Linux系统的安装,一般都是在虚拟机里面玩,所以了解了Linux基础概念后,我们给虚拟机安装上操作系统,比如centos。
虚拟机安装 实操-VMware安装 1 2 3 4 虚拟机:一台虚拟的电脑. 独立的 虚拟机软件: VmWare:收费的 VirtualBox:免费的. Oracle的产品 .
什么是虚拟软件:
常用的虚拟原件:
VMware workstation下载
VMware workstation安装
3.选择安装方式
Typical:典型安装
Custom:自定义安装
4.选择程序安装位置
点击change选择程序安装位置,然后点击next
5.选择是否自动检测更新
如勾选,有新版时会提示你跟新版本,点next进行下一步
6.创建快捷方式
选择后点击next
7.配置完成,开始安装程序
点击continue
8.开始安装虚拟原件
9.完成
点击finish完成安装
注意:
虚拟软件安装完成后会在 \控制面板\网络和Internet\网络连接 下多出来两个虚拟网卡VMware Network Adapter
VMnet1和VMware Network Adapter VMnet8
在我们的虚拟机中有三种模式,分别对应仅主机、桥接、nat模式
分别对应0、1、8如下
VMnet0:这是VMware用于虚拟桥接网络下的虚拟交换机
VMnet1:这是VMware用于虚拟Host-Only网络下的虚拟交换机
VMnet8:这是VMware用于虚拟NAT网络下的虚拟交换机
激活码随便百度找一个填写就行了
开启虚拟化 检查是否开启
不开启虚拟化的报错信息如下:
我们在创建虚拟机的时候如果不开启虚拟化,会报下面的一个错误,此时,我们就要根据下面的步骤去开启硬件的虚拟化支持
注意:
目前大部分硬件版本都支持虚拟化的开启,只有很少的Blos硬件不支持
如果遇到不支持的VMware是无法使用的。
开启虚拟化的步骤:
1、开机(或重启)时进入Blos
注意:不同计算机使用的快捷键不同例如F2、F12、DEL、ESC等键就可以进入到BIOS
进入到BIOS后,找到Confifiguration选项或者Security选项,然后选择Virtualization,或者Intel Virtual Technology,就可以开始设置了
这里ThinkPad为例
2、然后选择Virtualization,或者Intel Virtual Technology然后回车,将其值设置为Enabled。
3、在保存BIOS设置之后,重启计算机。
实操-Centos7安装
镜像可以看成是类似ZIP的压缩文件,与rar ZIP压缩包类似,镜像文件是无法直接使用的,需要利用一些虚拟光驱工具进行解压后才能使用
我们这里就是CentOS系统的镜像文件
为什么选择CentOS
主流: 目前的Linux操作系统主要应用于生产环境,主流企业级Linux系统仍旧是RedHat或者CentOS
免费: RedHat 和CentOS差别不大,CentOS是一个基于Red Hat Linux 提供的可自由使用源代码 的企业级Linux 发行版本
更新方便:CentOS独有的yum命令支持在线升级,可以即时更新系统,不像RED HAT那样需要花钱购买支持服务!
centos7下载
我们在下载的时候建议使用国内镜像源,速度快也稳定
比如:
点击【CentOS-7-x86_64-DVD-1810.iso】进行下载,由于文件比较大,下载时间会比较长,请耐心等待…
centos7安装 进入VMware 1)安装完VMware后,双击桌面图标,创建新的虚拟机,如下图:
自定义新的虚拟机
解决虚拟机的兼容性
选择当前虚拟机的操作系统 我们先配置电脑,再安装系统
选择虚拟机将来需要安装的系统 因为不同的操作系统需要解决不同的兼容性问题,所以需要选择将来用什么系统,提前做适配
客户机操作系统:选择Linux
版本:选择CentOS7 64位
配置电脑 给自己配置电脑取个名字,并存放在物理机的位置在哪
虚拟机名称可以自定义(注意:不要出现特殊字符即可)
虚拟机运行文件路径选择本地磁盘路径(注意:磁盘空间尽量要大写,因为一个虚拟机的运行文件大约要在4G以上)
选择CPU的个数 有个原则就是选满(跟物理机的CPU个数相同,但是不能超过)
1 ) 查看物理机CPU 个数(Windows10为例)
2 )设置虚拟机处理器的数量
安装注意事项
处理器设置:
处理器 1 每个处理器的核数 2 ==> 单核双进程(伪双核)
笔记本自身:4核。则虚拟机设置 1处理器 1核数
笔记本自身:8核。则虚拟机设置 1处理器 2核数 => 可以启动6个虚拟机,剩下2核用来运行母机
cpu数量看主板插槽、每个cpu有多个内核,超线程技术(HT)每个内核扩展出2个逻辑核心(也就是逻辑处理器)。
设置虚拟机的内存 内存大小有一定要求,建议4G,不能给太多,后期会有多台虚拟机同时启动
内存设置: 4G(512M) 8G(1,2G) 16G(1,2,4,8G) => 括号内为虚拟机推荐的设置
选择虚拟机上网方式 1) 选择NAT的方式
2) 没有VMware之前物理机的网络适配器信息(每个人不同,我只有3个)
3)安装VMware之后物理机的网络适配器信息(会多两个vmnet1和vmnet8)
注:vmnet8是虚拟机使用NAT模式上网的网卡
选择对应的文件系统的IO方式
选择磁盘的类型
选择磁盘的种类
选择虚拟机的磁盘大小 设置磁盘容量,根据自己的需要设置
虚拟机文件的存放位置
选择安装系统镜像
选择硬件【cd/dvd】,在【使用ISO镜像文件】中选择下载的镜像centos_xxx.iso文件
设置完成后点击【关闭】
centos7启动
系统安装引导页面
centos6有检查磁盘是否完整,一般不用检查,比较耗时。tab+skip+回车enter跳过检查
或者遇到这种的
你得需要将鼠标点击进入界面中,但是鼠标会消失,你此刻得用键盘的上下键 来控制选项,图标变白了表示当前选中的是哪个选项,然后敲回车,表示执行所选选项。
注意:如果这个时候你需要鼠标可以使用ctrl+alt一起按呼出鼠标
设置语言 在第一步设置完成后,我们一直等待,即可来到语言设置界面
此处我们设置【中文】
设置安装信息 将下面带有【感叹号图标】的内容进行设置,比如时间和键盘,可根据自己的需要进行初始化设置,继续往下看…
设置自动分区感叹号
采取默认设置,点击完成
此处我们设置下CentOS的桌面,设置软件安装
在软件选择安装我们的桌面,此处选择GNOME桌面
如果选择centos7 最小安装忘记勾选开发 工具了,可以事后通过yum groupinstall 'Development Tools'安装
最小安装:功能比较少,可能存在问题,不推荐
推荐:基本网页服务器/GNOME桌面
4、点击开始安装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 此处kdump,开发个人学习没有必要开启,可以关闭节省内存。 如果此处没有操作,可以用命令在安装后关闭 # 关闭kdump服务 systemctl stop kdump.service # 禁止开机启动 systemctl disable kdump.service # 修改grub文件 vim /etc/default/grub 可以看到类似如下的内容,将crashkernel改为0M GRUB_TIMEOUT=2 GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)" GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" +GRUB_CMDLINE_LINUX="crashkernel=0M rhgb net.ifnames=0 biosdevname=0" GRUB_DISABLE_RECOVERY="true" # 重新生成grub配置文件后重启系统生效 grub2-mkconfig -o /boot/grub2/grub.cfg reboot
修改主机名
安装时间比较长,大概需要10几分钟(设置root用户密码,一定要设置)
配置用户信息 此处设置root账号密码,我们设置为root,暂时不创建新的用户(进入到欢迎页面的时候会提示我们创建用户)
设置密码root
设置完毕后不在有【感叹号图标】警告提示了
执行重启操作
接受许可
在重启过程中,会有【未接受许可证】的警告提示,点击提示信息
设置(打勾)同意许可
开机进入欢迎页面 此处设置为语言为【汉语】
选择键盘输入 键盘输入类型此处我们选择美国
关闭隐私服务
设置国家和地区 我们设置中国上海
绑定账号 此处我们选择跳过【skip】
创建用户 我们新建用户zuoer
全名:zueor
用户名
为用户zuoer设置密码zuoer
此处注意密码设置规范:大小写+数字
设置完毕,进入CentOS桌面
重启,输入用户名、密码就可以登录了(如果要root登陆,点击未列出)
命令行模式和图形化模式 如果想要默认命令行启动:
1 2 3 4 5 6 7 8 9 10 11 -- 查看当前模式 systemctl get-default -- 图形 systemctl set-default graphical.target -- 命令行 systemctl set-default multi-user.target 用ctrl+alt+f2也可以切到命令行界面 用ctrl+alt+f1也可以切到图形化界面
网络配置
静态IP设置 引子
在上面,我们成功的将CentOS镜像安装到了我们的虚拟机上,可是这个时候,虚拟机还没有配置IP信息,为了后面开发方便,我们需要设置一个静态IP
配置网络链接时,有三种形式,需要注意:
1 2 3 4 5 6 桥连: 假如在局域网内,桥连的话,虚拟机的IP和主机的IP在同一个网段,这样,别的系统也可以连通Linux系统.但是有可能造成IP冲突,毕竟,就那么些IP(0~255). 比如李四主机ip,20,虚拟机可能是30,这有可能和张三的ip冲突的。 NAT: 比如王五的IP,40,如果用nat,主机会有2个IP,100.200,这样,Linux使用100.50,不会和0.10和0.20张三李四的冲突。但是这时候,张三找不到100.50的Linux系统.因为不在同一个网段。但是100.50可以找到张三,因为可以通过王五主机0.40代理出去,也可以访问公网。 所以,一般安装NAT模式,即可以访问主机,还可以访问外网
1.NAT模式设置
首先设置虚拟机中NAT模式的选项,打开VMware,点击“编辑”下的“虚拟网络编辑器”,设置NAT参数
注意:
VMware Network Adapter VMnet8保证是启用状态
2、设置静态ip
注意:
下面的命令我们先使用,后续我们会慢慢讲解到
在普通用户下不能修改网卡的配置信息;所以我们要切换到root用户进行ip配置
1 2 3 4 5 6 用户名root 密码root # 修改网卡配置文件 su root vi /etc/sysconfig/network-scripts/ifcfg-ens33
静态IP设置内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 修改文件的内容 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static IPADDR=192.168.23.129 NETMASK=255.255.255.0 GATEWAY=192.168.23.2 DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=2c2371f1-ef29-4514-a568-c4904bd11c82 DEVICE=ens33 ONBOOT=true
内容说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 BOOTPROTO设置为静态static # 系统启动的地址协议,可选参数static(静态地址),dhcp(DHCP动态地址),none(不指定地址),bootp(BOOTP协议) IPADDR设置ip地址 # IP地址 NETMASK设置子网掩码 # 子网掩码 GATEWAY设置网关 ONBOOT设置为true在系统启动时是否激活网卡 默认是ON,如果ifconfig获取不到ip,改成yes,或True UUID="e83804c1-3257-4584-81bb-660665ac22f6" # 随机MAC id DEVICE="ens33" # 接口名(设备,网卡) HWADDR(mac地址)、UUID(唯一标识): 可以删除,因为如果是克隆的,这个n太虚拟机就一样了。删掉会自动分配。 还可以配置域名解析的地址 DNS1=192.168.23.2 (如果想在虚拟机做静态ip映射的话) DNS2=114.114.114.114 (不配置DNS,可能ping不通百度) # 执行保存 :wq!
重启网络:
1 2 3 4 5 # 重启网络 systemctl restart network # 查看ip(mini版访问不了,要安装yum install net-tools) ifconfig
如上图所示,我们配置的静态IP起作用了,目前是192.168.23.129
4、宿主机ping虚拟机
由此可见宿主机与虚拟机之间是互通的
如果ping不同,且xshell连接不上,可以配置sshd
5、虚拟机ping宿主主机
由此可见,虚拟机与宿主机是互通的
如果ping不同百度,可以参考这篇文章 ,看是否是DNS未配置
注意:如果开着vpn时无法ping通,请关掉vpn后重试。
6、如果想在虚拟机中访问网络,增加一块NAT网卡(这步很重要!)
1)【虚拟机】–【设置】–【添加】
设置为NAT模式,如下图
此时,我们通过虚拟机的浏览器访问https://www.baidu.com/
由此可见,我们通过通过NAT模式可以访问外网。
mini版无法访问网络,如果网络按照上面的都配置了,可能是需要在配置一下dns
1 2 3 4 5 6 vim /etc/resolv.conf nameserver 8.8.8.8 # 必要的安装 yum install net-tools yum install vim yum -y install yum-utils
如果DNS修改后会自动还原可以参考文章:https://blog.csdn.net/qq_43445867/article/details/142874167
修改主机名和hosts文件 1)修改主机名称
1 2 [root@hadoop100 ~]# vim /etc/hostname hadoop100
2)配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
1 2 3 4 5 6 7 8 9 10 11 [root@hadoop100 ~]# vim /etc/hosts 添加如下内容 192.168.199.130 hadoop01 192.168.199.131 hadoop02 192.168.199.132 hadoop03 192.168.199.133 hadoop04 192.168.199.134 hadoop05 192.168.199.135 hadoop06 192.168.199.136 hadoop07 192.168.199.137 hadoop08 192.168.199.138 hadoop09
3)重启克隆机hadoop102
1 [root@hadoop100 ~]# reboot
4)修改windows的主机映射文件(hosts文件)C:\Windows\System32\drivers\etc
1 2 3 4 5 6 7 8 9 192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
配置yum的源
可以不用做,会根据你的IP选则最近的节点下载(如果yum update没有网络,可以替换国内源)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 yum -y install wget # 备份CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget -P /etc/yum.repos.d/ http://mirrors.aliyun.com/repo/epel-7.repo yum clean all yum makecache 如果有报错:yum Could not resolve host: mirrors.cloud.aliyuncs.com; Unknown error 解决: 进入 cd /etc/yum.repos.d/ 该目录下 修改文件 CentOS-Base.repo 和 epel.repo 中所有 http://mirrors.cloud.aliyuncs.com 为 http://mirrors.aliyun.com/centos 最后运行 yum -y update 即可
其他操作-为了基础客隆准备 windows
1 2 3 4 5 6 7 8 9 10 11 # /etc/hosts添加 192.168.199.130 hadoop00 192.168.199.131 hadoop01 192.168.199.132 hadoop02 192.168.199.133 hadoop03 192.168.199.134 hadoop04 192.168.199.135 hadoop05 192.168.199.136 hadoop06 192.168.199.137 hadoop07 192.168.199.138 hadoop08 192.168.199.139 hadoop09
规划
hadoop00
192.168.199.130
基础模板机器,专门用来克隆的
hadoop01
192.168.199.131
单机伪分布
hadoop02
192.168.199.132
分布式
hadoop03
192.168.199.133
分布式
hadoop04
192.168.199.134
分布式
关闭防火墙,关闭防火墙开机自启
1 2 3 [root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service 注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
配置zuoer用户具有root权限,方便后期加sudo执行root权限的命令
信息
1 2 |- root用户:root/root |- 普通用户:zuoer/zuoer
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@hadoop100 ~]# vim /etc/sudoers 修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示 root ALL=(ALL) ALL ## Allows members of the 'sys' group to run networking, software, ## service management apps and more. # %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL +zuoer ALL=(ALL) NOPASSWD:ALL 注意:zuoer 这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了 zuoer 具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以 zuoer 要放到%wheel这行下面。
目录规范建设
这里时用普通用户创建的,也可以直接用root用户操作
在/opt目录下创建文件夹,并修改所属主和所属组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 在/opt目录下创建文件夹,并修改所属主和所属组 软件安装包目录:/opt/install 软件安装目录:/opt/apps 软件数据存放目录:/opt/data (1)在/opt目录下创建module、software文件夹 [root@hadoop100 ~]# mkdir /opt/apps [root@hadoop100 ~]# mkdir /opt/install [root@hadoop100 ~]# mkdir /opt/data (2)修改module、software文件夹的所有者和所属组均为 zuoer 用户 [root@hadoop100 ~]# chown zuoer:zuoer /opt/apps [root@hadoop100 ~]# chown zuoer:zuoer /opt/install [root@hadoop100 ~]# chown zuoer:zuoer /opt/data (3)查看module、software文件夹的所有者和所属组 [root@hadoop100 ~]# cd /opt/ [root@hadoop100 opt]# ll 总用量 12 drwxr-xr-x. 2 zuoer zuoer 4096 5月 28 17:18 apps
卸载虚拟机自带的JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。
1 [root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
重启虚拟
时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
1)需求
2)时间服务器配置(必须root用户)
1 2 3 4 5 6 7 (1)查看所有节点ntpd服务状态和开机自启动状态 [zuoer@hadoop02 ~]$ sudo systemctl status ntpd [zuoer@hadoop02 ~]$ sudo systemctl start ntpd [zuoer@hadoop02 ~]$ sudo systemctl is-enabled ntpd (2)修改hadoop102的ntp.conf配置文件 [zuoer@hadoop02 ~]$ sudo vim /etc/ntp.conf
修改内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 (a)修改1(授权192.168.199.0-192.168.199.255网段上的所有机器可以从这台机器上查询和同步时间) # restrict 192.168.199.0 mask 255.255.255.0 nomodify notrap 为restrict 192.168.199.0 mask 255.255.255.0 nomodify notrap (b)修改2(集群在局域网中,不使用其他互联网上的时间) server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst 为 # server 0.centos.pool.ntp.org iburst # server 1.centos.pool.ntp.org iburst # server 2.centos.pool.ntp.org iburst # server 3.centos.pool.ntp.org iburst (c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步) server 127.127.1.0 fudge 127.127.1.0 stratum 10 (3)修改hadoop02的/etc/sysconfig/ntpd 文件 [zuoer@hadoop02 ~]$ sudo vim /etc/sysconfig/ntpd 增加内容如下(让硬件时间与系统时间一起同步) SYNC_HWCLOCK=yes (4)重新启动ntpd服务 [zuoer@hadoop02 ~]$ sudo systemctl start ntpd (5)设置ntpd服务开机启动 [zuoer@hadoop02 ~]$ sudo systemctl enable ntpd
3)其他机器配置(必须root用户)
1 2 3 4 5 6 7 8 9 10 11 12 13 (1)关闭所有节点上ntp服务和自启动 [zuoer@hadoop03 ~]$ sudo systemctl stop ntpd [zuoer@hadoop03 ~]$ sudo systemctl disable ntpd [zuoer@hadoop04 ~]$ sudo systemctl stop ntpd [zuoer@hadoop04 ~]$ sudo systemctl disable ntpd (2)在其他机器配置1分钟与时间服务器同步一次 [zuoer@hadoop03 ~]$ sudo crontab -e 编写定时任务如下: */1 * * * * /usr/sbin/ntpdate hadoop102 (3)修改任意机器时间 [zuoer@hadoop03 ~]$ sudo date -s "2021-9-11 11:11:11" (4)1分钟后查看机器是否与时间服务器同步 [zuoer@hadoop03 ~]$ sudo date
虚拟机克隆
虚拟机先处于关闭状态,如果是基于上面的基础搭建的机器克隆的,需要再修改ip,主机名
万一把源系统玩坏了。可以恢复
1 右键虚拟机->管理->点击克隆
2 点击下一页
3 从当前虚拟机状态克隆,单击下一页
4 创建完整克隆,点击下一步
5 保存克隆
6 加载虚拟机克隆的vmx文件,打开即可
克隆后如果是静态ip记得修改
1 2 3 4 5 6 7 [root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 改成 BOOTPROTO="static" IPADDR=192.168.199.130 NETMASK=255.255.255.0 GATEWAY=192.168.199.2 DNS1=192.168.199.2
克隆后主机名记得改
1 2 vim /etc/hostname vim /etc/hosts
保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
虚拟机快照和还原 把系统当前的状态保留了,不是拷贝完整的系统。占用空间比较小。
如果源系统删除了,快照也就没了。
如果要恢复快照,使用快照管理器
VM虚拟机强制关闭后无法开启 解决办法:
找到虚拟机系统文件目录
1.以记事本方式打开*.VMX文件把“vmci0.present = “TRUE””中的“TRUE”改为“FALSE”
2.以记事本方式打开*.VMX文件上加上一行代码disk.locking = “FALSE”
3.删除以.lck为后缀名的文件。
4.win+R 输入services.msc,手动查看并关闭五个VM服务,重启计算机。
计算机开启后,确保五个服务重新打开,点击虚拟机,可以成功开启。
实操-Centos-mini
最小化安装需要额外做一些步骤
初始化mini基础环境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 yum update # 没有wget命令 yum -y install wget # 没有vim命令 yum -y install vim # 没有ifconfig命令 yum install net-tools # 创建应用安装目录 cd /usr/local mkdir apps cd apps # 关闭防火墙 查看防火墙状态 firewall-cmd --state 关闭防火墙 systemctl stop firewalld.service 开启防火墙 systemctl start firewalld.service 禁止开机启动启动防火墙 systemctl disable firewalld.service
修改localhost主机名
你可能会发现centos7这样改无效,可以尝试通过
1 2 3 hostnamectl set-hostname node0 ,来修改hostname 查看: hostname
重连ssh可以看到生效了。
设置本地hosts解析,(为hadoop其他节点访问便利)
这样ping node0就可以访问到ip
实操-Linux客户端工具Xshell 到官网下载个人版,可以免费使用
然后连接到创建的虚拟机
连接成功
技巧:设置右键粘贴
乱码处理
实操-Linux客户端工具SecureCRT CRT安装 步骤 1:安装scrt_sfx731-x86.exe
步骤 2:欢迎页面
步骤 3:如果是 64 位操作系统,存在此提示
步骤 4:同意许可
步骤 5:选择配置文件是否共享(默认)
步骤 6:安装类型,自定义
步骤 7:选择安装路径
步骤 8:快捷方式(默认)
步骤 9:开始安装
步骤 10:完成
激活 步骤 1:将对应的激活程序拷贝到安装目录下
步骤 2:以“管理员”运行“SecureCRT v7.0 注册机.exe”激活程序,打补丁
步骤 3:生成序列号
步骤 4:运行程序,“SecureCRT 7.3”,并输入激活码
1)不输入任何内容,下一步
2)点击输入详情选项
3)输入详细内容
连接 步骤 1:登录 linux 成功之后,输入“ifconfig”查询 ip 地址
步骤 2:运行“SecureCRT.exe”进行连接
步骤 3:保存当次连接
步骤 4:输入密码并连接
常见设置 设置操作窗口“背景黑色”。运行“SecureCRT 7.3”
修改后结果
设置操作窗口“字体”和“字符集”
实操篇,实践是检验真理的唯一标准,理论让你不至于摸着石头过河,而最终要学以致用才行。
软件安装(java)
能放到/user/local/apps下的我都放到该目录下了
实操-安装文件上传工具 实操-安装Git 1.检查安装
2.卸载安装
1 rpm -e --nodeps git 或者 rpm -e git
3.安装Git(在线)
4.检验
实操-安装JDK 下载jdk并上传到linux http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
需要登录,用下面的账号,如果失效,再查找
1 2 1287019365@qq.com Oracle@1234
卸载默认JDK 检查系统上是否安装了jdk(若安装了就需要先卸载再使用我们自己的)
查看出安装的java的软件包
卸载linux自带的openjdk
历史原因,openjdk相当于简化版的jdk,不完整
1 2 3 4 5 6 7 rpm -qa | grep openjdk # 查询openjdk rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.i686 rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.i686 tzdata-java-2013g-1.el6.noarch # 删不掉加--nodeps # 或者用这个命令,卸载所有Java rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
解压安装包 进入 /opt/java 目录,解压jdk
1 2 cd /opt/apps/ tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/apps
配置环境变量 1 2 3 4 5 vi /etc/profile # 在文件的最后面添加如下代码 export JAVA_HOME=/opt/apps/jdk1.8.0_321 export PATH=$JAVA_HOME/bin:$PATH
更好的做法: 配置到/etc/profile.d/下
1 2 3 4 5 6 7 # /etc/profile或加载/etc/profile.d/下的文件配置 cd /etc/profile.d/ sudo vim my_env.sh # JAVA配置 export JAVA_HOME=/opt/apps/jdk1.8.0_321 export PATH=$JAVA_HOME/bin:$PATH
检测是否安装成功 显示出对应的版本信息则代表安装成功。
1 2 3 java version "1.8.0_321" Java(TM) SE Runtime Environment (build 1.8.0_321-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)
实操-安装Tomcat(防火墙)
下载tomcat,上传到linux
https://archive.apache.org/dist/tomcat/tomcat-8/
https://archive.apache.org/dist/tomcat/tomcat-8/v8.5.75/bin/
在 /usr/local 新建一个文件夹tomcat
1 mkdir /usr/local/apps/tomcat
移动 tomcat…tar.gz 到 /usr/local/tomcat
1 mv apache-tomcat-8.5.32.tar.gz /usr/local/apps/tomcat/
进入/usr/local/tomcat目录,解压Tomcat
1 2 cd /usr/local/apps/tomcat tar -xvf apache-tomcat-8.5.32.tar.gz
进入 /usr/local/tomcat/apache-tomcat-8.5.32/bin
1 cd /usr/local/apps/tomcat/apache-tomcat-8.5.32/bin
启动tomcat
1 2 3 4 方式1: sh startup.sh 方式2: ./startup.sh
修改防火墙的规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 方式1:service iptables stop 关闭防火墙(不建议); 用到哪一个端口号就放行哪一个(80,8080,3306...) 方式2:放行8080 端口 修改配置文件 cd /etc/sysconfig vi iptables 复制(yy , p) -A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT 改成 -A INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEPT 重启加载防火墙或者重启防火墙 service iptables reload 或者 service iptables restart
centos7 防火墙添加端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 # 查看防火墙状态 firewall-cmd --state # 启动firewall:(centos7 默认防火墙是关闭的,要重启防护墙) systemctl start firewalld.service # 设置开机自启: systemctl enable firewalld.service # 查看防火墙设置开机自启是否成功: systemctl is-enabled firewalld.service;echo $? # 开启特定端口 在开启防火墙之后,我们有些服务就会访问不到,是因为服务的相关端口没有打开。 在此以打开80端口为例 开端口命令:firewall-cmd --zone=public --add-port=80/tcp --permanent 重启防火墙:systemctl restart firewalld.service 或:(此方式不需要重启) firewall-cmd --add-port=80/tcp --permanent && firewall-cmd --reload # tomcat防火墙 firewall-cmd --add-port=8080/tcp --permanent && firewall-cmd --reload # MySQL防火墙 firewall-cmd --add-port=3306/tcp --permanent && firewall-cmd --reload # redis防火墙 firewall-cmd --add-port=6379/tcp --permanent && firewall-cmd --reload # rabbitmq防火墙 firewall-cmd --add-port=5672/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=15672/tcp --permanent && firewall-cmd --reload # consul防火墙 firewall-cmd --add-port=8500/tcp --permanent && firewall-cmd --reload # apollo防火墙 firewall-cmd --add-port=8070/tcp --permanent && firewall-cmd --reload # MongoDB防火墙 firewall-cmd --add-port=27017/tcp --permanent && firewall-cmd --reload # elastic search防火墙 firewall-cmd --add-port=9200/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9300/tcp --permanent && firewall-cmd --reload # kibana防火墙 firewall-cmd --add-port=5601/tcp --permanent && firewall-cmd --reload # zookeeper firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=20880/tcp --permanent && firewall-cmd --reload # nacos firewall-cmd --add-port=8848/tcp --permanent && firewall-cmd --reload # docker firewall-cmd --add-port=2375/tcp --permanent && firewall-cmd --reload 命令含义: --zone #作用域 --add-port=80/tcp #添加端口,格式为:端口/通讯协议 --permanent #永久生效,没有此参数重启后失效
端口占用
1 2 3 Caused by: java.net.BindException: 地址已在使用 netstat -alnp | grep 8080 kill - 9 1899
实操-安装maven (1)将Maven压缩包上传至服务器(虚拟机)
(2)解压
1 tar zxvf apache-maven-3.3.9-bin.tar.gz
(3)移动目录
1 mv apache-maven-3.3.9 /usr/local/apps/maven
(4)编辑setting.xml配置文件 vi /usr/local/apps/maven/conf/settings.xml,配置本地仓库目录,内容如下
1 <localRepository>/usr/local/apps/maven/repository</localRepository>
(5)将开发环境的本地仓库上传至服务器(虚拟机)并移动到/usr/local/repository 。
1 mv reponsitory_boot /usr/local/repository
执行此步是为了以后在打包的时候不必重新下载,缩短打包的时间。
(6)编辑setting.xml配置文件 vi /usr/local/maven/conf/settings.xml
1 2 3 <pluginGroups> <pluginGroup>com.spotify</pluginGroup> </pluginGroups>
实操-安装MySql
下载mysql,上传到linux
http://ftp.ntu.edu.tw/MySQL/Downloads/MySQL-5.7/
检查系统上是否安装了mysql( 若安装了就需要先卸载再使用我们自己的)
1 2 rpm -qa |grep -i mysql #查看 rpm -e --nodeps mysql-libs-5.1.71-1.el6.i686 #卸载
在 /usr/local 新建一个文件夹mysql
把mysql压缩包移动 到/usr/local/mysql
1 mv MySQL-5.5.49-1.linux2.6.i386.rpm-bundle.tar /usr/local/mysql/
进入 /usr/local/mysql,解包mysql
1 2 cd /usr/local/mysql tar -xvf MySQL-5.5.49-1.linux2.6.i386.rpm-bundle.tar
安装 服务器端
1 rpm -ivh MySQL-server-5.5.49-1.linux2.6.i386.rpm
安装 客户端
1 rpm -ivh MySQL-client-5.5.49-1.linux2.6.i386.rpm
启动Mysql
1 service mysql start #启动mysql (注意:只启动一次)
先查看随机密码登录(cat /root/.mysql_secret)
登录mysql
修改密码
1 set password for root@localhost = password('123');
登录mysql
放行3306端口号
1 2 3 4 5 6 7 8 9 10 11 修改配置文件 cd /etc/sysconfig vi iptables 复制(yy p) -A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT 改成 -A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT 重启加载防火墙或者重启防火墙 service iptables reload 或者 service iptables restart
允许远程连接 mysql
1 2 3 4 5 6 7 8 9 10 在linux上 先登录mysql cd /usr/local/mysql #进入mysql目录 mysql -uroot -p123 #登录 创建远程账号 create user 'root'@'%' identified by '123'; 授权 grant all on *.* to 'root'@'%' with grant option; 刷新权限 flush privileges;
实操-安装MySql5.7.38 下载
通过ftp上传到服务器
卸载 检查系统上是否安装了mysql( 若安装了就需要先卸载再使用我们自己的)
1 2 3 rpm -qa |grep -i mysql #查看 rpm -e --nodeps mysql-libs-5.1.71-1.el6.i686 #卸载
解压 1 tar -xvf mysql-5.7.38-1.el7.x86_64.rpm-bundle.tar -C /usr/local/apps/mysql
安装服务端 1 rpm -ivh mysql-community-server-5.7.38-1.el7.x86_64.rpm --force --nodeps
安装客户端 1 rpm -ivh mysql-community-client-5.7.38-1.el7.x86_64.rpm --force --nodeps
配置 配置文件添加以下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cd /etc/ vim /etc/my.cnf [mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8
启动MySQL 登录mysql 1 2 3 4 5 mysql -uroot -p 初始化的密码:cat /var/log/mysqld.log # 在root@localhost: 后面的就是初始化密码
修改密码 1 2 3 4 5 6 7 8 9 # 忽略复杂密码验证 set global validate_password_policy=0; set global validate_password_length=1; SET PASSWORD = PASSWORD('root');
开启远程访问 1 2 3 4 5 grant all privileges on *.* to 'root'@'%' identified by'root'; # 第2个root是密码 FLUSH PRIVILEGES; exit # 退出窗口
环境变量配置 加入到环境变量配置文件中,实现通过 : mysql -u root -p 登录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vi /etc/profile 一直往下找到之前加入的环境变量,在下方加入 export MYSQL_HOME=/usr/local/apps/mysql export PATH=$MYSQL_HOME/bin:$PATH # 运行 source /etc/profile 让修改后的环境变量配置文件生效 # 运行 mysql -uroot -p 输入之前修改的密码
关闭防火墙 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 firewall-cmd --add-port=3306/tcp --permanent && firewall-cmd --reload 永久关闭防火墙(学习使用) systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 编辑虚拟机的Selinux的配置文件 vim /etc/selinux/config SELINUX=disabled #该选项默认是: SELINUX=enforcing
解决断电后无法重启 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 查看配置文件位置 mysql --help | grep my.cnf # 在 /etc/my.cnf 中找到log-error的位置: log-error=/var/log/mysqld.log # 定位到ERROR问题 Invalid pid in unix socket lock file /var/lib/mysql/mysql.sock.lock # 删除lock文件 rm -rf mysql.sock.lock # 重启服务 service mysqld start # 成功
实操-安装MySql5.7.35(离线)
下载mysql,上传到linux
http://ftp.ntu.edu.tw/MySQL/Downloads/MySQL-5.7/
http://ftp.ntu.edu.tw/MySQL/Downloads/MySQL-5.7/mysql-5.7.38-1.el7.x86_64.rpm-bundle.tar
检查系统上是否安装了mysql( 若安装了就需要先卸载再使用我们自己的)
1 2 rpm -qa |grep -i mysql #查看 rpm -e --nodeps mysql-libs-5.1.71-1.el6.i686 #卸载
解压
1 tar -xzvf mysql-5.7.35-linux-glibc2.12-x86_64.tar.gz
移动解压后的文件至/usr/local/apps并重命名为mysql(必)
1 mv mysql-5.7.35-linux-glibc2.12-x86_64 /usr/local/apps/mysql
切换到目录下,创建data文件夹,用于存放数据
创建mysql用户和组
1 2 3 groupadd mysql useradd -r -g mysql mysql # useradd -r 表示mysql用户是系统用户, 不可用于登录系统 id mysql
将安装目录所有者及所属组改为mysql
1 2 3 chown -R mysql.mysql /usr/local/apps/mysql 或者 chown -R mysql:mysql /usr/local/apps/mysql
安装依赖包并初始化数据库,这一步在bin下运行
1 2 3 4 cd /usr/local/apps/mysql/bin yum install libaio ./mysqld --initialize --user=mysql --basedir=/usr/local/apps/mysql/ --datadir=/usr/local/apps/mysql/data # 记住初始密码 qLAx+FdC-3ZZ
编辑配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cd /etc/ vim /etc/my.cnf [mysqld] datadir=/usr/local/apps/mysql/data basedir=/usr/local/apps/mysql socket=/tmp/mysql.sock user=mysql port=3306 character-set-server=utf8 # 取消密码验证 # skip-grant-tables symbolic-links=0 # skip-grant-tables [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid !includedir /etc/my.cnf.d
可以设置取消密码验证,skip-grant-tables,取消注释。
将mysql加入到服务中
1 2 cd /usr/local/apps/mysql cp /usr/local/apps/mysql/support-files/mysql.server /etc/init.d/mysql
设置开启启动
启动mysql服务
登录mysql
1 2 3 4 5 cd /usr/local/apps/mysql/bin /usr/local/apps/mysql/bin/mysql -uroot -p 输入之前记录的密码,或者之前设置了跳过密码验证,直接回车进入mysql
如果报错 Can't connect to local MySQL server through socket
尝试重启服务systemctl restart mysql,/tmp/下有mysql.sock了
修改mysql登录密码
1 2 3 4 5 6 7 8 修改mysql登录密码 SET PASSWORD = PASSWORD('root'); # 设置秘密不过期 ALTER USER 'root'@'localhost' PASSWORD EXPIRE NEVER; FLUSH PRIVILEGES; exit
加入到环境变量配置文件中,实现通过 : mysql -u root -p 登录
1 2 3 4 5 6 7 8 9 10 11 12 vi /etc/profile 一直往下找到之前加入的环境变量,在下方加入 export MYSQL_HOME=/usr/local/apps/mysql export PATH=$MYSQL_HOME/bin:$PATH # 运行 source /etc/profile 让修改后的环境变量配置文件生效 # 运行 mysql -uroot -p 输入之前修改的密码
开启远程访问
1 2 grant all privileges on *.* to 'root'@'%' identified by'root'; # 第2个root是密码 FLUSH PRIVILEGES;
防火墙
1 firewall-cmd --add-port=3306/tcp --permanent && firewall-cmd --reload
永久关闭防火墙(学习使用)
1 2 3 4 5 6 7 systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 编辑虚拟机的Selinux的配置文件 vim /etc/selinux/config #该选项默认是: SELINUX=enforcing,修改为以下值 SELINUX=disabled
实操-安装MySql(在线) 第一步:在线安装mysql相关的软件包
1 yum install mysql mysql-server mysql-devel
第二步:启动mysql的服务
1 /etc/init.d/mysqld start
第三步:通过mysql安装自带脚本进行设置
1 /usr/bin/mysql_secure_installation
第四步:进入mysql的客户端然后进行授权
1 2 grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; flush privileges;
实操-安装Nexus 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 nexus 前提:jdk mkdir /usr/local/apps/nexus 解压:tar -zxvf nexus-2.11.2-03-bundle.tar.gz -C /usr/local/apps/nexus 修改nexus-2.11.2-03/bin/nexus: RUN_AS_USER=root #修改后的内容,代表Nexus私服使用root用户权限。 修改防火墙 vi /etc/sysconfig/iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 8081 -j ACCEPT service iptables restart 启动: /usr/local/apps/nexus/nexus-2.11.2-03/bin/nexus start /usr/local/apps/nexus/nexus-2.11.2-03/bin/nexus status 访问:http://ip:8081/nexus 登录admin /admin123 cofniguration down remote index--> true
实操-安装VSFTPD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 安装:yum -y install vsftpd 添加用户(登录FTP服务器):useradd ftpuser (默认用不目录:/home/ftpuser.) 设置密码:passwd ftpuser 关闭防火墙: 1.vim /etc/sysconfig/iptables post:21 重启服务:service iptables restart 2.永久关闭:service iptables stop chkconfig iptables off 修改selinux: getsebool -a | grep ftp setsebool -P allow_ftpd_full_access on setsebool -P ftp_home_dir on 关闭匿名访问:(配置文件:/etc/vsftpd/vsftpd.conf) anonymous_enable=NO 服务: 开启: service vsftpd start 重启: service vsftpd restart 关闭: service vsftpd stop 开启启动:chkconfig vsftpd on
实操-安装redis
下载redis
https://redis.io/download
wget http://download.redis.io/releases/redis-5.0.14.tar.gz
在 /usr/local 新建一个文件夹redis
1 mkdir /usr/local/apps/redis # 实际redis命令存放目录
移动 redis…tar.gz 到 /usr/local/apps
1 mv redis-5.0.14.tar.gz /usr/local/apps/
进入/usr/local/apps目录,解压redis
1 2 cd /usr/local/apps tar -zxvf redis-5.0.14.tar.gz
编译需要的C环境
1 2 3 yum install gcc-c++ # 验证 gcc -v
进入 /usr/local/apps/redis-5.0.14/
1 2 3 4 5 6 7 cd /usr/local/apps/redis-5.0.14/ # redis解压的目录 # 编译(编译后的文件在src目录) make # 安装 make PREFIX=/usr/local/apps/redis/ install # 其实就是将bin目录拷贝到redis目录下,不指定默认安装到/usr/local/bin下 # 还要拷贝配置文件 cp redis.conf /usr/local/apps/redis/bin/
启动redis
1 2 3 4 5 6 7 8 cd /usr/local/apps/redis/bin # 服务端 ./redis-server # 客户端 ./redis-cli # 此处完整命令 /usr/local/apps/redis/bin/redis-server
后台启动redis
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vi /usr/local/apps/redis/bin/redis.conf # 后台启动 将daemonize no 改成daemonize yes # 设置数据存放目录 mkdir /usr/local/apps/redis/data 配置文件 dir ./ 改为 dir /usr/local/apps/redis/data # 关闭保护 protected-mode no # 指定配置文件启动 ./redis-server ./redis.conf # bind 127.0.0.1 改为 0.0.0.0 # 查看redis进程 ps -ef |grep redis # 结束redis进程 kill -9 redis进程号
将redis加入到开机启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vi /etc/rc.local //在里面添加内容: /usr/local/apps/redis/redis-5.0.14/src/redis-server /usr/local/apps/redis/redis-5.0.14/redis.conf (意思就是开机调用这段开启redis的命令) =================== 另一种方式: =================== 在系统服务目录里创建redis-server.service文件 vim /etc/systemd/system/redis-server.service [Unit] Description=The redis-server Process Manager After=syslog.target network.target [Service] Type=forking ExecStart=/usr/local/apps/redis/bin/redis-server /usr/local/apps/redis/bin/redis.conf [Install] WantedBy=multi-user.target # 重新加载系统服务 systemctl daemon-reload # 开机启动 systemctl enable redis-server.service
开启redis
1 /usr/local/apps/redis/bin/redis-server /usr/local/apps/redis/bin/redis.conf
将redis-cli,redis-server拷贝到bin下,让redis-cli指令可以在任意目录下直接使用
1 2 cp /usr/local/apps/redis/bin/redis-server /usr/local/bin/ cp /usr/local/apps/redis/bin/redis-cli /usr/local/bin/
防火墙
1 firewall-cmd --add-port=6379/tcp --permanent && firewall-cmd --reload
13.远程链接
1 2 3 4 5 6 7 8 报错:Redis Client On Error: Error: connect ECONNREFUSED 192.168.xxx.105:6379 Config right? vim redis.conf #注释 这一行重新启动redis即可 #bind 127.0.0.1 -::1 #bind 127.0.0.1 bind 0.0.0.0
实操-安装RabbitMQ 离线安装
卸载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 删除安装包 [root@zabbix_server lib]# rpm -qa|grep rabbitmq rabbitmq-server-3.6.5-1.noarch [root@zabbix_server lib]# rpm -e --nodeps rabbitmq-server # 删除所有的rabbitmq目录 [root@de9f15cd4e56 ~]# whereis rabbitmq rabbitmq: /usr/lib/rabbitmq [root@de9f15cd4e56 ~]# rm -rf /usr/lib/rabbitmq/ rabbitmq:[root@de9f15cd4e56 ~]# find / -name rabbitmq /var/lib/rabbitmq /var/log/rabbitmq /root/.m2/repository/com/rabbitmq /usr/lib/ocf/resource.d/rabbitmq [root@de9f15cd4e56 ~]# [root@de9f15cd4e56 ~]# rm -rf /var/lib/rabbitmq [root@de9f15cd4e56 ~]# rm -rf /var/log/rabbitmq [root@de9f15cd4e56 ~]# rm -rf /usr/lib/ocf/resource.d/rabbitmq # 删除rabbitmq rabbitmqctl app_stop # 停止服务 yum list | grep rabbitmq yum -y remove rabbitmq-server.noarch # 删除erlang yum list | grep erlang yum -y remove erlang-* yum remove erlang.x86_64
1.安装依赖环境
1 2 # rpm包安装前需要安装下面的依赖包 yum install build‐essential openssl openssl‐devel unixODBC unixODBC‐devel make gcc gcc‐c++ kernel‐devel m4 ncurses‐devel tk tc xz
2. 离线安装
下载包:
1 2 3 4 5 6 wget https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-23.2.7-2.el7.x86_64.rpm/download.rpm mv download.rpm erlang-23.2.7-2.el7.x86_64.rpm wget http://repo.iotti.biz/CentOS/7/x86_64/socat-1.7.3.2-5.el7.lux.x86_64.rpm wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.17/rabbitmq-server-3.8.17-1.el7.noarch.rpm
安装包:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 上传rpm安装包 erlang-18.3-1.el7.centos.x86_64.rpm socat-1.7.3.2-5.el7.lux.x86_64.rpm rabbitmq-server-3.6.5-1.noarch.rpm # 解压安装 erlang rpm -ivh erlang-23.2.7-2.el7.x86_64.rpm --nodeps --force # 解压安装 socat rpm -ivh socat-1.7.3.2-5.el7.lux.x86_64.rpm --nodeps --force # 离线解压安装 rabbitmq rpm -ivh --prefix=/usr/local/apps/rabbitmq/ rabbitmq-server-3.8.14-1.el7.noarch.rpm --nodeps --force # 到这里就可以用service rabbitmq‐server start启动rabbitmq了
3.启动
1 2 3 service rabbitmq‐server start # 启动服务 service rabbitmq‐server stop # 停止服务 service rabbitmq‐server restart # 重启服务
4.开启管理界面及配置
1 2 3 4 5 6 7 8 9 # 开启管理界面(不然只能通过命令操作,不方便) rabbitmq-plugins enable rabbitmq_management # 修改默认配置信息 vim /usr/lib/rabbitmq/lib/rabbitmq_server‐3.6.5/ebin/rabbit.app # 比如修改密码、配置等等,例如:loopback_users 中的 <<"guest" >>,只保留guest # 重启服务 service rabbitmq‐server restart systemctl start rabbitmq‐server.service
5.开启防火墙
1 2 3 4 5 6 7 访问不到可能是防火墙拦截了。(或者单独开放15672端口) service iptables stop # 关闭防火墙 或者用单独的 firewall-cmd --add-port=15672/tcp --permanent && firewall-cmd --reload # tcp连接时需要开放端口(比如用java连接) firewall-cmd --add-port=5672/tcp --permanent && firewall-cmd --reload
6.拷贝一份配置文件
1 2 3 # 拷贝一份配置文件 cd /usr/share/doc/rabbitmq‐server‐3.6.5/ cp rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
在线安装 1.添加rabbitmq yum源 yum源配置文件夹(/etc/yum.repos.d)下添加rabbitmq.repo,文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 # In /etc/yum.repos.d/rabbitmq.repo # # # [rabbitmq_erlang] name=rabbitmq_erlang baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/$basearch repo_gpgcheck=1 gpgcheck=1 enabled=1 # PackageCloud's repository key and RabbitMQ package signing key gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt metadata_expire=300 [rabbitmq_erlang-source] name=rabbitmq_erlang-source baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/SRPMS repo_gpgcheck=1 gpgcheck=0 enabled=1 gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt metadata_expire=300 # # # # RabbitMQ server # # [rabbitmq_server] name=rabbitmq_server baseurl=https://packagecloud.io/rabbitmq/rabbitmq-server/el/7/$basearch repo_gpgcheck=1 gpgcheck=1 enabled=1 # PackageCloud' s repository key and RabbitMQ package signing keygpgkey=https://packagecloud.io/rabbitmq/rabbitmq-server/gpgkey https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt metadata_expire=300 [rabbitmq_server-source] name=rabbitmq_server-source baseurl=https://packagecloud.io/rabbitmq/rabbitmq-server/el/7/SRPMS repo_gpgcheck=1 gpgcheck=0 enabled=1 gpgkey=https://packagecloud.io/rabbitmq/rabbitmq-server/gpgkey sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt metadata_expire=300
猜测:使用这个yum之后,可以解决Erlang版本和操作系统版本问题。
2.yum安装rabbitmq 1 2 3 4 5 6 7 8 9 #更新yum源 yum update -y #install these dependencies from standard OS repositories yum install socat logrotate -y #安装erlang和rabbitmq yum install erlang rabbitmq-server -y # 指定目录: --installroot=/usr/local/apps/rabbitmq/
3.查看安装版本 1 2 3 4 5 6 7 8 9 10 #查看Erlang erl -v Erlang/OTP 24 [erts-12.1.5] [source] [64-bit] [smp:2:2] [ds:2:2:10] [async-threads:1] Eshell V12.1.5 (abort with ^G) 1> #查看rabbitmq,可能要启动后才能使用rabbitmqctl rabbitmqctl version 3.9.10
4.启动rabbitmq 1 2 3 4 5 6 #启动 systemctl start rabbitmq-server #查看状态 systemctl status rabbitmq-server
5.防火墙开放端口访问 需要开发5672即15672端口,15672端口为管理界面使用
1 2 3 4 firewall-cmd --add-port=5672/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=15672/tcp --permanent && firewall-cmd --reload
6.启用管理页面插件 1 sudo /sbin/rabbitmq-plugins enable rabbitmq_management
7.添加访问用户远程访问 1 2 3 4 5 6 7 8 9 10 11 #查询安装默认的用户(一般有一个guest 用户和一个administrator管理员用户) rabbitmqctl list_users #其中admin 是用户名,123456是密码 rabbitmqctl add_user admin 123456 #通过命令给用户增加角色权限 rabbitmqctl set_user_tags admin administrator #给用户增加所有访问权限 rabbitmqctl set_permissions -p "/" admin '.*' '.*' '.*'
到此rabbitmq安装完成,页面URL:http://ip:15672/。
8.启动
1 2 3 4 5 6 7 8 9 10 [root@localhost home]# rabbitmq-server RabbitMQ 3.6.12. Copyright (C) 2007-2017 Pivotal Software, Inc. ## ## Licensed under the MPL. See http://www.rabbitmq.com/ ## ## ########## Logs: /var/log/rabbitmq/rabbit@localhost.log ###### ## /var/log/rabbitmq/rabbit@localhost-sasl.log ########## Starting broker... completed with 6 plugins. #这里显示6,说明web插件已经安装好啦
实操-安装Zookeeper 1.安装 jdk(略)
2.把 zookeeper 的压缩包(zookeeper-3.4.6.tar.gz)上传到 linux 系统
3.解压缩压缩包
1 2 3 tar -zxvf zookeeper-3.4.6.tar.gz # 可以改个名字 mv zookeeper-3.4.6 zookeeper
4.进入zookeeper-3.4.6目录,创建data目录 mkdir data
5.进入conf目录 ,把zoo_sample.cfg 改名为zoo.cfg
1 2 cd conf mv zoo_sample.cfg zoo.cfg 或 cp zoo_sample.cfg zoo.cfg
6.打开 zoo.cfg文件, 修改data属性:dataDir=/usr/local/apps/zookeeper/data
7.启动、停止Zookeeper
1 2 3 4 5 6 # 进入Zookeeper的bin目录,启动服务命令 ./zkServer.sh start # 停止服务命令 ./zkServer.sh stop # 查看服务状态: ./zkServer.sh status
8.开放防火墙
1 2 3 4 5 访问不到可能是防火墙拦截了。(或者单独开放2181、20880端口) service iptables stop # 关闭防火墙 或者用单独的 firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=20880/tcp --permanent && firewall-cmd --reload
注意:
zookeeper-3.7.0 下载的包是带bin的,3.7和3.42个版本命令差别挺大的
实操-安装ElasticSearch
为了模拟真实场景,我们将在linux下安装Elasticsearch。
1 2 3 # 环境要求: centos 64位 JDK8及以上
如果有的同学vmvare存在问题,可以在安装windows版本。
1 2 3 4 5 6 # 出于安全考虑,elasticsearch默认不允许以root账号运行。 useradd elastic # 设置密码: passwd elastic # 切换用户: su - elastic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 我们将安装包上传到:/home/elastic目录 # 安装rz插件,一路 yes yum -y install lrzs # 切换到 cd /home/elastic rz -be # 解压缩: tar xvf elasticsearch-6.8.0.tar.gz # 目录重命名: mv elasticsearch-6.8.0/ elasticsearch # 修改权限(可选) chown elastic:elastic -R elasticsearch # 目录说明 bin 二进制脚本,包含启动命令等 config 配置文件目录 lib 依赖包目录 logs 日志文件目录 modules 模块库 plugins 插件目录,这里存放一些常用的插件比如IK分词器插件 data 数据储存目录(暂时没有,需要在配置文件中指定存放位置,启动es时会自动根据指定位置创建)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 我们进入config目录: cd config ll # 修改jvm配置 # Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数设置堆大小 vim jvm.options # 默认配置如下: -Xms1g -Xmx1g # 内存占用太多了,我们调小一些,大家虚拟机内存设置为2G: # 最小设置128m,如果虚机内存允许的话设置为512m -Xms128m -Xmx128m # 修改elasticsearch.yml vim elasticsearch.yml # 修改数据和日志目录: path.data: /home/elastic/elasticsearch/data # 数据目录位置 path.logs: /home/elastic/elasticsearch/logs # 日志目录位置 # 修改绑定的ip: network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问 默认只允许本机访问,修改为0.0.0.0后则可以远程访问 目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。 elasticsearch.yml的其它可配置信息:
1 2 3 4 5 6 7 8 9 10 11 # 进入elasticsearch/bin目录,可以看到下面的执行文件: ./elasticsearch # 后台启动 ./elasticsearch -d 1.查找ES进程 ps -ef | grep elastic 2.杀掉ES进程 kill -9 2382(进程号) 3.重启ES sh elasticsearch -d
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # [1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] # elasticsearch用户拥有的可创建文件描述的权限太低,至少需要65536; 我们用的是elastic用户,而不是root,所以文件权限不足。 首先用root用户登录。 然后修改配置文件: vim /etc/security/limits.conf 添加下面的内容: 注意下面的 “*” 号不要去除 # 可打开的文件描述符的最大数(软限制) * soft nofile 65536 #可打开的文件描述符的最大数(硬限制) * hard nofile 131072 #单个用户可用的最大进程数量(软限制) * soft nproc 4096 #单个用户可用的最大进程数量(硬限制) * hard nproc 4096 # 重新登录即生效 # [1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096] 这是线程数不够。 继续修改配置 vim /etc/security/limits.d/90-nproc.conf 修改下面的内容: * soft nproc 1024 改为: * soft nproc 4096 # [3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144] # elasticsearch用户拥有的最大虚拟内存太小,至少需要262144; vim /etc/sysctl.conf 添加下面内容: vm.max_map_count=262144 然后执行命令: sysctl -p # 内核过低unable to install syscall filter 使用的centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。不过没关系,我们禁用这个插件即可。 修改elasticsearch.yml文件,在最下面添加以后配置 bootstrap.system_call_filter: false 重启终端窗口 所有错误修改完毕,如果启动还是失败则需要重启你的 Xshell终端,使配置生效
1 2 3 4 5 可以看到绑定了两个端口: 9300:集群节点间通讯接口,接收tcp协议 9200:客户端访问接口,接收Http协议 验证是否启动成功: 在浏览器中访问:http://192.168.88.128:9200/,如果不能访问,则需要关闭虚拟机防火墙,需要root权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 查看防火墙: service iptables status (centos 6) firewall-cmd --state (centos7) # 关闭防火墙: service iptables stop (centos 6) systemctl stop firewalld.service (centos7) # 禁止开机启动防火墙: chkconfig iptables off (centos 6) systemctl disable firewalld.service (centos7) firewall-cmd --add-port=9200/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9300/tcp --permanent && firewall-cmd --reload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 使用插件安装(方式一)=> 在线安装真香! 1)在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成: ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.0/elasticsearch-analysis-ik-6.8.0.zip 2)下载完成后会提示 Continue with installation?输入 y 即可完成安装 3)重启es 和kibana 上传安装包安装(方式二) 1)在elasticsearch的plugins目录下新建 analysis-ik 目录 # 新建analysis-ik文件夹 mkdir analysis-ik # 切换至 analysis-ik文件夹下 cd analysis-ik # rz上传资料中的 elasticsearch-analysis-ik-6.8.0.zip rz # 解压 unzip elasticsearch-analysis-ik-6.8.0.zip # 解压完成后删除zip rm -rf elasticsearch-analysis-ik-6.8.0.zip 2)重启es 和kibana
注意:
1 2 3 如果用root启动,会导致一些文件变为root,下次用elatic启动没有权限写入, 要么一个一个删除,要么修改权限, elastic要有修改文件所属root组的权限的话,要修改soduers文件配置。
实操-安装Kibana 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 安装 # 将资料中的kibana-6.8.0-linux-x86_64.tar.gz上传至虚机,解压即可: tar xvf kibana-6.8.0-linux-x86_64.tar.gz # 配置运行 ## 进入安装目录下的config目录,修改kibana.yml文件: #修改server.host地址: server.host: "0.0.0.0" #界面中文显示,在最后一行修改 i18n.locale: "zh-CN" # 运行 # 进入安装目录下的bin目录运行: ./kibana # 发现kibana的监听端口是5601 # 我们访问: http://192.168.129.134:5601 # 开放端口(可选) firewall-cmd --add-port=5601/tcp --permanent && firewall-cmd --reload
1 2 3 # kibana dev tools快捷键 ctrl+enter 提交请求 ctrl+i 自动缩进
1 2 3 # Another Kibana instance appears to be migrating the index. Waiting for that migration to complete. If no other Kibana instance is attempting migrations, you can get past this message by deleting index .kibana_1 and restarting Kibana. 如果出现上述问题,可以使用elasticsearch-head删除kibana的相关索引,然后再启动kibana
实操-安装consul 1、下载consul安装源
1 官网地址:https://www.consul.io/downloads
2、解压安装包
1 unzip consul_1.9.0_linux_amd64.zip -d /usr/local/apps/consul/
解压出的文件是一个可以执行的文件 consul
3、查看consul版本 确定是否可用
4、将可执行程序设置成全局变量
(1)拷贝文件到/usr/local/bin下
1 cp consul /usr/local/bin/
(2)配置环境变量
1 2 3 4 5 6 7 8 9 10 #编辑~/.bashrc vi ~/.bashrc #新增下面代码 export CONSUL_HOME=/usr/local/bin/consul export PATH=$PATH:CONSUL_HOME #重新加载~/.bashrc source ~/.bashrc #测试是否能使用,输出版本及为正常 consul --version
5、启动服务
1 consul agent -dev -ui -client=0.0.0.0
6、设置启动脚本
(1)添加脚本,找一个自己脚本存放的位置
1 2 3 4 5 6 #新增启动脚本 consul_start.sh vi consul_start.sh #输入 nohup consul agent -dev -ui -client=0.0.0.0 >/tmp/consul.log & echo 'consul start success' #保存并退出
(2)设置脚本执行权限
1 chmod +x consul_start.sh
(3)运行脚本
7、浏览器访问
8、启动linux server
1 2 consul agent -server -bootstrap-expect 1 -data-dir /usr/local/apps/consul/data -node=n1 -ui -client=0.0.0.0 -bind=192.168.213.129 # 启动后直接访问 http://192.168.213.129:8500 就行了
9、防火墙
1 2 # consul防火墙 firewall-cmd --add-port=8500/tcp --permanent && firewall-cmd --reload
实操-安装nginx 卸载nginx
1 2 3 4 5 6 7 rm -rf /etc/nginx/ rm -rf /usr/sbin/nginx yum remove nginx # 查找相关目录删除 find / -name nginx
安装编译环境
一般系统中已经装了了make和g++,无须再装
安装make
1 yum -y install autoconf automake make
安装g++
1 yum -y install gcc gcc-c++ (nginx是c语言开发的)
安装nginx依赖的库
1 2 3 yum -y install pcre pcre-devel (http模块使用pcre解析正则) yum -y install zlib zlib-devel (是用zlib对http内容打包) yum -y install openssl openssl-devel (hhttps协议)
下载nginx
1 wget http://nginx.org/download/nginx-1.21.1.tar.gz
也可以先下载好这个tar包,离线安装
解压nginx
1 tar -zxvf nginx-1.21.1.tar.gz
编译安装
1 2 ./configure --prefix=/usr/local/nginx make && make install
--prefix默认就是该目录
配置环境变量
编辑/etc/profile
在最后一行加入
1 2 PATH=$PATH:/usr/local/nginx/sbin export PATH
生效环境变量
关闭防火墙
1 2 3 4 5 systemctl status firewalld systemctl stop firewalld systemctl disable firewalld firewall-cmd --add-port=80/tcp --permanent && firewall-cmd --reload
启动
1 2 3 nginx # 如果执行配置文件 nginx -c nginx.conf #如果不指定,默认为NGINX_HOME/conf/nginx.conf
停止
退出
关闭
1 2 3 4 5 # 查看nginx进程号 ps -aux | grep nginx # 杀掉进程(杀进程要先杀master,否则会再启动进程) kill -9 nginx
重新加载配置文件
检查配置文件是否正确
1 nginx -t -c /路径/nginx.conf
查看nginx的版本信息
实操-安装Apollo[失败] 前提:
Github安装包下载地址:https://github.com/nobodyiam/apollo-build-scripts
上传zip包到/usr/local/apps并解压
1 unzip apollo-build-scripts-master.zip
创建数据库
1 2 3 cd apollo-build-scripts-master/sql source apolloconfigdb.sql source apolloportaldb.sql
配置demo.sh的数据库
1 2 3 4 5 6 7 8 9 10 vim ./demo.sh apollo_config_db_url ="jdbc:mysql://192.168.200.129:3306/ApolloConfigDB? characterEncoding=utf8&serverTimezone=Asia/Shanghai" apollo_config_db_username =root apollo_config_db_password =root apollo_portal_db_url ="jdbc:mysql://192.168.200.129:3306/ApolloPortalDB? characterEncoding=utf8&serverTimezone=Asia/Shanghai" apollo_portal_db_username =root apollo_portal_db_password =root
检查端口是否被占用
1 2 3 4 5 6 7 8 Quick Start脚本会在本地启动3个服务,分别使用8070, 8080, 8090端口,请确保这3个端口当前没有被使用,如果端口没有被使用 lsof -i:8070 lsof -i:8080 lsof -i:8090 [root@localhost apollo-build-scripts-master]# netstat -anp | grep 8070 [root@localhost apollo-build-scripts-master]# netstat -anp | grep 8080 [root@localhost apollo-build-scripts-master]# netstat -anp | grep 8090
如果有端口占用
启动服务
1 2 cd /usr/local/apps/apollo-build-scripts-master/ ./demo.sh start
启动完成后访问 : http://192.168.200.129:8070/
防火墙:
1 firewall-cmd --add-port=8070/tcp --permanent && firewall-cmd --reload
实操-安装MongoDB 1.下载安装包
1 2 3 4 5 cd /usr/local/apps yum -y install wget wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.5.tgz tar -zxvf mongodb-linux-x86_64-rhel70-4.4.5.tgz mv mongodb-linux-x86_64-rhel70-4.4.5 mongodb4.4.5
2.配置环境变量
1 2 3 4 5 6 7 vi /etc/profile ... export MONGO_HOME=/usr/local/apps/mongodb4.4.5 ... export PATH=$MYSQL_HOME/bin:$JAVA_HOME/bin:$NGINX_HOME:$MONGO_HOME/bin:$PATH ... source /etc/profile
3.安装MongoDB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 mkdir data logs #创建mongodb的日志文件 touch logs/mongodb.log vi mongodb.conf #端口号 默认为27017 port=27017 #数据库数据存放目录 dbpath=/usr/local/apps/mongodb4.4.5/data #数据库日志存放目录 logpath=/usr/local/apps/mongodb4.4.5/logs/mongodb.log # pid存储路径 pidfilepath = /var/run/mongo.pid #以追加的方式记录日志 logappend = true #以后台方式运行进程 fork=true #开启用户认证 #auth=true #最大同时连接数 maxConns=100 #这样就可外部访问了,例如从win10中去连虚拟机中的MongoDB bind_ip = 0.0.0.0 #每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。 #启用日志文件,默认启用 journal=true #这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false quiet=true
4.作为服务启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 vi /etc/init.d/mongod #!/bin/sh # chkconfig: #MogoDB home directory MONGODB_HOME=/usr/local/apps/mongodb4.4.5/ #mongodb command MONGODB_BIN=$MONGODB_HOME/bin/mongod #mongodb config file MONGODB_CONF=$MONGODB_HOME/bin/mongodb.conf #mongodb PID MONGODB_PID=/var/run/mongo.pid #set open file limit SYSTEM_MAXFD=65535 MONGODB_NAME="mongodb" . /etc/rc.d/init.d/functions if [ ! -f $MONGODB_BIN ] then echo "$MONGODB_NAME startup: $MONGODB_BIN not exists! " exit fi start(){ ulimit -HSn $SYSTEM_MAXFD $MONGODB_BIN --config="$MONGODB_CONF" --fork ##added ret=$? if [ $ret -eq 0 ]; then action $"Starting $MONGODB_NAME: " /bin/true else action $"Starting $MONGODB_NAME: " /bin/false fi } stop(){ PID=$(ps aux |grep "$MONGODB_NAME" |grep "$MONGODB_CONF" |grep -v grep |wc -l) if [[ $PID -eq 0 ]];then action $"Stopping $MONGODB_NAME: " /bin/false exit fi kill -HUP `cat $MONGODB_PID` ret=$? if [ $ret -eq 0 ]; then action $"Stopping $MONGODB_NAME: " /bin/true rm -f $MONGODB_PID else action $"Stopping $MONGODB_NAME: " /bin/false fi } restart() { stop sleep 2 start } case "$1" in start) start ;; stop) stop ;; status) status $prog ;; restart) restart ;; *) echo $"Usage: $0 {start|stop|status|restart}" esac
设置文件权限
1 chmod 755 /etc/init.d/mongod
5.启动MongoDB
1 2 3 4 5 # 启动mongodb service mongod start # 检查服务是否存在 ps -ef|grep mongo
6.关闭防火墙
1 2 # MongoDB防火墙 firewall-cmd --add-port=27017/tcp --permanent && firewall-cmd --reload
7.优雅关机
1 2 3 4 >mongo show dbs; use admin db.shutdownServer()
实操-安装Jenkins
前置:jdk、git、maven
1.下载jenkins
1 2 3 4 5 wget https://pkg.jenkins.io/redhat/jenkins-2.83-1.1.noarch.rpm 下面这个可以: yum -y install epel-release yum -y install daemonize wget https://mirrors.tuna.tsinghua.edu.cn/jenkins/redhat-stable/jenkins-2.319.1-1.1.noarch.rpm
2.安装jenkins
1 2 rpm -ivh jenkins-2.83-1.1.noarch.rpm rpm -ivh jenkins-2.319.1-1.1.noarch.rpm
3.配置Jenkins用户和端口
1 2 3 4 vim /etc/sysconfig/jenkins JENKINS_USER="root" JENKINS_PORT="8888"
配置jdk路径(如果默认路径不是/usr/local/java的话)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vim /etc/rc.d/init.d/jenkins candidates=" /etc/alternatives/java /usr/lib/jvm/java-1.8.0/bin/java /usr/lib/jvm/jre-1.8.0/bin/java /usr/lib/jvm/java-1.7.0/bin/java /usr/lib/jvm/jre-1.7.0/bin/java /usr/lib/jvm/java-11.0/bin/java /usr/lib/jvm/jre-11.0/bin/java /usr/lib/jvm/java-11-openjdk-amd64 /usr/bin/java /usr/local/apps/java/jdk1.8.0_321/bin/java #把自己配置的目录加进去 systemctl daemon-reload
4.启动服务
5.访问Jenkins
访问链接 http://192.168.213.130:8888
如果访问不了开放防火墙
1 firewall-cmd --add-port=8888/tcp --permanent && firewall-cmd --reload
从cat /var/lib/jenkins/secrets/initialAdminPassword中获取初始密码串
如果报错:
1 An error occurred during installation: No such plugin: cloudbees-folder
重启一下Jenkins
1 2 3 http://localhost:8888/restart 或者 systemctl restart jenkins
6.新建用户
7.完成安装进入主界面
8.安装插件-maven插件
(1)点击左侧的“系统管理”菜单 ,然后点击 管理插件
(2)选择“可选插件”选项卡,搜索maven,在列表中选择Maven Integration ,点击“直 接安装”按钮
看到如下图时,表示已经完成
9.安装插件-git插件
步骤同8,搜索git
10.全局工具配置-安装maven和本地仓库
安装maven,将开发maven库上传到服务器的maven仓库(否则后续在线下载可能比较慢)
11.全局工具配置-jdk配置,设置javahome
12.全局工具配置-git配置
13.全局工具配置-maven配置
14.持续集成
(1)回到首页,点击新建按钮 .如下图,输入名称,选择创建一个Maven项目,点击OK
(2)源码管理,选择Git
(3)Build
命令:
1 clean package docker:build -DpushImage
用于清除、打包,构建docker镜像
最后点击“保存”按钮
15.执行任务
返回首页,在列表中找到我们刚才创建的任务
点击右边的绿色箭头按钮,即可执行此任务.
点击下面正在执行的任务
可以看到实时输出的日志
这就是镜像做好了在上传,如果你之前没有将你的本地仓库上传到服务器,会首先下载
依赖的jar包,接下来就是漫长的等待了。
看到下面的结果就表示你已经成功了
首战告捷!哈哈,兴奋不?返回首页 看到列表
我们在浏览器看一下docker私有仓库
1 2 3 4 http://192.168.184.135:5000/v2/_catalog 会看到tensquare_eureka已经上传成功了 {"repositories":["jdk1.8","tensquare_eureka"]}
按此方法完成其它微服务的构建
16.卸载Jenkins
1 2 3 4 5 6 1、卸载rpm方式安装的jenkins: rpm -e jenkins 2、检查是否卸载成功: rpm -ql jenkins 3、彻底删除残留文件: find / -iname jenkins | xargs -n 1000 rm -rf
实操-安装CAT3 前提:
linux安装了jdk1.8(参考上面的实操-安装JDK)
linux安装了tomcat8(参考上面的实操-安装Tomcat)
linux-docker安装了MySQL7(我用的镜像是: centos/mysql-57-centos7)
1 docker run -di --name=cat_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root centos/mysql-57-centos7
安装cat-3.0.0:
服务器创建目录
1 2 3 4 mkdir /datachmod -R 777 /data/mkdir -p /data/appdatas/cat/ mkdir -p /data/applogs/cat/
客户端配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 cd /data/appdatas/cat/ # 配置文件一 vim client.xml <?xml version="1.0" encoding="utf-8" ?> <config mode ="client" > <servers > <server ip ="192.168.213.135" port ="2280" http-port ="8080" /> </servers > </config > 注意: 2280是默认的CAT服务端接受数据的端口,不允许修改, http-port是Tomcat启动的端口,默认是8080,建议使用默认端口
服务端配置文件:配置自己独立的MySQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cd /data/appdatas/cat/ # 配置文件二 vim datasources.xml <?xml version="1.0" encoding="utf-8" ?> <data-sources > <data-source id ="cat" > <maximum-pool-size > 3</maximum-pool-size > <connection-timeout > 1s</connection-timeout > <idle-timeout > 10m</idle-timeout > <statement-cache-size > 1000</statement-cache-size > <properties > <driver > com.mysql.jdbc.Driver</driver > <url > <![CDATA[jdbc:mysql://192.168.213.135:3306/cat]]></url > <user > root</user > <password > root</password > <connectionProperties > <![CDATA[useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&socketTimeout=120000]]></connectionProperties > </properties > </data-source > </data-sources > 注意: 源码目录docker/下有配置文件,拷贝修改也可以
创建CAT数据库,并导入源码工程目录SCRIPT/下的SQL脚本
1 2 3 create database cat charset utf8mb4 collate utf8mb4_general_ci;注意1 :一套独立的CAT集群只需要一个数据库(之前碰到过个别同学在每台cat的服务端节点都安装了一个数据库) 注意2 :数据库编码使用utf8mb4,否则可能造成中文乱码等问题
源码打包(这一步可以在windows先打包好) 【直接用下载的war包的话这一步就省略了】
1 2 mvn clean install -DskipTests 注意: 打出来的jar包重命名为cat.war进行部署,此war是用jdk8,服务端请使用jdk8版本
war包部署
1 2 将war包扔到192.168.213.135的tomcat的webapps目录下,启动tomcat即可 tomcat目录/bin/startup.sh
访问
http://192.168.213.135:8080/cat/s/config?op=routerConfigUpdate
默认用户名:admin 默认密码:admin
如果访问不了,防火墙要关闭
1 firewall-cmd --add-port=8080/tcp --permanent && firewall-cmd --reload
进入配置(在网页里修改)
configs=>全局系统配置=>服务端配置中修改为: 将127.0.0.1改为实际的ip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 <?xml version="1.0" encoding="utf-8" ?> <server-config > <server id ="default" > <properties > <property name ="local-mode" value ="false" /> <property name ="job-machine" value ="false" /> <property name ="send-machine" value ="false" /> <property name ="alarm-machine" value ="false" /> <property name ="hdfs-enabled" value ="false" /> <property name ="remote-servers" value ="192.168.213.135:8080" /> </properties > <storage local-base-dir ="/data/appdatas/cat/bucket/" max-hdfs-storage-time ="15" local-report-storage-time ="2" local-logivew-storage-time ="1" har-mode ="true" upload-thread ="5" > <hdfs id ="dump" max-size ="128M" server-uri ="hdfs://127.0.0.1/" base-dir ="/user/cat/dump" /> <harfs id ="dump" max-size ="128M" server-uri ="har://127.0.0.1/" base-dir ="/user/cat/dump" /> <properties > <property name ="hadoop.security.authentication" value ="false" /> <property name ="dfs.namenode.kerberos.principal" value ="hadoop/dev80.hadoop@testserver.com" /> <property name ="dfs.cat.kerberos.principal" value ="cat@testserver.com" /> <property name ="dfs.cat.keytab.file" value ="/data/appdatas/cat/cat.keytab" /> <property name ="java.security.krb5.realm" value ="value1" /> <property name ="java.security.krb5.kdc" value ="value2" /> </properties > </storage > <consumer > <long-config default-url-threshold ="1000" default-sql-threshold ="100" default-service-threshold ="50" > <domain name ="cat" url-threshold ="500" sql-threshold ="500" /> <domain name ="OpenPlatformWeb" url-threshold ="100" sql-threshold ="500" /> </long-config > </consumer > </server > <server id ="192.168.213.135" > <properties > <property name ="job-machine" value ="true" /> <property name ="send-machine" value ="true" /> <property name ="alarm-machine" value ="true" /> </properties > </server > </server-config >
改完点提交
configs=>全局系统配置=>客户端路由中修改为: 将127.0.0.1改为实际的ip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?xml version="1.0" encoding="utf-8" ?> <router-config backup-server ="192.168.213.135" backup-server-port ="2280" > <default-server id ="192.168.213.135" weight ="1.0" port ="2280" enable ="true" /> <network-policy id ="default" title ="默认" block ="false" server-group ="default_group" > </network-policy > <server-group id ="default_group" title ="default-group" > <group-server id ="192.168.213.135" /> </server-group > <domain id ="cat" > <group id ="default" > <server id ="192.168.213.135" port ="2280" weight ="1.0" /> </group > </domain > </router-config >
改完点提交
这样就可以了
真TM的难搞有一说一,各种各样的问题,我装个链路跟踪装了N遍,裂开了。
实操-安装Nacos 1.1.4 1.获取包
1 wget https://github.com/alibaba/nacos/releases/download/1.1.4/nacos-server-1.1.4.tar.gz
2、解压安装包
1 tar -zxvf nacos-server-1.1.4.tar.gz
启动错误
启动日志可在nacos/logs/start.out 查看
解决办法:删除 nacos/data/derby-data 文件,重启
3、配置MySQL
1 2 3 4 5 6 7 8 9 10 11 修改配置文件,支持mysql,修改nacos/conf/application.properties文件,增加支持mysql数据源配置(目前只支持mysql),添加mysql数据源的url、用户名和密码,代码如下图: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=root db.password=root
创建nacos-config数据库,并且将/config/nacos-mysql.sql执行。
4、无密码登录
开发方便些
修改Nacos配置文件application.properties
1 2 3 4 spring.security.enabled=false management.security=false security.basic.enabled=false nacos.security.ignore.urls=/**
5、单机启动
1 2 cd /usr/local/apps/nacos/bin sh startup.sh -m standalone
6、防火墙
1 2 # nacos firewall-cmd --add-port=8848/tcp --permanent && firewall-cmd --reload
访问地址为:http://127.0.0.1:8848/nacos
7、nacos开机启动配置
安装完成nacos后进行配置开机启动。
编写开机启动文件
vim /lib/systemd/system/nacos.service
文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 [Unit] Description=nacos After=network.target [Service] Type=forking ExecStart=/opt/nacos/bin/startup.sh -m standalone ExecReload=/opt/nacos/bin/shutdown.sh ExecStop=/opt/nacos/bin/shutdown.sh PrivateTmp=true [Install] WantedBy=multi-user.target
其中/opt/nacos为本机安装的nacos文件路径,-m standalone表示作为单机启动,不加的话表示集群启动,目前先作为单机启动。
设置开机启动
1 2 3 4 systemctl daemon-reload #先进行文件生效配置 systemctl enable nacos.service #设置为开机启动 systemctl start nacos.service #启动nacos服务 systemctl stop nacos.service
启动并查看是否成功
实操-安装Nacos 2.1.1 1.下载:https://github.com/alibaba/nacos/releases
2.修改config/application.yaml配置mysql
3.导入config/nacos-mysql.sql建表语句
1 mysql新建库:nacos,字符集:utf8 ,排序规则:utf8_general_ci
4.便捷启动
1 2 3 4 5 touch nacos-start.sh ./nacos/bin/startup.sh -m standalone touch nacos-stop.sh ./nacos/bin/shutdown.sh ps: 注意设置脚本执行权限
5.防火墙
1 2 3 firewall-cmd --add-port=8848/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9848/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9849/tcp --permanent && firewall-cmd --reload
2.0需要多开放2个端口,否则后台链接报错
实操-安装sentinel-dashboard 1.下载:https://github.com/alibaba/Sentinel/releases
2.上传并启动
1 java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.5.jar
后台启动
1 nohup java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.5.jar &
默认登陆账号与密码都是sentinel,也可以通过启动参数修改:
1 2 -Dsentinel.dashboard.auth.username=sentinel -Dsentinel.dashboard.auth.password=123456
3.防火墙
1 firewall-cmd --add-port=8090/tcp --permanent && firewall-cmd --reload
实操-安装Docker ⭐ 1、yum 包更新到最新
2、安装需要的软件包, yum‐util 提供yum‐config‐manager功能,另外两个是devicemapper驱动依赖的
1 yum install -y yum‐utils device-mapper-persistent-data lvm2
3、 设置yum源
1 2 3 4 5 6 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 或者用 # 阿里云地址(国内地址,相对更快) yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4、 安装docker,出现输入的界面都按 y
1 2 3 4 5 yum install docker-ce docker-ce-cli containerd.io 或者用 yum install -y docker-ce # #docker-ce-cli、containerd.io 会作为依赖包被安装 或者用: sudo yum install -y docker-ce docker-ce-cli containerd.io
5、 查看docker版本,验证是否验证成功
6.配置阿里云镜像加速
1 2 3 4 5 6 7 8 mkdir -p /etc/docker vim /etc/docker/daemon.json { "registry-mirrors": ["https://xbmcwm0u.mirror.aliyuncs.com"] } systemctl daemon-reload systemctl restart docker
7.启动停止docker服务
1 2 3 4 5 6 7 8 9 10 # 启动docker服务: (安装玩要启动一下) systemctl start docker # 停止docker服务: systemctl stop docker # 重启docker服务: systemctl restart docker # 查看docker服务状态: systemctl status docker # 设置开机启动docker服务: systemctl enable docker
查找下有哪些版本可以安装
1 yum list docker-ce --showduplicates | sort -r
9.卸载docker
1 2 3 4 5 6 7 8 yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine
或者很详细的:
1 2 3 4 5 6 7 8 9 10 11 12 13 # 所有下列命令包含了诸多情况,实际上可能没有,若报错文件不存在忽略即可 yum remove docker-ce \ docker-ce-cli \ containerd systemctl stop docker rm -rf /etc/systemd/system/docker.service.d rm -rf /etc/systemd/system/docker.service rm -rf /var/lib/docker rm -rf /var/run/docker rm -rf /usr/local/docker rm -rf /etc/docker rm -rf /usr/bin/docker* /usr/bin/containerd* /usr/bin/runc /usr/bin/ctr
10.开启Docker自动补全
使用docker时无法自动补全镜像名和其他参数,这样使用效率大大降低,下面是解决方法
bash-complete
1 yum install -y bash-completion
刷新文件
1 2 source /usr/share/bash-completion/completions/docker source /usr/share/bash-completion/bash_completion
测试
11.Docker-Maven-Plugin 通过Maven插件自动部署
1 2 vi /lib/systemd/system/docker.service 在ExecStart=后添加配置 ‐H tcp://0.0.0.0:2375 ‐H unix:///var/run/docker.sock
1 2 3 4 5 ystemctl daemon-reload //加载docker守护线程 systemctl restart docker //重启docker 关闭防火墙: firewall-cmd --add-port=2375/tcp --permanent && firewall-cmd --reload
12.拉取镜像失败
1 2 3 4 5 6 7 8 Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled 报错 # 修改配置 vim /etc/resolv.conf 将 nameserver 改为 8.8.8.8 # 重启docker systemctl restart docker
实操-Docker-安装Redis 1.搜索redis镜像
2.拉取redis镜像
3.创建容器,设置端口映射
1 2 3 4 docker run -id \ -p 6379:6379 \ --name=c_redis \ redis:5.0
4.使用外部机器连接redis
1 ./redis-cli.exe -h 192.168.149.135 -p 6379
上面只是简单使用,实际上要挂载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 mkdir -p /opt/data/docker/redis/conf/ mkdir -p /opt/data/docker/redis/data/ # 拷贝配置文件 cd /opt/data/docker/redis/conf wget http://download.redis.io/redis-stable/redis.conf # 修改配置文件 bind 127.0.0.1 #注释掉这部分,使redis可以外部访问 requirepass 你的密码#给redis设置密码 appendonly yes#redis持久化 默认是no tcp-keepalive 300 #防止出现远程主机强迫关闭了一个现有的连接的错误 默认是300 protected-mode no参数是为了禁止外网访问redis,如果启用了,则只能够通过localhost ip (127.0.0.1)访问Redis daemonize yes 默认no 为不守护进程模式,修改为yes # 当 docker 重启时,容器自动启动 docker update redis --restart=always # 创建容器 cd /opt/data/docker/redis/ docker run -d \ --privileged=true \ --restart always \ -p 6379:6379 \ --name redis \ -v $PWD/conf:/etc/redis/redis.conf \ -v $PWD/data:/data \ redis:5.0 redis-server /etc/redis/redis.conf ps:--appendonly yes #开启AOF模式
1 docker exec -it redis /bin/bash
实操-Docker-安装Mysql5.6 1.搜索mysql镜像
2.拉取mysql镜像
3.创建容器,设置端口映射、目录映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 在/root目录下创建mysql目录用于存储mysql数据信息 mkdir ~/mysql cd ~/mysql docker run -id \ -p 3306:3306 \ --name=c_mysql \ -v $PWD/conf:/etc/mysql/conf.d \ -v $PWD/logs:/logs \ -v $PWD/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=root \ mysql:5.6 参数说明: -p 3307:3306:将容器的 3306 端口映射到宿主机的 3307 端口。 -v $PWD/conf:/etc/mysql/conf.d:将主机当前目录下的 conf/my.cnf 挂载到容器的 /etc/mysql/my.cnf。配置目录 -v $PWD/logs:/logs:将主机当前目录下的 logs 目录挂载到容器的 /logs。日志目录 -v $PWD/data:/var/lib/mysql :将主机当前目录下的data目录挂载到容器的 /var/lib/mysql 。数据目 录 -e MYSQL_ROOT_PASSWORD=123456:初始化 root 用户的密码。
4.进入容器,操作mysql
1 docker exec -it c_mysql /bin/bash
5.使用外部机器连接容器中的mysql
实操-Docker-安装Mysql8.0.26 1.搜索mysql镜像
2.拉取mysql镜像
1 docker pull mysql:8.0.26
3.创建容器,设置端口映射、目录映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 在/root目录下创建mysql目录用于存储mysql数据信息 mkdir /opt/data/docker/mysql cd /opt/data/docker/mysql docker run -id \ -p 3306:3306 \ --name=mysql \ -v $PWD/conf:/etc/mysql/conf.d \ -v $PWD/logs:/logs \ -v $PWD/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=root \ mysql:8.0.26 参数说明: -p 3307:3306:将容器的 3306 端口映射到宿主机的 3307 端口。 -v $PWD/conf:/etc/mysql/conf.d:将主机当前目录下的 conf/my.cnf 挂载到容器的 /etc/mysql/my.cnf。配置目录 -v $PWD/logs:/logs:将主机当前目录下的 logs 目录挂载到容器的 /logs。日志目录 -v $PWD/data:/var/lib/mysql :将主机当前目录下的data目录挂载到容器的 /var/lib/mysql 。数据目 录 -e MYSQL_ROOT_PASSWORD=123456:初始化 root 用户的密码。
4.进入容器,操作mysql
1 docker exec -it c_mysql /bin/bash
5.使用外部机器连接容器中的mysql
实操-Docker-安装Tomcat 1.搜索tomcat镜像
2.拉取tomcat镜像
3.创建容器,设置端口映射、目录映射
1 2 3 4 5 6 7 8 9 10 11 12 13 # 在/root目录下创建tomcat目录用于存储tomcat数据信息 mkdir /opt/data/docker/tomcat cd /opt/data/docker/tomcat docker run -id \ -p 8080:8080 \ --name=tomcat \ -v $PWD:/usr/local/tomcat/webapps \ tomcat 参数说明: -p 8080:8080:将容器的8080端口映射到主机的8080端口 -v $PWD:/usr/local/tomcat/webapps:将主机中当前目录挂载到容器的webapps
4.webapps复制文件
1 2 3 4 5 # 进入tomcat容器 docker exec -it tomcat /bin/bash # 复制文件 cp -r webapps.dist/. webapps exit
4.使用外部机器访问tomcat
实操-Docker-安装Nginx 1.搜索nginx镜像
2.拉取nginx镜像
3.创建容器,设置端口映射、目录映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # 在/root目录下创建nginx目录用于存储nginx数据信息 mkdir /opt/data/docker/nginx cd /opt/data/docker/nginx mkdir conf cd conf # 在~/nginx/conf/下创建nginx.conf文件,粘贴下面内容 vim nginx.conf ------------------ nginx.conf ------------------- user nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet‐stream; log_format main '$remote_addr ‐ $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; }
创建首页index.html,放到nginx/html目录下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <!DOCTYPE html > <html > <head > <title > Welcome to nginx!</title > <style > html { color-scheme : light dark; }body { width : 35em ; margin : 0 auto;font-family : Tahoma, Verdana, Arial, sans-serif; }</style > </head > <body > <h1 > Welcome to nginx!</h1 > <p > If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.</p > <p > For online documentation and support please refer to<a href ="http://nginx.org/" > nginx.org</a > .<br /> Commercial support is available at <a href ="http://nginx.com/" > nginx.com</a > .</p > <p > <em > Thank you for using nginx.</em > </p > </body > </html >
4.启动容器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 到nginx,不然$PWD 受影响 cd /opt/data/docker/nginx docker run -id \ -p 80:80 \ --name=nginx \ -v $PWD/conf/nginx.conf:/etc/nginx/nginx.conf \ -v $PWD/logs:/var/log/nginx \ -v $PWD/html:/usr/share/nginx/html \ nginx 参数说明: -p80:80:将容器的80端口映射到宿主机的80端口。 -v$ PWD/conf/nginx.conf:/etc/nginx/nginx.conf:将主机当前目录下的/conf/nginx.conf挂载到容器的:/etc/nginx/nginx.conf。配置目录 -v$ PWD/logs:/var/log/nginx:将主机当前目录下的logs目录挂载到容器的/var/log/nginx。日志目录
5.使用外部机器访问nginx
1 2 # 如果访问不了,看是否是防火墙的原因 firewall-cmd --add-port=80/tcp --permanent && firewall-cmd --reload
实操-Docker-安装MongoDB 1.搜索mongo镜像
2.拉取mongo镜像
3.启动容器
1 docker run -di --name=c_mongo -p 27017:27017 mongo
远程登录
实操-Docker-安装ElasticSearch 1.搜索mongo镜像
1 docker search elasticsearch:5.6.8
2.拉取mongo镜像
1 docker pull elasticsearch:5.6.8
3.启动容器
1 docker run -di --name=elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
http://192.168.25.129:9200/
4.拷贝配置文件到宿主机
1 docker cp elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml /usr/share/elasticsearch.yml
5.停止和删除原来创建的容器
6.重新创建容器
1 docker run -di --name=tensquare_elasticsearch -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:5.6.8
修改/usr/share/elasticsearch.yml 将 transport.host: 0.0.0.0 前的#去掉后保
1 2 3 4 5 6 7 8 9 修改/etc/security/limits.conf ,追加内容 * soft nofile 65536 * hard nofile 65536 修改/etc/sysctl.conf,追加内容 vm.max_map_count=655360 sysctl -p
7.重启
8.IK分词器安装
拷贝宿主机的ik目录到容器里
1 docker cp ik elasticsearch:/usr/share/elasticsearch/plugins/
重新启动,即可加载IK分词器
9.HEAD插件安装
1)修改/usr/share/elasticsearch.yml ,添加允许跨域配置
1 2 http.cors.enabled: true http.cors.allow-origin: "*"
重新启动elasticseach容器
10.下载head镜像
1 docker pull mobz/elasticsearch-head:5
创建head容器
1 docker run -di --name=elasticsearch_head -p 9100:9100 mobz/elasticsearch-head:5
实操-Docker-安装Nacos1.4.1 1、拉取镜像
1 docker pull nacos/nacos-server:1.4.1
2、创建数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 CREATE TABLE `config_info` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (255 ) DEFAULT NULL , `content` longtext NOT NULL COMMENT 'content' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , `app_name` varchar (128 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , `c_desc` varchar (256 ) DEFAULT NULL , `c_use` varchar (64 ) DEFAULT NULL , `effect` varchar (64 ) DEFAULT NULL , `type` varchar (64 ) DEFAULT NULL , `c_schema` text, PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info' ; CREATE TABLE `config_info_aggr` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (255 ) NOT NULL COMMENT 'group_id' , `datum_id` varchar (255 ) NOT NULL COMMENT 'datum_id' , `content` longtext NOT NULL COMMENT '内容' , `gmt_modified` datetime NOT NULL COMMENT '修改时间' , `app_name` varchar (128 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '增加租户字段' ; CREATE TABLE `config_info_beta` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL COMMENT 'content' , `beta_ips` varchar (1024 ) DEFAULT NULL COMMENT 'betaIps' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info_beta' ; CREATE TABLE `config_info_tag` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT 'tenant_id' , `tag_id` varchar (128 ) NOT NULL COMMENT 'tag_id' , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL COMMENT 'content' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info_tag' ; CREATE TABLE `config_tags_relation` ( `id` bigint (20 ) NOT NULL COMMENT 'id' , `tag_name` varchar (128 ) NOT NULL COMMENT 'tag_name' , `tag_type` varchar (64 ) DEFAULT NULL COMMENT 'tag_type' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT 'tenant_id' , `nid` bigint (20 ) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`nid`), UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_tag_relation' ; CREATE TABLE `group_capacity` ( `id` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID' , `group_id` varchar (128 ) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群' , `quota` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值' , `usage` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '使用量' , `max_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值' , `max_aggr_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值' , `max_aggr_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值' , `max_history_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_group_id` (`group_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '集群、各Group容量信息表' ; CREATE TABLE `his_config_info` ( `id` bigint (64 ) unsigned NOT NULL , `nid` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT, `data_id` varchar (255 ) NOT NULL , `group_id` varchar (128 ) NOT NULL , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL , `md5` varchar (32 ) DEFAULT NULL , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP , `src_user` text, `src_ip` varchar (50 ) DEFAULT NULL , `op_type` char (10 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`nid`), KEY `idx_gmt_create` (`gmt_create`), KEY `idx_gmt_modified` (`gmt_modified`), KEY `idx_did` (`data_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '多租户改造' ; CREATE TABLE `tenant_capacity` ( `id` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID' , `tenant_id` varchar (128 ) NOT NULL DEFAULT '' COMMENT 'Tenant ID' , `quota` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值' , `usage` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '使用量' , `max_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值' , `max_aggr_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数' , `max_aggr_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值' , `max_history_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '租户容量信息表' ; CREATE TABLE `tenant_info` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `kp` varchar (128 ) NOT NULL COMMENT 'kp' , `tenant_id` varchar (128 ) default '' COMMENT 'tenant_id' , `tenant_name` varchar (128 ) default '' COMMENT 'tenant_name' , `tenant_desc` varchar (256 ) DEFAULT NULL COMMENT 'tenant_desc' , `create_source` varchar (32 ) DEFAULT NULL COMMENT 'create_source' , `gmt_create` bigint (20 ) NOT NULL COMMENT '创建时间' , `gmt_modified` bigint (20 ) NOT NULL COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'tenant_info' ; CREATE TABLE `users` ( `username` varchar (50 ) NOT NULL PRIMARY KEY, `password` varchar (500 ) NOT NULL , `enabled` boolean NOT NULL ); CREATE TABLE `roles` ( `username` varchar (50 ) NOT NULL , `role` varchar (50 ) NOT NULL , UNIQUE INDEX `idx_user_role` (`username` ASC , `role` ASC ) USING BTREE ); CREATE TABLE `permissions` ( `role` varchar (50 ) NOT NULL , `resource` varchar (255 ) NOT NULL , `action` varchar (8 ) NOT NULL , UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE ); INSERT INTO users (username, password, enabled) VALUES ('nacos' , '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu' , TRUE ); INSERT INTO roles (username, role) VALUES ('nacos' , 'ROLE_ADMIN' );
3、创建容器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 docker run \ -d --name c_nacos \ -p 8848:8848 \ -p 9848:9848 \ -p 9849:9849 \ --restart=always \ -e JVM_XMS=256m \ -e JVM_XMX=256m \ -e MODE=standalone \ -e SPRING_DATASOURCE_PLATFORM=mysql \ -e MYSQL_SERVICE_HOST=192.168.88.88 \ -e MYSQL_SERVICE_PORT=3306 \ -e MYSQL_SERVICE_DB_NAME=nacos \ -e MYSQL_SERVICE_USER=root \ -e MYSQL_SERVICE_PASSWORD=root \ -e MYSQL_SERVICE_DB_PARAM="characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&serverTimezone=Asia/Shanghai" \ nacos/nacos-server:1.4.1 这样服务注册的ip才对 # 访问地址 默认账号密码是nacos/nacos http://ip:8848/nacos
实操-Docker-安装gogs (1)下载镜像
(2)创建容器
1 2 docker run -di --name=c_gogs -p 10022:22 -p 3000:3000 -v /root/docker_volumn/gogs:/data gogs/gogs # gogs的/data目录挂载到宿主机的/root/docker_volumn/gogs目录
注册一下用户,创建仓库
实操-Docker-安装Jenkins 搜索镜像
拉取Jenkins镜像
1 docker pull jenkins/jenkins:lts
生成Jenkins的docker容器
1 2 3 4 5 6 7 8 9 10 11 mkdir /opt/data/docker/jenkins cd /opt/data/docker/jenkins docker run -d \ -uroot \ -p 9095:8080 \ -p 50000:50000 \ --name jenkins \ -v $PWD:/var/jenkins \ -v /etc/localtime:/etc/localtime \ jenkins/jenkins:lts
参数说明
命令
描述
-d
后台运行容器,并返回容器ID
-uroot
使用 root 身份进入容器,推荐加上,避免容器内执行某些命令时报权限错误
-p 9095:8080
将容器内8080端口映射至宿主机9095端口,这个是访问jenkins的端口
-p 50000:50000
将容器内50000端口映射至宿主机50000端口
–name jenkins
设置容器名称为jenkins
-v /home/jenkins_home:/var/jenkins_home
:/var/jenkins_home目录为容器jenkins工作目录,我们将硬盘上的一个目录挂载到这个位置,方便后续更新镜像后继续使用原来的工作目录
-v /etc/localtime:/etc/localtime
让容器使用和服务器同样的时间设置
jenkins/jenkins
镜像的名称,这里也可以写镜像ID
这个命令执行完后结尾处会有一个提示,提示了初始密码和初始密码文件路径。可以先复制初始密码,为后面使用
1 2 3 # 查看日志 docker logs jenkins # 拿到初始化密码: 16bbb3a596ee4f2cb41ccf3a288f1dfe
启动容器
通过ip地址:Jenkins容器端口来访问Jenkins。例如http://192.168.30.142:8080/。
如果上面没有记住密码,可以手动查看密码
1 2 3 4 5 6 7 //进入提示路径查看密码,查看密码需要输入命令进入容器 //docker exec -u 0 -it [容器 id] /bin/bash [root@192 yff]# docker exec -u 0 -it 578a9bdfe6fa /bin/bash root@578a9bdfe6fa:/# //查看密码 root@578a9bdfe6fa:/# cat /var/jenkins_home/secrets/initialAdminPassword 054a52cbdbaf45c2b6a56e001ab721ac
安装插件 一般是会安装默认的插件,如果网速不佳可以跳过这个默认安装的流程,后面去插件管理安装需要的插件。经常会用到的插件有下面这些。
配置jdk、mvn、git 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //配置方式:点击系统管理->全局工具配置 其中别名可以随便写,路径填写服务器中容器 //1.jdk配置 //进入Jenkins容器中 [root@localhost yff]# docker exec -it 578a9bdfe6fa /bin/bash //查看jdk路径 jenkins@578a9bdfe6fa:/$ echo $JAVA_HOME /usr/local/openjdk-8 //2.git配置 //进入Jenkins容器中 [root@localhost yff]# docker exec -it 578a9bdfe6fa /bin/bash //查看git路径 [root@localhost yff]# docker exec -it 578a9bdfe6fa /bin/bash jenkins@578a9bdfe6fa:/$ which git /usr/bin/git //3.maven配置 填写name名称,勾选自动安装,版本选择最新版
配置中文显示 点击 系统管理->全局配置->找到Locale,输入zh_CN,并勾选 忽略浏览器…选项
邮件相关配置
配置Extended E-mail Notification
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 点击 系统管理->全局配置->找到Extended E-mail Notification(我这里配置的是我的QQ邮箱) # SMTP server SMTP 服务器 smtp.qq.com # Default user E-mail suffix 默认用户邮箱后缀 @qq.com # 勾选 Use SMTP Authentication 表示使用 SMTP 认证 # User Name 用户,这里填写qq邮箱 xxxxxx@qq.com # Password 填写 smtp 授权码,这个得在邮箱中获取 xxxxxx # 勾选 Use SSL # SMTP port 填写 465 # Default Content Type 默认内容类型选择 HTML (text/html) # Default Recipients 默认接收人 邮箱号 # Default Subject 默认主题填写 $ {BUILD_STATUS} - ${PROJECT_NAME} - Build # Default Content 默认内容用 html 写,这个请见下方的 html 代码 # 勾选 Allow sending to unregistered users 允许发送给未注册用户
配置E-mail Notification(邮件通知)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # SMTP server SMTP 服务器 smtp.qq.com # 用户默认邮件后缀 @qq.com # 勾选使用 SMTP 认证 # 用户名填写 qq 号 xxxxxx@qq.com # 密码填写 smtp 授权码,这个在邮箱中获取 xxxxxx # 勾选使用 SSL 协议 # SMTP 端口 465 # 勾选通过发送测试邮件测试配置,在 Test e-mail recipient 中填写个人邮箱用来接收验证。 若显示 Email was successfully sent 表示成功 如果测试不通过,就在Location中配置系统管理员邮件地址 xxxxxx@qq.com
实操-Docker-安装InfluxDB (1)下载镜像
1 docker pull tutum/influxdb
(2)创建容器
1 docker run -di -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 --name c_influxsrv tutum/influxdb
打开浏览器 http://192.168.213.131:8083/
实操-Docker-安装cAdvisor (1)下载镜像
1 docker pull google/cadvisor
(2)创建容器
1 2 3 docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086 # --link influxsrv:influxsrv 是influxDB的--name参数 # -storage_driver_db=cadvisor 数据库
WEB前端访问地址
http://192.168.213.131:8080/containers/
性能指标含义参照如下地址
https://blog.csdn.net/ZHANG_H_A/article/details/53097084
再次查看influxDB,发现已经有很多数据被采集进去了。
实操-Docker-安装grafana (1)下载镜像
1 docker pull grafana/grafana
(2)创建容器
1 docker run -d -p 3001:3000 -e INFLUXDB_HOST=influxsrv -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=cadvisor -e INFLUXDB_PASS=cadvisor --link influxsrv:influxsrv --name grafana grafana/grafana
(3)访问
http://192.168.213.131:3001/
用户名密码均为admin
实操-Docker-安装rabbitmq 1 2 3 4 5 6 7 docker search rabbitmq:management docker pull rabbitmq:management docker run -di --name c_rabbit -p 15672:15672 -p 5673:5672 rabbitmq:management 要自动启动加上--restart=always 6个端口的: docker run -di --name=c_rabbit -p 5671:5617 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:25672 rabbitmq:management
通过docker ps -a查看部署的mq容器id,在通过 docker exec -it 容器id /bin/bash 进入容器内部在rabbitmq-plugins enable rabbitmq_management
http://linuxip:15672,访问web界面,这里的用户名和密码默认都是guest
实操-Docker-安装sentinel-dashboard Sentinel控制台安装可以基于jar包启动的方式安装,也可以基于docker安装,为了方便操作,我们这里采用docker安装方式:
1 docker run --name=sentinel-dashboard -d -p 8858:8858 -d --restart=on-failure bladex/sentinel-dashboard:1.8.0
安装好了后,我们可以直接访问 http://192.168.200.129:8858/,默认用户名和密码都是 sentinel
实操-Docker-安装seata 1 docker run --name seata-server -p 8091:8091 -d -e SEATA_IP=192.168.213.130 -e SEATA_PORT=8091 --restart=on-failure seataio/seata-server:1.3.0
实操-Docker-安装Rancher (1)下载Rancher 镜像
1 docker pull rancher/server
(2)创建Rancher容器
1 docker run -d --name=c_rancher --restart=always -p 9090:8080 rancher/server
restart为重启策略
no,默认策略,在容器退出时不重启容器
on-failure,在容器非正常退出时(退出状态非0),才会重启容器
on-failure:3,在容器非正常退出时重启容器,最多重启3次
always,在容器退出时总是重启容器
unless-stopped,在容器退出时总是重启容器,但是不考虑在Docker守护进程启动 时就已经停止了的容器
(3)防火墙
1 firewall-cmd --add-port=9090/tcp --permanent && firewall-cmd --reload
(4)在浏览器输入地址: http://192.168.213.131:9090 即可看到高端大气的欢迎页
点击gotit,右下角切换中文
添加镜像,添加主机,添加应用
实操-Docker-安装Minio 镜像
1 2 docker pull minio/minio docker pull minio/minio:RELEASE.2022-06-20T23-13-45Z.fips
创建目录
1 2 mkdir -p /root/minio/config mkdir -p /root/minio/data
创建容器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 docker run -p 9000:9000 -p 9090:9090 \ --name c_minio \ -d --restart=always \ -e "MINIO_ACCESS_KEY=minioadmin" \ -e "MINIO_SECRET_KEY=minioadmin" \ -v /root/minio/data:/data \ -v /root/minio/config:/root/.minio \ minio/minio server \ /data --console-address ":9090" -address ":9000" # -d 后台运行 # -p 9000:9000 前面的9000是打开本机的9000端口映射docker容器中MinIO的9000端口 # -e "MINIO_ROOT_USER=admin" \ 改用户名 # -e "MINIO_ROOT_PASSWORD=12345678" \ 改密码 # -v /mnt/data:/data \ 挂载卷 # -v /mnt/config:/root/.minio \ 挂载卷 # --console-address ":50000" 指定控制台端口为静态端口
访问:http://192.168.124.132:9090/login 用户名:密码 minioadmin:minioadmin
实操-Docker-安装xxl-job2.3.1 1、拉取镜像
1 docker pull xuxueli/xxl-job-admin:2.3.1
4、导入mysql数据库,执行tables_xxl_job.sql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 # # XXL- JOB v2.4 .0 - SNAPSHOT # Copyright (c) 2015 - present, xuxueli. CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;use `xxl_job`; SET NAMES utf8mb4;CREATE TABLE `xxl_job_info` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `job_group` int (11 ) NOT NULL COMMENT '执行器主键ID' , `job_desc` varchar (255 ) NOT NULL , `add_time` datetime DEFAULT NULL , `update_time` datetime DEFAULT NULL , `author` varchar (64 ) DEFAULT NULL COMMENT '作者' , `alarm_email` varchar (255 ) DEFAULT NULL COMMENT '报警邮件' , `schedule_type` varchar (50 ) NOT NULL DEFAULT 'NONE' COMMENT '调度类型' , `schedule_conf` varchar (128 ) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型' , `misfire_strategy` varchar (50 ) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略' , `executor_route_strategy` varchar (50 ) DEFAULT NULL COMMENT '执行器路由策略' , `executor_handler` varchar (255 ) DEFAULT NULL COMMENT '执行器任务handler' , `executor_param` varchar (512 ) DEFAULT NULL COMMENT '执行器任务参数' , `executor_block_strategy` varchar (50 ) DEFAULT NULL COMMENT '阻塞处理策略' , `executor_timeout` int (11 ) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒' , `executor_fail_retry_count` int (11 ) NOT NULL DEFAULT '0' COMMENT '失败重试次数' , `glue_type` varchar (50 ) NOT NULL COMMENT 'GLUE类型' , `glue_source` mediumtext COMMENT 'GLUE源代码' , `glue_remark` varchar (128 ) DEFAULT NULL COMMENT 'GLUE备注' , `glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间' , `child_jobid` varchar (255 ) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔' , `trigger_status` tinyint(4 ) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行' , `trigger_last_time` bigint (13 ) NOT NULL DEFAULT '0' COMMENT '上次调度时间' , `trigger_next_time` bigint (13 ) NOT NULL DEFAULT '0' COMMENT '下次调度时间' , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_log` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT, `job_group` int (11 ) NOT NULL COMMENT '执行器主键ID' , `job_id` int (11 ) NOT NULL COMMENT '任务,主键ID' , `executor_address` varchar (255 ) DEFAULT NULL COMMENT '执行器地址,本次执行的地址' , `executor_handler` varchar (255 ) DEFAULT NULL COMMENT '执行器任务handler' , `executor_param` varchar (512 ) DEFAULT NULL COMMENT '执行器任务参数' , `executor_sharding_param` varchar (20 ) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2' , `executor_fail_retry_count` int (11 ) NOT NULL DEFAULT '0' COMMENT '失败重试次数' , `trigger_time` datetime DEFAULT NULL COMMENT '调度-时间' , `trigger_code` int (11 ) NOT NULL COMMENT '调度-结果' , `trigger_msg` text COMMENT '调度-日志' , `handle_time` datetime DEFAULT NULL COMMENT '执行-时间' , `handle_code` int (11 ) NOT NULL COMMENT '执行-状态' , `handle_msg` text COMMENT '执行-日志' , `alarm_status` tinyint(4 ) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败' , PRIMARY KEY (`id`), KEY `I_trigger_time` (`trigger_time`), KEY `I_handle_code` (`handle_code`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_log_report` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `trigger_day` datetime DEFAULT NULL COMMENT '调度-时间' , `running_count` int (11 ) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量' , `suc_count` int (11 ) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量' , `fail_count` int (11 ) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量' , `update_time` datetime DEFAULT NULL , PRIMARY KEY (`id`), UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_logglue` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `job_id` int (11 ) NOT NULL COMMENT '任务,主键ID' , `glue_type` varchar (50 ) DEFAULT NULL COMMENT 'GLUE类型' , `glue_source` mediumtext COMMENT 'GLUE源代码' , `glue_remark` varchar (128 ) NOT NULL COMMENT 'GLUE备注' , `add_time` datetime DEFAULT NULL , `update_time` datetime DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_registry` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `registry_group` varchar (50 ) NOT NULL , `registry_key` varchar (255 ) NOT NULL , `registry_value` varchar (255 ) NOT NULL , `update_time` datetime DEFAULT NULL , PRIMARY KEY (`id`), KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_group` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `app_name` varchar (64 ) NOT NULL COMMENT '执行器AppName' , `title` varchar (12 ) NOT NULL COMMENT '执行器名称' , `address_type` tinyint(4 ) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入' , `address_list` text COMMENT '执行器地址列表,多地址逗号分隔' , `update_time` datetime DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_user` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `username` varchar (50 ) NOT NULL COMMENT '账号' , `password` varchar (50 ) NOT NULL COMMENT '密码' , `role` tinyint(4 ) NOT NULL COMMENT '角色:0-普通用户、1-管理员' , `permission` varchar (255 ) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割' , PRIMARY KEY (`id`), UNIQUE KEY `i_username` (`username`) USING BTREE ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; CREATE TABLE `xxl_job_lock` ( `lock_name` varchar (50 ) NOT NULL COMMENT '锁名称' , PRIMARY KEY (`lock_name`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1 , 'xxl-job-executor-sample' , '示例执行器' , 0 , NULL , '2018-11-03 22:21:31' );INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1 , 1 , '测试任务1' , '2018-11-03 22:21:31' , '2018-11-03 22:21:31' , 'XXL' , '' , 'CRON' , '0 0 0 * * ? *' , 'DO_NOTHING' , 'FIRST' , 'demoJobHandler' , '' , 'SERIAL_EXECUTION' , 0 , 0 , 'BEAN' , '' , 'GLUE代码初始化' , '2018-11-03 22:21:31' , '' );INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1 , 'admin' , 'e10adc3949ba59abbe56e057f20f883e' , 1 , NULL );INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock' );commit ;
5、执行docker命令
1 2 3 4 5 docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://192.168.88.88:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 \ --spring.datasource.username=root \ --spring.datasource.password=root" \ -p 8888:8080 -v /tmp:/data/applogs \ --name c_job --restart=always -d xuxueli/xxl-job-admin:2.3.1
6、访问:http://192.168.88.88:8888/xxl-job-admin/ admin/123456
实操-安装Docker Compose 1.安装
1 2 3 4 5 6 7 curl -L https://github.com/docker/compose/releases/download/1.16.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose 或者 curl -L "https://github.com/docker/compose/releases/download/1.26.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose # 因为Docker Compose存放在GitHub,可能不太稳定。可以通过DaoCloud加速下载 curl -L https://get.daocloud.io/docker/compose/releases/download/1.26.2/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
2.授权
1 chmod +x /usr/local/bin/docker-compose
3.查看
1 docker-compose --version
4.卸载
1 rm /usr/local/bin/docker-compose
实操-DC-安装skywalking 编写docker-compose.yml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 version: '3.3' services: elasticsearch: image: elasticsearch:7.6.2 container_name: elasticsearch restart: always privileged: true hostname: elasticsearch ports: - 9200 :9200 - 9300 :9300 environment: - discovery.type=single-node - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - TZ=Asia/Shanghai networks: - skywalking ulimits: memlock: soft: -1 hard: -1 elasticsearch-hq: image: elastichq/elasticsearch-hq container_name: elasticsearch-hq restart: always privileged: true hostname: elasticsearch-hq ports: - 5000 :5000 environment: - TZ=Asia/Shanghai networks: - skywalking oap: image: apache/skywalking-oap-server:8.3.0-es7 container_name: oap hostname: oap privileged: true depends_on: - elasticsearch links: - elasticsearch restart: always ports: - 11800 :11800 - 12800 :12800 environment: SW_STORAGE: elasticsearch7 SW_STORAGE_ES_CLUSTER_NODES: elasticsearch:9200 TZ: Asia/Shanghai volumes: - ./config/alarm-settings.yml:/skywalking/config/alarm-settings.yml networks: - skywalking ui: image: apache/skywalking-ui:8.3.0 container_name: ui privileged: true depends_on: - oap links: - oap restart: always ports: - 8080 :8080 environment: SW_OAP_ADDRESS: oap:12800 TZ: Asia/Shanghai networks: - skywalking networks: skywalking: driver: bridge
通过命令一键启动:docker-compose up -d
启动成功后访问skywalking的webui页面:http://192.168.200.129:8080/
实操-DC-安装Nacos 1 2 3 4 5 6 7 #克隆项目 git clone https://github.com/nacos-group/nacos-docker.git #进入nacos-docker目录 cd nacos-docker #查看文件列表 ce example ll
