【数据存储系列】手牵手学习TiDB
互联网环境,数据是第一生产力,数据的存储至关重要,而数据库发展从SQL到NoSQL,到NewSQL。简单的说就是结合了SQL和NoSQL的优点。在传统关系型数据库上集成了 NoSQL 强大的可扩展性。
TiDB-亿级订单数据亚秒响应查询方案

1. 什么是TiDB
TiDB 是一个分布式 NewSQL 数据库,它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适合 OLAP 场景的混合数据库。
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
1.1 什么是NewSQL
数据库发展至今已经有3代了:
- SQL,传统关系型数据库,例如 MySQL
- NoSQL,例如 MongoDB,Redis
- NewSQL
1.1.1 传统SQL的问题
互联网在本世纪初开始迅速发展,互联网应用的用户规模、数据量都越来越大,并且要求7X24小时在线。
传统关系型数据库在这种环境下成为了瓶颈,通常有2种解决方法:
1.1.1.1 升级服务器硬件
虽然提升了性能,但总有天花板。
1.1.1.2 数据分片
使用分布式集群结构
对单点数据库进行数据分片,存放到由廉价机器组成的分布式的集群里,可扩展性更好了,但也带来了新的麻烦。
以前在一个库里的数据,现在跨了多个库,应用系统不能自己去多个库中操作,需要使用数据库分片中间件。
分片中间件做简单的数据操作时还好,但涉及到跨库join、跨库事务时就很头疼了,很多人干脆自己在业务层处理,复杂度较高。
1.1.2 NoSQL 的问题
后来 NoSQL 出现了,放弃了传统SQL的强事务保证和关系模型,重点放在数据库的高可用性和可扩展性。
1.1.2.1 优点
- 高可用性和可扩展性,自动分区,轻松扩展
- 不保证强一致性,性能大幅提升
- 没有关系模型的限制,极其灵活
1.1.2.2 缺点
- 不保证强一致性,对于普通应用没问题,但还是有不少像金融一样的企业级应用有强一致性的需求。
- 不支持 SQL 语句,兼容性是个大问题,不同的 NoSQL 数据库都有自己的 api 操作数据,比较复杂。
1.1.3 NewSQL 特性
NewSQL 提供了与 NoSQL 相同的可扩展性,而且仍基于关系模型,还保留了极其成熟的 SQL 作为查询语言,保证了ACID事务特性。
简单来讲,NewSQL 就是在传统关系型数据库上集成了 NoSQL 强大的可扩展性。
传统的SQL架构设计基因中是没有分布式的,而 NewSQL 生于云时代,天生就是分布式架构。(未来的主流)
1.1.3.1 NewSQL 的主要特性:
- SQL 支持,支持复杂查询和大数据分析。
- 支持 ACID 事务,支持隔离级别。
- 弹性伸缩,扩容缩容对于业务层完全透明。
- 高可用,自动容灾。
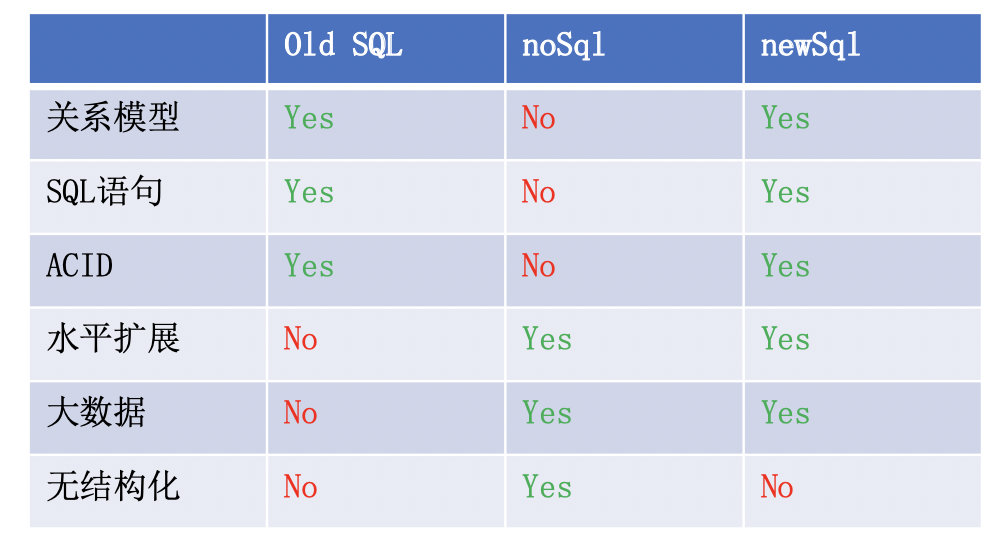
1.1.4 三种SQL的对比
1.2 TiDB怎么来的
著名的开源分布式缓存服务 Codis 的作者,PingCAP联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
直到 2012 年底,他看到 Google 发布的两篇论文,如同棱镜般,折射出他自己内心微烁的光彩。这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
公司历史可以参考下PingCAP
1.3 TiDB社区版和企业版
TiDB分为社区版以及企业版,企业版收费提供服务以及安全性的支持

1.4 TIDB核心特性
1.4.1 水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景
得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
1.4.2 分布式事务支持
TiDB 100% 支持标准的 ACID 事务
1.4.3 金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入
数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
1.4.4 实时 HTAP
TiDB 作为典型的 OLTP 数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP 无需传统繁琐的 ETL 过程
提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
1.4.5 云原生的分布式数据库
TiDB 是为云而设计的数据库,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。 TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力
1.4.6 高度兼容 MySQL
兼容 MySQL 5.7 协议、MySQL 常用的功能、MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。
提供丰富的数据迁移工具帮助应用便捷完成数据迁移,大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
1.5 OLTP&OLAP(自学)
1.5.1 OLTP(联机事务处理)
OLTP(Online Transactional Processing) 即联机事务处理,OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查,比如在银行存取一笔款,就是一个事务交易
联机事务处理是事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
1.5.2 OLAP(联机分析处理)
OLAP(Online Analytical Processing) 即联机分析处理,是数据仓库的核心部心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统
在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
1.5.3 特性对比
OLTP和OLAP的特性对比
| — | OLTP | OLAP |
|---|---|---|
| 实时性 | OLTP 实时性要求高,OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务 | OLAP 的实时性要求不是很高,很多应用顶多是每天更新一下数据 |
| 数据量 | OLTP 数据量不是很大,一般只读 / 写数十条记录,处理简单的事务 | OLAP 数据量大,因为 OLAP 支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大 |
| 用户和系统的面向性 | OLTP 是面向顾客的,用于事务和查询处理 | OLAP 是面向市场的,用于数据分析 |
| 数据库设计 | OLTP 采用实体 - 联系 ER 模型和面向应用的数据库设计 | OLAP 采用星型或雪花模型和面向主题的数据库设计 |
1.5.4 设计角度区别
| — | OLTP | OLAP |
|---|---|---|
| 用户 | 操作人员,低层管理人员 | 决策人员,高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| 主要工作 | 增、删、改 | 查询 |
| DB 设计 | 面向应用 | 面向主题 |
| 数据 | 当前的,最新的细节,二维的,分立的 | 历史的,聚集的,多维集成的,统一的 |
| 存取 | 读/写数十条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的查询 |
| 用户数 | 上千个 | 上百个 |
| DB 大小 | 100MB-GB | 100GB-TB |
2. TiDB 整体架构
2.1 TiDB的优势
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
2.2 TiDB的组件
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server,此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
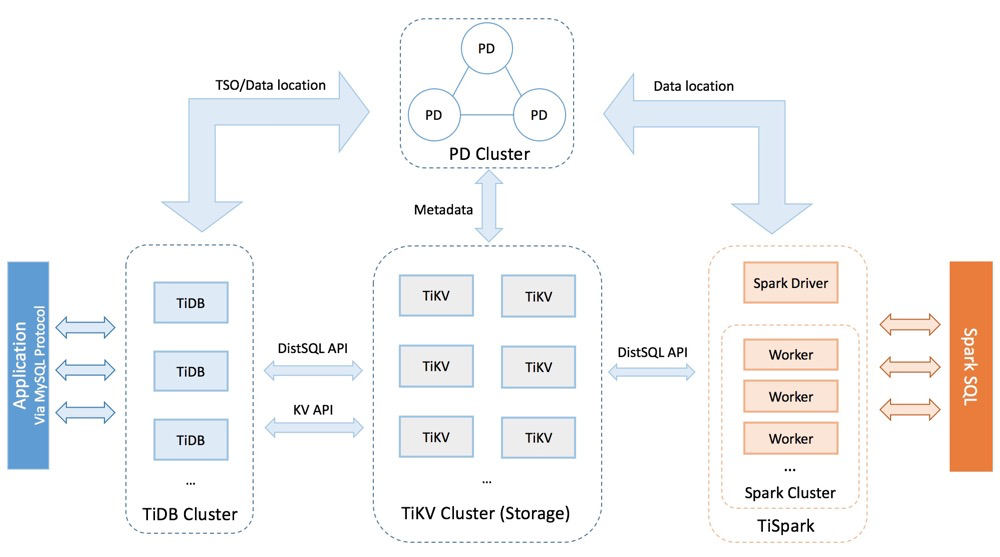
2.2.1 TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.2.2 PD (Placement Driver) Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- 二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
- 三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点
2.2.3 TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.2.4 TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
2.2.5 TiFlash
TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
2.3 TiKV整体架构
与传统的整节点备份方式不同的,TiKV是将数据按照 key 的范围划分成大致相等的切片(下文统称为 Region),每一个切片会有多个副本(通常是 3 个),其中一个副本是 Leader,提供读写服务。TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀地分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
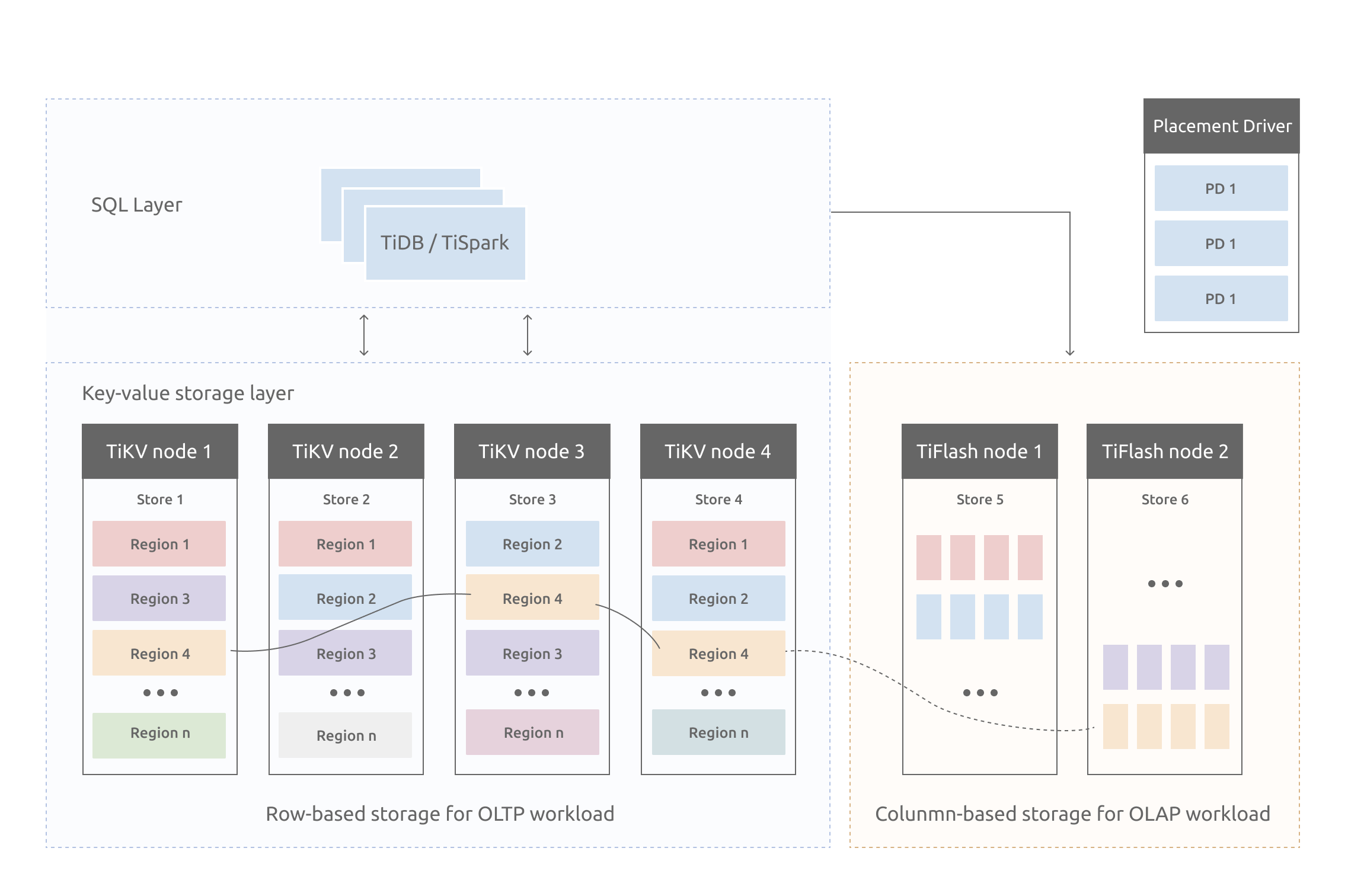
2.3.1 Region分裂与合并
当某个 Region 的大小超过一定限制(默认是 144MB)后,TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,这样更有利于 PD 进行调度决策。同样,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
2.3.2 Region调度
Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 Leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
当 PD 需要把某个 Region 的一个副本从一个 TiKV 节点调度到另一个上面时,PD 会先为这个 Raft Group 在目标节点上增加一个 Learner 副本(复制 Leader 的数据)。当这个 Learner 副本的进度大致追上 Leader 副本时,Leader 会将它变更为 Follower,之后再移除操作节点的 Follower 副本,这样就完成了 Region 副本的一次调度。
Leader 副本的调度原理也类似,不过需要在目标节点的 Learner 副本变为 Follower 副本后,再执行一次 Leader Transfer,让该 Follower 主动发起一次选举成为新 Leader,之后新 Leader 负责删除旧 Leader 这个副本。
2.3.3 分布式事务
TiKV 支持分布式事务,用户(或者 TiDB)可以一次性写入多个 key-value 而不必关心这些 key-value 是否处于同一个数据切片 (Region) 上,TiKV 通过两阶段提交保证了这些读写请求的 ACID 约束。
2.4 高可用架构
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
2.4.1 TiDB高可用
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
2.4.2 PD高可用
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
2.4.3 TiKV高可用
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
2.5 应用场景
2.5.1 MySQL分片与合并
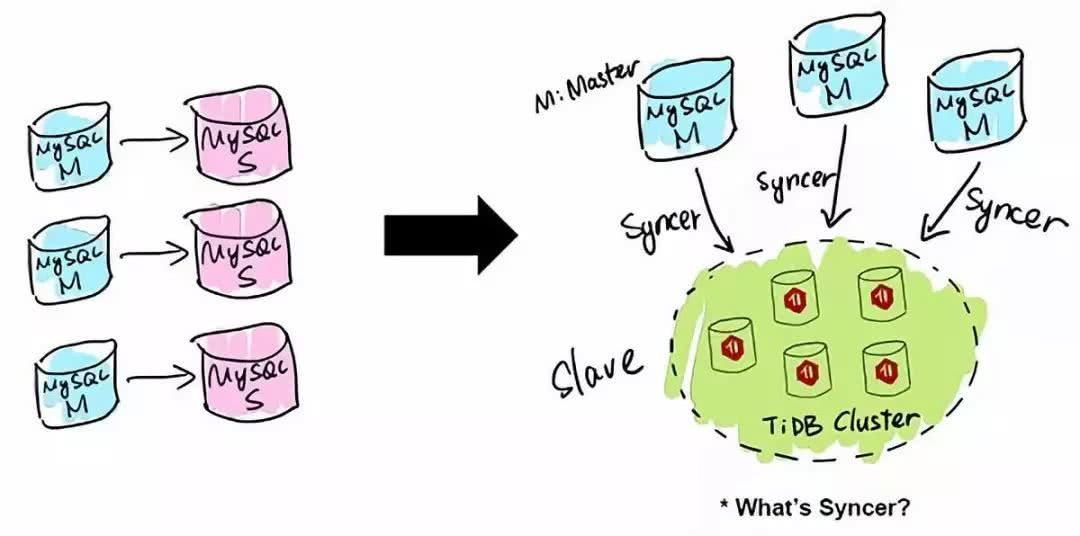
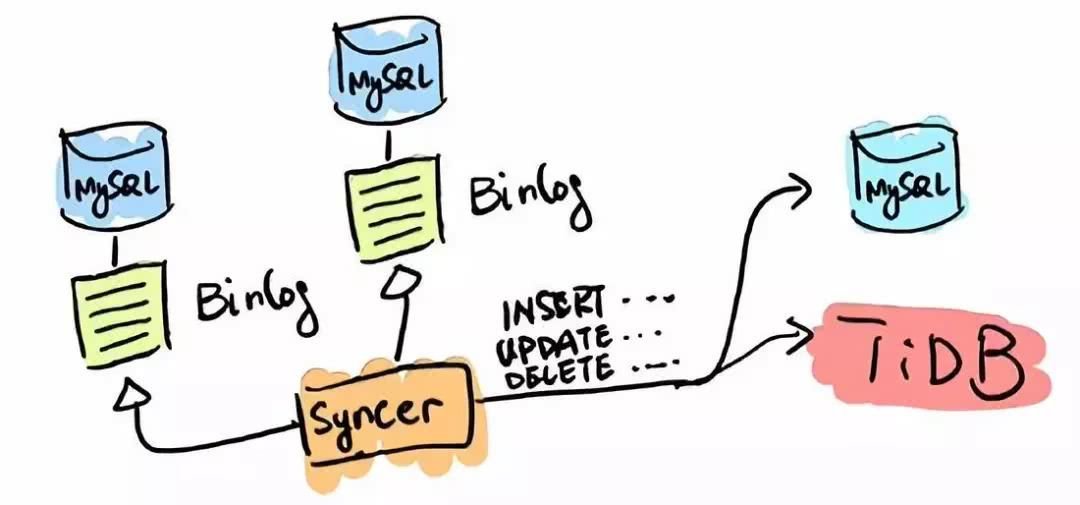
TiDB 应用的第一类场景是 MySQL 的分片与合并。对于已经在用 MySQL 的业务,分库、分表、分片、中间件是常用手段,随着分片的增多,跨分片查询是一大难题。TiDB 在业务层兼容 MySQL 的访问协议,PingCAP 做了一个数据同步的工具——Syncer,它可以把黄东旭 TiDB 作为一个 MySQL Slave,将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,在这一层将数据打通,可以直接进行复杂的跨库、跨表、跨业务的实时 SQL 查询。黄东旭提到,“过去的数据库都是一主多从,有了 TiDB 以后,可以反过来做到多主一从。”
2.5.2 直接替换MySQL
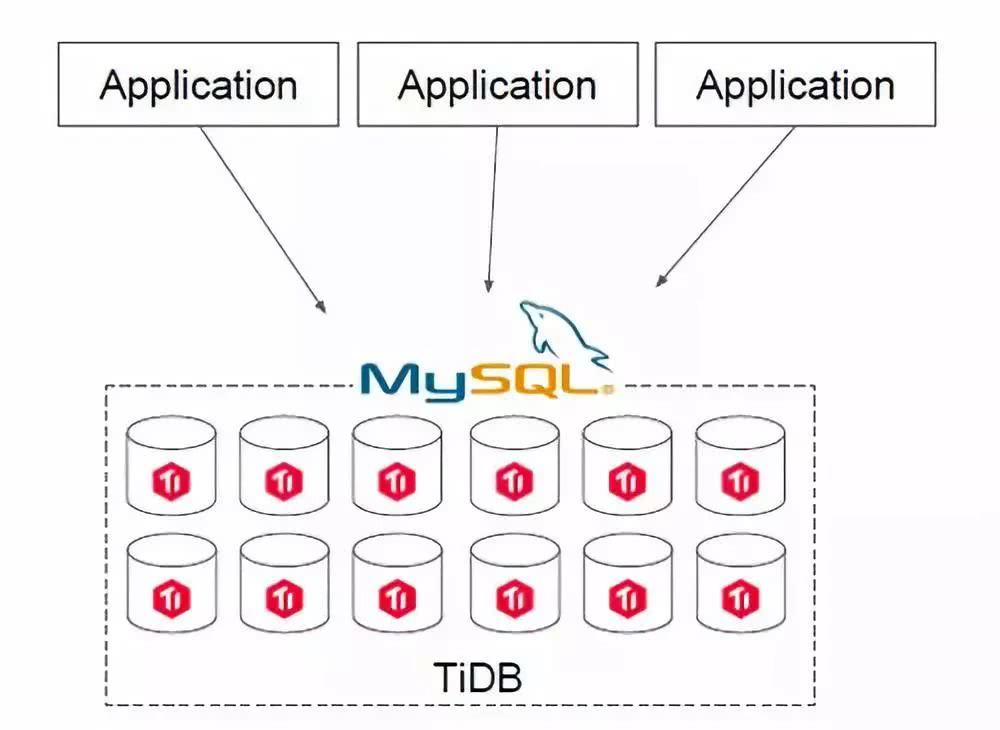
第二类场景是用 TiDB 直接去替换 MySQL。如果你的IT架构在搭建之初并未考虑分库分表的问题,全部用了 MySQL,随着业务的快速增长,海量高并发的 OLTP 场景越来越多,如何解决架构上的弊端呢?
在一个 TiDB 的数据库上,所有业务场景不需要做分库分表,所有的分布式工作都由数据库层完成。TiDB 兼容 MySQL 协议,所以可以直接替换 MySQL,而且基本做到了开箱即用,完全不用担心传统分库分表方案带来繁重的工作负担和复杂的维护成本,友好的用户界面让常规的技术人员可以高效地进行维护和管理。另外,TiDB 具有 NoSQL 类似的扩容能力,在数据量和访问流量持续增长的情况下能够通过水平扩容提高系统的业务支撑能力,并且响应延迟稳定。
2.5.3 数据仓库
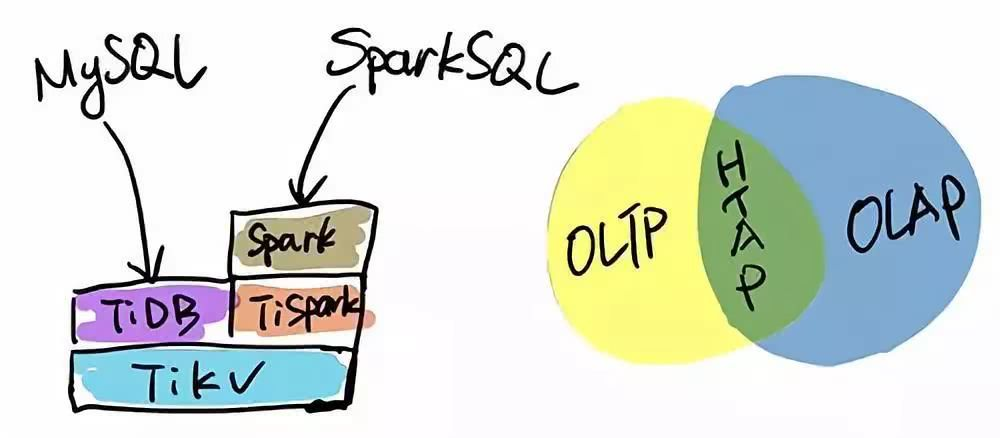
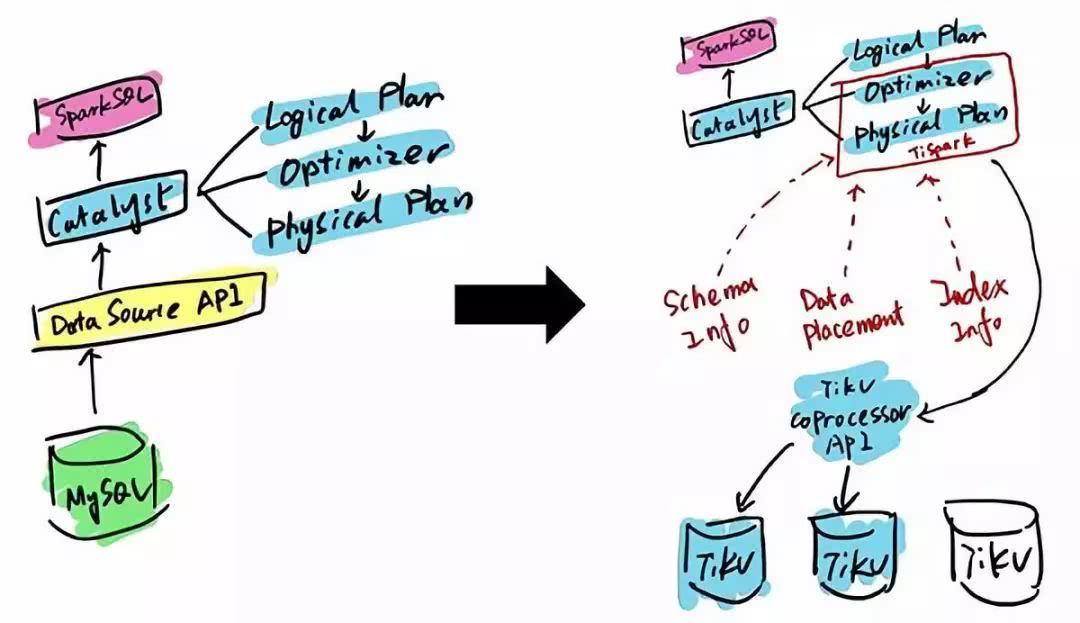
TiDB 本身是一个分布式系统,第三种使用场景是将 TiDB 当作数据仓库使用。TPC-H 是数据分析领域的一个测试集,TiDB 2.0 在 OLAP 场景下的性能有了大幅提升,原来只能在数据仓库里面跑的一些复杂的 Query,在 TiDB 2.0 里面跑,时间基本都能控制在 10 秒以内。当然,因为 OLAP 的范畴非常大,TiDB 的 SQL 也有搞不定的情况,为此 PingCAP 开源了 TiSpark,TiSpark 是一个 Spark 插件,用户可以直接用 Spark SQL 实时地在 TiKV 上做大数据分析。
2.5.4 作为其他系统的模块
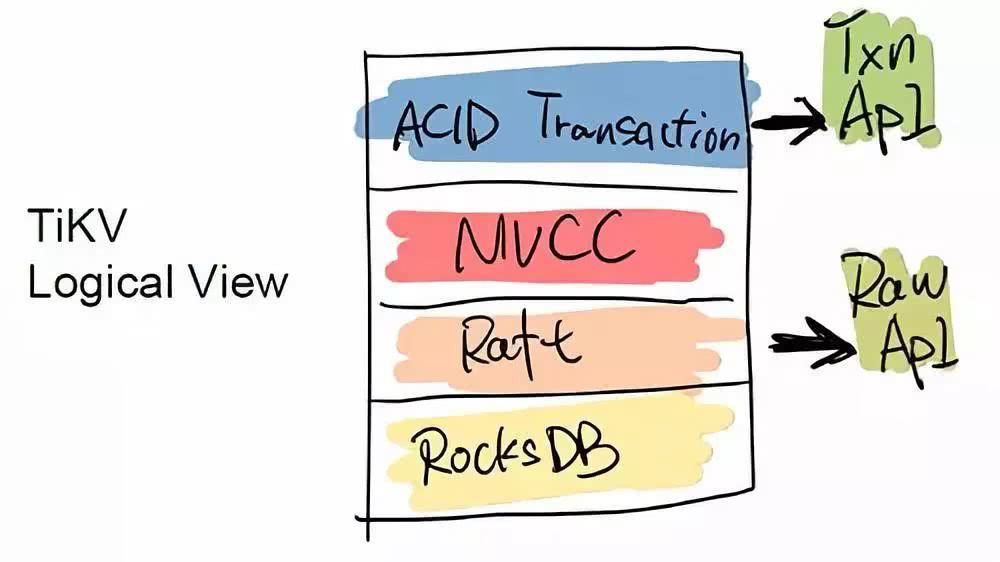
TiDB 是一个传统的存储跟计算分离的项目,其底层的 Key-Value 层,可以单独作为一个 HBase 的 Replacement 来用,它同时支持跨行事务。TiDB 对外提供两个 API 接口,一个是 ACID Transaction 的 API,用于支持跨行事务;另一个是 Raw API,它可以做单行的事务,换来的是整个性能的提升,但不提供跨行事务的 ACID 支持。用户可以根据自身的需求在两个 API 之间自行选择。例如有一些用户直接在 TiKV 之上实现了 Redis 协议,将 TiKV 替换一些大容量,对延迟要求不高的 Redis 场景。
2.6 应用案例

