前置 为什么需要写并行代码
Linux Torvalds: 并行计算只有在图像处理,服务端编程2个领域可以使用。(java主要是服务端编程)
如果我们的CPU主频可以达到100G(现在还停留在4GHZ),我们可能就不会把并行看得这么重要,直接写串行代码就行了,而不需要多个CPU来写代码。
在我看来,这种现象(并发)或多或少是由于硬件设计者已经无计可施了导致的,他们将摩尔定律失效的责任推脱给软件开发者。
– 顶级计算机科学家唐纳德·尔文·克努斯
嘿嘿,就像普罗大众”不需要”关注GC一样,可能若干年后,也”不需要”关注并发编程了呢
同步(synchronous)和异步(asynchronous)
方法级别的,异步调用的任务是在另一个线程里处理。
同步是调用者主动等待这个调用的结果,异步是调用后,被调用者通过通知回调等告知调用者。
讲人话:
兰陵王对孙尚香说:香香,我喜欢你
孙尚香对兰陵王说:你等着,我考虑一下。
100 hundred years later …
孙尚香对兰陵王说: 对不起,我不爱你,你去找别人吧。
兰陵王对孙尚香说:香香,我喜欢你
孙尚香对兰陵王说:我考虑一下,如果喜欢你我打电话告诉你。
100 hundred years later …
孙尚香对兰陵王说: 对不起,我不爱你。
兰陵王对孙尚香说:没关系,我爱上妲己了。
并发(Concurrency)和并行(Parallelism)
单个CPU只能处理一个进程,多CPU可以处理多个进程。
并行的关键是:是可以可以同时 进行。而并发是在本质上不是同时,但是站在宏观角度可能展现出同时 进行的效果。
讲人话:
海王孙策和孙尚香、妲己谈恋爱。孙尚香、妲己同时给孙策发微信消息。
并发就是:孙策有1部手机,给孙尚香回了么么哒,又赶紧给妲己回了个么么哒。
并行就是:孙策有2部手机,左右开弓,同时给香香和妲己回了个么么哒。
临界区 临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
阻塞(Blocking)和非阻塞(Non-Blocking) 阻塞和非阻塞通常用来形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待 ,等待会导致线程挂起。这种情况就是阻塞。此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。
非阻塞允许多个线程同时进入临界区
讲人话:
拿上面的兰陵王x孙尚香的例子,阻塞非阻塞关注的是兰陵王。
阻塞:可怜的兰陵王要一直等香香的答复
非阻塞:兰陵王不用一直等香香的答复,在没收到答复时,可以去和小妲己谈恋爱。
ps: 同步异步关注的是孙尚香!
锁(Deadlock)、饥饿(Starvation)和活锁(Livelock)
饥饿:饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。
活锁:电梯遇人。2个人进出相互谦让
并行的级别
阻塞
非阻塞
无障碍(Obstruction-Free)
无障碍是一种最弱的非阻塞调度
自由出入临界区
无竞争时,有限步内完成操作
有竞争时,回滚数据
无锁(Lock-Free)
是无障碍 的
保证有一个线程可以胜出
1 2 3 while (!atomicVar.compareAndSet(localVar, localVar+1 )) { localVar = atomicVar.get(); }
无等待(Wait-Free)
无锁的 要求所有的线程都必须在有限步内完成
无饥饿的
有关并行的2个重要定律 了解一下,看不懂就算了,只要知道站在不同的角度看待优化这件事是不一样的就行了。
定义了串行系统并行化后的加速比的计算公式和理论上限,加速比定义:加速比=优化前系统耗时/优化后系统耗时
我们把一个程序改成了并行程序,能优化多少?
加速比=优化前系统耗时/优化后系统耗时=500/400=1.25
增加CPU处理器的数量并不一定能起到有效的作用提高系统内可并行化的模块比重,合理增加并行处理器数量,才能以最小的投入,得到最大的加速比。(如果程序串行比例很大,接近1,那么CPU数n再大,后面也接近于0.所以加速比不会大。)
这里用在上图: n是2个cpu,F是并行占比2/5. 计算下来也是1.25
说明处理器个数,串行比例和加速比之间的关系
只要有足够的并行化,那么加速比和CPU个数成正比
多线程 我们在之前,学习的程序在没有跳转语句的前提下,都是由上至下依次执行,那现在想要设计一个程序,边打游戏边听歌,怎么设计?
要解决上述问题,咱们得使用多进程或者多线程来解决.
并发与并行
并行 :指两个或多个事件在同一时刻 发生(同时执行)。并发 :指两个或多个事件在同一个时间段内 发生(交替执行)。
在操作系统中,安装了多个程序,并发指的是在一段时间内宏观上有多个程序同时运行,这在单 CPU 系统中,每一时刻只能有一道程序执行,即微观上这些程序是分时的交替运行,只不过是给人的感觉是同时运行,那是因为分时交替运行的时间是非常短的。
而在多个 CPU 系统中,则这些可以并发执行的程序便可以分配到多个处理器上(CPU),实现多任务并行执行,即利用每个处理器来处理一个可以并发执行的程序,这样多个程序便可以同时执行。目前电脑市场上说的多核 CPU,便是多核处理器,核越多,并行处理的程序越多,能大大的提高电脑运行的效率。
注意:单核处理器的计算机肯定是不能并行的处理多个任务的,只能是多个任务在单个CPU上并发运行。同理,线程也是一样的,从宏观角度上理解线程是并行运行的,但是从微观角度上分析却是串行运行的,即一个线程一个线程的去运行,当系统只有一个CPU时,线程会以某种顺序执行多个线程,我们把这种情况称之为线程调度。
线程与进程
进程 :进程是程序的一次执行过程,是系统运行程序的基本单位;系统运行一个程序即是一个进程从创建、运行到消亡的过程。每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程;
进程:其实就是应用程序的可执行单元(.exe文件)
每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程;
线程 :是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。一个进程中是可以有多个线程的,这个应用程序也可以称之为多线程程序。
线程:其实就是进程的可执行单元
每条线程都有独立的内存空间,一个进程可以同时运行多个线程;
多线程并行: 多条线程在同一时刻同时执行
多线程并发:多条线程在同一时间段交替执行 在java中线程的调度是:抢占式调度 在java中只有多线程并发(高并发),没有多线程并行
进程
线程
进程与线程的区别
进程:有独立的内存空间,进程中的数据存放空间(堆空间和栈空间)是独立的,至少有一个线程。
线程:堆空间是共享的,栈空间是独立的,线程消耗的资源比进程小的多。
注意: 下面内容为了解知识点
1:因为一个进程中的多个线程是并发运行的,那么从微观角度看也是有先后顺序的,哪个线程执行完全取决于 CPU 的调度,程序员是干涉不了的。而这也就造成的多线程的随机性。
2:Java 程序的进程里面至少包含两个线程,主进程也就是 main()方法线程,另外一个是垃圾回收机制线程。每当使用 java 命令执行一个类时,实际上都会启动一个 JVM,每一个 JVM 实际上就是在操作系统中启动了一个线程,java 本身具备了垃圾的收集机制,所以在 Java 运行时至少会启动两个线程。
3:由于创建一个线程的开销比创建一个进程的开销小的多,那么我们在开发多任务运行的时候,通常考虑创建多线程,而不是创建多进程。
线程调度:
Thread类 Thread类的概述
表示线程,也叫做线程类,创建该类的对象,就是创建线程对象(或者说创建线程)
线程的任务: 执行一段代码
Runnable : 接口,线程任务接口
Thread类的构造方法 线程开启我们需要用到了java.lang.Thread类,API中该类中定义了有关线程的一些方法,具体如下:
public Thread():分配一个新的线程对象,线程名称是默认生成的。
public Thread(String name):分配一个指定名字的新的线程对象。
public Thread(Runnable target):分配一个带有指定目标新的线程对象,线程名称是默认生成的。
public Thread(Runnable target,String name):分配一个带有指定目标新的线程对象并指定名字。
创建线程的方式有2种:
一种是通过继承Thread类的方式
一种是通过实现Runnable接口的方法
Thread类的常用方法
public String getName():获取当前线程名称。public void start():导致此线程开始执行; Java虚拟机调用此线程的run方法。public void run():此线程要执行的任务在此处定义代码。public static void sleep(long millis):使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。public static Thread currentThread() :返回对当前正在执行的线程对象的引用。
翻阅API后得知创建线程的方式总共有两种,一种是继承Thread类方式,一种是实现Runnable接口方式,
创建线程方式1_继承方式 Java使用java.lang.Thread类代表线程 ,所有的线程对象都必须是Thread类或其子类的实例。每个线程的作用是完成一定的任务,实际上就是执行一段程序流即一段顺序执行的代码。Java使用线程执行体来代表这段程序流。Java中通过继承Thread类来创建 并启动多线程 的步骤如下:
定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,因此把run()方法称为线程执行体。
创建Thread子类的实例,即创建了线程对象
调用线程对象的start()方法来启动该线程
代码如下:
1 2 3 4 5 6 7 8 9 public class MyThread extends Thread { @Override public void run () { for (int i = 0 ; i < 100 ; i++) { System.out.println("子线程 第" +(i+1 )+"次循环" ); } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test { public static void main (String[] args) { MyThread mt1 = new MyThread (); mt1.start(); for (int j = 0 ; j < 100 ; j++) { System.out.println("主线程 第" +(j+1 )+"次循环" ); } } }
图片效果:
创建线程方式2_实现方式 采用java.lang.Runnable也是非常常见的一种,我们只需要重写run方法即可。
步骤如下:
定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
调用线程对象的start()方法来启动线程。
代码如下:
1 2 3 4 5 6 7 8 9 10 public class MyRunnable implements Runnable { @Override public void run () { for (int i = 0 ; i < 100 ; i++) { System.out.println("子线程 第" +(i+1 )+"次循环" ); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t1 = new Thread (mr); t1.start(); for (int j = 0 ; j < 100 ; j++) { System.out.println("主线程 第" +(j+1 )+"次循环" ); } } }
图片效果:
通过实现Runnable接口,使得该类有了多线程类的特征。run()方法是多线程程序的一个执行目标。所有的多线程代码都在run方法里面。Thread类实际上也是实现了Runnable接口的类。
在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是继承Thread类还是实现Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程编程的基础。
tips:Runnable对象仅仅作为Thread对象的target,Runnable实现类里包含的run()方法仅作为线程执行体。而实际的线程对象依然是Thread实例,只是该Thread线程负责执行其target的run()方法。
创建线程方式3_匿名内部类方式 使用线程的内匿名内部类方式,可以方便的实现每个线程执行不同的线程任务操作。
使用匿名内部类的方式实现Runnable接口,重新Runnable接口中的run方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Test { public static void main (String[] args) { Thread t = new Thread (new Runnable () { @Override public void run () { for (int i = 0 ; i < 100 ; i++) { System.out.println("子线程 第" +(i+1 )+"次循环" ); } } }); t.start(); for (int j = 0 ; j < 100 ; j++) { System.out.println("主线程 第" +(j+1 )+"次循环" ); } } }
图片效果:
Thread和Runnable的区别 如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
总结:
实现Runnable接口比继承Thread类所具有的优势:
可以避免java中的单继承的局限性。
增加程序的健壮性,实现解耦操作,代码可以被多个线程共享,代码和线程独立。
适合多个相同的程序代码的线程去共享同一个资源。
线程池只能放入实现Runable或Callable类线程,不能直接放入继承Thread的类。
线程基本操作 终止线程
Thread.stop() 不推荐使用 。它会释放所有monitor
1 2 记录1:ID=1,NAME=小明 记录2:ID=2,NAME=小王
中断线程
public void Thread.interrupt() // 中断线程
public boolean Thread.isInterrupted() // 判断是否被中断
public static boolean Thread.interrupted() // 判断是否被中断,并清除当前中断状态
1 2 3 4 5 6 7 8 9 10 11 public void run () { while (true ){ if (Thread.currentThread().isInterrupted()){ System.out.println("Interruted!" ); break ; } Thread.yield (); } } t1.interrupt();
图片效果:
sleep 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static native void sleep (long millis) throws InterruptedException public void run () { while (true ){ if (Thread.currentThread().isInterrupted()){ System.out.println("Interruted!" ); break ; } try { Thread.sleep(2000 ); } catch (InterruptedException e) { System.out.println("Interruted When Sleep" ); Thread.currentThread().interrupt(); } Thread.yield (); } } } ... t1.interrupt();
图片效果:
挂起(suspend)和继续执行(resume)线程
suspend()不会释放锁
如果加锁发生在resume()之前 ,则死锁发生
2个方法都不推荐使用
实际上呢?
查看java中的线程
我们看到只有t2,t1没有了,因为t1,start,sleep了一会,所以t1可能是已经suspend挂起了.
而t2可能还没执行suspend,就先执行resume了。导致线程被冻住了。
等待线程结束(join)和谦让(yeild)
public final void join() throws InterruptedExceptionpublic final synchronized void join(long millis) throws InterruptedException
yeild,是释放当前自己的CPU,给你机会和我一起争抢,所以可能下次还是被我抢到
join,是等待你结束,我再加入,有些任务希望依赖前面的任务执行完再执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class JoinMain { public volatile static int i=0 ; public static class AddThread extends Thread { @Override public void run () { for (i=0 ;i<10000000 ;i++); } } public static void main (String[] args) throws InterruptedException { AddThread at=new AddThread (); at.start(); at.join(); System.out.println(i); } }
图片效果:
join本质
守护线程
在后台默默地完成一些系统性的服务,比如垃圾回收线程、JIT线程就可以理解为守护线程
当一个Java应用内,只有守护线程时,Java虚拟机就会自然退出
1 2 3 Thread t=new DaemonT(); t.setDaemon(true); t.start();
线程优先级
public final static int MIN_PRIORITY = 1;
public final static int NORM_PRIORITY = 5;
public final static int MAX_PRIORITY = 10;
1 2 3 4 5 6 Thread high=new HightPriority(); LowPriority low=new LowPriority(); high.setPriority(Thread.MAX_PRIORITY); low.setPriority(Thread.MIN_PRIORITY); low.start(); high.start();
高优先级的线程更容易再竞争中获胜
线程状态 线程由生到死的完整过程:技术素养和面试的要求。
当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中,有几种状态呢?在API中java.lang.Thread.State这个枚举中给出了六种线程状态 :
这里先列出各个线程状态发生的条件,下面将会对每种状态进行详细解析
线程状态
导致状态发生条件
NEW(新建)
线程刚被创建,但是并未启动。还没调用start方法。MyThread t = new MyThread()只有线程对象,没有线程特征。创建线程对象时
Runnable(可运行)
线程可以在java虚拟机中运行的状态,可能正在运行自己代码,也可能没有,这取决于操作系统处理器。调用了t.start()方法 :就绪(经典教法)。调用start方法时
Blocked(锁阻塞)
当一个线程试图获取一个对象锁,而该对象锁被其他的线程持有,则该线程进入Blocked状态;当该线程持有锁时,该线程将变成Runnable状态。等待锁对象时
Waiting(无限等待)
一个线程在等待另一个线程执行一个(唤醒)动作时,该线程进入Waiting状态。进入这个状态后是不能自动唤醒的,必须等待另一个线程调用notify或者notifyAll方法才能够唤醒。调用wait()方法时
Timed Waiting(计时等待)
同waiting状态,有几个方法有超时参数,调用他们将进入Timed Waiting状态。这一状态将一直保持到超时期满或者接收到唤醒通知。带有超时参数的常用方法有Thread.sleep 、Object.wait。调用sleep()方法时
Teminated(被终止)
因为run方法正常退出而死亡,或者因为没有捕获的异常终止了run方法而死亡。run方法执行结束时
无限等待:
进入无限等待: 使用锁对象调用wait()方法
唤醒无限等待线程: 其他线程使用锁对象调用notify()或者notifyAll()方法
特点: 不会霸占cpu,也不会霸占锁对象(释放)
线程状态的切换:
我们不需要去研究这几种状态的实现原理,我们只需知道在做线程操作中存在这样的状态。那我们怎么去理解这几个状态呢,新建与被终止还是很容易理解的,我们就研究一下线程从Runnable(可运行)状态与非运行状态之间的转换问题。
等待唤醒机制 子线程: 打印1000次i循环
主线程: 打印1000次j循环
规律: 打印1次i循环,就打印1次j循环,以此类推…
假如子线程先执行,打印1次i循环,让子线程进入无限等待,执行j循环,唤醒子线程,主线程就进入无限等待
值班: 2个人值班
什么是等待唤醒机制
这是多个线程间的一种协作 机制。就好比在公司里你和你的同事们,你们可能存在在晋升时的竞争,但更多时候你们更多是一起合作以完成某些任务。
就是在一个线程进行了规定操作后,就进入无限等待状态(**wait()**),调用notfiy()方法唤醒其他线程来执行,其他线程执行完后,进入无限等待,唤醒等待线程执行,依次类推…. 如果需要,可以使用 notifyAll()来唤醒所有的等待线程。
wait/notify 就是线程间的一种协作机制。
实现等待唤醒机制程序:
必须使用锁对象调用wait方法,让当前线程进入无限等待状态
必须使用锁对象调用notify\notifyAll方法唤醒等待线程
调用wait\notfiy\notfiyAll方法的锁对象必须一致
分析的等待唤醒机制程序:
线程的调度依然是抢占式调度
线程进入无限等待状态,就不会霸占cpu和锁对象(释放),也不会抢占cpu和锁对象
如果是在同步锁中\Lock锁中,调用sleep()方法进入计时等待,不会释放cpu和锁对象(依然占用)
等待唤醒机制相关方法介绍
public void wait() : 让当前线程进入到无限等待状态 此方法必须锁对象调用.public void notify() : 唤醒当前锁对象上等待状态的线程 此方法必须锁对象调用.案例一: 进入无限等待
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Test { static Object obj = new Object (); public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { System.out.println("准备进入无限等待状态..." ); synchronized (obj){ try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class Test1 { static Object lock = new Object (); public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { synchronized (lock){ System.out.println("无限等待线程:准备进入无限等待状态..." ); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("无限等待线程:被其他线程唤醒..." ); } } }).start(); new Thread (new Runnable () { @Override public void run () { synchronized (lock){ System.out.println("唤醒线程: 准备唤醒无限等待线程..." ); lock.notify(); try { Thread.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("唤醒线程: 唤醒完毕" ); } } }).start(); } }
图片效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class Test1 { static Object lock = new Object (); public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { while (true ){ synchronized (lock){ System.out.println("无限等待线程:准备进入无限等待状态..." ); try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("无限等待线程:被其他线程唤醒=========================================" ); } } } }).start(); new Thread (new Runnable () { @Override public void run () { while (true ){ synchronized (lock){ System.out.println("唤醒线程: 准备唤醒无限等待线程..." ); lock.notify(); System.out.println("唤醒线程: 唤醒完毕" ); } } } }).start(); } }
图片效果:
实现等待唤醒机制程序:
必须使用锁对象调用wait方法,让当前线程进入无限等待状态
必须使用锁对象调用notify\notifyAll方法唤醒等待线程
调用wait\notfiy\notfiyAll方法的锁对象必须一致
分析的等待唤醒机制程序:
线程的调度依然是抢占式调度
线程进入无限等待状态,就不会霸占cpu和锁对象(释放),也不会抢占cpu和锁对象
如果是在同步锁中\Lock锁中,调用sleep()方法进入计时等待,不会释放cpu和锁对象(依然占用)
实操:等待唤醒案例 需求
分析 创建一个包子类,并拥有一个状态属性,通过判断包子的状态属性,如果为true,包子铺生产包子,否则吃货吃包子。
包子铺线程生产包子,吃货线程消费包子。当包子没有时(包子状态为false),吃货线程等待,包子铺线程生产包子(即包子状态为true),并通知吃货线程(解除吃货的等待状态),因为已经有包子了,那么包子铺线程进入等待状态。
接下来,吃货线程能否进一步执行则取决于锁的获取情况。如果吃货获取到锁,那么就执行吃包子动作,包子吃完(包子状态为false),并通知包子铺线程(解除包子铺的等待状态),吃货线程进入等待。包子铺线程能否进一步执行则取决于锁的获取情况。
实现 包子类:
1 2 3 4 5 6 public class BaoZi { boolean flag = false ; String xianer; }
生成包子类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class BaoZiPu extends Thread { BaoZi bz; public BaoZiPu (BaoZi bz) { this .bz = bz; } @Override public void run () { while (true ){ synchronized (bz) { if (bz.flag == true ){ try { bz.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } if (bz.flag == false ){ System.out.println("包子铺线程:开始制作包子..." ); bz.xianer = "韭菜鸡蛋" ; bz.flag = true ; System.out.println("包子铺线程:包子做好了,吃货快来吃包子..." ); bz.notify(); } } } } }
消费包子类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class ChiHuo extends Thread { BaoZi bz; public ChiHuo (BaoZi bz) { this .bz = bz; } @Override public void run () { while (true ){ synchronized (bz) { if (bz.flag == false ){ try { bz.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } if (bz.flag == true ){ System.out.println("吃货线程:开始吃包子,包子的馅儿是:" +bz.xianer); bz.flag = false ; System.out.println("吃货线程:吃完了包子,包子铺线程快来做包子========================================" ); bz.notify(); } } } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 public class Test { public static void main (String[] args) { BaoZi bz = new BaoZi (); new BaoZiPu (bz).start(); new ChiHuo (bz).start(); } }
图片效果:
死锁 什么是死锁: 在多线程程序中,使用了多把锁,造成线程之间相互等待.程序不往下走了。
产生死锁的条件
1.有多把锁
2.有多个线程
3.有同步代码块嵌套
死锁代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Test { public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { synchronized ("锁A" ){ System.out.println("线程1:拿到锁A,准备拿锁B..." ); synchronized ("锁B" ){ System.out.println("线程1:拿到了锁A和锁B,开始执行" ); } } } }, "线程1" ).start(); new Thread (new Runnable () { @Override public void run () { synchronized ("锁B" ){ System.out.println("线程2:拿到锁B,准备拿锁A..." ); synchronized ("锁A" ){ System.out.println("线程2:拿到了锁B和锁A,开始执行" ); } } } }, "线程2" ).start(); } }
图片效果:
这里是有可能产生死锁,并不是每次都会
注意:我们应该尽量避免死锁
线程安全 高并发及线程安全
高并发 :是指在某个时间点上,有大量的用户(线程)同时访问同一资源。例如:天猫的双11购物节、12306的在线购票在某个时间点上,都会面临大量用户同时抢购同一件商品/车票的情况。线程安全 :在某个时间点上,当大量用户(线程)访问同一资源时,由于多线程运行机制的原因,可能会导致被访问的资源出现”数据污染”的问题。线程安全指某个函数、函数库在多线程环境中被调用时,能够正确地处理各个线程的局部变量,使程序功能正确完成。
i++在多线程下访问的情况:
可以看到是可能发生同时操作的现象,可以加个synchronize阻塞解决
线程安全问题 我们通过一个案例,演示线程的安全问题:
电影院要卖票,我们模拟电影院的卖票过程。假设要播放的电影是 “葫芦娃大战奥特曼”,本次电影的座位共100个(本场电影只能卖100张票)。
售票窗口: 使用线程来模拟。
共同卖100张票
窗口卖票的任务是一样的(线程的任务代码是一样的)
我们来模拟电影院的售票窗口,实现多个窗口同时卖 “葫芦娃大战奥特曼”这场电影票(多个窗口一起卖这100张票)需要窗口,采用线程对象来模拟;需要票,Runnable接口子类来模拟。
模拟票:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class MyRunnable implements Runnable { int tickets = 100 ; @Override public void run () { while (true ) { if (tickets < 1 ) { break ; } try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":正在出售第" + tickets + "张票" ); tickets--; } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Test { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t1 = new Thread (mr, "窗口1" ); Thread t2 = new Thread (mr, "窗口2" ); Thread t3 = new Thread (mr, "窗口3" ); Thread t4 = new Thread (mr, "窗口4" ); t1.start(); t2.start(); t3.start(); t4.start(); } }
程序执行后,结果会出现的问题
发现程序出现了两个问题:
相同的票数,比如100这张票被卖了四回。
不存在的票,比如0票与-1票,-2票,是不存在的。
遗漏票,例如:99,98,97没有出现
这种问题,几个窗口(线程)票数不同步了,这种问题称为线程不安全。
卖票案例问题分析:
synchronized
synchronized关键字:表示“同步”的。它可以对“多行代码”进行“同步”——将多行代码当成是一个完整的整体,一个线程如果进入到这个代码块中,会全部执行完毕,执行结束后,其它线程才会执行。这样可以保证这多行的代码作为完整的整体,被一个线程完整的执行完毕。
synchronized被称为“重量级的锁”方式,也是“悲观锁”——效率比较低。
synchronized有几种使用方式:
b).同步方法【常用】
当我们使用多个线程访问同一资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题。
要解决上述多线程并发访问一个资源的安全性问题:也就是解决重复票与不存在票问题 ,Java中提供了同步机制(synchronized )来解决。
根据案例简述:
1 窗口1线程进入操作的时候,窗口2和窗口3线程只能在外等着,窗口1操作结束,窗口1和窗口2和窗口3才有机会进入代码去执行。也就是说在某个线程修改共享资源的时候,其他线程不能修改该资源,等待修改完毕同步之后,才能去抢夺CPU资源,完成对应的操作,保证了数据的同步性,解决了线程不安全的现象。
同步代码块
同步代码块 :synchronized关键字可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。
格式:
1 2 3 synchronized (同步锁){ 需要同步操作的代码 }
同步锁 :
对象的同步锁只是一个概念,可以想象为在对象上标记了一个锁.
锁对象 可以是任意类型。
多个线程对象 要使用同一把锁。
注意:在任何时候,最多允许一个线程拥有同步锁,谁拿到锁就进入代码块,其他的线程只能在外等着(BLOCKED)。
使用同步代码块解决代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public class MyRunnable implements Runnable { int tickets = 100 ; @Override public void run () { while (true ) { synchronized (this ) { if (tickets < 1 ) { break ; } try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":正在出售第" + tickets + "张票" ); tickets--; } } } } public class Test { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t1 = new Thread (mr, "窗口1" ); Thread t2 = new Thread (mr, "窗口2" ); Thread t3 = new Thread (mr, "窗口3" ); Thread t4 = new Thread (mr, "窗口4" ); t1.start(); t2.start(); t3.start(); t4.start(); } }
图片效果:
当使用了同步代码块后,上述的线程的安全问题,解决了。
小结
1 2 3 4 5 6 7 格式: synchronized (锁对象){ } 锁对象: 1. 语法上,锁对象可以是任意类的对象 2. 多条线程想要实现同步,必须锁对象一致
同步方法
同步方法 :使用synchronized修饰的方法,就叫做同步方法,保证A线程执行该方法的时候,其他线程只能在方法外等着。
格式:
1 2 3 public synchronized void method () { 可能会产生线程安全问题的代码 }
同步锁是谁?
对于非static方法,同步锁就是this。
对于static方法,我们使用当前方法所在类的字节码对象(类名.class)。
使用同步方法代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class MyRunnable implements Runnable { int tickets = 100 ; @Override public void run () { while (true ) { if (sellTickets()) break ; } } private synchronized boolean sellTickets () { if (tickets < 1 ) { return true ; } try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":正在出售第" + tickets + "张票" ); tickets--; return false ; } } public class Test { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t1 = new Thread (mr, "窗口1" ); Thread t2 = new Thread (mr, "窗口2" ); Thread t3 = new Thread (mr, "窗口3" ); Thread t4 = new Thread (mr, "窗口4" ); t1.start(); t2.start(); t3.start(); t4.start(); } }
图片效果:
小结
1 2 3 4 5 6 7 格式: 修饰符 synchronized 返回值类型 方法名(形参列表){ } 锁对象: 非静态同步方法: 锁对象是this 静态同步方法: 锁对象是该方法所在类的字节码对象(类名.class)
扩展:同步方法的锁对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 开发中,一条线程使用的是同步代码块,一条线程使用的是同步方法,但这2 条线程需要实现同步 --->实现这个需求,同步代码块和同步方法的锁对象必须一致,而同步方法的锁对象是默认的,所以必须清楚同步方法的锁对象 public class Demo { public synchronized void method1 () { System.out.println(Thread.currentThread().getName() + ":打开厕所门..." ); System.out.println(Thread.currentThread().getName() + ":关闭厕所门..." ); System.out.println(Thread.currentThread().getName() + ":脱裤子..." ); System.out.println(Thread.currentThread().getName() + ":蹲下..." ); System.out.println(Thread.currentThread().getName() + ":用力..." ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":擦屁股..." ); System.out.println(Thread.currentThread().getName() + ":穿裤子..." ); System.out.println(Thread.currentThread().getName() + ":冲厕所..." ); System.out.println(Thread.currentThread().getName() + ":打开厕所门,洗手,走人..." ); } public static synchronized void method2 () { System.out.println(Thread.currentThread().getName() + ":打开厕所门..." ); System.out.println(Thread.currentThread().getName() + ":关闭厕所门..." ); System.out.println(Thread.currentThread().getName() + ":脱裤子..." ); System.out.println(Thread.currentThread().getName() + ":蹲下..." ); System.out.println(Thread.currentThread().getName() + ":用力..." ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":擦屁股..." ); System.out.println(Thread.currentThread().getName() + ":穿裤子..." ); System.out.println(Thread.currentThread().getName() + ":冲厕所..." ); System.out.println(Thread.currentThread().getName() + ":打开厕所门,洗手,走人..." ); } } public class Test { public static void main (String[] args) { Demo d = new Demo (); new Thread (new Runnable () { @Override public void run () { synchronized (d) { System.out.println(Thread.currentThread().getName() + ":打开厕所门..." ); System.out.println(Thread.currentThread().getName() + ":关闭厕所门..." ); System.out.println(Thread.currentThread().getName() + ":脱裤子..." ); System.out.println(Thread.currentThread().getName() + ":蹲下..." ); System.out.println(Thread.currentThread().getName() + ":用力..." ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":擦屁股..." ); System.out.println(Thread.currentThread().getName() + ":穿裤子..." ); System.out.println(Thread.currentThread().getName() + ":冲厕所..." ); System.out.println(Thread.currentThread().getName() + ":打开厕所门,洗手,走人..." ); } } }, "张三" ).start(); new Thread (new Runnable () { @Override public void run () { d.method1(); } }, "李四" ).start(); } }
图片效果:
使用的都是实例锁对象:
使用的都是静态锁对象:
以上都是锁对象一致,正常的情况,
如果不一样,就会出现线程乱套的现象。
Lock锁 java.util.concurrent.locks.Lock机制提供了比synchronized 代码块和synchronized 方法更广泛的锁定操作,同步代码块/同步方法具有的功能Lock都有,除此之外更强大,更加面向对象
Lock锁也称同步锁,加锁与释放锁方法化了,如下:
public void lock() :加同步锁。public void unlock():释放同步锁。
使用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;public class MyRunnable implements Runnable { int tickets = 100 ; Lock lock = new ReentrantLock (); @Override public void run () { while (true ) { lock.lock(); if (tickets < 1 ) { lock.unlock(); break ; } try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":正在出售第" + tickets + "张票" ); tickets--; lock.unlock(); } } } public class Test { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t1 = new Thread (mr, "窗口1" ); Thread t2 = new Thread (mr, "窗口2" ); Thread t3 = new Thread (mr, "窗口3" ); Thread t4 = new Thread (mr, "窗口4" ); t1.start(); t2.start(); t3.start(); t4.start(); } }
图片效果:
多线程的运行机制 当一个线程启动后,JVM会为其分配一个独立的”线程栈区”,这个线程会在这个独立的栈区中运行。
看一下简单的线程的代码:
一个线程类:
1 2 3 4 5 6 7 8 public class MyThread extends Thread { @Override public void run () { for (int i = 0 ; i < 20 ; i++) { System.out.println("小强: " + i); } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 public class Demo { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); for (int i = 0 ; i < 20 ; i++) { System.out.println("旺财: " + i); } } }
启动后,内存的运行机制:
多个线程在各自栈区中独立、无序的运行,当访问一些代码,或者同一个变量时,就可能会产生一些问题
多线程的安全性问题-可见性
除了编译器重排优化,以及硬件优化,还可能是其他方面的优化导致可见性问题的.比如JVM层面的
-server模式(server模式会做优化)运行上述代码,永远不会停止
解决方案也很简单,给stop加volatile,每次循环都会get一下stop的值
例如下面的程序,先启动一个线程,在线程中将一个变量的值更改,而主线程却一直无法获得此变量的新值。
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class MyThread extends Thread { boolean flag = false ; @Override public void run () { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } flag = true ; System.out.println("修改后flag的值为:" +flag); } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Test { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); while (true ){ if (MyThread.flag == true ){ System.out.println("死循环结束" ); break ; } } } }
原因:
Java内存模型(Java Memory Model)描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
简而言之: 就是所有共享变量都是存在主内存中的,线程在执行的时候,有单独的工作栈内存,会把共享变量拷贝一份到线程的单独工作内存中,并且对变量所有的操作,都是在单独的工作内存中完成的,不会直接读写主内存中的变量值