1 2 3 4 5 6 # 启动 docker-compose -f standalone-derby.yaml up -d # 停止 docker-compose -f standalone-derby.yaml stop # 删除 docker-compose -f standalone-derby.yaml down
1 2 3 4 5 6 # 启动 docker-compose -f standalone-mysql-5.7.yaml up -d # 停止 docker-compose -f standalone-mysql-5.7.yaml stop # 删除 docker-compose -f standalone-mysql-5.7.yaml down
1 2 3 4 5 6 # 启动 docker-compose -f cluster-ip.yaml up -d # 停止 docker-compose -f cluster-ip.yaml stop # 删除 docker-compose -f cluster-ip.yaml down
如果nacos一直在starting,可能是内存不够,把其他没在用的先停了
实操-DC-安装Apollo 前提:
要现有mysql数据库,导入SQL文件,创建2个库
1 2 source apolloconfigdb.sql source apolloportaldb.sql
docker-compose.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 version: "3" services: apollo-configservice: image: apolloconfig/apollo-configservice:1.8.1 restart: always volumes: - ./logs/apollo-configservice:/opt/logs ports: - "8080:8080" environment: - TZ='Asia/Shanghai' - SERVER_PORT=8080 - EUREKA_INSTANCE_IP_ADDRESS=192.168.213.130 - EUREKA_INSTANCE_HOME_PAGE_URL=http://192.168.213.130:8080 - SPRING_DATASOURCE_URL=jdbc:mysql://192.168.213.130:3306/ApolloConfigDB?characterEncoding=utf8&serverTimezone=Asia/Shanghai - SPRING_DATASOURCE_USERNAME=root - SPRING_DATASOURCE_PASSWORD=root apollo-adminservice: image: apolloconfig/apollo-adminservice:1.8.1 restart: always volumes: - ./logs/apollo-adminservice:/opt/logs ports: - "8090:8090" depends_on: - apollo-configservice environment: - TZ='Asia/Shanghai' - SERVER_PORT=8090 - EUREKA_INSTANCE_IP_ADDRESS=192.168.213.130 - SPRING_DATASOURCE_URL=jdbc:mysql://192.168.213.130:3306/ApolloConfigDB?characterEncoding=utf8&serverTimezone=Asia/Shanghai - SPRING_DATASOURCE_USERNAME=root - SPRING_DATASOURCE_PASSWORD=root apollo-portal: image: apolloconfig/apollo-portal:1.8.1 restart: always container_name: apollo-portal volumes: - ./logs/apollo-portal:/opt/logs ports: - "8070:8070" depends_on: - apollo-adminservice environment: - TZ='Asia/Shanghai' - SERVER_PORT=8070 - EUREKA_INSTANCE_IP_ADDRESS=192.168.213.130 - APOLLO_PORTAL_ENVS=dev - DEV_META=http://192.168.213.130:8080 - SPRING_DATASOURCE_URL=jdbc:mysql://192.168.213.130:3306/ApolloPortalDB?characterEncoding=utf8&serverTimezone=Asia/Shanghai - SPRING_DATASOURCE_USERNAME=root - SPRING_DATASOURCE_PASSWORD=root
直接启动即可
启动完成后访问 : http://192.168.200.129:8070/ 登录账号apollo,密码admin
Zookeeper集群搭建(亲测可用) 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。
1 2 3 4 5 单机伪集群不屑玩了 真机集群: zookeeper-node1:192.168 .213 .141 zookeeper-node2:192.168 .213 .142 zookeeper-node3:192.168 .213 .143
这里基于Centos-mini镜像克隆的节点,可看上面镜像安装设置过程
前提:
1.1 下载 & 解压 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
1 2 3 4 5 6 7 8 9 10 11 # 创建目录 cd /usr/local mkdir apps cd apps # 下载 wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz # 解压 tar -zxvf zookeeper-3.4.14.tar.gz -C /usr/local/apps/ # 删除安装包 rm -rf zookeeper-3.4.14.tar.gz
配置环境变量(3台都要要配置)
1 2 3 4 5 6 7 8 vim /etc/profile # 添加zookeeper环境变量 export ZOOKEEPER_HOME=/usr/local/apps/zookeeper-3.4.14 export PATH=$ZOOKEEPER_HOME/bin:$PATH # 使得配置的环境变量生效 source /etc/profile
1.2 修改配置 1 2 3 4 # 进入配置文件目录 cd /usr/local/apps/zookeeper-3.4.14/conf # 拷贝配置样本1 cp zoo_sample.cfg zoo.cfg
指定数据存储目录和日志文件目录(目录不用预先创建,程序会自动创建),修改后完整配置如下:
注意,这里的data和log是可以另外指定目录的,我直接在安装目录下了,别问,问就是懒~
编辑:vim zoo.cfg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 tickTime =2000 initLimit =10 syncLimit =5 dataDir =/usr/local/apps/zookeeper-3.4.14/data dataLogDir =/usr/local/apps/zookeeper-3.4.14/log clientPort =2181 autopurge.snapRetainCount =3 autopurge.purgeInterval =1 server.1 =192.168.213.141:2888:3888 server.2 =192.168.213.142:2888:3888 server.3 =192.168.213.143:2888:3888
配置参数说明:
tickTime :用于计算的基础时间单元。比如 session 超时:N*tickTime;initLimit :用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;syncLimit :用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);dataDir :数据存储位置;dataLogDir :日志目录;clientPort :用于客户端连接的端口,默认 2181
1.3 标识节点 分别在三个节点的数据存储目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 leader 节点。
创建存储目录:
1 2 cd /usr/local/apps/zookeeper-3.4.14/ mkdir data
创建并写入节点标识到 myid 文件:(注意要和上面zoo.cfg设置的server.id一样)
1 echo "1" > /usr/local/apps/zookeeper-3.4.14/data/myid
克隆出另外2个节点
在node1主机上,将安装包分发到其他机器
第一台机器上面执行以下两个命令
1 2 scp -r /usr/local/apps/zookeeper-3.4.14/ node2:/usr/local/apps/ scp -r /usr/local/apps/zookeeper-3.4.14/ node3:/usr/local/apps/
其他2个节点依样画葫芦,分别设置为2,3
echo “2” > /usr/local/apps/zookeeper-3.4.14/data/myid
echo “3” > /usr/local/apps/zookeeper-3.4.14/data/myid
1.4 启动集群 分别启动三个节点:
1 2 3 4 5 /usr/local/apps/zookeeper-3.4.14/bin/zkServer.sh start # 查看状态 zkServer.sh status # 停止服务 zkServer.sh stop
同级目录可以看到zkServer.out,可以看启动的日志
1.5 集群验证 使用 jps 查看进程,并且使用 zkServer.sh status 查看集群各个节点状态。如图三个节点进程均启动成功,并且两个节点为 follower 节点,一个节点为 leader 节点。
Kafka集群搭建 1 2 3 4 3 节点集群:zookeeper-node1:192.168 .213 .151 zookeeper-node2:192.168 .213 .152 zookeeper-node3:192.168 .213 .153
前提:
2.1 下载解压 Kafka 安装包官方下载地址:http://kafka.apache.org/downloads ,本用例下载的版本为 2.2.0,下载命令:
1 2 3 4 5 6 7 8 9 10 cd /usr/local/apps/ # 下载 wget https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz(无效) wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.1.0/kafka_2.13-3.1.0.tgz # 解压 tar -xzf kafka_2.12-2.2.0.tgz 拷贝到另外2台机器: scp kafka_2.13-3.1.0.tgz 192.168.213.152:/usr/local/apps/ scp kafka_2.13-3.1.0.tgz 192.168.213.153:/usr/local/apps/
这里解释一下 kafka 安装包的命名规则:以 kafka_2.12-2.2.0.tgz 为例,前面的 2.12 代表 Scala 的版本号(Kafka 采用 Scala 语言进行开发),后面的 2.2.0 则代表 Kafka 的版本号。
2.3 修改配置 设置环境变量
1 2 3 4 5 6 7 8 9 vim /etc/profile export JAVA_HOME=/usr/local/apps/jdk1.8.0_321 export KAFKA_HOME=/usr/local/apps/kafka_2.13-3.1.0 export PATH=$JAVA_HOME/bin:$KAFKA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME PATH CLASSPATH source /etc/profile
进入/usr/local/apps/kafka_2.13-3.1.0/config目录,修改配置文件server.properties中的部分配置,如下:
1 2 3 4 5 6 7 8 9 broker.id =0 listeners =PLAINTEXT://192.168.213.151:9092 log.dirs =/usr/local/apps/kafka_2.13-3.1.0/logs zookeeper.connect =192.168.213.141:2181,192.168.213.142:2181,192.168.213.143:2181
其他2个节点参考上面的修改下, 其中id、listeners 每个节点不一样的,要注意下!!!
这里需要说明的是 log.dirs 指的是数据日志的存储位置,确切的说,就是分区数据的存储位置,而不是程序运行日志的位置。程序运行日志的位置是通过同一目录下的 log4j.properties 进行配置的。
2.4 启动集群 启动三个 Kafka 节点。启动后可以使用 jps 查看进程
1 2 3 4 5 6 7 8 # 启动 bin/kafka-server-start.sh config/server.properties # 后台启动 nohup bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 & # 或者这样启动: ./kafka-server-start.sh -daemon ../config/server.properties # 停止 bin/kafka-server-stop.sh
2.5 创建测试主题 创建测试主题:
1 2 3 bin/kafka-topics.sh --create --bootstrap-server 192.168.213.151:9092 \ --replication-factor 3 \ --partitions 1 --topic my-replicated-topic
创建后可以使用以下命令查看创建的主题信息:
1 bin/kafka-topics.sh --describe --bootstrap-server 192.168.213.151:9092 --topic my-replicated-topic
可以看到分区 0 的有 0,1,2 三个副本,且三个副本都是可用副本,都在 ISR(in-sync Replica 同步副本) 列表中,其中 1 为首领副本,此时代表集群已经搭建成功。
其他操作命令 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 创建 kafka-topics.sh --bootstrap-server 192.168.213.151:9092 --create --topic test --partitions 2 --replication-factor 1 # 查看所有 kafka-topics.sh --bootstrap-server 192.168.213.153:9092 --list # 查看单个 kafka-topics.sh --bootstrap-server 192.168.213.151:9092 test --describe # 消费者-监听 kafka-console-consumer.sh --bootstrap-server 192.168.213.151:9092 --topic test # 分组消费 kafka-console-consumer.sh --bootstrap-server 192.168.213.151:9092 --topic test --group group_a # 生产者-发送 kafka-console-producer.sh --broker-list 192.168.213.151:9092 --topic test
效果:创建了一个测试主题,并且在所有节点可以访问到
效果:模拟生产者消费者,不同节点之间进行消息发送,通信成功
分组消费只会消费一次:
学习大数据时的环境搭建,大数据讲究集群,懂不懂就是35个节点。哦,真是见鬼,我想让笔记本亲吻我的地板。
软件安装(大数据) 实操-安装JDK
见第四章-软件安装(java)/ 实操-安装JDK
实操-安装Python
系统环境 :centos 7.6
Python 版本 :Python-3.6.8
环境依赖
Python3.x 的安装需要依赖这四个组件:gcc, zlib,zlib-devel,openssl-devel;所以需要预先安装,命令如下:
1 2 3 4 yum install gcc -y yum install zlib -y yum install zlib-devel -y yum install openssl-devel -y
下载编译
Python 源码包下载地址: https://www.python.org/downloads/
1 # wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tgz
解压编译
1 # tar -zxvf Python-3.6.8.tgz
进入根目录进行编译,可以指定编译安装的路径,这里我们指定为 /usr/app/python3.6 :
1 2 3 # cd Python-3.6.8# ./configure --prefix=/usr/app/python3.6 # make && make install
环境变量配置
1 2 export PYTHON_HOME=/usr/app/python3.6 export PATH=${PYTHON_HOME}/bin:$PATH
使得配置的环境变量立即生效:
验证安装是否成功
输入 python3 命令,如果能进入 python 交互环境,则代表安装成功:
1 2 3 4 5 6 7 8 [root@hadoop001 app]# python3 Python 3.6.8 (default, Mar 29 2019, 10:17:41) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux Type "help", "copyright", "credits" or "license" for more information. > >> 1+1 2 > >> exit () [root@hadoop001 app]#
实操-安装Hadoop-单机
配置不行,只能用单机版学习使用了,内存4G ,硬盘80G
下载 1 2 3 cd /opt/setup/hadoop # 替换后缀版本即可下载其他版本 wget http://archive.apache.org/dist/hadoop/core/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压 1 2 mkdir -p /usr/local/apps/hadoop tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local/apps/hadoop
配置环境变量 1 2 3 4 5 6 7 # vim /etc/profile 在文件末尾补充: export HADOOP_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 配置生效 # source /etc/profile
校验 配置Hadoop文件 1 cd hadoop-3.3.4/etc/hadoop
hadoop-env.sh 1 2 3 4 5 6 export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_321/ export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://localhost:9820</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /usr/hadoop/hadoopdata</value > </property > <property > <name > hadoop.proxyuser.root.groups</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.root.hosts</name > <value > *</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > root</value > </property > <property > <name > dfs.permissions.enabled</name > <value > false</value > </property > </configuration >
hdfs-site.xml
单机只有一个副本
1 2 3 4 5 6 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
mapred-site.xml 1 2 3 4 5 6 7 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarm-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 对安装目录进行授权 chmod -R 777 hadoop-3.3.4 # 格式化hdfs文件系统 cd /usr/local/apps/hadoop/hadoop-3.3.4/ bin/hdfs namenode -format # 配置ssh ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh localhost # 输入yes cd /usr/local/apps/hadoop/hadoop-3.3.4/ sbin/start-all.sh
防火墙 1 2 3 firewall-cmd --add-port=9870/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9864/tcp --permanent && firewall-cmd --reload firewall-cmd --add-port=9000/tcp --permanent && firewall-cmd --reload
访问 打开namenode,http://192.168.199.199:9870/
打开datanode,http://192.168.199.199:9864/
修改主机名
不修改会报错:hdfs Couldn’t preview the file.
1 2 3 4 5 6 7 8 9 # linux 修改/etc/hosts,内容如下: 192.168.199.199 zuoer # 重启 reboot # windows 修改c:\Windows\System32\drivers\etc\hosts,添加如下内容: 192.168.199.199 zuoer
实操-安装Hadoop-单机-本地编译 前提
Hadoop3.3 的运行依赖 JDK8
是否有ssh和sshd(一般Linux默认有,无的话yum安装一下,检查:which ssh/which sshd)
下载并解压 下载地址
如果需要本地库需要编译 1.准备Linux环境 准备一台linux环境,内存4G或以上,硬盘40G或以上,我这里使用的是Centos7.7 64位的操作系统(注意:一定要使用64位的操作系统),需要虚拟机联网,关闭防火墙,关闭selinux,安装好JDK8。
根据以上需求,只需要将node1再克隆一台即可,命名为node4,专门用来进行Hadoop编译。
2.安装maven 这里使用maven3.x以上的版本应该都可以,不建议使用太高的版本,强烈建议使用3.0.5的版本即可将maven的安装包上传到/opt/setup
然后解压maven的安装包到/usr/local/apps
1 2 cd /opt/setup/tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /usr/local/apps
配置maven的环境变量
填写以下内容
1 2 3 export MAVEN_HOME=/usr/local/apps/apache-maven-3.0.5export MAVEN_OPTS="-Xms4096m -Xmx4096m" export PATH=:$MAVEN_HOME /bin:$PATH
让修改立即生效
解压maven的仓库
1 tar -zxvf mvnrepository.tar.gz -C /usr/local/apps/
修改maven的配置文件
1 2 cd /usr/local/apps/apache-maven-3.0.5/confvim settings.xml
指定我们本地仓库存放的路径
1 <localRepository > /opt/data/mavenrepo</localRepository >
添加一个我们阿里云的镜像地址,会让我们下载jar包更快
1 2 3 4 5 6 <mirror > <id > alimaven</id > <name > aliyun maven</name > <url > http://maven.aliyun.com/nexus/content/groups/public/</url > <mirrorOf > central</mirrorOf > </mirror >
3.安装findbugs 解压findbugs
1 tar -zxvf findbugs-1.3.9.tar.gz -C /usr/local/apps
配置findbugs的环境变量
添加以下内容:
1 2 3 4 5 export MAVEN_HOME=/usr/local/apps/apache-maven-3.0.5export PATH=:$MAVEN_HOME /bin:$PATH export FINDBUGS_HOME=/usr/local/apps/findbugs-1.3.9export PATH=:$FINDBUGS_HOME /bin:$PATH
让修改立即生效
4.在线安装一些依赖包 1 2 3 4 5 yum -y install autoconf automake libtool cmake yum -y install ncurses-devel yum -y install openssl-devel yum -y install lzo-devel zlib-devel gcc gcc-c++ yum -y install bzip2-devel
5.安装protobuf 解压protobuf并进行编译
1 2 3 4 5 cd /opt/setuptar -zxvf protobuf-2.5.0.tar.gz -C /usr/local/apps/ cd /usr/local/apps/protobuf-2.5.0./configure make && make install
6.安装snappy 1 2 3 4 5 cd /opt/setuptar -zxvf snappy-1.1.1.tar.gz -C /usr/local/apps/ cd /usr/local/apps/snappy-1.1.1/./configure make && make install
7.编译hadoop源码 对源码进行编译
1 2 3 cd /opt/setup tar -zxvf hadoop-3.3.0-src.tar.gz -C /usr/local/apps/ cd /usr/local/apps/hadoop-3.3.0
编译支持snappy压缩:
1 mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
编译完成之后我们需要的压缩包就在下面这个路径里面,生成的文件名为hadoop-3.3.0.tar.gz
1 cd /export/server/hadoop-3.3.0/hadoop-dist/target
将编译后的Hadoop安装包导出即可。
解压安装包或者是编译后的安装包
1 tar -zxvf hadoop-3.3.0.tar.gz -C /usr/local/apps/
hdfs配置java环境变量 修改 etc/hadoop/hadoop-env.sh(查询添加JAVA的环境变量)
1 2 3 4 5 6 7 8 9 10 11 12 $ echo ${JAVA_HOME} $ vim etc/hadoop/hadoop-env.sh 修改: export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_321 #你的JAVA环境变量 # 文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
配置Hadoop单机节点运行的伪分布式模式,进入我们的Hadoop目录,以下所有操作的根目录都是如下的Hadoop目录。
1 cd /usr/local/apps/hadoop-3.3.0
修改核心配置文件 etc/hadoop/core-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 <configuration > <property > <name > hadoop.tmp.dir</name > <value > /opt/data/hadoop-3.3.0</value > </property > <property > <name > fs.defaultFS</name > <value > hdfs://localhost:9000</value > </property > </configuration >
修改HDFS配置文件 etc/hadoop/hdfs-site.xml:
指定副本系数和临时文件存储位置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <configuration > <property > <name > dfs.replication</name > <value > 1</value > </property > <property > <name > dfs.namenode.http-address</name > <value > localhost:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > localhost:9868</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > file:/opt/data/hadoop-3.3.0/namenode</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:/opt/data/hadoop-3.3.0/datanode</value > </property > </configuration >
修改YARN 配置文件 etc/hadoop/yarn-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > master</value > </property > <property > <name > yarn.application.classpath</name > <value > 输入'$ hadoop classpath'的Hadoop classpath路径</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > localhost:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > </configuration >
修改MapReduce配置文件 etc/hadoop/mapred-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > localhost:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > localhost:19888</value > </property > </configuration >
配置Hadoop环境变量 1 2 3 4 5 6 7 8 9 $ vim ~/.bash_profile # 添加环境变量 export HADOOP_HOME=/usr/local/apps/hadoop-3.3.0 export PATH=$PATH:HADOOP_HOME/sbin:$HADOOP_HOME/bin export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/ export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native:$HADOOP_COMMON_LIB_NATIVE_DIR"
修改完环境变量不要忘记source一下
测试Hadoop环境是否配置成功
无密码登录 另外,ssh每次试图连接localhost都会对身份进行验证检查,因此需要确认能否无密码ssh连接localhost,尝试:
若不能,则需配置无密码连接
1 $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果没有.ssh,可以用命令生成公钥私钥
启动Hadoop集群 首次启动HDFS需要格式化NameNode(只有第一次需要!!)
1 $ bin/hdfs namenode -format
进入${HADOOP_HOME}/sbin/目录下,启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动Yarn
也可以一次性开启全部Hadoop的守护进程
同理关闭全部守护进程
启动查看程序历史运行情况的历史服务器
1 2 $ mapred --daemon start historyserver $ mapred --daemon stop historyserver
jps查看当前运行的守护进程
1 2 3 4 5 6 7 8 9 $ jps 85393 Jps 85376 JobHistoryServer 84866 NodeManager 84436 DataNode 84332 NameNode 84767 ResourceManager 84575 SecondaryNameNode
查看集群的web页面 NameNode: http://localhost:9870
Secondary NameNode: http://localhost:9868
DataNode: 在NameNode中查看到当前有一个默认的DataNode节点在 http://localhost:9864/datanode.html
Yarn: http://localhost:8088
HistoryServer: http://localhost:19888
查看本地库 通过查看本地库来检查当前Hadoop环境支持的压缩方式
1 2 3 4 5 6 7 8 9 10 11 $ hadoop checknative -a 2021-08-05 11:09:11,047 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Native library checking: hadoop: false zlib: false zstd : false bzip2: false openssl: false ISA-L: false PMDK: false
官网的压缩包中不包含这些本地库,如果有需要可以自己去编译生成本地库放到lib/native目录下。参考:自己编译hadoop本地库
实操-安装Hadoop-集群 1.上传hadoop的安装包到三台虚拟机上(或者先配置好,然后通过SCP拷贝过去)
2.解压hadoop的压缩包 tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
3.配置虚拟机的环境
修改三台机器的host文件vim /etc/hosts
1 2 3 192.168.253.130 master 192.168.253.131 slave1 192.168.253.132 slave2
修改hostname vim /etc/sysconfig/network master的机器修改成以下内容
slave1机器修改成
依次类推,你有几个节点修改几个。
3.修改hadoop的配置文件 cd /usr/local/hadoop-2.6.4/etc/hadoop/
这个配置用来指定namenode的地址hdfs://master:8020以及指定使用hadoop时产生文件的存放目录。
1 2 3 4 5 6 7 8 9 10 configuration> <property > <name > fs.defaultFS</name > <value > hdfs://master:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /var/log/hadoop/tmp</value > </property > </configuration >
引入java的环境
1 export JAVA_HOME=/usr/java/jdk1.7.0_80
这个配置用来指定hdfs中namenode的存储位置和指定hdfs中datanode的存储位置 同时指定hdfs保存数据的副本数量为3。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <configuration > <property > <name > dfs.namenode.name.dir</name > <value > file:///data/hadoop/hdfs/name</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:///data/hadoop/hdfs/data</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > master:50090</value > </property > <property > <name > dfs.replication</name > <value > 3</value > </property > </configuration >
cp mapred-site.xml.template mapred-site.xml
指定hadoop以后Map/Reduce运行在YARN上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > master:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > master:19888</value > </property > </configuration >
指定nomenodeManager获取数据的方式是shuffl以及指定ResourceManager的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 <configuration > <property > <name > yarn.resourcemanager.hostname</name > <value > master</value > </property > <property > <name > yarn.resourcemanager.address</name > <value > ${yarn.resourcemanager.hostname}:8032</value > </property > <property > <name > yarn.resourcemanager.scheduler.address</name > <value > ${yarn.resourcemanager.hostname}:8030</value > </property > <property > <name > yarn.resourcemanager.webapp.address</name > <value > ${yarn.resourcemanager.hostname}:8088</value > </property > <property > <name > yarn.resourcemanager.webapp.https.address</name > <value > ${yarn.resourcemanager.hostname}:8090</value > </property > <property > <name > yarn.resourcemanager.resource-tracker.address</name > <value > ${yarn.resourcemanager.hostname}:8031</value > </property > <property > <name > yarn.resourcemanager.admin.address</name > <value > ${yarn.resourcemanager.hostname}:8033</value > </property > <property > <name > yarn.nodemanager.local-dirs</name > <value > /data/hadoop/yarn/local</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.nodemanager.remote-app-log-dir</name > <value > /data/tmp/logs</value > </property > <property > <name > yarn.log.server.url</name > <value > http://master:19888/jobhistory/logs/</value > <description > URL for job history server</description > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.aux-services.mapreduce.shuffle.class</name > <value > org.apache.hadoop.mapred.ShuffleHandler</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 2048</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 512</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 4096</value > </property > <property > <name > mapreduce.map.memory.mb</name > <value > 2048</value > </property > <property > <name > mapreduce.reduce.memory.mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.resource.cpu-vcores</name > <value > 1</value > </property > </configuration >
4.修改slaves文件
vim slaves 修改slaves文件,修改后的内容如下:
5.ssh免密登陆
ssh-keygen -t rsa
1 2 3 ssh-copy-id -i /root/.ssh/id_rsa.pub master ssh-copy-id -i /root/.ssh/id_rsa.pub slave1 ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
输入shh slave1 测试可以无密码登陆slave1
6.配置时间同步问题
挂载media
安装ntp yum install -y ntp
修改master机器vim /etc/ntp.conf。 注释server开头行并添加
1 2 3 restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap server 127.127.1.0 fudge 127.127.1.0 stratum 10
因为我们这里使用的虚拟机,为了防止防火墙的问题,我们直接关闭防火墙,如果你是真实的服务器,切记不要这么干。
1 2 service iptables stop & chkconfig iptables off service ntpd start & chkconfig ntpd on
在子节点上执行 ntpdate master。
实操-安装Hadoop-高可用集群-基于zookeeper 一、高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解:
1.1 高可用整体架构 HDFS 高可用架构如下:
图片引用自:https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-high-availability/
HDFS 高可用架构主要由以下组件所构成:
Active NameNode 和 Standby NameNode :两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
主备切换控制器 ZKFailoverController :ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
Zookeeper 集群 :为主备切换控制器提供主备选举支持。
共享存储系统 :共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和 NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
DataNode 节点 :除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
1.2 基于 QJM 的共享存储系统的数据同步机制分析 目前 Hadoop 支持使用 Quorum Journal Manager (QJM) 或 Network File System (NFS) 作为共享的存储系统,这里以 QJM 集群为例进行说明:Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog,当 Active NameNode 宕机后, Standby NameNode 在确认元数据完全同步之后就可以对外提供服务。
需要说明的是向 JournalNode 集群写入 EditLog 是遵循 “过半写入则成功” 的策略,所以你至少要有 3 个 JournalNode 节点,当然你也可以继续增加节点数量,但是应该保证节点总数是奇数。同时如果有 2N+1 台 JournalNode,那么根据过半写的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
1.3 NameNode 主备切换 NameNode 实现主备切换的流程下图所示:
HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
1.4 YARN高可用 YARN ResourceManager 的高可用与 HDFS NameNode 的高可用类似,但是 ResourceManager 不像 NameNode ,没有那么多的元数据信息需要维护,所以它的状态信息可以直接写到 Zookeeper 上,并依赖 Zookeeper 来进行主备选举。
二、集群规划 按照高可用的设计目标:需要保证至少有两个 NameNode (一主一备) 和 两个 ResourceManager (一主一备) ,同时为满足“过半写入则成功”的原则,需要至少要有 3 个 JournalNode 节点。这里使用三台主机进行搭建,集群规划如下:
三、前置条件
四、集群配置 4.1 下载并解压 下载 Hadoop。这里我下载的是 CDH 版本 Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 # tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
4.2 配置环境变量 编辑 profile 文件:
增加如下配置:
1 2 export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2 export PATH=${HADOOP_HOME}/bin:$PATH
执行 source 命令,使得配置立即生效:
4.3 修改配置 进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh 1 2 # 指定JDK的安装位置 export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop001:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /home/hadoop/tmp</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > hadoop001:2181,hadoop002:2181,hadoop003:2181</value > </property > <property > <name > ha.zookeeper.session-timeout.ms</name > <value > 10000</value > </property > </configuration >
3. hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 <configuration > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > /home/hadoop/namenode/data</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > /home/hadoop/datanode/data</value > </property > <property > <name > dfs.nameservices</name > <value > mycluster</value > </property > <property > <name > dfs.ha.namenodes.mycluster</name > <value > nn1,nn2</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn1</name > <value > hadoop001:8020</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn2</name > <value > hadoop002:8020</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn1</name > <value > hadoop001:50070</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn2</name > <value > hadoop002:50070</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /home/hadoop/journalnode/data</value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_rsa</value > </property > <property > <name > dfs.ha.fencing.ssh.connect-timeout</name > <value > 30000</value > </property > <property > <name > dfs.client.failover.proxy.provider.mycluster</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > </property > </configuration >
4. yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 86400</value > </property > <property > <name > yarn.resourcemanager.ha.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.cluster-id</name > <value > my-yarn-cluster</value > </property > <property > <name > yarn.resourcemanager.ha.rm-ids</name > <value > rm1,rm2</value > </property > <property > <name > yarn.resourcemanager.hostname.rm1</name > <value > hadoop002</value > </property > <property > <name > yarn.resourcemanager.hostname.rm2</name > <value > hadoop003</value > </property > <property > <name > yarn.resourcemanager.webapp.address.rm1</name > <value > hadoop002:8088</value > </property > <property > <name > yarn.resourcemanager.webapp.address.rm2</name > <value > hadoop003:8088</value > </property > <property > <name > yarn.resourcemanager.zk-address</name > <value > hadoop001:2181,hadoop002:2181,hadoop003:2181</value > </property > <property > <name > yarn.resourcemanager.recovery.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.store.class</name > <value > org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value > </property > </configuration >
5. mapred-site.xml 1 2 3 4 5 6 7 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
5. slaves 配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动。
1 2 3 hadoop001 hadoop002 hadoop003
4.4 分发程序 将 Hadoop 安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下 Hadoop 的环境变量。
1 2 3 4 # 将安装包分发到hadoop002 scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/ # 将安装包分发到hadoop003 scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
五、启动集群 5.1 启动ZooKeeper 分别到三台服务器上启动 ZooKeeper 服务:
5.2 启动Journalnode 分别到三台服务器的的 ${HADOOP_HOME}/sbin 目录下,启动 journalnode 进程:
1 hadoop-daemon.sh start journalnode
5.3 初始化NameNode 在 hadop001 上执行 NameNode 初始化命令:
执行初始化命令后,需要将 NameNode 元数据目录的内容,复制到其他未格式化的 NameNode 上。元数据存储目录就是我们在 hdfs-site.xml 中使用 dfs.namenode.name.dir 属性指定的目录。这里我们需要将其复制到 hadoop002 上:
1 scp -r /home/hadoop/namenode/data hadoop002:/home/hadoop/namenode/
5.4 初始化HA状态 在任意一台 NameNode 上使用以下命令来初始化 ZooKeeper 中的 HA 状态:
5.5 启动HDFS 进入到 hadoop001 的 ${HADOOP_HOME}/sbin 目录下,启动 HDFS。此时 hadoop001 和 hadoop002 上的 NameNode 服务,和三台服务器上的 DataNode 服务都会被启动:
5.6 启动YARN 进入到 hadoop002 的 ${HADOOP_HOME}/sbin 目录下,启动 YARN。此时 hadoop002 上的 ResourceManager 服务,和三台服务器上的 NodeManager 服务都会被启动:
需要注意的是,这个时候 hadoop003 上的 ResourceManager 服务通常是没有启动的,需要手动启动:
1 yarn-daemon.sh start resourcemanager
六、查看集群 6.1 查看进程 成功启动后,每台服务器上的进程应该如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@hadoop001 sbin]# jps 4512 DFSZKFailoverController 3714 JournalNode 4114 NameNode 3668 QuorumPeerMain 5012 DataNode 4639 NodeManager [root@hadoop002 sbin]# jps 4499 ResourceManager 4595 NodeManager 3465 QuorumPeerMain 3705 NameNode 3915 DFSZKFailoverController 5211 DataNode 3533 JournalNode [root@hadoop003 sbin]# jps 3491 JournalNode 3942 NodeManager 4102 ResourceManager 4201 DataNode 3435 QuorumPeerMain
6.2 查看Web UI HDFS 和 YARN 的端口号分别为 50070 和 8080,界面应该如下:
此时 hadoop001 上的 NameNode 处于可用状态:
而 hadoop002 上的 NameNode 则处于备用状态:
hadoop002 上的 ResourceManager 处于可用状态:
hadoop003 上的 ResourceManager 则处于备用状态:
同时界面上也有 Journal Manager 的相关信息:
七、集群的二次启动 上面的集群初次启动涉及到一些必要初始化操作,所以过程略显繁琐。但是集群一旦搭建好后,想要再次启用它是比较方便的,步骤如下(首选需要确保 ZooKeeper 集群已经启动):
在 hadoop001 启动 HDFS,此时会启动所有与 HDFS 高可用相关的服务,包括 NameNode,DataNode 和 JournalNode:
在 hadoop002 启动 YARN:
这个时候 hadoop003 上的 ResourceManager 服务通常还是没有启动的,需要手动启动:
1 yarn-daemon.sh start resourcemanager
实操-安装Spark 一、安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载:
解压安装包:
1 # tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
1.2 配置环境变量 添加环境变量:
1 2 export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6 export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
1.3 Local模式 Local 模式是最简单的一种运行方式,它采用单节点多线程方式运行,不用部署,开箱即用,适合日常测试开发。
1 2 # 启动spark-shell spark-shell --master local[2]
local :只启动一个工作线程;**local[k]**:启动 k 个工作线程;
*local[ ]**:启动跟 cpu 数目相同的工作线程数。
进入 spark-shell 后,程序已经自动创建好了上下文 SparkContext,等效于执行了下面的 Scala 代码:
1 2 val conf = new SparkConf ().setAppName("Spark shell" ).setMaster("local[2]" )val sc = new SparkContext (conf)
二、词频统计案例 安装完成后可以先做一个简单的词频统计例子,感受 spark 的魅力。准备一个词频统计的文件样本 wc.txt,内容如下:
1 2 3 hadoop,spark,hadoop spark,flink,flink,spark hadoop,hadoop
在 scala 交互式命令行中执行如下 Scala 语句:
1 2 3 val file = spark.sparkContext.textFile("file:///usr/app/wc.txt" )val wordCounts = file.flatMap(line => line.split("," )).map((word => (word, 1 ))).reduceByKey(_ + _)wordCounts.collect
执行过程如下,可以看到已经输出了词频统计的结果:
同时还可以通过 Web UI 查看作业的执行情况,访问端口为 4040:
实操-安装Spark-高可用集群-基于zookeeper 一、集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
二、前置条件 搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:
Linux+ jdk
zookeeper单机/集群
Hadoop集群
三、Spark集群搭建 3.1 下载解压 下载所需版本的 Spark,官网下载地址:http://spark.apache.org/downloads.html
下载后进行解压:
1 # tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量 添加环境变量:
1 2 export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6 export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
3.3 集群配置 进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh 1 cp spark-env.sh.template spark-env.sh
1 2 3 4 5 6 # 配置JDK安装位置 JAVA_HOME=/usr/java/jdk1.8.0_201 # 配置hadoop配置文件的位置 HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop # 配置zookeeper地址 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves 1 cp slaves.template slaves
配置所有 Woker 节点的位置:
1 2 3 hadoop001 hadoop002 hadoop003
3.4 安装包分发 将 Spark 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Spark 的环境变量。
1 2 scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/ scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
四、启动集群 4.1 启动ZooKeeper集群 分别到三台服务器上启动 ZooKeeper 服务:
4.2 启动Hadoop集群 1 2 3 4 # 启动dfs服务 start-dfs.sh # 启动yarn服务 start-yarn.sh
4.3 启动Spark集群 进入 hadoop001 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
分别在 hadoop002 和 hadoop003 上执行下面的命令,启动备用的 Master 服务:
1 2 # ${SPARK_HOME} /sbin 下执行start-master.sh
4.4 查看服务 查看 Spark 的 Web-UI 页面,端口为 8080。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。
五、验证集群高可用 此时可以使用 kill 命令杀死 hadoop001 上的 Master 进程,此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002,可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。
Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。
此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
六、提交作业 和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
1 2 3 4 5 6 7 8 spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --executor-memory 1G \ --num-executors 10 \ /usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \ 100
实操-安装Flink-单机集群 一、部署模式 Flink 支持使用多种部署模式来满足不同规模应用的需求,常见的有单机模式,Standalone Cluster 模式,同时 Flink 也支持部署在其他第三方平台上,如 YARN,Mesos,Docker,Kubernetes 等。以下主要介绍其单机模式和 Standalone Cluster 模式的部署。
二、单机模式 单机模式是一种开箱即用的模式,可以在单台服务器上运行,适用于日常的开发和调试。具体操作步骤如下:
2.1 安装部署 1. 前置条件
Flink 的运行依赖 JAVA 环境,故需要预先安装好 JDK,具体步骤可以参考:Linux 环境下 JDK 安装
2. 下载 & 解压 & 运行
Flink 所有版本的安装包可以直接从其官网 进行下载,这里我下载的 Flink 的版本为 1.9.1 ,要求的 JDK 版本为 1.8.x +。 下载后解压到指定目录:
1 tar -zxvf flink-1.9.1-bin-scala_2.12.tgz -C /usr/app
不需要进行任何配置,直接使用以下命令就可以启动单机版本的 Flink:
3. WEB UI 界面
Flink 提供了 WEB 界面用于直观的管理 Flink 集群,访问端口为 8081:
Flink 的 WEB UI 界面支持大多数常用功能,如提交作业,取消作业,查看各个节点运行情况,查看作业执行情况等,大家可以在部署完成后,进入该页面进行详细的浏览。
2.2 作业提交 启动后可以运行安装包中自带的词频统计案例,具体步骤如下:
1. 开启端口
2. 提交作业
1 bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9999
该 JAR 包的源码可以在 Flink 官方的 GitHub 仓库中找到,地址为 :SocketWindowWordCount ,可选传参有 hostname, port,对应的词频数据需要使用空格进行分割。
3. 输入测试数据
4. 查看控制台输出
可以通过 WEB UI 的控制台查看作业统运行情况:
也可以通过 WEB 控制台查看到统计结果:
2.3 停止作业 可以直接在 WEB 界面上点击对应作业的 Cancel Job 按钮进行取消,也可以使用命令行进行取消。使用命令行进行取消时,需要先获取到作业的 JobId,可以使用 flink list 命令查看,输出如下:
1 2 3 4 5 6 [root@hadoop001 flink-1.9.1]# ./bin/flink list Waiting for response... ------------------ Running/Restarting Jobs ------------------- 05.11.2019 08:19:53 : ba2b1cc41a5e241c32d574c93de8a2bc : Socket Window WordCount (RUNNING) -------------------------------------------------------------- No scheduled jobs.
获取到 JobId 后,就可以使用 flink cancel 命令取消作业:
1 bin/flink cancel ba2b1cc41a5e241c32d574c93de8a2bc
2.4 停止 Flink 命令如下:
三、Standalone Cluster Standalone Cluster 模式是 Flink 自带的一种集群模式,具体配置步骤如下:
3.1 前置条件 使用该模式前,需要确保所有服务器间都已经配置好 SSH 免密登录服务。这里我以三台服务器为例,主机名分别为 hadoop001,hadoop002,hadoop003 , 其中 hadoop001 为 master 节点,其余两台为 slave 节点,搭建步骤如下:
3.2 搭建步骤 修改 conf/flink-conf.yaml 中 jobmanager 节点的通讯地址为 hadoop001:
1 jobmanager.rpc.address: hadoop001
修改 conf/slaves 配置文件,将 hadoop002 和 hadoop003 配置为 slave 节点:
将配置好的 Flink 安装包分发到其他两台服务器上:
1 2 scp -r /usr/app/flink-1.9.1 hadoop002:/usr/app scp -r /usr/app/flink-1.9.1 hadoop003:/usr/app
在 hadoop001 上使用和单机模式相同的命令来启动集群:
此时控制台输出如下:
启动完成后可以使用 Jps 命令或者通过 WEB 界面来查看是否启动成功。
3.3 可选配置 除了上面介绍的 jobmanager.rpc.address 是必选配置外,Flink h还支持使用其他可选参数来优化集群性能,主要如下:
jobmanager.heap.size :JobManager 的 JVM 堆内存大小,默认为 1024m 。taskmanager.heap.size :Taskmanager 的 JVM 堆内存大小,默认为 1024m 。taskmanager.numberOfTaskSlots :Taskmanager 上 slots 的数量,通常设置为 CPU 核心的数量,或其一半。parallelism.default :任务默认的并行度。io.tmp.dirs :存储临时文件的路径,如果没有配置,则默认采用服务器的临时目录,如 LInux 的 /tmp 目录。
更多配置可以参考 Flink 的官方手册:Configuration
四、Standalone Cluster HA 上面我们配置的 Standalone 集群实际上只有一个 JobManager,此时是存在单点故障的,所以官方提供了 Standalone Cluster HA 模式来实现集群高可用。
4.1 前置条件 在 Standalone Cluster HA 模式下,集群可以由多个 JobManager,但只有一个处于 active 状态,其余的则处于备用状态,Flink 使用 ZooKeeper 来选举出 Active JobManager,并依赖其来提供一致性协调服务,所以需要预先安装 ZooKeeper 。
另外在高可用模式下,还需要使用分布式文件系统来持久化存储 JobManager 的元数据,最常用的就是 HDFS,所以 Hadoop 也需要预先安装。关于 Hadoop 集群和 ZooKeeper 集群的搭建可以参考:
4.2 搭建步骤 修改 conf/flink-conf.yaml 文件,增加如下配置:
1 2 3 4 5 6 7 8 9 10 high-availability: zookeeper high-availability.zookeeper.quorum: hadoop003:2181 high-availability.zookeeper.path.root: /flink high-availability.cluster-id: /standalone_cluster_one high-availability.storageDir: hdfs://hadoop001:8020/flink/recovery
修改 conf/masters 文件,将 hadoop001 和 hadoop002 都配置为 master 节点:
1 2 hadoop001:8081 hadoop002:8081
确保 Hadoop 和 ZooKeeper 已经启动后,使用以下命令来启动集群:
此时输出如下:
可以看到集群已经以 HA 的模式启动,此时还需要在各个节点上使用 jps 命令来查看进程是否启动成功,正常情况如下:
只有 hadoop001 和 hadoop002 的 JobManager 进程,hadoop002 和 hadoop003 上的 TaskManager 进程都已经完全启动,才表示 Standalone Cluster HA 模式搭建成功。
4.3 常见异常 如果进程没有启动,可以通过查看 log 目录下的日志来定位错误,常见的一个错误如下:
1 2 3 4 5 6 7 8 9 10 11 2019-11-05 09:18:35,877 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Shutting StandaloneSessionClusterEntrypoint down with application status FAILED. Diagnostics java.io.IOException: Could not create FileSystem for highly available storage (high-availability.storageDir) ....... Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. ..... Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies. ......
可以看到是因为在 classpath 目录下找不到 Hadoop 的相关依赖,此时需要检查是否在环境变量中配置了 Hadoop 的安装路径,如果路径已经配置但仍然存在上面的问题,可以从 Flink 官网 下载对应版本的 Hadoop 组件包:
下载完成后,将该 JAR 包上传至所有 Flink 安装目录的 lib 目录即可。
实操-安装Storm-单机
安装环境要求
you need to install Storm’s dependencies on Nimbus and the worker machines. These are:
Java 7+ (Apache Storm 1.x is tested through travis ci against both java 7 and java 8 JDKs)
Python 2.6.6 (Python 3.x should work too, but is not tested as part of our CI enviornment)
按照官方文档 的说明:storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。由于这两个软件在多个框架中都有依赖,安装
下载并解压
下载并解压,官方下载地址:http://storm.apache.org/downloads.html
1 # tar -zxvf apache-storm-1.2.2.tar.gz
配置环境变量
添加环境变量:
1 2 export STORM_HOME=/usr/app/apache-storm-1.2.2 export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
启动相关进程
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,依次执行下面的命令:
1 2 3 4 5 6 7 8 9 10 # 启动zookeeper nohup sh storm dev-zookeeper & # 启动主节点 nimbus nohup sh storm nimbus & # 启动从节点 supervisor nohup sh storm supervisor & # 启动UI界面 ui nohup sh storm ui & # 启动日志查看服务 logviewer nohup sh storm logviewer &
验证是否启动成功
验证方式一:jps 查看进程:
1 2 3 4 5 6 [root@hadoop001 app]# jps 1074 nimbus 1283 Supervisor 620 dev_zookeeper 1485 core 9630 logviewer
验证方式二: 访问 8080 端口,查看 Web-UI 界面:
实操-安装Storm-集群 集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
前置条件 Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,安装步骤
集群搭建 下载并解压 下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
1 2 3 # 解压 tar -zxvf apache-storm-1.2.2.tar.gz
配置环境变量 添加环境变量:
1 2 export STORM_HOME=/usr/app/apache-storm-1.2.2 export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
集群配置 修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 storm.zookeeper.servers: - "hadoop001" - "hadoop002" - "hadoop003" nimbus.seeds: ["hadoop001" ,"hadoop002" ]storm.local.dir: "/home/storm" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
安装包分发 将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
1 2 scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/ scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/
启动集群 启动ZooKeeper集群 分别到三台服务器上启动 ZooKeeper 服务:
启动Storm集群 因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
1 2 3 4 5 6 7 8 # 启动主节点 nimbus nohup sh storm nimbus & # 启动从节点 supervisor nohup sh storm supervisor & # 启动UI界面 ui nohup sh storm ui & # 启动日志查看服务 logviewer nohup sh storm logviewer &
hadoop003 :
hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
1 2 3 4 # 启动从节点 supervisor nohup sh storm supervisor & # 启动日志查看服务 logviewer nohup sh storm logviewer &
查看集群 使用 jps 查看进程,三台服务器的进程应该分别如下:
访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
高可用验证 这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。
实操-安装HBase-单机 安装前置条件说明 JDK版本说明 HBase 需要依赖 JDK 环境,同时 HBase 2.0+ 以上版本不再支持 JDK 1.7 ,需要安装 JDK 1.8+ 。JDK 安装方式见-linux-JDK安装
Standalone模式和伪集群模式的区别
在 Standalone 模式下,所有守护进程都运行在一个 jvm 进程/实例中;
在伪分布模式下,HBase 仍然在单个主机上运行,但是每个守护进程 (HMaster,HRegionServer 和 ZooKeeper) 则分别作为一个单独的进程运行。
说明:两种模式任选其一进行部署即可,对于开发测试来说区别不大。
Standalone 模式 下载并解压 从官方网站 下载所需要版本的二进制安装包,并进行解压:
1 # tar -zxvf hbase-2.1.4-bin.tar.gz
配置环境变量 添加环境变量:
1 2 export HBASE_HOME=/usr/app/hbase-2.1.4 export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量生效:
进行HBase相关配置 修改安装目录下的 conf/hbase-env.sh,指定 JDK 的安装路径:
1 2 # The java implementation to use. Java 1.8+ required. export JAVA_HOME=/usr/java/jdk1.8.0_201
修改安装目录下的 conf/hbase-site.xml,增加如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <configuration > <property > <name > hbase.rootdir</name > <value > file:///home/hbase/rootdir</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /home/zookeeper/dataDir</value > </property > <property > <name > hbase.unsafe.stream.capability.enforce</name > <value > false</value > </property > </configuration >
hbase.rootdir: 配置 hbase 数据的存储路径;
hbase.zookeeper.property.dataDir: 配置 zookeeper 数据的存储路径;
hbase.unsafe.stream.capability.enforce: 使用本地文件系统存储,不使用 HDFS 的情况下需要禁用此配置,设置为 false。
启动HBase 由于已经将 HBase 的 bin 目录配置到环境变量,直接使用以下命令启动:
验证启动是否成功 验证方式一 :使用 jps 命令查看 HMaster 进程是否启动。
1 2 3 [root@hadoop001 hbase-2.1.4]# jps 16336 Jps 15500 HMaster
验证方式二 :访问 HBaseWeb UI 页面,默认端口为 16010 。
伪集群模式安装(Pseudo-Distributed) Hadoop单机伪集群安装 这里我们采用 HDFS 作为 HBase 的存储方案,需要预先安装 Hadoop。Hadoop 的安装方式见linux-Hadoop安装。
Hbase版本选择 HBase 的版本必须要与 Hadoop 的版本兼容,不然会出现各种 Jar 包冲突。这里我 Hadoop 安装的版本为 hadoop-2.6.0-cdh5.15.2,为保持版本一致,选择的 HBase 版本为 hbase-1.2.0-cdh5.15.2 。所有软件版本如下:
Hadoop 版本: hadoop-2.6.0-cdh5.15.2
HBase 版本: hbase-1.2.0-cdh5.15.2
JDK 版本:JDK 1.8
软件下载解压 下载后进行解压,下载地址:http://archive.cloudera.com/cdh5/cdh/5/
1 # tar -zxvf hbase-1.2.0-cdh5.15.2.tar.gz
配置环境变量 添加环境变量:
1 2 export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2 export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量生效:
进行HBase相关配置 1.修改安装目录下的 conf/hbase-env.sh,指定 JDK 的安装路径:
1 2 # The java implementation to use. Java 1.7+ required. export JAVA_HOME=/usr/java/jdk1.8.0_201
2.修改安装目录下的 conf/hbase-site.xml,增加如下配置 (hadoop001 为主机名):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <configuration > <property > <name > hbase.cluster.distributed</name > <value > true</value > </property > <property > <name > hbase.rootdir</name > <value > hdfs://hadoop001:8020/hbase</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /home/zookeeper/dataDir</value > </property > </configuration >
3.修改安装目录下的 conf/regionservers,指定 region servers 的地址,修改后其内容如下:
验证启动是否成功 验证方式一 :使用 jps 命令查看进程。其中 HMaster,HRegionServer 是 HBase 的进程,HQuorumPeer 是 HBase 内置的 Zookeeper 的进程,其余的为 HDFS 和 YARN 的进程。
1 2 3 4 5 6 7 8 9 10 11 12 [root@hadoop001 conf]# jps 28688 NodeManager 25824 GradleDaemon 10177 Jps 22083 HRegionServer 20534 DataNode 20807 SecondaryNameNode 18744 Main 20411 NameNode 21851 HQuorumPeer 28573 ResourceManager 21933 HMaster
验证方式二 :访问 HBase Web UI 界面,需要注意的是 1.2 版本的 HBase 的访问端口为 60010
实操-安装HBase-集群 集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Region Server。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
前置条件 HBase 的运行需要依赖 Hadoop 和 JDK(HBase 2.0+ 对应 JDK 1.8+) 。同时为了保证高可用,这里我们不采用 HBase 内置的 Zookeeper 服务,而采用外置的 Zookeeper 集群。相关搭建步骤可以参阅:
Linux-jdk安装
Linux-zookeeper安装
Linux-hadoop安装
集群搭建 下载并解压 下载并解压,这里我下载的是 CDH 版本 HBase,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 2 3 # tar -zxvf hbase-1.2.0-cdh5.15.2.tar.gz # [可选]配置软连接 ln -s hbase-2.1.0/ hbase
配置环境变量 添加环境变量:
1 2 export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2 export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量立即生效:
集群配置 进入 ${HBASE_HOME}/conf 目录下,修改配置:
1. hbase-env.sh 1 2 3 4 # 配置JDK安装位置 export JAVA_HOME=/usr/java/jdk1.8.0_201 # 不使用内置的zookeeper服务 export HBASE_MANAGES_ZK=false
2. hbase-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <configuration > <property > <name > hbase.cluster.distributed</name > <value > true</value > </property > <property > <name > hbase.rootdir</name > <value > hdfs://hadoop001:8020/hbase</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > hadoop001:2181,hadoop002:2181,hadoop003:2181</value > </property > </configuration >
3. regionservers 1 2 3 hadoop001 hadoop002 hadoop003
4. backup-masters backup-masters 这个文件是不存在的,需要新建,主要用来指明备用的 master 节点,可以是多个,这里我们以 1 个为例。
HDFS客户端配置 这里有一个可选的配置:如果您在 Hadoop 集群上进行了 HDFS 客户端配置的更改,比如将副本系数 dfs.replication 设置成 5,则必须使用以下方法之一来使 HBase 知道,否则 HBase 将依旧使用默认的副本系数 3 来创建文件:
Add a pointer to your HADOOP_CONF_DIR to the HBASE_CLASSPATH environment variable in hbase-env.sh.
Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
if only a small set of HDFS client configurations, add them to hbase-site.xml.
以上是官方文档的说明,这里解释一下:
第一种 :将 Hadoop 配置文件的位置信息添加到 hbase-env.sh 的 HBASE_CLASSPATH 属性,示例如下:
1 export HBASE_CLASSPATH=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
第二种 :将 Hadoop 的 hdfs-site.xml 或 hadoop-site.xml 拷贝到 ${HBASE_HOME}/conf 目录下,或者通过符号链接的方式。如果采用这种方式的话,建议将两者都拷贝或建立符号链接,示例如下:
1 2 3 4 5 # 拷贝 cp core-site.xml hdfs-site.xml /usr/app/hbase-1.2.0-cdh5.15.2/conf/ # 使用符号链接 ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/core-site.xml ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hdfs-site.xml
注:hadoop-site.xml 这个配置文件现在叫做 core-site.xml
第三种 :如果你只有少量更改,那么直接配置到 hbase-site.xml 中即可。
安装包分发 将 HBase 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 HBase 的环境变量。
1 2 scp -r /usr/app/hbase-1.2.0-cdh5.15.2/ hadoop002:usr/app/ scp -r /usr/app/hbase-1.2.0-cdh5.15.2/ hadoop003:usr/app/
四、启动集群 4.1 启动ZooKeeper集群 分别到三台服务器上启动 ZooKeeper 服务:
4.2 启动Hadoop集群 1 2 3 4 # 启动dfs服务 start-dfs.sh # 启动yarn服务 start-yarn.sh
4.3 启动HBase集群 进入 hadoop001 的 ${HBASE_HOME}/bin,使用以下命令启动 HBase 集群。执行此命令后,会在 hadoop001 上启动 Master 服务,在 hadoop002 上启动备用 Master 服务,在 regionservers 文件中配置的所有节点启动 region server 服务。
4.5 查看服务 访问 HBase 的 Web-UI 界面,这里我安装的 HBase 版本为 1.2,访问端口为 60010,如果你安装的是 2.0 以上的版本,则访问端口号为 16010。可以看到 Master 在 hadoop001 上,三个 Regin Servers 分别在 hadoop001,hadoop002,和 hadoop003 上,并且还有一个 Backup Matser 服务在 hadoop002 上。
hadoop002 上的 HBase 出于备用状态:
实操-安装Flume 前置条件 Flume 需要依赖 JDK 1.8+
下载并解压 下载所需版本的 Flume,这里我下载的是 CDH 版本的 Flume。下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 2 # 下载后进行解压 tar -zxvf flume-ng-1.6.0-cdh5.15.2.tar.gz
配置环境变量 添加环境变量:
1 2 export FLUME_HOME=/usr/app/apache-flume-1.6.0-cdh5.15.2-bin export PATH=$FLUME_HOME/bin:$PATH
使得配置的环境变量立即生效:
修改配置 进入安装目录下的 conf/ 目录,拷贝 Flume 的环境配置模板 flume-env.sh.template:
1 # cp flume-env.sh.template flume-env.sh
修改 flume-env.sh,指定 JDK 的安装路径:
1 2 # Enviroment variables can be set here. export JAVA_HOME=/usr/java/jdk1.8.0_201
验证 由于已经将 Flume 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
出现对应的版本信息则代表配置成功。
实操-按照Sqoop1.4.6-适配Hadoop单机 下载:
安装: 1 2 3 # 下载后进行解压 tar -zxvf sqoop-1.4.6.bin__hadoop-0.23.tar.gz -C /usr/local/apps/sqoop/ mv sqoop-1.4.6.bin__hadoop-0.23 sqoop-1.4.6
配置环境变量 添加环境变量:
1 2 export SQOOP_HOME=/usr/local/apps/sqoop/sqoop-1.4.6 export PATH=$SQOOP_HOME/bin:$PATH
使得配置的环境变量立即生效:
修改配置 进入安装目录下的 conf/ 目录,拷贝 Sqoop 的环境配置模板 sqoop-env.sh.template
1 cp sqoop-env-template.sh sqoop-env.sh
修改 sqoop-env.sh,内容如下 (以下配置中 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME 是必选的,其他的是可选的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # Set Hadoop-specific environment variables here. # Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 # Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 # set the path to where bin/hbase is available# export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2# Set the path to where bin/hive is available export HIVE_HOME=/usr/local/apps/hive/hive-3.1.2 # Set the path for where zookeper config dir is # export ZOOCFGDIR=/usr/app/zookeeper-3.4.13/conf
拷贝数据库驱动 将 MySQL 驱动包拷贝到 Sqoop 安装目录的 lib 目录下
验证 由于已经将 sqoop 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
出现对应的版本信息则代表配置成功:
去掉警告 这里出现的两个 Warning 警告是因为我们本身就没有用到 HCatalog 和 Accumulo,忽略即可。Sqoop 在启动时会去检查环境变量中是否有配置这些软件,如果想去除这些警告,可以修改 bin/configure-sqoop,注释掉不必要的检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # Check: If we can't find our dependencies, give up here. if [ ! -d "${HADOOP_COMMON_HOME}" ]; then echo "Error: $HADOOP_COMMON_HOME does not exist!" echo 'Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation.' exit 1 fi if [ ! -d "${HADOOP_MAPRED_HOME}" ]; then echo "Error: $HADOOP_MAPRED_HOME does not exist!" echo 'Please set $HADOOP_MAPRED_HOME to the root of your Hadoop MapReduce installation.' exit 1 fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HBASE_HOME}" ]; then echo "Warning: $HBASE_HOME does not exist! HBase imports will fail." echo 'Please set $HBASE_HOME to the root of your HBase installation.' fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HCAT_HOME}" ]; then echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail." echo 'Please set $HCAT_HOME to the root of your HCatalog installation.' fi if [ ! -d "${ACCUMULO_HOME}" ]; then echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail." echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.' fi if [ ! -d "${ZOOKEEPER_HOME}" ]; then echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail." echo 'Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.' fi
链接MySQL报错 1 NoClassDefFoundError: org/apache/commons/lang/StringUtils
在https://mvnrepository.com/下载
一直不知道,原来这里也可以下载jar!
上传到lib目录下就行了。
链接hive报错 1 2 3 4 # 报错:Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf # 解决 cp /usr/local/apps/hive/hive-3.1.2/lib/hive-common-3.1.2.jar /usr/local/apps/sqoop/sqoop-1.4.6/lib/
导入hdfs报错 1 2 3 4 5 6 找不到或无法加载主类 org.apache.sqoop.sqoop 1.sqoop-1.4.x.tar.gz在1.4.5以上的安装包已经没有了这个jar包,必须下载sqoop-1.4.6.bin_hadoop-2.0.4-alpha.tar.gz这个安装包。 2.然后解压这个安装包,打开安装包取出sqoop-1.4.6.jar放在hadoop的lib下,或者放到share/hadoop/yarn下. /usr/local/apps/hadoop/hadoop-3.3.4/share/hadoop/yarn 3.再次导入数据,查看报错是否存在,一般情况都会解决。
还是不行
hcatalog报错 报错:
1 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/hcatalog/mapreduce/HCatOutputFormat
解决:
下载jar:https://mvnrepository.com/artifact/org.apache.hive.hcatalog/hive-hcatalog-core/3.1.2
放到:/usr/hive/hcatalog/share/hcatalog/下
实操-按照Sqoop1.4.7-适配Hadoop单机 下载:
安装: 1 2 3 # 下载后进行解压 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/apps/sqoop/ mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.7
配置环境变量 添加环境变量:
1 2 export SQOOP_HOME=/usr/local/apps/sqoop/sqoop-1.4.7 export PATH=$SQOOP_HOME/bin:$PATH
使得配置的环境变量立即生效:
修改配置 进入安装目录下的 conf/ 目录,拷贝 Sqoop 的环境配置模板 sqoop-env.sh.template
1 cp sqoop-env-template.sh sqoop-env.sh
修改 sqoop-env.sh,内容如下 (以下配置中 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME 是必选的,其他的是可选的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # Set Hadoop-specific environment variables here. # Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 # Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 # set the path to where bin/hbase is available# export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2# Set the path to where bin/hive is available export HIVE_HOME=/usr/local/apps/hive/hive-3.1.2 # Set the path for where zookeper config dir is # export ZOOCFGDIR=/usr/app/zookeeper-3.4.13/conf
拷贝数据库驱动 将 MySQL 驱动包拷贝到 Sqoop 安装目录的 lib 目录下
验证 由于已经将 sqoop 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
出现对应的版本信息则代表配置成功:
去掉警告 这里出现的两个 Warning 警告是因为我们本身就没有用到 HCatalog 和 Accumulo,忽略即可。Sqoop 在启动时会去检查环境变量中是否有配置这些软件,如果想去除这些警告,可以修改 bin/configure-sqoop,注释掉不必要的检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # Check: If we can't find our dependencies, give up here. if [ ! -d "${HADOOP_COMMON_HOME}" ]; then echo "Error: $HADOOP_COMMON_HOME does not exist!" echo 'Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation.' exit 1 fi if [ ! -d "${HADOOP_MAPRED_HOME}" ]; then echo "Error: $HADOOP_MAPRED_HOME does not exist!" echo 'Please set $HADOOP_MAPRED_HOME to the root of your Hadoop MapReduce installation.' exit 1 fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HBASE_HOME}" ]; then echo "Warning: $HBASE_HOME does not exist! HBase imports will fail." echo 'Please set $HBASE_HOME to the root of your HBase installation.' fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HCAT_HOME}" ]; then echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail." echo 'Please set $HCAT_HOME to the root of your HCatalog installation.' fi if [ ! -d "${ACCUMULO_HOME}" ]; then echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail." echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.' fi if [ ! -d "${ZOOKEEPER_HOME}" ]; then echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail." echo 'Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.' fi
链接MySQL报错 1 NoClassDefFoundError: org/apache/commons/lang/StringUtils
在https://mvnrepository.com/下载
一直不知道,原来这里也可以下载jar!
上传到lib目录下就行了。
链接hive报错 1 2 3 4 # 报错:Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf # 解决 cp /usr/local/apps/hive/hive-3.1.2/lib/hive-common-3.1.2.jar /usr/local/apps/sqoop/sqoop-1.4.7/lib/
实操-安装Sqoop -适配Hadoop集群 版本选择:目前 Sqoop 有 Sqoop 1 和 Sqoop 2 两个版本,但是截至到目前,官方并不推荐使用 Sqoop 2,因为其与 Sqoop 1 并不兼容,且功能还没有完善,所以这里优先推荐使用 Sqoop 1。
Apache 1.4.x 之后的版本属于sqoop1,1.99.x之上的版本属于sqoop2
下载并解压 下载所需版本的 Sqoop ,这里我下载的是 CDH 版本的 Sqoop 。下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
1 2 # 下载后进行解压 tar -zxvf sqoop-1.4.6-cdh5.15.2.tar.gz
配置环境变量 添加环境变量:
1 2 export SQOOP_HOME=/usr/app/sqoop-1.4.6-cdh5.15.2 export PATH=$SQOOP_HOME/bin:$PATH
使得配置的环境变量立即生效:
修改配置 进入安装目录下的 conf/ 目录,拷贝 Sqoop 的环境配置模板 sqoop-env.sh.template
1 # cp sqoop-env-template.sh sqoop-env.sh
修改 sqoop-env.sh,内容如下 (以下配置中 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME 是必选的,其他的是可选的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # Set Hadoop-specific environment variables here. # Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2 # Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2 # set the path to where bin/hbase is availableexport HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2 # Set the path to where bin/hive is available export HIVE_HOME=/usr/app/hive-1.1.0-cdh5.15.2 # Set the path for where zookeper config dir is export ZOOCFGDIR=/usr/app/zookeeper-3.4.13/conf
拷贝数据库驱动 将 MySQL 驱动包拷贝到 Sqoop 安装目录的 lib 目录下, 驱动包的下载地址为 https://dev.mysql.com/downloads/connector/j/ 。在本仓库的resources 目录下我也上传了一份,有需要的话可以自行下载。
2.5 验证 由于已经将 sqoop 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
出现对应的版本信息则代表配置成功:
这里出现的两个 Warning 警告是因为我们本身就没有用到 HCatalog 和 Accumulo,忽略即可。Sqoop 在启动时会去检查环境变量中是否有配置这些软件,如果想去除这些警告,可以修改 bin/configure-sqoop,注释掉不必要的检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # Check: If we can't find our dependencies, give up here. if [ ! -d "${HADOOP_COMMON_HOME}" ]; then echo "Error: $HADOOP_COMMON_HOME does not exist!" echo 'Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation.' exit 1 fi if [ ! -d "${HADOOP_MAPRED_HOME}" ]; then echo "Error: $HADOOP_MAPRED_HOME does not exist!" echo 'Please set $HADOOP_MAPRED_HOME to the root of your Hadoop MapReduce installation.' exit 1 fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HBASE_HOME}" ]; then echo "Warning: $HBASE_HOME does not exist! HBase imports will fail." echo 'Please set $HBASE_HOME to the root of your HBase installation.' fi # # Moved to be a runtime check in sqoop. if [ ! -d "${HCAT_HOME}" ]; then echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail." echo 'Please set $HCAT_HOME to the root of your HCatalog installation.' fi if [ ! -d "${ACCUMULO_HOME}" ]; then echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail." echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.' fi if [ ! -d "${ZOOKEEPER_HOME}" ]; then echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail." echo 'Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.' fi
实操-安装Azkaban3 一、Azkaban 源码编译 1.1 下载并解压 Azkaban 在 3.0 版本之后就不提供对应的安装包,需要自己下载源码进行编译。
下载所需版本的源码,Azkaban 的源码托管在 GitHub 上,地址为 https://github.com/azkaban/azkaban 。可以使用 git clone 的方式获取源码,也可以使用 wget 直接下载对应 release 版本的 tar.gz 文件,这里我采用第二种方式:
1 2 3 4 # 下载 wget https://github.com/azkaban/azkaban/archive/3.70.0.tar.gz # 解压 tar -zxvf azkaban-3.70.0.tar.gz
1.2 准备编译环境 1. JDK Azkaban 编译依赖 JDK 1.8+
2. Gradle Azkaban 3.70.0 编译需要依赖 gradle-4.6-all.zip。Gradle 是一个项目自动化构建开源工具,类似于 Maven,但由于采用 Groovy 语言进行项目配置,所以比 Maven 更为灵活,目前广泛用于 Android 开发、Spring 项目的构建。
需要注意的是不同版本的 Azkaban 依赖 Gradle 版本不同,可以在解压后的 /gradle/wrapper/gradle-wrapper.properties 文件查看
在编译时程序会自动去图中所示的地址进行下载,但是下载速度很慢。为避免影响编译过程,建议先手动下载至 /gradle/wrapper/ 目录下:
1 # wget https://services.gradle.org/distributions/gradle-4.6-all.zip
然后修改配置文件 gradle-wrapper.properties 中的 distributionUrl 属性,指明使用本地的 gradle。
3. Git Azkaban 的编译过程需要用 Git 下载部分 JAR 包,所以需要预先安装 Git:
1.3 项目编译 在根目录下执行编译命令,编译成功后会有 BUILD SUCCESSFUL 的提示:
1 # ./gradlew build installDist -x test
编译过程中需要注意以下问题:
因为编译的过程需要下载大量的 Jar 包,下载速度根据网络情况而定,通常都不会很快,如果网络不好,耗费半个小时,一个小时都是很正常的;
编译过程中如果出现网络问题而导致 JAR 无法下载,编译可能会被强行终止,这时候重复执行编译命令即可,gradle 会把已经下载的 JAR 缓存到本地,所以不用担心会重复下载 JAR 包。
二、Azkaban 部署模式
After version 3.0, we provide two modes: the stand alone “solo-server” mode and distributed multiple-executor mode. The following describes thedifferences between the two modes.
按照官方文档的说明,Azkaban 3.x 之后版本提供 2 种运行模式:
solo server model(单服务模式) :元数据默认存放在内置的 H2 数据库(可以修改为 MySQL),该模式中 webServer(管理服务器) 和 executorServer(执行服务器) 运行在同一个进程中,进程名是 AzkabanSingleServer。该模式适用于小规模工作流的调度。
multiple-executor(分布式多服务模式) :存放元数据的数据库为 MySQL,MySQL 应采用主从模式进行备份和容错。这种模式下 webServer 和 executorServer 在不同进程中运行,彼此之间互不影响,适合用于生产环境。
下面主要介绍 Solo Server 模式。
三 、Solo Server 模式部署 2.1 解压 Solo Server 模式安装包在编译后的 /azkaban-solo-server/build/distributions 目录下,找到后进行解压即可:
1 2 # 解压 tar -zxvf azkaban-solo-server-3.70.0.tar.gz
2.2 修改时区 这一步不是必须的。但是因为 Azkaban 默认采用的时区是 America/Los_Angeles,如果你的调度任务中有定时任务的话,就需要进行相应的更改,这里我更改为常用的 Asia/Shanghai
2.3 启动 执行启动命令,需要注意的是一定要在根目录下执行,不能进入 bin 目录下执行,不然会抛出 Cannot find 'database.properties' 异常。
2.4 验证 验证方式一:使用 jps 命令查看是否有 AzkabanSingleServer 进程:
验证方式二:访问 8081 端口,查看 Web UI 界面,默认的登录名密码都是 azkaban,如果需要修改或新增用户,可以在 conf/azkaban-users.xml 文件中进行配置:
实操-安装Hive-适配Hadoop单机 下载:apache-hive-3.1.2-bin.tar.gz
解压
1 2 3 4 mkdir -p /usr/local/apps/hive tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/apps/hive cd /usr/local/apps/hive mv apache-hive-3.1.2-bin hive-3.1.2
guave版本处理
1 2 3 cd /usr/local/apps/hive/hive-3.1.2/lib/ cp /usr/local/apps/hadoop/hadoop-3.3.4/share/hadoop/common/lib/guava-27.0-jre.jar . rm -rf guava-19.0.jar
mysql驱动处理
1 将mysql-connector-java-5.1.47.jar上传到/usr/local/apps/hive/hive-3.1.2/lib/
修改hive配置
1 2 3 4 5 6 7 cd /usr/local/apps/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/usr/local/apps/hadoop/hadoop-3.3.4 export HIVE_CONF_DIR=/usr/local/apps/hive/hive-3.1.2/conf export HIVE_AUX_JARS_PATH=/usr/local/apps/hive/hive-3.1.2/lib
vim hive-site.xml 新增文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <configuration > <property > <name > javax.jdo.option.ConnectionURL</name > <value > jdbc:mysql://192.168.199.199:3306/hive3?createDatabaseIfNotExist=true& useSSL=false& useUnicode=true& characterEncoding=UTF-8</value > </property > <property > <name > javax.jdo.option.ConnectionDriverName</name > <value > com.mysql.jdbc.Driver</value > </property > <property > <name > javax.jdo.option.ConnectionUserName</name > <value > root</value > </property > <property > <name > javax.jdo.option.ConnectionPassword</name > <value > root</value > </property > <property > <name > hive.server2.thrift.bind.host</name > <value > 192.168.199.199</value > </property > <property > <name > hive.metastore.uris</name > <value > thrift://192.168.199.199:9083</value > </property > <property > <name > hive.metastore.event.db.notification.api.auth</name > <value > false</value > </property > <property > <name > hive.metastore.schema.verification</name > <value > false</value > </property > </configuration >
添加环境变量
1 2 3 4 5 6 7 8 9 #添加环境变量 vim /etc/profile export HIVE_HOME=/usr/local/apps/hive/hive-3.1.2 export PATH=:$HIVE_HOME/bin:$PATH #让环境变量生效 source /etc/profile
初始化元数据
1 2 3 4 cd /usr/local/apps/hive/hive-3.1.2/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表
修改hive元数据信息
1 2 3 4 5 6 7 8 9 10 use hive3; show tables;alter table hive3.COLUMNS_V2 modify column COMMENT varchar (256 ) character set utf8;alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8;alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8 ;alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar (4000 ) character set utf8;alter table hive3.INDEX_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8;
启动
1 2 nohup /usr/local/apps/hive/hive-3.1.2/bin/hive --service metastore & nohup /usr/local/apps/hive/hive-3.1.2/bin/hive --service hiveserver2 &
实操-安装Hive-适配Hadoop集群 下载并解压 下载所需版本的 Hive,这里我下载版本为 cdh5.15.2。下载地址:http://archive.cloudera.com/cdh5/cdh/5/
1 2 # 下载后进行解压 tar -zxvf hive-1.1.0-cdh5.15.2.tar.gz
配置环境变量 添加环境变量:
1 2 export HIVE_HOME=/usr/app/hive-1.1.0-cdh5.15.2 export PATH=$HIVE_HOME/bin:$PATH
使得配置的环境变量立即生效:
修改配置 1. hive-env.sh
进入安装目录下的 conf/ 目录,拷贝 Hive 的环境配置模板 hive-env.sh.template
1 cp hive-env.sh.template hive-env.sh
修改 hive-env.sh,指定 Hadoop 的安装路径:
1 HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
2. hive-site.xml
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > javax.jdo.option.ConnectionURL</name > <value > jdbc:mysql://hadoop001:3306/hadoop_hive?createDatabaseIfNotExist=true</value > </property > <property > <name > javax.jdo.option.ConnectionDriverName</name > <value > com.mysql.jdbc.Driver</value > </property > <property > <name > javax.jdo.option.ConnectionUserName</name > <value > root</value > </property > <property > <name > javax.jdo.option.ConnectionPassword</name > <value > root</value > </property > </configuration >
拷贝数据库驱动 将 MySQL 驱动包拷贝到 Hive 安装目录的 lib 目录下, MySQL 驱动的下载地址为:https://dev.mysql.com/downloads/connector/j/ , 在本仓库的resources 目录下我也上传了一份,有需要的可以自行下载。
初始化元数据库
这里我使用的是 CDH 的 hive-1.1.0-cdh5.15.2.tar.gz,对应 Hive 1.1.0 版本,可以跳过这一步。
启动 由于已经将 Hive 的 bin 目录配置到环境变量,直接使用以下命令启动,成功进入交互式命令行后执行 show databases 命令,无异常则代表搭建成功。
在 Mysql 中也能看到 Hive 创建的库和存放元数据信息的表
HiveServer2/beeline Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,因此产生了 HiveServer2。HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于目前 HiveServer2 是 Hive 开发维护的重点,所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主要讲解 Beeline 的配置方式。
修改Hadoop配置 修改 hadoop 集群的 core-site.xml 配置文件,增加如下配置,指定 hadoop 的 root 用户可以代理本机上所有的用户。
1 2 3 4 5 6 7 8 <property > <name > hadoop.proxyuser.root.hosts</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.root.groups</name > <value > *</value > </property >
之所以要配置这一步,是因为 hadoop 2.0 以后引入了安全伪装机制,使得 hadoop 不允许上层系统(如 hive)直接将实际用户传递到 hadoop 层,而应该将实际用户传递给一个超级代理,由该代理在 hadoop 上执行操作,以避免任意客户端随意操作 hadoop。如果不配置这一步,在之后的连接中可能会抛出 AuthorizationException 异常。
关于 Hadoop 的用户代理机制,可以参考:hadoop 的用户代理机制 或 Superusers Acting On Behalf Of Other Users
启动hiveserver2 由于上面已经配置过环境变量,这里直接启动即可:
使用beeline 可以使用以下命令进入 beeline 交互式命令行,出现 Connected 则代表连接成功。
1 # beeline -u jdbc:hive2://hadoop001:10000 -n root
实操-安装Zookeeper-单机和集群 一、单机环境搭建 1.1 下载 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
1 # wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
1.2 解压 1 # tar -zxvf zookeeper-3.4.14.tar.gz
1.3 配置环境变量 添加环境变量:
1 2 export ZOOKEEPER_HOME=/usr/app/zookeeper-3.4.14 export PATH=$ZOOKEEPER_HOME/bin:$PATH
使得配置的环境变量生效:
1.4 修改配置 进入安装目录的 conf/ 目录下,拷贝配置样本并进行修改:
1 # cp zoo_sample.cfg zoo.cfg
指定数据存储目录和日志文件目录(目录不用预先创建,程序会自动创建),修改后完整配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 tickTime =2000 initLimit =10 syncLimit =5 dataDir =/usr/local/zookeeper/data dataLogDir =/usr/local/zookeeper/log clientPort =2181
配置参数说明:
tickTime :用于计算的基础时间单元。比如 session 超时:N*tickTime;initLimit :用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;syncLimit :用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);dataDir :数据存储位置;dataLogDir :日志目录;clientPort :用于客户端连接的端口,默认 2181
1.5 启动 由于已经配置过环境变量,直接使用下面命令启动即可:
1.6 验证 使用 JPS 验证进程是否已经启动,出现 QuorumPeerMain 则代表启动成功。
1 2 [root@hadoop001 bin]# jps 3814 QuorumPeerMain
二、集群环境搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里演示搭建一个三个节点的集群。这里我使用三台主机进行搭建,主机名分别为 hadoop001,hadoop002,hadoop003。
2.1 修改配置 解压一份 zookeeper 安装包,修改其配置文件 zoo.cfg,内容如下。之后使用 scp 命令将安装包分发到三台服务器上:
1 2 3 4 5 6 7 8 9 10 11 12 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-cluster/data/ dataLogDir=/usr/local/zookeeper-cluster/log/ clientPort=2181 # server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里 # 指名集群间通讯端口和选举端口 server.1=hadoop001:2287:3387 server.2=hadoop002:2287:3387 server.3=hadoop003:2287:3387
2.2 标识节点 分别在三台主机的 dataDir 目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
创建存储目录:
1 2 # 三台主机均执行该命令 mkdir -vp /usr/local/zookeeper-cluster/data/
创建并写入节点标识到 myid 文件:
1 2 3 4 5 6 # hadoop001主机 echo "1" > /usr/local/zookeeper-cluster/data/myid # hadoop002主机 echo "2" > /usr/local/zookeeper-cluster/data/myid # hadoop003主机 echo "3" > /usr/local/zookeeper-cluster/data/myid
2.3 启动集群 分别在三台主机上,执行如下命令启动服务:
1 /usr/app/zookeeper-cluster/zookeeper/bin/zkServer.sh start
2.4 集群验证 启动后使用 zkServer.sh status 查看集群各个节点状态。如图所示:三个节点进程均启动成功,并且 hadoop002 为 leader 节点,hadoop001 和 hadoop003 为 follower 节点。
实操-安装Kafka-高可用集群-基于zookeeper 一、Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。
1.1 下载 & 解压 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
1 2 3 4 # 下载 wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz # 解压 tar -zxvf zookeeper-3.4.14.tar.gz
1.2 修改配置 拷贝三份 zookeeper 安装包。分别进入安装目录的 conf 目录,拷贝配置样本 zoo_sample.cfg 为 zoo.cfg 并进行修改,修改后三份配置文件内容分别如下:
zookeeper01 配置:
1 2 3 4 5 6 7 8 9 10 11 12 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-cluster/data/01 dataLogDir=/usr/local/zookeeper-cluster/log/01 clientPort=2181 # server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里 # 指名集群间通讯端口和选举端口 server.1=127.0.0.1:2287:3387 server.2=127.0.0.1:2288:3388 server.3=127.0.0.1:2289:3389
如果是多台服务器,则集群中每个节点通讯端口和选举端口可相同,IP 地址修改为每个节点所在主机 IP 即可。
zookeeper02 配置,与 zookeeper01 相比,只有 dataLogDir、dataLogDir 和 clientPort 不同:
1 2 3 4 5 6 7 8 9 10 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-cluster/data/02 dataLogDir=/usr/local/zookeeper-cluster/log/02 clientPort=2182 server.1=127.0.0.1:2287:3387 server.2=127.0.0.1:2288:3388 server.3=127.0.0.1:2289:3389
zookeeper03 配置,与 zookeeper01,02 相比,也只有 dataLogDir、dataLogDir 和 clientPort 不同:
1 2 3 4 5 6 7 8 9 10 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-cluster/data/03 dataLogDir=/usr/local/zookeeper-cluster/log/03 clientPort=2183 server.1=127.0.0.1:2287:3387 server.2=127.0.0.1:2288:3388 server.3=127.0.0.1:2289:3389
配置参数说明:
tickTime :用于计算的基础时间单元。比如 session 超时:N*tickTime;initLimit :用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;syncLimit :用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);dataDir :数据存储位置;dataLogDir :日志目录;clientPort :用于客户端连接的端口,默认 2181
1.3 标识节点 分别在三个节点的数据存储目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 leader 节点。
创建存储目录:
1 2 3 4 5 6 # dataDir mkdir -vp /usr/local/zookeeper-cluster/data/01 # dataDir mkdir -vp /usr/local/zookeeper-cluster/data/02 # dataDir mkdir -vp /usr/local/zookeeper-cluster/data/03
创建并写入节点标识到 myid 文件:
1 2 3 4 5 6 # server1 echo "1" > /usr/local/zookeeper-cluster/data/01/myid # server2 echo "2" > /usr/local/zookeeper-cluster/data/02/myid # server3 echo "3" > /usr/local/zookeeper-cluster/data/03/myid
1.4 启动集群 分别启动三个节点:
1 2 3 4 5 6 # 启动节点1 /usr/app/zookeeper-cluster/zookeeper01/bin/zkServer.sh start # 启动节点2 /usr/app/zookeeper-cluster/zookeeper02/bin/zkServer.sh start # 启动节点3 /usr/app/zookeeper-cluster/zookeeper03/bin/zkServer.sh start
1.5 集群验证 使用 jps 查看进程,并且使用 zkServer.sh status 查看集群各个节点状态。如图三个节点进程均启动成功,并且两个节点为 follower 节点,一个节点为 leader 节点。
二、Kafka集群搭建 2.1 下载解压 Kafka 安装包官方下载地址:http://kafka.apache.org/downloads ,本用例下载的版本为 2.2.0,下载命令:
1 2 3 4 # 下载 wget https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz # 解压 tar -xzf kafka_2.12-2.2.0.tgz
这里解释一下 kafka 安装包的命名规则:以 kafka_2.12-2.2.0.tgz 为例,前面的 2.12 代表 Scala 的版本号(Kafka 采用 Scala 语言进行开发),后面的 2.2.0 则代表 Kafka 的版本号。
2.2 拷贝配置文件 进入解压目录的 config 目录下 ,拷贝三份配置文件:
1 2 3 # cp server.properties server-1.properties# cp server.properties server-2.properties# cp server.properties server-3.properties
2.3 修改配置 分别修改三份配置文件中的部分配置,如下:
server-1.properties:
1 2 3 4 5 6 7 8 broker.id =0 listeners =PLAINTEXT://hadoop001:9092 log.dirs =/usr/local/kafka-logs/00 zookeeper.connect =hadoop001:2181,hadoop001:2182,hadoop001:2183
server-2.properties:
1 2 3 4 broker.id =1 listeners =PLAINTEXT://hadoop001:9093 log.dirs =/usr/local/kafka-logs/01 zookeeper.connect =hadoop001:2181,hadoop001:2182,hadoop001:2183
server-3.properties:
1 2 3 4 broker.id =2 listeners =PLAINTEXT://hadoop001:9094 log.dirs =/usr/local/kafka-logs/02 zookeeper.connect =hadoop001:2181,hadoop001:2182,hadoop001:2183
这里需要说明的是 log.dirs 指的是数据日志的存储位置,确切的说,就是分区数据的存储位置,而不是程序运行日志的位置。程序运行日志的位置是通过同一目录下的 log4j.properties 进行配置的。
2.4 启动集群 分别指定不同配置文件,启动三个 Kafka 节点。启动后可以使用 jps 查看进程,此时应该有三个 zookeeper 进程和三个 kafka 进程。
1 2 3 bin/kafka-server-start.sh config/server-1.properties bin/kafka-server-start.sh config/server-2.properties bin/kafka-server-start.sh config/server-3.properties
2.5 创建测试主题 创建测试主题:
1 2 3 bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 \ --replication-factor 3 \ --partitions 1 --topic my-replicated-topic
创建后可以使用以下命令查看创建的主题信息:
1 bin/kafka-topics.sh --describe --bootstrap-server hadoop001:9092 --topic my-replicated-topic
可以看到分区 0 的有 0,1,2 三个副本,且三个副本都是可用副本,都在 ISR(in-sync Replica 同步副本) 列表中,其中 1 为首领副本,此时代表集群已经搭建成功。
集群环境 3节点虚拟机搭建 本案例使用VMware Workstation Pro虚拟机创建虚拟服务器来搭建HADOOP集群,所用软件及版本如下:
Centos7 64bit
注意事项 1.注意:windows系统确认所有的关于VmWare的服务都已经启动
确认好VmWare生成的网关地址
3.确认VmNet8网卡已经配置好了IP地址和DNS
复制虚拟机 将虚拟机文件夹复制三份,并分别重命名, 并使用VM打开重命名
或者通过界面操作,克隆node1(完整克隆)
1.分别设置三台虚拟机的内存
需要三台虚拟机, 并且需要同时运行, 所以总体上的占用为: 每台虚拟机X3
每台机器的内存=(总内存-4)/3
虚拟机修改Mac和IP 1.集群规划
IP
主机名
环境配置
安装
192.168.213.150
node01
关防火墙和selinux, host映射, 时钟同步
JDK, DataNode, NodeManager, Zeekeeper
192.168.213.160
node02
关防火墙和selinux, host映射, 时钟同步
JDK, DataNode, NodeManager, Zeekeeper
192.168.213.170
node03
关防火墙和selinux, host映射, 时钟同步
JDK, DataNode, NodeManager, Zeekeeper
2.设置ip和Mac地址
每台虚拟机更改mac地址:
1 vim /etc/udev/rules.d/70-persistent-net.rules
将mac删掉,编辑->设置->虚拟机设置->网络适配器->Mac地址生成,可以拿到可用的mac地址,填到上面的address
每台虚拟机更改IP地址:
1 2 3 4 5 6 vim /etc/sysconfig/network-scripts/ifcfg-eth0 或 vim /etc/sysconfig/network-scripts/ifcfg-ens33 # 重启网络 systemctl restart network
HWADDR填上面生成的mac地址,要和节点的一致。
每台虚拟机修改对应主机名
1 2 3 4 5 6 vi /etc/sysconfig/network HOSTNAME=node01 # 如果不生效 vim /etc/hostname node1 # 3个都修改 node2 node3
每台虚拟机 设置ip和域名映射
3.Linux系统重启
虚拟机关闭防火墙和SELinux 1.关闭防火墙
1 2 service iptables stop #关闭防火墙 chkconfig iptables off #禁止开机启动
2.三台机器关闭selinux
SELinux是Linux的一种安全子系统
Linux中的权限管理是针对于文件的, 而不是针对进程的, 也就是说, 如果root启动了某个进程, 则这个进程可以操作任何一个文件
SELinux在Linux的文件权限之外, 增加了对进程的限制, 进程只能在进程允许的范围内操作资源
为什么要关闭SELinux
如果开启了SELinux, 需要做非常复杂的配置, 才能正常使用系统, 在学习阶段, 在非生产环境, 一般不使用SELinux
SELinux的工作模式
enforcing 强制模式
permissive 宽容模式
disable 关闭
1 2 # 修改selinux的配置文件 vi /etc/selinux/config
虚拟机免密码登录
1.为什么要免密登录
Hadoop 节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦
2.免密 SSH 登录的原理
需要先在 B节点 配置 A节点 的公钥
A节点 请求 B节点 要求登录
B节点 使用 A节点 的公钥, 加密一段随机文本
A节点 使用私钥解密, 并发回给 B节点
B节点 验证文本是否正确
第一步:三台机器生成公钥与私钥在三台机器执行以下命令 ,生成公钥与私钥
执行该命令之后,按下三个回车即可
第二步:拷贝公钥到同一台机器三台机器执行命令 :
第三步:复制第一台机器的认证到其他机器
1 2 scp /root/.ssh/authorized_keys node02:/root/.ssh scp /root/.ssh/authorized_keys node03:/root/.ssh
后续直接ssh node2/node3,不用个输入密码了, 退出 exit.
三台机器时钟同步 为什么需要时间同步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 第一步:在node1虚拟机安装ntp并启动 # 1.安装ntp服务 yum -y install ntp # 2.启动ntp服务 systemctl start ntpd # 3.设置ntpd的服务开机启动 # 关闭chrony,Chrony是NTP的另一种实现 systemctl disable chrony # 设置ntp服务为开机启动 systemctl enable ntpd 第二步:编辑node1的/etc/ntp.conf文件 1.编辑node1机器的/etc/ntp.conf vim /etc/ntp.conf 2.在文件中添加如下内容(授权192.168.88.0-192.168.88.255网段上的所有机器可以从这台机器上查询和同步时间) restrict 192.168.88.0 mask 255.255.255.0 nomodify notrap 注释一下四行内容:(集群在局域网中,不使用其他互联网上的时间) # server 0.centos.pool.ntp.org # server 1.centos.pool.ntp.org # server 2.centos.pool.ntp.org # server 3.centos.pool.ntp.org 去掉以下内容的注释,如果没有这两行注释,那就自己添加上(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步) server 127.127.1.0 fudge 127.127.1.0 stratum 10
1 2 3 4 5 配置以下内容,保证BIOS与系统时间同步 vim /etc/sysconfig/ntpd 添加一行内容 SYNC_HWLOCK=yes
1 2 3 4 5 6 第三步:另外两台机器与第一台机器时间同步 另外两台机器与192.168.88.161进行时钟同步,在node2和node3机器上分别进行以下操作 crontab -e 添加以下内容:(每隔一分钟与node1进行时钟同步) */1 * * * * /usr/sbin/ntpdate 192.168.88.161
方式2:
1 2 3 4 # yum install -y ntp # crontab -e
随后在输入界面键入
1 */1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
[优化项]禁止透明大页 (1) 所有主机输入以下命令:
1 2 echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag
(2) 所有主机的/etc/rc.local中也需要加入这两条命令,配置为开机启动时自动配置。
[优化项]减少集群使用交换内存 运行以下三条命令:
1 2 3 sysctl -w vm.swappiness=0 echo 'vm.swappiness=0' >> /etc/sysctl.conf sysctl -p
CHD规划
已做操作:修改IP,关闭防火墙,关闭SELINUX,邮件通知,免密登录,时钟同步,禁止透明大页,减少集群使用交换内存
安装wget
安装JDK1.8
安装mysql5.7
已做操作:修改IP,关闭防火墙,关闭SELINUX,邮件通知,免密登录,时钟同步,禁止透明大页,减少集群使用交换内存
安装JDK1.8
已做操作:修改IP,关闭防火墙,关闭SELINUX,邮件通知,免密登录,时钟同步,禁止透明大页,减少集群使用交换内存
安装JDK1.8
分布式环境(3) 克隆专用-环境同步 编写集群分发脚步xsync 1)scp(secure copy)安全拷贝
第一次同步可以用scp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 (1)scp定义 scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2) (2)基本语法 scp -r $pdir/$fname $user@$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 (3)案例实操 前提:在hadoop02、hadoop03、hadoop04 都已经创建好的/opt/install、/opt/apps 两个目录,并且已经把这两个目录修改为zuoer:zuoer [zuoer@hadoop02 ~]$ sudo chown zuoer:zuoer -R /opt/apps # 下面是3种拷贝的场景 (a)在hadoop02上,将hadoop02中/opt/apps/jdk1.8.0_321目录拷贝到hadoop03上。 [zuoer@hadoop02 ~]$ scp -r /opt/apps/jdk1.8.0_212 zuoer@hadoop03:/opt/apps (b)在hadoop03上,将hadoop02中/opt/apps/hadoop-3.1.3目录拷贝到hadoop03上。 [zuoer@hadoop03 ~]$ scp -r zuoer@hadoop02:/opt/apps/hadoop-3.1.3 /opt/apps/ (c)在hadoop03上操作,将hadoop02中/opt/module目录下所有目录拷贝到hadoop04上。 [zuoer@hadoop03 opt]$ scp -r zuoer@hadoop02:/opt/apps/* zuoer@hadoop04:/opt/apps
2)rsync远程同步工具
后续更新,同步可以用rsync
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。rsync只对差异文件做更新。scp是把所有文件都复制过去。 第一次同步等同于拷贝
1 2 3 4 5 6 7 8 9 10 11 12 (1)基本语法 rsync -av $pdir/$fname $user@$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 选项参数说明 -a 归档拷贝 -v 显示复制过程 (2)案例实操 (a)删除hadoop03中/opt/apps/hadoop-3.1.3/wcinput [zuoer@hadoop03 hadoop-3.1.3]$ rm -rf wcinput/ (b)同步hadoop02中的/opt/apps/hadoop-3.1.3到hadoop03 [zuoer@hadoop02 apps]$ rsync -av hadoop-3.1.3/ zuoer@hadoop03:/opt/apps/hadoop-3.1.3/
3)xsync集群分发脚本
以上2种操作都比较繁琐,直接用这种脚步比较方便
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 (1)需求:循环复制文件到所有节点的相同目录下 (2)需求分析: (a)rsync命令原始拷贝: rsync -av /opt/apps zuoer@hadoop03:/opt/ (b)期望脚本: xsync要同步的文件名称 (c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径) [zuoer@hadoop02 ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/zuoer/.local/bin:/home/zuoer/bin:/opt/apps/jdk1.8.0_321/bin 路径有/home/zuoer,所以再这个家目录下的脚步可以直接执行 (3)脚本实现 (a)在/home/zuoer/bin目录下创建xsync文件 [zuoer@hadoop02 opt]$ cd /home/zuoer [zuoer@hadoop02 ~]$ mkdir bin [zuoer@hadoop02 ~]$ cd bin [zuoer@hadoop02 bin]$ vim xsync 在该文件中编写如下代码 # !/bin/bash # 1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi # 2. 遍历集群所有机器 for host in hadoop02 hadoop03 hadoop04 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done (b)修改脚本 xsync 具有执行权限 [zuoer@hadoop02 bin]$ chmod +x xsync (c)测试脚本 [zuoer@hadoop02 ~]$ xsync /home/zuoer/bin (d)将脚本复制到/bin中,以便全局调用(否则有一些文件路径没有权限分发,比如/目录下的文件) [zuoer@hadoop02 bin]$ sudo cp xsync /bin/ (e)同步环境变量配置(root所有者) [zuoer@hadoop02 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh 注意:如果用了sudo,那么xsync一定要给它的路径补全。 让03和04的环境变量生效 [zuoer@hadoop03 bin]$ source /etc/profile [zuoer@hadoop04 opt]$ source /etc/profile
ssh免密登录 配置ssh: ssh另一台电脑的IP地址,然后回车,输入yes,就可以链接到另一台计算机,但是这样很麻烦
1)无密钥配置
2)生成公钥和私钥
1 2 3 4 5 6 7 8 9 10 11 12 13 公钥私钥和授权文件在/当前用户目录/.ssh下 ssh-keygen -t rsa 然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥) ssh-copy-id hadoop02 ssh-copy-id hadoop03 ssh-copy-id hadoop04 注意: 还需要在hadoop03上采用zuoer账号配置一下无密登录到hadoop02、hadoop03、hadoop04服务器上。 还需要在hadoop04上采用zuoer账号配置一下无密登录到hadoop02、hadoop03、hadoop04服务器上。 这里配置的是zuoer,如果root用户也需要,也要重复上面的生成key和拷贝的操作一下。
known_hosts
记录ssh访问过计算机的公钥(public key)
id_rsa
生成的私钥
id_rsa.pub
生成的公钥
authorized_keys
存放授权过的无密登录服务器公钥
root用户和zuoer用户可以无缝切换主机,以及xsync拷贝不用再输入密码了
如果有新增的节点,如果hadoop05,需要将05分发给其他人,并且将其他人分发给05
实操-安装JDK (1.8.0_321) 下载jdk并上传到linux http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
需要登录,用下面的账号,如果失效,再查找
1 2 1287019365@qq.com Oracle@1234
卸载默认JDK 检查系统上是否安装了jdk(若安装了就需要先卸载再使用我们自己的)
查看出安装的java的软件包
卸载linux自带的openjdk
历史原因,openjdk相当于简化版的jdk,不完整
1 2 3 4 5 6 7 rpm -qa | grep openjdk # 查询openjdk rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.i686 rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.i686 tzdata-java-2013g-1.el6.noarch # 删不掉加--nodeps # 或者用这个命令,卸载所有Java rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
解压安装包 进入 /opt/java 目录,解压jdk
1 2 cd /opt/apps/ tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/apps
配置环境变量 1 2 3 4 5 vi /etc/profile # 在文件的最后面添加如下代码 export JAVA_HOME=/opt/apps/jdk1.8.0_321 export PATH=$JAVA_HOME/bin:$PATH
更好的做法: 配置到/etc/profile.d/下
1 2 3 4 5 6 7 # /etc/profile或加载/etc/profile.d/下的文件配置 cd /etc/profile.d/ sudo vim my_env.sh # JAVA配置 export JAVA_HOME=/opt/apps/jdk1.8.0_321 export PATH=$PATH:$JAVA_HOME/bin
检测是否安装成功 显示出对应的版本信息则代表安装成功。
1 2 3 java version "1.8.0_321" Java(TM) SE Runtime Environment (build 1.8.0_321-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)
实操-安装hadoop (3.1.3) 集群规划
给你1000台服务器,你怎么安装规划?
角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上?
角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
HDFS集群守护进程
YARN集群守护进程
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
HistoryServer
hadoop02
✅
❌
✅
✅
✅
✅
hadoop03
❌
✅
✅
❌
✅
❌
hadoop04
❌
❌
✅
❌
✅
❌
注意:
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
这个规划要根据配置文件去制定各个组件在哪个节点
环境前提
安装jdk:参考: 实操-安装JDK (1.8.0_321)
下载并上传到服务器 http://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz
解压安装包 1 tar -zxvf hadoop-3.1.3.tar.gz -C /opt/apps/
配置环境变量 1 2 3 4 sudo vim /etc/profile.d/my_env.sh # Hadoop配置 export HADOOP_HOME=/opt/apps/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
校验是否安装成功 1 2 [zuoer@hadoop02 ~]$ hadoop version Hadoop 3.1.3
xsync同步安装包 使用自定义的xsync和ssh免登录将按照包同步到其他节点
1 2 3 4 cd /usr/local/apps scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
Hadoop配置文件修改说明
配置文件的名称 作用
hadoop-env.sh
主要配置我们的java路径
core-site.xml
核心配置文件,主要定义了我们文件访问的格式 hdfs://
hdfs-site.xml
主要定义配置我们的hdfs的相关配置
mapred-site.xml
主要定义我们的mapreduce相关的一些配置
slaves
控制我们的从节点在哪里 datanode nodemanager在哪些机器上
yarm-site.xml
配置我们的resourcemanager资源调度
core-site.xml hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <property > <name > fs.defaultFS</name > <value > hdfs://hadoop02:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/data/hadoop-3.1.3/data</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > zuoer</value > </property >
hdfs-site.xml HDFS的核心配置文件,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 <property > <name > dfs.namenode.http-address</name > <value > hadoop02:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop04:9868</value > </property >
回收站开启配置
曾经有一份珍贵的数据摆在我面前,可我不懂得珍惜,等到失去了才后悔莫及,如果上天能给我重来一次的机会,我一个对她说三个字:回收你。
频繁删除的时候开一下,会让你笑的。
1 2 3 4 5 6 7 8 9 10 11 12 13 需求:配置,一个文件放在回收站时间60分钟,每10分钟检测一次,当超过60分钟后,文件就会被彻底删除 <property > <name > fs.trash.interval</name > <value > 60</value > </property > <property > <name > fs.trash.checkpoint.interval</name > <value > 10</value > </property >
mapred-site.xml MapReduce的核心配置文件,有默认的配置项mapred-default.xml。
mapred-default.xml与mapred-site.xml的功能是一样的,如果在mapred-site.xml里没有配置的属性,则会自动会获取mapred-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > hadoop02:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop02:19888</value > </property >
yarn-site.xml YARN的核心配置文件,有默认的配置项yarn-default.xml。
yarn-default.xml与yarn-site.xml的功能是一样的,如果在yarn-site.xml里没有配置的属性,则会自动会获取yarn-default.xml里的相同属性的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop03</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://hadoop02:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > <property > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value > </property >
worker 集群群起配置: workers文件里面记录的是集群主机名。主要作用是配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色(DataNode和NodeManager)所在的机器 。
1 2 3 4 5 6 7 vim /opt/apps/hadoop-3.1.3/etc/hadoop/workers hadoop02 hadoop03 hadoop04 注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
分发文件 1 2 # 同步所有节点配置文件 在某个节点,比如hadoop02 [zuoer@hadoop02 hadoop]$ xsync /opt/apps/hadoop-3.1.3/etc/hadoop/
启动集群 如果集群是第一次启动,需要在hadoop102节点格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
1 [zuoer@hadoop02 hadoop-3.1.3]$ hdfs namenode -format
(2)启动HDFS
1 [zuoer@hadoop02 hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了ResourceManager的节点(hadoop03)启动YARN
1 [zuoer@hadoop03 hadoop-3.1.3]$ sbin/start-yarn.sh
集群启动/停止方式总结 1)各个模块分开启动/停止(配置ssh是前提)常用
1 2 3 4 (1)整体启动/停止HDFS start-dfs.sh/stop-dfs.sh (2)整体启动/停止YARN start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
1 2 3 4 5 6 (1)分别启动/停止HDFS组件 hdfs --daemon start/stop namenode/datanode/secondarynamenode (2)启动/停止YARN yarn --daemon start/stop resourcemanager/nodemanager (3)启动/停止 历史服务 mapred --daemon start/stop historyserver
节点少这么搞可以,但是我如果给你100台服务器,阁下又该如何应对?
编写Hadoop集群常用脚本 Hadoop集群启停脚本 1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cd /home/zuoer/bin vim myhadoop.sh # !/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop02 "/opt/apps/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop03 "/opt/apps/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop02 "/opt/apps/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop02 "/opt/apps/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop03 "/opt/apps/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop02 "/opt/apps/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac chmod +x myhadoop.sh
查看三台服务器Java进程脚本 2)查看三台服务器Java进程脚本:jpsall
1 2 3 4 5 6 7 8 9 10 11 12 cd /home/zuoer/bin vim jpsall # !/bin/bash for host in hadoop02 hadoop03 hadoop04 do echo =============== $host =============== ssh $host jps done chmod +x jpsall
分发/home/zuoer/bin目录,保证自定义脚本在三台机器上都可以使用
查看集群 (4)Web端查看HDFS的NameNode
(5)Web端查看YARN的ResourceManager
(6)历史服务器查看日志地址
实操-安装zookeeper (3.4.6) 集群规划
zk集群一般2n+1架构。比如3台,5台。就已经够用了
节点
myid
hadoop02
1
hadoop03
2
hadoop04
3
环境前提
安装jdk:参考: 实操-安装JDK (1.8.0_321)
下载上传安装 下载地址:https://archive.apache.org/dist/zookeeper/
上传安装包到/opt/install
解压软件包到/opt/apps
1 tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/apps
修改zk配置文件 创建数据数据存放目录到/opt/data
1 mkdir -p /opt/data/zookeeper-3.4.6/data
拷贝配置文件
1 2 cd /opt/apps/zookeeper-3.4.6/confcp zoo_sample.cfg zoo.cfg
修改配置文件vim zoo.cfg
1 2 3 4 dataDir=/opt/data/zookeeper-3.4.6/data server.1=hadoop02:2888:3888 server.2=hadoop03:2888:3888 server.3=hadoop04:2888:3888
设置myid 1 echo "1" > /opt/data/zookeeper-3.4.6/data/myid
分发zookeeper 1 2 3 4 5 6 scp -r /opt/apps/zookeeper-3.4.6 zuoer@hadoop03:/opt/apps scp -r /opt/data/zookeeper-3.4.6 zuoer@hadoop03:/opt/data scp -r /opt/apps/zookeeper-3.4.6 zuoer@hadoop04:/opt/apps scp -r /opt/data/zookeeper-3.4.6 zuoer@hadoop04:/opt/data
分发后修改myid
1 2 3 4 # hadoop03 echo "2" > /opt/data/zookeeper-3.4.6/data/myid # hadoop04 echo "3" > /opt/data/zookeeper-3.4.6/data/myid
启动zk集群 1 2 3 4 5 6 7 8 # 启动节点hadoop02 /opt/apps/zookeeper-3.4.6/bin/zkServer.sh start # 启动节点hadoop03 /opt/apps/zookeeper-3.4.6/bin/zkServer.sh start # 启动节点hadoop04 /opt/apps/zookeeper-3.4.6/bin/zkServer.sh start # 观察节点leader和fowller jps
配置环境变量 1 2 3 4 sudo vim /etc/profile.d/my_env.sh #Zookeeper配置 export ZOOKEEPER_HOME=/opt/apps/zookeeper-3.4.6 export PATH=$PATH:$ZOOKEEPER_HOME/bin
同步环境变量 1 2 3 4 5 6 7 # 同步环境变量配置(所有者root) [zuoer@hadoop02 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh 注意:如果用了sudo,那么xsync一定要给它的路径补全。 让03和04的环境变量生效 [zuoer@hadoop03 bin]$ source /etc/profile [zuoer@hadoop04 opt]$ source /etc/profile
一键启动脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 cd /home/zuoer/bin vim myzk.sh # ! /bin/bash # 操作 option="" # 选择 echo "你要进行什么操作?" PS3="请输入你的选择:" select var in "停止集群" "启动集群" "查看集群状态" do case $var in "启动集群") option="start" ;; "停止集群") option="stop" ;; "查看集群状态") option="status" ;; *) echo "选择错误" ;; esac break; done echo " =================== $var ===================" for i in hadoop02 hadoop03 hadoop04 do ssh $i "source /etc/profile;/opt/apps/zookeeper-3.4.6/bin/zkServer.sh $option" done chmod +x myzk.sh
分发到/home/zuoer/bin目录,保证自定义脚本在三台机器上都可以使用
使用:myzookeeper.sh,根据菜单选择功能即可
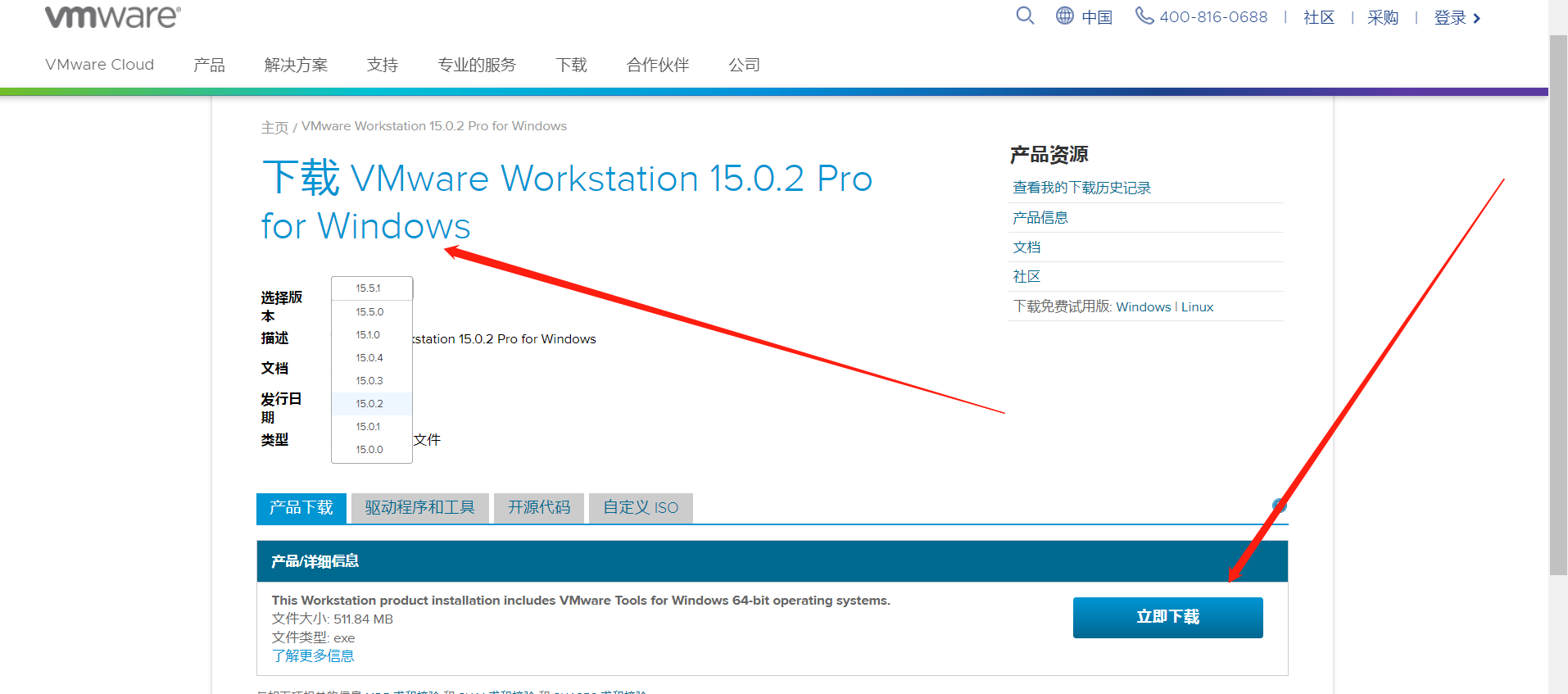
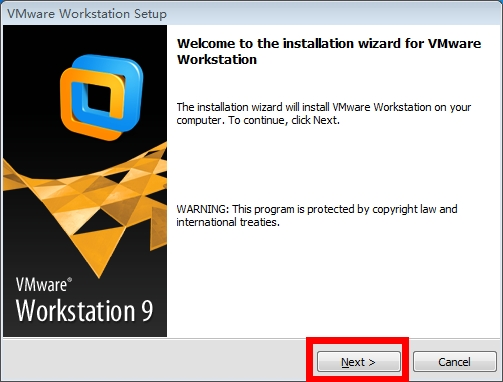
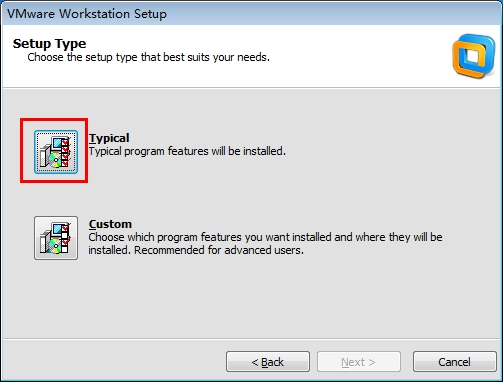
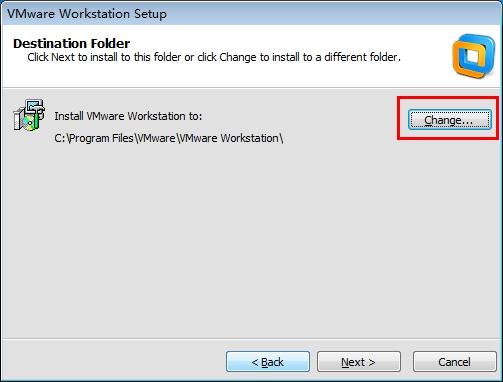
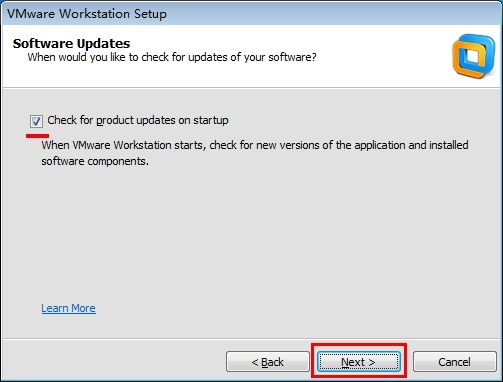
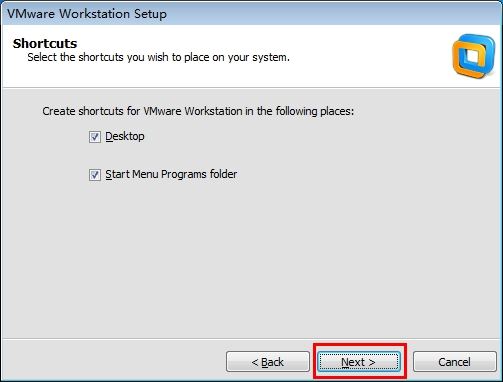
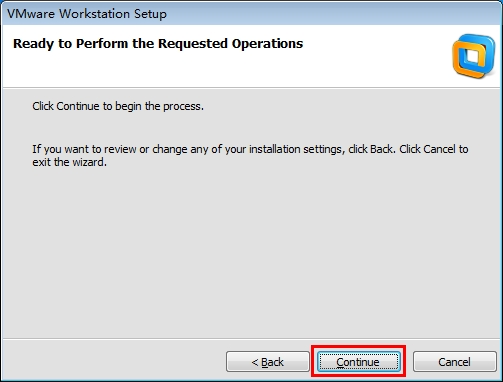
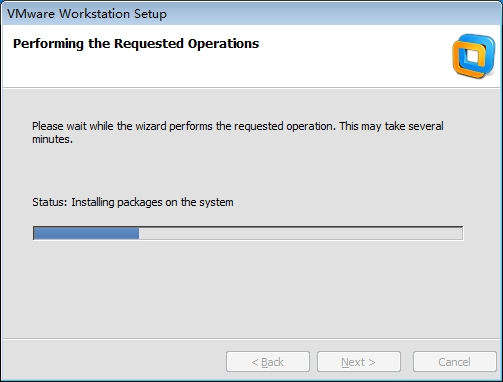
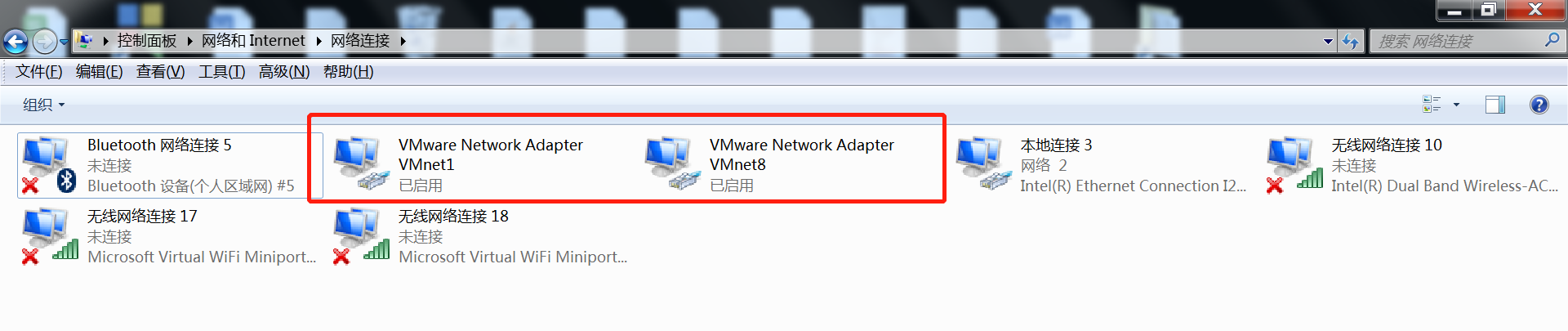
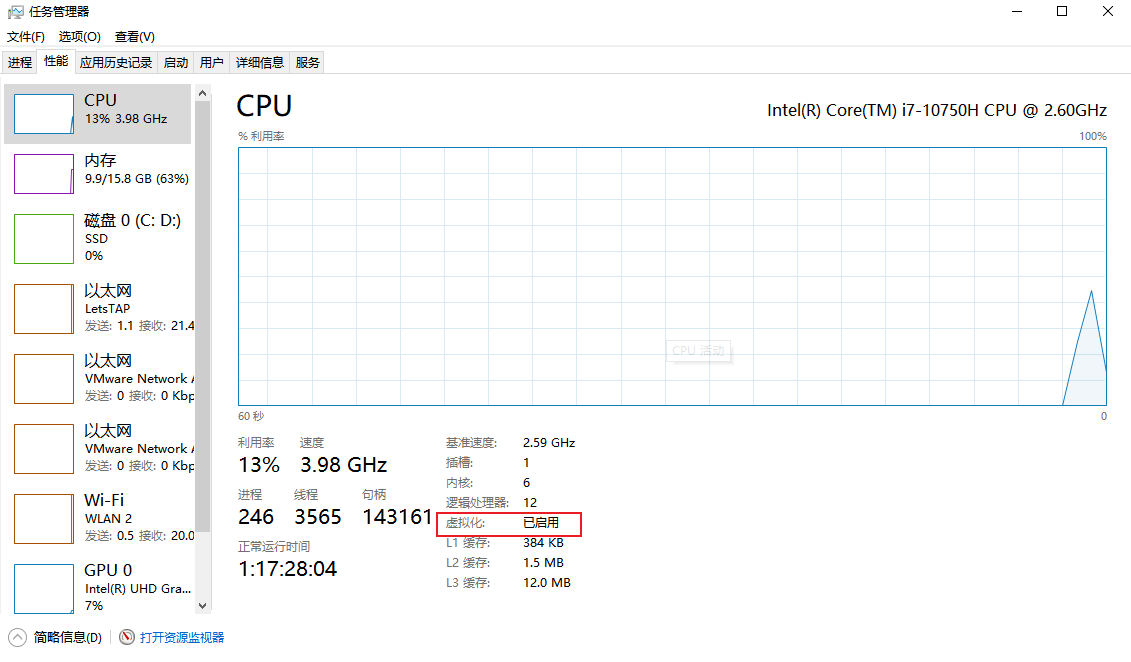

