【新手入门】Scala基础语法
Scala简介及开发环境配置
Scala简介
概念
Scala 全称为 Scalable Language,即“可伸缩的语言”,之所以这样命名,是因为它的设计目标是希望伴随着用户的需求一起成长。Scala 是一门综合了面向对象和函数式编程概念的静态类型的编程语言,它运行在标准的 Java 平台上,可以与所有的 Java 类库无缝协作。
特点
Scala是面向对象的
Scala 是一种面向对象的语言,每个值都是对象,每个方法都是调用。举例来说,如果你执行 1+2,则对于 Scala 而言,实际是在调用 Int 类里定义的名为 + 的方法。
Scala是函数式的
Scala 不只是一门纯的面对对象的语言,它也是功能完整的函数式编程语言。函数式编程以两大核心理念为指导:
- 函数是一等公民;
- 程序中的操作应该将输入值映射成输出值,而不是当场修改数据。即方法不应该有副作用。
Scala的优点
与Java的兼容
Scala 可以与 Java 无缝对接,其在执行时会被编译成 JVM 字节码,这使得其性能与 Java 相当。Scala 可以直接调用 Java 中的方法、访问 Java 中的字段、继承 Java 类、实现 Java 接口。Scala 重度复用并包装了原生的 Java 类型,并支持隐式转换。
精简的语法
Scala 的程序通常比较简洁,相比 Java 而言,代码行数会大大减少,这使得程序员对代码的阅读和理解更快,缺陷也更少。
高级语言的特性
Scala 具有高级语言的特定,对代码进行了高级别的抽象,能够让你更好地控制程序的复杂度,保证开发的效率。
静态类型
Scala 拥有非常先进的静态类型系统,Scala 不仅拥有与 Java 类似的允许嵌套类的类型系统,还支持使用泛型对类型进行参数化,用交集(intersection)来组合类型,以及使用抽象类型来进行隐藏类型的细节。通过这些特性,可以更快地设计出安全易用的程序和接口。
配置IDEA开发环境
前置条件
Scala 的运行依赖于 JDK,Scala 2.12.x 需要 JDK 1.8+。
可以再windows本地安装Scala:https://scala-lang.org/download/all.html
环境变量配置SCALA_HOME,path配置%SCALA_HOME%\bin
cmder输入scala验证:(:quit退出dos)

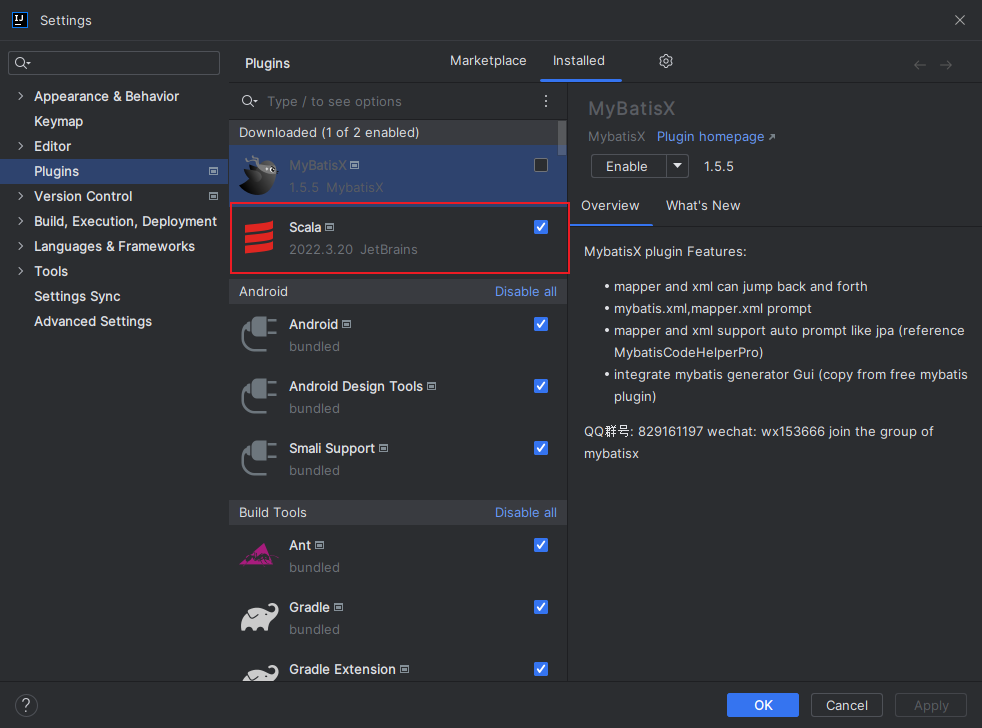
安装Scala插件
IDEA 默认不支持 Scala 语言的开发,需要通过插件进行扩展。打开 IDEA,依次点击 File => settings=> plugins 选项卡,搜索 Scala 插件 (如下图)。找到插件后进行安装,并重启 IDEA 使得安装生效。
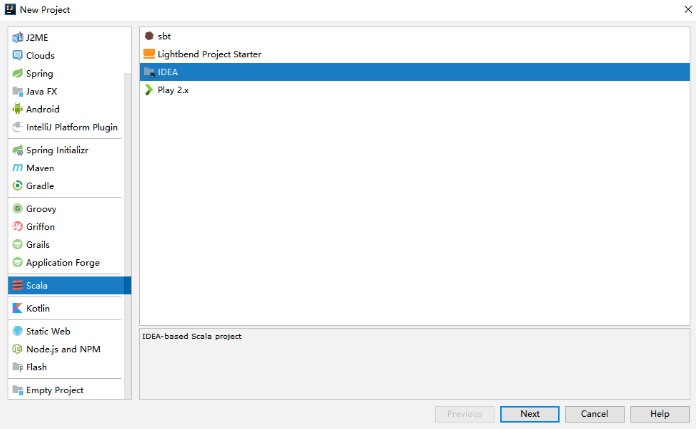
创建Scala项目
在 IDEA 中依次点击 File => New => Project 选项卡,然后选择创建 Scala—IDEA 工程:
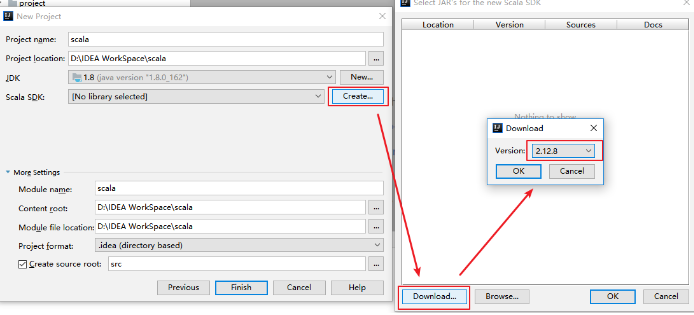
下载Scala SDK
方式一
此时看到 Scala SDK 为空,依次点击 Create => Download ,选择所需的版本后,点击 OK 按钮进行下载,下载完成点击 Finish 进入工程。
方式二
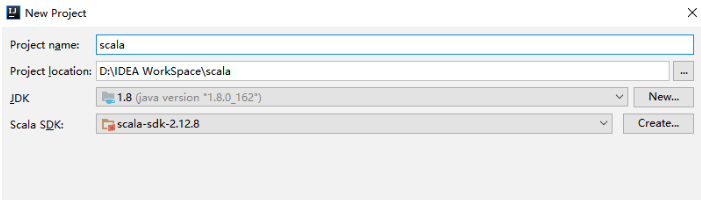
方式一是 Scala 官方安装指南里使用的方式,但下载速度通常比较慢,且这种安装下并没有直接提供 Scala 命令行工具。所以个人推荐到官网下载安装包进行安装,下载地址:https://www.scala-lang.org/download/
这里我的系统是 Windows,下载 msi 版本的安装包后,一直点击下一步进行安装,安装完成后会自动配置好环境变量。

由于安装时已经自动配置好环境变量,所以 IDEA 会自动选择对应版本的 SDK。
手动创建scala目录,右键标识为source目录(和Java目录一样)
给项目添加Scala框架的支持
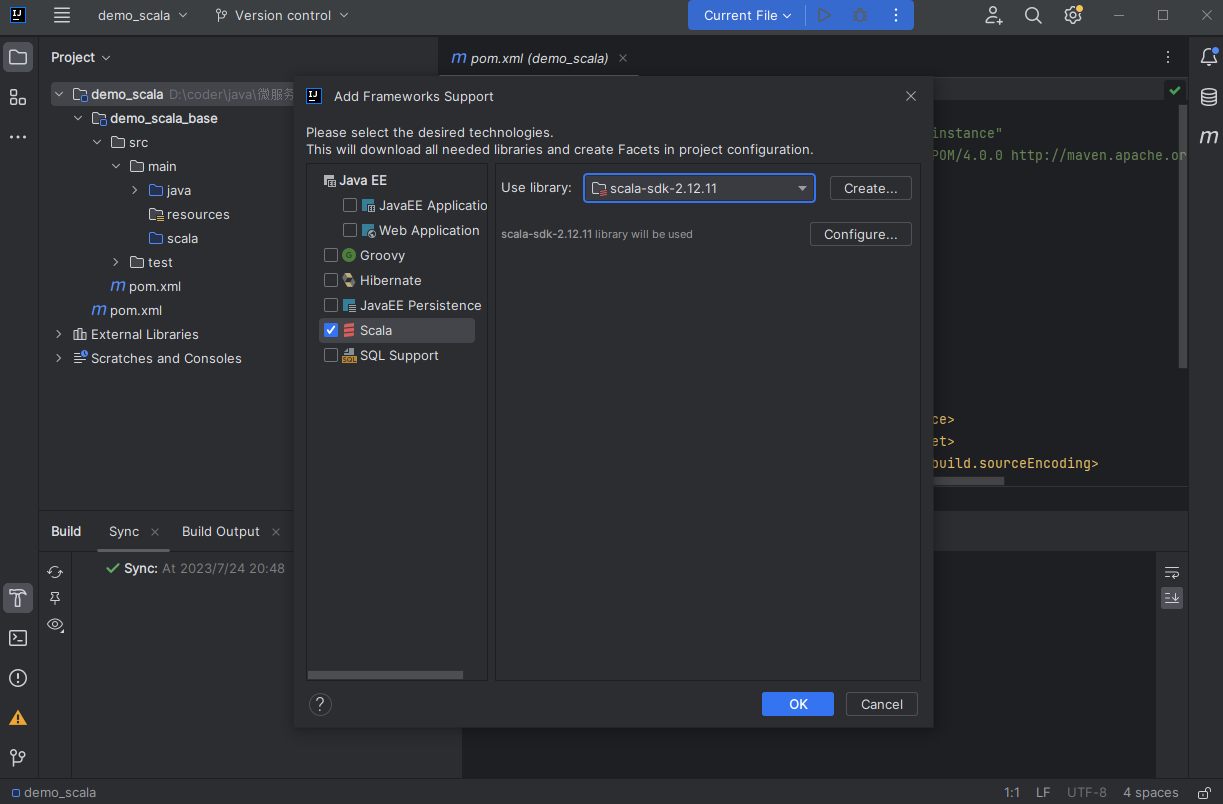
这里也可以看到
然后就可以右键创建scala class了
创建Hello World
在工程 src 目录上右击 New => Scala class 创建 Hello.scala。输入代码如下,完成后点击运行按钮,成功运行则代表搭建成功。
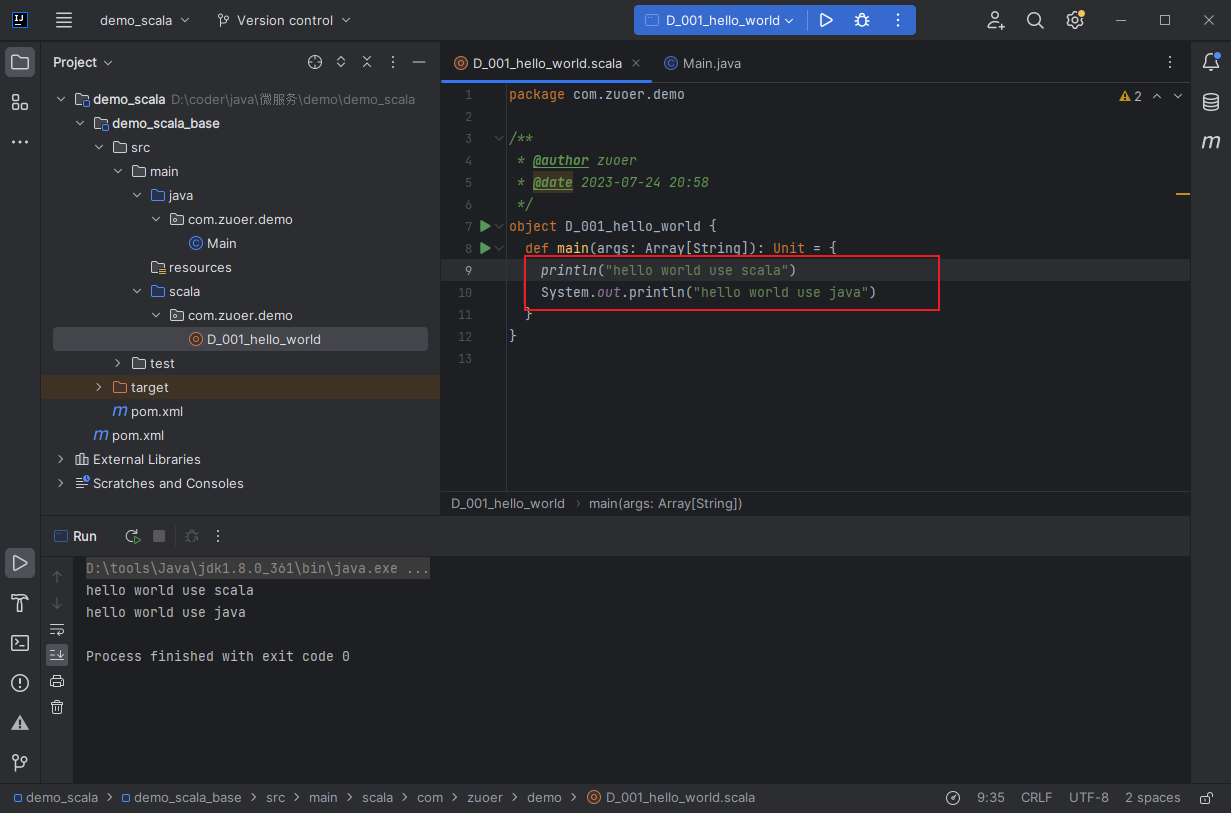
可以直接调用Java的类库
切换Scala版本
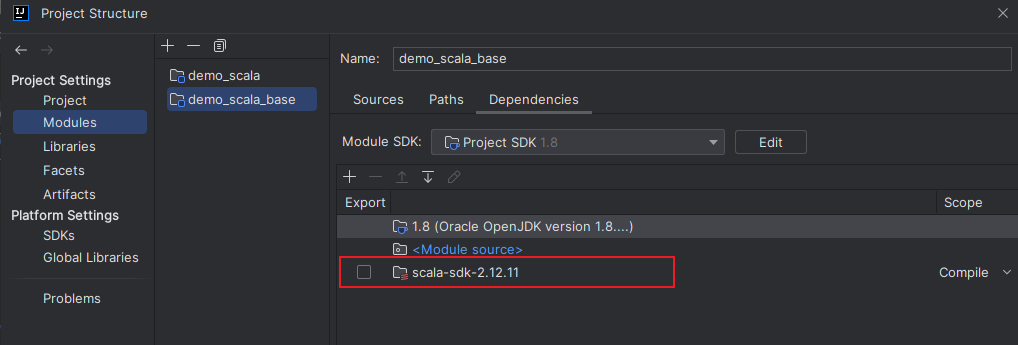
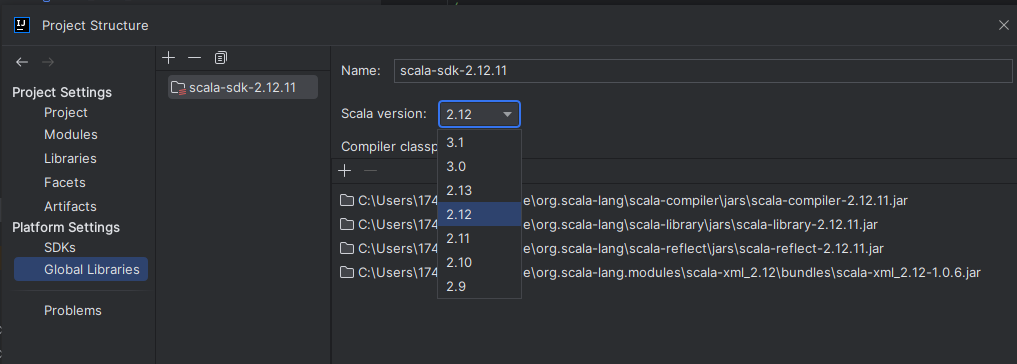
在日常的开发中,由于对应软件(如 Spark)的版本切换,可能导致需要切换 Scala 的版本,则可以在 Project Structures 中的 Global Libraries 选项卡中进行切换。
使用scala命令行
采用 msi 方式安装,程序会自动配置好环境变量。此时可以直接使用命令行工具:
基本数据类型和运算符
标识符
Scala 对各种变量、方法、函数等命名时使用的字符序列称为标识符。
Scala 中的标识符声明,基本和 Java 是一致的,但是细节上会有所变化,有以下三种规则:
(1)以字母或者下划线开头,后接字母、数字、下划线
(2)以操作符开头,且只包含操作符(+ - * / # !等)
(3)用反引号....包括的任意字符串,即使是 Scala 关键字(39 个)也可以
package, import, class, object, trait, extends, with, type, for
private, protected, abstract, sealed, final, implicit, lazy, override
try, catch, finally, throw
if, else, match, case, do, while, for, return, yield
def, val, var
this, super
new
true, false, null
数据类型
由于Java有基本类型,而且基本类型不是真正意义的对象,即使后面产生了基本类型的包装类,但是仍然存在基本数据类型,所以Java语言并不是真正意思的面向对象。
类型支持
Scala 拥有下表所示的数据类型,其中 Byte、Short、Int、Long 和 Char 类型统称为整数类型,整数类型加上 Float 和 Double 统称为数值类型。Scala 数值类型的取值范围和 Java 对应类型的取值范围相同。
| 数据类型 | 描述 |
|---|---|
| Byte | 8 位有符号补码整数。数值区间为 -128 到 127 |
| Short | 16 位有符号补码整数。数值区间为 -32768 到 32767 |
| Int | 32 位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long | 64 位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
| Float | 32 位, IEEE 754 标准的单精度浮点数 |
| Double | 64 位 IEEE 754 标准的双精度浮点数 |
| Char | 16 位无符号 Unicode 字符, 区间值为 U+0000 到 U+FFFF |
| String | 字符序列 |
| Boolean | true 或 false |
Unit |
表示无值,等同于 Java 中的 void。用作不返回任何结果的方法的结果类型。Unit 只有一个实例值,写成 ()。 |
| Null | null 或空引用 |
| Nothing | Nothing 类型在 Scala 的类层级的最低端;它是任何其他类型的子类型。 |
| Any | Any 是所有其他类的超类 |
| AnyRef | AnyRef 类是 Scala 里所有引用类 (reference class) 的基类 |
定义变量
Scala 的变量分为两种,val 和 var,其区别如下:
- val :类似于 Java 中的 final 变量,一旦初始化就不能被重新赋值;(variable)
- var :类似于 Java 中的非 final 变量,在整个声明周期内 var 可以被重新赋值;(value)
1 | scala> val a=1 |
能用常量的地方不用变量,常量类型值的使用比较符合函数式编程的思路。
类型推断
在上面的演示中,并没有声明 a 是 Int 类型,但是程序还是把 a 当做 Int 类型,这就是 Scala 的类型推断。在大多数情况下,你都无需指明变量的类型,程序会自动进行推断。如果你想显式的声明类型,可以在变量后面指定,如下:
1 | scala> val c:String="hello scala" |
Scala解释器
在 scala 命令行中,如果没有对输入的值指定赋值的变量,则输入的值默认会赋值给 resX(其中 X 是一个从 0 开始递增的整数),res 是 result 的缩写,这个变量可以在后面的语句中进行引用。
1 | scala> 5 |
字面量
Scala 和 Java 字面量在使用上很多相似,比如都使用 F 或 f 表示浮点型,都使用 L 或 l 表示 Long 类型。下文主要介绍两者差异部分。
1 | scala> 1.2 |