一个线程没有看见另一个线程对共享变量的修改
多线程的安全性问题-有序性 在并发时,程序的执行可能就会出现乱序
一条指令的执行是可以分为很多步骤的
取指 IF
译码和取寄存器操作数 ID
执行或者有效地址计算 EX
存储器访问 MEM
写回 WB
更复杂的操作:
为了尽可能减少气泡(空拍),提升性能 => 指令重排
重排后:
有些时候“编译器”在编译代码时,会对代码进行“重排”,例如:
int a = 10; //1
int b = 20; //2
int c = a + b; //3
第一行和第二行可能会被“重排”:可能先编译第二行,再编译第一行,总之在执行第三行之前,会将1,2编译完毕。1和2先编译谁,不影响第三行的结果。
但在“多线程”情况下,代码重排,可能会对另一个线程访问的结果产生影响:
多线程环境下,我们通常不希望对一些代码进行重排的!!
多线程的安全性问题-原子性 概述:所谓的原子性是指在一次操作或者多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行,多个操作是一个不可以分割的整体。
请看以下示例:
一条子线程和一条主线程都对共享变量a进行++操作,每条线程对a++操作100000次
1.制作线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class MyThread extends Thread { static int a = 0 ; @Override public void run () { for (int i = 0 ; i < 100000 ; i++) { a++; } System.out.println("子线程执行完毕!" ); } }
2.制作测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class Test { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); for (int i = 0 ; i < 100000 ; i++) { MyThread.a++; } try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("最终:" +MyThread.a); } }
图片效果:
没有达到期望
原因:两个线程对共享变量的操作产生覆盖的效果
Happen-Before规则
程序顺序原则:一个线程内保证语义的串行性
volatile规则:volatile变量的写,先发生于读,这保证了volatile变量的可见性
锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
传递性:A先于B,B先于C,那么A必然先于C
线程的start()方法先于它的每一个动作
线程的所有操作先于线程的终结(Thread.join())
线程的中断(interrupt())先于被中断线程的代码
对象的构造函数执行结束先于finalize()方法
volatile关键字 什么是volatile关键字
volatile是一个”变量修饰符”,它只能修饰”成员变量”,它能强制线程每次从主内存获取值,并能保证此变量不会被编译器优化。
volatile能解决变量的可见性、有序性;
volatile不能解决变量的原子性
volatile解决可见性
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class MyThread extends Thread { volatile static boolean flag = false ; @Override public void run () { try { Thread.sleep(5000 ); } catch (InterruptedException e) { e.printStackTrace(); } flag = true ; System.out.println("子线程把flag的值修改为true了" ); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Test { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); while (true ){ if (MyThread.flag == true ){ System.out.println("结束死循环" ); break ; } } } }
图片效果:
当变量被修饰为volatile时,会迫使线程每次使用此变量,都会去主内存获取,保证其可见性
volatile解决有序性 当变量被修饰为volatile时,会禁止代码重排
volatile不能解决原子性
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.itheima.demo10_volatile不能解决原子性;public class MyThread extends Thread { volatile static int a = 0 ; @Override public void run () { for (int i = 0 ; i < 800000 ; i++) { a++; } System.out.println("子线程执行完毕!" ); } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.itheima.demo10_volatile不能解决原子性;public class Test { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); for (int i = 0 ; i < 800000 ; i++) { MyThread.a++; } try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("最终:" + MyThread.a); } }
图片效果:
所以,volatile关键字只能解决”变量”的可见性、有序性问题,并不能解决原子性问题
原子类
也叫无锁类
在java.util.concurrent.atomic包下定义了一些对“变量”操作的“原子类”:它们可以保证对“变量”操作的:原子性、有序性、可见性。
CAS原理 CAS(compare and swap)算法的过程是这样:它包含3个参数CAS(V,E,N)。V表示要更新的变量,E表示预期值,N表示新值。
仅当V值等于E值时,才会将V的值设为N。
如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。
最后,CAS返回当前V的真实值。
CAS操作是抱着乐观的态度进行的(乐观锁),它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
基于这样的原理,CAS操作即时没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理 。
CAS整体是一条CPU指令完成的,是原子性,所以不用担心 读值、比值、设值 步骤之间有其他步骤干扰。
1 2 3 4 5 6 7 8 9 10 11 12 cmpxchg /* accumulator = AL, AX, or EAX, depending on whether a byte, word, or doubleword comparison is being performed */ if(accumulator == Destination) { ZF = 1; Destination = Source; } else { ZF = 0; accumulator = Destination; }
一般我们认为这种无锁的(非阻塞的),比有锁的(阻塞的)效率要好
一个线程如果在系统层面被挂起,做一次上下文交换,要花大约8W次系统时钟周期。而无锁可能重启(一个循环体)操作,成本小很多。
AtomicInteger java.util.concurrent.atomic.AtomicInteger:对int变量操作的“原子类”;
1 2 3 4 5 6 7 8 9 10 11 主要接口: public final int get () public final void set (int newValue) public final int getAndSet (int newValue) public final boolean compareAndSet (int expect, int u) public final int getAndIncrement () public final int getAndDecrement () public final int getAndAdd (int delta) public final int incrementAndGet () public final int decrementAndGet () public final int addAndGet (int delta)
我们可以通过AtomicInteger类,来看看它们是怎样工作的
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.concurrent.atomic.AtomicInteger;public class MyThread extends Thread { static AtomicInteger a = new AtomicInteger (0 ); @Override public void run () { for (int i = 0 ; i < 100000 ; i++) { a.getAndIncrement(); } System.out.println("子线程执行完毕!" ); } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Test { public static void main (String[] args) { MyThread mt = new MyThread (); mt.start(); for (int i = 0 ; i < 100000 ; i++) { MyThread.a.getAndIncrement(); } try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("最终:" + MyThread.a); } }
解决了原子性的问题,图片效果:
我们能看到,无论程序运行多少次,其结果总是正确的!
AtomicInteger工作原理-CAS机制
这个应该比较好理解:
举例:
比如一个很简单的操作,把变量 A = 2 加 1,结果为 3.
则先读取 A 的当前值 E 为 2,在内存计算结果 V 为 3,比较之前读出来的 A 的当前值 2 和 最新值,如果最新值为 2 ,表示这个值没有被别人改过,则放心的把最终的值更新为 3.
ABA 问题 :有一种情况是,在你更新结果之前,其他有个线程在中途把 A 更新成了 5 ,又更新回了 2。但是在当前线程看起来,没有被改过。
Unsafe 非安全的操作,比如:
根据偏移量设置值(偏移量是C中的指针操作的概念)
park(): 停止线程
底层的CAS操作: 比如AtomicInteger原理是CAS机制,他的方法如getAndIncrement等,就用到了Unsafe操作
非公开API,在不同版本的JDK中,可能有较大差异 (不保证向前/向后兼容,他也不希望你用这个东西,jdk内部用得多)
1 2 3 4 5 6 7 8 9 10 11 12 13 主要接口 public native int getInt (Object o, long offset) ;public native void putInt (Object o, long offset, int x) ;public native long objectFieldOffset (Field f) ;public native void putIntVolatile (Object o, long offset, int x) ;public native int getIntVolatile (Object o, long offset) ;public native void putOrderedInt (Object o, long offset, int x) ;
AtomicReference 对对象的引用(比如String)进行修改可以用这个类来保证线程的安全。AtomicReference是一个模板类,抽象化了数据类型
get()
set(V)
compareAndSet()
getAndSet(V)
多个线程修改引用的时候希望可以保证安全,可以使用AtomicReference
可以看到只有一个线程能修改成功
AtomicStampedReference AtomicReference+时间戳
1 2 3 4 5 6 7 8 9 主要接口 public boolean compareAndSet (V expectedReference,V newReference,int expectedStamp,int newStamp) public V getReference () public int getStamp () public void set (V newReference, int newStamp)
主要是用来解决ABA问题
一个线程拿到Reference是A,做自己的额外计算操作,准备开始赋值时,第二个线程把A改成B,第三个线程把B改成A。第一个线程开始做CAS操作,读取了以下,感觉还是A。认为这个数据没有被改过,就成功把值设置回去。设置成了C。
这样一个过程,如果只是加法(跟过程状态无关,跟结果相关的)。问题不大。但是如果是对过程状态敏感的。
比如给一个用户充10块钱,不能说花了之后再充10块钱。
解决办法就是加个时间戳,我们不仅拿到A,还拿到时间戳s。然后2个都做对比。
如果timestamp不加1,相当于普通的AtomicReference类,就会有ABA问题,就会出现图中的重复充值的问题。
AtomicIntegerArray 支持无锁的数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 主要接口 public final int get (int i) public final int length () public final int getAndSet (int i, int newValue) public final boolean compareAndSet (int i, int expect, int update) public final int getAndIncrement (int i) public final int getAndDecrement (int i) public final int getAndAdd (int i, int delta)
常用的数组操作的原子类:java.util.concurrent.atomic.AtomicIntegetArray:对int数组操作的原子类。 int[]
2)java.util.concurrent.atomic.AtomicLongArray:对long数组操作的原子类。long[]
3)java.util.concurrent.atomic.AtomicReferenceArray:对引用类型数组操作的原子类。Object[]
数组的多线程并发访问的安全性问题 :
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 public class MyThread extends Thread { public static int [] arr = new int [1000 ]; @Override public void run () { for (int i = 0 ; i < arr.length(); i++) { arr[i]++; } System.out.println("结束" ); } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Demo { public static void main (String[] args) throws InterruptedException { for (int i = 0 ; i < 1000 ; i++) { new MyThread ().start(); } Thread.sleep(1000 * 5 ); System.out.println("主线程休息5秒醒来" ); for (int i = 0 ; i < MyThread.arr.length; i++) { System.out.println(MyThread.arr[i]); } } }
正常情况,数组的每个元素最终结果应为:1000,而实际打印:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1000 1000 1000 1000 999 999 999 999 999 999 999 999 1000 1000 1000 1000
可以发现,有些元素并不是1000.
为保证数组的多线程安全,改用AtomicIntegerArray 类,演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class MyThread extends Thread { public static AtomicIntegerArray arr = new AtomicIntegerArray (1000 ); @Override public void run () { for (int i = 0 ; i < arr.length(); i++) { arr.addAndGet(i, 1 ); } System.out.println("结束" ); } } public class Demo { public static void main (String[] args) throws InterruptedException { for (int i = 0 ; i < 1000 ; i++) { new MyThread ().start(); } Thread.sleep(1000 * 5 ); System.out.println("主线程休息5秒醒来" ); for (int i = 0 ; i < MyThread.arr.length(); i++) { System.out.println(MyThread.arr.get(i)); } } }
先在能看到,每次运行的结果都是正确的。
AtomicIntegerFieldUpdater 让普通变量也享受原子操作。
如果一个类的成员变量,一开始是普通的int,但是后面操作的时候,想要用Atomic特性,但是又不想动原类型.改原类型可能要牵扯改动很多
1 2 3 主要接口 AtomicIntegerFieldUpdater.newUpdater() incrementAndGet()
Updater只能修改它可见范围内的变量。因为Updater使用反射得到这个变量。如果变量不可见,就会出错。比如如果score申明为private,就是不可行的。
为了确保变量被正确的读取,它必须是volatile类型的。如果我们原有代码中未申明这个类型,那么简单得申明一下就行,这不会引起什么问题
由于CAS操作会通过对象实例中的偏移量直接进行赋值,因此,它不支持static字段(Unsafe.objectFieldOffset()不支持静态变量)。
Vector实现
无锁算法
并发包 在JDK的并发包里提供了几个非常有用的并发容器和并发工具类 。供我们在多线程开发中进行使用。
多线程的控制不是个简单的事情,一般意义上的控制用synchronize、wait,notify等操作,而并发工具类是更高级的工具,功能上更强大,使用上封装了更常用的场景工具类,
同步控制工具:
ReentrantLock 可重入锁:是synchronize的替代品/增强版。synchronize使用简单,功能比较薄弱,让线程死等。jdk1.5后的synchronize性和ReentrantLock不相上下。如果只是简单的使用,不用刻意使用ReentrantLock.
是一个应用实现的锁
CAS状态:判断锁是不是有被人占用。用CAS改状态,能改成功,说明可以拿到这把锁.是重入锁的关键。
等待队列: 如果没有拿到锁,线程应该入等待队列。多个的话就排队。
park(): 进入等待队列的线程,用户park()挂起,然后等掐面的锁释放了,用unpack()唤醒。
可重入 单线程可以重复进入,但要重复退出
比synchronize更灵活,但是也要更加注意锁的释放!
可中断 lockInterruptibly()
然后就可以通过死锁检查终端线程
可限时 超时不能获得锁,就返回false,不会永久等待构成死锁
公平锁 先来先得.一般情况下,锁的获取不公平的,先来的线程不一定先拿到锁。就会导致一些线程可能一直拿不到锁,导致”饥饿”。
但是公平锁虽然不会导致饥饿,但是性能比非公平锁差很多。
1 2 public ReentrantLock (boolean fair) public static ReentrantLock fairLock = new ReentrantLock (true );
Condition 类似于 Object.wait()和Object.notify(),与ReentrantLock结合使用
1 2 3 4 5 6 7 8 主要接口 void await () throws InterruptedException; void awaitUninterruptibly () ; long awaitNanos (long nanosTimeout) throws InterruptedException;boolean await (long time, TimeUnit unit) throws InterruptedException;boolean awaitUntil (Date deadline) throws InterruptedException;void signal () ; void signalAll () ;
Semaphore 共享锁
Semaphore的主要作用是控制线程的并发数量。
Semaphore可以设置同时允许几个线程执行。synchronized可以起到”锁”的作用,但某个时间段内,只能有一个线程允许执行。
Semaphore字面意思是信号量的意思,它的作用是控制访问特定资源的线程数目。
1 2 3 4 5 6 7 8 构造方法 public Semaphore (int permits ) permits 表示许可线程的数量重要方法 public void acquire () public void acquireUninterruptibly () public boolean tryAcquire () public boolean tryAcquire (long timeout, TimeUnit unit) public void release ()
示例一:同时允许1个线程执行
演示:5名同学要进教室,但要设置每次只能2个同学进入教室
1). 制作一个ClassRoom类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import java.util.concurrent.Semaphore;public class ClassRoom { Semaphore sp = new Semaphore (3 ); public void comeIn () { try { sp.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":获得许可,进入教室..." ); try { Thread.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":离开教室,释放许可..." ); sp.release(); } }
2). 测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Test { public static void main (String[] args) { ClassRoom cr = new ClassRoom (); new Thread (cr::comeIn, "张三1" ).start(); new Thread (cr::comeIn, "张三2" ).start(); new Thread (cr::comeIn, "张三3" ).start(); new Thread (cr::comeIn, "张三4" ).start(); new Thread (cr::comeIn, "张三5" ).start(); } }
图片效果:
ReadWriteLock 读写锁
ReadWriteLock是JDK5中提供的读写分离锁
读-读不互斥:读读之间不阻塞。
读-写互斥:读阻塞写,写也会阻塞读。
写-写互斥:写写阻塞。
1 2 3 private static ReentrantReadWriteLock readWriteLock=new ReentrantReadWriteLock ();private static Lock readLock = readWriteLock.readLock();private static Lock writeLock = readWriteLock.writeLock();
CountDownLatch 倒数计时器
一种典型的场景就是火箭发射。在火箭发射前,为了保证万无一失,往往还要进行各项设备、仪器的检查。
只有等所有 检查完毕后,引擎才能点火。这种场景就非常适合使用CountDownLatch。它可以使得点火线程,等待所有检查线程全部完工后,再执行
CountDownLatch允许一个或多个线程等待其他线程完成操作。
例如:线程1要执行打印:A和C,线程2要执行打印:B,但线程1在打印A后,要线程2打印B之后才能打印C,所以:线程1在打印A后,必须等待线程2打印完B之后才能继续执行。
CountDownLatch构造方法:
1 public CountDownLatch (int count)
CountDownLatch重要方法:
1 2 public void await () throws InterruptedExceptionpublic void countDown ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.concurrent.CountDownLatch;public class MyThread1 extends Thread { CountDownLatch cdl; public MyThread1 (CountDownLatch cdl) { this .cdl = cdl; } @Override public void run () { System.out.println("打印A..." ); try { cdl.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("打印C..." ); } }
2). 制作线程2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.concurrent.CountDownLatch;public class MyThread2 extends Thread { CountDownLatch cdl; public MyThread2 (CountDownLatch cdl) { this .cdl = cdl; } @Override public void run () { System.out.println("打印B..." ); cdl.countDown(); } }
3).制作测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import java.util.concurrent.CountDownLatch;public class Test { public static void main (String[] args) throws InterruptedException { CountDownLatch cdl = new CountDownLatch (1 ); new MyThread1 (cdl).start(); Thread.sleep(5000 ); new MyThread2 (cdl).start(); } }
4). 执行结果:
会保证按:A B C的顺序打印。
说明:
CountDownLatch中count down是倒数的意思,latch则是门闩的含义。整体含义可以理解为倒数的门栓,似乎有一点“三二一,芝麻开门”的感觉。
CountDownLatch是通过一个计数器来实现的,每当一个线程完成了自己的任务后,可以调用countDown()方法让计数器-1,当计数器到达0时,调用CountDownLatch。
await()方法的线程阻塞状态解除,继续执行。
火箭发射的例子:
CyclicBarrier 循环栅栏
Cyclic意为循环,也就是说这个计数器可以反复使用。比如,假设我们将计数器设置为10。那么凑齐第一批10个线程后,计数器就会归零,然后接着凑齐下一批10个线程
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
例如:公司召集5名员工开会,等5名员工都到了,会议开始。
我们创建5个员工线程,1个开会线程,几乎同时启动,使用CyclicBarrier保证5名员工线程全部执行后,再执行开会线程。
CyclicBarrier构造方法:
1 2 3 public CyclicBarrier (int parties, Runnable barrierAction)
CyclicBarrier重要方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.itheima.demo17_CyclicBarrier使用;import java.util.concurrent.BrokenBarrierException;import java.util.concurrent.CyclicBarrier;public class MyRunnable implements Runnable { CyclicBarrier cb; public MyRunnable (CyclicBarrier cb) { this .cb = cb; } @Override public void run () { System.out.println(Thread.currentThread().getName()+":到达了会议室" ); try { cb.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":离开会议室" ); } }
2). 制作测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import java.util.concurrent.CyclicBarrier;public class Test { public static void main (String[] args) { CyclicBarrier cb = new CyclicBarrier (5 , new Runnable () { @Override public void run () { System.out.println("好了,人到齐了,咱们开始开会..." ); try { Thread.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("好了,咱们今天的会议就到这结束,晚上聚餐!" ); } }); MyRunnable mr = new MyRunnable (cb); new Thread (mr,"员工1" ).start(); new Thread (mr,"员工2" ).start(); new Thread (mr,"员工3" ).start(); new Thread (mr,"员工4" ).start(); new Thread (mr,"员工5" ).start(); } }
4). 执行结果:
使用场景:CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。
需求:使用两个线程读取2个文件中的数据,当两个文件中的数据都读取完毕以后,进行数据的汇总操作。
LockSupport 在jdk内部使用的比较多,偏底层的一个操作
提供线程阻塞原语,与suspend()比较:不容易引起线程冻结
能够响应中断,但不抛出异常。中断响应的结果是,park()函数的返回,可以从Thread.interrupted()得到中断标志
1 2 3 主要接口 LockSupport.park(); LockSupport.unpark(t1);
并发容器使用:
CopyOnWriteArrayList
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import java.util.ArrayList;public class MyThread1 extends Thread { static ArrayList<Integer> list = new ArrayList <>(); @Override public void run () { for (int i = 0 ; i < 100000 ; i++) { list.add(i); } } } public class Test1 { public static void main (String[] args) { new MyThread1 ().start(); for (int i = 0 ; i < 100000 ; i++) { MyThread1.list.add(i); } try { Thread.sleep(5000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("list集合元素个数:" + MyThread1.list.size()); } }
最终结果可能会抛异常 ,或者最终集合大小是不正确 的。
CopyOnWriteArrayList是线程安全的 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import java.util.ArrayList;import java.util.concurrent.CopyOnWriteArrayList;public class MyThread2 extends Thread { static CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList <>(); @Override public void run () { for (int i = 0 ; i < 1000 ; i++) { list.add(i); } } } public class Test2 { public static void main (String[] args) { new MyThread2 ().start(); for (int i = 0 ; i < 1000 ; i++) { MyThread2.list.add(i); } try { Thread.sleep(5000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("list集合元素个数:" + MyThread2.list.size()); } }
结果始终是正确的。
图片效果:
CopyOnWriteArraySet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class MyThread extends Thread { public static Set<Integer> set = new HashSet <>(); @Override public void run () { for (int i = 0 ; i < 10000 ; i++) { set.add(i); } System.out.println("添加完毕!" ); } } public class Demo { public static void main (String[] args) throws InterruptedException { MyThread t1 = new MyThread (); t1.start(); for (int i = 10000 ; i < 20000 ; i++) { MyThread.set.add(i); } Thread.sleep(1000 * 3 ); System.out.println("最终集合的长度:" + MyThread.set.size()); } }
最终结果可能会抛异常,也可能最终的长度是错误的!!
CopyOnWriteArraySet是线程安全的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class MyThread extends Thread { public static CopyOnWriteArraySet<Integer> set = new CopyOnWriteArraySet <>(); @Override public void run () { for (int i = 0 ; i < 10000 ; i++) { set.add(i); } System.out.println("添加完毕!" ); } } 测试类: public class Demo { public static void main (String[] args) throws InterruptedException { MyThread t1 = new MyThread (); t1.start(); for (int i = 10000 ; i < 20000 ; i++) { MyThread.set.add(i); } Thread.sleep(1000 * 3 ); System.out.println("最终集合的长度:" + MyThread.set.size()); } }
可以看到结果总是正确的!!
ConcurrentHashMap 高性能HashMap
如果在在多线程中使用HashMap可能会出现稀奇古怪的问题。
可以使用集合工具类包包装下非安全的集合 => 这是用于并发比较小的情况下 。本质是加了synchronize同步。
1 2 3 4 Collections.synchronizedMap public static Map m=Collections.synchronizedMap(new HashMap ());Collections.synchronizedList Collections.synchronizedSet
所以高并发下要用ConcurrentHashMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import java.util.HashMap;public class MyThread extends Thread { static HashMap<Integer, Integer> map = new HashMap <>(); @Override public void run () { for (int i = 0 ; i < 300000 ; i++) { map.put(i,i); } } } public class Test1 { public static void main (String[] args) throws InterruptedException { new MyThread ().start(); for (int i = 0 ; i < 300000 ; i++) { MyThread.map.put(i,i); } Thread.sleep(5000 ); System.out.println("集合键值对个数:" +MyThread.map.size()); } }
运行结果可能会出现异常、或者结果不准确!!
我们改用JDK提供的一个早期的线程安全的Hashtable类来改写此例,注意:我们加入了”计时”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import java.util.HashMap;import java.util.Hashtable;public class MyThread2 extends Thread { static Hashtable<Integer, Integer> map = new Hashtable <>(); @Override public void run () { for (int i = 0 ; i < 400000 ; i++) { map.put(i,i); } } } public class Test2 { public static void main (String[] args) throws InterruptedException { new MyThread2 ().start(); for (int i = 0 ; i < 400000 ; i++) { MyThread2.map.put(i,i); } Thread.sleep(5000 ); System.out.println("集合键值对个数:" + MyThread2.map.size()); } }
能看到结果是正确的,但耗时较长。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import java.util.Hashtable;import java.util.concurrent.ConcurrentHashMap;public class MyThread3 extends Thread { static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap <>(); @Override public void run () { for (int i = 0 ; i < 400000 ; i++) { map.put(i,i); } } } 测试类 public class Test3 { public static void main (String[] args) throws InterruptedException { new MyThread3 ().start(); for (int i = 0 ; i < 400000 ; i++) { MyThread3.map.put(i,i); } Thread.sleep(5000 ); System.out.println("集合键值对个数:" + MyThread3.map.size()); } }
可以看到效率提高了很多!!!
1 2 public synchronized V put (K key, V value) public synchronized V get (Object key)
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap高效的原因:CAS + 局部(synchronized)锁定
BlockingQueue 阻塞队列,性能不高,但是是一个非常好的多线程共享数据的容器
ConcurrentLinkedQueue 高性能的队列
Exchanger Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。
这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange()方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
A线程 exchange方法 把数据传递B线程
B线程 exchange方法 把数据传递A线程
Exchanger构造方法:
Exchanger重要方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import java.util.concurrent.Exchanger;public class MyThread1 extends Thread { Exchanger<String> ex; public MyThread1 (Exchanger<String> ex) { this .ex = ex; } @Override public void run () { System.out.println("线程1:准备把数据传递给线程2..." ); String msg = null ; try { msg = ex.exchange("数据1" ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("线程1: 接收到线程2的数据是" +msg); } } import java.util.concurrent.Exchanger;public class MyThread2 extends Thread { Exchanger<String> ex; public MyThread2 (Exchanger<String> ex) { this .ex = ex; } @Override public void run () { System.out.println("线程2:准备把数据传递给线程1..." ); String msg = null ; try { msg = ex.exchange("数据2" ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("线程2: 接收到线程1的数据是" +msg); } } import java.util.concurrent.Exchanger;public class Test { public static void main (String[] args) { Exchanger<String> ex = new Exchanger <>(); new MyThread1 (ex).start(); new MyThread2 (ex).start(); } }
图片效果:
使用场景:可以做数据校对工作
需求:比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水。为了避免错误,采用AB岗两人进行录入,录入到两个文件中,系统需要加载这两个文件,
并对两个文件数据进行校对,看看是否录入一致,
线程池 线程池的概念 线程池的思想
我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题:
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
那么有没有一种办法使得线程可以复用,就是执行完一个任务,并不被销毁,而是可以继续执行其他的任务?
在Java中可以通过线程池来达到这样的效果。
线程池的概念
线程池: 其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作,无需反复创建线程而消耗过多资源。
由于线程池中有很多操作都是与优化资源相关的,我们在这里就不多赘述。我们通过一张图来了解线程池的工作原理:
线程池的好处
降低资源消耗。减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
小结
线程池的原理: 创建线程池的时候初始化指定数量的线程,当有任务需要线程执行的时候,就在线程池中随机分配空闲线程来执行当前的任务;如果线程池中没有空闲的线程,那么该任务就进入任务队列中进行等待,等待其他线程空闲下来,再执行任务.(线程重复利用)
线程池的使用 Java里面线程池的顶级接口是java.util.concurrent.Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是java.util.concurrent.ExecutorService。
要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在java.util.concurrent.Executors线程工厂类里面提供了一些静态工厂,生成一些常用的线程池。官方建议使用Executors工厂类来创建线程池对象。
newFixedThreadPool
newSingleThreadExecutor
newCachedThreadPool
newScheduledThreadPool
Executors类中有个创建线程池的方法如下:
public static ExecutorService newFixedThreadPool(int nThreads):返回线程池对象。(创建的是有界线程池,也就是池中的线程个数可以指定最大数量)
获取到了一个线程池ExecutorService 对象,那么怎么使用呢,在这里定义了一个使用线程池对象的方法如下:
使用线程池中线程对象的步骤:
创建线程池对象。
创建Runnable接口子类对象。(task)
提交Runnable接口子类对象。(take task)
关闭线程池(一般不做)。
Runnable实现类代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class MyRunnable implements Runnable { @Override public void run () { System.out.println(Thread.currentThread().getName()+":开始执行实现Runnable方式的任务...." ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":执行完毕...." ); } }