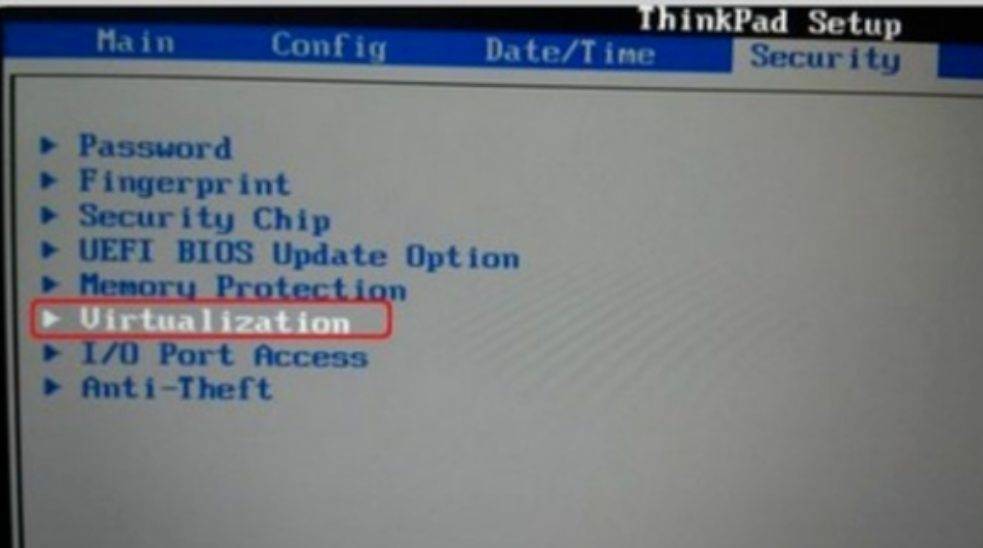
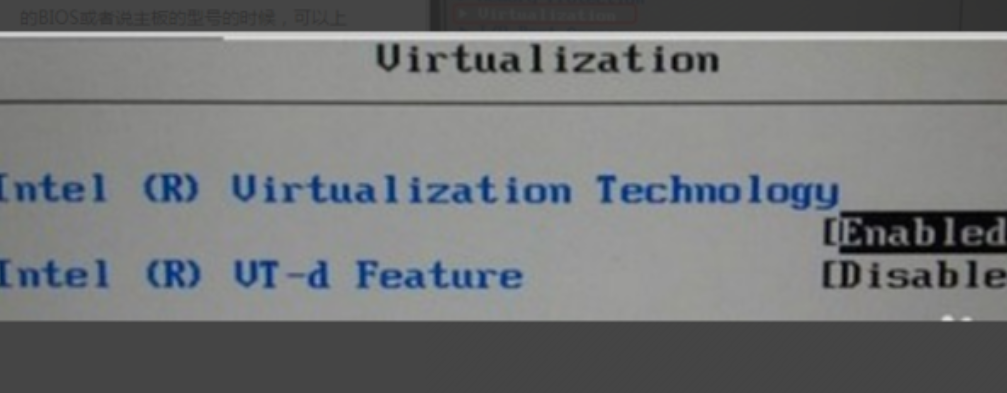
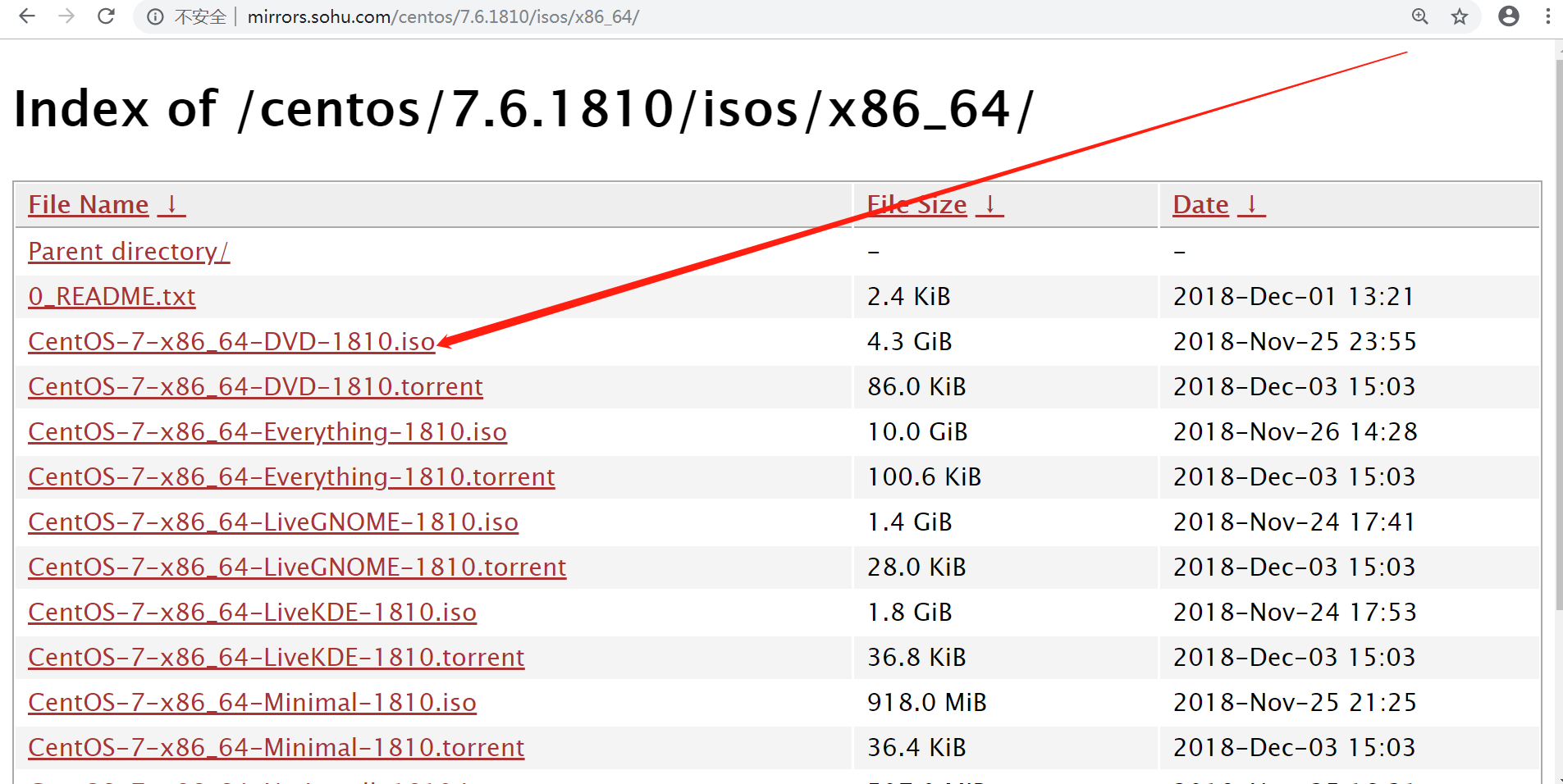
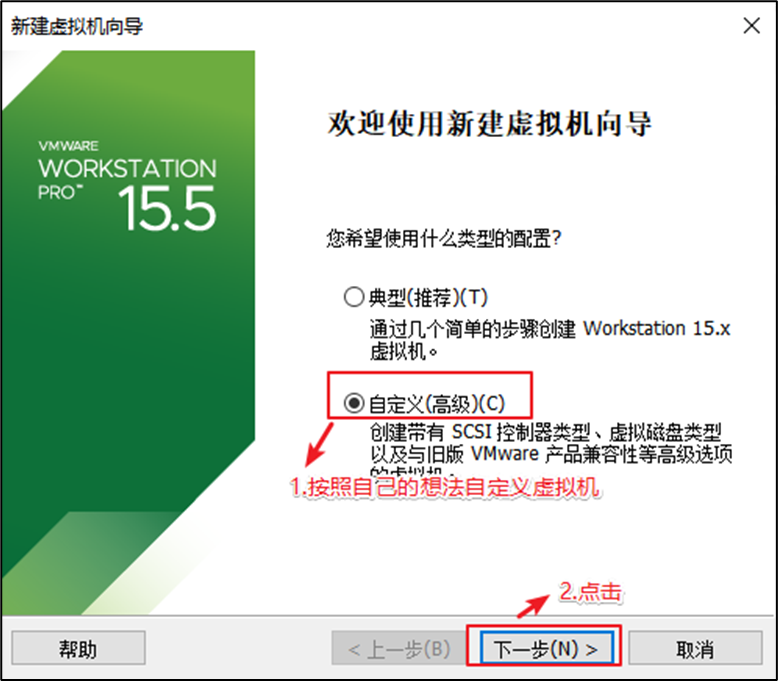
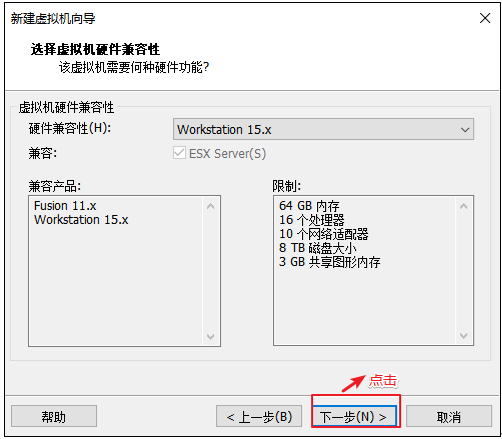
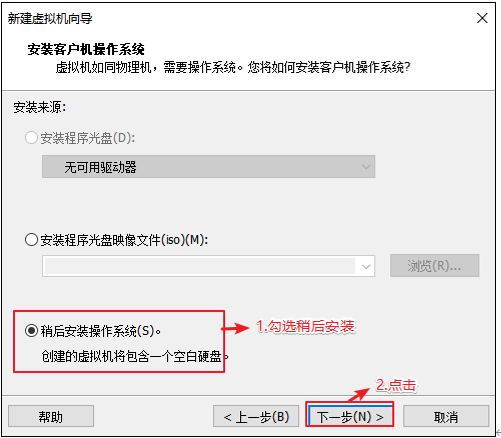
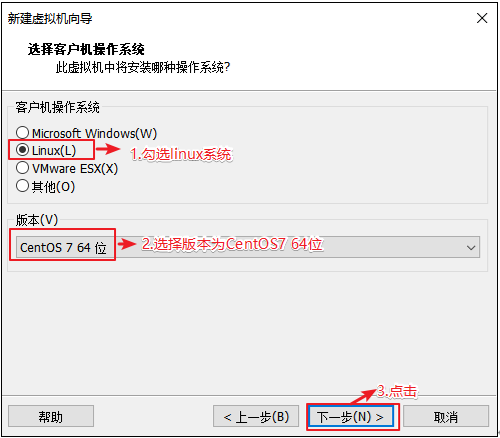
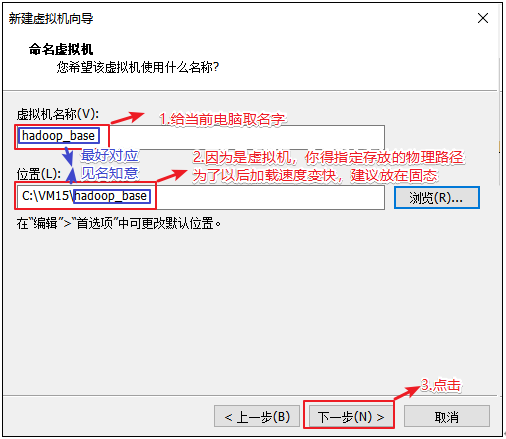
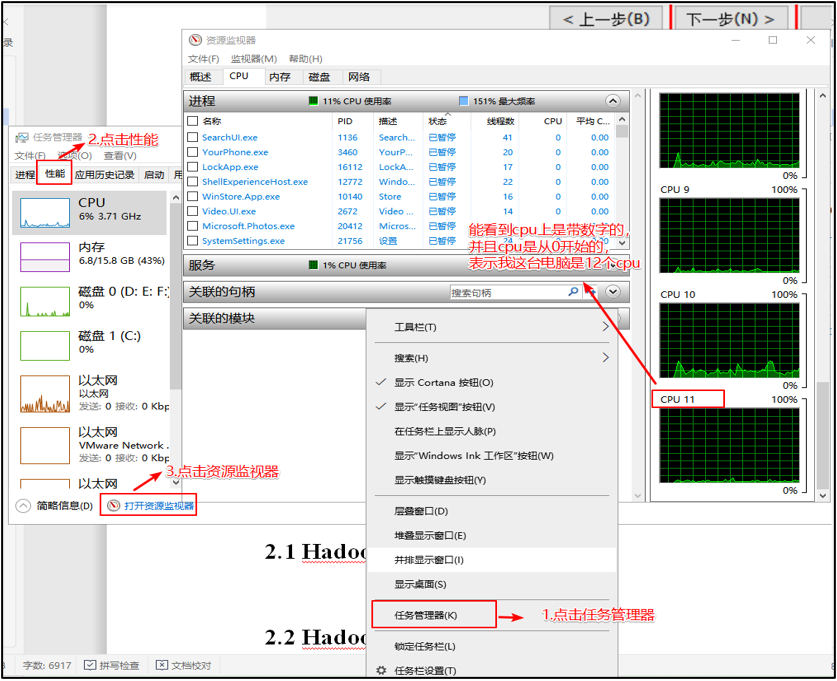
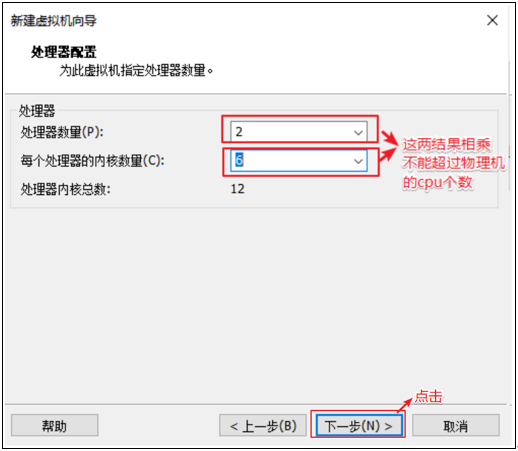
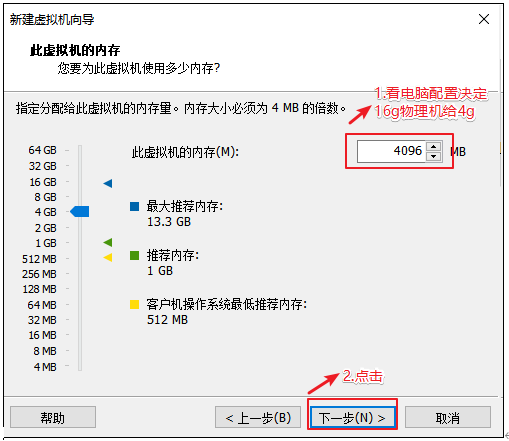
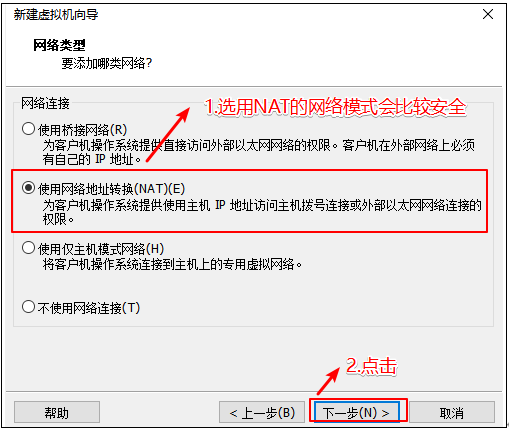


