HOME /sbin将修改后的环境变量同步其他机器 scp /etc/profile root@node2:/etc/ scp /etc/profile root@node3:/etc/ source /etc/profile
格式化HDFS 首次启动HDFS时,必须对其进行格式化操作。 本质上是一些清理和准备工作(创建元数据本地存储目录和一些初始化的元数据相关文件),因为此时的HDFS在物理上还是不存在的。只需要在node1上进行格式化,只能格式化一次
1 2 cd /usr/local/apps/hadoop-3.3.0 bin/hdfs namenode -format
如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别。通过删除所有机器hadoop.tmp.dir配置对应的目录,重新format解决
集群启动和关闭-方式1
节点服务挂了,可以用方式1单独启动某个服务,比如你有1000台服务器,总不能群起群停吧。
启动HDFS集群 1 2 3 4 5 6 7 8 # 选择node1节点启动NameNode节点 hdfs --daemon start namenode # 在所有节点上启动DataNode hdfs --daemon start datanode # 在node2启动Secondary NameNode hdfs --daemon start secondarynamenode
启动YARN集群 1 2 3 4 5 6 7 8 # 选择node1节点启动ResourceManager节点 yarn --daemon start resourcemanager # 在所有节点上启动NodeManager yarn --daemon start nodemanager # 启动历史服务 mr-jobhistory-daemon.sh start historyserver
注意:如果在启动之后,有些服务没有启动成功,则需要查看启动日志,Hadoop的启动日志在每台主机的/usr/local/apps/hadoop-3.3.0/logs/目录,需要根据哪台主机的哪个服务启动情况去对应的主机上查看相应的日志,以下是node1主机的日志目录.
关闭HDFS集群 1 2 3 4 5 6 7 8 # 5.1 关闭NameNode hdfs --daemon stop namenode # 5.2 每个节点关闭DataNode hdfs --daemon stop datanode # 关闭Secondary NameNode hdfs --daemon stop secondarynamenode
关闭YARN集群 1 2 3 4 5 6 7 8 # 5.3 每个节点关闭ResourceManager yarn --daemon stop resourcemanager # 5.4 每个节点关闭NodeManager yarn --daemon stop nodemanager # 关闭历史服务 mr-jobhistory-daemon.sh stop historyserver
集群启动和关闭-方式2
我们使用集群时,只用到HDFS,用不到YARN,可以用一键启动HDFS
1 2 3 4 5 6 # HDFS一键脚本 start-dfs.sh stop-dfs.sh # YARN一键脚本 start-yarn.sh stop-yarn.sh
集群启动和关闭-方式3
一键启动HDFS和YARN,可以重复执行,哪怕只是缺某个服务。除非不需要YARN。
1 2 3 4 # 一键启动HDFS、YARN start-all.sh # 一键关闭HDFS、YARN stop-all.sh
一键启动不包括历史服务,可以自己添加
启动可以通过jps验证进程是否都启动了。如果有问题,去hadoop-3.3.0/logs/下找对应进程的log日志
配置windows域名映射
后面用的是主机名访问,所以需要配置,不用IP访问 , 建议用Switchhosts。
以管理员身份打开C:\Windows\System32\drivers\etc目录下的hosts文件
在文件最后添加以下映射域名和ip映射关系
1 2 3 192.168.88.161 node1 192.168.88.162 node2 192.168.88.163 node3
保存退出
测试映射是否生效
1 2 3 4 5 DOS ping node1 ping node2 ping node3 ...
访问WebUI
如果使用主机名访问,别忘了在Windows配置hosts
访问NameNode: http://node1:9870
访问YARN: http://node1:8088
访问历史任务: http://node1:19888
HDFS基准测试
实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试Hadoop集群的读取和写入速度,测试网络带宽是否足够等一些基准测试。
测试写入速度 向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
1 2 3 4 1.启动YARN集群 start-yarn.sh 2.启动写入基准测试 hadoop jar /usr/local/apps/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
我们可以看到Hadoop启动了一个MapReduce作业来运行benchmark测试。
等待约2-5分钟,MapReduce程序运行成功后,就可以查看测试结果了
观察服务日志可以看到吞吐量为11.64Mb/s
我们看到目前在虚拟机上的IO吞吐量约为:11.64MB/s
测试读取速度 测试hdfs的读取文件性能,在HDFS文件系统中读入10个文件,每个文件10M
1 hadoop jar /usr/local/apps/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
同样,Hadoop也会启动一个MapReduce程序来进行测试。
以看到读取的吞吐量为:99.11Mb/s
清除测试数据 测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录
1 hdfs dfs -ls -R /benchmarks
执行清理:
1 hadoop jar /usr/local/apps/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -clean
删除命令会将 /benchmarks目录中内容删除
Hadoop初体验 使用HDFS 1.从Linux本地上传一个文件到hfds/目录下
1 2 3 4 5 6 7 # 在/opt/data/目录中创建a.txt文件,并写入数据 cd /opt/data/ touch a.txt echo "hello" > a.txt # 将a.txt上传到HDFS的根目录 hadoop fs -put a.txt /
2.通过页面查看
通过NameNode页面.进入HDFS:http://node1:9870/
查看文件是否创建成功.
运行mapreduce程序
一个最终完整版本的MR程序需要用户编写的代码 和Hadoop自己实现的代码 整合在一起才可以;
由于MapReduce计算引擎天生的弊端(慢 ),当下企业中直接使用率已经日薄西山了,所以在企业中工作很少涉及到MapReduce直接编程 ,但是某些软件的背后还依赖MapReduce引擎
在Hadoop安装包的share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。(示例程序jar:hadoop-mapreduce-examples-3.3.0.jar计算圆周率)
1 2 3 4 yarn jar /usr/local/apps/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 50 第一个参数:pi表示MapReduce程序执行圆周率计算任务; 第二个参数:用于指定map阶段运行的任务task次数,并发度,这里是10; 第三个参数:用于指定每个map任务取样的个数,这里是50。
关于圆周率的估算,感兴趣的可以查询资料蒙特卡洛方法来计算Pi值,计算命令中2表示计算的线程数,50表示投点数,该值越大,则计算的pi值越准确
思考一下
执行MapReduce的时候,为什么首先请求YARN? => 提交到YARN集群上分布式执行。
MapReduce看上去好像是两个阶段?先Map,再Reduce?
处理小数据的时候,MapReduce速度快吗?=> 好像一个简单的程序,并不快,是吧。
带着疑问看下去
Hadoop集群无法访问 1)防火墙没关闭、或者没有启动YARN
1 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.199.108:8032
2)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和atguigu两个用户启动集群不统一
6)配置文件修改不细心
7)不识别主机名称
1 2 3 4 5 6 7 8 java.net.UnknownHostException: hadoop02: hadoop02 at java.net.InetAddress.getLocalHost(InetAddress.java:1475) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts文件中添加192.168.199.02 hadoop02
(2)主机名称不要起hadoop hadoop000等特殊名称
8)DataNode和NameNode进程同时只能工作一个。
9)执行命令不生效,粘贴Word中命令时,遇到-和长–没区分开。导致命令失效
10)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。
11)jps不生效
12)8088端口连接不上
1 2 #127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 #::1 hadoop102
分布式文件存储系统——HDFS
通过统一的入口,像访问一个普通文件系统一样,访问分布式文件系统,本质就是一个文件系统。
HDFS 概述 HDFS (Hadoop Distributed File System )是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
HDFS 定义 HDFS(Hadoop Distributed File System),它是一个文件系统 ,用于存储文件,通过目录树来定位文件;其次,它是分布式的 ,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。 一个文件经过创建、写入和关闭之后就不需要改变。
HDFS 优缺点 高容错 HDFS 采用数据的多副本方案, 由于可构建在廉价机器上,所以部分硬件的损坏不会导致全部数据的丢失。
高吞吐量 HDFS 设计的重点是支持高吞吐量 的数据访问,而不是低延迟的数据访问。
大文件支持 HDFS 适合于大文件 的存储,文档的大小应该是是 GB 到 TB 级别的。
256G内存大概18亿文件,如果存小文件,就不划算了(寻址慢,且一个文件一个线程写),如果namenode瓶颈了,可以分集群或者压缩。或者联邦机制实现namenode扩展(国际顶级公司才考虑这个)。
1 2 3 4 5 6 7 8 小知识:为什么时128M 寻址时间为传输时间的1%时,则为最佳状态(专家说的),因此传输时间为=10ms/0.01=1000ms=1s 目前磁盘的传输率普遍为100MB/s,则block大小=1s*100MB/s=100MB 小知识:为什么块大小不能太大,也不能太小 如果太小,会增加寻址时间。程序一直在找块的开始位置。 如果太大,则磁盘传输时间会明显大于定位这个块开始位置所需时间。导致程序在处理这块数据时,会非常慢。 块的大小设置主要取决于磁盘传输速率。
简单一致性模型 HDFS 更适合于一次写入多次读取 (write-once-read-many) 的访问模型。支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
也因为如此,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高
跨平台移植性 HDFS 具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
HDFS 设计原理
HDFS 架构 HDFS 遵循主/从 架构,由单个 NameNode(NN,主) 和多个 DataNode(DN,从) 组成:
NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件自身的属性信息 和各个数据块的位置信息 。DataNode :负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
文件系统命名空间 HDFS 的 文件系统命名空间 的层次结构与大多数文件系统类似 (如 Linux),也就是统一抽象目录树。支持目录和文件的创建、移动、删除和重命名等操作,支持配置用户和访问权限,但不支持硬链接和软连接。
NameNode 负责维护文件系统名称空间,记录对名称空间或其属性的任何更改。
HDFS会给客户端提供一个统一的抽象目录树 ,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
数据复制 由于 Hadoop 被设计运行在廉价的机器上,这意味着硬件是不可靠的,为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列块 ,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M【参数位于hdfs-site.xml中:dfs.blocksize】;默认复制因子是 3 ,也就是会额外复制2份,加自身共3份【参数位于hdfs-site.xml中:dfs.replication】)。
数据复制的实现原理 大型的 HDFS 实例在通常分布在多个机架的多台服务器上,不同机架上的两台服务器之间通过交换机进行通讯。在大多数情况下,同一机架中的服务器间的网络带宽大于不同机架中的服务器之间的带宽。因此 HDFS 采用机架感知副本放置策略,对于常见情况,当复制因子为 3 时,HDFS 的放置策略是:
第一块副本:优先客户端本地,否则随机
第二块副本:不同于第一块副本的不同机架。
第三块副本:第二块副本相同机架不同机器。
在写入程序位于 datanode 上时,就优先将写入文件的一个副本放置在该 datanode 上,否则放在随机 datanode 上。
之后在另一个远程机架上的任意一个节点上放置另一个副本,并在该机架上的另一个节点上放置最后一个副本。
此策略可以减少机架间的写入流量,从而提高写入性能。
如果复制因子大于 3,则随机确定第 4 个和之后副本的放置位置,同时保持每个机架的副本数量低于上限,上限值通常为 (复制系数 - 1)/机架数量 + 2,需要注意的是不允许同一个 dataNode 上具有同一个块的多个副本。
机架感知说明:http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
源码说明 :Crtl + n 查找BlockPlacementPolicyDefault,在该类中查找chooseTargetInOrder方法。
副本的选择 为了最大限度地减少带宽消耗和读取延迟,HDFS 在执行读取请求时,优先读取距离读取器最近的副本。如果在与读取器节点相同的机架上存在副本,则优先选择该副本。如果 HDFS 群集跨越多个数据中心,则优先选择本地数据中心上的副本。
元数据 内存元数据 为了保证用户操作元数据交互高效,延迟低,NameNode把所有的元数据都存储在内存中,我们叫做内存元数据。内存中的元数据是最完整的,包括文件自身属性信息、文件块位置映射信息。
但是内存的致命问题是,断点数据丢失,数据不会持久化。因此NameNode又辅佐了元数据文件来保证元数据的安全完整。
磁盘元数据 FsImage是内存元数据的一个持久化的检查点,fsimage中仅包含Hadoop文件系统中文件自身属性相关的元数据信息,但不包含文件块位置的信息
持久化的动作是一种数据从内存到磁盘的IO过程。会对namenode正常服务造成一定的影响,不能频繁的进行持久化。
Editslog编辑日志 为了避免两次持久化之间数据丢失的问题,又设计了Edits log编辑日志文件。文件中记录的是HDFS所有更改操作(文件创建,删除或修改)的日志 ,文件系统客户端执行的更改操作首先会被记录到edits文件中。
加载元数据顺序 在NameNode启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步 ,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
当客户端对HDFS中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存元数据中。因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢。
HDFS这种设计实现着手于:一是内存中数据更新、查询快,极大缩短了操作响应时间;二是内存中元数据丢失风险颇高(断电等),因此辅佐元数据镜像文件(fsimage)+编辑日志文件(edits)的备份机制进行确保元数据的安全。
NameNode维护整个文件系统元数据。因此,元数据的准确管理,影响着HDFS提供文件存储服务的能力。
元数据存储目录 在Hadoop的HDFS首次部署好配置文件之后,并不能马上启动使用,而是先要对文件系统进行格式化操作:hdfs namenode -format
在这里要注意两个概念,一个是format之前,HDFS在物理上还不存在;二就是此处的format 并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。其中就会创建元数据本地存储目录和一些初始化的元数据相关文件。
namenode元数据存储目录由hdfs-site.xml文件中参数:dfs.namenode.name.dir指定,格式化完成之后,将会在$dfs.namenode.name.dir/current目录下创建如下的文件:
其中的dfs.namenode.name.dir是在/usr/local/apps/hadoop-3.3.0/etc/hadoop/hdfs-site.xml文件中配置的,默认值如下:
dfs.namenode.name.dir属性可以配置多个目录 ,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
fsimage是元数据镜像文件。每个fsimage文件还有一个对应的.md5文件,其中包含MD5校验和,HDFS使用该文件来防止磁盘损坏文件异常。
已完成且不可修改的编辑日志。这些文件中的每个文件都包含文件名定义的范围内的所有编辑日志事务。在HA高可用性部署中,主备namenode之间可以通过edits log进行数据同步。
Fsimage查看
记录HDFS当前的状态,可以用于 NameNode 的快速加载
fsimage 文件是Hadoop文件系统元数据的一个永久性的检查点,包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;对于文件来说,包含的信息有修改时间、访问时间、块大小和组成一个文件块信息等;而对于目录来说,包含的信息主要有修改时间、访问控制权限等信息。
oiv是offline image viewer 的缩写,用于将fsimage文件的内容转储到指定文件中以便于阅读,该工具还提供了只读的WebHDFS API以允许离线分析和检查hadoop集群的命名空间。
oiv在处理非常大的fsimage文件时是相当快的,如果该工具不能够处理fsimage,它会直接退出。该工具不具备向后兼容性,比如使用hadoop-2.4版本的oiv不能处理hadoop-2.3版本的fsimage,只能使用hadoop-2.3版本的oiv。就像它的名称所提示的(offline),oiv不需要hadoop集群处于运行状态。
命令:hdfs oiv -i fsimage_0000000000000000050 -p XML -o fsimage.xml
editslog查看
记录HDFS的变更操作,可以用来恢复已经提交但尚未被永久化到磁盘的操作。
edits log 文件存放的是Hadoop文件系统的所有更新操作记录日志,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
NameNode起来之后,HDFS中的更新操作会重新写到edits文件中,因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢,但是如果往edits文件里面写就不会这样,每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。如果一个文件比较大,使得写操作需要向多台机器进行操作,只有当所有的写操作都执行完成之后,写操作才会返回成功,这样的好处是任何的操作都不会因为机器的故障而导致元数据的不同步。
oev是offline edits viewer (离线edits查看器)的缩写,该工具不需要hadoop集群处于运行状态。
命令:hdfs oev -i edits_0000000000000000011-0000000000000000025 -o edits.xml
在输出文件中,每个RECORD记录了一次操作,示例如下:
SecondaryNamenode SNN职责概述
NameNode职责是管理元数据信息,DataNode的职责是负责数据具体存储,那么SecondaryNameNode的作用是什么?对很多初学者来说是非常迷惑的。它为什么会出现在HDFS中。从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。
当HDFS集群运行一段事件后,就会出现下面一些问题:
edits logs会变的很大,fsimage将会变得很旧;
namenode重启会花费很长时间,因为有很多改动要合并到fsimage文件上;
如果频繁进行fsimage持久化,又会影响NameNode正常服务,毕竟IO操作是一种内存到磁盘的耗精力操作
因此为了克服这个问题,需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件 ,这样也会减小在NameNode上的压力。
SecondaryNameNod e就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中 。
SNN checkpoint机制 概述
Checkpoint 核心是把fsimage与edits log合并以生成新的fsimage的过程。此过程有两个好处:fsimage版本不断更新不会太旧、edits log文件不会太大。
流程
当触发checkpoint操作条件(每隔一个小时,或者edits文件达到64M)时,SNN发生请求给NN滚动edits log。然后NN会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
同时SNN会将edits文件和fsimage复制到本地(使用HTTP GET方式)。
SNN首先将fsimage载入到内存,然后一条一条地执行edits文件中的操作,使得内存中的fsimage不断更新,这个过程就是edits和fsimage文件合并。合并结束,SNN将内存中的数据dump生成一个新的fsimage文件。
SNN将新生成的Fsimage new文件复制到NN节点。
刚好是一个轮回,等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
触发机制
Checkpoint触发条件受两个参数控制,可以通过core-site.xml 进行配置:
1 2 dfs.namenode.checkpoint.period=3600 //两次连续的checkpoint之间的时间间隔。默认1小时 dfs.namenode.checkpoint.txns=1000000 //最大没有执行checkpoint事务的数量,满足将强制执行紧急
checkpoint,即使尚未达到检查点周期。默认100万事务数量。
从上面的描述我们可以看出,SecondaryNamenode根本就不是Namenode的一个热备,只是将fsimage和edits合并 。
Namenode 元数据恢复 NameNode存储多目录 namenode元数据存储目录由参数:dfs.namenode.name.dir指定。
dfs.namenode.name.dir属性可以配置多个目录 ,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
从SecondaryNameNode恢复 SecondaryNameNode在checkpoint的时候会将fsimage和edits log下载到自己的本机上本地存储目录下。并且在checkpoint之后也不会进行删除。
如果NameNode中的fsimage真的出问题了,还是可以用SecondaryNamenode中的fsimage替换一下NameNode上的fsimage,虽然已经不是最新的fsimage,但是我们可以将损失减小到最少!
HDFS 的架构稳定性 心跳机制和重新复制 每个 DataNode 定期向 NameNode 发送心跳消息,如果超过指定时间没有收到心跳消息,则将 DataNode 标记为死亡。NameNode 不会将任何新的 IO 请求转发给标记为死亡的 DataNode,也不会再使用这些 DataNode 上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode 会跟踪这些块,并在必要的时候进行重新复制。
数据的完整性 由于存储设备故障等原因,存储在 DataNode 上的数据块也会发生损坏。为了避免读取到已经损坏的数据而导致错误,HDFS 提供了数据完整性校验机制(crc循环冗余校验)来保证数据的完整性,具体操作如下:
当客户端创建 HDFS 文件时,它会计算文件的每个块的 校验和,并将 校验和 存储在同一 HDFS 命名空间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其他 DataNode 获取该块的其他可用副本。
元数据的磁盘故障 FsImage(内存元数据的一个持久化的检查点) 和 EditLog 是 HDFS 的核心数据,这些数据的意外丢失可能会导致整个 HDFS 服务不可用。为了避免这个问题,可以配置 NameNode 使其支持 FsImage 和 EditLog 多副本同步,这样 FsImage 或 EditLog 的任何改变都会引起每个副本 FsImage 和 EditLog 的同步更新。
支持快照 快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
HDFS 存储原理 写入原理
1、HDFS客户端创建对象实例DistributedFileSystem , 该对象中封装了与HDFS文件系统操作的相关方法。
2、调用DistributedFileSystem对象的create()方法,通过RPC请求 NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流 对象给客户端用于写数据。
3、客户端通过FSDataOutputStream输出流开始写入数据。
4、客户端写入数据时,将数据分成一个个数据包(packet 默认64k ), 内部组件DataStreamer 请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
5、传输的反方向上,会通过ACK机制校验数据包传输是否成功;
6、客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
7、DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回 。默认是1.
下载原理
1、HDFS客户端创建对象实例DistributedFileSystem , 调用该对象的open()方法来打开希望读取的文件。
2、DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取)信息 。对于每个块,namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的,与客户端的网络拓扑距离近的排序靠前。
3、DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
