【devops系列】一文了解OpenResty
OpenResty
OpenResty介绍
OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。
用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
OpenResty通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台,这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
OpenResty的目标是让你的Web服务直接跑在Nginx服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
Nginx 的流程定义
nginx实际把请求处理流程划分为了11个阶段,这样划分的原因是将请求的执行逻辑细分,各阶段按照处理时机定义了清晰的执行语义,开发者可以很容易分辨自己需要开发的模块应该定义在什么阶段。
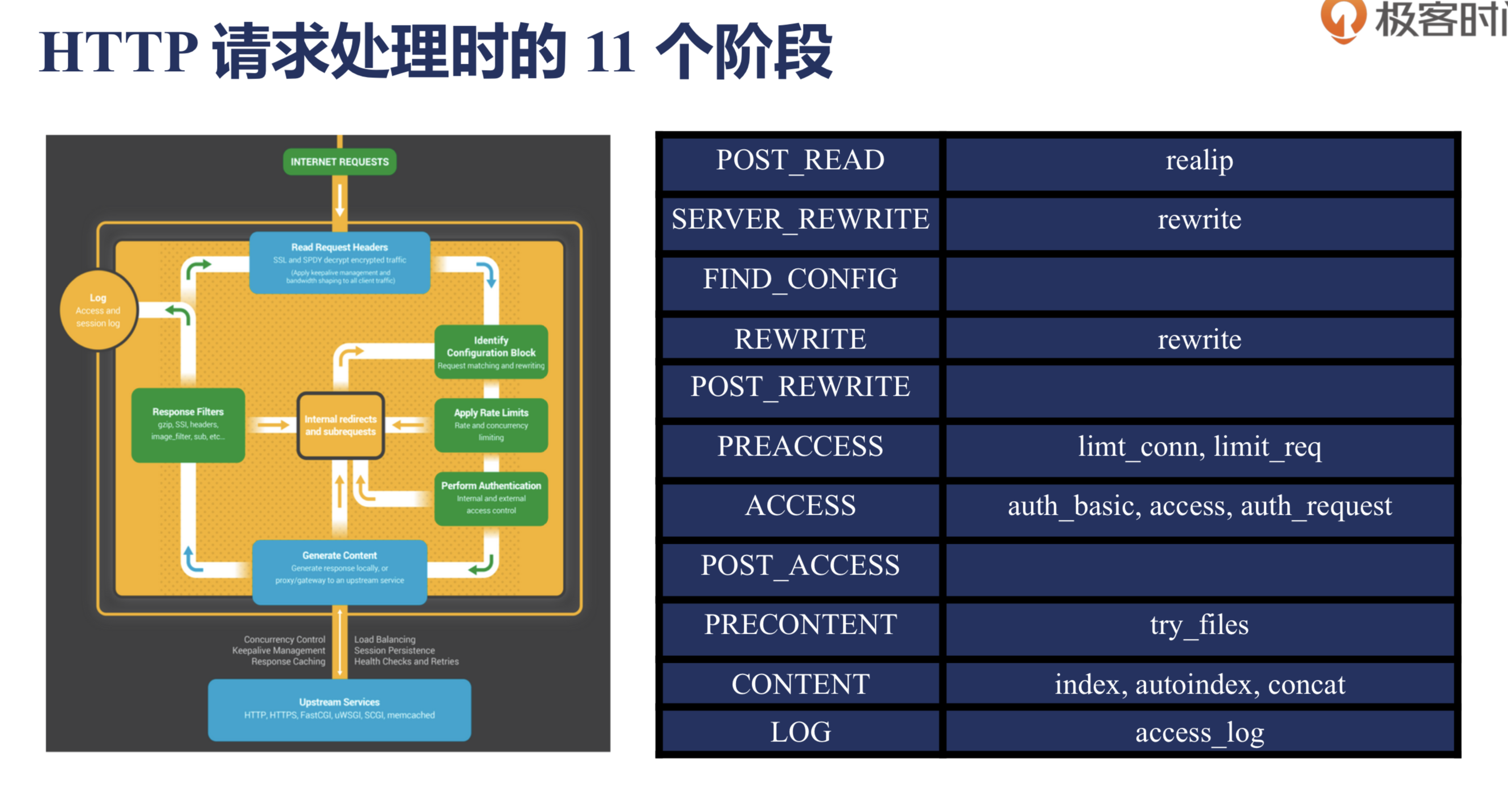
- 当请求进入Nginx后先READ REQUEST HEADERS 读取头部 然后再分配由哪个指令操作
- Identity 寻找匹配哪个Location*
- Apply Rate Limits 是否要对该请求限制
- Preform Authertication 权限验证
- Generate Content 生成给用户的响应内容
- 如果配置了反向代理 那么将要和上游服务器通信 Upstream Services
- 当返回给用户请求的时候要经过过滤模块 Response Filter
- 发送给用户的同时 记录一个Log日志
流程详解
| 阶段 | 描述 |
|---|---|
| post-read | 接收到完整的http头部后处理的阶段,在uri重写之前。一般跳过 |
| server-rewrite | location匹配前,修改uri的阶段,用于重定向,location块外的重写指令(多次执行) |
| find-config | uri寻找匹配的location块配置项(多次执行) |
| rewrite | 找到location块后再修改uri,location级别的uri重写阶段(多次执行) |
| post-rewrite | 防死循环,跳转到对应阶段 |
| preaccess | 权限预处理 |
| access | 判断是否允许这个请求进入 |
| post-access | 向用户发送拒绝服务的错误码,用来响应上一阶段的拒绝 |
| try-files | 访问静态文件资源 |
| content | 内容生成阶段,该阶段产生响应,并发送到客户端 |
| log | 记录访问日志 |
OpenResty处理流程
由于 Nginx 把一个请求分成了很多阶段,第三方模块就可以根据自己的行为,挂载到不同阶段处理达到目的,OpenResty 也应用了同样的特性。不同的阶段,有不同的处理行为,这是 OpenResty 的一大特色,OpenResty 处理一个请求的流程参考下图
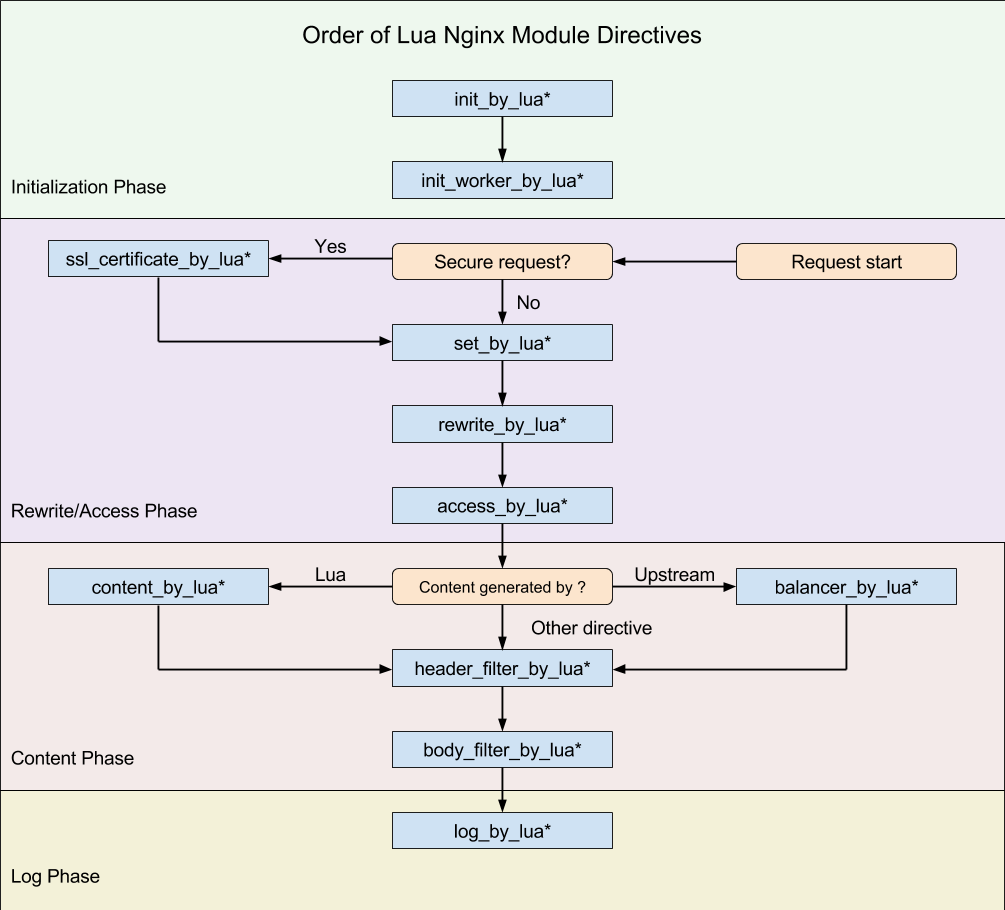
| 指令 | 描述 |
|---|---|
| init_by_lua,init_by_lua_block | 运行在Nginx loading-config 阶段,注册Nginx Lua全局变量,和一些预加载模块。是Nginx master进程在加载Nginx配置时执行 |
| init_worker_by_lua | 在Nginx starting-worker阶段,即每个nginx worker启动时会调用,通常用来hook worker进程,并创建worker进行的计时器,用来健康检查,或者设置熔断记时窗口等等。 |
| access_by_lua | 在access tail阶段,用来对每次请求做访问控制,权限校验等等,能拿到很多相关变量。例如:请求体中的值,header中的值,可以将值添加到ngx.ctx, 在其他模块进行相应的控制 |
| balancer_by_lua | 通过Lua设置不同的负载均衡策略, 具体可以参考lua-resty-balancer |
| content_by_lua | 在content阶段,即content handler的角色,即对于每个api请求进行处理,注意不能与proxy_pass放在同一个location下 |
| proxy_pass | 真正发送请求的一部分, 通常介于access_by_lua和log_by_lua之间 |
| header_filter_by_lua | 在output-header-filter阶段,通常用来重新响应头部,设置cookie等,也可以用来作熔断触发标记 |
| body_filter_by_lua | 对于响应体的content进行过滤处理 |
| log_by_lua | 记录日志即,记录一下整个请求的耗时,状态码等 |
Openresty安装
yum安装
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum update 命令)
添加OpenResty仓库
运行下面的命令就可以添加我们的仓库:
1 | sudo yum install yum-utils |
安装OpenResty
然后就可以像下面这样安装软件包,比如 openresty
1 | sudo yum install openresty |
源代码编译安装
