Sqoop-数据迁移
数据怎么从业务关系数据库到大数据层存储,这是个问题。sqoop属于一种好用的解决方案。
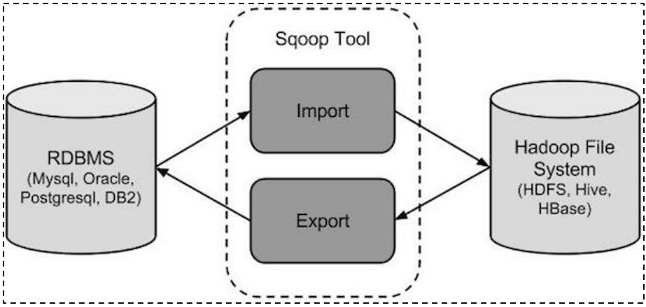
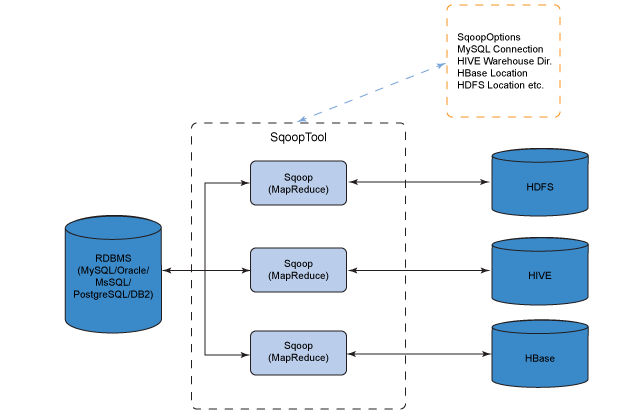
Sqoop 简介 sqoop是隶属于Apache旗下的, 最早是属于cloudera公司的,是一个用户进行数据的导入导出的工具, 主要是将关系型的数据库(MySQL, oracle…)导入到hadoop生态圈(HDFS,HIVE,Hbase…) , 以及将hadoop生态圈数据导出到关系型数据库中
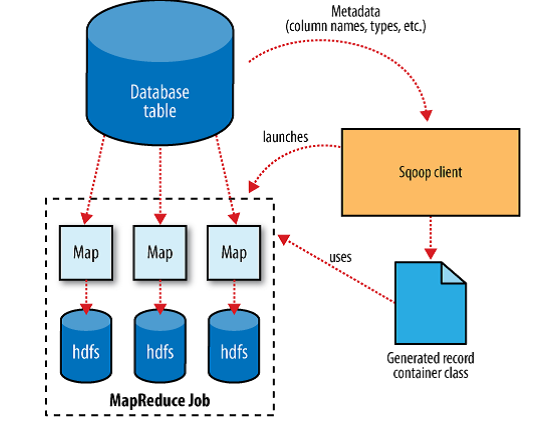
将导入或导出命令翻译成mapreduce程序来实现。
Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出:
其原理是将执行命令转化成 MapReduce 作业来实现数据的迁移,如下图:
Sqoop的重点是写导入导出的命令: 在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
为什么用sqoop 我们常用的ETL工具有Sqoop、Kettle、Nifi。
1 2 3 4 5 特点: 1:图形化操作 2:底层是Java 3: 支持集群 4: 数据量大时,性能一般
1 2 3 特点: 1 :图形化操作 2 :采集数据时会造成大量的IO操作,性能一般
1 2 3 特点: 1 :单进程,多线程 2 :不能支撑海量数据的迁移操作
1 2 3 特点: 1 :主要用于实时操作 2 : 底层是MapReduce
1 2 3 4 特点: 1 :为Hadoop而生 2 :底层是MapReduce 3 :支撑大数据量的数据迁移工作
比如做一个教育数仓项目,ETL的数据量较大,但是数据来源的类型简单(mysql):
Kettle虽然功能较完善,但当处理大数据量的时候瓶颈问题比较突出,不适合此项目;
NiFi的功能强大,且支持大数据量操作,但NiFi集群是独立于Hadoop集群的,需要独立的服务器来支撑,强大也就意味着有上手门槛,学习难度大,用人成本高;
Sqoop专为关系型数据库和Hadoop之间的ETL而生,支持海量数据,符合项目的需求,且操作简单门槛低,因此选择Sqoop作为ETL工具。
增量全量概念
全量数据(Full data)
就是全部数据,所有数据。如对于表来说,就是表中的所有数据。
增量数据(Incremental data)
就是上次操作之后至今产生的新数据。
数据子集
也叫做部分数据。整体当中的一部分。
Sqoop 安装 见Linux-大数据篇
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 你的hive安装在哪一台主机,你的sqoop就要装在哪一台主机,该操作是以node1为例 1 、在node1中,上传sqoop的安装包到/ export/ software目录2 、在node1中,解压sqoop安装包到/ export/ server目录 tar - xvf sqoop-1.4 .7 .bin__hadoop-2.6 .0 .tar.gz - C / export/ server/ 3 、在node1中,对解压后的sqoop目录进行重命名 cd / export/ server/ mv sqoop-1.4 .7 .bin__hadoop-2.6 .0 sqoop-1.4 .7 4 、在node1中,修改sqoop的配置文件, cd / export/ server/ sqoop-1.4 .7 / conf mv sqoop- env- template.sh sqoop- env.sh 修改sqoop- env.sh 文件,设置以下内容 export HADOOP_COMMON_HOME= / export/ server/ hadoop-3.3 .0 export HADOOP_MAPRED_HOME= / export/ server/ hadoop-3.3 .0 export HIVE_HOME= / export/ server/ hive-3.1 .2 5 、在node1中,加入mysql的jdbc驱动包和hive的执行包 cp / export/ server/ hive-3.1 .2 / lib/ mysql- connector- java-5.1 .32 - bin.jar / export/ server/ sqoop-1.4 .7 / lib/ cp / export/ servers/ hive-3.1 .2 / lib/ hive- exec -3.1 .2 .jar / export/ servers/ sqoop-1.4 .7 / lib/ cp / export/ server/ hive-3.1 .2 / hcatalog/ share/ hcatalog/ hive- hcatalog- core-3.1 .2 .jar / export/ server/ sqoop-1.4 .7 / lib/ 6 、在node1,node2、node3中,配置环境变量 vim / etc/ profile 添加以下内容 export SQOOP_HOME= / export/ server/ sqoop-1.4 .7 export PATH= :$SQOOP_HOME/ bin:$PATH # HCatelog export HCAT_HOME= / export/ server/ hive-3.1 .2 / hcatalog export hive_dependency= $HIVE_HOME/ conf:$HIVE_HOME/ lib
sqoop测试:
1 2 3 4 5 #测试你的sqoop是否能查看MySQL中所有的数据库 sqoop list- databases \
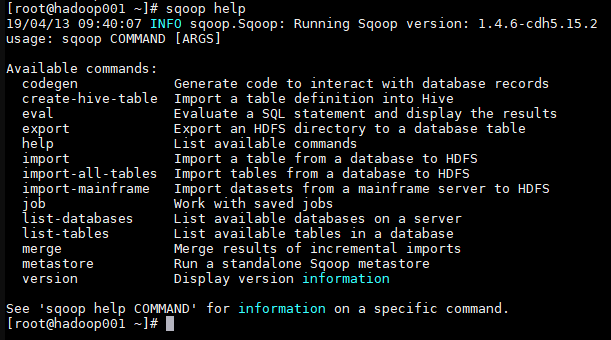
一、Sqoop 基本命令 1. 查看所有命令
2. 查看某条命令的具体使用方法 sqoop相关常用参数
参数
说明
--connect连接关系型数据库的URL
--username连接数据库的用户名
--password连接数据库的密码
--driverJDBC的driver class
--query或--e <statement>将查询结果的数据导入,使用时必须伴随参–target-dir,–hcatalog-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字。 如果使用双引号包含sql,则$CONDITIONS前要加上\以完成转义:$CONDITIONS
--hcatalog-database指定HCatalog表的数据库名称。如果未指定,default则使用默认数据库名称。提供 –hcatalog-database不带选项–hcatalog-table是错误的。
--hcatalog-table此选项的参数值为HCatalog表名。该–hcatalog-table选项的存在表示导入或导出作业是使用HCatalog表完成的,并且是HCatalog作业的必需选项。
--create-hcatalog-table此选项指定在导入数据时是否应自动创建HCatalog表。表名将与转换为小写的数据库表名相同。
--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \建表时追加存储格式到建表语句中,tblproperties修改表的属性,这里设置orc的压缩格式为SNAPPY
-m指定并行处理的MapReduce任务数量。 -m不为1时,需要用split-by指定分片字段进行并行导入,尽量指定int型。
--split-by id如果指定-split by, 必须使用$CONDITIONS关键字, 双引号的查询语句还要加\
