0.学习目标
- 了解过滤功能的基本思路
- 独立实现分类和品牌展示
- 了解规格参数展示
- 实现过滤条件筛选
- 实现已选过滤项回显
- 实现取消选择过滤项
1.过滤功能分析
1.1.功能模块
首先看下页面要实现的效果:
整个过滤部分有3块:
- 顶部的导航,已经选择的过滤条件展示:
- 商品分类面包屑,根据用户选择的商品分类变化
- 其它已选择过滤参数
- 过滤条件展示,又包含3部分
- 展开或收起的过滤条件的按钮
顶部导航要展示的内容跟用户选择的过滤条件有关。
- 比如用户选择了某个商品分类,则面包屑中才会展示具体的分类
- 比如用户选择了某个品牌,列表中才会有品牌信息。
所以,这部分需要依赖第二部分:过滤条件的展示和选择。因此我们先不着急去做。
展开或收起的按钮是否显示,取决于过滤条件现在有多少,如果有很多,那么就没必要展示。所以也是跟第二部分的过滤条件有关。
这样分析来看,我们必须先做第二部分:过滤条件展示。
1.2.问题分析
过滤条件包括:分类过滤、品牌过滤、规格过滤项等。我们必须弄清楚几个问题:
- 什么时候查询这些过滤项?
- 这些过滤项的数据从何而来?
我们先以分类和品牌来讨论一下:
问题1,什么时候查询这些过滤项?
现在,页面加载后就会调用loadData方法,向服务端发起请求,查询商品数据。我们有两种选择:
- 方式1:在查询商品数据的同时,顺便把分类和品牌的过滤数据一起查出来
- 优点:只有一次请求,逻辑简单
- 缺点:该请求处理业务较多,业务复杂,效率较差
- 方式2:在查询商品后,再发一个ajax请求,专门查询分类和品牌的过滤数据
- 优点:每个请求做个业务,耦合度低,每次请求处理效率较高
- 缺点:需要发多次请求
这里考虑使用方式2,让每次请求做自己的事情,减少业务耦合。
问题2,过滤项的数据从何而来?
在我们的数据库中已经有所有的分类和品牌信息。在这个位置,是不是把所有的分类和品牌信息都展示出来呢?
显然不是,用户搜索的条件会对商品进行过滤,而在搜索结果中,不一定包含所有的分类和品牌,直接展示出所有商品分类,让用户选择显然是不合适的。
比如,用户搜索:小米手机,结果中肯定只有手机,而且还得是小米的手机,就把分类和品牌限定死了,此时显示出其它品牌和分类过滤项显然是不合适的。
因此,只有**在搜索过滤的结果中存在的分类和品牌才能作为过滤项让用户选择**。
那么问题来了:我们怎么知道搜索结果中有哪些分类和品牌呢?
答案是:利用elasticsearch提供的聚合功能,**在搜索条件基础上,对搜索结果聚合**,就能知道结果中包含哪些分类和品牌了。当然,规格参数也是一样的。;
2.分类和品牌过滤项
首先,我们先完成分类和品牌的过滤项的查询。
2.1.发起查询请求
首先,定义一个函数,在函数内部发起ajax请求,查询各种过滤项:
1
2
3
4
5
6
7
| loadFilterList(){
ly.http.post("/search/filter", this.search)
.then(resp => {
})
}
|
注意:请求的参数与搜索商品时的请求参数是一致的,因为我们需要**在搜索条件基础上,对搜索结果聚合**。
在created钩子函数中,在查询商品数据的之后,调用这个方法:

2.2.请求分析
上面的请求发出了,我们就知道了下面的信息:
- 请求方式:Post
- 请求路径:/search/filter
- 请求参数:与商品搜索一样,是SearchRequest对象
那么问题来了:以什么格式返回呢?
来看下页面的展示效果:

虽然分类、品牌等过滤内容都不太一样,但是结构相似,都是key和value的结构。
key是过滤参数名称,如:分类
value是过滤的待选项,如:手机,儿童手表。
类似这样的键值对结构,是不是可以用一个Map来表示呢?
而这样的过滤条件很多,所以可以用一个数组表示,其基本结构是这样的:
1
2
3
4
| {
"过滤字段名称1":['过滤项1','过滤项2',...],
"过滤字段名称2":['过滤项1','过滤项2',...]
}
|
类似于java中的:Map<String,List<?>>
注意,这里的分类和品牌过滤项,不仅仅是分类和品牌的名称,还有品牌的图片,id等。所以待选项应该是一个分类和品牌的对象。
2.3.聚合商品分类和品牌
大家不要忘了,索引库中存储的分类和品牌只有id,因此聚合出来的结果也只有id。
而页面中需要的是分类和品牌的对象,所以
我们对分类和品牌聚合,先获取得到的分类和品牌的id,然后再根据id去查询分类和品牌数据。
所以,商品微服务需要提供接口:
- 根据品牌id集合,批量查询品牌;
- 根据分类id集合查询分类(之前已经 写过)
2.2.1.提供查询品牌接口
我们在ly-item-interface中的ItemClient中定义一个新的API:
1
2
3
4
5
6
7
8
|
@GetMapping("/brand/list")
List<BrandDTO> queryBrandByIds(@RequestParam("ids") List<Long> idList);
|
然后再ly-item-service中实现:
BrandController:
1
2
3
4
5
6
7
8
9
|
@GetMapping("list")
public ResponseEntity<List<BrandDTO>> queryBrandByIds(@RequestParam("ids") List<Long> ids){
return ResponseEntity.ok(this.brandService.queryBrandByIds(ids));
}
|
BrandService
1
2
3
4
5
6
7
8
| public List<BrandDTO> queryBrandByIds(List<Long> ids) {
List<Brand> list = brandMapper.selectByIdList(ids);
if(CollectionUtils.isEmpty(list)){
throw new LyException(ExceptionEnum.BRAND_NOT_FOUND);
}
return BeanHelper.copyWithCollection(list, BrandDTO.class);
}
|
BrandMapper,需要基础BaseMapper,以拓展更多功能。
1
2
3
4
5
6
7
8
| package com.leyou.item.mapper;
import com.leyou.common.mapper.BaseMapper;
public interface BrandMapper extends BaseMapper<Brand> {
}
|
2.2.2.查询过滤项的接口
handler
在SearchController中新增一个Handler:
1
2
3
4
5
6
7
8
9
|
@PostMapping("filter")
public ResponseEntity<Map<String, List<?>>> queryFilters(@RequestBody SearchRequest request) {
return ResponseEntity.ok(searchService.queryFilters(request));
}
|
searchService
因为在业务中,与商品搜索一样,都需要构建查询条件,我们把构建查询条件的代码封装成一个方法:
1
2
3
4
| private QueryBuilder buildBasicQuery(SearchRequest request) {
return QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND);
}
|
然后将原来的搜索逻辑修改一下,调用这个方法:

新增searchService业务逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| @Autowired
private ElasticsearchTemplate esTemplate;
public Map<String, List<?>> queryFilters(SearchRequest request) {
Map<String, List<?>> filterList = new LinkedHashMap<>();
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
QueryBuilder basicQuery = buildBasicQuery(request);
queryBuilder.withQuery(basicQuery);
queryBuilder.withPageable(PageRequest.of(0, 1));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
String categoryAgg = "categoryAgg";
queryBuilder.addAggregation(AggregationBuilders.terms(categoryAgg).field("categoryId"));
String brandAgg = "brandAgg";
queryBuilder.addAggregation(AggregationBuilders.terms(brandAgg).field("brandId"));
AggregatedPage<Goods> result = esTemplate.queryForPage(queryBuilder.build(), Goods.class);
Aggregations aggregations = result.getAggregations();
LongTerms cTerms = aggregations.get(categoryAgg);
handleCategoryAgg(cTerms, filterList);
LongTerms bTerms = aggregations.get(brandAgg);
handleBrandAgg(bTerms, filterList);
return filterList;
}
private void handleBrandAgg(LongTerms terms, Map<String, List<?>> filterList) {
List<Long> idList = terms.getBuckets().stream()
.map(LongTerms.Bucket::getKeyAsNumber)
.map(Number::longValue)
.collect(Collectors.toList());
List<BrandDTO> brandList = itemClient.queryBrandByIds(idList);
filterList.put("品牌", brandList);
}
private void handleCategoryAgg(LongTerms terms, Map<String, List<?>> filterList) {
List<Long> idList = terms.getBuckets().stream()
.map(LongTerms.Bucket::getKeyAsNumber)
.map(Number::longValue)
.collect(Collectors.toList());
List<CategoryDTO> categoryList = itemClient.queryCategoryByIds(idList);
filterList.put("分类", categoryList);
}
|
测试:

2.4.页面渲染数据
2.4.1.过滤参数数据结构
来看下页面的展示效果:
虽然分类、品牌内容都不太一样,但是结构相似,都是key和value的结构。
而且页面结构也极为类似:

所以,利用v-for遍历一次生成。
后台返回的数据其基本结构是这样的:
1
2
3
4
| {
"过滤字段名称1":['过滤项1','过滤项2',...],
"过滤字段名称2":['过滤项1','过滤项2',...]
}
|
我们先在data中定义变量,接收这个结果:

然后在查询过滤项的回调函数中,对过滤参数进行保存:
1
2
3
4
5
6
7
| loadFilterList(){
ly.http.post("/search/filter", this.search)
.then(resp => {
this.filterList = resp.data;
})
}
|
然后刷新页面,通过浏览器工具,查看封装的结果:
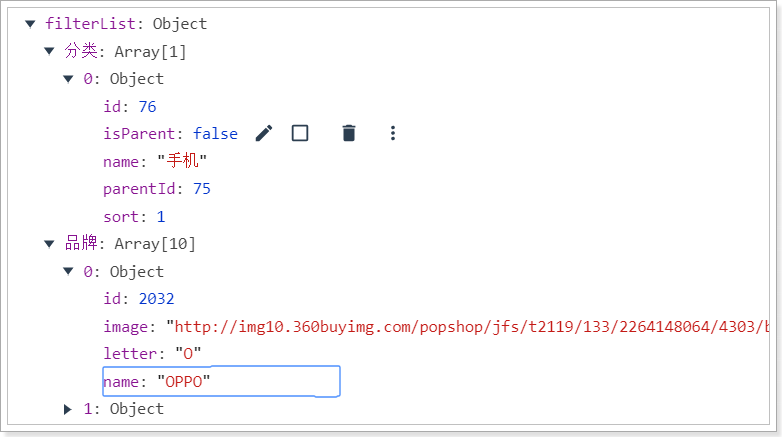
2.4.2.页面渲染数据
首先看页面原来的代码:
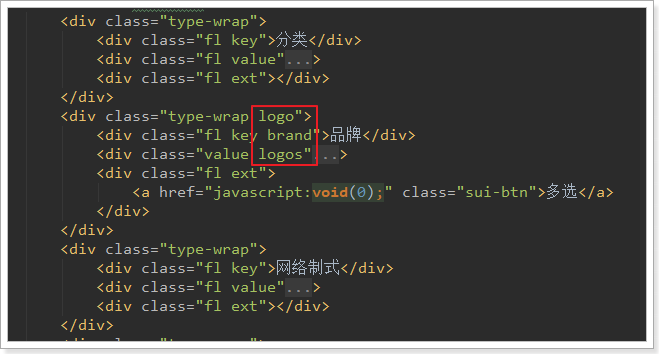
我们注意到,虽然页面元素是一样的,但是品牌会比其它搜搜条件多出一些样式,因为品牌是以图片展示。需要进行特殊处理。数据展示是一致的,我们采用v-for处理,然后通过v-if判断分为两种情况:
- 如果不是品牌,则按照第一个div样式处理
- 是品牌,则按照第二个div样式处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| <div class="type-wrap" v-for="(v,k,i) in filterList" :key="k" v-if="k!=='品牌'">
<div class="fl key">{{k}}</div>
<div class="fl value">
<ul class="type-list">
<li v-for="(o,j) in v" :key="j">
<a>{{o.name}}</a>
</li>
</ul>
</div>
<div class="fl ext"></div>
</div>
<div class="type-wrap logo" v-else>
<div class="fl key brand">{{k}}</div>
<div class="value logos">
<ul class="logo-list">
<li v-for="(o,j) in v" :key="j" v-if="o.image"><img :src="o.image"/></li>
<li style="text-align: center" v-else>
<a style="line-height: 30px; font-size: 12px" href="#">{{o.name}}</a>
</li>
</ul>
</div>
<div class="fl ext">
<a href="javascript:void(0);" class="sui-btn">多选</a>
</div>
</div>
|
结果:

3.生成规格参数过滤
3.1.谋而后动
有3个问题需要先思考清楚:
- 什么时候显示规格参数过滤?
- 如何知道哪些规格需要过滤?
- 要过滤的参数,其可选值是如何获取的?
什么情况下显示有关规格参数的过滤?
可能有同学会想,这还要思考吗?查询商品分类和品牌过滤项的同时,把规格参数过滤项一起返回啊!
但是,如果用户尚未选择商品分类,或者聚合得到的分类数大于1,那么就没必要进行规格参数的聚合。因为不同分类的商品,其规格是不同的,我们无法确定到底有多少规格需要聚合,代码无法进行。
因此,我们在后台需要对聚合得到的商品分类数量进行判断,如果等于1,我们才继续进行规格参数的聚合。
此时,只需要聚合当前分类下的规格参数即可,数量可以确定。
如何知道哪些规格需要过滤?
那么,我们是不是把数据库中的所有规格参数都拿来过滤呢?
显然不是!
因为并不是所有的规格参数都可以用来过滤。
庆幸的是,我们在设计规格参数时,已经标记了某些规格可搜索,某些不可搜索,还记得SpecParam中的searching字段吗?
因此,一旦商品分类确定,我们就可以根据商品分类查询到其对应的规格参数,并过滤哪些searching值为true的规格参数,然后对这些参数聚合即可。
要过滤的参数,其可选值是如何获取的?
虽然数据库中有所有的规格参数的可能值,但是不能把一切数据都用来供用户选择。
与商品分类和品牌一样,应该是结果中有哪些规格参数值,就显示哪些。
即:**在搜索条件基础上,对搜索结果聚合**,得到规格参数的待选项。
比如:用户搜索了OPPO 手机,那么过滤项中只应该有OPPO可能存在的屏幕尺寸,比如5.5以上的,不会存在5.5以下的尺寸让你选择。
3.3.动手实践
接下来,我们就用代码实现刚才的思路。
总结一下,应该是以下几步:
- 1)用户搜索得到商品,并聚合出商品分类(已完成)
- 2)判断分类数量是否等于1,如果是则进行规格参数聚合
- 3)先根据分类,查找可以用来搜索的规格
- 4)在用户搜索结果的基础上,对规格参数进行聚合
- 5)将规格参数聚合结果整理后返回
3.3.1. 返回聚合得到的分类id
我们修改处理分类聚合的方法,使其返回得到的分类id集合,方便下面判断分类的数量:
1
2
3
4
5
6
7
8
9
10
11
12
| private List<Long> handleCategoryAgg(LongTerms terms, Map<String, List<?>> filterList) {
List<Long> idList = terms.getBuckets().stream()
.map(LongTerms.Bucket::getKeyAsNumber)
.map(Number::longValue)
.collect(Collectors.toList());
List<CategoryDTO> categoryList = itemClient.queryCategoryByIds(idList);
filterList.put("分类", categoryList);
return idList;
}
|
3.3.2.判断是否需要聚合
在queryFilter方法中,聚合得到商品分类后,判断分类的个数,如果是1个则进行规格聚合:

此处调用了一个handleSpecAgg方法,处理规格参数聚合。
3.3.3.获取需要聚合的规格参数
然后,在handleSpecAgg中我们需要根据商品分类,查询所有可用于搜索的规格参数:

3.3.4.聚合规格参数
在handleSpecAgg中,添加聚合条件。
因为规格参数保存时是specs的属性,因此所有的规格参数都会有一个specs.的前缀,以及.keyword后缀

这里把规格参数的名称作为了聚合名称,因此取出结果时,也要以参数名来取
3.3.5.解析聚合结果
在handleSpecAgg中,解析聚合得到的结果,并封装到map中