线程池测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test1_Runnable { public static void main (String[] args) { ExecutorService es = Executors.newFixedThreadPool(3 ); MyRunnable mr = new MyRunnable (); es.submit(mr); es.submit(mr); es.submit(mr); es.submit(mr); } }
图片效果:
Callable测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import java.util.concurrent.Callable;public class MyCallable implements Callable <String> { @Override public String call () throws Exception { System.out.println("任务开始..." ); Thread.sleep(5000 ); System.out.println("任务结束..." ); return "itheima" ; } } import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;public class Test2 { public static void main (String[] args) throws ExecutionException, InterruptedException { ExecutorService pools = Executors.newFixedThreadPool(2 ); MyCallable mc = new MyCallable (); pools.submit(mc); pools.submit(mc); pools.submit(mc); pools.submit(mc); pools.submit(mc); pools.submit(mc); pools.submit(mc); Future<String> f = pools.submit(mc); System.out.println(f.get()); pools.shutdown(); } }
图片效果:
固定线程池:
每个3s执行一次的线程池:
线程池的练习 使用线程池方式执行任务,返回1-n的和
因为需要返回求和结果,所以使用Callable方式的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;public class Test { public static void main (String[] args) throws ExecutionException, InterruptedException { ExecutorService pools = Executors.newFixedThreadPool(2 ); MyCallable mc = new MyCallable (100 ); Future<Integer> f = pools.submit(mc); System.out.println("n的累加和:" +f.get()); pools.shutdown(); } } import java.util.concurrent.Callable;public class MyCallable implements Callable <Integer> { int n; public MyCallable (int n) { this .n = n; } @Override public Integer call () throws Exception { int sum = 0 ; for (int i = 1 ; i <= n; i++) { sum += i; } return sum; } }
回调接口 可以在线程执行前后做操作
beforeExecute
afterExecute
terminated
拒绝策略 一般我们不会准备一个无限大小的缓冲队列。当我们任务达到一定的数量,可能会考虑丢弃一些,但是丢弃后我们要想记录这些任务。
自定义ThreadFactory 创建线程的
ForkJoin 分而治之的思想
RecursiveAction:没返回值
RecursiveTask: 有返回值
工作窃取:
ThreadPoolExecutor
在实际开发中,线程池通常不会直接使用 Executors 工具类提供的静态方法来创建线程池,而是采用更灵活和可控的方式,比如 ThreadPoolExecutor,原因如下:
可控性更强:
可以根据需求明确指定队列类型(有界/无界)、核心线程数、最大线程数、空闲线程超时时间等。
避免隐式行为:
Executors 方法的隐式行为(例如无界队列)容易导致问题,而手动配置时,开发者必须显式考虑这些参数,更加清晰明确。
符合最佳实践:
阿里巴巴《Java开发手册》中明确建议避免使用 Executors 静态方法,直接使用 ThreadPoolExecutor 是更推荐的方式。
1 2 3 4 5 6 7 8 9 ExecutorService executor = new ThreadPoolExecutor ( 10 , 10 , 0L , TimeUnit.MILLISECONDS, new ArrayBlockingQueue <>(100 ), new ThreadPoolExecutor .AbortPolicy() );
锁优化
一般来说,无锁性能高于有锁(阻塞的),而锁优化指的是怎么在并发下尽可能提升性能。(有个线程的挂起,再怎么优化也比不上无锁,但是有总比没有好,尽人事=.=)
无锁
锁是悲观的操作
无锁是乐观的操作
无锁的一种实现方式
CAS(Compare And Swap)
非阻塞的同步
CAS(V,E,N)
在应用层面判断多线程的干扰,如果有干扰,则通知线程重试
1 2 3 4 5 6 7 8 9 10 11 12 java.util.concurrent.atomic.AtomicInteger public final int getAndSet (int newValue) { for (;;) { int current = get(); if (compareAndSet(current, newValue)) return current; } } public final boolean compareAndSet (int expect, int update) 更新成功返回true
减少锁持有时间 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public synchronized void syncMethod () { othercode1(); mutextMethod(); othercode2(); } public void syncMethod2 () { othercode1(); synchronized (this ){ mutextMethod(); } othercode2(); }
减少锁粒度 将大对象,拆成小对象,大大增加并行度,降低锁竞争
偏向锁,轻量级锁成功率提高
ConcurrentHashMap
HashMap的同步实现
Collections.synchronizedMap(Map<K,V> m)
返回SynchronizedMap对象
1 2 3 4 5 6 public V get (Object key) { synchronized (mutex) {return m.get(key);} } public V put (K key, V value) { synchronized (mutex) {return m.put(key, value);} }
ConcurrentHashMap
若干个Segment :Segment<K,V>[] segments
Segment中维护HashEntry<K,V>
put操作时
先定位到Segment,锁定一个Segment,执行put
在减小锁粒度后, ConcurrentHashMap允许若干个线程同时进入
思考:减少锁粒度后,可能会带来什么负面影响呢?以ConcurrentHashMap为例,说明分割为多个Segment后,在什么情况下,会有性能损耗?
锁分离
根据功能进行锁分离
ReadWriteLock
读多写少的情况,可以提高性能
读不会改变数据,所以不需要同步(synchronize),可以一起访问而不会相互阻塞。
读写分离思想可以延伸,只要操作互不影响,锁就可以分离
LinkedBlockingQueue
热点分离的重要思想,工作窃取,从头拿,加数据的话加到尾部,这样就会较少冲突。
锁分离相当于把阻塞型的并发改成了无等待的并发了,性能会好很多
锁粗化 通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其他线程才能尽早的获得资源执行任务。但是,凡事都有一个度,如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化 。可以将很快完成的操作做锁粗化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void demoMethod () { synchronized (lock){ } synchronized (lock){ } public void demoMethod () { synchronized (lock){ } } } for (int i=0 ;i<CIRCLE;i++){ synchronized (lock){ } } synchronized (lock){ for (int i=0 ;i<CIRCLE;i++){ } }
锁消除 在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main (String args[]) throws InterruptedException { long start = System.currentTimeMillis(); for (int i = 0 ; i < CIRCLE; i++) { craeteStringBuffer("JVM" , "Diagnosis" ); } long bufferCost = System.currentTimeMillis() - start; System.out.println("craeteStringBuffer: " + bufferCost + " ms" ); } public static String craeteStringBuffer (String s1, String s2) { StringBuffer sb = new StringBuffer (); sb.append(s1); sb.append(s2); return sb.toString(); } CIRCLE= 2000000 -server -XX:+DoEscapeAnalysis -XX:+EliminateLocks craeteStringBuffer: 187 ms -server -XX:+DoEscapeAnalysis -XX:-EliminateLocks craeteStringBuffer: 254 ms
虚拟机内的锁优化 偏向锁,轻量级锁,自旋锁不是Java语言层面的锁优化方法
内置于JVM中的获取锁的优化方法和获取锁的步骤
偏向锁可用会先尝试偏向锁
轻量级锁可用会先尝试轻量级锁
以上都失败,尝试自旋锁
再失败,尝试普通锁,使用OS互斥量在操作系统层挂起
对象头Mark jvm中的对象头信息
Mark Word,对象头的标记,32位
描述对象的hash、锁信息,垃圾回收标记,年龄
指向锁记录的指针
指向monitor的指针
GC标记
偏向锁 线程ID
偏向锁
大部分情况是没有竞争的,所以可以通过偏向来提高性能
所谓的偏向,就是偏心,即锁会偏向于当前已经占有锁的线程
将对象头Mark的标记设置为偏向,并将线程ID写入对象头Mark
只要没有竞争,获得偏向锁的线程,在将来进入同步块,不需要做同步
当其他线程请求相同的锁时,偏向模式结束
-XX:+UseBiasedLocking: 默认启用
在竞争激烈的场合,偏向锁会增加系统负担。(如果每次偏向判断都失败,相当于做了额外多余的操作)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static List<Integer> numberList =new Vector <Integer>();public static void main (String[] args) throws InterruptedException { long begin=System.currentTimeMillis(); int count=0 ; int startnum=0 ; while (count<10000000 ){ numberList.add(startnum); startnum+=2 ; count++; } long end=System.currentTimeMillis(); System.out.println(end-begin); } -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 -XX:-UseBiasedLocking
本例中,使用偏向锁,可以获得5%以上的性能提升
轻量级锁 BasicObjectLock: 嵌入在线程栈 中的对象
1 2 3 4 5 6 7 lock->set_displaced_header(mark); if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) { TEVENT (slow_enter: release stacklock) ; return ; } lock位于线程栈中
如果轻量级锁失败,表示存在竞争,升级为重量级锁(常规锁)
在没有锁竞争的前提下,减少传统锁使用OS互斥量产生的性能损耗
在竞争激烈时,轻量级锁会多做很多额外操作,导致性能下降
自旋锁
当竞争存在时,如果线程可以很快获得锁,那么可以不在OS层挂起线程(os挂起成本大),让线程做几个空操作(自旋)
JDK1.6中-XX:+UseSpinning开启
JDK1.7中,去掉此参数,改为内置实现
如果同步块很长,自旋失败,会降低系统性能
如果同步块很短,自旋成功,节省线程挂起切换时间,提升系统性能
错误使用锁案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class IntegerLock { static Integer i=0 ; public static class AddThread extends Thread { public void run () { for (int k=0 ;k<100000 ;k++){ synchronized (i){ i++; } } } } public static void main (String[] args) throws InterruptedException { AddThread t1=new AddThread (); AddThread t2=new AddThread (); t1.start();t2.start(); t1.join();t2.join(); System.out.println(i); } }
ThreadLocal 为每个线程都提供一个自己的对象实例,这样锁就没有存在的必要了。线程局部的变量
SimpleDateFormat不是线程安全的,被多线程访问 :x:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static final SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss" );public static class ParseDate implements Runnable { int i=0 ; public ParseDate (int i) {this .i=i;} public void run () { try { Date t=sdf.parse("2015-03-29 19:29:" +i%60 ); System.out.println(i+":" +t); } catch (ParseException e) { e.printStackTrace(); } } } public static void main (String[] args) { ExecutorService es=Executors.newFixedThreadPool(10 ); for (int i=0 ;i<1000 ;i++){ es.execute(new ParseDate (i)); } }
为每一个线程分配一个实例,:heavy_check_mark:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static ThreadLocal<SimpleDateFormat> tl=new ThreadLocal <SimpleDateFormat>();public static class ParseDate implements Runnable { int i=0 ; public ParseDate (int i) {this .i=i;} public void run () { try { if (tl.get()==null ){ tl.set(new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss" )); } Date t=tl.get().parse("2015-03-29 19:29:" +i%60 ); System.out.println(i+":" +t); } catch (ParseException e) { e.printStackTrace(); } } } public static void main (String[] args) { ExecutorService es=Executors.newFixedThreadPool(10 ); for (int i=0 ;i<1000 ;i++){ es.execute(new ParseDate (i)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static ThreadLocal<SimpleDateFormat> tl=new ThreadLocal <SimpleDateFormat>();private static final SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss" );public static class ParseDate implements Runnable { int i=0 ; public ParseDate (int i) {this .i=i;} public void run () { try { if (tl.get()==null ){ tl.set(sdf); } Date t=tl.get().parse("2015-03-29 19:29:" +i%60 ); System.out.println(i+":" +t); } catch (ParseException e) { e.printStackTrace(); } } } public static void main (String[] args) { ExecutorService es=Executors.newFixedThreadPool(10 ); for (int i=0 ;i<1000 ;i++){ es.execute(new ParseDate (i)); } }
多线程调优 多线程调试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class UnsafeArrayList { static ArrayList al=new ArrayList (); static class AddTask implements Runnable { @Override public void run () { try { Thread.sleep(100 ); } catch (InterruptedException e) { } for (int i=0 ;i<1000000 ;i++) al.add(new Object ()); } } public static void main (String[] args) throws InterruptedException { Thread t1=new Thread (new AddTask (),"t1" ); Thread t2=new Thread (new AddTask (),"t2" ); t1.start(); t2.start(); Thread t3=new Thread (new Runnable (){ @Override public void run () { while (true ){ try { Thread.sleep(1000 ); } catch (InterruptedException e) {} } } },"t3" ); t3.start(); } }
在ArrayList的add方法打断点
可以看到主线程的堆栈信息,主线程并没有使用到ArrayList.add
设置条件断点,只希望观察在某个线程下的情况
设置主线程不进行断点操作
可以观察到t1、t2两个线程中的ArrayList的情况了
挂起/中断VM,如果线程之间相互影响线程结果。我们可以中断线程的时候,中断VM。可能会VM报错
可以看到所有线程都挂起了
线程dump及分析
系统出问题的时候,可以看看系统中到底有哪些线程在运行,每个线程在堆栈中的情况,只有锁的情况。如果我们发现某个线程被卡死了。则可以从堆栈中获取有价值的信息,从而知道这个线程为什么被卡在哪里不动
jstack 3992 :找出正在运行的虚拟机(jps)下的所有线程。在%JAVA_HOME%/bin 下
jdk8并发支持 LongAdder
把一个整数分解成数组。高并发下冲突概率减小。性能提高。
CompletableFuture CompletableFuture
1 stage.thenApply(x -> square(x)).thenAccept(x -> System.out.print(x)).thenRun(() -> System.out.println())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public static class AskThread implements Runnable { CompletableFuture<Integer> re = null ; public AskThread (CompletableFuture<Integer> re) { this .re = re; } @Override public void run () { int myRe = 0 ; try { myRe = re.get() * re.get(); } catch (Exception e) { } System.out.println(myRe); } } public static void main (String[] args) throws InterruptedException { final CompletableFuture<Integer> future = new CompletableFuture <>(); new Thread (new AskThread (future)).start(); Thread.sleep(1000 ); future.complete(60 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static Integer calc (Integer para) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { } return para*para; } public static void main (String[] args) throws InterruptedException, ExecutionException { final CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> calc(50 )); System.out.println(future.get()); }
1 2 3 4 static <U> CompletableFuture<U> supplyAsync (Supplier<U> supplier) ;static <U> CompletableFuture<U> supplyAsync (Supplier<U> supplier, Executor executor) ;static CompletableFuture<Void> runAsync (Runnable runnable) ;static CompletableFuture<Void> runAsync (Runnable runnable, Executor executor) ;
supplyAsync:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static Integer calc (Integer para) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { } return para*para; } public static void main (String[] args) throws InterruptedException, ExecutionException { CompletableFuture<Void> fu=CompletableFuture.supplyAsync(() -> calc(50 )) .thenApply((i)->Integer.toString(i)) .thenApply((str)->"\"" +str+"\"" ) .thenAccept(System.out::println); fu.get(); }
1 public <U> CompletableFuture<U> thenCompose (Function<? super T, ? extends CompletionStage<U>> fn)
1 2 3 4 5 6 7 8 9 10 11 12 public static Integer calc (Integer para) { return para/2 ; } public static void main (String[] args) throws InterruptedException, ExecutionException { CompletableFuture<Void> fu = CompletableFuture.supplyAsync(() -> calc(50 )) .thenCompose((i)->CompletableFuture.supplyAsync(() -> calc(i))) .thenApply((str)->"\"" + str + "\"" ).thenAccept(System.out::println); fu.get(); } "12"
StampedLock 读写锁的改进: 读不阻塞写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Point { private double x, y; private final StampedLock sl = new StampedLock (); void move (double deltaX, double deltaY) { long stamp = sl.writeLock(); try { x += deltaX; y += deltaY; } finally { sl.unlockWrite(stamp); } } double distanceFromOrigin () { long stamp = sl.tryOptimisticRead(); double currentX = x, currentY = y; if (!sl.validate(stamp)) { stamp = sl.readLock(); try { currentX = x; currentY = y; } finally { sl.unlockRead(stamp); } } return Math.sqrt(currentX * currentX + currentY * currentY); } }
StampedLock的实现思想
CLH自旋锁
锁维护一个等待线程队列,所有申请锁,但是没有成功的线程都记录在这个队列中。每一个节点(一个节点代表一个线程),保存一个标记位(locked),用于判断当前线程是否已经释放锁。
当一个线程试图获得锁时,取得当前等待队列的尾部节点作为其前序节点。并使用类似如下代码判断前序节点是否已经成功释放锁:
jetty分析
这里主要看作为一个性能非常高的http服务器,后面采用了什么样的技术,什么的多线程手段来达到高吞吐量
new Server() 1 2 3 4 5 6 public Server (@Name("port") int port) { this ((ThreadPool)null ); ServerConnector connector=new ServerConnector (this ); connector.setPort(port); setConnectors(new Connector []{connector}); }
初始化线程池 像jetty这种服务器的容器/产品,后台执行的时候一定使用线程池的,不可能是每次有什么任务就new一个出来.
1 2 3 4 5 public Server (@Name("threadpool") ThreadPool pool) { _threadPool=pool!=null ?pool:new QueuedThreadPool (); addBean(_threadPool); setServer(this ); }
QueuedThreadPool
实现了SizedThreadPool
1 2 3 4 5 6 7 8 9 10 11 12 @Override public void execute (Runnable job) { if (!isRunning() || !_jobs.offer(job)) { LOG.warn("{} rejected {}" , this , job); throw new RejectedExecutionException (job.toString()); } else { if (getThreads() == 0 ) startThreads(1 ); } }
BlockingQueue
1 2 将任务推入 BlockingQueue<Runnable> org.eclipse.jetty.util.thread.QueuedThreadPool._jobs
初始化ServerConnector HTTP connector using NIO ByteChannels and Selectors
初始化ScheduledExecutorScheduler
based on JDK's {@link ScheduledThreadPoolExecutor}.
在数据传输过程中,不可避免需要byte数组
buffer池 : 默认产生 ArrayByteBufferPool
ByteBufferPool 接口有2个方法:
1 2 public ByteBuffer acquire (int size, boolean direct) ;public void release (ByteBuffer buffer) ;
这是一个很好的对象池范本
ArrayByteBufferPool
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public ArrayByteBufferPool (int minSize, int increment, int maxSize) public ArrayByteBufferPool () { this (0 ,1024 ,64 *1024 ); } _direct=new Bucket [maxSize/increment]; _indirect=new Bucket [maxSize/increment]; 1. Bucketint size=0 ;for (int i=0 ;i<_direct.length;i++) { size+=_inc; _direct[i]=new Bucket (size); _indirect[i]=new Bucket (size); } 一个Bucekt存放大小相同的所有的ByteBuffer _size :bytebuffer大小 _queue:public final Queue<ByteBuffer> _queue= new ConcurrentLinkedQueue <>(); 2. acquire: public ByteBuffer acquire (int size, boolean direct) 取得合适的Bucket,每个Bucket的大小不同,这里找到最合适的 Bucket bucket = bucketFor(size,direct); 从Bucket中取得ByteBuffer ByteBuffer buffer = bucket==null ?null :bucket._queue.poll(); 不存在则新建 if (buffer == null ){ int capacity = bucket==null ?size:bucket._size; buffer = direct ? BufferUtil.allocateDirect(capacity) : BufferUtil.allocate(capacity); } 3. releasepublic void release (ByteBuffer buffer) { if (buffer!=null ) { Bucket bucket = bucketFor(buffer.capacity(),buffer.isDirect()); if (bucket!=null ) { BufferUtil.clear(buffer); bucket._queue.offer(buffer); } } } 取得合适的Bucket Bucket bucket = bucketFor(buffer.capacity(),buffer.isDirect())清空Buffer BufferUtil.clear(buffer); 归还Pool bucket._queue.offer(buffer); 4. 例外处理如果申请的ByteBuffer过大或者过小 无法在POOL中满足,则可以申请成功,但无法归还给POOL。
维护ConnectionFactory
HttpConnectionFactory 用于创建连接,比如Accept后,需要创建一个表示连接的对象
取得可用CPU数量
1 int cores = Runtime.getRuntime().availableProcessors();
更新acceptor数量
1 2 if (acceptors < 0 ) acceptors=Math.max(1 , Math.min(4 ,cores/8 ))
创建acceptor线程组
1 _acceptors = new Thread[acceptors];
初始化ServerConnectorManager 继承自 SelectorManager
1 2 _manager = new ServerConnectorManager (getExecutor(), getScheduler(), selectors>0 ?selectors:Math.max(1 ,Math.min(4 ,Runtime.getRuntime().availableProcessors()/2 )
保存selector线程数量
1 Math.min(4 ,Runtime.getRuntime().availableProcessors()/2 ))
设置port 1 connector.setPort(port);
关联Sever和Connector 1 setConnectors(new Connector[]{connector});
Server.start() org.eclipse.jetty.server.Server
启动web服务器
1 2 3 4 5 6 WebAppContext context = new WebAppContext ();context.setContextPath("/" ); context.setResourceBase("./web/" ); context.setClassLoader(Thread.currentThread().getContextClassLoader()); server.setHandler(context); server.start();
设置启动状态 AbstractLifeCycle
1 2 3 4 5 6 7 8 private void setStarting () { if (LOG.isDebugEnabled())LOG.debug("starting {}" ,this ); _state = __STARTING; for (Listener listener : _listeners)listener.lifeCycleStarting(this ); }
启动过程doStart() Server : 启动整个server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 protected void doStart () throws Exception{ if (getStopAtShutdown()) ShutdownThread.register(this ); ShutdownMonitor.register(this ); ShutdownMonitor.getInstance().start(); LOG.info("jetty-" + getVersion()); HttpGenerator.setJettyVersion(HttpConfiguration.SERVER_VERSION); MultiException mex=new MultiException (); SizedThreadPool pool = getBean(SizedThreadPool.class); int max=pool==null ?-1 :pool.getMaxThreads(); int selectors=0 ; int acceptors=0 ; if (mex.size()==0 ) { for (Connector connector : _connectors) { if (connector instanceof AbstractConnector) acceptors+=((AbstractConnector)connector).getAcceptors(); if (connector instanceof ServerConnector) selectors+=((ServerConnector)connector).getSelectorManager().getSelectorCount(); } } int needed=1 +selectors+acceptors; if (max>0 && needed>max) { throw new IllegalStateException (String.format("Insufficient threads: max=%d < needed(acceptors=%d +selectors=%d + request=1)" ,max,acceptors,selectors)); } try { super .doStart(); } catch (Throwable e) { mex.add(e); } for (Connector connector : _connectors) { try { connector.start(); } catch (Throwable e) { mex.add(e); } } if (isDumpAfterStart()) dumpStdErr(); mex.ifExceptionThrow(); LOG.info(String.format("Started @%dms" ,Uptime.getUptime())); }
注册ShutdownMonitor 远程控制接口
1 2 3 4 5 ShutdownMonitor.register(this ); ShutdownMonitor.getInstance().start();
获取化线程池 1 2 SizedThreadPool pool = getBean(SizedThreadPool.class);
QueuedThreadPool
设置selector数量 根据Connector数量进行累计
大部分情况下,只有一个ServerConnector
1 2 3 4 5 6 7 8 for (Connector connector : _connectors){ if (connector instanceof AbstractConnector) acceptors+=((AbstractConnector)connector).getAcceptors(); if (connector instanceof ServerConnector) selectors+=((ServerConnector)connector).getSelectorManager().getSelectorCount(); }
累计所有Connector的需求
计算所需的所有线程数量 int needed=1+selectors+acceptors;
如果大于默认的200则中断程序
1 2 if (max>0 && needed>max) throw new IllegalStateException (String.format("Insufficient threads: max=%d < needed(acceptors=%d+ selectors=%d + request=1)" ,max,acceptors,selectors));
维护Bean 启动QueuedThreadPool
doStart()
startThreads() 建立需要的线程
创建线程
1 2 3 4 5 6 7 Thread thread = newThread(_runnable);_runnable _jobs中取任务并执行 设置线程的属性 thread.setDaemon(isDaemon()); thread.setPriority(getThreadsPriority()); thread.setName(_name + "-" + thread.getId()); _threads.add(thread);
启动线程
启动WebAppContext
如果需要使用,在此处启动
启动Connector 取得ConnectionFactory
1 _defaultConnectionFactory = getConnectionFactory(_defaultProtocol);
创建selector线程并启动
1 2 3 4 5 6 7 8 for (int i = 0 ; i < _selectors.length; i++){ ManagedSelector selector = newSelector(i); _selectors[i] = selector; selector.start(); execute(new NonBlockingThread (selector)); }
newSelector()
1 2 3 4 5 6 7 8 9 10 11 protected ManagedSelector newSelector (int id) { return new ManagedSelector (id); } 创建Acceptor线程 参见: 创建acceptor线程组 _stopping=new CountDownLatch (_acceptors.length); for (int i = 0 ; i < _acceptors.length; i++){ Acceptor a = new Acceptor (i); addBean(a); getExecutor().execute(a); }
Acceptor
设置线程名字
1 2 3 4 5 final Thread thread = Thread.currentThread();String name=thread.getName(); _name=String.format("%s-acceptor-%d@%x- %s" ,name,_acceptor,hashCode(),AbstractConnector.this .toString()); thread.setName(_name);
设置优先级
将自己放入_acceptors数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 synchronized (AbstractConnector.this ){ _acceptors[_acceptor] = thread; } 监听端口 try { while (isAccepting()) { try { accept(_acceptor); } catch (Throwable e) { if (isAccepting()) LOG.warn(e); else LOG.ignore(e); } } } finally { thread.setName(name); if (_acceptorPriorityDelta!=0 ) thread.setPriority(priority); synchronized (AbstractConnector.this ) { _acceptors[_acceptor] = null ; } CountDownLatch stopping=_stopping; if (stopping!=null ) stopping.countDown(); } ServerConnector.accept() public void accept (int acceptorID) throws IOException { ServerSocketChannel serverChannel = _acceptChannel; if (serverChannel != null && serverChannel.isOpen()) { SocketChannel channel = serverChannel.accept(); accepted(channel); } }
在accept的地方等待
没有Acceptor的情况
channle默认是blocking的
如果acceptor数量为0,没有安排线程专门进行accept,则设置为非阻塞模式
若是非0,有专门线程进行accept,因此,为阻塞模式
1 2 3 4 5 6 7 8 9 protected void doStart () throws Exception{ super .doStart();if (getAcceptors()==0 ){ _acceptChannel.configureBlocking(false ); _manager.acceptor(_acceptChannel); } }
启动完毕 AbstractLifeCycle
1 2 3 4 5 6 7 8 private void setStarted () { _state = __STARTED; if (LOG.isDebugEnabled()) LOG.debug(STARTED+" @{}ms {}" ,Uptime.getUptime(),this ); for (Listener listener : _listeners) listener.lifeCycleStarted(this ); }
Http请求 Accept成功 1 2 3 4 5 6 7 private void accepted (SocketChannel channel) throws IOException{ channel.configureBlocking(false ); Socket socket = channel.socket();configure(socket); _manager.accept(channel); }
设置为非阻塞模式
1 channel.configureBlocking(false);
配置Socket
1 2 Socket socket = channel.socket(); configure(socket);
正式处理
1 2 SelectorManager _manager; _manager.accept(channel);
选择可用的
1 2 3 4 5 6 7 8 9 10 11 选择可用的ManagedSelector线程 private ManagedSelector chooseSelector () { long s = _selectorIndex++; int index = (int )(s % getSelectorCount()); return _selectors[index]; }
ManagedSelector处理
ManagedSelector 是一个线程
封装了Selector 的使用
提交任务
1 2 3 selector.submit(selector.new Accept (channel, attachment)); private final Queue<Runnable> _changes = new ConcurrentArrayQueue <>(); _changes.offer(change);
