前面学习的RPC,注册中心等.思想融合在SpringCloud底层,然后提供一站式服务。
大家谈起的微服务,大多来讲说的只不过是种架构方式。其实现方式很多种:Spring Cloud,Dubbo,华为的Service Combo,Istio 。
那么这么多的微服务架构产品中,我们为什么要用Spring Cloud?因为它后台硬、技术强、群众基础好,使用方便;
SpringCloud引言 技术选择,写在前头
注册中心:nacos 替代 eureka、consul、zookeeper
配置中心: nacos 替代 spring cloud config、consul(config)
调用: openFeign 替代 feign、restTempate
熔断:sentinel 替代 hystrix、Resilience4j
网关:spring cloud gateway
链路:skywalking 代替 spring cloud sleuth+zipkin
熔断监控:sentinel dashboard
负载均衡:spring cloud loadbalancer
集群和分布式的概念 集群是一种物理形态,分布式是一种工作方式。
分布式:一个业务拆分成多个子业务,部署在不同的服务器上,对外提供不同的服务。
将一个大的系统划分为多个业务模块,每个业务模块部署在不同服务器上。多个模块协同合作完成整个系统的任务。其中每个业务模块也叫子系统。
上图中:service A、service B、service C、service D分别是业务组件,共同完成商城系统的业务
系统架构演变 随着互联网的发展,网站应用的规模不断扩大。需求的激增,带来的是技术上的压力。系统架构也因此也不断的演进、升级、迭代。从单一应用,到垂直拆分,到分布式服务,到SOA,以及现在火热的微服务架构,还有在Google带领下来势汹涌的Service Mesh。我们到底是该乘坐微服务的船只驶向远方,还是偏安逸得过且过?
其实生活不止眼前的苟且,还有诗和远方。所以我们今天就回顾历史,看一看系统架构演变的历程;把握现在,学习现在最火的技术架构;展望未来,争取成为一名优秀的Java工程师
集中式架构 当网站流量很小时,只需要一个应用,所有功能部署在一起,减少部署节点成本的框架称之为集中式框架。此时,用于简化增删改查工作量的数据访问框架(ORM)是影响项目开发的关键。
优点:
系统开发速度快
维护成本低
适用于并发要求较低的系统
缺点:
代码耦合度高,后期维护困难
无法针对不同模块进行针对性优化
无法水平扩展
单点容错率低,并发能力差
垂直拆分架构 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,此时为了应对更高的并发和业务需求,我们根据业务功能将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
优点:
系统拆分实现了流量分担,解决了并发问题
可以针对不同模块进行优化
方便水平扩展,负载均衡,容错率提高
缺点:
系统间相互独立,会有很多重复开发工作,影响开发效率
分布式服务架构 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
优点:
将基础服务进行了抽取,系统间相互调用,提高了代码复用和开发效率
缺点:
SOA面向服务架构
面向服务架构典型代表有两个:流动计算架构和微服务架构;
流动计算架构:
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。流动计算架构的最佳实践阿里的Dubbo。
微服务架构
与流动计算架构很相似,除了具备流动计算架构优势外,微服务架构中的微服务可以独立部署,独立发展。且微服务的开发不会限制于任何技术栈。微服务架构的最佳实践是SpringCloud。
SOA(Service Oriented Architecture)面向服务的架构:它是一种设计方法,其中包含多个服务, 服务之间通过相互依赖最终提供一系列的功能。一个服务 通常以独立的形式存在与操作系统进程中。各个服务之间 通过网络调用。
SOA结构图:
ESB(企业服务总线),简单来说 ESB 就是一根管道,用来连接各个服务节点。为了集成不同系统,不同协议的服务,ESB 做了消息的转化解释和路由工作,让不同的服务互联互通。
SOA缺点 :每个供应商提供的ESB产品有偏差,自身实现较为复杂;应用服务粒度较大,ESB集成整合所有服务和协议、数据转换使得运维、测试部署困难。所有服务都通过一个通路通信,直接降低了通信速度
微服务架构 SOA使用了ESB组件的面向服务架构:ESB自身实现复杂;应用服务粒度较大,所有服务之间的通信都经过ESB会降低通信速度;部署、测试ESB比较麻烦。所以有了微服务。
微服务架构 是使用一套小服务来开发单个应用的方式或途径 ,每个服务基于单一业务能力构建,运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,并能够通过自动化部署机制来独立部署。这些服务可以使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。
微服务结构图:
或者这样的:
API Gateway网关是一个服务器,是系统的唯一入口。为每个客户端提供一个定制的API。API网关核心是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。如它还可以具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。通常,网关提供RESTful/HTTP的方式访问服务。而服务端通过服务注册中心进行服务注册和管理。
特点:
单一职责:微服务中每一个服务都对应唯一的业务能力,做到单一职责
微:微服务的服务拆分粒度很小 ,例如一个用户管理就可以作为一个服务。每个服务虽小,但“五脏俱全”。
面向服务:面向服务 是说每个服务都要对外暴露Rest风格服务接口API。并不关心服务的技术实现,做到与平台和语言无关,也不限定用什么技术实现,只要提供Rest的接口即可。
自治:自治是说服务间互相独立 ,互不干扰
团队独立:每个服务都是一个独立的开发团队,人数不能过多。
技术独立:因为是面向服务,提供Rest接口,使用什么技术没有别人干涉
前后端分离:采用前后端分离开发,提供统一Rest接口 ,后端不用再为PC、移动端开发不同接口
数据库分离:每个服务都使用自己的数据源
部署独立:服务间虽然有调用,但要做到服务重启不影响其它服务。有利于持续集成和持续交付。每个服务都是独立的组件,可复用,可替换,降低耦合,易维护
微服务架构与SOA都是对系统进行拆分 ;微服务架构基于SOA思想,可以把微服务当做去除了ESB的SOA 。ESB是SOA架构中的中心总线,设计图形应该是星形的,而微服务是去中心化的分布式软件架构。两者比较类似,但其实也有一些差别
1 2 SOA : 更加侧重于 分层,没有集成的servlet容器 在统一的语言环境实现。 微服务:更加侧重于 功能拆分 三层都有,集成servelt容器,跨平台和语言。
演变历史 1 2 3 4 5 集中式架构 垂直拆分 分布式服务 SOA面向服务架构 微服务架构
拆分出来SOA/微服务架构需要考虑问题 1 2 3 4 5 6 + 1 系统通信问题? dubbo + 2 服务的治理的问题? zookeeper + 3 负载均衡的问题? nginx,ribbon + 4 登录一次的问题? sso -->springseucity/cas/ + 5 配置文件集中管理问题?apollo,nacos,spring cloud config + 6 级联失败的问题? hystrix ,alibaba sentinel
spring cloud 组件解决。
spring cloud 是基于【springboot】 的一系列框架的有序集合,通过springboot提供了自动配置,进行自动的配置,屏蔽掉复杂的配置和原理。提供简单易用的功能。提高开发效率。
1 1.添加起步依赖 2. 添加注解 Eanble*
服务调用方式 无论是微服务还是SOA,都面临着服务间的远程调用。那么服务间的远程调用方式 有哪些呢?
常见的远程调用方式有以下2种:
RPC Remote Produce Call远程过程调用,RPC基于Socket,工作在会话层。自定义数据格式 ,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型代表
HTTP http其实是一种网络传输协议,基于TCP,工作在应用层,规定了数据传输的格式 。现在客户端浏览器与服务端通信基本都是采用Http协议,也可以用来进行远程服务调用。缺点是消息封装臃肿、传输速度比较慢,优势是对服务的提供和调用方没有任何技术限定,自由灵活,更符合微服务理念。
现在热门的Rest风格,就可以通过http协议来实现。
区别 :RPC的机制是根据语言的API(language API)来定义的,而不是根据基于网络的应用来定义的。
如果你们公司全部采用Java技术栈,那么使用Dubbo作为微服务架构是一个不错的选择。
相反,如果公司的技术栈多样化,而且你更青睐Spring家族,那么Spring Cloud搭建微服务是不二之选。在我们的项目中,会选择Spring Cloud套件,因此会使用Http方式来实现服务间调用
spring cloud 和dubbo的区别 1 2 3 4 5 6 7 8 dubbo 实现通信的框架 实现通信的协议 RPC 性能高 spring cloud 是一些列框架集合 实现通信 HTTP 性能低
1 2 3 4 微服务架构:就是将相关的功能独立出来,单独创建一个项目,并且连数据库也独立出来,单独创建对应的数据库。 Spring Cloud本身也是基于SpringBoot开发而来,SpringCloud是一系列框架的有序集合,也是把非常流行的微服务的技术整合到一起。 dubbo本身只是众多分布式开发中解决问题的一种方式而spring cloud 是一系列的有序集合。
restTemplate
restTemplate 是spring的组件 (http的客户端) 理解:可以模拟浏览器发送请求 和接收响应。restTemplate是封装了httpclient/okhttp/urlconnection(理解成浏览器内核)。 默认的情况下使用的是urlconnection。
既然微服务选择了Http,那么我们就需要考虑自己来实现对请求和响应的处理。不过开源世界已经有很多的http客户端工具,能够帮助我们做这些事情,例如:
HttpClient
okHttp
JDK原生URLConnection
不过这些不同的客户端,API各不相同。而Spring也有对http的客户端进行封装,提供了工具类叫RestTemplate。
Spring 提供了工具类RestTemplate
Spring提供了一个RestTemplate模板工具类,对基于Http的客户端进行了封装,并且实现了对象与json的序列化和反序列化,非常方便。RestTemplate并没有限定Http的客户端类型,而是进行了抽象,目前常用的3种都有支持:
HttpClient
okHttp
JDK原生URLConnection(默认的)
restTemplate测试:
spring Cloud简介 微服务是一种架构方式,最终肯定需要技术架构去实施。
微服务的实现方式很多,但是最火的莫过于Spring Cloud了。为什么?
后台硬:作为Spring家族的一员,有整个Spring全家桶靠山,背景十分强大。
技术强:Spring作为Java领域的前辈,可以说是功力深厚。有强力的技术团队支撑,一般人还真比不了
群众基础好:可以说大多数程序员的成长都伴随着Spring框架,试问:现在有几家公司开发不用Spring?Spring Cloud与Spring的各个框架无缝整合,对大家来说一切都是熟悉的配方,熟悉的味道。
使用方便:相信大家都体会到了SpringBoot给我们开发带来的便利,而Spring Cloud完全支持Spring Boot的开发,用很少的配置就能完成微服务框架的搭建
简介 Spring Cloud是Spring旗下的项目之一,官网地址:http://projects.spring.io/spring-cloud/
Spring最擅长的就是集成,把世界上最好的框架拿过来,集成到自己的项目中。
Spring Cloud也是一样,它本身是基于SpringBoot开发而来的。它将现在非常流行的一些技术整合到一起,实现了诸如:配置管理,服务发现,智能路由,负载均衡,熔断器,控制总线,集群状态等功能;协调分布式环境中各个系统,为各类服务提供模板性配置。属于微服务架构的一站式技术解决方案。其主要涉及的组件包括:
注册中心:Eureka、consul、Zookeeper、nacos
负载均衡:Ribbon
熔断器:Hystrix、Resilience4j
服务调用/通信:Feign、OpenFeign
服务网关:Zuul、Gateway
配置中心 :config、nacos
消息总线:Bus
集群状态等等功能。
版本 Spring Cloud不是一个组件,而是许多组件的集合;它的版本命名比较特殊,是以A到Z的为首字母的一些单词(其实是伦敦地铁站的名字)组成
版本说明:
1 2 3 4 5 6 SpringCloud是一系列框架组合,为了避免与框架版本产生混淆,采用新的版本命名方式,形式为大版本名+子版本名称 大版本名用伦敦地铁站名 子版本名称三种 SNAPSHOT:快照版本,尝鲜版,随时可能修改 M版本,MileStone,M1表示第一个里程碑版本,一般同时标注PRE,表示预览版 SR,Service Release,SR1表示第一个正式版本,同时标注GA(Generally Available),稳定版
SpringCloud与SpringBoot版本匹配关系
SpringBoot
SpringCloud
1.2.x
Angel版本
1.3.x
Brixton版本
1.4.x
Camden版本
1.5.x
Dalston版本、Edgware
2.0.x
Finchley版本
2.1.x
Greenwich GA版本 (2019年2月发布)
鉴于SpringBoot与SpringCloud关系,SpringBoot建议采用2.1.x版本
SpringCloud经典组件 Eureka
spring cloud eureka 作为注册中心来使用。
关于自我保护机制:默认的情况下开启了自我保护机制,当在15分钟内,错误率低于85% 是不会剔除,超过了85 ,就会剔除。
搭建步骤
1 2 3 4 5 6 7 8 9 10 11 12 服务端 微服务 +搭建步骤: + 1.添加起步依赖(eureka-server) + 2.@enbaleServer + 3.配置注册的地址 客户端 微服务 +搭建步骤: + 1.添加起步依赖(eureka-client) + 2.@enbaleclient + 3.配置注册的地址 使用:从eureka中动态获取ip和端口进行调用
搭建工程 首先,我们需要模拟一个服务调用的场景。方便后面学习微服务架构。
父工程 添加spring boot父坐标和管理其它组件的依赖
微服务中需要同时创建多个项目,为了方便课堂演示,先创建一个父工程,然后后续的工程都以这个工程为父,实现maven的聚合。这样可以在一个窗口看到所有工程,方便讲解。在实际开发中,每个微服务可独立一个工程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.pointink</groupId> <artifactId>demo-springcloud</artifactId> <version>1.0-SNAPSHOT</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.5.RELEASE</version> <relativePath/> </parent> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <java.version>1.8</java.version> <spring-cloud.version>Greenwich.SR1</spring-cloud.version> <mapper.starter.version>2.1.5</mapper.starter.version> <mysql.version>5.1.46</mysql.version> </properties> <dependencyManagement> <dependencies> <!-- springCloud 上面只是引入了spirngboot的依赖,如果想要用SpringCloud,还需要下面的依赖。--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> <!-- 通用Mapper启动器 --> <dependency> <groupId>tk.mybatis</groupId> <artifactId>mapper-spring-boot-starter</artifactId> <version>${mapper.starter.version}</version> </dependency> <!-- mysql驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
服务提供工程user-servcie 整合mybatis查询数据库中用户数据;提供查询用户服务
服务消费工程consumer-demo 利用查询用户服务获取用户数据并输出到浏览器
思考存在的问题 简单回顾一下,刚才我们写了什么:
user-service :对外提供了查询用户的接口
consumer-demo :通过RestTemplate访问 http://locahost:9091/user/{id} 接口,查询用户数据
存在什么问题?
在consumer中,我们把url地址硬编码到了代码中,不方便后期维护
consumer需要记忆user-service的地址,如果出现变更,可能得不到通知,地址将失效
consumer不清楚user-service的状态,服务宕机也不知道
user-service只有1台服务,不具备高可用性
即便user-service形成集群,consumer还需自己实现负载均衡
其实上面说的问题,概括一下就是分布式服务必然要面临的问题:
服务管理
如何自动注册和发现
如何实现状态监管
如何实现动态路由
服务如何实现负载均衡
服务如何解决容灾问题
服务如何实现统一配置
而上面的问题都可以通过SpringCloud的各种组件解决
服务注册中心eureka-server Eureka解决了第一个问题:服务的管理:注册和发现、状态监管、动态路由。
Eureka负责管理记录服务提供者的信息。服务调用者无需自己寻找服务,Eureka自动匹配服务给调用者。
Eureka与服务之间通过心跳机制进行监控;
问题分析 在刚才的案例中,user-service对外提供服务,需要对外暴露自己的地址。而consumer-demo(调用者)需要记录服务提供者的地址。将来地址出现变更,还需要及时更新。这在服务较少的时候并不觉得有什么,但是在现在日益复杂的互联网环境,一个项目可能会拆分出十几,甚至几十个微服务。此时如果还人为管理地址,不仅开发困难,将来测试、发布上线都会非常麻烦,这与DevOps的思想是背道而驰的。
DevOps的思想是系统可以通过一组过程、方法或系统;提高应用发布和运维的效率,降低管理成本。
网约车
这就好比是 网约车出现以前,人们出门叫车只能叫出租车。一些私家车想做出租却没有资格,被称为黑车。而很多人想要约车,但是无奈出租车太少,不方便。私家车很多却不敢拦,而且满大街的车,谁知道哪个才是愿意载人的。
一个想要,一个愿意给,就是缺少引子,缺乏管理啊。
此时滴滴这样的网约车平台出现了,所有想载客的私家车全部到滴滴注册,记录你的车型(服务类型),身份信息(联系方式)。这样提供服务的私家车,在滴滴那里都能找到,一目了然。
此时要叫车的人,只需要打开APP,输入你的目的地,选择车型(服务类型),滴滴自动安排一个符合需求的车到你面前,为你服务,完美
Eureka做什么?
Eureka就好比是滴滴,负责管理、记录服务提供者的信息。服务调用者无需自己寻找服务,而是把自己的需求告诉Eureka,然后Eureka会把符合你需求的服务告诉你。
同时,服务提供方与Eureka之间通过 “心跳” 机制进行监控,当某个服务提供方出现问题,Eureka自然会把它从服务列表中剔除。
这就实现了服务的自动注册、发现、状态监控。
原理图 基本架构:
Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的地址
提供者:启动后向Eureka注册自己信息(地址,提供什么服务)
消费者:向Eureka订阅服务,Eureka会将对应服务的所有提供者地址列表发送给消费者,并且定期更新
心跳(续约):提供者定期通过http方式向Eureka刷新自己的状态
搭建项目 Eureka是服务注册中心,只做服务注册;自身并不提供服务也不消费服务。可以搭建web工程使用Eureka,可以 使用Spring Boot方式搭建
搭建步骤:
创建工程;
添加启动器依赖;
编写启动引导类(添加Eureka的服务注解)和配置文件;
修改配置文件(端口,应用名称…);
启动测试
核心角色
Eureka的服务端应用,提供服务注册和发现功能,就是刚刚我们建立的eureka-server
提供服务的应用,可以是SpringBoot应用,也可以是其它任意技术实现,只要对外提供的是Rest风格服务即可。本例中就是我们实现的user-service
消费应用从注册中心获取服务列表,从而得知每个服务方的信息,知道去哪里调用服务方。本例中就是我们实现的consumer-demo
高可用server Eureka Server即服务的注册中心,在刚才的案例中,我们只有一个EurekaServer,事实上EurekaServer也可以是一个集群,形成高可用的Eureka中心。
服务同步
多个Eureka Server之间也会互相注册为服务,当服务提供者注册到Eureka Server集群中的某个节点时,该节点会把服务的信息同步给集群中的每个节点,从而实现数据同步 。因此,无论客户端访问到Eureka Server集群中的任意一个节点,都可以获取到完整的服务列表信息
而作为客户端,需要把信息注册到每个Eureka中:
如果有三个Eureka,则每一个EurekaServer都需要注册到其它几个Eureka服务中,例如:有三个分别为10086、10087、10088,则:
10086要注册到10087和10088上
10087要注册到10086和10088上
10088要注册到10086和10087上
动手搭建高可用的EurekaServer
我们假设要搭建两台EurekaServer的集群,端口分别为:10086和10087
1.修改原来的EurekaServer配置;修改 eureka-server\src\main\resources\application.yml 如下
所谓的高可用注册中心,其实就是把EurekaServer自己也作为一个服务,注册到其它EurekaServer上,这样多个EurekaServer之间就能互相发现对方,从而形成集群。因此我们做了以下修改:
注意把register-with-eureka和fetch-registry修改为true或者注释掉
在上述配置文件中的${}表示在jvm启动时候若能找到对应port或者defaultZone参数则使用,若无则使用后面的默认值
2.把service-url的值改成了另外一台EurekaServer的地址,而不是自己
另外一台在启动的时候可以指定端口port和defaultZone配置:
修改原来的启动配置组件;在如下界面中的 VM options 中
在10086上,设置 -DdefaultZone=http:127.0.0.1:10087/eureka
设置 -Dport=10087 -DdefaultZone=http:127.0.0.1:10086/eureka
3)启动测试;同时启动两台eureka server
4)客户端注册服务到集群
因为EurekaServer不止一个,因此 user-service 项目注册服务或者 consumer-demo 获取服务的时候,service-url参数需要修改为如下:
ps:这时候客户端注册的时候,可以写多个注册地址
Eureka客户端 服务提供者在启动时,会检测配置属性中的: eureka.client.register-with-erueka=true 参数是否正确,事实上默认就是true。如果值确实为true,则会向EurekaServer发起一个Rest请求,并携带自己的元数据信息,EurekaServer会把这些信息保存到一个双层Map结构中。
第一层Map的Key就是服务id,一般是配置中的 spring.application.name 属性
第二层Map的key是服务的实例id。一般host+ serviceId + port,例如: localhost:user-service:8081值则是服务的实例对象,也就是说一个服务,可以同时启动多个不同实例,形成集群。
默认注册时使用的是主机名或者localhost,如果想用ip进行注册,可以在 user-service 中添加配置如下:
修改完后先后重启 user-service 和 consumer-demo ;在调用服务的时候就已经变成ip地址;需要注意的是:不是在eureka中的控制台服务实例状态显示。
断点调试的时候,host指的是localhost,设置为ip地址则是127.0.0.1这样的地址
在注册服务完成以后,服务提供者会维持一个心跳(定时向EurekaServer发起Rest请求),告诉EurekaServer:“我还活着”。这个我们称为服务的续约(renew);
有两个重要参数可以修改服务续约的行为;可以在 user-service 中添加如下配置项:
lease-renewal-interval-in-seconds:服务续约(renew)的间隔,默认为30秒
lease-expiration-duration-in-seconds:服务失效时间,默认值90秒
也就是说,默认情况下每隔30秒服务会向注册中心发送一次心跳,证明自己还活着。如果超过90秒没有发送心跳,EurekaServer就会认为该服务宕机,会定时(eureka.server.eviction-interval-timer-in-ms设定的时间)从服务列表中移除,这两个值在生产环境不要修改,默认即可。
当服务消费者启动时,会检测 eureka.client.fetch-registry=true 参数的值,如果为true,则会从Eureka Server服务的列表拉取只读备份,然后缓存在本地。并且 每隔30秒 会重新拉取并更新数据。可以在 consumer-demo 项目中通过下面的参数来修改:
失效剔除和自我保护 如下的配置都是在Eureka Server服务端进行:
当服务进行正常关闭操作时,它会触发一个服务下线的REST请求给Eureka Server,告诉服务注册中心:“我要下线了”。服务中心接受到请求之后,将该服务置为下线状态。
有时我们的服务可能由于内存溢出或网络故障等原因使得服务不能正常的工作,而服务注册中心并未收到“服务下
线”的请求。相对于服务提供者的“服务续约”操作,服务注册中心在启动时会创建一个定时任务,默认每隔一段时间(默认为60秒)将当前清单中超时(默认为90秒)没有续约的服务剔除,这个操作被称为失效剔除。
可以通过 eureka.server.eviction-interval-timer-in-ms 参数对其进行修改,单位是毫秒。
我们关停一个服务,很可能会在Eureka面板看到一条警告:
这是触发了Eureka的自我保护机制。当服务未按时进行心跳续约时,Eureka会统计服务实例最近15分钟心跳续约的比例是否低于了85%。在生产环境下,因为网络延迟等原因,心跳失败实例的比例很有可能超标,但是此时就把服务剔除列表并不妥当,因为服务可能没有宕机。Eureka在这段时间内不会剔除任何服务实例,直到网络恢复正常。生产环境下这很有效,保证了大多数服务依然可用,不过也有可能获取到失败的服务实例,因此服务调用者必须做好服务的失败容错。
可以通过下面的配置来关停自我保护:
Ribbon
ribbon负载均衡
思考: 在刚才的案例中,我们启动了一个 user-service ,然后通过DiscoveryClient来获取服务实例信息,然后获取ip和端口来访问。但是实际环境中,往往会开启很多个 user-service 的集群。此时获取的服务列表中就会有多个,到底该访问哪一个呢?
负载均衡是一个算法,可以通过该算法实现从地址列表中获取一个地址进行服务调用。
在Spring Cloud中提供了负载均衡器:Ribbon,根据服务名到Eureka服务中获取服务地址列表,再根据或利用Ribbon负载均衡算法从地址列表中获取一个服务地址并访问.Ribbon提供了轮询、随机两种负载均衡算法(默认是轮询)
配置修改轮询策略:Ribbon默认的负载均衡策略是轮询,通过如下
1 2 3 4 5 6 7 8 9 10 11 # 修改服务地址轮询策略,默认是轮询,配置之后变随机 user-provider: ribbon: #轮询 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #随机算法 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #重试算法,该算法先按照轮询的策略获取服务,如果获取服务失败则在指定的时间内会进行重试,获取可用的服务 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RetryRule #加权法,会根据平均响应时间计算所有服务的权重,响应时间越快服务权重越大被选中的概率越大。刚启动时如果同统计信息不足,则使用轮询的策略,等统计信息足够会切换到自身规则。 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.ZoneAvoidanceRule
SpringBoot可以修改负载均衡规则,配置为ribbon.NFLoadBalancerRuleClassName
格式{服务名称}.ribbon.NFLoadBalancerRuleClassName
需求: 可以使用RestTemplate访问http://user-service/user/8获取服务数据
可以使用Ribbon负载均衡:在执行RestTemplate发送服务地址请求的时候,使用负载均衡拦截器拦截,根据服务名获取服务地址列表,使用Ribbon负载均衡算法从服务地址列表中选择一个服务地址,访问该地址获取服务数据。
实现: Eureka中已经集成了负载均衡组件:Ribbon,简单修改代码即可使用
实现步骤:
启动多个user-service实例(9091,9092);
修改RestTemplate实例化方法,添加负载均衡注解;
修改ConsumerController;
测试
在实例化RestTemplate的时候使用@LoadBalanced,服务地址直接可以使用服务名。
了解:Ribbon默认的负载均衡策略是轮询。SpringBoot也帮提供了修改负载均衡规则的配置入口在consumer
demo的配置文件中添加如下,就变成随机的了:
源码跟踪
为什么只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然是有组件根据service名称,获取到了服务实例的ip和端口。因为 consumer-demo 使用的是RestTemplate,spring的负载均衡自动配置类LoadBalancerAutoConfiguration.LoadBalancerInterceptorConfig 会自动配置负载均衡拦截器(在spring-cloud-commons-**.jar包中的spring.factories中定义的自动配置类), 它就是LoadBalancerInterceptor ,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
继续跟入execute方法:发现获取了9092端口的服务
再跟下一次,发现获取的是9091、9092之间切换:
多次访问 consumer-demo 的请求地址;然后跟进代码,发现其果然实现了负载均衡
Hystrix
Hystrix熔断器
Hystrix 在英文里面的意思是 豪猪,它的logo 看下面的图是一头豪猪,它在微服务系统中是一款提供保护机制的组件,和eureka一样也是由netflflix公司开发。
主页:https://github.com/Netflflix/Hystrix/
那么Hystrix的作用是什么呢?具体要保护什么呢?
Hystrix是Netflflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败 。
为什么用hystrix
可以在调用服务的时候,在服务出现异常时进行服务降级
避免一直长时间等待服务返回结果而出现雪崩效应
微服务中,服务间调用关系错综复杂,一个请求,可能需要调用多个微服务接口才能实现,会形成非常复杂的调用链路:
如果某服务出现异常,请求阻塞,用户得不到响应,容器中线程不会释放,于是越来越多用户请求堆积,越来越多线程阻塞。
单服务器支持线程和并发数有限,请求如果一直阻塞,会导致服务器资源耗尽,从而导致所有其他服务都不可用,从而形成雪崩效应
这就好比,一个汽车生产线,生产不同的汽车,需要使用不同的零件,如果某个零件因为种种原因无法使用,那么就会造成整台车无法装配,陷入等待零件的状态,直到零件到位,才能继续组装。 此时如果有很多个车型都需要这个零件,那么整个工厂都将陷入等待的状态,导致所有生产都陷入瘫痪。一个零件的波及范围不断扩大。
Hystrix解决雪崩问题的手段主要是服务降级,包括:
1 指Hystrix为每个依赖服务调用一个小的线程池,如果线程池用尽,调用立即被拒绝,默认不采用排队
1 优先保证核心服务,而非核心服务不可用或弱可用。触发Hystrix服务降级的情况:线程池已满、请求超时。
使用:
1 2 3 4 1.加入起步依赖 是在调用方 加入起步依赖 2.启用注解enable* 3.在方法中修饰一个HystrixCommand注解指定兜底的方法 4.兜底的方法要求:和被修饰的方法的返回值一致,方法的参数类型和个数和被修饰的方法保持一致
线程隔离:加速失败判断
Hystrix为每个依赖服务调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间 。
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满 ,或者请求超时 ,则会进行降级处理,什么是服务降级?
服务降级:及时返回服务失败结果 服务降级: 优先保证核心服务,而非核心服务不可用或弱可用。
用户的请求故障时,不会被阻塞,更不会无休止的等待或者看到系统崩溃,至少可以看到一个执行结果(例如返回友好的提示信息) 。
服务降级虽然会导致请求失败,但是不会导致阻塞,而且最多会影响这个依赖服务对应的线程池中的资源,对其它服务没有响应。
触发Hystrix服务降级的情况:
隔离降级实操 引入依赖
在 consumer-demo 消费端系统的pom.xml 添加如下依赖
1 2 3 4 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
开启熔断
在启动类 ConsumerApplication 上添加注解:@EnableCircuitBreaker
1 2 3 4 5 //@SpringBootApplication //@EnableDiscoveryClient //@EnableCircuitBreaker @SpringCloudApplication // 这一个相当于上面3个注解 public class ConsumerApplication { // ... }
编写降级逻辑
当目标服务的调用出现故障,我们希望快速失败,给用户一个友好提示。因此需要提前编写好失败时的降级处理逻辑,要使用HystrixCommand来完成。
要注意;因为熔断的降级逻辑方法必须跟正常逻辑方法保证:相同的参数列表和返回值声明 。
失败逻辑中返回User对象没有太大意义,一般会返回友好提示。所以把queryById的方法改造为返回String,反正也是Json数据。这样失败逻辑中返回一个错误说明,会比较方便。
说明:
@HystrixCommand(fallbackMethod = “queryByIdFallBack”):用来声明一个降级逻辑的方法测试
当 user-service 正常提供服务时,访问与以前一致。但是当将 user-service 停机时,会发现页面返回了降级处理信息
默认的Fallback
刚才把fallback写在了某个业务方法上,如果这样的方法很多,那岂不是要写很多。所以可以把Fallback配置加在类上,实现默认fallback;
@DefaultProperties(defaultFallback = “defaultFallBack”):在类上指明统一的失败降级方法;该类中所有方法返回类型要与处理失败的方法的返回类型一致。
java第一次请求比较慢,可能会超过1s
超时设置
在之前的案例中,请求在超过1秒后都会返回错误信息,这是因为Hystrix的默认超时时长为1 ,我们可以通过配置修改这个值;
服务熔断演示 在服务熔断中,使用的熔断器,也叫断路器,其英文单词为:Circuit Breaker
熔断机制与家里使用的电路熔断原理类似;当如果电路发生短路的时候能立刻熔断电路,避免发生灾难。在分布式系统中应用服务熔断后;服务调用方可以自己进行判断哪些服务反应慢或存在大量超时,可以针对这些服务进行主动熔断,防止整个系统被拖垮。
Hystrix的服务熔断机制,可以实现弹性容错;当服务请求情况好转之后,可以自动重连。通过断路的方式,将后续请求直接拒绝,一段时间(默认5秒)之后允许部分请求通过,如果调用成功则回到断路器关闭状态,否则继续打开,拒绝请求的服务。
Hystrix的熔断状态机模型:
状态机有3个状态:
Closed:关闭状态(断路器关闭),所有请求都正常访问。
Open:打开状态(断路器打开),所有请求都会被降级。Hystrix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全打开。默认失败比例的阈值是50%,请求次数最少不低于20次。
Half Open:半开状态,不是永久的,断路器打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会关闭断路器,否则继续保持打开,再次进行休眠计时
threshold reached 到达阈(yu:四声)值 , under threshold 阈值以下
这样如果参数是id为1,一定失败,其它情况都成功。(不要忘了清空user-service中的休眠逻辑)
我们准备两个请求窗口:
当我们疯狂访问id为1的请求时(超过20次),就会触发熔断。断路器会打开,一切请求都会被降级处理。
此时你访问id为2的请求,会发现返回的也是失败,而且失败时间很短,只有20毫秒左右;因进入半开状态之后2是可以的。
不过,默认的熔断触发要求较高,休眠时间窗较短,为了测试方便,我们可以通过配置修改熔断策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 配置熔断策略: hystrix: command: default: circuitBreaker: # 强制打开熔断器 默认false关闭的。测试配置是否生效 forceOpen: false # 触发熔断错误比例阈值,默认值50% errorThresholdPercentage: 50 # 熔断后休眠时长,默认值5秒 sleepWindowInMilliseconds: 10000 # 熔断触发最小请求次数,默认值是20 requestVolumeThreshold: 10 execution: isolation: thread: # 熔断超时设置,默认为1秒 timeoutInMilliseconds: 2000
1 2 3 4 1. 熔断后休眠时间:sleepWindowInMilliseconds 2. 熔断触发最小请求次数:requestVolumeThreshold 3. 熔断触发错误比例阈值:errorThresholdPercentage 4. 熔断超时时间:timeoutInMilliseconds
Feign 为什么用 有了restTemplate,为什么还要Feign?前面使用了Ribbon的负载均衡功能简化了远程调用时的代码。
1 String url = "http://user-service/user/" + id; User user = this.restTemplate.getForObject(url, User.class) 12
如果就学到这里,你可能以后需要编写类似的大量重复代码,格式基本相同,无非参数不一样。有没有更优雅的方式,来对这些代码再次优化呢? => Feign
概念 项目主页:https://github.com/OpenFeign/feign
Feign可以把Rest的请求进行隐藏,伪装成类似SpringMVC的Controller一样。你不用再自己拼接url,拼接参数等等操作,一切都交给Feign去做。
快速入门
1 2 3 4 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
开启Feign功能:@EnableFeignClients
编写Feign客户端
编写处理器ConsumerFeignController
负载均衡 Feign中本身已经集成了Ribbon依赖和自动配置,因此不需要额外引入依赖,也不需要再注册 RestTemplate 对象。
Fegin内置的ribbon默认设置了请求超时时长,默认是1000,我们可以通过手动配置来修改这个超时时长
1 2 3 ribbon: ConnectTimeout: 1000 # 建立链接的超时时长 ReadTimeout: 2000 # 读取超时时长
因为ribbon内部有重试机制,一旦超时,会自动重新发起请求。如果不希望重试 ,可以在consumer-demo\src\main\resources\application.yml 添加如下配置
1 2 3 4 5 6 7 8 9 10 # 修改服务地址轮询策略,默认是轮询,配置之后变随机 user-provider: ribbon: #轮询 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule ConnectTimeout: 10000 # 连接超时时间 ReadTimeout: 2000 # 数据读取超时时间 MaxAutoRetries: 0 # 最大重试次数(第一个服务) MaxAutoRetriesNextServer: 0 # 最大重试下一个服务次数(集群的情况才会用到) OkToRetryOnAllOperations: false # 无论是请求超时或者socket read timeout都进行重试
重新给UserService的方法设置上线程沉睡时间2秒可以测试上述配置
如果服务A处理业务的时间太久,超过了服务B设置的ribbon时间.则服务B不等待服务A返回结果,直接报错。
Hystrix熔断器支持 Feign默认也有对Hystrix的集成
只不过,默认情况下是关闭的。需要通过下面的参数来开启;修改 consumer-demo\src\main\resources\application.yml 添加如下配置:
1 2 3 feign: hystrix: enabled: true # 开启Feign的熔断功能
但是,Feign中的Fallback配置不像Ribbon中那样简单了。要定义一个类,实现刚才编写的UserFeignClient,作为fallback的处理类
关于ribbon和hystrix超时的疑惑
如果请求时间超过 ribbon 的超时配置,会触发重试;
在配置 fallback 的情况下,如果请求的时间(包括 ribbon 的重试时间),超出了 ribbon 的超时限制,或者 hystrix 的超时限制,那么就会熔断;
一般来说,会设置 ribbon 的超时时间 < hystrix, 这是因为 ribbon 有重试机制。(这里说的 ribbon 超时时间是包括重试在内的,即,最好要让 ribbon 的重试全部执行,直到 ribbon 超时被触发)。
由于 connectionTime 一般比较短,可以忽略。那么,设置的超时时间应该满足:
(1 + MaxAutoRetries) * (1 + MaxAutoRetriesNextServer)* ReadTimeOut < hystrix 的 *timeoutInMilliseconds*
所以正确姿势应该是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ribbon: ConnectTimeout: 1000 # 连接超时时长 ReadTimeout: 3000 # 数据通信超时时长 MaxAutoRetries: 0 # 当前服务器的重试次数 MaxAutoRetriesNextServer: 0 # 重试多少次服务 OkToRetryOnAllOperations: false # 是否对所有的请求方式都重试 feign: hystrix: enabled: true # 开启Feign的熔断功能 # hystrix 的默认超时时间是 1s hystrix: command: default: #default全局有效,service id指定应用有效 execution: timeout: #如果enabled设置为false,则请求超时交给ribbon控制,为true,则超时作为熔断根据 enabled: true isolation: thread: timeoutInMilliseconds: 10000 #断路器超时时间,默认1000ms
请求压缩 Spring Cloud Feign 支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。通过下面的参数即可开启请求与响应的压缩功能:
1 2 3 4 5 6 feign: compression: request: enabled: true # 开启请求压缩 response: enabled: true # 开启响应压缩
同时,我们也可以对请求的数据类型,以及触发压缩的大小下限进行设置:
1 2 3 4 5 6 feign: compression: request: enabled: true # 开启请求压缩 mime-types: text/html,application/xml,application/json # 设置压缩的数据类型 min-request-size: 2048 # 设置触发压缩的大小下限
注:上面的数据类型、压缩大小下限均为默认值
日志级别 前面讲过,通过 logging.level.xx=debug 来设置日志级别。然而这个对Fegin客户端而言不会产生效果。因为@FeignClient 注解修改的客户端在被代理时,都会创建一个新的Fegin.Logger实例。我们需要额外指定这个日志的级别才可以
1)在 consumer-demo 的配置文件中设置com.pointink包下的日志级别都为 debug
修改 consumer-demo\src\main\resources\application.yml 添加如下配置:
1 2 3 logging: level: com.pointink: debug # com.itheima 包下的日志级别都为Debug
2)在 consumer-demo 编写FeignConfifig配置类,定义日志级别
这里指定的Level级别是FULL,Feign支持4种级别:
NONE:不记录任何日志信息,这是默认值。
BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
效果:
Spring Cloud Gateway 简介
Spring Cloud Gateway是Spring官网基于Spring 5.0、 Spring Boot 2.0、Project Reactor等技术开发的网关服务。
Spring Cloud Gateway基于Filter链提供网关基本功能:安全、监控/埋点、限流等。
Spring Cloud Gateway为微服务架构提供简单、有效且统一的API路由管理方式。
Spring Cloud Gateway是替代Netflix Zuul的一套解决方案。
Spring Cloud Gateway组件的核心是一系列的过滤器,通过这些过滤器可以将客户端发送的请求转发(路由)到对应的微服务。 Spring Cloud Gateway是加在整个微服务最前沿的防火墙和代理器,隐藏微服务结点IP端口信息,从而加强安全保护。Spring Cloud Gateway本身也是一个微服务,需要注册到Eureka服务注册中心
服务之间的调用,避免直接暴露服务地址,需要通过gateway统一入口,进行隔离,增强服务调用的安全性。
网关的核心功能是:过滤和路由
路由:配置文件中指定服务名和地址、过滤器、断言
过滤:可以在服务执行之前和之后处理一些非功能性业务
Gateway加入后的架构
不管是来自客户端的请求,还是服务内部调用。一切对服务的请求都可经过网关。
网关实现鉴权、动态路由等等操作。
Gateway就是我们服务的统一入口
核心概念
路由(route) 路由信息的组成:由一个ID、一个目的URL、一组断言工厂、一组Filter组成。如果路由断言为真,说明请求URL和配置路由匹配。断言(Predicate) Spring Cloud Gateway中的断言函数输入类型是Spring 5.0框架中的ServerWebExchange。Spring Cloud Gateway的断言函数允许开发者去定义匹配来自于Http Request中的任何信息比如请求头和参数。过滤器(Filter) 一个标准的Spring WebFilter。 Spring Cloud Gateway中的Filter分为两种类型的Filter,分别是Gateway Filter和Global Filter。过滤器Filter将会对请求和响应进行修改处理。
快速入门:搭建gateway网关服务 需求:通过gateway网关,将包含/user的请求路由到http://127.0.0.1/user/{id}
1 2 3 4 5 6 7 8 9 10 <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> </dependencies>
1 2 3 4 5 6 7 @SpringBootApplication @EnableDiscoveryClient public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring: application: name: api-gateway cloud: gateway: routes: - id: user-service-route # 路由id,可以任意 uri: http://127.0.0.1:9091 # 代理地址 predicates: - Path=/user/** # 路由断言,可以匹配映射路径 server: port: 10010 eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka instance: prefer-ip-address: true # 使用ip
面向服务的路由 在刚才的路由规则中,把路径对应的服务地址写死了!如果同一服务有多个实例的话,这样做显然不合理。
应该根据服务的名称,去Eureka注册中心查找 服务对应的所有实例列表,然后进行动态路由!
1 2 3 4 5 6 7 8 9 spring: cloud: gateway: routes: - id: user-service-route # 路由id,可以任意 # uri: http://127.0.0.1:9091 # 代理地址;lb表示从eureka中获取具体服务 uri: lb://user-service # 这个服务名必须在eureka中注册,不然找不到的 predicates: - Path=/user/** # 路由断言,可以匹配映射路径
gateway将使用 LoadBalancerClient把user-service通过eureka解析为实际的主机和端口,并进行ribbon负载均衡
效果:
路由前置处理 目标: 可以对请求到网关服务的地址添加或去除前缀
分析:
提供服务的地址:http://127.0.0.1:9091/user/8
添加前缀:对请求地址添加前缀路径后,作为代理的服务地址
http://localhost:10010/8 –> http://localhost:9091/user/8 添加前缀/user
去除前缀:对请求地址去除前缀路径后,作为代理的服务地址
http://localhost:10010/api/user/8 –> http://localhost:9091/user/8 去除前缀/api
过滤器 Gateway作为网关的其中一个重要功能,就是实现请求的鉴权。而这个动作往往是通过网关提供的过滤器来实现的。前面的 路由前缀 章节中的功能也是使用过滤器实现的。Gateway自带的过滤器有十几个,常见自带过滤器有:
过滤器名称
说明
AddRequestHeader
对匹配上的请求加上Header
AddRequestParameters
对匹配上的请求路由
AddResponseHeader
对从网关返回的响应添加Header
StripPrefix
对匹配上的请求路径去除前缀
详细说明官方链接
详见:官网文档
通过 spring.cloud.gateway.routes.filters 配置在具体路由下,只作用在当前路由上;自带的过滤器都可以配置或者自定义按照自带过滤器的方式。如果配置spring.cloud.gateway.default-filters 上会对所有路由生效也算是全局的过滤器;但是这些过滤器的实现上都是要实现GatewayFilterFactory接口。
这些自带的过滤器可以和使用 路由前缀 章节中的用法类似,也可以将这些过滤器配置成不只是针对某个路由;而是可以对所有路由生效,也就是配置默认过滤器:
可以配置多个:
效果:
执行声明周期 Spring Cloud Gateway 的 Filter 的生命周期也类似Spring MVC的拦截器有两个:“pre” 和 “post”。“pre”和 “post” 分别会在请求被执行前调用和被执行后调用
这里的 pre 和 post 可以通过过滤器的 GatewayFilterChain 执行fifilter方法前后来实现。
使用场景 常见的应用场景如下:
请求鉴权: 一般 GatewayFilterChain 执行fifilter方法前,如果发现没有访问权限,直接就返回空。异常处理 :一般 GatewayFilterChain 执行fifilter方法后,记录异常并返回。服务调用时长统计 : GatewayFilterChain 执行fifilter方法前后根据时间统计。
自定义局部过滤器 需求: 在过滤器(MyParamGatewayFilterFactory)中将http://localhost:10010/api/user/8?name=itcast中的参数name的值获取到并输出到控制台;并且参数名是可变的,也就是不一定每次都是name;需要可以通过配置过滤器的时候做到配置参数名。
自定义全局过滤器 需求:模拟登陆校验 。编写全局过滤器,在过滤器中检查请求地址是否携带token参数。如果token参数的值存在则放行;如果 token的参数值为空或者不存在则设置返回的状态码为:未授权也不再执行下去
负载均衡&服务熔断配置 Gateway中默认就已经集成了Ribbon负载均衡和Hystrix熔断机制。但是所有的超时策略都是走的默认值,比如熔断超时时间只有1S,很容易就触发了。因此建议手动进行配置:
1 2 3 4 5 6 7 8 9 10 11 12 hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 6000 ribbon: ConnectTimeout: 1000 ReadTimeout: 2000 MaxAutoRetries: 0 MaxAutoRetriesNextServer: 0
跨域配置 一般网关都是所有微服务的统一入口,必然在被调用的时候会出现跨域问题
跨域 :在js请求访问中,如果访问的地址与当前服务器的域名、ip或者端口号不一致则称为跨域请求。若不解决则不能获取到对应地址的返回结果。
如:从在http://localhost:9090 中的js访问 http://localhost:9000 的数据,因为端口不同,所以也是跨域请求
在访问Spring Cloud Gateway网关服务器的时候,出现跨域问题的话;可以在网关服务器中通过配置解决,允许哪些服务是可以跨域请求的;具体配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 spring: application: name: api-gateway cloud: gateway: globalcors: cors-configurations: '[/**]': #allowedOrigins: * # 这种写法或者下面的都可以,*表示全部 allowdOrigins: - "http://docs.spring.io" allowedMethods: - GET
上述配置表示:
详见官网具体说明
Gateway的高可用 启动多个Gateway服务,自动注册到Eureka,形成集群。如果是服务内部访问,访问Gateway,自动负载均衡,没问题。
但是,Gateway更多是外部访问,PC端、移动端等。它们无法通过Eureka进行负载均衡,那么该怎么办?
此时,可以使用其它的服务网关,来对Gateway进行代理。比如:Nginx
Gateway与Feign区别
Feign主要是用在服务之间调用
gateway是一般的请求,它是所有的微服务入口
Gateway 作为整个应用的流量入口,接收所有的请求,如PC、移动端等,并且将不同的请求转发至不同的处理微服务模块,其作用可视为nginx;大部分情况下用作权限鉴定、服务端流量控制
Feign 则是将当前微服务的部分服务接口暴露出来,并且主要用于各个微服务之间的服务调用
Spring Cloud Config 在分布式系统中,由于服务数量非常多,配置文件分散在不同的微服务项目中,管理不方便。为了方便配置文件集中管理,需要分布式配置中心组件。在Spring Cloud中,提供了Spring Cloud Confifig,它支持配置文件放在配置服务的本地,也支持放在远程Git仓库(GitHub、码云)。
配置中心本质上也是一个微服务,同样需要注册到Eureka服务注册中心!
知名的Git远程仓库有国外的GitHub和国内的码云(gitee);但是使用GitHub时,国内的用户经常遇到的问题是访问速度太慢,有时候还会出现无法连接的情况。如果希望体验更好一些,可以使用国内的Git托管服务——码云(gitee.com)。
与GitHub相比,码云也提供免费的Git仓库。此外,还集成了代码质量检测、项目演示等功能。对于团队协作开发,码云还提供了项目管理、代码托管、文档管理的服务。本章中使用的远程Git仓库是码云。
码云访问地址:https://gitee.com/
如果是内网,gitlab也可以,自建git仓库也可以
远程Git仓库 首先要使用码云上的私有远程git仓库需要先注册帐号;请先自行访问网站并注册帐号,然后使用帐号登录码云控制台并创建公开仓库
配置仓库 名称和路径
创建配置文件
在新建的仓库中创建需要被统一配置管理的配置文件。
配置文件的命名方式 :{application}-{profifile}.yml 或 {application}-{profifile}.properties
application为应用名称
profifile用于区分开发环境,测试环境、生产环境等。如user-dev.yml,表示用户微服务开发环境下使用的配置文件。
1 2 3 开发环境 user-dev.yml 测试环境 user-test.yml 生产环境 user-pro.yml
这里将user-service工程的配置文件application.yml文件的内容复制作为user-dev.yml文件的内容,具体配置如下
创建完user-provider-dev.yml配置文件之后,gitee中的仓库如下:
搭建配置中心服务config-server
1 2 3 4 5 6 7 8 9 10 <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency> </dependencies>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 server: port: 12000 spring: application: name: config-server cloud: config: server: git: uri: https://github.com/pointink/gateway-config.git # force-pull: true # 非公开项目需要填入username和password # username: # password: # search-paths: config-files # 设置路径 default-label: main # master # github分支变了,网上的一些教程没有更新! eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka
1 2 3 4 5 6 7 @SpringBootApplication @EnableConfigServer public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class); } }
**测试:**启动eureka注册中心和配置中心;然后访问http://localhost:12000/user-dev.yml ,查看能否输出在码云存储管理的user-dev.yml文件。并且可以在gitee上修改user-dev.yml然后刷新上述测试地址也能及时到最新数据。
改造user-service 将配置文件删除配置成从配置中心获取
问题:git仓库中修改了配置项,微服务系统中的配置项没有及时更新,需要重启
1 2 3 4 5 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> <version>2.1.1.RELEASE</version> </dependency>
创建bootstrap.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 spring: cloud: config: name: user # 与git中文件的application名称一直 profile: dev label: main # master discovery: enabled: true # 使用配置中心 service-id: config-server # 配置中心服务名 eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka
bootstrap.yml文件也是Spring Boot的默认配置文件,而且其加载的时间相比于application.yml更早。
application.yml和bootstrap.yml虽然都是Spring Boot的默认配置文件,但是定位却不相同。bootstrap.yml可以理解成系统级别的一些参数配置 ,这些参数一般是不会变动的。application.yml 可以用来定义应用级别的参数,如果搭配 spring cloud confifig 使用,application.yml 里面定义的文件可以实现动态替换
总结就是,bootstrap.yml文件相当于项目启动时的引导文件,内容相对固定。application.yml文件是微服务的一些常规配置参数,变化比较频繁
配置中心存在的问题 (1)修改码云配置文件
修改在码云上的user-provider-dev.yml文件,添加一个属性test.message,如下操作:
(2)读取配置文件数据
在user-provider工程中创建一个com.itheima.controller.LoadConfigController读取配置文件信息,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @RestController @RequestMapping(value = "/config") public class LoadConfigController { @Value("${test.message}") private String msg; /*** * 响应配置文件中的数据 * @return */ @RequestMapping(value = "/load") public String load(){ return msg; } }
启动运行user-provider,访问<http://localhost:18081/config/load>
修改码云上的配置后,发现项目中的数据仍然没有变化,只有项目重启后才会变化。
Spring Cloud Bus 前面已经完成了将微服务中的配置文件集中存储在远程Git仓库,并且通过配置中心微服务从Git仓库拉取配置文件,当用户微服务启动时 会连接配置中心获取配置信息从而启动用户微服务。
如果我们更新Git仓库中的配置文件,那用户微服务是否可以及时接收到新的配置信息并更新呢?
通过测试可以发现,我们对于Git仓库中配置文件的修改并没有及时更新到用户微服务,只有重启用户微服务才能生效。
如果想在不重启微服务的情况下更新配置该如何实现呢? 可以使用Spring Cloud Bus来实现配置的自动更新。
需要注意的是Spring Cloud Bus底层是基于RabbitMQ实现的,默认使用本地的消息队列服务,所以需要提前启动本地RabbitMQ服务(安装RabbitMQ以后才有),如下:
Spring Cloud Bus是用轻量的消息代理将分布式的节点连接起来,可以用于广播配置文件的更改 或者服务的监控管理。也就是消息总线可以为微服务做监控,也可以实现应用程序之间相互通信。 Spring Cloud Bus可选的消息代理有RabbitMQ和Kafka。广播出去的配置文件服务会进行本地缓存。
可以实现修改git仓库中的配置文件并及时同步和不重启微服务系统的情况下更新到配置项
使用了RabbtMQ进行程序之间消息通信
访问刷新配置中心的一个地址bus-refresh,发送MQ消息,微服务接收消息之后获取最新的配置项
消息总线实现消息分发过程:
请求地址访问配置中心的消息总线
消息总线接收到请求
消息总线向消息队列发送消息
user-service微服务会监听消息队列
user-service微服务接到消息队列中消息后
user-service微服务会重新从配置中心获取最新配置信息
改造config-server实现配置项同步 1 2 3 4 5 6 7 8 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-bus</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-rabbit</artifactId> </dependency>
application.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 server: port: 12000 spring: application: name: config-server cloud: config: server: git: uri: https://github.com/pointink/gateway-config.git force-pull: true # 非公开项目需要填入username和password # username: # password: # rabbitmq的配置信息;如下配置的rabbit都是默认值,其实可以完全不配置 rabbitmq: host: localhost port: 5672 username: guest password: guest eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka management: endpoints: web: exposure: # 暴露触发消息总线的地址 include: bus-refresh
user-service 1 2 3 4 5 6 7 8 9 10 11 12 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-bus</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring: cloud: config: name: user # 与git中文件的application名称一直 profile: dev # 远程仓库中的配置文件的profile保持一致 label: main # master # 远程仓库中的版本保持一致 discovery: enabled: true # 使用配置中心 service-id: config-server # 配置中心服务名 rabbitmq: host: localhost port: 5672 username: guest password: guest eureka: client: service-url: defaultZone: http://127.0.0.1:10086/eureka
改造用户微服务 user-service 项目的UserController
测试步骤 :
第一步:依次启动注册中心 eureka-server 、配置中心 config-server 、用户服务 user-service
第二步:访问用户微服务http://localhost:9091/user/8;查看IDEA控制台输出结果
第三步:修改Git仓库中配置文件 user-dev.yml 的 test.name 内容
第四步:使用Postman或者RESTClient工具发送POST方式请求访问地址http://127.0.0.1:12000/actuator/bus-refresh
第五步:访问用户微服务系统控制台查看输出结果
说明 :
1、Postman或者RESTClient是一个可以模拟浏览器发送各种请求(POST、GET、PUT、DELETE等)的工具
2、请求地址http://127.0.0.1:12000/actuator/bus-refresh中 /actuator是固定的,/bus-refresh对应的是配置中心confifig-server中的application.yml文件的配置项include的内容
3、请求http://127.0.0.1:12000/actuator/bus-refresh地址的作用是访问配置中心的消息总线服务,消息总线服务接收到请求后会向消息队列中发送消息,各个微服务会监听消息队列。当微服务接收到队列中的消息后,会重新从配置中心获取最新的配置信息。
总览
SpringCloud 技术栈 spring cloud
开发分布式系统可能具有挑战性,复杂性已从应用程序层转移到网络层,并要求服务之间进行更多的交互。将代码设为“cloud-native”就需要解决12-factor,例如外部配置,服务无状态,日志记录以及连接到备份服务之类的问题,Spring Cloud项目套件包含使您的应用程序在云中运行所需的许多服务。
12-factor(云原生应用程序的12要素):
SpringCloud架构:
SpringCloud技术栈
SpringCloud技术栈非常丰富,这也是SpringCloud为什么在微服务领域中如此受欢迎的原因之一,技术栈如上图,在服务注册与配置、服务调用、微服务网关、消息组件、链路追踪、配置中心、安全控制、将极限流等诸多方面技术栈都比较完善,而且阿里巴巴也出了一套SpringCloud Alibaba版本,主要集成了Alibaba中主流的技术栈。
SpringCloud经典技术介绍
经典的咋都是过时的 =。=
微服务项目近几年非常火爆,推出来的相关技术解决方案热度也非常活跃,但SpringCloud技术栈中也有一部分技术组件在逐步被淘汰或者闭源,但都有更优秀的技术方案替代。在不久的将来,那些闭源或者将被淘汰的技术有很大概率将不在项目中使用,所以我们学习的时候可以直接学习更优秀的替代技术方案。
Eureka闭源:
上面英文大概意思是: Eureka 2.0 的开源工作已经停止,依赖于开源库里面的 Eureka 2.x 分支构建的项目或者相关代码,风险自负。
Eureka在微服务项目中主要承担服务注册与发现工作,可以替代的技术方案比较多,而且很多方案都比Eureka优秀,比如Consul、Nacos等。
Hystrix停止更新:
Hystrix在项目中主要做服务熔断、降级,但官方宣布将不在开发,目前处于维护状态,但官方表示 1.5.18 版本的 Hystrix 已经足够稳定,可以满足Netflix 现有应用的需求。
关于Hystrix可替代的产品也比较多,比如官方推荐的 resilience4j , resilience4j 是一个轻量级熔断框架,但 resilience4j 目前在国内使用频率还不高,功能也不够强,我们更推荐使用功能更加强悍的 SpringCloud Alibaba Sentinel 。
Zuul过时: Zuul 是一个微服务网关技术,但 Zuul1.x 使用的是阻塞式的API,不支持长连接,没有提供异步,高并发场景下性能低。 SpringCloud 官网推出了全新的微服务网关技术 SpringCloud Gateway ,比 Zuul 性能更强悍、功能更丰富、且支持异步等多种特性。
SpringCloud Config实用性差: SpringCloud Config 主要用于管理项目的配置文件,每次要使用SpringCloud Config 的时候,总得经过一波操作和配置的折腾,才可以使用SpringCloud Config 实现配置管理,而且单独使用无法支持配置实时刷新,在项目中用起来,真比较头疼的。
当前有很多技术可以取代 SpringCloud Config ,比如携程的 Apollo 、 SpringCloud Alibaba Nacos ,功能都比 SpringCloud Config 强,并且支持实时刷新配置。
SpringCloud Bus实用性差: SpringCloud Bus是服务消息总线,主要实现通知多个服务执行某个任务,一般和SpringCloud Config一起使用。这个功能其实不太使用,因为很多任务组件基本都具备消息通知功能,比如Nacos、Apollo都能实现所有服务订阅执行相关操作。
SpringCloud项目场景
模拟用的
微服务技术目前已经在很多国内外大厂中都在广泛使用,那么在项目中该如何使用微服务技术呢?我们以滴滴快车业务未来,来讲解一下微服务技术结合业务应用讲解一下。
打车业务如上图:
1 2 3 1:打车的时候会选择车型,选择车型我们调用过程是:Gateway->Driver(加载司机列表) 2:选择车型后确认打车,相当于要下单了,调用过程是:Gateway->Order(下单)->Driver(司机状态更改) 3:打车结束后,用户进入支付,调用过程是:Gateway->Pay(支付)->Driver(更新司机状态)->Order(更新订单状态)
SpringCloud Consul 我们知道 Eureka 2.X 遇到困难停止开发了,所以我们需要寻找其他的替代技术替代Eureka,这一小节我们就讲解一个新的组件Consul。
后面还会将nacos,这里先学习怎么用consul做注册中心、配置中心、数据中心
Consul 介绍 consul.io
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其它分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具(比如 ZooKeeper 等)。使用起来也较为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署 ,与Docker 等轻量级容器可无缝配合。
我们来对比下当前服务注册与发现的主流技术:
对比项
euerka
Consul
zookeeper
etcd
服务健康检查
可配支持
服务状态、内存、硬盘等
(弱)长连接、keepalive
连接心跳
多数据中心
—-
支持
—-
—-
kv存储服务
—-
支持
支持
支持
一致性
—-
raft
paxos
raft
cap
ap
cp
cp
cp
使用接口(多语言能力)
http
支持http和dns
客户端
http/grpc
watch支持
支持long polling/大部分增量
全量/支持long polling
支持
支持long polling
自身监控
metrics
metrics
—-
metrics
安全
—-
act/https
acl
https支持(弱)
SpringCloud集成
已支持
已支持
已支持
已支持
特性:
服务发现
健康检查
Key/Value 存储
多数据中心
社区活跃
Consul的优势:
使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接. 相比较而言,zookeeper 采用的是 Paxos, 而 etcd 使用的则是 Raft。
支持多数据中心,内外网的服务采用不同的端口进行监听。 多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟,分片等情况等。 zookeeper 和 etcd 均不提供多数据中心功能的支持。
支持健康检查。 etcd 不提供此功能。
支持 http 和 dns 协议接口。 zookeeper 的集成较为复杂, etcd 只支持http 协议。
官方提供 web 管理界面, etcd 无此功能。
综合比较, Consul 作为服务注册和配置管理的新星, 比较值得关注和研究。
提供了rest api 便于集成:https://www.consul.io/api-docs/index
Consul 角色
client: 客户端, 无状态, 将 HTTP 和 DNS 接口请求转发给局域网内的服务端集群。
server: 服务端, 保存配置信息, 高可用集群, 在局域网内与本地客户端通讯, 通过广域网与其它数据中心通讯。 每个数据中心的 server 数量推荐为 3 个或是 5 个。
Consul 客户端、服务端还支持夸中心的使用,更加提高了它的高可用性。
Consul 基础架构 Glossary:术语 见官方文档:https://www.consul.io/docs/install/glossary
组成 consul 集群的每个成员上都要运行一个 agent,可以通过 consulagent 命令来启动。agent可以运行在 server 状态或者 client 状态。自然的,运行在 server 状态的节点被称为 server 节点;运行在 client 状态的节点被称为 client 节点。
负责组成 cluster 的复杂工作(选举server 自行选举一个 leader、状态维护、转发请求到 lead),以及 consul 提供的服务(响应RPC 请求),以及存放和复制数据。考虑到容错和收敛,一般部署 3 ~ 5 个比较合适。
负责转发所有的 RPC 到 server 节点。本身无状态,且轻量级,因此,可以部署大量的client 节点。
虽然数据中心的定义似乎很明显,但仍有一些细微的细节必须考虑。我们将一个数据中心定义为一个私有、低延迟和高带宽的网络环境。这不包括通过公共互联网的通信,但是为了我们的目的,单个EC2 区域内的多个可用区域将被视为单个数据中心的一部分。
另外:
server 自行选举一个 leader。虽然 Consul 可以运行在一台 server ,但是建议使用 3 到 5 台来避免失败情况下数据的丢失。每个数据中心建议配置一个server 集群。
在基础设施中需要发现其他服务的组件可以查询任何一个 Consul 的server 或者agent,Agent 会自动转发请求到 server。
每个数据中心运行了一个 Consul server 集群。当一个跨数据中心的服务发现和配置请求创建时,本地 Consul Server 转发请求到远程的数据中心并返回结果。
如何实现服务注册和发现
Consul在项目中发挥服务注册与发现的功能,我们讲解下它的工作原理:
1 2 3 4 1:当Producer启动的时候,会向Consul发送一个post请求,并向Consul传 输自己的IP和Port。 2:Consul 接收到Producer的注册后,每隔10s(默认)会向Producer发 送一个健康检查的请求,检验Producer是否健康。 3:当Consumer以Http的方式向Producer发起请求,会先从Consul中拿到 一个存储服务IP和Port的临时表,从表中拿到Producer的IP和Port后再发 送请求。 4:该临时表每隔10s会更新,只包含有通过了健康检查的Producer。
Consul 安装启动 Consul 不同于 Eureka, 需要单独安装,访问Consul 官网下载 Consul 的最新版本,当前最新版本是 1.9.0 ,我们使用 consul_1.9.0_windows_amd64版本。
下载 下载地址:https://www.consul.io/downloads.html;linux上如何下载可点击对应标签页查看。
历史版本下载地址:https://releases.hashicorp.com/consul/
下载后的文件是 consul_1.9.0_windows_amd64.zip ,我们解压这个文件,里面有个文件 consul.exe ,我们将该文件所在目录添加到环境变量path中。
基础命令 1 2 3 4 5 6 7 8 9 10 11 12 #查看环境变量是否添加成功 consul #启动 consul agent -dev #浏览器访问 http://localhost:8500 #查看成员 consul members #查看成员及元数据 consul members -detailed #查看节点 curl localhost:8500/v1/catalog/nodes
安装启动 1 server模式 Consul 的 Server 模式,表明这个 Consul 是个 Server ,这种模式下,功能和 Client都一样,唯一不同的是,它会把所有的信息持久化的本地,这样遇到故障,信息是可以被保留的。
Server模式可以单独运行,实现单机模式,bootstrap-expect为1即可。
以consul server运行,参考如下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # linux(可以) consul agent -server -bootstrap-expect 1 -data-dir /root/consul/data -node=n1 -ui -client=0.0.0.0 - bind=192.168.200.129 然后就启动了,就这么简单。 可以通过http://192.168.200.129:8500来访问这个consul的ui界面。 # windows consul agent -server -bootstrap-expect 1 -data-dir D:\tools\consul\consul_1.9.6\server1 -node=n1 -ui -client=0.0.0.0 -bind=26.26.26.1 然后就启动了,就这么简单。 可以通过http://26.26.26.1:8500来访问这个consul的ui界面。 consul agent -server -bootstrap-expect 1 -data-dir D:\tools\consul\consul_1.9.6\multiserver1 -node=n1 -ui -client=0.0.0.0 -bind=26.26.26.1 @echo off echo 当前正在运行的批处理文件所在路径:%~dp0 start /b title consul && %~dp0consul.exe agent -server -ui -bootstrap -client 0.0.0.0 -data-dir=. -bind 127.0.0.1 pause
参数说明
-server 定义 agent 运行在 server 模式
-bootstrap-expect 1 在一个 datacenter 中期望提供的 server 节点数目,当该值提供的时候,consul一直等到达到指定 sever 数目的时候才会引导整个集群。这里我们为了方便演示只启动一个服务端
-data-dir 参数设置 Consul 自己的维护的数据存储路径
-node=n1 节点在集群中的名称,在一个集群中必须是唯一的,默认是该节点的主机名
-bind=127.0.0.1 该地址用来在集群内部的通讯,集群内的所有节点到地址都必须是可达的,默认是 0.0.0.0
-datacenter=dc1 指定当前数据中心名字,该参数可以不设置
-ui 指定可以以 UI 的方式呈现,当前的 UI 访问地址是:http://本机IP:8500
-client=0.0.0.0 consul 服务侦听地址,这个地址提供 HTTP、DNS、RPC 等服务,默认是127.0.0.1所以不对外提供服务,如果你要对外提供服务改成 0.0.0.0,我们当前配置为外提供地址。
完整启动选项参数见官方文档:https://www.consul.io/docs/agent/options
启动后访问控制台UI: http://localhost:8500/
1 2 3 4 5 Services :服务信息。 Nodes :节点信息,Consul支持集群。 Key/Value :存储的动态配置信息。 ACL :权限信息。 Intentions :通过命令的方式对consul进行管理。
2 client模式 Consul 的 Client模式,就是客户端模式。是 Consul 节点的一种模式,这种模式下,所有注册到当前节点的服务会被转发到Server,本身是不持久化这些信息。
Client模式不能脱离Server单独运行,因此无法实现单机模式
以consul client运行,参考命令如下:
1 2 3 4 # linux consul agent -data-dir C:\developer\consul_1.9.6_windows_amd64\data\client -node=n2 -ui -client=0.0.0.0 -bind=192.168.200.10 -join 192.168.200.129 # windows consul agent -data-dir D:\tools\consul\consul_1.9.6\multiclient1 -node=n3 -bind=26.26.26.1 -dc=dc1
通过以上两部操作,就启动了一个完整的数据中心。
3 开发者模式 如果为了方便使用,可以使用如下命令启动一个agent server,
1 2 3 consul agent -dev 然后就启动了,就这么简单,可以通过http://127.0.0.1:8500来访问这个consul的ui界面。 但是,这种模式一般是自己开发的时候用的,因为它不带记忆功能,也不能与其他consul互通。
Linux 单机伪集群 集群和单机的启动方式是一样的,只需要指定并接入到其他Server即可。
集群Server 我这里使用3台机器作为集群测试,两台在linux上,一台在windows上。
Server1:
1 consul agent -server -bootstrap-expect 3 -data-dir /soft/data/consul -node=consulServer1 -bind=10.247.63.210 -ui -rejoin -config-dir=/soft/config/consul/ -client 0.0.0.0
Server2:
1 consul agent -server -bootstrap-expect 3 -data-dir /soft/data/consul -node=consulServer2 -bind=10.247.62.76 -ui -rejoin -config-dir=/soft/config/consul/ -client 0.0.0.0 -join 10.247.63.210
Server3:
1 consul.exe agent -server -bootstrap-expect 3 -data-dir E:/data/consul/data/ -node=consulServer3 -bind=10.247.62.91 -ui -rejoin -config-dir=E:/data/consul/config/ -client 0.0.0.0 -join 10.247.63.210
注意:上面命令在windows上不能使用powershell启动consul,用cmd就可以。
查看consul集群状态
集群Client 将停掉的server改为client加入到集群中去。
1 consul.exe agent -data-dir E:/data/consul/data/ -node=cc1 -bind=10.247.62.91 -ui -config-dir=E:/data/consul/config/ -client 0.0.0.0 -join 10.247.63.210
windows 单机伪集群
以windows服务形式,运行consul 伪集群
示例带注释 server run_install.bat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 :: 转到当前目录 cd /d %~dp0 :: 服务名称 set serviceName="YLSoft Consul Server-01" :: 运行, -config-file需要绝对位置 set serviceFilePath=consul agent -config-file=D:\tools\consul\consul_1.9.6\Server-01\config\server.json :: 服务描述 set serviceDescription="nbchen-发现服务-01节点" :: 注意Binpath后面要有空格 sc create %serviceName% BinPath= "%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
server server.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 { "node_name": "server1", //节点名 "bootstrap_expect": 3, //三个节点 "datacenter": "ylsoft", //数据中心名 "bind_addr": "192.168.0.121", //本地IP "client_addr":"0.0.0.0", //允许同一局域网其它电脑访问 "data_dir": "C:\\Publish\\Consul\\Server-01\\data", //数据文件位置,绝对路径 "ui":false, // "server": true, "log_level": "INFO", "log_file": "C:\\Publish\\Consul\\Server-01\\log\\consul.log", //日志文件位置,绝对路径 "log_rotate_duration": "24h", "enable_syslog": false, "enable_debug": true, "disable_host_node_id": true, "ports": { "http": 8501, "https": 8511, "dns": 8601, "grpc": 8401, "serf_lan": 8311, "serf_wan": 8312, "server": 8310 }, "retry_join": ["192.168.0.121:8311","192.168.0.121:8321","192.168.0.121:8331"] }
