Hbase-非结构化数据存储
需求在驱动世界的发展,由于我们需要海量数据存储,并且要能够随机访问,所以有了HBase。又因为API直接用不好用,又有了Phoenix。Phoenix相对于Hbase,就相当于Hive相当于HDFS。都是将服务能力抽象到SQL层面。真是站在巨人的肩膀上。
HBase是一个分布式的、面向列的开源数据库,来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。
HBase在Hadoop之上提供了类似于Bigtable的能力。
HBase是Apache的Hadoop项目的子项目。
HBase是一个适合于非结构化数据存储 的数据库。
HBase 简介 Hadoop 局限 HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
但是 Hadoop 的缺陷在于它只能执行批处理,并且只能以顺序方式访问数据,这意味着即使是最简单的工作,也必须搜索整个数据集, 无法实现对数据的随机访问(比如想随意读写一行数据)。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
KUDU用的人不多
注:数据结构分类:
结构化数据:即以关系型数据库表形式管理的数据;
半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
HBase 简介 HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。它具有以下特性:
不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
支持通过增加机器进行横向扩展;
支持数据分片;
支持 RegionServers 之间的自动故障转移;
易于使用的 Java 客户端 API;
支持 BlockCache 和布隆过滤器;
过滤器支持谓词下推。
HBase 和其他软件的区别
1 2 3 HBase : 以表的形式存储 存在行键(row key) 不支持SQL 不支持事务(仅行级事务) 无表关系 不支持Join 采用分布式存储引擎 基于HDFS的文件存储系统 支持 结构化 和半结构化的数据 RDBMS : 以表的形式存储 存在主键(primary key) 支持SQL 支持事务 存在表关系 支持Join 采用单机的存储引擎 基于本地文件系统 支持存储结构化数据
1 2 3 4 5 HBase : 基于HDFS, 与HDFS是一种强依赖的关系, 启动HBase, 必须先启动HDFS, 数据最终落在HDFS上, 支持高效的随机读写的特性, 吞吐量相对于HDFS比较低, 适合于实时处理 HDFS : 适合于批处理, 吞吐量极高, 不支持随机读写的能力, 存储更多是一些过去已经发生过的数据 矛盾 : 基于HDFS的hbase支持随机读写, 但是HDFS本身自己并不支持, 既有联系 , 又有矛盾, 说明在HBaase的上面一定是做了N多处理的, 才达到这样的效果
1 2 3 4 5 HIVE : 数据仓库的工具 主要是用于离线数据分析处理 主要对接的离线的处理业务 基于hadoop 高延时 HBASE : nosql型数据库 主要是用于数据的存储工作 主要对接实时业务 基于HADOOP 低延迟 注意 : 可以让HIVE 和 HBase集成在一起, 由HIVE读取HBase中数据, 进行离线处理分析, 本质上就是让HIVE换一个地方读取数据
HBase 适合场景
满足2个及以上就可以选择Hbase了
数据是否需要进行随机读写的操作
数据体量是否比较大(建议TB级别以上(包括TB))
数据是否是比较稀疏的
适合应用:写密集型应用,每天写入量巨大,而相对读数量较小的应用
比如互联网公司的社交软件的历史消息,大型系统的各种日志。
a、Facebook用Hbase进行社交信息的存储、查询与分析 ,主要存储在线消息,每天数据量近百亿,每月数据量超过200T。
基于HBase,Facebook可以很方便地横向扩展服务规模,提供给数百万用户。该系统每天处理数百亿条事件, HBase读写比基本在1:1,吞吐量达到150w QPS。
b、米聊历史数据,消息push系统 等多个重要应用系统都建立在HBase基础之上。
c、网易的哨兵监控系统,云信历史数据,日志归档数据 等一系列重要应用底层都由HBase提供服务。
d、京东用Hbase存储卖家操作日志 ,即几十万商家时时刻刻进行的各种操作。以便进行分析,并且可以保证商家可以精确查询自己的各种操作。卖家操作日志的特点是:数据量大、实时性强、增多查少。
e、互联网公司还需要收集和存储海量用户的操作行为,比如转发、评论和点赞 ,通过这些行为来分析用户的特征,形成用户画像 ,精准投放广告,提升广告收入。
Hbase适合做海量数据(亿万条记录)的最底层数据源。
HBase Table HBase 是一个面向 列 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 列族 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell )组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
下图为 HBase 中一张表的:
RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
该表具有两个列族,分别是 personal 和 office;
其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
Hbase 的表具有以下特点:
容量大:一个表可以有数十亿行,上百万列;
面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
Phoenix Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
Phoenix相对于Hbase,就相当于Hive相当于HDFS。都是将服务能力抽象到SQL层面。
Hbase 系统架构及数据结构 基本概念 一个典型的 Hbase Table 表如下:
Row Key (行键) Row Key 是用来检索记录的主键。想要访问 HBase Table 中的数据,只有以下三种方式:
Row Key 可以是任意字符串,存储时数据按照 Row Key 的字典序进行排序。这里需要注意以下两点:
因为字典序对 Int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充。
行的一次读写操作是原子性的 (不论一次读写多少列)。
Column Family(列族) HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。列族的所有列都以列族名作为前缀,例如 courses:history,courses:math 都属于 courses 这个列族。
一个表中建议列族不要太多了, 能少则少, 能用一个解决的, 坚决不用多个,在一个列族下可以有多个列(列限定符号), 最大支持上百万个列
Column Qualifier (列限定符) 列限定符,你可以理解为是具体的列名,例如 courses:history,courses:math 都属于 courses 这个列族,它们的列限定符分别是 history 和 math。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列。
一个列族下可以有多个列名, 但是一个列名只能被一个列族所管理, 列的数量可以达到上百万, 在建表的时候, 不需要指定的, 在插入数据的时候, 动态执行即可
Column(列) HBase 中的列由列族和列限定符组成,它们由 :(冒号) 进行分隔,即一个完整的列名应该表述为 列族名 :列限定符。
Cell(单元格) Cell 是行,列族和列限定符的组合,并包含值和时间戳。你可以等价理解为关系型数据库中由指定行和指定列确定的一个单元格,但不同的是 HBase 中的一个单元格是由多个版本的数据组成的,每个版本的数据用时间戳进行区分。
rowkey + 列族 + 列名 + 列值
Timestamp(时间戳) HBase 中通过 row key 和 column 确定的为一个存储单元称为 Cell。每个 Cell 都保存着同一份数据的多个版本。版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个 Cell 中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面。
version(版本号) 在hbase中每一个单元格都是有版本号的概念的, 可以基于版本管理, 存储每一个单元格的历史变化信息,默认版本号为1, 表示只保留最新的版本数据
注意: 在建表的时候, 必须指定两项内容: 表名 + 列族
存储结构 Regions HBase Table 中的所有行按照 Row Key 的字典序排列。HBase Tables 通过行键的范围 (row key range) 被水平切分成多个 Region, 一个 Region 包含了在 start key 和 end key 之间的所有行。
每个表一开始只有一个 Region,随着数据不断增加,Region 会不断增大,当增大到一个阀值的时候,Region 就会等分为两个新的 Region。当 Table 中的行不断增多,就会有越来越多的 Region。
Region 是 HBase 中分布式存储和负载均衡的最小单元 。这意味着不同的 Region 可以分布在不同的 Region Server 上。但一个 Region 是不会拆分到多个 Server 上的。
Region Server Region Server 运行在 HDFS 的 DataNode 上。它具有以下组件:
**WAL(Write Ahead Log,预写日志)**:用于存储尚未进持久化存储的数据记录,以便在发生故障时进行恢复。
BlockCache :读缓存。它将频繁读取的数据存储在内存中,如果存储不足,它将按照 最近最少使用原则 清除多余的数据。MemStore :写缓存。它存储尚未写入磁盘的新数据,并会在数据写入磁盘之前对其进行排序。每个 Region 上的每个列族都有一个 MemStore。HFile :将行数据按照 Key\Values 的形式存储在文件系统上。
Region Server 存取一个子表时,会创建一个 Region 对象,然后对表的每个列族创建一个 Store 实例,每个 Store 会有 0 个或多个 StoreFile 与之对应,每个 StoreFile 则对应一个 HFile,HFile 就是实际存储在 HDFS 上的文件。
Hbase系统架构
Region是HBase数据管理的基本单位
系统架构 HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
Zookeeper
保证任何时候,集群中只有一个 Master;
存贮所有 Region 的寻址入口;
实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master
为 Region Server 分配 Region ;
负责 Region Server 的负载均衡 ;
发现失效的 Region Server 并重新分配其上的 Region;
GFS 上的垃圾文件回收;
处理 Schema 的更新请求。
Region Server
Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
Region Server 负责切分在运行过程中变得过大的 Region。
组件间的协作 HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。 Zookeeper 负责维护可用服务列表,并提供服务故障通知等服务:
每个 Region Server 都会在 ZooKeeper 上创建一个临时节点,Master 通过 Zookeeper 的 Watcher 机制对节点进行监控,从而可以发现新加入的 Region Server 或故障退出的 Region Server;
所有 Masters 会竞争性地在 Zookeeper 上创建同一个临时节点,由于 Zookeeper 只能有一个同名节点,所以必然只有一个 Master 能够创建成功,此时该 Master 就是主 Master,主 Master 会定期向 Zookeeper 发送心跳。备用 Masters 则通过 Watcher 机制对主 HMaster 所在节点进行监听;
如果主 Master 未能定时发送心跳,则其持有的 Zookeeper 会话会过期,相应的临时节点也会被删除,这会触发定义在该节点上的 Watcher 事件,使得备用的 Master Servers 得到通知。所有备用的 Master Servers 在接到通知后,会再次去竞争性地创建临时节点,完成主 Master 的选举。
数据的读写流程简述 写入数据的流程
Client 向 Region Server 提交写请求;
Region Server 找到目标 Region;
Region 检查数据是否与 Schema 一致;
如果客户端没有指定版本,则获取当前系统时间作为数据版本;
将更新写入 WAL Log;
将更新写入 Memstore;
判断 Memstore 存储是否已满,如果存储已满则需要 flush 为 Store Hfile 文件。
更为详细写入流程可以参考:HBase - 数据写入流程解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 更详细的写入数据流程: 1) 由客户端发起写入数据的请求, 首先 先连接zookeeper集群 2) 从zookeeper集群中获取hbase:meta 表被那个RegionServer所管理 3) 连接对应RegionServer, 从meta表获取要写入数据的表有哪些Region, 然后根据Region的startRow和endRow, 判断需要将数据写入到那个Region上, 并确定这个Region被哪个RegionServer所管理, 将RegionServer的地址返回 大白话: 查询写入到哪个Region, 这个Region被哪个RegionServer所管理 4) 连接对应RegionServer,开始进行数据写入操作, 写入时需要将数据写入到对应的Store模块下的MemStore中(可能写入多个MemStore),同时也会将本次写入操作记录在对应RegionServer的HLog中, 当这个两个位置都写入完成后, 客户端才认为数据写入完成了 -----------------------------以上为客户端写入流程------------------------------------------ 异步操作: 当上述客户端可能执行了N多次后, 后续才会干活 5) 随着客户端不断的写入操作, MemStore中数据会越来越多, 当MemStore的数据达到一定的阈值(128M/1H)后,就会启动Flush 刷新线程, 将内存中数据 "最终" 刷新到HDFS上,形成一个StoreFile文件 6) 随着不断地Flush的刷新, 在HDFS上StoreFile文件会越来越多, 当StoreFile文件达到一定的阈值(3个及以上)后, 就会启动compact合并压缩机制, 将多个StoreFile "最终" 合并为一个大的HFile 7) 随着不断的合并, HFile文件会越来越大,当这个大的HFile文件达到一定的阈值( "最终" 10GB)后,就会触发Split的分裂机制, 将大的HFile进行一分为二操作, 形成两个新的大HFile文件, 此时Region也会进行一分为二操作, 形成两个新的Region, 一个Region管理一个新的大HFile, 旧的大HFile和对应Region就会下线删除
读取数据的流程 以下是客户端首次读写 HBase 上数据的流程:
客户端从 Zookeeper 获取 META 表所在的 Region Server;
客户端访问 META 表所在的 Region Server,从 META 表中查询到访问行键所在的 Region Server,之后客户端将缓存这些信息以及 META 表的位置;
客户端从行键所在的 Region Server 上获取数据。
如果再次读取,客户端将从缓存中获取行键所在的 Region Server。这样客户端就不需要再次查询 META 表,除非 Region 移动导致缓存失效,这样的话,则将会重新查询并更新缓存。
注:META 表是 HBase 中一张特殊的表,它保存了所有 Region 的位置信息,META 表自己的位置信息则存储在 ZooKeeper 上。
更为详细读取数据流程参考:
HBase 原理-数据读取流程解析
HBase 原理-迟到的‘数据读取流程部分细节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 更详细的读取数据的流程: 1) 客户端发起读取数据的请求, 首先要先连接zookeeper集群 2) 从zookeeper中获取一张 hbase:meta 表, 目前被哪个RegionServer所管理 说明: hbase:meta 是HBase专门用于存储元数据的表, 此表只会有一个Region, 也就说这个表只会被一个Region所管理, 一个Region也只能被一个RegionServer所管理 3) 连接Meta表对应的RegionServer, 从这个表中获取, 要读取的表有哪些Region,以及这些Region对应被哪个RegionServer所管理, 从而确定要操作哪个RegionServer 注意: 如果执行scan, 返回这个表所有Region对应的RegionServer的地址 如果执行get, 返回查询rowkey所对应Region所在RegionServer的地址 4) 连接对应的RegionServer, 从RegionServer中对应Region中读取数据 读取顺序: 先内存 --> blockCache(块缓存) ---> storeFile ---> 大HFile 注意: 读取块缓存只有在get操作才有效, 如果scan扫描. 意义不大
HBase的核心工作机制 HBase的Flush刷新机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Flush刷新机制 : 流程 : 客户端不断的将数据写入到MemStore内存中, 当内存数据达到一定的阈值后, 需要将数据刷新到HDFS中, 形成一个StoreFile文件 阈值 : 128M(Region级别) / 1H(1小时,RegionServer级别) 不管满足了哪一个阈值, 都会触发Flush刷新机制 内部详细流程 : HBase 2.x以上的版本 1) 客户端不断向MemStore中写入数据, 当MemStore中数据达到阈值后, 就会启动Flush刷新操作 2) 首先HBase会先关闭当前这个已经达到阈值的内存空间, 然后开启一个新的MemStore的空间, 继续写入 3) 将这个达到阈值的内存空间数据放入到内存队列中, 此队列的特性是只读的, 在HBase的2.x版本中, 可以设置此队列尽可能晚的刷新到HDFS中,当这个队列中数据达到某个阈值后(内存不足),这个时候触发Flush刷新操作(希望队列中尽可能多的memstore的数据, 让更多的数据存储在内存中) 4) Flush线程会将队列中所有的数据全部都读取出来, 然后对数据进行排序合并操作, 将合并后数据存储到HDFS中, 形成一个StoreFile的文件 注意 : 在HBase2.0以下版本中, 不存在推迟刷新功能, 理解为达到一个MemStore阈值后, 就会进行刷新到HDFS上, 形成一个StoreFile文件, 也不存在合并操作. 在2.0版本以上, 支持了推迟刷新, 合并刷新策略, 但是默认是不使用的, 与2.0以下版本是一样的, 但是2.0以上版本支持开启的
Flush刷新的条件配置: hbase-site.xml
如何配置内存合并功能:
1 2 3 4 5 6 HBase2.0以上, 只是提供了基于内存合并的功能, 但是默认情况下不开启的, 所以在默认情况下整个Flush刷新机制与2.0版本以下的是一致的, 但是一旦开启, 就是刚刚所描述的整个Flush流程 合并方案 : 三种 basic(基础型) : 直接将多个MemStore数据合并为一个StoreFile. 写入到HDFS上, 如果数据中存在过期的数据,或者已经标记为删除的数据, 基础型不做任何处理的 eager(饥渴型) : 在将多个memstore合并的过程中, 积极判断数据是否存在过期, 或者是否已经被标记删除了, 如果有, 直接过滤掉这些标记删除或者已经过期的数据 adaptive(适应性) : 检测数据是否有过期的内容, 如果过期数据比较多的时候, 就会自动选择饥渴型,否则就是基础型
全局配置:
针对某一个表的列族开启: 优先级最高的
HBase的StoreFile合并机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 compact合并压缩机制 : MemStore的数据会不断的进行Flush刷新操作, 就会产生多个StoreFile的文件, 当StoreFile文件达到一定的阈值后, 就会触发compact的合并压缩的机制, 将多个StoreFile合并为一个大的HFile文件 阈值 : 达到3个及以上 整个Compact合并压缩机制共计分为二大阶段 :minor : 作用 : 将多个小的StoreFile合并为一个较大的HFile的操作 阈值 : 达到3个及以上 注意 : 此合并过程中, 仅仅是将多个StoreFile合并为一个较大的HFile文件, 对数据进行排序操作, 如果此时有过期或者有标记删除的数据, 此时不做任何处理的(类似于: 内存合并中基础型合并方案) 所以说, 此合并操作, 效率比较高 major : 作用 : 将较大的HFile 和 之前的大HFile进行合并, 形成一个更大的HFile文件 (全局合并) 阈值 : 默认7天 / 集群启动的时候(验证是否要做) 在此处合并过程中, 会将那些过期的数据或者已经标记删除的数据, 在这次合并中, 全部都清除掉 注意 : 由于是一个全局合并操作, 对性能影响比较大,在实际生产中, 建议关闭掉7天自动合并, 采用手动触发的方式 具体方案 : 将默认的周期调整到公司定时重启范围外即可, 比如说公司每隔一周会全部服务进行重启, 那么我们这个时候大于这个周期即可, 然后一旦重启, HBase会主动监测是否需要进行major的合并操作
相关配置: hbase-site.xml
HBase的Split分裂机制 指的是当StoreFile不断的进行合并操作, 这个大的HFile就会变得越来越大, 当这个HFile达到一定阈值后, 就会触发Split分裂机制
为什么是最终10GB呢 ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 上述公式, 其实就是HBase用于计算在何时进行分裂 相关的变量说明 :R :表对应的Region的数量 hbase.hregion.memstore.flush.size : 默认为128M hbase.hregion.max.filesize : 默认 10GB 第一次分裂 : 默认表在创建的时候, 只有一个Region min(1 * 128M , 10GB) = 128M 在128M的时候, 就会被触发Split分裂机制, 表的Region数量变为2个(各为64M) 第二次分裂 : 此时表已经有2个Region min(2^2 * 128 , 10GB) = 512M 在512M的时候, 就会触发, 触发后, 表的Region数量会变为3个,其中二个为256M, 还有一个可能是500M 第三次分裂 : 此时表已经有3个Region min(3^3 * 128 , 10GB) = 1152M 在 1152M的时候, 就会触发, 触发后, 表的Region数量会变为4个 ..... 以此类推 直到当Region的数量为9的时候, 计算后为10.125GB, 此时大于10GB, 此时从第九个region开始, 达到10GB才会触发分裂
思考: 为啥要分裂呢? 分裂有什么用呢?
1 2 3 由于表一开始默认只有一个Region, 也就意味着只有一个RegionServer管理, 如果此时这个表有大量的数据写入和数据读取操作, 就意味着这些庞大的请求全部打向到同一个RegionServer上, 导致这个RegionServer可能无法承载庞大的并发访问, 直接宕机, 而且一旦宕机后, 对应的Region就会被分配给其他的RegionServer, 然后其他的RegionServer也会跟着一起宕机, 最终导致整个HBase集群从节点全部都宕机了(雪崩问题) 此时可以通过快速早的进行分裂, 可以有多个Region, 有了多个Region后, 就可以将Region分布给不同的RegionServer上, 这样当大量的请求过来后, 就可以由多个RegionServer一起来承担, 提供并发能力, 提供稳定性
思考: 如果从一开始, 就有大量的并发, 如何解决呢?
1 解决方案 : 可以让HBase的表在一开始创建的时候, 直接拥有多个Region, 在建表的时候, 直接创建多个Region(Region 预分区)
HBase的RegionServer上下线流程 思考: Master是如何感知到RegionServer上线和下线呢?
HBase的Master上下线流程
思考: 请问 多个Master启动后, 如何选定谁成为Active Master呢?
思考: Master是如何分配Region的呢?
1 2 3 4 5 6 7 8 9 10 11 1- Master启动完成后, 根据zookeeper来获取当下有多少个RegionServer已经启动了 2- Master接着读取hbase:meta表, 从元数据表中获取当前有多少个Region, 以及每个Region被哪个RegionServer所管理 3- 各个RegionServer要向Master汇报自己当下所管理的Region信息 4- Master根据RegionServer上报信息以及从Meta表获取信息进行比对, 了解哪些Region被分配了, 哪些Region还没有被分配(或者可能分配的RegionServer还没有启动) 5- Master将没有分配的Region, 重新分配给已经启动的各个RegionServer,在分配的过程中, 会尽可能保证负载均衡: 负载均衡1 : 保证在HBase表中有多个Region, 均衡的被不同的RegionServer所管理, 避免出现1个RegionServer上管理同一个表的多个Region问题 负载均衡2 : 保证每一个RegionServer管理的Region数量大致相等
思考: 请问HBase的Master节点在进行数据读写的时候, 是否会参与呢?
1 不会参与, 也就说将Master宕机, 依然也可以进行数据读写的操作, 短暂Master的宕机, 一般不会造成太大影响
那么Master宕机会影响什么呢?