--hcatalog-partition-keys --hcatalog-partition-valueskeys和values必须同时存在,相当于指定静态分区。允许将多个键和值提供为静态分区键。多个选项值之间用,(逗号)分隔。比如: –hcatalog-partition-keys year,month,day –hcatalog-partition-values 1999,12,31
--null-string '\N' --null-non-string '\N'指定mysql数据为空值时用什么符号存储,null-string针对string类型的NULL值处理,–null-non-string针对非string类型的NULL值处理
--hive-drop-import-delims设置无视字符串中的分割符(hcatalog默认开启)
--fields-terminated-by '\t'设置字段分隔符
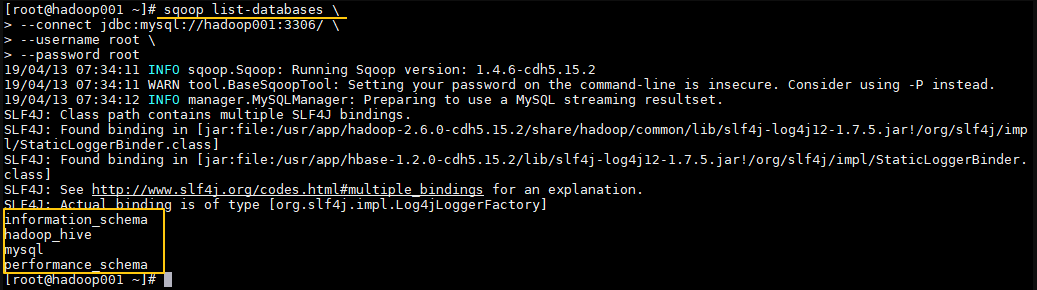
二、Sqoop 与 MySQL 1. 查询MySQL所有数据库 通常用于 Sqoop 与 MySQL 连通测试:
1 2 3 4 sqoop list-databases \ --connect jdbc:mysql://hadoop001:3306/ \ --username root \ --password root
\表示换行写,你也可以写一行命令
2. 查询指定数据库中所有数据表 1 2 3 4 sqoop list-tables \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root
3. 报错SSLHandshakeException 设置useSSL为false
1 2 3 4 5 # 如果报错:Caused by: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate) sqoop list-databases \ --connect jdbc:mysql://192.168.199.199:3306/?useSSL=false \ --username root \ --password root
三、Sqoop 与 HDFS 3.1 MySQL数据导入到HDFS
1. 导入命令 示例:导出 MySQL 数据库中的 help_keyword 表到 HDFS 的 /sqoop 目录下,如果导入目录存在则先删除再导入,使用 3 个 map tasks 并行导入。
注:help_keyword 是 MySQL 内置的一张字典表,之后的示例均使用这张表。
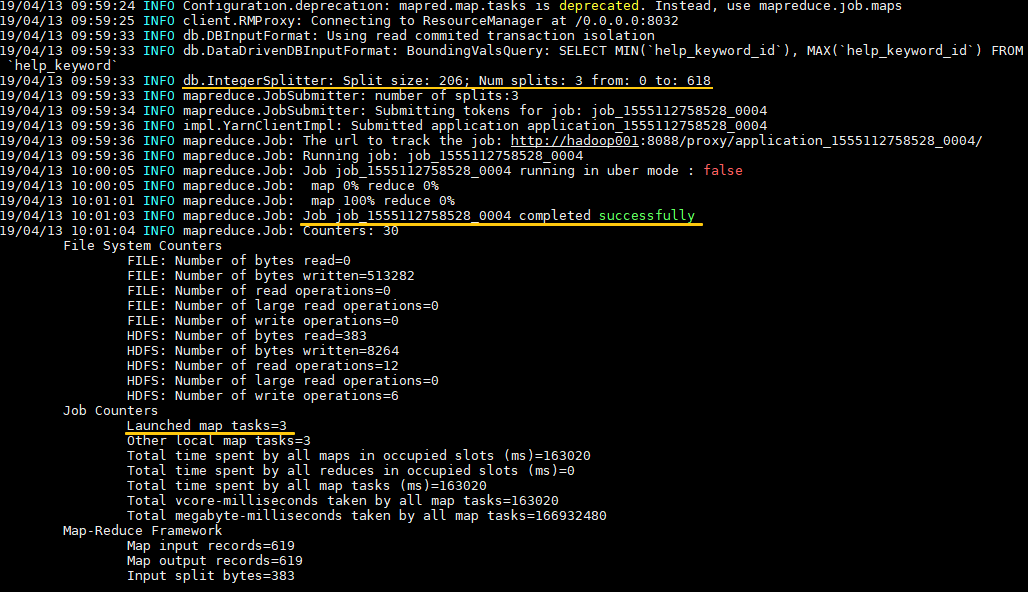
1 2 3 4 5 6 7 8 9 sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword \ # 待导入的表 --delete-target-dir \ # 目标目录存在则先删除 --target-dir /sqoop \ # 导入的目标目录 --fields-terminated-by '\t' \ # 指定导出数据的分隔符,默认分隔符是逗号 -m 3 # 指定并行执行的 map tasks 数量
日志输出如下:
可以看到输入数据被平均 split 为三份,分别由三个 map task 进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
添加 --autoreset-to-one-mapper 参数,代表只启动一个 map task,即不并行执行;
若仍希望并行执行,则可以使用 --split-by <column-name> 指明拆分数据的参考列。
如果拆分的是数字字符串类型,需要添加-Drog.apache.sqoop.splitter.allow_text_splitter=true
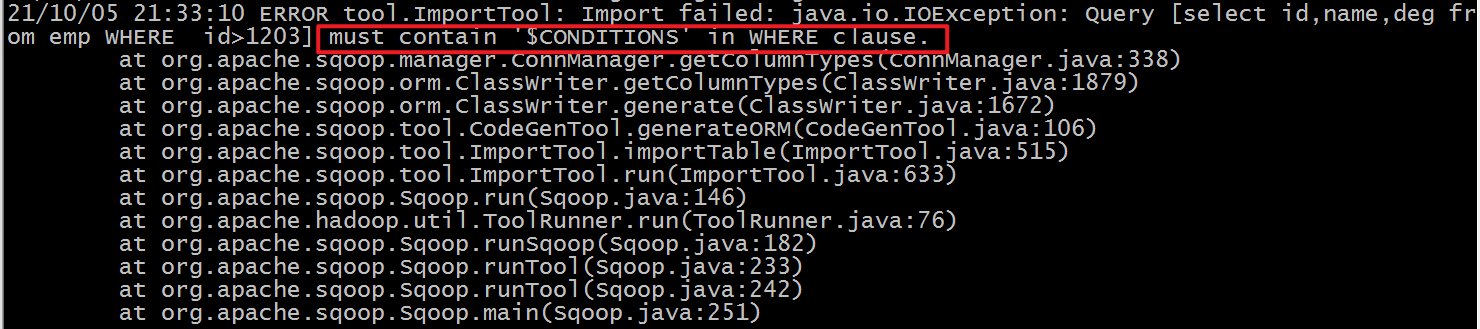
如果希望增量导出,则添加参数:--query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \
1 2 3 4 5 6 7 8 9 10 11 sqoop import \ - Dorg.apache.sqoop.splitter.allow_text_splitter= true \
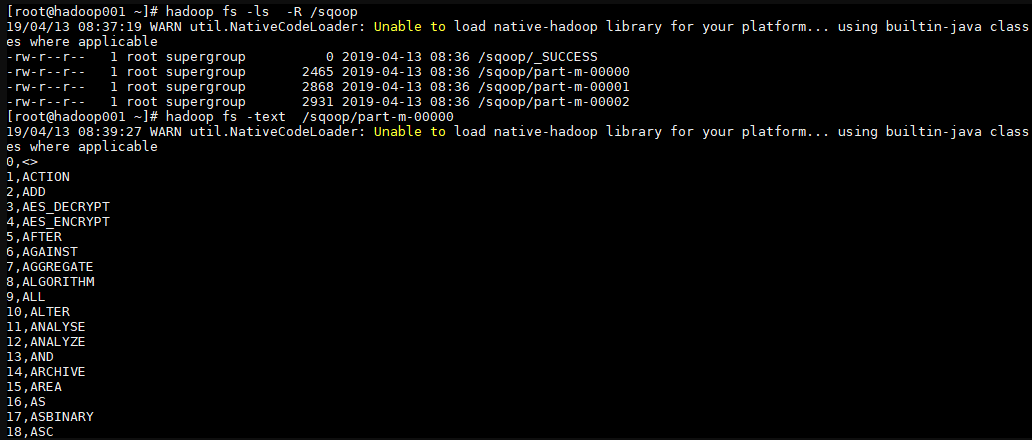
2. 导入验证 1 2 3 4 # 查看导入后的目录 hadoop fs -ls -R /sqoop # 查看导入内容 hadoop fs -text /sqoop/part-m-00000
查看 HDFS 导入目录,可以看到表中数据被分为 3 部分进行存储,这是由指定的并行度决定的。
3.2 HDFS数据导出到MySQL sqoop导出操作最大的特点是,==目标表需要自己手动提前创建==。
1、在大数据中,数据的导出一般发生在大数据分析的最后一个阶段
1 2 3 4 5 6 7 8 9 10 11 12 sqoop export \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword_from_hdfs \ # 导出数据存储在 MySQL 的 help_keyword_from_hdf 的表中 --export-dir /sqoop \ --input-fields-terminated-by '\t'\ --m 3 # 解释:将HDFS /sqoop 目录下的文件内容,导出到mysql中 mysql 数据库下的 help_keyword_from_hdfs 表 如果乱码: --connect "jdbc:mysql://hadoop001:3306/userdb? useUnicode=true&characterEncoding=utf-8" \
表必须预先创建,建表语句如下:
1 CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;
全量数据导出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #step1:MySQL中建表 mysql> use userdb; mysql> create table employee ( id int not null primary key, name varchar (20 ), deg varchar (20 ), salary int , dept varchar (10 )); #step2:从HDFS导出数据到MySQL sqoop export \ #解释:将HDFS/ sqoop/ result1/ 目录下的文件内容,导出到mysql中userdb数据库下的employee表 #step3:从Hive导出数据到MySQL #首先清空MySQL表数据 truncate table employee;sqoop export \ - m 1 #解释: 将Hive中test数据库下的emp_hive表导出到MySQL的userdb数据库中employee表 # #注意,如果Hive中的表底层是使用ORC格式存储的,那么必须使用hcatalog API进行操作。
