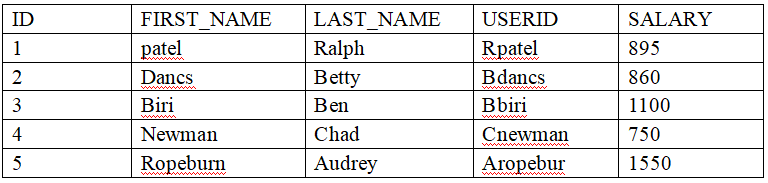
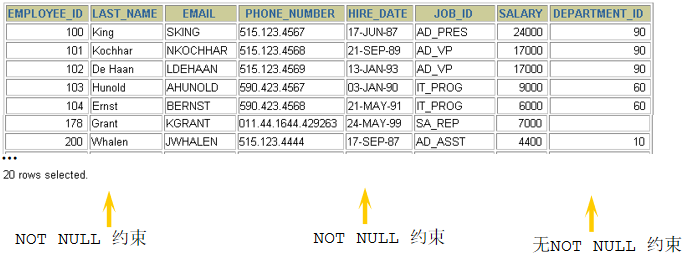
1. 查询工资大于12000的员工姓名和工资 select last_name,salary from employees where salary > 12000
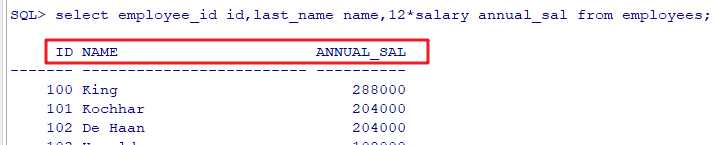
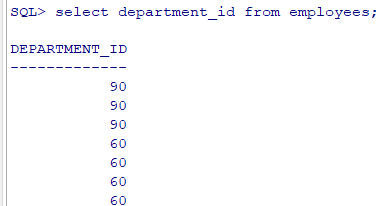
2. 查询员工号为176的员工的姓名和部门号 select last_name,department_id from employees where employee_id = 176
3. 选择工资不在5000到12000的员工的姓名和工资 select last_name,salary from employees where salary >=5000 AND salary <=12000
select last_name,salary from employees where salary between 5000 AND 12000;
4. 选择雇用时间在1998-02-01到1998-05-01之间的员工姓名,job_id和雇用时间 select last_name,job_id,hire_date from employees where hire_date between '1-2月-1998' and '1-5月-1998'
select last_name,job_id,hire_date from employees where to_char(hire_date,'yyyy-mm-dd') between '1998-02-01' and '1998-05-01'
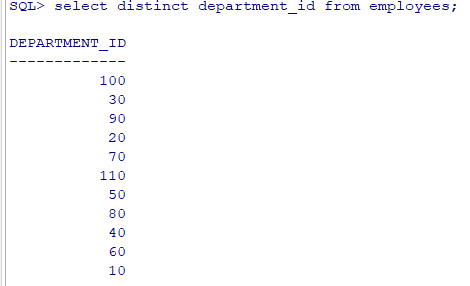
5. 选择在20或50号部门工作的员工姓名和部门号 select last_name,department_id from employees where department_id in(20,50)
select last_name,department_id from employees where department_id = 20 or department_id = 50
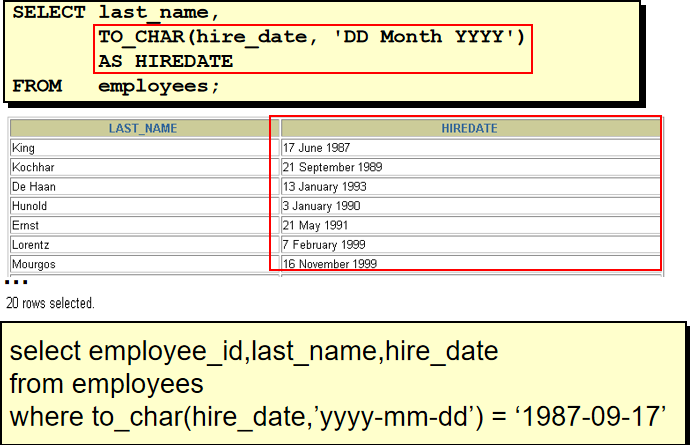
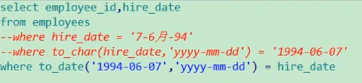
6. 选择在1994年雇用的员工的姓名和雇用时间 select last_name,hire_date from employees where hire_date like '%94'
select last_name,hire_date from employees where to_char(hire_date,'yyyy') = '1994'
7. 选择公司中没有管理者的员工姓名及job_id select last_name,job_id from employees where manager_id is null
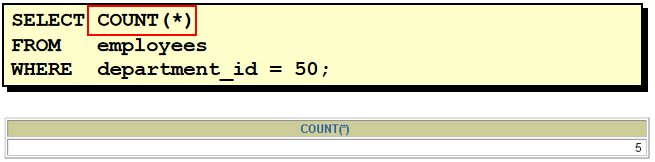
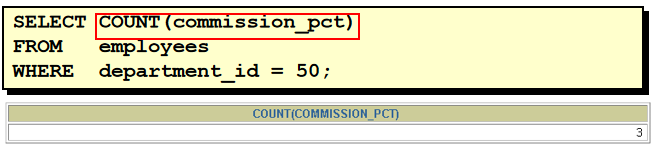
8. 选择公司中有奖金的员工姓名,工资和奖金级别 select last_name,salary,commission_pct from employees where commission_pct is not null
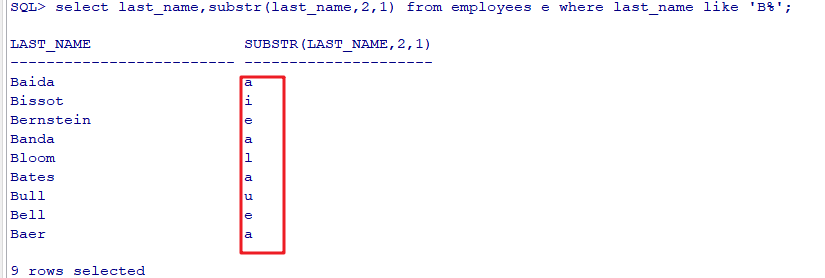
9. 选择员工姓名的第三个字母是a的员工姓名 select last_name from employees where last_name like '__a%'
10.选择姓名中有字母a和e的员工姓名 select last_name from employees where last_name like '%a%e%' or last_name like '%e%a%'
select last_name from employees where last_name like '%a%' and last_name like '%e%'
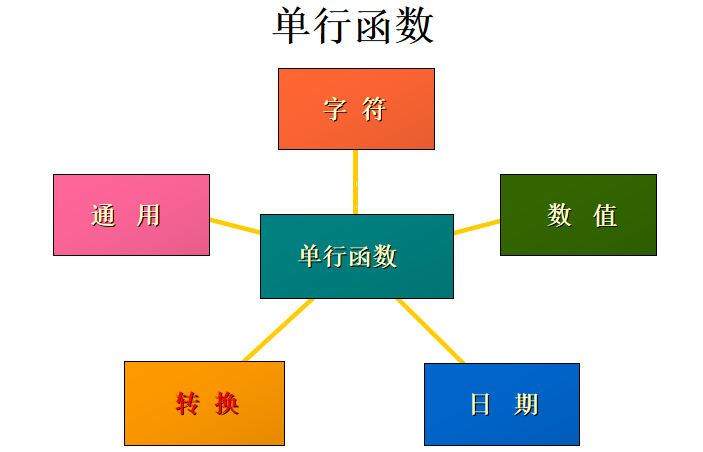
03_单行函数
单行函数
操作数据对象
接受参数返回一个结果
只对一行进行变换
每行返回一个结果
可以转换数据类型
可以嵌套
参数可以是一列或一个值
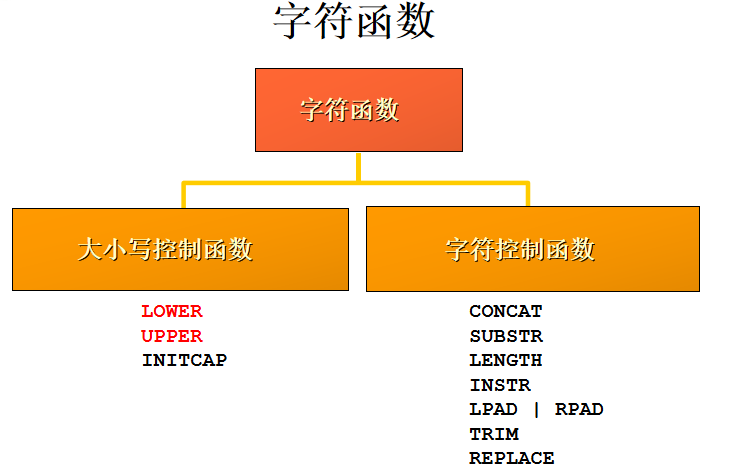
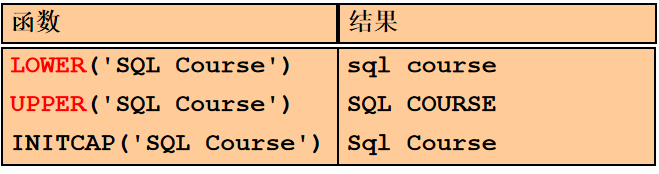
大小写控制函数: 这类函数改变字符的大小写。
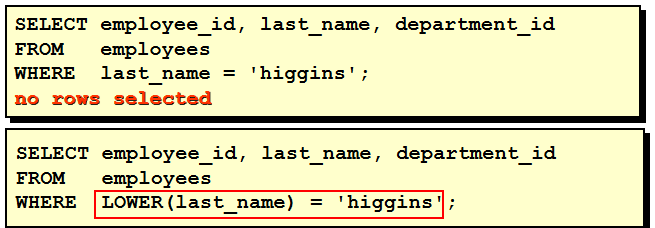
显示员工 Higgins的信息:
字符控制函数: 这类函数控制字符
ps:
substr是从第1位开始,取5个,数据库索引下标从1开始的.
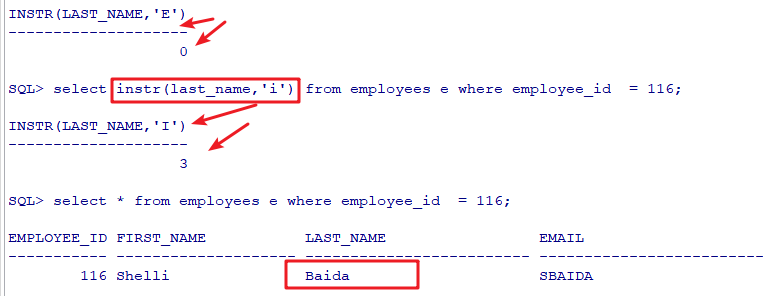
instr是返回字符的索引位置,不存在返回0
replace是替换匹配的所有字符
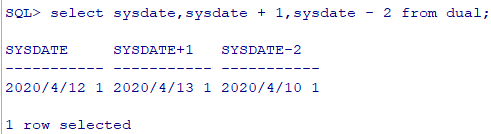
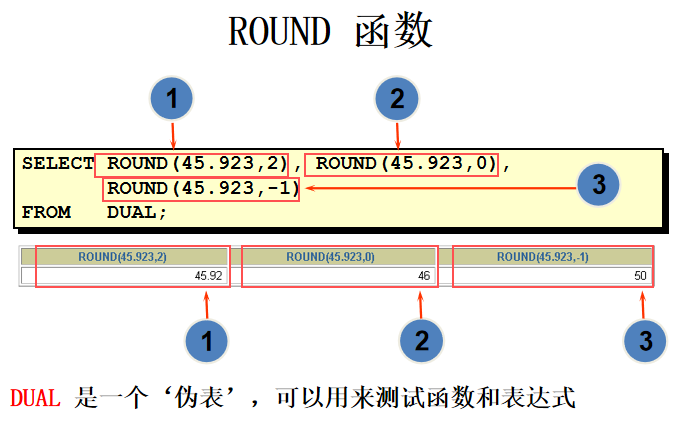
函数SYSDATE 返回:
日期
时间
日期的数学运算
在日期上加上或减去一个数字结果仍为日期
两个日期相减返回日期之间相差的天数。
日期不允许做加法运算,无意义
可以用数字除24来向日期中加上或减去天数
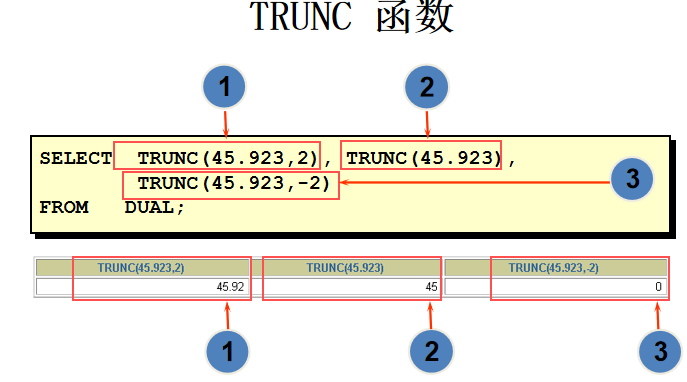
日期函数
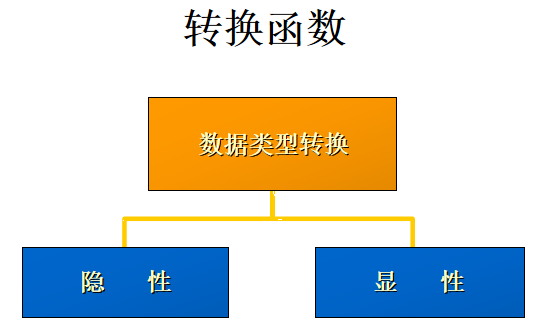
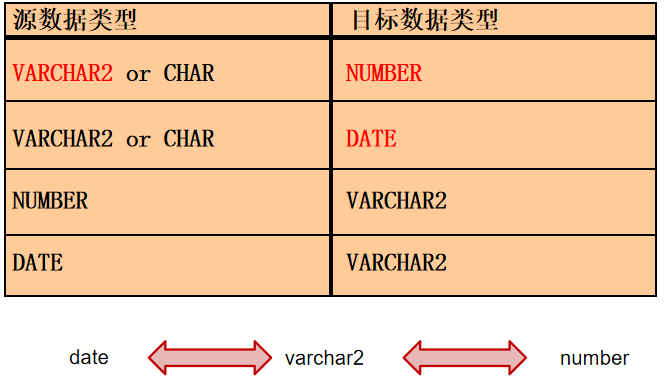
隐式数据类型转换
Oracle 自动完成下列转换:
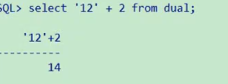
varchar2隐式转换为number运算
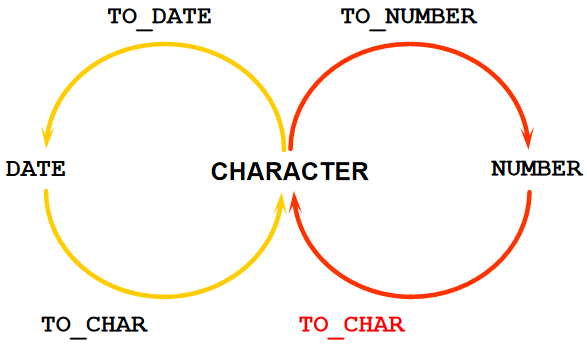
显式数据类型转换
TO_CHAR函数对日期的转换
格式:
必须包含在单引号中而且大小写敏感。
可以包含任意的有效的日期格式。
日期之间用逗号隔开。
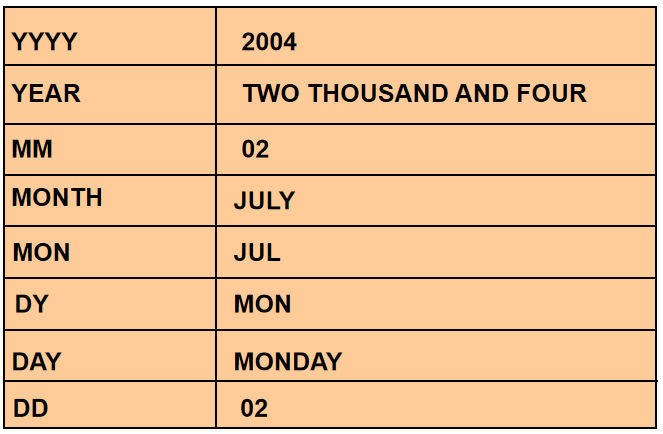
日期格式的元素
时间格式
使用双引号向日期中添加字符
TO_DATE 函数对字符的转换
使用
使用
练习:返回hire_date 为 ****/**/**的员工信息,使用显示日期表达
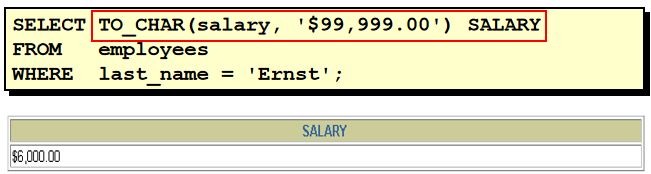
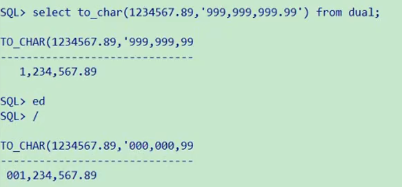
TO_CHAR函数对数字的转换
下面是在TO_CHAR 函数中经常使用的几种格式:
TO_NUMBER 函数对字符的转换
使用
使用
通用函数
这些函数适用于任何数据类型,同时也适用于空值:
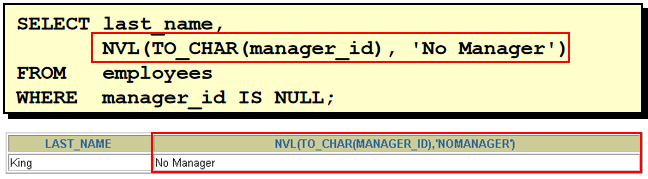
NVL (expr1, expr2)
NVL2 (expr1, expr2, expr3)
NULLIF (expr1, expr2)
COALESCE (expr1, expr2, …, exprn)
NVL 函数
将空值转换成一个已知的值:
可以使用的数据类型有日期、字符、数字。
函数的一般形式:
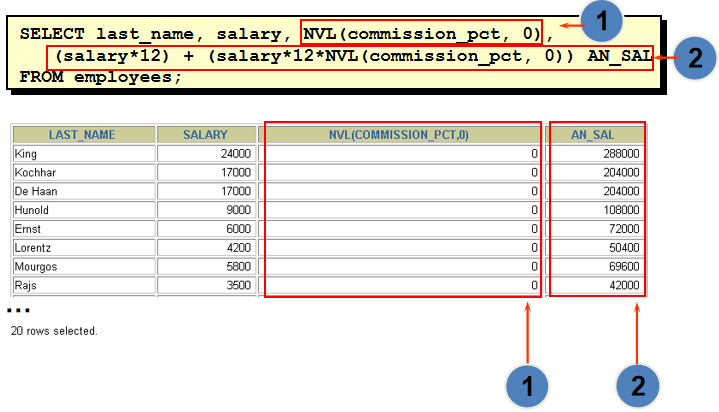
NVL(commission_pct,0)
NVL(hire_date,’01-JAN-97’)
NVL(job_id,’No Job Yet’)
1 2 3 4 5 6
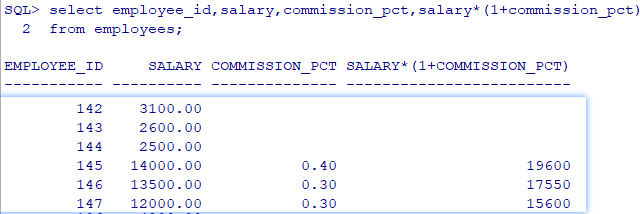
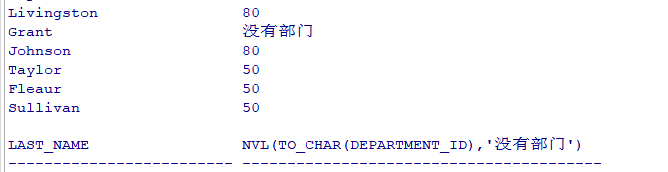
练习1:求公司员工的年薪(含commission_pct) select employee_id,last_name,salary*12*(1+nvl(commission_pct,0)) "annual sal" from employees 练习2:输出last_name,department_id,当department_id为null时,显示‘没有部门’。 select last_name,nvl(to_char(department_id,'999999'),'没有部门') from employees select last_name,nvl(to_char(department_id),'没有部门') from employees # nvl 类型不匹配的时候,要用到转换函数,这里department_id是number类型的,和'没有部门'不是同种类型,所以to_char转换
使用NVL函数
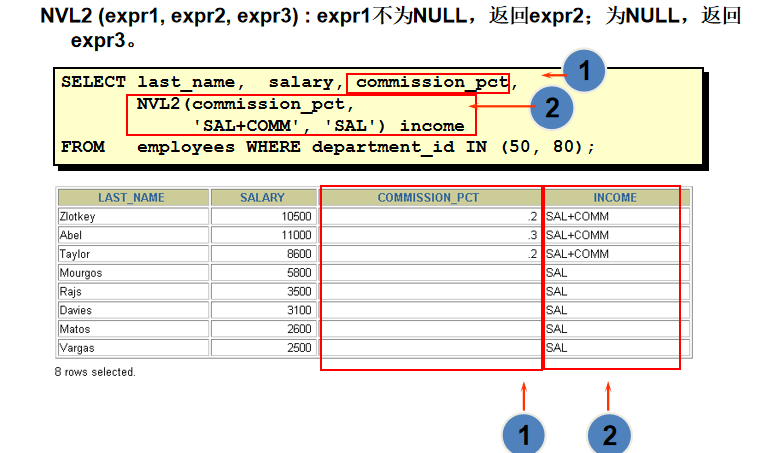
使用 NVL2 函数
1 2
练习:查询员工的奖金率,若为空,返回0.01,若不为空,返回实际奖金率+0.015 select employee_id,last_name,commission_pct,nvl2(commission_pct,commission_pct+0.015,0.01) from employees
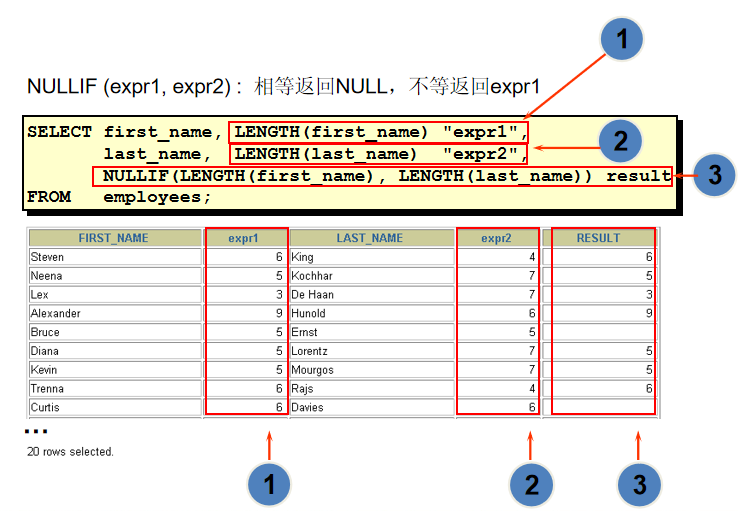
使用 NULLIF 函数
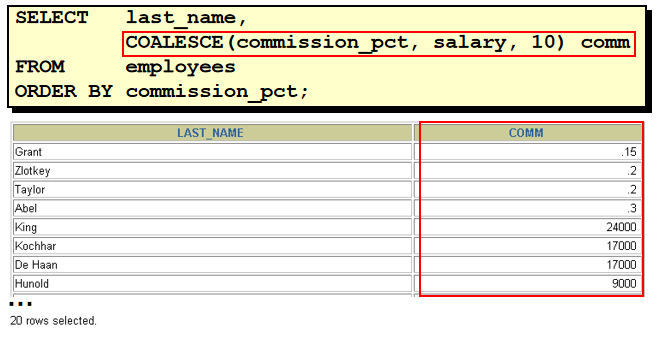
使用 COALESCE 函数
COALESCE 与 NVL 相比的优点在于 COALESCE 可以同时处理交替的多个值。
如果第一个表达式为空,则返回下一个表达式,对其他的参数进行COALESCE 。
条件表达式
在 SQL 语句中使用IF-THEN-ELSE 逻辑
使用两种方法:
CASE 表达式
DECODE 函数
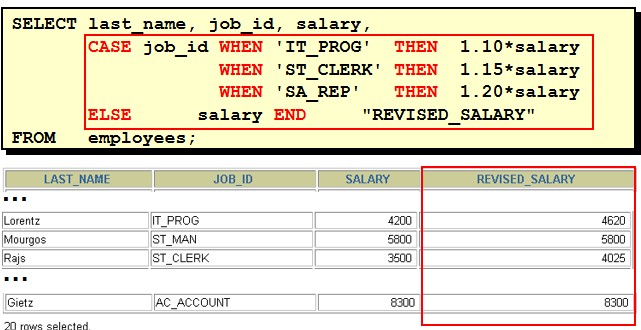
CASE 表达式
在需要使用 IF-THEN-ELSE 逻辑时:
1 2 3 4 5 6 7 8 9
练习:查询部门号为 10, 20, 30 的员工信息, 若部门号为 10, 则打印其工资的 1.1 倍, 20 号部门, 则打印其工资的 1.2 倍, 30 号部门打印其工资的 1.3 倍数 select employee_id,last_name,department_id, case department_id when 10 then salary * 1.1 when 20 then salary * 1.2 else salary * 1.3 end salary from employees where department_id in (10,20,30)
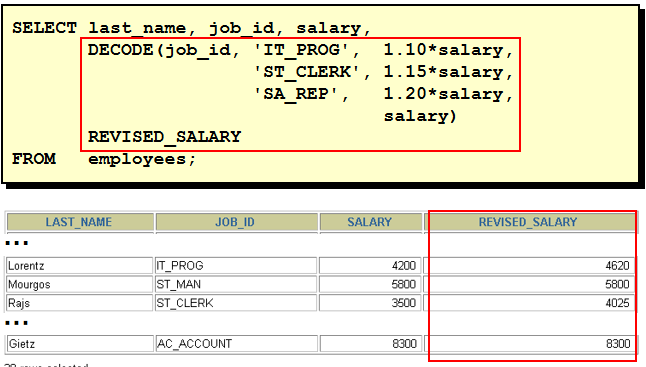
DECODE 函数
在需要使用 IF-THEN-ELSE 逻辑时:
练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
1. 显示系统时间(注:日期+时间) select to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual 2. 查询员工号,姓名,工资,以及工资提高百分之20%后的结果(new salary) select employee_id,last_name,salary,salary*1.2 "new salary" from employees 3. 将员工的姓名按首字母排序,并写出姓名的长度(length) select last_name,length(last_name) from employees order by last_name asc 4. 查询各员工的姓名,并显示出各员工在公司工作的月份数(worked_month)。 select last_name,hire_date,round(months_between(sysdate,hire_date),1) workded_month from employees 5. 查询员工的姓名,以及在公司工作的月份数(worked_month),并按月份数降序排列 Select last_name,hire_date,round(months_between(sysdate,hire_date),1) workded_month from employees order by workded_month desc 6. 做一个查询,产生下面的结果 <last_name> earns <salary> monthly but wants <salary*3>
job grade AD_PRES A ST_MAN B IT_PROG C SA_REP D ST_CLERK E 产生下面的结果
1 2 3 4 5 6 7 8 9 10