整数字面量
Scala 支持 10 进制和 16 进制,但不支持八进制字面量和以 0 开头的整数字面量。
1 | scala> 012 |
字符串字面量
字符字面量
字符字面量由一对单引号和中间的任意 Unicode 字符组成。你可以显式的给出原字符、也可以使用字符的 Unicode 码来表示,还可以包含特殊的转义字符。
1 | scala> '\u0041' |
字符串字面量
字符串字面量由双引号包起来的字符组成。
1 | scala> "hello world" |
字符串一些需要注意的地方
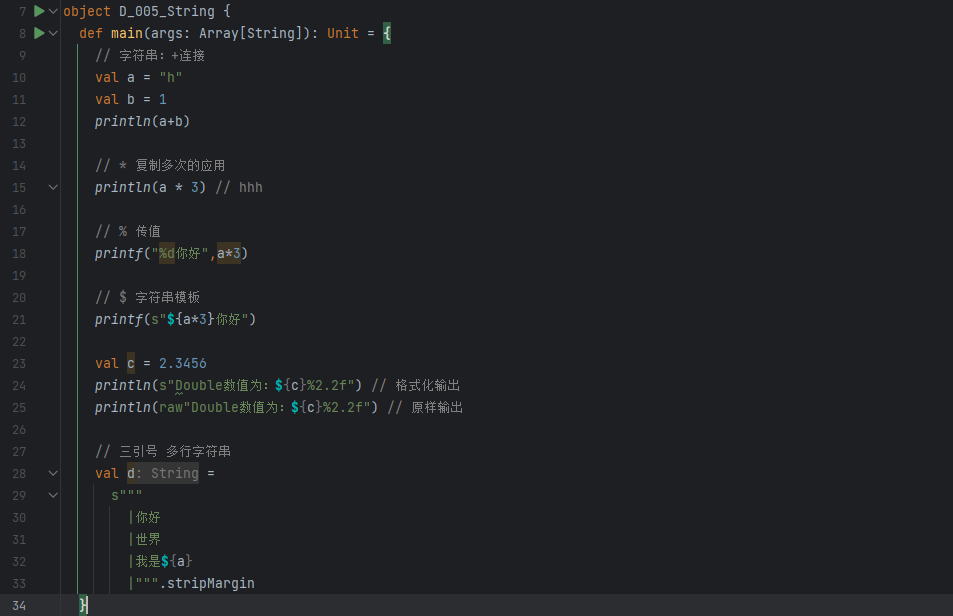
原生字符串
Scala 提供了 """ ... """ 语法,通过三个双引号来表示原生字符串和多行字符串,使用该种方式,原生字符串中的特殊字符不会被转义。
1 | scala> "hello \tool" |
符号字面量
符号字面量写法为: '标识符 ,这里 标识符可以是任何字母或数字的组合。符号字面量会被映射成 scala.Symbol 的实例,如:符号字面量 'x 会被编译器翻译为 scala.Symbol("x")。符号字面量可选方法很少,只能通过 .name 获取其名称。
注意:具有相同 name 的符号字面量一定指向同一个 Symbol 对象,不同 name 的符号字面量一定指向不同的 Symbol 对象。
1 | scala> val sym = 'ID008 |
插值表达式
Scala 支持插值表达式。
1 | scala> val name="xiaoming" |
运算符
Scala 和其他语言一样,支持大多数的操作运算符:
- 算术运算符(+,-,*,/,%)
- 关系运算符(==,!=,>,<,>=,<=)
- 逻辑运算符 (&&,||,!,&,|)
- 位运算符 (~,&,|,^,<<,>>,>>>)
- 赋值运算符 (=,+=,-=,*=,/=,%=,<<=,>>=,&=,^=,|=)
以上操作符的基本使用与 Java 类似,下文主要介绍差异部分和注意事项。
运算符即方法
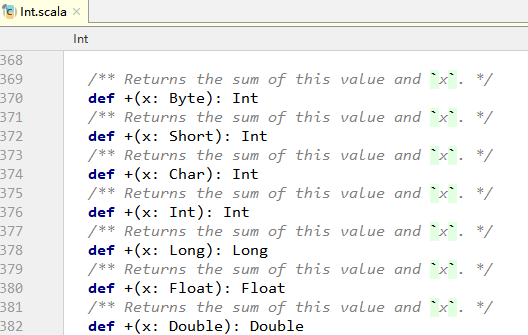
Scala 的面向对象比 Java 更加纯粹,在 Scala 中一切都是对象。所以对于 1+2,实际上是调用了 Int 类中名为 + 的方法,所以 1+2,也可以写成 1.+(2)。
1 | scala> 1+2 |
Int 类中包含了多个重载的 + 方法,用于分别接收不同类型的参数。
逻辑运算符
和其他语言一样,在 Scala 中 &&,|| 的执行是短路的,即如果左边的表达式能确定整个结果,右边的表达式就不会被执行,这满足大多数使用场景。但是如果你需要在无论什么情况下,都执行右边的表达式,则可以使用 & 或 | 代替。
赋值运算符
在 Scala 中没有 Java 中的 ++ 和 -- 运算符,如果你想要实现类似的操作,只能使用 +=1,或者 -=1。
1 | scala> var a=1 |
运算符优先级
操作符的优先级如下:优先级由上至下,逐级递减。

在表格中某个字符的优先级越高,那么以这个字符打头的方法就拥有更高的优先级。如 + 的优先级大于 <,也就意味则 + 的优先级大于以 < 开头的 <<,所以 2<<2+2 , 实际上等价于 2<<(2+2) :
1 | scala> 2<<2+2 |
对象相等性
如果想要判断两个对象是否相等,可以使用 == 和 !=,这两个操作符可以用于所有的对象,包括 null。
1 | scala> 1==2 |
流程控制
条件表达式if
Scala 中的 if/else 语法结构与 Java 中的一样,唯一不同的是,Scala 中的 if 表达式是有返回值的。
1 | object ScalaApp extends App { |
在 Java 中,每行语句都需要使用 ; 表示结束,但是在 Scala 中并不需要。除非你在单行语句中写了多行代码。
块表达式
在 Scala 中,可以使用 {} 块包含一系列表达式,块中最后一个表达式的值就是块的值。
1 | object ScalaApp extends App { |
如果块中的最后一个表达式没有返回值,则块的返回值是 Unit 类型。
1 | scala> val result ={ val a = 1 + 1; val b = 2 + 2 } |
循环表达式while
Scala 和大多数语言一样,支持 while 和 do ... while 表达式。
1 | object ScalaApp extends App { |
循环表达式for
for 循环的基本使用如下:
1 | object ScalaApp extends App { |
1 to 10,本质上是1.to(10)是一个方法调用
除了基本使用外,还可以使用 yield 关键字从 for 循环中产生 Vector,这称为 for 推导式。
1 | scala> for (i <- 1 to 10) yield i * 6 |
异常处理try
和 Java 中一样,支持 try...catch...finally 语句。
1 | import java.io.{FileNotFoundException, FileReader} |
这里需要注意的是因为 finally 语句一定会被执行,所以不要在该语句中返回值,否则返回值会被作为整个 try 语句的返回值,如下:
1 | scala> def g():Int = try return 1 finally return 2 |
条件选择表达式match
match 类似于 java 中的 switch 语句。
1 | object ScalaApp extends App { |
但是与 Java 中的 switch 有以下三点不同:
- Scala 中的 case 语句支持任何类型;而 Java 中 case 语句仅支持整型、枚举和字符串常量;
- Scala 中每个分支语句后面不需要写 break,因为在 case 语句中 break 是隐含的,默认就有;
- 在 Scala 中 match 语句是有返回值的,而 Java 中 switch 语句是没有返回值的。如下:
1 | object ScalaApp extends App { |
没有break和continue
额外注意一下:Scala 中并不支持 Java 中的 break 和 continue 关键字。
输入与输出
在 Scala 中可以使用 print、println、printf 打印输出,这与 Java 中是一样的。如果需要从控制台中获取输入,则可以使用 StdIn 中定义的各种方法。
1 | object D_006_StdIn { |
输入输入也可以对文件操作
1 | object D_007_FileIO { |
数组
定长数组
在 Scala 中,如果你需要一个长度不变的数组,可以使用 Array。但需要注意以下两点:
- 在 Scala 中使用
(index)而不是[index]来访问数组中的元素,因为访问元素,对于 Scala 来说是方法调用,(index)相当于执行了.apply(index)方法。 - Scala 中的数组与 Java 中的是等价的,
Array[Int]()在虚拟机层面就等价于 Java 的int[]。
1 | // 10 个整数的数组,所有元素初始化为 0 |
变长数组
在 scala 中通过 ArrayBuffer 实现变长数组 (又称缓冲数组)。在构建 ArrayBuffer 时必须给出类型参数,但不必指定长度,因为 ArrayBuffer 会在需要的时候自动扩容和缩容。变长数组的构建方式及常用操作如下:
1 | import scala.collection.mutable.ArrayBuffer |
需要注意的是:使用 += 在末尾插入元素是一个高效的操作,其时间复杂度是 O(1)。而使用 insert 随机插入元素的时间复杂度是 O(n),因为在其插入位置之后的所有元素都要进行对应的后移,所以在 ArrayBuffer 中随机插入元素是一个低效的操作。
数组遍历
1 | object ScalaApp extends App { |
这里我们没有将代码写在 main 方法中,而是继承自 App.scala,这是 Scala 提供的一种简写方式,此时将代码写在类中,等价于写在 main 方法中,直接运行该类即可。
数组转换
数组转换是指由现有数组产生新的数组。假设当前拥有 a 数组,想把 a 中的偶数元素乘以 10 后产生一个新的数组,可以采用下面两种方式来实现:
1 | object ScalaApp extends App { |
多维数组
和 Java 中一样,多维数组由单维数组组成。
1 | object ScalaApp extends App { |
与Java互操作
由于 Scala 的数组是使用 Java 的数组来实现的,所以两者之间可以相互转换。
1 | import java.util |
集合
集合简介
Scala 中拥有多种集合类型,主要分为可变的和不可变的集合两大类:
可变集合: 可以被修改。即可以更改,添加,删除集合中的元素;
不可变集合类:不能被修改。对集合执行更改,添加或删除操作都会返回一个新的集合,而不是修改原来的集合。
集合结构
Scala 中的大部分集合类都存在三类变体,分别位于 scala.collection, scala.collection.immutable, scala.collection.mutable 包中。还有部分集合类位于 scala.collection.generic 包下。