3.3.6.完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| private void handleSpecAgg(Long cid, QueryBuilder basicQuery, Map<String, List<?>> filterList) {
List<SpecParamDTO> specParams = itemClient.querySpecParams(null, cid, true);
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(basicQuery);
queryBuilder.withPageable(PageRequest.of(0, 1));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
for (SpecParamDTO param : specParams) {
String name = param.getName();
queryBuilder.addAggregation(AggregationBuilders.terms(name).field("specs." + name + ".keyword"));
}
AggregatedPage<Goods> result = esTemplate.queryForPage(queryBuilder.build(), Goods.class);
Aggregations aggregations = result.getAggregations();
for (SpecParamDTO param : specParams) {
String name = param.getName();
StringTerms terms = aggregations.get(name);
List<String> paramValues = terms.getBuckets()
.stream()
.map(StringTerms.Bucket::getKeyAsString)
.filter(StringUtils::isNotEmpty)
.collect(Collectors.toList());
filterList.put(name, paramValues);
}
}
|
3.3.7.测试结果:
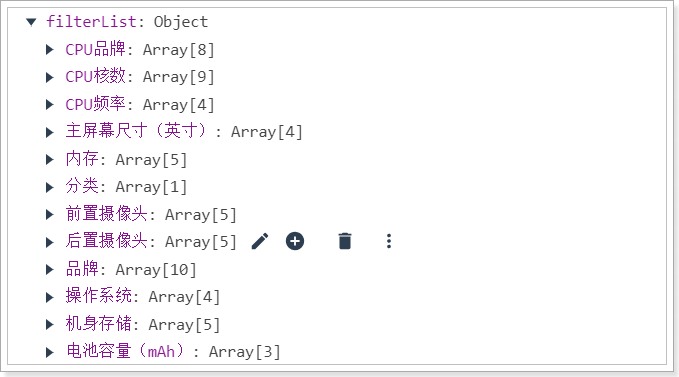
3.3.8.整个SearchService的完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
| package com.leyou.search.service;
import com.fasterxml.jackson.core.type.TypeReference;
import com.leyou.common.enums.ExceptionEnum;
import com.leyou.common.exceptions.LyException;
import com.leyou.common.utils.JsonUtils;
import com.leyou.common.utils.NumberUtils;
import com.leyou.common.vo.PageResult;
import com.leyou.item.client.ItemClient;
import com.leyou.item.dto.*;
import com.leyou.search.pojo.Goods;
import com.leyou.search.pojo.SearchRequest;
import com.leyou.search.repository.GoodsRepository;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.LongTerms;
import org.elasticsearch.search.aggregations.bucket.terms.StringTerms;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.query.FetchSourceFilter;
import org.springframework.data.elasticsearch.core.query.FetchSourceFilterBuilder;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.stream.Collectors;
@Service
public class SearchService {
@Autowired
private ItemClient itemClient;
public Goods buildGoods(SpuDTO spu) {
String categoryNames = itemClient.queryCategoryByIds(spu.getCategoryIds())
.stream().map(CategoryDTO::getName).collect(Collectors.joining(","));
BrandDTO brand = itemClient.queryBrandById(spu.getBrandId());
String all = spu.getName() + categoryNames + brand.getName();
List<SkuDTO> skuList = itemClient.querySkuBySpuId(spu.getId());
List<Map<String, Object>> skuMap = new ArrayList<>();
for (SkuDTO sku : skuList) {
Map<String, Object> map = new HashMap<>();
map.put("id", sku.getId());
map.put("price", sku.getPrice());
map.put("title", sku.getTitle());
map.put("image", StringUtils.substringBefore(sku.getImages(), ","));
skuMap.add(map);
}
Set<Long> price = skuList.stream().map(SkuDTO::getPrice).collect(Collectors.toSet());
Map<String, Object> specs = new HashMap<>();
List<SpecParamDTO> specParams = itemClient.querySpecParams(null, spu.getCid3(), true);
SpuDetailDTO spuDetail = itemClient.querySpuDetailById(spu.getId());
Map<Long, Object> genericSpec = JsonUtils.toMap(spuDetail.getGenericSpec(), Long.class, Object.class);
Map<Long, List<String>> specialSpec = JsonUtils.nativeRead(spuDetail.getSpecialSpec(), new TypeReference<Map<Long, List<String>>>() {
});
for (SpecParamDTO specParam : specParams) {
String key = specParam.getName();
Object value = null;
if (specParam.getGeneric()) {
value = genericSpec.get(specParam.getId());
} else {
value = specialSpec.get(specParam.getId());
}
if(specParam.getNumeric()){
value = chooseSegment(value, specParam);
}
specs.put(key, value);
}
Goods goods = new Goods();
goods.setBrandId(spu.getBrandId());
goods.setCategoryId(spu.getCid3());
goods.setId(spu.getId());
goods.setSubTitle(spu.getSubTitle());
goods.setCreateTime(spu.getCreateTime().getTime());
goods.setSkus(JsonUtils.toString(skuMap));
goods.setSpecs(specs);
goods.setPrice(price);
goods.setAll(all);
return goods;
}
private String chooseSegment(Object value, SpecParamDTO p) {
if(value == null || StringUtils.isBlank(value.toString())){
return "其它";
}
double val = NumberUtils.toDouble(value.toString());
String result = "其它";
for (String segment : p.getSegments().split(",")) {
String[] segs = segment.split("-");
double begin = NumberUtils.toDouble(segs[0]);
double end = Double.MAX_VALUE;
if(segs.length == 2){
end = NumberUtils.toDouble(segs[1]);
}
if(val >= begin && val < end){
if(segs.length == 1){
result = segs[0] + p.getUnit() + "以上";
}else if(begin == 0){
result = segs[1] + p.getUnit() + "以下";
}else{
result = segment + p.getUnit();
}
break;
}
}
return result;
}
@Autowired
private GoodsRepository goodsRepository;
public PageResult<Goods> search(SearchRequest request) {
String key = request.getKey();
if (StringUtils.isBlank(key)) {
throw new LyException(ExceptionEnum.GOODS_NOT_FOUND);
}
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withSourceFilter(new FetchSourceFilter(
new String[]{"id","skus","subTitle"}, null));
QueryBuilder basicQuery = buildBasicQuery(request);
queryBuilder.withQuery(basicQuery);
int page = request.getPage() - 1;
int size = request.getSize();
queryBuilder.withPageable(PageRequest.of(page, size));
Page<Goods> result = goodsRepository.search(queryBuilder.build());
int totalPages = result.getTotalPages();
long total = result.getTotalElements();
List<Goods> list = result.getContent();
return new PageResult<>(total, totalPages, list);
}
private QueryBuilder buildBasicQuery(SearchRequest request) {
return QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND);
}
@Autowired
private ElasticsearchTemplate esTemplate;
public Map<String, List<?>> queryFilters(SearchRequest request) {
Map<String, List<?>> filterList = new LinkedHashMap<>();
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
QueryBuilder basicQuery = buildBasicQuery(request);
queryBuilder.withQuery(basicQuery);
queryBuilder.withPageable(PageRequest.of(0, 1));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
String categoryAgg = "categoryAgg";
queryBuilder.addAggregation(AggregationBuilders.terms(categoryAgg).field("categoryId"));
String brandAgg = "brandAgg";
queryBuilder.addAggregation(AggregationBuilders.terms(brandAgg).field("brandId"));
AggregatedPage<Goods> result = esTemplate.queryForPage(queryBuilder.build(), Goods.class);
Aggregations aggregations = result.getAggregations();
LongTerms cTerms = aggregations.get(categoryAgg);
List<Long> idList = handleCategoryAgg(cTerms, filterList);
LongTerms bTerms = aggregations.get(brandAgg);
handleBrandAgg(bTerms, filterList);
if (idList != null && idList.size() == 1) {
handleSpecAgg(idList.get(0), basicQuery, filterList);
}
return filterList;
}
private void handleSpecAgg(Long cid, QueryBuilder basicQuery, Map<String, List<?>> filterList) {
List<SpecParamDTO> specParams = itemClient.querySpecParams(null, cid, true);
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(basicQuery);
queryBuilder.withPageable(PageRequest.of(0, 1));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
for (SpecParamDTO param : specParams) {
String name = param.getName();
queryBuilder.addAggregation(AggregationBuilders.terms(name).field("specs." + name+".keyword"));
}
AggregatedPage<Goods> result = esTemplate.queryForPage(queryBuilder.build(), Goods.class);
Aggregations aggregations = result.getAggregations();
for (SpecParamDTO param : specParams) {
String name = param.getName();
StringTerms terms = aggregations.get(name);
List<String> paramValues = terms.getBuckets()
.stream()
.map(StringTerms.Bucket::getKeyAsString)
.filter(StringUtils::isNotEmpty)
.collect(Collectors.toList());
filterList.put(name, paramValues);
}
}
private void handleBrandAgg(LongTerms terms, Map<String, List<?>> filterList) {
List<Long> idList = terms.getBuckets().stream()
.map(LongTerms.Bucket::getKeyAsNumber)
.map(Number::longValue)
.collect(Collectors.toList());
List<BrandDTO> brandList = itemClient.queryBrandByIds(idList);
filterList.put("品牌", brandList);
}
private List<Long> handleCategoryAgg(LongTerms terms, Map<String, List<?>> filterList) {
List<Long> idList = terms.getBuckets().stream()
.map(LongTerms.Bucket::getKeyAsNumber)
.map(Number::longValue)
.collect(Collectors.toList());
List<CategoryDTO> categoryList = itemClient.queryCategoryByIds(idList);
filterList.put("分类", categoryList);
return idList;
}
}
|
3.4.页面渲染
3.4.1.渲染规格过滤条件
刷新页面,发现出事了:

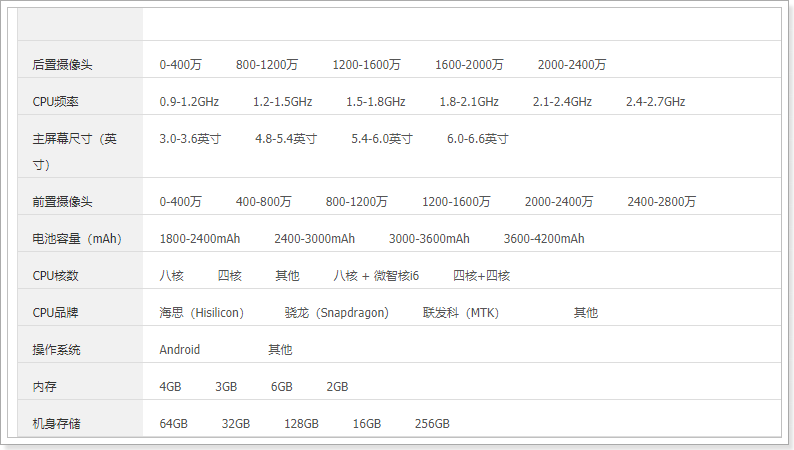
除了分类和品牌外,其它的规格过滤项没有正常显示出数据,为什么呢?
原因是待选项的格式不同:
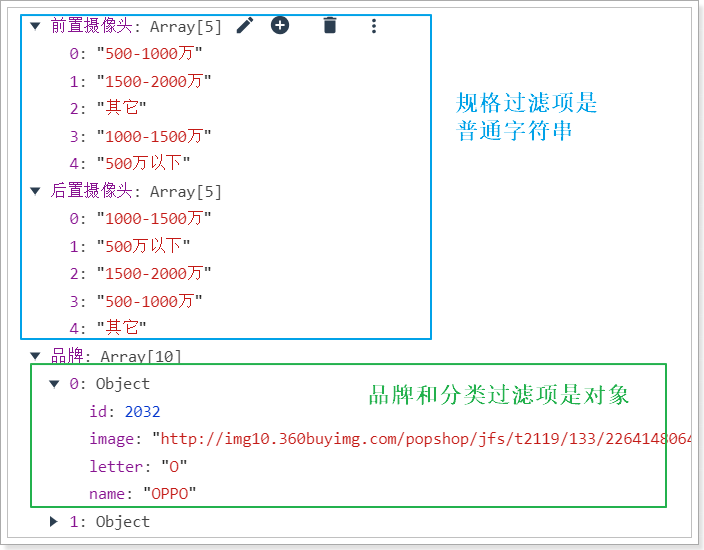
我们需要略做处理:

最后的结果:
3.4.2.展示或收起过滤条件
是不是感觉显示的太多了,我们可以通过按钮点击来展开和隐藏部分内容:
我们在data中定义变量,记录展开或隐藏的状态:

然后在按钮绑定点击事件,以改变showMore的取值:

在展示规格时,对showMore进行判断:

OK!
4.过滤条件的筛选
当我们点击页面的过滤项,要做哪些事情?
- 把过滤条件保存在search对象中
- 监控search属性变化,如果有新的值,则发起请求,重新查询商品及过滤项
- 在页面顶部展示已选择的过滤项
4.1.保存过滤项
4.1.1.定义属性
我们把已选择的过滤项保存在search中,因为不确定用户会选中几个,会选中什么,所以我们用一个对象(Map)来保存可能被选中的键值对:

要注意,在created构造函数中会对search进行初始化,可能会覆盖filter的值,所以我们在created函数中对filter做初始化判断:

4.1.2.绑定点击事件
给所有的过滤项绑定点击事件:

要注意,点击事件传2个参数:
- k:过滤项的名称
- option或option.id:当前过滤项的值或者id(因为分类和品牌要拿id去索引库过滤)
在点击事件中,保存过滤项到selectedFilter:
1
2
3
4
5
6
7
8
| selectFilter(key,val){
const {...obj} = this.search.filter;
obj[key] = val;
this.search.filter = obj;
}
|
然后通过watch监控search.filter的变化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| watch: {
"search.filter":{
handler(val) {
const {key, ...obj} = this.search;
window.location.hash = "#" + ly.stringify(obj);
this.loadData();
this.loadFilterList();
}
}
}
|
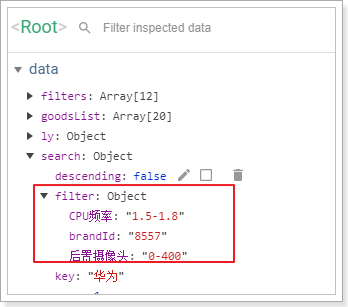
我们刷新页面,点击后通过浏览器功能查看search.filter的属性变化:
并且,此时浏览器地址也发生了变化:
1
| http://www.leyou.com/search.html?key=%E6%89%8B%E6%9C%BA#%E5%93%81%E7%89%8C=15127&CPU%E5%93%81%E7%89%8C=%E8%81%94%E5%8F%91%E7%A7%91%EF%BC%88MTK%EF%BC%89&CPU%E6%A0%B8%E6%95%B0=%E5%9B%9B%E6%A0%B8
|
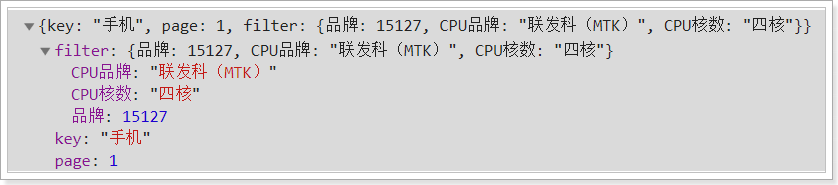
网络请求也正常发出:
4.2.后台添加过滤条件
既然请求已经发送到了后台,那接下来我们就在后台去添加这些条件:
4.2.1.拓展请求对象
我们需要在请求类:SearchRequest中添加属性,接收过滤属性。过滤属性都是键值对格式,但是key不确定,所以用一个map来接收即可,记得加 getter,setter方法。
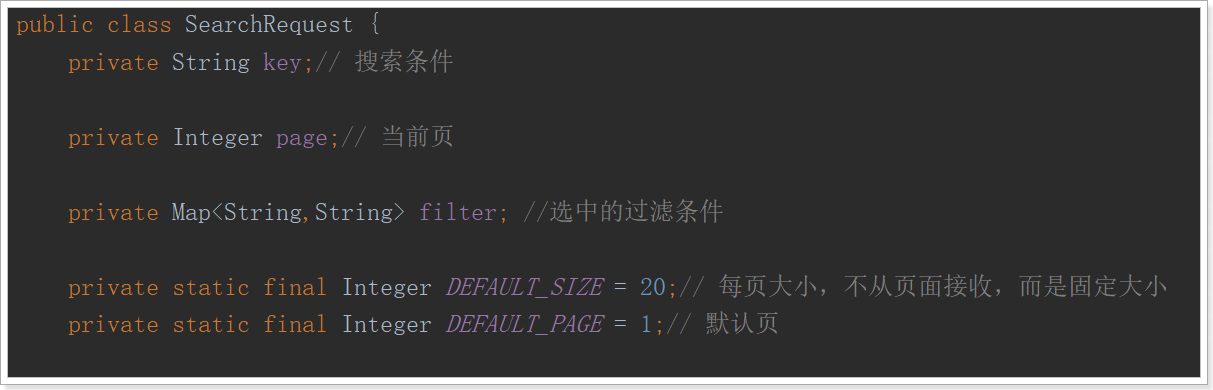
4.2.2.添加过滤条件
目前,我们的基本查询是这样的:
1
2
3
4
| private QueryBuilder buildBasicQuery(SearchRequest request) {
return QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND);
}
|
现在,我们要把页面传递的过滤条件也进入进去。
因此不能在使用普通的查询,而是要用到BooleanQuery,基本结构是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| GET goods/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"all": {
"query": "手机",
"operator": "and"
}
}
}
],
"filter": [
{
"term": {
"brandId": 18374
}
},
{
"term": {
"specs.前置摄像头.keyword": "1500-2000万"
}
}
]
}
}
}
|
所以,我们对原来的基本查询进行改造:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
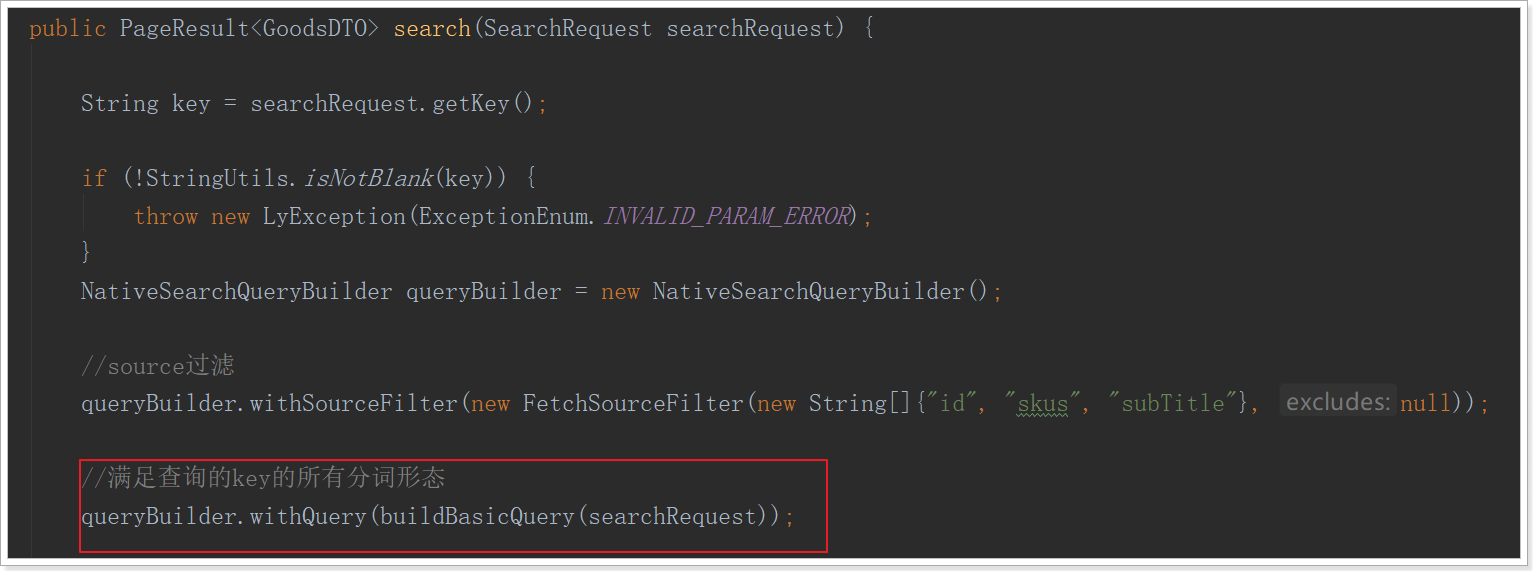
| private QueryBuilder buildBasicQuery(SearchRequest request) {
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.must(QueryBuilders.matchQuery("all", request.getKey()).operator(Operator.AND));
