前置知识 Lucene 简介 Lucene是免费开源用于全文检索的程序工具包(API),由Apache软件基金会支持和提供。目前主流的java搜索框架都是依赖Lucene,官网:http://lucene.apache.org
搜索介绍 数据库搜索的问题 使用传统的数据库存储数据,那么会存在下述的问题:
在某些搜索业务场景下(如模糊搜索,海量数据搜索),效率极低,因为模糊搜索可能导致全表扫描。
而在海量数据下进行模糊搜索是企业中比较常见的业务需求 , 那么问题来了:如何才能解决上述问题
呢?
答案是:使用全文检索技术
什么是全文检索 全文检索是利用倒排索引 技术对需要搜索的数据进行处理,然后提供快速匹配的技术。
其实全文检索还有另外一种专业定义,先创建索引然后对索引进行搜索的过程 ,就是全文检索。
倒排索引 倒排索引是一种存储数据的方式,与传统查找有很大区别:
创建倒排索引流程 当我们需要把这些数据创建倒排索引时,会分为两步:
1)创建文档列表
首先将数据按列进行拆分存储,类型于mysql的表存储,每一条数据,就是一个文档,形成文档列表:
2)创建倒排索引列表
然后对文档中的数据进行分词,得到词条。对词条进行编号,并以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)
流程如下:
搜索流程 搜索的基本流程:
当用户输入任意的搜索关键词时,首先对用户输入的内容进行词拆分,得到要搜索的所有词条,如用户搜索“java培训传智播客”,拆分后就是“java 、培训、传智播客、传智”,
然后拿着这些拆分后的词去倒排索引列表中进行匹配。找到这些词对应的所有文档编号
然后根据这些编号去文档列表中找到文档
简单的说:被搜索的对象构建索引,然后把搜索关键词拆分(2个分词规则一致)。
全文检索应用场景 1.当数据库搜索不能满足我们的业务需求的时候,比如海量数据搜索
2.需要进行相关度排序,高亮显示等操作
分词器 Analyzer(分词器)的作用是把一段文本中的词按规则取出所包含的所有词。对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言(规则),要用不同的分词器。如下图
注意: 在创建索引时会用到分词器,在使用字符串搜索时也会用到分词器,这两个地方要使用同一个分词器,否则可能会搜索不出结果。所以当改变分词器的时候,需要重新建立索引库
常见的中文分词器 中文的分词比较复杂,因为不是一个字就是一个词,而且一个词在另外一个地方就可能不是一个词,如在“帽子和服装”中,“和服”就不是一个词。对于中文分词,通常有三种方式:单字分词、二分法分词、词典分词
就是按照中文一个字一个字地进行分词,效率比较低。如:“我们是中国人”,效果:“我”、“们”、“是”、 “中”、“国”、“人”。(StandardAnalyzer就是这样)
Analyzer analyzer2 = new StandardAnalyzer();
按两个字进行切分,把相邻的两个字组成词分解出来,效率也比较低。而且很多情况下分的词不对。如:“我们是中国人”,效果:“我们”、“们是”、“是中”、“中国”、“国人”。(CJKAnalyzer就是这样)
Analyzer analyzer3 = new CJKAnalyzer();
按某种算法构造词,然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法。如:“我们是中国人”,效果为:“我们”、“中国人”。(使用极易分词的MMAnalyzer。可以使用“极易分词”,或者是“庖丁分词”分词器、IKAnalyzer)。
为什么要用es,不直接用Lucene?因为Lucene复杂,es对其做了封装,好用些
分布式检索引擎Elasticsearch实践 Elasticsearch6.8(旧笔记) 简介 Elaticsearch简称为es,是一个开源的可扩展的全文检索引擎服务器 ,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB 级别的数据。es使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI 和javaAPI 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch
Es 企业使用场景企业使用场景一般分为2种情况:
1)已经上线的系统,某些模块的搜索功能是使用数据库搜索实现的,但是已经出现性能问题或者不满足产品的高亮相关度排序的需求时候,就会对系统的搜索功能进行技术改造,使用全文检索,而es就是首选。针对这种情况企业改造的业务流程如下图:
2)系统新增加的模块,产品一开始就要实现高亮相关度排序等全文检索的功能或者技术分析觉得该模块使用全文检索更适合。针对这种情况企业改造的业务流程如下图
3)索引库存什么数据
索引库的数据是用来搜索用的,里面存储的数据和数据库一般不会是完全一样的,一般都比数据库的数据少。
那索引库存什么数据呢?
以业务需求为准,需求决定页面要显示什么字段以及会按什么字段进行搜索,那么这些字段就都要保存到索引库中。
版本 目前Elasticsearch最新的版本是7.3.2,我们使用6.8.0版本,建议使用JDK1.8及以上
安装和配置 为了模拟真实场景,我们将在linux下安装Elasticsearch。
1 2 3 # 环境要求: centos 64位 JDK8及以上
如果有的同学vmvare存在问题,可以在安装windows版本。
1 2 3 4 5 6 # 出于安全考虑,elasticsearch默认不允许以root账号运行。 useradd elastic # 设置密码: passwd elastic # 切换用户: su - elastic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 我们将安装包上传到:/home/elastic目录 # 安装rz插件,一路 yes yum -y install lrzsz # 切换到 cd /home/elastic rz # 解压缩: tar xvf elasticsearch-6.8.0.tar.gz # 目录重命名: mv elasticsearch-6.8.0/ elasticsearch # 修改权限(可选) chown elastic:elastic -R elasticsearch # 目录说明 bin 二进制脚本,包含启动命令等 config 配置文件目录 lib 依赖包目录 logs 日志文件目录 modules 模块库 plugins 插件目录,这里存放一些常用的插件比如IK分词器插件 data 数据储存目录(暂时没有,需要在配置文件中指定存放位置,启动es时会自动根据指定位置创建)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 我们进入config目录: cd config ll # 修改jvm配置 # Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数设置堆大小 vim jvm.options # 默认配置如下: -Xms1g -Xmx1g # 内存占用太多了,我们调小一些,大家虚拟机内存设置为2G: # 最小设置128m,如果虚机内存允许的话设置为512m -Xms128m -Xmx128m # 修改elasticsearch.yml vim elasticsearch.yml # 修改数据和日志目录: path.data: /home/elastic/elasticsearch/data # 数据目录位置 path.logs: /home/elastic/elasticsearch/logs # 日志目录位置 # 修改绑定的ip: network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问 默认只允许本机访问,修改为0.0.0.0后则可以远程访问 目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。 elasticsearch.yml的其它可配置信息:
1 2 3 4 # 进入elasticsearch/bin目录,可以看到下面的执行文件: ./elasticsearch # 后台启动 ./elasticsearch -d
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 # [1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] # elasticsearch用户拥有的可创建文件描述的权限太低,至少需要65536; 我们用的是elastic用户,而不是root,所以文件权限不足。 首先用root用户登录。 然后修改配置文件: vim /etc/security/limits.conf 添加下面的内容: 注意下面的 “*” 号不要去除 # 可打开的文件描述符的最大数(软限制) * soft nofile 65536 #可打开的文件描述符的最大数(硬限制) * hard nofile 131072 #单个用户可用的最大进程数量(软限制) * soft nproc 4096 #单个用户可用的最大进程数量(硬限制) * hard nproc 4096 # [1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096] 这是线程数不够。 继续修改配置 vim /etc/security/limits.d/90-nproc.conf 修改下面的内容: * soft nproc 1024 改为: * soft nproc 4096 # [3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144] # elasticsearch用户拥有的最大虚拟内存太小,至少需要262144; vim /etc/sysctl.conf 添加下面内容: vm.max_map_count=262144 然后执行命令: sysctl -p # 内核过低unable to install syscall filter 使用的centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。不过没关系,我们禁用这个插件即可。 修改elasticsearch.yml文件,在最下面添加以后配置 bootstrap.system_call_filter: false 重启终端窗口 所有错误修改完毕,如果启动还是失败则需要重启你的 Xshell终端,使配置生效
1 2 3 4 5 可以看到绑定了两个端口: 9300:集群节点间通讯接口,接收tcp协议 9200:客户端访问接口,接收Http协议 验证是否启动成功: 在浏览器中访问:http://192.168.88.128:9200/,如果不能访问,则需要关闭虚拟机防火墙,需要root权限
防火墙 1 2 3 4 5 6 7 8 9 10 11 # 查看防火墙: service iptables status (centos 6) firewall-cmd --state (centos7) # 关闭防火墙: service iptables stop (centos 6) systemctl stop firewalld.service (centos7) # 禁止开机启动防火墙: chkconfig iptables off (centos 6) systemctl disable firewalld.service (centos7)
图形化可视工具安装 ElasticSearch没有自带图形化界面,我们可以通过安装ElasticSearch的图形化插件,完成图形化界面的效果,完成索引数据的查看。
Kibana Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 安装 # 将资料中的kibana-6.8.0-linux-x86_64.tar.gz上传至虚机,解压即可: tar xvf kibana-6.8.0-linux-x86_64.tar.gz # 配置运行 # # 修改server.host地址: server.host: "0.0.0.0" # 界面中文显示,在最后一行修改 i18n.locale: "zh-CN" # 运行 # 进入安装目录下的bin目录运行: ./kibana # 发现kibana的监听端口是5601 # 我们访问: http://192.168.129.134:5601
1 2 3 # kibana dev tools快捷键 ctrl+enter 提交请求 ctrl+i 自动缩进
1 2 3 # Another Kibana instance appears to be migrating the index. Waiting for that migration to complete. If no other Kibana instance is attempting migrations, you can get past this message by deleting index .kibana_1 and restarting Kibana. 如果出现上述问题,可以使用elasticsearch-head删除kibana的相关索引,然后再启动kibana
elasticsearch-head 1 2 3 4 5 1.在Chrome浏览器地址栏中输入:chrome://extensions/ 2. 打开Chrome扩展程序的开发者模式 3. 将资料中的elastic-head0.1.5_0.crx插件拖入浏览器的插件页面 或者在线装:https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm?utm_source=chrome-ntp-icon
集成ik分词器 Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致:https://github.com/medcl/elasticsearch-analysis-ik
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 使用插件安装(方式一)=> 在线安装真香! 1)在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成: ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.0/elasticsearch-analysis-ik-6.8.0.zip 2)下载完成后会提示 Continue with installation?输入 y 即可完成安装 3)重启es 和kibana 上传安装包安装(方式二) 1)在elasticsearch的plugins目录下新建 analysis-ik 目录 # 新建analysis-ik文件夹 mkdir analysis-ik # 切换至 analysis-ik文件夹下 cd analysis-ik # rz上传资料中的 elasticsearch-analysis-ik-6.8.0.zip rz # 解压 unzip elasticsearch-analysis-ik-6.8.0.zip # 解压完成后删除zip rm -rf elasticsearch-analysis-ik-6.8.0.zip 2)重启es 和kibana
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word (常用)
会将文本做最细粒度的拆分
1 2 3 4 5 POST _analyze { "analyzer": "ik_max_word", "text": "南京市长江大桥" }
这个粒度细
2、ik_smart
会做最粗粒度的拆分
大家先不管语法,我们先在kibana测试一波输入下面的请求:
这个粒度粗
默认的中文ik分词器有的分词也不够合理。可能不符合业务需求。
添加扩展词典和停用词典 停用词 :有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
扩展词 :就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
自定义扩展词库
进入到 config/analysis-ik/(插件安装方式 ) 或 plugins/analysis-ik/confifig(安装包安装方式 ) 目录下,新增自定义词典
输入 :江大桥
将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中
然后重启
多了个分词:江大桥
问题 1 # Caused by: java.lang.IllegalStateException: failed to obtain node locks, tried [[/home/elastic/elasticsearch/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
杀掉进程重启
1 2 ps -ef | grep elastic kill -9 进程号
客户端 在elasticsearch官网中提供了各种语言的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html
我们接下来要学习的是JavaRestClient的客户端。注意点击进入后,选择版本到 6.8 ,和我们的es版本
对应Low Level Rest Client是低级别封装,提供一些基础功能,但更灵活High Level Rest Client,是在Low Level Rest Client基础上进行的高级别封装,功能更丰富和完善,而且API会变的简单
相关概念 Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
在kibana上操作es 索引库操作 Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
语法
settings:就是索引库设置,其中可以定义索引库的各种属性,目前我们可以不设置,都走默认
可以看到索引创建成功了。
类型操作 有了 索引库 ,等于有了数据库中的 database 。接下来就需要索引库中的 类型 了,也就是数据库中的表 。创建数据库表需要设置字段约束,索引库也一样,在创建索引库的类型时,需要知道这个类型下
有哪些字段,每个字段有哪些约束信息,这就叫做 字段映射(mapping)
字段的约束包括但不限于:
字段的数据类型
是否要存储
是否要索引
是否分词
分词器是什么
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 创建索引库(相当于数据库) PUT /heima # 创建type类型(相当于表) PUT /heima/_mapping/goods { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" } , "subtitle" : { "type" : "text" , "analyzer" : "ik_max_word" } , "images" : { "type" : "keyword" , "index" : false } , "prices" : { "type" : "float" } } } # 查找type GET /heima/_mapping/goods
type:类型,可以是text、long、short、date、integer、object等
index:是否索引,默认为true
store:是否存储,默认为false
analyzer:分词器,这里的 ik_max_word 即使用ik分词器
映射属性详解 type
如果存储到索引库的是对象类型,例如上面的girl,会把girl编程两个字段:girl.name和girl.age
index index影响字段的索引情况。
true:字段会被索引,则可以用来进行搜索。默认值就是true
false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false
store 是否将数据进行独立存储。
原始的文本会存储在 _source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false。
一次创建索引库和类型(常用) 刚才 的案例中我们是把创建索引库和类型分开来做,其实也可以在创建索引库的同时,直接制定索引库中的类型,基本语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 创建索引库,同时创建mapping PUT /heima2 { "settings" : { } , "mappings" : { "goods" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" } , "subtitle" : { "type" : "text" , "analyzer" : "ik_max_word" } , "images" : { "type" : "keyword" , "index" : false } , "prices" : { "type" : "float" } } } } } # 查找验证索引库 GET /heima2/_mapping/goods
文档增删改操作 文档,即索引库中某个类型下的数据,会根据规则创建索引,将来用来搜索。可以类比做数据库中的每一行数据
新增文档 1 2 3 4 5 6 POST /heima/goods { "title": "小米手机", "images": "http://image.leyou.com/12479122.jpg", "price": 2699 }
另外,需要注意的是,在响应结果中有个 _id 字段,这个就是这条文档数据的 唯一标示 ,以后的增删改查都依赖这个id作为唯一标示。
可以看到id的值为: 2a3UTW0BTp_XthqB6lMH ,这里我们新增时没有指定id,所以是ES帮我们随机生成的id。
_version这个字段,初始是1,每次修改+1
查看文档 根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把刚刚生成数据的id带上。
1 GET /heima/goods/rhJVdH0BXgqEXAbvxP-M
_source :源文档信息,所有的数据都在里面。
_id :这条文档的唯一标示
创建文档的时候也可以指定id
修改数据 把刚才新增的请求方式改为PUT,就是修改了。不过修改必须指定id,
id对应文档存在,则修改
id对应文档不存在,则新增
比如,我们把使用id为3,不存在,则应该是新增:
删除数据
根据id进行删除:DELETE heima/goods/1001
可以看到结果是: deleted ,显然是删除数据
1 2 3 4 5 6 7 8 POST heima/_delete_by_query { "query" : { "match" : { "title" : "小米" } } }
1 2 3 4 5 6 POST heima/_delete_by_query { "query" : { "match_all" : { } } }
文档查询操作 初始化练习数据(_bulk,这里是批量操作接口,数据不能json格式化,直接执行就好了)
1 2 3 4 5 6 7 POST /heima/goods/_bulk { "index" : { } } { "title" : "大米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 3288 } { "index" : { } } { "title" : "小米手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 2699 } { "index" : { } } { "title" : "小米电视 4A" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 4288 }
基本查询 1 2 3 4 5 6 7 8 9 # 语法 POST /索引库名/_search { "query": { "查询类型": { "查询条件": "查询条件值" } } }
这里的query代表一个查询对象,里面可以有不同的查询属性
1 2 3 4 5 6 POST /heima/_search { "query" : { "match_all" : { } } }
query :代表查询对象
match_all :代表查询所有
1 2 3 4 5 6 7 8 9 10 11 12 - took:查询花费时间,单位是毫秒 - time_out:是否超时 - _shards:分片信息 - hits:搜索结果总览对象 - total:搜索到的总条数 - max_score:所有结果中文档得分的最高分 - hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息 - _index:索引库 - _type:文档类型 - _id:文档id - _score:文档得分 - _source:文档的源数据
现在,索引库中有2部手机,1台电视
or关系
match 类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
1 2 3 4 5 6 7 8 POST /heima/_search { "query" : { "match" : { "title" : "小米电视4A" } } }
在上面的案例中,不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是 or 的关系
and关系
某些情况下,我们需要更精确查找,我们希望这个关系变成 and ,可以这样做
1 2 3 4 5 6 7 8 9 10 11 POST /heima/_search { "query" : { "match" : { "title" : { "query" : "小米电视" , "operator" : "and" } } } }
本例中,只有同时包含 小米 和 电视 的词条才会被搜索到。
多字段查询(multi_match)
multi_match 与 match 类似,不同的是它可以在多个字段中查询
为了测试效果我们在这里新增一条数据
1 2 3 4 5 6 7 POST /heima/goods { "title" : "华为手机" , "images" : "http://image.leyou.com/12479122.jpg" , "price" : 5288 , "subtitle" : "小米" }
本例中,我们会假设在title字段和subtitle字段中查询 小米 这个词
词条匹配(term)
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词 的字符串
1 2 3 4 5 6 7 8 POST /heima/_search { "query" : { "term" : { "price" : 2699 } } }
2种写法都可以
多词条精确匹配(terms)
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql的in:
_source 过滤&结果过滤 默认情况下,elasticsearch在搜索的结果中,会把文档中保存在 _source 的所有字段都返回。
如果我们只想获取其中的部分字段 ,我们可以添加 _source 的过滤
指定includes和excludes
我们也可以通过:
includes:来指定想要显示的字段
excludes:来指定不想要显示的字段
二者都是可选的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 POST /heima/_search { "_source" : { "includes" : [ "title" , "price" ] } , "query" : { "term" : { "price" : 2699 } } } POST /heima/_search { "_source" : { "excludes" : [ "price" ] } , "query" : { "term" : { "price" : 2699 } } }
高级查询 布尔组合(bool)
bool 把各种其它查询通过 must (与)、 must_not (非)、 should (或) 的方式进行组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 POST /heima/_search { "query" : { "bool" : { "must" : [ { "match" : { "title" : "小米" } } ] , "must_not" : [ { "match" : { "title" : "电视" } } ] , "should" : [ { "match" : { "title" : "手机" } } ] } } }
范围查询(range)
range 查询找出那些落在指定区间内的数字或者时间
range 查询允许以下字符
模糊查询(fuzzy)
fuzzy自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据它允许用户搜索词条与实际词条出现偏差,但是偏差的编辑距离不得超过2:
1 2 3 4 5 6 7 # 新增一条数据 POST /heima/goods/4 { "title": "apple手机", "images": "http://image.leyou.com/12479122.jpg", "price": 5899 }
默认只允许你写错一个单词,我们可以通过fuzziness设置运行错误几个。(最多就支持2)
排序 单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 POST /heima/_search { "query" : { "match_all" : { } } , "sort" : [ { "price" : { "order" : "desc" } } ] }
多字段排序
假定我们想要结合使用 price和 _score(得分)进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 POST /heima/_search { "query" : { "match_all" : { } } , "sort" : [ { "price" : { "order" : "desc" } } , { "_score" : { "order" : "desc" } } ] }
高亮 elasticsearch中实现高亮的语法比较简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 POST /heima/_search { "query" : { "match" : { "title" : "小米" } } , "highlight" : { "pre_tags" : "<front color='pink'>" , "post_tags" : "</front>" , "fields" : { "title" : { } } } }
在使用match查询的同时,加上一个highlight属性:
pre_tags:前置标签
post_tags:后置标签
fifields:需要高亮的字段
title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
分页 elasticsearch中实现分页的语法非常简单:
1 2 3 4 5 6 7 8 9 10 11 POST /heima/_search { "query" : { "match" : { "title" : "小米" } } , "size" : 1 , "from" : 0 }
size:每页显示多少条
from:当前页起始索引, int start = (pageNum - 1) * size;
Elasticsearch 集群在之前的课程中,我们都是使用单点的elasticsearch,接下来我们会学习如何搭建Elasticsearch的集群
单点的问题 单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
单台机器存储容量有限
单服务器容易出现单点故障,无法实现高可用
单服务的并发处理能力有限
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
数据分片 首先,我们面临的第一个问题就是数据量太大,单点存储量有限的问题 。大家觉得应该如何解决?
没错,我们可以把数据拆分成多份,每一份存储到不同机器节点(node) ,从而实现减少每个节点数据量
数据备份 数据分片解决了海量数据存储的问题,但是如果出现单点故障,那么分片数据就不再完整,这又该如何解决呢?
没错,就像大家为了备份手机数据,会额外存储一份到移动硬盘一样。我们可以给每个分片数据进行备份,存储到其它节点,防止数据丢失,这就是数据备份,也叫 数据副本(replica) 。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
首先对数据分片,存储到不同节点
然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
在这个集群中,如果出现单节点故障,并不会导致数据缺失,所以保证了集群的高可用,同时也减少了节点中数据存储量。并且因为是多个节点存储数据,因此用户请求也会分发到不同服务器,并发能力也得到了一定的提升。
ps: 每个服务器放2个分片就可以相对减少容量了。
搭建集群 集群需要多台机器,我们这里用一台机器来模拟,因此我们需要在一台虚拟机中部署多个elasticsearch节点,每个elasticsearch的端口都必须不一样。
我们计划集群名称为:heima-elastic,部署3个elasticsearch节点,分别是:
1 2 3 node-01:http端口9201,TCP端口9301 node-02:http端口9202,TCP端口9302 node-03:http端口9203,TCP端口9303
接下来的所有操作,记得要使用 elastic 用户来操作 !
另外, 建议先对当前虚拟机进行快照 ,以后好恢复成单点结构
首先把已经启动的elasticsearch关闭,然后通过命令把之前写入的数据都删除。
1 rm -rf /elasticsearch/data
进入 /home/elastic/elasticsearch/config 目录,修改elasticsearch.yml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # ========================ElasticsearchConfiguration=========================#集群名称,三台服务器保持一致 cluster.name:heima-elastic # node.name:node-01 # path.data:/home/elastic/elasticsearch-01/data # path.logs:/home/elastic/elasticsearch-01/logs # network.host:0.0.0.0 # http.port:9201 # transport.tcp.port:9301 # discovery.zen.ping.unicast.hosts:["127.0.0.1:9301", "127.0.0.1:9302","127.0.0.1:9303"] # discovery.zen.minimum_master_nodes:2 # bootstrap.system_call_filter:false
回到 /home/elastic 目录,将 elasticsearch 目录修改为ealsticsearch-01`
1 mv elasticsearch elasticsearch-01
然后输入下面命令,拷贝两份elasticsearch实例:
1 2 cp elasticsearch-01 elasticsearch-02 -R cp elasticsearch-01 elasticsearch-03 -R
进入elasticsearch-02/confifig目录,修改elasticsearch.yml中的下列配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 # 节点名称 node.name:node-02 # path.data:/home/elastic/elasticsearch-02/data # # 日志目录 path.logs:/home/elastic/elasticsearch-02/logs # http.port:9202 # transport.tcp.port:9302
注意到,注意是把01改成了02,但不是所有,切勿自动全局替换!!!
同理,进入elasticsearch-3/config/,修改elasticsearch.yml文件,与上面类似,不过修改成03.
分别启动3台elasticsearch,可以用后台启动方式(要使用 elastic 用户来操作 ):
1 2 3 ./elasticsearch-01/bin/elasticsearch -d ./elasticsearch-02/bin/elasticsearch -d ./elasticsearch-03/bin/elasticsearch -d
通过启动运行chrome的 elasticsearch-head插件,可以查看到节点信息:
启动错误1:
原因是:是因为复制的elasticsearch文件夹下包含了data文件中示例一的节点数据,需要把示例二data文件下的文件清空。删除es集群data数据库文件夹下所有文件即可
启动错误2:
elasticsearch6.8默认分配jvm空间大小为1g,虚拟机内存不够大,修改jvm空间分配128m或256m、512m,最少需要128m
集群健康 可以通过elasticsearch-head插件查看集群健康状态,有以下三个状态:
所有的主分片和副本分片都已分配。你的集群是 100% 可用的
所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow想象成一个需要及时调查的警告。
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
测试集群中创建索引库 搭建集群以后就要创建索引库了,那么问题来了,当我们创建一个索引库后,数据会保存到哪个服务节点上呢?如果我们对索引库分片,那么每个片会在哪个节点呢?
这个要亲自尝试才知道。
还记得创建索引库的API吗?
1 2 3 4 5 6 7 8 # 这里给搭建看看集群中分片和备份的设置方式,示例: PUT /heima3 { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }
settings:就是索引库设置,其中可以定义索引库的各种属性,目前我们可以不设置,都走默认。
这里有两个配置:
number_of_shards:分片数量,这里设置为3
number_of_replicas:副本数量,这里设置为1,每个分片一个备份,一个原始数据,共2份。
通过chrome浏览器的head查看,我们可以查看到分片的存储结构:
可以看到,heima这个索引库,有三个分片,分别是0、1、2,每个分片有1个副本,共6份。
1 2 3 node-01上保存了0号分片和1号分片的副本 node-02上保存了1号分片和2号分片的副本 node-03上保存了0号分片和2号分片的副本
demo工程 6.8版本文档
pom 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.5.7</version > <relativePath /> </parent > <groupId > com.pointink</groupId > <artifactId > es-java-client</artifactId > <version > 0.0.1-SNAPSHOT</version > <name > es-java-client</name > <description > Demo project for Spring Boot</description > <properties > <java.version > 1.8</java.version > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > fastjson</artifactId > <version > 1.2.75</version > </dependency > <dependency > <groupId > org.elasticsearch.client</groupId > <artifactId > elasticsearch-rest-high-level-client</artifactId > <version > 6.8.3</version > </dependency > <dependency > <groupId > org.elasticsearch</groupId > <artifactId > elasticsearch</artifactId > <version > 6.8.3</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > <configuration > <excludes > <exclude > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > </exclude > </excludes > </configuration > </plugin > </plugins > </build > </project >
索引库及映射 创建索引库的同时,我们也会创建type及其映射关系,但是这些操作不建议使用java客户端完成,原因如下:
这些操作建议还是使用我们昨天学习的Rest风格API去实现 。
我们接下来以这样一个商品数据为例来创建索引库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Data @AllArgsConstructor @NoArgsConstructor public class Product { private Long id; private String title; private String category; private String brand; private Double price; private String images; }
分析一下数据结构:
id:可以认为是主键,将来判断数据是否重复的标示,不分词,可以使用keyword类型
title:商品标题,搜索字段,需要分词,可以用text类型
category:商品分类,这个是整体,不分词,可以使用keyword类型
brand:品牌,与分类类似,不分词,可以使用keyword类型
price:价格,这个是double类型
images:图片,用来展示的字段,不搜索,index为false,不分词,可以使用keyword类型
我们可以编写这样的映射配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 PUT /heima/ { "mappings" :{ "product" :{ "properties" :{ "id" :{ "type" :"keyword" }, "title" :{ "type" :"text" , "analyzer" :"ik_max_word" }, "category" :{ "type" :"keyword" }, "brand" :{ "type" :"keyword" }, "images" :{ "type" :"keyword" , "index" :false }, "price" :{ "type" :"double" } } } } }
文档操作 有了索引库,我们接下来看看如何新增索引数据
初始化客户端 客户端和es服务器完成任何操作都需要通过RestHighLevelClient对象,我们编写一个测试类,在@Before测试方法初始化该对象,通信完需要关闭RestHighLevelClient对象,我们在@After测试方法关闭:
然后再@Before的方法中编写client初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class TestES01 { private RestHighLevelClient restHighLevelClient; @Before public void initClient () { client = new RestHighLevelClient (RestClient.builder(new HttpHost ("192.168.129.139" , 9200 , "http" ))); } @After public void closeClient () { if (null != client) { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @SpringBootTest class EsJavaClientApplicationTests { private RestHighLevelClient client; @BeforeEach void init () { client = new RestHighLevelClient ( RestClient.builder( new HttpHost ("192.168.88.128" , 9200 , "http" ) )); } @AfterEach void close () { if (null != client) { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } }
新增文档 接下来我们看看如何通过代码往es服务器新增一个文档。新增时,如果传递的id是已经存在的,则会完成修改操作,如果不存在,则是新增。
1)流程如下:
2)步骤:
1.准备需要保存到索引库的json文档数据
2.创建IndexRequest请求对象,指定索引库、类型、id(可选)
3.调用source方法将请求数据封装到IndexRequest请求对象中
4.调用方法进行数据通信
5.解析输出结果
3)代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void addDoc () { Product product = new Product (1l , "小米手机" , "手机" , "小米" , 2899.00 , "http://www.baidu.com" ); String jsonString = JSON.toJSONString(product); IndexRequest indexRequest = new IndexRequest ("heima" , "product" , "1" ); indexRequest.source(jsonString, XContentType.JSON); try { IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT); System.out.println("结果: " + JSON.toJSONString(indexResponse)); } catch (IOException e) { e.printStackTrace(); } }
看下响应,成功了:
查看文档 刚刚我们保存了一条数据进行,接下来我们根据rest风格,查看应该是根据id进行get查询,难点是对结果的解析:相关类:
GetRquest :封装get请求参数
GetResponse:封装get数据响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void getDocById () { GetRequest getRequest = new GetRequest ("heima" , "product" , "1" ); try { GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT); System.out.println("结果: " + JSON.toJSONString(getResponse)); } catch (IOException e) { e.printStackTrace(); } }
批量新增 当需要新增的数据较多时,单个新增比较耗费性能,所以这时候批量新增功能就比较好用了
构建批量新增BulkRequest请求对象
准备需要保存到索引库的json文档数据封装到IndexRequest请求对象中
添加IndexRequest请求对象至批量新增BulkRequest请求对象
调用方法进行数据通信
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Test public void bulkAddDoc () { BulkRequest bulkRequest = new BulkRequest (); for (long i = 2 ; i < 9 ; i++) { Product product = new Product (i, "小米手机" + i, "手机" , "小米" , 2899.00 + i, "http://www.baidu.com" ); String jsonString = JSON.toJSONString(product); IndexRequest indexRequest = new IndexRequest ("heima" , "product" , "" + i); indexRequest.source(jsonString, XContentType.JSON); bulkRequest.add(indexRequest); } try { client.bulk(bulkRequest, RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } }
通过kibana查询所有
关键点:
BulkRequest:批量请求,可以添加多个IndexRequest对象,完成批处理
修改文档 restAPI只提供了按文档id进行修改的操作
构建修改请求对象,指定索引库、类型、id
准备需要修改的json文档数据
将需要修改的json文档数据封装到UpdateRequest请求对象中
调用方法进行数据通信
解析输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Test public void updataDocById () { UpdateRequest updateRequest = new UpdateRequest ("heima" , "product" , "1" ); Product product = new Product (1l , "大米手机" , "手机" , "大米" , 2899.00 , "http://www.baidu.com" ); String jsonString = JSON.toJSONString(product); updateRequest.doc(jsonString, XContentType.JSON); try { UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT); System.out.println("结果:" + JSON.toJSONString(updateResponse)); } catch (IOException e) { e.printStackTrace(); } }
删除文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void delDocById () { try { DeleteRequest deleteRequest = new DeleteRequest ("heima" , "product" , "2" ); DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT); System.out.println("结果" + JSON.toJSONString(deleteResponse)); } catch (IOException e) { e.printStackTrace(); } }