增量数据导出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #在HDFS文件系统中/ sqoop/ updateonly/ 目录的下创建一个文件updateonly_1.txt hadoop fs - mkdir - p / sqoop/ updateonly/ hadoop fs - put updateonly_1.txt / sqoop/ updateonly/ 1201 ,gopal,manager,50000 1202 ,manisha,preader,50000 1203 ,kalil,php dev,30000 #手动创建mysql中的目标表 mysql> USE userdb; mysql> CREATE TABLE updateonly ( id INT NOT NULL PRIMARY KEY, name VARCHAR (20 ), deg VARCHAR (20 ), salary INT ); #先执行全部导出操作: sqoop export \ #新增一个文件updateonly_2.txt:修改了前三条数据并且新增了一条记录 1201 ,gopal,manager,1212 1202 ,manisha,preader,1313 1203 ,kalil,php dev,1414 1204 ,allen,java,1515 hadoop fs - put updateonly_2.txt / sqoop/ updateonly/ #执行更新导出: sqoop export \ #解释:
allowerinsert:既导出更新的数据,也导出新增的数据
hive -> mysql ,mysql要先创建表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #手动创建mysql中的目标表 mysql> USE userdb; mysql> CREATE TABLE allowinsert ( id INT NOT NULL PRIMARY KEY, name VARCHAR (20 ), deg VARCHAR (20 ), salary INT ); #先执行全部导出操作 sqoop export \ #执行更新导出 sqoop export \
四、Sqoop 与 Hive 通过sqoop将数据导入到HIVE主要有二种方式: 原生API 和 hcatalog API
数据格式支持:
原生API 仅支持 textFile格式
hcatalog API 支持多种hive的存储格式(textFile、ORC 、sequenceFile parquet…)
数据覆盖:
原生API 支持数据覆盖操作
hcatalog API 不支持数据覆盖,每一次都是追加操作
字段名:
原生API: 字段名比较随意, 更多关注字段的顺序, 会将关系型数据库的第一个字段给hive表的第一个字段…
hcatalog API: 按照字段名进行导入操作, 不关心顺序
建议: 在导入的时候, 不管是顺序还是名字都保持一致
目前主要采用 hcatalog的方式
4.1 MySQL数据导入到Hive Sqoop 导入数据到 Hive 是通过先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 Load 到 Hive 中,最后将临时目录删除。可以使用 target-dir 来指定临时目录。
1. 导入命令 1 2 3 4 5 6 7 8 9 10 11 sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword \ # 待导入的表 --delete-target-dir \ # 如果临时目录存在删除 --target-dir /sqoop_hive \ # 临时目录位置 --hive-database sqoop_test \ # 导入到 Hive 的 sqoop_test 数据库,数据库需要预先创建。不指定则默认为 default 库 --hive-import \ # 导入到 Hive --hive-overwrite \ # 如果 Hive 表中有数据则覆盖,这会清除表中原有的数据,然后再写入 -m 3 # 并行度
导入到 Hive 中的 sqoop_test 数据库需要预先创建,不指定则默认使用 Hive 中的 default 库。
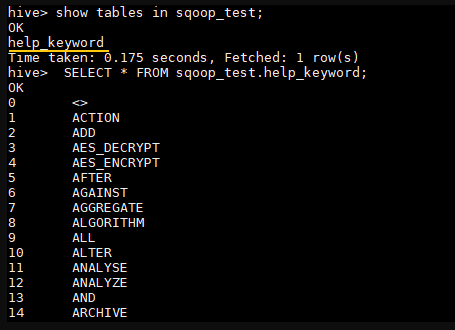
1 2 3 4 # 查看 hive 中的所有数据库 hive> SHOW DATABASES; # 创建 sqoop_test 数据库 hive> CREATE DATABASE sqoop_test;
2. 导入验证 1 2 3 4 # 查看 sqoop_test 数据库的所有表 hive> SHOW TABLES IN sqoop_test; # 查看表中数据 hive> SELECT * FROM sqoop_test.help_keyword;
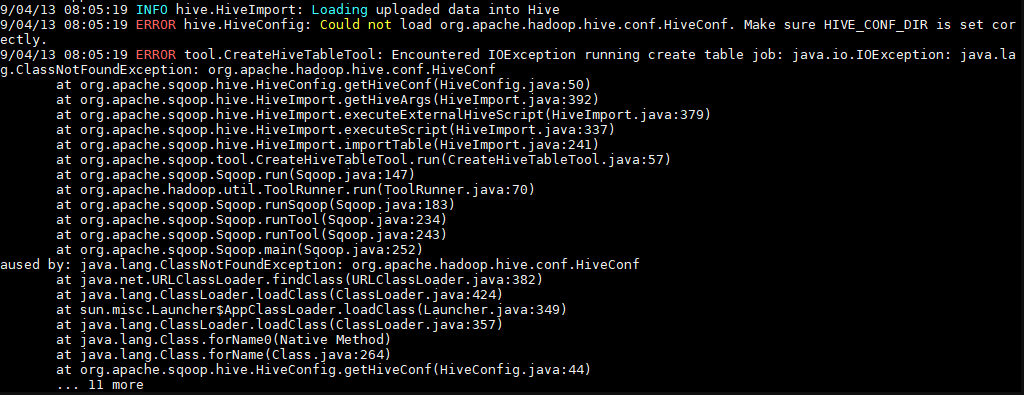
3. 可能出现的问题
如果执行报错 java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,则需将 Hive 安装目录下 lib 下的 hive-exec-**.jar 放到 sqoop 的 lib 。
1 2 3 [root@hadoop001 lib]# ll hive-exec-* -rw-r--r--. 1 1106 4001 19632031 11 月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar [root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib
测试准备 1 2 3 drop database if exists test cascade ;create database if not exists test;
方式1-先复制mysql的表结构到Hive,然后再导入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1、先复制表结构到hive中再导入数据,将关系型数据的表结构复制到hive中 sqoop create-hive-table \ --connect jdbc:mysql://hadoop01:3306/userdb \ --table emp_add \ --username root \ --password 123456 \ --hive-table test.emp_add_sp 其中: --table emp_add为mysql中的数据库userdb中的表。 --hive-table emp_add_sp 为hive中新建的表名称。 复制表结构默认分隔符是'\001' 2、从关系数据库导入文件到hive中 sqoop import \ --connect jdbc:mysql://hadoop01:3306/userdb \ --username root \ --password 123456 \ --table emp_add \ --hive-table test.emp_add_sp \ --hive-import \ --m 1
方式2:直接导入数据(建表 + 导入数据) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 -- 1、使用hive默认分隔符 '\001' sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp_conn \ --hive-import \ --hive-database test \ --m 1 # 从MySQL的userdb数据库的emp_conn表导入到hive的test 数据库的emp_conn表 # 如果多次导入,则会进行数据追加 # 如果要覆盖操作,需要加参数: --hive-overwrite -- 2、使用指定分隔符 '\t' sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp_conn \ --hive-import \ --hive-database test \ --fields-terminated-by '\t' \ --m 1 帮助手册: sqoop help sqoop help import
HCatalog API sqoop API 原生方式
所谓sqoop原生的方式指的是sqoop自带的参数完成的数据导入。
