【大数据系列】Presto
Preso框架
在经过原生Hive+MR,将大数据量大的,聚合聚合,到了数据量小的层次,这时候去做分析,可以借助Hive+Presto(或者Hive+Impala)基于内存去跑。速度会快10倍以上。
当然,数据量大的时候,如果hive MR都跑不出来,用Presto更跑不出来,所以这个工具一般是对聚合到一定程度(中后期)的hive里的数据进行分析查询。
Presto基础介绍
Presto背景
2011年,FaceBook的数据仓库存储在少量大型hadoop/hdfs集群,在这之前,FaceBook的科学家和分析师一直靠hive进行数据分析,但hive使用MR作为底层计算框架,是专为批处理设计的,但是随着数据的不断增多,使用hive进行一个简单的数据查询可能要花费几分钟或者几个小时,显然不能满足查询需求,Facebook也调研了其他比hive更快的工具,但是他们需要在功能有限的条件下做简单操作,以至于无法操作Facebook庞大的数据要求。
2012年 开始研究自己的框架–presto, 每日可以超过1pb查 询 , 而且速度比较快 ,faceBook声称Presto的性能比hive要好上10倍或者100倍,presto和hive都是facebook开发的。2013年Facebook正式宣布开源Presto。
2018年,Facebook管理层希望对该项目及其未来进行更严格的控制,最终他们决定授予Facebook开发者在没有任何Presto经验的情况下参与该项目的权利。部分核心开发成员认为这个决定与拥有一个健康、开放的社区不相容,于是离开成立PrestoSQL,Presto自此划分为PrestoDB和PrestoSql两个阵营,两者互相发力互相抄袭,支持的数据源越来越多,性能也越来越快。两者相似度较高,PrestoSql后来被迫改名为Trino。
Presto介绍
- PrestoDB官方网站:https://prestodb.io/
- Trino(PrestoSql)官方网站:https://trino.io/
1 | 1、Presto是FaceBook研发,和Hive是同一个母公司 |
Presto特点
1 | Presto支持在线数据查询,包括Hive、kafka、Cassandra、关系数据库以及专门数据存储; |
- 免费:Presto和Trino都是开源的。
- 速度:Presto/Trino是一个高度并行的分布式查询引擎,适用于高效、低延迟的交互式查询,能够解决Facebook这样大规模的商业数据仓库交互式分析和处理的速度问题。
- 规模:数据量支持EB级的数仓和数据湖;
- 简单:它支持标准的ANSI SQL,包括复杂查询、聚合(Aggregation)、连接(Join)和窗口
- 函数(Window Functions),安装配置简单;
- 多才多艺:快速的交互式即席分析、数小时的大规模批处理查询,以及执行亚秒级查询的大容量应用;
- 广泛兼容:Presto本身并不存储数据,但是可以接入多种数据源:不仅支持Hive,还支持mysql、oracle等关系型数据库,也支持kafka、redis、MongoDB等非关系型数据库,对于实时数据库ClickHouse也能够完美支持。
- 就地分析:通过Presto,可以在Hadoop、Mysql等数据库本地查询数据,而无需进行复杂、缓慢且容易出错的数据复制过程;
- 联合查询:Presto支持跨数据源的联合查询,一个Presto查询可以跨越多个系统进行分析。例如将Hive中的学生表与Mysql中的班级表进行关联。也可以将mysql库中的表数据直接读取插入到hive中。
1 | select * from mysql.A表 join hive.B表 join ES.C表 |
Presto终结了数据分析的两难选择:要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
presto优缺点
- 优点
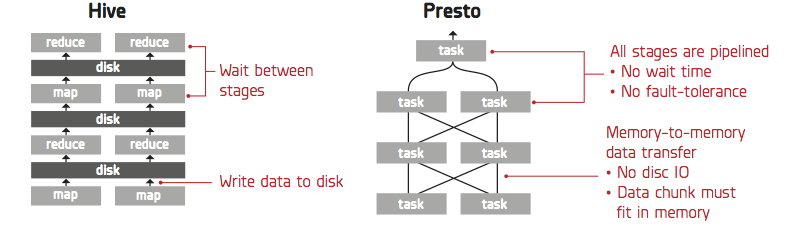
1)Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
2)能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
3)部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
- 缺点
1)虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
2)为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
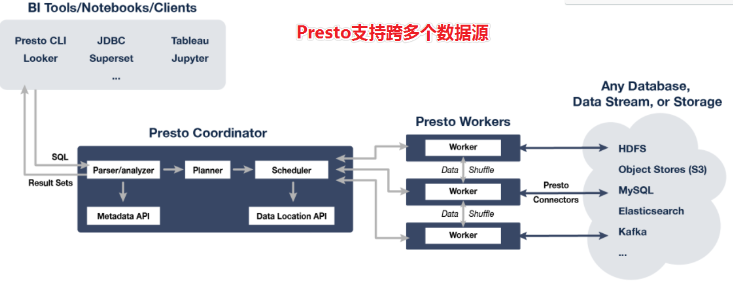
Presto架构
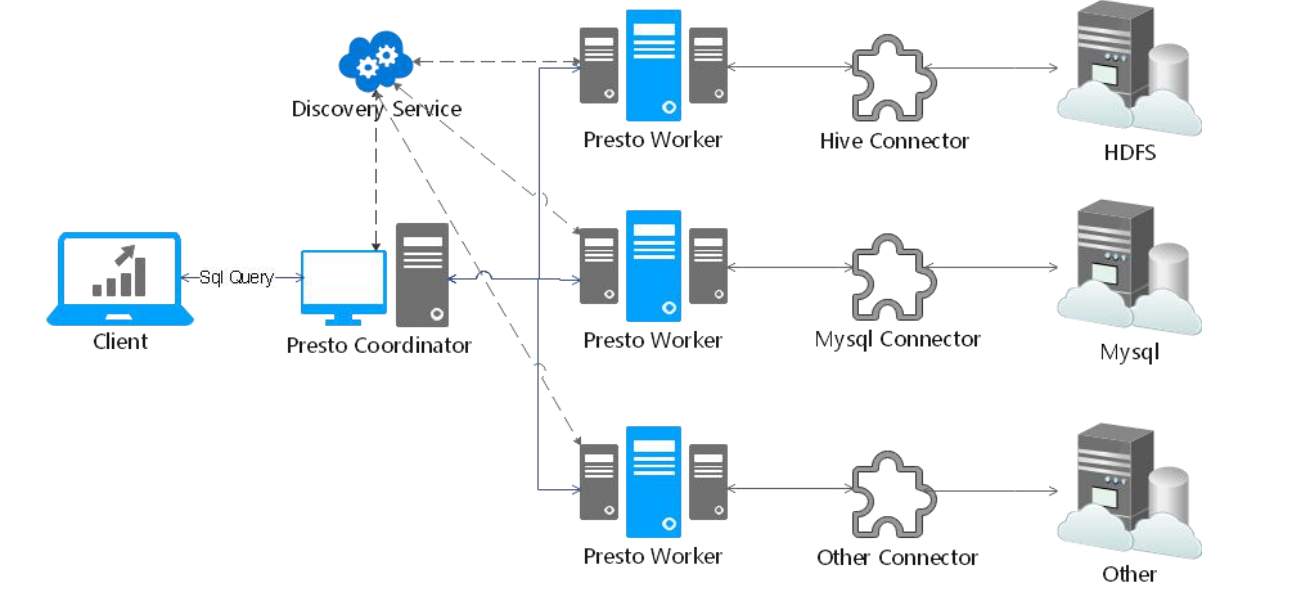
Presto是一个运行在多台服务器上的分布式系统。完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker
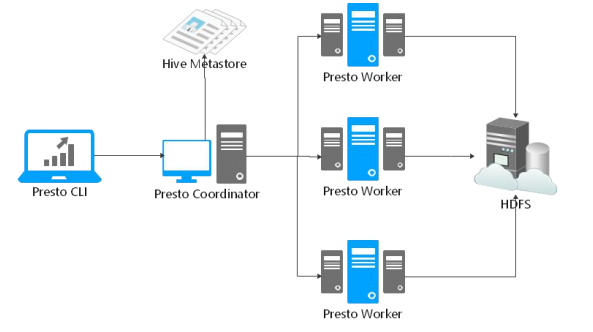
Presto查询引擎是一个M-S的架构,由一个coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌在Coordinator节点中。Coordinator负责SQL的解析,生成执行计划,分发给Worker节点进行执行,Worker节点负责实时查询执行任务。Worker节点启动后向discovery Server服务注册,Coordinator 从discovery server获取可以工作的Worker节点。如果配置了hive connector,需要配置hive MetaSote服务为Presto提供元信息,worker节点和HDFS进行交互数据
Presto术语
Connector 连接器
Presto通过Connector连接器来适应数据源,例如Hive或关系数据库。功能类似于数据库的驱动程序。允许Presto使用标准API与资源进行交互。
Presto包含几个内置连接器:JMX连接器,可访问内置系统表的System连接器,Hive连接器和旨在提供TPC-H基准数据的TPCH连接器。许多第三方开发人员都贡献了连接器,因此Presto可以访问各种数据源中的数据,比如:ES、Kafka、MongoDB、Redis、Postgre、Druid、Cassandra等。