Consul-Server2, Consul-Server3 服务点按上面表格改就可以了
client run_install.bat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 :: 转到当前目录 cd /d %~dp0 :: 服务名称 set serviceName="YLSoft Consul Agent" :: 运行, -config-file需要绝对位置 set serviceFilePath=consul agent -config-dir=D:\tools\consul\consul_1.9.6\Client\config\client.json :: 服务描述 set serviceDescription="nbchen-发现服务-代理客户端" :: 注意Binpath后面要有空格 sc create %serviceName% BinPath= "%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
client client.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 { "node_name": "client1", "data_dir": "C:\\Publish\\Consul\\Client\\data", "server": false, //代理端为false "bind_addr": "192.168.0.121", //本地IP "advertise_addr":"121.37.136.160", //公网可以访问的IP "advertise_addr_wan":"121.37.136.160", //公网可以访问的IP "client_addr": "0.0.0.0", "bootstrap": false, "datacenter": "ylsoft", "log_level": "INFO", "log_file": "C:\\Publish\\Consul\\Client\\log\\consul.log", "log_rotate_duration": "24h", "enable_syslog": false, "disable_host_node_id": true, "rejoin_after_leave": true, "ui": true, "ports": { "http": 8500, "https": 8510, "dns": 8600, "grpc": 8400, "serf_lan": 8301, "serf_wan": 8302, "server": 8300 }, "start_join": ["192.168.0.121:8311", "192.168.0.121:8321","192.168.0.121:8331"] }
前提重要重要 要把consul.exe放到C:\Windows\System32下
脚本目录结构
consul,1。9.6 ui字段已经弃用 ,使用 ui_config.enabled
server01
“bind_addr”: “26.26.26.1” 要用本机的ip
server.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 { "datacenter": "nbchenSoft", "data_dir": "D:\\tools\\consul\\consul_1.9.6\\Server-01\\data", "log_level": "INFO", "node_name": "server1", "server": true, "bootstrap_expect": 3, "bind_addr": "26.26.26.1", "client_addr":"0.0.0.0", "ui_config": { "enabled": true }, "log_file": "D:\\tools\\consul\\consul_1.9.6\\Server-01\\log\\consul.log", "log_rotate_duration": "24h", "enable_syslog": false, "enable_debug": true, "disable_host_node_id": true, "ports": { "http": 8501, "https": 8511, "dns": 8601, "grpc": 8401, "serf_lan": 8311, "serf_wan": 8312, "server": 8310 }, "retry_join": ["26.26.26.1:8311","26.26.26.1:8321","26.26.26.1:8331"] }
run_install.bat 1 2 3 4 5 6 7 8 9 10 cd /d %~dp0 set serviceName="nbchenSoft Consul Server-01" set serviceFilePath=consul agent -config-file=D:\tools\consul\consul_1.9.6\Server-01\config\server.json set serviceDescription="nbchen-findServer-01node" sc create %serviceName% BinPath= "%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
run_unstall.bat 1 2 3 4 5 6 set serviceName="nbchenSoft Consul Server-01" sc stop %serviceName% sc delete %serviceName% pause
右键管理员启动run_unstall.bat,清理服务
右键管理员启动run_install.bat,创建并启动服务
服务是坏的才需要清理,如果是正常的服务,直接运行run_install就行了。
实际上是注册成服务了
Server02 server.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 { "node_name": "server2", "bootstrap_expect": 3, "datacenter": "nbchenSoft", "bind_addr": "26.26.26.1", "client_addr":"0.0.0.0", "data_dir": "D:\\tools\\consul\\consul_1.9.6\\Server-02\\data", "server": true, "ui_config": { "enabled": true }, "log_level": "DEBUG", "log_file": "D:\\tools\\consul\\consul_1.9.6\\Server-02\\log\\consul.log", "log_rotate_duration": "24h", "enable_syslog": false, "disable_host_node_id": true, "rejoin_after_leave": true, "ports": { "http": 8502, "https": 8512, "dns": 8602, "grpc": 8402, "serf_lan": 8321, "serf_wan": 8322, "server": 8320 }, "retry_join": ["26.26.26.1:8311","26.26.26.1:8321","26.26.26.1:8331"] }
run_install.bat 1 2 3 4 5 6 7 8 9 10 cd /d %~dp0 set serviceName="nbchenSoft Consul Server-02" set serviceFilePath=consul agent -config-dir=D:\tools\consul\consul_1.9.6\Server-02\config\server.json set serviceDescription="nbchen-findServer-02node" sc create %serviceName% BinPath="%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
run_unstall.bat 1 2 3 4 5 6 set serviceName="nbchenSoft Consul Server-02" sc stop %serviceName% sc delete %serviceName% pause
右键管理员启动run_unstall.bat,清理服务
右键管理员启动run_install.bat,创建并启动服务
实际上是注册成服务了
Server03 server.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 { "node_name": "server3", "bootstrap_expect":3, "datacenter": "nbchenSoft", "bind_addr": "26.26.26.1", "client_addr":"0.0.0.0", "data_dir": "D:\\tools\\consul\\consul_1.9.6\\Server-03\\data", "server": true, "ui_config": { "enabled": true }, "bootstrap": false, "log_level": "INFO", "log_file": "D:\\tools\\consul\\consul_1.9.6\\Server-03\\log\\consul.log", "log_rotate_duration": "24h", "enable_syslog": false, "disable_host_node_id": true, "rejoin_after_leave": true, "ports": { "http": 8503, "https": 8513, "dns": 8603, "grpc": 8403, "serf_lan": 8331, "serf_wan": 8332, "server": 8330 }, "retry_join": ["26.26.26.1:8311","26.26.26.1:8321","26.26.26.1:8331"] }
run_install.bat 1 2 3 4 5 6 7 8 9 10 cd /d %~dp0 set serviceName="nbchenSoft Consul Server-03" set serviceFilePath=consul agent -config-dir=D:\tools\consul\consul_1.9.6\Server-03\config\server.json set serviceDescription="nbchen-findServer-03node" sc create %serviceName% BinPath="%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
run_unstall.bat 1 2 3 4 5 6 set serviceName="nbchenSoft Consul Server-03" sc stop %serviceName% sc delete %serviceName% pause
右键管理员启动run_unstall.bat,清理服务
右键管理员启动run_install.bat,创建并启动服务
实际上是注册成服务了
成功可以访问客户端的http://外网ip:8500
Client client.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "node_name": "client1", "data_dir": "D:\\tools\\consul\\consul_1.9.6\\Client\\data", "server": false, "bind_addr": "26.26.26.1", "advertise_addr":"127.0.0.1", "advertise_addr_wan":"127.0.0.1", "client_addr": "0.0.0.0", "bootstrap": false, "datacenter": "nbchenSoft", "log_level": "INFO", "log_file": "D:\\tools\\consul\\consul_1.9.6\\Client\\log\\consul.log", "log_rotate_duration": "24h", "enable_syslog": false, "disable_host_node_id": true, "rejoin_after_leave": true, "ui_config": { "enabled": true }, "ports": { "http": 8500, "https": 8510, "dns": 8600, "grpc": 8400, "serf_lan": 8301, "serf_wan": 8302, "server": 8300 }, "start_join": ["26.26.26.1:8311", "26.26.26.1:8321","26.26.26.1:8331"] }
run_install.bat 1 2 3 4 5 6 7 8 9 10 cd /d %~dp0 set serviceName="nbchenSoft Consul Agent" set serviceFilePath=consul agent -config-dir=D:\tools\consul\consul_1.9.6\Client\config\client.json set serviceDescription="nbchen-findServer-agent-client" sc create %serviceName% BinPath="%serviceFilePath%" sc config %serviceName% start=auto sc description %serviceName% %serviceDescription% sc start %serviceName% pause
run_unstall.bat 1 2 3 4 5 6 set serviceName="nbchenSoft Consul Agent" sc stop %serviceName% sc delete %serviceName% pause
右键管理员启动run_unstall.bat,清理服务
右键管理员启动run_install.bat,创建并启动服务
实际上是注册成服务了
感动死了,终于可以了
项目中作为注册中心使用 项目中要想使用Consul作为服务注册中心,只需要引入如下依赖包,在启动类上添加 @EnableDiscoveryClient 注解,并在 application.yml 中添加Consul服务地址即可:
1)添加依赖
在项目 hailtaxi-gateway 添加依赖包:
1 2 3 4 5 6 7 8 9 10 11 <!--consul--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-consul-discovery</artifactId> <version>2.2.1.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <version>2.2.10.RELEASE</version> </dependency>
2)添加 @EnableDiscoveryClient 注解在 hailtaxi-gateway 启动类 GatewayApplication 上添加@EnableDiscoveryClient 注解:
1 2 3 4 5 6 7 8 @EnableDiscoveryClient @SpringBootApplication public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class,args); } }
3)application.yml配置Consul服务信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 server: port: 8001 spring: application: name: hailtaxi-gateway main: allow-bean-definition-overriding: true cloud: #Consul配置 consul: host: 127.0.0.1 port: 8500 discovery: #注册到Consul中的服务名字 service-name: ${spring.application.name} #注册的服务的实例 Id,最好不要重复,这里参考官网建议的方 式 带随机数 默认:应用名:port #instance-id: ${spring.application.name}:${vcap.application.instance_id: ${spring.application.i nstance_id:${random.value}}} # 自定义实例id为:应用名:ip:port instance-id: ${spring.application.name}:${spring.cloud.client.ip-address}:${server.port} # 开启服务注册 register: true # 开启服务发现 enabled: true #2 分钟之后健康检查未通过取消注册 health-check-critical-timeout: 2m #consul 健康检查的轮询周期 health-check-interval: 10s #能否看到ip prefer-ip-address: true management: endpoint: health: show-details: always
4)Consul服务数据
项目中作为配置中心使用
1 2 3 4 5 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-consul-config</artifactId> <version>2.2.1.RELEASE</version> </dependency>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # consul作为配置中心,一些配置项在应用启动的时候就需要加载和初始化了,所以consul的配置必须写在bootstrap.yml server: port: 8001 spring: application: name: hailtaxi-gateway main: allow-bean-definition-overriding: true cloud: #Consul配置 consul: host: 127.0.0.1 port: 8500 discovery: #注册到Consul中的服务名字 service-name: ${spring.application.name} #注册的服务的实例 Id,最好不要重复,这里参考官网建议的方 式 带随机数 默认:应用名:port #instance-id: ${spring.application.name}:${vcap.application.instance_id: ${spring.application.i nstance_id:${random.value}}} # 自定义实例id为:应用名:ip:port instance-id: ${spring.application.name}:${spring.cloud.client.ip-address}:${server.port} # 开启服务注册 register: true # 开启服务发现 enabled: true #2 分钟之后健康检查未通过取消注册 health-check-critical-timeout: 2m #consul 健康检查的轮询周期 health-check-interval: 10s config: enabled: true # 启用 consul 配置中心.默认是true format: YAML # 配置转码方式,默认 key-value,其他可选:yaml/files/properties data-key: data # 配置 key 值,value 对应整个配置文件。例如config/application,dev/data prefix: config # 基础文件夹,默认值 config. default-context: hailtaxi-gateway #应用文件夹,默认值 application,consul 会加载 config/<applicationName> 和 config/<defaultContext> 两份配置,设置为相同值,则只加载一份.sets the folder name used by all applications # profile-separator: '-' #环境分隔符,默认值 ",例如例如config/application,dev/data修改后是config/application-dev/data management: endpoint: health: show-details: always
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 // @RefreshScope // 用来刷新配置用的 @EnableDiscoveryClient @SpringBootApplication public class GatewayApplication implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class,args); } @Value("${myname}") public String myname; @Override public void run(String... args) throws Exception { System.out.println("hello:"+myname); } }
效果:可以从第三方读取配置了
启动工程可以看到成功拿到配置信息
这里只是简单的用了下,还要更改后热生效
用controller+注解动态刷新(刷新配置而不重启应用)
1 2 3 4 5 6 7 8 @RestController @RefreshScope public class GatewayApplication implements CommandLineRunner { @GetMapping("fresh") public String fresh() { return myname; }
SpringCloud Gateway
Spring Cloud Gateway 是Spring Cloud团队的一个全新项目,基于Spring5.0、SpringBoot2.0、Project Reactor 等技术开发的网关。旨在为微服务架构提供一种简单有效统一的API路由管理方式。
Spring Cloud Gateway 作为SpringCloud生态系统中的网关,目标是替代Netflix Zuul。Gateway不仅提供统一路由方式,并且基于Filter链的方式提供网关的基本功能。例如:安全,监控/指标,和限流。
总结:微服务网关就是一个系统,通过暴露该微服务网关系统,方便我们进行相关的鉴权,安全控制,日志统一处理,易于监控,限流等相关功能。
实现微服务网关的技术有很多,
nginx:Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务
zuul :Zuul 是 Netflflix 出品的一个基于 JVM 路由和服务端的负载均衡器。
spring-cloud-gateway:是spring 出品的基于spring的网关项目,集成断路器,路径重写,性能比Zuul好。
我们使用gateway这个网关技术,无缝衔接到基于spring cloud的微服务开发中来。
gateway官网:https://spring.io/projects/spring-cloud-gateway
Gateway工作原理 我们在学习Gateway之前,先弄清楚Gateway的工作原理,后面使用它的各个功能时,就知道该如何使用了,工作流程图如下:
Gateway的执行流程如下:
1 2 3 4 5 1:Gateway的客户端回向SpringCloudGateway发起请求,请求首先会被HttpWebHandlerAdapter进行提取组装成网关的上下文,然后网关的上下文会传递到DispatcherHandler。 2:DispatcherHandler是所有请求的分发处理器,DispatcherHandler主要负责分发请求对应的处理器,比如将请求分发到对应RoutePredicateHandlerMapping(路由断言处理器映射器)。 3:路由断言处理映射器主要用于路由的查找,以及找到路由后返回对应的FilteringWebHandler。 4:FilteringWebHandler主要负责组装Filter链表并调用Filter执行一系列Filter处理,然后把请求转到后端对应的代理服务处理,处理完毕后,将Response返回到Gateway客户端。 在Filter链中,通过虚线分割Filter的原因是,过滤器可以在转发请求之前处理或者接收到被代理服务的返回结果之后处理。所有的Pre类型的Filter 执行完毕之后,才会转发请求到被代理的服务处理。被代理的服务把所有请求完毕之后,才会执行Post类型的过滤器。
Gateway路由 Gateway路由配置分为基于配置的静态路由 设置和基于代码动态路由 配置,
静态路由是指在application.yml中把路由信息配置好了,而动态路由则支持在代码中动态加载路由信息,更加灵活,我们接下来把这2种路由操作都实现一次。
业务说明
如上图:
1 2 3 1:用户所有请求以/order开始的请求,都路由到 hailtaxi-order服务 2:用户所有请求以/driver开始的请求,都路由到 hailtaxi-driver服务 3:用户所有请求以/pay开始的请求,都路由到 hailtaxi-pay服务
基于配置路由设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 spring: cloud: # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - id: hailtaxi-driver uri: lb://hailtaxi-order #路由断言 predicates: - Path=/order/** - id: hailtaxi-driver uri: lb://hailtaxi-pay #路由断言 predicates: - Path=/pay/**
如上图所示,正是Gateway静态路由配置:
1 2 3 1:用户所有请求以/order开始的请求,都路由到 hailtaxi-order服务 2:用户所有请求以/driver开始的请求,都路由到 hailtaxi-driver服务 3:用户所有请求以/pay开始的请求,都路由到 hailtaxi-pay服务 123
配置参数说明:
1 2 3 4 5 6 7 routes:路由配置 - id:唯一标识符 uri:路由地址,可以是 lb://IP:端口 也可以是 lb://${spring.application.name} predicates:断言,是指路由条件 - Path=/driver/**:路由条件。Predicate 接受一个输入参数,返回一 个布尔值结果。这里表示匹配所有以driver开始的请求。 filters:过滤器 - StripPrefix=1:真实路由的时候,去掉第1个路径,路径个数以/分割区 分
测试url:http://localhost:8001/driver/info/1
基于代码路由配置 我们同样实现上面的功能,但这里基于代码方式实现。所有路由规则我们可以从数据库中读取并加载到程序中。基于代码的路由配置我们只需要创建RouteLocator 并添加路由配置即可,代码如下
1 2 3 4 5 6 7 8 9 10 11 @Configuration public class RouterConfig { @Bean public RouteLocator routeLocator(RouteLocatorBuilder builder) { return builder.routes() .route("hailtaxi-driver",r->r.path("/driver/**").uri("lb://hailtaxi-driver")) .route("hailtaxi-order",r->r.path("/order/**").uri("lb://hailtaxi-order")) .route("hailtaxi-pay",r->r.path("/pay/**").uri("lb://hailtaxi-pay")) .build(); } }
在真实场景中,基于配置文件的方式更直观、简洁,但代码的路由配置是更强大,可以实现很丰富的功能,可以把路由规则存在数据库中,每次直接从数据库中加载规则,这样的好处是可以动态刷新路由规则,通常应用于权限系统动态配置。
Gateway-Predicate 上面路由匹配规则中我们都用了 - Path 方式,其实就是路径匹配方式,除了路径匹配方式,Gateway还支持很多丰富的匹配方式,我们对这些方式分别进行讲解。
关于 Predicate 学习地址,可以参考官网:
https://docs.spring.io/spring-cloud-gateway/docs/2.2.5.RELEASE/reference/html/#gateway-request-predicates-factories
或者:
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.1.1.RELEASE/single/spring-cloud-gateway.html#gateway-request-predicates-factories
routes下面的属性含义如下:
1 2 3 id:我们自定义的路由 ID,保持唯一 uri:目标服务地址 predicates:路由条件,Predicate 接受一个输入参数,返回一个布尔值 结果。该属性包含多种默认方法来将 Predicate 组合成其他复杂的逻辑 (比如:与,或,非)
Predicate 来源于 Java 8,Predicate 接受一个输入参数,返回一个布尔值结果。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非)。
在 Spring Cloud Gateway 中 Spring 利用 Predicate 的特性实现了各种路由匹配规则,通过 Header、请求参数等不同的条件来作为条件匹配到对应的路由。
下面的一张图(来自网络)总结了 Spring Cloud 内置的几种 Predicate 的实现:
我们在这里讲解几个断言匹配 方式。
每个参数都有对应的RoutePredicateFactory后缀断言类对应,会自动查找
Cookie Gateway的Cookie匹配接收两个参数:一个是 Cookie name ,一个是正则表达式。路由规则就是通过获取对应的 Cookie name 值和正则表达式去匹配,如果匹配上就会执行路由,如果没有匹配上则不执行。如下配置:
1 2 3 4 5 6 7 8 9 10 11 # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima
这里表示请求携带了cookie为username的数据,并且值为itheima,就允许通过。否则请求不让通过。
Header 匹配 和 Cookie 匹配 一样,也是接收两个参数,一个 header 中属
性名称和一个正则表达式,这个属性值和正则表达式匹配则执行。配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima - Header=token,^(?!\d+$)[\da-zA-Z]+$
上面的匹配规则,就是请求头要有token属性,并且值必须为数字和字母组合的正则表达式,例如携带token= 19and30 就可以通过访问。
请求方式匹配 通过请求的方式是 POST、GET、PUT、DELETE 等进行路由。配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima - Header=token,^(?!\d+$)[\da-zA-Z]+$ - Method=GET,POST
断言是怎么起作用的?
断言源码剖析 拿 Cookie 断言来说,首先看它的体系结构
尽管Spring Cloud Gateway已经包含了很多路由匹配规则,有时候我们需要开发自定义路由匹配规则来满足需求,下面简单的介绍一下如何自定义路由匹配规则。
自定义断言 案例 :
需求:转发带token的请求到 hailtaxi-drvier 服务中,这里定义请求带token是指包含某个请求头的请求,至于是什么请求头可以由配置指定
1、修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima - Header=token,^(?!\d+$)[\da-zA-Z]+$ - Method=GET,POST # 自定义一个Token断言,如果请求包含Authorization的 token信息则通过 - Token=Authorization
2、创建 RoutePredicateFactory
断言工厂默认命名规则必须按照名称+RoutePredicateFactory,如TokenRoutePredicateFactory的断言名称为Token
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Slf4j @Component // 要交给spring容器管理 public class TokenRoutePredicateFactory extends AbstractRoutePredicateFactory<TokenRoutePredicateFactory.Config> { public static final String NAME = "headerName"; public TokenRoutePredicateFactory() { super(TokenRoutePredicateFactory.Config.class); } public Predicate<ServerWebExchange> apply(Config config) { return exchange -> { List<String> header = exchange.getRequest().getHeaders().get(config.getHeaderName()); log.info("token predicate headers:{}",header); // 断言返回的是boolean值 return header!=null && header.size()>0; }; } @Override public ShortcutType shortcutType() { return ShortcutType.DEFAULT; // default,将配置的值按顺序填充到config } @Override public List<String> shortcutFieldOrder() { return Arrays.asList(NAME); // 指定配置文件中 加载到的配置信息应填充到Config的哪个属性上 } @Data public static class Config { //static class private String headerName;//存储从配置文件中加载的配置 } }
启动测试:http://localhost:8001/driver/info/1
Gateway过滤器
经过路由的断言筛选,在到达请求之前,还可以通过filter过滤一下
Spring Cloud Gateway根据作用范围划分为GatewayFilter 和GlobalFilter ,二者区别如下:
GatewayFilter : 需要通过spring.cloud.routes.filters 配置在具体路由下,只作用在当前路由上或通过spring.cloud.default-filters配置在全局,作用在所有路由上;gateway内置了多种过滤器工厂,配套的过滤器可以直接使用,如下图所示:
GlobalFilter : 全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过GatewayFilterAdapter包装成GatewayFilterChain可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上。
过滤器作为Gateway的重要功能。常用于请求鉴权、服务调用时长统计、修改请求或响应header、限流、去除路径等等。关于Gateway过滤器的更多使用,大家可以参考官方地址:
https://docs.spring.io/spring-cloud-gateway/docs/2.2.5.RELEASE/reference/html/#gatewayfilter-factories
或者:
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.1.1.RELEASE/single/spring-cloud-gateway.html#_gatewayfilter_factories
过滤器分类 1 2 3 4 5 6 默认过滤器:出厂自带,实现好了拿来就用,不需要实现 全局默认过滤器 局部默认过滤器 自定义过滤器:根据需求自己实现,实现后需配置,然后才能用哦。 全局过滤器:作用在所有路由上。 局部过滤器:配置在具体路由下,只作用在当前路由上。
默认过滤器十好几个,常见如下
默认过滤器的使用 所谓默认过滤器就是系统自带的。有很多,这里简要说明几个:
1)添加响应头
AddResponseHeaderGatewayFilterFactory 属于 GatewayFilter对输出响应头设置属性,比如对输出的响应设置其头部属性名称为:X-Response-Default-MyName , 值为itheima修改配置文件,配置如下:
1 2 3 4 5 6 # gateway配置 gateway: # 配置全局默认过滤器 作用在所有路由上,也可单独为某个路由配置 default-filters: # 往响应过滤器中加入信息 - AddResponseHeader=X-Response-Default-MyName,itheima
请求 http://localhost:8001/driver/info/1 ,响应数据添加了 X-Response-Default-MyName: itheima ,如下图:
2)前缀处理
在项目中做开发对接接口的时候,我们很多时候需要统一API路径,比如统一以 /api 开始的请求调用 hailtaxi-driver 服务,但真实服务接口地址又没有 /api 路径,我们可以使用Gateway的过滤器处理请求路径。在gateway中可以通过配置路由的过滤器StripPrefix实现映射路径中的前缀处理,我们来使用一下该过滤器,再进一步做说明。
1 2 3 4 5 6 7 8 9 10 11 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/api/driver/** filters: - StripPrefix=1
此处 - StripPrefix=1 表示真实请求地址是当前用户请求以 /api 开始的uri中去除第1个路径 /api .
上面配置最终执行如下表:
有时候为了简化用户请求地址,比如用户请求http://localhost:8001/info/1 我们想统一路由到http://localhost:18081/driver/info/1 ,可以使用 PrefixPath 过滤器增加前缀。
1 2 3 4 5 6 7 8 9 10 11 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/** filters: - PrefixPath=/driver
上面配置最终执行如下表:
自定义GatewayFilter 1 实现GatewayFilter接口 GatewayFilter 一般作用在某一个路由上,需要实例化创建才能使用,局部过滤器需要实现接口 GatewayFilter、Ordered 。
创建 com.itheima.filter.PayFilter 代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class PayFilter implements GatewayFilter, Ordered { // 过滤器执行拦截 @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { System.out.println("GatewayFilter拦截器执行---pre-- ---PayFilter"); return chain.filter(exchange) .then(Mono.fromRunnable(() -> { System.out.println("GatewayFilter拦截器执行--- post-----PayFilter"); })); } @Override public int getOrder() { return 0; } }
使用局部过滤器:(使用下面RouteLocator的时候,配置文件中的路由记得注释或删除)
这种过滤器,在配置文件里面就不好自动识别了。要在代码配置里添加过滤器
为了更好看到效果,我们在 RouterFilter 添加System.out.println(“GlobalFilter拦截器执行”); 再访问测试。
访问:http://localhost:8001/api/driver/info/1,注意使用postman发送请求时添加请求头,添加cookie。
这种是在代码里配置的,而要在配置文件中配置自定义的filter,需要继承GatewayFilterFactory
2、继承GatewayFilterFactory 如果定义局部过滤器,想在配置文件中进行配置来使用,可以继承AbstractGatewayFilterFactory<T> 抽象类或者AbstractNameValueGatewayFilterFactory整个体系结构为:
这两个抽象类的区别就是前者接收一个参数(像StripPrefix和我们创建的这种),后者接收两个参数(像AddResponseHeader)代码的编写可以参考: StripPrefixGatewayFilterFactory 和 AddRequestHeaderGatewayFilterFactory
过滤器工厂默认命名规则必须按照名称+GatewayFilterFactory,如上StripPrefixGatewayFilterFactory的过滤器名称为StripPrefix
继承AbstractGatewayFilterFactory
需求:在网关中统一支付方式,编写一个过滤器:PayMethodGatewayFilterFactory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @Slf4j @Component //一定要将其交给spring容器管理 public class PayMethodGatewayFilterFactory extends AbstractGatewayFilterFactory<PayMethodGatewayFilterFactory.Config> { public PayMethodGatewayFilterFactory() { super(PayMethodGatewayFilterFactory.Config.class); } @Override public GatewayFilter apply(Config config) { return (exchange, chain) -> { String payMethod = config.getPayMethod(); String msg = config.getMsg(); log.info("PayMethodGatewayFilterFactory 加载到 的配置信息为:{}---{}",payMethod,msg); //将 payMethod 添加到请求头中 exchange.getRequest().mutate().header("payMethod",payMethod); return chain.filter(exchange); }; } @Override public ShortcutType shortcutType() { return ShortcutType.DEFAULT; //默认规则 } @Override public List<String> shortcutFieldOrder() { return Arrays.asList("payMethod","msg");//指定从 yml中提前出来的配置信息填充到配置类中哪个属性,按规则配置 } // 加载从yml中提取出来的配置信息 @Data public static class Config { private String payMethod; private String msg; } }
使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # gateway配置 gateway: # 配置全局默认过滤器 作用在所有路由上,也可单独为某个路由配置 default-filters: # 往响应过滤器中加入信息 - AddResponseHeader=X-Response-Default-MyName,itheima #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima - Header=token,^(?!\d+$)[\da-zA-Z]+$ - Method=GET,POST # 自定义一个Token断言,如果请求包含Authorization的 token信息则通过 - Token=Authorization # - Path=/api/driver/** filters: # - StripPrefix=1 - PayMethod=alipay,业务整合
再次测试,查看hailtaxi-driver 服务接收到请求后是否多了 paymethod 请求头信息
继承 AbstractNameValueGatewayFilterFactory
直接查看 AddRequestHeaderGatewayFilterFactory 源码,分析即可
继承AbstractNameValueGatewayFilterFactory就不用添加config类了
自定义GlobalFilter 定义全局过滤器需要实现GlobalFilter,Ordered接口
1 2 3 GlobalFilter:过滤器拦截处理方法 Ordered:过滤器也有多个,这里主要定义过滤器执行顺序,里面有个方法 getOrder()会返回过滤器执行顺序,返回值越小,越靠前执行
需求 :
我们创建全局过滤器并完成常见业务用户权限校验,如果请求中有带有一个名字为 token 的请求参数,则认为请求有效放行,如果没有则拦截提示授权无效。
创建全局过滤器: com.itheima.filter.RouterFilter ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Slf4j @Component public class RouterFilter implements GlobalFilter, Ordered { // 路由拦截 @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { log.info("RouterFilter----------------"); //获取请求参数 String token = exchange.getRequest().getQueryParams().getFirst("token"); //如果token为空,则表示没有登录 if (StringUtils.isEmpty(token)) { //没登录,状态设置403 exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN); //结束请求 return exchange.getResponse().setComplete(); } return chain.filter(exchange); } // 拦截器顺序 @Override public int getOrder() { return 0; } }
此时请求,我们不携带token参数,效果如下:
给请求增加token
网关案例配置小结:
跨域配置 出于浏览器的同源策略限制。同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。
在Spring Cloud Gateway中配置跨域是非常简单的,如下面application.yml 所示:
1 2 3 4 5 6 7 8 9 10 # gateway配置 gateway: globalcors: cors-configurations: '[/**]': allowedOrigins: "*" allowedMethods: - GET - POST - PUT
但如果涉及到Cookie跨域,上面的配置就不生效了,如果涉及到Cookie跨域,需要创建 CorsWebFilter 过滤器,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /*** 配置跨域 * @return */ @Bean public CorsWebFilter corsFilter() { CorsConfiguration config = new CorsConfiguration(); // cookie跨域 config.setAllowCredentials(Boolean.TRUE); config.addAllowedMethod("*"); config.addAllowedOrigin("*"); config.addAllowedHeader("*"); // 配置前端js允许访问的自定义响应头 config.addExposedHeader("Authorization"); UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(new PathPatternParser()); source.registerCorsConfiguration("/**", config); return new CorsWebFilter(source); }
限流 网关可以做很多的事情,比如,限流,当我们的系统 被频繁的请求的时候,就有可能 将系统压垮,所以 为了解决这个问题,需要在每一个微服务中做限流操作,但是如果有了网关,那么就可以在网关系统做限流,因为所有的请求都需要先通过网关系统才能路由到微服务中
漏桶算法讲解
漏桶算法是常见的限流算法之一,我们讲解一下漏桶算法:
1 2 3 4 5 1)所有的请求在处理之前都需要拿到一个可用的令牌才会被处理; 2)根据限流大小,设置按照一定的速率往桶里添加令牌; 3)桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒 绝; 4)请求达到后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务 逻辑,处理完业务逻辑之后,将令牌直接删除; 5)令牌桶有最低限额,当桶中的令牌达到最低限额的时候,请求处理完之后 将不会删除令牌,以此保证足够的限流
漏桶算法的实现,有很多技术,Guaua是其中之一,redis客户端也有其实现
限流案例 spring cloud gateway 默认使用redis的RateLimter限流算法来实现,外面来简要实现一下:
1、引入依赖
首先需要引入redis的依赖:
1 2 3 4 5 6 <!--redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis-reactive</artifactId> <version>2.2.1.RELEASE</version> </dependency>
同时不要忘记Redis配置:
1 2 3 redis: host: 127.0.0.1 port: 6379
2、定义KeyResolver
在Application引导类中添加如下代码,KeyResolver用于计算某一个类型的限流的KEY也就是说,可以通过KeyResolver来指定限流的Key。我们可以根据IP来限流,比如每个IP每秒钟只能请求一次,在GatewayApplication定义key的获取,获取客户端IP,将IP作为key,如下代码:
1 2 3 4 5 6 7 8 9 @Bean(name = "ipKeyResolver") public KeyResolver userKeyResolver() { return exchange -> { //获取远程客户端IP String hostName = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress(); System.out.println("hostName:"+hostName); return Mono.just(hostName); }; }
在路由中配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # gateway配置 gateway: #路由配置 routes: #唯一标识符 - id: hailtaxi-driver uri: lb://hailtaxi-driver #路由断言 predicates: - Path=/driver/** - Cookie=username,itheima - Header=token,^(?!\d+$)[\da-zA-Z]+$ - Method=GET,POST # 自定义一个Token断言,如果请求包含Authorization的 token信息则通过 - Token=Authorization # - Path=/api/driver/** filters: # - StripPrefix=1 - PayMethod=alipay,业务整合 - name: RequestRateLimiter #请求数限流 名字不能 随便写 ,使用默认的facatory args: # 用于通过SPEL表达式来指定使用哪一个KeyResolver key-resolver: "#{@ipKeyResolver}" # 是您希望允许用户每秒执行多少请求,而不会丢弃任何请求。这是令牌桶填充的速率 redis-rate-limiter.replenishRate: 1 # 是指令牌桶的容量,允许在一秒钟内完成的最大请求数,将此值设置为零将阻止所有请求。 redis-rate-limiter.burstCapacity: 1
如上配置:
表示 一秒内,允许 一个请求通过,令牌桶的填充速率也是一秒钟添加一个令牌。
最大突发状况 也只允许 一秒内有一次请求,可以根据业务来调整 。
我们请求 http://localhost:8001/driver/info/1?token=aa 执行测试,效果如下:(1s内点击多次)
后期会有更强的限流组件,sentinel.
SpringCloud OpenFeign
我们想在java代码里面发起http调用的方法有很多种,比如httpclient,OKhttp,resttemplate,OpenFeign…
1、先说Feign
Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。
Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务
Feign支持的注解和用法请参考官方文档:https://github.com/OpenFeign/feign
Feign本身不支持Spring MVC的注解,它有一套自己的注解
2、再说OpenFign
OpenFeign是Spring Cloud 在Feign的基础上支持了Spring MVC的注解,如@RequesMapping等,是一个轻量级的Http封装工具对象,大大简化了Http请求,使得我们对服务的调用转换成了对本地接口方法的调用。
OpenFeign 的 @FeignClient 可以解析SpringMVC的 @RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
集成了Ribbon的负载均衡功能
集成Hystrix的熔断器功能
支持请求压缩
大大简化了远程调用的代码,同时功能还增强啦
以更加优雅的方式编写远程调用代码,并简化重复代码
业务分析
需求:
如上图,我们现在要实现打车用户打车下单,打车下单的时候需要匹配指定司机并更改司机状态,由之前空闲状态改成接单状态。
技术支持:
这时候就涉及到 hailtaxi-order 服务调用 hailtaxi-driver 服务了,此时如果使用HttpClient工具,操作起来非常麻烦,我们可以使用 SpringCloud OpenFeign 实现调用。
OpenFeign应用 使用OpenFeign实现服务之间调用,可以按照如下步骤实现:
1 2 3 4 5 6 在 hailtaxi-api 中导入如下依赖: <!--配置feign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
2:编写openfeign客户端接口-将请求地址写到该接口上
修改 hailtaxi-api 创建 com.itheima.driver.feign.DriverFeign 接口,代码如下:
1 2 3 4 5 6 7 8 9 @FeignClient(value = "hailtaxi-driver") // 声明Feign的客户端,value指明服务名称 接口定义的方法 public interface DriverFeign { // 更新司机信息,该方法和hailtaxi-driver服务中的方法保持一致 @PutMapping(value = "/driver/status/{id}/{status}") // 注解@RequestMapping中的/driver,不要忘记。因为Feign需要拼接可访问地址 public Driver status(@PathVariable(value = "id") String id, @PathVariable(value = "status") Integer status); } Feign会通过动态代理,帮我们生成实现类。 接口定义的方法,采用SpringMVC的注解。Feign会根据注解帮我们生成URL地址
3:消费者启动引导类开启openfeign功能注解
Controller调用,修改 hailtaix-order 的下单方法,在下单方法中调用 DriverFeign 修改司机状态,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @RestController @RequestMapping(value = "/order") public class OrderInfoController { @Autowired private OrderInfoService orderInfoService; @Autowired private DriverFeign driverFeign; /*** * 下单 */ @PostMapping public OrderInfo add(){ //修改司机信息 司机ID=1 Driver driver = driverFeign.status("1", 2); //创建订单 OrderInfo orderInfo = new OrderInfo("No"+((int)(Math.random()*10000)), (int)(Math.random()*100), new Date(), "深圳北站", "罗湖港", null); orderInfoService.add(orderInfo); return orderInfo; } }
上面所有业务逻辑写完了,但OpenFeign还并未生效,我们需要在hailtaxi-order 中开启 OpenFeign ,只需要在 OrderApplication 启动类上添加 @EnableFeignClients(basePackages = “com.itheima.driver.feign”) 即可。
1 2 3 4 5 6 7 8 9 10 @EnableFeignClients(basePackages = "com.itheima.driver.feign") // 启用openfeign @SpringBootApplication @EnableDiscoveryClient public class OrderApplication { public static void main(String[] args) { SpringApplication.run(OrderApplication.class,args); } }
测试地址:http://localhost:8001/order?token=123456
效果如下
OpenFeign 日志配置
异常信息排查是很经常的事情,如果面对大型的微服务应用,可能需要调用其他团队的API接口.避免不了联调和问题排查。
你的Request参数是什么?
请求的入参和出参是排查的重要线索.我们一般就是打印日志,在程序中log.info。但是复杂的业务场景就不太方便了。
通过loggin.level.xx=debug来设置日志级别。然而这个对Feign客户端不会产生效果。因为@FeignClient注解修饰的客户端在被代理时,都会创建一个新的Feign.Logger实例。我们需要额外通过配置类的方式指定这个日志的级别才可以。
实现步骤:
1 在application.yml配置文件中开启日志级别配置
在 hailtaxi-order的配置文件中设置com.itheima包下的日志级别都为debug:
1 2 3 4 # com.itheima 包下的日志级别都为Debug logging: level: com.itheima: debug # openFeign组件默认将日志信息以Debug输出,但是SpringBoot默认日志级别是Info.所以必须该为Debug才能看到OpenFeign的日志。
在 hailtaxi-order 启动类 OrderApplication 中创建 Logger.Level ,定义日志级别
1 2 3 4 5 6 7 8 9 10 11 12 13 /*** * 日志级别 * @return * */ @Bean public Logger.Level feignLoggerLevel() { return Logger.Level.FULL; } Feign支持4中级别: NONE:不记录任何日志,默认值 BASIC:仅记录请求的方法,URL以及响应状态码和执行时间 HEADERS:在BASIC基础上,额外记录了请求和响应的头信息 FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据
3 在接口的@FeignClient中指定配置类
4 重启项目,测试访问
数据压缩 用户在网络请求过程中,如果网络不佳、传输数据过大,会造成体验差的问题,我们需要将传输数据压缩提升体验。SpringCloud OpenFeign支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。通过配置开启请求与响应的压缩功能,在openfeign的客户端配置,即hailtaxi-order 中
1 2 3 4 5 6 feign: compression: request: enabled: true # 开启请求压缩 response: enabled: true # 开启响应压缩
也可以对请求的数据类型,以及触发压缩的大小下限进行设置:
1 2 3 4 5 6 7 8 9 feign: compression: request: enabled: true # 开启请求压缩 mime-types: text/html,application/xml,application/json # 设置压缩的数据类 型 min-request-size: 2048 # 设置触发压缩的大小下限(表示小于2048,不需要压缩,大于2048,需要压缩) #以上数据类型,压缩大小下限均为默认值 response: enabled: true # 开启响应压缩
超时判定 超时判定是一种保障可用性的手段,如果你要调用的目标服务的RT(response Time)值非常高,那么你调用请求也会处于一个长时间挂起的状态。这是造成服务雪崩的一个重要因素。为了隔离下游接口调用超时所带来的影响,我们可以在程序中设置一个超时判定的阈值,一旦下游接口的响应时间超过了这个阈值,那么程序会自动取消此次调用并返回一个异常。
1 2 3 4 5 6 7 8 9 10 11 feign: client: config: # 全局默认配置 default: connectTimeout: 1000 readTimeout: 5000 # 针对某个特定服务的超时配置 hailtaxi-driver: connectTimeout: 1000 readTimeout: 2000
被调用方模拟处理业务长
效果:
调用方报错:
一般拿不到具体的信息,会配合服务降级处理,而不是直接看到报错
服务降级 降级逻辑是在远程服务调用发生超时或者异常(比如400,500error code)的时候,自动执行的一段业务逻辑.你可以根据具体的业务逻辑需要编写降级逻辑。比如执行一段兜底逻辑将服务请求从失败状态中恢复,或者发送一个失败通知到相关团队提醒它们来线上排查问题。
OpenFeign支持两种不同的方式来指定降级逻辑,一种是定义fallback类,另一种是定义fallback工厂
比如这里使用fallback工厂,编写DriverFeignFallBackFactory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Slf4j @Component public class DriverFeignFallBackFactory implements FallbackFactory<DriverFeign> { @Override public DriverFeign create(Throwable throwable) { return new DriverFeign() { @Override public Driver status(String id, Integer status) { log.info("走DriverFeignFallBackFactory----cause={}",throwable.getMessage()); return new Driver(); } }; } }
使用
1 2 3 4 5 6 @FeignClient(value = "hailtaxi-driver",fallbackFactory = DriverFeignFallBackFactory.class) // 服务名字 public interface DriverFeign { // 更新司机信息,该方法和hailtaxi-driver服务中的方法保持一致 @PutMapping(value = "/driver/status/{id}/{status}") public Driver status(@PathVariable(value = "id") String id, @PathVariable(value = "status") Integer status); }
hailtaxi-order还要开启hystrix
1 2 3 4 feign: ... hystrix: enabled: true
效果:
日志打印了,Driver类返回null(降级处理)
拦截器 用 Feign 来调用远程服务,比如远程服务的权限验证,需要在 header 中传递 token 之类的。在方法中显示传递又过于麻烦了,这时候就可以考虑使用Feign 提供的 RequestInterceptor 接口,只要实现了该接口,那么 Feign 每次做远程调用之前都可以被它拦截下来在进行包装
1、在 hailtaxi-api 中创建拦截器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Slf4j public class MyRequestInterceptor implements RequestInterceptor { @Override public void apply(RequestTemplate requestTemplate) { String url = requestTemplate.url(); Map<String, Collection<String>> headers = requestTemplate.headers(); String method = requestTemplate.method(); Map<String, Collection<String>> queries = requestTemplate.queries(); Request.Body body = requestTemplate.requestBody(); log.info("url={},headers={},method={},queries= {},body={}",url,headers,method,queries,body); //添加头信息 requestTemplate.header("GlobalId", UUID.randomUUID().toString()); } }
2、在 hailtaxi-order 中创建配置类,加入容器即可
1 2 3 4 5 6 7 8 @Configuration public class InterceptorConfiguration { @Bean public MyRequestInterceptor interceptor() { return new MyRequestInterceptor(); } }
测试!
order 传递了 globalID 给 driver
SpringCloud Ribbon 什么是Ribbon?
Ribbon是Netflix发布的负载均衡 器,有助于控制HTTP客户端行为。为Ribbon配置服务提供者地址列表后,Ribbon就可基于负载均衡算法,自动帮助服务消费者请求。
Ribbon默认提供的负载均衡算法:轮询,随机,重试法,加权。当然,我们可用自己定义负载均衡算法
使用:
1 2 3 1.在user-consumer工程中添加起步依赖 2.加一个注解@loadBalanced 3.修改调用的方式
Ribbon使用 业务分析:
如上图,当用户下单调用 hailtaxi-order 服务的时候,该服务会调用hailtaxi-driver ,此时如果是抢单过程,查询压力也会很大,我们可以为hailtaxi-driver 做集群,做集群只需要把工程复制多分即可,多个工程如下图:
简单的做法是在idea中将项目的启动配置复制一份出来,修改启动端口号
2)调用测试
此时我们执行:http://localhost:8001/order?token=zhangsan调用,可以发现已经实现负载均衡了, 18081 和 18085 , 18086 服务默认是轮询访问
Ribbon算法 我们上面没做任何相关操作,只是把服务换成了多个就实现了负载均衡,这是因为OpenFeign默认使用了Ribbon的轮询算法,如下图依赖包,引入OpenFeign的时候会传递依赖Ribbon包:
Ribbon支持多种负载均衡算法,我们可以按照自己的需求使用相关算法,在 hailtaxi-order 配置类中配置如下规则
1 2 3 4 5 6 7 8 9 10 11 // 负载均衡算法设置 @Bean //要交给容器管理 public IRule randomRule(){ //随机算法 return new RandomRule(); //重试算法 //return new RetryRule(); //加权法 //return new ZoneAvoidanceRule(); }
1 RoundRobinRule:轮询 RoundRobinRule 源码剖析
这里解决并发不是用的加锁,而是用的原子操作
2 RandomRule:随机算法
测试:http://localhost:8001/order?token=123456
RandomRule 源码剖析
3 RetryRule: 重试算法,该算法先按照轮询的策略获取服务,如果获取服务失败则在指定的 时间内会进行重试,获取可用的服务
源码剖析
4 ZoneAvoidanceRule 加权法,会根据平均响应时间计算所有服务的权重,响应时间越快服务权重越 大被选中的概率越大。刚启动时如果同统计信息不足,则使用轮询的策略,等统计信息足够会切换到自身规则。
Gateway使用Ribbon 在网关处,Gateway在进行路由调用微服务时,默认也采用了Ribbon的负载均衡策略,现检测如下:
1、启动两个 hailtaxi-order 如下:
2、在网关处的全局过滤器 RouterFilter 中打上断点,查看过滤器链,GatewayApplication 以 debug 模式启动
3、发送请求:http://localhost:8001/order?token=123456
4、断点查看:
5、查看:org.springframework.cloud.gateway.filter.LoadBalancerClientFilter
6、最终找到:org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient
SpringCloud Stream Spring Cloud Stream 是一个用来为微服务应用构建消息驱动能力的框架。它可以基于 Spring Boot 来创建独立的、可用于生产的 Spring 应用程序。 Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,并引入了发布-订阅、消费组、分区这三个核心概念。通过使用Spring Cloud Stream ,可以有效简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。目前 Spring Cloud Stream 支持 RabbitMQ 、 Kafka 自动化配置。
官方项目地址:https://spring.io/projects/spring-cloud-stream
SpringCloud Stream工作流程
通过Stream可以很好的屏蔽各个中间件的API差异,它统一了API,生产者通过OUTPUT向消息中间件发送消息,此时并不需要关心消息中间件是Kafka还 是RabbitMQ,不需要关注他们的API,只需要用到Stream的API,这样可以降低学习成本。消费方通过INPUT消费指定的消息,也不需要关注消息中间件的API,架构图如上图:
我们对上图中的对象进行说明
1 2 3 4 5 Application Core:生产者/消费者 inputs:消费者管道 outputs:生产者管道 binder:绑定器,主要和消息中间件之间进行绑定操作 Middleware:消息中间件服务
我们项目中真正用应用到Stream,只需要按照如上流程图操作即可。
1 2 3 4 5 6 7 8 生产者: 1:使用Source绑定消息输出通道。 2:通过MessageChannel输出消息。 3:通过@EnableBinding开启Binder,将生产者绑定到指定MQ服务。 消费者: 1:通过@EnableBinding绑定到指定MQ。 2:通过Sink绑定输入数据通道。 3:@StreamListener监听指定通道数据。
SpringCloud Stream实战
如上图,当用户行程结束,用户需进入支付操作,当用户支付完成时,我们需要更新订单状态,此时我们可以让支付系统将支付状态发送到MQ中,订单系统订阅MQ消息,根据MQ消息修改订单状态。我们将使用 SpringCloud Stream 实现该功能。
生产者 1)引入依赖
在 hailtaxi-pay 中引入依赖:
1 2 3 4 5 <!--stream--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency>
2)配置MQ服务
修改 hailtaxi-pay 的 application.yml 添加如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 spring: cloud: ... #Stream stream: binders: # 在此处配置要绑定的rabbitmq的服务信息; defaultRabbit: # 表示定义的名称,用于于binding整合 type: rabbit # 消息组件类型 environment: # 设置rabbitmq的相关的环境配置 spring: rabbitmq: host: 192.168.200.129 port: 5672 username: guest password: guest bindings: # 服务的整合处理 output: # 这个名字是一个通道的名称 destination: payExchange # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
3)消息输出管道绑定
创建 com.itheima.pay.mq.MessageSender 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 /*** * 消息发送【消息生产者】 */ @EnableBinding(Source.class) public class MessageSender { //发送消息的对象 @Resource private MessageChannel output; /*** * 发消息 */ public Boolean send(Object message){ return output.send((Message<Object>) MessageBuilder.withPayload(message).build()); } } Source.class:绑定一个输出消息通道Channel。 MessageChannel:消息发送对象,默认是 DirectWithAttributesChannel,发消息在AbstractMessageChannel 中完成。 MessageBuilder.withPayload:构建消息。
4)消息发送
在 com.itheima.pay.controller.TaxiPayController 中创建支付方法
用于发送消息,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @RestController @RequestMapping(value = "/pay") public class TaxiPayController { /*** * 对象实例已创建 * 在SpringIOC容器中 */ @Autowired private MessageSender messageSender; /*** * 支付 http://localhost:18083/pay/wxpay/1 * @return */ @GetMapping(value = "/wxpay/{id}") public TaxiPay pay(@PathVariable(value = "id")String id){ //支付操作 TaxiPay taxiPay = new TaxiPay("No"+(int)(Math.random()*1000000),id,310,3); //发送消息 messageSender.send(taxiPay); return taxiPay; } /*** * 查询指定订单支付状态 * @return */ @GetMapping(value = "/status/{id}") public TaxiPay status(@PathVariable(value = "id")String id){ TaxiPay taxiPay = new TaxiPay("No"+(int)(Math.random()*1000000),id,310,1); return taxiPay; } }
消费者 0)添加依赖
1)修改配置
修改 hailtaxi-order 的核心配置文件 application.yml ,在文件中配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #Stream stream: binders: # 在此处配置要绑定的rabbitmq的服务信息; defaultRabbit: # 表示定义的名称,用于于binding整合 type: rabbit # 消息组件类型 environment: # 设置rabbitmq的相关的环境配置 spring: rabbitmq: host: 192.168.200.129 port: 5672 username: guest password: guest bindings: # 服务的整合处理 input: # 这个名字是一个通道的名称 destination: payExchange # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: defaultRabbit
要监听的MQ信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @EnableBinding(Sink.class) public class MessageReceiver { @Value("${server.port}") private String port; /**** * 消息监听 * @param message */ @StreamListener(Sink.INPUT) public void receive(String message) { System.out.println("消息监听(增加用户积分、修改订单状态)-->" + message+"-->port:"+port); } } Sink.class:绑定消费者管道信息。 @StreamListener(Sink.INPUT):监听消息配置,指定了消息为 application中的input。
测试:http://localhost:18083/pay/wxpay/1
测试效果如下:
1 hailtaxi-order : 消息监听(增加用户积分、修改订单状态)--> {"outTradeNo":"1","money":310,"status":3}-->port:18082
消息分组 消息分组有2个好处,分别是集群合理消费、数据持久化。
集群消费下的分组 1)分组的意义
分组在项目中是有非常重大的意义,通常应用于消息并发高、消息堆积的场景,这些场景服务消费方通常会做集群操作,一旦做集群操作,我们又需要项目中的消费者合理消费,比如用户打车支付完成后,我们需要增加用户积分同时修改订单状态,如果集群环境中有2台服务器都执行该消费操作,此时用户积分会增加两次,就会造成非幂等问题。
此时集群中相同服务应该属于同一个组,同一个组中只允许有一个足节点消费某一个信息,这样就可以避免非幂等问题的出现。
2)分组实战
新增一个 hailtaxi-order 消费者节点
此时运行起来, 18082 和 18088 节点会同时消费所有数据。
修改 hailtaxi-order 的核心配置文件 application.yml ,添加分组:
此时再次测试,可以发现消费者不会重复消费数据。
数据持久化 我们把分组去掉,停掉 hailtaxi-order 服务,然后请求 http://localhost:18083/pay/wxpay/1 发送数据,发送完数据后,再启动 hailtaxi-order 服务,此时发现没有数据可以消费,这是因为数据没有持久化,是一种广播模式,如果需要数据持久化,得给每个消费节点添加group组即可。
Sleuth+Zipkin链路追踪
主要是为了生产上出问题快速定位问题。
在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面)然后通过远程调用,到达系统中间件B,C(负载均衡,网关等),最后达到后端服务D,E,后端经过一系列的业务逻辑计算最后将数据返回给用户,对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
Sleuth/Zipkin介绍 是一个开放源代码分布式的跟踪系统,它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示多少跟踪请求经过了哪些服务,该系统让开发者可通过一个web前端轻松地收集和分析数据,可非常方便的监测系统中存在的瓶颈。
它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示多少跟踪请求经过了哪些服务,该系统让开发者可通过一个web前端轻松地收集和分析数据,可非常方便的监测系统中存在的瓶颈
为服务之间的调用提供链路追踪,通过使用Sleuth可以让我们快速定位某个服务的问题。分布式服务追踪系统包括:数据收集、数据存储、数据展示。通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台不太方便查看。
将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin UI来展示信息。
SpringCloudSleuth有4个特点
Zipkin安装 关于zipkin在上面我们已经介绍了,我们接下来讲解zipkin的安装。
1)下载
下载地址:
下载后的文件 zipkin-server-2.12.9-exec.jar
2)运行
运行 zipkin-server-2.12.9-exec.jar
java -jar zipkin-server-2.12.9-exec.jar 回车即可运行,并访问http://localhost:9411/zipkin/
http://localhost:9411/zipkin/ 效果如下:
Sleuth链路监控 1)引入依赖
引入 zipkin ,它自身已经依赖了 sleuth ,在 parent 的 pom 中引入依赖包,如下:
1 2 3 4 5 6 <!--zipkin--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> <version>2.2.2.RELEASE</version> </dependency>
依赖关系如下图:
2)配置服务地址
修改 hailtaxi-order 的配置文件 applicatin.yml 添加如下配置:
1 2 3 4 5 6 7 spring: zipkin: #zipkin服务地址 base-url: http://localhost:9411 sleuth: sampler: probability: 1 #采样值,0~1之间,1表示全部信息都收集,值越大,效率越低
我们执行一次下单调用 http://localhost:8001/order ,再看zipkin控制台:
我们刚才调用的链路如下图:
调用链路如下分析:
1 2 1:调用了hailtaxi-order的POST->order()方法,该方法耗时333毫秒。 2:该方法调用了hailtaxi-driver的put /driver/status/{id}/{status}方法,耗时11毫秒。
分布式服务追踪系统包括:数据收集、数据存储、数据展示通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台不太方便查看。
Sleuth和Zipkin结合,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin UI来展示信息
会占用一部分性能,但是不会太多,采样是异步的
源码导入 1 2 3 4 5 1:Spring5.2.2源码 2:Spring-Cloud-Stream3.0.1源码 3:Spring-Cloud-Gateway2.2.1源码 4:Spring-Cloud-OpenFeign2.2.1源码 其他源码导入都比较简单,但唯独Spring5.2.2导入是比较麻烦的,需要配置Gradle而且IDEA和Gradle版本要匹配,我这里选的环境是 IDEA2020.3 和 Gradle5.4.6 ,这样的版本导入Spring源码就不费劲了。
Spring源码导入 这里注意,spring源码可在后续学习spring源码课程的时候再进行导入,此处不导入并不影响!!!
SpringCloud-Gateway源码导入 首先要下载SpringCloud-Gateway源码,下载地址https://github.com/spring-cloud/spring-cloud-gateway。下载源码后,在 资料 目录中已经提供了对应版本的源码包,可以直接将源码放到工程对应的目录下并导入:
1)导入
点击 + 号,再选择 import module
项目此时和hailtaxi-parent放在了同一个目录下,如下图:
项目以maven模板导入。
2)安装
导入后,一定要记得安装到本地,安装到本地后,在 hailtaxi 中找源码包的时候会直接跳转到该工程中,如下图:
注意:编译安装时最好跳过测试,跳过测试,跳过测试!!!
3)调试的时候设置hailtaxi-gateway健康检查时间,避免调试时间太长,影响调试
1 2 3 4 #2 分钟之后健康检查未通过取消注册 health-check-critical-timeout: 10m #consul 健康检查的轮询周期 health-check-interval: 1000s
Stream/OpenFeign源码导入 SpringCloud-Stream下载地址:https://github.com/spring-cloud/springcloud-stream/tree/v3.0.1.RELEASE