select last_name "Last_name",job_id "Job_id",decode(job_id,'AD_PRES','A','ST_MAN','B', 'IT_PROG','C', 'SA_REP','D', 'ST_CLERK','E') "Grade" from employees 8. 将第7题的查询用case函数再写一遍。 select last_name "Last_name",job_id "Job_id",case job_id when 'AD_PRES'then 'A' when 'ST_MAN' then 'B' when 'IT_PROG' then 'C' when 'SA_REP' then 'D' when 'ST_CLERK' then'E' end "Grade" from employees
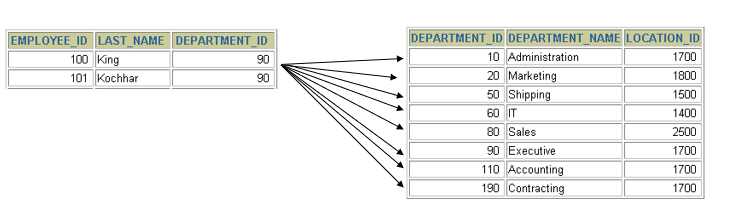
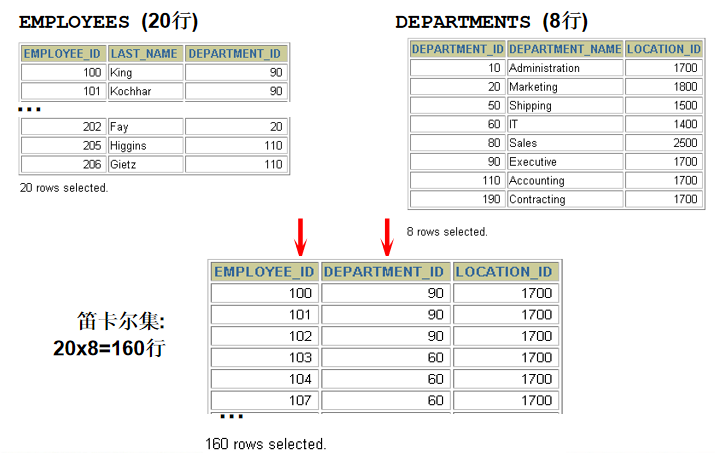
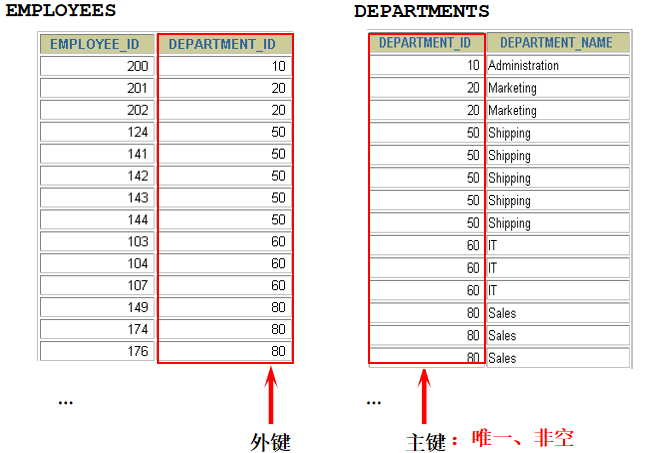
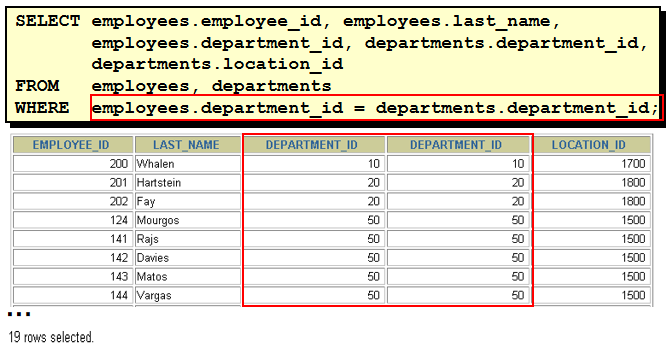
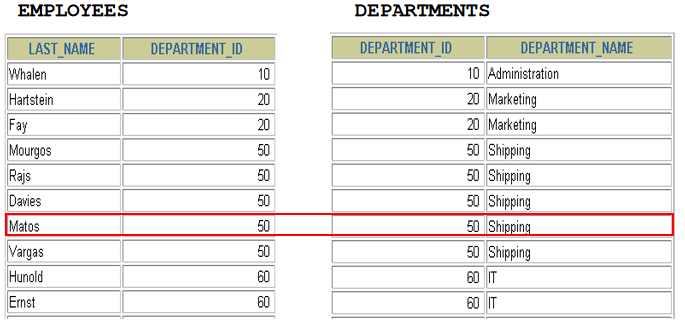
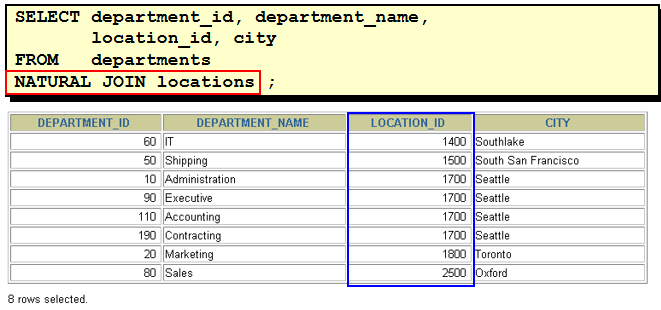
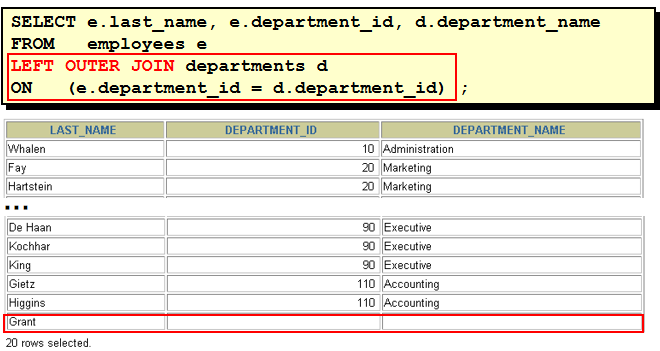
1. 显示所有员工的姓名,部门号和部门名称。 方法一: select last_name,e.department_id,department_name from employees e,departments d where e.department_id = d.department_id(+) 方法二: select last_name,e.department_id,department_name from employees e left outer join departments d on e.department_id = d.department_id
2. 查询90号部门员工的job_id和90号部门的location_id select distinct job_id,location_id from employees e left outer join departments d on e.department_id = d.department_id where d.department_id = 90
3. 选择所有有奖金的员工的last_name , department_name , location_id , city select last_name,department_name,d.location_id,city from employees e join departments d on e.department_id = d.department_id join locations l on d.location_id = l.location_id where e.commission_pct is not null
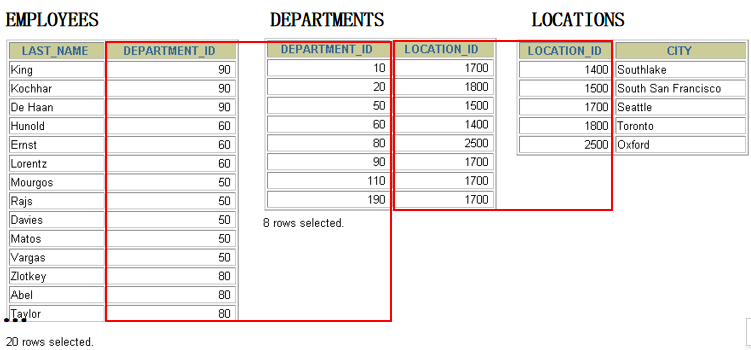
4. 选择city在Toronto工作的员工的last_name , job_id , department_id , department_name select last_name , job_id , e.department_id , department_name from employees e ,departments d,locations l where e.department_id = d.department_id and l.city = 'Toronto' and d.location_id = l.location_id
5.选择指定员工的姓名,员工号,以及他的管理者的姓名和员工号,结果类似于下面的格式
1 2 3
select e1.last_name "employees",e1.employee_id "Emp#",e2.last_name"Manger",e2.employee_id "Mgr#" from employees e1,employees e2 where e1.manager_id = e2.employee_id(+)
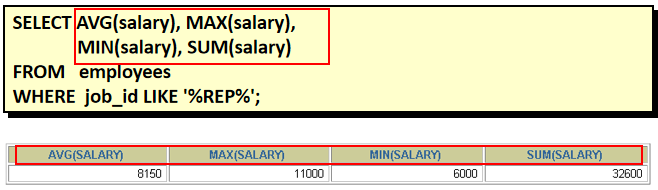
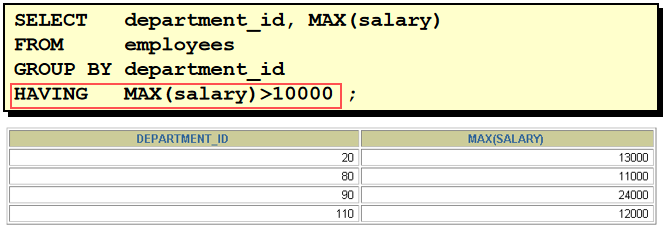
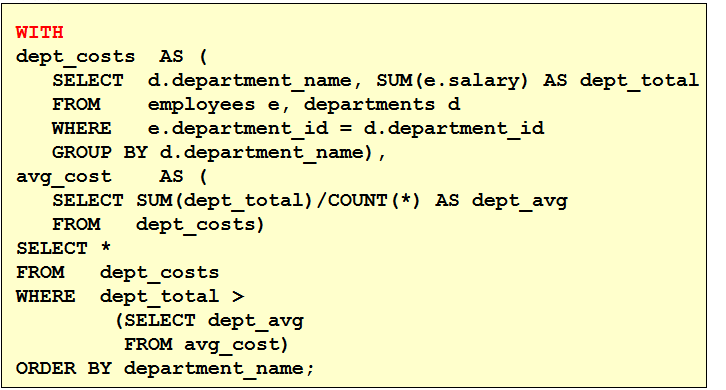
不可以,用having替代 4. 查询公司员工工资的最大值,最小值,平均值,总和 select max(salary),min(salary),avg(salary),sum(salary) from employees 5. 查询各job_id的员工工资的最大值,最小值,平均值,总和 select job_id,max(salary),min(salary),avg(salary),sum(salary) from employees group by job_id 6. 选择具有各个job_id的员工人数 select job_id,count(employee_id) from employees group by job_id 7. 查询员工最高工资和最低工资的差距(DIFFERENCE) select max(salary),min(salary),max(salary)-min(salary) "DIFFERENCE" from employees 8. 查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内 select manager_id,min(salary) from employees where manager_id is not null group by manager_id having min(salary) >= 6000 9. 查询所有部门的名字,location_id,员工数量和工资平均值 select department_name,location_id,count(employee_id),avg(salary) from employees e right outer join departments d on e.department_id = d.department_id group by department_name,location_id 10. 查询公司在1995-1998年之间,每年雇用的人数,结果类似下面的格式
1 2 3 4 5 6 7
select count(*) "total", count(decode(to_char(hire_date,'yyyy'),'1995',1,null)) "1995", count(decode(to_char(hire_date,'yyyy'),'1996',1,null)) "1996", count(decode(to_char(hire_date,'yyyy'),'1997',1,null)) "1997", count(decode(to_char(hire_date,'yyyy'),'1998',1,null)) "1998" from employees where to_char(hire_date,'yyyy') in ('1995','1996','1997','1998')
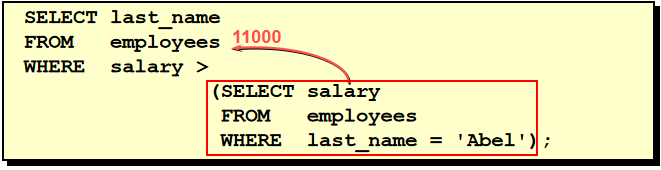
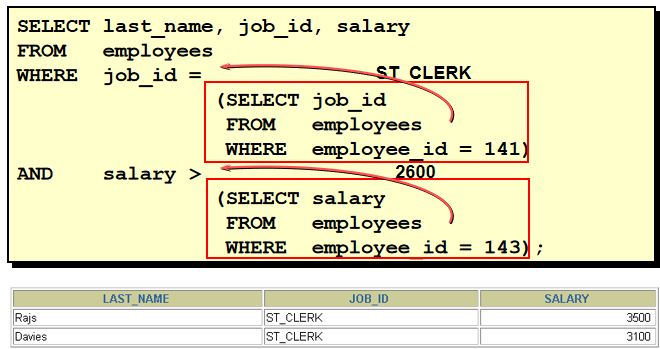
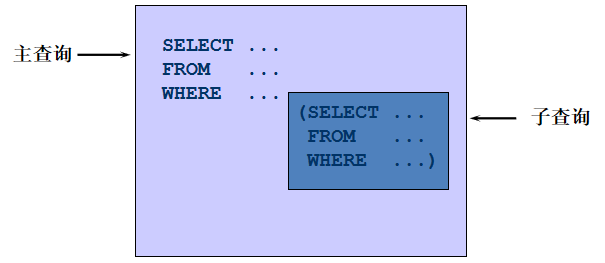
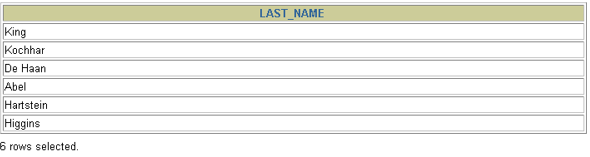
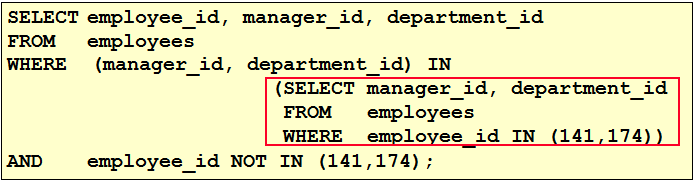
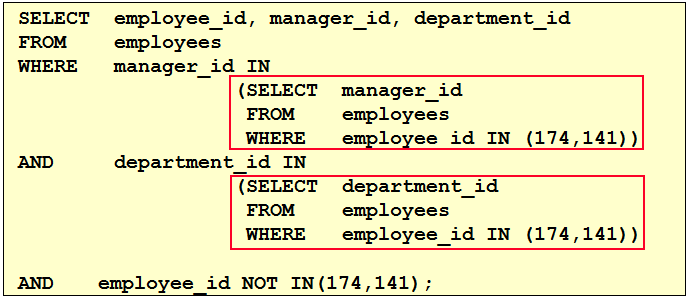
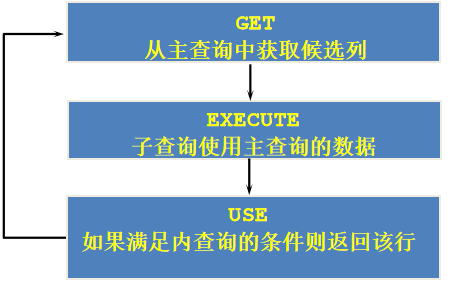
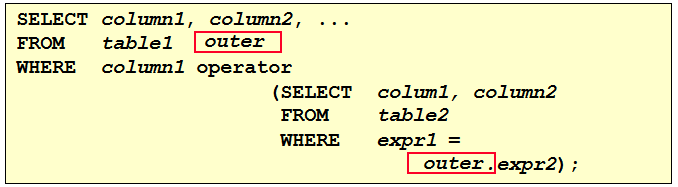
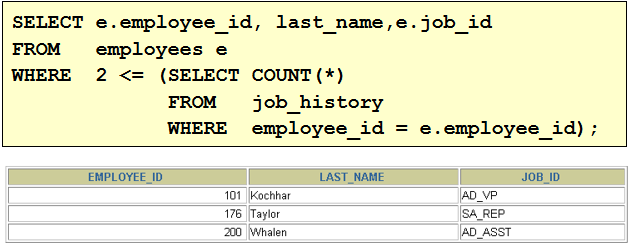
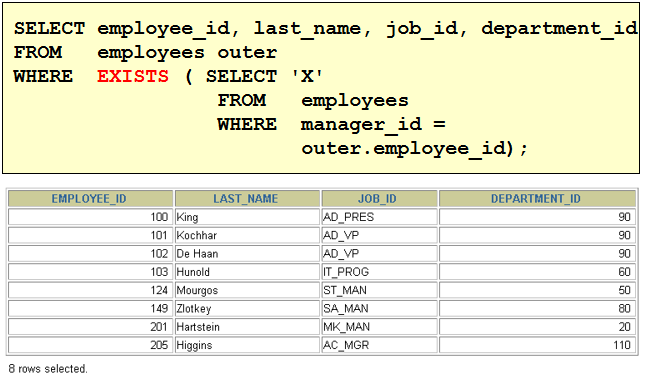
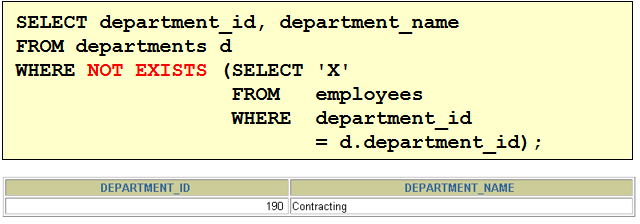
1. 查询和Zlotkey相同部门的员工姓名和雇用日期 select last_name,hire_date from employees where department_id = ( select department_id from employees where last_name = 'Zlotkey' ) and last_name <> 'Zlotkey' 2. 查询工资比公司平均工资高的员工的员工号,姓名和工资。 select last_name,employee_id,salary from employees where salary > (select avg(salary) from employees) 3. 查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资 select employee_id,last_name,salary from employees e1 where salary > ( select avg(salary) from employees e2 where e1.department_id = e2.department_id group by department_id ) 4. 查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名 select employee_id,last_name from employees where department_id in ( select department_id from employees where last_name like '%u%' ) and last_name not like '%u%'
5. 查询在部门的location_id为1700的部门工作的员工的员工号 select employee_id from employees where department_id in ( select department_id from departments where location_id = 1700 ) 6.查询管理者是King的员工姓名和工资 select last_name,salary from employees where manager_id in ( select employee_id from employees where last_name = 'King' )
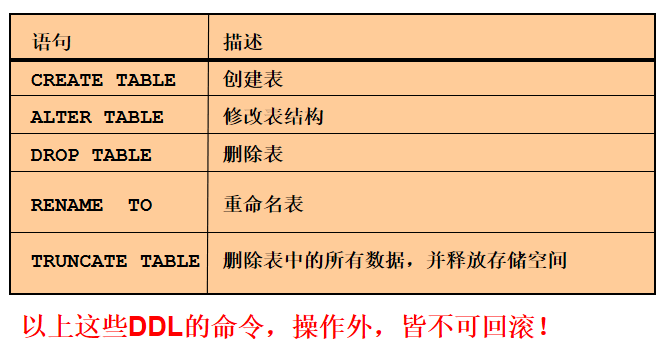
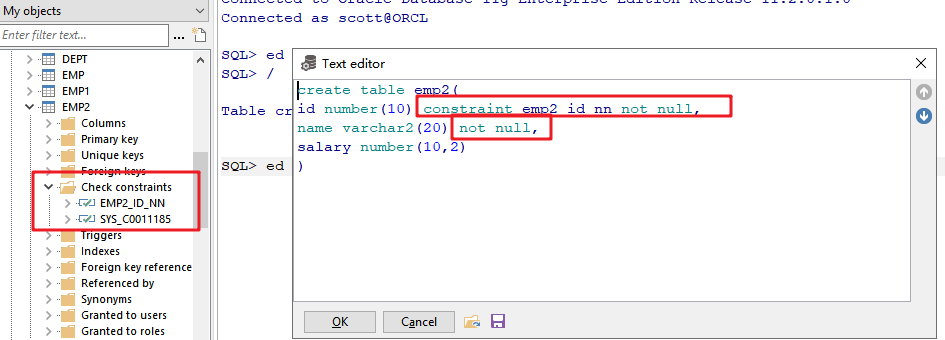
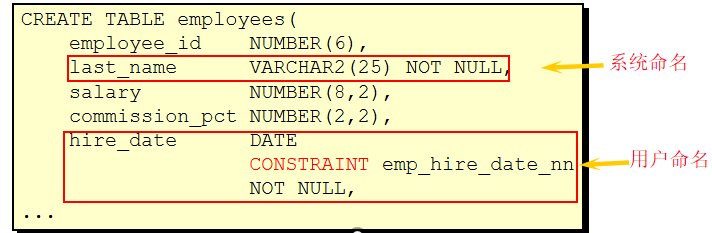
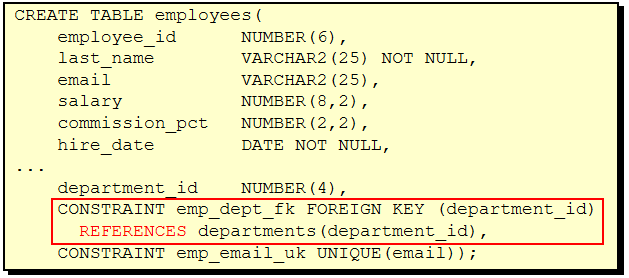
07_创建和管理表
常见的数据库对象
Oracle 数据库中的表
用户定义的表:
用户自己创建并维护的一组表
包含了用户所需的信息
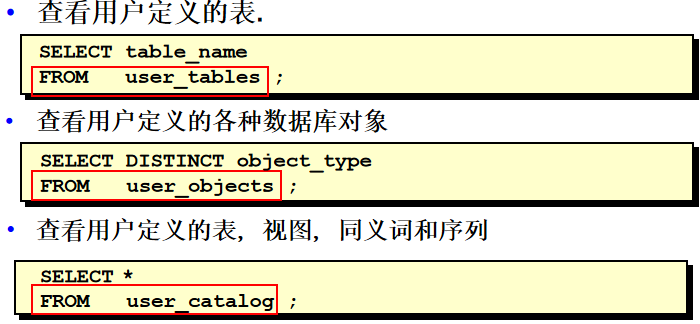
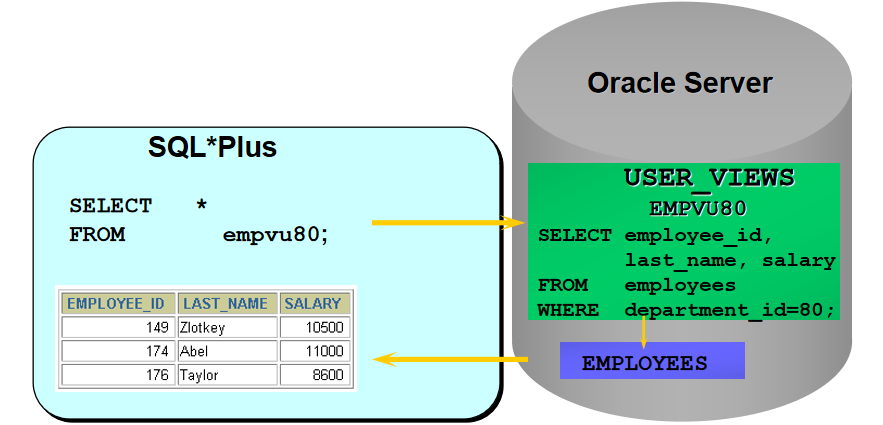
如:SELECT * FROM user_tables;查看用户创建的表
数据字典:
由 Oracle Server 自动创建的一组表
包含数据库信息
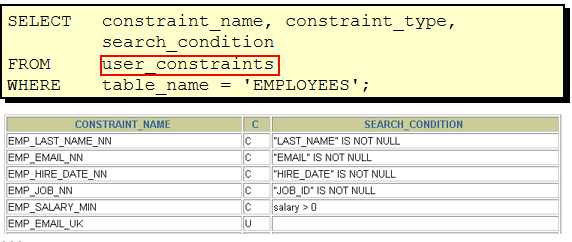
查询数据字典
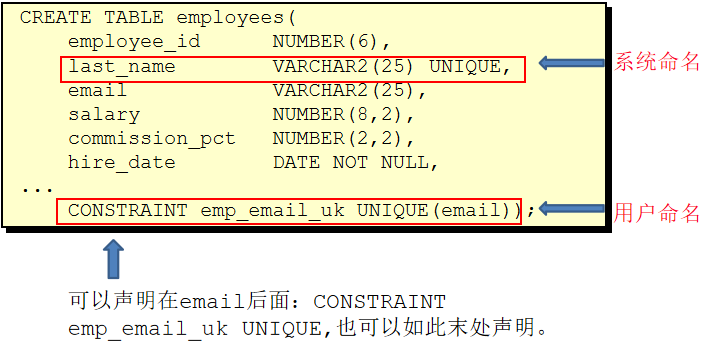
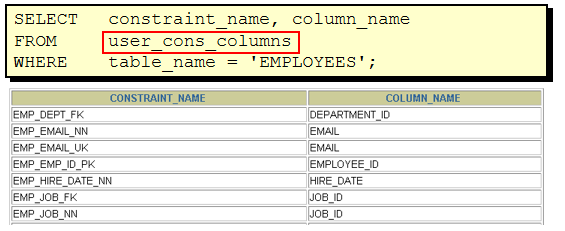
命名规则
表名和列名:
必须以字母开头
必须在 1–30 个字符之间
必须只能包含 A–Z, a–z, 0–9, _, $, 和 #
必须不能和用户定义的其他对象重名
必须不能是Oracle 的保留字
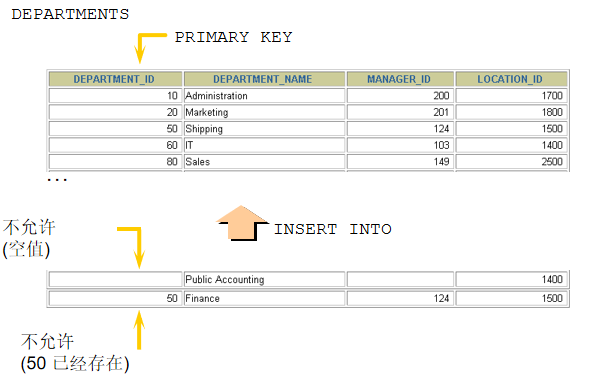
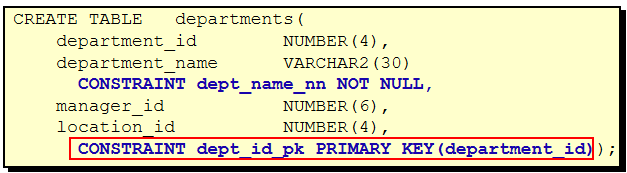
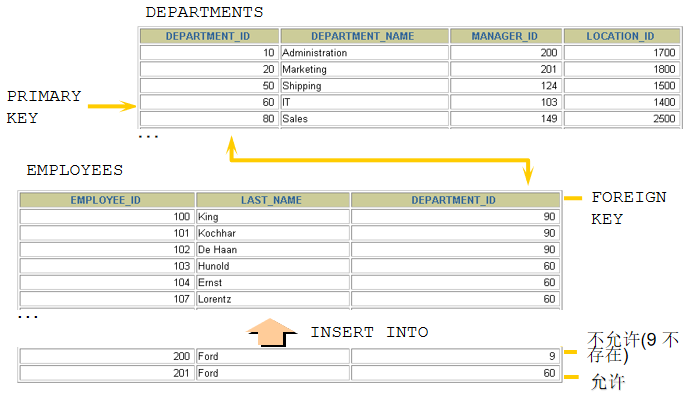
CREATE TABLE 语句
必须具备:
CREATE TABLE权限
存储空间
必须指定:
表名
列名, 数据类型, 尺寸
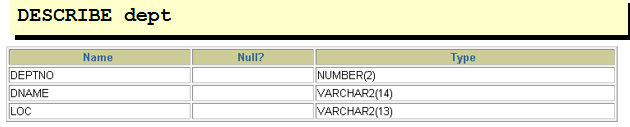
创建表
语法
确认
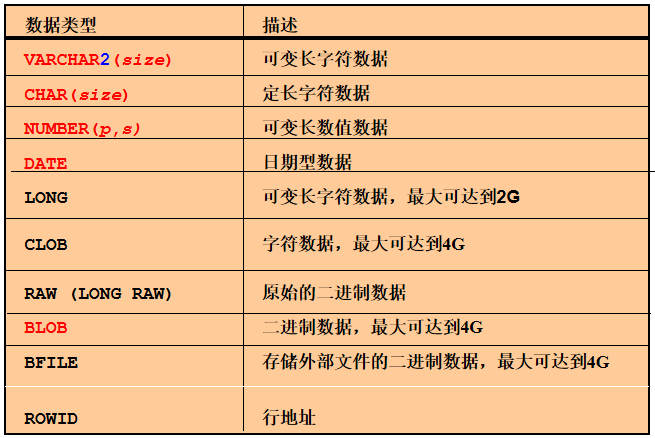
数据类型
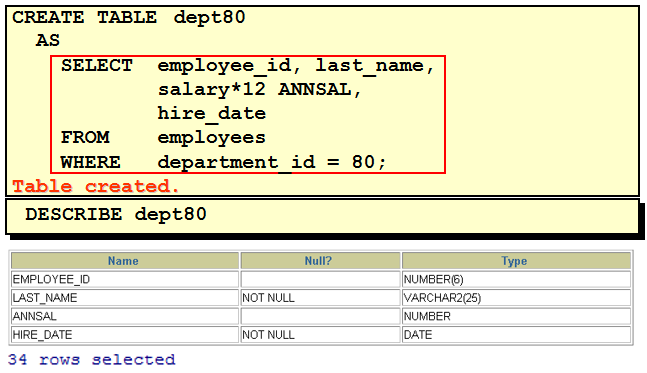
