Storm和流处理简介 一、Storm 1.1 简介 Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理。通常用于实时分析,在线机器学习、持续计算、分布式 RPC、ETL 等场景。Storm 具有以下特点:
支持水平横向扩展;
具有高容错性,通过 ACK 机制每个消息都不丢失;
处理速度非常快,每个节点每秒能处理超过一百万个 tuples ;
易于设置和操作,并可以与任何编程语言一起使用;
支持本地模式运行,对于开发人员来说非常友好;
支持图形化管理界面。
1.2 Storm 与 Hadoop对比 Hadoop 采用 MapReduce 处理数据,而 MapReduce 主要是对数据进行批处理,这使得 Hadoop 更适合于海量数据离线处理的场景。而 Strom 的设计目标是对数据进行实时计算,这使得其更适合实时数据分析的场景。
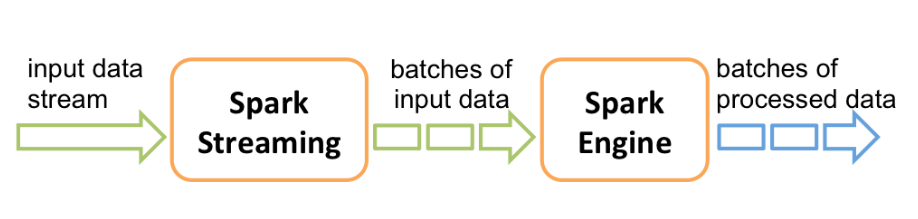
1.3 Storm 与 Spark Streaming对比 Spark Streaming 并不是真正意义上的流处理框架。 Spark Streaming 接收实时输入的数据流,并将数据拆分为一系列批次,然后进行微批处理。只不过 Spark Streaming 能够将数据流进行极小粒度的拆分,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
1.4 Strom 与 Flink对比 storm 和 Flink 都是真正意义上的实时计算框架。其对比如下:
storm
flink
状态管理
无状态
有状态
窗口支持
对事件窗口支持较弱,缓存整个窗口的所有数据,窗口结束时一起计算
窗口支持较为完善,自带一些窗口聚合方法,
消息投递
At Most Once
At Most OnceExactly Once
容错方式
ACK 机制:对每个消息进行全链路跟踪,失败或者超时时候进行重发
检查点机制:通过分布式一致性快照机制,
注 : 对于消息投递,一般有以下三种方案:
At Most Once : 保证每个消息会被投递 0 次或者 1 次,在这种机制下消息很有可能会丢失;
At Least Once : 保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失;
Exactly Once : 每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
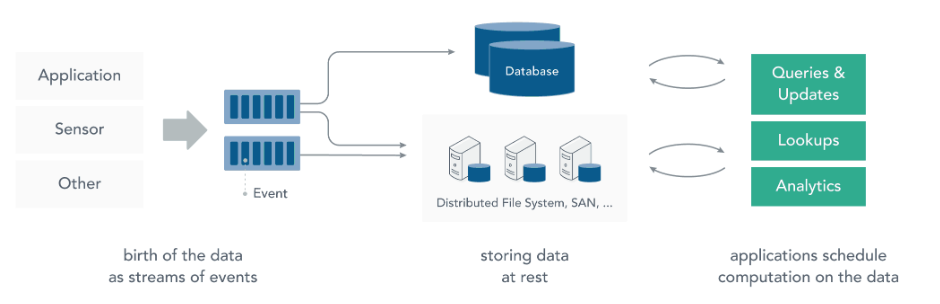
二、流处理 2.1 静态数据处理 在流处理之前,数据通常存储在数据库或文件系统中,应用程序根据需要查询或计算数据,这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
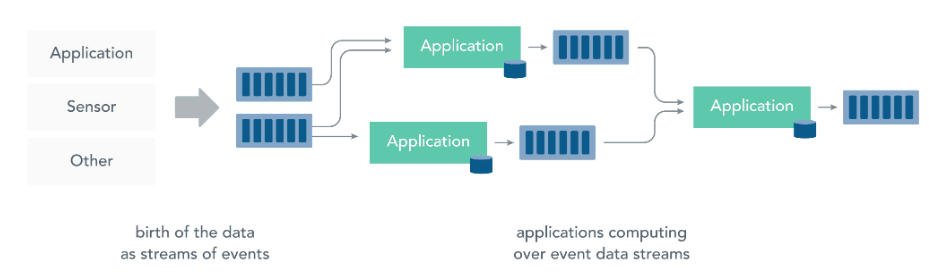
2.2 流处理 而流处理则是直接对运动中数据的处理,在接收数据的同时直接计算数据。实际上,在真实世界中的大多数数据都是连续的流,如传感器数据,网站用户活动数据,金融交易数据等等 ,所有这些数据都是随着时间的推移而源源不断地产生。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器 。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
流处理带来了很多优点:
可以立即对数据做出反应 :降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
可以处理更大的数据量 :直接处理数据流,并且只保留数据中有意义的子集,然后将其传送到下一个处理单元,通过逐级过滤数据,从而降低实际需要处理的数据量;
更贴近现实的数据模型 :在实际的环境中,一切数据都是持续变化的,想要通过历史数据推断未来的趋势,必须保证数据的不断输入和模型的持续修正,典型的就是金融市场、股票市场,流处理能更好地处理这些场景下对数据连续性和及时性的需求;
分散和分离基础设施 :流式处理减少了对大型数据库的需求。每个流处理程序通过流处理框架维护了自己的数据和状态,这使其更适合于当下最流行的微服务架构。
参考资料
What is stream processing? 流计算框架 Flink 与 Storm 的性能对比
Storm 核心概念详解 一、Storm核心概念
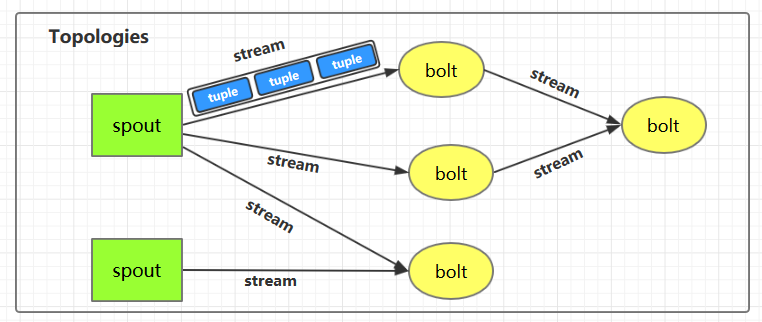
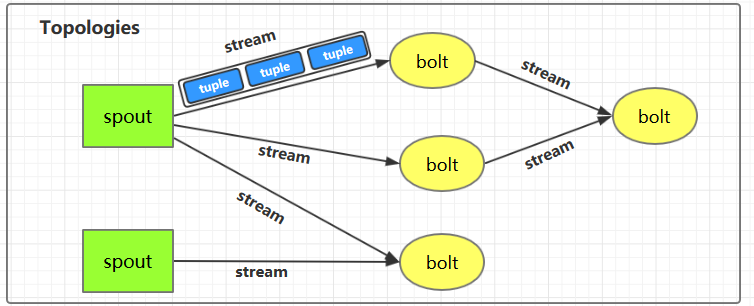
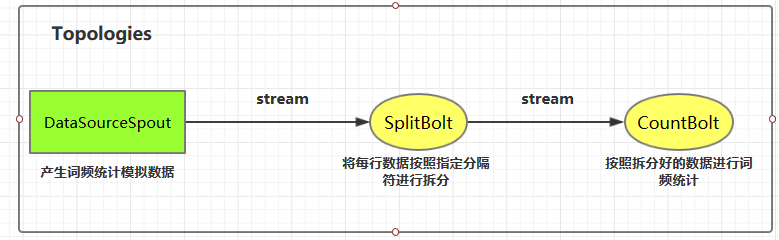
1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑)。它是一个是由 Spouts 和 Bolts 通过 Stream 连接起来的有向无环图,Storm 会保持每个提交到集群的 topology 持续地运行,从而处理源源不断的数据流,直到你将其主动杀死 (kill) 为止。
1.2 Streams(流) Stream 是 Storm 中的核心概念。一个 Stream 是一个无界的、以分布式方式并行创建和处理的 Tuple 序列。Tuple 可以包含大多数基本类型以及自定义类型的数据。简单来说,Tuple 就是流数据的实际载体,而 Stream 就是一系列 Tuple。
1.3 Spouts Spouts 是流数据的源头,一个 Spout 可以向不止一个 Streams 中发送数据。Spout 通常分为可靠 和不可靠 两种:可靠的 Spout 能够在失败时重新发送 Tuple, 不可靠的 Spout 一旦把 Tuple 发送出去就置之不理了。
1.4 Bolts Bolts 是流数据的处理单元,它可以从一个或者多个 Streams 中接收数据,处理完成后再发射到新的 Streams 中。Bolts 可以执行过滤 (filtering),聚合 (aggregations),连接 (joins) 等操作,并能与文件系统或数据库进行交互。
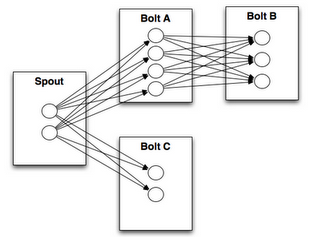
1.5 Stream groupings(分组策略)
spouts 和 bolts 在集群上执行任务时,是由多个 Task 并行执行 (如上图,每一个圆圈代表一个 Task)。当一个 Tuple 需要从 Bolt A 发送给 Bolt B 执行的时候,程序如何知道应该发送给 Bolt B 的哪一个 Task 执行呢?