SpringCloud-OpenFeign下载地址:https://github.com/spring-cloud/spring-cloud-openfeign/tree/v2.2.1.RELEASE
关于SpringCloud-Stream和OpenFeign的源码导入是一样的操作,最主要记住放在同一个目录下,方便管理和一同打开(不放在同一个目录也能一同打开,但管理不方便)。
SpringCloud Gateway源码 通过前面的学习,我们知道SpringCloud Gateway是一个微服务网关,主要实现不同功能服务路由,关于SpringCloud Gateway的实战使用我们就告一段落,我们接下来深入学习SpringCloud Gateway源码。
Gateway工作流程源码剖析 Gateway工作流程分析
前面我们已经学习过Gateway的工作流程,如上工作流程图,我们回顾一下工作流程:
1:所有都将由ReactorHttpHandlerAdapter.apply()方法拦截处理,此 时会封装请求对象和响应对象,并传递到 HttpWebHandlerAdapter.handle()方法。
2:HttpWebHandlerAdapter.handle(),将request和response封装成上 下文对象ServerWebExchange,方法通过getDelegate()获取全局异常处 理器ExceptionHandlingWebHandler执行全局异常处理
3:ExceptionHandlingWebHandler执行完成后,调用 DispatcherHandler.handle(),循环所有handlerMappings查找处理当 前请求的Handler
4:找到Handler后调用DispatcherHandler.invokeHandler()执行找到 的Handler,此时会调用FilteringWebHandler.handle()
5:DefaultGatewayFilterChain.filter()是关键流程,所有过滤器都会 在这里执行,比如服务查找、负载均衡、远程调用等,都在这一块。
上面工作流程我们都是基于说的层面,接下来我们一层一层分析Gateway源码,深入学习Gateway。
Gateway工作流程源码 我们首先来看一下Gateway拦截处理所有请求的方法handle():
1 2 3 4 5 6 7 8 9 10 11 12 /**** *处理所有请求 ****/ @Override public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) { if (this.forwardedHeaderTransformer != null) { request = this.forwardedHeaderTransformer.apply(request); } //创建网关上下文对象 ServerWebExchange exchange = createExchange(request, response); LogFormatUtils.traceDebug(logger, traceOn -> exchange.getLogPrefix() + formatRequest(exchange.getRequest()) + (traceOn ? ", headers=" + formatHeaders(exchange.getRequest().getHeaders()) : "")); //getDelegate()获取当前的Handler return getDelegate().handle(exchange).doOnSuccess(aVoid -> logResponse(exchange)).onErrorResume(ex -> handleUnresolvedError(exchange, ex)).then(Mono.defer(response::setComplete)); }
上面getDelegate()方法源码如下:
1 2 3 4 5 6 /** * Return the wrapped delegate. * 返回WebHandler:处理web请求的对象 */ public WebHandler getDelegate() { return this.delegate; }
我们进行Debug测试如下:
当前返回的WebHandler是 ExceptionHandlingWebHandler ,而ExceptionHandlingWebHandler 的delegate是 FilteringWebHandler ,而FilteringWebHandler 的delegate是 delegate 是 DispatcherHandler ,所有的delegate的 handle() 方法都会依次执行,我们可以把断点放到DispatcherHandler.handler() 方法上:
handler()方法会调用所有handlerMappings的 getHandler(exchange) 方法,而 getHandler(exchange) 方法会调用 getHandlerInternal(exchange)方法:
getHandlerInternal(exchange) 该方法由各个 HandlerMapping 自行实现,我们可以观察下断言处理的 RoutePredicateHandlerMapping 的 getHandlerInternal(exchange) 方法会调用lookupRoute方法,该方法用于返回对应的路由信息:
这里的路由匹配其实就是我们项目中对应路由配置的一个一个服务的信息,这些服务信息可以帮我们找到我们要调用的真实服务:
每个Route对象如下:
Route的DEBUG数据如下:
找到对应Route后会返回指定的FilterWebHandler,如下代码:
FilterWebHandler主要包含了所有的过滤器,过滤器按照一定顺序排序,主要是order值,越小越靠前排,过滤器中主要将请求交给指定真实服务处理了,debug测试如下
这里有 RouteToRequestUrlFilter 和 ForwardRoutingFilter 以及LoadBalancerClientFilter 等多个过滤器。
请求处理 在上面FilterWebHandler中有2个过滤器,分别为RouteToRequestUrlFilter 和 ForwardRoutingFilter 。
RouteToRequestUrlFilter :用于根据匹配 的 Route,计算请求地址得到lb://hailtaxi-order/order/list
ForwardRoutingFilter :转发路由网关过滤器。其根据 forward:// 前缀(Scheme )过滤处理,将请求转发到当前网关实例本地接口
RouteToRequestUrlFilter真实服务查找 RouteToRequestUrlFilter源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 /** * 真实服务查找 * @param exchange the current server exchange * @param chain provides a way to delegate to the next filter * @return */ @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { Route route = exchange.getAttribute(GATEWAY_ROUTE_ATTR); //获取当前的route if (route == null) { return chain.filter(exchange); } log.trace("RouteToRequestUrlFilter start"); //得到uri = http://localhost:8001/driver/info/1?token=123456 URI uri = exchange.getRequest().getURI(); boolean encoded = containsEncodedParts(uri); URI routeUri = route.getUri(); // lb://hailtaxi-driver if (hasAnotherScheme(routeUri)) { // this is a special url, save scheme to special attribute // replace routeUri with schemeSpecificPart exchange.getAttributes().put(GATEWAY_SCHEME_PREFIX_ATTR, routeUri.getScheme()); routeUri = URI.create(routeUri.getSchemeSpecificPart()); } if ("lb".equalsIgnoreCase(routeUri.getScheme()) && routeUri.getHost() == null) { // Load balanced URIs should always have a host. If the host is null it is // most // likely because the host name was invalid (for example included an // underscore) throw new IllegalStateException("Invalid host: " + routeUri.toString()); } //将uri换成 lb://hailtaxi-driver/driver/info/1?token=123456 URI mergedUrl = UriComponentsBuilder.fromUri(uri) // .uri(routeUri) .scheme(routeUri.getScheme()).host(routeUri.getHost()) .port(routeUri.getPort()).build(encoded).toUri(); exchange.getAttributes().put(GATEWAY_REQUEST_URL_ATTR, mergedUrl); // 继续下一个过滤器 return chain.filter(exchange); }
debug调试结果如下:
从上面调试结果我们可以看到所选择的Route以及uri和routeUri和mergedUrl,该过滤器其实就是将用户请求的地址换成服务地址,换成服务地址可以用来做负载均衡。
问题:
自定义GatewayFilter不生效
服务老是挂掉。OperationException(statusCode=500, statusMessage=’Internal Server Error’, statusContent=’rpc error getting client: failed to get conn: rpc error: lead thread didn’t get connection’)
NettyRoutingFilter远程调用 SpringCloud在实现对后端服务远程调用是基于Netty发送Http请求实现,核心代码在 NettyRoutingFilter.filter() 中,其中核心代码为send()方法,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 /** * 通过netty 实现远程调用,采用http请求 * @param exchange the current server exchange * @param chain provides a way to delegate to the next filter * @return */ @Override @SuppressWarnings("Duplicates") public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { URI requestUrl = exchange.getRequiredAttribute(GATEWAY_REQUEST_URL_ATTR); String scheme = requestUrl.getScheme(); if (isAlreadyRouted(exchange) || (!"http".equals(scheme) && !"https".equals(scheme))) { return chain.filter(exchange); } setAlreadyRouted(exchange); ServerHttpRequest request = exchange.getRequest(); final HttpMethod method = HttpMethod.valueOf(request.getMethodValue()); final String url = requestUrl.toASCIIString(); HttpHeaders filtered = filterRequest(getHeadersFilters(), exchange); final DefaultHttpHeaders httpHeaders = new DefaultHttpHeaders(); filtered.forEach(httpHeaders::set); boolean preserveHost = exchange .getAttributeOrDefault(PRESERVE_HOST_HEADER_ATTRIBUTE, false); Route route = exchange.getAttribute(GATEWAY_ROUTE_ATTR); Flux<HttpClientResponse> responseFlux = httpClientWithTimeoutFrom(route) .headers(headers -> { // 请求头信息设置 headers.add(httpHeaders); // Will either be set below, or later by Netty headers.remove(HttpHeaders.HOST); if (preserveHost) { String host = request.getHeaders().getFirst(HttpHeaders.HOST); headers.add(HttpHeaders.HOST, host); } }).request(method).uri(url).send((req, nettyOutbound) -> { // 发送数据 if (log.isTraceEnabled()) { nettyOutbound .withConnection(connection -> log.trace("outbound route: " + connection.channel().id().asShortText() + ", inbound: " + exchange.getLogPrefix())); } return nettyOutbound.send(request.getBody() .map(dataBuffer -> ((NettyDataBuffer) dataBuffer) .getNativeBuffer())); }).responseConnection((res, connection) -> { // Defer committing the response until all route filters have run // Put client response as ServerWebExchange attribute and write // response later NettyWriteResponseFilter exchange.getAttributes().put(CLIENT_RESPONSE_ATTR, res); exchange.getAttributes().put(CLIENT_RESPONSE_CONN_ATTR, connection); ServerHttpResponse response = exchange.getResponse(); // put headers and status so filters can modify the response HttpHeaders headers = new HttpHeaders(); res.responseHeaders().forEach( entry -> headers.add(entry.getKey(), entry.getValue())); String contentTypeValue = headers.getFirst(HttpHeaders.CONTENT_TYPE); if (StringUtils.hasLength(contentTypeValue)) { exchange.getAttributes().put(ORIGINAL_RESPONSE_CONTENT_TYPE_ATTR, contentTypeValue); } setResponseStatus(res, response); // make sure headers filters run after setting status so it is // available in response HttpHeaders filteredResponseHeaders = HttpHeadersFilter.filter( getHeadersFilters(), headers, exchange, Type.RESPONSE); if (!filteredResponseHeaders .containsKey(HttpHeaders.TRANSFER_ENCODING) && filteredResponseHeaders .containsKey(HttpHeaders.CONTENT_LENGTH)) { // It is not valid to have both the transfer-encoding header and // the content-length header. // Remove the transfer-encoding header in the response if the // content-length header is present. response.getHeaders().remove(HttpHeaders.TRANSFER_ENCODING); } exchange.getAttributes().put(CLIENT_RESPONSE_HEADER_NAMES, filteredResponseHeaders.keySet()); response.getHeaders().putAll(filteredResponseHeaders); return Mono.just(res); }); Duration responseTimeout = getResponseTimeout(route); if (responseTimeout != null) { responseFlux = responseFlux .timeout(responseTimeout, Mono.error(new TimeoutException( "Response took longer than timeout: " + responseTimeout))) .onErrorMap(TimeoutException.class, th -> new ResponseStatusException(HttpStatus.GATEWAY_TIMEOUT, th.getMessage(), th)); } return responseFlux.then(chain.filter(exchange)); }
上面send方法最终会调用 ChannelOperations>send() 方法,而该方法其实是基于了Netty实现数据发送,核心代码如下:
Netty特性
Netty是一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,他的并发性能得到了很大提高,对比于BIO(Blocking I/O,阻塞IO),隐藏其背后的复杂性而提供一个易于使用的 API 的客户端/服务器框架。Netty 是一个广泛使用的 Java 网络编程框架。
传输极快
Netty的传输快其实也是依赖了NIO的一个特性——零拷贝。我们知道,Java的内存有堆内存、栈内存和字符串常量池等等,其中堆内存是占用内存空间最大的一块,也是Java对象存放的地方,一般我们的数据如果需要从IO读取到堆内存,中间需要经过Socket缓冲区,也就是说一个数据会被拷贝两次才能到达他的的终点,如果数据量大,就会造成不必要的资源浪费。
Netty针对这种情况,使用了NIO中的另一大特性——零拷贝,当他需要接收数据的时候,他会在堆内存之外开辟一块内存,数据就直接从IO读到了那块内存中去,在netty里面通过ByteBuf可以直接对这些数据进行直接操作,从而加快了传输速度。
良好的封装
Netty无论是性能还是封装性都远远超越传统Socket编程
Channel:表示一个连接,可以理解为每一个请求,就是一个Channel。
ChannelHandler:核心处理业务就在这里,用于处理业务请求。
ChannelHandlerContext:用于传输业务数据。
ChannelPipeline:用于保存处理过程需要用到的ChannelHandler和ChannelHandlerContext。
ByteBuf是一个存储字节的容器,最大特点就是使用方便,它既有自己的读索引和写索引,方便你对整段字节缓存进行读写,也支持get/set,方便你对其中每一个字节进行读写,他的数据结构如下图所示:
Gateway负载均衡源码剖析 前面源码剖析主要剖析了Gateway的工作流程,我们接下来剖析Gateway的负载均衡流程。在最后的过滤器集合中有 LoadBalancerClientFilter 过滤器,该过滤器是用于实现负载均衡
地址转换
LoadBalancerClientFilter 过滤器首先会将用户请求地址转换成真实服务地址,也就是IP:端口号,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Override @SuppressWarnings("Duplicates") public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { URI url = exchange.getAttribute(GATEWAY_REQUEST_URL_ATTR); // url:lb://hailtaxi-driver/driver/info/1?token=123456 String schemePrefix = exchange.getAttribute(GATEWAY_SCHEME_PREFIX_ATTR); if (url == null || (!"lb".equals(url.getScheme()) && !"lb".equals(schemePrefix))) { return chain.filter(exchange); } // preserve the original url addOriginalRequestUrl(exchange, url); if (log.isTraceEnabled()) { log.trace("LoadBalancerClientFilter url before: " + url); } // 负载均衡选择服务实例 final ServiceInstance instance = choose(exchange); if (instance == null) { throw NotFoundException.create(properties.isUse404(), "Unable to find instance for " + url.getHost()); } //用户提交的URI = http://localhost:8001/driver/info/1?token=123456 URI uri = exchange.getRequest().getURI(); // if the `lb:<scheme>` mechanism was used, use `<scheme>` as the default, // if the loadbalancer doesn't provide one. String overrideScheme = instance.isSecure() ? "https" : "http"; if (schemePrefix != null) { overrideScheme = url.getScheme(); } // 真正要请求的url = http://172.16.17.251:18081/driver/info/1?token=123456 URI requestUrl = loadBalancer.reconstructURI( new DelegatingServiceInstance(instance, overrideScheme), uri); if (log.isTraceEnabled()) { log.trace("LoadBalancerClientFilter url chosen: " + requestUrl); } // 将真正要请求的url设置到上下文中 exchange.getAttributes().put(GATEWAY_REQUEST_URL_ATTR, requestUrl); return chain.filter(exchange); }
负载均衡服务选择
上面代码的关键是 choose(exchange) 的调用,该方法调用其实就是选择指定服务,这里涉及到负载均衡服务轮询调用算法等,我们可以跟踪进去查看方法执行流程
Gateway自身已经集成Ribbon,所以看到的对象是RibbonLoadBalancerClient,我们跟踪进去接着查看:
上面方法会依次调用到getInstance()方法,该方法会返回所有可用实例,有可能有多个实例,如果有多个实例就涉及到负载均衡算法,方法调用如下图
此时调用getServer()方法,再调用BaseLoadBalancer.chooseServer() ,这里是根据指定算法获取对应实例,代码如下:
BaseLoadBalancer 是属于Ribbon的算法,我们可以通过如下依赖包了解,并且该算法默认用的是 RoundRobinRule ,也就是随机算法,如下代码
以下侧重图解 相关技术栈
了解以下技术,学习 gateway 会更加容易
1、project reactor,遵循 Reactive Streams Specification,使用非阻塞编程模型。
2、webflux,基于 spring 5.x 和 reactor-netty 构建,不依赖于 Servlet 容器,但是可以在支持 Servlet 3.1 Non-Blocking IO API 的容器上运行。
初始化 自动装配:springcloud是基于springboot的,gateway各个组件的初始化入口在自动装配。
1、GatewayClassPathWarningAutoConfiguration
2、GatewayAutoConfiguration
2.1、 网关的开启与关闭
2.2、 初始化 NettyConfiguration
2.3 、初始化 GlobalFilter
2.4 、初始化 FilteringWebHandler
2.5 、初始化 GatewayProperties
2.6 、初始化 PrefixPathGatewayFilterFactory
2.7 、初始化 RoutePredicateFactory
2.8 、初始化 RouteDefinitionLocator
2.9 、初始化 RouteLocator
2.10、 初始化 RoutePredicateHandlerMapping
2.11 、初始化 GatewayWebfluxEndpoint
3、GatewayLoadBalancerClientAutoConfiguration
4、GatewayRedisAutoConfiguration
Gateway 工作机制
1、Gateway 接收客户端请求。
2、客户端请求与路由信息进行匹配 ,匹配成功的才能够被路由转发 到相应的下游服务。
3、请求经过 Filter 过滤器 链,执行 pre 处理逻辑,如修改请求头信息等。
4、请求被转发至下游服务并返回响应。
5、响应经过 Filter 过滤器链,执行 post 处理逻辑。
6、向客户端响应应答。
核心组件 gateway的三个核心组件是:
1、Route,
2、RoutePredicate,
3、GatewayFilter
请求处理流程
我们主要通过跟踪源码,验证请求->dispatcherhandler->routePredicate->filter的过程
API GATEWAY - 入口 spring-web:ReactorHttpHandlerAdapter.apply
spring-web:HttpWebHandlerAdapter.handle
我们首先来看一下Gateway拦截处理所有请求的方法handle():
这里断点打到web层了,太深了,要懂reator编程,我们先从DispatcherHandler看就好了
API GATEWAY - DispatcherHandler spring-webflux:DispatcherHandler.handle
我们这里比较关系RoutePredicateHandlerMapping
API GATEWAY - RoutePredicateHandlerMapping 跟踪mapping.gethandler到=>
gateway:RoutePredicateHandlerMapping.getHandler—>getHandlerInternal
RoutePredicateHandlerMapping.getHandler 在父类 org.springframework.web.reactive.handler.AbstractHandlerMapping#getHandler
gateway:RoutePredicateHandlerMapping.lookupRoute
gateway:RoutePredicateHandlerMapping 路由断言,执行指定的RouteRredicate
gateway:AbstractHandlerMapping#getHandler 获得handler之后
最终获得的handler是FilteringWebHandler,里面包含了globalFilters
API GATEWAY - invokeHandler
spring-webflux:DispatcherHandler.handle,2:invokeHandler
gateway:FilteringWebHandler.handle
这里就用责任链了
gateway:FilteringWebHandler.DefaultGatewayFilterChain(内部类)#filter
这里我们关注RouteToRequestUrlFilter就行了,看gateway怎么将请求真正转发到对应的url
API GATEWAY - RouteToRequestUrlFilter
拿到mergeUrl给下个过滤器,还要替换为具体的ip端口
API GATEWAY - LoadBalancerClientFilter
gateway:请求处理,所有Filter执行;2、LoadBalancerClientFilter负载均衡
这里就拿到真正的请求了
API GATEWAY - NettyRoutingFilter
gateway:请求处理,所有Filter执行;3、NettyRoutingFilter远程调用
SpringCloud OpenFeign源码 openfeign 基础模型 1、对于使用openfeign而言,我们将对服务的http调用转换成对接口方法的调用。涉及的相关技术栈有:代理,http请求响应……..
feign的核心功能就是通过接口去访问网络资源,里面也是用动态代理来实现的,就跟Mybatis用接口去访问数据库一样,我们就来看下源码的处理,核心就一个包
注解处理 - @EnableFeignClients 使用OpenFeign的时候会用到2个注解,分别是 @FeignClient(value = “hailtaxi-driver”) 和 @EnableFeignClients(basePackages = “com.itheima.driver.feign”) ,这两个注解其实就是学习OpenFeign的入口。
@EnableFeignClients 这 个注解的作用其实就是开启了一个FeignClient 的扫描,那么点击启动类的 @EnableFeignClients 注解看下他是怎么开启 FeignClient 的扫描的,进去后发现里面有个@Import(FeignClientsRegistrar.class),这个FeignClientsRegistrar跟Bean的动态装载有关。
1 2 3 4 5 @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Documented @Import(FeignClientsRegistrar.class) // 开启了 `FeignClient`扫描 public @interface EnableFeignClients {
启动扫描feign接口并注册
扫描feign接口获得bean定义,1、FeignClientsRegistrar#registerBeanDefinitions
FeignClientsRegistrar类中有一个方法 registerBeanDefinitions 用于注入Bean的,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /** * bean注入的 入口函数 * @param metadata * @param registry */ @Override public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { // SpringBoot启动类上检查是否有@EnableFeignClients, 有该注解, 则完成 Feign 框架相关的配置注册 registerDefaultConfiguration(metadata, registry); // 注册由 @FeignClient 修饰的接口 bean *****核心***** // 从 classpath 中, 扫描获得 @FeignClient 修饰的类, 将类 的内容解析为 BeanDefifinition , // 最终通过调用 Spring 框架中的 BeanDefifinitionReaderUtils.resgisterBeanDefifinition // 将解析处理过的 FeignClientBeanDeififinition 添加到 spring 容器中. registerFeignClients(metadata, registry); }
扫描feign接口获得bean定义,2、FeignClientsRegistrar#registerFeignClients
我们主要关注 registerFeignClients() 方法,该方法会通过解析@EnableFeignClients 并解析 @FeignClient 实现Feign的注册,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 /** * 向容器中注册由 @FeignClient 修饰的接口bean * @param metadata 包含了@EnableFeignClients 注解的元信息 * @param registry */ public void registerFeignClients(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { // ClassPath Scanner // ClassPath的条件扫描组件提供者 ClassPathScanningCandidateComponentProvider scanner = getScanner(); // 设置资源加载器 scanner.setResourceLoader(this.resourceLoader); // 接收 @EnableFeignClients(basePackages = {"com.itheima.driver.feign"}) // 要扫描的包(@EnableFeignClients注解上添的那个) Set<String> basePackages; // 获取注解上的配置 Map<String, Object> attrs = metadata.getAnnotationAttributes(EnableFeignClients.class.getName()); // 注解过滤器,设置只过滤出FeignClient注解标识的Bean AnnotationTypeFilter annotationTypeFilter = new AnnotationTypeFilter(FeignClient.class); final Class<?>[] clients = attrs == null ? null : (Class<?>[]) attrs.get("clients"); if (clients == null || clients.length == 0) { // 扫描器设置过滤器 scanner.addIncludeFilter(annotationTypeFilter); // 获取 @EnableFeignClients中配置的 @FeignClient 接口扫描路径 basePackages = getBasePackages(metadata); }else { final Set<String> clientClasses = new HashSet<>(); basePackages = new HashSet<>(); for (Class<?> clazz : clients) { basePackages.add(ClassUtils.getPackageName(clazz)); clientClasses.add(clazz.getCanonicalName()); } AbstractClassTestingTypeFilter filter = new AbstractClassTestingTypeFilter() { @Override protected boolean match(ClassMetadata metadata) { // 将类名上的[$]替换成[.] String cleaned = metadata.getClassName().replaceAll("\\$", "."); return clientClasses.contains(cleaned); } }; scanner.addIncludeFilter( new AllTypeFilter(Arrays.asList(filter, annotationTypeFilter))); } // 拿到 @EnableFeignClients 中配置的 @FeignClient 接口扫描路径 后开始 扫描 // 循环所有要解析的Feign的包 for (String basePackage : basePackages) { // 查找 basePackage 包路径下所有 由 @FeignClient 修饰的候选bean,返回其 BeanDefinition 的集合 Set<BeanDefinition> candidateComponents = scanner.findCandidateComponents(basePackage); // 针对每个标注了 @FeignClient 的候选 BeanDefinition (接口的BeanDefinition) 准备向容器中注册 for (BeanDefinition candidateComponent : candidateComponents) { // 扫描的Bean是否是AnnotatedBeanDefinition的子类 if (candidateComponent instanceof AnnotatedBeanDefinition) { // verify annotated class is an interface AnnotatedBeanDefinition beanDefinition = (AnnotatedBeanDefinition) candidateComponent; // 获取beanDefinition的元数据,你想要的他基本都有 AnnotationMetadata annotationMetadata = beanDefinition.getMetadata(); // 验证@FeignClient修饰的必须是接口 Assert.isTrue(annotationMetadata.isInterface(),"@FeignClient can only be specified on an interface");// @FeignClient标注的必须是接口 // 获取 @FeignClient 注解的相关属性信息 Map<String, Object> attributes = annotationMetadata.getAnnotationAttributes(FeignClient.class.getCanonicalName()); // 获取@FeignClient(value = "hailtaxi-driver"),name属性,name属性和value属性是相同的含义,都是配置服务名 // 获取客户端名称 String name = getClientName(attributes);// name = hailtaxi-driver // 为FeignClient指定配置类 registerClientConfiguration(registry, name, attributes.get("configuration")); // 针对当前标注了 @FeignClient 注解的候选接口 BeanDefinition 向容器中注册bean信息 // 注册客户端 registerFeignClient(registry, annotationMetadata, attributes); } } } }
向容器中注册接口bean,1、FeignClientsRegistrar#registerFeignClient
上面注解解析后,会调用 registerFeignClient() 注册客户端,我们来看下 registerFeignClient() 方法具体实现流程,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 /** * 向容器中注册 每个标注了 @FeignClient 的接口bean * @param registry * @param annotationMetadata * @param attributes */ private void registerFeignClient(BeanDefinitionRegistry registry, AnnotationMetadata annotationMetadata, Map<String, Object> attributes) { // 接口全路径 // 被@FeignClient修饰的类名,比如 com.itheima.DriverFeign,是自己定义的接口 String className = annotationMetadata.getClassName();// className=com.itheima.driver.feign.DriverFeign /** * 每个标注了@FeignClient 的接口,真正向容器中注册的其实是一个 FeignClientFactoryBean * 1、创建 FeignClientFactoryBean的 BeanDefinition * 2、向 BeanDefinition 中填充相关属性,属性来源于接口上@FeignClient的属性信息 */ // BeanDefinitionBuilder通过FeignClientFactoryBean这个 类来生成BeanDefinition BeanDefinitionBuilder definition = BeanDefinitionBuilder.genericBeanDefinition(FeignClientFactoryBean.class); validate(attributes);// 验证fallback和fallbackFactory是不是接口 // 通过BeanDefinitionBuilder给beanDefinition增加属性 definition.addPropertyValue("url", getUrl(attributes)); definition.addPropertyValue("path", getPath(attributes)); String name = getName(attributes); definition.addPropertyValue("name", name); String contextId = getContextId(attributes); definition.addPropertyValue("contextId", contextId); definition.addPropertyValue("type", className); // 把接口全路径也设置到 definition definition.addPropertyValue("decode404", attributes.get("decode404")); definition.addPropertyValue("fallback", attributes.get("fallback")); definition.addPropertyValue("fallbackFactory", attributes.get("fallbackFactory")); definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE); String alias = contextId + "FeignClient"; // 用Builder获取实际的BeanDefinition AbstractBeanDefinition beanDefinition = definition.getBeanDefinition(); boolean primary = (Boolean) attributes.get("primary"); // has a default, won't be null beanDefinition.setPrimary(primary); String qualifier = getQualifier(attributes); if (StringUtils.hasText(qualifier)) { alias = qualifier; } // 创建一个Bean定义的持有者 BeanDefinitionHolder holder = new BeanDefinitionHolder(beanDefinition, className,new String[] { alias }); // 这里就是将Bean注册到Spring容器中 BeanDefinitionReaderUtils.registerBeanDefinition(holder, registry); /** * 由于标注了@FeignClient的每个接口真正向容器中注册时注册的是与该接口相关的:FeignClientFactoryBean * 而 FeignClientFactoryBean 实现了 FactoryBean 接口,也就是说当需要从容器中获取 这个bean时,获取出来的bean其实是由它的getObject方法返回的bean * * 所以:下一个入口是: FeignClientFactoryBean#getObject */ }
Feign代理注册 上面方法中创建 BeanDefinitionBuilder 的时候传入了一个参数FeignClientFactoryBean.class ,注册的Bean就是参数中自己传进来的beanClass是工厂Bean,可以用来创建Feign的代理对象,我们来看一下FeignClientFactoryBean 源码,可以发现它实现了FactoryBean,所以它可以获取对象实例,同时也能创建对象的代理对象,部分源码如下:
从容器中获取代理对象,1、FeignClientFactoryBean#getObject
它里面有一个方法 getObject() ,该方法就是用于返回一个对象实例,而对象其实是代理对象,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 /** * 代理创建的入口,返回接口真正的实例 * @return * @throws Exception */ @Override public Object getObject() throws Exception { return getTarget(); } /** * @param <T> the target type of the Feign client * @return a {@link Feign} client created with the specified data and the context * information */ <T> T getTarget() { /** * FeignContext注册到容器是在 FeignAutoConfiguration 上完成的; 在初始化FeignContext时,会把 configurations 放入FeignContext中。 * configurations 的来源就是在前面 registerFeignClients 方法中 @FeignClient的配置 configuration。 */ FeignContext context = this.applicationContext.getBean(FeignContext.class); //构建出Builder对象 用于构造代理对象,builder将会构建出 feign 的代理, Feign.Builder builder = feign(context);// builder= Feign$Builder //如果url为空,则走负载均衡,生成有负载均衡功能的代理类 if (!StringUtils.hasText(this.url)) { // 没在@FigenClient注解中配 url if (!this.name.startsWith("http")) { this.url = "http://" + this.name; }else { this.url = this.name; } this.url += cleanPath(); // this.url= http://hailtaxi-driver /** * HardCodedTarget里封装了:接口type Class,服务名称,服务地址url ; 根据 Feign.Builder ,FeignContext,HardCodedTarget 构建 返回的对象 */ return (T) loadBalance(builder, context, new HardCodedTarget<>(this.type, this.name, this.url)); } //如果指定了url,则生成默认的代理类 if (StringUtils.hasText(this.url) && !this.url.startsWith("http")) { this.url = "http://" + this.url; } String url = this.url + cleanPath(); Client client = getOptional(context, Client.class); if (client != null) { if (client instanceof LoadBalancerFeignClient) { // not load balancing because we have a url, // but ribbon is on the classpath, so unwrap client = ((LoadBalancerFeignClient) client).getDelegate(); } if (client instanceof FeignBlockingLoadBalancerClient) { // not load balancing because we have a url, // but Spring Cloud LoadBalancer is on the classpath, so unwrap client = ((FeignBlockingLoadBalancerClient) client).getDelegate(); } builder.client(client); } //生成默认代理类 Targeter targeter = get(context, Targeter.class); return (T) targeter.target(this, builder, context, new HardCodedTarget<>(this.type, this.name, url)); }
Builder对象 上面片段代码中 Feign.Builder builder = feign(context) 是用于构建Builder,关于Builder源码属性我们进行详细讲解,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static class Builder { //这个就是拦截器,可以在请求之前设置请求头、设置请求体、设置参 数、设置url等等,类型是:RequestInterceptor: private final List<RequestInterceptor> requestInterceptors = new ArrayList(); //日志等级 private Level logLevel; //默认是Contract.Default(),它主要是用来解析feign接口上的 那些注解,比如:@QueryMap、@Param、@RequestLine、@Header、 @Body、@HeaderMap等,比如@Header操作,可以把 @Header(“name=value”)这里面的name=value取出来,重新设置到 RequestTemplate里面。 private Contract contract; //client是真正去执行request,得到response的客户端,它的入参 是一个Request,这个Request是用RequestTemplate构造出来的。 private Client client; private Retryer retryer; private Logger logger; //encoder是用来编码请求的,默认能处理String和byte[]数组类型 的参数,最终是存放在RequestTemplate里面 private Encoder encoder; //decoder用来解码响应,默认可以返回字节数组和字符串。 private Decoder decoder; private QueryMapEncoder queryMapEncoder; //异常处理 private ErrorDecoder errorDecoder; private Options options; //就是在这里面创建的动态代理类。当客户端调用Feign.builder() 的时候,其实就是去设置builder里面的这些参数的值。 private InvocationHandlerFactory invocationHandlerFactory; private boolean decode404; private boolean closeAfterDecode; private ExceptionPropagationPolicy propagationPolicy; }
builder构建如下方法(FeignClientFactoryBean中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 构建Builder独享 protected Feign.Builder feign(FeignContext context) { FeignLoggerFactory loggerFactory = get(context, FeignLoggerFactory.class); Logger logger = loggerFactory.create(this.type); // @formatter:off Feign.Builder builder = get(context, Feign.Builder.class) // required values .logger(logger) // 设置日志 .encoder(get(context, Encoder.class)) // 编码设置 .decoder(get(context, Decoder.class)) // 解码设置 .contract(get(context, Contract.class)); // @formatter:on configureFeign(context, builder); return builder; }
Feign代理创建 上面的builder构造完后继续向下走,配置完Feign.Builder之后,再判断是否需要LoadBalance,如果需要,则通过loadBalance(builder, context,newHardCodedTarget<>(this.type, this.name, this.url));的方法来设置。实际上他们最终调用的是Target.target()方法。
从容器中获取代理对象,2、FeignClientFactoryBean#loadBalance
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 protected <T> T loadBalance(Feign.Builder builder, FeignContext context, HardCodedTarget<T> target) { // 获取feign 客户端,得到的是:LoadBalancerFeignClient loadbalance基于 RibbonLoadBalanced 用于执行http请求 Client client = getOptional(context, Client.class); if (client != null) { // 将 feign 的 Client 对象设置进 Feign.Builder,相当于增加了客户端负载均衡解析的机制 builder.client(client); // Targeter默认是 HystrixTargeter 在 FeignAutoConfiguration 中有配置 Targeter targeter = get(context, Targeter.class); /** * 实例创建(开启熔断后具有熔断降级效果) * this= FeignClientFactoryBean * builder= Feign$Builder * context = FeignContext * target = HardCodedTarget */ return targeter.target(this, builder, context, target); } throw new IllegalStateException( "No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-netflix-ribbon?"); }
上面方法会调用 targeter.target(this, builder, context, target); ,它支持服务熔断降级,我们直接看默认的 DefaultTrageter 就可以了
DefaultTargeter 的 target() 方法是一个非常简单的调用,但开启了Feign代理对象创建的开始:
从容器中获取代理对象,3、HystrixTargeter#target—>4、Feign.Builder#target
target 方法调用了build().newInstance(),这个方法信息量比较大,我们要拆分这看 build() 和 newInstance(target) :
1 2 3 public <T> T target(Target<T> target) { return build().newInstance(target); }
build()方法是创建客户端对象 ReflectiveFeign ,看着名字就像代理的意思,源码如下:(Feign.class)
1 2 3 4 5 6 7 8 // 就是构造Feign客户端对象ReflectiveFeign,并且添加默认值, // 注意下synchronousMethodHandlerFactory创建出来的 MethodHandler的类型是SynchronousMethodHandler。 // handlersByName可以把feign接口解析成Map<String, MethodHandler>。 public Feign build() { Factory synchronousMethodHandlerFactory = new Factory(this.client, this.retryer, this.requestInterceptors, this.logger, this.logLevel, this.decode404, this.closeAfterDecode, this.propagationPolicy); ParseHandlersByName handlersByName = new ParseHandlersByName(this.contract, this.options, this.encoder, this.decoder, this.queryMapEncoder, this.errorDecoder, synchronousMethodHandlerFactory); return new ReflectiveFeign(handlersByName, this.invocationHandlerFactory, this.queryMapEncoder); }
我们再来看 ReflectiveFeign ,它继承了 Feign 同时也有一个属性InvocationHandlerFactory ,该对象其实就是代理工厂对象,源码如下:
ReflectiveFeign 源码:
InvocationHandlerFactory 源码:
从容器中获取代理对象,4、Feign.Builder#build
我们再来看 newInstance(Target<T> target) 方法,该方法就是用来创建Feign的代理对象,源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public <T> T newInstance(Target<T> target) { ///根据接口类和Contract协议解析方式,解析接口类上的方法和注 解,转换成内部的MethodHandler处理方式 Map<String, MethodHandler> nameToHandler = this.targetToHandlersByName.apply(target); Map<Method, MethodHandler> methodToHandler = new LinkedHashMap(); List<DefaultMethodHandler> defaultMethodHandlers = new LinkedList(); Method[] var5 = target.type().getMethods(); int var6 = var5.length; for(int var7 = 0; var7 < var6; ++var7) { Method method = var5[var7]; if (method.getDeclaringClass() != Object.class) { if (Util.isDefault(method)) { DefaultMethodHandler handler = new DefaultMethodHandler(method); defaultMethodHandlers.add(handler); methodToHandler.put(method, handler); } else { methodToHandler.put(method, nameToHandler.get(Feign.configKey(target.type(), method))); } } } // 基于Proxy.newProxyInstance 为接口类创建动态实现,将所有 的请求转换给InvocationHandler 处理 InvocationHandler handler = this.factory.create(target, methodToHandler); T proxy = Proxy.newProxyInstance(target.type().getClassLoader(), new Class[]{target.type()}, handler); Iterator var12 = defaultMethodHandlers.iterator(); while(var12.hasNext()) { DefaultMethodHandler defaultMethodHandler = (DefaultMethodHandler)var12.next(); defaultMethodHandler.bindTo(proxy); } return proxy; }
从容器中获取代理对象,5、ReflectiveFeign#newInstance
远程请求 远程请求一定是要有IP和端口的,OpenFeign将IP和端口封装到RequestTemplate中了,我们来看一下RequestTemplate源码:
在 SynchronousMethodHandler 类中执行远程调用,源码如下:
代理拦截,ReflectiveFeign.FeignInvocationHandler#invoke
方法处理器执行请求,SynchronousMethodHandler#invoke
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 // 远程调用 public Object invoke(Object[] argv) throws Throwable { // 封装成RequestTemplate RequestTemplate template = this.buildTemplateFromArgs.create(argv); Options options = this.findOptions(argv); Retryer retryer = this.retryer.clone(); while(true) { try { // 执行远程调用 return this.executeAndDecode(template, options); } catch (RetryableException var9) { RetryableException e = var9; try { retryer.continueOrPropagate(e); } catch (RetryableException var8) { Throwable cause = var8.getCause(); if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) { throw cause; } throw var8; } if (this.logLevel != Level.NONE) { this.logger.logRetry(this.metadata.configKey(), this.logLevel); } } } }
上面调用会调用 executeAndDecode() 方法,该方法是执行远程请求,同时解析响应数据,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 Object executeAndDecode(RequestTemplate template, Options options) throws Throwable { //转换为HTTP请求报文 Request request = this.targetRequest(template); if (this.logLevel != Level.NONE) { this.logger.logRequest(this.metadata.configKey(), this.logLevel, request); } long start = System.nanoTime(); Response response; try { //发起远程通信 response = this.client.execute(request, options); } catch (IOException var16) { if (this.logLevel != Level.NONE) { this.logger.logIOException(this.metadata.configKey(), this.logLevel, var16, this.elapsedTime(start)); } throw FeignException.errorExecuting(request, var16); } long elapsedTime = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start); boolean shouldClose = true; Object var11; try { if (this.logLevel != Level.NONE) { response = this.logger.logAndRebufferResponse(this.metadata.configKey(), this.logLevel, response, elapsedTime); } if (Response.class == this.metadata.returnType()) { Response var19; if (response.body() == null) { var19 = response; return var19; } if (response.body().length() != null && (long)response.body().length() <= 8192L) { //获取返回结果 byte[] bodyData = Util.toByteArray(response.body().asInputStream()); Response var21 = response.toBuilder().body(bodyData).build(); return var21; } shouldClose = false; var19 = response; return var19; } Object result; if (response.status() >= 200 && response.status() < 300) { if (Void.TYPE == this.metadata.returnType()) { result = null; return result; } result = this.decode(response); shouldClose = this.closeAfterDecode; var11 = result; return var11; } if (!this.decode404 || response.status() != 404 || Void.TYPE == this.metadata.returnType()) { throw this.errorDecoder.decode(this.metadata.configKey(), response); } result = this.decode(response); shouldClose = this.closeAfterDecode; var11 = result; } catch (IOException var17) { if (this.logLevel != Level.NONE) { this.logger.logIOException(this.metadata.configKey(), this.logLevel, var17, elapsedTime); } throw FeignException.errorReading(request, response, var17); } finally { if (shouldClose) { Util.ensureClosed(response.body()); } } return var11; }
方法处理器执行请求,SynchronousMethodHandler#invoke
feign客户端发送请求获取响应,LoadBalancerFeignClient#execute
feign客户端发送请求获取响应,AbstractLoadBalancerAwareClient#executeWithLoadBalancer
SpringCloud Stream源码 前面我们已经学过,Spring Cloud Stream 是一个消息驱动微服务的框架。
应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中binder 交互,通过我们配置来 binding ,而 Spring Cloud Stream 的 binder 负责与消息中间件交互。所以,我们只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
为了更深层次的学习SpringCloud Stream,我们展开对它的源码学习。
@EnableBinding注解解析 在Stream中,要想实现发消息,首先得注册绑定通信管道,注册绑定通信管道我们需要用到 BindingBeansRegistrar 类,例如我们写了@EnableBinding(Source.class) ,此时该类就会解析这个注解,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { //获取@EnableBinding(Source.class)注解信息 AnnotationAttributes attrs = AnnotatedElementUtils.getMergedAnnotationAttributes( ClassUtils.resolveClassName(metadata.getClassName(), null), EnableBinding.class); //循环注解属性,value值是个数组,可以指定多个管道绑定对 象字节码 for (Class<?> type : collectClasses(attrs, metadata.getClassName())) { //此时如果创建的是生产者,则创建Source的实例, 如果是消费者,则创建Sink的实例 if (!registry.containsBeanDefinition(type.getName())) { BindingBeanDefinitionRegistryUtils.registerBindingTargetBeanDefinitions( type, type.getName(), registry); BindingBeanDefinitionRegistryUtils .registerBindingTargetsQualifiedBeanDefinitions(ClassUtils .resolveClassName(metadata.getClassName(), null), type, registry); } } } // 获取@EnableBinding注解中的value集合 private Class<?>[] collectClasses(AnnotationAttributes attrs, String className) { EnableBinding enableBinding = AnnotationUtils.synthesizeAnnotation(attrs, EnableBinding.class, ClassUtils.resolveClassName(className, null)); return enableBinding.value(); }
Channel信道创建 上面调用的实例化通信管道并注册通信管道对象的方法是registerBindingTargetBeanDefinitions() ,源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void registerBindingTargetBeanDefinitions(Class<?> type, final String bindingTargetInterfaceBeanName, final BeanDefinitionRegistry registry) { ReflectionUtils.doWithMethods(type, method -> { //input类 Input input = AnnotationUtils.findAnnotation(method, Input.class); if (input != null) { //获取注解后面的值:@EnableBinding(Sink.class) String name = getBindingTargetName(input, method); if (!registry.containsBeanDefinition(name)) { //创建Sink的实例,并注入到SpringIOC容器中 registerInputBindingTargetBeanDefinition(input.value(), name, bindingTargetInterfaceBeanName, method.getName(), registry); } } //output类型 Output output = AnnotationUtils.findAnnotation(method, Output.class); if (output != null) { //获取注解后面的值:@EnableBinding(Source.class) String name = getBindingTargetName(output, method); if (!registry.containsBeanDefinition(name)) { //创建Source的实例,并注入到SpringIOC容器中 registerOutputBindingTargetBeanDefinition(output.value(), name, bindingTargetInterfaceBeanName, method.getName(), registry); } } }); }
此时运行时,我们可以发现消息发送绑定对象是DirectWithAttributesChannel
消息发送 消息发送比较抽象,需要根据引入不同MQ中间件依赖包决定,但主题流程保持一致,其中消息检查和消息发送会和引入的包不同有差异,发送消息前会适配不同MQ的Binder,如果是RabbitMQ,Binder是 RabbitMessageChannelBinder ,消息发送的源码在AbstractMessageChannel#send() 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 public boolean send(Message<?> messageArg, long timeout) { Assert.notNull(messageArg, "message must not be null"); Assert.notNull(messageArg.getPayload(), "message payload must not be null"); Message<?> message = messageArg; if (this.shouldTrack) { message = MessageHistory.write(messageArg, this, this.getMessageBuilderFactory()); } Deque<ChannelInterceptor> interceptorStack = null; boolean sent = false; boolean metricsProcessed = false; MetricsContext metricsContext = null; boolean countsAreEnabled = this.countsEnabled; AbstractMessageChannel.ChannelInterceptorList interceptorList = this.interceptors; AbstractMessageChannelMetrics metrics = this.channelMetrics; SampleFacade sample = null; try { message = this.convertPayloadIfNecessary(message); boolean debugEnabled = this.loggingEnabled && this.logger.isDebugEnabled(); if (debugEnabled) { this.logger.debug("preSend on channel '" + this + "', message: " + message); } if (interceptorList.getSize() > 0) { interceptorStack = new ArrayDeque(); //拦截器拦截,处理信息 message = interceptorList.preSend(message, this, interceptorStack); if (message == null) { return false; } } //是否限制发送消息数量,如果限制,需要拦截器检查 if (countsAreEnabled) { metricsContext = metrics.beforeSend(); if (this.metricsCaptor != null) { sample = this.metricsCaptor.start(); } //执行消息发送 sent = this.doSend(message, timeout); if (sample != null) { sample.stop(this.sendTimer(sent)); } metrics.afterSend(metricsContext, sent); metricsProcessed = true; } else { //执行消息发送 sent = this.doSend(message, timeout); } if (debugEnabled) { this.logger.debug("postSend (sent=" + sent + ") on channel '" + this + "', message: " + message); } if (interceptorStack != null) { interceptorList.postSend(message, this, sent); interceptorList.afterSendCompletion(message, this, sent, (Exception)null, interceptorStack); } return sent; } catch (Exception var14) { if (countsAreEnabled && !metricsProcessed) { if (sample != null) { sample.stop(this.buildSendTimer(false, var14.getClass().getSimpleName())); } metrics.afterSend(metricsContext, false); } if (interceptorStack != null) { interceptorList.afterSendCompletion(message, this, sent, var14, interceptorStack); } throw IntegrationUtils.wrapInDeliveryExceptionIfNecessary(message, () -> { return "failed to send Message to channel '" + this.getComponentName() + "'"; }, var14); } }
在执行消息发送的时候,获取消息发送对象前,会获取Binder,如果我们用的是RabbitMQ,此时通信信道是RabbitMQ的Binder,源码如下:
消息监听 消息的监听在 StreamListenerAnnotationBeanPostProcessor 类中注册,每次监听到消息后,会调用mappedListenerMethods中指定队列的方法,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 // 注册所有监听消息的方法 private void registerHandlerMethodOnListenedChannel(Method method, StreamListener streamListener, Object bean) { Assert.hasText(streamListener.value(), "The binding name cannot be null"); if (!StringUtils.hasText(streamListener.value())) { throw new BeanInitializationException( "A bound component name must be specified"); } final String defaultOutputChannel = StreamListenerMethodUtils .getOutboundBindingTargetName(method); if (Void.TYPE.equals(method.getReturnType())) { Assert.isTrue(StringUtils.isEmpty(defaultOutputChannel), "An output channel cannot be specified for a method that does not return a value"); } else { Assert.isTrue(!StringUtils.isEmpty(defaultOutputChannel), "An output channel must be specified for a method that can return a value"); } //对每个方法进行校验 StreamListenerMethodUtils.validateStreamListenerMessageHandler(method); //将方法添加到mappedListenerMethods中,它是这样的结构: <String, StreamListenerHandlerMethodMapping> //信道的input值是key(可以理解成队列,但不同MQ意义不一样), 每次可以用监听的input作为ke去取出方法,进行调用 StreamListenerAnnotationBeanPostProcessor.this.mappedListenerMethods.add( streamListener.value(), new StreamListenerHandlerMethodMapping(bean, method, streamListener.condition(), defaultOutputChannel, streamListener.copyHeaders())); }
我们调试后,可以发现此时会注册对应的监听方法,测试效果如下:
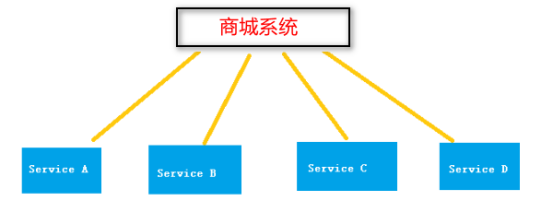
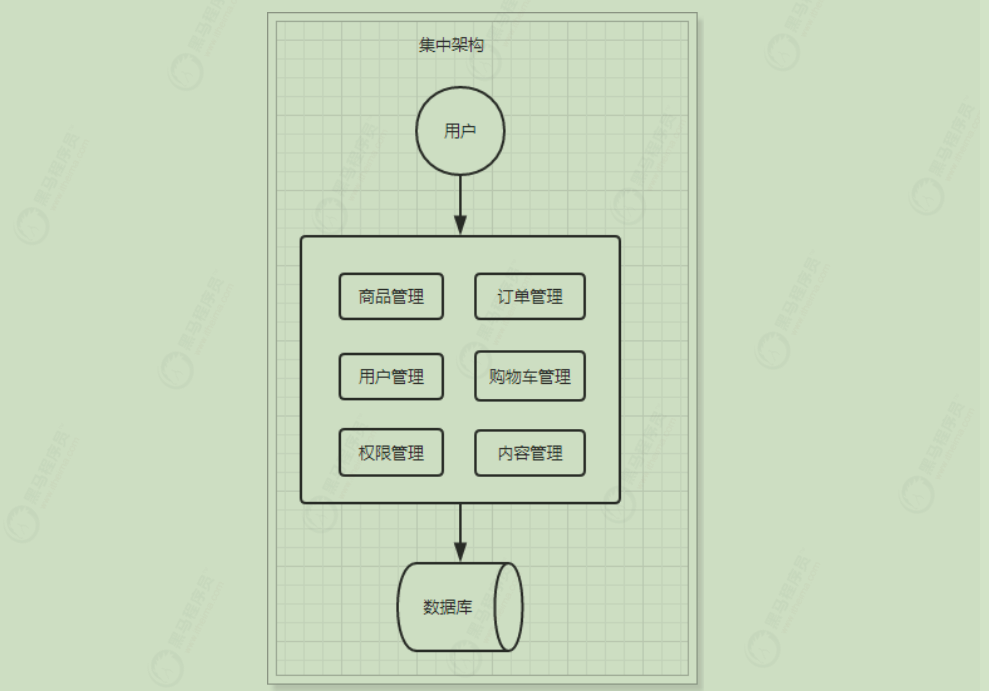
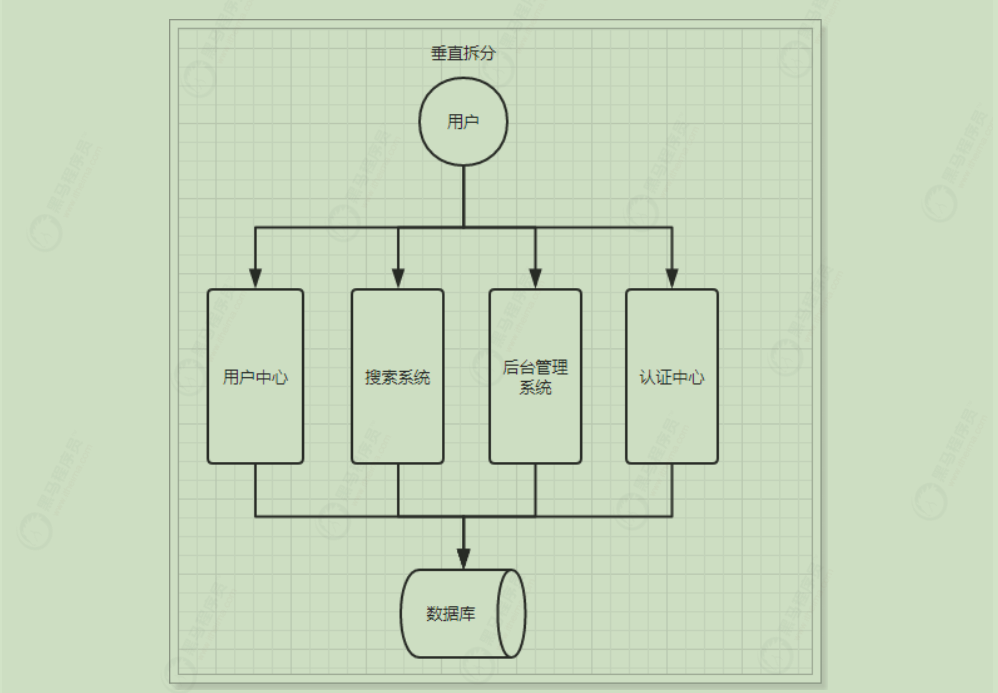
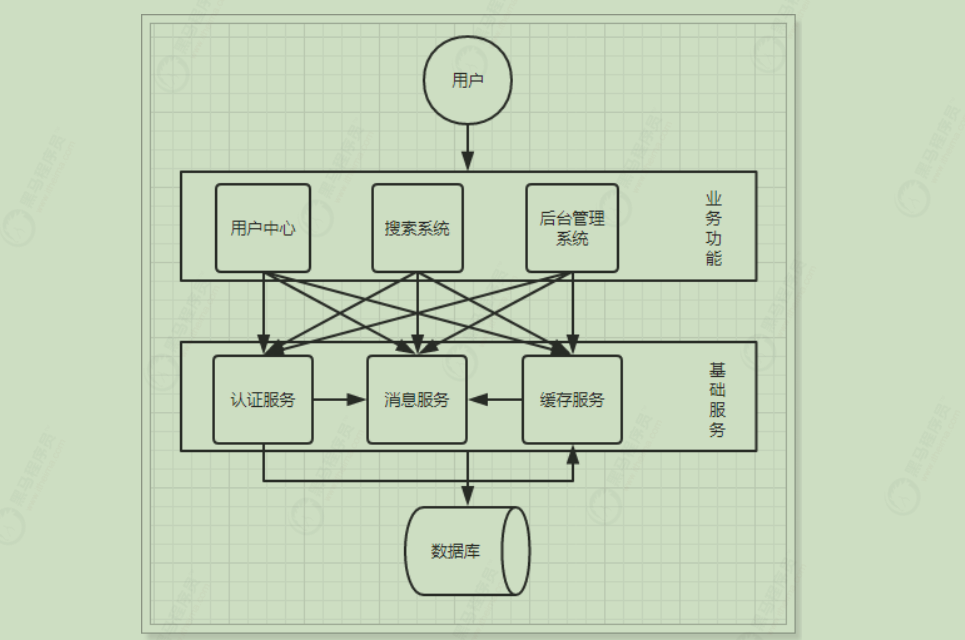
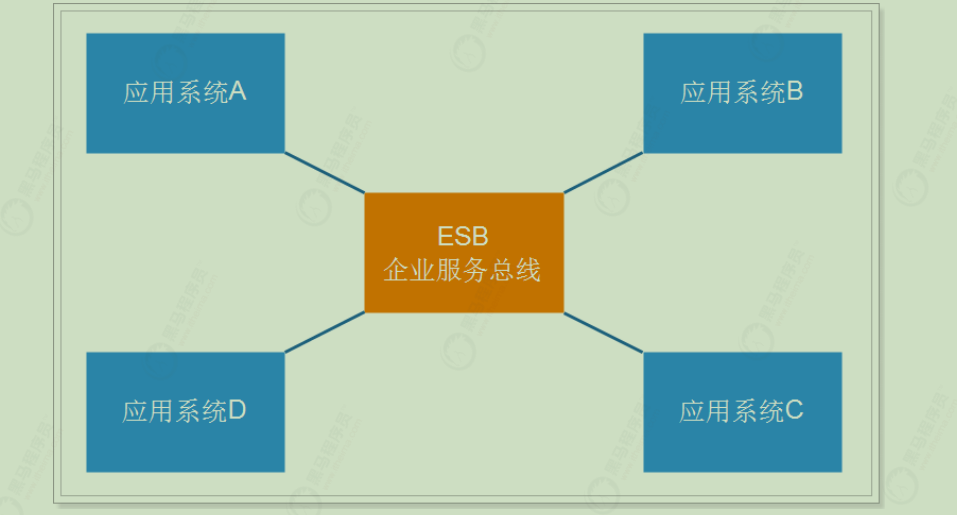
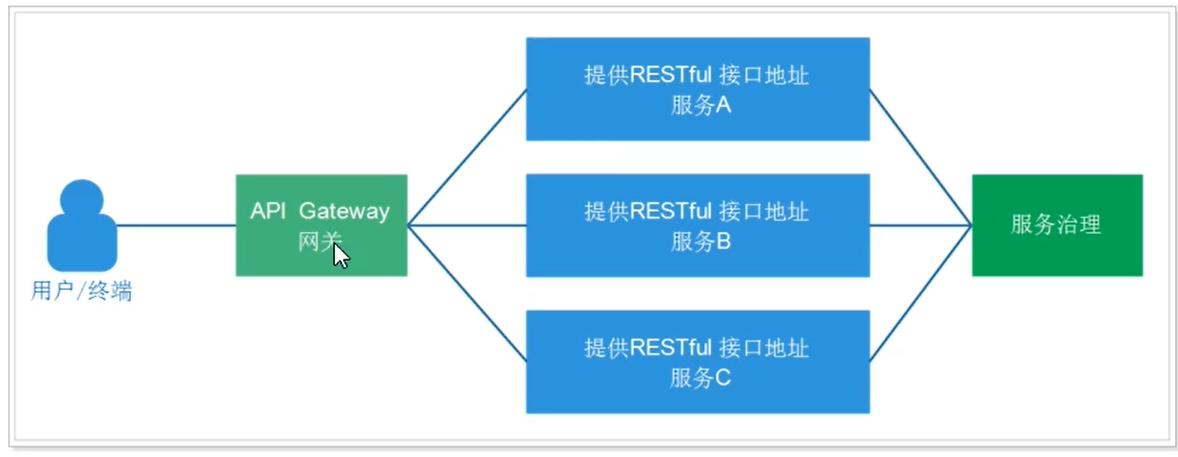
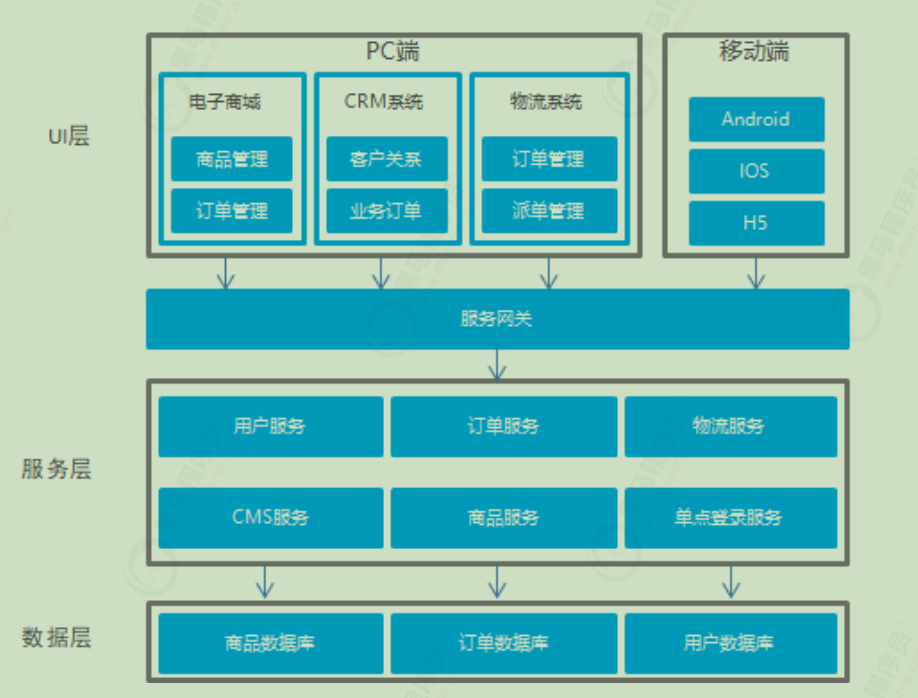
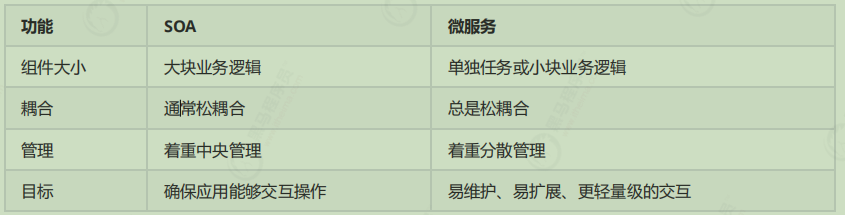
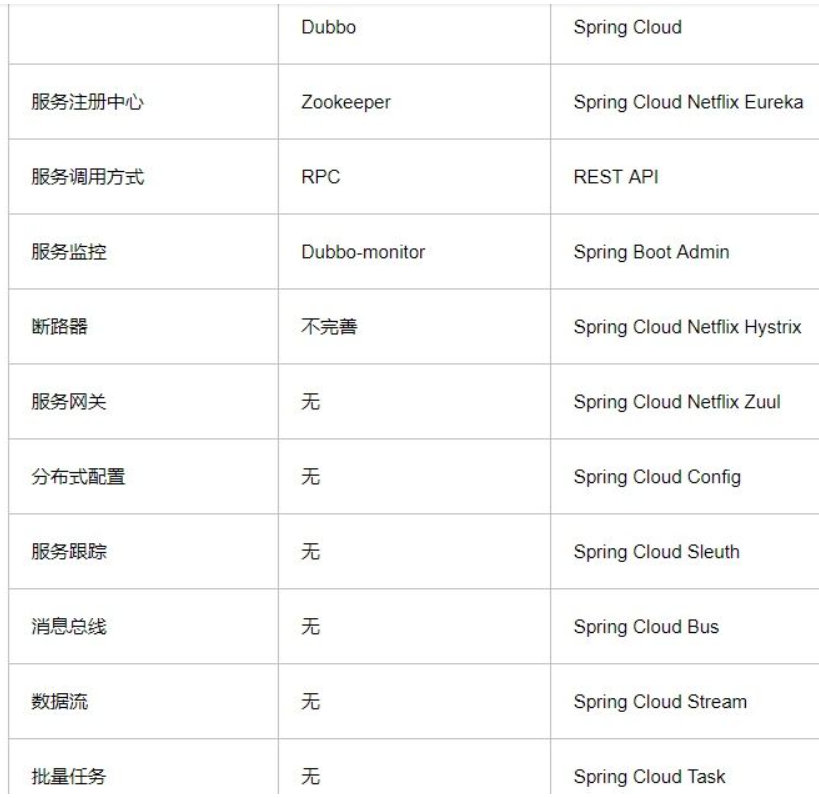
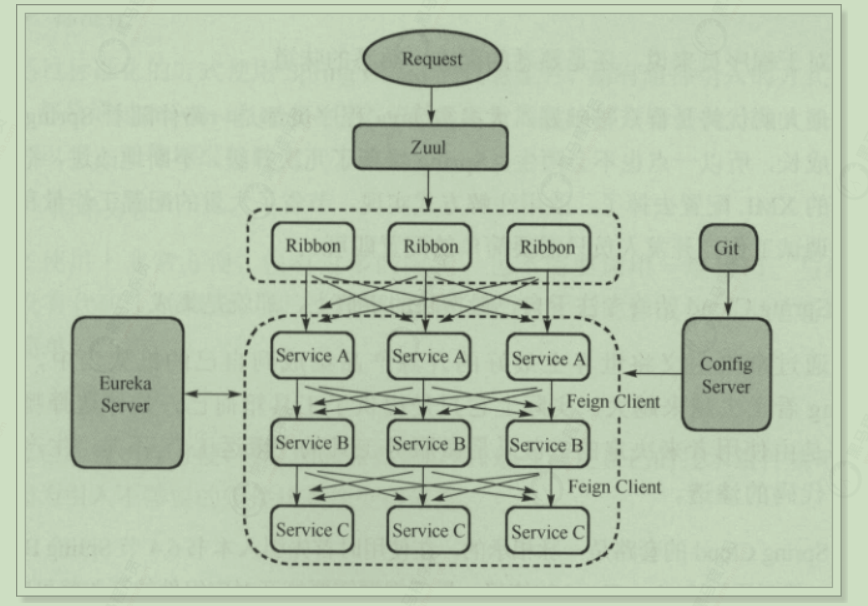
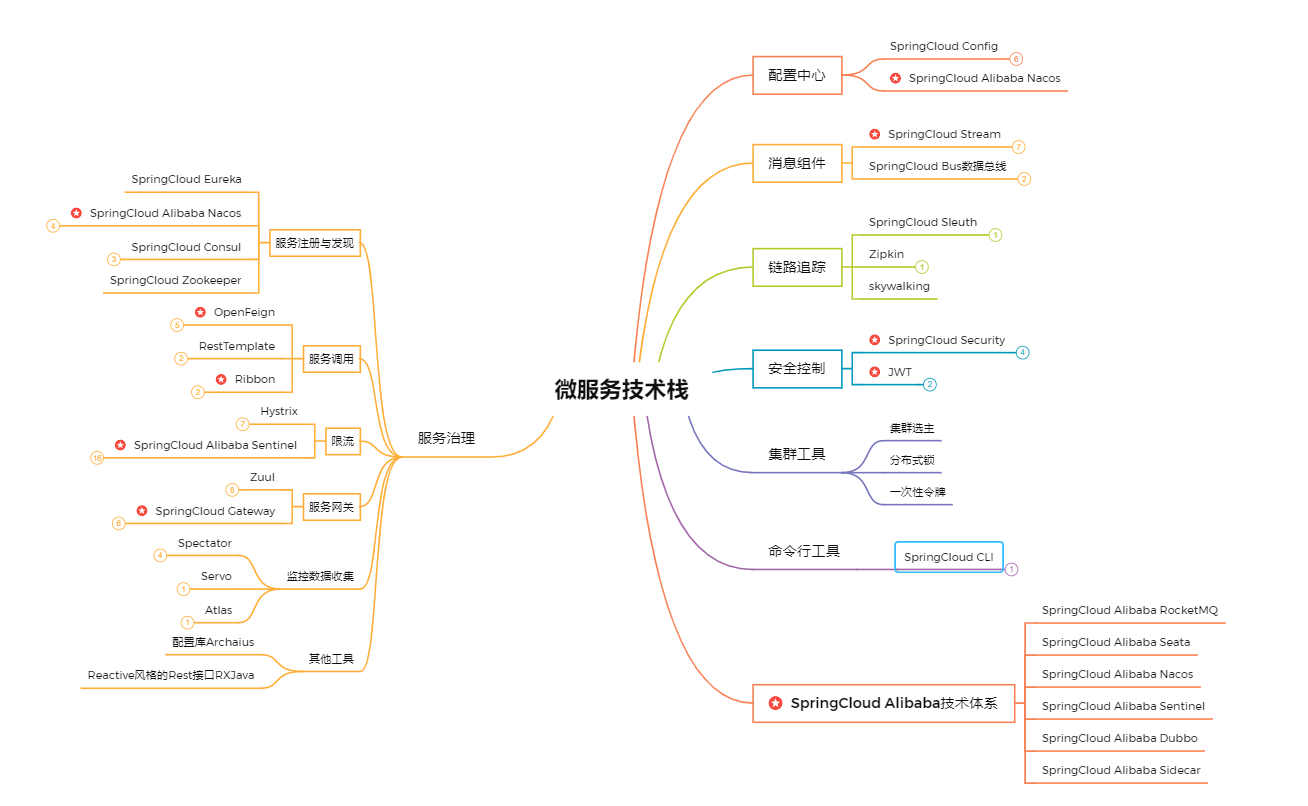
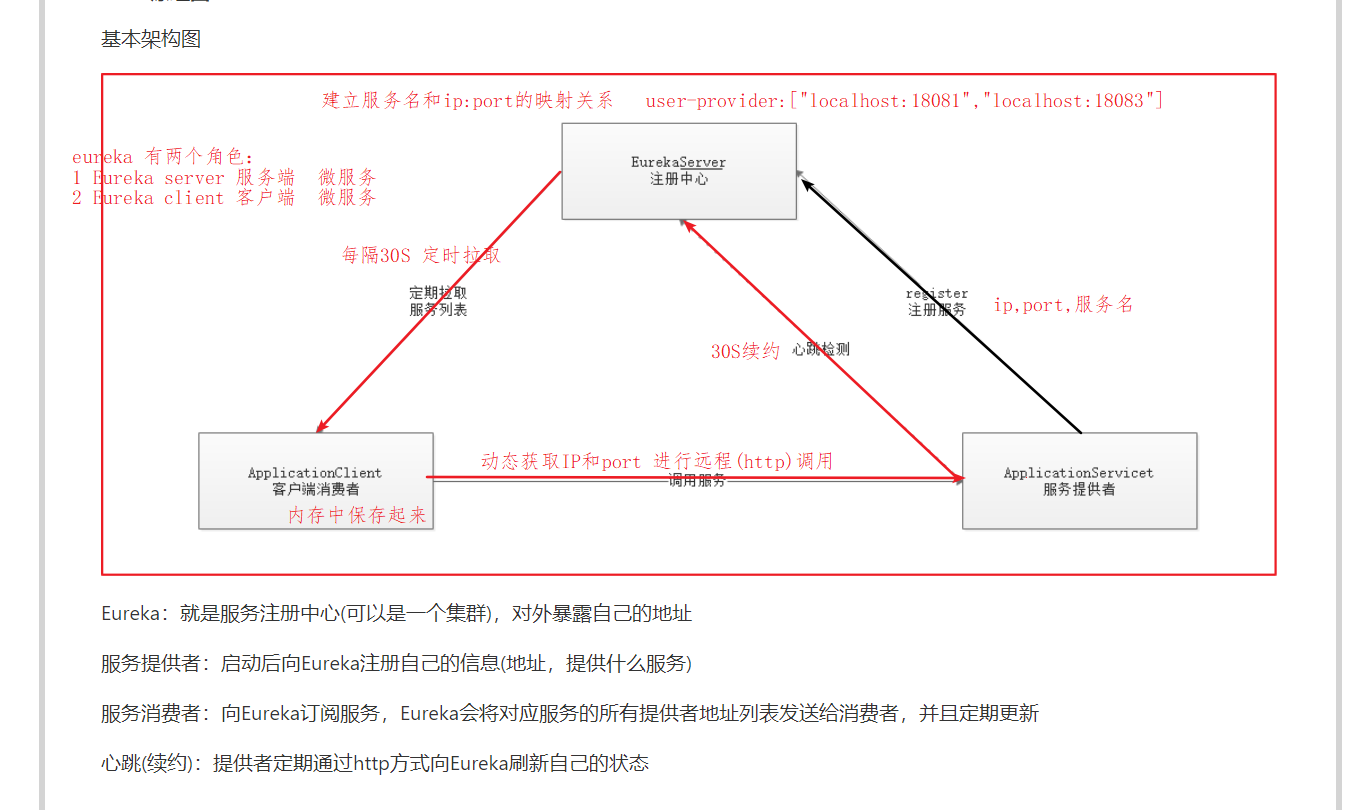
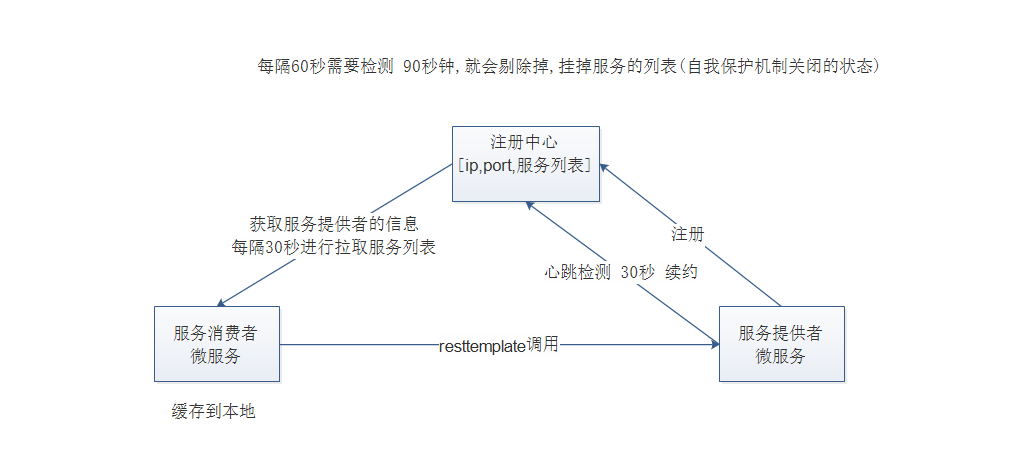
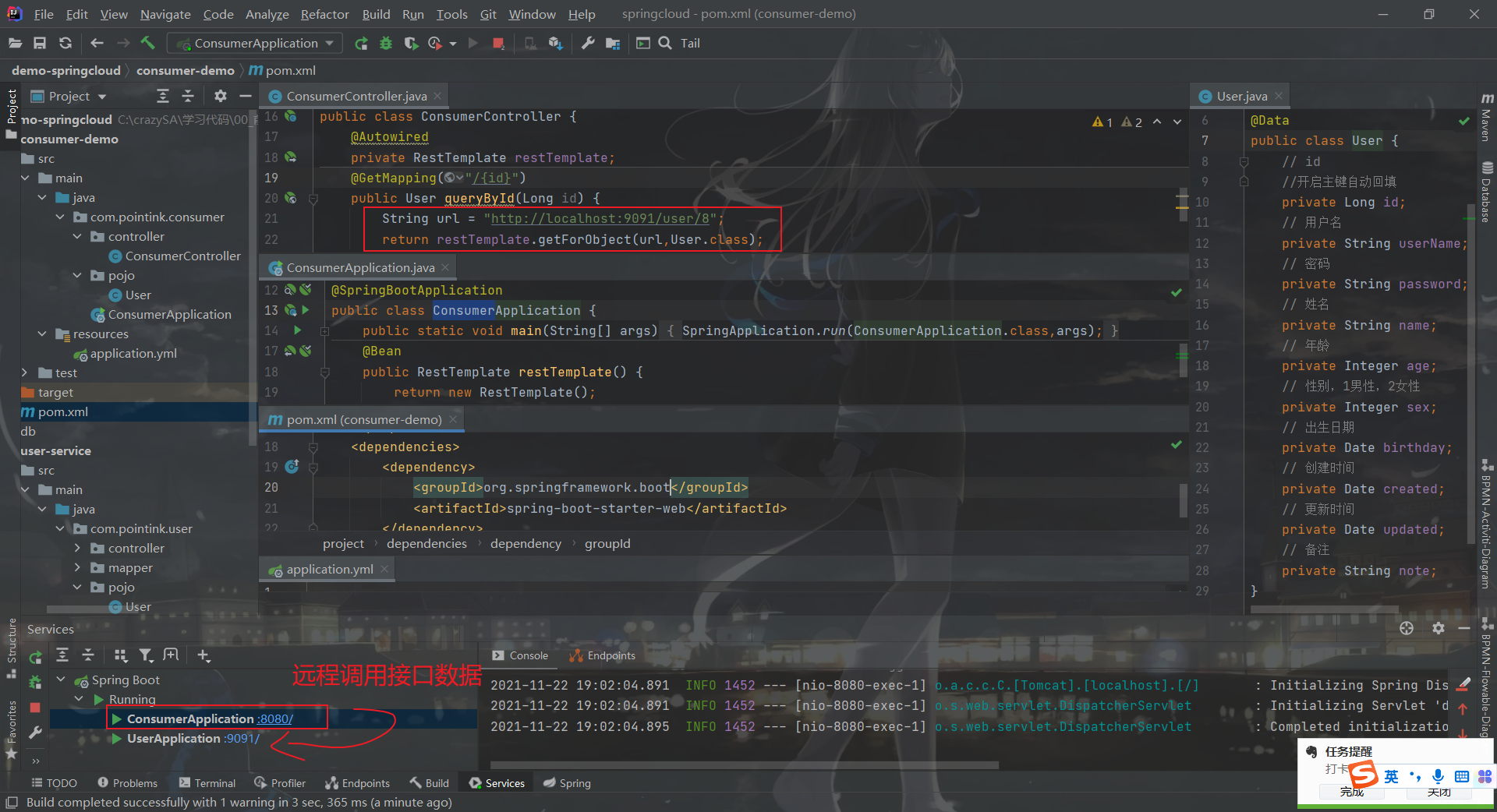
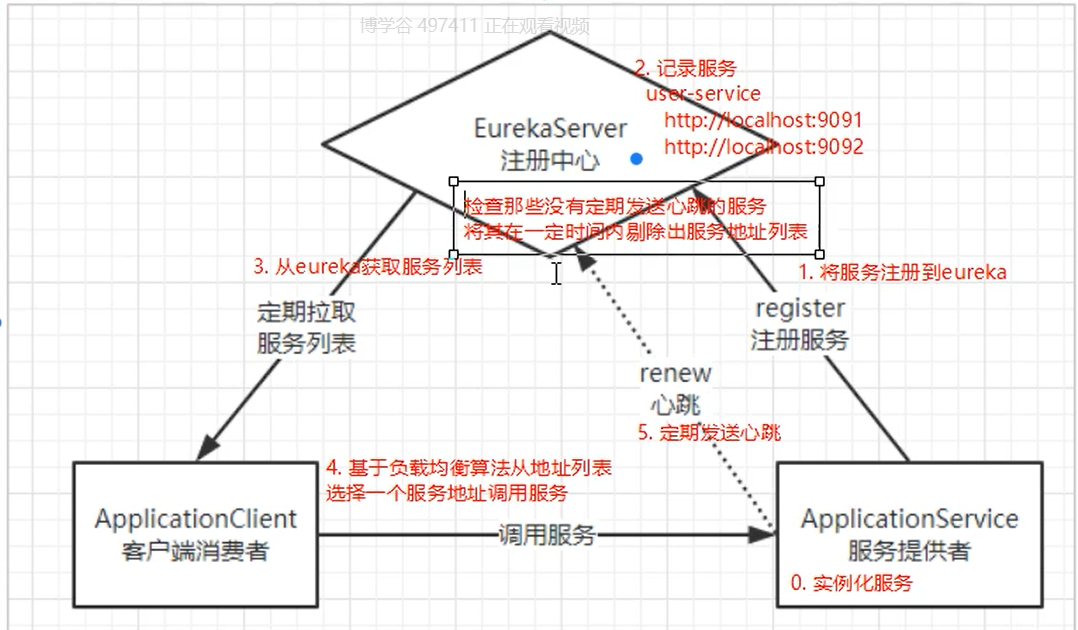
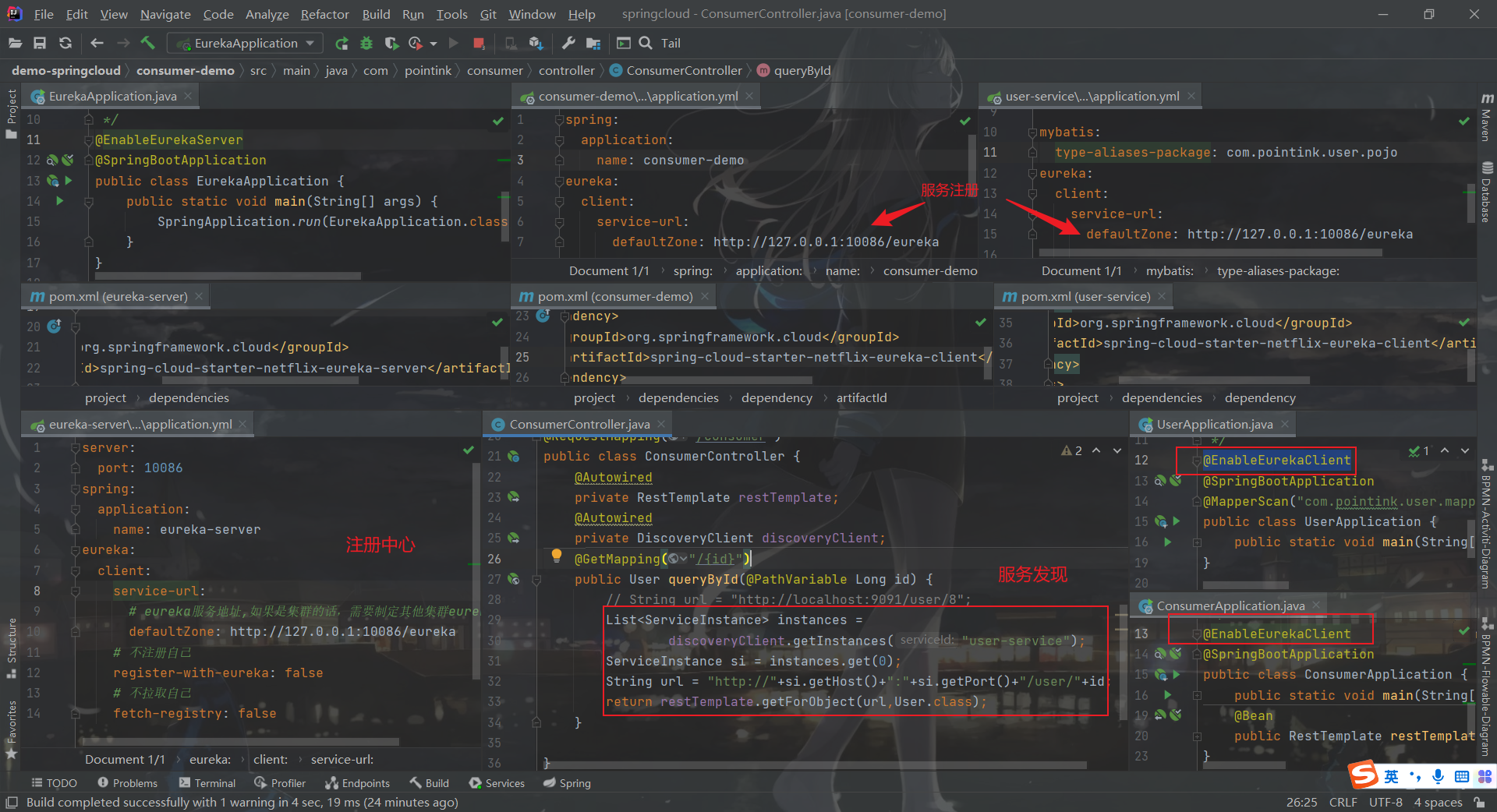
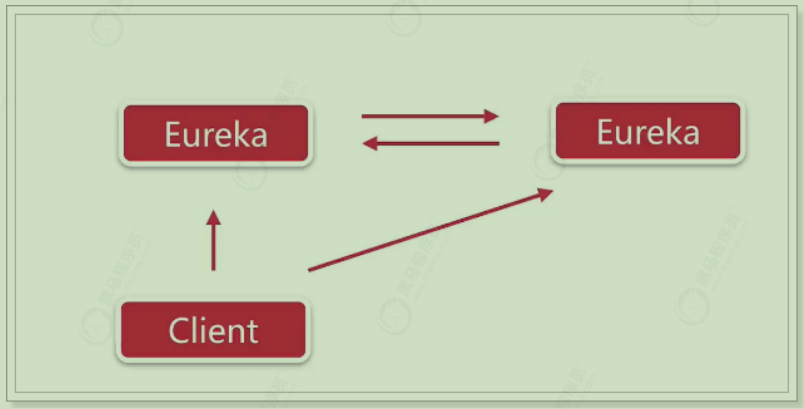
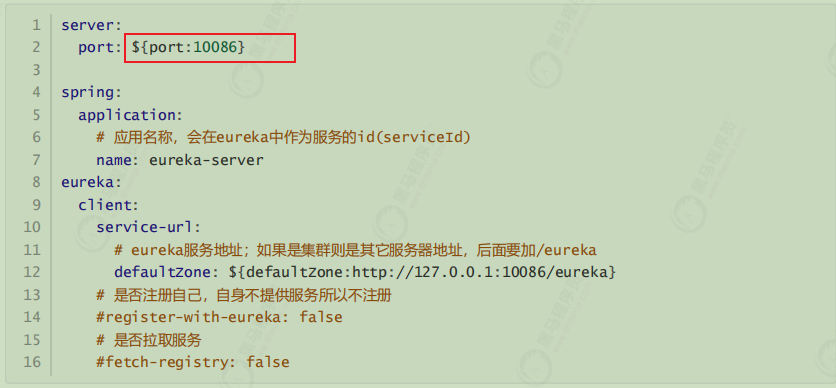
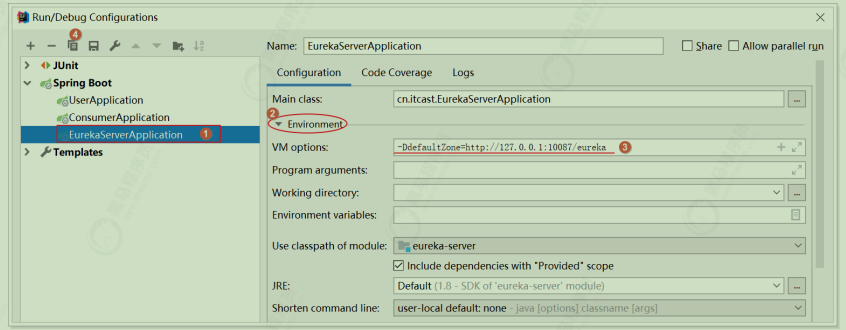 复制一份并修改;在如下界面中的 VM options 中
复制一份并修改;在如下界面中的 VM options 中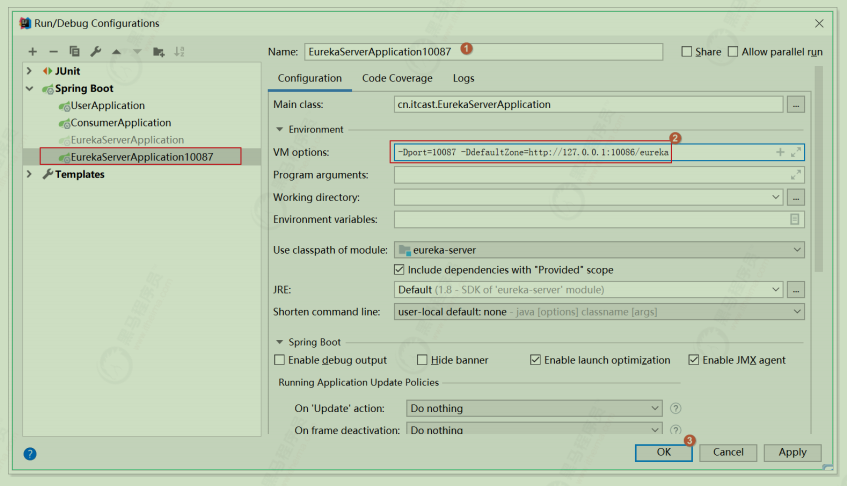
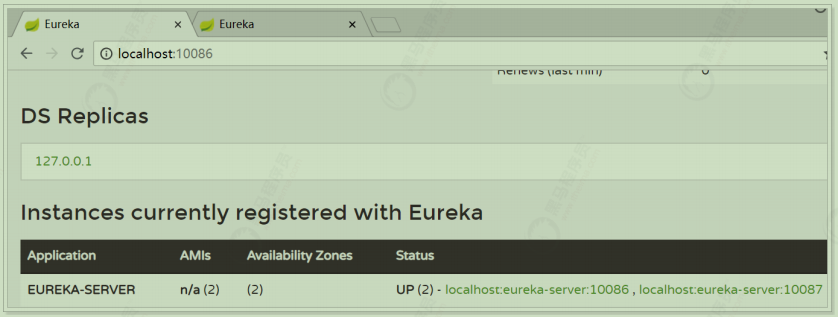