每个Catalog都与一个特定的连接器关联。如果检查Catalog配置文件,将会看到每个都包含一个强制性属性connector.name,Catalog Manager使用此属性指定Catalog的连接器。可能有多个Catalog使用同一连接器来访问相似数据库的两个不同实例。比如,有两个Hive群集,则可以在单个Presto群集中配置两个都使用Hive连接器的Catalog,从而允许从两个不同的Hive集群中查询数据(可以在同一SQL中查询)。
Catalog 连接目录
Presto Catalog是数据源schema的上一级,并通过连接器访问数据源。例如,可以配置HiveCatalog以通过Hive Connector连接器提供对Hive信息的访问。
在Presto中使用表时,标准表名始终是被支持的。例如,hive.test_data.test的标准表名将引用hive catalog中test_data schema中的test table。
Catalog需要在Presto的配置文件中进行配置。
Schema
Schema是组织表的一种方式。Catalog和Schema共同定义了一组可以查询的表。当使用Presto访问Hive或关系数据库(例如MySQL)时,Schema会转换为目标数据库中的对应Schema。
Table
Table表是一组无序的行,它们被组织成具有类型的命名列。与关系数据库中的含义相同
Presto单机安装
Presto-Server安装
环境要求
linux或者MacOS
Java8 64位(Trino需要Java11)
Python 2.4+
Java8安装
1 | yum install java-1.8.0-openjdk* -y |
下载解压
1、下载安装包
https://prestodb.io/download.html
在资料目录中已经下载好。
2、上传presto-server-0.245.1.tar到 hadoop01 的/export/server目录
3、解压
1 | tar -xzvf presto-server-0.245.1.tar.gz |
4、查/看目录结构
1 | cd /export/server/presto |
bin—可执行文件
lib—对应的jar包
plugin—第三方库插件
5、Presto需要一个用于存储日志等的data目录。建议在安装目录之外创建一个data目录,以便在升级Presto时可以保留此目录。
配置
在安装目录中创建一个etc目录,此目录下将会包含以下配置文件:
node.properties: 每个节点的环境配置
jvm.config: JVM的命令行选项
config.properties: Presto Server的配置项
catalog/hive.properties: 数据源连接器的配置,此课程将使用hive数据源北京市昌平区建材城西路金燕龙办公楼一层
电话:400-618-9090
节点环境配置
etc/node.properties,每个节点的特定配置。
一个节点指的是服务器上Presto的单个已安装实例。
1 | node.environment=production |
node.environment:环境的名称。群集中的所有Presto节点必须具有相同的环境名称。
node.id:此Presto安装的唯一标识符。这对于每个节点都必须是唯一的。在重新启动或升级Presto时,此标识符应保持一致。如果在一台计算机上运行多个Presto安装(即同一台计算机上有多个节点),则每个安装必须具有唯一的标识符。
node.data-dir:数据目录的位置(文件系统路径)。Presto将在此处存储日志和其他数据。
JVM虚拟机配置
etc/jvm.config,包含用于启动Java虚拟机的命令行选项列表。文件的格式是选项列表,每行一个。不能使用空格或其他特殊字符。
1 | -server |
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是记录下dump heap中的信息(用于debugging),然后强制终止进程。
Presto服务配置
etc/config.properties,包含Presto服务器的配置。
Presto服务氛围三种角色:coordinator、worker、coordinator&worker。每个Presto服务都可以充当coordinator和worker,但是独立出一台服务器专用于coordinator协调工作将在较大的群集上提供最佳性能。
coordinator配置
1 | coordinator=true |
worker配置
1 | coordinator=false |
coordinator&worker配置
单机版使用此配置进行测试。
1 | coordinator=true |
配置项含义
coordinator:允许此Presto实例充当coordinator协调器角色(接受来自客户端的查询并管理查询执行)。
node-scheduler.include-coordinator:允许此Presto实例充当coordinator&worker角色。对于较大的群集,coordinator上的worker工作可能会影响查询性能,因为两者互相争抢计算机的资源会导致调度的关键任务受到影响。
http-server.http.port:指定HTTP服务器的端口。Presto使用HTTP进行内部和外部所有通信。
query.max-memory:单个query操作可以使用的最大集群内存量。
query.max-memory-per-node:单个query操作在单个节点上用户内存能用的最大值。
query.max-total-memory-per-node:单个query操作可在单个节点上使用的最大用户内存量和系统内存量,其中系统内存是读取器、写入器和网络缓冲区等在执行期间使用的内存。
discovery-server.enabled:Presto使用发现服务Discovery service来查找群集中的所有节点。
每个Presto实例在启动时都会向Discovery服务注册。为了简化部署并避免运行其他服务,Presto协调器coordinator可以运行Discovery服务的嵌入式版本。它与Presto共享HTTP服务器,因此使用相同的端口。