使用子查询创建表
使用 AS subquery 选项,将创建表和插入数据结合起来
指定的列和子查询中的列要一一对应
通过列名和默认值定义列
使用子查询创建表
使用 AS subquery 选项,将创建表和插入数据结合起来
指定的列和子查询中的列要一一对应
通过列名和默认值定义列
复制现有的表:
1 2
create table emp1 as select * from employees; create table emp2 as select * from employees where 1=2; --创建的emp2是空表。
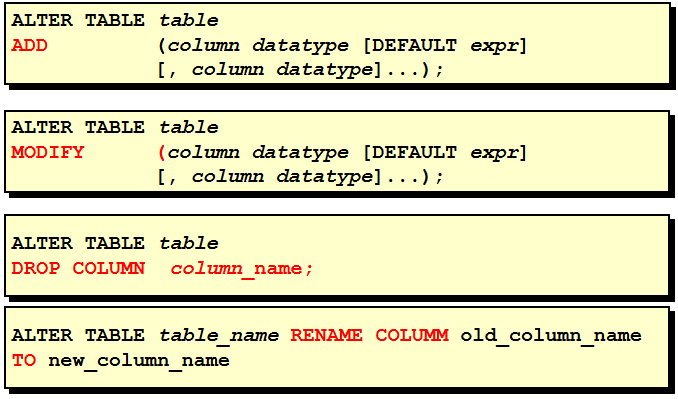
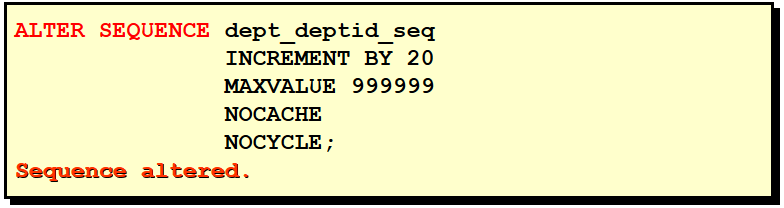
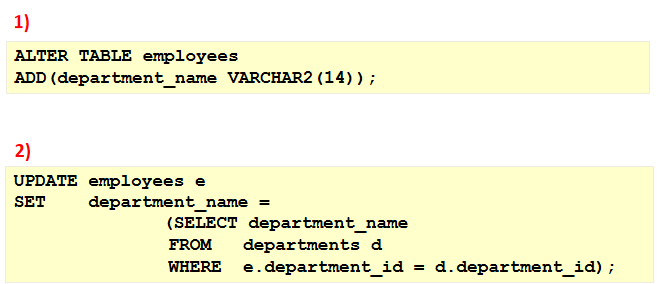
ALTER TABLE 语句
使用 ALTER TABLE 语句可以:
追加新的列
修改现有的列
为新追加的列定义默认值
删除一个列
重命名表的一个列名
使用 ALTER TABLE 语句追加, 修改, 或删除列的语法
ps: 如果有数据的时候,modify修改数据类型不能成功,修改默认值对后续数据生效。
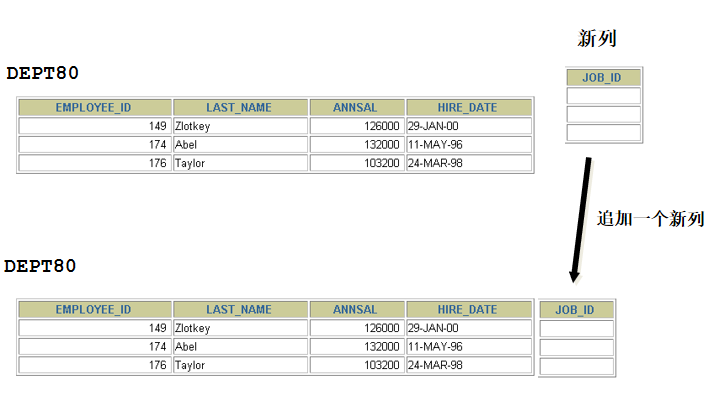
追加一个新列
使用 ADD 子句追加一个新列
新列是表中的最后一列
修改一个列
可以修改列的数据类型, 尺寸和默认值
对默认值的修改只影响今后对表的修改
删除一个列
使用 DROP COLUMN 子句删除不再需要的列.
重命名一个列
使用 RENAME COLUMN [table_name] TO子句重命名列
删除表
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
DROP TABLE 语句不能回滚
清空表
TRUNCATE TABLE 语句:
删除表中所有的数据
释放表的存储空间
TRUNCATE语句
可以使用 DELETE 语句删除数据,可以回滚 对比:
改变对象的名称
执行RENAME语句改变表, 视图, 序列, 或同义词的名称
必须是对象的拥有者
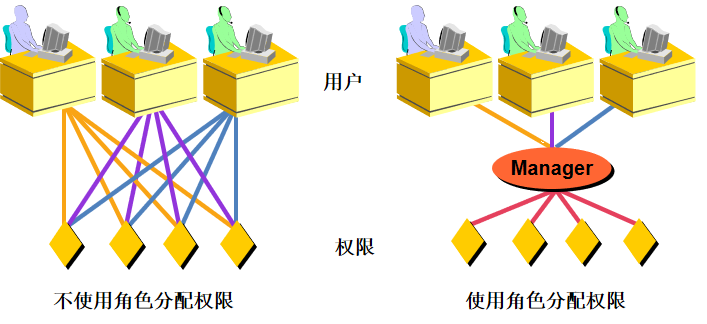
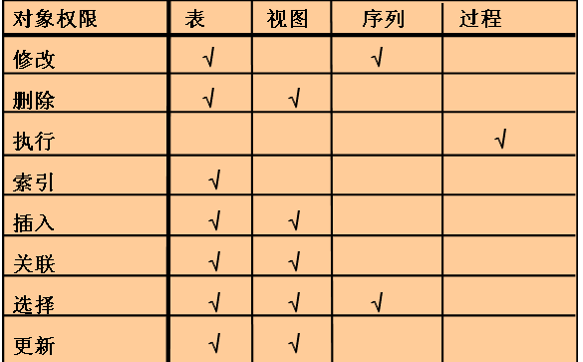
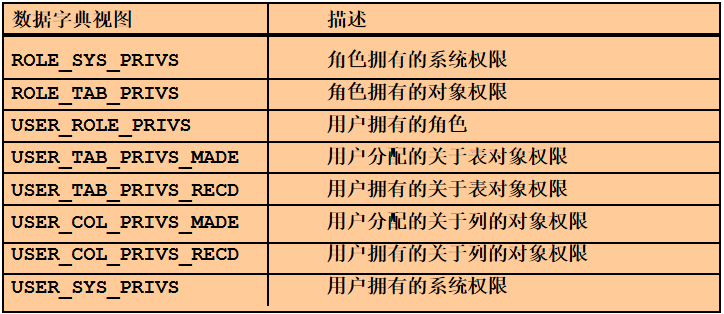
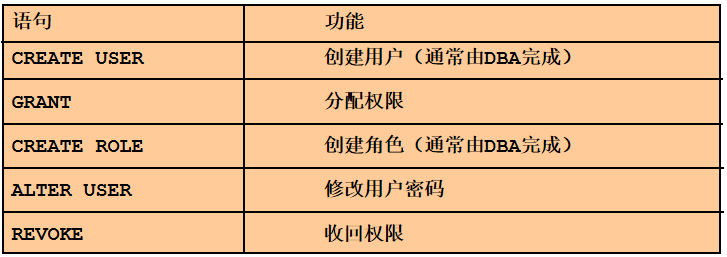
总 结
练习
1
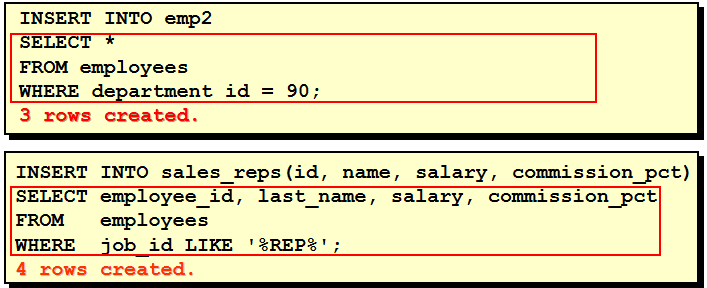
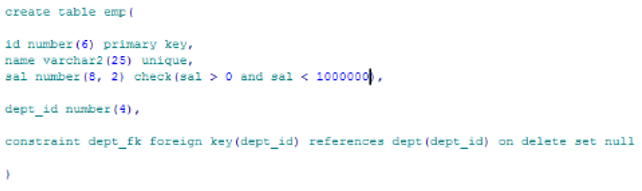
1. 创建表dept1
1 2 3 4 5 6 7 8 9
create table dept1( id number(7), name varchar2(25) ) 2. 将表departments中的数据插入新表dept2中 create table dept2 as select * from departments 3. 创建表emp5
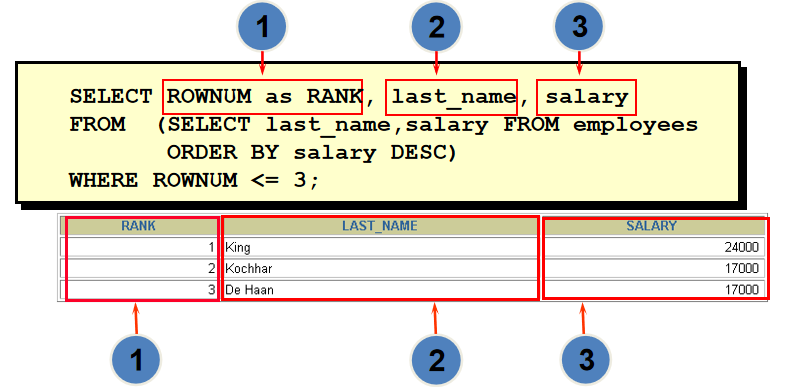
select *from( select rownum rn,employee_id,salary from( select employee_id,salary,last_name from employees order by salary desc ) ) where rn <=50 and rn >40
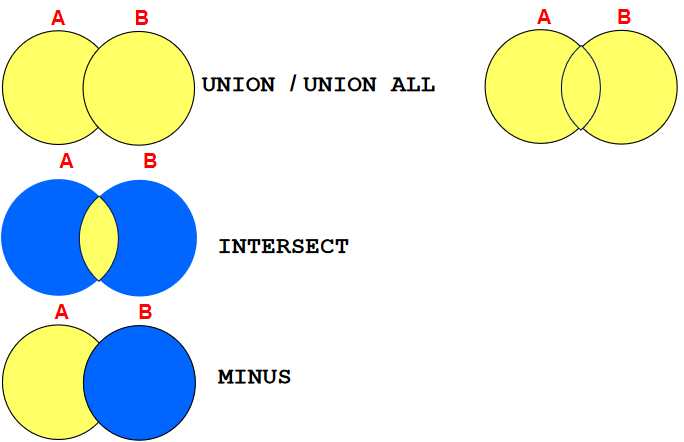
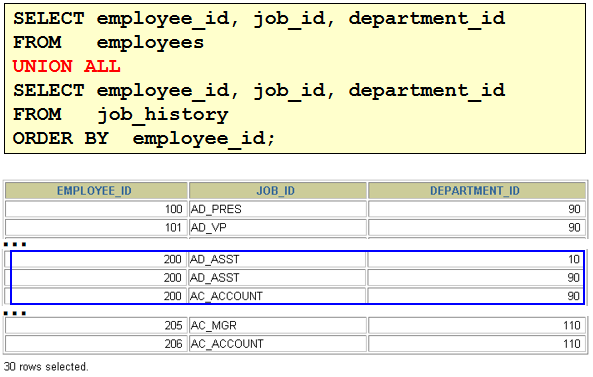
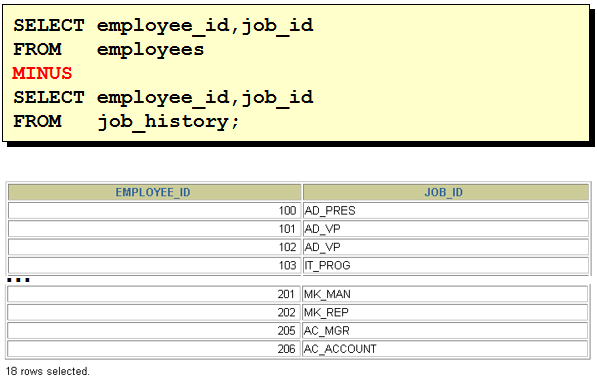
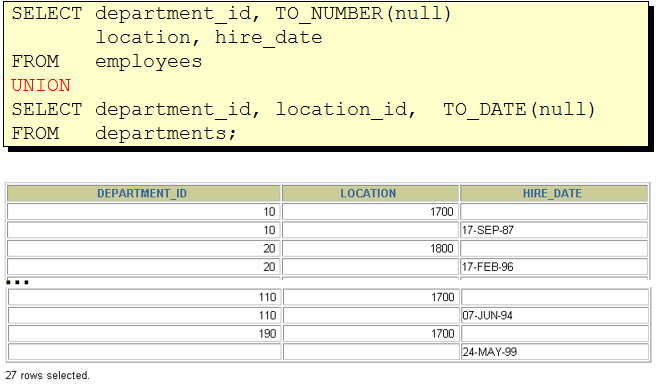
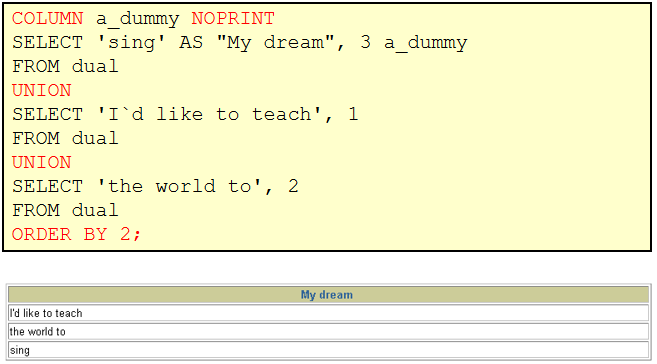
/* select department_id from departments where department_id not in ( select distinct department_id from employees where job_id = 'ST_CLERK' ) */ select department_id from departments minus select department_id from employees where job_id = 'ST_CLERK' 2. 查询10,50,20号部门的job_id,department_id并且department_id按10,50,20的顺序排列
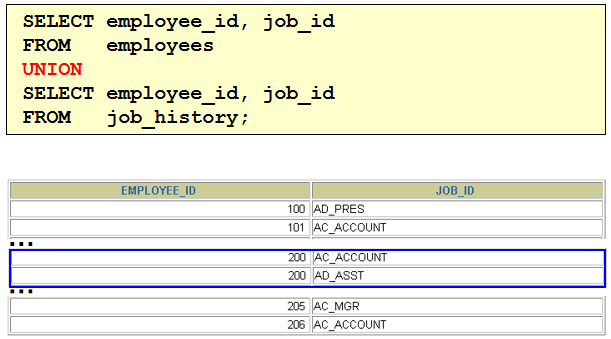
1)column a_dummy noprint; 2) SELECT job_id,department_id,1 a_dummy from employees where department_id = 10 union SELECT job_id,department_id,2 from employees where department_id = 50 union SELECT job_id,department_id,3 from employees where department_id = 20 order by 3 asc > 后面用decode就行了
1. 查询员工的last_name, department_id, salary.其中员工的salary,department_id与有奖金的任何一个员工的salary,department_id相同即可 1. select last_name, department_id, salary 2. from employees 3. where (salary,department_id) in ( 4. select salary,department_id 5. from employees 6. where commission_pct is not null 7. )
declare -- 声明一个记录类型 type emp_record is record( v_sal employees.salary%type, v_email employees.email%type, v_hire_date employees.hire_date%type ); -- 定义一个记录类型的成员变量 v_emp_record emp_record; begin -- sql 语句的操作: select .. into ... from ... where ... select salary,email,hire_date into v_emp_record from employees where employee_id=100; -- 打印 dbms_output.put_line(v_emp_record.v_sal||','||v_emp_record.v_email||','||v_emp_record.v_hire_date); end;
declare -- 声明的变量,类型,游标 v_sal employees.salary%type; v_email employees.email%type; v_hire_date employees.hire_date%type; begin -- 程序的执行部分,类似于java里的main()方法 dbms_output.put_line('helloworld'); -- sql 语句的操作: select .. into ... from ... where ... select salary,email,hire_date into v_sal,v_email,v_hire_date from employees where employee_id=100; -- 打印 dbms_output.put_line(v_sal||','||v_email||','||v_hire_date); --exception -- 针对begin块中出现的异常,提供处理的机制 -- when ... then ... -- when ... then ... end;
declare v_emp employees%rowtype; begin select * into v_emp from employees where employee_id = 200; dbms_output.put_line(v_emp.v_sal ||','||v_emp.v_email ||','||v_emp.v_hire_date); end;
TYPE type_name IS TABLE OF {datatype | {variable | table.column} % type | table%rowtype};
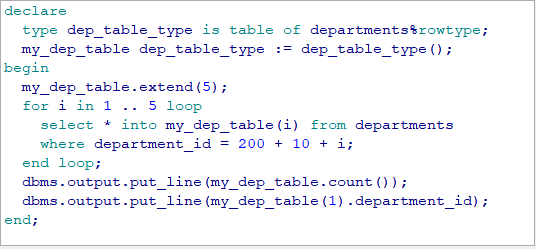
例 4:
1 2 3 4 5 6 7 8 9 10 11 12
declare type dep_table_type is table of departments%rowtype; my_dep_table dep_table_type := dep_table_type(); begin my_dep_table.extend(5); for i in 1 .. 5 loop select * into my_dep_table(i) from departments where department_id = 200 + 10 + i; end loop; dbms_output.put_line(my_dep_table.count()); dbms_output.put_line(my_dep_table(1).department_id); end;
/* 本例子仅是一个简单的删除例子,不是实际应用。 */ DECLARE v_empno number(4) := 8888; BEGIN DELETE FROM emp WHERE empno=v_empno; COMMIT; END;
PL/SQL流程控制语句
介绍 PL/SQL 的流程控制语句, 包括如下三类:
控制语句: IF 语句
循环语句: LOOP 语句, EXIT 语句
顺序语句: GOTO 语句, NULL 语句
条件语句
1 2 3
IF <布尔表达式> THEN PL/SQL 和 SQL 语句; END IF;
1 2 3 4 5
IF <布尔表达式> THEN PL/SQL 和 SQL 语句; ELSE 其它语句; END IF;
1 2 3 4 5 6 7 8 9
IF <布尔表达式> THEN PL/SQL 和 SQL 语句; ELSIF < 其它布尔表达式> THEN 其它语句; ELSIF < 其它布尔表达式> THEN 其它语句; ELSE 其它语句; END IF;
提示: ELSIF不能写成ELSEIF
例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
DECLARE v_empno emp.empno%TYPE; V_salary emp.sal%TYPE; V_comment VARCHAR2(35); BEGIN SELECT sal INTO v_salary FROM emp WHERE empno=v_empno; IF v_salary<1500 THEN V_comment:= 'Fairly less'; ELSIF v_salary <3000 THEN V_comment:= 'A little more'; ELSE V_comment:= 'Lots of salary'; END IF; DBMS_OUTPUT.PUT_LINE(V_comment); END;
CASE 表达式
1 2 3 4 5 6
CASE selector WHEN expression1 THEN result1 WHEN expression2 THEN result2 WHEN expressionN THEN resultN [ ELSE resultN+1] END;
例 2:
1 2 3 4 5 6 7 8 9 10 11 12 13
DECLARE V_grade char(1) ; V_appraisal VARCHAR2(20); BEGIN V_appraisal := CASE v_grade WHEN 'A' THEN 'Excellent' WHEN 'B' THEN 'Very Good' WHEN 'C' THEN 'Good' ELSE 'No such grade' END; DBMS_OUTPUT.PUT_LINE('Grade:'||v_grade||'Appraisal: '|| v_appraisal); END;
循环
1.简单循环
1 2 3 4
LOOP 要执行的语句; EXIT WHEN <条件语句> ; /*条件满足,退出循环语句*/ END LOOP;
例3.
