【系列教程】Java基础语法(十八):JDK类库
我们站在巨人的肩膀上,造轮子可以,但是仅学习时推荐,实际开发中建议直接用写好的类库,提高效率。很多人内心觉得用了类库,是不是不够牛逼之类的,但是实际上他在用的语言也是别人定的规则,为什么不重新写门语言的矛盾思想。难道是因为难度太高所以内心逃避把它归于不用想太多直接用的类别。总之,对于类库,不用想太多,直接用。
经典类库

1. 概述
我们使用Java代码开发,我们使用了大量的类库,比如Spring框架相关的,以及其他的类库
1.1 为什么学习类库
下面我们看下为什么要使用类型
1.1.1 提高效率
这是使用类库最重要的原因
使用别人写好的类库可以很大程度上提高开发效率,在Java开发中我们正在写的代码是很少的,更多的代码是由各种类库来提供的,否则重复造轮子,开发周期会非常的长。
1.1.2 提高安全性
使得代码安全性更高
各种的经典类库被非常多的公司引用,并且运行了无数次,很少出现bug,但是我们自己实现这些功能浪费时间不说,并且还容易出现一些意想不到的bug,说不定什么时候就暴雷了,而经典的类库都是经常时间考验的。
1.1.3 学习设计思想
可以学习好的实际思想
一般类库都是比较简单的,但是类库在于好用并且扩展性好,我们可以从中学习到好的设计思想,在我们的项目或者代码中使用这些思想,让我们的代码更加的健全以及优雅。
2. Guava

2.1 概述
Guava是一个基于Java的开源库,包含许多Google核心库,这些库正在许多项目中使用
有助于最佳编码实践,并有助于减少编码错误。 它为集合,缓存,基元支持,并发,通用注释,字符串处理,I/O和验证提供实用程序方法
2.1.1 Guava的优点
- 高效设计良好的API,被Google的开发者设计,实现和使用
- 遵循高效的java语法实践
- 使代码更刻度,简洁,简单
- 节约时间,资源,提高生产力
2.1.2 源码结构
源码包包含了以下这些用户的工具,可以根据需求使用,其中比较经典的有cache,collect,eventbus,concurrent,其它的是比较简单易懂的工具类
1 | com.google.common.annotations:普通注解类型。 |
2.1.3 引入坐标
我们可以引入最新的坐标,然后就可以使用了
1 | <dependency> |
2.2 基础工具类
Guava的经典很大一部分原因来源于对于基础工具类的封装,使用这些类能够让我们的代码更加优雅且完善,这些类大部分都在com.google.common.base包下
2.2.1 注意事项
JDK有很多借鉴guava的地方,这里只讲guava,并且JDK在不断的完善,如果JDK中有已经存这些工具类,建议就不要用guava了
2.2.2 Optional
2.2.2.1 作用
在构造对象的时候就明确申明该对象是否可能为null,快速失败拒绝null值,可以避免空指针异常。
2.2.2.2 使用
1 | public class OptionTest { |
2.2.2.3 源码结构
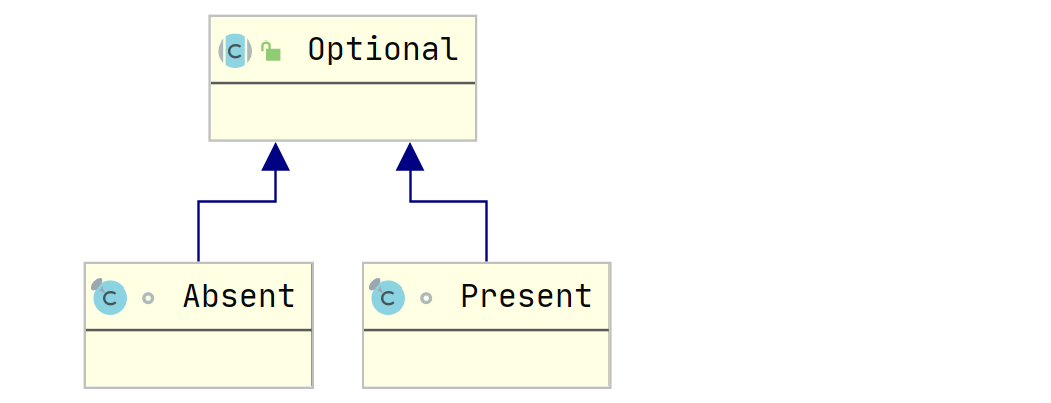
Optional封装了Absent对象以及Present对象,如果参数为空,则Optional封装
Absent否则封装Present
2.2.2.4 JDK8替代
JDK中也有Optional,在JDK8可以使用
java.util.Optional来代替使用
2.2.3 Preconditions
2.2.3.1 作用
封装了前置条件校验,让方法中的条件检查更简单
实际开发中需要做入参校验的情况比比皆是,比如开发一个rest接口,肯定要对参数各种校验,防止错误的输入导致程序出错。我们可以使用Preconditions(前置条件),这样我们自己代码中就不会出现大段的if代码了
2.2.3.2 以前的做法
以前我们都是大段的用if写各种判断,如果入参很多,或者校验逻辑很复杂,这个函数中if会越来越多,圈复杂度越来越高
1 | public static void query(String name, int age) { |
2.2.3.3 代码优化
使用Preconditions对我们的代码进行优化
1 | public static void query(String name, int age) { |
使用
Preconditions就可以消除代码中的if了
2.2.3.4 常见的一些校验
- checkArgument: 检查boolean是否为真,用作方法中检查参数,失败时抛出的异常类型: IllegalArgumentException
- checkNotNull:检查value不为null, 直接返回value,失败时抛出的异常类型:NullPointerException