- scala.collection.immutable :包是中的集合是不可变的;
- scala.collection.mutable :包中的集合是可变的;
- scala.collection :包中的集合,既可以是可变的,也可以是不可变的。
1 | val sortSet = scala.collection.SortedSet(1, 2, 3, 4, 5) |
如果你仅写了 Set 而没有加任何前缀也没有进行任何 import,则 Scala 默认采用不可变集合类。
1 | scala> Set(1,2,3,4,5) |
scala.collection
scala.collection 包中所有集合如下图:

scala.collection.mutable
scala.collection.mutable 包中所有集合如下图:

scala.collection.immutable
scala.collection.immutable 包中所有集合如下图:

Trait Traversable
Scala 中所有集合的顶层实现是 Traversable 。它唯一的抽象方法是 foreach:
1 | def foreach[U](f: Elem => U) |
实现 Traversable 的集合类只需要实现这个抽象方法,其他方法可以从 Traversable 继承。Traversable 中的所有可用方法如下:
| 方法 | 作用 |
|---|---|
| Abstract Method: | |
xs foreach f |
为 xs 的每个元素执行函数 f |
| Addition: | |
xs ++ ys |
一个包含 xs 和 ys 中所有元素的新的集合。 ys 是一个 Traversable 或 Iterator。 |
| Maps: | |
xs map f |
对 xs 中每一个元素应用函数 f,并返回一个新的集合 |
xs flatMap f |
对 xs 中每一个元素应用函数 f,最后将结果合并成一个新的集合 |
xs collect f |
对 xs 中每一个元素调用偏函数 f,并返回一个新的集合 |
| Conversions: | |
xs.toArray |
将集合转化为一个 Array |
xs.toList |
将集合转化为一个 List |
xs.toIterable |
将集合转化为一个 Iterable |
xs.toSeq |
将集合转化为一个 Seq |
xs.toIndexedSeq |
将集合转化为一个 IndexedSeq |
xs.toStream |
将集合转化为一个延迟计算的流 |
xs.toSet |
将集合转化为一个 Set |
xs.toMap |
将一个(key, value)对的集合转化为一个 Map。 如果当前集合的元素类型不是(key, value)对形式, 则报静态类型错误。 |
| Copying: | |
xs copyToBuffer buf |
拷贝集合中所有元素到缓存 buf |
xs copyToArray(arr,s,n) |
从索引 s 开始,将集合中最多 n 个元素复制到数组 arr。 最后两个参数是可选的。 |
| Size info: | |
xs.isEmpty |
判断集合是否为空 |
xs.nonEmpty |
判断集合是否包含元素 |
xs.size |
返回集合中元素的个数 |
xs.hasDefiniteSize |
如果 xs 具有有限大小,则为真。 |
| Element Retrieval: | |
xs.head |
返回集合中的第一个元素(如果无序,则随机返回) |
xs.headOption |
以 Option 的方式返回集合中的第一个元素, 如果集合为空则返回 None |
xs.last |
返回集合中的最后一个元素(如果无序,则随机返回) |
xs.lastOption |
以 Option 的方式返回集合中的最后一个元素, 如果集合为空则返回 None |
xs find p |
以 Option 的方式返回满足条件 p 的第一个元素, 如果都不满足则返回 None |
| Subcollection: | |
xs.tail |
除了第一个元素之外的其他元素组成的集合 |
xs.init |
除了最后一个元素之外的其他元素组成的集合 |
xs slice (from, to) |
返回给定索引范围之内的元素组成的集合 (包含 from 位置的元素但不包含 to 位置的元素) |
xs take n |
返回 xs 的前 n 个元素组成的集合(如果无序,则返回任意 n 个元素) |
xs drop n |
返回 xs 的后 n 个元素组成的集合(如果无序,则返回任意 n 个元素) |
xs takeWhile p |
从第一个元素开始查找满足条件 p 的元素, 直到遇到一个不满足条件的元素,返回所有遍历到的值。 |
xs dropWhile p |
从第一个元素开始查找满足条件 p 的元素, 直到遇到一个不满足条件的元素,返回所有未遍历到的值。 |
xs filter p |
返回满足条件 p 的所有元素的集合 |
xs withFilter p |
集合的非严格的过滤器。后续对 xs 调用方法 map、flatMap 以及 withFilter 都只用作于满足条件 p 的元素,而忽略其他元素 |
xs filterNot p |
返回不满足条件 p 的所有元素组成的集合 |
| Subdivisions: | |
xs splitAt n |
在给定位置拆分集合,返回一个集合对 (xs take n, xs drop n) |
xs span p |
根据给定条件拆分集合,返回一个集合对 (xs takeWhile p, xs dropWhile p)。即遍历元素,直到遇到第一个不符合条件的值则结束遍历,将遍历到的值和未遍历到的值分别放入两个集合返回。 |
xs partition p |
按照筛选条件对元素进行分组 |
xs groupBy f |
根据鉴别器函数 f 将 xs 划分为集合映射 |
| Element Conditions: | |
xs forall p |
判断集合中所有的元素是否都满足条件 p |
xs exists p |
判断集合中是否存在一个元素满足条件 p |
xs count p |
xs 中满足条件 p 的元素的个数 |
| Folds: | |
(z /: xs) (op) |
以 z 为初始值,从左到右对 xs 中的元素执行操作为 op 的归约操作 |
(xs :\ z) (op) |
以 z 为初始值,从右到左对 xs 中的元素执行操作为 op 的归约操作 |
xs.foldLeft(z) (op) |
同 (z /: xs) (op) |
xs.foldRight(z) (op) |
同 (xs :\ z) (op) |
xs reduceLeft op |
从左到右对 xs 中的元素执行操作为 op 的归约操作 |
xs reduceRight op |
从右到左对 xs 中的元素执行操作为 op 的归约操作 |
| Specific Folds: | |
xs.sum |
累计求和 |
xs.product |
累计求积 |
xs.min |
xs 中的最小值 |
xs.max |
xs 中的最大值 |
| String: | |
xs addString (b, start, sep, end) |
向 StringBuilder b 中添加一个字符串, 该字符串包含 xs 的所有元素。start、seq 和 end 都是可选的,seq 为分隔符,start 为开始符号,end 为结束符号。 |
xs mkString (start, seq, end) |
将集合转化为一个字符串。start、seq 和 end 都是可选的,seq 为分隔符,start 为开始符号,end 为结束符号。 |
xs.stringPrefix |
返回 xs.toString 字符串开头的集合名称 |
| Views: | |
xs.view |
生成 xs 的视图 |
xs view (from, to) |
生成 xs 上指定索引范围内元素的视图 |
下面为部分方法的使用示例:
1 | scala> List(1, 2, 3, 4, 5, 6).collect { case i if i % 2 == 0 => i * 10 } |
Trait Iterable
Scala 中所有的集合都直接或者间接实现了 Iterable 特质,Iterable 拓展自 Traversable,并额外定义了部分方法:
| 方法 | 作用 |
|---|---|
| Abstract Method: | |
xs.iterator |
返回一个迭代器,用于遍历 xs 中的元素, 与 foreach 遍历元素的顺序相同。 |
| Other Iterators: | |
xs grouped size |
返回一个固定大小的迭代器 |
xs sliding size |
返回一个固定大小的滑动窗口的迭代器 |
| Subcollections: | |
xs takeRigtht n |
返回 xs 中最后 n 个元素组成的集合(如果无序,则返回任意 n 个元素组成的集合) |
xs dropRight n |
返回 xs 中除了最后 n 个元素外的部分 |
| Zippers: | |
xs zip ys |
返回 xs 和 ys 的对应位置上的元素对组成的集合 |
xs zipAll (ys, x, y) |
返回 xs 和 ys 的对应位置上的元素对组成的集合。其中较短的序列通过附加元素 x 或 y 来扩展以匹配较长的序列。 |
