【项目系列】十次方项目(一):后端
第1章 - 项目介绍和工程搭建
学习目标:
- 了解十次方项目需求;
- 了解前后端分离开发模式
- 理解RESTful
- 完成项目开发环境搭建
- 完成父工程、公共模块和文章微服务的搭建
- 掌握mybatis plus的使用,并开发完成文章微服务中文章的增删改查功能
- 掌握公共异常处理类的使用
1 十次方项目需求分析
1.1 项目介绍
十次方是程序员的专属社交平台,包括头条、问答、活动、交友、吐槽、招聘六大频道。
十次方名称的由来:2的10次方为1024,程序员都懂的。
如果你是一位技术大咖,那么赶快发布文章,增加知名度吧。
如果你是一名技术小白,那么赶快到问答频道寻求帮助的,这里高手如云哦!
如果你不想错过各种技术交流会,那么请经常关注活动频道吧。
如果你还是单身,那么赶快到交友频道找到你心仪的另一半。
如果你有太多的苦恼,那么赶快吐个槽吧。
如果你正在找工作或是想跳槽拿高薪,那么来招聘频道淘金吧。
1.2 项目需求
详见: 资源\文档\十次方需求规格说明书.docx
2 系统设计
2.1 开发模式
十次方项目采用前后端分离的开发模式
2.2 技术选型
后端:springboot + springcloud + mybatis plus + mysql5.7
前端:nodejs + NUXT + elementUI + vue
2.3 技术架构
采用前后端分离的系统架构
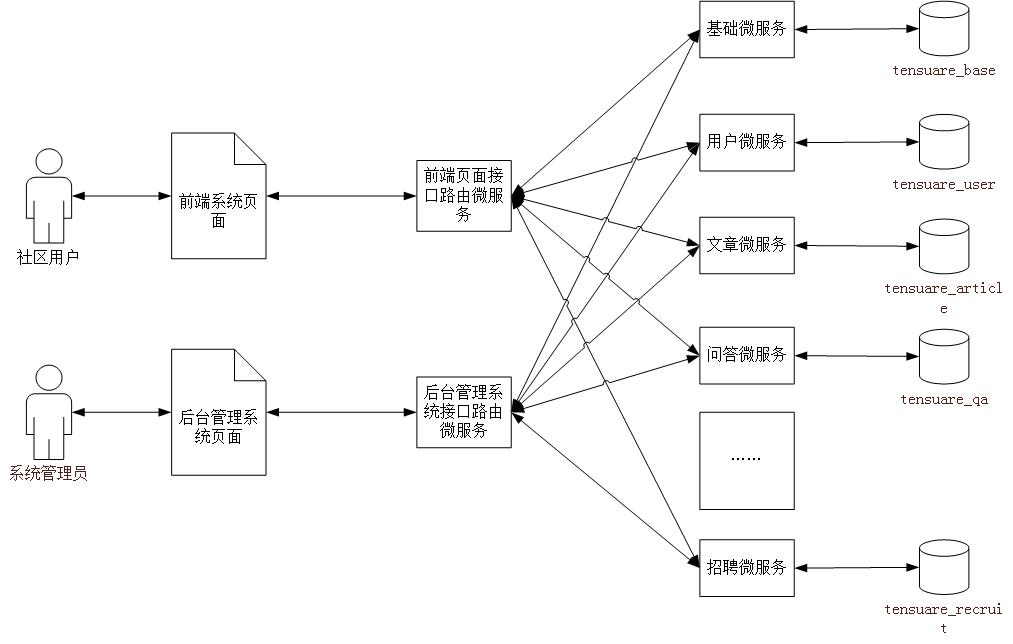
2.4 微服务模块划分
| 模块名称 | 模块中文名称 |
|---|---|
| tensquare_common | 公共模块 |
| tensquare_base | 基础微服务 |
| tensquare_article | 文章微服务 |
| tensquare_friend | 交友微服务 |
| tensquare_gathering | 活动微服务 |
| tensquare_qa | 问答微服务 |
| tensquare_recruit | 招聘微服务 |
| tensquare_user | 用户微服务 |
| tensquare_spit | 吐槽微服务 |
| tensquare_search | 搜索微服务 |
| tensquare_web | 前台微服务网关 |
| tensquare_manager | 后台微服务网关 |
| tensquare_eureka | 注册中心 |
| tensquare_config | 配置中心 |
| tensquare_sms | 短信微服务 |
| tensquare_notice | 消息通知微服务 |
2.5 数据库表结构分析
采用的分库分表设计,每个微服务模块为1个独立的数据库。
tensquare_article 文章
tensquare_base 基础
tensquare_friend 交友
tensquare_gathering 活动
tensquare_qa 问答
tensquare_recruit 招聘
tensquare_user 用户
tensquare_spit 吐槽
详见 资源\文档\十次方数据库文档.xlsx
2.6 API文档
课程提供了前后端开发接口文档(采用Swagger语言进行编写),并与Nginx进行了整 合。双击Nginx执行文件启动后,在地址栏输入http://localhost:801 即可访问API文档
前后端约定的返回码列表:
| 状态描述 | 返回码 |
|---|---|
| 成功 | 20000 |
| 失败 | 20001 |
| 用户名或密码错误 | 20002 |
| 权限不足 | 20003 |
| 远程调用失败 | 20004 |
| 重复操作 | 20005 |
3 RESTful架构说明
3.1 何为RESTful
RESTful架构是目前最流行的一种互联网软件架构
是Roy Thomas Fielding在他2000年的博士论文中提出的
是Representational State Transfer的缩写,翻译过来是”表现层状态转化”
是所有Web应用都应该遵守的架构设计指导原则
7个HTTP方法:GET、POST、PUT、DELETE、PATCH、HEAD、OPTIONS
3.2 接口规范
十次方项目使用GET、POST、PUT、DELETE四种方法
幂等性:不论你请求多少次,资源的状态是一样的。
3.2.1 GET
- 安全且幂等
- 获取表示
- 变更时获取表示(缓存)
==适合查询类的接口使用==
3.2.2 POST
- 不安全且不幂等
- 使用服务端管理的(自动产生)的实例号创建资源
- 创建子资源
- 部分更新资源
- 如果没有被修改,则不过更新资源(乐观锁)
==适合数据提交类的接口使用==
3.2.3 PUT
- 不安全但幂等
- 用客户端管理的实例号创建一个资源
- 通过替换的方式更新资源
- 如果未被修改,则更新资源(乐观锁)
==适合更新数据的接口使用==
3.2.4 DELETE
- 不安全但幂等
- 删除资源
==适合删除数据的接口使用==
请求返回响应码:
| 代码 | 含义 |
|---|---|
| ==200== | (OK)- 如果现有资源已被更改 |
| 201 | (created)- 如果新资源被创建 |
| 202 | (accepted)- 已接受处理请求但尚未完成(异步处理) |
| 301 | (Moved Permanently)- 资源的URI被更新 |
| 303 | (See Other)- 其他(如,负载均衡) |
| ==400== | (bad request)- 指代坏请求 |
| ==404== | (not found)- 资源不存在 |
| 406 | (not acceptable)- 服务端不支持所需表示 |
| 409 | (conflict)- 通用冲突 |
| 412 | (Precondition Failed)- 前置条件失败(如执行条件更新时的冲突) |
| 415 | (unsupported media type)- 接受到的表示不受支持 |
| ==500== | (internal server error)- 通用错误响应 |
| 503 | (Service Unavailable)- 服务当前无法处理请求 |
4 项目开发准备
4.1 开发环境
- 虚拟系统环境 VMware Workstation
- 虚拟机系统 CentOS 7
- 容器 docker
- JDK1.8
- 数据库 mysql 5.7
- 开发工具 idea
- 项目构建工具 maven
所有的第三方工具如mysql等都是运行在docker容器中的
1 | 注:虚拟机的帐户名root 密码itcast |
4.2 mysql建库建表
进入安装了docker的虚拟机中,按以下顺序执行命令
(1)下载镜像(此步可省略)
1 | docker pull centos/mysql‐57‐centos7 |
注:docker默认从国外的镜像网站拉取镜像,速度很慢。可以使用国内的阿里云镜像加速站点提升镜像拉取速度。具体步骤可以参考文档
docker配置国内镜像加速站点.pdf
(2)创建容器
1 | docker run -di --name=tensquare_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root centos/mysql-57-centos7 |
(3)连接MYSQL ,并执行资料中的建表脚本,创建article数据库
4.3 接口测试工具postman
postman是一款强大网页调试工具
- 能够发送任何类型的HTTP 请求 (GET,HEAD, POST,PUT。。。)
- 附带任意数量的参数
5 项目工程搭建
5.1 父工程搭建
创建项目类型为maven的父工程
打开idea开发工具
选择菜单file-new project ,弹出窗口中左侧菜单选择Maven ,点击next按钮
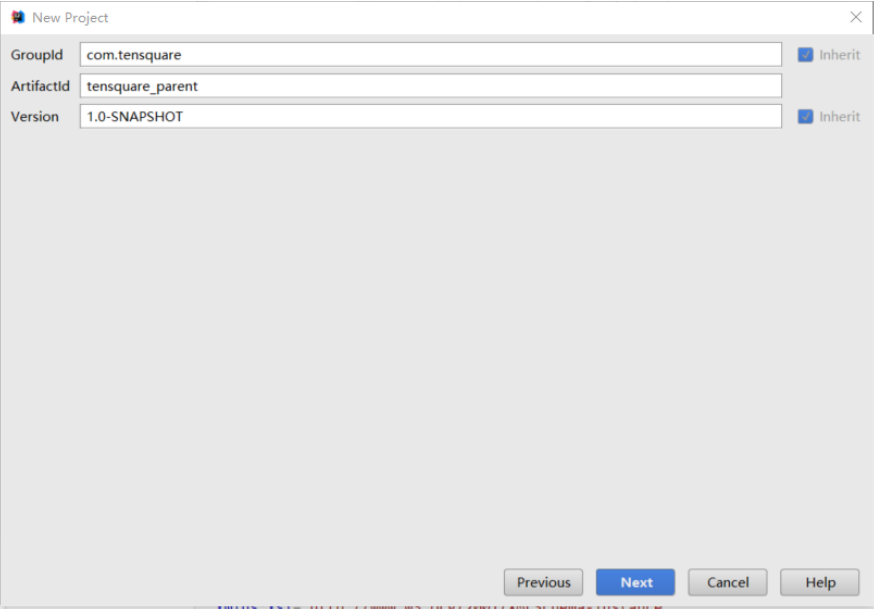
GroupId填写com.tensquare,ArtifacetId填写tensquare_parent,点击next按钮
点击Finish 完成
修改pom.xml文件,添加以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<mybatisplus-spring-boot-starter.version>1.0.5</mybatisplus-spring-boot-starter.version>
<mybatisplus.version>2.2.0</mybatisplus.version>
<fastjson.version>1.2.39</fastjson.version>
<gson.version>2.8.0</gson.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
5.2 搭建公共子模块
5.2.1 搭建子模块步骤
右键点击父工程tensquare_parent,选择 New -> Module 弹出窗口选择Maven ,点击next按钮
ArtifacetId填写tensquare_common,点击next按钮
点击finish
5.2.2 创建公共实体类和工具类
新建com.tensquare.entity包,包下创建Result类,用于controller返回结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56public class Result {
private boolean flag;//是否成功
private Integer code;// 返回码
private String message;//返回信息
private Object data;// 返回数据
public Result(boolean flag, Integer code, String message, Object data) {
super();
this.flag = flag;
this.code = code;
this.message = message;
this.data = data;
}
public Result() { }
public Result(boolean flag, Integer code, String message) {
super();
this.flag = flag;
this.code = code;
this.message = message;
}
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
}创建类PageResult ,用于返回分页结果
1
2
3
4
5
6
7
8
9
10
11
12public class PageResult<T> {
private Long total;
private List<T> rows;
public PageResult(Long total, List<T> rows) {
super();
this.total = total;
this.rows = rows;
}
//getter and setter ....
}返回码定义类
1
2
3
4
5
6
7
8public class StatusCode {
public static final int OK=20000;//成功
public static final int ERROR =20001;//失败
public static final int LOGINERROR =20002;//用户名或密码错误
public static final int ACCESSERROR =20003;//权限不足
public static final int REMOTEERROR =20004;//远程调用失败
public static final int REPERROR =20005;//重复操作
}分布式ID生成器
课程中已经提供了分布式ID生成器
资源\微服务相关\工具类\IdWorker.java
tensquare_common工程创建util包,将IdWorker.java直接拷贝到tensquare_common工程的util包中。
不能使用数据库本身的自增功能来产生主键值,原因是生产环境为分片部署的。
使用snowflake (雪花)算法(twitter出品)生成***唯一***的主键值
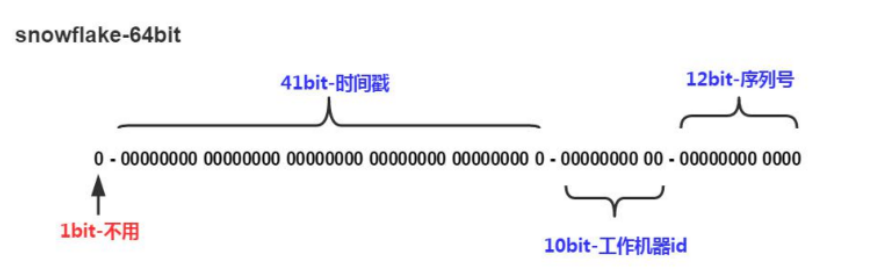
- 41bit的时间戳可以支持该算法使用到2082年
- 10bit的工作机器id可以支持1024台机器
- 序列号支持1毫秒产生4096个自增序列id
- 整体上按照时间自增排序
- 整个分布式系统内不会产生ID碰撞
- 每秒能够产生26万ID左右
6 文章微服务-文章管理
6.1 模块搭建
在tensquare_parent项目下创建tensquare_article模块,创建过程参考第4.2节公共子模块的创建过程
修改tensquare_article模块的pom.xml文件,添加以下依赖
1
2
3
4
5
6
7
8
9
10
11<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.tensquare</groupId>
<artifactId>tensquare_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>创建com.tensquare.article包,并创建BaseApplication启动类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17package com.tensquare.article;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import util.IdWorker;
@SpringBootApplication
public class ArticleApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleApplication.class, args);
}
@Bean
public IdWorker idWorker(){
return new IdWorker(1,1);
}
}在resources文件夹下创建application.yml,并添加以下内容
1
2
3
4
5
6
7
8
9
10server:
port: 9004
spring:
application:
name: tensquare-article #指定服务名
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.200.129:3306/tensquare_article?characterEncoding=utf-8
username: root
password: root
6.2 文章管理-CRUD
6.2.1 表结构分析
tensquare_article数据库,tb_article表
| 文章表 | tb_article | ||
|---|---|---|---|
| 字段名称 | 字段含义 | 字段类型 | 备注 |
| id | ID | 文本 | |
| columnid | 专栏ID | 文本 | |
| userid | 用户ID | 文本 | |
| title | 文章标题 | 文本 | |
| content | 文章内容 | 文本 | |
| image | 文章封面 | 文本 | |
| createtime | 发表日期 | 日期 | |
| updatetime | 修改日期 | 日期 | |
| ispublic | 是否公开 | 文本 | 0:不公开 |
| istop | 是否置顶 | 文本 | 0:不置顶 |
| visits | 浏览量 | 整型 | |
| thumbup | 点赞数 | 整型 | |
| comment | 评论数 | 整型 | |
| state | 审核状态 | 文本 | 0:未审核 1:已审核 |
| channelid | 所属频道 | 整型 | 关联频道表ID |
| url | URL地址 | 文本 | |
| type | 文章类型 | 文本 | 0:分享 |
6.2.2 集成mybatis plus
mybatis plus概述
- 是对Mybatis框架的二次封装和扩展
- 纯正血统:完全继承原生 Mybatis 的所有特性
- 最少依赖:仅仅依赖Mybatis以及Mybatis-Spring
- 性能损耗小:启动即会自动注入基本CURD ,性能无损耗,直接面向对象操作
- 自动热加载:Mapper对应的xml可以热加载,大大减少重启Web服务器时间,提升开发效率
- 性能分析:自带Sql性能分析插件,开发测试时,能有效解决慢查询
- 全局拦截:提供全表delete、update操作智能分析阻断
- 避免Sql注入:内置Sql注入内容剥离器,预防Sql注入攻击
在pom.xml文件中引入相关依赖
1
2
3
4
5
6
7
8
9
10
11
12<!-- mybatis-plus begin -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatisplus-spring-boot-starter</artifactId>
<version>${mybatisplus-spring-boot-starter.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus</artifactId>
<version>${mybatisplus.version}</version>
</dependency>
<!-- mybatis-plus end -->在配置文件application.yml中添加相关配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# Mybatis-Plus 配置
mybatis-plus:
# mapper-locations: classpath:/mapper/*Mapper.xml
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.tensquare.article.pojo
global-config:
id-type: 1 #0:数据库ID自增 1:用户输入id
db-column-underline: false
refresh-mapper: true
configuration:
map-underscore-to-camel-case: true
cache-enabled: true #配置的缓存的全局开关
lazyLoadingEnabled: true #延时加载的开关
multipleResultSetsEnabled: true #开启延时加载,否则按需加载属性
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #打印sql语句,调试用修改启动类,增加Mapper扫描注解
1
2
3
4
5
6
7
8
9
10
11
12
13@SpringBootApplication
//Mapper扫描注解
@MapperScan("com.tensquare.article.dao")
public class ArticleApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleApplication.class, args);
}
@Bean
public IdWorker idWorker() {
return new IdWorker(1, 1);
}
}
6.2.3 实现查询所有文章和根据id号查询文章功能
在com.tensquare.article包下面创建pojo包,并创建Article实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35package com.tensquare.article.pojo;
import com.baomidou.mybatisplus.annotations.TableId;
import com.baomidou.mybatisplus.annotations.TableName;
import com.baomidou.mybatisplus.enums.IdType;
import java.io.Serializable;
import java.util.Date;
@TableName("tb_article")
public class Article implements Serializable {
@TableId(type = IdType.INPUT)
private String id;//ID
private String columnid; //专栏ID
private String userid; //用户ID
private String title; //标题
private String content; //文章正文
private String image; //文章封面
private Date createtime; //发表日期
private Date updatetime; //修改日期
private String ispublic; //是否公开
private String istop; //是否置顶
private Integer visits; //浏览量
private Integer thumbup; //点赞数
private Integer comment; //评论数
private String state; //审核状态
private String channelid; //所属频道
private String url; //URL
private String type; //类型
//getters and setters
}编写数据访问接口dao
1
2public interface ArticleDao extends BaseMapper<Article> {
}编写service
1
2
3
4
5
6
7
8
9
10
11
12
13
14@Service
public class ArticleService {
@Autowired
private ArticleDao articleDao;
public List<Article> findAll() {
return articleDao.selectList(null);
}
public Article findById(String id) {
return articleDao.selectById(id);
}
}编写controller
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19@RestController
@RequestMapping("/article")
public class ArticleController {
@Autowired
private ArticleService articleService;
@RequestMapping(method = RequestMethod.GET)
public Result findAll() {
List list = articleService.findAll();
return new Result(true, StatusCode.OK, "查询成功", list);
}
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
public Result findById(@PathVariable String id) {
Article Article = articleService.findById(id);
return new Result(true, StatusCode.OK, "查询成功", Article);
}
}
6.2.4 添加文章、修改文章和删除文章
添加文章 ArticleController中添加代码
1
2
3
4
5
6
7//新增标签数据接口
@RequestMapping(method = RequestMethod.POST)
public Result add(@RequestBody Article article) {
articleService.add(article);
return new Result(true, StatusCode.OK, "添加成功");
}ArticleService中添加代码
1
2
3
4
5
6
7@Autowired
private IdWorker idWorker;
public void add(Article article) {
article.setId(idWorker.nextId() + "");
articleDao.insert(article);
}修改文章
ArticleController中添加代码
1
2
3
4
5
6
7//修改标签数据接口
@RequestMapping(value = "{id}", method = RequestMethod.PUT)
public Result update(@PathVariable String id, @RequestBody Article article) {
article.setId(id);
articleService.update(article);
return new Result(true, StatusCode.OK, "修改成功");
}ArticleService中添加代码
1
2
3
4
5
6
7
8
9
10public void update(Article article) {
//根据id号更新
//方法1
articleDao.updateById(article);
//方法2
EntityWrapper wrapper = new EntityWrapper<Article>();
wrapper.eq("id", article.getId());
articleDao.update(article, wrapper);
}删除文章
ArticleController中添加代码
1
2
3
4
5
6
7//删除文章数据接口
@RequestMapping(value = "{id}", method = RequestMethod.DELETE)
public Result delete(@PathVariable String id) {
articleService.delete(id);
return new Result(true, StatusCode.OK, "删除成功");
}ArticleService中添加代码
1
2
3public void delete(String id) {
articleDao.deleteById(id);
}
6.2.5 条件查询和分页
条件查询
使用Mybatis Plus 提供的EntityWrapper对象封装where查询条件,例如以下使用方式:
1
2
3
4
5EntityWrapper wrapper = new EntityWrapper<Article>();
wrapper.eq("id", article.getId());
//动态sql,例如<if test="null != field"> and field='xxx' </if>
wrapper.eq(null != map.get(field), field, map.get(field));分页
- 使用 Mybatis Plus 提供的Page对象
- 向Mybatis Plus中注入PaginationInterceptor插件
- 新建config包,创建MybatisPlusConfig对象,添加下面的代码
1
2
3
4
5
6
7
8@Configuration
public class MybatisPlusConfig {
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}完整代码
ArticleController中添加代码
1
2
3
4
5@RequestMapping(value="/search/{page}/{size}", method = RequestMethod.POST)
public Result search(@RequestBody Map map, @PathVariable int page, @PathVariable int size) {
Page page1 = articleService.search(map, page, size);
return new Result(true, StatusCode.OK, "查询成功", new PageResult((int) page1.getTotal(), page1.getRecords()));
}ArticleService中添加代码
1
2
3
4
5
6
7
8
9
10
11
12
13public Page search(Map map, int page, int size) {
EntityWrapper wrapper = new EntityWrapper<Article>();
Set<String> fieldSet = map.keySet();
for(String field : fieldSet) {
//wrapper.eq(field, map.get(field));
wrapper.eq(null != map.get(field), field, map.get(field));
}
Page page1 = new Page(page, size);
List list = articleDao.selectPage(page1, wrapper);
page1.setRecords(list);
return page1;
}
6.3 公共异常处理类
为了使代码容易维护,减少冗余,我们创建一个类集中处理异常
在com.tensquare.user.controller包下创建公共异常处理类BaseExceptionHandler,并添加代码
1 | @ControllerAdvice |
ArticleController中添加测试代码
1 | @RequestMapping(value="/exception", method = RequestMethod.GET) |
6.4 跨域处理
何谓跨域
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域 。
十次方项目是采用前后端分离开发的,也是前后端分离部署的,必然会存在跨域问题。
如何解决跨域
只需要在controller类上添加注解
@CrossOrigin即可!
第2章 - MongoDB和评论管理
学习目标:
- 了解什么是MongoDB
- 掌握MongoDB的安装
- 掌握MongoDB的常用命令
- 掌握mongodb-driver的基本使用
- 掌握SpringDataMongoDB的使用
- 能够实现文章评论功能开发
1 MongoDB简介
1.1 文章评论数据分析
文章评论两项功能存在以下特点:
- 数据量大
- 写入操作频繁
- 价值较低
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
1.2 什么是MongoDB
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
1.3 MongoDB特点
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性。
- 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- 文件存储格式为BSON(一种JSON的扩展)。
1.5 MongoDB体系结构
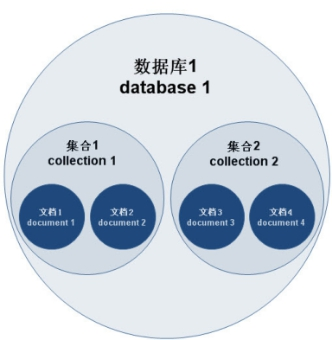
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document)、集合(collection)、数据库(database)这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
- MongoDB 的文档(document),相当于关系数据库中的一行记录。
- 多个文档组成一个集合(collection),相当于关系数据库的表。
- 多个集合(collection),逻辑上组织在一起,就是数据库(database)。
- 一个 MongoDB 实例支持多个数据库(database)。
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
| MongoDb | 关系型数据库Mysql |
|---|---|
| 数据库(databases) | 数据库(databases) |
| 集合(collections) | 表(table) |
| 文档(document) | 行(row) |
1.6 MongoDB数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
特殊说明:
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
时间戳
BSON 有一个特殊的时间戳类型,与普通的日期类型不相关。时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值【与Unix新纪元(1970年1月1日)相差的秒数】
- 后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
2 MongoDB基本使用
2.1 window系统MongoDB安装
安装
安装资料中的
mongodb-win32-x86_64-2008plus-ssl-3.2.10-signed.msi按照提示步骤安装即可。安装完成后,软件会安装在C:\Program Files\MongoDB 目录中
我们要启动的服务程序就是C:\Program Files\MongoDB\Server\3.2\bin目录下的mongod.exe,为了方便我们每次启动,我们可以像配置jdk一样,将C:\Program Files\MongoDB\Server\3.2\bin 设置到环境变量path中。
- 启动
- 创建一个文件夹
d:\data,用于存放数据的目录data - 打开命令行窗口,执行以下命令
1 | mongod --dbpath=D:\data |
我们在启动信息中可以看到,mongoDB的默认端口是27017,如果我们想改变默认的启动端口,可以通过–port来指定端口,例如
1 | mongod --dbpath=D:\data -port 8989 |
- 登录
再打开一个新的命令行窗口,执行以下命令:()
1 | mongo 127.0.0.1:27017 |
以上命令中,如果ip是本地服务,端口号是27017,则后面的127.0.0.1:27017可以省略
- 退出
1 | exit |
2.2 Docker 环境下MongoDB安装
在Linux虚拟机中创建mongo容器,命令如下:
1 | docker run -id --name mongo -p 27017:27017 mongo |
在Window命令行窗口出入登录命令:
1 | mongo 192.168.200.128 |
2.3 常用命令
2.3.1 选择和创建数据库
选择和创建数据库的语法格式:
1 | use 数据库名称 |
如果数据库存在则选择该数据库,如果数据库不存在则自动创建。以下语句创建commentdb数据库:
1 | use commentdb |
查看数据库:
1 | show dbs |
查看集合,需要先选择数据库之后,才能查看该数据库的集合:
1 | show collections |
2.3.2 插入与查询文档
选择数据库后,使用集合来对文档进行操作,插入文档语法格式:
1 | db.集合名称.insert(数据); |
插入以下测试数据:
1 | db.comment.insert({content:"十次方课程",userid:"1011"}) |
查询集合的语法格式:
1 | db.集合名称.find() |
查询spit集合的所有文档,输入以下命令:
1 | db.comment.find() |
发现文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
输入以下测试语句:
1 | db.comment.insert({_id:"1",content:"到底为啥出错",userid:"1012",thumbup:2020}); |
按一定条件来查询,比如查询userid为1013的记录,只要在find()中添加参数即可,参数也是json格式,如下:
1 | db.comment.find({userid:'1013'}) |
只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现:
1 | db.comment.findOne({userid:'1013'}) |
返回指定条数的记录,可以在find方法后调用limit来返回结果,例如:
1 | db.comment.find().limit(2) |
2.3.3 修改与删除文档
修改文档的语法结构:
1 | db.集合名称.update(条件,修改后的数据) |
修改_id为1的记录,点赞数为1000,输入以下语句:
1 | db.comment.update({_id:"1"},{thumbup:1000}) |
执行后发现,这条文档除了thumbup字段其它字段都不见了。
为了解决这个问题,我们需要使用修改器$set来实现,命令如下:
1 | db.comment.update({_id:"2"},{$set:{thumbup:2000}}) |
删除文档的语法结构:
1 | db.集合名称.remove(条件) |
以下语句可以将数据全部删除,慎用~
1 | db.comment.remove({}) |
删除条件可以放到大括号中,例如删除thumbup为1000的数据,输入以下语句:
1 | db.comment.remove({thumbup:1000}) |
2.3.4 统计条数
统计记录条件使用count()方法。以下语句统计spit集合的记录数:
1 | db.comment.count() |
按条件统计 ,例如统计userid为1013的记录条数:
1 | db.comment.count({userid:"1013"}) |
2.3.5 模糊查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
1 | /模糊查询字符串/ |
查询评论内容包含“流量”的所有文档,代码如下:
1 | db.comment.find({content:/流量/}) |
查询评论内容中以“加班”开头的,代码如下:
1 | db.comment.find({content:/^加班/}) |
2.3.6 大于 小于 不等于
<, <=, >, >= 这个操作符也是很常用的,格式如下:
1 | db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value |
查询评论点赞数大于1000的记录:
1 | db.comment.find({thumbup:{$gt:1000}}) |
2.3.7 包含与不包含
包含使用$in操作符
查询评论集合中userid字段包含1013和1014的文档:
1 | db.comment.find({userid:{$in:["1013","1014"]}}) |
不包含使用$nin操作符
查询评论集合中userid字段不包含1013和1014的文档:
1 | db.comment.find({userid:{$nin:["1013","1014"]}}) |
2.3.8 条件连接
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联(相当于SQL的and)。格式为:
1 | $and:[ {条件},{条件},{条件} ] |
查询评论集合中thumbup大于等于1000 并且小于2000的文档:
1 | db.comment.find({$and:[ {thumbup:{$gte:1000}} ,{thumbup:{$lt:2000} }]}) |
如果两个以上条件之间是或者的关系,我们使用操作符进行关联,与前面and的使用方式相同,格式为:
1 | $or:[ {条件},{条件},{条件} ] |
查询评论集合中userid为1013,或者点赞数小于2000的文档记录:
1 | db.comment.find({$or:[ {userid:"1013"} ,{thumbup:{$lt:2000} }]}) |
2.3.9 列值增长
对某列值在原有值的基础上进行增加或减少,可以使用$inc运算符:
1 | db.comment.update({_id:"2"},{$inc:{thumbup:1}}) |
2.4 可视化工具robomongo
Mongodb有很多可视化工具,这里我们使用robomongo,可以访问官网:https://robomongo.org/

我们可以看到有两个版本Studio 3T和Robo 3T
Studio 3T是一个功能很强大的收费版。。。
Robo 3T前身就是Robomongo,是一个免费的可视化工具,我们使用他可以很轻松的进行Mongodb的管理。
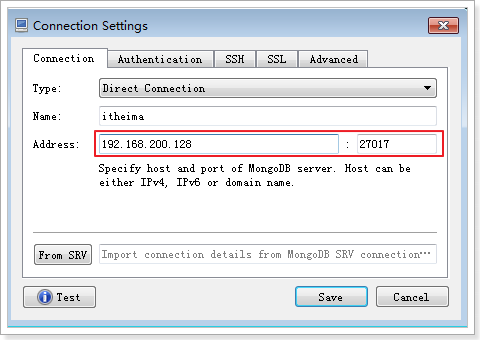
在资料中找到robo3t-1.3.1-windows-x86_64-7419c406.exe并双击安装。打开后看到以下界面:
点击Create创建连接,进行如下配置即可:
3 mongodb-driver使用
mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动。我们现在来使用mongodb-driver完成对Mongodb的操作。
3.1 环境准备
创建工程,并添加以下依赖:
1 | <dependency> |
3.2 使用mongodb-driver
3.2.1 查询所有
1 | @Test |
3.2.2 根据_id查询
每次使用都要用到MongoCollection,进行抽取:
1 | private MongoClient client; |
测试根据_id查询:
1 | @Test |
3.2.3 新增
1 | @Test |
3.2.4 修改
1 | @Test |
3.2.5 删除
1 | @Test |
4 文章评论实现
SpringDataMongoDB是SpringData家族成员之一,用于操作MongoDb的持久层框架,封装了底层的mongodb-driver。本功能使用SpringDataMongoDB进行开发
4.1 需求分析
评论集合结构:
| 专栏文章评论 | comment | ||
|---|---|---|---|
| 字段名称 | 字段含义 | 字段类型 | 备注 |
| _id | ID | 文本 | |
| articleid | 文章ID | 文本 | |
| content | 评论内容 | 文本 | |
| userid | 评论人ID | 文本 | |
| parentid | 评论ID | 文本 | 如果为0表示文章的顶级评论 |
| publishdate | 评论日期 | 日期 | |
| thumbup | 点赞数 | 数字 |
需要实现以下功能:
- 基本增删改查API
- 根据文章id查询评论
- 评论点赞
4.2 开发准备
在文章微服务添加依赖:
1 | <dependency> |
添加配置文件:
1 | data: |
4.3 功能实现
4.3.1 基本增删改查API
创建实体类:
1 | public class Comment implements Serializable { |
在com.tensquare.article.repository包中编写CommentRepository,注意不要和MyBatis的接口放在一个包:
1 | public interface CommentRepository extends MongoRepository<Comment, String> { |
编写Service:
1 | @Service |
编写Controller:
1 | @RestController |
4.3.2 根据文章id查询评论
编写Controller
1 | //根据文章id查询评论列表 |
编写Service
1 | public List<Comment> findByarticleId(String articleId) { |
编写dao
1 | public interface CommentDao extends MongoRepository<Comment, String> { |
4.3.4 评论点赞
先根据评论的id查询,再对点赞数加一
编写service
1 | public void thumbup(String id) { |
编写Controller
1 | //评论点赞 |
以上操作需要操作两次数据库,性能较低,service方法优化如下:
1 | @Autowired |
4.3.5 不能重复点赞
点赞功能完成后,发现可以重复点赞,我们应该改为一个人只能点赞一次。
可以使用评论id+用户id进行标记,一个用户只能点赞一次。可以使用redis保存点赞信息,速度较快
pom.xml添加依赖:
1 | <dependency> |
在Linux虚拟机中创建redis容器:
1 | docker run -id --name=tensquare_redis -p 6379:6379 redis |
配置文件添加配置:
1 | redis: |
修改Controller方法:
1 | @Autowired |
第3章 - 即时通讯和接口加密
学习目标:
- 了解即时通讯业务场景和需求;
- 了解短连接和长连接
- 了解websocket协议
- 使用环信im云实现十次方即时通讯功能
- 了解接口加密业务需求
- 掌握常用加密算法和密钥格式
- 实现十次方的接口加密微服务
1 即时通讯的业务场景和需求
即时通信(Instant Messaging,简称IM)是一个允许两人或多人使用网络实时的传递文字消息、文件、语音与视频交流。 即时通讯技术应用于需要实时收发消息的业务场景。
现在各种各样的即时通讯软件也层出不穷:
客服系统
直播互动


抖音 全民直播 斗鱼
社交APP

微信 陌陌
智能硬件,物联网


摩拜单车 小黄车
2 短连接和长连接
即时通讯使用的是长连接,这里我们介绍一下短连接和长连接。
2.1 短连接
客户端和服务器每进行一次通讯,就建立一次连接,通讯结束就中断连接。

HTTP是一个简单的请求-响应协议,它通常运行在TCP之上。HTTP/1.0使用的TCP默认是短连接。
2.2 长连接
是指在建立连接后可以连续多次发送数据,直到双方断开连接。