- checkState:检查对象的一些状态,不依赖方法参数,失败时抛出的异常类型:IllegalStateException
- checkElementIndex:检查index是否为在一个长度为size的list, string或array合法的范围,失败时抛出的异常类型:IndexOutOfBoundsException
- checkPositionIndex:检查位置index是否为在合法的范围,index的范围区间是[0, size]失败时抛出的异常类型:IndexOutOfBoundsException
2.2.4 Splitter
2.2.4.1 作用
Splitter 可以让你使用一种非常简单流畅的模式来控制字符分割的行为
2.2.4.2 String.split的问题
Java 中关于分词的工具类会有一些古怪的行为,
String.split函数会悄悄地丢弃尾部分割符,而StringTokenizer处理5个空格字符串,结果将会什么都没有
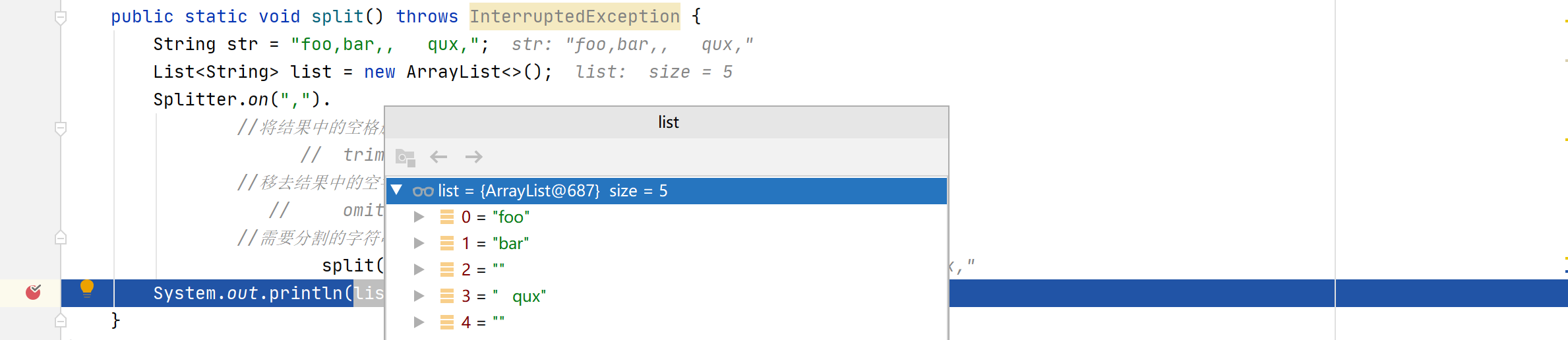
1 | public static void split() throws InterruptedException { |
上面代码执行结果是
"foo", "bar", "", " qux"只有尾部空格被跳过了,令人困惑

2.2.4.3 Splitter优化
Splitter 可以让你使用一种非常简单流畅的模式来控制这些令人困惑的行为
1 | public static void split() throws InterruptedException { |
这样尾部空格不会被跳过,可以正常显示尾部空格
2.2.4.4 去除空格
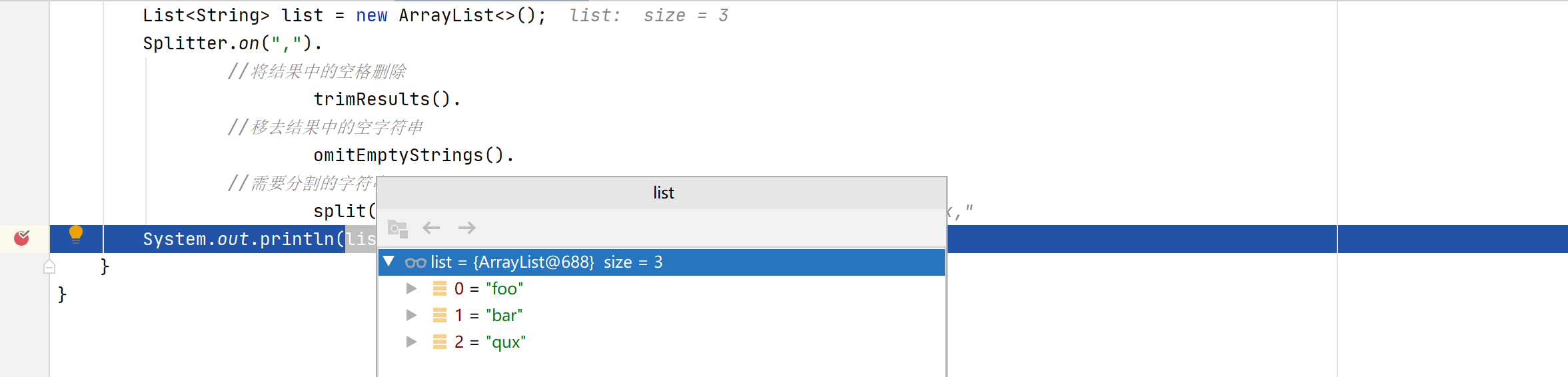
Splitter还支持自定义分割字符串,比如去掉空格、去掉空字符串等等,上面代码可以优化为
1 | public static void split() throws InterruptedException { |
执行后将空格以及空字符串都给去除了
2.2.4.5 MapSplitter
Splitter除了可以对字符进行拆分,还可以对URL参数进行拆分,比如URL参数
id=123&name=green
1 | public static void split() { |
2.2.5 Joiner
2.2.5.1 作用
Guava 的 Joiner 让字符串连接变得极其简单,即使字符串中包含 null,也很容易处理
Joiner相当于spliter的反操作,可以将数组或者集合等可遍历的数据转换成使用分隔符连接的字符串
2.2.5.2 Java实现方式
对于这样的list进行数据进行拼接,需要排除空字符串和null的数据
1 | List<String> list = new ArrayList<String>() {{ |
如果只使用Java方式需要使用以下的方式进行实现
1 | public static String join(List<String> strList, String delimiter) { |
实现方式很简单,但是很繁琐
2.2.5.3 Joiner方式优化
我们不在考虑更多的细节,并且很有语义的告诉代码的阅读者,用什么分隔符,需要过滤null值再join
1 | public static String join(List<String> strList, String delimiter) { |
2.2.5.4 MapJoinner
Joiner还可以处理URL编码的生成,将MAP数据转换成对应的URL参数
1 | public static void join() { |
2.2.6 StopWatch
StopWatch用来计算经过的时间(精确到纳秒)
2.2.6.1 原始的计时方式
原始的方式代码复杂,并且很不美观,性能也存在问题
1 | public static void task() throws InterruptedException { |
2.2.6.2 优化代码
我们发现优化后从代码上来看优雅很多,并且使用起来也比较简单
1 | public static void task() throws InterruptedException { |
2.3 集合增强
2.3.1 Guava集合操作工具类
我们一般习惯使用java.util.Collections 包含的工具方法对集合进行创建操作,Guava 沿着这些路线提供了更多的工具方法:适用于所有集合的静态方法,这是 Guava 最流行和成熟的部分之一
我们用相对直观的方式把工具类与特定集合接口的对应关系归纳如下