4、客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件中第一个块的最近的DataNode。数据从DataNode流回客户端,结果客户端可以在流上重复调用read()
5、当该块结束时,FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息 。
6、一旦客户端完成读取,就对FSDataInputStream调用close()方法。
HDFS 图解存储原理(形象生动)
Maneesh Varshney, mvarshney@gmail.com
系统构成:客户端,NAMENODE(主节点),DATANODE(数据节点)
HDFS写数据原理
解读:
1.管道线性传输
datanode之间采用Pipeline(管道)线性传输,而不采用拓扑式传输,是因为这样可以充分利用每个机器的带宽,避免网络瓶颈和高延迟的连接,最小化推送所有数据的延时。
在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带、
2.ACK应答
两两之间反方向做ACK应答检验,确保数据传输安全。
HDFS读数据原理
HDFS故障类型和其检测方法
HDFS 常用 shell 命令
hadoop fs 推荐使用
hadoop dfs,过期命令,
hdfs dfs,底层用的还是hadoop fs
显示当前目录结构 1 2 3 4 5 6 7 8 9 10 # 显示当前目录结构 hadoop fs -ls <path> # 递归显示当前目录结构 hadoop fs -ls -R <path> # 显示根目录下内容 hadoop fs -ls / # 直接根目录,没有指定协议 将加载读取fs.defaultFS值,我这里设置的是 hdfs://node1:8020 # 访问其他文件系统 hadoop fs -ls file:/// #操作本地文件系统 hadoop fs -ls hdfs://node1:8020/ #操作HDFS分布式文件系统
创建目录 1 2 3 4 # 创建目录(注意加绝对路径/) hadoop fs -mkdir <path> # 递归创建目录 hadoop fs -mkdir -p <path>
删除操作 1 2 3 4 # 删除文件 hadoop fs -rm <path> # 递归删除目录和文件 hadoop fs -rm -R <path>
从本地加载文件到 HDFS 1 2 3 4 5 6 7 8 9 # 二选一执行即可 hadoop fs -put [localsrc] [dst] 比如:hadoop fs -put 1.txt /config hadoop fs -copyFromLocal [localsrc] [dst] # 从本地加载文件到HDFS,并且删除本地文件 hadoop fs -moveFromLocal [localsrc] [dst]
合并上传多个文件
应用场景:小文件合并上传
1 2 3 # 追加一个或者多个文件到hdfs指定文件中.也可以从命令行读取输入. hadoop fs -appendToFile <localsrc> ... <dst> hadoop fs -appendToFile *.txt /big.txt
从 HDFS 导出文件到本地 1 2 3 # 二选一执行即可 hadoop fs -get [dst] [localsrc] hadoop fs -copyToLocal [dst] [localsrc]
查看文件内容 1 2 3 # 二选一执行即可 hadoop fs -cat <path> hadoop fs -text <path>
显示文件的最后一千字节 1 2 3 hadoop fs -tail <path> # 和Linux下一样,会持续监听文件内容变化 并显示文件的最后一千字节 hadoop fs -tail -f <path>
拷贝文件 1 hadoop fs -cp [src] [dst]
移动文件 1 2 # hadoop文件系统目录中移动 hadoop fs -mv [src] [dst]
统计当前目录下各文件大小
默认单位字节
-s : 显示所有文件大小总和,-h : 将以更友好的方式显示文件大小(例如 64.0m 而不是 67108864)
1 2 hadoop fs -du <path> hadoop fs -du -h /
合并下载多个文件
-nl 在每个文件的末尾添加换行符(LF)
-skip-empty-file 跳过空文件
1 2 3 hadoop fs -getmerge # 示例 将HDFS上的hbase-policy.xml和hbase-site.xml文件合并后下载到本地的/usr/test.xml hadoop fs -getmerge -nl /test/hbase-policy.xml /test/hbase-site.xml /usr/test.xml
统计文件系统的可用空间信息 更改文件复制因子 1 hadoop fs -setrep [-R] [-w] <numReplicas> <path>
更改文件的复制因子。如果 path 是目录,则更改其下所有文件的复制因子
-w : 请求命令是否等待复制完成
1 2 # 示例 hadoop fs -setrep -w 3 /user/hadoop/dir1
权限控制 1 2 3 4 5 6 7 # 权限控制和Linux上使用方式一致 # 变更文件或目录的所属群组。 用户必须是文件的所有者或超级用户。 hadoop fs -chgrp [-R] GROUP URI [URI ...] # 修改文件或目录的访问权限 用户必须是文件的所有者或超级用户。 hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...] # 修改文件的拥有者 用户必须是超级用户。 hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
文件检测 1 hadoop fs -test - [defsz] URI
可选选项:
-d:如果路径是目录,返回 0。
-e:如果路径存在,则返回 0。
-f:如果路径是文件,则返回 0。
-s:如果路径不为空,则返回 0。
-r:如果路径存在且授予读权限,则返回 0。
-w:如果路径存在且授予写入权限,则返回 0。
-z:如果文件长度为零,则返回 0。
1 2 # 示例 hadoop fs -test -e filename
关闭安全模式 在HDFS启动,会自动进入安全模式(只能对文件增[追加]删改),该模式下回进行BLOCK数量检测和自我修复,当BLOCK阈值率达到99.9%,会自动离开安全模式。
非正常关闭hadoop,直接关闭hdfs有些块丢失了或者损坏,就会进入安全模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 第一种:正常退出安全模式 hdfs dfsadmin -safemode leave # 如提示Safe mode is OFF,那就说明退出成功,但有时候这个命令也没办法退出安全模式,就需要使用强制退出 第二种:强制退出安全模式 hdfs dfsadmin -safemode forceExit # safemode 后面可以接 enter 进入安全模式 get 获取安全模式的状态 leave 退出安全模式 forceExit 强制退出安全模式 # 删除损坏的block hdfs fsck / -delete
将fsimage文件转为xml 1 hdfs oiv -i fsimage_0000000000000000050 -p XML -o fsimage.xml
将editslog文件转为xml 1 hdfs oev -i edits_0000000000000000011-0000000000000000025 -o edits.xml
更多命令:https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
HDFS Java API操作 HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件。
java api 官方文档:https://hadoop.apache.org/docs/r3.3.0/api/index.html
相当于用java代码实现node1:9870中的界面操作
配置Windows下Hadoop环境 环境要求:在windows上做HDFS客户端应用开发,需要设置Hadoop环境,而且要求是windows平台编译的Hadoop,不然会报以下的错误:
1 2 3 4 缺少winutils.exe Could not locate executable null \bin\winutils.exe in the hadoop binaries 缺少hadoop.dll Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
搭建步骤
将已经编译好的Windows版本Hadoop解压到到一个没有中文没有空格的路径下面
在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中
配置HADOOP_HOME
配置PATH目录
把hadoop3.3.0文件夹中bin目录下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录
重启windows系统
验证系统是否兼容hadoop
双击bin目录下的:winutils.exe文件,如果一闪而过则正常,否则百度原因
创建项目 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 <repositories > <repository > <id > cental</id > <url > http://maven.aliyun.com/nexus/content/groups/public//</url > <releases > <enabled > true</enabled > </releases > <snapshots > <enabled > true</enabled > <updatePolicy > always</updatePolicy > <checksumPolicy > fail</checksumPolicy > </snapshots > </repository > </repositories > <dependencies > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 3.3.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 3.3.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 3.3.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-mapreduce-client-core</artifactId > <version > 3.3.0</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.13</version > </dependency > <dependency > <groupId > com.github.pcj</groupId > <artifactId > google-options</artifactId > <version > 1.0.0</version > </dependency > <dependency > <groupId > commons-io</groupId > <artifactId > commons-io</artifactId > <version > 2.6</version > </dependency > </dependencies >
涉及的主要类 在java中操作HDFS,主要涉及以下Class:
Configuration: 该类的对象封转了客户端或者服务器的配置;
FileSystem: 该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过FileSystem的静态方法get获得该对象。
1 FileSystem fs = FileSystem.get(conf);
get方法从conf中的一个参数 fs.defaultFS的配置值判断具体是什么类型的文件系统。如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为:file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象。
获取FileSystem方式
相当于拿到文件系统的句柄,可以对hdfs文件系统做一系列操作
1 2 3 4 5 @Test public void getFileSystem2 () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); System.out.println("fileSystem:" +fileSystem); }
遍历HDFS中所有文件 1 2 3 4 5 6 7 8 9 10 11 @Test public void listMyFiles () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); RemoteIterator<LocatedFileStatus> files = fileSystem.listFiles(new Path ("/hdfs-api" ), true ); while (files.hasNext()) { System.out.println(files.next().getPath()); } fileSystem.close(); }
HDFS上创建文件夹 1 2 3 4 5 6 @Test public void mkdirs () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); boolean mkdirs = fileSystem.mkdirs(new Path ("/hello/mydir/test" )); fileSystem.close(); }
下载文件-方式1 1 2 3 4 5 6 7 8 9 10 @Test public void getFileToLocal () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); FSDataInputStream inputStream = fileSystem.open(new Path ("/timer.txt" )); FileOutputStream outputStream = new FileOutputStream (new File ("e:\\timer.txt" )); IOUtils.copy(inputStream,outputStream ); IOUtils.closeQuietly(inputStream); IOUtils.closeQuietly(outputStream); fileSystem.close(); }
下载文件-方式2 1 2 3 4 5 6 7 8 9 10 11 @Test public void downLoadFile () throws URISyntaxException, IOException, InterruptedException { FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); fileSystem.copyToLocalFile(new Path ("/anaconda-ks.cfg" ), new Path ("E:\\test" )); fileSystem.close(); }
上传文件 1 2 3 4 5 6 @Test public void putData () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); fileSystem.copyFromLocalFile(new Path ("file:///c:\\install.log" ),new Path ("/hello/mydir/test" )); fileSystem.close(); }
小文件合并 由于 Hadoop 擅长存储大文件,因为大文件的元数据信息比较少,如果 Hadoop 集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理,可以在上传的时候将小文件合并到一个大文件里面去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Test public void mergeFile () throws Exception{ FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration (),"root" ); FSDataOutputStream outputStream = fileSystem.create(new Path ("/bigfile.txt" )); LocalFileSystem local = FileSystem.getLocal(new Configuration ()); FileStatus[] fileStatuses = local.listStatus(new Path ("file:///E:\\input" )); for (FileStatus fileStatus : fileStatuses) { FSDataInputStream inputStream = local.open(fileStatus.getPath()); IOUtils.copy(inputStream,outputStream); IOUtils.closeQuietly(inputStream); } IOUtils.closeQuietly(outputStream); local.close(); fileSystem.close(); }
集群之间的数据复制 在我们实际工作当中,极有可能会遇到将测试集群的数据拷贝到生产环境集群,或者将生产环境集群的数据拷贝到测试集群,那么就需要我们在多个集群之间进行数据的远程拷贝,hadoop自带也有命令可以帮我们实现这个功能。
集群内部文件拷贝scp
指的是集群单节点和本机之间的拷贝
本地复制到远程 方式1:指定用户名,命令执行后需要再输入密码;
1 scp -r local_folder remote_username@remote_ip:remote_folder
方式2:没有指定用户名,命令执行后需要输入用户名和密码;
1 scp -r local_folder remote_ip:remote_folder
注意,如果实现了ssh免密登录之后,则不需要输入密码即可拷贝。
实例:
1 2 3 4 5 6 7 8 # 复制文件-将 /root/test.txt 拷贝到 192.168.88.161 的 /root/ 目录下,文件名还是 text.txt,使用 root 用户,此时会提示输入远程 root 用户的密码。 scp /root/test.txt root@192.168.88.161:/root/ # 复制文件并重命名-将 /root/test.txt 拷贝到 192.168.88.161 的 /root/ 目录下,文件名还是 text1.txt,使用 root 用户,此时会提示输入远程 root 用户的密码。 scp /root/test.txt root@192.168.88.161:/root/test1.txt # 复制目录-将整个目录 /root/test/ 复制到 192.168.88.161 的 /root/ 下,即递归的复制,使用 root 用户,此时会提示输入远程 root 用户的密码。 scp -r /root/test/ root@192.168.88.161:/root/
远程复制到本地 远程复制到本地 与 从本地复制到远程命令类似,不同的是 远程文件作为源文件在前,本地文件作为目标文件在后。
1 2 # 复制文件-将192.168.88.162的/root目录下的test.txt拷贝到当前主机的/root/目录下,文件名不变 scp root@192.168.88.162:/root/test.txt /root/test.txt
HDFS分布式拷贝工具:DistCp
集群之间拷贝,指的是不同节点的文件系统之间的拷贝
DistCp介绍
DistCp是Apache Hadoop中的一种流行工具,在hadoop-tools工程下,作为独立子工程存在。其定位就是用于数据迁移的,定期在集群之间和集群内部备份数据。(在备份过程中,每次运行DistCp都称为一个备份周期。)尽管性能相对较慢,但它的普及程度已经越来越高。
DistCp命令
1 2 3 4 5 6 7 8 9 10 11 12 $ hadoop distcp usage: distcp OPTIONS [source_path...] <target_path> -append //拷贝文件时支持对现有文件进行追加写操作 -async //异步执行distcp拷贝任务 -bandwidth <arg> //对每个Map任务的带宽限速 -delete //删除相对于源端,目标端多出来的文件 -diff <arg> //通过快照diff信息进行数据的同步 -overwrite //以覆盖的方式进行拷贝,如果目标端文件已经存在,则直接覆盖 -p <arg> //拷贝数据时,扩展属性信息的保留,包括权限信息、块大小信息等等 -skipcrccheck //拷贝数据时是否跳过cheacksum的校验 -update //拷贝数据时,只拷贝相对于源端 ,目标端不存在的文件数据
其中 source_path 、target_path 需要带上地址前缀以区分不同的集群 :
例如 :hadoop distcp hdfs://nnl:8020/foo/a hdfs://nn2:8020/bar/foo
上面的命令表示从nnl集群 拷贝/foo/a 路径下的数据到nn2集群 的/bar/foo 路径下。
1 2 cd /export/servers/hadoop-2.7.5/ bin/hadoop distcp hdfs://node1:8020/jdk-8u241-linux-x64.tar.gz hdfs://cluster2:8020/
同步集群配置文件
指的是集群节点之间本地的文件的拷贝
1 2 scp -r /export/server/hadoop-3.3.0/etc/hadoop/core-site.xml node2:/export/server/hadoop-3.3.0/etc/hadoop/ scp -r /export/server/hadoop-3.3.0/etc/hadoop/core-site.xml node3:/export/server/hadoop-3.3.0/etc/hadoop/
回收站Trash 删除文件到Trash 开启Trash功能后,正常执行删除操作,文件实际并不会被直接删除,而是被移动到了垃圾回收站。
当然也可以去Trash回收站下面查看一下:
删除文件跳过Trash 有的时候,我们希望直接把文件删除,不需要再经过Trash回收站了,可以在执行删除操作的时候添加一个参数:-skipTrash
hadoop fs -rm -skipTrash /smallfile1/3.txt
从Trash中恢复文件 回收站里面的文件,在到期被自动删除之前,都可以通过命令恢复出来。使用mv、cp命令把数据文件从Trash目录下复制移动出来就可以了。
hadoop fs -mv /user/root/.Trash/Current/smallfile1/* /smallfile1/
清空Trash 除了fs.trash.interval参数控制到期自动删除之外,用户还可以通过命令手动清空回收站,释放HDFS磁盘存储空间。
首先想到的是删除整个回收站目录,将会清空回收站,这是一个选择。此外。HDFS提供了一个命令行工具来完成这个工作:
hadoop fs -expunge
该命令立即从文件系统中删除过期的检查点。
Archive档案的使用 HDFS并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode占用内存,如果存在大量的小文件,它们会吃掉NameNode节点的大量内存。
Hadoop Archives可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
如何创建Archive 1 Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>
其中-archiveName是指要创建的存档的名称。比如test.har。archive的名字的扩展名应该是*.har。 -p参数指定文件存档文件(src)的相对路径。
例如:如果你只想存档一个目录/config下的所有文件:
1 hadoop archive -archiveName test.har -p /config /outputdir
这样就会在/outputdir目录下创建一个名为test.har的存档文件。
如何查看Archive 首先我们来看下创建好的har文件。使用如下的命令:
1 hadoop fs -ls /outputdir/test.har
这里可以看到har文件包括:两个索引文件,多个part文件(本例只有一个)以及一个标识成功与否的文件。part文件是多个原文件的集合,根据index文件去找到原文件。
例如上述的/input目录下有很多小的xml文件。进行archive操作之后,这些小文件就归档到test.har里的part-0一个文件里。
1 hadoop fs -cat /outputdir/test.har/part-0
archive作为文件系统层暴露给外界。所以所有的fs shell命令都能在archive上运行,但是要使用不同的URI。Hadoop Archives的URI是:har://scheme-hostname:port/archivepath/fileinarchive
scheme-hostname格式为hdfs-域名:端口,如果没有提供scheme-hostname,它会使用默认的文件系统。这种情况下URI是这种形式:har:///archivepath/fileinarchive
如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
查看归档文件中的小文件 ,使用har uri
hadoop fs -ls har://hdfs-node1:8020/outputdir/test.har
查看归档文件中的小文件,不使用har uri
hadoop fs -ls har:///outputdir/test.har
查看har归档文件中小文件的内容
hadoop fs -cat har:///outputdir/test.har/core-site.xml
如何解压Archive 1 2 hadoop fs -mkdir /config2 hadoop fs -cp har:///outputdir/test.har/* /config2
查看HDFS页面,发现/config2目录中已经有解压后的小文件了
Archive注意事项
Hadoop archives是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。Hadoop archive的扩展名是*.har;
创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令,要提前启动Yarn集群;
创建archive文件要消耗和原文件一样多的硬盘空间;
archive文件不支持压缩,尽管archive文件看起来像已经被压缩过;
archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日;
当创建archive时,源文件不会被更改或删除;
HDFS的权限问题
操作
1 2 3 hadoop fs -chmod 750 /user/itcast/foo //变更目录或文件的权限位 hadoop fs -chown :portal /user/itcast/foo // 变更目录或文件的所属用户 hadoop fs -chgrp itcast _group1 /user/itcast/foo //变更用户组
原理
1 2 1、HDFS的权限有一个总开关,在hdfs-site.xml中配置,只有该参数的值为true,则HDFS的权限才可以起作用 dfs.permissions.enabled #在Hadoop3.3.0中该值默认是 true
Java代码权限问题