3. TiDB与MySQL兼容性对比
- TiDB支持MySQL传输协议及其绝大多数的语法。这意味着您现有的MySQL连接器和客户端都可以继续使用。 大多数情况下您现有的应用都可以迁移至 TiDB,无需任何代码修改。
- 当前TiDB服务器官方支持的版本为MySQL 5.7。大部分MySQL运维工具(如PHPMyAdmin, Navicat, MySQL Workbench等),以及备份恢复工具(如 mysqldump, Mydumper/myloader)等都可以直接使用。
- 不过一些特性由于在分布式环境下没法很好的实现,目前暂时不支持或者是表现与MySQL有差异
- 一些MySQL语法在TiDB中可以解析通过,但是不会做任何后续的处理,例如Create Table语句中Engine,是解析并忽略。
3.1 TiDB不支持的MySql特性
- 存储过程与函数
- 触发器
- 事件
- 自定义函数
- 外键约束
- 临时表
- 全文/空间函数与索引
- 非
ascii/latin1/binary/utf8/utf8mb4的字符集 - SYS schema
- MySQL 追踪优化器
- XML 函数
- X-Protocol
- Savepoints
- 列级权限
XA语法(TiDB 内部使用两阶段提交,但并没有通过 SQL 接口公开)CREATE TABLE tblName AS SELECT stmt语法CHECK TABLE语法CHECKSUM TABLE语法GET_LOCK和RELEASE_LOCK函数
3.2 自增ID
TiDB 的自增列仅保证唯一,也能保证在单个 TiDB server 中自增,但不保证多个 TiDB server 中自增,不保证自动分配的值的连续性,建议不要将缺省值和自定义值混用,若混用可能会收 Duplicated Error 的错误信息。
TiDB 可通过 tidb_allow_remove_auto_inc 系统变量开启或者关闭允许移除列的 AUTO_INCREMENT 属性。删除列属性的语法是:alter table modify 或 alter table change。
TiDB 不支持添加列的 AUTO_INCREMENT 属性,移除该属性后不可恢复。
3.3 SELECT 的限制
- 不支持
SELECT ... INTO @变量语法。 - 不支持
SELECT ... GROUP BY ... WITH ROLLUP语法。 - TiDB 中的
SELECT .. GROUP BY expr的返回结果与 MySQL 5.7 并不一致。MySQL 5.7 的结果等价于GROUP BY expr ORDER BY expr。而 TiDB 中该语法所返回的结果并不承诺任何顺序,与 MySQL 8.0 的行为一致。
3.4 视图
目前TiDB不支持对视图进行UPDATE、INSERT、DELETE等写入操作。
3.5 默认设置差异
3.5.1 字符集
- TiDB 默认:
utf8mb4。 - MySQL 5.7 默认:
latin1。 - MySQL 8.0 默认:
utf8mb4。
3.5.2 排序规则
- TiDB 中
utf8mb4字符集默认:utf8mb4_bin。 - MySQL 5.7 中
utf8mb4字符集默认:utf8mb4_general_ci。 - MySQL 8.0 中
utf8mb4字符集默认:utf8mb4_0900_ai_ci。
3.5.3 大小写敏感
关于
lower_case_table_names的配置
- TiDB 默认:
2,且仅支持设置该值为2。 - MySQL 默认如下:
- Linux 系统中该值为
0 - Windows 系统中该值为
1 - macOS 系统中该值为
2
- Linux 系统中该值为
3.5.3.1 参数解释
- lower_case_table_names=0 表名存储为给定的大小和比较是区分大小写的
- lower_case_table_names = 1 表名存储在磁盘是小写的,但是比较的时候是不区分大小写
- lower_case_table_names=2 表名存储为给定的大小写但是比较的时候是小写的
3.5.4 timestamp类型字段更新
默认情况下,timestamp类型字段所在数据行被更新时,该字段会自动更新为当前时间,而参数explicit_defaults_for_timestamp控制这一种行为。
- TiDB 默认:
ON,且仅支持设置该值为ON。 - MySQL 5.7 默认:
OFF。 - MySQL 8.0 默认:
ON。
3.5.4.1 参数解释
- explicit_defaults_for_timestamp=off,数据行更新时,timestamp类型字段更新为当前时间
- explicit_defaults_for_timestamp=on,数据行更新时,timestamp类型字段不更新为当前时间。
3.5.5 外键支持
- TiDB 默认:
OFF,且仅支持设置该值为OFF。 - MySQL 5.7 默认:
ON。
4. 集群部署
4.1 环境要求
4.1.1 操作系统建议配置
TiDB 作为一款开源分布式 NewSQL 数据库,可以很好的部署和运行在 Intel 架构服务器环境、ARM 架构的服务器环境及主流虚拟化环境,并支持绝大多数的主流硬件网络。作为一款高性能数据库系统,TiDB 支持主流的 Linux 操作系统环境。
| Linux 操作系统平台 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.3 及以上 |
| CentOS | 7.3 及以上 |
| Oracle Enterprise Linux | 7.3 及以上 |
| Ubuntu LTS | 16.04 及以上 |
4.1.2 服务器建议配置
TiDB 支持部署和运行在 Intel x86-64 架构的 64 位通用硬件服务器平台或者 ARM 架构的硬件服务器平台。对于开发,测试,及生产环境的服务器硬件配置(不包含操作系统 OS 本身的占用)有以下要求和建议:
4.1.2.1 开发及测试环境
| 组件 | CPU | 内存 | 本地存储 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 8 核+ | 16 GB+ | 无特殊要求 | 千兆网卡 | 1(可与 PD 同机器) |
| PD | 4 核+ | 8 GB+ | SAS, 200 GB+ | 千兆网卡 | 1(可与 TiDB 同机器) |
| TiKV | 8 核+ | 32 GB+ | SSD, 200 GB+ | 千兆网卡 | 3 |
| TiFlash | 32 核+ | 64 GB+ | SSD, 200 GB+ | 千兆网卡 | 1 |
| TiCDC | 8 核+ | 16 GB+ | SAS, 200 GB+ | 千兆网卡 | 1 |
4.1.2.2 生产环境
| 组件 | CPU | 内存 | 硬盘类型 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 16 核+ | 32 GB+ | SAS | 万兆网卡(2 块最佳) | 2 |
| PD | 4核+ | 8 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiKV | 16 核+ | 32 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiFlash | 48 核+ | 128 GB+ | 1 or more SSDs | 万兆网卡(2 块最佳) | 2 |
| TiCDC | 16 核+ | 64 GB+ | SSD | 万兆网卡(2 块最佳) | 2 |
| 监控 | 8 核+ | 16 GB+ | SAS | 千兆网卡 | 1 |
4.2 环境准备
准备一台部署主机,确保其软件满足需求:
- 推荐安装 CentOS 7.3 及以上版本
- Linux 操作系统开放外网访问,用于下载 TiDB 及相关软件安装包
最小规模的 TiDB 集群拓扑
| 实例 | 个数 | IP | 配置 |
|---|---|---|---|
| TiKV | 3 | 192.168.64.146 | 避免端口和目录冲突 |
| TiDB | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| PD | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| TiFlash | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| Monitoring & Grafana | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
4.3 安装TiUP
4.3.1 什么是TiUP
从 TiDB 4.0 版本开始,TiUP 作为新的工具,承担着包管理器的角色,管理着 TiDB 生态下众多的组件,如 TiDB、PD、TiKV 等。用户想要运行 TiDB 生态中任何组件时,只需要执行 TiUP 一行命令即可,相比以前,极大地降低了管理难度。
4.3.2 安装TiUP组件
使用普通用户登录中控机,以 tidb 用户为例,后续安装 TiUP 及集群管理操作均通过该用户完成
TiUP 安装过程十分简洁,无论是 Darwin 还是 Linux 操作系统,执行一行命令即可安装成功:
1 | curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh |
该命令将 TiUP 安装在 $HOME/.tiup 文件夹下,之后安装的组件以及组件运行产生的数据也会放在该文件夹下。同时,它还会自动将 $HOME/.tiup/bin 加入到 Shell Profile 文件的 PATH 环境变量中,这样你就可以直接使用 TiUP 了。

4.3.3 配置TiUP环境
重新声明全局环境变量
1 | source .bash_profile |
4.3.4 检查TiUP 工具是否安装
1 | which tiup |

4.3.5 安装 cluster 组件
1 | tiup cluster |
4.3.6 升级cluster组件
如果机器已经安装 TiUP cluster,需要更新软件版本
1 | tiup update --self && tiup update cluster |
预期输出
“Update successfully!”字样。

4.4 编辑部署文件
请根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。
4.4.1 常见的部署场景(自学)
4.4.1.1 最小拓扑架构
最基本的集群拓扑,包括 tidb-server、tikv-server、pd-server,适合 OLTP 业务。
4.4.1.2 增加 TiFlash 拓扑架构
包含最小拓扑的基础上,同时部署 TiFlash。TiFlash 是列式的存储引擎,已经逐步成为集群拓扑的标配。适合 Real-Time HTAP 业务。
4.4.1.3 增加 TiCDC 拓扑架构
包含最小拓扑的基础上,同时部署 TiCDC。TiCDC 是 4.0 版本开始支持的 TiDB 增量数据同步工具,支持多种下游 (TiDB/MySQL/MQ)。相比于 TiDB Binlog,TiCDC 有延迟更低、天然高可用等优点。在部署完成后,需要启动 TiCDC,通过 cdc cli 创建同步任务。
4.4.1.4 增加 TiDB Binlog 拓扑架构
包含最小拓扑的基础上,同时部署 TiDB Binlog。TiDB Binlog 是目前广泛使用的增量同步组件,可提供准实时备份和同步功能。
4.4.1.5 增加 TiSpark 拓扑架构
包含最小拓扑的基础上,同时部署 TiSpark 组件。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。TiUP cluster 组件对 TiSpark 的支持目前为实验性特性。
4.4.1.6 混合部署拓扑架构
适用于单台机器,混合部署多个实例的情况,也包括单机多实例,需要额外增加目录、端口、资源配比、label 等配置。
4.4.2 单机极简部署
部署主机软件和环境要求:
- 部署需要使用部署主机的 root 用户及密码
- 部署主机关闭防火墙或者开放 TiDB 集群的节点间所需端口
4.4.2..1 单机极简拓扑
| 实例 | IP | 开放端口 |
|---|---|---|
| grafana | 192.168.64.152 | 3000 |
| pd | 192.168.64.152 | 2379/2380 |
| prometheus | 192.168.64.152 | 9090 |
| tidb | 192.168.64.152 | 4000/10080 |
| tiflash | 192.168.64.152 | 9000/8123/3930/20170/20292/8234 |
| tikv | 192.168.64.152 | 20160/20180 |
| tikv | 192.168.64.152 | 20161/20181 |
| tikv | 192.168.64.152 | 20162/20182 |
4.4.2.2 编辑配置文件
按下面的配置模板,编辑配置文件,命名为
topo.yaml
user: "tidb":表示通过tidb系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行host:设置为本部署主机的 IP
1 | # # Global variables are applied to all deployments and used as the default value of |
4.5 执行集群部署命令
4.5.1 命令格式
1 | tiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p |
4.5.11 参数解释
- 参数
<cluster-name>表示设置集群名称 - 参数
<tidb-version>表示设置集群版本,可以通过tiup list tidb命令来查看当前支持部署的 TiDB 版本 - 参数:
--user root通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。
4.5.2 检查TiDB最新版本
可以通过执行
tiup list tidb来查看 TiUP 支持的版本
1 | tiup list tidb |
经过执行发现 可用的TiDB版本有 v5.3.0
4.5.3 执行部署命令
1 | tiup cluster deploy tidb-cluster 5.3.0 ./topo.yaml --user root -p |
下面输入
y继续后输入密码进行安装界面
进入安装界面,等待安装即可
如果出现
deployed successfully表示部署成功,集群名称是tidb-cluster
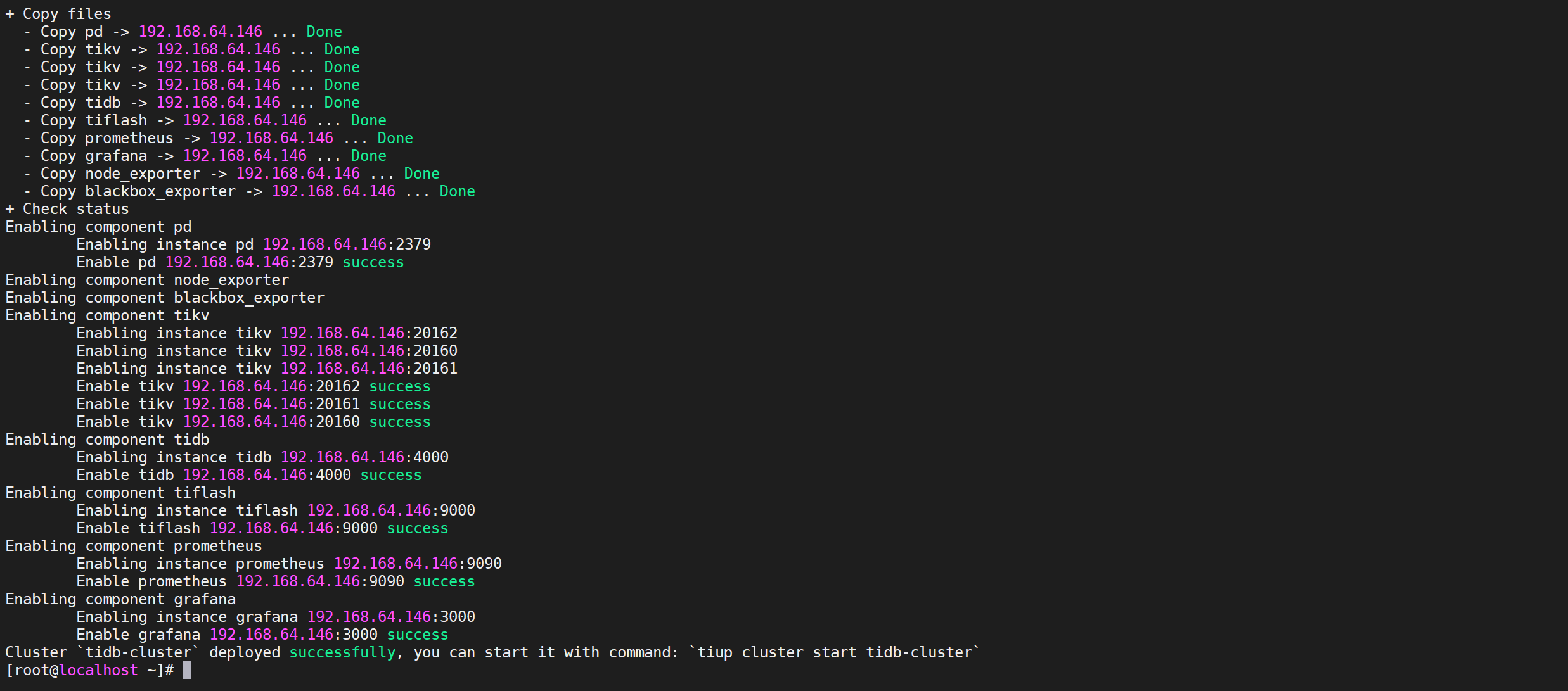
4.5.4 启动集群
1 | tiup cluster start tidb-cluster |
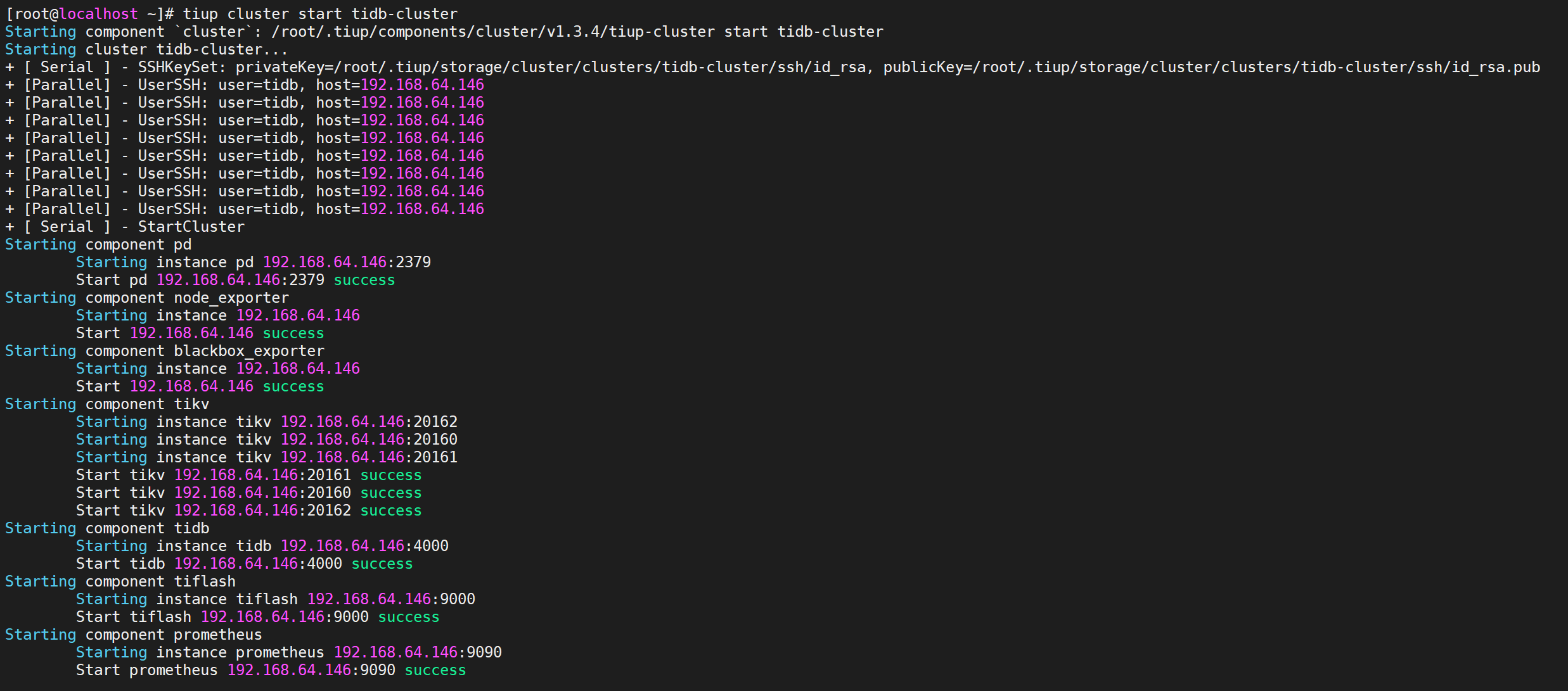
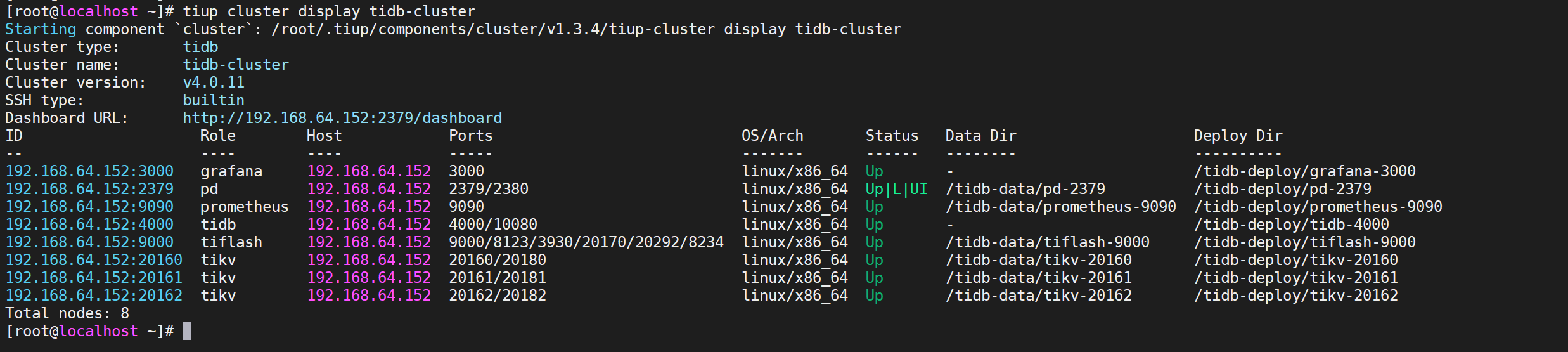
4.5.5 查看节点状态
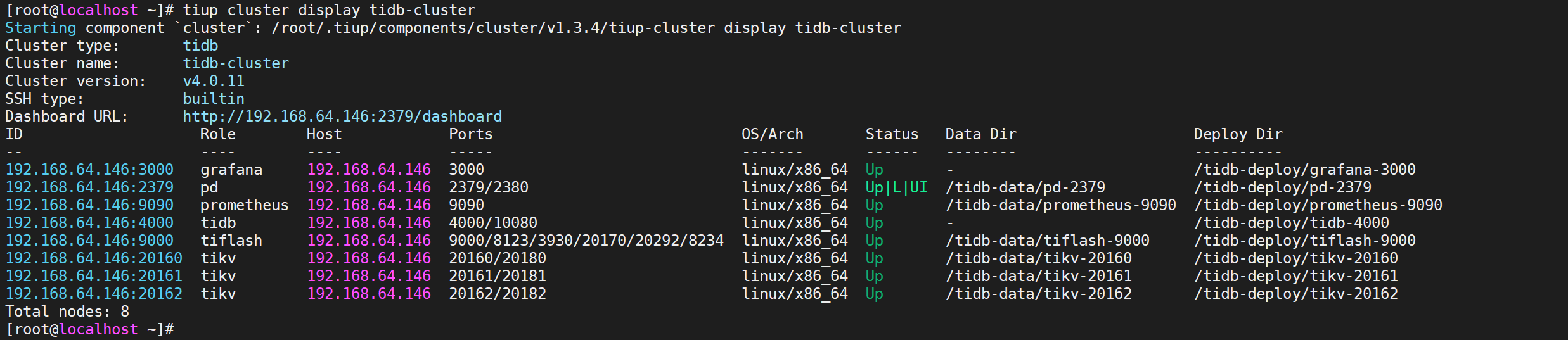
1 | tiup cluster display tidb-cluster |
所有节点都是Up状态说明都已经启动就绪了
5. 测试TiDB集群
5.1 Mysql连接集群
TiDB的连接端口默认是4000, 密码是空,可用使用Mysql客户端以及第三方工具进行连接
5.1.1 安装MySql客户端
1 | yum -y install mysql |
5.1.1.1 MySql客户端连接
访问 TiDB 数据库,密码为空
1 | mysql -h 192.168.64.146 -P 4000 -u root |