1 2 3 4 5 会影响涉及到元数据变更的操作, 都无法执行了 比如说 : 创建表 修改表 删除表 负载均衡.... 但是分裂操作依然是可以进行的, 只不过分裂后, 形成的多个Region, 都会被分到同一个RegionServer上管理, 因为无法进行负载均衡
Hbase 环境安装
见Linux-大数据篇
上传解压HBase安装包 1 2 3 4 5 6 7 8 9 cd /opt/setup rz 上传 解压操作: tar -zxf hbase-2.1.0.tar.gz -C /usr/local/apps/ 配置软连接: cd /usr/local/apps/ ln -s hbase-2.1.0/ hbase
修改HBase配置文件 hbase-env.sh 1 2 3 4 5 6 7 注意: 记得将前面的 # 号删除 cd /usr/local/apps/hbase-2.1.0/conf vim hbase-env.sh # 第28行 export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_321/ # 第125行 export HBASE_MANAGES_ZK=false
hbase-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 vim hbase-site.xml ------------------------------ <configuration > <property > <name > hbase.rootdir</name > <value > hdfs://node1:8020/hbase</value > </property > <property > <name > hbase.cluster.distributed</name > <value > true</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > node1:2181,node2:2181,node3:2181</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /usr/local/apps/zookeeper-3.4.14/data</value > </property > <property > <name > hbase.unsafe.stream.capability.enforce</name > <value > false</value > </property > </configuration >
配置环境变量 1 2 3 4 5 6 7 # 配置Hbase环境变量 vim /etc/profile export HBASE_HOME=/usr/local/apps/hbase-2.1.0 export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin #加载环境变量 source /etc/profile
复制jar包到lib 1 cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
修改regionservers文件 1 2 3 4 5 cd /usr/local/apps/hbase-2.1.0/conf vim regionservers node1 node2 node3
分发安装包与配置文件 1 2 3 4 5 cd /usr/local/apps scp -r hbase-2.1.0/ node2:$PWD scp -r hbase-2.1.0/ node3:$PWD 在node2和node3配置软连接和环境变量
启动HBase 1 2 3 4 5 6 7 cd /usr/local/apps # 启动ZK : 命令只是告诉大家需要启动zookeeper, 之前该怎么启动就怎么启动 (三个节点依次启动) ./start-zk.sh # 启动hadoop: 仅需要启动HDFS即可, 但是一般建议都启动了 node1执行即可 start-all.sh # 启动hbase : node1执行即可 start-hbase.sh
主节点配置高可用
1- 在HBase的conf目录下, 创建一个backup-masters 文件
1 2 cd /usr/local/apps/hbase-2.1.0/conf/ vim backup-masters
2- 在文件中, 添加需要将哪些节点设置为备份的Master
1 2 3 4 node2 node3 注意 : 添加后, 切记不要在文件后面有空行
3- 重启HBase, 查看是否可以启动多个Master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 停止hbase集群 : stop-hbase.sh 启动hbase集群 : start-hbase.sh 如何单独启动和停止服务器 : 启动 : hbase-daemon.sh start master hbase-daemon.sh start regionserver 停止 : hbase-daemon.sh stop master hbase-daemon.sh stop regionserver
验证Hbase是否启动成功 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 启动hbase shell客户端 hbase shell # 输入status [root@node1 onekey]# hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 2.1.0, re1673bb0bbfea21d6e5dba73e013b09b8b49b89b, Tue Jul 10 17:26:48 CST 2018 Took 0.0034 seconds Ignoring executable-hooks-1.6.0 because its extensions are not built. Try: gem pristine executable-hooks --version 1.6.0 Ignoring gem-wrappers-1.4.0 because its extensions are not built. Try: gem pristine gem-wrappers --version 1.4.0 2.4.1 :001 > status 1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load Took 0.4562 seconds 2.4.1 :002 >
hbase出错排查 在安装过程中, 如果启动失败了, 一般出现错误的位置:
1- 在hbase-env.sh中, 没有将注释打开
2- 在hbase-site.xml中, 没有修改zookeeper的存储路径地址, 或者说整个内容 拷贝错误
3- 没有将jar包(htrace-core-3.1.0-incubating.jar) 拷贝到hbase的lib目录下
4- zookeeper或者 hadoop集群压根没有启动良好
如果检测后, 以上这几项内容, 都没有任何的问题, 停止hbase, 将hbase产生的元数据信息, 全部删除清空, 重启hbase:
1 2 3 4 5 6 7 8 9 如何删除元数据: 主要删除二个位置 1) zk上: 进入zookeeper的bin目录下 cd /usr/local/apps/zookeeper-3.4.14/bin/ ./zkCli.sh 进入客户端后, 执行: rmr /hbase 2) hdfs上: 在linux的shell窗口下执行: hdfs dfs -rm -r /hbase
WebUI http://node1:16010/master-status
安装目录说明
目录名
说明
bin
所有hbase相关的命令都在该目录存放
conf
所有的hbase配置文件
hbase-webapps
hbase的web ui程序位置
lib
hbase依赖的java库
logs
hbase的日志文件
参考硬件配置 针对大概800TB存储空间的集群中每个Java进程的典型内存配置:
进程
堆
描述
NameNode
8 GB
每100TB数据或每100W个文件大约占用NameNode堆1GB的内存
SecondaryNameNode
8GB
在内存中重做主NameNode的EditLog,因此配置需要与NameNode一样
DataNode
1GB
适度即可
ResourceManager
4GB
适度即可(注意此处是MapReduce的推荐配置)
NodeManager
2GB
适当即可(注意此处是MapReduce的推荐配置)
HBase HMaster
4GB
轻量级负载,适当即可
HBase RegionServer
12GB
大部分可用内存、同时为操作系统缓存、任务进程留下足够的空间
ZooKeeper
1GB
适度
推荐:
Master机器要运行NameNode、ResourceManager、以及HBase HMaster,推荐24GB左右
Slave机器需要运行DataNode、NodeManager和HBase RegionServer,推荐24GB(及以上)
根据CPU的核数来选择在某个节点上运行的进程数,例如:两个4核CPU=8核,每个Java进程都可以独立占有一个核(推荐:8核CPU)
内存不是越多越好,在使用过程中会产生较多碎片,Java堆内存越大, 会导致整理内存需要耗费的时间越大。例如:给RegionServer的堆内存设置为64GB就不是很好的选择,一旦FullGC就会造成较长时间的等待,而等待较长,Master可能就认为该节点已经挂了,然后移除掉该节点
Hbase 常用 Shell 命令 一、基本命令 打开 Hbase Shell:
1.1 获取帮助 1 2 3 4 # 获取帮助 help # 获取命令的详细信息 help 'status'
1.2 查看服务器状态 1.3 查看版本信息 1.4 查看登录用户 二、关于表的操作 2.1 查看所有表 2.2 创建表 命令格式 : create ‘表名称’, ‘列族名称 1’,’列族名称 2’,’列名称 N’
1 2 # 创建一张名为Student的表,包含基本信息(baseInfo)、学校信息(schoolInfo)两个列族 create 'Student','baseInfo','schoolInfo'
2.3 查看表的基本信息 命令格式 :desc ‘表名’
2.4 表的启用/禁用 enable 和 disable 可以启用/禁用这个表,is_enabled 和 is_disabled 来检查表是否被禁用
1 2 3 4 5 6 7 8 # 禁用表 disable 'Student' # 检查表是否被禁用 is_disabled 'Student' # 启用表 enable 'Student' # 检查表是否被启用 is_enabled 'Student'
2.5 检查表是否存在 2.6 删除表 1 2 3 4 # 删除表前需要先禁用表 disable 'Student' # 删除表 drop 'Student'
三、增删改 3.1 添加列族 命令格式 : alter ‘表名’, ‘列族名’
1 alter 'Student', 'teacherInfo'
3.2 删除列族 命令格式 :alter ‘表名’, {NAME => ‘列族名’, METHOD => ‘delete’}
1 alter 'Student', {NAME => 'teacherInfo', METHOD => 'delete'}
3.3 更改列族存储版本的限制 默认情况下,列族只存储一个版本的数据,如果需要存储多个版本的数据,则需要修改列族的属性。修改后可通过 desc 命令查看。
1 alter 'Student',{NAME=>'baseInfo',VERSIONS=>3}
3.4 插入数据 命令格式 :put ‘表名’, ‘行键’,’列族:列’,’值’
注意:如果新增数据的行键值、列族名、列名与原有数据完全相同,则相当于更新操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 put 'Student', 'rowkey1','baseInfo:name','tom' put 'Student', 'rowkey1','baseInfo:birthday','1990-01-09' put 'Student', 'rowkey1','baseInfo:age','29' put 'Student', 'rowkey1','schoolInfo:name','Havard' put 'Student', 'rowkey1','schoolInfo:localtion','Boston' put 'Student', 'rowkey2','baseInfo:name','jack' put 'Student', 'rowkey2','baseInfo:birthday','1998-08-22' put 'Student', 'rowkey2','baseInfo:age','21' put 'Student', 'rowkey2','schoolInfo:name','yale' put 'Student', 'rowkey2','schoolInfo:localtion','New Haven' put 'Student', 'rowkey3','baseInfo:name','maike' put 'Student', 'rowkey3','baseInfo:birthday','1995-01-22' put 'Student', 'rowkey3','baseInfo:age','24' put 'Student', 'rowkey3','schoolInfo:name','yale' put 'Student', 'rowkey3','schoolInfo:localtion','New Haven' put 'Student', 'wrowkey4','baseInfo:name','maike-jack'
3.5 获取指定行、指定行中的列族、列的信息 1 2 3 4 5 6 # 获取指定行中所有列的数据信息 get 'Student','rowkey3' # 获取指定行中指定列族下所有列的数据信息 get 'Student','rowkey3','baseInfo' # 获取指定行中指定列的数据信息 get 'Student','rowkey3','baseInfo:name'
3.6 删除指定行、指定行中的列 1 2 3 4 # 删除指定行 delete 'Student','rowkey3' # 删除指定行中指定列的数据 delete 'Student','rowkey3','baseInfo:name'
3.7 清空表 1 2 3 4 格式: truncate '表名' 底层: 先将表禁用 --> 删除表 --> 创建表
四、查询 hbase 中访问数据有两种基本的方式:
按指定 rowkey 获取数据:get 方法;
按指定条件获取数据:scan 方法。
scan 可以设置 begin 和 end 参数来访问一个范围内所有的数据。get 本质上就是 begin 和 end 相等的一种特殊的 scan。
4.1 Get查询 1 2 3 4 5 6 # 获取指定行中所有列的数据信息 get 'Student','rowkey3' # 获取指定行中指定列族下所有列的数据信息 get 'Student','rowkey3','baseInfo' # 获取指定行中指定列的数据信息 get 'Student','rowkey3','baseInfo:name'
4.2 查询整表数据 1 2 3 4 scan 'Student' # 查询标有多少数据 count '表名'
4.3 查询指定列簇的数据 1 scan 'Student', {COLUMN=>'baseInfo'}
4.4 条件查询 1 2 # 查询指定列的数据 scan 'Student', {COLUMNS=> 'baseInfo:birthday'}
除了列 (COLUMNS) 修饰词外,HBase 还支持 Limit(限制查询结果行数),STARTROW(ROWKEY 起始行,会先根据这个 key 定位到 region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和 FILTER(按条件过滤行),FORMATTER=>'toString'用于显示中文等。
如下代表从 rowkey2 这个 rowkey 开始,查找下两个行的最新 3 个版本的 name 列的数据:
1 scan 'Student', {COLUMNS=> 'baseInfo:name',STARTROW => 'rowkey2',STOPROW => 'wrowkey4',LIMIT=>2, VERSIONS=>3}
1- 每一个属性 都可以随意使用, 并不是必须组合在一起
2- 也不存在先后的顺序
3- 大小写是区分, 不要写错
4.5 条件过滤 Filter 可以设定一系列条件来进行过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 格式 : scan '表名',{FILTER=>"过滤器的名字(比较运算符,比较器表达式)"} 常见的过滤器 : rowkey相关的过滤器 : RowFilter : 实现行键字符串的比较和过滤操作 PrefixFilter : rowkey的前缀过滤器 列族过滤器 : FamilyFilter : 列族过滤器 列名过滤器 : QualifierFilter : 列名过滤器 列值过滤器 : ValueFilter : 列值过滤器, 找到符合对应列的数据值 SingleColumnValueFilter : 在指定的列族和列名中进行比较具体的值, 将符合的数据全部都返回(包含条件的内容字段) SingleColumnValueExcludeFilter : 在指定的列族和列名中进行比较具体的值, 将符合的数据全部都返回(不包含条件的内容字段) 比较运算符 : > < >= <= != 比较器 : 比较器 比较器表达式 BinaryComparator binary:值 完整匹配字节数据 BinaryPrefixComparator binaryprefix: 值 匹配字节数据的前缀 NullComparator null 匹配null值 SubstringComparator substring:值 模糊匹配操作
HBase的 API 文档: https://hbase.apache.org/2.1/apidocs/index.html
如我们要查询列值 等于 24 的所有数据:
1 2 3 4 5 6 scan 'Student', FILTER=>"ValueFilter(=,'binary:24')" # 找到后, 将整个数据全部都返回了 scan 'Student',{FILTER=>"SingleColumnValueFilter('baseInfo','name',=,'substring:z')"} # 相反效果: scan 'Student',{FILTER=>"SingleColumnValueExcludeFilter('baseInfo','name',=,'substring:z')"}
值包含 yale 的所有数据:
1 scan 'Student', FILTER=>"ValueFilter(=,'substring:yale')"
列名中的前缀为 birth 的:
1 scan 'Student', FILTER=>"ColumnPrefixFilter('birth')"
FILTER 中支持多个过滤条件通过括号、AND 和 OR 进行组合:
1 2 # 列名中的前缀为birth且列值中包含1998的数据 scan 'Student', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter ValueFilter(=,'substring:1998')"
PrefixFilter 用于对 Rowkey 的前缀进行判断:
1 scan 'Student', FILTER=>"PrefixFilter('wr')"
查询在列名 中包含 a字段的列有哪些?
1 scan 'Student',{FILTER=>"QualifierFilter(=,'substring:a')"}
五、导入数据操作
1 2 3 hbase org.apache.hadoop.hbase.mapreduce.Import 表名 HDFS数据文件路径 注意 : 此命令需要在linux的命令窗口下执行(而非Hbase的shell窗口下)
1 2 3 hbase org.apache.hadoop.hbase.mapreduce.Export 表名 导出路径 注意 : 此命令需要在linux的命令窗口下执行(而非Hbase的shell窗口下)
完成10W抄表数据导入操作:
1 2 3 4 5 6 7 8 1- 将资料中 10w的抄表数据上传到Linux 2- 在linux中将文件上传到HDFS中: hdfs dfs -mkdir -p /hbase/water_bill/input hdfs dfs -put part-m-00000_10w /hbase/water_bill/input 3- 执行导入数据操作 hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /hbase/water_bill/input/part-m-00000_10w
HBase Java API 的基本使用 简述 截至到目前 (2019.04),HBase 有两个主要的版本,分别是 1.x 和 2.x ,两个版本的 Java API 有所不同,1.x 中某些方法在 2.x 中被标识为 @deprecated 过时。所以下面关于 API 的样例,我会分别给出 1.x 和 2.x 两个版本。完整的代码见本仓库:
同时你使用的客户端的版本必须与服务端版本保持一致,如果用 2.x 版本的客户端代码去连接 1.x 版本的服务端,会抛出 NoSuchColumnFamilyException 等异常。
Java API 1.x 基本使用 新建Maven工程,导入项目依赖 要使用 Java API 操作 HBase,需要引入 hbase-client。这里选取的 HBase Client 的版本为 1.2.0。
1 2 3 4 5 <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-client</artifactId > <version > 1.2.0</version > </dependency >
API 基本使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 public class HBaseUtils { private static Connection connection; static { Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.property.clientPort" , "2181" ); configuration.set("hbase.zookeeper.quorum" , "hadoop001" ); try { connection = ConnectionFactory.createConnection(configuration); } catch (IOException e) { e.printStackTrace(); } } public static boolean createTable (String tableName, List<String> columnFamilies) { try { HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); if (admin.tableExists(tableName)) { return false ; } HTableDescriptor tableDescriptor = new HTableDescriptor (TableName.valueOf(tableName)); columnFamilies.forEach(columnFamily -> { HColumnDescriptor columnDescriptor = new HColumnDescriptor (columnFamily); columnDescriptor.setMaxVersions(1 ); tableDescriptor.addFamily(columnDescriptor); }); admin.createTable(tableDescriptor); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean deleteTable (String tableName) { try { HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); admin.disableTable(tableName); admin.deleteTable(tableName); } catch (Exception e) { e.printStackTrace(); } return true ; } public static boolean putRow (String tableName, String rowKey, String columnFamilyName, String qualifier, String value) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put (Bytes.toBytes(rowKey)); put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value)); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean putRow (String tableName, String rowKey, String columnFamilyName, List<Pair<String, String>> pairList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put (Bytes.toBytes(rowKey)); pairList.forEach(pair -> put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(pair.getKey()), Bytes.toBytes(pair.getValue()))); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } public static Result getRow (String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get (Bytes.toBytes(rowKey)); return table.get(get); } catch (IOException e) { e.printStackTrace(); } return null ; } public static String getCell (String tableName, String rowKey, String columnFamily, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get (Bytes.toBytes(rowKey)); if (!get.isCheckExistenceOnly()) { get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); Result result = table.get(get); byte [] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); return Bytes.toString(resultValue); } else { return null ; } } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName, String startRowKey, String endRowKey, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); scan.setStartRow(Bytes.toBytes(startRowKey)); scan.setStopRow(Bytes.toBytes(endRowKey)); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static boolean deleteRow (String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete (Bytes.toBytes(rowKey)); table.delete(delete); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean deleteColumn (String tableName, String rowKey, String familyName, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete (Bytes.toBytes(rowKey)); delete.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(qualifier)); table.delete(delete); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } }
单元测试 以单元测试的方式对上面封装的 API 进行测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public class HBaseUtilsTest { private static final String TABLE_NAME = "class" ; private static final String TEACHER = "teacher" ; private static final String STUDENT = "student" ; @Test public void createTable () { List<String> columnFamilies = Arrays.asList(TEACHER, STUDENT); boolean table = HBaseUtils.createTable(TABLE_NAME, columnFamilies); System.out.println("表创建结果:" + table); } @Test public void insertData () { List<Pair<String, String>> pairs1 = Arrays.asList(new Pair <>("name" , "Tom" ), new Pair <>("age" , "22" ), new Pair <>("gender" , "1" )); HBaseUtils.putRow(TABLE_NAME, "rowKey1" , STUDENT, pairs1); List<Pair<String, String>> pairs2 = Arrays.asList(new Pair <>("name" , "Jack" ), new Pair <>("age" , "33" ), new Pair <>("gender" , "2" )); HBaseUtils.putRow(TABLE_NAME, "rowKey2" , STUDENT, pairs2); List<Pair<String, String>> pairs3 = Arrays.asList(new Pair <>("name" , "Mike" ), new Pair <>("age" , "44" ), new Pair <>("gender" , "1" )); HBaseUtils.putRow(TABLE_NAME, "rowKey3" , STUDENT, pairs3); } @Test public void getRow () { Result result = HBaseUtils.getRow(TABLE_NAME, "rowKey1" ); if (result != null ) { System.out.println(Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name" )))); } } @Test public void getCell () { String cell = HBaseUtils.getCell(TABLE_NAME, "rowKey2" , STUDENT, "age" ); System.out.println("cell age :" + cell); } @Test public void getScanner () { ResultScanner scanner = HBaseUtils.getScanner(TABLE_NAME); if (scanner != null ) { scanner.forEach(result -> System.out.println(Bytes.toString(result.getRow()) + "->" + Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name" ))))); scanner.close(); } } @Test public void getScannerWithFilter () { FilterList filterList = new FilterList (FilterList.Operator.MUST_PASS_ALL); SingleColumnValueFilter nameFilter = new SingleColumnValueFilter (Bytes.toBytes(STUDENT), Bytes.toBytes("name" ), CompareOperator.EQUAL, Bytes.toBytes("Jack" )); filterList.addFilter(nameFilter); ResultScanner scanner = HBaseUtils.getScanner(TABLE_NAME, filterList); if (scanner != null ) { scanner.forEach(result -> System.out.println(Bytes.toString(result.getRow()) + "->" + Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name" ))))); scanner.close(); } } @Test public void deleteColumn () { boolean b = HBaseUtils.deleteColumn(TABLE_NAME, "rowKey2" , STUDENT, "age" ); System.out.println("删除结果: " + b); } @Test public void deleteRow () { boolean b = HBaseUtils.deleteRow(TABLE_NAME, "rowKey2" ); System.out.println("删除结果: " + b); } @Test public void deleteTable () { boolean b = HBaseUtils.deleteTable(TABLE_NAME); System.out.println("删除结果: " + b); } }
Java API 2.x 基本使用 新建Maven工程,导入项目依赖 这里选取的 HBase Client 的版本为最新的 2.1.4。
1 2 3 4 5 <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-client</artifactId > <version > 2.1.4</version > </dependency >
API 的基本使用 2.x 版本相比于 1.x 废弃了一部分方法,关于废弃的方法在源码中都会指明新的替代方法,比如,在 2.x 中创建表时:HTableDescriptor 和 HColumnDescriptor 等类都标识为废弃,取而代之的是使用 TableDescriptorBuilder 和 ColumnFamilyDescriptorBuilder 来定义表和列族。
以下为 HBase 2.x 版本 Java API 的使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 public class HBaseUtils { private static Connection connection; static { Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.quorum" , "node1:2181,node2:2181,node3:2181" ); try { connection = ConnectionFactory.createConnection(configuration); } catch (IOException e) { e.printStackTrace(); } } public static boolean createTable (String tableName, List<String> columnFamilies) { try { HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); if (admin.tableExists(TableName.valueOf(tableName))) { return false ; } TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)); columnFamilies.forEach(columnFamily -> { ColumnFamilyDescriptorBuilder cfDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)); cfDescriptorBuilder.setMaxVersions(1 ); ColumnFamilyDescriptor familyDescriptor = cfDescriptorBuilder.build(); tableDescriptor.setColumnFamily(familyDescriptor); }); admin.createTable(tableDescriptor.build()); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean deleteTable (String tableName) { try { HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); admin.disableTable(TableName.valueOf(tableName)); admin.deleteTable(TableName.valueOf(tableName)); } catch (Exception e) { e.printStackTrace(); } return true ; } public static boolean putRow (String tableName, String rowKey, String columnFamilyName, String qualifier, String value) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put (Bytes.toBytes(rowKey)); put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value)); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean putRow (String tableName, String rowKey, String columnFamilyName, List<Pair<String, String>> pairList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put (Bytes.toBytes(rowKey)); pairList.forEach(pair -> put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(pair.getKey()), Bytes.toBytes(pair.getValue()))); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } public static Result getRow (String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get (Bytes.toBytes(rowKey)); return table.get(get); } catch (IOException e) { e.printStackTrace(); } return null ; } public static String getCell (String tableName, String rowKey, String columnFamily, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get (Bytes.toBytes(rowKey)); if (!get.isCheckExistenceOnly()) { get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); Result result = table.get(get); byte [] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); return Bytes.toString(resultValue); } else { return null ; } } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static ResultScanner getScanner (String tableName, String startRowKey, String endRowKey, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan (); scan.withStartRow(Bytes.toBytes(startRowKey)); scan.withStopRow(Bytes.toBytes(endRowKey)); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null ; } public static boolean deleteRow (String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete (Bytes.toBytes(rowKey)); table.delete(delete); } catch (IOException e) { e.printStackTrace(); } return true ; } public static boolean deleteColumn (String tableName, String rowKey, String familyName, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete (Bytes.toBytes(rowKey)); delete.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(qualifier)); table.delete(delete); table.close(); } catch (IOException e) { e.printStackTrace(); } return true ; } }
正确连接Hbase 在上面的代码中,在类加载时就初始化了 Connection 连接,并且之后的方法都是复用这个 Connection,这时我们可能会考虑是否可以使用自定义连接池来获取更好的性能表现?实际上这是没有必要的。
首先官方对于 Connection 的使用说明如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Connection Pooling For applications which require high-end multithreaded access (e.g., web-servers or application servers that may serve many application threads in a single JVM), you can pre-create a Connection, as shown in the following example: 对于高并发多线程访问的应用程序(例如,在单个 JVM 中存在的为多个线程服务的 Web 服务器或应用程序服务器), 您只需要预先创建一个 Connection。例子如下: // Create a connection to the cluster. Configuration conf = HBaseConfiguration.create(); try (Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tablename))) { // use table as needed, the table returned is lightweight }
之所以能这样使用,这是因为 Connection 并不是一个简单的 socket 连接,接口文档 中对 Connection 的表述是:
1 2 3 4 5 6 7 A cluster connection encapsulating lower level individual connections to actual servers and a connection to zookeeper. Connections are instantiated through the ConnectionFactory class. The lifecycle of the connection is managed by the caller, who has to close() the connection to release the resources. Connection 是一个集群连接,封装了与多台服务器(Matser/Region Server)的底层连接以及与 zookeeper 的连接。 连接通过 ConnectionFactory 类实例化。连接的生命周期由调用者管理,调用者必须使用 close() 关闭连接以释放资源。
之所以封装这些连接,是因为 HBase 客户端需要连接三个不同的服务角色:
Zookeeper :主要用于获取 meta 表的位置信息,Master 的信息;HBase Master :主要用于执行 HBaseAdmin 接口的一些操作,例如建表等;HBase RegionServer :用于读、写数据。
Connection 对象和实际的 Socket 连接之间的对应关系如下图:
上面两张图片引用自博客:连接 HBase 的正确姿势
在 HBase 客户端代码中,真正对应 Socket 连接的是 RpcConnection 对象。HBase 使用 PoolMap 这种数据结构来存储客户端到 HBase 服务器之间的连接。PoolMap 的内部有一个 ConcurrentHashMap 实例,其 key 是 ConnectionId(封装了服务器地址和用户 ticket),value 是一个 RpcConnection 对象的资源池。当 HBase 需要连接一个服务器时,首先会根据 ConnectionId 找到对应的连接池,然后从连接池中取出一个连接对象。
1 2 3 4 5 6 7 8 9 10 11 12 @InterfaceAudience .Privatepublic class PoolMap <K, V> implements Map <K, V> { private PoolType poolType; private int poolMaxSize; private Map<K, Pool<V>> pools = new ConcurrentHashMap <>(); public PoolMap (PoolType poolType) { this .poolType = poolType; } .....