1 2 3 4 5 6 1 、关闭HDFS权限的总开关,设置 dfs.permissions.enabled 为 false 2 、使用 hadoop fs -chmod -R 777 /tmp 修改权限3 、使用root用户的身份去获取FileSystem对象 FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration (),"root" );
HDFS的动态上下线 动态扩容
介绍
1 2 1、当集群的存储容量达到上限时,我们可以通过添加主机的方式来扩展DataNode节点,来横向增加集群的存储空间 2、我们在动态扩容时,不要一影响当前集群的正常工作
操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 ==================1、基础环境配置 ==================== 1、从node1克隆一台主机:node4 2、修改node4的Mac地址、IP地址为164,主机名为node4 3、关闭node4的防火墙、安装JDK,关闭Selinux (已做) 4、node1、node2、node3、node4要修改域名映射 192.168.88.161 node1 node1.itcast.cn 192.168.88.162 node2 node2.itcast.cn 192.168.88.163 node3 node3.itcast.cn 192.168.88.164 node4 node4.itcast.cn 5、node1、node2、node3、node4重新构建免密登录 5.1)在node4上,生成一个密钥对 : ssh-keygen -t rsa 5.2)在node4上,将node4的公钥发送给node1: ssh-copy-id node1 5.3)将node1上,将所有公钥发送给:node2,node3,node4 scp /root/.ssh/authorized_keys node2:/root/.ssh scp /root/.ssh/authorized_keys node3:/root/.ssh scp /root/.ssh/authorized_keys node4:/root/.ssh 6、在node4上,删除Hadoop的所有痕迹 6.1)删除Hadoop安装包: rm -fr /export/server/hadoop-3.3.0/ 6.2)删除Hadoop数据: rm -fr /export/data/hadoop-3.3.0/ 6.3)删除Hadoop的环境变量:vim /etc/profile ==================1、Hadoop上线核心配置 ==================== 7、在node1上修改namenode(node1)节点workers配置文件,增加新节点主机名 vim /export/server/hadoop-3.3.0/etc/hadoop/workers node1 node2 node3 node4 8、在node1上,将Hadoop分发给node4 scp -r /export/server/hadoop-3.3.0 node4:/export/server 9、在node4上,新机器上配置hadoop环境变量 vim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 最后:source /etc/profile 10、在node4上启动datanode hdfs --daemon start datanode 11、通过页面查看 http ://node1:9870/dfshealth.html#tab-datanode hdfs dfsadmin -setBalancerBandwidth 104857600 hdfs balancer -threshold 5
动态缩容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 1、在node1上,保证你的hdfs-site.xml文件中有以下黑名单配置 <property> <name>dfs.hosts.exclude</name> <value>/export/server/hadoop-3.3.0/etc/hadoop/excludes</value> </property> 2、在node1上,将你要退役的主机的主机名加入黑名单,编辑以下文件,加入node4 vim /export/server/hadoop-3.3.0/etc/hadoop/excludes 3、在ndoe1上,刷新集群 hdfs dfsadmin -refreshNodes 4、通过datanode页面查看node4的退役状态 http ://node1:9870/dfshealth.html#tab-datanode hdfs dfsadmin -setBalancerBandwidth 104857600 hdfs balancer -threshold 5
HDFS的高可用 介绍 1 2 3 4 1、HDFS的高可用是由NameNode组成,一个是Active状态的NameNode,一个是Standby状态的NameNode 2、Journal Node集群两个NamNode之间元数据的同步,同步的数据是日志文件Edits,由NameNode自己完成fsimage文件的生成,没有SecondaryNameNode 3、两个NameNode的主备切换,是由ZKFC和Zookeeper集群共同来完成 3.1 正常情况下由ZKFC来监控 Active NameNode的健康状态,一旦发现主NameNode健康不良,则立刻通知Zookeeper,Zookeeper会通知备ZKFC,然后备ZKFC会改变备NameNode状态由Standby改为Active,备NameNode成为新的主节点
脑裂问题
原因
1 由于极端情况下,主NameNode发生了假死现象,临时假死,后来又复活,这样原来的主NameNode状态是Active,后来的备用NameNode状态也改为Active,这样就会有两个Active状态的NameNode,会造成元数据的管理混乱,就相当于一个大脑被拆分了。
解决方案
1 2 方案1:调用旧Active状态的RPC接口中的相关方法,将其状态由Active强制改为StandBy 方案2:如果方案1没有实现,则ZK会远程登录到旧Active的NameNode主机上,将NameNode进程杀死
环境搭建
搭建方案
操作步骤
1、备份单节点Hadoop
1 2 # 在node1,node2,node3主机上,分别执行以下操作: mv /usr/local/apps/hadoop-3.3.0 /export/server/hadoop-3.3.0_bak
2、解压Hadoop
1 tar -xvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /usr/local/apps/
3、配置环境变量(可以不做)
1 2 3 4 5 6 7 8 # 在node1,node2,node3主机上,分别执行以下操作: vim /etc/profile export HADOOP_HOME=/usr/local/apps/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
4、配置hadoop-env.sh文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cd /usr/local/apps/hadoop-3.3.0/etc/hadoop vim hadoop-env.sh export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_321 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root
5、core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://cluster1</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/data/ha-hadoop</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > node1:2181,node2:2181,node3:2181</value > </property > </configuration >
6、配置 hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 <configuration > <property > <name > dfs.nameservices</name > <value > cluster1</value > </property > <property > <name > dfs.ha.namenodes.cluster1</name > <value > nn1,nn2</value > </property > <property > <name > dfs.namenode.rpc-address.cluster1.nn1</name > <value > node1:8020</value > </property > <property > <name > dfs.namenode.http-address.cluster1.nn1</name > <value > node1:9870</value > </property > <property > <name > dfs.namenode.rpc-address.cluster1.nn2</name > <value > node2:8020</value > </property > <property > <name > dfs.namenode.http-address.cluster1.nn2</name > <value > node2:9870</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://node1:8485;node2:8485;node3:8485/cluster1</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /opt/data/journaldata</value > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > </property > <property > <name > dfs.client.failover.proxy.provider.cluster1</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_rsa</value > </property > <property > <name > dfs.ha.fencing.ssh.connect-timeout</name > <value > 30000</value > </property > </configuration >
配置mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > yarn.app.mapreduce.am.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.map.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > <property > <name > mapreduce.reduce.env</name > <value > HADOOP_MAPRED_HOME=${HADOOP_HOME}</value > </property > </configuration >
配置yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 <configuration > <property > <name > yarn.resourcemanager.ha.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.cluster-id</name > <value > yrc</value > </property > <property > <name > yarn.resourcemanager.ha.rm-ids</name > <value > rm1,rm2</value > </property > <property > <name > yarn.resourcemanager.hostname.rm1</name > <value > node1</value > </property > <property > <name > yarn.resourcemanager.hostname.rm2</name > <value > node2</value > </property > <property > <name > yarn.resourcemanager.webapp.address.rm1</name > <value > node1:8088</value > </property > <property > <name > yarn.resourcemanager.webapp.address.rm2</name > <value > node2:8088</value > </property > <property > <name > yarn.resourcemanager.zk-address</name > <value > node1:2181,node2:2181,node3:2181</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > </configuration >
配置workers
分发
1 2 3 cd /usr/local/apps scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
启动集群
HA集群的初始化(只在第一次执行)
HA集群的启动
在node1上,启动hdfs集群
在node1上,启动yarn集群
在node1上,启动历史任务
1 mapred --daemon start historyserver
后续启动和关闭
1 2 3 4 1、以上的启动至用于刚搭建完集群的第一次启动使用 2、以后高可用集群的启动和关闭直接使用以下命令: start-all.sh stop-all.sh
验证
验证HDFS高可用
1 2 3 4 5 6 7 8 9 1、网页访问NameNode http ://node1:9870/ http ://node2:9870/ 2、文件上传 hadoop fs -put a.txt / 3、杀死主NameNode,观察备用NameNode是否称为主节点 kill -9 9024
验证Yarn高可用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 1、网页访问NameNode http ://node1:8088/ http ://node2:8088/ yarn rmadmin -getServiceState rm1 #active yarn rmadmin -getServiceState rm2 #standby kill -9 ResourceManager进程号 yarn rmadmin -getServiceState rm1/rm2 hadoop jar /usr/local/apps/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 10000 8088页面: Yarn集群的信息 + 正在运行的任务 + 已经执行完成的任务 19888页面: 已经执行完成的任务 8020端口: 是HDFS客户端和NameNode之间的内部数据通信端口 9870端口: 是浏览器和网页服务器之间的访问端口
如何还原单节点(namenode)服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1:在node1中 stop-all.sh cd /usr/local/apps/ mv hadoop-3.3.0 hadoop-3.3.0_ha mv hadoop-3.3.0_bak hadoop-3.3.0 2:在node2中 cd /usr/local/apps/ mv hadoop-3.3.0 hadoop-3.3.0_ha mv hadoop-3.3.0_bak hadoop-3.3.0 3:在node3中 cd /usr/local/apps/ mv hadoop-3.3.0 hadoop-3.3.0_ha mv hadoop-3.3.0_bak hadoop-3.3.0 4:在node1中 start-all.sh
HA(高可用) + Federation (联邦)
namenode做横向扩展,可以像datanode一样有多组。
按不同的目录管理不同的namenode的元数据,然后每个目录做HA高可用(主备)
ps: blk指block,块。
为高可用保存hadoop配置 1 2 3 4 5 6 7 8 1.1 进入$HADOOP_HOME/etc/目录 [root@hadoop1 ~]# cd /opt/test/hadoop-2.6.5/etc 1.2 备份hadoop高可用配置,供以后使用 [root@hadoop1 etc]# cp -r hadoop/ hadoop-ha 1.3 查看$HADOOP_HOME/etc/目录,备份成功 [root@hadoop1 etc]# ls hadoop hadoop-full hadoop-ha # hadoop-full保留了已有配置,接下来高可用的配置继续在hadoop文件夹内修改
增加federation配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 2.0 在hadoop1上进入$HADOOP_HOME/etc/hadoop目录 [root@hadoop1 ~]# cd /opt/test/hadoop-2.6.5/etc/hadoop 2.1 在hadoop1上修改hdfs-site.xml文件,将原有配置替换如下 [root@hadoop1 hadoop]# vim hdfs-site.xml <configuration > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.nameservices</name > <value > mycluster,mycluster2</value > </property > <property > <name > dfs.ha.namenodes.mycluster</name > <value > nn1,nn2</value > </property > <property > <name > dfs.ha.namenodes.mycluster2</name > <value > nn3,nn4</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn1</name > <value > hadoop1:8020</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn2</name > <value > hadoop2:8020</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster2.nn3</name > <value > hadoop3:8020</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster2.nn4</name > <value > hadoop4:8020</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn1</name > <value > hadoop1:50070</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn2</name > <value > hadoop2:50070</value > </property > <property > <name > dfs.namenode.http-address.mycluster2.nn3</name > <value > hadoop3:50070</value > </property > <property > <name > dfs.namenode.http-address.mycluster2.nn4</name > <value > hadoop4:50070</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /var/test/hadoop/fed/jn</value > </property > <property > <name > dfs.client.failover.proxy.provider.mycluster</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.client.failover.proxy.provider.mycluster2</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_dsa</value > </property > <property > <name > dfs.ha.automatic-failover.enabled.mycluster</name > <value > true</value > </property > <property > <name > dfs.ha.automatic-failover.enabled.mycluster2</name > <value > true</value > </property > </configuration > 2.2 在hadoop1上修改core-site.xml文件,将原有配置替换如下 [root@hadoop1 hadoop]# vim core-site.xml <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://mycluster</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /var/test/hadoop/fed</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > hadoop2:2181,hadoop3:2181,hadoop4:2181</value > </property > </configuration > 2.3 在hadoop1上操作,将更新后的hdfs-site.xml,core-site.xml分发到其他节点 [root@hadoop1 hadoop]# scp hdfs-site.xml core-site.xml hadoop2:`pwd` [root@hadoop1 hadoop]# scp hdfs-site.xml core-site.xml hadoop3:`pwd` [root@hadoop1 hadoop]# scp hdfs-site.xml core-site.xml hadoop4:`pwd` 2.4 修改hadoop3上的hdfs-site.xml和core-site.xml文件 2.4.1 进入$HADOOP_HOME/etc/hadoop目录 [root@hadoop3 ~]# cd /opt/test/hadoop-2.6.5/etc/hadoop 2.4.2 在hadoop3上修改hdfs-site.xml文件的dfs.namenode.shared.edits.dir属性 [root@hadoop3 hadoop]# vim hdfs-site.xml <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster2</value > </property > 2.4.3 在haoop3上修改core-site.xml文件的fs.defaultFS属性 [root@hadoop3 hadoop]# vim core-site.xml <property > <name > fs.defaultFS</name > <value > hdfs://mycluster2</value > </property >
首次启动HA+Federation集群part1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 3. 首次启动HA+Federation集群part1:启动journalnode和zookeeper,格式化zookeeper集群 3.1 在hadoop1,hadoop2,hadoop3上启动journalnode [root@hadoop1 ~]# hadoop-daemon.sh start journalnode [root@hadoop2 ~]# hadoop-daemon.sh start journalnode [root@hadoop3 ~]# hadoop-daemon.sh start journalnode 3.1.1 hadoop1, hadoop2, hadoop3, hadoop4进程显示如下 [root@hadoop1 ~]# jps [root@hadoop2 ~]# jps [root@hadoop3 ~]# jps 1*** JournalNode 1*** Jps [root@hadoop3 ~]# jps jps 3.2 在hadoop2,hadoop3,hadoop4上分别启动zookeeper [root@hadoop2 ~]# zkServer.sh start [root@hadoop3 ~]# zkServer.sh start [root@hadoop4 ~]# zkServer.sh start 3.3 在hadoop1和hadoop3上格式化zookeeper [root@hadoop1 ~]# hdfs zkfc -formatZK [root@hadoop3 ~]# hdfs zkfc -formatZK 3.3.1 格式化zookeeper后在hadoop2,hadoop3,hadoop4查看zookeeper进程 [root@hadoop2 ~]# zkCli.sh [root@hadoop2 ~]# zkCli.sh [root@hadoop2 ~]# zkCli.sh Connecting to localhost:2181 [zk: localhost:2181(CONNECTED) 0] ls / [hadoop-ha, zookeeper] [zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha [mycluster, mycluster2] [zk: localhost:2181(CONNECTED) 2]
首次启动HA+Federation集群part2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 4. 首次启动HA+Federation集群part2:格式化第一组的namenode,即hadoop1 4.1 在hadoop1上操作,指定clusterid格式化namenode, 4.1.1 命令 hadoop namenode -format -clusterid ${CLUSTER_ID}${CLUSTER_ID}为自行指定的clusterID,本例中使用cluster1 4.1.2 执行命令 [root@hadoop1 ~]# hadoop namenode -format -clusterid cluster1 4.2 格式化完成后在hadoop1上启动namenode [root@hadoop1 ~]# hadoop-daemon.sh start namenode starting namenode, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-namenode-hadoop1.out 4.3 hadoop1进程显示如下 [root@hadoop1 ~]# jps **** Jps **** JournalNode **** NameNode 4.4 在hadoop2,即另一台namenode上同步hadoop1的CID等信息 [root@hadoop2 ~]# hdfs namenode -bootstrapStandby 4.5 在备用namenode,即hadoop2上启动namenode [root@hadoop2 ~]# hadoop-daemon.sh start namenode 4.5.1 在hadoop2上查看进程 [root@hadoop2 ~]# jps 1406 JournalNode 1476 QuorumPeerMain 1710 NameNode 1791 Jps
