【深入代码系列】手牵手一起了解代码质量
代码当量
学习目标
- 什么是代码当量,原理是什么?
- 代码当量的计算公式是什么?
- 相比代码行数,代码当量好在哪?
前言
代码当量,即开发当量(ELOC,Equivalent Line of Code,下文称”代码当量”),是一种由思码逸原创,对开发者代码工作量进行合理量化和度量的指标。与代码行数、提交数等浅层工作量指标相比,代码当量的优势体现在两个方面:不易受到编程习惯或特定代码行为的干扰(如换行、空行、注释、括号等),且能更好地反映代码开发所涉及的逻辑量。
看到这里你可能还是一头雾水:代码当量的原理是什么?它如何排除噪音的干扰?它的科学性到底如何?希望这篇文章能够帮助你初步了解代码当量和它背后的故事
代码当量从哪来,计算原理是什么
软件开发是一个动态的过程,代码随着提交发生变化,相应的抽象语法树也会演变。代码当量指标正是基于抽象语法树复杂度的计算。这一指标的原型来自思码逸创始团队2018年在软件工程顶级会议 FSE 上发布的论文《关于量化代码贡献的开发价值》。
计算代码当量时,我们既可以计算绝对值,也可以计算累积值:
- 代码当量的绝对值,可以理解为对代码在一个提交切面上的抽象语法树进行计算,会考虑抽象语法树的节点数、不同节点的权重等。
- 代码当量的累积值,则是计算代码在每一次提交前后的变化,并累加。针对某一次提交而言,其代码当量的计算是基于提交前后的抽象语法树之间的最小编辑距离。在思码逸的算法设计中,代码删减也被视为贡献,只是权重会显著低于代码增加。
- 代码当量的绝对值随着开发过程而上下浮动,通常呈现“持续增加—小幅回落”的模式并不断重复;而代码当量的累积值单调递增,主要用于反映团队或项目的产出和进度。
如何计算某个提交的代码当量
下图简单演示了这个过程如何从代码的修改计算出代码当量的数值。

首先,将源代码解析为抽象语法树(AST),AST是源代码抽象语法结构的树型表示。它的抽象性质有助于消除代码中不重要的噪音,如代码风格、换行习惯等。后面我们会举例说明这一特性的好处。
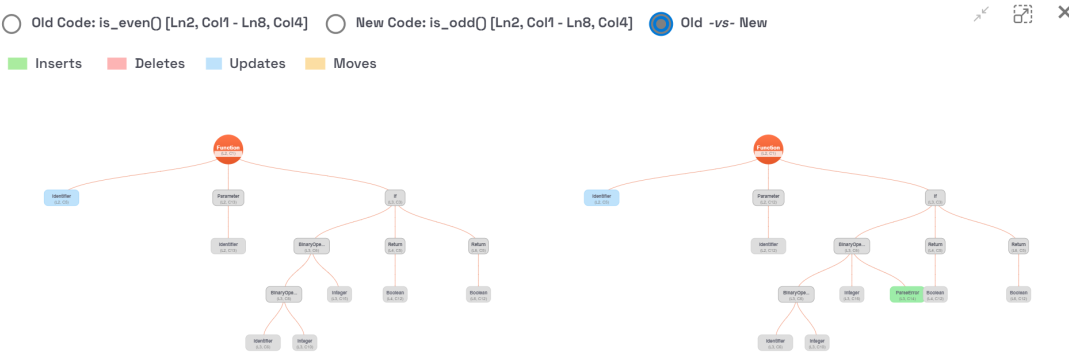
其次,计算新旧树之间的树的差异(树diff)。树diff步骤的输出是一个编辑脚本,由一系列编辑操作组成,正是这些操作一步步将旧AST转换成新AST。编辑操作分为四种类型:插入、删除、移动和更新。例如,插入操作可以将新节点作为AST中现有节点的子节点插入;更新操作可以更新现有节点的值。
最后,我们计算所有编辑操作的加权总和,根据编辑操作的类型和此编辑操作的AST节点的类型为每个操作分配权重,最终得到代码当量的数值。
总结一下,从源码到代码当量的基础计算过程一共分三步:
将旧/新源代码解析为ASTs + 通过在旧/新ASTs之间进行树状转换来生成编辑脚本 + 从编辑脚本加权计算代码当量。
相比代码行数,代码当量好在哪
不受编程习惯影响
代码行数指标(LOC,Line of Code)很容易被简单的代码习惯差异所影响。
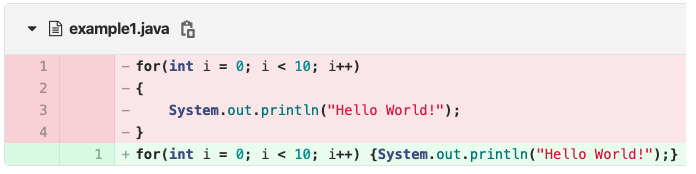
在下图中,我们删除红色代码,新增绿色代码,实质上只是简单的代码格式变动,并不实际改变基本逻辑和代码质量,却表现为1行添加和4行删除(总共5行更改)。
相比之下,由于纯句法变化对AST没有影响,此段代码的新旧ASTs是相同的,所以这个操作的代码当量为0。
代码行数不擅长检测代码块的移动。
比如下面的代码变动,简单地交换类中函数的顺序会产生4行添加和4行删除。
但是从抽象语法树的角度,这次修改只是改变了myMethod()函数对应节点在其父节点下的顺序,该节点本身未发生任何修改。因此修改myMethod()的代码当量为0。

代码行数无法区分不同性质的代码的工作量。
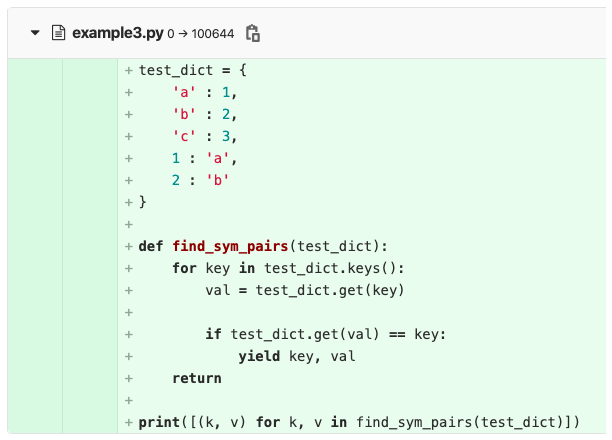
考察以下Python代码,它的功能是在给定的字典中找到对称对。测试数据test_dict和实际功能函数find_sym_pairs()贡献了相等数量的行数(7行),这当然不能反映编写这两段代码所付出的不同的工作量。
但是通过为每个AST节点类型分配不同的权重,我们可以对不同类型AST节点的编辑操作进行更合理的评估,更合理的量化开发过程中的工作量。
不受代码删减提交的影响
一个真实的案例:Bitcoin 项目中一个名为 Fix CRLF 的提交,修改了62个文件,删除了32876行代码,又将这32876行加了回去。
从代码行数的角度看,这是一个体量相当巨大的修改,但实际上对代码没有任何改动。这个提交的代码当量为0。
 微信
微信 支付宝
支付宝