1 2 3 4 5 6 7 8 9
DECLARE int NUMBER(2) :=0; BEGIN LOOP int := int + 1; DBMS_OUTPUT.PUT_LINE('int 的当前值为:'||int); EXIT WHEN int =10; END LOOP; END;
2. WHILE循环(相较1,推荐使用** 2)
1 2 3
WHILE <布尔表达式> LOOP 要执行的语句; END LOOP;
例 4.
1 2 3 4 5 6 7 8
DECLARE x NUMBER :=1; BEGIN WHILE x<=10 LOOP DBMS_OUTPUT.PUT_LINE('X 的当前值为:'||x); x:= x+1; END LOOP; END;
3. 数字式循环
1 2 3
FOR 循环计数器 IN [ REVERSE ] 下限 .. 上限 LOOP 要执行的语句; END LOOP;
每循环一次,循环变量自动加 1;使用关键字 REVERSE,循环变量自动减 1。跟在 IN REVERSE 后面的数字必须是从小到大的顺序,而且必须是整数,不能是变量或表达式。可以使用 EXIT 退出循环。
例5.
1 2 3 4 5
BEGIN FOR int in 1..10 LOOP DBMS_OUTPUT.PUT_LINE('int 的当前值为: '||int); END LOOP; END;
例6.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
CREATE TABLE temp_table(num_col NUMBER); DECLARE V_counter NUMBER := 10; BEGIN INSERT INTO temp_table(num_col) VALUES (v_counter ); FOR v_counter IN 20 .. 25 LOOP INSERT INTO temp_table (num_col ) VALUES ( v_counter ); END LOOP; INSERT INTO temp_table(num_col) VALUES (v_counter ); FOR v_counter IN REVERSE 20 .. 25 LOOP INSERT INTO temp_table (num_col ) VALUES ( v_counter ); END LOOP; END ; DROP TABLE temp_table;
DECLARE V_counter NUMBER := 1; BEGIN LOOP DBMS_OUTPUT.PUT_LINE('V_counter 的当前值为:'||V_counter); V_counter := v_counter + 1; IF v_counter > 10 THEN GOTO l_ENDofLOOP; END IF; END LOOP; <<l_ENDofLOOP>> DBMS_OUTPUT.PUT_LINE('V_counter 的当前值为:'||V_counter); END ;
FOR index_variable IN cursor_name[value[, value]…] LOOP -- 游标数据处理代码 END LOOP;
其中:
index_variable 为游标 FOR 循环语句隐含声明的索引变量,该变量为记录变量,其结构与游标查询语句返回的结构集合的结构相同。在程序中可以通过引用该索引记录变量元素来读取所提取的游标数据,index_variable 中各元素的名称与游标查询语句选择列表中所制定的列名相同。如果在游标查询语句的选择列表中存在计算列,则必须为这些计算列指定别名后才能通过游标FOR循环语句中的索引变量来访问这些列数据。
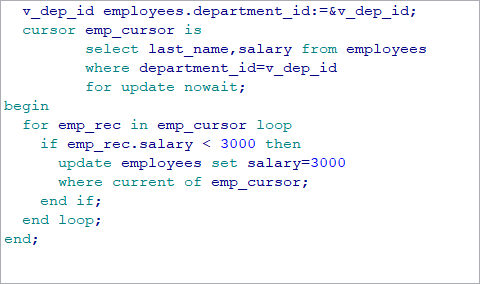
游标修改和删除操作是指在游标定位下,修改或删除表中指定的数据行。这时,要求游标查询语句中必须使用 FOR UPDATE选项,以便在打开游标时锁定游标结果集合在表中对应数据行的所有列和部分列。为了对正在处理(查询)的行不被另外的用户改动,ORACLE 提供一个FOR UPDATE子句来对所选择的行进行锁住。该需求迫使 ORACLE 锁定游标结果集合的行,可以防止其他事务处理更新或删除相同的行,直到您的事务处理提交或回退为止。
1
语法:SELECT . . . FROM … FOR UPDATE [OF column[, column]…] [NOWAIT]
如果另一个会话已对活动集中的行加了锁,那么 SELECT FOR UPDATE 操作一直等待到其它的会话释放这些锁后才继续自己的操作,对于这种情况,当加上 NOWAIT 子句时,如果这些行真的被另一个会话锁定,则 OPEN 立即返回并给出:ORA-0054 :resource busy and acquire with nowait specified.
如果使用FOR UPDATE声明游标,则可在DELETE和UPDATE语句中使用WHERE CURRENT OFcursor_name 子句,修改或删除游标结果集合当前行对应的数据库表中的数据行。
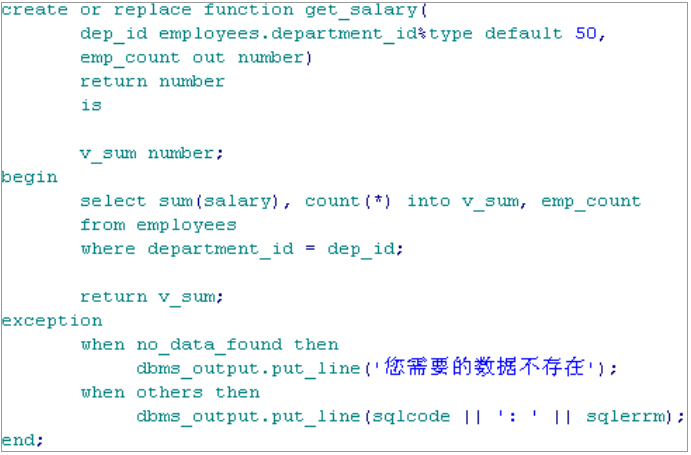
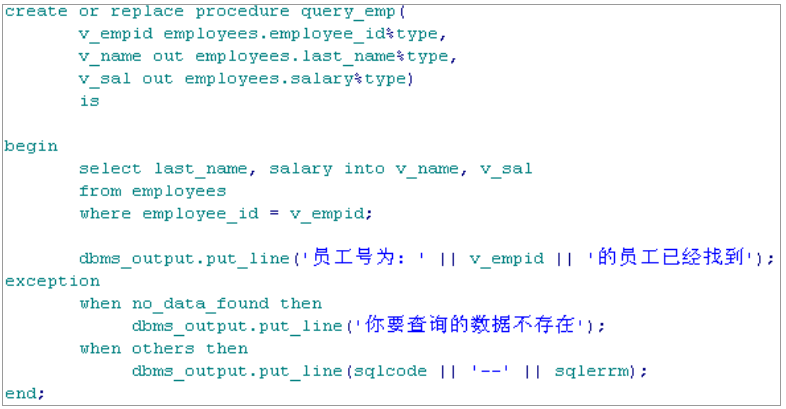
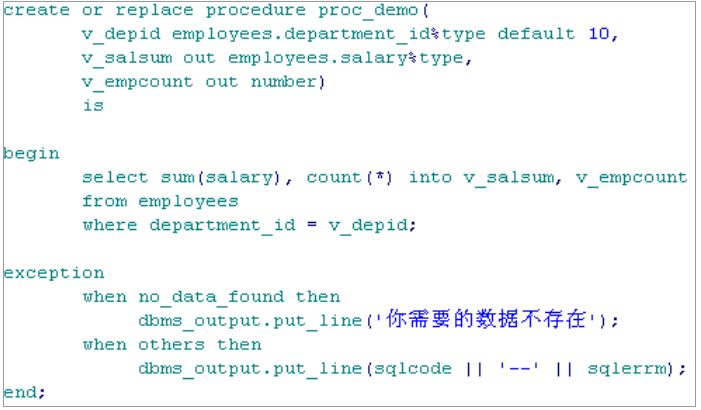
CREATE [OR REPLACE] FUNCTION function_name [ (argment [ { IN | IN OUT }] Type, argment [ { IN | OUT | IN OUT } ] Type ] [ AUTHID DEFINER | CURRENT_USER ] RETURN return_type { IS | AS } <类型.变量的说明> BEGIN FUNCTION_body EXCEPTION 其它语句 END;
说明:
1) OR REPLACE 为可选. 有了它, 可以或者创建一个新函数或者替换相同名字的函数, 而不会出现冲突
2) 函数名后面是一个可选的参数列表, 其中包含 IN, OUT 或 IN OUT 标记. 参数之间用逗号隔开. IN参数标记表示传递给函数的值在该函数执行中不改变**; OUT 标记表示一个值在函数中进行计算并通过该参数传递给调用语句; **IN OUT 标记表示传递给函数的值可以变化并传递给调用语句. 若省略标记, 则参数隐含为 IN。
在 ORACLE SERVER 上建立存储过程,可以被多个应用程序调用,可以向存储过程传递参数,也可以向存储过程传回参数.
创建过程语法:
1 2 3 4 5 6 7 8 9 10 11
CREATE [OR REPLACE] PROCEDURE Procedure_name [ (argment [ { IN | IN OUT }] Type, argment [ { IN | OUT | IN OUT } ] Type ] [ AUTHID DEFINER | CURRENT_USER ] { IS | AS } <类型.变量的说明> BEGIN <执行部分> EXCEPTION <可选的异常错误处理程序> END;
CREATE OR REPLACE PACKAGE demo_pack IS DeptRec dept%ROWTYPE; FUNCTION add_dept( dept_no NUMBER, dept_name VARCHAR2, location VARCHAR2) RETURN NUMBER; FUNCTION remove_dept(dept_no NUMBER) RETURN NUMBER; PROCEDURE query_dept(dept_no IN NUMBER); END demo_pack;
CREATE OR REPLACE PACKAGE BODY demo_pack IS FUNCTION add_dept (dept_no NUMBER, dept_name VARCHAR2, location VARCHAR2) RETURN NUMBER IS empno_remaining EXCEPTION; PRAGMA EXCEPTION_INIT(empno_remaining, -1); /* -1 是违反唯一约束条件的错误代码 */ BEGIN INSERT INTO dept VALUES(dept_no, dept_name, location); IF SQL%FOUND THEN RETURN 1; END IF; EXCEPTION WHEN empno_remaining THEN RETURN 0; WHEN OTHERS THEN RETURN -1; END add_dept;
1 2 3 4 5 6 7 8 9 10 11 12 13 14
FUNCTION remove_dept(dept_no NUMBER) RETURN NUMBER IS BEGIN DELETE FROM dept WHERE deptno=dept_no; IF SQL%FOUND THEN RETURN 1; ELSE RETURN 0; END IF; EXCEPTION WHEN OTHERS THEN RETURN -1; END remove_dept;
1 2 3 4 5 6 7 8 9 10 11 12 13
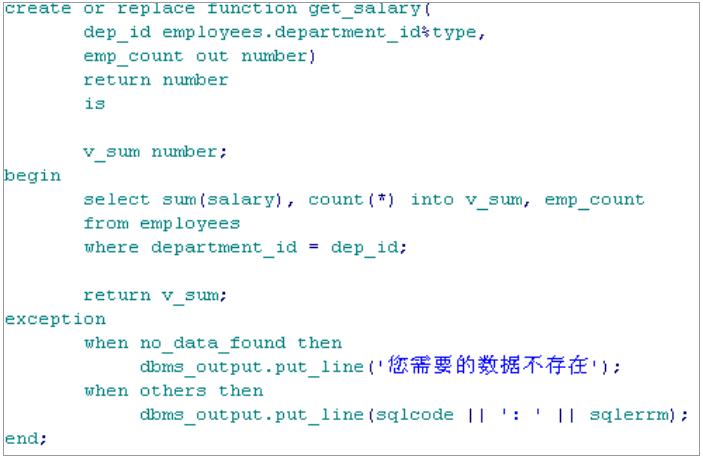
PROCEDURE query_dept (dept_no IN NUMBER) IS BEGIN SELECT * INTO DeptRec FROM dept WHERE deptno=dept_no; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('数据库中没有编码为'||dept_no||'的部门'); WHEN TOO_MANY_ROWS THEN DBMS_OUTPUT.PUT_LINE('程序运行错误!请使用游标'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE(SQLCODE||’----‘||SQLERRM); END query_dept;
DECLARE Var NUMBER; BEGIN Var := demo_pack.add_dept(90,’Administration’, ‘Beijing’); IF var =-1 THEN DBMS_OUTPUT.PUT_LINE(SQLCODE||’----‘||SQLERRM); ELSIF var =0 THEN DBMS_OUTPUT.PUT_LINE(‘该部门记录已经存在!’); ELSE DBMS_OUTPUT.PUT_LINE(‘添加记录成功!’); Demo_pack.query_dept(90); DBMS_OUTPUT.PUT_LINE(demo_pack.DeptRec.deptno||’---‘|| demo_pack.DeptRec.dname||’---‘||demo_pack.DeptRec.loc); var := demo_pack.remove_dept(90); IF var =-1 THEN DBMS_OUTPUT.PUT_LINE(SQLCODE||’----‘||SQLERRM); ELSIF var=0 THEN DBMS_OUTPUT.PUT_LINE(‘该部门记录不存在!’); ELSE DBMS_OUTPUT.PUT_LINE(‘删除记录成功!’); END IF; END IF; END;
例2: 创建包 emp_package
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
CREATE OR REPLACE PACKAGE emp_package IS TYPE emp_table_type IS TABLE OF emp%ROWTYPE INDEX BY BINARY_INTEGER; PROCEDURE read_emp_table (p_emp_table OUT emp_table_type); END emp_package; CREATE OR REPLACE PACKAGE BODY emp_package IS PROCEDURE read_emp_table (p_emp_table OUT emp_table_type) IS I BINARY_INTEGER := 0; BEGIN FOR emp_record IN ( SELECT * FROM emp ) LOOP P_emp_table(i) := emp_record; I := I + 1; END LOOP; END read_emp_table; END emp_package;
1 2 3 4 5 6 7 8
DECLARE E_table emp_package.emp_table_type; BEGIN Emp_package.read_emp_table(e_table); FOR I IN e_table.FIRST .. e_table.LAST LOOP DBMS_OUTPUT.PUT_LINE(e_table(i).empno||’ ‘||e_table(i).ename); END LOOP; END;
例3: 创建包 emp_mgmt:
1 2 3 4 5 6 7 8 9
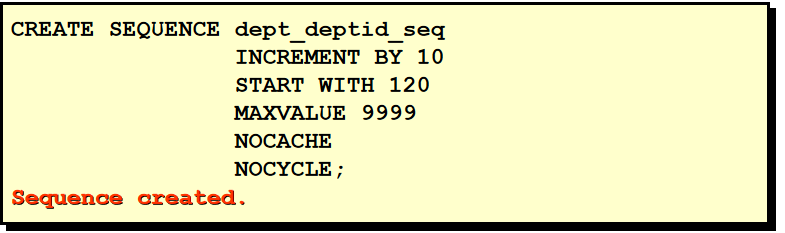
CREATE SEQUENCE empseq START WITH 1000 INCREMENT BY 1 ORDER NOCYCLE;
CREATE SEQUENCE deptseq START WITH 50 INCREMENT BY 10 ORDER NOCYCLE;
1 2 3 4 5 6 7 8 9 10 11 12
CREATE OR REPLACE PACKAGE emp_mgmt AS FUNCTION hire(ename VARCHAR2, job VARCHAR2, mgr NUMBER, sal NUMBER, comm NUMBER, deptno NUMBER) RETURN NUMBER; FUNCTION create_dept(dname VARCHAR2, loc VARCHAR2) RETURN NUMBER; PROCEDURE remove_emp(empno NUMBER); PROCEDURE remove_dept(deptno NUMBER); PROCEDURE increase_sal(empno NUMBER, sal_incr NUMBER); PROCEDURE increase_comm(empno NUMBER, comm_incr NUMBER); END emp_mgmt;
CREATE OR REPLACE PACKAGE BODY emp_mgmt AS tot_emps NUMBER; tot_depts NUMBER; no_sal EXCEPTION; no_comm EXCEPTION; FUNCTION hire(ename VARCHAR2, job VARCHAR2, mgr NUMBER, sal NUMBER, comm NUMBER, deptno NUMBER) RETURN NUMBER IS new_empno NUMBER(4); BEGIN SELECT empseq.NEXTVAL INTO new_empno FROM dual; INSERT INTO emp VALUES (new_empno, ename, job, mgr, sysdate, sal, comm, deptno); tot_emps:=tot_emps+1; RETURN(new_empno); EXCEPTION WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END hire;
1 2 3 4 5 6 7 8 9 10 11 12
FUNCTION create_dept(dname VARCHAR2, loc VARCHAR2) RETURN NUMBER IS new_deptno NUMBER(4); BEGIN SELECT deptseq.NEXTVAL INTO new_deptno FROM dual; INSERT INTO dept VALUES (new_deptno, dname, loc); Tot_depts:=tot_depts; RETURN(new_deptno); EXCEPTION WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END create_dept;
1 2 3 4 5 6 7 8 9 10 11 12 13 14
PROCEDURE remove_emp(empno NUMBER) IS No_result EXCEPTION; BEGIN DELETE FROM emp WHERE emp.empno=remove_emp.empno; IF SQL%NOTFOUND THEN RAISE no_result; END IF; tot_emps:=tot_emps-1; EXCEPTION WHEN no_result THEN DBMS_OUTPUT.PUT_LINE('你需要的数据不存在!'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END remove_emp;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
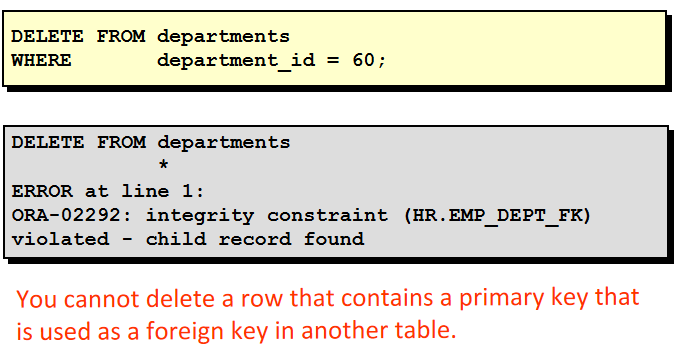
PROCEDURE remove_dept(deptno NUMBER) IS No_result EXCEPTION; e_deptno_remaining EXCEPTION; PRAGMA EXCEPTION_INIT(e_deptno_remaining, -2292); /* -2292 是违反一致性约束的错误代码 */ BEGIN DELETE FROM dept WHERE dept.deptno=remove_dept.deptno; IF SQL%NOTFOUND THEN RAISE no_result; END IF; Tot_depts:=tot_depts-1; EXCEPTION WHEN no_result THEN DBMS_OUTPUT.PUT_LINE('你需要的数据不存在!'); WHEN e_deptno_remaining THEN DBMS_OUTPUT.PUT_LINE('违反数据完整性约束!'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END remove_dept;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