请求处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 ManagedSelector.run() while (isRunning()) select(); runChanges(); private void runChanges () { Runnable change; while ((change = _changes.poll()) != null ) runChange(change); } runChange() change.run(); Accept.run SelectionKey key = channel.register(_selector, 0 , attachment); EndPoint endpoint = createEndPoint(channel, key);key.attach(endpoint); select() int selected = _selector.select(); 处理SelectionKey Set<SelectionKey> selectedKeys = _selector.selectedKeys(); for (SelectionKey key : selectedKeys){ if (key.isValid()) { processKey(key); } else { if (debug) LOG.debug("Selector loop ignoring invalid key for channel {}" , key.channel()); Object attachment = key.attachment(); if (attachment instanceof EndPoint) ((EndPoint)attachment).close(); } } selectedKeys.clear(); processKey() private void processKey (SelectionKey key) { Object attachment = key.attachment(); try { if (attachment instanceof SelectableEndPoint) { ((SelectableEndPoint)attachment).onSelected(); } else if (key.isConnectable()) { processConnect(key, (Connect)attachment); } else if (key.isAcceptable()) { processAccept(key); } else { throw new IllegalStateException (); } } catch (CancelledKeyException x) { LOG.debug("Ignoring cancelled key for channel {}" , key.channel()); if (attachment instanceof EndPoint) closeNoExceptions((EndPoint)attachment); } catch (Throwable x) { LOG.warn("Could not process key for channel " + key.channel(), x); if (attachment instanceof EndPoint) closeNoExceptions((EndPoint)attachment); } } onSelected() @Override public void onSelected () { assert _selector.isSelectorThread(); int oldInterestOps = _key.interestOps(); int readyOps = _key.readyOps(); int newInterestOps = oldInterestOps & ~readyOps; setKeyInterests(oldInterestOps, newInterestOps); updateLocalInterests(readyOps, false ); if (_key.isReadable()) getFillInterest().fillable(); if (_key.isWritable()) getWriteFlusher().completeWrite(); } 会使用新的线程进行HTTP业务处理 (提交到线程池)
第三章 Lambda表达式 函数式编程思想概述
面向对象编程思想 面向对象强调的是对象 , “必须通过对象的形式来做事情 ”,相对来讲比较复杂,有时候我们只是为了做某件事情而不得不创建一个对象 , 例如线程执行任务,我们不得不创建一个实现Runnable接口对象,但我们真正希望的是将run方法中的代码传递给线程对象执行
函数编程思想 在数学中,函数 就是有输入量、输出量的一套计算方案,也就是“拿什么东西做什么事情”。相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语法——强调做什么,而不是以什么形式做 。例如线程执行任务 , 使用函数式思想 , 我们就可以通过传递一段代码给线程对象执行,而不需要创建任务对象
Lambda表达式的体验 实现Runnable接口的方式创建线程执行任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 实现类: 1. 创建一个实现类,实现Runnable接口2. 在实现类中,重写run()方法,把任务放入run()方法中3. 创建实现类对象4. 创建Thread线程对象,传入实现类对象5. 使用线程对象调用start()方法,启动并执行线程 总共需要5 个步骤,一步都不能少,为什么要创建实现类,为了得到线程的任务 public class MyRunnable implements Runnable { @Override public void run () { System.out.println("实现的方法创建线程的任务执行了..." ); } } public class Demo { public static void main (String[] args) { MyRunnable mr = new MyRunnable (); Thread t = new Thread (mr); t.start(); } }
匿名内部类方式创建线程执行任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 匿名内部类: 1. 创建Thread线程对象,传入Runnable接口的匿名内部类 2. 在匿名内部类中重写run()方法,把任务放入run()方法中 3. 使用线程对象调用start()方法,启动并执行线程 总共需要3 个步骤,一步都不能少,为什么要创建Runnable的匿名内部类类,为了得到线程的任务 public class Demo { public static void main (String[] args) { Thread t2 = new Thread (new Runnable () { @Override public void run () { System.out.println("匿名内部类的方式创建线程的任务执行了" ); } }); t2.start(); } }
Lambda方式创建线程执行任务 以上2种方式都是通过Runnable接口的实现类对象,来传入线程需要执行的任务(面向对象编程)
思考: 是否能够不通过Runnable接口的实现类对象来传入任务,而是直接把任务传给线程????
Lambda表达式的概述: 它是一个JDK8开始一个新语法。它是一种“代替语法”——可以代替我们之前编写的“面向某种接口”编程的情况
1 2 3 4 5 6 7 8 public class Demo { public static void main (String[] args) { Thread t3 = new Thread (()->{System.out.println("Lambda表达式的方式" );}); t3.start(); } }
Lambda表达式的作用就是简化代码,省略了面向对象中类和方法的书写。
Lambda表达式的格式 作用
Lambda表达式的作用就是简化代码,省略了面向对象中类和方法,对象的书写。
标准格式 Lambda省去面向对象的条条框框,格式由3个部分 组成:
Lambda表达式的标准格式 为:
1 (参数类型 参数名,参数类型 参数名,...) -> { 代码语句 }
格式说明
小括号内的语法与传统方法参数列表一致:无参数则留空;多个参数则用逗号分隔。
->是新引入的语法格式,代表指向动作。大括号内的语法与传统方法体要求基本一致。
案例演示
线程案例演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Test { public static void main (String[] args) { Thread t1 = new Thread (new Runnable () { @Override public void run () { System.out.println("线程需要执行的任务代码1..." ); } }); t1.start(); Thread t2 = new Thread (()->{ System.out.println("线程需要执行的任务代码2..." );}); t2.start(); } }
比较器案例演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class Test { public static void main (String[] args) { List<Integer> list = new ArrayList <>(); Collections.addAll(list,100 ,200 ,500 ,300 ,400 ); System.out.println("排序之前的集合:" +list); Collections.sort(list,(Integer o1, Integer o2)->{return o2 - o1;}); System.out.println("排序之后的集合:" +list); } }
小结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Lambda表达式的标准格式: Lambda表达式的作用: 就是简化代码,省略了面向对象中类和方法,对象的书写。 Lambda表达式的标准格式: (参数类型 参数名,参数类型 参数名,...) -> { 代码语句 } Lambda表达式的格式说明: 1. 小括号中的参数要和接口中抽象方法的形参列表一致,无参数则留空;多个参数则用逗号分隔。 2. ->是新引入的语法格式,代表指向动作。可以理解为把小括号中的参数传递给大括号中使用 3. 大括号中的内容其实就是存放以前重写抽象方法的方法体 Lambda表达式的使用条件: 接口中有且仅有一个抽象方法的接口,才可以使用Lambda表达式 1. 接口中只有一个抽象方法的接口,叫做函数式接口 2. 如果是函数式接口,那么就可以使用@FunctionalInterface 注解来标识 使用Lambda表达式: 1. 判断接口是否是函数式接口 2. 如果是函数式接口,那么就直接写()->{} 3. 然后填充小括号和大括号中的内容
Lambda表达式省略格式 省略规则 在Lambda标准格式的基础上,使用省略写法的规则为:
小括号内参数的类型可以省略;
如果小括号内有且仅有一个参数 ,则小括号可以省略;
如果大括号内有且仅有一条语句 ,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。
案例演示
线程案例演示
1 2 3 4 5 6 7 8 public class Demo_ 线程演示 { public static void main (String[] args) { Thread t2 = new Thread (()-> System.out.println("执行了" )); t2.start(); } }
比较器案例演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Demo_ 比较器演示 { public static void main (String[] args) { ArrayList<Integer> list = new ArrayList <>(); list.add(324 ); list.add(123 ); list.add(67 ); list.add(987 ); list.add(5 ); System.out.println(list); Collections.sort(list, ( o1, o2)-> o2 - o1); System.out.println(list); } }
综合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package com.itheima.demo6_Lambda表达式省略格式;import java.util.ArrayList;import java.util.Collections;@FunctionalInterface interface A { void method (int num) ; } public class Test { public static void show (A a) { a.method(10 ); } public static void main (String[] args) { new Thread (() -> System.out.println("任务代码" ) ).start(); ArrayList<Integer> list = new ArrayList <>(); list.add(300 ); list.add(200 ); list.add(100 ); list.add(500 ); list.add(400 ); System.out.println("排序前:" + list); Collections.sort(list, (i1, i2) -> i2 - i1); System.out.println("排序后:" + list); System.out.println("=======================================" ); show((int num) -> { System.out.println(num); }); show(num -> System.out.println(num) ); } }
Lambda的前提条件和表现形式 Lambda的前提条件
Lambda的表现形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.itheima.demo7_Lambda的表现形式;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;public class Test { public static void main (String[] args) { Runnable r = ()->{ System.out.println("任务代码" ); }; Comparator<Integer> com = (Integer i1,Integer i2)->{return i2 - i1;}; ArrayList<Integer> list = new ArrayList <>(); list.add(300 ); list.add(200 ); list.add(100 ); list.add(500 ); list.add(400 ); System.out.println("排序前:" + list); Collections.sort(list,(Integer i1,Integer i2)->{return i2 - i1;}); System.out.println("排序后:" + list); Collections.sort(list, getComparator()); System.out.println("排序后:" + list); } public static Comparator<Integer> getComparator () { return (Integer i1 , Integer i2)->{return i1 - i2;}; } }
第四章 Stream 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念 ,用于解决已有集合类库既有的弊端。
Stream流的引入 例如: 有一个List集合,要求:
将List集合中姓张的的元素过滤到一个新的集合中
然后将过滤出来的姓张的元素,再过滤出长度为3的元素,存储到一个新的集合中
传统方式操作集合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class Demo { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); List<String> listB = new ArrayList <>(); for (String e : list) { if (e.startsWith("张" )) { listB.add(e); } } List<String> listC = new ArrayList <>(); for (String e : listB) { if (e.length() == 3 ){ listC.add(e); } } for (String e : listC) { System.out.println(e); } } }
Stream流操作集合 1 2 3 4 5 6 7 8 public class Demo { public static void main (String[] args) { list.stream().filter(e->e.startsWith("张" )).filter(e->e.length()==3 ).forEach(e-> System.out.println(e)); System.out.println(list); } }
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印 。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
流式思想概述 整体来看,流式思想类似于工厂车间的“生产流水线 ”。
小结
流式思想: 待会学了常用方法后验证
搭建好函数模型,才可以执行
Stream流的操作方式也是流动操作的,也就是说每一个流都不会存储元素
3.一个Stream流只能操作一次,不能重复使用
获取流方式 根据Collection获取流
Collection接口中有一个stream()方法,可以获取流 , default Stream stream():获取一个Stream流
通过List集合获取:
通过Set集合获取
根据Map获取流
使用所有键的集合来获取流
使用所有值的集合来获取流
使用所有键值对的集合来获取流
根据数组获取流
Stream流中有一个static Stream of(T… values)
案例演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 package com.itheima.demo9_获取流;import java.util.*;import java.util.stream.Stream;public class Test { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); Stream<String> stream1 = list.stream(); Set<String> set = new HashSet <>(); set.add("张无忌" ); set.add("周芷若" ); set.add("赵敏" ); set.add("张杰" ); set.add("张三丰" ); Stream<String> stream2 = set.stream(); Map<Integer, String> map = new HashMap <>(); map.put(1 , "java" ); map.put(2 , "php" ); map.put(3 , "c" ); map.put(4 , "c++" ); map.put(5 , "Python" ); Set<Integer> keys = map.keySet(); Stream<Integer> stream3 = keys.stream(); Collection<String> values = map.values(); Stream<String> stream4 = values.stream(); Set<Map.Entry<Integer, String>> entrys = map.entrySet(); Stream<Map.Entry<Integer, String>> stream5 = entrys.stream(); String[] arr = {"张无忌" , "周芷若" , "赵敏" , "张杰" , "张三丰" }; Stream<String> stream6 = Stream.of(arr); Stream<String> stream7 = Stream.of("张三" , "李四" , "王五" ); } }
小结
1 2 Collection<E>接口中有一个stream()方法,可以获取流 , default Stream<E> stream () Stream<T>接口中有一个方法,可以获取流, public static <T> Stream<T> of (T... values)
常用方法 流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
终结方法 :返回值类型不再是Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。本小节中,终结方法包括count和forEach方法。非终结方法 (延迟方法):返回值类型仍然是Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
函数拼接与终结方法 在上述介绍的各种方法中,凡是返回值仍然为Stream接口的为函数拼接方法 ,它们支持链式调用;而返回值不再为Stream接口的为终结方法 ,不再支持链式调用。如下表所示:
方法名
方法作用
方法种类
是否支持链式调用
count
统计个数
终结
否
forEach
逐一处理
终结
否
filter
过滤
函数拼接
是
limit
取用前几个
函数拼接
是
skip
跳过前几个
函数拼接
是
map
映射
函数拼接
是
concat
组合
函数拼接
是
备注:本小节之外的更多方法,请自行参考API文档。
forEach : 逐一处理 虽然方法名字叫forEach,但是与for循环中的“for-each”昵称不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的 。
1 void forEach (Consumer<? super T> action) ;
该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.itheima.demo10_Stream流常用方法;import java.util.ArrayList;import java.util.List;public class Test1_forEach { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); list.stream().forEach((String e)->{ System.out.println(e); }); System.out.println("========================================" ); list.parallelStream().forEach((String e)->{ System.out.println(e); }); } }
count:统计个数 正如旧集合Collection当中的size方法一样,流提供count方法来数一数其中的元素个数:
该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.itheima.demo10_Stream流常用方法;import java.util.ArrayList;import java.util.List;public class Test2_count { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); long count = list.stream().count(); System.out.println("流中元素的个数:" +count); } }
filter:过滤 可以通过filter方法将一个流转换成另一个子集流。方法声明:
1 Stream<T> filter (Predicate<? super T> predicate) ;
该接口接收一个Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
基本使用
Stream流中的filter方法基本使用的代码如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.itheima.demo10_Stream流常用方法;import java.util.stream.Stream;public class Test3_filter { public static void main (String[] args) { Stream<String> stream = Stream.of("张三丰" , "张无忌" , "灭绝师太" , "周芷若" , "张翠山" , "殷素素" ); stream.filter((String s) -> { return s.startsWith("张" ); }).forEach((String name)->{ System.out.println(name); }); } }
在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
limit:取用前几个 limit方法可以对流进行截取,只取用前n个。方法签名:
1 Stream<T> limit (long maxSize) ;
参数是一个long型,如果流的当前长度大于参数则进行截取;否则不进行操作。基本使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.itheima.demo10_Stream流常用方法;import java.util.stream.Stream;public class Test4_limit { public static void main (String[] args) { Stream<String> stream = Stream.of("张三丰" , "张无忌" , "灭绝师太" , "周芷若" , "张翠山" , "殷素素" ); stream.limit(3 ).forEach(name-> System.out.println(name)); System.out.println("===============================" ); Stream<String> stream1 = Stream.of("张三丰" , "张无忌" , "灭绝师太" , "周芷若" , "张翠山" , "殷素素" ); stream1.limit(7 ).forEach(name-> System.out.println(name)); } }
skip:跳过前几个 如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流:
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.itheima.demo10_Stream流常用方法;import java.util.stream.Stream;public class Test5_skip { public static void main (String[] args) { Stream<String> stream = Stream.of("张三丰" , "张无忌" , "灭绝师太" , "周芷若" , "张翠山" , "殷素素" ); stream.skip(3 ).forEach(name-> System.out.println(name)); } }
map:映射 如果需要将流中的元素映射到另一个流中,可以使用map方法。方法签名:
1 <R> Stream<R> map (Function<? super T, ? extends R> mapper) ;
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
基本使用
Stream流中的map方法基本使用的代码如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.itheima.demo10_Stream流常用方法;import java.util.stream.Stream;public class Test6_map { public static void main (String[] args) { Stream<String> stream1 = Stream.of("10" , "20" , "30" , "40" ); stream1.map((String s)->{return Integer.parseInt(s);}).forEach((Integer i)->{ System.out.println(i+1 ); }); System.out.println("=========================" ); Stream<String> stream2 = Stream.of("10" , "20" , "30" , "40" ); stream2.map((String s)->{return s+"itheima" ;}).forEach((String i)->{ System.out.println(i+1 ); }); } }
这段代码中,map方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为Integer类对象)。
concat:组合 如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat:
1 static <T> Stream<T> concat (Stream<? extends T> a, Stream<? extends T> b)
备注:这是一个静态方法,与java.lang.String当中的concat方法是不同的。
该方法的基本使用代码如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.itheima.demo10_Stream流常用方法;import java.util.stream.Stream;public class Test7_concat { public static void main (String[] args) { Stream<String> stream1 = Stream.of("10" , "20" , "30" , "40" ); Stream<String> stream2 = Stream.of("张三丰" , "张无忌" , "灭绝师太" , "周芷若" , "张翠山" , "殷素素" ); Stream<String> stream = Stream.concat(stream1, stream2); stream.forEach(name-> System.out.println(name)); } }
实操– Stream综合案例 需求 现在有两个ArrayList集合存储队伍当中的多个成员姓名,要求使用Stream流,依次进行以下若干操作步骤:
第一个队伍只要名字为3个字的成员姓名;
第一个队伍筛选之后只要前3个人;
第二个队伍只要姓张的成员姓名;
第二个队伍筛选之后不要前2个人;
将两个队伍合并为一个队伍;
根据姓名创建Person对象;
打印整个队伍的Person对象信息。
两个队伍(集合)的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class DemoArrayListNames { public static void main (String[] args) { List<String> one = new ArrayList <>(); one.add("迪丽热巴" ); one.add("宋远桥" ); one.add("苏星河" ); one.add("老子" ); one.add("庄子" ); one.add("孙子" ); one.add("洪七公" ); List<String> two = new ArrayList <>(); two.add("古力娜扎" ); two.add("张无忌" ); two.add("张三丰" ); two.add("赵丽颖" ); two.add("张二狗" ); two.add("张天爱" ); two.add("张三" ); } }
分析
实现 Person类的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Person { public String name; public Person (String name) { this .name = name; } @Override public String toString () { return "Person{" + "name='" + name + '\'' + '}' ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class Test { public static void main (String[] args) { List<String> one = new ArrayList <>(); one.add("迪丽热巴" ); one.add("宋远桥" ); one.add("苏星河" ); one.add("老子" ); one.add("庄子" ); one.add("孙子" ); one.add("洪七公" ); List<String> two = new ArrayList <>(); two.add("古力娜扎" ); two.add("张无忌" ); two.add("张三丰" ); two.add("赵丽颖" ); two.add("张二狗" ); two.add("张天爱" ); two.add("张三" ); Stream<String> stream1 = one.stream().filter((String name) -> { return name.length() == 3 ; }).limit(3 ); Stream<String> stream2 = two.stream().filter((String name) -> { return name.startsWith("张" ); }).skip(2 ); Stream.concat(stream1,stream2).map((String name)->{ return new Person (name); }).forEach(p-> System.out.println(p)); } }
运行效果完全一样:
1 2 3 4 5 6 Person{name='宋远桥'} Person{name='苏星河'} Person{name='洪七公'} Person{name='张二狗'} Person{name='张天爱'} Person{name='张三'}
收集Stream结果 收集到集合中
Stream流中提供了一个方法,可以把流中的数据收集到单列集合中
<R,A> R collect(Collector<? super T,A,R> collector): 把流中的数据收集到单列集合中
参数Collector<? super T,A,R>: 决定把流中的元素收集到哪个集合中
返回值类型是R,也就是说R指定为什么类型,就是收集到什么类型的集合
参数Collector如何得到? 使用java.util.stream.Collectors工具类中的静态方法:
public static Collector<T, ?, List> toList():转换为List集合。
public static Collector<T, ?, Set> toSet():转换为Set集合。
下面是这两个方法的基本使用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package com.itheima.demo12_收集Stream结果;import java.util.ArrayList;import java.util.List;import java.util.Set;import java.util.stream.Collectors;import java.util.stream.Stream;public class Test2_ 收集到集合中 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); Stream<String> stream = list.stream().filter(name -> name.startsWith("张" )).filter(name -> name.length() == 3 ); Set<String> set = stream.collect(Collectors.toSet()); System.out.println(set); } }
收集到数组中 Stream提供toArray方法来将结果放到一个数组中,返回值类型是Object[]的:
其使用场景如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.itheima.demo12_收集Stream结果;import java.util.ArrayList;import java.util.Arrays;import java.util.List;import java.util.stream.Stream;public class Test1_ 收集到数组中 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张杰" ); list.add("张三丰" ); Stream<String> stream = list.stream().filter(name -> name.startsWith("张" )).filter(name -> name.length() == 3 ); Object[] arr = stream.toArray(); System.out.println(Arrays.toString(arr)); } }
总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 必须练习: 1. 处理异常---->alt+回车-->选择throws \try ...catch 2. 创建并启动线程的三种方式-->继承\实现\匿名内部类 3. 排序\查找 4. 预习 - 能够理解冒泡排序的执行原理 1. 冒泡排序---->相邻的两个元素进行比较,较大的数据放在后面 for (int i = 0 ;i<数组长度-1 ;i++){ for (int j = 0 ;j<数组长度-1 -i;j++){ } } - 能够理解选择排序的执行原理 2. 选择排序---->选择某个元素(从前往后选择),与该元素后面的所有元素一一进行比较,较大的放在后面 for (int i = 0 ;i<数组长度-1 ;i++){ for (int j = i+1 ;j<数组长度;j++){ } } - 能够理解二分查找的执行原理 二分查找: 原理: 每一次都去获取数组的中间索引所对应的元素,然后和要查找的元素进行比对,如果相同就返回索引; 如果不相同,就比较中间元素和要查找的元素的值; 如果中间元素的值大于要查找的元素,说明要查找的元素在左侧,那么就从左侧按照上述思想继续查询(忽略右侧数据); 如果中间元素的值小于要查找的元素,说明要查找的元素在右侧,那么就从右侧按照上述思想继续查询(忽略左侧数据); 二分查找对数组是有要求的,数组必须已经排好序 - 能够辨别程序中异常和错误的区别 Error:表示错误,程序员是无法通过代码进行纠正使得程序继续往下执行,只能事先避免 Exception:表示异常,程序员是可以通过代码进行纠正使得程序继续往下执行 - 说出异常的分类 编译异常:在编译期间出现的异常,如果编译期间不处理,无法通过编译,程序就无法执行 运行异常:在运行期间出现的异常,如果编译期间不处理,可以通过编译,程序可以执行 - 列举出常见的三个运行期异常 NullPointerException ArrayIndexOutOfBoundsException ArithmeticException ClassCastException ... - 能够使用try ...catch 关键字处理异常 格式: try { 编写可能会出现异常的代码 }catch (异常类型 变量名){ 处理异常的代码 } 执行步骤: 1. 首先执行try 中的代码,如果try 中的代码出现了异常,那么就直接执行catch ()里面的代码,执行完后,程序继续往下执行 2. 如果try 中的代码没有出现异常,那么就不会执行catch ()里面的代码,而是继续往下执行 - 能够使用throws 关键字处理异常 格式: 修饰符 返回值类型 方法名(形参列表) throws 异常类名1 ,异常类名2 …{ } 特点: 声明处理异常,处理完后,如果程序运行的时候出现异常,程序还是无法继续往下执行; 如果程序运行的时候不出现异常,程序就可以继续往下执行 使用场景: 声明处理异常一般处理运行的时候不会出现异常的编译异常 - 能够自定义并使用异常类 自定义编译异常:创建一个类继承Exception 自定义运行异常:创建一个类继承RuntimeException - 说出进程和线程的概念 进程: 其实就是应用程序的可执行单元(.exe) 线程: 其实就是进程的可执行单元 一个应用程序可以有多个进程,一个进程可以有多条线程 - 能够理解并发与并行的区别 并发: 多个事情在同一时间段交替发生 并行; 多个事情在同一时刻同时发生 多线程并发: 多条线程同时请求,但交替执行 - 能够描述Java中多线程运行原理 抢占式 - 能够使用继承类的方式创建多线程 1. 创建子类继承Thread类 2. 在子类中重写run方法,把线程需要执行的任务代码写入run方法中 3. 创建子类线程对象 4. 调用start()方法,启动线程,执行任务 - 能够使用实现接口的方式创建多线程 1. 创建实现类实现Runnable接口 2. 在实现类中重写run方法,把线程需要执行的任务代码写入run方法中 3. 创建实现类对象 4. 创建Thread线程对象,并传入实现类对象 5. 调用start()方法,启动线程,执行任务 - 能够说出实现接口方式的好处 1. 解决单继承的弊端 2. 线程和任务代码是独立分块的,启动解耦操作 3. 任务可以被多条线程共享 4. 线程池中的线程都是通过实现Runnable或者Callable接口方式的线程,不能放入继承Thread类方式的线程 必须练习: 1. 同步代码块和同步锁案例 2. volatile 关键字的使用 3. 原子类的使用 4. 线程池的使用 5. 理解高并发线程安全问题出现的原因\解决办法 并发包:---->理解做好笔记--(休息的时候复习) - 能够解释安全问题的出现的原因 可见性问题: 原因:一条线程对共享变量的修改,对其他线程不可见 解决办法: volatile 关键字修饰共享变量 有序性问题: 原因: 编译器可能会对代码进行重排,造成数据混乱 解决办法:volatile 关键字修饰共享变量 原子性问题: 共享变量原子性问题: 原因:多条线程对共享变量的多次操作,产生了覆盖的效果 解决办法: 原子类,同步锁,Lock锁 代码块原子性问题: 原因:一段代码,被一条线程执行,可能会被其他线程打断,从而造成数据混乱 解决办法: 同步锁,Lock锁 - 能够使用同步代码块解决线程安全问题 同步代码块: 格式: synchronized (锁对象){ } 锁对象: 1. 语法上,可以是任意类的对象 2. 如果多条线程想要实现同步,那么这多条线程的锁对象必须一致 - 能够使用同步方法解决线程安全问题 同步方法: 格式: 修饰符 synchronized 返回值类型 方法名(形参列表){} 锁对象; 非静态同步方法: 锁对象this 静态同步方法:该方法所在类的字节码对象(类名.class) - 能够说出volatile 关键字的作用 解决可见性,有序性问题,不能解决原子性问题 - 能够说明volatile 关键字和synchronized 关键字的区别 1. volatile 只能修饰成员变量,synchronized 可以修饰代码块或者方法 2. volatile 是强制要求子线程每次使用共享变量都是重新从主内存中获取 synchronized 实现的是互斥访问 3. volatile 只能解决可见性,有序性问题,不能解决原子性问题,但synchronize都可以解决 - 能够理解原子类的工作机制 cas机制: 比较并交换 - 能够掌握原子类AtomicInteger的使用 构造方法\成员方法 - 能够描述ConcurrentHashMap类的作用 当成Map集合使用,只是线程安全 - 能够描述CountDownLatch类的作用 h允许一个或多个线程等待其他线程完成操作 - 能够描述CyclicBarrier类的作用 。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。 - 能够表述Semaphore类的作用 控制线程并发的数量 - 能够描述Exchanger类的作用 2 条线程之间交换数据 - 能够描述Java中线程池运行原理 线程池的原理: 创建线程池的时候初始化指定数量的线程,当有任务需要线程执行的时候,就在线程池中随机分配空闲线程来执行当前的任务;如果线程池中没有空闲的线程,那么该任务就进入任务队列中进行等待,等待其他线程空闲下来,再执行任务.(线程重复利用) 必须练习: 1. 绘制线程状态之间的切换 2. 编写和分析等待唤醒机制案例---吃包子案例 3. Stream综合案例,并收集最终的结果--->Stream流的方法\Lambda表达式 - 能够理解死锁出现的原因 当前线程在等待另一条线程获取的锁对象,而另一条线程也在获取当前线程获取的锁对象 - 能够说出线程6 个状态的名称 新建 创建线程对象时 可运行 调用start()方法时 锁阻塞 没有获取到锁对象 无限等待 使用锁对象调用wait()方法时 计时等待 调用sleep(时间)方法时\调用wait(时间)方法时 被终止 run方法正常运行结束\run方法没有捕获处理异常结束 线程状态之间的切换 - 能够理解等待唤醒案例 - 实现等待唤醒机制程序: - 必须使用锁对象调用wait方法,让当前线程进入无限等待状态 - 必须使用锁对象调用notify\notifyAll方法唤醒等待线程 - 调用wait\notfiy\notfiyAll方法的锁对象必须一致 - 分析的等待唤醒机制程序: - 线程的调度依然是抢占式调度 - 线程进入无限等待状态,就不会霸占cpu和锁对象(释放),也不会抢占cpu和锁对象 - 如果是在同步锁中\Lock锁中,调用sleep()方法进入计时等待,不会释放cpu和锁对象(依然占用) - 能够掌握Lambda表达式的标准格式与省略格式 作用: 就是用来简化代码的,不用去定义类\方法\对象等 格式: (类型 变量名,类型变量名,...)->{代码...} 格式解释: 1. 小括号中的内容和函数式接口中抽象方法的形参列表一致 2. 大括号中的内容其实就是以前重写函数式接口抽象方法的方法体 前提条件: 当且仅当接口是函数式接口的,才可以使用Lambda表达式 函数式接口:接口中有且仅有一个抽象方法的接口就是函数式接口,可以使用@FunctionalInterface 注解来标识 使用步骤: 1. 分析接口是否是函数式接口 2. 如果是函数式接口,就写()->{} 3. 然后填充小括号和大括号中的内容 省略规则: 1. 小扩号中的类型可以省略 2. 小括号中有且仅有一个参数,那么小括号也可以省略 3. 大括号中有且仅有一条语句,那么大括号,分号,return 都可以省略(一起) 表现形式: 变量形式 参数形式 返回值形式 - 能够通过集合、映射或数组方式获取流 单列集合: Collection的stream方法 根据List集合获取流 根据Set集合获取流 映射(双列集合): Collection的Stream方法 根据键获取流 根据值获取流 根据键值对对象获取流 数组: Stream的of(T... args)方法 - 能够掌握常用的流操作 终结方法: forEach,count 延迟方法: filter:过滤 limit: 取前几个 skip: 跳过 map: 映射 concat: 组合\合并流 - 能够将流中的内容收集到集合和数组中 收集到集合: List集合: Stream流对象.collect(Collectors.toList())方法 Set集合: Stream流对象.collect(Collectors.toSet())方法 收集到数组: Stream流对象.toArray();
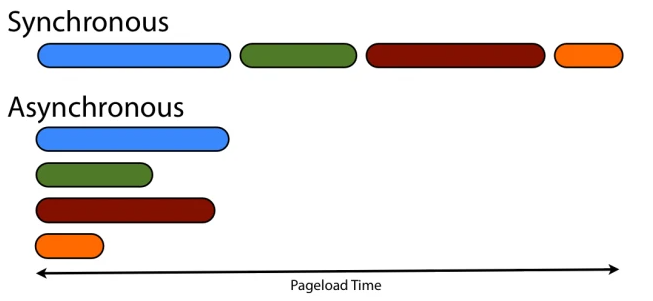
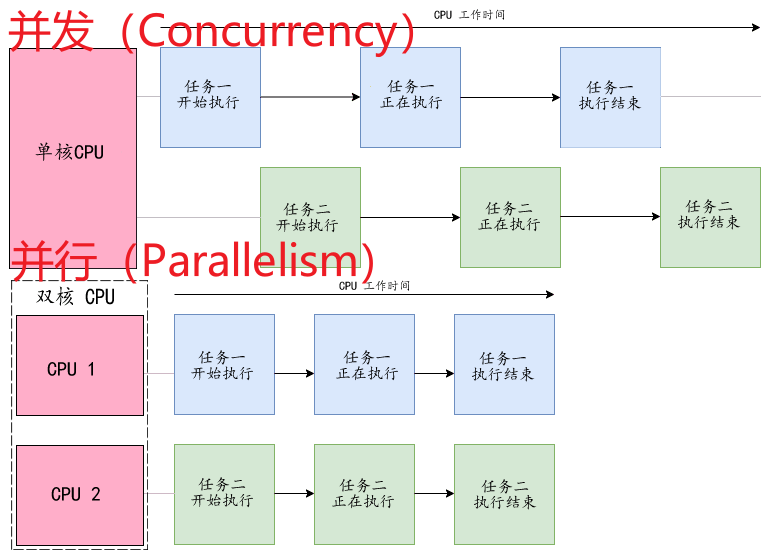
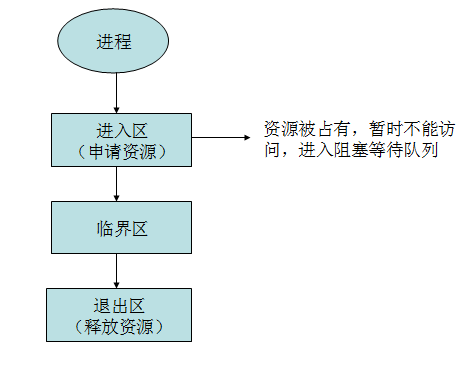
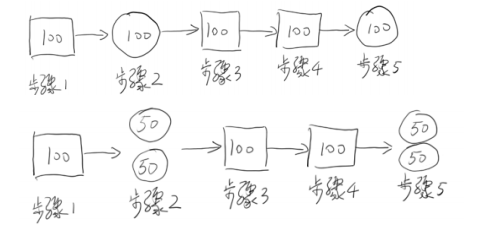