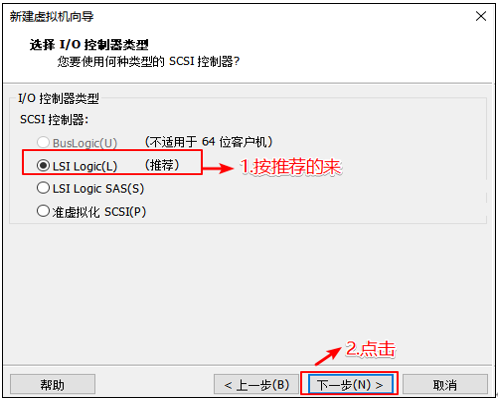
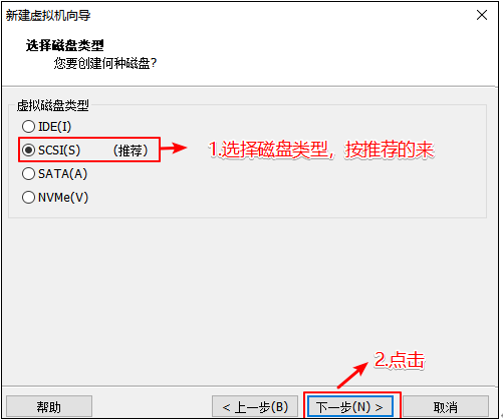
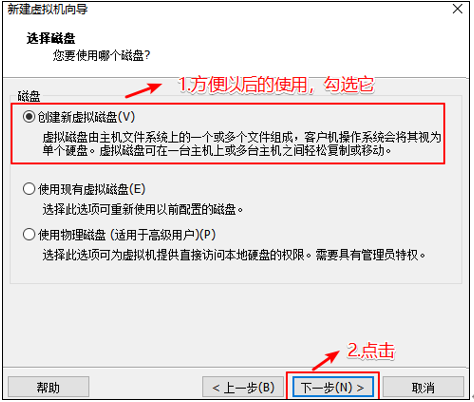
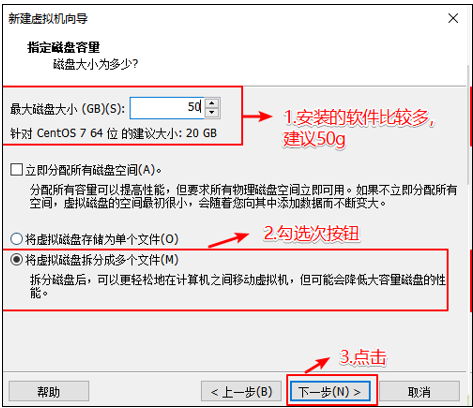
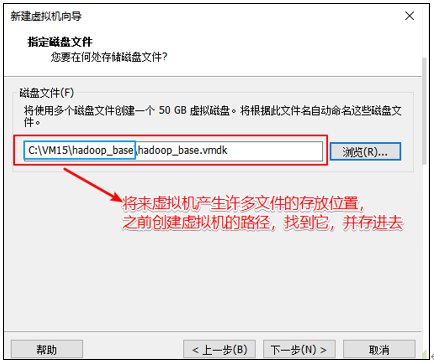
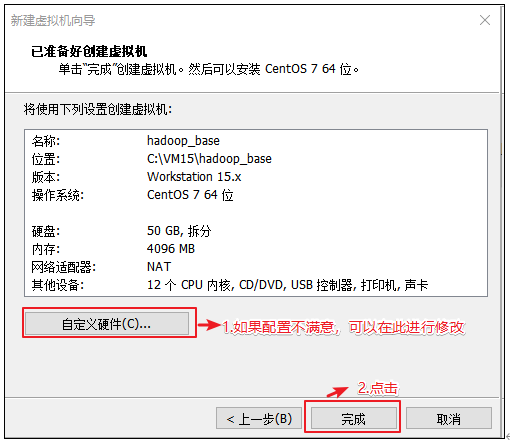
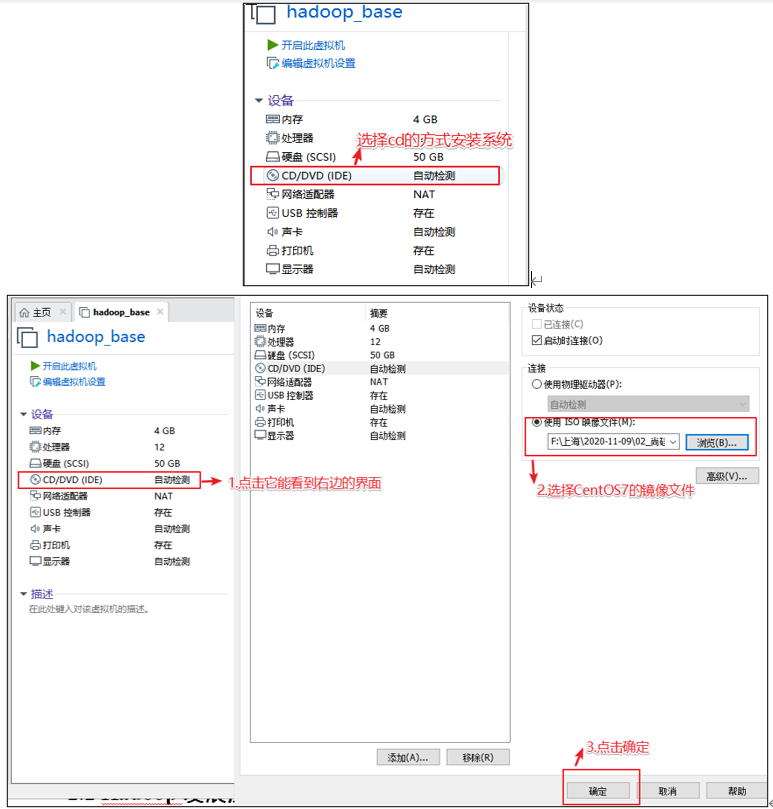
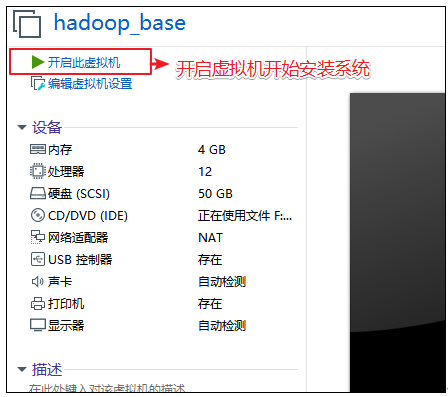
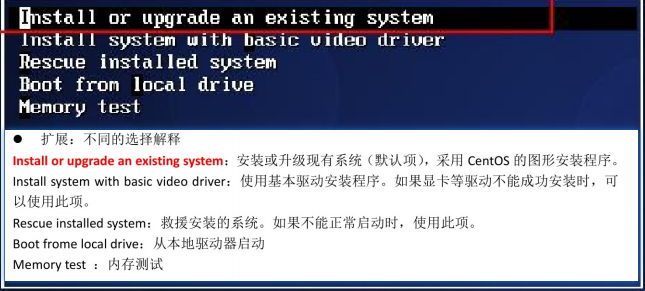
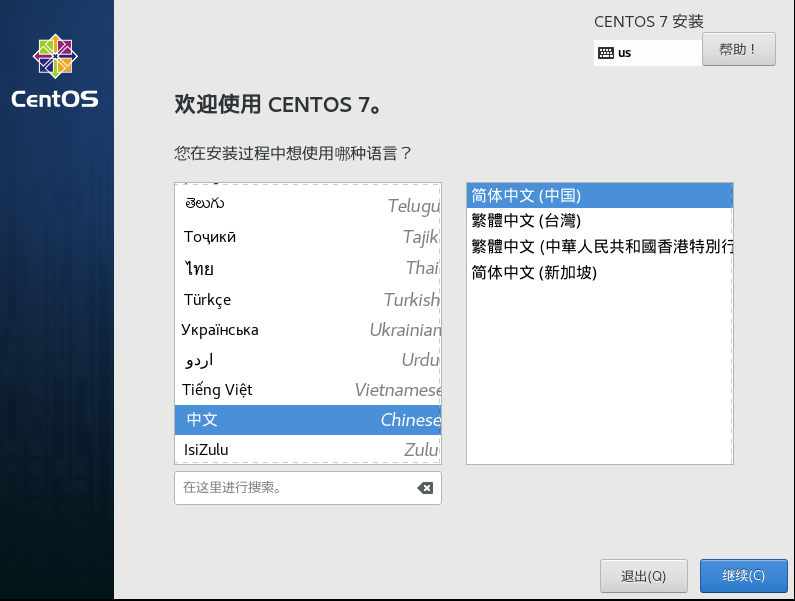
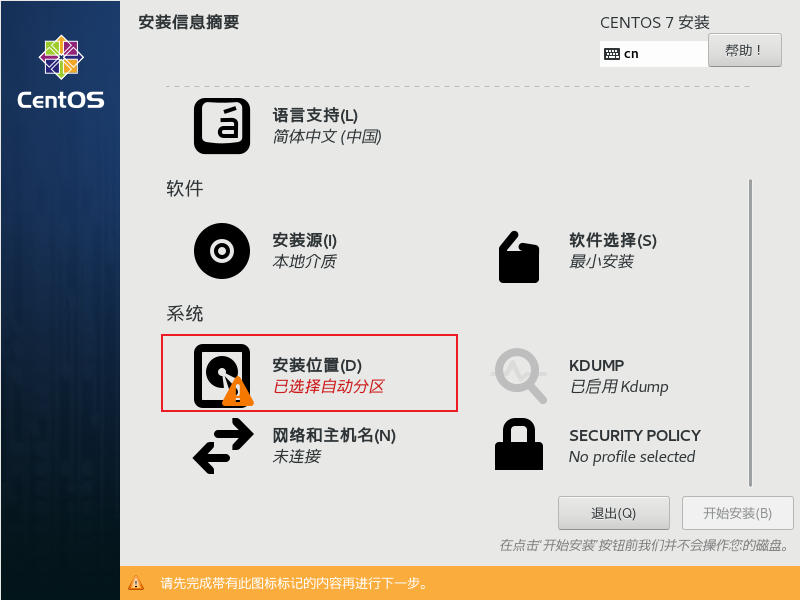
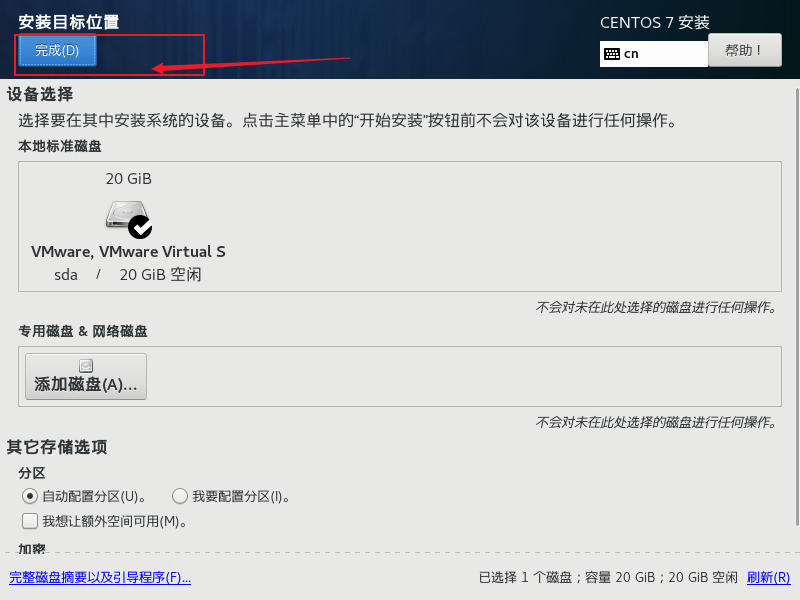
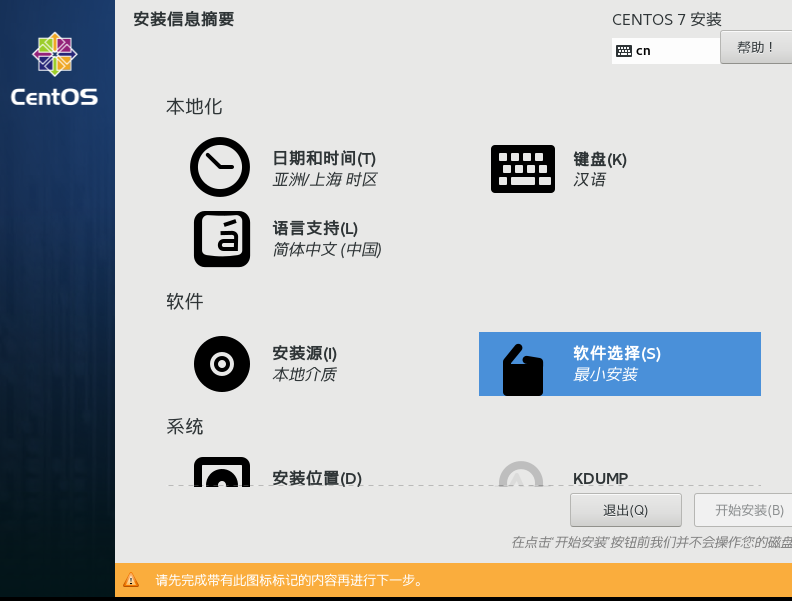
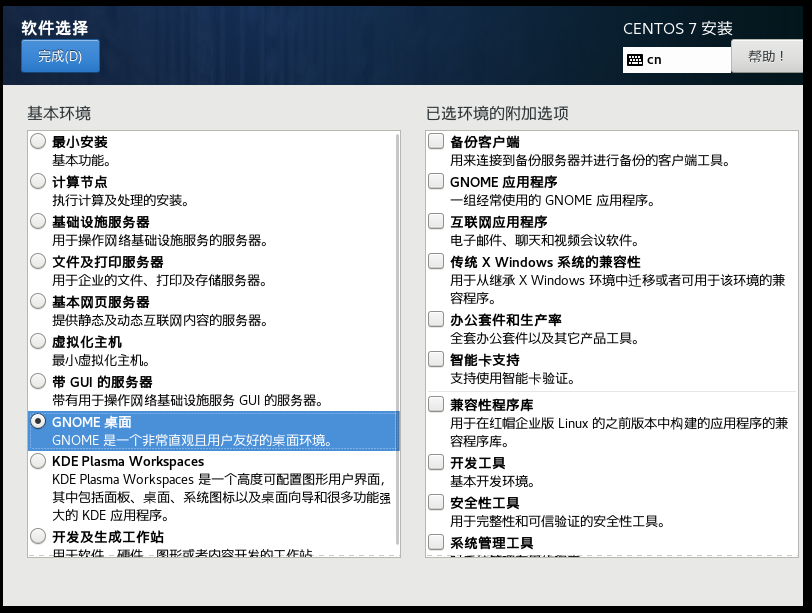
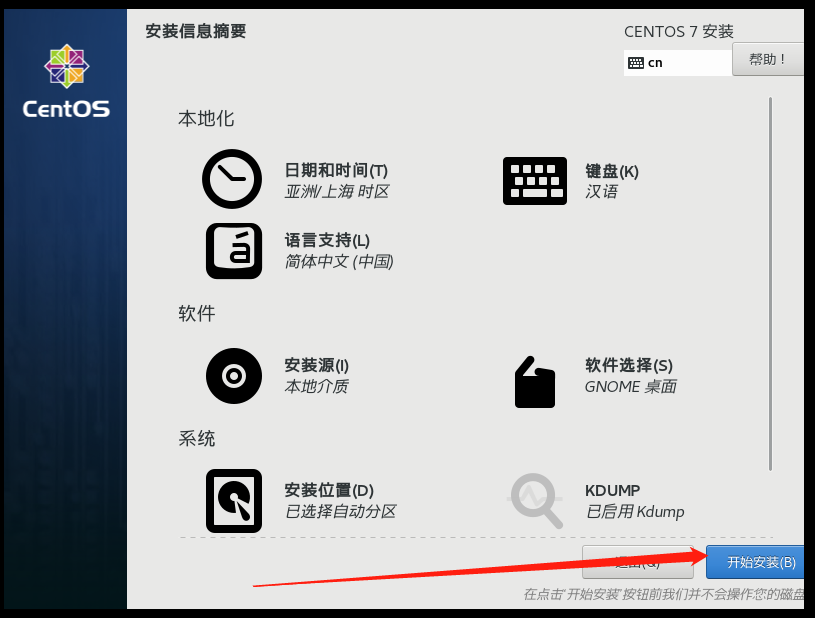
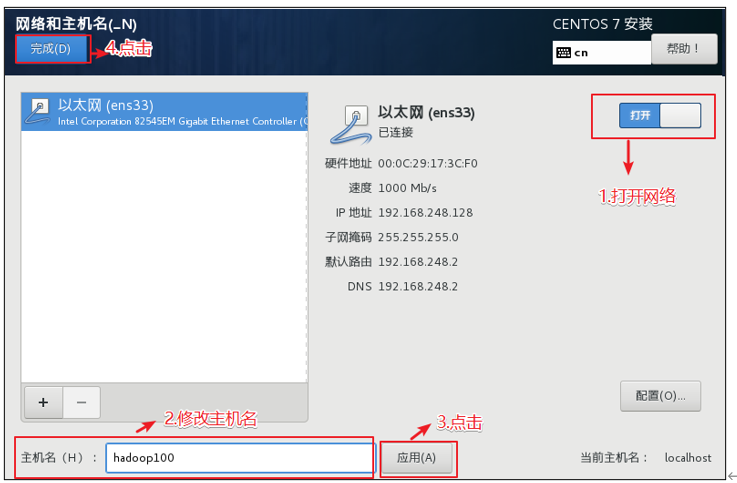
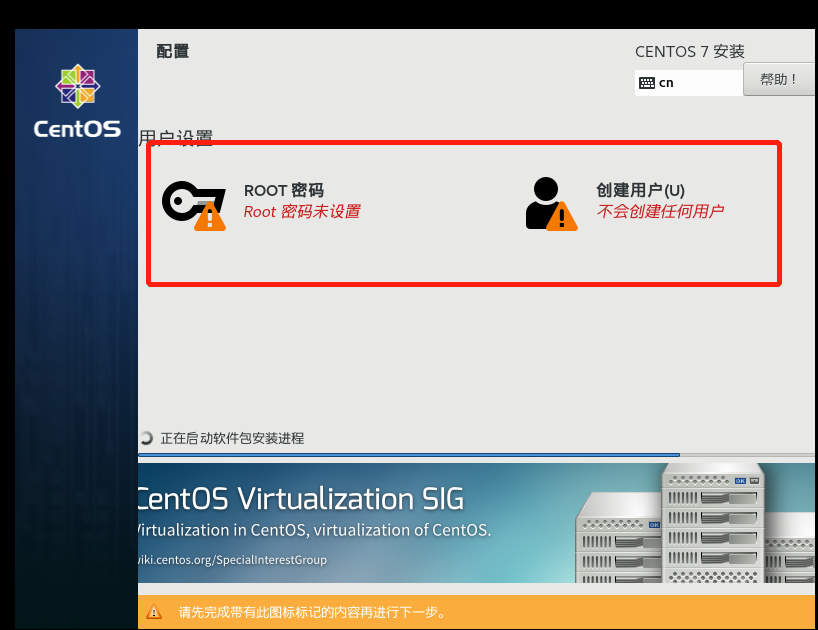
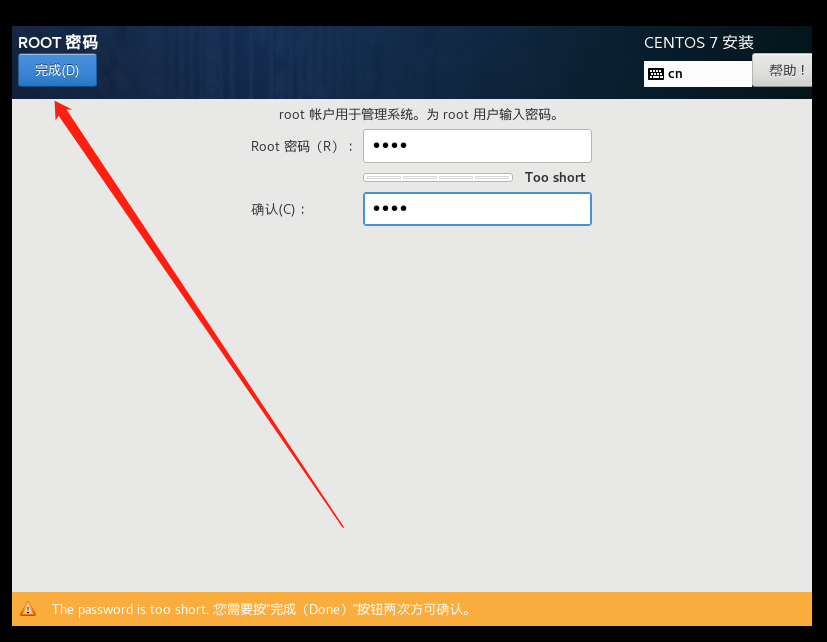