首次启动HA+Federation集群part3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 5. 首次启动HA+Federation集群part3:格式化第一组的namenode,即hadoop3 #备注:步骤4和步骤5除操作的虚拟机不同,过程完全相同 5.1 在hadoop3上操作,指定clusterid格式化namenode, [root@hadoop3 ~]# hadoop namenode -format -clusterid cluster1 5.2 格式化完成后在hadoop3上启动namenode [root@hadoop3 ~]# hadoop-daemon.sh start namenode starting namenode, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-namenode-hadoop3.out 5.3 hadoop3进程显示如下 [root@hadoop3 ~]# jps **** Jps **** JournalNode **** NameNode 5.4 在hadoop4,即该组另一台namenode上同步hadoop3的CID等信息 [root@hadoop4 ~]# hdfs namenode -bootstrapStandby 5.5 在备用namenode上启动namenode [root@hadoop4 ~]# hadoop-daemon.sh start namenode 5.5.1 在hadoop4上查看进程 [root@hadoop4 ~]# jps 1407 QuorumPeerMain 1615 NameNode 1696 Jps
首次启动HA+Federation集群part4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 6. 首次启动HA+Federation集群part4:启动ZKFC, datanode和yarn 6.1 启动zkfc 6.1.1 在hadoop1,hadoop2,hadoop3,hadoop4上启动zkfc [root@hadoop1 ~]# hadoop-daemon.sh start zkfc [root@hadoop2 ~]# hadoop-daemon.sh start zkfc [root@hadoop3 ~]# hadoop-daemon.sh start zkfc [root@hadoop4 ~]# hadoop-daemon.sh start zkfc starting zkfc, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-zkfc-hadoop*.out 6.1.2 启动zkfc后在hadoop2,hadoop3,hadoop4查看已有进程 [root@hadoop1 ~]# jps1404 JournalNode1727 DFSZKFailoverController1601 NameNode1794 Jps [root@hadoop2 ~]# jps1668 Jps1406 JournalNode1476 QuorumPeerMain1623 DFSZKFailoverController [root@hadoop3 ~]# jps1836 Jps1404 JournalNode1474 QuorumPeerMain1664 NameNode1769 DFSZKFailoverController [root@hadoop4 ~]# jps1407 QuorumPeerMain1546 DFSZKFailoverController1591 Jps 6.2 启动datanode 6.2.1 在active的namenode上启动datanode [root@hadoop1 ~]# hadoop-daemons.sh start datanode # 因为hadoop1已经启动了所有datanode,不用在hadoop3上重复启动 6.2.2 启动datanode后查看hadoop1,hadoop2,hadoop3,hadoop4进程 [root@hadoop1 ~]# jps1404 JournalNode1885 Jps1727 DFSZKFailoverController1601 NameNode [root@hadoop2 ~]# jps1406 JournalNode1476 QuorumPeerMain2007 Jps1710 NameNode1911 DataNode1623 DFSZKFailoverController [root@hadoop3 ~]# jps1404 JournalNode1991 Jps1474 QuorumPeerMain1664 NameNode1904 DataNode1769 DFSZKFailoverController [root@hadoop4 ~]# jps1407 QuorumPeerMain1546 DFSZKFailoverController1615 NameNode1811 DataNode1908 Jps 6.3 启动yarn 6.3.1 在hadoop1上启动yarn [root@hadoop1 ~]# start-yarn.sh 6.3.2 启动yarn后查看hadoop1, hadoop2, hadoop3, hadoop4进程 [root@hadoop1 ~]# jps 1404 JournalNode 1727 DFSZKFailoverController 1601 NameNode 1947 ResourceManager 2199 Jps [root@hadoop2 ~]# jps 1406 JournalNode 1476 QuorumPeerMain 2114 Jps 1710 NameNode 1911 DataNode 1623 DFSZKFailoverController 2078 NodeManager [root@hadoop3 ~]# jps 1404 JournalNode 2035 NodeManager 2068 Jps 1474 QuorumPeerMain 1664 NameNode 1904 DataNode 1769 DFSZKFailoverController [root@hadoop4 ~]# jps 1407 QuorumPeerMain 2035 Jps 1546 DFSZKFailoverController 1970 NodeManager 1615 NameNode 1811 DataNode 6.4 通过web查看集群运行状态, http://192.168.111.211:50070/dfshealth.html#tab-overview'hadoop1:8020' (active) http://192.168.111.212:50070/dfshealth.html#tab-overview'hadoop1:8020' (standby) http://192.168.111.213:50070/dfshealth.html#tab-overview'hadoop1:8020' (active) http://192.168.111.214:50070/dfshealth.html#tab-overview'hadoop1:8020' (standby)
常规启动HA+Federation集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 7. 常规启动HA+Federation集群 7.1 在hadoop2, hadoop3, hadoop4上启动zookeeper [root@hadoop2 ~]# zkServer.sh start [root@hadoop3 ~]# zkServer.sh start [root@hadoop4 ~]# zkServer.sh start JMX enabled by default Using config: /opt/test/zookeeper-3.4.6/bin/../conf/zoo.cfg Starting zookeeper ... STARTED 7.1.1 在hadoop2, hadoop3, hadoop4上查看进程 [root@hadoop2 ~]# jps [root@hadoop3 ~]# jps [root@hadoop4 ~]# jps 2*** Jps 2*** QuorumPeerMain 7.2 在hadoop1上执行start-dfs.sh [root@hadoop1 ~]# start-dfs.sh Starting namenodes on [hadoop1 hadoop2 hadoop3 hadoop4] hadoop*: starting namenode, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-namenode-hadoop*.out hadoop*: starting datanode, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-datanode-hadoop*.out Starting journal nodes [hadoop1 hadoop2 hadoop3] Hadoop*: starting journalnode, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-journalnode-hadoop*.out 7.2.1 在hadoop1, hadoop2, hadoop3, hadoop4上查看进程 [root@hadoop1 mapreduce]# jps 3243 Jps 2926 NameNode 3121 JournalNode [root@hadoop2 ~]# jps 2565 Jps 2240 QuorumPeerMain 2305 NameNode 2462 JournalNode 2371 DataNode [root@hadoop3 ~]# jps 3095 Jps 2767 QuorumPeerMain 2832 NameNode 2989 JournalNode 2901 DataNode [root@hadoop4 ~]# jps 2389 Jps 2133 QuorumPeerMain 2204 NameNode 2270 DataNode 7.3 在hadoop1上启动yarn [root@hadoop1 ~]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/test/hadoop-2.6.5/logs/yarn-root-resourcemanager-hadoop1.out hadoop*: starting nodemanager, logging to /opt/test/hadoop-2.6.5/logs/yarn-root-nodemanager-hadoop*.out 7.3.1 在hadoop1,hadoop2,hadoop3,hadoop4上查看进程 [root@hadoop1 mapreduce]# jps 3588 Jps 2926 NameNode 3121 JournalNode 3313 ResourceManager [root@hadoop2 ~]# jps 2773 Jps 2240 QuorumPeerMain 2305 NameNode 2462 JournalNode 2371 DataNode 2626 NodeManager [root@hadoop3 ~]# jps 3308 Jps 2767 QuorumPeerMain 2832 NameNode 2989 JournalNode 2901 DataNode 3155 NodeManager [root@hadoop4 ~]# jps 2598 Jps 2133 QuorumPeerMain 2204 NameNode 2270 DataNode 2451 NodeManager 7.4 在hadoop1,hadoop2,hadoop3,hadoop4上启动zkfc [root@hadoop1 ~]# hadoop-daemon.sh start zkfc [root@hadoop2 ~]# hadoop-daemon.sh start zkfc [root@hadoop3 ~]# hadoop-daemon.sh start zkfc [root@hadoop4 ~]# hadoop-daemon.sh start zkfc starting zkfc, logging to /opt/test/hadoop-2.6.5/logs/hadoop-root-zkfc-hadoop*.out 7.4.1 在hadoop1,hadoop2,hadoop3,hadoop4上查看进程 [root@hadoop1 mapreduce]# jps 3588 Jps 2926 NameNode 3121 JournalNode 3313 ResourceManager 3641 DFSZKFailoverController [root@hadoop2 ~]# jps 2773 Jps 2240 QuorumPeerMain 2305 NameNode 2462 JournalNode 2371 DataNode 2626 NodeManager 2826 DFSZKFailoverController [root@hadoop3 ~]# jps 3308 Jps 2767 QuorumPeerMain 2832 NameNode 2989 JournalNode 2901 DataNode 3155 NodeManager 3362 DFSZKFailoverController [root@hadoop4 ~]# jps 2598 Jps 2133 QuorumPeerMain 2204 NameNode 2270 DataNode 2451 NodeManager 2651 DFSZKFailoverController 7.5 通过web查看集群运行状态, http://192.168.111.211:50070/dfshealth.html#tab-overview'hadoop1:8020' (active) http://192.168.111.212:50070/dfshealth.html#tab-overview'hadoop1:8020' (standby) http://192.168.111.213:50070/dfshealth.html#tab-overview'hadoop1:8020' (active) http://192.168.111.214:50070/dfshealth.html#tab-overview'hadoop1:8020' (standby)
在HA+Federation集群上测试wordcount程序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 8. 在HA+Federation集群上测试wordcount程序 8.1 从hadoop1或hadoop3进入$HADOOP_HOME/share/hadoop/mapreduce/ 目录,本例选择hadoop1 [root@hadoop1 ~]# cd /opt/test/hadoop-2.6.5/share/hadoop/mapreduce/ 8.2 上传test.txt文件到根目录 8.2.1 默认上传 [root@hadoop1 mapreduce]# hadoop fs -put test.txt / 8.2.2 也可以指定blocksize [root@hadoop1 mapreduce]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt / 8.3 运行wordcount测试程序,输出到/output [root@hadoop1 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /test.txt /output#运行时会首先看到如下信息 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 8.4 查看mapreduce运行结果 [root@hadoop1 mapreduce]# hadoop dfs -text /output/part-* hello 100003 world 200002 “hello 100000
为HA+Federation(高可用+联邦)配置viewfs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 9. 为HA+Federation(高可用+联邦)配置viewfs 9.1 进入$HADOOP_HOME/etc/hadoop目录 [root@hadoop1 ~]# cd /opt/test/hadoop-2.6.5/etc/hadoop 9.2 在hadoop1上修改core-site.xml文件,将原有配置替换如下 [root@hadoop1 hadoop]# vim core-site.xml <configuration xmlns:xi="http://www.w3.org/2001/XInclude"> <!--cmt.xml前使用绝对路径--> <xi:include href="/opt/test/hadoop-2.6.5/etc/hadoop/cmt.xml" /> <property> <name>fs.default.name</name> <value>viewfs://clusterX</value> </property> <!--设置zookeeper数据存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/var/test/hadoop/fed</value> </property> <!--设置zookeeper位置信息--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value> </property> </configuration> 9.3 在hadoop1的/opt/test/hadoop-2.6.5/etc/hadoop目录下新增cmt.xml文件 [root@hadoop1 hadoop]# vim cmt.xml <configuration> <property> <name>fs.viewfs.mounttable.clusterX.link./ns1</name> <value>hdfs://mycluster</value> </property> <property> <name>fs.viewfs.mounttable.clusterX.link./ns2</name> <value>hdfs://mycluster2</value> </property> <property> <!-- 指定 /tmp 目录,许多依赖hdfs的组件可能会用到此目录 --> <name>fs.viewfs.mounttable.clusterX.link./tmp</name> <value>hdfs://mycluster/tmp</value> </property> </configuration>
在HA+Federation+viewFs集群上测试wordcount程序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 10. 在HA+Federation+viewFs集群上测试wordcount程序 10.1 从hadoop1或hadoop3进入$HADOOP_HOME/share/hadoop/mapreduce/目录,本例选择hadoop1 [root@hadoop1 ~]# cd /opt/test/hadoop-2.6.5/share/hadoop/mapreduce/ 10.2上传test.txt文件到根目录 10.2.1 默认上传 [root@hadoop1 mapreduce]# hadoop fs -put test.txt / 10.2.2 也可以指定blocksize [root@hadoop1 mapreduce]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt / 10.3 运行wordcount测试程序,输出到/output [root@hadoop1 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /ns1/test.txt /ns1/output # 运行时会首先看到如下信息 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 10.4 查看mapreduce运行结果 [root@hadoop1 mapreduce]# hadoop dfs -cat /ns1/output/part-* hello 100003 world 200002 “hello 100000
分布式计算框架——MapReduce MapReduce概述 为什么要学习MapReduce 1 2 3 4 1、MapReduce是人类有史以来第一代分布式计算引擎 2、后期的绝大多数的分布式计算引擎都借鉴了MapReduce的思想 3、学习了MapReduce可以为以后学习其他的分布式计算引擎打好基础 4、目前还有很多的框架底层代码就是MapReduce: Hive、Sqoop、Oozie
要学习到什么程度? 1 2 1、MapReduce的学习是一半理论,一半代码 2、指导思想是:重理论,轻代码
分布式计算历代引擎 1 2 3 4 5 第一代:MapReduce(MR) 离线分析 第二代:Tez 离线分析 第三代:Spark 离线分析 + 实时分析 第四代:Flink 离线分析 + 实时分析 第五代:Doris , kylin ,ClickHouse, ES,
MapReduce简介 Hadoop MapReduce 是一个分布式计算 框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模 的数据集。
分布式计算是一种思想,相对于集中式计算(单机),可以用多节点并行计算,提供大规模数据的处理效率。
MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值对处理,它将作业的输入视为一组 <key,value> 对,并生成一组 <key,value> 对作为输出。输入和输出的 key 和 value 都必须实现Writable 接口。
1 (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
MapReduce的思想核心是“先分再合,分而治之 ”,
(map阶段)先把复制任务分解为若干个“简单的子任务”来并行处理 。任务间几乎没有依赖关系。
(reduce阶段)对map阶段的结果进行汇总合并。
MapReduce优缺点
易编程:提供二次开发接口,简单的使用就可以完成一个分布式程序,任务计算交给框架处理。集群节点可以扩展到成百上千个。
良好的扩展性:计算资源如果不够,就加及其,增加计算能力。计算能力和节点成线性增长,理论上可以处理庞大的离线数据。
高容错:hadoop集群任一节点宕机会将计算任务转移到另一节点,不影响整体任务
适合海量数据离线处理:可以处理GB、TB、PB级别的数据
实时计算性能差: 只适合做离线计算
不能做流式计算:只适合处理静态数据集
MapReduce实例进程 一个完整的MapReduce程序在分布式运行时有三类
MRAppMaster:负责整个MR程序的过程调度及状态协调
MapTask:负责map阶段的整个数据处理流程
ReduceTask:负责reduce阶段的整个数据处理流程
MapReduce阶段组成
一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段 ;
不能有诸如多个map阶段、多个reduce阶段的情景出现;
如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序串行运行
MapReduce慢的原因 1 2 3 4 1、MapReduce在运行的过程中,要经过多次的IO操作,数据要多次落硬盘 2、后期几乎所有大数据计算框架都是基于内存处理 MR = 文件---》内存 ---》硬盘 --》内存 ---》文件 Spark = 文件---》内存 ---》内存 --》内存 ---》文件
MapReduce编程模型简述 这里以词频统计 为例进行说明,MapReduce 处理的流程如下:
input : 读取文本文件;
splitting : 将文件按照行进行拆分(不同于hdfs的物理拆分,此处是逻辑拆分) ,此时得到的 K1 行数,V1 表示对应行的文本内容;【自动】
mapping : 并行将每一行按照空格进行拆分 ,拆分得到的 List(K2,V2),其中 K2 代表每一个单词,由于是做词频统计,所以 V2 的值为 1 ,代表出现 1 次;【编程写】
shuffling :由于 Mapping 操作可能是在不同的机器上并行处理的,所以需要通过 shuffling 将相同 key 值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到 K2 为每一个单词,List(V2) 为可迭代集合,V2 就是 Mapping 中的 V2;【自动】
Reducing : 这里的案例是统计单词出现的总次数,所以 Reducing 对 List(V2) 进行归约求和操作,最终输出。【编程写】
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
MapReduce执行过程
Map阶段执行过程
第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片 ,形成切片规划。128M ),每一个切片由一个MapTask处理。(getSplits)
第二阶段:对切片中的数据按照一定的规则读取解析返回<key,value>对。按行读取数据 。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormat)
第三阶段:调用Mapper类中的map方法处理数据 。
第四阶段:按照一定的规则对Map输出的键值对进行分区partition 。默认不分区,因为只有一个reducetask。
第五阶段:Map输出数据写入内存缓冲区 ,达到比例溢出到磁盘上。溢出spill 的时候根据key进行排序sort 。
第六阶段:对所有溢出文件进行最终的merge合并 ,成为一个文件,再做一次排序(归并排序),然后如果有combiner的话,就做一次优化聚合。
Reduce阶段执行过程
第一阶段:ReduceTask会主动 从MapTask复制拉取 属于需要自己处理的数据。
第二阶段:把拉取来数据,全部进行合并merge ,即把分散的数据合并成一个大的数据。再对合并后的数据排序 (归并排序:适合每一份数据有序,然后合并成整体有序数据的场景)
第三阶段是对排序后的键值对调用reduce方法 。键相等 的键值对调用一次reduce方法。最后把这些输出的键值对
shuffle机制 shuffle概念
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle
Map端Shuffle
Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算,默认Hash分区。
Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Reducer端shuffle
Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
shuffle机制弊端
Shuffle是MapReduce程序的核心与精髓,是MapReduce的灵魂所在。
Shuffle也是MapReduce被诟病最多的地方所在。MapReduce相比较于Spark、Flink计算引擎慢的原因,跟
Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