搜索数据
关键字搜索match SearchRequest :封装搜索请求
SearchSourceBuilder :指定查询类型、排序、高亮等,后面几乎所有的操作都需要该类参与
QueryBuilders :用来构建各种查询类型和查询条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Test public void matchDoc () { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); QueryBuilder queryBuilder = QueryBuilders.matchQuery("title" , "大米" ); sourceBuilder.query(queryBuilder); searchRequest.source(sourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
注意,上面的代码中,搜索条件是通过sourceBuilder.query(QueryBuilders.matchAllQuery())来添加的。这个 query() 方法接受的参数是: QueryBuilder 接口类型。
这个接口提供了很多实现类,分别对应我们在之前中学习的不同类型的查询,例如:term查询、match查询、range查询、boolean查询等,我们如果要使用各种不同查询,其实仅仅是传递给sourceBuilder.query() 方法的参数不同而已。而这些实现类不需要我们去 new ,官方提供了QueryBuilders 工厂帮我们构建各种实现类:
查询所有match_all 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Test public void matchAllDoc () { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); QueryBuilder queryBuilder = QueryBuilders.matchAllQuery(); sourceBuilder.query(queryBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
其实搜索类型的变化,仅仅是利用QueryBuilders构建的查询对象不同而已,其他代码基本一致。因此,我们可以把这段代码封装,然后把查询条件作为参数传递:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private void commonSearch (QueryBuilder queryBuilder) { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); sourceBuilder.query(queryBuilder); searchRequest.source(sourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
source过滤 默认情况下,索引库中所有字段都会返回,如果我们想只返回部分字段,可以通过source fifilter来控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private void commonSearch (QueryBuilder queryBuilder) { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); sourceBuilder.query(queryBuilder); sourceBuilder.fetchSource(new String []{"id" , "title" , "prict" }, null ); searchRequest.source(sourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private void commonSearch (QueryBuilder queryBuilder) { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); sourceBuilder.query(queryBuilder); sourceBuilder.sort("id" , SortOrder.DESC); sourceBuilder.sort("price" , SortOrder.DESC); searchRequest.source(sourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
备注 :默认不能使用text类型的字段进行排序。不然那会报错
解决方法:将需要进行排序的text类型的字段,设置fifielddata=true即可
分页 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 private void commonSearch (QueryBuilder queryBuilder) { SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); sourceBuilder.query(queryBuilder); sourceBuilder.sort("id" , SortOrder.DESC); sourceBuilder.sort("price" , SortOrder.DESC); sourceBuilder.from(0 ); sourceBuilder.size(4 ); searchRequest.source(sourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" + sourceAsString); } } catch (IOException e) { e.printStackTrace(); } }
高亮 高亮就是对匹配的内容里的关键词通过html+css进行加颜色处理显示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Test public void highLightMatch () throws IOException { QueryBuilder queryBuilder = QueryBuilders.matchQuery("title" ,"小米" ); SearchRequest searchRequest = new SearchRequest ("heima" ); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder (); sourceBuilder.query(queryBuilder); HighlightBuilder highlightBuilder = new HighlightBuilder (); highlightBuilder.field("title" ); highlightBuilder.preTags("<font color='pink'>" ); highlightBuilder.postTags("</font>" ); sourceBuilder.highlighter(highlightBuilder); searchRequest.source(sourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { String sourceAsString = hit.getSourceAsString(); System.out.println("结果:" +sourceAsString); Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField title = highlightFields.get("title" ); Text[] fragments = title.getFragments(); for (Text fragment : fragments) { System.err.println("高亮结果:" +fragment.toString()); } } }
1 2 3 new HighlightBuilder () :创建高亮构建器.field("title" ) :指定高亮字段 .preTags("" ) 和 .postTags("" ) :指定高亮的前置和后置标签
SpringDataElasticsearch 简介
Spring Data是一个用于==简化数据访问==,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷 。 Spring Data可以极大的简化数据操作的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
查看 Spring Data的官网:https://spring.io/projects/spring-data
Spring Data 的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(如MySQL),还是非关系数据库(如Redis),或者类Elasticsearch这样的索引数据库。从而简化开发人员的代码,提高开发效率。包含很多不同数据操作的模块
SpringDataElasticsearch(以后简称SDE )是Spring Data项目下的一个子模块,是Spring提供的操作ElasticSearch的数据层,封装了大量的基础操作,通过它可以很方便的操作ElasticSearch的数据。
Spring Data Elasticsearch的页面:https://projects.spring.io/spring-data-elasticsearch/
特征:
支持Spring的基于 @Configuration 的java配置方式,或者XML配置方式
提供了用于操作ES的便捷工具类 ElasticsearchTemplate 。包括实现文档到POJO之间的自动智能映射。
利用Spring的数据转换服务实现的功能丰富的对象映射
基于注解的元数据映射方式,而且可扩展以支持更多不同的数据格式
根据持久层接口自动生成对应实现方法,无需人工编写基本操作代码(类似mybatis,根据接口自动得到实现)。当然,也支持人工定制查询
创建es工程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.1.8.RELEASE</version > <relativePath /> </parent > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-elasticsearch</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > </dependencies >
在application.yml文件中引入elasticsearch的host和port即可:
1 2 3 4 5 spring: data: elasticsearch: cluster-name: elasticsearch cluster-nodes: 192.168 .88 .128 :9300
需要注意的是,SpringDataElasticsearch底层使用的不是Elasticsearch提供的RestHighLevelClient,而是TransportClient,并不采用Http协议通信,而是访问elasticsearch对外开放的tcp端口,ElasticSearch默认tcp端口。
另外,SpringBoot已经帮我们配置好了各种SDE配置,并且注册了一个ElasticsearchTemplate供我们使用。接下来一起来试试吧。
创建索引库和映射 1)新建实体类Goods,作为与索引库对应的文档,通过实体类上的注解来配置索引库信息的,比如:索引库名、类型名、分片、副本数量、还有映射信息;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Data @AllArgsConstructor @NoArgsConstructor @Document(indexName = "goods", type = "goods") public class Goods { @Id private Long id; @Field(type = FieldType.Text,analyzer = "ik_max_word") private String title; @Field(type = FieldType.Keyword) private String category; @Field(type = FieldType.Keyword) private String brand; @Field(type = FieldType.Double) private Double price; @Field(type = FieldType.Keyword,index = false) private String images; } @Document :声明索引库配置 indexName:索引库名称 type:类型名称,默认是“docs” shards:分片数量,默认5 replicas:副本数量,默认1 @Id :声明实体类的id@Field :声明字段属性 type:字段的数据类型 analyzer:指定分词器类型 index:是否创建索引 默认为true store:是否存储 默认为false
1 2 3 4 5 6 7 8 9 10 @Autowired private ElasticsearchTemplate template;public void testCreateIndex () { boolean index = template.createIndex(Goods.class); System.out.println("创建索引库是否成功 = " + index); boolean putMapping = template.putMapping(Goods.class); System.out.println("创建映射是否成功 = " + putMapping); }
删除所有 1 2 3 4 5 6 7 8 9 10 @Test public void testDeleteIndex () { boolean deleteIndex = template.deleteIndex(Goods.class); System.out.println("删除是否成功 = " + deleteIndex); }
对数据CRUD SDE的文档索引数据CRUD并没有封装在ElasticsearchTemplate中,而是有一个叫做ElasticsearchRepository的接口
我们需要自定义接口,继承ElasticsearchRespository:
1 2 public interface GoodsRepository extends ElasticsearchRepository <Goods,Long> {}
创建文档数据 创建索引有单个创建和批量创建之分,先来看单个创建.如果文档已经存在则执行更新操作
1 2 3 4 5 6 7 8 9 10 @Autowired private GoodsRepository goodsRepository; @Test public void addDoc () { Goods goods = new Goods (1l , "小米手机" , "手机" , "小米" , 19999.00 , "http://www.baidu.com" ); goodsRepository.save(goods); }
1 2 3 4 5 6 7 8 9 10 11 @Test public void batchAddDoc () { List<Goods> goodsList = new ArrayList <>(); for (long i = 2 ; i < 10 ; i++) { Goods goods = new Goods (i, "小米手机" + i, "手机" , "小米" , 19999.00 + i, "http://www.baidu.com" ); goodsList.add(goods); } goodsRepository.saveAll(goodsList); }
查询文档数据 根据id查询
1 2 3 4 5 6 7 8 9 10 11 @Test public void findDocById () { Optional<Goods> optional = goodsRepository.findById(1L ); if (optional.isPresent()) { Goods goods = optional.get(); System.out.println("结果: " + goods); } }
查询所有
1 2 3 4 5 6 7 8 9 10 @Test public void findAllDoc () { Iterable<Goods> all = goodsRepository.findAll(); for (Goods goods : all) { System.out.println("结果 : " + goods); } }
使用search查询
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void search () { QueryBuilder queryBuilder = QueryBuilders.termQuery("title" , "大米" ); Iterable<Goods> iterable = goodsRepository.search(queryBuilder); for (Goods goods : iterable) { System.out.println("结果:" + goods); } }
使用search查询并分页排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void pageSortQuery () { Sort sort = new Sort (Sort.Direction.ASC, "id" ); Pageable pageable = PageRequest.of(0 , 2 , sort); Page<Goods> page = goodsRepository.search(QueryBuilders.matchQuery("title" , "小米" ), pageable); long totalElements = page.getTotalElements(); System.out.println("totalElements:" + totalElements); int totalPages = page.getTotalPages(); System.out.println("totalPages:" + totalPages); for (Goods goods : page) { System.out.println("结果:" + goods); } }
自定义方法查询
oodsRepository提供的查询方法有限,但是它却提供了非常强大的自定义查询功能;只要遵循SpringData提供的语法,我们可以任意定义方法声明:
1 2 3 4 5 6 7 8 9 10 11 12 List<Goods> findByPriceBetween (Double from, Double to) ; @Test public void findGoodsByPriceRang () { List<Goods> byPriceBetween = goodsRepository.findByPriceBetween(19999.0 , 20006.0 ); for (Goods goods : byPriceBetween) { System.out.println(goods); } }
1 2 3 支持的一些语法示例: findGoods By Price Between 语法:findBy+字段名+Keyword+字段名+....
删除文档 1 2 3 4 5 6 7 8 @Test public void deleteDoc () { Goods goods = new Goods (1l , "小米手机" , "手机" , "小米" , 19999.00 , "http://www.baidu.com" ); goodsRepository.delete(goods); }
使用ElasticsearchTempldate查询 SDE也支持使用ElasticsearchTemplate进行原生查询
而查询条件的构建是通过一个名为 NativeSearchQueryBuilder 的类来完成的,不过这个类的底层还是使用的原生API中的 QueryBuilders 、HighlightBuilders 等工具。
分页和排序
可以通过NativeSearchQueryBuilder类来构建分页和排序、聚合等操作
queryBuilder.withQuery() //设置查询类型和查询条件
queryBuilder.withPageable() //设置分页
queryBuilder.withSort()//设置排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Test public void nativeSearchQuery () { NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder (); searchQueryBuilder.withQuery(QueryBuilders.matchQuery("title" , "小米" )); searchQueryBuilder.withSort(SortBuilders.fieldSort("id" ).order(SortOrder.DESC)); searchQueryBuilder.withPageable(PageRequest.of(0 , 2 )); NativeSearchQuery searchQuery = searchQueryBuilder.build(); AggregatedPage<Goods> page = template.queryForPage(searchQuery, Goods.class); long totalElements = page.getTotalElements(); System.out.println("totalElements:" + totalElements); int totalPages = page.getTotalPages(); System.out.println("totalPages:" + totalPages); for (Goods goods : page) { System.out.println("结果:" + goods); } }
1. ElasticSearch 7快速入门 1.1. 基本介绍 1.1.1 ElasticSearch特色 Elasticsearch是实时的分布式搜索分析引擎,内部使用Lucene做索引与搜索
准实时性:新增到 ES 中的数据在1秒后就可以被检索到,这种新增数据对搜索的可见性称为“准实时搜索”
分布式:意味着可以动态调整集群规模,弹性扩容
集群规模:可以扩展到上百台服务器,处理PB级结构化或非结构化数据
各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作
Lucene是Java语言编写的全文搜索框架,用于处理纯文本的数据,但它只是一个库,提供建立索引、执行搜索等接口,但不包含分布式服务,这些正是 ES 做的
1.1.2 ElasticSearch使用场景 ElasticSearch广泛应用于各行业领域, 比如维基百科, GitHub的代码搜索,电商网站的大数据日志统计分析, BI系统报表统计分析等。
提供分布式的搜索引擎和数据分析引擎
比如百度,网站的站内搜索,IT系统的检索, 数据分析比如热点词统计, 电商网站商品TOP排名等。
全文检索,结构化检索,数据分析
支持全文检索, 比如查找包含指定名称的商品信息; 支持结构检索, 比如查找某个分类下的所有商品信息;
还可以支持高级数据分析, 比如统计某个商品的点击次数, 某个商品有多少用户购买等等。
支持海量数据准实时的处理
采用分布式节点, 将数据分散到多台服务器上去存储和检索, 实现海量数据的处理, 比如统计用户的行为日志, 能够在秒级别对数据进行检索和分析。
1.1.3 ElasticSearch基本概念介绍
ElasticSearch
Relational Database
Index
Database
Type
Table
Document
Row
Field
Column
Mapping
Schema
Everything is indexed
Index
Query DSL
SQL
GET http://…
SELECT * FROM table…
PUT http://…
UPDATE table SET…
索引(Index)
相比传统的关系型数据库,索引相当于SQL中的一个【数据库】,或者一个数据存储方案(schema)。
类型(Type)
一个索引内部可以定义一个或多个类型, 在传统关系数据库来说, 类型相当于【表】的概念。
文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,采用JSON格式表示。相当于传统数据库【行】概念
集群(Cluster)
集群是由一台及以上主机节点组成并提供存储及搜索服务, 多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
节点(Node)
Node为集群中的单台节点,其可以为master节点亦可为slave节点(节点属性由集群内部选举得出)并提供存储相关数据的功能
切片(shards)
切片是把一个大文件分割成多个小文件然后分散存储在集群中的多个节点上, 可以将其看作mysql的分库分表概念。 Shard有两种类型:primary主片和replica副本,primary用于文档存储,Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
注意: ES7之后Type被舍弃,只有Index(等同于数据库+表定义)和Document(文档,行记录)。
1.2 ElasticSearch安装 1.2.1 下载ElasticSearch服务 下载最新版ElasticSearch7.10.2: https://www.elastic.co/cn/start
1.2.2 解压安装包 1 tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz
1.2.3 创建elsearch用户 1 2 3 4 5 6 ## ElasticSearch不能以Root身份运行, 需要单独创建一个用户, 并赋予目录权限 groupadd elsearch useradd elsearch -g elsearch -p elasticsearch chown -R elsearch:elsearch /opt/elasticsearch/elasticsearch-7.10.2
1.2.4 修改配置文件 vi config/elasticsearch.yml, 默认情况下会绑定本机地址, 外网不能访问, 这里要修改下:
1 2 3 4 5 6 # node名称 node.name: node-1 # 外网访问地址 network.host: 0.0.0.0 discovery.seed_hosts: ["node-1"] cluster.initial_master_nodes: ["node-1"]
1.2.5 关闭防火墙 1 2 systemctl stop firewalld.service systemctl disable firewalld.service
1.2.6 JDK环境变量的配置 1)最新版的ElasticSearch需要JDK11版本, 下载JDK11压缩包 , 并进行解压。
2)修改环境配置文件
vi bin/elasticsearch-env ,参照以下位置, 追加一行, 设置JAVA_HOME, 指定JDK11路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 JAVA_HOME=/opt/jdk-11.0.11 # now set the path to java if [ ! -z "$JAVA_HOME" ]; then JAVA="$JAVA_HOME/bin/java" else if [ "$(uname -s)" = "Darwin" ]; then # OSX has a different structure JAVA="$ES_HOME/jdk/Contents/Home/bin/java" else JAVA="$ES_HOME/jdk/bin/java" fi fi
1.2.7 启动ElasticSearch 1 2 3 4 ## 切换用户 su elsearch ## 以后台常驻方式启动 bin/elasticsearch -d
PS: 出现max virtual memory areas vm.max_map_count [65530] is too low, increase to at least 错误信息,如图:
修改系统配置:
vi /etc/sysctl.conf , 添加 vm.max_map_count=655360,保存退出后,执行 sysctl -p,使之生效。
vi /etc/security/limits.conf,在文件末尾添加如下配置:
1 2 3 4 5 6 7 8 9 10 11 * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 elsearch soft nproc 125535 elsearch hard nproc 125535
1.2.8 访问验证 访问地址:http://192.168.10.30:9200/_cat/health
启动状态有green、yellow和red。 green是代表启动正常。
1.3 Kibana服务安装 Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
1.3.1 下载安装包 到官网下载, Kibana安装包 , 与之对应7.10.2版本, 选择Linux 64位版本下载,并进行解压。
1 2 3 4 # 解压 tar -xvf kibana-7.10.2-linux-x86_64.tar.gz # 重命名为 kibana-7.10.2 mv kibana-7.10.2-linux-x86_64/ kibana-7.10.2
1.3.2 创建的elsearch用户 Kibana启动不能使用root用户, 使用上面创建的elsearch用户, 进行赋权:
1 chown -R elsearch:elsearch kibana-7.10.2
1.3.3 修改配置文件 vi config/kibana.yml , 修改以下配置:
1 2 3 4 5 6 # 服务端口 server.port: 5601 # 服务地址 server.host: "0.0.0.0" # elasticsearch服务地址 elasticsearch.hosts: ["http://192.168.10.30:9200"]
1.3.4 启动kibana 看到以下日志, 代表启动正常
1 log [01:40:00.143] [info][listening] Server running at http://0.0.0.0:5601
如果出现启动失败的情况, 要检查集群各节点的日志, 确保服务正常运行状态。
1.3.5 访问服务 http://192.168.10.30:5601/app/home#/
1.4 ES的基础操作 1.4.1 登录Kibana管理后台 地址: http://192.168.10.30:5601
进入”Dev Tools”栏,在Console中输入命令进行操作:
1.4.2 索引 1)新建索引 orders
2)查询索引 orders
3)删除索引 orders
4)索引的设置
1 2 3 4 5 6 7 8 9 10 ## 设置索引 PUT orders { "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } } }
1.4.3 文档 1)创建文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ## 创建文档,生成默认的文档id POST orders/_doc { "name": "袜子1双", "price": "200", "count": 1, "address": "北京市" } ## 创建文档,生成自定义文档id POST orders/_doc/1 { "name": "袜子1双", "price": "2", "count": 1, "address": "北京市" }
2)查询文档
1 2 3 4 5 6 7 8 9 10 11 12 13 ## 根据指定的id查询 GET orders/_doc/1 ## 根据指定条件查询文档 GET orders/_search { "query": { "match": { "address": "北京市" } } } ## 查询全部文档 GET orders/_search
3) 更新文档
1 2 3 4 5 6 7 8 9 10 11 12 ## 更新文档 覆盖 POST orders/_doc/1 { "price": "200" } ## 更新文档 跟新指定字段值 POST orders/_update/1 { "doc": { "price": "200" } }
4)删除文档
1 2 ## 删除文档 DELETE orders/_doc/1
1.4.4 映射 对于映射,只能进行字段添加,不能对字段进行修改或删除,如有需要,则重新创建映射。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ## 设置mapping信息 PUT orders/_mappings { "properties":{ "price": { "type": "long" } } } ## 设置分片和映射 PUT orders { "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } }, "mappings": { "properties": { "name": { "type": "text" }, "price": { "type": "long" }, "count": { "type": "long" }, "address": { "type": "text" } } } }
1.5 ES数据类型 1.5.1 整体数据类型结构
1.5.2 String 类型 主要分为text与keyword两种类型。两者区别主要在于能否分词。
1.5.3 Date时间类型 数据库里的日期类型需要规范具体的传入格式, ES是可以控制,自适应处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ## ES的Date类型允许可以使用的格式:yyyy-MM-dd PUT my_date_index/_doc/1 { "date": "2021-01-01" } ## ES的Date类型允许可以使用的格式:yyyy-MM-dd HH:mm:ss PUT my_date_index/_doc/2 { "date": "2021-01-01T12:10:30Z" } ## ES的Date类型允许可以使用的格式:epoch_millis(毫秒值) PUT my_date_index/_doc/3 { "date": 1520071600001 } ## 查看日期数据: GET my_date_index/_mapping
1.5.4 复合类型 1)数组
在Elasticsearch中,数组不需要声明专用的字段数据类型。但是,在数组中的所有值都必须具有相同的数据类型。
1 2 3 4 5 6 7 8 9 10 ## 错误示例 POST orders/_doc/1 { "goodsName":["足球","篮球","兵乓球", 3] } ## 正确示例 POST orders/_doc/1 { "goodsName":["足球","篮球","兵乓球"] }
2)对象
用于存储单个JSON对象, 类似于JAVA中的对象类型, 可以有多个值, 比如LIST,可以包含多个对象。但是,LIST< Object >只能作为整体, 不能独立的索引查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # 新增第一组数据, 组别为美国,两个人。 POST my_index/_doc/1 { "group" : "america", "users" : [ { "name" : "John", "age" : "22" }, { "name" : "Alice", "age" : "21" } ] } # 新增第二组数据, 组别为英国, 两个人。 POST my_index/_doc/2 { "group" : "england", "users" : [ { "name" : "lucy", "age" : "21" }, { "name" : "John", "age" : "32" } ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ## 搜索name为John,age为21的数据 GET my_index/_search { "query": { "bool": { "must": [ { "match": { "users.name": "John" } }, { "match": { "users.age": "21" } } ] } } }
结果可以看到, 这两组数据都能找出,因为每一组数据都是作为一个整体进行搜索匹配, 而非具体某一条数据。
3)嵌套
用于存储多个JSON对象组成的数组,nested 类型是 object 类型中的一个特例,可以让对象数组独立索引和查询。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 ## 1. 创建nested类型的索引 PUT my_index { "mappings": { "properties": { "users": { "type": "nested" } } } } ## 2. 新增数据 ## 3. 再次查询 GET my_index/_search { "query": { "bool": { "must": [ { "nested": { "path": "users", "query": { "bool": { "must": [ { "match": { "users.name": "John" } }, { "match": { "users.age": "21" } } ] } } } } ] } } }
采用以前的条件, 这个时候查不到任何结果, 将年龄改成22, 就可以找出对应的数据
1.5.5 GEO地理位置类型 现在大部分APP都有基于位置搜索的功能, 比如交友、购物应用等。这些功能是基于GEO搜索实现的。
对于GEO地理位置类型,分为地理坐标类型:Geo-point, 和形状:Geo-shape 两种类型。
经纬度
英文
简写
正数
负数
纬度
latitude
lat
北纬
南纬
经度
longitude
lon或lng
东经
西经
1)创建地理位置索引
1 2 3 4 5 6 7 8 9 10 PUT my_locations { "mappings": { "properties": { "location": { "type": "geo_point" } } } }
2)添加地理位置数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 # 采用object对象类型 PUT my_locations/_doc/1 { "user": "张三", "text": "Geo-point as an object", "location": { "lat": 41.12, "lon": -71.34 } } # 采用string类型 PUT my_locations/_doc/2 { "user": "李四", "text": "Geo-point as a string", "location": "45.12,-75.34" } # 采用geohash类型(geohash算法可以将多维数据映射为一串字符) PUT my_locations/_doc/3 { "user": "王二麻子", "text": "Geo-point as a geohash", "location": "drm3btev3e86" } # 采用array数组类型 PUT my_locations/_doc/4 { "user": "木头老七", "text": "Geo-point as an array", "location": [ -80.34, 51.12 ] }
3)需求
搜索出距离我{“lat” : 40,”lon” : -70} 200km范围内的人
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 GET my_locations/_search { "query": { "bool": { "must": { "match_all": {} }, "filter": { "geo_distance": { "distance": "200km", "location": { "lat": 40, "lon": -70 } } } } } }
2. ES高可用集群配置 2.1 集群介绍 2.1.1 主节点(候选主节点)
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作, 主节点负荷相对较轻, 客户端请求可以直接发往任何节点, 由对应节点负责分发和返回处理结果。
一个节点启动之后, 采用 Zen Discovery机制去寻找集群中的其他节点, 并与之建立连接, 集群会从候选主节点中选举出一个主节点, 并且一个集群只能选举一个主节点, 在某些情况下, 由于网络通信丢包等问题, 一个集群可能会出现多个主节点, 称为“脑裂现象”, 脑裂会存在丢失数据的可能, 因为主节点拥有最高权限, 它决定了什么时候可以创建索引, 分片如何移动等, 如果存在多个主节点, 就会产生冲突, 容易产生数据丢失。要尽量避免这个问题, 可以通过 discovery.zen.minimum_master_nodes 来设置最少可工作的候选主节点个数。 建议设置为(候选主节点/2) + 1 比如三个候选主节点,该配置项为 (3/2)+1 ,来保证集群中有半数以上的候选主节点, 没有足够的master候选节点, 就不会进行master节点选举,减少脑裂的可能。
主节点的参数设置:
1 2 node.master = true node.data = false
2.1.2 数据节点
数据节点负责数据的存储和CRUD等具体操作,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。
数据节点的参数设置:
1 2 node.master = false node.data = true
2.1.3 客户端节点
客户端节点不做候选主节点, 也不做数据节点的节点,只负责请求的分发、汇总等等,增加客户端节点类型更多是为了负载均衡的处理。
客户端节点的参数设置:
1 2 node.master = false node.data = false
2.1.4 提取节点(预处理)
能执行预处理管道,有自己独立的任务要执行, 在索引数据之前可以先对数据做预处理操作, 不负责数据存储也不负责集群相关的事务。
参数设置:
2.1.5 协调节点
协调节点,是一种角色,而不是真实的Elasticsearch的节点,不能通过配置项来指定哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。
ES的一次请求非常类似于Map-Reduce操作。在ES中对应的也是两个阶段,称之为scatter-gather。客户端发出一个请求到集群的任意一个节点,这个节点就是所谓的协调节点,它会把请求转发给含有相关数据的节点(scatter阶段),这些数据节点会在本地执行请求然后把结果返回给协调节点。协调节点将这些结果汇总(reduce)成一个单一的全局结果集(gather阶段) 。
2.1.6 部落节点
在多个集群之间充当联合客户端, 它是一个特殊的客户端 , 可以连接多个集群,在所有连接的集群上执行搜索和其他操作。 部落节点从所有连接的集群中检索集群状态并将其合并成全局集群状态。 掌握这一信息,就可以对所有集群中的节点执行读写操作,就好像它们是本地的。 请注意,部落节点需要能够连接到每个配置的集群中的每个单个节点。
2.2 集群原理 2.2.1 集群分布式原理 集群可以根据节点数, 动态调整主分片与副本数, 做到整个集群有效均衡负载。
单节点状态下:
两个节点状态下, 副本数为1:
三个节点状态下, 副本数为1:
三个节点状态下, 副本数为2:
2.2.2 分片处理机制 设置分片大小的时候, 需预先做好容量规划, 如果节点数过多, 分片数过少, 那么新的节点将无法分片, 不能做到水平扩展, 并且单个分片数据量太大, 导致数据重新分配耗时过长。
假设一个集群中有一个主节点、两个数据节点。orders索引的分片分布情况如下所示:
1 2 3 4 5 6 7 PUT orders { "settings":{ "number_of_shards": 2, ## 主分片一共 2 "number_of_replicas": 2 ## 副分片一共 4 } }
整个集群中存在P0和P1两个主分片, P0对应的两个R0副本分片, P1对应的是两个R1副本分片。
2.2.3 写索引处理流程 1)客户端向NODE1发送写请求。
2)NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0的主分片位于NODE3,因此请求被转发到NODE3上。
3)NODE3上的主分片执行写操作。如果写入成功,则它将请求并行转发到 NODE1和NODE2的副分片上,等待返回结果。当所有的副分片都报告成功,NODE3将向协调节点报告成功,协调节点再向客户端报告成功。
2.2.4 读取索引处理流程 1)客户端向NODE1发送读请求。
2)NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0有三个副本数据,位于所有的三个节点中,此时它可以将请求发送到任意节点,这里它将请求转发到NODE2。
3)NODE2将文档返回给 NODE1,NODE1将文档返回给客户端。
NODE1作为协调节点,会将客户端请求轮询发送到集群的所有副本来实现负载均衡。
2.3 集群部署规划 准备一台虚拟机:
192.168.10.30: node1 (节点一), 端口:9200, 9300
192.168.10.30: node2 (节点二),端口:9201, 9301
192.168.10.30: node3 (节点三),端口:9202, 9302
2.4 集群配置 2.4.1 下载安装包 下载最新版ElasticSearch7.10.2: https://www.elastic.co/cn/start
2.4.2 解压安装包 将安装包解压至/opt/elasticsearch/cluster目录
1 2 3 mkdir -p /opt/elasticsearch/cluster cd /opt/elasticsearch/cluster tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz
2.4.3 修改集群配置文件 vi node1/config/elasticsearch.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 集群名称 cluster.name: my-application #节点名称 node.name: node-1 # 绑定IP地址 network.host: 192.168.10.30 # 指定服务访问端口 http.port: 9200 # 指定API端户端调用端口 transport.tcp.port: 9300 #集群通讯地址 discovery.seed_hosts: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #集群初始化能够参选的节点信息 cluster.initial_master_nodes: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #开启跨域访问支持,默认为false http.cors.enabled: true ##跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"
修改目录权限
1 chown -R elsearch:elsearch /opt/elasticsearch/cluster/node1
2.4.4 创建其余两个节点 复制node1安装目录:
1 2 3 cd /opt/elasticsearch/cluster cp -r node1 node2 cp -r node1 node3
2.4.5 修改其余节点的配置 1)node2节点配置内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 集群名称 cluster.name: my-application #节点名称 node.name: node-2 # 绑定IP地址 network.host: 192.168.10.30 # 指定服务访问端口 http.port: 9201 # 指定API端户端调用端口 transport.tcp.port: 9301 #集群通讯地址 discovery.seed_hosts: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #集群初始化能够参选的节点信息 cluster.initial_master_nodes: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #开启跨域访问支持,默认为false http.cors.enabled: true ##跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"
2)node3节点配置内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 集群名称 cluster.name: my-application #节点名称 node.name: node-3 # 绑定IP地址 network.host: 192.168.10.30 # 指定服务访问端口 http.port: 9202 # 指定API端户端调用端口 transport.tcp.port: 9302 #集群通讯地址 discovery.seed_hosts: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #集群初始化能够参选的节点信息 cluster.initial_master_nodes: ["192.168.10.30:9300", "192.168.10.30:9301","192.168.10.30:9302"] #开启跨域访问支持,默认为false http.cors.enabled: true ##跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"
2.4.6 启动集群节点 1 2 3 4 5 6 ## 切换elsearch用户 su elsearch ## 分别启动三个ES服务 /opt/elasticsearch/cluster/node1/bin/elasticsearch -d /opt/elasticsearch/cluster/node2/bin/elasticsearch -d /opt/elasticsearch/cluster/node3/bin/elasticsearch -d