| 集合接口 | 属于JDK还是Guava | 对应的Guava工具类 |
|---|---|---|
| Collection | JDK | Collections2,不要和 java.util.Collections 混淆 |
| List | JDK | Lists |
| Set | JDK | Sets |
| SortedSet | JDK | Sets |
| Map | JDK | Maps |
| SortedMap | JDK | Maps |
| Queue | JDK | Queues |
| Multiset | Guava | Multisets |
| Multimap | Guava | Multimaps |
| BiMap | Guava | Maps |
| Table | Guava | Tables |
2.3.2 静态工厂方法
2.3.2.1 JDK创建集合
在 JDK 7之前,构造新的范型集合时要讨厌地重复声明范型
1 | List<String> list = new ArrayList<String>(); |
这种创建方式是比较繁琐的
2.3.2.2 guava创建集合
因此 Guava 提供了能够推断范型的静态工厂方法,现在JDK7以及以上也支持自动类型推断了
1 | List<String> list =Lists.newArrayList(); |
2.3.2.3 指定初始值
Guava 的静态工厂方法远不止这么简单,用工厂方法模式,我们可以方便地在初始化时就指定起始元素
1 | List<String> list =Lists.newArrayList("张三","李四","王五"); |
2.3.2.4 指定初始容量
通过为工厂方法命名 ,我们可以提高集合初始化大小的可读性
1 | //设置初始容量为100 |
2.3.3 不可变集合
2.3.3.1 不可变集合的意义
不可变对象有很多优点,包括:
- 当对象被不可信的库调用时,不可变形式是安全的;
- 不可变对象被多个线程调用时,不存在竞态条件问题
- 不可变集合不需要考虑变化,因此可以节省时间和空间,所有不可变的集合都比它们的可变形式有更好的内存利用率(分析和测试细节);
- 不可变对象因为有固定不变,可以作为常量来安全使用。
2.3.3.2 JDK的不可变操作
JDK也提供了Collections.unmodifiableXXX方法把集合包装为不可变形式,但是有以下缺点
- 笨重而且累赘:不能舒适地用在所有想做防御性拷贝的场景;
- 不安全:要保证没人通过原集合的引用进行修改,返回的集合才是事实上不可变的;
- 低效:包装过的集合仍然保有可变集合的开销,比如并发修改的检查、散列表的额外空间,等等。
2.3.3.3 注意事项
所有Guava不可变集合的实现都不接受null值
如果你需要在不可变集合中使用null,请使用JDK中的Collections.unmodifiableXXX方法
2.3.3.4 创建不可变集合
建造者模式进行创建
1 | public class ImmutableTest { |
还可以使用
of方式进行快速创建
1 | ImmutableList.of("red", "green", "black", "white", "grey"); |
也可以通过
copyOf进行创建
1 | ImmutableList.copyOf(new String[]{"red","green","black","white","grey"}); |
2.3.3.5 不可变集合的使用
不可变集合的使用和普通集合一样,只是不能使用他们的add,remove等修改集合的方法,并且代码结构如下
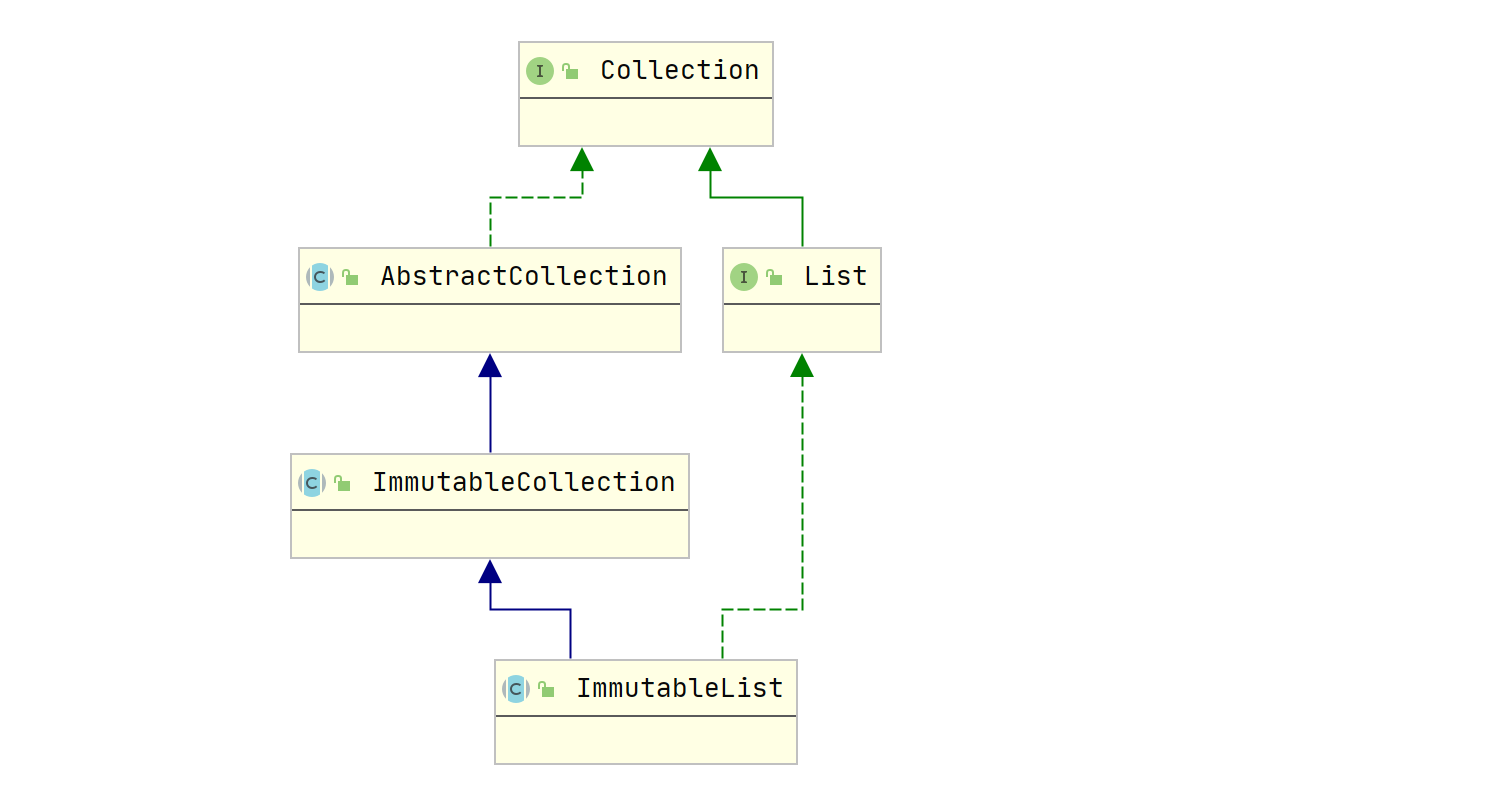
其中add以及remove方法执行后会直接报错
1 | /** @deprecated */ |
2.3.4 Multiset
Guava提供了一个新集合类型Multiset,它可以多次添加相等的元素,且和元素顺序无关,Multiset继承于JDK的Cllection接口,而不是Set接口

2.3.4.1 代码结构
Multiset代码结构如下
2.3.4.2 作用
Multiset和Set的区别就是可以保存多个相同的对象
在JDK中,List和Set有一个基本的区别,就是List可以包含多个相同对象,且是有顺序的,而Set不能有重复,且不保证顺序,所以Multiset占据了List和Set之间的一个灰色地带:允许重复,但是不保证顺序
常见使用场景:Multiset有一个有用的功能,就是跟踪每种对象的数量,所以你可以用来进行数字统计。
2.3.4.3 案例场景
由于某些的需求,我们经常会这样去用Map数据结构,比如对一系列key计数