5.1.2 第三方客户端访问Mysql
使用SQLyog访问TiDB
5.1.2.1 创建TiDB连接
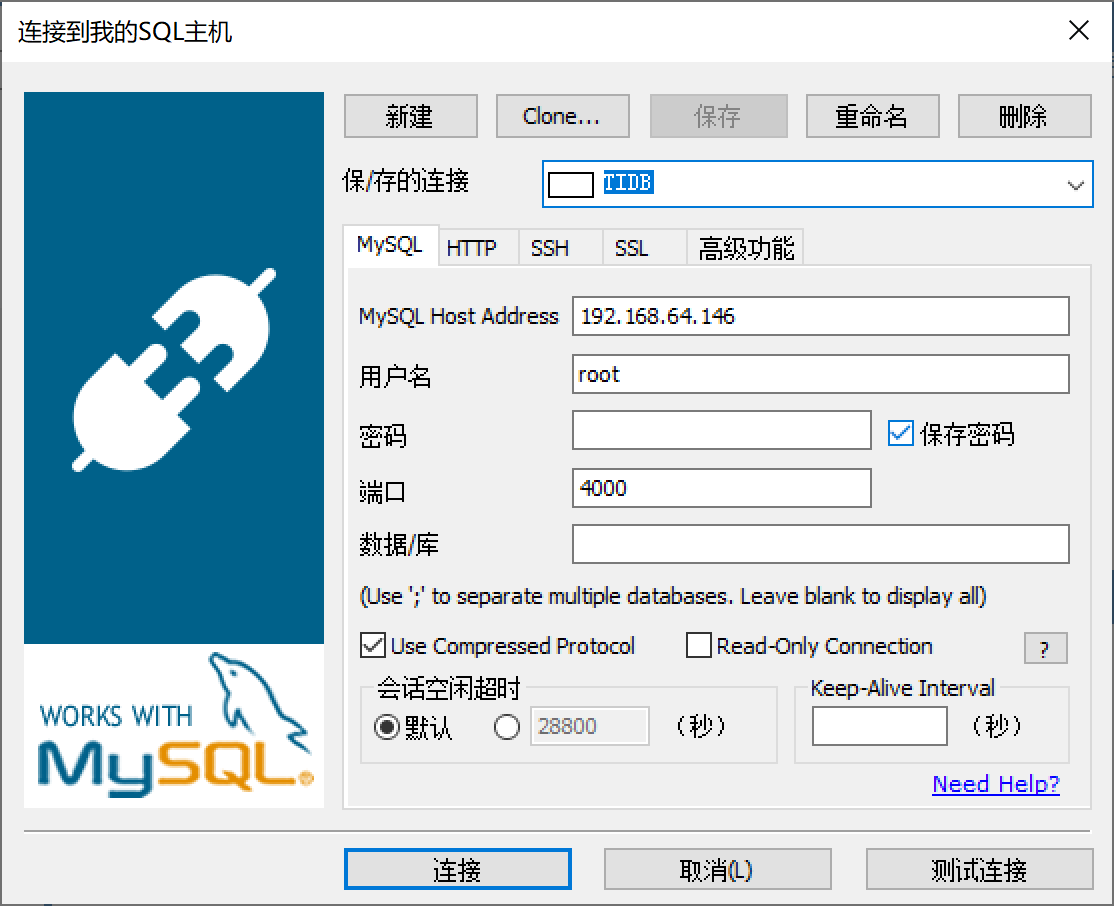
连接后就可以操作数据库了
5.2 访问Grafana监控
通过 http://{grafana-ip}:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。
5.3 访问Dashboard
通过 http://{pd-ip}:2379/dashboard 访问集群 TiDB Dashboard监控页面,默认用户名为 root,密码为空。
5.4 查看集群列表
1 | tiup cluster list |

5.5 查看集群拓扑
1 | tiup cluster display tidb-cluster |
6. 将MySql数据迁移到TiDB
6.1 MySQL环境准备
6.1.1 MySQL测试数据库
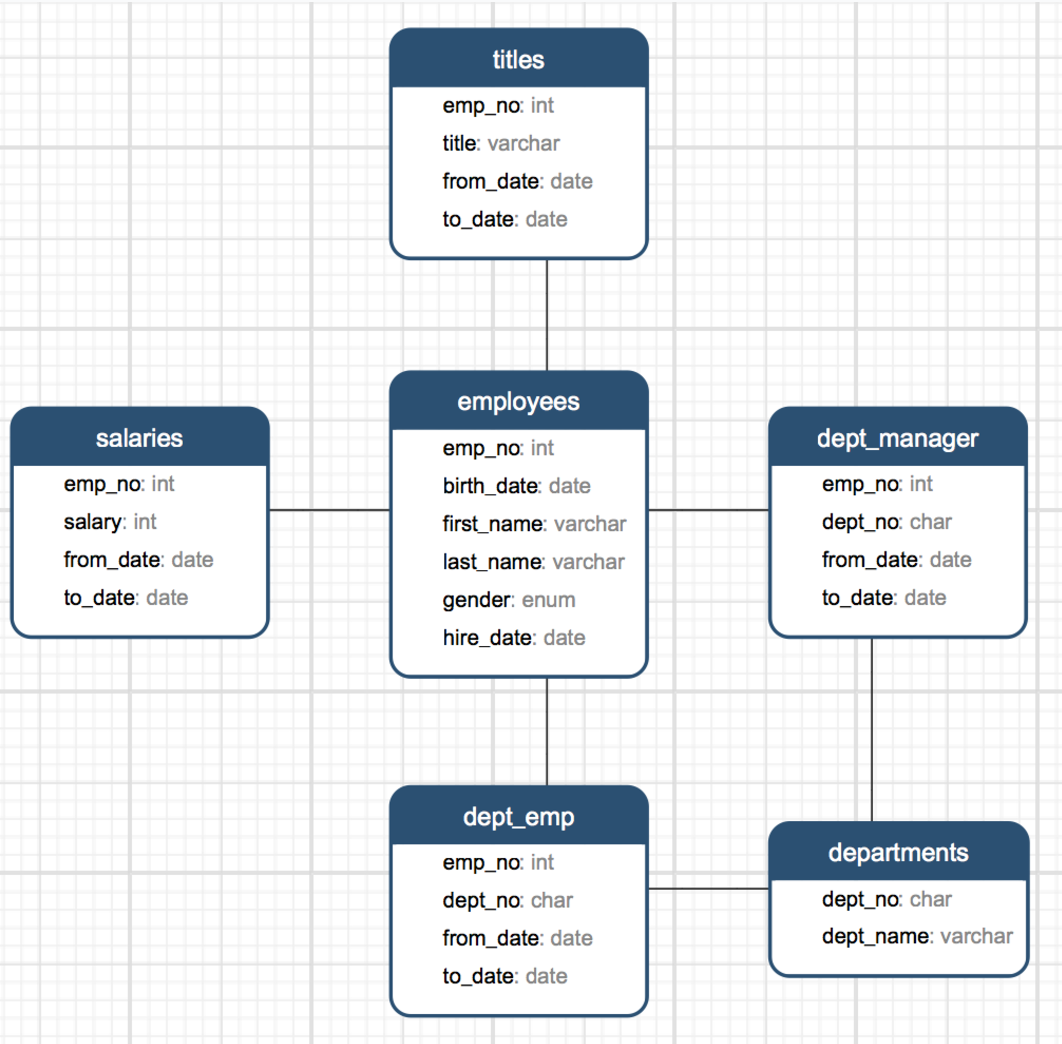
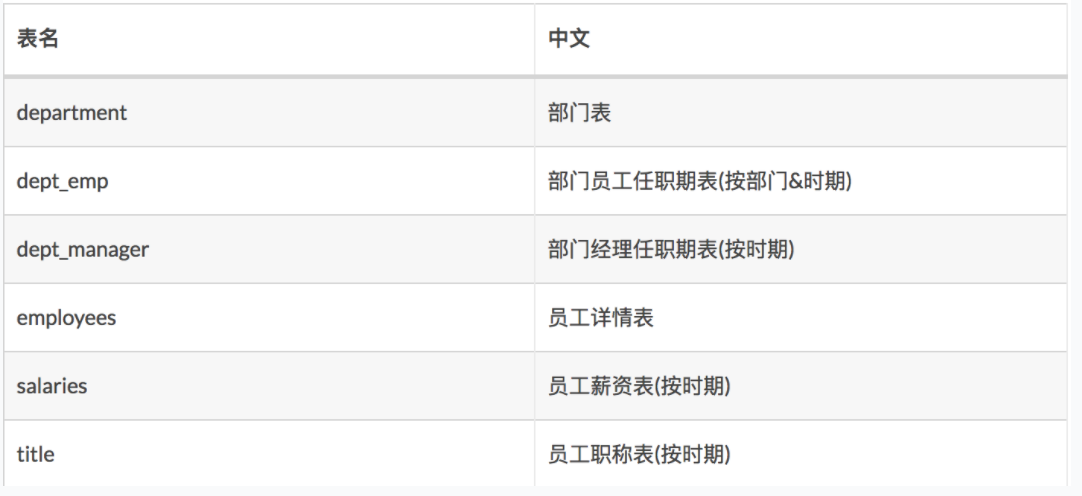
Mysql 官方提供了了一套名为:Employees Sample Database 的测试库(该测试库含有6个表,总计4百万数据记录)
表结构
6.1.1.1 导入数据
下载后解压
test_db-master.zip,然后登录 mysql 导入即可
1 | mysql -u root -p < employees.sql |

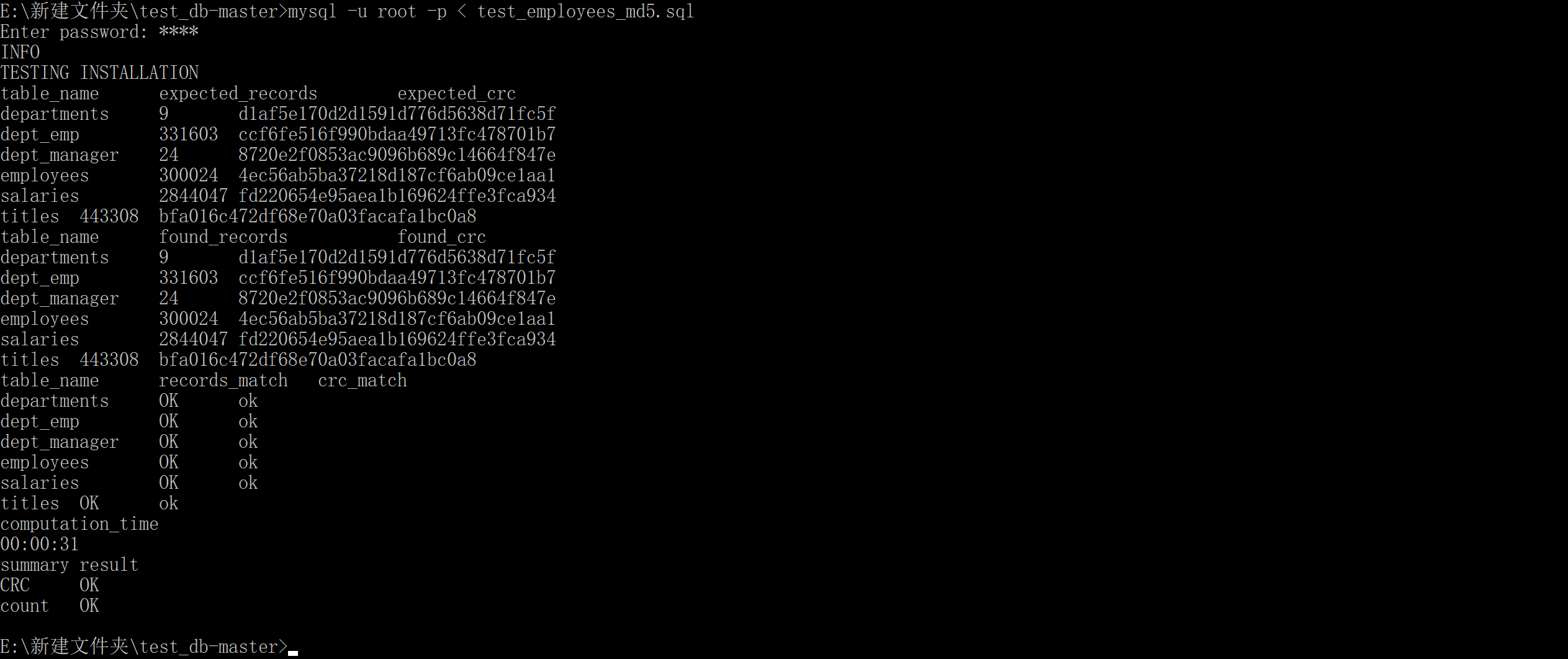
6.1.1.2 验证是否成功
1 | mysql -u root -p < test_employees_md5.sql |
6.2 DM数据迁移
6.2.1 TiUP DM 组件简介
TiDB Data Migration (DM) 是一体化的数据迁移任务管理工具,支持从与 MySQL 协议兼容的数据库(MySQL、MariaDB、Aurora MySQL)到 TiDB 的数据迁移,DM 工具旨在降低数据迁移的运维成本。
6.2.1.1 基本功能
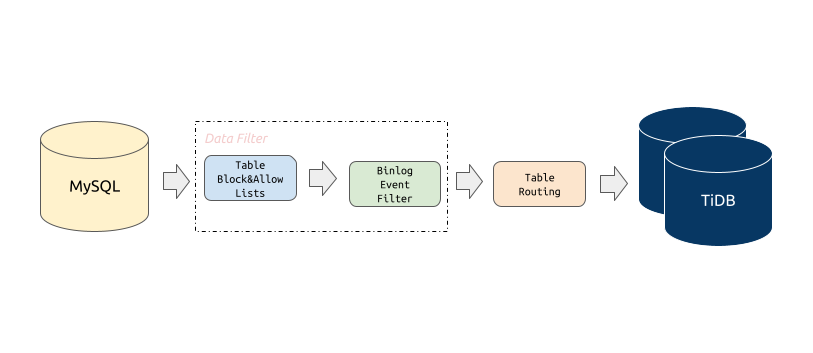
Block & allow lists
上游数据库实例表的黑白名单过滤规则,可以用来过滤或者只迁移某些
database/table的所有操作。
Block & Allow Lists 的过滤规则类似于 MySQL replication-rules-db/replication-rules-table,用于过滤或指定只迁移某些数据库或某些表的所有操作。
1 | block-allow-list: # 如果 DM 版本 <= v2.0.0-beta.2 则使用 black-white-list。 |
do-dbs:要迁移的库的白名单,类似于 MySQL 中的replicate-do-db。ignore-dbs:要迁移的库的黑名单,类似于 MySQL 中的replicate-ignore-db。do-tables:要迁移的表的白名单,类似于 MySQL 中的replicate-do-table。ignore-tables:要迁移的表的黑名单,类似于 MySQL 中的replicate-ignore-table。
以上参数值以
~开头时均支持使用正则表达式来匹配库名、表名。
Binlog event filter
Binlog event filter 是比迁移表黑白名单更加细粒度的过滤规则,可以指定只迁移或者过滤掉某些
schema / table的指定类型 binlog,比如INSERT、TRUNCATE TABLE。
Binlog Event Filter 用于过滤源数据库中特定表的特定类型操作,比如过滤掉表 test.sbtest 的 INSERT 操作或者过滤掉库 test 下所有表的 TRUNCATE TABLE 操作。
1 | filters: |
schema-pattern/table-pattern:对匹配上的上游 MySQL/MariaDB 实例的表的 binlog events 或者 DDL SQL 语句通过以下规则进行过滤。events:binlog events 数组,仅支持从以下Event中选择一项或多项。Event 分类 解释 all 代表包含下面所有的 events all dml 代表包含下面所有 DML events all ddl 代表包含下面所有 DDL events none 代表不包含下面所有 events none ddl 代表不包含下面所有 DDL events none dml 代表不包含下面所有 DML events insert DML insert DML event update DML update DML event delete DML delete DML event create database DDL create database event drop database DDL drop database event create table DDL create table event create index DDL create index event drop table DDL drop table event truncate table DDL truncate table event rename table DDL rename table event drop index DDL drop index event alter table DDL alter table event sql-pattern:用于过滤指定的 DDL SQL 语句,支持正则表达式匹配,例如上面示例中的"^DROP\\s+PROCEDURE"。
Table routing
Table routing 提供将上游 MySQL/MariaDB 实例的某些表迁移到下游指定表的功能。
Table Routing 是将源数据库的表迁移到下游指定表的路由功能,比如将源数据表 test.sbtest1 的数据同步到 TiDB 的表 test.sbtest2。它也是分库分表合并迁移所需的一个核心功能。
1 | routes: |
6.2.1.2 使用限制
数据库版本
- 5.5 < MySQL 版本 < 8.0
- MariaDB 版本 >= 10.1.2
DDL 语法兼容性
- 目前,TiDB 部分兼容 MySQL 支持的 DDL 语句。因为 DM 使用 TiDB parser 来解析处理 DDL 语句,所以目前仅支持 TiDB parser 支持的 DDL 语法
- DM 遇到不兼容的 DDL 语句时会报错。要解决此报错,需要使用 dmctl 手动处理,要么跳过该 DDL 语句,要么用指定的 DDL 语句来替换它
6.2.2 TiUP安装 DM组件
6.2.2.1 安装TiUP DM 组件
1 | tiup install dm |
6.2.2.2 更新 TiUP DM 组件
如果已经安装,则更新 TiUP DM 组件至最新版本:
1 | tiup update --self && tiup update dm |
预期输出
Update successfully!字样。

6.2.3 TiUP部署 DM组件
6.2.3.1 编辑初始化配置
需要根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。
新建一个配置文件
topology.yaml,部署 1 个 DM-master、1个 DM-worker 的配置如下
1 | vi topology.yaml |
注意:
- 如果不需要确保 DM 集群高可用,则可只部署 1 个 DM-master 节点,且部署的 DM-worker 节点数量不少于上游待迁移的 MySQL/MariaDB 实例数。
- 如果需要确保 DM 集群高可用,则推荐部署 3 个 DM-master 节点,且部署的 DM-worker 节点数量大于上游待迁移的 MySQL/MariaDB 实例数(如 DM-worker 节点数量比上游实例数多 2 个)。
6.2.3.2 部署命令格式
通过 TiUP 进行集群部署可以使用密钥或者交互密码方式来进行安全认证:
- 如果是密钥方式,可以通过
-i或者--identity_file来指定密钥的路径; - 如果是密码方式,可以通过
-p进入密码交互窗口; - 如果已经配置免密登录目标机,则不需填写认证。
1 | tiup dm deploy dm-test ${version} ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa] |
以上部署命令中:
- 通过 TiUP DM 部署的集群名称为
dm-test。 --user root:通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。-i及-p:非必选项,如果已经配置免密登录目标机,则不需填写,否则选择其一即可。-i为可登录到目标机的 root 用户(或--user指定的其他用户)的私钥,也可使用-p交互式输入该用户的密码。
预期日志结尾输出会有
Deployed clusterdm-testsuccessfully关键词,表示部署成功。
6.2.3.3 检查最新版本DM组件
部署版本为
${version},可以通过执行tiup list dm-master来查看 TiUP 支持的最新版本
1 | tiup list dm-master |

我们发现最新版本是v2.0.1
6.2.3.4 执行部署命令
1 | tiup dm deploy dm-test 5.3.0 ./topology.yaml --user root -p |
出现如下界面,选择y继续,输入密码后继续安装
继续安装后,安装完成后输出
deployed successfully代表安装完成
6.2.3.5 TiUP 查看集群情况
TiUP 支持管理多个 DM 集群,该命令会输出当前通过 TiUP DM 管理的所有集群信息,包括集群名称、部署用户、版本、密钥信息等
1 | tiup dm list |

6.2.3.6 检查部署的 DM 集群
执行如下命令检查
dm-test集群情况
1 | tiup dm display dm-test |

预期输出包括 dm-test 集群中实例 ID、角色、主机、监听端口和状态(由于还未启动,所以状态为 Down/inactive)、目录信息。
6.2.3.7 启动集群
预期结果输出
Started clusterdm-testsuccessfully表示启动成功。
1 | tiup dm start dm-test |
6.2.3.8 验证集群运行状态
在输出结果中,如果 Status 状态信息为
Up,说明集群状态正常。
1 | tiup dm display dm-test |

6.2.4 安装dmctl 运维组件
dmctl 是用来运维 DM 集群的命令行工具,支持交互模式和命令模式。
6.2.4.1 检查dmctl最新版本
通过如下命令可用查看
dmctl版本列表
1 | tiup list dmctl |
我们发现 最新版本是
v2.0.1

6.2.4.2 安装dmctl组件
通过如下命令可用安装dmctl组件,冒号后面是需要安装的版本号
1 | tiup install dmctl:v5.3.0 |

6.2.5 使用 DM 迁移数据
6.2.4.1 需要的权限
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
- REPLICATION SLAVE
6.2.4.2 MySQL服务授权
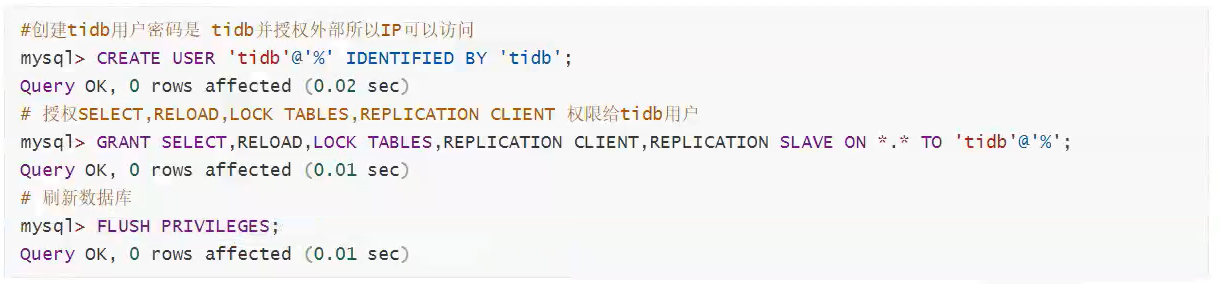
1 | GRANT SELECT,RELOAD,LOCK TABLES,REPLICATION CLIENT,REPLICATION SLAVE ON *.* TO 'tidb'@'%'; |
6.2.4.3 打开mysql的binlog
因为DM同步需要MySQL开启binlog日志,修改my.cnf配置文件,并重启
1 | [mysqld] |
6.2.4.4 MySQL检查
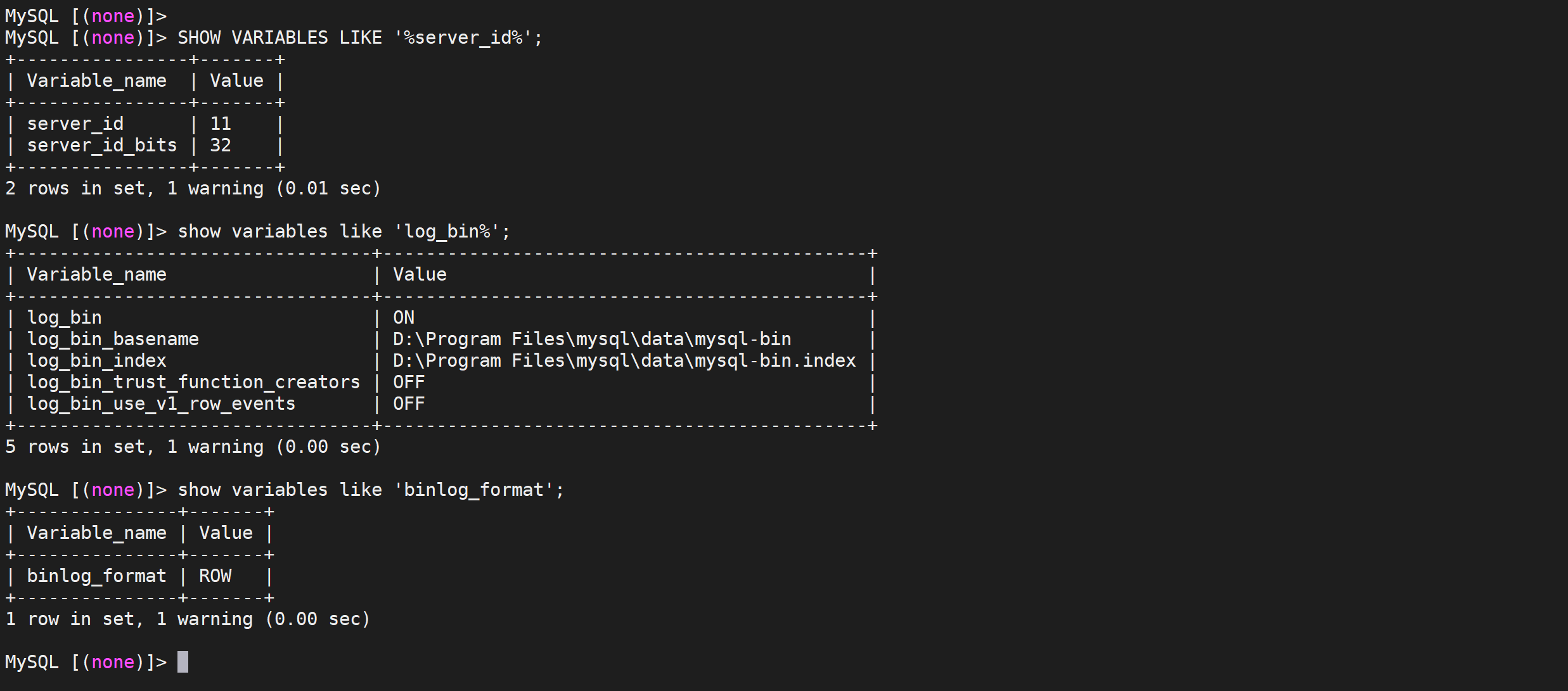
1 | SHOW VARIABLES LIKE '%server_id%'; |
6.2.4.5 加密数据库密码
在 DM 相关配置文件中,推荐使用经 dmctl 加密后的密码,对于同一个原始密码,每次加密后密码不同。
1 | tiup dmctl -encrypt 'tidb' |