HBase 中提供了三种资源池的实现,分别是 Reusable,RoundRobin 和 ThreadLocal。具体实现可以通 hbase.client.ipc.pool.type 配置项指定,默认为 Reusable。连接池的大小也可以通过 hbase.client.ipc.pool.size 配置项指定,默认为 1,即每个 Server 1 个连接。也可以通过修改配置实现:
1 2 3 config.set("hbase.client.ipc.pool.type" ,...); config.set("hbase.client.ipc.pool.size" ,...); connection = ConnectionFactory.createConnection(config);
由此可以看出 HBase 中 Connection 类已经实现了对连接的管理功能,所以我们不必在 Connection 上在做额外的管理。
另外,Connection 是线程安全的,但 Table 和 Admin 却不是线程安全的,因此正确的做法是一个进程共用一个 Connection 对象,而在不同的线程中使用单独的 Table 和 Admin 对象。Table 和 Admin 的获取操作 getTable() 和 getAdmin() 都是轻量级,所以不必担心性能的消耗,同时建议在使用完成后显示的调用 close() 方法来关闭它们。
Hbase 过滤器详解 一、HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。
二、过滤器基础 2.1 Filter接口和FilterBase抽象类 Filter 接口中定义了过滤器的基本方法,FilterBase 抽象类实现了 Filter 接口。所有内置的过滤器则直接或者间接继承自 FilterBase 抽象类。用户只需要将定义好的过滤器通过 setFilter 方法传递给 Scan 或 put 的实例即可。
1 setFilter(Filter filter)
1 2 3 4 5 6 @Override public Scan setFilter (Filter filter) { super .setFilter(filter); return this ; }
1 2 3 4 5 6 @Override public Get setFilter (Filter filter) { super .setFilter(filter); return this ; }
FilterBase 的所有子类过滤器如下:
说明:上图基于当前时间点(2019.4)最新的 Hbase-2.1.4 ,下文所有说明均基于此版本。
2.2 过滤器分类 HBase 内置过滤器可以分为三类:分别是比较过滤器,专用过滤器和包装过滤器。分别在下面的三个小节中做详细的介绍。
三、比较过滤器 所有比较过滤器均继承自 CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符 和比较器实例 。
1 2 3 4 public CompareFilter (final CompareOp compareOp,final ByteArrayComparable comparator) { this .compareOp = compareOp; this .comparator = comparator; }
3.1 比较运算符
LESS (<)
LESS_OR_EQUAL (<=)
EQUAL (=)
NOT_EQUAL (!=)
GREATER_OR_EQUAL (>=)
GREATER (>)
NO_OP (排除所有符合条件的值)
比较运算符均定义在枚举类 CompareOperator 中
1 2 3 4 5 6 7 8 9 10 @InterfaceAudience .Publicpublic enum CompareOperator { LESS, LESS_OR_EQUAL, EQUAL, NOT_EQUAL, GREATER_OR_EQUAL, GREATER, NO_OP, }
注意:在 1.x 版本的 HBase 中,比较运算符定义在 CompareFilter.CompareOp 枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用 CompareOperator 这个枚举类。
3.2 比较器 所有比较器均继承自 ByteArrayComparable 抽象类,常用的有以下几种:
BinaryComparator : 使用 Bytes.compareTo(byte [],byte []) 按字典序比较指定的字节数组。BinaryPrefixComparator : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。RegexStringComparator : 使用给定的正则表达式与指定的字节数组进行比较。仅支持 EQUAL 和 NOT_EQUAL 操作。SubStringComparator : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持 EQUAL 和 NOT_EQUAL 操作。NullComparator :判断给定的值是否为空。BitComparator :按位进行比较。
BinaryPrefixComparator 和 BinaryComparator 的区别不是很好理解,这里举例说明一下:
在进行 EQUAL 的比较时,如果比较器传入的是 abcd 的字节数组,但是待比较数据是 abcdefgh:
如果使用的是 BinaryPrefixComparator 比较器,则比较以 abcd 字节数组的长度为准,即 efgh 不会参与比较,这时候认为 abcd 与 abcdefgh 是满足 EQUAL 条件的;
如果使用的是 BinaryComparator 比较器,则认为其是不相等的。
3.3 比较过滤器种类 比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同),见下图:
RowFilter :基于行键来过滤数据;FamilyFilterr :基于列族来过滤数据;QualifierFilterr :基于列限定符(列名)来过滤数据;ValueFilterr :基于单元格 (cell) 的值来过滤数据;DependentColumnFilter :指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。
前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 setFilter 方法传递给 scan:
1 2 Filter filter = new RowFilter (CompareOperator.LESS_OR_EQUAL, new BinaryComparator (Bytes.toBytes("xxx" )));scan.setFilter(filter);
DependentColumnFilter 的使用稍微复杂一点,这里单独做下说明。
3.4 DependentColumnFilter 可以把 DependentColumnFilter 理解为一个 valueFilter 和一个时间戳过滤器的组合 。DependentColumnFilter 有三个带参构造器,这里选择一个参数最全的进行说明:
1 2 3 DependentColumnFilter(final byte [] family, final byte [] qualifier, final boolean dropDependentColumn, final CompareOperator op, final ByteArrayComparable valueComparator)
family :列族qualifier :列限定符(列名)dropDependentColumn :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃op :比较运算符valueComparator :比较器
这里举例进行说明:
1 2 3 4 5 6 DependentColumnFilter dependentColumnFilter = new DependentColumnFilter ( Bytes.toBytes("student" ), Bytes.toBytes("name" ), false , CompareOperator.EQUAL, new BinaryPrefixComparator (Bytes.toBytes("xiaolan" )));
首先会去查找 student:name 中值以 xiaolan 开头的所有数据获得 参考数据集,这一步等同于 valueFilter 过滤器;
其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为 结果数据集,这一步等同于时间戳过滤器;
最后如果 dropDependentColumn 为 true,则返回 参考数据集+结果数据集,若为 false,则抛弃参考数据集,只返回 结果数据集。
四、专用过滤器 专用过滤器通常直接继承自 FilterBase,适用于范围更小的筛选规则。
4.1 单列列值过滤器 (SingleColumnValueFilter) 基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法:
setFilterIfMissing(boolean filterIfMissing) :默认值为 false,即如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含;setLatestVersionOnly(boolean latestVersionOnly) :默认为 true,即只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。
1 2 3 4 5 6 7 SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( "student".getBytes(), "name".getBytes(), CompareOperator.EQUAL, new SubstringComparator("xiaolan")); singleColumnValueFilter.setFilterIfMissing(true); scan.setFilter(singleColumnValueFilter);
4.2 单列列值排除器 (SingleColumnValueExcludeFilter) SingleColumnValueExcludeFilter 继承自上面的 SingleColumnValueFilter,过滤行为与其相反。
4.3 行键前缀过滤器 (PrefixFilter) 基于 RowKey 值决定某行数据是否被过滤。
1 2 PrefixFilter prefixFilter = new PrefixFilter (Bytes.toBytes("xxx" ));scan.setFilter(prefixFilter);
4.4 列名前缀过滤器 (ColumnPrefixFilter) 基于列限定符(列名)决定某行数据是否被过滤。
1 2 ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter (Bytes.toBytes("xxx" ));scan.setFilter(columnPrefixFilter);
4.5 分页过滤器 (PageFilter) 可以使用这个过滤器实现对结果按行进行分页,创建 PageFilter 实例的时候需要传入每页的行数。
1 2 3 4 public PageFilter (final long pageSize) { Preconditions.checkArgument(pageSize >= 0 , "must be positive %s" , pageSize); this .pageSize = pageSize; }
下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明:
客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
分页查询主要实现逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 byte [] POSTFIX = new byte [] { 0x00 };Filter filter = new PageFilter (15 );int totalRows = 0 ;byte [] lastRow = null ;while (true ) { Scan scan = new Scan (); scan.setFilter(filter); if (lastRow != null ) { byte [] startRow = Bytes.add(lastRow, POSTFIX); System.out.println("start row: " + Bytes.toStringBinary(startRow)); scan.withStartRow(startRow); } ResultScanner scanner = table.getScanner(scan); int localRows = 0 ; Result result; while ((result = scanner.next()) != null ) { System.out.println(localRows++ + ": " + result); totalRows++; lastRow = result.getRow(); } scanner.close(); if (localRows == 0 ) break ; } System.out.println("total rows: " + totalRows);
需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
4.6 时间戳过滤器 (TimestampsFilter) 1 2 3 4 List<Long> list = new ArrayList <>(); list.add(1554975573000L ); TimestampsFilter timestampsFilter = new TimestampsFilter (list);scan.setFilter(timestampsFilter);
4.7 首次行键过滤器 (FirstKeyOnlyFilter) FirstKeyOnlyFilter 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。
1 2 FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter ();scan.set(firstKeyOnlyFilter);
五、包装过滤器 包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
5.1 SkipFilter过滤器 SkipFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
1 2 3 4 5 Filter filter1 = new ValueFilter (CompareOperator.NOT_EQUAL, new BinaryComparator (Bytes.toBytes("xxx" ))); Filter filter2 = new SkipFilter (filter1);
5.2 WhileMatchFilter过滤器 WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Filter filter1 = new RowFilter (CompareOperator.NOT_EQUAL, new BinaryComparator (Bytes.toBytes("rowKey4" ))); Scan scan = new Scan ();scan.setFilter(filter1); ResultScanner scanner1 = table.getScanner(scan);for (Result result : scanner1) { for (Cell cell : result.listCells()) { System.out.println(cell); } } scanner1.close(); System.out.println("--------------------" ); Filter filter2 = new WhileMatchFilter (filter1);scan.setFilter(filter2); ResultScanner scanner2 = table.getScanner(scan);for (Result result : scanner1) { for (Cell cell : result.listCells()) { System.out.println(cell); } } scanner2.close();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 rowKey0/student :name/1555035006994/Put/vlen=8/seqid=0 rowKey1/student :name/1555035007019/Put/vlen=8/seqid=0 rowKey2/student :name/1555035007025/Put/vlen=8/seqid=0 rowKey3/student :name/1555035007037/Put/vlen=8/seqid=0 rowKey5/student :name/1555035007051/Put/vlen=8/seqid=0 rowKey6/student :name/1555035007057/Put/vlen=8/seqid=0 rowKey7/student :name/1555035007062/Put/vlen=8/seqid=0 rowKey8/student :name/1555035007068/Put/vlen=8/seqid=0 rowKey9/student :name/1555035007073/Put/vlen=8/seqid=0 -------------------- rowKey0/student :name/1555035006994/Put/vlen=8/seqid=0 rowKey1/student :name/1555035007019/Put/vlen=8/seqid=0 rowKey2/student :name/1555035007025/Put/vlen=8/seqid=0 rowKey3/student :name/1555035007037/Put/vlen=8/seqid=0
可以看到被包装后,只返回了 rowKey4 之前的数据。
六、FilterList 以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
1 2 3 4 5 6 7 8 public FilterList (final Operator operator, final List<Filter> filters) public FilterList (final List<Filter> filters) public FilterList (final Filter... filters) public void addFilter (List<Filter> filters) public void addFilter (Filter filter)
多个过滤器组合的结果由 operator 参数定义 ,其可选参数定义在 Operator 枚举类中。只有 MUST_PASS_ALL 和 MUST_PASS_ONE 两个可选的值:
MUST_PASS_ALL :相当于 AND,必须所有的过滤器都通过才认为通过;MUST_PASS_ONE :相当于 OR,只有要一个过滤器通过则认为通过。
1 2 3 4 5 6 7 @InterfaceAudience .Publicpublic enum Operator { MUST_PASS_ALL, MUST_PASS_ONE }
使用示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 List<Filter> filters = new ArrayList <Filter>(); Filter filter1 = new RowFilter (CompareOperator.GREATER_OR_EQUAL, new BinaryComparator (Bytes.toBytes("XXX" ))); filters.add(filter1); Filter filter2 = new RowFilter (CompareOperator.LESS_OR_EQUAL, new BinaryComparator (Bytes.toBytes("YYY" ))); filters.add(filter2); Filter filter3 = new QualifierFilter (CompareOperator.EQUAL, new RegexStringComparator ("ZZZ" )); filters.add(filter3); FilterList filterList = new FilterList (filters);Scan scan = new Scan ();scan.setFilter(filterList);
七、练习过滤器-基于SCAN扫描数据 需求: 查询 2020年 6月份的所有用户的用水量 :
日期字段: C1: RECORD_DATE (String)
用水量字段: C1:NUM_USAGE (Double)
用户字段: C1:NAME(String)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 @Test public void test06_findScan () throws Exception{ Scan scan = new Scan (); SingleColumnValueFilter filter1 = new SingleColumnValueFilter ( "C1" .getBytes(),"RECORD_DATE" .getBytes(), CompareOperator.GREATER_OR_EQUAL,new BinaryComparator ("2020-06-01" .getBytes())); SingleColumnValueFilter filter2 = new SingleColumnValueFilter ( "C1" .getBytes(),"RECORD_DATE" .getBytes(), CompareOperator.LESS,new BinaryComparator ("2020-07-01" .getBytes())); FilterList filterList = new FilterList (); filterList.addFilter(filter1); filterList.addFilter(filter2); scan.addColumn("C1" .getBytes(),"NAME" .getBytes()); scan.addColumn("C1" .getBytes(),"RECORD_DATE" .getBytes()); scan.addColumn("C1" .getBytes(),"NUM_USAGE" .getBytes()); scan.setLimit(10 ); scan.setFilter(filterList); ResultScanner results = table.getScanner(scan); for (Result result : results) { List<Cell> cellList = result.listCells(); for (Cell cell : cellList) { String rowkey = Bytes.toString(CellUtil.cloneRow(cell)); String family = Bytes.toString(CellUtil.cloneFamily(cell)); String columnName = Bytes.toString(CellUtil.cloneQualifier(cell)); Object columnValue; if (columnName.equals("NUM_USAGE" )){ columnValue = Bytes.toDouble(CellUtil.cloneValue(cell)); }else { columnValue = Bytes.toString(CellUtil.cloneValue(cell)); } System.out.println("rowkey:" + rowkey+";列族:" +family+";列名为:" +columnName+";列值为:" +columnValue); } System.out.println("========================" ); } }
HBase BulkLoad批量加载
HBase的批量加载: 将一批数据一次性全部加入到HBase中
原生写入流程: 读取数据 - - > hbase的内存 - - > storeFile - -> HFile - -> 分裂 到更多的Region中
思考: 如果采用原生的方式写入, 会存在什么问题呢?
1 2 3 4 1) 写入效率比较慢 2) 由于数据量比较大, 写入操作会长期占用HBase的带宽资源 这个时候, 如果还有大量的读取数据操作, 此时会发现读取的操作可能会边的异常的缓慢, 因为没有带宽 3) 导致HBase的压力剧增, 不断的进行溢写, 不断的进行合并, 不断的进行分裂
HBase的Bulk Load的应用场景: 适合于需要一次性写入到了的数据场景
思考: BulkLoad是如何实现呢?
1 2 3 4 5 6 原理: 1- 将这一批数据 转换为HBase能够识别的文件格式: HFile 2- 将HFile文件格式数据直接放置盒到HBase对应的HDFS的数据目录下 好处 : 不需要与HBase直接关联, 也就不会占用HBase的带宽, 同时对HBase的压力几乎没有, 执行效率更高
利用技术: MR. 读取 数据源的数据, 将数据输出为HFile文件格式 不存在任何的聚合工作, 所以整个MR只需要Map, 不需要Reduce参与
需求说明 需求: 将银行的转账记录数据加载到HBase中, 由于一次性需要加载的数据比较多, 采用BulkLoad方式实现
准备工作
1 create 'TRANSFORM_RECORD','C1'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 <repositories><!--代码库--> <repository> <id>aliyun</id> <url>http ://maven.aliyun.com/nexus/content/groups/public/</url> <releases><enabled>true</enabled></releases> <snapshots> <enabled>false</enabled> <updatePolicy>never</updatePolicy> </snapshots> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.6</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-mapreduce</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.5</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <target>1.8</target> <source>1.8</source> </configuration> </plugin> </plugins> </build>
3- 创建包结构: com.zuoer.hbase.bulkLoad
4- 导入 log4j.properties 配置文件放置到resource目录下(方便查看日志)
5- 将银行转账测试数据上传到HDFS中
1 2 hdfs dfs -mkdir -p /hbase/bulkload/input hdfs dfs -put bank_record.csv /hbase/bulkload/input
将CSV文件转换为HFile文件格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.zuoer.hbase.bulkLoad; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class BulkLoadMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put> { private ImmutableBytesWritable k2 = new ImmutableBytesWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1. 获取一行数据 String line = value.toString(); //2. 判断数据是否为空 if(line != null && !"".equals(line.trim())){ //3. 执行数据切割操作, 将其转换为k2和v2 String[] fields = line.split(","); // 3.1 封装k2(rowkey) k2.set(fields[0].getBytes()); //3.2 封装v2 一行数据 Put v2 = new Put(fields[0].getBytes()); v2.addColumn("C1".getBytes(),"code".getBytes(),fields[1].getBytes()); v2.addColumn("C1".getBytes(),"rec_account".getBytes(),fields[2].getBytes()); v2.addColumn("C1".getBytes(),"rec_bank_name".getBytes(),fields[3].getBytes()); v2.addColumn("C1".getBytes(),"rec_name".getBytes(),fields[4].getBytes()); v2.addColumn("C1".getBytes(),"pay_account".getBytes(),fields[5].getBytes()); v2.addColumn("C1".getBytes(),"pay_name".getBytes(),fields[6].getBytes()); v2.addColumn("C1".getBytes(),"pay_comments".getBytes(),fields[7].getBytes()); v2.addColumn("C1".getBytes(),"pay_channel".getBytes(),fields[8].getBytes()); v2.addColumn("C1".getBytes(),"pay_way".getBytes(),fields[9].getBytes()); v2.addColumn("C1".getBytes(),"status".getBytes(),fields[10].getBytes()); v2.addColumn("C1".getBytes(),"timestamp".getBytes(),fields[11].getBytes()); v2.addColumn("C1".getBytes(),"money".getBytes(),fields[12].getBytes()); //4. 写出去 context.write(k2,v2); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package com.itheima.hbase.bulkLoad; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; public class BulkLoadDriver { public static void main(String[] args) throws Exception{ //1. 创建Job对象 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum","node1 :2181,node2:2181,node3:2181"); Job job = Job.getInstance(conf); //2. 设置提交Yarn的必备参数 job.setJarByClass(BulkLoadDriver.class); //3. 设置MR的天龙八大步 // 3.1 设置输入类和输入的路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/hbase/bulkload/input/bank_record.csv")); // 3.2 设置Mapper类 和 输出 k2和v2 的类型 job.setMapperClass(BulkLoadMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); //3.3 设置Shuffle: 3.3 分区 3.4 排序 3.5规约 3.6分组 (全部都是默认值) // 3.7 设置Reudce 和 输出 k3和v3的类型: 没有Reduce job.setNumReduceTasks(0); // 建议: 不管有没有reduce, 都设置k3和v3 的类型, 如果没有reduce, 直接使用k2和v2的类型 job.setOutputKeyClass(ImmutableBytesWritable.class); job.setOutputValueClass(Put.class); // 3.8 设置输出类 和 输出的路径: 输出HFile文件格式 // 3.8.1 设置HFile文件格式输出类 job.setOutputFormatClass(HFileOutputFormat2.class); // 3.8.2 设置HFile的相关信息: 表信息 和 Region信息 Connection hbaseConn = ConnectionFactory.createConnection(conf); Table table = hbaseConn.getTable(TableName.valueOf("TRANSFORM_RECORD")); HFileOutputFormat2.configureIncrementalLoad(job,table,hbaseConn.getRegionLocator(TableName.valueOf("TRANSFORM_RECORD"))); // 3.8.3 设置输出路径 HFileOutputFormat2.setOutputPath(job,new Path("hdfs://node1:8020/hbase/bulkload/output")); // 4 提交任务 boolean flag = job.waitForCompletion(true); System.exit(flag ? 0:1); } }
如何加载HFile到HBase中
1 2 3 4 hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles 数据路径 HBase表名 注意 : 数据路径 指的就是MR中设置的输出路径
案例实现:
1 hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles hdfs://node1.itcast.cn:8020/hbase/bulkload/output TRANSFORM_RECORD
查看HBase的表数据量, 发现数据都回来了
1 hbase shell中执行: count 'TRANSFORM_RECORD'
或者:
1 2 3 4 5 6 7 8 错误原因 : 无法加载到本地Hadoop环境信息 解决方案 : 1- 第一步: 在 C:\Windows\System32 下 放置一个hadoop.dll文件 2- 在环境变量中, 配置 HADOOP_HOME 并添加到Path中 建议此问题解决 : 参考在讲解HADOOP的时候 在本地配置环境信息
可能遇到问题2: 在加载数据到HBase中的时候, 提示尝试了10次 依然无法导入数据 (大家非常有可能遇到)
1 2 3 4 5 6 7 8 9 原因 : HBase在配置的时候,我们的配置文件中使用服务器的名称都是全称(node1.itcast.cn, node2.itcast.cn ...) 但是, 大家伙之前在配置Hadoop的时候, hadoop中核心配置文件中, 使用服务器名称为简称(node1,node2...) 此时导致名称不一致, 从而无法实现导入数据 解决方案 : cd /export/server/hadoop/etc/hadoop/ vim core-site.xml
HBase和Hive的整合 HBase和Hive的对比说明 HBase 和 Hive 都是基于Hadoop的两种不同的技术
HIVE: 是一个数据仓库的工具, 主要是用于对HDFS上数据进行映射, 采用SQL的方式操作数据, HIVE主要适用于离线数据统计分析操作, 延迟性比较高, SQL最终会翻译为MR
HBase: 是一个nosql型数据库, 主要是用于存储数据, 不支持SQL, 也不支持join操作, 延迟性比较低, 交互性比较强
HBase和HIVE在实际生产环境中, 也是可以同时使用的, 我们可以基于HIVE加载HBase中数据, 从而实现离线数据分析工作, 同时还可以使用HBase做实时查询数据操作, HBase后续也可以和Phoenix集成, 可以通过SQL方式查询HBase中的数据, 从而实现实时数据检索(即席查询)
HBase如何集成Hive 集成步骤:
1- 拷贝HIVE提供的一个专门用于集成HBase的通信jar包, 将此jar包拷贝到HBase的lib目录下
1 2 3 4 5 6 7 8 hive安装在node1节点上 : 在node1执行操作 cd /usr/local/apps/hive-3.1.2/lib/ cp hive-hbase-handler-3.1.2.jar /usr/local/apps/hbase-2.1.0/lib/ 拷贝后, 将此jar包, 分发给node2和node3的hbase的lib目录 cd /usr/local/apps/hbase-2.1.0/lib/ scp hive-hbase-handler-3.1.2.jar node2:$PWD scp hive-hbase-handler-3.1.2.jar node3:$PWD
2- 修改HIVE的配置文件: hive-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cd /usr/local/apps/hive-3.1.2/conf vim hive-site.xml 输入i , 进入插入模式: 添加以下内容: <property > <name > hive.zookeeper.quorum</name > <value > node1,node2,node3</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > node1,node2,node3</value > </property > <property > <name > hive.server2.enable.doAs</name > <value > false</value > </property >
3- 修改hive的配置文件: hive-env.sh
1 2 3 4 5 6 7 cd /usr/local/apps/hive-3.1.2/conf vim hive-env.sh 输入i , 进入插入模式: 添加以下内容 : export HBASE_HOME=/usr/local/apps/hbase-2.1.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 先zookeeper 然后启动 hadoop集群 接着启动 HIVE 和 HBase 注意 : 每启动完一个软件, 一定要确保是启动ok的 启动zookeeper : 三个节点都要启动 cd /export/server/zookeeper/bin ./zkServer.sh start 查看是否启动成功 : jps / ./zkServer.sh status 启动 hadoop: node1执行即可 start-all.sh 校验 : 查看进程是否全部都正常启动 以及通过 web ui查看是否启动良好 启动HBase : node1执行即可 start-hbase.sh 校验 : 查看进程是否全部都正常启动 以及通过 web ui查看是否启动良好 启动hive : node1执行 cd /export/server/hive/bin nohup ./hive --service metastore & nohup ./hive --service hiveserver2 & 校验 : jps 以及 通过 ./beeline连接测试
集成操作:
1- 在hbase中创建一张表, 并且向表添加一些数据 (准备工作)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 create 'hbase_hive_score', 'cf' put 'hbase_hive_score','rk001','cf:name','张三' put 'hbase_hive_score','rk001','cf:age',20 put 'hbase_hive_score','rk001','cf:address','北京' put 'hbase_hive_score','rk001','cf:score',92 put 'hbase_hive_score','rk002','cf:name','李四' put 'hbase_hive_score','rk002','cf:age',28 put 'hbase_hive_score','rk002','cf:address','上海' put 'hbase_hive_score','rk002','cf:score',89 put 'hbase_hive_score','rk003','cf:name','王五' put 'hbase_hive_score','rk003','cf:age',26 put 'hbase_hive_score','rk003','cf:address','广州' put 'hbase_hive_score','rk003','cf:score',94 put 'hbase_hive_score','rk004','cf:name','赵六' put 'hbase_hive_score','rk004','cf:age',23 put 'hbase_hive_score','rk004','cf:address','深圳' put 'hbase_hive_score','rk004','cf:score',96
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 集成的格式 :create external table 库名.表名( 字段1 数据类型, 字段2 数据类型, 字段3 数据类型, .... ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,列族:列名,列族:列名...') tblproperties('hbase.table.name'='表名') 注意事项 : 1) 表名: 建议与HBase表名保持一致(可以不一致) 2) 定义字段的时候, 第一个字段为主键字段, 但是不能添加primary key, 其余字段与hbase中列名建议保持一致(可以不一致) 3) 在mapping中设置映射关系 : :key 表示rowkey , 剩余其他列, 正常设置即可 mapping中设置顺序与表中字段的顺序 和 数量都要保持一致, 因为是按序映射的 4) hbase表名: 设置对应在hbase的哪个表 实操 : create database day08_hbase_hive; create external table day08_hbase_hive.hbase_hive_score( id string, name string, age int, address string, score int ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,cf:name,cf:age,cf:address,cf:score') tblproperties('hbase.table.name'='hbase_hive_score');
HBase 表结构设计 HBase的名称空间 HBase的名称空间类似于MySQL中的库, 只不过叫法不同而已
思考: MySQL为什么要设计库的概念呢? 直接创建表不好吗?