下面的代码实现方式没有问题,只是代码实在是丑陋不堪,尤其是其中的if判断,代码噪音极重
1 | /** |
2.3.4.4 Multiset优化代码
可以使用guava的一种Multiset的数据结构,专门用于简化这类问题,如果使用实现Multiset接口的具体类就可以很容易实现以上的功能需求
1 | /** |
我们发现代码经过优化后简洁多了,操作有原来的四行变成了一行
2.3.4.5 Multiset的实现类
Guava提供了Multiset的多种实现,这些实现基本对应了JDK中Map的实现
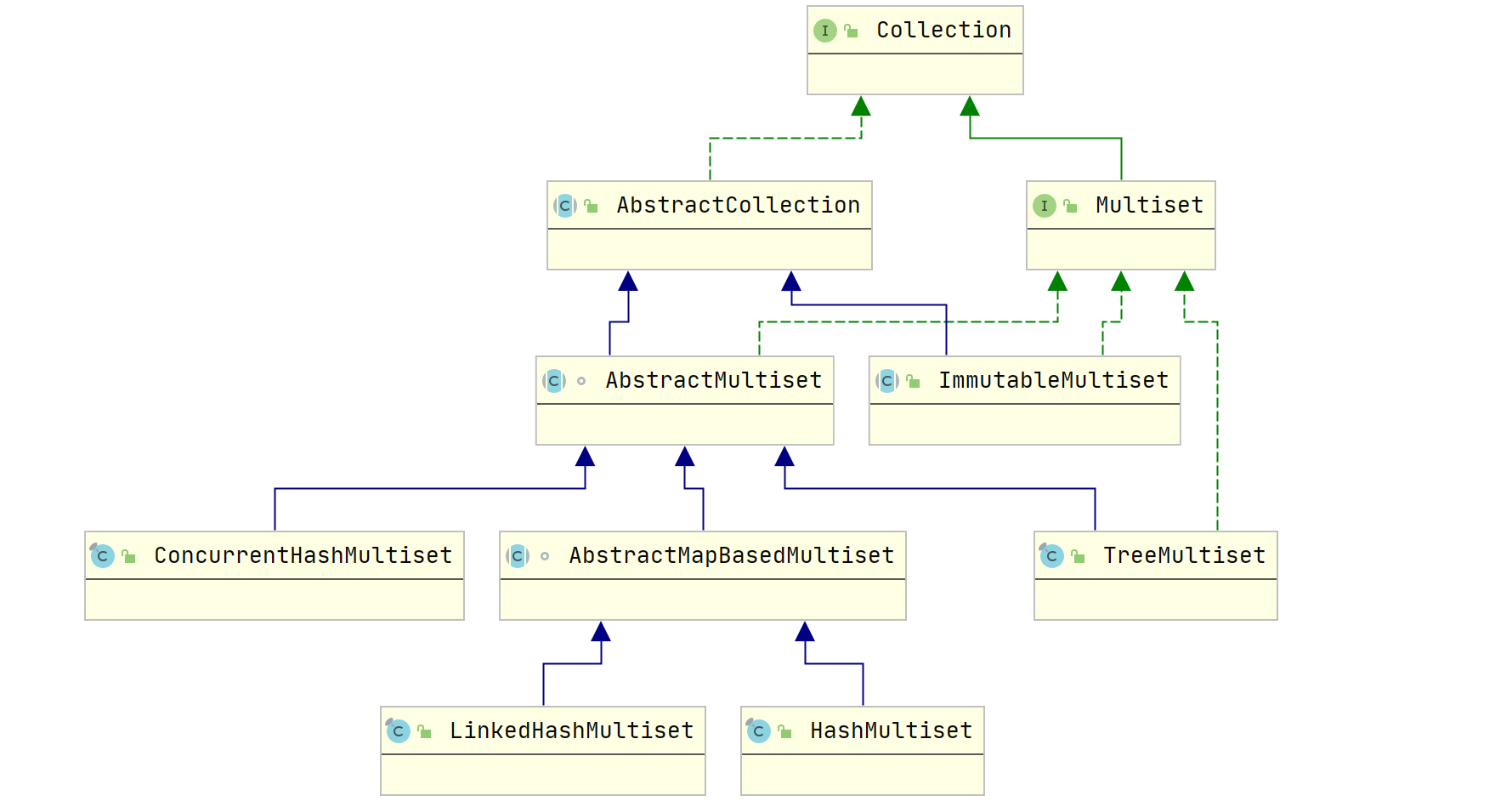
- HashMultiset: 元素存放于 HashMap
- LinkedHashMultiset: 元素存放于 LinkedHashMap,即元素的排列顺序由第一次放入的顺序决定
- TreeMultiset:元素被排序存放于TreeMap
- EnumMultiset: 元素必须是 enum 类型
- ImmutableMultiset: 不可修改的 Mutiset
2.3.4.6 Multiset主要方法
- add(E element) :向其中添加单个元素
- add(E element,int occurrences) : 向其中添加指定个数的元素
- count(Object element) : 返回给定参数元素的个数
- remove(E element) : 移除一个元素,其count值 会响应减少
- remove(E element,int occurrences): 移除相应个数的元素
- elementSet() : 将不同的元素放入一个Set中
- entrySet(): 类似与Map.entrySet 返回Set<Multiset.Entry>。包含的Entry支持使用getElement()和getCount()
- setCount(E element ,int count): 设定某一个元素的重复次数
- setCount(E element,int oldCount,int newCount): 将符合原有重复个数的元素修改为新的重复次数
- retainAll(Collection c) : 保留出现在给定集合参数的所有的元素
- removeAll(Collectionc) : 去除出现给给定集合参数的所有的元素
2.3.4.7 Multiset和Map区别
需要注意的是Multiset不是一个Map<E,Integer>,尽管Multiset提供一部分类似的功能实现
- Multiset中的元素的重复个数只会是正数,且最大不会超过Integer.MAX_VALUE,设定计数为0的元素将不会出现multiset中,也不会出现elementSet()和entrySet()的返回结果中。
- multiset.size() 方法返回的是所有的元素的总和,相当于是将所有重复的个数相加,如果需要知道每个元素的个数可以使用elementSet().size()得到.(因而调用add(E)方法会是multiset.size()增加1).
- multiset.iterator() 会循环迭代每一个出现的元素,迭代的次数与multiset.size()相同。
- Multiset 支持添加、移除多个元素以及重新设定元素的个数。执行setCount(element,0)相当于移除multiset中所有的相同元素。
- 调用multiset.count(elem)方法时,如果该元素不在该集中,那么返回的结果只会是0
2.3.5 双向Map
我们知道Map是一种键值对映射,这个映射是键到值的映射,而BiMap首先也是一种Map,他的特别之处在于,既提供键到值的映射,也提供值到键的映射,所以它是双向Map

2.3.5.1 作用
Java类库中的Map是一种映射的数据结构,由键值对组成一个Map的集合元素,这种映射是单方向的,由键(key)到值(value)的映射,开发者可以通过key获得对应的唯一value的值,但是无法通过value反向获得与之对应的唯一key的值。
BiMap可以理解为是一种双向的键值对映射,既可以通过key获取value的值,也可以通过value反向获取key的值
2.3.5.2 案例场景
我们需要做一个星期几的中英文表示的相互映射,例如Monday对应的中文表示是星期一,同样星期一对应的英文表示是Monday如果使用传统的Map来实现
1 | public static void main(String[] args) { |
通过value获取key需要遍历,并且还需要进行判断,代码不简洁,并且可能存在一些问题
- 如何处理重复的value的情况,不考虑的话,反转的时候就会出现覆盖的情况.