InputFormat 将输出文件拆分为多个 InputSplit,并由 RecordReaders 将 InputSplit 转换为标准的<key,value>键值对,作为 map 的输出。这一步的意义在于只有先进行逻辑拆分并转为标准的键值对格式后,才能为多个 map 提供输入,以便进行并行处理。
Combiner 1 2 3 4 5 6 1、规约是MapReduce的一种优化手段,可有可无,有了就属于锦上添花,有或者没有,都不会改变最终的结果 2、规约并不是所有MapReduce任务都能使用,前提是不能影响最终结果 3、规约主要是对每一个Map端的数据做提前的聚合,减少Map端和Reduce端传输的数据量,提交计算效率 4、规约可以理解为将Reduce端代码在Map端提前做一次本地执行 5、如果你的规约代码和Reducer代码一致,则规约代码可以不用写,直接使用Reducer代码即可 job.setCombinerClass(WordCountReducer.class);
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量 ,以提高网络IO性能,是MapReduce的一种优化手段之一。
combiner中文叫做数据规约 。数据归约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量。
combiner是MR程序中Mapper和Reducer之外的一种组件,默认情况下不启用 。
combiner组件的父类就是Reducer,combiner和reducer的区别在于运行的位置:
combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
combiner 是 map 运算后的可选操作,它实际上是一个本地化 的 reduce 操作,它主要是在 map 计算出中间文件后做一个简单的合并重复 key 值的操作。这里以词频统计为例:
map 在遇到一个 hadoop 的单词时就会记录为 1,但是这篇文章里 hadoop 可能会出现 n 多次,那么 map 输出文件冗余就会很多,因此在 reduce 计算前对相同的 key 做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
但并非所有场景都适合使用 combiner,使用它的原则是 combiner 的输出不会影响到 reduce 计算的最终输入,例如:求总数,最大值,最小值时都可以使用 combiner,但是做平均值计算则不能使用 combiner。
不使用 combiner 的情况:
使用 combiner 的情况:
对每个map在本地做提前聚合,从而减少到reduce的网络传输的数据量。
可以看到使用 combiner 的时候,需要传输到 reducer 中的数据由 12keys,降低到 10keys。降低的幅度取决于你 keys 的重复率,下文词频统计案例会演示用 combiner 降低数百倍的传输量。
具体实现步骤
1、自定义一个combiner继承Reducer,重写reduce方法
2、在job中设置: job.setCombinerClass(CustomCombiner.class)
combiner能够应用的前提是不能影响最终的业务逻辑 ,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来。下述场景禁止使用,不仅优化了数据量,还改变了最终的结果
Partitioner
分区按照一定的key规则分区,如果分区的key不均衡,就会出现常见的数据倾斜
我们一般增加随机数,但是这样一般会导致聚合的不够充分。
所以一般可以嵌套MR,每一次MR一般都会指数级降低数据量。每次MR的输出作为下次MR的输入。这样就可以了。
partitioner 可以理解成分类器,将 map 的输出按照 key 值的不同分别分给对应的 reducer,支持自定义实现,下文案例会给出演示。
在默认情况下,不管map阶段有多少个并发执行task,到reduce阶段,所有的结果都将有一个reduce来处理,并且最终结果输出到一个文件中
执行流程如下图:
只有一个reduce,可能会造成计算性能问题
修改reduceTask个数 默认为1,可以在MR中可以通过Job的方法修改
比如修改成6,则生成文件如下:
流程如下:
分区概念 当MapReduce中有多个reducetask执行的时候,此时maptask的输出就会面临一个问题:究竟将自己的输出数据交给哪一个reducetask来处理,这就是所谓的数据分区 (partition)问题。
默认分区规则: MapReduce默认分区规则是HashPartitioner(哈希分区) 。跟map输出的数据key有关
实际打开中reduce的个数是按实际数仓数据量设置的(每个reduce能够聚合的数据量默认是1个G)。
MapReduce单词统计案例
MR经典场景
案例介绍 这里给出一个经典的词频统计的案例:统计如下样本数据中每个单词出现的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive
工具类 WordCountDataUtils,用于模拟产生词频统计的样本,生成的文件支持输出到本地或者直接写到 HDFS 上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 package com.nbchen.hadoop.demo.utils;import org.apache.commons.lang3.StringUtils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import java.io.IOException;import java.net.URI;import java.nio.file.Files;import java.nio.file.Paths;import java.nio.file.StandardOpenOption;import java.util.Arrays;import java.util.Collections;import java.util.List;import java.util.Random;public class WordCountDataUtils { public static final List<String> WORD_LIST = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private static String generateData () { StringBuilder builder = new StringBuilder (); for (int i = 0 ; i < 1000 ; i++) { Collections.shuffle(WORD_LIST); Random random = new Random (); int endIndex = random.nextInt(WORD_LIST.size()) % (WORD_LIST.size()) + 1 ; String line = StringUtils.join(WORD_LIST.toArray(), "\t" , 0 , endIndex); builder.append(line).append("\n" ); } return builder.toString(); } private static void generateDataToLocal (String outputPath) { try { java.nio.file.Path path = Paths.get(outputPath); if (Files.exists(path)) { Files.delete(path); } Files.write(path, generateData().getBytes(), StandardOpenOption.CREATE); } catch (IOException e) { e.printStackTrace(); } } private static void generateDataToHDFS (String hdfsUrl, String user, String outputPathString) { FileSystem fileSystem = null ; try { fileSystem = FileSystem.get(new URI (hdfsUrl), new Configuration (), user); Path outputPath = new Path (outputPathString); if (fileSystem.exists(outputPath)) { fileSystem.delete(outputPath, true ); } FSDataOutputStream out = fileSystem.create(outputPath); out.write(generateData().getBytes()); out.flush(); out.close(); fileSystem.close(); } catch (Exception e) { e.printStackTrace(); } } public static void main (String[] args) { generateDataToHDFS("hdfs://192.168.0.107:8020" , "root" , "/wordcount/input.txt" ); } }
项目依赖 想要进行 MapReduce 编程,需要导入 hadoop-client 依赖:
1 2 3 4 5 <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > ${hadoop.version}</version > </dependency >
WordCountMapper
SQL中分组条件封装成对象,要求和的当成值(对象)往后传:https://blog.csdn.net/qq_15076569/article/details/84206393
将每行数据按照指定分隔符进行拆分。这里需要注意在 MapReduce 中必须使用 Hadoop 定义的类型,因为 Hadoop 预定义的类型都是可序列化,可比较的,所有类型均实现了 WritableComparable 接口。
1 2 3 4 5 6 7 8 9 public class WordCountMapper extends Mapper <LongWritable, Text, Text, IntWritable> { @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split("\t" ); for (String word : words) { context.write(new Text (word), new IntWritable (1 )); } } }
将传给你的K1,V1转成你认为合理的K2,V2.
WordCountMapper 对应下图的 Mapping 操作:
WordCountMapper 继承自 Mapper 类,这是一个泛型类,定义如下:
1 2 3 4 5 WordCountMapper extends Mapper <LongWritable, Text, Text, IntWritable> public class Mapper <KEYIN, VALUEIN, KEYOUT, VALUEOUT> { ...... }
KEYIN : mapping 输入 key 的类型,即每行的偏移量 (每行第一个字符在整个文本中的位置 ),Long 类型,对应 Hadoop 中的 LongWritable 类型;VALUEIN : mapping 输入 value 的类型,即每行数据 ;String 类型,对应 Hadoop 中 Text 类型;KEYOUT :mapping 输出的 key 的类型,即每个单词 ;String 类型,对应 Hadoop 中 Text 类型;VALUEOUT :mapping 输出 value 的类型,即每个单词出现的次数 ;这里用 int 类型,对应 IntWritable 类型。
WordCountReducer 在 Reduce 中进行单词出现次数的统计:
1 2 3 4 5 6 7 8 9 10 11 public class WordCountReducer extends Reducer <Text, IntWritable, Text, IntWritable> { @Override protected void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0 ; for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable (count)); } }
如下图,shuffling 的输出是 reduce 的输入。这里的 key 是每个单词,values 是一个可迭代的数据类型,类似 (1,1,1,...)。
将拿到的K2,V3转成你想要的K3,V3.
WordCountApp 组装 MapReduce 作业,并提交到服务器运行,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public class WordCountApp { private static final String HDFS_URL = "hdfs://node1:8020" ; private static final String HADOOP_USER_NAME = "root" ; public static void main (String[] args) throws Exception { if (args.length < 2 ) { System.out.println("Input and output paths are necessary!" ); return ; } System.setProperty("HADOOP_USER_NAME" , HADOOP_USER_NAME); Configuration configuration = new Configuration (); configuration.set("fs.defaultFS" , HDFS_URL); Job job = Job.getInstance(configuration); job.setJarByClass(WordCountApp.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileSystem fileSystem = FileSystem.get(new URI (HDFS_URL), configuration, HADOOP_USER_NAME); Path outputPath = new Path (args[1 ]); if (fileSystem.exists(outputPath)) { fileSystem.delete(outputPath, true ); } FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, outputPath); boolean result = job.waitForCompletion(true ); fileSystem.close(); System.exit(result ? 0 : -1 ); } }
需要注意的是:如果不设置 Mapper 操作的输出类型,则程序默认它和 Reducer 操作输出的类型相同。
提交到服务器运行
在实际开发中,可以在本机配置 hadoop 开发环境(windows上安装hadoop),然后用本地文件测试(file:///),直接在 IDE 中启动进行测试。
这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除 Hadoop 外的第三方依赖,直接打包即可:
使用以下命令提交作业:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \ com.nbchen.hadoop.demo.WordCountApp \ /wordcount/input.txt /wordcount/output/WordCountApp /wordcount/input.txt => 指的是在hdfs的位置 /wordcount/output/WordCountApp => 指的是在hdfs输出的路径 比如: 普通统计 hadoop jar /opt/data/testdata/hadoop_test_data/hadoop-word-count-1.0.jar com.heibaiying.WordCountApp \ /mapreduce/input/wordcount/input.txt \ /mapreduce/output/wordcount 分区统计 hadoop jar /opt/data/testdata/hadoop_test_data/hadoop-word-count-1.0.jar com.heibaiying.WordCountCombinerPartitionerApp \ /mapreduce/input/wordcount/input.txt \ /mapreduce/output/wordcount
作业完成后查看 HDFS 上生成目录:
1 2 3 4 5 # 查看目录 hadoop fs -ls /wordcount/output/WordCountApp # 查看统计结果 hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000
词频统计案例进阶之Combiner
规约的代码和reduce的代码一样的话,只需要设置一行代码就行。
代码实现 想要使用 combiner 功能只要在组装作业时,添加下面一行代码即可:
1 2 job.setCombinerClass(WordCountReducer.class);
执行结果 加入 combiner 后统计结果是不会有变化的,但是可以从打印的日志看出 combiner 的效果:
没有加入 combiner 的打印日志:
加入 combiner 后的打印日志如下:
这里我们只有一个输入文件并且小于 128M,所以只有一个 Map 进行处理。可以看到经过 combiner 后,records 由 3519 降低为 6(样本中单词种类就只有 6 种),在这个用例中 combiner 就能极大地降低需要传输的数据量。
词频统计案例进阶之Partitioner 默认的Partitioner 这里假设有个需求:将不同单词的统计结果输出到不同文件 。这种需求实际上比较常见,比如统计产品的销量时,需要将结果按照产品种类进行拆分。要实现这个功能,就需要用到自定义 Partitioner。
这里先介绍下 MapReduce 默认的分类规则:在构建 job 时候,如果不指定,默认的使用的是 HashPartitioner:对 key 值进行哈希散列并对 numReduceTasks 取余。其实现如下:
1 2 3 4 5 public class HashPartitioner <K, V> extends Partitioner <K, V> { public int getPartition (K key, V value,int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
自定义Partitioner 这里我们继承 Partitioner 自定义分类规则,这里按照单词进行分类:
1 2 3 4 5 public class CustomPartitioner extends Partitioner <Text, IntWritable> { public int getPartition (Text text, IntWritable intWritable, int numPartitions) { return WordCountDataUtils.WORD_LIST.indexOf(text.toString()); } }
在入口类构建 job 时候指定使用我们自己的分类规则,并设置 reduce 的个数:
1 2 3 4 job.setPartitionerClass(CustomPartitioner.class); job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());
正常情况下: 分区的个数 = reducetask个数。
分区的个数 > reducetask个数 程序执行报错
分区的个数 < reducetask个数 有空文件产生
执行结果 执行结果如下,分别生成 6 个文件,每个文件中为对应单词的统计结果:
reduce的partition就相当于map后用多个reduce分担压力。
然后如果多层partition,就是分而治之的思想体现。多层可以参考SQL的子查询嵌套。也就是hive SQL转为MapReduce的情况。
稍微复杂的例子: https://blog.csdn.net/baidu_41833099/article/details/121602844
定位:了解一下就行,这玩意一般不写,这里只是简单的例子,更复杂的例子维护成本巨高:https://zhuanlan.zhihu.com/p/195715234
案例:美国新冠疫情COVID-19统计 MapReduce 自定义分区 需求:将美国每个州的疫情数据输出到各自不同的文件中,即一个州的数据在一个结果文件中。
分析:
1 输出到不同文件中-->reducetask有多个(>2)-->默认只有1个,如何有多个?--->可以设置,job.setNumReduceTasks(N)--->当有多个reducetask 意味着数据分区---->默认分区规则是什么?hashPartitioner--->默认分区规则符合你的业务需求么?---->符合,直接使用--->不符合,自定义分区。
partitioner
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class CustomPartitioner extends Partitioner <Text, IntWritable> { public static HashMap<String, Integer> stateMap = new HashMap <String, Integer>(); static { stateMap.put("Alabama" , 0 ); stateMap.put("Arkansas" , 1 ); stateMap.put("California" , 2 ); stateMap.put("Florida" , 3 ); stateMap.put("Indiana" , 4 ); } @Override public int getPartition (Text text, IntWritable intWritable, int numPartitions) { Integer code = stateMap.get(text.toString()); if (code!=null ) { return code; } return 5 ; } }
mapper
它自动给你了k1,v1,我们要写一个map方法,将k1,v1转成合适的k2,v2
1 2 3 4 5 6 7 8 9 10 11 public class CovidPartitionMapper extends Mapper <LongWritable, Text, Text, Text> { Text outkey = new Text (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] splits = value.toString().split("," ); outkey.set(splits[2 ]); context.write(outkey,value); } } 解析到每一行数据,每行的第3 列是州,map时用州作为key,每行数据作为value
reducer
然后通过shuffle后,拿到k2,v2,我们要写一个reduce方法,将k2,v2转成合适的k3,v3
1 2 3 4 5 6 7 8 9 public class CovidPartitionReducer extends Reducer <Text, Text, Text, NullWritable> { @Override protected void reduce (Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { context.write(value, NullWritable.get()); } } } 解析到一行数据,reduce时拿到这一行的每个列值作为key,统计的逻辑作为value(此处value不做逻辑处理,设置为空)
MapReduce 自定义类
一般V2会封装成一个Javabean类传递,更方便。(传递的类在分布式网络中传输,一定要可以序列化和反序列化)
需求
1 2 3 4 5 6 7 8 9 10 11 根据疫情数据,统计美国每个州的确诊病例数和死亡病例数 时间 县名 州名, 县编码 确诊人数 死亡人数 2021-01-28,Autauga,Alabama, 01001, 5554, 69 select 州名,sum(确诊人数),sum(死亡人数) from t_covid group by 州名 Alabama 192898 345 Arkansa 25109 875
思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 1 、将州名作为K2,将确诊人数 死亡人数作为V22 、可以将V2封装成一个Java类,如果一个自定义类出现在MapReduce中,必须保证该类能够被序列化和反序列化--方式1 :实现Writable #应用场景:JavaBean类对象不作为K2,不需要能够被排序 public class CovidBean implements Writable { @Override public void write (DataOutput out) throws IOException { } @Override public void readFields (DataInput in) throws IOException { } } --方式2 :实现WritableComparable #应用场景:JavaBean类对象作为K2,需要能够被排序 public class CovidBean implements WritableComparable <CovidBean> { @Override public int compareTo (CovidBean o) { return 0 ; } @Override public void write (DataOutput out) throws IOException { } @Override public void readFields (DataInput in) throws IOException { } }