discovery.uri:Discovery服务的URI地址。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri。修改example.net:8090,根据你的实际环境设置该URI。此URI不得以“/“结尾。
日志级别
etc/log.properties
在这个配置文件中允许你根据不同的日志结构设置不同的日志级别。
Loggers通过名字中的“.“来表示层级和集成关系(像java里面的包)。
1 | com.facebook.presto=INFO |
这会将com.facebook.presto.server和com.facebook.presto.hive的日志级别都设置为INFO。
共有四个级别:DEBUG,INFO,WARN和ERROR。
trino这里配置不同
1 | io.trino=INFO |
连接器配置
Presto通过catalogs中的连接器connectors访问数据。connector提供了对应catalog中的所有schema和table。比如,如果在catalog中配置了Hive connector,并且此Hive的’web’数据库中有一个’clicks’表,该表在Presto中就可以通过hive.web.clicks来访问。
通过在etc/catalog目录中创建配置文件来注册connector。比如,通过创建etc/catalog/hive.properties,即可用来注册hive的connector:
1 | connector.name=hive-hadoop2 |
Presto连接器支持以下版本hive:
1.Apache Hive 1.x
2.Apache Hive 2.x
3.Cloudera CHD 4
4.Cloudera CHD 5
Presto的Hive连接器支持的文件类型:
1.ORC
2.Parquet
3.Avro
4.RCFile
5.SequenceFile
6.JSON
7.Text
运行Presto
在安装目录的bin/launcher文件,就是启动脚本。Presto可以使用如下命令作为一个后台进程启动:
1 | bin/launcher start |
另外,也可以在前台运行,日志和相关输出将会写入stdout/stderr(可以使用类似daemontools的工具捕捉这两个数据流):
1 | bin/launcher run |
运行bin/launcher –help,Presto将会列出支持的命令和命令行选项。另外可以通过运行时使用–verbose参数,来调试安装是否正确。
访问web:http://192.168.88.80:8090/ui/
启动完之后,日志将会写在node.data-dir 配置目录的子目录var/log下,该目录下有如下三个文件:
launcher.log:这个日志文件由launcher创建,并且server的stdout和stderr都被重定向到了这个日志文件中。这份日志文件中只会有很少的信息,包括:在server日志系统初始化的时候产生的日志和JVM产生的诊断和测试信息。
server.log:这个是Presto使用的主要日志文件。一般情况下,该文件中将会包括server初始化失败时产生的相关信息。这份文件会被自动轮转和压缩。
http-request.log:这是HTTP请求的日志文件,包括server收到的每个HTTP请求信息,这份文件会被自动轮转和压缩。
Presto-Cli安装
Presto CLI提供了基于终端的交互式命令程序,用于运行查询。Presto CLI是一个可执行的JAR文件,这意味着它的行为类似于普通的UNIX可执行文件。
下载presto-cli-0.245.1-executable.jar(https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.245.1/presto-cli-0.245.1-executable.jar),将其重命名为presto,使用chmod +x分配执行权限后,运行:
1 | #上传presto-cli-0.245.1-executable.jar到/export/server/presto/bin |
Presto验证
创建数据库(Hive)
create database myhive;
查看数据库(Hive)
show databases;
数据准备(Hive)
vim employees.txt
1 | 1201 Gopal 45000 Technical manager |
通过Hue将employees.txt文件上传至HDFS的/root/目录下。
创建表(Hive)
1 | use myhive; |
加载数据(Hive)
load data local inpath ‘/root/employees.txt’ into table employee;
查询表(Hive)
select * from employee;
Presto测试数据(Presto)
use myhive;
select * from employee;
Presto启动
- 命令行启动
1 | hadoop01启动 |
- 脚本启动
1 | !/bin/bash |
Presto集群搭建(旧)
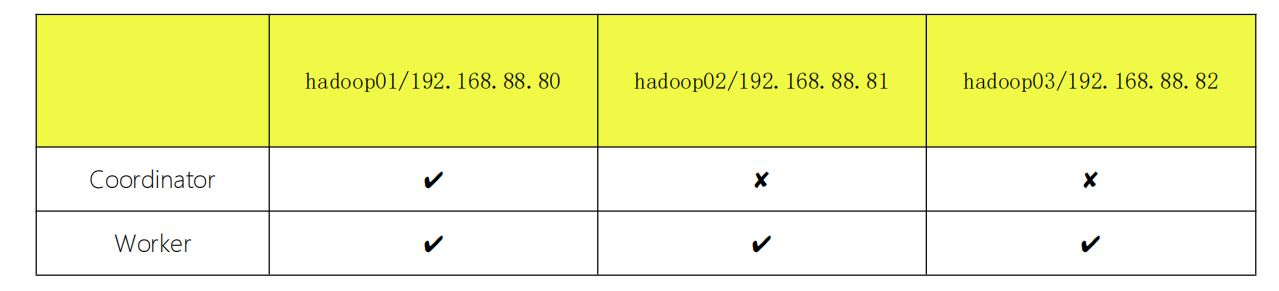
集群规划
分发配置文件
先在第二台和第三台服务器上创建对应的目录:
mkdir -p /export/server
在第一台执行复制命令:
scp -r presto root@hadoop02:/export/server
scp -r presto root@hadoop03:/export/server
配置
hadoop01节点作为coordinator节点,其余两个节点为Worker节点。
hadoop01-coordinator配置
- etc/config.properties
1 | coordinator=true |
- etc/jvm.config
1 | -server |
- etc/node.properties
1 | node.environment=cdhpresto |
- etc/catalog/hive.properties