这是由 Stream groupings 分组策略来决定的,Storm 中一共有如下 8 个内置的 Stream Grouping。当然你也可以通过实现 CustomStreamGrouping 接口来实现自定义 Stream 分组策略。
Shuffle grouping
Tuples 随机的分发到每个 Bolt 的每个 Task 上,每个 Bolt 获取到等量的 Tuples。
Fields grouping
Streams 通过 grouping 指定的字段 (field) 来分组。假设通过 user-id 字段进行分区,那么具有相同 user-id 的 Tuples 就会发送到同一个 Task。
Partial Key grouping
Streams 通过 grouping 中指定的字段 (field) 来分组,与 Fields Grouping 相似。但是对于两个下游的 Bolt 来说是负载均衡的,可以在输入数据不平均的情况下提供更好的优化。
All grouping
Streams 会被所有的 Bolt 的 Tasks 进行复制。由于存在数据重复处理,所以需要谨慎使用。
Global grouping
整个 Streams 会进入 Bolt 的其中一个 Task,通常会进入 id 最小的 Task。
None grouping
当前 None grouping 和 Shuffle grouping 等价,都是进行随机分发。
Direct grouping
Direct grouping 只能被用于 direct streams 。使用这种方式需要由 Tuple 的生产者直接指定由哪个 Task 进行处理。
Local or shuffle grouping
如果目标 Bolt 有 Tasks 和当前 Bolt 的 Tasks 处在同一个 Worker 进程中,那么则优先将 Tuple Shuffled 到处于同一个进程的目标 Bolt 的 Tasks 上,这样可以最大限度地减少网络传输。否则,就和普通的 Shuffle Grouping 行为一致。
二、Storm架构详解
2.1 Nimbus进程 也叫做 Master Node,是 Storm 集群工作的全局指挥官。主要功能如下:
通过 Thrift 接口,监听并接收 Client 提交的 Topology;
根据集群 Workers 的资源情况,将 Client 提交的 Topology 进行任务分配,分配结果写入 Zookeeper;
通过 Thrift 接口,监听 Supervisor 的下载 Topology 代码的请求,并提供下载 ;
通过 Thrift 接口,监听 UI 对统计信息的读取,从 Zookeeper 上读取统计信息,返回给 UI;
若进程退出后,立即在本机重启,则不影响集群运行。
2.2 Supervisor进程 也叫做 Worker Node , 是 Storm 集群的资源管理者,按需启动 Worker 进程。主要功能如下:
定时从 Zookeeper 检查是否有新 Topology 代码未下载到本地 ,并定时删除旧 Topology 代码 ;
根据 Nimbus 的任务分配计划,在本机按需启动 1 个或多个 Worker 进程,并监控所有的 Worker 进程的情况;
若进程退出,立即在本机重启,则不影响集群运行。
2.3 zookeeper的作用 Nimbus 和 Supervisor 进程都被设计为快速失败 (遇到任何意外情况时进程自毁)和无状态 (所有状态保存在 Zookeeper 或磁盘上)。 这样设计的好处就是如果它们的进程被意外销毁,那么在重新启动后,就只需要从 Zookeeper 上获取之前的状态数据即可,并不会造成任何数据丢失。
2.4 Worker进程 Storm 集群的任务构造者 ,构造 Spoult 或 Bolt 的 Task 实例,启动 Executor 线程。主要功能如下:
根据 Zookeeper 上分配的 Task,在本进程中启动 1 个或多个 Executor 线程,将构造好的 Task 实例交给 Executor 去运行;
向 Zookeeper 写入心跳 ;
维持传输队列,发送 Tuple 到其他的 Worker ;
若进程退出,立即在本机重启,则不影响集群运行。
2.5 Executor线程 Storm 集群的任务执行者 ,循环执行 Task 代码。主要功能如下:
执行 1 个或多个 Task;
执行 Acker 机制,负责发送 Task 处理状态给对应 Spout 所在的 worker。
2.6 并行度
1 个 Worker 进程执行的是 1 个 Topology 的子集,不会出现 1 个 Worker 为多个 Topology 服务的情况,因此 1 个运行中的 Topology 就是由集群中多台物理机上的多个 Worker 进程组成的。1 个 Worker 进程会启动 1 个或多个 Executor 线程来执行 1 个 Topology 的 Component(组件,即 Spout 或 Bolt)。
Executor 是 1 个被 Worker 进程启动的单独线程。每个 Executor 会运行 1 个 Component 中的一个或者多个 Task。
Task 是组成 Component 的代码单元。Topology 启动后,1 个 Component 的 Task 数目是固定不变的,但该 Component 使用的 Executor 线程数可以动态调整(例如:1 个 Executor 线程可以执行该 Component 的 1 个或多个 Task 实例)。这意味着,对于 1 个 Component 来说,#threads<=#tasks(线程数小于等于 Task 数目)这样的情况是存在的。默认情况下 Task 的数目等于 Executor 线程数,即 1 个 Executor 线程只运行 1 个 Task。
总结如下:
一个运行中的 Topology 由集群中的多个 Worker 进程组成的;
在默认情况下,每个 Worker 进程默认启动一个 Executor 线程;
在默认情况下,每个 Executor 默认启动一个 Task 线程;
Task 是组成 Component 的代码单元。
参考资料
storm documentation -> Concepts
Internal Working of Apache Storm
Understanding the Parallelism of a Storm Topology
Storm nimbus 单节点宕机的处理
Storm 编程模型 一、简介 下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它们之间进行关联,形成 Topology。
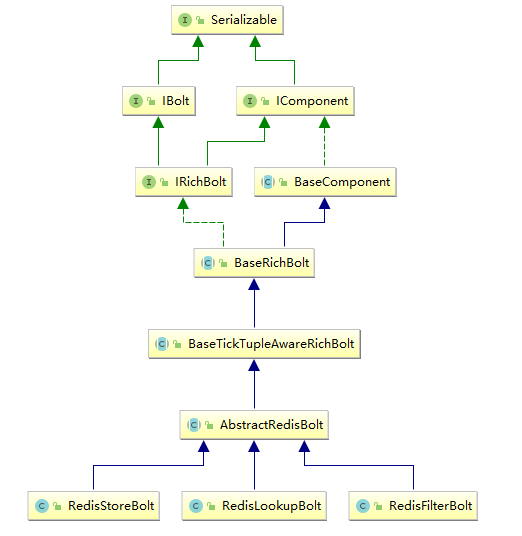
二、IComponent接口 IComponent 接口定义了 Topology 中所有组件 (spout/bolt) 的公共方法,自定义的 spout 或 bolt 必须直接或间接实现这个接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface IComponent extends Serializable { void declareOutputFields (OutputFieldsDeclarer declarer) ; Map<String, Object> getComponentConfiguration () ; }
三、Spout 3.1 ISpout接口 自定义的 spout 需要实现 ISpout 接口,它定义了 spout 的所有可用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public interface ISpout extends Serializable { void open (Map conf, TopologyContext context, SpoutOutputCollector collector) ; void close () ; void activate () ; void deactivate () ; void nextTuple () ; void ack (Object msgId) ; void fail (Object msgId) ; }
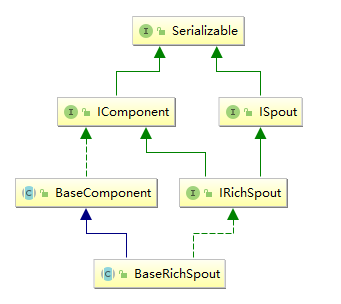
3.2 BaseRichSpout抽象类 通常情况下,我们实现自定义的 Spout 时不会直接去实现 ISpout 接口,而是继承 BaseRichSpout。 BaseRichSpout 继承自 BaseCompont,同时实现了 IRichSpout 接口。
IRichSpout 接口继承自 ISpout 和 IComponent,自身并没有定义任何方法:
1 2 3 public interface IRichSpout extends ISpout , IComponent {}
BaseComponent 抽象类空实现了 IComponent 中 getComponentConfiguration 方法:
1 2 3 4 5 6 public abstract class BaseComponent implements IComponent { @Override public Map<String, Object> getComponentConfiguration () { return null ; } }
BaseRichSpout 继承自 BaseCompont 类并实现了 IRichSpout 接口,并且空实现了其中部分方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public abstract class BaseRichSpout extends BaseComponent implements IRichSpout { @Override public void close () {} @Override public void activate () {} @Override public void deactivate () {} @Override public void ack (Object msgId) {} @Override public void fail (Object msgId) {} }
通过这样的设计,我们在继承 BaseRichSpout 实现自定义 spout 时,就只有三个方法必须实现:
open : 来源于 ISpout,可以通过此方法获取用来发送 tuples 的 SpoutOutputCollector;nextTuple :来源于 ISpout,必须在此方法内部发送 tuples;declareOutputFields :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接受。
四、Bolt bolt 接口的设计与 spout 的类似:
4.1 IBolt 接口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public interface IBolt extends Serializable { void prepare (Map stormConf, TopologyContext context, OutputCollector collector) ; void execute (Tuple input) ; void cleanup () ;
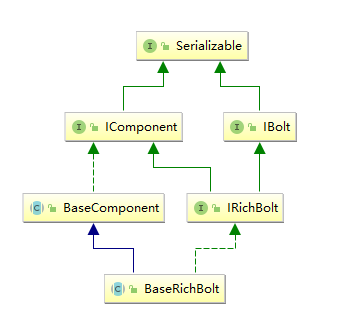
4.2 BaseRichBolt抽象类 同样的,在实现自定义 bolt 时,通常是继承 BaseRichBolt 抽象类来实现。BaseRichBolt 继承自 BaseComponent 抽象类并实现了 IRichBolt 接口。
IRichBolt 接口继承自 IBolt 和 IComponent,自身并没有定义任何方法:
1 2 3 public interface IRichBolt extends IBolt, IComponent { }
通过这样的设计,在继承 BaseRichBolt 实现自定义 bolt 时,就只需要实现三个必须的方法:
prepare : 来源于 IBolt,可以通过此方法获取用来发送 tuples 的 OutputCollector;execute :来源于 IBolt,处理 tuples 和发送处理完成的 tuples;declareOutputFields :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接收。
五、词频统计案例 5.1 案例简介 这里我们使用自定义的 DataSourceSpout 产生词频数据,然后使用自定义的 SplitBolt 和 CountBolt 来进行词频统计。
案例源码下载地址:storm-word-count
5.2 代码实现 1. 项目依赖 1 2 3 4 5 <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-core</artifactId > <version > 1.2.2</version > </dependency >
2. DataSourceSpout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class DataSourceSpout extends BaseRichSpout { private List<String> list = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private SpoutOutputCollector spoutOutputCollector; @Override public void open (Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this .spoutOutputCollector = spoutOutputCollector; } @Override public void nextTuple () { String lineData = productData(); spoutOutputCollector.emit(new Values (lineData)); Utils.sleep(1000 ); } @Override public void declareOutputFields (OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields ("line" )); } private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); } }