1 2 3 4 1- 便于管理维护工作 2- 业务划分更加明确 3- 权限管理能够细致 .....
hbase的名称空间, 其实也有类似的作用
一般在生产中, 建议每一个业务模块, 或者每一个项目 都要去单独创建一个名称空间, 用于管理属于当前这个模块或者这个项目相关的表数据
在HBase中, 默认提供了两个名称空间:
1- default: 默认的名称空间, 在创建表的时候, 如果不指定名称空间, 默认就会将表创建在这个default名称空间下
2- hbase: 此名称空间是hbase专门用于放置hbase系统表的名称空间, 例如: meta 表就是存储在这个名称空间下, 此名称空间, 一般不使用的
如何使用hbase的名称空间呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1) 如何创建名称空间: create_namespace '名称空间名字' 2) 如何查看当前有那些名称空间 list_namespace 3) 如何在指定的名称空间下创建表: 格式 : create '名称空间:表名','列族1','列族2'... 4) 如何删除名称空间: 格式 : drop_namespace '名称空间' 注意 : 删除名称空间的时候, 此名称空间下, 不能有表存在, 否则无法删除 5) 查看某一个名称空间 格式 : describe_namespace '名称空间'
注意: 一旦在其他的名称空间下创建表, 在使用这个表的时候, 必须带上对应名称空间
HBase的列族的设计 在构建表的时候, 列族建议越少越好, 能用一个解决的, 坚决不使用多个
思考: 在什么情况下, 我们需要构建多个列族呢? 建议 2~5个
1 2 3 情况一 :需要将一份数据存储到HBase的时候, 整个数据集中只有某几列数据经常使用到, 其他列的数据使用频次并不高,建议将其分为两个列族, 一个列族中用于放置经常使用的字段, 一个列族放置其他的字段 情况二 : 一份数据集主要是用于对接两个不同的业务, 不同的业务的体系使用的数据集中不同的字段, 根据业务要求, 将不同业务数据划分到不同的列族中, 便于各个业务读取不同列族的下数据
Hbase的表压缩方案的选择 为什么要压缩数据呢? 压缩有什么作用呢?
1 目的 : 在有限的存储空间下, 能够存储更多的数据
注意: 在HBase中, 压缩的操作是存在与磁盘(HDFS)上,只有当数据落在HDFS上才会进行压缩, 如果数据在内存中是不存在压缩的
在生产中, 如何选择压缩方案呢? 前提数据量比较大, 需要对数据进行压缩
1- 如果写入请求远远大于读取数据请求(写多读少),建议大家采用GZ(GZIP),保证在有限的空间下, 存储更多的数据
2- 如果读取请求远远大于写入数据的请求(读多写少),建议采用SNAPPY压缩方案, 在保证一定的压缩率下, 更好的提高压缩和解压的效率
在HBase中如何设置压缩呢?
默认在建表的时候, 是不设置压缩的
配置压缩的格式:
1 2 3 新建表设置压缩 : create '表名', {NAME => '列族', COMPRESSION => '压缩算法'} 修改已有的表 : alter '表名', {NAME => '列族', COMPRESSION => '压缩算法'}
注意: 在设置压缩方案的时候, 默认GZ是被支持的, 如果使用LZO 或者 SNAPPY , 有可能出现无法使用的情况, 如果非要尝试, 需要将HBase重新编译, 设置其支持其他的压缩方案, 以及增加相关的压缩方案的jar包, 或者 使用CDH版本的HBase
HBase的预分区 在HBase中默认情况下, 创建一个表只有一个Region, 只有一个Region也就意味着只能被一个RegionServer所管理
在此种情况下, 如果遇到大量的并发访问, 此时所有的请求全部打向同一个RegionServer上, 从而导致这个RegionServer承担更大的并发, 出现宕机的风险, 宕机后, 如果region被其他的RegionServer接管了, 可能还会接着宕机, 最终导致出现雪崩问题, 全部节点一起奔溃
如何解决呢?
1 2 3 4 让表的Region数量变得更多, 当Region变多了, 那么就可以让更多的RegionServer参与, 从而让更多RegionServer一起来承担并发读写请求 前序讲过 : 自动分裂 这种模式, 依然存在热点问题, 从 0~128M 期间, 如果有并发, 还是无法避免
更希望能否在一创建表的时候, 就让这个表一次性拥有多个Region呢? 这就是HBase的预分区要解决的问题
如何在HBase中设置预分区呢?
1 2 3 4 5 6 7 8 9 格式 : create '表','列族1','列族2'...., SPLITS => [自定义分区方案] 例如 : create 'test04_split' ,'C1',SPLITS=> ['10','20','30','40','50'] 注意 : 此种方式更适合于对表的rowkey数据非常了解, 非常熟悉的情况下, 采用此方案
1 2 3 4 5 6 7 8 格式 : create '表名','列族1','列族2'...,{NUMREGIONS => N, SPLITALGO => 'HexStringSplit'} 例子 : create 'test05_split','C1',{NUMREGIONS => 16, SPLITALGO => 'HexStringSplit'} 说明 : 这种方式比较适合于对未来不清楚rowkey的范围有那些的时候, 可以采用此方案
建议: 不管采用哪种预分区的方式, 建议预分区的数量为RegionServer数量的2~5倍左右即可
思考: 通过预分区, 就真的能完全解决之前的数据热点问题了吗? (数据打向同一个RegionServer情况)
HBase中rowkey的设计原则 通过预分区, 可以保证在创建表的时候, 就可以让表一开始拥有多个Region, 但是Region的划分方案是基于rowkey的范围来划分的, 如果说, rowkey在设计的过程中, 前缀都是以固定的名称来命名. 此时可能会导致所有的数据全部写入到某一个Region或者某几个Region上, 从而导致预分区设置没有效果的
解决方案: 通过对rowkey进行设计, 保证能够让数据均匀落在不同的Region中
1 2 3 4 1- 避免使用递增的行键/时序的数据作为rowkey的前缀 : 不要以固定的前缀作为rowkey 2- 在设计的时候rowkey和列的长度不能太长了, 建议越短越好, 一般建议在1~30区间,最长不能超过100字节 3- 使用数值类型的要比使用string更加节省空间 4- 保证rowkey的唯一性
1 2 1- 保证相关性的数据放置到同一个Region中 2- rowkey的设计能够满足一些固定的查询需求
如果rowkey的设计不良好, 就会导致数据热点的问题: 所谓数据热点, 指的就是大量的数据集中放置到某一个, 或者某几个Region中, 而其他的Region中没有数据, 或者数据极少
解决方案:
1- 加盐处理(加随机数)
好处: 基本保证数据落在不同的Region中
弊端: 相关性无法保证, 会将数据完全打散
2- 反转的策略: 手机号的反转 时间戳反转
好处: 基本保证数据落在不同的Region中
弊端: 相关性无法保证, 会将数据完全打散
3- hash处理: 后续此种方式可以和Hash预分区配合使用, 基于HBase提供MD5HASH 方案生成rowkey的前缀(推荐)
好处: 相关性的数据可以放置到一起
弊端: 如果相关性的数据比较多, 依然会导致热点问题的发生
HBase的版本确界和TTL 对于版本确界 和 TTL 在实际中需要根据实际生产需求进行设置, 如果生产环境中没有要求, 选择默认即可
什么是版本的确界 所谓的版本的确界, 本质上指的就是是否需要保留历史版本, 以及保留多少个问题
下界: 指的至少需要保留多少个历史版本, 即使数据过期了, 也是需要保留的 默认为 0 (禁用)
上界: 指的最多需要保留多少个历史版本数据, 默认值: 1
什么是数据TTL 在HBase中可以对数据设置过期时间, 当达到时间后, 数据就会自动被删除掉了
代码演示版本确界和TTL 代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 package com.itheima.hbase; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; public class HBaseVersionAndTTL { public static void main(String[] args) throws Exception { //1. 根据连接工厂, 创建HBase的连接对象 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum","node1 :2181,node2:2181,node3:2181"); Connection hbaseConn = ConnectionFactory.createConnection(conf); //2. 根据连接对象, 获取相关管理对象 Admin admin = hbaseConn.getAdmin(); // 2.1 判断某个表是否存在 if(!admin.tableExists(TableName.valueOf("VERSION_TTL"))){ // 2.2 如果表不存在, 创建这个表 ColumnFamilyDescriptor columnFamily = ColumnFamilyDescriptorBuilder .newBuilder("C1".getBytes()) .setMaxVersions(5) .setMinVersions(3) .setTimeToLive(180) .build(); TableDescriptor tableDesc = TableDescriptorBuilder.newBuilder(TableName.valueOf("VERSION_TTL")).setColumnFamily(columnFamily).build(); admin.createTable(tableDesc); } // 2.3 如果表存在, 获取这个表对象 Table table = hbaseConn.getTable(TableName.valueOf("VERSION_TTL")); // 3. 执行相关操作: 添加数据(添加一条, 修改N次) /*for(int i = 1; i<=2; i++){ Put put = new Put("rk0001".getBytes()); //put.setTTL(1000); // 毫秒单位 put.addColumn("C1".getBytes(),"NAME".getBytes(),("张三"+i).getBytes()); table.put(put); }*/ // 4- 查看数据: 查看历史版本的数据 Get get = new Get("rk0001".getBytes()); // 设置读取所有的版本数据 get.readAllVersions(); Result result = table.get(get); Cell[] cells = result.rawCells();// 获取所有版本的单元格信息 for (Cell cell : cells) { System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));// } //5. 释放资源: table.close(); admin.close(); hbaseConn.close(); } }
注意: 设置版本的上界和下界, 是针对列族设置, 对于过期时间, 可以在列族上设置, 也可以在每一行数据进行设置
说明:
即使所有数据都过期了, 那么至少应该有min_version个版本会保留下来, 这样可以确保我们在查询的时候能够满足至少版本的要求
Hbase 协处理器 一、简述 在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求。在这种情况下,协处理器(Coprocessors)应运而生。它允许你将业务计算代码放入在 RegionServer 的协处理器中,将处理好的数据再返回给客户端,这可以极大地降低需要传输的数据量,从而获得性能上的提升。同时协处理器也允许用户扩展实现 HBase 目前所不具备的功能,如权限校验、二级索引、完整性约束等。
二、协处理器类型 思考: 请从HBase表中的Age列, 找到年龄最大值, 请问 如何做呢?
1 2 3 4 5 6 7 8 9 10 做法 : 1) 基于scan 扫描全表 2) 在扫描的过程中, 基于Java代码, 一个一个进行比对, 将最大值获取出来即可 弊端 : 客户端需要查询整个数据集, 所有的数据比对工作全部都集中在客户端进行,对客户端的压力是比较大的, 效率也不高 解决思路 : 如果可以将求最大值代码交给各个RegionServer, 由各个RegionServer计算出各个Region中最大值,然后将各个Region的最大值返回给客户端, 客户端基于结果进行二次比对, 得出最终的最大值 这种思路的实现, 其实就是HBase的协处理即可解决
2.1 Observer协处理器 1. 功能 Observer 协处理器类似于关系型数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。
类似于MySQL中触发器, 还可以理解为监听器, 当触发某种事件(hook)的时候,执行observer中定义的相关代码功能
作用:
通常可以用来实现下面功能:
权限校验 :在执行 Get 或 Put 操作之前,您可以使用 preGet 或 prePut 方法检查权限;完整性约束 : HBase 不支持关系型数据库中的外键功能,可以通过触发器在插入或者删除数据的时候,对关联的数据进行检查;二级索引 : 可以使用协处理器来维护二级索引。
2. 类型 当前 Observer 协处理器有以下四种类型:
RegionObserver :RegionServerObserver :MasterObserver :WalObserver :
3. 接口 以上四种类型的 Observer 协处理器均继承自 Coprocessor 接口,这四个接口中分别定义了所有可用的钩子方法,以便在对应方法前后执行特定的操作。通常情况下,我们并不会直接实现上面接口,而是继承其 Base 实现类,Base 实现类只是简单空实现了接口中的方法,这样我们在实现自定义的协处理器时,就不必实现所有方法,只需要重写必要方法即可。
这里以 RegionObservers 为例,其接口类中定义了所有可用的钩子方法,下面截取了部分方法的定义,多数方法都是成对出现的,有 pre 就有 post:
4. 执行流程
客户端发出 put 请求
该请求被分派给合适的 RegionServer 和 region
coprocessorHost 拦截该请求,然后在该表的每个 RegionObserver 上调用 prePut()
如果没有被 prePut() 拦截,该请求继续送到 region,然后进行处理
region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut()
假如没有 postPut() 拦截该响应,最终结果被返回给客户端
如果大家了解 Spring,可以将这种执行方式类比于其 AOP 的执行原理即可,官方文档当中也是这样类比的:
If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as applying advice by intercepting a request and then running some custom code,before passing the request on to its final destination (or even changing the destination).