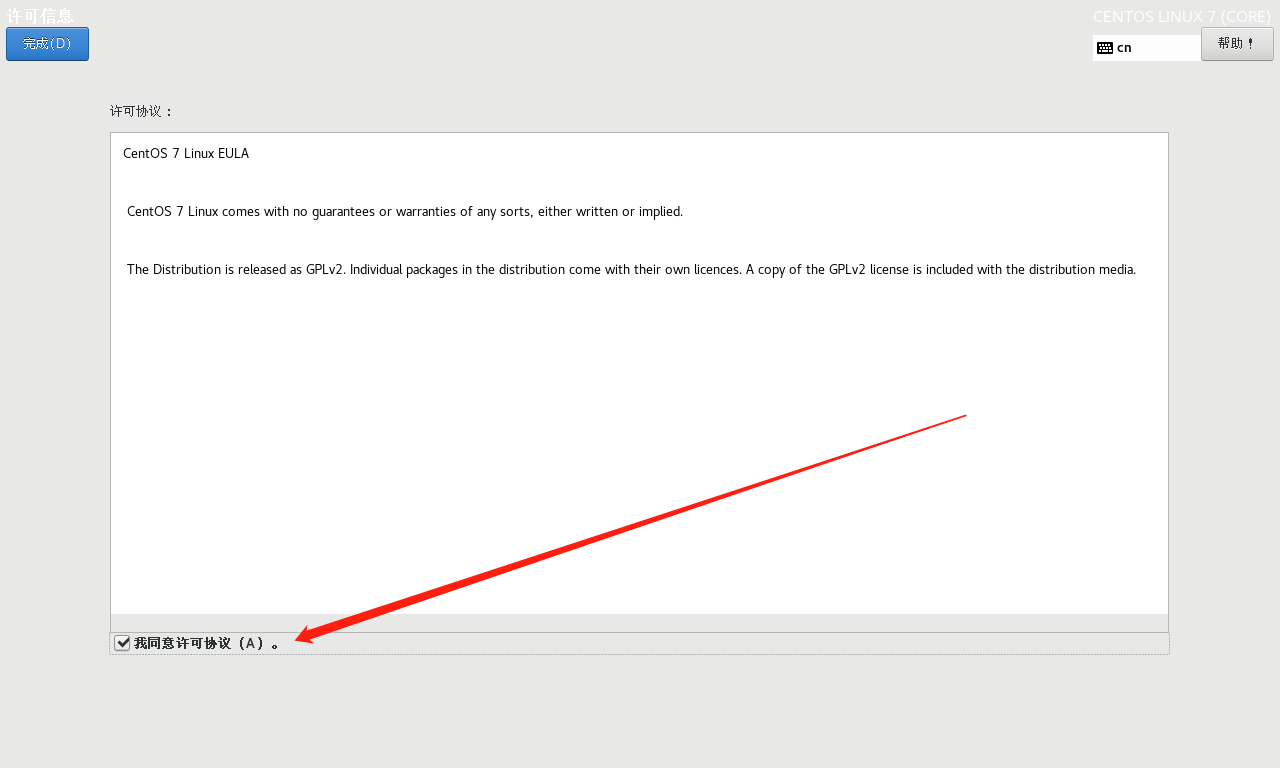
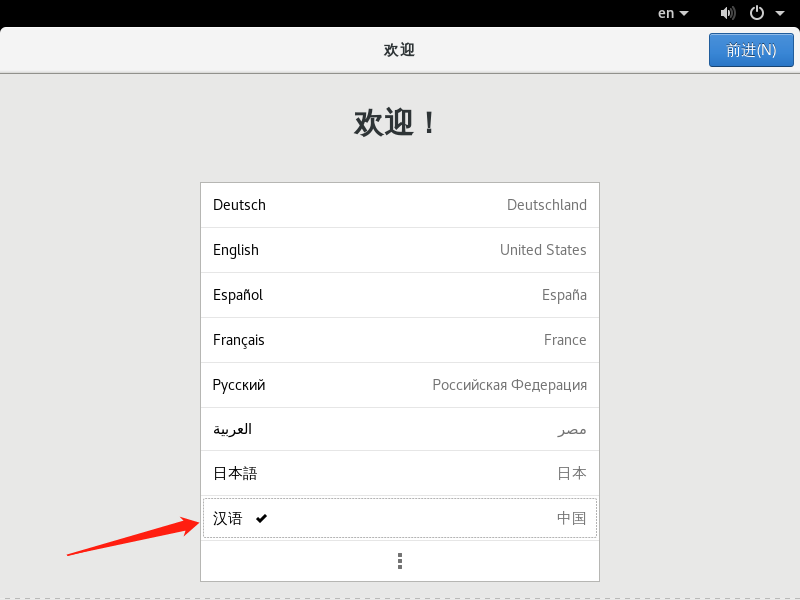
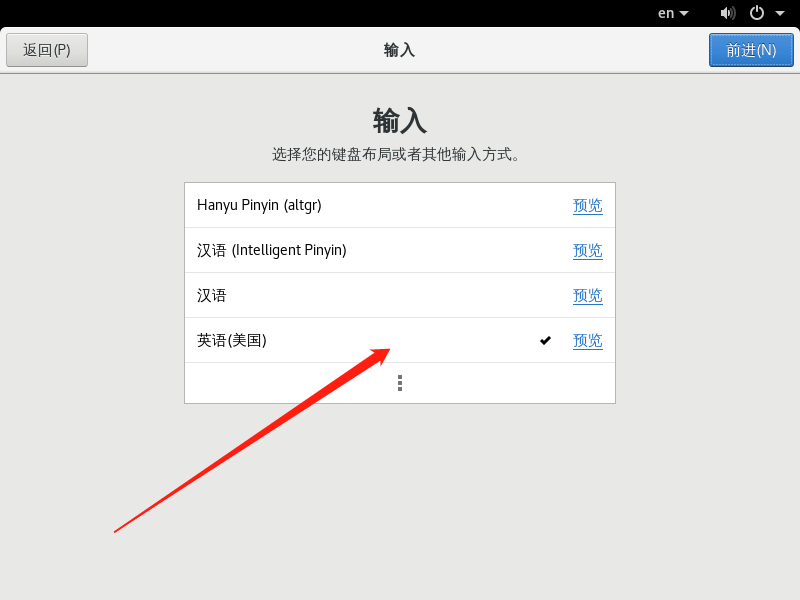
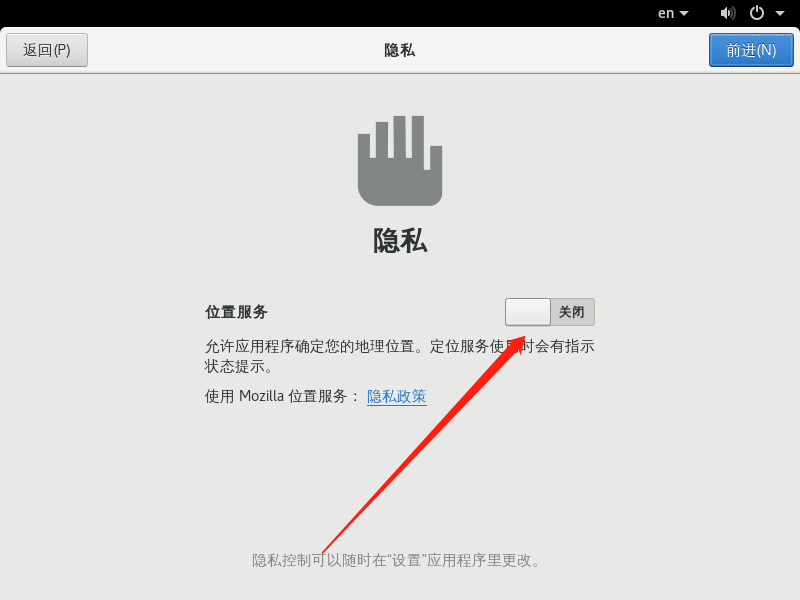
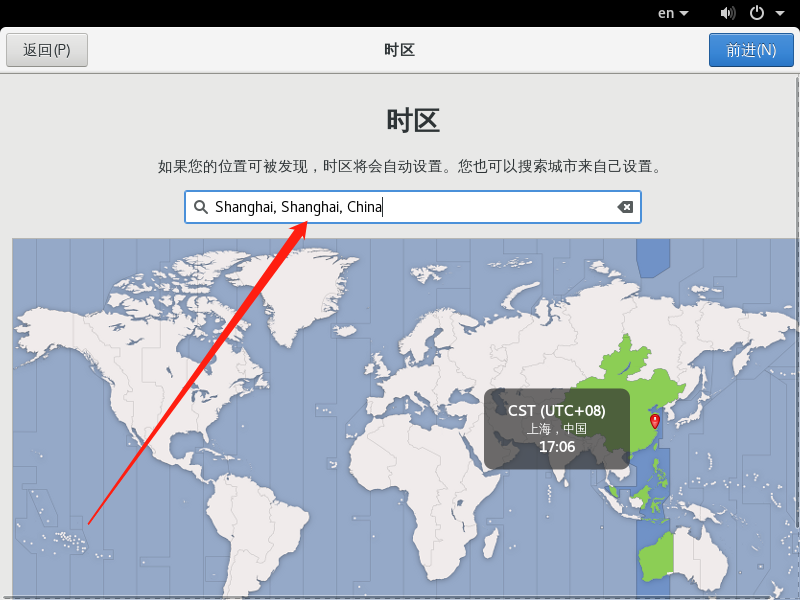
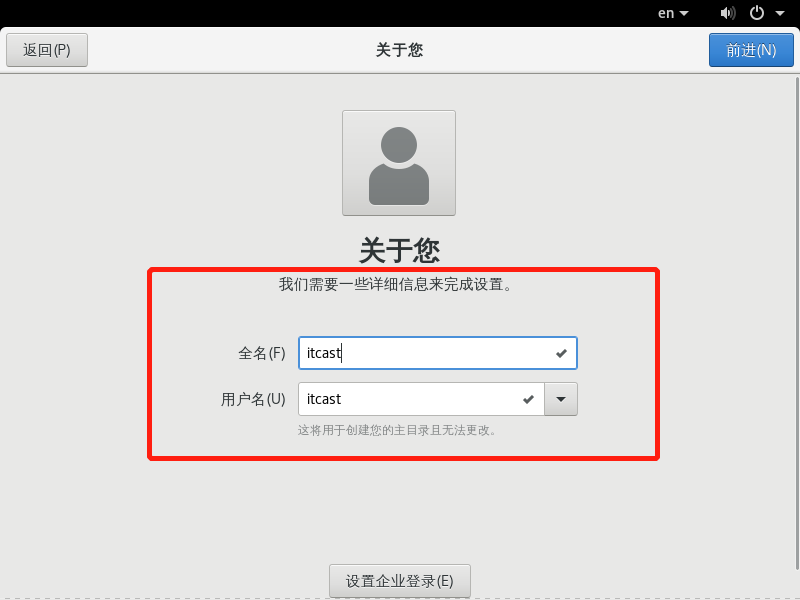
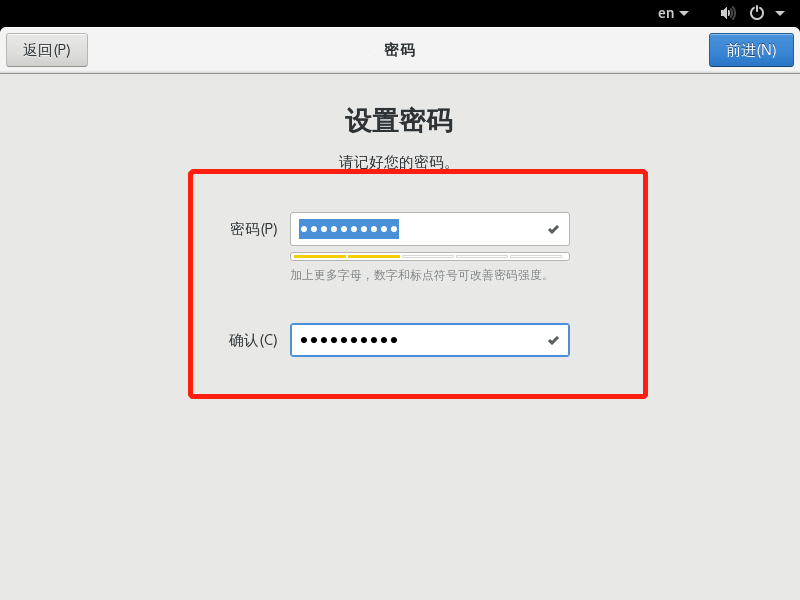
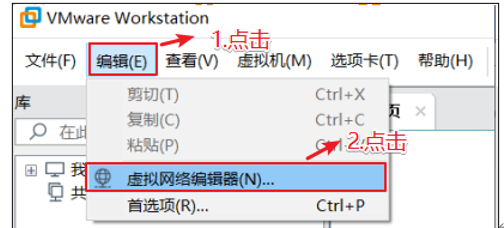
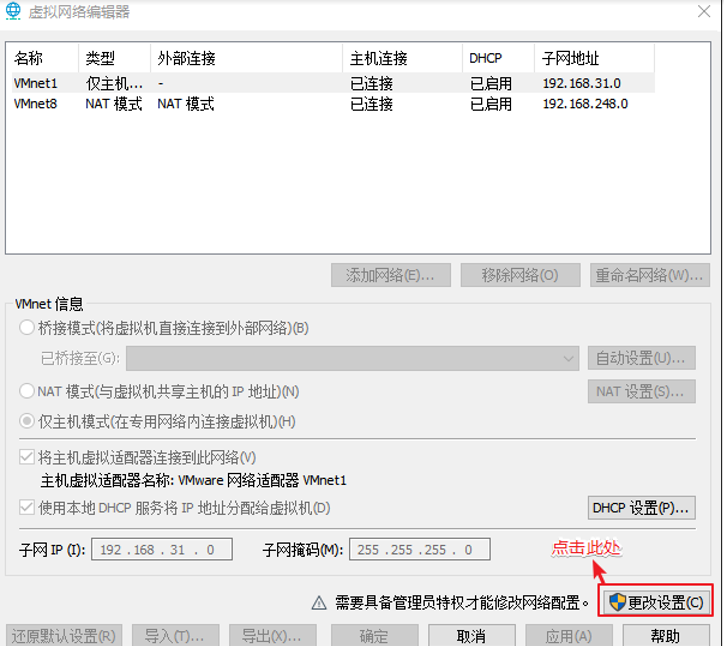
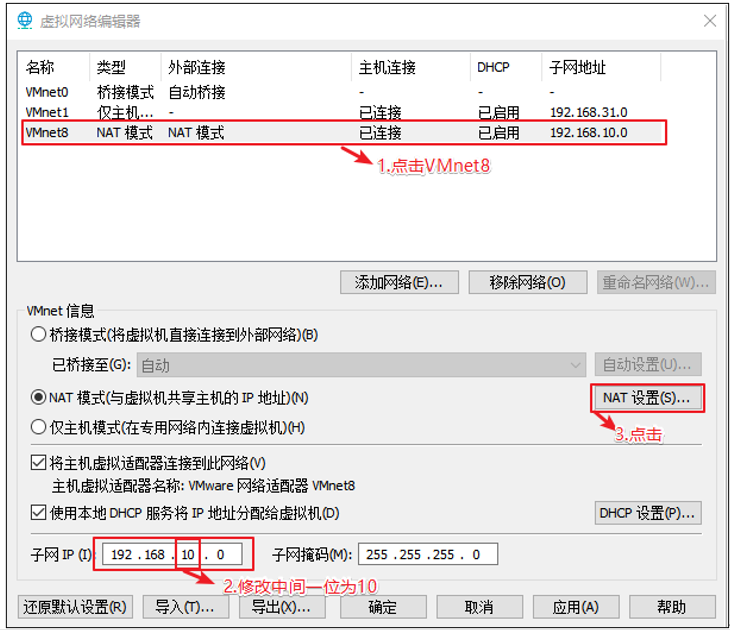
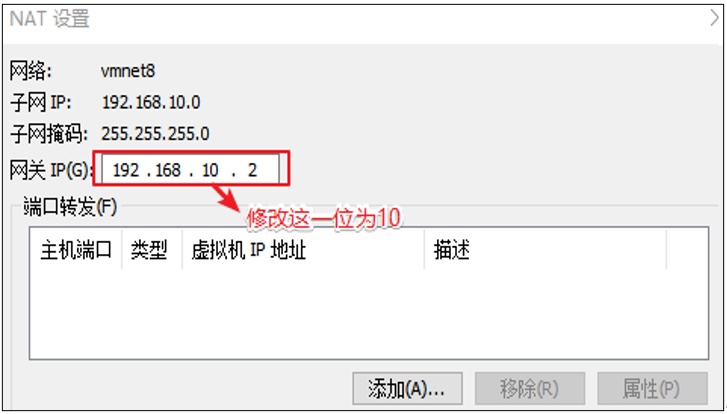
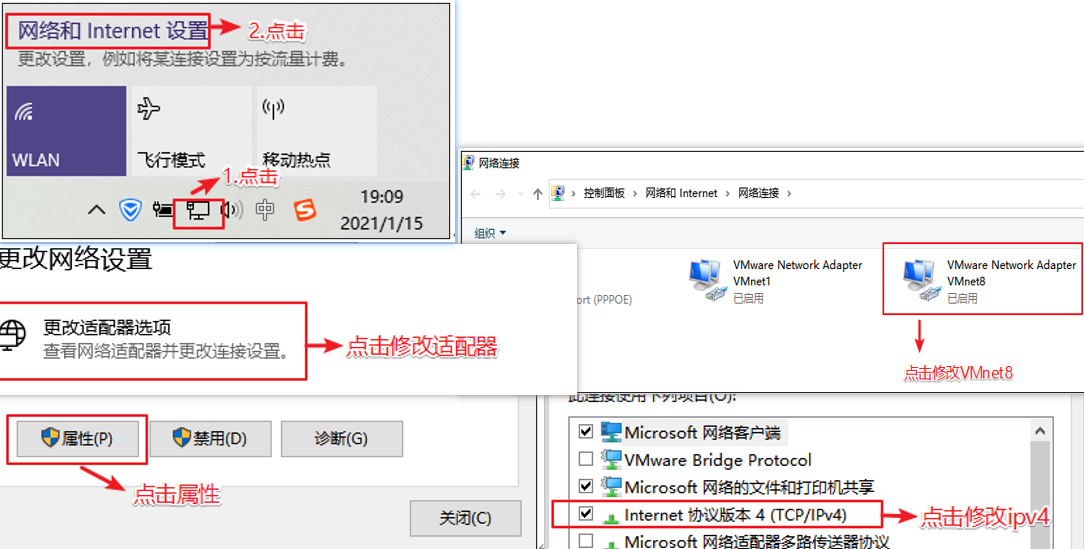