但是有什么不好的地方呢?请看下面案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 create table test.emp_hive( id int , name string, deg string, salary int , dept string ) row format delimited fields terminated by '\t' stored as orc;
1 2 3 4 5 6 7 8 9 sqoop import \ --connect jdbc:mysql://hadoop01:3306/userdb \ --username root \ --password 123456 \ --table emp \ --fields-terminated-by '\t' \ --hive-database test \ --hive-table emp_hive \ -m 1
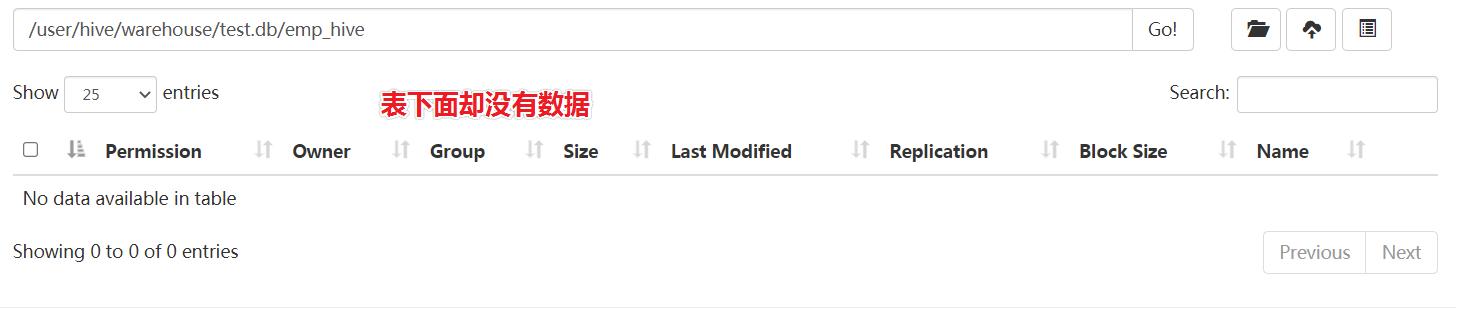
执行之后,可以发现虽然针对表emp_hive的sqoop任务成功,但是Hive表中却没有数据 。
HCatalog API方式
Apache HCatalog是基于Apache Hadoop之上的数据表和存储管理服务。
包括:
提供一个共享的模式和数据类型的机制。
抽象出表,使用户不必关心他们的数据怎么存储,底层什么格式。
提供可操作的跨数据处理工具,如Pig,MapReduce,Streaming,和Hive。
sqoop的官网也做了相关的描述说明,使用HCatalog支持ORC等数据格式。
1 2 3 4 5 6 7 8 9 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp \ --fields-terminated-by '\t' \ --hcatalog-database test \ --hcatalog-table emp_hive \ -m 1
可以发现数据导入成功,并且底层是使用ORC格式存储的。sqoop+hcatalog=> 直接导入数据到ORC的表
sqoop原生API和 HCatalog区别 1 2 3 4 5 6 7 8 9 10 # 数据格式支持(这是实际中使用HCatalog的主要原因,否则还是原生的灵活一些) Sqoop方式支持的数据格式较少; HCatalog支持的数据格式多,包括RCFile, ORCFile, CSV, JSON和SequenceFile等格式。 # 数据覆盖 Sqoop方式允许数据覆盖,HCatalog不允许数据覆盖,每次都只是追加。 # 字段名匹配 Sqoop方式比较随意,不要求源表和目标表字段相同(字段名称和个数都可以不相同),它抽取的方式是将字段按顺序插入,比如目标表有3个字段,源表有一个字段,它会将数据插入到Hive表的第一个字段,其余字段为NULL。 但是HCatalog不同,源表和目标表字段名需要相同,字段个数可以不相等,如果字段名不同,抽取数据的时候会报NullPointerException错误。HCatalog抽取数据时,会将字段对应到相同字段名的字段上,哪怕字段个数不相等。
行存储和列存储 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 1 、行存储 1 )表数据在硬盘上以行为单位,一行的数据是连续存储在一起 ,select * from A 查询效率高。 2 )行存储代表:TextFile、SequenceFile create table test.emp_hive ( id int , name string, deg string, salary int , dept string ) row format delimited fields terminated by '\t' stored as textfile; 2 、列存储 1 )表数据在硬盘上以列为单位,一列的数据是连续存储在一起 ,select 字段 from A 查询效率高。 2 )列存储代表:ORC、Parquet create table test.emp_hive ( id int , name string, deg string, salary int , dept string ) row format delimited fields terminated by '\t' stored as orc; 3 、ORC格式插入数据的步骤 1 )准备数据:log.dat 18.2 M 2 )创建普通表,存储格式是TEXTFILE create temporary table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ; 3 )给普通表插入数据 load data local inpath '/root/log.data' into table log_text; 4 )创建ORC存储的表 create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc ; 5 )从普通表查询数据插入到orc表 insert into table log_orc select * from log_text;
条件部分导入 1 在实际开发中,有时候我们从RDBMS(MySQL)中导入数据时,不需要将数据全部导入,而只需要导入满足条件的数据,则需要进行条件导入
query查询 1 2 3 4 5 6 7 8 9 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --target-dir /sqoop/result5 \ --query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \ --delete-target-dir \ --fields-terminated-by '\001' \ --m 1
使用sql query语句来进行查找时,不能加参数–table ;
并且必须要添加where条件 ;
并且where条件后面必须带一个$CONDITIONS 这个字符串;
并且这个sql语句必须用单引号 ,不能用双引号。
增量导入 1 2 3 4 5 6 7 1、全量导入,表所有数据全部导入 2、条件导入,只要满足查询条件的就导入 3、增量导入,之前已经导入过一次,下一次只导入新增加或者修改的数据 方式1-使用sqoop自带的参数实现增量导入 方式2-使用用户自定义条件来实现增量导入(使用该方式比较多) 增量导入的难点: 因为你之前已经导入多一次,下一次导入时一定要判断哪些数据是已经导入过的,则不要导入,哪些数据是新增加的或者修改的,则需要导入
方式一:sqoop自带参数实现
设计思路:对某一列值进行判断,只要大于上一次的值就会导入。
所谓的增量实现,肯定需要一个判断的依据,上次到哪里了,这次从哪里开始。
1 2 3 4 5 6 --check-column <column> Source column to check for incremental change --incremental <import-type> Define an incremental import of type 'append' or 'lastmodified' --last-value <value> Last imported value in the incremental check column
append模式 要求:必须有一列自增的值,按照自增的int值 进行判断
特点:只能导入增加的数据,无法导入更新的数据
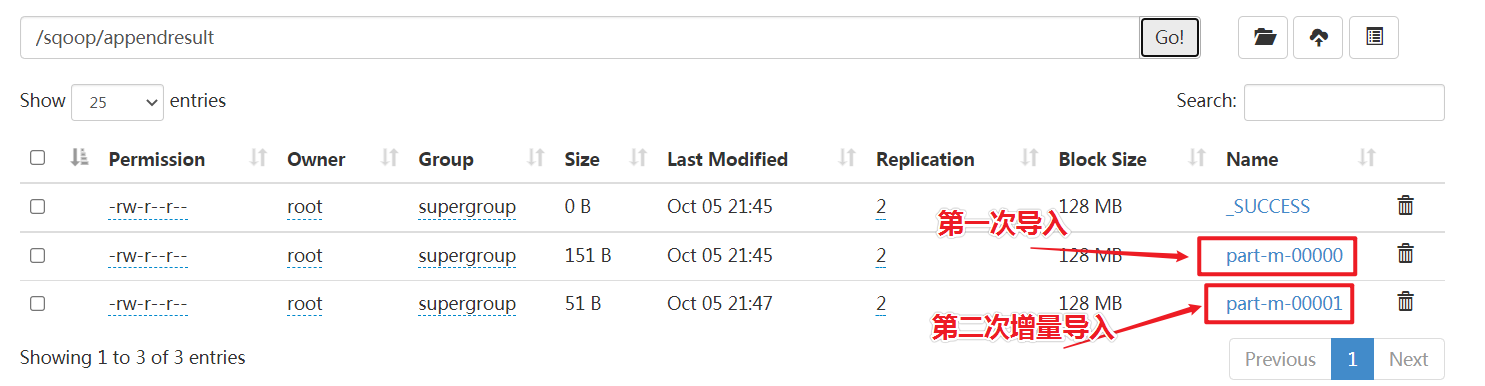
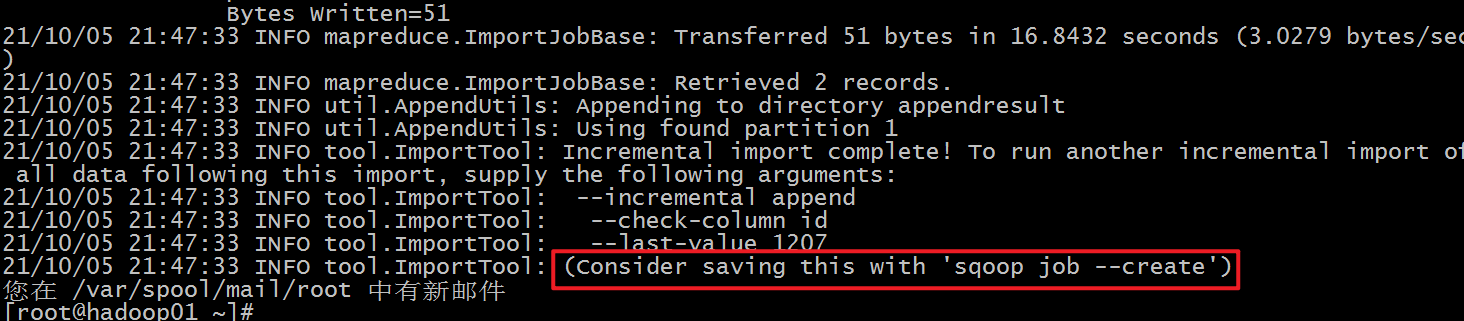