PROCEDURE increase_sal(empno NUMBER, sal_incr NUMBER) IS curr_sal NUMBER(7, 2); BEGIN SELECT sal INTO curr_sal FROM emp WHERE emp.empno=increase_sal.empno; IF curr_sal IS NULL THEN RAISE no_sal; ELSE UPDATE emp SET sal=sal+increase_sal.sal_incr WHERE emp.empno=increase_sal.empno; END IF; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('你需要的数据不存在!'); WHEN no_sal THEN DBMS_OUTPUT.PUT_LINE('此员工的工资不存在!'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END increase_sal;
PROCEDURE increase_comm(empno NUMBER, comm_incr NUMBER) IS curr_comm NUMBER(7,2); BEGIN SELECT comm INTO curr_comm FROM emp WHERE emp.empno=increase_comm.empno; IF curr_comm IS NULL THEN RAISE no_comm; ELSE UPDATE emp SET comm=comm+increase_comm.comm_incr WHERE emp.empno=increase_comm.empno; END IF; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('你需要的数据不存在!'); WHEN no_comm THEN DBMS_OUTPUT.PUT_LINE('此员工的奖金不存在!'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('发生其它错误!'); END increase_comm;
CREATE OR REPLACE PACKAGE CurVarPack AS TYPE DeptCurType IS REF CURSOR RETURN dept%ROWTYPE; --强类型定义 TYPE CurType IS REF CURSOR;-- 弱类型定义
PROCEDURE OpenDeptVar( Cv IN OUT DeptCurType, Choice INTEGER DEFAULT 0, Dept_no NUMBER DEFAULT 50, Dept_name VARCHAR DEFAULT ‘%’); END;
CREATE OR REPLACE PACKAGE BODY CurVarPack AS PROCEDURE OpenDeptvar( Cv IN OUT DeptCurType, Choice INTEGER DEFAULT 0, Dept_no NUMBER DEFAULT 50, Dept_name VARCHAR DEFAULT ‘%’) IS BEGIN IF choice =1 THEN OPEN cv FOR SELECT * FROM dept WHERE deptno <= dept_no; ELSIF choice = 2 THEN OPEN cv FOR SELECT * FROM dept WHERE dname LIKE dept_name; ELSE OPEN cv FOR SELECT * FROM dept; END IF; END OpenDeptvar; END CurVarPack;
--定义一个过程 CREATE OR REPLACE PROCEDURE OpenCurType( Cv IN OUT CurVarPack.CurType, Tab CHAR) AS BEGIN --由于 CurVarPack.CurType 采用弱类型定义 --所以可以使用它定义的游标变量打开不同类型的查询语句 IF tab = ‘D’ THEN OPEN cv FOR SELECT * FROM dept; ELSE OPEN cv FOR SELECT * FROM emp; END IF; END OpenCurType;
--定义一个应用 DECLARE DeptRec Dept%ROWTYPE; EmpRec Emp%ROWTYPE; Cv1 Curvarpack.deptcurtype; Cv2 Curvarpack.curtype; BEGIN DBMS_OUTPUT.PUT_LINE(’游标变量强类型定义应用’); Curvarpack.OpenDeptVar(cv1, 1, 30); FETCH cv1 INTO DeptRec; WHILE cv1%FOUND LOOP DBMS_OUTPUT.PUT_LINE(DeptRec.deptno||’:’||DeptRec.dname); FETCH cv1 INTO DeptRec; END LOOP; CLOSE cv1; DBMS_OUTPUT.PUT_LINE(’游标变量弱类型定义应用’); CurVarPack.OpenDeptvar(cv2, 2, dept_name => ‘A%’); FETCH cv2 INTO DeptRec; WHILE cv2%FOUND LOOP DBMS_OUTPUT.PUT_LINE(DeptRec.deptno||’:’||DeptRec.dname); FETCH cv2 INTO DeptRec; END LOOP; DBMS_OUTPUT.PUT_LINE(’游标变量弱类型定义应用—dept 表’); OpenCurtype(cv2, ‘D’); FETCH cv2 INTO DeptRec; WHILE cv2%FOUND LOOP DBMS_OUTPUT.PUT_LINE(deptrec.deptno||’:’||deptrec.dname); FETCH cv2 INTO deptrec; END LOOP; DBMS_OUTPUT.PUT_LINE(’游标变量弱类型定义应用—emp 表’); OpenCurtype(cv2, ‘E’); FETCH cv2 INTO EmpRec; WHILE cv2%FOUND LOOP DBMS_OUTPUT.PUT_LINE(emprec.empno||’:’||emprec.ename); FETCH cv2 INTO emprec; END LOOP; CLOSE cv2; END;
CREATE OR REPLACE PACKAGE demo_pack1 IS DeptRec dept%ROWTYPE; V_sqlcode NUMBER; V_sqlerr VARCHAR2(2048); FUNCTION query_dept(dept_no IN NUMBER) RETURN INTEGER; FUNCTION query_dept(dept_no IN VARCHAR2) RETURN INTEGER; END demo_pack1; CREATE OR REPLACE PACKAGE BODY demo_pack1 IS FUNCTION check_dept(dept_no NUMBER) RETURN INTEGER IS Flag INTEGER; BEGIN SELECT COUNT(*) INTO flag FROM dept WHERE deptno=dept_no; IF flag > 0 THEN RETURN 1; ELSE RETURN 0; END IF; END check_dept; FUNCTION check_dept(dept_no VARCHAR2) RETURN INTEGER IS Flag INTEGER; BEGIN SELECT COUNT(*) INTO flag FROM dept WHERE deptno=dept_no; IF flag > 0 THEN RETURN 1; ELSE RETURN 0; END IF; END check_dept; FUNCTION query_dept(dept_no IN NUMBER) RETURN INTEGER IS BEGIN IF check_dept(dept_no) =1 THEN SELECT * INTO DeptRec FROM dept WHERE deptno=dept_no; RETURN 1; ELSE RETURN 0; END IF; END query_dept; FUNCTION query_dept(dept_no IN VARCHAR2) RETURN INTEGER IS BEGIN IF check_dept(dept_no) =1 THEN SELECT * INTO DeptRec FROM dept WHERE deptno=dept_no; RETURN 1; ELSE RETURN 0; END IF; END query_dept; END demo_pack1;
删除
可以使用 DROP PACKAGE 命令对不需要的包进行删除,语法如下:
1 2 3 4 5
DROP PACKAGE [BODY] [user.]package_name; DROP PACKAGE demo_pack; DROP PACKAGE demo_pack1; DROP PACKAGE emp_mgmt; DROP PACKAGE emp_package;
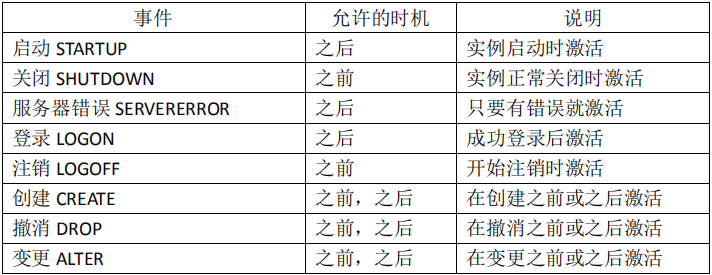
CREATE [OR REPLACE] TRIGGER trigger_name {BEFORE | AFTER } {INSERT | DELETE | UPDATE [OF column [, column …]]} ON [schema.] table_name [FOR EACH ROW ] [WHEN condition] trigger_body;
其中:
BEFORE 和 AFTER 指出触发器的触发时序分别为前触发和后触发方式,前触发是在执行触发事件之前触发当前所创建的触发器,后触发是在执行触发事件之后触发当前所创建的触发器。
FOR EACH ROW 选项说明触发器为行触发器。行触发器和语句触发器的区别表现在:行触发器要求当一个 DML 语句操做影响数据库中的多行数据时,对于其中的每个数据行,只要它们符合触发约束条件,均激活一次触发器;而语句触发器将整个语句操作作为触发事件,当它符合约束条件时,激活一次触发器。当省略** FOR EACH ROW选项时,BEFORE 和 AFTER 触发器为语句触发器,而 INSTEAD OF 触发器则为行触发器。
WHEN 子句说明触发约束条件。Condition 为一个逻辑表达时,其中必须包含相关名称,而不能包含查询语句,也不能调用 PL/SQL 函数。WHEN 子句指定的触发约束条件只能用在 BEFORE 和 AFTER 行触发器中,不能用在 INSTEAD OF 行触发器和其它类型的触发器中。
BEFORE INSERT BEFORE INSERT FOR EACH ROW AFTER INSERT AFTER INSERT FOR EACH ROW BEFORE UPDATE BEFORE UPDATE FOR EACH ROW AFTER UPDATE AFTER UPDATE FOR EACH ROW BEFORE DELETE BEFORE DELETE FOR EACH ROW AFTER DELETE AFTER DELETE FOR EACH ROW
触发器触发次序
执行 BEFORE 语句级触发器;
对与受语句影响的每一行:
执行BEFORE行级触发器
执行DML语句
执行AFTER行级触发器
执行 AFTER 语句级触发器
创建DML触发器
触发器名可以和表或过程有相同的名字,但在一个模式中触发器名不能相同。
触发器的限制
CREATE TRIGGER语句文本的字符长度不能超过32KB;
触发器体内的SELECT语句只能为SELECT … INTO …结构,或者为定义游标所使用的SELECT语句。
CREATE [OR REPLACE] TRIGGER trigger_name INSTEAD OF {INSERT | DELETE | UPDATE [OF column [, column …]]} ON [schema.] view_name [FOR EACH ROW ] [WHEN condition] trigger_body;
其中:
BEFORE 和 AFTER 指出触发器的触发时序分别为前触发和后触发方式,前触发是在执行触发事件之前触发当前所创建的触发器,后触发是在执行触发事件之后触发当前所创建的触发器。
INSTEAD OF 选项使 ORACLE 激活触发器,而不执行触发事件。只能对视图和对象视图建立INSTEAD OF触发器**,而不能对表、模式和数据库建立 INSTEAD OF 触发器。
FOR EACH ROW 选项说明触发器为行触发器。行触发器和语句触发器的区别表现在:行触发器要求当一个 DML 语句操做影响数据库中的多行数据时,对于其中的每个数据行,只要它们符合触发约束条件,均激活一次触发器;而语句触发器将整个语句操作作为触发事件,当它符合约束条件时,激活一次触发器。当省略 FOR EACH ROW 选项时,BEFORE 和 AFTER 触发器为语句触发器,而 INSTEAD OF 触发器则为行触发器。
WHEN 子句说明触发约束条件。Condition 为一个逻辑表达时,其中必须包含相关名称,而不能包含查询语句,也不能调用 PL/SQL 函数。WHEN 子句指定的触发约束条件只能用在 BEFORE 和 AFTER 行触发器中,不能用在 INSTEAD OF 行触发器和其它类型的触发器中。
CREATE OR REPLACE TRIGGER emp_view_delete INSTEAD OF DELETE ON emp_view FOR EACH ROW BEGIN DELETE FROM emp WHERE deptno= :old.deptno; END emp_view_delete; DELETE FROM emp_view WHERE deptno=10; DROP TRIGGER emp_view_delete; DROP VIEW emp_view;
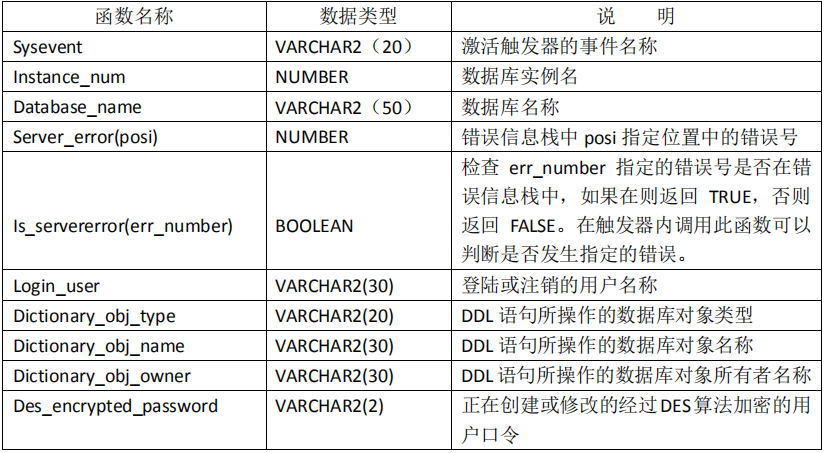
创建系统事件触发器
ORACLE 提供的系统事件触发器可以在 DDL 或数据库系统上被触发。DDL 指的是数据定义语言,如CREATE 、ALTER 及 DROP 等。而数据库系统事件包括数据库服务器的启动或关闭,用户的登录与退出、数据库服务错误等。创建系统触发器的语法如下:
创建触发器的一般语法是:**
1 2 3 4 5 6
CREATE OR REPLACE TRIGGER [sachema.] trigger_name {BEFORE|AFTER} {ddl_event_list | database_event_list} ON { DATABASE | [schema.] SCHEMA } [WHEN_clause] trigger_body;
其中: ddl_event_list:一个或多个 DDL 事件,事件间用 OR 分开;
database_event_list:一个或多个数据库事件,事件间用 OR 分开;
系统事件触发器既可以建立在一个模式上,又可以建立在整个数据库上。当建立在模式(SCHEMA)之上时,只有模式所指定用户的 DDL 操作和它们所导致的错误才激活触发器, 默认时为当前用户模式。当建立在数据库(DATABASE)之上时,该数据库所有用户的 DDL 操作和他们所导致的错误,以及数据库的启动和关闭均可激活触发器。要在数据库之上建立触发器时,要求用户具有 ADMINISTER DATABASE TRIGGER 权限。
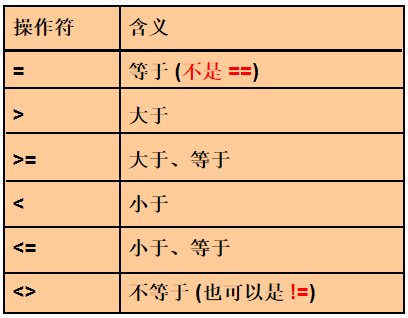
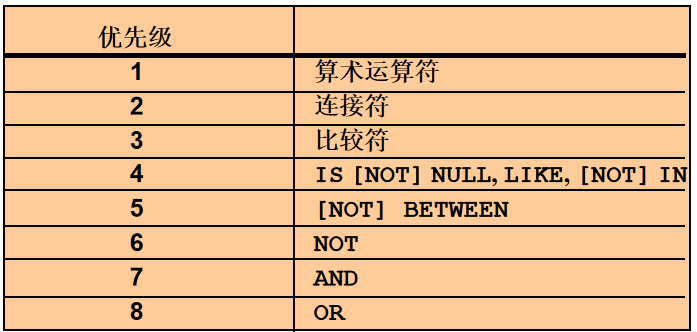
/*************************************************************************************************/ 第 2 章 过滤和排序数据 /*************************************************************************************************/ 7. WHERE 子句紧随 FROM 子句
8. 查询 last_name 为 'King' 的员工信息
错误1: King 没有加上 单引号
select first_name, last_name from employees where last_name = King
错误2: 在单引号中的值区分大小写
select first_name, last_name from employees where last_name = 'king'
正确
select first_name, last_name from employees where last_name = 'King'
9. 查询 1998-4-24 来公司的员工有哪些?
注意: 日期必须要放在单引号中, 且必须是指定的格式
select last_name, hire_date from employees where hire_date = '24-4月-1998'
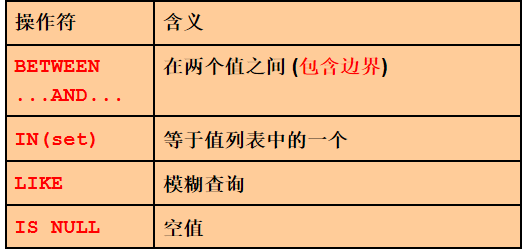
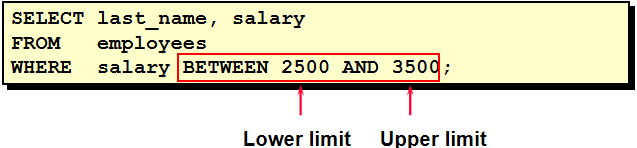
10. 查询工资在 5000 -- 10000 之间的员工信息. 1). 使用 AND select * from employees where salary >= 5000 and salary <= 10000 2). 使用 BETWEEN .. AND .., 注意: 包含边界!! select * from employees where salary between 5000 and 10000
11. 查询工资等于 6000, 7000, 8000, 9000, 10000 的员工信息 1). 使用 OR select * from employees where salary = 6000 or salary = 7000 or salary = 8000 or salary = 9000 or salary = 10000 2). 使用 IN select * from employees where salary in (6000, 7000, 8000, 9000, 10000)
12. 查询 LAST_NAME 中有 'o' 字符的所有员工信息. select * from employees where last_name like '%o%' 13. 查询 LAST_NAME 中第二个字符是 'o' 的所有员工信息.