2.3.5.3 BiMap优化代码
这里使用BiMap是一个非常好的场景,让我们上面的代码变得十分简洁
1 | public static void main(String[] args) { |
BiMap的值键对的Map可以通过inverse()方法得到
2.3.5.4 数据的强制唯一
在使用BiMap时,会要求Value的唯一性。如果value重复了则会抛出错误:
java.lang.IllegalArgumentException
1 | BiMap<String, String> weekNameMap = HashBiMap.create(); |
如果我们确实需要插入重复的value值,那可以选择forcePut方法,但是我们需要注意的是前面的key也会被覆盖了
1 | BiMap<String, String> weekNameMap = HashBiMap.create(); |
输出结果
1 | weekNameMap:{星期一=Monday, 星期二=Tuesday, 星期三=Wednesday, 星期四=Thursday, 星期五=Friday, 星期六=Saturday, 星期某=Sunday} |
2.3.5.5 理解inverse方法
inverse方法会返回一个反转的BiMap,但是注意这个反转的map不是新的map对象,它实现了一种视图关联,这样你对于反转后的map的所有操作都会影响原先的map对象
1 | BiMap<String, String> weekNameMap = HashBiMap.create(); |
输出结果
1 | 反转前后是否是同一个对象true |
2.3.6 一键多值的Map
有时候我们需要这样的数据类型
Map<String,Collection<String>>,Multimap就是为了解决这类问题的
2.3.6.1 相关实现类
Multimap提供了丰富的实现,所以你可以用它来替代程序里的
Map<K, Collection<V>>
| 实现 | Key实现 | Value实现 |
|---|---|---|
| ArrayListMultimap | HashMap | ArrayList |
| HashMultimap | HashMap | HashSet |
| LinkedListMultimap | LinkedHashMap | LinkedList |
| LinkedHashMultimap | LinkedHashMap | LinkedHashSet |
| TreeMultimap | TreeMap | TreeSet |
| ImmutableListMultimap | ImmutableMap | ImmutableList |
| ImmutableSetMultimap | ImmutableMap | ImmutableSet |
2.3.6.2 案例场景
假如目前有个需求是给对学生的成绩进行统计,统计出来各个成绩的学员分布
1 | Map<Integer, List<String>> scoreMap = new HashMap<>(); |
打印结果
1 | {80=[张三, 吴九, 赵六], 70=[陈二, 王五, 周八], 60=[李四, 孙七, 郑十, 刘一]} |
可以看到我们实现起来特别麻烦,需要检查key是否存在,不存在时则创建一个,存在时在List后面添加上一个
2.3.6.3 代码优化
Multimap 提供了一个方便地把一个键对应到多个值的数据结构,可以通过下面代码简单实现
1 | Multimap<Integer,String> multimap = HashMultimap.create(); |
2.4 缓存增强
Guava Cache 是
Guava中的一个内存缓存模块,用于将数据缓存到JVM内存中
2.4.1 功能介绍
- 提供了get、put封装操作,能够集成数据源
- 线程安全的缓存,与
ConcurrentMap相似,但前者增加了更多的元素失效策略,后者只能显示的移除元素 - Guava Cache提供了多种基本的缓存回收方式
- 监控缓存加载/命中情况
2.4.2 使用场景
- 愿意花费一些内存来提高速度。
- 使用场景有时会多次查询key。
- 缓存将不需要存储超出
RAM容量的数据
2.4.3 JVM缓存的缺点
JVM 缓存,是堆缓存。其实就是创建一些全局容器,比如List、Set、Map等
这些容器用来做数据存储,存在着很多的问题
- 不能按照一定的规则淘汰数据,如 LRU,LFU,FIFO 等。
- 清除数据时的回调通知
- 并发处理能力差,针对并发可以使用CurrentHashMap,但缓存的其他功能需要自行实现缓存过期处理,缓存数据加载刷新等都需要手工实现
2.4.4 缓存分类
2.4.4.1 Cache
Cache是通过CacheBuilder的build()方法构建,它是Gauva提供的最基本的缓存接口,并且它提供了一些常用的缓存api
1 | //构建Cache缓存 |
2.4.4.2 LoadingCache
LoadingCache继承自Cache,在构建LoadingCache时,需要通过CacheBuilder的build(CacheLoader<? super K1, V1> loader)方法构建
1 | //构建Cache缓存 |
2.4.5 缓存配置策略
2.4.5.1 缓存的并发级别
Guava提供了设置并发级别的
API,使得缓存支持并发的写入和读取。
与ConcurrentHashMap类似,Guava cache的并发也是通过分片锁实现,在通常情况下,推荐将并发级别设置为服务器cpu核心数
1 | CacheBuilder.newBuilder() |
2.4.5.2 初始容量设置
我们在构建缓存时可以为缓存设置一个合理大小初始容量,由于Guava的缓存使用了分片锁的机制,扩容的代价非常昂贵,所以合理的初始容量能够减少缓存容器的扩容次数
1 | CacheBuilder.newBuilder() |
2.4.5.3 设置最大存储
Guava Cache可以在构建缓存对象时指定缓存所能够存储的最大记录数量
当Cache中的记录数量达到最大值后再调用put方法向其中添加对象,Guava会先从当前缓存的对象记录中选择一条删除掉,腾出空间后再将新的对象存储到Cache中
1 | CacheBuilder.newBuilder() |
2.4.6 缓存清除策略
Guava Cache可以在构建缓存对象时指定缓存的清除策略,当缓存满的时候根据情况进行清除数据
2.4.6.1 基于存活时间的清除策略
可以根据设置的读写的存活事件进行设置,
expireAfterWrite参数设置写缓存后多久过期,expireAfterAccess参数设置读缓存后多久过期,存活时间策略可以单独设置或组合配置