如果您熟悉面向切面编程(AOP),您可以将协处理器视为通过拦截请求然后运行一些自定义代码来使用 Advice,然后将请求传递到其最终目标(或者更改目标)。
2.2 Endpoint协处理器 Endpoint 协处理器类似于关系型数据库中的存储过程。客户端可以调用 Endpoint 协处理器在服务端对数据进行处理,然后再返回给客户端,客户端根据结果进行操作。
以聚集操作为例,如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,然后在客户端上遍历扫描结果,这必然会加重了客户端处理数据的压力。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出来,仅仅将该 max 值返回给客户端。之后客户端只需要将每个 Region 的最大值进行比较而找到其中最大的值即可。
作用:
三、协处理的加载方式 要使用我们自己开发的协处理器,必须通过静态(使用 HBase 配置)或动态(使用 HBase Shell 或 Java API)加载它。
静态加载的协处理器称之为 System Coprocessor (系统级协处理器),作用范围是整个 HBase 上的所有表,需要重启 HBase 服务;
动态加载的协处理器称之为 Table Coprocessor (表处理器),作用于指定的表,不需要重启 HBase 服务。
其加载和卸载方式分别介绍如下。
四、静态加载与卸载 4.1 静态加载 静态加载分以下三步:
在 hbase-site.xml 定义需要加载的协处理器。
1 2 3 4 <property > <name > hbase.coprocessor.region.classes</name > <value > org.myname.hbase.coprocessor.endpoint.SumEndPoint</value > </property >
<name> 标签的值必须是下面其中之一:
RegionObservers 和 Endpoints 协处理器:hbase.coprocessor.region.classes
WALObservers 协处理器: hbase.coprocessor.wal.classes
MasterObservers 协处理器:hbase.coprocessor.master.classes
<value> 必须是协处理器实现类的全限定类名。如果为加载指定了多个类,则类名必须以逗号分隔。
将 jar(包含代码和所有依赖项) 放入 HBase 安装目录中的 lib 目录下;
重启 HBase。
4.2 静态卸载
从 hbase-site.xml 中删除配置的协处理器的<property>元素及其子元素;
从类路径或 HBase 的 lib 目录中删除协处理器的 JAR 文件(可选);
重启 HBase。
五、动态加载与卸载 使用动态加载协处理器,不需要重新启动 HBase。但动态加载的协处理器是基于每个表加载的,只能用于所指定的表。
以下示例基于两个前提:
coprocessor.jar 包含协处理器实现及其所有依赖项。
JAR 包存放在 HDFS 上的路径为:hdfs:// <namenode>:<port> / user / <hadoop-user> /coprocessor.jar
5.1 HBase Shell动态加载
使用 HBase Shell 禁用表
1 hbase > disable 'tableName'
使用如下命令加载协处理器
1 hbase > alter 'tableName', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/ user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823| arg1=1,arg2=2'
Coprocessor 包含由管道(|)字符分隔的四个参数,按顺序解释如下:
JAR 包路径 :通常为 JAR 包在 HDFS 上的路径。关于路径以下两点需要注意:
允许使用通配符,例如:hdfs://<namenode>:<port>/user/<hadoop-user>/*.jar 来添加指定的 JAR 包;
可以使指定目录,例如:hdfs://<namenode>:<port>/user/<hadoop-user>/ ,这会添加目录中的所有 JAR 包,但不会搜索子目录中的 JAR 包。
类名 :协处理器的完整类名。
优先级 :协处理器的优先级,遵循数字的自然序,即值越小优先级越高。可以为空,在这种情况下,将分配默认优先级值。
可选参数 :传递的协处理器的可选参数。
启用表
1 hbase > enable 'tableName'
验证协处理器是否已加载
1 hbase > describe 'tableName'
协处理器出现在 TABLE_ATTRIBUTES 属性中则代表加载成功。
5.2 HBase Shell动态卸载
禁用表
1 hbase> disable 'tableName'
移除表协处理器
1 hbase> alter 'tableName' , METHOD => 'table_att_unset' , NAME => 'coprocessor$1'
启用表
1 hbase> enable 'tableName'
5.3 Java API 动态加载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 TableName tableName = TableName.valueOf("users" );String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar" ;Configuration conf = HBaseConfiguration.create();Connection connection = ConnectionFactory.createConnection(conf);Admin admin = connection.getAdmin();admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor (tableName);HColumnDescriptor columnFamily1 = new HColumnDescriptor ("personalDet" );columnFamily1.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor ("salaryDet" );columnFamily2.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily2); hTableDescriptor.setValue("COPROCESSOR$1" , path + "|" + RegionObserverExample.class.getCanonicalName() + "|" + Coprocessor.PRIORITY_USER); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);
在 HBase 0.96 及其以后版本中,HTableDescriptor 的 addCoprocessor() 方法提供了一种更为简便的加载方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 TableName tableName = TableName.valueOf("users" );Path path = new Path ("hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar" );Configuration conf = HBaseConfiguration.create();Connection connection = ConnectionFactory.createConnection(conf);Admin admin = connection.getAdmin();admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor (tableName);HColumnDescriptor columnFamily1 = new HColumnDescriptor ("personalDet" );columnFamily1.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor ("salaryDet" );columnFamily2.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily2); hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path, Coprocessor.PRIORITY_USER, null ); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);
5.4 Java API 动态卸载 卸载其实就是重新定义表但不设置协处理器。这会删除所有表上的协处理器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 TableName tableName = TableName.valueOf("users" );String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar" ;Configuration conf = HBaseConfiguration.create();Connection connection = ConnectionFactory.createConnection(conf);Admin admin = connection.getAdmin();admin.disableTable(tableName); HTableDescriptor hTableDescriptor = new HTableDescriptor (tableName);HColumnDescriptor columnFamily1 = new HColumnDescriptor ("personalDet" );columnFamily1.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily1); HColumnDescriptor columnFamily2 = new HColumnDescriptor ("salaryDet" );columnFamily2.setMaxVersions(3 ); hTableDescriptor.addFamily(columnFamily2); admin.modifyTable(tableName, hTableDescriptor); admin.enableTable(tableName);
六、协处理器案例 这里给出一个简单的案例,实现一个类似于 Redis 中 append 命令的协处理器,当我们对已有列执行 put 操作时候,HBase 默认执行的是 update 操作,这里我们修改为执行 append 操作。
1 2 3 4 5 6 7 8 9 # redis append 命令示例 redis> EXISTS mykey (integer) 0 redis> APPEND mykey "Hello" (integer) 5 redis> APPEND mykey " World" (integer) 11 redis> GET mykey "Hello World"
6.1 创建测试表 1 2 # 创建一张杂志表 有文章和图片两个列族 hbase > create 'magazine','article','picture'
6.2 协处理器编程
完整代码可见本仓库:hbase-observer-coprocessor
新建 Maven 工程,导入下面依赖:
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-common</artifactId > <version > 1.2.0</version > </dependency > <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-server</artifactId > <version > 1.2.0</version > </dependency >
继承 BaseRegionObserver 实现我们自定义的 RegionObserver,对相同的 article:content 执行 put 命令时,将新插入的内容添加到原有内容的末尾,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class AppendRegionObserver extends BaseRegionObserver { private byte [] columnFamily = Bytes.toBytes("article" ); private byte [] qualifier = Bytes.toBytes("content" ); @Override public void prePut (ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException { if (put.has(columnFamily, qualifier)) { Result rs = e.getEnvironment().getRegion().get(new Get (put.getRow())); String oldValue = "" ; for (Cell cell : rs.rawCells()) if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) { oldValue = Bytes.toString(CellUtil.cloneValue(cell)); } List<Cell> cells = put.get(columnFamily, qualifier); String newValue = "" ; for (Cell cell : cells) { if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) { newValue = Bytes.toString(CellUtil.cloneValue(cell)); } } put.addColumn(columnFamily, qualifier, Bytes.toBytes(oldValue + newValue)); } } }
6.3 打包项目 使用 maven 命令进行打包,打包后的文件名为 hbase-observer-coprocessor-1.0-SNAPSHOT.jar
6.4 上传JAR包到HDFS 1 2 3 4 # 上传项目到HDFS上的hbase目录 hadoop fs -put /usr/app/hbase-observer-coprocessor-1.0-SNAPSHOT.jar /hbase # 查看上传是否成功 hadoop fs -ls /hbase
6.5 加载协处理器
加载协处理器前需要先禁用表
1 hbase > disable 'magazine'
加载协处理器
1 hbase > alter 'magazine', METHOD => 'table_att', 'Coprocessor'=>'hdfs://hadoop001:8020/hbase/hbase-observer-coprocessor-1.0-SNAPSHOT.jar|com.heibaiying.AppendRegionObserver|1001|'
启用表
1 hbase > enable 'magazine'
查看协处理器是否加载成功
协处理器出现在 TABLE_ATTRIBUTES 属性中则代表加载成功,如下图:
6.6 测试加载结果 插入一组测试数据:
1 2 3 4 hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','World' hbase > get 'magazine','rowkey1','article:content'
可以看到对于指定列的值已经执行了 append 操作:
插入一组对照数据:
1 2 3 4 hbase > put 'magazine', 'rowkey1','article:author','zhangsan' hbase > get 'magazine','rowkey1','article:author' hbase > put 'magazine', 'rowkey1','article:author','lisi' hbase > get 'magazine','rowkey1','article:author'
可以看到对于正常的列还是执行 update 操作:
6.7 卸载协处理器
卸载协处理器前需要先禁用表
1 hbase > disable 'magazine'
卸载协处理器
1 hbase > alter 'magazine', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
启用表
1 hbase > enable 'magazine'
查看协处理器是否卸载成功
6.8 测试卸载结果 依次执行下面命令可以测试卸载是否成功
1 2 3 hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content'
Hbase 容灾与备份 一、前言 本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable 、Export /Import 、Snapshot 。分别介绍如下:
二、CopyTable 2.1 简介 CopyTable 可以将现有表的数据复制到新表中,具有以下特点:
支持时间区间 、row 区间 、改变表名称 、改变列族名称 、以及是否 Copy 已被删除的数据等功能;
执行命令前,需先创建与原表结构相同的新表;
CopyTable 的操作是基于 HBase Client API 进行的,即采用 scan 进行查询, 采用 put 进行写入。
2.2 命令格式 1 Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename>
2.3 常用命令
同集群下 CopyTable
1 hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy tableOrig
不同集群下 CopyTable
1 2 3 4 5 6 7 8 # 两表名称相同的情况 hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --peer.adr=dstClusterZK:2181:/hbase tableOrig # 也可以指新的表名 hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --peer.adr=dstClusterZK:2181:/hbase \ --new.name=tableCopy tableOrig
下面是一个官方给的比较完整的例子,指定开始和结束时间,集群地址,以及只复制指定的列族:
1 2 3 4 5 hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --starttime=1265875194289 \ --endtime=1265878794289 \ --peer.adr=server1,server2,server3:2181:/hbase \ --families=myOldCf:myNewCf,cf2,cf3 TestTable
2.4 更多参数 可以通过 --help 查看更多支持的参数
1 # hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
三、Export/Import 3.1 简介
Export 支持导出数据到 HDFS, Import 支持从 HDFS 导入数据。Export 还支持指定导出数据的开始时间和结束时间,因此可以用于增量备份。Export 导出与 CopyTable 一样,依赖 HBase 的 scan 操作
3.2 命令格式 1 2 3 4 5 # Export hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]] # Inport hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
导出的 outputdir 目录可以不用预先创建,程序会自动创建。导出完成后,导出文件的所有权将由执行导出命令的用户所拥有。
默认情况下,仅导出给定 Cell 的最新版本,而不管历史版本。要导出多个版本,需要将 <versions> 参数替换为所需的版本数。
3.3 常用命令
导出命令
1 hbase org.apache.hadoop.hbase.mapreduce.Export tableName hdfs 路径/tableName.db
导入命令
1 hbase org.apache.hadoop.hbase.mapreduce.Import tableName hdfs 路径/tableName.db
四、Snapshot 4.1 简介 HBase 的快照 (Snapshot) 功能允许您获取表的副本 (包括内容和元数据),并且性能开销很小。因为快照存储的仅仅是表的元数据和 HFiles 的信息。快照的 clone 操作会从该快照创建新表,快照的 restore 操作会将表的内容还原到快照节点。clone 和 restore 操作不需要复制任何数据,因为底层 HFiles(包含 HBase 表数据的文件) 不会被修改,修改的只是表的元数据信息。
4.2 配置 HBase 快照功能默认没有开启,如果要开启快照,需要在 hbase-site.xml 文件中添加如下配置项:
1 2 3 4 <property > <name > hbase.snapshot.enabled</name > <value > true</value > </property >
4.3 常用命令 快照的所有命令都需要在 Hbase Shell 交互式命令行中执行。
1. Take a Snapshot 1 2 # 拍摄快照 hbase> snapshot '表名' , '快照名'
默认情况下拍摄快照之前会在内存中执行数据刷新。以保证内存中的数据包含在快照中。但是如果你不希望包含内存中的数据,则可以使用 SKIP_FLUSH 选项禁止刷新。
1 2 # 禁止内存刷新 hbase> snapshot '表名' , '快照名' , {SKIP_FLUSH => true }
2. Listing Snapshots 1 2 # 获取快照列表 hbase> list_snapshots
3. Deleting Snapshots 1 2 # 删除快照 hbase> delete_snapshot '快照名'
4. Clone a table from snapshot 1 2 # 从现有的快照创建一张新表 hbase> clone_snapshot '快照名' , '新表名'
5. Restore a snapshot 将表恢复到快照节点,恢复操作需要先禁用表
1 2 hbase> disable '表名' hbase> restore_snapshot '快照名'
这里需要注意的是:是如果 HBase 配置了基于 Replication 的主从复制,由于 Replication 在日志级别工作,而快照在文件系统级别工作,因此在还原之后,会出现副本与主服务器处于不同的状态的情况。这时候可以先停止同步,所有服务器还原到一致的数据点后再重新建立同步。
Hbase SQL中间层——Phoenix
Phoenix的出现仅仅时为HBase提供了权限的方式, 并不是数据分析的引擎, 所以一般也不会使用Phoenix + HBase构建数仓, 传统的离线数仓 依然是基于Hadoop + HIVE
Phoenix更主要做的是一种即席查询
一、Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
二、Phoenix安装
我们可以按照官方安装说明进行安装,官方说明如下:
download and expand our installation tar
copy the phoenix server jar that is compatible with your HBase installation into the lib directory of every region server
restart the region servers
add the phoenix client jar to the classpath of your HBase client
download and setup SQuirrel as your SQL client so you can issue adhoc SQL against your HBase cluster
2.1 下载并解压 官方针对 Apache 版本和 CDH 版本的 HBase 均提供了安装包,按需下载即可。官方下载地址: http://phoenix.apache.org/download.html
1 2 3 4 5 6 7 8 9 # 下载 wget http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-4.14.0-cdh5.14.2/bin/apache-phoenix-4.14.0-cdh5.14.2-bin.tar.gz # 解压 cd /opt/setup/ tar -zxf phoenix-hbase-2.1-5.1.2-bin.tar.gz -C /usr/local/apps/ 建立软连接: cd /export/server/ ln -s phoenix-hbase-2.1-5.1.2-bin/ phoenix
2.2 拷贝Jar包 按照官方文档的说明,需要将 phoenix server jar 添加到所有 Region Servers 的安装目录的 lib 目录下。
1 2 3 4 5 6 7 cd /usr/local/apps/phoenix-hbase-2.1-5.1.2-bin/ cp -r phoenix-server-hbase-2.1-5.1.2.jar /usr/local/apps/hbase-2.1.0/lib/ 将其拷贝到其他两台 cd /usr/local/apps/hbase-2.1.0/lib/ scp phoenix-server-hbase-2.1-5.1.2.jar node2:$PWD scp phoenix-server-hbase-2.1-5.1.2.jar node3:$PWD
修改hbase的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cd /usr/local/apps/hbase-2.1.0/conf/ vim hbase-site.xml ------ # 1. 将以下配置添加到 hbase-site.xml <!-- 支持HBase命名空间映射 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <!-- 支持索引预写日志编码 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> # 2. 将hbase-site.xml分发到每个节点 scp hbase-site.xml node2:$PWD scp hbase-site.xml node3:$PWD # 3.将配置后的hbase-site.xml拷贝到phoenix的bin目录 cp /usr/local/apps/hbase-2.1.0/conf/hbase-site.xml /usr/local/apps/phoenix-hbase-2.1-5.1.2-bin/bin
2.3 重启 Region Servers 1 2 3 4 # 停止Hbase stop-hbase.sh # 启动Hbase start-hbase.sh
2.4 启动连接Phoenix 在 Phoenix 解压目录下的 bin 目录下执行如下命令,需要指定 Zookeeper 的地址:
如果 HBase 采用 Standalone 模式或者伪集群模式搭建,则默认采用内置的 Zookeeper 服务,端口为 2181;
如果是 HBase 是集群模式并采用外置的 Zookeeper 集群,则按照自己的实际情况进行指定。
1 2 3 4 5 6 7 8 9 # ./sqlline.py hadoop001:2181 cd /usr/local/apps/phoenix-hbase-2.1-5.1.2-bin/bin ./sqlline.py 注意: 说明第一次启动可能会等待的比较长一些 退出客户端: :quit
异常说明:
一般出现此错误, 可能是因为第一次启动出现问题, 后期第二个启动在历史记录有说明, 建议将其直接删除, 下次就没问题了
执行:
2.5 启动结果 启动后则进入了 Phoenix 交互式 SQL 命令行,可以使用 !table 或 !tables 查看当前所有表的信息
三、Phoenix 简单使用 3.1 创建表 1 2 3 4 5 CREATE TABLE IF NOT EXISTS us_population ( state CHAR (2 ) NOT NULL , city VARCHAR NOT NULL , population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
新建的表会按照特定的规则转换为 HBase 上的表,关于表的信息,可以通过 Hbase Web UI 进行查看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 语法 :create table [if not exists] 表名 ( rowkey名称 数据类型 primary key, 列族名.列名1 数据类型 , 列族名.列名2 数据类型 , 列族名.列名2 数据类型 ...... ); 注意 : 表的第一个字段必须是主键字段, 必须添加primary key关键词进行修饰 其他字段必须是列族.列名方式 案例 : 创建一张订单表 create table if not exists order_dtl( id varchar primary key, c1.status varchar, c1.money integer, c2.pay_way integer, c1.user_id integer, c2.operation_time varchar, c2.category varchar ); 默认情况下 : Phoenix会将所有的小写的字段 表名 以及列族都变更为大写 思考 : 如果就想使用小写呢? HBASE 区分大小写的 答 : 只需要在需要小写的字段或者表名或者列族上添加双引号, 基于双引号包裹起来即可 create table if not exists "order_dtl"( id varchar primary key, "c1".status varchar, c1."money" integer, "c2".pay_way integer, c1.user_id integer, c2."operation_time" varchar, c2.category varchar ); 需要注意 : 一旦使用小写, 以后只要使用小写的内容, 必须使用双引号进行包裹, 所以一般建议使用大写, 而不是小写
3.2 插入数据 Phoenix 中插入数据采用的是 UPSERT 而不是 INSERT,因为 Phoenix 并没有更新操作,插入相同主键的数据就视为更新,所以 UPSERT 就相当于 UPDATE+INSERT
1 2 3 4 5 6 7 8 9 10 UPSERT INTO us_population VALUES('NY','New York',8143197); UPSERT INTO us_population VALUES('CA','Los Angeles',3844829); UPSERT INTO us_population VALUES('IL','Chicago',2842518); UPSERT INTO us_population VALUES('TX','Houston',2016582); UPSERT INTO us_population VALUES('PA','Philadelphia',1463281); UPSERT INTO us_population VALUES('AZ','Phoenix',1461575); UPSERT INTO us_population VALUES('TX','San Antonio',1256509); UPSERT INTO us_population VALUES('CA','San Diego',1255540); UPSERT INTO us_population VALUES('TX','Dallas',1213825); UPSERT INTO us_population VALUES('CA','San Jose',912332);
3.3 修改数据 1 2 UPSERT INTO us_population VALUES ('NY' ,'New York' ,999999 );
3.4 删除数据 1 DELETE FROM us_population WHERE city= 'Dallas' ;
3.5 查询数据
仅支持单表的操作, 不支持子查询, 也不支持Join的操作
1 2 3 4 SELECT state as "州",count (city) as "市",sum (population) as "热度"FROM us_populationGROUP BY stateORDER BY sum (population) DESC ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 添加一些数据 :UPSERT INTO "ORDER_DTL" VALUES('000002','已提交',4070,1,4944191,'2020-04-25 12:09:16','手机;'); UPSERT INTO "ORDER_DTL" VALUES('000003','已完成',4350,1,1625615,'2020-04-25 12:09:37','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('000004','已提交',6370,3,3919700,'2020-04-25 12:09:39','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000005','已付款',6370,3,3919700,'2020-04-25 12:09:44','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000006','已提交',9380,1,2993700,'2020-04-25 12:09:41','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000007','已付款',9380,1,2993700,'2020-04-25 12:09:46','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000008','已完成',6400,2,5037058,'2020-04-25 12:10:13','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('000009','已付款',280,1,3018827,'2020-04-25 12:09:53','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('000010','已完成',5600,1,6489579,'2020-04-25 12:08:55','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000011','已付款',5600,1,6489579,'2020-04-25 12:09:00','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000012','已提交',8340,2,2948003,'2020-04-25 12:09:26','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000013','已付款',8340,2,2948003,'2020-04-25 12:09:30','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000014','已提交',7060,2,2092774,'2020-04-25 12:09:38','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('000015','已提交',640,3,7152356,'2020-04-25 12:09:49','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000016','已付款',9410,3,7152356,'2020-04-25 12:10:01','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000017','已提交',9390,3,8237476,'2020-04-25 12:10:08','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('000018','已提交',7490,2,7813118,'2020-04-25 12:09:05','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000019','已付款',7490,2,7813118,'2020-04-25 12:09:06','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000020','已付款',5360,2,5301038,'2020-04-25 12:08:50','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000021','已提交',5360,2,5301038,'2020-04-25 12:08:53','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000022','已取消',5360,2,5301038,'2020-04-25 12:08:58','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000023','已付款',6490,0,3141181,'2020-04-25 12:09:22','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000024','已付款',3820,1,9054826,'2020-04-25 12:10:04','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('000025','已提交',4650,2,5837271,'2020-04-25 12:08:52','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000026','已付款',4650,2,5837271,'2020-04-25 12:08:57','机票;文娱;'); 执行分页操作 : 从第几条开始计算公式 = (当前页 -1) * 每页条数 格式 : limit 每页显示条数 offset 从第几条开始; select * from order_dtl limit 5 offset 0; 第一页 select * from order_dtl limit 5 offset 5; 第二页 select * from order_dtl limit 5 offset 10; 第三页
3.6 退出命令 3.7 扩展 从上面的操作中可以看出,Phoenix 支持大多数标准的 SQL 语法。关于 Phoenix 支持的语法、数据类型、函数、序列等详细信息,因为涉及内容很多,可以参考其官方文档,官方文档上有详细的说明:
四、Phoenix的预分区 基于Phoenix构建表, 默认情况下, 也是只有一个Region, 可以基于Phoenix预分区在建表的时候, 可以直接拥有多个Region
Phoenix如何进行预分区呢? 主要有二种方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 create table [if not exists] 表名 ( rowkey名称 数据类型 primary key, 列族名.列名1 数据类型 , 列族名.列名2 数据类型 , 列族名.列名2 数据类型 ...... ) compression = '压缩方案' split on (自定义分区方案); 例子 :create table if not exists order_dtl_1( id varchar primary key, c1.status varchar, c1.money integer, c2.pay_way integer, c1.user_id varchar, c2.operation_time varchar, c2.category varchar ) compression = 'GZ' split on ('A','C','E','F','H'); 导入一些数据, 观察数据落入到各个Region的情况, 是否均衡, 以及观察数据本身是否有问题 通过手动预分区, 如果不了解未来插入数据rowkey的情况, 可能会导致出现分配不均衡的情况 通过hbase查询写入的数据, 根据rowkey是可以查询的到, 只不过格式会基于Phoenix格式, 无法直接看到具体的内容 未来基于Phoenix完成数据插入后, 后续的读取处理都建议直接基于Phoenix来处理, 不建议直接读取hbase中数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 格式 :create table [if not exists] 表名 ( rowkey名称 数据类型 primary key, 列族名.列名1 数据类型 , 列族名.列名2 数据类型 , 列族名.列名2 数据类型 ...... ) compression ='压缩方案', salt_buckets=N; 演示 create table if not exists order_dtl_2( id varchar primary key, c1.status varchar, c1.money integer, c2.pay_way integer, c1.user_id varchar, c2.operation_time varchar, c2.category varchar ) compression ='GZ', salt_buckets=6; 导入一些数据, 观察数据落入到各个Region的情况, 是否均衡, 以及观察数据本身是否有问题 数据可以到各个Region中, 基本可以保持均衡, 依然可以通过Phoenix检索到数据, 但是通过hbase 无法跟进id查询到结果
注意: 通过Phoenix加盐预分区的方案, 从HBase的原始客户端中查看发现新添加的数据rowkey的前缀进行了加盐的处理, 从而可以保证数据可以均匀的落在不同的region, 但是从Phoenix客户端查看数据, 无法感知到这个加盐操作的, 这样对使用Phoenix的用户来讲就是无感的, 无需关系这个操作
五、Phoenix的视图 Phoenix的视图主要目的: 对HBase的表进行映射
1 主要是用户在HBase上构建的表, 但是在Phoenix中无法查看的, 那么也就无法通过Phoenix来操作, 此时可以通过Phoenix的视图来进行映射, 从而能够让Phoenix去操作不基于Phoenix构建的表
适用场景: 表在HBase中已经提前构建好了, 但是需要通过Phoenix来进行操作, 此时可以基于Phoenix的视图来处理
1 2 3 4 5 6 7 8 9 10 11 12 格式 :create view 视图名称( rowkey 数据类型 primary key, 列族.列名1 数据类型, 列族.列名2 数据类型, ...... ) 注意事项 : 1- 视图的名称必须是与要映射的HBase的表名称保持一致, 如果有名称空间, 写法: 名称空间.表名 (区分大小写) 2- rowkey的字段名称是可以自定义, 但是必须添加primary key 必须放置第一个 3- 列族列名必须与HBase中表列族列名保存一致(区分大小写)
案例需求: 在Phoenix中 映射HBase中WATER_BILL表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1- 构建视图 create view WATER_BILL( id varchar primary key, C1.ADDRESS varchar, C1.LATEST_DATE varchar, C1.NAME varchar, C1.NUM_CURRENT unsigned_double, C1.NUM_PREVIOUS unsigned_double, C1.NUM_USAGE unsigned_double, C1.PAY_DATE varchar, C1.RECORD_DATE varchar, C1.SEX varchar, C1.TOTAL_MONEY unsigned_double );
需求: 查询 2020年 6月份的所有用户的用水量 :
1 2 3 日期字段 : C1: RECORD_DATE (String) 用水量字段 : C1:NUM_USAGE (Double) 用户字段 : C1:NAME(String)
如何使用SQL实现呢?
1 select count(1) as cnt from water_bill where RECORD_DATE >= '2020-06-01' and RECORD_DATE < '2020-07-01';
整个查询的时间: 基本维持在 0.2s左右
六.Phoenix的二级索引 在HBase中, 仅支持rowkey构建索引, 默认rowkey也是有索引的, 对于其他的字段是不支持索引操作, 所以说根据其他的字段查询数据的时候, 基本都是一种全局的scan扫描的方案
但是在Phoenix中, 可以针对HBase表中各个字段来构建索引, 依次来提升查询的性能
19.1 Phoenix的索引分类
1 2 3 4 5 6 7 8 9 10 11 12 13 指的在创建索引的时候, 会单独的形成一张索引表, 索引表与目标表拥有相同的Region数量, 这样在查询数据的时候, 先查询索引表, 然后根据索引表的查询的结果, 再到目标表中检索对应的数据即可 因为多构建了索引表, 当对目标表进行更改数据操作的时候, 索引表也同时需要进行更新操作, 此时读写效率受到一定的影响, 索引表越多, 影响越多 适用于 : 读多 写少 注意事项 : 当我们在查询数据的时候, 如果出现了非索引的字段, 全局索引是不生效的 如何创建全局索引呢? 格式 : create index 索引名字 on 表名(列1,列2,列3...) 如何删除索引 : 格式 : drop index 索引名称 on 表名;
1 2 3 4 5 6 7 8 9 10 11 12 13 指的创建本地索引的时候, 不会单独的构建一张索引表, 索引数据和目标表放置在一块(其底层是基于特殊列族来保存索引数据), 在查询数据的时候, 只需要SQL中存在本地索引的字段, 本地索引就会生效 因为索引数据和原始数据都在同一个表中, 这样在写入数据的时候, 直接对索引数据进行修改操作, 不需要额外进行写入, 对写入效率影响不大 适合于 : 写比较多, 读相关少 注意事项 : 本地索引 和 Hash加盐预分区方案有一定的冲突, 如果使用了Hash加盐预分区方案的表, 可能会导致本地索引无法使用, 或者支持力度不高 如何构建本地索引呢? create local index 索引名称 on 表名(列1,列2,列3...); 删除索引 : drop index 索引名称 on 表名;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 覆盖索引一般无法单独使用,一般都是结合全局索引来使用, 覆盖索引主要将对应索引字段数据放置到全局索引的后面 比如说 : 对A字段构建全局索引, 对B字段构建覆盖索引, 此时B字段的原始数据会直接放置到A字段索引后面 执行SQL : select A,B from 表 where A = xxx; 此条SQL 不需要查询目标表,只需要查询A字段对应全局索引的表, 因为索引中SQL中所需要的字段都存在 适用于 : 如果字段不参与查询, 只是参与展示, 此时可以将这类字段构建为覆盖索引 如何构建覆盖索引呢? create [local] index 索引名称 on 表(列1,列2,列3...) include(列4,列5...) 其中列4和列5 就是构建覆盖索引的操作; 好处 : 提高查询的效率, 只需要查询索引表, 即可将需要的数据全部获取到 弊端 : 冗余会更大, 占用磁盘空间
1 2 3 4 5 6 7 8 9 指的是 : 将执行某个函数的结果构建为索引, 这样当使用这个函数的时候, 直接可以使用这个函数的结果来进行处理 比如说 : substr(字段,1,7); 构建函数索引, 指的将这个函数的执行结果作为索引信息, 当执行SQL的时候, 如果使用到了这个函数(必须一致),那么可以直接使用这个函数的结果来处理 适合于 : 需要频繁使用某个函数的结果 如何构建呢? create [local] index 索引名称 on 表名(列1,列2,函数1(xx),函数2(xx)...)