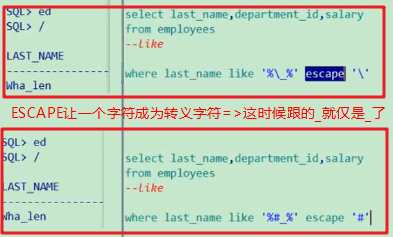
select * from employees where last_name like '_o%' 14. 查询 LAST_NAME 中含有 '_' 字符的所有员工信息 1). 准备工作: update employees set last_name = 'Jones_Tom' where employee_id = 195 2). 使用 escape 说明转义字符. select * from employees where last_name like '%\_%' escape '\'
15. 查询 COMMISSION_PCT 字段为空的所有员工信息 select last_name, commission_pct from employees where commission_pct is null 16. 查询 COMMISSION_PCT 字段不为空的所有员工信息 select last_name, commission_pct from employees where commission_pct is not null
17. ORDER BY: 1). 若查询中有表达式运算, 一般使用别名排序 2). 按多个列排序: 先按第一列排序, 若第一列中有相同的, 再按第二列排序. 格式: ORDER BY 一级排序列 ASC/DESC,二级排序列 ASC/DESC;
--使用 case-when-then-else-end select last_name, department_id, salary, case department_id when 10 then salary * 1.1 when 20 then salary * 1.2 when 30 then salary * 1.3 end new_sal from employees where department_id in (10, 20, 30)
--使用 decode select last_name, department_id, salary, decode(department_id, 10, salary * 1.1, 20, salary * 1.2, 30, salary * 1.3 ) new_sal from employees where department_id in (10, 20, 30)
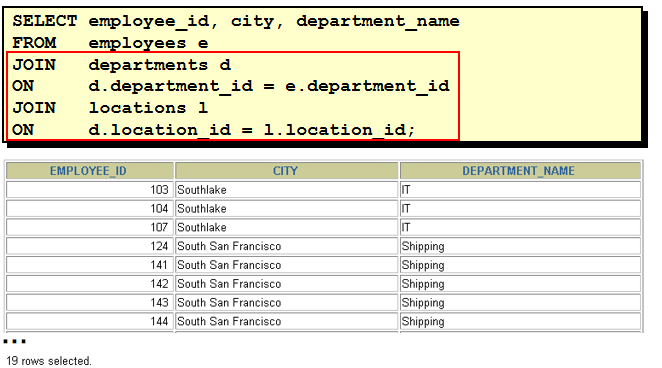
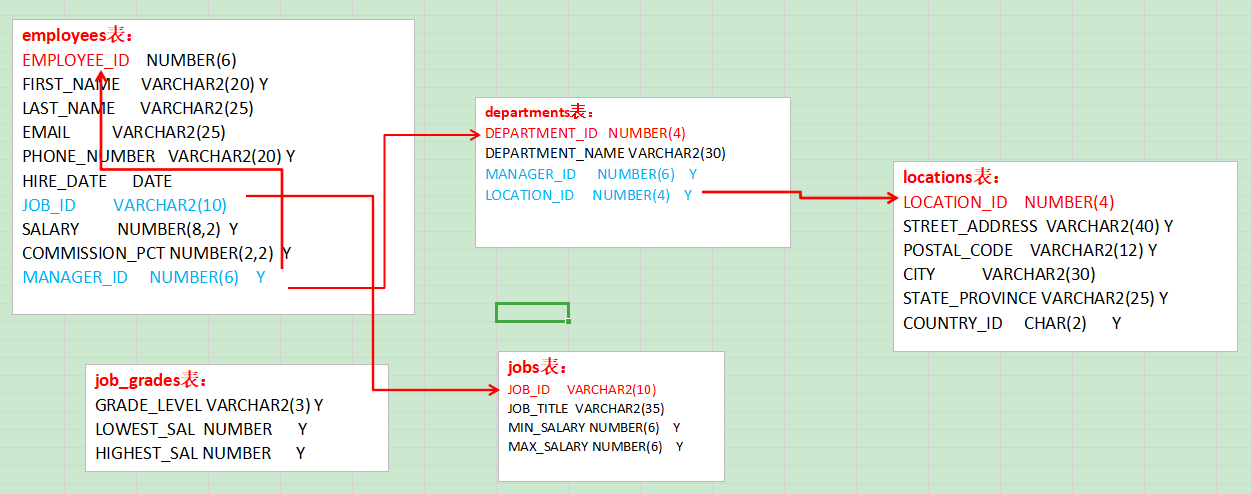
select last_name, department_name, city from departments d, employees e, locations l where d.department_id = e.department_id and d.location_id = l.location_id
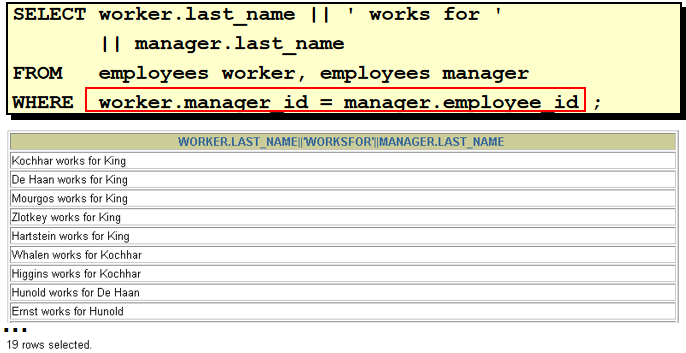
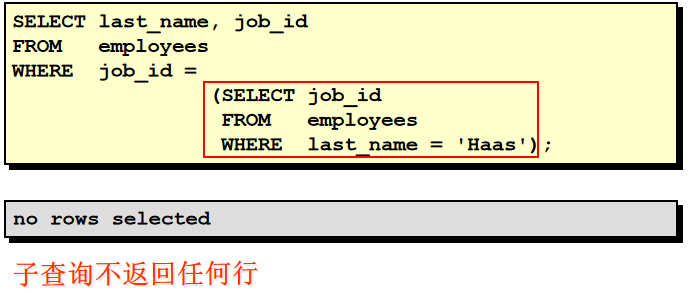
28. 查询出 last_name 为 'Chen' 的 manager 的信息. (员工的 manager_id 是某员工的 employee_id) 0). 例如: 老张的员工号为: "1001", 我的员工号为: "1002", 我的 manager_id 为 "1001" --- 我的 manager 是"老张" 1). 通过两条 sql 查询: select manager_id from employees where lower(last_name) = 'chen' --返回的结果为 108 select * from employees where employee_id = 108 2). 通过一条 sql 查询(自连接): select m.* from employees e, employees m where e.manager_id = m.employee_id and e.last_name = 'Chen' 3). 通过一条 sql 查询(子查询): select * from employees where employee_id = ( select manager_id from employees where last_name = 'Chen' )
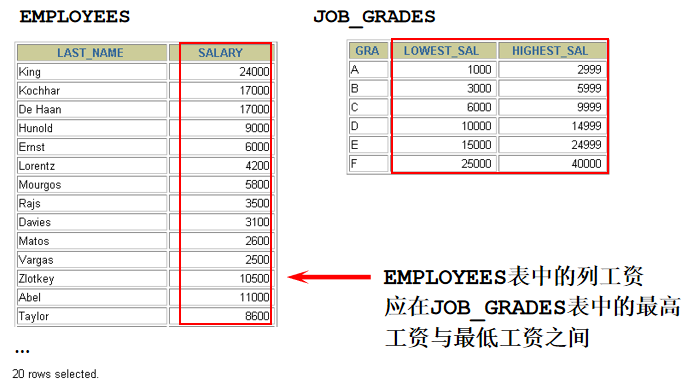
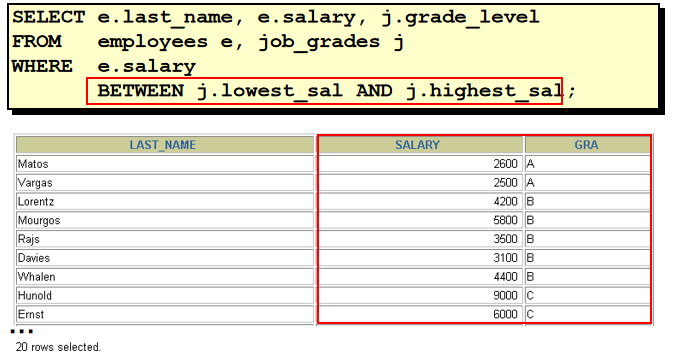
select last_name, salary, grade_level, lowest_sal, highest_sal from employees e, job_grades j where e.salary >= j.lowest_sal and e.salary <= j.highest_sal 30. 左外连接和右外连接
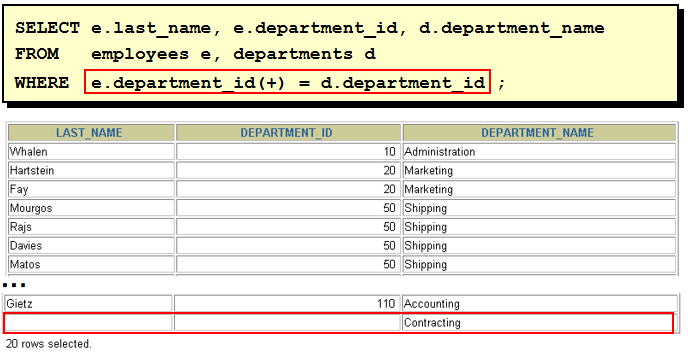
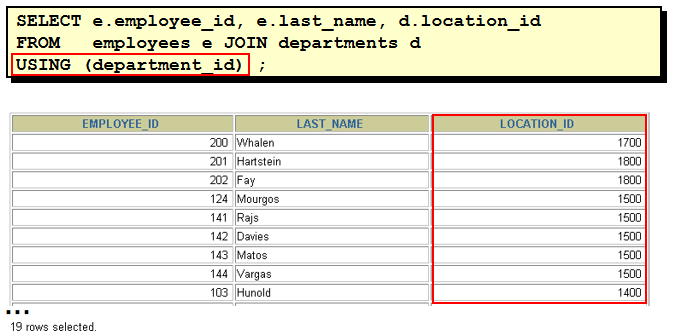
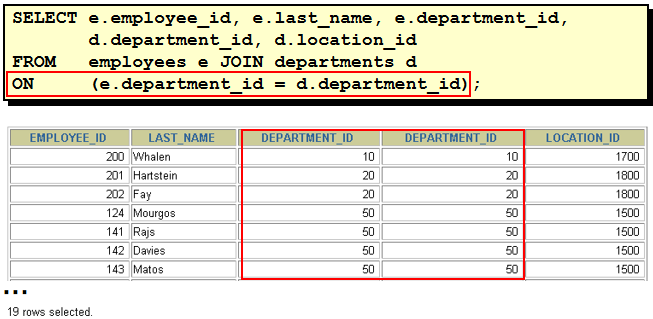
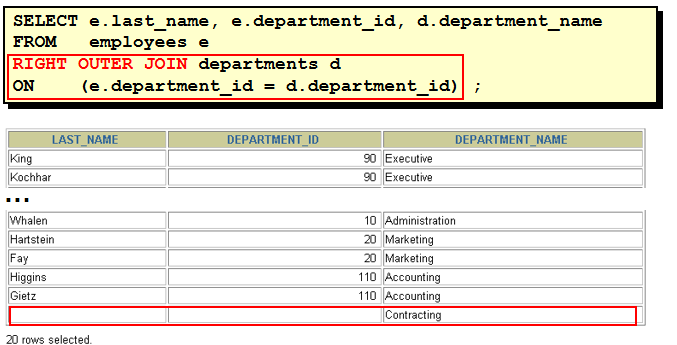
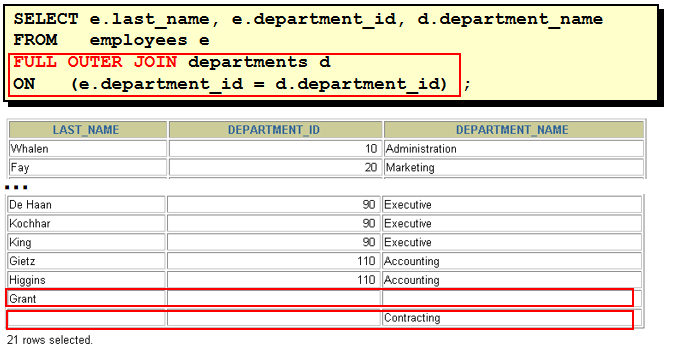
select last_name, e.department_id, department_name from employees e, departments d where e.department_id = d.department_id(+) select last_name, d.department_id, department_name from employees e, departments d where e.department_id(+) = d.department_id 理解 "(+)" 的位置: 以左外连接为例, 因为左表需要返回更多的记录, 右表就需要 "加上" 更多的记录, 所以在右表的链接条件上加上 "(+)" 注意: 1). 两边都加上 "(+)" 符号, 会发生语法错误! 2). 这种语法为 Oracle 所独有, 不能在其它数据库中使用. 31. SQL 99 连接 Employees 表和 Departments 表 1). select * from employees join departments using(department_id) 缺点: 要求两个表中必须有一样的列名. 2). select * from employees e join departments d on e.department_id = d.department_id 3).多表连接 select e.last_name, d.department_name, l.city from employees e join departments d on e.department_id = d.department_id join locations l on d.location_id = l.location_id 32. SQL 99 的左外连接, 右外连接, 满外连接 1). select last_name, department_name from employees e left outer join departments d on e.department_id = d.department_id 2). select last_name, department_name from employees e right join departments d on e.department_id = d.department_id 3). select last_name, department_name from employees e full join departments d on e.department_id = d.department_id
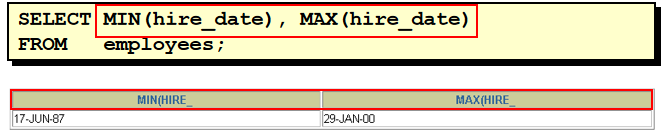
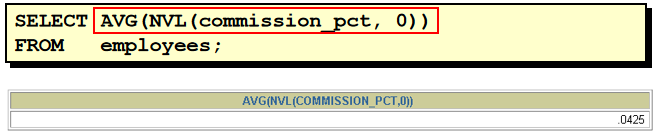
select count(distinct department_id) from employees 34. 查询全公司奖金基数的平均值(没有奖金的人按 0 计算)
select avg(nvl(commission_pct, 0)) from employees 35. 查询各个部门的平均工资
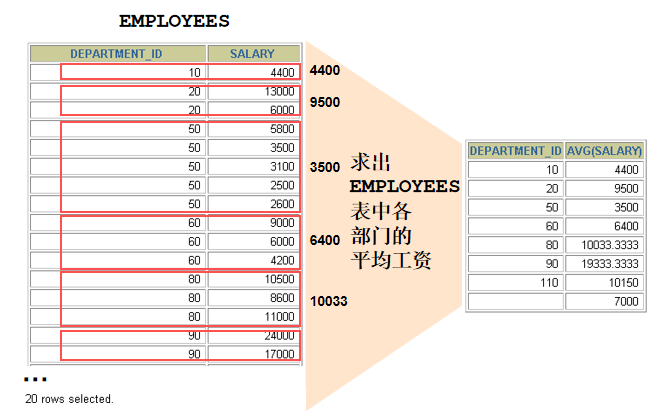
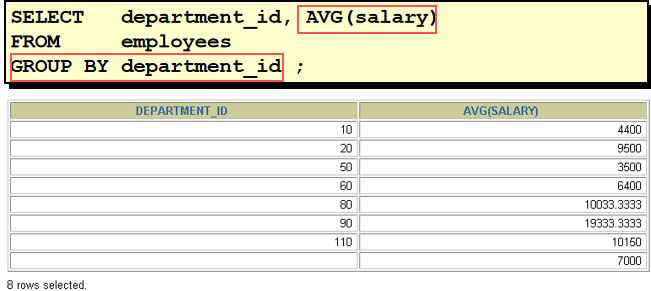
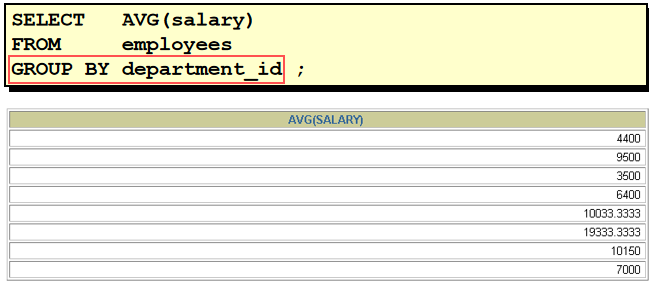
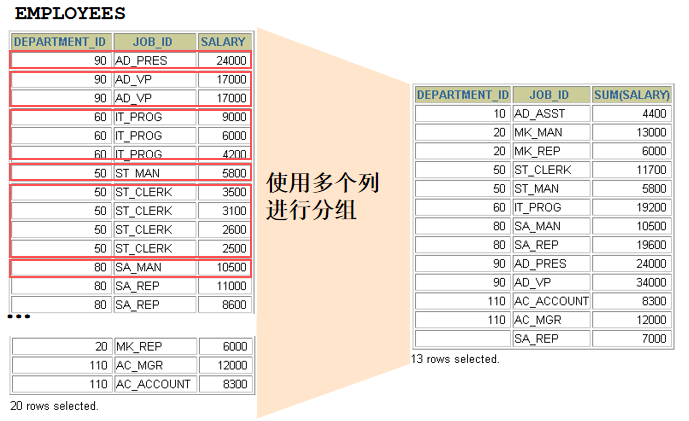
--错误: avg(salary) 返回公司平均工资, 只有一个值; 而 department_id 有多个值, 无法匹配返回 select department_id, avg(salary) from employees **在 SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中 --正确: 按 department_id 进行分组 select department_id, avg(salary) from employees group by department_id 36. Toronto 这个城市的员工的平均工资 SELECT avg(salary) FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id WHERE city = 'Toronto'
37. (有员工的城市)各个城市的平均工资 SELECT city, avg(salary) FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id GROUP BY city
38. 查询平均工资高于 8000 的部门 id 和它的平均工资.
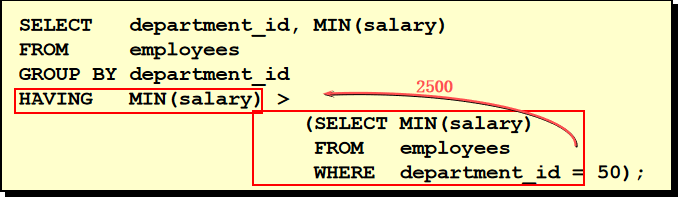
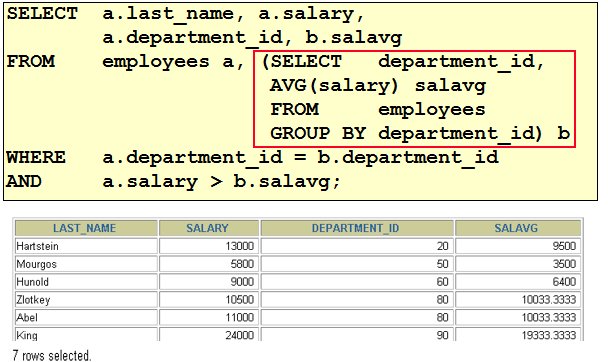
SELECT department_id, avg(salary) FROM employees e GROUP BY department_id HAVING avg(salary) > 8000 39. 查询平均工资高于 6000 的 job_title 有哪些
SELECT job_title, avg(salary) FROM employees e join jobs j ON e.job_id = j.job_id GROUP BY job_title HAVING avg(salary) > 6000
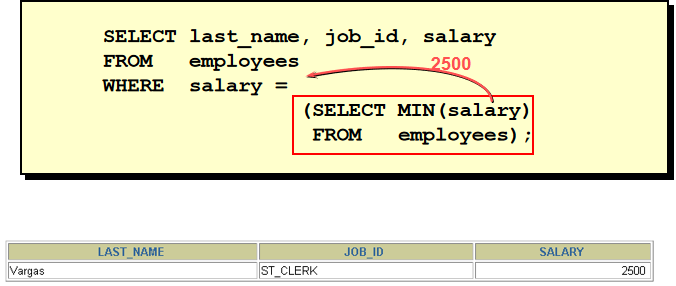
SELECT last_name, salary FROM employees WHERE salary = ( SELECT min(salary) FROM employees )
42. 查询平均工资最低的部门信息 SELECT * FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) = ( SELECT min(avg(salary)) FROM employees GROUP BY department_id ) )
43. 查询平均工资最低的部门信息和该部门的平均工资
select d.*, (select avg(salary) from employees where department_id = d.department_id) from departments d where d.department_id = ( SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) = ( SELECT min(avg(salary)) FROM employees GROUP BY department_id ) ) 44. 查询平均工资最高的 job 信息
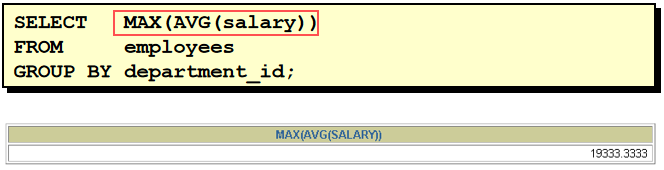
1). 按 job_id 分组, 查询最高的平均工资 SELECT max(avg(salary)) FROM employees GROUP BY job_id 2). 查询出平均工资等于 1) 的 job_id SELECT job_id FROM employees GROUP BY job_id HAVING avg(salary) = ( SELECT max(avg(salary)) FROM employees GROUP BY job_id ) 3). 查询出 2) 对应的 job 信息 SELECT * FROM jobs WHERE job_id = ( SELECT job_id FROM employees GROUP BY job_id HAVING avg(salary) = ( SELECT max(avg(salary)) FROM employees GROUP BY job_id ) )
45. 查询平均工资高于公司平均工资的部门有哪些?
1). 查询出公司的平均工资 SELECT avg(salary) FROM employees 2). 查询平均工资高于 1) 的部门 ID SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) > ( SELECT avg(salary) FROM employees )
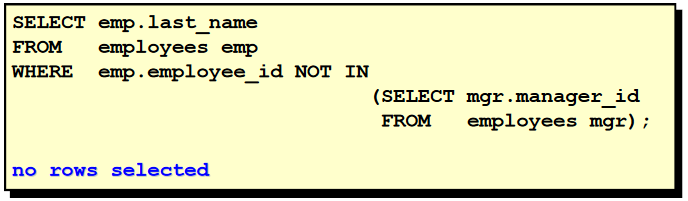
46. 查询出公司中所有 manager 的详细信息. 1). 查询出所有的 manager_id SELECT distinct manager_id FROM employeess 2). 查询出 employee_id 为 1) 查询结果的那些员工的信息 SELECT employee_id, last_name FROM employees WHERE employee_id in ( SELECT distinct manager_id FROM employees ) 47. 各个部门中 最高工资中最低的那个部门的 最低工资是多少 1). 查询出各个部门的最高工资 SELECT max(salary) FROM employees GROUP BY department_id 2). 查询出 1) 对应的查询结果的最低值: 各个部门中最低的最高工资(无法查询对应的 department_id) SELECT min(max(salary)) FROM employees GROUP BY department_id 3). 查询出 2) 所对应的部门 id 是多少: 各个部门中最高工资等于 2) 的那个部门的 id SELECT department_id FROM employees GROUP BY department_id HAVING max(salary) = ( SELECT min(max(salary)) FROM employees GROUP BY department_id ) 4). 查询出 3) 所在部门的最低工资 SELECT min(salary) FROM employees WHERE department_id = ( SELECT department_id FROM employees GROUP BY department_id HAVING max(salary) = ( SELECT min(max(salary)) FROM employees GROUP BY department_id ) )
48. 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary 1). 各个部门中, 查询平均工资最高的平均工资是多少 SELECT max(avg(salary)) FROM employees GROUP BY department_id 2). 各个部门中, 平均工资等于 1) 的那个部门的部门号是多少 SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) = ( SELECT max(avg(salary)) FROM employees GROUP BY department_id ) 3). 查询出 2) 对应的部门的 manager_id SELECT manager_id FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) = ( SELECT max(avg(salary)) FROM employees GROUP BY department_id ) ) 4). 查询出 employee_id 为 3) 查询的 manager_id 的员工的 last_name, department_id, email, salary SELECT last_name, department_id, email, salary FROM employees WHERE employee_id = ( SELECT manager_id FROM departments WHERE department_id = ( SELECT department_id FROM employees GROUP BY department_id HAVING avg(salary) = ( SELECT max(avg(salary)) FROM employees GROUP BY department_id ) ) )
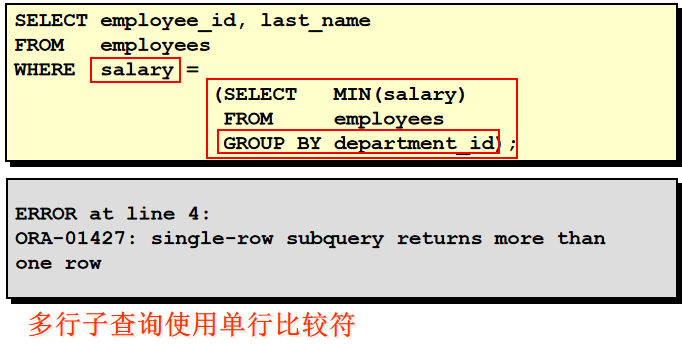
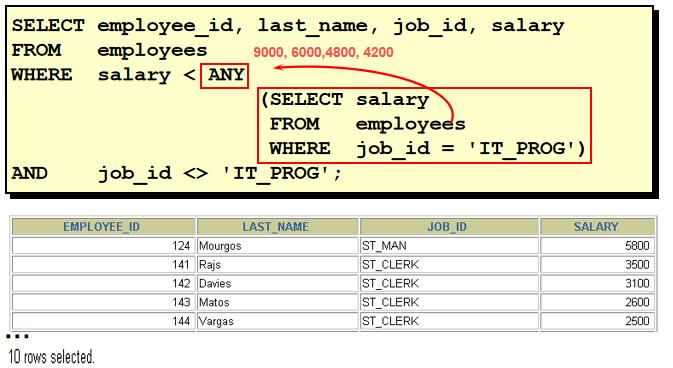
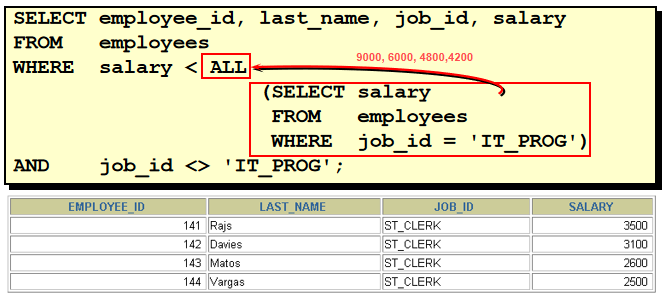
49. 查询 1999 年来公司的人所有员工的最高工资的那个员工的信息. 1). 查询出 1999 年来公司的所有的员工的 salary SELECT salary FROM employees WHERE to_char(hire_date, 'yyyy') = '1999' 2). 查询出 1) 对应的结果的最大值 SELECT max(salary) FROM employees WHERE to_char(hire_date, 'yyyy') = '1999' 3). 查询工资等于 2) 对应的结果且 1999 年入职的员工信息 SELECT * FROM employees WHERE to_char(hire_date, 'yyyy') = '1999' AND salary = ( SELECT max(salary) FROM employees WHERE to_char(hire_date, 'yyyy') = '1999' ) 50. 多行子查询的 any 和 all
select department_id from employees group by department_id having avg(salary) >= any( --所有部门的平均工资 select avg(salary) from employees group by department_id ) any 和任意一个值比较, 所以其条件最为宽松, 所以实际上只需和平均工资最低的比较, 返回所有值 而 all 是和全部的值比较, 条件最为苛刻, 所以实际上返回的只需和平均工资最高的比较, 所以返回 平均工资最高的 department_id
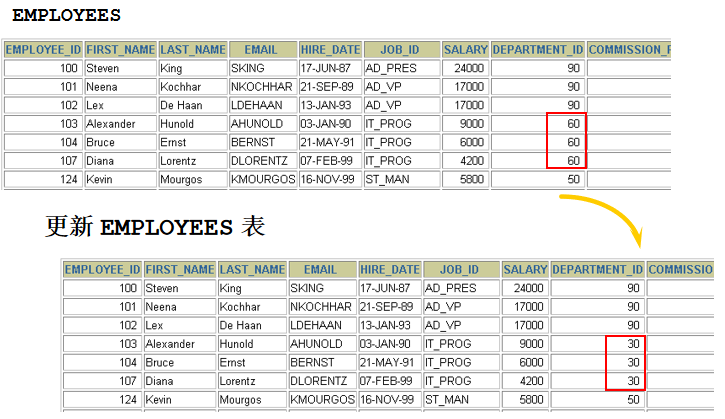
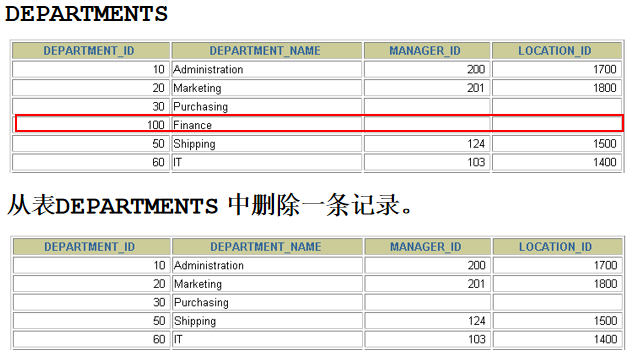
) where employee_id = 108; 2). 所在部门中的最高工资 select max(salary) from employees where department_id = ( select department_id from employees where employee_id = 108 ) 3). 公司中平均工资最低的 job select job_id from employees group by job_id having avg(salary) = ( select min(avg(salary)) from employees group by job_id ) 4). 填充 update employees e set salary = ( select max(salary) from employees where department_id = e.department_id ), job_id = ( select job_id from employees group by job_id having avg(salary) = ( select min(avg(salary)) from employees group by job_id ) ) where employee_id = 108; 56. 删除 108 号员工所在部门中工资最低的那个员工.