OpenResty插件分为自带插件以及第三方插件,如果是自带插件直接激活就可以,如果是第三方插件需要手动下载插件添加进去,这里我们以本地缓存插件安装举例
安装编译环境
1 | yum install -y make cmake gcc gcc-c++ autoconf automake libpng-devel libjpeg-devel zlib libxml2-devel ncurses-devel bison libtool-ltdl-devel libiconv libmcrypt mhash mcrypt pcre-devel openssl-devel freetype-devel libcurl-devel lua-devel readline-devel curl wget |
下载最新版源码
1 | mkdir /usr/local/openresty |
下载缓存插件
到 缓存插件地址 下载最新版 缓存插件
1 | wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz |
编译OpenResty
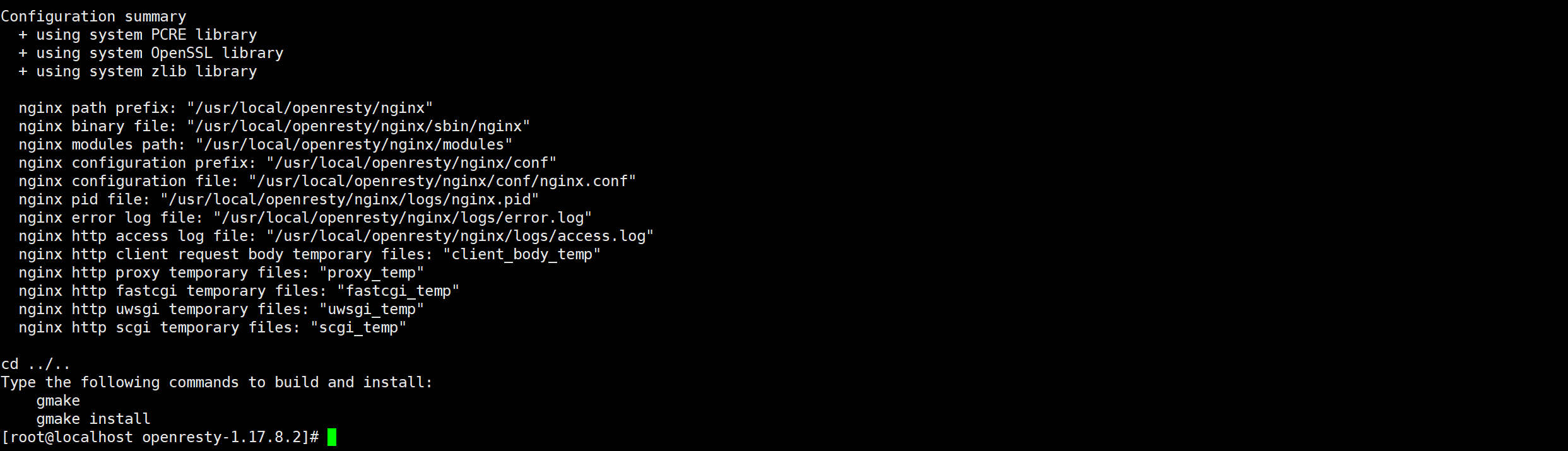
选择需要的插件启用, –with-Components 激活组件,–without 则是禁止组件 ,–add-module是安装第三方模块
1 | ./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module --add-module=/usr/local/openresty/modules/ngx_cache_purge-2.3 #配置缓存插件的源码路径 |
这里禁用了 redis组件 并且 安装了第三方缓存组件
出现如下界面表示编译成功
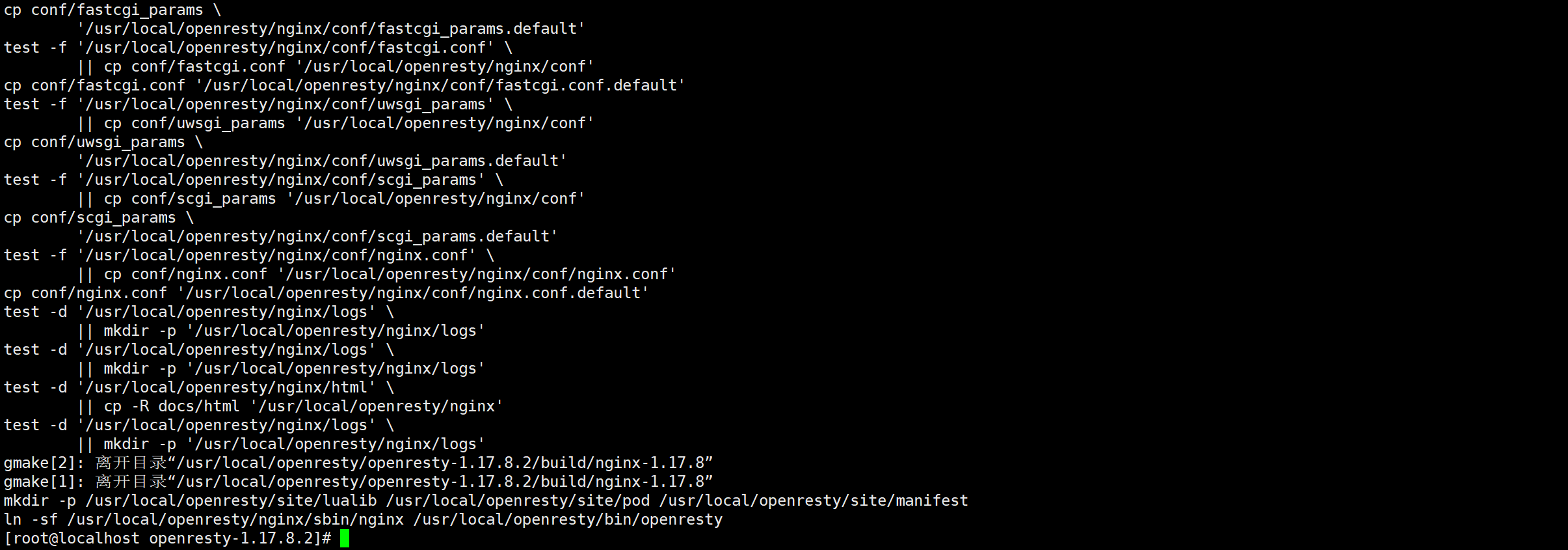
安装OpenResty
1 | gmake && gmake install |
出现如下界面表示安装成功
环境设置
1 | vi /etc/profile ##加入path路径 |
查看环境
1 | nginx -v |
查看安装的组件
1 | nginx -V |

运行测试
创建Nginx配置文件
我们在 conf 目录下创建一个 nginx.conf 文件 代码如下
1 | worker_processes 1; |
如果你熟悉 nginx 的配置,应该对以上代码就很熟悉。这里我们将 html 代码直接写在了配置文件中。
启动 OpenResty
1 | nginx -c /usr/local/openresty/nginx/conf/nginx.conf |
接下来我们可以使用 curl 来测试是否能够正常范围
1 | > curl http://localhost:9000/ |
我们在配置文件写的 html 已正常输出。
OpenResty常用命令
主要帮助对http请求取参、取header头、输出等
| 命令 | 描述 |
|---|---|
| ngx.arg | 指令参数,如跟在content_by_lua_file后面的参数 |
| ngx.var | request变量,ngx.var.VARIABLE引用某个变量,lua使用nginx内置的绑定变量. ngx.var.remote_addr为获取远程的地址, |
| ngx.ctx | 请求的lua上下文,每次请求的上下文,可以在ctx里记录,每次请求上下文的一些信息,例如:request_id, access_key等等 |
| ngx.header | 响应头,ngx.header.HEADER引用某个头 |
| ngx.status | 响应码 |
| ngx.log | 输出到error.log |
| ngx.send_headers | 发送响应头 |
| ngx.headers_sent | 响应头是否已发送 |
| ngx.resp.get_headers | 获取响应头 |
| ngx.is_subrequest | 当前请求是否是子请求 |
| ngx.location.capture | 发布一个子请求 |
| ngx.location.capture_multi | 发布多个子请求 |
| ngx.print | 输出响应 |
| ngx.say | 输出响应,自动添加‘\n‘ |
| ngx.flush | 刷新响应 |
| ngx.exit | 结束请求 |
商品详情页系统架构介绍
商品详情页架构的要求 ->高可用 ,-> 高性能,-> 高并发 ;一般来说 业界分为两种主流的方案
中小公司的详情页方案
很多中小型 电商的商品详情页 可能一分钟都没有一个访问,这种的话,就谈不上并发设计,一个tomcat 就能搞定。
还有一种中小型公司呢?虽然说公司不大,但是也是有几十万日活。然后几百万用户,这种公司,就是稍微大点的公司,他们的商品详情用,采取的方案可能是全局的一个静态页面这样子
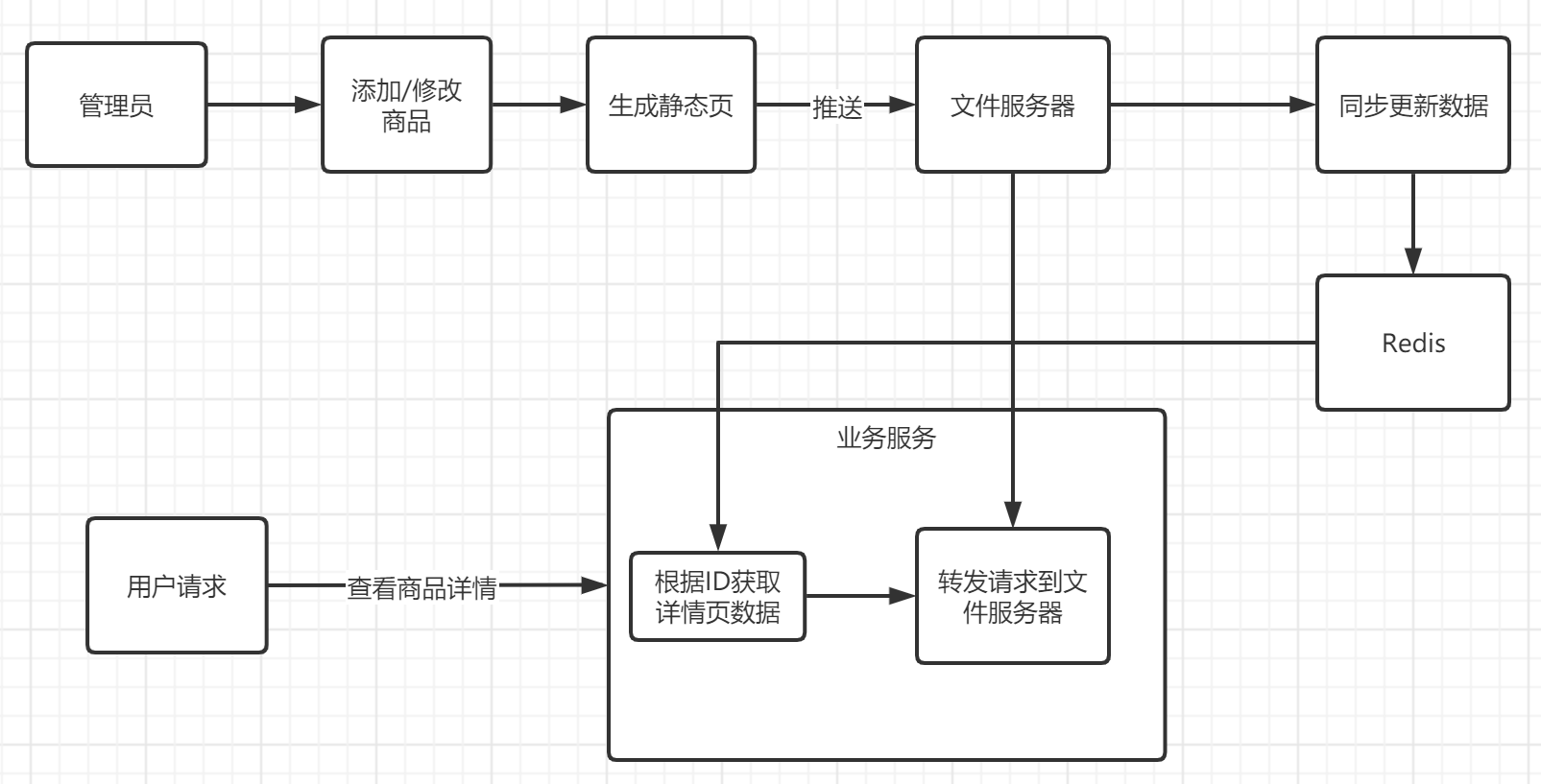
就是我们有把商品详情页直接做成一个静态页面,然后这样子每次全量的更新,把数据全部静态放到redis里面,每次数据变化的时候,我们就通过一个Java服务去渲染这个数据,然后把这个静态页面推送到到文件服务器
缺点
- 这种方案的缺点,如果商品很多,那么渲染的时间会很长,达不到实时的效果
- 文件服务器性能高,tomcat性能差,压力都在Tomcat服务器了
- 只能处理一些静态的东西,如果动态数据很多,比如有库存的,你不可能说每次去渲染,然后推送到文件服务器,那不是更加慢?