1 | connector.name=hive-hadoop2 |
hadoop02/03-worker配置
- etc/config.properties
1 | coordinator=false |
- etc/jvm.config
1 | -server -Xmx8G |
- etc/node.properties
1 | node.environment=cdhpresto |
- etc/catalog/hive.properties
1 | connector.name=hive-hadoop2 |
运行
创建快捷启动脚本
在用户根目录创建脚本文件:
1 | cd ~ |
在文件中写入:
1 | /export/server/presto/bin/launcher start |
分配执行权限:
1 | chmod +x start_presto.sh |
启动三台presto:
1 | ./start_presto.sh |
查看是否启动成功:
1 | ps -ef|grep presto |

启动Presto客户端
启动三台presto,然后通过CLI分别登录三台server进行测试。
设置presto环境变量:
1 | vim /etc/profile |
在文件末尾写入:
1 | export PRESTO_HOME=/export/server/presto |
执行生效:
1 | source /etc/profile |
启动presto-cli:
1 | presto --server 192.168.88.80:8090 --catalog hive --schema default |
测试SQL:
1 | use myhive; |
集群管理页面介绍
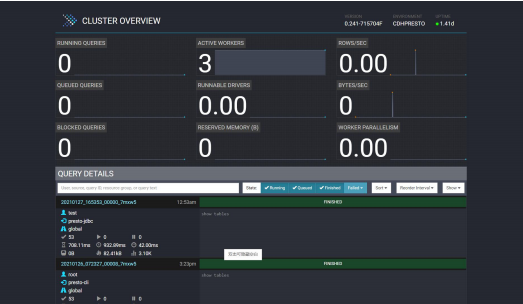
主页面显示了正在执行的查询数,正常活动的Worker数,排队的查询数,阻塞的查询数,并行度等等;以及每个查询的列表区域(包括查询的ID,查询语句,查询状态,用户名,数据源等等)。
正在查询的排在最上面,紧接着依次为最近完成的查询,失败的查询等。
查询的状态有以下几种:
- QUEUED-查询以及被接受,正等待执行
- PLANNING-查询在计划中
- STARTING-查询已经开始执行
- RUNNING-查询已经运行,至少有一个task开始执行
- BLOCKED-查询被阻塞,并且在等待资源(缓存空间,内存,切片)
- FINISHING-查询正完成(比如commit forautocommit queries)
- FINISHED-查询已经完成(比如数据已输出)
- FAILED-查询执行失败
分布式SQL查询引擎性能对比
大数据分析类软件发展历程。
- Apache Hadoop MapReduce
- 优点:统一、通用、简单的编程模型,分而治之思想处理海量数据。
- 缺点:java学习成本、MR执行慢、内部过程繁琐
- Apache Hive
- 优点:SQL on Hadoop。sql语言上手方便。学习成本低。
- 缺点:底层默认还是MapReduce引擎、慢、延迟高
- 各种SQL类计算引擎开始出现,主要追求的就是一个问题:==怎么能计算的更快,延迟低==。
- Spark On Hive、Spark SQL
- Impala
- Presto
- ClickHouse
- ……..
hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 Mapper 和 Reducer 来处理内建的Mapper 和 Reducer 无法完成的复杂的分析工作。
性能:
Hive相对于其他查询引擎来说性能一般,主要的优势体现在系统负载低、稳定性高、数据格式支持面广、社区活跃度高,可以为其他多款查询引擎提供底层元数据,SparkSql、Presto、Impala、HAWQ等都支持基于Hive的查询。
成本低、稳定性好,生态兼容性好,因此Hive在企业中应用的较多。
spark sql
SparkSQL是Hadoop中另一个著名的SQL引擎,它以Spark作为底层计算框架,Spark使用RDD作为分布式程序的工作集合,它提供一种分布式共享内存的受限形式。 在分布式共享内存系统中,应用可以向全局地址空间的任意位置进行读写操作,而RDD是只读的,对其只能进行创建、转化和求值等操作。这种内存操作大大提高了计算速度。
SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive。可以利用hive作为数据源,Spark作为计算引擎,通过SQL解析引擎,实现基于Hive数据源,Spark作为计算引擎的方案。
性能:
SparkSQL的性能相对其他的组件要差一些,多表单表查询性能都不突出
Impala
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,它拥有和Hadoop一样的可扩展性、它提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分,除此之外,Impala还能够共享Hive Metastore,甚至可以直接使用Hive的JDBC jar和beeline等直接对Impala进行查询、支持丰富的数据存储格式(Parquet、Avro等)。
此外,Impala 没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎,可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
性能:
Impala官方宣传其计算速度是一大优点,在实际测试中它的多表查询性能和presto差不多,但是单表查询方面却不如presto好。 而且Impala有很多不支持的地方,例如:不支持update、delete操作,不支持grouping sets语法,不支持Date数据类型,不支持ORC文件格式等等,所以impala 一般采用Parquet格式进行查询,而且Impala在查询时占用的内存很大。
HAWQ