注意: 如果启动出现错误, 将各节点的data目录清空, 再重启服务。
2.4.7 集群状态查看 http://192.168.10.30:9200/_cat/nodes?pretty
可以看到三个节点信息,三个节点会自行选举出主节点。
2.5 集群分片测试 2.5.1 修改kibana配置 1 elasticsearch.hosts: ["http://192.168.10.30:9200","http://192.168.10.30:9201","http://192.168.10.30:9202"]
重启kibana服务, 进入控制台:http://192.168.10.30:5601/app/home#/
2.5.2 设置分片数 1)2个主分片、2个副分片
1 2 3 4 5 6 7 8 9 10 ## 再次创建索引(副本数量范围内) PUT orders { "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 2 } } }
结果正常:
2)2个主分片、5个副分片
1 2 3 4 5 6 7 8 9 PUT orders { "settings": { "index": { "number_of_shards": 2, "number_of_replicas": 5 } } }
yellow警告错误:
2.5.3 分片设置总结 集群并非可以随意增加副本数量
3. ELK部署应用与工作机制 3.1 ELK日志分析平台介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash和Kibana。Elasticsearch和Kibana我们上面做过讲解。 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,适用大数据量场景, 一般采用c/s模式,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作, 再一并发往Elasticsearch上做数据分析。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志分析平台。
3.2 ELK部署架构模式 3.2.1 简单架构 这是最简单的一种ELK部署架构方式, 由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。 优点是搭建简单, 易于上手, 缺点是Logstash耗资源较大, 依赖性强, 没有消息队列缓存, 存在数据丢失隐患
3.2.2 消息队列架构 该队列架构引入了KAFKA消息队列, 解决了各采集节点上Logstash资源耗费过大, 数据丢失的问题, 各终端节点上的Logstash Agent 先将数据/日志传递给Kafka, 消息队列再将数据传递给Logstash, Logstash过滤、分析后将数据传递给Elasticsearch存储, 由Kibana将日志和数据呈现给用户。
3.2.3 BEATS架构 该架构的终端节点采用Beats工具收集发送数据, 更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询, 官方也推荐采用此工具, 下面我们采用此架构模式进行配置讲解(如果在生产环境中, 可以再增加kafka消息队列, 实现了beats+消息队列的部署架构 )。
Beats工具包含四种:
1、Packetbeat(搜集网络流量数据)
2、Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
3、Filebeat(搜集文件数据)
4、Winlogbeat(搜集 Windows 事件日志数据)
3.3 ELK工作机制 3.3.1 Filebeat工作机制 Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
1)Harvester(收割机)
负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到指定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive。
filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m。
2)Prospector(勘测者)
负责管理Harvester并找到所有读取源。
1 2 3 4 filebeat.prospectors: - input_type: log paths: - /apps/logs/*/info.log
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
3)Filebeat如何记录发送状态
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
4)Filebeat如何保证数据发送成功
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会在关闭之前确认所有事件。任何在filebeat关闭之前未确认的事件,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
3.3.2 Logstash工作机制 Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志等。
1)Input:输入数据到logstash
支持的输入类型:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
2)Filters:数据中间处理,对数据进行操作
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。官方提供的grok表达式
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
3)Outputs:outputs是logstash处理管道的最末端组件
一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
4)Codecs:codecs 是基于数据流的过滤器
它可以作为input,output的一部分配置,可以帮助你轻松的分割发送过来已经被序列化的数据。
常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
3.4 Logstash安装配置 3.4.1 下载安装包 1 2 3 4 5 cd /opt/elasticsearch ## 下载 wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.2-linux-x86_64.tar.gz ## 解压 tar -xvf logstash-7.10.2-linux-x86_64.tar.gz
3.4.2 创建目录 1 2 3 4 ## 创建数据存储目录 [root@localhost logstash-7.10.2]# mkdir -p /opt/elasticsearch/logstash-7.10.2/data ## 创建日志记录目录 [root@localhost logstash-7.10.2]# mkdir -p /opt/elasticsearch/logstash-7.10.2/logs
3.4.3 修改配置文件 vi /opt/elasticsearch/logstash-7.10.2/config/logstash.yml
1 2 3 4 5 6 7 8 9 10 # 数据存储路径 path.data: /opt/elasticsearch/logstash-7.10.2/data # 监听主机地址 http.host: "192.168.10.30" # 日志存储路径 path.logs: /opt/elasticsearch/logstash-7.10.2/logs #启动监控插件 xpack.monitoring.enabled: true #Elastic集群地址 xpack.monitoring.elasticsearch.hosts: ["http://192.168.10.30:9200","http://192.168.10.30:9201","http://192.168.10.30:9202"]
3.4.4 创建监听配置文件 vi /opt/elasticsearch/logstash-7.10.2/config/logstash.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 input { beats { # 监听端口 port => 5044 } } output { stdout { # 输出编码插件 codec => rubydebug } elasticsearch { # 集群地址 hosts => ["http://192.168.10.30:9200","http://192.168.10.30:9201","http://192.168.10.30:9202"] } }
3.4.5 启动Logstash服务 以root用户身份执行:
1 2 3 4 ## 后台启动方式 nohup ./bin/logstash -f config/logstash.conf & ## ./bin/logstash -f config/logstash.conf
3.4.6 访问Logstash http://192.168.10.30:9600/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "host": "linux30", "version": "7.10.2", "http_address": "192.168.10.30:9600", "id": "44030329-eb2f-461e-b861-9068312570d1", "name": "linux30", "ephemeral_id": "4101fc4f-8961-43e5-8492-dd8941dbadf7", "status": "green", "snapshot": false, "pipeline": { "workers": 4, "batch_size": 125, "batch_delay": 50 }, "monitoring": { "hosts": ["http://192.168.10.30:9200", "http://192.168.10.30:9201", "http://192.168.10.30:9202"], "username": "logstash_system" }, "build_date": "2021-01-13T02:43:06Z", "build_sha": "7cebafee7a073fa9d58c97de074064a540d6c317", "build_snapshot": false }
3.5 Filebeat安装配置 3.5.1 下载安装包 与ElasticSearch版本一致, 下载7.10.2版本。
1 2 3 4 5 6 cd /opt/elasticsearch ## 下载 wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.2-linux-x86_64.tar.gz ## 解压 tar -xvf filebeat-7.10.2-linux-x86_64.tar.gz mv filebeat-7.10.2-linux-x86_64/ filebeat-7.10.2
3.5.2 修改配置文件 vi /opt/elasticsearch/filebeat-7.10.2/filebeat.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 需要收集发送的日志文件 filebeat.inputs: - type: log enabled: true paths: - /var/log/messages # 如果需要添加多个日志,只需要添加 - type: log enabled: true paths: - /opt/elasticsearch/test.log # filebeat 配置模块, 可以加载多个配置 filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false # 索引分片数量设置 setup.template.settings: index.number_of_shards: 2 # kibana 信息配置 setup.kibana: host: "192.168.10.30:5601" # logstash 信息配置 (注意只能开启一项output设置, 如果采用logstash, 将output.elasticsearch关闭) output.logstash: hosts: ["192.168.10.30:5044"] # 附加metadata元数据信息 processors: - add_host_metadata: ~ - add_cloud_metadata: ~
3.5.3 启动服务 1 2 3 4 ## 后台启动 nohup ./filebeat -e -c filebeat.yml & ## ./filebeat -e -c filebeat.yml
我们监听的是/var/log/messages系统日志信息, 当日志发生变化后, filebeat会通过logstash上报到Elasticsearch中。 我们可以查看下集群的全部索引信息(http://192.168.10.30:9200/_cat/indices?v)
可以看到, 已经生成了名为logstash-2021.11.15-000001索引
3.6 Kibana配置与查看数据 3.6.1 登录Kibana http://192.168.10.30:5601 ,进入【Management】–> 在Index Pattern中输入”logstash-*” –> 点击【next step】, 选择”@timestamp”,点击【 Create index pattern 】进行创建
3.6.2 查看数据 进入【Discover】, 可以查看到收集的数据,如果没有显示, 可以重新调整Time Range时间范围。
1 
课后作业:
1.了解ES中涉及到的基本概念,如 index、document、field、mapping等
2.实现ELK日志分析平台的部署、并收集test.txt文件内容到es,通过kibana进行查看test.txt文件内容
4. ElasticSearch高阶操作 4.1 准备数据 4.1.1 创建数据库 1)使用es.sql文件,完成初始化库表创建与数据准备
2)使用docker开启数据库
1 docker run -d --name mysql8-es -p 3306:3306 -v /opt/elasticsearch/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD="123456" mysql:8.0
4.1.2 SpringBoot整合ES 1)导入项目
2)依赖的引入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <!-- elasticsearch--> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.10.2</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>7.10.2</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.10.2</version> </dependency>
3)ESConfig连接配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Configuration @ConfigurationProperties(prefix = "elasticsearch") public class ESConfig { private String host; private int port; public String getHost() { return host; } public void setHost(String host) { this.host = host; } public int getPort() { return port; } public void setPort(int port) { this.port = port; } /** * es java客户端 * * @return */ @Bean public RestHighLevelClient restHighLevelClient() { RestClientBuilder builder = RestClient.builder(new HttpHost(host, port, "http")); builder.setRequestConfigCallback(requestConfigBuilder -> { requestConfigBuilder.setConnectionRequestTimeout(500000); requestConfigBuilder.setSocketTimeout(500000); requestConfigBuilder.setConnectTimeout(500000); return requestConfigBuilder; }); return new RestHighLevelClient(builder); } }
4)通过kibana创建索引结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 PUT hotel { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "name":{ "type": "text" }, "address":{ "type": "text" }, "brand":{ "type": "keyword" }, "type":{ "type": "keyword" }, "price":{ "type": "integer" }, "specs":{ "type": "keyword" }, "salesVolume":{ "type": "integer" }, "area":{ "type": "text" }, "imageUrl":{ "type": "text" }, "synopsis":{ "type": "text" }, "createTime":{ "type": "date", "format": "yyyy-MM-dd" }, "isAd":{ "type":"integer" } } } }
5)导入数据
调用接口: http://127.0.0.1:8081/importData,会读取数据库, 自动导入数据到es。
6)查看导入结果
通过kibana后台,查看导入的数据
4.2 倒排索引 4.2.1 概念 要想理解倒排索引,首先先思考一个问题,获取某个文件夹下所有文件名中包含Spring的文件
1 2 3 1)确定要搜索的文件夹 2)遍历文件夹下所有文件 3)判断文件名中是否包含Spring
这种思维可以理解为是一种正向思维的方式,从外往内,根据key找value。这种方式可以理解为正向索引。
4.2.2 结构 而ElasticSearch为了提升查询效率,采用反向思维方式,根据value找key。
4.3 IK分词器 4.3.1 认识分词器 查询出了很多万豪相关的酒店,现在以北京市东城区万豪酒店查询name域,可以发现无法查询到结果。
1 2 3 4 5 6 7 8 GET hotel/_search { "query": { "term": { "name": "北京市东城区万豪酒店" } } }
在创建索引时,对于name域,数据类型是text。当添加文档时,对于该域的值会进行分词,形成若干term(词条)存储在倒排索引中。
根据倒排索引结构,当查询条件在词条中存在,则会查询到数据。如果词条中没有,则查询不到数据。
那么对于北京市东城区万豪酒店的分词结果是什么呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 GET hotel/_analyze { "field": "name", "text": "北京市东城区万豪酒店" } GET hotel/_analyze { "field": "name", "analyzer": "standard", "text": "北京市东城区万豪酒店" } GET _analyze { "analyzer": "ik_smart", "text": "北京市东城区万豪酒店" } GET _analyze { "analyzer": "ik_max_word", "text": "北京市东城区万豪酒店" }
此时可以发现,每个字形成了一个词,所以并没有找到相匹配的词,导致无法查询到结果
在ElasticSearch默认内置了多种分词器:
Standard Analyzer - 默认分词器,按英文空格切分 Simple Analyzer - 按照非字母切分(符号被过滤)
Stop Analyzer - 小写处理,停用词过滤(the,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当作输出
Patter Analyzer - 正则表达式,默认\W+(非字符分割)
而我们想要的是,分词器能够智能的将中文按照词义分成若干个有效的词。此时就需要额外安装中文分词器。 对于中文分词器的类型也有很多,其中首选的是:IK分词器。
4.3.2 安装IK分词器 1)安装IK分词插件
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.2/elasticsearch-analysis-ik-7.10.2.zip
2)采用本地文件安装方式, 进入ES安装目录, 执行插件安装命令
1 2 3 [root@linux30 cluster]# ./node1/bin/elasticsearch-plugin install file:///opt/elasticsearch/elasticsearch-analysis-ik-7.10.2.zip [root@linux30 cluster]# ./node2/bin/elasticsearch-plugin install file:///opt/elasticsearch/elasticsearch-analysis-ik-7.10.2.zip [root@linux30 cluster]# ./node3/bin/elasticsearch-plugin install file:///opt/elasticsearch/elasticsearch-analysis-ik-7.10.2.zip
安装成功后, 会给出对应提示:
1 2 3 4 5 6 7 8 9 10 11 12 -> Installing file:///usr/local/elasticsearch-7.10.2/elasticsearch-analysis-ik-7.10.2.zip -> Downloading file:///usr/local/elasticsearch-7.10.2/elasticsearch-analysis-ik-7.10.2.zip [=================================================] 100% @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: plugin requires additional permissions @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ * java.net.SocketPermission * connect,resolve See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html for descriptions of what these permissions allow and the associated risks. Continue with installation? [y/N]y -> Installed analysis-ik
3)重启ElasticSearch服务
4.3.3 测试IK分词器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ## standard标准分词器 GET _analyze { "analyzer": "standard", "text": "北京市东城区万豪酒店" } ## IK智能化分词器 GET _analyze { "analyzer": "ik_smart", "text": "北京市东城区万豪酒店" } ## ik_max_word最大化分词 GET _analyze { "analyzer": "ik_max_word", "text": "北京市东城区万豪酒店" }
4.3.4 IK分词器最佳运用 analyzer指定的是构建索引的分词,search_analyzer指定的是搜索关键字的分词。
实践运用的时候, 构建索引的时候采用max_word,将分词最大化; 查询的时候则使用smartword智能化分词,这样能够最大程度的匹配出结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 PUT hotel { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "name":{ "type": "text", "analyzer": "ik_max_word", "search_analyzer":"ik_smart" }, "address":{ "type": "text", "analyzer": "ik_max_word" }, "brand":{ "type": "keyword" }, "type":{ "type": "keyword" }, "price":{ "type": "integer" }, "specs":{ "type": "keyword" }, "salesVolume":{ "type": "integer" }, "area":{ "type": "text", "analyzer": "ik_max_word", "search_analyzer":"ik_smart" }, "imageUrl":{ "type": "text" }, "synopsis":{ "type": "text", "analyzer": "ik_max_word" }, "createTime":{ "type": "date", "format": "yyyy-MM-dd" }, "isAd":{ "type":"integer" } } } }
4.3.5 自定义扩展词、停用词 1)编辑 IKAnalyzer.cfg.xml文件,配置自定义扩展词 my_ext.dic 和 停用词 my_stopword.dic。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@linux30 cluster]# cat node1/config/analysis-ik/IKAnalyzer.cfg.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my_ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">my_stopword.dic</entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> [root@linux30 cluster]#
2)创建 my_ext.dic 和 my_stopword.dic
1 2 3 4 5 6 [root@linux30 cluster]# vi node1/config/analysis-ik/my_ext.dic ## 添加如下内容 我爱我的祖国 [root@linux30 cluster]# vi node1/config/analysis-ik/my_stopword.dic ## 添加如下内容 祖国
3)只需要重启node1节点即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ## 分词验证 GET _analyze { "analyzer": "ik_smart", "text": "我爱我的祖国" } ## 返回结果: { "tokens" : [ { "token" : "我爱我的祖国", "start_offset" : 0, "end_offset" : 6, "type" : "CN_WORD", "position" : 0 } ] }
4.4 基础查询 4.4.1 查询所有酒店信息 match_all
1 2 3 4 5 6 7 ## 查询所有酒店 GET hotel/_search { "query": { "match_all": {} } }
4.4.2 分页查询酒店列表 from:从哪开始
size:查询条数
1 2 3 4 5 6 7 8 9 ## 分页查询酒店列表 GET hotel/_search { "query": { "match_all": {} }, "from": 0, "size": 5 }
4.4.3 品牌精确搜索 term:不会对查询条件进行分词
1 2 3 4 5 6 7 8 9 ## 展示出"万豪"品牌下的所有酒店信息 GET hotel/_search { "query": { "term": { "brand": "万豪" } } }
4.4.4 酒店名称分词查询 matchQuery会对查询条件进行分词
1 2 3 4 5 6 7 8 9 ## 酒店名称分词查询 GET hotel/_search { "query": { "match": { "name": "北京市东城区瑞麟湾酒店" } } }
4.4.5 酒店品牌模糊搜索 wildcard:不会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
1 2 3 4 5 6 7 8 9 ## 酒店品牌模糊搜索 GET hotel/_search { "query": { "wildcard": { "brand": "万*" } } }
4.4.6 多域搜索 queryStringQuery:可以指定多个域、会对搜索条件分词、将分词后的搜索条件与term匹配、取结果并集OR、交集AND
1 2 3 4 5 6 7 8 9 10 ## 多域搜索 GET hotel/_search { "query": { "query_string": { "fields": ["name", "address", "area", "synopsis"], "query": "spa OR 商务" } } }
4.4.7 销量排序搜索 sort order: asc升序 或 desc降序
1 2 3 4 5 6 7 8 9 ## 销量排序 GET hotel/_search { "sort": { "salesVolume": { "order": "asc" } } }
4.4.8 价格范围搜索 range: gt 大于、gte 大于等于、 lt 小于、lte 小于等于
1 2 3 4 5 6 7 8 9 10 11 12 ## 价格范围搜索 GET hotel/_search { "query": { "range": { "price": { "gte": 600, "lt": 1600 } } } }
4.4.9 自动纠错搜索 fuzzyQuery:自动尝试将条件纠错,并和词条匹配、fuzziness 允许对几个字进行纠错、prefix_length 设置前几个字符不允许编辑
在未经处理的情况下,一旦条件存在错别字,找不到term,则无法查询到结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ## 正常搜索 GET hotel/_search { "query": { "term": { "area": "北京市" } } } ## 错别字 经 GET hotel/_search { "query": { "term": { "area": "北经市" } } } ## 自动纠错搜索 经 GET hotel/_search { "query": { "fuzzy": { "area": { "fuzziness": 1, "prefix_length": 1, "value": "北经市" } } } }
4.4.10 搜索结果高亮显示 highlight:如需将搜索条件以高亮形式展示,则需要在查询时,设置需要对哪一个域以何种样式进行展示,fields 设置要对哪个域高亮、pre_tags 设置高亮样式前缀、post_tags 设置高亮样式后缀
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 GET hotel/_search { "query": { "term": { "name": "新乐" } }, "highlight": { "fields": { "name": { "pre_tags": "<font color='red'>", "post_tags": "</font>" } } } }
4.5 bool查询 boolQuery: 对多个查询条件拼接、must(and)条件必须成立、must_not (not)条件必须不成立、should(or)条件可以成立、filter 条件过滤,必须成立
4.5.1 must 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ## must单独使用 品牌必须是万豪,地区必须是北京市 GET hotel/_search { "query": { "bool": { "must": [ { "term": { "brand": "万豪" } },{ "term": { "area": "北京市" } } ] } } }
4.5.2 filter 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ## filter单独使用 GET hotel/_search { "query": { "bool": { "filter": [ { "term": { "brand": "万豪" } },{ "term": { "area": "北京市" } } ] } } }
4.5.3 must和filter组合使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ## must和filter组合使用 品牌为万豪下的,地区为北京市、价格范围在500和2000之间的酒店 GET hotel/_search { "query": { "bool": { "must": [ { "term": { "brand": "万豪" } } ], "filter": [ { "term": { "area": "北京市" } },{ "range": { "price": { "gte": 500, "lte": 2000 } } } ] } } }
4.6 聚合查询 聚合介绍:在MySQL中提供了许多聚合函数,如max、min、avg、count等。并且也提供了分组实现group by。对于这些功能,在es中同样提供,主要用于对数据统计分析。
ES中的聚合搜索分为两类:指标聚合、桶聚合
指标聚合:如max、min、sum等。作用等同MySQL中相关聚合函数
桶聚合:用于数据分组,作用等同于MySQL中的group by。
ps:不能对Text类型分组,因为会分词。
4.6.1 指标聚合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ## 统计品牌为万豪下最贵酒店价格 GET hotel/_search { "query": { "term": { "brand": "万豪" } }, "aggs": { "my_max_price": { "max": { "field": "price" } } } }
4.6.2 桶聚合 1)统计品牌为万豪下有哪些星级
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ## 统计品牌为万豪下有哪些星级 GET hotel/_search { "query": { "term": { "brand": "万豪" } }, "aggs": { "my_group": { "terms": { "field": "specs", "size": 5 } } } }
2)根据搜索条件对品牌分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ## 根据搜索条件对品牌分组 GET hotel/_search { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "三亚 OR 商务" } }, "aggs": { "hotel_brand": { "terms": { "field": "brand", "size": 100 } } } }
4.6.3 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ## 自定义时间段统计某品牌下酒店销量 GET hotel/_search { "query": { "range": { "createTime": { "gte": "2016-01-01", "lte": "2021-01-01" } } }, "aggs": { "hotel_brand": { "terms": { "field": "brand", "size": 100 }, "aggs": { "sale_count": { "sum": { "field": "salesVolume" } } } } } }
5. ElasticSearch实战技巧 5.1 优化多字段查询 搜索时,对于每条搜索结果ES都会对其按照匹配度进行打分,分数越高,在结果中排名越靠前。
在ES中提供了两种设置权重的方式:索引设置、查询设置。
索引设置:创建索引时配置权重,该方式应用较少,因为一旦需求发生改变,则需要重新创建索引。
查询设置:在查询时,根据需求灵活的配置权重,该方式使用最多。
5.1.1 提升字段查询得分 将name字段查询比重提升10倍
1 2 3 4 5 6 7 8 9 10 GET hotel/_search { "explain": true, "query":{ "multi_match":{ "query": "北京金龙", "fields": ["name^10", "address"] } } }
5.1.2 综合提升字段查询得分 tie_breaker:将其他query的分数也考虑进去(最大值加上其他值的0.3倍)
1 2 3 4 5 6 7 8 9 10 11 GET hotel/_search { "explain": true, "query":{ "multi_match":{ "query": "北京金龙", "fields": ["name", "address"], "tie_breaker": 0.3 } } }
使用 tie_breaker 和不使用tie_breaker ,查询出来的某一条数据的 _score 分数,会有相应的提高,例如:
name中包含关键词matched query 的得分,假设是 0.1984226
address中包含关键词matched query的得分,假设是 12.07466
添加了 tie_breaker = 0.3,那么就是这样的了, 0.1984226 * 0.3 + 12.07466 = 12.13418678;
大于最高一条的得分12.07466,这样搜索的关联性就提升上去了, 更为合理。
5.1.3 自定义评分 1)创建索引时设置权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ## 查询多域展示相关结果数据 GET hotel/_search { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "北京市万豪spa三星" } } } ## 评分扩大10倍 GET hotel/_search { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "北京市万豪spa三星", "boost": 10 } } }
2)查询设置权重
function_score
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 ## 为品牌为万豪的酒店,权重值增加50倍 GET hotel/_search { "query": { "function_score": { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "北京市万豪spa三星" } }, "functions": [ { "filter": { "term": { "brand": "万豪" } }, "weight": 50 } ] } } } ## 将广告酒店的权重增加100倍,使其靠前 GET hotel/_search { "query": { "function_score": { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "北京市万豪spa三星" } } } } } GET hotel/_search { "query": { "function_score": { "query": { "query_string": { "fields": ["name", "synopsis", "area", "address"], "query": "北京市万豪spa三星" } }, "functions": [ { "filter": { "term": { "isAd": "1" } }, "weight": 100 } ] } } }
5.2 全量索引构建 5.21 下载logstash 下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-7.10.2-linux-x86_64.tar.gz
1 bin/logstash-plugin install logstash-input-jdbc
5.2.3 配置mysql驱动包 1 2 3 4 5 6 [root@linux30 logstash-7.10.2]# mkdir mysql [root@linux30 logstash-7.10.2]# cd mysql/ [root@linux30 mysql]# ll 总用量 940 -rw-r--r--. 1 root root 960372 11月 15 15:19 mysql-connector-java-5.1.34.jar [root@linux30 mysql]#
5.2.4 配置JDBC连接 创建索引数据是从mysql中通过select语句查询, 然后再通过logstash-input-jdbc的配置文件方式导入 elasticsearch中。
在/opt/elasticsearch/logstash-7.10.2/mysql/full-sync目录创建jdbc.conf与jdbc.sql文件。
jdbc.conf文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 input { stdin { } jdbc { # mysql 数据库链接,users为数据库名 jdbc_connection_string => "jdbc:mysql://192.168.10.30:3306/elasticsearch_db" # 用户名和密码 jdbc_user => "root" jdbc_password => "123456" # 驱动 jdbc_driver_library => "/opt/elasticsearch/logstash-7.10.2/mysql/mysql-connector-java-8.0.21.jar" # 驱动类名 jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" # 执行的sql 文件路径+名称 statement_filepath => "/opt/elasticsearch/logstash-7.10.2/mysql/full-sync/jdbc.sql" # 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新 schedule => "* * * * *" } } output { elasticsearch { #ES的连接信息 hosts => ["192.168.10.30:9200"] #索引名称 index => "hotel" document_type => "_doc" #自增ID, 需要关联的数据库的ID字段, 对应索引的ID标识 document_id => "%{id}" } stdout { #JSON格式输出 codec => json_lines } }
jdbc.sql文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SELECT id, NAME, address, brand, type, price, specs, salesVolume, synopsis, area, imageUrl, createTime, isAd FROM t_hotel
5.2.5 执行全量同步 1 2 [root@linux30 full-sync]# ../../bin/logstash -f jdbc.conf
5.2.6 检查结果 5.3 增量索引同步 5.3.1 修改jdbc.conf配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 input { stdin { } jdbc { # mysql 数据库链接,users为数据库名 jdbc_connection_string => "jdbc:mysql://192.168.10.30:3306/elasticsearch_db" # 用户名和密码 jdbc_user => "root" jdbc_password => "123456" # 驱动 jdbc_driver_library => "/opt/elasticsearch/logstash-7.10.2/mysql/mysql-connector-java-8.0.21.jar" # 驱动类名 jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" # 执行的sql 文件路径+名称 statement_filepath => "/opt/elasticsearch/logstash-7.10.2/mysql/inc-sync/jdbc.sql" # 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新 schedule => "* * * * *" #设置timezone jdbc_default_timezone => "Asia/Shanghai" # 增量同步属性标识 last_run_metadata_path => "/opt/elasticsearch/logstash-7.10.2/mysql/inc-sync/last_value" } } output { elasticsearch { #ES的连接信息 hosts => ["192.168.10.30:9200"] #索引名称 index => "hotel" document_type => "_doc" #自增ID, 需要关联的数据库的ID字段, 对应索引的ID标识 document_id => "%{id}" } stdout { #JSON格式输出 codec => json_lines } }
5.3.2 修改jdbc.sql配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SELECT id, NAME, address, brand, type, price, specs, salesVolume, synopsis, area, imageUrl, createTime, isAd FROM t_hotel WHERE createTime >= :sql_last_value
5.3.3 创建同步最后记录时间 1 vi /opt/elasticsearch/logstash-7.10.2/mysql/inc-sync/last_value
给定一个初始的时间:
5.3.4 验证 启动logstash, 会根据初始时间,加载对应的数据。
如果修改的数据的更新时间, 会自动检测, 同步增量的数据。
5.4 查全率与查准率(扩展知识) 5.4.1 查全率 索引内符合条件的结果有N个,查询出来的符合条件的结果有X个, 则查全率为: X/N
比如: 用户的关键词为笔记本(笔记本包含写字的笔记本以及电脑笔记本, 在索引中, 这些记录为1000条,即N),查询出来的结果如果是100条,即X(包含写字的笔记本以及电脑笔记本), 则查全率为10%。
5.4.2 查准率 查询出来的X个文档中, 有M个是正确的, 则查准率为:M/X
比如: 用户的关键词为笔记本, 这些记录为1000条,查询出来的结果如果是100条, 而在这100条(X)当中只有20条(M)为用户期望的电脑笔记本, 则查准率为20%。
5.5 评分TF/IDF/BM25计算(扩展知识) 每条搜索记录ES都会给出一个评分,ES有两个打分计算方式:
TF: Term Frequency,即词频。它表示一个词在内容中出现的次数。定义:
TF = 某个词在文档中出现的次数 / 文档的总词数
某个词出现越多,表示越重要,如果某篇文章出现了elasticsearch多次, 而spring出现了两三次, 那很可能就是一篇关于elasticsearch的专业文章。
IDF : Inverse Document Frequency,即逆文档频率,它是一个表达词语重要性的指标。计算公式:
IDF=log(库中的文档数/(包含该词的文档数+1))
log为对数函数,如果所有文章内容都包涵某一个词,那这个词的IDF=log(1)=0, 重要性为零。停用词的IDF约等于0。
如果某个词只在很少的文章中出现,则IDF很大,其重要性也越高。为了避免分母为0,所以+1.
BM25
BM25 实质是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大。
随着TF(t) 的逐步加大,该算法的返回值会趋于一个数值,BM25 就针对这点进行来优化。
例如, 某个文章的关键词出现的频率不断增多, 得分就会越来越高, 有的文章关键词出现40次, 和有的文章关键词出现60次或80次, 但实际上出现40次的文章,可能就是所期望的结果。
查看ES评分计算 :
增加explain标识为true,会列出计算执行计划:
1 2 3 4 5 6 7 8 9 GET hotel/_search { "explain": true, "query":{ "match":{ "name":"北京金龙" } } }
里面会详细记录评分细则:
整个评分计算: boost * idf * tf (boost为放大系数, 默认为2.2)
BM25的计算在tf的描述中: (freq + k1 * (1 - b + b * dl / avgdl))
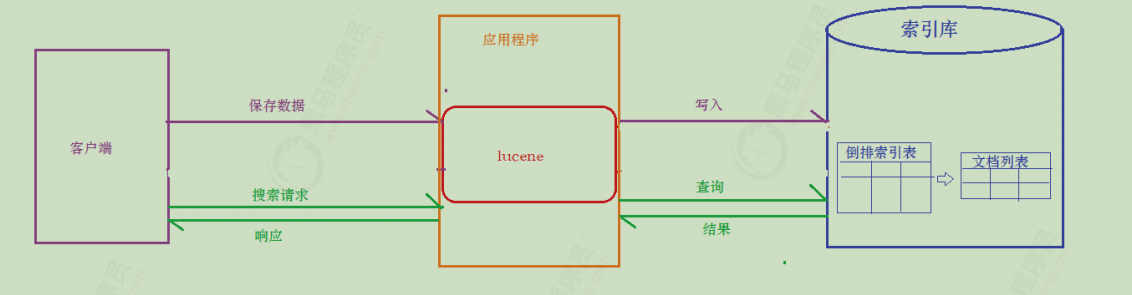
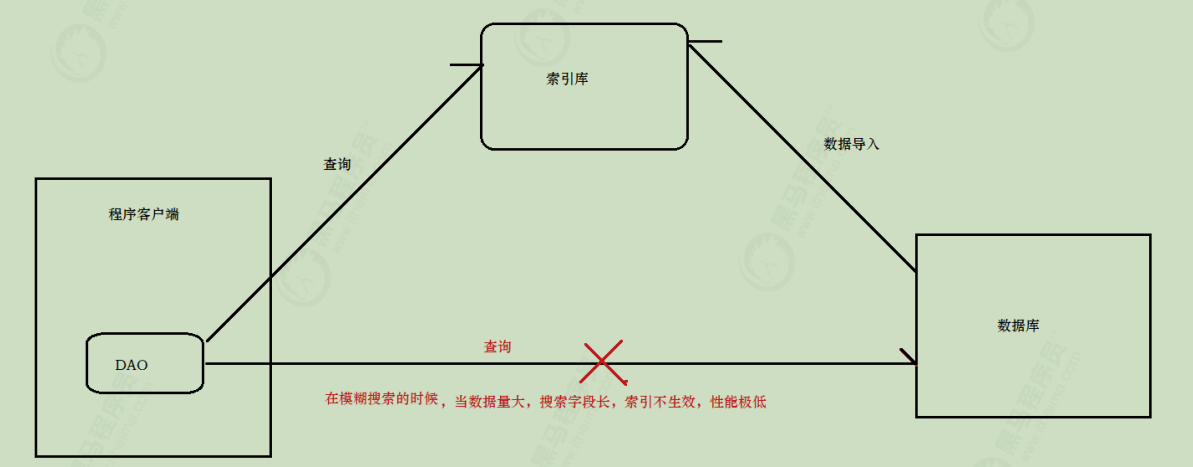
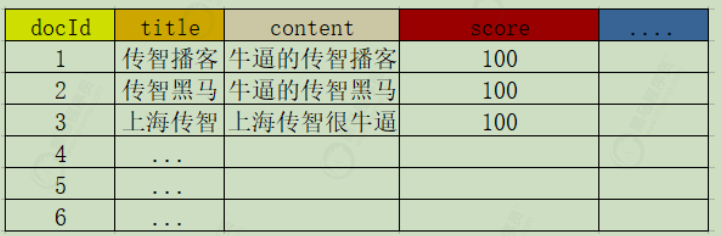
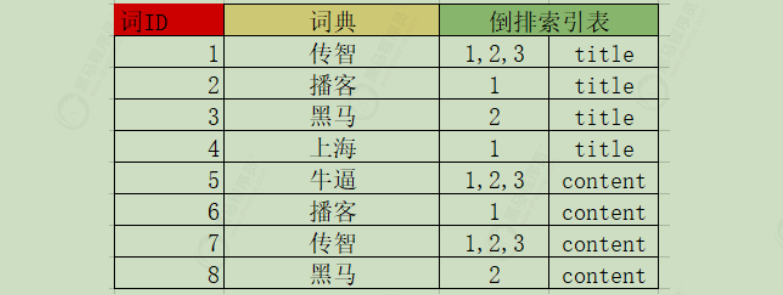
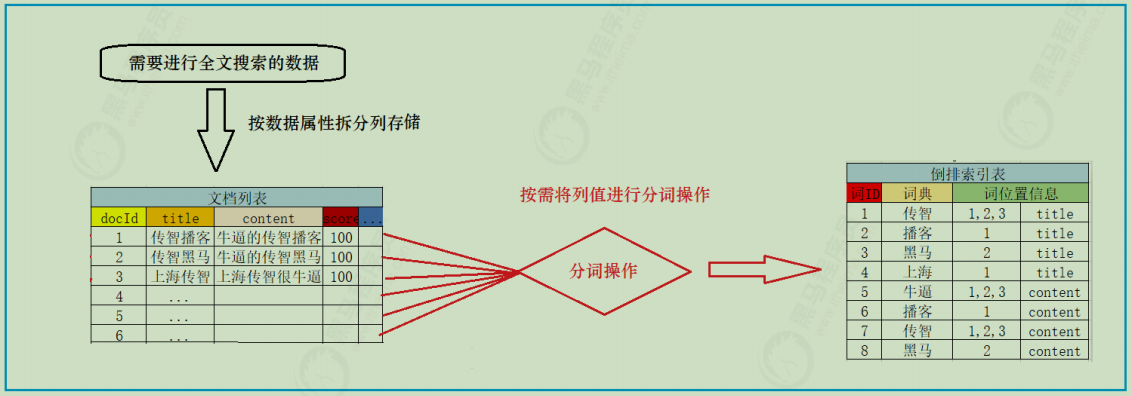
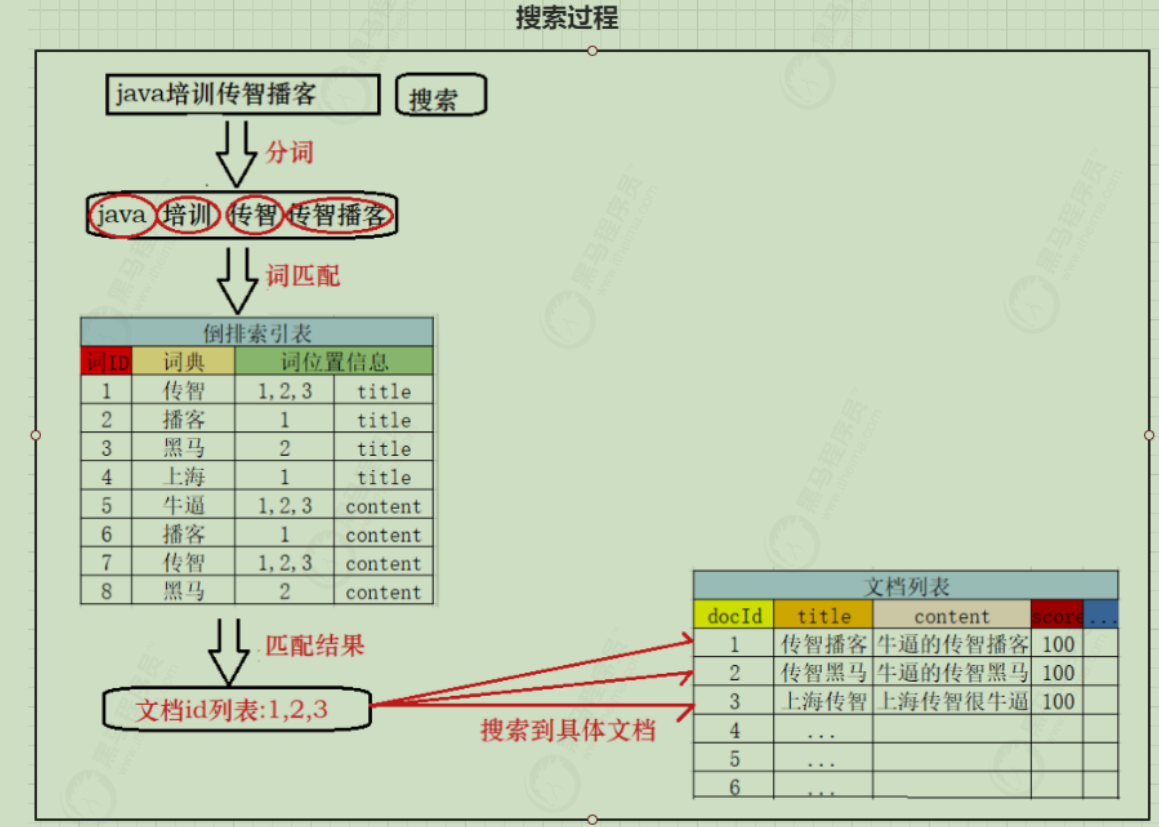

