【devops系列】一文了解IaaS
架构设计基础设施保障
0. 能力目标
能够掌握IaaS之基本计算与应用
能够掌握IaaS之全面存储与应用
能够掌握IaaS之典型网络与应用
能够操作IaaS之高阶实践
1. IaaS之计算
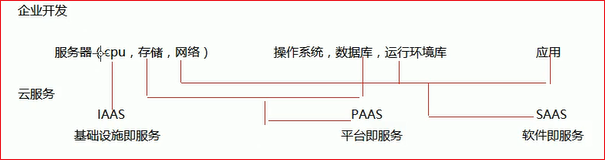
1.1 IaaS概述
IaaS(Infrastructure as a Service )提供托管的 IT 基础架构,供用户调配处理能力、存储、网络和其他基础计算资源。IaaS 提供商运行并管理此基础架构,用户可以在此基础架构上运行选择的操作系统和应用程序软件。
在云平台中还会涉及以下概念:
- PaaS:平台即服务。对应于上面所说的提供常用的技术组件方便系统的开发和维护;
- SaaS:软件即服务。对应于上面所说的提供开发好的应用或服务,按功能或性能要求付费。
- Faas:函数即服务。服务商提供一个平台,允许客户开发、运行和管理应用程序功能,而无需构建和维护通常与开发和启动应用程序相关的基础架构。
1.2 服务部署演进历程
- 应用拆分
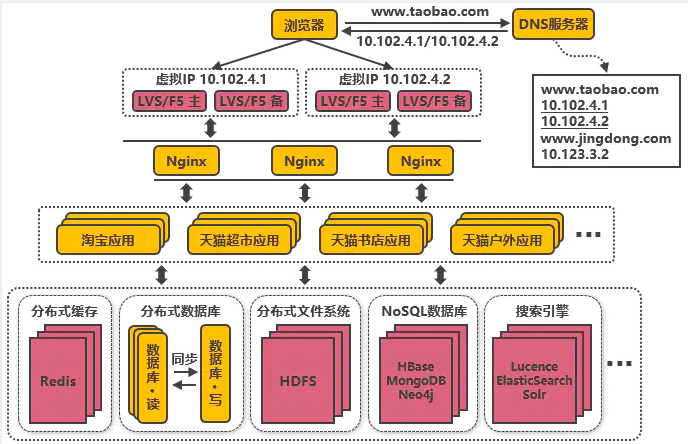
按照业务功能来划分应用服务,整个职责更清晰,相互之间可以做到独立升级迭代。应用之间可能会涉及到一些公共配置,可以通过分布式配置中心Zookeeper来解决。
架构瓶颈:
不同应用服务之间存在共用的组件,会导致相同代码存在多份,公共功能升级时全部应用代码都要跟着升级。
比如说JSON字符串处理组件, 加密处理组件等。
- 微服务应用
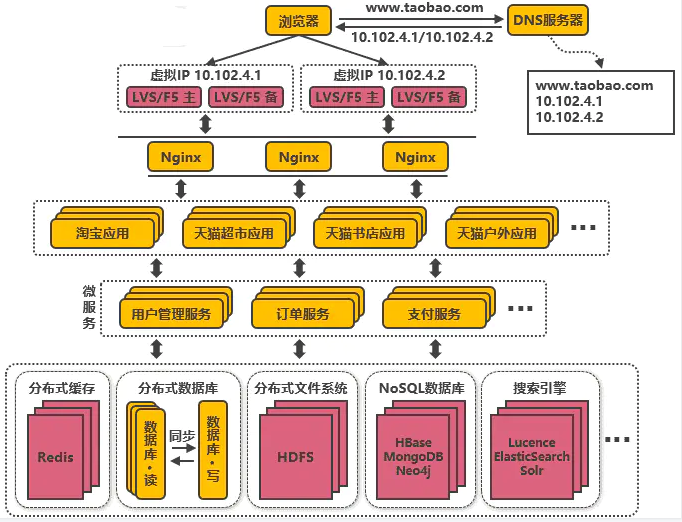
如用户管理、订单、支付、鉴权等功能在多个应用中都存在,那么可以把这些功能的代码单独抽取出来形成一个单独的服务来管理, 比如说加密封装,鉴权处理接口等。
微服务架构,应用和服务之间通过HTTP、TCP或RPC请求等多种方式来访问公共服务,每个单独的服务都可以由单独的团队来管理。
在服务治理层面, 可以通过SpringCloud等框架实现服务治理、限流、熔断、降级等功能,提高服务的稳定性和可用性。
架构瓶颈:
不同服务的接口访问方式不同,应用服务可能需要适配多种访问方式, 才能使用服务,应用服务之间也可能相互访问,调用链将会变得非常复杂冗长,逻辑变得混乱。
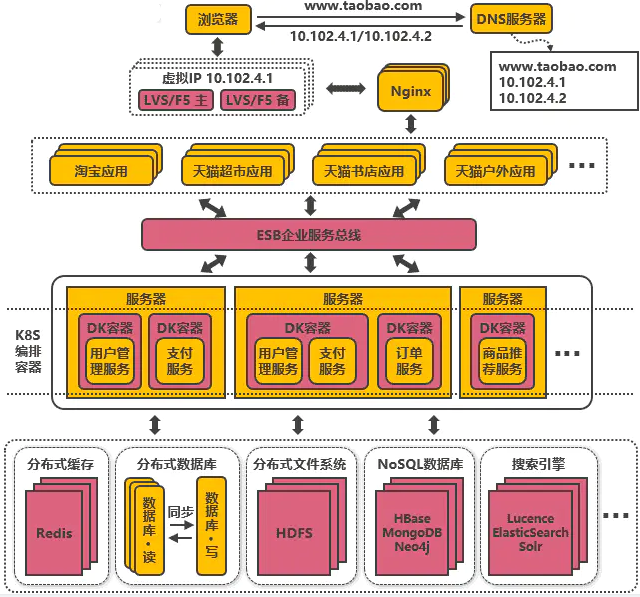
- 企业服务总线ESB
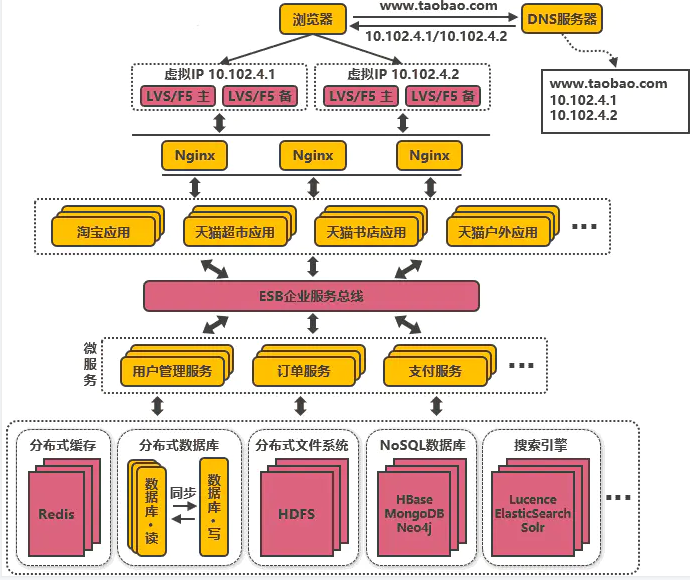
应用统一通过ESB来访问后端服务,服务与服务之间也通过ESB来相互调用,以此降低系统的耦合程度。
使用企业消息总线来解除服务之间耦合问题的架构,就是所谓的SOA(面向服务)架构,这种架构与微服务架构容易混淆,因为表现形式比较相似。
微服务架构更多是指把系统里的公共服务抽取出来单独运维管理的思想,而SOA架构则是指一种拆分服务并使服务接口访问变得统一的架构思想,SOA架构中包含了微服务的思想。
架构瓶颈:
业务不断发展,应用和服务都会不断变多,应用和服务的部署变得复杂,同一台服务器上部署多个服务还要解决运行环境冲突的问题。
对于如大促这类需要动态扩缩容的场景,需要水平扩展服务的性能,就需要在新增的服务上准备运行环境,部署服务等,运维将变得十分困难。
- 容器化技术
目前最流行的容器化技术是Docker,最流行的容器管理服务是Kubernetes(K8S),应用/服务可以打包为Docker镜像,通过K8S来动态分发和部署镜像。
Docker镜像可理解为一个能运行你的应用/服务的最小的操作系统,里面放着应用/服务的运行代码,运行环境根据实际的需要设置好。
把整个“操作系统”打包为一个镜像后,就可以分发到需要部署相关服务的机器上,直接启动Docker镜像就可以把服务起起来,使服务的部署和运维变得简单。
架构瓶颈:
使用容器化技术后服务动态扩缩容问题得以解决,但是机器还是需要公司自身来管理,在非大促的时候,还是需要闲置着大量的机器资源来应对大促,机器自身成本和运维成本都极高,资源利用率低。
- 云平台
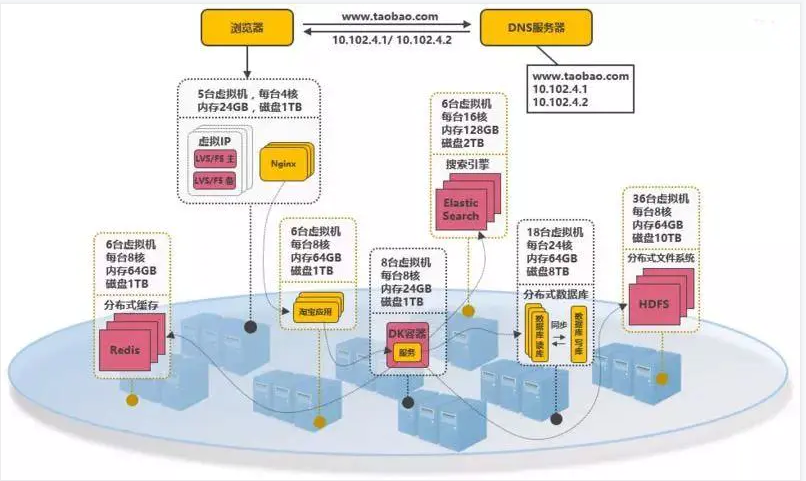
系统可部署到公有云上,利用公有云的海量机器资源,解决动态硬件资源的问题
在大促的时间段里,在云平台中临时申请更多的资源,结合Docker和K8S来快速部署服务,在大促结束后释放资源,真正做到按需付费,资源利用率大大提高,同时大大降低了运维成本。
所谓的云平台,就是把海量机器资源,通过统一的资源管理,抽象为一个资源整体
在云平台上可按需动态申请硬件资源(如CPU、内存、网络等),并且之上提供通用的操作系统,提供常用的技术组件(如Hadoop技术栈,MPP数据库等)供用户使用,甚至提供开发好的应用
用户不需要关心应用内部使用了什么技术,就能够解决需求(如音视频转码服务、邮件服务、个人博客等)。
1.3 云虚拟机
- 介绍
阿里云ECS
ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。
亚马逊EC2
EC2(Amazon Elastic Compute Cloud),是一种 Web 服务,能在云中提供安全且可调整大小的计算能力。该服务旨在让开发人员能够更轻松地进行 Web 规模的云计算。
腾讯云CVM
CVM(Cloud Virtual Machine),提供安全可靠的弹性计算服务,可以在云端获取和启用 CVM,来实现计算需求。随着业务需求的变化,可以实时扩展或缩减计算资源。