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # 第一次,全量导入-首先执行以下指令先将我们之前的数据导入 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp \ --target-dir /sqoop/appendresult \ --m 1 # 查看生成的数据文件,发现数据已经导入到hdfs中. # 模拟新增加数据,然后在mysql的emp中插入2条数据: insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1206', 'allen', 'admin', '30000', 'tp'); insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1207', 'woon', 'admin', '40000', 'tp'); # 第二次导入,执行如下的指令,实现增量的导入: sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1205 \ --target-dir /sqoop/appendresult # 21/10/09 15:03:37 INFO tool.ImportTool: --incremental append 21/10/09 15:03:37 INFO tool.ImportTool: --check-column id 21/10/09 15:03:37 INFO tool.ImportTool: --last-value 1207 21/10/09 15:03:37 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
并且还可以结合sqoop job作业,实现sqoop自动记录维护last-value值,详细可以参考课程资料。
用的不多,因为要自己记录增量的列和从哪个值开始,不方便
lastmodifield模式 要求:必须包含动态时间变化这一列 ,按照数据变化的时间进行判断
特点:既导入新增的数据也导入更新的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 # 首先我们要在mysql中创建一个customer表,指定一个时间戳字段 create table userdb.customertest( id int , name varchar (20 ), last_mod timestamp default current_timestamp on update current_timestamp ); #此处的时间戳设置为在数据的产生和更新时都会发生改变. #插入如下记录: insert into userdb.customertest(id,name) values (1 ,'neil' );insert into userdb.customertest(id,name) values (2 ,'jack' );insert into userdb.customertest(id,name) values (3 ,'martin' );insert into userdb.customertest(id,name) values (4 ,'tony' );insert into userdb.customertest(id,name) values (5 ,'eric' );#第一次全量导入:此时执行sqoop指令将数据导入hdfs: sqoop import \ #再次插入一条数据进入customertest表 insert into userdb.customertest(id,name) values (6 ,'james' );#更新一条已有的数据,这条数据的时间戳会更新为我们更新数据时的系统时间. update userdb.customertest set name = 'NEIL' where id = 1 ;#第二次导入:执行如下指令,把id字段作为merge - key: sqoop import \ #解释: #由于merge - key这种模式是进行了一次完整的mapreduce操作, #因此最终我们在lastmodifiedresult文件夹下可以发现id= 1 的name已经得到修改,同时新增了id= 6 的数据
也要记住上次导到哪里,也不用
方式二:用户条件过滤实现(不用敲)
通过where对字段进行过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 -- 导入从某一个时间点的数据 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --query "select * from customertest where last_mod >'2022-06-10 10:59:36' and \$CONDITIONS" \ --fields-terminated-by '\001' \ --hcatalog-database test \ --hcatalog-table customertest \ -m 1 -- 导入上一天数据,指定时间区间 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --query "select * from customertest where last_mod >= '2022-09-12 00:00:00' and last_mod <= '2022-09-12 23:59:59' and \$CONDITIONS" \ --fields-terminated-by '\001' \ --hcatalog-database test \ --hcatalog-table customertest \ -m 1 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --query "select * from emp where id>1203 and \$CONDITIONS" \ --fields-terminated-by '\001' \ --hcatalog-database test \ --hcatalog-table emp_hive \ -m 1
这里的时间可以通过shell命令来获取,就达到了动态。方便。所以基本上使用中都用--query
4.2 Hive 导出数据到MySQL 由于 Hive 的数据是存储在 HDFS 上的,所以 Hive 导入数据到 MySQL,实际上就是 HDFS 导入数据到 MySQL。
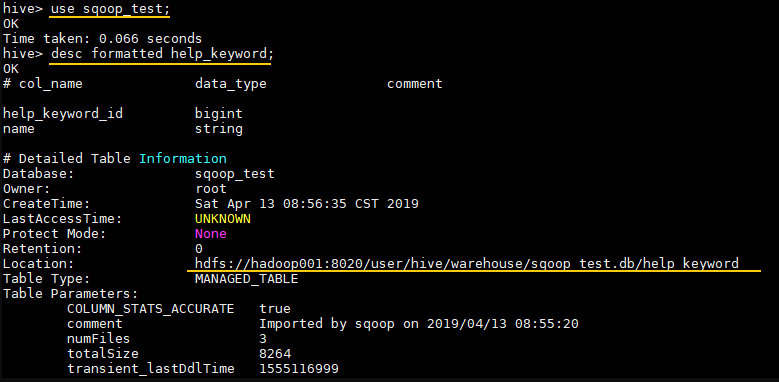
查看Hive表在HDFS的存储位置 1 2 3 4 # 进入对应的数据库 hive> use sqoop_test; # 查看表信息 hive> desc formatted help_keyword;
Location 属性为其存储位置:
这里可以查看一下这个目录,文件结构如下:
执行导出命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 sqoop export \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword_from_hive \ --export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \ -input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001 --m 3 # 解释: 将Hive中 sqoop_test 数据库下的 help_keyword 表导出到MySQL的 mysql 数据库中 help_keyword_from_hive 表 # 注意,如果Hive中的表底层是使用ORC格式存储的,那么必须使用hcatalog API进行操作。 mysql连接: --connect "jdbc:mysql://192.168.88.80:3306/userdb? useUnicode=true&characterEncoding=utf-8" \