HAWQ 是一个 Hadoop 上的 SQL 引擎,是以 Greenplum Database 为代码基础逐渐发展起来的。HAWQ 采用 MPP 架构,改进了针对 Hadoop 的基于成本的查询优化器。除了能高效处理本身的内部数据,还可通过 PXF 访问 HDFS、Hive、HBase、JSON 等外部数据源。HAWQ全面兼容 SQL 标准,能编写 SQL UDF,还可用 SQL 完成简单的数据挖掘和机器学习。无论是功能特性,还是性能表现,HAWQ 都比较适用于构建 Hadoop 分析型数据仓库应用。
性能:
HAWQ 吸收了先进的基于成本的 SQL 查询优化器,自动生成执行计划,可优化使用Hadoop集群资源。 HAWQ 采用 Dynamic Pipelining 技术解决这一关键问题。Dynamic Pipelining 是一种并行数据流框架,利用线性可扩展加速Hadoop查询,数据直接存储在HDFS上,并且其SQL查询优化器已经为基于HDFS的文件系统性能特征进行过细致的优化。
但是HAWQ在多表查询时比Presto、Impala差一些;而且不适合单表的复杂聚合操作,单表测试性能方面要比其余四种组件差很多,HAWQ环境搭建也会遇到诸多问题。
ClickHouse
ClickHouse由俄罗斯Yandex公司开发。专为在线数据分析而设计。Yandex是俄罗斯搜索引擎公司。官方提供的文档表名,ClickHouse日处理记录数”十亿级”。
特性:
- 采用列式存储
- 数据压缩
- 基于磁盘的存储,大部分列式存储数据库为了追求速度,会将数据直接写入内存,按时内存的空间往往很小
- CPU 利用率高,在计算时会使用机器上的所有 CPU 资源
- 支持分片,并且同一个计算任务会在不同分片上并行执行,计算完成后会将结果汇总
- 支持SQL,SQL 几乎成了大数据的标准工具,使用门槛较低
- 支持联表查询
- 支持实时更新
- 自动多副本同步
- 支持索引
- 分布式存储查询
性能:
ClickHouse 作为目前所有开源MPP计算框架中计算速度最快的,它在做多列的表,同时行数很多的表的查询时,性能是很让人兴奋的,但是在做多表的Join时,它的性能是不如单宽表查询的。
性能测试结果表明ClickHouse在单表查询方面表现出很大的性能优势,但是在多表查询中性能却比较差,不如Presto和Impala、HAWQ的效果好。
Greenplum
Greenplum是一个开源的大规模并行数据分析引擎。借助MPP架构,在大型数据集上执行复杂SQL分析的速度比很多解决方案都要快。
特性:
- GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展。
- 从应用编程接口上讲,它支持ODBC和JDBC。
- 完善的标准支持使得系统开发、维护和管理都大为方便。
- 支持分布式事务,支持ACID。
- 保证数据的强一致性。
- 做为分布式数据库,拥有良好的线性扩展能力。
- GPDB有完善的生态系统,可以与很多企业级产品集成,譬如SAS、Cognos、Informatic、Tableau等。
- 也可以很多种开源软件集成,譬如Pentaho、Talend 等
性能:
Greenplum作为关系型数据库产品,它的特点主要就是查询速度快,数据装载速度快,批量DML处理快。 而且性能可以随着硬件的添加,呈线性增加,拥有非常良好的可扩展性。因此,它主要适用于面向分析的应用。 比如构建企业级ODS/EDW,或者数据集市等,Greenplum都是不错的选择。
整体性能上Greenplum的表现比较中庸,单表查询不如clickhouse,多表查询不如impala,整体性能不如presto。
Presto/Trino
介绍:
速度:Presto/Trino是一个高度并行的分布式查询引擎,适用于高效、低延迟的交互式查询,能够解决Facebook这样大规模的商业数据仓库交互式分析和处理的速度问题。
规模:数据量支持EB级的数仓和数据湖;
简单:它支持标准的ANSI SQL,包括复杂查询、聚合(Aggregation)、连接(Join)和窗口函数(Window Functions),且安装配置简单;
多才多艺:快速的交互式即席分析、数小时的大规模批处理查询,以及执行亚秒级查询的大容量应用;
广泛兼容:Presto本身并不存储数据,但是可以接入多种数据源:不仅支持Hive,还支持mysql、oracle等关系型数据库,也支持kafka、redis、MongoDB等非关系型数据库,对于实时数据库ClickHouse也能够完美支持。
就地分析:通过Presto,可以在Hadoop、Mysql等数据库本地查询数据,而无需进行复杂、缓慢且容易出错的数据复制过程;
联合查询:Presto支持跨数据源的联合查询,一个Presto查询可以跨越多个系统进行分析。例如将Hive中的学生表与Mysql中的班级表进行关联。也可以将mysql库中的表数据直接读取插入到hive中。
免费:Presto和Trino都是开源的。
Presto终结了数据分析的两难选择:要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
性能:
Presto综合性能比起来要比其余组件好一些,无论是查询性能还是支持的数据源和数据格式方面都要突出一些,在单表查询时性能靠前,多表查询方面性能也很突出。
由于Presto是完全基于内存的并行计算,所以Presto在查询时占用的内存也不少,但是要比Impala少一些,比如多表Join时需要很大的内存,Impala占用的内存比Presto要多。
总结
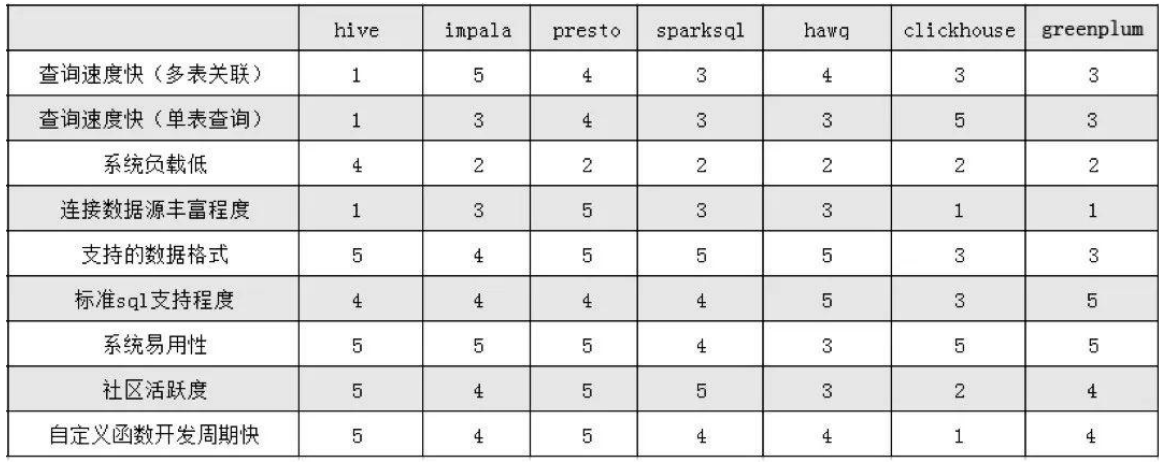
多表查询
Presto、Impala以及HAWQ在多表查询方面更有优势。
虽说Presto和Impala在多表查询方面的性能差别不大,但是Impala的功能有一些局限性,Impala不支持的功能是没有办法参与性能对比测试的,例如:不支持update、delete操作,不支持grouping sets语法,不支持Date数据类型,不支持ORC文件格式等等,而Presto则基本没有这些局限问题。
单大表聚合
在单表测试方面ClickHouse性能最好,其次是Presto,相比于HAWQ和impala以及SparkSQL在单大表聚合操作方面的表现也相对优秀。
综合对比表格
使用场景
Presto
多数据源时,presto可以基于标准SQL进行统一的跨DB/Schema读写。
快速查询时,presto综合性能更好;Presto/Trino 也能够极大地加速 ETL 过程。
但Presto需要的硬件资源也更昂贵。因此ODS和DWD数据量较大的分层,使用hive会更节省资