上面类使用 productData 方法来产生模拟数据,产生数据的格式如下:
1 2 3 4 5 6 7 8 9 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm
3. SplitBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class SplitBolt extends BaseRichBolt { private OutputCollector collector; @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector=collector; } @Override public void execute (Tuple input) { String line = input.getStringByField("line" ); String[] words = line.split("\t" ); for (String word : words) { collector.emit(new Values (word)); } } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("word" )); } }
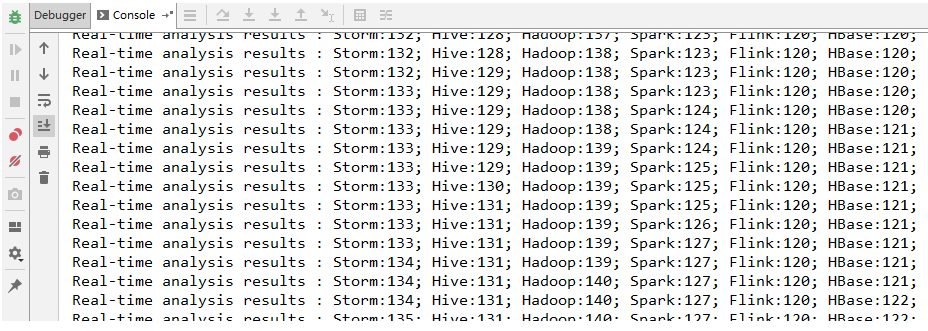
4. CountBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class CountBolt extends BaseRichBolt { private Map<String, Integer> counts = new HashMap <>(); @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { } @Override public void execute (Tuple input) { String word = input.getStringByField("word" ); Integer count = counts.get(word); if (count == null ) { count = 0 ; } count++; counts.put(word, count); System.out.print("当前实时统计结果:" ); counts.forEach((key, value) -> System.out.print(key + ":" + value + "; " )); System.out.println(); } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { } }
5. LocalWordCountApp 通过 TopologyBuilder 将上面定义好的组件进行串联形成 Topology,并提交到本地集群(LocalCluster)运行。通常在开发中,可先用本地模式进行测试,测试完成后再提交到服务器集群运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class LocalWordCountApp { public static void main (String[] args) { TopologyBuilder builder = new TopologyBuilder (); builder.setSpout("DataSourceSpout" , new DataSourceSpout ()); builder.setBolt("SplitBolt" , new SplitBolt ()).shuffleGrouping("DataSourceSpout" ); builder.setBolt("CountBolt" , new CountBolt ()).shuffleGrouping("SplitBolt" ); LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalWordCountApp" , new Config (), builder.createTopology()); } }
6. 运行结果 启动 WordCountApp 的 main 方法即可运行,采用本地模式 Storm 会自动在本地搭建一个集群,所以启动的过程会稍慢一点,启动成功后即可看到输出日志。
六、提交到服务器集群运行 6.1 代码更改 提交到服务器的代码和本地代码略有不同,提交到服务器集群时需要使用 StormSubmitter 进行提交。主要代码如下:
为了结构清晰,这里新建 ClusterWordCountApp 类来演示集群模式的提交。实际开发中可以将两种模式的代码写在同一个类中,通过外部传参来决定启动何种模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ClusterWordCountApp { public static void main (String[] args) { TopologyBuilder builder = new TopologyBuilder (); builder.setSpout("DataSourceSpout" , new DataSourceSpout ()); builder.setBolt("SplitBolt" , new SplitBolt ()).shuffleGrouping("DataSourceSpout" ); builder.setBolt("CountBolt" , new CountBolt ()).shuffleGrouping("SplitBolt" ); try { StormSubmitter.submitTopology("ClusterWordCountApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } }
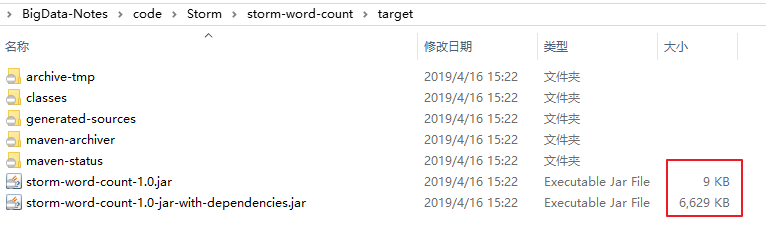
6.2 打包上传 打包后上传到服务器任意位置,这里我打包后的名称为 storm-word-count-1.0.jar
1 # mvn clean package -Dmaven.test.skip=true
6.3 提交Topology 使用以下命令提交 Topology 到集群:
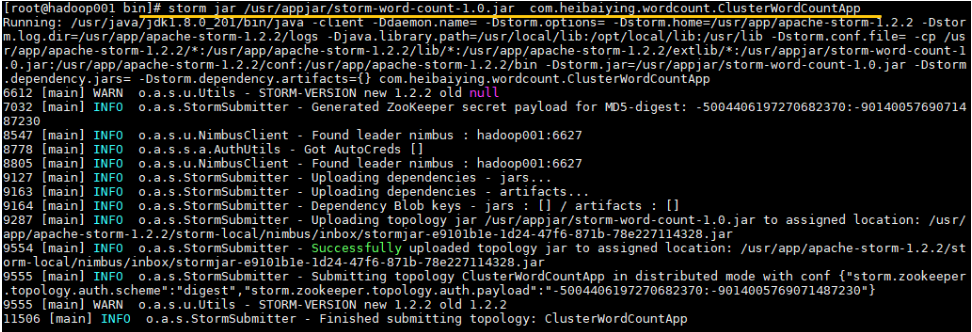
1 2 # 命令格式: storm jar jar包位置 主类的全路径 ...可选传参 storm jar /usr/appjar/storm-word-count-1.0.jar com.heibaiying.wordcount.ClusterWordCountApp
出现 successfully 则代表提交成功:
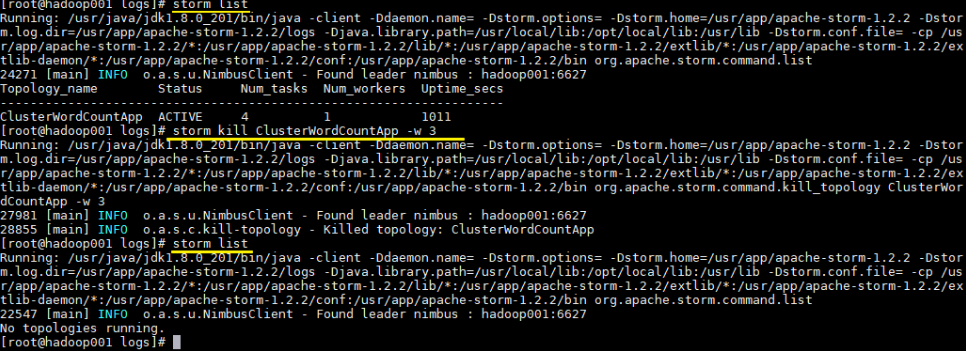
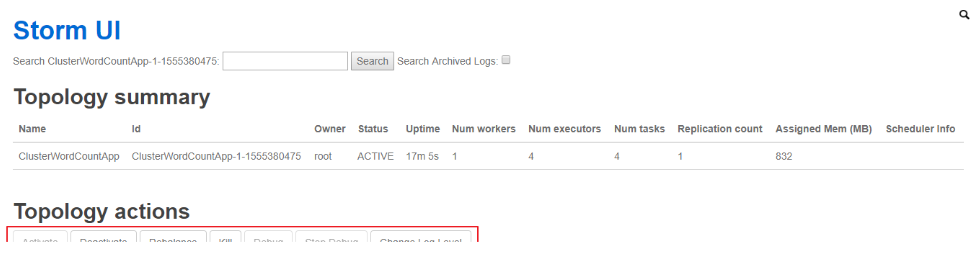
6.4 查看Topology与停止Topology(命令行方式) 1 2 3 4 5 # 查看所有Topology storm list # 停止 storm kill topology-name [-w wait-time-secs] storm kill ClusterWordCountApp -w 3
6.5 查看Topology与停止Topology(界面方式) 使用 UI 界面同样也可进行停止操作,进入 WEB UI 界面(8080 端口),在 Topology Summary 中点击对应 Topology 即可进入详情页面进行操作。
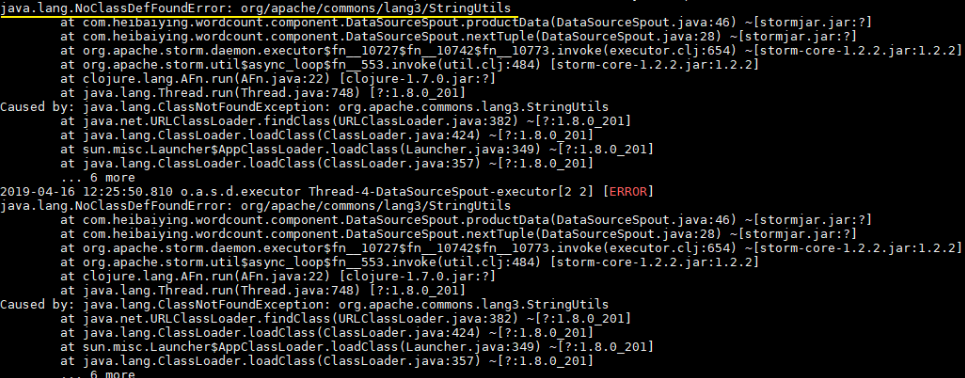
七、关于项目打包的扩展说明 mvn package的局限性 在上面的步骤中,我们没有在 POM 中配置任何插件,就直接使用 mvn package 进行项目打包,这对于没有使用外部依赖包的项目是可行的。但如果项目中使用了第三方 JAR 包,就会出现问题,因为 package 打包后的 JAR 中是不含有依赖包的,如果此时你提交到服务器上运行,就会出现找不到第三方依赖的异常。
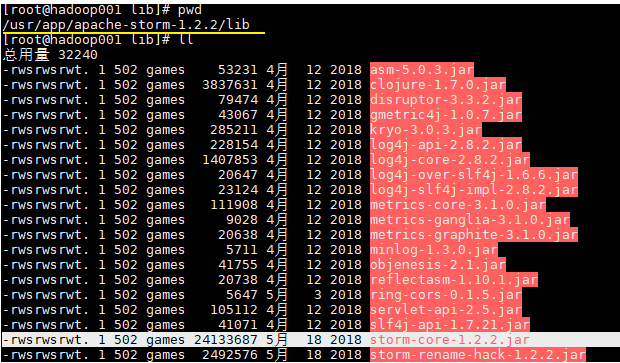
这时候可能大家会有疑惑,在我们的项目中不是使用了 storm-core 这个依赖吗?其实上面之所以我们能运行成功,是因为在 Storm 的集群环境中提供了这个 JAR 包,在安装目录的 lib 目录下:
1 2 3 4 5 <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-lang3</artifactId > <version > 3.8.1</version > </dependency >
StringUtils.join() 这个方法在 commons.lang3 和 storm-core 中都有,原来的代码无需任何更改,只需要在 import 时指明使用 commons.lang3。
1 2 3 4 5 6 7 8 import org.apache.commons.lang3.StringUtils;private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); }
此时直接使用 mvn clean package 打包运行,就会抛出下图的异常。因此这种直接打包的方式并不适用于实际的开发,因为实际开发中通常都是需要第三方的 JAR 包。
想把依赖包一并打入最后的 JAR 中,maven 提供了两个插件来实现,分别是 maven-assembly-plugin 和 maven-shade-plugin。鉴于本篇文章篇幅已经比较长,且关于 Storm 打包还有很多需要说明的地方,所以关于 Storm 的打包方式单独整理至下一篇文章:
Storm 三种打包方式对比分析
参考资料
Running Topologies on a Production Cluster Pre-defined Descriptor Files
Storm三种打包方式对比分析 一、简介 在将 Storm Topology 提交到服务器集群运行时,需要先将项目进行打包。本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明。主要打包方式有以下三种:
第一种:不加任何插件,直接使用 mvn package 打包;
第二种:使用 maven-assembly-plugin 插件进行打包;
第三种:使用 maven-shade-plugin 进行打包。
以下分别进行详细的说明。
二、mvn package 2.1 mvn package的局限 不在 POM 中配置任何插件,直接使用 mvn package 进行项目打包,这对于没有使用外部依赖包的项目是可行的。
但如果项目中使用了第三方 JAR 包,就会出现问题,因为 mvn package 打包后的 JAR 中是不含有依赖包的,如果此时你提交到服务器上运行,就会出现找不到第三方依赖的异常。
如果你想采用这种方式进行打包,但是又使用了第三方 JAR,有没有解决办法?答案是有的,这一点在官方文档的Command Line Client 章节有所讲解,主要解决办法如下。
2.2 解决办法 在使用 storm jar 提交 Topology 时,可以使用如下方式指定第三方依赖:
如果第三方 JAR 包在本地,可以使用 --jars 指定;
如果第三方 JAR 包在远程中央仓库,可以使用 --artifacts 指定,此时如果想要排除某些依赖,可以使用 ^ 符号。指定后 Storm 会自动到中央仓库进行下载,然后缓存到本地;
如果第三方 JAR 包在其他仓库,还需要使用 --artifactRepositories 指明仓库地址,库名和地址使用 ^ 符号分隔。
以下是一个包含上面三种情况的命令示例:
1 2 3 4 5 6 ./bin/storm jar example/storm-starter/storm-starter-topologies-*.jar \ org.apache.storm.starter.RollingTopWords blobstore-remote2 remote \ --jars "./external/storm-redis/storm-redis-1.1.0.jar,./external/storm-kafka/storm-kafka-1.1.0.jar" \ --artifacts "redis.clients:jedis:2.9.0,org.apache.kafka:kafka_2.10:0.8.2.2^org.slf4j:slf4j-log4j12" \ --artifactRepositories "jboss-repository^http://repository.jboss.com/maven2, \ HDPRepo^http://repo.hortonworks.com/content/groups/public/"
这种方式是建立在你能够连接到外网的情况下,如果你的服务器不能连接外网,或者你希望能把项目直接打包成一个 ALL IN ONE 的 JAR,即包含所有相关依赖,此时可以采用下面介绍的两个插件。
三、maven-assembly-plugin插件 maven-assembly-plugin 是官方文档中介绍的打包方法,来源于官方文档:Running Topologies on a Production Cluster
If you’re using Maven, the Maven Assembly Plugin can do the packaging for you. Just add this to your pom.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 <plugin > <artifactId > maven-assembly-plugin</artifactId > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > <archive > <manifest > <mainClass > com.path.to.main.Class</mainClass > </manifest > </archive > </configuration > </plugin >
Then run mvn assembly:assembly to get an appropriately packaged jar. Make sure you exclude the Storm jars since the cluster already has Storm on the classpath.