二级索引的大致意思:堆hbase的一级索引上构建全局索引+覆盖索引,称为二级索引
19.2 演示一: 全局索引+覆盖索引 需求: 查询已付款的订单的ID和支付的金额
1 select id,money,STATUS from ORDER_DTL_2 where STATUS = '已付款';
1 2 设置索引 :create index order_dtl_index on order_dtl_2(STATUS) include(money);
查询 当前这个SQL是否会执行索引呢?
1 explain select id,money,STATUS from ORDER_DTL_2 where STATUS = '已付款';
1 2 3 思考 : 如果 SQL中出现非索引的字段? 默认是不会走索引 explain select id,money,STATUS, PAY_WAY from ORDER_DTL_2 where STATUS = '已付款'; explain select id,money,STATUS from ORDER_DTL_2 where STATUS = '已付款' and PAY_WAY = 1;
1 2 思考 : 如果非要走索引呢? 如何解决呢? 可以强制使用索引 explain select /*+ index(order_dtl_2 order_dtl_index) */ id,money,STATUS, PAY_WAY from ORDER_DTL_2 where STATUS = '已付款';
1 2 删除索引 : drop index order_dtl_index on order_dtl_2;
19.3 演示二: 本地索引 需求: 在查询的时候, 可能会根据订单ID, 订单状态, 支付金额 支付的方式 用户ID 来查询订单数据
1 2 3 尝试给可能参与查询的字段构建索引, 构建本地索引: create local index order_dtl_local_index on order_dtl_2(id,status,money,pay_way,user_id); create local index order_dtl_local2_index on order_dtl_1(id,status,money,pay_way,user_id);
案例一: 所有的字段, 都是有索引的 [走索引的]
1 explain select id,money,STATUS, PAY_WAY from ORDER_DTL_2 where STATUS = '已付款';
案例二: 有部分字段为非索引的字段 [不走索引, 正常是可以走的, 原因由于这个表示HASH加盐的]
1 explain select id,money,STATUS, PAY_WAY,category from ORDER_DTL_2 where STATUS = '已付款';
1 explain select * from ORDER_DTL_2 where STATUS = '已付款'; // 无法走索引的
这种本地索引, 会对数据本身产生影响, 导致无法通过HBase的原生方式查看和处理数据, 必须使用Phoenix
19.4 演示三: WATER_BILL需求 需求: 查询 2020年 6月份的所有用户的用水量 :
1 2 3 日期字段 : C1: RECORD_DATE (String) 用水量字段 : C1:NUM_USAGE (Double) 用户字段 : C1:NAME(String)
如何使用SQL实现呢?
1 select count(1) as cnt from water_bill where RECORD_DATE >= '2020-06-01' and RECORD_DATE < '2020-07-01';
整个查询使用, 基本恒定在 0.2s左右
引入索引优化:
1 create local index water_bill_index on water_bill(RECORD_DATE);
执行查询操作:
1 explain select count(1) as cnt from water_bill where RECORD_DATE >= '2020-06-01' and RECORD_DATE < '2020-07-01';
查询后时间:
从原来的平均 0.2s 提升到 0.032s 搞定, 提升速度为: 8倍左右
1 2 3 在生产环境中, 更多是基于Phoenix构建视图, 映射HBase中原有的表, 然后通过Phoenix提供一些更加方便的快速的查询相关的数据(即席查询), 同时加入索引, 加快查询速度 当然 Phoenix支持 JDBC方式, 所以通过Java代码 采用JDBC方案 也是可以连接到Phoenix的
七、Phoenix Java API 因为 Phoenix 遵循 JDBC 规范,并提供了对应的数据库驱动 PhoenixDriver,这使得采用 Java 语言对其进行操作的时候,就如同对其他关系型数据库一样,下面给出基本的使用示例。
6.1 引入Phoenix core JAR包 如果是 maven 项目,直接在 maven 中央仓库找到对应的版本,导入依赖即可:
1 2 3 4 5 6 <dependency > <groupId > org.apache.phoenix</groupId > <artifactId > phoenix-core</artifactId > <version > 4.14.0-cdh5.14.2</version > </dependency >
如果是普通项目,则可以从 Phoenix 解压目录下找到对应的 JAR 包,然后手动引入:
6.2 简单的Java API实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.ResultSet;public class PhoenixJavaApi { public static void main (String[] args) throws Exception { Class.forName("org.apache.phoenix.jdbc.PhoenixDriver" ); Connection connection = DriverManager.getConnection("jdbc:phoenix:192.168.200.226:2181" ); PreparedStatement statement = connection.prepareStatement("SELECT * FROM us_population" ); ResultSet resultSet = statement.executeQuery(); while (resultSet.next()) { System.out.println(resultSet.getString("city" ) + " " + resultSet.getInt("population" )); } statement.close(); connection.close(); } }
结果如下:
实际的开发中我们通常都是采用第三方框架来操作数据库,如 mybatis,Hibernate,Spring Data 等。
Spring/Spring Boot 整合 Mybatis + Phoenix 一、前言 使用 Spring+Mybatis 操作 Phoenix 和操作其他的关系型数据库(如 Mysql,Oracle)在配置上是基本相同的,下面会分别给出 Spring/Spring Boot 整合步骤,完整代码见本仓库:
二、Spring + Mybatis + Phoenix 2.1 项目结构
2.2 主要依赖 除了 Spring 相关依赖外,还需要导入 phoenix-core 和对应的 Mybatis 依赖包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <dependency > <groupId > org.mybatis</groupId > <artifactId > mybatis-spring</artifactId > <version > 1.3.2</version > </dependency > <dependency > <groupId > org.mybatis</groupId > <artifactId > mybatis</artifactId > <version > 3.4.6</version > </dependency > <dependency > <groupId > org.apache.phoenix</groupId > <artifactId > phoenix-core</artifactId > <version > 4.14.0-cdh5.14.2</version > </dependency >
2.3 数据库配置文件 在数据库配置文件 jdbc.properties 中配置数据库驱动和 zookeeper 地址
1 2 3 4 phoenix.driverClassName =org.apache.phoenix.jdbc.PhoenixDriver phoenix.url =jdbc:phoenix:192.168.0.105:2181