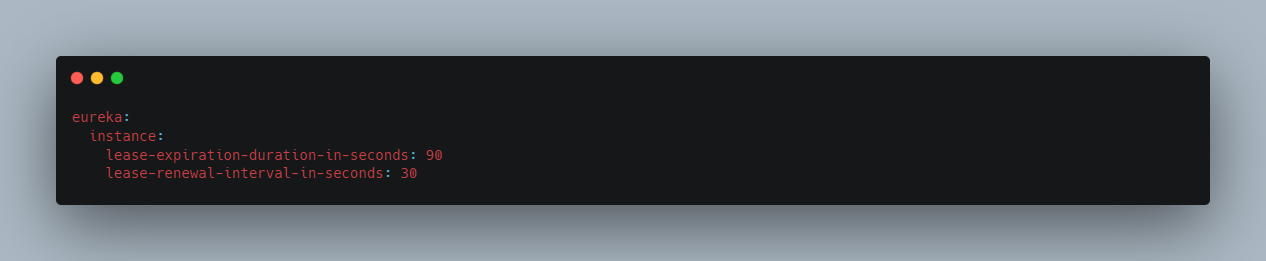

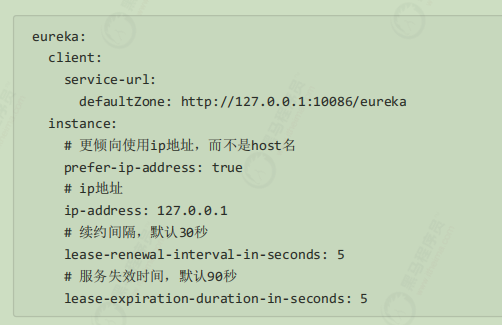
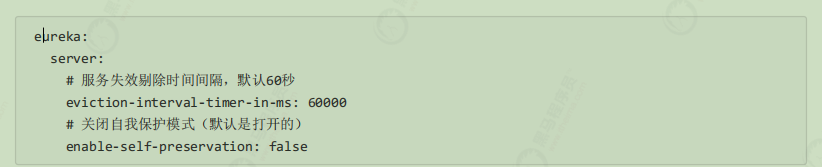
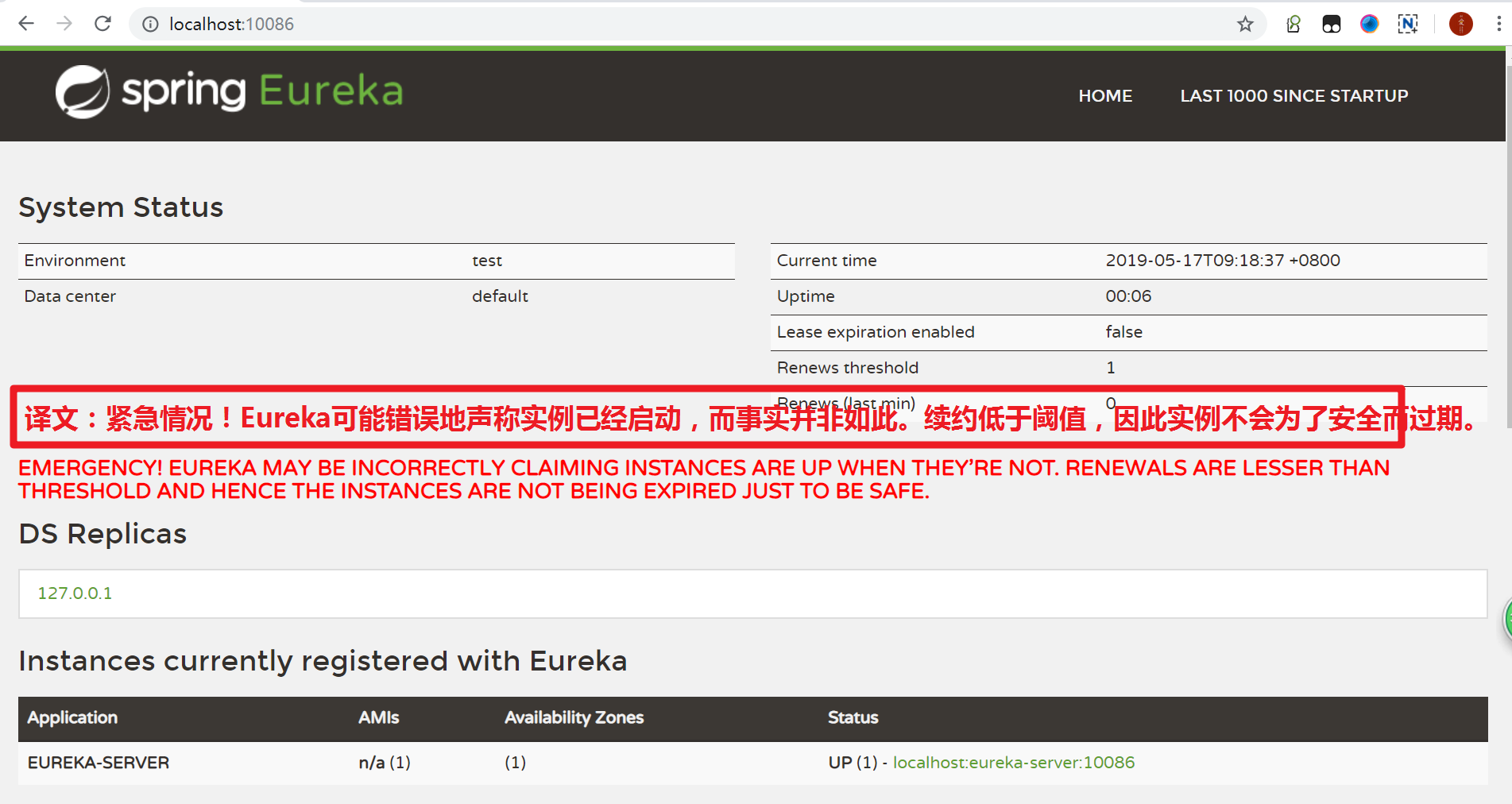

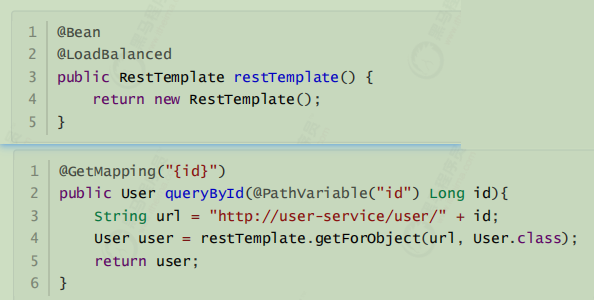

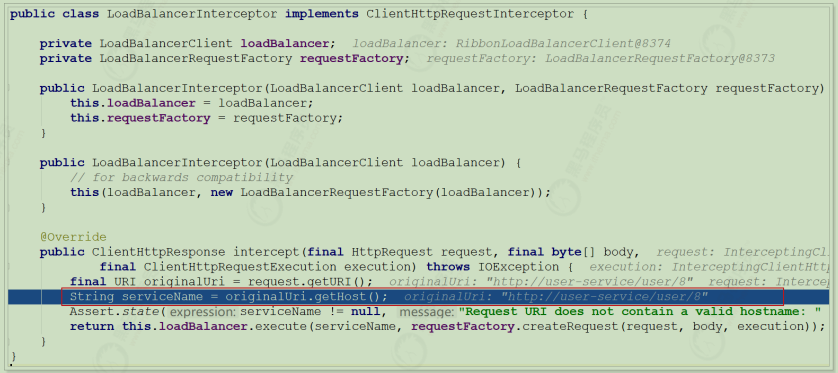
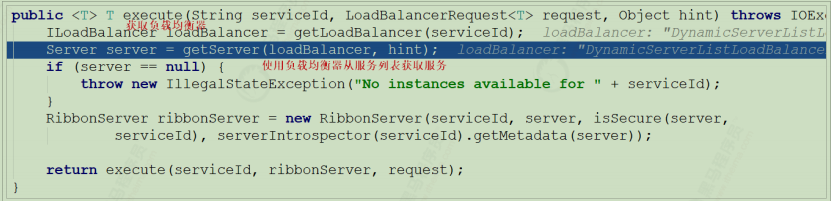
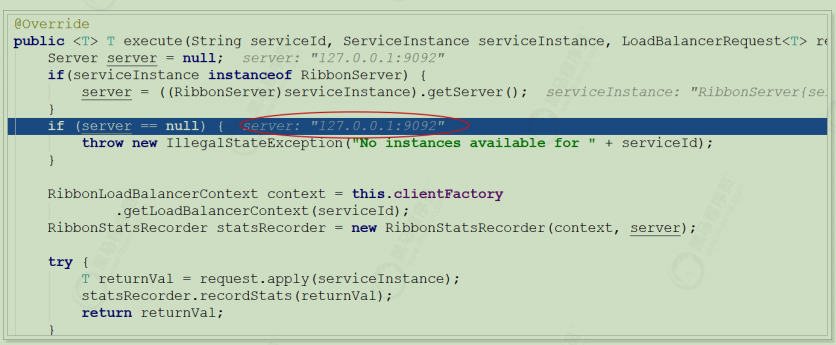

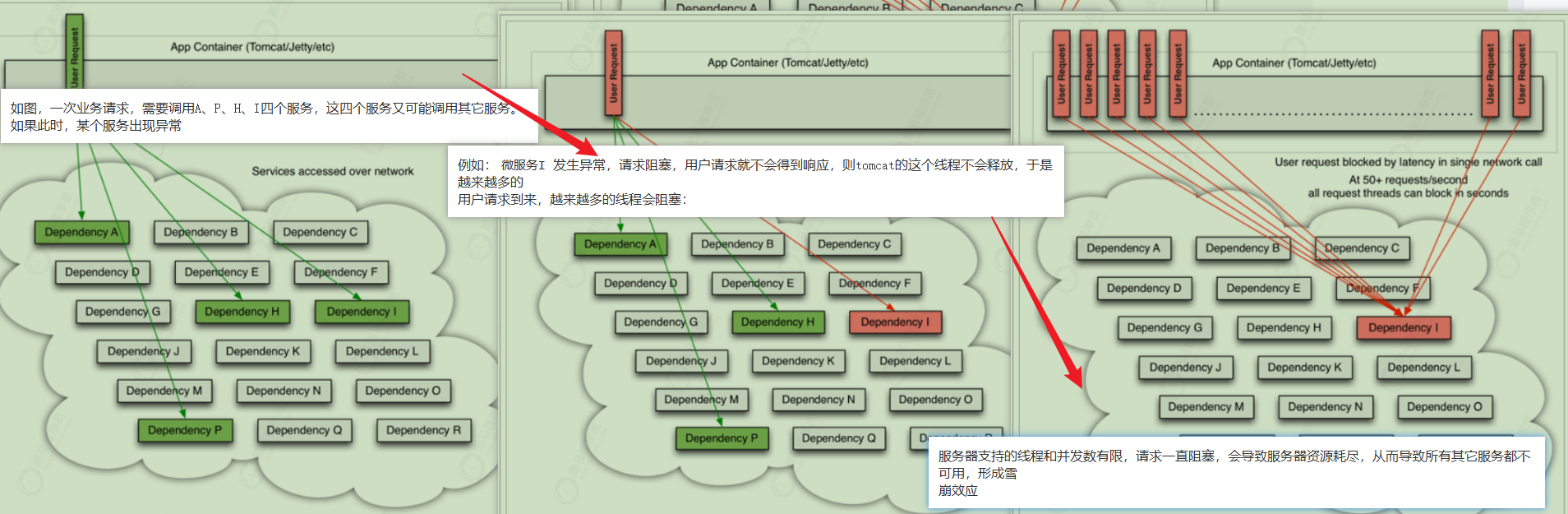
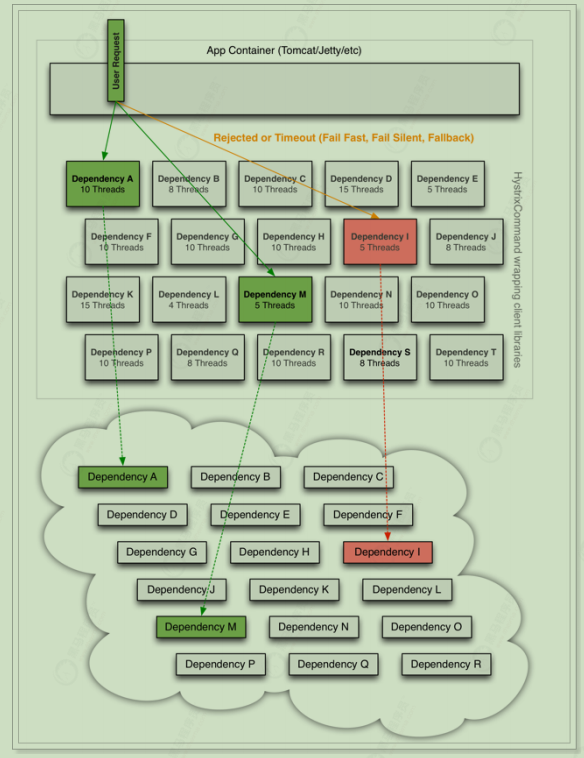
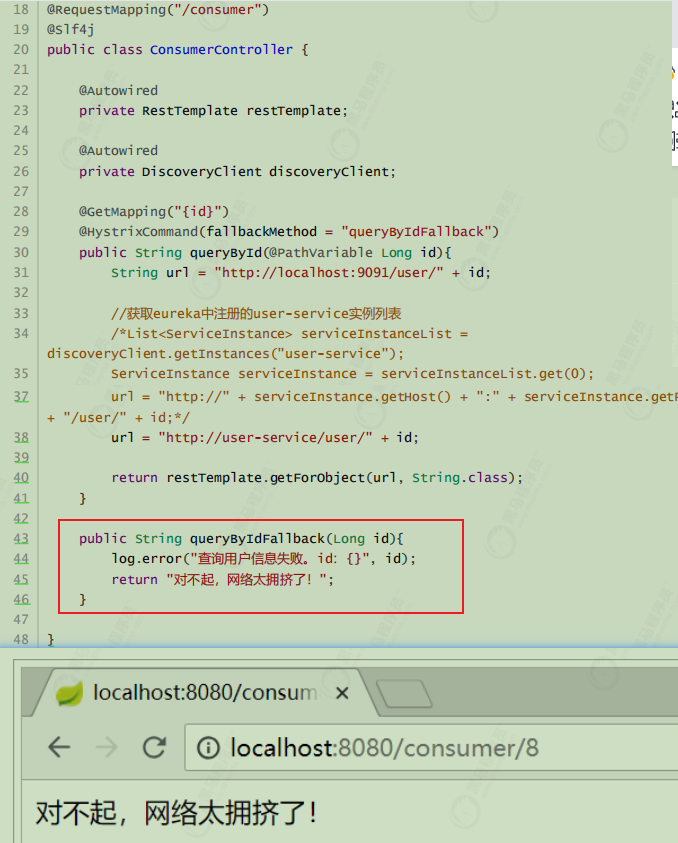
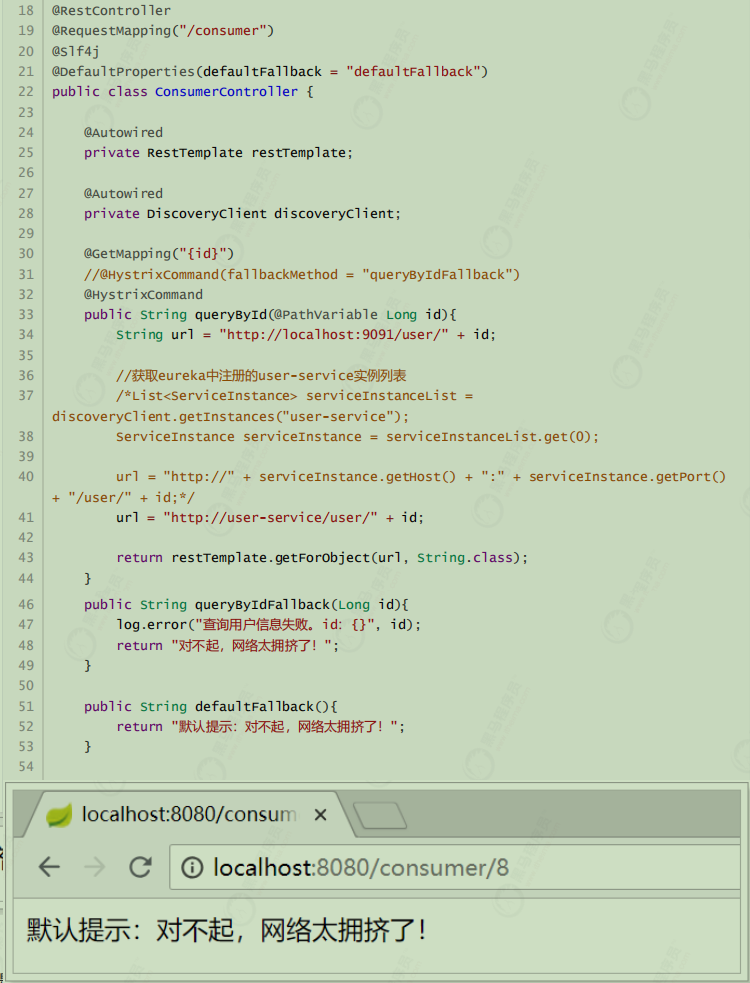
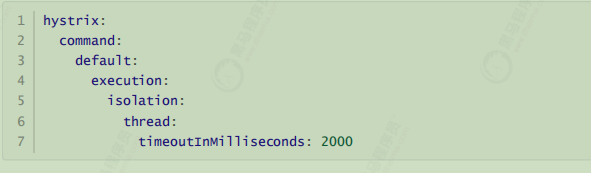
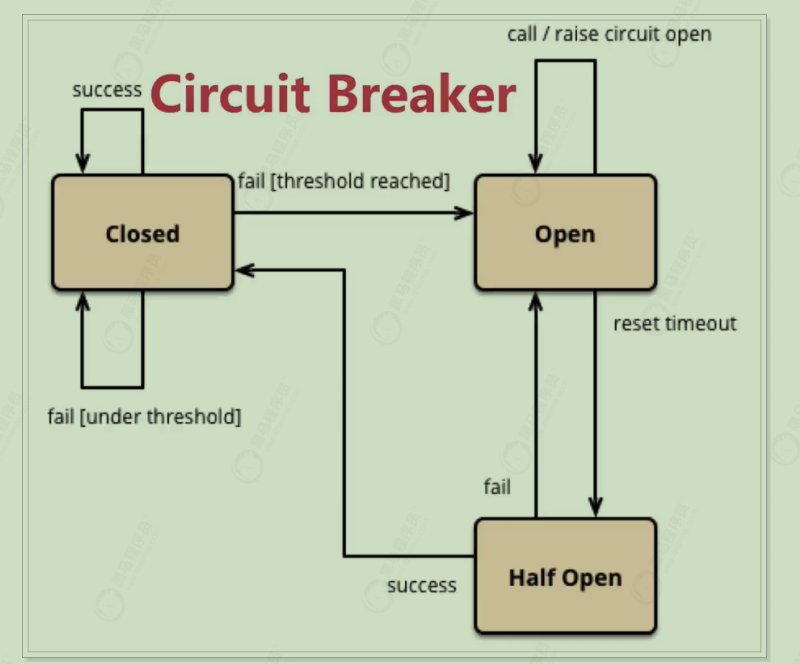
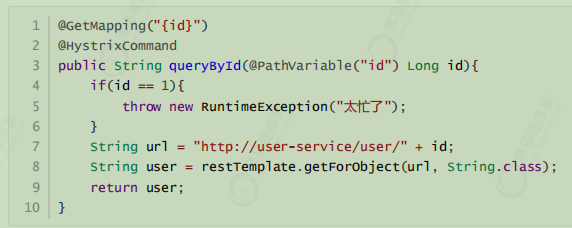
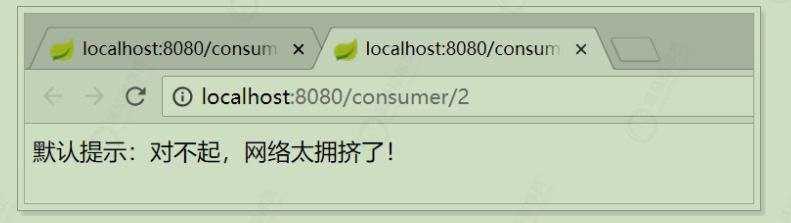

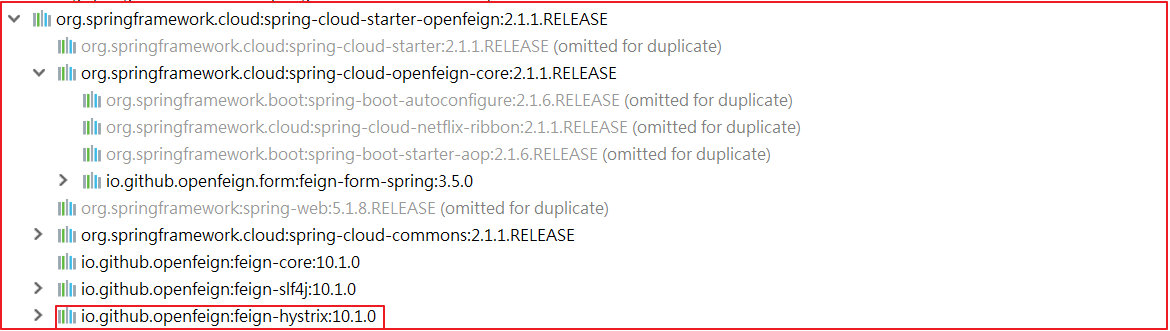
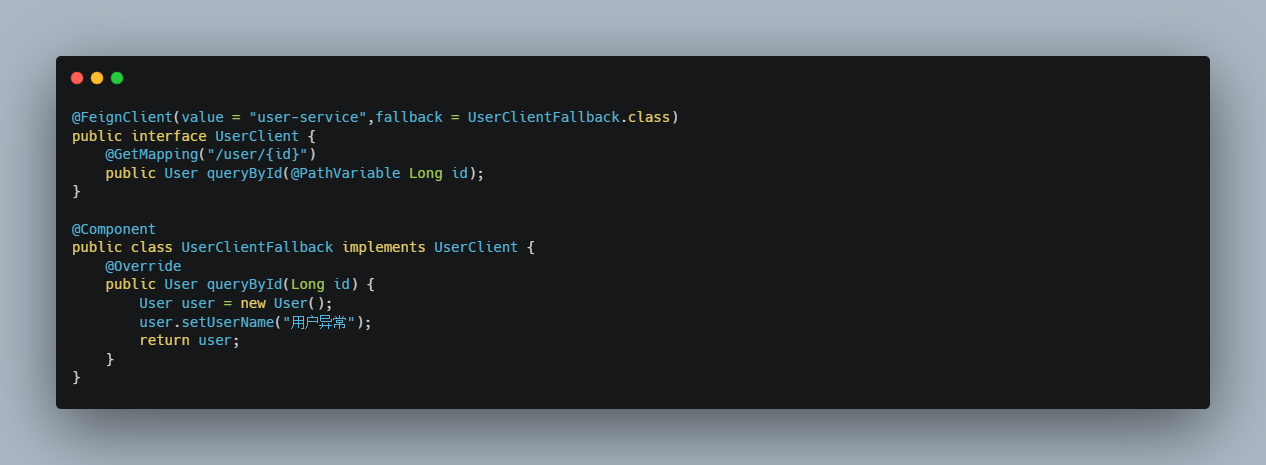
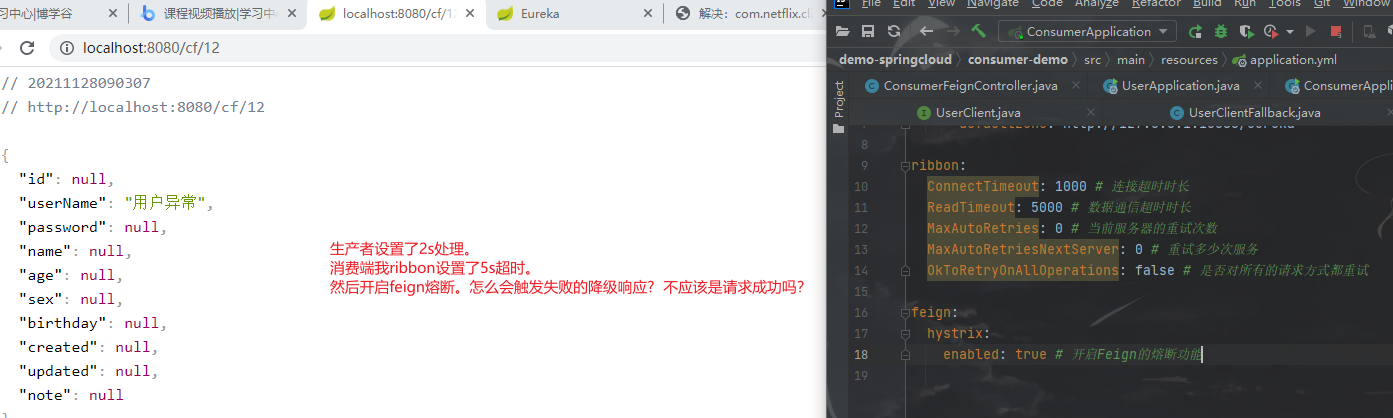
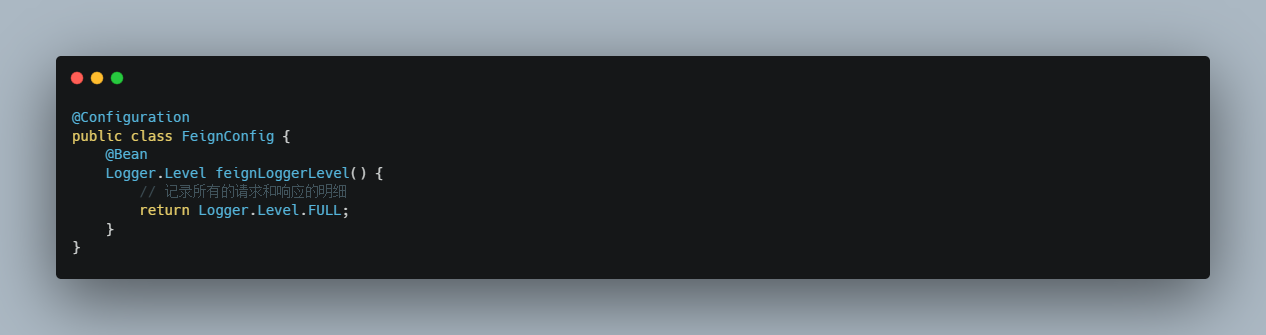
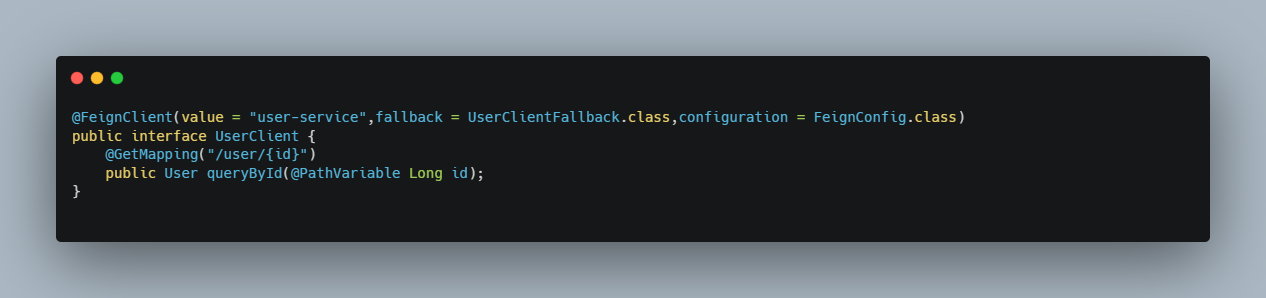

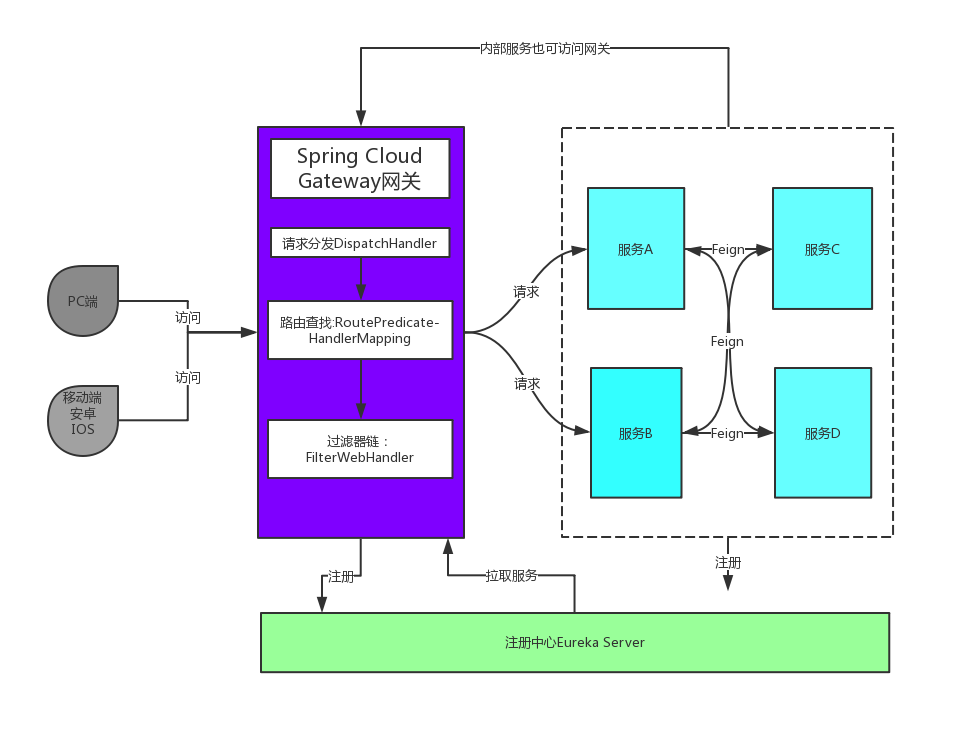

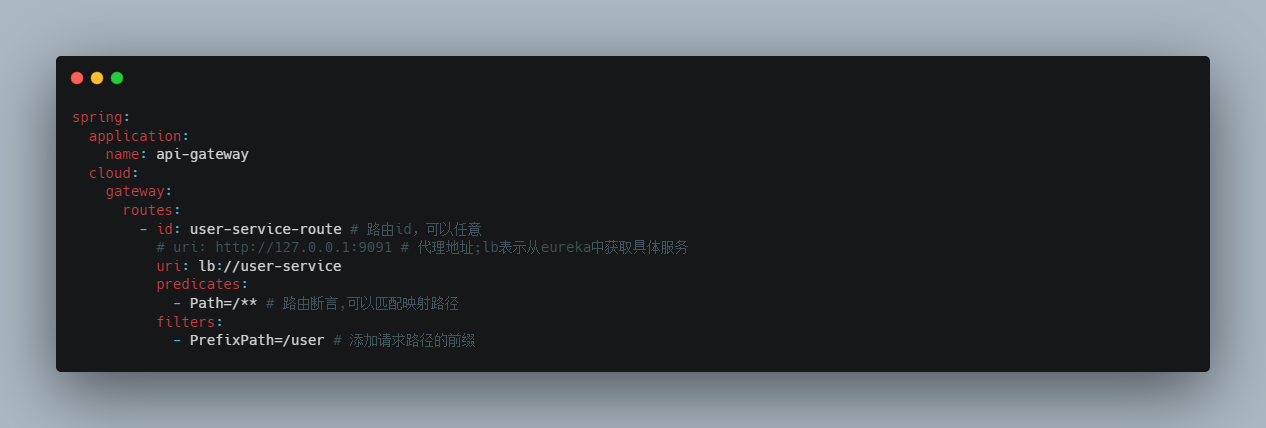
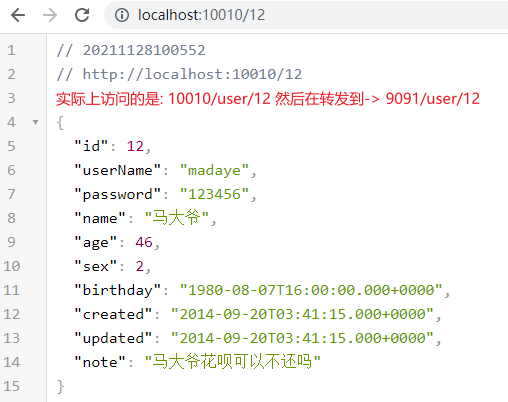
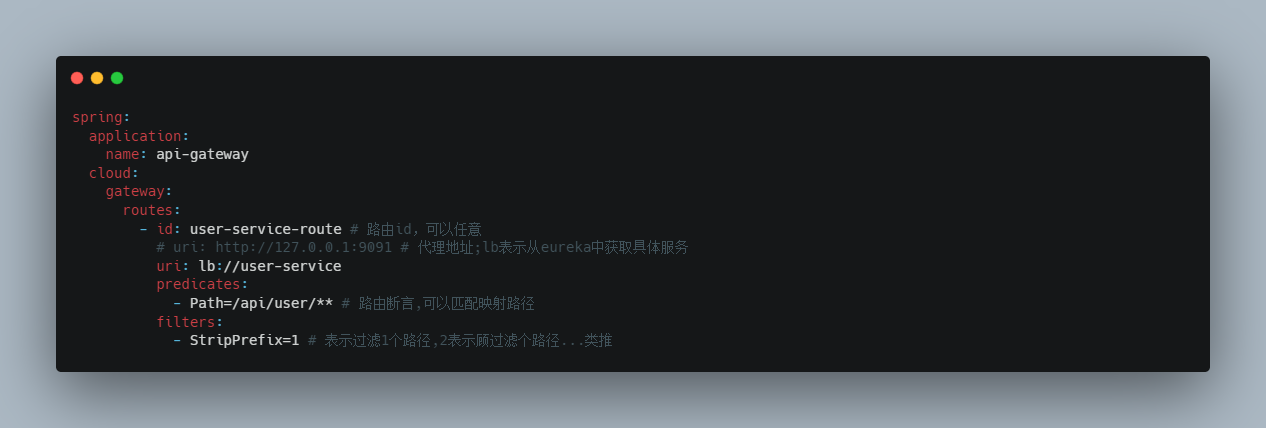
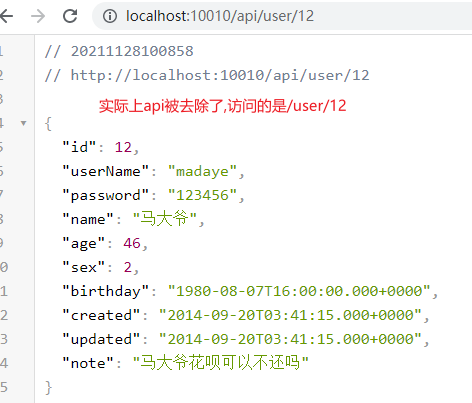
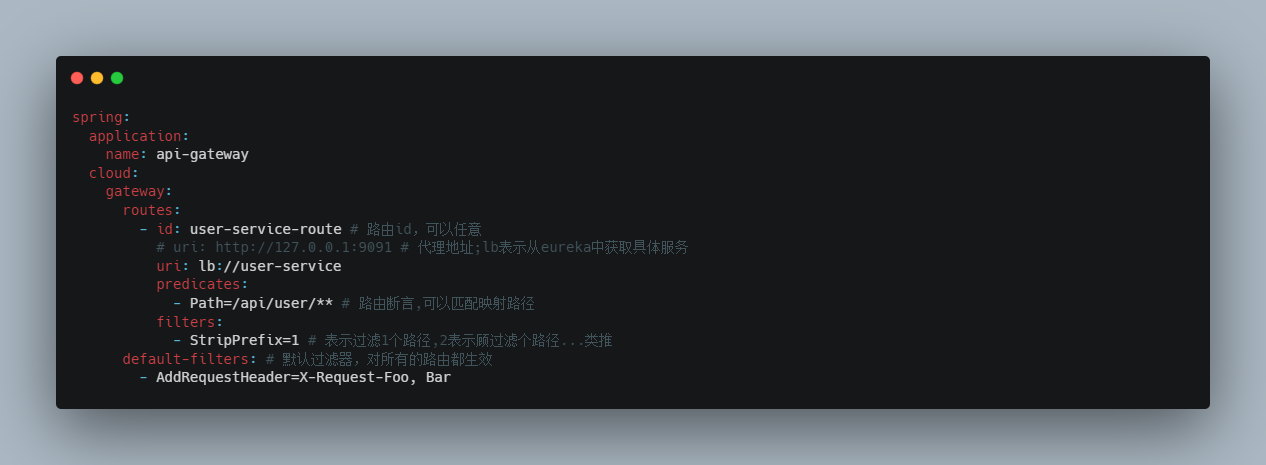
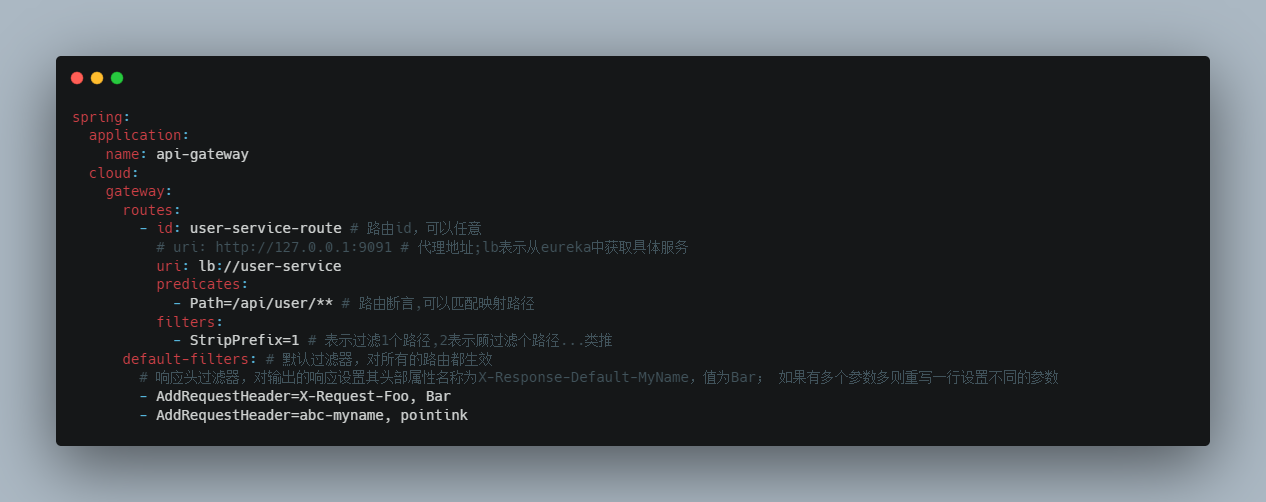
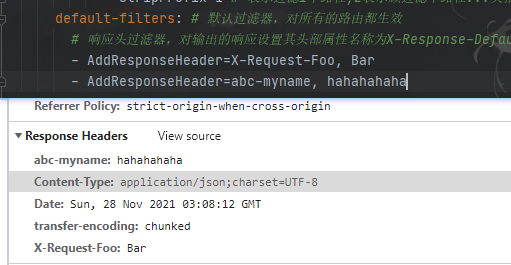
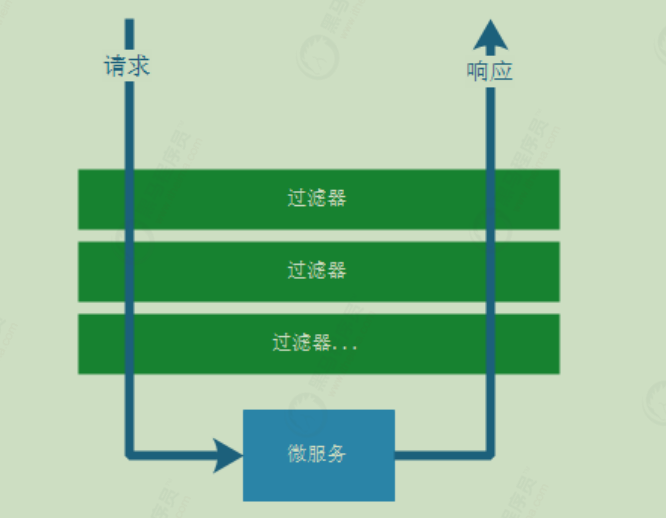
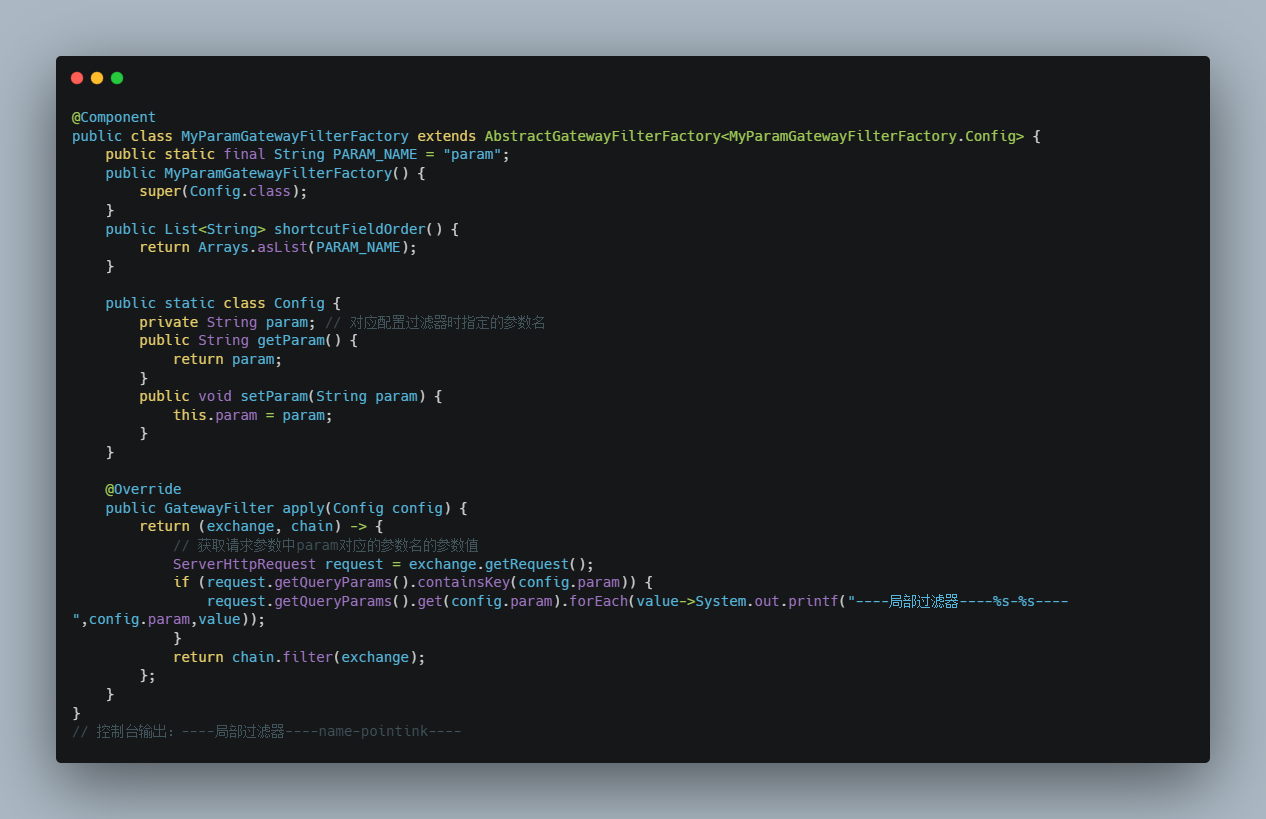
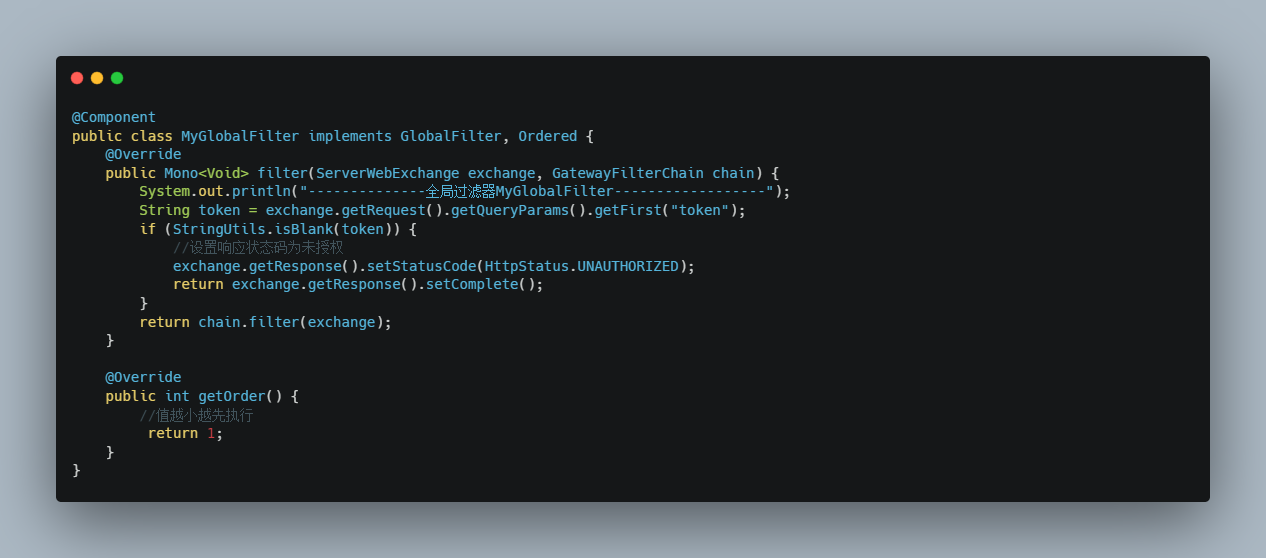
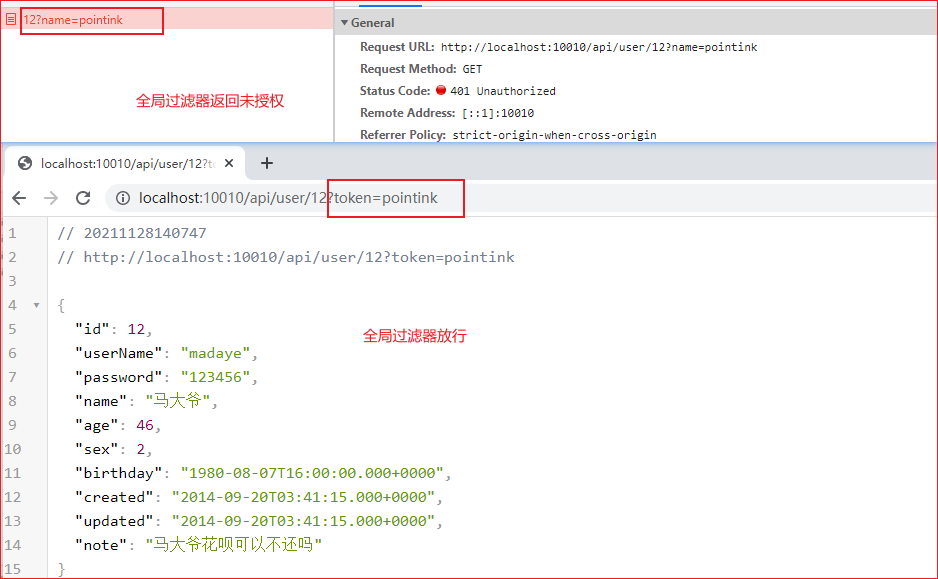
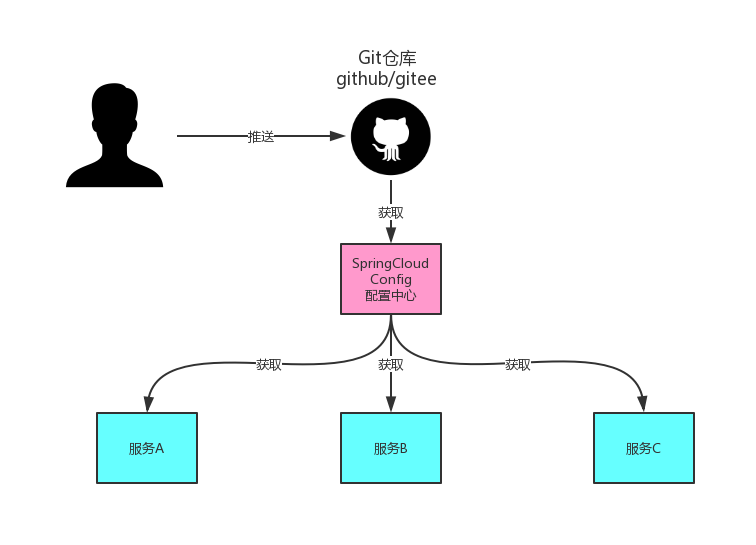
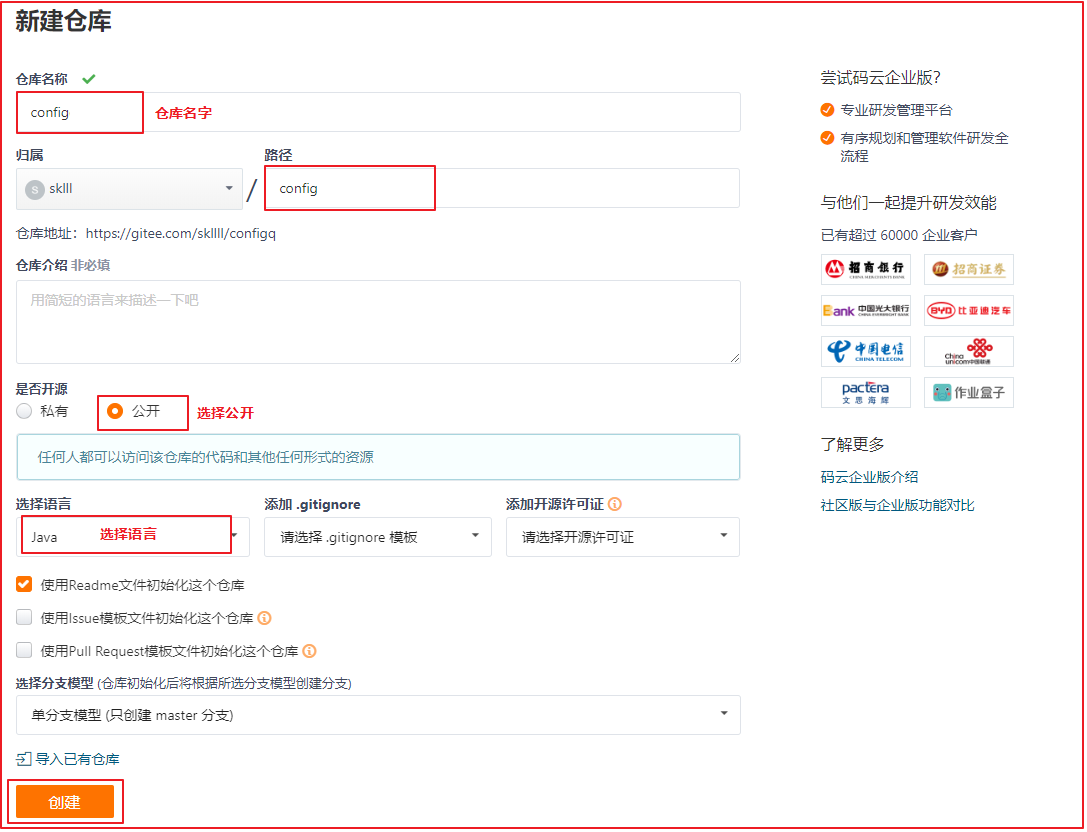
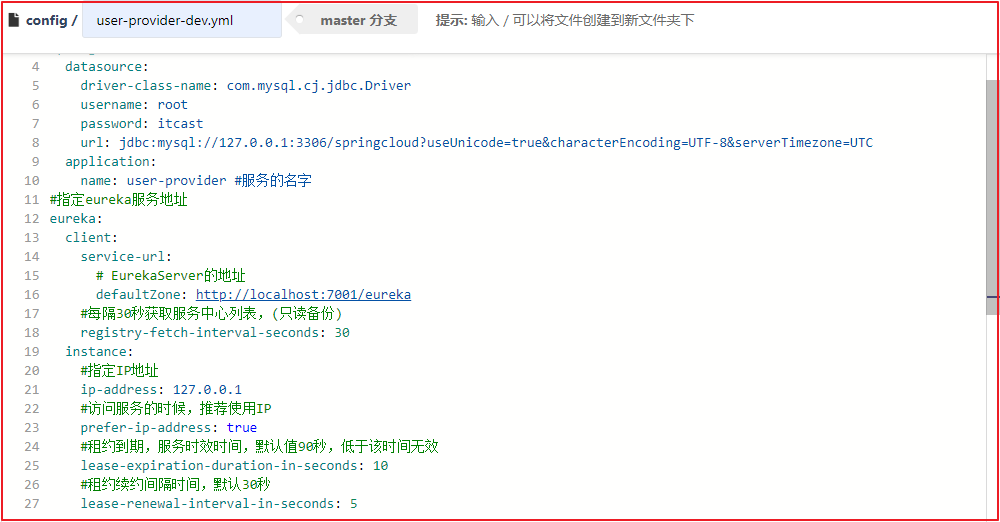
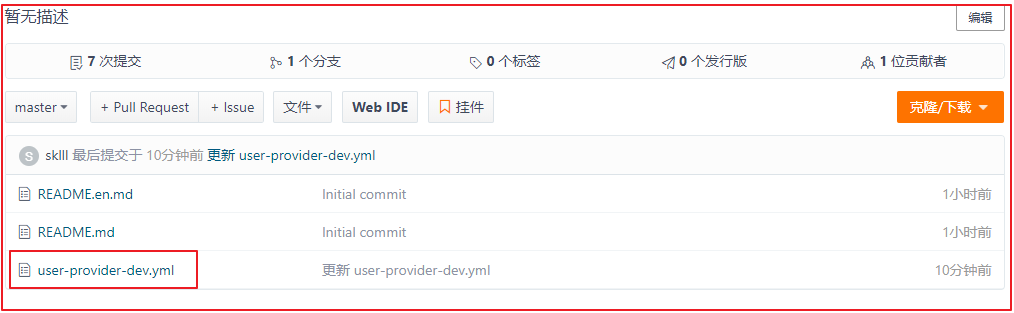
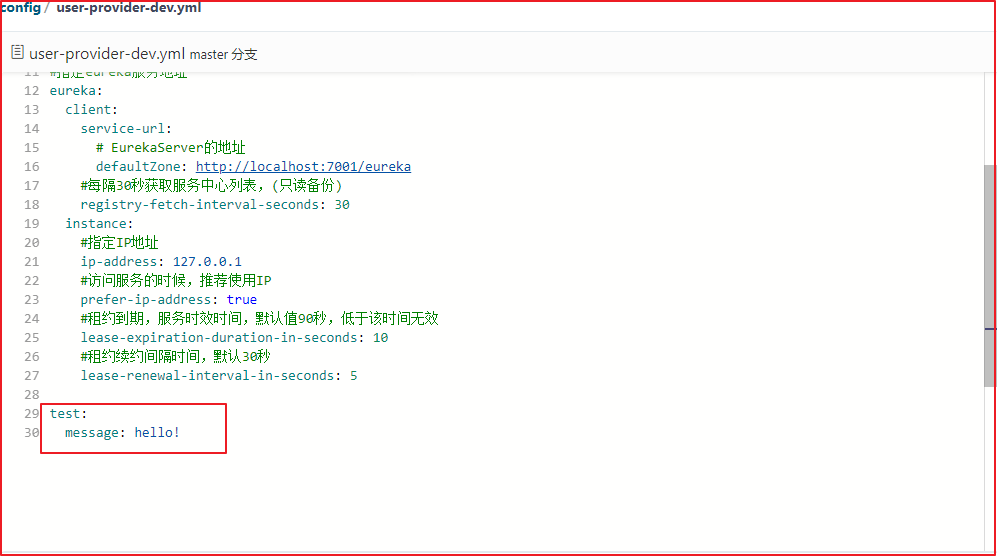