HTTP从1.1版本起,底层的TCP使用的长连接。
使用长连接的HTTP协议,会在响应头加入代码:Connection:keep-alive
2.3 短连接和长连接的区别
2.3.1 通讯流程
短连接:创建连接 -> 传输数据 -> 关闭连接 长连接:创建连接 -> 传输数据 -> 保持连接 -> 传输数据 -> …… -> 关闭连接
2.3.2 适用场景
短连接:并发量大,数据交互不频繁情况
长连接:数据交互频繁,点对点的通讯
2.3.3 通讯方式
| 方式 | 说明 |
|---|---|
| 短连接 | 我跟你发信息,必须等到你回复我或者等了一会等不下去了,就结束通讯了 |
| 长连接 | 我跟你发信息,一直保持通讯,在保持通讯这个时段,我去做其他事情的当中你回复我了,我能立刻你回复了我什么,然后可以回应或者不回应,继续做事 |
3 websocket协议
3.1 何为websocket协议
WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。
- 何谓全双工:全双工(Full Duplex)是通讯传输的一个术语。双方在通信时允许数据在两个方向上同时传输,它在能力上相当于两个单工通信方式的结合。全双工指可以同时进行信号的双向传输。指A→B的同时B→A,就像是双向车道。
- 单工就就像是汽车的单行道,是在只允许甲方向乙方传送信息,而乙方不能向甲方传送 。
参考资料:https://baike.baidu.com/item/%E5%85%A8%E5%8F%8C%E5%B7%A5/310007?fr=aladdin
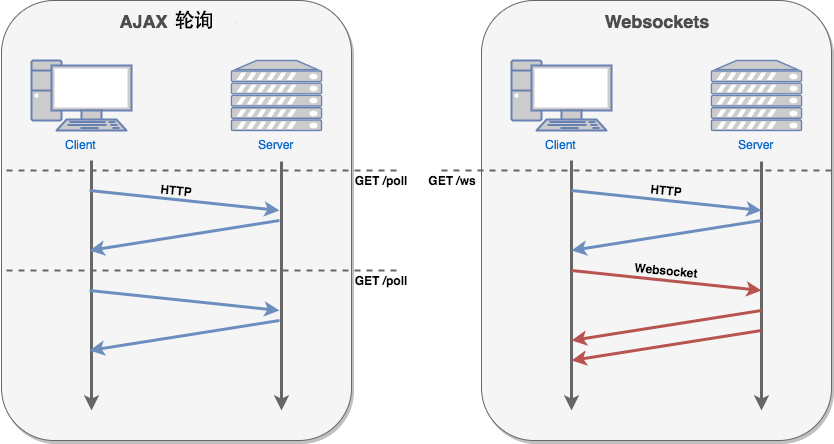
在 WebSocket中,浏览器和服务器只需要完成一次握手,就可以创建持久性的连接,并进行双向数据传输。
在推送功能的实现技术上,相比使用Ajax 定时轮询的方式(setInterval),WebSocket 更节省服务器资源和带宽。
服务器向客户端发送数据的功能是websocket协议的典型使用场景
3.2 websocket常用事件方法
以下 API 用于创建 WebSocket 对象。
1 | var Socket = new WebSocket(url, [protocol] ); |
WebSocket 事件
以下是 WebSocket 对象的相关事件。假定我们使用了以上代码创建了 Socket 对象:
| 事件 | 事件处理程序 | 描述 |
|---|---|---|
| open | Socket.onopen | 连接建立时触发 |
| message | Socket.onmessage | 客户端接收服务端数据时触发 |
| error | Socket.onerror | 通信发生错误时触发 |
| close | Socket.onclose | 连接关闭时触发 |
WebSocket 方法
| 方法 | 描述 |
|---|---|
| Socket.send() | 使用连接发送数据 |
| Socket.close() | 关闭连接 |
使用资料中的案例Spring-websocket演示WebSocket
4 十次方的im功能
4.1 系统设计
4.1.1 技术选型
- 环信im云
- 前端框架 vue
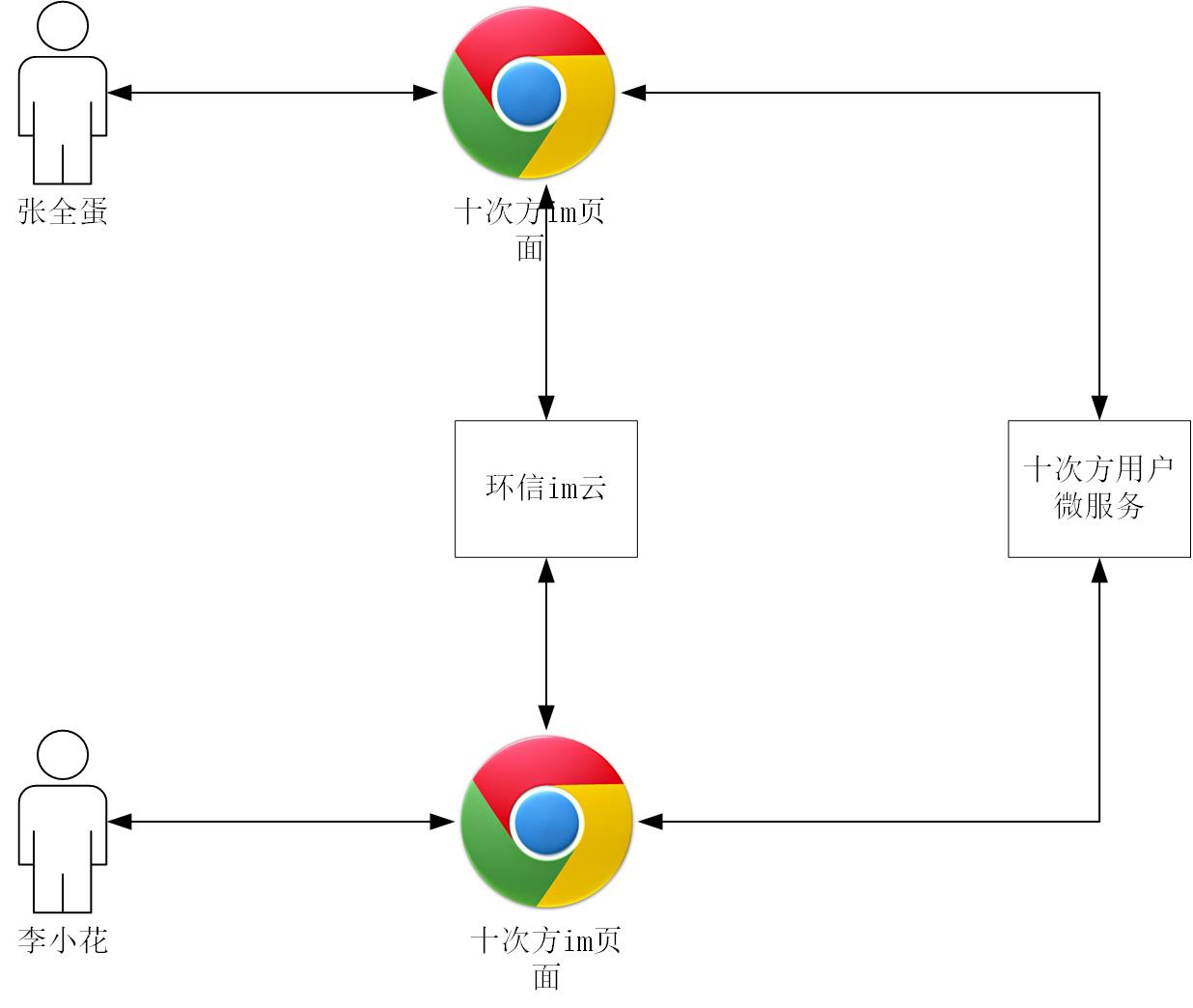
4.1.2 架构设计
前端页面使用十次方用户微服务认证用户身份,使用环信im云进行即时消息通信。
4.2 环境和工具
- nodejs
- npm
- 前端框架 vue
- 开发工具 vscode
4.3 环信im云介绍
环信im云是即时通讯云 PaaS 平台,开发者可以通过简单的SDK和REST API对接。
- 支持安卓,iOS,Web等客户端SDK对接
- 提供单聊,群聊,聊天室等即时通讯功能
- 支持富媒体消息,实时音视频和各种自定义的扩展消息
4.3.1 注册账号
网址:https://console.easemob.com/user/register
4.3.2 创建应用
- 登录环信im云,按照下图进行操作
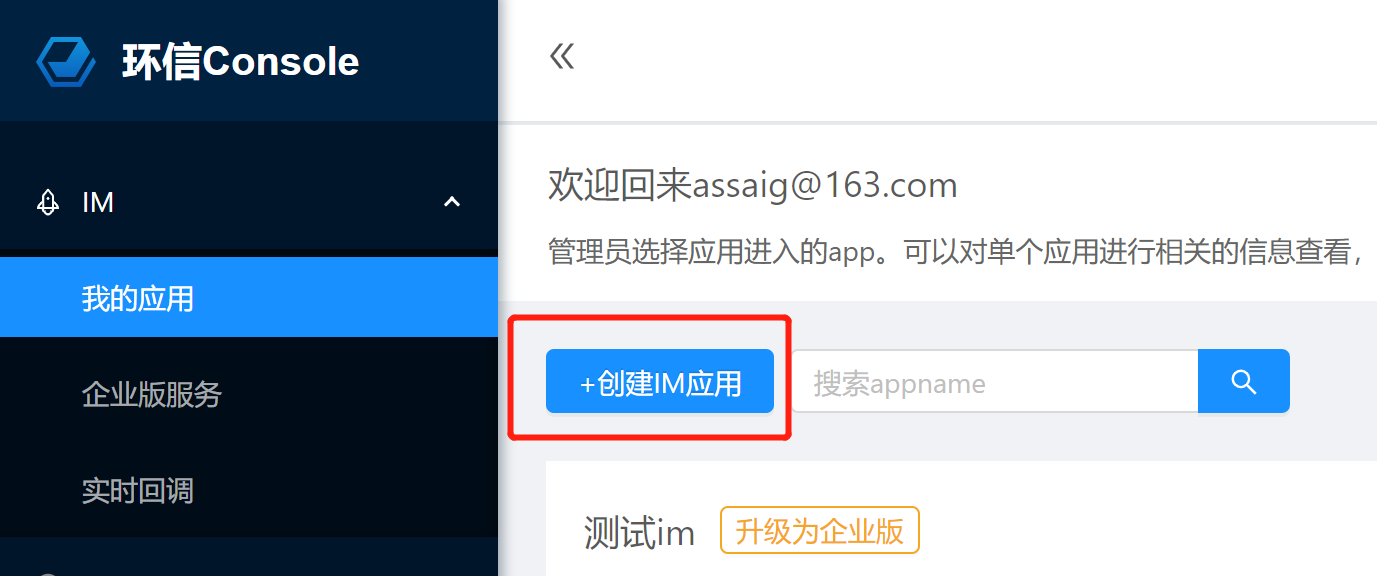
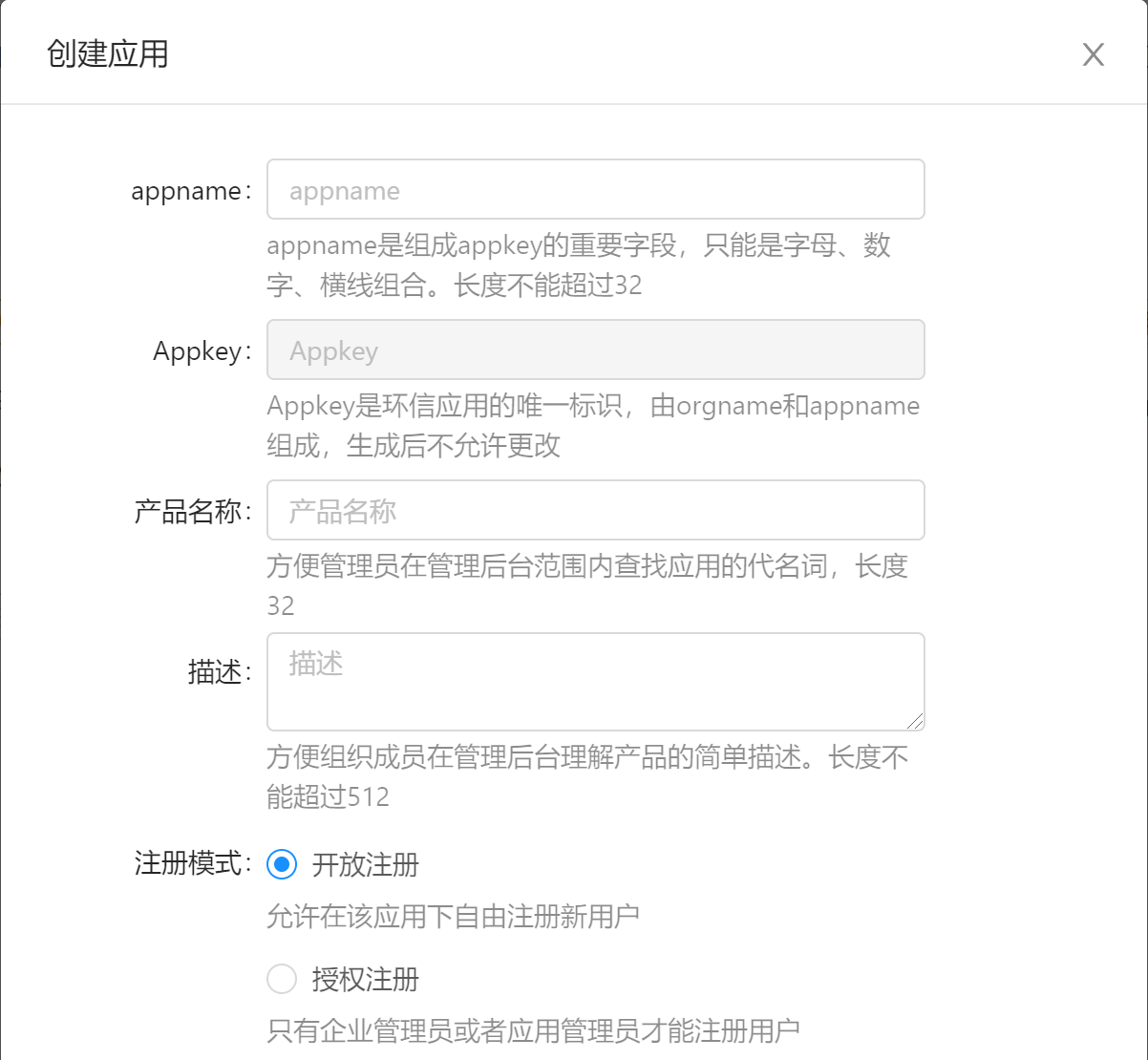
输入appname后,appkey会自动生成
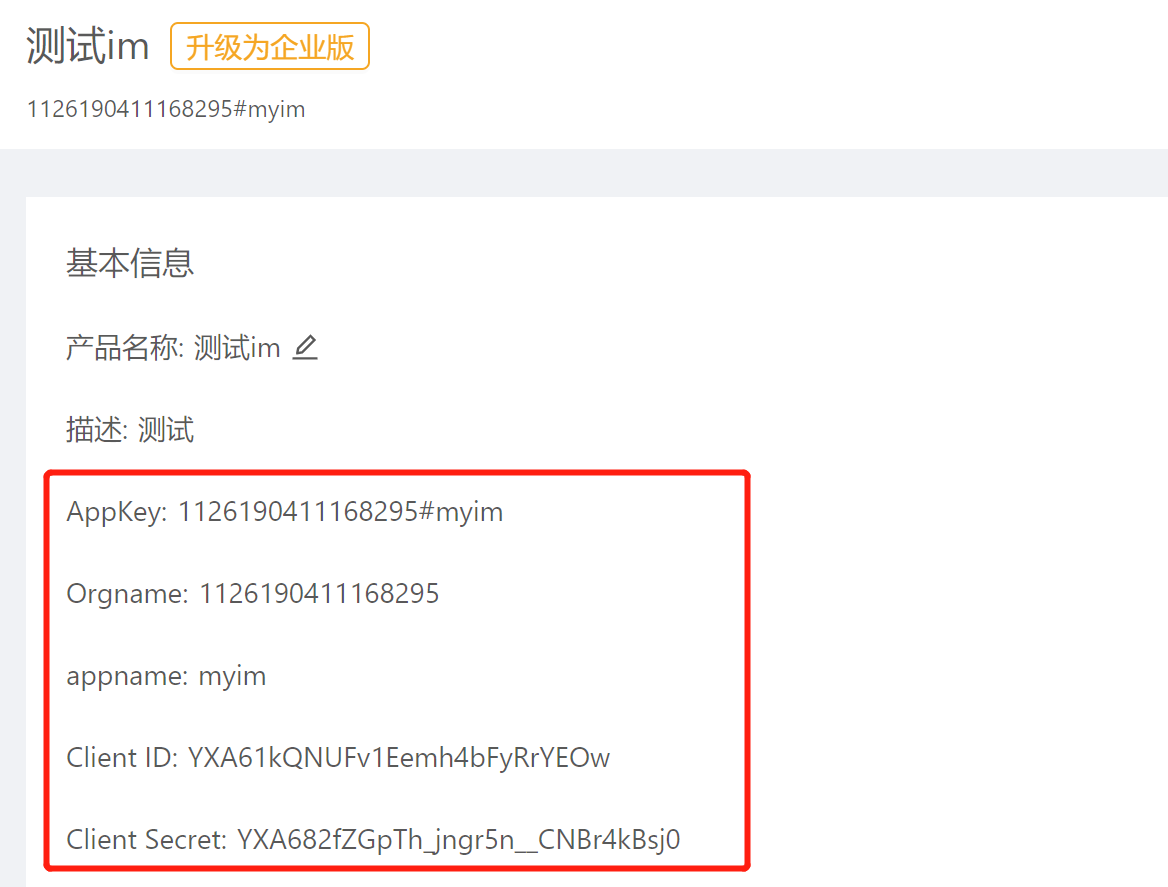
进入刚才创建的应用,获取appkey,orgname,client id,client secret等字段
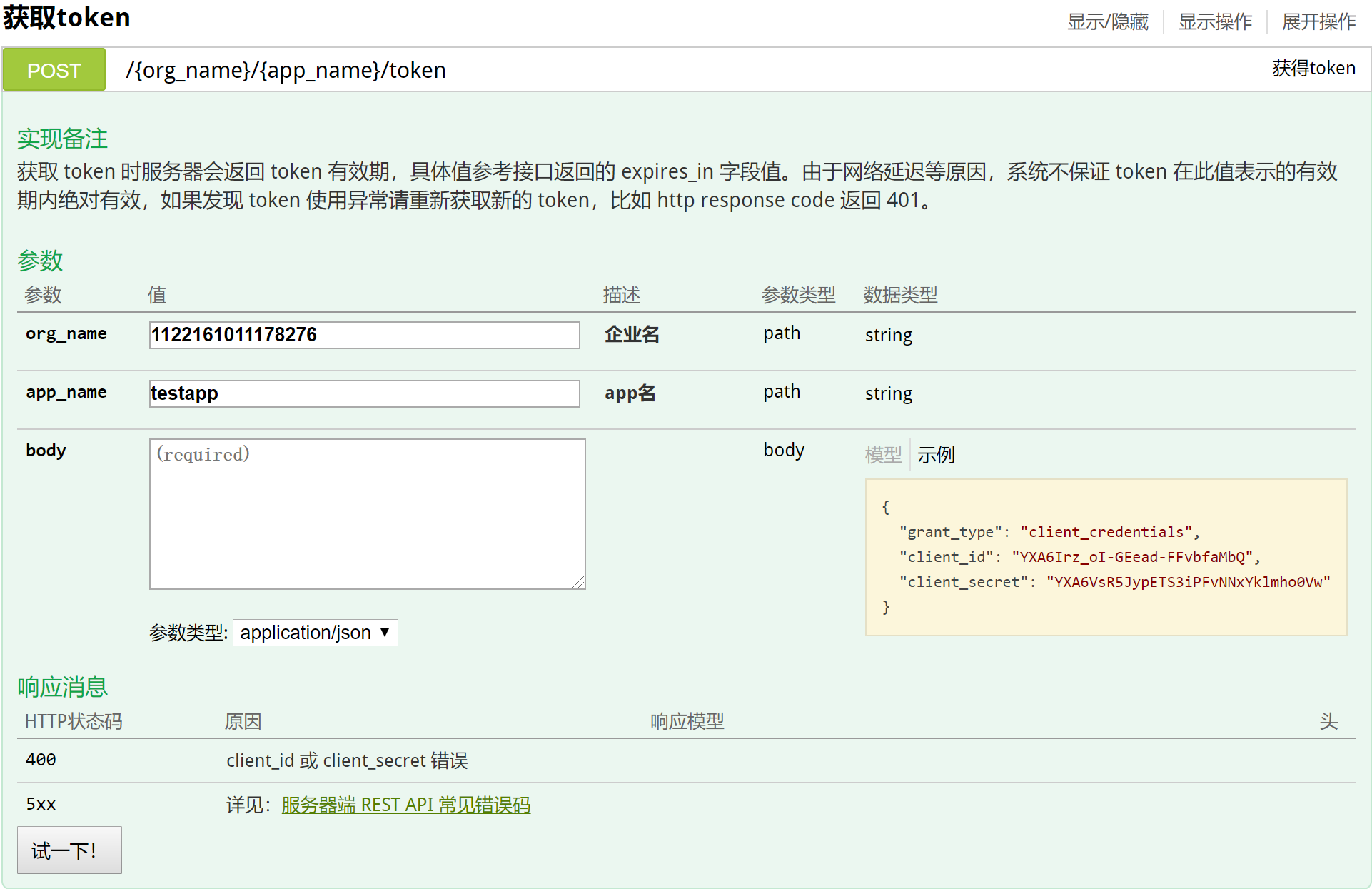
4.3.3 接口测试-获取token
使用环信提供的swagger接口调试页面测试接口
页面网址:http://api-docs.easemob.com/#/%E8%8E%B7%E5%8F%96token
使用postman测试接口
注意:请求方式选择POST
4.3.4 im系统架构
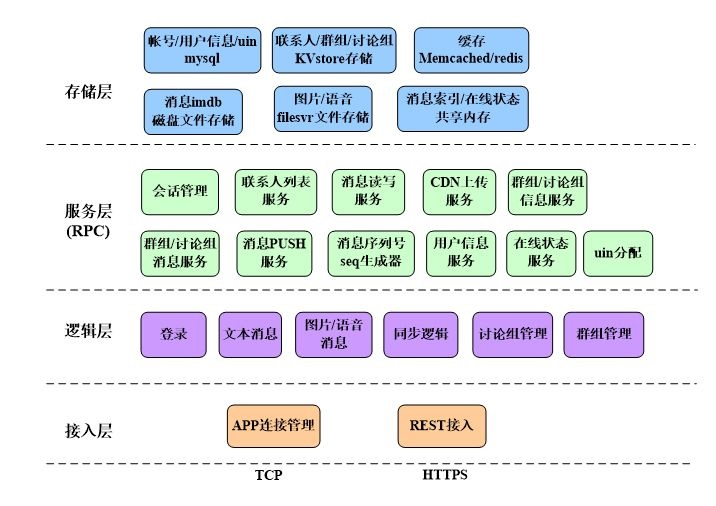
4.4 十次方即时通讯功能
4.4.1 用户微服务实现
1) 创建tensquare_user子模块
创建Maven工程
2) 在pom.xml中添加依赖
1 | <dependencies> |
3) 编写application.yml配置文件
1 | server: |
4)编写MyBatis配置Bean
1 | @Configuration |
5) 编写引导类
1 | @SpringBootApplication |
6) 编写pojo
1 | @TableName("tb_user") |
7) 编写dao
1 | public interface UserDao extends BaseMapper<User> { |
8) 编写service
1 | @Service |
9) 编写controller
1 | @RestController |
4.4.2 即时通讯前端准备
访问环信IM开发文档–> Web客户端 –> SDK集成介绍 –》Web IM 集成介绍
或者直接访问http://docs-im.easemob.com/im/web/intro/integration
- 按照文档,使用git下载集成案例:
1 | $ git clone https://github.com/easemob/webim.git |
复制案例中的\webim\sdk目录下的所有js文件到项目resources\static\js中
复制webim\simpleDemo中的资料到resources\static中
效果如下:
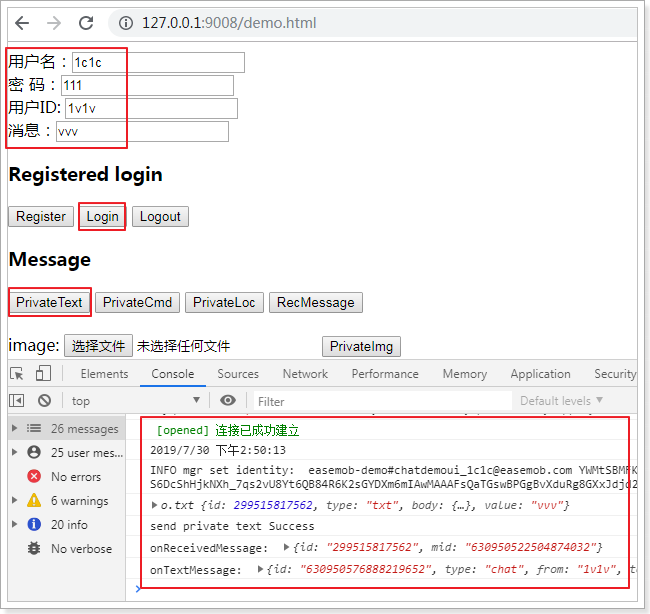
测试demo.html,确认即时通讯的用户登录,发文本消息,效果如下
4.4.3 发送和接收消息
复制Spring-websocket项目中的chatroom.jsp改造为chatroom.html,根据demo.html案例实现用户注册和登录和即时消息功能。最终效果:
1 | <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> |
5 接口加密
5.1 业务场景介绍
数据安全性 - 抓包工具
![]()