大型公司的商品详情页的核心思想
下面这张图就是整体的思路
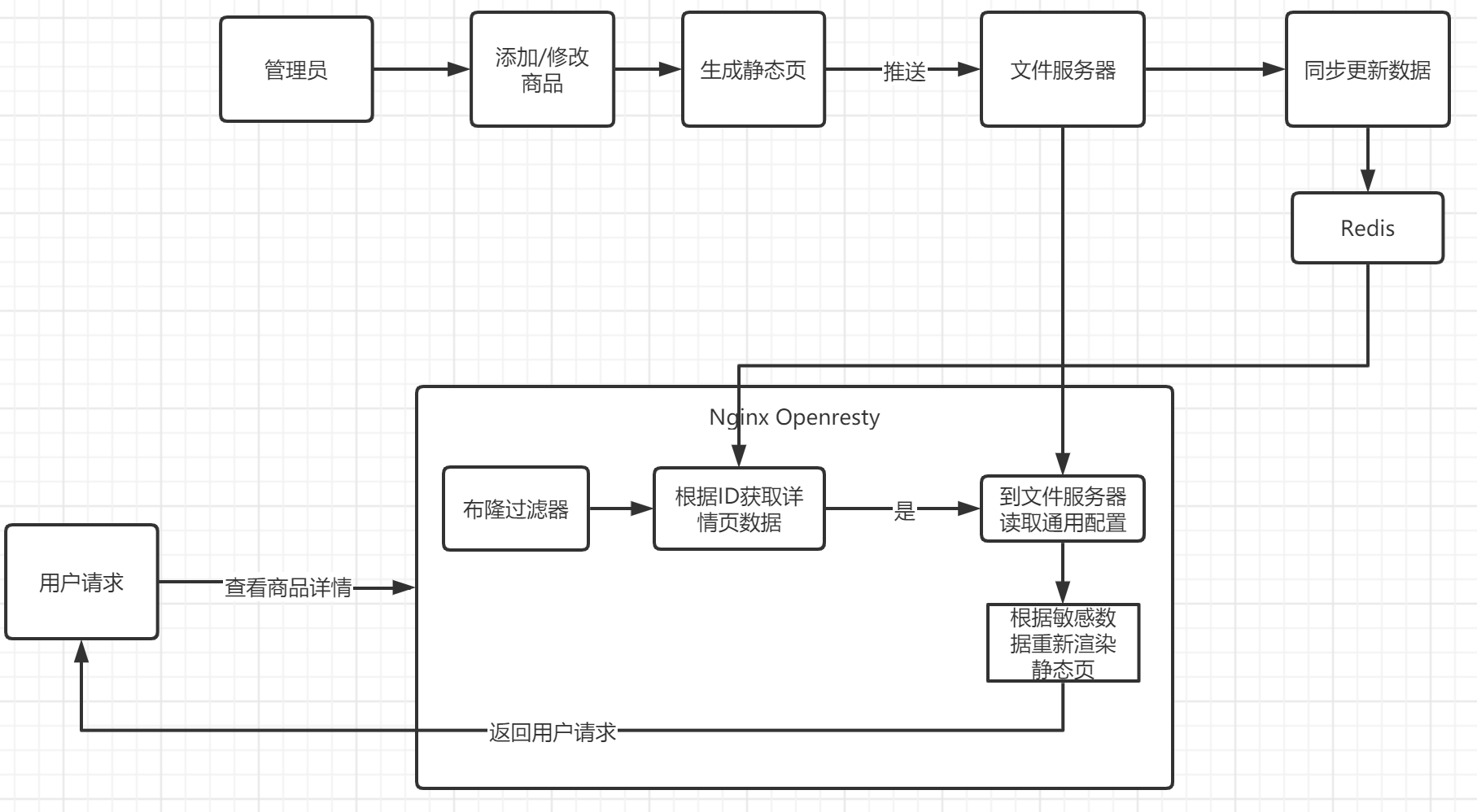
上图展示了核心思想主要有以下五步来完成
生成静态页
添加修改页面的时候生成静态页,这个地方生成的是一个通用的静态页,敏感数据比如 价格,商品名称等,通过占位符来替换,然后将生成的静态页的链接,以及敏感数据同步到redis中,如果只修改价格不需要重新生成静态页,只需要修改redis敏感数据即可。
推送到文件服务器
这个的文件服务器泛指能够提供静态文件处理的文件服务器,nginx代理静态文件,tomcat,以及OSS等都算静态文件服务器,生成完静态文件后将文件推送到文件服务器,并将请求连接存放进redis中
布隆过滤器过滤请求
Redis和nginx的速度很快,但是如果有人恶意请求不存在的请求会造成redis很大的开销,那么可以采用布隆过滤器将不存在的请求过滤出去。
lua直连Redis读取数据
因为java连接Reids进行操作并发性能很弱,相对于OpenResty来说性能差距很大,这里使用OpenResty,读取Redis中存放的URL以及敏感数据。
OpenResty 渲染数据
从Redis获取到URL后lua脚本抓取模板页面内容,然后通过redis里面的敏感数据进行渲染然后返回前端,因为都是lua脚本操作性能会很高
环境准备
下面我们就基于这个架构来安装和搭建所需要的环境
配置资源服务器
创建目录
创建资源文件夹
1 | mkdir -p /root/www/nginx/iphone/ |
然后将我们的资源文件复制到该路径下

nginx配置文件
通过nginx来配置资源服务器
1 | server { |
访问测试
可以通过访问
www.itcast.com访问测试
Redis安装布隆过滤器
什么是布隆过滤器
使用布隆过滤器来解决缓存穿透问题
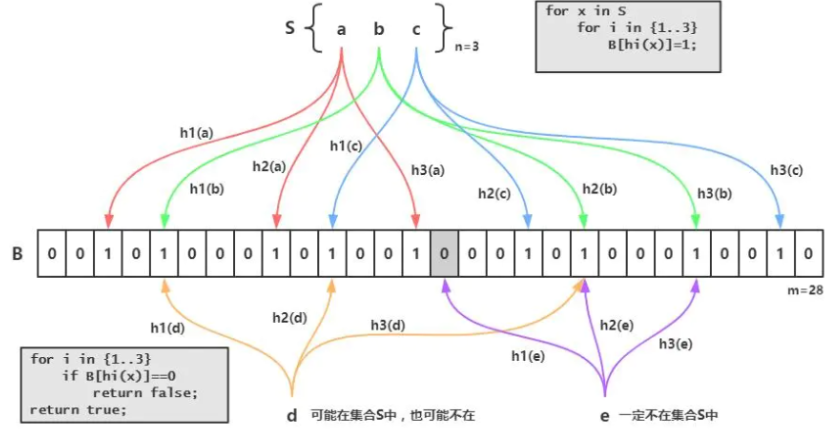
布隆过滤器的原理
布隆过滤器其本质就是一个只包含0和1的数组。具体操作当一个元素被加入到集合里面后,该元素通过K个Hash函数运算得到K个hash后的值,然后将K个值映射到这个位数组对应的位置,把对应位置的值设置为1。查询是否存在时,我们就看对应的映射点位置如果全是1,他就很可能存在(跟hash函数的个数和hash函数的设计有关),如果有一个位置是0,那这个元素就一定不存在。
布隆过滤器缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom Filter
插件形式安装
下载布隆过滤器插件
在redis布隆过滤器插件地址下载最新的release源码,在编译服务器进行解压编译
1 | wget https://github.com/RedisBloom/RedisBloom/archive/v2.2.4.tar.gz |
解压插件进行插件的编译
1 | tar RedisBloom-2.2.4.tar.gz |
编译得到动态库rebloom.so 启动redis时,如下启动即可加载bloom filter插件
配置文件形式配置
1 | #在redis配置文件(redis.conf)中加入该模块即可 |
启动命令挂载
1 | redis-server redis.conf --loadmodule /usr/rebloom/rebloom.so INITIAL_SIZE 1000000 ERROR_RATE 0.0001 |
docker方式单机安装
1 | docker run -d -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest |
Redis集群部署安装
创建目录
1 | mkdir -p /tmp/etc/redis/ |
redis配置文件
将配置文件写入到redis文件中
1 | cat > /tmp/etc/redis/redis.conf<< EOF |
这里将本地编译好的redisbloom.so挂载到/etc/redis/redisbloom.so目录
配置docker-compose.yml文件
1 | version: '2' |
启动布隆过滤器集群
1 | docker-compose up -d |
配置集群
进入一个容器
1 | docker exec -ti redis01 /bin/bash |
执行创建集群命令
1 | redis-cli --cluster create 172.18.0.2:6379 172.18.0.3:6379 172.18.0.4:6379 172.18.0.5:6379 172.18.0.6:6379 172.18.0.7:6379 --cluster-replicas 1 |