加密后的密码是:
mAQsswzaluwbDPkNNv1fH0DGjMZC
6.2.4.6 检查集群信息
使用 TiUP 部署 DM 集群后,相关配置信息如下:
- DM 集群相关组件配置信息
| 组件 | 主机 | 端口 |
|---|---|---|
| dm_worker | 192.168.64.152 | 8262 |
| dm_master | 192.168.64.152 | 8261 |
- 上下游数据库实例相关信息
| 数据库实例 | 主机 | 端口 | 用户名 | 加密密码 |
|---|---|---|---|---|
| 上游 MySQL | 172.16.44.47 | 3306 | tidb | 4hHRKVKVUHpJENL8bEUWpkDsjwFs |
| 下游 TiDB | 192.168.64.152 | 4000 | root |
6.2.4.7 创建数据源
将 MySQL 的相关信息写入到
mysql.yaml中
1 | vi mysql.yaml |
6.2.4.8 MySql数据源加入到DM集群
在终端中执行下面的命令,使用
tiup dmctl将 MySQL 的数据源配置加载到 DM 集群中:
1 | tiup dmctl --master-addr 192.168.245.147:8261 operate-source create mysql.yaml |
出现如下界面返回
true表示添加到集群成功

6.2.4.9 配置任务
假设需要将 MySQL实例的
employees库的 所有 表以全量+增量的模式迁移到下游 TiDB 的employees库 编辑任务配置文件sync_task.yaml
1 | vi sync_task.yaml |
6.2.4.10 MySQL 实例配置前置检查
为了提前发现数据迁移任务的一些配置错误,DM 中增加了前置检查功能:
- 启动数据迁移任务时,DM 自动检查相应的权限和配置。
check-task命令用于对上游 MySQL 实例配置是否满足 DM 要求进行前置检查。
1 | tiup dmctl --master-addr 192.168.245.147:8261 check-task sync_task.yaml |
如果出现返回结果是true表示检查成功

6.2.4.11 开启任务
使用
tiup dmctl执行以下命令启动数据迁移任务。其中,sync_task.yaml是之前编辑的配置文件。
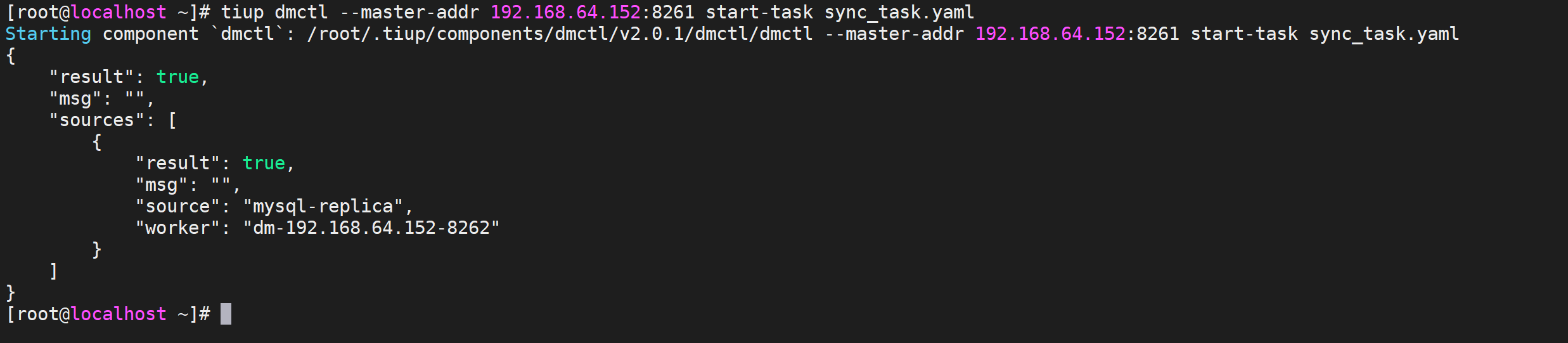
1 | tiup dmctl --master-addr 192.168.245.147:8261 start-task sync_task.yaml |
返回结果为true表示启动成功
6.2.4.12 查询任务
如需了解 DM 集群中是否存在正在运行的迁移任务及任务状态等信息,可使用
tiup dmctl执行以下命令进行查询:
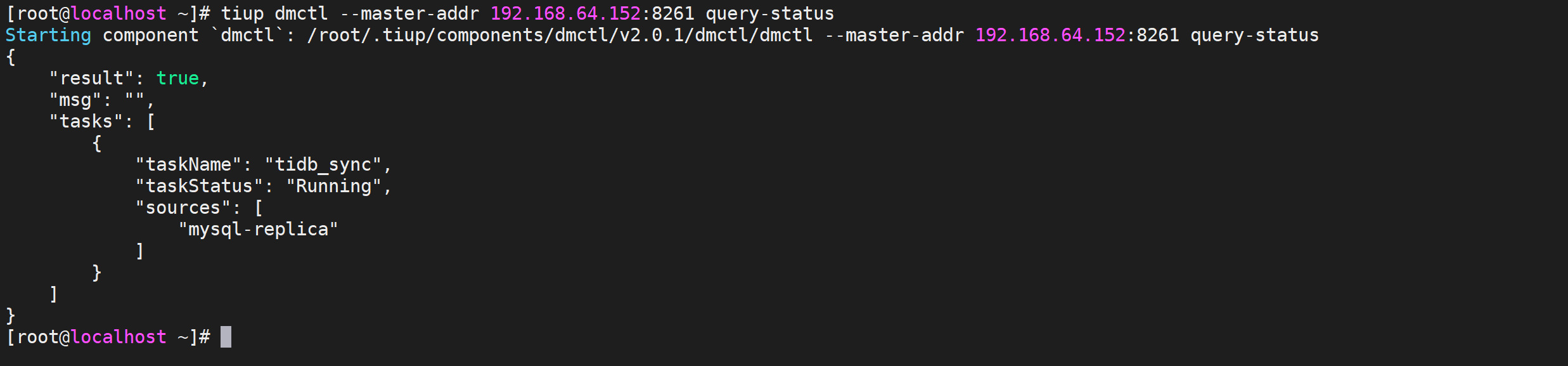
1 | tiup dmctl --master-addr 192.168.245.147:8261 query-status |
query-status命令的查询结果、任务状态与子任务状态
6.2.4.13 查询迁移详情
1 | tiup dmctl --master-addr 192.168.245.146:8261 query-status tidb_sync |
任务详情如下
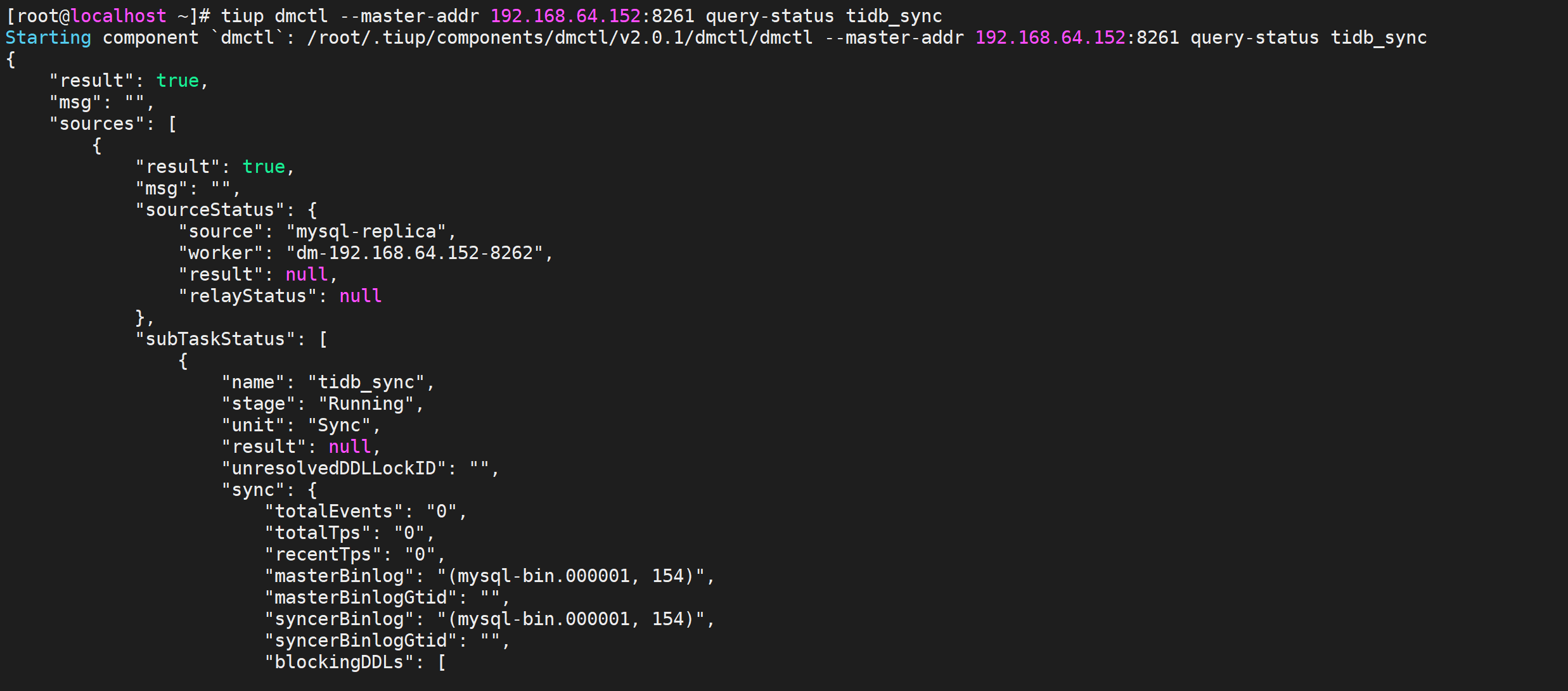
同步文本详情如下
1 | { |
6.2.5 检查全量同步
6.2.5.1 登录TIDB
登录TiDB 查看数据库是否同步
1 | mysql -u root -h 192.168.245.146 -P 4000 -p |