官方文档主要说明了以下几点:
使用 maven-assembly-plugin 可以把所有的依赖一并打入到最后的 JAR 中;
需要排除掉 Storm 集群环境中已经提供的 Storm jars;
通过 <mainClass> 标签指定主入口类;
通过 <descriptorRef> 标签指定打包相关配置。
jar-with-dependencies 是 Maven预定义 的一种最基本的打包配置,其 XML 文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <assembly xmlns ="http://maven.apache.org/ASSEMBLY/2.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/ASSEMBLY/2.0.0 http://maven.apache.org/xsd/assembly-2.0.0.xsd" > <id > jar-with-dependencies</id > <formats > <format > jar</format > </formats > <includeBaseDirectory > false</includeBaseDirectory > <dependencySets > <dependencySet > <outputDirectory > /</outputDirectory > <useProjectArtifact > true</useProjectArtifact > <unpack > true</unpack > <scope > runtime</scope > </dependencySet > </dependencySets > </assembly >
我们可以通过对该配置文件进行拓展,从而实现更多的功能,比如排除指定的 JAR 等。使用示例如下:
1. 引入插件 在 POM.xml 中引入插件,并指定打包格式的配置文件为 assembly.xml(名称可自定义):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <build > <plugins > <plugin > <artifactId > maven-assembly-plugin</artifactId > <configuration > <descriptors > <descriptor > src/main/resources/assembly.xml</descriptor > </descriptors > <archive > <manifest > <mainClass > com.heibaiying.wordcount.ClusterWordCountApp</mainClass > </manifest > </archive > </configuration > </plugin > </plugins > </build >
assembly.xml 拓展自 jar-with-dependencies.xml,使用了 <excludes> 标签排除 Storm jars,具体内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <assembly xmlns ="http://maven.apache.org/ASSEMBLY/2.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/ASSEMBLY/2.0.0 http://maven.apache.org/xsd/assembly-2.0.0.xsd" > <id > jar-with-dependencies</id > <formats > <format > jar</format > </formats > <includeBaseDirectory > false</includeBaseDirectory > <dependencySets > <dependencySet > <outputDirectory > /</outputDirectory > <useProjectArtifact > true</useProjectArtifact > <unpack > true</unpack > <scope > runtime</scope > <excludes > <exclude > org.apache.storm:storm-core</exclude > </excludes > </dependencySet > </dependencySets > </assembly >
在配置文件中不仅可以排除依赖,还可以排除指定的文件,更多的配置规则可以参考官方文档:Descriptor Format
2. 打包命令 采用 maven-assembly-plugin 进行打包时命令如下:
打包后会同时生成两个 JAR 包,其中后缀为 jar-with-dependencies 是含有第三方依赖的 JAR 包,后缀是由 assembly.xml 中 <id> 标签指定的,可以自定义修改。提交该 JAR 到集群环境即可直接使用。
四、maven-shade-plugin插件 4.1 官方文档说明 第三种方式是使用 maven-shade-plugin,既然已经有了 maven-assembly-plugin,为什么还需要 maven-shade-plugin,这一点在官方文档中也是有所说明的,来自于官方对 HDFS 整合讲解的章节Storm HDFS Integration ,原文如下:
When packaging your topology, it’s important that you use the maven-shade-plugin as opposed to the maven-assembly-plugin .
The shade plugin provides facilities for merging JAR manifest entries, which the hadoop client leverages for URL scheme resolution.
If you experience errors such as the following:
1 >java.lang.RuntimeException: Error preparing HdfsBolt: No FileSystem for scheme: hdfs
it’s an indication that your topology jar file isn’t packaged properly.
If you are using maven to create your topology jar, you should use the following maven-shade-plugin configuration to create your topology jar。
这里第一句就说的比较清晰,在集成 HDFS 时候,你必须使用 maven-shade-plugin 来代替 maven-assembly-plugin,否则会抛出 RuntimeException 异常。
采用 maven-shade-plugin 打包有很多好处,比如你的工程依赖很多的 JAR 包,而被依赖的 JAR 又会依赖其他的 JAR 包,这样,当工程中依赖到不同的版本的 JAR 时,并且 JAR 中具有相同名称的资源文件时,shade 插件会尝试将所有资源文件打包在一起时,而不是和 assembly 一样执行覆盖操作。
4.2 配置 采用 maven-shade-plugin 进行打包时候,配置示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <configuration > <createDependencyReducedPom > true</createDependencyReducedPom > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.sf</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.dsa</exclude > <exclude > META-INF/*.RSA</exclude > <exclude > META-INF/*.rsa</exclude > <exclude > META-INF/*.EC</exclude > <exclude > META-INF/*.ec</exclude > <exclude > META-INF/MSFTSIG.SF</exclude > <exclude > META-INF/MSFTSIG.RSA</exclude > </excludes > </filter > </filters > <artifactSet > <excludes > <exclude > org.apache.storm:storm-core</exclude > </excludes > </artifactSet > </configuration > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <transformers > <transformer implementation ="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" /> <transformer implementation ="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" > </transformer > </transformers > </configuration > </execution > </executions > </plugin >
以上配置示例来源于 Storm Github,这里做一下说明:
在上面的配置中,排除了部分文件,这是因为有些 JAR 包生成时,会使用 jarsigner 生成文件签名(完成性校验),分为两个文件存放在 META-INF 目录下:
a signature file, with a .SF extension;
a signature block file, with a .DSA, .RSA, or .EC extension;
如果某些包的存在重复引用,这可能会导致在打包时候出现 Invalid signature file digest for Manifest main attributes 异常,所以在配置中排除这些文件。
4.3 打包命令 使用 maven-shade-plugin 进行打包的时候,打包命令和普通的一样:
打包后会生成两个 JAR 包,提交到服务器集群时使用 非 original 开头的 JAR。
五、结论 通过以上三种打包方式的详细介绍,这里给出最后的结论:建议使用 maven-shade-plugin 插件进行打包 ,因为其通用性最强,操作最简单,并且 Storm Github 中所有examples 都是采用该方式进行打包。
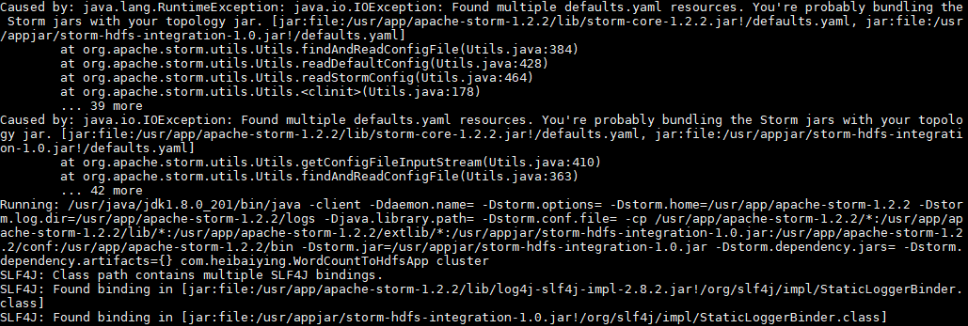
六、打包注意事项 无论采用任何打包方式,都必须排除集群环境中已经提供的 storm jars。这里比较典型的是 storm-core,其在安装目录的 lib 目录下已经存在。
如果你不排除 storm-core,通常会抛出下面的异常:
1 2 3 4 5 6 7 8 9 Caused by: java.lang.RuntimeException: java.io.IOException: Found multiple defaults.yaml resources. You're probably bundling the Storm jars with your topology jar. [jar :file:/usr/app/apache-storm-1.2.2/lib/storm-core-1.2.2.jar!/defaults.yaml, jar :file:/usr/appjar/storm-hdfs-integration-1.0.jar!/defaults.yaml] at org.apache.storm.utils.Utils.findAndReadConfigFile(Utils.java:384) at org.apache.storm.utils.Utils.readDefaultConfig(Utils.java:428) at org.apache.storm.utils.Utils.readStormConfig(Utils.java:464) at org.apache.storm.utils.Utils.<clinit>(Utils.java:178) ... 39 more
参考资料 关于 maven-shade-plugin 的更多配置可以参考: maven-shade-plugin 入门指南
Storm 集成 Redis 详解 一、简介 Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用:
1 2 3 4 5 6 <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-redis</artifactId > <version > ${storm.version}</version > <type > jar</type > </dependency >
Storm-Redis 使用 Jedis 为 Redis 客户端,并提供了如下三个基本的 Bolt 实现:
RedisLookupBolt :从 Redis 中查询数据;RedisStoreBolt :存储数据到 Redis;RedisFilterBolt : 查询符合条件的数据;
RedisLookupBolt、RedisStoreBolt、RedisFilterBolt 均继承自 AbstractRedisBolt 抽象类。我们可以通过继承该抽象类,实现自定义 RedisBolt,进行功能的拓展。
二、集成案例 2.1 项目结构 这里首先给出一个集成案例:进行词频统计并将最后的结果存储到 Redis。项目结构如下:
用例源码下载地址:storm-redis-integration
2.2 项目依赖 项目主要依赖如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <properties > <storm.version > 1.2.2</storm.version > </properties > <dependencies > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-core</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-redis</artifactId > <version > ${storm.version}</version > </dependency > </dependencies >
2.3 DataSourceSpout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class DataSourceSpout extends BaseRichSpout { private List<String> list = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private SpoutOutputCollector spoutOutputCollector; @Override public void open (Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this .spoutOutputCollector = spoutOutputCollector; } @Override public void nextTuple () { String lineData = productData(); spoutOutputCollector.emit(new Values (lineData)); Utils.sleep(1000 ); } @Override public void declareOutputFields (OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields ("line" )); } private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); } }
产生的模拟数据格式如下:
1 2 3 4 5 6 7 8 9 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm
2.4 SplitBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class SplitBolt extends BaseRichBolt { private OutputCollector collector; @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector = collector; } @Override public void execute (Tuple input) { String line = input.getStringByField("line" ); String[] words = line.split("\t" ); for (String word : words) { collector.emit(new Values (word, String.valueOf(1 ))); } } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("word" , "count" )); } }
2.5 CountBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class CountBolt extends BaseRichBolt { private Map<String, Integer> counts = new HashMap <>(); private OutputCollector collector; @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector=collector; } @Override public void execute (Tuple input) { String word = input.getStringByField("word" ); Integer count = counts.get(word); if (count == null ) { count = 0 ; } count++; counts.put(word, count); collector.emit(new Values (word, String.valueOf(count))); } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("word" , "count" )); } }
2.6 WordCountStoreMapper 实现 RedisStoreMapper 接口,定义 tuple 与 Redis 中数据的映射关系:即需要指定 tuple 中的哪个字段为 key,哪个字段为 value,并且存储到 Redis 的何种数据结构中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class WordCountStoreMapper implements RedisStoreMapper { private RedisDataTypeDescription description; private final String hashKey = "wordCount" ; public WordCountStoreMapper () { description = new RedisDataTypeDescription ( RedisDataTypeDescription.RedisDataType.HASH, hashKey); } @Override public RedisDataTypeDescription getDataTypeDescription () { return description; } @Override public String getKeyFromTuple (ITuple tuple) { return tuple.getStringByField("word" ); } @Override public String getValueFromTuple (ITuple tuple) { return tuple.getStringByField("count" ); } }
2.7 WordCountToRedisApp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class WordCountToRedisApp { private static final String DATA_SOURCE_SPOUT = "dataSourceSpout" ; private static final String SPLIT_BOLT = "splitBolt" ; private static final String COUNT_BOLT = "countBolt" ; private static final String STORE_BOLT = "storeBolt" ; private static final String REDIS_HOST = "192.168.200.226" ; private static final int REDIS_PORT = 6379 ; public static void main (String[] args) { TopologyBuilder builder = new TopologyBuilder (); builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout ()); builder.setBolt(SPLIT_BOLT, new SplitBolt ()).shuffleGrouping(DATA_SOURCE_SPOUT); builder.setBolt(COUNT_BOLT, new CountBolt ()).shuffleGrouping(SPLIT_BOLT); JedisPoolConfig poolConfig = new JedisPoolConfig .Builder() .setHost(REDIS_HOST).setPort(REDIS_PORT).build(); RedisStoreMapper storeMapper = new WordCountStoreMapper (); RedisStoreBolt storeBolt = new RedisStoreBolt (poolConfig, storeMapper); builder.setBolt(STORE_BOLT, storeBolt).shuffleGrouping(COUNT_BOLT); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterWordCountToRedisApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalWordCountToRedisApp" , new Config (), builder.createTopology()); } } }
2.8 启动测试 可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 # mvn clean package -D maven.test.skip=true
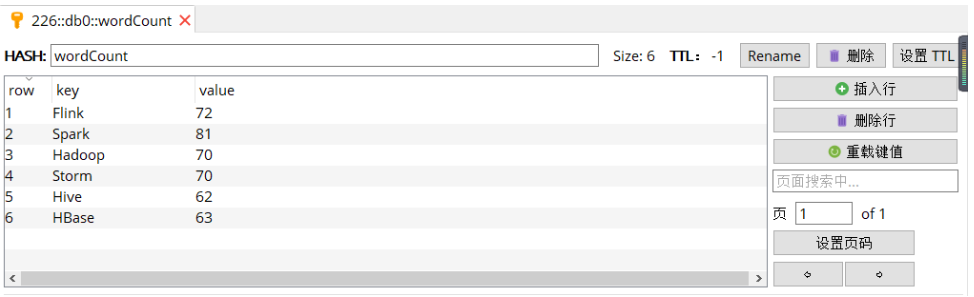
启动后,查看 Redis 中的数据:
三、storm-redis 实现原理 3.1 AbstractRedisBolt RedisLookupBolt、RedisStoreBolt、RedisFilterBolt 均继承自 AbstractRedisBolt 抽象类,和我们自定义实现 Bolt 一样,AbstractRedisBolt 间接继承自 BaseRichBolt。
AbstractRedisBolt 中比较重要的是 prepare 方法,在该方法中通过外部传入的 jedis 连接池配置 ( jedisPoolConfig/jedisClusterConfig) 创建用于管理 Jedis 实例的容器 JedisCommandsInstanceContainer。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public abstract class AbstractRedisBolt extends BaseTickTupleAwareRichBolt { protected OutputCollector collector; private transient JedisCommandsInstanceContainer container; private JedisPoolConfig jedisPoolConfig; private JedisClusterConfig jedisClusterConfig; ...... @Override public void prepare (Map map, TopologyContext topologyContext, OutputCollector collector) { this .collector = collector; if (jedisPoolConfig != null ) { this .container = JedisCommandsContainerBuilder.build(jedisPoolConfig); } else if (jedisClusterConfig != null ) { this .container = JedisCommandsContainerBuilder.build(jedisClusterConfig); } else { throw new IllegalArgumentException ("Jedis configuration not found" ); } } ....... }
JedisCommandsInstanceContainer 的 build() 方法如下,实际上就是创建 JedisPool 或 JedisCluster 并传入容器中。
1 2 3 4 5 6 7 8 9 public static JedisCommandsInstanceContainer build (JedisPoolConfig config) { JedisPool jedisPool = new JedisPool (DEFAULT_POOL_CONFIG, config.getHost(), config.getPort(), config.getTimeout(), config.getPassword(), config.getDatabase()); return new JedisContainer (jedisPool); } public static JedisCommandsInstanceContainer build (JedisClusterConfig config) { JedisCluster jedisCluster = new JedisCluster (config.getNodes(), config.getTimeout(), config.getTimeout(), config.getMaxRedirections(), config.getPassword(), DEFAULT_POOL_CONFIG); return new JedisClusterContainer (jedisCluster); }
3.2 RedisStoreBolt和RedisLookupBolt RedisStoreBolt 中比较重要的是 process 方法,该方法主要从 storeMapper 中获取传入 key/value 的值,并按照其存储类型 dataType 调用 jedisCommand 的对应方法进行存储。
RedisLookupBolt 的实现基本类似,从 lookupMapper 中获取传入的 key 值,并进行查询操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 public class RedisStoreBolt extends AbstractRedisBolt { private final RedisStoreMapper storeMapper; private final RedisDataTypeDescription.RedisDataType dataType; private final String additionalKey; public RedisStoreBolt (JedisPoolConfig config, RedisStoreMapper storeMapper) { super (config); this .storeMapper = storeMapper; RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription(); this .dataType = dataTypeDescription.getDataType(); this .additionalKey = dataTypeDescription.getAdditionalKey(); } public RedisStoreBolt (JedisClusterConfig config, RedisStoreMapper storeMapper) { super (config); this .storeMapper = storeMapper; RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription(); this .dataType = dataTypeDescription.getDataType(); this .additionalKey = dataTypeDescription.getAdditionalKey(); } @Override public void process (Tuple input) { String key = storeMapper.getKeyFromTuple(input); String value = storeMapper.getValueFromTuple(input); JedisCommands jedisCommand = null ; try { jedisCommand = getInstance(); switch (dataType) { case STRING: jedisCommand.set(key, value); break ; case LIST: jedisCommand.rpush(key, value); break ; case HASH: jedisCommand.hset(additionalKey, key, value); break ; case SET: jedisCommand.sadd(key, value); break ; case SORTED_SET: jedisCommand.zadd(additionalKey, Double.valueOf(value), key); break ; case HYPER_LOG_LOG: jedisCommand.pfadd(key, value); break ; case GEO: String[] array = value.split(":" ); if (array.length != 2 ) { throw new IllegalArgumentException ("value structure should be longitude:latitude" ); } double longitude = Double.valueOf(array[0 ]); double latitude = Double.valueOf(array[1 ]); jedisCommand.geoadd(additionalKey, longitude, latitude, key); break ; default : throw new IllegalArgumentException ("Cannot process such data type: " + dataType); } collector.ack(input); } catch (Exception e) { this .collector.reportError(e); this .collector.fail(input); } finally { returnInstance(jedisCommand); } } ......... }
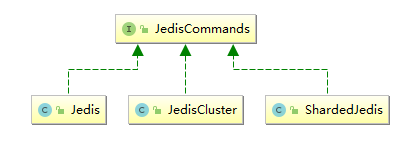
3.3 JedisCommands JedisCommands 接口中定义了所有的 Redis 客户端命令,它有以下三个实现类,分别是 Jedis、JedisCluster、ShardedJedis。Strom 中主要使用前两种实现类,具体调用哪一个实现类来执行命令,由传入的是 jedisPoolConfig 还是 jedisClusterConfig 来决定。