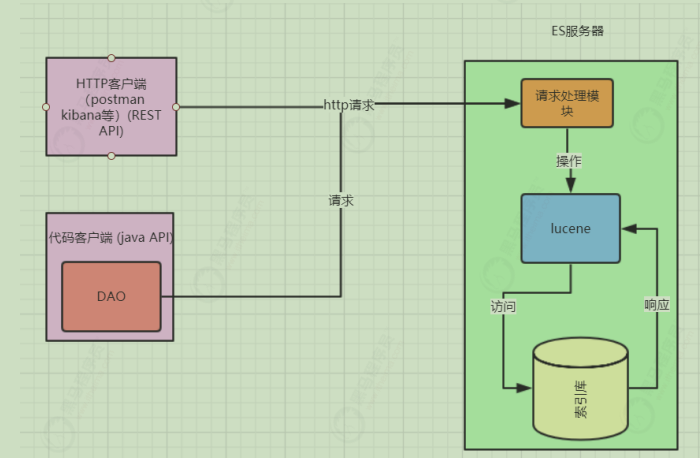

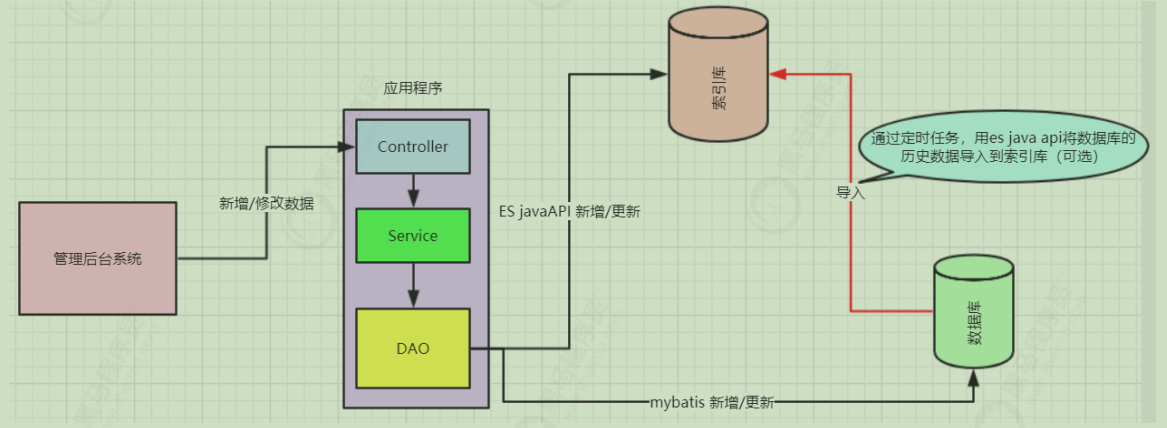
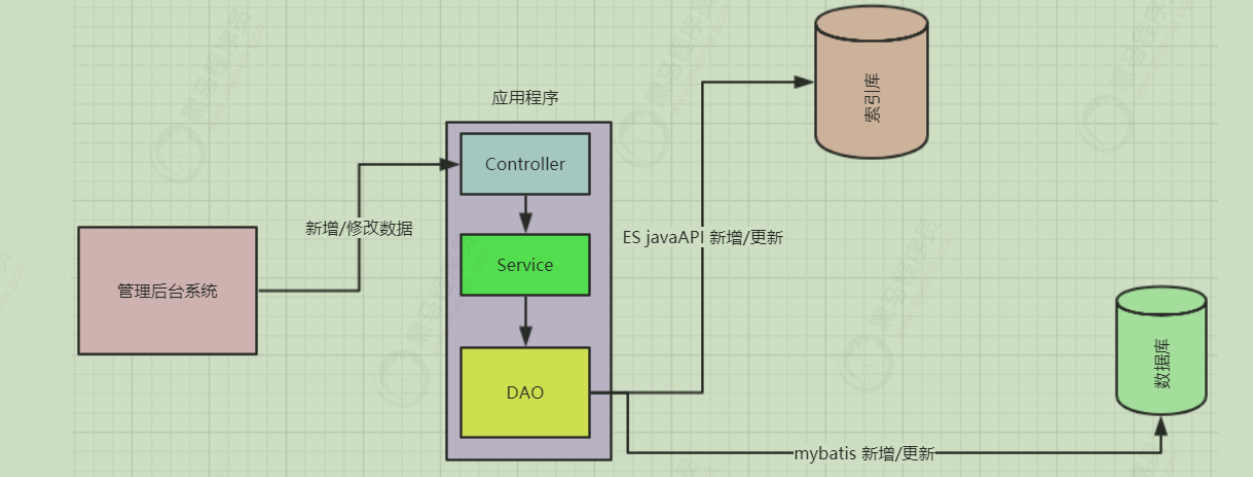

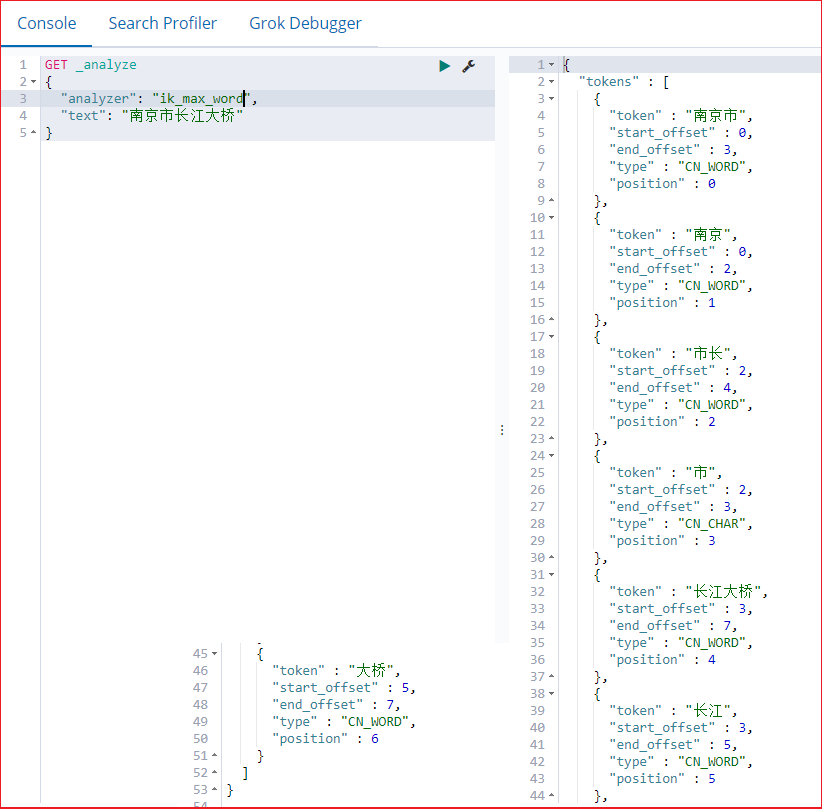
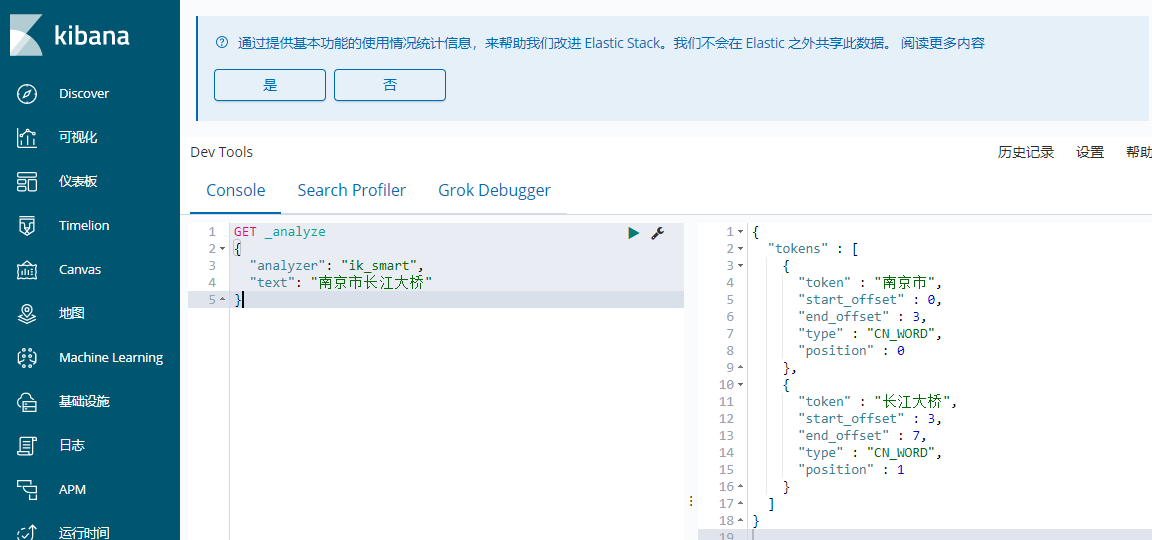
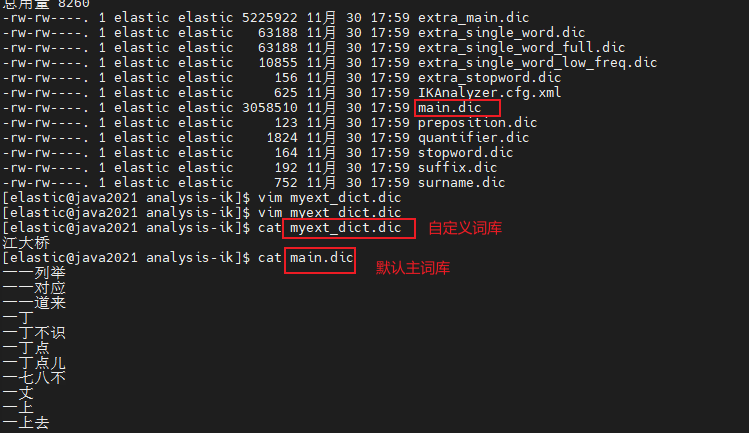
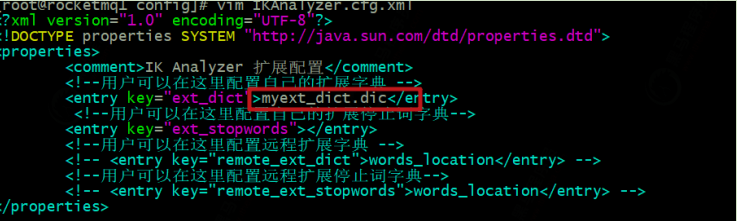

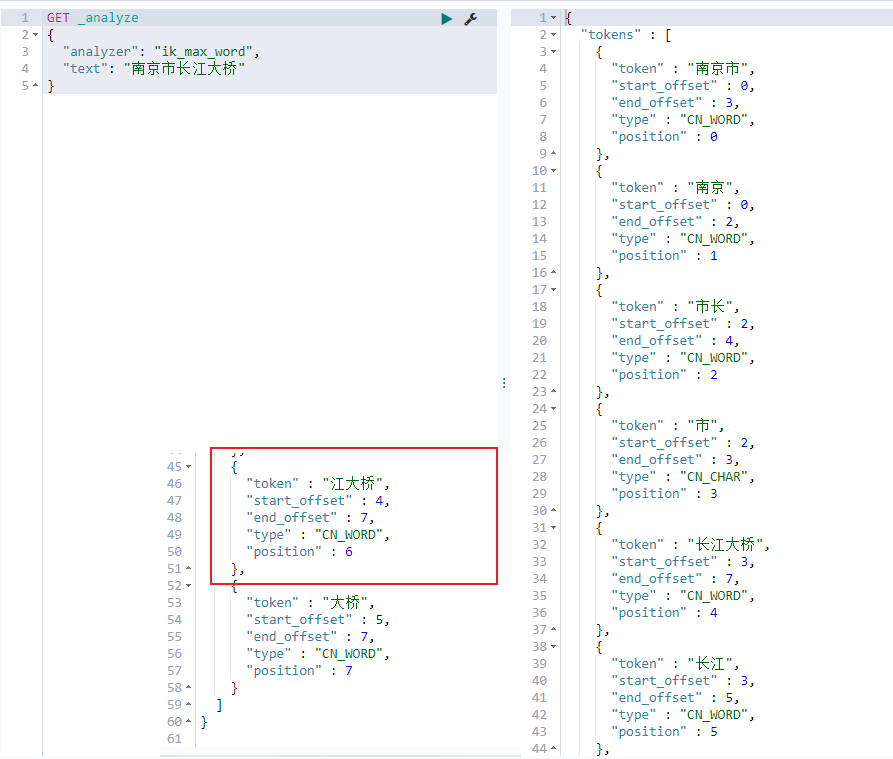
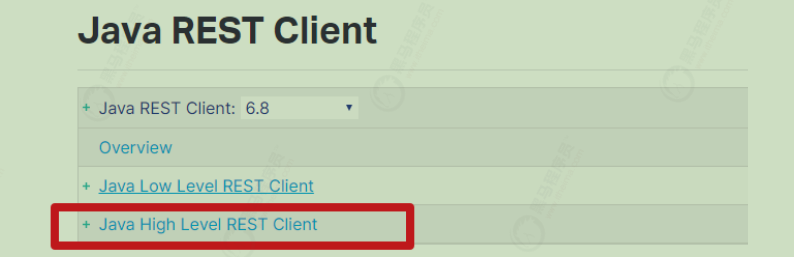