- 云虚拟机对比
- 性能评测:
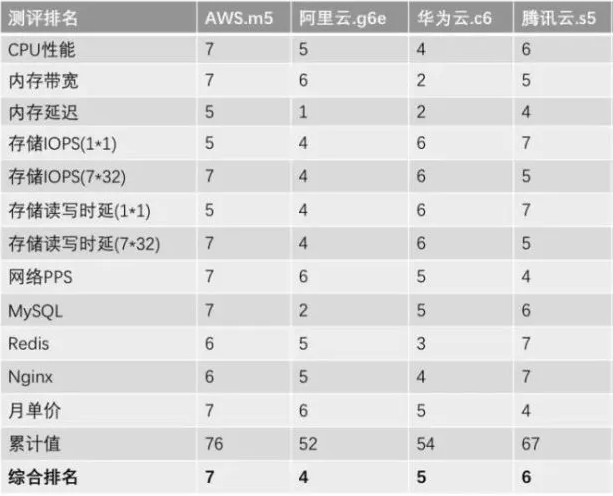
(累计值越小, 综合排名越高。)
- 成本对比:
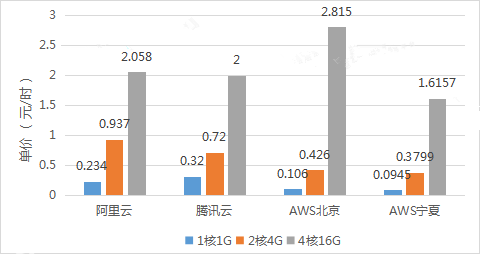
1.4 云虚拟机如何选型
虚拟机类型
主要类型对比:
类型 AWS代号 阿里云代号 腾讯云代号 通用型 M G S 计算型 C C C、CN 内存型 R R M GPU计算型 P GN AMD、NVIDIA 存储型 I、D I、D D 阿里云还包含: 本地SSD型、高主频型、FPGA计算型、NPU计算型、超级计算集群(SCC)、弹性裸金属服务器(自研新一代云服务器)等。
腾讯云还包含: 高 IO 型实例族、批量型实例族等。
代别更新
随着虚拟化技术不断发展, 云厂商需要不断地对虚拟机进行更新:
硬件方面, 比如CPU的换代, 内存升级等;
软件层面,比如内核的改进,虚拟化技术的提升等。
实例配置
实例按业界标准划分为micro、small、medium、large、xlarge。
类型 vCPU 内存 micro 1 1 small 1 2 medium 2 4 large 2 8 xlarge 4 16 2xlarge 8 32
1.5 云虚拟机的创建操作
- 选择虚拟机类型
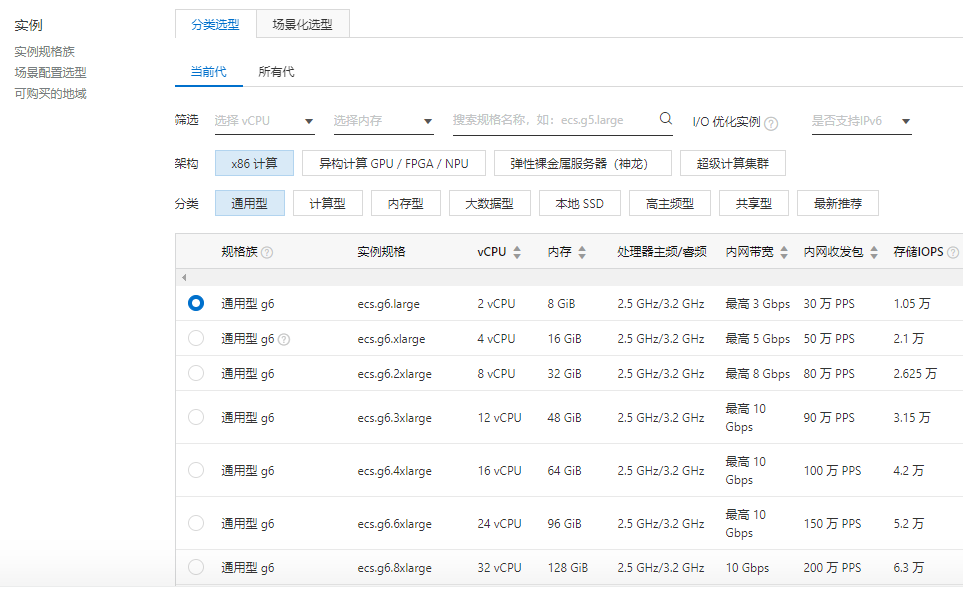
如果测试, 可以选取抢占实例, 节省成本。

- 网路和安全组配置
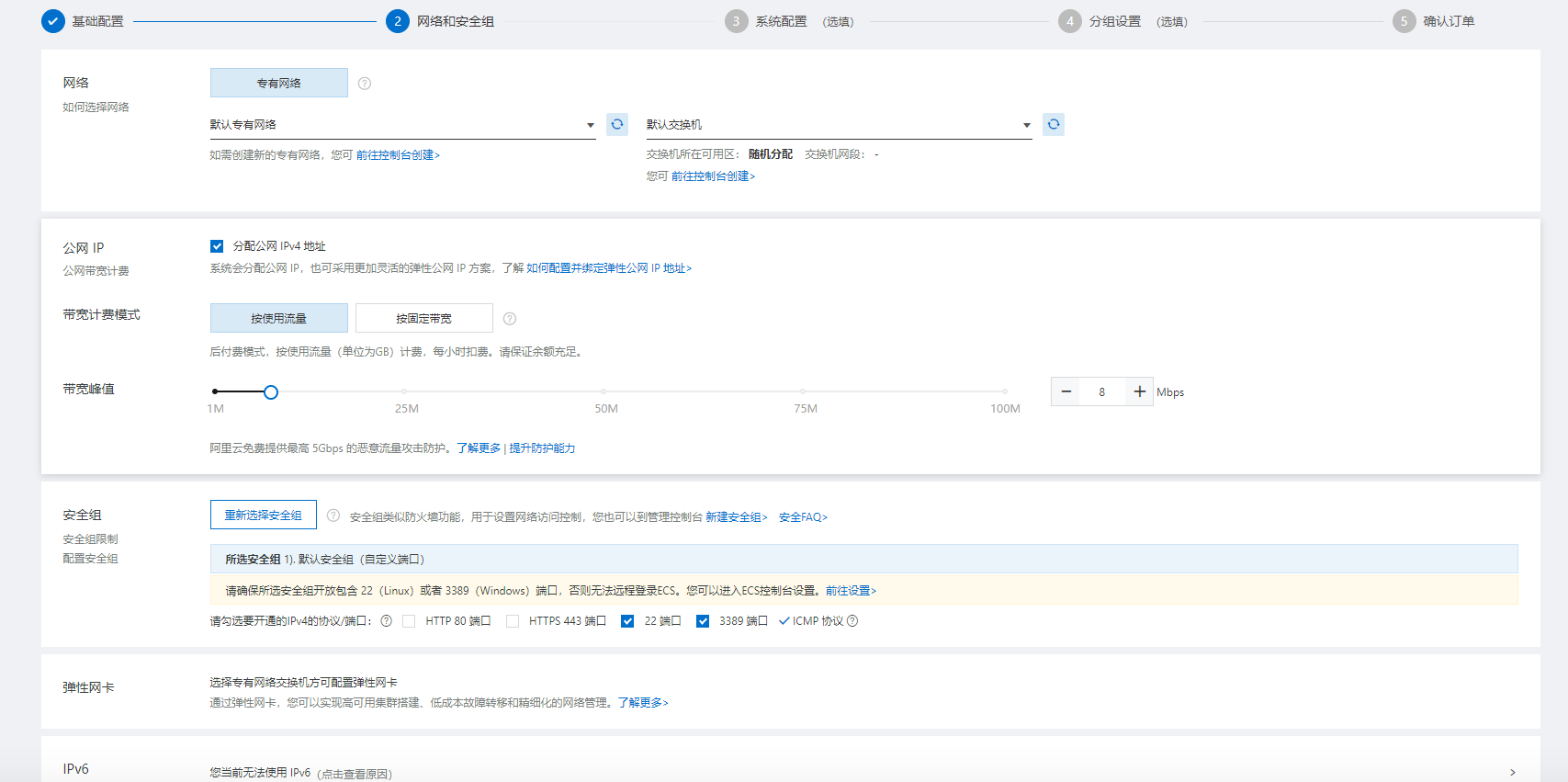
- 系统配置
- 分组设置
- 远程连接

通过远程连接可以直接进行操作, 一般会采用远程连接工具进行管理, 比如VNC或SSH连接工具。
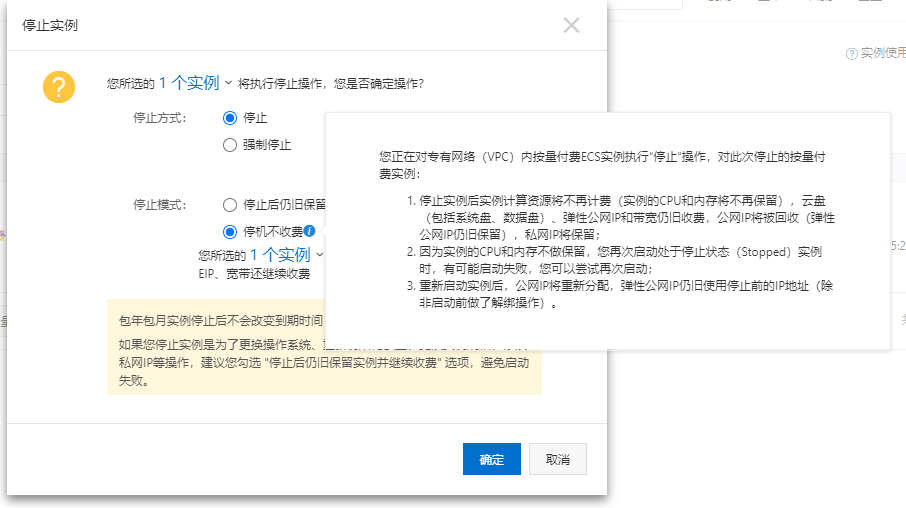
如果需要节省成本, 可以选择“停机不收费”, 但不能保障稳定性。
1.6 服务部署访问
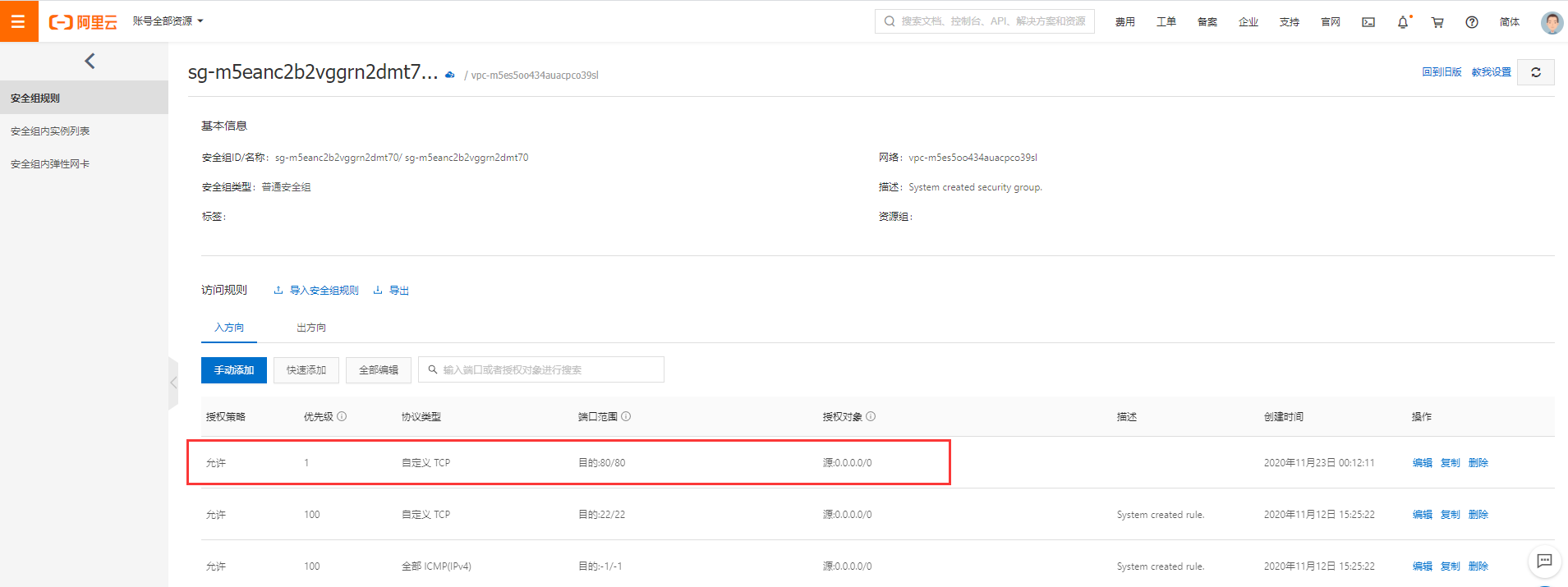
开通80端口访问权限
在网络与安全 -> 安全组里面, 新增配置:
安装JDK
1
yum -y install java-1.8.0-openjdk.x86_64
打包服务
1
maven clean install
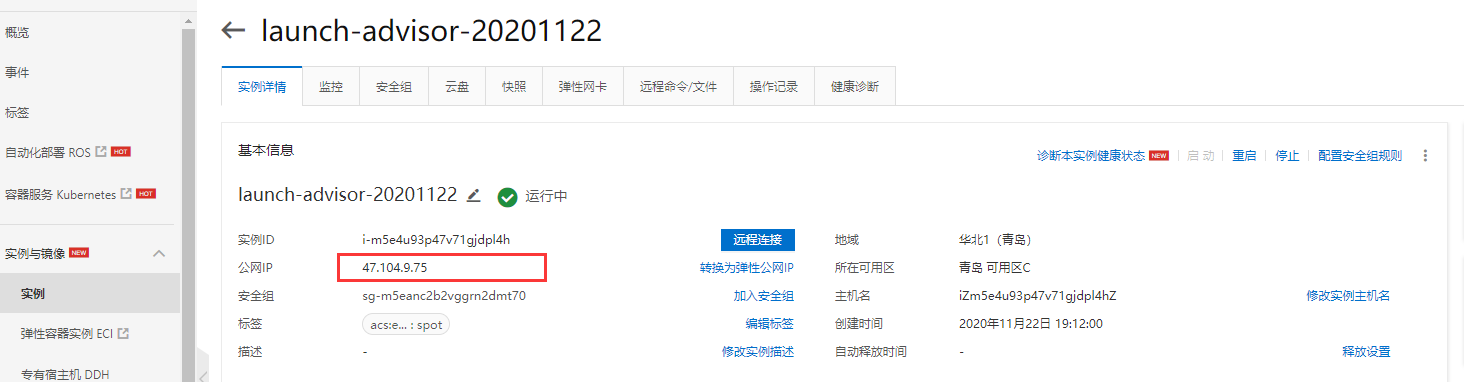
配置服务器连接
直接通过外网IP访问:
运行服务
1
java -jar app-basic.jar
访问验证
2. IaaS之存储
2.1 云硬盘
HDD(普通云盘)
特征: 性能一般, IOPS大概在数百左右。
应用场景: 数据不被经常访问或者低I/O负载的应用场景,需要低成本并且有随机读写I/O的应用环境。
混合HDD(高效云盘)
特征: 结合HDD和SSD硬盘构建, IOPS为1000~5000左右。
应用场景: 开发与测试业务、系统盘。
SSD云盘
特征: 具有稳定的IO能力, IOPS能够达到10000~25000左右。
应用场景:I/O密集型应用、中小型关系数据库、NoSQL数据库。
企业级SSD(ESSD云盘)
特征: 优化增强的SSD云盘, 一般是采用企业级的闪存硬件, IOPS能够达到10000~1000000左右。
应用场景: 大型OLTP数据库等关系型数据库、NoSQL数据库、ELK分布式日志存储等。
测试:
安装fio工具
1
yum -y install fio
iops测试
1
fio --name=disktest --filename=~/disktest --rw=randread --refill_buffers --bs=4k --size=1G -runtime=5 -direct=1 -iodepth=128 -ioengine=libaio
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33[root@iZm5egp1t778ocdk7f1j6fZ ~]# fio --name=disktest --filename=~/disktest --rw=randread --refill_buffers --bs=4k --size=1G -runtime=5 -direct=1 -iodepth=128 -ioengine=libaio
disktest: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=128
fio-3.7
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=8560KiB/s,w=0KiB/s][r=2140,w=0 IOPS][eta 00m:00s]
disktest: (groupid=0, jobs=1): err= 0: pid=1417: Thu Nov 12 22:09:25 2020
read: IOPS=2151, BW=8606KiB/s (8812kB/s)(42.3MiB/5032msec)
slat (usec): min=2, max=166, avg= 6.54, stdev= 3.69
clat (usec): min=794, max=157946, avg=59467.61, stdev=47971.33
lat (usec): min=799, max=157950, avg=59474.73, stdev=47971.03
clat percentiles (usec):