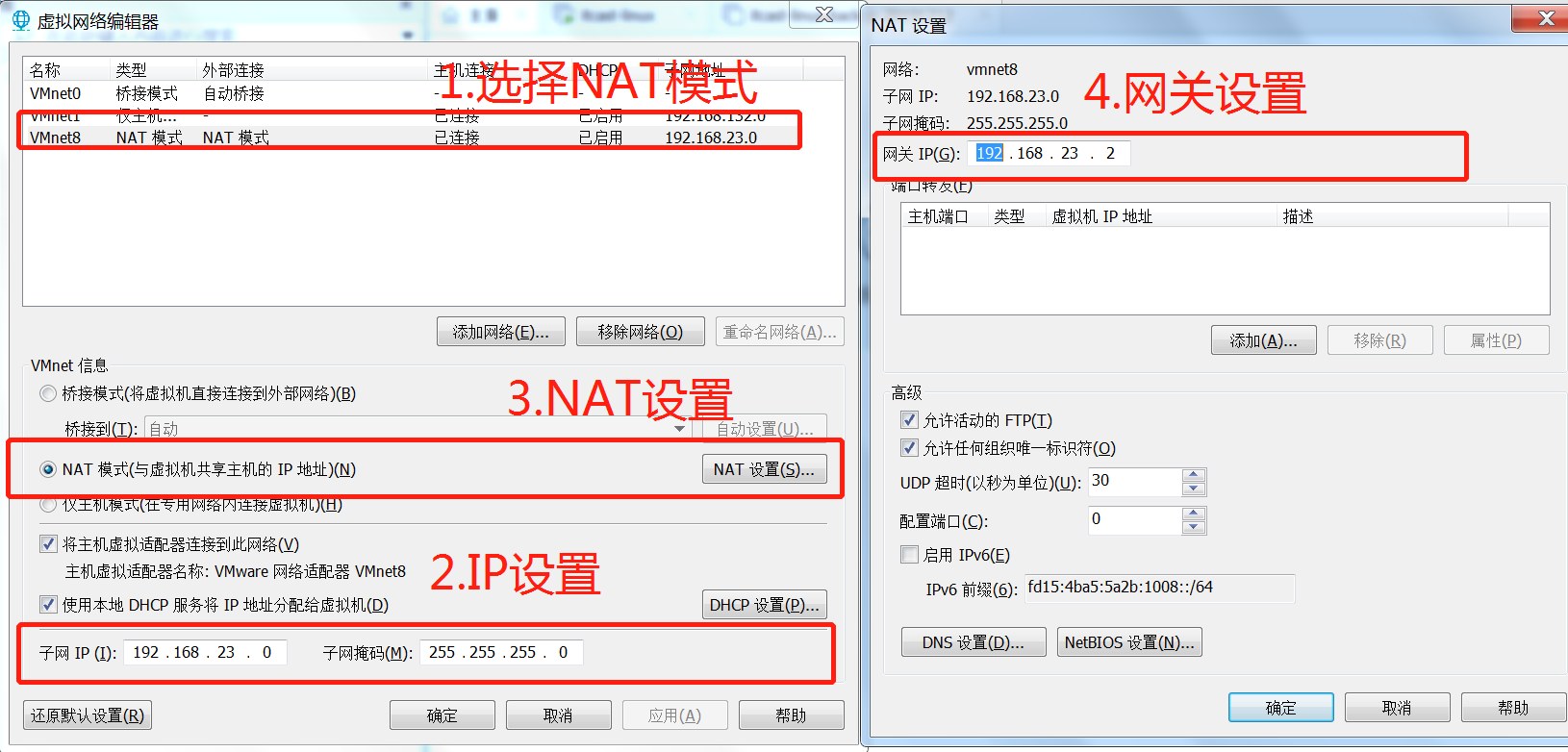

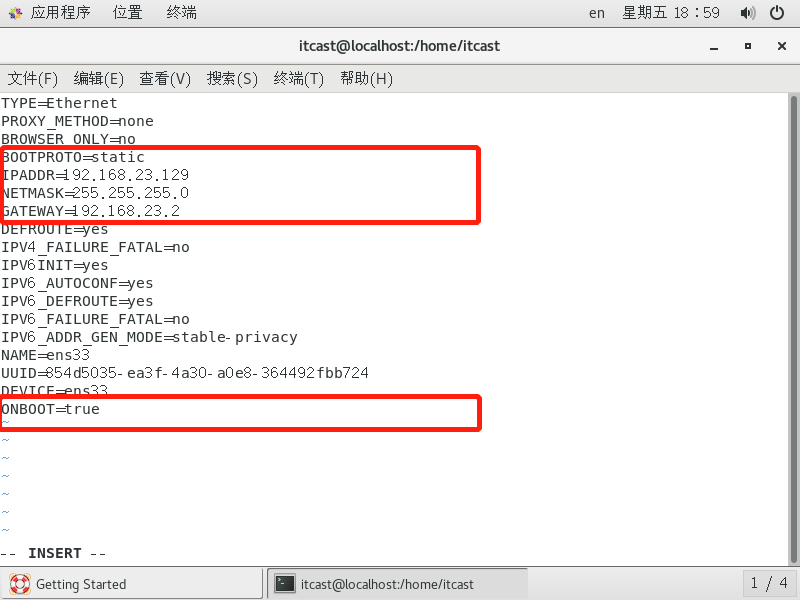
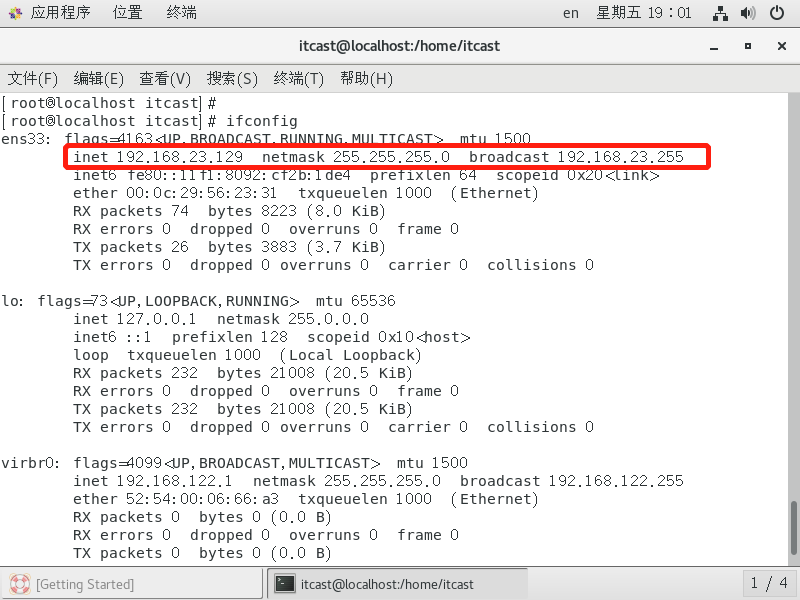

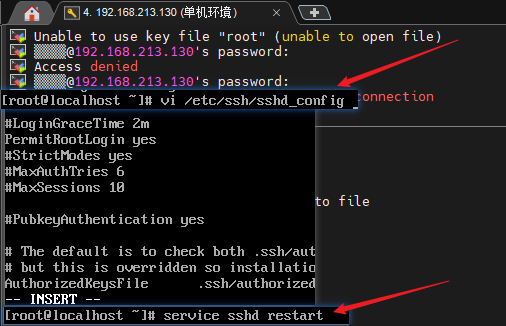
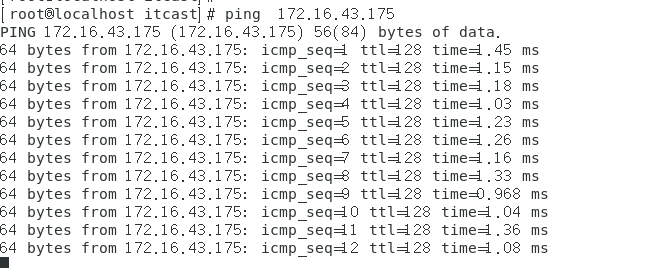
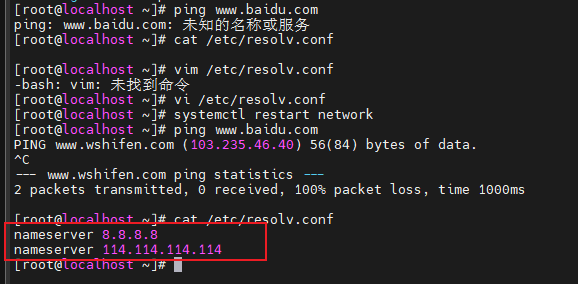
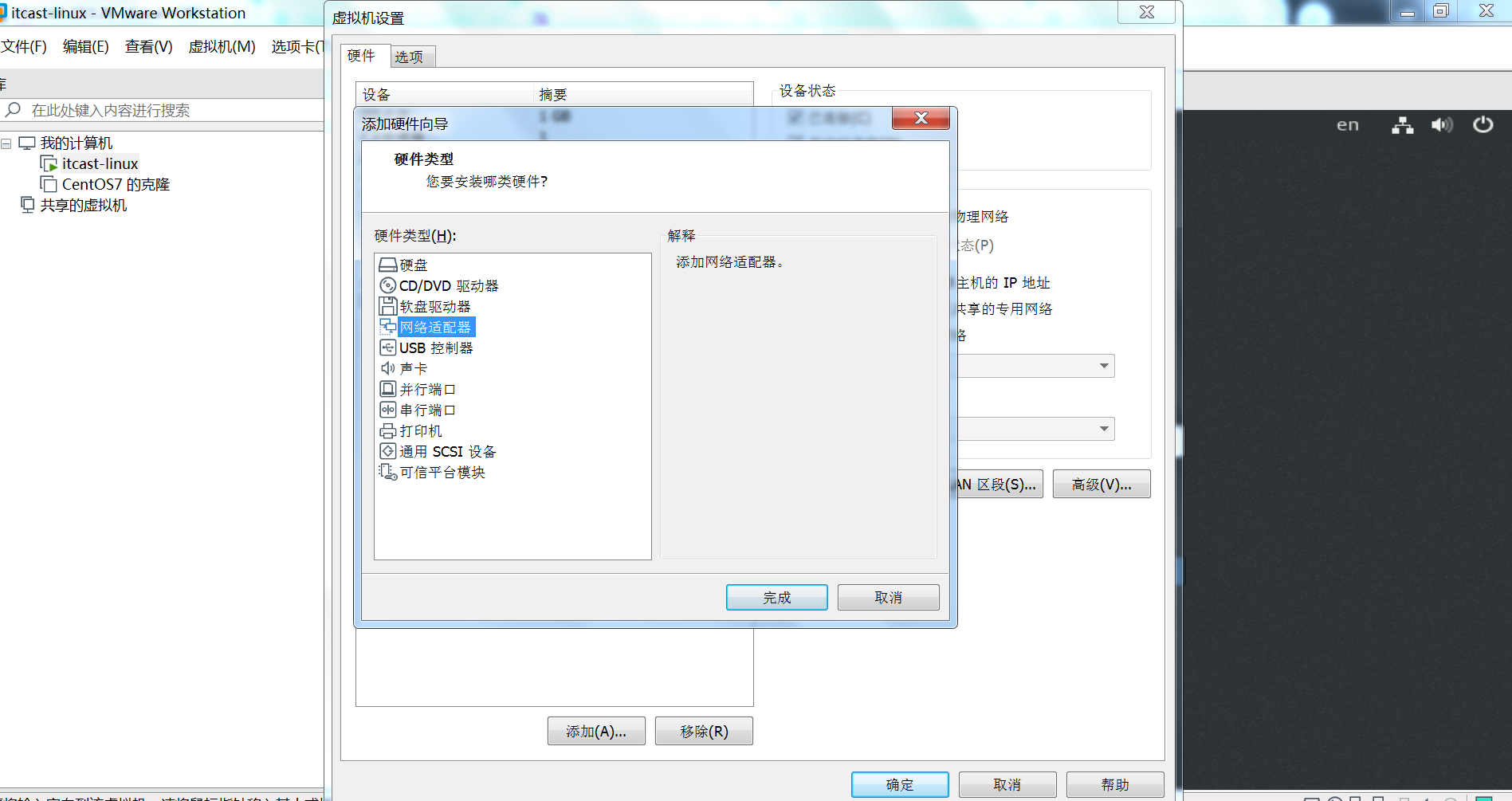
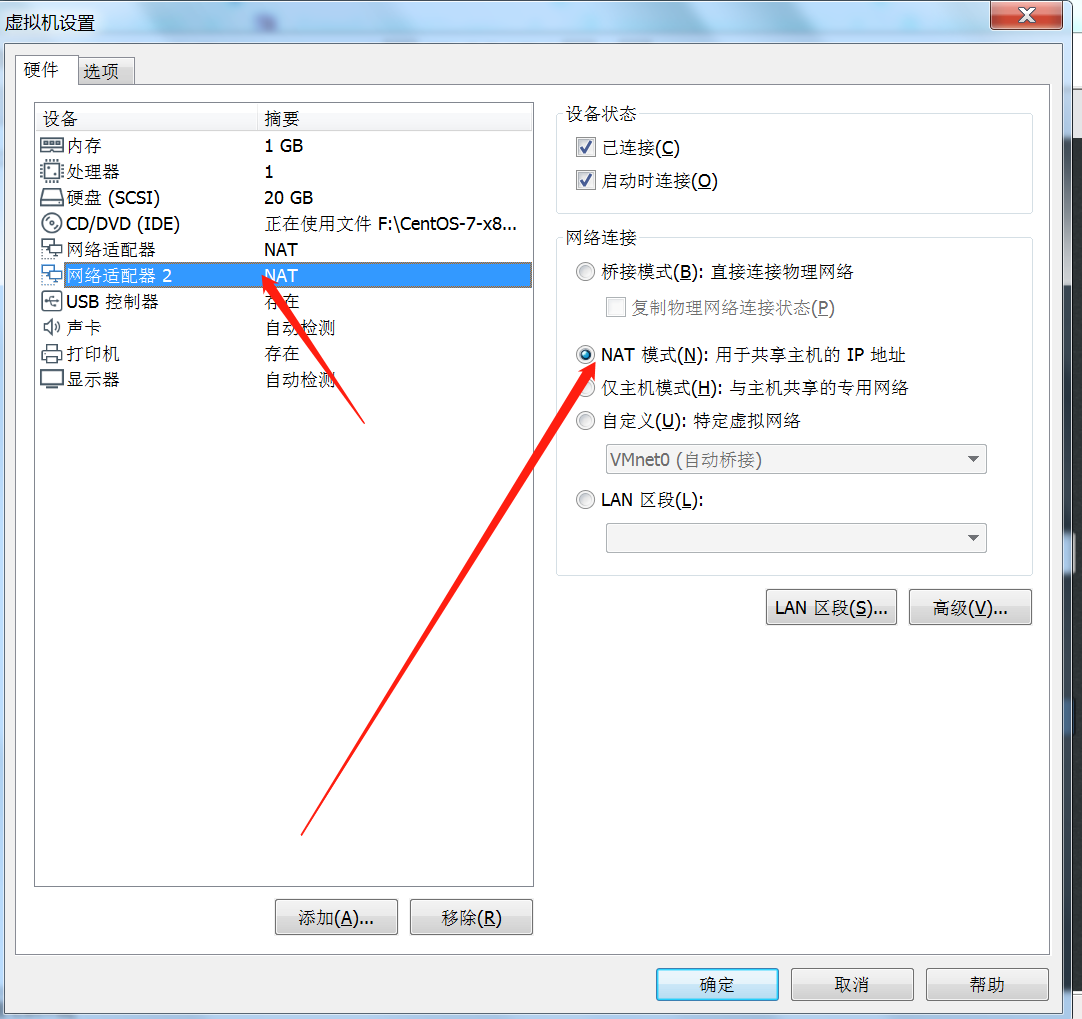
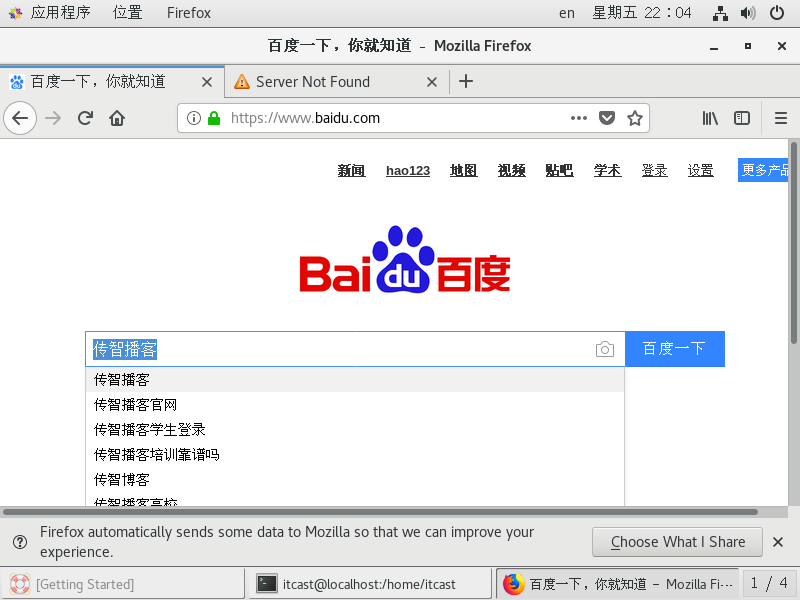
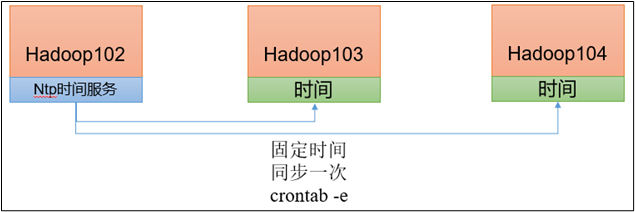
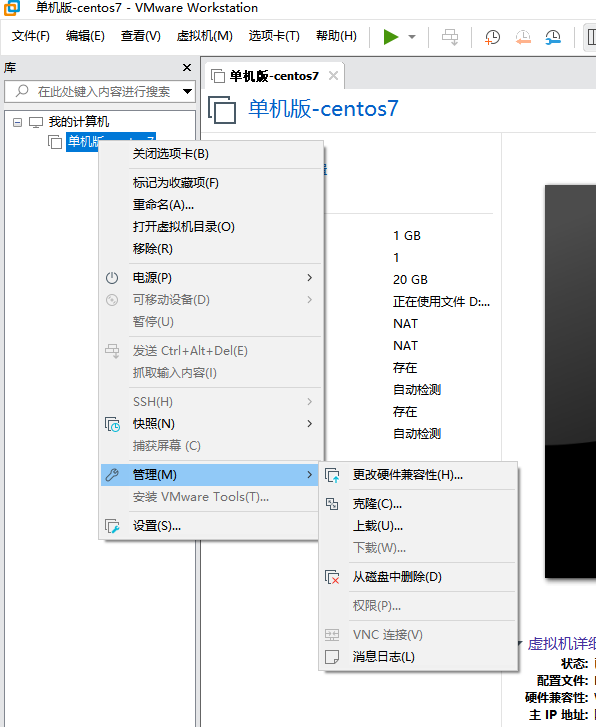
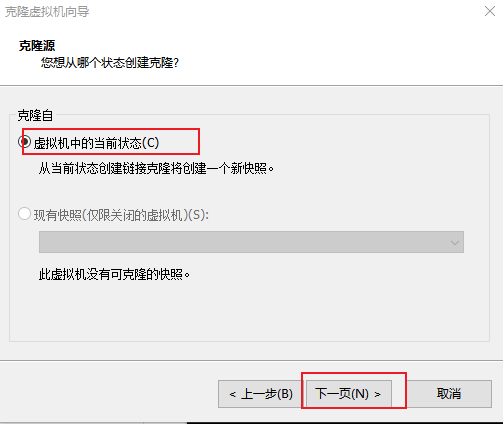
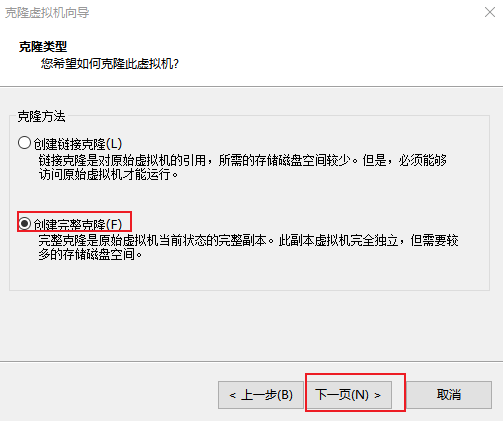
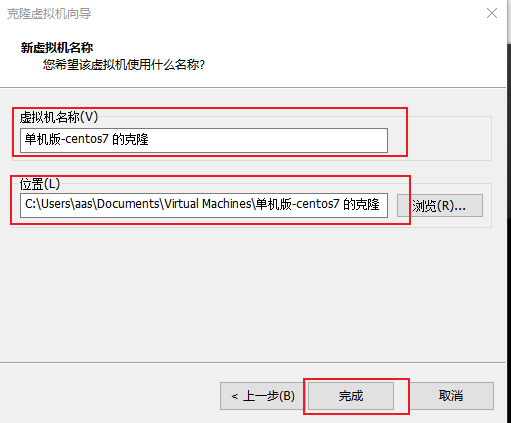
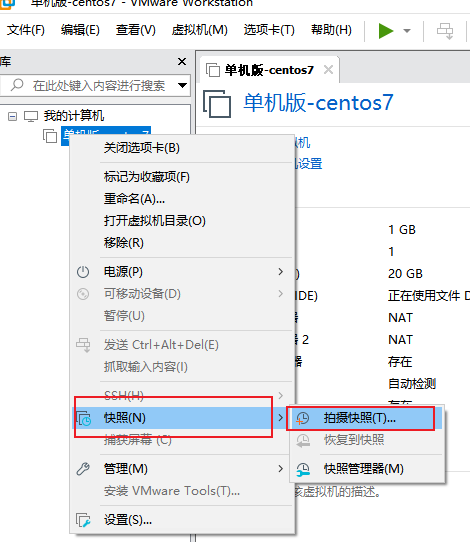
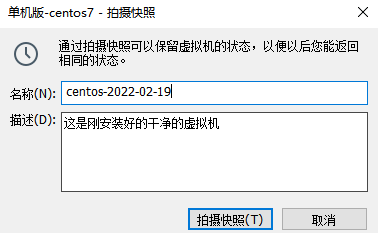
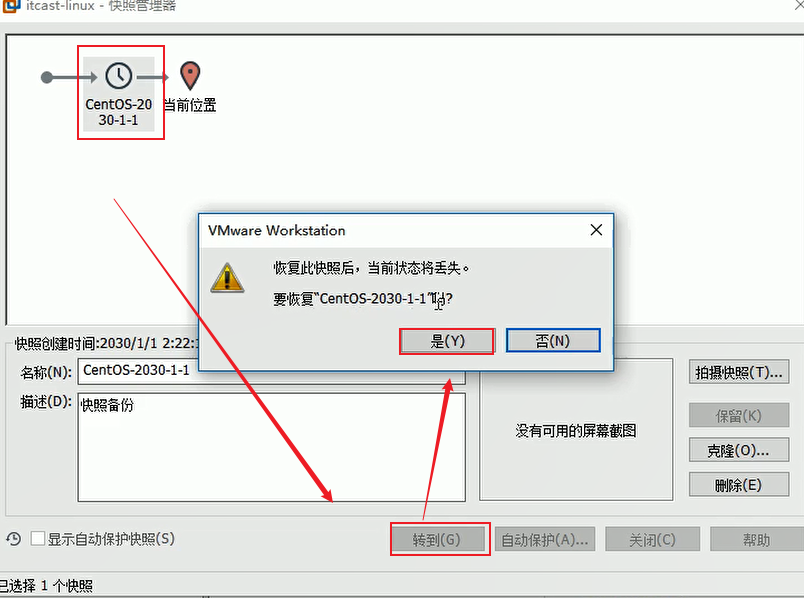
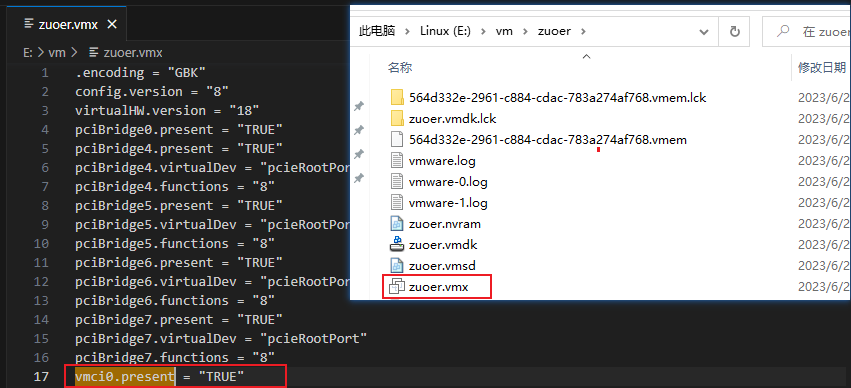
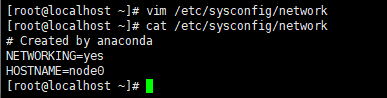
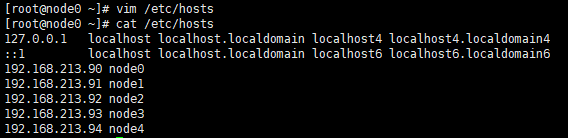