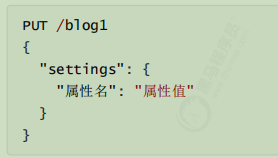
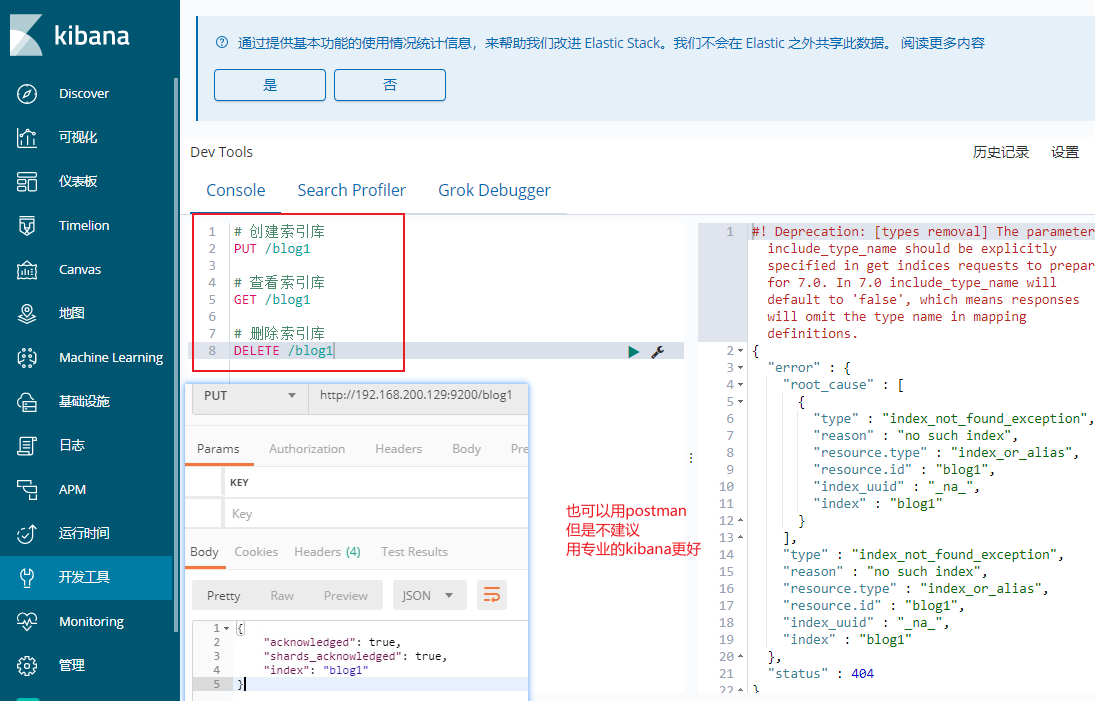
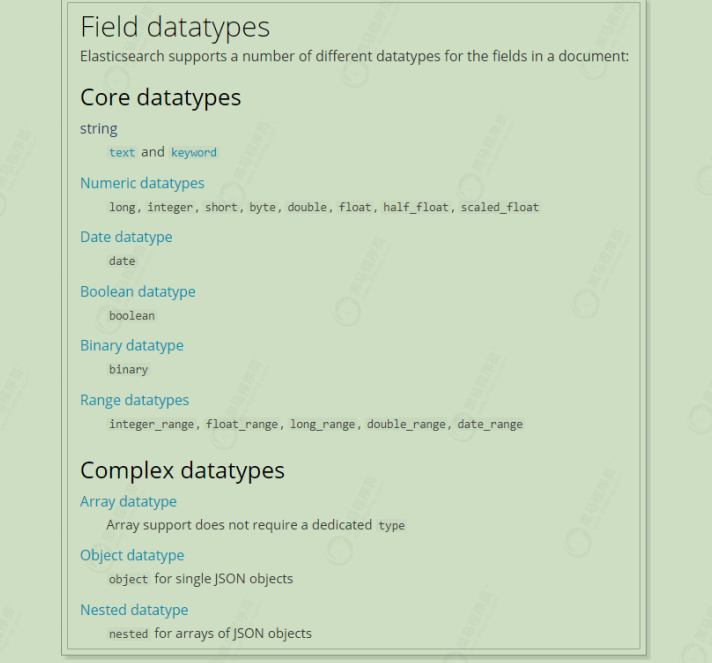
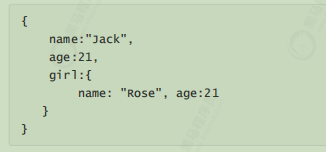
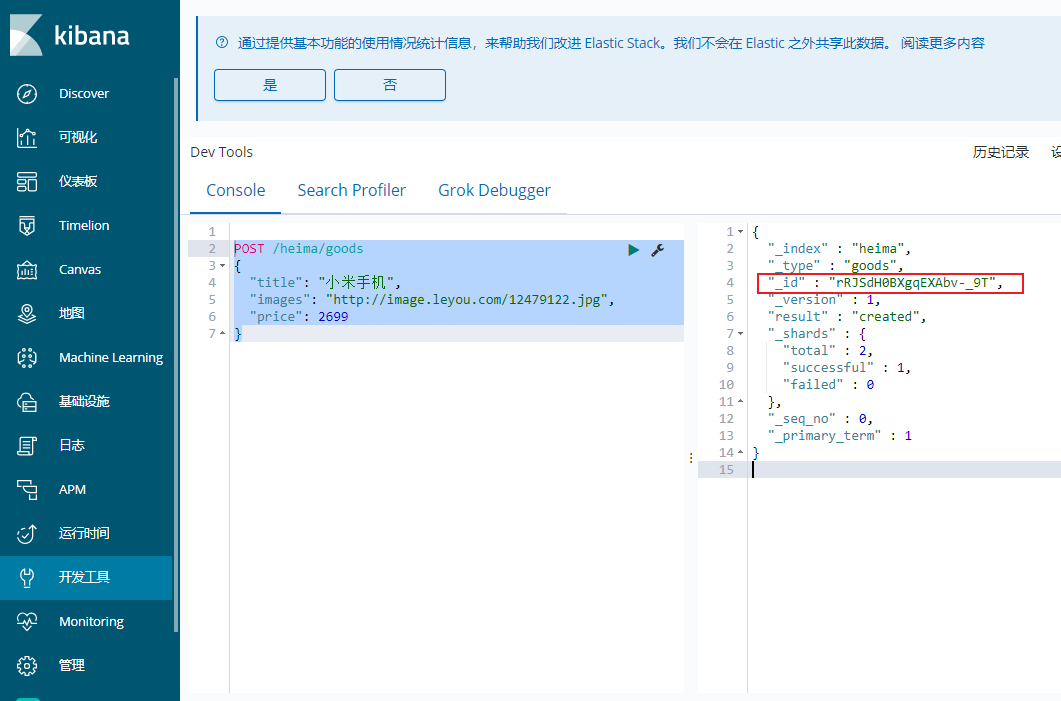
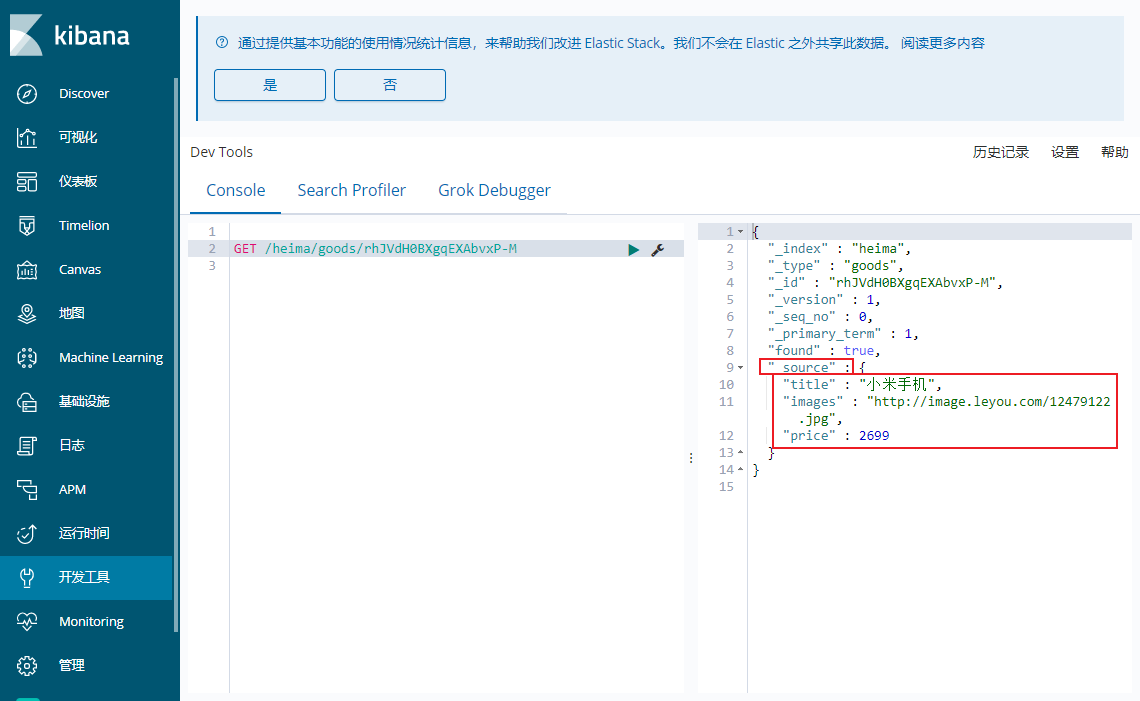
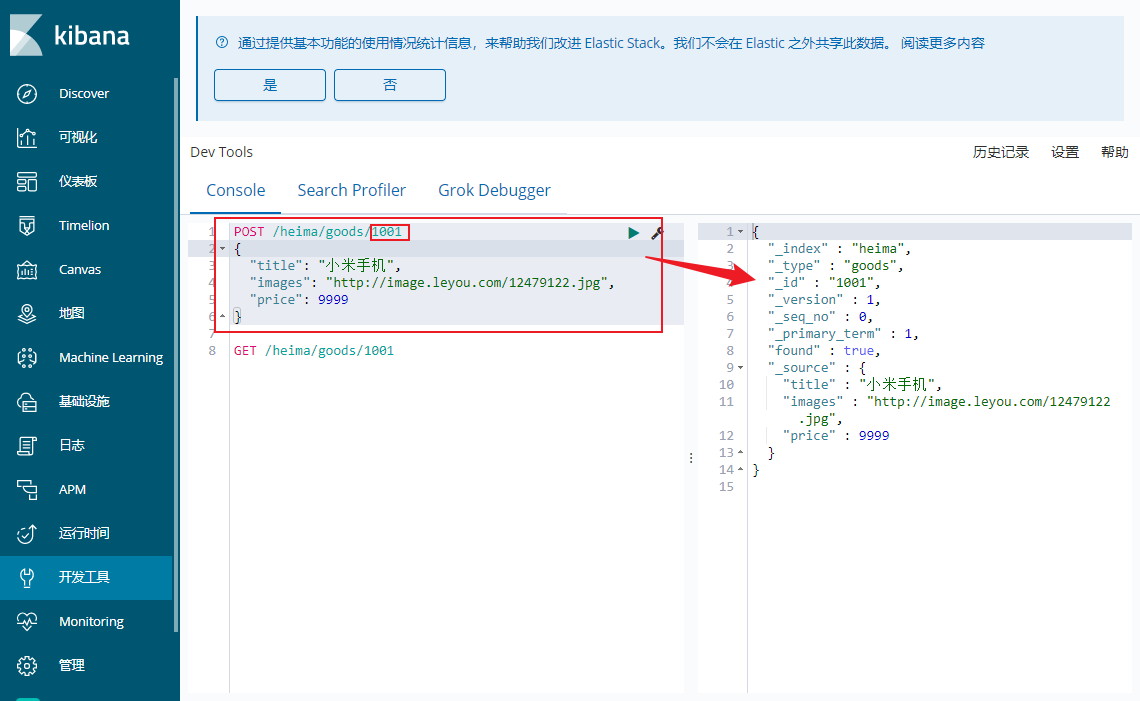
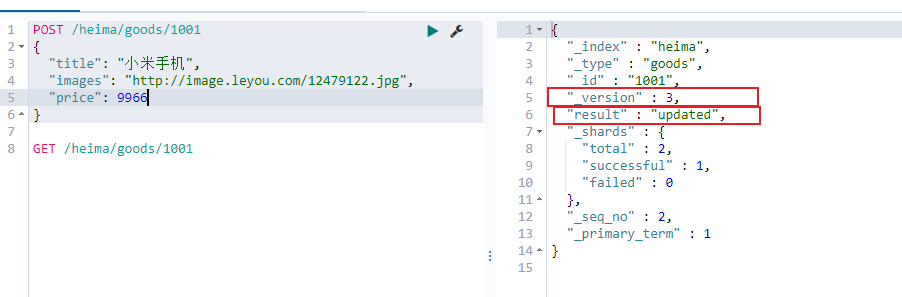
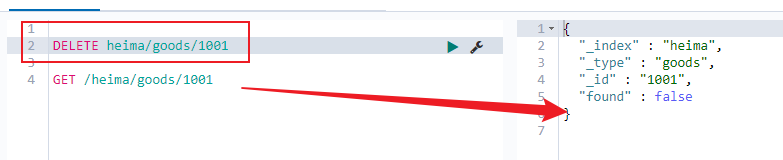
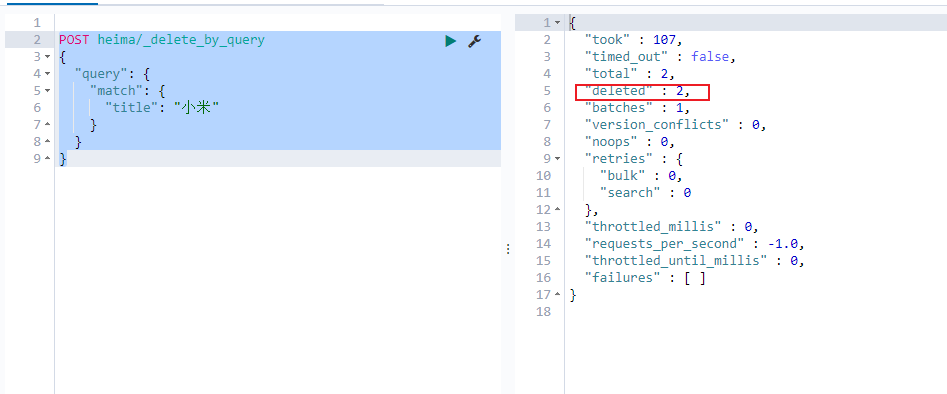
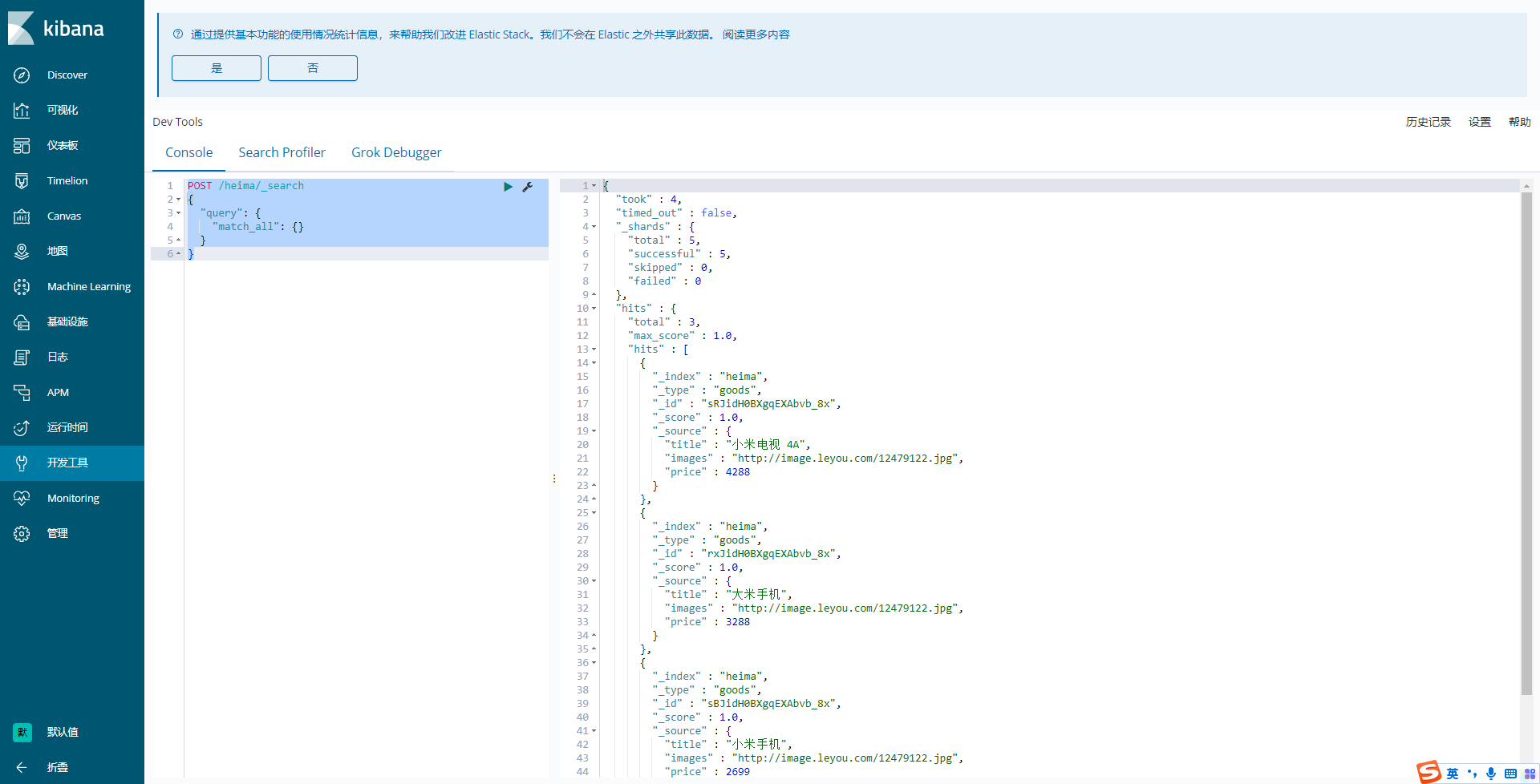
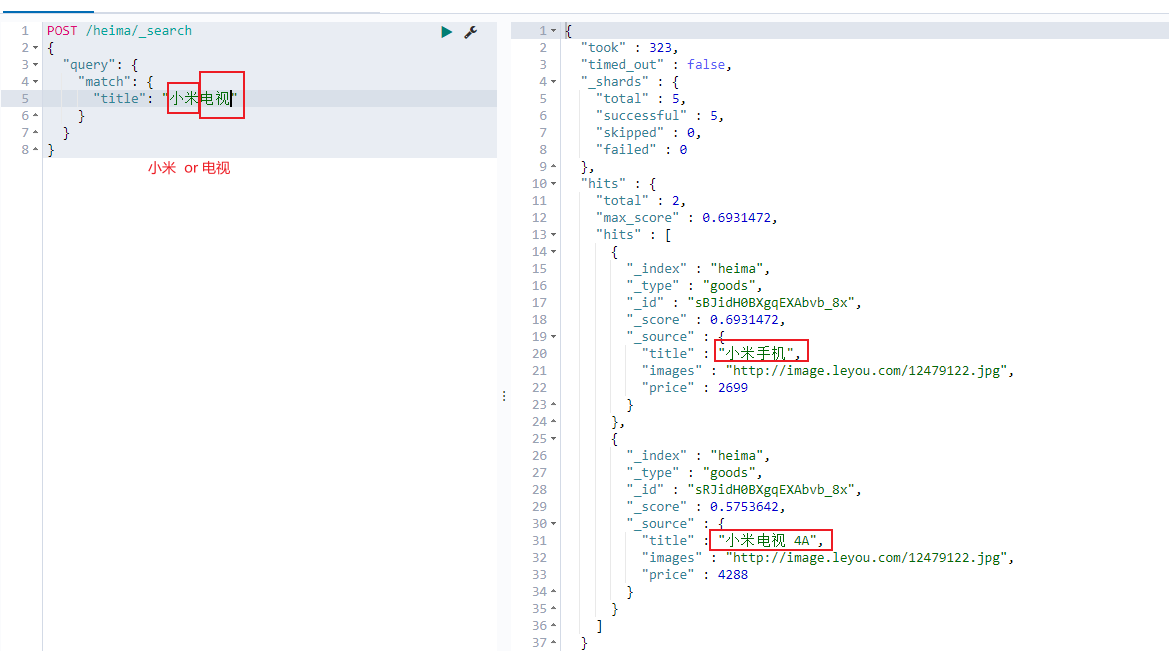
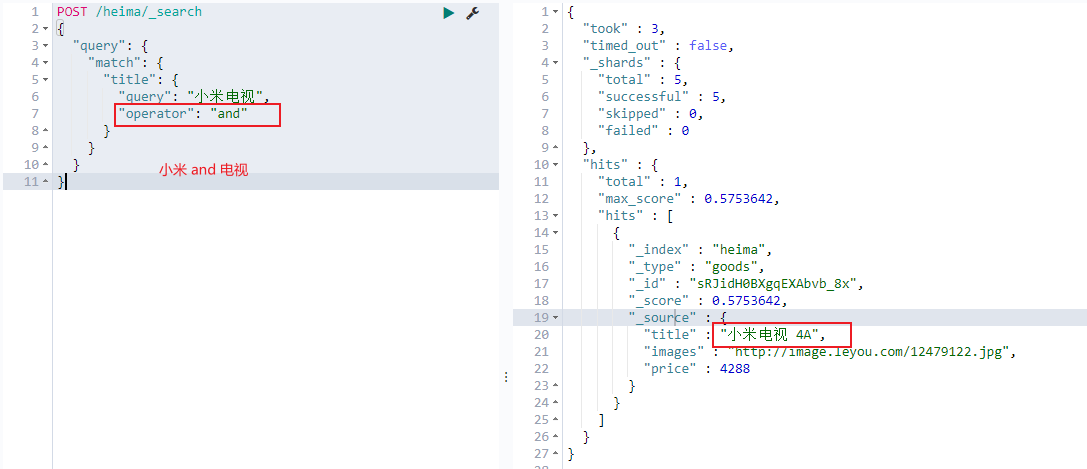
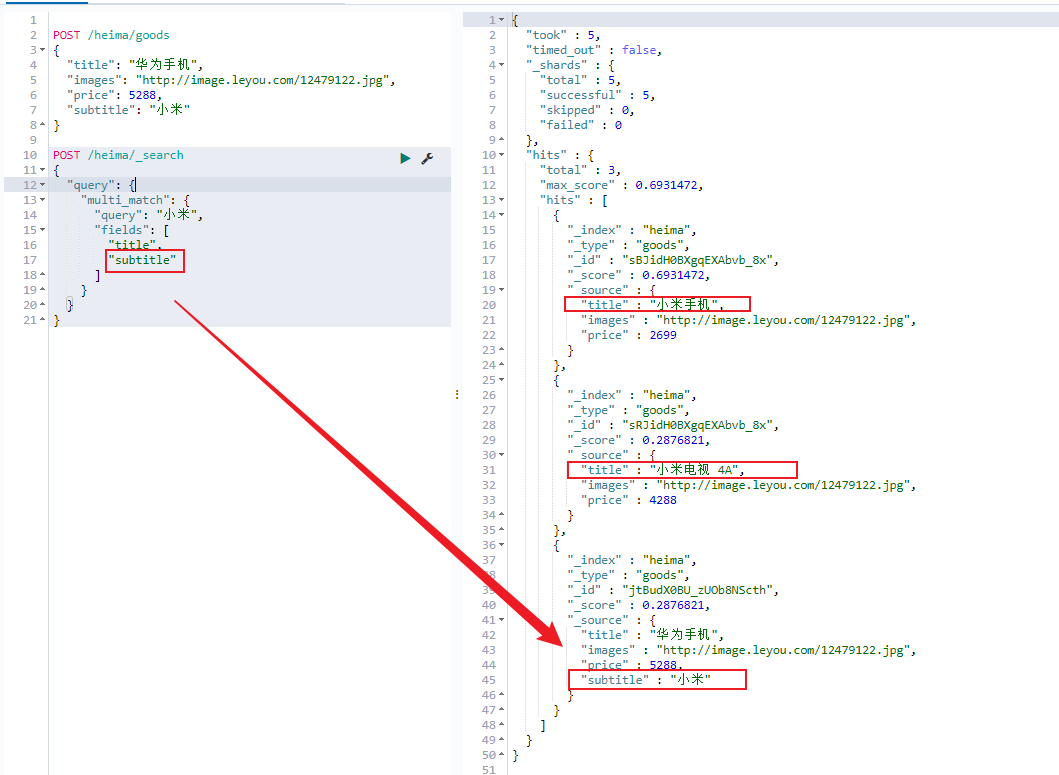
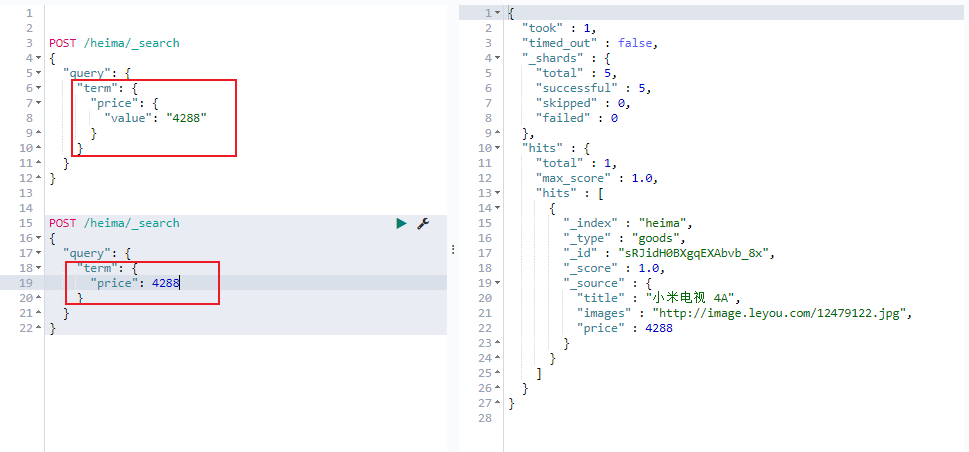
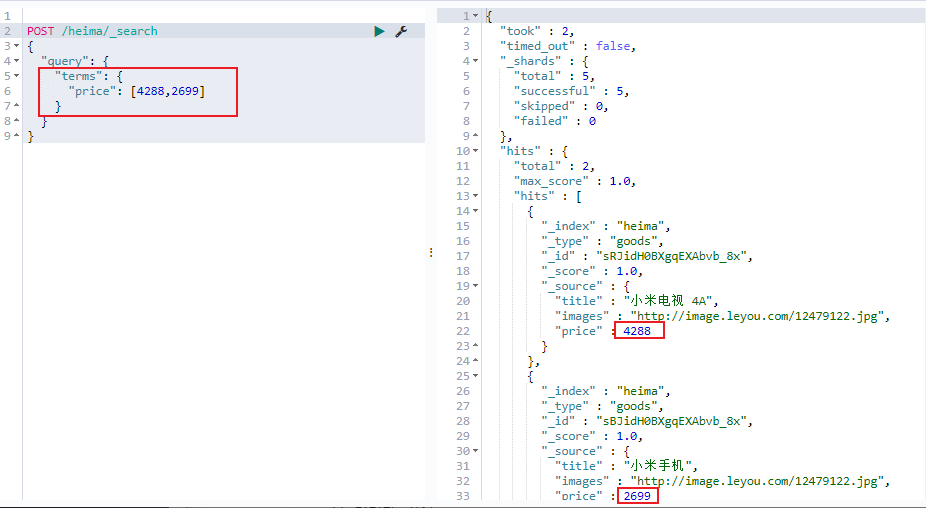
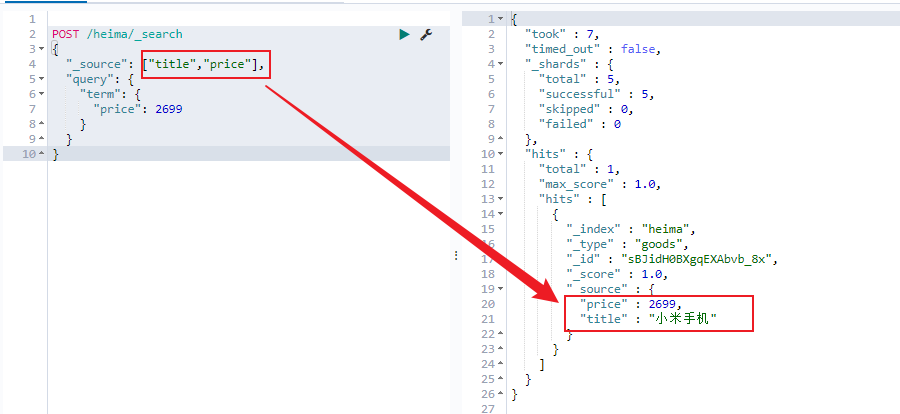
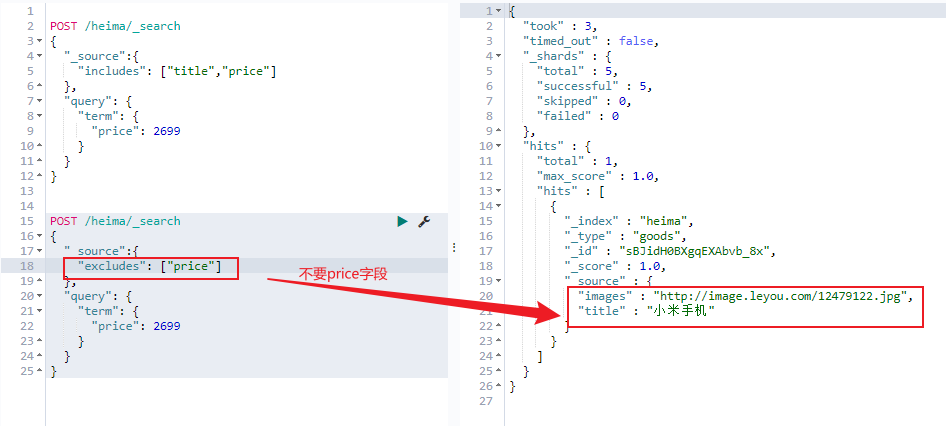
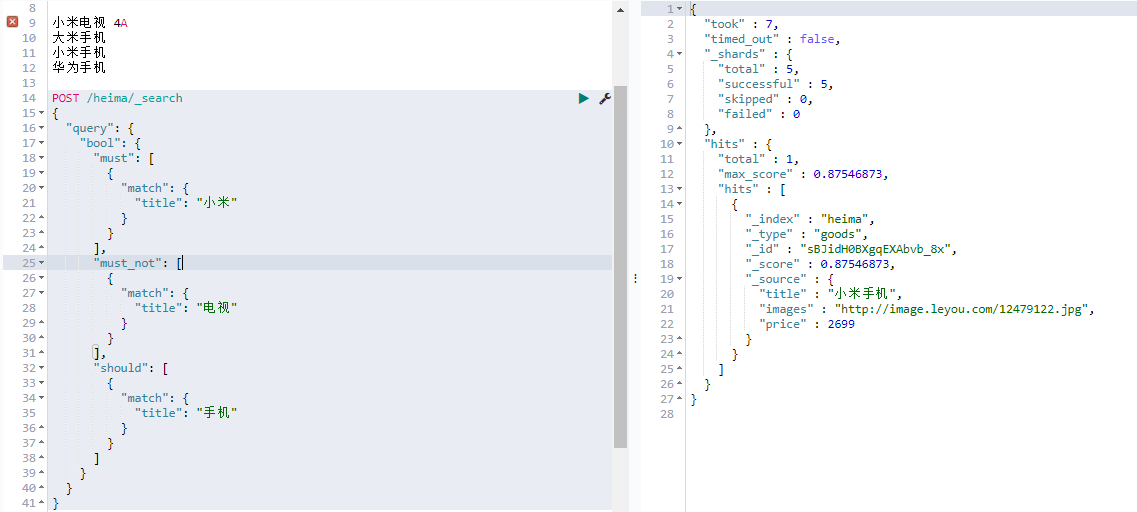
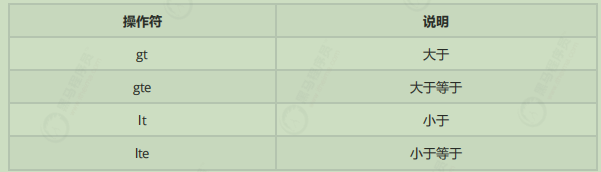
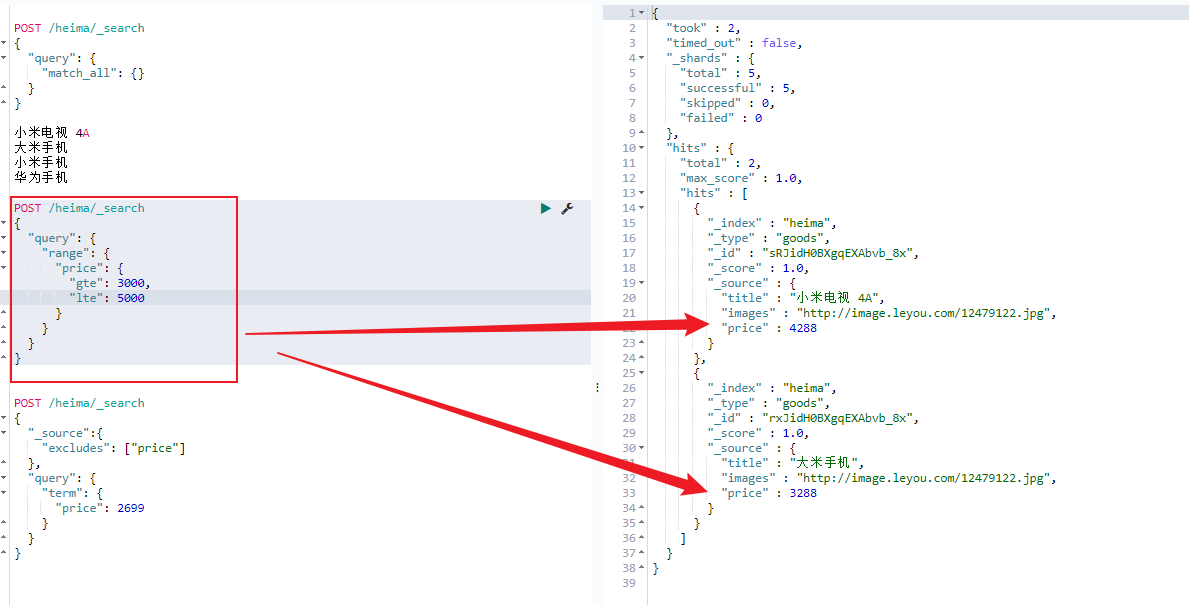
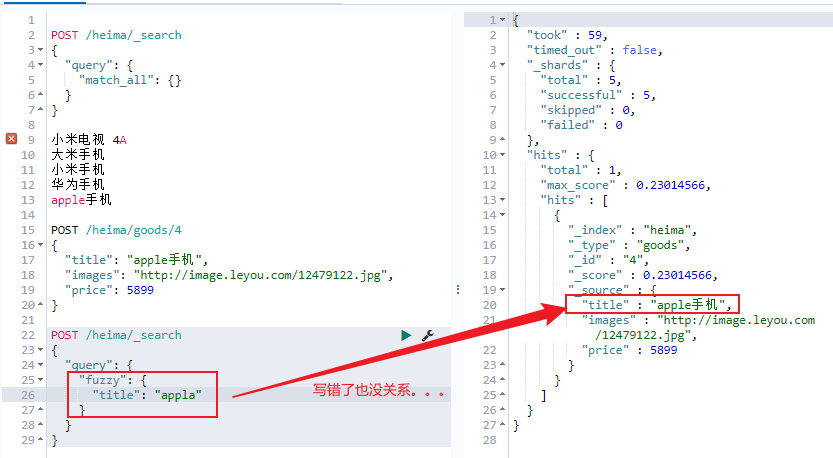
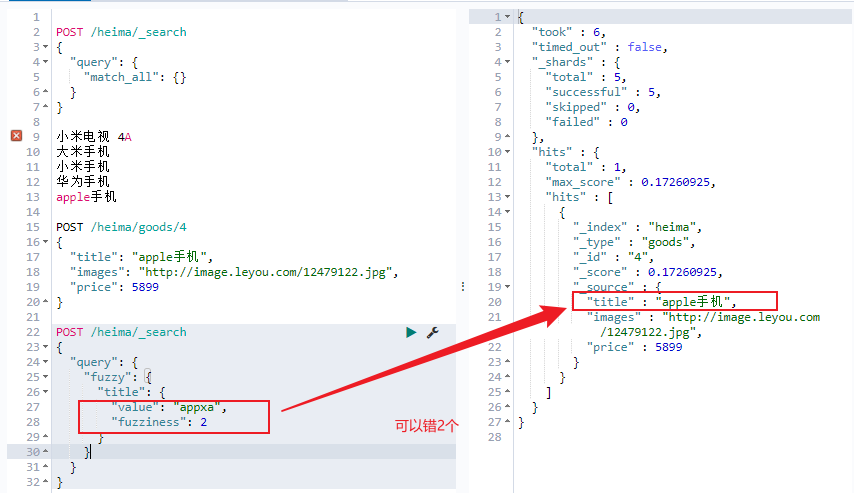
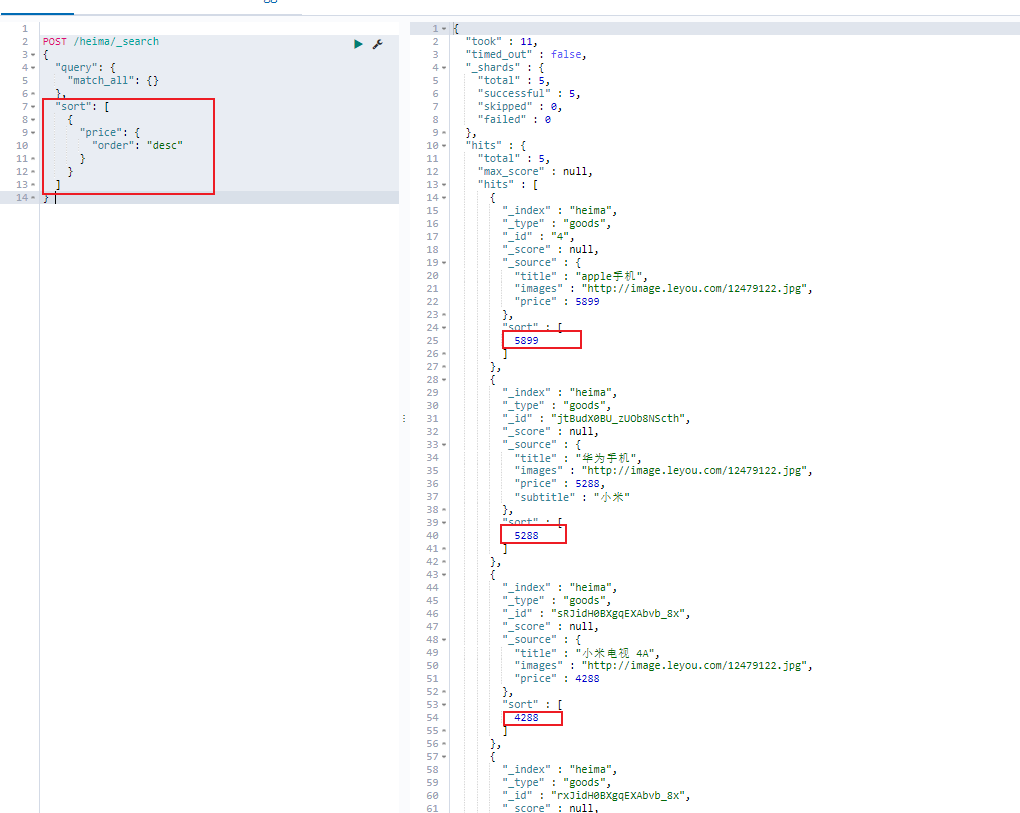
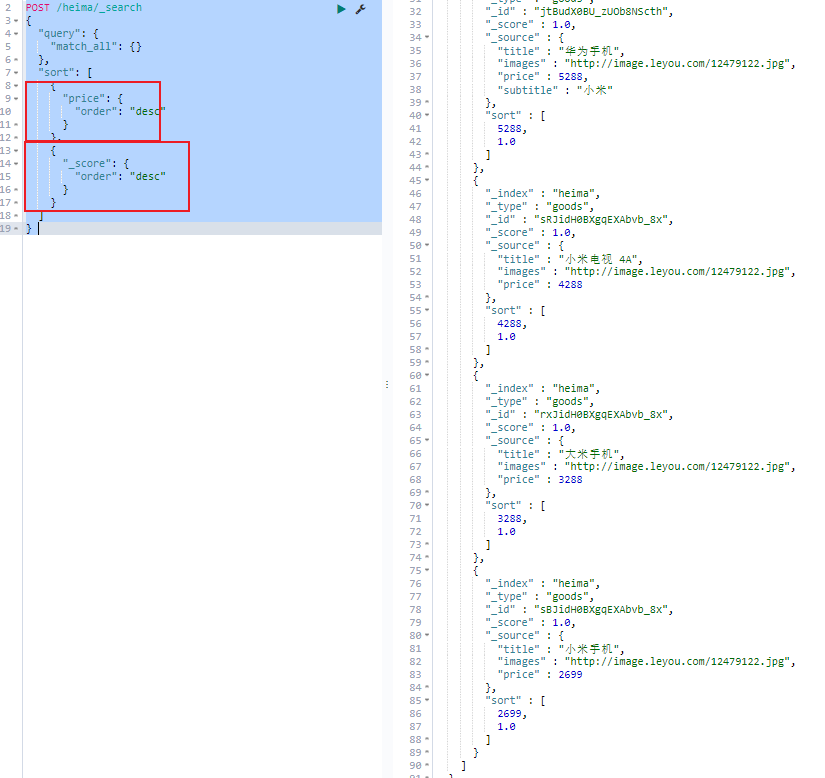
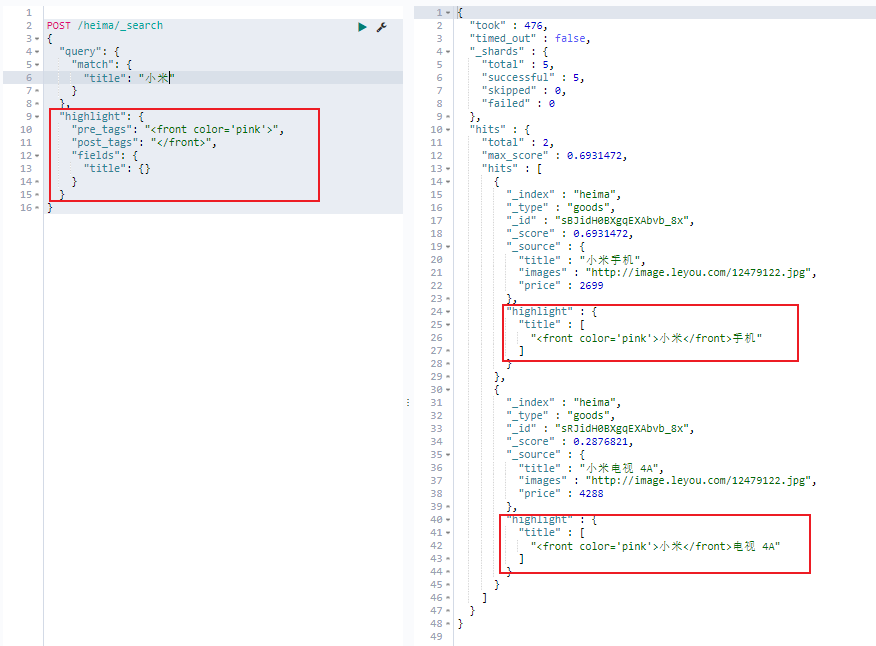
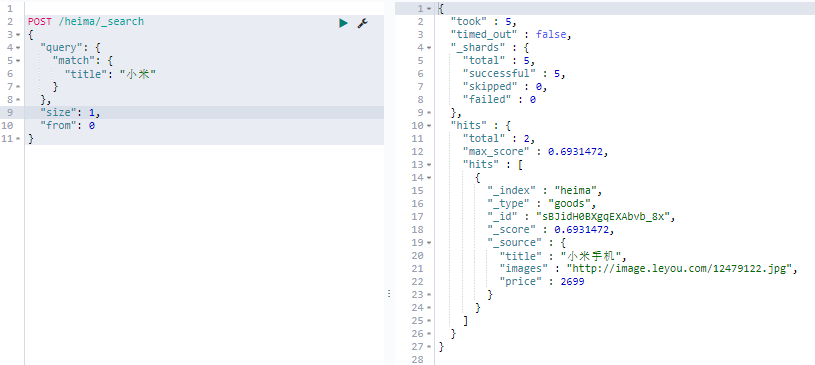
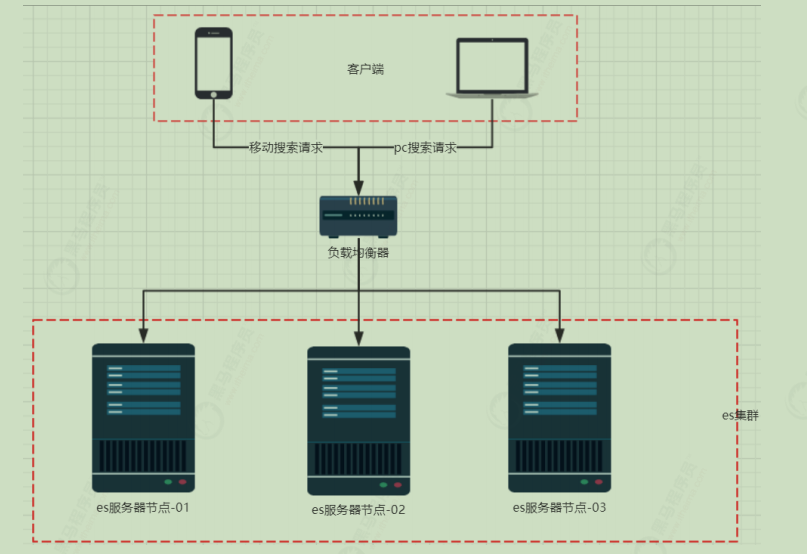
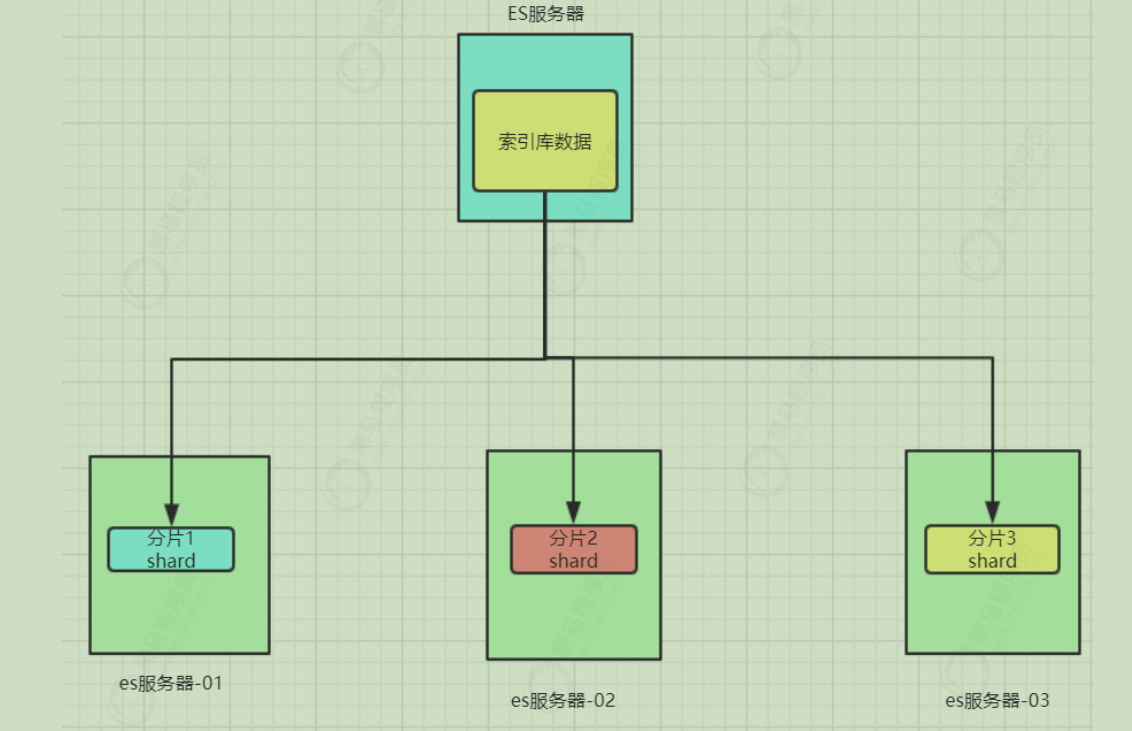
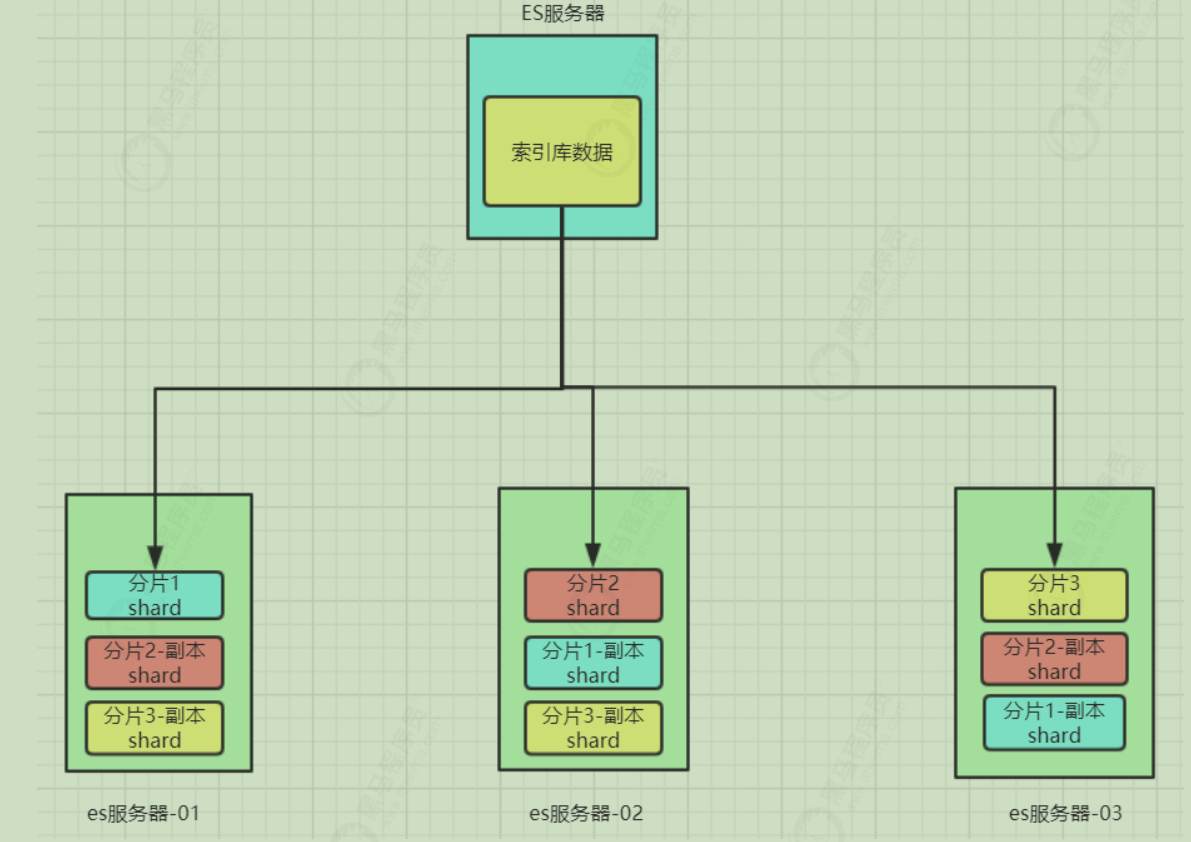
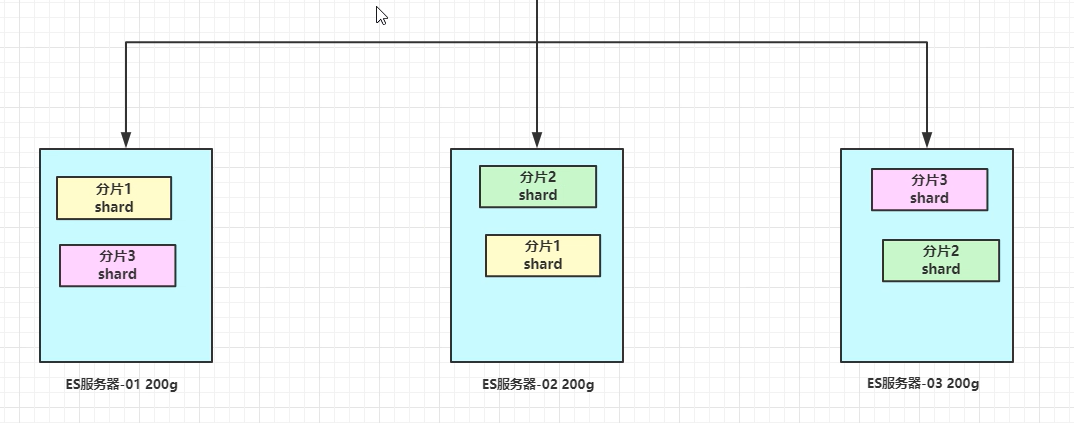
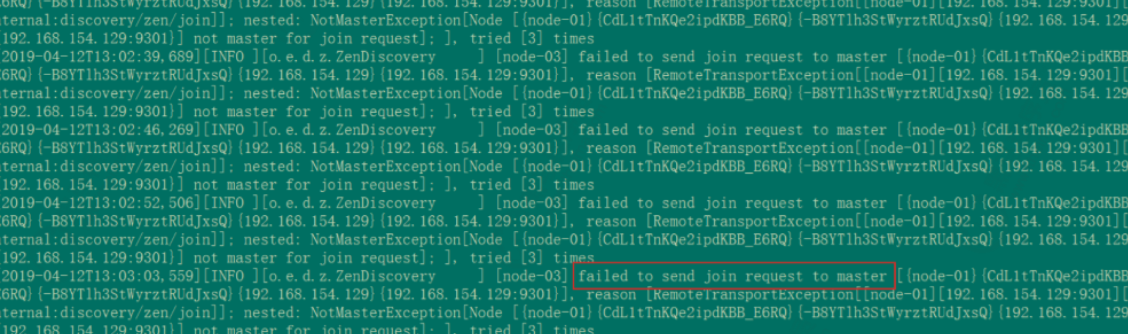