 wireshark fiddler charles
wireshark fiddler charles
系统明文传输的数据会被不明身份的人用抓包工具抓取,从而威胁系统和数据的安全性
5.2 加密方式
5.2.1 摘要算法
消息摘要是把任意长度的输入揉和而产生长度固定的信息。
消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。
消息摘要的主要特点有:
- 无论输入的消息有多长,计算出来的消息摘要的长度总是固定的。
- 消息摘要看起来是“随机的”。这些数据看上去是胡乱的杂凑在一起的。
- 只要输入的消息不同,对其进行摘要后产生的摘要消息也必不相同;但相同的输入必会产生相同的输出。
- 只能进行正向的消息摘要,而无法从摘要中恢复出任何消息,甚至根本就找不到任何与原信息相关的信息。
- 虽然“碰撞”是肯定存在的,但好的摘要算法很难能从中找到“碰撞”。即无法找到两条不同消息,但是它们的摘要相同。
常见的摘要算法:CRC、MD5、SHA等
5.2.2 对称加密
对称加密的特点:
- 速度快,通常在消息发送方需要加密大量数据时使用。
- 密钥是控制加密及解密过程的指令。
- 算法是一组规则,规定如何进行加密和解密。
典型应用场景:离线的大量数据加密(用于存储的)
常用的加密算法:DES、3DES、AES、TDEA、Blowfish、RC2、RC4、RC5、IDEA、SKIPJACK等。
对称加密的工作过程如下图所示
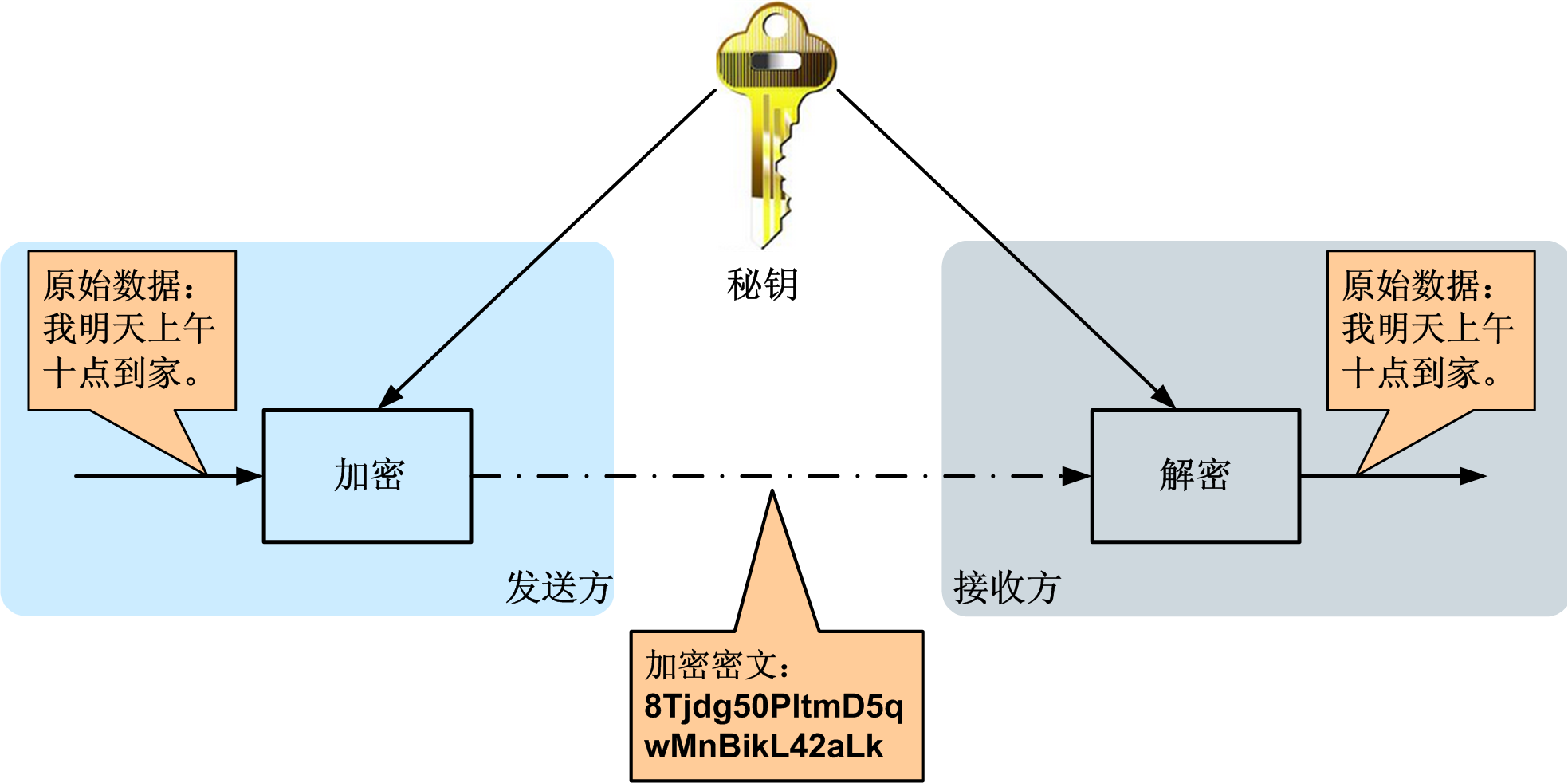
加密的安全性不仅取决于加密算法本身,密钥管理的安全性更是重要。如何把密钥安全地传递到解密者手上就成了必须要解决的问题。
5.2.3 非对称加密
非对称加密算法是一种密钥的保密方法,加密和解密使用两个不同的密钥,公开密钥(publickey:简称公钥)和私有密钥(privatekey:简称私钥)。公钥与私钥是一对,如果用公钥对数据进行加密,只有用对应的私钥才能解密。
非对称加密算法的特点:
- 算法强度复杂
- 加密解密速度没有对称密钥算法的速度快
经典应用场景:数字签名(私钥加密,公钥验证)
常用的算法:RSA、Elgamal、背包算法、Rabin、D-H、ECC(椭圆曲线加密算法)。
非对称加密算法示意图如下
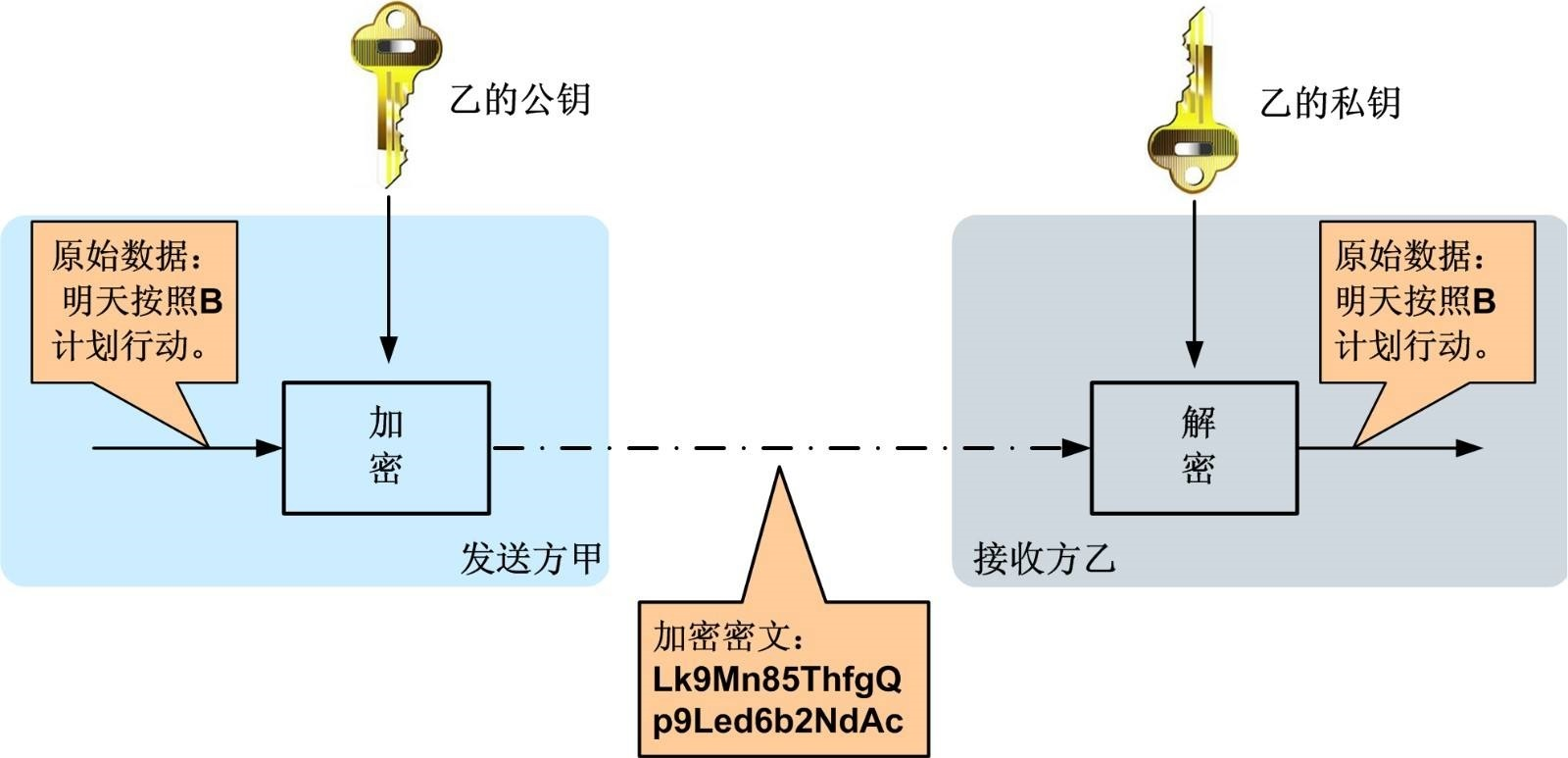
5.2.4 数字签名
数字签名(又称公钥数字签名)是一种类似写在纸上的普通的物理签名,是使用了公钥加密领域的技术实现,用于鉴别数字信息的方法。
数字签名通常使用私钥生成签名,使用公钥验证签名。
签名及验证过程:
- 发送方用一个哈希函数(例如MD5)从报文文本中生成报文摘要,然后用自己的私钥对这个摘要进行加密
- 将加密后的摘要作为报文的数字签名和报文一起发送给接收方
- 接收方用与发送方一样的哈希函数从接收到的原始报文中计算出报文摘要,
- 接收方再用发送方的公用密钥来对报文附加的数字签名进行解密
- 如果这两个摘要相同、接收方就能确认该数字签名是发送方的。
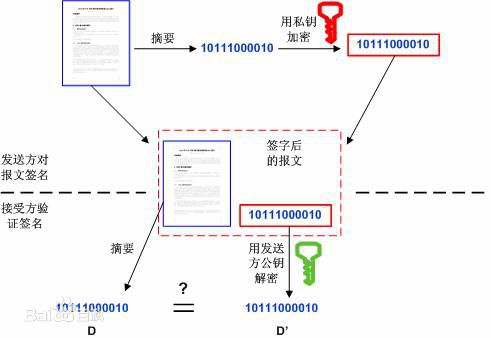
数字签名验证的两个作用:
- 确定消息确实是由发送方签名并发出来的
- 确定消息的完整性
5.3 OpenSSL生成rsa密钥对
5.3.1 RSA算法的密钥格式
密钥长度介于 512 - 65536 之间(JDK 中默认长度是1024),且必须是64 的倍数。密钥的常用文件格式有pem(文本存储)或者der(二进制存储)。
当使用Java API生成RSA密钥对时,公钥以X.509格式编码,私钥以PKCS#8格式编码
RSA使用pkcs协议定义密钥的存储结构等内容
| 协议 | 说明 |
|---|---|
| PKCS#1 | 定义了RSA公钥函数的基本格式标准,特别是数字签名。 |
| PKCS#2 | 涉及了RSA的消息摘要加密,已被并入PKCS#1中。 |
| PKCS#3 | Diffie-Hellman密钥协议标准。 |
| PKCS#4 | 最初是规定RSA密钥语法的,现已经被包含进PKCS#1中。 |
| PKCS#5 | 基于口令的加密标准,描述了使用由口令生成的密钥来加密8位位组串并产生一个加密的8位位组串的方法。PKCS#5可以用于加密私钥,以便于密钥的安全传输(这在PKCS#8中描述)。 |
| PKCS#6 | 扩展证书语法标准,定义了提供附加实体信息的X.509证书属性扩展的语法。 |
| PKCS#7 | 密码消息语法标准。为使用密码算法的数据规定了通用语法,比如数字签名和数字信封。 |
| PKCS#8 | 私钥信息语法标准。定义了私钥信息语法和加密私钥语法,其中私钥加密使用了PKCS#5标准。 |
| PKCS#9 | 可选属性类型。 |
| PKCS#10 | 证书请求语法标准。 |
| PKCS#11 | 密码令牌接口标准。 |
| PKCS#12 | 个人信息交换语法标准。 |
| PKCS#13 | 椭圆曲线密码标准。 |
| PKCS#14 | 伪随机数产生标准。 |
| PKCS#15 | 密码令牌信息语法标准。 |
- pkcs标准详细说明:https://www.rfc-editor.org/search/rfc_search_detail.php?title=pkcs&pubstatus%5B%5D=Any&pub_date_type=any
- RSA官方网站:https://www.rsa.com
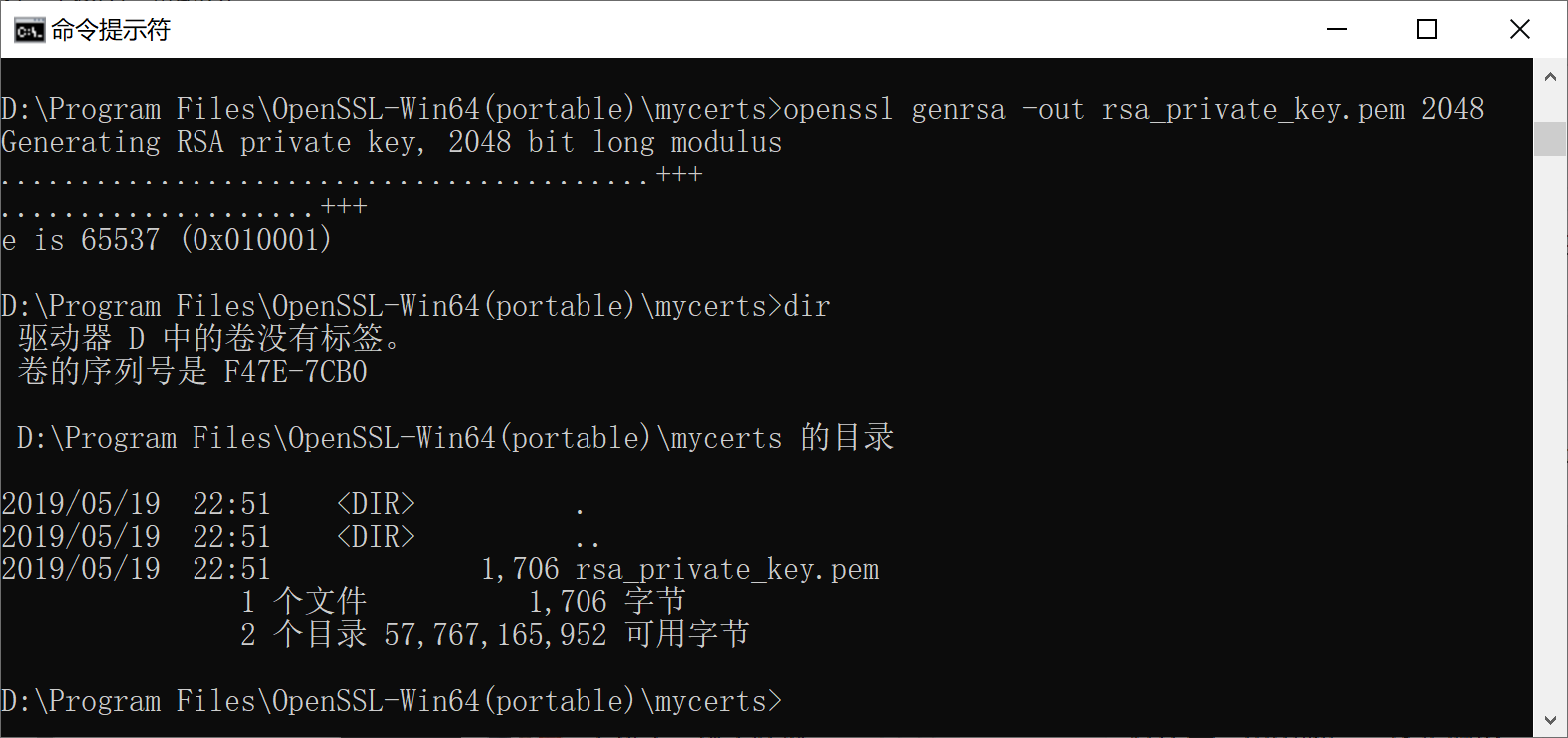
5.3.2 openssl生成rsa密钥对的命令
openssl genrsa -out ../mycerts/rsa_private_key.pem 2048
生成rsa私钥,文本存储格式,长度2048
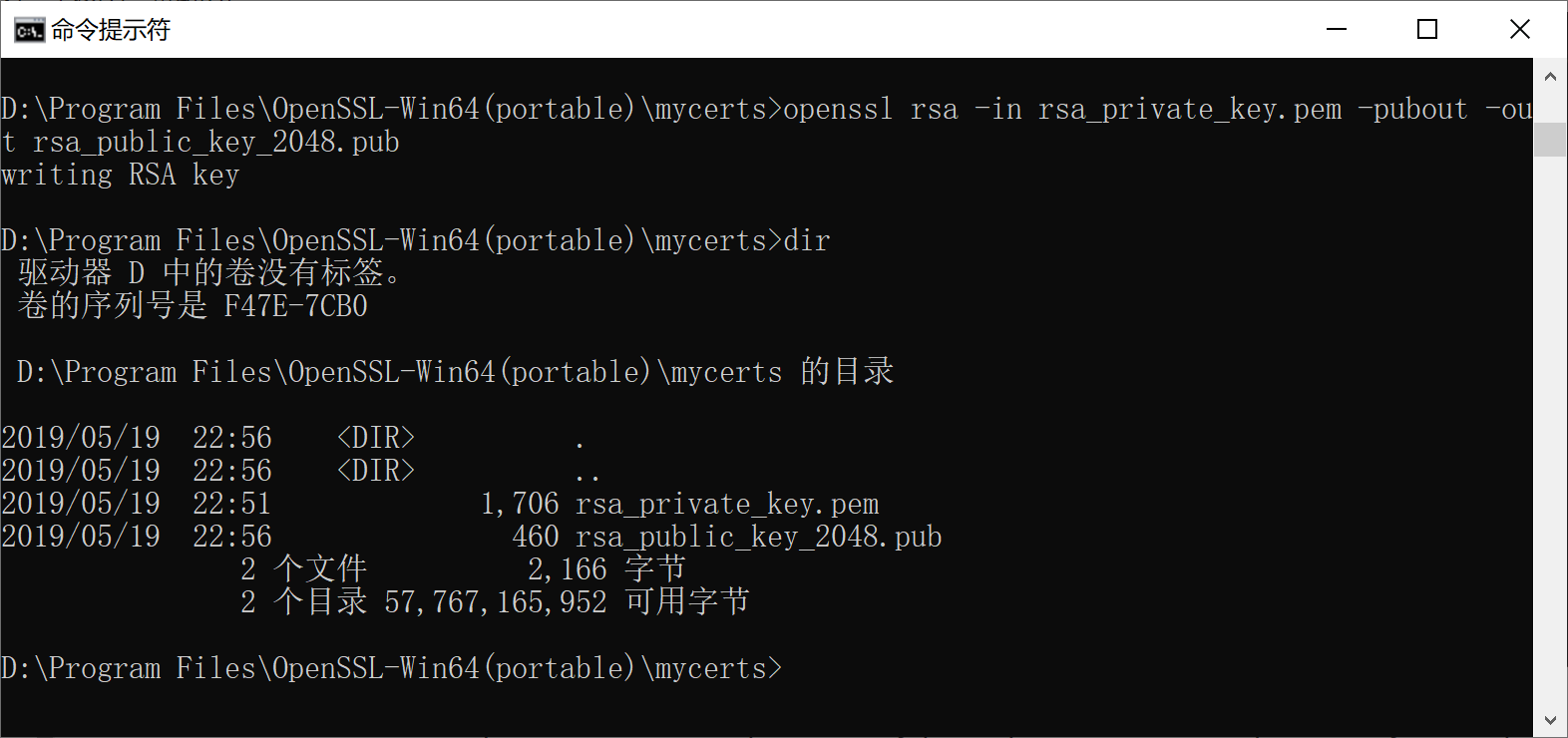
openssl rsa -in ../mycerts/rsa_private_key.pem -pubout -out ../mycerts/rsa_public_key_2048.pub
根据私钥生成对应的公钥
openssl pkcs8 -topk8 -inform PEM -in ../mycerts/rsa_private_key.pem -outform PEM -nocrypt > ../mycerts/rsa_private_key_pkcs8.pem
私钥转化成pkcs8格式
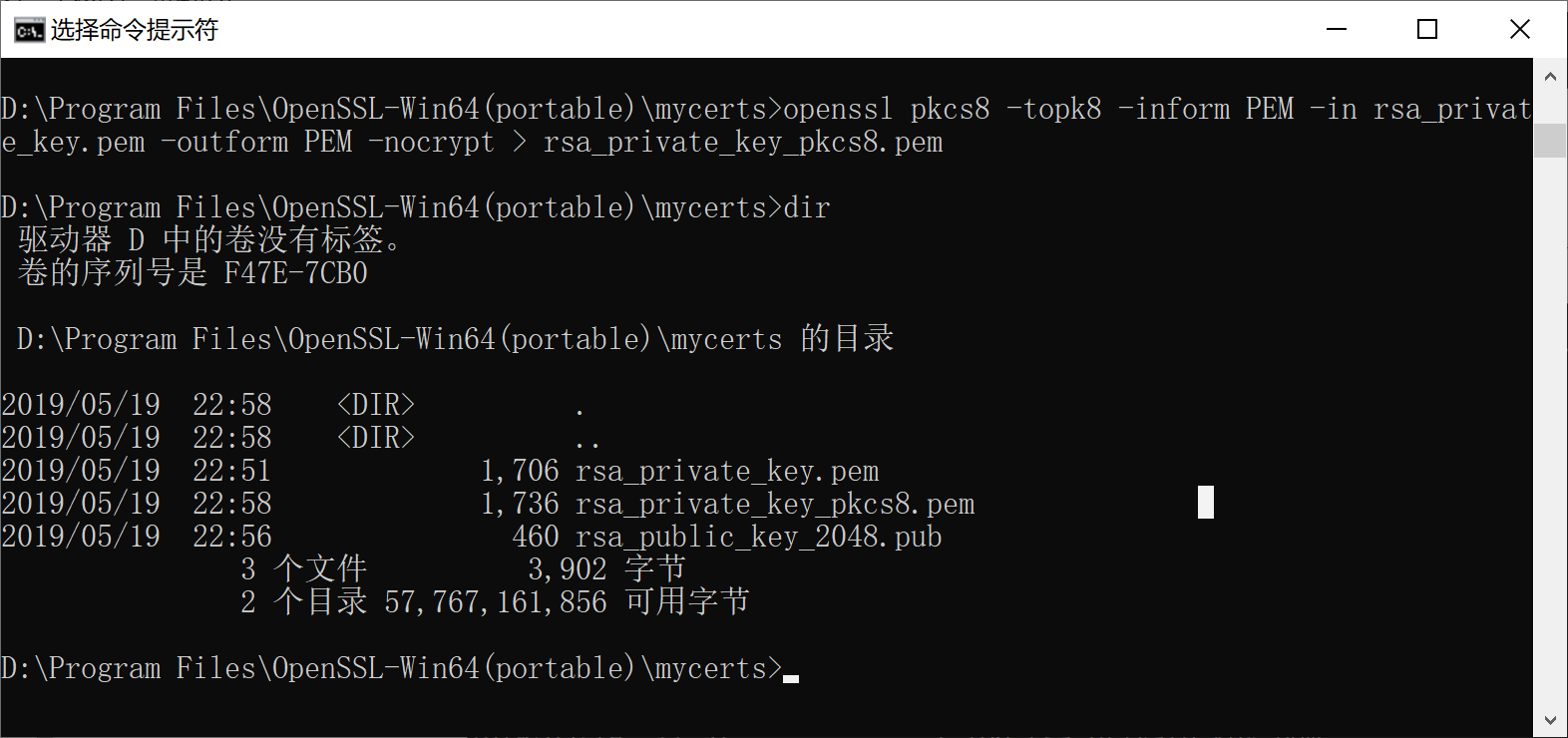
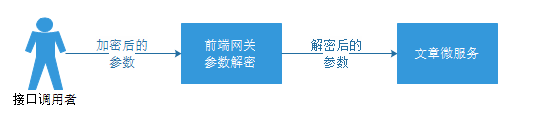
5.4 搭建接口加密微服务
接口加解密请求参数的流程
5.4.1 修改tensquare_parent
在十次方parent父工程pom.xml中添加SpringCloud依赖
1 | <dependencyManagement> |
5.4.2 创建Eureka微服务
创建Maven工程tensquare_eureka,在pom.xml中添加以下依赖:
1 | <dependencies> |
添加配置文件:
1 | server: |
编写启动类:
1 | @SpringBootApplication |
5.4.3 修改文章微服务
在pom.xml中添加Eureka依赖
1 | <dependency> |
修改配置文件,使用Eureka
1 | eureka: |
在ArticleApplication添加@EnableEurekaClient依赖
1 | @SpringBootApplication |
5.4.3 创建tensquare_encrypt网关服务
在tensquare_parent父工程下新建tensquare_encrypt子模块,并按下面的步骤添加配置和代码
在pom.xml文件中添加以下配置
1
<dependencies>
1
<dependency>
1
<groupId>org.springframework.cloud</groupId>
1
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
1
</dependency>
1
<dependency>
1
<groupId>org.springframework.cloud</groupId>
1
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
1
</dependency>
1
</dependencies>
在resource文件夹下新建application.yml文件,并添加如下配置
1
server:
1
port: 9013
1
spring:
1
application:
1
name: tensquare-encrypt
1
zuul:
1
routes:
1
tensquare-article: #文章
1
path: /article/** #配置请求URL的请求规则
1
serviceId: tensquare-article #指定Eureka注册中心中的服务id
1
strip-prefix: true
1
sentiviteHeaders:
1
customSensitiveHeaders: true
1
1
eureka:
1
client:
1
service-url:
1
defaultZone: http://127.0.0.1:6868/eureka/
1
instance:
1
prefer-ip-address: true
1
新建com.tensquare.encrypt包,并在包下新建启动类EncryptApplication,添加如下代码
1
package com.tensquare.encrypt;
1
1
import org.springframework.boot.SpringApplication;
1
import org.springframework.boot.autoconfigure.SpringBootApplication;
1
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
1
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
1
1
@SpringBootApplication
1
@EnableEurekaClient
1
@EnableZuulProxy
1
public class EncryptApplication {
1 | public static void main(String[] args) { |
}
1 | 4. 将rsa相关的工具类复制到在com.tensquare.encrypt包下 |
编写filter
在com.tensquare.encrypt包下新建filters包,然后新建过滤器类RSARequestFilter,添加下面的代码
1
package com.tensquare.encrypt.filters;
1
1
import com.google.common.base.Strings;
1
import com.netflix.zuul.ZuulFilter;
1
import com.netflix.zuul.context.RequestContext;
1
import com.netflix.zuul.http.HttpServletRequestWrapper;
1
import com.netflix.zuul.http.ServletInputStreamWrapper;
1
import com.tensquare.encrypt.rsa.RsaKeys;
1
import com.tensquare.encrypt.service.RsaService;
1
import org.springframework.beans.factory.annotation.Autowired;
1
import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants;
1
import org.springframework.http.MediaType;
1
import org.springframework.stereotype.Component;
1
import org.springframework.util.StreamUtils;
1
1
import javax.servlet.ServletInputStream;
1
import javax.servlet.http.HttpServletRequest;
1
import javax.servlet.http.HttpServletResponse;
1
import java.io.IOException;
1
import java.io.InputStream;
1
import java.nio.charset.Charset;
1
import java.util.HashMap;
1
1
@Component
1
public class RSARequestFilter extends ZuulFilter {
1
1
@Autowired private RsaService rsaService;
1
1
@Override
1
public String filterType() {
1
return FilterConstants.PRE_TYPE;
1
}
1
1
@Override
1
public int filterOrder() {
1
return FilterConstants.PRE_DECORATION_FILTER_ORDER + 1;
1
}
1
1
@Override
1
public boolean shouldFilter() {
1
return true;
1
}
1
1
@Override
1
public Object run() {
1
RequestContext ctx = RequestContext.getCurrentContext();
1
HttpServletRequest request = ctx.getRequest();
1
HttpServletResponse response = ctx.getResponse();
1
1
try {
1
1
String decryptData = null;
1
HashMap dataMap = null;
1
String token = null;
1
1
String url = request.getRequestURL().toString();
1
InputStream stream = ctx.getRequest().getInputStream();
1
String requestParam = StreamUtils.copyToString(stream, Charsets.UTF_8);
1
1
if(!Strings.isNullOrEmpty(requestParam)) {
1
System.out.println(String.format("请求体中的密文: %s", requestParam));
1
decryptData = rsaService.RSADecryptDataPEM(requestParam, RsaKeys.getServerPrvKeyPkcs8());
1
1
System.out.println(String.format("解密后的内容: %s", decryptData));
1
}
1
1
System.out.println(String.format("request: %s >>> %s, data=%s", request.getMethod(), url, decryptData));
1
1
if(!Strings.isNullOrEmpty(decryptData)) {
1
System.out.println("json字符串写入request body");
1
final byte[] reqBodyBytes = decryptData.getBytes();
1
ctx.setRequest(new HttpServletRequestWrapper(request) {
1
@Override
1
public ServletInputStream getInputStream() throws IOException {
1
return new ServletInputStreamWrapper(reqBodyBytes);
1
}
1
1
@Override
1
public int getContentLength() {
1
return reqBodyBytes.length;
1
}
1
1
@Override
1
public long getContentLengthLong() {
1
return reqBodyBytes.length;
1
}
1
});
1
}
1
1
System.out.println("转发request");
1
// 设置request请求头中的Content-Type为application/json,否则api接口模块需要进行url转码操作
1
ctx.addZuulRequestHeader("Content-Type", String.valueOf(MediaType.APPLICATION_JSON) + ";charset=UTF-8");
1
1
} catch (Exception e) {
1
System.out.println(this.getClass().getName() + "运行出错" + e.getMessage());
1
}
1
1
return null;
1
}
1
}
将openssl生成的公钥和私钥添加进RsaKeys中
公钥变量:
private static final String serverPubKey私钥变量:
private static final String serverPrvKeyPkcs8测试请求参数加解密微服务
启动tensquare_eureka,tensquare_article,tensquare_encrypt,使用EncryptTest类加密请求参数,然后使用postman进行接口调用测试
第4章 - 消息通知系统
学习目标:
- 了解消息通知系统的业务场景
- 了解消息通知和即时通讯区别
- 实现消息通知微服务的基本功能
- 实现文章订阅和群发消息
- 实现文章点赞和点对点消息
- 了解基于数据库实现的通知系统的问题
- 了解通知系统的改进方案
1 消息通知的业务场景
消息通知微服务的定位是“平台内”的“消息”功能,分为全员消息,订阅类消息,点对点消息。例如系统通知,私信,@类消息
全员消息
系统通知,活动通知,管理员公告等全部用户都会收到的消息
订阅类消息
关注某一类数据的用户,该类数据有更新时向用户发送的消息。例如关注某位大v的微博,公众号,订阅某位知名作家的专栏
点对点消息
某位用户对另外一位用户进行操作后,系统向被操作的用户发送的消息。例如点赞,发红包。
2 消息通知与即时通讯的区别
| 即时通信 | 消息通知 | |
|---|---|---|
| 传输的内容 | 包括文字聊天、语音消息发送、文件传输、音视频播放等吗,内容极其丰富。 | 以文字,超链接为主,辅以图片,不能再多了。 |
| 核心需求点 | 要求连接稳定可靠。就像网络游戏,如果总是掉线,你还玩的下去吗? | 要求消息的高送达率,也就是说“这件事儿一定要想尽办法通知到对方”。对延时要求不高。 |
| 系统建设成本 | 存储成本高(图片,视频等)。基于TCP协议,需建设或租用多线机房,基建成本高。 | 一般只保存文本消息,存储成本低。可根据用户量自由调整服务器集群配置。 |
| 交互方式 | 任何消息均可回复 | 消息一般被设计为“仅通知,不需要回复” |
| 技术实现 | XMPP,MQTT,Strophe等全双工长连接协议 | JMS,AMQP,http等等各种协议 |
3 搭建消息通知微服务
3.1 业务分析
用户可以对文章作者进行订阅,当被订阅的用户发布新的文章时,可以通过消息通知系统发送消息给订阅者。
流程如下:
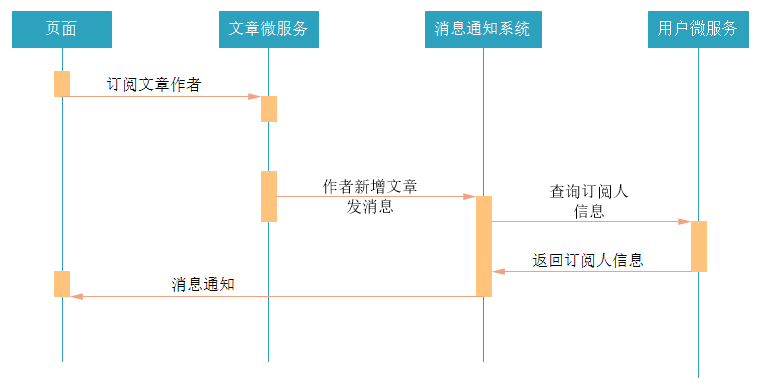
3.2 表结构分析
把资料中的sql脚本导入到数据库中,创建数据库和表。
十次方消息通知微服务总共需要两张数据库表,tb_notice 和 tb_notice_fresh。
消息通知表 tb_notice
保存用户的消息通知
字段名 类型 字段说明 id int ID receiverId varchar 接收消息用户的ID(userId) operatorId varchar 进行操作用户的ID action varchar 操作类型(评论,点赞等) targetType varchar 被操作的对象,例如文章,评论等 targetId varchar 被操作对象的id,例如文章的id,评论的id createtime datetime 发表日期 type varchar 消息通知类型 state varchar 状态:0 未读;1 已读 待推送消息表 tb_notice_fresh
保存准备推送给用户的消息通知
字段名 类型 字段说明 userId varchar 用户ID noticeId varchar 通知id
3.2 搭建消息通知微服务
在tensquare_parent父工程下创建tensquare_notice子模块
修改pom.xml文件,添加下面的配置
1
<dependencies>
1
<!-- mybatis-plus begin -->
1
<dependency>
1
<groupId>com.baomidou</groupId>
1
<artifactId>mybatisplus-spring-boot-starter</artifactId>
1
<version>${mybatisplus-spring-boot-starter.version}</version>
1
</dependency>
1
<dependency>
1
<groupId>com.baomidou</groupId>
1
<artifactId>mybatis-plus</artifactId>
1
<version>${mybatisplus.version}</version>
1
</dependency>
1
<!-- mybatis-plus end -->
1
<dependency>
1
<groupId>com.alibaba</groupId>
1
<artifactId>druid-spring-boot-starter</artifactId>
1
<version>1.1.9</version>
1
</dependency>
1
<dependency>
1
<groupId>mysql</groupId>
1
<artifactId>mysql-connector-java</artifactId>
1
</dependency>
1
<dependency>
1
<groupId>com.tensquare</groupId>
1
<artifactId>tensquare_common</artifactId>
1
<version>1.0-SNAPSHOT</version>
1
</dependency>
1
<dependency>
1
<groupId>org.springframework.boot</groupId>
1
<artifactId>spring-boot-starter-data-redis</artifactId>
1
</dependency>
1
<dependency>
1
<groupId>org.springframework.cloud</groupId>
1
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
1
</dependency>
1
<dependency>
1
<groupId>org.springframework.cloud</groupId>
1
<artifactId>spring-cloud-starter-openfeign</artifactId>
1
</dependency>
1
</dependencies>
在resources文件夹下添加application.yml文件,并添加下面的配置
1
server:
1
port: 9014
1
spring:
1
application:
1
name: tensquare-notice
1
datasource:
1
driver-class-name: com.mysql.jdbc.Driver
1
url: jdbc:mysql://192.168.200.128:3306/tensquare_notice?characterEncoding=utf-8
1
username: root
1
password: root
1
redis:
1
host: 192.168.200.128
1
# Mybatis-Plus 配置
1
mybatis-plus:
1
# mapper-locations: classpath:/mapper/*Mapper.xml
1
#实体扫描,多个package用逗号或者分号分隔
1
typeAliasesPackage: com.tensquare.notice.pojo
1
global-config:
1
id-type: 1 #0:数据库ID自增 1:用户输入id
1
db-column-underline: false
1
refresh-mapper: true
1
configuration:
1
map-underscore-to-camel-case: true
1
cache-enabled: true #配置的缓存的全局开关
1
lazyLoadingEnabled: true #延时加载的开关
1
multipleResultSetsEnabled: true #开启延时加载,否则按需加载属性
1
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #打印sql语句,调试用
1
eureka:
1
client:
1
service-url:
1
defaultZone: http://127.0.0.1:6868/eureka/
1
instance:
1
prefer-ip-address: true
创建启动类
新建com.tensquare.notice包,并在该包下新建NoticeApplication,添加如下代码
1
@SpringBootApplication
1
@EnableEurekaClient
1
@EnableFeignClients
1
public class NoticeApplication {
1
1
public static void main(String[] args) {
1
SpringApplication.run(NoticeApplication.class, args);
1
}
1
1
@Bean
1
public IdWorker idWorkker(){
1
return new IdWorker(1, 1);
1
}
1
}
编写pojo
1
@TableName("tb_notice")
1
public class Notice implements Serializable {
1
1
@TableId(type = IdType.INPUT)
1
private String id;//ID
1
1
private String receiverId;//接收消息的用户ID
1
private String operatorId;//进行操作的用户ID
1
1
@TableField(exist = false)
1
private String operatorName;//进行操作的用户昵称
1
private String action;//操作类型(评论,点赞等)
1
private String targetType;//对象类型(评论,点赞等)
1
1
@TableField(exist = false)
1
private String targetName;//对象名称或简介
1
private String targetId;//对象id
1
private Date createtime;//创建日期
1
private String type; //消息类型
1
private String state; //消息状态(0 未读,1 已读)
1
1
//set get...
1
}
1
@TableName("tb_notice_fresh")
1
public class NoticeFresh {
1
1
private String userId;
1
private String noticeId;
1
1
//set get...
1
}
1
编写dao
1
public interface NoticeDao extends BaseMapper<Notice> {
1
}
1
public interface NoticeFreshDao extends BaseMapper<NoticeFresh> {
1
}
com.tensquare.notice.config添加配置
1
@Configuration
1
//配置Mapper包扫描
1
@MapperScan("com.tensquare.notice.dao")
1
public class MyBatisPlusConfig {
1
1
@Bean
1
public PaginationInterceptor createPaginationInterceptor() {
1
return new PaginationInterceptor();
1
}
1
}
1
3.3 实现基本增删改查功能
需要实现功能:
- 根据id查询消息通知
- 根据条件分页查询消息通知
- 新增通知
- 修改通知
- 根据用户id查询该用户的待推送消息(新消息)
- 删除待推送消息(新消息)
编写Controller
1 | @RestController |
编写Service
1 | @Service |
3.4 完善返回的消息内容
数据库表设计的时候,为了提高性能,并没有保存用户昵称,文章标题等信息,只保存了主键id。但用户在查看消息的时候,只有id是很难阅读的,所以需要根据id,把用户昵称,文章标题等信息查询,并在返回消息之前设置到消息中。
由于消息通知微服务需要调用其他微服务获取字段信息,所以需要做 feign client 调用。
1) com.tensquare.notice.client包下添加ArticleClient和UserClient
1 | @FeignClient(value="tensquare-article") |
2) 修改用户微服务,添加根据id查询用户
编写Controller,添加以下逻辑
1 | /** |
编写Service,添加以下逻辑
1 | public User selectById(String id) { |
3) 改造消息通知微服务,获取消息内容数据
修改com.tensquare.notice.service中的NoticeService,增加getNoticeInfo方法,修改selectById和selectList查询方法,为以下内容:
1 | /** |
4)测试功能
需要开启tensquare-eureka,tensquare-user,tensquare-article,tensquare-notice四个微服务进行测试
4 文章订阅 - 实现群发消息功能
4.1 订阅文章作者
用户在登录十次方以后,可以查看文章。如果觉得文章好,可以订阅文章作者,从而可以收到这个作者发布的新文章的消息。所以需要完成根据文章id,订阅文章作者。
1) 功能分析