布隆过滤器常用命令
| 命令 | 功能 | 参数 |
|---|---|---|
| BF.RESERVE | 创建一个大小为capacity,错误率为error_rate的空的Bloom | BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] [NONSCALING] |
| BF.ADD | 向key指定的Bloom中添加一个元素item | BF.ADD {key} {item} |
| BF.MADD | 向key指定的Bloom中添加多个元素 | BF.MADD {key} {item} [item…] |
| BF.INSERT | 向key指定的Bloom中添加多个元素,添加时可以指定大小和错误率,且可以控制在Bloom不存在的时候是否自动创建 | BF.INSERT {key} [CAPACITY {cap}] [ERROR {error}] [EXPANSION expansion] [NOCREATE] [NONSCALING] ITEMS {item…} |
| BF.EXISTS | 检查一个元素是否可能存在于key指定的Bloom中 | BF.EXISTS {key} {item} |
| BF.MEXISTS | 同时检查多个元素是否可能存在于key指定的Bloom中 | BF.MEXISTS {key} {item} [item…] |
| BF.SCANDUMP | 对Bloom进行增量持久化操作 | BF.SCANDUMP {key} {iter} |
| BF.LOADCHUNK | 加载SCANDUMP持久化的Bloom数据 | BF.LOADCHUNK {key} {iter} {data} |
| BF.INFO | 查询key指定的Bloom的信息 | BF.INFO {key} |
| BF.DEBUG | 查看BloomFilter的内部详细信息(如每层的元素个数、错误率等) | BF.DEBUG {key} |
测试
可以登录集群执行命令
1 | # 进入一个redis集群的节点内部 |
OpenResty支持Reids集群配置
下载安装lua_resty_redis
lua_resty_redis 它是一个基于rockspec API的为ngx_lua模块提供Lua redis客户端的驱动。
resty-redis-cluster模块地址:https://github.com/steve0511/resty-redis-cluster
- 将
resty-redis-cluster/lib/resty/下面的文件 拷贝到openresty/lualib/resty
总共两个文件rediscluster.lua,xmodem.lua
连接Redis集群封装
创建
redisUtils.lua的文件
1 | --操作Redis集群,封装成一个模块 |
配置lua脚本路径
我们编写了lua脚本需要交给nginx服务器去执行,我们需要将创建一个lua目录,并在全局的nginx‘配置文件中配置lua目录,配置参数使用
lua_package_path
1 | # 配置redis 本地缓存 |
完整的配置如下
1 | user root; |
测试脚本
在 nginx配置文件嵌入lua脚本进行测试
1 | server { |
设置Redis数据
1 | # 登录Redis |
访问测试
访问查看nginx日志打印
1 | tail -f /usr/local/openresty/nginx/logs/error.log |

请求参数封装
nginx为了能够处理请求需要获取请求数据,需要将获取请求参数的lua脚本封装以下,创建
requestUtils.lua的文件
1 | --定义一个对象 |
测试脚本
1 | server { |

抓取模板内容封装
下载安装lua-resty-http
将lua-resty-http-master\lib\resty下的所有文件复制到openresty/lualib/resty httpclient
总共两个文件http.lua,http_headers.lua
因为需要从远程服务器抓取远程页面的内容,需要用到http模块,将其封装起来,创建
requestHtml.lua
1 | -- 引入Http库 |
测试脚本
模板文件我们用
1 | server { |
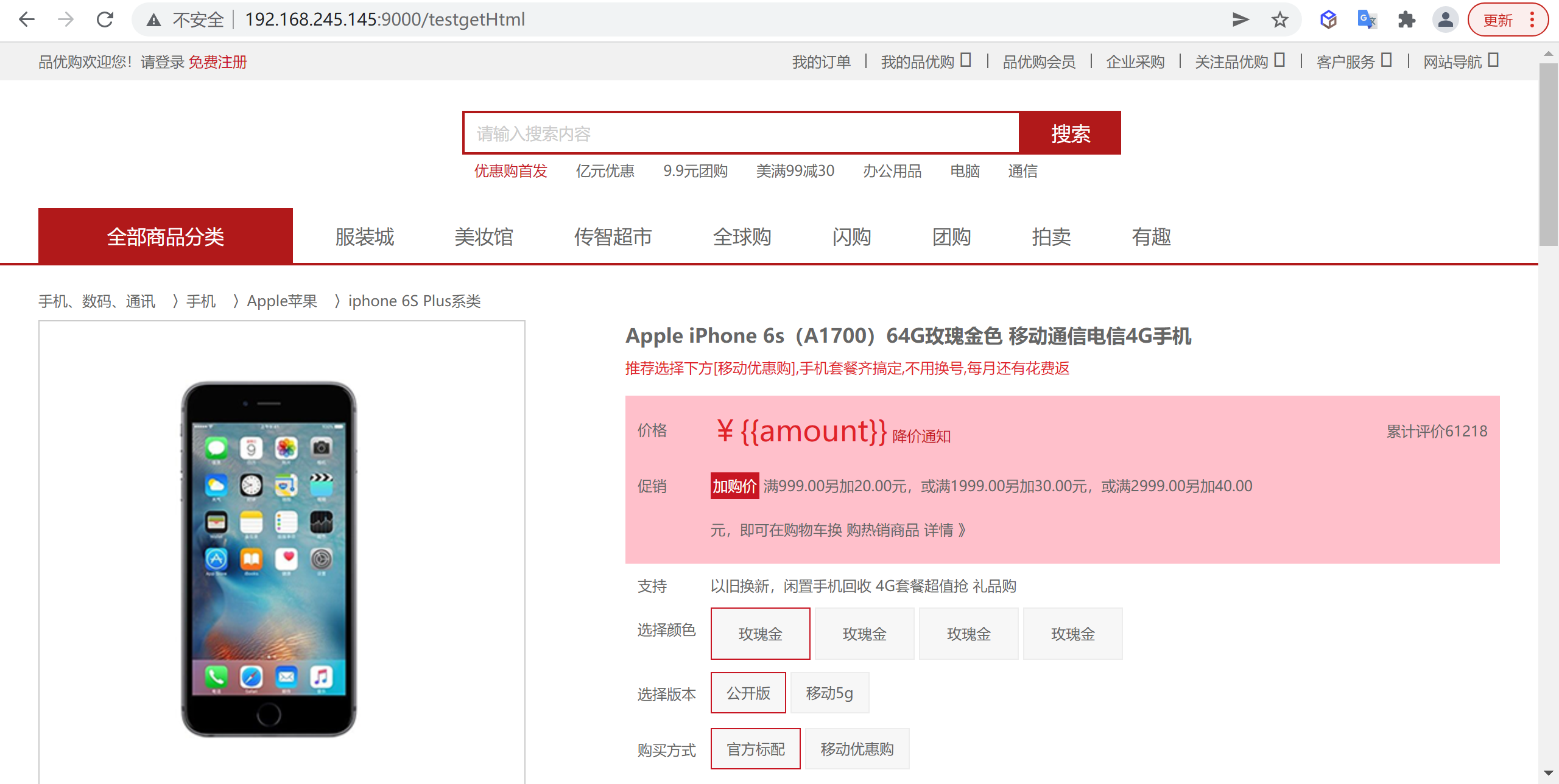
模版渲染配置
下载安装lua-resty-template