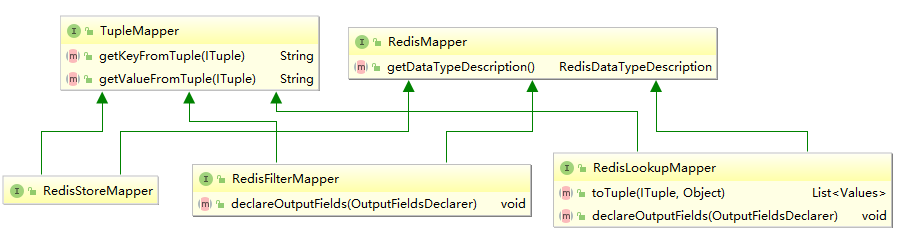
3.4 RedisMapper 和 TupleMapper RedisMapper 和 TupleMapper 定义了 tuple 和 Redis 中的数据如何进行映射转换。
1. TupleMapper TupleMapper 主要定义了两个方法:
2. RedisMapper 定义了获取数据类型的方法 getDataTypeDescription(),RedisDataTypeDescription 中 RedisDataType 枚举类定义了所有可用的 Redis 数据类型:
1 2 3 4 5 public class RedisDataTypeDescription implements Serializable { public enum RedisDataType { STRING, HASH, LIST, SET, SORTED_SET, HYPER_LOG_LOG, GEO } ...... }
3. RedisStoreMapper RedisStoreMapper 继承 TupleMapper 和 RedisMapper 接口,用于数据存储时,没有定义额外方法。
4. RedisLookupMapper RedisLookupMapper 继承 TupleMapper 和 RedisMapper 接口:
定义了 declareOutputFields 方法,声明输出的字段。
定义了 toTuple 方法,将查询结果组装为 Storm 的 Values 的集合,并用于发送。
下面的例子表示从输入 Tuple 的获取 word 字段作为 key,使用 RedisLookupBolt 进行查询后,将 key 和查询结果 value 组装为 values 并发送到下一个处理单元。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class WordCountRedisLookupMapper implements RedisLookupMapper { private RedisDataTypeDescription description; private final String hashKey = "wordCount" ; public WordCountRedisLookupMapper () { description = new RedisDataTypeDescription ( RedisDataTypeDescription.RedisDataType.HASH, hashKey); } @Override public List<Values> toTuple (ITuple input, Object value) { String member = getKeyFromTuple(input); List<Values> values = Lists.newArrayList(); values.add(new Values (member, value)); return values; } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("wordName" , "count" )); } @Override public RedisDataTypeDescription getDataTypeDescription () { return description; } @Override public String getKeyFromTuple (ITuple tuple) { return tuple.getStringByField("word" ); } @Override public String getValueFromTuple (ITuple tuple) { return null ; } }
5. RedisFilterMapper RedisFilterMapper 继承 TupleMapper 和 RedisMapper 接口,用于查询数据时,定义了 declareOutputFields 方法,声明输出的字段。如下面的实现:
1 2 3 4 5 @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("wordName" , "count" )); }
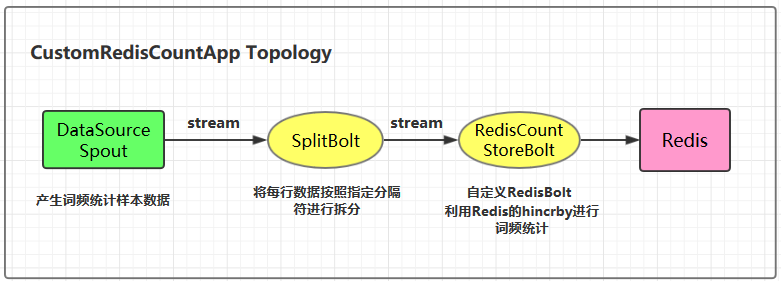
四、自定义RedisBolt实现词频统计 4.1 实现原理 自定义 RedisBolt:主要利用 Redis 中哈希结构的 hincrby key field 命令进行词频统计。在 Redis 中 hincrby 的执行效果如下。hincrby 可以将字段按照指定的值进行递增,如果该字段不存在的话,还会新建该字段,并赋值为 0。通过这个命令可以非常轻松的实现词频统计功能。
1 2 3 4 5 6 7 8 9 redis> HSET myhash field 5 (integer) 1 redis> HINCRBY myhash field 1 (integer) 6 redis> HINCRBY myhash field -1 (integer) 5 redis> HINCRBY myhash field -10 (integer) -5 redis>
4.2 项目结构
4.3 自定义RedisBolt的代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class RedisCountStoreBolt extends AbstractRedisBolt { private final RedisStoreMapper storeMapper; private final RedisDataTypeDescription.RedisDataType dataType; private final String additionalKey; public RedisCountStoreBolt (JedisPoolConfig config, RedisStoreMapper storeMapper) { super (config); this .storeMapper = storeMapper; RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription(); this .dataType = dataTypeDescription.getDataType(); this .additionalKey = dataTypeDescription.getAdditionalKey(); } @Override protected void process (Tuple tuple) { String key = storeMapper.getKeyFromTuple(tuple); String value = storeMapper.getValueFromTuple(tuple); JedisCommands jedisCommand = null ; try { jedisCommand = getInstance(); if (dataType == RedisDataTypeDescription.RedisDataType.HASH) { jedisCommand.hincrBy(additionalKey, key, Long.valueOf(value)); } else { throw new IllegalArgumentException ("Cannot process such data type for Count: " + dataType); } collector.ack(tuple); } catch (Exception e) { this .collector.reportError(e); this .collector.fail(tuple); } finally { returnInstance(jedisCommand); } } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { } }
4.4 CustomRedisCountApp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class CustomRedisCountApp { private static final String DATA_SOURCE_SPOUT = "dataSourceSpout" ; private static final String SPLIT_BOLT = "splitBolt" ; private static final String STORE_BOLT = "storeBolt" ; private static final String REDIS_HOST = "192.168.200.226" ; private static final int REDIS_PORT = 6379 ; public static void main (String[] args) { TopologyBuilder builder = new TopologyBuilder (); builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout ()); builder.setBolt(SPLIT_BOLT, new SplitBolt ()).shuffleGrouping(DATA_SOURCE_SPOUT); JedisPoolConfig poolConfig = new JedisPoolConfig .Builder() .setHost(REDIS_HOST).setPort(REDIS_PORT).build(); RedisStoreMapper storeMapper = new WordCountStoreMapper (); RedisCountStoreBolt countStoreBolt = new RedisCountStoreBolt (poolConfig, storeMapper); builder.setBolt(STORE_BOLT, countStoreBolt).shuffleGrouping(SPLIT_BOLT); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterCustomRedisCountApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalCustomRedisCountApp" , new Config (), builder.createTopology()); } } }
参考资料
Storm Redis Integration
Storm集成HDFS和HBase 一、Storm集成HDFS 1.1 项目结构
本用例源码下载地址:storm-hdfs-integration
1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意:
这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用 <repository> 标签指定 CDH 的仓库地址;
hadoop-common、hadoop-client、hadoop-hdfs 均需要排除 slf4j-log4j12 依赖,原因是 storm-core 中已经有该依赖,不排除的话有 JAR 包冲突的风险;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 <properties > <storm.version > 1.2.2</storm.version > </properties > <repositories > <repository > <id > cloudera</id > <url > https://repository.cloudera.com/artifactory/cloudera-repos/</url > </repository > </repositories > <dependencies > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-core</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-hdfs</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.6.0-cdh5.15.2</version > <exclusions > <exclusion > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 2.6.0-cdh5.15.2</version > <exclusions > <exclusion > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.6.0-cdh5.15.2</version > <exclusions > <exclusion > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > </exclusion > </exclusions > </dependency > </dependencies >
1.3 DataSourceSpout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class DataSourceSpout extends BaseRichSpout { private List<String> list = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private SpoutOutputCollector spoutOutputCollector; @Override public void open (Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this .spoutOutputCollector = spoutOutputCollector; } @Override public void nextTuple () { String lineData = productData(); spoutOutputCollector.emit(new Values (lineData)); Utils.sleep(1000 ); } @Override public void declareOutputFields (OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields ("line" )); } private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); } }
产生的模拟数据格式如下:
1 2 3 4 5 6 7 8 9 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm
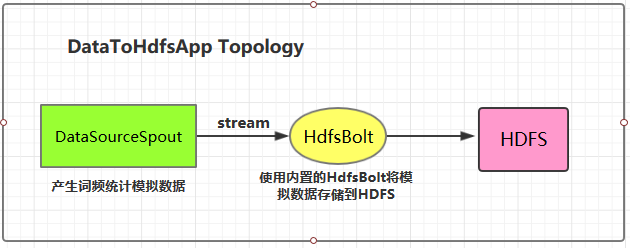
1.4 将数据存储到HDFS 这里 HDFS 的地址和数据存储路径均使用了硬编码,在实际开发中可以通过外部传参指定,这样程序更为灵活。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public class DataToHdfsApp { private static final String DATA_SOURCE_SPOUT = "dataSourceSpout" ; private static final String HDFS_BOLT = "hdfsBolt" ; public static void main (String[] args) { System.setProperty("HADOOP_USER_NAME" , "root" ); RecordFormat format = new DelimitedRecordFormat () .withFieldDelimiter("|" ); SyncPolicy syncPolicy = new CountSyncPolicy (100 ); FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy (1.0f , Units.MB); FileNameFormat fileNameFormat = new DefaultFileNameFormat () .withPath("/storm-hdfs/" ); HdfsBolt hdfsBolt = new HdfsBolt () .withFsUrl("hdfs://hadoop001:8020" ) .withFileNameFormat(fileNameFormat) .withRecordFormat(format) .withRotationPolicy(rotationPolicy) .withSyncPolicy(syncPolicy); TopologyBuilder builder = new TopologyBuilder (); builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout ()); builder.setBolt(HDFS_BOLT, hdfsBolt, 1 ).shuffleGrouping(DATA_SOURCE_SPOUT); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterDataToHdfsApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalDataToHdfsApp" , new Config (), builder.createTopology()); } } }