源。
Hive
海量数据的场景下,一是需要大量的硬件资源,二是海量的数据极可能造成内存溢出等各种异
常。此时推荐使用Hive:成本低、稳定性好,且生态兼容性好。
Grouping sets语法
hive sql和presto sql是由区别的!语法上有略微差异
Hive的写法
1 | select |
Presto写法
1 | select |
Grouping的写法
hive
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17-- 有就是 1 ,没有就是0
select
month,
day,
count(userid), -- 0 0
case when grouping__id = 3 -- month_day 1 1
then 'month_day'
when grouping__id = 2 -- month 1 0
then 'month'
when grouping__id = 1 -- day 0 1
then 'day'
when grouping__id = 0 -- all 0 0
then 'all'
end as group_type
from test.t_user
group by day,month -- 这里的顺序要和select后边的字段顺序相反
grouping sets (month,day,(month,day),());presto
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20-- 有就是 0 ,没有就是1
select
month,
day,
count(userid), -- 0 0
case when grouping(month,day) = 0 -- month_day
then 'month_day'
-- 0 1
when grouping(month,day) = 1 -- month
then 'month'
-- 1 0
when grouping(month,day) = 2 -- day
then 'day'
-- 1 1
when grouping(month,day) = 3 -- all
then 'all'
end as group_type
from test.t_user
group by
grouping sets (month,day,(month,day),())
Presto集群模式安装
集群规划

项目集群环境安装JDK
1 | 可以手动安装oracle JDK |
上传Presto安装包
hadoop01
1 | 创建安装目录 |
添加配置文件
hadoop01
etc/config.properties
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20cd /export/server/presto
vim etc/config.properties
#---------添加如下内容---------------
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8090
query.max-memory=6GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://192.168.88.80:8090
#---------end-------------------
#参数说明
coordinator:是否为coordinator节点,注意worker节点需要写false
node-scheduler.include-coordinator:coordinator在调度时是否也作为worker
discovery-server.enabled:Discovery服务开启功能。presto通过该服务来找到集群中所有的节点。每一个Presto实例都会在启动的时候将自己注册到discovery服务; 注意:worker节点不需要配
discovery.uri:Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery服务,因此这个uri就是Presto coordinator的uri。etc/jvm.config
1
2
3
4
5
6
7
8
9
10vim etc/jvm.config
-server
-Xmx3G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryErroretc/node.properties
1
2
3
4
5
6mkdir -p /export/data/presto
vim etc/node.properties
node.environment=cdhpresto
node.id=presto-cdh01
node.data-dir=/export/data/prestoetc/catalog/hive.properties
1
2
3
4
5
6mkdir -p etc/catalog
vim etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.88.80:9083
hive.max-partitions-per-writers=300step4:scp安装包到其他机器
1
2
3
4
5
6
7
8在hadoop02创建文件夹
mkdir -p /export/server
在hadoop01远程cp安装包
cd /export/server
scp -r presto hadoop02:$PWD
ssh的时候如果没有配置免密登录 需要输入密码scp 密码:123456
hadoop02配置修改
etc/config.properties
1
2
3
4
5
6
7
8
9
10cd /export/server/presto
vim etc/config.properties
#----删除之前文件中的全部内容 替换为以下的内容 vim编辑器删除命令 8dd
coordinator=false
http-server.http.port=8090
query.max-memory=6GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=2GB