| 1.00th=[ 1172], 5.00th=[ 1434], 10.00th=[ 1614], 20.00th=[ 1860],
| 30.00th=[ 2147], 40.00th=[ 2999], 50.00th=[ 98042], 60.00th=[ 98042],
| 70.00th=[ 99091], 80.00th=[ 99091], 90.00th=[ 99091], 95.00th=[100140],
| 99.00th=[127402], 99.50th=[127402], 99.90th=[156238], 99.95th=[156238],
| 99.99th=[158335]
bw ( KiB/s): min= 8544, max= 8560, per=99.46%, avg=8558.40, stdev= 5.06, samples=10
iops : min= 2136, max= 2140, avg=2139.60, stdev= 1.26, samples=10
lat (usec) : 1000=0.16%
lat (msec) : 2=25.15%, 4=15.13%, 10=0.03%, 50=0.59%, 100=56.23%
lat (msec) : 250=2.71%
cpu : usr=0.58%, sys=1.93%, ctx=1154, majf=0, minf=163
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.3%, >=64=99.4%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued rwts: total=10826,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs):
READ: bw=8606KiB/s (8812kB/s), 8606KiB/s-8606KiB/s (8812kB/s-8812kB/s), io=42.3MiB (44.3MB), run=5032-5032msec
Disk stats (read/write):
vda: ios=10486/0, merge=0/1, ticks=614779/0, in_queue=485314, util=75.89%iops平均达到2139.60,与高效云盘标示的2120基本是一致。
也可以挂载动态硬盘进行测试, 不同的类型和存储空间, IOPS是不一样:
2.2 对象存储
Amazon S3 vs 阿里云 OSS
Amazon S3,全称亚马逊简易存储服务(Amazon Simple Storage Service)
阿里云 OSS(Object Storage Service,简称OSS),是阿里云对外提供的海量、安全、低成本、高可靠的云存储服务。
对比:
功能特性 Amazon S3 阿里云OSS 存储对象 对象 对象 对象ACL 支持 支持 最大对象大小 5T 48.8T 数据可靠性 99.999999999(11个9) 99.999999999(11个9) 对象元数据 元数据 对象元 对象生命周期管理 支持 支持 对象版本控制 支持 支持(可选) 更新事件通知 支持 支持 跨地域复制 支持 支持 对象追加写入 不支持 支持 并行或分段上传 支持 支持 高一致性 支持 支持 数据加密 在客户端和服务端加密 在客户端和服务端加密 请求协议 HTTP/HTTPS HTTP/HTTPS/Bit Torrent 图片处理 不支持 支持 对象存储VS云硬盘
提供接口访问
对象存储本质是一个网络化的服务, 云硬盘是挂载到虚拟机的虚拟硬盘,必须连接到虚拟机才能操作。
存储结构不一致
云硬盘是一个可以作为一个真正的文件系统, 而云存储是一个近似键值(key和value)的存储服务。
海量数据存储
云硬盘一般会受自身容量的限制, 不能支撑海量数据存储, 对象存储得益于其底层设计, 天生就能够支撑大数据存储。对象存储服务不仅可以支持海量的小文件, 也适合处理大型文件。
实践操作
流程:

开通OSS服务OSS产品详情页
创建存储空间, Bucket名称要具备唯一性。
开通对应的访问权限
不要采用主账号,会存在安全隐患, 授权给RAM用户。
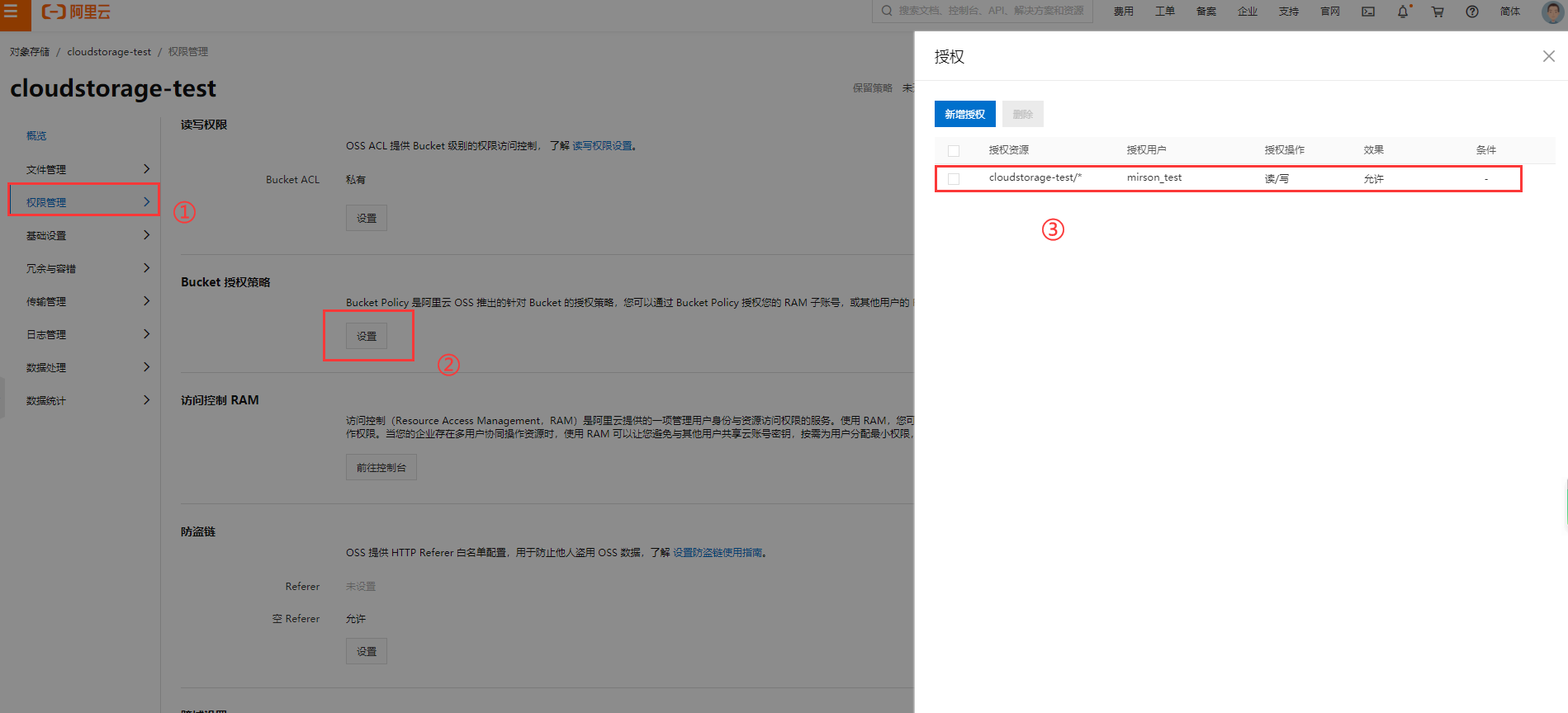
添加依赖
1
2
3
4
5<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.10.2</version>
</dependency>上传文件
UploadApplication:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class UploadApplication {
public static void main(String[] args) throws Exception{
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(Constants.endpoint, Constants.accessKeyId, Constants.accessKeySecret);
// 创建PutObjectRequest对象。
PutObjectRequest putObjectRequest = new PutObjectRequest(Constants.bucketName, "readme", new File("d:/readme.txt"));