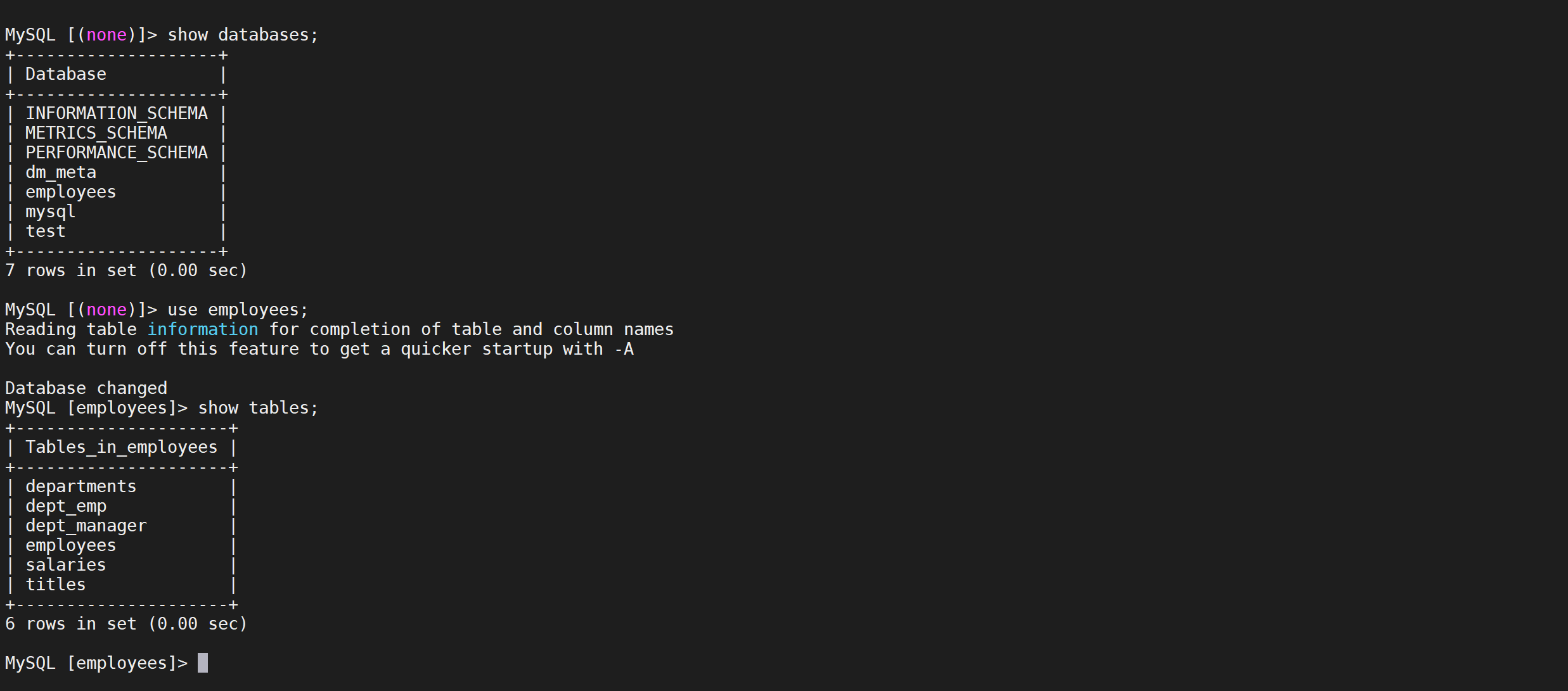
6.2.5.2 查看employees数据库
1 | show databases; |
我们发现数据库已经同步
6.2.6 测试增量同步
6.2.6.1 插入MySQL数据
部门表插入一条数据
1 | INSERT INTO `departments`(dept_no,dept_name)VALUES('d010','test dept'); |
6.2.6.2 更新MySQL数据
将
dept_emp中的d001改为d010
1 | UPDATE dept_emp SET dept_no='d010' WHERE dept_no='d001'; |
共 20211 行受到影响
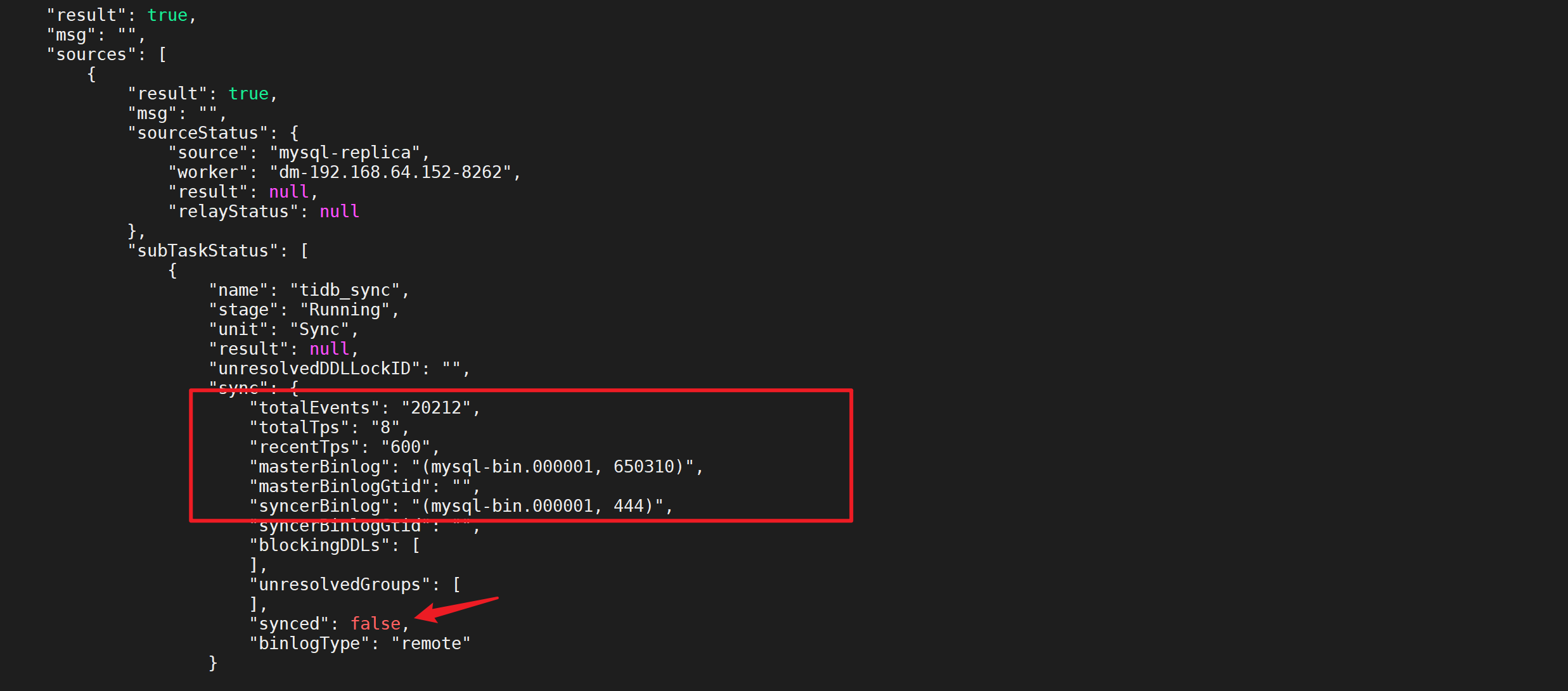
6.2.6.3 查看DM的任务状态
1 | tiup dmctl --master-addr 192.168.64.152:8261 query-status tidb_sync |
“synced”: false正在同步
稍等后在进行查看任务状态,发现已经同步完成
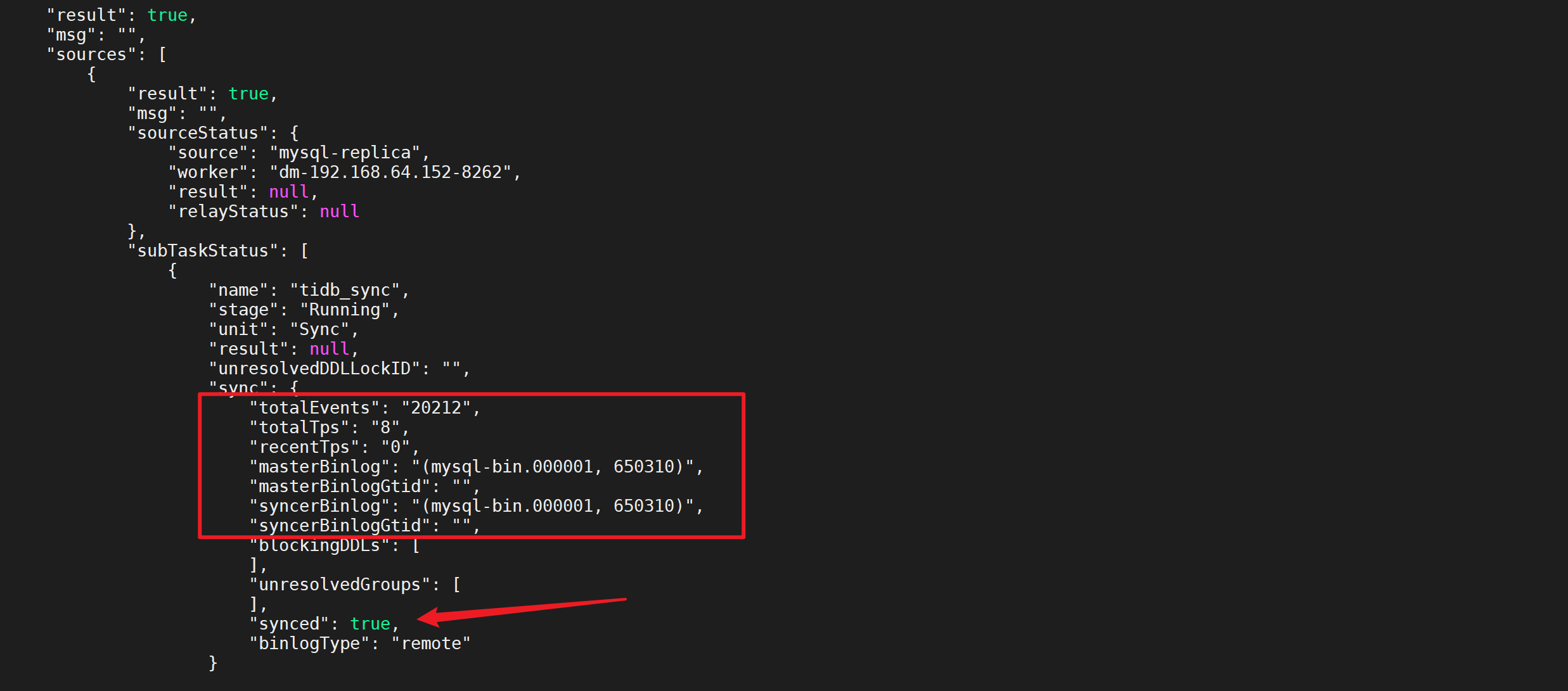
6.2.6.4 检查增量同步数据
登录MySQL后检查MySQL中的数据是否同步到TiDB
1 | mysql -u root -h 192.168.64.152 -P 4000 -p |
我们发现
d010的更新数据都已经同步过来了
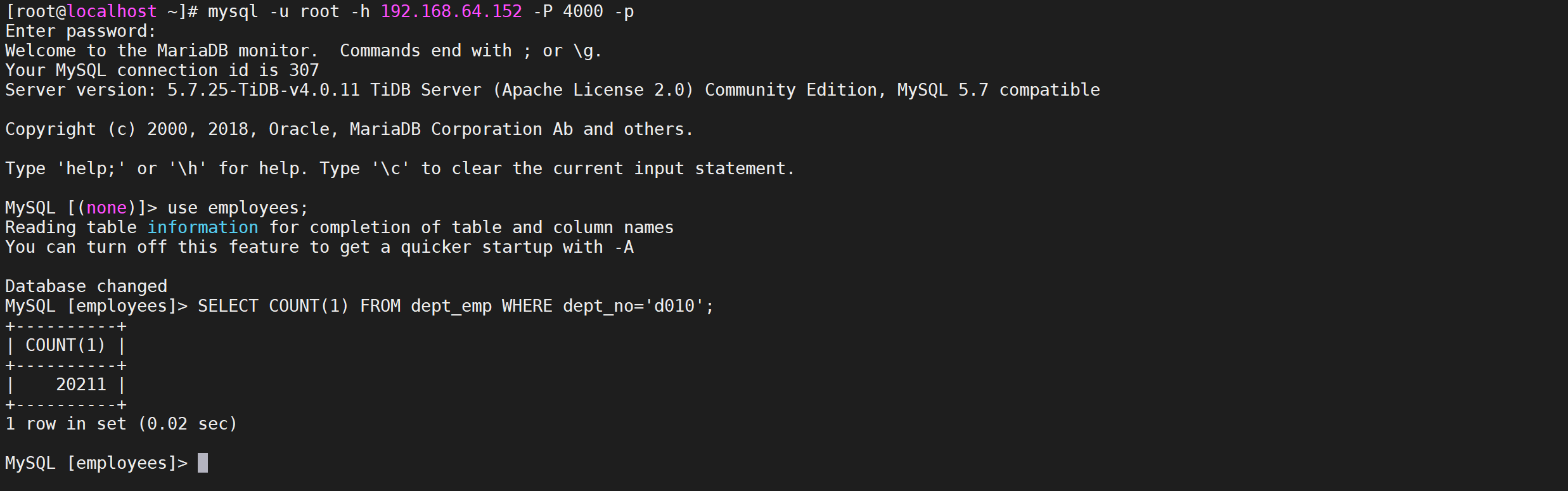
6.5.7 DM的其他操作(自学)
6.2.7.1 暂停数据迁移任务
pause-task命令用于暂停数据迁移任务。有关
pause-task与stop-task的区别如下
- 使用
pause-task仅暂停迁移任务的执行,但仍然会在内存中保留任务的状态信息等,且可通过query-status进行查询;使用stop-task会停止迁移任务的执行,并移除内存中与该任务相关的信息,且不可再通过query-status进行查询,但不会移除已经写入到下游数据库中的数据以及其中的 checkpoint 等dm_meta信息。 - 使用
pause-task暂停迁移任务期间,由于任务本身仍然存在,因此不能再启动同名的新任务,且会阻止对该任务所需 relay log 的清理;使用stop-task停止任务后,由于任务不再存在,因此可以再启动同名的新任务,且不会阻止对 relay log 的清理。 pause-task一般用于临时暂停迁移任务以排查问题等;stop-task一般用于永久删除迁移任务或通过与start-task配合以更新配置信息。
1 | tiup dmctl --master-addr 192.168.64.152:8261 pause-task tidb_sync |
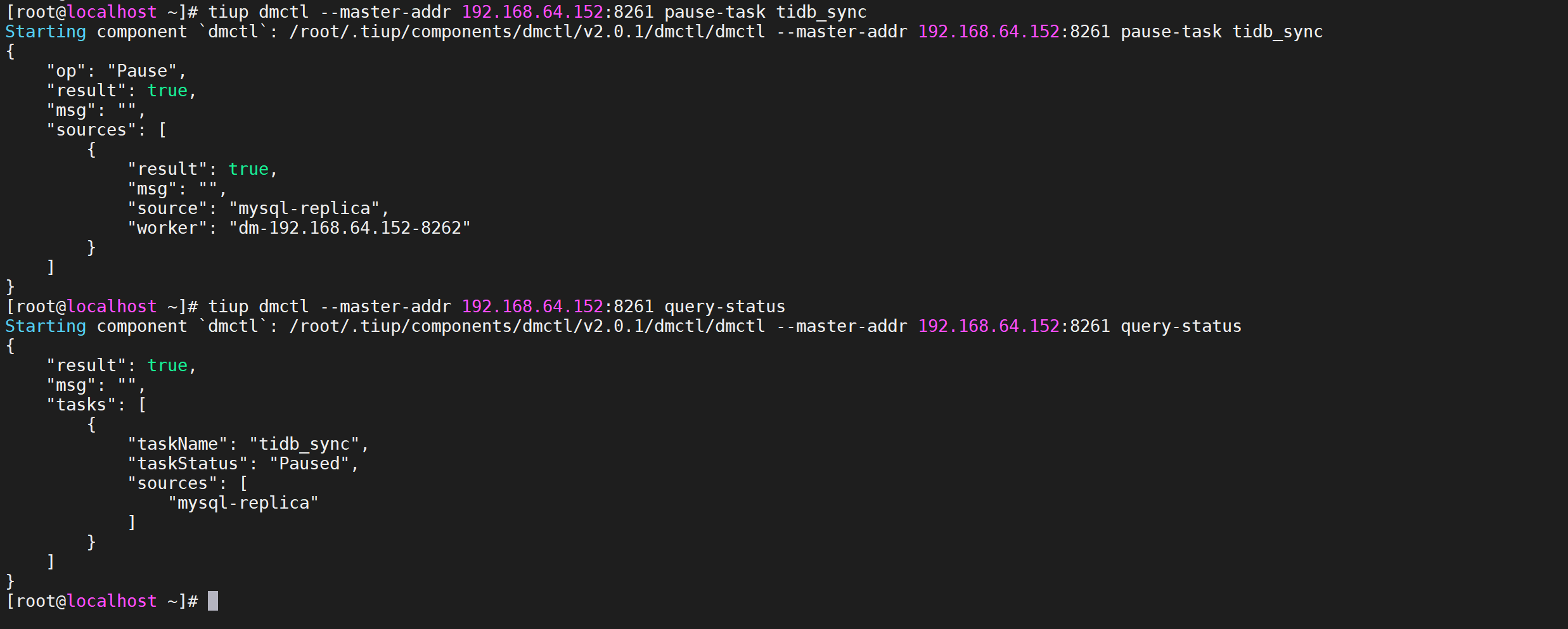
6.2.7.2 恢复数据迁移任务
resume-task命令用于恢复处于Paused状态的数据迁移任务,通常用于在人为处理完造成迁移任务暂停的故障后手动恢复迁移任务。
1 | tiup dmctl --master-addr 192.168.64.152:8261 resume-task tidb_sync |
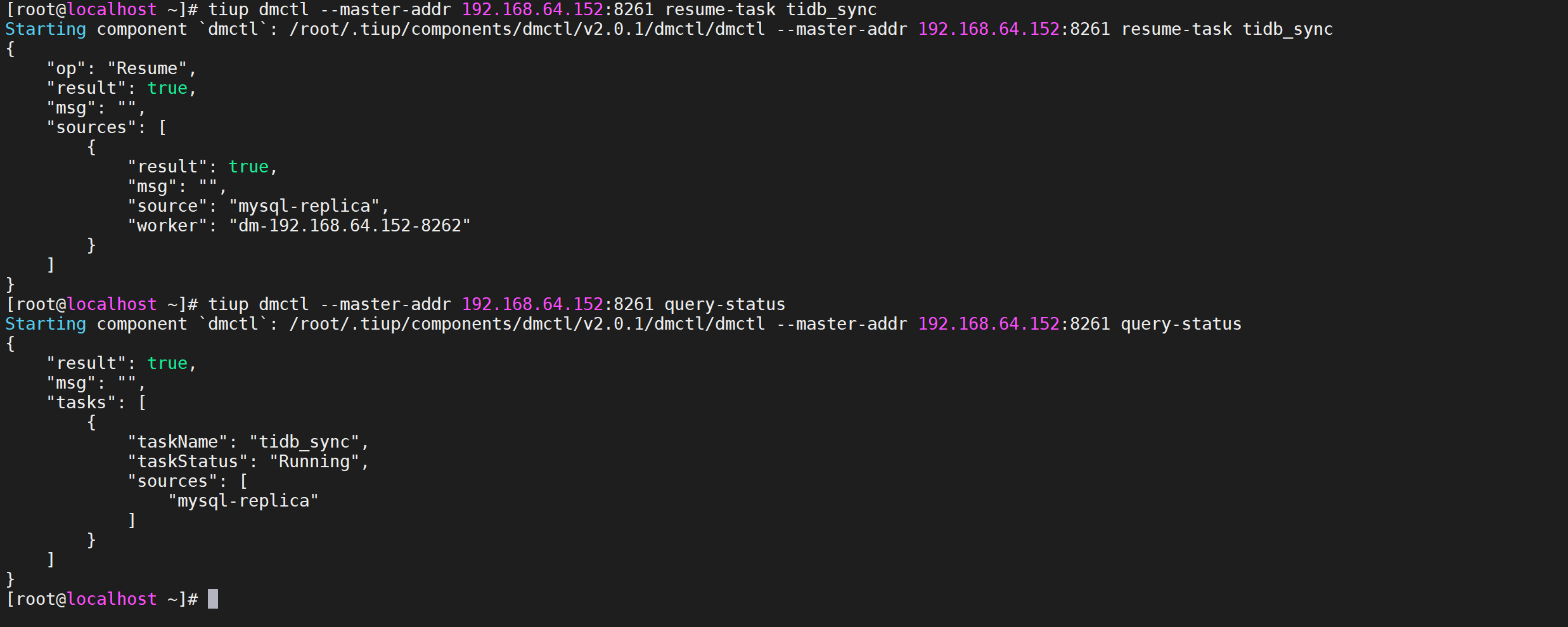
6.2.7.3 停止数据迁移任务
stop-task命令用于停止数据迁移任务
1 | tiup dmctl --master-addr 192.168.64.152:8261 stop-task tidb_sync |
6.3 全量数据迁移(自学)
6.3.1 下载安装TiDB工具包
安装包位置在
https://download.pingcap.org/tidb-toolkit-{version}-linux-amd64.tar.gz
- {version}:为 Dumpling 的版本号,可以通过 Dumpling Release 查看当前已发布版本
6.3.1.1 检查最新版本
通过 Dumpling Release 查看当前已发布版本,检查发现Dumpling当前版本是
4.0.11
6.3.1.2 下载tidb-toolkit
1 | # 下载工具包 |
6.3.2 Dumpling导出数据
6.3.2.1 Dumpling工具简介
Dumpling是使用 go 开发的数据备份工具,项目地址可以参考Dumpling。Dumpling命令参数列表
| 主要选项 | 用途 | 默认值 |
|---|---|---|
| -V 或 –version | 输出 Dumpling 版本并直接退出 | |
| -B 或 –database | 导出指定数据库 | |
| -T 或 –tables-list | 导出指定数据表 | |
| -f 或 –filter | 导出能匹配模式的表,语法可参考 table-filter | *.*(导出所有库表) |
| –case-sensitive | table-filter 是否大小写敏感 | false,大小写不敏感 |
| -h 或 –host | 连接的数据库主机的地址 | “127.0.0.1” |
| -t 或 –threads | 备份并发线程数 | 4 |
| -r 或 –rows | 将 table 划分成 row 行数据,一般针对大表操作并发生成多个文件。 | |
| -L 或 –logfile | 日志输出地址,为空时会输出到控制台 | “” |
| –loglevel | 日志级别 {debug,info,warn,error,dpanic,panic,fatal} | “info” |
| –logfmt | 日志输出格式 {text,json} | “text” |
| -d 或 –no-data | 不导出数据,适用于只导出 schema 场景 | |
| –no-header | 导出 csv 格式的 table 数据,不生成 header | |
| -W 或 –no-views | 不导出 view | true |
| -m 或 –no-schemas | 不导出 schema,只导出数据 | |
| -s 或–statement-size | 控制 INSERT SQL 语句的大小,单位 bytes |
|
| -F 或 –filesize | 将 table 数据划分出来的文件大小,需指明单位(如 128B, 64KiB, 32MiB, 1.5GiB) |
|
| –filetype | 导出文件类型(csv/sql) | “sql” |
| -o 或 –output | 导出文件路径 | "./export-${time}" |
| -S 或 –sql | 根据指定的 sql 导出数据,该选项不支持并发导出 | |
| –consistency | flush: dump 前用 FTWRL snapshot: 通过 TSO 来指定 dump 某个快照时间点的 TiDB 数据 lock: 对需要 dump 的所有表执行 lock tables read 命令 none: 不加锁 dump,无法保证一致性 auto: 对 MySQL 使用 –consistency flush;对 TiDB 使用 –consistency snapshot |
“auto” |
| –snapshot | snapshot tso,只在 consistency=snapshot 下生效 | |
| –where | 对备份的数据表通过 where 条件指定范围 | |
| -p 或 –password | 连接的数据库主机的密码 | |
| -P 或 –port | 连接的数据库主机的端口 | 4000 |
| -u 或 –user | 连接的数据库主机的用户名 | “root” |
| –dump-empty-database | 导出空数据库的建库语句 | true |
| –ca | 用于 TLS 连接的 certificate authority 文件的地址 | |
| –cert | 用于 TLS 连接的 client certificate 文件的地址 | |
| –key | 用于 TLS 连接的 client private key 文件的地址 | |
| –csv-delimiter | csv 文件中字符类型变量的定界符 | ‘“‘ |
| –csv-separator | csv 文件中各值的分隔符 | ‘,’ |
| –csv-null-value | csv 文件空值的表示 | “\N” |
| –escape-backslash | 使用反斜杠 (\) 来转义导出文件中的特殊字符 |
true |
| –output-filename-template | 以 golang template 格式表示的数据文件名格式 支持 {{.DB}}、{{.Table}}、{{.Index}} 三个参数 分别表示数据文件的库名、表名、分块 ID |
'{{.DB}}.{{.Table}}.{{.Index}}' |
| –status-addr | Dumpling 的服务地址,包含了 Prometheus 拉取 metrics 信息及 pprof 调试的地址 | “:8281” |
| –tidb-mem-quota-query | 单条 dumpling 命令导出 SQL 语句的内存限制,单位为 byte。对于 v4.0.10 或以上版本,若不设置该参数,默认使用 TiDB 中的 mem-quota-query 配置项值作为内存限制值。对于 v4.0.10 以下版本,该参数值默认为 32 GB |
34359738368 |
| –params | 为需导出的数据库连接指定 session 变量,可接受的格式: “character_set_client=latin1,character_set_connection=latin1” |
6.3.2.2 导出需要的权限
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
6.3.2.3 创建用户并授权
1 | #创建tidb用户密码是 tidb并授权外部所以IP可以访问 |
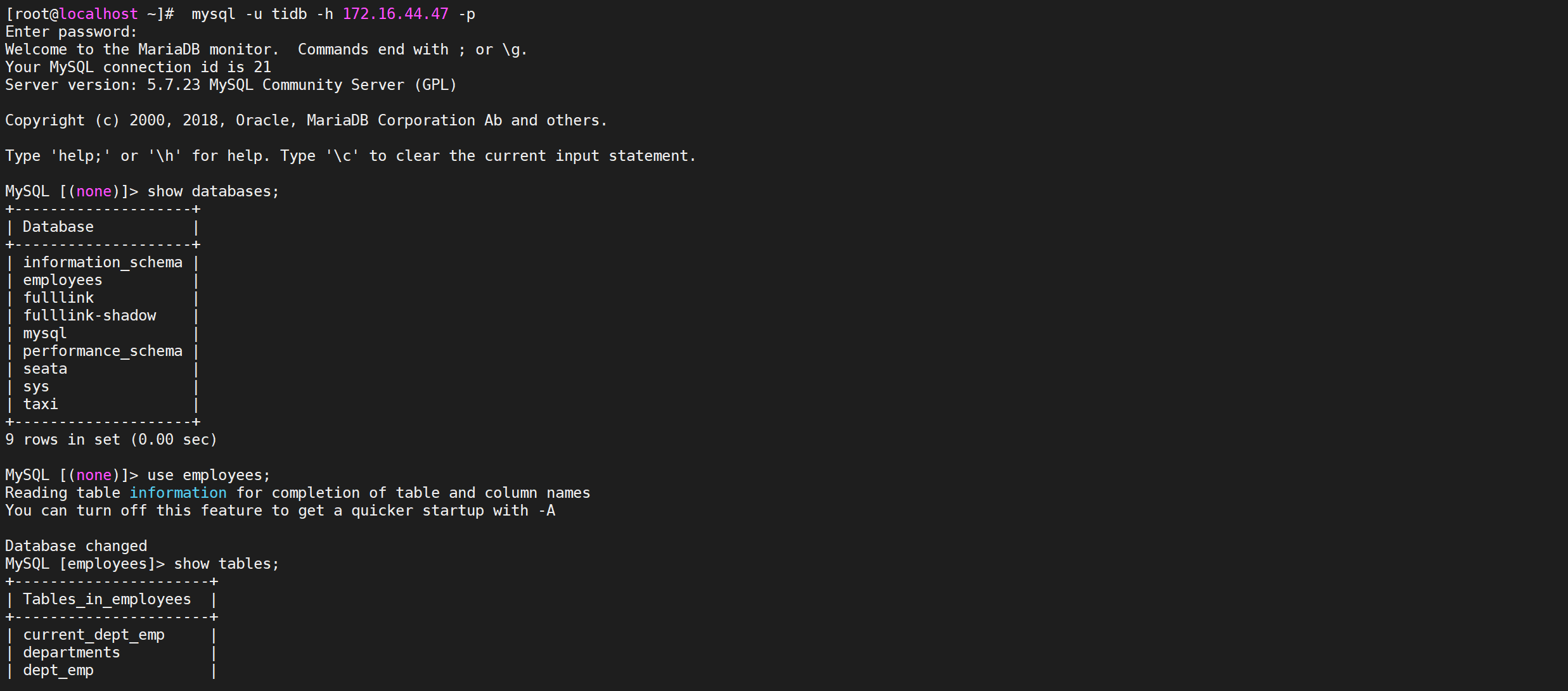
6.3.2.4 验证数据库
1 | mysql -u tidb -h 172.16.44.47 -p |
6.3.2.5 导出sql文件
Dumpling 默认导出数据格式为 sql 文件。也可以通过设置
--filetype sql导出数据到 sql 文件:
1 | ./bin/dumpling -h 172.16.44.47 -P 3306 -B employees -u tidb -p tidb --filetype sql --threads 10 -o /tmp/test -F 256MiB |
执行命令后从mysql中导出了文件