xs.zipWithIndex |
返回一个由 xs 中元素及其索引所组成的元素对的集合 |
| Comparison: | |
xs sameElements ys |
测试 xs 和 ys 是否包含相同顺序的相同元素 |
所有方法示例如下:
1 | scala> List(1, 2, 3).iterator.reduce(_ * _ * 10) |
修改集合
当你想对集合添加或者删除元素,需要根据不同的集合类型选择不同的操作符号:
| 操作符 | 描述 | 集合类型 |
|---|---|---|
| coll(k) 即 coll.apply(k) |
获取指定位置的元素 | Seq, Map |
| coll :+ elem elem +: coll |
向集合末尾或者集合头增加元素 | Seq |
| coll + elem coll + (e1, e2, …) |
追加元素 | Seq, Map |
| coll - elem coll - (e1, e2, …) |
删除元素 | Set, Map, ArrayBuffer |
| coll ++ coll2 coll2 ++: coll |
合并集合 | Iterable |
| coll – coll2 | 移除 coll 中包含的 coll2 中的元素 | Set, Map, ArrayBuffer |
| elem :: lst lst2 :: lst |
把指定列表 (lst2) 或者元素 (elem) 添加到列表 (lst) 头部 | List |
| list ::: list2 | 合并 List | List |
| set | set2 set & set2 set &~ set2 |
并集、交集、差集 | Set |
| coll += elem coll += (e1, e2, …) coll ++= coll2 coll -= elem coll -= (e1, e2, …) coll –= coll2 |
添加或者删除元素,并将修改后的结果赋值给集合本身 | 可变集合 |
| elem +=: coll coll2 ++=: coll |
在集合头部追加元素或集合 | ArrayBuffer |
蚌埠住了 集合的操作直接通过运算符搞定
List & Set
List字面量
List 是 Scala 中非常重要的一个数据结构,其与 Array(数组) 非常类似,但是 List 是不可变的,和 Java 中的 List 一样,其底层实现是链表。
1 | scala> val list = List("hadoop", "spark", "storm") |
List类型
Scala 中 List 具有以下两个特性:
- **同构 (homogeneous)**:同一个 List 中的所有元素都必须是相同的类型;
- **协变 (covariant)**:如果 S 是 T 的子类型,那么
List[S]就是List[T]的子类型,例如List[String]是List[Object]的子类型。
需要特别说明的是空列表的类型为 List[Nothing]:
1 | scala> List() |
构建List
所有 List 都由两个基本单元构成:Nil 和 ::(读作”cons”)。即列表要么是空列表 (Nil),要么是由一个 head 加上一个 tail 组成,而 tail 又是一个 List。我们在上面使用的 List("hadoop", "spark", "storm") 最终也是被解释为 "hadoop"::"spark":: "storm"::Nil。
1 | scala> val list01 = "hadoop"::"spark":: "storm"::Nil |
模式匹配
Scala 支持展开列表以实现模式匹配。
1 | scala> val list = List("hadoop", "spark", "storm") |
如果只需要匹配部分内容,可以如下:
1 | scala> val a::rest=list |
列表的基本操作
常用方法
1 | object ScalaApp extends App { |
indices
indices 方法返回所有下标。
1 | scala> list.indices |
take & drop & splitAt
- take:获取前 n 个元素;
- drop:删除前 n 个元素;
- splitAt:从第几个位置开始拆分。
1 | scala> list take 2 |
flatten
flatten 接收一个由列表组成的列表,并将其进行扁平化操作,返回单个列表。
1 | scala> List(List(1, 2), List(3), List(), List(4, 5)).flatten |
zip & unzip
对两个 List 执行 zip 操作结果如下,返回对应位置元素组成的元组的列表,unzip 则执行反向操作。
1 | scala> val list = List("hadoop", "spark", "storm") |
toString & mkString
toString 返回 List 的字符串表现形式。
1 | scala> list.toString |
如果想改变 List 的字符串表现形式,可以使用 mkString。mkString 有三个重载方法,方法定义如下:
1 | // start:前缀 sep:分隔符 end:后缀 |
使用示例如下:
1 | scala> list.mkString |
iterator & toArray & copyToArray
iterator 方法返回的是迭代器,这和其他语言的使用是一样的。
1 | object ScalaApp extends App { |
toArray 和 toList 用于 List 和数组之间的互相转换。
1 | scala> val array = list.toArray |
copyToArray 将 List 中的元素拷贝到数组中指定位置。
1 | object ScalaApp extends App { |
列表的高级操作
列表转换:map & flatMap & foreach
map 与 Java 8 函数式编程中的 map 类似,都是对 List 中每一个元素执行指定操作。
1 | scala> List(1,2,3).map(_+10) |
flatMap 与 map 类似,但如果 List 中的元素还是 List,则会对其进行 flatten 操作。
1 | scala> list.map(_.toList) |
foreach 要求右侧的操作是一个返回值为 Unit 的函数,你也可以简单理解为执行一段没有返回值代码。
1 | scala> var sum = 0 |
列表过滤:filter & partition & find & takeWhile & dropWhile & span
filter 用于筛选满足条件元素,返回新的 List。
1 | scala> List(1, 2, 3, 4, 5) filter (_ % 2 == 0) |
partition 会按照筛选条件对元素进行分组,返回类型是 tuple(元组)。
1 | scala> List(1, 2, 3, 4, 5) partition (_ % 2 == 0) |
find 查找第一个满足条件的值,由于可能并不存在这样的值,所以返回类型是 Option,可以通过 getOrElse 在不存在满足条件值的情况下返回默认值。
1 | scala> List(1, 2, 3, 4, 5) find (_ % 2 == 0) |
takeWhile 遍历元素,直到遇到第一个不符合条件的值则结束遍历,返回所有遍历到的值。
1 | scala> List(1, 2, 3, -4, 5) takeWhile (_ > 0) |
dropWhile 遍历元素,直到遇到第一个不符合条件的值则结束遍历,返回所有未遍历到的值。
1 | // 第一个值就不满足条件,所以返回列表中所有的值 |
span 遍历元素,直到遇到第一个不符合条件的值则结束遍历,将遍历到的值和未遍历到的值分别放入两个 List 中返回,返回类型是 tuple(元组)。
1 | scala> List(1, 2, 3, -4, 5) span (_ > 0) |
列表检查:forall & exists
forall 检查 List 中所有元素,如果所有元素都满足条件,则返回 true。
1 | scala> List(1, 2, 3, -4, 5) forall ( _ > 0 ) |
exists 检查 List 中的元素,如果某个元素已经满足条件,则返回 true。
1 | scala> List(1, 2, 3, -4, 5) exists (_ > 0 ) |
列表排序:sortWith
sortWith 对 List 中所有元素按照指定规则进行排序,由于 List 是不可变的,所以排序返回一个新的 List。
1 | scala> List(1, -3, 4, 2, 6) sortWith (_ < _) |
List对象的方法
上面介绍的所有方法都是 List 类上的方法,下面介绍的是 List 伴生对象中的方法。
List.range
List.range 可以产生指定的前闭后开区间内的值组成的 List,它有三个可选参数: start(开始值),end(结束值,不包含),step(步长)。
1 | scala> List.range(1, 5) |
List.fill