// 上传文件。
PutObjectResult result = ossClient.putObject(putObjectRequest);
System.out.println("upload complete.");
// 关闭OSSClient。
ossClient.shutdown();
}
}下载文件
DownloadApplication:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class DownloadApplication {
public static void main(String[] args) {
// Endpoint以杭州为例,其它Region请按实际情况填写。
String endpoint = Constants.endpoint;
// 阿里云主账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM账号进行API访问或日常运维,请登录 https://ram.console.aliyun.com 创建RAM账号。
String accessKeyId = Constants.accessKeyId;
String accessKeySecret = Constants.accessKeySecret;
String bucketName = Constants.bucketName;
String objectName = "readme";
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
// 下载OSS文件到本地文件。如果指定的本地文件存在会覆盖,不存在则新建。
ossClient.getObject(new GetObjectRequest(bucketName, objectName), new File("e:/"+ objectName));
// 关闭OSSClient。
ossClient.shutdown();
System.out.println("download complete.");
}
}
2.3 表单上传(高阶操作)
应用场景
表单上传非常适合嵌入在HTML网页中来上传Object,比较常见的场景是网站应用,以招聘网站为例, 流程比对:
不使用表单上传
- 网站用户上传简历。
- 网站服务器回应上传页面。
- 简历被上传到网站服务器。
- 网站服务器再将简历上传到OSS。
采用表单上传
- 网站用户上传简历。
- 网站服务器回应上传页面。
- 简历上传到OSS。
使用表单上传,少了一步转发流程, 并且在上传量过大时, 减少了业务应用方服务扩容的压力。
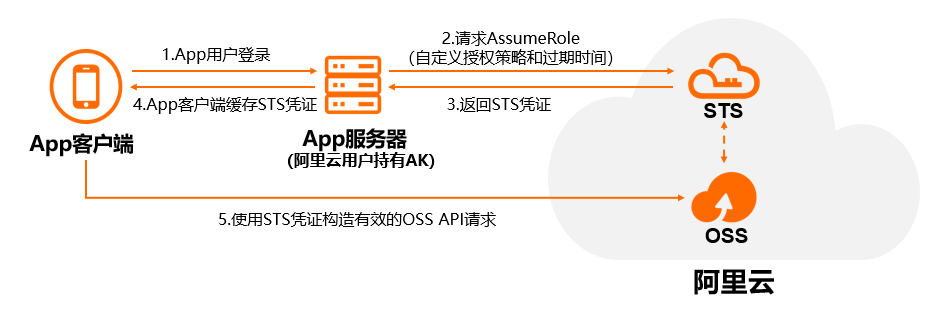
通过STS临时授权访问OSS
通过阿里云STS(Security Token Service)进行临时授权访问, 可以为第三方应用颁发一个自定义时效和权限的访问凭证, 用以保障服务安全性(类似于OAuth2的授权码访问模式)。
实现机制:
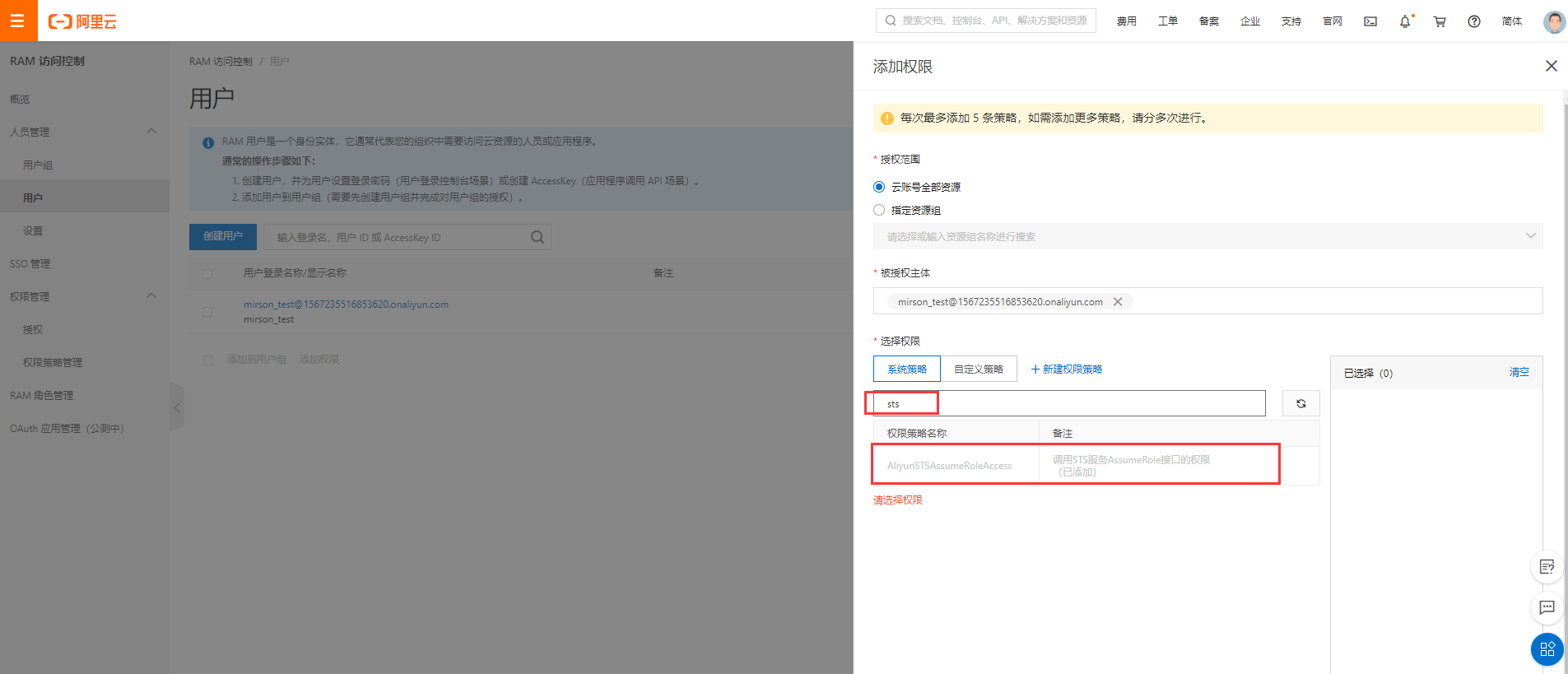
RAM用户STS授权配置
进入RAM访问控制后台->用户->添加权限, 输入框填写”sts”过滤, 选择AliyunSTSAssumeRoleAccess权限。
创建权限策略
输入权限策略名称, 可以选择脚本配置, 更为灵活。
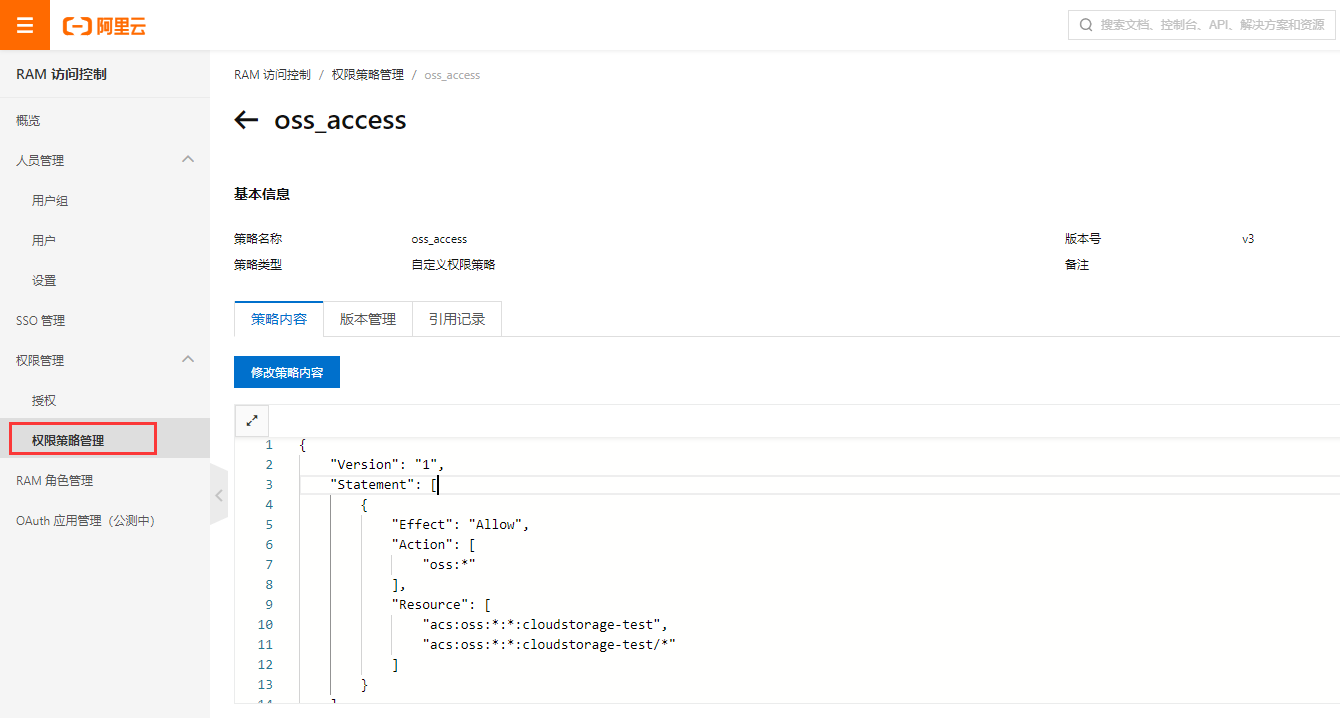
策略内容:
1 | { |
意思是对名称为cloudstorage-test的Bucket具有完全控制权限。如果更细力度的控制, 可以修改Action,例如:
2
3
4
5
6
7
"oss:ListBuckets",
"oss:GetBucketStat",
"oss:GetBucketInfo",
"oss:GetBucketTagging",
"oss:GetBucketAcl"
],
创建访问角色
打开”RAM角色管理”,点击”创建RAM角色“,可信实体类型选择“阿里云账号”
接下来输入角色名称, 选择当前云账号;添加上面所创建的权限策略“oss_access”。
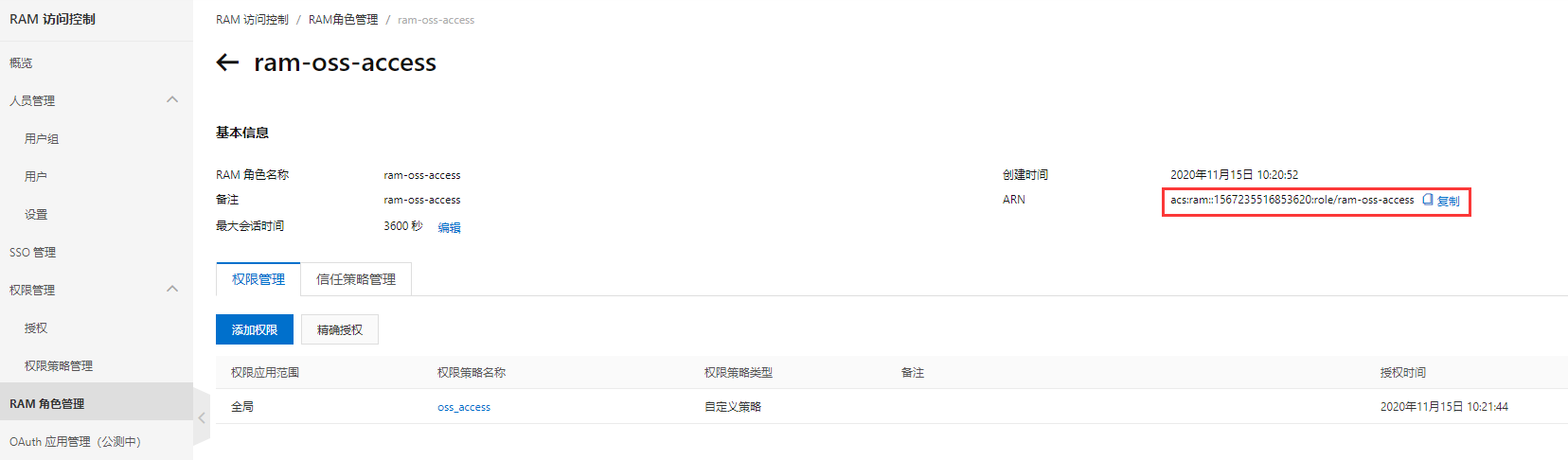
配置完成后, 会生成一个ARN值, 需要将它记录下来。
申请STS的访问TOKEN信息
StsServiceApplication:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48public class StsServiceApplication {
public static void main(String[] args) {
String endpoint = "sts.cn-beijing.aliyuncs.com";
String AccessKeyId = Constants.accessKeyId;
String accessKeySecret = Constants.accessKeySecret;
String roleArn = "acs:ram::1567235516853620:role/ram-oss-access";
String roleSessionName = "oss_access_session";