1 | wget https://github.com/bungle/lua-resty-template/archive/v1.9.tar.gz |
解压后可以看到lib/resty下面有一个template.lua,这个就是我们所需要的,在template目录中还有两个lua文件,将这两个文件复制到/usr/openResty/lualib/resty中即可。
使用方式
1 | local template = require "resty.template" |
测试
在nginx中配置文件中嵌入lua脚本执行测试
1 | server { |
访问
http://192.168.64.150:9999/testtemplate?title=123456

整体业务分析
整个调用流程如下,需要使用lua脚本编写,整体流程分为7 步

上面我们将各个组件都给封装了,下面我们需要将各个组件组合起来
编写lua脚本
创建一个
requestTemplateRendering.lua的lua脚本
1 | --- |
编写nginx配置
添加本地缓存
在nginx主配置文件中添加模板缓存
1 | lua_shared_dict html_template_cache 10m; |
编写nginx配置文件
我们这里使用
content_by_lua_file的方式执行脚本
1 | server { |
初始化数据
1 | # 进入一个redis集群的节点内部 |
访问测试
访问
http://192.168.64.181:8888/template?id=1进行测试
kong网关
kong网关简介
Kong是一款基于OpenResty(Nginx + Lua模块)编写的高可用、易扩展的,由Mashape公司开源的API Gateway项目。Kong是基于NGINX和Apache Cassandra或PostgreSQL构建的,能提供易于使用的RESTful API来操作和配置API管理系统,所以它可以水平扩展多个Kong服务器,通过前置的负载均衡配置把请求均匀地分发到各个Server,来应对大批量的网络请求。
为什么需要 API 网关
API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。
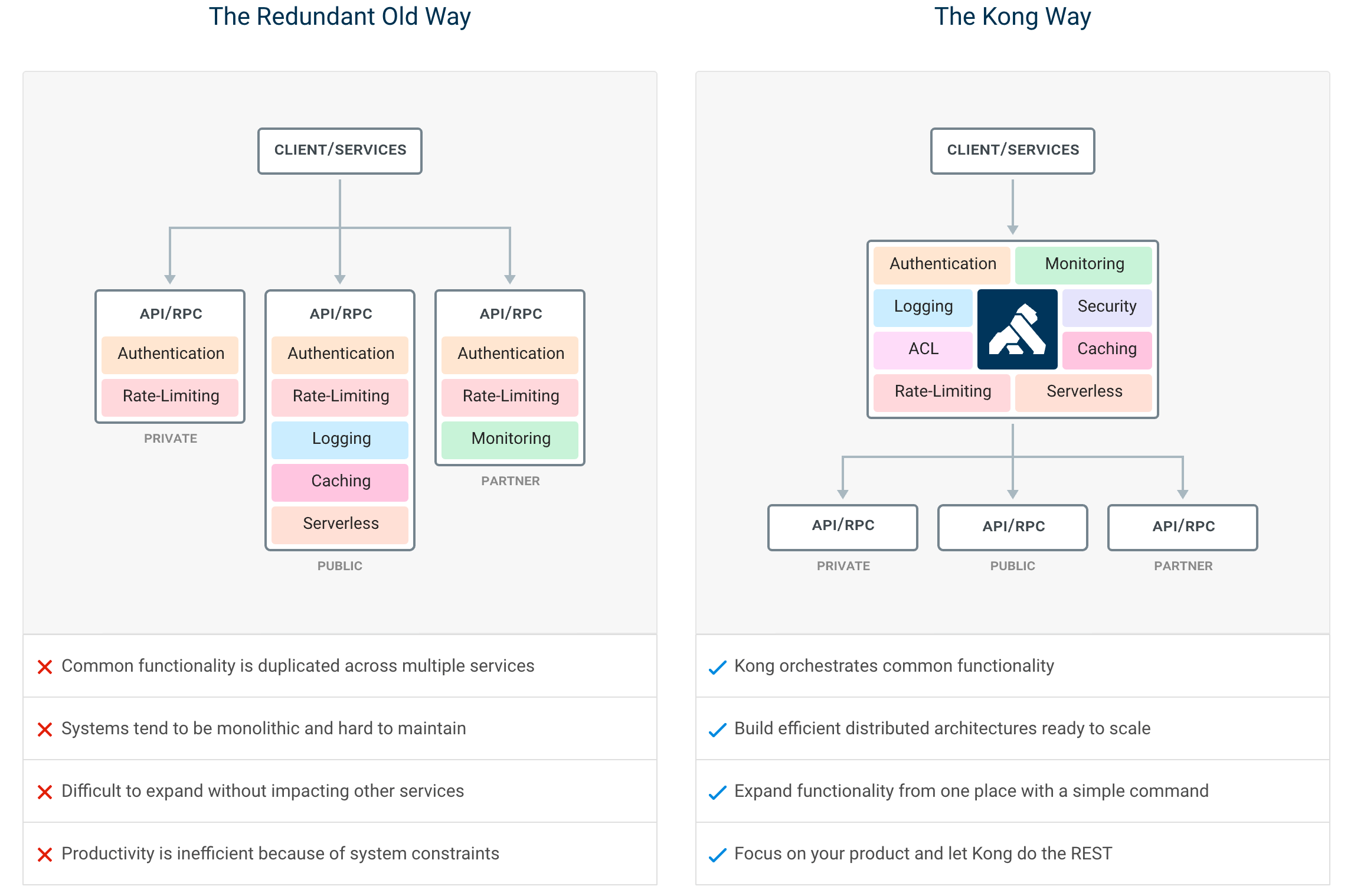
在微服务架构之下,服务被拆的非常零散,降低了耦合度的同时也给服务的统一管理增加了难度。如上图左所示,在旧的服务治理体系之下,鉴权,限流,日志,监控等通用功能需要在每个服务中单独实现,这使得系统维护者没有一个全局的视图来统一管理这些功能。API 网关致力于解决的问题便是为微服务纳管这些通用的功能,在此基础上提高系统的可扩展性。如右图所示,微服务搭配上 API 网关,可以使得服务本身更专注于自己的领域,很好地对服务调用者和服务提供者做了隔离。
目前,比较流行的网关有:Nginx 、 Kong 、Orange等等,还有微服务网关Zuul 、Spring Cloud Gateway等等
对于 API Gateway,常见的选型有基于 Openresty 的 Kong、基于 Go 的 Tyk 和基于 Java 的 gateway,这三个选型本身没有什么明显的区别,主要还是看技术栈是否能满足快速应用和二次开发。
和Spring Cloud Gateway区别
- 像Nginx这类网关,性能肯定是没得说,它适合做那种门户网关,是作为整个全局的网关,是对外的,处于最外层的;而Gateway这种,更像是业务网关,主要用来对应不同的客户端提供服务的,用于聚合业务的。各个微服务独立部署,职责单一,对外提供服务的时候需要有一个东西把业务聚合起来。
- 像Nginx这类网关,都是用不同的语言编写的,不易于扩展;而Gateway就不同,它是用Java写的,易于扩展和维护
- Gateway这类网关可以实现熔断、重试等功能,这是Nginx不具备的
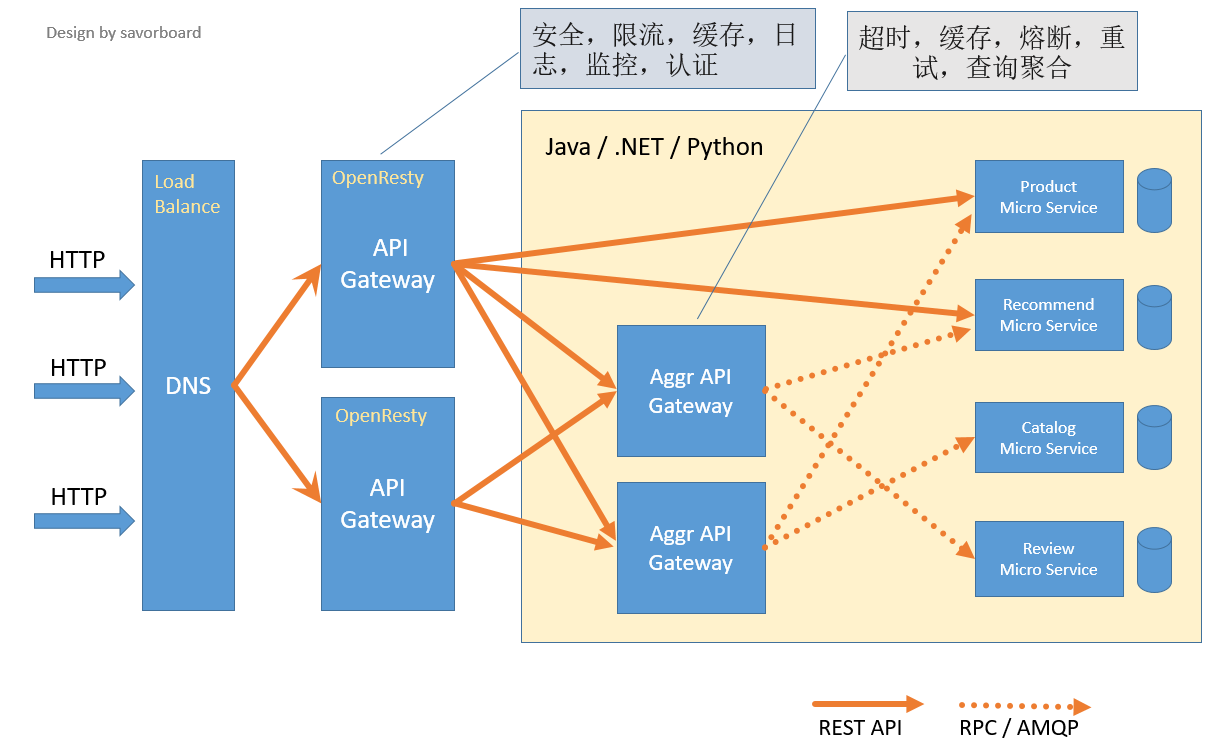
所以,你看到的网关可能是这样的
为什么要使用kong
- 插件市场丰富,很多插件可以降低开发成本;
- 可扩展性,可以编写lua脚本来定制自己的参数验证权限验证等操作;
- 基于openResty,openResty基于Nginx保障了强劲的性能;
- 便捷性能扩容,只需要水平增加服务器资源性能就能提升 ;
- 负载均衡健康检查
kong的组成部分
Kong主要有三个组件
- Kong Server :基于nginx的服务器,用来接收API请求。
- Apache Cassandra/PostgreSQL :用来存储操作数据。
- Kong dashboard:官方推荐UI管理工具,当然,也可以使用 restfull 方式 管理admin api