1 | CacheBuilder.newBuilder(). |
2.4.6.2 基于容量的清除策略
通过
CacheBuilder.maximumSize(long)方法可以设置Cache的最大容量数,当缓存数量达到或接近该最大值时,Cache将清除掉那些最近最少使用的缓存
1 | CacheBuilder.newBuilder(). |
2.4.6.3 基于权重的清除策略
使用
CacheBuilder.weigher(Weigher)指定一个权重函数,并且用CacheBuilder.maximumWeight(long)指定最大总重
如每一项缓存所占据的内存空间大小都不一样,可以看作它们有不同的“权重”(weights),作为执行清除策略时优化回收的对象
2.4.6.4 显式清除
自动清除实时性没有那么好,如果条件允许可以采用手动清除
- 清除单个key:
Cache.invalidate(key) - 批量清除key:
Cache.invalidateAll(keys) - 清除所有缓存项:
Cache.invalidateAll()
2.4.6.5 引用清除
在构建Cache实例过程中,通过设置使用弱引用的键、或弱引用的值、或软引用的值,从而使JVM在GC时顺带实现缓存的清除
- CacheBuilder.weakKeys():使用弱引用存储键,当键没有其它(强或软)引用时,缓存项可以被垃圾回收
- CacheBuilder.weakValues():使用弱引用存储值, 当值没有其它(强或软)引用时,缓存项可以被垃圾回
- CacheBuilder.softValues():使用软引用存储值,软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。考虑到使用软引用的性能影响,我们通常建议使用更有性能预测性的缓存大小限定
1 | CacheBuilder.newBuilder(). |
2.4.7 缓存刷新
在Guava cache中支持定时刷新和显式刷新两种方式,其中只有LoadingCache能够进行定时刷新。
2.4.7.1 定时刷新
在进行缓存定时刷新时,我们需要指定缓存的刷新间隔,和一个用来加载缓存的CacheLoader,当达到刷新时间间隔后,下一次获取缓存时,会调用CacheLoader的load方法刷新缓存
例如构建个刷新频率为10秒的缓存
1 | //构建Cache缓存 |
执行后查看执行效果
1 | key的值是:xxxx |
2.4.7.2 显式刷新
在缓存构建完毕后,我们可以通过Cache提供的一些借口方法,显式的对缓存进行刷新覆盖
1 | //构建Cache缓存 |
2.5 单机限流
在互联网高并发场景下,限流是用来保证系统稳定性的一种手段,当系统遭遇瞬时流量激增时,可能会由于系统资源耗尽导致宕机。而限流可以把一小部分流量拒绝掉,保证大部分流量可以正常访问,从而保证系统只接收承受范围以内的请求,多余的请求给拒绝掉
2.5.1 常见的限流算法
常用的限流算法有 漏桶算法、令牌桶算法
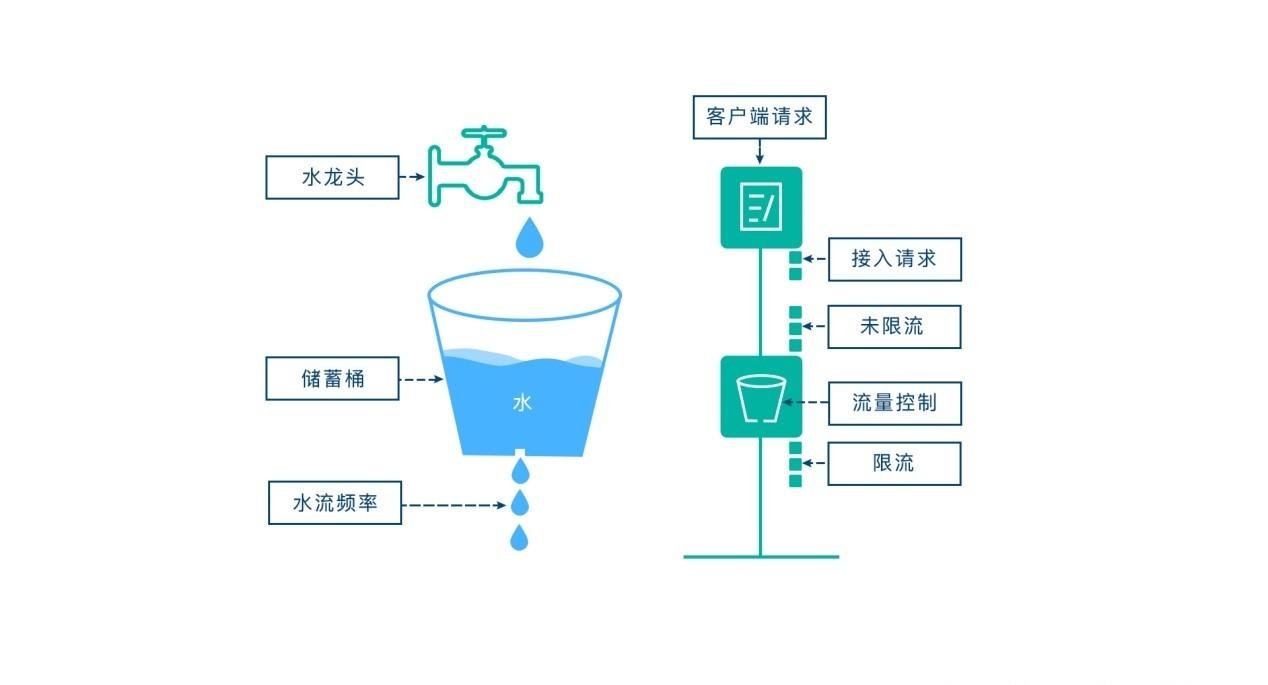
2.5.1.1 漏桶算法
漏桶的意思就像一个漏斗一样,水一滴一滴的滴下去,流出是匀速的。
当访问量过大的时候这个漏斗就会积水,漏桶算法的实现依赖队列,一个处理器从队头依照固定频率取出数据进行处理。如果请求量过大导致队列堆满那么新来的请求就会被抛弃,漏桶一般按照固定的速率流出
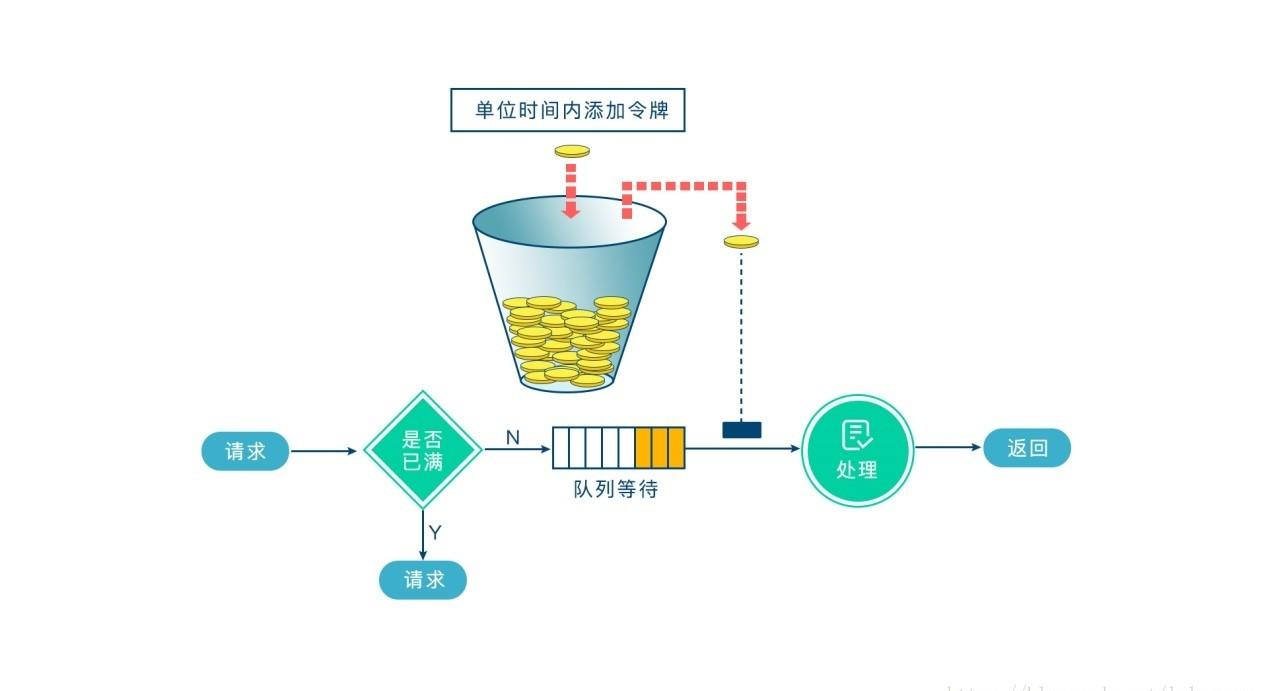
2.5.1.2 令牌桶算法
令牌桶则是存放固定容量的令牌,按照固定速率从桶中取出令牌。
初始给桶中添加固定容量令牌,当桶中令牌不够取出的时候则拒绝新的请求,令牌桶不限制取出令牌的速度,只要有令牌就能处理,所以令牌桶允许一定程度的突发
2.5.1.3 两种区别
- 漏桶算法是桶中有水就需要等待,桶满就拒绝请求,而令牌桶是桶变空了需要等待令牌产生
- 漏桶算法漏水的速率固定,令牌桶算法往桶中放令牌的速率固定
- 令牌桶可以接收的瞬时流量比漏桶大,比如桶的容量为100,令牌桶会装满100个令牌,当有瞬时80个并发过来时可以从桶中迅速拿到令牌进行处理,而漏桶的消费速率固定,当瞬时80个并发过来时,可能需要进行排队等待
2.5.2 RateLimiter
Guava中的限流使用的是令牌桶算法,RateLimiter提供了两种限流实现
2.5.2.1 平滑突发限流(SmoothBursty)
每秒以固定的速率输出令牌,以达到平滑输出的效果
1 | public class RateLimiterTest { |
输出结果
1 | 获取令牌等待:0.0秒 |
平均每个0.2秒左右,很均匀,但是当产生令牌的速率大于取令牌的速率时,是不需要等待令牌时间的
1 | public class RateLimiterTest { |
输出结果
1 | 获取令牌等待:0.0秒 |
由于令牌可以积累,所以我一次可以取多个令牌,只要令牌充足,可以快速响应
1 | public class RateLimiterTest { |
打印结果
1 | 获取5个令牌等待:0.0秒 |
2.5.2.2 平滑预热限流(SmoothWarmingUp)
平滑预热限流带有预热期的平滑限流,它启动后会有一段预热期,逐步将令牌产生的频率提升到配置的速率,这种方式适用于系统启动后需要一段时间来进行预热的场景
比如,我设置的是每秒5个令牌,预热期为5秒,那么它就不会是0.2左右产生一个令牌,在前5秒钟它不是一个均匀的速率,5秒后恢复均匀的速率
1 | public class RateLimiterTest { |
输出结果,我们发现随着时间发展,令牌的获取速度越来越快,一直到5S后速度维持稳定
1 | 获取1个令牌等待:0.0秒 |
2.6 数学增强
2.6.1 Guava数据工具类优点
2.6.1.1 充分测试
Guava Math针对各种不常见的溢出情况都有充分的测试;
对溢出语义,Guava文档也有相应的说明;如果运算的溢出检查不能通过,将导致快速失败;
2.6.1.2 性能优异
Guava Math的性能经过了精心的设计和调优;
虽然性能不可避免地依据具体硬件细节而有所差异,但Guava Math的速度通常可以与Apache Commons的MathUtils相比,在某些场景下甚至还有显著提升;
2.6.1.3 可读性高
Guava Math在设计上考虑了可读性和正确的编程习惯
IntMath.log2(x, CEILING) 所表达的含义,即使在快速阅读时也是清晰明确的,而32-Integer.numberOfLeadingZeros(x – 1)对于阅读者来说则不够清晰
2.6.2 整数运算
Guava Math主要处理三种整数类型:int、long和BigInteger,这三种类型的运算工具类分别叫做IntMath、LongMath和BigIntegerMath