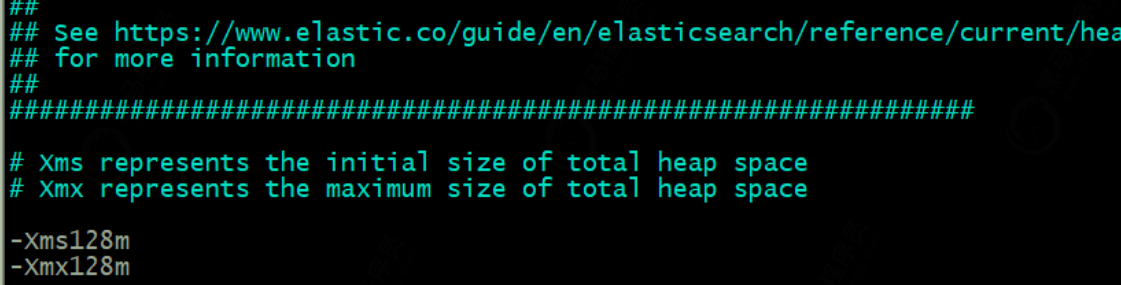

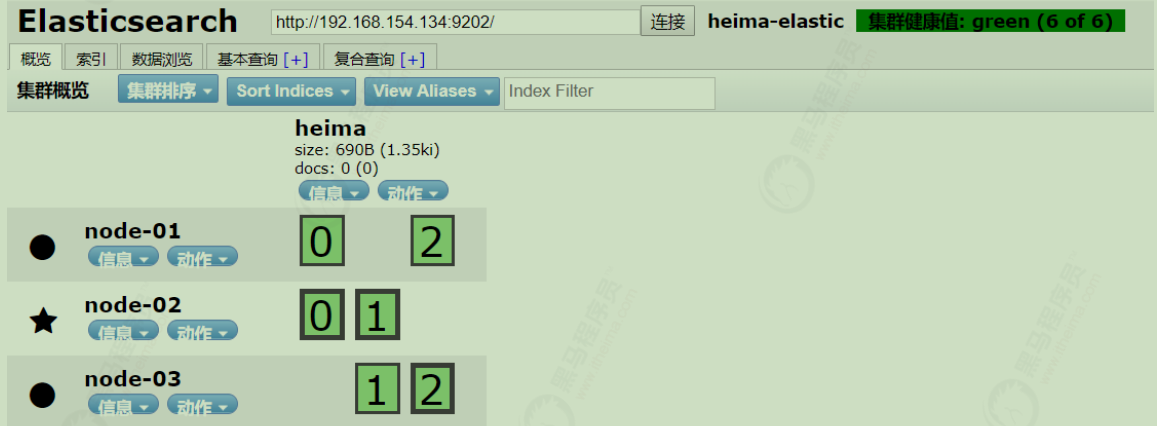
 因此,这些操作建议还是使用我们昨天学习的Rest风格API去实现。
因此,这些操作建议还是使用我们昨天学习的Rest风格API去实现。
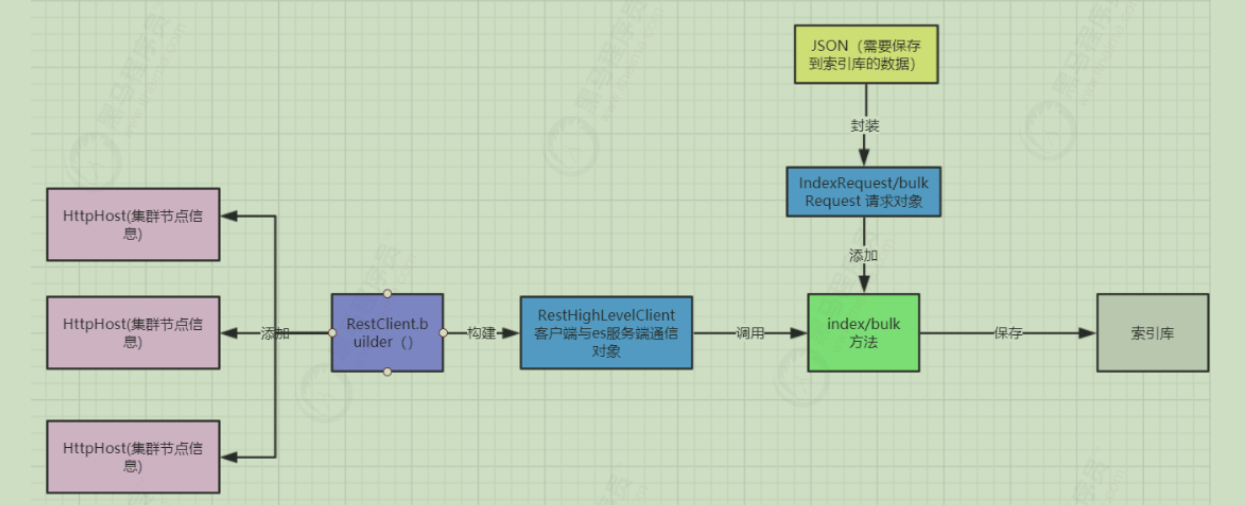