String policy = "{\n" +
" \"Version\": \"1\", \n" +
" \"Statement\": [\n" +
" {\n" +
" \"Action\": [\n" +
" \"oss:*\"\n" +
" ], \n" +
" \"Resource\": [\n" +
" \"acs:oss:*:*:*\" \n" +
" ], \n" +
" \"Effect\": \"Allow\"\n" +
" }\n" +
" ]\n" +
"}";
try {
// 添加endpoint(直接使用STS endpoint,前两个参数留空,无需添加region ID)
DefaultProfile.addEndpoint("", "", "Sts", endpoint);
// 构造default profile(参数留空,无需添加region ID)
IClientProfile profile = DefaultProfile.getProfile("", AccessKeyId, accessKeySecret);
// 用profile构造client
DefaultAcsClient client = new DefaultAcsClient(profile);
final AssumeRoleRequest request = new AssumeRoleRequest();
request.setMethod(MethodType.POST);
request.setRoleArn(roleArn);
request.setRoleSessionName(roleSessionName);
request.setPolicy(policy); // 若policy为空,则用户将获得该角色下所有权限
request.setDurationSeconds(1000L); // 设置凭证有效时间
final AssumeRoleResponse response = client.getAcsResponse(request);
System.out.println("Expiration: " + response.getCredentials().getExpiration());
System.out.println("Access Key Id: " + response.getCredentials().getAccessKeyId());
System.out.println("Access Key Secret: " + response.getCredentials().getAccessKeySecret());
System.out.println("Security Token: " + response.getCredentials().getSecurityToken());
System.out.println("RequestId: " + response.getRequestId());
} catch (ClientException e) {
System.out.println("Failed:");
System.out.println("Error code: " + e.getErrCode());
System.out.println("Error message: " + e.getErrMsg());
System.out.println("RequestId: " + e.getRequestId());
}
}
}返回结果:
1
2
3
4
5Expiration: 2020-11-15T06:37:51Z
Access Key Id: STS.xx
Access Key Secret: xx
Security Token: CAISjwJ1q6Ft5B2yfSjIr5eHBsnclepE1omJTnXSpXo2e9dgo46etDz2IHxMenFgA+sfv/0ynGBR5/YSlrt0UIRyTEfPYNBr2Y9a6higZIyZdz4iUQhC2vOfAmG2J0PR7q27OpfELr70fvOqdCqz9Etayqf7cjOPRkGsNYbz57dsctUQWHvXD1dBH8wEZHEhyqkgOGDWKOymPzPzn2PUFzAIgAdnjn5l4qnNpa/54xHF3lrh0b1X9cajYLrcNpQyY80kDorsgrwrLfSbiBQ9sUYaqP1E64Vf4irCs92nBF1c3g6LKeK88Kc0cFcnPvhgQPcV9aWkxaQp6rzJ8Z7+zlNKJvoQWi/USZu70Fd2+ykG8lpTGoABiIGFt+WCBkX/yLkY3uHDiWq4Uud32DzXWQAQpGmOWXwYzPRepi0XCcC029hPoXwCsj6mWbd/Ls2bUQsLUPtG3ozr6WawG2XUBXgZI5dNip8dZJCWZSet9qGsNXubhA3hTC+Wi7MNOariEkmr1kjqnG6N/YNaWuMYJ3BUobvLL4g=
RequestId: 480E0B98-ACA5-4C98-AA82-6D9901CD7EE4表单上传
FormPostApplication:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177public class FormPostApplication {
// The local file path to upload.