discovery.uri=http://192.168.88.80:8090etc/jvm.config
和hadoop01一样,不变,唯一注意的就是如果机器内存小,需要调整-Xmx参数
1
2
3
4
5
6
7
8
9
10vim etc/jvm.config
-server
-Xmx3G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryErroretc/node.properties
修改编号node.id
1
2
3
4
5
6mkdir -p /export/data/presto
vim etc/node.properties
node.environment=cdhpresto
node.id=presto-cdh02
node.data-dir=/export/data/prestoetc/catalog/hive.properties
保持不变
1
2
3
4
5vim etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.88.80:9083
hive.max-partitions-per-writers=300
Presto集群启停
注意,每台机器都需要启动
后台启动
1 | [root@hadoop01 ~]# cd ~ |
web UI页面
启动日志
1 | 日志路径:/export/data/presto/var/log/ |
Presto命令行客户端
下载CLI客户端
1
presto-cli-0.241-executable.jar
上传客户端到Presto安装包
1
2
3
4上传presto-cli-0.245.1-executable.jar到/export/server/presto/bin
mv presto-cli-0.245.1-executable.jar presto
chmod +x prestoCLI客户端启动
1
/export/server/presto/bin/presto --server localhost:8090 --catalog hive --schema default
Datagrip连接使用
- JDBC 驱动:==presto-jdbc-0.245.1.jar==
- JDBC 地址:==jdbc:presto://192.168.88.80:8090/hive==
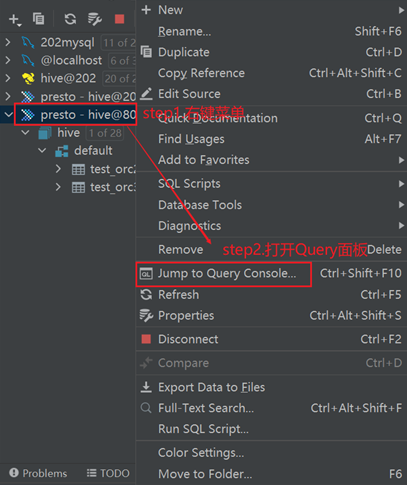
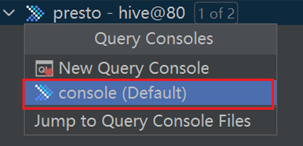
配置驱动
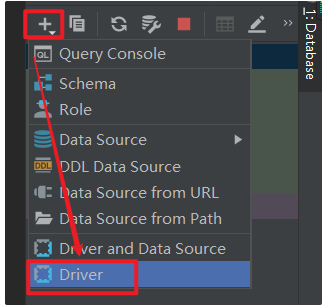
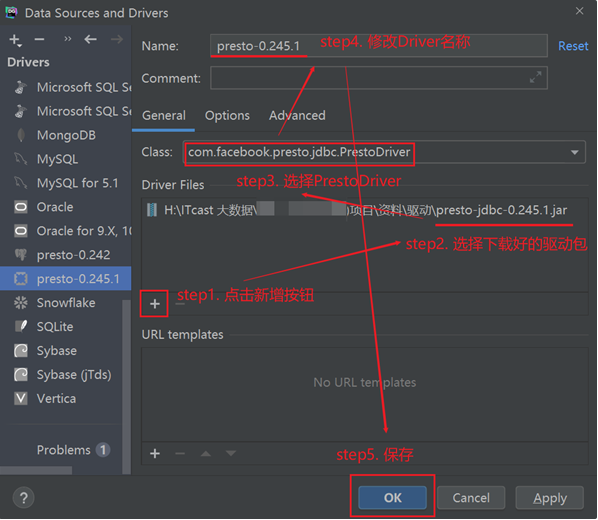
创建连接
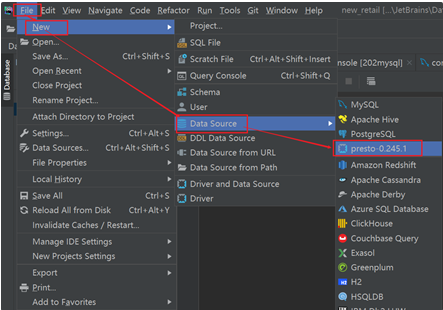
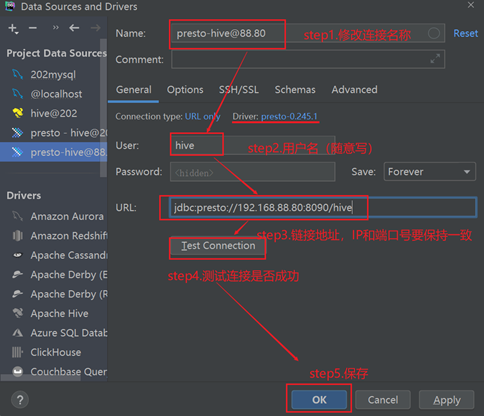
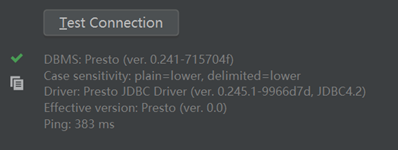
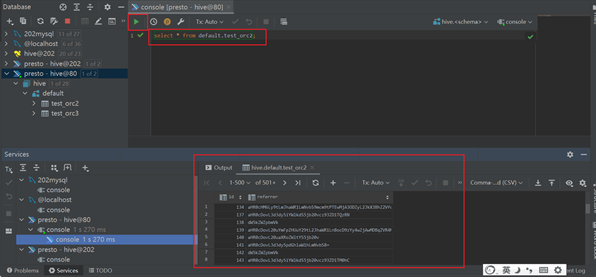
测试体验
时间日期类型注意事项
==date_format==(timestamp, format) ==> varchar
- 作用: 将指定的日期对象转换为字符串操作
==date_parse==(string, format) → timestamp
- 作用: 用于将字符串的日期数据转换为日期对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#hive的写法,将日期转为:2020/10/10 12:50:50
select from_unixtime(unix_timestamp('2020-10-10 12:50:50') , 'yyyy/MM/dd hh:mm:ss');
#presto写法,将日期转为:2020/10/10 12:50:50
select date_format( timestamp '2020-10-10 12:50:50' , '%Y/%m/%d %H:%i:%s');
select date_format( date '2020-10-10' , '%Y/%m/%d');
----
注意: 参数一必须是日期对象
所以如果传递的是字符串, 必须将先转换为日期对象:
方式一: 标识为日期对象, 但是格式必须为标准日期格式
timestamp '2020-10-10 12:50:50'
date '2020-10-10'
方式二: 如果不标准,先用date_parse解析成为标准
date_parse('2020-10-10 12:50:50','%Y-%m-%d %H:%i:%s')
扩展说明: 日期format格式说明
年:%Y
月:%m
日:%d
时:%H
分:%i
秒:%s
周几:%w(0..6)==date_add==(unit, value, timestamp) → [same as input]
- 作用: 用于对日期数据进行 加 减 操作
==date_diff==(unit, timestamp1, timestamp2) → bigint
- 作用: 用于比对两个日期之间差值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#hive的写法
-- 将日期向前推3天
select date_sub('2023-03-18',3);
select date_add('2023-03-18',-3);
#presto的写法
-- 将日期向前推3天
select date_add('hour',3,timestamp '2021-09-02 15:59:50'); -- 向后推3个小时
select date_add('day',-3,timestamp '2021-09-02 15:59:50'); -- 向前推1天
select date_add('month',-1,timestamp '2021-09-02 15:59:50'); -- 向前推1月
-- 计算日期的差值
#hive的写法
select datediff('2022-12-23','2021-10-18')