Kong采用插件机制进行功能定制,插件集(可以是0或N个)在API请求响应循环的生命周期中被执行。插件使用Lua编写,目前已有几个基础功能:HTTP基本认证、密钥认证、CORS(Cross-Origin Resource Sharing,跨域资源共享)、TCP、UDP、文件日志、API请求限流、请求转发以及Nginx监控。
Kong网关的特性
Kong网关具有以下的特性
- 可扩展性: 通过简单地添加更多的服务器,可以轻松地进行横向扩展,这意味着您的平台可以在一个较低负载的情况下处理任何请求;
- 模块化: 可以通过添加新的插件进行扩展,这些插件可以通过RESTful Admin API轻松配置;
- 在任何基础架构上运行: Kong网关可以在任何地方都能运行。您可以在云或内部网络环境中部署Kong,包括单个或多个数据中心设置,以及public,private 或invite-only APIs。
kong网关架构
- Kong核心基于OpenResty构建,实现了请求/响应的Lua处理化;
- Kong插件拦截请求/响应,如果接触过Java Servlet,等价于拦截器,实现请求/响应的AOP处理;
- Kong Restful 管理API提供了API/API消费者/插件的管理;
- 数据中心用于存储Kong集群节点信息、API、消费者、插件等信息,目前提供了PostgreSQL和Cassandra支持,如果需要高可用建议使用Cassandra;
- Kong集群中的节点通过gossip协议自动发现其他节点,当通过一个Kong节点的管理API进行一些变更时也会通知其他节点。每个Kong节点的配置信息是会缓存的,如插件,那么当在某一个Kong节点修改了插件配置时,需要通知其他节点配置的变更。
Kong网关请求流程
为了更好地理解系统,这是使用Kong网关的API接口的典型请求工作流程:

当Kong运行时,每个对API的请求将先被Kong命中,然后这个请求将会被代理转发到最终的API接口。在请求(Requests)和响应(Responses)之间,Kong将会执行已经事先安装和配置好的任何插件,授权您的API访问操作。Kong是每个API请求的入口点(Endpoint)。
kong 部署
搭建网络
首先我们创建一个Docker自定义网络,以允许容器相互发现和通信。在下面的创建命令中kong-net是我们创建的Docker网络名称。
1 | docker network create kong-net |
搭建数据库环境
Kong 目前使用Cassandra(Facebook开源的分布式的NoSQL数据库) 或者PostgreSql,你可以执行以下命令中的一个来选择你的Database。请注意定义网络 --network=kong-net 。
1 | docker run -d --name kong-database --network=kong-net -p 5432:5432 -v /tmp/data/kong:/var/lib/postgresql/data -e "POSTGRES_USER=kong" -e "POSTGRES_DB=kong" -e "POSTGRES_PASSWORD=kong" postgres:11.7 |
kong网关部署
初始化kong数据
使用
docker run --rm来初始化数据库,该命令执行后会退出容器而保留内部的数据卷(volume)。
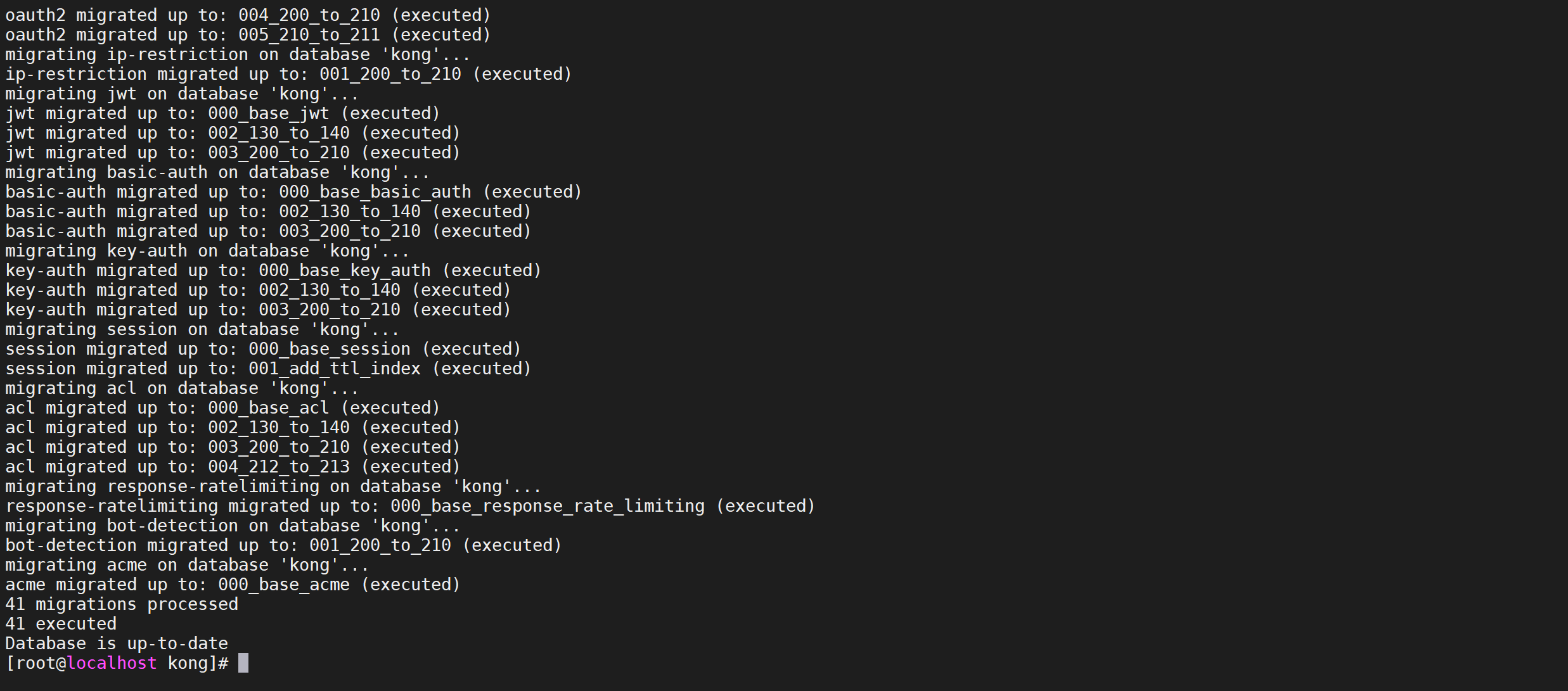
1 | docker run --rm --network=kong-net -e "KONG_DATABASE=postgres" -e "KONG_PG_HOST=kong-database" -e "KONG_PG_PASSWORD=kong" -e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" kong:latest kong migrations bootstrap |
这个命令我们还是要注意的,一定要跟你声明的网络,数据库类型、host名称一致。同时注意Kong的版本号,本文是在Kong 1.4.x 版本下完成的。
出现如下信息说明数据初始化成功
启动Kong容器
完成初始化数据库后,我们就可以启动一个连接到数据库容器的Kong容器,请务必保证你的数据库容器启动状态,同时检查所有的环境参数 -e 是否是你定义的环境
1 | docker run -d --name kong \ |
验证
通过服务器执行curl访问尝试服务是否已经启动