2.4 配置数据源和会话工厂 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?xml version="1.0" encoding="UTF-8" ?> <beans xmlns ="http://www.springframework.org/schema/beans" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xmlns:context ="http://www.springframework.org/schema/context" xmlns:tx ="http://www.springframework.org/schema/tx" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.1.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd" > <context:component-scan base-package ="com.heibaiying.*" /> <context:property-placeholder location ="classpath:jdbc.properties" /> <bean id ="dataSource" class ="org.springframework.jdbc.datasource.DriverManagerDataSource" > <property name ="driverClassName" value ="${phoenix.driverClassName}" /> <property name ="url" value ="${phoenix.url}" /> </bean > <bean id ="sqlSessionFactory" class ="org.mybatis.spring.SqlSessionFactoryBean" > <property name ="dataSource" ref ="dataSource" /> <property name ="mapperLocations" value ="classpath*:/mappers/**/*.xml" /> <property name ="configLocation" value ="classpath:mybatisConfig.xml" /> </bean > <bean class ="org.mybatis.spring.mapper.MapperScannerConfigurer" > <property name ="sqlSessionFactoryBeanName" value ="sqlSessionFactory" /> <property name ="basePackage" value ="com.heibaiying.dao" /> </bean > </beans >
2.5 Mybtais参数配置 新建 mybtais 配置文件,按照需求配置额外参数, 更多 settings 配置项可以参考官方文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd" > <configuration > <settings > <setting name ="mapUnderscoreToCamelCase" value ="true" /> <setting name ="logImpl" value ="STDOUT_LOGGING" /> </settings > </configuration >
2.6 查询接口 1 2 3 4 5 6 7 8 9 10 public interface PopulationDao { List<USPopulation> queryAll () ; void save (USPopulation USPopulation) ; USPopulation queryByStateAndCity (@Param("state") String state, @Param("city") String city) ; void deleteByStateAndCity (@Param("state") String state, @Param("city") String city) ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.heibaiying.dao.PopulationDao" > <select id ="queryAll" resultType ="com.heibaiying.bean.USPopulation" > SELECT * FROM us_population </select > <insert id ="save" > UPSERT INTO us_population VALUES( #{state}, #{city}, #{population} ) </insert > <select id ="queryByStateAndCity" resultType ="com.heibaiying.bean.USPopulation" > SELECT * FROM us_population WHERE state=#{state} AND city = #{city} </select > <delete id ="deleteByStateAndCity" > DELETE FROM us_population WHERE state=#{state} AND city = #{city} </delete > </mapper >
2.7 单元测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @RunWith(SpringRunner.class) @ContextConfiguration({"classpath:springApplication.xml"}) public class PopulationDaoTest { @Autowired private PopulationDao populationDao; @Test public void queryAll () { List<USPopulation> USPopulationList = populationDao.queryAll(); if (USPopulationList != null ) { for (USPopulation USPopulation : USPopulationList) { System.out.println(USPopulation.getCity() + " " + USPopulation.getPopulation()); } } } @Test public void save () { populationDao.save(new USPopulation ("TX" , "Dallas" , 66666 )); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } @Test public void update () { populationDao.save(new USPopulation ("TX" , "Dallas" , 99999 )); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } @Test public void delete () { populationDao.deleteByStateAndCity("TX" , "Dallas" ); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } }
三、SpringBoot + Mybatis + Phoenix 3.1 项目结构
3.2 主要依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 1.3.2</version > </dependency > <dependency > <groupId > org.apache.phoenix</groupId > <artifactId > phoenix-core</artifactId > <version > 4.14.0-cdh5.14.2</version > </dependency > <dependency >
spring boot 与 mybatis 版本的对应关系:
MyBatis-Spring-Boot-Starter 版本
MyBatis-Spring 版本
Spring Boot 版本
1.3.x (1.3.1) 1.3 or higher
1.5 or higher
1.2.x (1.2.1) 1.3 or higher
1.4 or higher
1.1.x (1.1.1) 1.3 or higher
1.3 or higher
1.0.x (1.0.2) 1.2 or higher
1.3 or higher
3.3 配置数据源 在 application.yml 中配置数据源,spring boot 2.x 版本默认采用 Hikari 作为数据库连接池,Hikari 是目前 java 平台性能最好的连接池,性能好于 druid。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 spring: datasource: url: jdbc:phoenix:192.168.0.105:2181 driver-class-name: org.apache.phoenix.jdbc.PhoenixDriver type: com.zaxxer.hikari.HikariDataSource hikari: minimum-idle: 10 maximum-pool-size: 20 auto-commit: true idle-timeout: 30000 pool-name: custom-hikari max-lifetime: 1800000 connection-timeout: 30000 connection-test-query: SELECT 1 mybatis: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