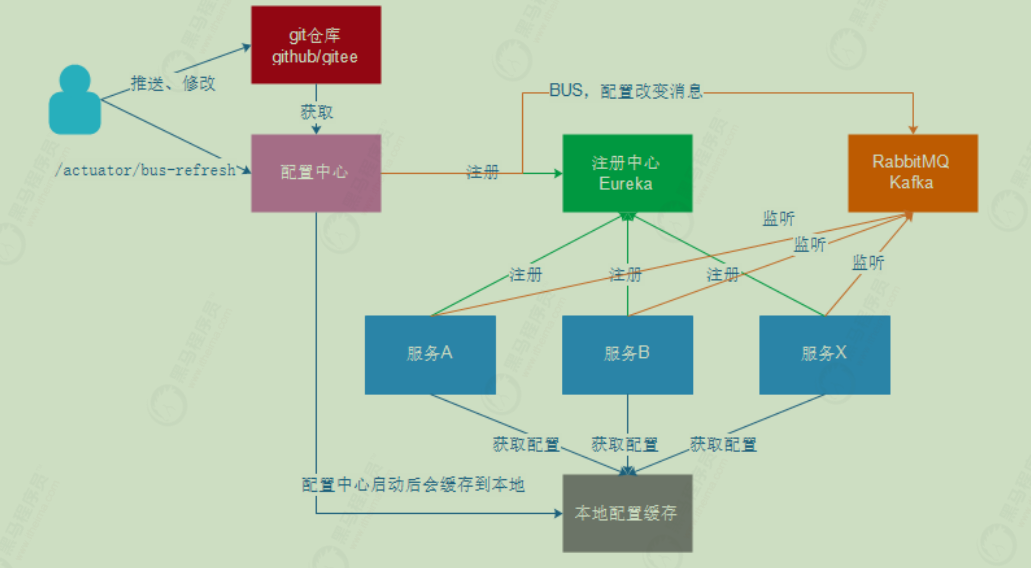
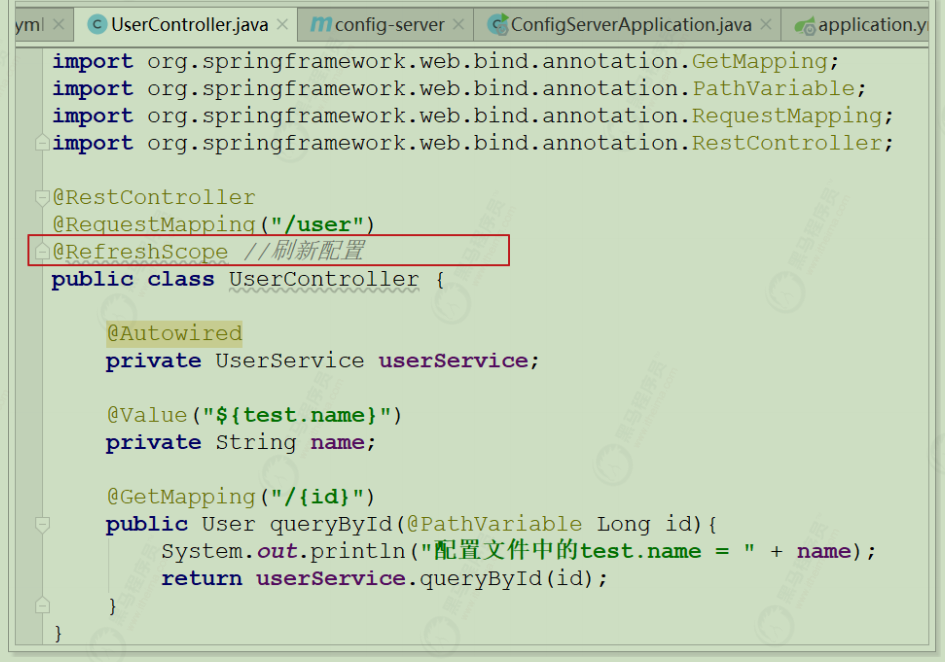
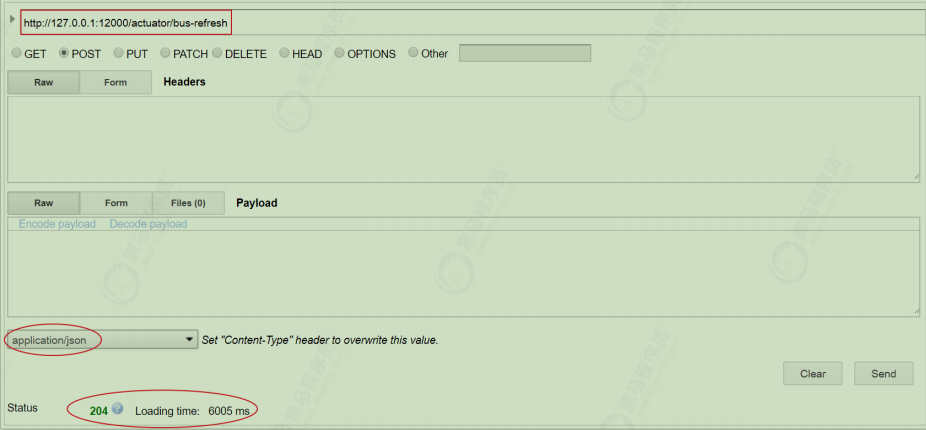
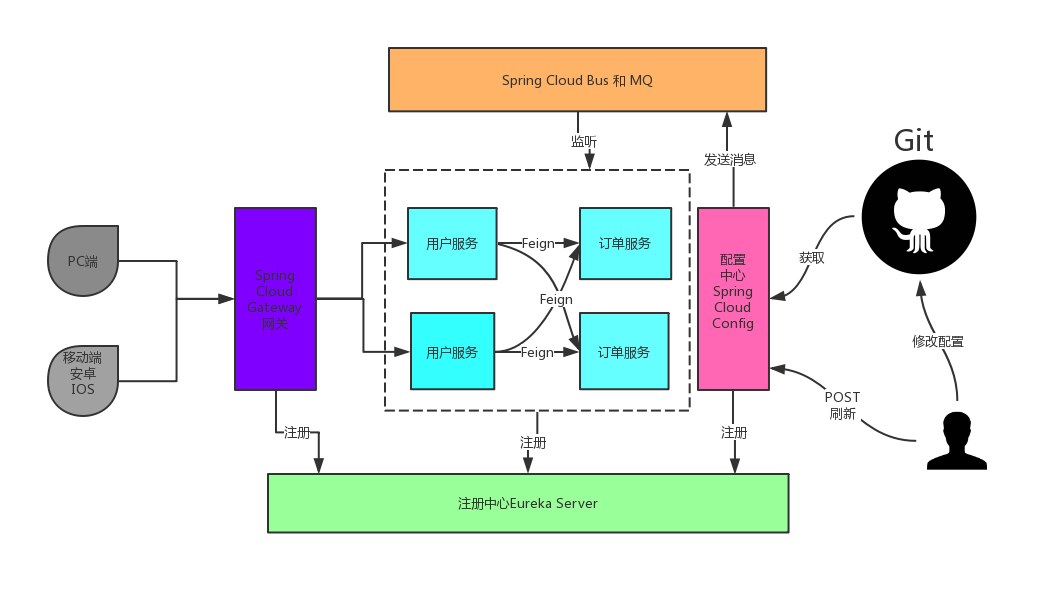
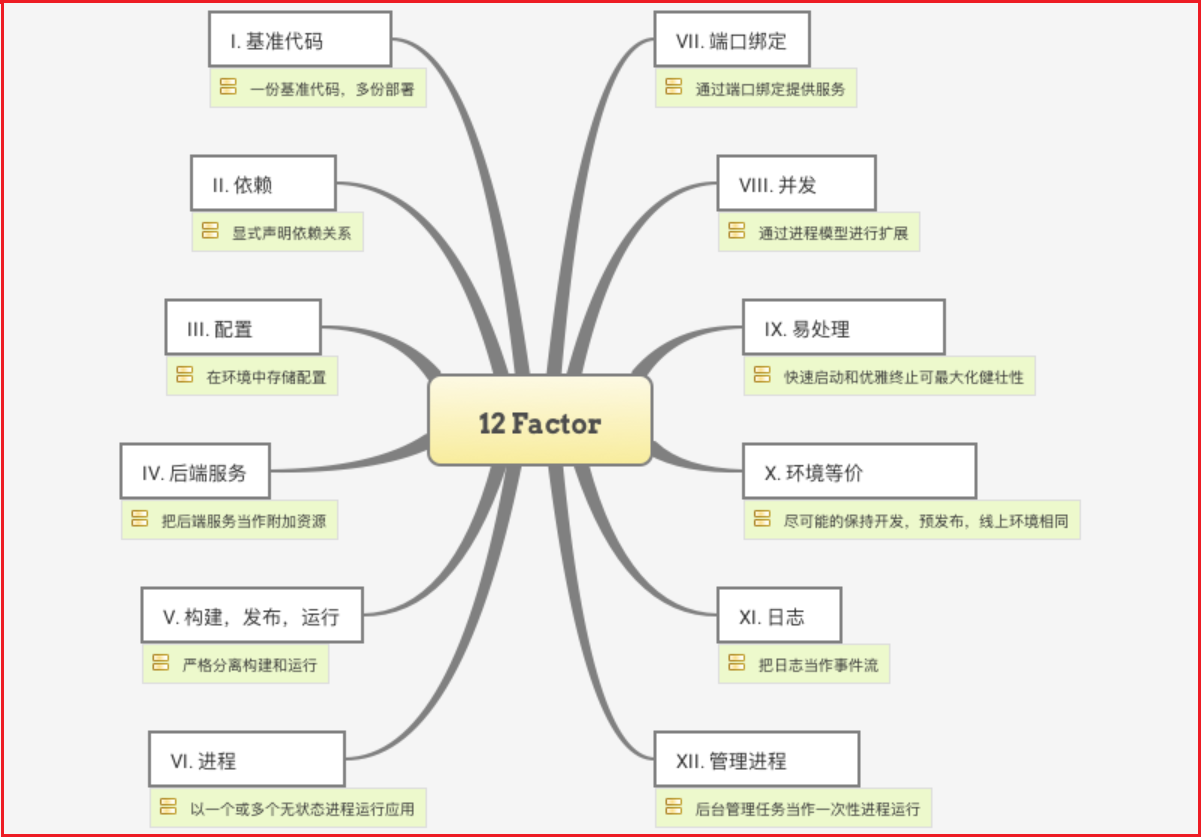
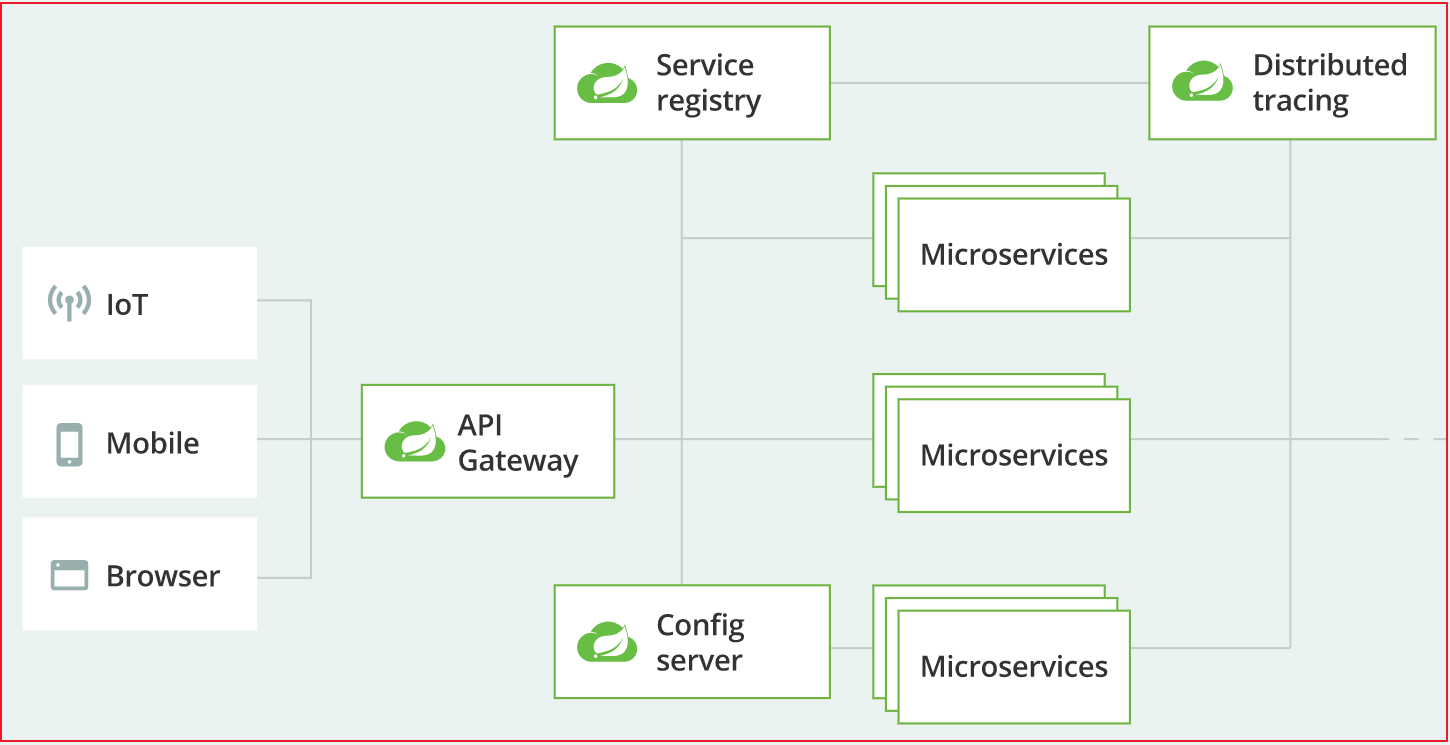
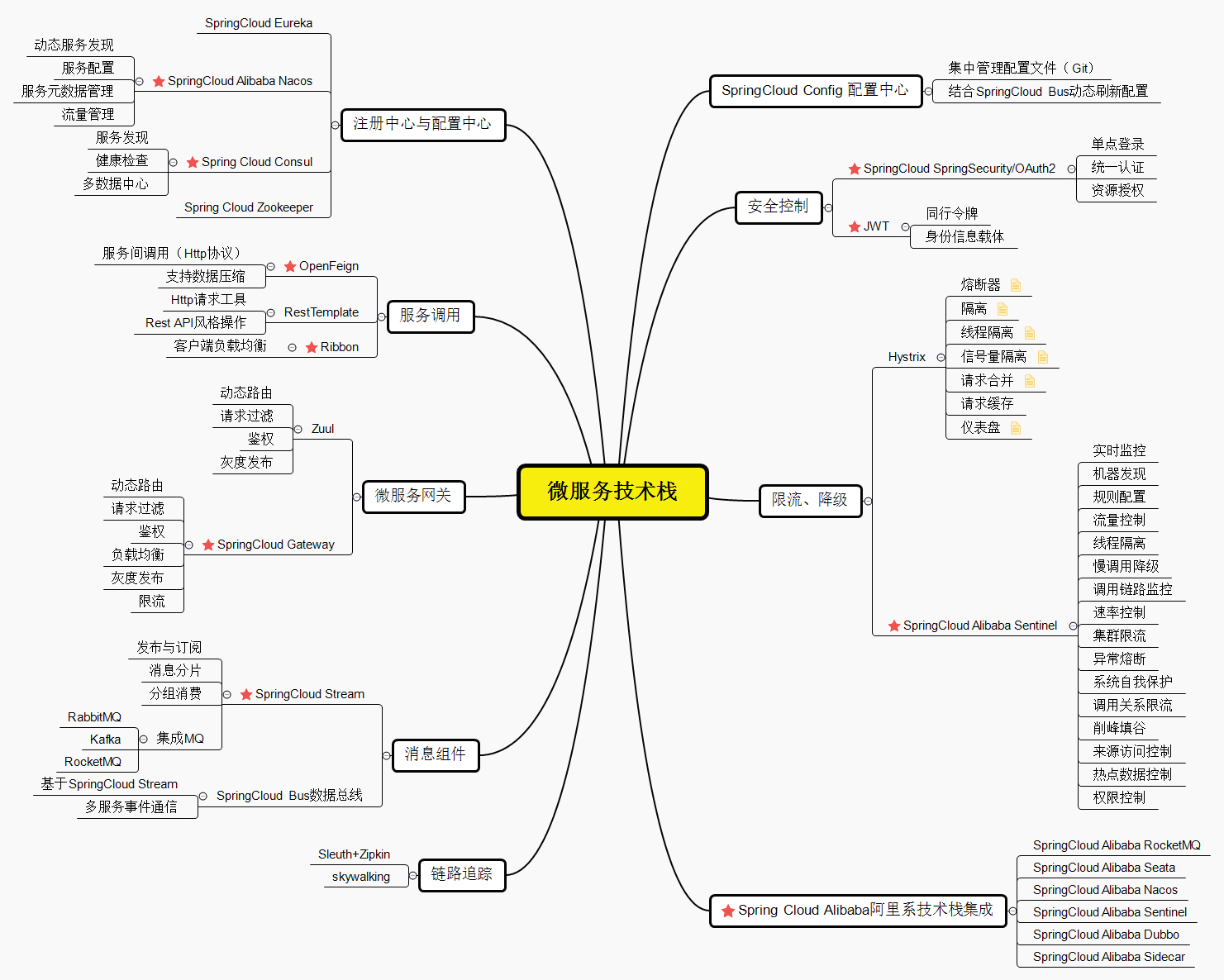



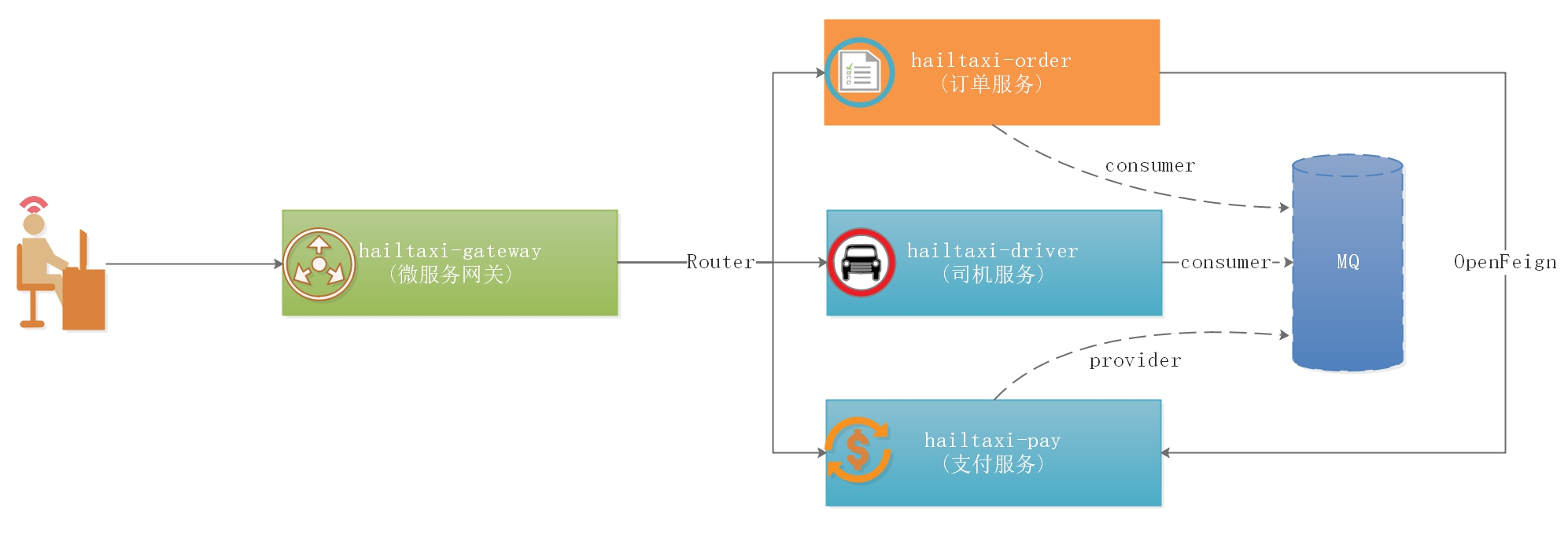
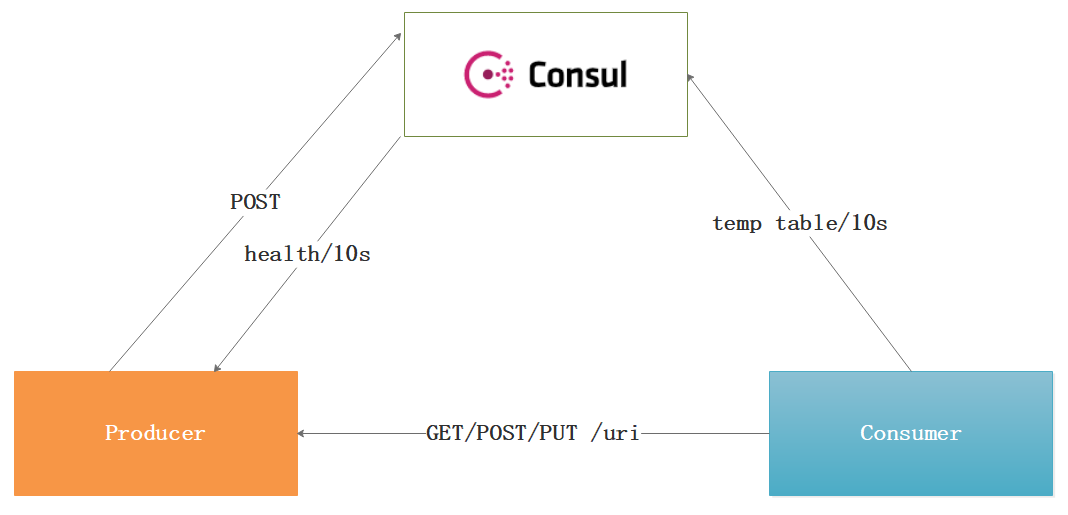
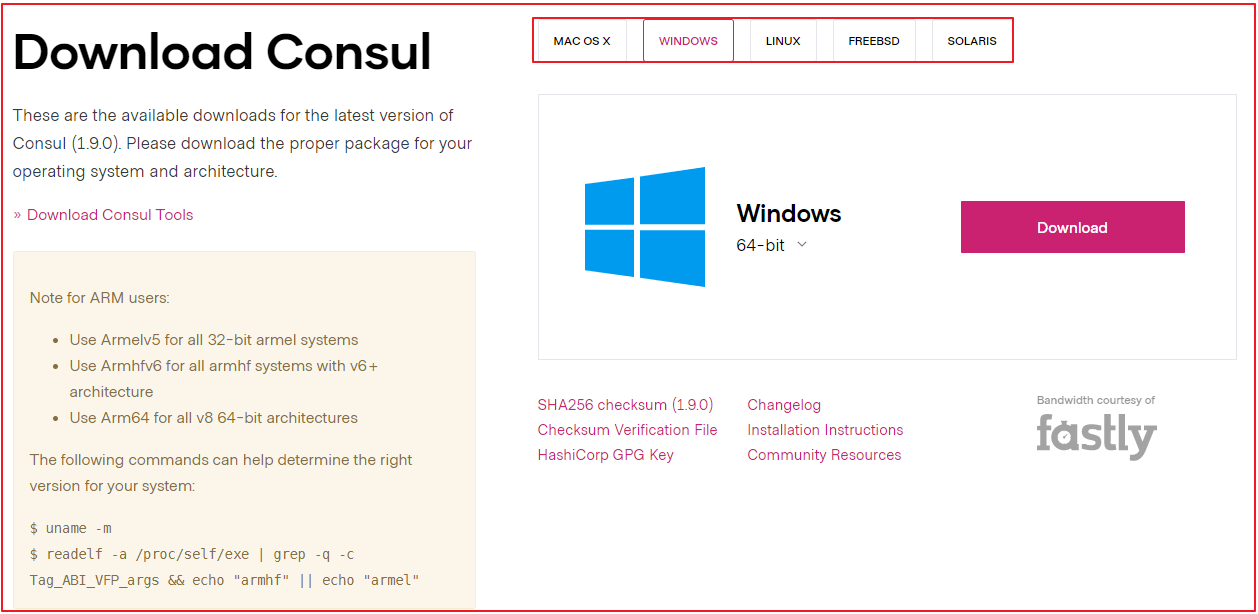
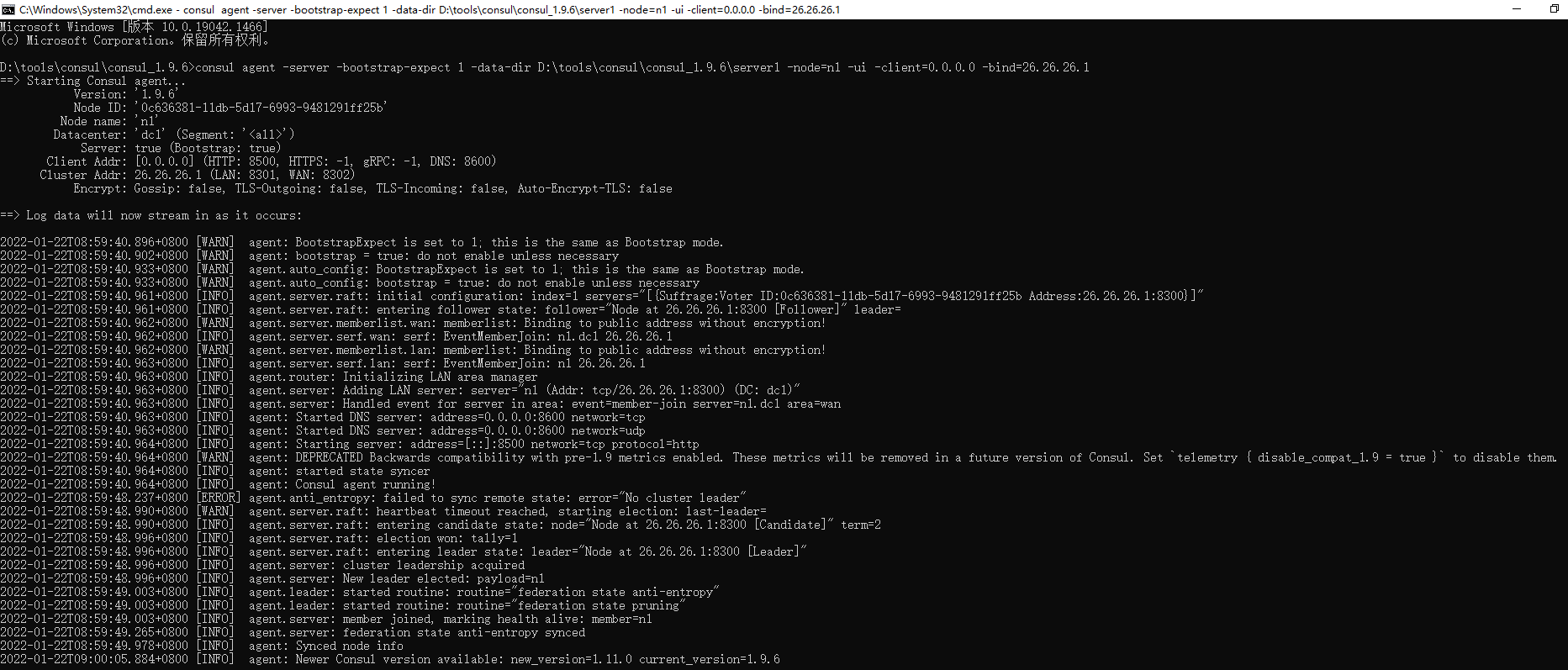
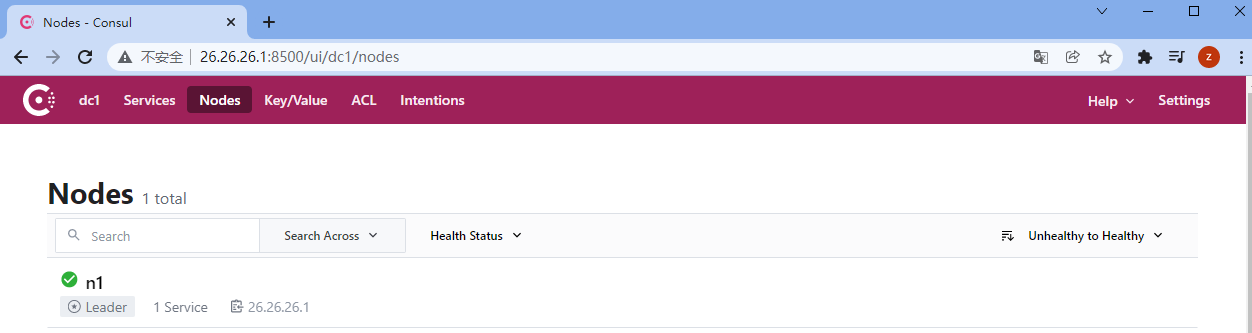


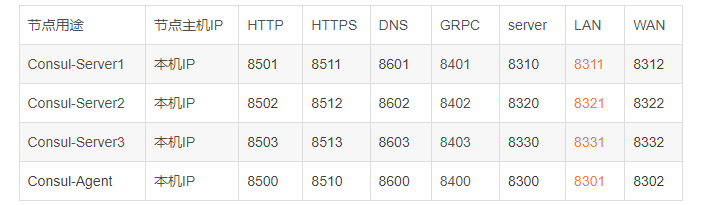
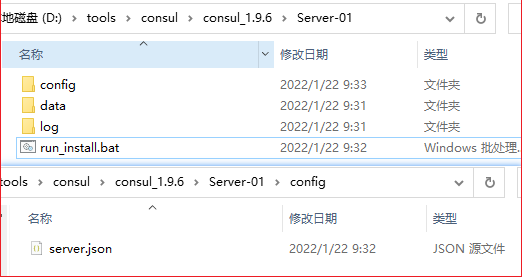
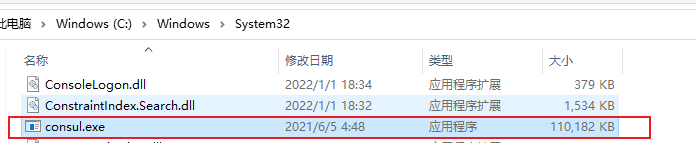
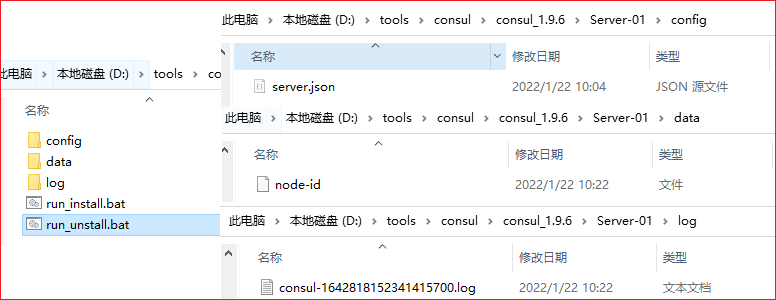
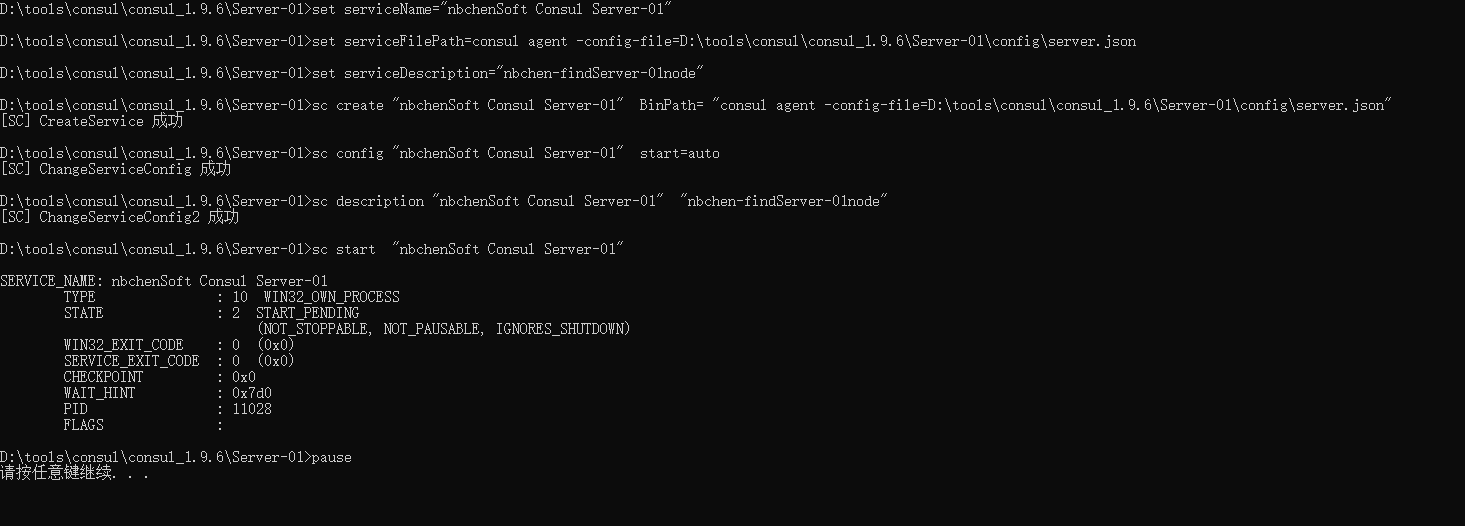
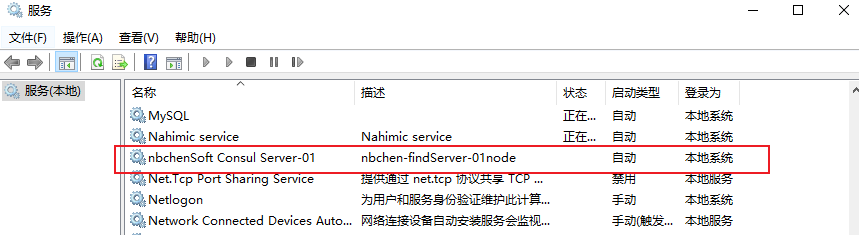
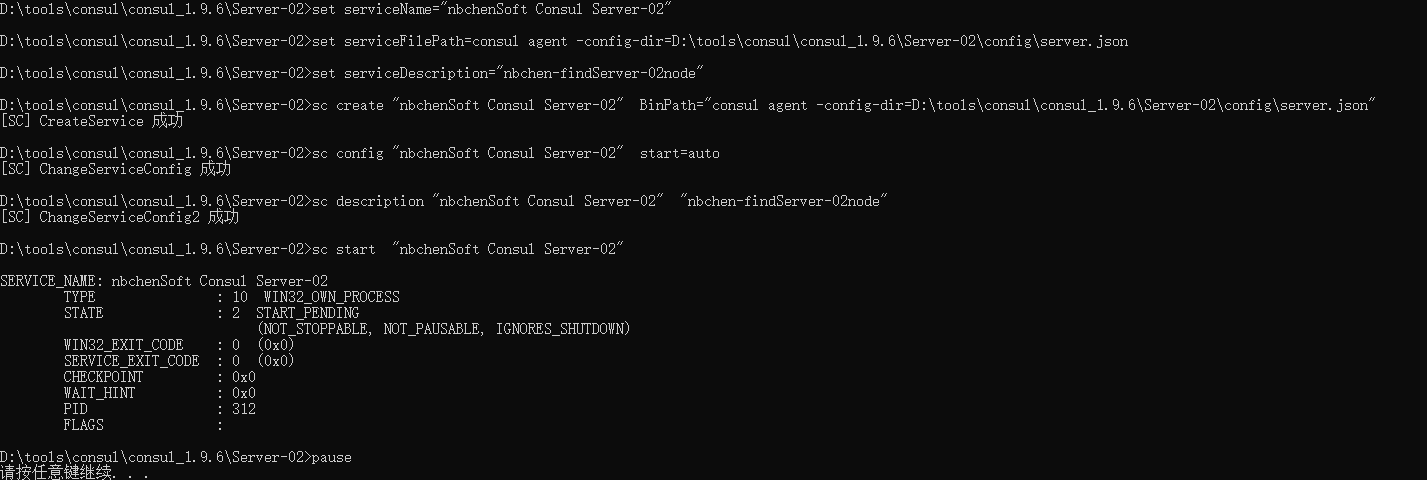
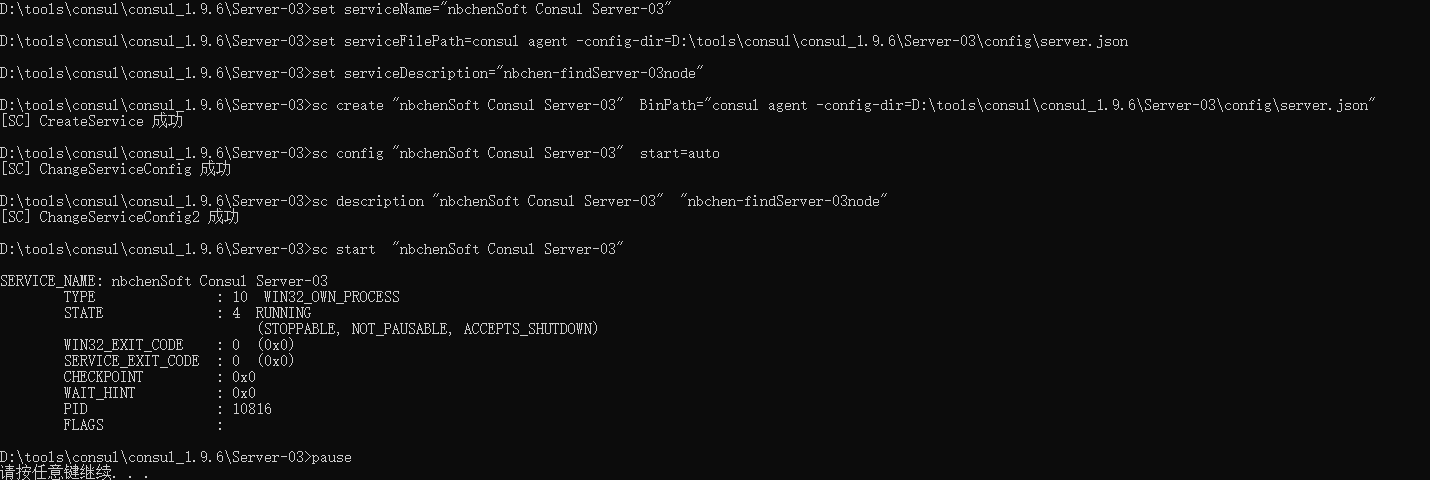
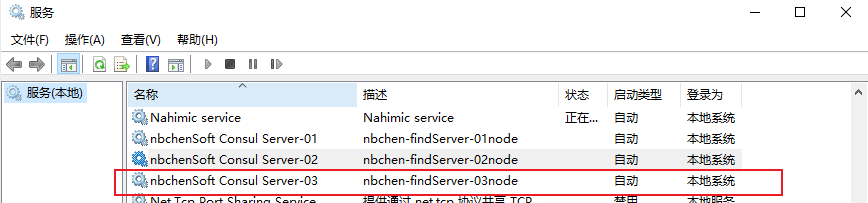
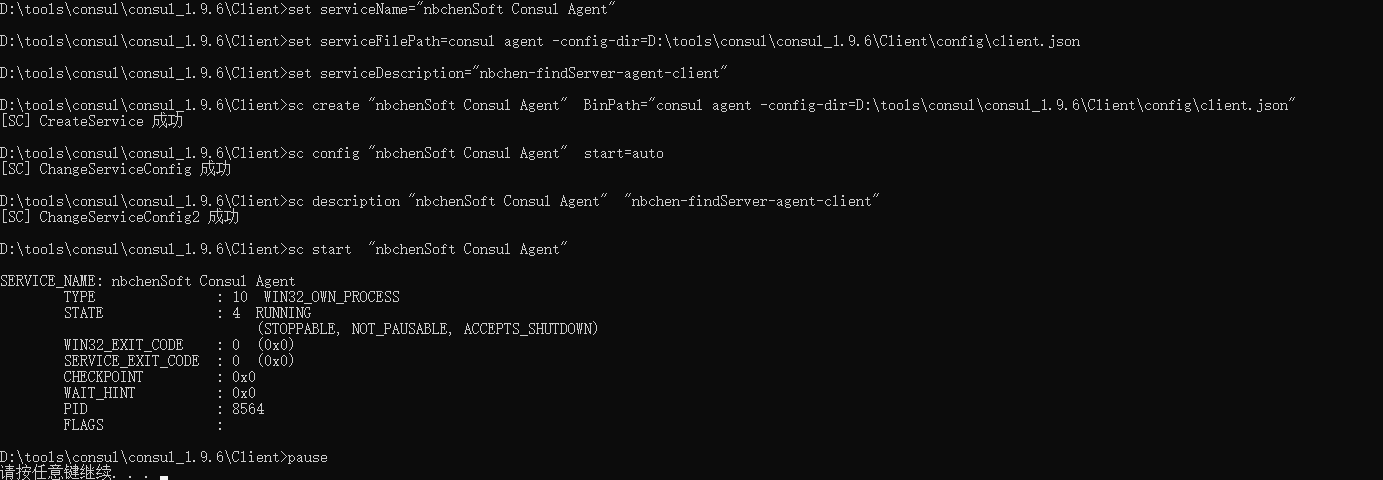
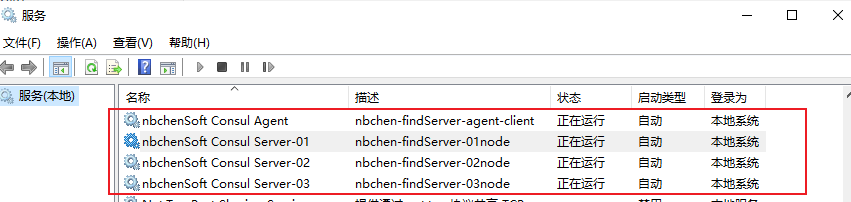
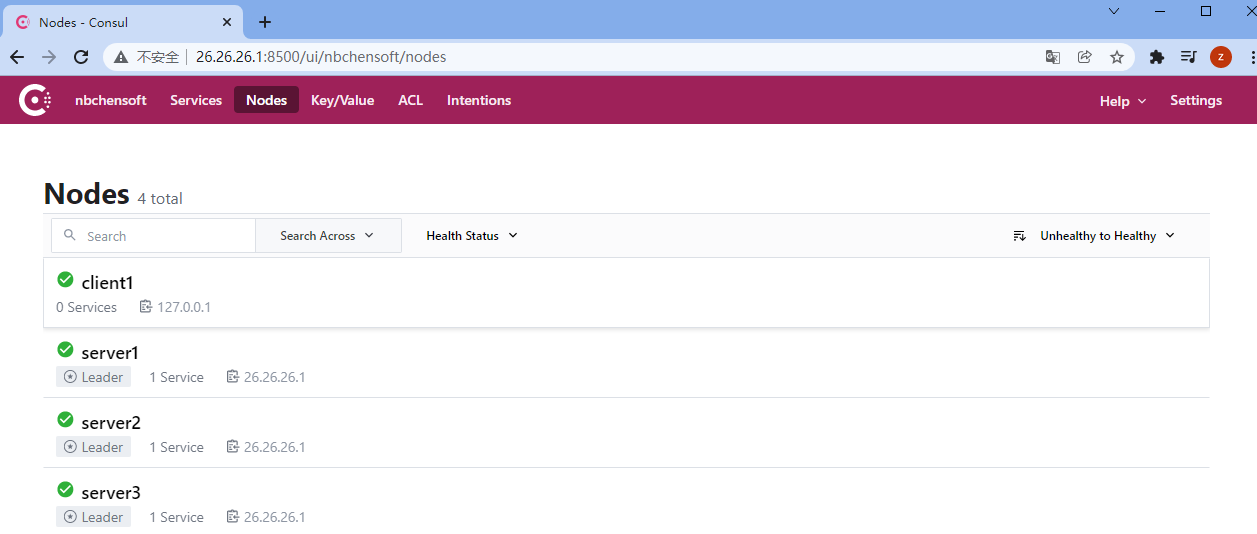
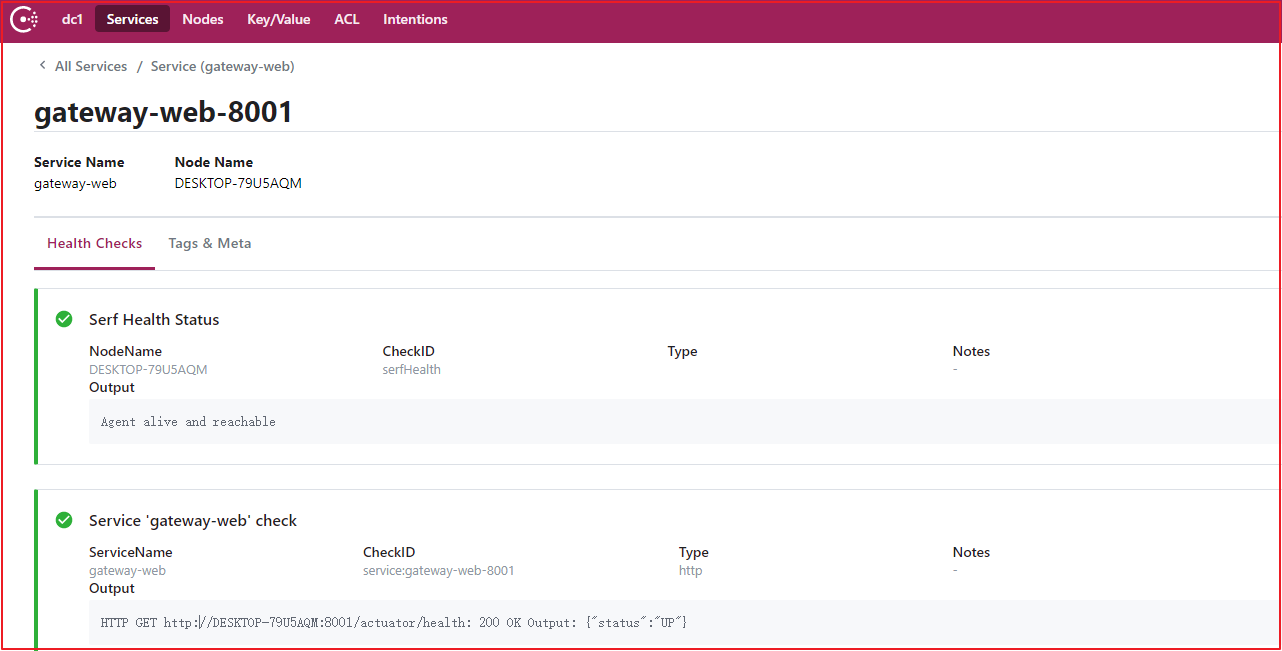
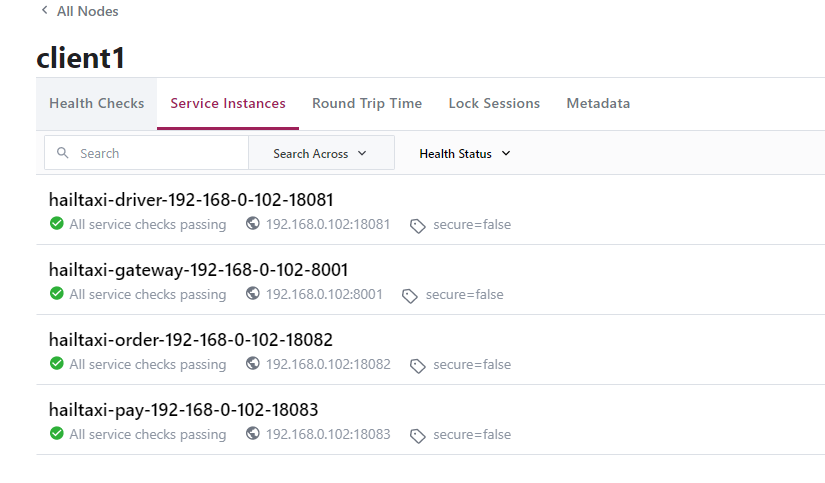
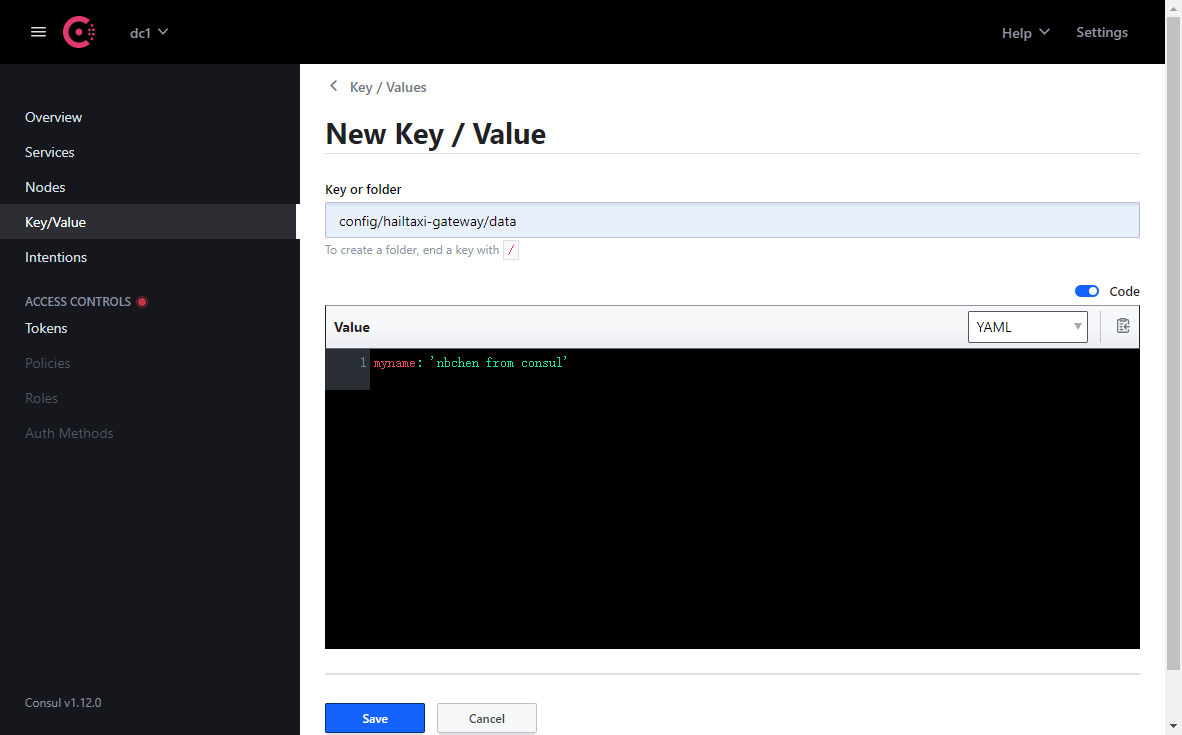
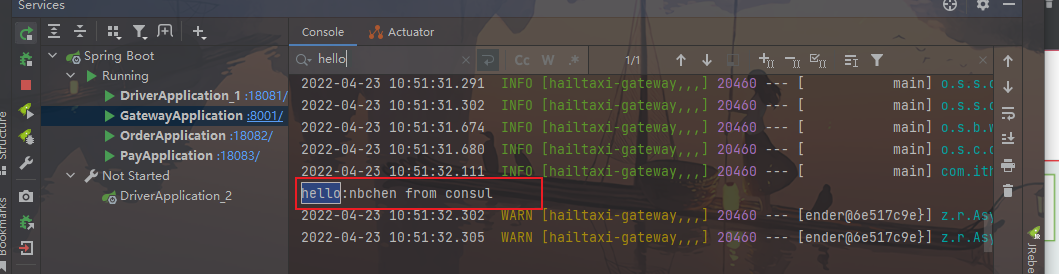
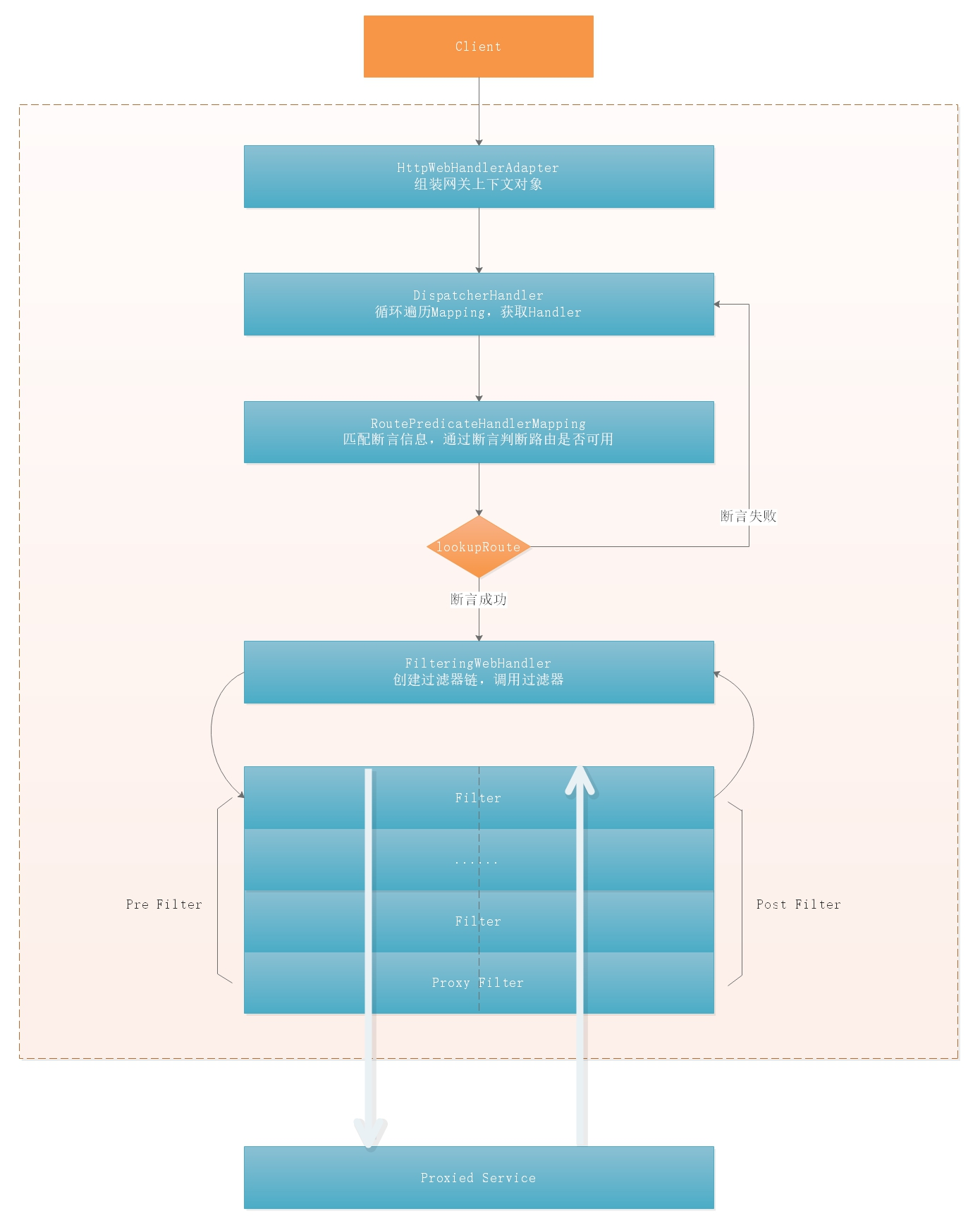
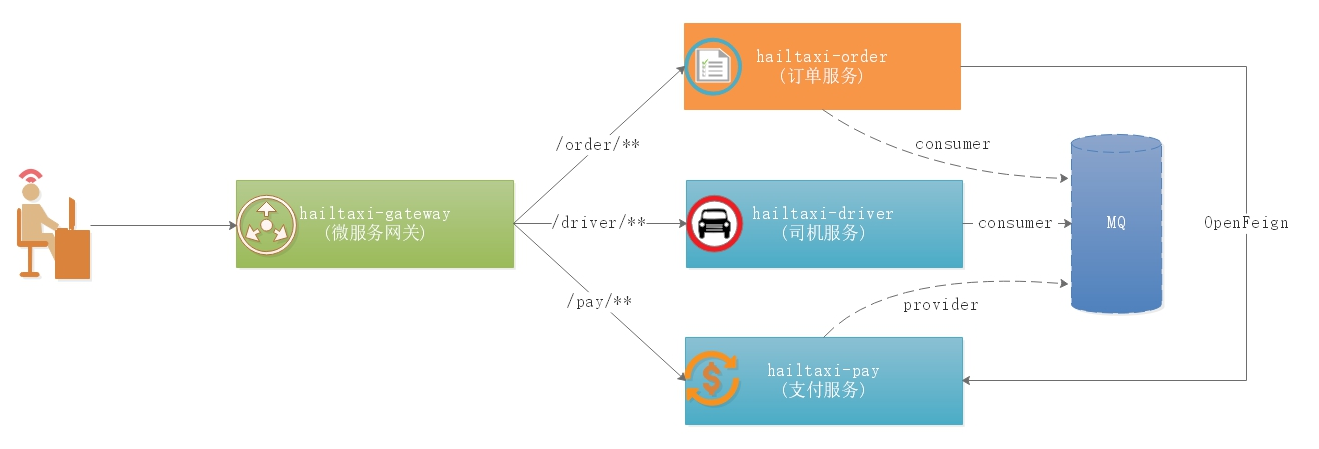
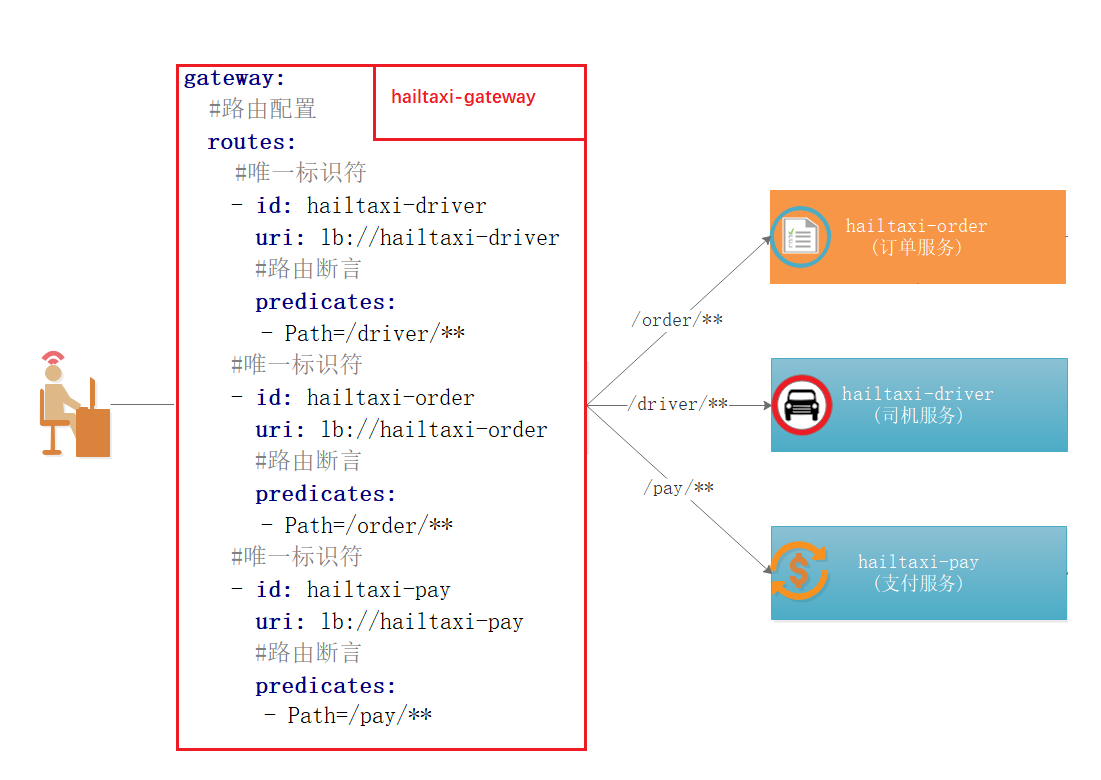
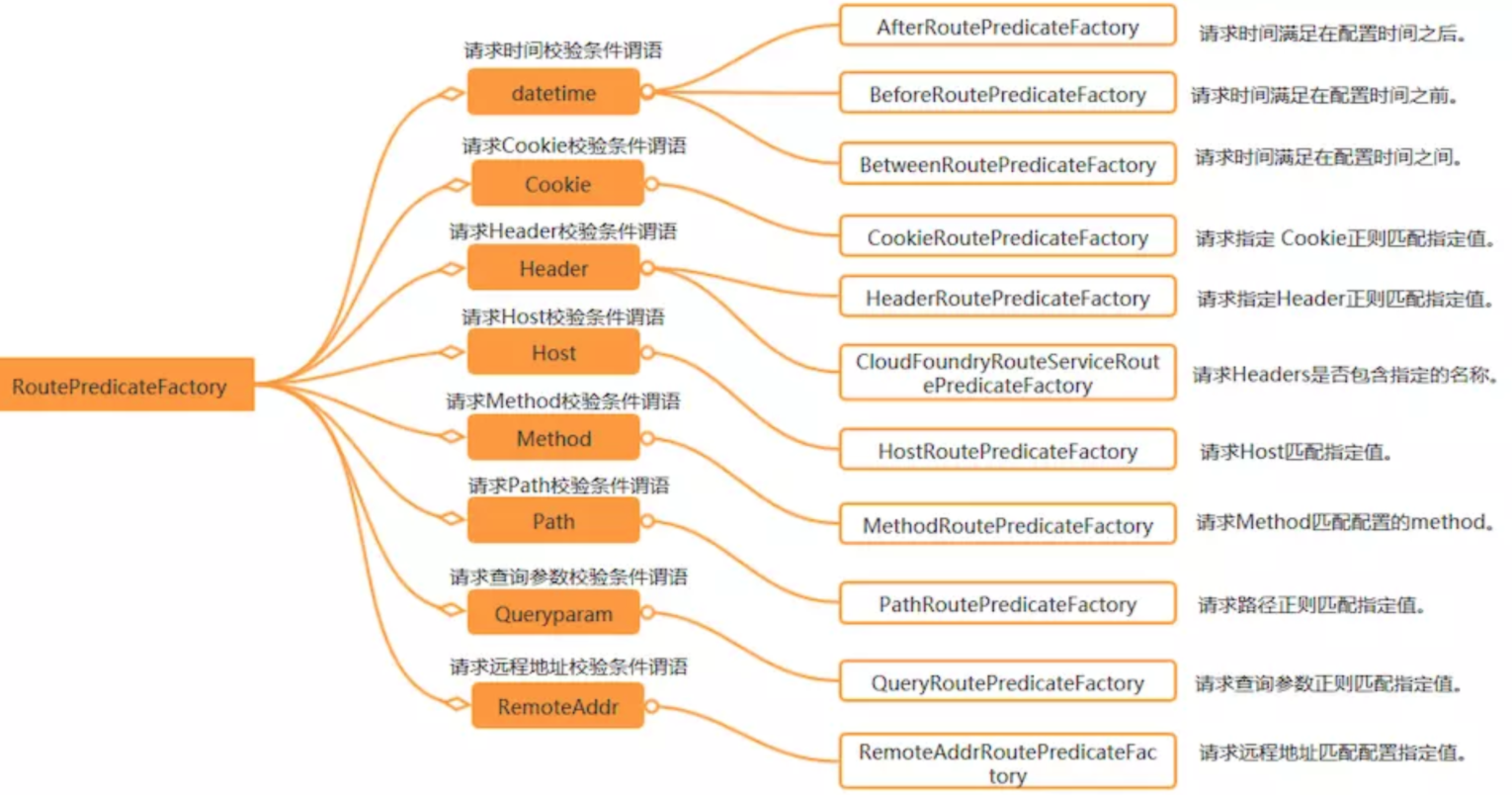
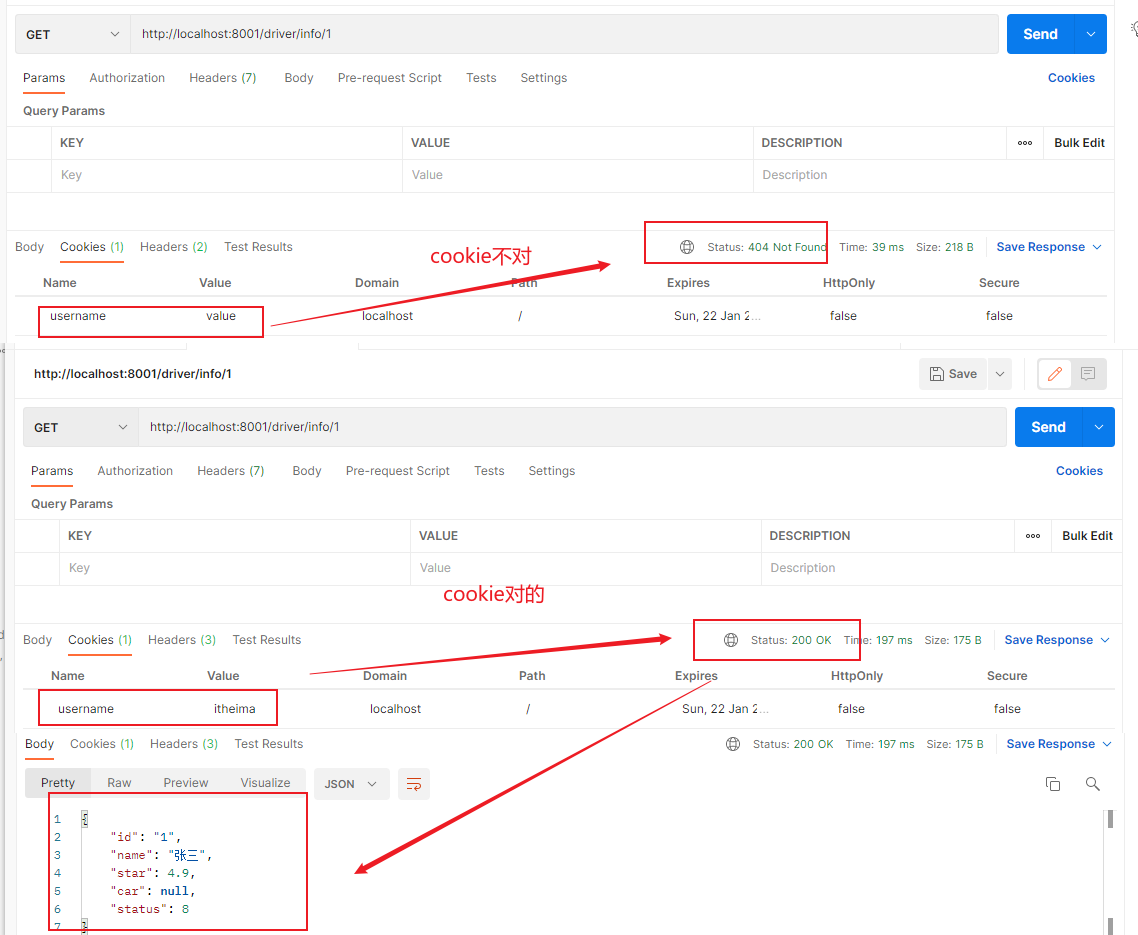
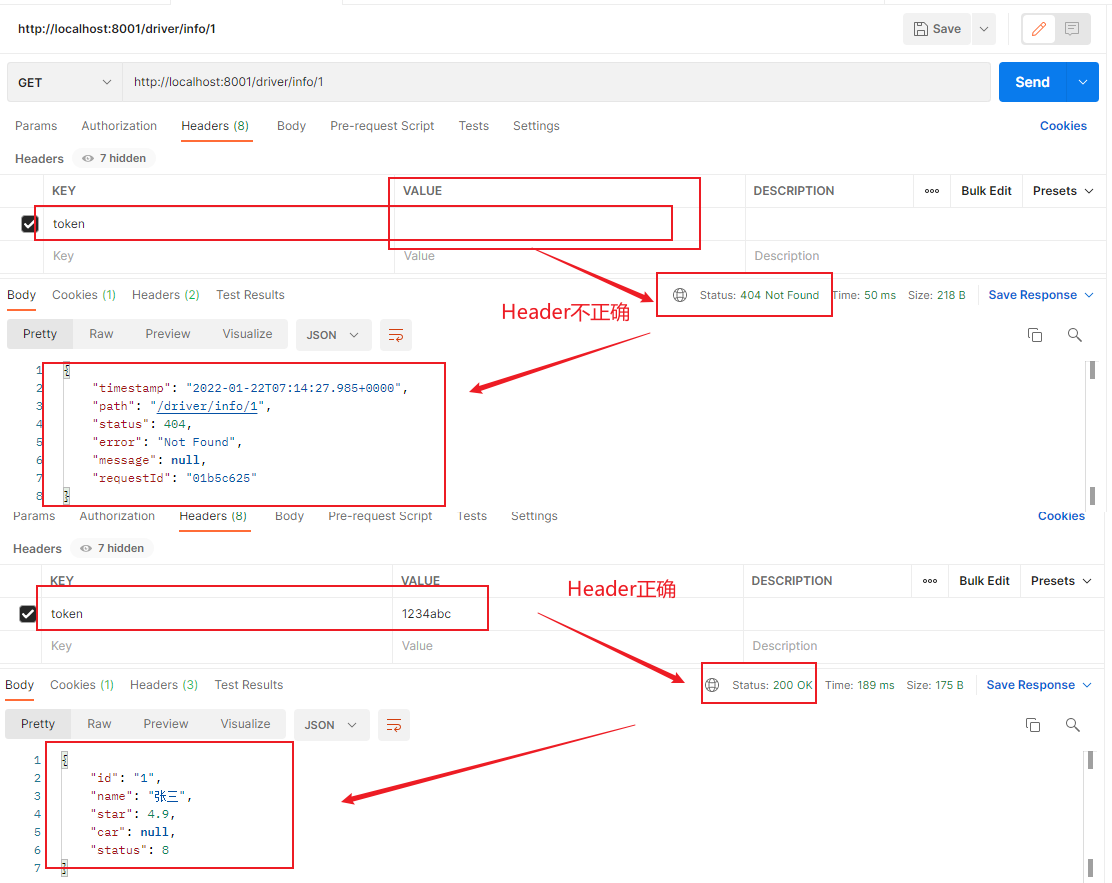
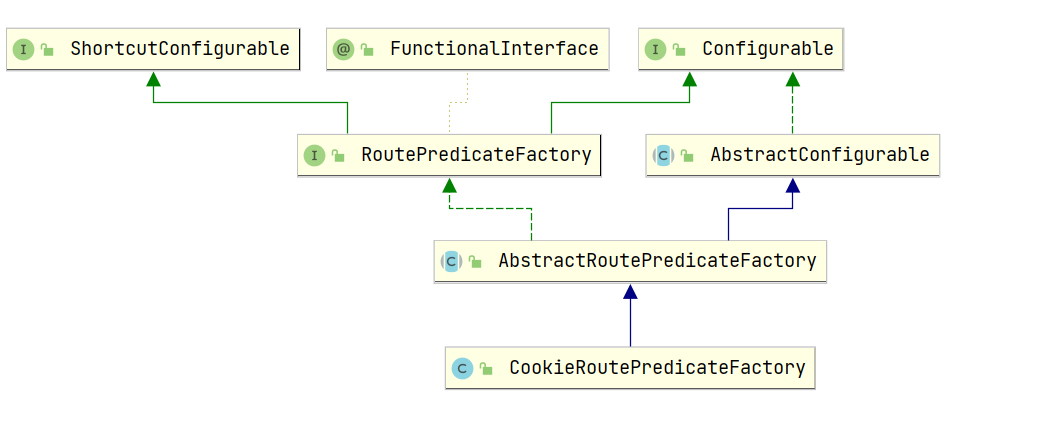
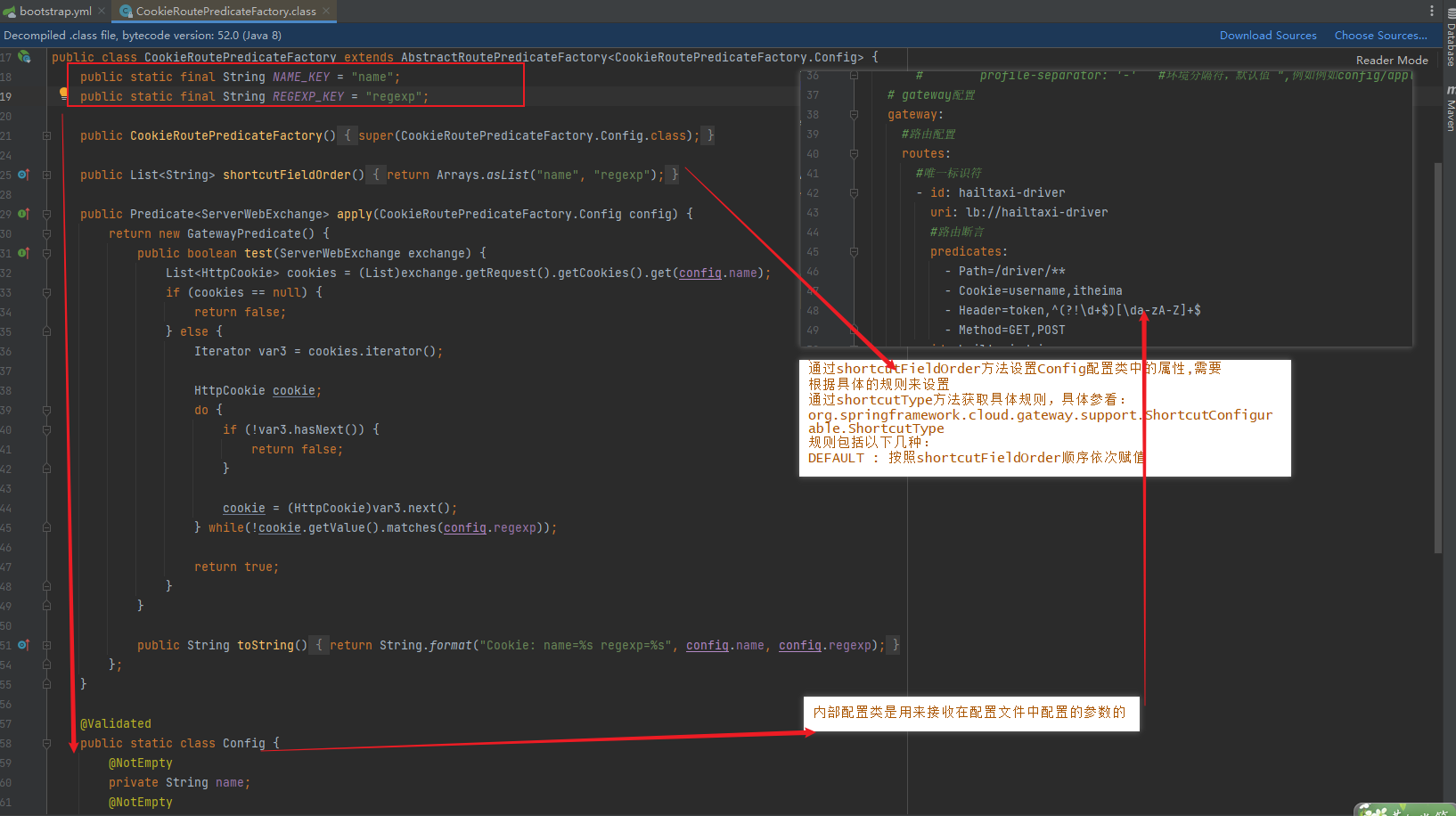
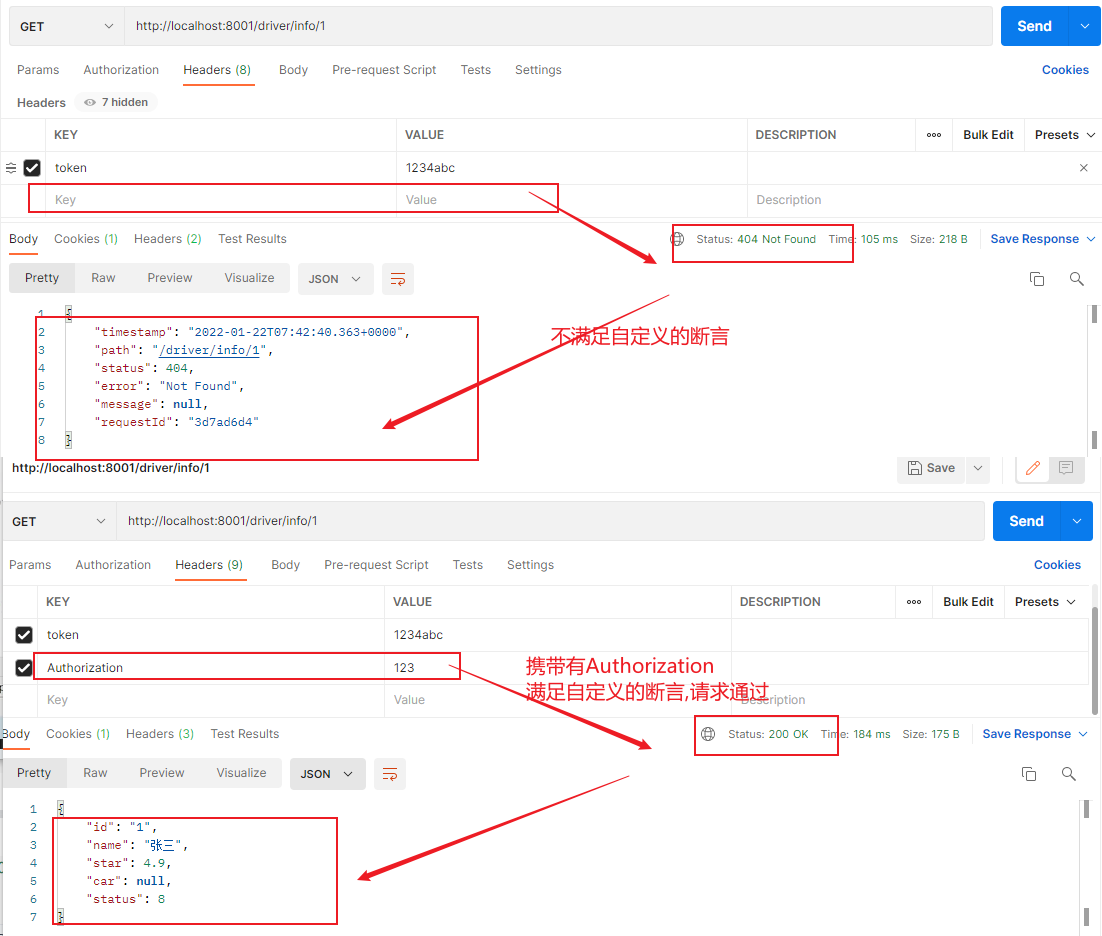
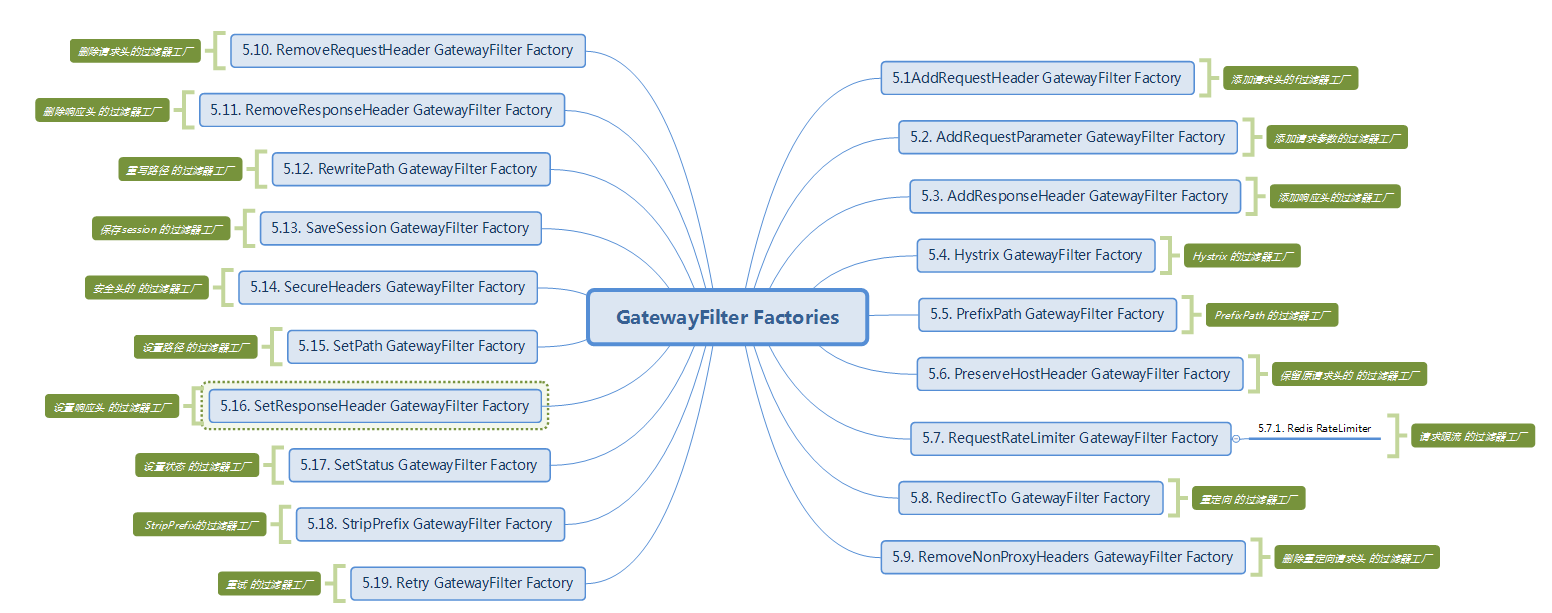