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 package pack07_covid_bean;import org.apache.hadoop.io.Writable;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class CovidBean implements Writable { private int cases; private int deaths; public CovidBean (int cases, int deaths) { this .cases = cases; this .deaths = deaths; } public CovidBean () { } public int getCases () { return cases; } public void setCases (int cases) { this .cases = cases; } public int getDeaths () { return deaths; } public void setDeaths (int deaths) { this .deaths = deaths; } @Override public void write (DataOutput out) throws IOException { out.writeInt(cases); out.writeInt(deaths); } @Override public void readFields (DataInput in) throws IOException { this .cases = in.readInt(); this .deaths = in.readInt(); } @Override public String toString () { return cases + "\t" + deaths ; } } package pack07_covid_bean;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class CovidMapper extends Mapper <LongWritable, Text,Text,CovidBean> { @Override protected void map (LongWritable key, Text value, Mapper<LongWritable, Text, Text, CovidBean>.Context context) throws IOException, InterruptedException { String[] array = value.toString().split("," ); if (array.length != 6 ){ return ; } String k2 = array[2 ]; CovidBean v2 = new CovidBean (); v2.setCases(Integer.parseInt(array[4 ])); v2.setDeaths(Integer.parseInt(array[5 ])); context.write(new Text (k2),v2); } } package pack07_covid_bean;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class CovidReducer extends Reducer <Text,CovidBean,Text,CovidBean> { @Override protected void reduce (Text key, Iterable<CovidBean> values, Reducer<Text, CovidBean, Text, CovidBean>.Context context) throws IOException, InterruptedException { int casesCount= 0 ; int deathsCount= 0 ; for (CovidBean value : values) { casesCount += value.getCases(); deathsCount += value.getDeaths(); } CovidBean covidBean = new CovidBean (); covidBean.setCases(casesCount); covidBean.setDeaths(deathsCount); context.write(key,covidBean); } } package pack07_covid_bean;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import pack05_wordcount.WorCountMapper;import pack05_wordcount.WordCountDriver;import pack05_wordcount.WordCountReducer;import java.net.URI;public class CovidDriver { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "covid_bean_demo" ); job.setJarByClass(CovidDriver.class); FileInputFormat.addInputPath(job, new Path (args[0 ])); job.setMapperClass(CovidMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(CovidBean.class); job.setReducerClass(CovidReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(CovidBean.class); String fsType = "file:///" ; String outputPath = args[1 ]; URI uri = new URI (fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path (outputPath)); if (flag == true ){ fileSystem.delete(new Path (outputPath),true ); } FileOutputFormat.setOutputPath(job, new Path (outputPath)); boolean resultFlag = job.waitForCompletion(true ); System.exit(resultFlag ? 0 :1 ); } }
MapReduce 自定义排序 现有美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
1 2 3 4 5 6 7 8 9 10 11 2021-01-28,Juneau City and Borough,Alaska,02110,1108,3 2021-01-28,Kenai Peninsula Borough,Alaska,02122,3866,18 2021-01-28,Ketchikan Gateway Borough,Alaska,02130,272,1 2021-01-28,Kodiak Island Borough,Alaska,02150,1021,5 2021-01-28,Kusilvak Census Area,Alaska,02158,1099,3 2021-01-28,Lake and Peninsula Borough,Alaska,02164,5,0 2021-01-28,Matanuska-Susitna Borough,Alaska,02170,7406,27 2021-01-28,Nome Census Area,Alaska,02180,307,0 2021-01-28,North Slope Borough,Alaska,02185,973,3 2021-01-28,Northwest Arctic Borough,Alaska,02188,567,1 2021-01-28,Petersburg Borough,Alaska,02195,43,0
字段含义如下:date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)。
需求
将美国2021-01-28,每个州state的确诊案例数进行倒序排序 。
1 2 3 4 5 6 7 8 #数据 Alabama 452734 7340 Alaska 53524 253 Arizona 745976 12861 #要求 基于以上数据对确诊病例数进行降序排序,如果确诊病例数相同 ,则按照死亡病例数升序排序 select * from A order by cases desc , deaths asc;
思路
1 2 1、MR的排序只能按照K2排序,哪个字段要参与排序,则哪个字段就应该包含在K2中 2、如果你自定义类作为K2,则必须指定排序规则,实现WritableComparable接口,重写compareTo方法,其他的地方不需要再做任何的设置
分析
如果你的需求中需要根据某个属性进行排序 ,不妨把这个属性作为key。因为MapReduce中key有默认排序行为的。但是需要进行如下考虑:
如果你的需求是正序,并且数据类型是Hadoop封装好的基本类型。这种情况下不需要任何修改,直接使用基本类型作为key即可。因为Hadoop封装好的类型已经实现了排序规则。
比如:LongWritable类型:
如果你的需求是倒序,或者数据类型是自定义对象。需要重写排序规则。需要对象实现Comparable接口,重写ComparTo方法 。
1 2 3 4 5 6 compareTo方法用于将当前对象与方法的参数进行比较。 如果指定的数与参数相等返回0。 如果指定的数小于参数返回 -1。 如果指定的数大于参数返回 1。 例如:o1.compareTo(o2); 返回正数的话,当前对象(调用compareTo方法的对象o1)要排在比较对象(compareTo传参对象o2)后面,返回负数的话,放在前面。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 package pack08_covid_sort;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class CovidSortBean implements WritableComparable <CovidSortBean> { private String state; private int cases; private int deaths; public String getState () { return state; } public void setState (String state) { this .state = state; } public int getCases () { return cases; } public void setCases (int cases) { this .cases = cases; } public int getDeaths () { return deaths; } public void setDeaths (int deaths) { this .deaths = deaths; } @Override public String toString () { return state + "\t" + cases + "\t" +deaths ; } @Override public int compareTo (CovidSortBean o) { int result = this .cases - o.cases; if (result == 0 ){ return this .deaths - o.deaths; } return result * -1 ; } @Override public void write (DataOutput out) throws IOException { out.writeUTF(state); out.writeInt(cases); out.writeInt(deaths); } @Override public void readFields (DataInput in) throws IOException { this .state = in.readUTF(); this .cases = in.readInt(); this .deaths = in.readInt(); } } #---------------------------------------- package pack08_covid_sort;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class CovidSortMapper extends Mapper <LongWritable, Text,CovidSortBean, NullWritable> { @Override protected void map (LongWritable key, Text value, Mapper<LongWritable, Text, CovidSortBean, NullWritable>.Context context) throws IOException, InterruptedException { String[] array = value.toString().split("\t" ); CovidSortBean k2 = new CovidSortBean (); k2.setState(array[0 ]); k2.setCases(Integer.parseInt(array[1 ])); k2.setDeaths(Integer.parseInt(array[2 ])); context.write(k2,NullWritable.get()); } } #---------------------------------- package pack08_covid_sort;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class CovidSortReducer extends Reducer <CovidSortBean, NullWritable,CovidSortBean,NullWritable> { @Override protected void reduce (CovidSortBean key, Iterable<NullWritable> values, Reducer<CovidSortBean, NullWritable, CovidSortBean, NullWritable>.Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } } #---------------------------------- package pack08_covid_sort;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;public class CovidSortDriver { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "covid_sort_demo" ); job.setJarByClass(CovidSortDriver.class); FileInputFormat.addInputPath(job, new Path (args[0 ])); job.setMapperClass(CovidSortMapper.class); job.setMapOutputKeyClass(CovidSortBean.class); job.setMapOutputValueClass(NullWritable.class); job.setReducerClass(CovidSortReducer.class); job.setOutputKeyClass(CovidSortBean.class); job.setOutputValueClass(NullWritable.class); String fsType = "file:///" ; String outputPath = args[1 ]; URI uri = new URI (fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path (outputPath)); if (flag == true ){ fileSystem.delete(new Path (outputPath),true ); } FileOutputFormat.setOutputPath(job, new Path (outputPath)); boolean resultFlag = job.waitForCompletion(true ); System.exit(resultFlag ? 0 :1 ); } }
MapReduce 串联 介绍
1 2 当我们在使用MapReduce进行大数据分析时,很多时候使用一个MR并不能完成分析任务,需要使用多个MR进行串联 则我们可以使用MR提供的Job控制器来实现多个MR的依赖串联执行
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 package pack09_mapreduce_series;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import pack07_covid_bean.CovidBean;import pack07_covid_bean.CovidDriver;import pack07_covid_bean.CovidMapper;import pack07_covid_bean.CovidReducer;import pack08_covid_sort.CovidSortBean;import pack08_covid_sort.CovidSortDriver;import pack08_covid_sort.CovidSortMapper;import pack08_covid_sort.CovidSortReducer;import java.net.URI;public class MapReduceSeriesJob { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); Job job1 = Job.getInstance(configuration, "covid_bean_demo" ); job1.setJarByClass(CovidDriver.class); FileInputFormat.addInputPath(job1, new Path (args[0 ])); job1.setMapperClass(CovidMapper.class); job1.setMapOutputKeyClass(Text.class); job1.setMapOutputValueClass(CovidBean.class); job1.setReducerClass(CovidReducer.class); job1.setOutputKeyClass(Text.class); job1.setOutputValueClass(CovidBean.class); String fsType = "file:///" ; String outputPath = args[1 ]; URI uri = new URI (fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path (outputPath)); if (flag == true ){ fileSystem.delete(new Path (outputPath),true ); } FileOutputFormat.setOutputPath(job1, new Path (outputPath)); ControlledJob cj1 = new ControlledJob (configuration); cj1.setJob(job1); Job job2 = Job.getInstance(configuration, "covid_sort_demo" ); job2.setJarByClass(CovidSortDriver.class); FileInputFormat.addInputPath(job2, new Path (args[1 ])); job2.setMapperClass(CovidSortMapper.class); job2.setMapOutputKeyClass(CovidSortBean.class); job2.setMapOutputValueClass(NullWritable.class); job2.setReducerClass(CovidSortReducer.class); job2.setOutputKeyClass(CovidSortBean.class); job2.setOutputValueClass(NullWritable.class); String fsType2 = "file:///" ; String outputPath2 = args[2 ]; URI uri2 = new URI (fsType); FileSystem fileSystem2 = FileSystem.get(uri2, configuration); boolean flag2 = fileSystem.exists(new Path (outputPath2)); if (flag2 == true ){ fileSystem2.delete(new Path (outputPath2),true ); } FileOutputFormat.setOutputPath(job2, new Path (outputPath2)); ControlledJob cj2 = new ControlledJob (configuration); cj2.setJob(job2); cj2.addDependingJob(cj1); JobControl jc = new JobControl ("myctrl" ); jc.addJob(cj1); jc.addJob(cj2); Thread t = new Thread (jc); t.start(); while (true ){ if (jc.allFinished()){ System.out.println(jc.getSuccessfulJobList()); jc.stop(); break ; } } } }
MapReduce Combiner combiner规约此处要做的事情和reduce一样,所以直接设置reduce,让每个map提前做本地的reduce操作
1 2 job.setCombinerClass(CovidPartitionReducer.class);
MapReduce 自定义分组 1 2 3 4 5 6 7 8 9 10 11 12 1、分组是对Map端传输过来的数据进行去重聚合 # K2 V2 hello 1 hello 1 --分组--> hello [1,1,1] --reduce方法--> hello 3 hello 1 world 1 2、分区和分组区别? 分区是决定K2和V2去往哪一个Reduce进行处理 分组是在同一个Reduce内部进行聚合 3、一般默认的分组就能完成分析操作,但是有时候在特定场景下,默认的分组不能满足我们的需求,则需要我们自定义分组
分组在发生在reduce阶段,决定了同一个reduce中哪些数据将组成一组去调用reduce方法 处理。默认分组规则是:key相同的就会分为一组(前后两个key直接比较是否相等)。
需要注意的是,在reduce阶段进行分组之前,因为进行数据排序行为,因此排序+分组将会使得key一样的数据一定被分到同一组,一组去调用reduce方法处理。
此外,用户还可以自定义分组规则:
写类继承 WritableComparator ,重写Compare方法。
只要Compare方法返回为0,MapReduce框架在分组的时候就会认为前后两个相等,分为一组。还需要在job对象中进行设置 才能让自己的重写分组类生效。
1 2 1. 写类继承 WritableComparator,重写Compare方法。2. job.setGroupingComparatorClass(xxxx.class);
需求
找出美国2021-01-28,每个州state的确诊案例数最多的县county是哪一个。该问题也是俗称的TopN问题。
1 2 3 4 5 6 找出美国每个州state的确诊案例数最多的县county是哪一个。该问题也是俗称的TopN问题。 select * from t_covid order by cases desc limit 1 ;找出美国每个州state的确诊案例数最多前三个县county是哪些。该问题也是俗称的TopN问题。 select * from t_covid order by cases desc limit 3 ;
分析
自定义对象,在map阶段将”州state和累计确诊病例数cases”作为key输出,重写对象的排序规则,首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序 ,发送到reduce。
在reduce端利用自定义分组规则,将州state相同的分为一组 ,然后取第一个即是最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 package com.nbchen.custom_group;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class CovidBean implements WritableComparable <CovidBean> { private String state; private String county; private long cases; public CovidBean () { } public CovidBean (String state, String county, long cases) { this .state = state; this .county = county; this .cases = cases; } public void set (String state, String county, long cases) { this .state = state; this .county = county; this .cases = cases; } public String getState () { return state; } public void setState (String state) { this .state = state; } public String getCounty () { return county; } public void setCounty (String county) { this .county = county; } public long getCases () { return cases; } public void setCases (long cases) { this .cases = cases; } @Override public String toString () { return "CovidBean{" + "state='" + state + '\'' + ", county='" + county + '\'' + ", cases=" + cases + '}' ; } @Override public int compareTo (CovidBean o) { int result ; int i = state.compareTo(o.getState()); if ( i > 0 ) { result =1 ; } else if (i <0 ) { result = -1 ; } else { result = cases > o.getCases() ? -1 : 1 ; } return result; } @Override public void write (DataOutput out) throws IOException { out.writeUTF(state); out.writeUTF(county); out.writeLong(cases); } @Override public void readFields (DataInput in) throws IOException { this .state =in.readUTF(); this .county =in.readUTF(); this .cases =in.readLong(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.nbchen.custom_group;import java.io.IOException;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class CovidTop1Mapper extends Mapper <LongWritable, Text, CovidBean, NullWritable> { CovidBean outKey = new CovidBean (); NullWritable outValue = NullWritable.get(); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("," ); outKey.set(fields[2 ],fields[1 ],Long.parseLong(fields[4 ])); context.write(outKey,outValue); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.nbchen.custom_group;import