List.fill 使用指定值填充 List。
1 | scala> List.fill(3)("hello") |
List.concat
List.concat 用于拼接多个 List。
1 | scala> List.concat(List('a', 'b'), List('c')) |
处理多个List
当多个 List 被放入同一个 tuple 中时候,可以通过 zipped 对多个 List 进行关联处理。
1 | // 两个 List 对应位置的元素相乘 |
缓冲列表ListBuffer
上面介绍的 List,由于其底层实现是链表,这意味着能快速访问 List 头部元素,但对尾部元素的访问则比较低效,这时候可以采用 ListBuffer,ListBuffer 提供了在常量时间内往头部和尾部追加元素。
1 | import scala.collection.mutable.ListBuffer |
集(Set)
Set 是不重复元素的集合。分为可变 Set 和不可变 Set。
可变Set
1 | object ScalaApp extends App { |
不可变Set
不可变 Set 没有 add 方法,可以使用 + 添加元素,但是此时会返回一个新的不可变 Set,原来的 Set 不变。
1 | object ScalaApp extends App { |
Set间操作
多个 Set 之间可以进行求交集或者合集等操作。
1 | object ScalaApp extends App { |
Map & Tuple
映射(Map)
构造Map
1 | // 初始化一个空 map |
采用上面方式得到的都是不可变 Map(immutable map),想要得到可变 Map(mutable map),则需要使用:
1 | val scores04 = scala.collection.mutable.Map("hadoop" -> 10, "spark" -> 20, "storm" -> 30) |
获取值
1 | object ScalaApp extends App { |
新增/修改/删除值
可变 Map 允许进行新增、修改、删除等操作。
1 | object ScalaApp extends App { |
不可变 Map 不允许进行新增、修改、删除等操作,但是允许由不可变 Map 产生新的 Map。
1 | object ScalaApp extends App { |
遍历Map
1 | object ScalaApp extends App { |
yield关键字
可以使用 yield 关键字从现有 Map 产生新的 Map。
1 | object ScalaApp extends App { |
其他Map结构
在使用 Map 时候,如果不指定,默认使用的是 HashMap,如果想要使用 TreeMap 或者 LinkedHashMap,则需要显式的指定。
1 | object ScalaApp extends App { |
可选方法
1 | object ScalaApp extends App { |
与Java互操作
1 | import java.util |
元组(Tuple)
元组与数组类似,但是数组中所有的元素必须是同一种类型,而元组则可以包含不同类型的元素。
1 | scala> val tuple=(1,3.24f,"scala") |
模式匹配
可以通过模式匹配来获取元组中的值并赋予对应的变量:
1 | scala> val (a,b,c)=tuple |
如果某些位置不需要赋值,则可以使用下划线代替:
1 | scala> val (a,_,_)=tuple |
zip方法
1 | object ScalaApp extends App { |
类和对象
初识类和对象
Scala 的类与 Java 的类具有非常多的相似性,示例如下:
1 | // 1. 在 scala 中,类不需要用 public 声明,所有的类都具有公共的可见性 |
类
成员变量可见性
Scala 中成员变量的可见性默认都是 public,如果想要保证其不被外部干扰,可以声明为 private,并通过 getter 和 setter 方法进行访问。
getter和setter属性
getter 和 setter 属性与声明变量时使用的关键字有关:
- 使用 var 关键字:变量同时拥有 getter 和 setter 属性;
- 使用 val 关键字:变量只拥有 getter 属性;
- 使用 private[this]:变量既没有 getter 属性、也没有 setter 属性,只能通过内部的方法访问;
需要特别说明的是:假设变量名为 age,则其对应的 get 和 set 的方法名分别叫做 age 和 age_=。
1 | class Person { |
解释说明:
示例代码中
person.age=30在执行时内部实际是调用了方法person.age_=(30),而person.age内部执行时实际是调用了person.age()方法。想要证明这一点,可以对代码进行反编译。同时为了说明成员变量可见性的问题,我们对下面这段代码进行反编译:
2
3
4
var name = ""
private var age = ""
}依次执行下面编译命令:
2
javap -private Person编译结果如下,从编译结果可以看到实际的 get 和 set 的方法名 (因为 JVM 不允许在方法名中出现=,所以它被翻译成$eq),同时也验证了成员变量默认的可见性为 public。
2
3
4
5
6
7
8
9
10
11
12
13
public class Person {
private java.lang.String name;
private java.lang.String age;
public java.lang.String name();
public void name_$eq(java.lang.String);
private java.lang.String age();
private void age_$eq(java.lang.String);
public Person();
}
@BeanProperty
在上面的例子中可以看到我们是使用 . 来对成员变量进行访问的,如果想要额外生成和 Java 中一样的 getXXX 和 setXXX 方法,则需要使用@BeanProperty 进行注解。
1 | class Person { |
主构造器
和 Java 不同的是,Scala 类的主构造器直接写在类名后面,但注意以下两点:
- 主构造器传入的参数默认就是 val 类型的,即不可变,你没有办法在内部改变传参;
- 写在主构造器中的代码块会在类初始化的时候被执行,功能类似于 Java 的静态代码块
static{}
1 | class Person(val name: String, val age: Int) { |
辅助构造器
辅助构造器有两点硬性要求:
- 辅助构造器的名称必须为 this;
- 每个辅助构造器必须以主构造器或其他的辅助构造器的调用开始。
1 | class Person(val name: String, val age: Int) { |
方法传参不可变
在 Scala 中,方法传参默认是 val 类型,即不可变,这意味着你在方法体内部不能改变传入的参数。这和 Scala 的设计理念有关,Scala 遵循函数式编程理念,强调方法不应该有副作用。
1 | class Person() { |
对象
Scala 中的 object(对象) 主要有以下几个作用:
- 因为 object 中的变量和方法都是静态的,所以可以用于存放工具类;
- 可以作为单例对象的容器;
- 可以作为类的伴生对象;
- 可以拓展类或特质;
- 可以拓展 Enumeration 来实现枚举。
工具类&单例&全局静态常量&拓展特质
这里我们创建一个对象 Utils,代码如下:
1 | object Utils { |
其中 Person 类代码如下:
1 | class Person() { |
新建测试类:
1 | // 1.ScalaApp 对象扩展自 trait App |
伴生对象
在 Java 中,你通常会用到既有实例方法又有静态方法的类,在 Scala 中,可以通过类和与类同名的伴生对象来实现。类和伴生对象必须存在与同一个文件中。
1 | class Person() { |
实现枚举类
Scala 中没有直接提供枚举类,需要通过扩展 Enumeration,并调用其中的 Value 方法对所有枚举值进行初始化来实现。
1 | object Color extends Enumeration { |
使用枚举类:
1 | // 1.使用类型别名导入枚举类 |
继承和特质
继承
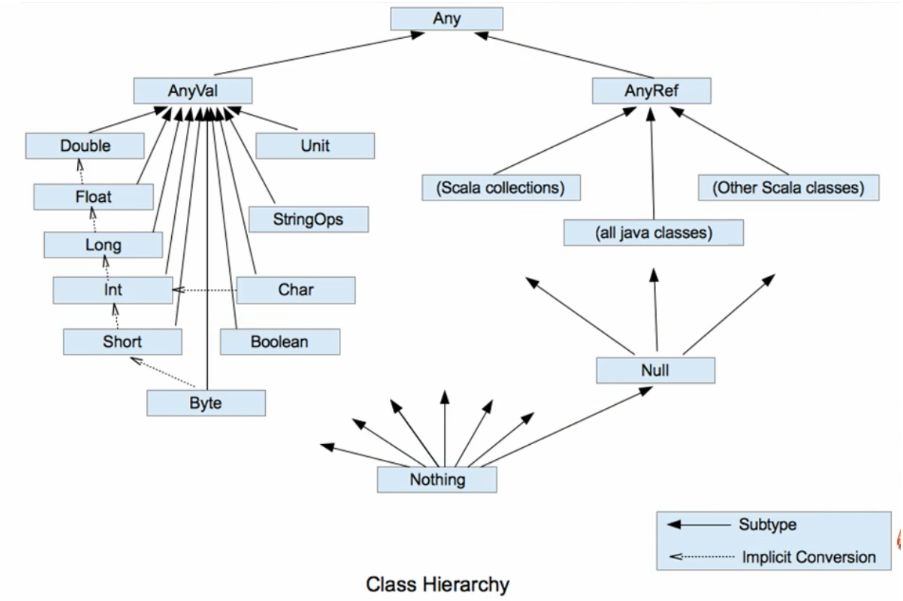
Scala中的继承结构
Scala 中继承关系如下图:
- Any 是整个继承关系的根节点;
- AnyRef 包含 Scala Classes 和 Java Classes,等价于 Java 中的 java.lang.Object;
- AnyVal 是所有值类型的一个标记;
- Scala中的StringOps是对Java中的String增强
- Scala数据类型仍然遵守,低精度的值类型向高精度值类型,自动转换(隐式转换)(图中虚线)
- Unit:对应Java中的void,用于方法返回值的位置,表示方法没有返回值。Unit是 一个数据类型,只有一个对象就是()。Void不是数据类型,只是一个关键字