#presto写法
select date_diff('year',timestamp '2020-09-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('month',timestamp '2021-06-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('day',timestamp '2021-08-02 06:30:30',timestamp '2021-09-02 15:59:50')
插入数据的写法不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#hive的写法
set 参数名 = 参数值
with t1 as (
查询语句
)
insert overwrite table yp_dws.dws_sale_daycount partition (dt)
select
字段
from t1;
#presto的写法
#presto不支持overwrite,要覆盖之前,只能truncate表
insert into yp_dws.dws_sale_daycount
with t1 as (
查询语句
)
select
字段
from t1;
Presto常规优化
数据存储优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17--1)合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
--2)使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
Parquet和ORC一样都支持列式存储,但是Presto对ORC支持更好,而Impala对Parquet支持更好。在数仓设计时,要根据后续可能的查询引擎合理设置数据存储格式。
--3)使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
--4)预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
INSERT INTO table nation_orc partition(p) SELECT * FROM nation SORT BY n_name;
如果需要过滤n_name字段,则性能将提升。
SELECT count(*) FROM nation_orc WHERE n_name=’AUSTRALIA’;SQL优化
- 列裁剪
- 分区裁剪
- group by优化
- 按照数据量大小降序排列
- order by使用limit
- 用regexp_like代替多个like语句
- join时候大表放置在左边
替换非ORC格式的Hive表
Presto内存调优
内存管理机制–内存分类
Presto管理的内存分为两大类:==user memory==和==system memory==
user memory用户内存
1
跟用户数据相关的,比如读取用户输入数据会占据相应的内存,这种内存的占用量跟用户底层数据量大小是强相关的
system memory系统内存
1
执行过程中衍生出的副产品,比如tablescan表扫描,write buffers写入缓冲区,跟查询输入的数据本身不强相关的内存。
内存管理机制–内存池
==内存池中来实现分配user memory和system memory==。
内存池为常规内存池GENERAL_POOL、预留内存池RESERVED_POOL。

1 | 1、GENERAL_POOL:在一般情况下,一个查询执行所需要的user/system内存都是从general pool中分配的,reserved pool在一般情况下是空闲不用的。 |
内存相关参数
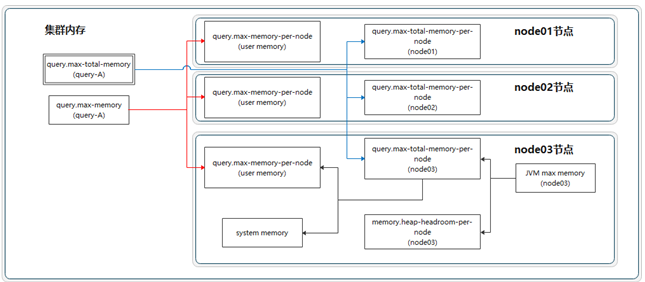
1 | 1、user memory用户内存参数 |
内存优化建议
常见的报错解决
1
2
3
4
5
6
7
81、Query exceeded per-node total memory limit of xx
适当增加query.max-total-memory-per-node。
2、Query exceeded distributed user memory limit of xx
适当增加query.max-memory。
3、Could not communicate with the remote task. The node may have crashed or be under too much load
内存不够,导致节点crash,可以查看/var/log/message。建议参数设置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
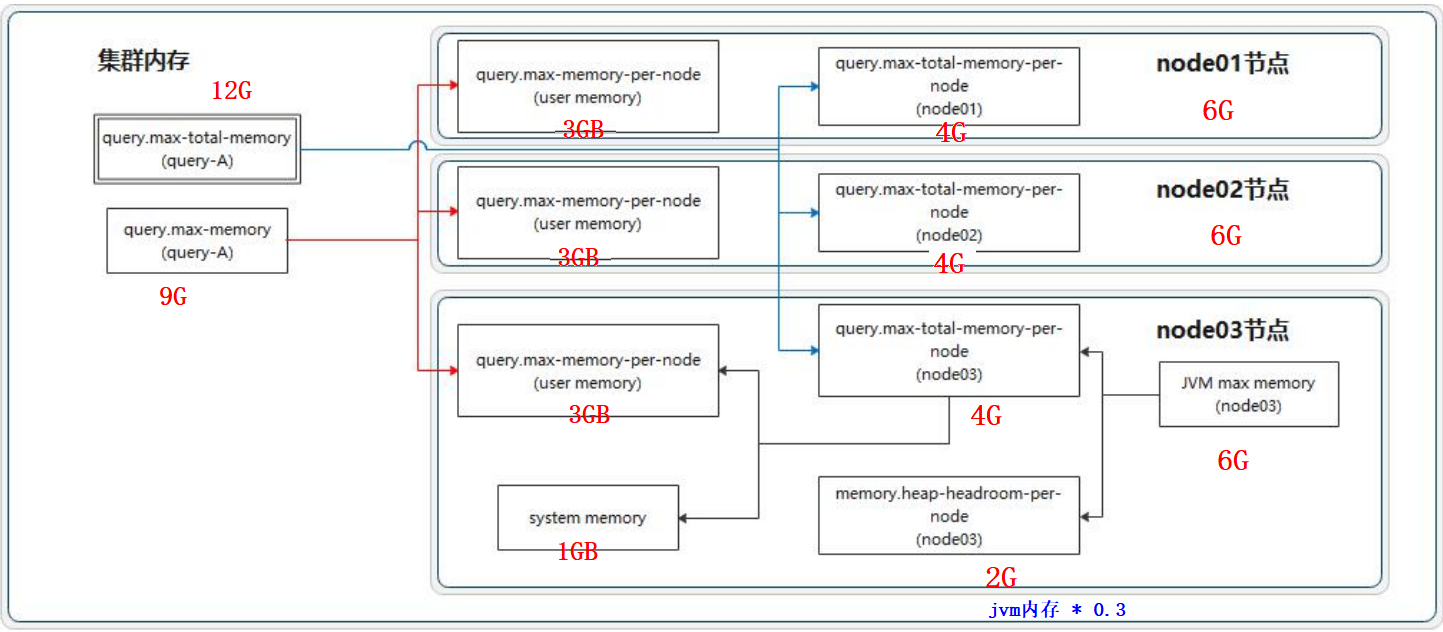
151、query.max-memory-per-node和query.max-total-memory-per-node是query操作使用的主要内存配置,因此这两个配置可以适当加大。
memory.heap-headroom-per-node是三方库的内存,默认值是JVM-Xmx * 0.3,可以手动改小一些。
1) 各节点JVM内存推荐大小: 当前节点剩余内存*80%
2) 对于heap-headroom-pre-node第三方库的内存配置: 建议jvm内存的%15左右
3) 在配置的时候, 不要正正好好, 建议预留一点点, 以免出现问题
数据量在35TB , presto节点数量大约在30台左右 (128GB内存 + 8核CPU)
注意:
1、query.max-memory-per-node小于query.max-total-memory-per-node。
2、query.max-memory小于query.max-total-memory。
3、query.max-total-memory-per-node 与memory.heap-headroom-per-node 之和必须小于 jvm max memory,也就是jvm.config 中配置的-Xmx。
 微信
微信 支付宝
支付宝