1.5 启动测试 可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 # mvn clean package -D maven.test.skip=true
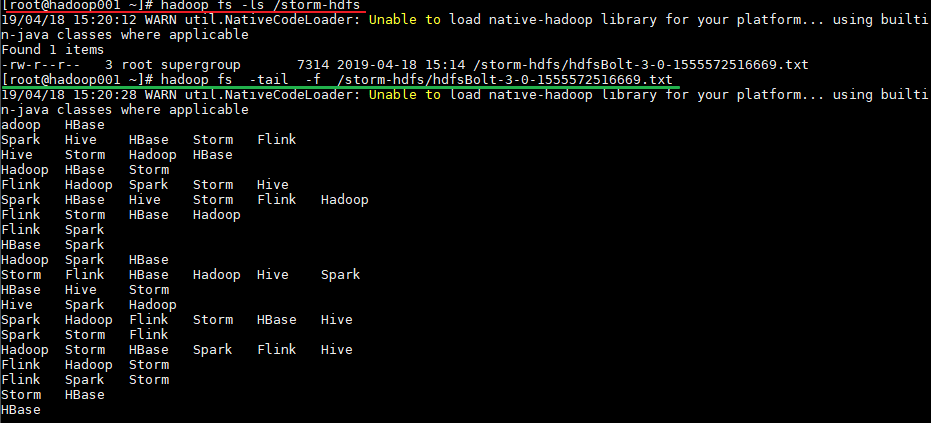
运行后,数据会存储到 HDFS 的 /storm-hdfs 目录下。使用以下命令可以查看目录内容:
1 2 3 4 # 查看目录内容 hadoop fs -ls /storm-hdfs # 监听文内容变化 hadoop fs -tail -f /strom-hdfs/文件名
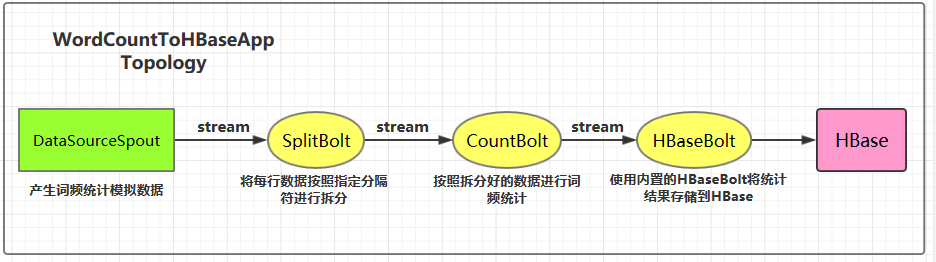
二、Storm集成HBase 2.1 项目结构 集成用例: 进行词频统计并将最后的结果存储到 HBase,项目主要结构如下:
本用例源码下载地址:storm-hbase-integration
2.2 项目主要依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <properties > <storm.version > 1.2.2</storm.version > </properties > <dependencies > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-core</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-hbase</artifactId > <version > ${storm.version}</version > </dependency > </dependencies >
2.3 DataSourceSpout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class DataSourceSpout extends BaseRichSpout { private List<String> list = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private SpoutOutputCollector spoutOutputCollector; @Override public void open (Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this .spoutOutputCollector = spoutOutputCollector; } @Override public void nextTuple () { String lineData = productData(); spoutOutputCollector.emit(new Values (lineData)); Utils.sleep(1000 ); } @Override public void declareOutputFields (OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields ("line" )); } private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); } }
产生的模拟数据格式如下:
1 2 3 4 5 6 7 8 9 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm
2.4 SplitBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class SplitBolt extends BaseRichBolt { private OutputCollector collector; @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector = collector; } @Override public void execute (Tuple input) { String line = input.getStringByField("line" ); String[] words = line.split("\t" ); for (String word : words) { collector.emit(tuple(word, 1 )); } } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("word" , "count" )); } }
2.5 CountBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class CountBolt extends BaseRichBolt { private Map<String, Integer> counts = new HashMap <>(); private OutputCollector collector; @Override public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector=collector; } @Override public void execute (Tuple input) { String word = input.getStringByField("word" ); Integer count = counts.get(word); if (count == null ) { count = 0 ; } count++; counts.put(word, count); collector.emit(new Values (word, String.valueOf(count))); } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) { declarer.declare(new Fields ("word" , "count" )); } }
2.6 WordCountToHBaseApp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class WordCountToHBaseApp { private static final String DATA_SOURCE_SPOUT = "dataSourceSpout" ; private static final String SPLIT_BOLT = "splitBolt" ; private static final String COUNT_BOLT = "countBolt" ; private static final String HBASE_BOLT = "hbaseBolt" ; public static void main (String[] args) { Config config = new Config (); Map<String, Object> hbConf = new HashMap <>(); hbConf.put("hbase.rootdir" , "hdfs://hadoop001:8020/hbase" ); hbConf.put("hbase.zookeeper.quorum" , "hadoop001:2181" ); config.put("hbase.conf" , hbConf); SimpleHBaseMapper mapper = new SimpleHBaseMapper () .withRowKeyField("word" ) .withColumnFields(new Fields ("word" ,"count" )) .withColumnFamily("info" ); HBaseBolt hbase = new HBaseBolt ("WordCount" , mapper) .withConfigKey("hbase.conf" ); TopologyBuilder builder = new TopologyBuilder (); builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout (),1 ); builder.setBolt(SPLIT_BOLT, new SplitBolt (), 1 ).shuffleGrouping(DATA_SOURCE_SPOUT); builder.setBolt(COUNT_BOLT, new CountBolt (),1 ).shuffleGrouping(SPLIT_BOLT); builder.setBolt(HBASE_BOLT, hbase, 1 ).shuffleGrouping(COUNT_BOLT); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterWordCountToRedisApp" , config, builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalWordCountToRedisApp" , config, builder.createTopology()); } } }
2.7 启动测试 可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 # mvn clean package -D maven.test.skip=true
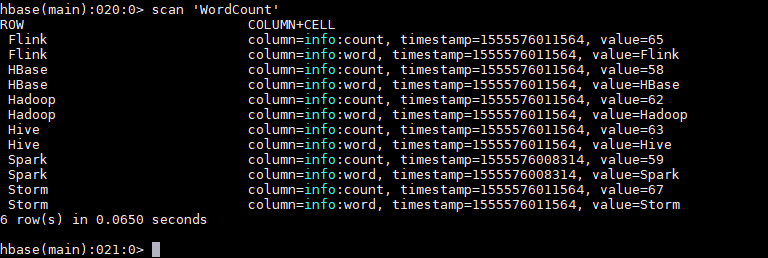
运行后,数据会存储到 HBase 的 WordCount 表中。使用以下命令查看表的内容:
1 hbase > scan 'WordCount'
2.8 withCounterFields 在上面的用例中我们是手动编码来实现词频统计,并将最后的结果存储到 HBase 中。其实也可以在构建 SimpleHBaseMapper 的时候通过 withCounterFields 指定 count 字段,被指定的字段会自动进行累加操作,这样也可以实现词频统计。需要注意的是 withCounterFields 指定的字段必须是 Long 类型,不能是 String 类型。
1 2 3 4 5 SimpleHBaseMapper mapper = new SimpleHBaseMapper () .withRowKeyField("word" ) .withColumnFields(new Fields ("word" )) .withCounterFields(new Fields ("count" )) .withColumnFamily("cf" );
参考资料
Apache HDFS Integration Apache HBase Integration
Storm集成Kafka 一、整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下:
这里我服务端安装的 Kafka 版本为 2.2.0(Released Mar 22, 2019) ,按照官方 0.10.x+ 的整合文档进行整合,不适用于 0.8.x 版本的 Kafka。
二、写入数据到Kafka 2.1 项目结构
2.2 项目主要依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <properties > <storm.version > 1.2.2</storm.version > <kafka.version > 2.2.0</kafka.version > </properties > <dependencies > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-core</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.storm</groupId > <artifactId > storm-kafka-client</artifactId > <version > ${storm.version}</version > </dependency > <dependency > <groupId > org.apache.kafka</groupId > <artifactId > kafka-clients</artifactId > <version > ${kafka.version}</version > </dependency > </dependencies >
2.3 DataSourceSpout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class DataSourceSpout extends BaseRichSpout { private List<String> list = Arrays.asList("Spark" , "Hadoop" , "HBase" , "Storm" , "Flink" , "Hive" ); private SpoutOutputCollector spoutOutputCollector; @Override public void open (Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this .spoutOutputCollector = spoutOutputCollector; } @Override public void nextTuple () { String lineData = productData(); spoutOutputCollector.emit(new Values (lineData)); Utils.sleep(1000 ); } @Override public void declareOutputFields (OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields ("line" )); } private String productData () { Collections.shuffle(list); Random random = new Random (); int endIndex = random.nextInt(list.size()) % (list.size()) + 1 ; return StringUtils.join(list.toArray(), "\t" , 0 , endIndex); } }
产生的模拟数据格式如下:
1 2 3 4 5 6 7 8 9 Spark HBase Hive Flink Storm Hadoop HBase Spark Flink HBase Storm HBase Hadoop Hive Flink HBase Flink Hive Storm Hive Flink Hadoop HBase Hive Hadoop Spark HBase Storm
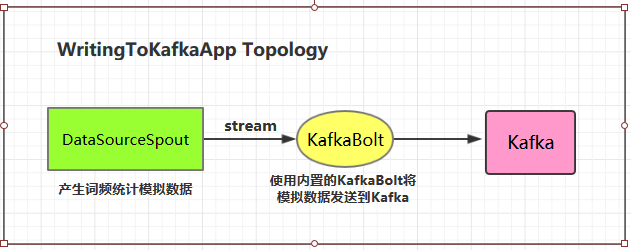