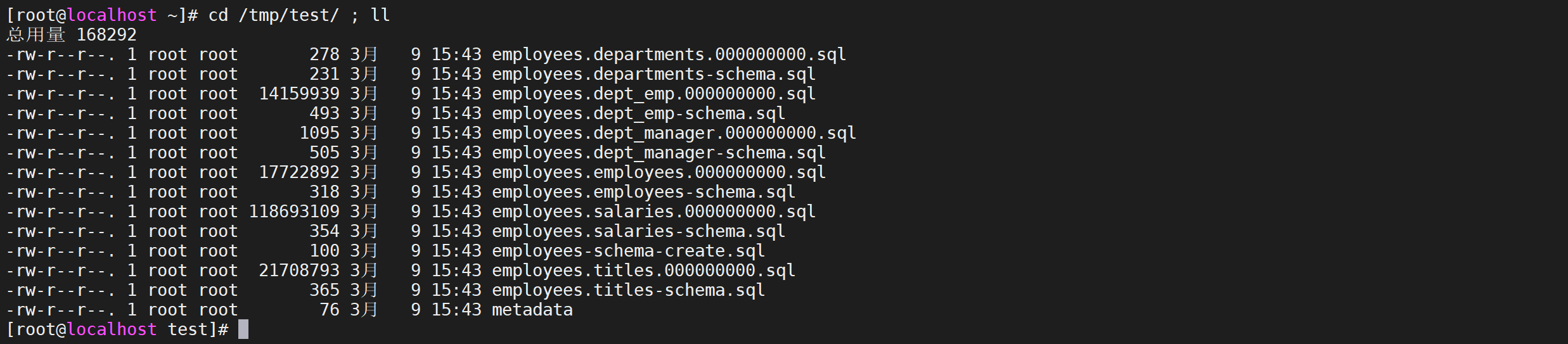
6.3.2.6 查看导出文件
1 | cd /tmp/test/ ; ll |
6.3.3 TiDB Lightning导入数据
6.3.3.1 TiDB Lightning简介
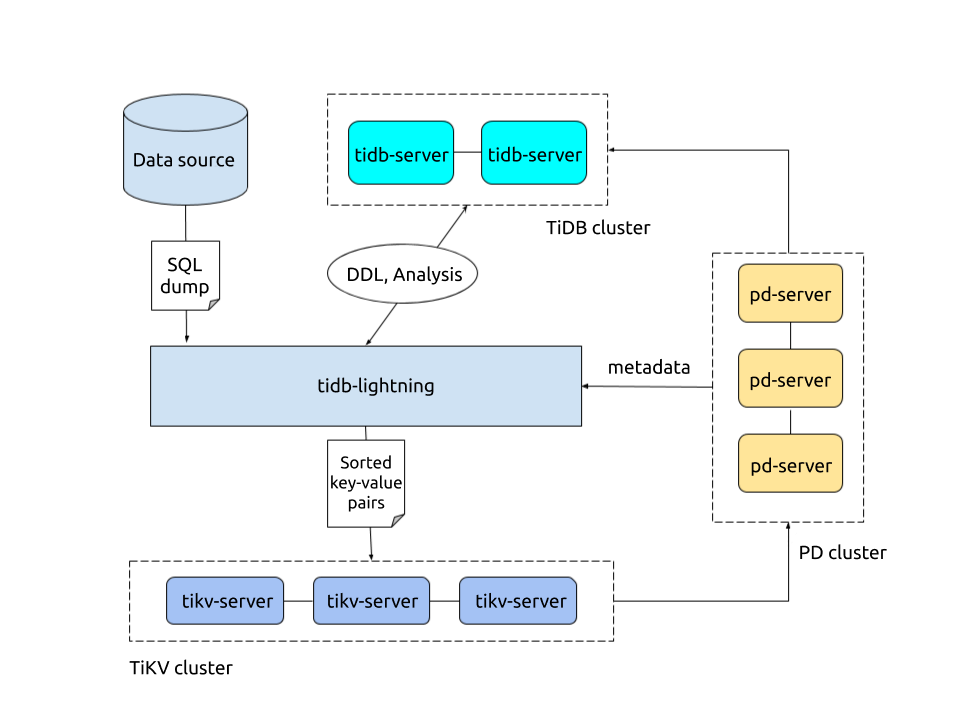
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具。
TiDB Lightning 有以下两个主要的使用场景:一是大量新数据的快速导入;二是全量备份数据的恢复。目前,Lightning 支持 Dumpling 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:
- 迅速导入大量新数据。
- 恢复所有备份数据。
6.3.3.2 TiDB Lightning 整体架构
6.3.3.3 配置tidb-lightning.toml
1 | vi tidb-lightning.toml |
6.3.3.4 执行导入命令
1 | ./bin/tidb-lightning -config tidb-lightning.toml |
出现错误不需要理会,等待导入完成
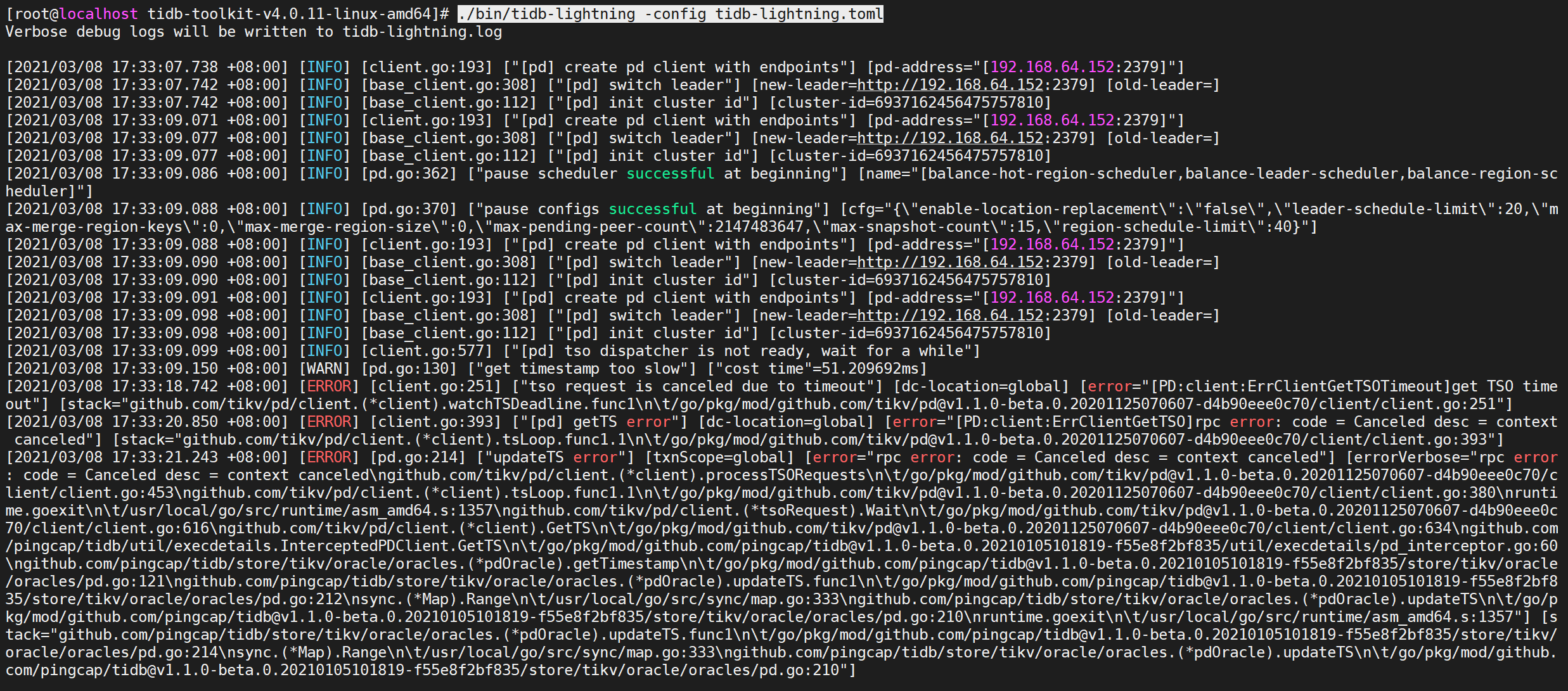
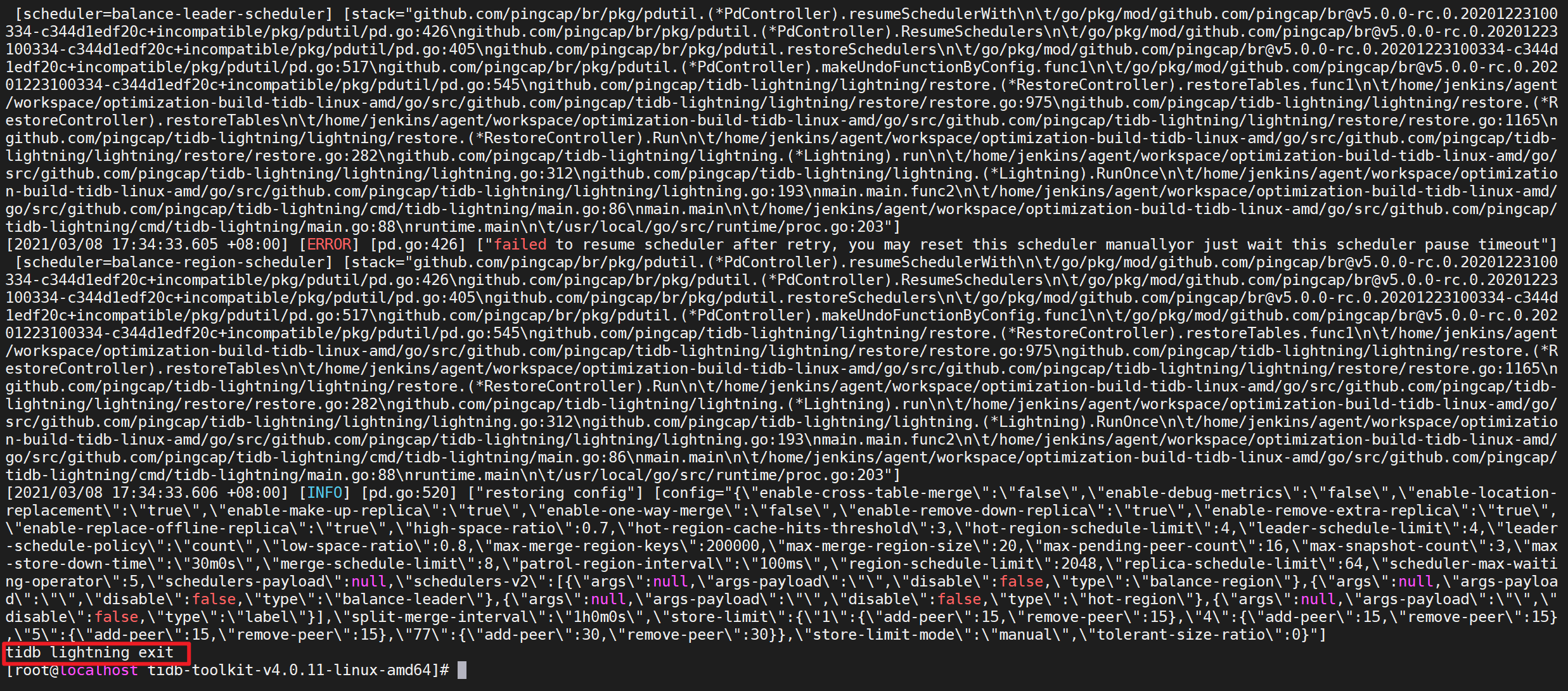
导入完毕后,TiDB Lightning 会自动退出。若导入成功,日志的最后一行会显示
tidb lightning exit。
6.3.3.5 检查是否导入成功
登录TiDB检查导入是否成功
1 | mysql -u root -P 4000 -h 192.168.64.152 |
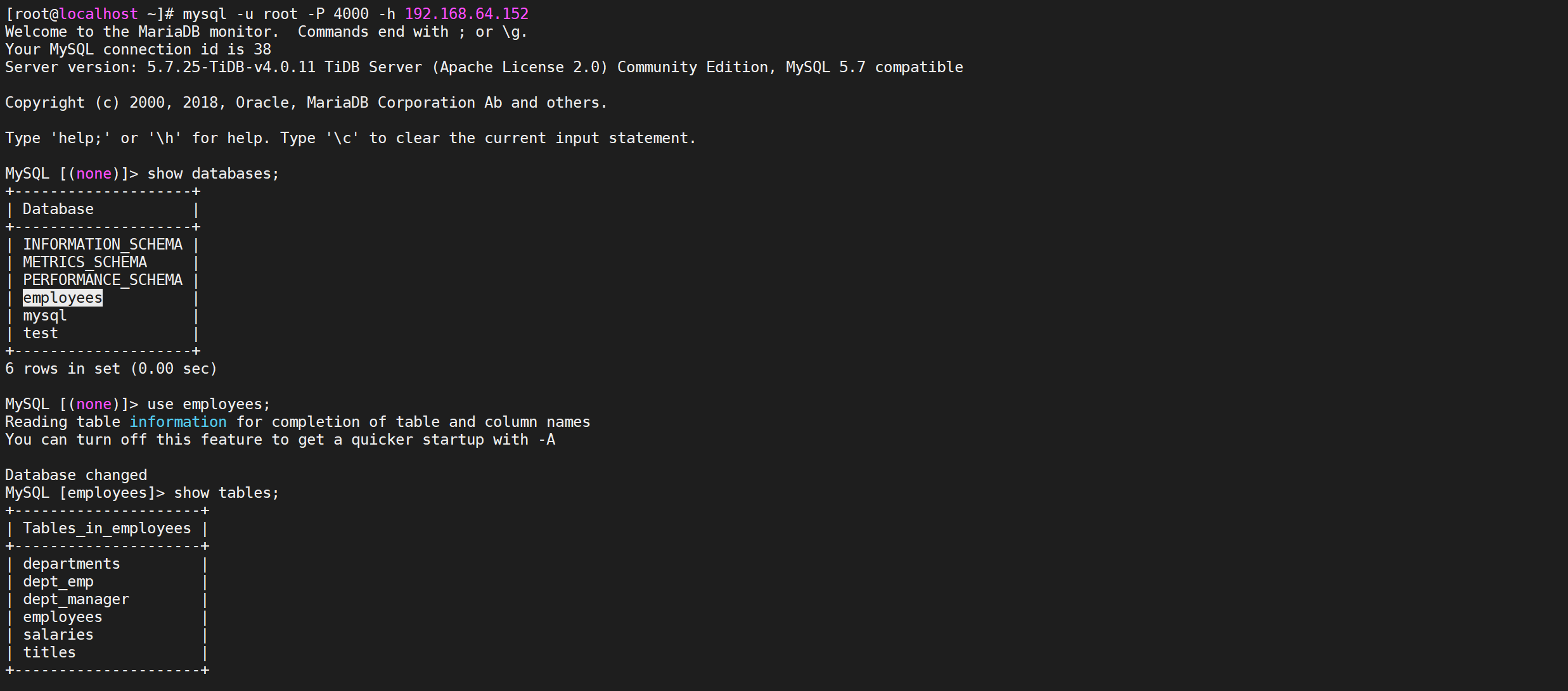
到这里基本上已经确定导入成功
7. TiDB扩缩容
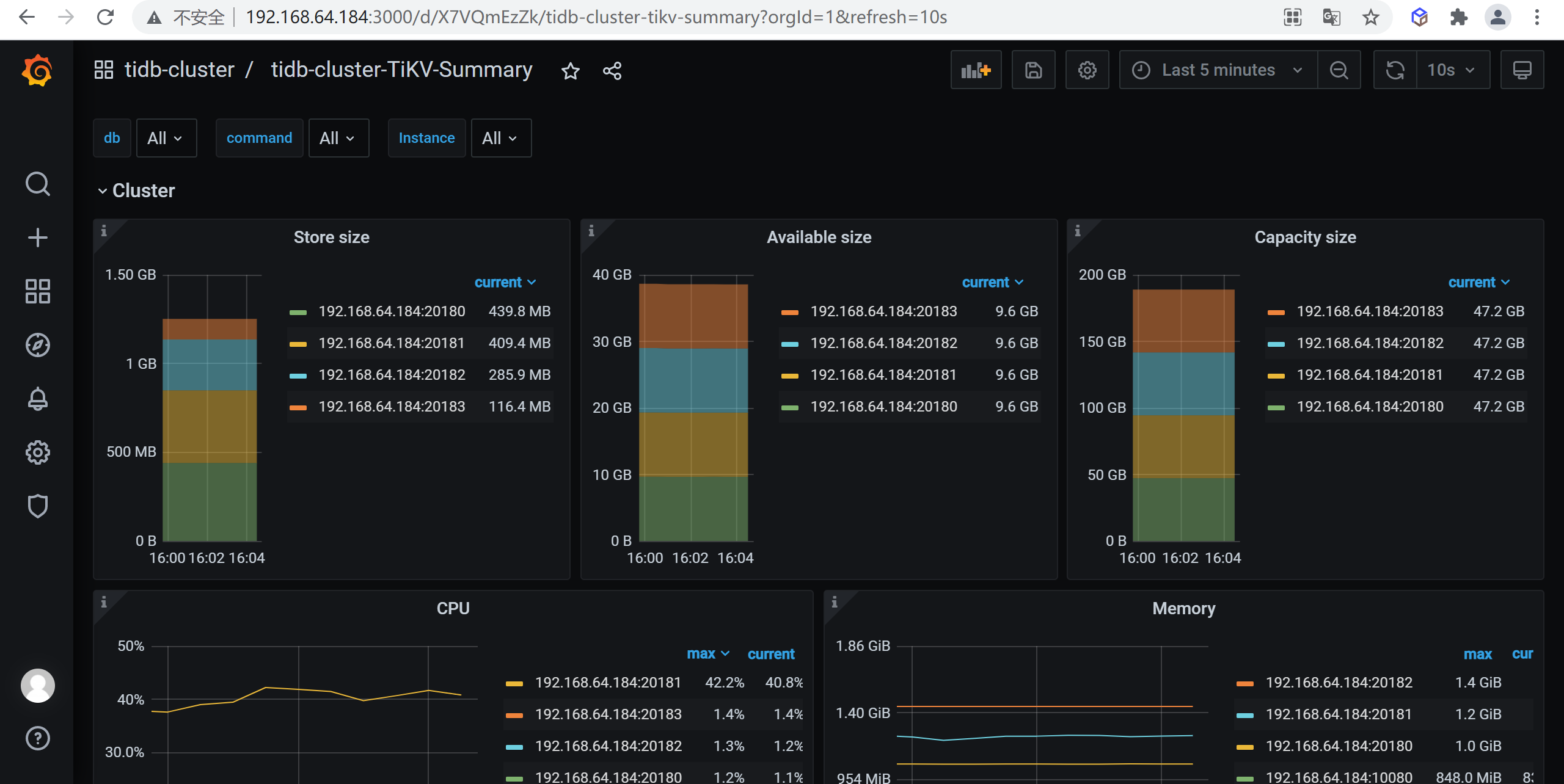
7.2 查看数据分布
可以在gafana中的
tidb-cluster-tikv-summary查看tidb的数据在服务器中的分布情况
7.2 当前集群部署拓扑
| 实例 | IP | 端口 | 存储路径 | 部署路径 |
|---|---|---|---|---|
| grafana | 192.168.64.152 | 3000 | – | /tidb-deploy/grafana-3000 |
| pd | 192.168.64.152 | 2379/2380 | /tidb-data/pd-2379 | /tidb-deploy/pd-2379 |
| prometheus | 192.168.64.152 | 9090 | /tidb-data/prometheus-9090 | /tidb-deploy/prometheus-9090 |
| tidb | 192.168.64.152 | 4000/10080 | – | /tidb-deploy/tidb-4000 |
| tiflash | 192.168.64.152 | 9000/8123/3930/20170/20292/8234 | /tidb-data/tiflash-9000 | /tidb-deploy/tiflash-9000 |
| tikv | 192.168.64.152 | 20160/20180 | /tidb-data/tikv-20160 | /tidb-deploy/tikv-20160 |
| tikv | 192.168.64.152 | 20161/20181 | /tidb-data/tikv-20161 | /tidb-deploy/tikv-20161 |
| tikv | 192.168.64.152 | 20162/20182 | /tidb-data/tikv-20162 | /tidb-deploy/tikv-20162 |
7.3 扩容TiKV节点
需要扩容一个TiKV节点
| 实例 | IP | 端口 | 存储路径 | 部署路径 |
|---|---|---|---|---|
| tikv | 192.168.64.152 | 20163/20183 | /tidb-data/tikv-20163 | /tidb-deploy/tikv-20163 |
7.3.1 编写扩容脚本
在 scale-out.yaml 文件添加扩容拓扑配置
1 | vi scale-out.yaml |
7.3.2 执行扩容命令
7.3.2.1 命令格式
1 | tiup cluster scale-out <cluster-name> scale-out.yaml -p |
- cluster-name:TiDB集群名称
- p:使用密码方式登录当前机器
7.3.2.2 执行命令
1 | tiup cluster scale-out tidb-cluster scale-out.yaml -p |
输入命令后,确认输入机器密码

出现
successfully表示节点扩容成功
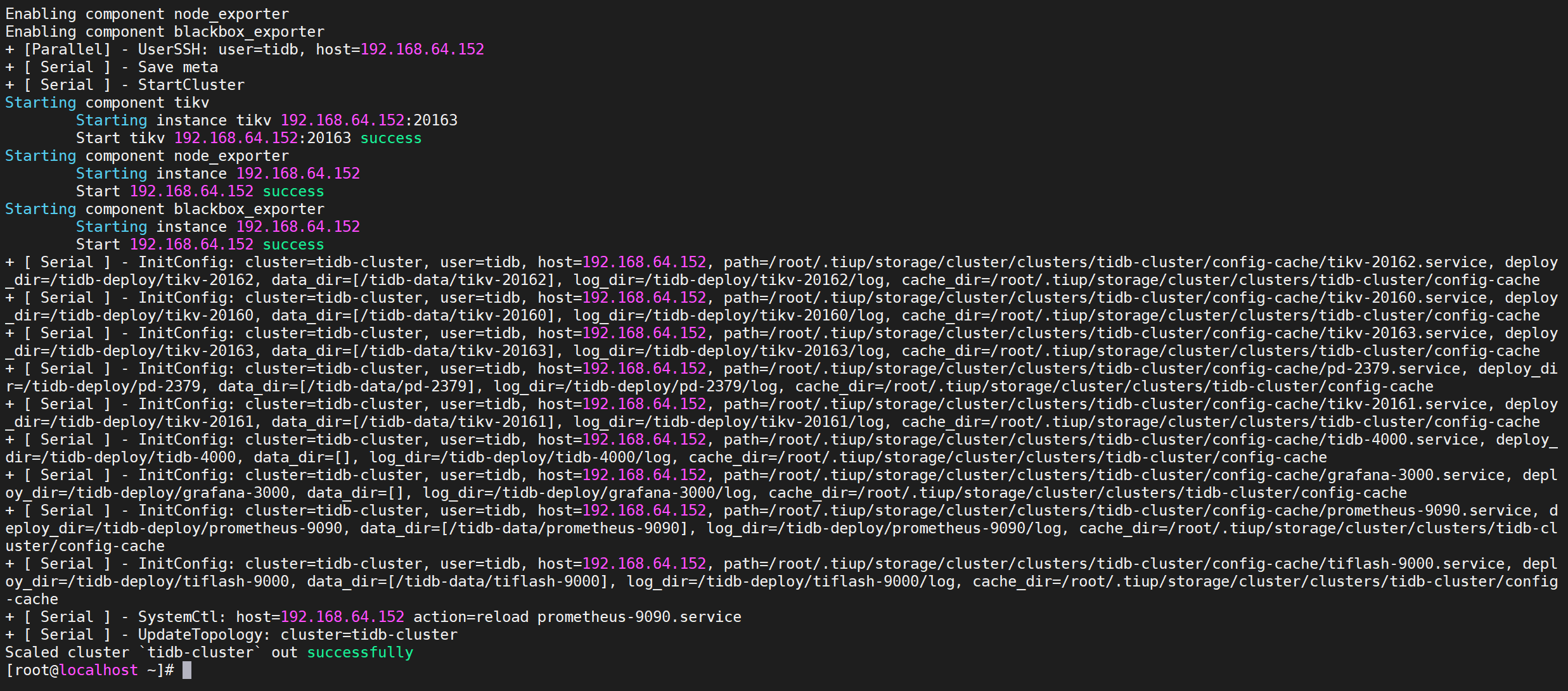
7.3.3 验证扩容信息
7.3.3.1 查看节点信息
1 | tiup cluster display tidb-cluster |
我们看到Tikv已经增加了一个节点
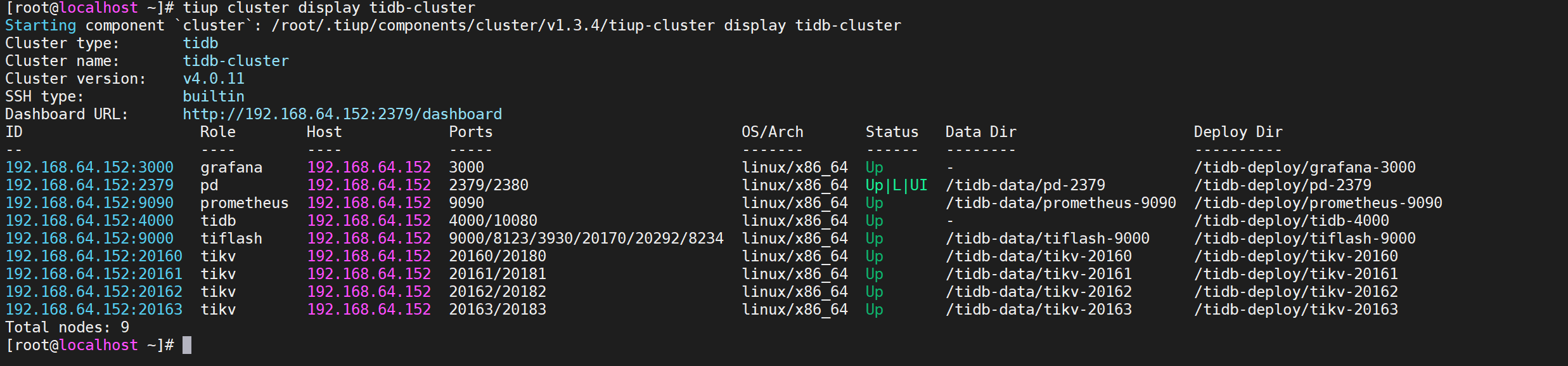
7.3.3.2 通过dashboard查看
也可以看到扩容的节点信息
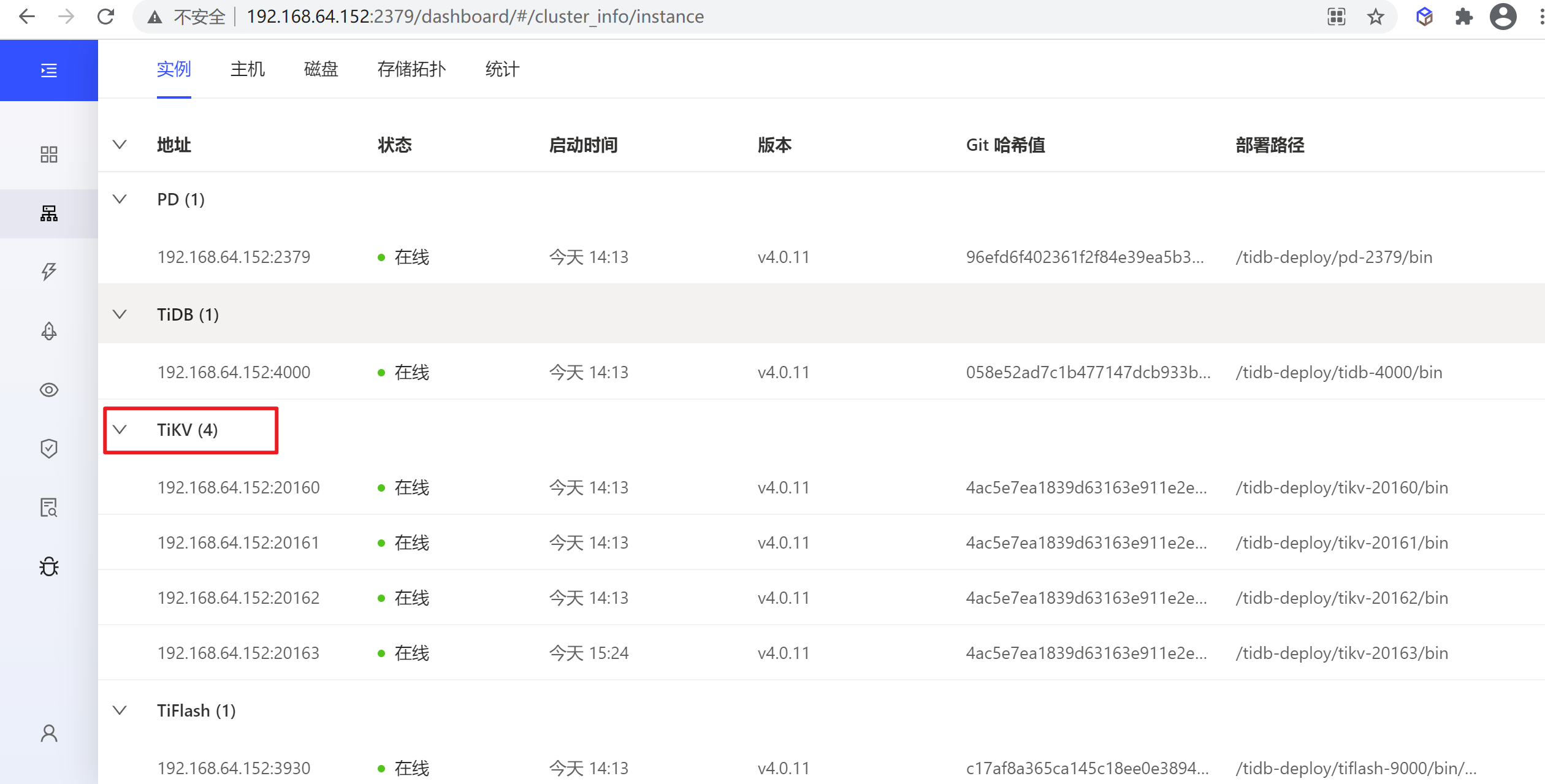
7.4 缩容TiKV节点
7.4.1 查看节点信息
1 | tiup cluster display tidb-cluster |
当前TiKV是4个节点
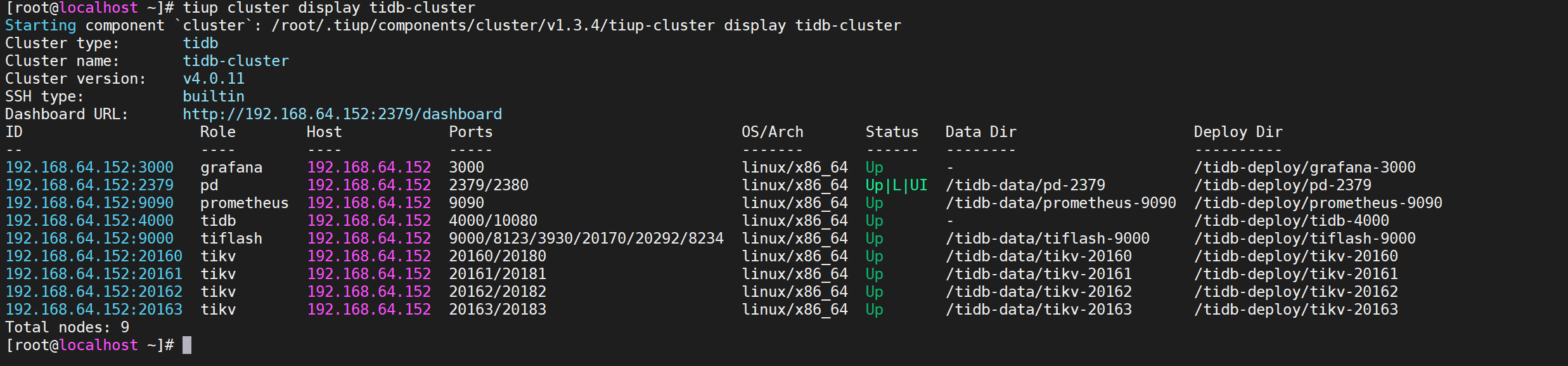
7.4.2 执行缩容操作
7.4.2.1 缩容命令
1 | tiup cluster scale-in <cluster-name> --node 192.168.64.152:20163 |
参数解释
- cluster-name:集群名称
- node:需要删除的节点地址
7.4.2.2 执行命令
1 | tiup cluster scale-in tidb-cluster --node 192.168.245.146:20163 |
出现确认操作后,输入y确认执行就可以执行缩容操作了
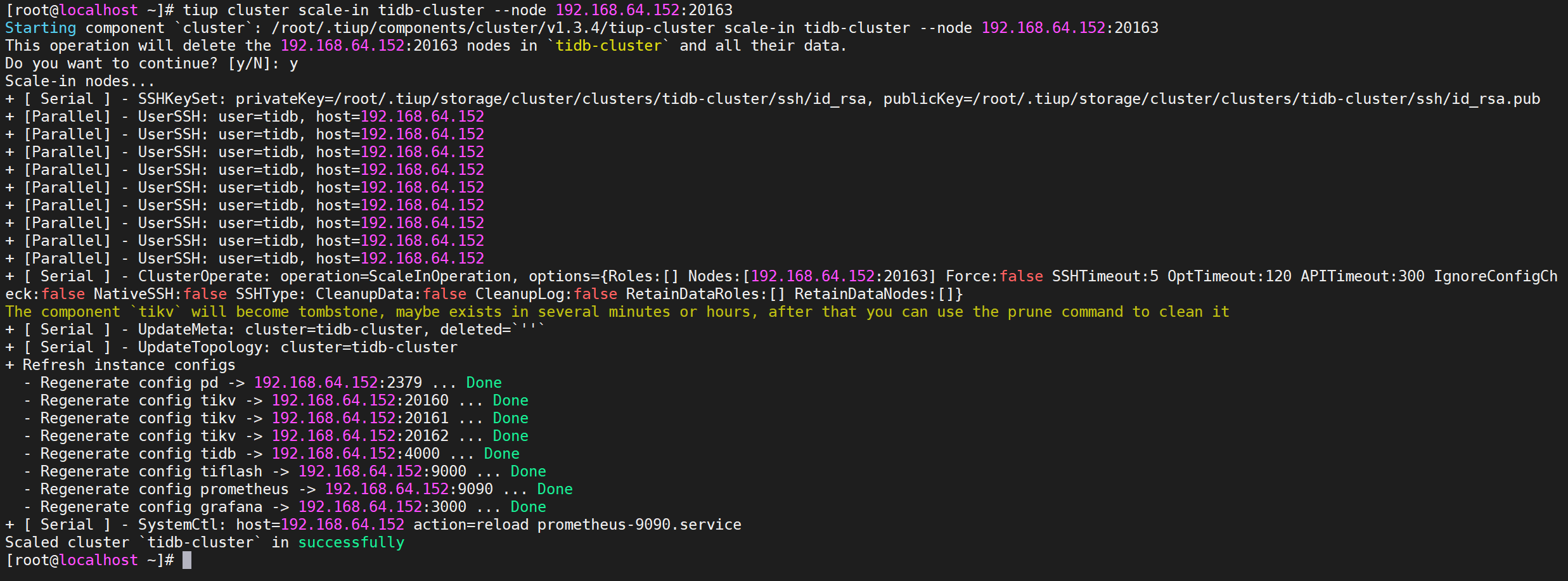
7.4.3 验证缩容信息
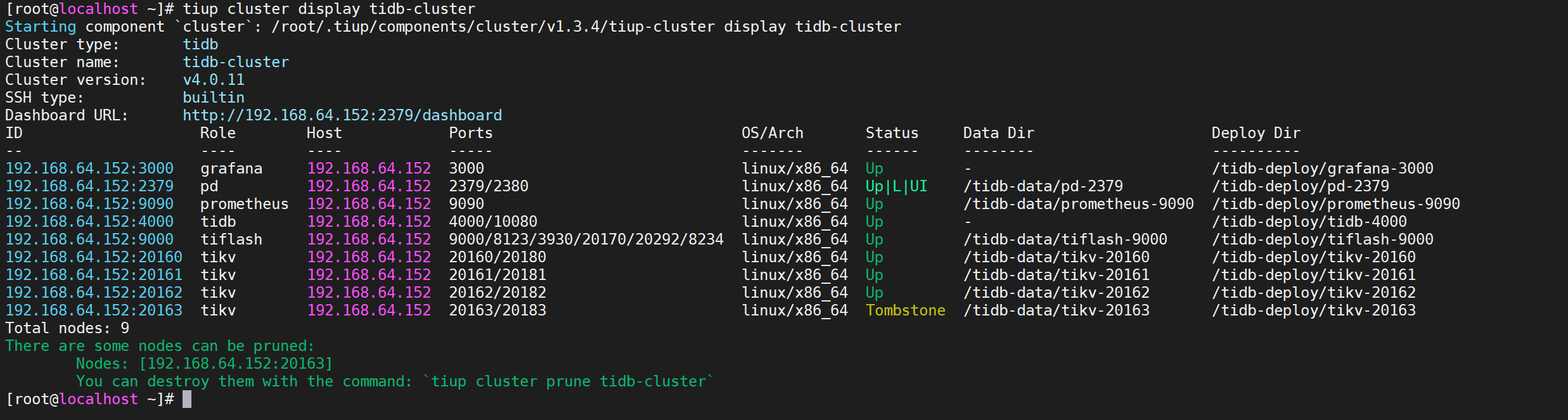
7.4.3.1 查看节点信息
1 | tiup cluster display tidb-cluster |
我们看到需要缩容的节点状态是
Tombstone说明已经下线,下线需要一定时间,下线节点的状态变为Tombstone就说明下线成功
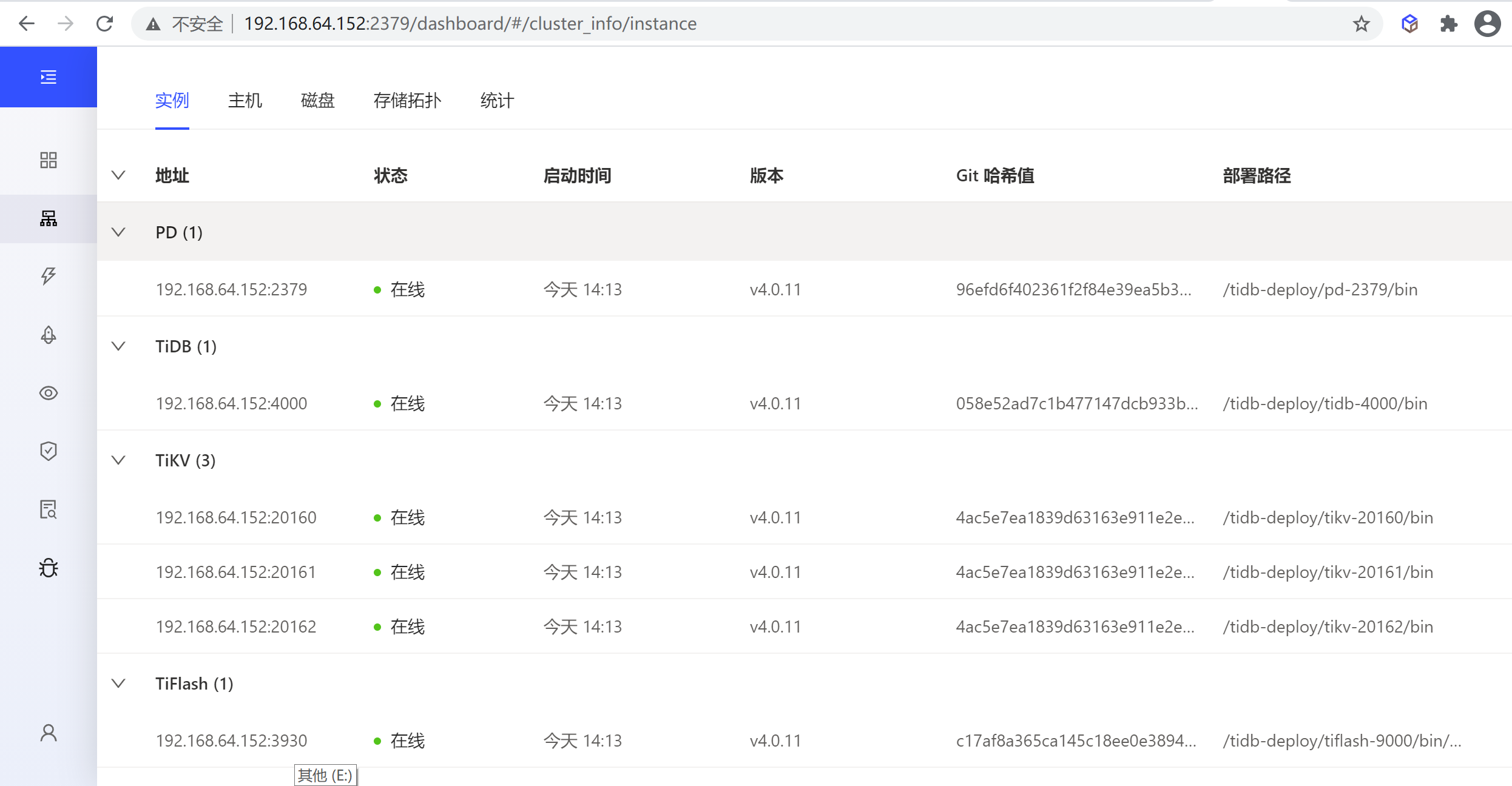
7.4.3.2 通过dashboard查看
也可以看到缩容的节点已经不存在了,说明缩容成功
8. TiDB dashboard使用
TiDB Dashboard 是 TiDB 自 4.0 版本起提供的图形化界面,可用于监控及诊断 TiDB 集群。TiDB Dashboard 内置于 TiDB 的 PD 组件中,无需独立部署。