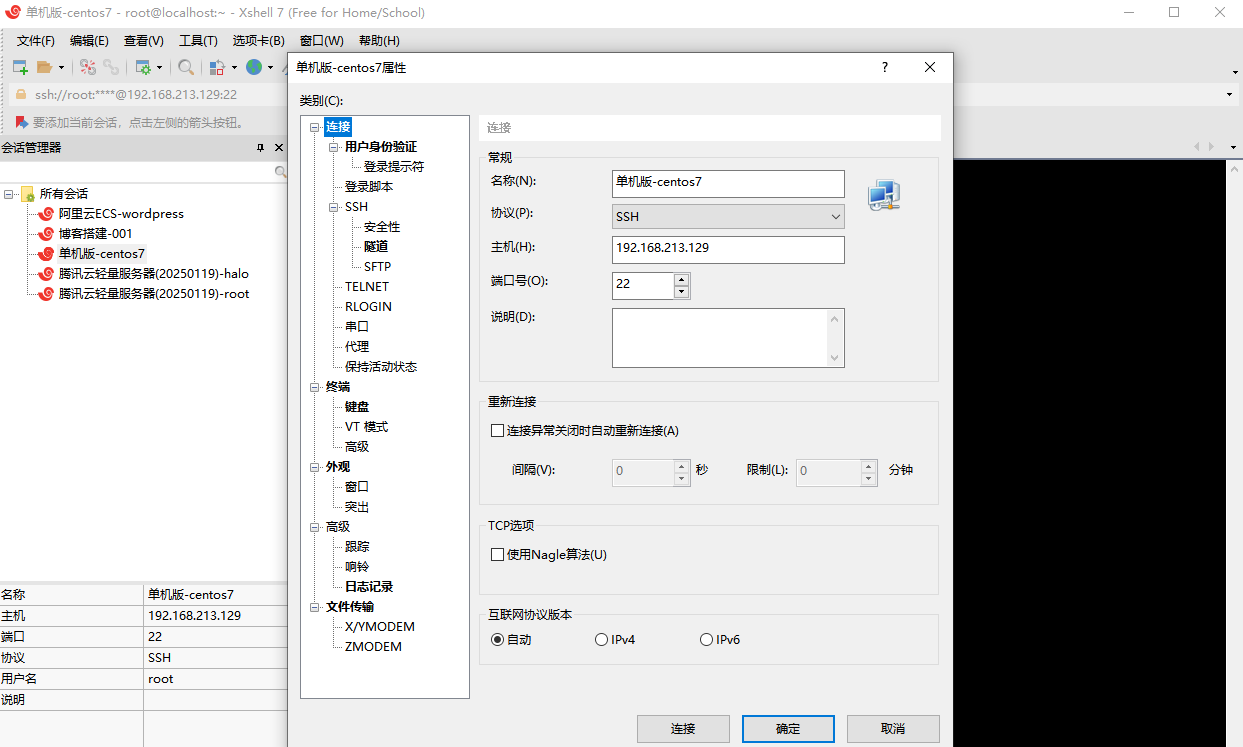
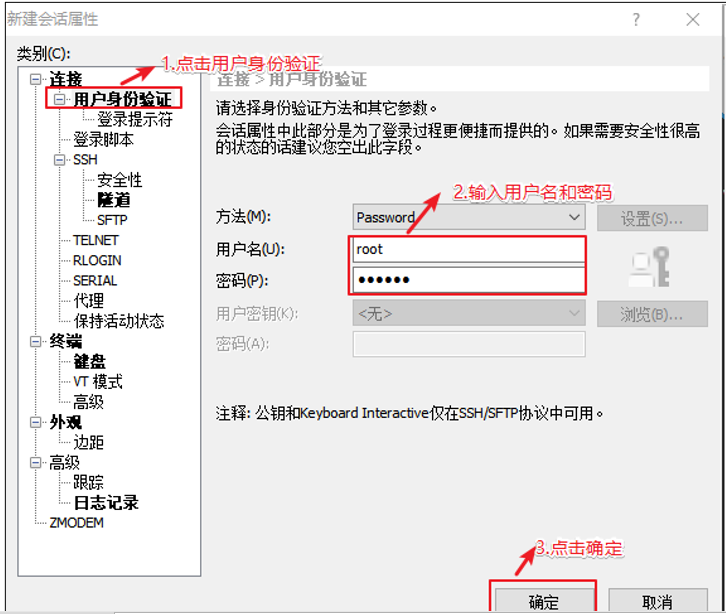
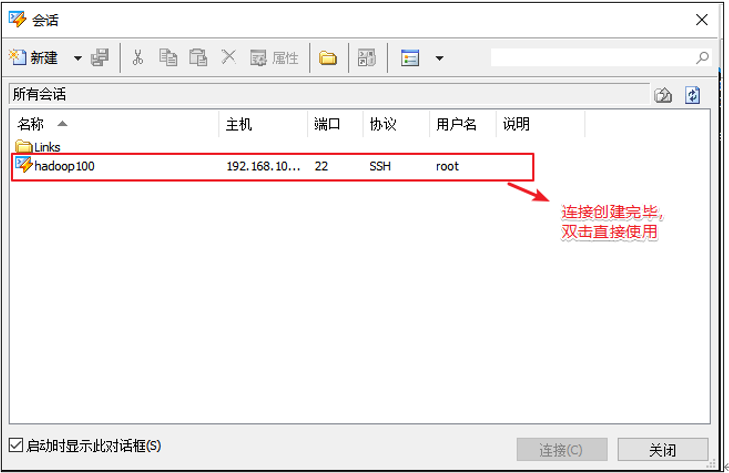
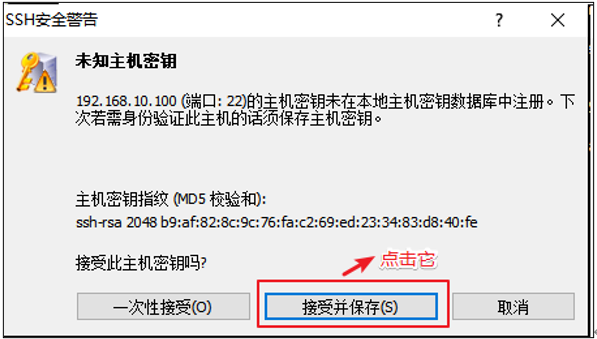
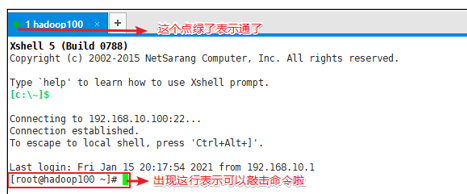
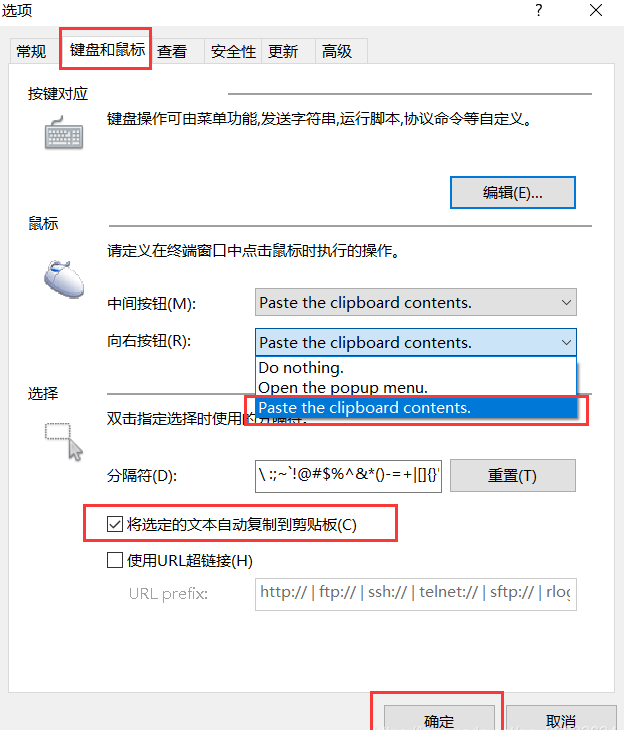
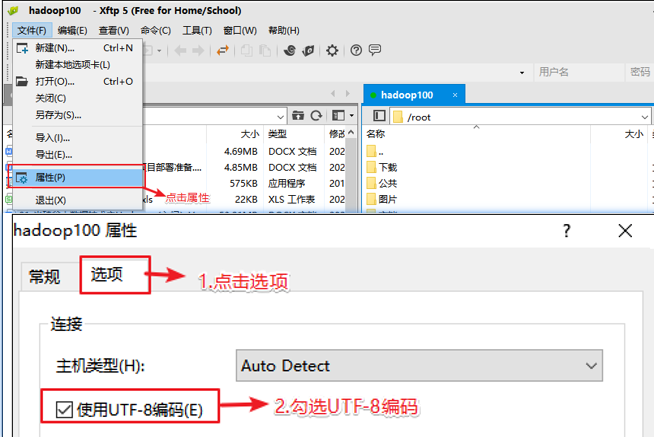
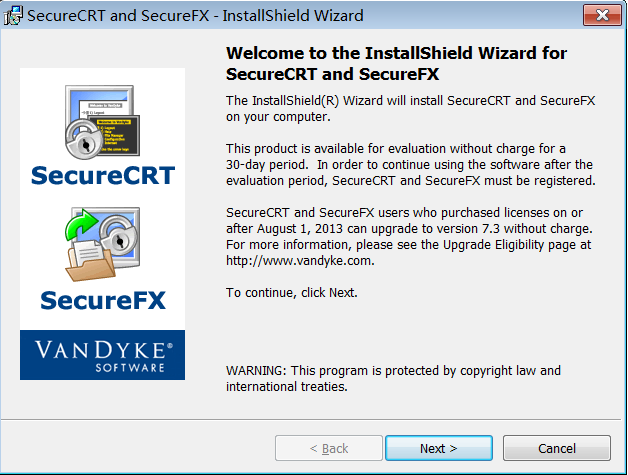
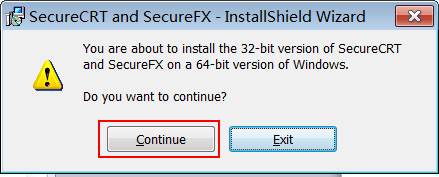
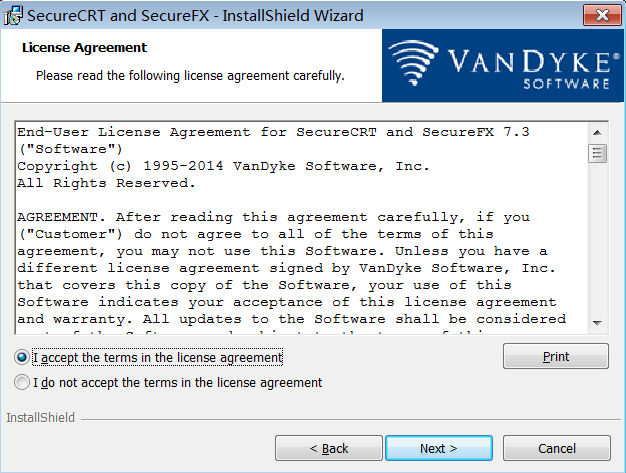
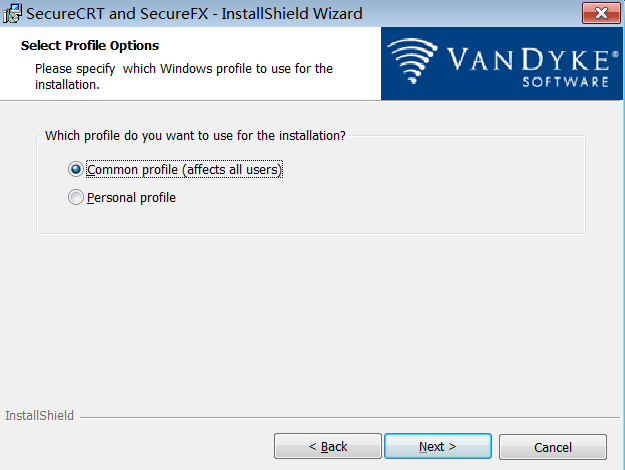
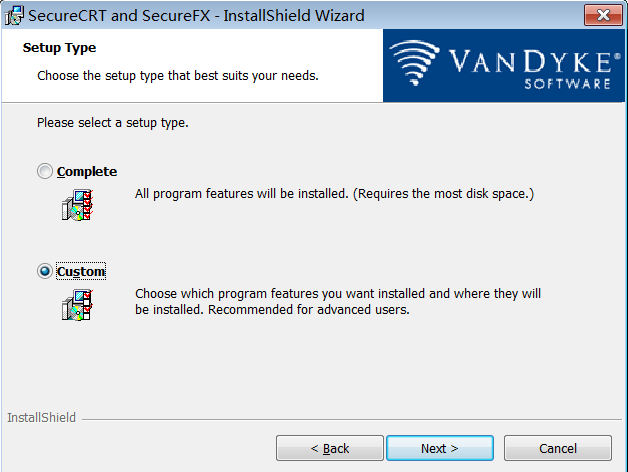
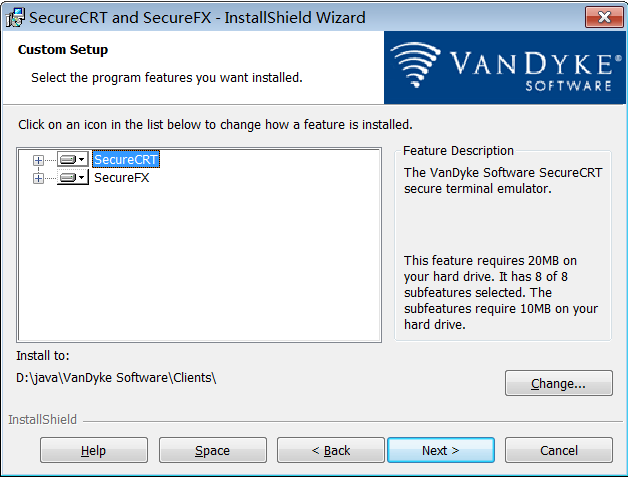
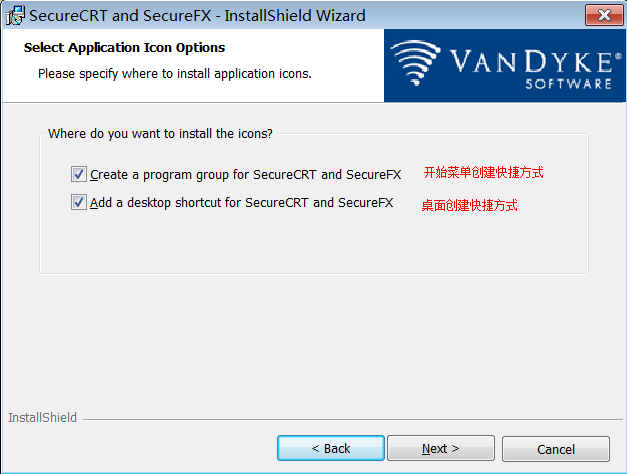
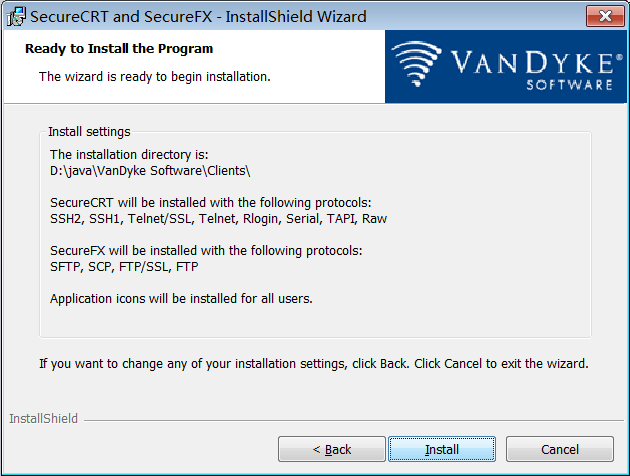
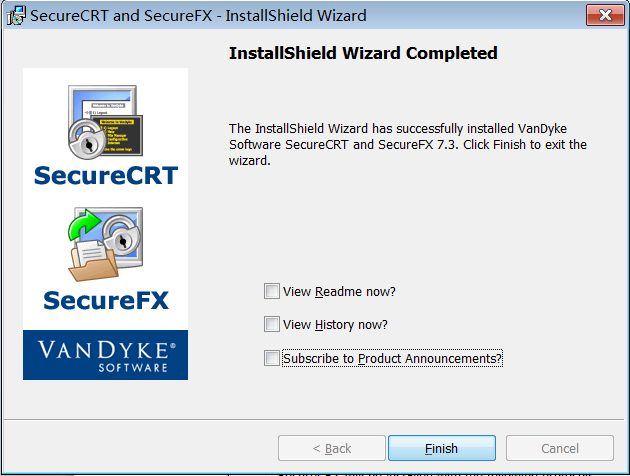
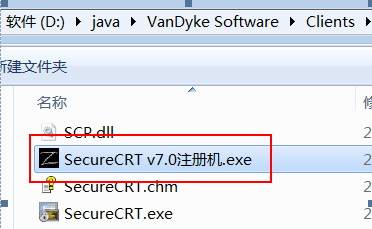
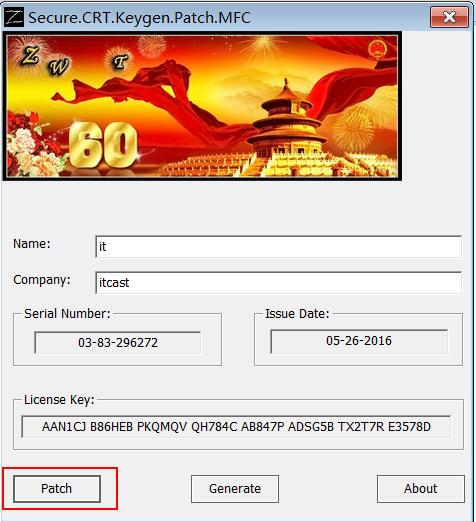
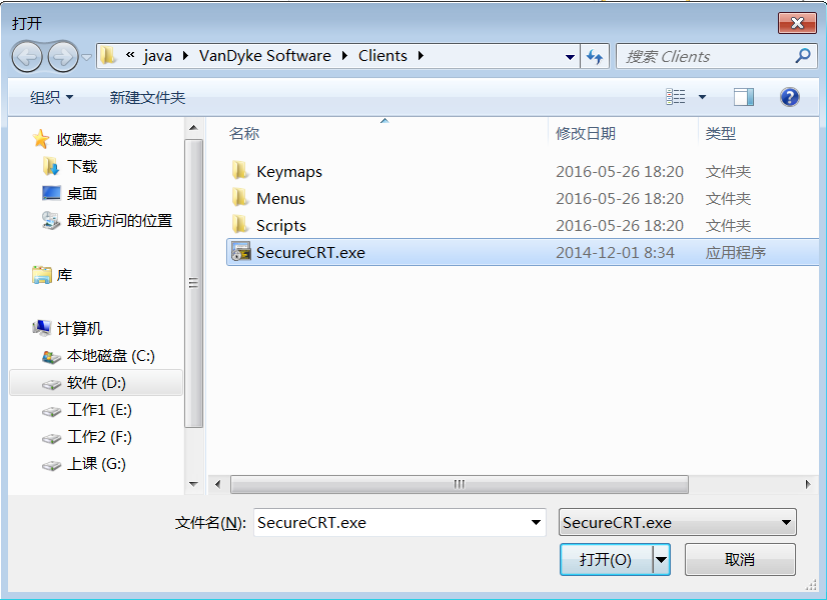
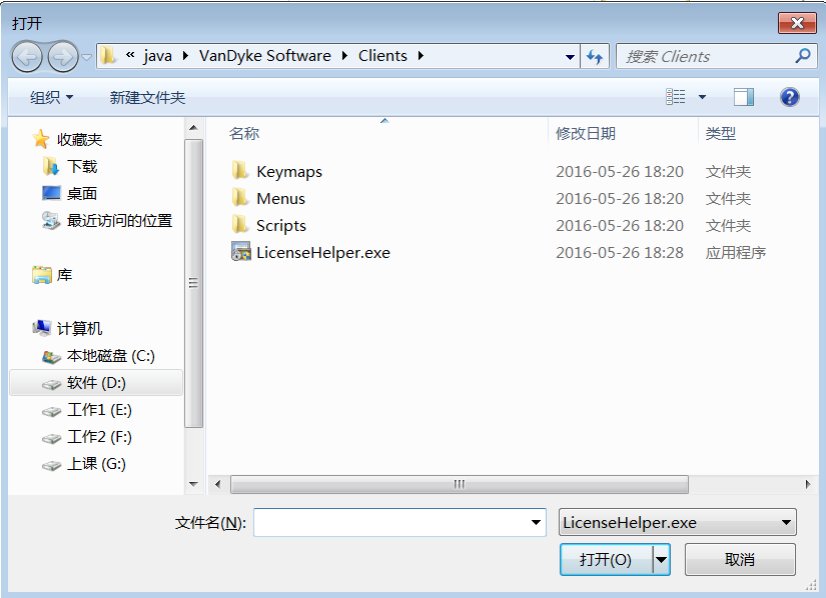
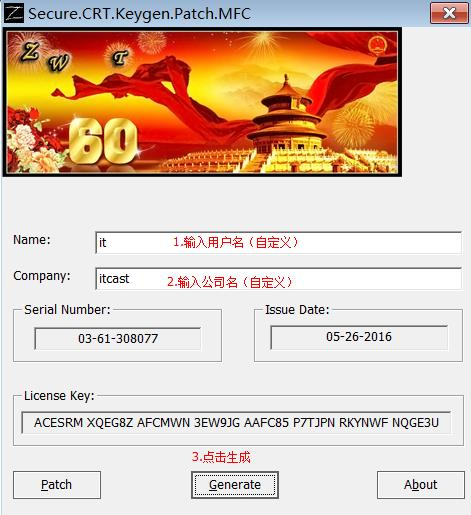
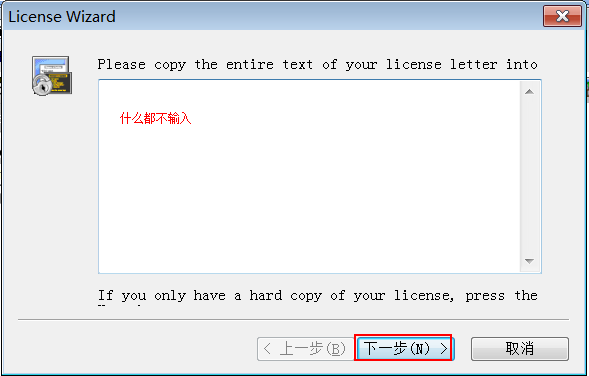
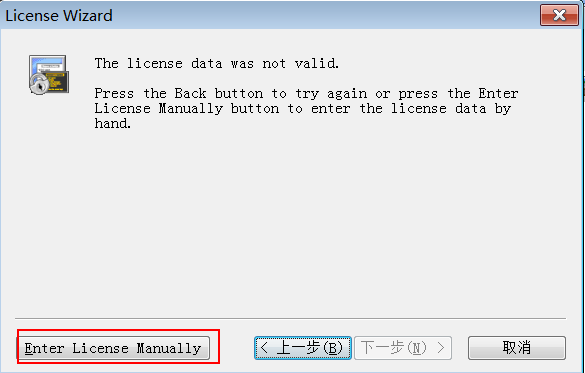
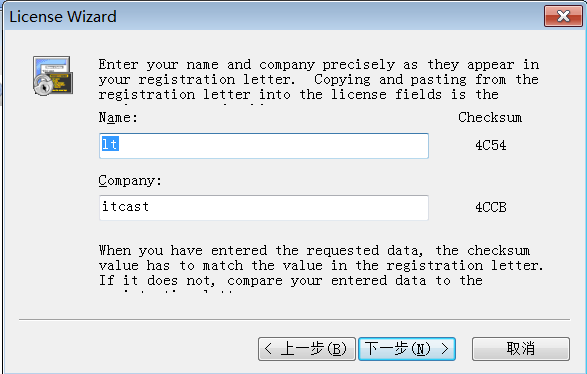
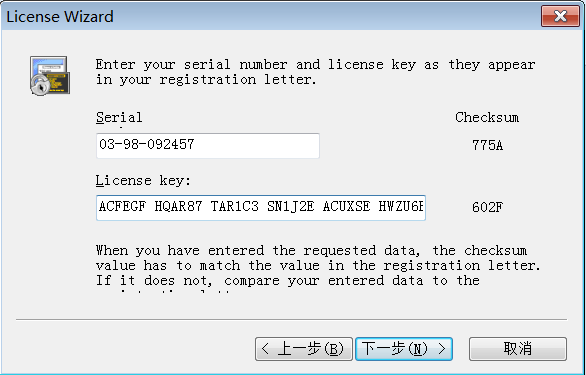
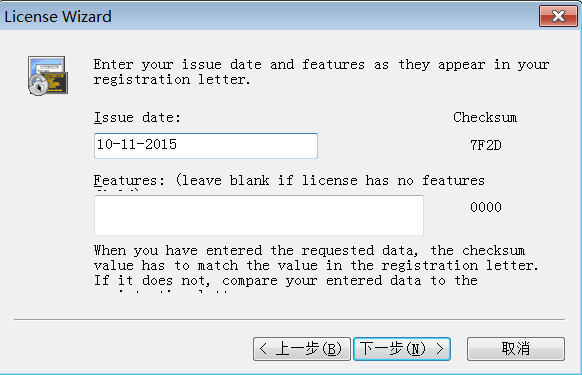
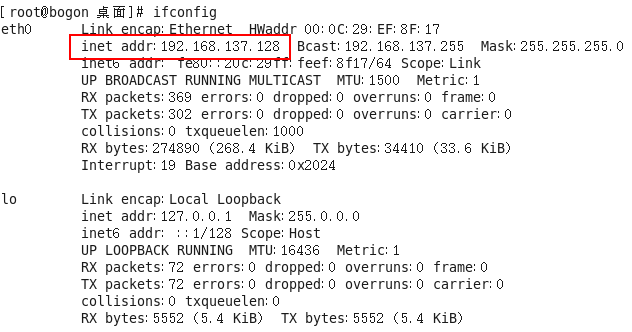
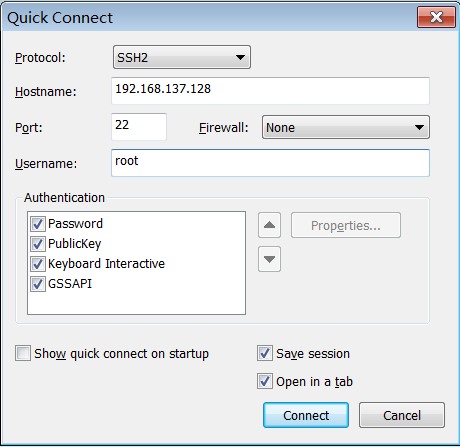
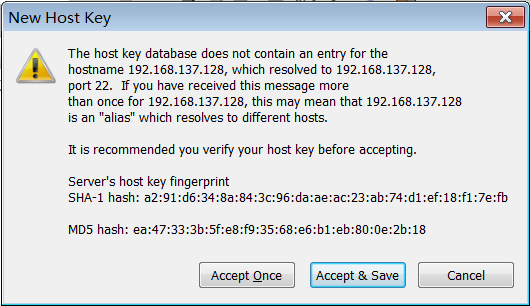
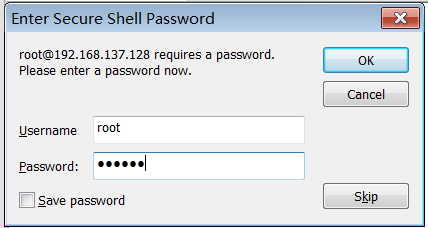
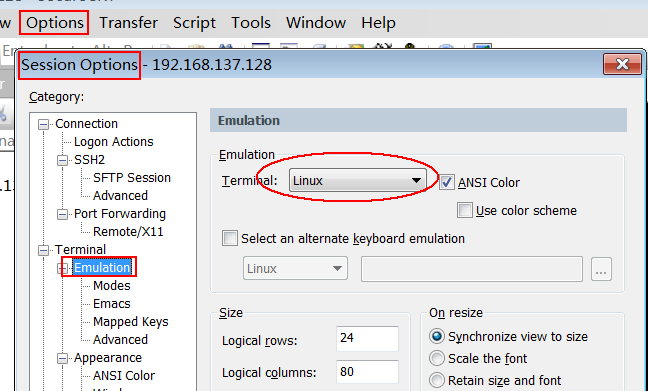
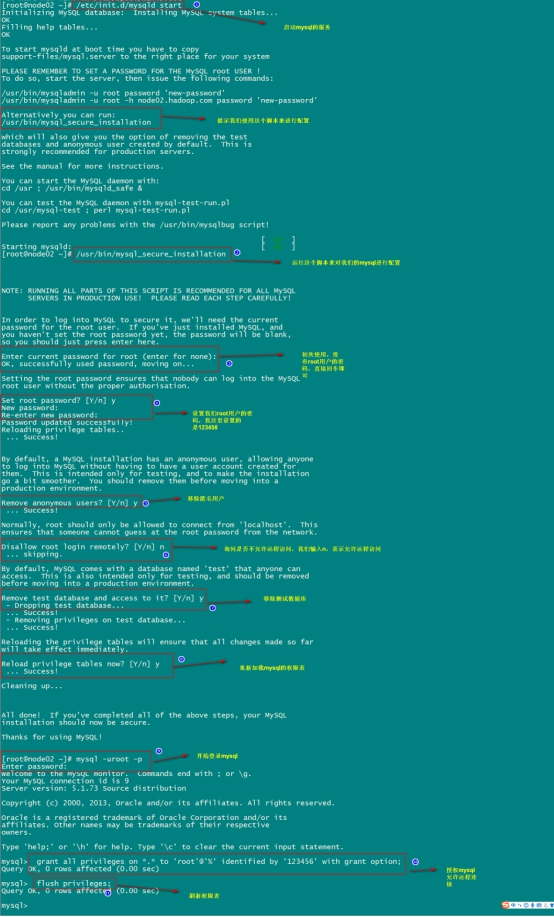
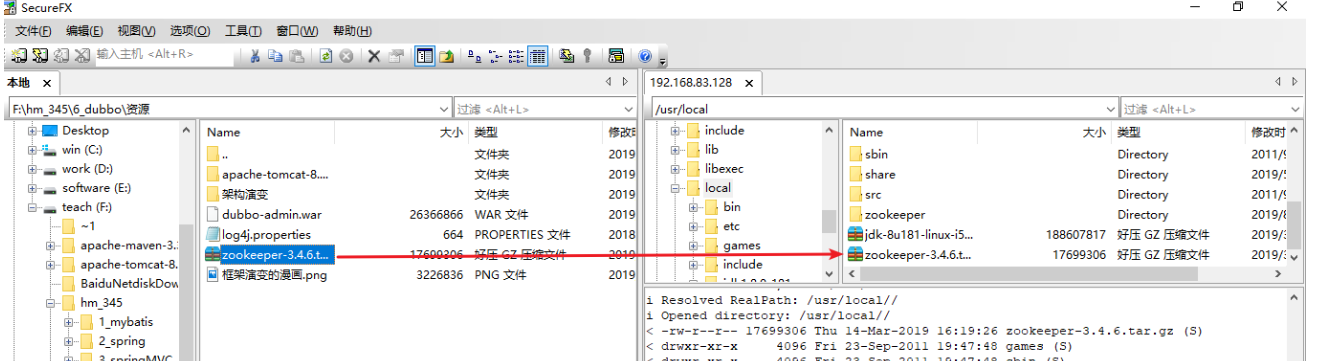
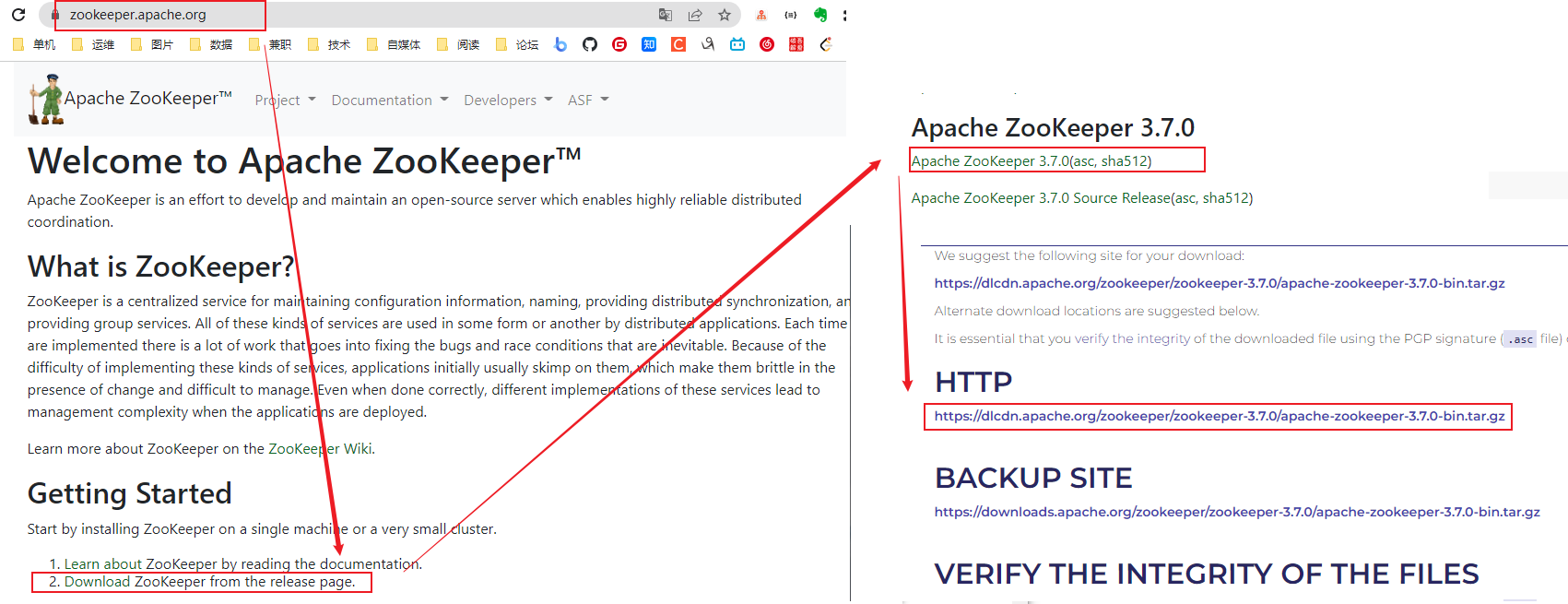
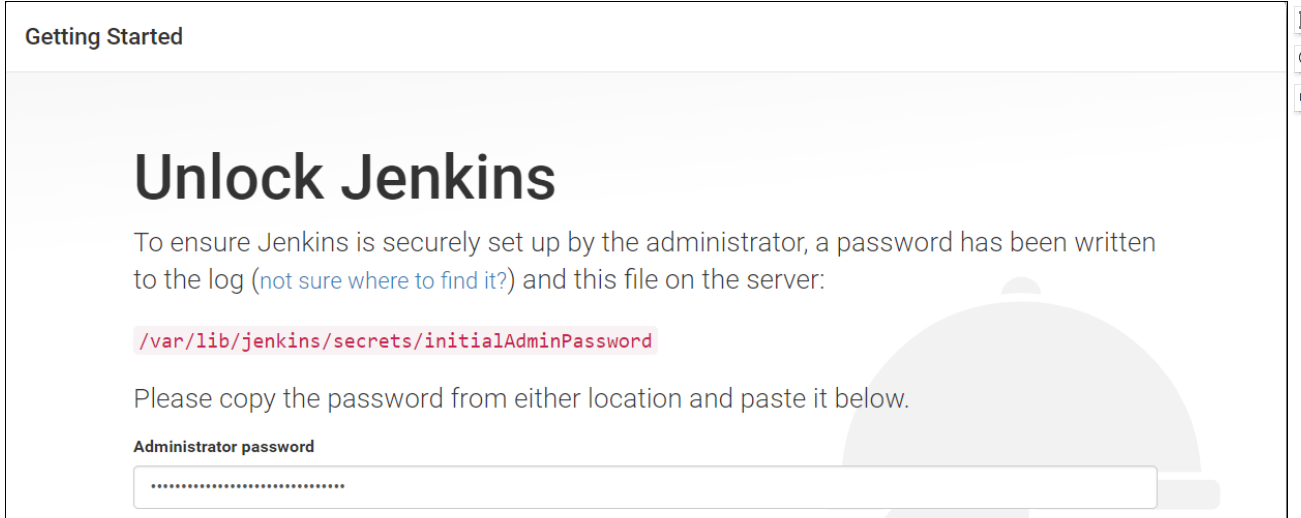
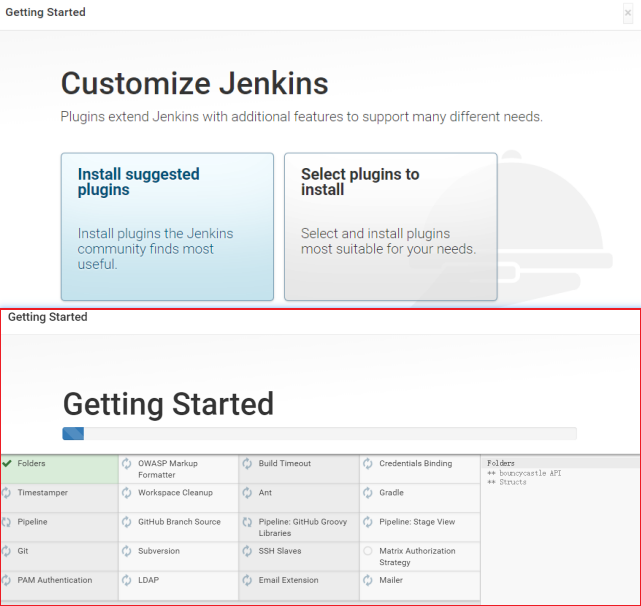
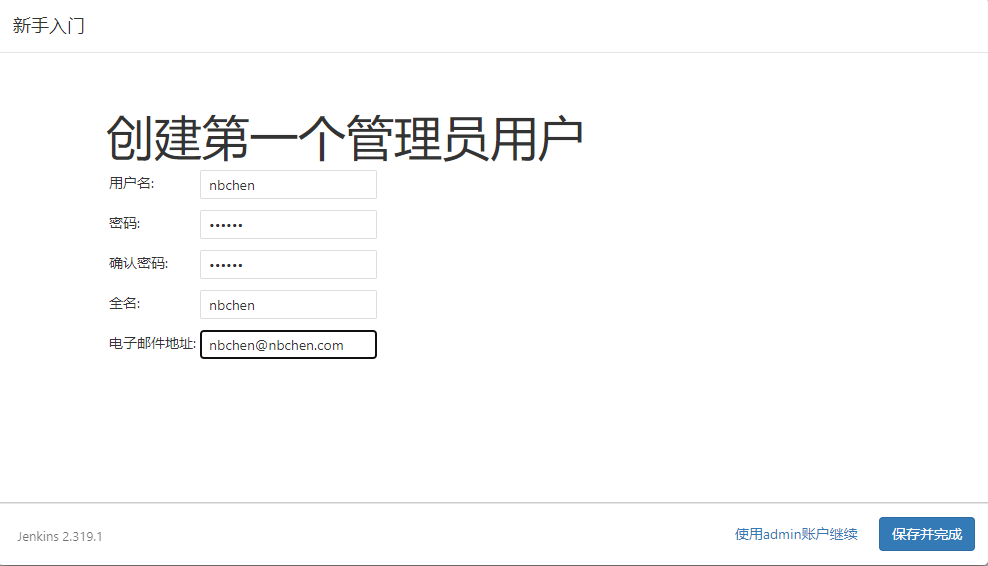
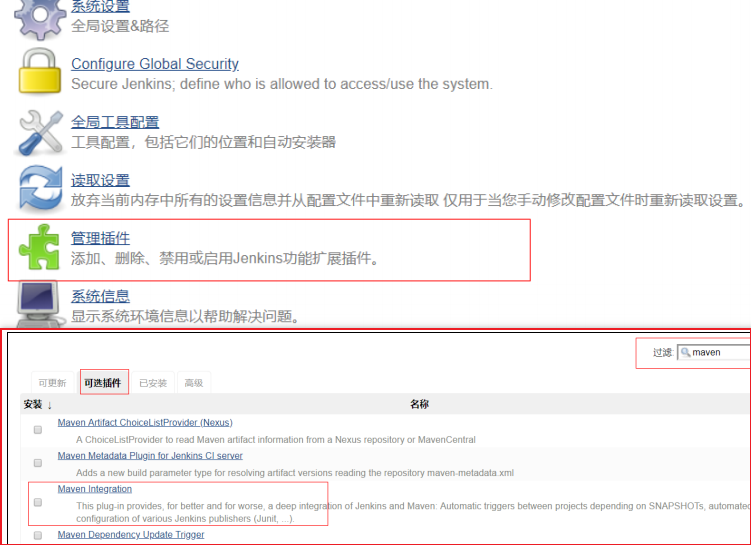
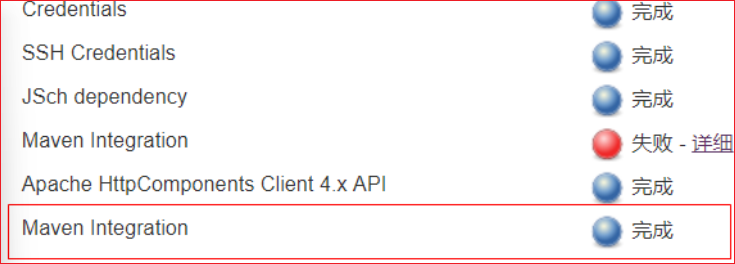
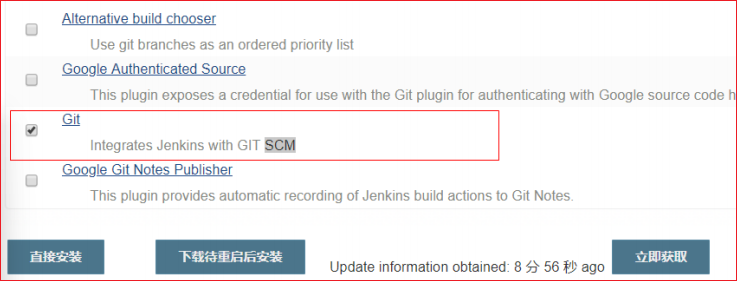
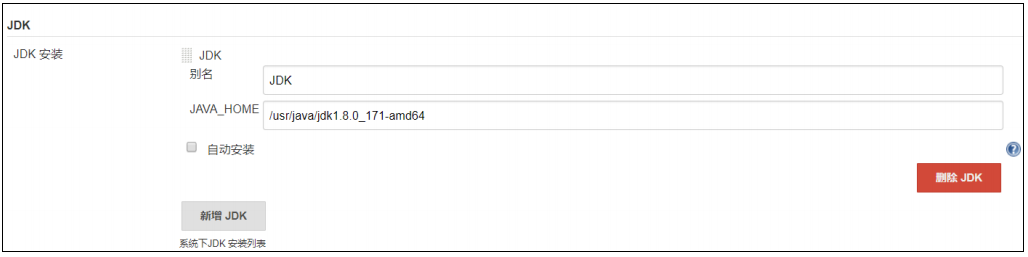


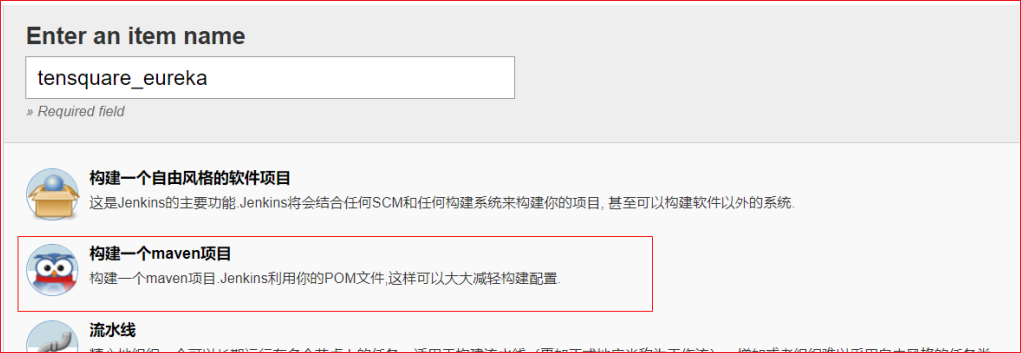
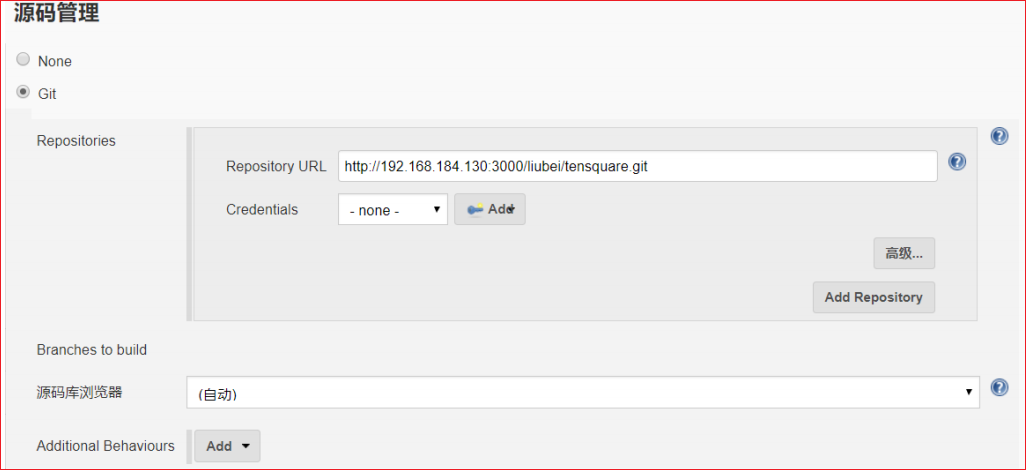


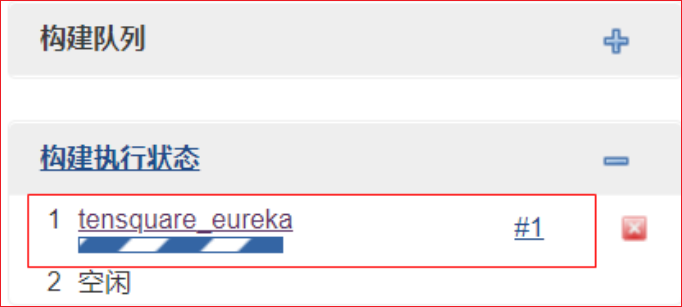


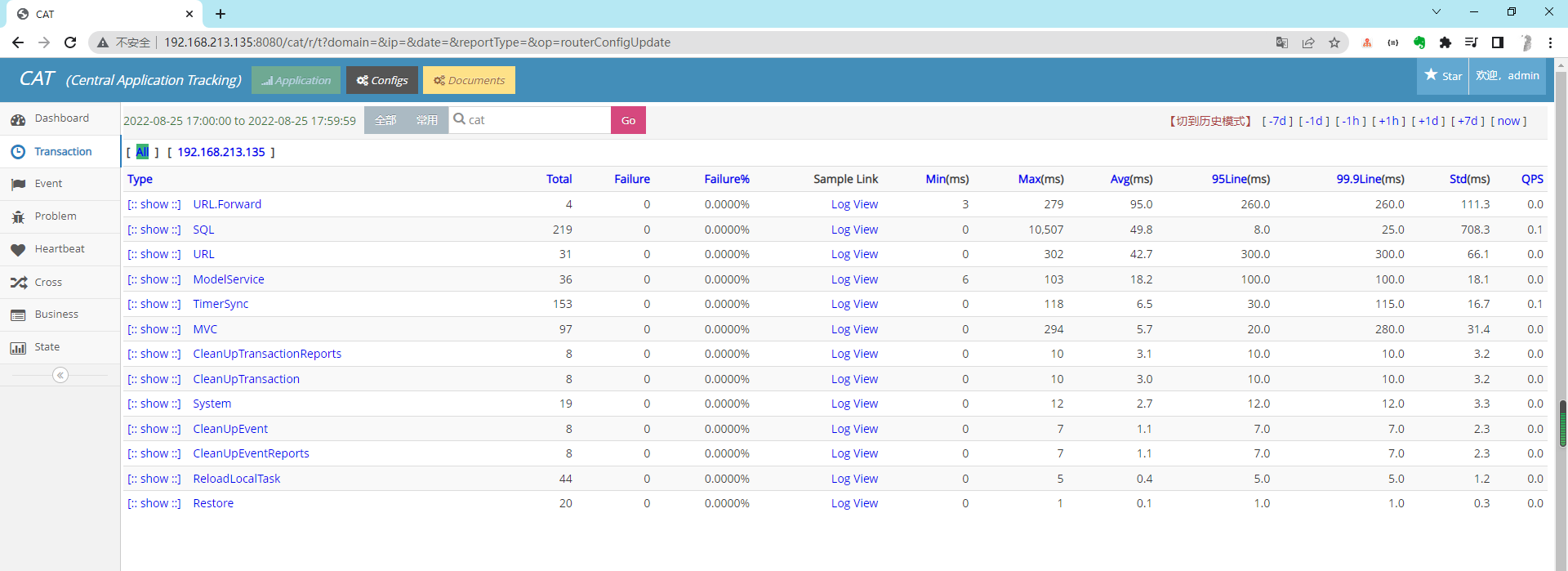
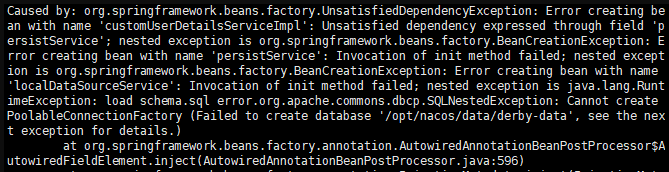



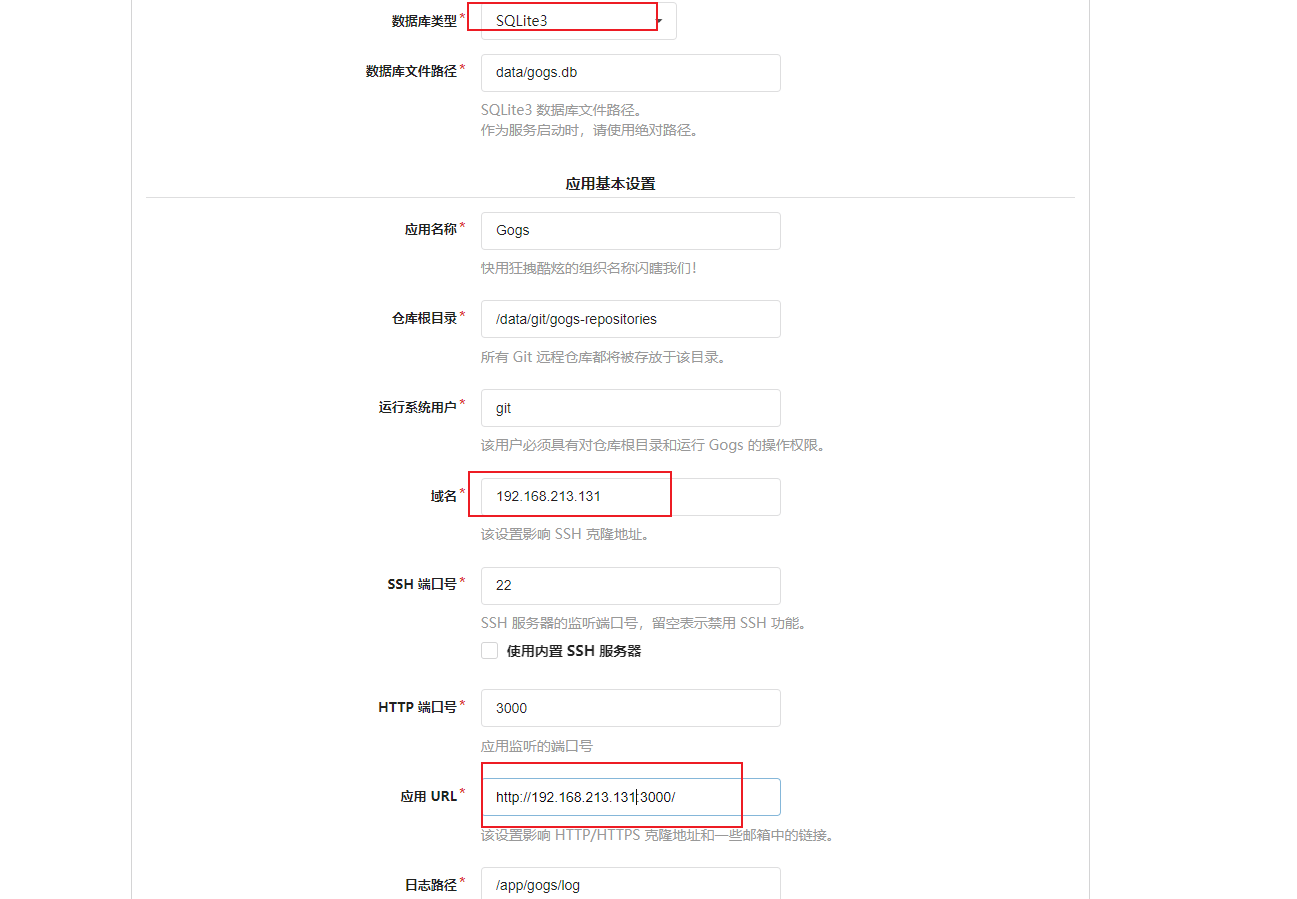
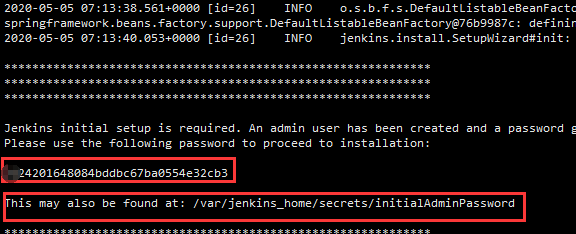