3.4 新建查询接口 上面 Spring+Mybatis 我们使用了 XML 的方式来写 SQL,为了体现 Mybatis 支持多种方式,这里使用注解的方式来写 SQL。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Mapper public interface PopulationDao { @Select("SELECT * from us_population") List<USPopulation> queryAll () ; @Insert("UPSERT INTO us_population VALUES( #{state}, #{city}, #{population} )") void save (USPopulation USPopulation) ; @Select("SELECT * FROM us_population WHERE state=#{state} AND city = #{city}") USPopulation queryByStateAndCity (String state, String city) ; @Delete("DELETE FROM us_population WHERE state=#{state} AND city = #{city}") void deleteByStateAndCity (String state, String city) ; }
3.5 单元测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @RunWith(SpringRunner.class) @SpringBootTest public class PopulationTest { @Autowired private PopulationDao populationDao; @Test public void queryAll () { List<USPopulation> USPopulationList = populationDao.queryAll(); if (USPopulationList != null ) { for (USPopulation USPopulation : USPopulationList) { System.out.println(USPopulation.getCity() + " " + USPopulation.getPopulation()); } } } @Test public void save () { populationDao.save(new USPopulation ("TX" , "Dallas" , 66666 )); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } @Test public void update () { populationDao.save(new USPopulation ("TX" , "Dallas" , 99999 )); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } @Test public void delete () { populationDao.deleteByStateAndCity("TX" , "Dallas" ); USPopulation usPopulation = populationDao.queryByStateAndCity("TX" , "Dallas" ); System.out.println(usPopulation); } }
建表语句 上面单元测试涉及到的测试表的建表语句如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 CREATE TABLE IF NOT EXISTS us_population ( state CHAR (2 ) NOT NULL , city VARCHAR NOT NULL , population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city)); UPSERT INTO us_population VALUES ('NY' ,'New York' ,8143197 ); UPSERT INTO us_population VALUES ('CA' ,'Los Angeles' ,3844829 ); UPSERT INTO us_population VALUES ('IL' ,'Chicago' ,2842518 ); UPSERT INTO us_population VALUES ('TX' ,'Houston' ,2016582 ); UPSERT INTO us_population VALUES ('PA' ,'Philadelphia' ,1463281 ); UPSERT INTO us_population VALUES ('AZ' ,'Phoenix' ,1461575 ); UPSERT INTO us_population VALUES ('TX' ,'San Antonio' ,1256509 ); UPSERT INTO us_population VALUES ('CA' ,'San Diego' ,1255540 ); UPSERT INTO us_population VALUES ('CA' ,'San Jose' ,912332 );

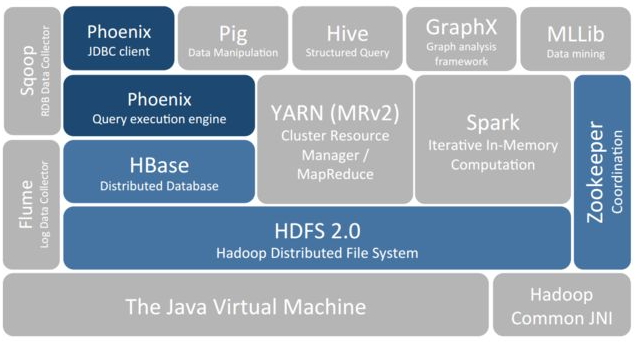
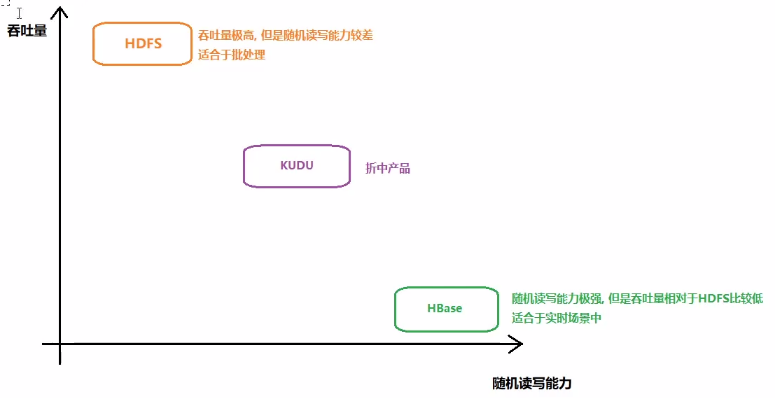
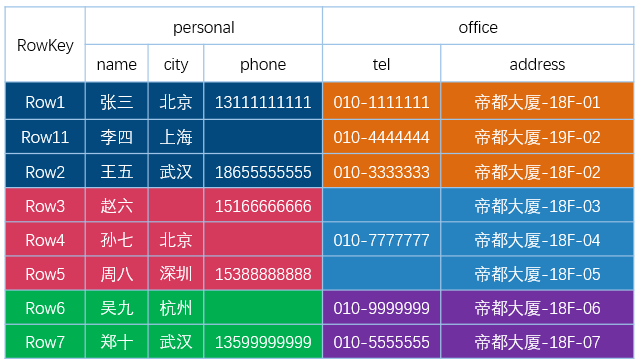
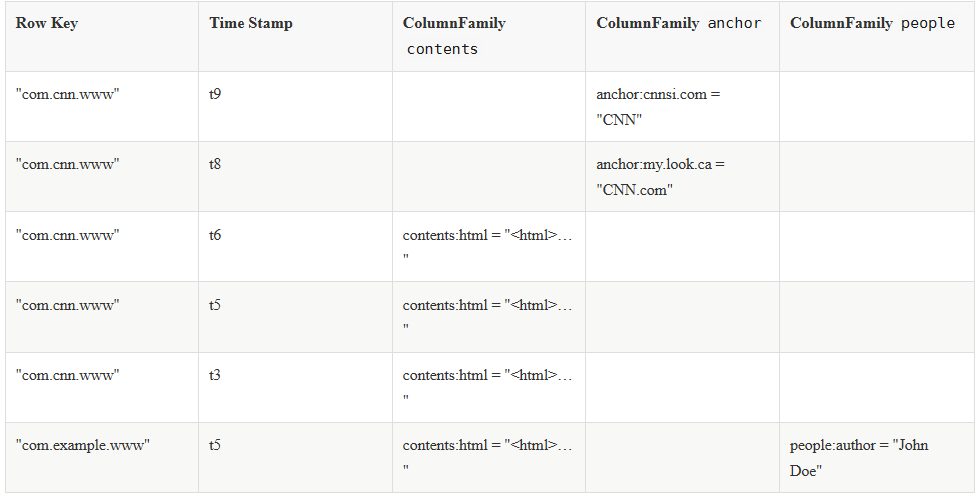
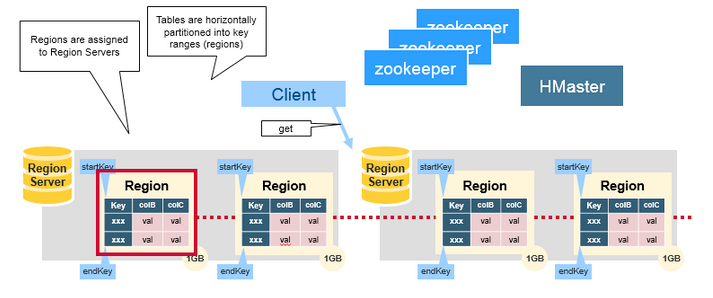
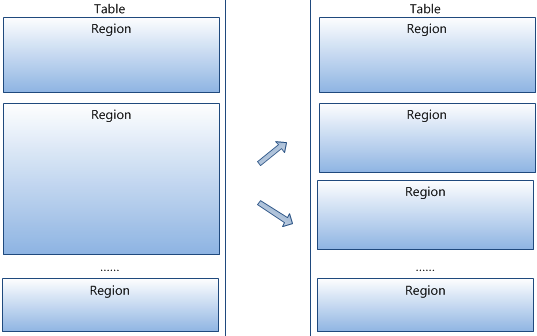
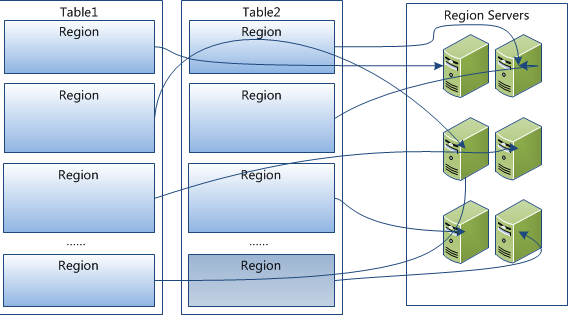
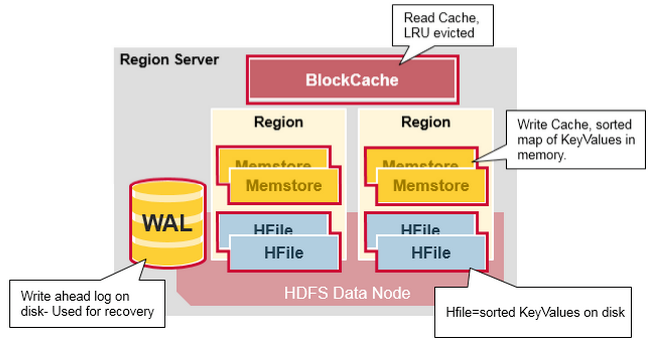
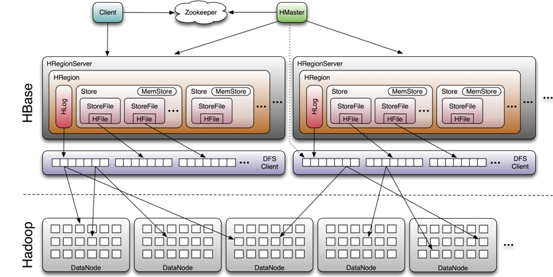
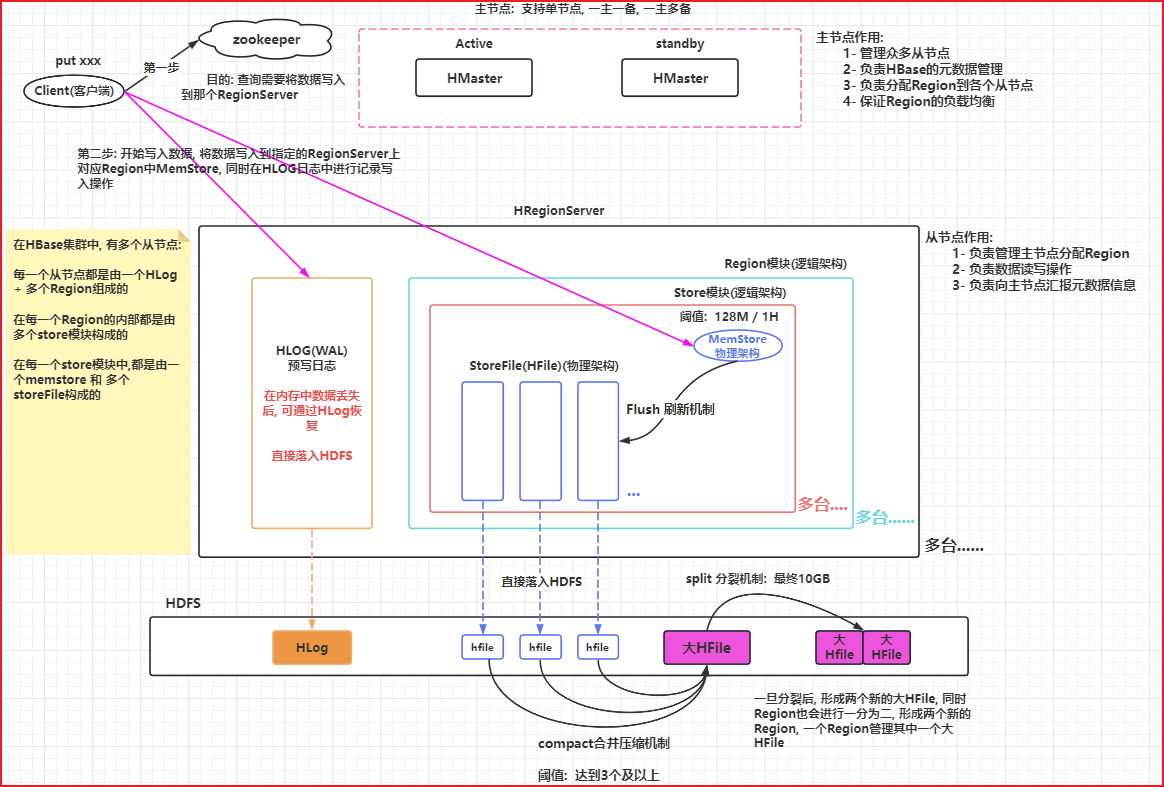
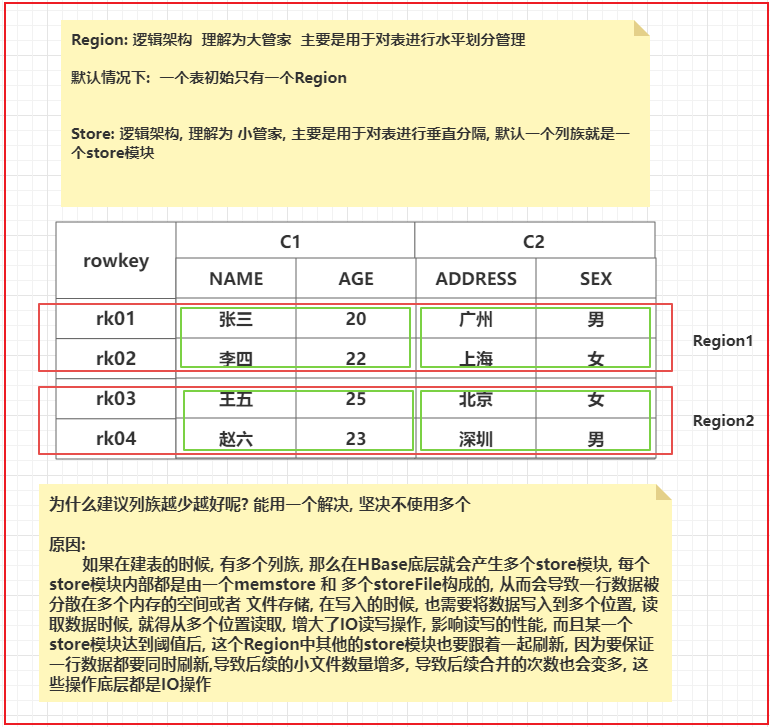
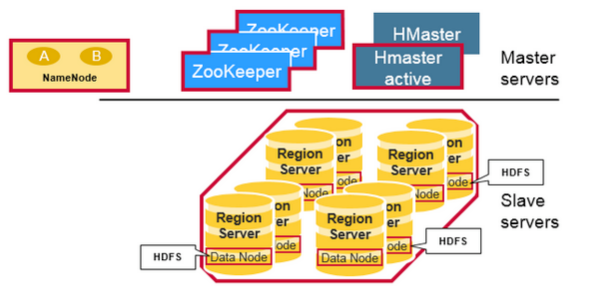
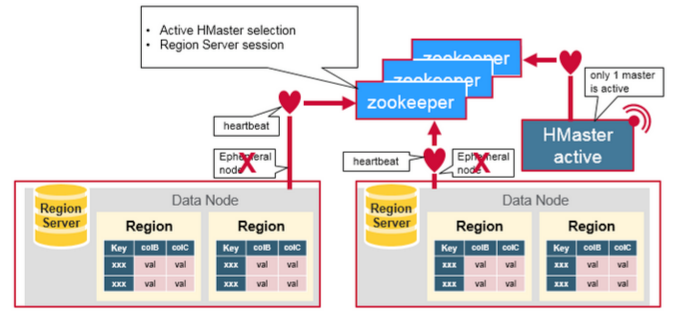
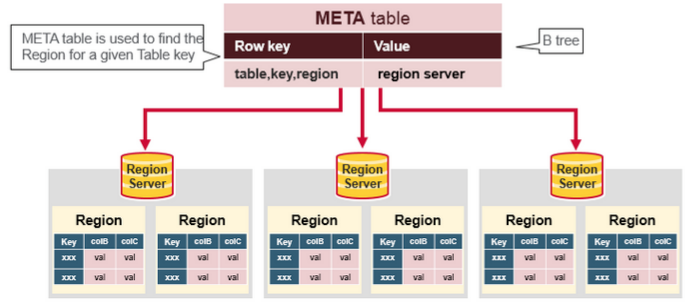



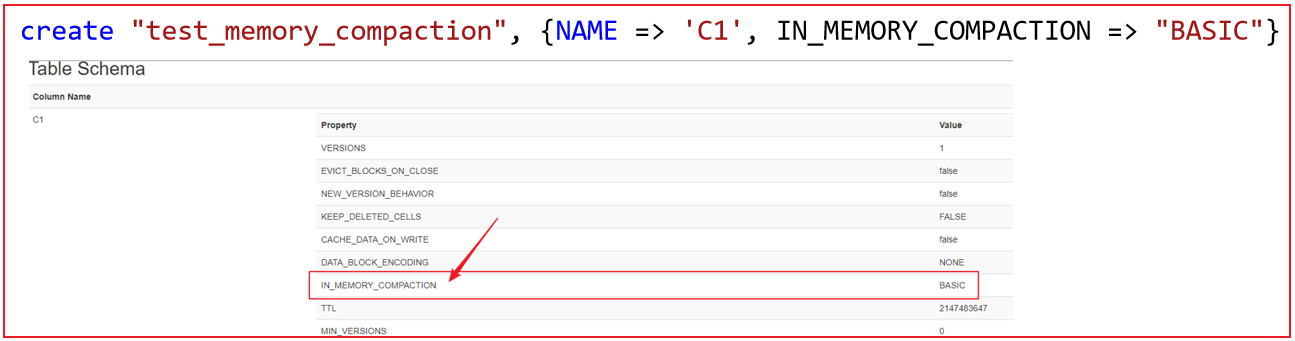
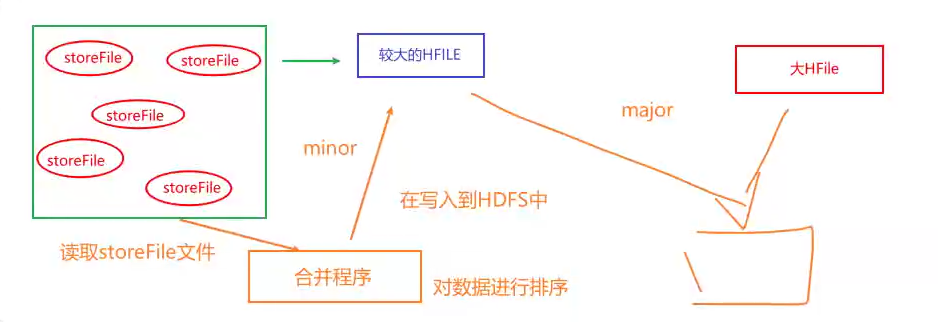


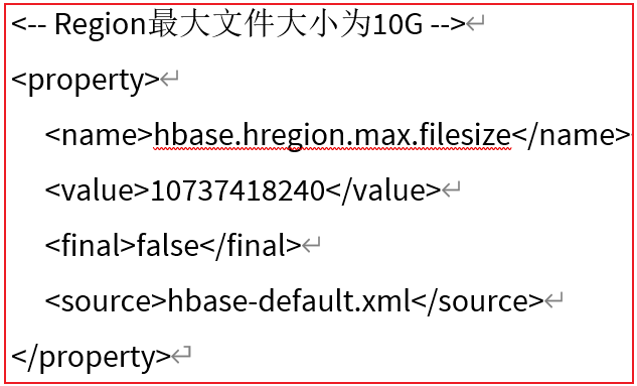
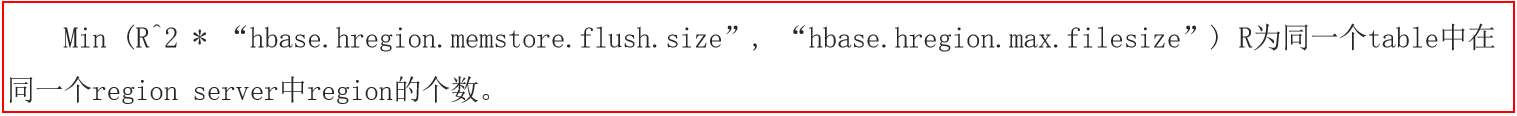
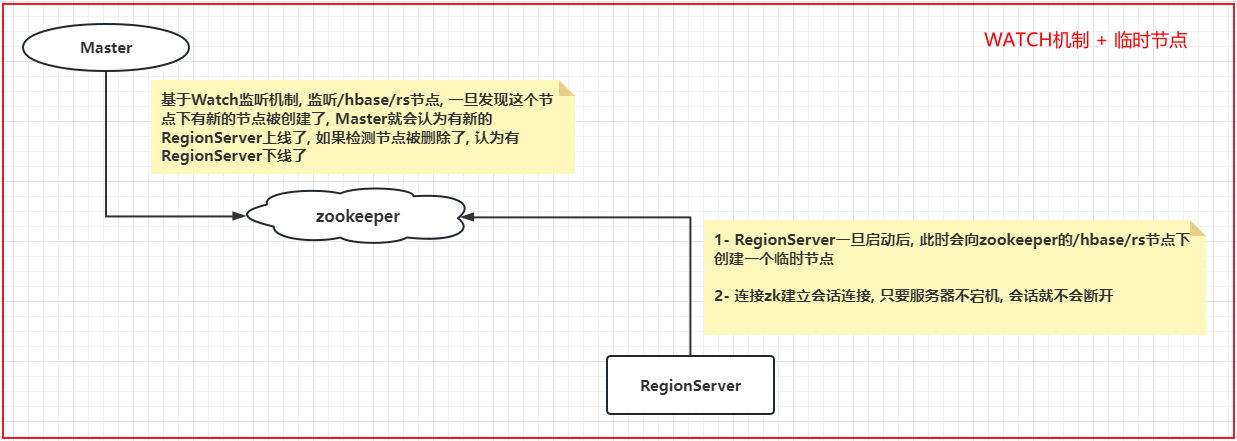
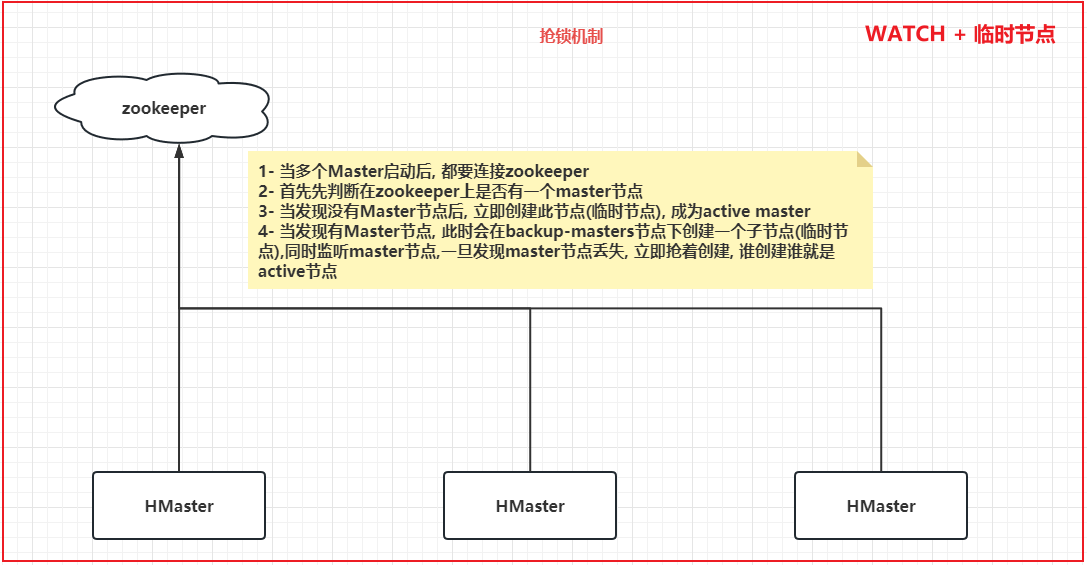

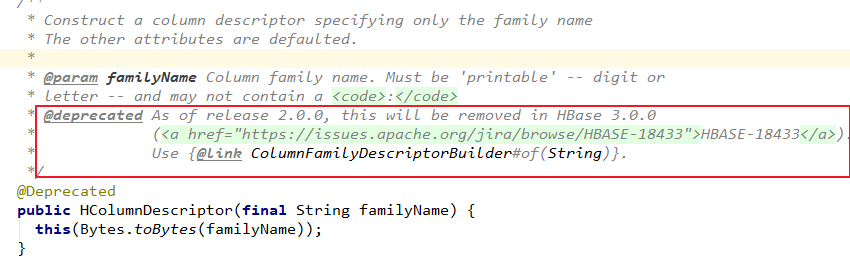
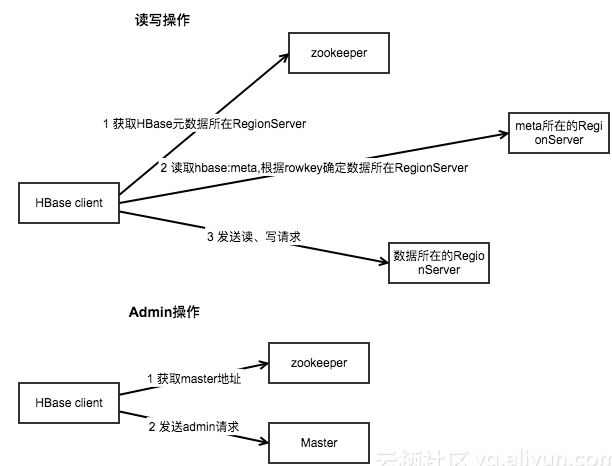
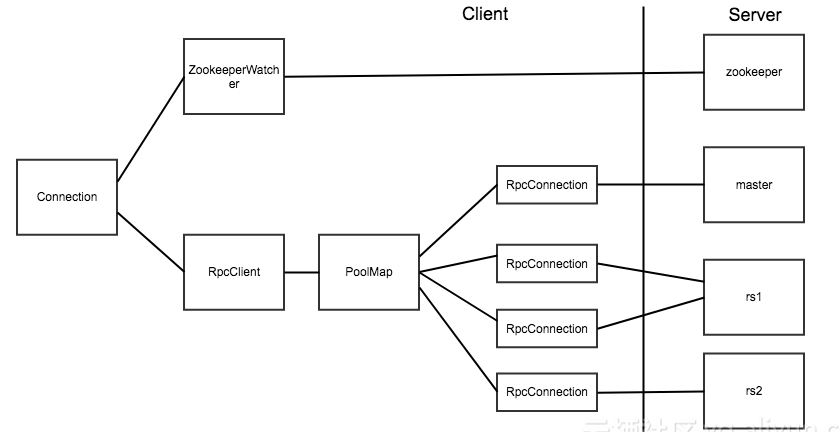
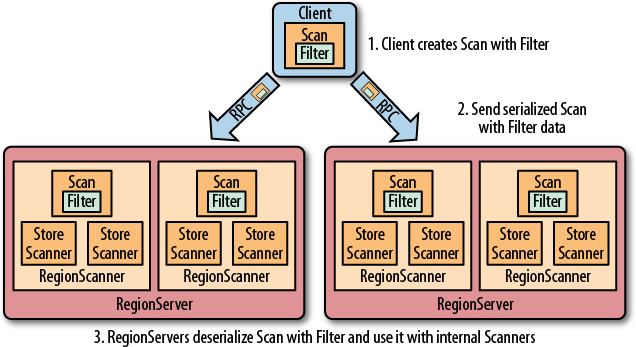
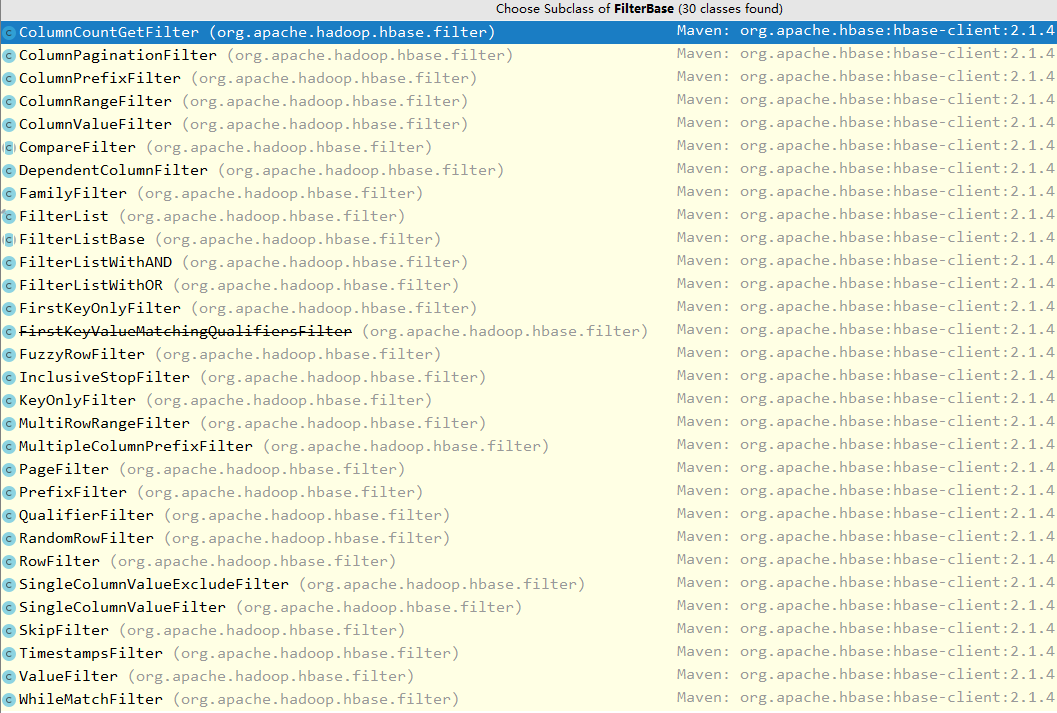

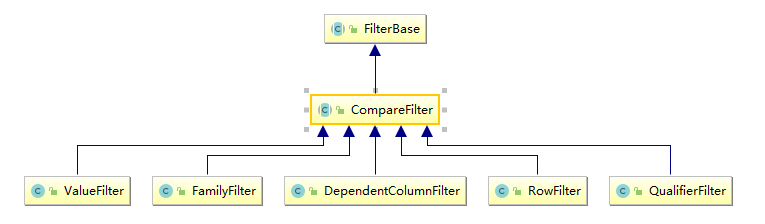
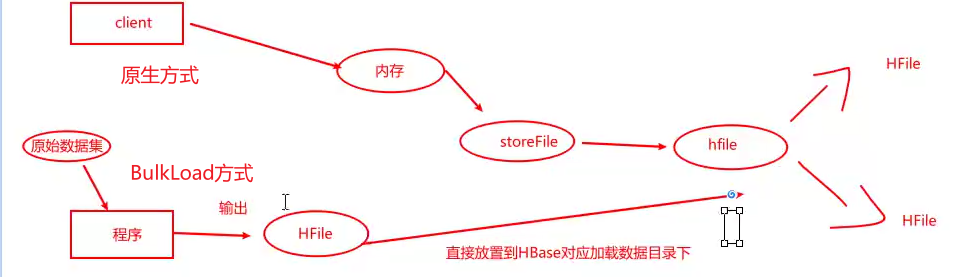

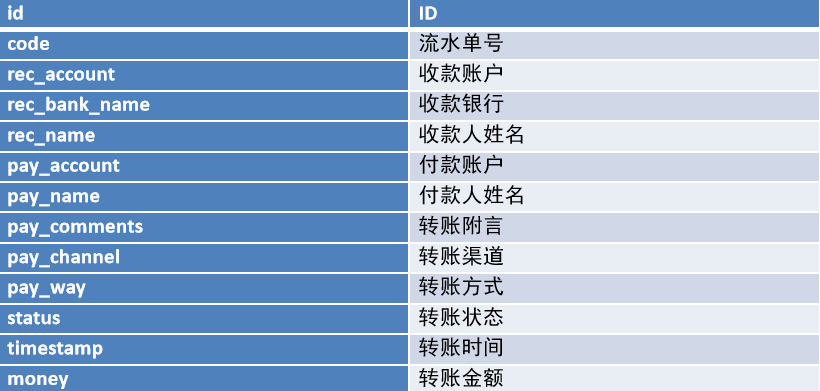

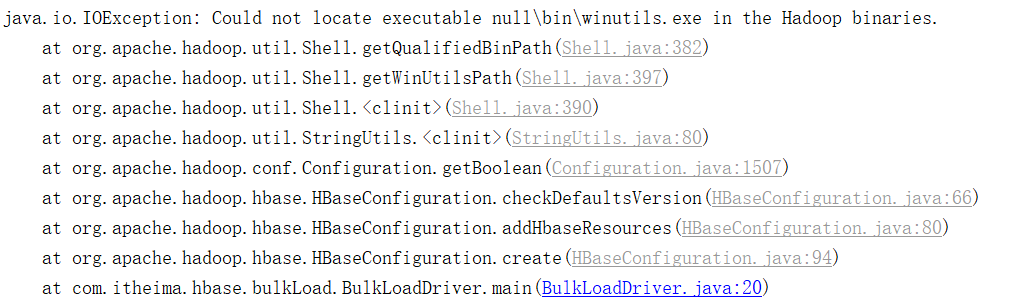

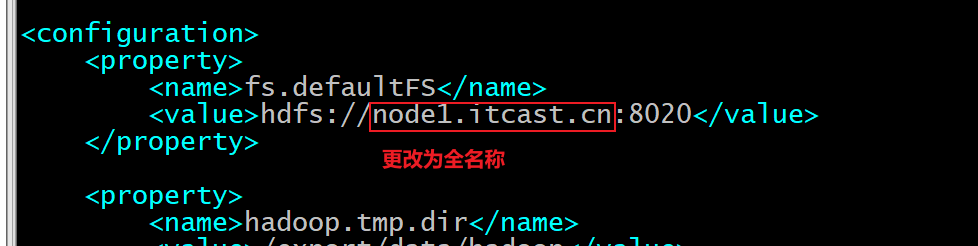
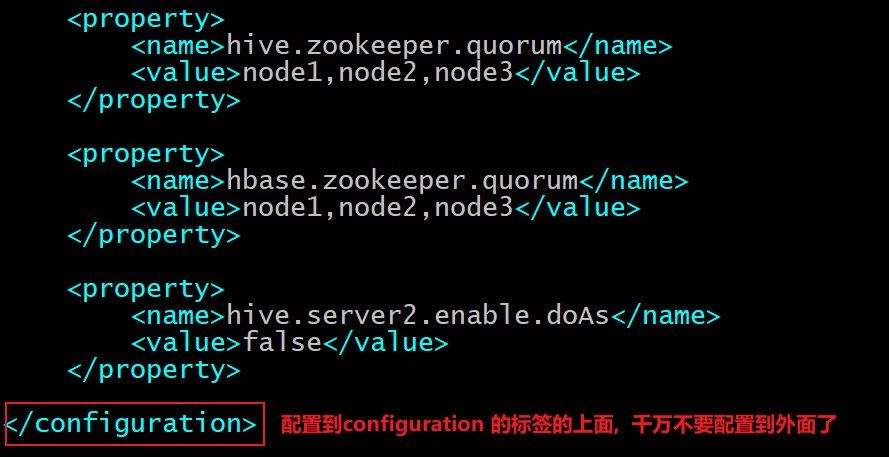
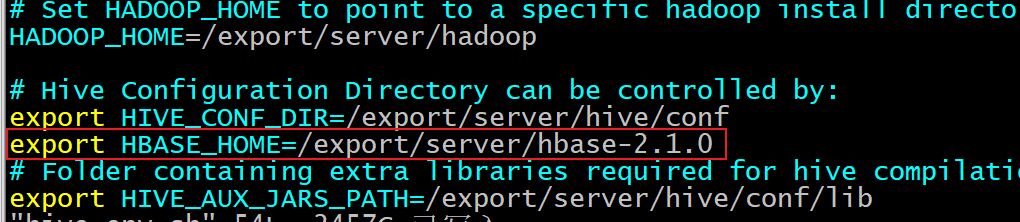
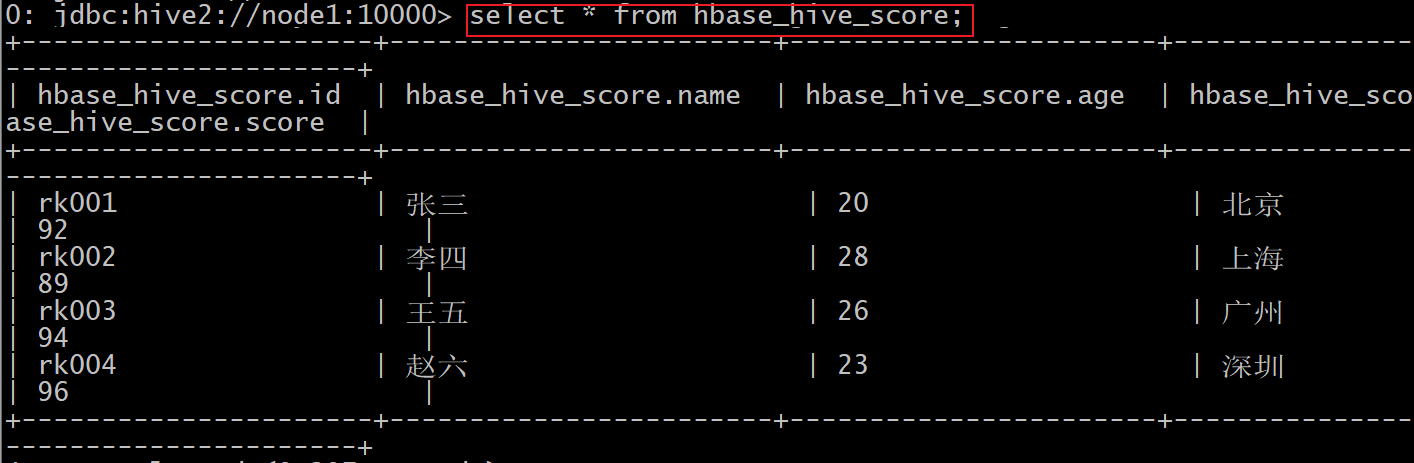


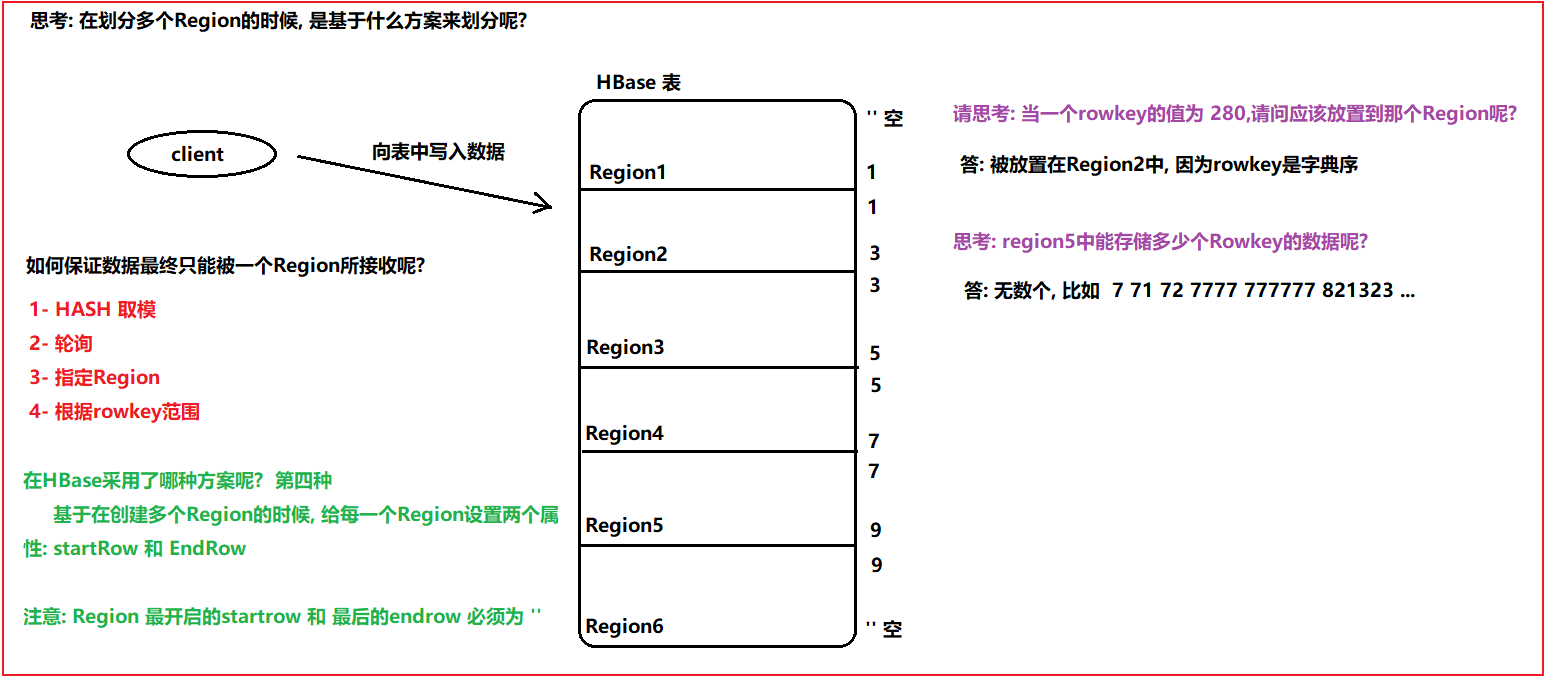
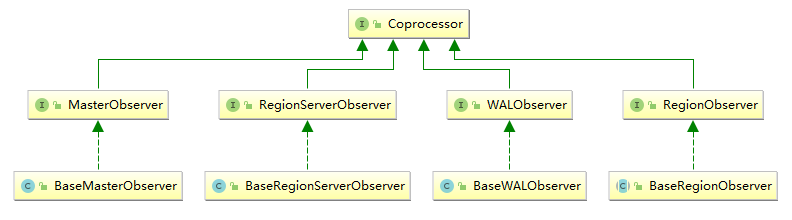
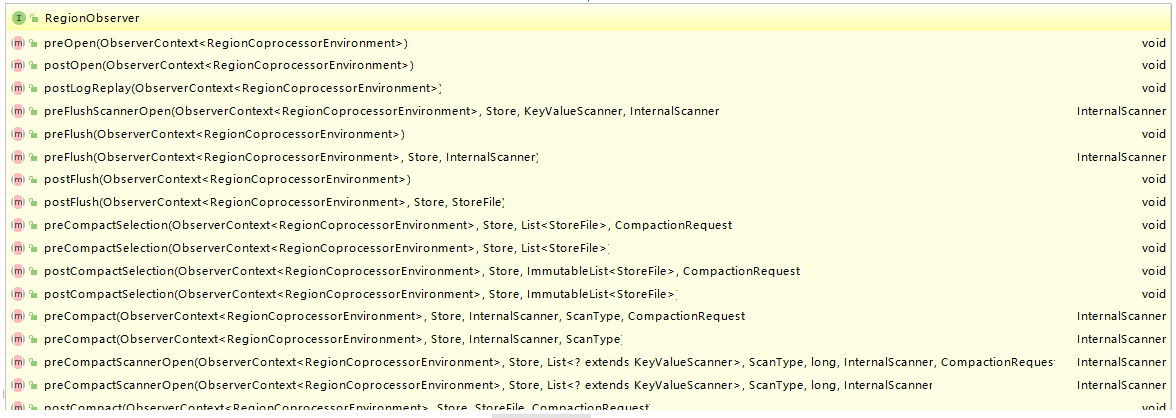
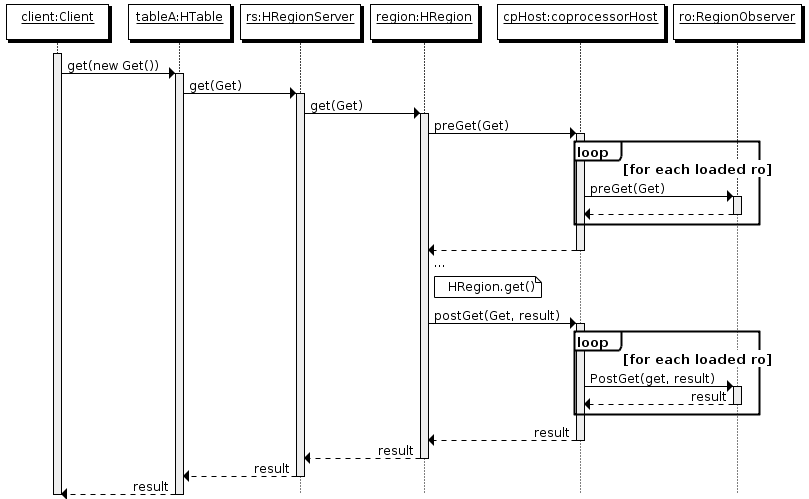
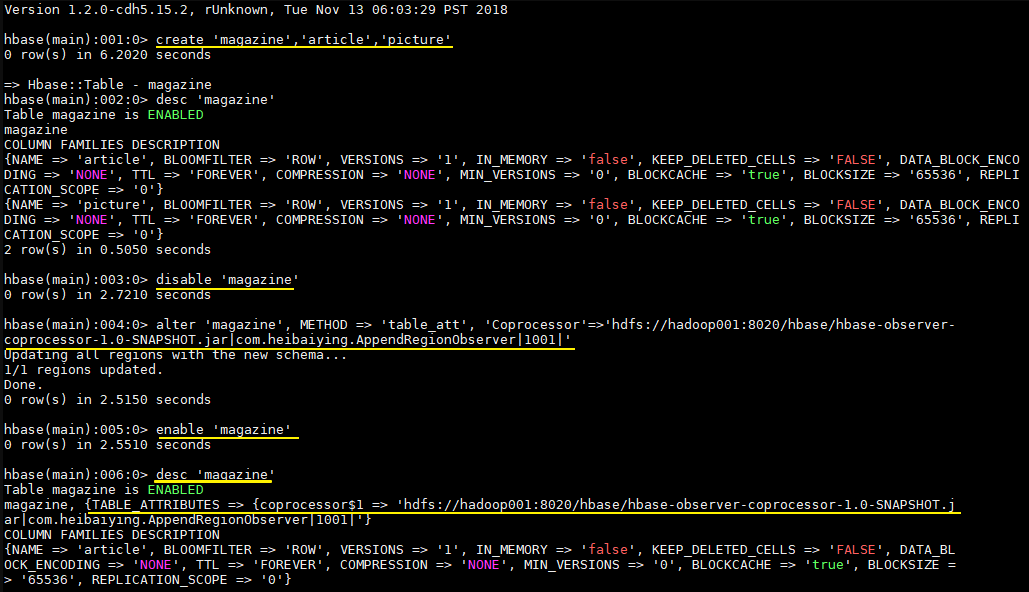
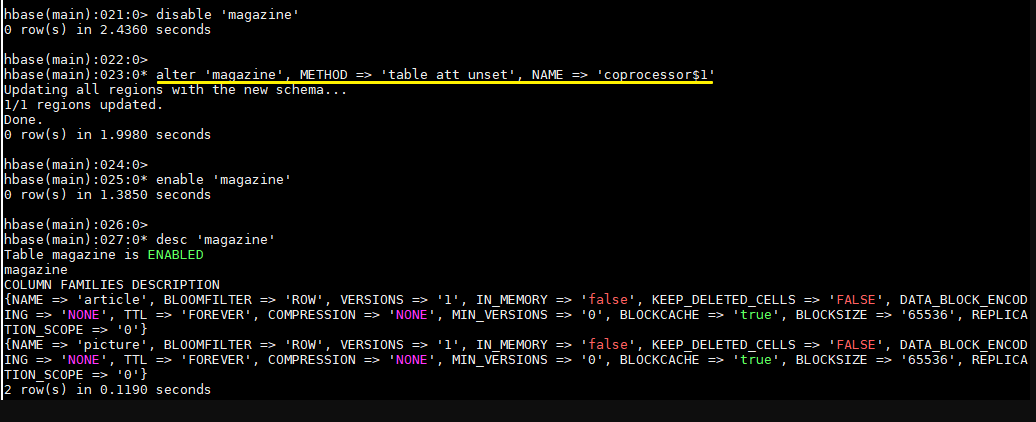
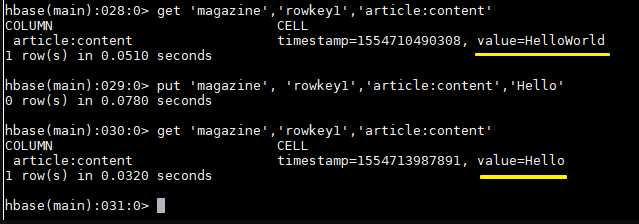
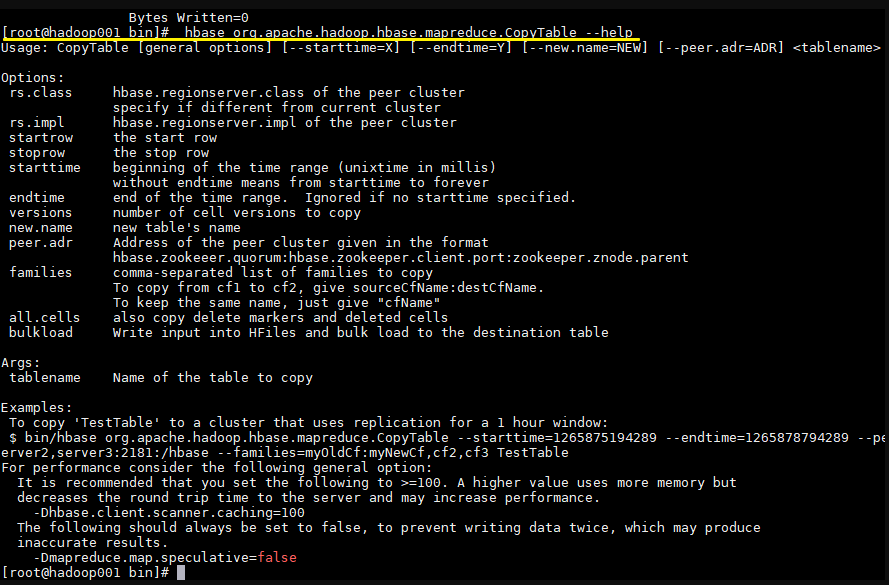
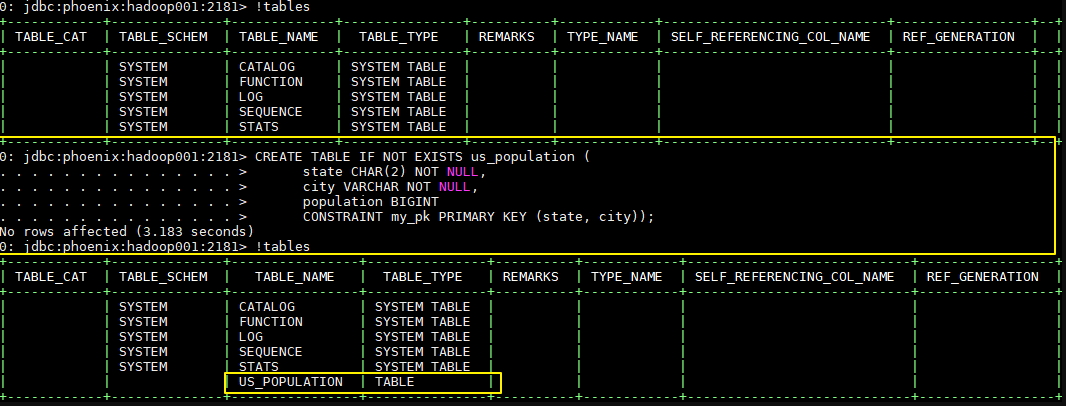

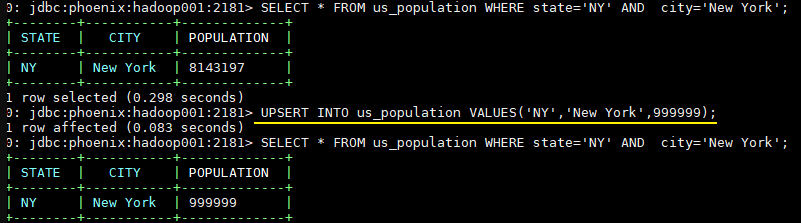
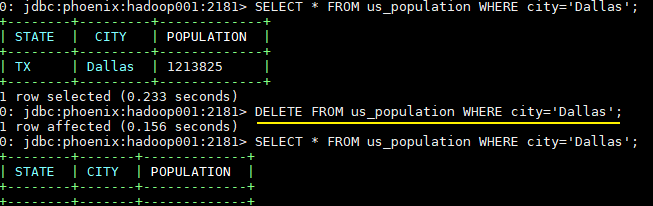
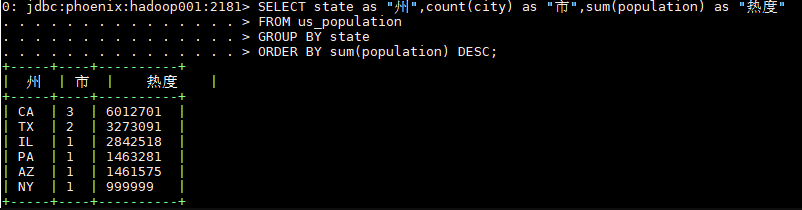
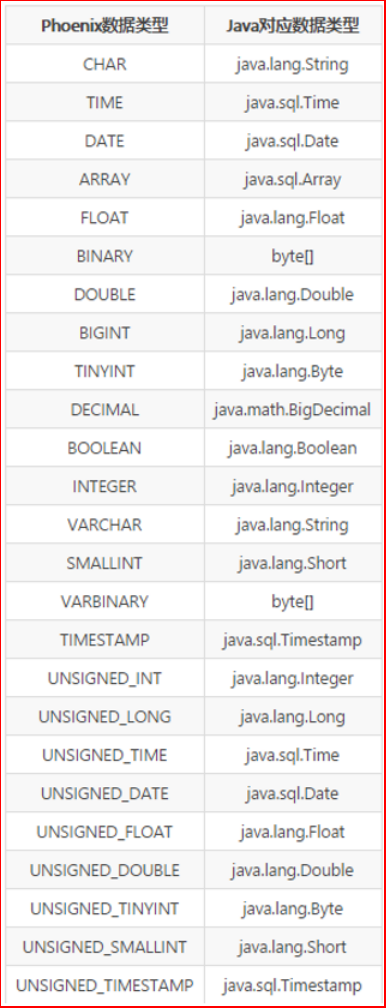
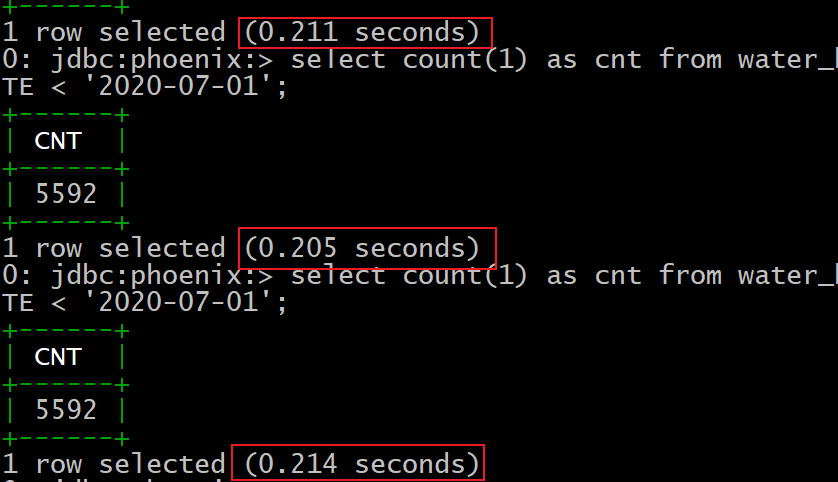



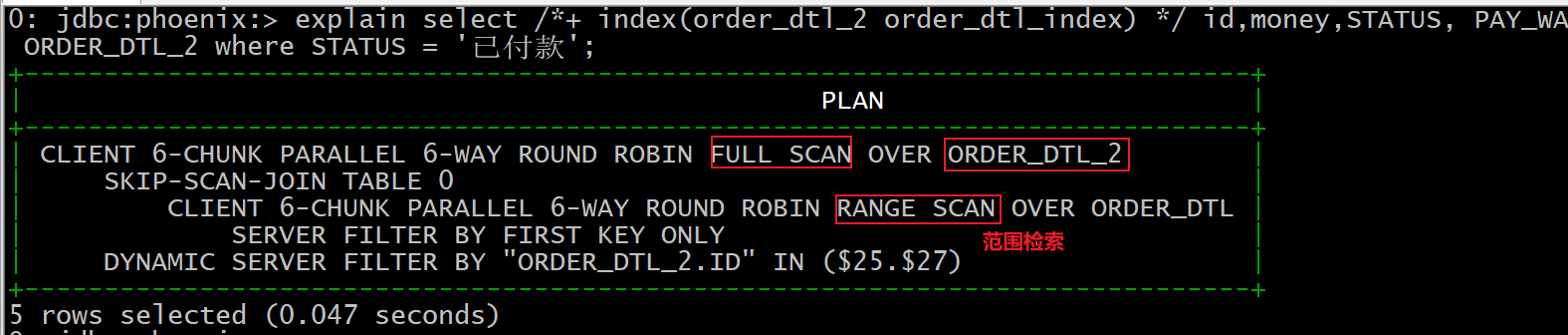



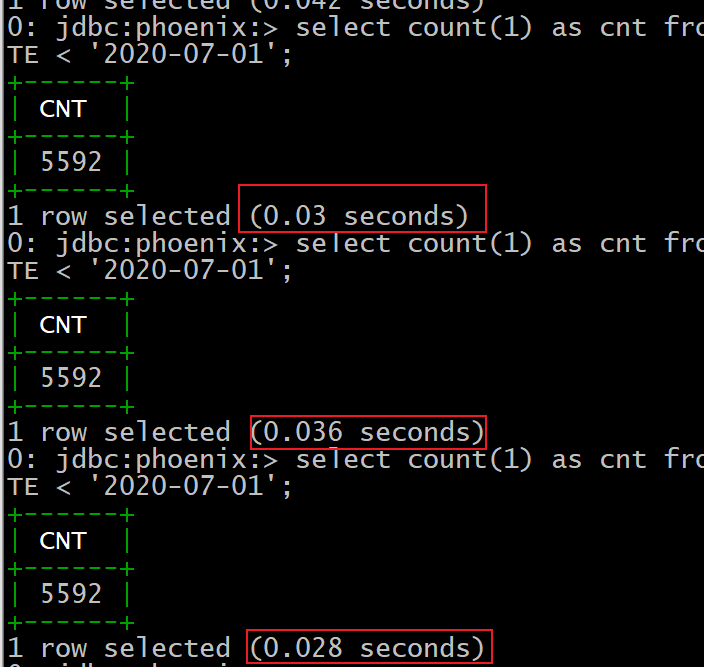
 微信
微信 支付宝
支付宝