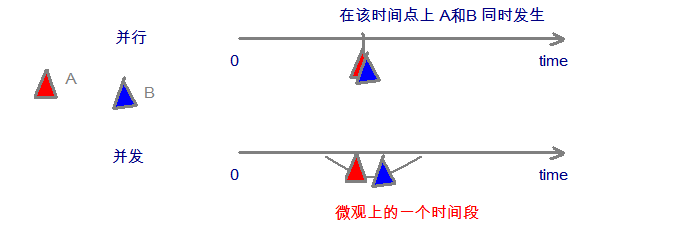

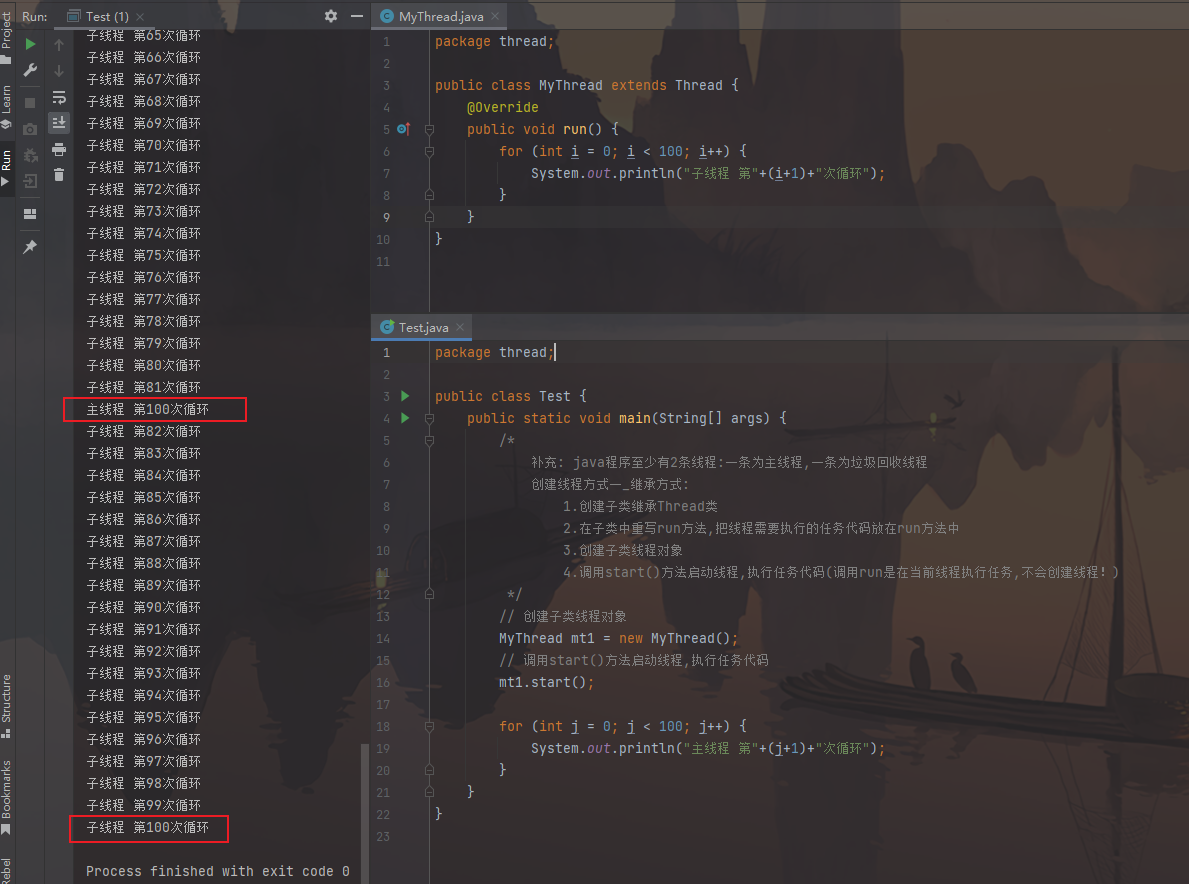
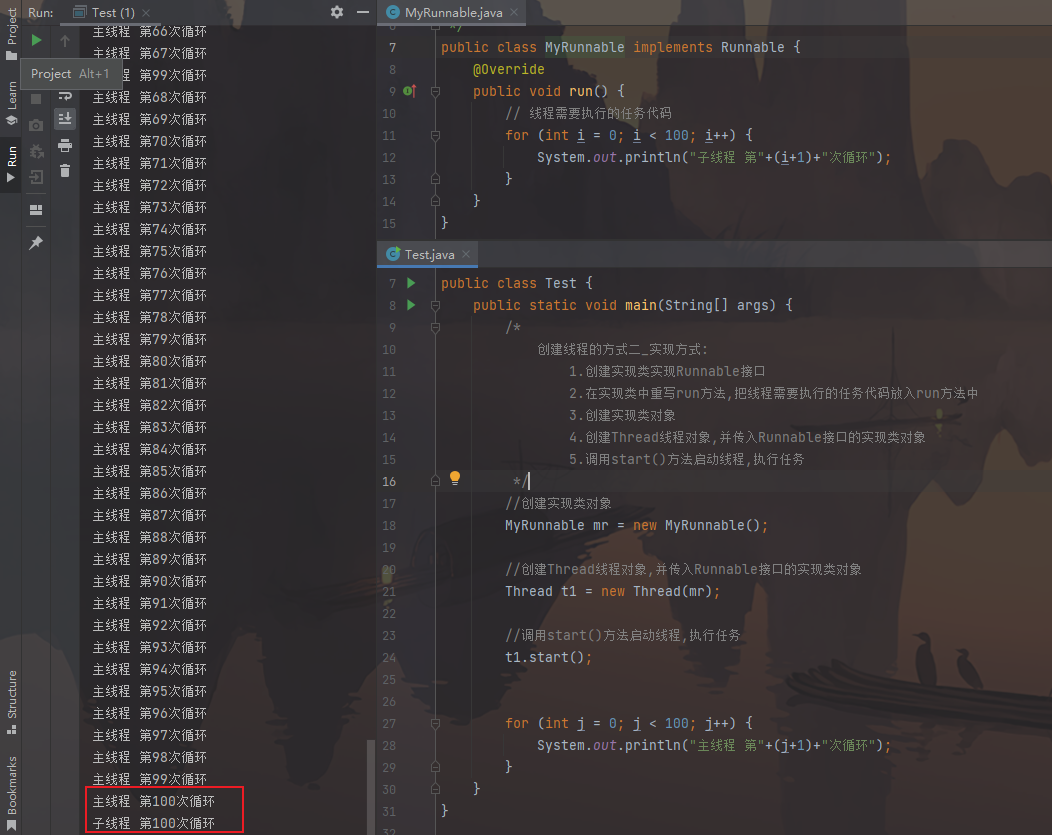
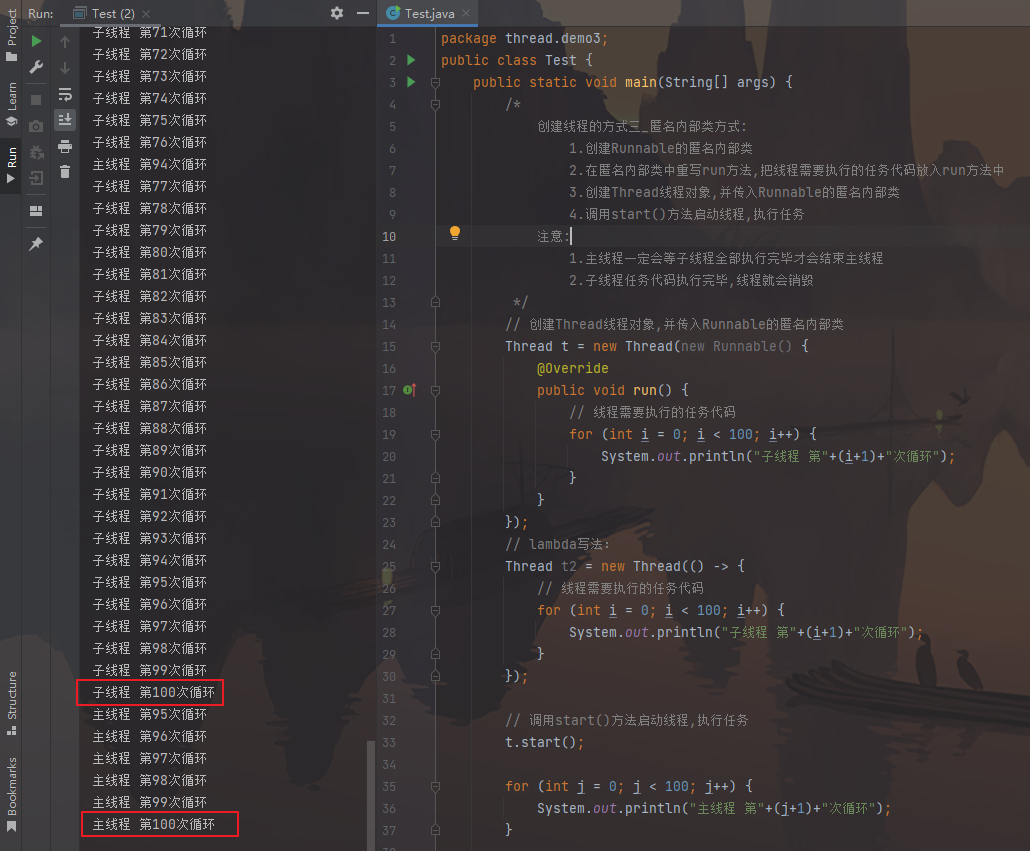
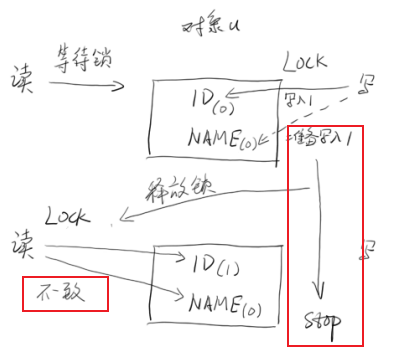
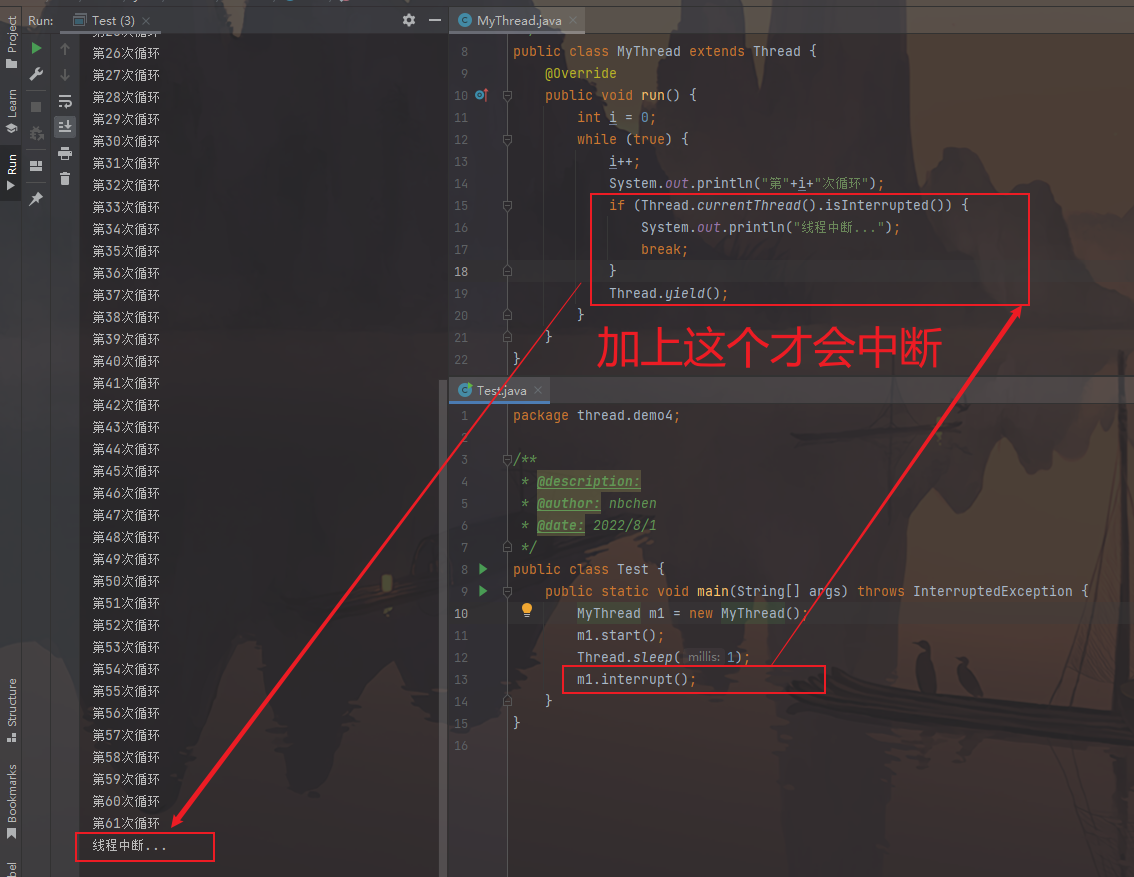
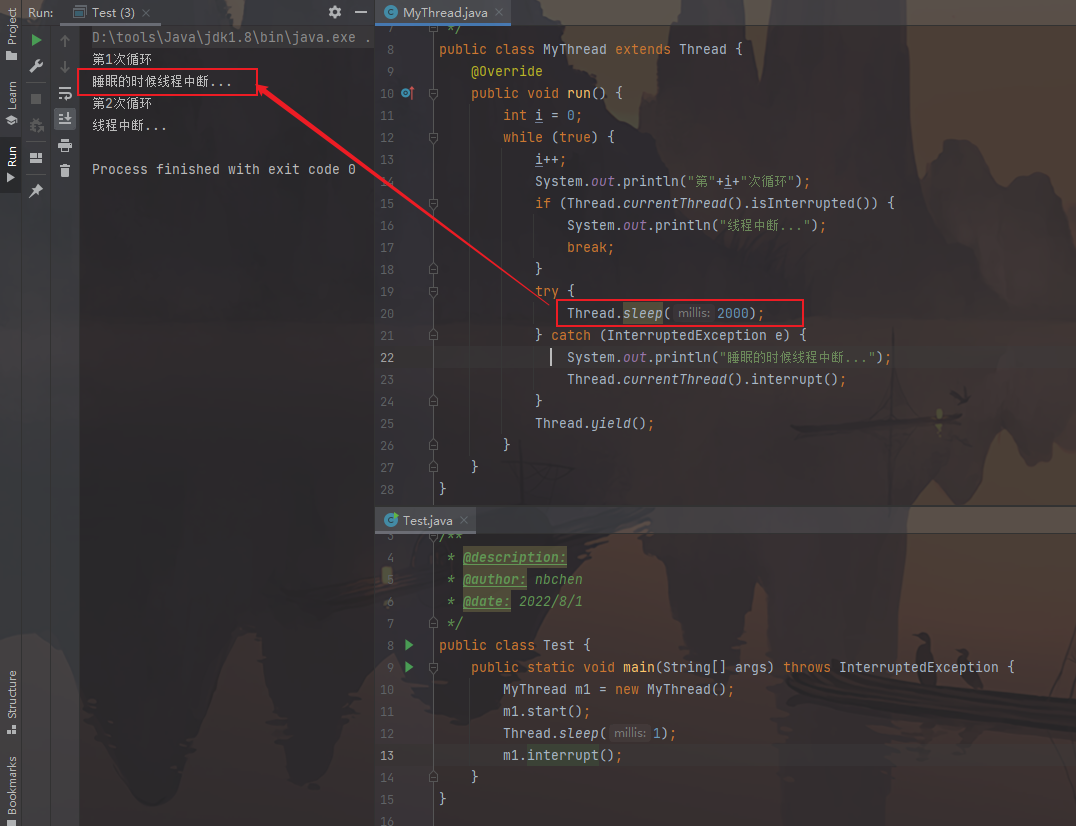
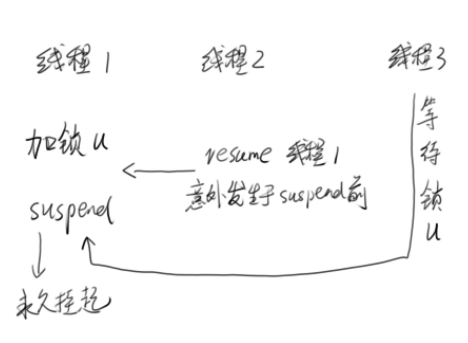
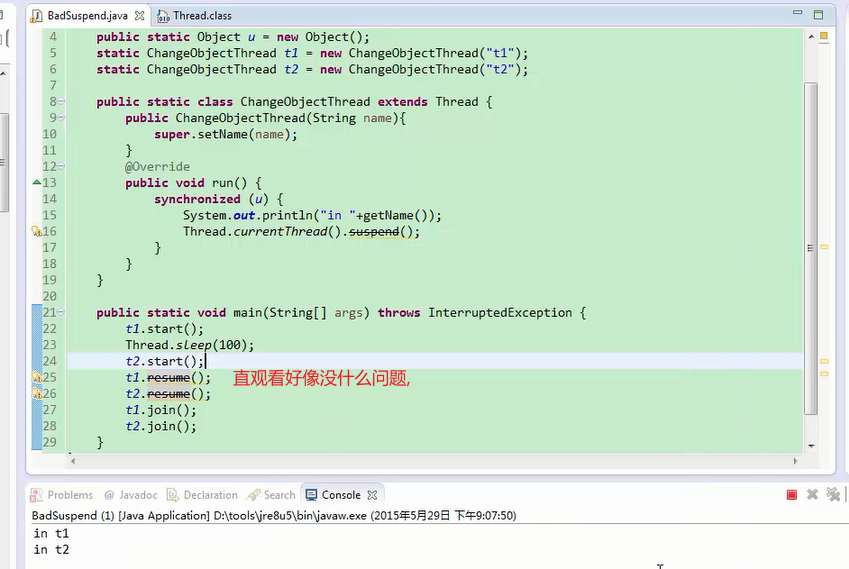
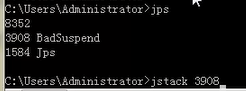
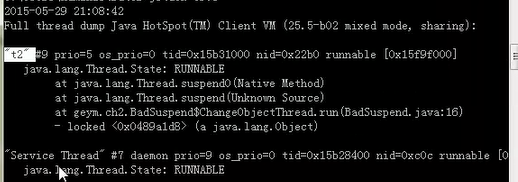
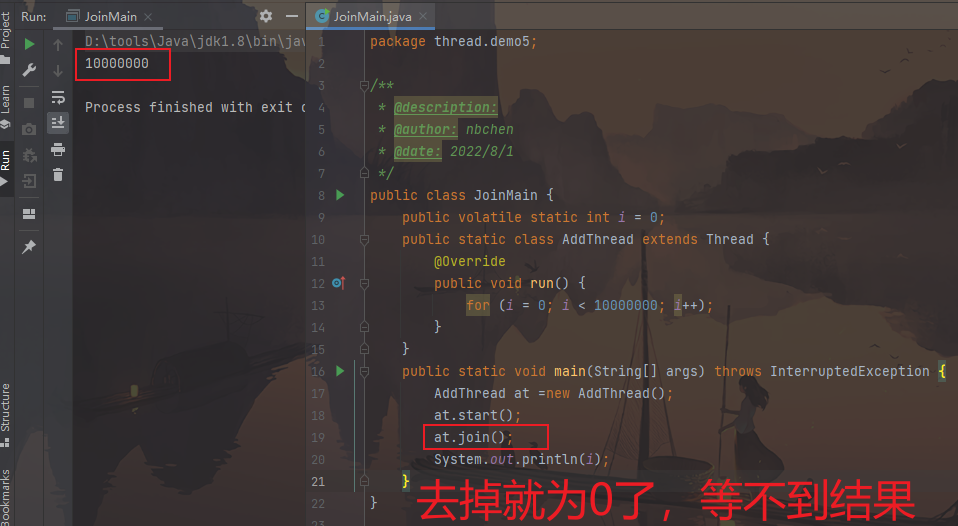
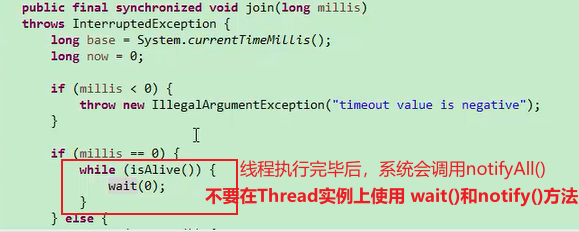
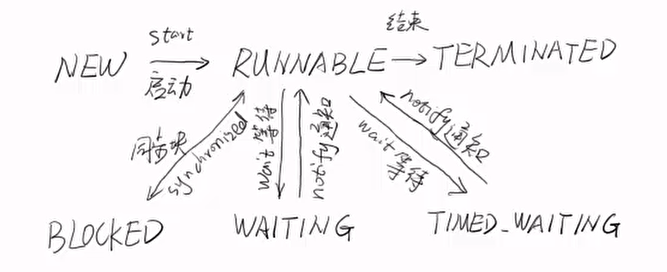
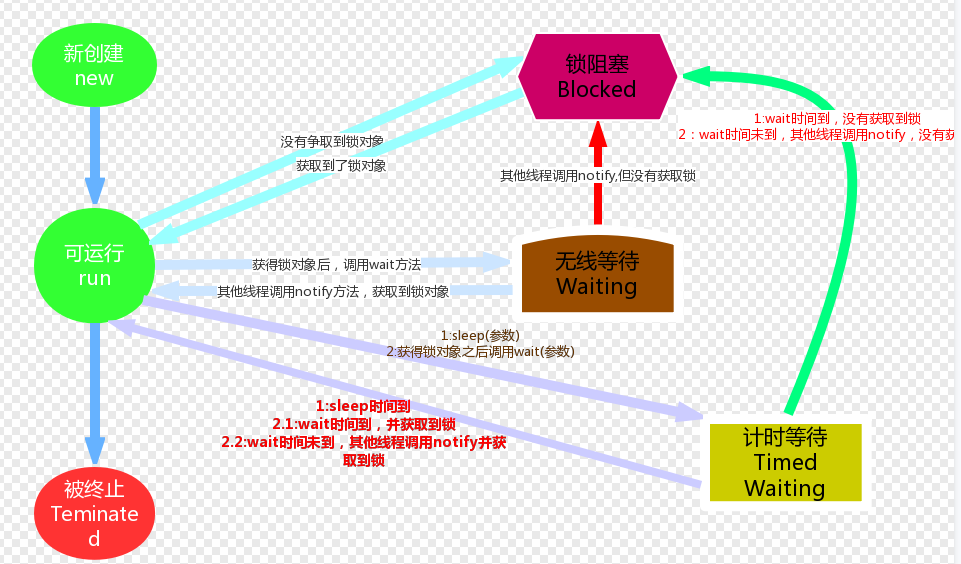
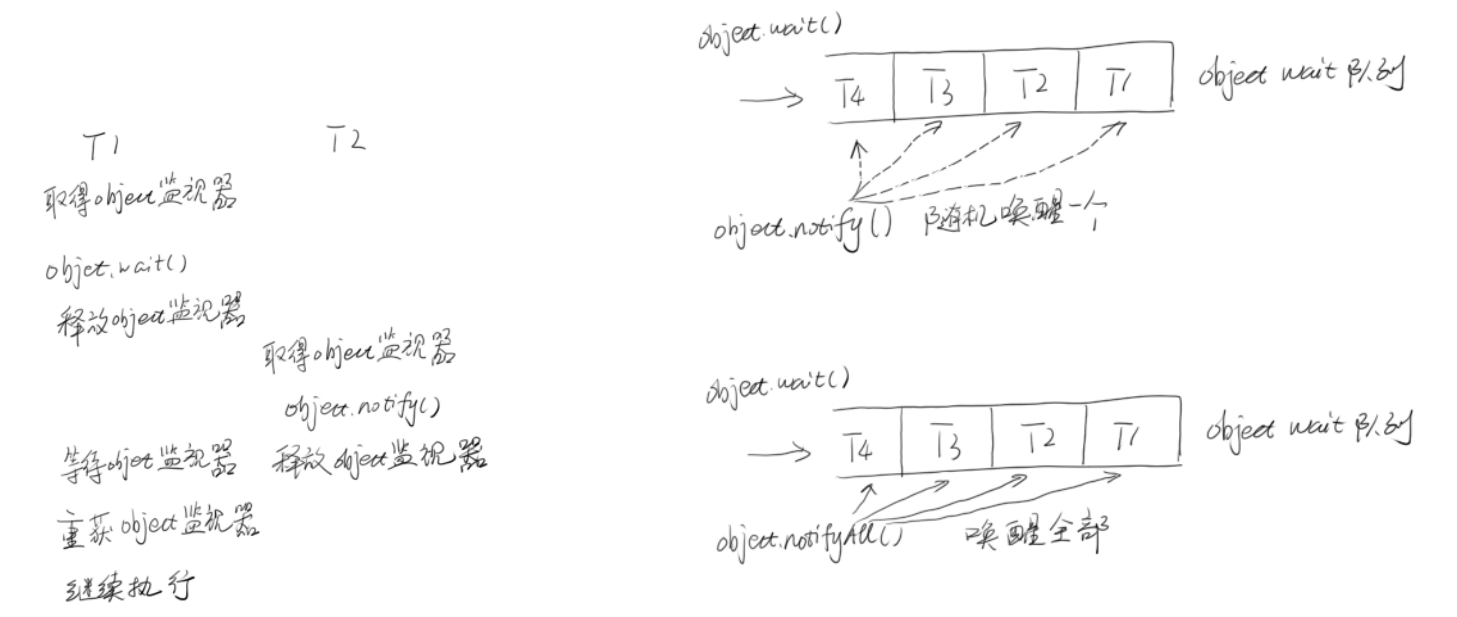
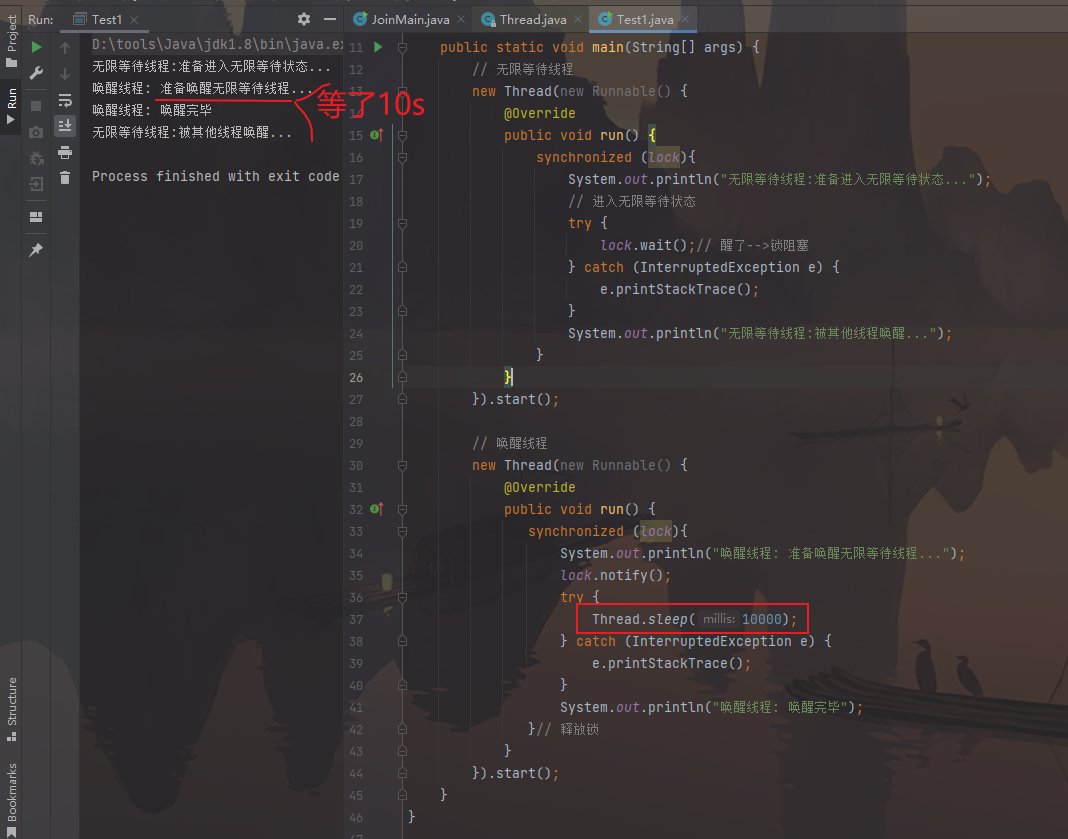
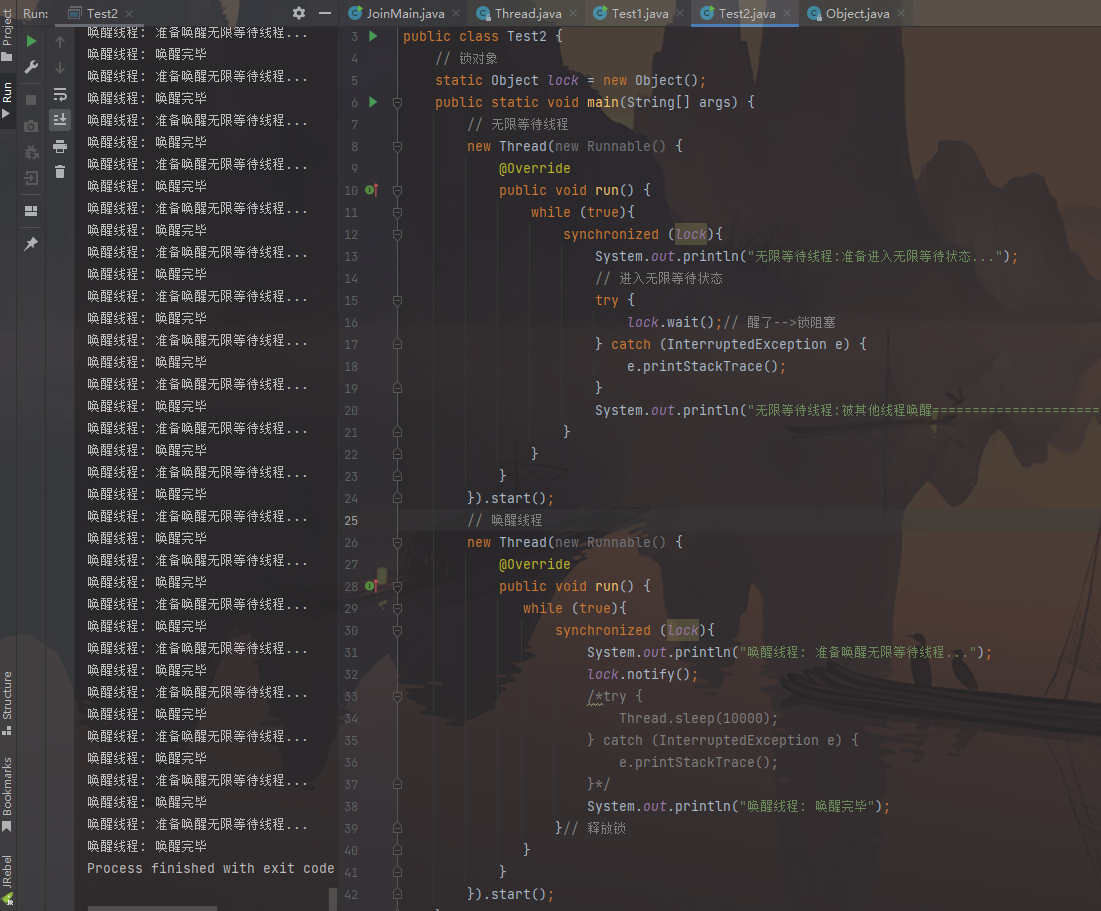

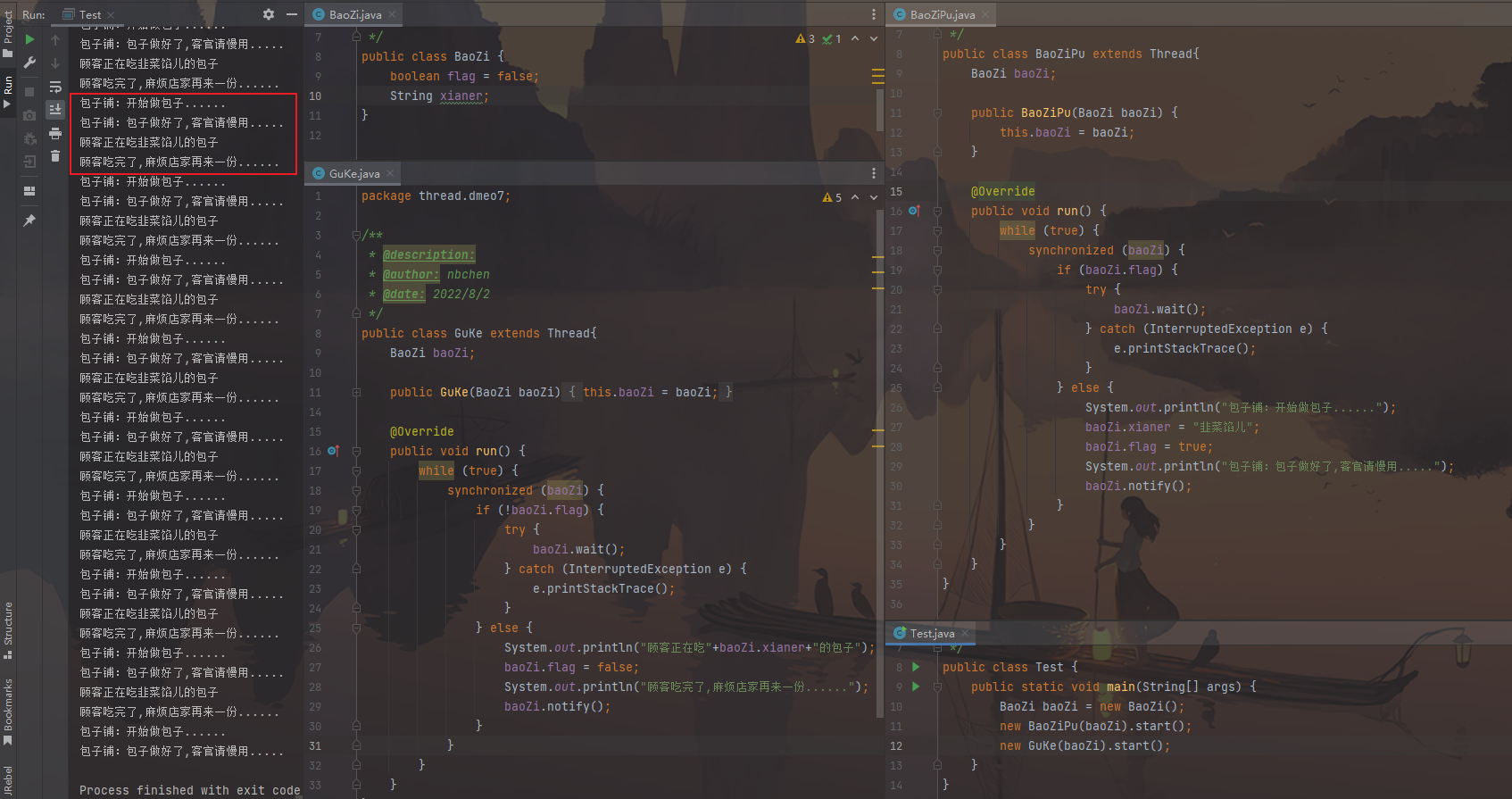
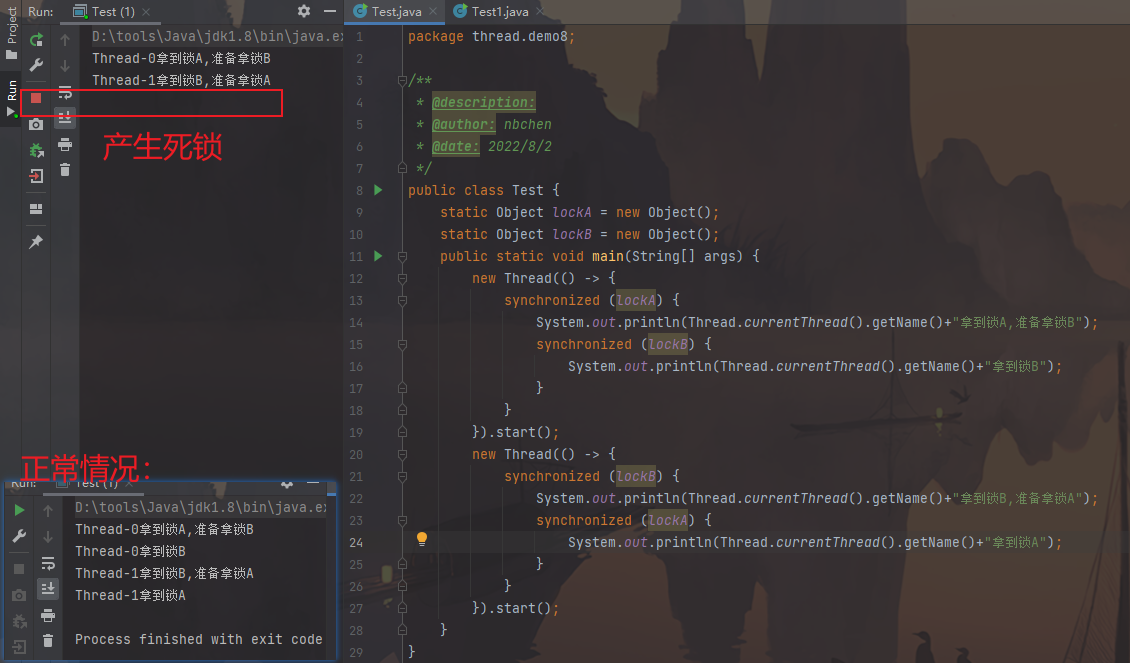