2.4 WritingToKafkaApp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class WritingToKafkaApp { private static final String BOOTSTRAP_SERVERS = "hadoop001:9092" ; private static final String TOPIC_NAME = "storm-topic" ; public static void main (String[] args) { TopologyBuilder builder = new TopologyBuilder (); Properties props = new Properties (); props.put("bootstrap.servers" , BOOTSTRAP_SERVERS); props.put("acks" , "1" ); props.put("key.serializer" , "org.apache.kafka.common.serialization.StringSerializer" ); props.put("value.serializer" , "org.apache.kafka.common.serialization.StringSerializer" ); KafkaBolt bolt = new KafkaBolt <String, String>() .withProducerProperties(props) .withTopicSelector(new DefaultTopicSelector (TOPIC_NAME)) .withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper <>()); builder.setSpout("sourceSpout" , new DataSourceSpout (), 1 ); builder.setBolt("kafkaBolt" , bolt, 1 ).shuffleGrouping("sourceSpout" ); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterWritingToKafkaApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalWritingToKafkaApp" , new Config (), builder.createTopology()); } } }
2.5 测试准备工作 进行测试前需要启动 Kakfa:
1. 启动Kakfa Kafka 的运行依赖于 zookeeper,需要预先启动,可以启动 Kafka 内置的 zookeeper,也可以启动自己安装的:
1 2 3 4 5 # zookeeper启动命令 bin/zkServer.sh start # 内置zookeeper启动命令 bin/zookeeper-server-start.sh config/zookeeper.properties
启动单节点 kafka 用于测试:
1 # bin/kafka-server-start.sh config/server.properties
2. 创建topic 1 2 3 4 5 # 创建用于测试主题 bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 --replication-factor 1 --partitions 1 --topic storm-topic # 查看所有主题 bin/kafka-topics.sh --list --bootstrap-server hadoop001:9092
3. 启动消费者 启动一个消费者用于观察写入情况,启动命令如下:
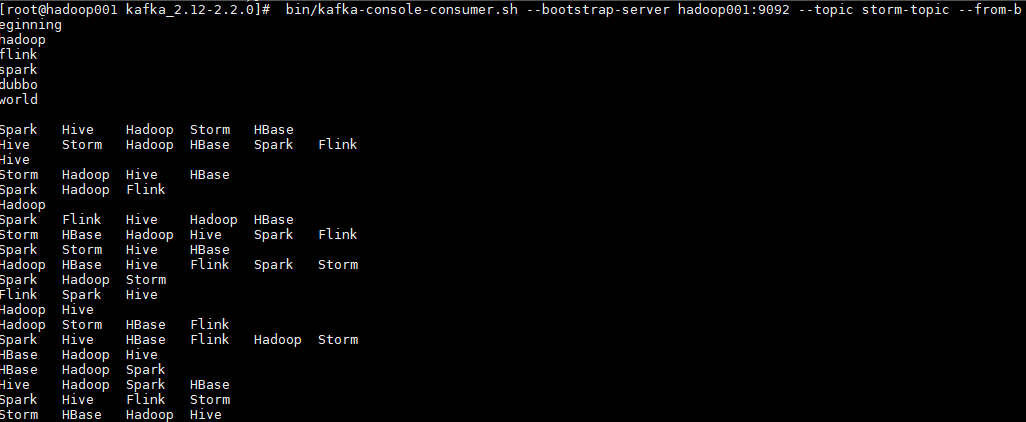
1 # bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic storm-topic --from-beginning
2.6 测试 可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
1 # mvn clean package -D maven.test.skip=true
启动后,消费者监听情况如下:
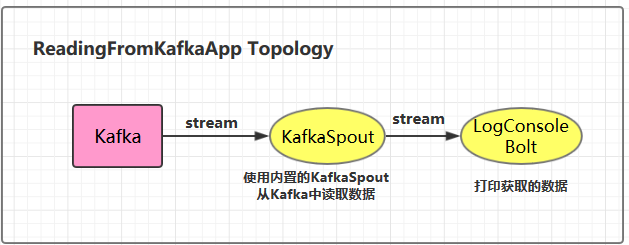
三、从Kafka中读取数据 3.1 项目结构
3.2 ReadingFromKafkaApp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class ReadingFromKafkaApp { private static final String BOOTSTRAP_SERVERS = "hadoop001:9092" ; private static final String TOPIC_NAME = "storm-topic" ; public static void main (String[] args) { final TopologyBuilder builder = new TopologyBuilder (); builder.setSpout("kafka_spout" , new KafkaSpout <>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1 ); builder.setBolt("bolt" , new LogConsoleBolt ()).shuffleGrouping("kafka_spout" ); if (args.length > 0 && args[0 ].equals("cluster" )) { try { StormSubmitter.submitTopology("ClusterReadingFromKafkaApp" , new Config (), builder.createTopology()); } catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) { e.printStackTrace(); } } else { LocalCluster cluster = new LocalCluster (); cluster.submitTopology("LocalReadingFromKafkaApp" , new Config (), builder.createTopology()); } } private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig (String bootstrapServers, String topic) { return KafkaSpoutConfig.builder(bootstrapServers, topic) .setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup" ) .setRetry(getRetryService()) .setOffsetCommitPeriodMs(10_000 ) .build(); } private static KafkaSpoutRetryService getRetryService () { return new KafkaSpoutRetryExponentialBackoff (TimeInterval.microSeconds(500 ), TimeInterval.milliSeconds(2 ), Integer.MAX_VALUE, TimeInterval.seconds(10 )); } }
3.3 LogConsoleBolt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class LogConsoleBolt extends BaseRichBolt { private OutputCollector collector; public void prepare (Map stormConf, TopologyContext context, OutputCollector collector) { this .collector=collector; } public void execute (Tuple input) { try { String value = input.getStringByField("value" ); System.out.println("received from kafka : " + value); collector.ack(input); }catch (Exception e){ e.printStackTrace(); collector.fail(input); } } public void declareOutputFields (OutputFieldsDeclarer declarer) { } }
这里从 value 字段中获取 kafka 输出的值数据。
在开发中,我们可以通过继承 RecordTranslator 接口定义了 Kafka 中 Record 与输出流之间的映射关系,可以在构建 KafkaSpoutConfig 的时候通过构造器或者 setRecordTranslator() 方法传入,并最后传递给具体的 KafkaSpout。
默认情况下使用内置的 DefaultRecordTranslator,其源码如下,FIELDS 中 定义了 tuple 中所有可用的字段:主题,分区,偏移量,消息键,值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class DefaultRecordTranslator <K, V> implements RecordTranslator <K, V> { private static final long serialVersionUID = -5782462870112305750L ; public static final Fields FIELDS = new Fields ("topic" , "partition" , "offset" , "key" , "value" ); @Override public List<Object> apply (ConsumerRecord<K, V> record) { return new Values (record.topic(), record.partition(), record.offset(), record.key(), record.value()); } @Override public Fields getFieldsFor (String stream) { return FIELDS; } @Override public List<String> streams () { return DEFAULT_STREAM; } }
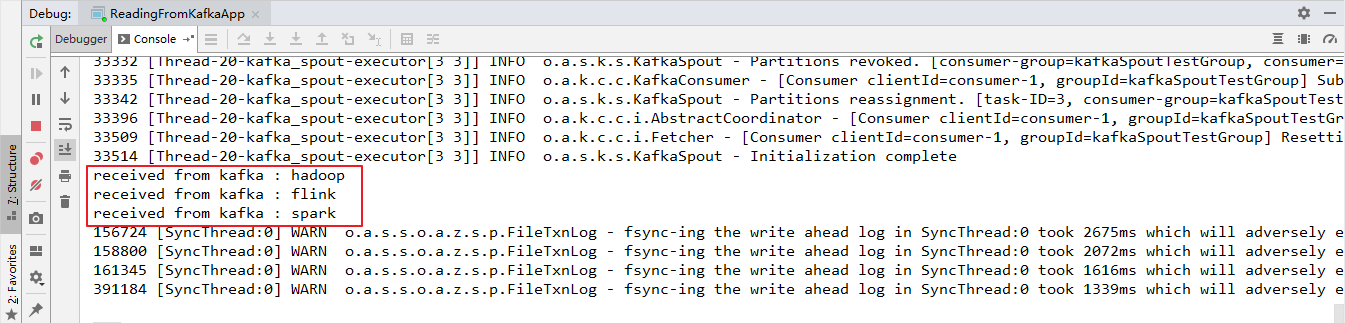
3.4 启动测试 这里启动一个生产者用于发送测试数据,启动命令如下:
1 # bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic storm-topic
本地运行的项目接收到从 Kafka 发送过来的数据:
用例源码下载地址:storm-kafka-integration
参考资料
Storm Kafka Integration (0.10.x+)
Storm单机版本环境搭建 1. 安装环境要求
you need to install Storm’s dependencies on Nimbus and the worker machines. These are:
Java 7+ (Apache Storm 1.x is tested through travis ci against both java 7 and java 8 JDKs)
Python 2.6.6 (Python 3.x should work too, but is not tested as part of our CI enviornment)
按照官方文档 的说明:storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。由于这两个软件在多个框架中都有依赖,其安装步骤单独整理至 :
2. 下载并解压 下载并解压,官方下载地址:http://storm.apache.org/downloads.html
1 # tar -zxvf apache-storm-1.2.2.tar.gz
3. 配置环境变量 添加环境变量:
1 2 export STORM_HOME=/usr/app/apache-storm-1.2.2 export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
4. 启动相关进程 因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,依次执行下面的命令:
1 2 3 4 5 6 7 8 9 10 # 启动zookeeper nohup sh storm dev-zookeeper & # 启动主节点 nimbus nohup sh storm nimbus & # 启动从节点 supervisor nohup sh storm supervisor & # 启动UI界面 ui nohup sh storm ui & # 启动日志查看服务 logviewer nohup sh storm logviewer &
5. 验证是否启动成功 验证方式一:jps 查看进程:
1 2 3 4 5 6 [root@hadoop001 app]# jps 1074 nimbus 1283 Supervisor 620 dev_zookeeper 1485 core 9630 logviewer
验证方式二: 访问 8080 端口,查看 Web-UI 界面:
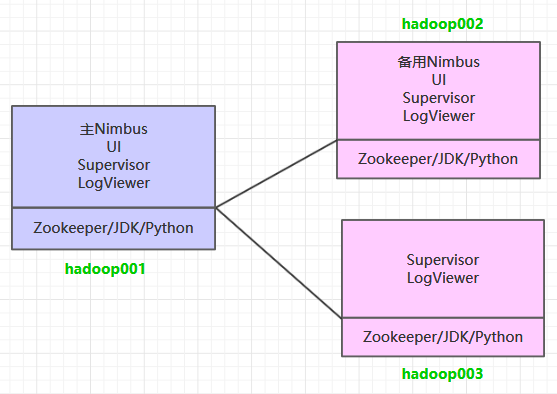
Storm集群环境搭建 一、集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
二、前置条件 Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建 1. 下载并解压 下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
1 2 3 # 解压 tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量 添加环境变量:
1 2 export STORM_HOME=/usr/app/apache-storm-1.2.2 export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
3. 集群配置 修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 storm.zookeeper.servers: - "hadoop001" - "hadoop002" - "hadoop003" nimbus.seeds: ["hadoop001" ,"hadoop002" ]storm.local.dir: "/home/storm" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
4. 安装包分发 将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
1 2 scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/ scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/
四. 启动集群 4.1 启动ZooKeeper集群 分别到三台服务器上启动 ZooKeeper 服务:
4.2 启动Storm集群 因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
1 2 3 4 5 6 7 8 # 启动主节点 nimbus nohup sh storm nimbus & # 启动从节点 supervisor nohup sh storm supervisor & # 启动UI界面 ui nohup sh storm ui & # 启动日志查看服务 logviewer nohup sh storm logviewer &
hadoop003 :
hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
1 2 3 4 # 启动从节点 supervisor nohup sh storm supervisor & # 启动日志查看服务 logviewer nohup sh storm logviewer &
4.3 查看集群 使用 jps 查看进程,三台服务器的进程应该分别如下:
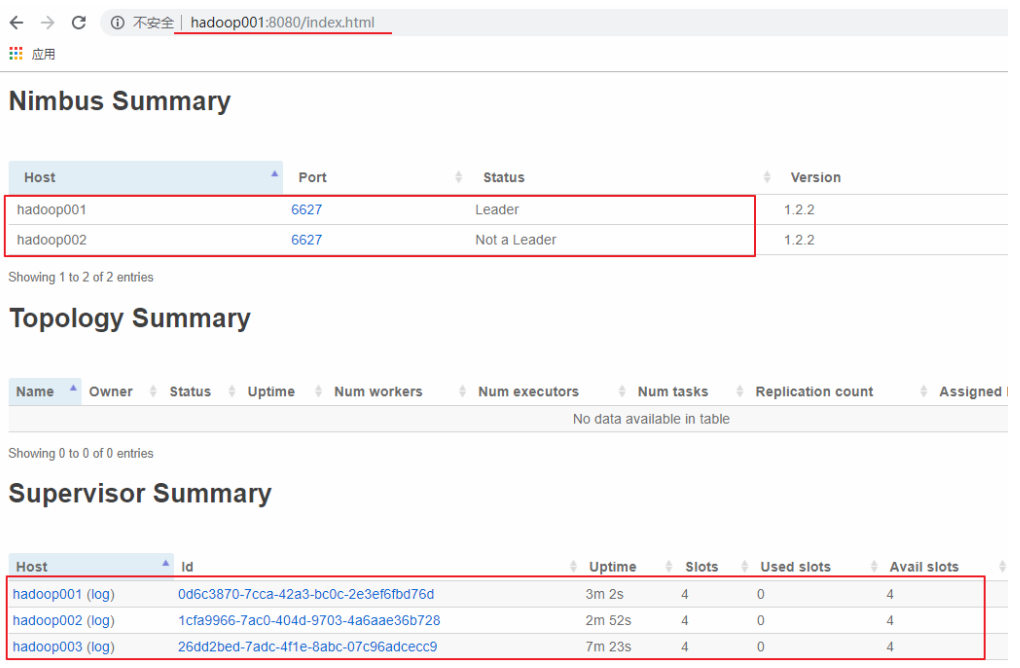
访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
五、高可用验证
这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。






 微信
微信 支付宝
支付宝