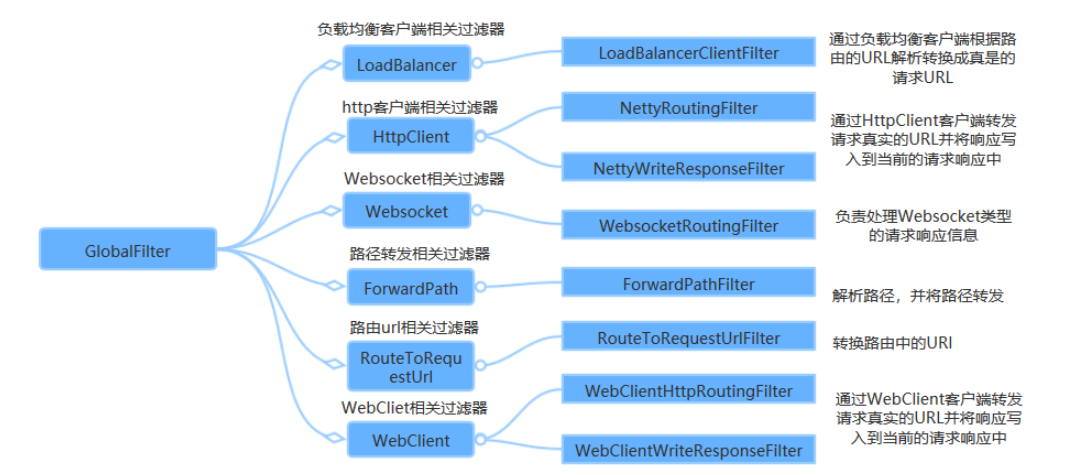
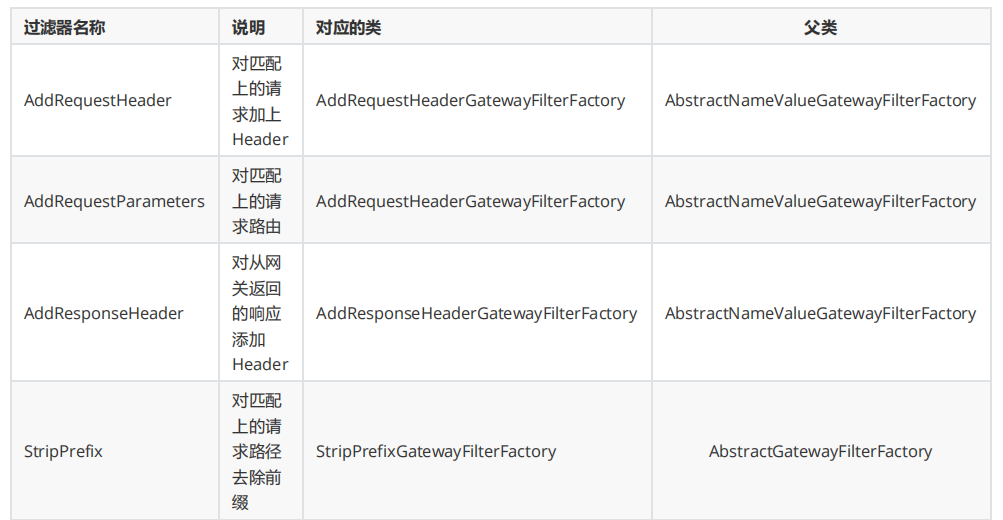
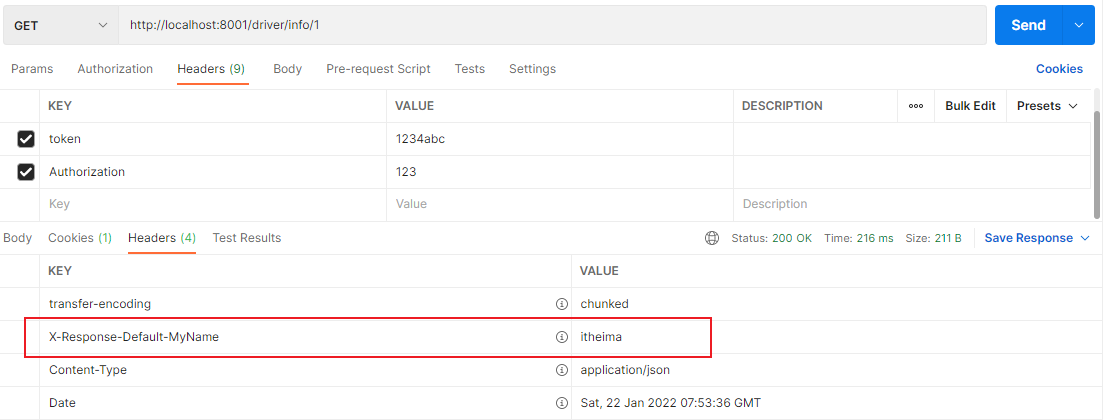
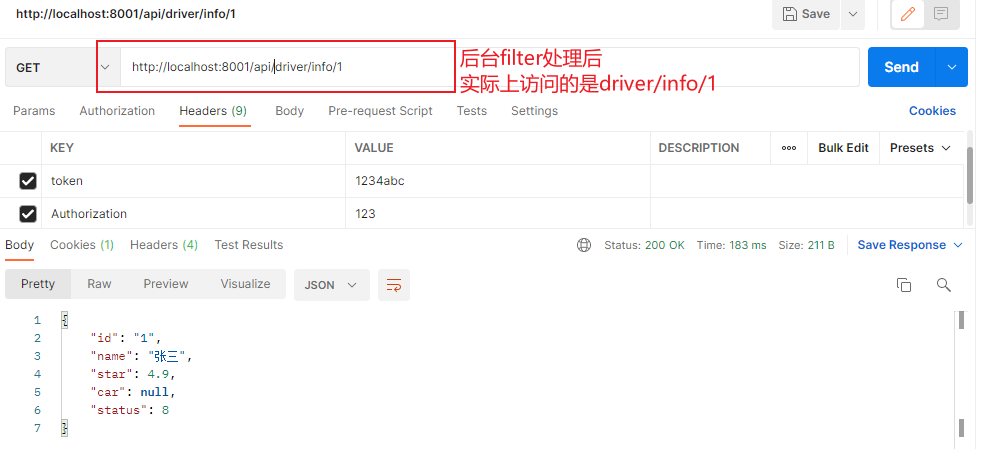
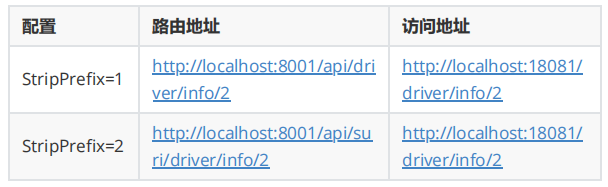

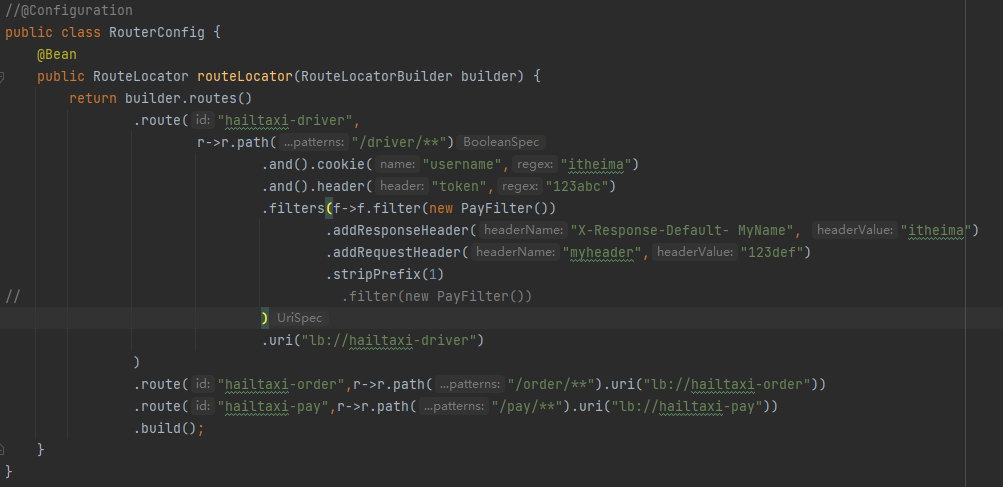
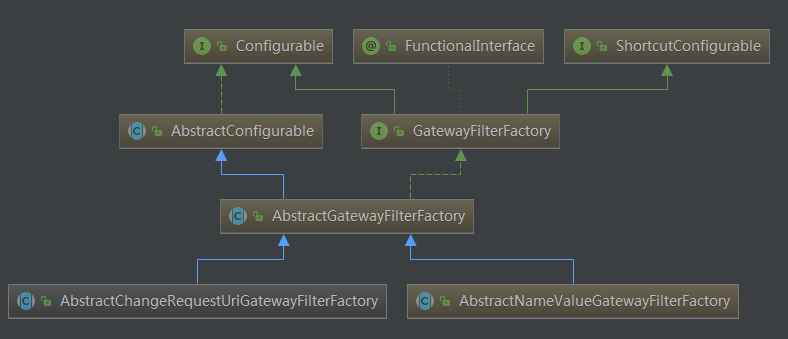
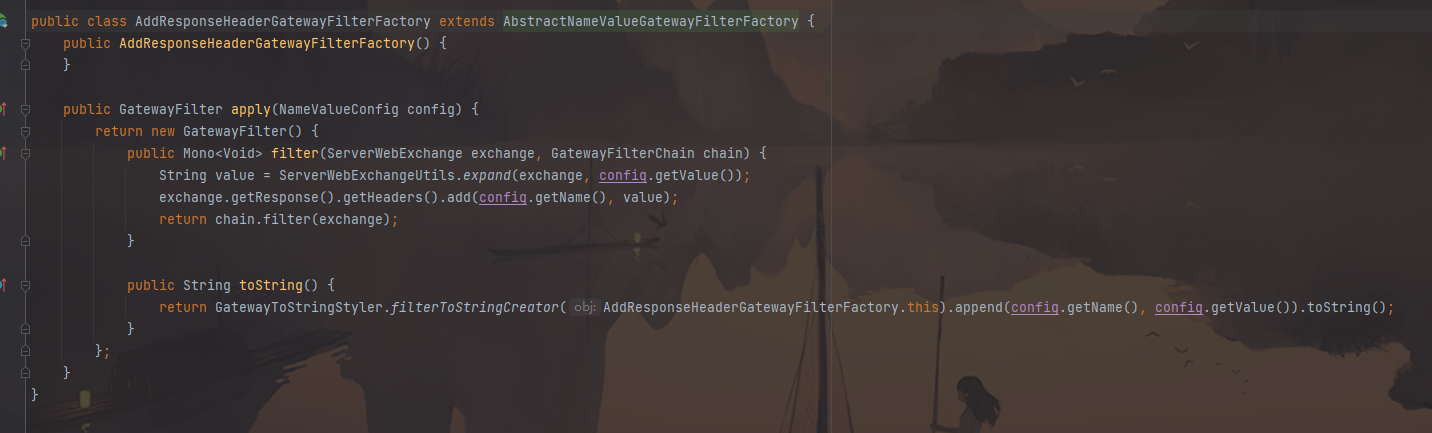
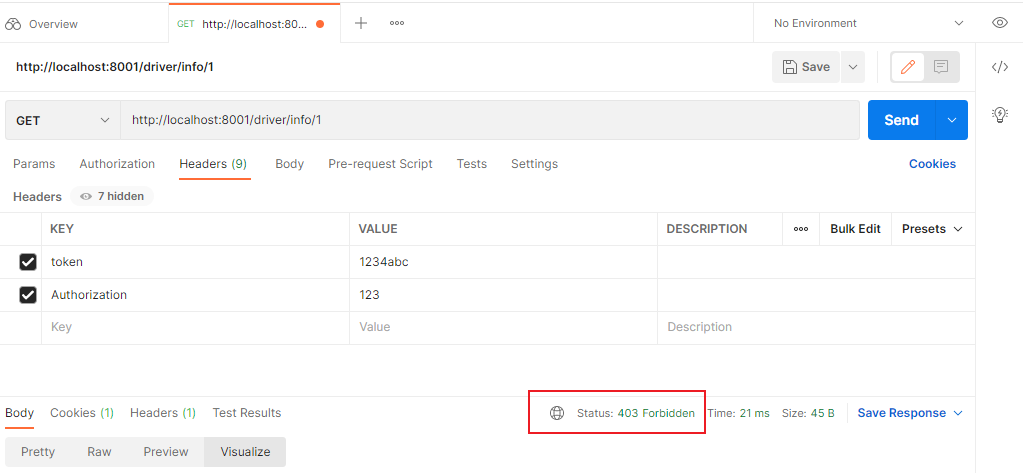
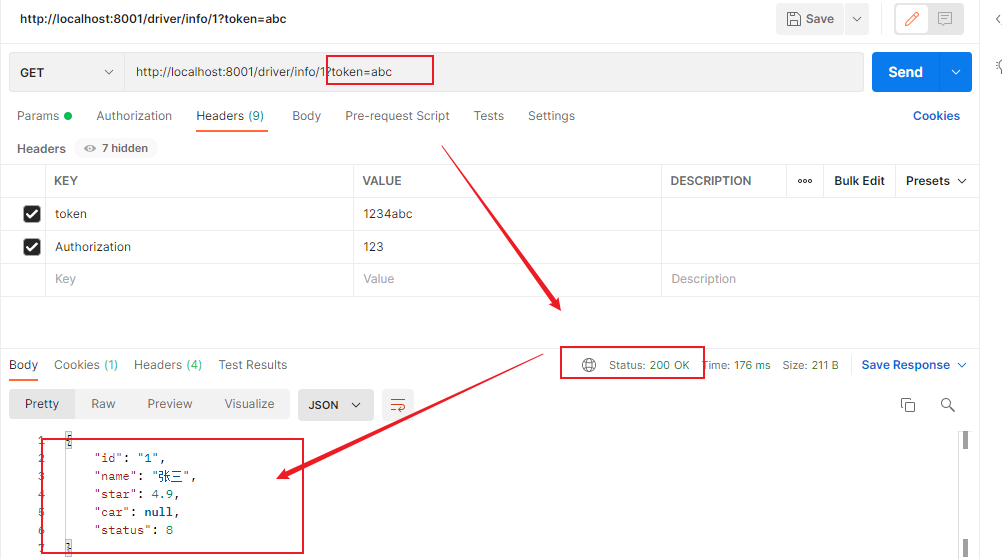
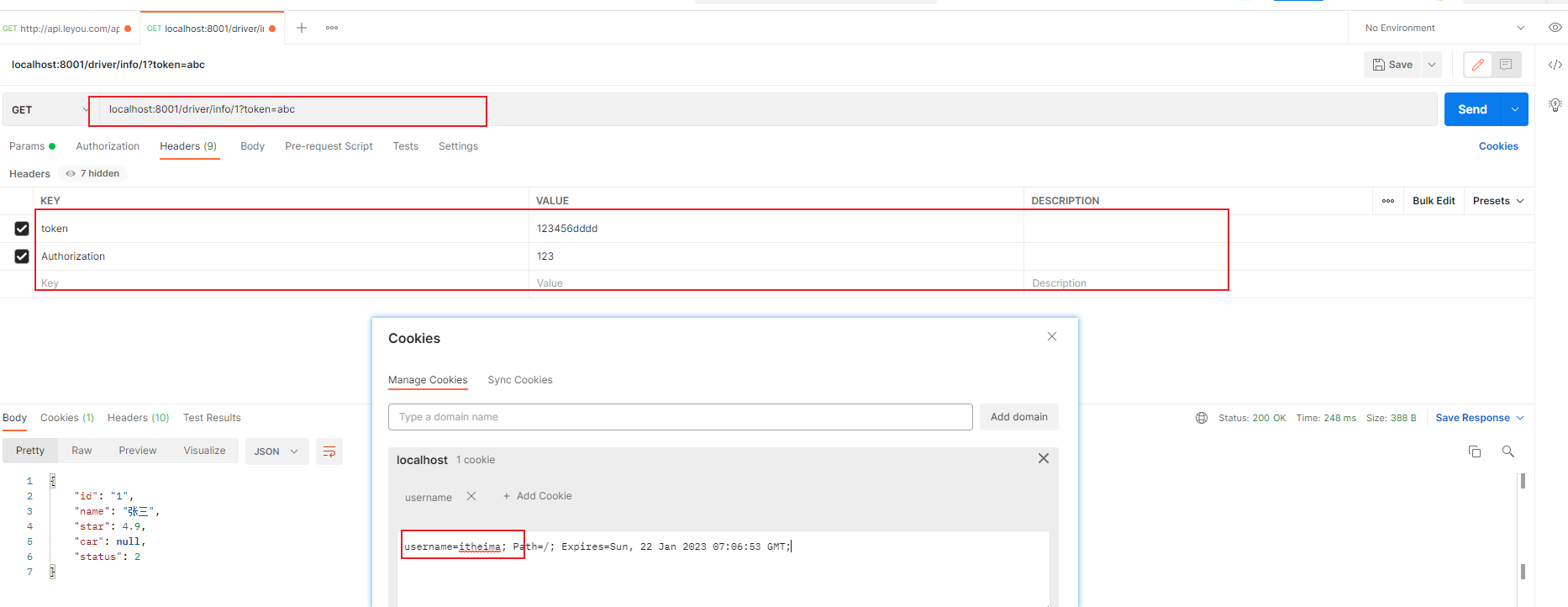
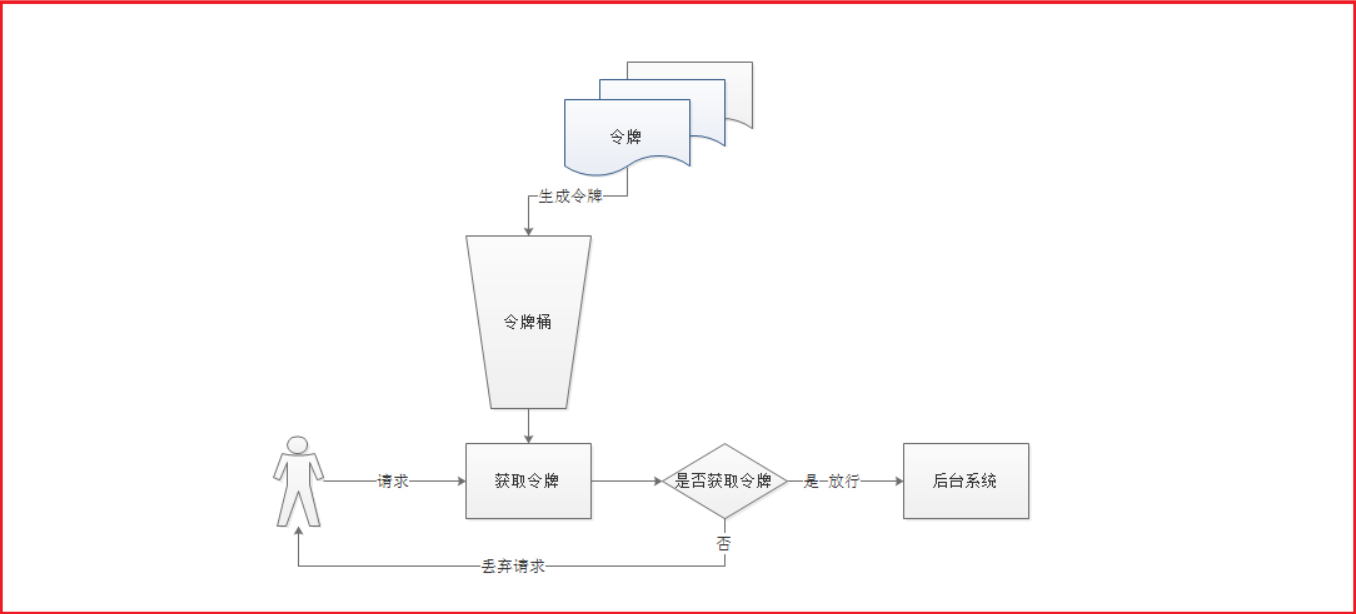
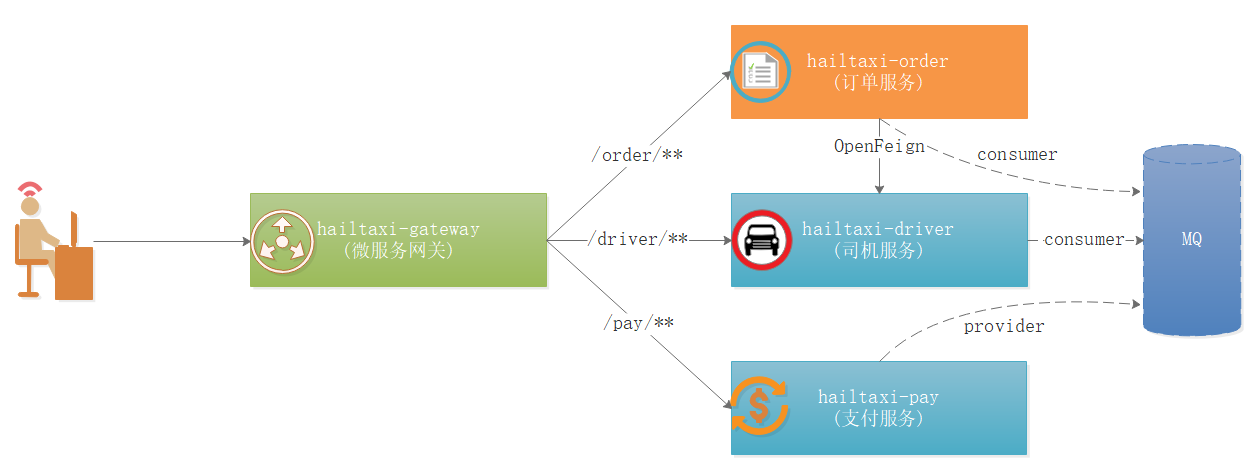
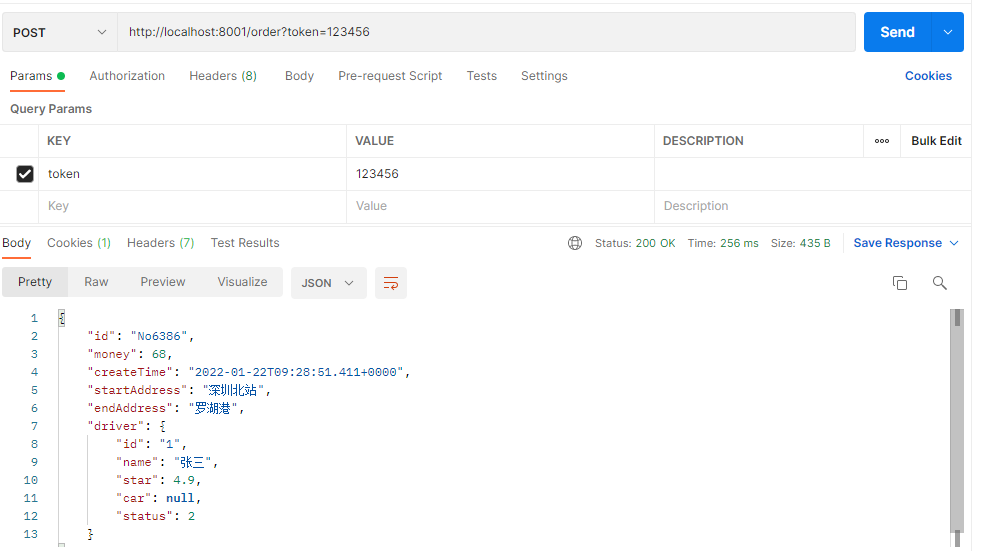
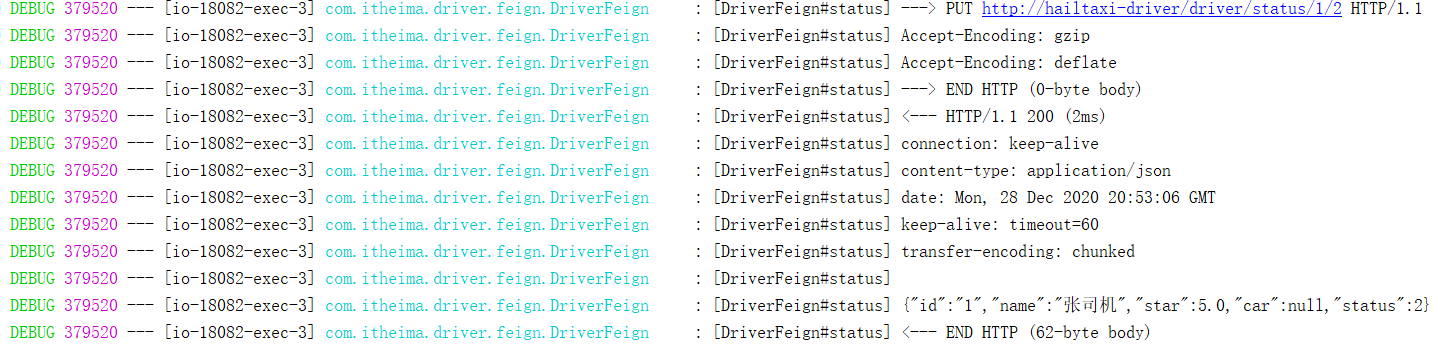
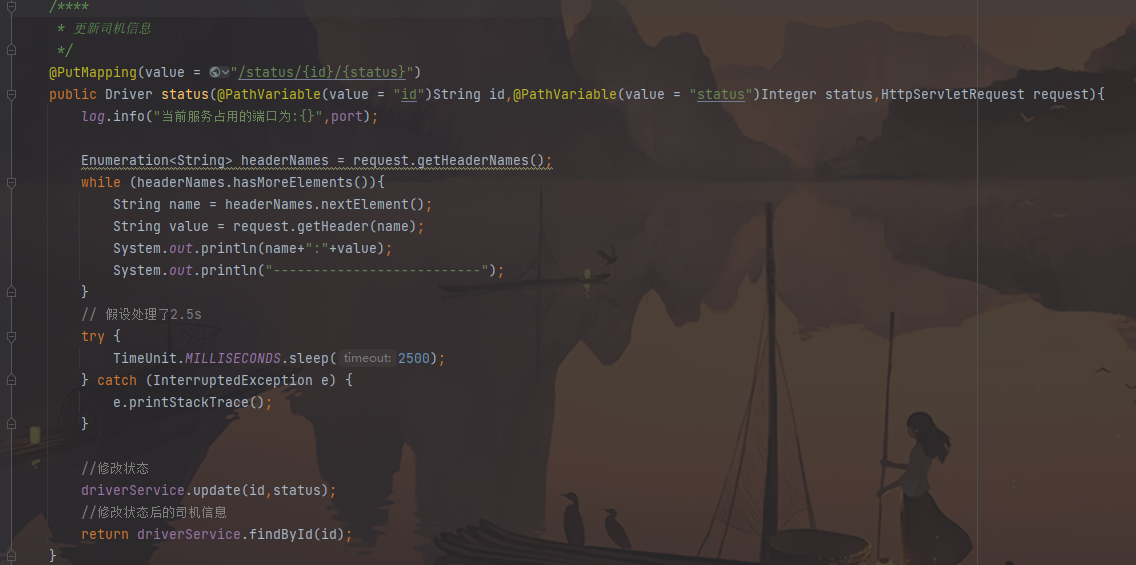
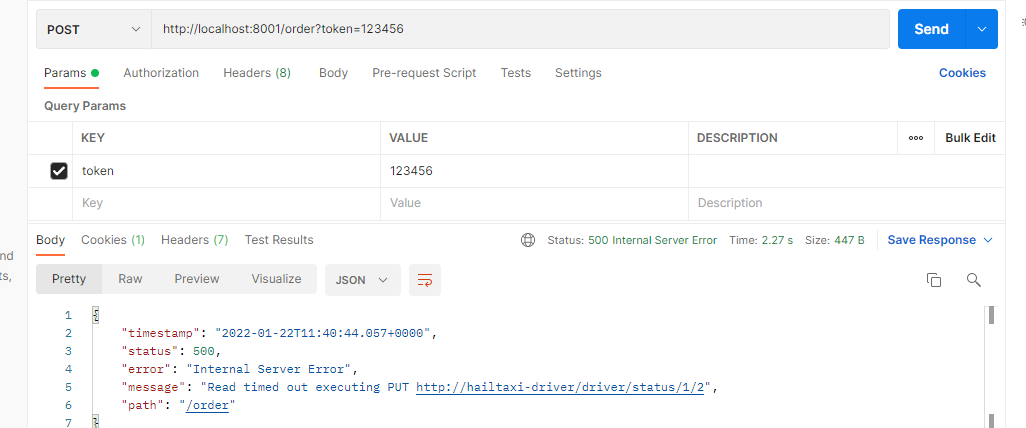
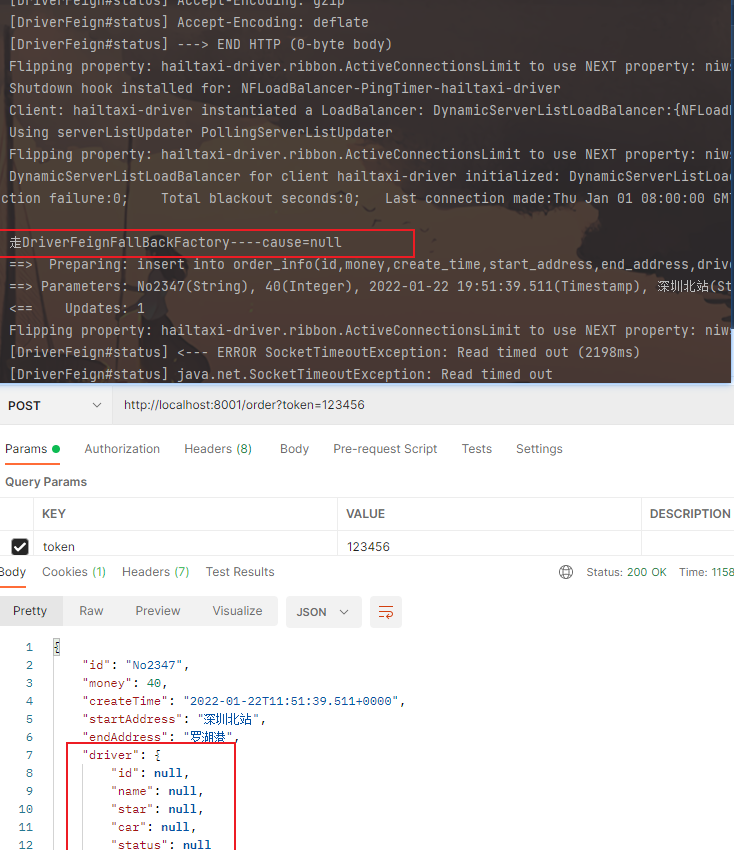
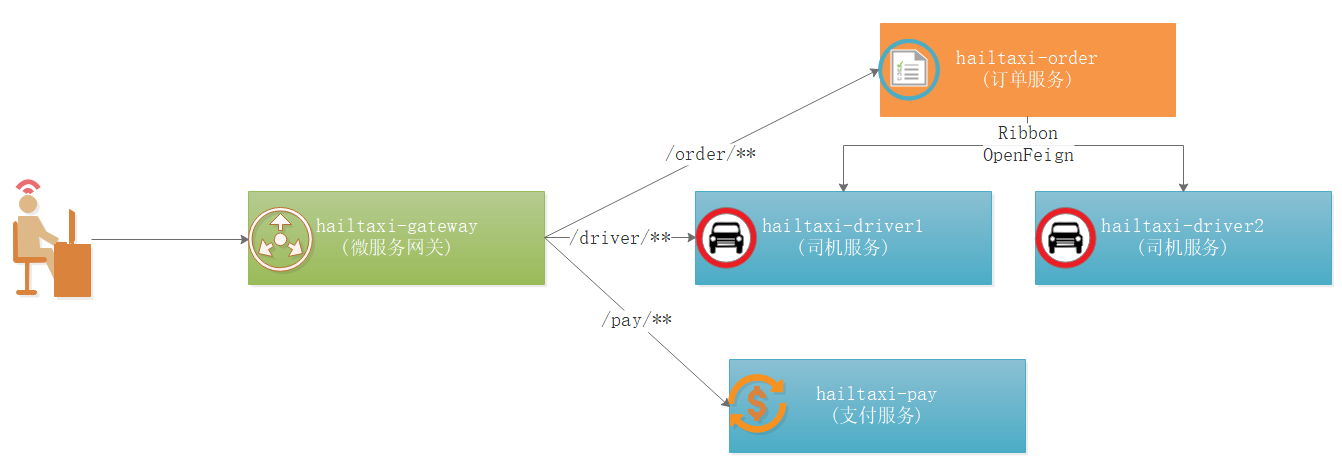
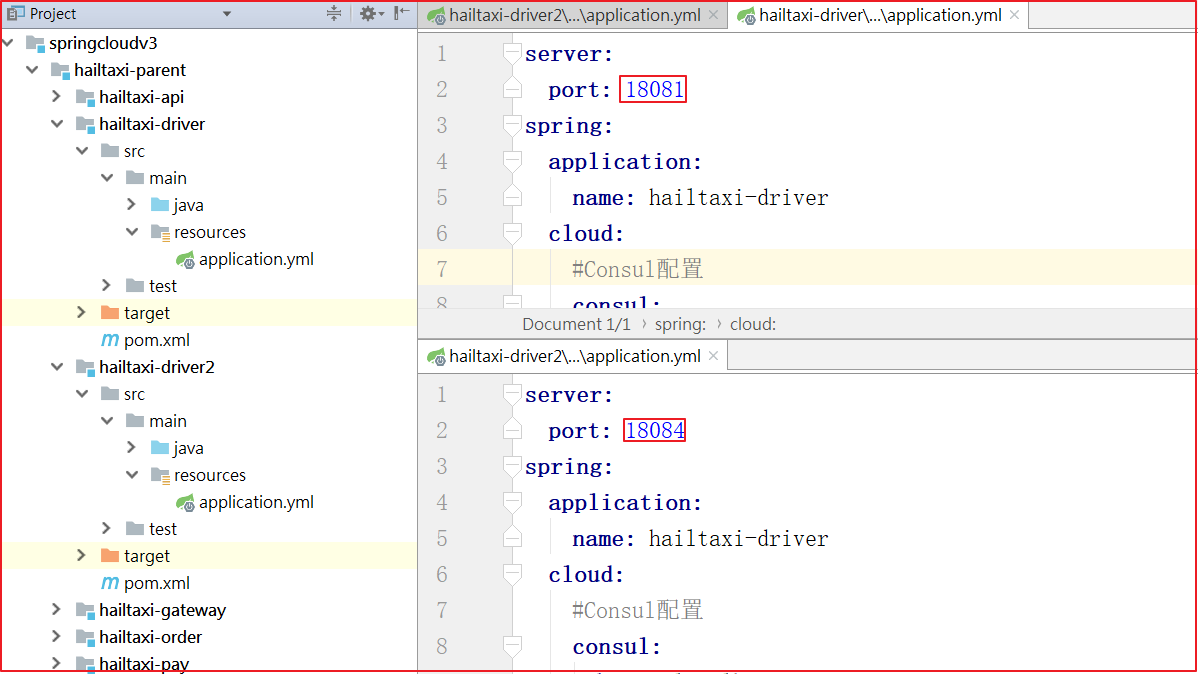
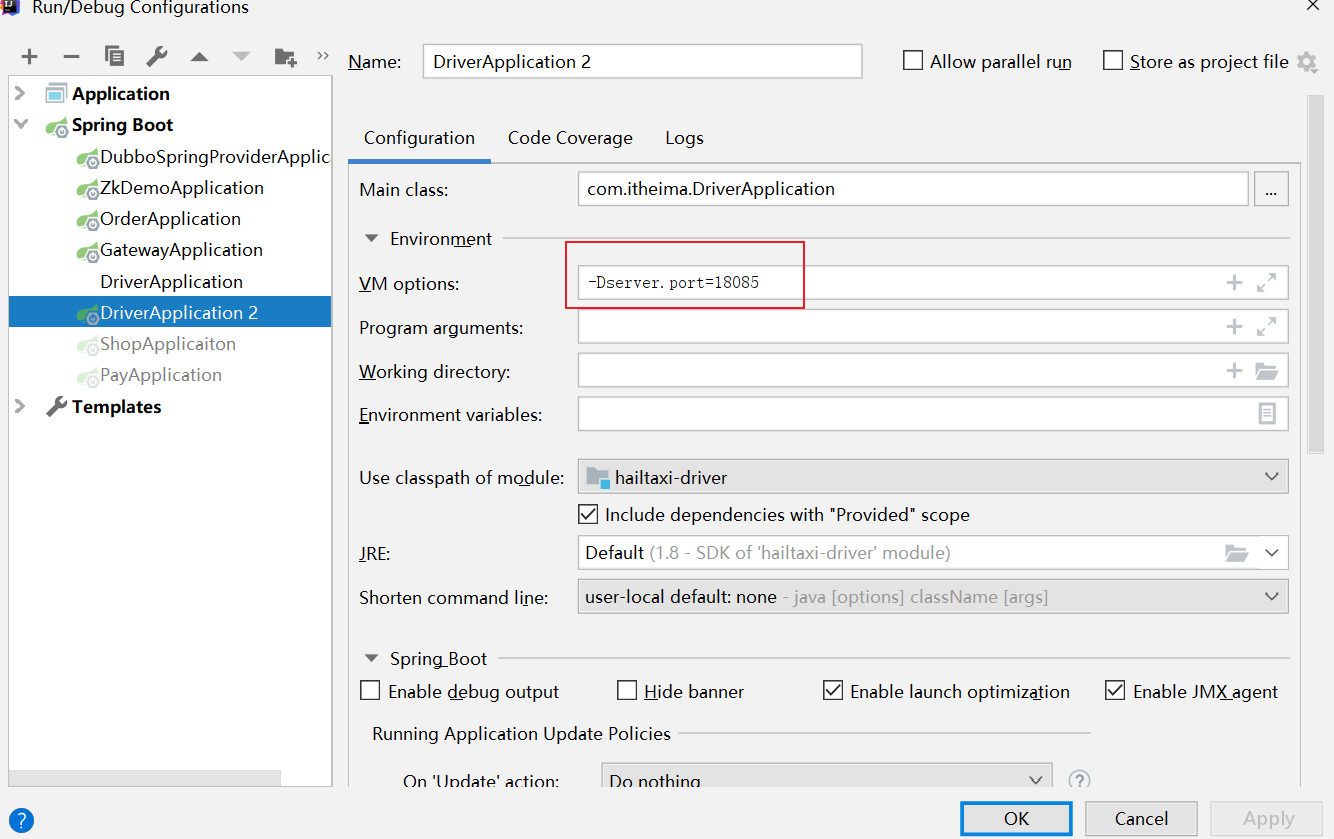
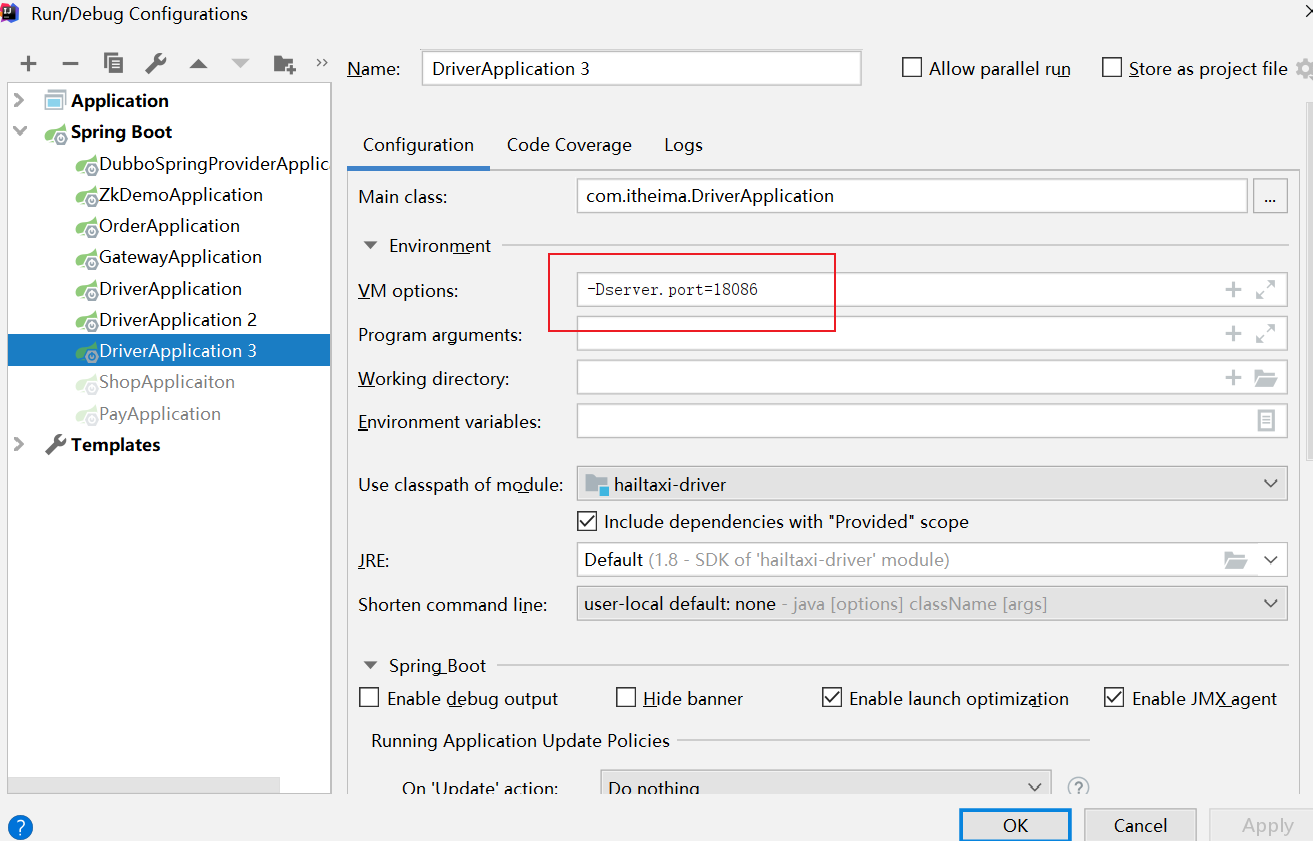