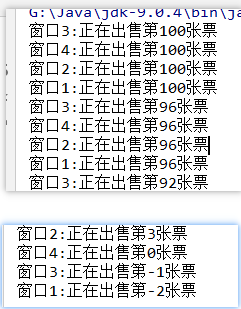
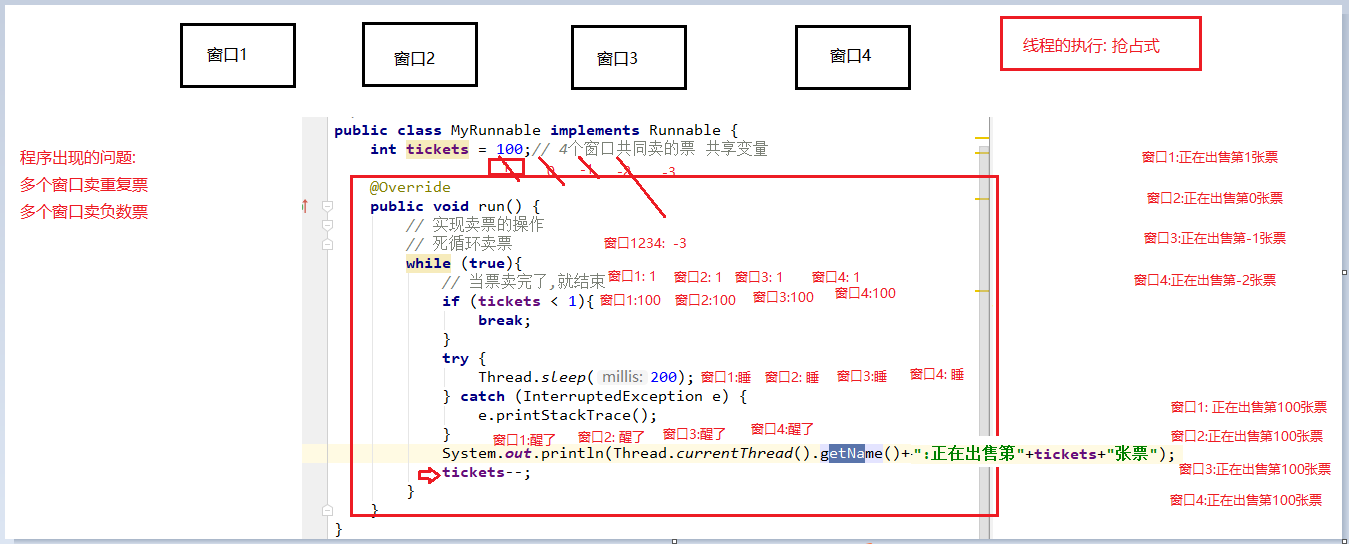
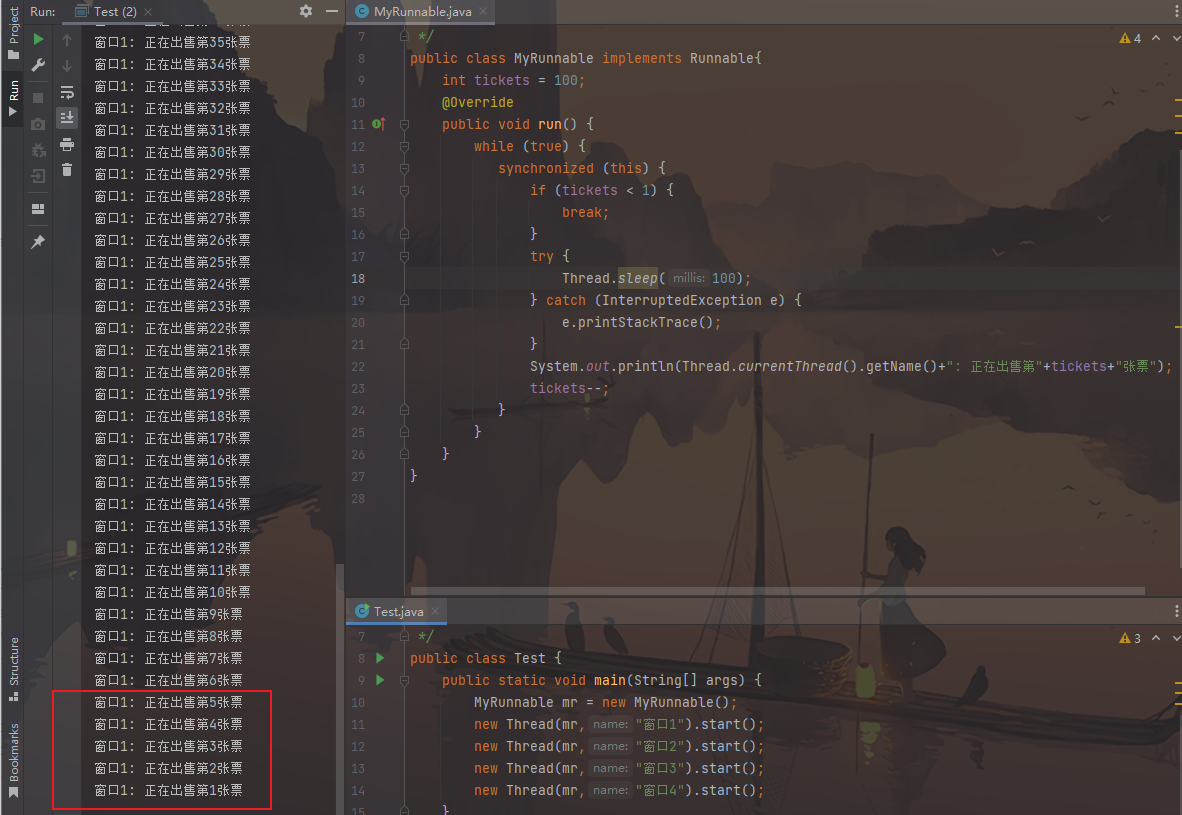
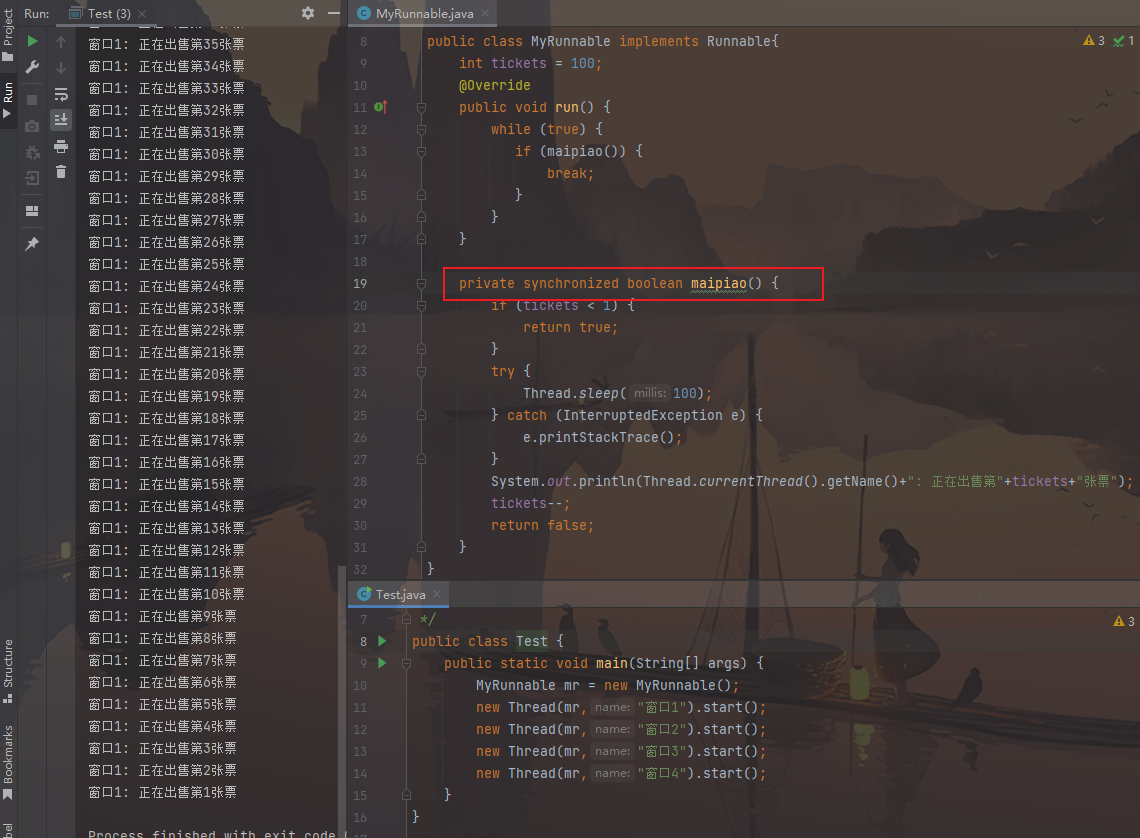
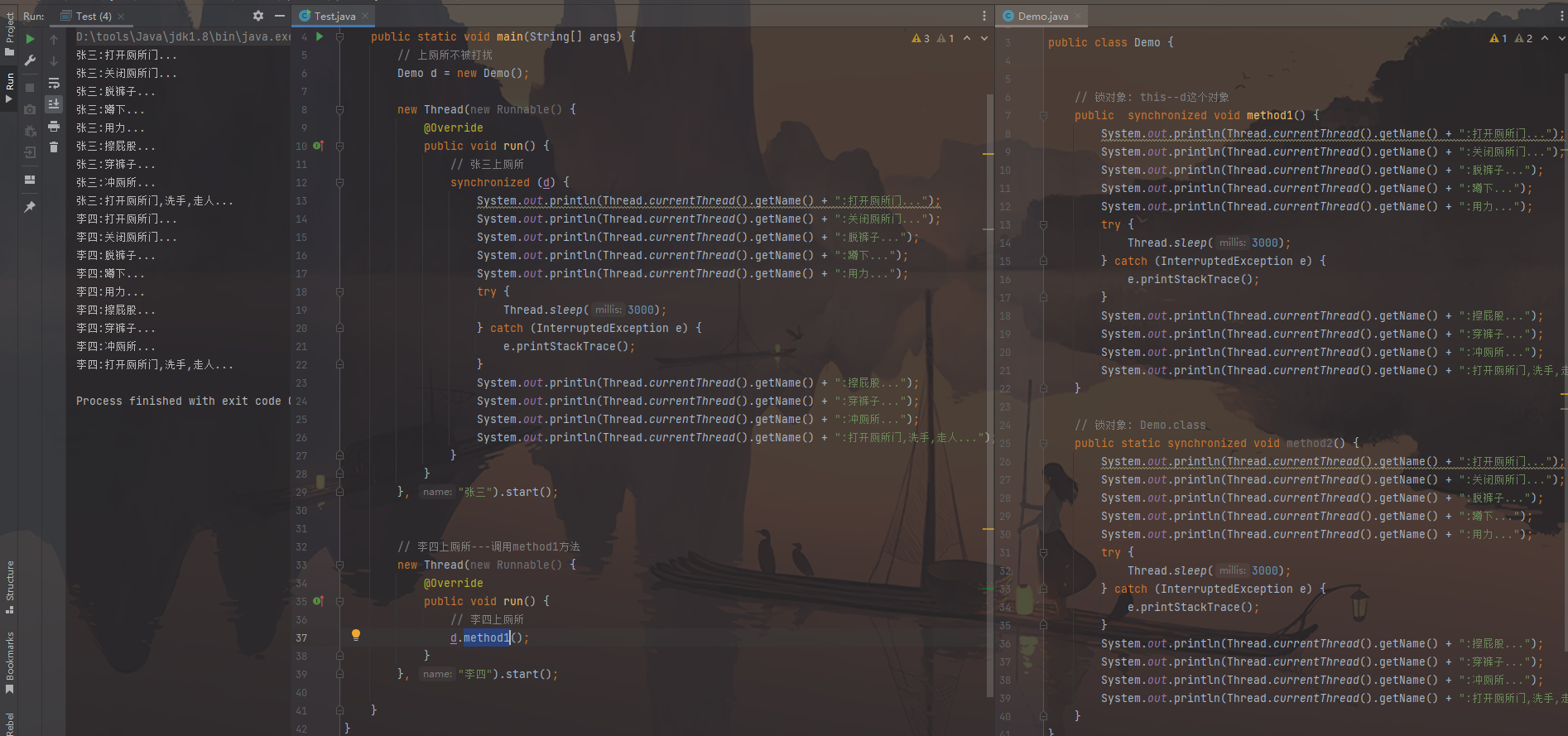
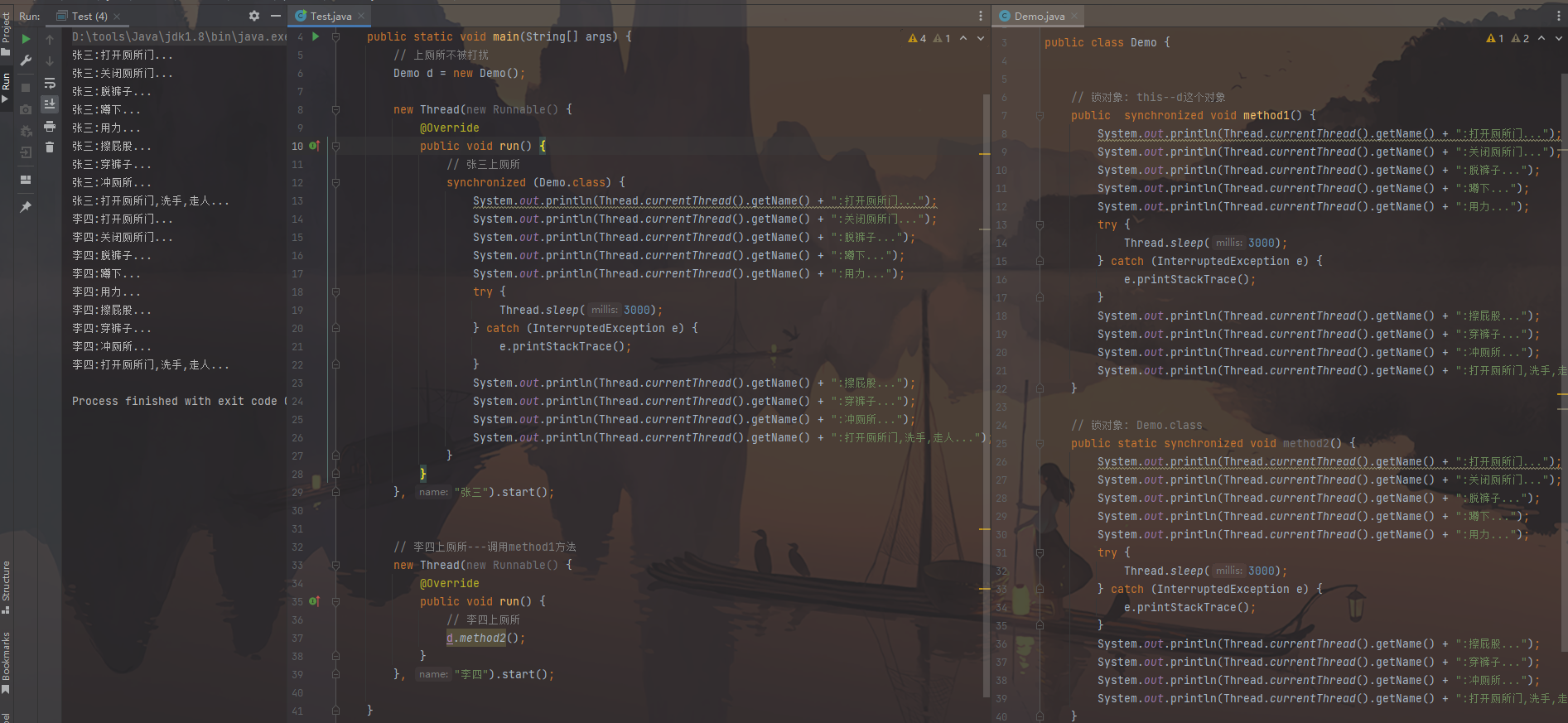
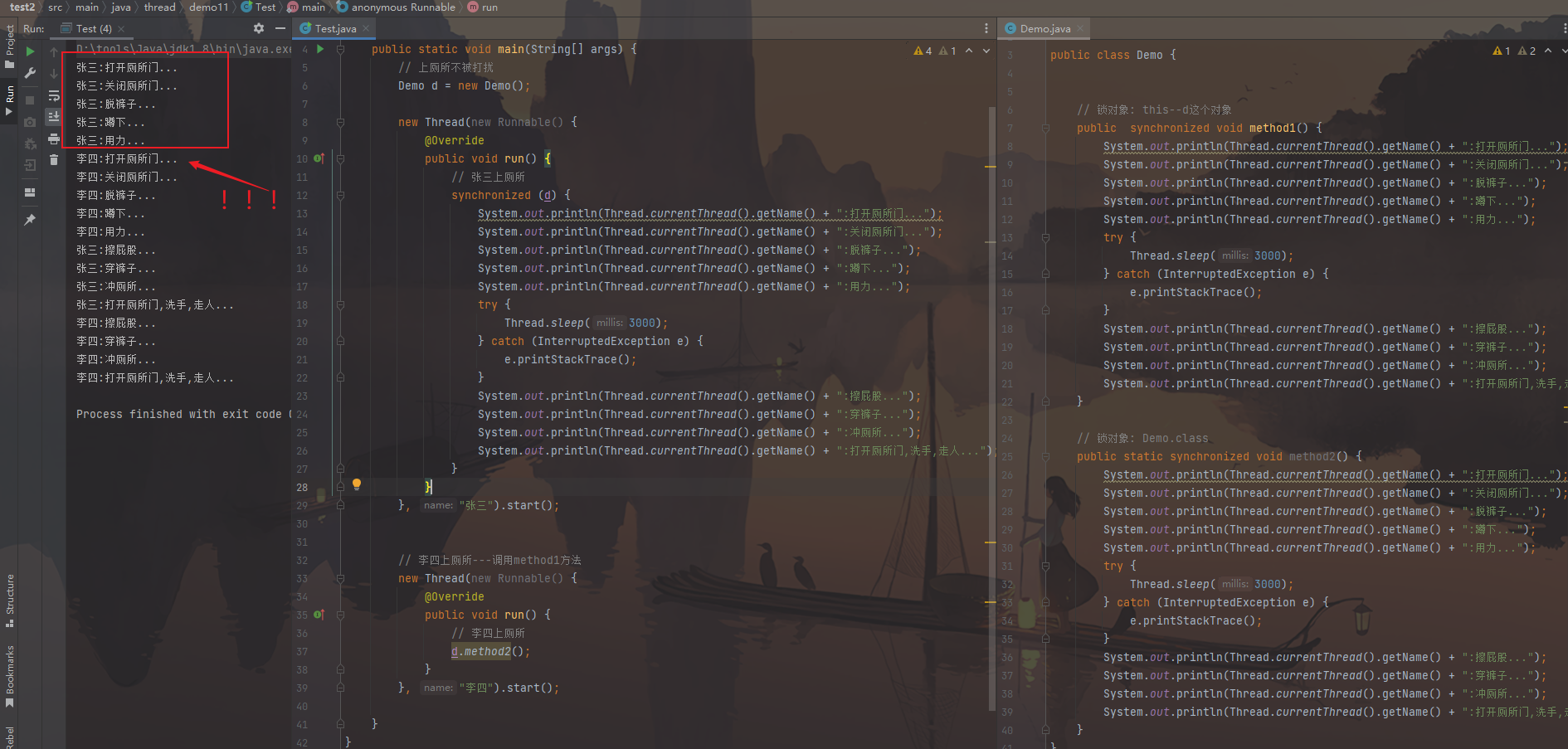
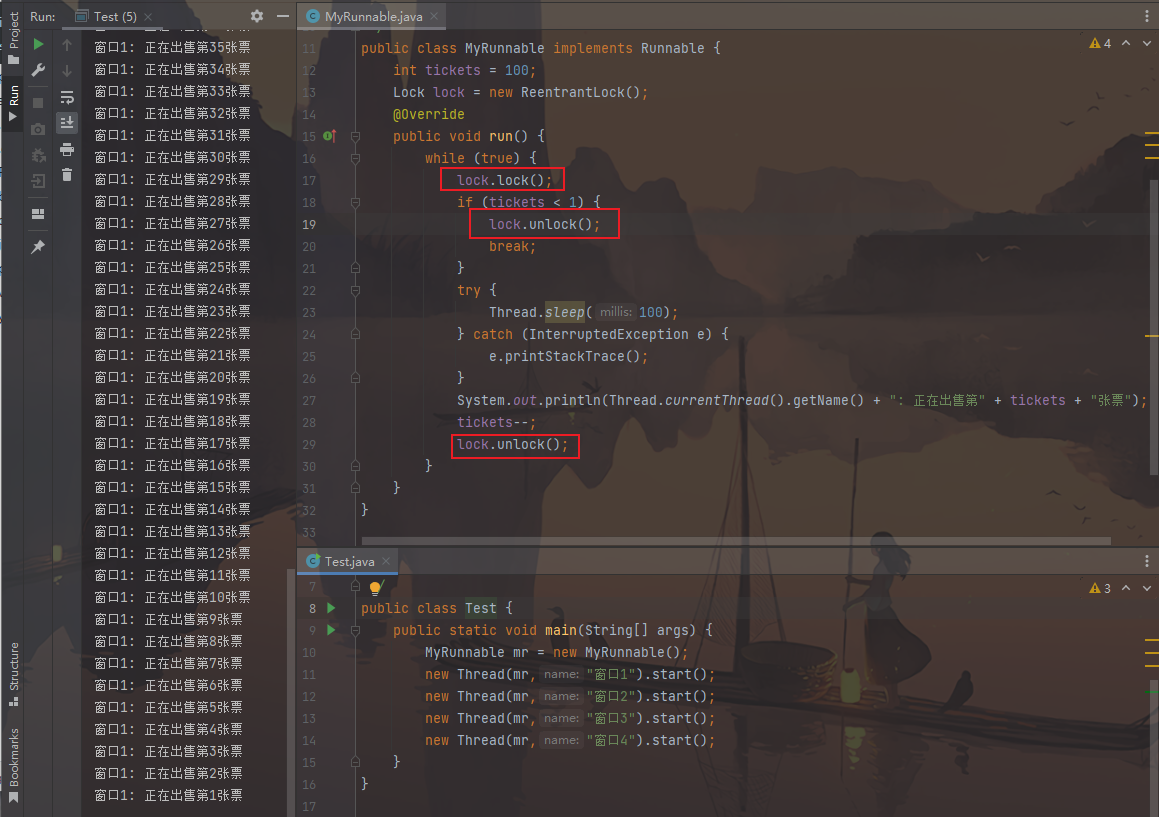
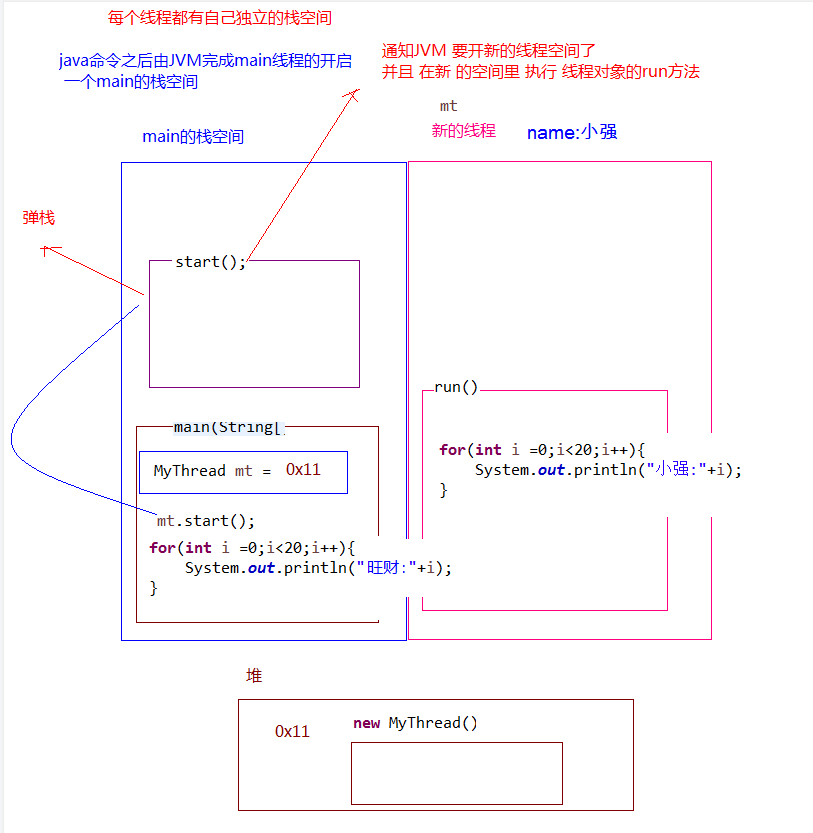
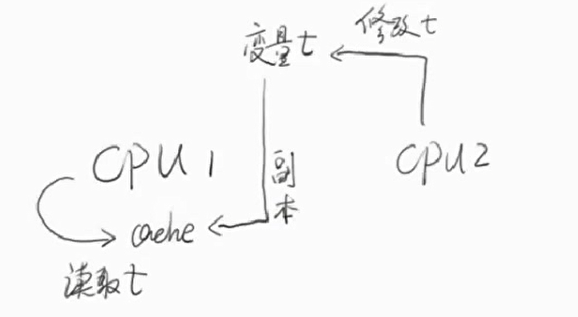

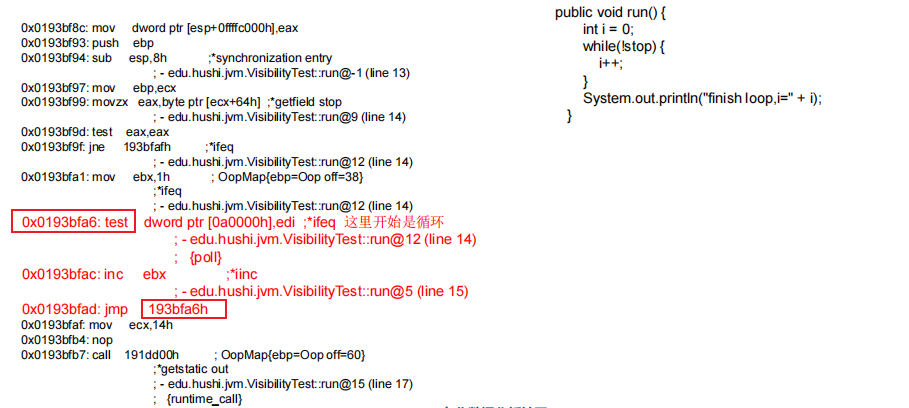

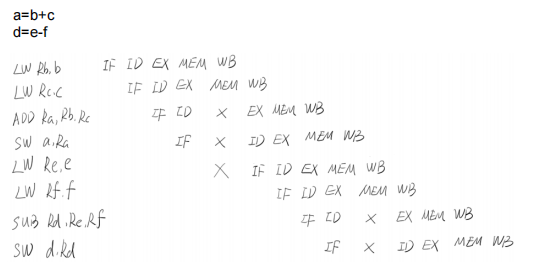
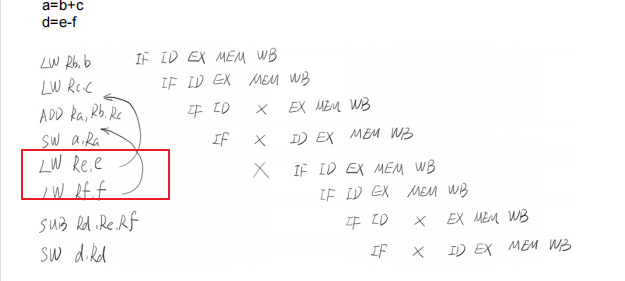
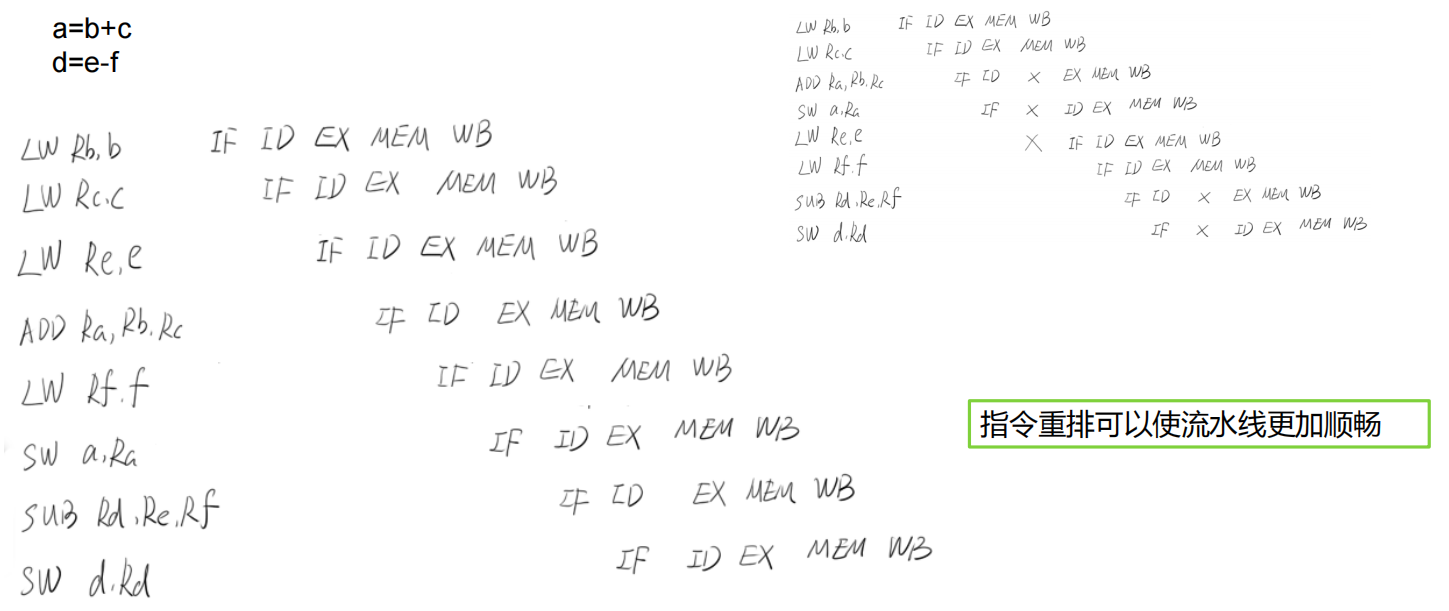