MySQL 中的表需要预先创建:
1 CREATE TABLE help_keyword_from_hive LIKE help_keyword ;
全量和增量导出
sqoop导出操作最大的特点是,==目标表需要自己手动提前创建==。
1 2 3 1、在大数据中,数据的导出一般发生在大数据分析的最后一个阶段 2、将分析后的指标导入一些通用的数据库系统中,用于进一步使用 3、导入到MySQL时,需要在MySQL中提前创建表
全量数据导出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # step1:MySQL中建表 mysql> use userdb; mysql> create table employee ( id int primary key, name varchar(20), deg varchar(20), salary int, dept varchar(10)); # step2:从HDFS导出数据到MySQL sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table employee \ --export-dir /sqoop/result1/ # 解释:将HDFS/sqoop/result1/目录下的文件内容,导出到mysql中userdb数据库下的employee表 # step3:从Hive导出数据到MySQL # 首先清空MySQL表数据 truncate table employee; sqoop export \ --connect "jdbc:mysql://192.168.88.80:3306/userdb? useUnicode=true&characterEncoding=utf-8" \ --username root \ --password 123456 \ --table employee \ --hcatalog-database test \ --hcatalog-table emp_hive \ --input-fields-terminated-by '\t' \ -m 1 # 解释: 将Hive中test 数据库下的emp_hive表导出到MySQL的userdb数据库中employee表 # --input-fields-terminated-by '\t' :表示sqoop去hive的表目录下读取文件时,使用'\t' 对文件进行切割,如果hive文件分隔符是'\001' ,则该参数不用指定 # 注意,如果Hive中的表底层是使用ORC格式存储的,那么必须使用hcatalog API进行操作。
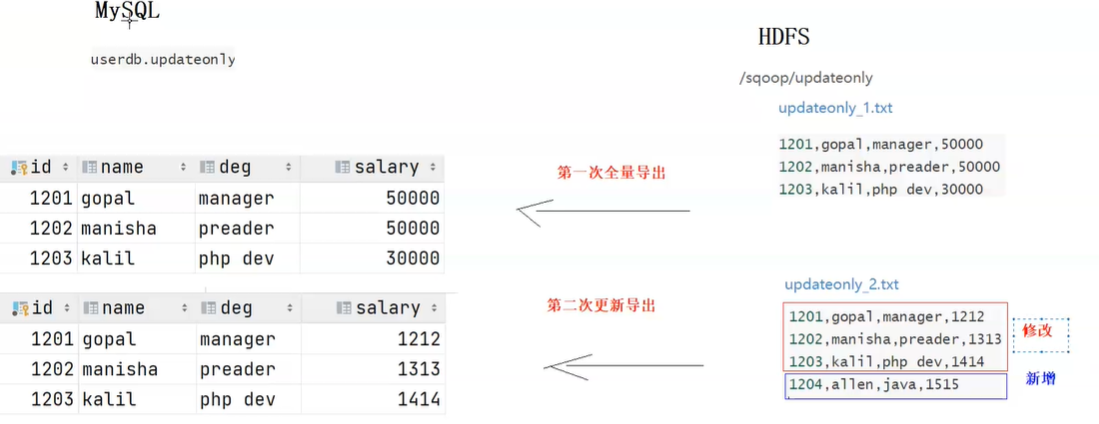
增量数据导出 updateonly:只增量导出更新的数据
allowerinsert:既导出更新的数据,也导出新增的数据
updateonly模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 # 在HDFS文件系统中/sqoop/updateonly/目录的下创建一个文件updateonly_1.txt hadoop fs -mkdir -p /sqoop/updateonly/ hadoop fs -put updateonly_1.txt /sqoop/updateonly/ 1201,gopal,manager,50000 1202,manisha,preader,50000 1203,kalil,php dev,30000 # 手动创建mysql中的目标表 CREATE TABLE userdb.updateonly ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT ); # 先执行全部导出操作: sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table updateonly \ --export-dir /sqoop/updateonly/updateonly_1.txt # 新增一个文件updateonly_2.txt:修改了前三条数据并且新增了一条记录 1201,gopal,manager,1212 1202,manisha,preader,1313 1203,kalil,php dev,1414 1204,allen,java,1515 hadoop fs -put updateonly_2.txt /sqoop/updateonly/ # 执行更新导出: sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table updateonly \ --export-dir /sqoop/updateonly/updateonly_2.txt \ --update-key id \ --update-mode updateonly # 解释: --update-key id 根据id这列来判断id两次导出的数据是否是同一条数据,如果是则更新 --update-mode updateonly 导出时,只导出第一次和第二次的id都有的数据,进行更新,不会导出HDFS中新增加的数据
allowinsert模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 手动创建mysql中的目标表 CREATE TABLE userdb.allowinsert ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT); # 先执行全部导出操作 sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table allowinsert \ --export-dir /sqoop/updateonly/updateonly_1.txt # 执行更新导出 sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root --password 123456 \ --table allowinsert \ --export-dir /sqoop/updateonly/updateonly_2.txt \ --update-key id \ --update-mode allowinsert
sqoop完整例子 sqoop的数据导入操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 create database test default character set utf8mb4 collate utf8mb4_unicode_ci;use test; create table emp( id int not null primary key, name varchar (32 ) null , deg varchar (32 ) null , salary int null , dept varchar (32 ) null ); INSERT INTO emp (id, name, deg, salary, dept) VALUES (1201 , 'gopal' , 'manager' , 50000 , 'TP' );INSERT INTO emp (id, name, deg, salary, dept) VALUES (1202 , 'manisha' , 'Proof reader' , 50000 , 'TP' );INSERT INTO emp (id, name, deg, salary, dept) VALUES (1203 , 'khalil' , 'php dev' , 30000 , 'AC' );INSERT