8.1 集群概况
查看集群整体 QPS 数值、执行耗时、消耗资源最多的几类 SQL 语句等概况信息。
该页面显示了整个集群的概况,包含以下信息:
- 整个集群的 QPS
- 整个集群的查询延迟
- 最近一段时间内累计耗时最多的若干 SQL 语句
- 最近一段时间内运行时间超过一定阈值的慢查询
- 各个实例的节点数和状态
- 监控及告警信息
8.1.1 QPS
该区域显示最近一小时整个集群的每秒成功和失败查询数量
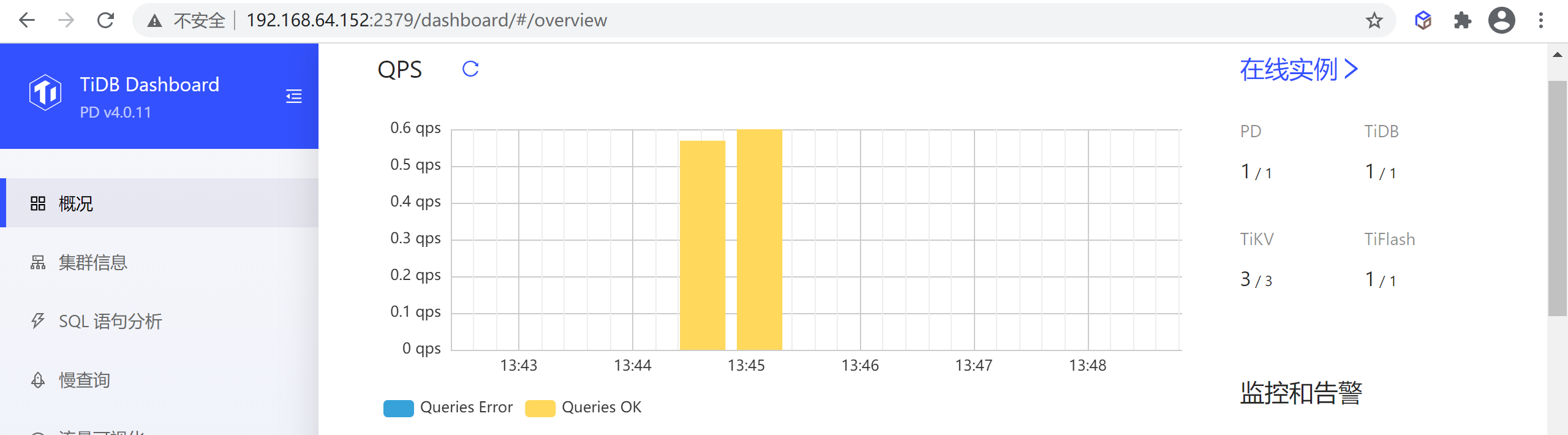
注意:该功能仅在部署了 Prometheus 监控组件的集群上可用,未部署监控组件的情况下会显示为失败。
8.1.1.1 延迟
该区域显示最近一小时整个集群中 99.9%、99% 和 90% 查询的延迟:
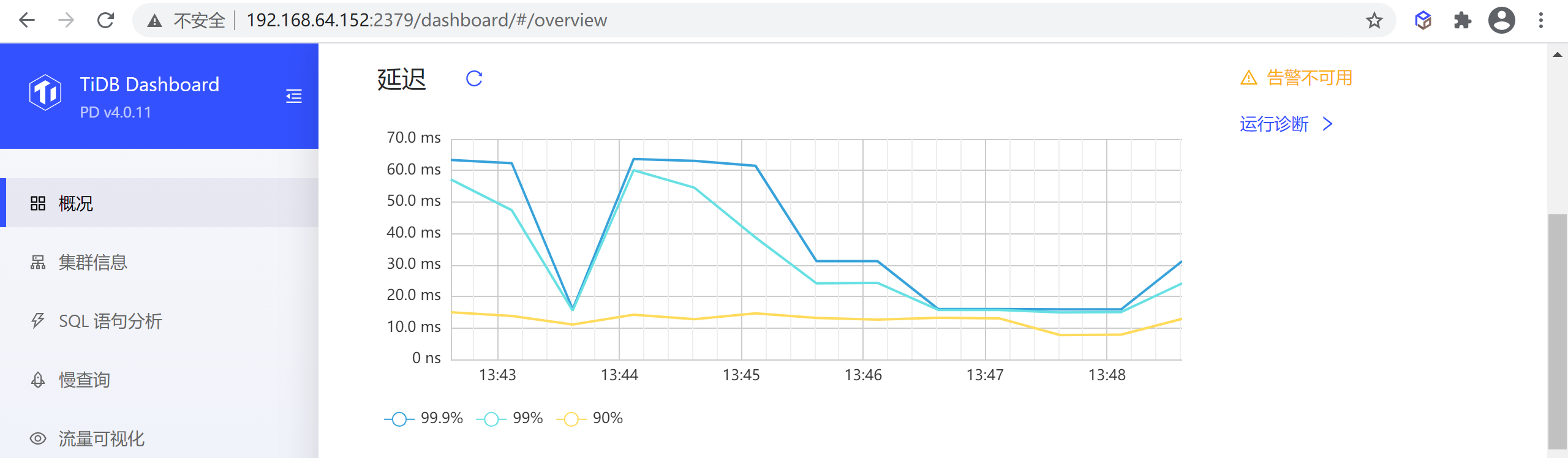
注意:该功能仅在部署了 Prometheus 监控组件的集群上可用,未部署监控组件的情况下会显示为失败。
8.1.1.2 Top SQL 语句
该区域显示最近一段时间内整个群集中累计耗时最长的 10 类 SQL 语句。查询参数不一样但结构一样的 SQL 会归为同一类 SQL 语句,在同一行中显示
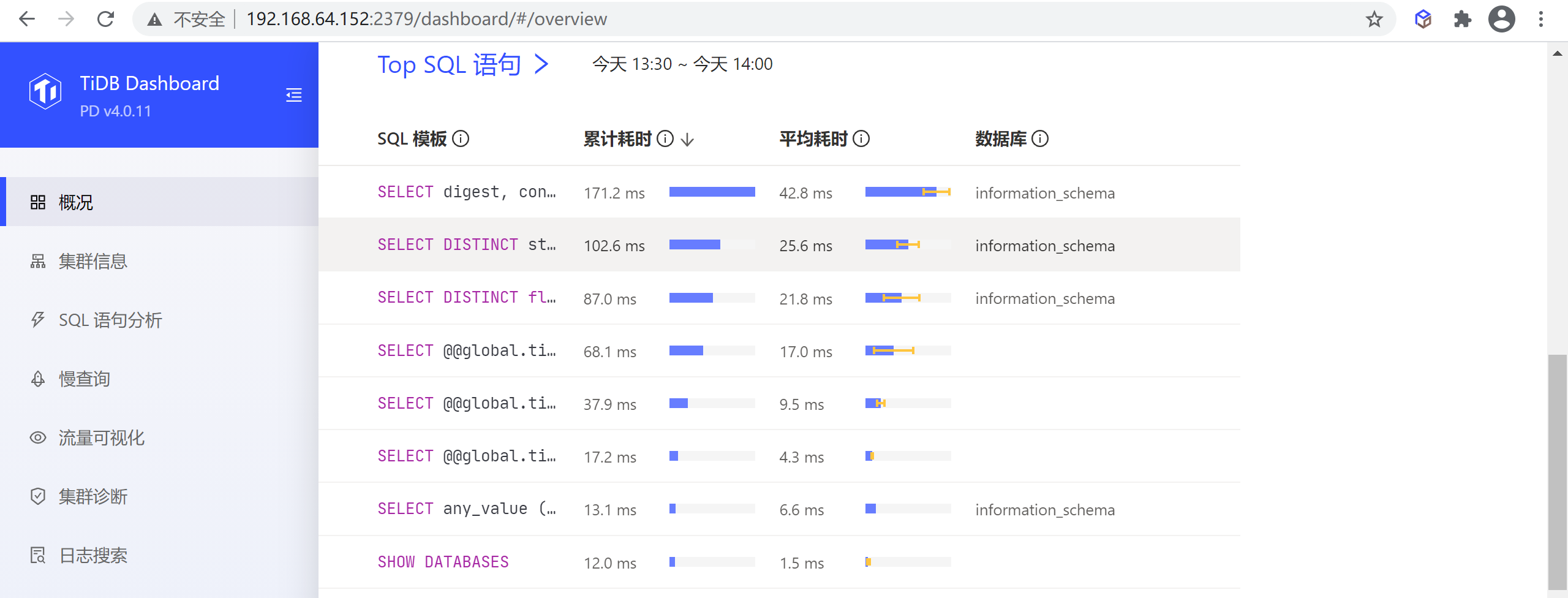
注意:该功能仅在开启了 SQL 语句分析功能的集群上可用。
8.1.1.3 最近的慢查询
该区域默认显示最近 30 分钟内整个集群中最新的 10 条慢查询
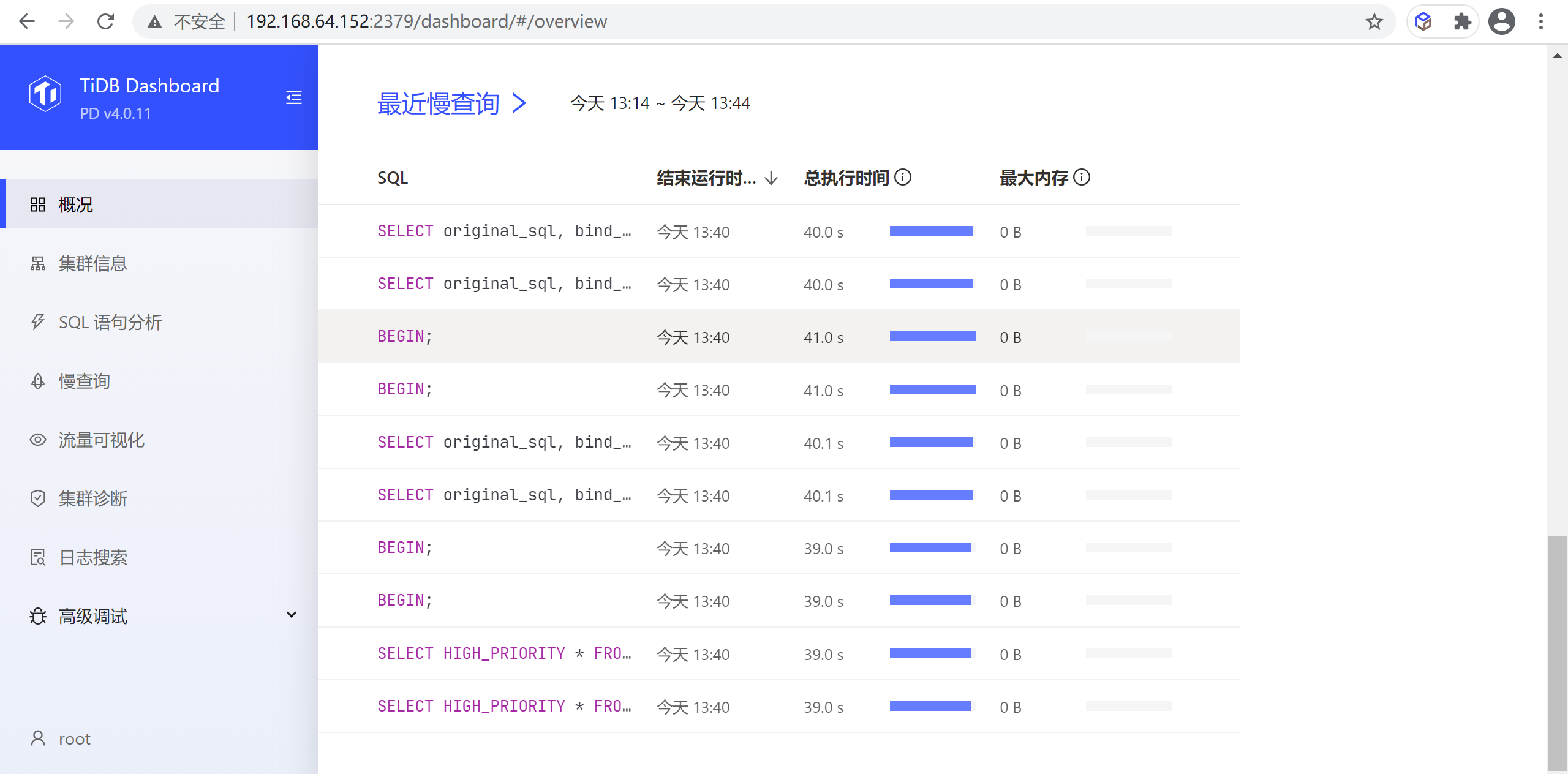
默认情况下运行时间超过 300ms 的SQL 查询即会被计为慢查询并显示在该表格中。
8.2 集群信息
该页面上允许用户查看整个集群中 TiDB、TiKV、PD、TiFlash 组件的运行状态及其所在主机的运行状态。
8.2.1 实例列表
实例列表列出了该集群中 TiDB、TiKV、PD 和 TiFlash 组件所有实例的概况信息。
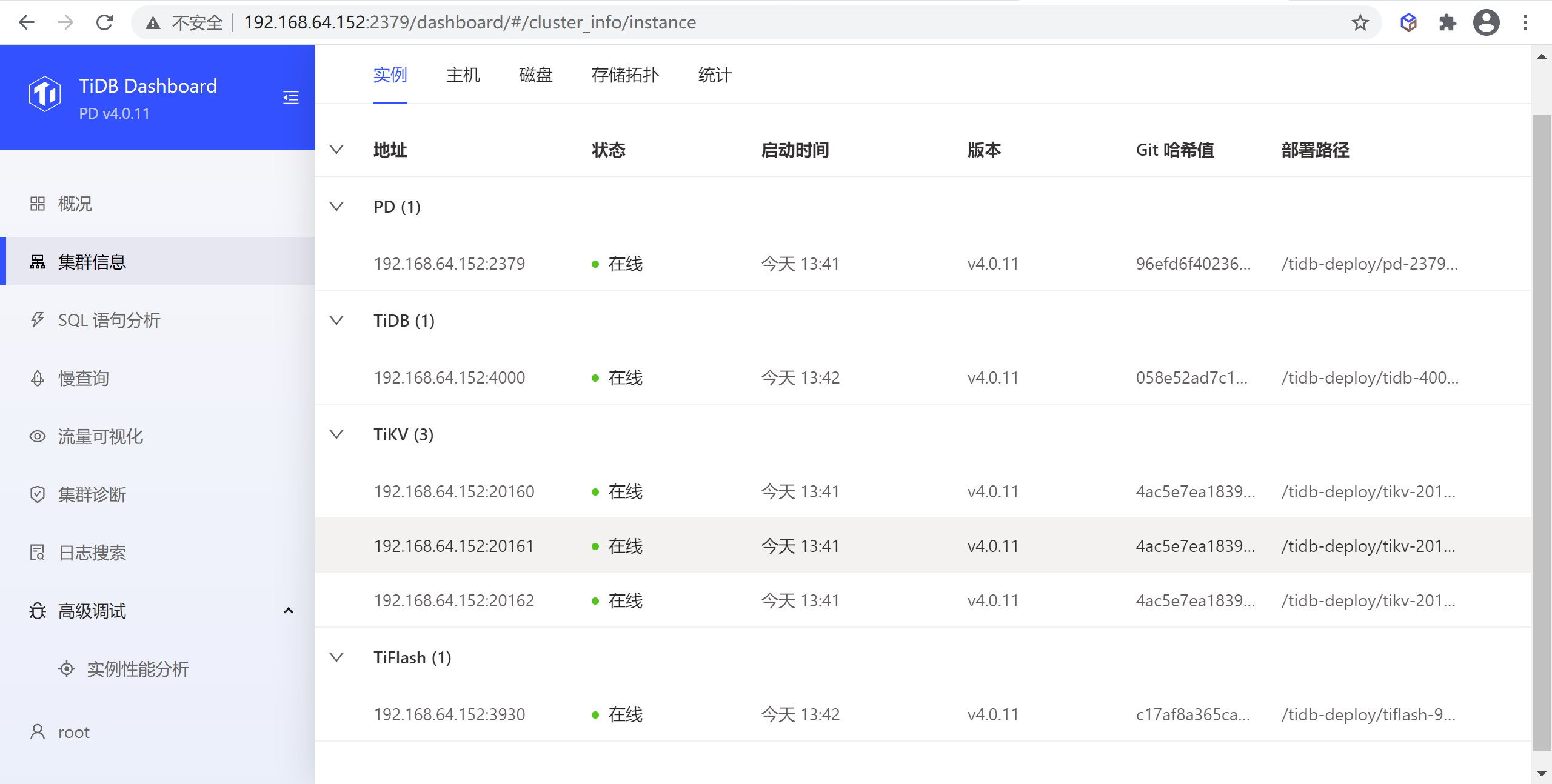
8.2.1.1 表格列解释
表格包含以下列:
- 地址:实例地址
- 状态:实例的运行状态
- 启动时间:实例的启动时间
- 版本:实例版本号
- 部署路径:实例二进制文件所在目录路径
- Git 哈希值:实例二进制对应的 Git 哈希值
8.2.1.2 实例状态解释
实例的运行状态有:
- 在线 (Up):实例正常运行。
- 离线 (Down) 或无法访问 (Unreachable):实例未启动或对应主机存在网络问题。
- 已缩容下线 (Tombstone):实例上的数据已被完整迁出并缩容完毕。仅 TiKV 或 TiFlash 实例存在该状态。
- 下线中 (Offline):实例上的数据正在被迁出并缩容。仅 TiKV 或 TiFlash 实例存在该状态。
- 未知 (Unknown):未知的实例运行状态。
8.2.2 主机列表
主机列表列出了该集群中 TiDB、TiKV、PD 和 TiFlash 组件所有实例对应主机的运行情况。