2.6.2.1 直接计算的问题
在JDK中进行数值计算需要判断边界,如果一旦判断不好就容易出现问题
1 | //数据一旦溢出后,数据就变成了负数 |
类似于上面的代码,一旦溢出就变成了负数,出现了Bug
2.6.1.2 有溢出检查的运算
Guava Math提供了若干有溢出检查的运算方法:结果溢出时,这些方法将快速失败而不是忽略溢出
1 | //一旦溢出就会报错,不会出现出现溢出值 |
2.6.1.3 常用的API
常见的检查并进行操作的有以下几个API
| Int类型 | Long类型 | 检查操作 |
|---|---|---|
| IntMath.checkedAdd | LongMath.checkedAdd | 加 |
| IntMath.checkedSubtrac | LongMath.checkedSubtract | 减 |
| IntMath.checkedMultiply | LongMath.checkedMultiply | 乘 |
| IntMath.checkedPow | LongMath.checkedPow | 次方 |
3. Spring中的工具类
在
Spring Framework里的spring-core核心包里面,有个org.springframework.util里面有不少非常实用的工具类
该工具包里面的工具类虽然是被定义在Spring下面的,但是由于Spring框架目前几乎成了JavaEE实际的标准了,因此我们直接使用也是无妨的,很多时候能够大大的提高我们的生产力
3.1 UUID生成器增强
Spring给我提供了接口:IdGenerator 来生成id代表唯一箭,它内置提供了三个实现
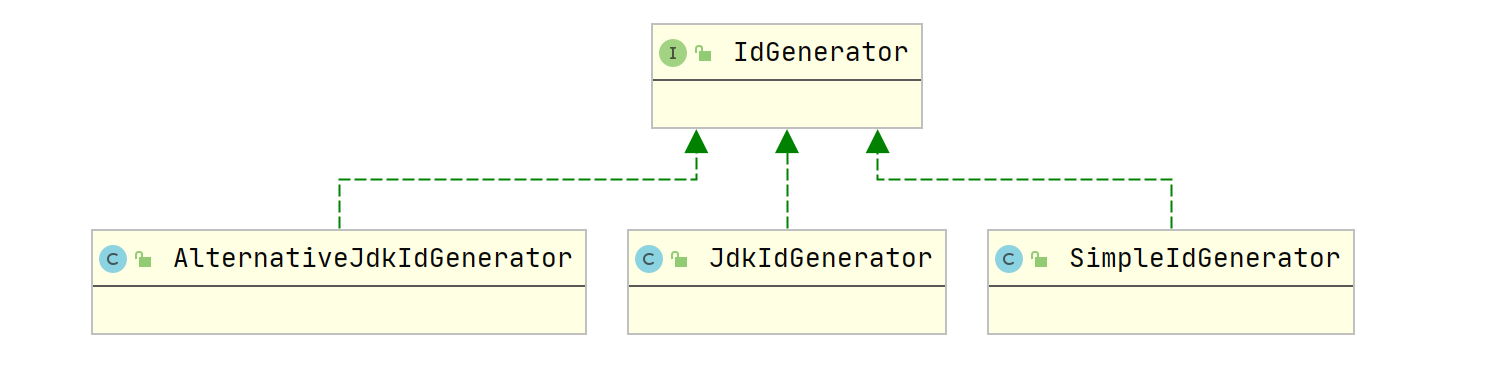
3.1.1 JdkIdGenerator
JDK的工具类包util包中就为我们提供了一个很好的工具类,即UUID,该类就是对JDK的UUID做了封装
1 | public class JdkIdGenerator implements IdGenerator { |
3.1.2 AlternativeJdkIdGenerator
这是Spring提供给我们的一个重要实现,用它来取代JDK的UUID的生成,它提供了一个更好、更高性能的表现
1 | IdGenerator idGenerator = new AlternativeJdkIdGenerator(); |
3.1.3 SimpleIdGenerator
类似于自增的Id生成器,每调用一次,自增1,可以用于计数生成流水号等
1 | IdGenerator idGenerator = new SimpleIdGenerator(); |
3.1.4 三者性能比较
我们可以通过以下代码对三种UUID生成器进行测试
1 | public static void main(String[] args) { |
输出结果
1 | jdkIdGenerator循环1000000次耗时:448ms |
通过结果我们发现Spring提供的
alternativeJdkIdGenerator生成器性能比JDK提供的性能高一个数量级
3.2 Assert 断言工具类
Assert断言工具类,通常用于数据合法性检查,
3.2.1 正常代码方式
这种方式代码比较繁琐,并且不太优雅
1 | if (message== null || message.equls("")) { |
3.2.2 Assert方式
可以通过Assert方式优化的进行验证参数
1 | Assert.hasText("","输入信息错误!"); |
3.2.3 常用的断言
1 | Assert.notNull(Object object, "object is required") //对象非空 |
3.3 PathMatcher 路径匹配器
Spring提供的实现:
AntPathMatcherAnt路径匹配规则
SpringMVC的路径匹配规则是依照Ant的来的,实际上不只是SpringMVC,整个Spring框架的路径解析都是按照Ant的风格来的
AntPathMatcher不仅可以匹配Spring的@RequestMapping路径,也可以用来匹配各种字符串,包括文件路径等
3.3.1 什么是Ant路径
Ant路径就是我们常用的路径模式
3.3.1.1 Ant通配符
ANT通配符有三种
| 通配符 | 说明 |
|---|---|
| ? | 匹配任何单字符 |
| * | 匹配0或者任意数量的字符 |
| ** | 匹配0或者更多的目录 |
3.3.1.2 Ant路径举例
| URL路径 | 说明 |
|---|---|
/app/*.x |
匹配(Matches)所有在app路径下的.x文件 |
/app/p?ttern |
匹配(Matches) /app/pattern 和 /app/pXttern,但是不包括/app/pttern |
/**/example |
匹配(Matches) /app/example, /app/foo/example, 和 /example |
/app/*/dir/file.* |
匹配(Matches) /app/dir/file.jsp, /app/foo/dir/file.html,/app/foo/bar/dir/file.pdf, 和 /app/dir/file.java |
/**/*.jsp |
匹配(Matches)任何的.jsp文件 |
3.3.2 路径匹配问题
你是否曾今在你们的Filter里看过类似下面的代码
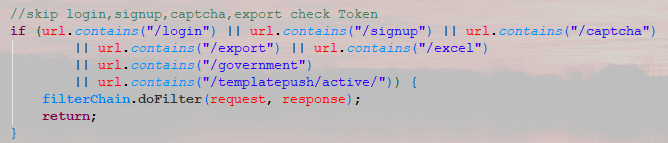
这种所谓的白名单URL这样来匹配,可谓非常的不优雅并且难于阅读,而且通过穷举法的扩展性非常差
3.3.3 优化代码
我们可以使用Spring的路径匹配器来进行代码的优化
1 | PathMatcher pathMatcher = new AntPathMatcher(); |
3.4 PropertyPlaceholderHelper
将字符串里的占位符内容,用我们配置的properties里的替换
这个是一个单纯的类,没有继承没有实现,并且没有依赖Spring框架其他的任何类
3.4.1 原始代码
是否有过这种场景,定义一个模板,根据不同的变量生成不同的值
1 | String template = "姓名:{name},年龄:{age}, 性别:{sex}"; |
上面的模板如何根据变量来生成内容呢?我们可以使用
MessageFormat来实现,但是要求必须使用{index}方式
1 | String template = "姓名:{0},年龄:{1}, 性别:{2}"; |
感觉明显不太好用,并且还限定了边界的符号,不能自定义符号
3.4.2 优化代码