- Null 是所有引用类型的子类型,唯一实例是 null,可以将 null 赋值给除了值类型外的所有类型的变量;
- Nothing 是所有类型的子类型。(主要用在一个函数没有明确返回值时使用,因为这样我们可以把抛出的返回值,返回给任何的变量或者函数。)
extends & override
Scala 的集成机制和 Java 有很多相似之处,比如都使用 extends 关键字表示继承,都使用 override 关键字表示重写父类的方法或成员变量。示例如下:
1 | //父类 |
使用 extends 关键字实现继承:
1 | // 1.使用 extends 关键字实现继承 |
测试继承:
1 | object ScalaApp extends App { |
调用超类构造器
在 Scala 的类中,每个辅助构造器都必须首先调用其他构造器或主构造器,这样就导致了子类的辅助构造器永远无法直接调用超类的构造器,只有主构造器才能调用超类的构造器。所以想要调用超类的构造器,代码示例如下:
1 | class Employee(name:String,age:Int,salary:Double) extends Person(name:String,age:Int) { |
类型检查和转换
想要实现类检查可以使用 isInstanceOf,判断一个实例是否来源于某个类或者其子类,如果是,则可以使用 asInstanceOf 进行强制类型转换。
1 | object ScalaApp extends App { |
构造顺序和提前定义
构造顺序
在 Scala 中还有一个需要注意的问题,如果你在子类中重写父类的 val 变量,并且超类的构造器中使用了该变量,那么可能会产生不可预期的错误。下面给出一个示例:
1 | // 父类 |
这里初始化 array 用到了变量 range,这里你会发现实际上 array 既不会被初始化 Array(10),也不会被初始化为 Array(2),实际的输出应该如下:
1 | 父类的默认构造器 |
可以看到 array 被初始化为 Array(0),主要原因在于父类构造器的执行顺序先于子类构造器,这里给出实际的执行步骤:
- 父类的构造器被调用,执行
new Array[Int](range)语句; - 这里想要得到 range 的值,会去调用子类 range() 方法,因为
override val重写变量的同时也重写了其 get 方法; - 调用子类的 range() 方法,自然也是返回子类的 range 值,但是由于子类的构造器还没有执行,这也就意味着对 range 赋值的
range = 2语句还没有被执行,所以自然返回 range 的默认值,也就是 0。
这里可能比较疑惑的是为什么 val range = 2 没有被执行,却能使用 range 变量,这里因为在虚拟机层面,是先对成员变量先分配存储空间并赋给默认值,之后才赋予给定的值。想要证明这一点其实也比较简单,代码如下:
1 | class Person { |
提前定义
想要解决上面的问题,有以下几种方法:
(1) . 将变量用 final 修饰,代表不允许被子类重写,即 final val range: Int = 10 ;
(2) . 将变量使用 lazy 修饰,代表懒加载,即只有当你实际使用到 array 时候,才去进行初始化;
1 | lazy val array: Array[Int] = new Array[Int](range) |
(3) . 采用提前定义,代码如下,代表 range 的定义优先于超类构造器。
1 | class Employee extends { |
但是这种语法也有其限制:你只能在上面代码块中重写已有的变量,而不能定义新的变量和方法,定义新的变量和方法只能写在下面代码块中。
注意事项:类的继承和下文特质 (trait) 的继承都存在这个问题,也同样可以通过提前定义来解决。虽然如此,但还是建议合理设计以规避该类问题。
抽象类
Scala 中允许使用 abstract 定义抽象类,并且通过 extends 关键字继承它。
定义抽象类:
1 | abstract class Person { |
继承抽象类:
1 | class Employee extends Person { |
特质
trait & with
Scala 中没有 interface 这个关键字,想要实现类似的功能,可以使用特质 (trait)。trait 等价于 Java 8 中的接口,因为 trait 中既能定义抽象方法,也能定义具体方法,这和 Java 8 中的接口是类似的。
1 | // 1.特质使用 trait 关键字修饰 |
想要使用特质,需要使用 extends 关键字,而不是 implements 关键字,如果想要添加多个特质,可以使用 with 关键字。
1 | // 1.使用 extends 关键字,而不是 implements,如果想要添加多个特质,可以使用 with 关键字 |
特质中的字段
和方法一样,特质中的字段可以是抽象的,也可以是具体的:
- 如果是抽象字段,则混入特质的类需要重写覆盖该字段;
- 如果是具体字段,则混入特质的类获得该字段,但是并非是通过继承关系得到,而是在编译时候,简单将该字段加入到子类。
1 | trait Logger { |
覆盖抽象字段:
1 | class InfoLogger extends Logger { |
带有特质的对象
Scala 支持在类定义的时混入 父类 trait,而在类实例化为具体对象的时候指明其实际使用的 子类 trait。示例如下:
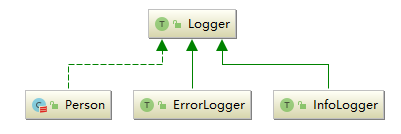
trait Logger:
1 | // 父类 |
trait ErrorLogger:
1 | // 错误日志打印,继承自 Logger |
trait InfoLogger:
1 | // 通知日志打印,继承自 Logger |
具体的使用类:
1 | // 混入 trait Logger |
这里通过 main 方法来测试:
1 | object ScalaApp extends App { |
这里前面两个输出比较明显,因为只指明了一个具体的 trait,这里需要说明的是第三个输出,因为 trait 的调用是由右到左开始生效的,所以这里打印出 Error:scala。
特质构造顺序
trait 有默认的无参构造器,但是不支持有参构造器。一个类混入多个特质后初始化顺序应该如下:
1 | // 示例 |
- 超类首先被构造,即 Person 的构造器首先被执行;
- 特质的构造器在超类构造器之前,在类构造器之后;特质由左到右被构造;每个特质中,父特质首先被构造;
- Logger 构造器执行(Logger 是 InfoLogger 的父类);
- InfoLogger 构造器执行;
- ErrorLogger 构造器执行;
- 所有超类和特质构造完毕,子类才会被构造。
函数和闭包
函数
函数与方法
Scala 中函数与方法的区别非常小,如果函数作为某个对象的成员,这样的函数被称为方法,否则就是一个正常的函数。
1 | // 定义方法 |
也可以使用 def 定义函数:
1 | def multi3 = (x: Int) => {x * x} |
multi2 和 multi3 本质上没有区别,这是因为函数是一等公民,val multi2 = (x: Int) => {x * x} 这个语句相当于是使用 def 预先定义了函数,之后赋值给变量 multi2。
函数类型
上面我们说过 multi2 和 multi3 本质上是一样的,那么作为函数它们是什么类型的?两者的类型实际上都是 Int => Int,前面一个 Int 代表输入参数类型,后面一个 Int 代表返回值类型。
1 | scala> val multi2 = (x: Int) => {x * x} |
一等公民&匿名函数
在 Scala 中函数是一等公民,这意味着不仅可以定义函数并调用它们,还可以将它们作为值进行传递:
1 | import scala.math.ceil |
在 Scala 中你不必给每一个函数都命名,如 (x: Int) => 3 * x 就是一个匿名函数:
1 | object ScalaApp extends App { |
特殊的函数表达式
可变长度参数列表
在 Java 中如果你想要传递可变长度的参数,需要使用 String ...args 这种形式,Scala 中等效的表达为 args: String*。
1 | object ScalaApp extends App { |
传递具名参数
向函数传递参数时候可以指定具体的参数名。
1 | object ScalaApp extends App { |
默认值参数
在定义函数时,可以为参数指定默认值。
1 | object ScalaApp extends App { |
闭包
闭包的定义
1 | var more = 10 |
如上函数 addMore 中有两个变量 x 和 more:
- x : 是一个绑定变量 (bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量 (free variable),因为函数字面量本生并没有给 more 赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
修改自由变量
这里需要注意的是,闭包捕获的是变量本身,即是对变量本身的引用,这意味着:
- 闭包外部对自由变量的修改,在闭包内部是可见的;
- 闭包内部对自由变量的修改,在闭包外部也是可见的。
1 | // 声明 more 变量 |