private String localFilePath = "d:/trade_stock.sql";
// OSS domain, such as http://oss-cn-hangzhou.aliyuncs.com
private String endpoint = Constants.endpoint;
// Access key Id. Please get it from https://ak-console.aliyun.com
private String accessKeyId = "STS.NTcqigyooFzFUeV2GRZPWDLt8";
private String accessKeySecret = "HwdZYJ8wVUopdNscwDYFf7oPgBpA4WXgG6K4JggztqW9";
private String oss_security_token= "CAISjwJ1q6Ft5B2yfSjIr5fWOtPTlLBO8bitV0Pn1kcHVt97q4nf2jz2IHxMenFgA+sfv/0ynGBR5/YSlrt0UIRyTEfPYNBr2Y9a6higZIyZW2tYUAhC2vOfAmG2J0PR7q27OpfELr70fvOqdCqz9Etayqf7cjOPRkGsNYbz57dsctUQWHvXD1dBH8wEZHEhyqkgOGDWKOymPzPzn2PUFzAIgAdnjn5l4qnNpa/54xHF3lrh0b1X9cajYLrcNpQyY80kDorsgrwrLfSbiBQ9sUYaqP1E64Vf4irCs92nBF1c3g6LKeK88Kc0cFcnPvhgQPcV9aWkxaQp6rzJ8Z7+zlNKJvoQWi/USZu70Fd2+ykG8lpTGoABUJly6VzNT0fNrAW2uTyuuGX+PI/PaV7df5cewy7WoAnvtjDe0PM8vBWuD6zY3dQFgQOPFkY8RxxQUrSkZ9wpS3E7FBjzTfkFGlRHmmc+ad8uCLPaWIb/B9QGI6uKidSXnEnLqcK+8xsB1HBsyCkL600PJfcuSWBs9CHh9uiJTG0=";
// The existing bucket name
private String bucketName = Constants.bucketName;
// The key name for the file to upload.
private String key = "trade_stock";
private void postObject() throws Exception {
// append the 'bucketname.' prior to the domain, such as http://bucket1.oss-cn-hangzhou.aliyuncs.com.
String urlStr = endpoint.replace("http://", "http://" + bucketName + ".");
// form fields
Map<String, String> formFields = new LinkedHashMap<String, String>();
// key
formFields.put("key", this.key);
// Content-Disposition
formFields.put("Content-Disposition", "attachment;filename="
+ localFilePath);
// OSSAccessKeyId
formFields.put("OSSAccessKeyId", accessKeyId);
// policy
String policy
= "{\"expiration\": \"2120-01-01T12:00:00.000Z\",\"conditions\": [[\"content-length-range\", 0, 104857600]]}";
String encodePolicy = new String(Base64.encodeBase64(policy.getBytes()));
formFields.put("policy", encodePolicy);
// Signature
String signaturecom = computeSignature(accessKeySecret, encodePolicy);
formFields.put("Signature", signaturecom);
// Set security token.
formFields.put("x-oss-security-token", oss_security_token);
String ret = formUpload(urlStr, formFields, localFilePath);
System.out.println("Post Object [" + this.key + "] to bucket [" + bucketName + "]");
System.out.println("post reponse:" + ret);
}
private static String computeSignature(String accessKeySecret, String encodePolicy)