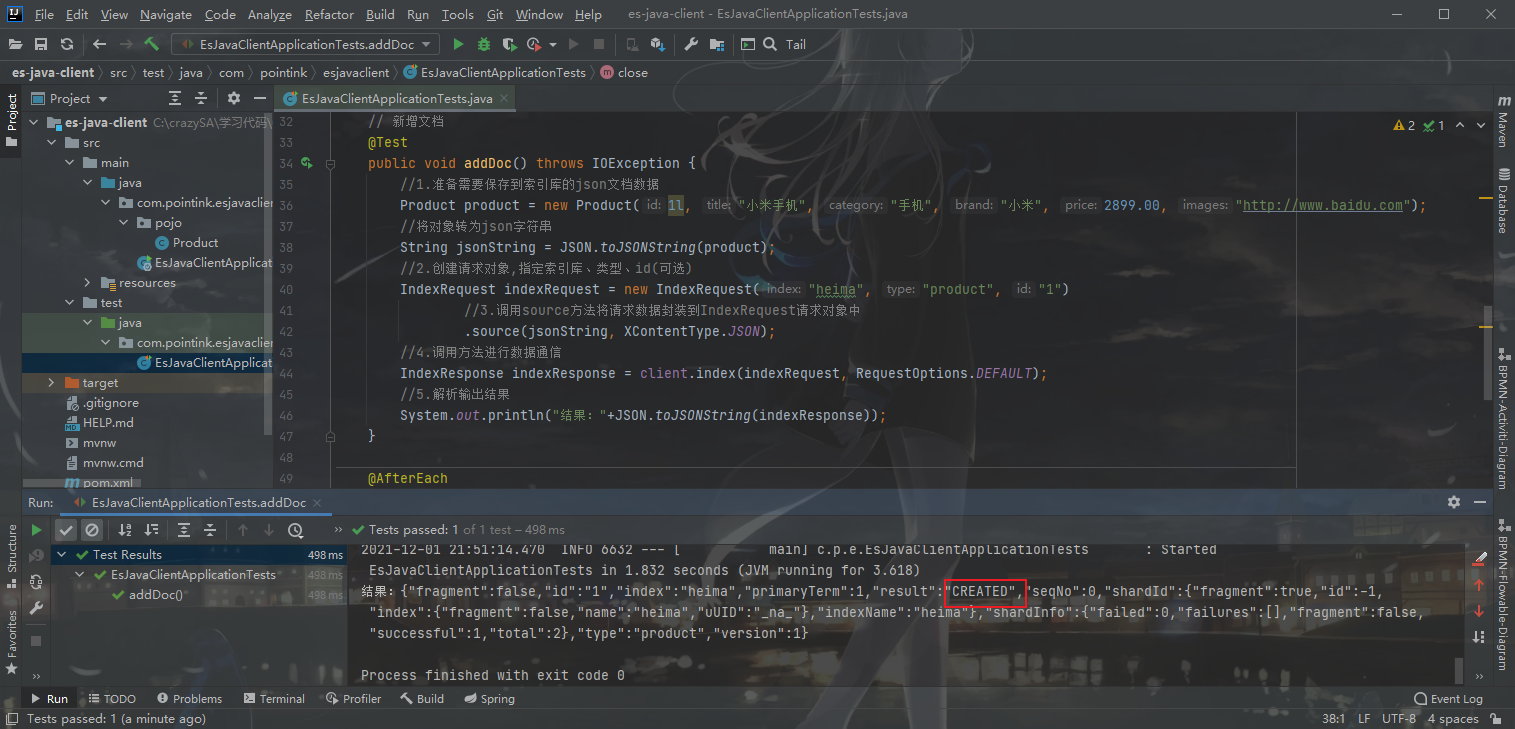
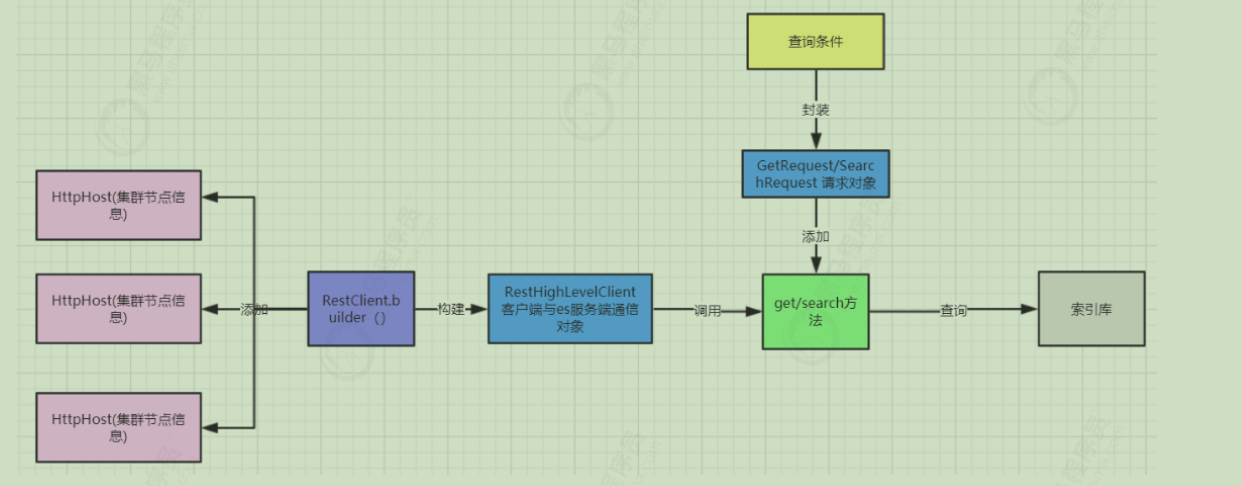

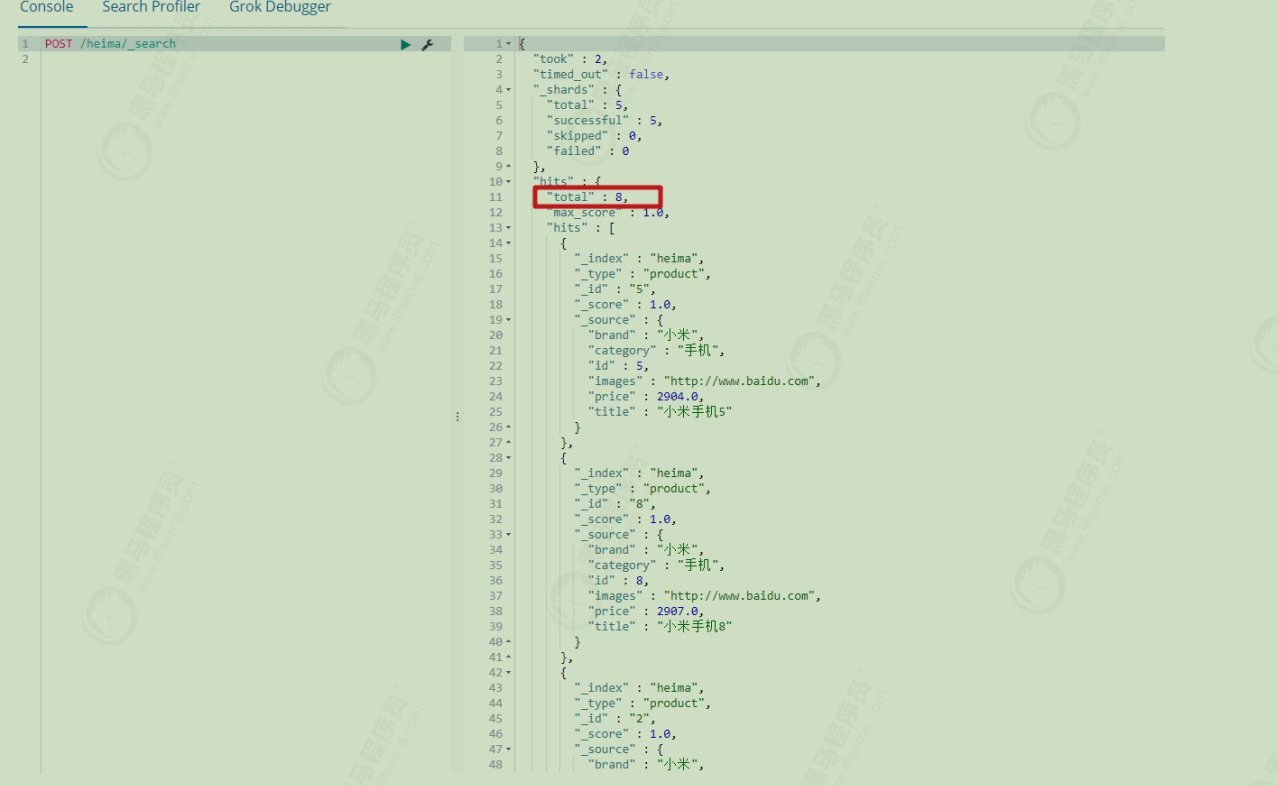
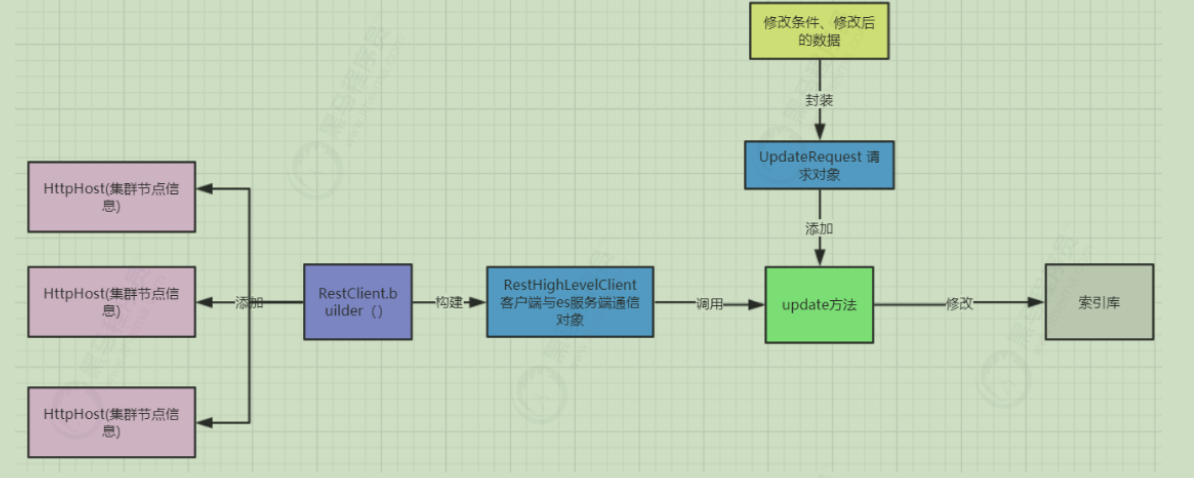





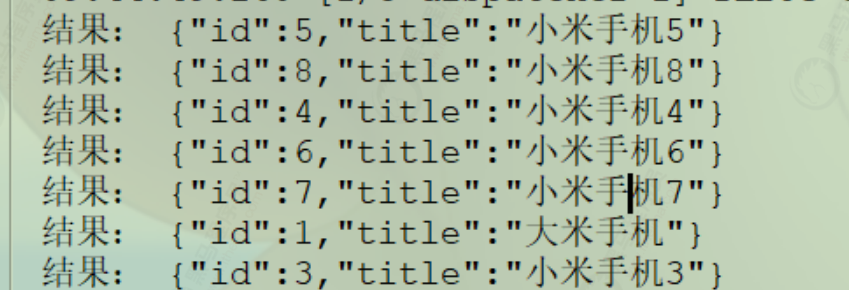

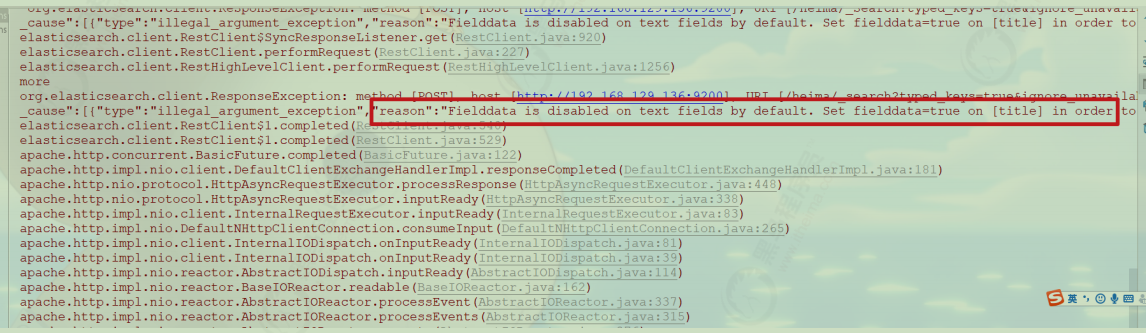

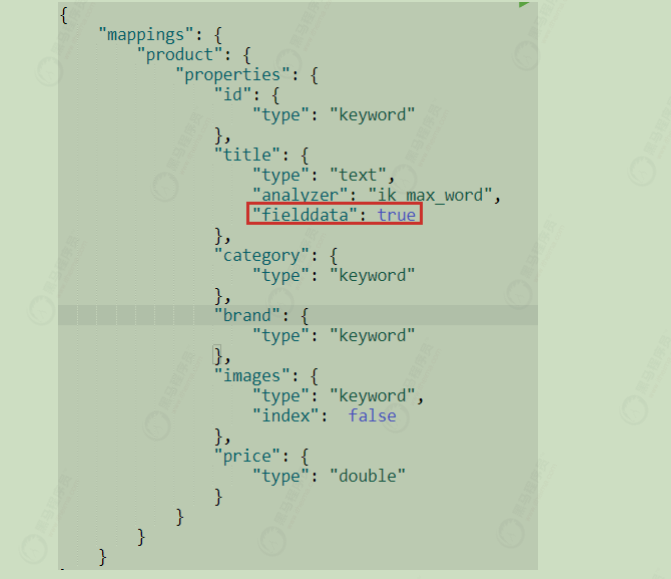
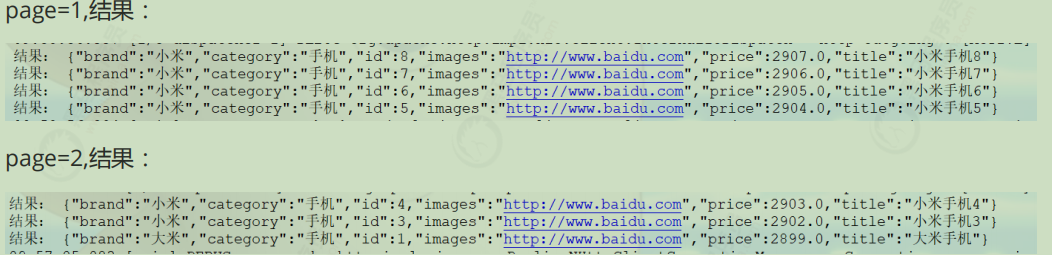
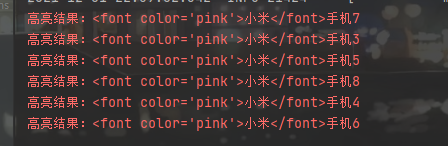


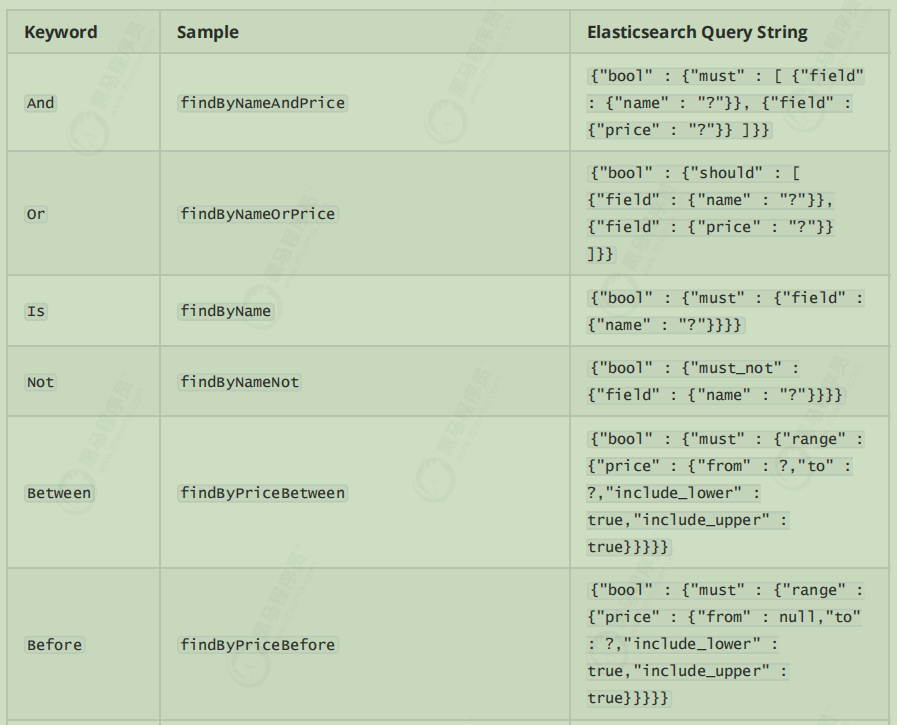
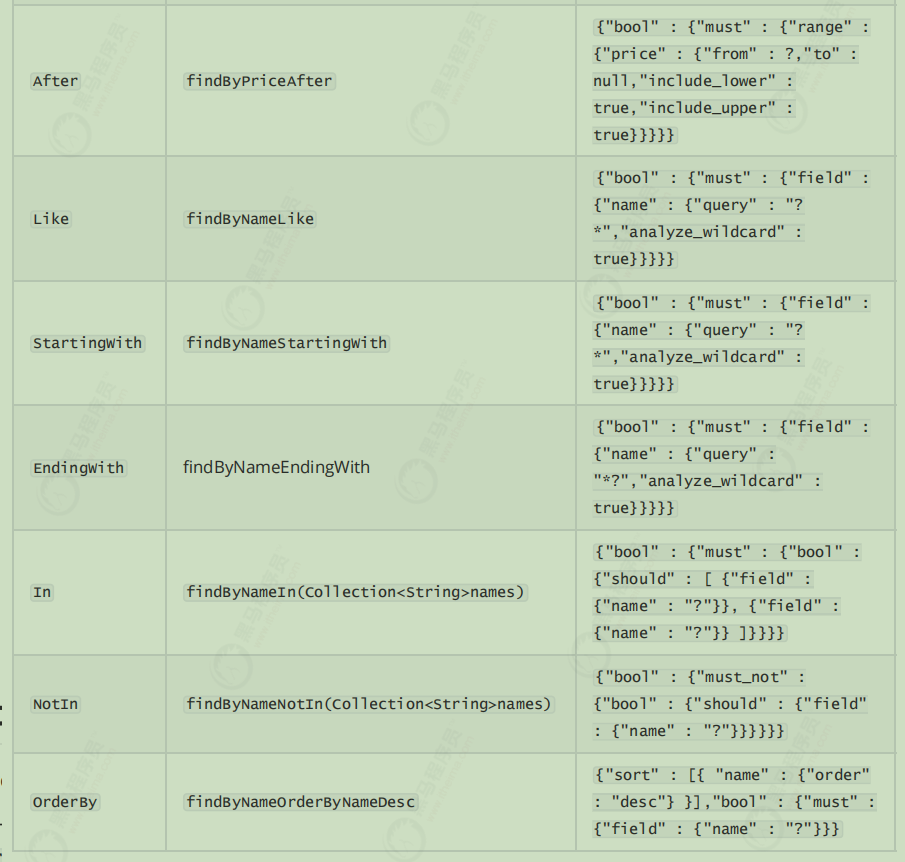
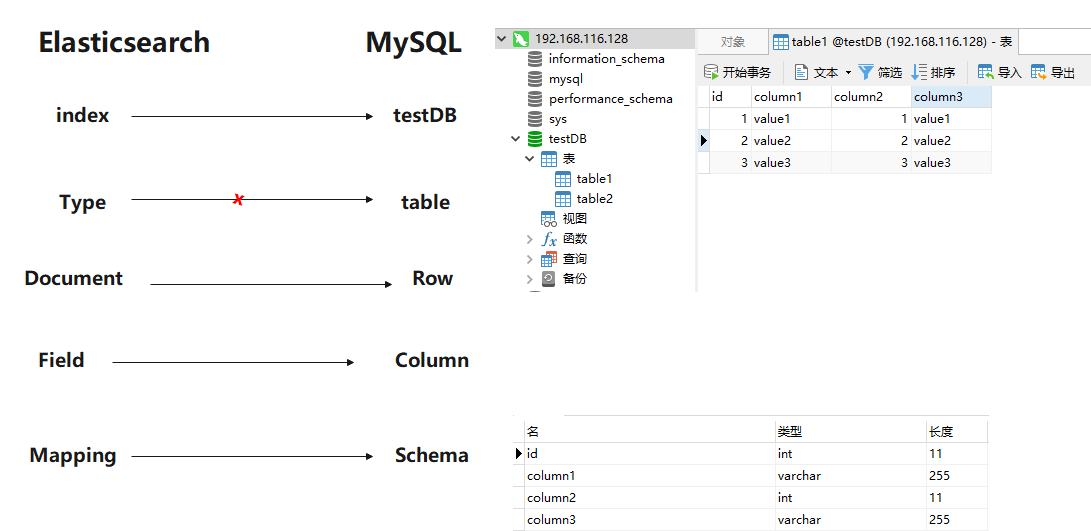
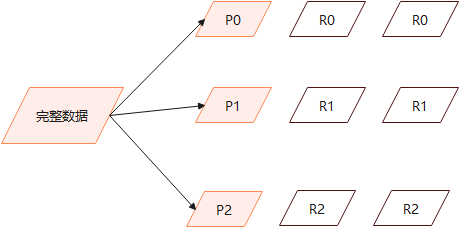
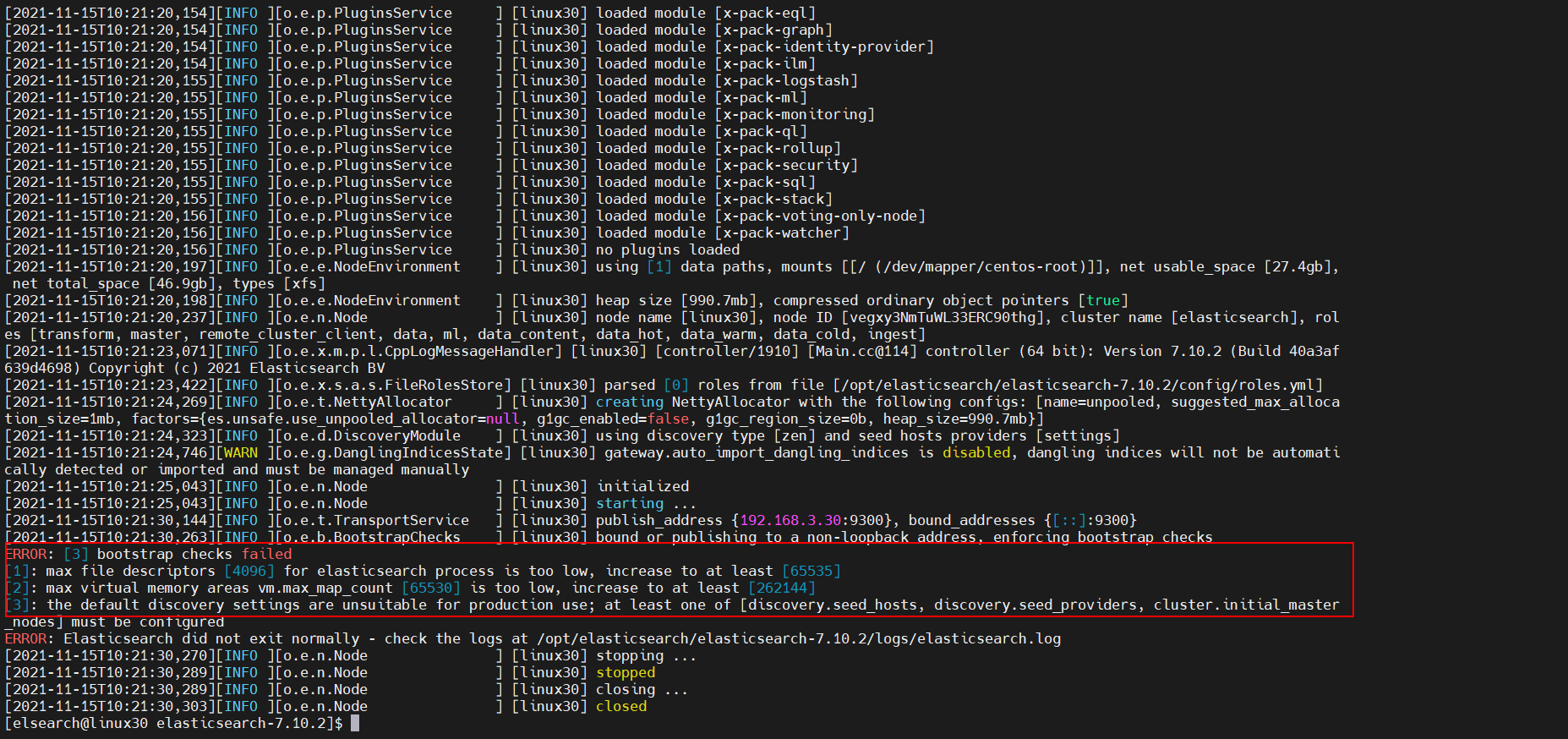

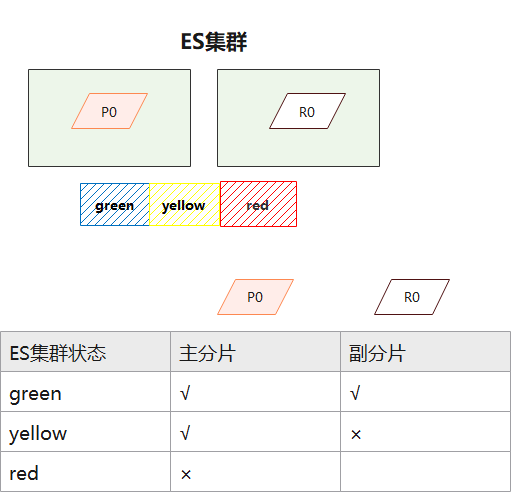
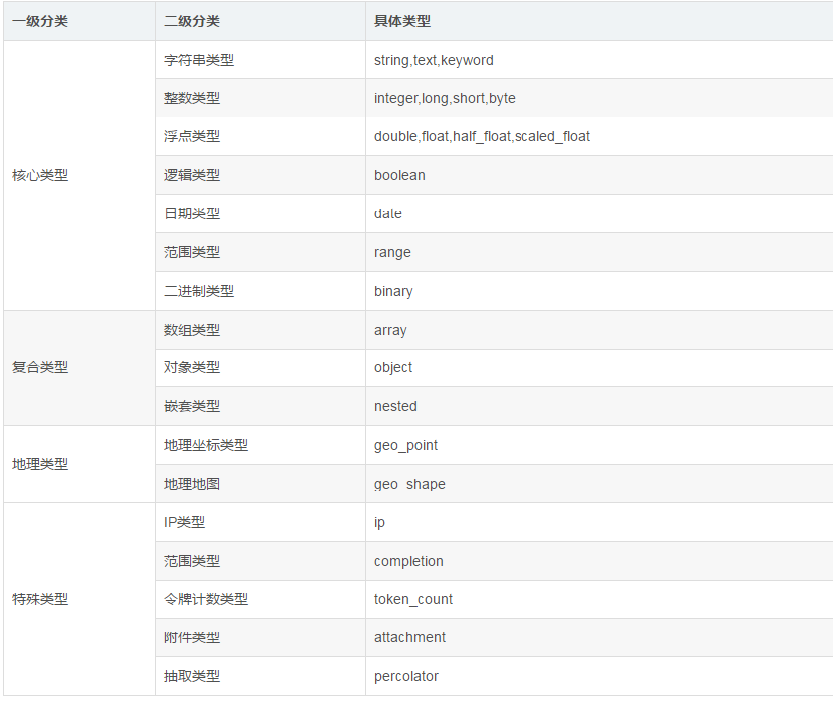
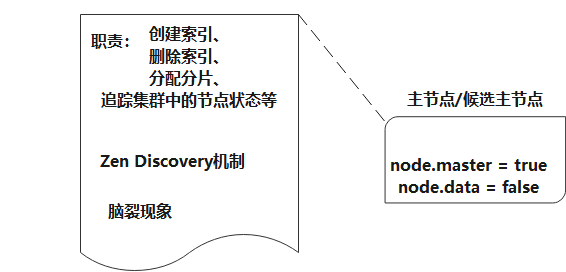
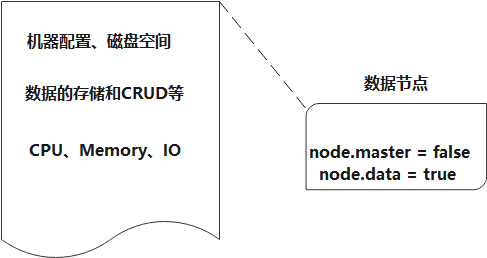
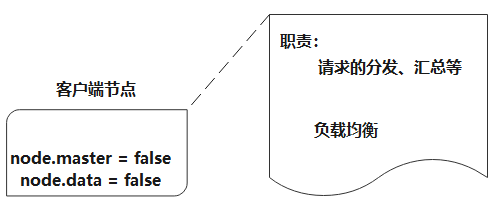
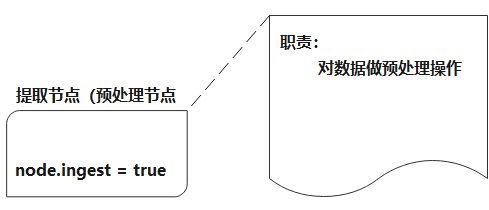
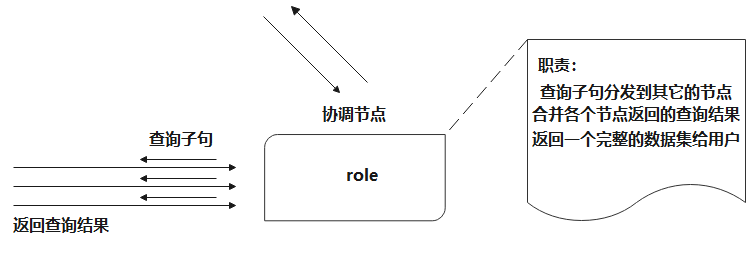
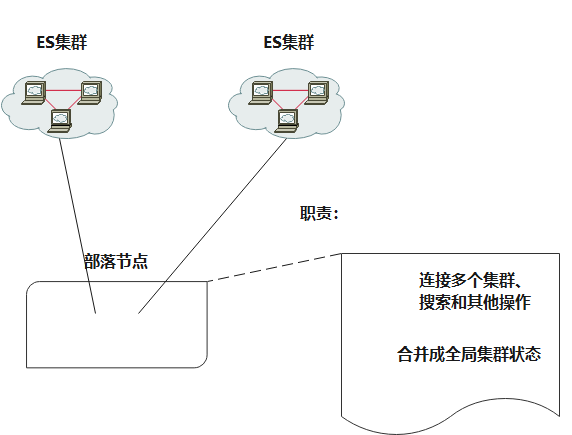
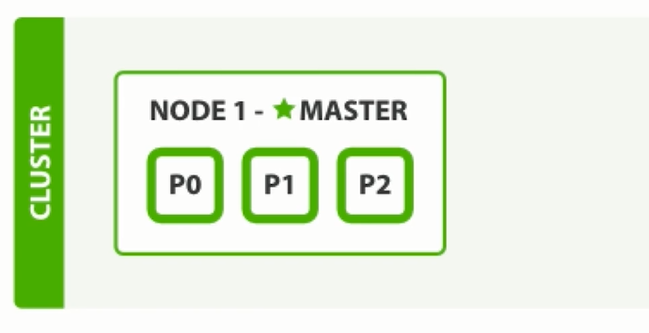