org.apache.hadoop.io.WritableComparable;import org.apache.hadoop.io.WritableComparator;public class CovidGroupingComparator extends WritableComparator { protected CovidGroupingComparator () { super (CovidBean.class,true ); } @Override public int compare (WritableComparable a, WritableComparable b) { CovidBean aBean = (CovidBean) a; CovidBean bBean = (CovidBean) b; return aBean.getState().compareTo(bBean.getState()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.nbchen.custom_group;import java.io.IOException;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Reducer;public class CovidTop1Reducer extends Reducer <CovidBean, NullWritable,CovidBean,NullWritable> { @Override protected void reduce (CovidBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 package com.nbchen.custom_group;import java.net.URI;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class CovidTop1Driver { private static final String HDFS_URL = "hdfs://node1:8020" ; private static final String HADOOP_USER_NAME = "root" ; public static void main (String[] args) throws Exception { if (args.length < 2 ) { System.out.println("Input and output paths are necessary!" ); return ; } System.setProperty("HADOOP_USER_NAME" , HADOOP_USER_NAME); Configuration configuration = new Configuration (); configuration.set("fs.defaultFS" , HDFS_URL); Job job = Job.getInstance(configuration); job.setJarByClass(CovidTop1Driver.class); job.setMapperClass(CovidTop1Mapper.class); job.setReducerClass(CovidTop1Reducer.class); job.setMapOutputKeyClass(CovidBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(CovidBean.class); job.setOutputValueClass(NullWritable.class); job.setGroupingComparatorClass(CovidGroupingComparator.class); FileSystem fileSystem = FileSystem.get(new URI (HDFS_URL), configuration, HADOOP_USER_NAME); Path outputPath = new Path (args[1 ]); if (fileSystem.exists(outputPath)) { fileSystem.delete(outputPath, true ); } FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, outputPath); boolean result = job.waitForCompletion(true ); fileSystem.close(); System.exit(result ? 0 : -1 ); } }
MapReduce 自定义分组 TOPN 问题 需求
找出美国2021-01-28,每个州state的确诊案例数最多的县county前3个。Top3问题。
分析
自定义对象,在map阶段将“州state和累计确诊病例数cases”作为key输出,重写对象的排序规则,首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序 ,发送到reduce。
在reduce端利用自定义分组规则,将州state相同的分为一组,然后遍历取值,取出每组中的前3个即可。
为了验证验证结果方便,可以在输出的时候以cases作为value,实际上为空即可,value并不实际意义。
自定义对象、自定义分组类
这两个和上述的Top1一样,此处就不再重复编写。可以直接使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class CovidTopNMapper extends Mapper <LongWritable, Text, CovidBean,LongWritable> { CovidBean outKey = new CovidBean (); LongWritable outValue = new LongWritable (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("," ); outKey.set(fields[2 ],fields[1 ],Long.parseLong(fields[4 ])); outValue.set(Long.parseLong(fields[4 ])); context.write(outKey,outValue); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class CovidTopNReducer extends Reducer <CovidBean, LongWritable,CovidBean,LongWritable> { @Override protected void reduce (CovidBean key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { int num = 0 ; for (LongWritable value : values) { if (num < 3 ){ context.write(key,value); num++; }else { return ; } } } }
MapReduce的Join操作 Reduce端join 介绍
1 2 3 4 1、Reduce Join是在Reduce完成Join操作 2、Reduce端Join,Join的文件在Map阶段K2就是Join字段 3、Reduce会存在数据倾斜的风险,如果存在该文件,则可以使用MapJoin来解决 4、Reduce端Join的代码必须放在集群运行,不能在本地运行
案例思路
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 package pack12_reduce_join;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.InputSplit;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class ReduceJoinMapper extends Mapper <LongWritable, Text, Text, Text> { @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit fileSplit = (FileSplit) context.getInputSplit(); String fileName = fileSplit.getPath().getName(); String[] array = value.toString().split("\\|" ); if ("itheima_order_goods.txt" .equals(fileName)) { String k2 = array[1 ]; String v2 = "o_" +array[0 ] + "\t" + array[2 ]; context.write(new Text (k2), new Text (v2)); } if ("itheima_goods.txt" .equals(fileName)) { String k2 = array[0 ]; String v2 = "g_" +array[0 ] + "\t" + array[2 ]; context.write(new Text (k2), new Text (v2)); } } } package pack12_reduce_join;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;public class ReduceJoinReducer extends Reducer <Text,Text,Text, NullWritable> { ArrayList<String> orderList = new ArrayList <>(); @Override protected void reduce (Text key, Iterable<Text> values, Reducer<Text, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { orderList.clear(); String goods_value="" ; for (Text value : values) { if (value.toString().startsWith("o_" )){ orderList.add(value.toString().substring(2 )); } if (value.toString().startsWith("g_" )){ goods_value = value.toString().substring(2 ); } } for (String order : orderList) { System.out.println(order); context.write(new Text (order+"\t" +goods_value),NullWritable.get()); } } } package pack12_reduce_join;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;public class ReduceJoinDriver { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "reduce_join_demo" ); job.setJarByClass(ReduceJoinDriver.class); FileInputFormat.addInputPath(job, new Path (args[0 ])); job.setMapperClass(ReduceJoinMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(ReduceJoinReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); String fsType = "file:///" ; String outputPath = args[1 ]; URI uri = new URI (fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path (outputPath)); if (flag == true ){ fileSystem.delete(new Path (outputPath),true ); } FileOutputFormat.setOutputPath(job, new Path (outputPath)); boolean resultFlag = job.waitForCompletion(true ); System.exit(resultFlag ? 0 :1 ); } }
Map端Join
reduce段join如果数据量大都涌过去,可能会造成问题,所以可以先在map端做join
介绍
1 2 3 4 5 1、Map端join就是在Map端将Join操作完成 2、Map端join的前提是小表Join大表,小表的大小默认是20M 3、Map端Join需要将小表存在在分布式缓存中(所以大表不合适),然后读取到每一个MapTask的本地内存的Map集合中 4、Map端Join一般不会数据倾斜问题,因为Map的数量是由数据量大小自动决定的 5、Map端Join代码不需要Reduce
案例思路
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 package pack13_map_join;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;import java.util.HashMap;public class MapJoinMapper extends Mapper <LongWritable, Text,Text,NullWritable> { HashMap<String, String> goodsMap = new HashMap <>(); @Override protected void setup (Context context) throws IOException, InterruptedException { BufferedReader bufferedReader = new BufferedReader (new InputStreamReader (new FileInputStream ("itheima_goods.txt" ))); String line = null ; while ((line = bufferedReader.readLine()) != null ){ String[] array = line.split("\\|" ); goodsMap.put(array[0 ], array[2 ]); } } @Override protected void map (LongWritable key, Text value,Context context) throws IOException, InterruptedException { String[] array = value.toString().split("\\|" ); String k2 = array[1 ]; String v2 = array[0 ] + "\t" + array[2 ]; String mapValue = goodsMap.get(k2); context.write(new Text (v2 + "\t" + mapValue), NullWritable.get()); } } package pack13_map_join;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;public class MapJoinDriver { public static void main (String[] args) throws Exception{ Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "map_join" ); job.setJarByClass(MapJoinDriver.class); FileInputFormat.addInputPath(job,new Path ("hdfs://node1:8020/mapreduce/input/map_join/big_file" )); job.setMapperClass(MapJoinMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.addCacheFile(new URI ("hdfs://node1:8020/mapreduce/input/map_join/small_file/itheima_goods.txt" )); Path outputPath = new Path ("hdfs://node1:8020/output/map_join" ); FileOutputFormat.setOutputPath(job,outputPath); FileSystem fileSystem = FileSystem.get(new URI ("hdfs://node1:8020" ), new Configuration ()); boolean is_exists = fileSystem.exists(outputPath); if (is_exists == true ){ fileSystem.delete(outputPath,true ); } boolean bl = job.waitForCompletion(true ); System.exit(bl ? 0 : 1 ); } }
集群资源管理器——YARN YARN简介 Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。
YARN是一个通用 资源管理系统和调度平台,可为上层应用提供统一的资源管理 (CPU,内存)和调度。
不仅仅支持MapReduce程序,理论上支持各种计算程序 。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。正是因为YARN的包容,使得其他计算框架能专注于计算性能的提升 。
YARN架构
ResourceManager ResourceManager 通常在独立的机器上以后台进程的形式运行,它是整个集群资源的主要协调者和管理者 。ResourceManager 负责给用户提交的所有应用程序分配资源,它根据应用程序优先级、队列容量、ACLs、数据位置等信息,做出决策,然后以共享的、安全的、多租户的方式制定分配策略,调度集群资源。
NodeManager NodeManager 是 YARN 集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源 和跟踪节点健康。具体如下:
启动时向 ResourceManager 注册并定时发送心跳消息,等待 ResourceManager 的指令;
维护 Container 的生命周期,监控 Container 的资源使用情况;
管理任务运行时的相关依赖,根据 ApplicationMaster 的需要,在启动 Container 之前将需要的程序及其依赖拷贝到本地。
ApplicationMaster 在用户提交一个应用程序时,YARN 会启动一个轻量级的进程 ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错 。具体如下:
根据应用的运行状态来决定动态计算资源需求;
向 ResourceManager 申请资源,监控申请的资源的使用情况;
跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
负责任务的容错。
Container Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当 AM 向 RM 申请资源时,RM 为 AM 返回的资源是用 Container 表示的。YARN 会为每个任务分配一个 Container,该任务只能使用该 Container 中描述的资源。ApplicationMaster 可在 Container 内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。
YARN工作原理简述
Client 提交作业到 YARN 上(可以是MR任务,也可以是spark任务);
Resource Manager 选择一个 Node Manager,启动一个 Container 并运行 Application Master 实例;
Application Master 根据实际需要向 Resource Manager 请求更多的 Container 资源(如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务);
Application Master 通过获取到的 Container 资源执行分布式计算。
YARN工作原理详述
1. 作业提交 client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业 (第 1 步) 。
新的作业 ID(应用 ID) 由资源管理器分配 (第 2 步)。
作业的 client 核实作业的输出, 计算输入的 split, 将作业的资源 (包括 Jar 包,配置文件, split 信息) 拷贝给 HDFS(第 3 步)。
最后, 通过调用资源管理器的 submitApplication() 来提交作业 (第 4 步)。
2. 作业初始化 当资源管理器收到 submitApplciation() 的请求时, 就将该请求发给调度器 (scheduler) , 调度器分配 container, 然后资源管理器在该 container 内启动应用管理器进程, 由节点管理器监控 (第 5 步)。
调度器
在理想情况下,应用程序提出的请求将立即得到YARN批准。但是实际中,资源是有限的,并且在繁忙的群集上 ,应用程序通常将需要等待其某些请求得到满足。YARN调度程序的工作是根据一些定义的策略为应用程序分配资源 。Scheduler ,它是ResourceManager的核心组件之一。Scheduler完全专用于调度作业,它无法跟踪应用程序的状态。
FIFO Scheduler(先进先出调度器):有些任务优先比较急就没办法,或者有个大任务跑很久,其他业务线就干等着。
Capacity Scheduler(容量调度器): Apache版yarn默认使用,根据业务线自己划分队列,大小任务互不干扰。
Fair Scheduler(公平调度器): 用户之间的公平和用户内部程序的公平。允许资源抢占、分层队列等。
如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置
MapReduce 作业的应用管理器是一个主类为 MRAppMaster 的 Java 应用,其通过创造一些 bookkeeping 对象来监控作业的进度, 得到任务的进度和完成报告 (第 6 步)。
然后其通过分布式文件系统得到由客户端计算好的输入 split(第 7 步),
然后为每个输入 split 创建一个 map 任务, 根据 mapreduce.job.reduces 创建 reduce 任务对象。
3. 任务分配 如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务。
如果不是小作业, 那么应用管理器向资源管理器请求 container 来运行所有的 map 和 reduce 任务 (第 8 步)。
这些请求是通过心跳 来传输的, 包括每个 map 任务的数据位置,比如存放输入 split 的主机名和机架 (rack),调度器利用这些信息来调度任务,尽量将任务分配给存储数据的节点, 或者分配给和存放输入 split 的节点相同机架的节点。
4. 任务运行 当一个任务由资源管理器的调度器分配给一个 container 后,应用管理器通过联系节点管理器来启动 container(第 9 步)。
任务由一个主类为 YarnChild 的 Java 应用执行, 在运行任务之前首先本地化任务需要的资源,比如作业配置,JAR 文件, 以及分布式缓存的所有文件 (第 10 步)。
最后, 运行 map 或 reduce 任务 (第 11 步)。
YarnChild 运行在一个专用的 JVM 中, 但是 YARN 不支持 JVM 重用。
5. 进度和状态更新 YARN 中的任务将其进度和状态 (包括 counter) 返回给应用管理器, 客户端每秒 (通 mapreduce.client.progressmonitor.pollinterval 设置) 向应用管理器请求进度更新, 展示给用户。
6. 作业完成 除了向应用管理器请求作业进度外, 客户端每 5 分钟都会通过调用 waitForCompletion() 来检查作业是否完成,时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后, 应用管理器和 container 会清理工作状态, OutputCommiter 的作业清理方法也会被调用。作业的信息会被作业历史服务器存储以备之后用户核查。
YARN调度度Scheduler 理想情况下,我们应用对Yarn资源的请求应该立刻得到满足, 但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler 。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
在Yarn中有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,Fair Scheduler 。
FIFO Scheduler
FIFO Scheduler(先进先出调度器):有些任务优先比较急就没办法,或者有个大任务跑很久,其他业务线就干等着。
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出 队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
Capacity Scheduler(Apache)
Capacity Scheduler(容量调度器): Apache版yarn默认使用,根据业务线自己划分队列,大小任务互不干扰。
Capacity Scheduler调度器以队列为单位划分资源 。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的 ,如下图
default 队列占30%资源,analyst 和dev 分别占40%和30%资源;类似的,analyst 和dev 各有两个子队列,子队列在父队列的基础上再分配资源。
队列里的应用以FIFO方式调度,每个队列可设定一定比例的资源最低保证和使用上限;
每个用户也可以设定一定的资源使用上限以防止资源滥用;
而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
调度器配置 CapacityScheduler的配置项包括两部分,其中一部分在yarn-site.xml中,主要用于配置YARN集群使用的调度器;另一部分在capacity-scheduler.xml配置文件中,主要用于配置各个队列的资源量、权重等信息。
1、开启调度器 在ResourceManager中配置使用的调度器,修改HADOOP_CONF/yarn-site.xml ,设置属性:
1 2 3 4 <property > <name > yarn.resourcemanager.scheduler.class</name > <value > org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value > </property >
2、配置队列 调度器的核心就是队列的分配和使用 ,修改HADOOP_CONF/capacity-scheduler.xml 可以配置队列。Capacity调度器默认有一个预定义的队列:root ,所有的队列都是它的子队列 。队列的分配支持层次化的配置 ,使用.来进行分割,比如:yarn.scheduler.capacity.<queue-path>.queues
案例:root下面有三个子队列