INTO emp (id, name, deg, salary, dept) VALUES (1204 , 'prasanth' , 'php dev' , 30000 , 'AC' );INSERT INTO emp (id, name, deg, salary, dept) VALUES (1205 , 'kranthi' , 'admin' , 20000 , 'TP' );create table emp_add( id int not null primary key, hno varchar (32 ) null , street varchar (32 ) null , city varchar (32 ) null ); INSERT INTO emp_add (id, hno, street, city) VALUES (1201 , '288A' , 'vgiri' , 'jublee' );INSERT INTO emp_add (id, hno, street, city) VALUES (1202 , '108I' , 'aoc' , 'sec-bad' );INSERT INTO emp_add (id, hno, street, city) VALUES (1203 , '144Z' , 'pgutta' , 'hyd' );INSERT INTO emp_add (id, hno, street, city) VALUES (1204 , '78B' , 'old city' , 'sec-bad' );INSERT INTO emp_add (id, hno, street, city) VALUES (1205 , '720X' , 'hitec' , 'sec-bad' );create table emp_conn( id int not null primary key, phno varchar (32 ) null , email varchar (32 ) null ); INSERT INTO emp_conn (id, phno, email) VALUES (1201 , '2356742' , 'gopal@tp.com' );INSERT INTO emp_conn (id, phno, email) VALUES (1202 , '1661663' , 'manisha@tp.com' );INSERT INTO emp_conn (id, phno, email) VALUES (1203 , '8887776' , 'khalil@ac.com' );INSERT INTO emp_conn (id, phno, email) VALUES (1204 , '9988774' , 'prasanth@ac.com' );INSERT INTO emp_conn (id, phno, email) VALUES (1205 , '1231231' , 'kranthi@tp.com' );
第一个: 如何将数据从mysql中导入到HDFS中 (全量)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 以emp表为例: 命令1: sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp 说明: 默认情况下, 会将数据导入到操作sqoop用户的HDFS的家目录下,在此目录下会创建一个以导入表的表名为名称文件夹, 在此文件夹下每一条数据会运行一个mapTask, 数据的默认分隔符号为 逗号 思考: 是否更改其默认的位置呢? sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --delete-target-dir \ --target-dir '/sqoop_works/emp_1' 思考: 是否调整map的数量呢? sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --delete-target-dir \ --target-dir '/sqoop_works/emp_2' \ --split-by id \ -m 2 思考: 是否调整默认分隔符号呢? 比如调整为 \001,导出的就不是分隔符了 sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --fields-terminated-by '\001' \ --delete-target-dir \ --target-dir '/sqoop_works/emp_3' \ -m 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 以emp_add 表为例 第一步: 在HIVE中创建一个目标表 create database hivesqoop;use hivesqoop; create table hivesqoop.emp_add_hive( id int , hno string, street string, city string ) row format delimited fields terminated by '\t' stored as orc ; 第二步: 通过sqoop完成数据导入操作 sqoop import \ - m 1 # 也支持自动创建表,但是一般不这么做
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 方式一: 通过 where 的方式 sqoop import \ - m 2 方式二: 通过SQL 的方式 sqoop import \ - m 1 注意: 如果SQL 语句使用 双引号包裹, $CONDITIONS前面需要将一个\进行转义, 单引号是不需要的
第四个: 如何通过条件的方式导入到hive中 (后续模拟增量导入数据)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 sqoop import \ - m 1 或者: sqoop import \ - m 1
sqoop的数据导出操作 需求: 将hive中 emp_add_hive 表数据导出到MySQL中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 第一步: 在mysql中创建目标表 (必须创建) create table test.emp_add_mysql( id INT , hno VARCHAR(32) NULL, street VARCHAR(32) NULL, city VARCHAR(32) NULL ); # 第二步: 执行sqoop命令导出数据 sqoop export \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp_add_mysql \ --hcatalog-database hivesqoop \ --hcatalog-table emp_add_hive \ -m 1 存在问题: 如果hive中表数据存在中文, 通过上述sqoop命令, 会出现中文乱码的问题,需要在connect参数后面加编码UTF8之类的
Sqoop 导入到 Hive 1.1 Sqoop 导入命令概述 1 2 3 4 5 6 7 8 9 sqoop import \ --connect <数据库连接URL> \ --username <用户名> \ --password <密码> \ --table <表名> \ --hive-import \ --hive-table <Hive表名> \ --create-hive-table \ --hive-overwrite
参数解释:
--connect: 数据库连接URL,指定要连接的数据库地址和端口。--username: 数据库用户名。--password: 数据库密码。--table: 要导入的数据库表名。--hive-import: 将数据导入到Hive中。--hive-table: 指定要创建的Hive表名。--create-hive-table: 如果Hive表不存在,创建一个新的Hive表。--hive-overwrite: 如果Hive表已存在,覆盖已有的数据。
1.3 Sqoop 导入数据到新建 Hive 表 1.4 Sqoop 导入数据到已存在的 Hive 表 1.5 Sqoop 导入数据到分区表 1.6 Sqoop 导入数据时的数据类型自动映射 1.7 Sqoop 导入数据时的数据格式处理 1.8 Sqoop 导入数据时的字段映射和转换 Sqoop 导出从 Hive 2.1 Sqoop 导出命令概述 2.2 Sqoop 导出数据从 Hive 到关系型数据库 2.3 Sqoop 导出数据从 Hive 到其他数据源 2.4 Sqoop 导出数据时的数据类型映射和转换 2.5 Sqoop 导出数据时的数据格式处理 Hive 中的 Sqoop 导入导出优化 3.1 Sqoop 导入导出性能优化建议 3.2 使用并行导入导出提高性能 3.3 利用增量导入导出减少数据传输量 3.4 使用压缩技术减少数据存储和传输 实际示例和最佳实践 4.1 Sqoop 导入外部数据到 Hive 示例 4.2 Sqoop 导出 Hive 数据到关系型数据库示例 4.3 Sqoop 与 Hive 结合使用的最佳实践 五、Sqoop 与 HBase
本小节只讲解从 RDBMS 导入数据到 HBase,因为暂时没有命令能够从 HBase 直接导出数据到 RDBMS。
5.1 MySQL导入数据到HBase 1. 导入数据 将 help_keyword 表中数据导入到 HBase 上的 help_keyword_hbase 表中,使用原表的主键 help_keyword_id 作为 RowKey,原表的所有列都会在 keywordInfo 列族下,目前只支持全部导入到一个列族下,不支持分别指定列族。
1 2 3 4 5 6 7 8 sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword \ # 待导入的表 --hbase-table help_keyword_hbase \ # hbase 表名称,表需要预先创建 --column-family keywordInfo \ # 所有列导入到 keywordInfo 列族下 --hbase-row-key help_keyword_id # 使用原表的 help_keyword_id 作为 RowKey
导入的 HBase 表需要预先创建:
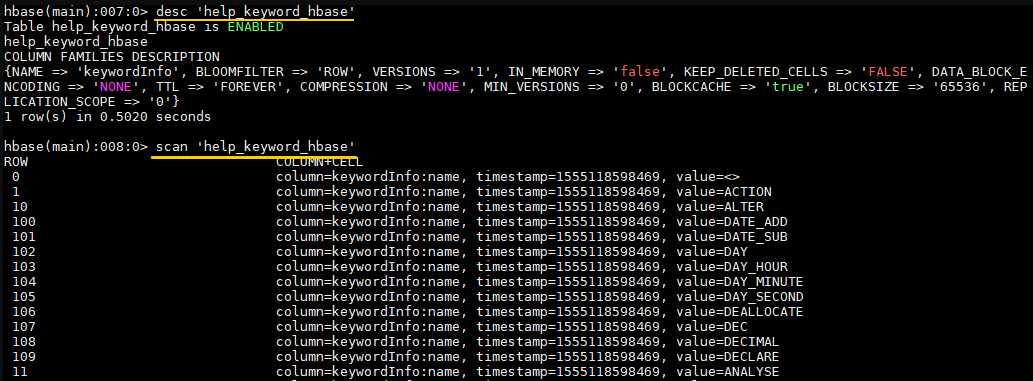
1 2 3 4 5 6 # 查看所有表 hbase> list # 创建表 hbase> create 'help_keyword_hbase' , 'keywordInfo' # 查看表信息 hbase> desc 'help_keyword_hbase'
2. 导入验证 使用 scan 查看表数据:
六、全库导出 Sqoop 支持通过 import-all-tables 命令进行全库导出到 HDFS/Hive,但需要注意有以下两个限制:
所有表必须有主键;或者使用 --autoreset-to-one-mapper,代表只启动一个 map task;
你不能使用非默认的分割列,也不能通过 WHERE 子句添加任何限制。
第二点解释得比较拗口,这里列出官方原本的说明:
You must not intend to use non-default splitting column, nor impose any conditions via a WHERE clause.
全库导出到 HDFS:
1 2 3 4 5 6 7 sqoop import-all-tables \ --connect jdbc:mysql://hadoop001:3306/数据库名 \ --username root \ --password root \ --warehouse-dir /sqoop_all \ # 每个表会单独导出到一个目录,需要用此参数指明所有目录的父目录 --fields-terminated-by '\t' \ -m 3
全库导出到 Hive:
1 2 3 4 5 6 7 8 sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \ --connect jdbc:mysql://hadoop001:3306/数据库名 \ --username root \ --password root \ --hive-database sqoop_test \ # 导出到 Hive 对应的库 --hive-import \ --hive-overwrite \ -m 3
七、Sqoop 数据过滤 7.1 query参数 Sqoop 支持使用 query 参数定义查询 SQL,从而可以导出任何想要的结果集。使用示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \ --delete-target-dir \ --target-dir /sqoop_hive \ --hive-database sqoop_test \ # 指定导入目标数据库 不指定则默认使用 Hive 中的 default 库 --hive-table filter_help_keyword \ # 指定导入目标表 --split-by help_keyword_id \ # 指定用于 split 的列 --hive-import \ # 导入到 Hive --hive-overwrite \ 、 -m 3
在使用 query 进行数据过滤时,需要注意以下三点:
7.2 增量导入 1 2 3 4 5 6 7 8 9 10 11 12 sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword \ --target-dir /sqoop_hive \ --hive-database sqoop_test \ --incremental append \ # 指明模式 --check-column help_keyword_id \ # 指明用于增量导入的参考列 --last-value 300 \ # 指定参考列上次导入的最大值 --hive-import \ -m 3
incremental 参数有以下两个可选的选项:
append :要求参考列的值必须是递增的,所有大于 last-value 的值都会被导入;lastmodified :要求参考列的值必须是 timestamp 类型,且插入数据时候要在参考列插入当前时间戳,更新数据时也要更新参考列的时间戳,所有时间晚于 last-value 的数据都会被导入。
通过上面的解释我们可以看出来,其实 Sqoop 的增量导入并没有太多神器的地方,就是依靠维护的参考列来判断哪些是增量数据。当然我们也可以使用上面介绍的 query 参数来进行手动的增量导出,这样反而更加灵活。
八、类型支持 Sqoop 默认支持数据库的大多数字段类型,但是某些特殊类型是不支持的。遇到不支持的类型,程序会抛出异常 Hive does not support the SQL type for column xxx 异常,此时可以通过下面两个参数进行强制类型转换:
–map-column-java<mapping> :重写 SQL 到 Java 类型的映射;–map-column-hive <mapping> : 重写 Hive 到 Java 类型的映射。
示例如下,将原先 id 字段强制转为 String 类型,value 字段强制转为 Integer 类型:
1 $ sqoop import ... --map-column-java id=String,value=Integer





 微信
微信 支付宝
支付宝