1 | curl http://localhost:8001/status |

出现如下信息说明服务已经启动
Kong配置
nginx模板
我们来看一个典型 Nginx 的配置对应在 Kong 上是怎么样的,下面是一个典型的 Nginx 配置
1 | upstream passportUpstream { |
kong配置案例
下面我们开看看其对应 Kong 中的配置
1 | # 配置 upstream |
这一切配置都是通过其 Http Restful API 来动态实现的,无需我们再手动的 reload Nginx.conf
测试验证
可以通过如下URL进行测试
1 | http://192.168.245.145:8000/hello/index |

Kong关键术语
在上述的配置中涉及到了几个概念: Upstream、Target、Service、Route 等概念,它们是 Kong 的几个核心概念,也是我们在使用 Kong API 时经常打交道的,下面我们就其几个核心概念做一下简单的说明。
Upstream
Upstream 对象表示虚拟主机名,可用于通过多个服务(目标)对传入请求进行负载均衡。例如:service.v1.xyz 为 Service 对象命名的上游 Host 是 service.v1.xyz 对此服务的请求将代理到上游定义的目标。
Target
目标 IP地址/主机名,其端口表示后端服务的实例。每个上游都可以有多个 Target,并且可以动态添加 Target。
由于上游维护 Target 的更改历史记录,因此无法删除或者修改 Target。要禁用目标,请发布一个新的 Targer weight=0,或者使用 DELETE 来完成相同的操作
Service
顾名思义,服务实体是每个上游服务的抽象,服务的示例是数据转换微服务,计费API等。
服务的主要属性是它的 URL(其中,Kong 应该代理流量),其可以被设置为单个JSON串或通过指定其 protocol, host,port 和path。
服务与路由相关联(服务可以有许多与之关联的路由),路由是 Kong 的入口点,并定义匹配客户端请求的规则。一旦匹配路由,Kong 就会将请求代理到其关联的服务。
Route
路由实体定义规则以匹配客户端的请求。每个 Route 与一个 Service 相关联,一个服务可能有多个与之关联的路由,与给定路由匹配的每个请求都将代理到其关联的 Service 上。可以配置的字段有:
- hosts
- paths
- methods
Service 和 Route 的组合(以及它们之间的关注点分离)提供了一种强大的路由机制,通过它可以在 Kong 中定义细粒度的入口点,从而使基础架构路由到不同上游服务。
Consumer
Consumer 对象表示服务的使用者或者用户,你可以依靠 Kong 作为主数据库存储,也可以将使用者列表与数据库映射,以保持Kong 与现有的主数据存储之间的一致性。
Plugin
插件实体表示将在 HTTP请求/响应生命周期 期间执行的插件配置。它是为在 Kong 后面运行的服务添加功能的,例如身份验证或速率限制。
将插件配置添加到服务时,客户端向该服务发出的每个请求都将运行所述插件。如果某个特定消费者需要将插件调整为不同的值,你可以通过创建一个单独的插件实例,通过 service 和 consumer 字段指定服务和消费者。
kongAPI操作
配置网关
配置服务
1 | # 添加服务 |
url 参数是一个简化参数,用于一次性添加 protocol,host,port 和 path。
添加路由
1 | # 添加service 的路由 |
访问测试
1 | # 通过如下URL访问 |
配置负载均衡
配置 upstream 和 target
创建一个名称 load 的 upstream
1 | curl -X POST http://192.168.64.181:8001/upstreams --data "name=load" |
添加3000 端口的负载
1 | curl -X POST http://192.168.64.181:8001/upstreams/load/targets --data "target=192.168.64.1:9001" --data "weight=10" |
如上的配置对应了 Nginx 的配置
1 | upstream load { |
配置service
host 的值便对应了 upstream 的名称,配置成功后会返回生成的 service 的 id
1 | curl -X POST http://192.168.64.181:8001/services --data "name=load-service" --data "host=load" |