for (Map.Entry<String, String> entry : request.getFilter().entrySet()) {
String key = entry.getKey();
if ("分类".equals(key)) {
key = "categoryId";
} else if ("品牌".equals(key)) {
key = "brandId";
} else {
key = "specs." + key + ".keyword";
}
queryBuilder.filter(QueryBuilders.termQuery(key, entry.getValue()));
}
return queryBuilder;
}
|
其它不变,确认search中的查询方法的查询参数也是调用buildBasicQuery。
4.3.页面测试
我们先不点击过滤条件,直接搜索手机:
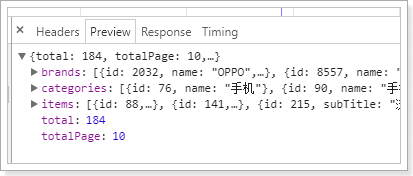
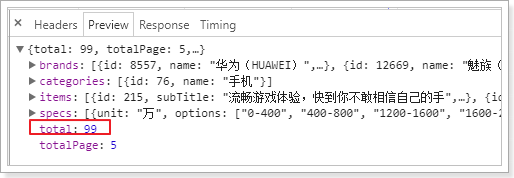
总共184条
接下来,我们点击一个过滤条件:
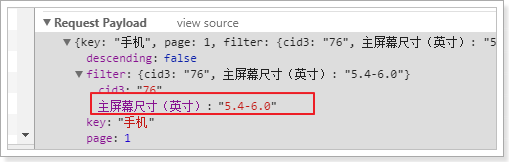
得到的结果:
5.页面展示选择的过滤项(作业)
5.1.商品分类面包屑
当用户选择一个商品分类以后,我们应该在过滤模块的上方展示一个面包屑,把三级商品分类都显示出来。
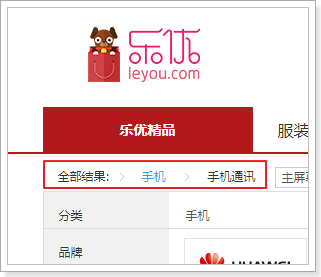
用户选择的商品分类就存放在search.filter中,但是里面只有第三级分类的id:cid3
我们需要根据它查询出所有三级分类的id及名称
5.1.1.提供查询分类接口
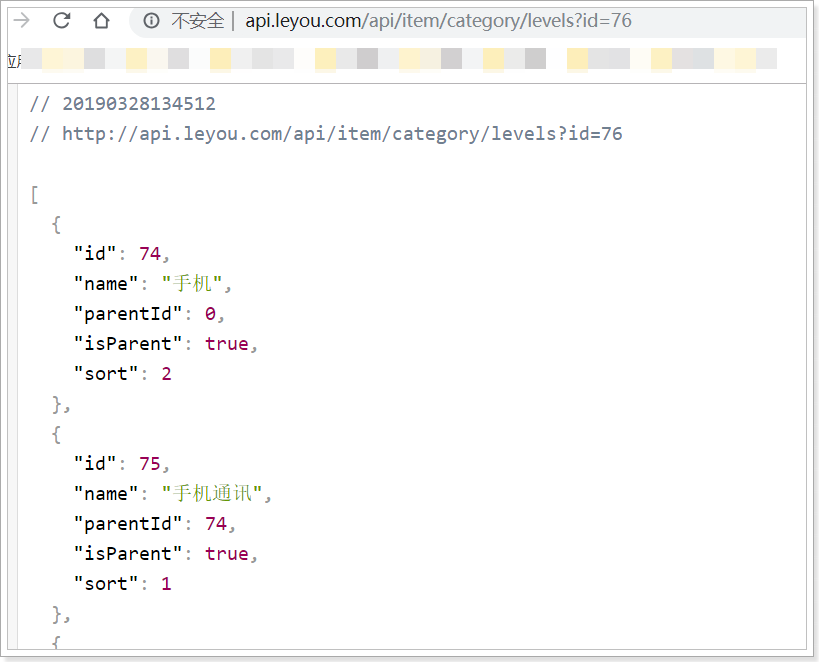
我们在商品微服务ly-item-service的CategoryController中提供一个根据三级分类id查询1~3级分类集合的方法:
Controller
1
2
3
4
5
6
7
8
9
|
@GetMapping("/levels/")
public ResponseEntity<List<CategoryDTO>> queryAllByCid3(@RequestParam("id") Long id){
return ResponseEntity.ok(categoryService.queryAllByCid3(id));
}
|
Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public List<CategoryDTO> queryAllByCid3(Long id) {
Category c3 = categoryMapper.selectByPrimaryKey(id);
if (c3 == null) {
throw new LyException(ExceptionEnum.CATEGORY_NOT_FOUND);
}
Category c2 = categoryMapper.selectByPrimaryKey(c3.getParentId());
if (c2 == null) {
throw new LyException(ExceptionEnum.CATEGORY_NOT_FOUND);
}
Category c1 = categoryMapper.selectByPrimaryKey(c2.getParentId());
if (c1 == null) {
throw new LyException(ExceptionEnum.CATEGORY_NOT_FOUND);
}
List<Category> list = Arrays.asList(c1, c2, c3);
return BeanHelper.copyWithCollection(list, CategoryDTO.class);
}
|
测试:
5.1.2.页面展示面包屑
我们先在data中定义变量,记录商品分类的信息:

后台提供了查询接口,下面的问题是,我们在哪里去查询接口?
大家首先想到的肯定是当用户点击以后。但是用户点击的可能不是分类,所以我们还要判断是否是分类选项,如果是,则查询分类即可。
但是,有没有考虑过这种情况:
- 如果在搜索条件基础上,本身就剩下了一种分类,此时不再需要对分类进行过滤 了,用户无需点击,那么查询也不会触发了。
所以,我们可以再过滤项加载完毕后,判断分类的数量是否只剩下一个,如果是,说明有两种情况:
- 用户点击了分类,过滤后只剩下一个
- 用户每点击,但是搜索结果本来就只有一个分类
无论是哪一种,我们都可以去查询分类信息,渲染面包屑了:

渲染:
刷新页面:
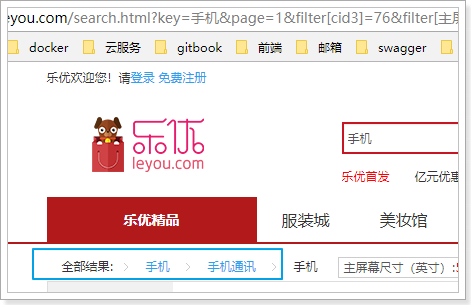
5.2.其它过滤项
接下来,我们需要在页面展示用户已选择的过滤项,如图:
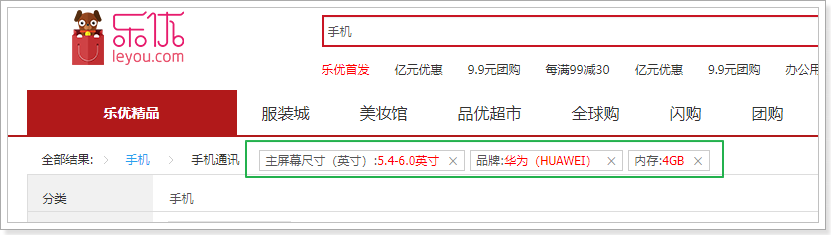
我们知道,所有已选择过滤项都保存在search.filter中,因此在页面遍历并展示即可。
但这里有个问题,filter中数据的格式:
基本有3类数据:
- 商品分类:这个不需要展示,分类展示在面包屑位置
- 品牌:这个要展示,但是其key和值不合适,我们不能显示一个id在页面。需要找到其name值
- 规格:直接展示
因此,我们在页面上这样处理:
1
2
3
4
5
6
7
|
<ul class="tags-choose">
<li class="tag" v-for="(v,k) in search.filter" v-if="k !== '分类'">
{{k}}:<span style="color: red">{{getFilterValue(k,v)}}</span>
<i class="sui-icon icon-tb-close"></i>
</li>
</ul>
|
- 判断如果
k !== '分类'说明是不商品分类,可以显示
- 值的处理比较复杂,我们用一个方法
getFilterValue(k,v)来处理,调用时把k和v都传递
方法内部:
1
2
3
4
5
6
7
8
9
| getFilterValue(key,value){
if(!this.filterList[key]){
return "";
}
if(key === '品牌'){
return this.filterList[key][0].name;
}
return value;
}
|
然后刷新页面,即可看到效果:
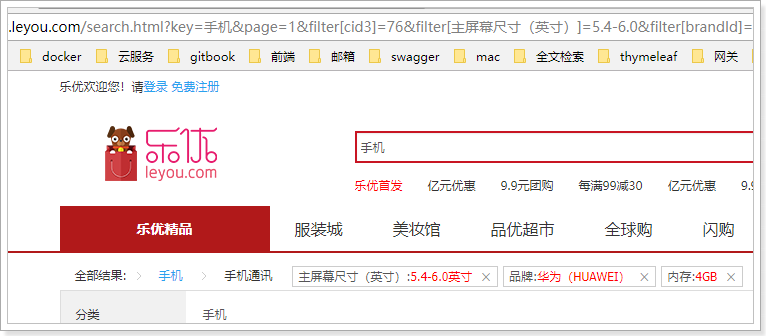
5.3.隐藏已经选择的过滤项
现在,我们已经实现了已选择过滤项的展示,但是你会发现一个问题:
已经选择的过滤项,在过滤列表中依然存在:
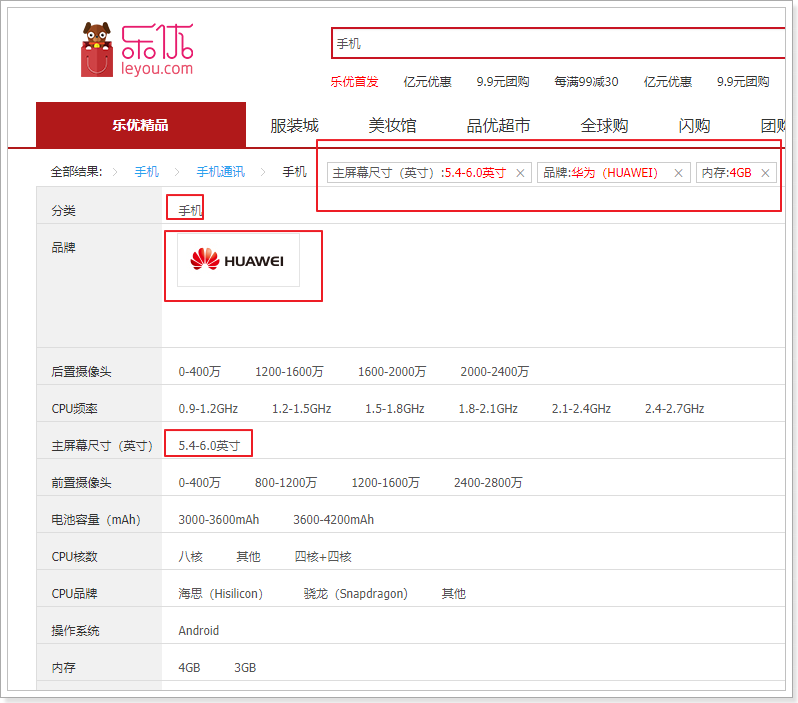
这些已经选择的过滤项,应该从列表中移除。
怎么做呢?
你必须先知道用户选择了什么。用户选择的项保存在search.filter中:
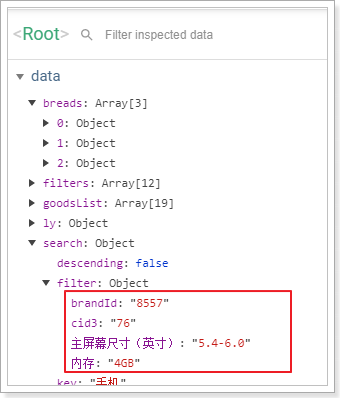
我们可以编写一个计算属性,把filters中的 已经被选择的key过滤掉:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| computed:{
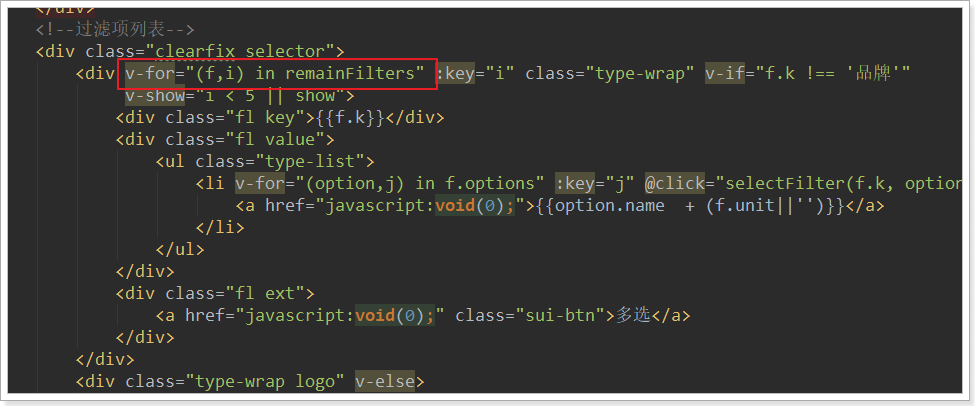
remainFilters(){
const keys = Object.keys(this.search.filter);
const obj = {};
Object.keys(this.filterList).forEach(key => {
if(!keys.includes(key) && this.filterList[key].length > 1){
obj[key] = this.filterList[key];
}
});
return obj;
}
}
|
然后页面不再直接遍历filters,而是遍历remainFilters
刷新页面:

6.取消过滤项(作业)
我们能够看到,每个过滤项后面都有一个小叉,当点击后,应该取消对应条件的过滤。
思路非常简单:
- 给小叉绑定点击事件
- 点击后把过滤项从
search.filter中移除,页面会自动刷新,OK
绑定点击事件:
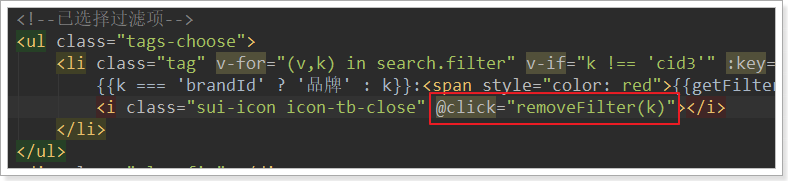
绑定点击事件时,把k传递过去,方便删除
删除过滤项
1
2
3
4
5
6
7
8
| removeFilter(k){
const {...obj} = this.search.filter;
delete obj[k]
this.search.filter=obj;
}
|
7.优化
搜索系统需要优化的点:
- 查询规格参数部分可以添加缓存
- elasticsearch本身有查询缓存,可以不进行优化
- 商品图片应该采用缩略图,减少流量,提高页面加载速度
- 图片采用延迟加载
- 图片还可以采用CDN服务器
- sku信息在页面异步加载,而不是放到索引库
 微信
微信 支付宝
支付宝