- 用户之间的文章订阅关系的数据存放在redis中。
- 用户订阅文章作者,则系统将作者的id放入用户自己的订阅集合(set类型),同时系统将用户的id放入文章作者的订阅者集合中。
- 由于redis的set集合,其中的数据是不重复的,所以不用担心重复数据的问题。
2) 代码实现
需要在tensquare_article微服务中添加根据文章id订阅文章作者的功能,在ArticleController中添加以下代码:
1 | /** |
编写ArticleService
1 | public Boolean subscribe(String userId, String articleId) { |
3) 启动微服务测试功能
需要开启tensquare-eureka,tensquare-article
4.2 新增文章群发消息
新增文章后,需要通知订阅的用户,文章微服务需要调用消息通知微服务,创建消息。
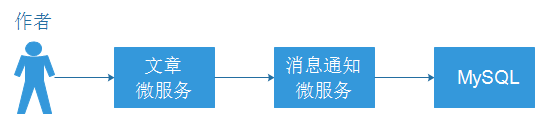
用户登录十次方后,访问的前端页面,页面需要定时轮询通知接口,获取消息。(接口已完成)
1) 新增NoticeClient,调用消息通知微服务
pom.xml添加依赖
1 | <dependency> |
启动类添加注解
1 | @EnableFeignClients |
在com.tensquare.article.client中编写NoticeClient,把消息通知的Notice类复制到文章微服务
1 | @FeignClient(value = "tensquare-notice") |
2) 修改ArticleService的save方法,进行消息通知
1 | public void save(Article article) { |
5 文章点赞 - 实现点对点消息功能
5.1 实现文章点赞
编写ArticleController添加点赞方法:
1 | //文章点赞 |
编写ArticleService:
1 | public void thumbup(String articleId) { |
5.2 实现点赞消息通知
修改ArticleService的点赞方法,增加消息通知:
1 | public void thumbup(String articleId,String userid) { |
6 基于db实现的通知系统存在的问题
6.1 消息通知系统的构成
一个消息通知系统,其主要的构成有消息发送者,消息存储,消息接收者,新消息提醒机制
6.1.1 消息发送者
消息是由系统的操作者发出的吗?不一定。
消息发送的常规流程:
系统的开发者设置了某种消息发送的规则,规则中包含一些条件
规则中的条件都满足后,触发系统生成消息数据
系统将消息数据保存并推送给接收者
以前面文章订阅群发消息作来举例的话
规则:
1.1 用户订阅文章作者
1.2 文章作者发布了新文章
上面规则中的两个条件都满足后,系统就生成消息通知并推送给接收者,告诉接收者有新的文章
在这个例子中,消息真正的发送者是消息通知系统,而非操作者。
用户提前为系统设定好规则,系统按照规则发送消息。
6.1.2 消息存储
消息通知的存储包含消息通知实体数据的存储和新消息提醒数据的存储。
- 消息通知实体数据保存在tb_notice表中的数据
- 新消息提醒数据保存在tb_notice_fresh表中的数据
6.1.3 消息接收者
也就是消息的阅读者,是一条消息通知的最终目的地。
6.1.4 新消息提醒机制
系统产生新的消息通知后,必须有一个合理的机制或者方法来告知接收者有新的消息。否则接收者会郁闷且痛苦地在茫茫的数据海洋中手动去查找新消息。可以使用以下两种方式提醒新消息:
提醒新消息的数量
消息通知列表中新消息置顶并标记
6.2 现在消息通知存在的问题
6.2.1 数据库访问压力大
用户的通知消息和新通知提醒数据都放在数据库中,数据库的读写操作频繁,尤其是tb_notice_refresh表,访问压力大。
6.2.2 服务器性能压力大
采用页面轮询调接口的方式实现服务器向用户推送消息通知,服务器的接口访问压力大。
6.2.3 改进的方法
- 使用 rabbitmq 实现新消息提醒数据的缓存功能,替代tb_notice_refresh表
- 使用全双工长连接的方式实现服务器向用户推送最新的消息通知,替换轮询
- 页面使用websocket
- 微服务端使用异步高性能框架netty
第5章 - 消息通知系统改进
学习目标:
- 了解最新消息上线主动索取方案
- 了解最新消息由系统主动推送方案
- 实现最新消息由RabbitMQ处理
- 了解IO编程和NIO编程
- 了解Netty的作用
- 了解Netty的核心组件
- 实现整合Netty和WebSocket
- 实现点对点消息的改进
1 获取新消息通知的两种模式
用户获取新的消息通知有两种模式
- 上线登录后向系统主动索取
- 在线时系统向接收者主动推送新消息
新消息提醒功能需要定时轮询接口的方式太低效,改进点如下
将新消息提醒数据由tb_notice_fresh表转移到rabbitmq中,减轻数据库访问压力
将轮询接口的伪推送改进为真正的使用全双工长连接进行的推送
2.1 消息通知微服务加入netty框架,为页面中的websocket连接提供接入服务
2.2 netty框架与rabbitmq对接,接收并下发新消息提醒数据
2.2 将页面中的定时轮询接口代码替换为websocket连接和事件处理
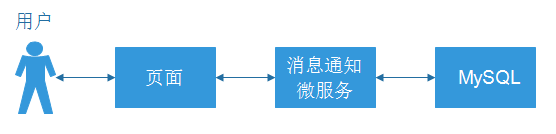
1.1 上线登录后向系统索取
此模式是接受者请求系统,系统将新的消息通知返回给接收者的模式,流程如下:
- 接收者向服务端netty请求WebSocket连接
- Netty服务吧连接放到自己的连接池中
- Netty根据接受者信息向RabbitMQ查询消息
- 如果有新消息,返回新消息通知
- 使用WebSocket连接向,接收者返回新消息的数量
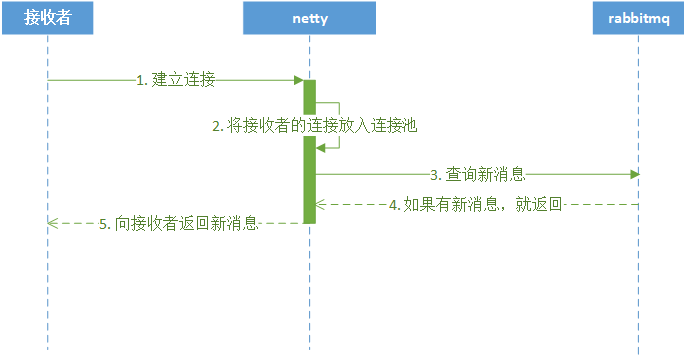
1.2 在线时系统向接收者主动推送
此模式是系统将新的消息通知返回给接收者的模式,流程如下:
- RabbitMQ将新消息数据推送给Netty
- Netty从连接池中取出接收者的WebSocket连接
- Netty通过接收者的WebSocket连接返回新消息的数量
2 文章订阅群发消息改进
文章订阅群发消息的改进步骤:
- 准备RabbitMQ消息中间件
- 改进文章订阅功能,创建RabbitMQ队列存放新消息通知
- 改进发布文章后群发消息通知功能
- 整合Netty和WebSocket实现双向通信
在虚拟机中启动RabbitMQ
1 | docker run -id --name=tensquare_rabbit -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15672:15672 -p 25672:25672 rabbitmq:management |
访问地址:http://192.168.200.128:15672
登录账号: guest
登录密码: guest
2.1 文章订阅功能改进
2.1.1 修改文章微服务配置文件
因为文章订阅功能需要增加Rabbitmq的交换机和队列的绑定、解绑等相关操作,所以需要让tensquare_article微服务具备操作Rabbitmq的能力。
修改tensquare_article微服务的application.yml配置文件,文件位置如下
在该文件中添加Rabbitmq相关的配置
1 | rabbitmq: |
然后修改tensquare_article微服务的pom.xml项目配置文件,添加如下依赖
1 | <dependency> |
2.1.2 修改文章订阅功能代码
在ArticleService中原有的subscribe方法中,增加了几个业务逻辑
- 定义Rabbitmq的direct类型的交换机
- 定义用户的Rabbitmq队列
- 将队列通过路由键绑定或解绑direct交换机
改进后完整的subscribe方法如下
1 | public Boolean subscribe(String userId, String articleId) { |
2.2 发布文章触发群发消息
在原有的处理逻辑中,增加向交换机发送Rabbitmq消息的业务逻辑,文章作者的用户id作为路由键。修改ArticleService中的 save方法,在新增方法的最后面添加下面的代码:
1 | //入库成功后,发送mq消息,内容是消息通知id |
删除消息通知微服务中的 新的通知提醒消息入库 逻辑,因为现在新通知由RabbitMQ发送。修改tensquare_notice微服务的NoticeService方法:
1 | @Transactional |
3 IO编程
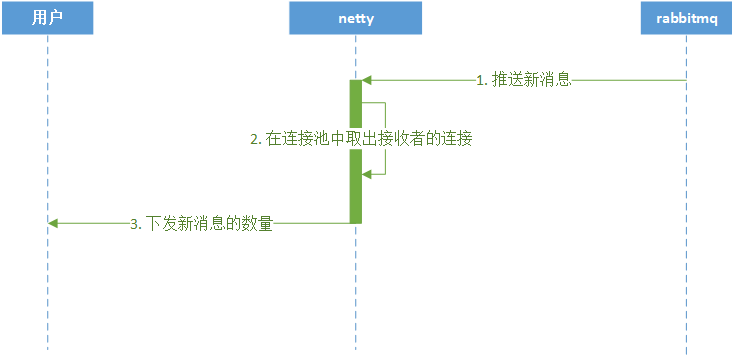
在开始了解Netty之前,先来实现一个客户端与服务端通信的程序,使用传统的IO编程和使用NIO编程有什么不一样。
3.1 传统IO编程
每个客户端连接过来后,服务端都会启动一个线程去处理该客户端的请求。阻塞I/O的通信模型示意图如下:
业务场景:客户端每隔两秒发送字符串给服务端,服务端收到之后打印到控制台。
服务端实现:
1 | public class IOServer { |
客户端实现:
1 | public class MyClient { |
从服务端代码中我们可以看到,在传统的IO模型中,每个连接创建成功之后都需要一个线程来维护,每个线程包含一个while死循环。
如果在用户数量较少的情况下运行是没有问题的,但是对于用户数量比较多的业务来说,服务端可能需要支撑成千上万的连接,IO模型可能就不太合适了。
如果有1万个连接就对应1万个线程,继而1万个while死循环,这种模型存在以下问题:
- 当客户端越多,就会创建越多的处理线程。线程是操作系统中非常宝贵的资源,同一时刻有大量的线程处于阻塞状态是非常严重的资源浪费。并且如果务器遭遇洪峰流量冲击,例如双十一活动,线程池会瞬间被耗尽,导致服务器瘫痪。
- 因为是阻塞式通信,线程爆炸之后操作系统频繁进行线程切换,应用性能急剧下降。
- IO编程中数据读写是以字节流为单位,效率不高。
3.2 NIO编程
NIO,也叫做new-IO或者non-blocking-IO,可理解为非阻塞IO。NIO编程模型中,新来一个连接不再创建一个新的线程,而是可以把这条连接直接绑定到某个固定的线程,然后这条连接所有的读写都由这个线程来负责,我们用一幅图来对比一下IO与NIO:
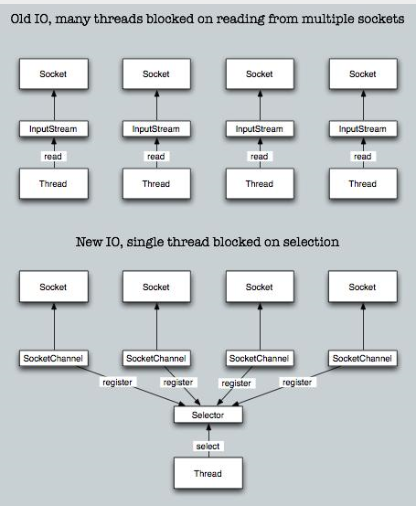
如上图所示,IO模型中,一个连接都会创建一个线程,对应一个while死循环,死循环的目的就是不断监测这条连接上是否有数据可以读。但是在大多数情况下,1万个连接里面同一时刻只有少量的连接有数据可读,因此,很多个while死循环都白白浪费掉了,因为没有数据。
而在NIO模型中,可以把这么多的while死循环变成一个死循环,这个死循环由一个线程控制。这就是NIO模型中选择器(Selector)的作用,一条连接来了之后,现在不创建一个while死循环去监听是否有数据可读了,而是直接把这条连接注册到选择器上,通过检查这个选择器,就可以批量监测出有数据可读的连接,进而读取数据。
举个栗子,在一家餐厅里,客人有点菜的需求,一共有100桌客人,有两种方案可以解决客人点菜的问题:
方案一:
每桌客人配一个服务生,每个服务生就在餐桌旁给客人提供服务。如果客人要点菜,服务生就可以立刻提供点菜的服务。那么100桌客人就需要100个服务生提供服务,这就是IO模型,一个连接对应一个线程。
方案二:
一个餐厅只有一个服务生(假设服务生可以忙的过来)。这个服务生隔段时间就询问所有的客人是否需要点菜,然后每一时刻处理所有客人的点菜要求。这就是NIO模型,所有客人都注册到同一个服务生,对应的就是所有的连接都注册到一个线程,然后批量轮询。
这就是NIO模型解决线程资源受限的方案,实际开发过程中,我们会开多个线程,每个线程都管理着一批连接,相对于IO模型中一个线程管理一条连接,消耗的线程资源大幅减少。
NIO的三大核心组件:通道(Channel)、缓冲(Buffer)、选择器(Selector)
通道(Channel)
是传统IO中的Stream(流)的升级版。Stream是单向的、读写分离(inputstream和outputstream),Channel是双向的,既可以进行读操作,又可以进行写操作。
缓冲(Buffer)
Buffer可以理解为一块内存区域,可以写入数据,并且在之后读取它。
选择器(Selector)
选择器(Selector)可以实现一个单独的线程来监控多个注册在她上面的信道(Channel),通过一定的选择机制,实现多路复用的效果。
NIO相对于IO的优势:
- IO是面向流的,每次都是从操作系统底层一个字节一个字节地读取数据,并且数据只能从一端读取到另一端,不能前后移动流中的数据。NIO则是面向缓冲区的,每次可以从这个缓冲区里面读取一块的数据,并且可以在需要时在缓冲区中前后移动。
- IO是阻塞的,这意味着,当一个线程读取数据或写数据时,该线程被阻塞,直到有一些数据被读取,或数据完全写入,在此期间该线程不能干其他任何事情。而NIO是非阻塞的,不需要一直等待操作完成才能干其他事情,而是在等待的过程中可以同时去做别的事情,所以能最大限度地使用服务器的资源。
- NIO引入了IO多路复用器selector。selector是一个提供channel注册服务的线程,可以同时对接多个Channel,并在线程池中为channel适配、选择合适的线程来处理channel。由于NIO模型中线程数量大大降低,线程切换效率因此也大幅度提高。
和前面一样的场景,使用NIO实现(复制代码演示效果即可):
1 | public class NIOServer { |
4 Netty
4.1 为什么使用Netty
我们已经有了NIO能够提高程序效率了,为什么还要使用Netty?
简单的说:Netty封装了JDK的NIO,让你用得更爽,你不用再写一大堆复杂的代码了。
官方术语:Netty是一个异步事件驱动的网络应用框架,用于快速开发可维护的高性能服务器和客户端。
下面是使用Netty不使用JDK原生NIO的一些原因:
- 使用JDK自带的NIO需要了解太多的概念,编程复杂
- Netty底层IO模型随意切换,而这一切只需要做微小的改动,就可以直接从NIO模型变身为IO模型
- Netty自带的拆包解包,异常检测等机制,可以从NIO的繁重细节中脱离出来,只需要关心业务逻辑
- Netty解决了JDK的很多包括空轮询在内的bug
- Netty底层对线程,selector做了很多细小的优化,精心设计的线程模型做到非常高效的并发处理
- 自带各种协议栈让你处理任何一种通用协议都几乎不用亲自动手
- Netty社区活跃,遇到问题随时邮件列表或者issue
- Netty已经历各大rpc框架,消息中间件,分布式通信中间件线上的广泛验证,健壮性无比强大
和IO编程一样的案例:
添加Netty依赖
1 | <dependency> |
服务端:
1 | public class NettyServer { |
客户端:
1 | public class NettyClient { |
4.2 Netty的事件驱动
例如很多系统都会提供 onClick() 事件,这个事件就代表鼠标按下事件。事件驱动模型的大体思路如下:
- 有一个事件队列;
- 鼠标按下时,往事件队列中增加一个点击事件;
- 有个事件泵,不断循环从队列取出事件,根据不同的事件,调用不同的函数;
- 事件一般都各自保存各自的处理方法的引用。这样,每个事件都能找到对应的处理方法;
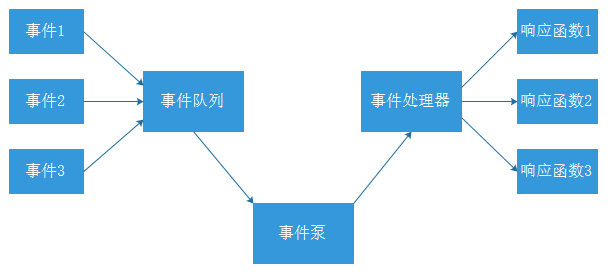
为什么使用事件驱动?
程序中的任务可以并行执行
任务之间高度独立,彼此之间不需要互相等待
在等待的事件到来之前,任务不会阻塞
Netty使用事件驱动的方式作为底层架构,包括:
- 事件队列(event queue):接收事件的入口。
- 分发器(event mediator):将不同的事件分发到不同的业务逻辑单元。
- 事件通道(event channel):分发器与处理器之间的联系渠道。
- 事件处理器(event processor):实现业务逻辑,处理完成后会发出事件,触发下一步操作。
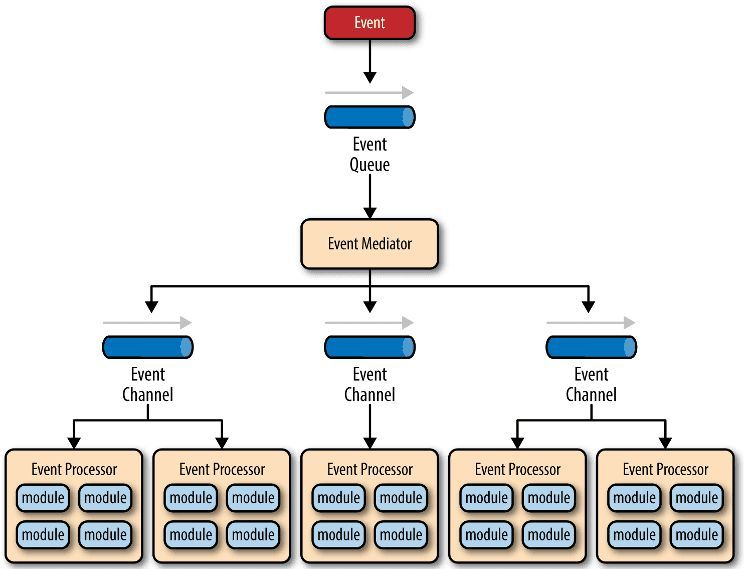
4.4 核心组件
Netty 的功能特性图:
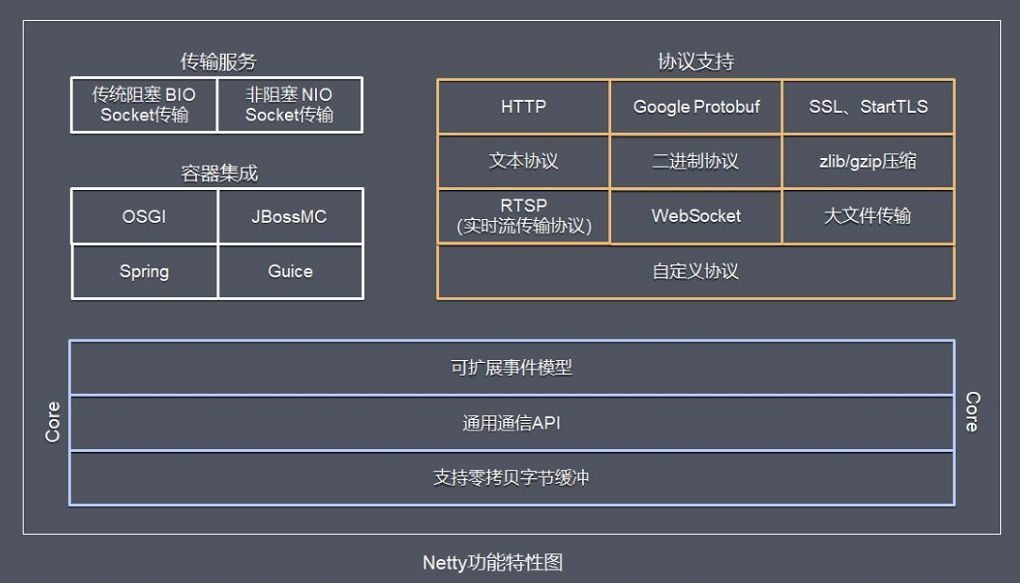
Netty 功能特性:
- 传输服务,支持 BIO 和 NIO。
- 容器集成:支持 OSGI、JBossMC、Spring、Guice 容器。
- 协议支持:HTTP、Protobuf、二进制、文本、WebSocket 等,支持自定义协议。
BIO和NIO的区别:
| 场景 | BIO | NIO |
|---|---|---|
| 有新连接请求时 | 开一个新的线程处理 | 使用多路复用原理,一个线程处理 |
| 适用场景 | 连接数小且固定 | 连接数特别多,连接比较短(轻操作)的场景 |
Netty框架包含如下的组件:
ServerBootstrap :用于接受客户端的连接以及为已接受的连接创建子通道,一般用于服务端。
Bootstrap:不接受新的连接,并且是在父通道类完成一些操作,一般用于客户端的。
Channel:对网络套接字的I/O操作,例如读、写、连接、绑定等操作进行适配和封装的组件。
EventLoop:处理所有注册其上的channel的I/O操作。通常情况一个EventLoop可为多个channel提供服务。
EventLoopGroup:包含有多个EventLoop的实例,用来管理 event Loop 的组件,可以理解为一个线程池,内部维护了一组线程。
ChannelHandler和ChannelPipeline:例如一个流水线车间,当组件从流水线头部进入,穿越流水线,流水线上的工人按顺序对组件进行加工,到达流水线尾部时商品组装完成。流水线相当于
ChannelPipeline,流水线工人相当于ChannelHandler,源头的组件当做event。ChannelInitializer:用于对刚创建的channel进行初始化,将ChannelHandler添加到channel的ChannelPipeline处理链路中。
ChannelFuture:与jdk中线程的Future接口类似,即实现并行处理的效果。可以在操作执行成功或失败时自动触发监听器中的事件处理方法。
上面的Netty框架包含如下的组件大概看的有点蒙,我们对之前编写的代码加上注释:
服务端:
1 | public class NettyServer { |
客户端:
1 | public class NettyClient { |
5 整合Netty和WebSocket
我们需要使用netty对接websocket连接,实现双向通信,这一步需要有服务端的netty程序,用来处理客户端的websocket连接操作,例如建立连接,断开连接,收发数据等。
5.1 修改配置
修改消息通知微服务模块tensquare_notice的pom文件,添加下面的dependency依赖
1
<dependency>
1
<groupId>org.springframework.boot</groupId>
1
<artifactId>spring-boot-starter-amqp</artifactId>
1
</dependency>
1
<dependency>
1
<groupId>io.netty</groupId>
1
<artifactId>netty-all</artifactId>
1
<version>4.1.5.Final</version>
1
</dependency>
修改application.yml文件,添加下面的配置
1
rabbitmq:
1
host: 192.168.200.128
这样消息通知微服务就引入了netty框架,并且具有了和Rabbitmq交互的能力
5.2 实现Netty的整合
5.2.1 整合分析
现在的通讯模式如下:
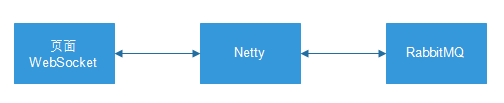
因为使用到了WebSocket和Netty,整合方式和以前有所不同,整合步骤:
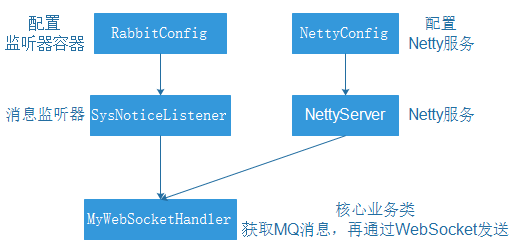
- 编写
NettyServer,启动Netty服务。 - 使用配置Bean创建Netty服务。编写
NettyConfig。 - 编写和WebSocket进行通讯处理类
MyWebSocketHandler,进行MQ和WebSocket的消息处理。 - 使用配置Bean创建Rabbit监听器容器,使用监听器。编写
RabbitConfig。 - 编写Rabbit监听器
SysNoticeListener,用来获取MQ消息并进行处理。
五个类的关系如下图:
5.2.2 实现整合
1) 复制资料中的ApplicationContextProvider.java到com.tensquare.notice.config
这个类是工具类,作用是获取Spring容器中的实例
2) 编写NettyServer
com.tensquare.notice.netty
1 | public class NettyServer { |
3) 编写NettyConfig
在com.tensquare.notice.config中编写
1 | @Configuration |
4) 编写MyWebSocketHandler
com.tensquare.notice.netty
1 | public class MyWebSocketHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> { |
5) 编写RabbitConfig
在com.tensquare.notice.config中编写
1 | @Configuration |
6) 编写SysNoticeListener
在com.tensquare.notice.listener中编写:
1 | public class SysNoticeListener implements ChannelAwareMessageListener { |
1) 复制资料中的工具config、listener、netty到tensquare_notice的com.tensquare.notice包中
MyWebSocketHandler中的channelRead0是核心代码,需要根据业务场景进行修改
2) 修改启动类,添加Netty服务的启动
1 | public static void main(String[] args) { |
3) 复制工具中的index.html到resources的static中,这个html是测试页面
4) 启动tensquare-eureka,tensquare-user,tensquare-article,tensquare-notice四个微服务进行测试
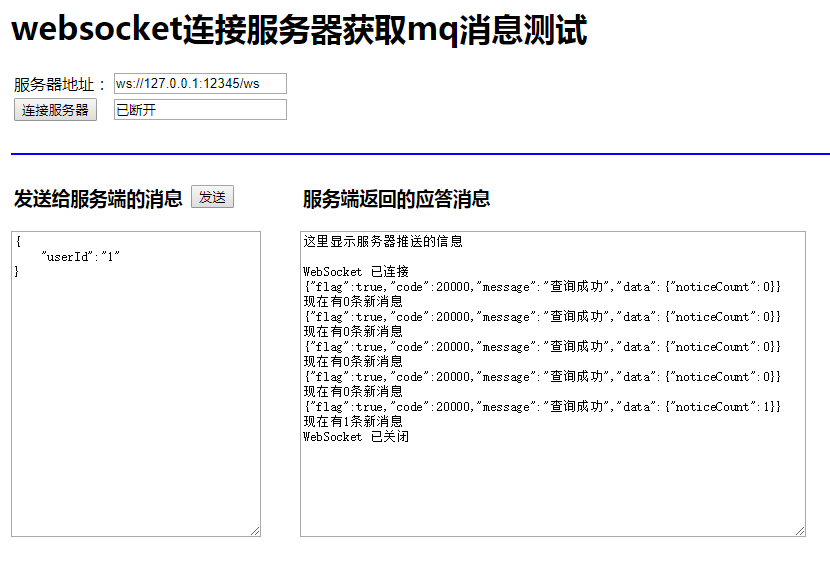
当新增一个文章数据的时候,就会发消息,最终页面显示的效果:
6 文章点赞点对点消息改进
6.1 文章点赞功能改进
在ArticleService中原有的thumbup方法中,增加向用户的点对点消息队列发送消息的功能
改进后完整的代码如下
1 | //文章点赞 |
6.2 消息通知改进
1) 在com.tensquare.notice.listeners包下新建 UserNoticeListener类,添加如下代码
1 | public class UserNoticeListener implements ChannelAwareMessageListener { |
2) RabbitConfig改造如下
1 | @Configuration |
3) MyWebSocketHandler改造如下
1 | public class MyWebSocketHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> { |
6.3 测试点对点消息
1) 启动tensquare-eureka,tensquare-user,tensquare-article,tensquare-notice四个微服务进行测试
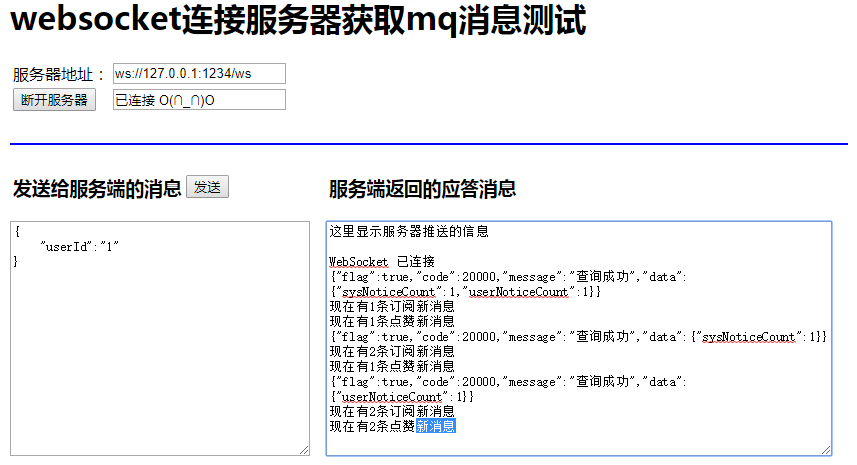
当作者的文章被点赞时,会收到点赞的新消息提示,最终页面显示的效果:
第6章 - Redis分布式缓存
学习目标:
- 掌握Redis性能测试
- 掌握Redis读写分离搭建
- 掌握Redis高可用Sentinel搭建
- 掌握Sentinel整合SpringBoot
- 掌握Redis内置集群搭建和维护
- 掌握内置集群整合SpringBoot
- 掌握twemProxy搭建Redis分片式集群
1. Redis读写分离
单机Redis的读写速度非常快,能够支持大量用户的访问。虽然Redis的性能很高,但是对于大型网站来说,每秒需要获取的数据远远超过单台redis服务所能承受的压力,所以我们迫切需要一种方案能够解决单台Redis服务性能不足的问题。
1.1 Redis性能测试
1.1.1 redis-benchmark
redis-benchmark是官方自带的Redis性能测试工具,用来测试Redis在当前环境下的读写性能。我们在使用Redis的时候,服务器的硬件配置、网络状况、测试环境都会对Redis的性能有所影响,我们需要对Redis实时测试以确定Redis的实际性能。
使用语法:
1 | redis-benchmark [参数] [参数值] |
参数说明:
| 选项 | 描述 | 默认值 |
|---|---|---|
| -h | 指定服务器主机名 | 127.0.0.1 |
| -p | 指定服务器端口 | 6379 |
| -s | 指定服务器 socket | |
| -c | 指定并发连接数 | 50 |
| -n | 指定请求数 | 10000 |
| -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| -k | 1=keep alive 0=reconnect | 1 |
| -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| -P | 通过管道传输 请求 | 1 |
| -q | 强制退出 redis。仅显示 query/sec 值 | |
| –csv | 以 CSV 格式输出 | |
| -l | 生成循环,永久执行测试 | |
| -t | 仅运行以逗号分隔的测试命令列表。 | |
| -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
安装redis
在虚拟机中安装c++环境:
1 | yum install gcc-c++ |
安装Redis,依次执行以下命令:
1 | # 解压 |
执行以下命令,测试性能:
1 | # 执行测试性能命令 |
执行结果如下:
1 | ====== SET ====== |
在上面的测试结果中,我们关注GET结果最后一行 52110.47 requests per second ,即每秒GET命令处理52110.47个请求,即QPS5.2万。但这里的数据都只是理想的测试数据,测出来的QPS不能代表实际生产的处理能力。
1.1.2 TPS、QPS、RT
在描述系统的高并发能力时,吞吐量(TPS)、QPS、响应时间(RT)经常提到,我们先了解这些概念:
- 响应时间RT
- 吞吐量TPS
- 每秒查询率QPS
响应时间(RT)
响应时间是指系统对请求作出响应的时间。
直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的业务逻辑也千差万别,因而不同功能的响应时间也不尽相同。
在讨论一个系统的响应时间时,通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。
吞吐量TPS
吞吐量是指系统在单位时间内处理请求的数量。
对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多。这是因为在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不随用户数的增加而线性增加。
实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。
每秒查询率QPS
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在互联网中,经常用每秒查询率来衡量服务器的性能。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
1.1.3 测算Redis性能
在实际生产中,我们需要关心在应用场景中,redis能够处理的QPS是多少。我们需要估计生产的报文大小,使用benchmark工具指定-d数据块大小来模拟:
1 | ./redis-benchmark -t get -n 100000 -c 100 -d 2048 |
测试结果:
1 | ====== GET ====== |
测得的QPS是4.2万
我们也可以使用redis客户端登陆到redis服务中,执行info命令查看redis的其他信息,执行命令:
1 | # 使用Redis客户端 |
查看结果(摘取部分结果):
1 | connected_clients:101 #redis连接数 |
1.2 Redis读写分离
在前面我们已经测试过,如果只有一台服务器,QPS是4.2万,而在大型网站中,可能要求更高的QPS,很明显,一台服务器就不能满足需要了。
1 | Redis在知乎的规模: |
我们可以对读写能力扩展,采用读写分离的方式解决性能瓶颈。运行新的服务器(称为从服务器),让从服务器与主服务器进行连接,然后主服务器发送数据副本,从服务器通过网络根据主服务器的数据副本进行准实时更新(具体的更新速度取决于网络带宽)。
这样我们就有额外的从服务器处理读请求,通过将读请求分散到不同的服务器上面进行处理, 用户可以从新添加的从服务器上获得额外的读查询处理能力。
redis已经发现了这个读写分离场景特别普遍,自身集成了读写分离供用户使用。我们只需在redis的配置文件里面加上一条,slaveof host port语句配置即可,我们现在开始配置主从环境。
执行命令:
1 | # 复制redis |
分别连接主库(6379)和从库(6380),测试发现主库的写操作,从库立刻就能看到相同的数据。但是在从库进行写操作,提示 READONLY You can't write against a read only slave 不能写数据到从库。
现在我们就可以通过这种方式配置多个从库读操作,主库进行写操作,实现读写分离,以提高redis的QPS。
1.3 Redis同步原理
通过上面的例子,我们知道redis的主从复制,主服务器执行写操作命令,从服务器会通过主服务器的数据的变化,同步数据到从服务器。但是如果主服务器下线,从服务器无法连接主服务器,那么数据同步该如何拿到不能连接主服务器这段时间的命令呢?
主从复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作数据库状态一致。
Redis数据库持久化有两种方式:RDB全量持久化和AOF增量持久化。
数据同步步骤:
redis2.8版本之前使用旧版复制功能SYNC,这是一个非常耗费资源的操作
- 主服务器需要执行BGSAVE命令来生成RDB文件,这个生成操作会耗费主服务器大量量的的CPU、内存和磁盘读写资源。
- 主服务器将RDB文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络带宽和流量,并对主服务器响应命令
- 请求的时间产生影响:接收到RDB文件的从服务器在载入文件的过程是阻塞的,无法处理命令请求
2.8之后使用PSYNC,具有完整重同步和部分重同步两种模式部分重同步两种模式。
第一种完整重同步:

第二种部分重同步:

功能由以下三个部分构成:
1) 主服务的复制偏移量(replication offset)和从服务器的复制偏移量量。
2) 主服务器的复制积压缓冲区(replication backlog),默认大小为1M。
3) 服务器的运行ID,用于存储服务器标识:
如果从服务器断线重新连接,获取主服务器的运行ID与重接后的主服务器运行ID进行对比,
判断是不是原来的主服务器,从而决定是执行部分重同步,还是执行完整重同步。
2. Redis高可用Sentinel
2.1 高可用介绍
高可用是分布式系统架构设计中必须考虑的因素之一,它是通过架构设计减少系统不能提供服务的时间。保证高可用通常遵循下面几点:
- 单点是系统高可用的大敌,应该尽量在系统设计的过程中避免单点。
- 通过架构设计而保证系统高可用的,其核心准则是:冗余。
- 每次出现故障需要人工介入恢复,会增加系统不可用的时间,实现自动故障转移。
我们现在已经给Redis实现了主从复制,可将主节点数据同步给从节点,从节点此时有两个作用:
- 从节点扩展主节点的读能力,分担主节点读压力。
- 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。(高可用)
2.2 手动主从切换
2.2.1 环境准备
一旦主节点宕机,就需要把从节点晋升成主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工操作。我们再准备一个从服务,依次执行以下命令:
1 | cd /usr/local/redis/ |
分别进入一主两从服务,执行info命令,看到服务的状态:
主服务器:
1 | # Replication |
从服务器:
1 | # Replication |
2.2.2 主从切换
主服务下线
登录6379端口号的主服务,并执行shutdown命令,关闭这个主redis,进入6381从服务执行info命令,我们可以看到从服务的信息变为:
1 | # Replication |
可以看到主的状态由原来的up变为down,说明主服务下线了。
主从切换
现在可以把6380升级为主服务,执行命令:
1 | slaveof no one |
修改6381对应的主服务器,执行命令:
1 | slaveof 192.168.200.129 6380 |
再次执行info命令,可以看到主从服务器都切换成功。现在变成了一主一从,对外是正常的。
2.3 Sentinel实现高可用
2.3.1 Sentinel介绍
在前面的例子中,主节点宕机,需要把从节点晋升成主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点。
这整个过程都是人工,费事费力,还会造成一段时间内服务不可用,而且需要人一直都在。这不是一种好的方式,更多时候,我们优先考虑Sentinel(哨兵)。
Sentinel工作模式:
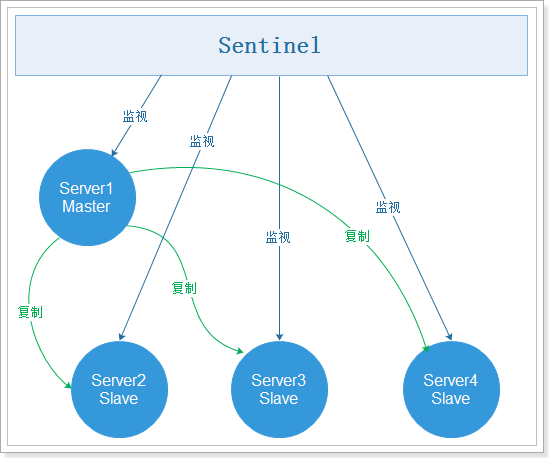
2.3.2 Sentinel使用
2.3.2.1 安装
Sentinel在redis的安装包中有,我们直接使用就可以了,但是先需要修改配置文件,执行命令:
1 | cd /usr/local/redis/ |
在sentinel01.conf配置文件中添加:
1 | # 外部可以访问 |
参数说明:
sentinel monitor mymaster 192.168.200.129 6379 1
mymaster主节点名,可以任意起名,但必须和后面的配置保持一致。192.168.200.129 6379主节点连接地址。1将主服务器判断为失效需要投票,这里设置至少需要 1个 Sentinel 同意。sentinel down-after-milliseconds mymaster 10000
设置Sentinel认为服务器已经断线所需的毫秒数。
sentinel failover-timeout mymaster 60000
设置failover(故障转移)的过期时间。当failover开始后,在此时间内仍然没有触发任何failoer操作,当前 sentinel 会认为此次failoer失败。
sentinel parallel-syncs mymaster 1
设置在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小,表示同时进行同步的从服务器越少,那么完成故障转移所需的时间就越长。
如果从服务器允许使用过期数据集, 那么我们可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求, 因为从服务器在载入主服务器发来的RDB文件时, 会造成从服务器在一段时间内不能处理命令请求。如果全部从服务器一起对新的主服务器进行同步, 那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。
配置文件修改后,执行以下命令,启动sentinel:
1 | /root/redis-4.0.14/src/redis-sentinel sentinel01.conf |
效果如下:

可以看到,6379是主服务,6380和6381是从服务。
2.3.2.2 测试
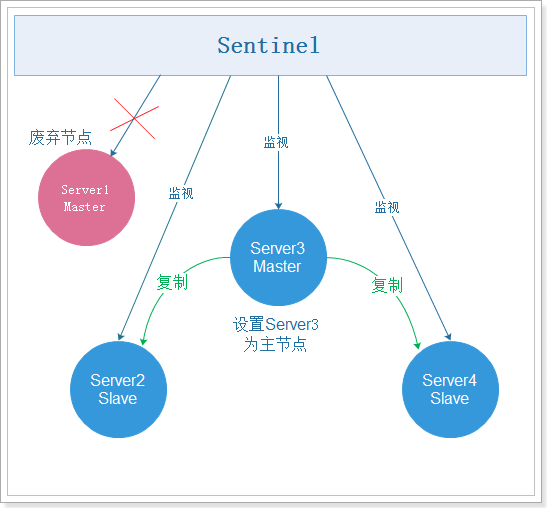
我们在6379执行shutdown,关闭主服务,Sentinel提示如下:
1 | +sdown master mymaster 192.168.200.129 6379 #主节点宕机 |
根据提示信息,我们可以看到,6379故障转移到了6380,通过投票选择6380为新的主服务器。
在6380执行info
1 | # Replication |
在6381执行info
1 | # Replication |
故障转移如下图:
2.3.3.3 原理
Sentinel主要是监控服务器的状态,并决定是否进行故障转移。如何进行故障转移在前面的部分已经给大家演示过人工的操作,那么Sentinel是如何判断服务是否下线呢,主要分为主观下线和客观下线:
主观下线:
概念:
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断
特点:
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复, 那么 Sentinel 就会将这个服务器标记为主观下线
客观下线
概念:
多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断ODOWN。 (一个Sentinel 可以通过向另一个 Sentinel 发送命令来询问对方是否认为给定的服务器已下线)
特点:
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm),而是使用了流言传播(Gossip): 如果Sentinel在给定的时间范围内, 从其他Sentinel那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。
注意点:
客观下线条件只适用于主服务器,对于其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不不需要进行协商, 所以从服务器或者其他 Sentinel 不会达到客观下线条件。 只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个Sentinel就可能会被其他 Sentinel 推选出,并对失效的主服务器执行自动故障迁移操作。
2.3.3.4 小结
Sentinel三大工作任务
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过API向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时,Sentinel会开始一次自动故障转移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器。
当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
互联网冷备和热备
冷备
概念:
冷备发生在数据库已经正常关闭的情况下,当正常关闭时会提供给我们一个完整的数据库
优点:
- 非常快速的备份方法(只需拷文件)
- 低度维护,高度安全
缺点:
- 单独使用时,只能提供“某一时间点上”的恢复
- 在实施备份的全过程中,数据库必须要作备份而不能作其他工作。也就是说,在冷备份过程中,数据库必须是关闭状态
热备
概念:
热备份是在数据库运行的情况下,采用归档模式(archivelog mode)方式备份数据库的方法
优点:
- 备份的时间短
- 备份时数据库仍可使用
- 可达到秒级恢复
缺点:
- 若热备份不成功,所得结果不可用于时间点的恢复
- 难于维护,要非常仔细小心
2.3.3 Sentinel整合SpringBoot
设置Redis密码
Redis 4.0.14默认开启保护模式protected-mode yes,我们要正常访问需要先设置redis的访问密码,然后才可以进行测试,在所有的redis配置文件redis.conf中,添加如下配置:
1 | # 设置密码 |
在Sentinel哨兵的配置文件sentinel01.conf中添加以下设置:
1 | sentinel auth-pass mymaster 123456 |
Redis命令行登录:
1 | ./redis-cli -h 192.168.200.129 -p 6381 -a 123456 |
其中-a 就是设置访问密码
整合SpringBoot
创建maven工程并在pom.xml添加以下依赖:
1 | <parent> |
编写application.yml配置文件:
1 | spring: |
编写启动类:
1 | @SpringBootApplication |
编写测试类:
1 | @RunWith(SpringRunner.class) |
3. Redis内置集群
3.1 搭建集群
3.1.1 准备redis节点
为了保证可以进行投票,需要至少3个主节点。
每个主节点都需要至少一个从节点,所以需要至少3个从节点。
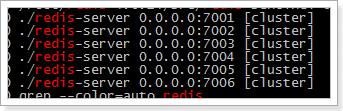
一共需要6台redis服务器,我们这里使用6个redis实例,端口号为7001~7006
先准备一个干净的redis环境,复制原来的bin文件夹,清理后作为第一个redis节点,具体命令如下:
1 | # 进入redis安装目录 |
集群环境redis节点的配置文件如下:
1 | # 不能设置密码,否则集群启动时会连接不上 |
第一个redis节点node1准备好之后,再复制5份,
1 | cp -R node1/ node2 |
修改六个节点的端口号为7001~7006,修改redis.conf配置文件即可
编写启动节点的脚本:
1 | vi start-all.sh |
内容为:
1 | cd node1 |
设置脚本的权限,并启动:
1 | chmod 744 start-all.sh |
使用命令 ps -ef | grep redis 查看效果如下:
3.1.2 启动redis集群
redis集群的管理工具使用的是ruby脚本语言,安装集群需要ruby环境,先安装ruby环境:
1 | # 安装ruby |
下载符合环境要求的gem,下载地址如下:
https://rubygems.org/gems/redis/versions/4.1.0
课程资料中已经提供了redis-4.1.0.gem,直接上传安装即可,安装命令:
1 | gem install redis-4.1.0.gem |
进入redis安装目录,使用redis自带的集群管理脚本,执行命令:
1 | # 进入redis安装包 |
效果如下:
1 | >>> Creating cluster |
3.1.3 使用redis集群
命令行使用
使用redis的客户端连接redis集群,命令如下:
1 | ./redis-cli -h 192.168.200.129 -p 7001 -c |
其中-c 一定要加,这个是redis集群连接时,进行节点跳转的参数
3.2 集群原理
3.2.1 集群架构图
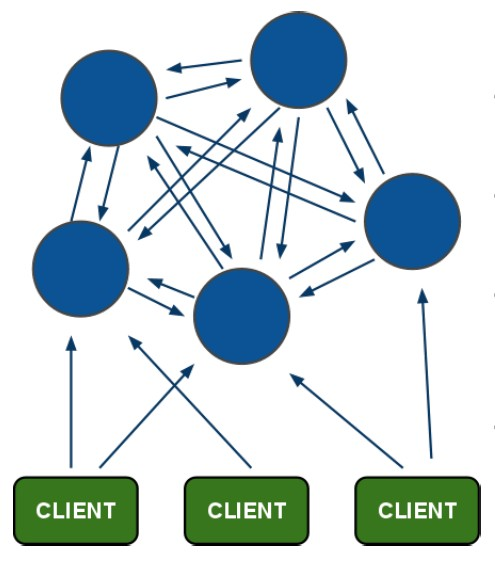
架构特点:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的master节点检测失效时才生效。
- 客户端与redis节点直连,不需要连接集群所有节点,只需要连接集群中任意可用节点即可。
- 集群把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<>slot<>key关系
3.2.2 集群的数据分配
在前面的特点中,最后一个node<>slot<>key关系是什么意思呢?这里是说数据是如何放到集群的节点中。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分哈希槽。可以使用命令查看集群信息:
1 | ./redis-cli -p 7001 cluster nodes | grep master |
结果:
1 | 192.168.200.129:7003@17003 master - 0 1560315648000 3 connected 10923-16383 |
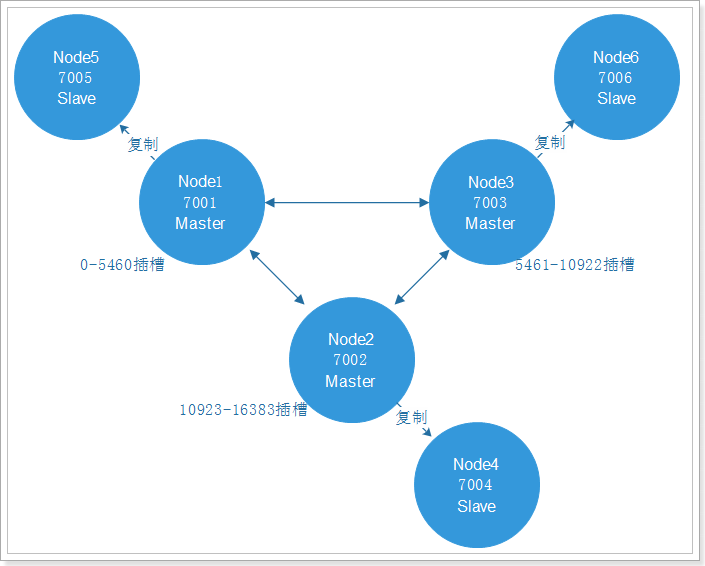
哈希槽的使用:
- 集群搭建的时候分配哈希槽到节点上
- 使用集群的时候,先对数据key进行CRC16的计算
- 对计算的结果求16384的余数,得到的数字范围是0~16383
- 根据余数找到对应的节点(余数对应的哈希槽在哪个节点)
- 跳转到对应的节点,执行命令
这种结构很容易添加或者删除节点。比如果我想新添加节点node4, 我需要从节点 node1, node2, node3中得部分槽到node4上. 如果我想移除节点node1,需要将node1中的槽移到node2和node3节点上,然后将没有任何槽的node1节点从集群中移除即可。
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不不会造成集群不可用的状态。
Redis 集群的主从复制模型
为了使部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有一个或多个复制品。
在我们例子中具有 node1, node2, node3三个节点的集群,在没有复制模型的情况下,如果节点node2失败了,那么整个集群就会以为缺少5461-10922这个范围的槽而不可用。Redis集群做主从备份解决了了这个问题。
Redis一致性保证
主节点对命令的复制工作发生在返回命令回复之后, 因为如果主节点每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 。
当然现在这种情况也是有问题的,当主节点执行完命令,返回命令回复之后宕机了,并没有完成复制操作,这个时候就有主从的数据不一致的问题。
redis这样设计,就是在性能和一致性之间做出的权衡。
3.3 集群维护
很多时候,我们需要对集群进行维护,调整数据的存储,其实就是对slot哈希槽和节点的调整。Redis内置的集群支持动态调整,可以在集群不停机的情况下,改变slot、添加或删除节点。
3.3.1 分片重哈希
Redis集群节点分片重哈希,调整哈希槽和节点的关系,执行以下命令:
1 | # 分片重哈希,可以连接任意节点 |
查看结果:
1 | # 执行命令,查看hash槽结果 |
我们可以看到7001的哈希槽500-5460,而7004的哈希槽11423-16383,都少了500个哈希槽
而7002的哈希槽0-499 5461-11422,比原来增加了1000个哈希槽
3.3.2 移除节点
移除节点命令的第一个参数是任意节点的地址,第二个节点是想要移除的节点id:
1 | ./redis-trib.rb del-node 192.168.200.129:7001 cbd415973b3e85d6f3ad967441f6bcb5b7da506a |
移除主节点:
- 在移除主节点前,需要确保这个主节点是空的。如果不是空的,需要将这个节点的数据重新分片到其他主节点上
- 替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据
移除从节点,直接移除成功
3.3.3 添加节点
添加节点前需要保证新的节点是一个干净的,空的redis,主要就是要删除持久化文件和节点配置文件:
1 | rm -rf appendonly.aof |
添加新的主节点
1 | ./redis-trib.rb add-node 192.168.200.129:7005 192.168.200.129:7001 |
添加的新节点默认是没有哈希槽的,需要手动分配哈希槽
添加新的从节点
1 | ./redis-trib.rb add-node --slave 192.168.200.129:7005 192.168.200.129:7001 |
添加的新的从节点,集群默认自动分配对应的主节点。
3.4 整合SpringBoot
使用之前哨兵整合SpringBoot的例子,把配置文件修改为如下内容:
1 | spring: |
编写测试方法:
1 | @Test |
4. Redis集群扩展
4.1 Redis集群现状
我们已经学完了Redis内置集群,是不是这一种方式就足够我们使用了呢?在这里,我们要对redis集群现在使用的情况进行分析。
集群使用现状
Redis Cluster内置集群,在Redis3.0才推出的实现方案。在3.0之前是没有这个内置集群的。
但是在3.0之前,有很多公司都有自己的一套Redis高可用集群方案。虽然现在有内置集群,但是因为历史原因,很多公司都没有切换到内置集群方案,而其原理就是集群方案的核心,这也是很多大厂为什么要问原理的的原因。
网络通信问题
Redis Cluster是无中心节点的集群架构,依靠Gossip协议(谣言传播)协同自动化修复集群的状态。
但Gossip有消息延时和消息冗余的问题,在集群节点数量过多的时候,节点之间需要不断进行PING/PANG通讯,不必须要的流量占用了大量的网络资源。虽然Redis4.0对此进行了优化,但这个问题仍然存在。
数据迁移问题
Redis Cluster可以进行节点的动态扩容缩容,在扩缩容的时候,就需要进行数据迁移。
而Redis 为了保证迁移的一致性, 迁移所有操作都是同步操作,执行迁移时,两端的 Redis 均会进入时长不等的 阻塞状态。对于小 Key,该时间可以忽略不计,但如果一旦 Key 的内存使用过大,严重的时候会接触发集群内的故障转移,造成不必要的切换。
以上原因说明只是学习Redis Cluster并不够,我们还需要学习新的集群方案。
1 | Gossip 的缺陷 |
4.2 一致性哈希算法
4.2.1 分片介绍
在前面我们讲了内置的集群因为一些原因,在节点数量过多的时候,并不能满足我们的要求,哪还有什么新的集群方案呢?我们在这里讲解使用twemproxy实现hash分片的Redis集群方案,这个方案也是知乎2000万QPS场景所使用的方案。
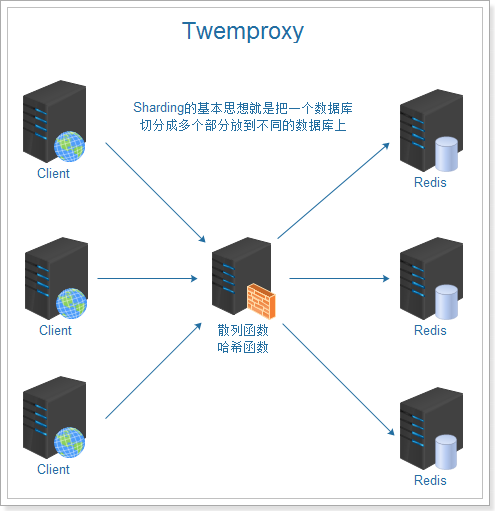
上图我们看到twemproxy主要的角色是代理服务器的作用,是对数据库进行分片操作。twemproxy的分片保证需要存储的数据散列存放在集群的节点上,尽量做到平均分布。如何实现呢,这里就涉及到一致性哈希算法,这个算法是分布式系统中常用的算法。
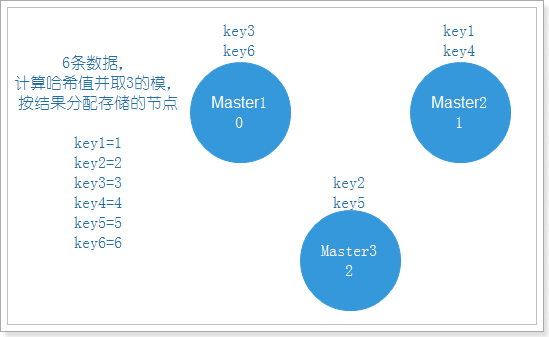
4.2.2 传统哈希方案
传统方案是使用对象的哈希值,对节点个数取模,再映射到相应编号的节点,这种方案在节点个数变动时,绝大多数对象的映射关系会失效而需要迁移。
1 | Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。 |
正常有3个节点,取3的模,分配数据,效果如下图:
如果节点挂了一个,那么久需要进行数据迁移,把数据分配到剩下的两个节点上,如下图:
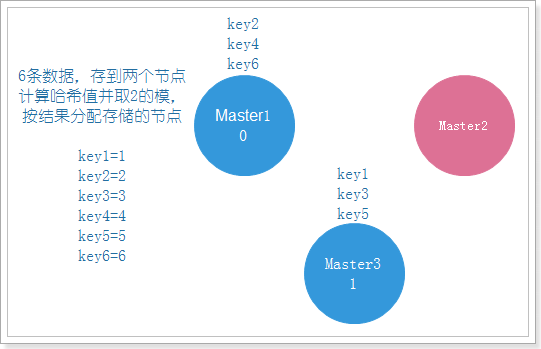
可以看到原本存在Master1上的key3,需要迁移到Master3上,而Master1始终是正常的,这就造成了没有必要的数据迁移,浪费资源,所以我们需要采取另一种方式,一致性哈希算法。
4.2.3 一致性哈希算法
一致性哈希算法(Consistent Hashing Algorithm)是一种分布式算法,常用于负载均衡。twemproxy也选择这种算法,解决将key-value均匀分配到众多 server上的问题。它可以取代传统的取模操作,解决了取模操作应对增删 Server的问题。
步骤
先用hash算法将对应的节点ip哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间。现在我们可以将这些数字头尾相连,连接成一个闭合的环形:
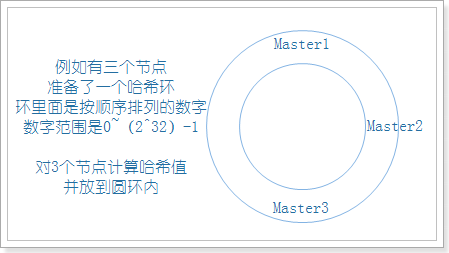
当用户在客户端进行请求时候,首先根据key计算路由hash值,然后看hash值落到了hash环的哪个地方,根据hash值在hash环上的位置顺时针找距离最近的节点:
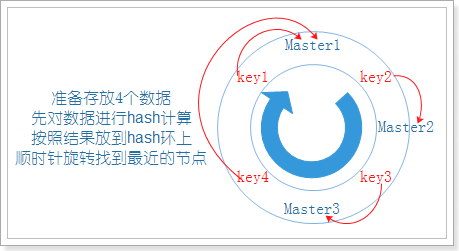
当新增节点的时候,和之前的做法一样,只需要把受到影响的数据迁移到新节点即可
新增Master4节点:
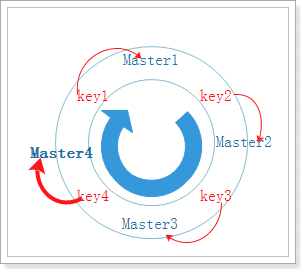
当移除节点的时候,和之前的做法一样,把移除节点的数据,迁移到顺时针距离最近的节点
移除Master2节点:
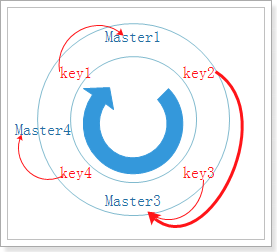
从上面的步骤可以看出,当节点个数变动时,使用哈希一致性映射关系失效的对象非常少,迁移成本也非常小。那么判断一个哈希算法好坏的指标有哪些呢?以下列出了4个指标:
平衡性(Balance):
平衡性是指哈希的结果能够尽可能分散到不同的缓存服务器上去,这样可以使得所有的服务器得到利用。一致性hash可以做到每个服务器都进行处理理请求,但是不能保证每个服务器处理的请求的数量大致相同
单调性(Monotonicity):
单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,哈希的结果应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其它服务器上去。
分散性(Spread):
分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的hash环。如果多个客户端都把部分服务器作为一个完整hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。好的哈希算法应尽量量避免尽量降低分散性。 而一致性hash具有很低的分散性。
4.2.4 虚拟节点
一部分节点下线之后,虽然剩余机器都在处理请求,但是明显每个机器的负载不不均衡,这样称 为一致性hash的倾斜,虚拟节点的出现就是为了了解决这个问题。
在刚才的例子当中,如果Master3节点也挂掉,那么一致性hash倾斜就很明显了:
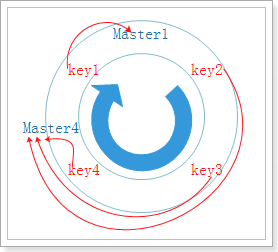
可以看到,理论上Master1需要存储25%的数据,而Master4要存储75%的数据。
上面这个例子中,我们可以对已有的两个节点创建虚拟节点,每个节点创建两个虚拟节点。那么实际的Master1节点就变成了两个虚拟节点Master1-1和Master1-2,而另一个实际的Master4节点就变成了两个虚拟节点Master4-1和Master4-2,这个时候数据基本均衡了:
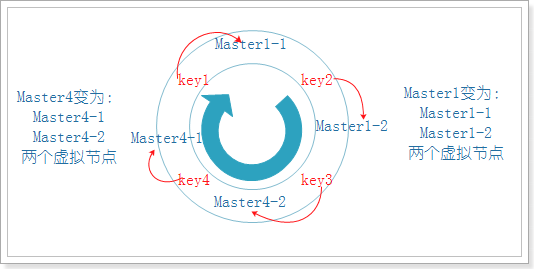
4.3 twemproxy实现hash分片
4.3.1 twemproxy介绍
Twemproxy由Twitter开源,是一个redis和memcache快速/轻量级代理服务器,利用中间件做分片的技术。twemproxy处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(sharding),再转发给后端真正的redis服务器。
官方网址:https://github.com/twitter/twemproxy
作用: Twemproxy通过引入一个代理层,可以将其后端的多台Redis或Memcached实例进行统一管理与分配,使应用程序只需要在Twemproxy上进行操作,而不用关心后面具体有多少个真实的Redis或Memcached存储 特性:
支持失败节点自动删除
可以设置重新连接该节点的时间
可以设置连接多少次之后删除该节点
减少客户端直接与服务器的连接数量
自动分片到后端多个redis实例上
多种哈希算法
md5,crc16,crc32,crc32a,fnv1_64,fnv1a_64,fnv1_32,fnv1a_32,hsieh,murmur,jenkins
多种分片算法
ketama(一致性hash算法的一种实现),modula,random
4.3.2 准备redis实例
执行以下命令
1 | # 准备一个redis实例 |
再复制两份,修改端口号为7602,7603,启动redis实例
这样我们就准备好了三个redis实例 7601 、 7602和7603
4.3.2 twemproxy安装
环境准备:
1 | yum -y install install autoconf automake libtool |
上传资料中的twemproxy.tar,并安装,执行以下命令:
1 | # 安装包解包 |
安装完成后,可以执行以下命令查看安装状态
1 | # 查看启动信息 |
4.3.3 twemproxy使用
命令行使用
使用twemproxy和单机版是一样,对外就像是用单机版redis一样。
但是有些命令不能用,例如info,因为这个毕竟twemproxy只是一个代理。
1 | cd /usr/local/redis/bin/ |
可以测试get、set方法
SpringDataRedis
使用Java代码操作twemproxy和操作redis也是一样的
配置文件修改为:
1 | spring: |
测试代码:
1 | @Test |
我们可以单独连接redis实例,发现数据是分别进行存放的
5. 总结
在这个章节,我们学习使用了Redis的单机版,主从复制,Sentinel,内置集群,twemproxy集群,那么是不是掌握一种就足够了呢。并不是的,我们需要根据具体的使用场景分别使用。
- 单机版:数据量,QPS不大的情况使用
- 主从复制:需要读写分离,高可用的时候使用
- Sentinel哨兵:需要自动容错容灾的时候使用
- 内置集群:数据量比较大,QPS有一定要求的时候使用,但集群节点不能过多
- twemproxy集群:数据量,QPS要求非常高,可以使用
以上描述了这几种模式的使用场景,但是其使用成本是从上往下递增的,所以到底是用那种模式,还是要结合具体的使用场景,预算成本来进行选择。
另外,这些模式也不是完全独立的,一般我们在使用twemproxy集群的时候都是高并发,大数据,高可用的环境,可以结合主从复制+哨兵保证集群的高可用,keepliaved保证代理服务器的高可用。其使用方式在本章节中都已经给大家介绍了,有兴趣的学员可以尝试自己整合一下。
JUC多线程 (一)
学习目标:
- 掌握多线程的创建
- 掌握线程安全的处理
- 了解线程状态
- 掌握线程停止的两种方法
- 了解线程的原子性,可见性和有序性
- 理解内存可见性的原理
- 掌握synchronized解决内存可见性
1. 多线程基础
一个采用了多线程技术的应用程序可以更好地利用系统资源。其主要优势在于充分利用了CPU的空闲时间片,可以用尽可能少的时间来对用户的要求做出响应,使得进程的整体运行效率得到较大提高,同时增强了应用程序的灵活性。
更为重要的是,由于同一进程的所有线程是共享同一内存,所以不需要特殊的数据传送机制,不需要建立共享存储区或共享文件,从而使得不同任务之间的协调操作与运行、数据的交互、资源的分配等问题更加易于解决。
1.1 线程和进程
进程:
是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程;进程也是程序的一次执行过程,是系统运行程序的基本单位;系统运行一个程序即是一个进程从创建、运行到消亡的过程。
线程:
进程内部的一个独立执行单元;一个进程可以同时并发的运行多个线程,可以理解为一个进程便相当于一个单 CPU 操作系统,而线程便是这个系统中运行的多个任务。
进程与线程的区别:
进程:有独立的内存空间,进程中的数据存放空间(堆空间和栈空间)是独立的,至少有一个线程。
线程:堆空间是共享的,栈空间是独立的,线程消耗的资源比进程小的多。
注意:
- 因为一个进程中的多个线程是并发运行的,那么从微观角度看也是有先后顺序的,哪个线程执行完全取决于 CPU 的调度,程序员是不能完全控制的(可以设置线程优先级)。而这也就造成的多线程的随机性。
- Java 程序的进程里面至少包含两个线程,主线程也就是 main()方法线程,另外一个是垃圾回收机制线程。每 当使用 java 命令执行一个类时,实际上都会启动一个 JVM,每一个 JVM 实际上就是在操作系统中启动了一个 线程,java 本身具备了垃圾的收集机制,所以在 Java 运行时至少会启动两个线程。
- 由于创建一个线程的开销比创建一个进程的开销小的多,那么我们在开发多任务运行的时候,通常考虑创建 多线程,而不是创建多进程。
1.2 多线程的创建
创建Maven工程,编写测试类
1.2.1 继承Thread类
第一种继承Thread类 重写run方法
1 | public class Demo1CreateThread extends Thread { |
1.2.2 实现Runnable接口
实现Runnable接口,重写run方法
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是继承Thread类还是实现Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的。
1 | public class Demo2CreateRunnable { |
实现Runnable接口比继承Thread类所具有的优势:
- 适合多个相同的程序代码的线程去共享同一个资源。
- 可以避免java中的单继承的局限性。
- 增加程序的健壮性,实现解耦操作,代码可以被多个线程共享,代码和数据独立。
- 线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
1.2.3 匿名内部类方式
使用线程的内匿名内部类方式,可以方便的实现每个线程执行不同的线程任务操作
1 | public class Demo3Runnable { |
1.2.4 守护线程
Java中有两种线程,一种是用户线程,另一种是守护线程。
用户线程是指用户自定义创建的线程,主线程停止,用户线程不会停止。
守护线程当进程不存在或主线程停止,守护线程也会被停止。
1 | public class Demo4Daemon { |
1.3 线程安全
1.3.1 卖票案例
如果有多个线程在同时运行,而这些线程可能会同时运行这段代码。程序每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的,反之则是线程不安全的。
1 | public class Demo5Ticket { |
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写 操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步, 否则的话就可能影响线程安全。
1.3.2 线程同步
当我们使用多个线程访问同一资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题。 要解决上述多线程并发访问一个资源的安全问题,Java中提供了同步机制(synchronized)来解决。
同步代码块
1 | Object lock = new Object(); //创建锁 |
同步方法
1 | //同步方法 |
同步方法使用的是this锁
证明方式: 一个线程使用同步代码块(this明锁),另一个线程使用同步函数。如果两个线程抢票不能实现同步,那么会出现数据错误。
1 | //使用this锁的同步代码块 |
Lock锁
1 | Lock lock = new ReentrantLock(); |
1.3.2 死锁
多线程死锁:同步中嵌套同步,导致锁无法释放。
死锁解决办法:不要在同步中嵌套同步
1 | public class Demo6DeadLock { |
1.4 线程状态
1.4.1 线程状态介绍
查看Thread源码,能够看到java的线程有六种状态:
1 | public enum State { |
NEW(新建) 线程刚被创建,但是并未启动。 RUNNABLE(可运行) 线程可以在java虚拟机中运行的状态,可能正在运行自己代码,也可能没有,这取决于操作系统处理器。 BLOCKED(锁阻塞) 当一个线程试图获取一个对象锁,而该对象锁被其他的线程持有,则该线程进入Blocked状态;当该线程持有锁时,该线程将变成Runnable状态。 WAITING(无限等待) 一个线程在等待另一个线程执行一个(唤醒)动作时,该线程进入Waiting状态。进入这个状态后是不能自动唤醒的,必须等待另一个线程调用notify或者notifyAll方法才能够唤醒。 TIMED_WAITING(计时等待) 同waiting状态,有几个方法有超时参数,调用他们将进入Timed Waiting状态。这一状态将一直保持到超时期满或者接收到唤醒通知。带有超时参数的常用方法有Thread.sleep 、Object.wait。 TERMINATED(被终止) 因为run方法正常退出而死亡,或者因为没有捕获的异常终止了run方法而死亡。
1.4.2 线程状态图
1.4.3 wait()、notify()
wait()、notify()、notifyAll()是三个定义在Object类里的方法,可以用来控制线程的状态。
wait 方法会使持有该对象的线程把该对象的控制权交出去,然后处于等待状态。 notify 方法会通知某个正在等待这个对象的控制权的线程继续运行。 notifyAll 方法会通知所有正在等待这个对象的控制权的线程继续运行。
注意:一定要在线程同步中使用,并且是同一个锁的资源
wait和notify方法例子,一个人进站出站:
1 | public class Demo7WaitAndNotify { |
1.4.4 wait与sleep区别
对于sleep()方法,首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
wait()是把控制权交出去,然后进入等待此对象的等待锁定池处于等待状态,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。而当调用wait()方法的时候,线程会放弃对象锁。
1.5 线程停止
结束线程有以下三种方法: (1)设置退出标志,使线程正常退出。 (2)使用interrupt()方法中断线程。 (3)使用stop方法强行终止线程(不推荐使用Thread.stop, 这种终止线程运行的方法已经被废弃,使用它们是极端不安全的!)
1.5.1 使用退出标志
一般run()方法执行完,线程就会正常结束,然而,常常有些线程是伺服线程。它们需要长时间的运行,只有在外部某些条件满足的情况下,才能关闭这些线程。使用一个变量来控制循环,例如:最直接的方法就是设一个boolean类型的标志,并通过设置这个标志为true或false来控制while循环是否退出,代码示例:
1 | public class Demo8Exit { |
1.5.2 使用interrupt()方法
使用interrupt()方法来中断线程有两种情况:
1)线程处于阻塞状态
如使用了sleep,同步锁的wait,socket中的receiver,accept等方法时,会使线程处于阻塞状态。当调用线程的interrupt()方法时,会抛出InterruptException异常。阻塞中的那个方法抛出这个异常,通过代码捕获该异常,然后break跳出循环状态,从而让我们有机会结束这个线程的执行。
2)线程未处于阻塞状态
使用isInterrupted()判断线程的中断标志来退出循环。当使用interrupt()方法时,中断标志就会置true,和使用自定义的标志来控制循环是一样的道理。
1 | public class Demo9Interrupt { |
1.6 线程优先级
1.6.1 优先级priority
现今操作系统基本采用分时的形式调度运行的线程,线程分配得到时间片的多少决定了线程使用处理器资源的多少,也对应了线程优先级这个概念。
在JAVA线程中,通过一个int priority来控制优先级,范围为1-10,其中10最高,默认值为5。
1 | public class Demo10Priorityt { |
1.6.2 join()方法
join作用是让其他线程变为等待。thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。
1 | public class Demo11Join { |
1.6.3 yield方法
Thread.yield()方法的作用:暂停当前正在执行的线程,并执行其他线程。(可能没有效果) yield()让当前正在运行的线程回到可运行状态,以允许具有相同优先级的其他线程获得运行的机会。因此,使用yield()的目的是让具有相同优先级的线程之间能够适当的轮换执行。但是,实际中无法保证yield()达到让步的目的,因为,让步的线程可能被线程调度程序再次选中。
查看源码介绍:

结论:大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
2. 多线程并发的3个特性
多线程并发开发中,要知道什么是多线程的原子性,可见性和有序性,以避免相关的问题产生。
2.1 原子性
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
2.2 可见性
可见性:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
举个简单的例子,看下面这段代码:
1 | //线程1执行的代码 |
当线程1执行int i = 0这句时,i的初始值0加载到内存中,然后再执行i = 10,那么在内存中i的值变为10了。
如果当线程1执行到int i = 0这句时,此时线程2执行 j = i,它读取i的值并加载到内存中,注意此时内存当中i的值是0,那么就会使得j的值也为0,而不是10。
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
2.3 有序性
有序性:程序执行的顺序按照代码的先后顺序执行
1 | int count = 0; |
以上代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
什么是重排序?一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致。
as-if-serial:无论如何重排序,程序最终执行结果和代码顺序执行的结果是一致的。Java编译器、运行时和处理器都会保证Java在单线程下遵循as-if-serial语意)
上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?
再看下面一个例子:
1 | int a = 10; //语句1 |
这段代码有4个语句,那么可能的一个执行顺序是: 语句2 语句1 语句3 语句4
不可能是这个执行顺序: 语句2 语句1 语句4 语句3
因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。虽然重排序不会影响单个线程内程序执行的结果,但是多线程会有影响
下面看一个例子:
1 | //线程1: |
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行execute(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
3. Java内存可见性
3.1 了解Java内存模型
JVM内存结构、Java对象模型和Java内存模型,这就是三个截然不同的概念,而这三个概念很容易混淆。这里详细区别一下
3.1.1 JVM内存结构
我们都知道,Java代码是要运行在虚拟机上的,而虚拟机在执行Java程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途。其中有些区域随着虚拟机进程的启动而存在,而有些区域则依赖用户线程的启动和结束而建立和销毁。
在《Java虚拟机规范(Java SE 8)》中描述了JVM运行时内存区域结构如下:
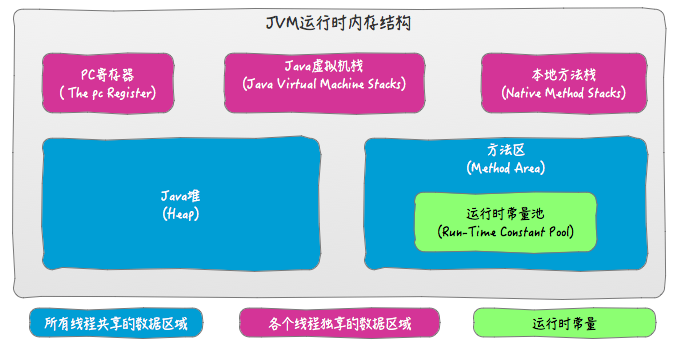
JVM内存结构,由Java虚拟机规范定义。描述的是Java程序执行过程中,由JVM管理的不同数据区域。各个区域有其特定的功能。
3.1.2 Java对象模型
Java是一种面向对象的语言,而Java对象在JVM中的存储也是有一定的结构的。而这个关于Java对象自身的存储模型称之为Java对象模型。
HotSpot虚拟机中(Sun JDK和OpenJDK中所带的虚拟机,也是目前使用范围最广的Java虚拟机),设计了一个OOP-Klass Model。OOP(Ordinary Object Pointer)指的是普通对象指针,而Klass用来描述对象实例的具体类型。
每一个Java类,在被JVM加载的时候,JVM会给这个类创建一个instanceKlass对象,保存在方法区,用来在JVM层表示该Java类。当我们在Java代码中,使用new创建一个对象的时候,JVM会创建一个instanceOopDesc对象,这个对象中包含了对象头以及实例数据。
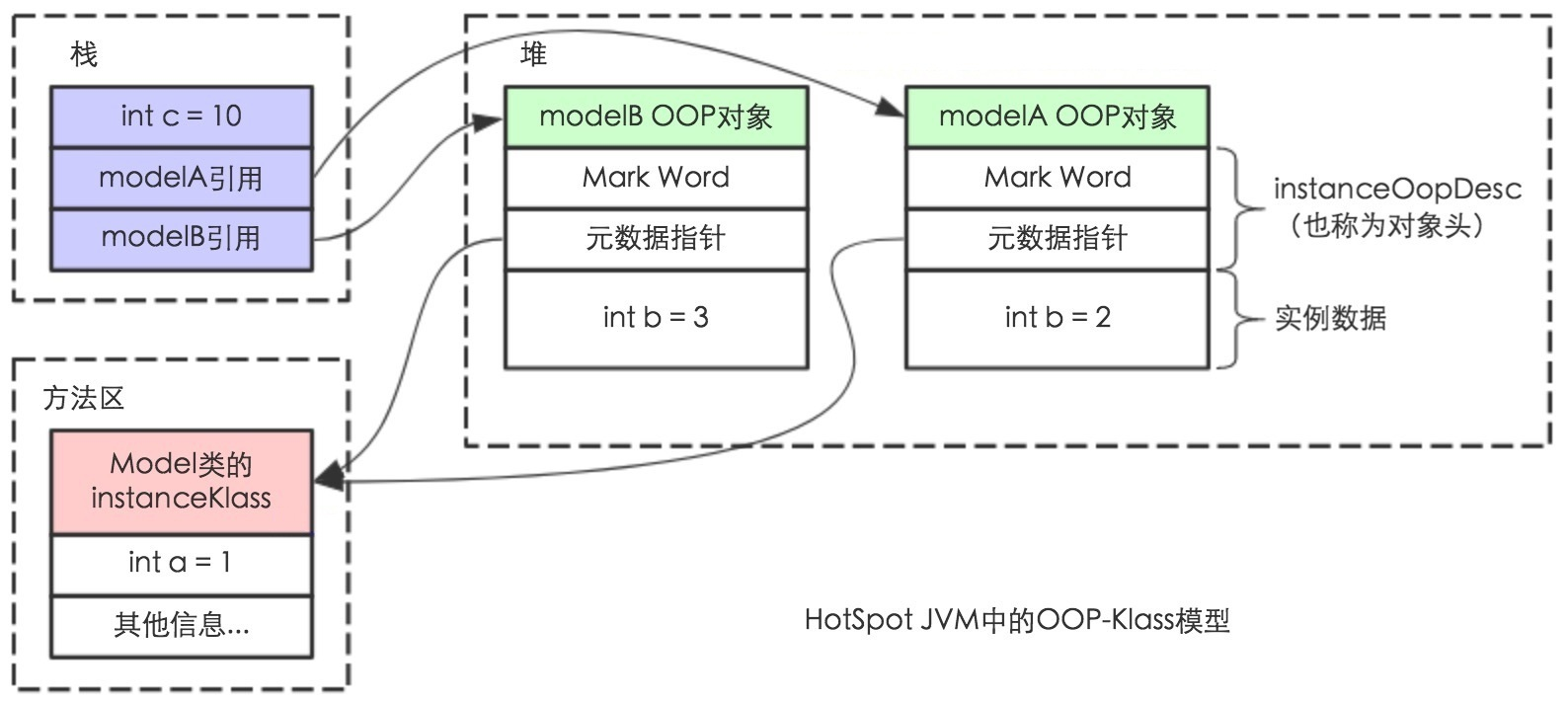
这就是一个简单的Java对象的OOP-Klass模型,即Java对象模型。
3.1.3 内存模型
Java内存模型就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
有兴趣详细了解Java内存模型是什么,为什么要有Java内存模型,Java内存模型解决了什么问题的学员,参考:https://www.hollischuang.com/archives/2550。
Java内存模型是根据英文Java Memory Model(JMM)翻译过来的。其实JMM并不像JVM内存结构一样是真实存在的。他只是一个抽象的概念。JSR-133: Java Memory Model and Thread Specification中描述了,JMM是和多线程相关的,他描述了一组规则或规范,这个规范定义了一个线程对共享变量的写入时对另一个线程是可见的。
简单总结下,Java的多线程之间是通过共享内存进行通信的,而由于采用共享内存进行通信,在通信过程中会存在一系列如可见性、原子性、顺序性等问题,而JMM就是围绕着多线程通信以及与其相关的一系列特性而建立的模型。JMM定义了一些语法集,这些语法集映射到Java语言中就是volatile、synchronized等关键字。
JMM线程操作内存的基本的规则:
第一条关于线程与主内存:线程对共享变量的所有操作都必须在自己的工作内存(本地内存)中进行,不能直接从主内存中读写
第二条关于线程间本地内存:不同线程之间无法直接访问其他线程本地内存中的变量,线程间变量值的传递需要经过主内存来完成。
主内存
主要存储的是Java实例对象,所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量还是方法中的本地变量(也称局部变量),当然也包括了共享的类信息、常量、静态变量。由于是共享数据区域,多条线程对同一个变量进行访问可能会发现线程安全问题。
本地内存
主要存储当前方法的所有本地变量信息(本地内存中存储着主内存中的变量副本拷贝),每个线程只能访问自己的本地内存,即线程中的本地变量对其它线程是不可见的,就算是两个线程执行的是同一段代码,它们也会各自在自己的工作内存中创建属于当前线程的本地变量,当然也包括了字节码行号指示器、相关Native方法的信息。注意由于工作内存是每个线程的私有数据,线程间无法相互访问工作内存,因此存储在工作内存的数据不存在线程安全问题。
3.1.4 小结
JVM内存结构,和Java虚拟机的运行时区域有关。 Java对象模型,和Java对象在虚拟机中的表现形式有关。 Java内存模型,和Java的并发编程有关。
3.2 内存可见性
3.2.1 内存可见性介绍
可见性:一个线程对共享变量值的修改,能够及时的被其他线程看到
共享变量:如果一个变量在多个线程的工作内存中都存在副本,那么这个变量就是这几个线程的共享变量
线程 A 与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
- 首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去。
- 然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
如上图所示,本地内存 A 和 B 有主内存中共享变量 x 的副本。假设初始时,这三个内存中的 x 值都为 0。线程 A 在执行时,把更新后的 x 值(假设值为 1)临时存放在自己的本地内存 A 中。当线程 A 和线程 B 需要通信时,线程 A 首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。随后,线程 B 到主内存中去读取线程 A 更新后的 x 值,此时线程 B 的本地内存的 x 值也变为了 1。
从整体来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 java 程序员提供内存可见性保证。
3.3.2 可见性问题
前面讲过多线程的内存可见性,现在我们写一个内存不可见的问题。
案例如下:
1 | public class Demo1Jmm { |
执行结果
按照main方法的逻辑,我们已经把flag设置为false,那么从逻辑上讲,子线程就应该跳出while死循环,因为这个时候条件不成立,但是我们可以看到,程序仍旧执行中,并没有停止。
原因:线程之间的变量是不可见的,因为读取的是副本,没有及时读取到主内存结果。 解决办法:强制线程每次读取该值的时候都去“主内存”中取值
4 synchronized
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个线程执行synchronized声明的代码块。还可以保证共享变量的内存可见性。同一时刻只有一个线程执行,这部分代码块的重排序也不会影响其执行结果。也就是说使用了synchronized可以保证并发的原子性,可见性,有序性。
4.1 解决可见性问题
JMM关于synchronized的两条规定:
线程解锁前(退出同步代码块时):必须把自己工作内存中共享变量的最新值刷新到主内存中
线程加锁时(进入同步代码块时):将清空本地内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(加锁与解锁是同一把锁)
做如下修改,在死循环中添加同步代码块
1 | while (flag) { |
synchronized实现可见性的过程
- 获得互斥锁(同步获取锁)
- 清空本地内存
- 从主内存拷贝变量的最新副本到本地内存
- 执行代码
- 将更改后的共享变量的值刷新到主内存
- 释放互斥锁
4.2 同步原理
synchronized的同步可以解决原子性、可见性和有序性的问题,那是如何实现同步的呢?
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象this
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
当一个线程访问同步代码块时,它首先是需要得到锁才能执行同步代码,当退出或者抛出异常时必须要释放锁。
synchronized的同步操作主要是monitorenter和monitorexit这两个jvm指令实现的,先写一段简单的代码:
1 | public class Demo2Synchronized { |
在cmd命令行执行javac编译和javap -c Java 字节码的指令
1 | javac Demo2Synchronized.java |
从结果可以看出,同步代码块是使用monitorenter和monitorexit这两个jvm指令实现的:

4.3 锁优化
synchronized是重量级锁,效率不高。但在jdk 1.6中对synchronize的实现进行了各种优化,使得它显得不是那么重了。jdk1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。
注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
4.3.1 自旋锁
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。怎么等待呢?执行一段无意义的循环即可(自旋)。
自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋锁在JDK 1.4.2中引入,默认关闭,但是可以使用-XX:+UseSpinning开开启,在JDK1.6中默认开启。同时自旋的默认次数为10次,可以通过参数-XX:PreBlockSpin来调整;
如果通过参数-XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬。于是JDK1.6引入自适应的自旋锁,让虚拟机会变得越来越聪明。
4.3.2 适应自旋锁
JDK 1.6引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。它怎么做呢?线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
4.3.3 锁消除
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行锁消除。锁消除的依据是逃逸分析的数据支持。
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是对于我们程序员来说这还不清楚么?我们会在明明知道不存在数据竞争的代码块前加上同步吗?但是有时候程序并不是我们所想的那样?我们虽然没有显示使用锁,但是我们在使用一些JDK的内置API时,如StringBuffer、Vector、HashTable等,这个时候会存在隐形的加锁操作。比如StringBuffer的append()方法,Vector的add()方法:
1 | public void test(){ |
在运行这段代码时,JVM可以明显检测到变量vector没有逃逸出方法vectorTest()之外,所以JVM可以大胆地将vector内部的加锁操作消除。
4.3.4 锁粗化
在使用同步锁的时候,需要让同步块的作用范围尽可能小,仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
在大多数的情况下,上述观点是正确的。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗化的概念。
锁粗话概念比较好理解,就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。如上面实例:vector每次add的时候都需要加锁操作,JVM检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到for循环之外。
4.3.5 偏向锁
轻量级锁的加锁解锁操作是需要依赖多次CAS原子指令的。而偏向锁只需要检查是否为偏向锁、锁标识为以及ThreadID即可,可以减少不必要的CAS操作。
4.3.6 轻量级锁
引入轻量级锁的主要目的是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁。轻量级锁主要使用CAS进行原子操作。
但是对于轻量级锁,其性能提升的依据是“对于绝大部分的锁,在整个生命周期内都是不会存在竞争的”,如果打破这个依据则除了互斥的开销外,还有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。
4.3.7 重量锁
重量级锁通过对象内部的监视器(monitor)实现,其中monitor的本质是依赖于底层操作系统的Mutex Lock(互斥锁)实现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高。
JUC多线程 (二)
学习目标:
- 掌握volatile解决内存可见性的使用
- 了解CAS原子操作
- 掌握JUC的atomic原子操作包的使用
- 了解AQS同步队列的作用
- 了解JUC的锁的基本概念
- 掌握ReentrantLock和ReentrantReadWriteLock的使用
- 掌握Condition的使用
5 Volatile
通过前面内容我们了解了synchronized,虽然JVM对它做了很多优化,但是它还是一个重量级的锁。而接下来要介绍的volatile则是轻量级的synchronized。如果一个变量使用volatile,则它比使用synchronized的成本更加低,因为它不会引起线程上下文的切换和调度。
Java语言规范对volatile的定义如下:
1 | Java允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量。 |
通俗点讲就是说一个变量如果用volatile修饰了,则Java可以确保所有线程看到这个变量的值是一致的,如果某个线程对volatile修饰的共享变量进行更新,那么其他线程可以立马看到这个更新,这就是内存可见性。
volatile虽然看起来比较简单,使用起来无非就是在一个变量前面加上volatile即可,但是要用好并不容易。
5.1 解决内存可见性问题
在可见性问题案例中进行如下修改,添加volatile关键词:
1 | private volatile boolean flag = true; |
Volatile实现内存可见性的过程
线程写Volatile变量的过程:
- 改变线程本地内存中Volatile变量副本的值;
- 将改变后的副本的值从本地内存刷新到主内存
线程读Volatile变量的过程:
- 从主内存中读取Volatile变量的最新值到线程的本地内存中
- 从本地内存中读取Volatile变量的副本
Volatile实现内存可见性原理:
写操作时,通过在写操作指令后加入一条store屏障指令,让本地内存中变量的值能够刷新到主内存中
读操作时,通过在读操作前加入一条load屏障指令,及时读取到变量在主内存的值
1 | PS: 内存屏障(Memory Barrier)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序 |
volatile的底层实现是通过插入内存屏障,但是对于编译器来说,发现一个最优布置来最小化插入内存屏障的总数几乎是不可能的,所以,JMM采用了保守策略。如下:
StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存中。
StoreLoad屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。
LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。
LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
5.2 原子性的问题
虽然Volatile 关键字可以让变量在多个线程之间可见,但是Volatile不具备原子性。
1 | public class Demo3Volatile { |
以上出现原子性问题的原因是count++并不是原子性操作。
count = 5 开始,流程分析:
- 线程1读取count的值为5
- 线程2读取count的值为5
- 线程2加1操作
- 线程2最新count的值为6
- 线程2写入值到主内存的最新值为6
这个时候,线程1的count为5,线程2的count为6
如果切换到线程1执行,那么线程1得到的结果是6,写入到主内存的值还是6
现在的情况是对count进行了两次加1操作,但是主内存实际上只是加1一次
解决方案:
- 使用synchronized
- 使用ReentrantLock(可重入锁)
- 使用AtomicInteger(原子操作)
使用synchronized
1 | public synchronized void addCount() { |
使用ReentrantLock(可重入锁)
1 | //可重入锁 |
使用AtomicInteger(原子操作)
1 | public static AtomicInteger count = new AtomicInteger(0); |
5.3 Volatile 适合使用场景
a)对变量的写入操作不依赖其当前值
不满足:number++、count=count*5等
满足:boolean变量、直接赋值的变量等
b)该变量没有包含在具有其他变量的不变式中
不满足:不变式 low<up
总结:变量真正独立于其他变量和自己以前的值,在单独使用的时候,适合用volatile
5.4 synchronized和volatile比较
a)volatile不需要加锁,比synchronized更轻便,不会阻塞线程
b)synchronized既能保证可见性,又能保证原子性,而volatile只能保证可见性,无法保证原子性
与锁相比,Volatile 变量是一种非常简单但同时又非常脆弱的同步机制,它在某些情况下将提供优于锁的性能和伸缩性。如果严格遵循 volatile 的使用条件(变量真正独立于其他变量和自己以前的值 ) 在某些情况下可以使用 volatile 代替 synchronized 来优化代码提升效率。
6 J.U.C之CAS
J.U.C 即 java.util.concurrent,是 JSR 166 标准规范的一个实现; JSR 166 以及 J.U.C 包的作者是 Doug Lea 。
J.U.C 框架是 Java 5 中引入的,而我们最熟悉的线程池机制就在这个包,J.U.C 框架包含的内容有:
- AbstractQueuedSynchronizer(AQS框架),J.U.C 中实现锁和同步机制的基础;
- Locks & Condition(锁和条件变量),比 synchronized、wait、notify 更细粒度的锁机制;
- Executor 框架(线程池、Callable、Future),任务的执行和调度框架;
- Synchronizers(同步器),主要用于协助线程同步,有 CountDownLatch、CyclicBarrier、Semaphore、Exchanger;
- Atomic Variables(原子变量),方便程序员在多线程环境下,无锁的进行原子操作,核心操作是 CAS 原子操作,所谓的 CAS 操作,即 compare and swap,指的是将预期值与当前变量的值比较(compare),如果相等则使用新值替换(swap)当前变量,否则不作操作;
- BlockingQueue(阻塞队列),阻塞队列提供了可阻塞的入队和出对操作,如果队列满了,入队操作将阻塞直到有空间可用,如果队列空了,出队操作将阻塞直到有元素可用;
- Concurrent Collections(并发容器),说到并发容器,不得不提同步容器。在 JDK1.5 之前,为了线程安全,我们一般都是使用同步容器,同步容器主要的缺点是:对所有容器状态的访问都串行化,严重降低了并发性;某些复合操作,仍然需要加锁来保护;迭代期间,若其它线程并发修改该容器,会抛出 ConcurrentModificationException 异常,即快速失败机制;
- Fork/Join 并行计算框架,这块内容是在 JDK1.7 中引入的,可以方便利用多核平台的计算能力,简化并行程序的编写,开发人员仅需关注如何划分任务和组合中间结果;
- TimeUnit 枚举,TimeUnit 是 java.util.concurrent 包下面的一个枚举类,TimeUnit 提供了可读性更好的线程暂停操作,以及方便的时间单位转换方法;
6.1 CAS介绍
CAS,Compare And Swap,即比较并交换。同步组件中大量使用CAS技术实现了Java多线程的并发操作。整个AQS同步组件、Atomic原子类操作等等都是以CAS实现的,甚至ConcurrentHashMap在1.8的版本中也调整为了CAS+Synchronized。可以说CAS是整个JUC的基石。
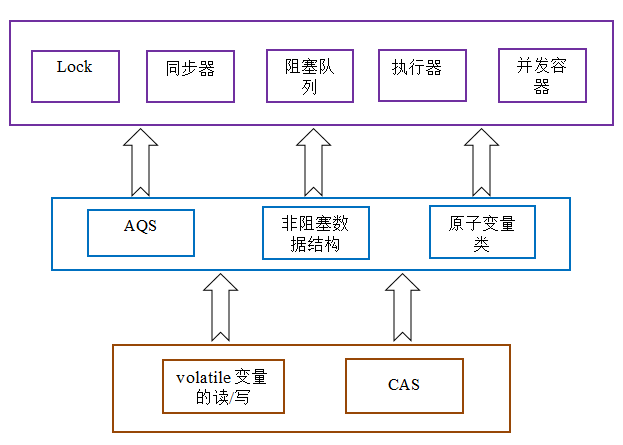
6.2 CAS原理剖析
再次测试之前Volatile的例子,把循环的次数调整为一亿(保证在一秒之内不能遍历完成,从而测试三种原子操作的性能),我们发现,AtomicInteger原子操作性能最高,他是用的就是CAS。
6.2.2 synchronized同步分析
注意,本小节是解释synchronized性能低效的原因,只要能理解synchronized同步过程其实还需要做很多事,这些逻辑的执行都需要占用资源,从而导致性能较低,是为了对比CAS的高效。这部分分析过于深入JMM底层原理,不适合初级甚至中级程序员学习。
我们之前讲过,synchronized的同步操作主要是monitorenter和monitorexit这两个jvm指令实现的,我们先写一段简单的代码:
1 | public class Demo2Synchronized { |
在cmd命令行执行javac编译和javap -c Java 字节码的指令
1 | javac Demo2Synchronized.java |
从结果可以看出,同步代码块是使用monitorenter和monitorexit这两个jvm指令实现的:
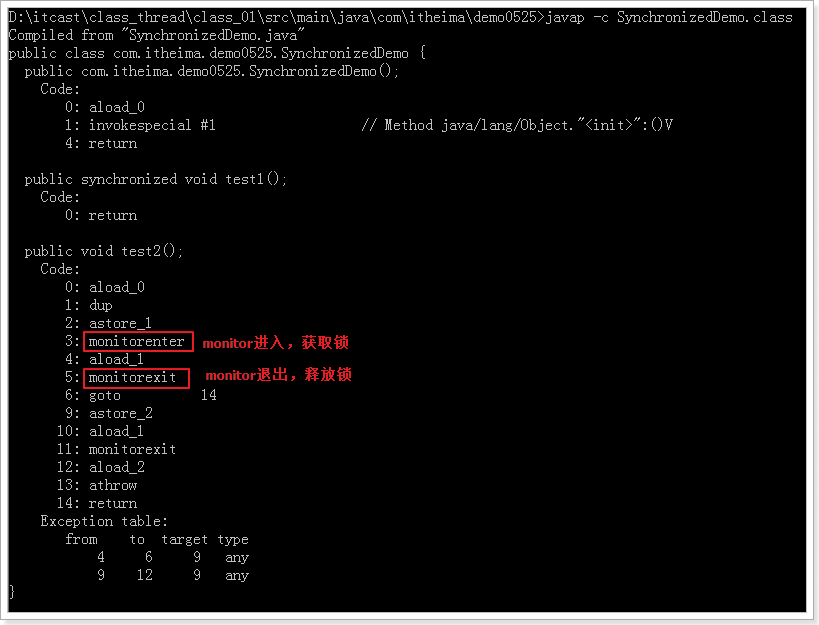
monitorenter和monitorexit这两个jvm指令实现锁的使用,主要是基于 Mark Word和、monitor。
Mark Word
Hotspot虚拟机的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。其中Klass Point是是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据,它是synchronized实现轻量级锁和偏向锁的关键。
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等。Java对象头一般占有两个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit),但是如果对象是数组类型,则需要三个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。下图是Java对象头的存储结构(32位虚拟机):