throws UnsupportedEncodingException, NoSuchAlgorithmException, InvalidKeyException {
// convert to UTF-8
byte[] key = accessKeySecret.getBytes("UTF-8");
byte[] data = encodePolicy.getBytes("UTF-8");
// hmac-sha1
Mac mac = Mac.getInstance("HmacSHA1");
mac.init(new SecretKeySpec(key, "HmacSHA1"));
byte[] sha = mac.doFinal(data);
// base64
return new String(Base64.encodeBase64(sha));
}
private static String formUpload(String urlStr, Map<String, String> formFields, String localFile)
throws Exception {
String res = "";
HttpURLConnection conn = null;
// String boundary = "9431149156168";
String boundary = "abc";
try {
URL url = new URL(urlStr);
conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(30000);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod("POST");
conn.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; zh-CN; rv:1.9.2.6)");
// Set Content-MD5. The MD5 value is calculated based on the whole message body.
// conn.setRequestProperty("Content-MD5", "<yourContentMD5>");
conn.setRequestProperty("Content-Type",
"multipart/form-data; boundary=" + boundary);
OutputStream out = new DataOutputStream(conn.getOutputStream());
// text
if (formFields != null) {
StringBuffer strBuf = new StringBuffer();
Iterator<Entry<String, String>> iter = formFields.entrySet().iterator();
int i = 0;
while (iter.hasNext()) {
Entry<String, String> entry = iter.next();
String inputName = entry.getKey();
String inputValue = entry.getValue();
if (inputValue == null) {
continue;
}
if (i == 0) {
strBuf.append("--").append(boundary).append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\""
+ inputName + "\"\r\n\r\n");
strBuf.append(inputValue);
} else {
strBuf.append("\r\n").append("--").append(boundary).append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\""
+ inputName + "\"\r\n\r\n");
strBuf.append(inputValue);
}
i++;
}
out.write(strBuf.toString().getBytes());
}
// file
File file = new File(localFile);
String filename = file.getName();
String contentType = new MimetypesFileTypeMap().getContentType(file);
if (contentType == null || contentType.equals("")) {
contentType = "application/octet-stream";
}
StringBuffer strBuf = new StringBuffer();
strBuf.append("\r\n").append("--").append(boundary)
.append("\r\n");
strBuf.append("Content-Disposition: form-data; name=\"file\"; "