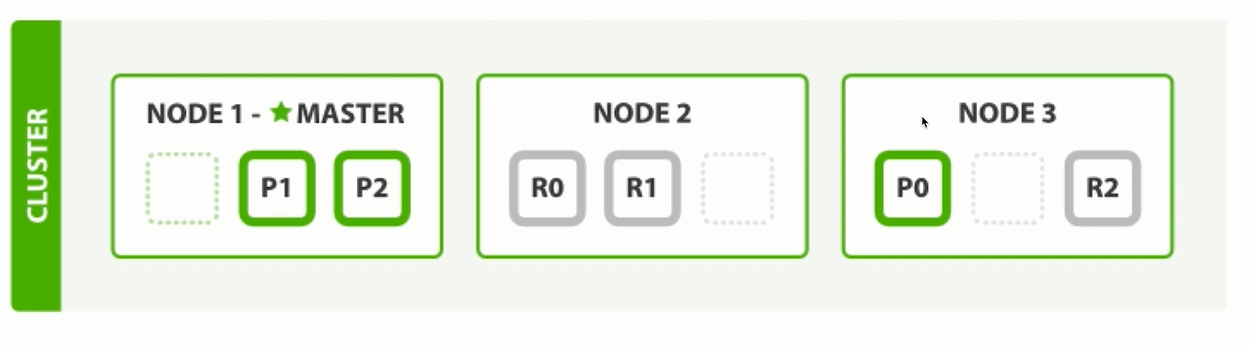
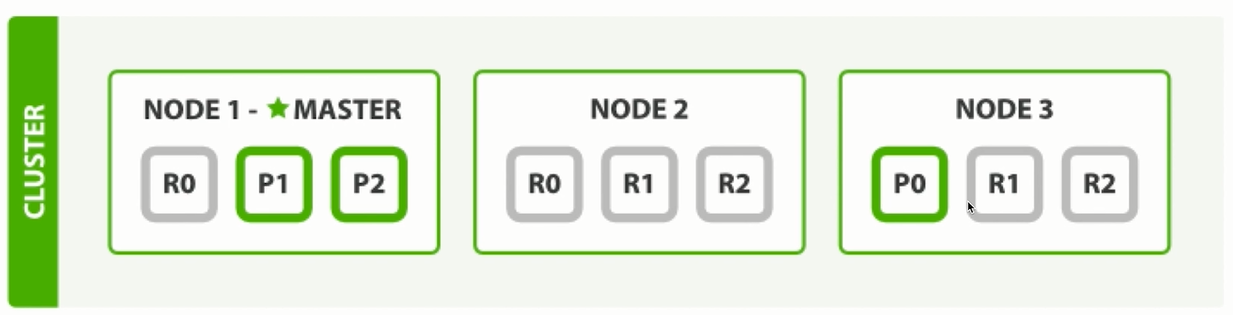
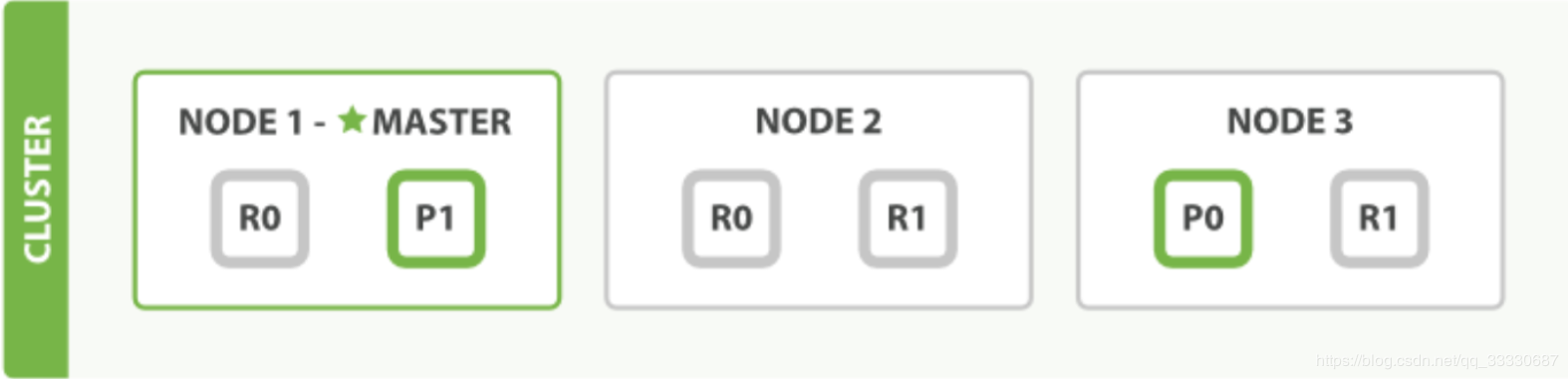
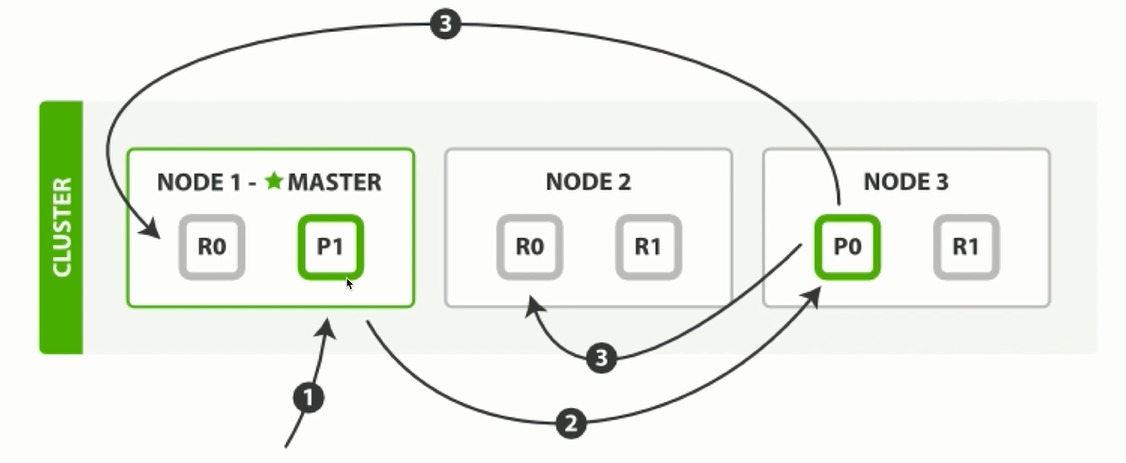
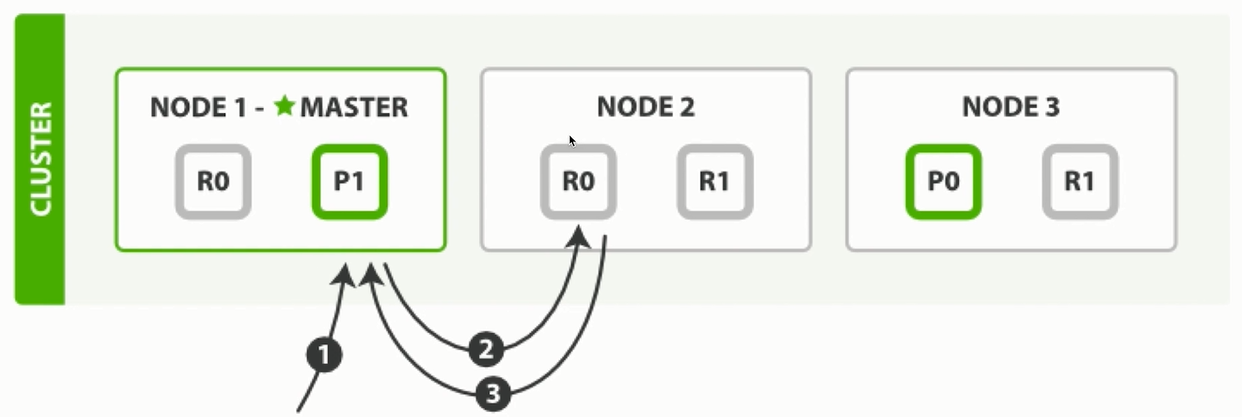
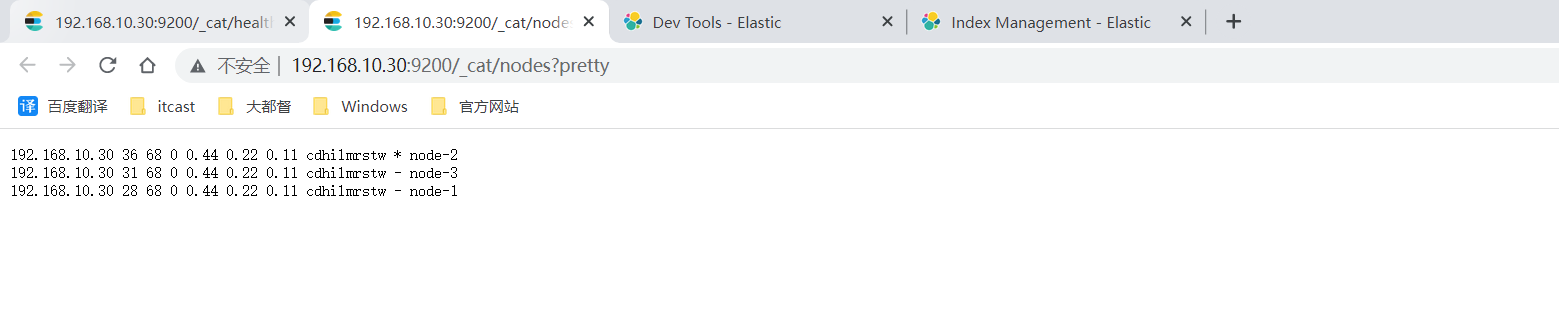
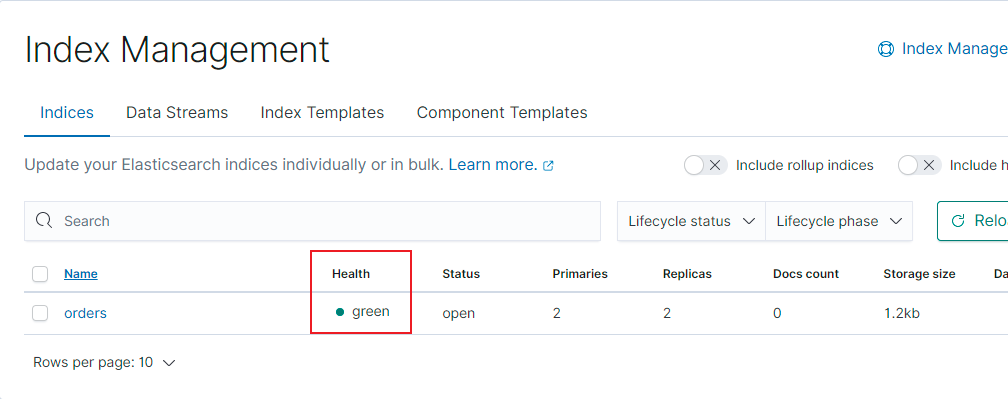
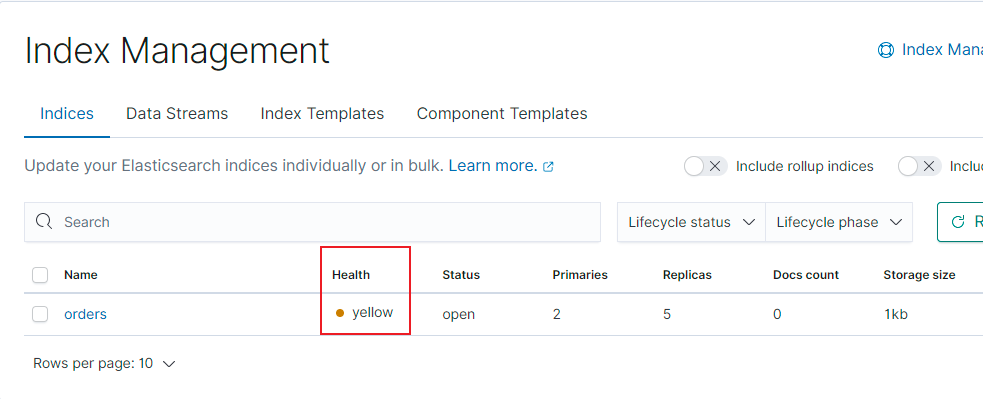
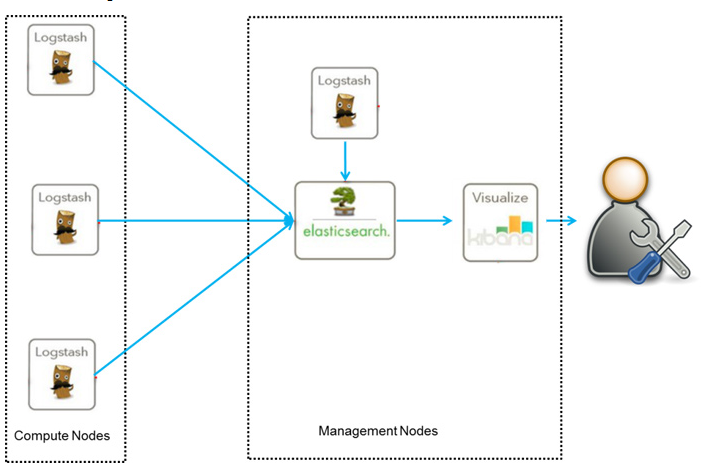
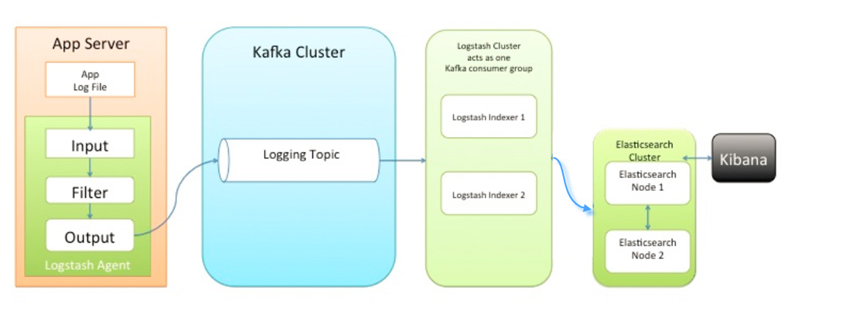
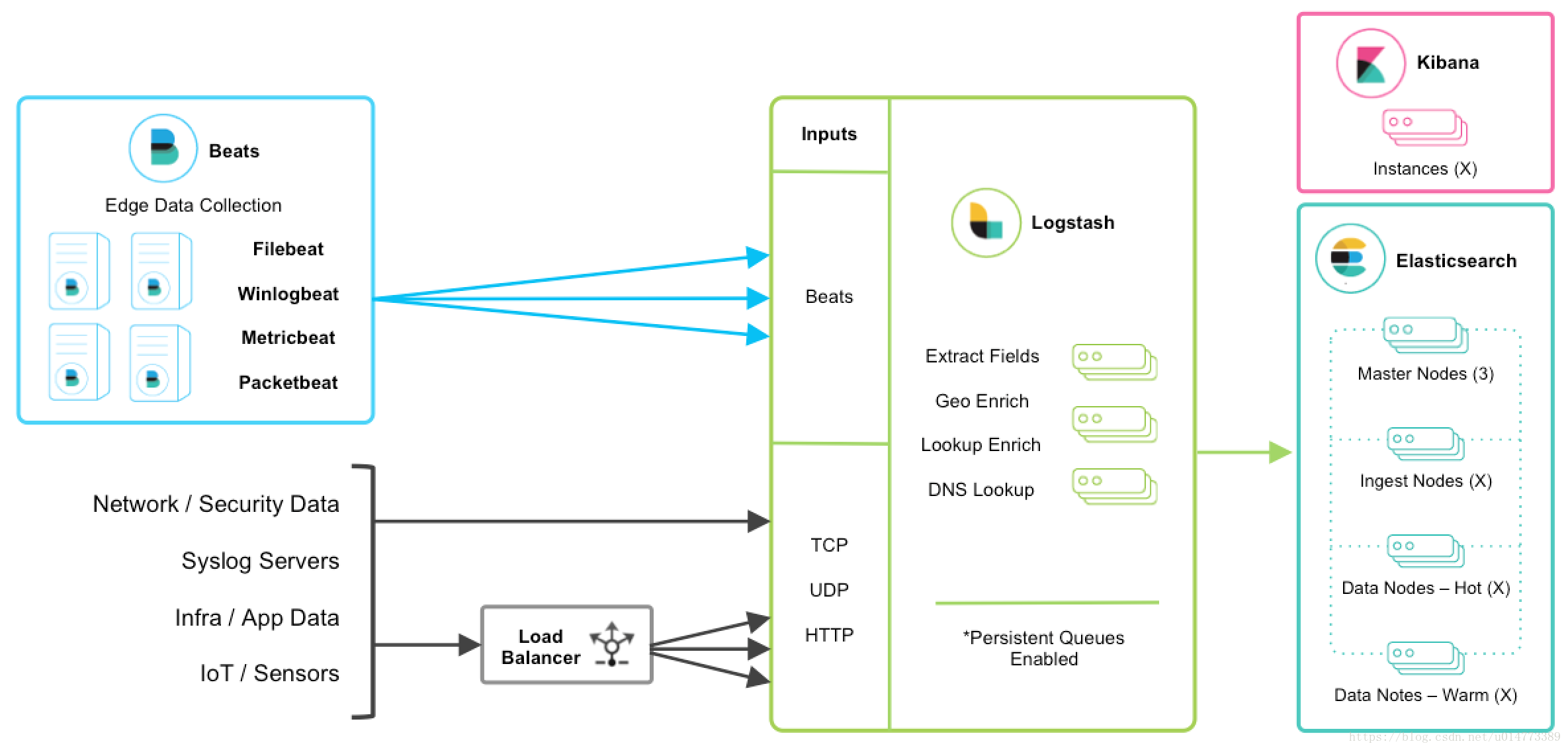
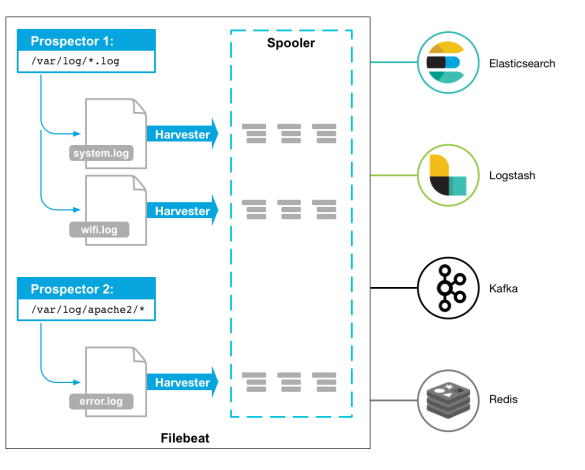
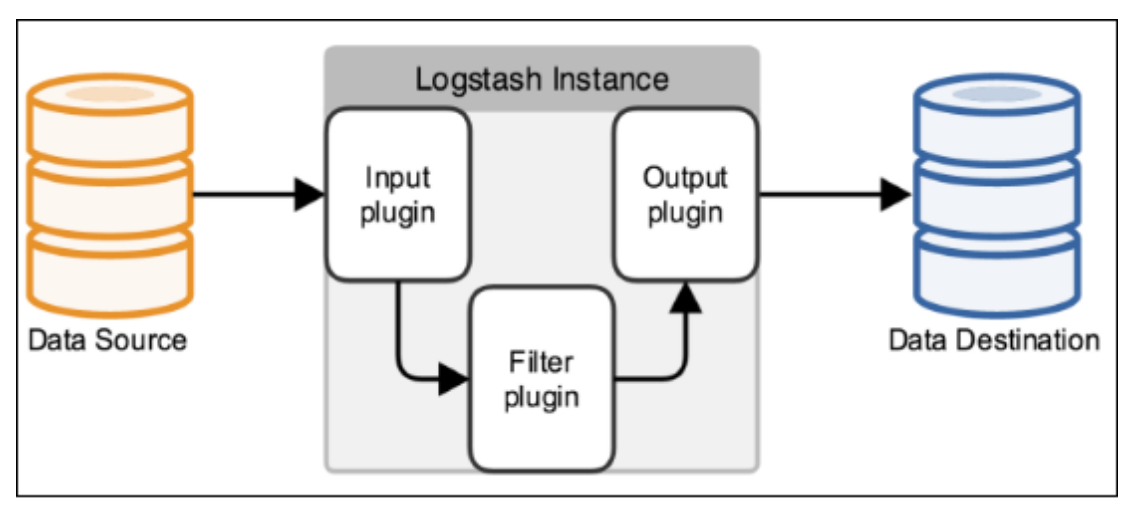
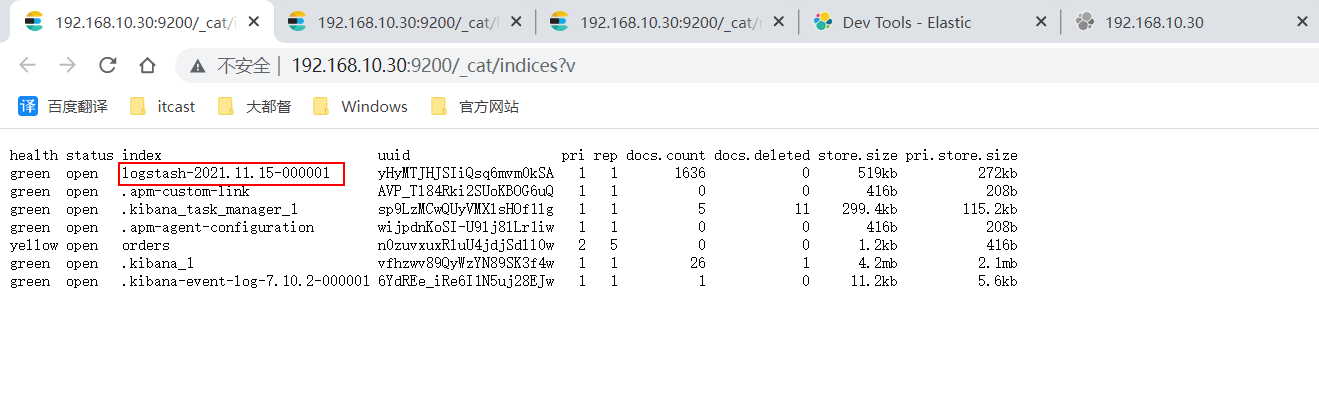
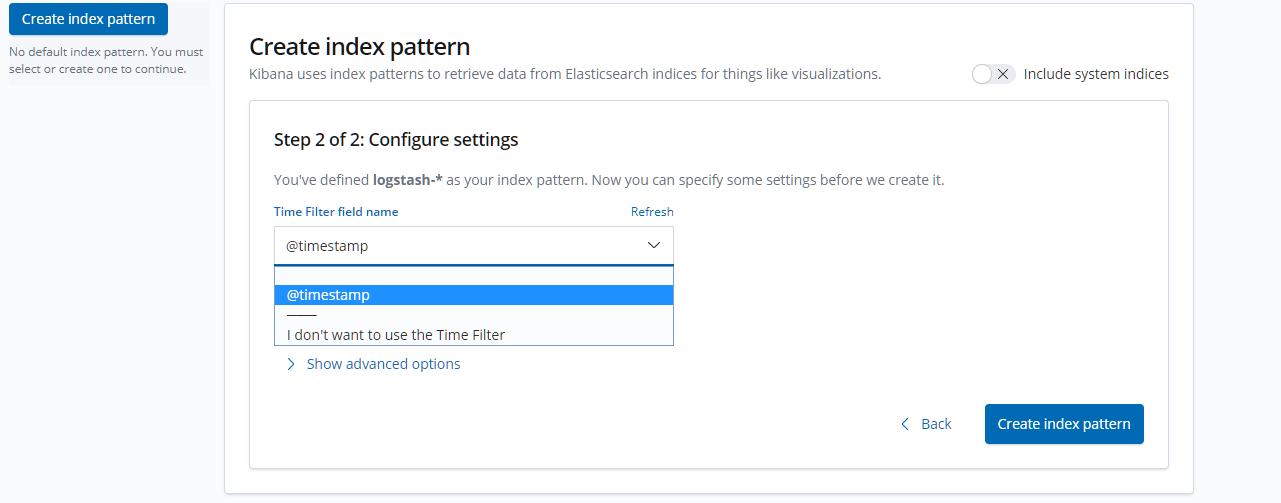
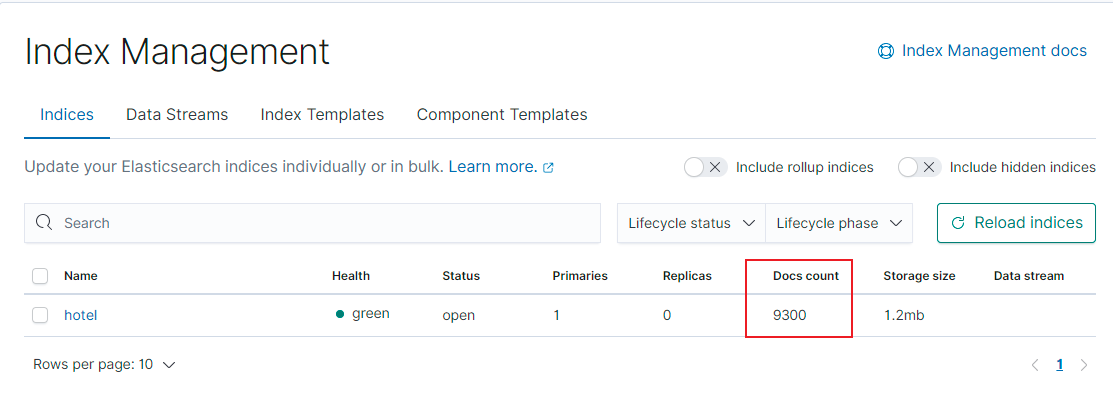


 微信
微信 支付宝
支付宝