我们可以使用
PropertyPlaceholderHelper来优化代码的实现
1 | //定义属性,可以从文件中读取 |
3.5 BeanUtils
BeanUtils 工具类提供了非常丰富的Java反射API,开发过程中使用恰当可以减少很懂工作量, 其中最常用的莫过于
copyProperties
3.5.1 使用场景
在开发中,经常用到属性copy,比如从一个各种VO,DTO,BO等的转换,大部分属性都差不多,如果手动转换会非常麻烦,比如这里用到一个
UserVO和UserBO,如果进行转换则需要如下的代码
1 | UserBO userBO = new UserBO(); |
3.5.2 使用属性copy优化
使用属性copy会非常方便
1 | UserBO userBO = new UserBO(); |
3.6 DigestUtils
可以对字节数组、InputStream流生成摘要
3.6.1 计算文件摘要
在开发中对于文件上传一般都是需要生成文件摘要的,防止文件重复,如果文件摘要是一样的就认为是同一个文件,不需要在将文件上传上去了,这样可以节省硬盘空间,防止产生大量重复的文件
1 | String digest = DigestUtils.md5DigestAsHex(new FileInputStream(new File("E:\\tmp\\out.txt"))); |
运行后就输出了文件的摘要
1 | 2645fc604371f0b7a0809f2b93abb21f |
3.6.2 密码加密
通过这种计算摘要算法还可以对密码进行加密,这个和MD5类似,也是不可破解的方式进行加密的
1 | String password = "123qwe!@#QWE"; |
可以直接通过Spring提供的工具类进行MD5加密
4. HuTool
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
4.1 HuTool简介
Hutool中的工具方法来自每个用户的精雕细琢,它涵盖了Java开发底层代码中的方方面面,它既是大型项目开发中解决小问题的利器,也是小型项目中的效率担当
4.1.1 设计哲学
Hutool的设计思想是尽量减少重复的定义,让项目中的
util这个package尽量少,
- 减少代码录入
- 常用功能组合起来,实现一个功能只用一个方法
- 简化Java API,原来需要几个类实现的功能我也只是用一个类甚至一个方法(想想为了个线程池我得new多少类……而且名字还不好记)
- 一些固定使用的算法收集到一起,不用每次问度娘了(例如Base64算法、MD5、Sha-1,还有Hash算法)
- 借鉴Python的很多小技巧(例如列表切片,列表支持负数index),让Java更加好用。
- 非常好用的ORM框架,同样借鉴Python的Django框架,以键值对的实体代替对象实体,大大降低数据库访问的难度(再也不用像Hibernate一样配置半天ORM Mapping了)。
- 极大简化了文件、日期的操作,尤其是相对路径和绝对路径问题做了非常好的封装,降低学习成本。
4.1.2 安装
在项目的pom.xml的dependencies中加入以下内容
1 | <dependency> |
4.2 包含的组件
一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件
| 模块 | 介绍 |
|---|---|
| hutool-aop | JDK动态代理封装,提供非IOC下的切面支持 |
| hutool-bloomFilter | 布隆过滤,提供一些Hash算法的布隆过滤 |
| hutool-cache | 简单缓存实现 |
| hutool-core | 核心,包括Bean操作、日期、各种Util等 |
| hutool-cron | 定时任务模块,提供类Crontab表达式的定时任务 |
| hutool-crypto | 加密解密模块,提供对称、非对称和摘要算法封装 |
| hutool-db | JDBC封装后的数据操作,基于ActiveRecord思想 |
| hutool-dfa | 基于DFA模型的多关键字查找 |
| hutool-extra | 扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等) |
| hutool-http | 基于HttpUrlConnection的Http客户端封装 |
| hutool-log | 自动识别日志实现的日志门面 |
| hutool-script | 脚本执行封装,例如Javascript |
| hutool-setting | 功能更强大的Setting配置文件和Properties封装 |
| hutool-system | 系统参数调用封装(JVM信息等) |
| hutool-json | JSON实现 |
| hutool-captcha | 图片验证码实现 |
| hutool-poi | 针对POI中Excel和Word的封装 |
| hutool-socket | 基于Java的NIO和AIO的Socket封装 |
| hutool-jwt | JSON Web Token (JWT)封装实现 |
4.3 文档介绍
hutool提供有很详细的官方文档,并且内容也比较详细,地址是
https://www.hutool.cn/docs/index.html,下面我们简单的介绍几个比较好用的
4.4 类型转换工具类
4.4.1 Convert类
Convert类可以说是一个工具方法类,里面封装了针对Java常见类型的转换,用于简化类型转换
Convert类中大部分方法为toXXX,参数为Object,可以实现将任意可能的类型转换为指定类型,同时支持第二个参数defaultValue用于在转换失败时返回一个默认值
1 | public class ConvertTest { |
输出结果
1 | 转成成数字:1234 |
4.2 IO工具类
下面列举几个比较常用的IO工具类的使用
4.2.1 获取文件类型
在文件上传时,有时候我们需要判断文件类型。但是又不能简单的通过扩展名来判断(防止恶意脚本等通过上传到服务器上),于是我们需要在服务端通过读取文件的首部几个二进制位来判断常用的文件类型
1 | File file = FileUtil.file("E:\\tmp\\out.txt"); |
上面的代码
out.txt实际是一张jpg图片,只是将图片的扩展名改成了txt,通过该工具可以将文件的真实格式读取出来
4.2.2 文件监听
很多时候我们需要监听一个文件的变化或者目录的变动,包括文件的创建、修改、删除,以及目录下文件的创建、修改和删除
1 | public class FileUtilTest { |
 微信
微信 支付宝
支付宝