1). 查询 108 员工所在的部门 id select department_id from employees where employee_id = 108; 2). 查询 1) 部门中的最低工资:
select min(salary) from employees where department_id = ( select department_id from employees where employee_id = 108 ) 3). 删除 1) 部门中工资为 2) 的员工信息: delete from employees e where department_id = ( select department_id from employees e where employee_id = 108 ) and salary = ( select min(salary) from employees where department_id = e.department_id )
declare --声明一个变量 v_name varchar2(25); begin --通过 select ... into ... 语句为变量赋值 select last_name into v_name from employees where employee_id = 186; -- 打印变量的值 dbms_output.put_line(v_name); end;
********************************************************************************************************* 流程控制 ********************************************************************************************************* ----------------------------------------------------- 条件判断 ----------------------------------------------------- 7. 使用 IF ... THEN ... ELSIF ... THEN ...ELSE ... END IF;
要求: 查询出 150号 员工的工资, 若其工资大于或等于 10000 则打印 'salary >= 10000'; 若在 5000 到 10000 之间, 则打印 '5000<= salary < 10000'; 否则打印 'salary < 5000' (方法一) declare v_salary employees.salary%type; begin --通过 select ... into ... 语句为变量赋值 select salary into v_salary from employees where employee_id = 150; dbms_output.put_line('salary: ' || v_salary); -- 打印变量的值 if v_salary >= 10000 then dbms_output.put_line('salary >= 10000'); elsif v_salary >= 5000 then dbms_output.put_line('5000 <= salary < 10000'); else dbms_output.put_line('salary < 5000'); end if; (方法二) declare v_emp_name employees.last_name%type; v_emp_sal employees.salary%type; v_emp_sal_level varchar2(20); begin select last_name,salary into v_emp_name,v_emp_sal from employees where employee_id = 150; if(v_emp_sal >= 10000) then v_emp_sal_level := 'salary >= 10000'; elsif(v_emp_sal >= 5000) then v_emp_sal_level := '5000<= salary < 10000'; else v_emp_sal_level := 'salary < 5000'; end if; dbms_output.put_line(v_emp_name||','||v_emp_sal||','||v_emp_sal); end;
7+ 使用 CASE ... WHEN ... THEN ...ELSE ... END 完成上面的任务
declare v_sal employees.salary%type; v_msg varchar2(50); begin select salary into v_sal from employees where employee_id = 150; --case 不能向下面这样用 /* case v_sal when salary >= 10000 then v_msg := '>=10000' when salary >= 5000 then v_msg := '5000<= salary < 10000' else v_msg := 'salary < 5000' end; */ v_msg := case trunc(v_sal / 5000) when 0 then 'salary < 5000' when 1 then '5000<= salary < 10000' else 'salary >= 10000' end; dbms_output.put_line(v_sal ||','||v_msg); end;
while (v_i<=100) loop while v_j <= sqrt(v_i) loop if (mod(v_i,v_j)=0) then v_flag:= 0; end if; v_j :=v_j +1; end loop; if(v_flag=1) then dbms_output.put_line(v_i); end if;
v_flag :=1; v_j := 2; v_i :=v_i +1; end loop;
end;
(法二)使用for循环实现1-100之间的素数的输出 declare --标记值, 若为 1 则是素数, 否则不是 v_flag number(1) := 0; begin for i in 2 .. 100 loop
v_flag := 1; for j in 2 .. sqrt(i) loop if i mod j = 0 then v_flag := 0; end if; end loop; if v_flag = 1 then dbms_output.put_line(i); end if; end loop; end;
11. 使用 goto declare --标记值, 若为 1 则是素数, 否则不是 v_flag number(1) := 0; begin for i in 2 .. 100 loop v_flag := 1; for j in 2 .. sqrt(i) loop if i mod j = 0 then v_flag := 0; goto label; end if; end loop; <<label>> if v_flag = 1 then dbms_output.put_line(i); end if; end loop; end;
11+.打印1——100的自然数,当打印到50时,跳出循环,输出“打印结束” (方法一) begin for i in 1..100 loop dbms_output.put_line(i); if(i = 50) then goto label; end if; end loop; <<label>> dbms_output.put_line('打印结束');
end; (方法二) begin for i in 1..100 loop dbms_output.put_line(i); if(i mod 50 = 0) then dbms_output.put_line('打印结束'); exit; end if; end loop; end;
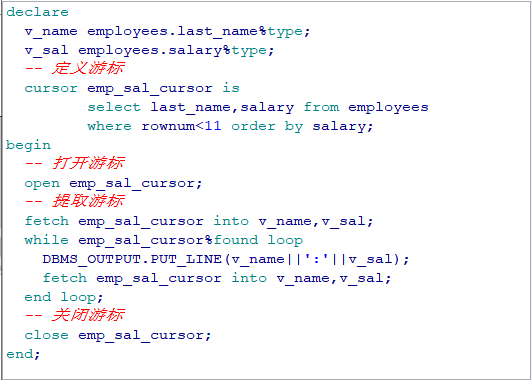
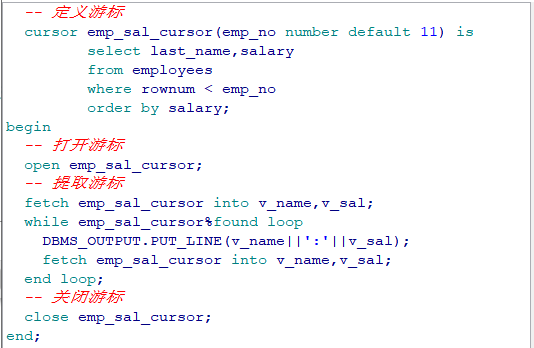
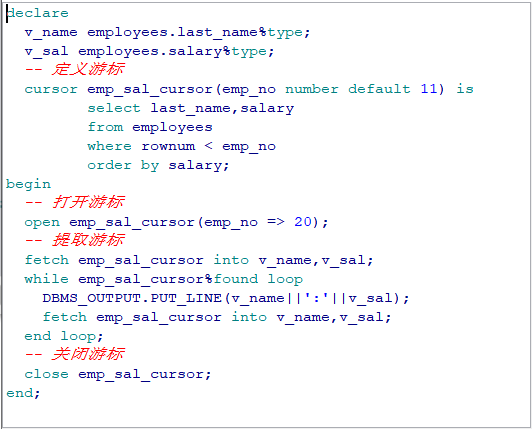
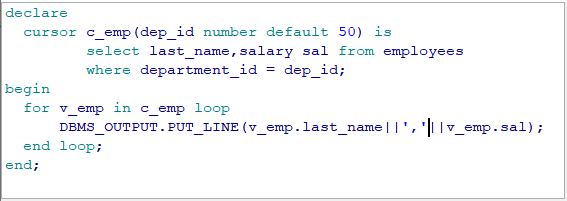
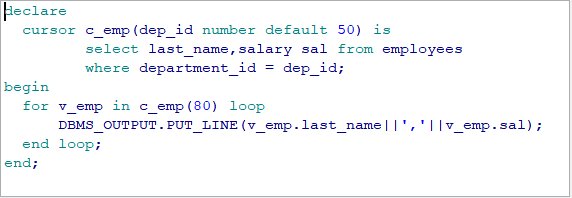
要求: 打印出 80 部门的所有的员工的工资:salary: xxx declare --1. 定义游标 cursor salary_cursor is select salary from employees where department_id = 80; v_salary employees.salary%type; begin --2. 打开游标 open salary_cursor;
--3. 提取游标 fetch salary_cursor into v_salary; --4. 对游标进行循环操作: 判断游标中是否有下一条记录 while salary_cursor%found loop dbms_output.put_line('salary: ' || v_salary); fetch salary_cursor into v_salary; end loop; --5. 关闭游标 close salary_cursor; end;
12.2 使用游标
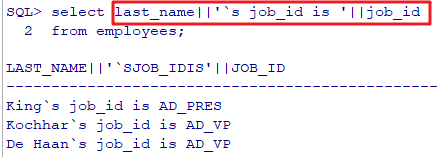
要求: 打印出 80 部门的所有的员工的工资: Xxx 's salary is: xxx declare cursor sal_cursor is select salary ,last_name from employees where department_id = 80; v_sal number(10); v_name varchar2(20); begin open sal_cursor; fetch sal_cursor into v_sal,v_name; while sal_cursor%found loop dbms_output.put_line(v_name||'`s salary is '||v_sal); fetch sal_cursor into v_sal,v_name; end loop; close sal_cursor; end;
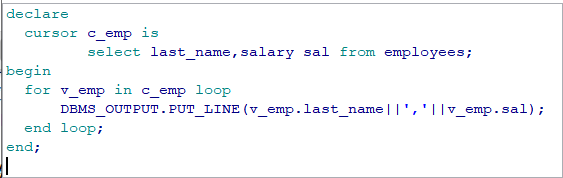
declare --声明游标 cursor emp_cursor is select last_name, email, salary from employees where manager_id = 100; --声明记录类型 type emp_record is record( name employees.last_name%type, email employees.email%type, salary employees.salary%type ); -- 声明记录类型的变量 v_emp_record emp_record; begin --打开游标 open emp_cursor; --提取游标 fetch emp_cursor into v_emp_record; --对游标进行循环操作 while emp_cursor%found loop dbms_output.put_line(v_emp_record.name || ', ' || v_emp_record.email || ', ' || v_emp_record.salary ); fetch emp_cursor into v_emp_record; end loop; --关闭游标 close emp_cursor; end; (法二:使用for循环) declare cursor emp_cursor is select last_name,email,salary from employees where manager_id = 100;
begin
for v_emp_record in emp_cursor loop dbms_output.put_line(v_emp_record.last_name||','||v_emp_record.email||','||v_emp_record.salary); end loop; end;
v_sal employees.salary%type; begin select salary into v_sal from employees where employee_id >100; dbms_output.put_line(v_sal);
exception when Too_many_rows then dbms_output.put_line('输出的行数太多了'); end;
[非预定义异常] declare
v_sal employees.salary%type; --声明一个异常 delete_mgr_excep exception; --把自定义的异常和oracle的错误关联起来 PRAGMA EXCEPTION_INIT(delete_mgr_excep,-2292); begin delete from employees where employee_id = 100; select salary into v_sal from employees where employee_id >100; dbms_output.put_line(v_sal);
exception when Too_many_rows then dbms_output.put_line('输出的行数太多了'); when delete_mgr_excep then dbms_output.put_line('Manager不能直接被删除'); end;
select salary into v_sal from employees where employee_id =100; if v_sal > 1000 then raise too_high_sal; end if; delete from employees where employee_id = 100;
dbms_output.put_line(v_sal);
exception when Too_many_rows then dbms_output.put_line('输出的行数太多了'); when delete_mgr_excep then dbms_output.put_line('Manager不能直接被删除'); --处理异常 when too_high_sal then dbms_output.put_line('工资过高了'); end;
declare --定义一个变量 v_sal employees.salary%type; begin --使用 select ... into ... 为 v_sal 赋值 select salary into v_sal from employees where employee_id = 1000; dbms_output.put_line('salary: ' || v_sal); exception when No_data_found then dbms_output.put_line('未找到数据'); end;
或
declare --定义一个变量 v_sal employees.salary%type; begin --使用 select ... into ... 为 v_sal 赋值 select salary into v_sal from employees; dbms_output.put_line('salary: ' || v_sal); exception when No_data_found then dbms_output.put_line('未找到数据!'); when Too_many_rows then dbms_output.put_line('数据过多!'); end;
19. 更新指定员工工资,如工资小于300,则加100;对 NO_DATA_FOUND 异常, TOO_MANY_ROWS 进行处理. declare v_sal employees.salary%type; begin select salary into v_sal from employees where employee_id = 100; if(v_sal < 300) then update employees set salary = salary + 100 where employee_id = 100; else dbms_output.put_line('工资大于300'); end if; exception when no_data_found then dbms_output.put_line('未找到数据'); when too_many_rows then dbms_output.put_line('输出的数据行太多'); end;
20. 处理非预定义的异常处理: "违反完整约束条件"
declare --1. 定义异常 temp_exception exception;
--2. 将其定义好的异常情况,与标准的 ORACLE 错误联系起来,使用 EXCEPTION_INIT 语句 PRAGMA EXCEPTION_INIT(temp_exception, -2292); begin delete from employees where employee_id = 100;
exception --3. 处理异常 when temp_exception then dbms_output.put_line('违反完整性约束!'); end;
********************************************************************************************************* 存储函数和过程 ********************************************************************************************************* [存储函数:有返回值,创建完成后,通过select function() from dual;执行] [存储过程:由于没有返回值,创建完成后,不能使用select语句,只能使用pl/sql块执行]
[格式] --函数的声明(有参数的写在小括号里) create or replace function func_name(v_param varchar2) --返回值类型 return varchar2 is --PL/SQL块变量、记录类型、游标的声明(类似于前面的declare的部分) begin --函数体(可以实现增删改查等操作,返回值需要return) return 'helloworld'|| v_logo; end;
22.1 函数的 helloworld: 返回一个 "helloworld" 的字符串
create or replace function hello_func return varchar2 is begin return 'helloworld'; end;
--函数的声明(有参数的写在小括号里) create or replace function hello_func(v_logo varchar2) --返回值类型 return varchar2 is --PL/SQL块变量的声明 begin --函数体 return 'helloworld'|| v_logo; end;
22.3 创建一个存储函数,返回当前的系统时间 create or replace function func1 return date is --定义变量 v_date date; begin --函数体 --v_date := sysdate; select sysdate into v_date from dual; dbms_output.put_line('我是函数哦'); return v_date; end;
执行法1: select func1 from dual; 执行法2: declare v_date date; begin v_date := func1; dbms_output.put_line(v_date); end; 23. 定义带参数的函数: 两个数相加
create or replace function add_func(a number, b number) return number is begin return (a + b); end;
执行函数
begin dbms_output.put_line(add_func(12, 13)); end; 或者 select add_func(12,13) from dual;
24. 定义一个函数: 获取给定部门的工资总和, 要求:部门号定义为参数, 工资总额定义为返回值.
create or replace function sum_sal(dept_id number) return number is cursor sal_cursor is select salary from employees where department_id = dept_id; v_sum_sal number(8) := 0; begin for c in sal_cursor loop v_sum_sal := v_sum_sal + c.salary; end loop;
25. 关于 OUT 型的参数: 因为函数只能有一个返回值, PL/SQL 程序可以通过 OUT 型的参数实现有多个返回值
要求: 定义一个函数: 获取给定部门的工资总和 和 该部门的员工总数(定义为 OUT 类型的参数). 要求: 部门号定义为参数, 工资总额定义为返回值.
create or replace function sum_sal(dept_id number, total_count out number) return number is cursor sal_cursor is select salary from employees where department_id = dept_id; v_sum_sal number(8) := 0; begin total_count := 0;
for c in sal_cursor loop v_sum_sal := v_sum_sal + c.salary; total_count := total_count + 1; end loop;
begin dbms_output.put_line(sum_sal(80, v_total)); dbms_output.put_line(v_total); end;
26*. 定义一个存储过程: 获取给定部门的工资总和(通过 out 参数), 要求:部门号和工资总额定义为参数
create or replace procedure sum_sal_procedure(dept_id number, v_sum_sal out number) is cursor sal_cursor is select salary from employees where department_id = dept_id; begin v_sum_sal := 0; for c in sal_cursor loop --dbms_output.put_line(c.salary); v_sum_sal := v_sum_sal + c.salary; end loop;
create or replace procedure add_sal_procedure(dept_id number, temp out number)
is
cursor sal_cursor is select employee_id id, hire_date hd, salary sal from employees where department_id = dept_id; a number(4, 2) := 0; begin temp := 0;
for c in sal_cursor loop a := 0; if c.hd < to_date('1995-1-1', 'yyyy-mm-dd') then a := 0.05; elsif c.hd < to_date('1998-1-1', 'yyyy-mm-dd') then a := 0.03; else a := 0.01; end if; temp := temp + c.sal * a; update employees set salary = salary * (1 + a) where employee_id = c.id; end loop; end;