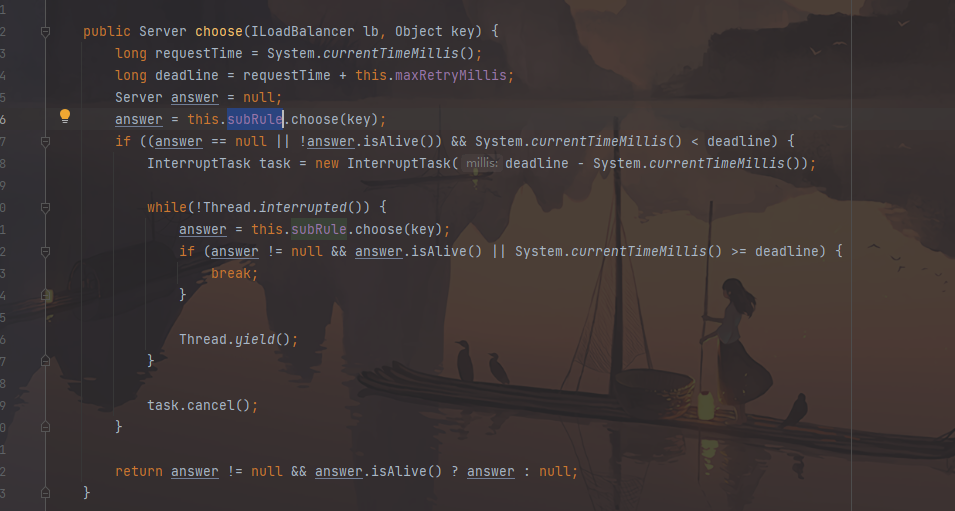
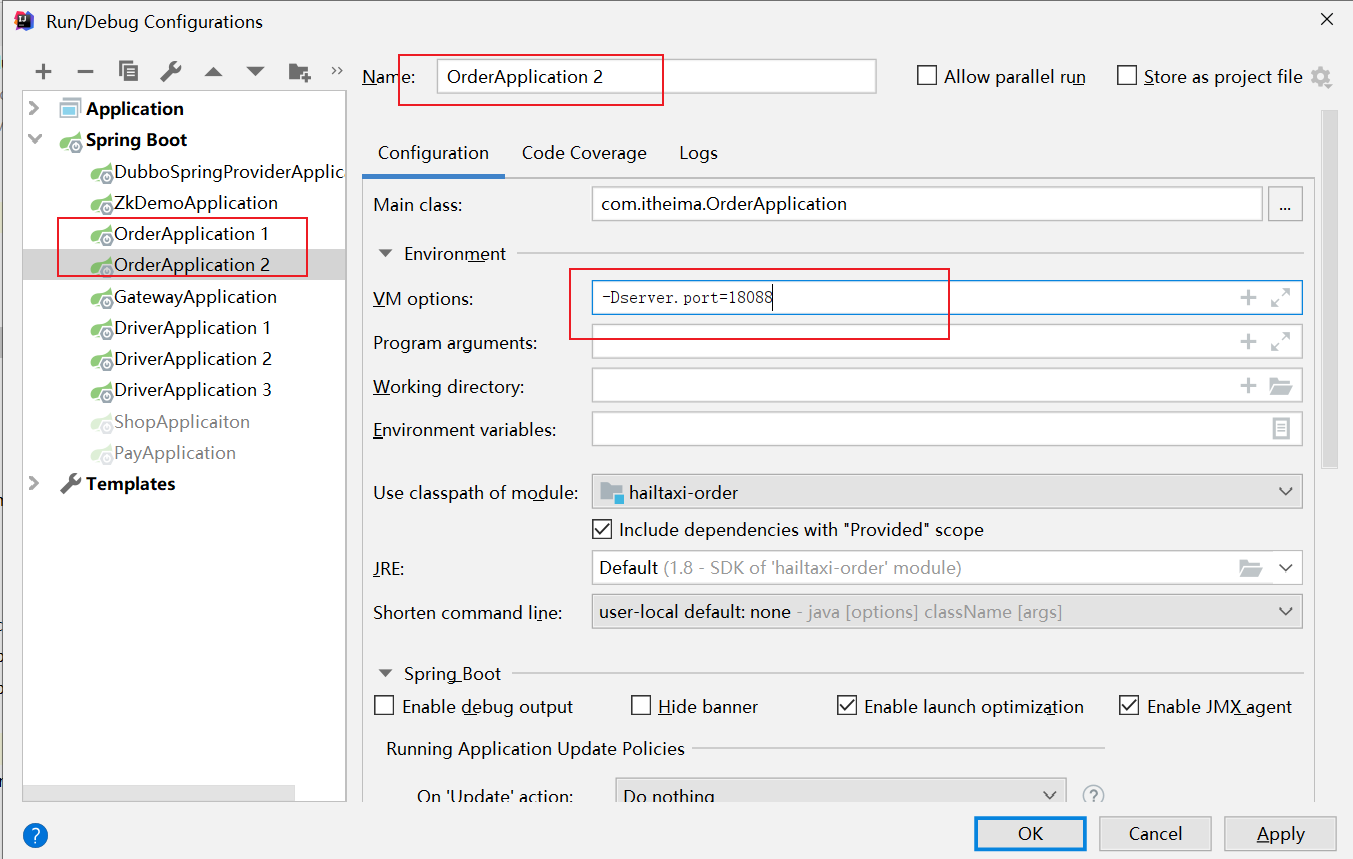
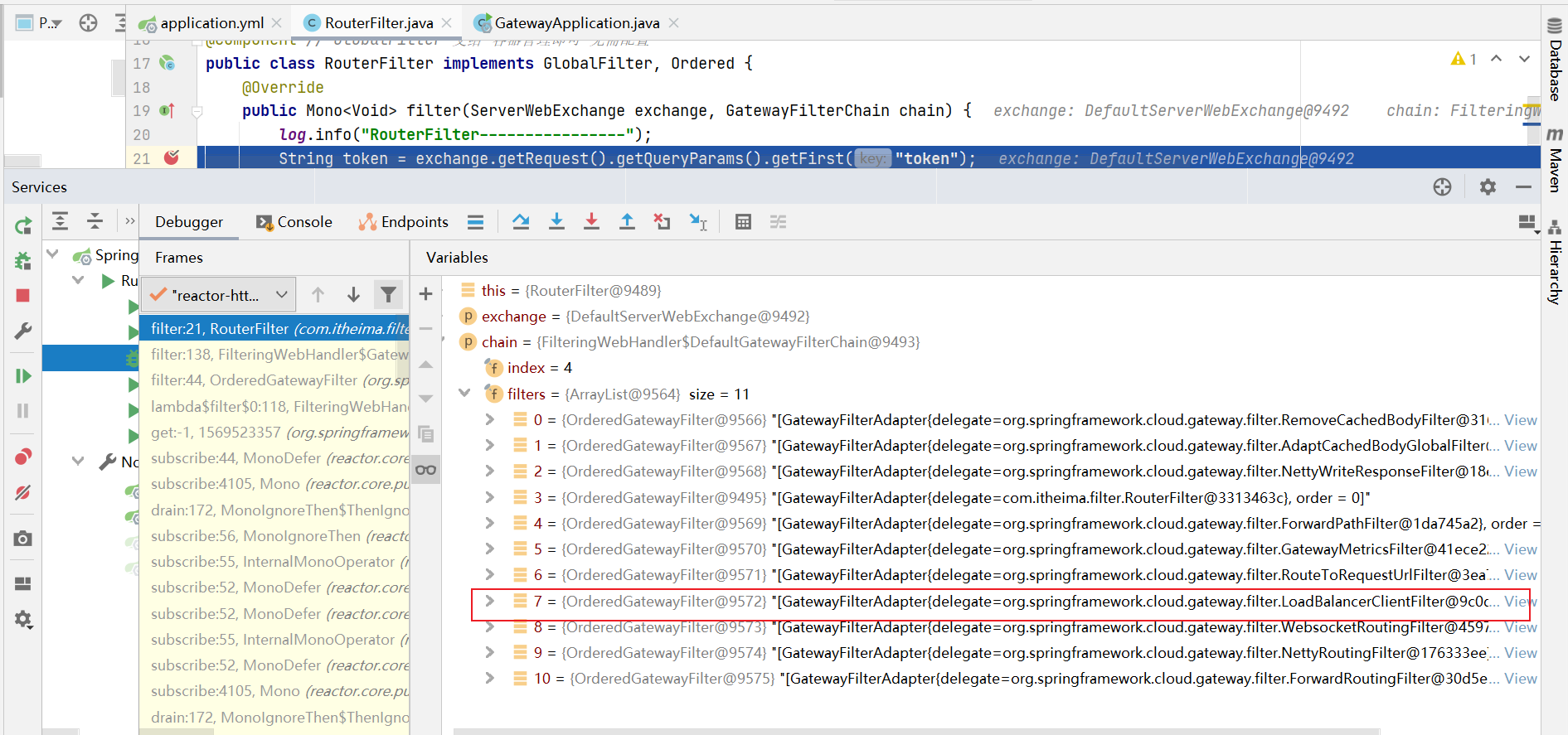
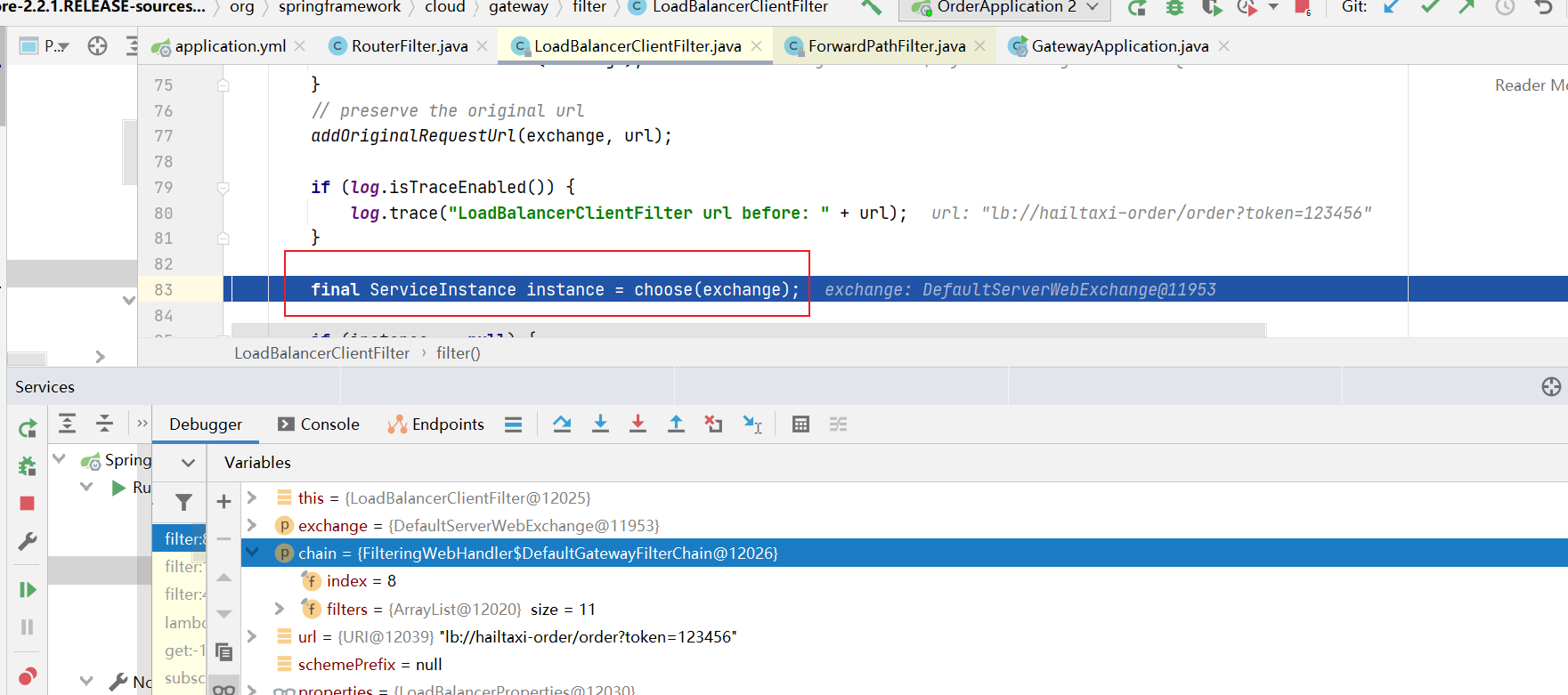
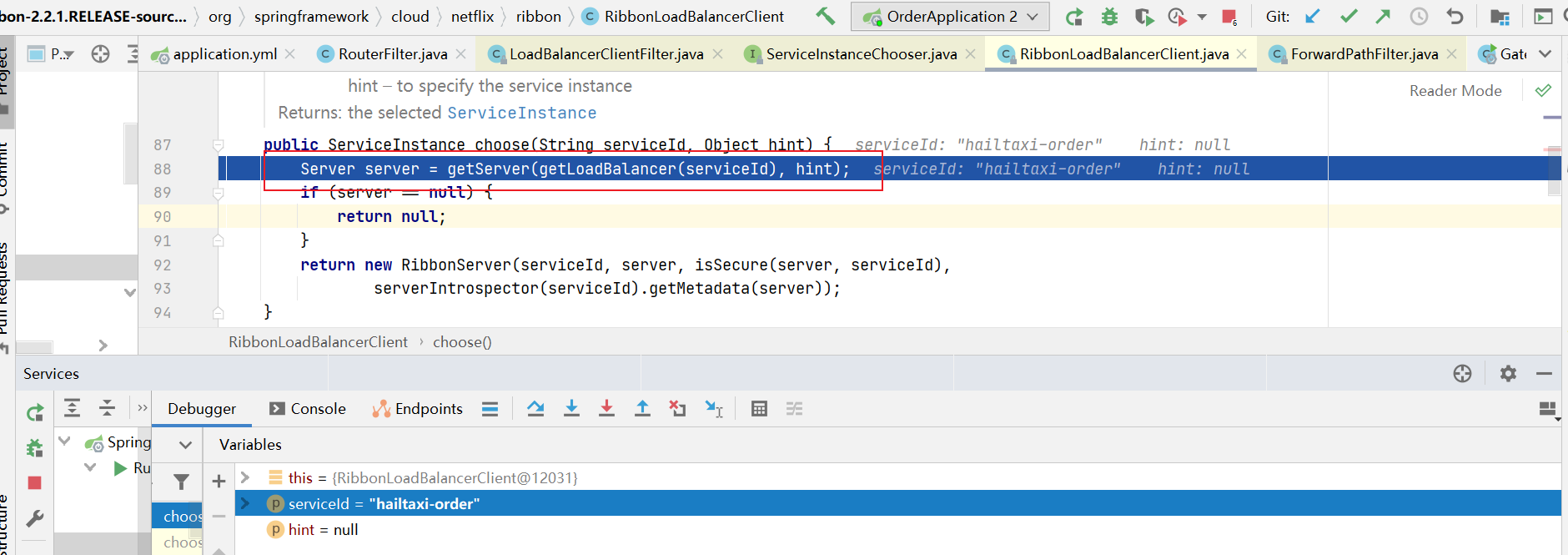
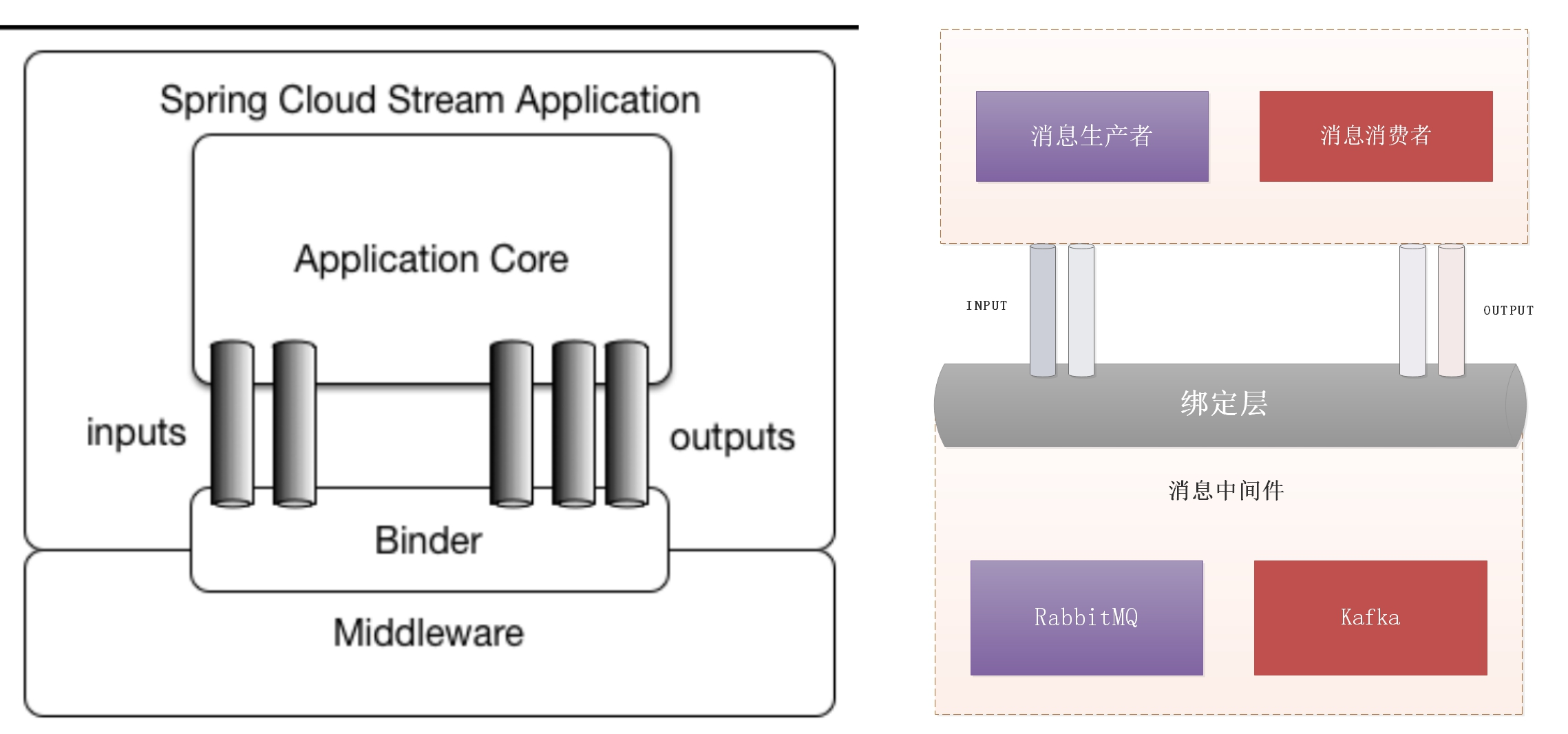
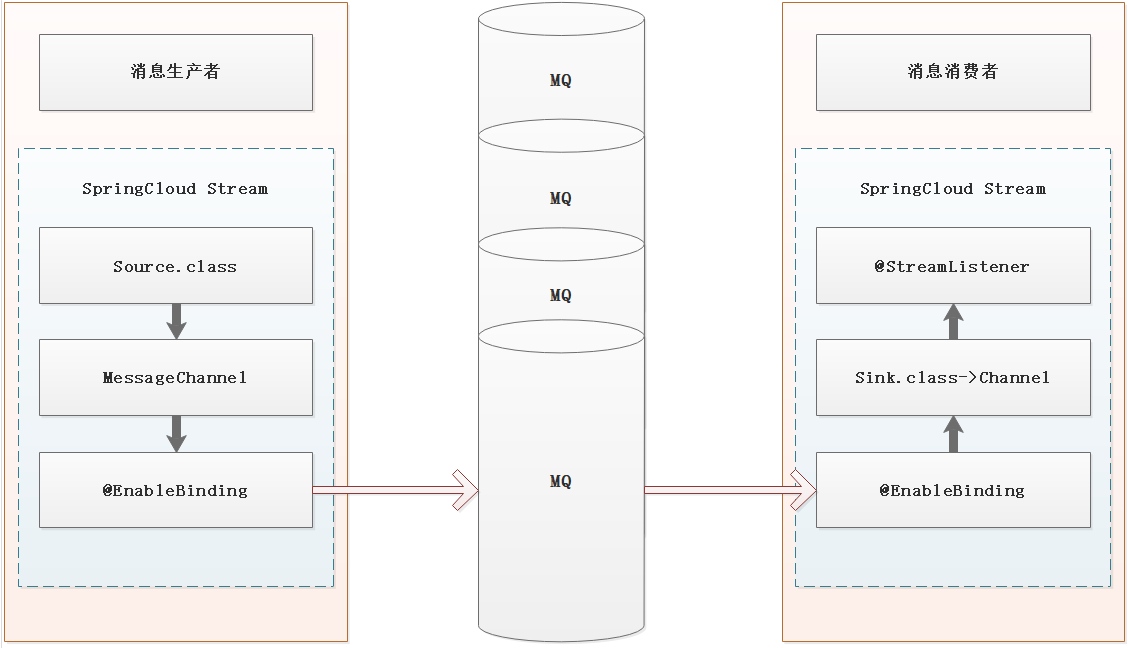
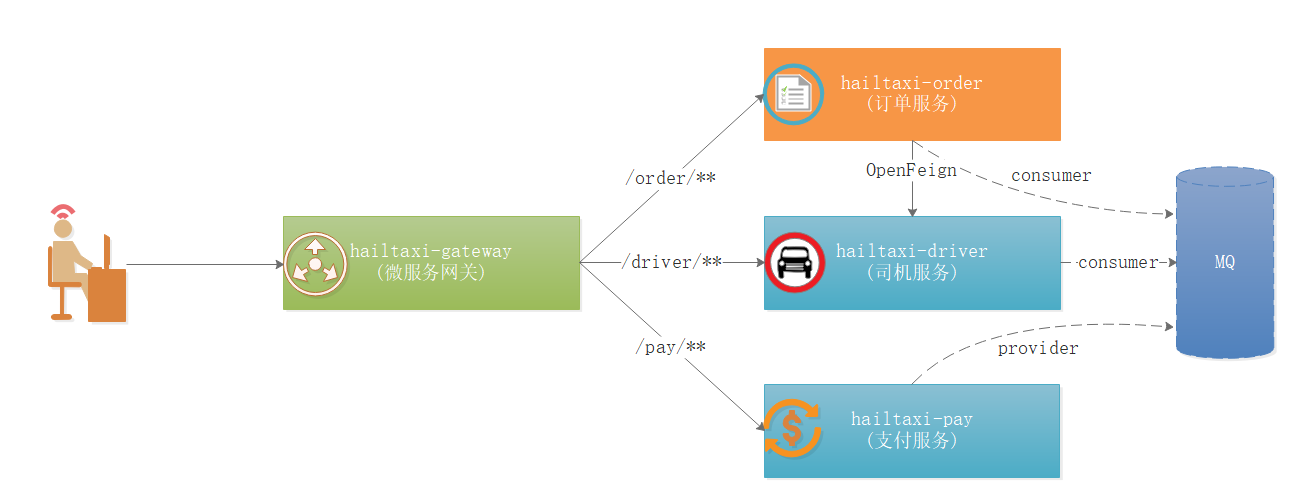
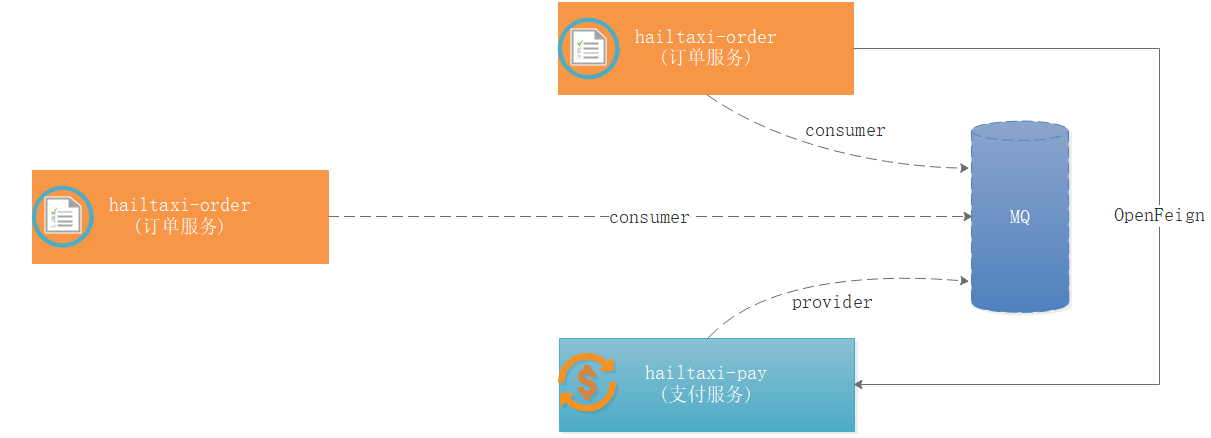
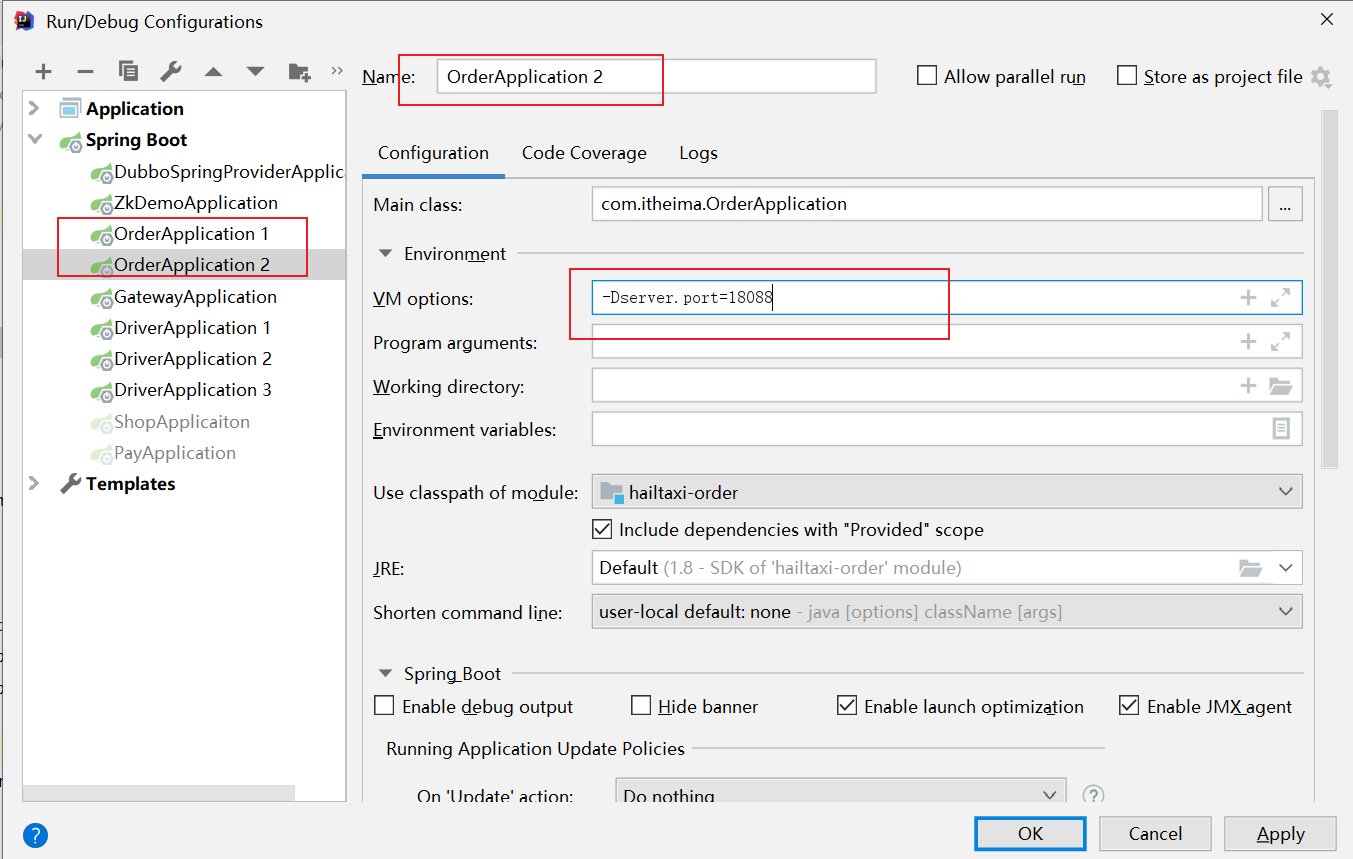

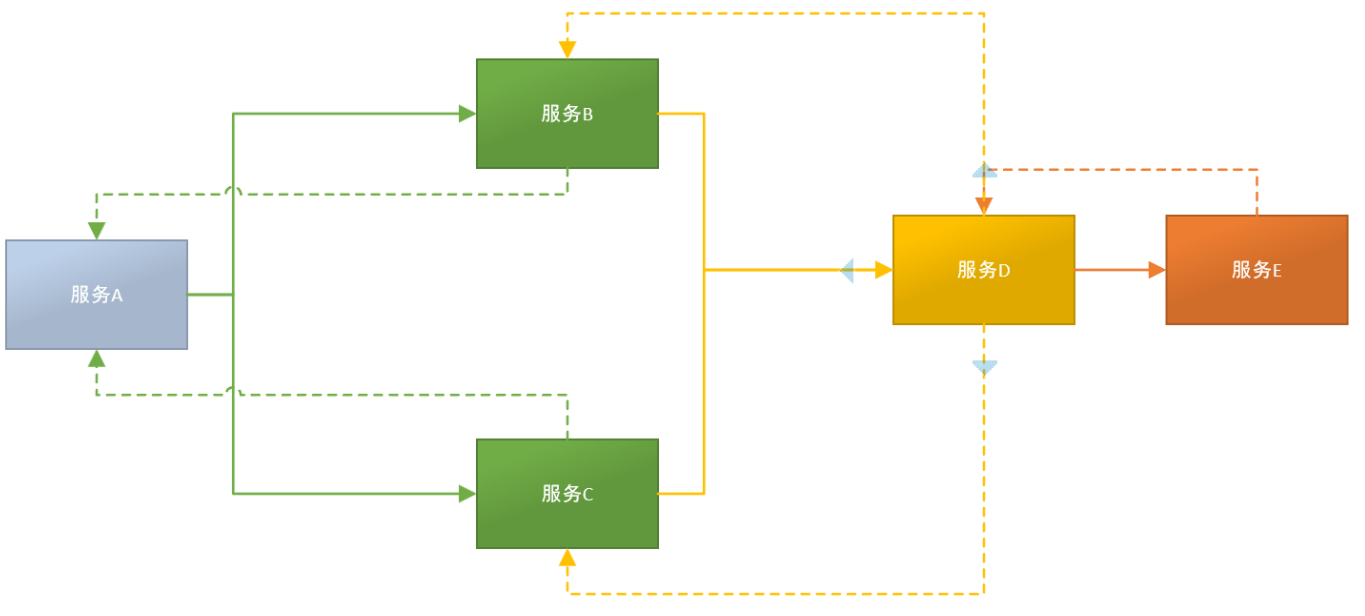


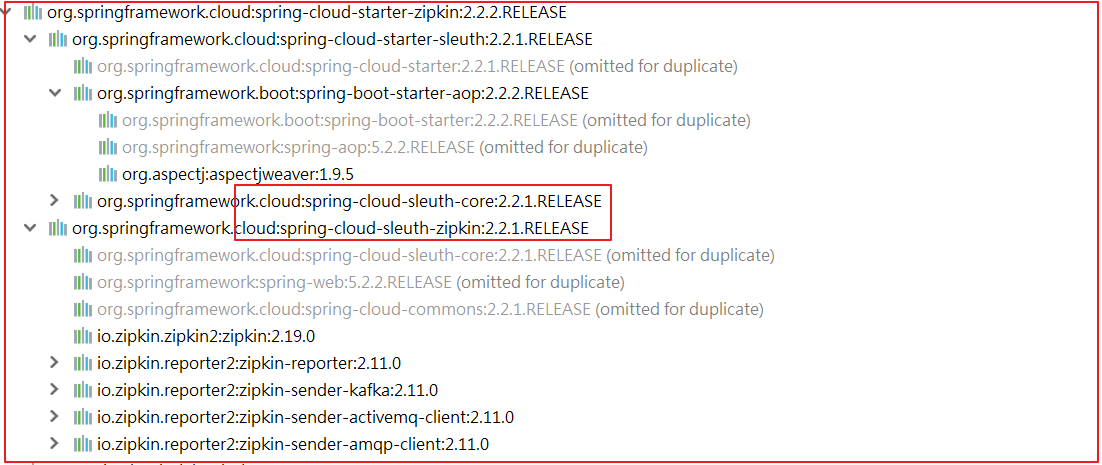



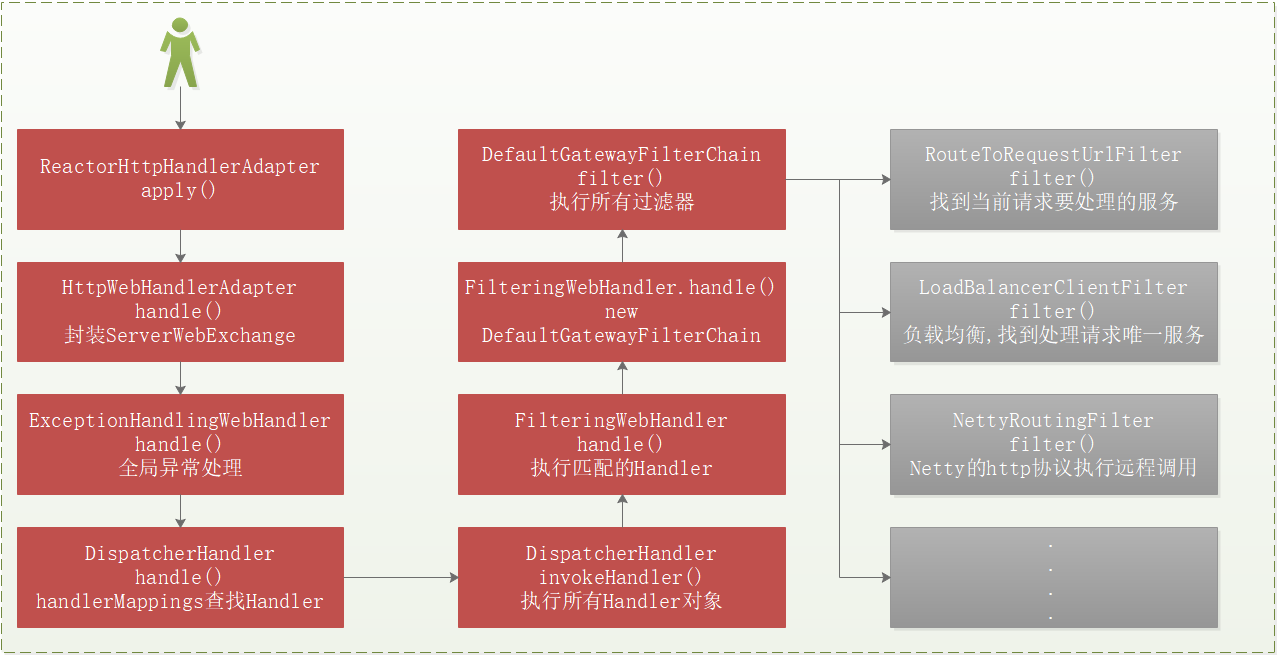

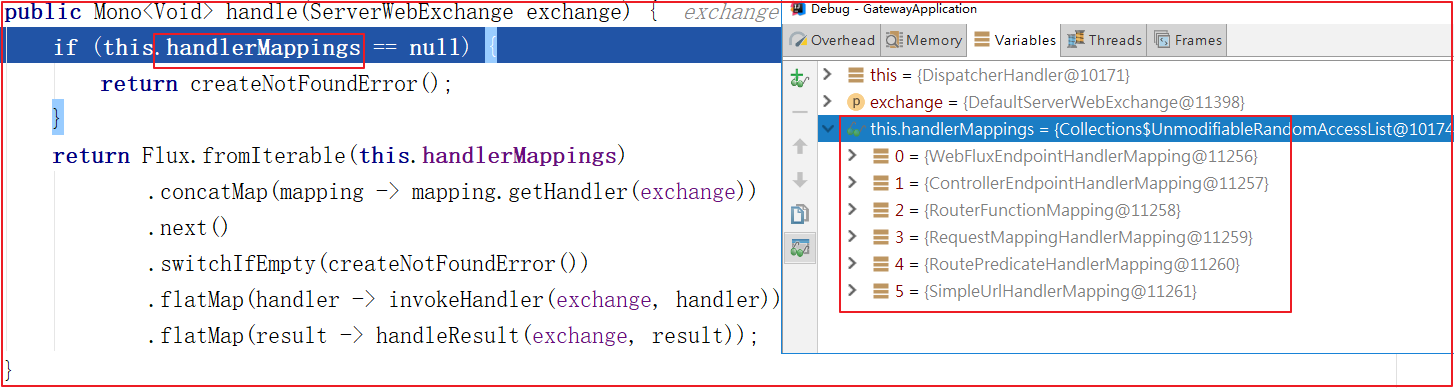
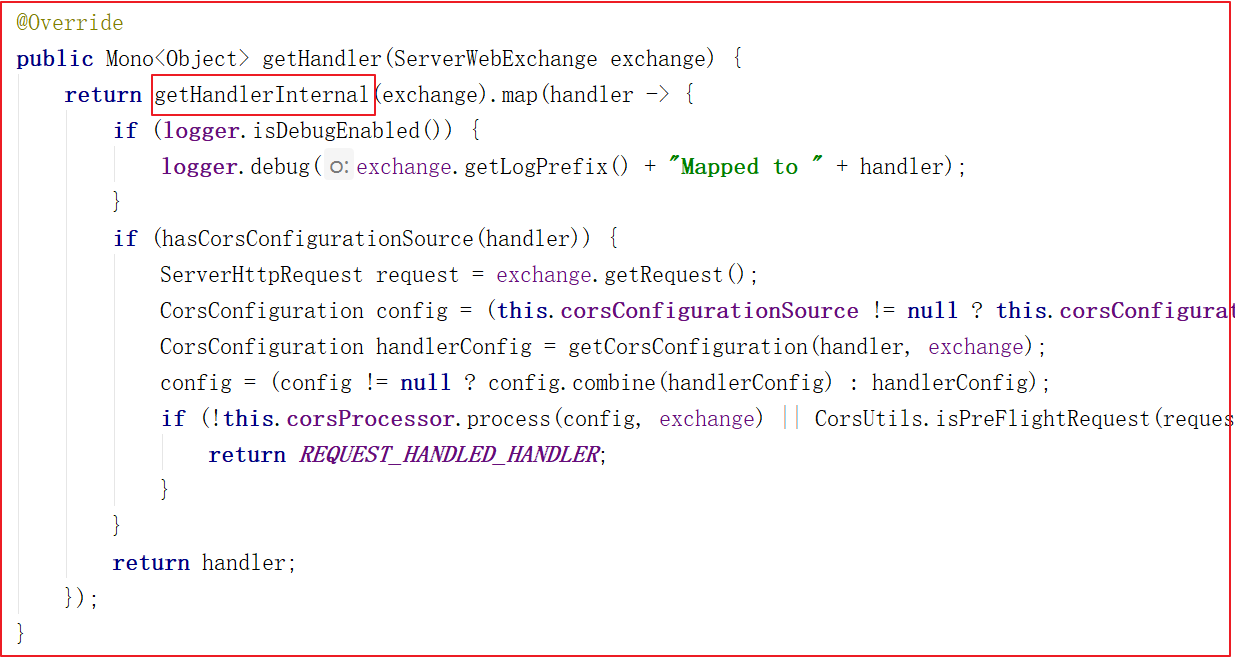
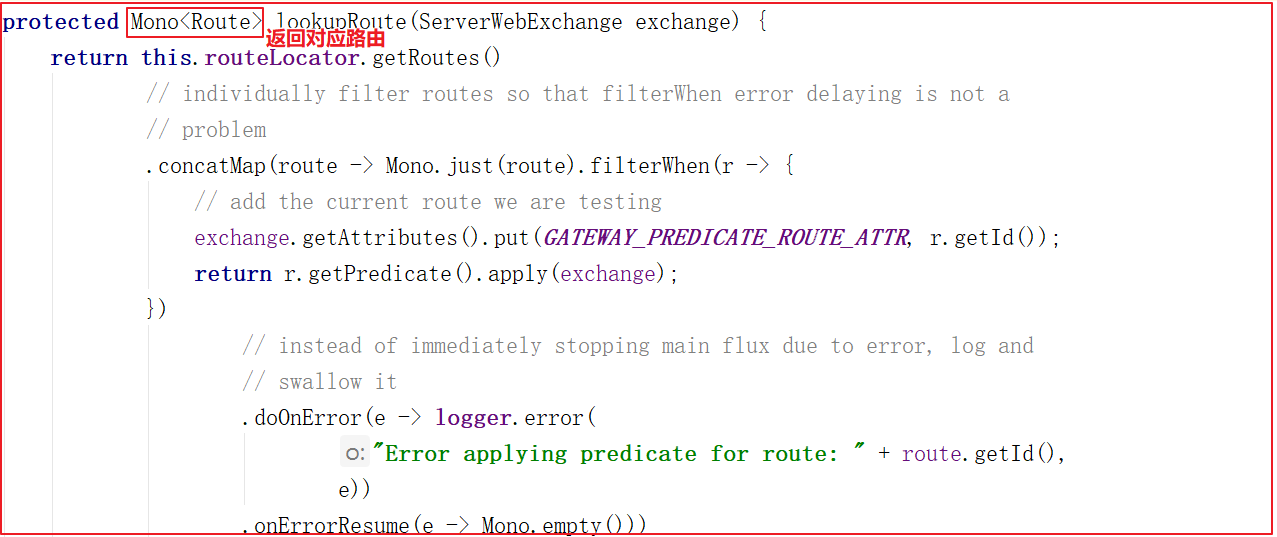
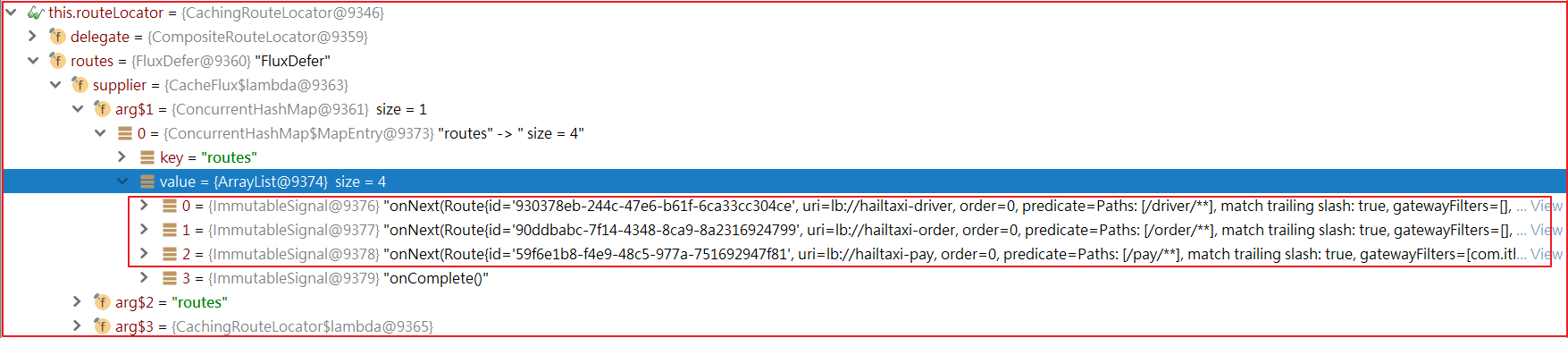
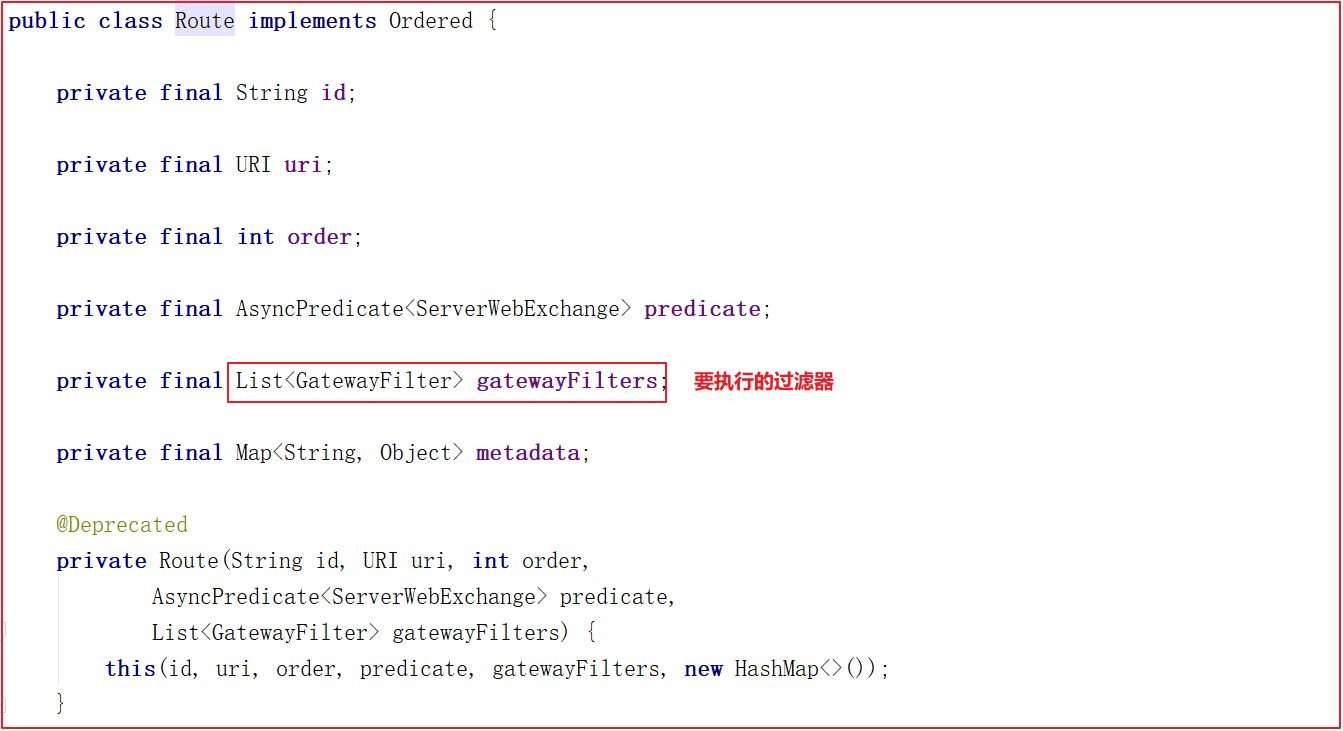


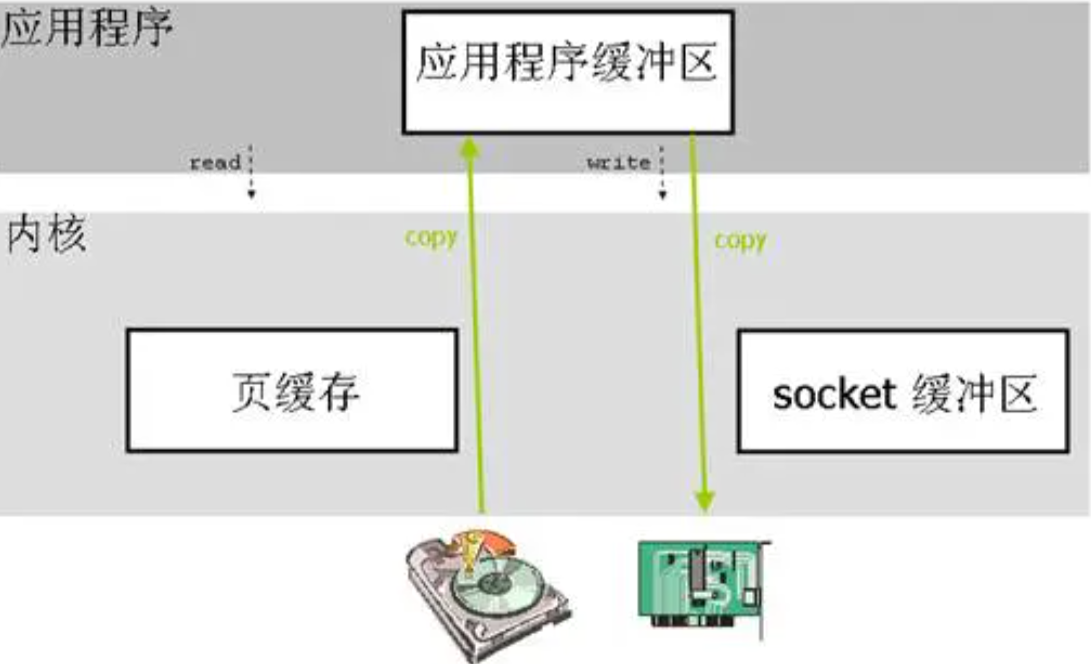


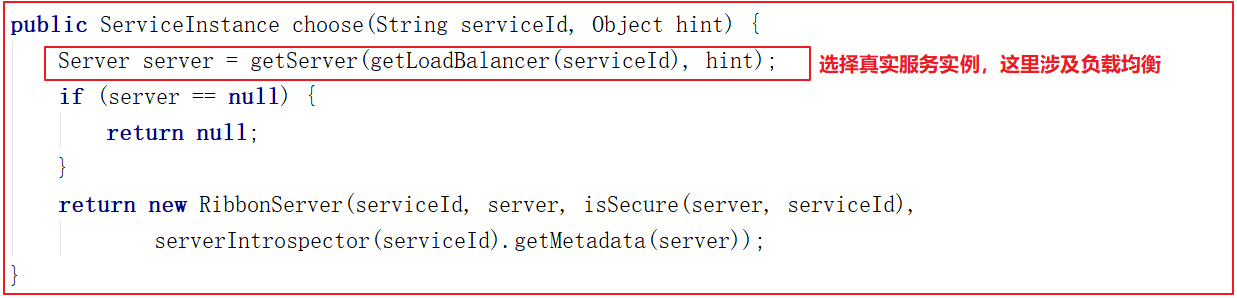
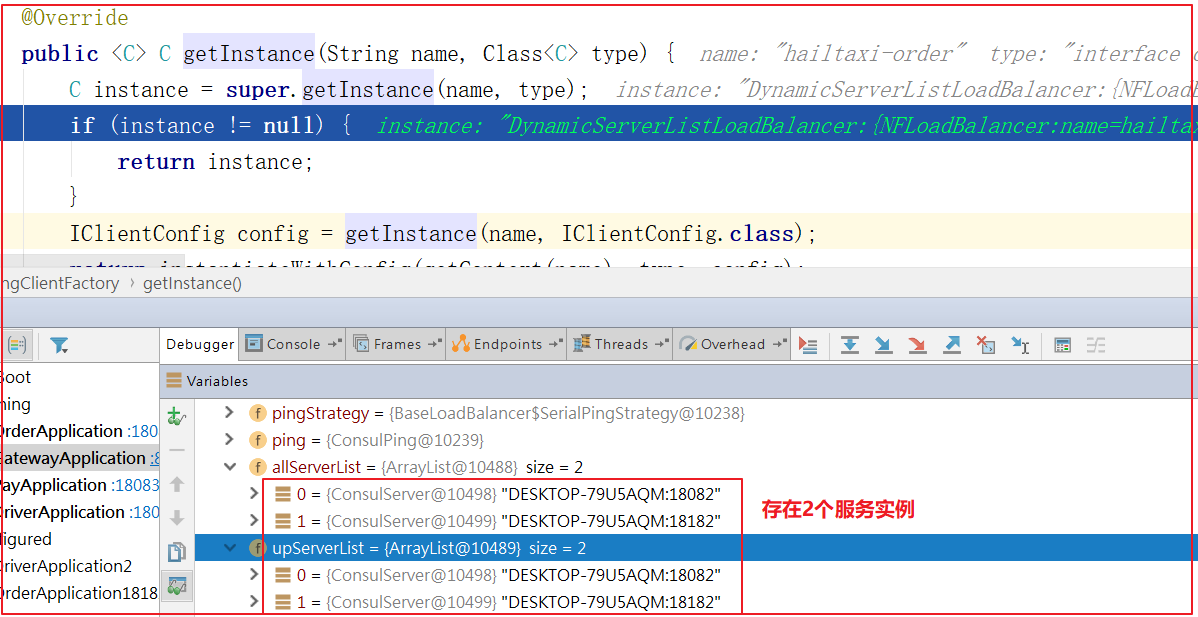

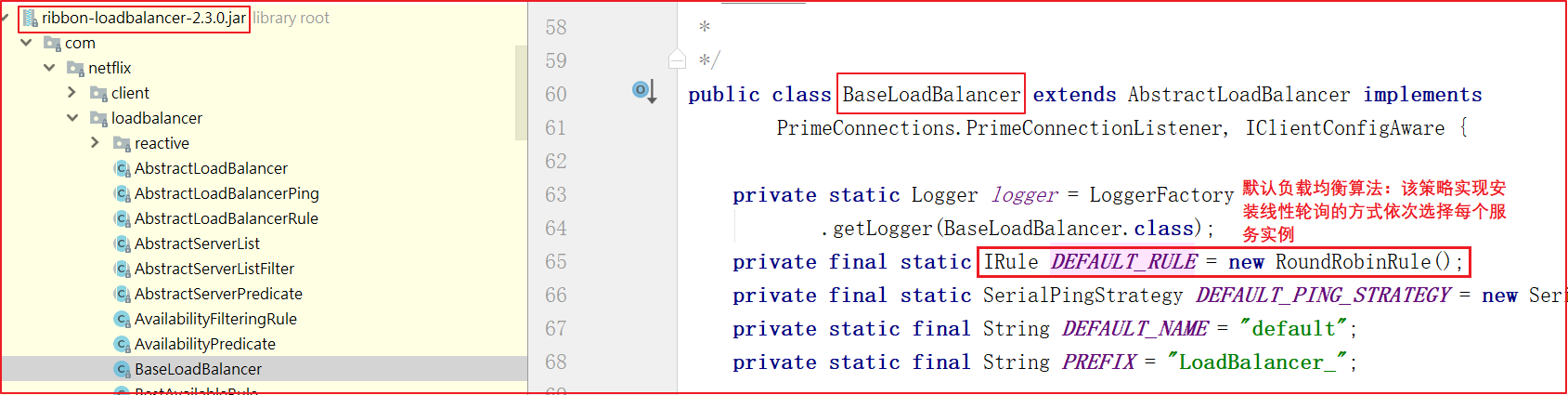

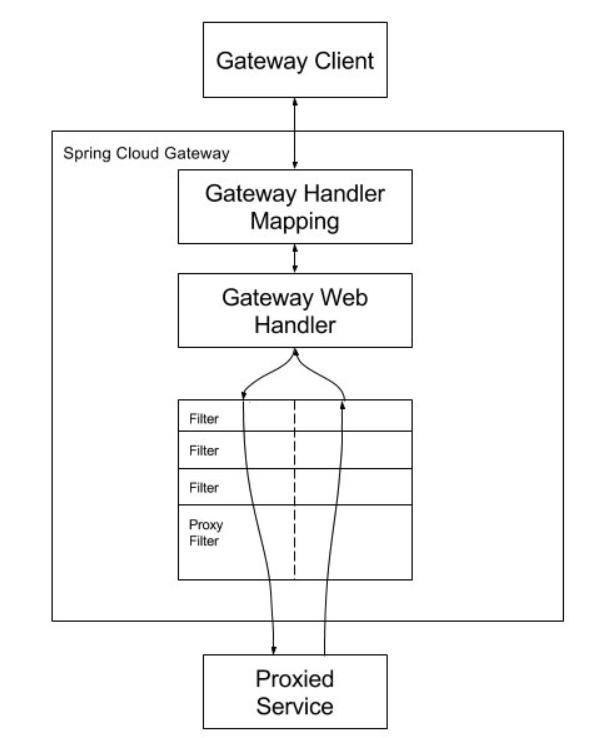
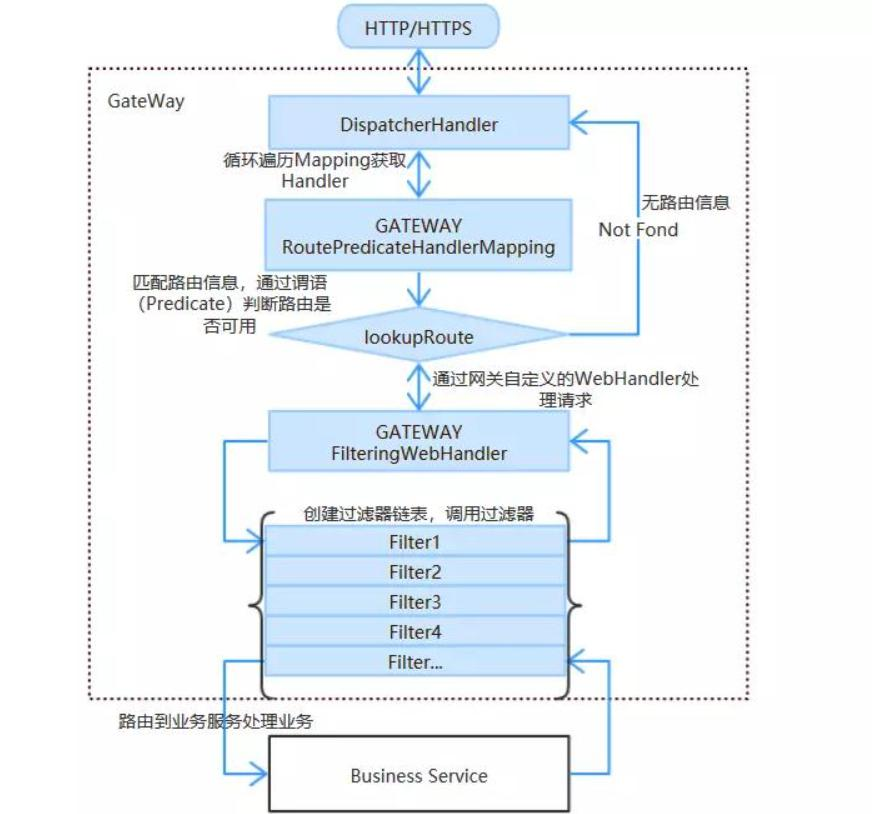
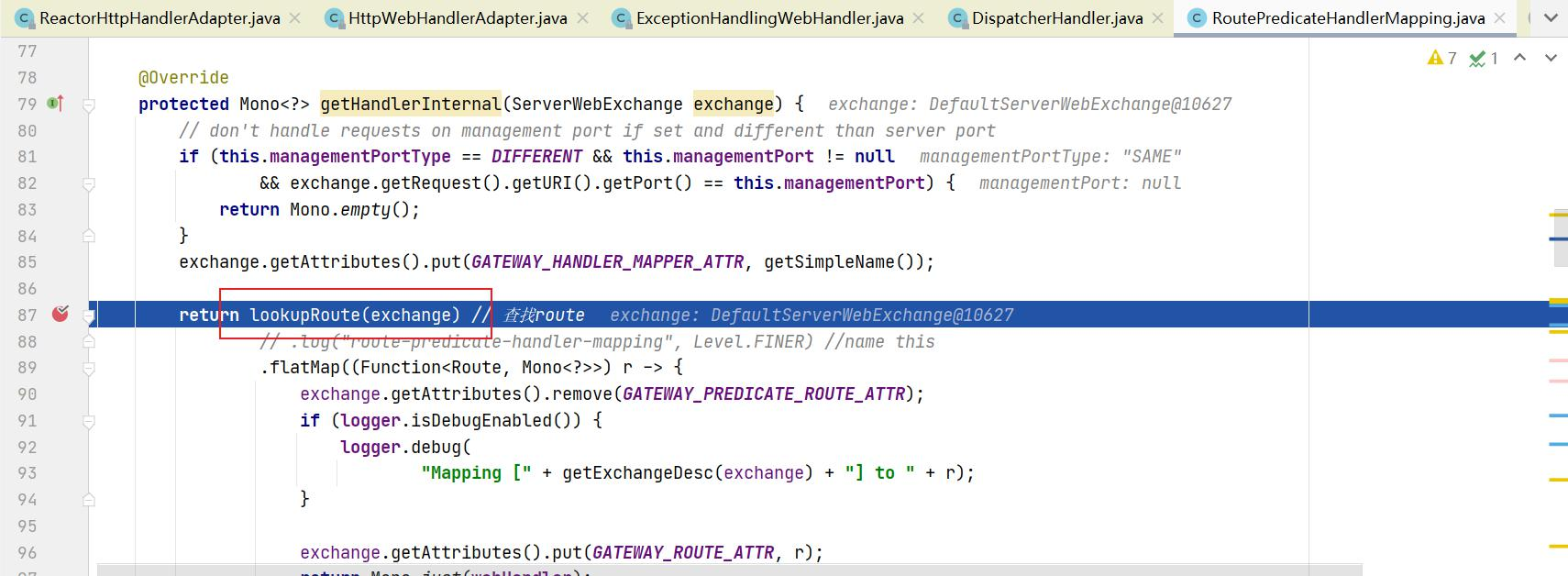
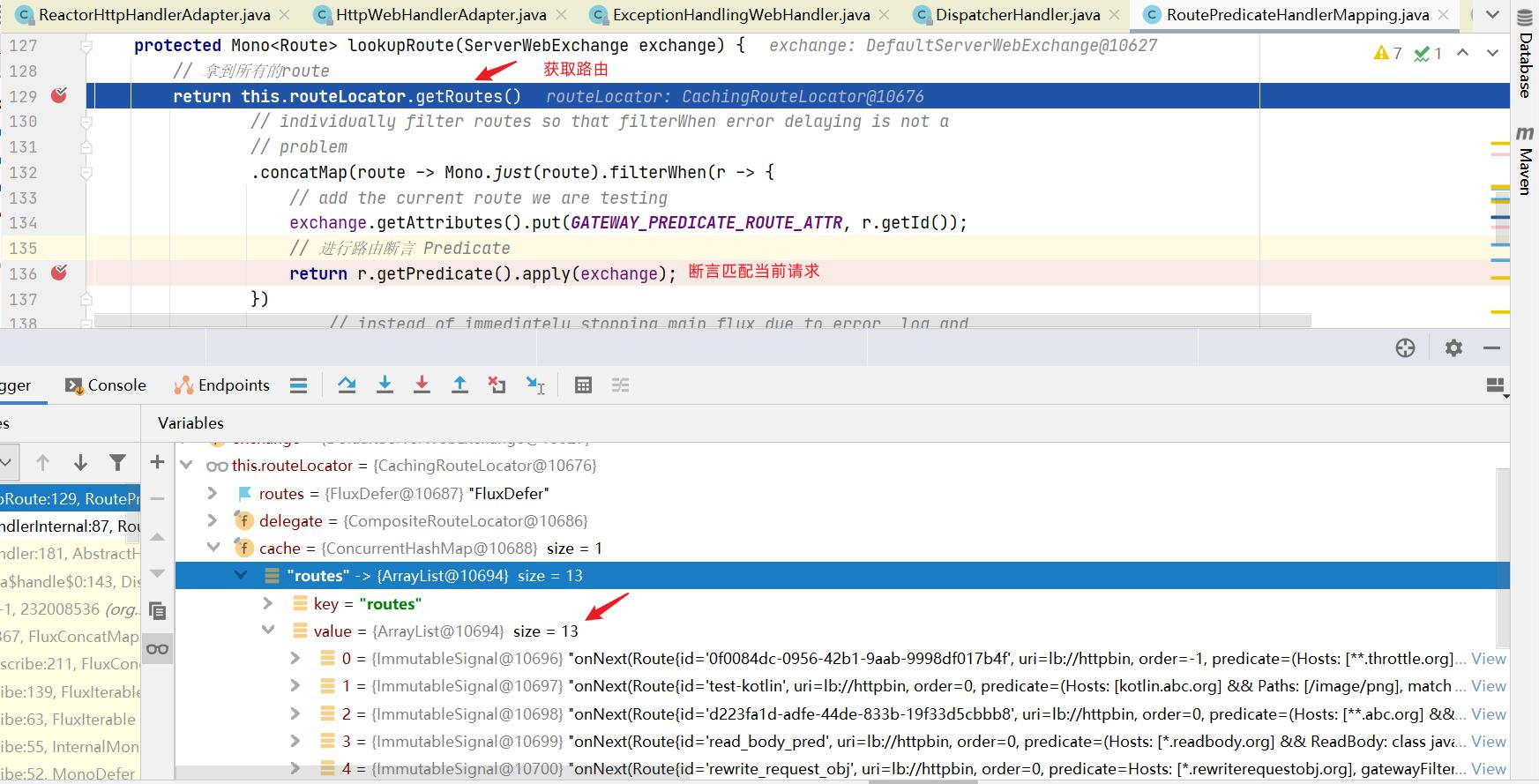
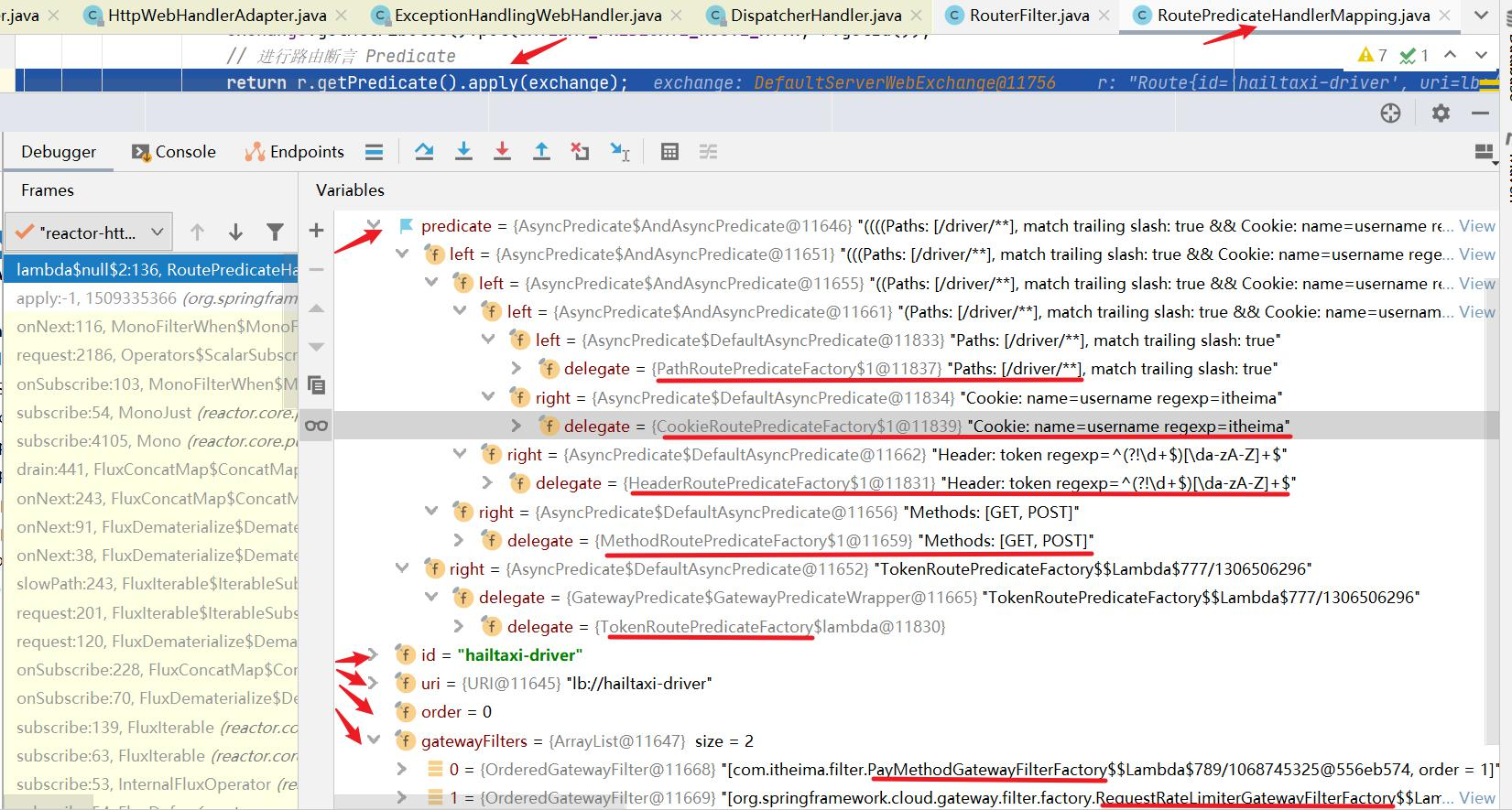
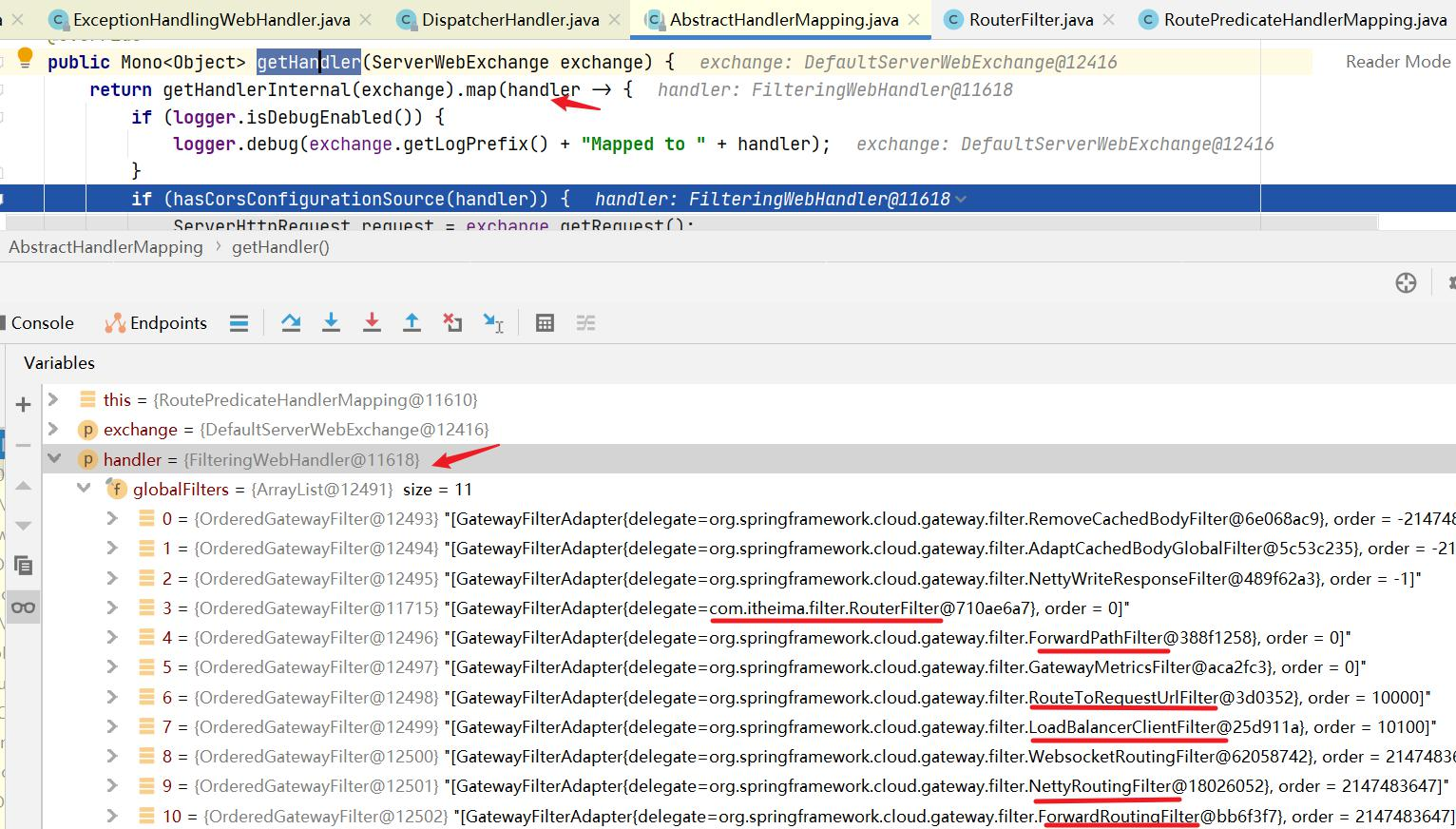
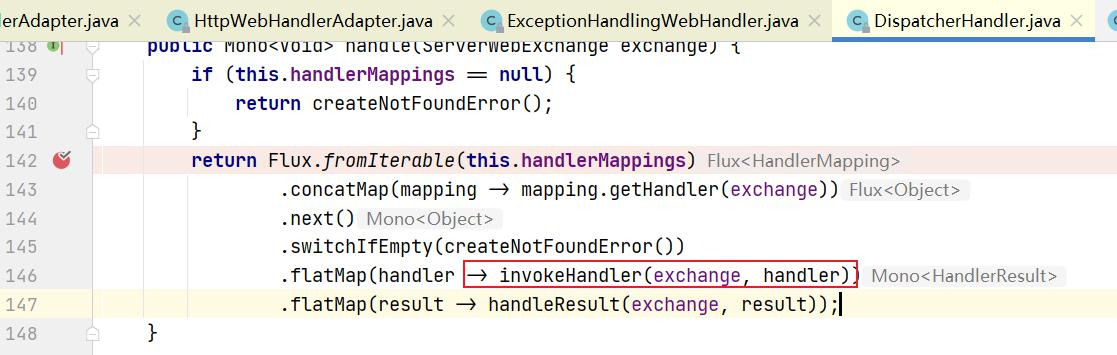
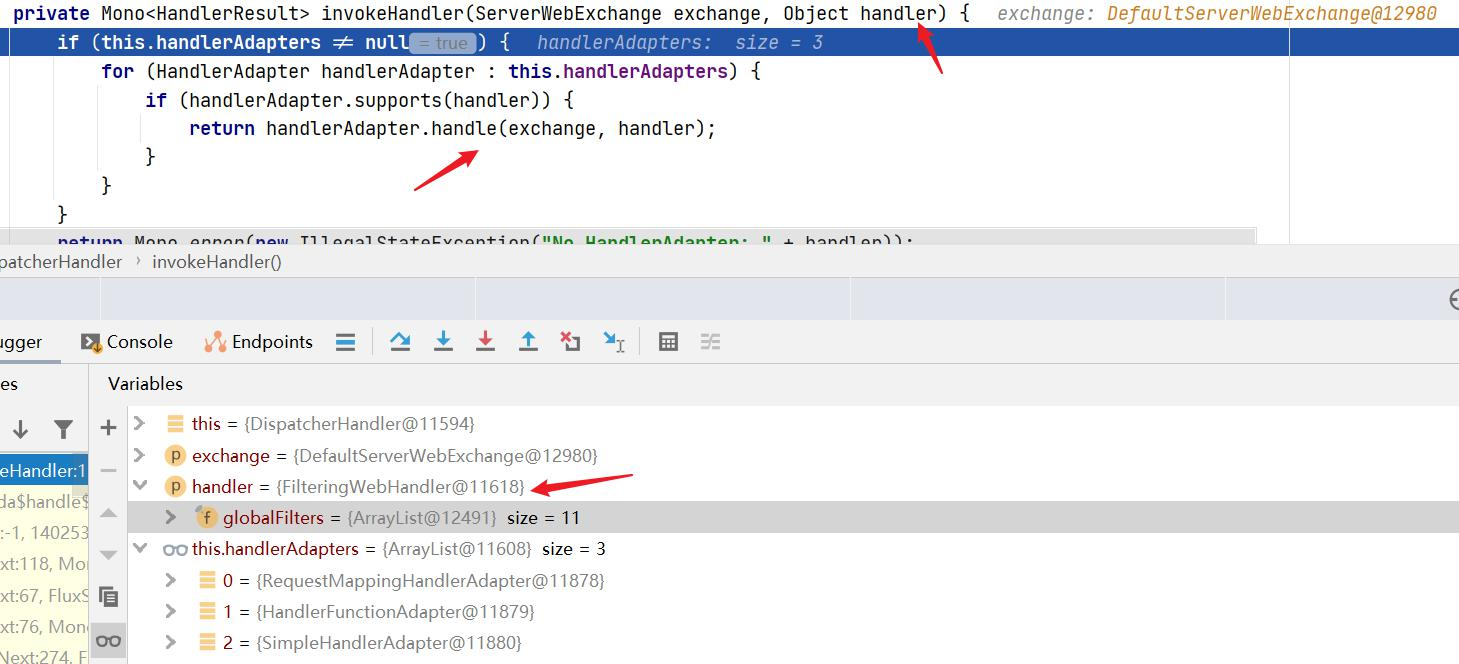
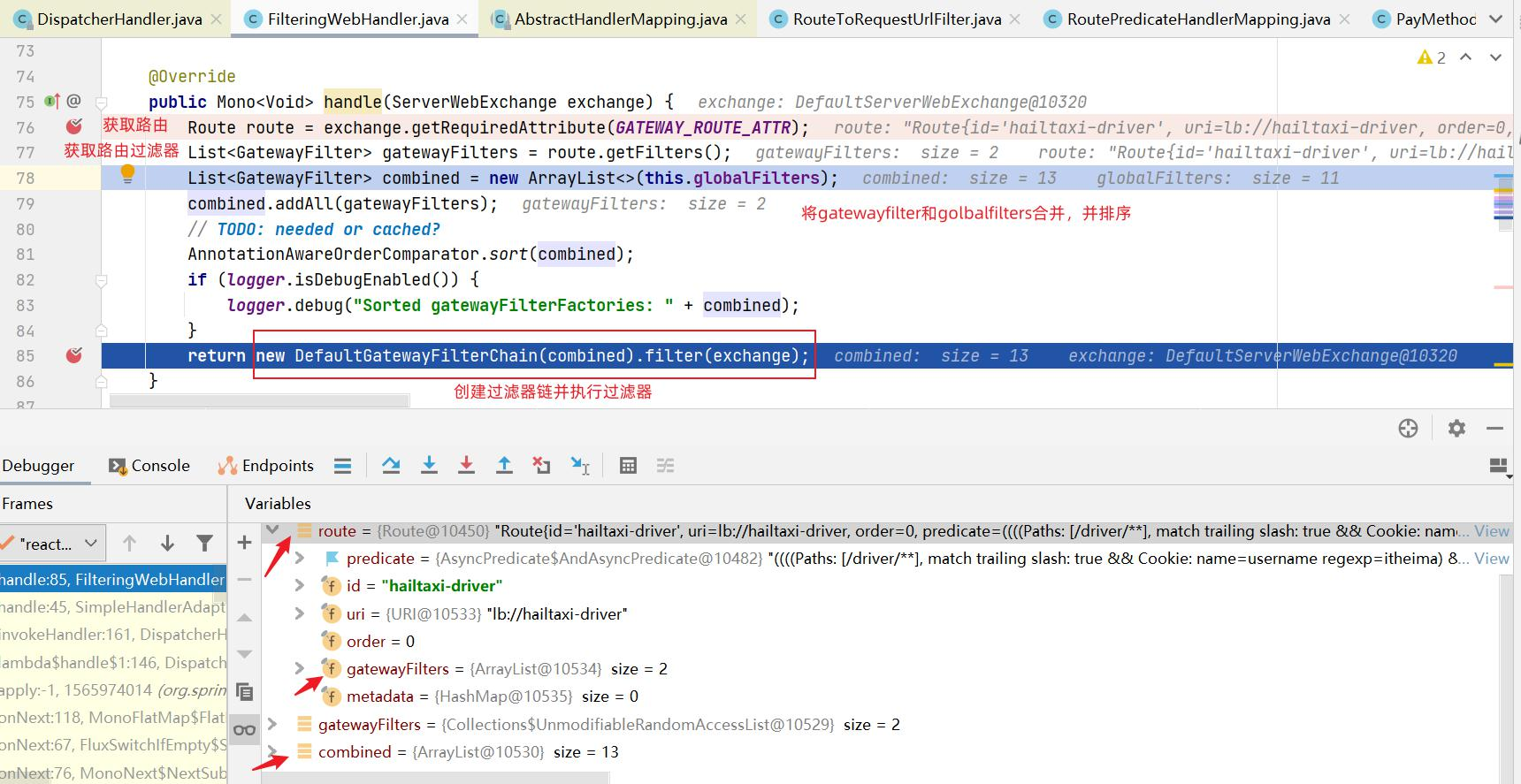
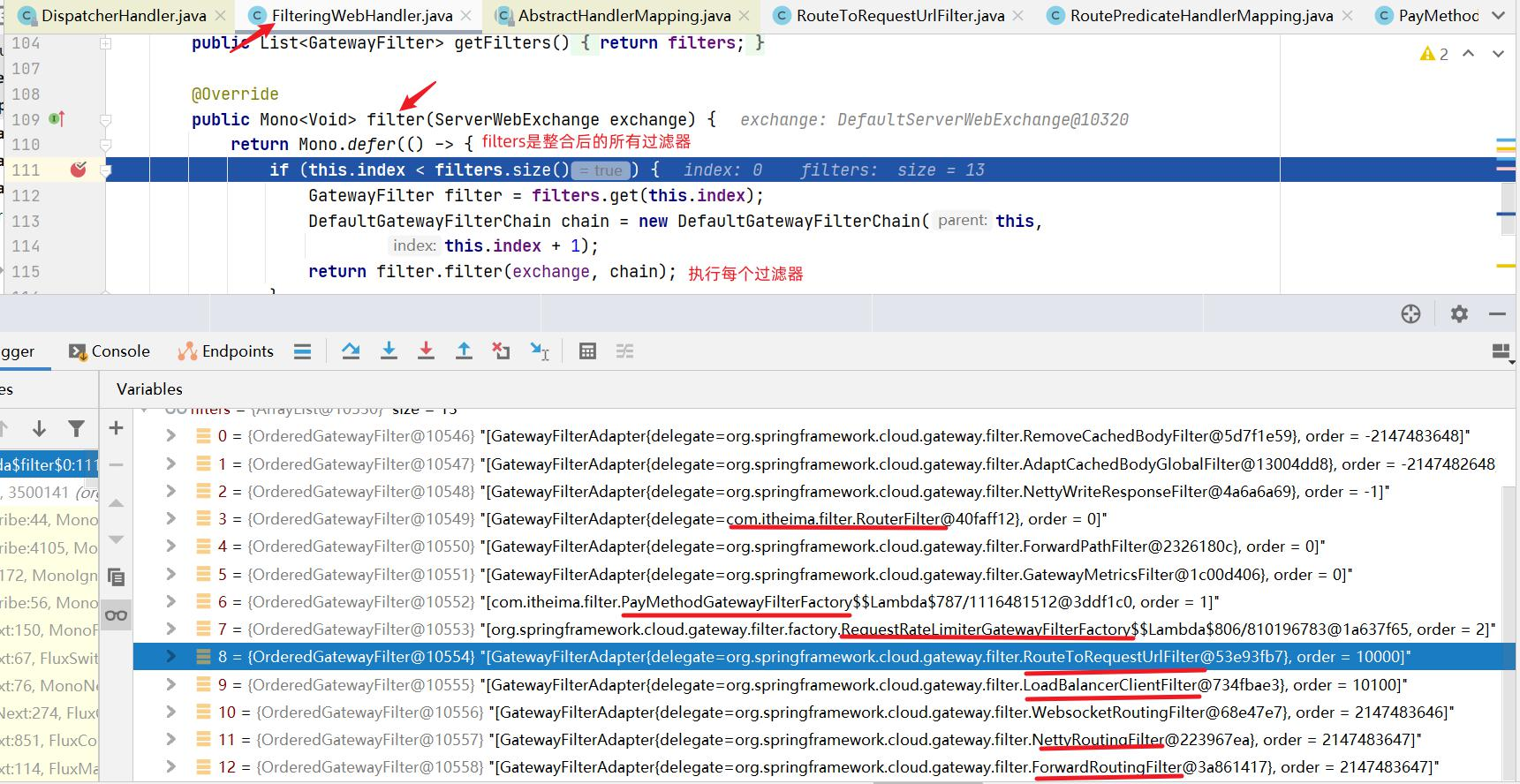
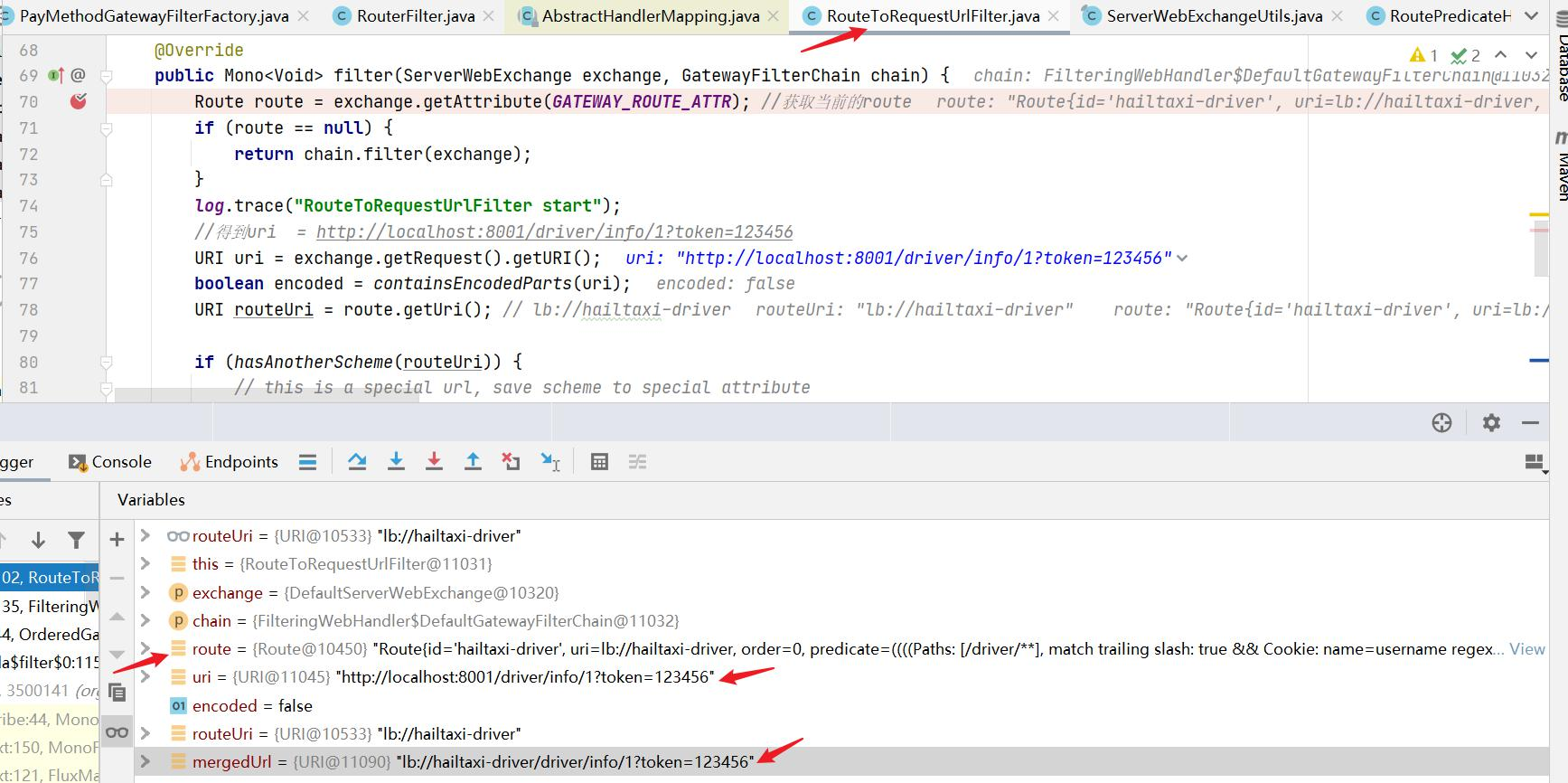
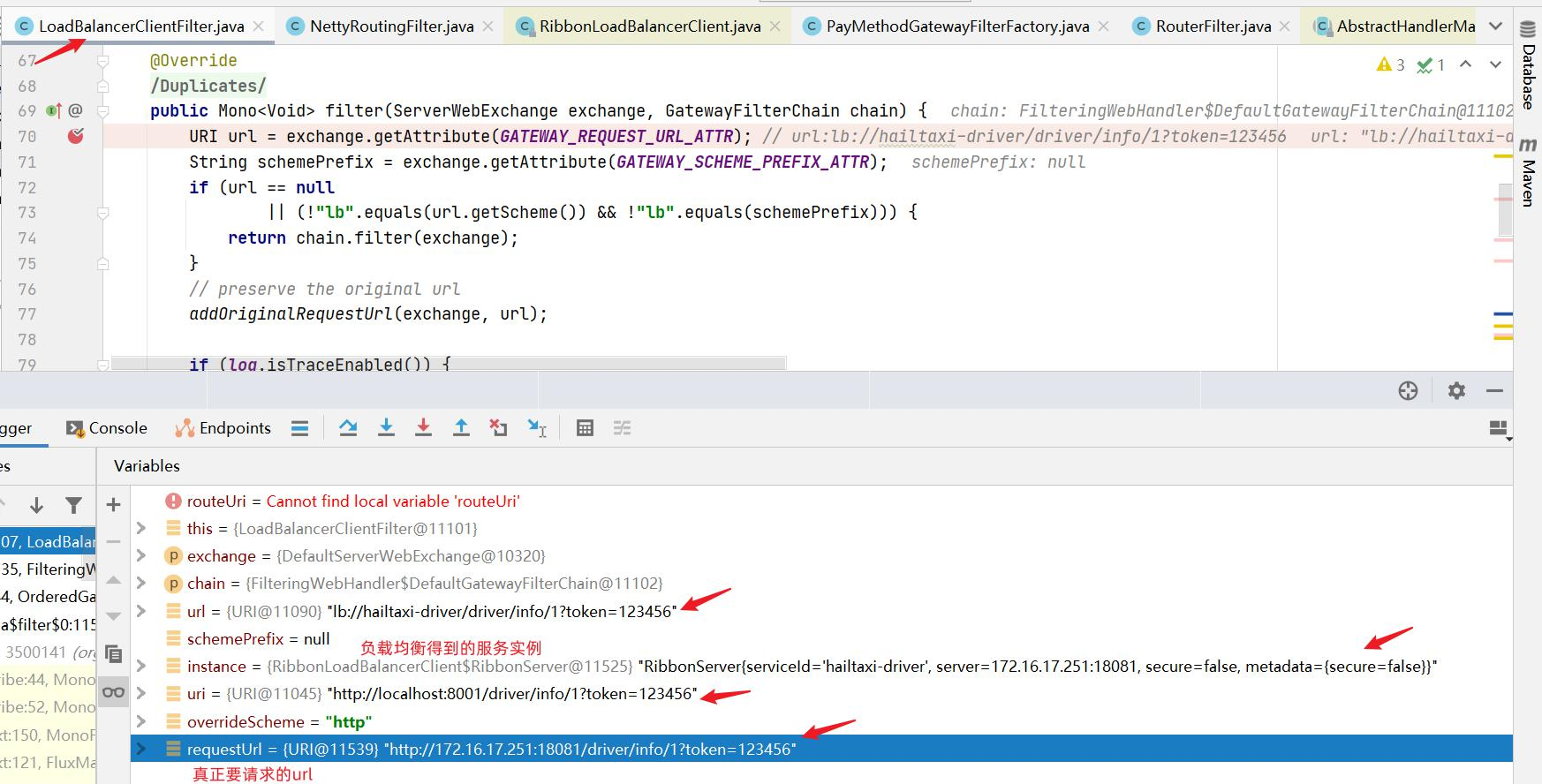
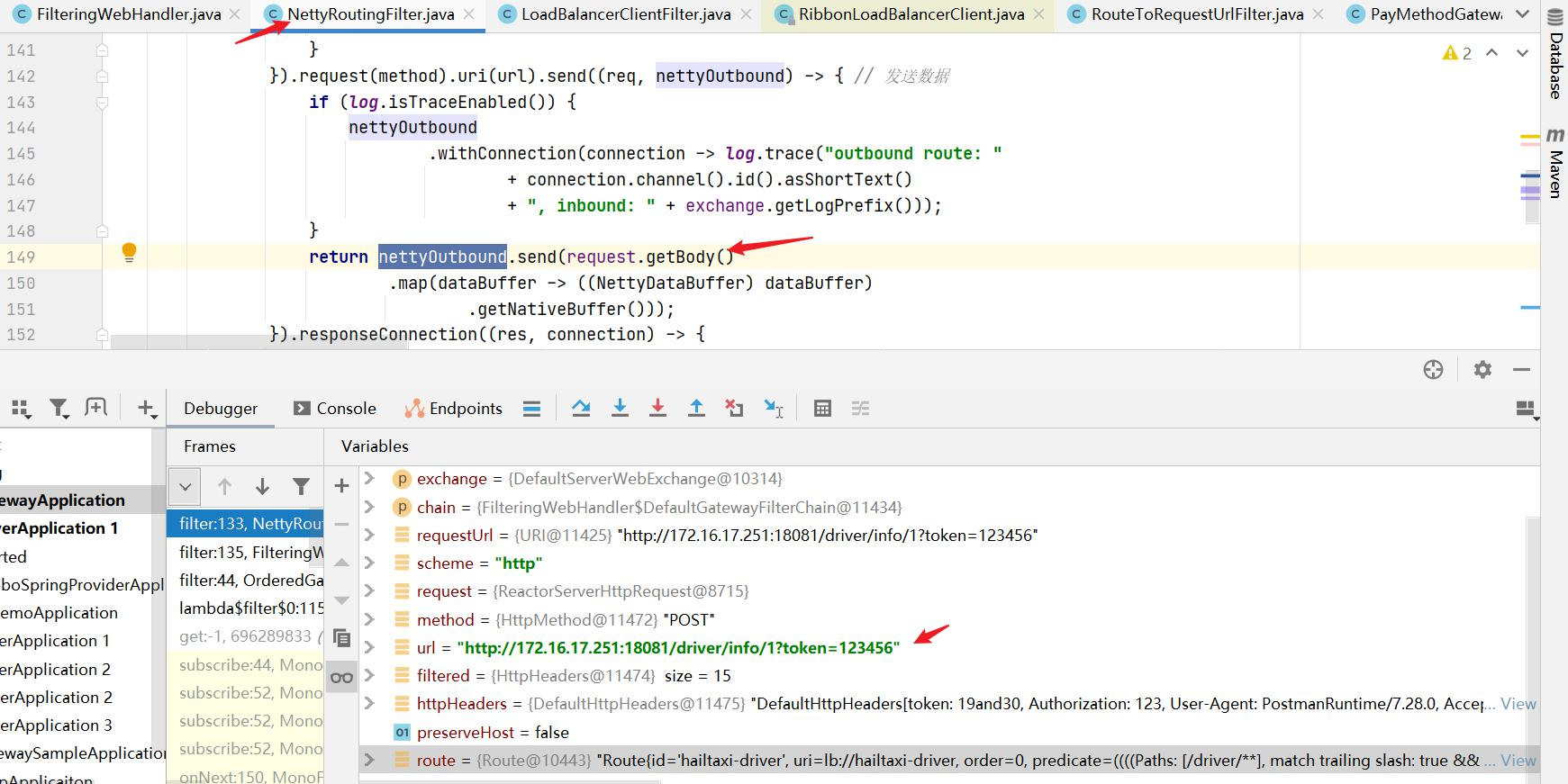