8.2.2.1 表格列解释
表格包含以下列:
- 地址:主机 IP 地址
- CPU:主机 CPU 逻辑核心数
- CPU 使用率:主机当前 1 秒的用户态和内核态 CPU 使用率
- 物理内存:主机总计的物理内存大小
- 内存使用率:主机当前内存使用率
- 部署磁盘:主机上运行实例所在磁盘的文件系统和磁盘挂载路径
- 磁盘使用率:主机上运行实例所在磁盘的空间使用率
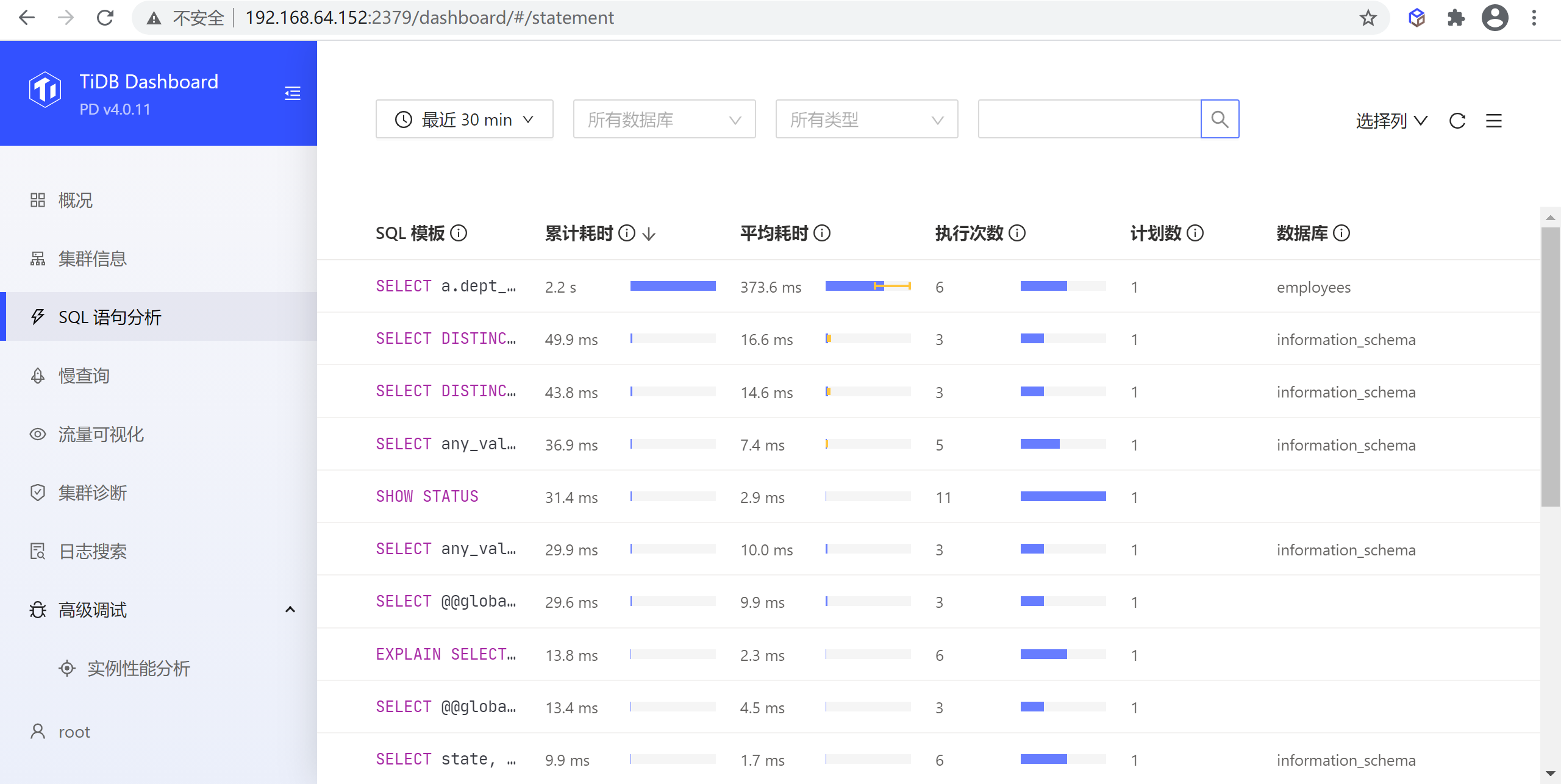
8.2.3 SQL语句分析
该页面可以查看所有 SQL 语句在集群上执行情况,常用于分析总耗时或单次耗时执行耗时较长的 SQL 语句。
8.2.3.1 执行列表页
在该页面中,结构一致的 SQL 查询(即使查询参数不一致)都会被归为同一个 SQL 语句,例如 SELECT * FROM employee WHERE id IN (1, 2, 3) 和 select * from EMPLOYEE where ID in (4, 5) 都属于同一 SQL 语句 select * from employee where id in (...)。
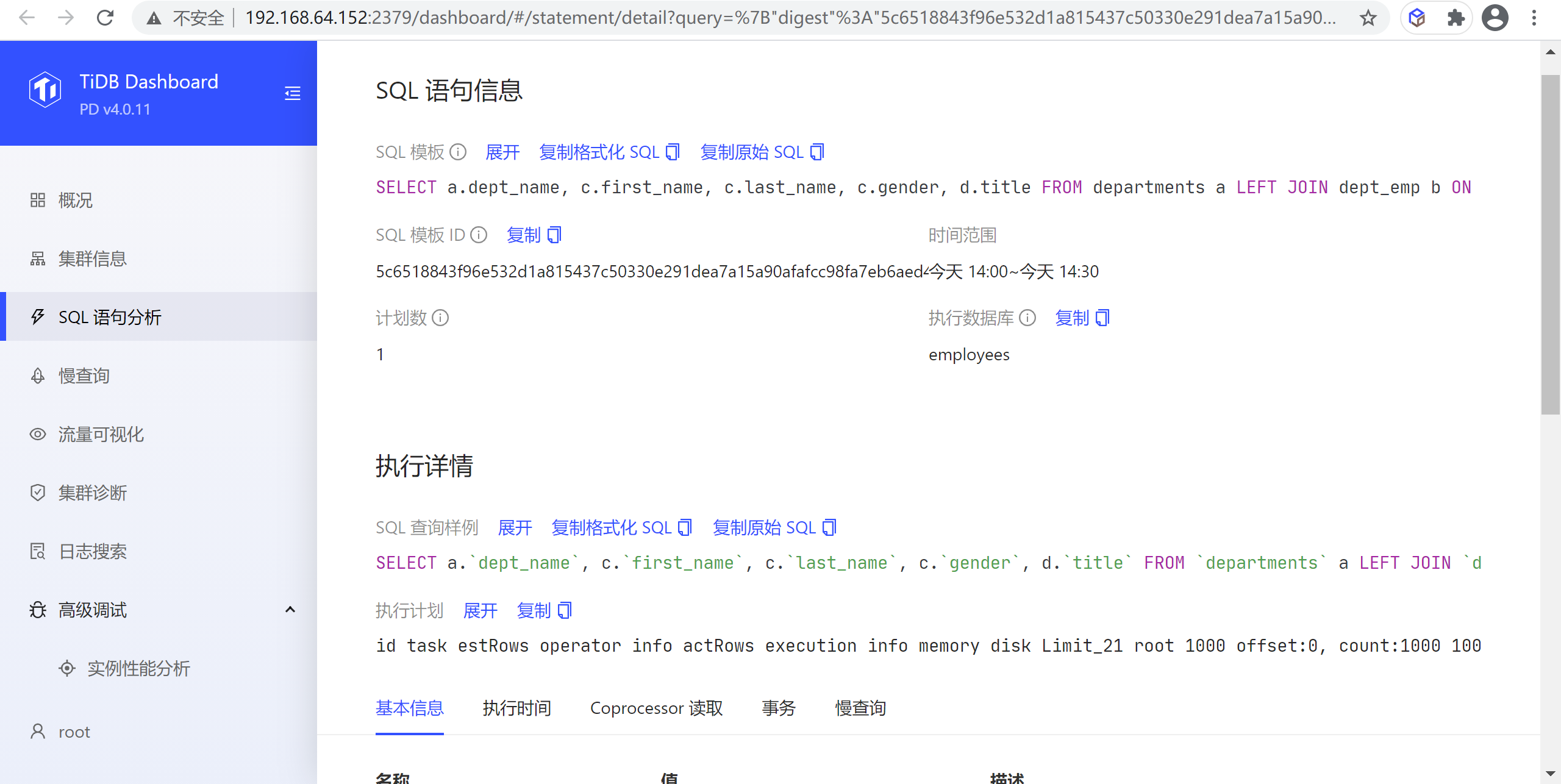
8.2.3.2 执行详情页面
在列表中点击任意一行可以进入该 SQL 语句的详情页查看更详细的信息,这此信息包括三大部分:
- SQL 语句概况:包括 SQL 模板,SQL 模板 ID,当前查看的时间范围,执行计划个数以及执行所在的数据库(下图区域 1)
- 执行计划列表:如果该 SQL 语句有多个执行计划,则显示该列表,可以选择不同的执行计划,在列表下方会显示选中的执行计划详情;如果只有一个执行计划,则该列表不显示(下图区域 2)
- 执行计划详情:显示选中的执行计划的详细信息,具体见下一小节(下图区域 3)
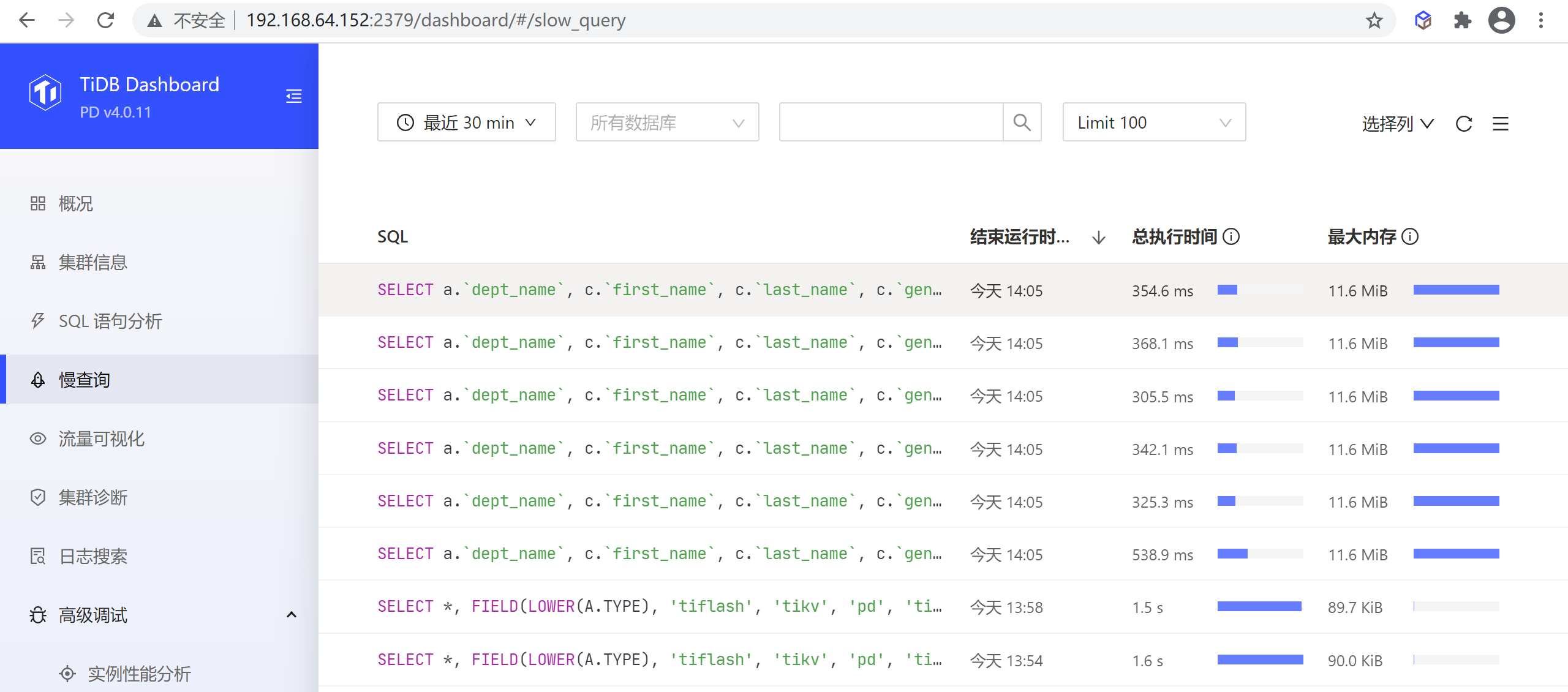
8.2.4 慢查询
该页面上能检索和查看集群中所有慢查询。
默认情况下,执行时间超过 300ms 的 SQL 查询就会被视为慢查询,被记录到慢查询日志中,并可通过本功能对记录到的慢查询进行查询。可调整 tidb_slow_log_threshold SESSION 变量或 TiDB slow-threshold 参数调整慢查询阈值。
若关闭了慢查询日志,则本功能不可用。慢查询日志默认开启,可通过修改 TiDB 配置 enable-slow-log 开启或禁用。
8.2.4.1 慢查询列表页
可按时间范围、慢查询语句关联的数据库、SQL 关键字、SQL 类型、显示的慢查询语句数量等条件过滤,筛选慢查询句。如下所示,默认显示 30 分钟内最近 100 条慢查询。
8.2.4.2 查看执行详情
在列表中点击任意一行可以显示该慢查询的详细执行信息,包含:
- SQL:慢查询 SQL 文本(
- 执行计划:慢查询的执行计划
- 其他分类好的 SQL 执行信息
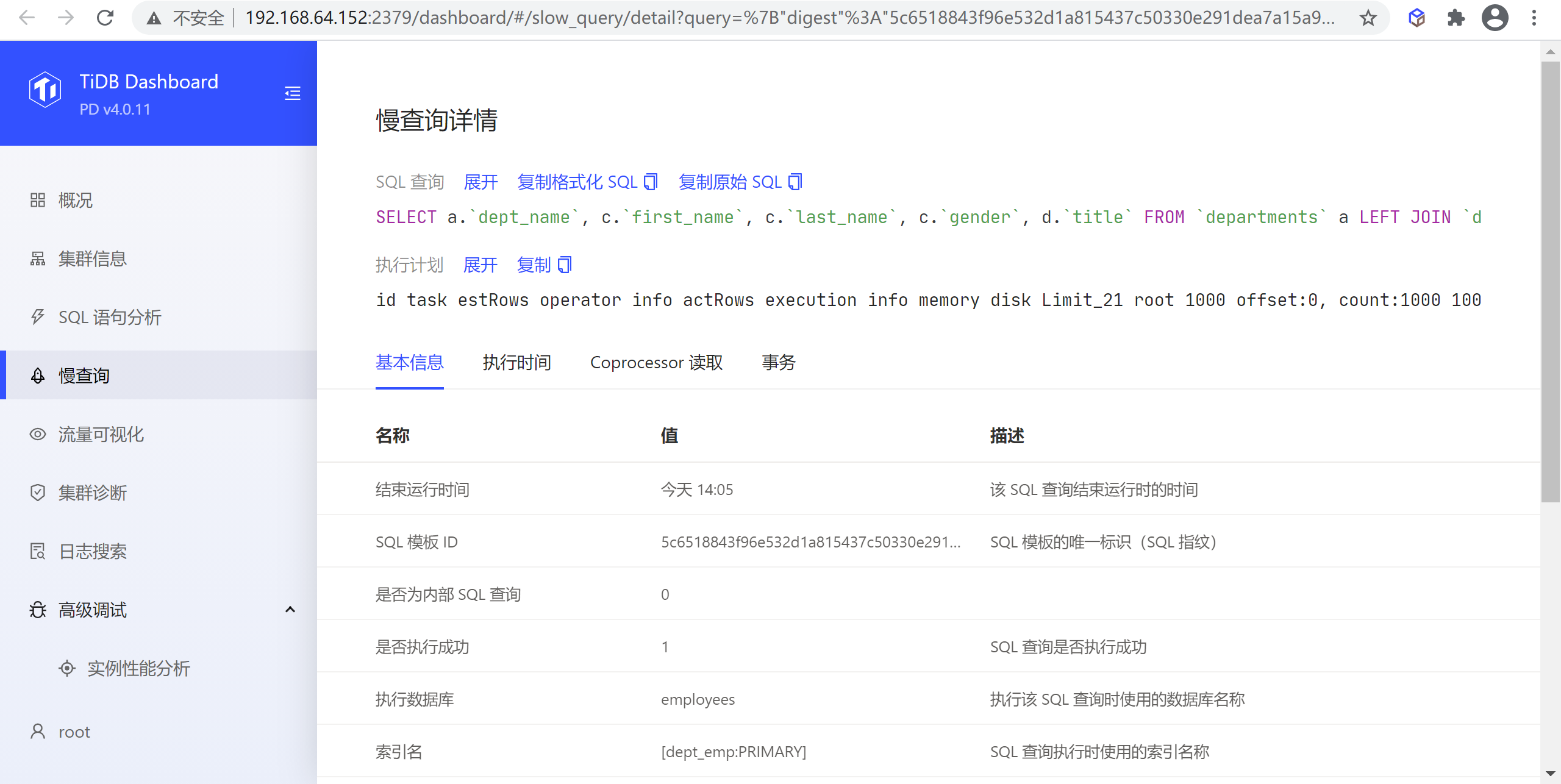
点击展开 (Expand) 链接可以展开相应项的完整内容,点击复制 (Copy) 链接可以复制完整内容到剪贴板。
8.2.5 集群诊断页面
集群诊断是在指定的时间范围内,对集群可能存在的问题进行诊断,并将诊断结果和一些集群相关的负载监控信息汇总成一个诊断报告。诊断报告是网页形式,通过浏览器保存后可离线浏览和传阅。
8.2.5.1 生成诊断报告
如果想对一个时间范围内的集群进行诊断,查看集群的负载等情况,可以使用以下步骤来生成一段时间范围的诊断报告:
- 设置区间的开始时间
- 设置区间长度,例如 10 min 。
- 点击开始。
建议生成报告的时间范围在 1 min ~ 60 min 内,目前不建议生成超过 1 小时范围的报告。
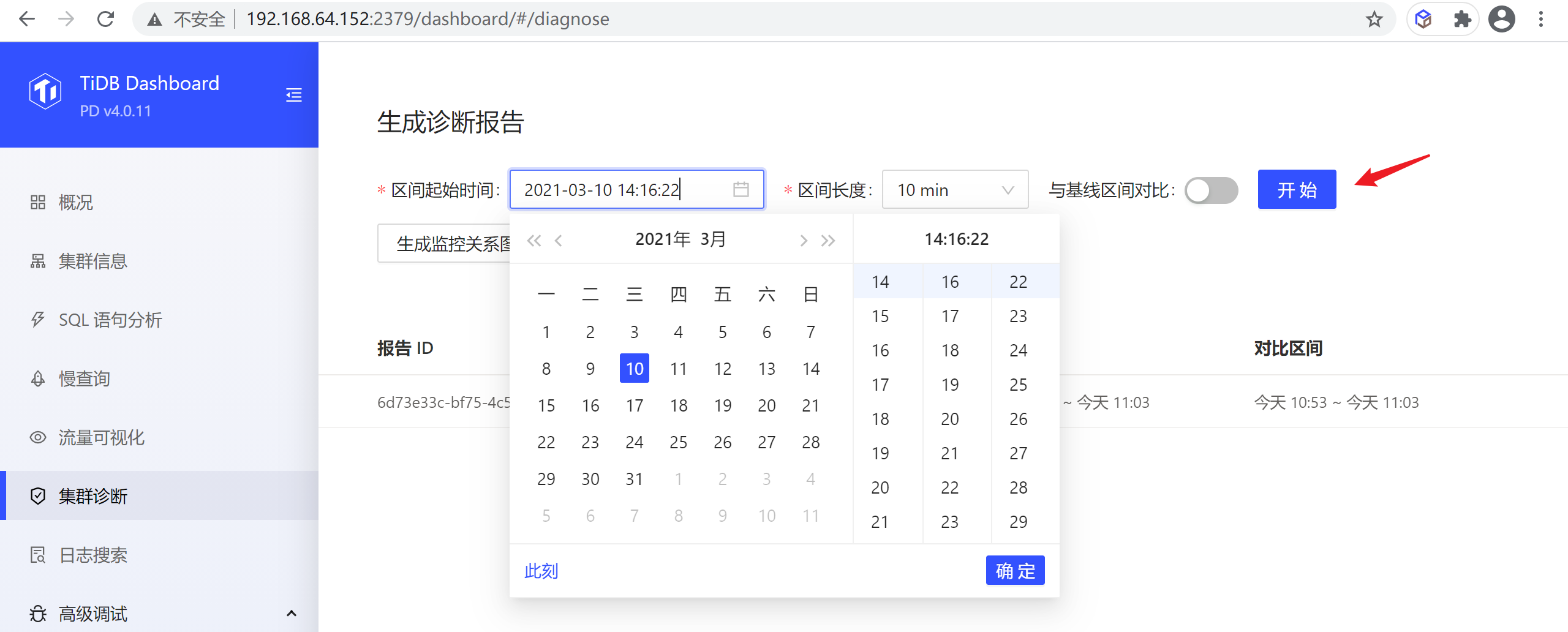
点击开始 (start) 后,会看到以下界面,生成进度 (progress) 是生成报告的进度条,生成报告完成后,点击查看报告 (View Full Report) 即可。
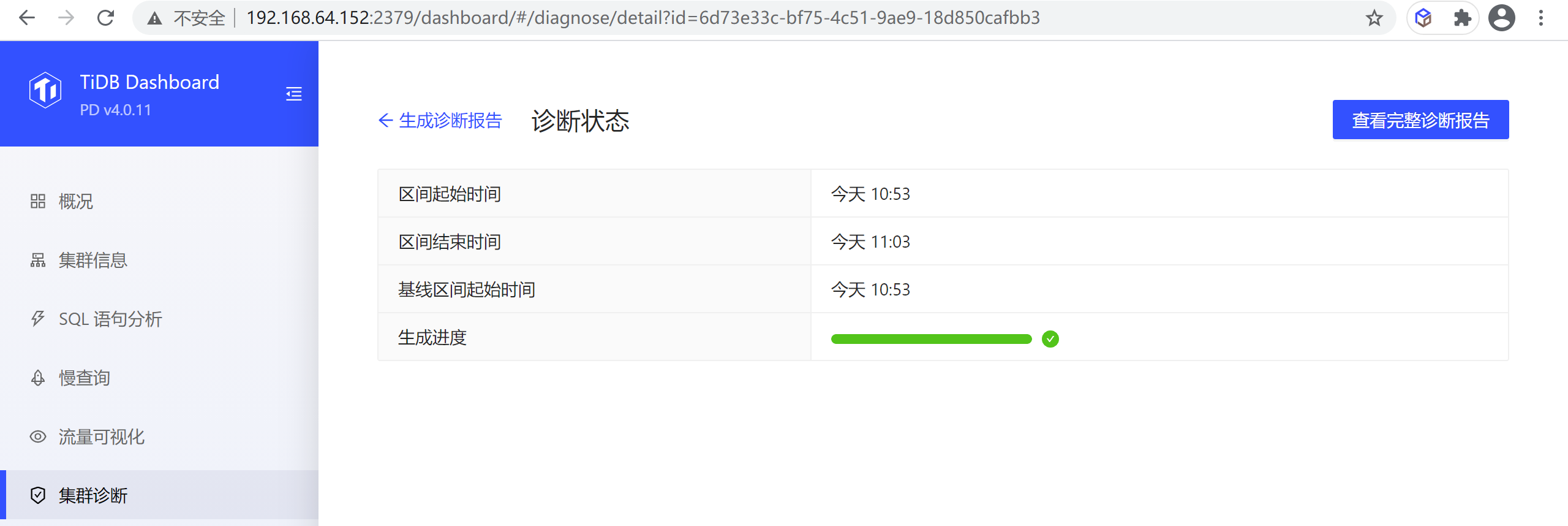
搞定
 微信
微信 支付宝
支付宝