自由变量多副本
自由变量可能随着程序的改变而改变,从而产生多个副本,但是闭包永远指向创建时候有效的那个变量副本。
1 | // 第一次声明 more 变量 |
从上面的示例可以看出重新声明 more 后,全局的 more 的值是 100,但是对于闭包函数 addMore10 还是引用的是值为 10 的 more,这是由虚拟机来实现的,虚拟机会保证 more 变量在重新声明后,原来的被捕获的变量副本继续在堆上保持存活。
高阶函数
使用函数作为参数
定义函数时候支持传入函数作为参数,此时新定义的函数被称为高阶函数。
1 | object ScalaApp extends App { |
函数柯里化
我们上面定义的函数都只支持一个参数列表,而柯里化函数则支持多个参数列表。柯里化指的是将原来接受两个参数的函数变成接受一个参数的函数的过程。新的函数以原有第二个参数作为参数。
1 | object ScalaApp extends App { |
这里当你调用 curriedSum 时候,实际上是连着做了两次传统的函数调用,实际执行的柯里化过程如下:
- 第一次调用接收一个名为
x的 Int 型参数,返回一个用于第二次调用的函数,假设x为 2,则返回函数2+y; - 返回的函数接收参数
y,并计算并返回值2+3的值。
想要获得柯里化的中间返回的函数其实也比较简单:
1 | object ScalaApp extends App { |
柯里化支持多个参数列表,多个参数按照从左到右的顺序依次执行柯里化操作:
1 | object ScalaApp extends App { |
Scala模式匹配
模式匹配
Scala 支持模式匹配机制,可以代替 swith 语句、执行类型检查、以及支持析构表达式等。
更好的swith
Scala 不支持 swith,可以使用模式匹配 match...case 语法代替。但是 match 语句与 Java 中的 switch 有以下三点不同:
- Scala 中的 case 语句支持任何类型;而 Java 中 case 语句仅支持整型、枚举和字符串常量;
- Scala 中每个分支语句后面不需要写 break,因为在 case 语句中 break 是隐含的,默认就有;
- 在 Scala 中 match 语句是有返回值的,而 Java 中 switch 语句是没有返回值的。如下:
1 | object ScalaApp extends App { |
用作类型检查
1 | object ScalaApp extends App { |
匹配数据结构
匹配元组示例:
1 | object ScalaApp extends App { |
匹配数组示例:
1 | object ScalaApp extends App { |
提取器
数组、列表和元组能使用模式匹配,都是依靠提取器 (extractor) 机制,它们伴生对象中定义了 unapply 或 unapplySeq 方法:
- unapply:用于提取固定数量的对象;
- unapplySeq:用于提取一个序列;
这里以数组为例,Array.scala 定义了 unapplySeq 方法:
1 | def unapplySeq[T](x : scala.Array[T]) : scala.Option[scala.IndexedSeq[T]] = { /* compiled code */ } |
unapplySeq 返回一个序列,包含数组中的所有值,这样在模式匹配时,才能知道对应位置上的值。
样例类
样例类
样例类是一种的特殊的类,它们被经过优化以用于模式匹配,样例类的声明比较简单,只需要在 class 前面加上关键字 case。下面给出一个样例类及其用于模式匹配的示例:
1 | //声明一个抽象类 |
1 | // 样例类 Employee |
1 | // 样例类 Student |
当你声明样例类后,编译器自动进行以下配置:
- 构造器中每个参数都默认为
val; - 自动地生成
equals, hashCode, toString, copy等方法; - 伴生对象中自动生成
apply方法,使得可以不用 new 关键字就能构造出相应的对象; - 伴生对象中自动生成
unapply方法,以支持模式匹配。
除了上面的特征外,样例类和其他类相同,可以任意添加方法和字段,扩展它们。
用于模式匹配
样例的伴生对象中自动生成 unapply 方法,所以样例类可以支持模式匹配,使用如下:
1 | object ScalaApp extends App { |
类型参数
泛型
Scala 支持类型参数化,使得我们能够编写泛型程序。
泛型类
Java 中使用 <> 符号来包含定义的类型参数,Scala 则使用 []。
1 | class Pair[T, S](val first: T, val second: S) { |
1 | object ScalaApp extends App { |
泛型方法
函数和方法也支持类型参数。
1 | object Utils { |
类型限定
类型上界限定
Scala 和 Java 一样,对于对象之间进行大小比较,要求被比较的对象实现 java.lang.Comparable 接口。所以如果想对泛型进行比较,需要限定类型上界为 java.lang.Comparable,语法为 S <: T,代表类型 S 是类型 T 的子类或其本身。示例如下:
1 | // 使用 <: 符号,限定 T 必须是 Comparable[T]的子类型 |
1 | // 测试代码 |
扩展:如果你想要在 Java 中实现类型变量限定,需要使用关键字 extends 来实现,等价的 Java 代码如下:
2
3
4
5
6
7
8
9
10
11
>private T first;
>private T second;
>Pair(T first, T second) {
>this.first = first;
>this.second = second;
>}
>public T smaller() {
>return first.compareTo(second) < 0 ? first : second;
>}
>}
视图界定
在上面的例子中,如果你使用 Int 类型或者 Double 等类型进行测试,点击运行后,你会发现程序根本无法通过编译:
1 | val pair1 = new Pair(10, 12) |
之所以出现这样的问题,是因为 Scala 中的 Int 类并没有实现 Comparable 接口。在 Scala 中直接继承 Comparable 接口的是特质 Ordered,它在继承 compareTo 方法的基础上,额外定义了关系符方法,源码如下:
1 | // 除了 compareTo 方法外,还提供了额外的关系符方法 |
之所以在日常的编程中之所以你能够执行 3>2 这样的判断操作,是因为程序执行了定义在 Predef 中的隐式转换方法 intWrapper(x: Int) ,将 Int 类型转换为 RichInt 类型,而 RichInt 间接混入了 Ordered 特质,所以能够进行比较。
1 | // Predef.scala |
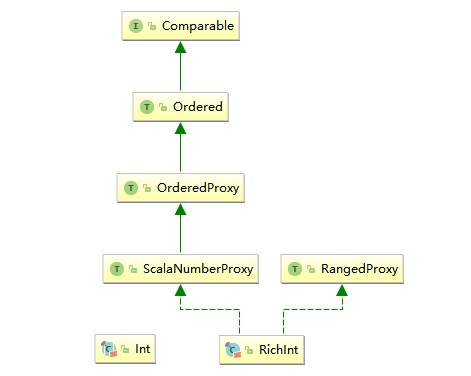
要想解决传入数值无法进行比较的问题,可以使用视图界定。语法为 T <% U,代表 T 能够通过隐式转换转为 U,即允许 Int 型参数在无法进行比较的时候转换为 RichInt 类型。示例如下:
1 | // 视图界定符号 <% |
注:由于直接继承 Java 中 Comparable 接口的是特质 Ordered,所以如下的视图界定和上面是等效的:
2
3
4
class Pair[T <% Ordered[T]](val first: T, val second: T) {
def smaller: T = if (first.compareTo(second) < 0) first else second
}
类型约束
如果你用的 Scala 是 2.11+,会发现视图界定已被标识为废弃。官方推荐使用类型约束 (type constraint) 来实现同样的功能,其本质是使用隐式参数进行隐式转换,示例如下:
1 | // 1.使用隐式参数隐式转换为 Comparable[T] |
当然,隐式参数转换也可以运用在具体的方法上:
1 | object PairUtils{ |
上下文界定
上下文界定的形式为 T:M,其中 M 是一个泛型,它要求必须存在一个类型为 M[T]的隐式值,当你声明一个带隐式参数的方法时,需要定义一个隐式默认值。所以上面的程序也可以使用上下文界定进行改写:
1 | class Pair[T](val first: T, val second: T) { |
在上面的示例中,我们无需手动添加隐式默认值就可以完成转换,这是因为 Scala 自动引入了 Ordering[Int]这个隐式值。为了更好的说明上下文界定,下面给出一个自定义类型的比较示例:
1 | // 1.定义一个人员类 |
ClassTag上下文界定
这里先看一个例子:下面这段代码,没有任何语法错误,但是在运行时会抛出异常:Error: cannot find class tag for element type T, 这是由于 Scala 和 Java 一样,都存在类型擦除,即泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉。对于下面的代码,在运行阶段创建 Array 时,你必须明确指明其类型,但是此时泛型信息已经被擦除,导致出现找不到类型的异常。