配置路由信息
这里的service.id 就是上面添加service
1 | curl -X POST http://192.168.64.181:8001/routes --data "paths[]=/load" --data "service.id=3a6b839b-00c1-49b7-b271-8024a12d19be" |
访问测试
安装Kong 管理UI
Kong 企业版提供了管理UI,开源版本是没有的。但是有很多的开源的管理 UI ,其中比较好用的是Konga。项目地址:https://github.com/pantsel/konga
初始化konga数据
使用
docker run --rm来初始化数据库,该命令执行后会退出容器而保留内部的数据卷(volume)。
1 | docker run --name konga --rm \ |
执行后出现如下界面说明执行成功
启动konga
1 | docker run -p 1337:1337 -d \ |
验证
通过浏览器请求 http://IP:1337 检查是否能够访问,如果能够访问说明已经启动成功

连接kong网关
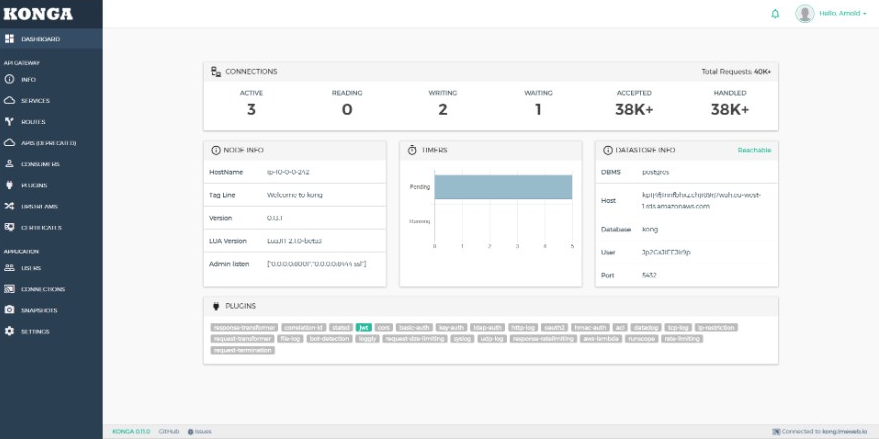
在这个界面添加一个用户 登录就可以看到如下页面
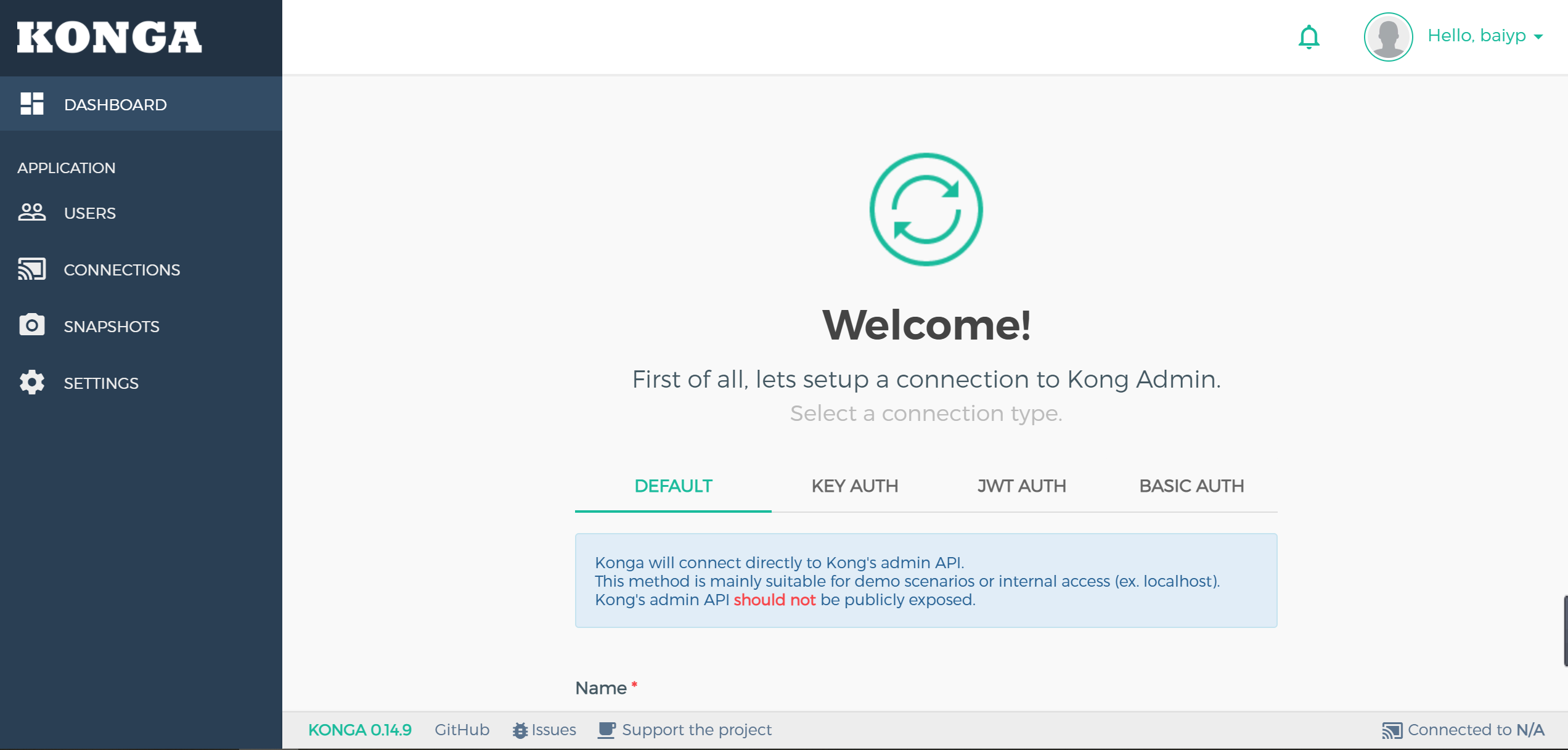
点击Connections 来填加kong的信息
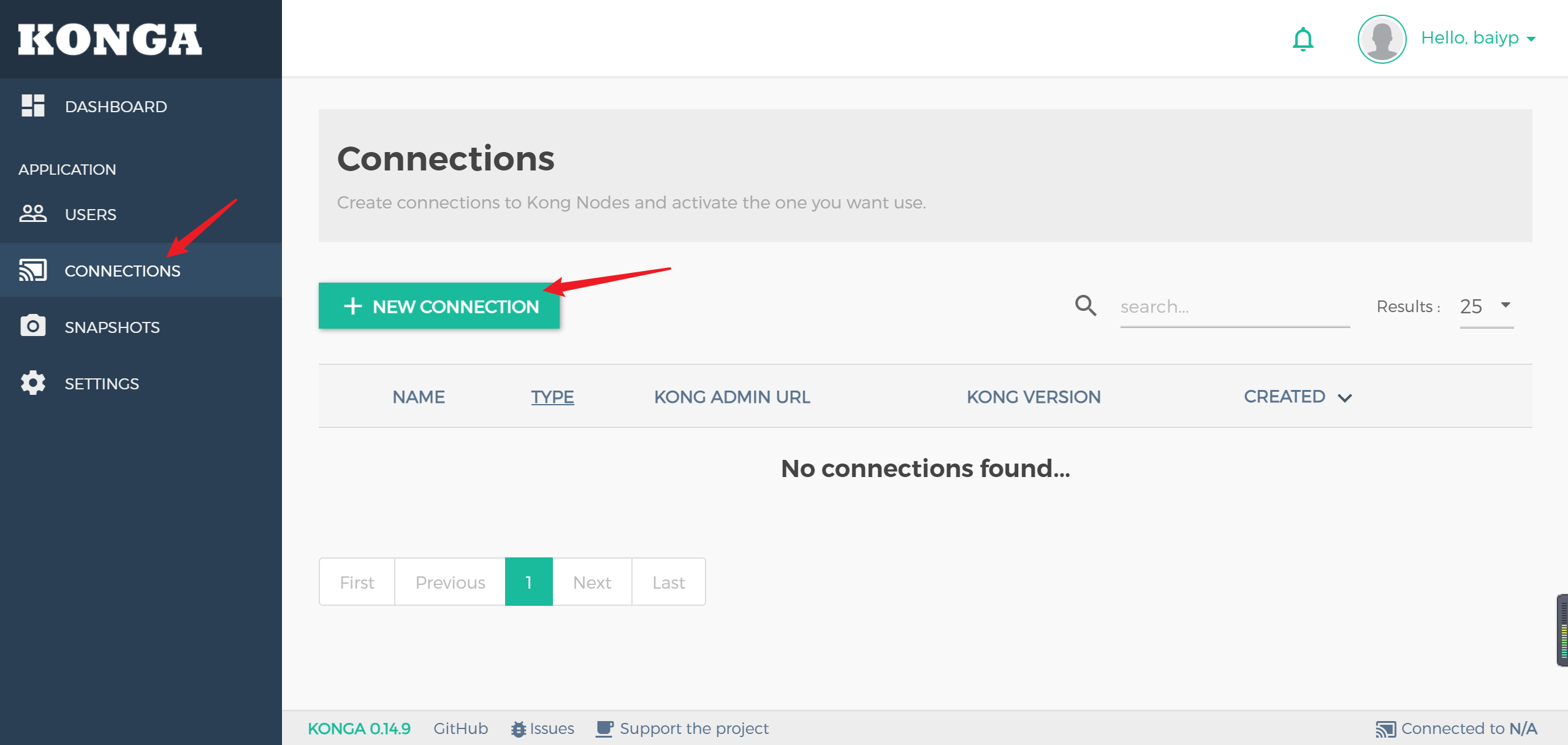
添加kong名称以及API地址就可以管理kong了
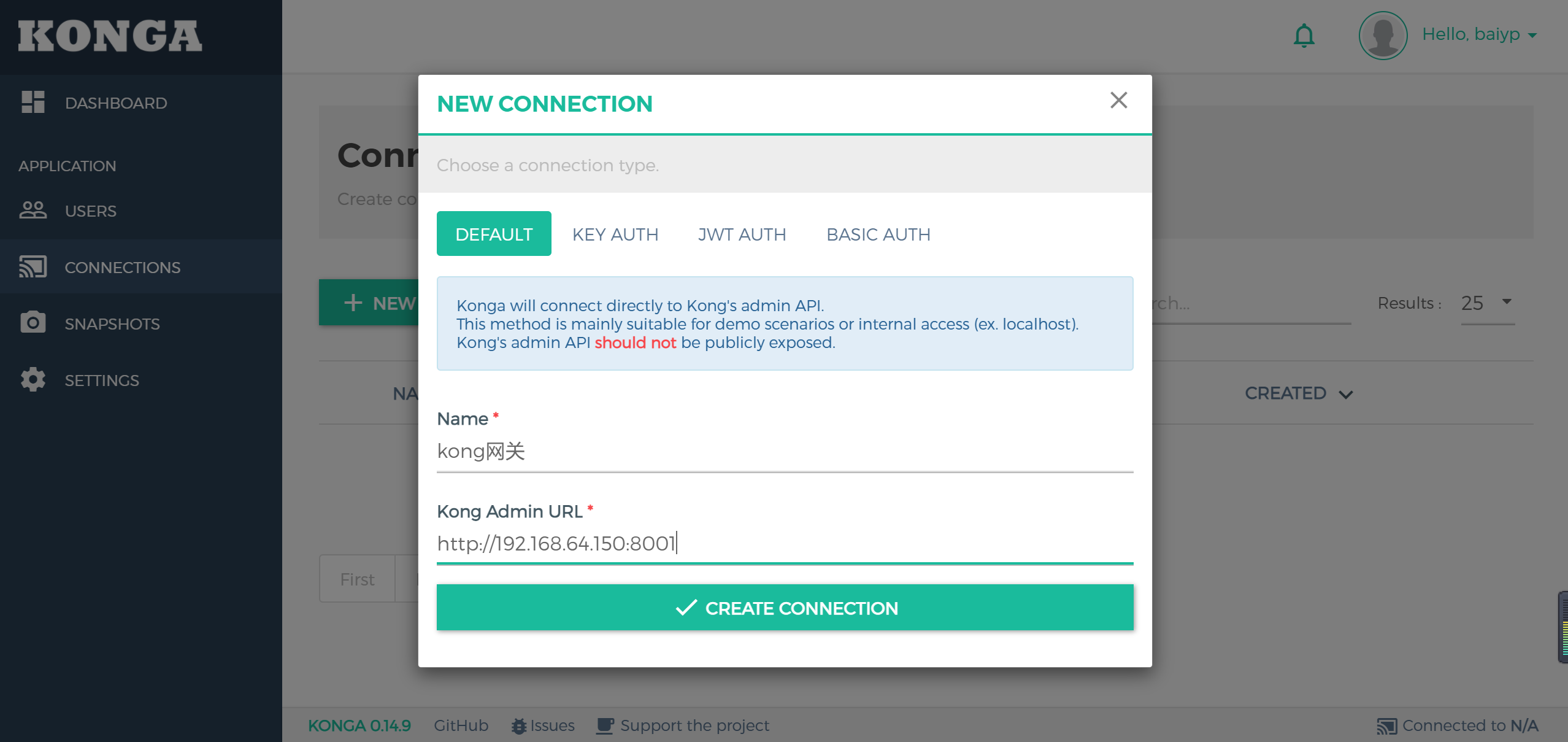
添加后点击’active’激活按钮就可以激活kong网关
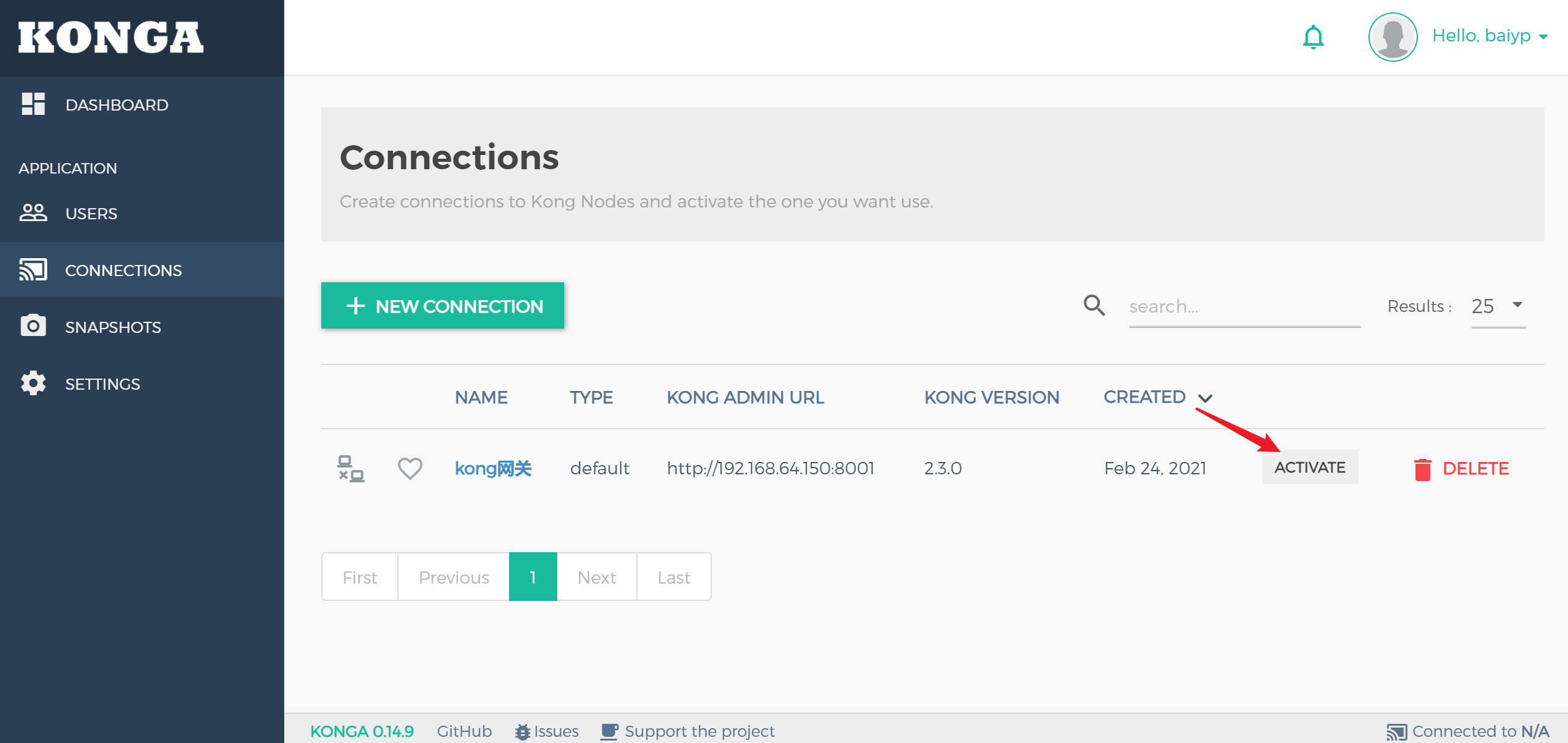
然后就会出现如下界面管理可以通过菜单操作管理kong
限流插件
限流的场景:服务提供的能力是有限的。为了防止大量的请求将服务拖垮,可以通过网关对服务的请求做限流。例如:某个服务1s只能处理100个请求,超过限流阈值的请求丢弃。
路由配置限流
为/load的路由添加限流插件
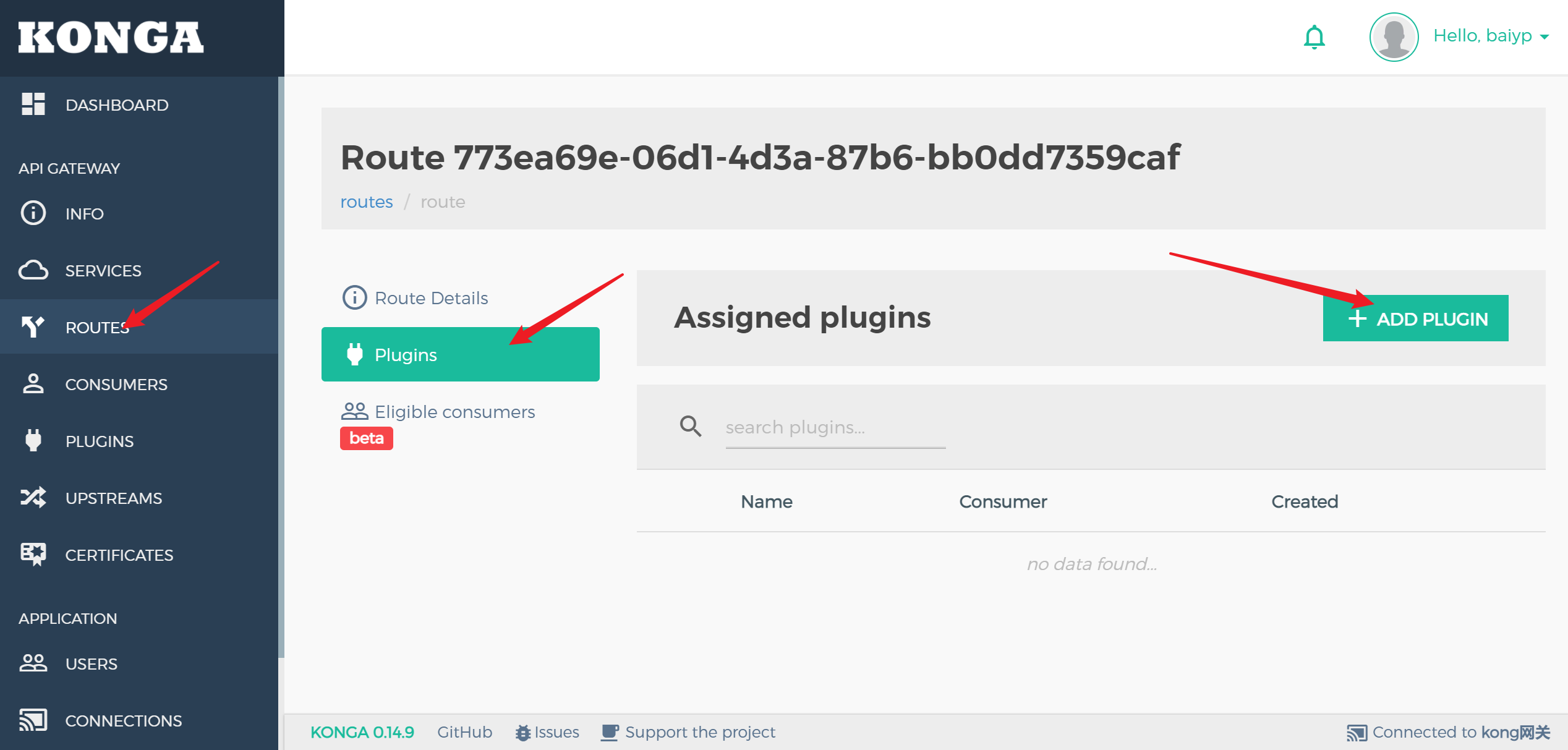
设置限流为每分钟2个
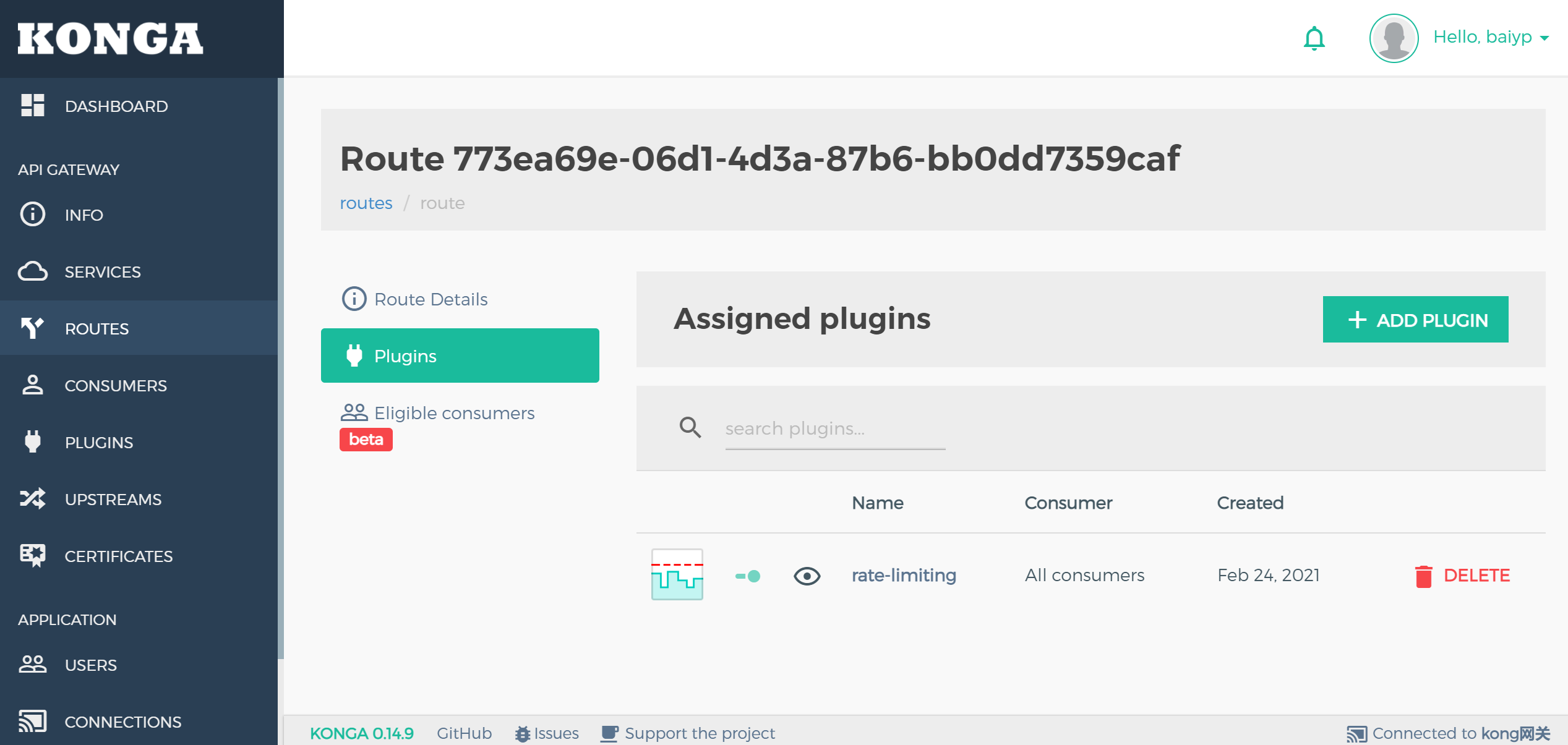
测试验证
多次访问 http://192.168.64.150:8000/load 发现已经被限流了

配置属性如下
| 属性 | 说明 | 是否必须 | 默认 | 示例 |
|---|---|---|---|---|
| consumer | 设置消费之,当时用身份认证时能够识别出消费者 | 否 | 所有消费者 | |
| second | 限制每秒最多有几个请求 | 是 | 无 | 2 |
| minute | 限制每分钟最多有几个请求 | 是 | 无 | 10 |
| hour | 限制每小时最多有几个请求 | 是 | 无 | 100 |
| day | 限制每天最多有几个请求 | 是 | 无 | 100 |
| year | 限制每年最多有几个请求 | 是 | 无 | 100 |
| limit by | 统计限额的标准,consumer, credential, ip, service,如果无法确定,将以IP为主 | 否 | consumer | consumer |
| policy | cluster:将计数器保存在数据库里,local:将计数器保存在本地,redsi:将计数器保存在redis里面 | 是 | cluster | cluster |
| fault tolerant | 第三方数据存储遇到问题时是否会代理请求,如果为YES,在数据库恢复正常前,限流将会禁用,如果为 NO,将会报500错误 | 是 | YES | YES |
| redis host | 当 policy 为 redis 时设置 | 否 | 无 | |
| redis port | 当 policy 为 redis 时设置 | 否 | 6379 | |
| redis password | 当 policy 为 redis 时设置 | 否 | 无 | |
| redis timeout | 当 policy 为 redis 时设置 | 否 | 2000 | |
| redis database | 当 policy 为 redis 时设置 | 否 | 0 | |
| hide client headers | 隐藏客户端响应头 | 是 | NO | NO |
 微信
微信 支付宝
支付宝