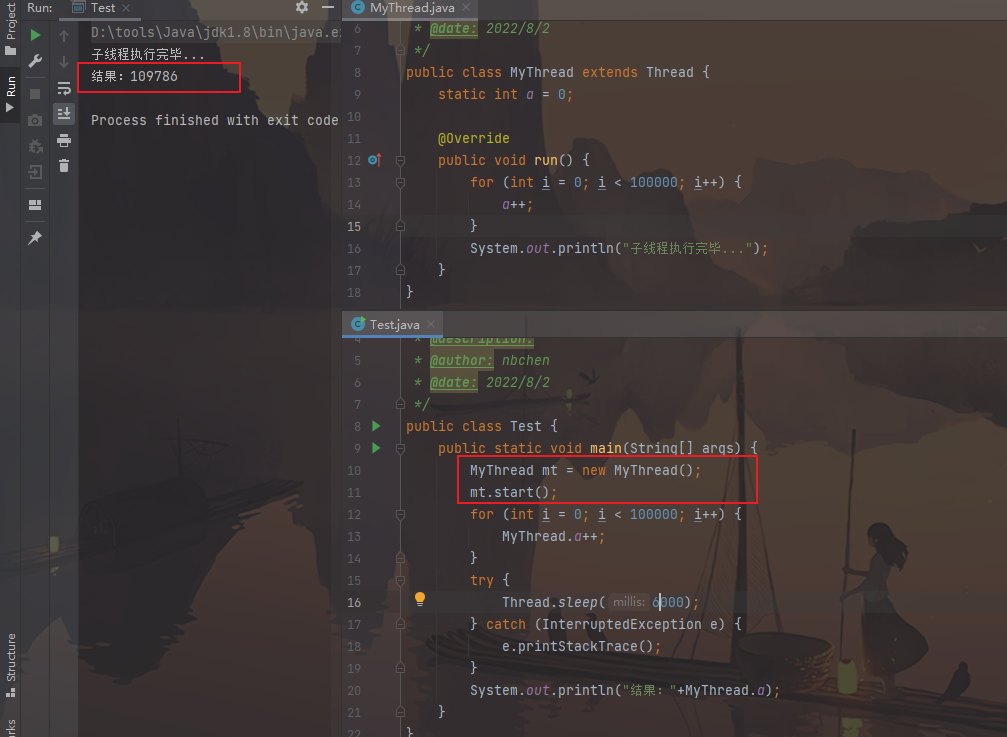
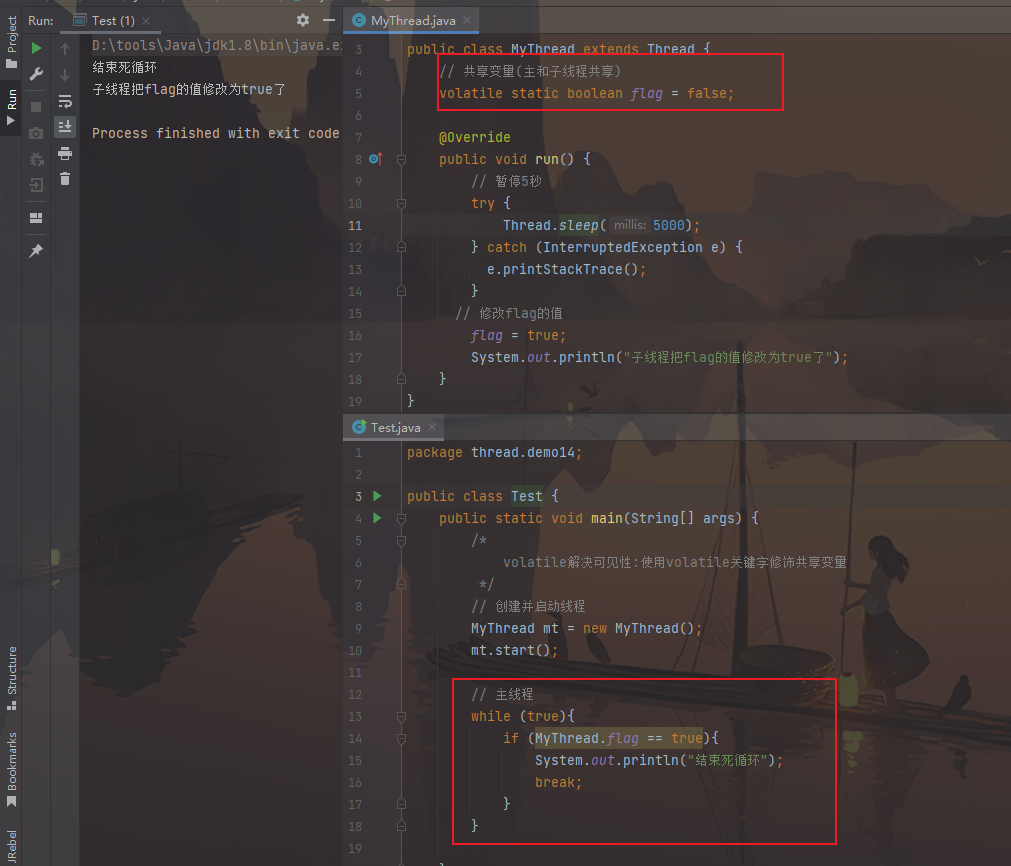

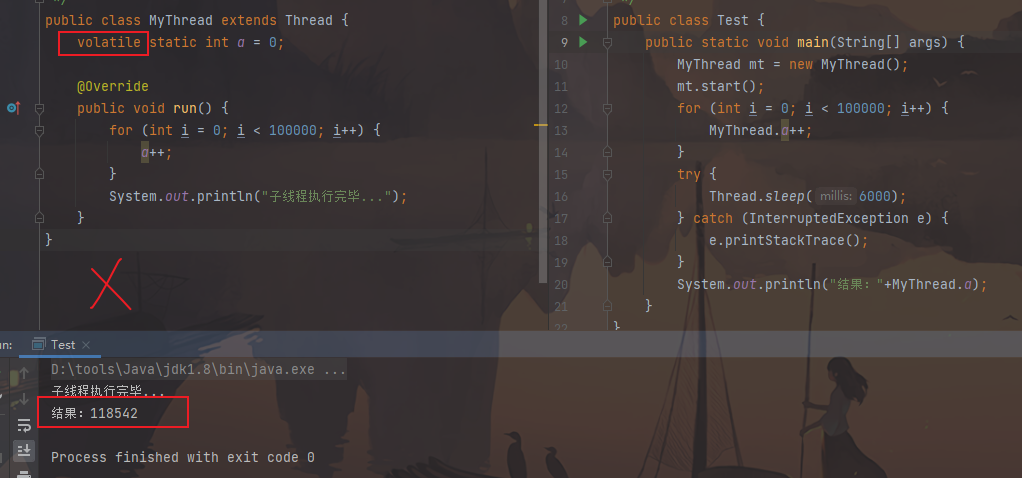
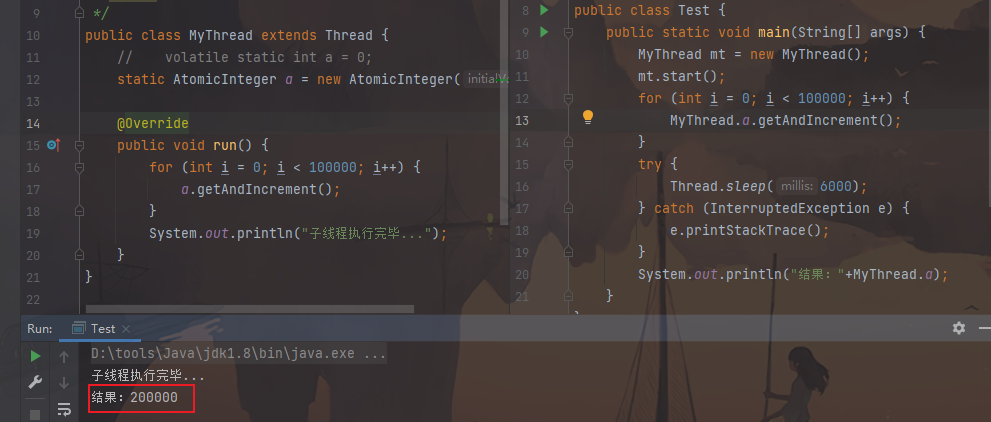

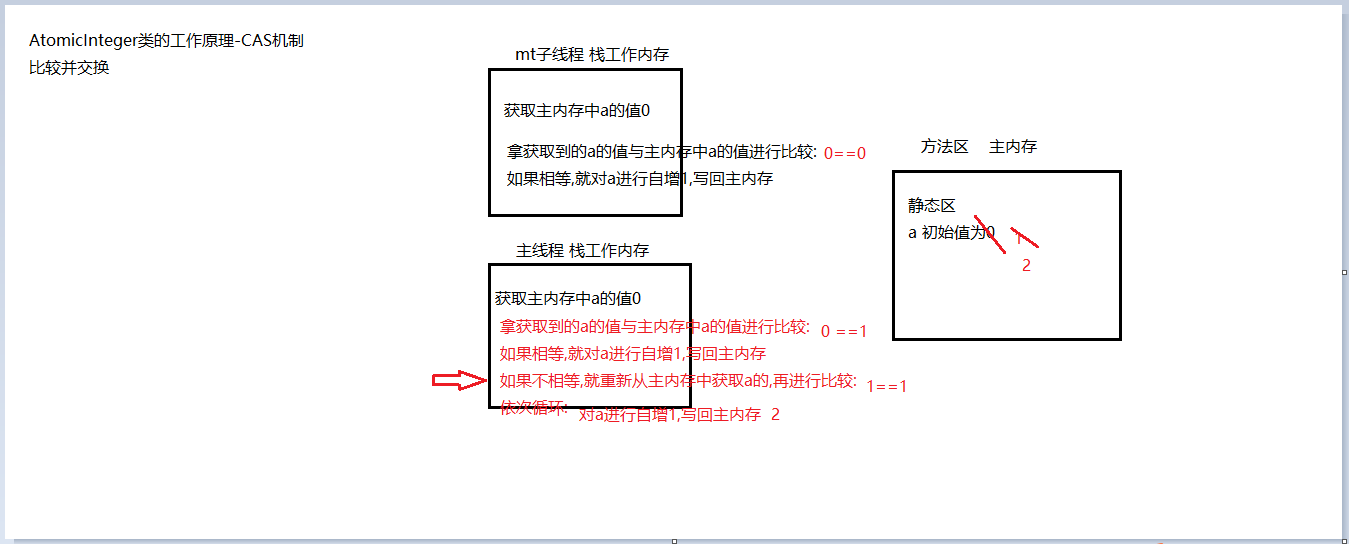
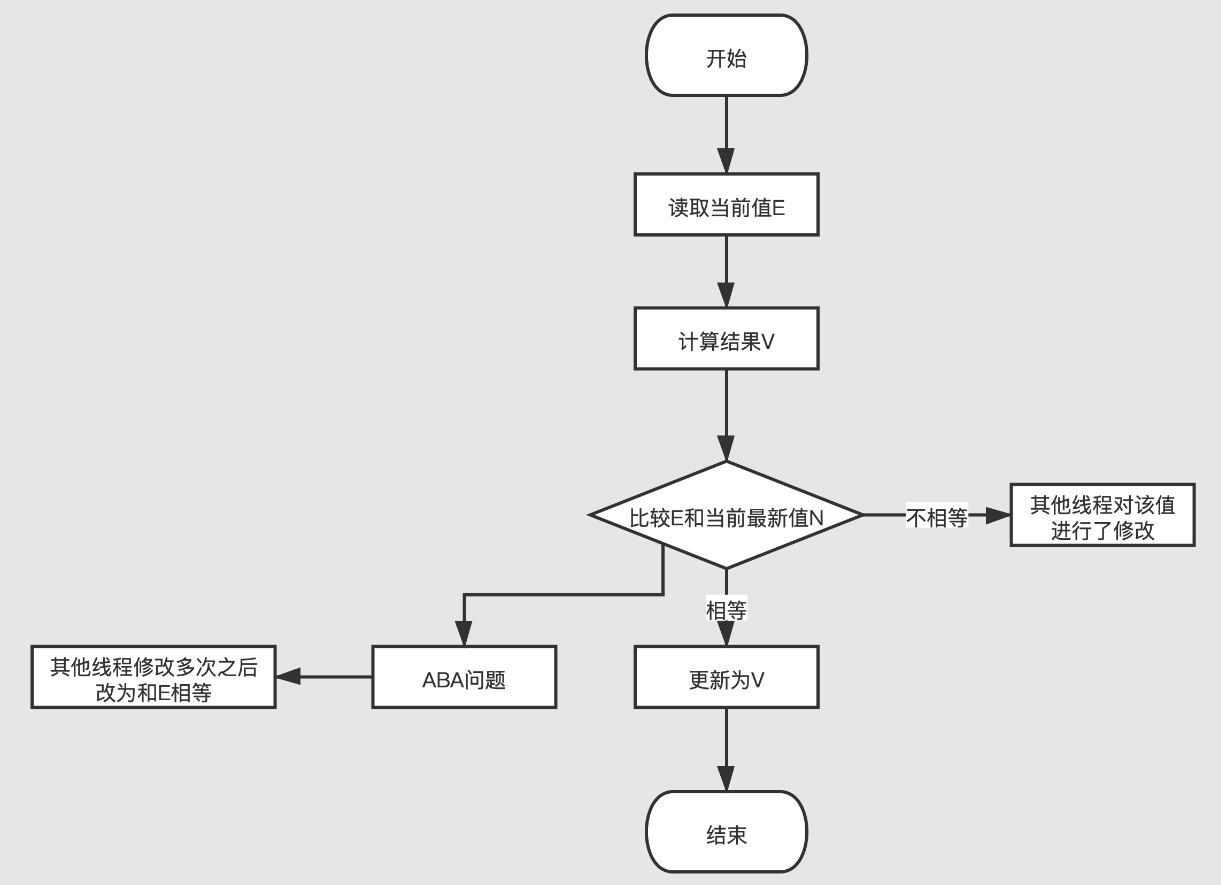
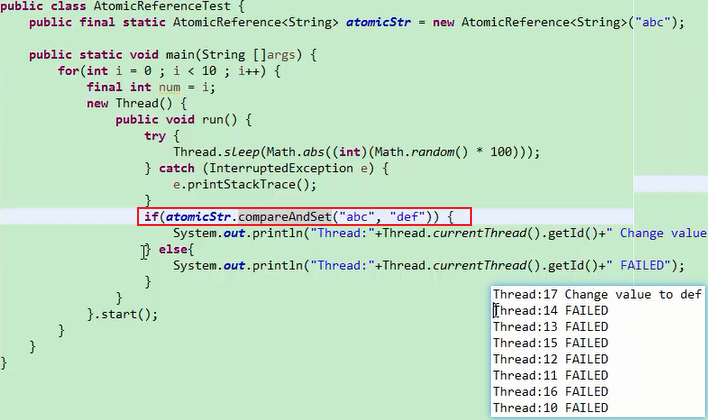
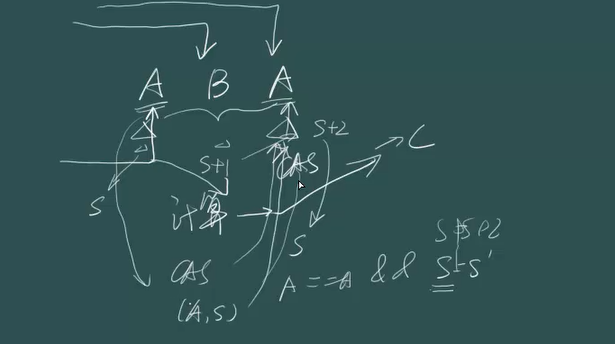
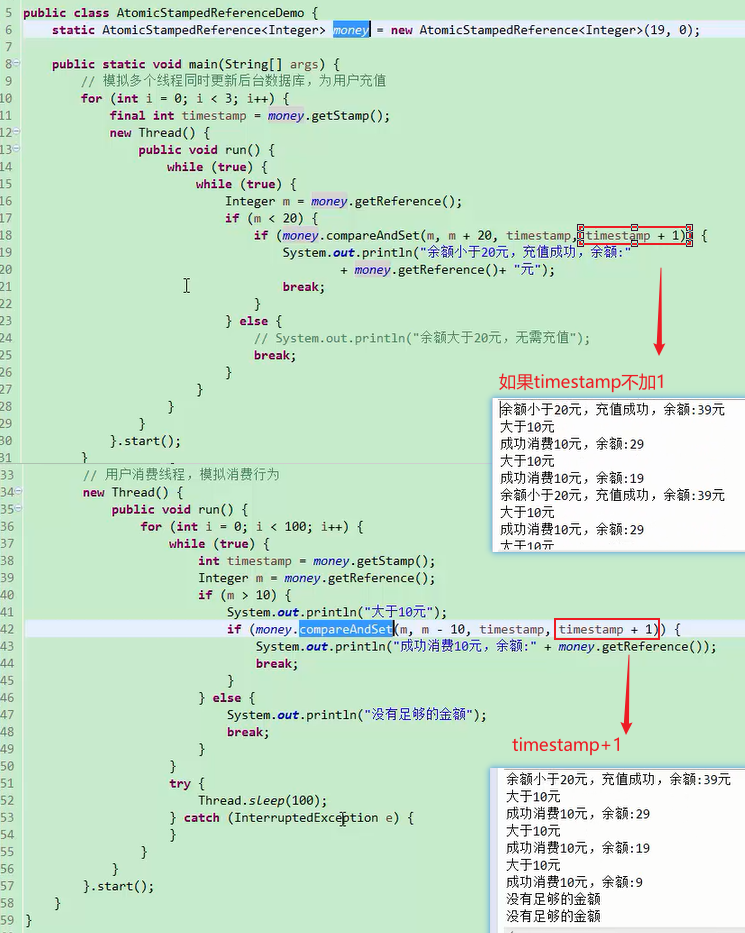
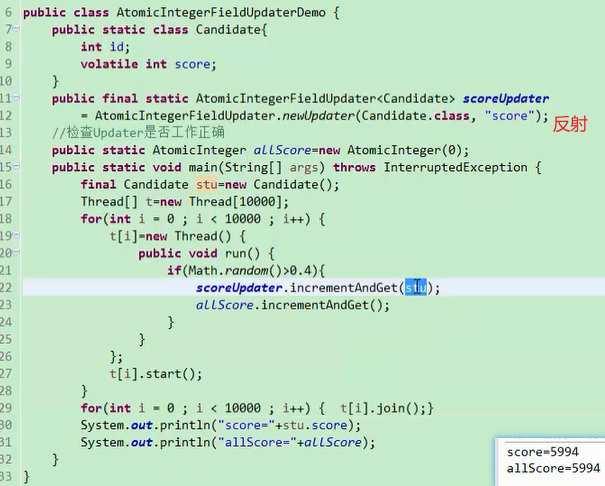
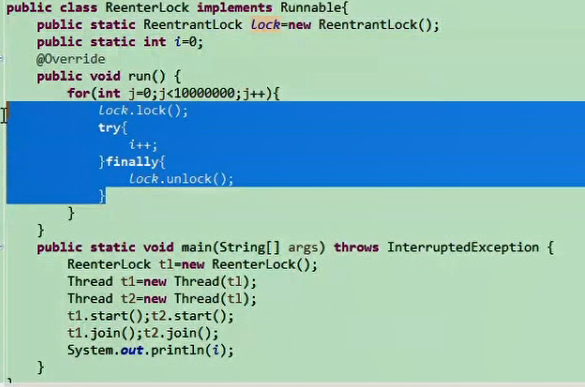
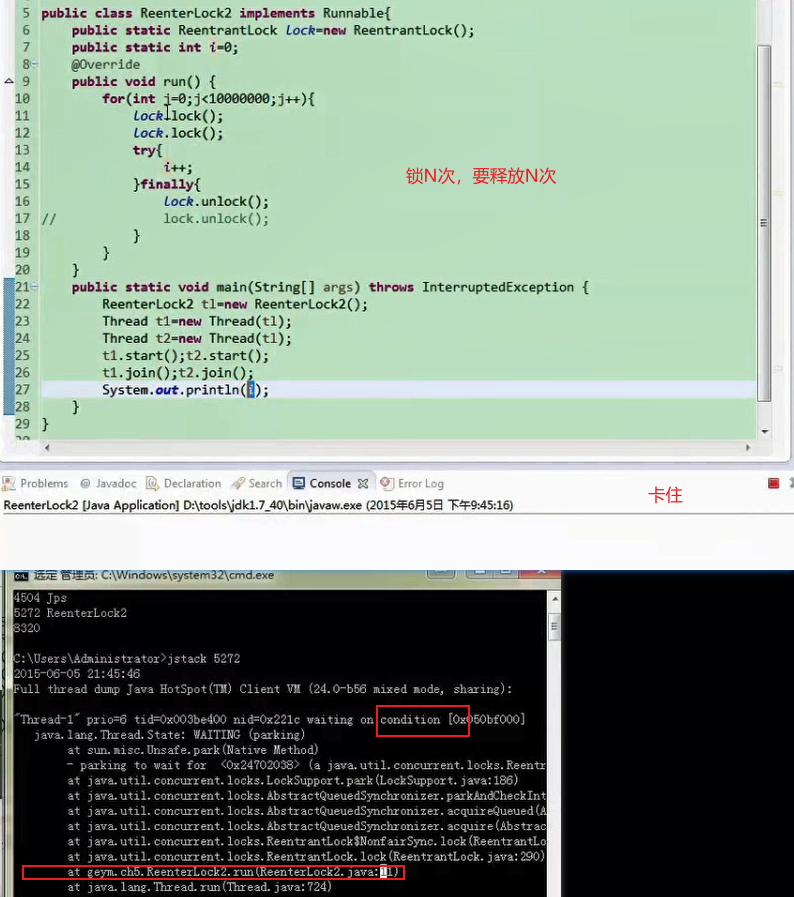
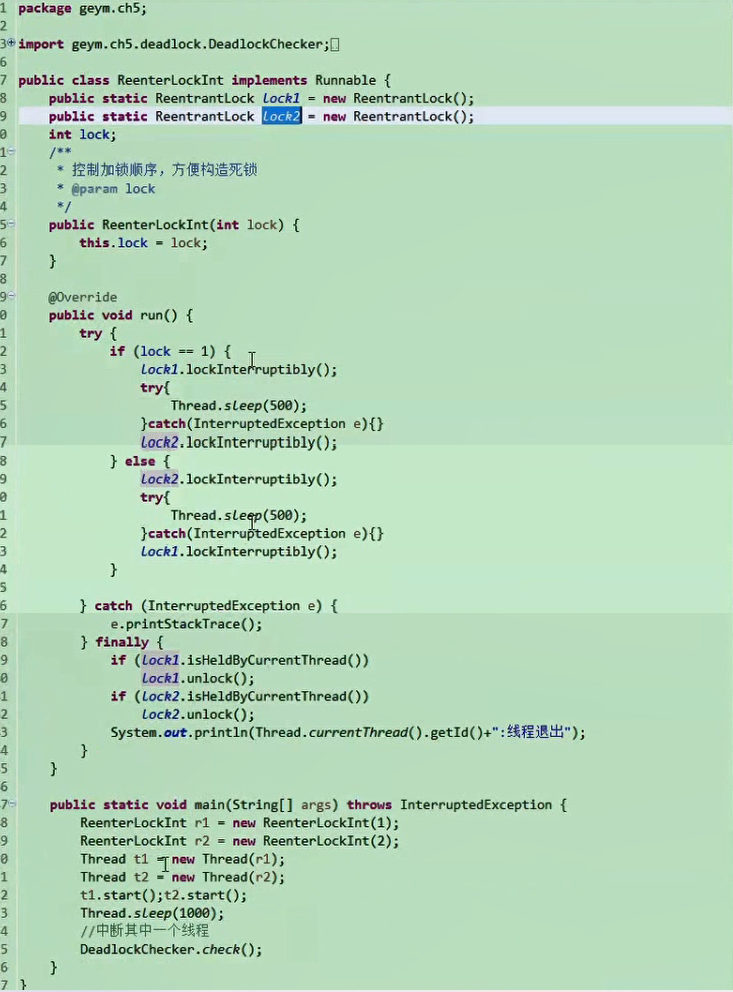
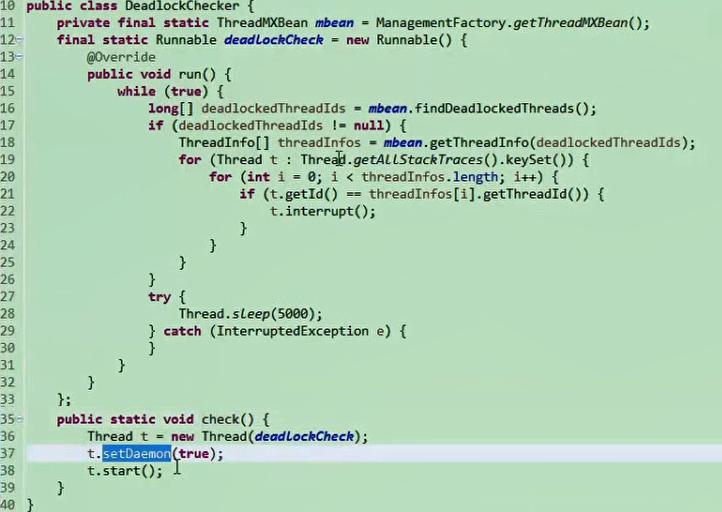
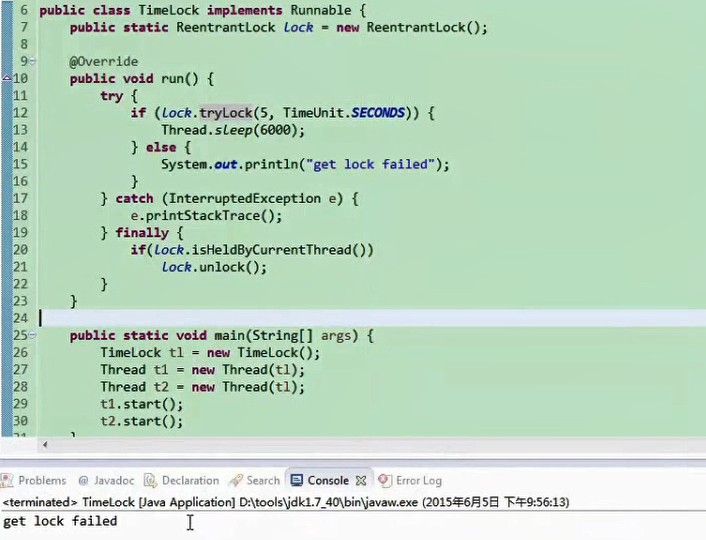
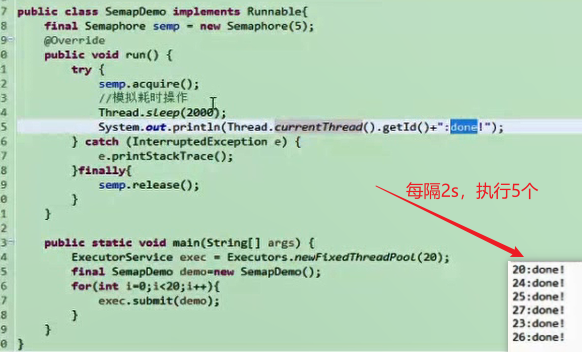
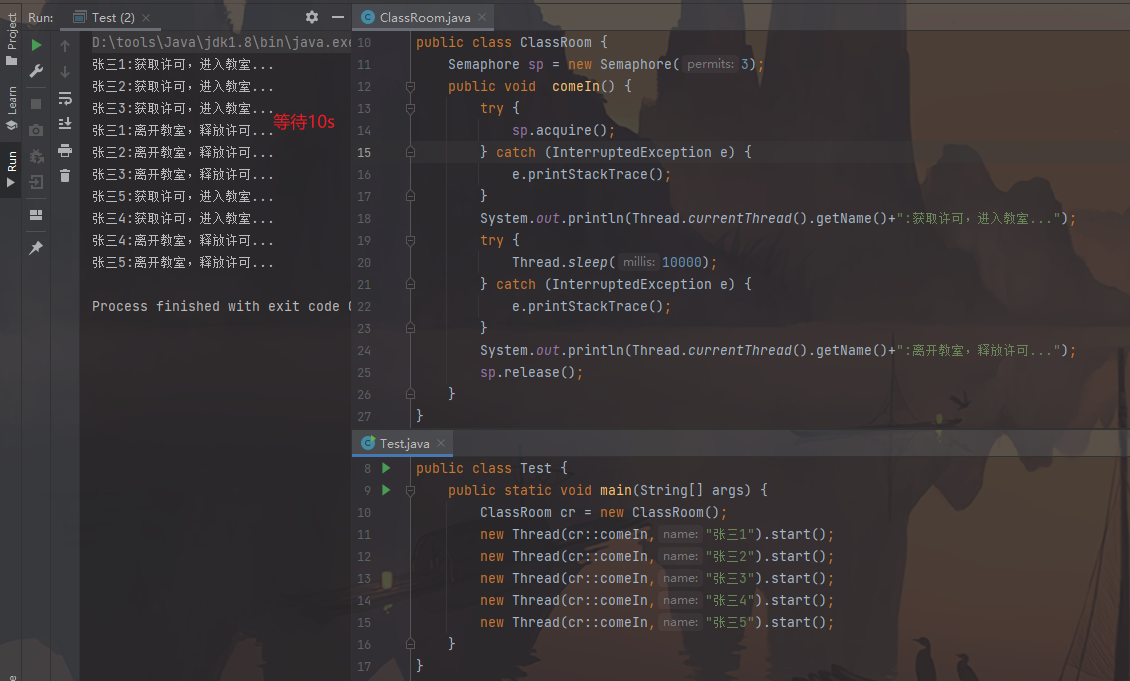