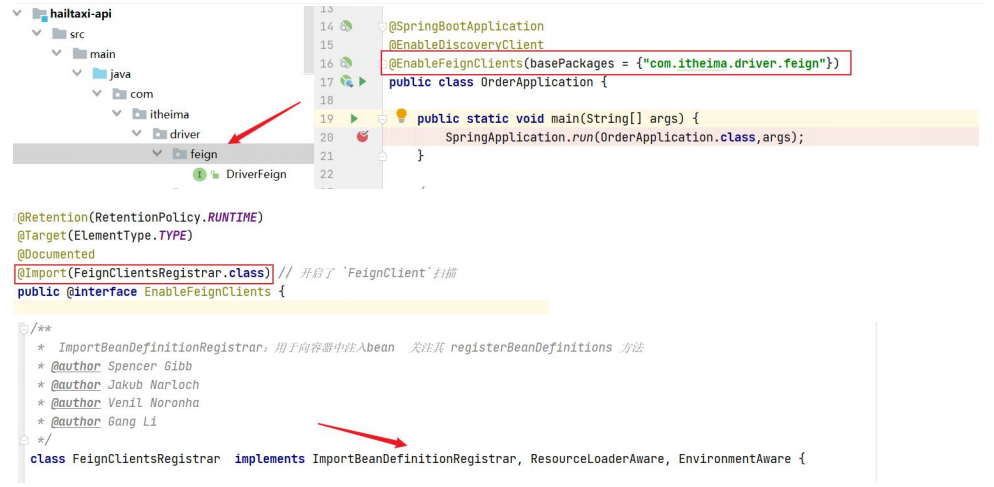
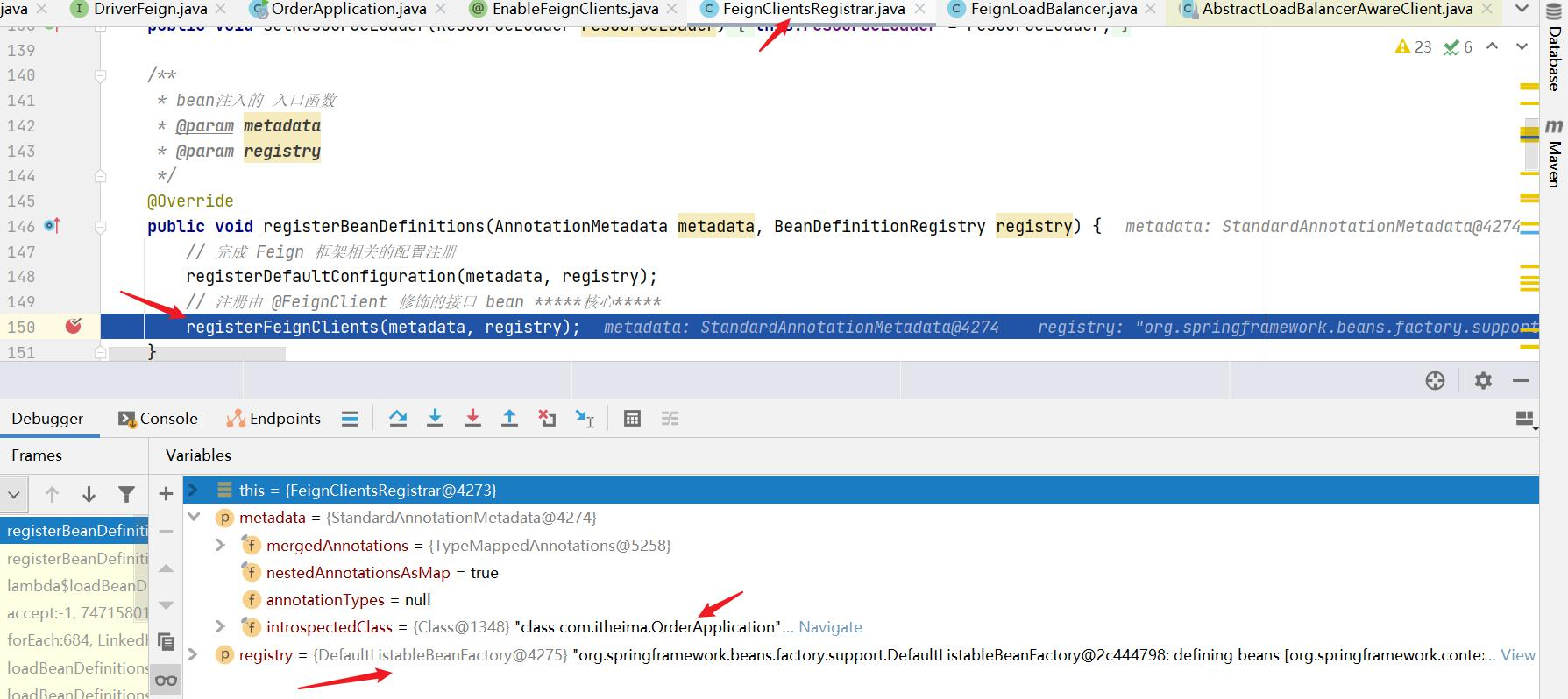
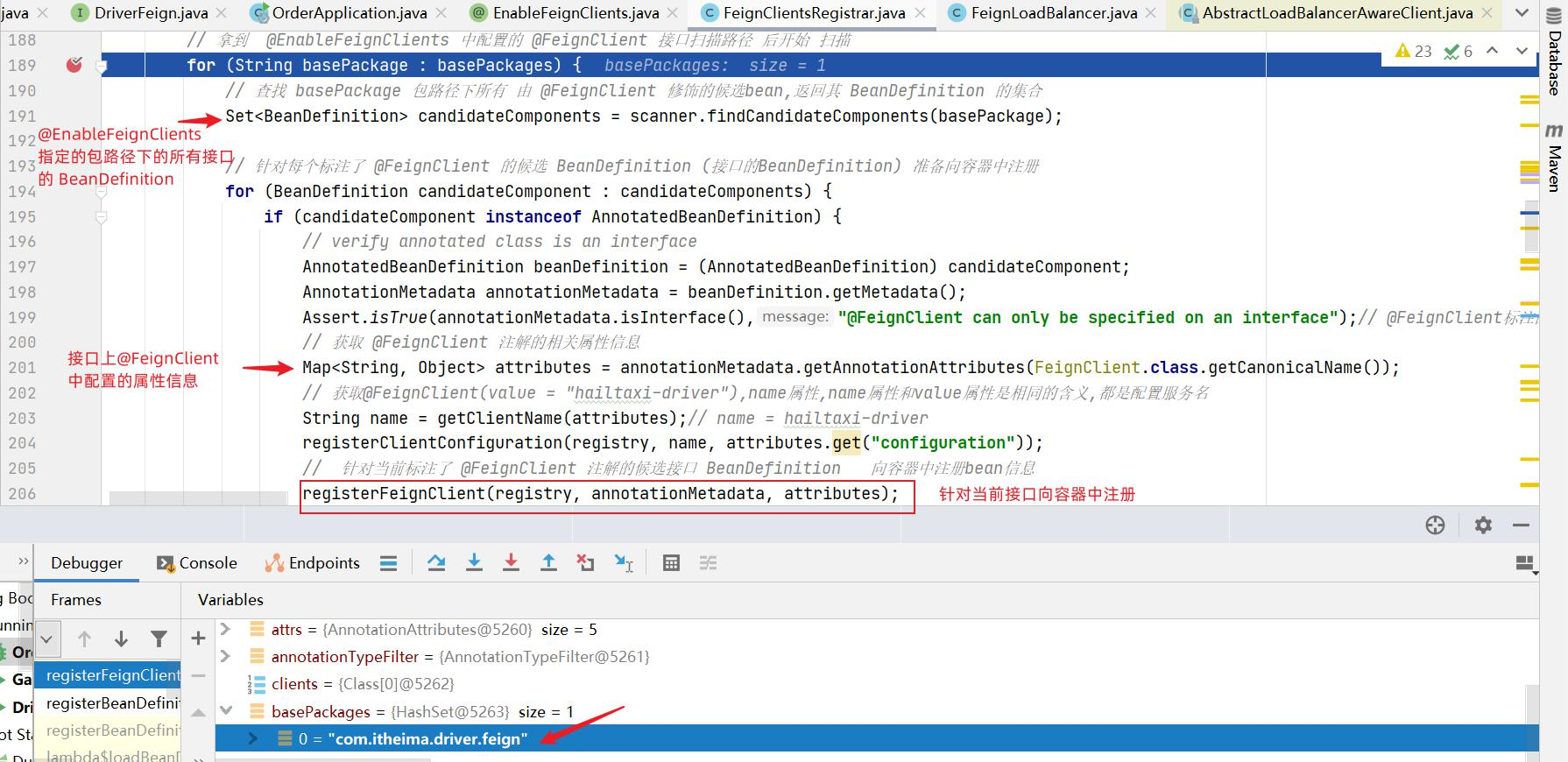


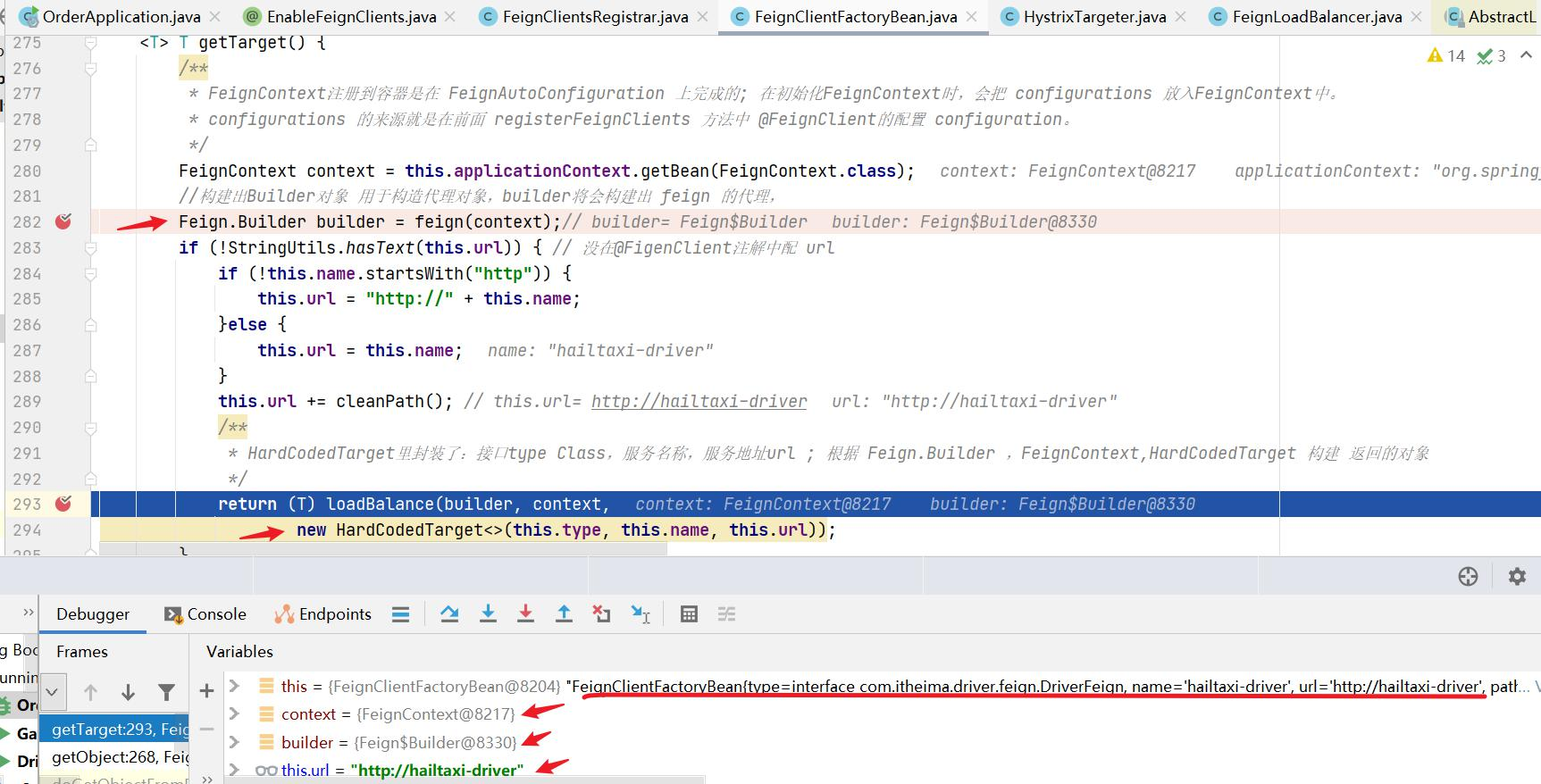
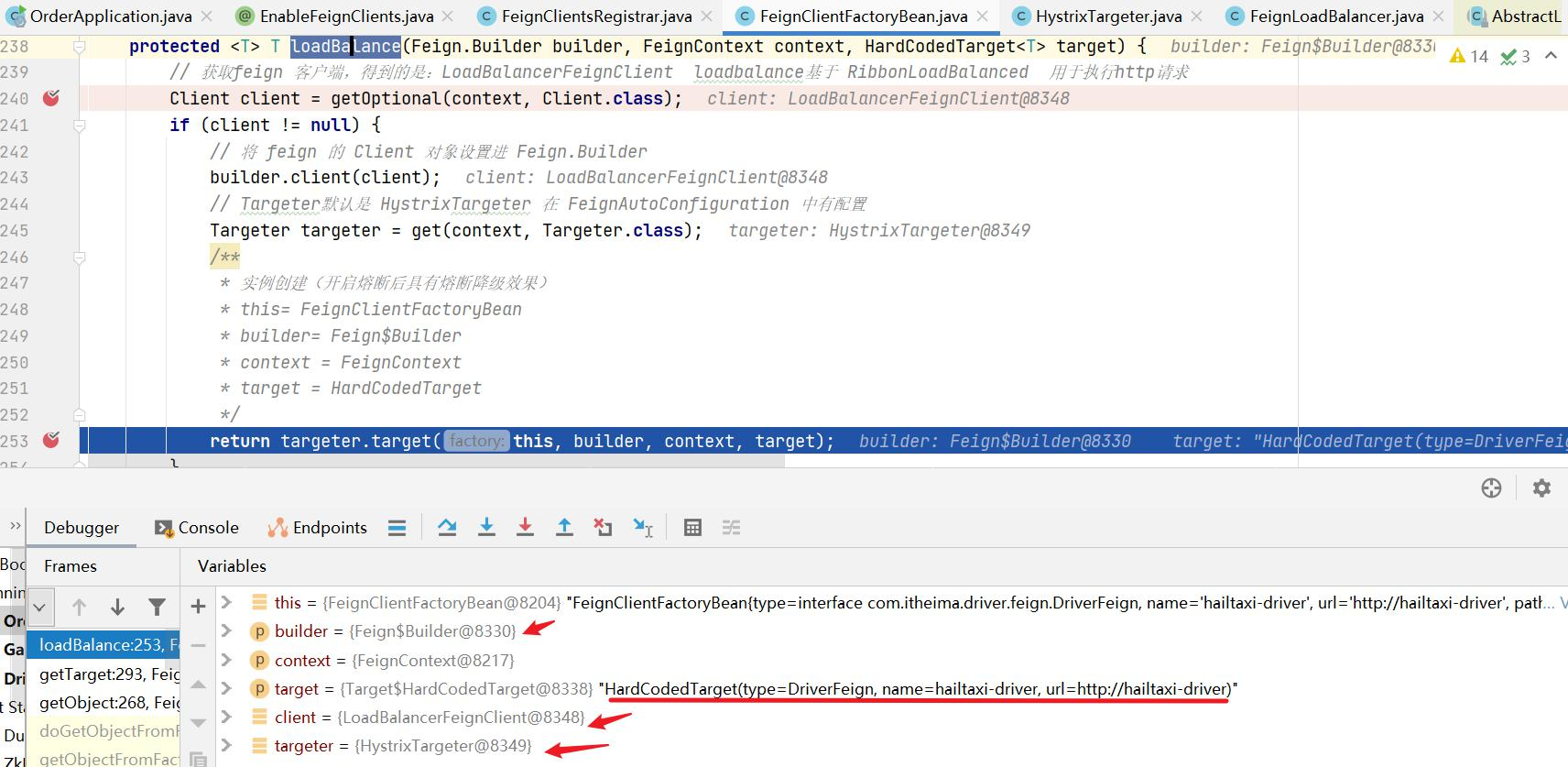


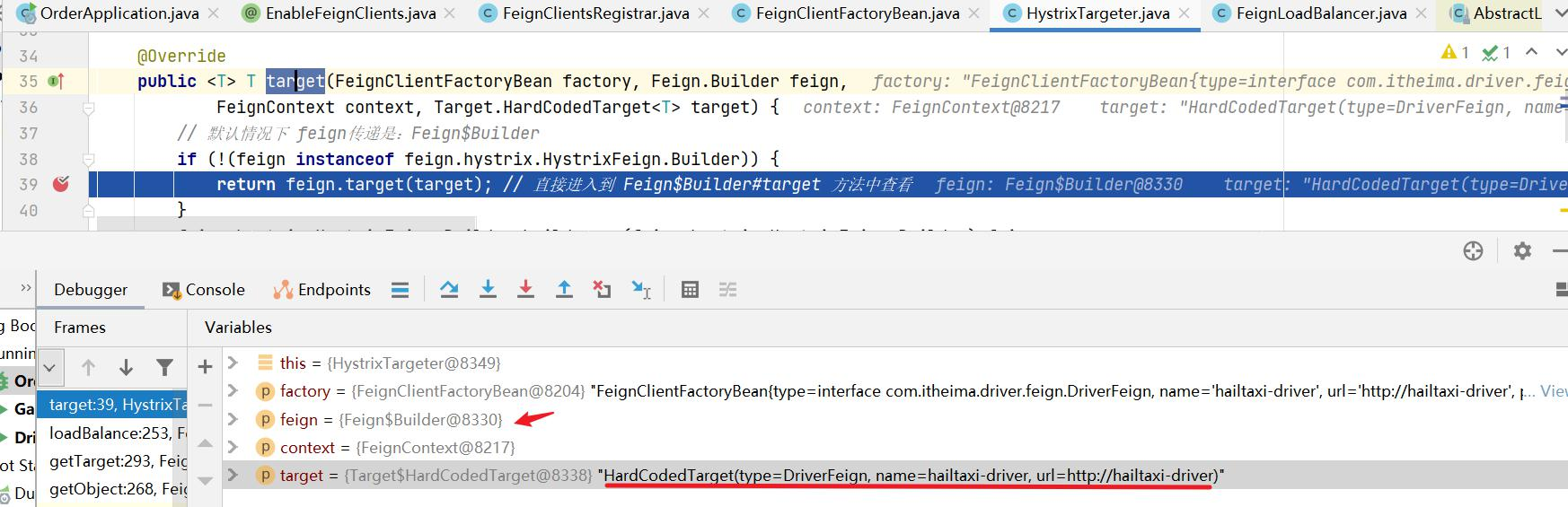

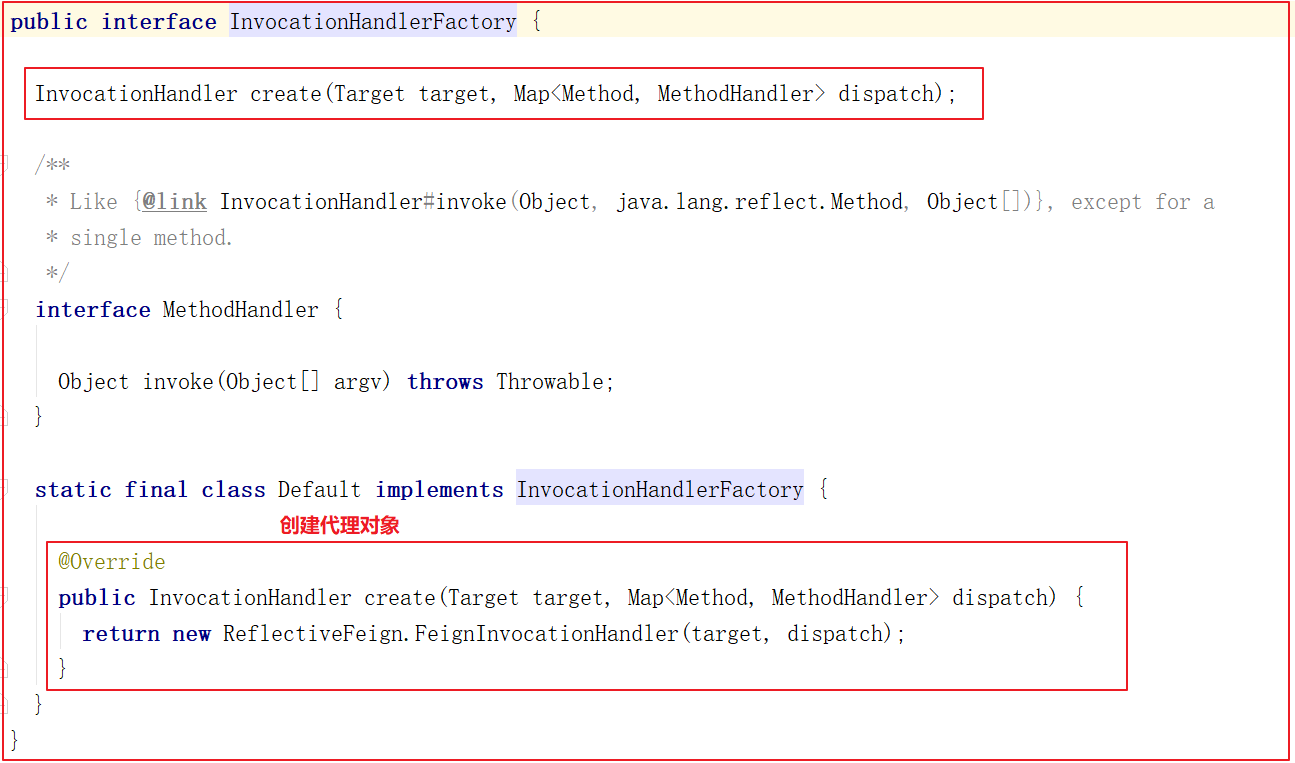
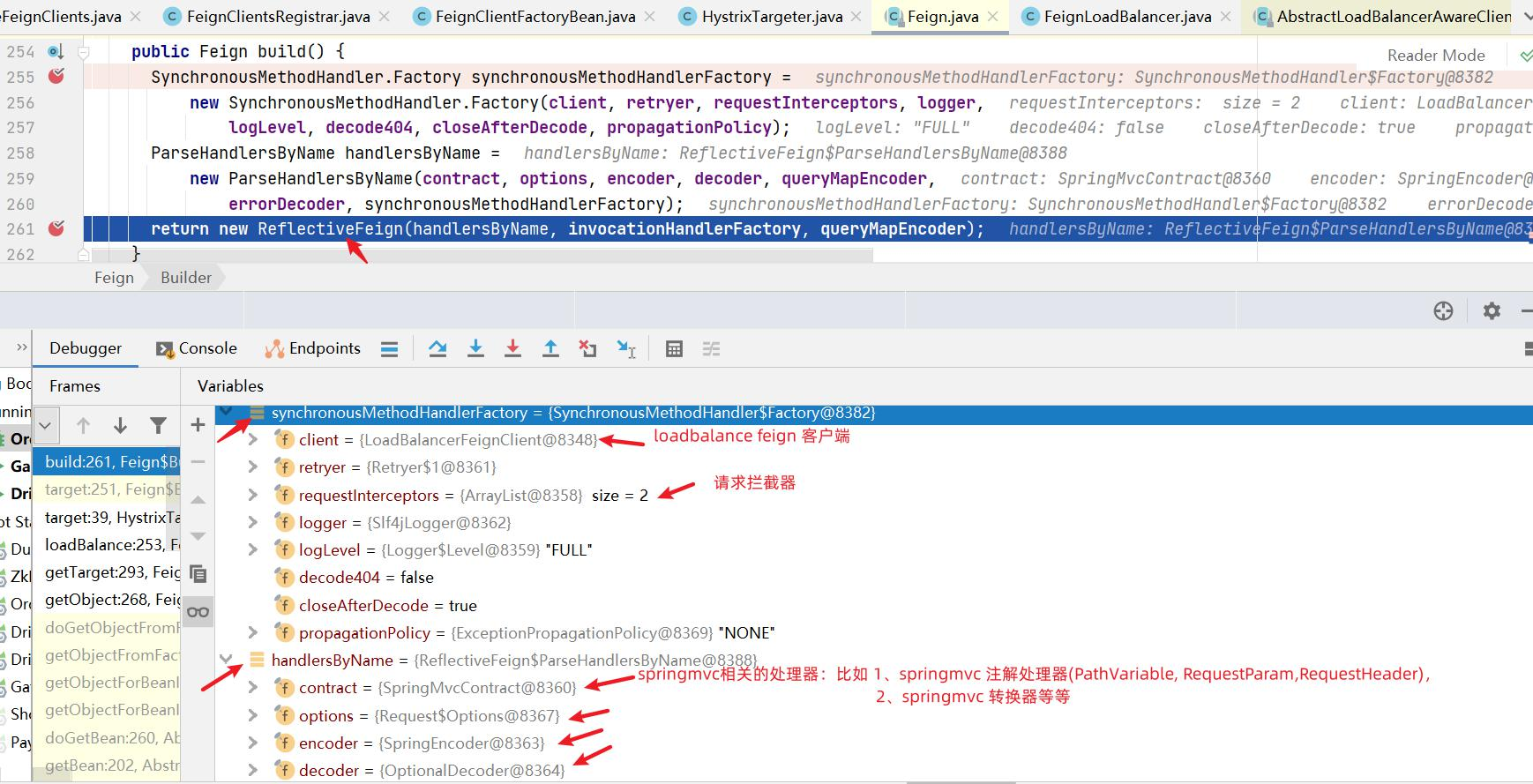
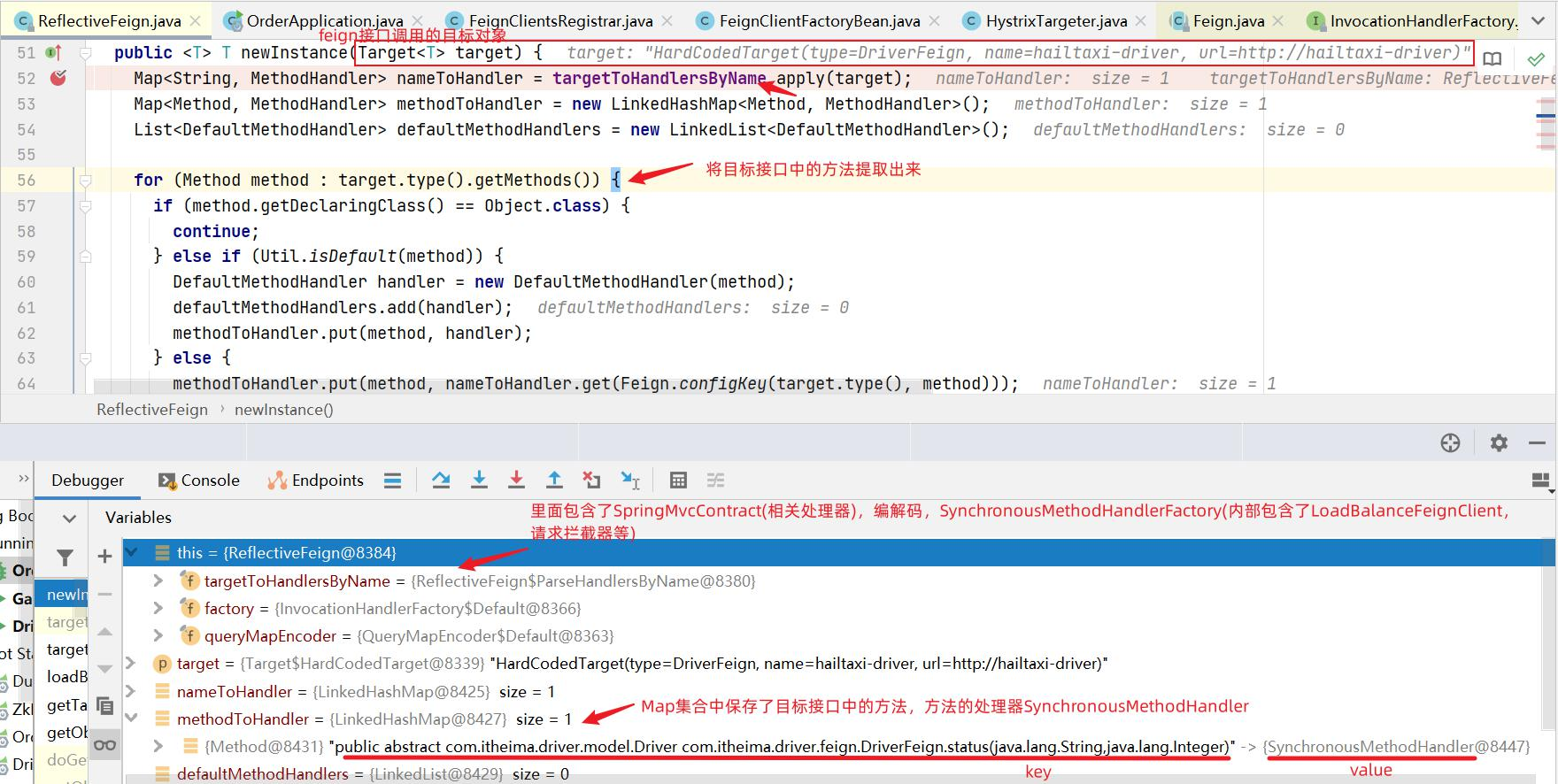
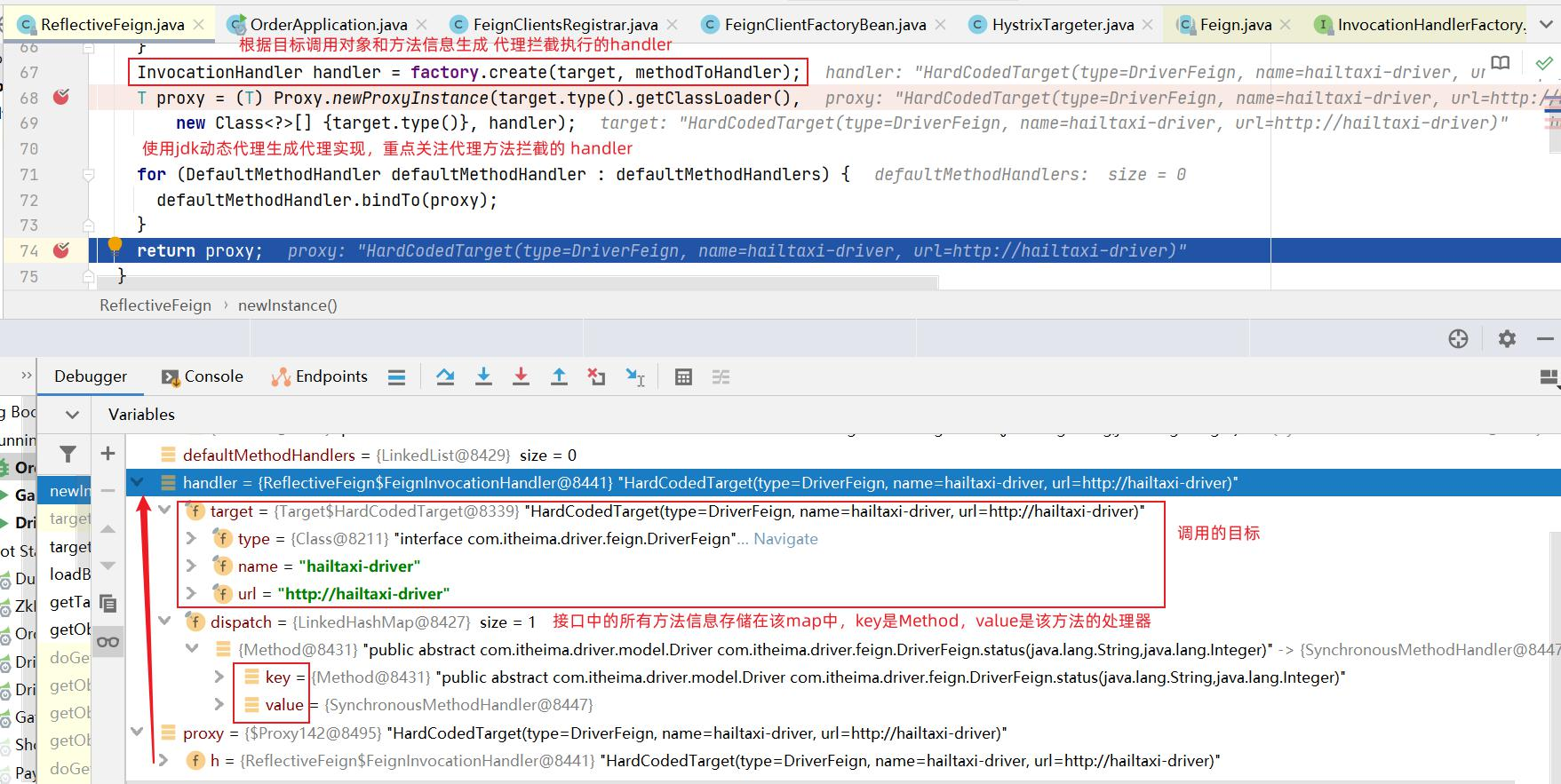
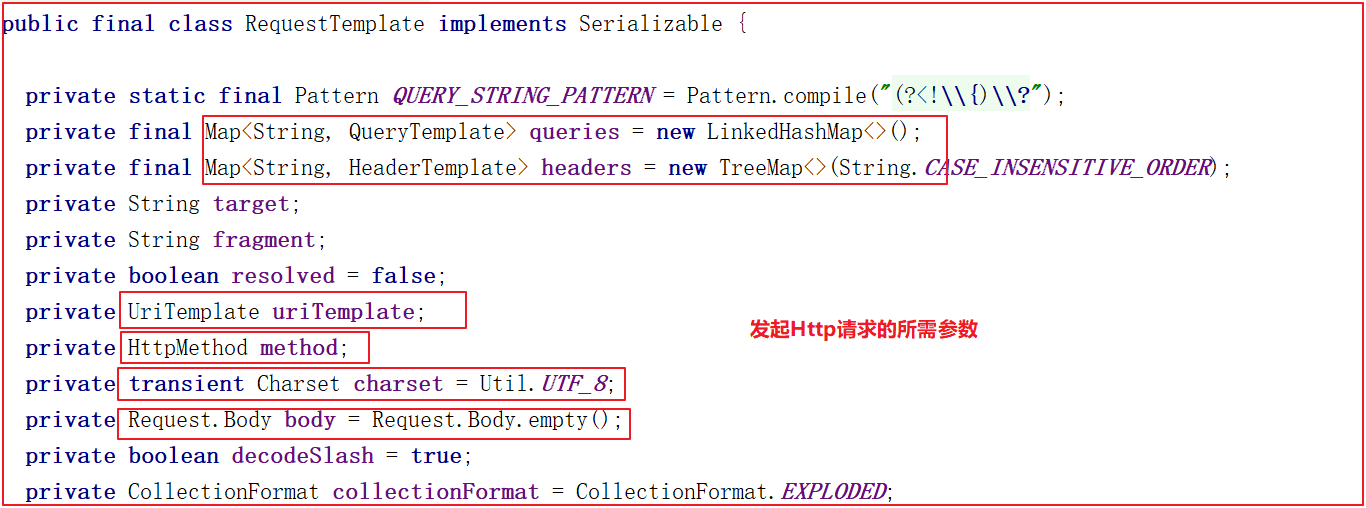
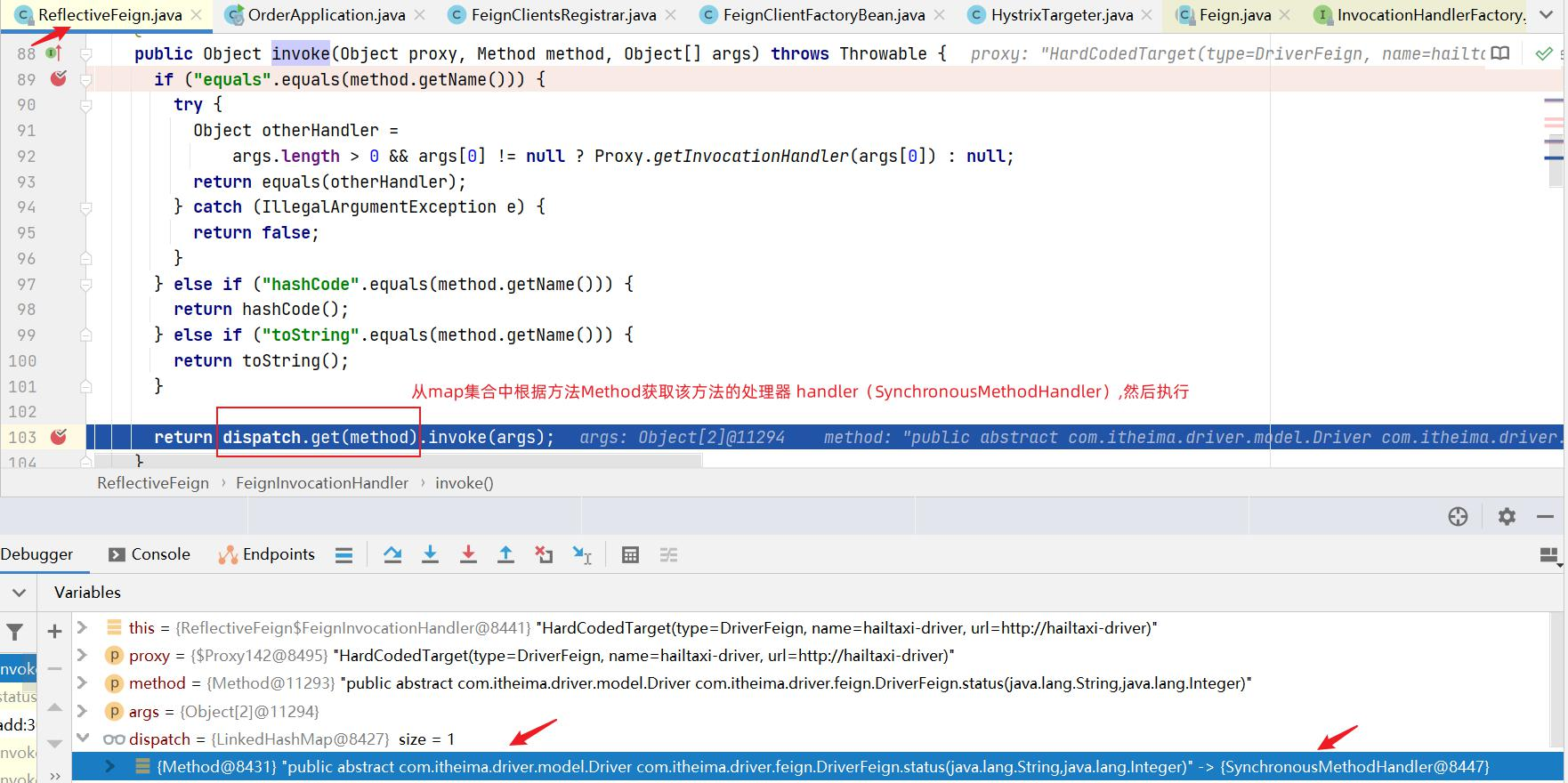
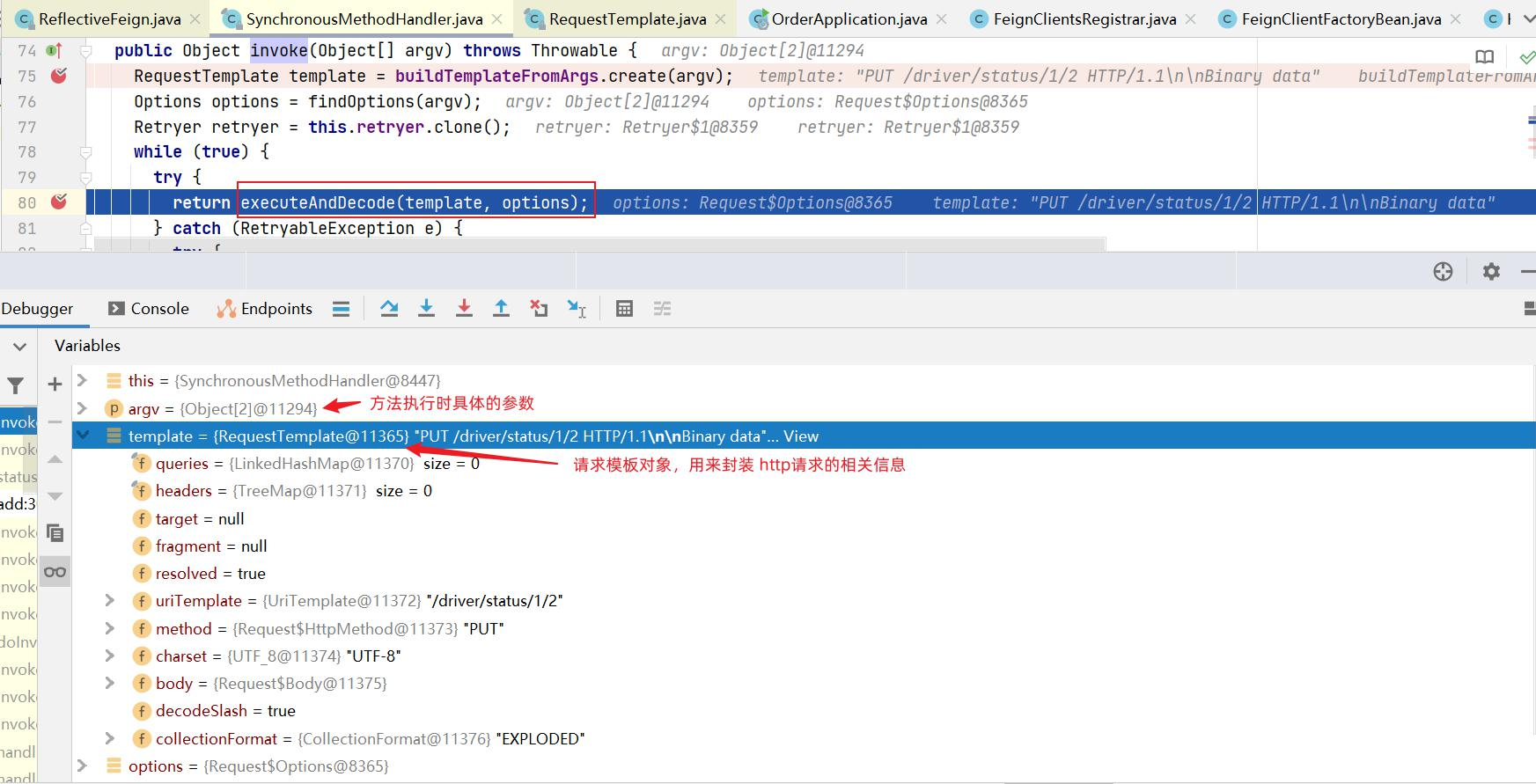
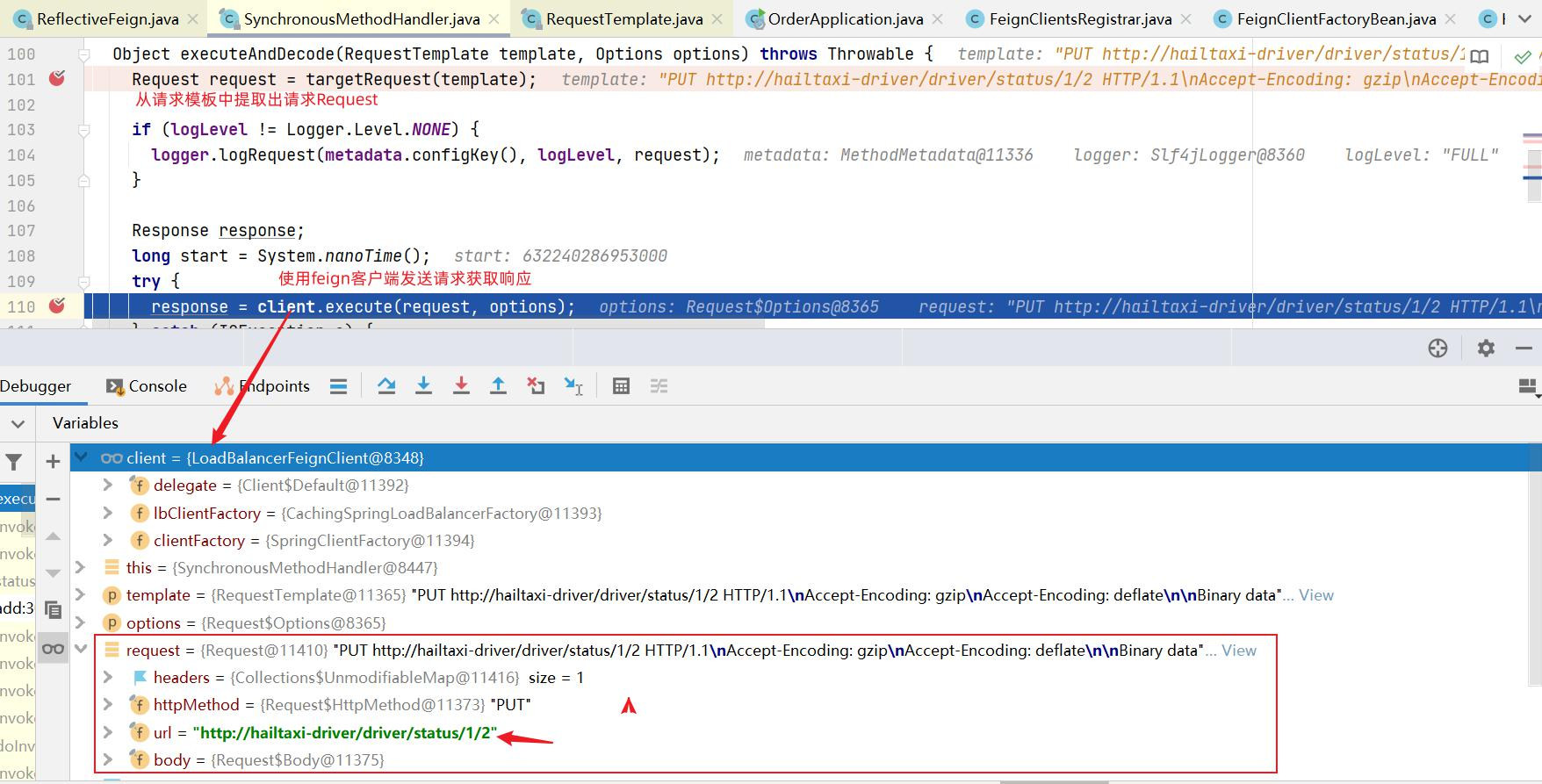
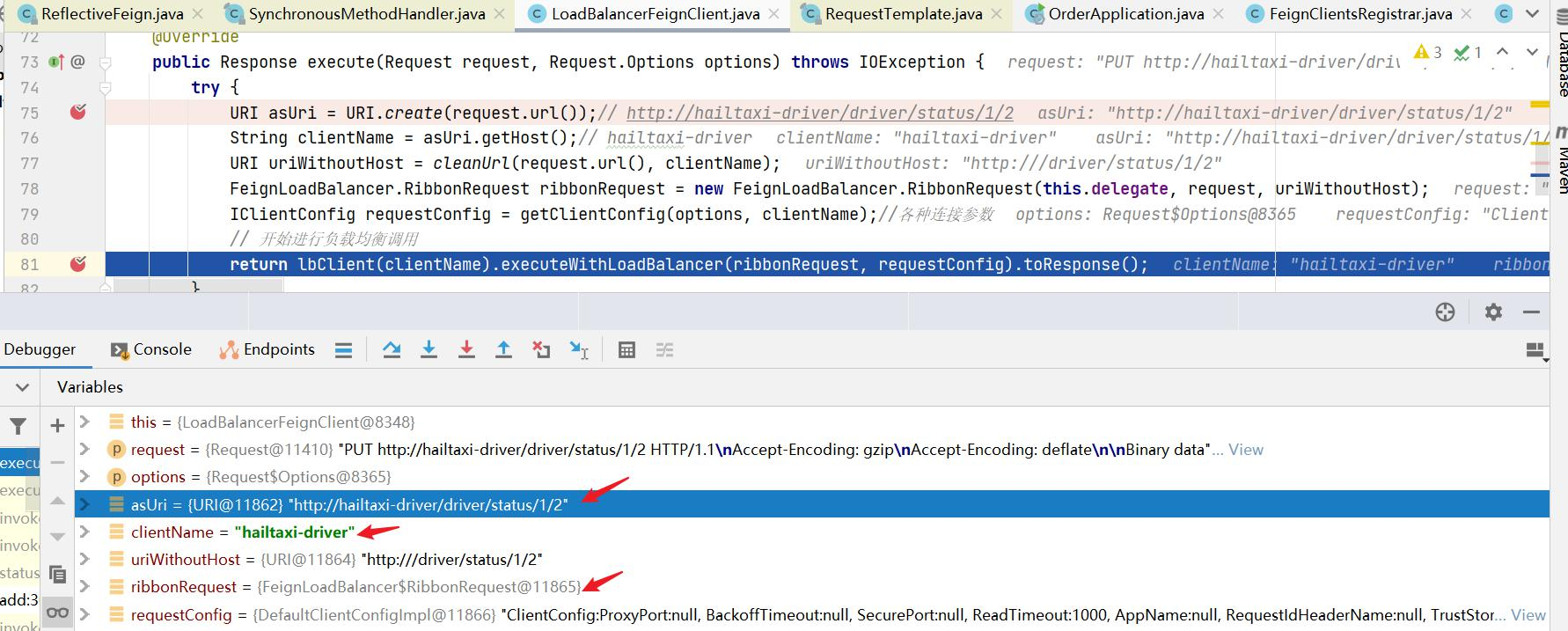
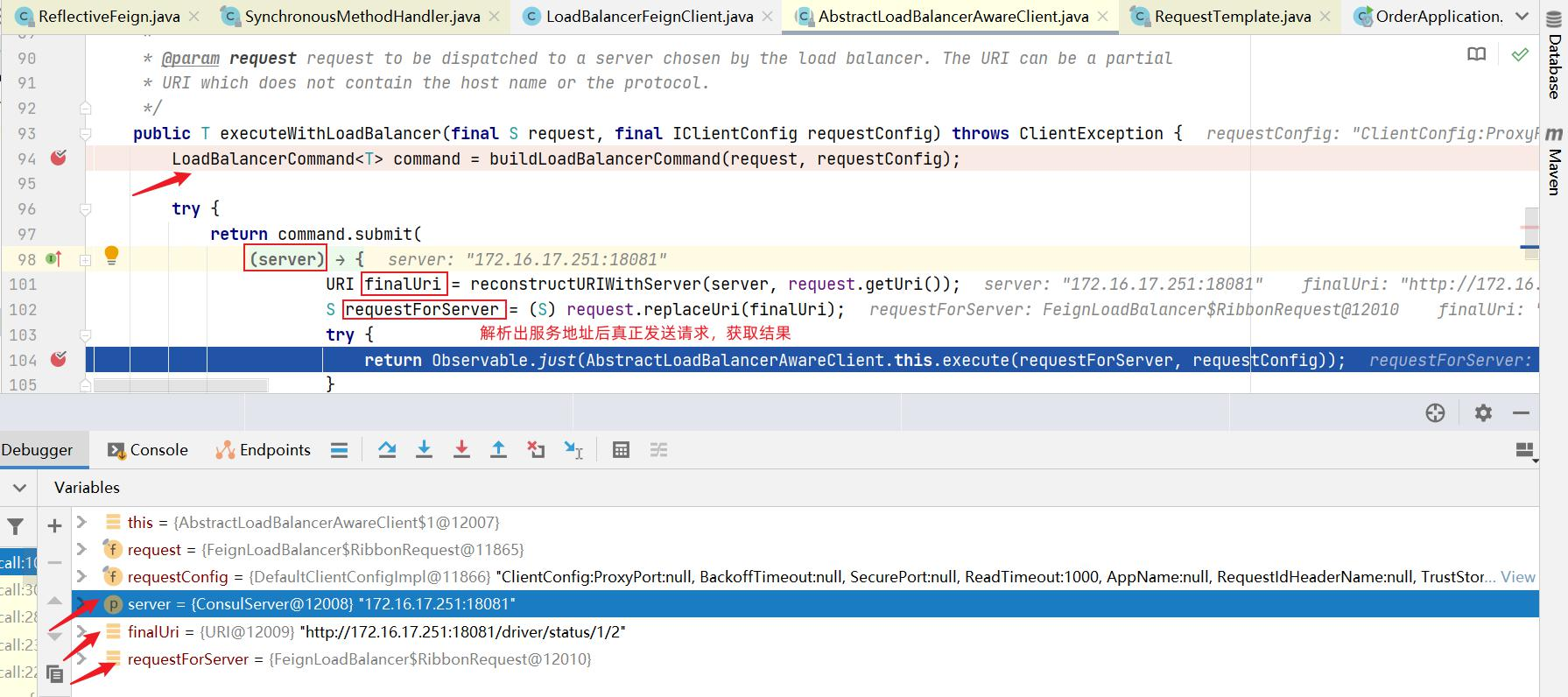
 微信
微信 支付宝
支付宝