********************************************************************************************************* 触发器 ********************************************************************************************************* 一个helloworld级别的触发器 create or replace trigger hello_trigger after update on employees --for each row begin dbms_output.put_line('hello...'); --dbms_output.put_line('old.salary:'|| :OLD.salary||',new.salary'||:NEW.salary); end; 然后执行:update employees set salary = salary + 1000;
create or replace trigger emp_trigger after insert on emp for each row begin dbms_output.put_line('helloworld'); end;
29. 行级触发器: 每更新 employees 表中的一条记录, 都会导致触发器执行
create or replace trigger employees_trigger after update on employees for each row begin dbms_output.put_line('修改了一条记录!'); end;
语句级触发器: 一个 update/delete/insert 语句只使触发器执行一次
create or replace trigger employees_trigger after update on employees begin dbms_output.put_line('修改了一条记录!'); end;
30. 使用 :new, :old 修饰符
create or replace trigger employees_trigger after update on employees for each row begin dbms_output.put_line('old salary: ' || :old.salary || ', new salary: ' || :new.salary); end;
1). 准备工作: create table my_emp as select employee_id id, last_name name, salary sal from employees create table my_emp_bak as select employee_id id, last_name name, salary sal from employees where 1 = 2
2). create or replace trigger bak_emp_trigger before delete on my_emp for each row begin insert into my_emp_bak values(:old.id, :old.name, :old.sal); end;
Oracle问题
环境问题
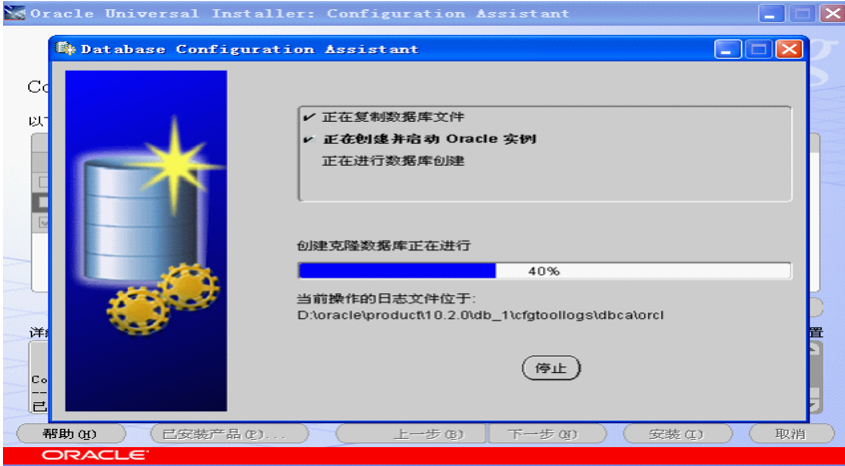
1.oracle用户登录后,执行sqlplus / as sysdba报错 ORA-12162错误:TNS:net service name is incorrectly specified
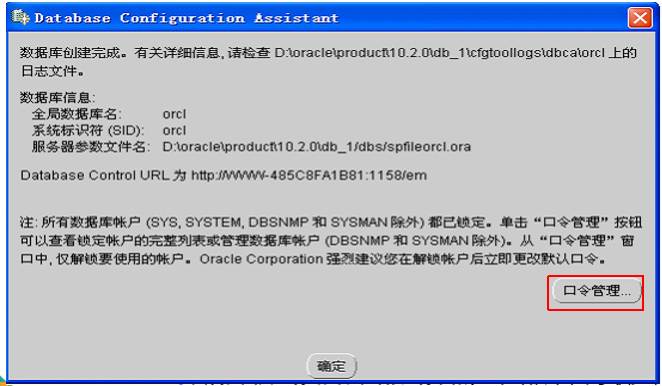
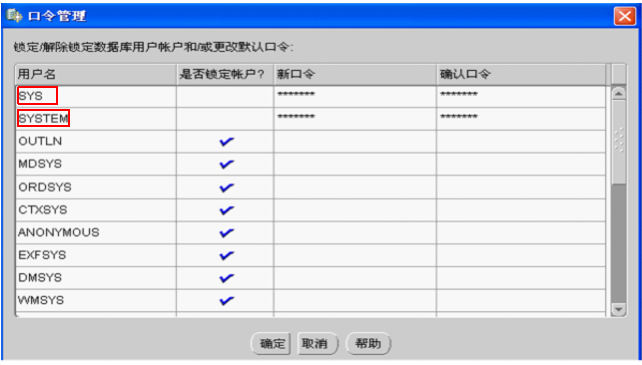
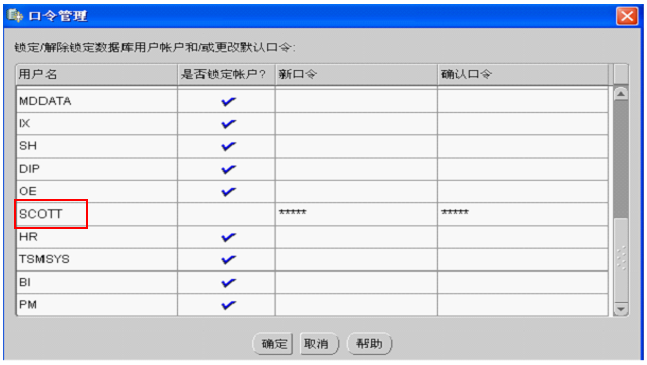
解决: 1.使用sysdba账号登录(运行cmd-->sqlplus / as sysdba) 2. 解除锁定账号(例如解除system用户) alter user system account unlock; 3. 为system用户设置新密码(例如设置密码为(推存设置):manager) alter user system identified by manager;
报错信息类似: ORA-01555: snapshot too old: rollback segment number 107 with name "_SYSSMU107_1253191395$" too small
问题发生时的跟踪日志文件
1 2 3
默认情况,ORA-01555错误发生时不会自动生成跟踪日志文件。但是可以在系统里设置下面的事件,让它在错误发生时同时生成: alter system set events '1555 trace name errorstack level 3'; 设置了1555事件后,一旦错误发生,就会生成相应的日志文件,类似如下:
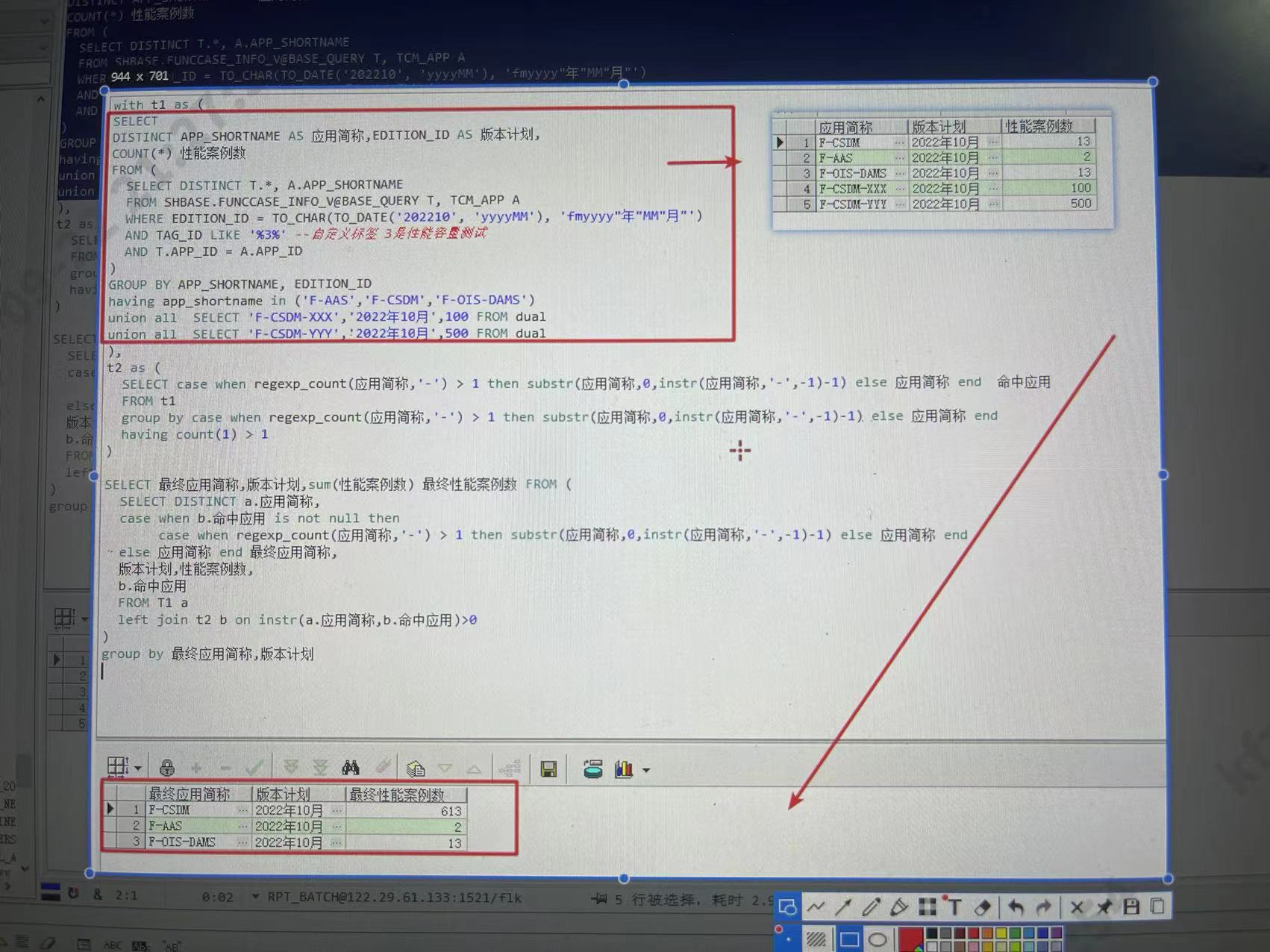
select to_char(sysdate,'yyyy"年"mm"月份版本"') from dual; // 2020年04月份版本 select to_char(sysdate,'fmyyyy"年"mm"月份版本"') from dual; // 2020年4月份版本
1.取日期中的年份
1 2 3 4 5 6
select to_number(to_char(sysdate,'yyyy')) from dual; 或者可以直接使用Oracle提供的 Extract 函数 select sysdate from dual; --获得当前系统时间 selectextract(yearfrom sysdate) from dual; --获得系统当前年 selectextract(monthfrom sysdate) from dual; --获得系统当前月 selectextract(dayfrom sysdate) from dual; --获得系统当前日
2.取去年的数据
1 2
# 筛选字段为 2020年4月份版本 ; 取去年数据 select * from qa_adapt_issue_unclosed_loop where substr(project_verison,0,4) = extract(year from sysdate) - 1
3.去年本月(去年同期)
1 2
# 2020年4月份版本 => 2019年4月份版本 select add_months(SYSDATE,-12),to_char(add_months(SYSDATE,-12),'fmyyyy"年"mm"月份版本"' from dual
4.oracle 去年第一天
1 2 3 4
# 返回日期格的话 select trunc(add_months(sysdate,-12),'year') from dual # 返回字符格式的话 select to_char(trunc(add_months(sysdate,-12),'year'),'yyyy-mm-dd') from dual
5.是否包含某个字符串
1
select * from table where instr(t.name,'天涯')>0
6.去除首尾指定字符串
1
SELECT LTRIM('thetomsbthhe', 'the'),RTRIM('thetomsbthhe', 'the') FROM dual;
7.今天是今年的第几天
1
select trunc(sysdate) - trunc(sysdate,'YYYY')+1 from dual
8.今年天数
1
SELECT ADD_MONTHS(TRUNC(SYSDATE, 'YYYY'), 12) - TRUNC(SYSDATE, 'YYYY') days FROM DUAL
9.造一行的数据,转为一列多行
1 2 3
with a as (select '/ABC/AA/AD/ABD/JI/CC/ALSKD/ALDKDJ' id from dual) select regexp_substr(id,'[^/]+',1,rownum) id from a connect by rownum <= length(regexp_replace(id,'[^/]+'))
10.oracle小数点补0
1 2
select to_char(0.12,'fm9999990.9999') || '%' from dual; SELECT regexp_replace(l_num, '^\.', '0.') FROM dual
11.拿到最近一周的日期
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT to_char (SYSDATE- LEVEL + 1, 'yyyy-mm-dd') createTime FROM DUAL connect BY LEVEL <= 7
select * from hrm_daily_monitor_data_detail_foreign where version between to_char(trunc(sysdate,'iw')-7,'yyyy/mm/dd') and to_char(trunc(sysdate,'iw')-1,'yyyy/mm/dd')
13.取第一条和最后一条
1 2 3 4 5 6
SELECT DISTINCT LAST_VALUE (E_VALUE) OVER (PARTITION BY E_CODE ORDER BY E_DATE ROWS BETWEEN unbounded preceding AND unbounded following) AS LAST_TIME_VALUE, FIRST_VALUE (E_VALUE) OVER (PARTITION BY E_CODE ORDER BY E_DATE ROWS BETWEEN unbounded preceding AND unbounded following) AS FIRST_TIME_VALUE FROM TABLE_TEST
14.取上一条和下一条
1 2 3 4
# lag 上一条 lead 下一条 select version,lag(version,1,0) over(order by version),lead(version,1,0) over(order by version) from hrm_capacity_workday_chart
15.判断为一周中第几天
1 2
select to_char(sysdate ,'d') from dual; -- 周末 1 周一2 周二3 周三4 周四5 周五6 周六7 select to_char(sysdate - 1,'d') from dual
16.模糊查询
1 2 3
and e.empId like CONCAT('%',#{empId},'%') X Oracle模糊查询CONCAT参数个数无效 and e.empId like CONCAT(CONCAT('%',#{empId}),'%') √ and e.empId like '%' || #{empId} ||'%'; √
17.查看数据库字符集
1 2
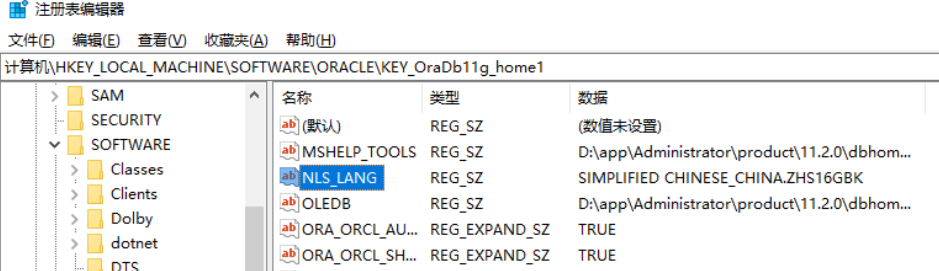
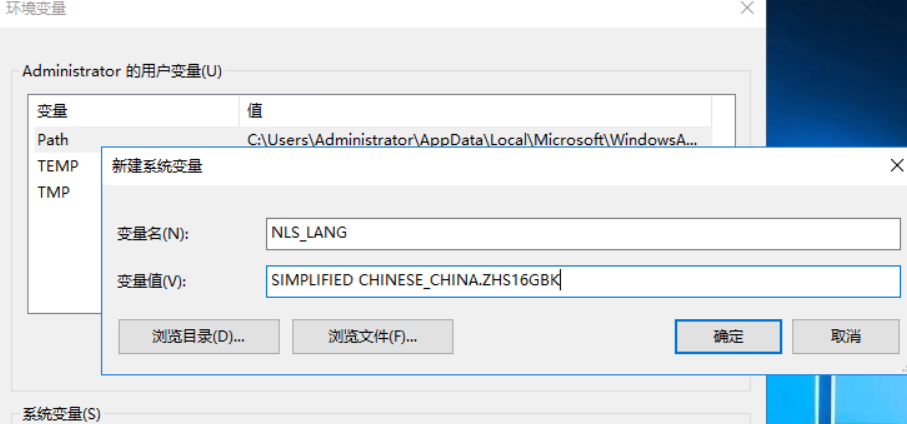
SELECT value$ FROM sys.props$ WHERE name = 'NLS_CHARACTERSET' ; # 如果是UTF-8 汉字3个字符,即最多1333个汉字,GBK 汉字2个字符 2000个汉字
18.根据季度获取所有月份
1 2 3 4 5 6 7 8 9 10 11
上季度所有月份: SELECT TO_CHAR(ADD_MONTHS(ADD_MONTHS(TRUNC(SYSDATE, 'YYYY'),A * 3),-ROWNUM),'YYYYMM') LAST_Q FROM (SELECT TO_CHAR(SYSDATE,'Q')-1 A FROM DUAL) CONNECT BY ROWNUM <= 3 ORDER BY 1;
本季度所有月份: SELECT TO_CHAR(ADD_MONTHS(ADD_MONTHS(TRUNC(SYSDATE, 'YYYY'),A * 3),-ROWNUM),'YYYYMM') LAST_Q FROM (SELECT TO_CHAR(SYSDATE,'Q') A FROM DUAL) CONNECT BY ROWNUM <= 3 ORDER BY 1;
oracle一些用的复杂效果
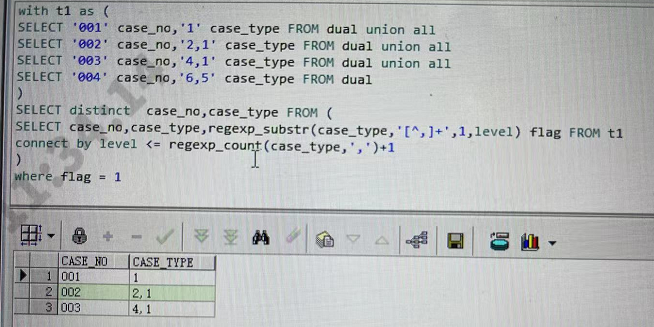
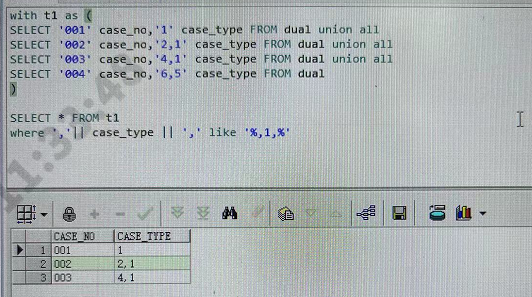
19.connect by
1 2 3 4 5 6 7 8 9
我有多行结果集,有部分行是用分割符隔开的. 想要: 单列结果集,分割符转为多行。
select REGEXP_SUBSTR(A, '[^,]+', 1, LEVEL) A,B,C from T CONNECT BY LEVEL <= REGEXP_COUNT(A, '[^,]+') and rowid= prior rowid and prior dbms_random.value is not null; ps:最后2个and防止重复行
ps: oracle 时间字符串比较的陷阱
比如时间字符串字段 > ‘2020年6月版本’。这样10月11月12月是筛选不出来的。!!!
20.substr
1 2
oracle去掉最后一个字符, select a, substr(a,1,length(a) -1 ) from t_table1
-增加大字段项 alter table DT_CORP_ENTERPRISE add hehe clob; --将需要改成大字段的项内容copy到大字段中 update DT_CORP_ENTERPRISE set hehe=ASSetsinvestment; --删除原有字段 alter table DT_CORP_ENTERPRISE drop column ASSetsinvestment; --将大字段名改成原字段名 alter table DT_CORP_ENTERPRISE rename column hehe to ASSetsinvestment;
我整合邮件服务的时候,要发送HTML邮件,用到大字段
23.需求:截取-及其以前的字符串
1.5有个需求里面的小需求是这样的,把一个字段的’-‘及其之前的字符格式化掉,其他保持不变。
1
select subnstr('上海一部-数据湖',instr('上海一部-数据湖','-')+1, length('上海一部-数据湖')) from dual
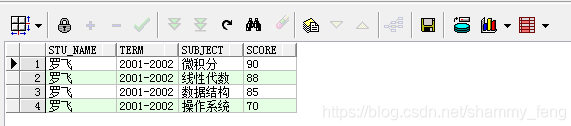
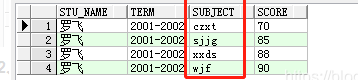
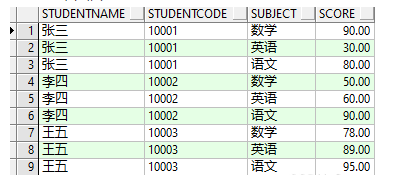
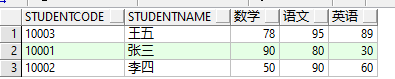
方案一:wm_concat函数 select username, id, wmsys.wm_concat(subject) as subject, wmsys.wm_concat(score) as score from STUDENTSCORES group by username, id
方案二:listagg函数 select username, id, LISTAGG(subject, '-') within group(order by subject) as subject, LISTAGG(score, ',') within group(order by score) as score from STUDENTSCORES group by username, id
select username, id, translate(ltrim(subject, '/'), '*/', '*,') as subject,translate(ltrim (score, '/'), '*/', '*,') as score from (select row_number() over (partition by username, id order by username, id, lvl desc) as rn, username, id, subject, score from (select username, id, level lvl, sys_connect_by_path (subject, '/') as subject, sys_connect_by_path (score, '/') as score from (select username, id, subject, score, row_number() over (partition by username,id order by username, id) as num from STUDENTSCORES order by username, id) connect by username = prior username and id = prior id and num - 1 = prior num)) where rn = 1;
一、显示中文星期天 select to_char(sysdate,'day','NLS_DATE_LANGUAGE=''SIMPLIFIED CHINESE''') from dual;
二、显示英文星期天 select to_char(sysdate,'day','nls_date_language=american') from dual;
三、显示中文月份 select to_char(sysdate,'month','NLS_DATE_LANGUAGE=''SIMPLIFIED CHINESE''') from dual;
四、显示英文月份 select to_char(sysdate,'month','nls_date_language=american') from dual;
解决问题
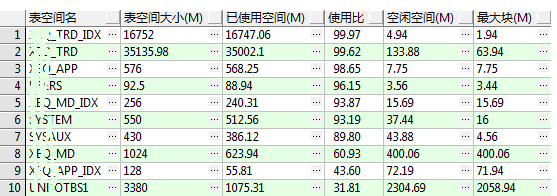
查询表空间
一般来说表的大小超过2G可以考虑分区表,怎么看表的大小?
1 2 3 4 5
select t.segment_name, t.segment_type, sum(t.bytes /1024/1024) "占用空间(M)" from dba_segments t where t.segment_type='TABLE' and t.segment_name='TABLE_NAME' groupby OWNER, t.segment_name, t.segment_type;
存储过程编译卡死
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
1:查V$DB_OBJECT_CACHE SELECT*FROM V$DB_OBJECT_CACHE WHERE name='CUX_OE_ORDER_RPT_PKG'AND LOCKS!='0';
注意:CUX_OE_ORDER_RPT_PKG 为存储过程的名称。 发现 locks=2
2:按对象查出sid的值 select/*+ rule*/ SID from V$ACCESS WHERE object='CUX_OE_ORDER_RPT_PKG';
注意:CUX_OE_ORDER_RPT_PKG 为存储过程的名称。
3:查sid,serial# SELECT SID,SERIAL#,PADDR FROM V$SESSION WHERE SID='刚才查到的SID';
set colsep','; //域(列)输出分隔符 set echo off; //不显示start启动的脚本中的每个sql命令,缺省为on set feedback off; //不回显本次sql命令处理(查询/修改)的记录条数,缺省为on set heading off; //不输出域(列)标题,缺省为on set pagesize 0; //输出每页行数,缺省为24,为了避免分页,可设定为0。 set termout off; //不显示脚本中的命令的执行结果,缺省为on set trimout on; //去除标准输出每行的拖尾空格,缺省为off set trimspool on; //去除重定向(spool)输出每行的拖尾空格,缺省为off set term off; //不在屏幕上显示 set linesize 10000; //设置行宽,根据需要设置,默认100 set wrap off; //让它不要自动换行,当行的长度大于LINESIZE的时候,超出的部分会被截掉。
PL/SQL下使用spool脚本导出txt
spool.sql脚本如下:
1 2 3 4 5 6 7 8
SPOOL D:\测试.txt set echo off --不显示脚本中正在执行的SQL语句 set feedback off --不显示sql查询或修改行数 set term off --不在屏幕上显示 set heading off --不显示列 set linesize 1000; //设置行宽,根据需要设置,默认100 select AAB301||','||AAE002|| ',' ||AAC001|| ',' ||AAE252|| ',' ||AAE091|| ',' ||AAE020|| ',' ||AAE022 FROM JGCA; --需要导出的数据查询sql SPOOL OFF
导入数据
不常用但是可能会用的命令
1、查询Oracle并发数、会话数、连接数:
1 2 3 4 5
selectcount(*) from v$session #当前的连接数 selectcount(*) from v$session where status='ACTIVE' #并发连接数 selectvaluefrom v$parameterwhere name ='processes' #数据库允许的最大连接数 showparameter processes #最大连接 select username,count(username) from v$session where username isnotnullgroupby username; #查看不同用户的连接数
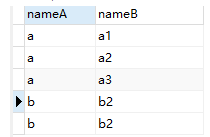
SELECT a.nameA,b.nameB FROM a LEFTJOIN b on instr(b.nameB,a.nameA)>0
2.模糊语音查询分组
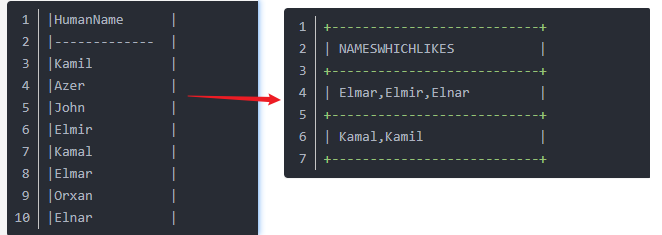
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
with your_table (HumanName) as ( select 'Kamil' from dual union all select 'Azer' from dual union all select 'John' from dual union all select 'Elmir' from dual union all select 'Kamal' from dual union all select 'Elmar' from dual union all select 'Orxan' from dual union all select 'Elnar' from dual ) ------ Test data setup ends here ------ select listagg(humanname,',') within group (order by humanname) nameswhichlikes from your_table group by soundex(humanname) having count(*) > 1;
3.统计字符串中的字符出现次数
1 2
select REGEXP_COUNT('1,2,6,8,7,9',',') from dual 结果:5

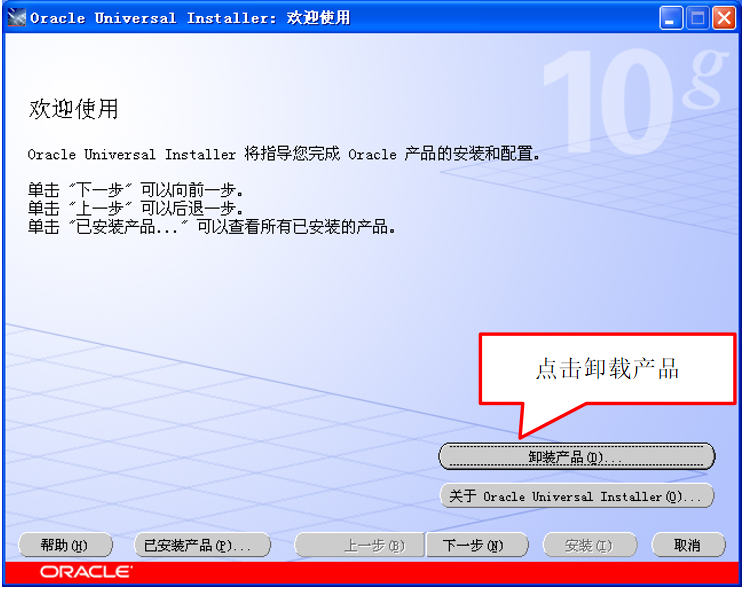
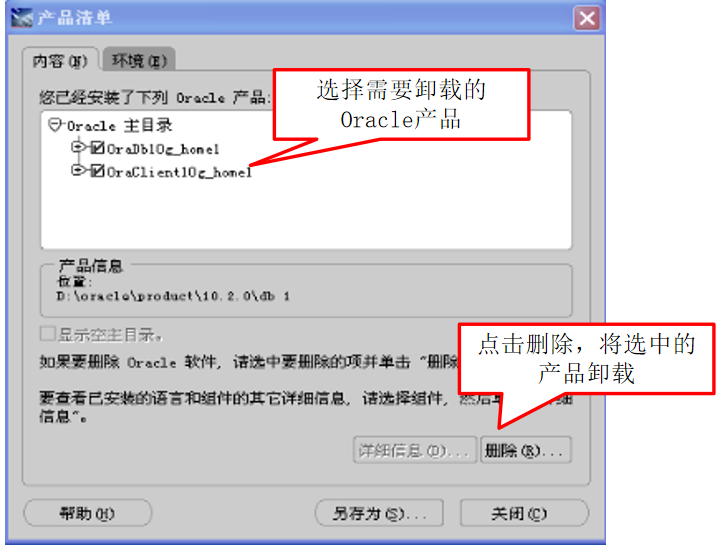
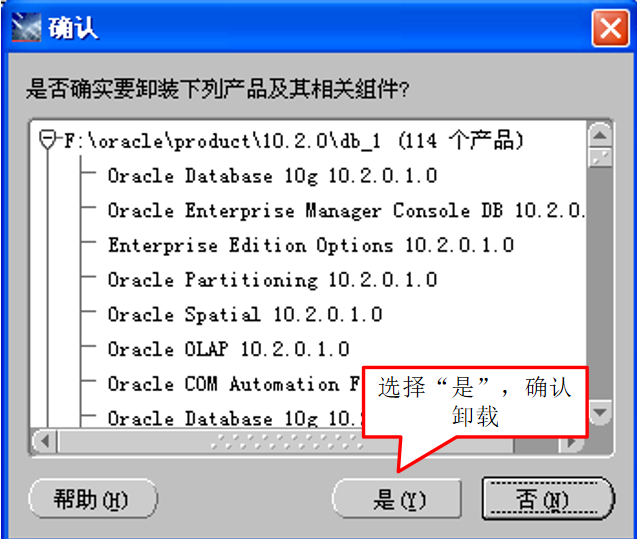
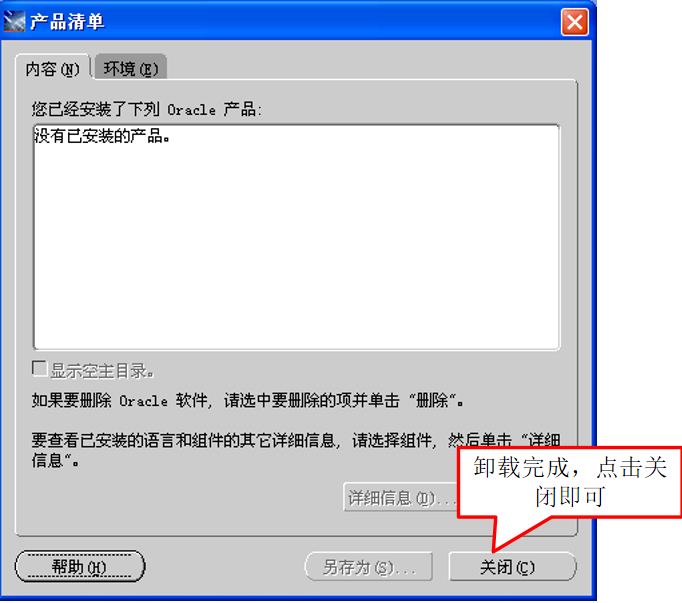








































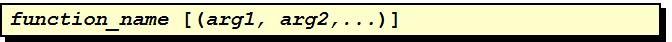









































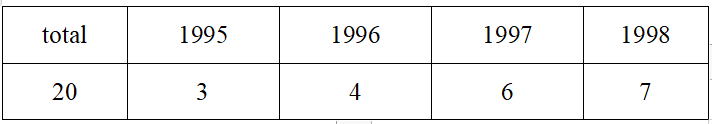
































































































































 微信
微信 支付宝
支付宝