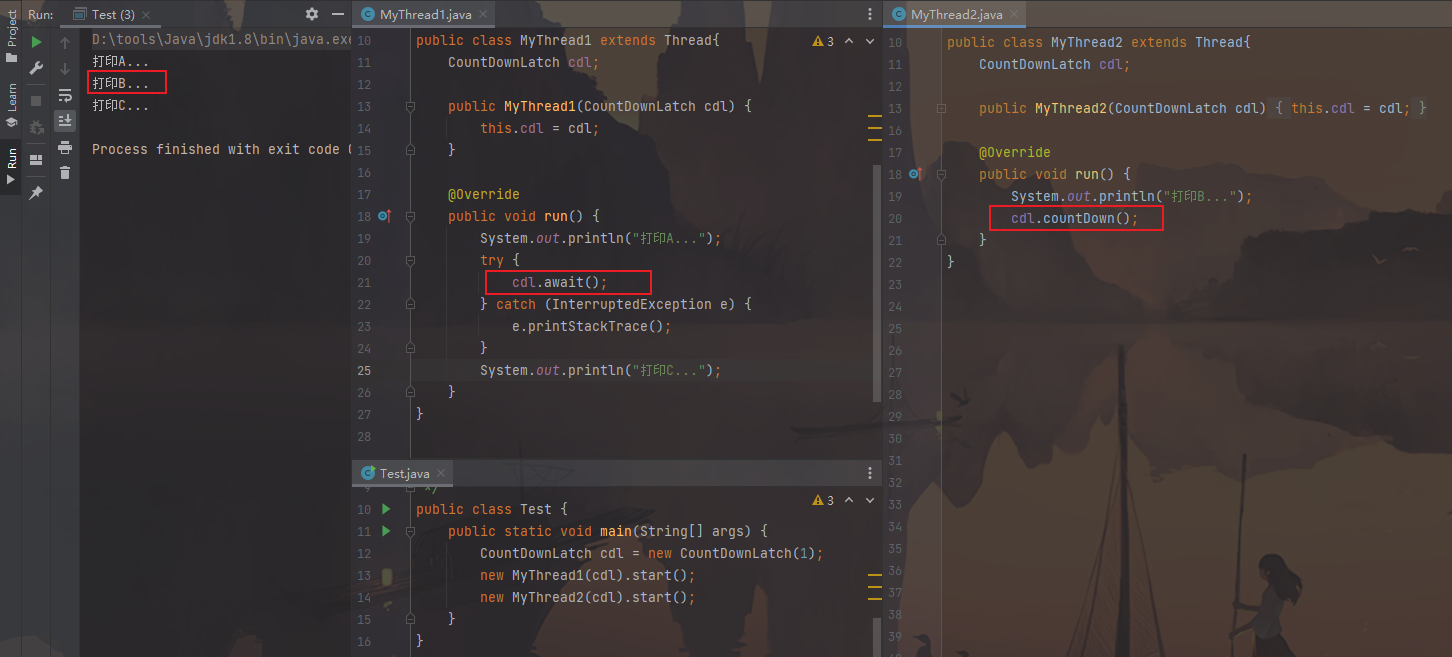
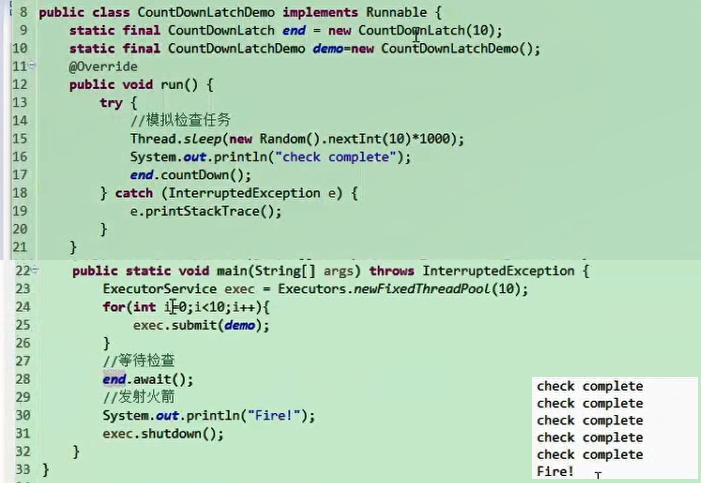
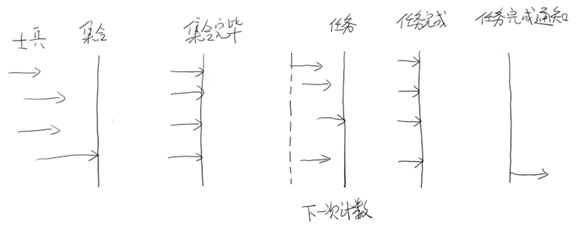

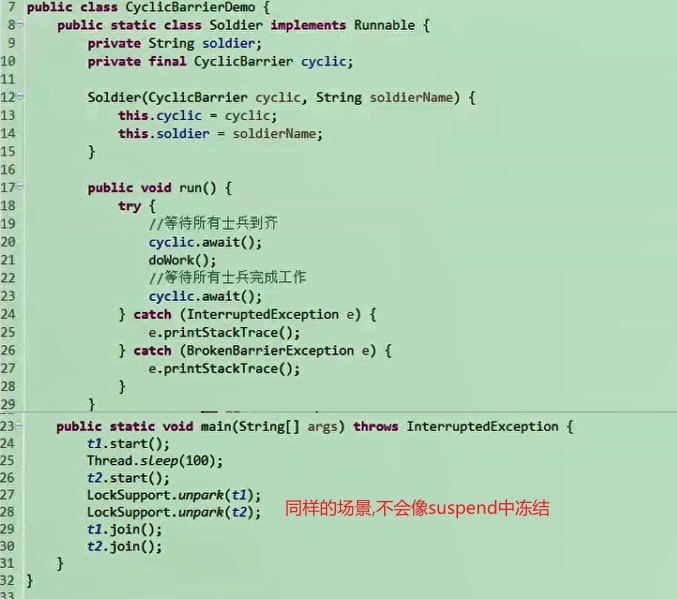
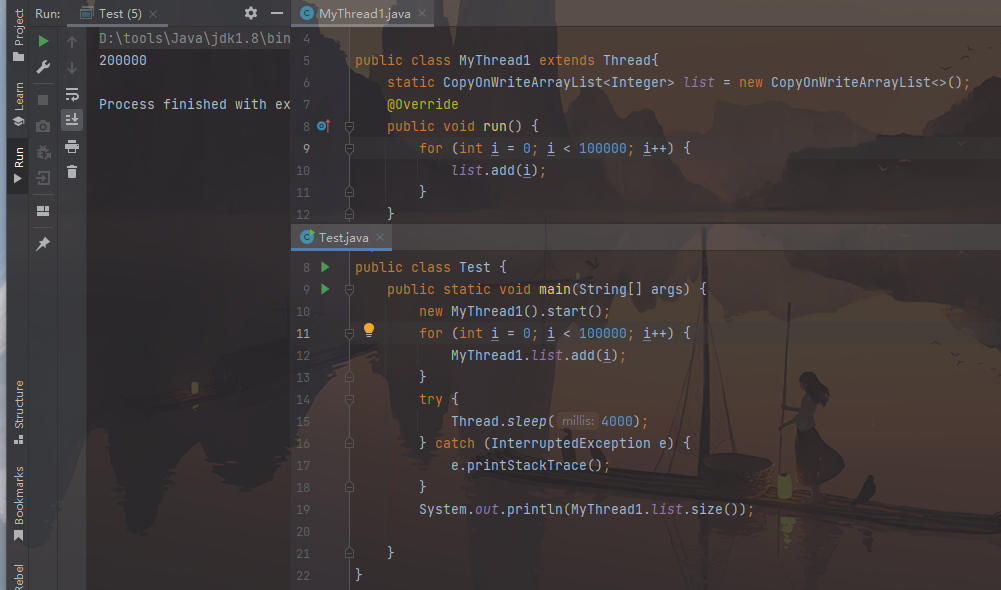
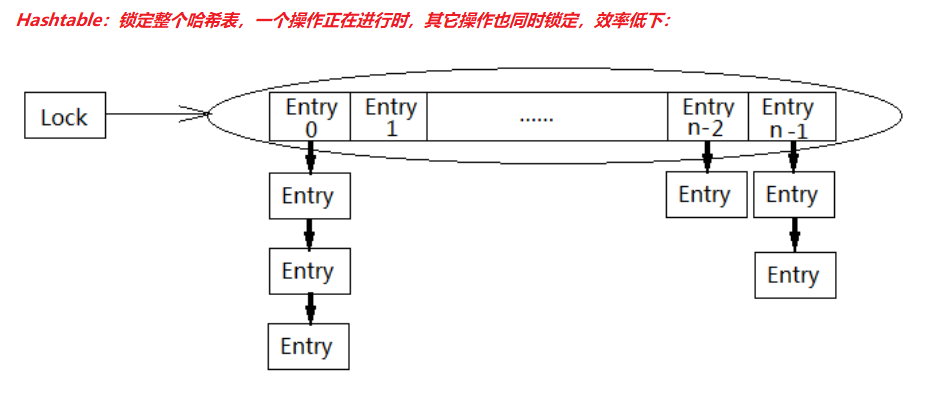
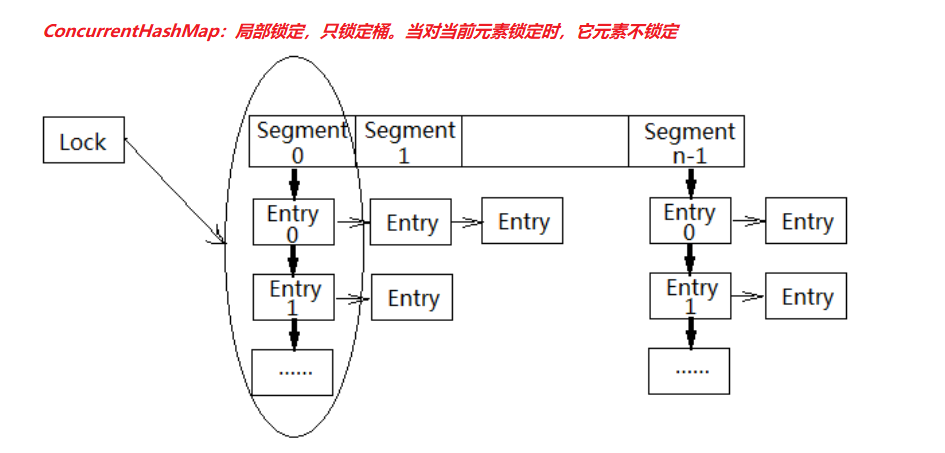
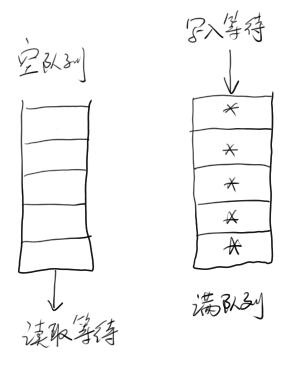
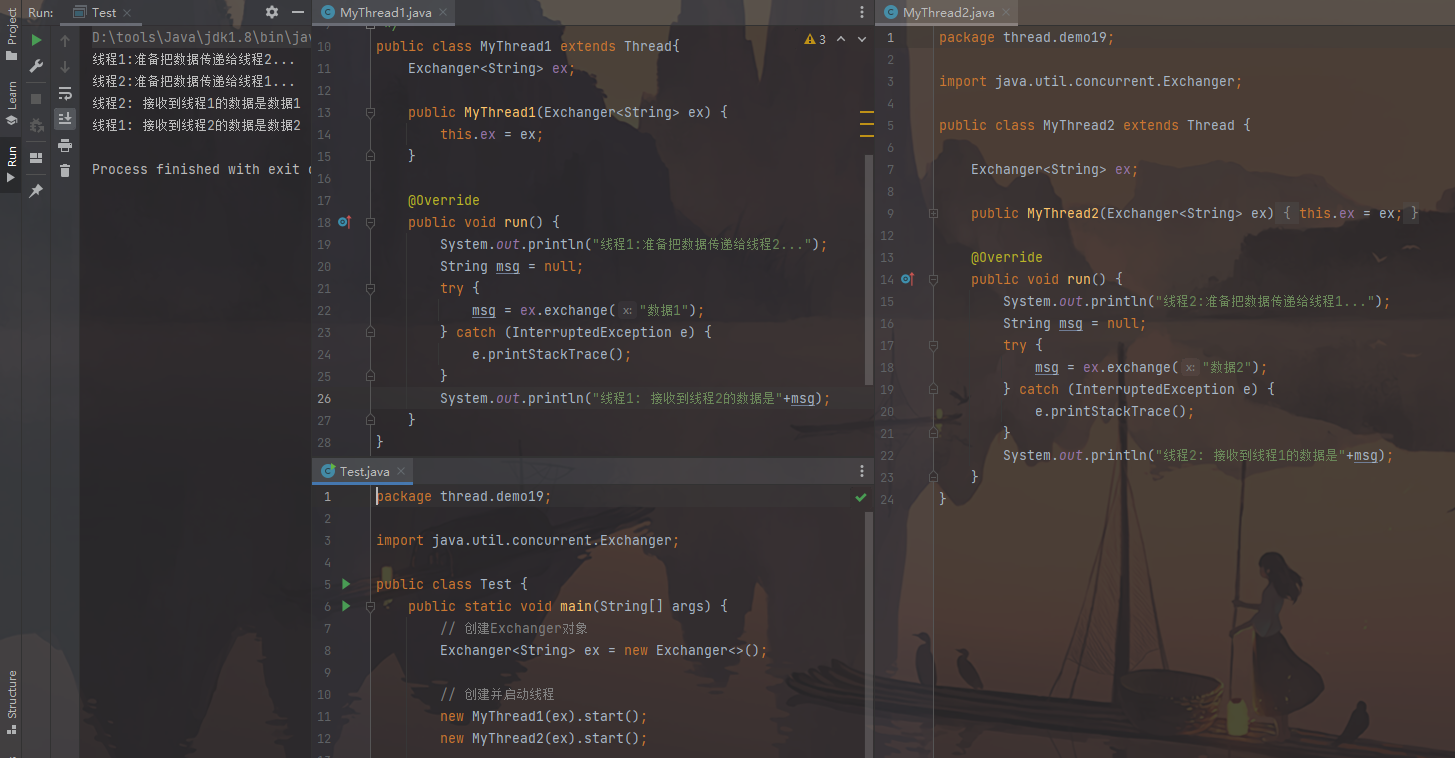

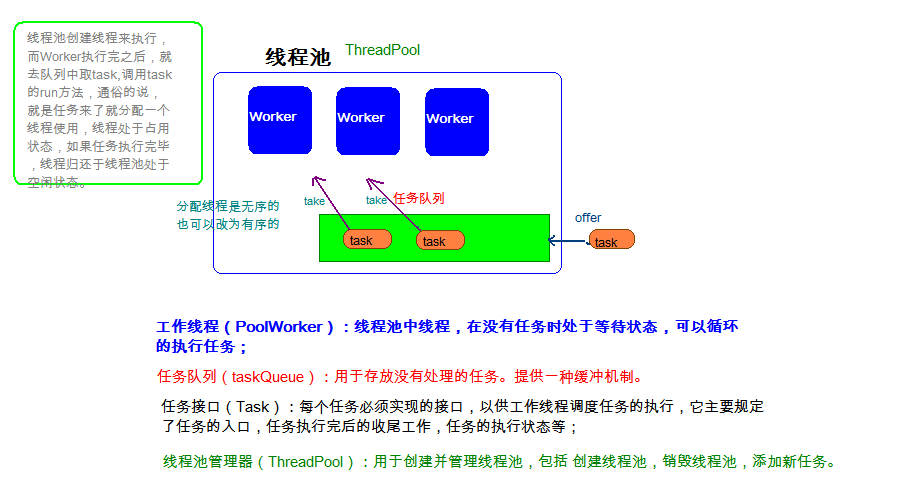
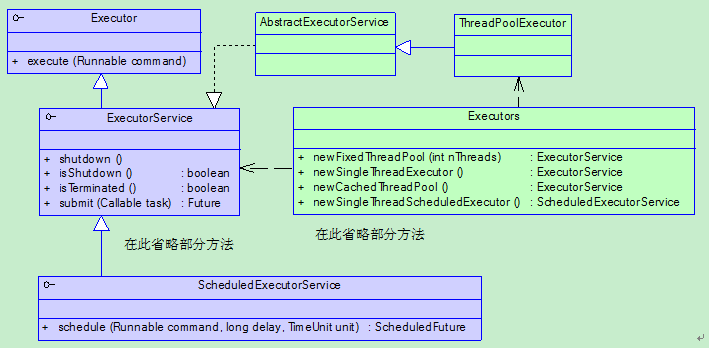
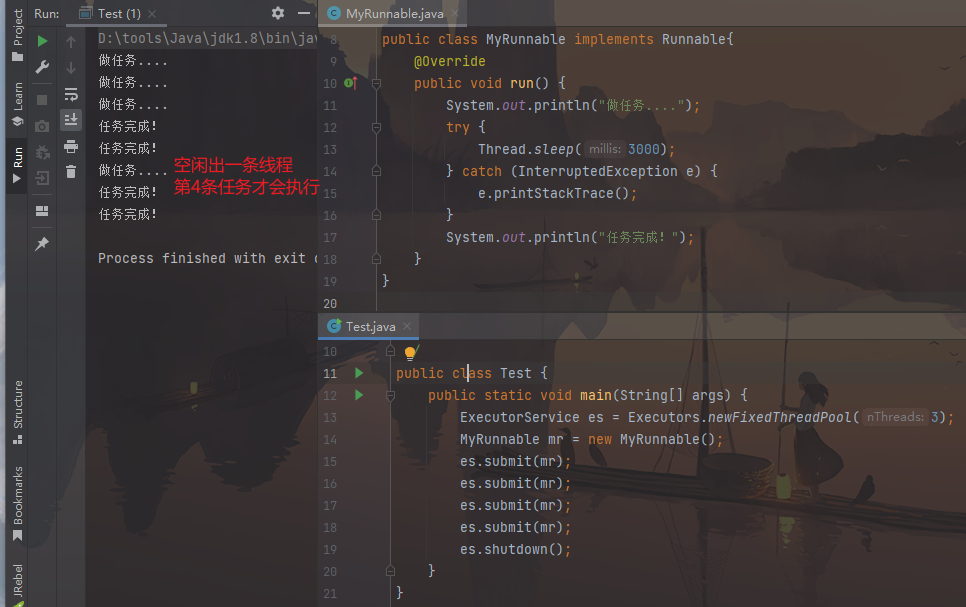
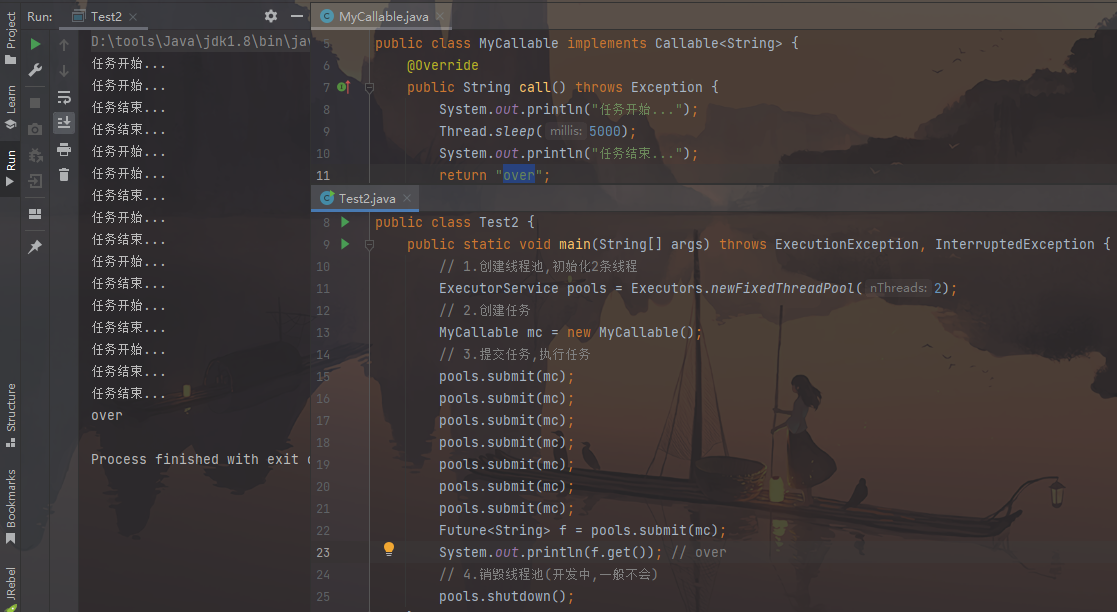
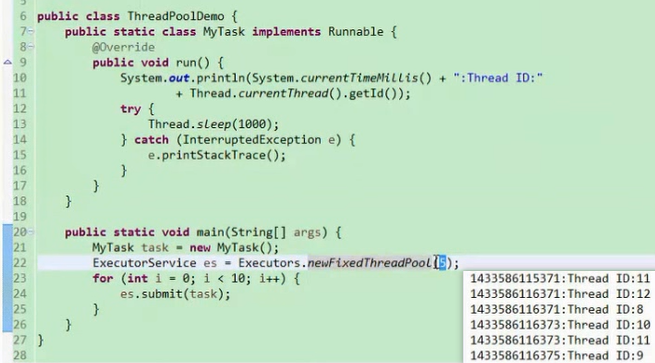
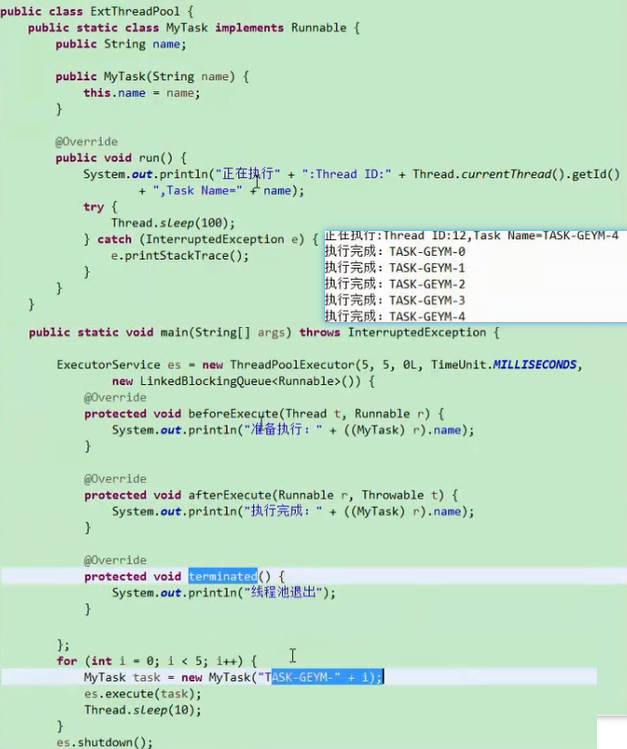
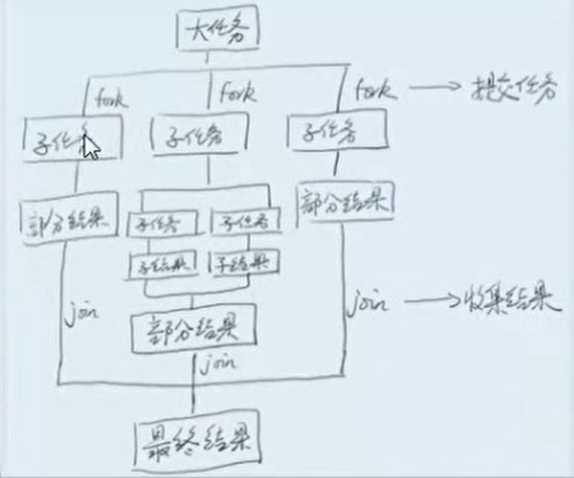
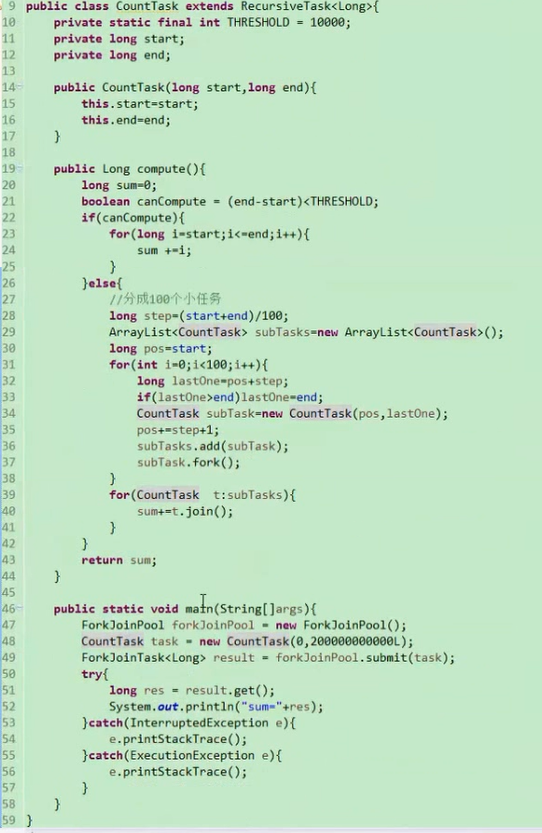
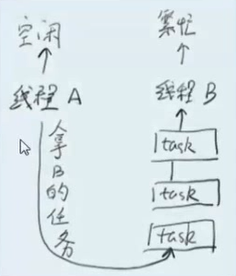


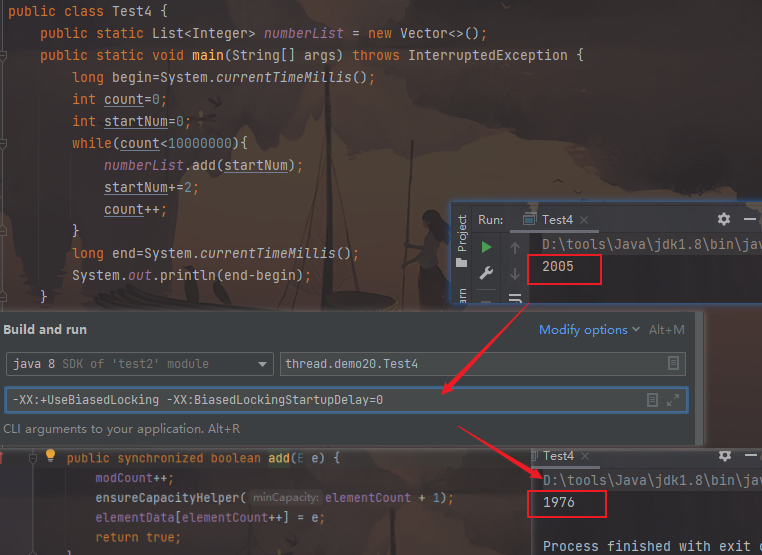

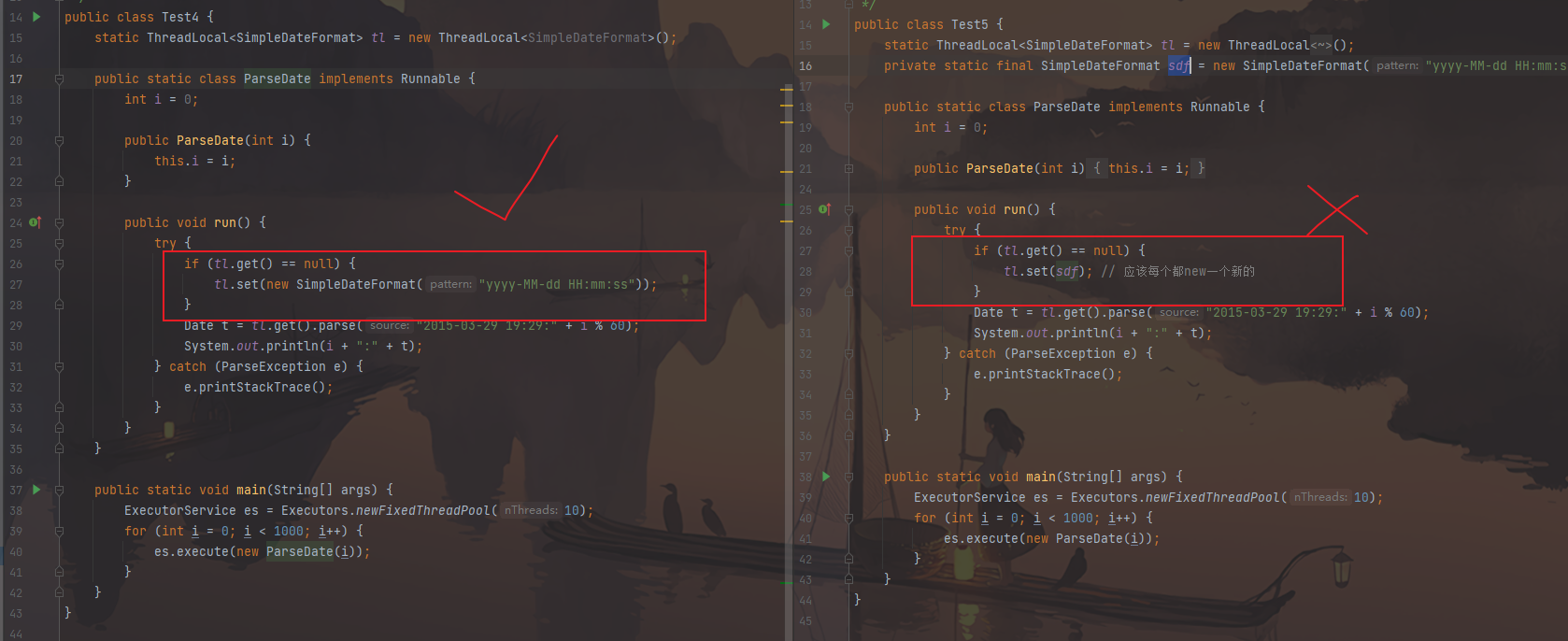

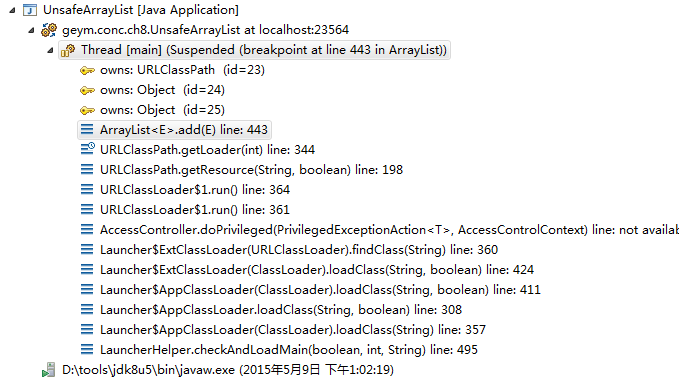
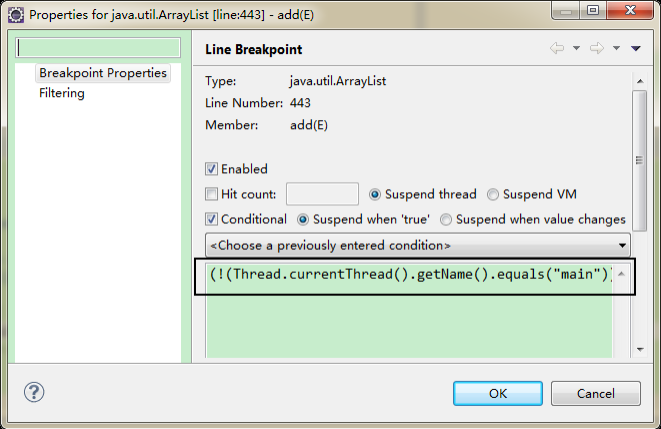
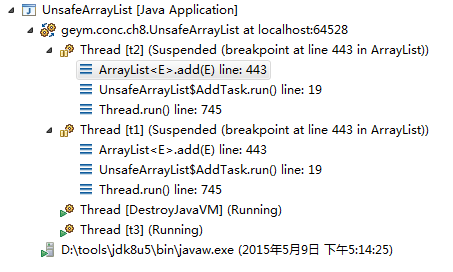
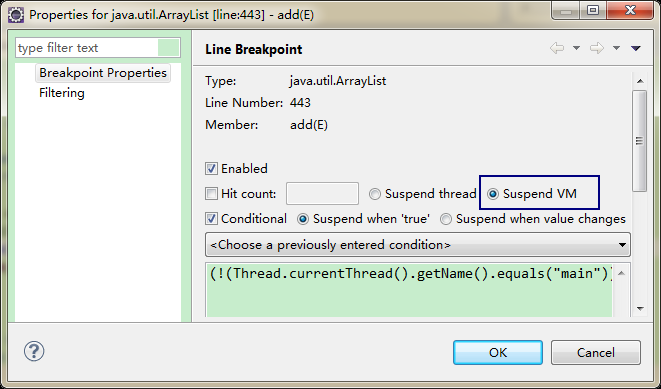
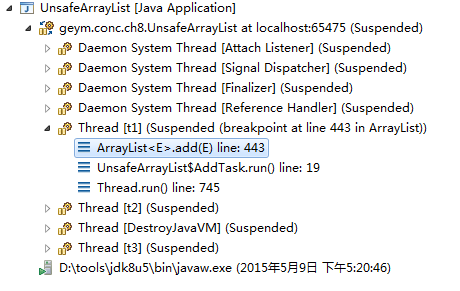
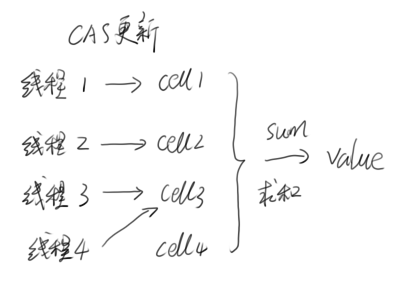



 微信
微信 支付宝
支付宝