1 | object ScalaApp extends App { |
Scala 针对这个问题,提供了 ClassTag 上下文界定,即把泛型的信息存储在 ClassTag 中,这样在运行阶段需要时,只需要从 ClassTag 中进行获取即可。其语法为 T : ClassTag,示例如下:
1 | import scala.reflect._ |
类型下界限定
2.1 小节介绍了类型上界的限定,Scala 同时也支持下界的限定,语法为:U >: T,即 U 必须是类型 T 的超类或本身。
1 | // 首席执行官 |
多重界定
类型变量可以同时有上界和下界。 写法为 :
T > : Lower <: Upper;不能同时有多个上界或多个下界 。但可以要求一个类型实现多个特质,写法为 :
T < : Comparable[T] with Serializable with Cloneable;你可以有多个上下文界定,写法为
T : Ordering : ClassTag。
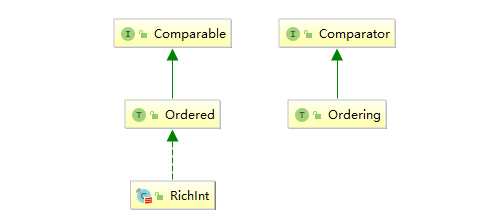
Ordering & Ordered
上文中使用到 Ordering 和 Ordered 特质,它们最主要的区别在于分别继承自不同的 Java 接口:Comparable 和 Comparator:
- Comparable:可以理解为内置的比较器,实现此接口的对象可以与自身进行比较;
- Comparator:可以理解为外置的比较器;当对象自身并没有定义比较规则的时候,可以传入外部比较器进行比较。
为什么 Java 中要同时给出这两个比较接口,这是因为你要比较的对象不一定实现了 Comparable 接口,而你又想对其进行比较,这时候当然你可以修改代码实现 Comparable,但是如果这个类你无法修改 (如源码中的类),这时候就可以使用外置的比较器。同样的问题在 Scala 中当然也会出现,所以 Scala 分别使用了 Ordering 和 Ordered 来继承它们。
下面分别给出 Java 中 Comparable 和 Comparator 接口的使用示例:
Comparable
1 | import java.util.Arrays; |
Comparator
1 | import java.util.Arrays; |
使用外置比较器还有一个好处,就是你可以随时定义其排序规则:
1 | // 按照年龄大小排序 |
上下文界定的优点
这里再次给出上下文界定中的示例代码作为回顾:
1 | // 1.定义一个人员类 |
使用上下文界定和 Ordering 带来的好处是:传入 Pair 中的参数不一定需要可比较,只要在比较时传入外置比较器即可。
需要注意的是由于隐式默认值二义性的限制,你不能像上面 Java 代码一样,在同一个上下文作用域中传入两个外置比较器,即下面的代码是无法通过编译的。但是你可以在不同的上下文作用域中引入不同的隐式默认值,即使用不同的外置比较器。
1 | implicit val ImpPersonOrdering = new PersonOrdering |
通配符
在实际编码中,通常需要把泛型限定在某个范围内,比如限定为某个类及其子类。因此 Scala 和 Java 一样引入了通配符这个概念,用于限定泛型的范围。不同的是 Java 使用 ? 表示通配符,Scala 使用 _ 表示通配符。
1 | class Ceo(val name: String) { |
目前 Scala 中的通配符在某些复杂情况下还不完善,如下面的语句在 Scala 2.12 中并不能通过编译:
1 | def min[T <: Comparable[_ >: T]](p: Pair[T]) ={} |
可以使用以下语法代替:
1 | type SuperComparable[T] = Comparable[_ >: T] |
隐式转换和隐式参数
隐式转换
使用隐式转换
隐式转换指的是以 implicit 关键字声明带有单个参数的转换函数,它将值从一种类型转换为另一种类型,以便使用之前类型所没有的功能。示例如下:
1 | // 普通人 |
隐式转换规则
并不是你使用 implicit 转换后,隐式转换就一定会发生,比如上面如果不调用 hammer() 方法的时候,普通人就还是普通人。通常程序会在以下情况下尝试执行隐式转换:
- 当对象访问一个不存在的成员时,即调用的方法不存在或者访问的成员变量不存在;
- 当对象调用某个方法,该方法存在,但是方法的声明参数与传入参数不匹配时。
而在以下三种情况下编译器不会尝试执行隐式转换:
- 如果代码能够在不使用隐式转换的前提下通过编译,则不会使用隐式转换;
- 编译器不会尝试同时执行多个转换,比如
convert1(convert2(a))*b; - 转换存在二义性,也不会发生转换。
这里首先解释一下二义性,上面的代码进行如下修改,由于两个隐式转换都是生效的,所以就存在了二义性:
1 | //两个隐式转换都是有效的 |
其次再解释一下多个转换的问题:
1 | class ClassA { |
引入隐式转换
隐式转换的可以定义在以下三个地方:
- 定义在原类型的伴生对象中;
- 直接定义在执行代码的上下文作用域中;
- 统一定义在一个文件中,在使用时候导入。
上面我们使用的方法相当于直接定义在执行代码的作用域中,下面分别给出其他两种定义的代码示例:
定义在原类型的伴生对象中:
1 | class Person(val name: String) |
1 | class Thor(val name: String) { |
1 | // 使用示例 |
定义在一个公共的对象中:
1 | object Convert { |
1 | // 导入 Convert 下所有的隐式转换函数 |
注:Scala 自身的隐式转换函数大部分定义在
Predef.scala中,你可以打开源文件查看,也可以在 Scala 交互式命令行中采用:implicit -v查看全部隐式转换函数。
隐式参数
使用隐式参数
在定义函数或方法时可以使用标记为 implicit 的参数,这种情况下,编译器将会查找默认值,提供给函数调用。
1 | // 定义分隔符类 |
关于隐式参数,有两点需要注意:
1.我们上面定义 formatted 函数的时候使用了柯里化,如果你不使用柯里化表达式,按照通常习惯只有下面两种写法:
1 | // 这种写法没有语法错误,但是无法通过编译 |
上面第一种写法编译的时候会出现下面所示 error 信息,从中也可以看出 implicit 是作用于参数列表中每个参数的,这显然不是我们想要到达的效果,所以上面的写法采用了柯里化。
1 | not enough arguments for method formatted: |
2.第二个问题和隐式函数一样,隐式默认值不能存在二义性,否则无法通过编译,示例如下:
1 | implicit val bracket = new Delimiters("(", ")") |
上面代码无法通过编译,出现错误提示 ambiguous implicit values,即隐式值存在冲突。
引入隐式参数
引入隐式参数和引入隐式转换函数方法是一样的,有以下三种方式:
- 定义在隐式参数对应类的伴生对象中;
- 直接定义在执行代码的上下文作用域中;
- 统一定义在一个文件中,在使用时候导入。
我们上面示例程序相当于直接定义执行代码的上下文作用域中,下面给出其他两种方式的示例:
定义在隐式参数对应类的伴生对象中;
1 | class Delimiters(val left: String, val right: String) |
1 | // 此时执行代码的上下文中不用定义 |
统一定义在一个文件中,在使用时候导入:
1 | object Convert { |
1 | // 在使用的时候导入 |
利用隐式参数进行隐式转换
1 | def smaller[T] (a: T, b: T) = if (a < b) a else b |
在 Scala 中如果定义了一个如上所示的比较对象大小的泛型方法,你会发现无法通过编译。对于对象之间进行大小比较,Scala 和 Java 一样,都要求被比较的对象需要实现 java.lang.Comparable 接口。在 Scala 中,直接继承 Java 中 Comparable 接口的是特质 Ordered,它在继承 compareTo 方法的基础上,额外定义了关系符方法,源码如下:
1 | trait Ordered[A] extends Any with java.lang.Comparable[A] { |
所以要想在泛型中解决这个问题,有两种方法:
使用视图界定
1 | object Pair extends App { |
视图限定限制了 T 可以通过隐式转换 Ordered[T],即对象一定可以进行大小比较。在上面的代码中 smaller(1,2) 中参数 1 和 2 实际上是通过定义在 Predef 中的隐式转换方法 intWrapper 转换为 RichInt。
1 | // Predef.scala |
为什么要这么麻烦执行隐式转换,原因是 Scala 中的 Int 类型并不能直接进行比较,因为其没有实现 Ordered 特质,真正实现 Ordered 特质的是 RichInt。
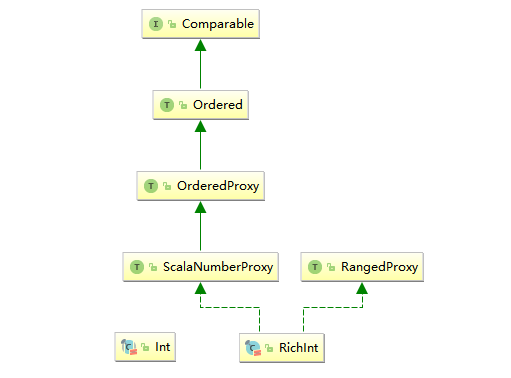
利用隐式参数进行隐式转换
Scala2.11+ 后,视图界定被标识为废弃,官方推荐使用类型限定来解决上面的问题,本质上就是使用隐式参数进行隐式转换。
1 | object Pair extends App { |
 微信
微信 支付宝
支付宝