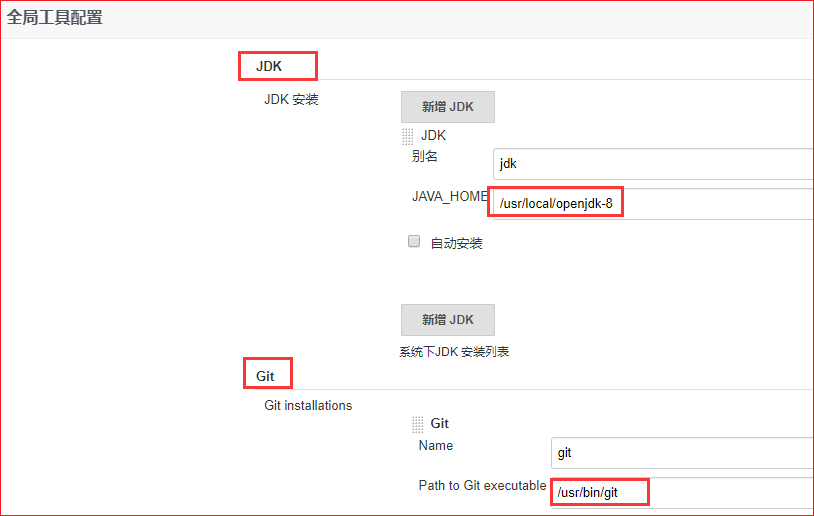




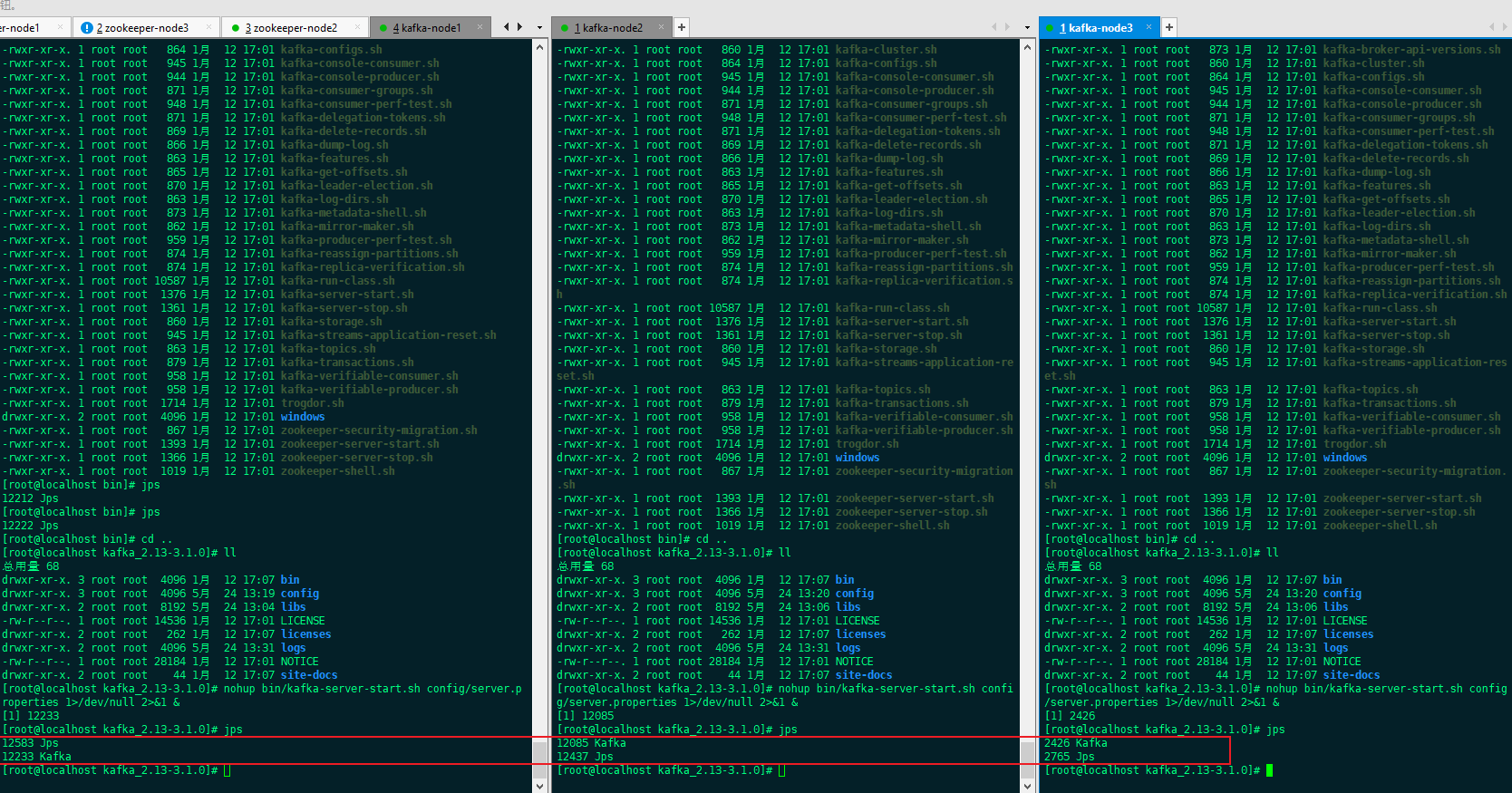

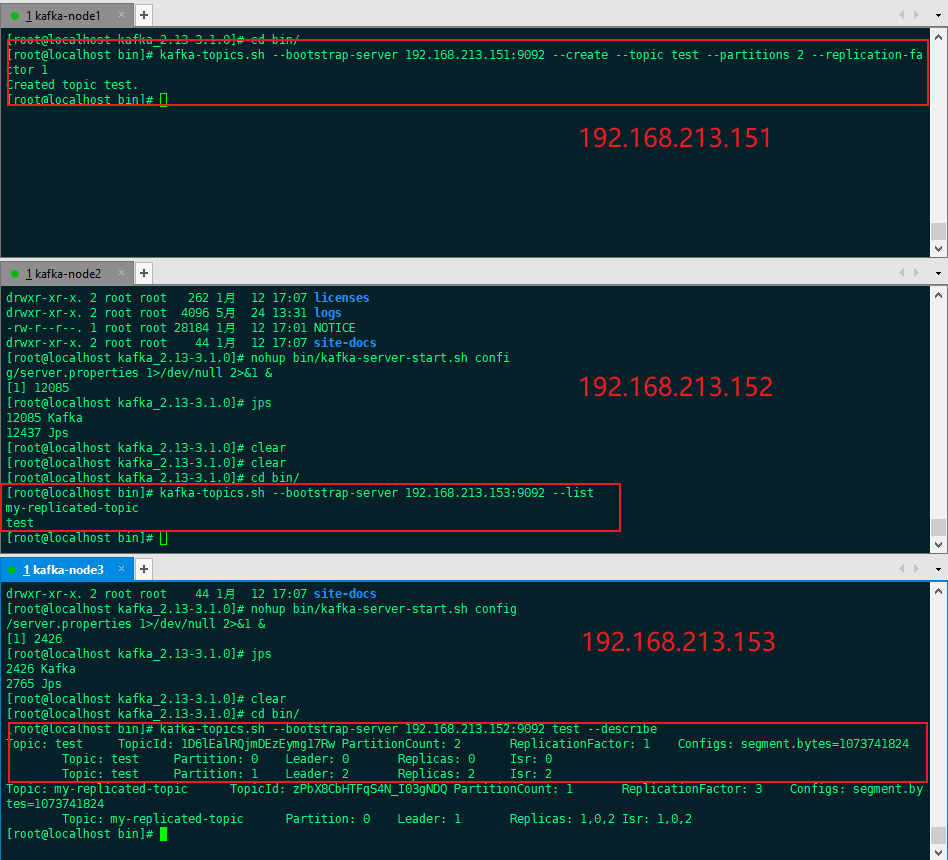
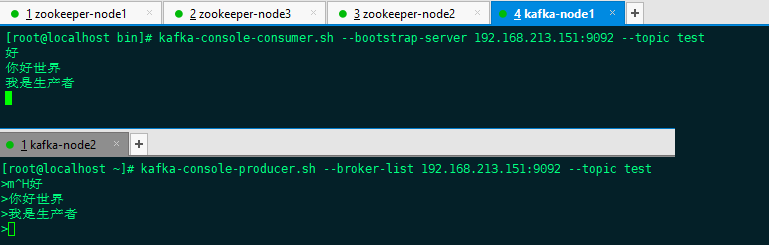
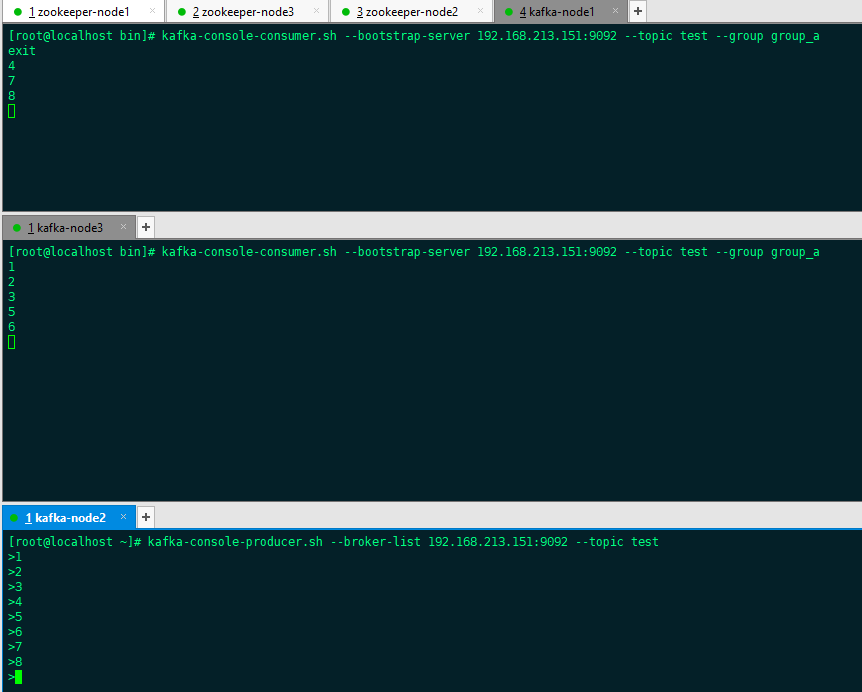
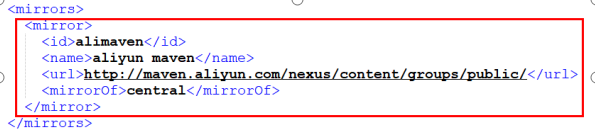

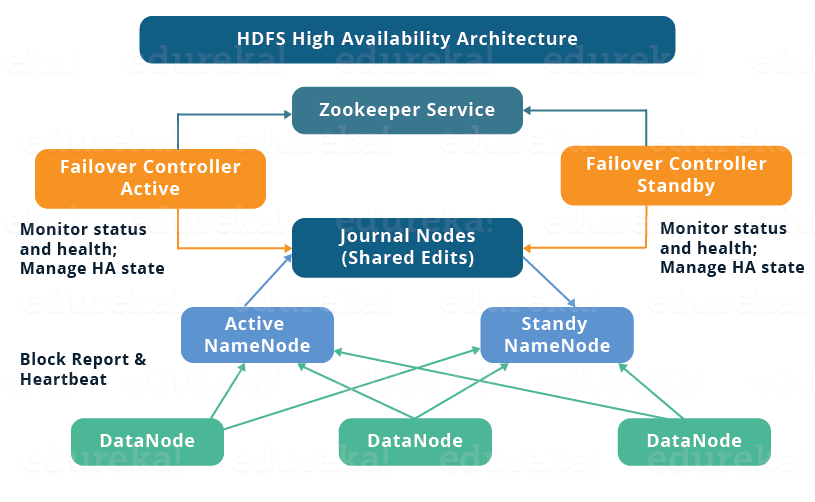
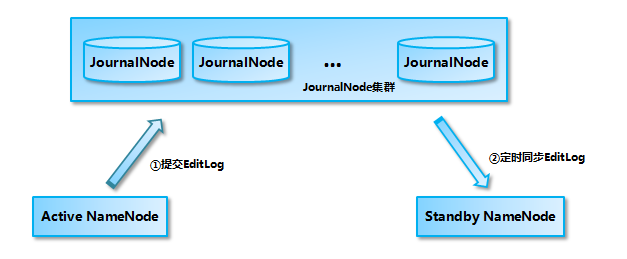
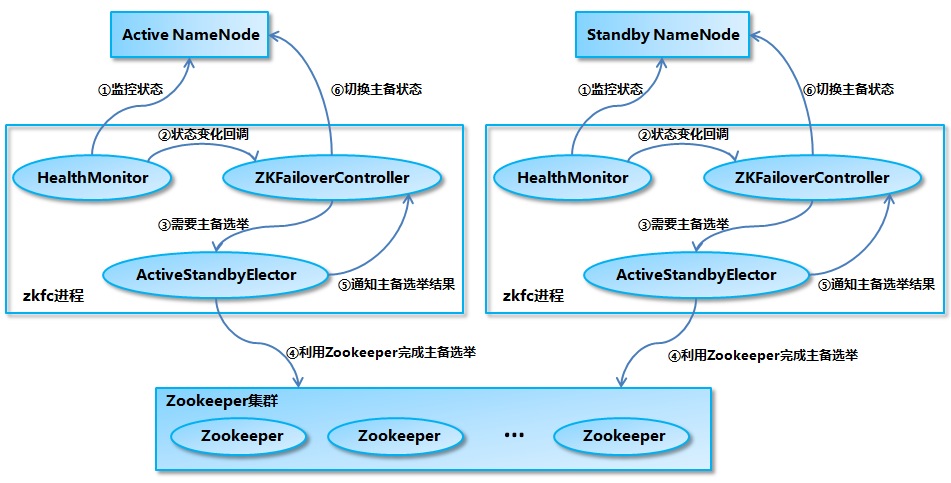
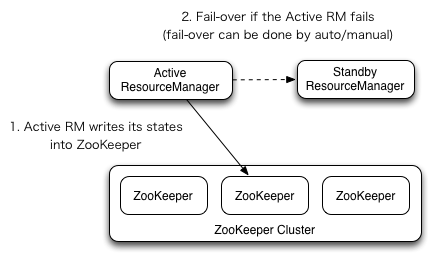
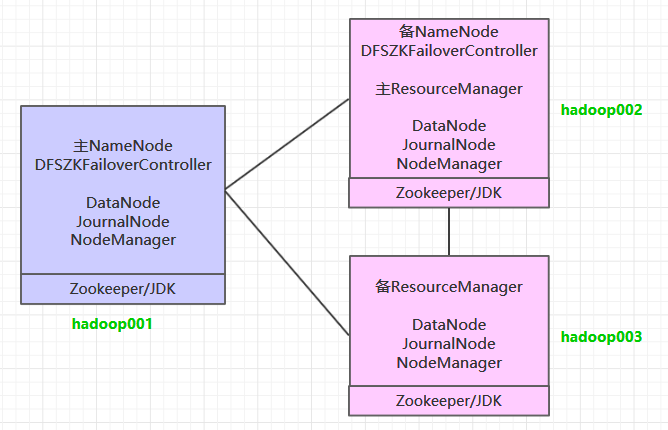
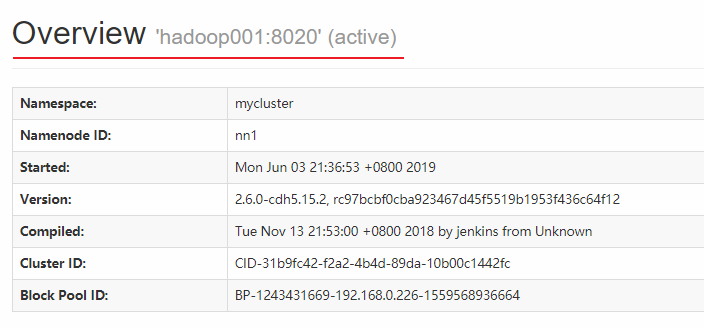
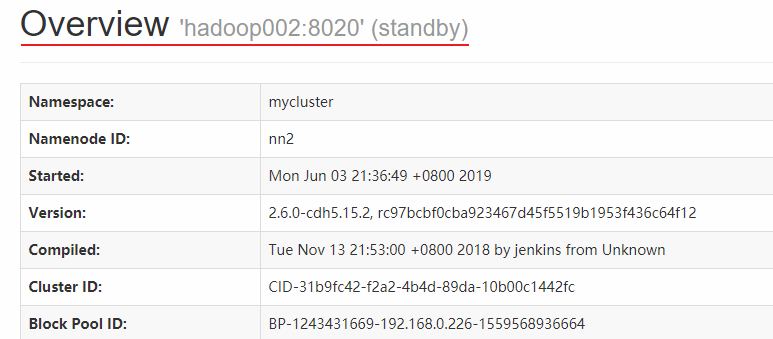
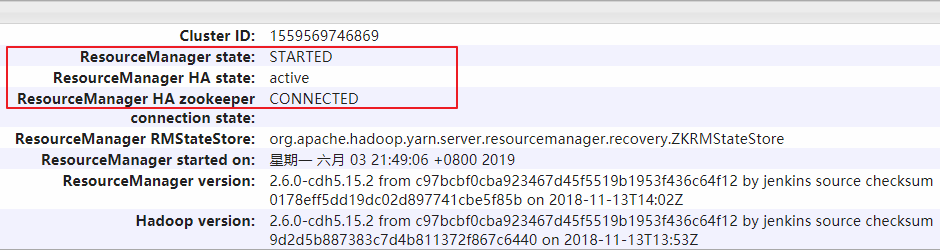
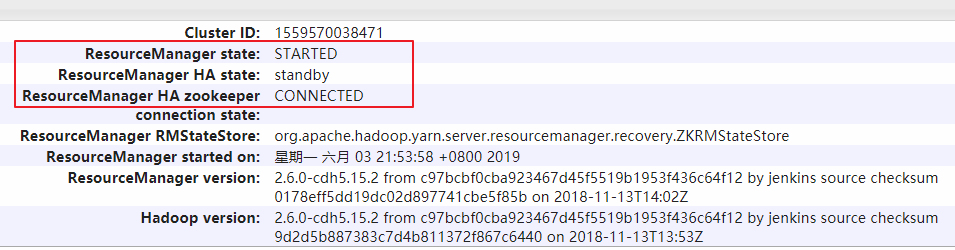
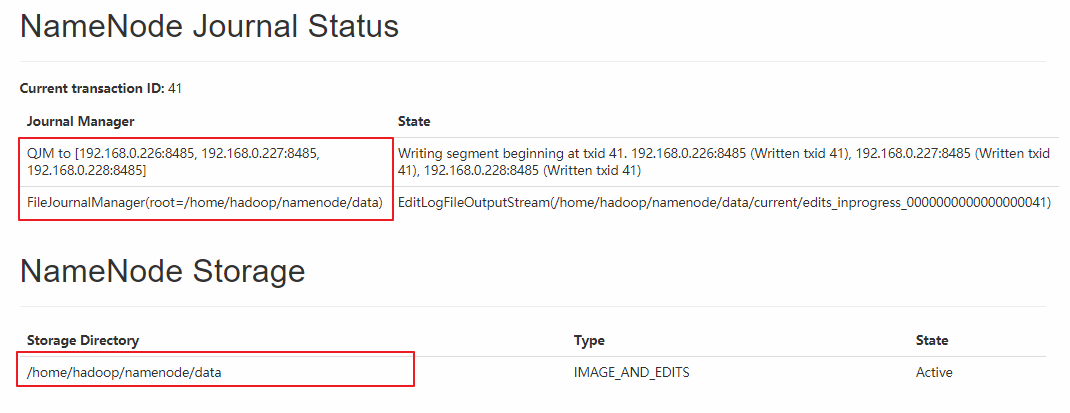
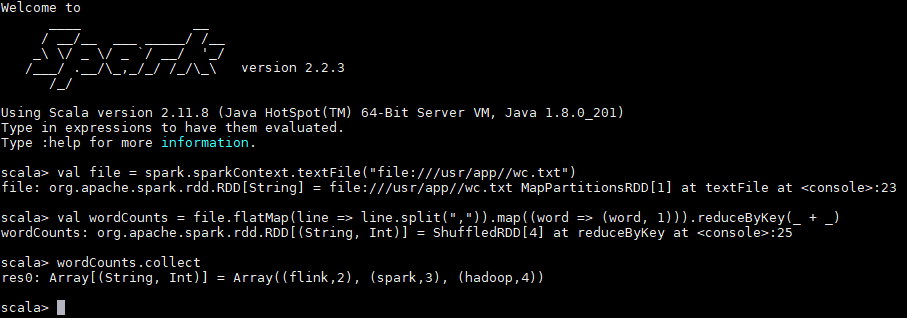
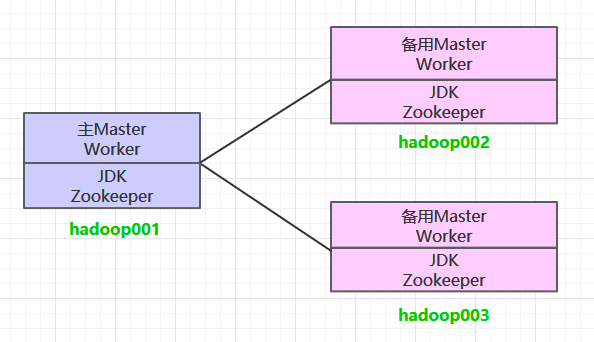
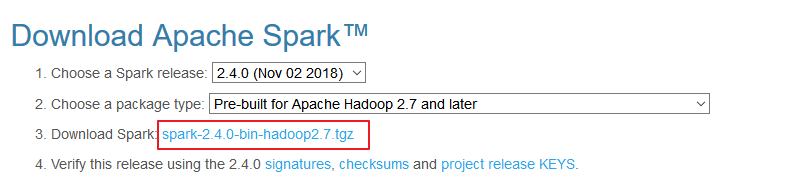
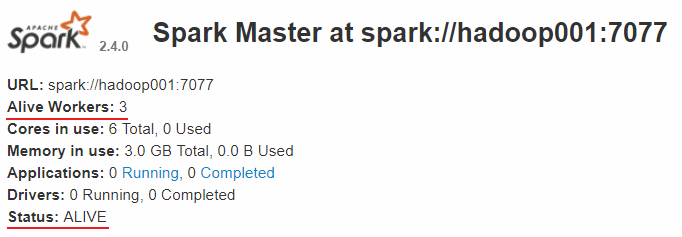
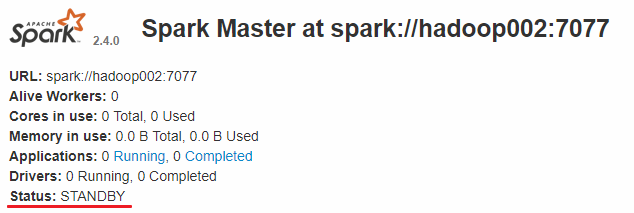
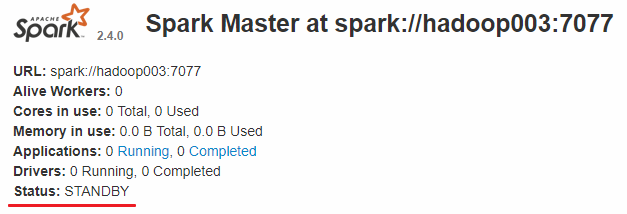
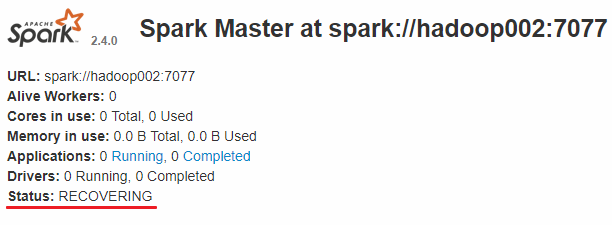
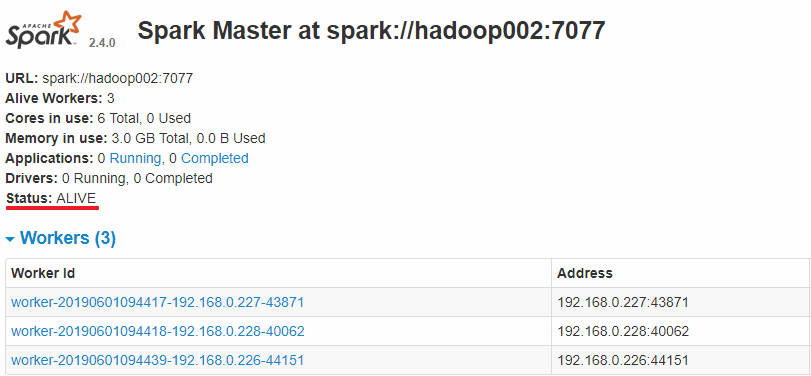

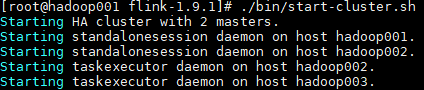
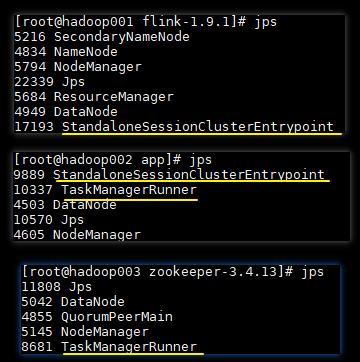

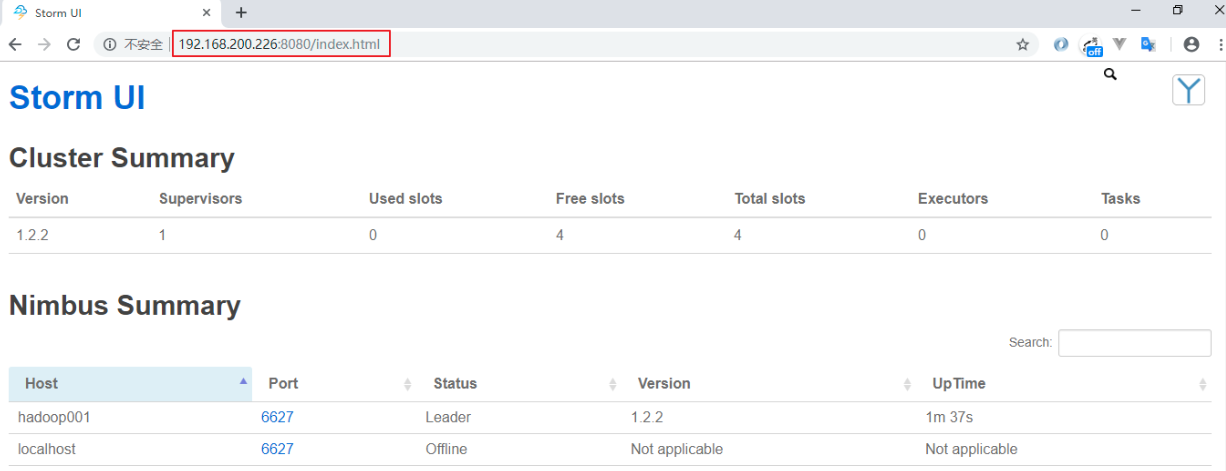
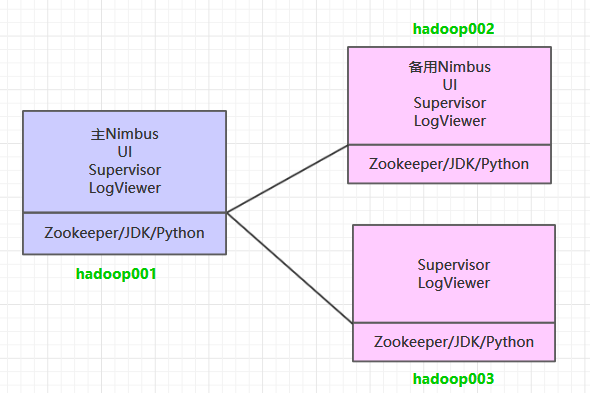

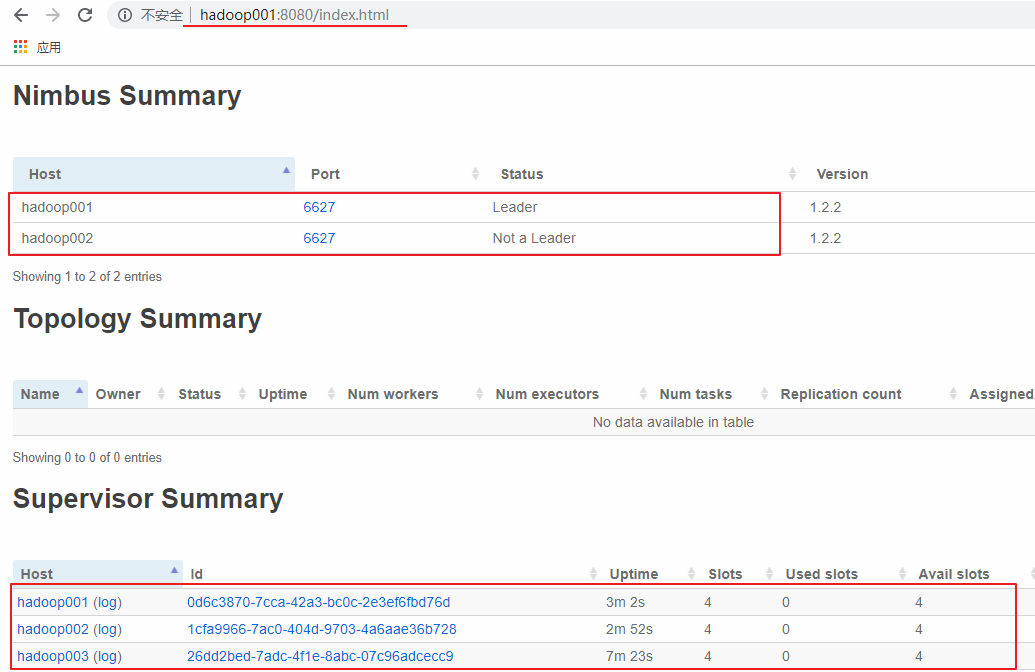
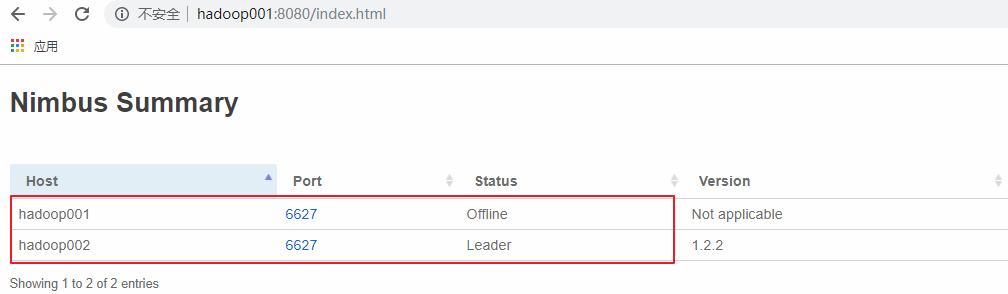
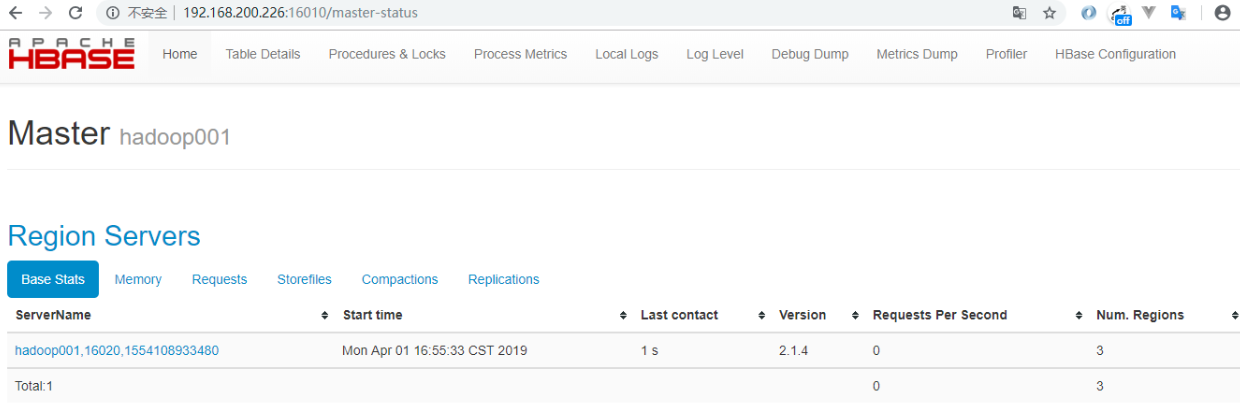
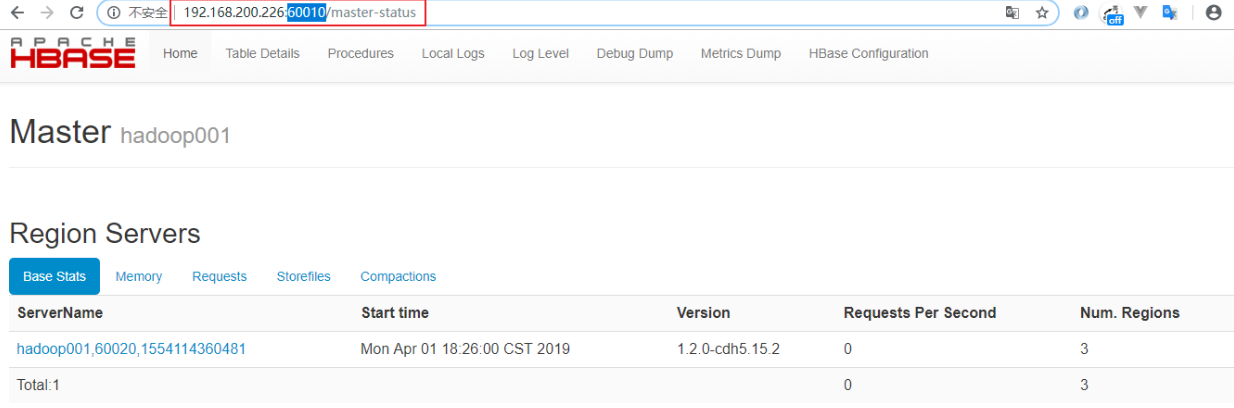
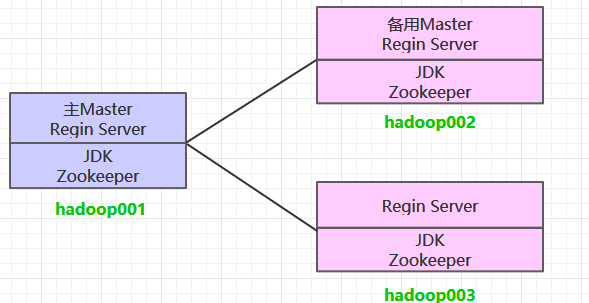
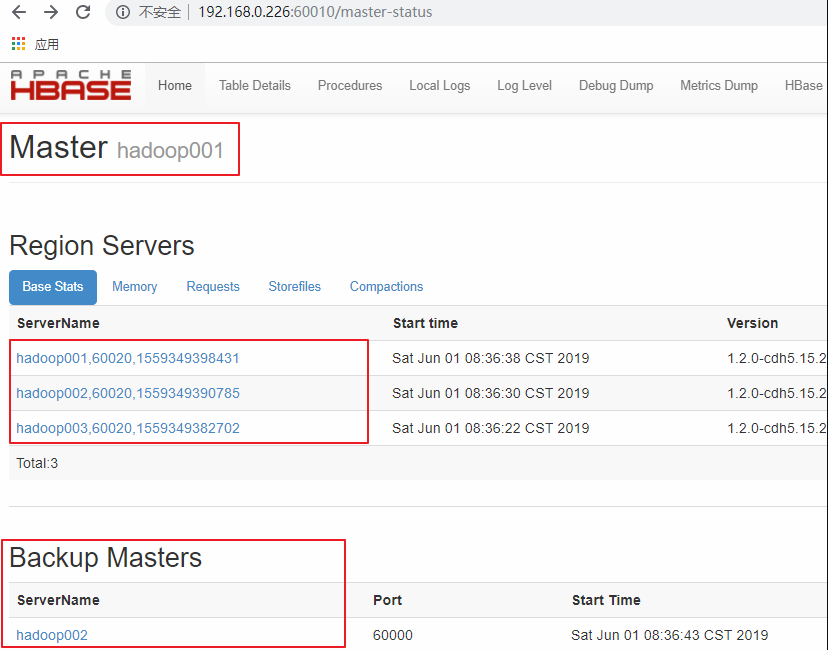
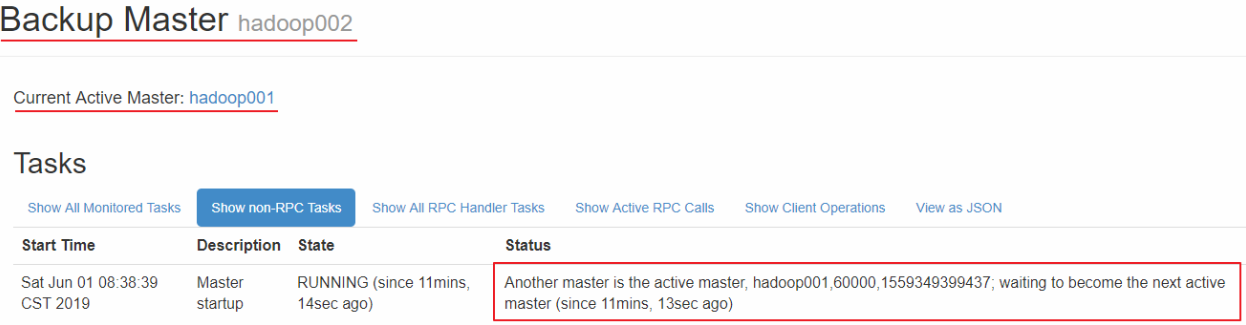



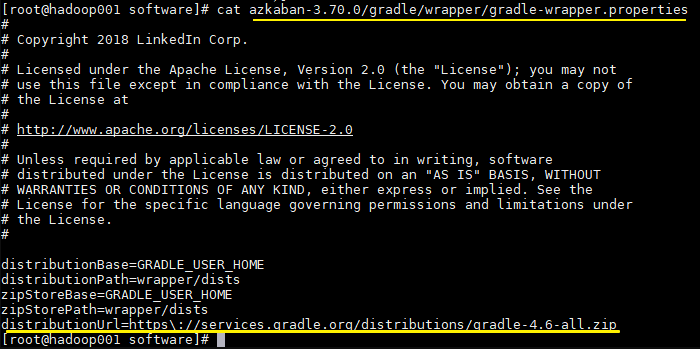
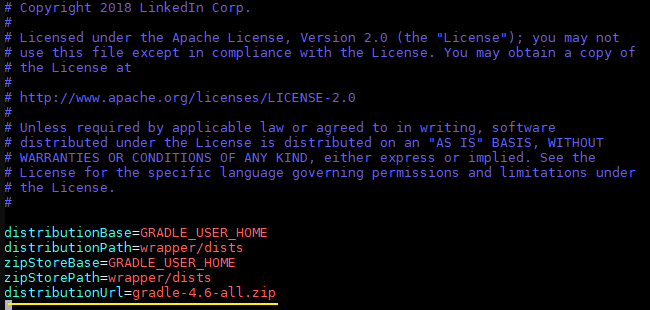
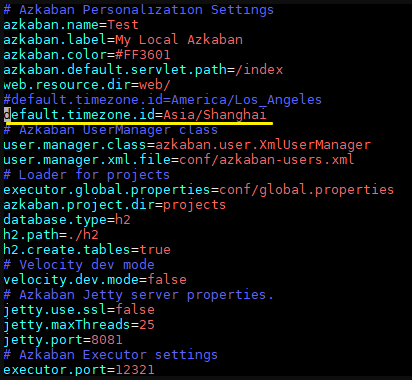


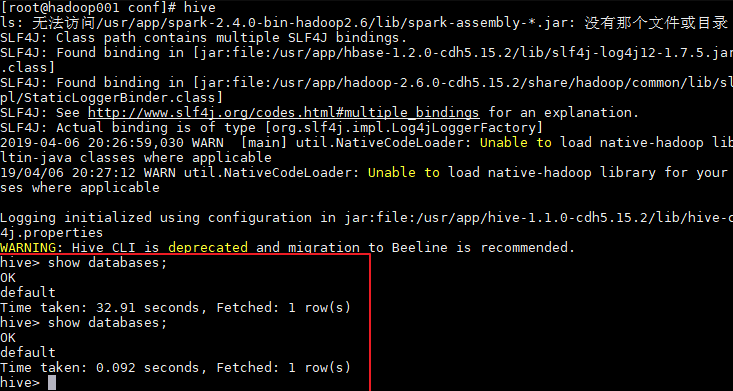
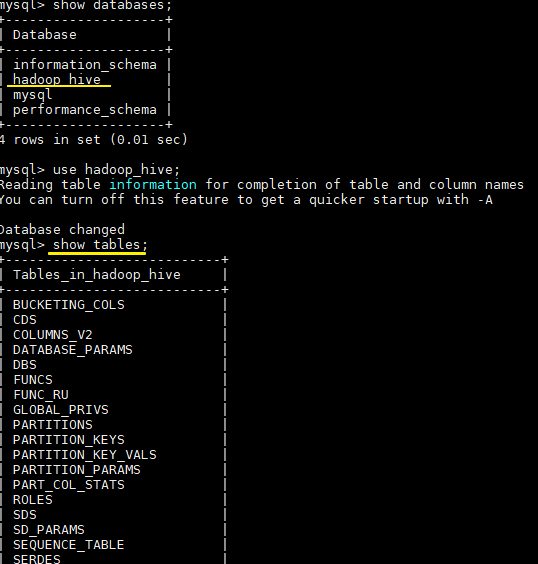
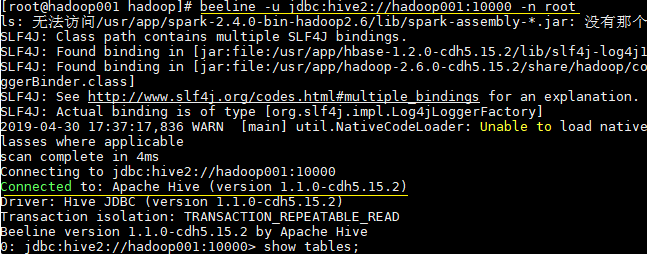



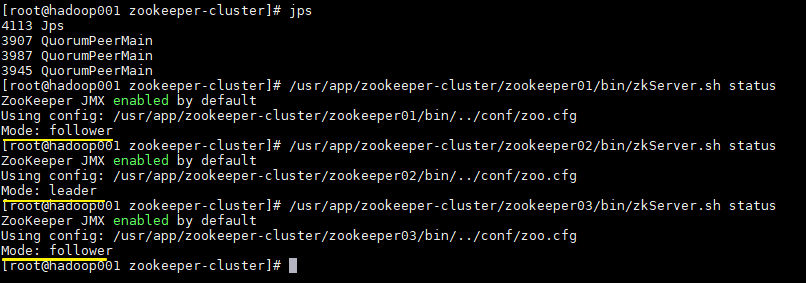
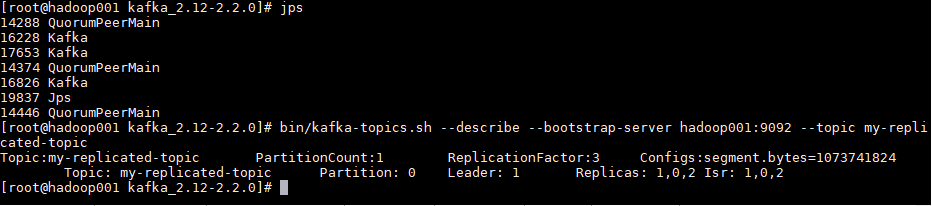
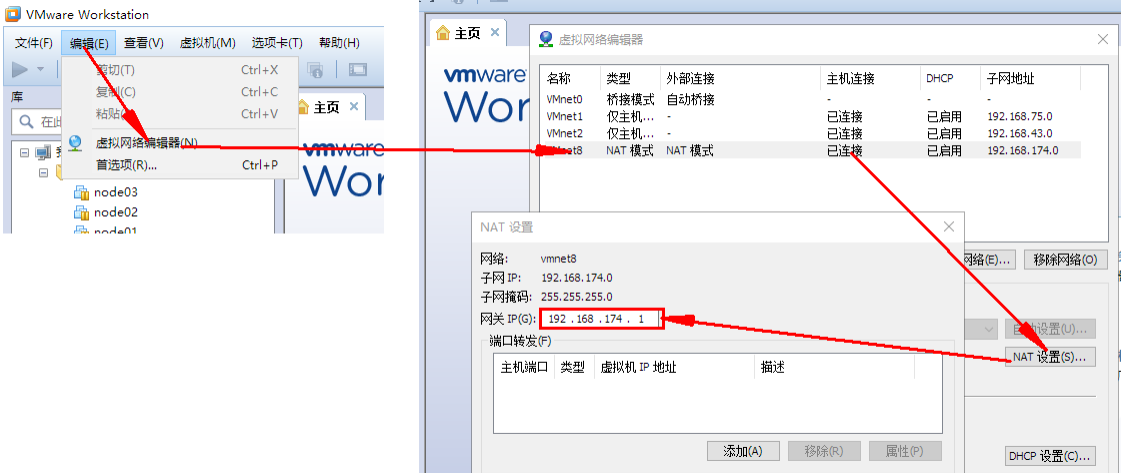
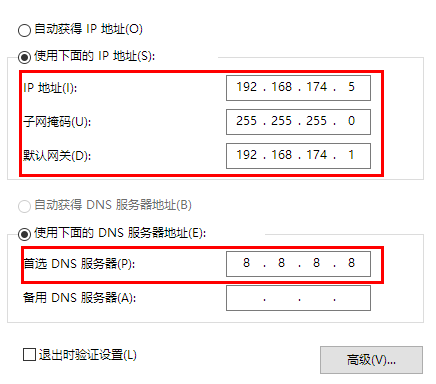
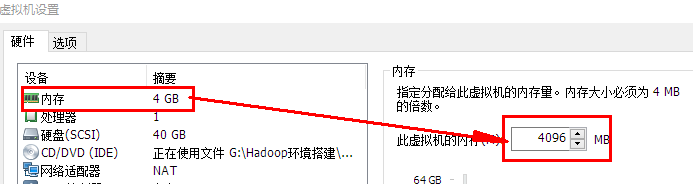
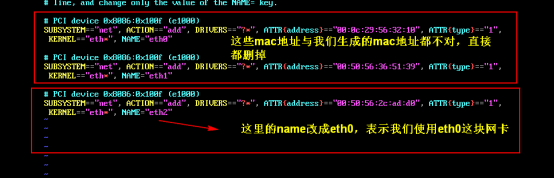
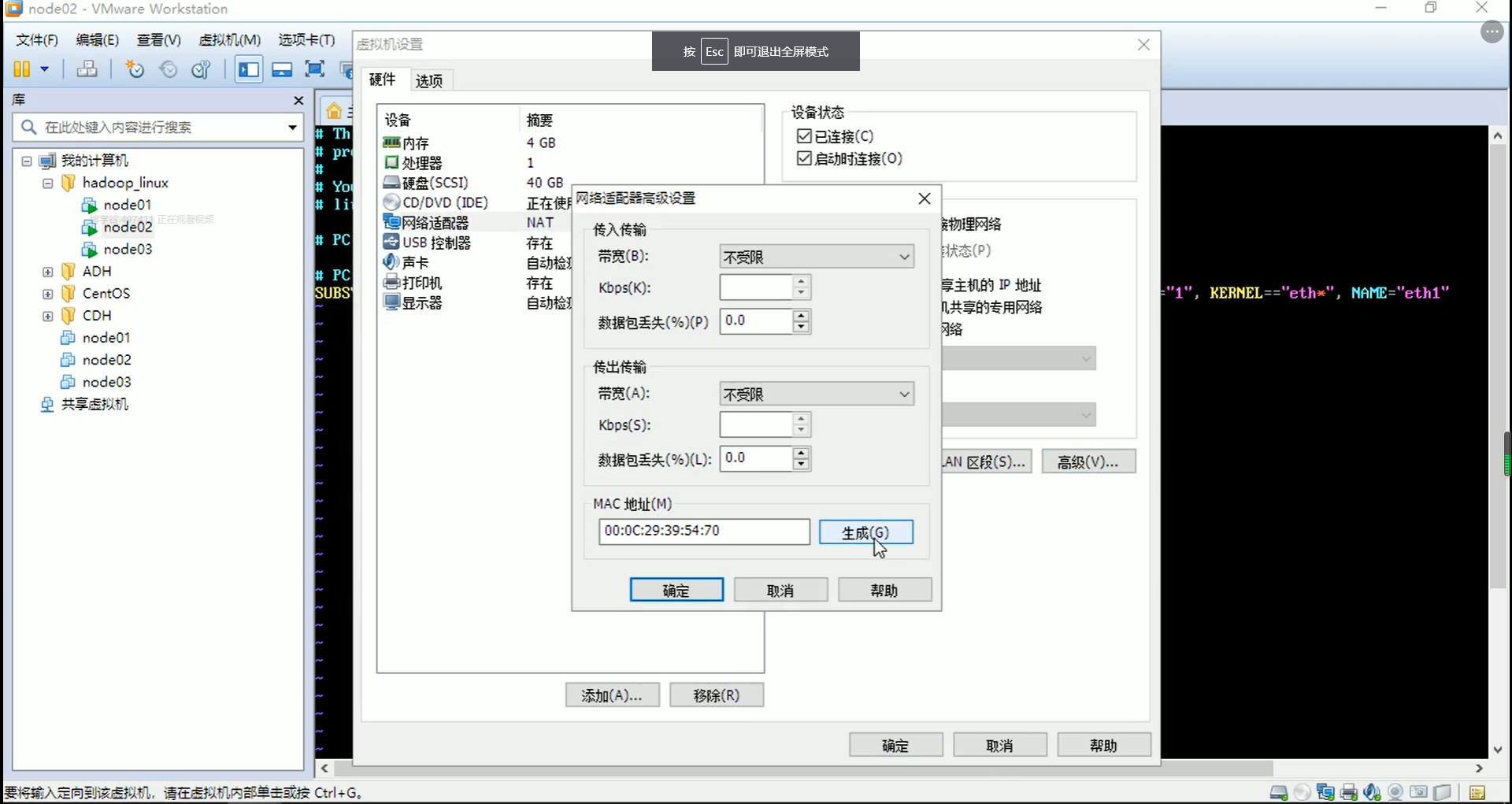
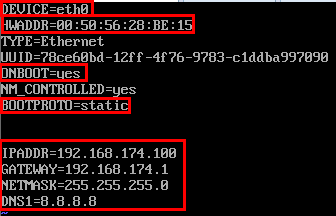

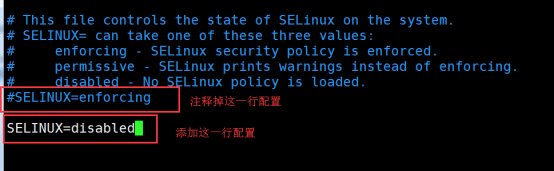

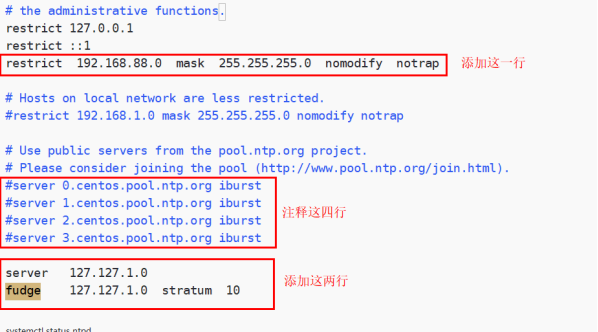
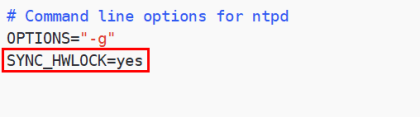
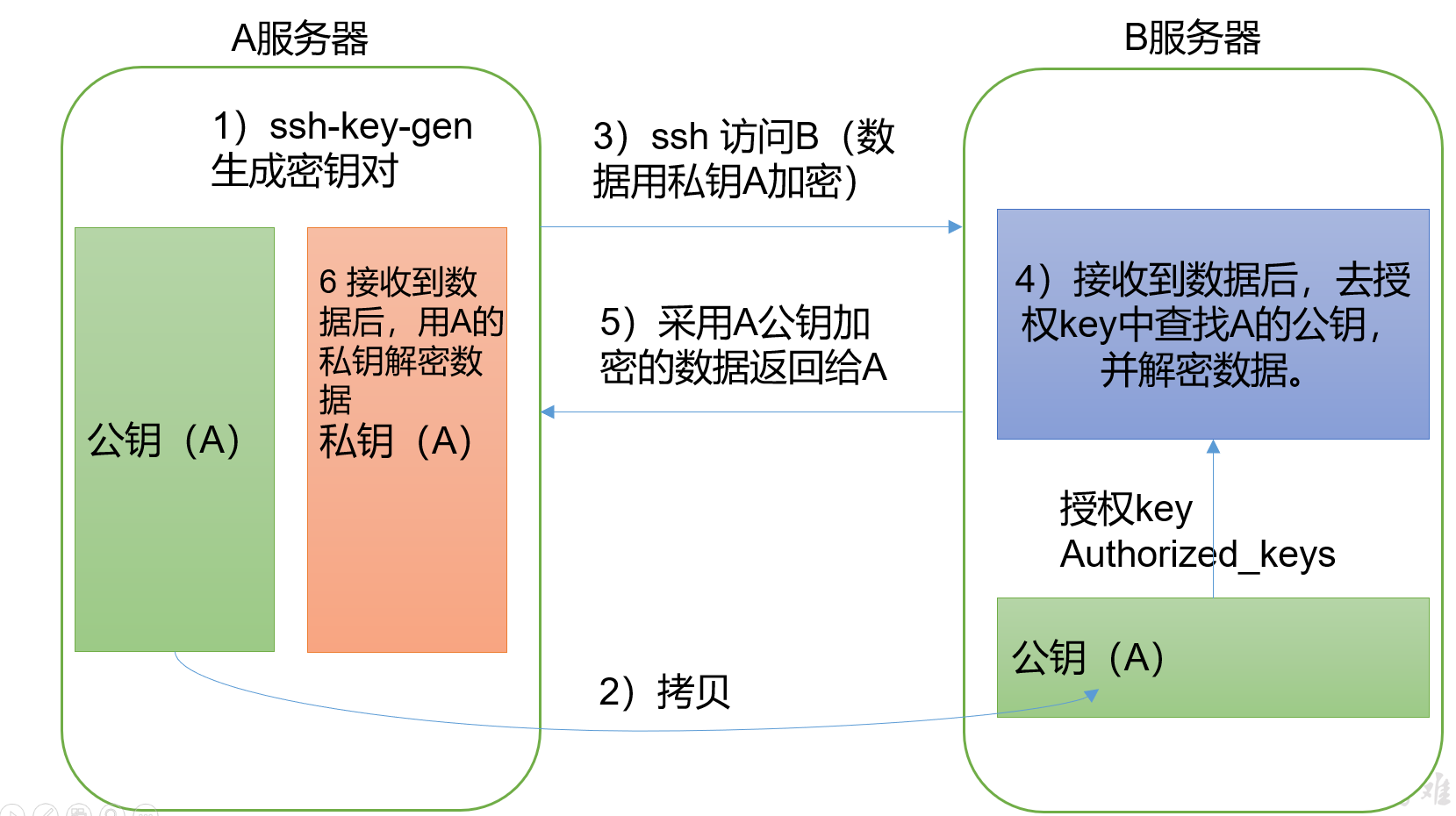
 微信
微信 支付宝
支付宝