3、队列属性
系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是100%。
系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是-1,即禁用。
比如,设置成25%。那么如果有两个用户提交任务,那么每个任务资源不超过50%。如果3个用户提交任务,那么每个任务资源不超过33%。如果4个用户提交任务,那么每个任务资源不超过25%。如果5个用户提交任务,那么第五个用户需要等待才能提交。默认是100,即不去做限制。
如果设置为50,那么每个用户使用的资源最多就是50%。
4、运行和提交应用限制 设置系统中可以同时运行和等待的应用数量,默认是10000
设置有多少资源可以用来运行app master,即控制当前激活状态的应用,默认是10%。
5、队列管理
队列的状态,可以使RUNNING或者STOPPED
如果队列是STOPPED状态,那么新应用不会提交到该队列或者子队列 。同样,如果root被设置成STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭 。
限定哪些Linux用户/用户组可向给定队列中提交应用程序。如果一个用户可以向该队列提交,那么也可以提交任务到它的子队列。配置该属性时,用户之间或用户组之间用“,”分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。
为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。
6、基于用户/组的队列映射 映射单个用户或者用户组到一个队列
语法:[u or g]:[name]:[queue_name][,next_mapping]*,列表可以多个,之间以逗号分隔。%user放在[name]部分,表示已经提交应用的用户。如果队列名称和用户一样,那可以使用%user表示队列。如果队列名称和用户主组一样,可以使用%primary_group表示队列。 u:%user:%user 表示-已经提交应用的用户,映射到和用户名称一样的队列上。 u:user2:%primary_group表示user2提交的应用映射到user2主组名称一样的队列上。如果用户组并不多,队列也不多,建议还是使用简单的语法,而不要使用带%的。
定义针对特定用户的队列是否可以被覆盖,默认值为false。
7、其他属性
默认是org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和CPU。
节点局部性延迟,在容器企图调度本地机栈容器后(失败),还可以错过错过多少次的调度次数。一般都是跟集群的节点数量有关。默认40(一个机架上的节点数)一旦设置完这些队列属性,就可以在web ui上看到了。
8、修改队列配置 如果想要修改队列或者调度器的配置,可以修改HADOOP_CONF_DIR/capacity-scheduler.xml,修改完成后,需要执行下面的命令:
1 HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues
注意事项:
案例:Capacity调度器配置 假设有如下层次的队列:
a、Capacity Scheduler 配置 上图中队列的一个调度器配置文件HADOOP_CONF/capacity-scheduler.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?xml version="1.0" ?> <configuration > <property > <name > yarn.scheduler.capacity.root.queues</name > <value > prod,dev</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.queues</name > <value > eng,science</value > </property > <property > <name > yarn.scheduler.capacity.root.prod.capacity</name > <value > 40</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.capacity</name > <value > 60</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.maximum-capacity</name > <value > 75</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.eng.capacity</name > <value > 50</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.science.capacity</name > <value > 50</value > </property > </configuration >
相关属性说明如下所示:
dev队列又被分成了eng和science两个相同容量的子队列;
dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急;
eng和science两个队列没有设置maximum-capacity属性,也就是说eng或science队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%);
而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
对于Capacity调度器,队列名必须是队列树中的最后一部分,如果使用队列树则不会被识别。比如,在上面配置中,使用prod和eng作为队列名是可以的,但是如果用root.dev.eng或者dev.eng是无效的。
b、测试运行 上述配置队列形式如下所示:
启动ResouceManager,打开8088页面:
运行MapReduce中WordCount程序,指定运行队列prod
1 2 3 4 5 6 HADOOP_HOME=/export/server/hadoop $ {HADOOP_HOME}/bin/yarn jar \ ${HADOOP_HOME} /share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \wordcount \ -Dmapreduce.job.queuename=prod \ datas/input.data /datas/output
查看8088界面如下所示:
不指定运行队列,默认运行在default队列,如果找不到default队列将会报如下错误 。
1 2 3 4 5 HADOOP_HOME=/export/server/hadoop $ {HADOOP_HOME}/bin/yarn jar \ ${HADOOP_HOME} /share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \wordcount \ datas/input.data /datas/output2
查看8088界面如下所示:
c、Capacity官方默认配置 在HADOOP 安装目录中,官方自带默认配置HADOOP_CONF/capacity-scheduler.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 <configuration > <property > <name > yarn.scheduler.capacity.maximum-applications</name > <value > 10000</value > <description > Maximum number of applications that can be pending and running. </description > </property > <property > <name > yarn.scheduler.capacity.maximum-am-resource-percent</name > <value > 0.1</value > <description > Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications. </description > </property > <property > <name > yarn.scheduler.capacity.resource-calculator</name > <value > org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value > <description > The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. </description > </property > <property > <name > yarn.scheduler.capacity.root.queues</name > <value > default</value > <description > The queues at the this level (root is the root queue). </description > </property > <property > <name > yarn.scheduler.capacity.root.default.capacity</name > <value > 100</value > <description > Default queue target capacity.</description > </property > <property > <name > yarn.scheduler.capacity.root.default.user-limit-factor</name > <value > 1</value > <description > Default queue user limit a percentage from 0.0 to 1.0. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.maximum-capacity</name > <value > 100</value > <description > The maximum capacity of the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.state</name > <value > RUNNING</value > <description > The state of the default queue. State can be one of RUNNING or STOPPED. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.acl_submit_applications</name > <value > *</value > <description > The ACL of who can submit jobs to the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.acl_administer_queue</name > <value > *</value > <description > The ACL of who can administer jobs on the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.node-locality-delay</name > <value > 40</value > <description > Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. Typically this should be set to number of nodes in the cluster, By default is setting approximately number of nodes in one rack which is 40. </description > </property > <property > <name > yarn.scheduler.capacity.queue-mappings</name > <value > </value > <description > A list of mappings that will be used to assign jobs to queues The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]* Typically this list will be used to map users to queues, for example, u:%user:%user maps all users to queues with the same name as the user. </description > </property > <property > <name > yarn.scheduler.capacity.queue-mappings-override.enable</name > <value > false</value > <description > If a queue mapping is present, will it override the value specified by the user? This can be used by administrators to place jobs in queues that are different than the one specified by the user. The default is false. </description > </property > </configuration >
Fair Scheduler(CDH)
Fair Scheduler(公平调度器): 用户之间的公平和用户内部程序的公平。允许资源抢占、分层队列等。
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源 。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成
公平调度器 Fair Scheduler 最初是由 Facebook 开发设计使得 Hadoop 应用能够被多用户公平地共享整个集群资源,现被 Cloudera CDH 所采用。
Fair Scheduler 不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源。
示例:Capacity调度器配置使用 调度器的使用是通过yarn-site.xml配置文件中的
yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器。
假设我们有如下层次的队列:
1 2 3 4 5 root ├── prod 40% -> 80% └── dev 60% -> 80% ├── mapreduce 50% _ 80% └── spark 50%
下面是一个简单的Capacity调度器的配置文件,文件名为capacity-scheduler.xml。在这个配置中,在root队列下面定义了两个子队列prod和dev,分别占40%和60%的容量。需要注意,一个队列的配置是通过属性yarn.sheduler.capacity.<queue-path>.<sub-property>指定的,<queue-path>代表的是队列的继承树,如root.prod队列,<sub-property>一般指capacity和maximum-capacity。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <configuration > <property > <name > yarn.scheduler.capacity.root.queues</name > <value > prod,dev</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.queues</name > <value > mapreduce,spark</value > </property > <property > <name > yarn.scheduler.capacity.root.prod.capacity</name > <value > 40</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.capacity</name > <value > 60</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.maximum-capacity</name > <value > 80</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.mapreduce.capacity</name > <value > 50</value > </property > <property > <name > yarn.scheduler.capacity.root.dev.spark.capacity</name > <value > 50</value > </property > </configuration >
我们可以看到,dev队列又被分成了mapreduce和spark两个相同容量的子队列。dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急。我们注意到,mapreduce和spark两个队列没有设置maximum-capacity属性,也就是说mapreduce或spark队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%)。而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
关于队列的设置,这取决于我们具体的应用。比如,在MapReduce中,我们可以通过mapreduce.job.queuename属性指定要用的队列。如果队列不存在,我们在提交任务时就会收到错误。如果我们没有定义任何队列,所有的应用将会放在一个default队列中 。
注意:对于Capacity调度器,我们的队列名必须是队列树中的最后一部分 ,如果我们使用队列树则不会被识别。比如,在上面配置中,我们使用prod和mapreduce作为队列名是可以的,但是如果我们用root.dev.mapreduce或者dev. mapreduce是无效的。
相比于FIFO,Capacity scheduler,我更喜欢Fair Scheduler,因为公司里用户申请权限分配容量后,不一定去用,甚至闲置很长时间,用Fair 更有利于资源使用。
关于yarn常用参数设置 设置container分配最小内存
1 yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存
设置container分配最大内存
1 yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存
设置每个container的最小虚拟内核个数
1 yarn.scheduler.minimum-allocation-vcores 1 每个container默认给分配的最小的虚拟内核个数
设置每个container的最大虚拟内核个数
1 yarn.scheduler.maximum-allocation-vcores 32 每个container可以分配的最大的虚拟内核的个数
设置NodeManager可以分配的内存大小
1 yarn.nodemanager.resource.memory-mb 8192 nodemanager 可以分配的最大内存大小,默认8192Mb
定义每台机器的内存使用大小
1 yarn.nodemanager.resource.memory-mb 8192
定义交换区空间可以使用的大小
1 2 交换区空间就是讲一块硬盘拿出来做内存使用,这里指定的是nodemanager的2.1倍 yarn.nodemanager.vmem-pmem-ratio 2.1
提交作业到YARN上运行 这里以提交 Hadoop 内置的 Examples 中计算 Pi 的 MApReduce 程序为例,相关 Jar 包在 Hadoop 安装目录的 share/hadoop/mapreduce 目录下:
1 2 # 提交格式: hadoop jar jar包路径 主类名称 主类参数 # hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3

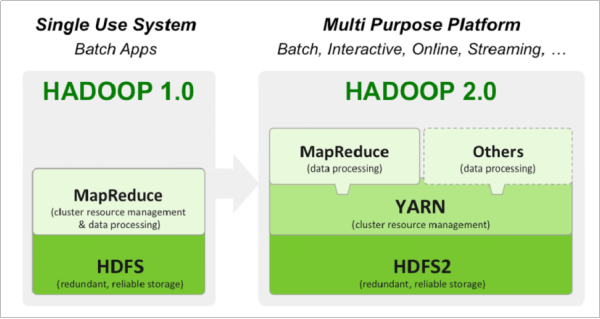
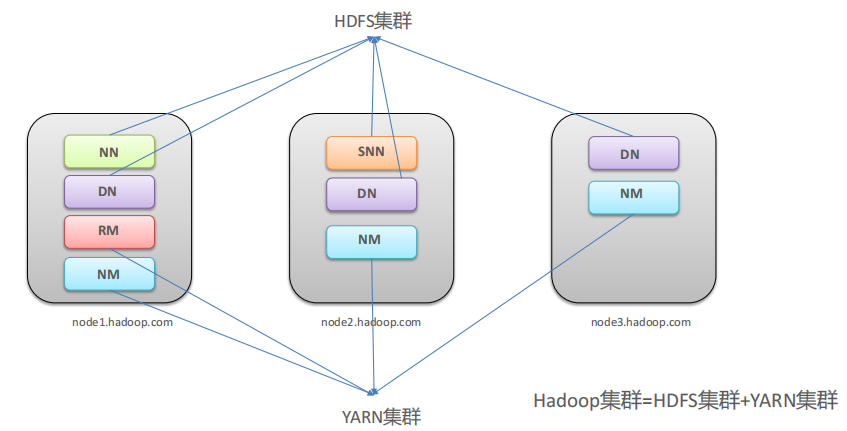
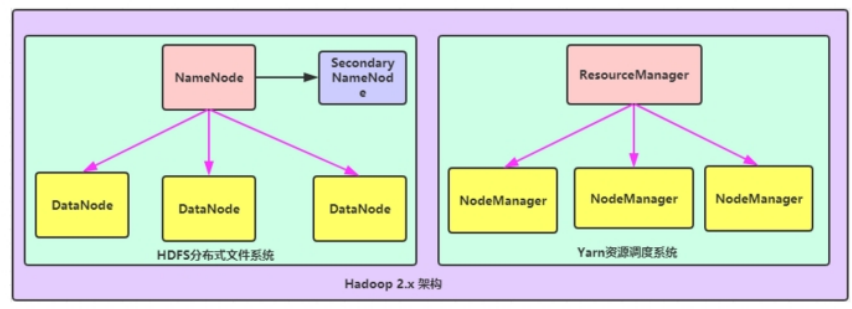
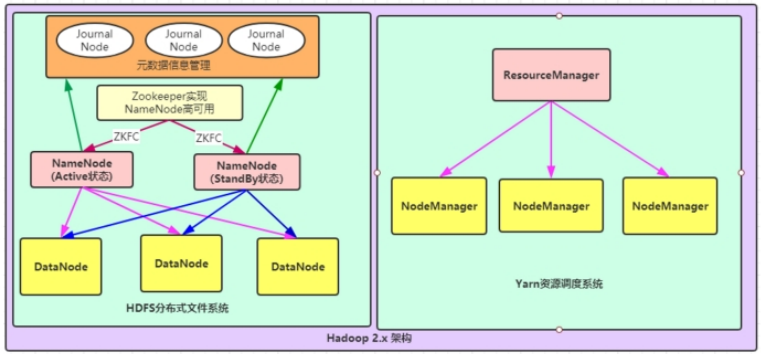
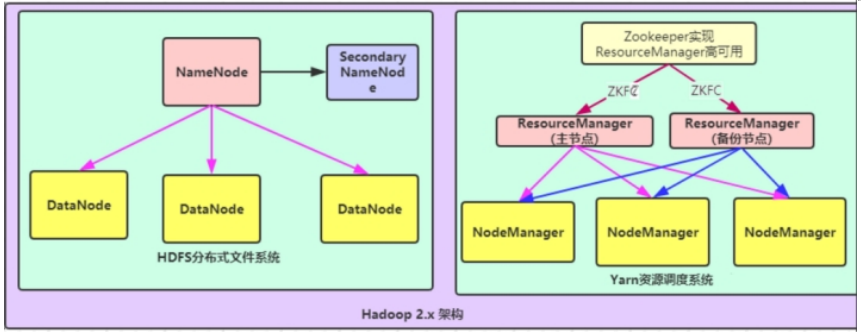
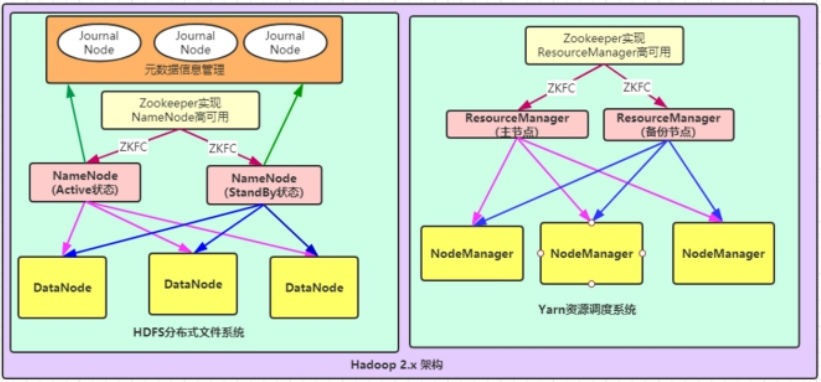
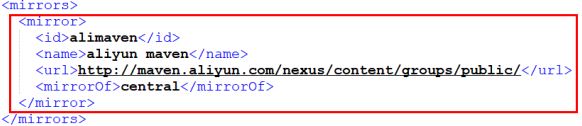
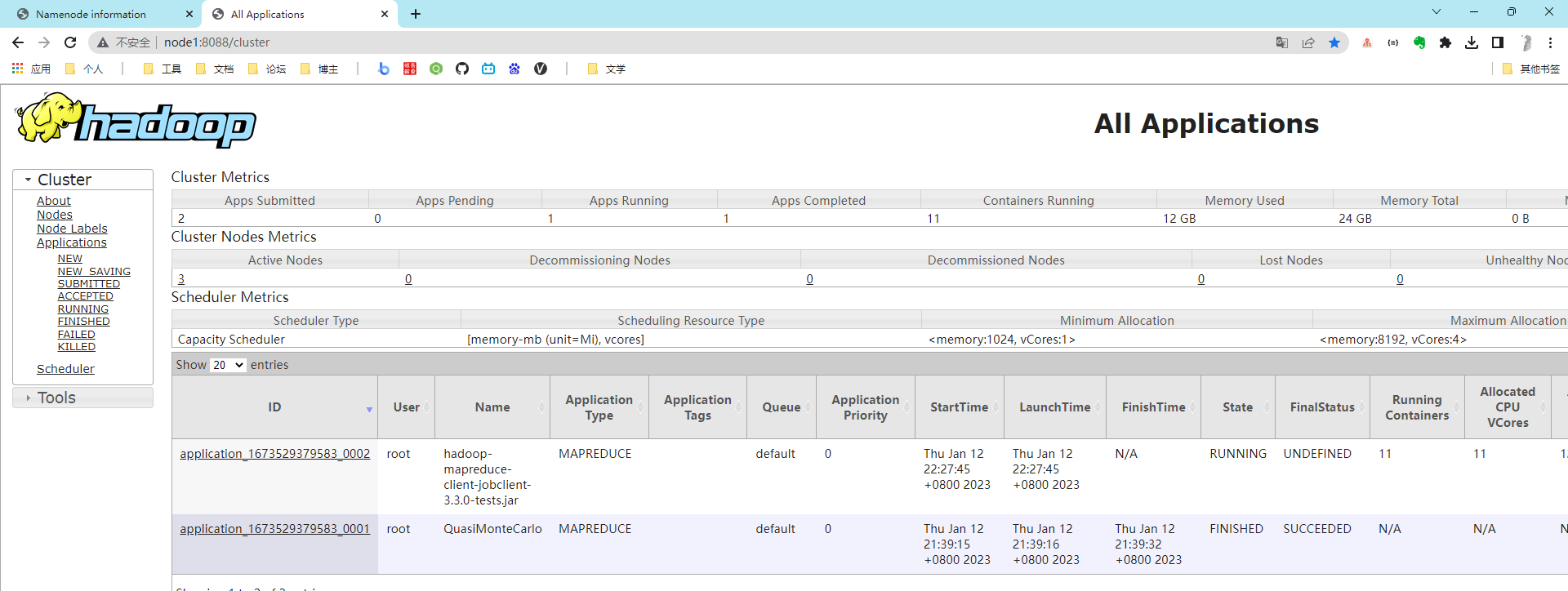
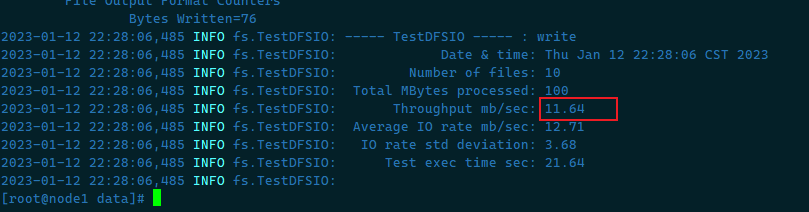
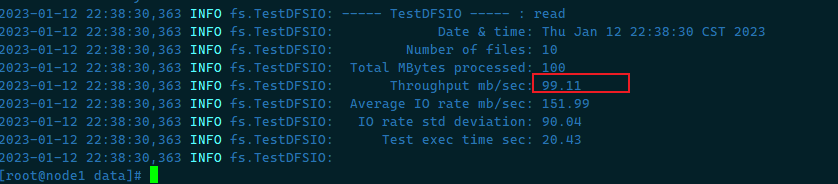
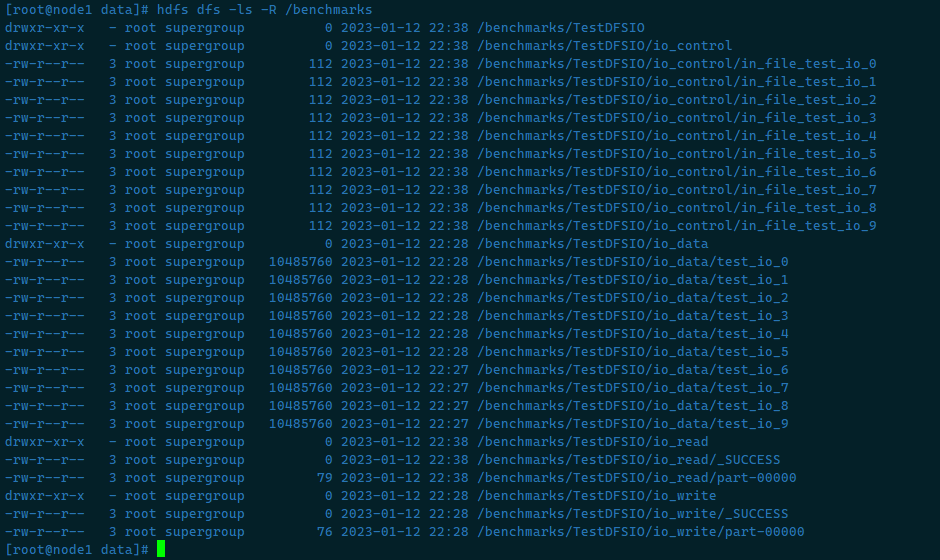

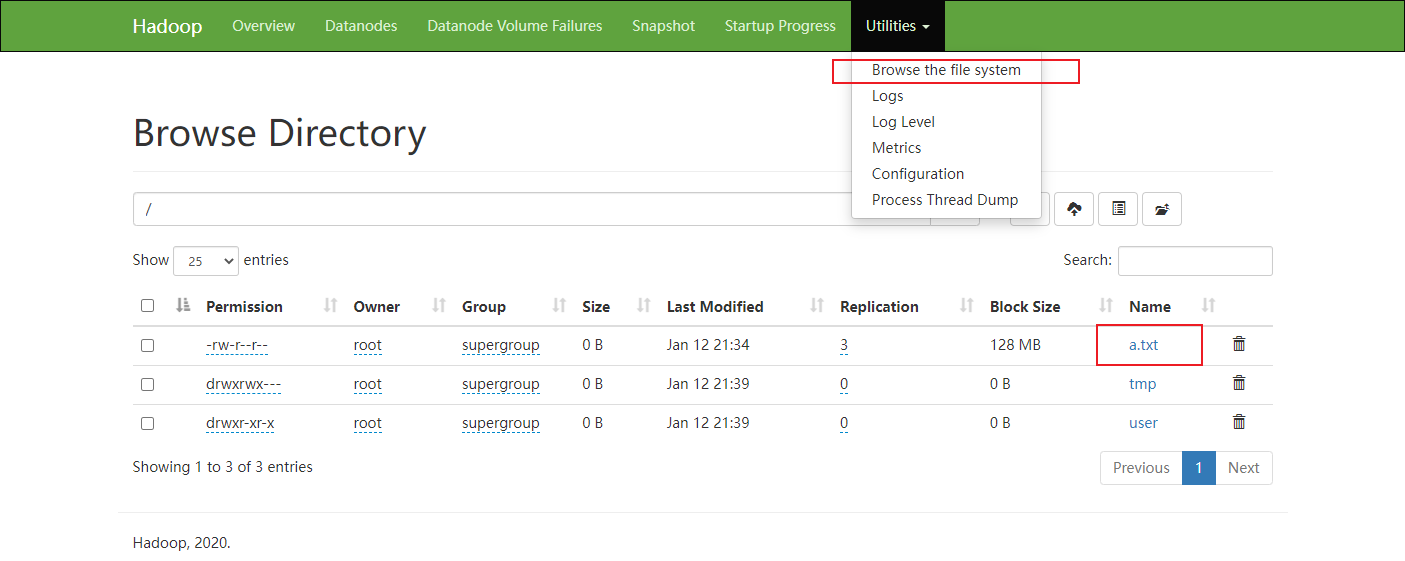
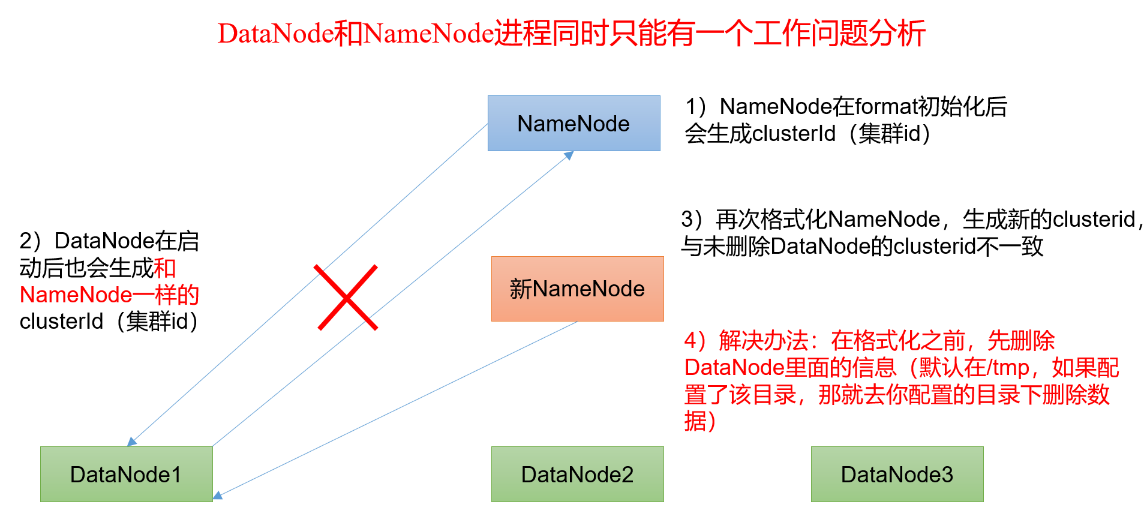
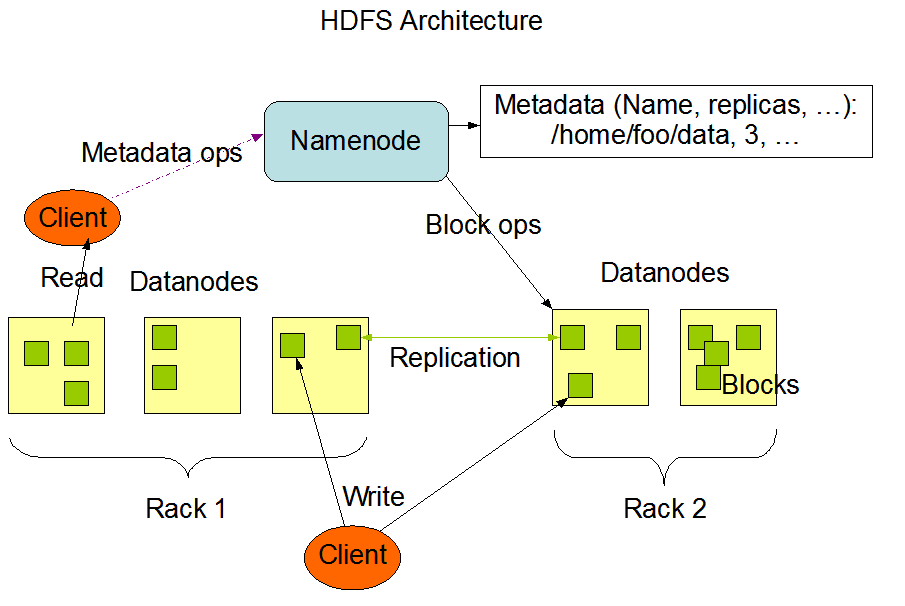
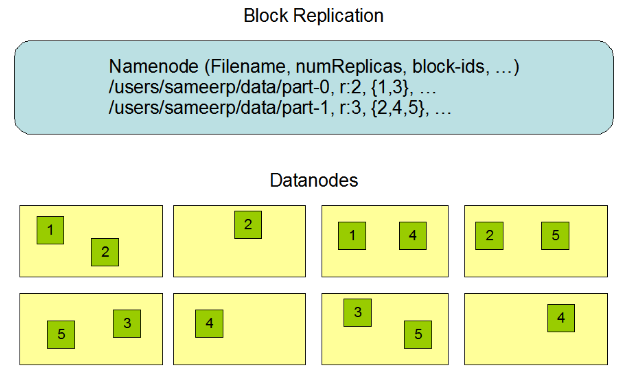
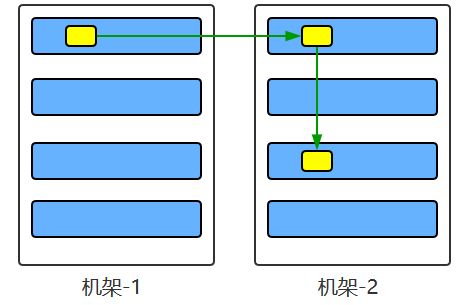


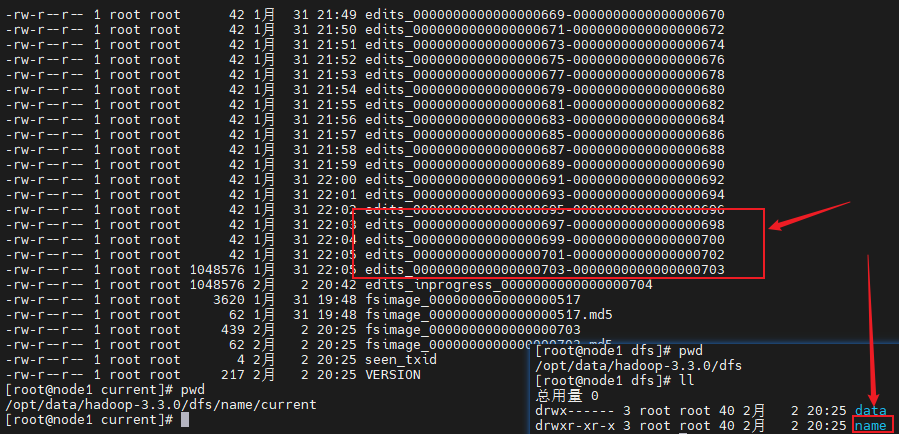
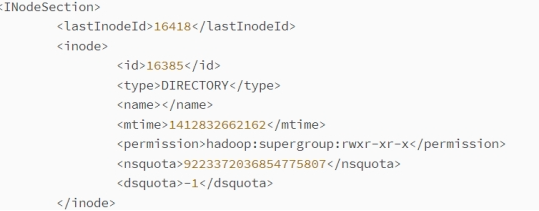
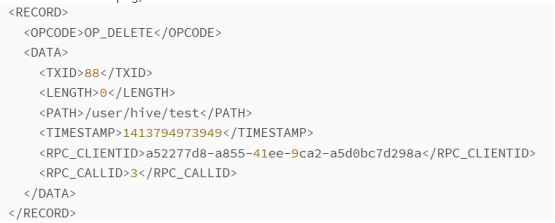
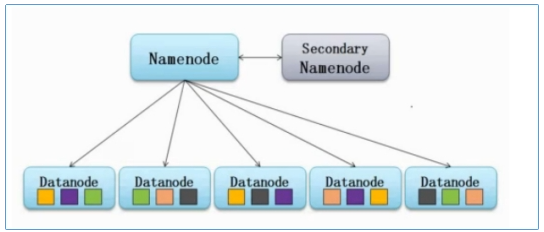
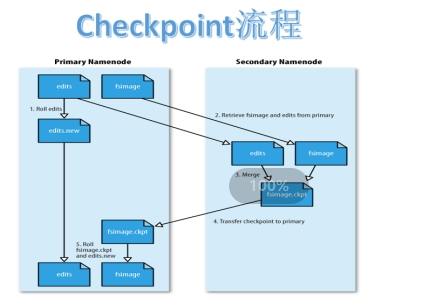
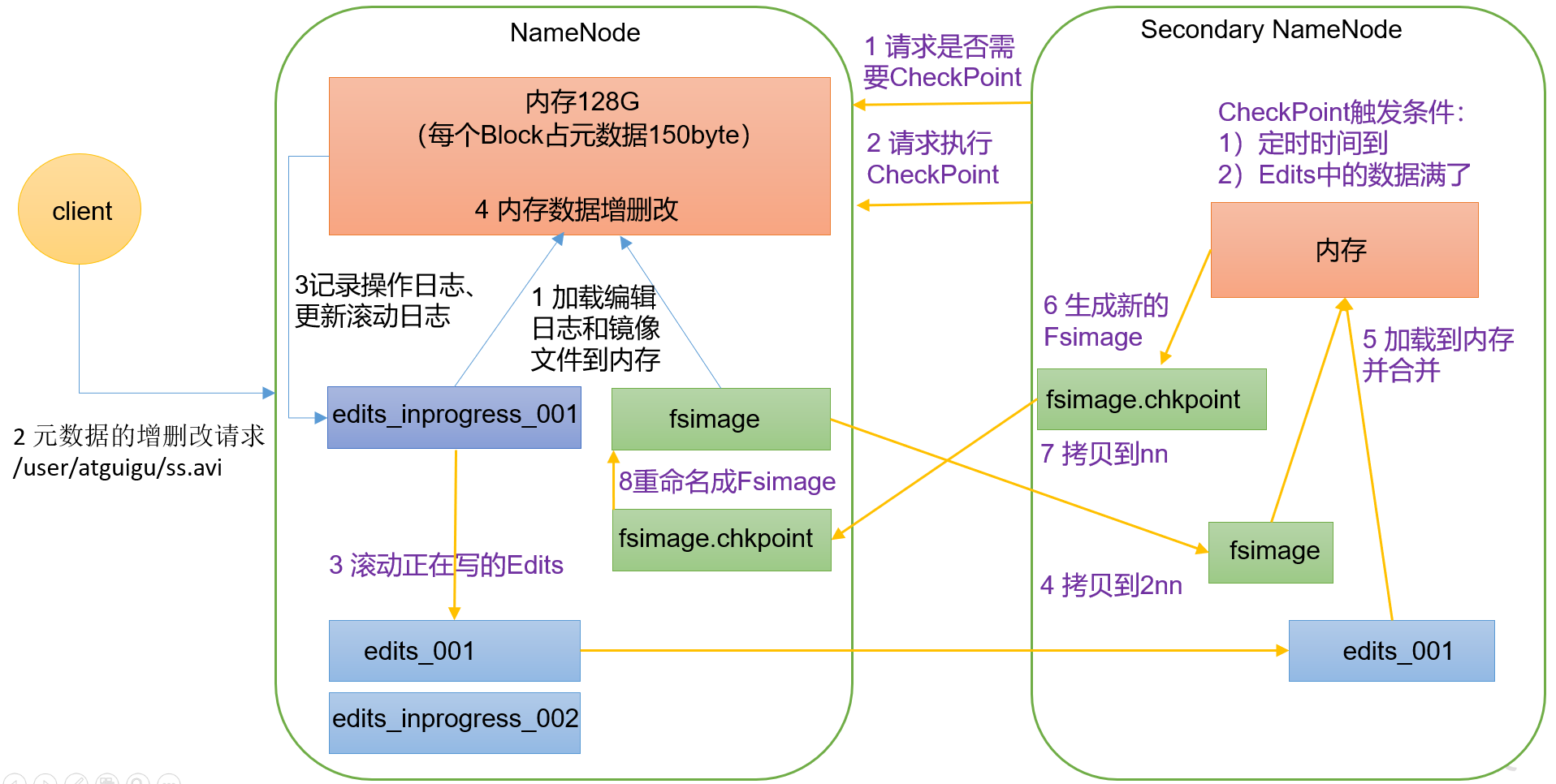
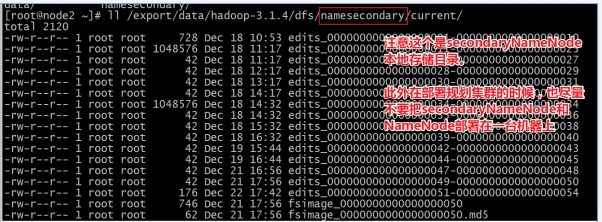
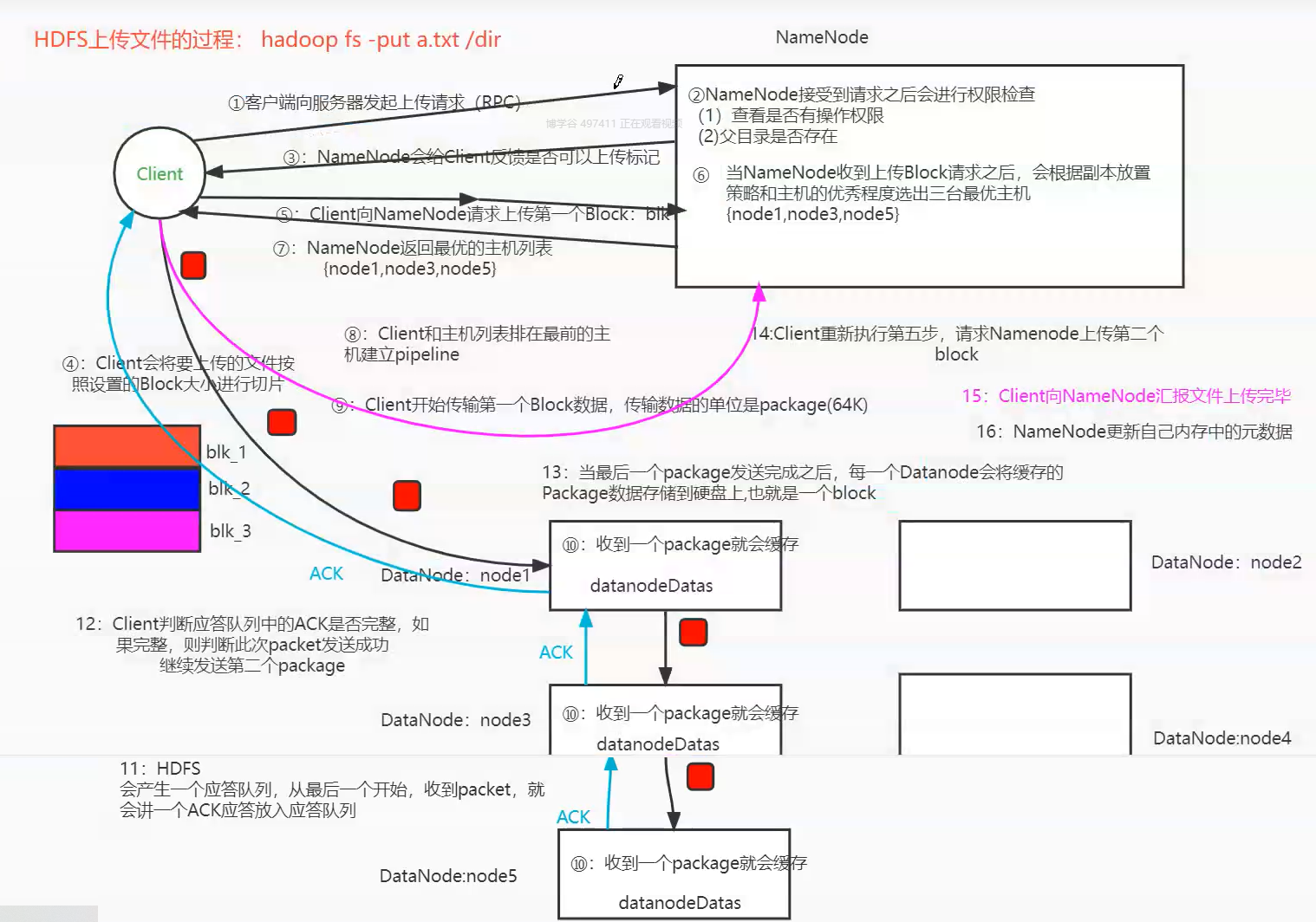
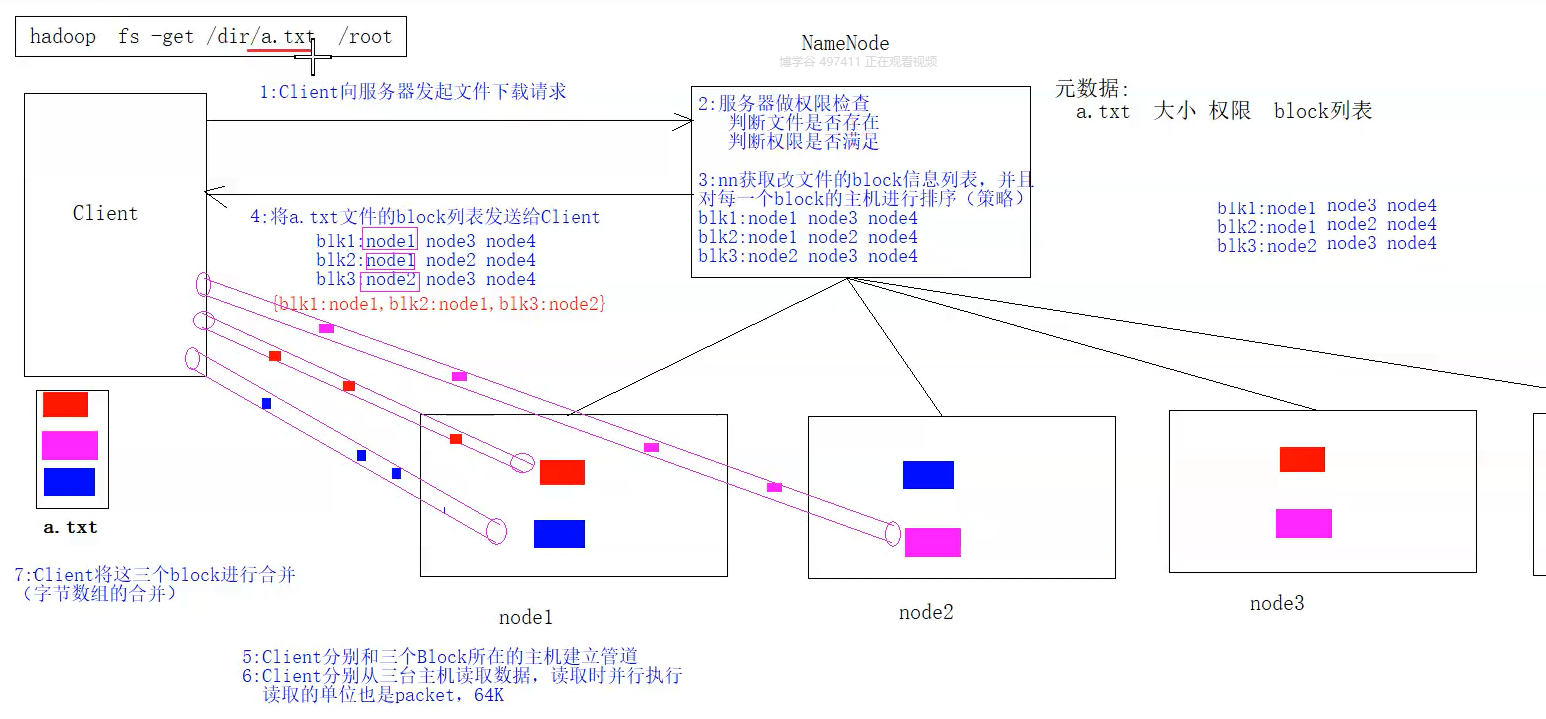
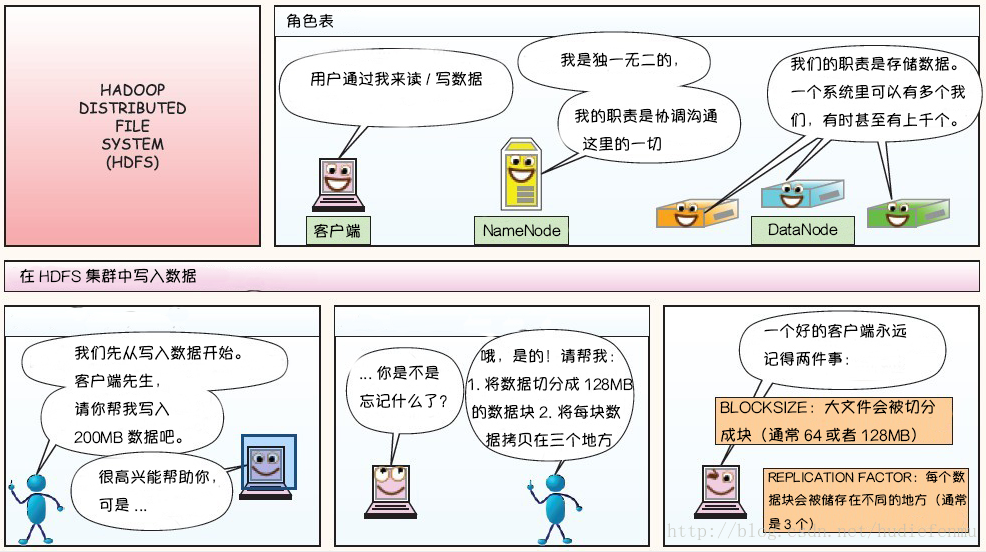
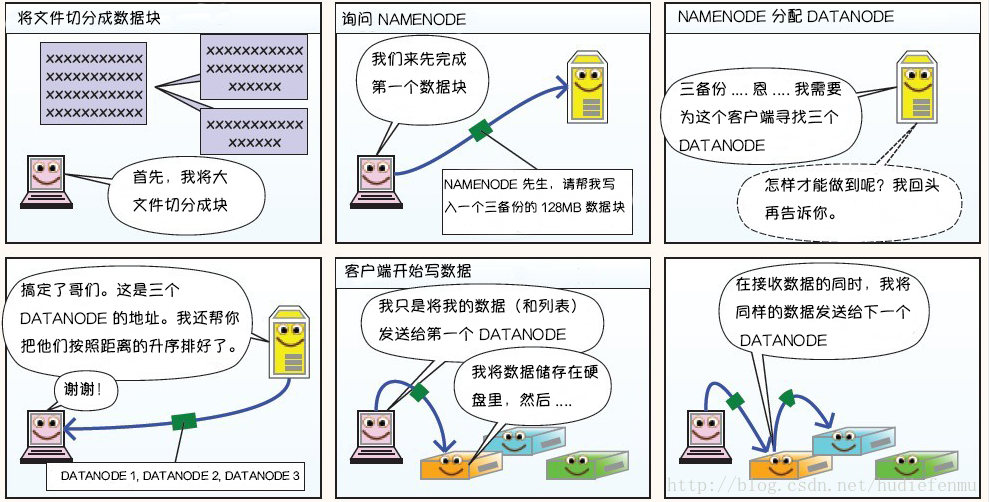
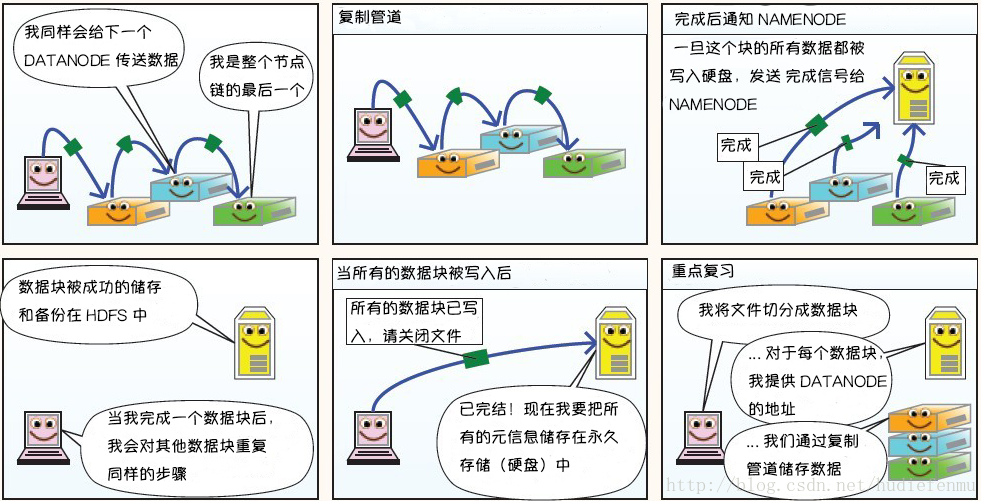
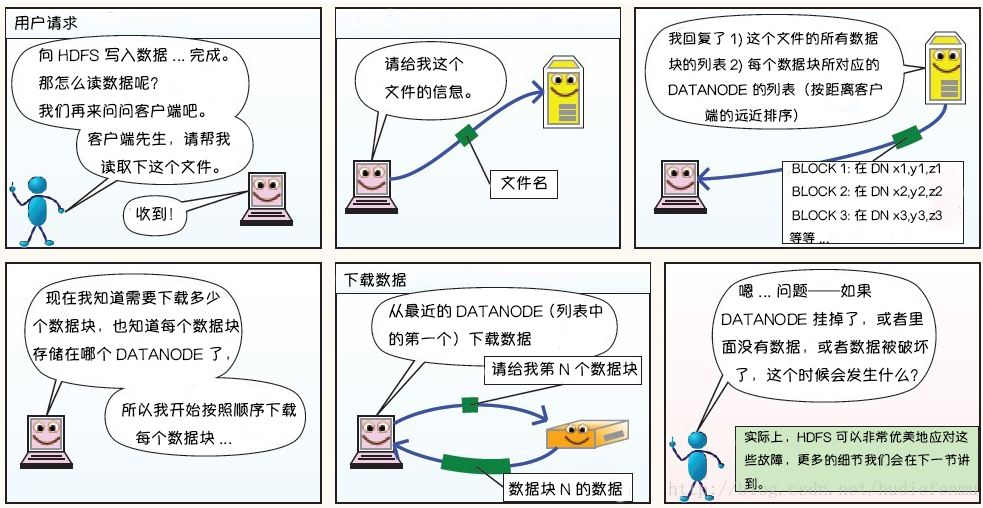
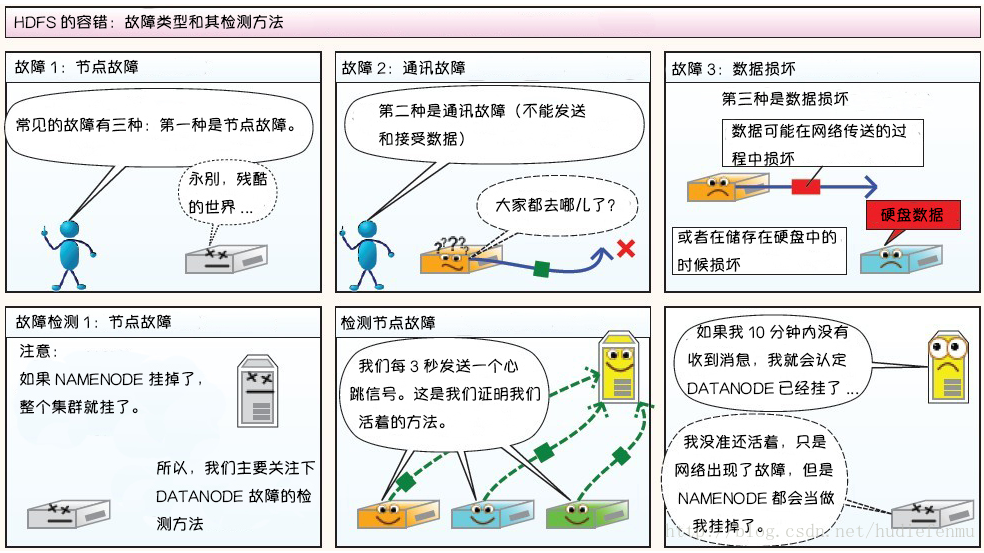
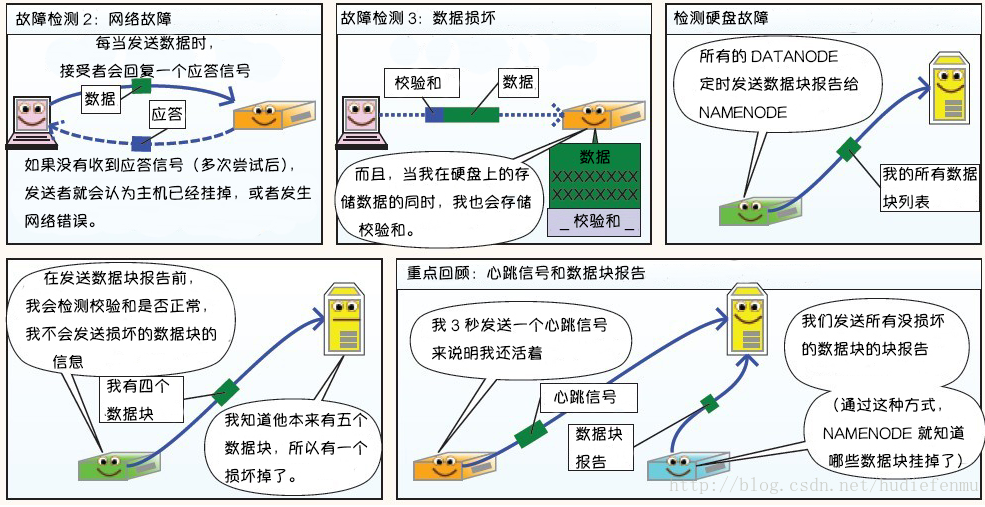
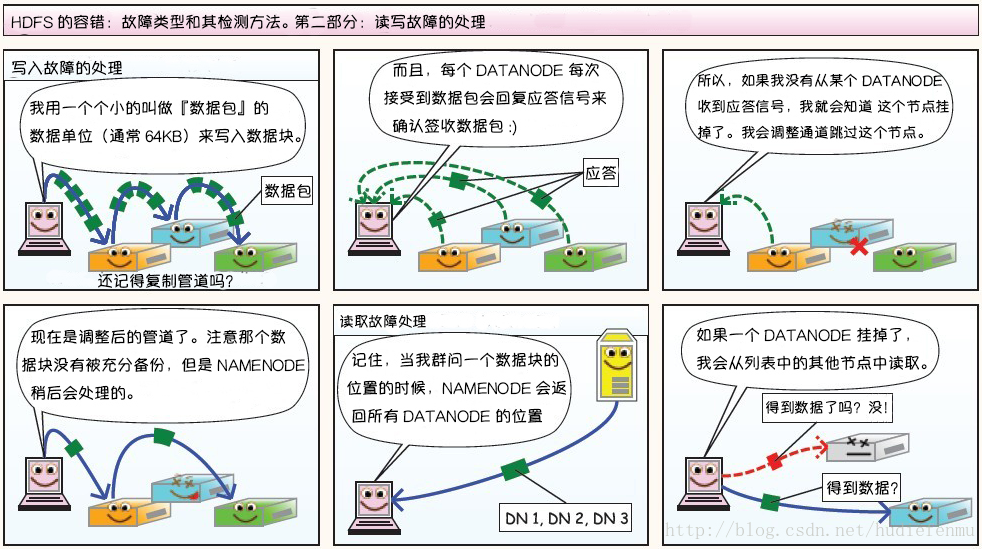
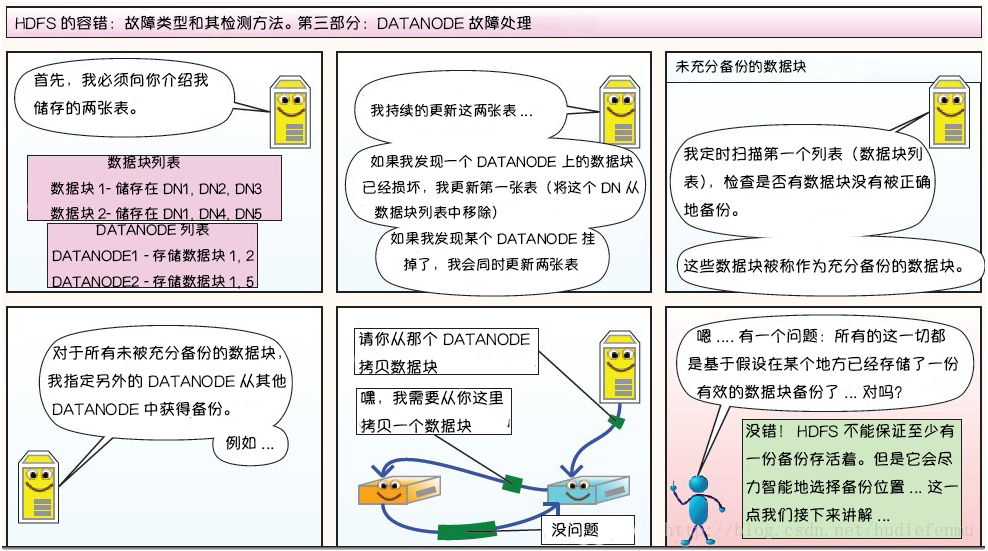
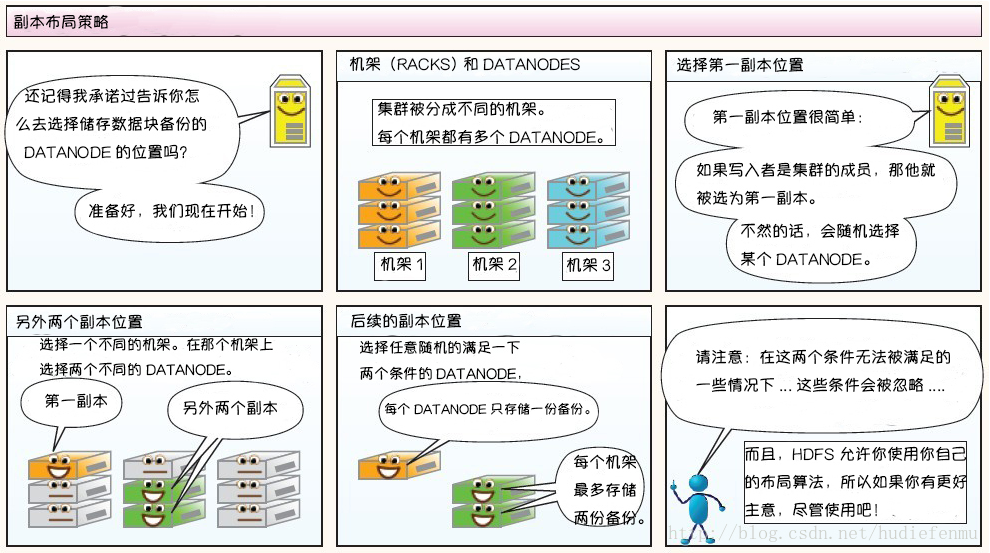
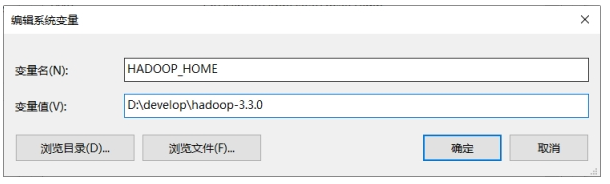
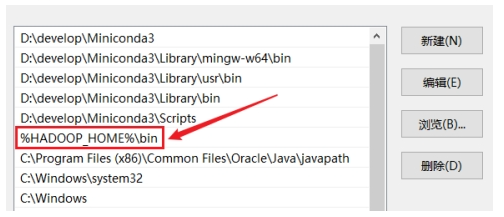
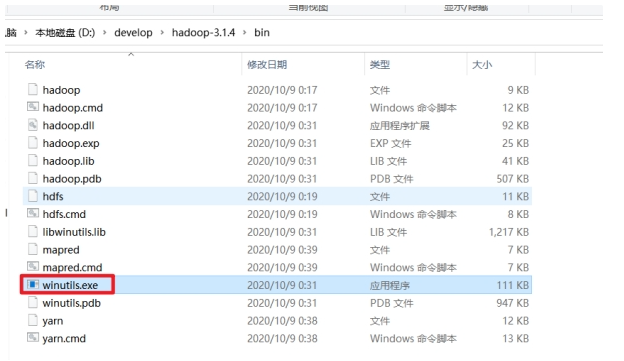
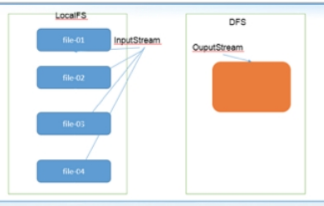
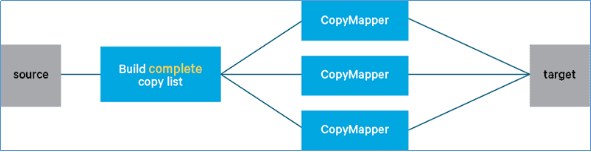
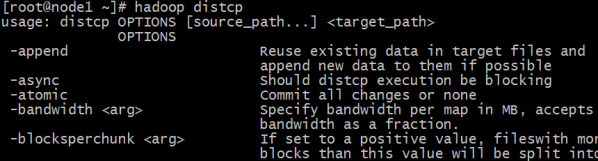

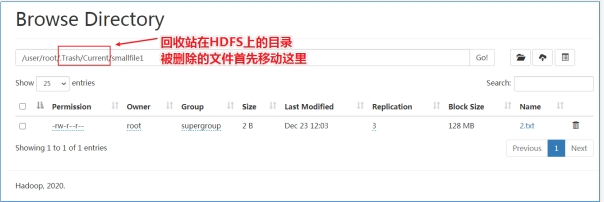


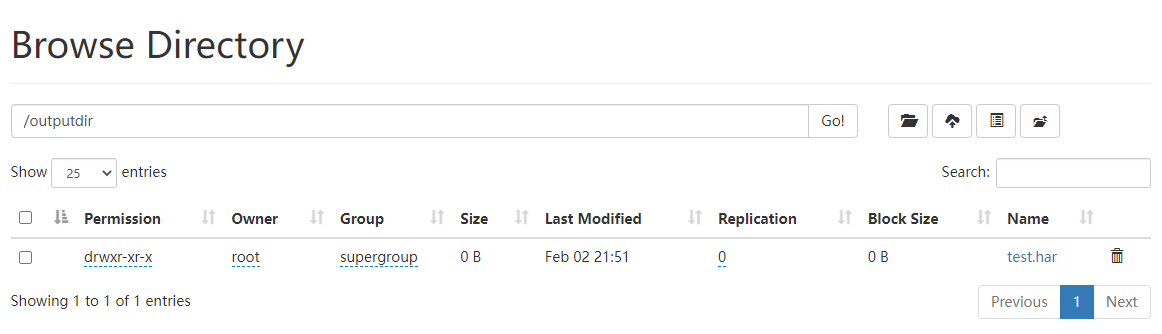


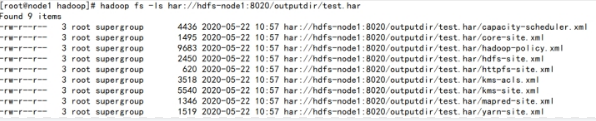
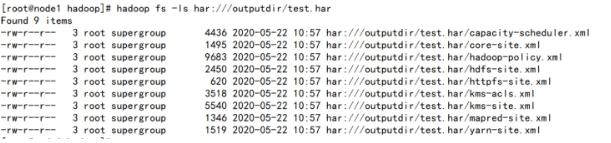

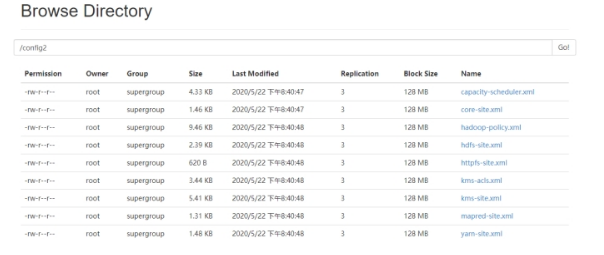
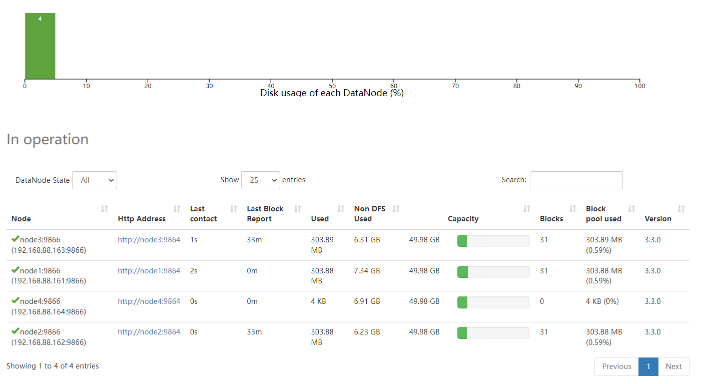
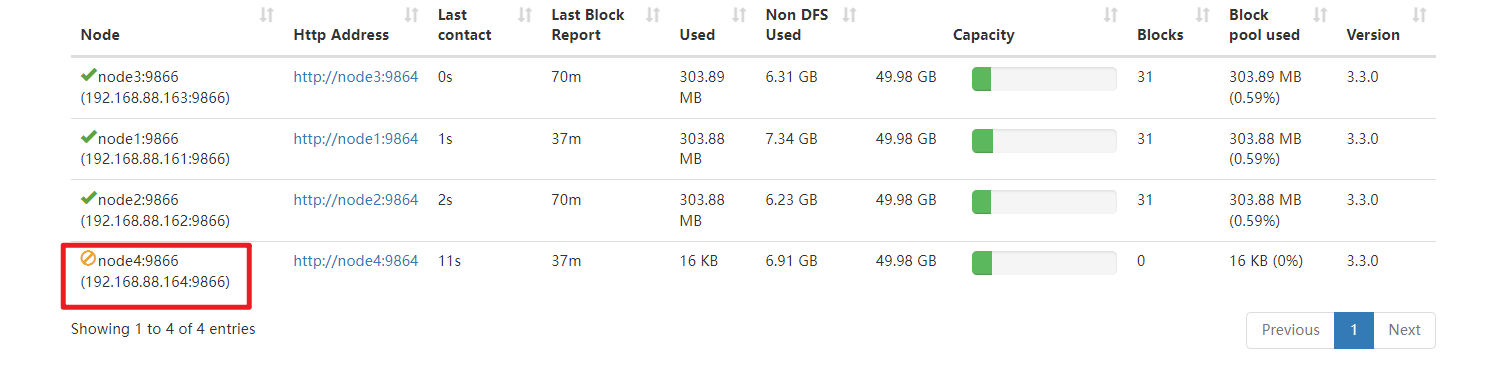
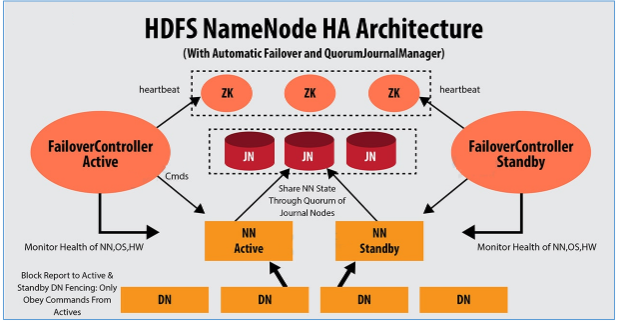

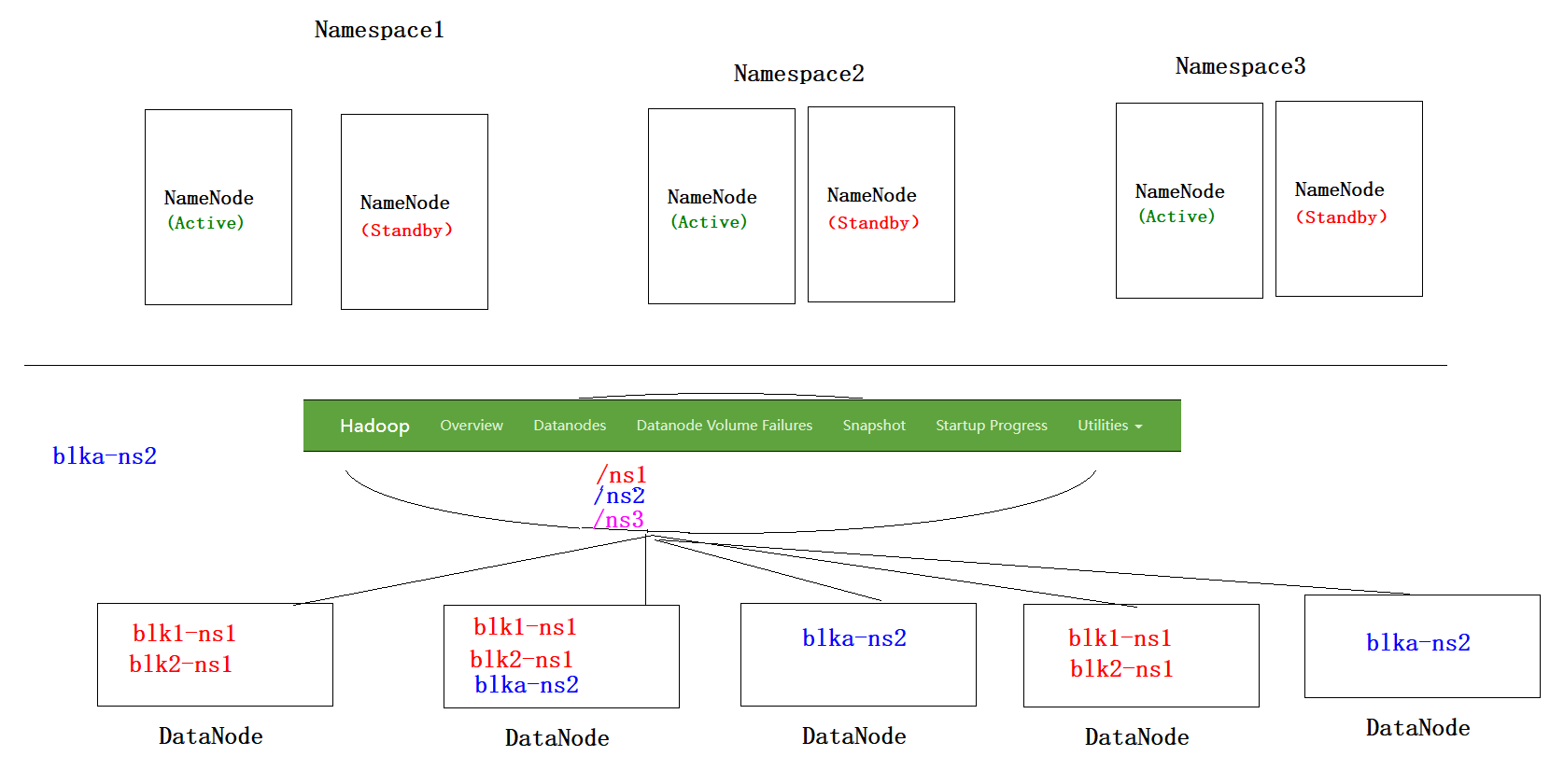
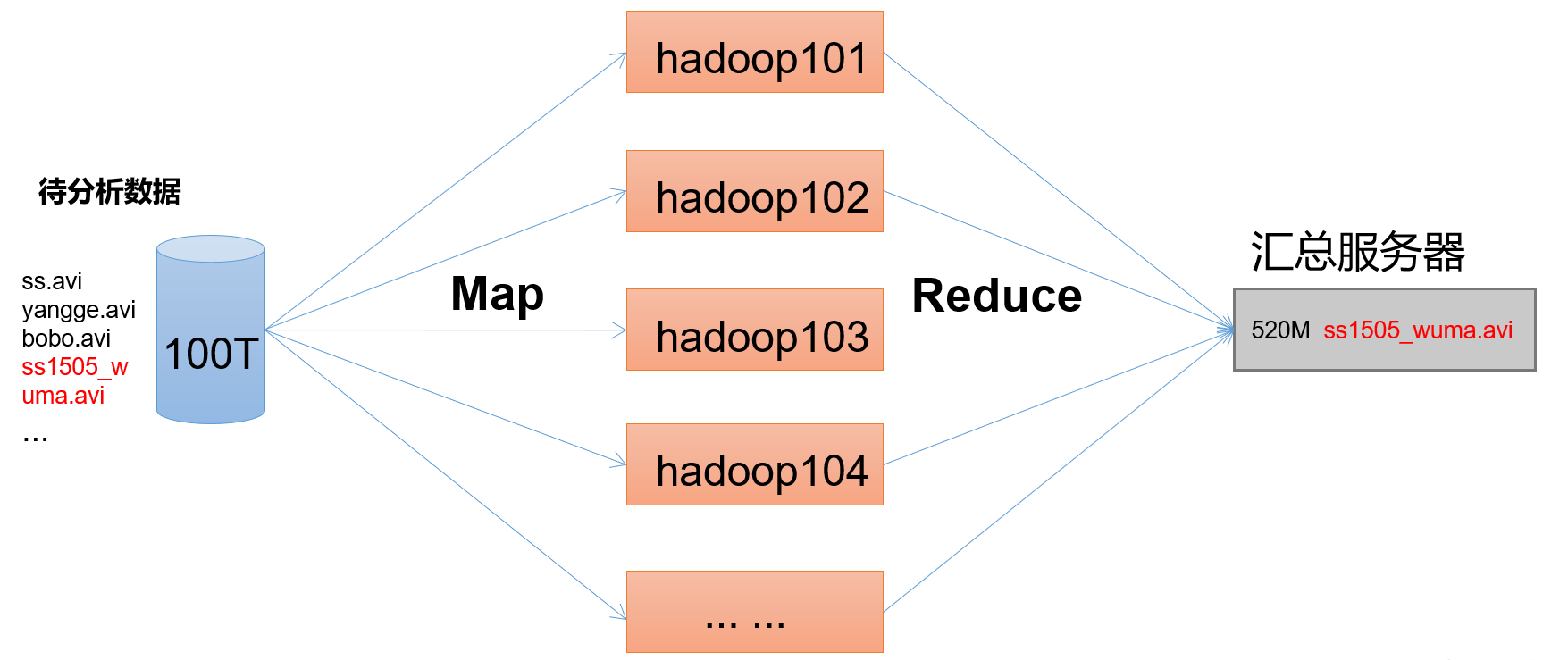
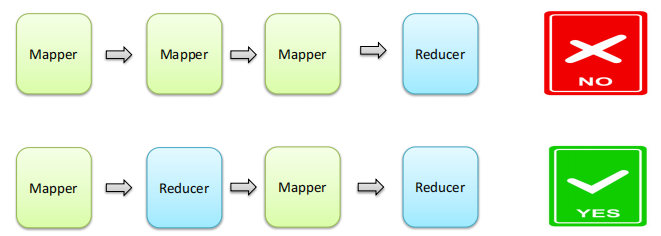
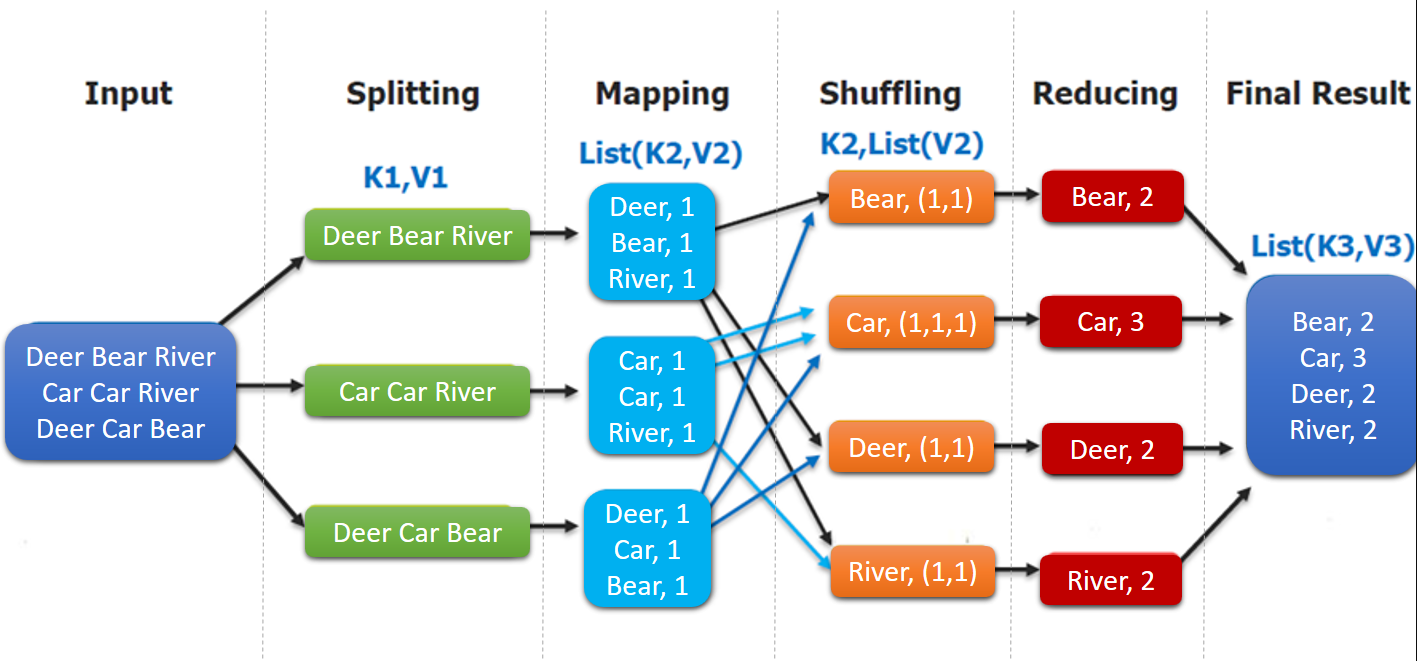
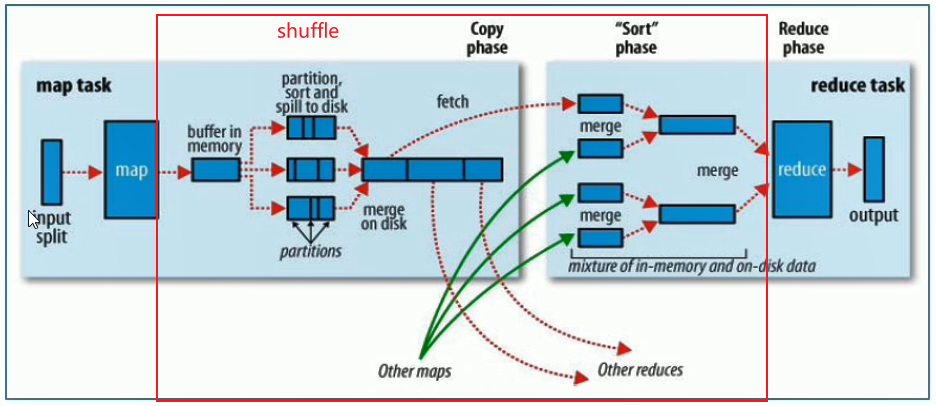

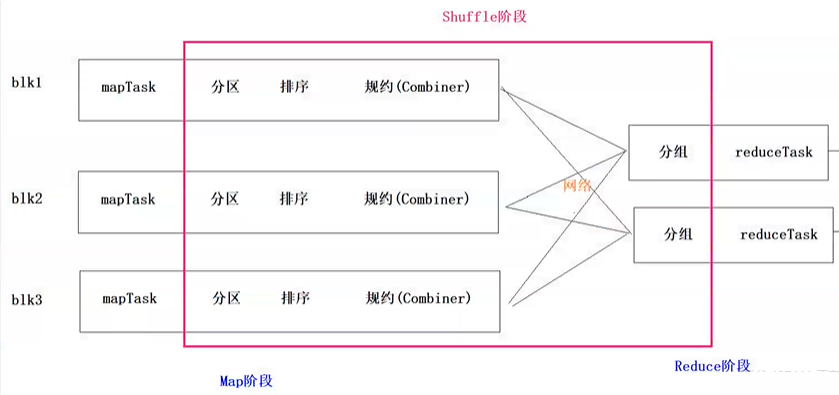
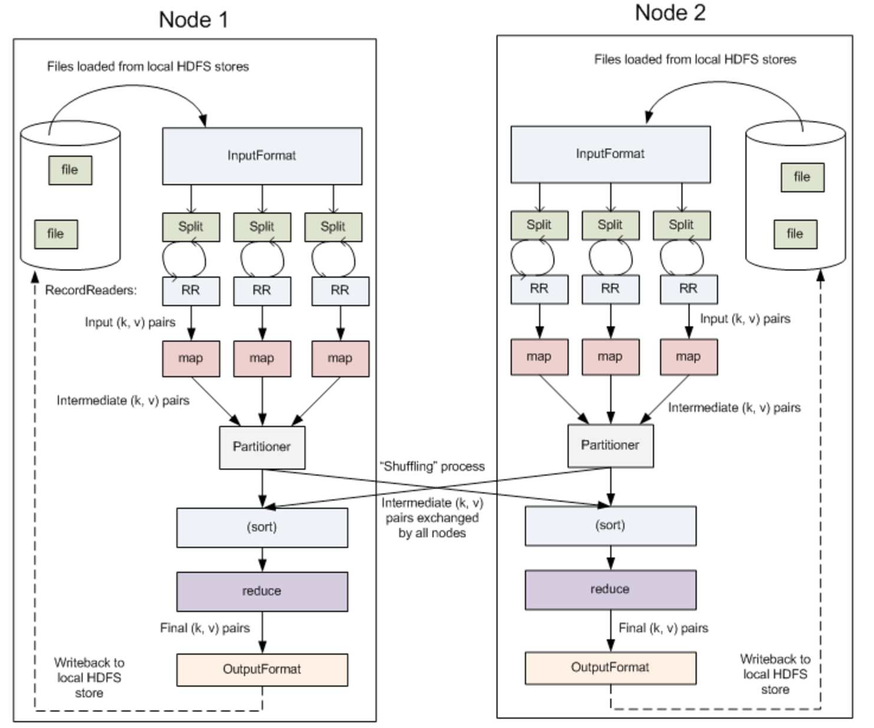
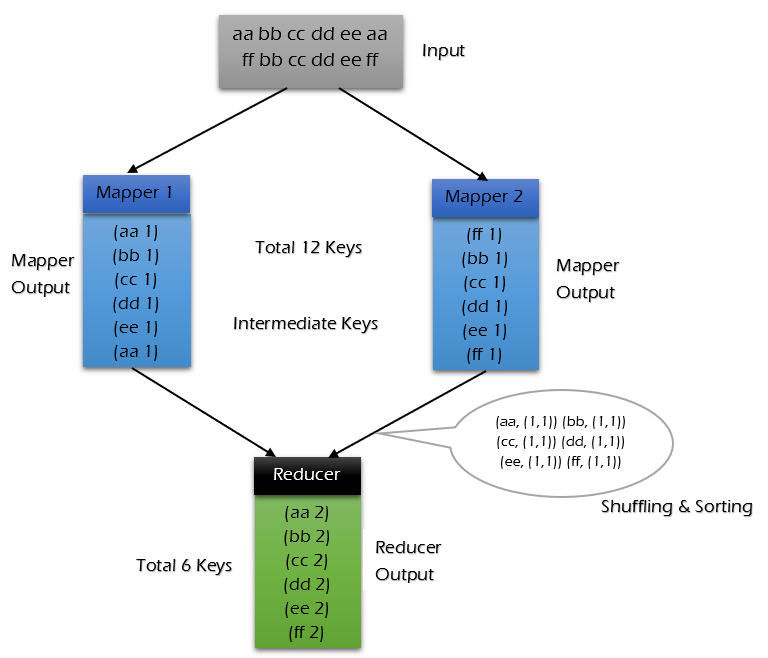
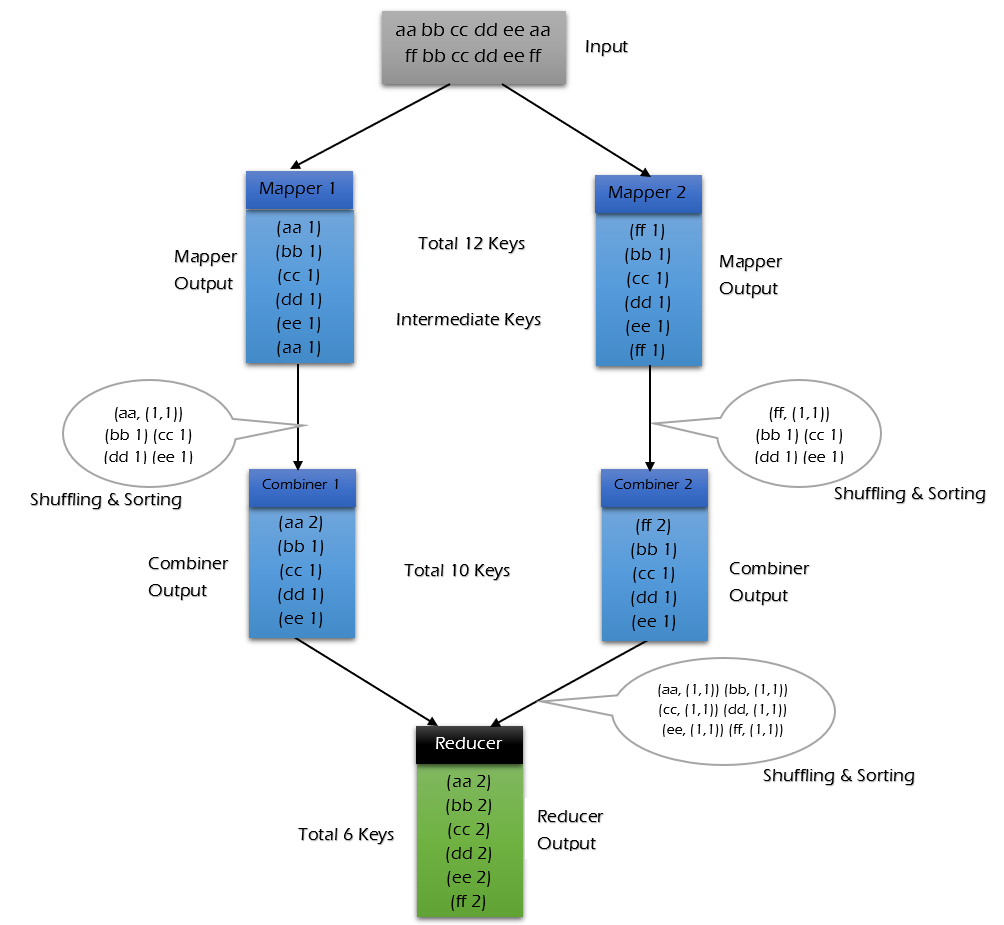
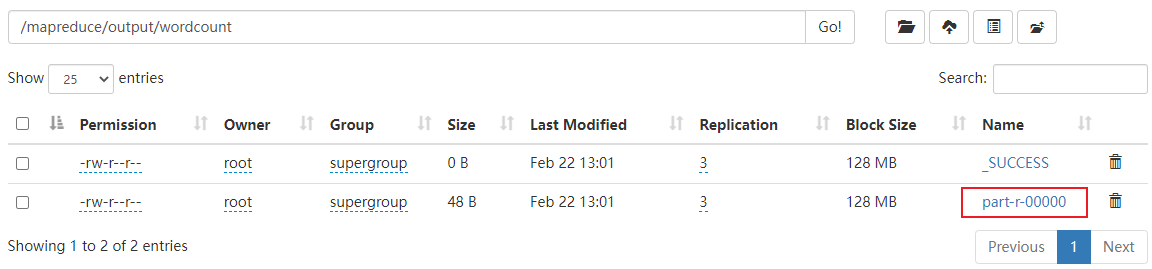
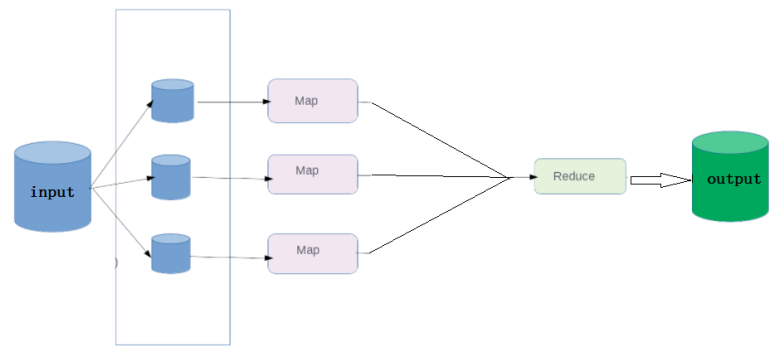
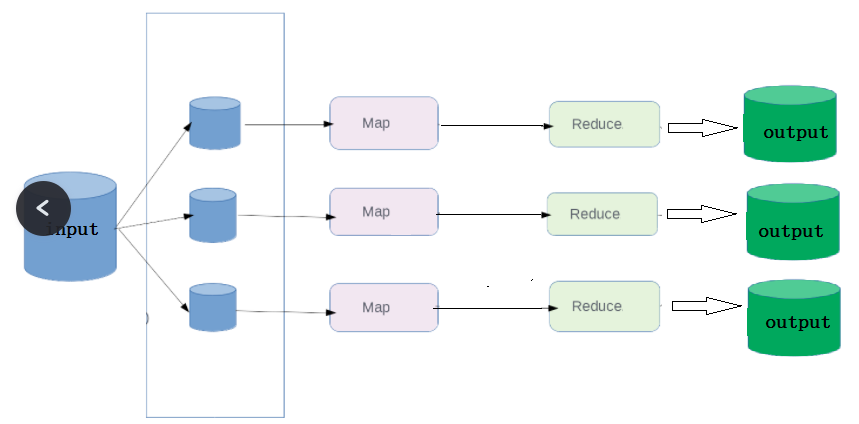

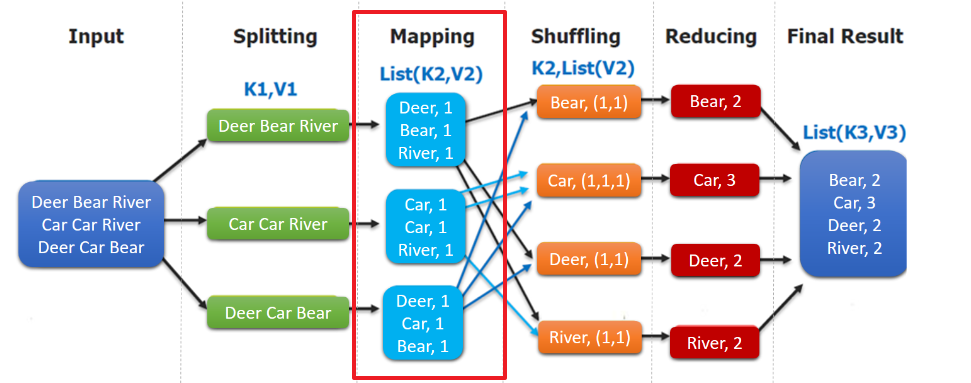
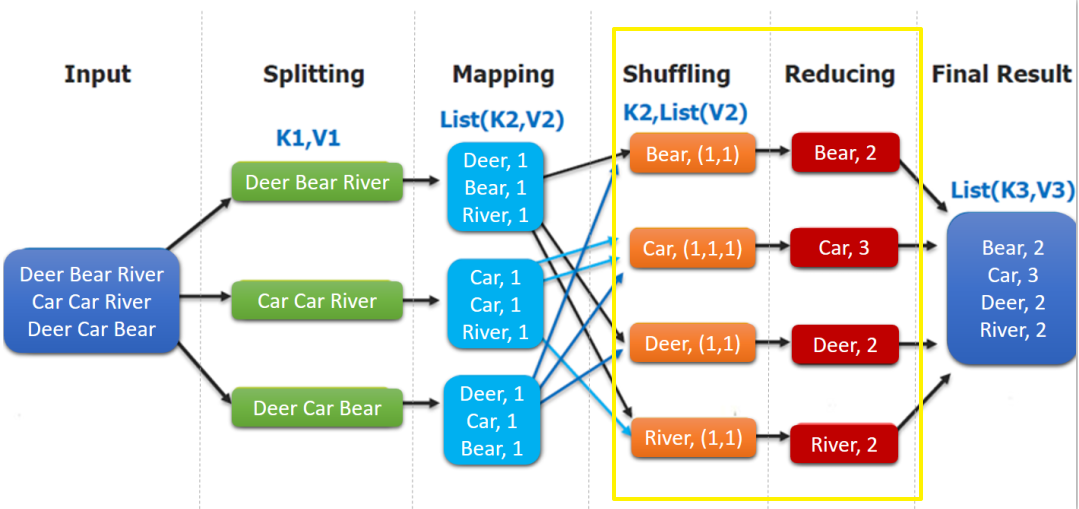
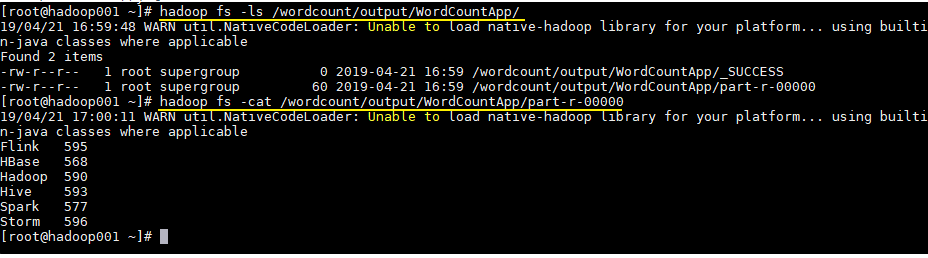
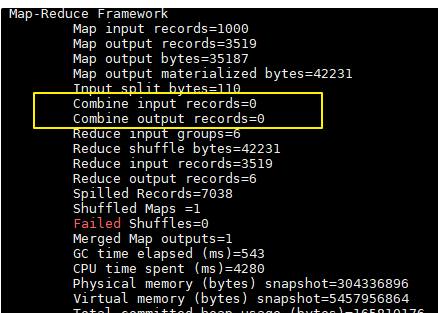
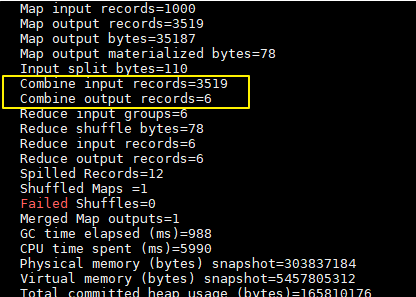

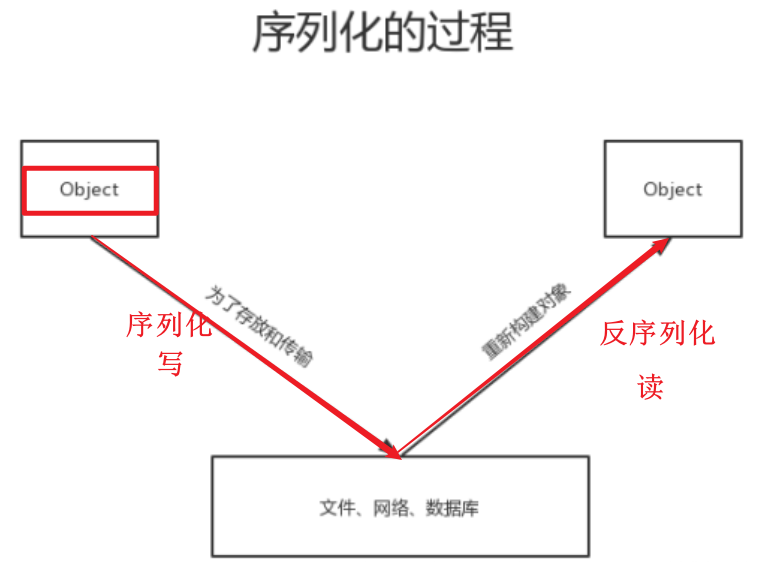
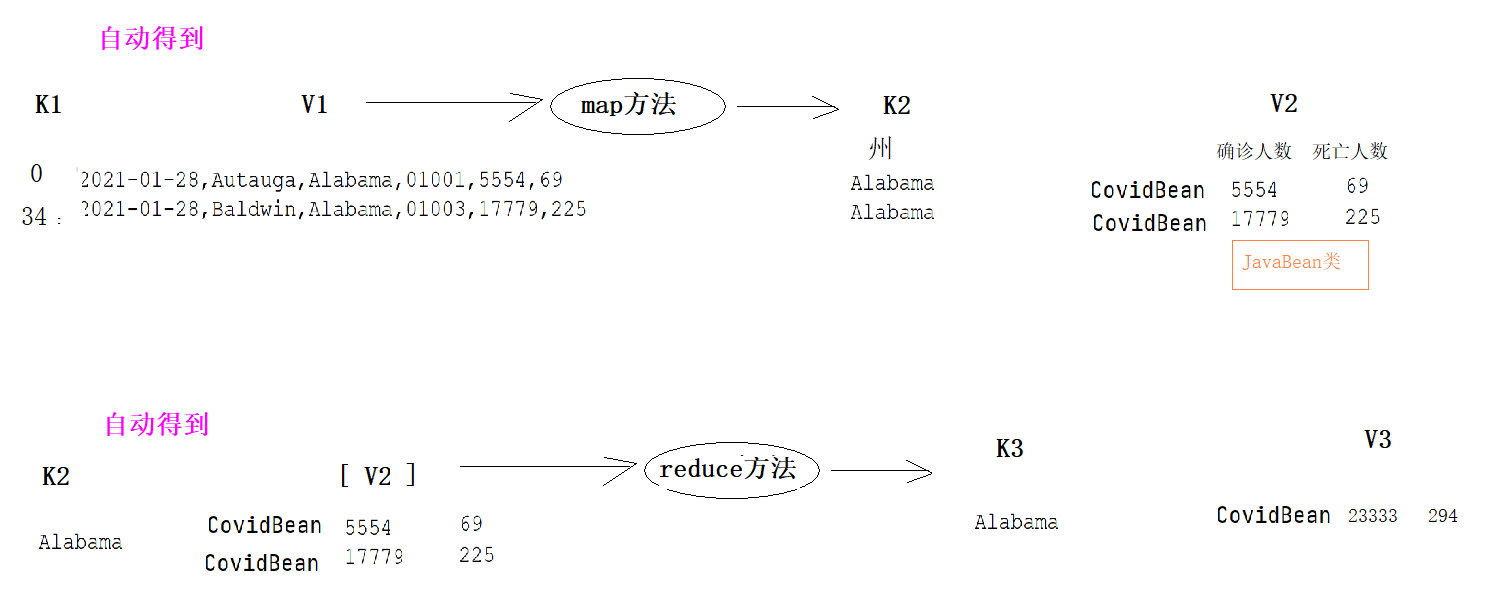




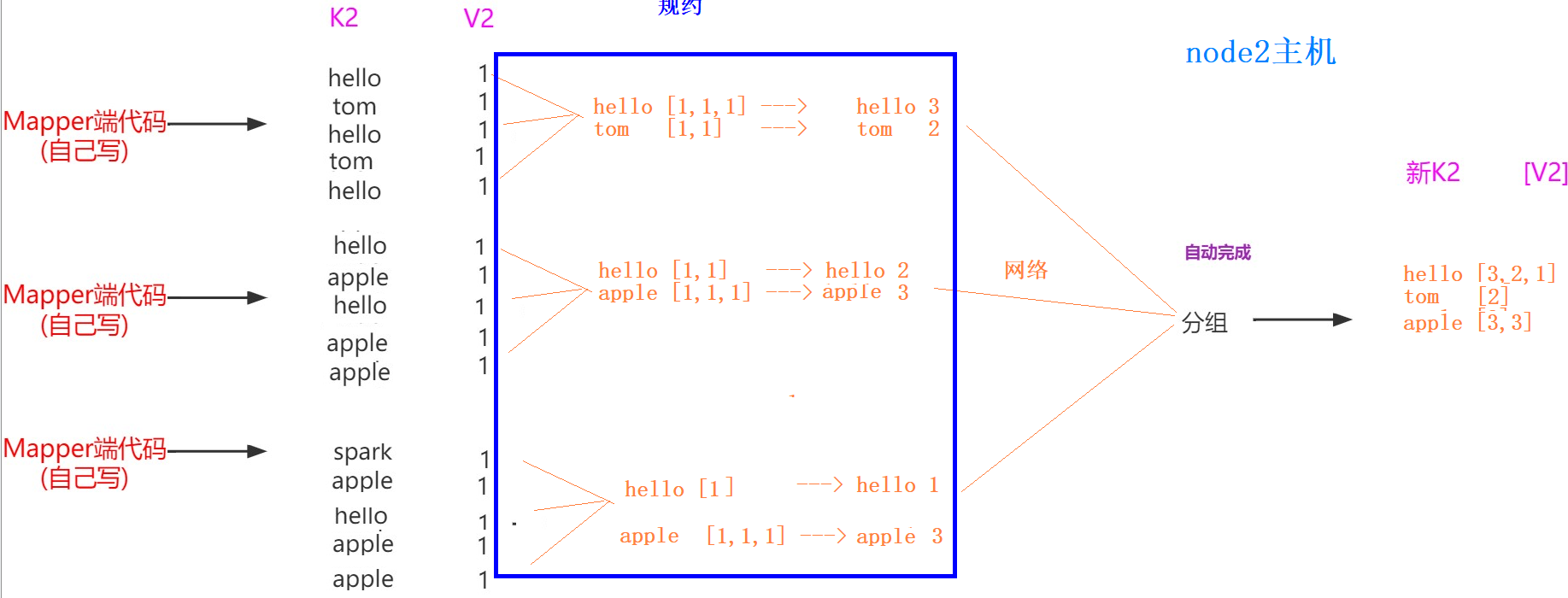
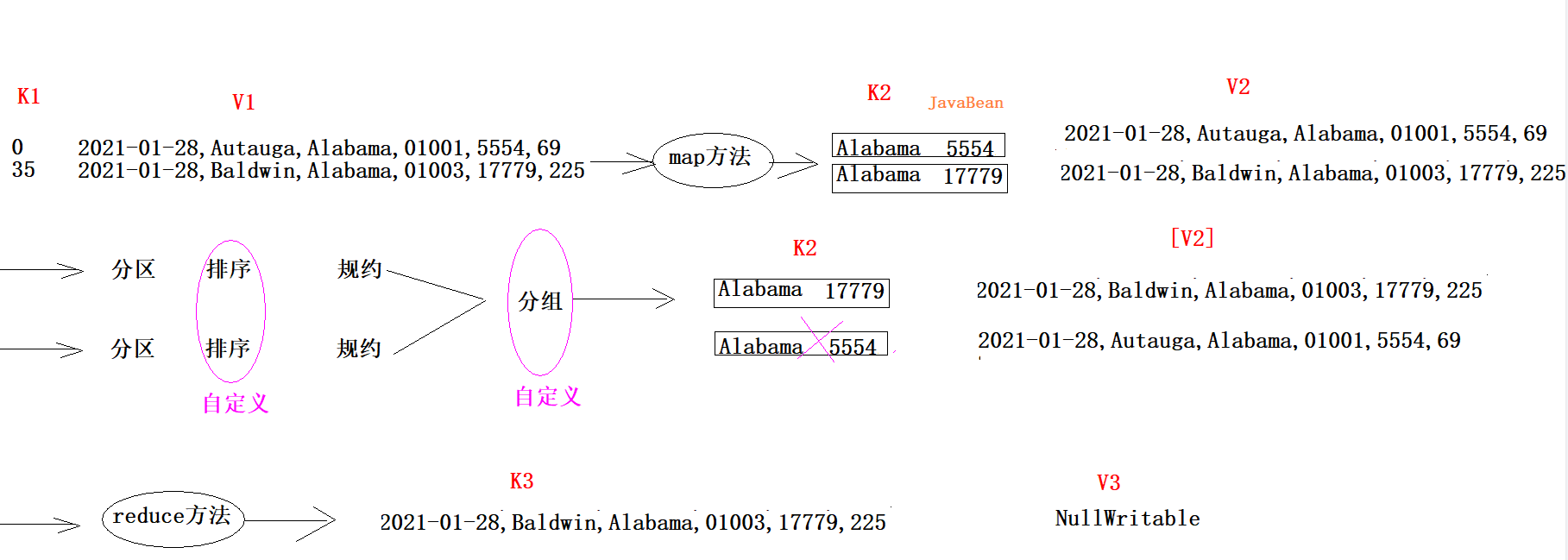

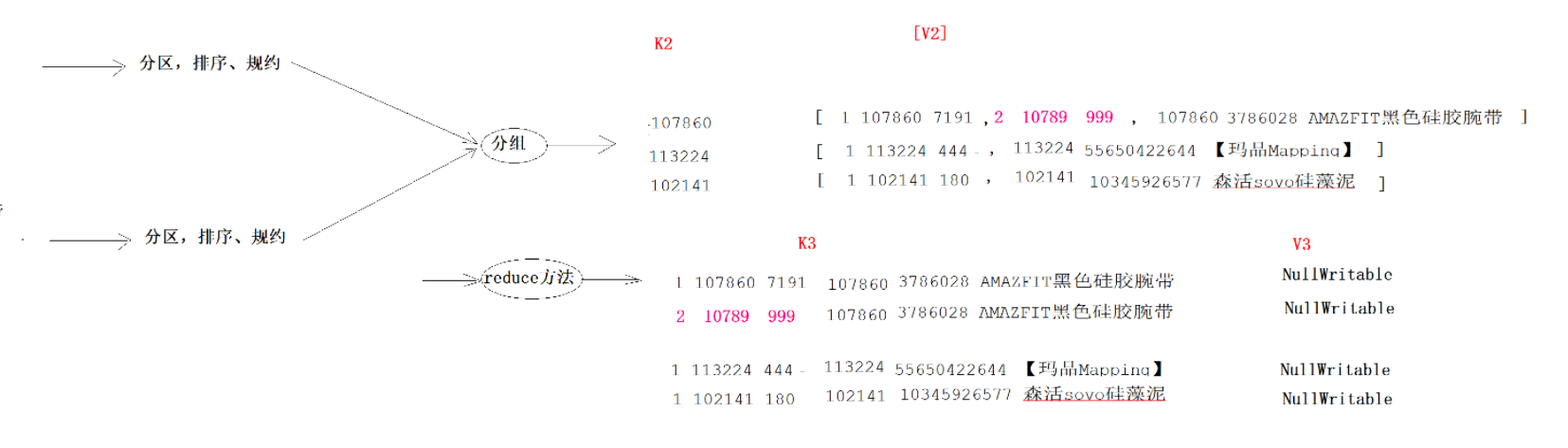
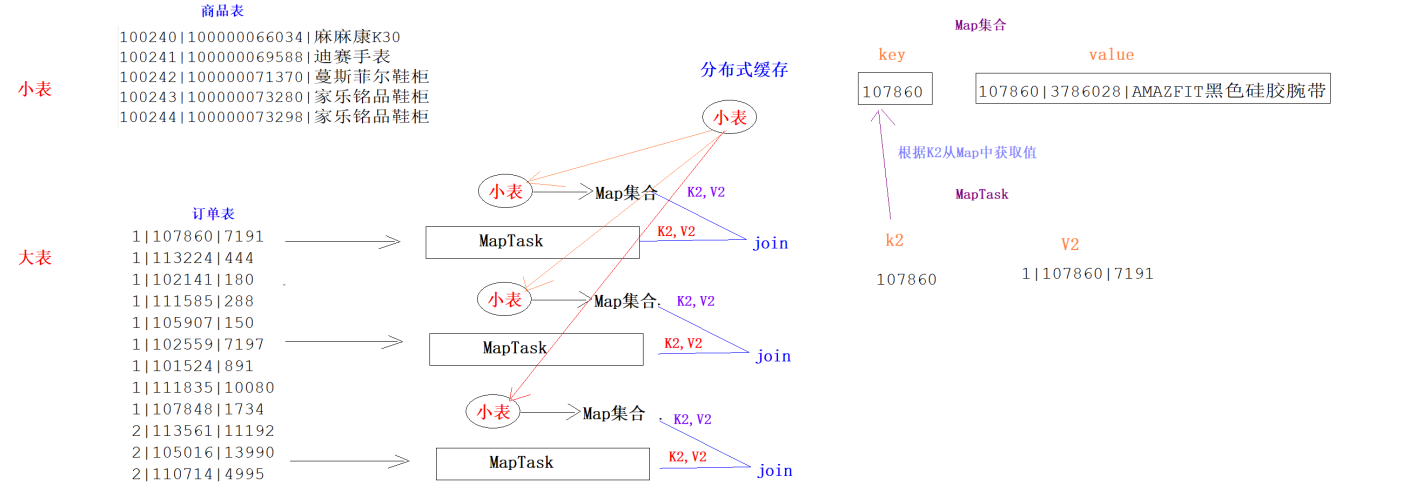
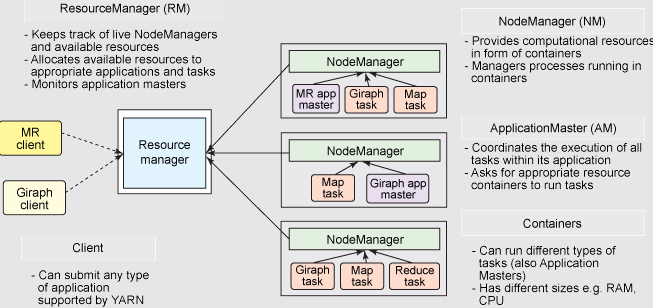
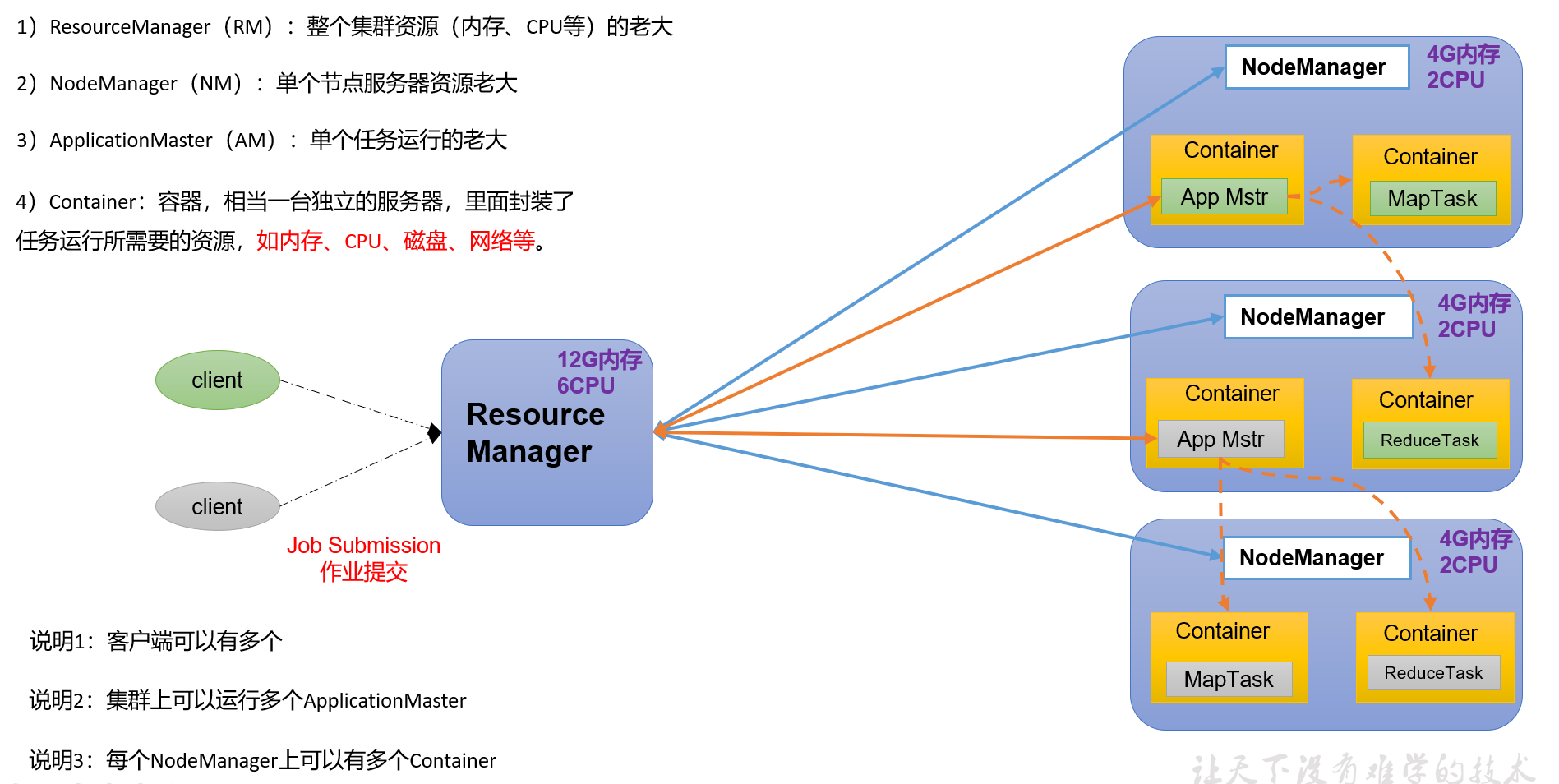
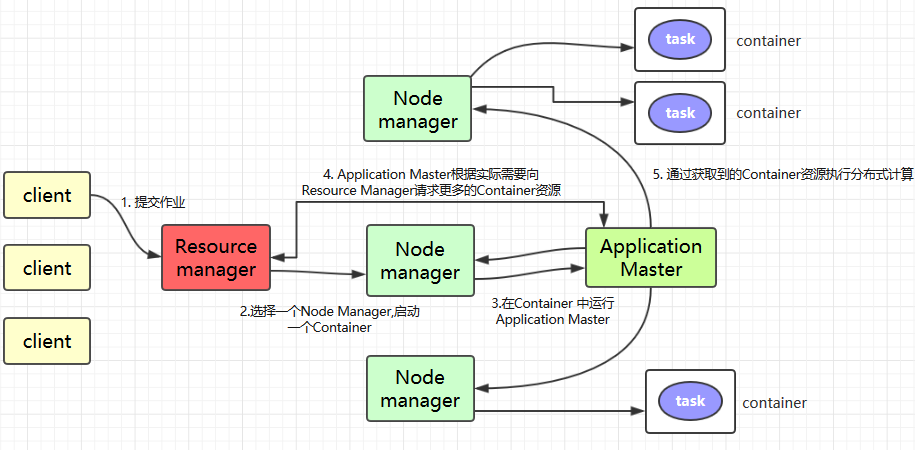
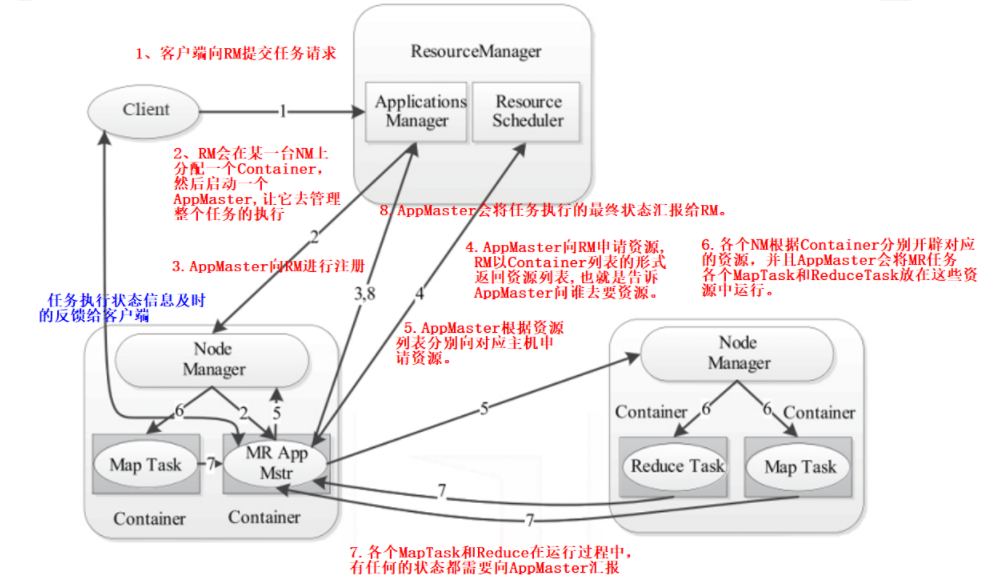
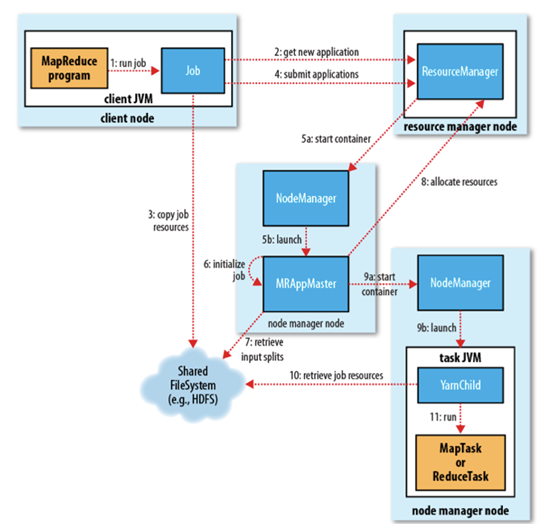
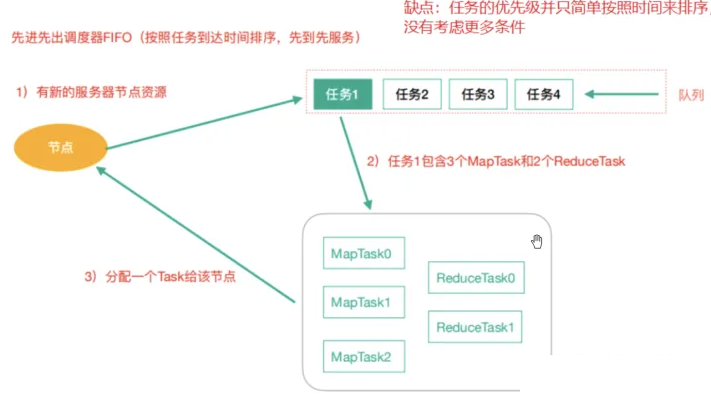















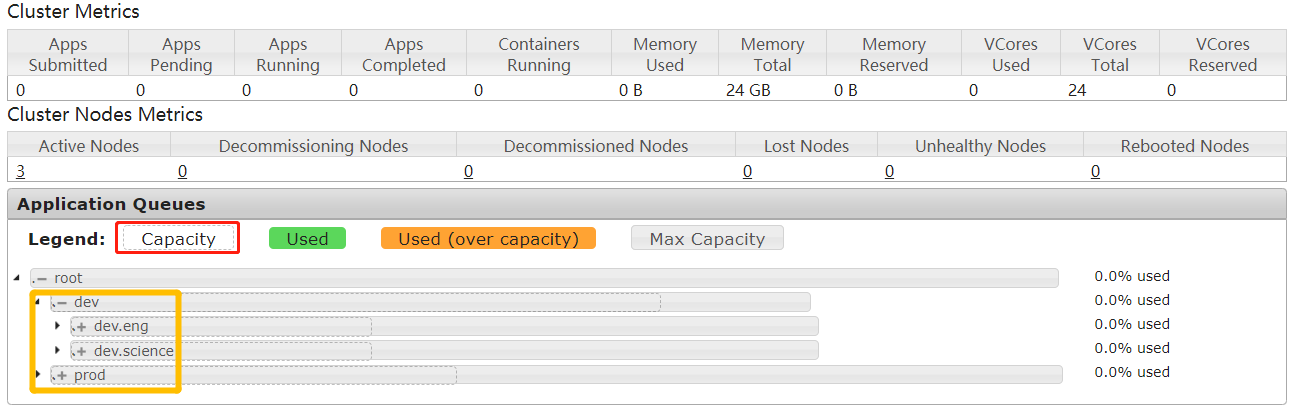
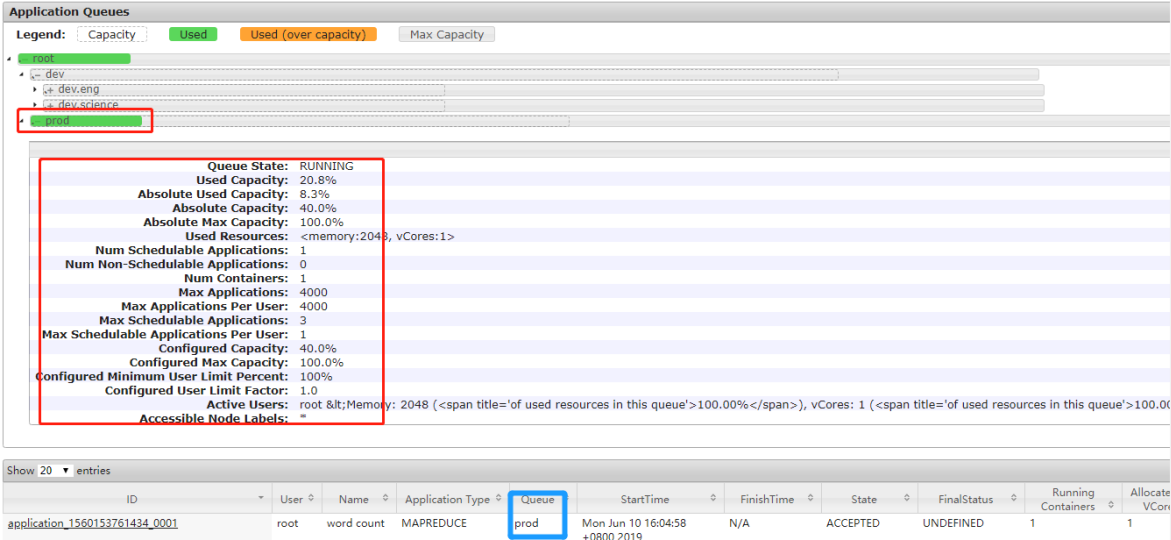
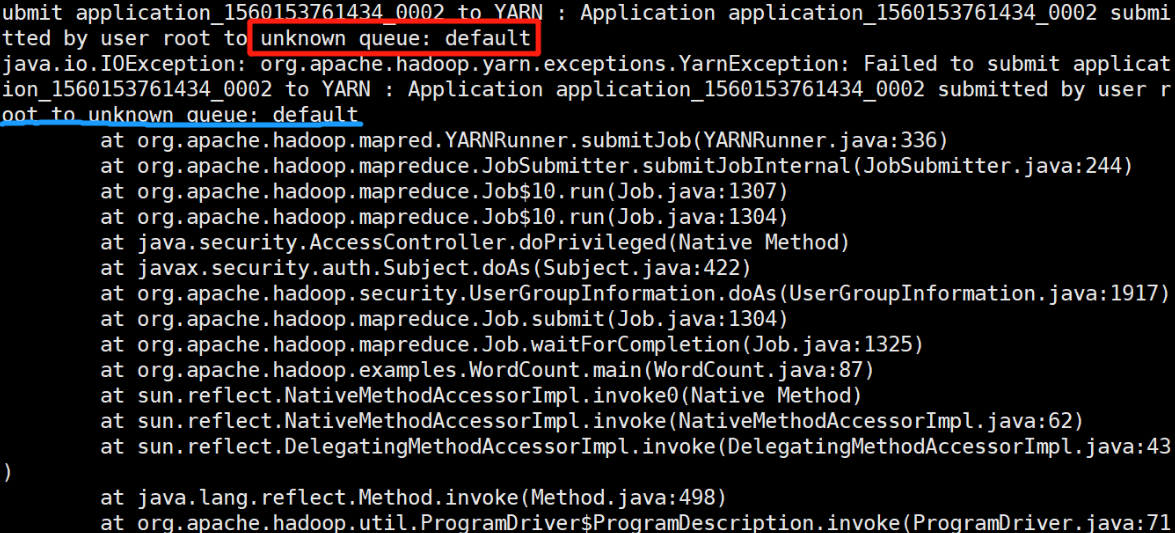
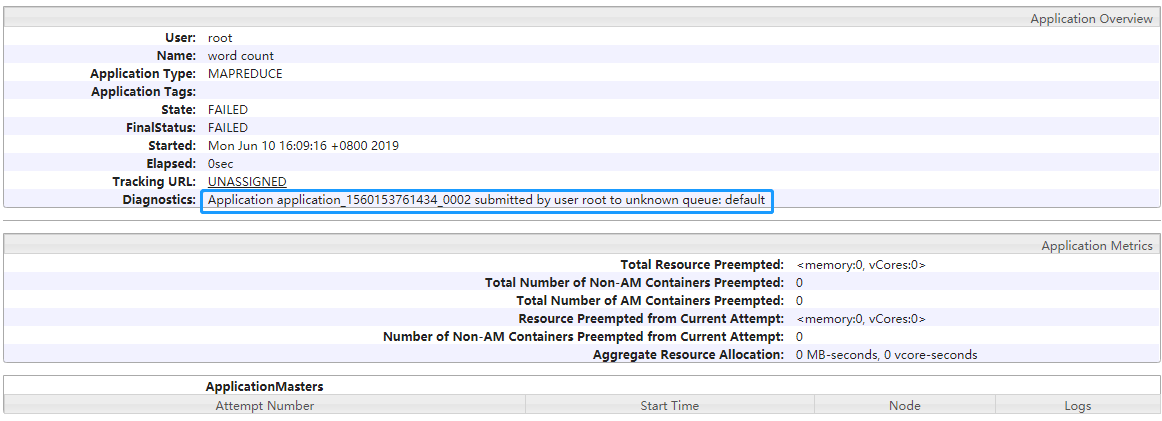
 微信
微信 支付宝
支付宝