对象头信息是与对象自身定义的数据无关的额外存储成本,但是考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word会随着程序的运行发生变化,变化状态如下(32位虚拟机):
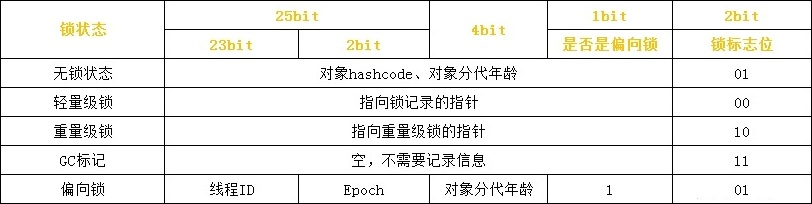
monitor
什么是Monitor?我们可以把它理解为一个同步工具,也可以描述为一种同步机制,它通常被描述为一个对象。与一切皆对象一样,所有的Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质,因为在Java的设计中 ,每一个Java对象都带了一把看不见的锁,它叫做内部锁或者Monitor锁。
Monitor 是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联(对象头的MarkWord中的LockWord指向monitor的起始地址),同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。其结构如下:

- Owner:初始时为NULL表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时又设置为NULL;
- EntryQ:关联一个系统互斥锁(semaphore),阻塞所有试图锁住monitor record失败的线程。
- RcThis:表示blocked或waiting在该monitor record上的所有线程的个数。
- Nest:用来实现重入锁的计数。
- HashCode:保存从对象头拷贝过来的HashCode值(可能还包含GC age)。
- Candidate:用来避免不必要的阻塞或等待线程唤醒,因为每一次只有一个线程能够成功拥有锁,如果每次前一个释放锁的线程唤醒所有正在阻塞或等待的线程,会引起不必要的上下文切换(从阻塞到就绪然后因为竞争锁失败又被阻塞)从而导致性能严重下降。Candidate只有两种可能的值0表示没有需要唤醒的线程1表示要唤醒一个继任线程来竞争锁。
6.2.3 CAS原理
在上一部分,我们介绍了synchronized底层做了大量的工作,才实现同步,而同步保证了原子操作。但是不可避免的是性能较低。CAS是如何提高性能的呢?
CAS的思想很简单:三个参数,一个当前内存值V、旧的预期值A、即将更新的值B,当且仅当旧的预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。如果CAS操作失败,通过自旋的方式等待并再次尝试,直到成功。
CAS在 先比较后修改 这个CAS过程中,根本没有获取锁,释放锁的操作,是硬件层面的原子操作,跟JMM内存模型没有关系。大家可以理解为直接使用其他的语言,在JVM虚拟机之外直接操作计算机硬件,正因为如此,对比synchronized的同步,少了很多的逻辑步骤,使得性能大为提高。
JUC下的atomic类都是通过CAS来实现的,下面就是一个AtomicInteger原子操作类的例子,在其中使用了Unsafe unsafe = Unsafe.getUnsafe()。Unsafe 是CAS的核心类,它提供了硬件级别的原子操作。
1 | private static final Unsafe unsafe = Unsafe.getUnsafe(); |
继续查看AtomicInteger的addAndGet()方法:
1 | public final int addAndGet(int delta) { |
其内部调用unsafe的getAndAddInt方法,查看看compareAndSwapInt方法,该方法为native方法,有四个参数,分别代表:对象、对象的地址、预期值、修改值。:
1 | public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); |
Unsafe 是一个比较危险的类,主要是用于执行低级别、不安全的方法集合。尽管这个类和所有的方法都是公开的(public),但是这个类的使用仍然受限,你无法在自己的java程序中直接使用该类,因为只有授信的代码才能获得该类的实例。可是为什么Unsafe的native方法就可以保证是原子操作呢?
6.3 native关键词
前面提到了sun.misc.Unsafe这个类,里面的方法使用native关键词声明本地方法,为什么要用native?
Java无法直接访问底层操作系统,但有能力调用其他语言编写的函数or方法,是通过JNI(Java Native Interfface)实现。使用时,通过native关键字告诉JVM这个方法是在外部定义的。但JVM也不知道去哪找这个原生方法,此时需要通过javah命令生成.h文件。
示例步骤(c语言为例):
javac生成.class文件,比如javac NativePeer.java
javah生成.h文件,比如javah NativePeer
编写c语言文件,在其中include进上一步生成的.h文件,然后实现其中声明而未实现的函数
生成dll共享库,然后Java程序load库,调用即可
native可以和任何除abstract外的关键字连用,这也说明了这些方法是有实体的,并且能够和其他Java方法一样,拥有各种Java的特性。
1
native方法有效地扩充了jvm,实际上我们所用的很多代码已经涉及到这种方法了,通过非常简洁的接口帮我们实现Java以外的工作。
native优势:
- 很多层次上用Java去实现是很麻烦的,而且Java解释执行的效率也差了c语言啥的很多,纯Java实现可能会导致效率不达标,或者可读性奇差。
- Java毕竟不是一个完整的系统,它经常需要一些底层的支持,通过JNI和native method我们就可以实现jre与底层的交互,得到强大的底层操作系统的支持,使用一些Java本身没有封装的操作系统的特性。
6.4 多CPU的CAS处理
CAS可以保证一次的读-改-写操作是原子操作,在单处理器上该操作容易实现,但是在多处理器上实现就有点儿复杂了。CPU提供了两种方法来实现多处理器的原子操作:总线加锁或者缓存加锁。
- 总线加锁:总线加锁就是就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。但是这种处理方式显得有点儿霸道,不厚道,他把CPU和内存之间的通信锁住了,在锁定期间,其他处理器都不能其他内存地址的数据,其开销有点儿大。
- 缓存加锁:其实针对于上面那种情况我们只需要保证在同一时刻对某个内存地址的操作是原子性的即可。缓存加锁就是缓存在内存区域的数据如果在加锁期间,当它执行锁操作写回内存时,处理器不在输出LOCK#信号,而是修改内部的内存地址,利用缓存一致性协议来保证原子性。缓存一致性机制可以保证同一个内存区域的数据仅能被一个处理器修改,也就是说当CPU1修改缓存行中的i时使用缓存锁定,那么CPU2就不能同时缓存了i的缓存行。
6.4 CAS缺陷
CAS虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方法:循环时间太长、只能保证一个共享变量原子操作、ABA问题。
循环时间太长
如果CAS一直不成功呢?这种情况绝对有可能发生,如果自旋CAS长时间地不成功,则会给CPU带来非常大的开销。在JUC中有些地方就限制了CAS自旋的次数,例如BlockingQueue的SynchronousQueue。
只能保证一个共享变量原子操作
看了CAS的实现就知道这只能针对一个共享变量,如果是多个共享变量就只能使用锁了。
ABA问题
CAS需要检查操作值有没有发生改变,如果没有发生改变则更新。但是存在这样一种情况:如果一个值原来是A,变成了B,然后又变成了A,那么在CAS检查的时候会发现没有改变,但是实质上它已经发生了改变,这就是所谓的ABA问题。对于ABA问题其解决方案是加上版本号,即在每个变量都加上一个版本号,每次改变时加1,即A —> B —> A,变成1A —> 2B —> 3A。
1
CAS的ABA隐患问题,Java提供了AtomicStampedReference来解决。AtomicStampedReference通过包装[E,Integer]的元组来对对象标记版本戳stamp,从而避免ABA问题。对于上面的案例应该线程1会失败。
下面我们将通过一个例子可以可以看到AtomicStampedReference和AtomicInteger的区别。我们定义两个线程,线程1负责将100 —> 110 —> 100,线程2执行 100 —>120,看两者之间的区别。
1 | public class Demo4ABA { |
运行结果充分展示了AtomicInteger的ABA问题和AtomicStampedReference解决ABA问题。
7 J.U.C之atomic包
7.1 atomic包介绍
通过前面CAS的学习,我们了解到AtomicInteger的工作原理,它们的内部都维护者一个对应的基本类型的成员变量value,这个变量是被volatile关键字修饰的,保证多线程环境下看见的是同一个(可见性)。
AtomicInteger在进行一些原子操作的时候,依赖Unsafe类里面的CAS方法,原子操作就是通过自旋方式,不断地使用CAS函数进行尝试直到达到自己的目的。
除了AtomicInteger类以外还有很多其他的类也有类似的功能,在JUC中有一个包java.util.concurrent.atomic存放原子操作的类,atomic里的类主要包括:
基本类型 使用原子的方式更新基本类型
AtomicInteger:整形原子类 AtomicLong:长整型原子类 AtomicBoolean :布尔型原子类
引用类型
AtomicReference:引用类型原子类 AtomicStampedReference:原子更新引用类型里的字段原子类 AtomicMarkableReference :原子更新带有标记位的引用类型
数组类型 使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类 AtomicLongArray:长整形数组原子类 AtomicReferenceArray :引用类型数组原子类
对象的属性修改类型
AtomicIntegerFieldUpdater:原子更新整形字段的更新器 AtomicLongFieldUpdater:原子更新长整形字段的更新器 AtomicReferenceFieldUpdater :原子更新引用类形字段的更新器
JDK1.8新增类
DoubleAdder:双浮点型原子类 LongAdder:长整型原子类 DoubleAccumulator:类似DoubleAdder,但要更加灵活(要传入一个函数式接口) LongAccumulator:类似LongAdder,但要更加灵活(要传入一个函数式接口)
虽然涉及到的类很多,但是原理和AtomicInteger都是一样,使用CAS进行的原子操作,其方法和使用都是大同小异的。
7.2 基本类型
使用原子的方式更新基本类型
AtomicInteger:整形原子类 AtomicLong:长整型原子类 AtomicBoolean :布尔型原子类
AtomicInteger主要API如下:
1 | get() //直接返回值 |
AtomicLong主要API和AtomicInteger,只是类型不是int,而是long
AtomicBoolean主要API如下:
1 | compareAndSet(boolean, boolean) //参数1为原始值,参数2为修改的新值,若修改成功返回true,否则返回false |
7.4 引用类型
AtomicReference:引用类型原子类 AtomicStampedRefrence:原子更新引用类型里的字段原子类 AtomicMarkableReference :原子更新带有标记位的引用类型
AtomicReference引用类型和基本类型的作用基本一样,例子如下:
1 | public class Demo5AtomicReference { |
AtomicStampedReference其实它仅仅是在AtomicReference类的再一次包装,里面增加了一层引用和计数器,其实是否为计数器完全由自己控制,大多数我们是让他自增的,你也可以按照自己的方式来标示版本号。案例参考前面的ABA例子
AtomicMarkableReference和AtomicStampedReference功能差不多,区别的是:它描述更加简单的是与否的关系。通常ABA问题只有两种状态,而AtomicStampedReference是多种状态。
1 | public class Demo6AtomicMrkableReference { |
7.3 数组类型
使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类 AtomicLongArray:长整形数组原子类 AtomicReferenceArray :引用类型数组原子类
AtomicIntegerArray主要API如下:
1 | addAndGet(int, int)//执行加法,第一个参数为数组的下标,第二个参数为增加的数量,返回增加后的结果 |
AtomicIntegerArray主要API和AtomicLongArray,只是类型不是int,而是long
AtomicIntegerArray案例:
1 | public class Demo7AtomicIntegerArray { |
AtomicReferenceArray 主要API:
1 | //参数1:数组下标; |
AtomicReferenceArray 案例:
1 | public class Demo8AtomicReferenceArray { |
7.5 对象的属性修改类型
如果需要原子更新某个类里的某个字段时,需要用到对象的属性修改类型原子类。
AtomicIntegerFieldUpdater:原子更新整形字段的更新器 AtomicLongFieldUpdater:原子更新长整形字段的更新器 AtomicReferenceFieldUpdater :原子更新引用类形字段的更新器
但是他们的使用通常有以下几个限制:
- 限制1:操作的目标不能是static类型,前面说到的unsafe提取的是非static类型的属性偏移量,如果是static类型在获取时如果没有使用对应的方法是会报错的,而这个Updater并没有使用对应的方法。
- 限制2:操作的目标不能是final类型的,因为final根本没法修改。
- 限制3:必须是volatile类型的数据,也就是数据本身是读一致的。
- 限制4:属性必须对当前的Updater所在的区域是可见的,也就是private如果不是当前类肯定是不可见的,protected如果不存在父子关系也是不可见的,default如果不是在同一个package下也是不可见的。
实现方式:通过反射找到属性,对属性进行操作。
例子:
1 | public class AtomicIntegerFieldUpdaterTest { |
7.6 JDK1.8新增类
LongAdder:长整型原子类 DoubleAdder:双浮点型原子类 LongAccumulator:类似LongAdder,但要更加灵活(要传入一个函数式接口) DoubleAccumulator:类似DoubleAdder,但要更加灵活(要传入一个函数式接口)
LongAdder是jdk1.8提供的累加器,基于Striped64实现,所提供的API基本上可以替换原先的AtomicLong。
LongAdder类似于AtomicLong是原子性递增或者递减类,AtomicLong已经通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说性能已经很好了,但是JDK开发组并不满足,因为在非常高的并发请求下AtomicLong的性能不能让他们接受,虽然AtomicLong使用CAS但是CAS失败后还是通过无限循环的自旋锁不断尝试。
1 | public final long incrementAndGet() { |
在高并发下N多线程同时去操作一个变量会造成大量线程CAS失败然后处于自旋状态,这大大浪费了cpu资源,降低了并发性。那么既然AtomicLong性能由于过多线程同时去竞争一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源那么性能问题不就解决了?是的,JDK8提供的LongAdder就是这个思路。下面通过图形来标示两者不同。
AtomicLong和LongAdder对比:
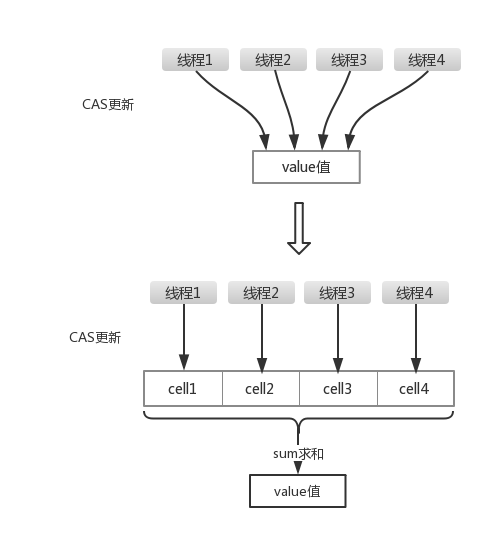
一段LongAdder和Atomic的对比测试代码:
1 | public class Demo9Compare { |
不同计算机因为CPU、内存等硬件不一样,所以测试的数值也不一样,但是得到的结论都是一样的
测试结果:
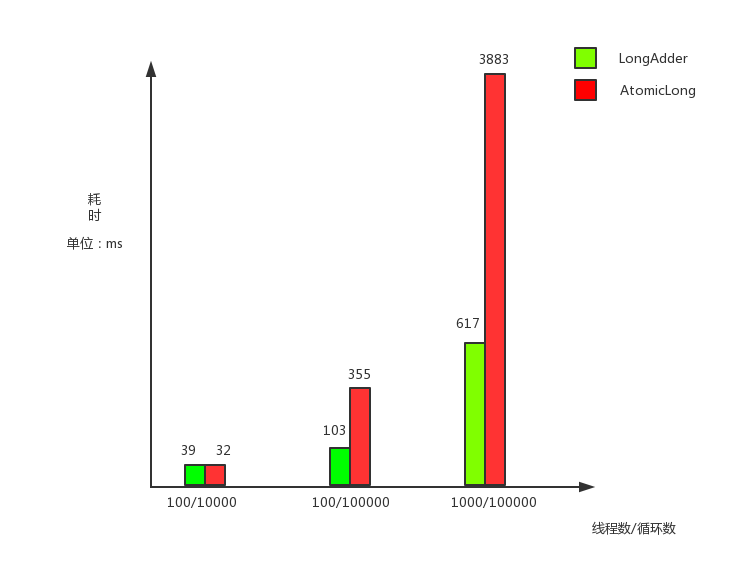
从上结果图可以看出,在并发比较低的时候,LongAdder和AtomicLong的效果非常接近。但是当并发较高时,两者的差距会越来越大。上图中在线程数为1000,每个线程循环数为100000时,LongAdder的效率是AtomicLong的6倍左右。
8 J.U.C之AQS
8.1 AQS简介
AQS(AbstractQueuedSynchronizer),即队列同步器。它是构建锁或者其他同步组件的基础框架(如ReentrantLock、ReentrantReadWriteLock、Semaphore等),JUC并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。它是JUC并发包中的核心基础组件。
在这里我们只是对AQS进行了解,它只是一个抽象类,但是JUC中的很多组件都是基于这个抽象类,也可以说这个AQS是多数JUC组件的基础。
8.1.1 AQS的作用
Java的内置锁一直都是备受争议的,在JDK 1.6之前,synchronized这个重量级锁其性能一直都是较为低下,虽然在1.6后,进行大量的锁优化策略,但是与Lock相比synchronized还是存在一些缺陷的:它缺少了获取锁与释放锁的可操作性,可中断、超时获取锁,而且独占式在高并发场景下性能大打折扣。
AQS解决了实现同步器时涉及到的大量细节问题,例如获取同步状态、FIFO同步队列。基于AQS来构建同步器可以带来很多好处。它不仅能够极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题。
8.1.2 state状态
AQS维护了一个volatile int类型的变量state表示当前同步状态。当state>0时表示已经获取了锁,当state = 0时表示释放了锁。
它提供了三个方法来对同步状态state进行操作:
getState():返回同步状态的当前值 setState():设置当前同步状态 compareAndSetState():使用CAS设置当前状态,该方法能够保证状态设置的原子性
这三种操作均是CAS原子操作,其中compareAndSetState的实现依赖于Unsafe的compareAndSwapInt()方法
8.1.3 资源共享方式
AQS定义两种资源共享方式:
- Exclusive(独占,只有一个线程能执行,如ReentrantLock)
- Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法:
- isHeldExclusively():当前同步器是否在独占式模式下被线程占用,一般该方法表示是否被当前线程所独占。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取同步状态,成功则返回true,失败则返回false。其他线程需要等待该线程释放同步状态才能获取同步状态。
- tryRelease(int):独占方式。尝试释放同步状态,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取同步状态。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放同步状态,如果释放后允许唤醒后续等待结点,返回true,否则返回false。
8.2 CLH同步队列
AQS内部维护着一个FIFO队列,该队列就是CLH同步队列,遵循FIFO原则( First Input First Output先进先出)。CLH同步队列是一个FIFO双向队列,AQS依赖它来完成同步状态的管理。
当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
8.2.3 入列
CLH队列入列非常简单,就是tail指向新节点、新节点的prev指向当前最后的节点,当前最后一个节点的next指向当前节点。
代码我们可以看看addWaiter(Node node)方法:
1 | private Node addWaiter(Node mode) { |
在上面代码中,两个方法都是通过一个CAS方法compareAndSetTail(Node expect, Node update)来设置尾节点,该方法可以确保节点是线程安全添加的。在enq(Node node)方法中,AQS通过“死循环”的方式来保证节点可以正确添加,只有成功添加后,当前线程才会从该方法返回,否则会一直执行下去。
8.2.4 出列
CLH同步队列遵循FIFO,首节点的线程释放同步状态后,将会唤醒它的后继节点(next),而后继节点将会在获取同步状态成功时将自己设置为首节点。head执行该节点并断开原首节点的next和当前节点的prev即可,注意在这个过程是不需要使用CAS来保证的,因为只有一个线程能够成功获取到同步状态。过程图如下:
9 J.U.C之锁
9.1 锁的基本概念
虽然在前面锁优化的部分已经提到过一些锁的概念,但不完全,这里是对锁的概念补充。
9.1.1 互斥锁
在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为” 互斥锁” 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
9.1.2 阻塞锁
阻塞锁,可以说是让线程进入阻塞状态进行等待,当获得相应的信号(唤醒,时间) 时,才可以进入线程的准备就绪状态,准备就绪状态的所有线程,通过竞争,进入运行状态。
9.1.3 自旋锁
自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时,才能进入临界区。
由于自旋锁只是将当前线程不停地执行循环体,不进行线程状态的改变,所以响应速度更快。但当线程数不停增加时,性能下降明显,因为每个线程都需要执行,占用CPU时间。如果线程竞争不激烈,并且保持锁的时间段。适合使用自旋锁。
9.1.4 读写锁
读写锁实际是一种特殊的自旋锁,它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。
读写锁相对于自旋锁而言,能提高并发性,因为在多处理器系统中,它允许同时有多个读者来访问共享资源,最大可能的读者数为实际的逻辑CPU数。写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数相关),但不能同时既有读者又有写者。
9.1.5 公平锁
公平锁(Fair):加锁前检查是否有排队等待的线程,优先排队等待的线程,先来先得
非公平锁(Nonfair):加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待
非公平锁性能比公平锁高,因为公平锁需要在多核的情况下维护一个队列。
9.2 ReentrantLock
ReentrantLock,可重入锁,是一种递归无阻塞的同步机制。它可以等同于synchronized的使用,但是ReentrantLock提供了比synchronized更强大、灵活的锁机制,可以减少死锁发生的概率。
ReentrantLock还提供了公平锁和非公平锁的选择,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。公平锁的效率往往没有非公平锁的效率高,在许多线程访问的情况下,公平锁表现出较低的吞吐量。
查看ReentrantLock源码中的构造方法:
1 | public ReentrantLock() { |
Sync为ReentrantLock里面的一个内部类,它继承AQS(AbstractQueuedSynchronizer),它有两个子类:公平锁FairSync和非公平锁NonfairSync。
9.2.1 获取锁
一般都是这么使用ReentrantLock获取锁的:(默认非公平锁)
1 | //非公平锁 |
lock方法:
1 | public void lock() { |
加锁最终可以看到会调用方法:
1 | public final void acquire(int arg) { |
其实底层就是使用AQS同步队列。
9.2.2 释放锁
获取同步锁后,使用完毕则需要释放锁,ReentrantLock提供了unlock释放锁:
1 | public void unlock() { |
unlock内部使用Sync的release()释放锁,release()是在AQS中定义的:
1 | public final boolean release(int arg) { |
释放同步状态的tryRelease()是同步组件自己实现:
1 | protected final boolean tryRelease(int releases) { |
只有当同步状态彻底释放后该方法才会返回true。当同步队列的状态state == 0 时,则将锁持有线程设置为null,free= true,表示释放成功。
9.2.3 公平锁与非公平锁原理
公平锁与非公平锁的区别在于获取锁的时候是否按照FIFO的顺序来。释放锁不存在公平性和非公平性,比较非公平锁和公平锁获取同步状态的过程,会发现两者唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors(),定义如下:
1 | public final boolean hasQueuedPredecessors() { |
该方法主要做一件事情:主要是判断当前线程是否位于CLH同步队列中的第一个。如果是则返回true,否则返回false。
9.2.4 ReentrantLock与synchronized的区别
前面提到ReentrantLock提供了比synchronized更加灵活和强大的锁机制,那么它的灵活和强大之处在哪里呢?他们之间又有什么相异之处呢?
- 与synchronized相比,ReentrantLock提供了更多,更加全面的功能,具备更强的扩展性。例如:时间锁等候,可中断锁等候,锁投票。
- ReentrantLock还提供了条件Condition,对线程的等待、唤醒操作更加详细和灵活,所以在多个条件变量和高度竞争锁的地方,ReentrantLock更加适合(以后会阐述Condition)。
- ReentrantLock提供了可轮询的锁请求。它会尝试着去获取锁,如果成功则继续,否则可以等到下次运行时处理,而synchronized则一旦进入锁请求要么成功要么阻塞,所以相比synchronized而言,ReentrantLock会不容易产生死锁些。
- ReentrantLock支持更加灵活的同步代码块,但是使用synchronized时,只能在同一个synchronized块结构中获取和释放。注:ReentrantLock的锁释放一定要在finally中处理,否则可能会产生严重的后果。
- ReentrantLock支持中断处理,且性能较synchronized会好些。
9.3 读写锁ReentrantReadWriteLock
可重入锁ReentrantLock是互斥锁,互斥锁在同一时刻仅有一个线程可以进行访问,但是在大多数场景下,大部分时间都是提供读服务,而写服务占有的时间较少。然而读服务不存在数据竞争问题,如果一个线程在读时禁止其他线程读势必会导致性能降低。所以就提供了读写锁。
读写锁维护着一对锁,一个读锁和一个写锁。通过分离读锁和写锁,使得并发性比一般的互斥锁有了较大的提升:在同一时间可以允许多个读线程同时访问,但是在写线程访问时,所有读线程和写线程都会被阻塞。
读写锁的主要特性:
- 公平性:支持公平性和非公平性。
- 重入性:支持重入。读写锁最多支持65535个递归写入锁和65535个递归读取锁。
- 锁降级:写锁能够降级成为读锁,遵循获取写锁、获取读锁在释放写锁的次序。读锁不能升级为写锁。
读写锁ReentrantReadWriteLock实现接口ReadWriteLock,该接口维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
1 | public interface ReadWriteLock { |
ReadWriteLock定义了两个方法。readLock()返回用于读操作的锁,writeLock()返回用于写操作的锁。ReentrantReadWriteLock定义如下:
1 | /** 内部类 读锁 */ |
ReentrantReadWriteLock与ReentrantLock一样,其锁主体依然是Sync,它的读锁、写锁都是依靠Sync来实现的。所以ReentrantReadWriteLock实际上只有一个锁,只是在获取读取锁和写入锁的方式上不一样而已,它的读写锁其实就是两个类:ReadLock、writeLock,这两个类都是lock实现。
在ReentrantLock中使用一个int类型的state来表示同步状态,该值表示锁被一个线程重复获取的次数。但是读写锁ReentrantReadWriteLock内部维护着一对锁,需要用一个变量维护多种状态。所以读写锁采用“按位切割使用”的方式来维护这个变量,将其切分为两部分,高16为表示读,低16为表示写。分割之后,读写锁是如何迅速确定读锁和写锁的状态呢?通过位运算。假如当前同步状态为S,那么写状态等于 S & 0x0000FFFF(将高16位全部抹去),读状态等于S >>> 16(无符号补0右移16位)。代码如下:
1 | static final int SHARED_SHIFT = 16; |
9.3.1 写锁的获取
写锁就是一个支持可重入的互斥锁。
写锁的获取最终会调用tryAcquire(int arg),该方法在内部类Sync中实现:
1 | protected final boolean tryAcquire(int acquires) { |
该方法和ReentrantLock的tryAcquire(int arg)大致一样,在判断重入时增加了一项条件:读锁是否存在。因为要确保写锁的操作对读锁是可见的,如果在存在读锁的情况下允许获取写锁,那么那些已经获取读锁的其他线程可能就无法感知当前写线程的操作。因此只有等读锁完全释放后,写锁才能够被当前线程所获取,一旦写锁开始获取了,所有其他读、写线程均会被阻塞。
9.3.2 写锁的释放
获取了写锁用完了则需要释放,WriteLock提供了unlock()方法释放写锁:
1 | public void unlock() { |
写锁的释放最终还是会调用AQS的模板方法release(int arg)方法,该方法首先调用tryRelease(int arg)方法尝试释放锁,tryRelease(int arg)方法为读写锁内部类Sync中定义了,如下:
1 | protected final boolean tryRelease(int releases) { |
写锁释放锁的整个过程和互斥锁ReentrantLock相似,每次释放均是减少写状态,当写状态为0时表示 写锁已经完全释放了,从而等待的其他线程可以继续访问读写锁,获取同步状态,同时此次写线程的修改对后续的线程可见。
9.3.3 读锁的获取
读锁为一个可重入的共享锁,它能够被多个线程同时持有,在没有其他写线程访问时,读锁总是获取成功。
读锁的获取可以通过ReadLock的lock()方法:
1 | public void lock() { |
Sync的acquireShared(int arg)定义在AQS中:
1 | public final void acquireShared(int arg) { |
9.3.4 读锁的释放
与写锁相同,读锁也提供了unlock()释放读锁:
1 | public void unlock() { |
unlcok()方法内部使用Sync的releaseShared(int arg)方法,该方法也定义AQS中:
1 | public final boolean releaseShared(int arg) { |
9.3.5 锁降级
读写锁有一个特性就是锁降级,锁降级就意味着写锁是可以降级为读锁的。锁降级需要遵循以下顺序:
1 | 获取写锁=>获取读锁=>释放写锁 |
9.3.6 读写锁例子
1 | public class Demo10ReentrantReadWriteLock { |
10 J.U.C之Condition
10.1 Condition介绍
在没有Lock之前,我们使用synchronized来控制同步,配合Object的wait()、notify()系列方法可以实现等待/通知模式。在JDK5后,Java提供了Lock接口,相对于Synchronized而言,Lock提供了条件Condition,对线程的等待、唤醒操作更加详细和灵活。
下图是Condition与Object的监视器方法的对比:
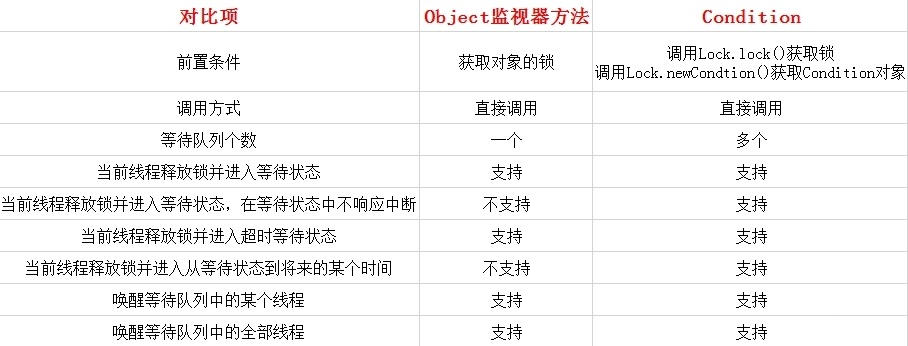
Condition提供了一系列的方法来对阻塞和唤醒线程:
await() :造成当前线程在接到信号或被中断之前一直处于等待状态。
await(long time, TimeUnit unit) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
awaitNanos(long nanosTimeout) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。返回值表示剩余时间,如果在nanosTimesout之前唤醒,那么返回值 = nanosTimeout – 消耗时间,如果返回值 <= 0 ,则可以认定它已经超时了。
awaitUninterruptibly() :造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
awaitUntil(Date deadline) :造成当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。如果没有到指定时间就被通知,则返回true,否则表示到了指定时间,返回返回false。
**signal()**:唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
signal()All:唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁。
Condition是一种广义上的条件队列(等待队列)。他为线程提供了一种更为灵活的等待/通知模式,线程在调用await方法后执行挂起操作,直到线程等待的某个条件为真时才会被唤醒。Condition必须要配合锁一起使用,因为对共享状态变量的访问发生在多线程环境下。一个Condition的实例必须与一个Lock绑定,因此Condition一般都是作为Lock的内部实现。
案例:
1 | public class Demo11Condition { |
10.2 Condition的实现
获取一个Condition必须通过Lock的newCondition()方法。该方法定义在接口Lock下面,返回的结果是绑定到此 Lock 实例的新 Condition 实例。Condition为一个接口,其下仅有一个实现类ConditionObject,由于Condition的操作需要获取相关的锁,而AQS则是同步锁的实现基础,所以ConditionObject则定义为AQS的内部类。定义如下:
1 | public class ConditionObject implements Condition, java.io.Serializable { |
10.2.1 等待队列
每个Condition对象都包含着一个FIFO队列,该队列是Condition对象通知/等待功能的关键。在队列中每一个节点都包含着一个线程引用,该线程就是在该Condition对象上等待的线程。源码如下:
1 | public class ConditionObject implements Condition, java.io.Serializable { |
从上面代码可以看出Condition拥有首节点(firstWaiter),尾节点(lastWaiter)。当前线程调用await()方法,将会以当前线程构造成一个节点(Node),并将节点加入到该队列的尾部。结构如下:
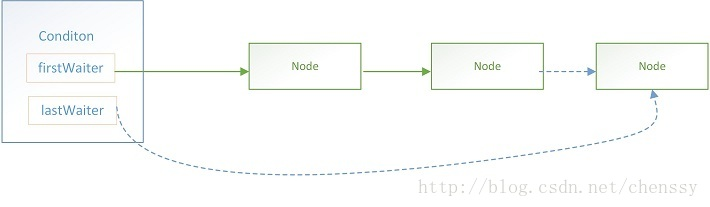
Node里面包含了当前线程的引用。Node定义与AQS的CLH同步队列的节点使用的都是同一个类(AbstractQueuedSynchronized.Node静态内部类)。
Condition的队列结构比CLH同步队列的结构简单些,新增过程较为简单只需要将原尾节点的nextWaiter指向新增节点,然后更新lastWaiter即可。
10.2.2 等待状态
调用Condition的await()方法会使当前线程进入等待状态,同时会加入到Condition等待队列同时释放锁。当从await()方法返回时,当前线程一定是获取了Condition相关连的锁。
1 | public final void await() throws InterruptedException { |
此段代码的逻辑是:首先将当前线程新建一个节点同时加入到条件队列中,然后释放当前线程持有的同步状态。然后则是不断检测该节点代表的线程释放出现在CLH同步队列中(收到signal信号之后就会在AQS队列中检测到),如果不存在则一直挂起,否则参与竞争同步状态。
10.2.3 通知
调用Condition的signal()方法,将会唤醒在等待队列中等待最长时间的节点(条件队列里的首节点),在唤醒节点前,会将节点移到CLH同步队列中。
1 | public final void signal() { |
该方法首先会判断当前线程是否已经获得了锁,这是前置条件。然后唤醒等待队列中的头节点。
doSignal(Node first):唤醒头节点
1 | private void doSignal(Node first) { |
doSignal(Node first)主要是做两件事:
1.修改头节点,
2.调用transferForSignal(Node first) 方法将节点移动到CLH同步队列中。
JUC多线程 (三)
学习目标:
- 掌握CyclicBarrier同步屏障的使用
- 掌握CountDownLatch的使用
- 掌握Semaphore信号量的使用
- 掌握ConcurrentHashMap同步容器的使用
- 掌握四种BlockingQueue阻塞队列的使用
- 掌握线程池的使用,了解内置的四种线程池
11 J.U.C之并发工具类
11.1 CyclicBarrier
11.1.1 介绍
CyclicBarrier也叫同步屏障,在JDK1.5被引入的一个同步辅助类,在API中是这么介绍的:
1 | 允许一组线程全部等待彼此达到共同屏障点的同步辅助。 循环阻塞在涉及固定大小的线程方的程序中很有用,这些线程必须偶尔等待彼此。 屏障被称为循环,因为它可以在等待的线程被释放之后重新使用。 |
CyclicBarrier好比一扇门,默认情况下关闭状态,堵住了线程执行的道路,直到所有线程都就位,门才打开,让所有线程一起通过。
11.1.2 实现分析
通过上图我们可以看到CyclicBarrier的内部是使用重入锁ReentrantLock和Condition。它有两个构造方法:
- CyclicBarrier(int parties):它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动屏障时执行预定义的操作。parties表示拦截线程的数量。
- CyclicBarrier(int parties, Runnable barrierAction) :创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,并在启动屏障时执行给定的屏障操作,该操作由最后一个进入屏障的线程执行。
构造方法如下:
1 | public CyclicBarrier(int parties, Runnable barrierAction) { |
在CyclicBarrier中最重要的方法莫过于await()方法,每个线程调用await方法告诉CyclicBarrier已经到达屏障位置,线程被阻塞。源码如下:
1 | public int await() throws InterruptedException, BrokenBarrierException { |
await()方法的逻辑:如果该线程不是到达的最后一个线程,则他会一直处于等待状态,除非发生以下情况:
- 最后一个线程到达,即index == 0
- 超出了指定时间(超时等待)
- 其他的某个线程中断当前线程
- 其他的某个线程中断另一个等待的线程
- 其他的某个线程在等待屏障超时
- 其他的某个线程在此屏障调用reset()方法。reset()方法用于将屏障重置为初始状态。
11.1.3 案例
田径比赛,所有运动员准备好了之后,大家一起跑,代码如下
1 | public class Demo1CyclicBarrier { |
11.2 CountDownLatch
11.2.1 介绍
CountDownLatch是一个计数的闭锁,作用与CyclicBarrier有点儿相似。
在API中是这样描述的:
用给定的计数 初始化 CountDownLatch。由于调用了 countDown() 方法,所以在当前计数到达零之前,await 方法会一直受阻塞。之后,会释放所有等待的线程,await 的所有后续调用都将立即返回。
这种现象只出现一次——计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。
- CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;
- CyclicBarrier:多个线程互相等待,直到到达同一个同步点,再继续一起执行。
对于CountDownLatch来说,重点是“一个线程(多个线程)等待”,而其他的N个线程在完成“某件事情”之后,可以终止,也可以等待。而对于CyclicBarrier,重点是多个线程,在任意一个线程没有完成,所有的线程都必须等待。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就会减1。当计数器值到达0时,它表示所有的线程已经完成了任务,然后就可以恢复等待的线程继续执行了。如下图
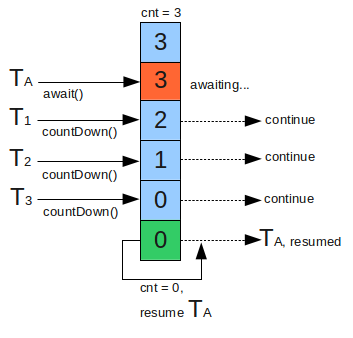
11.2.2 实现分析
CountDownLatch结构如下
通过上面的结构图我们可以看到,CountDownLatch内部依赖Sync实现,而Sync继承AQS。CountDownLatch仅提供了一个构造方法:
CountDownLatch(int count) : 构造一个用给定计数初始化的 CountDownLatch
1 | public CountDownLatch(int count) { |
sync为CountDownLatch的一个内部类,通过这个内部类Sync可以知道CountDownLatch是采用共享锁来实现的。最长用的两个方法是await()和countDown():
CountDownLatch提供await()方法来使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断。内部使用AQS的getState方法获取计数器,如果计数器值不等于0,则会以自旋方式会尝试一直去获取同步状态。
CountDownLatch提供countDown() 方法递减锁存器的计数,如果计数到达零,则释放所有等待的线程。内部调用AQS的releaseShared(int arg)方法来释放共享锁同步状态。
11.2.3 案例
在CyclicBarrier应用场景之上进行修改,添加接力运动员。
起点运动员应该等其他起点运动员准备好才可以起跑(CyclicBarrier)。
接力运动员不需要关心其他人,只需和自己有关的起点运动员到接力点即可开跑(CountDownLatch)。
1 | public class Demo2CountDownLatch { |
11.3 Semaphore
11.3.1 介绍
Semaphore是一个控制访问多个共享资源的计数器,和CountDownLatch一样,其本质上是一个“共享锁”。
Semaphore维护了一个信号量许可集。线程可以获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以释放它所持有的信号量许可,被释放的许可归还到许可集中,可以被其他线程再次获取。
举个例子:
假设停车场仅有5个停车位,一开始停车场没有车辆所有车位全部空着,然后先后到来三辆车,停车场车位够,安排进去停车,然后又来三辆,这个时候由于只剩两个停车位,所有只能停两辆,其余一辆必须在外面候着,直到停车场有空车位,当然以后每来一辆都需要在外面等着。当停车场有车开出去,里面有空位了,则安排一辆车进去(至于是哪辆车 要看选择的机制是公平还是非公平)。
Semaphore常用于约束访问一些(物理或逻辑)资源的线程数量。
当信号量初始化为 1 时,可以当作互斥锁使用,因为它只有两个状态:有一个许可能使用,或没有许可能使用。当以这种方式使用时,“锁”可以被其他线程控制和释放,而不是主线程控制释放。
11.3.2 实现分析
从上图可以看出Semaphore内部包含公平锁(FairSync)和非公平锁(NonfairSync),继承内部类Sync,其中Sync继承AQS(再一次阐述AQS的重要性)。
Semaphore提供了两个构造函数:
- Semaphore(int permits) :创建具有给定的许可数和非公平的 Semaphore。
- Semaphore(int permits, boolean fair) :创建具有给定的许可数和给定的公平设置的 Semaphore。
实现如下:(Semaphore默认选择非公平锁)
1 | public Semaphore(int permits) { |
信号量获取
Semaphore提供了acquire()方法来获取一个许可。
1 | public void acquire() throws InterruptedException { |
内部使用AQS以共享模式获取同步状态,核心源码:
1 | //公平 判断该线程是否位于CLH队列的列头 |
信号量释放
获取了许可,当用完之后就需要释放,Semaphore提供release()来释放许可。
1 | public void release() { |
内部调用AQS释放许可,核心代码:
1 | protected final boolean tryReleaseShared(int releases) { |
11.3.3 案例
停车为示例:
1 | public class Demo3Semaphore { |
12 J.U.C之并发容器ConcurrentHashMap
12.1 介绍
HashMap是我们用得非常频繁的一个集合,但是它是线程不安全的。并且在多线程环境下,put操作是有可能产生死循环,不过在JDK1.8的版本中更换了数据插入的顺序,已经解决了这个问题。
为了解决该问题,提供了Hashtable和Collections.synchronizedMap(hashMap)两种解决方案,但是这两种方案都是对读写加锁,独占式。一个线程在读时其他线程必须等待,吞吐量较低,性能较为低下。而J.U.C给我们提供了高性能的线程安全HashMap:ConcurrentHashMap。
在1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,但是1.8已经改变了这种思路,而是利用CAS+Synchronized来保证并发更新的安全,当然底层采用数组+链表+红黑树的存储结构。
12.2 JDK7 HashMap
HashMap 是最简单的,它不支持并发操作,下面这张图是 HashMap 的结构:
HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
public HashMap(int initialCapacity, float loadFactor)初始化方法的参数说明:
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。 loadFactor:负载因子,默认为 0.75。 threshold:扩容的阈值,等于 capacity * loadFactor
put 过程
- 数组初始化,在第一个元素插入 HashMap 的时候做一次数组的初始化,先确定初始的数组大小,并计算数组扩容的阈值。
- 计算具体数组位置,使用key进行hash值计算,根据hash值计算应该放在哪个数组中。
- 找到数组下标后,会先进行 key 判断是否重复,如果没有重复,就准备将新值放入到链表的表头(在多线程操作中,这种操作会造成死循环,在jdk1.8已解决)。
- 数组扩容,在插入新值的时候,如果当前的 size 已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的 2 倍。扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
get过程
- 根据 key 计算 hash 值。
- 根据hash值找到相应的数组下标。
- 遍历该数组位置处的链表,直到找到相等的 key。
12.3 JDK7 ConcurrentHashMap
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多人都会将其描述为分段锁。简单的说,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的。
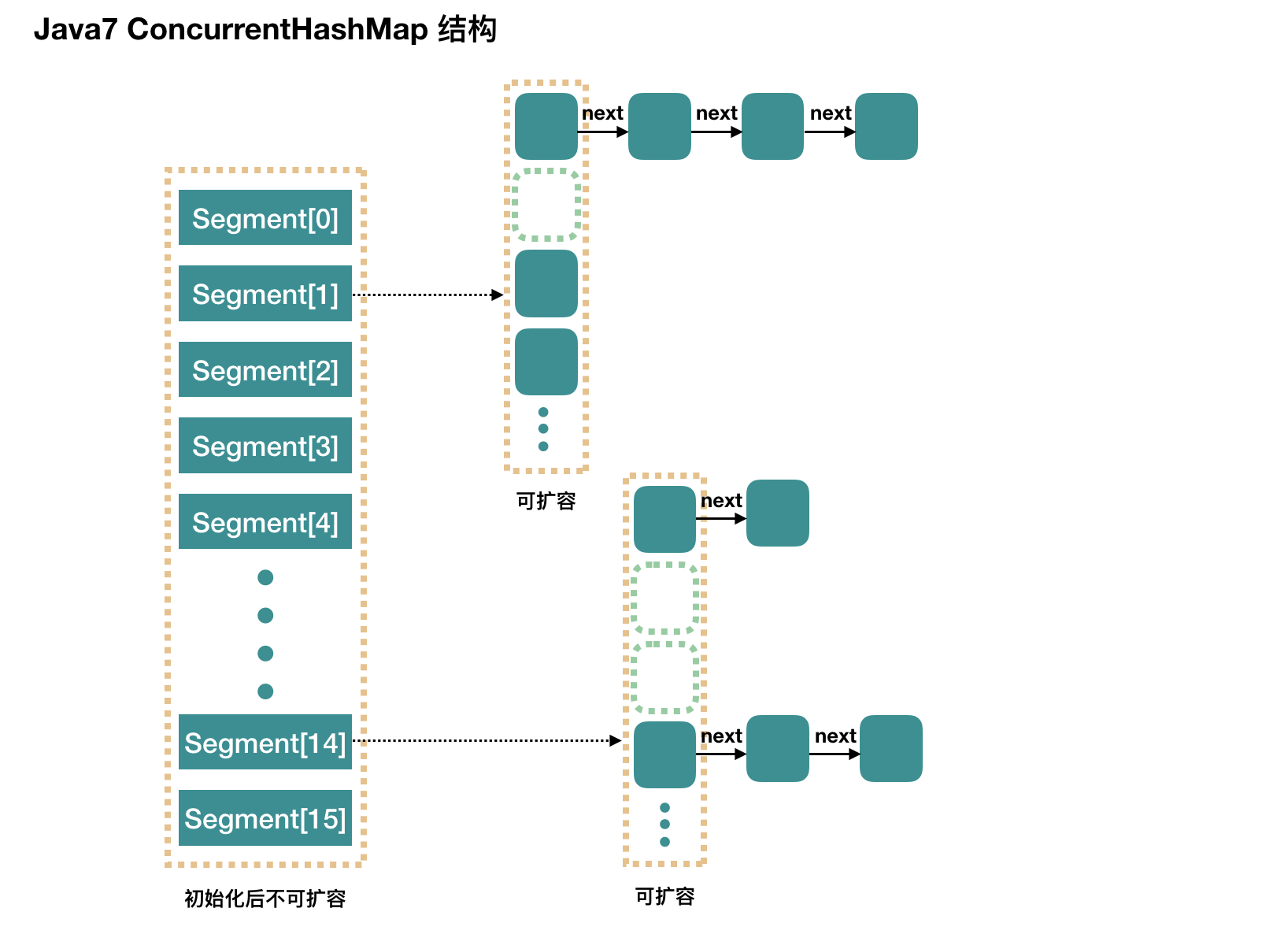
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,每次操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的。
初始化
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)初始化方法
- initialCapacity:整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
- concurrencyLevel:并发数(或者Segment 数,有很多叫法,重要的是如何理解)。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
- loadFactor:负载因子,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
举个简单的例子:
用 new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
- Segment 数组长度为 16,不可以扩容
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
- 这里初始化了 segment[0],其他位置还是 null,
put过程
- 根据 hash 值能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
- Segment 内部是由 数组+链表 组成的,由于有独占锁的保护,所以 segment 内部的操作并不复杂。保证多线程安全的,就是做了一件事,那就是获取该 segment 的独占锁。
- Segment 数组不能扩容,rehash方法扩容是 segment 数组某个位置内部的数组 HashEntry[] 进行扩容,扩容后,容量为原来的 2 倍。
get过程
- 计算 hash 值,找到 segment 数组中的具体位置
- segment 数组中也是数组,再根据 hash 找到数组中具体值的位置
- 到这里是链表了,顺着链表进行查找即可
12.4 JDK8 HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度。
为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度。
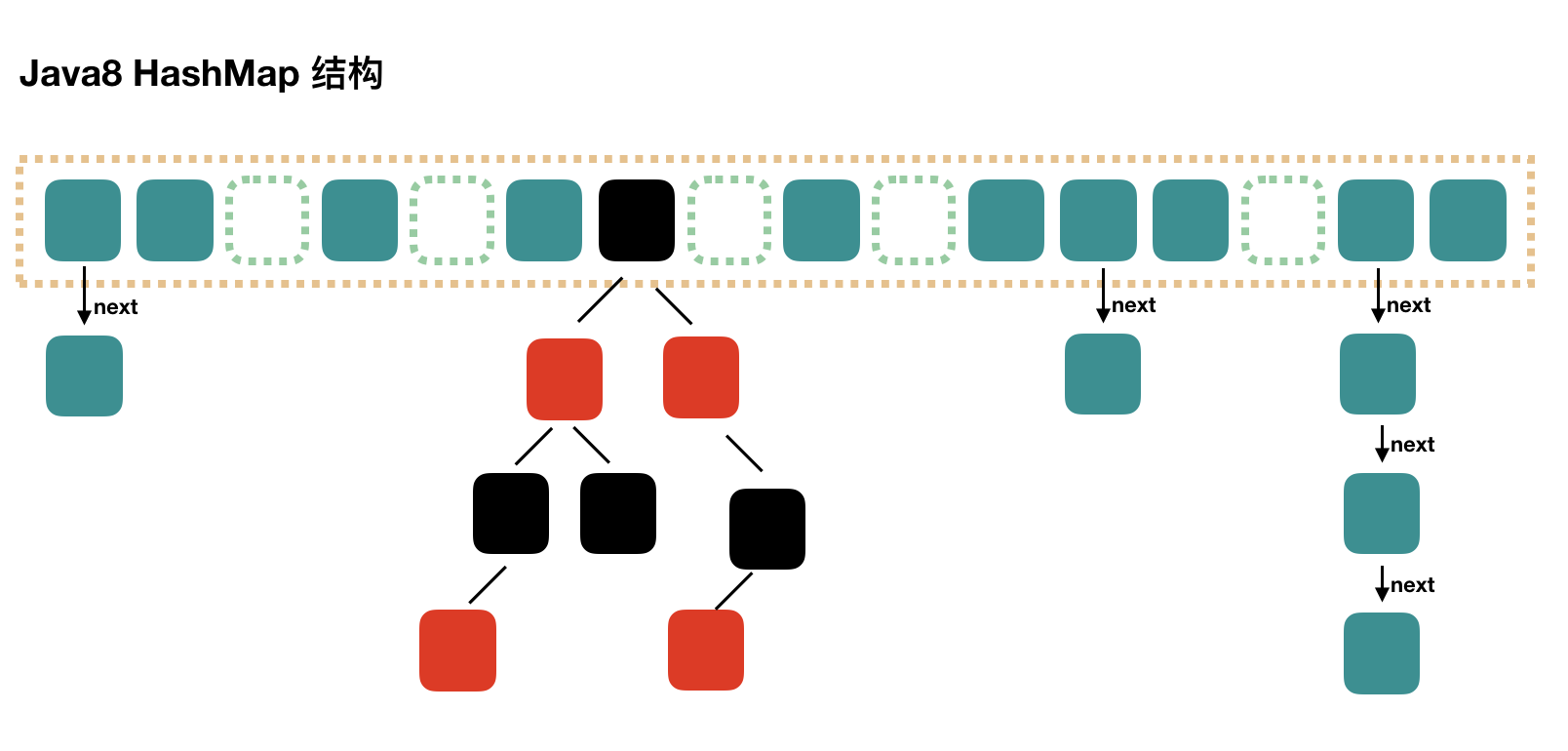
jdk7 中使用 Entry 来代表每个 HashMap 中的数据节点,jdk8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
put过程
和jdk7的put差不多
- 和 Jdk7 不一样的地方就是,jdk7是先扩容后插入新值的,jdk8 先插值再扩容
- 先使用链表进行存放数据,当数量超过8个的时候,将链表转为红黑树
get 过程分析
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标。
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步。
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步。
- 遍历链表,直到找到相等(==或equals)的 key。
12.5 JDK8 ConcurrentHashMap
Java7 中实现的 ConcurrentHashMap 还是比较复杂的,Java8 对 ConcurrentHashMap 进行了比较大的改动。可以参考 Java8 中 HashMap 相对于 Java7 HashMap 的改动,对于 ConcurrentHashMap,Java8 也引入了红黑树。
在1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,但是1.8已经改变了这种思路,而是利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
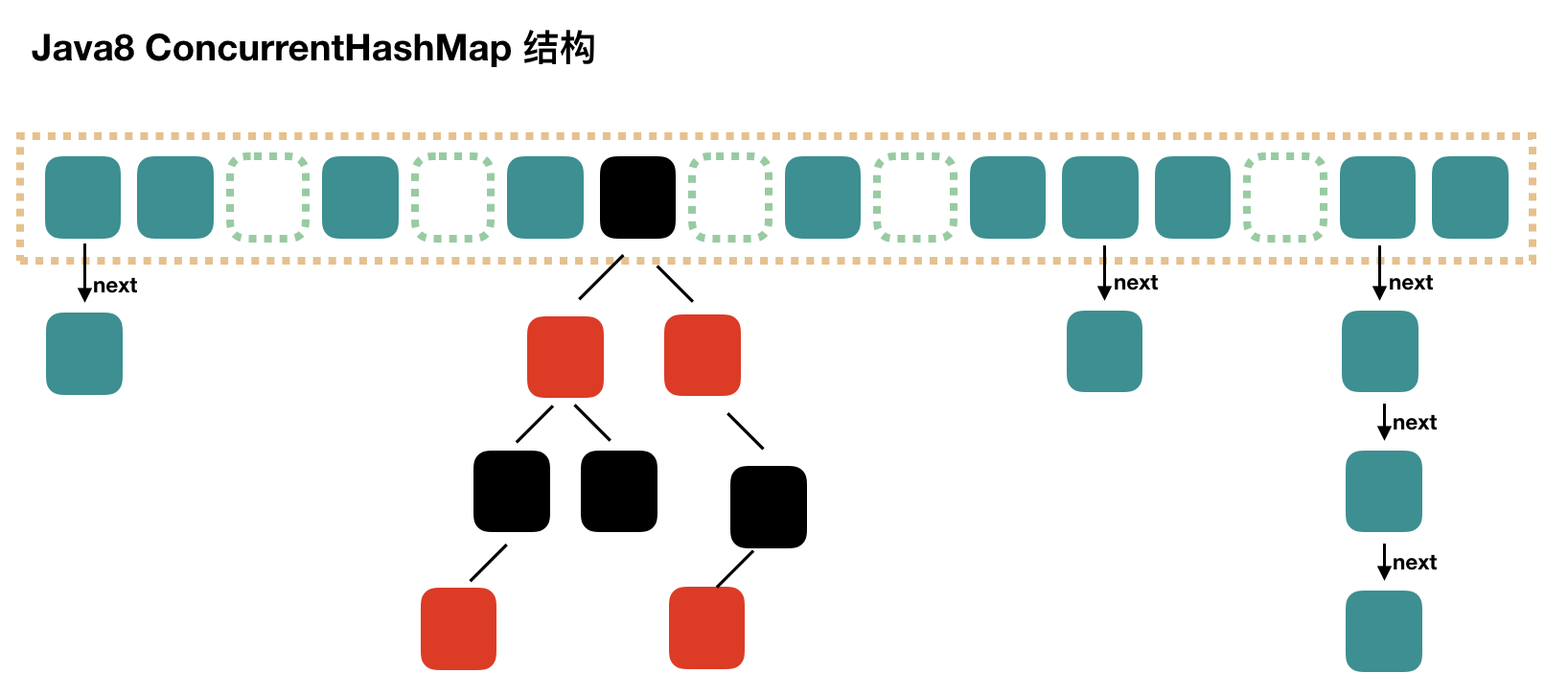
12.6 使用场景
ConcurrentHashMap通常只被看做并发效率更高的Map,用来替换其他线程安全的Map容器,比如Hashtable和Collections.synchronizedMap。线程安全的容器,特别是Map,很多情况下一个业务中涉及容器的操作有多个,即复合操作,而在并发执行时,线程安全的容器只能保证自身的数据不被破坏,和数据在多个线程间是可见的,但无法保证业务的行为是否正确。
ConcurrentHashMap总结:
- HashMap是线程不安全的,ConcurrentHashMap是线程安全的,但是线程安全仅仅指的是对容器操作的时候是线程安全的
- ConcurrentHashMap的public V get(Object key)不涉及到锁,也就是说获得对象时没有使用锁
- put、remove方法,在jdk7使用锁,但多线程中并不一定有锁争用,原因在于ConcurrentHashMap将缓存的变量分到多个Segment,每个Segment上有一个锁,只要多个线程访问的不是一个Segment就没有锁争用,就没有堵塞,各线程用各自的锁,ConcurrentHashMap缺省情况下生成16个Segment,也就是允许16个线程并发的更新而尽量没有锁争用。而在jdk8中使用的CAS+Synchronized来保证线程安全,比加锁的性能更高
- ConcurrentHashMap线程安全的,允许一边更新、一边遍历,也就是说在对象遍历的时候,也可以进行remove,put操作,且遍历的数据会随着remove,put操作产出变化,
案例1:遍历的同时删除
1 | public class Demo4ConcurrentHashMap1 { |
案例2:业务操作的线程安全不能保证
1 | public class Demo4ConcurrentHashMap2 { |
案例3:多线程删除
1 | public class Demo4ConcurrentHashMap3 { |
12.7 对比Hashtable
Hashtable和ConcurrentHashMap的不同点:
- Hashtable对get,put,remove都使用了同步操作,它的同步级别是正对Hashtable来进行同步的,也就是说如果有线程正在遍历集合,其他的线程就暂时不能使用该集合了,这样无疑就很容易对性能和吞吐量造成影响,从而形成单点。而ConcurrentHashMap则不同,它只对put,remove操作使用了同步操作,get操作并不影响。
- Hashtable在遍历的时候,如果其他线程,包括本线程对Hashtable进行了put,remove等更新操作的话,就会抛出ConcurrentModificationException异常,但如果使用ConcurrentHashMap的话,就不用考虑这方面的问题了
12.8 了解ConcurrentSkipListMap
通过对前面ConcurrentHashMap的学习,我们了解到Map存放数据的两种数据结构:链表和红黑树,这两种数据结构各自都有着优缺点。而ConcurrentSkipListMap使用的是第三种数据结构:SkipList。SkipList有着不低于红黑树的效率。
Skip List ,称之为跳表,它是一种可以替代平衡树的数据结构,其数据元素默认按照key值升序,天然有序。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过“空间来换取时间”的一个算法,在每个节点中增加了向前的指针,在插入、删除、查找时可以忽略一些不可能涉及到的结点,从而提高了效率。
我们先看一个简单的链表,如下:

如果我们需要查询9、21、30,则需要比较次数为3 + 6 + 8 = 17 次,那么有没有优化方案呢?有!我们将该链表中的某些元素提炼出来作为一个比较“索引”,如下:
我们先与这些索引进行比较来决定下一个元素是往右还是下走,由于存在“索引”的缘故,导致在检索的时候会大大减少比较的次数。当然元素不是很多,很难体现出优势,当元素足够多的时候,这种索引结构就会大显身手。
我们将上图再做一些扩展就可以变成一个典型的SkipList结构:
SkipListd的查找
对于上面我们我们要查找元素21,其过程如下:
- 比较3,大于,往后找(9),
- 比9大,继续往后找(25),但是比25小,则从9的下一层开始找(16)
- 16的后面节点依然为25,则继续从16的下一层找
- 找到21
绿线代表查询路径
SkipList的插入
SkipList的插入操作主要包括:
- 查找合适的位置。这里需要明确一点就是在确认新节点要占据的层次K时,采用丢硬币的方式,完全随机。如果占据的层次K大于链表的层次,则重新申请新的层,否则插入指定层次
- 申请新的节点
- 调整指针
假定我们要插入的元素为23,经过查找可以确认她是位于25后,9、16、21前。当然需要考虑申请的层次K。
如果层次K > 3,需要申请新层次(Level 4)
如果层次 K = 2,直接在Level 2 层插入即可
SkipList的删除
删除节点和插入节点思路基本一致:找到节点,删除节点,调整指针。
比如删除节点9,如下:
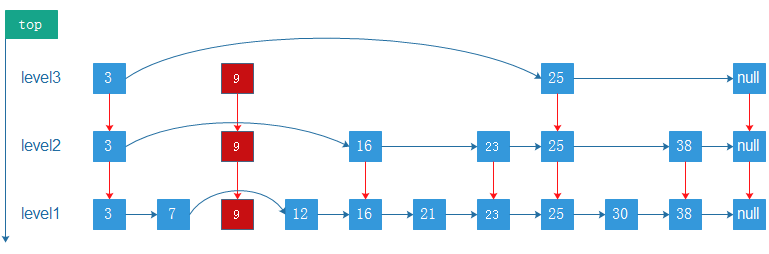
13 J.U.C队列
要实现一个线程安全的队列有两种方式:阻塞和非阻塞:
| queue | 阻塞与否 | 是否有界 | 线程安全保障 | 适用场景 | 注意事项 |
|---|---|---|---|---|---|
| ConcurrentLinkedQueue | 非阻塞 | 无界 | CAS | 对全局的集合进行操作的场景 | size() 是要遍历一遍集合,慎用 |
| ArrayBlockingQueue | 阻塞 | 有界 | 一把全局锁 | 生产消费模型,平衡两边处理速度 | – |
| LinkedBlockingQueue | 阻塞 | 可配置 | 存取采用2把锁 | 生产消费模型,平衡两边处理速度 | 无界的时候注意内存溢出问题 |
| PriorityBlockingQueue | 阻塞 | 无界 | 一把全局锁 | 支持优先级排序 | |
| SynchronousQueue | 阻塞 | 无界 | CAS | 不存储元素的阻塞队列 |
13.1 非阻塞队列ConcurrentLinkedQueue
在单线程编程中我们会经常用到一些集合类,比如ArrayList,HashMap等,但是这些类都不是线程安全的类。在面试中也经常会有一些考点,比如ArrayList不是线程安全的,Vector是线程安全。而保障Vector线程安全的方式,是非常粗暴的在方法上用synchronized独占锁,将多线程执行变成串行化。要想将ArrayList变成线程安全的也可以使用Collections.synchronizedList(List<T> list)方法ArrayList转换成线程安全的,但这种转换方式依然是通过synchronized修饰方法实现的,很显然这不是一种高效的方式,同时,队列也是我们常用的一种数据结构。
为了解决线程安全的问题,J.U.C为我们准备了ConcurrentLinkedQueue这个线程安全的队列。从类名就可以看的出来实现队列的数据结构是链式。ConcurrentLinkedQueue是一个基于链接节点的无边界的线程安全队列,遵循队列的FIFO原则,队尾入队,队首出队。采用CAS算法来实现的。
使用案例:
1 | public class ConcurrentLinkedQueueDemo { |
注意:
- ConcurrentLinkedQueue的.size() 是要遍历一遍集合的,很慢的,所以尽量要避免用size
- 使用了这个ConcurrentLinkedQueue 类之后还是需要自己进行同步或加锁操作。例如queue.isEmpty()后再进行队列操作queue.add()是不能保证安全的,因为可能queue.isEmpty()执行完成后,别的线程开始操作队列。
13.2 阻塞队列BlockingQueue
13.2.1 BlockingQueue介绍
BlockingQueue即阻塞队列,从阻塞这个词可以看出,在某些情况下对阻塞队列的访问可能会造成阻塞。被阻塞的情况主要有如下两种:
- 当队列满了的时候进行入队列操作
- 当队列空了的时候进行出队列操作
因此,当一个线程试图对一个已经满了的队列进行入队列操作时,它将会被阻塞,除非有另一个线程做了出队列操作;同样,当一个线程试图对一个空队列进行出队列操作时,它将会被阻塞,除非有另一个线程进行了入队列操作。
BlockingQueue 对插入操作、移除操作、获取元素操作提供了四种不同的方法用于不同的场景中使用:
- 抛出异常
- 返回特殊值(null 或 true/false,取决于具体的操作)
- 阻塞等待此操作,直到这个操作成功
- 阻塞等待此操作,直到成功或者超时指定时间。总结如下:
| 操作 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
接下来我们介绍这个接口的几个实现类。
13.2.1 ArrayBlockingQueue
ArrayBlockingQueue是一个由数组实现的有界阻塞队列。该队列采用FIFO的原则对元素进行排序添加的。
ArrayBlockingQueue为有界且固定,其大小在构造时由构造函数来决定,确认之后就不能再改变了。
ArrayBlockingQueue支持对等待的生产者线程和使用者线程进行排序的可选公平策略,但是在默认情况下不保证线程公平的访问,在构造时可以选择公平策略(fair = true)。公平性通常会降低吞吐量,但是减少了可变性和避免了“不平衡性”。
ArrayBlockingQueue继承AbstractQueue,实现BlockingQueue接口。java.util.AbstractQueue,在Queue接口中扮演着非常重要的作用,该类提供了对queue操作的骨干实现。BlockingQueue继承java.util.Queue为阻塞队列的核心接口,提供了在多线程环境下的出列、入列操作,作为使用者,则不需要关心队列在什么时候阻塞线程,什么时候唤醒线程,所有一切均由BlockingQueue来完成。
ArrayBlockingQueue内部使用可重入锁ReentrantLock + Condition来完成多线程环境的并发操作。
- items,一个定长数组,维护ArrayBlockingQueue的元素
- takeIndex,int,为ArrayBlockingQueue队首位置
- putIndex,int,ArrayBlockingQueue队尾位置
- count,元素个数
- lock,锁,ArrayBlockingQueue出列入列都必须获取该锁,两个步骤公用一个锁
1 | public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, Serializable { |
使用示例:
1 | public class Demo6BlockingQueueTest { |
13.2.3 LinkedBlockingQueue
LinkedBlockingQueue和ArrayBlockingQueue的使用方式基本一样,但还是有一定的区别:
队列的数据结构不同
ArrayBlockingQueue是一个由数组支持的有界阻塞队列
LinkedBlockingQueue是一个基于链表的有界(可设置)阻塞队列
队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock
- 在生产或消费时操作不同
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node进行插入或移除,会影响性能
- 队列大小初始化方式不同
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE
13.2.4 PriorityBlockingQueue
PriorityBlockingQueue类似于ArrayBlockingQueue内部使用一个独占锁来控制,同时只有一个线程可以进行入队和出队。
PriorityBlockingQueue是一个优先级队列,它在java.util.PriorityQueue的基础上提供了可阻塞的读取操作。它是无界的,就是说向Queue里面增加元素没有数量限制,但可能会导致内存溢出而失败。
PriorityBlockingQueue始终保证出队的元素是优先级最高的元素,并且可以定制优先级的规则,内部使用二叉堆,通过使用一个二叉树最小堆算法来维护内部数组,这个数组是可扩容的,当当前元素个数>=最大容量时候会通过算法扩容。值得注意的是为了避免在扩容操作时候其他线程不能进行出队操作,实现上使用了先释放锁,然后通过CAS保证同时只有一个线程可以扩容成功。
小结:
1、优先队列不允许空值,而且不支持non-comparable(不可比较)的对象,比如用户自定义的类。优先队列要求使用Java Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。
2、优先队列的头是基于自然排序或者Comparator排序的最小元素。如果有多个对象拥有同样的排序,那么就可能随机地取其中任意一个。也可以通过提供的Comparator(比较器)在队列实现自定的排序。当我们获取队列时,返回队列的头对象。
3、优先队列的大小是不受限制的,但在创建时可以指定初始大小,当我们向优先队列增加元素的时候,队列大小会自动增加。
4、PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
使用案例:
1 | public class Demo7PriorityBlockQueue { |
13.2.5 SynchronousQueue
SynchronousQueue,实际上它不是一个真正的队列,因为它不会为队列中元素维护存储空间。与其他队列不同的是,它维护一组线程,这些线程在等待着把元素加入或移出队列。SynchronousQueue没有存储功能,因此put和take会一直阻塞,直到有另一个线程已经准备好参与到交付过程中。
仅当有足够多的消费者,并且总是有一个消费者准备好获取交付的工作时,才适合使用同步队列。这种实现队列的方式看似很奇怪,但由于可以直接交付工作,从而降低了将数据从生产者移动到消费者的延迟。
直接交付方式还会将更多关于任务状态的信息反馈给生产者。当交付被接受时,它就知道消费者已经得到了任务,而不是简单地把任务放入一个队列——这种区别就好比将文件直接交给同事,还是将文件放到她的邮箱中并希望她能尽快拿到文件。
SynchronousQueue对于正在等待的生产者和使用者线程而言,默认是非公平排序,也可以选择公平排序策略。但是,使用公平所构造的队列可保证线程以 FIFO 的顺序进行访问。 公平通常会降低吞吐量,但是可以减小可变性并避免得不到服务。
SynchronousQueue特点:
- 是一种阻塞队列,其中每个 put 必须等待一个 take,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。
- 是线程安全的,是阻塞的。
- 不允许使用 null 元素。
- 公平排序策略是指调用put的线程之间,或take的线程之间的线程以 FIFO 的顺序进行访问。
- SynchronousQueue的方法:
- iterator(): 永远返回空,因为里面没东西。
- peek() :永远返回null。
- put() :往queue放进去一个element以后就一直wait直到有其他thread进来把这个element取走。
- offer() :往queue里放一个element后立即返回,如果碰巧这个element被另一个thread取走了,offer方法返回true,认为offer成功;否则返回false。
- offer(2000, TimeUnit.SECONDS) :往queue里放一个element但等待时间后才返回,和offer()方法一样。
- take() :取出并且remove掉queue里的element,取不到东西他会一直等。
- poll() :取出并且remove掉queue里的element,方法立即能取到东西返回。否则立即返回null。
- poll(2000, TimeUnit.SECONDS) :等待时间后再取,并且remove掉queue里的element,
- isEmpty():永远是true。
- remainingCapacity() :永远是0。
- remove()和removeAll() :永远是false。
使用案例:
1 | public class Demo8SynchronousQueue { |
14 J.U.C线程池
线程是一个程序员一定会涉及到的概念,但是线程的创建和切换都是代价比较大的。所以,我们需要有一个好的方案能做到线程的复用,这就涉及到一个概念——线程池。合理的使用线程池能够带来3个很明显的好处:
- 降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗
- 提高响应速度:任务到达时不需要等待线程创建就可以立即执行。
- 提高线程的可管理性:线程池可以统一管理、分配、调优和监控。
java的线程池支持主要通过ThreadPoolExecutor来实现,我们使用的ExecutorService的各种线程池策略都是基于ThreadPoolExecutor实现的,所以ThreadPoolExecutor十分重要。要弄明白各种线程池策略,必须先弄明白ThreadPoolExecutor。
14.1 线程池状态
线程池同样有五种状态:Running, SHUTDOWN, STOP, TIDYING, TERMINATED。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
变量ctl定义为AtomicInteger ,记录了“线程池中的任务数量”和“线程池的状态”两个信息。共32位,其中高3位表示”线程池状态”,低29位表示”线程池中的任务数量”。
RUNNING:处于RUNNING状态的线程池能够接受新任务,以及对新添加的任务进行处理。
SHUTDOWN:处于SHUTDOWN状态的线程池不可以接受新任务,但是可以对已添加的任务进行处理。
STOP:处于STOP状态的线程池不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
TIDYING:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
TERMINATED:线程池彻底终止的状态。
各个状态的转换如下:
14.2 构造方法
我现在分析线程池参数最全的构造方法,了解其内部的参数意义
1 | public ThreadPoolExecutor(int corePoolSize, |
共有七个参数,每个参数含义如下:
corePoolSize
线程池中核心线程的数量(也称为线程池的基本大小)。当提交一个任务时,线程池会新建一个线程来执行任务,直到当前线程数等于corePoolSize。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
maximumPoolSize
线程池中允许的最大线程数。线程池的阻塞队列满了之后,如果还有任务提交,如果当前的线程数小于maximumPoolSize,则会新建线程来执行任务。注意,如果使用的是无界队列,该参数也就没有什么效果了。
keepAliveTime
线程空闲的时间。线程的创建和销毁是需要代价的。线程执行完任务后不会立即销毁,而是继续存活一段时间:keepAliveTime。默认情况下,该参数只有在线程数大于corePoolSize时才会生效。
unit
keepAliveTime的单位。TimeUnit
workQueue
用来保存等待执行的任务的BlockQueue阻塞队列,等待的任务必须实现Runnable接口。选择如下:
ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。 LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。 PriorityBlockingQueue:具有优先级别的阻塞队列。 SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
threadFactory
用于设置创建线程的工厂。ThreadFactory的作用就是提供创建线程的功能的线程工厂。他是通过newThread()方法提供创建线程的功能,newThread()方法创建的线程都是“非守护线程”而且“线程优先级都是默认优先级”。
handler
RejectedExecutionHandler,线程池的拒绝策略。所谓拒绝策略,是指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。当向线程池中提交任务时,如果此时线程池中的线程已经饱和了,而且阻塞队列也已经满了,则线程池会选择一种拒绝策略来处理该任务。
线程池提供了四种拒绝策略:
AbortPolicy:直接抛出异常,默认策略; CallerRunsPolicy:用调用者所在的线程来执行任务; DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务; DiscardPolicy:直接丢弃任务; 当然我们也可以实现自己的拒绝策略,例如记录日志等等,实现RejectedExecutionHandler接口即可。
14.3 四种线程池
我们除了可以使用ThreadPoolExecutor自己根据实际情况创建线程池以外,Executor框架也提供了三种线程池,他们都可以通过工具类Executors来创建。
还有一种线程池ScheduledThreadPoolExecutor,它相当于提供了“延迟”和“周期执行”功能的ThreadPoolExecutor
14.3.1 FixedThreadPool
FixedThreadPool是复用固定数量的线程处理一个共享的无边界队列,其定义如下:
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
corePoolSize 和 maximumPoolSize都设置为创建FixedThreadPool时指定的参数nThreads,由于该线程池是固定线程数的线程池,当线程池中的线程数量等于corePoolSize 时,如果继续提交任务,该任务会被添加到阻塞队列workQueue中,而workQueue使用的是LinkedBlockingQueue,但没有设置范围,那么则是最大值(Integer.MAX_VALUE),这基本就相当于一个无界队列了。
案例:
1 | public class Demo9FixedThreadPoolCase { |
14.3.2 SingleThreadExecutor
SingleThreadExecutor只会使用单个工作线程来执行一个无边界的队列。
1 | public static ExecutorService newSingleThreadExecutor() { |
作为单一worker线程的线程池,它把corePool和maximumPoolSize均被设置为1,和FixedThreadPool一样使用的是无界队列LinkedBlockingQueue,所以带来的影响和FixedThreadPool一样。
SingleThreadExecutor只会使用单个工作线程,它可以保证认为是按顺序执行的,任何时候都不会有多于一个的任务处于活动状态。注意,如果单个线程在执行过程中因为某些错误中止,新的线程会替代它执行后续线程。
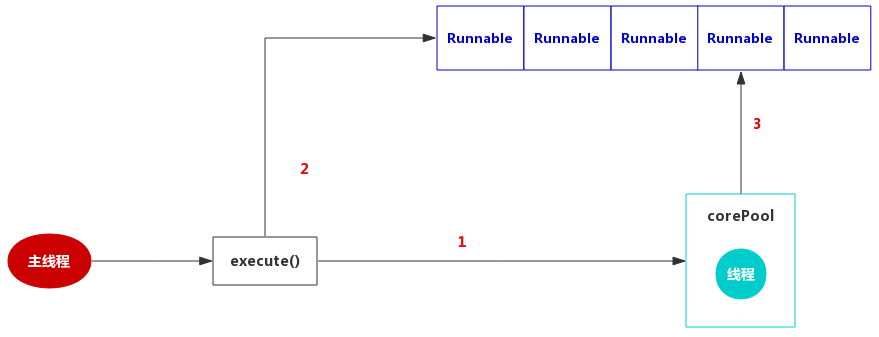
案例:
1 | public class Demo9SingleThreadPoolCase { |
14.3.3 CachedThreadPool
CachedThreadPool会根据需要,在线程可用时,重用之前构造好的池中线程,否则创建新线程:
1 | public static ExecutorService newCachedThreadPool() { |
它把corePool为0,maximumPoolSize为Integer.MAX_VALUE,这就意味着所有的任务一提交就会加入到阻塞队列中。因为线程池的基本大小设置为0,一般情况下线程池中没有程池,用的时候再创建。
但是keepAliveTime设置60,unit设置为秒,意味着空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。阻塞队列采用的SynchronousQueue,这是是一个没有元素的阻塞队列。
这个线程池在执行 大量短生命周期的异步任务时,可以显著提高程序性能。调用 execute 时,可以重用之前已构造的可用线程,如果不存在可用线程,那么会重新创建一个新的线程并将其加入到线程池中。如果线程超过 60 秒还未被使用,就会被中止并从缓存中移除。因此,线程池在长时间空闲后不会消耗任何资源。
但是这样就处理线程池会存在一个问题,如果主线程提交任务的速度远远大于CachedThreadPool的处理速度,则CachedThreadPool会不断地创建新线程来执行任务,这样有可能会导致系统耗尽CPU和内存资源,所以在使用该线程池是,一定要注意控制并发的任务数,否则创建大量的线程可能导致严重的性能问题。
案例:
1 | public class Demo9CachedThreadPoolCase { |
14.3.4 ScheduledThreadPool
Timer与TimerTask虽然可以实现线程的周期和延迟调度,但是Timer与TimerTask存在一些问题:
- Timer在执行定时任务时只会创建一个线程,所以如果存在多个任务,且任务时间过长,超过了两个任务的间隔时间,会发生一些缺陷。
- 如果TimerTask抛出RuntimeException,Timer会停止所有任务的运行。
- Timer执行周期任务时依赖系统时间,如果当前系统时间发生变化会出现一些执行上的变化
为了解决这些问题,我们一般都是推荐ScheduledThreadPoolExecutor来实现。
ScheduledThreadPoolExecutor,继承ThreadPoolExecutor且实现了ScheduledExecutorService接口,它就相当于提供了“延迟”和“周期执行”功能的ThreadPoolExecutor。
ScheduledThreadPoolExecutor,它可另行安排在给定的延迟后运行命令,或者定期执行命令。需要多个辅助线程时,或者要求 ThreadPoolExecutor 具有额外的灵活性或功能时,此类要优于Timer。
提供了四种构造方法:
1 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
在ScheduledThreadPoolExecutor的构造函数中,我们发现它都是利用ThreadLocalExecutor来构造的,唯一变动的地方就在于它所使用的阻塞队列变成了DelayedWorkQueue。
DelayedWorkQueue为ScheduledThreadPoolExecutor中的内部类,类似于延时队列和优先级队列。在执行定时任务的时候,每个任务的执行时间都不同,所以DelayedWorkQueue的工作就是按照执行时间的升序来排列,执行时间距离当前时间越近的任务在队列的前面,这样就可以保证每次出队的任务都是当前队列中执行时间最靠前的。
案例:
1 | public class Demo9ScheduledThreadPool { |
第10章 - MySQL性能优化
学习目标:
- 了解MySQL优化
- 了解常见的优化思路
- 了解查询优化
- 了解索引优化
- 了解存储优化
- 了解数据库结构优化
- 了解查询缓存等缓存优化
1 优化介绍
在进行优化讲解之前,先请大家记住不要听信你看到的关于优化的“绝对真理”,而应该是在实际的业务场景下通过测试来验证你关于执行计划以及响应时间的假设。本课程只是给大家提供一些优化方面的方向和思路,而具体业务场景的不同,使用的MySQL服务版本不同,都会使得优化方案的制定也不同。
1.1 MySQL介绍
MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库。可以看到Google,Facebook,Twitter,百度,新浪,腾讯,淘宝,网易,久游等绝大多数互联网公司数据库都是用的MySQL数据库,甚至将其作为核心应用的数据库系统。
虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
我们将这里进行一个较为全面的分析,让大家了解到MySQL的性能到底与哪些地方有关,以便于让大家寻找出其性能问题的根本原因,而尽可能清楚的知道该如何去优化自己的数据库。
1.2 优化要考虑的问题
注意:优化有风险,涉足需谨慎!
1.2.1 优化可能带来的问题
- 优化不总是对一个单纯的环境进行,还很可能是一个复杂的已投产的系统!
- 优化手段有很大的风险,一定要意识到和预见到!
- 任何的技术可以解决一个问题,但必然存在带来一个问题的风险!
- 对于优化来说调优而带来的问题,控制在可接受的范围内才是有成果。
- 保持现状或出现更差的情况都是失败!
1.2.2 优化的需求
- 稳定性和业务可持续性,通常比性能更重要!
- 优化不可避免涉及到变更,变更就有风险!
- 优化使性能变好,维持和变差是等概率事件!
- 优化应该是各部门协同,共同参与的工作,任何单一部门都不能对数据库进行优化!
所以优化工作,是由业务需要驱使的!!!
1.2.3 优化由谁参与
在进行数据库优化时,应由数据库管理员、业务部门代表、应用程序架构师、应用程序设计人员、应用程序开发人员、硬件及系统管理员、存储管理员等,业务相关人员共同参与。
1.3 优化的思路
1.3.1 优化的方向
在数据库优化上有两个主要方向:即安全与性能。
- 安全 —> 数据安全性
- 性能 —> 数据的高性能访问
本课程主要是在性能优化方向进行介绍
1.3.2 优化的维度
从上图中可以看出,我们把数据库优化分为四个纬度:硬件,系统配置,数据库表结构,SQL及索引
硬件: CPU、内存、存储、网络设备等
系统配置: 服务器系统、数据库服务参数等
数据库表结构: 高可用、分库分表、读写分离、存储引擎、表设计等
Sql及索引: sql语句、索引使用等
- 从优化成本进行考虑:硬件>系统配置>数据库表结构>SQL及索引
- 从优化效果进行考虑:硬件<系统配置<数据库表结构<SQL及索引
1.3.3 优化的工具
检查问题常用工具
1 | msyqladmin #mysql客户端,可进行管理操作 |
不常用但好用的工具
1 | zabbix #监控主机、系统、数据库(部署zabbix监控平台) |
1.3.4 数据库使用优化思路
本课程尽可能的全面介绍数据库的调优思路,但是在多数时候,我们进行调优不需要进行这么全面、大范围的调优,一般情况下,我们进行数据库层面的优化就可以了,那我们该如何调优的呢?
应急调优的思路:
针对突然的业务办理卡顿,无法进行正常的业务处理!需要立马解决的场景!
show processlist(查看链接session状态)
explain(分析查询计划),show index from table(分析索引)
通过执行计划判断,索引问题(有没有、合不合理)或者语句本身问题
show status like ‘%lock%’; # 查询锁状态
SESSION_ID; # 杀掉有问题的session
常规调优的思路:
针对业务周期性的卡顿,例如在每天10-11点业务特别慢,但是还能够使用,过了这段时间就好了。
- 查看slowlog,分析slowlog,分析出查询慢的语句。
- 按照一定优先级,进行一个一个的排查所有慢语句。
- 分析top sql,进行explain调试,查看语句执行时间。
- 调整索引或语句本身。
2 查询优化
2.1 MySQL查询流程
我们该如何进行sql优化呢, 首先我们需要知道,sql优化其实主要是解决查询的优化问题,所以我们先从数据库的查询开始入手,下面这幅图显示了查询的执行路径:
① 客户端将查询发送到服务器;
② 服务器检查查询缓存,如果找到了,就从缓存中返回结果,否则进行下一步。
③ 服务器解析,预处理。
④ 查询优化器优化查询
⑤ 生成执行计划,执行引擎调用存储引擎API执行查询
⑥服务器将结果发送回客户端。
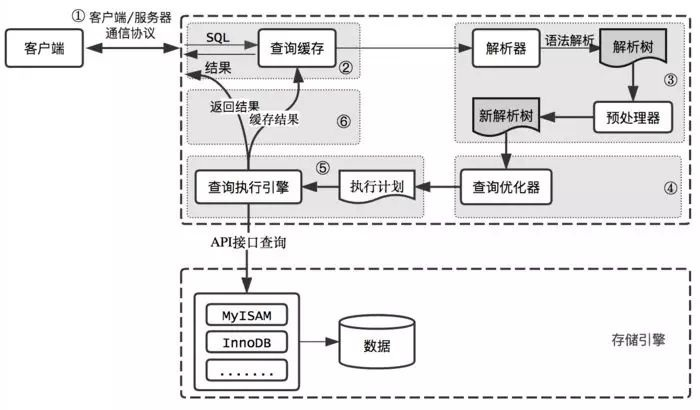
查询缓存 在解析一个查询语句之前,如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据,如果命中缓存直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
语法解析和预处理器 MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。
查询优化器 语法书被校验合法后由优化器转成查询计划,一条语句可以有很多种执行方式,最后返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
查询执行引擎 在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。最常使用的也是比较最多的引擎是MyISAM引擎和InnoDB引擎。mysql5.5开始的默认存储引擎已经变更为innodb了。
2.2 查询优化
前面的查询流程分析,我们大概了解了MySQL是如何执行的,其中涉及到的部分我们在后面会一一道来。现在我们先从查询优化部分开始。
sql是我们和数据库交流最重要的部分,所以我们在调优的时候,需要花费的大量时间就在sql调优上面。常见的分析手段有慢查询日志,EXPLAIN 分析查询,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
2.2.1 慢查询
- 慢查询日志开启
在配置文件my.cnf或my.ini中在[mysqld]一行下面加入两个配置参数
1 | log-slow-queries=/data/mysqldata/slow-query.log |
log-slow-queries参数为慢查询日志存放的位置,一般这个目录要有mysql的运行帐号的可写权限,一般都将这个目录设置为mysql的数据存放目录;
long_query_time=5中的5表示查询超过五秒才记录;
还可以在my.cnf或者my.ini中添加log-queries-not-using-indexes参数,表示记录下没有使用索引的查询。
- 慢查询分析
我们可以通过打开log文件查看得知哪些SQL执行效率低下 ,从日志中,可以发现查询时间超过5 秒的SQL,而小于5秒的没有出现在此日志中。
如果慢查询日志中记录内容很多,可以使用mysqldumpslow工具(MySQL客户端安装自带)来对慢查询日志进行分类汇总。mysqldumpslow对日志文件进行了分类汇总,显示汇总后摘要结果。
进入log的存放目录,运行:
1 | [root@mysql_data]# mysqldumpslow slow-query.log |
mysqldumpslow命令
1 | /path/mysqldumpslow -s c -t 10/database/mysql/slow-query.log |
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
例如:
1 | /path/mysqldumpslow -s r -t 10/database/mysql/slow-log |
得到返回记录集最多的10个查询。
1 | /path/mysqldumpslow -s t -t 10 -g “leftjoin” /database/mysql/slow-log |
得到按照时间排序的前10条里面含有左连接的查询语句。
使用mysqldumpslow命令可以非常明确的得到各种我们需要的查询语句,对MySQL查询语句的监控、分析、优化是MySQL优化非常重要的一步。开启慢查询日志后,由于日志记录操作,在一定程度上会占用CPU资源影响mysql的性能,但是可以阶段性开启来定位性能瓶颈。
2.2.2 EXPLAIN
EXPLAIN可以帮助开发人员分析SQL问题,EXPLAIN显示了MySQL如何使用使用SQL执行计划,可以帮助开发人员写出更优化的查询语句。使用方法,在select语句前加上Explain就可以了:
1 | EXPLAIN SELECT * FROM products |
结果的列的说明如下:
1) id
SELECT识别符。这是SELECT查询序列号。这个不重要
2) select_type
表示SELECT语句的类型。
- simple:简单select(不使用union或子查询)。
- primary:最外面的select。
- union:union中的第二个或后面的select语句。
- dependent union:union中的第二个或后面的select语句,取决于外面的查询。
- union result:union的结果。
- subquery:子查询中的第一个select。
- dependent subquery:子查询中的第一个select,取决于外面的查询。
- derived:导出表的select(from子句的子查询)。
3) table
显示这查询的数据是关于哪张表的。
4) type
区间索引,这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为:
system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
- system:表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计。
- const:数据表最多只有一个匹配行,因为只匹配一行数据,所以很快
- eq_ref:mysql手册是这样说的:”对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY”。eq_ref可以用于使用=比较带索引的列。
- ref:查询条件索引既不是UNIQUE也不是PRIMARY KEY的情况。ref可用于=或<或>操作符的带索引的列。
- ref_or_null:该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
- index_merge:该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
- unique_subquery:该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
- index_subquery:该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
- range:只检索给定范围的行,使用一个索引来选择行。
- index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
- ALL:对于每个来自于先前的表的行组合,进行完整的表扫描。(性能最差)
5) possible_keys
指出MySQL能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。
6) key
实际使用到的索引。如果为NULL,则没有使用索引。如果为primary的话,表示使用了主键。
7) key_len
最长的索引宽度。如果键是NULL,长度就是NULL。在不损失精确性的情况下,长度越短越好。
8) ref
显示使用哪个列或常数与key一起从表中选择行。
9) rows
显示MySQL认为它执行查询时必须检查的行数。
10) Extra
执行状态说明,该列包含MySQL解决查询的详细信息
- Distinct:MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。
- Not exists:MySQL能够对查询进行LEFT JOIN优化,发现1个匹配LEFT JOIN标准的行后,不再为前面的的行组合在该表内检查更多的行。
- range checked for each record (index map: #):MySQL没有发现好的可以使用的索引,但发现如果来自前面的表的列值已知,可能部分索引可以使用。
- Using filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行。
- Using index:从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。
- Using temporary:为了解决查询,MySQL需要创建一个临时表来容纳结果。
- Using where:WHERE 子句用于限制哪一个行匹配下一个表或发送到客户。
- Using sort_union(…), Using union(…), Using intersect(…):这些函数说明如何为index_merge联接类型合并索引扫描。
- Using index for group-by:类似于访问表的Using index方式,Using index for group-by表示MySQL发现了一个索引,可以用来查 询GROUP BY或DISTINCT查询的所有列,而不要额外搜索硬盘访问实际的表。
3 索引优化
3.1 索引的介绍
创建以下表:
1 | CREATE TABLE `tb_table` ( |
执行以下sql,批量添加10条数据:
1 | drop procedure if exists tb_insert; |
在表没有添加索引和添加索引的时候,都执行以下查询:
1 | SELECT * FROM tb_table WHERE number = 500000 |
然后再添加数据库的数据,插入100万条,再次测试有索引和没有索引的查询语句。
通过上面的对比测试可以看出,索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
索引的目的在于提高查询效率,大家可以回忆之前学习的全文检索技术。类似使用字典,如果没有目录(索引),那么我们要从字典的第一个字开始查询到最后一个字才能有结果,可能要把字典中所有的字看一遍才能找到要结果,而目录(索引)则能够让我们快速的定位到这个字的位置,从而找到我们要的结果。
3.2 索引的类型
主键索引 PRIMARY KEY
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。
1
PRIMARY KEY (`id`)
唯一索引 UNIQUE
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。可以在创建表的时候指定,也可以修改表结构。
1
UNIQUE KEY `num` (`number`) USING BTREE
普通索引 INDEX
这是最基本的索引,它没有任何限制。可以在创建表的时候指定,也可以修改表结构
1
KEY `num` (`number`) USING BTREE
组合索引 INDEX
索引分单列索引和组合索引(联合索引)。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
1
KEY `num` (`number`,`name`) USING BTREE
注意,组合索引前面索引必须要先使用,后面的索引才能使用。
全文索引 FULLTEXT
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
3.3 索引的存储结构
3.3.1 BTree索引
在前面的例子中我们看见有USING BTREE,这个是什么呢?这个就是MySQL所使用的索引方案,MySQL中普遍使用B+Tree做索引,也就是BTREE。
特点:
- BTREE索引以B+树的结构存储数据
- BTREE索引能够加快数据的查询速度
- BTREE索引更适合进行行范围查找
使用的场景:
- 全值匹配的查询,例如根据订单号查询 order_sn=’98764322119900’
- 联合索引时会遵循最左前缀匹配的原则,即最左优先
- 匹配列前缀查询,例如:order_sn like ‘9876%’
- 匹配范围值的查找,例如:order_sn > ‘98764322119900’
- 只访问索引的查询
3.3.2 哈希索引
Hash索引在MySQL中使用的并不是很多,目前主要是Memory存储引擎使用,在Memory存储引擎中将Hash索引作为默认的索引类型。所谓Hash索引,实际上就是通过一定的Hash算法,将需要索引的键值进行Hash运算,然后将得到的Hash值存入一个Hash表中。然后每次需要检索的时候,都会将检索条件进行相同算法的Hash运算,然后再和Hash表中的Hash值进行比较并得出相应的信息。
特点:
- Hash索引仅仅只能满足“=”,“IN”和“<=>”查询,不能使用范围查询;
- Hash索引无法被利用来避免数据的排序操作;
- Hash索引不能利用部分索引键查询;
- Hash索引在任何时候都不能避免表扫描;
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高;
3.3.2 Full-text全文索引
Full-text索引也就是我们常说的全文索引,MySQL中仅有MyISAM和InnoDB存储引擎支持。
对于文本的大对象,或者较大的CHAR类型的数据,如果使用普通索引,那么匹配文本前几个字符还是可行的,但是想要匹配文本中间的几个单词,那么就要使用LIKE %word%来匹配,这样需要很长的时间来处理,响应时间会大大增加,这种情况,就可使用时FULLTEXT索引了,在生成Full-text索引时,会为文本生成一份单词的清单,在索引时根据这个单词的清单来索引。
注意:
- 对于较大的数据集,把数据添加到一个没有Full-text索引的表,然后添加Full-text索引的速度比把数据添加到一个已经有Full-text索引的表快。
- 针对较大的数据,生成全文索引非常的消耗时间和空间。
- 5.6版本前的MySQL自带的全文索引只能用于MyISAM存储引擎,如果是其它数据引擎,那么全文索引不会生效。5.6版本和之后InnoDB存储引擎开始支持全文索引。
- 在MySQL中,全文索引支队英文有用,目前对中文还不支持。5.7版本之后通过使用ngram插件开始支持中文。
- 在MySQL中,如果检索的字符串太短则无法检索得到预期的结果,检索的字符串长度至少为4字节。
3.4 索引的使用
虽然索引能够为查找带来速度上的提升,但是也会对性能有一些损失。
- 索引会增加写操作的成本
- 太多的索引会增加查询优化器的选择时间
当创建索引带来的好处多过于消耗的时候,才是最优的选择~
使用索引的场景
- 主键自动建立唯一索引;
- 经常作为查询条件在WHERE或者ORDER BY 语句中出现的列要建立索引;
- 作为排序的列要建立索引;
- 查询中与其他表关联的字段,外键关系建立索引
- 高并发条件下倾向建立组合索引;
- 用于聚合函数的列可以建立索引,例如使用count(number)时,number列就要建立索引
不使用索引的场景
- 有大量重复的列不单独建立索引
- 表记录太少不要建立索引,因为没有太大作用。
- 不会作为查询的列不要建立索引
4 存储优化
MySQL中索引是在存储引擎层实现的,这里我们会讲解存储引擎。
执行查询引擎的命令show engines,可以看到MySQL支持的存储引擎结果如下:
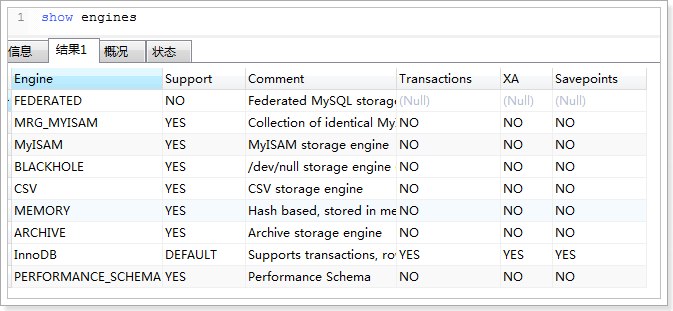
mysql支持存储引擎有好几种,咱们这里主要讨论一下常用的Innodb,MyISAM存储引擎。
4.1 存储引擎介绍
4.1.1 InnoDB存储引擎
特点:
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。相比较MyISAM存储引擎,InnoDB写的处理效率差一点并且会占用更多的磁盘空间保留数据和索引。
提供了对数据库事务ACID(原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability)的支持,实现了SQL标准的四种隔离级别。
设计目标就是处理大容量的数据库系统,MySQL运行时InnoDB会在内存中建立缓冲池,用于缓冲数据和索引。
执行“select count(*) from table”语句时需要扫描全表,因为使用innodb引擎的表不会保存表的具体行数,所以需要扫描整个表才能计算多少行。
InnoDB引擎是行锁,粒度更小,所以写操作不会锁定全表,在并发较高时,使用InnoDB会提升效率。即存在大量UPDATE/INSERT操作时,效率较高。
InnoDB清空数据量大的表时,是非常缓慢,这是因为InnoDB必须处理表中的每一行,根据InnoDB的事务设计原则,首先需要把“删除动作”写入“事务日志”,然后写入实际的表。所以,清空大表的时候,最好直接drop table然后重建。即InnoDB一行一行删除,不会重建表。
使用场景:
经常UPDETE/INSERT的表,使用处理多并发的写请求
支持事务,必选InnoDB。
可以从灾难中恢复(日志+事务回滚)
外键约束、列属性AUTO_INCREMENT支持
4.1.2 MyISAM存储引擎
特点:
MyISAM不支持事务,不支持外键,SELECT/INSERT为主的应用可以使用该引擎。
每个MyISAM在存储成3个文件,扩展名分别是:
1) frm:存储表定义(表结构等信息) 2) MYD(MYData),存储数据 3) MYI(MYIndex),存储索引不同MyISAM表的索引文件和数据文件可以放置到不同的路径下。
MyISAM类型的表提供修复的工具,可以用CHECK TABLE语句来检查MyISAM表健康,并用REPAIR TABLE语句修复一个损坏的MyISAM表。
在MySQL5.6以前,只有MyISAM支持Full-text全文索引
使用场景:
- 经常SELECT/INSERT的表,插入不频繁,查询非常频繁
- 不支持事务
- 做很多count 的计算。
4.1.3 MyISAM和Innodb区别
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个存储引擎,这两个存储引擎各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理,而InnoDB类型支持。MyISAM类型强调的是性能,其执行速度比InnoDB类型更快,而InnoDB提供事务支持已经外部键等高级数据库功能。
具体实现的差别:
MyISAM是非事务安全型的,而InnoDB是事务安全型的。
MyISAM锁的粒度是表级,而InnoDB支持行级锁定。
MyISAM不支持外键,而InnoDB支持外键
MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。
InnoDB表比MyISAM表更安全。
4.2 存储优化
4.2.1 禁用索引
对于使用索引的表,插入记录时,MySQL会对插入的记录建立索引。如果插入大量数据,建立索引会降低插入数据速度。为了解决这个问题,可以在批量插入数据之前禁用索引,数据插入完成后再开启索引。
禁用索引的语句: ALTER TABLE table_name DISABLE KEYS 开启索引语句: ALTER TABLE table_name ENABLE KEYS
MyISAM对于空表批量插入数据,则不需要进行操作,因为MyISAM引擎的表是在导入数据后才建立索引。
4.2.2 禁用唯一性检查
唯一性校验会降低插入记录的速度,可以在插入记录之前禁用唯一性检查,插入数据完成后再开启。
禁用唯一性检查的语句:SET UNIQUE_CHECKS = 0; 开启唯一性检查的语句:SET UNIQUE_CHECKS = 1;
4.2.3 禁用外键检查
插入数据之前执行禁止对外键的检查,数据插入完成后再恢复,可以提供插入速度。
禁用:SET foreign_key_checks = 0; 开启:SET foreign_key_checks = 1;
4.2.4批量插入数据
插入数据时,可以使用一条INSERT语句插入一条数据,也可以插入多条数据。
一个sql语句插入一条数据:
一个失去了语句插入多条数据:
4.2.5禁止自动提交
插入数据之前执行禁止事务的自动提交,数据插入完成后再恢复,可以提高插入速度。
禁用:SET autocommit = 0; 开启:SET autocommit = 1;
5 数据库结构优化
5.1 优化表结构
- 尽量将表字段定义为NOT NULL约束,这时由于在MySQL中含有空值的列很难进行查询优化,NULL值会使索引以及索引的统计信息变得很复杂。
- 对于只包含特定类型的字段,可以使用enum、set 等数据类型。
- 数值型字段的比较比字符串的比较效率高得多,字段类型尽量使用最小、最简单的数据类型。例如IP地址可以使用int类型。
- 尽量使用TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT,如果非负则加上UNSIGNED。但对整数类型指定宽度,比如INT(11),没有任何用,因为指定的类型标识范围已经确定。
- VARCHAR的长度只分配真正需要的空间
- 尽量使用TIMESTAMP而非DATETIME,但TIMESTAMP只能表示1970 - 2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。
- 单表不要有太多字段,建议在20以内
- 合理的加入冗余字段可以提高查询速度。
5.2 表拆分
5.2.1 垂直拆分
垂直拆分按照字段进行拆分,其实就是把组成一行的多个列分开放到不同的表中,这些表具有不同的结构,拆分后的表具有更少的列。例如用户表中的一些字段可能经常访问,可以把这些字段放进一张表里。另外一些不经常使用的信息就可以放进另外一张表里。
插入的时候使用事务,也可以保证两表的数据一致。缺点也很明显,由于拆分出来的两张表存在一对一的关系,需要使用冗余字段,而且需要join操作。但是我们可以在使用的时候可以分别取两次,这样的来说既可以避免join操作,又可以提高效率。
5.2.2 水平拆分
水平拆分按照行进行拆分,常见的就是分库分表。以用户表为例,可以取用户ID,然后对ID取10的余数,将用户均匀的分配进这 0-9这10个表中。查找的时候也按照这种规则,又快又方便。
有些表业务关联比较强,那么可以使用按时间划分的。例如每天的数据量很大,需要每天新建一张表。这种业务类型就是需要高速插入,但是对于查询的效率不太关心。表越大,插入数据所需要索引维护的时间也就越长。
5.3 表分区
分区适用于例如日志记录,查询少。一般用于后台的数据报表分析。对于这些数据汇总需求,需要很多日志表去做数据聚合,我们能够容忍1s到2s的延迟,只要数据准确能够满足需求就可以。
MySQL主要支持4种模式的分区:range分区、list预定义列表分区,hash 分区,key键值分区。
录入使用key键值分区:
1 | CREATE TABLE `test2` ( |
5.4 读写分离
大型网站会有大量的并发访问,如果还是传统的数据存储方案,只是靠一台服务器处理,如此多的数据库连接、读写操作,数据库必然会崩溃,数据丢失的话,后果更是不堪设想。这时候,我们需要考虑如何降低单台服务器的使用压力,提升整个数据库服务的承载能力。
我们发现一般情况对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,这样分析可以采用数据库集群的方案。其中一个是主库,负责写入数据,我们称为写库;其它都是从库,负责读取数据,我们称为读库。这样可以缓解一台服务器的访问压力。
MySql自带主从复制功能,我们可以使用主从复制的主库作为写库,从库和主库进行数据同步,那么可以使用多个从库作为读库,已完成读写分离的效果。
5.5 数据库集群
如果访问量非常大,虽然使用读写分离能够缓解压力,但是一旦写操作一台服务器都不能承受了,这个时候我们就需要考虑使用多台服务器实现写操作。
例如可以使用MyCat搭建MySql集群,对ID求3的余数,这样可以把数据分别存放到3台不同的服务器上,由MyCat负责维护集群节点的使用。
6 硬件优化
服务器硬件的性能瓶颈,直接决定MySQL数据库的运行速度和效率。
可以从以下几个方面考虑:
6.1 内存
足够大的内存,是提高MySQL数据库性能的方法之一。内存的IO比硬盘快的多,可以增加系统的缓冲区容量,使数据在内存停留的时间更长,以减少磁盘的IO。服务器内存建议不要小于2GB,推荐使用4GB以上的物理内存。
6.2 磁盘
MySQL每秒钟都在进行大量、复杂的查询操作,对磁盘的读写量可想而知。所以,通常认为磁盘I/O是制约MySQL性能的最大因素之一,对于日均访问量在100万PV以上的系统,由于磁盘I/O的制约,MySQL的性能会非常低下 考虑以下几种解决方案:
- 使用SSD或者PCIe SSD设备,至少获得数百倍甚至万倍的IOPS提升;
- 购置阵列卡,可明显提升IOPS
- 尽可能选用RAID-10,而非RAID-5
- 使用机械盘的话,尽可能选择高转速的,例如选用15000RPM,而不是7200RPM的盘
6.3 CPU
CPU仅仅只能决定运算速度,及时是运算速度都还取决于与内存之间的总线带宽以及内存本身的速度。但是一般情况下,我们都需要选择计算速度较快的CPU。
关闭节能模式。操作系统和CPU硬件配合,系统不繁忙的时候,为了节约电能和降低温度,它会将CPU降频。这对环保人士和抵制地球变暖来说是一个福音,但是对MySQL来说,可能是一个灾难。为了保证MySQL能够充分利用CPU的资源,建议设置CPU为最大性能模式。
6.4 网络
应该尽可能选择网络延时低,吞吐量高的设备。
- 网络延时:不同的网络设备其延时会有差异,延时自然是越小越好。
- 吞吐量:对于数据库集群来说,各个节点之间的网络吞吐量可能直接决定集群的处理能力。
7 缓存优化
7.1 查询缓存
query_cache_size:作用于整个 MySQL,主要用来缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集,所以仅仅只能针对select语句。查询缓存从MySQL 5.7.20开始已被弃用,并在MySQL 8.0中被删除。
当我们打开了 Query Cache功能,MySQL在接受到一条select语句的请求后,如果该语句满足Query Cache的要求,MySQL会直接根据预先设定好的HASH算法将接受到的select语句以字符串方式进行hash,然后到Query Cache中直接查找是否已经缓存。如果已经在缓存中,该select请求就会直接将数据返回,从而省略了后面所有的步骤(如SQL语句的解析,优化器优化以及向存储引擎请求数据等),极大的提高性能。
当然,Query Cache也有一个致命的缺陷,那就是当某个表的数据有任何任何变化,都会导致所有引用了该表的select语句在Query Cache中的缓存数据失效。所以,当我们的数据变化非常频繁的情况下,使用Query Cache可能会得不偿失。
如果缓存命中率非常高的话,有测试表明在极端情况下可以提高效率238%,而在糟糕时,QC会降低系统13%的处理能力。
通过以下命令查看缓存相关变量
1 | show variables like '%query_cache%'; |
- have_query_cache:表示此版本mysql是否支持缓存
- query_cache_limit :缓存最大值
- query_cache_size:缓存大小
- query_cache_type:off 表示不缓存,on表示缓存所有结果。
7.2全局缓存
数据库属于IO密集型的应用程序,其主职责就是数据的管理及存储工作。而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个 IO是在毫秒级别,二者相差3个数量级。所以,要优化数据库,首先第一步需要优化的就是IO,尽可能将磁盘IO转化为内存IO,也就是使用缓存
启动MySQL时就要分配并且总是存在的全局缓存,可以在MySQL的my.conf或者my.ini文件的[mysqld]组中配置。查询缓存属于全局缓存。
目前有:
key_buffer_size(默认值:402653184,即384M)、
innodb_buffer_pool_size(默认值:134217728即:128M)、
innodb_additional_mem_pool_size(默认值:8388608即:8M)、
innodb_log_buffer_size(默认值:8388608即:8M)、
query_cache_size(默认值:33554432即:32M)
1) key_buffer_size
用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),对MyISAM表性能影响最大的一个参数。如果你使它太大,系统将开始换页并且真的变慢了。
严格说是它决定了数据库索引处理的速度,尤其是索引读的速度。对于内存在4GB左右的服务器该参数可设置为256M或384M.
2) innodb_buffer_pool_size
主要针对InnoDB表性能影响最大的一个参数。功能与Key_buffer_size一样。InnoDB占用的内存,除innodb_buffer_pool_size用于存储页面缓存数据外,另外正常情况下还有大约8%的开销,主要用在每个缓存页帧的描述、adaptive hash等数据结构,如果不是安全关闭,启动时还要恢复的话,还要另开大约12%的内存用于恢复,两者相加就有差不多21%的开销。
3) innodb_additional_mem_pool_size
设置了InnoDB存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小,所以当我们一个MySQL Instance中的数据库对象非常多的时候,是需要适当调整该参数的大小以确保所有数据都能存放在内存中提高访问效率的。
4) innodb_log_buffer_size
这是InnoDB存储引擎的事务日志所使用的缓冲区。类似于Binlog Buffer。InnoDB在写事务日志的时候,为了提高性能,也是先将信息写入Innofb Log Buffer中,当满足innodb_flush_log_trx_commit参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。可以通过innodb_log_buffer_size 参数设置其可以使用的最大内存空间。
InnoDB 将日志写入日志磁盘文件前的缓冲大小。理想值为 1M 至 8M。大的日志缓冲允许事务运行时不需要将日志保存入磁盘而只到事务被提交(commit)。因此,如果有大的事务处理,设置大的日志缓冲可以减少磁盘I/O。这个参数实际上还和另外的flush参数相关。一般来说不建议超过32MB。
7.3局部缓存
除了全局缓冲,MySql还会为每个连接发放连接缓冲。个连接到MySQL服务器的线程都需要有自己的缓冲。大概需要立刻分配256K,甚至在线程空闲时,它们使用默认的线程堆栈,网络缓存等。事务开始之后,则需要增加更多的空间。运行较小的查询可能仅给指定的线程增加少量的内存消耗,然而如果对数据表做复杂的操作例如扫描、排序或者需要临时表,则需分配大约read_buffer_size,
sort_buffer_size,read_rnd_buffer_size,tmp_table_size大小的内存空间. 不过它们只是在需要的时候才分配,并且在那些操作做完之后就释放了。
1) read_buffer_size
是MySql读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能.
2) sort_buffer_size
是MySql执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小
3) read_rnd_buffer_size
是MySql的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
4) tmp_table_size
是MySql的heap (堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySql同时将增加heap表的大小,可达到提高联接查询速度的效果。
5) record_buffer:
record_buffer每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,你可能想要增加该值。
7.4 其它缓存
1) table_cache
TABLE_CACHE(5.1.3及以后版本又名TABLE_OPEN_CACHE),table_cache指定表高速缓存的大小。每当MySQL访问一个表时,如果在表缓冲区中还有空间,该表就被打开并放入其中,这样可以更快地访问表内容。
不能盲目地把table_cache设置成很大的值。如果设置得太高,可能会造成文件描述符不足,从而造成性能不稳定或者连接失败。
2) thread_cache_size
服务器线程缓存,默认的thread_cache_size=8,,这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
增加这个值可以改善系统性能.通过比较Connections 和 Threads_created 状态的变量,可以看到这个变量的作用。
8 服务器优化
8.1 MySQL参数
通过优化MySQL的参数可以提高资源利用率,从而达到提高MySQL服务器性能的目的。MySQL的配置参数都在my.conf或者my.ini文件的[mysqld]组中,常用的参数如下:
1) back_log
在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中(每个连接256kb,占用:125M)。也就是说,如果MySql的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
2) wait_timeout
当MySQL连接闲置超过一定时间后将会被强行关闭。MySQL默认的wait-timeout值为8个小时。
设置这个值是非常有意义的,比如你的网站有大量的MySQL链接请求(每个MySQL连接都是要内存资源开销的),由于你的程序的原因有大量的连接请求空闲啥事也不干,白白占用内存资源,或者导致MySQL超过最大连接数从来无法新建连接导致“Too many connections”的错误。在设置之前你可以查看一下你的MYSQL的状态(可用showprocesslist),如果经常发现MYSQL中有大量的Sleep进程,则需要修改wait-timeout值了。
3) max_connections
是指MySql的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySql会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。
MySQL服务器允许的最大连接数16384
4) max_user_connections
是指每个数据库用户的最大连接针对某一个账号的所有客户端并行连接到MYSQL服务的最大并行连接数。简单说是指同一个账号能够同时连接到mysql服务的最大连接数。设置为0表示不限制。
5) thread_concurrency
的值的正确与否, 对mysql的性能影响很大, 在多个cpu(或多核)的情况下,错误设置了thread_concurrency的值, 会导致mysql不能充分利用多cpu(或多核), 出现同一时刻只能一个cpu(或核)在工作的情况。thread_concurrency应设为CPU核数的2倍。
6) skip-name-resolve
禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!
7) default-storage-engine
default-storage-engine=InnoDB(设置InnoDB类型,另外还可以设置MyISAM类型)设置创建数据库及表默认存储类型
8.2 Linux系统优化
一般情况,我们都会使用Linux来进行MySQL的安装和部署,Linux系统在使用的时候,也需要进行相关的配置,以提高MySQL的使用性能,这里列举以下几点:
- 避免使用Swap交换分区,因为交换时是从硬盘读取的,速度很慢。
- 将操作系统和数据分区分开,不仅仅是逻辑上,还包括物理上,因为操作系统的读写会影响数据库的性能。
- 把MySQL临时空间和复制日志与数据放到不同的分区,数据库后台从磁盘进行读写时会影响数据库的性能。
- 避免使用软件磁盘阵列。
- 在Linux中设置swappiness的值为0,因为在数据库服务器中不需要缓存文件。
- 使用 noatime 和 nodirtime 挂载文件系统,因为不需要对数据库文件修改时间。
- 使用 XFS 文件系统,一种比ext3更快、更小的文件系统。
- 调整 XFS 文件系统日志和缓冲变量 – 为了最高性能标准。
- 使用64位的操作系统,这会支持更大的内存。
- 删除服务器上未使用的安装包和守护进程,节省系统的资源占用。
- 把使用MySQL的host和你的MySQL host放到一个hosts文件中。
 微信
微信 支付宝
支付宝