+ "filename=\"" + filename + "\"\r\n");
strBuf.append("Content-Type: " + contentType + "\r\n\r\n");
out.write(strBuf.toString().getBytes());
DataInputStream in = new DataInputStream(new FileInputStream(file));
int bytes = 0;
byte[] bufferOut = new byte[1024];
while ((bytes = in.read(bufferOut)) != -1) {
out.write(bufferOut, 0, bytes);
}
in.close();
byte[] endData = ("\r\n--" + boundary + "--\r\n").getBytes();
out.write(endData);
out.flush();
out.close();
// Gets the file data
strBuf = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null) {
strBuf.append(line).append("\n");
}
res = strBuf.toString();
reader.close();
reader = null;
} catch (Exception e) {
System.err.println("Send post request exception: " + e);
throw e;
} finally {
if (conn != null) {
conn.disconnect();
conn = null;
}
}
return res;
}
public static void main(String[] args) throws Exception {
FormPostApplication ossPostObject = new FormPostApplication();
ossPostObject.postObject();
}
}将上面所获取的key,secret和token填入。
bucket名称要和上面授权对应的bucket一致。
这里是模拟form表单提交,编码采用UTF-8。
policy里面可以配置超时时间, 内容长度范围等。
如果出现403错误,检查token等权限信息的配置是否正确。
如果出现400错误, 检查参数配置是否正确, 比如说MD5参数如果传递, 但没配置正确, 会出现此错误。
1
conn.setRequestProperty("Content-MD5", "<yourContentMD5>");
操作成功后, 能够在后台看到对应的文件信息。
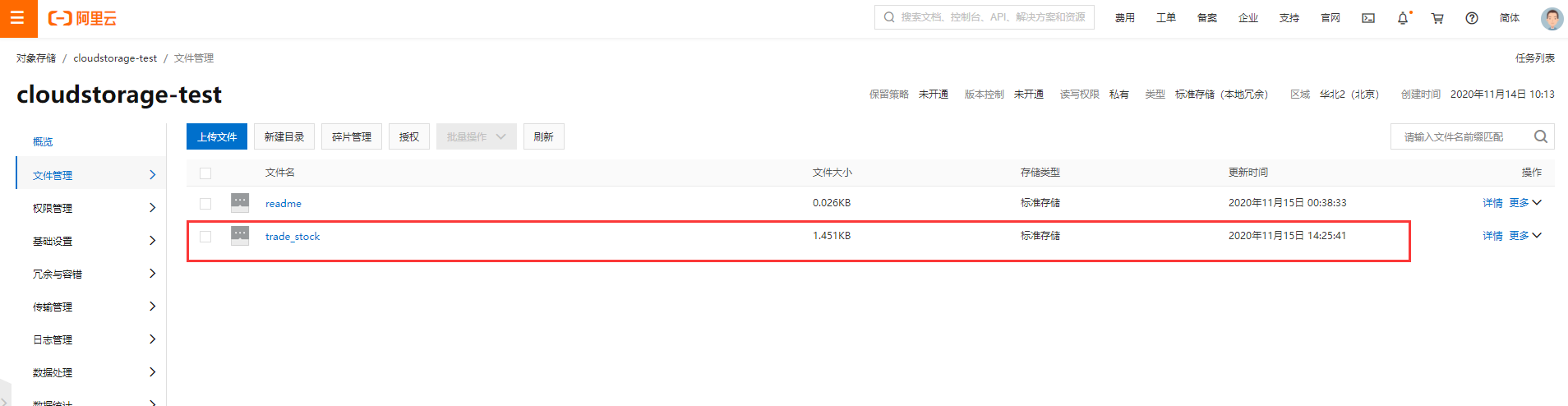
2.5 服务上传验证
代码:
添加阿里云依赖。
添加阿里云配置信息。
采用表单方式上传, 直接将数据存至OSS服务中。实现类: FormFileUploadServiceImpl。
打包app-file服务
1
maven clean install
上传至云服务器
运行:
1
java -jar app-file.jar
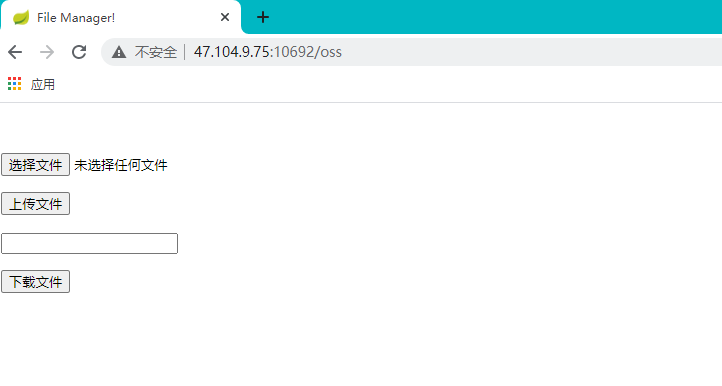
功能验证
对文件上传和下载进行验证。
2.6 云数据库
云数据库 VS 传统数据库
云数据库和传统数据库在搭建、运维、管理层面,云数据库提升了一个层次,实现了较高程度的智能化和自动化,极大地提升了用户友好度,降低了使用门槛。比如灵活的性能等级调整、详尽的监控体系、攻击防护机制等等。
云数据库的高级特性:
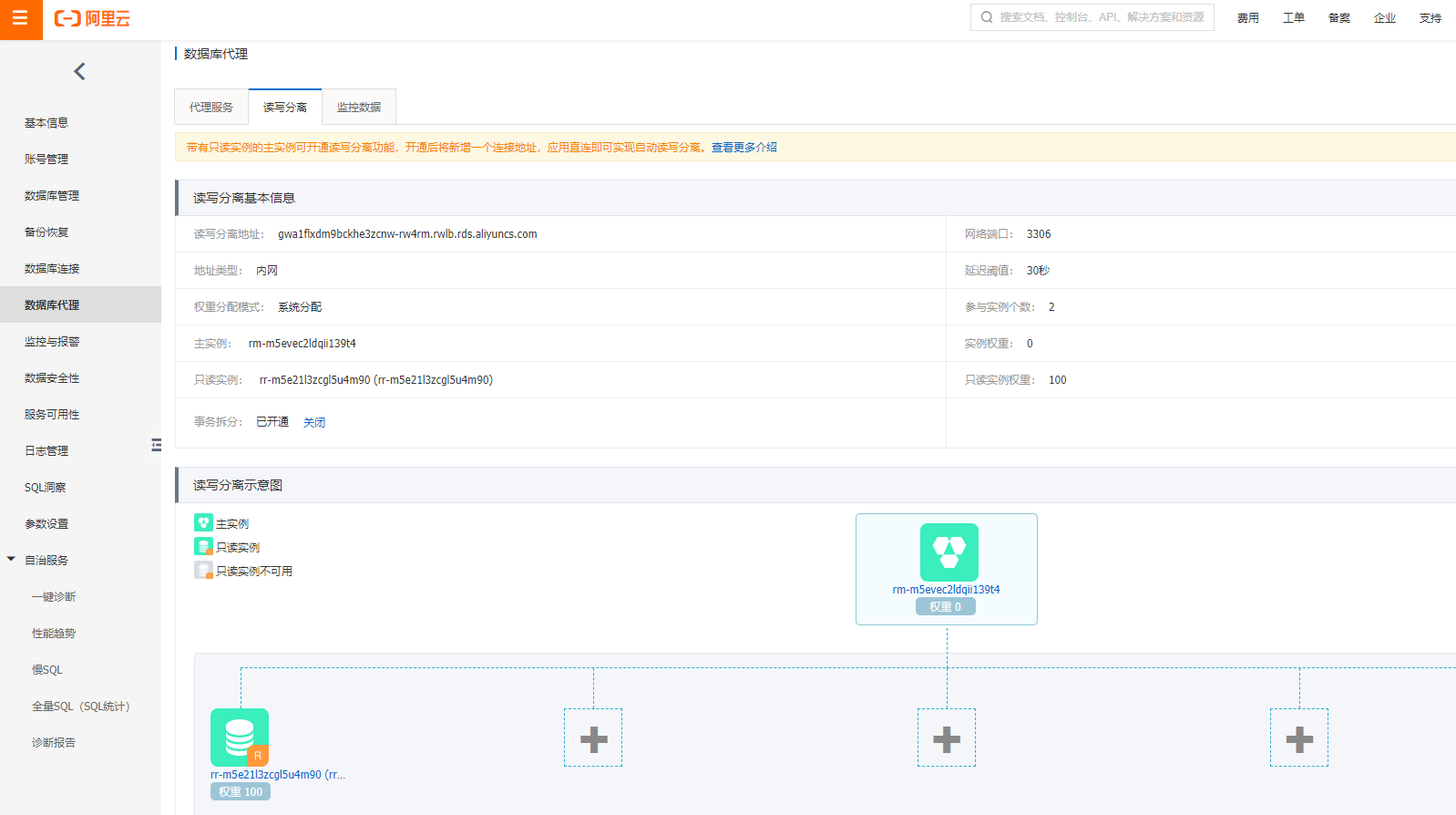
读写分离
提供可视化的读写分离配置管理功能。从数据库实例的创建, 到同步关系以及读写流量分发, 云数据库都能自动化完成。
自动调优
云数据库都自带性能分析和改进的模块, 能够自动地发现性能热点,还能够智能地给出调整建议,比如进行个别语句的调整,添加额外的索引等等。云数据库的性能分析和自动调优的能力,是将生产运行数据和服务内置的 AI 模型进行了结合,做到了真正的智能化运维, 极大的节省了成本。
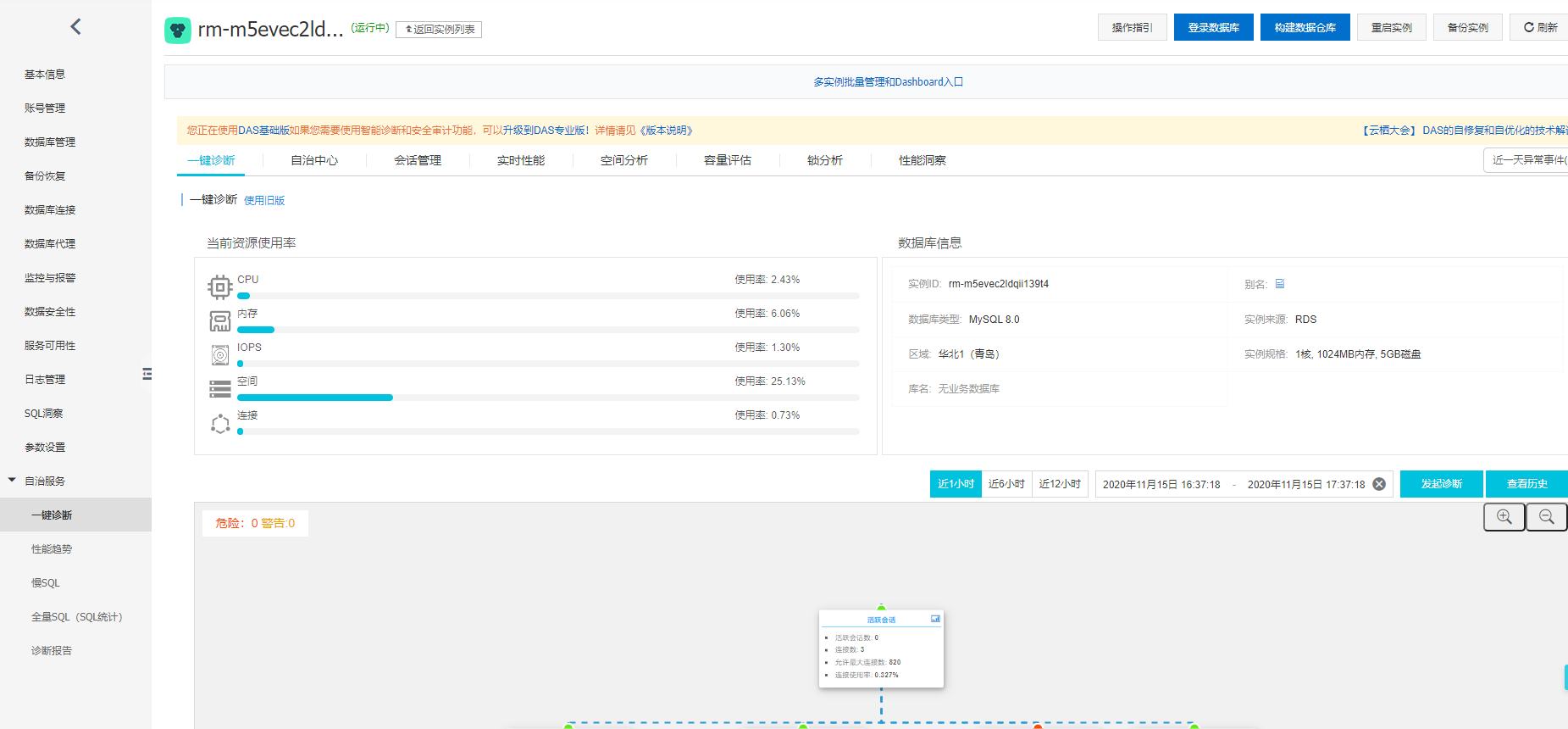
阿里云的数据库自治服务DAS:
自治服务DAS是一种基于机器学习和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务,使用了DAS之后您可以避免这样的复杂性和人工操作引起的故障,有效保障数据库服务的稳定、安全及高效。
监控维护
云数据库提供了全面强大的监控维护功能, 提供了丰富的性能监控项,能够及时发现并预警。
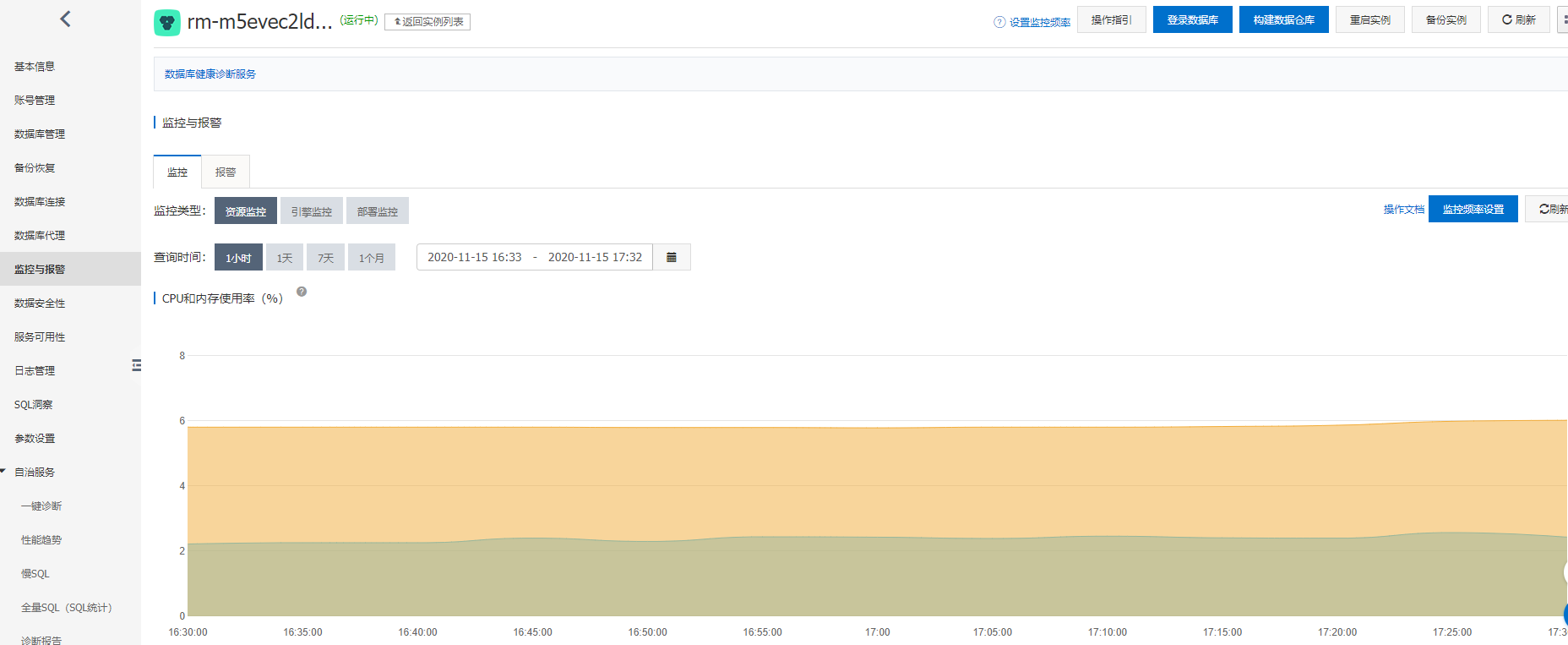
监控包含CPU和内存使用率、磁盘空间、IOPS、连接数、CPU内存使用率和网络流量等。
报警功能:
可以根据不同的规则来组合设定预警条件:
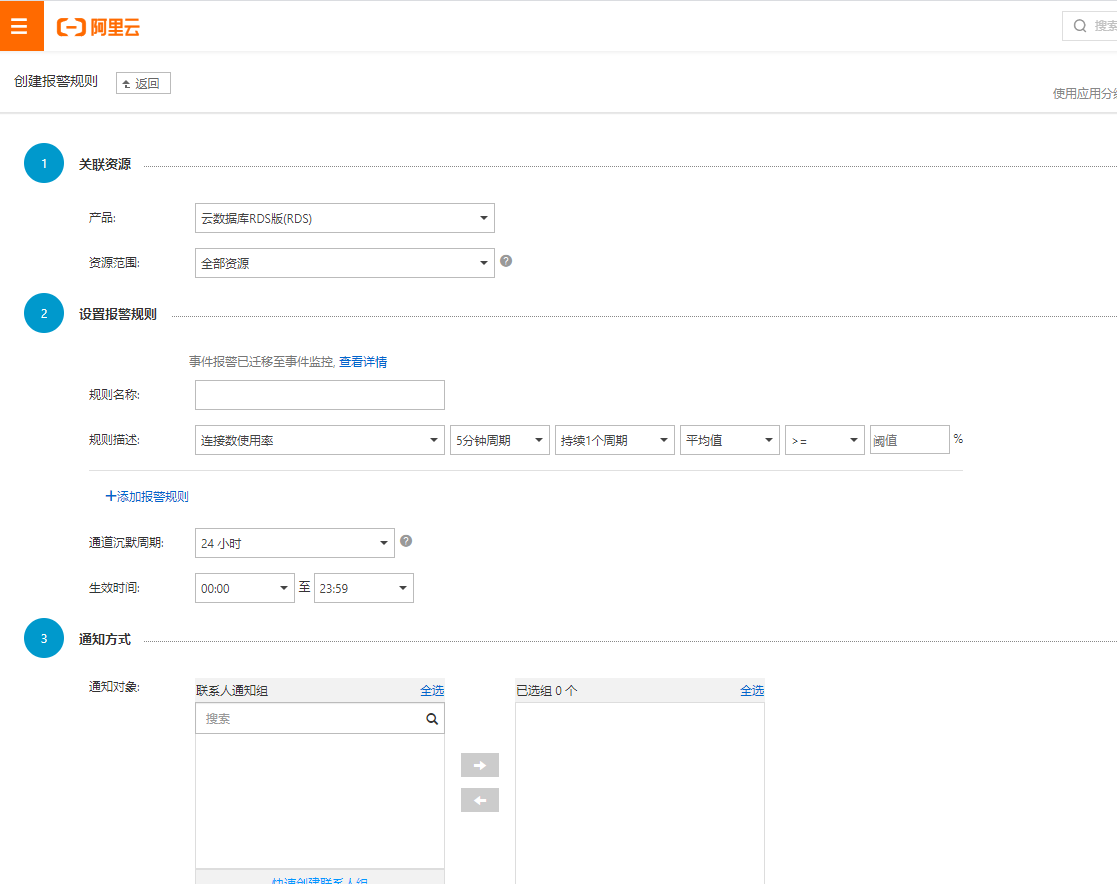
2.7 云数据库操作
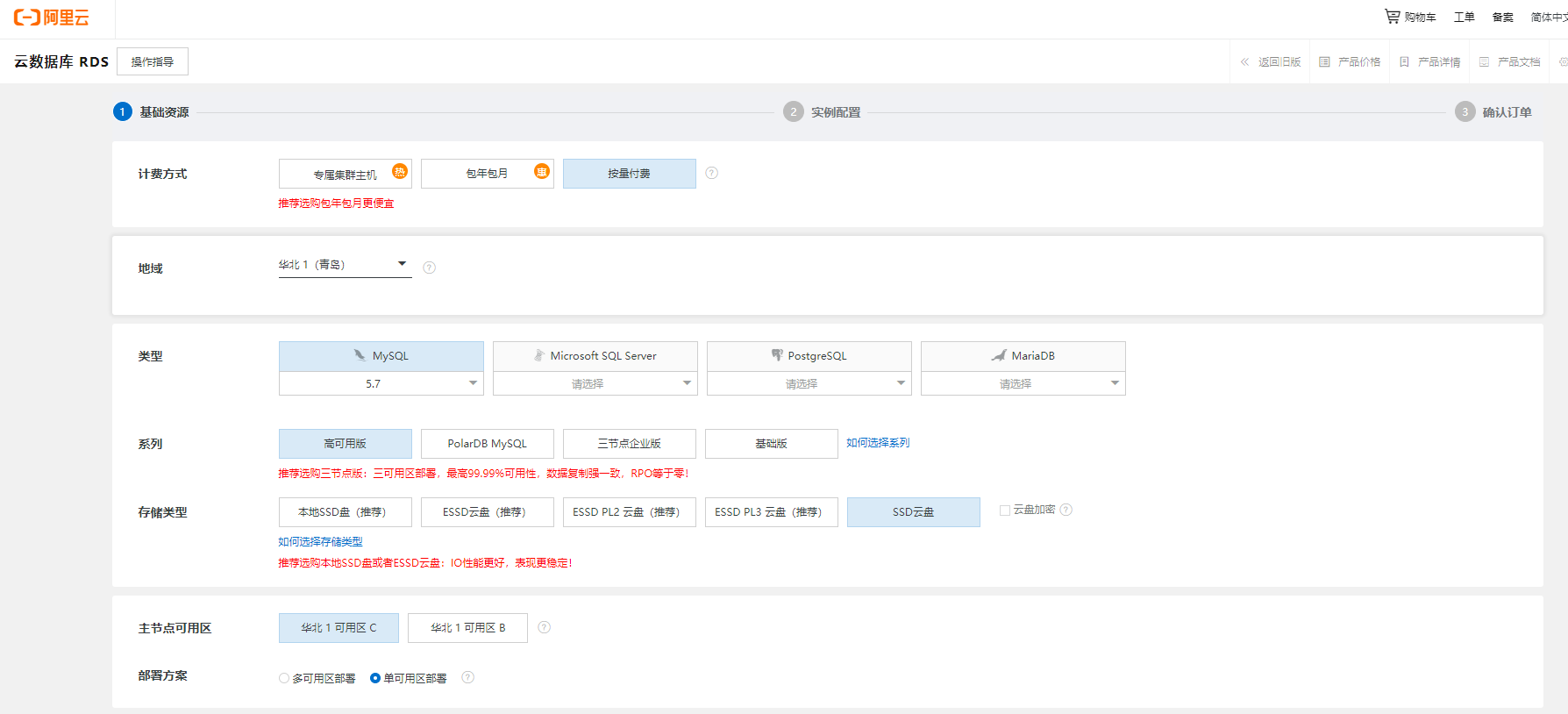
创建云数据库实例
根据自身需要, 选择相应配置:
访问权限配置
申请外网访问地址:
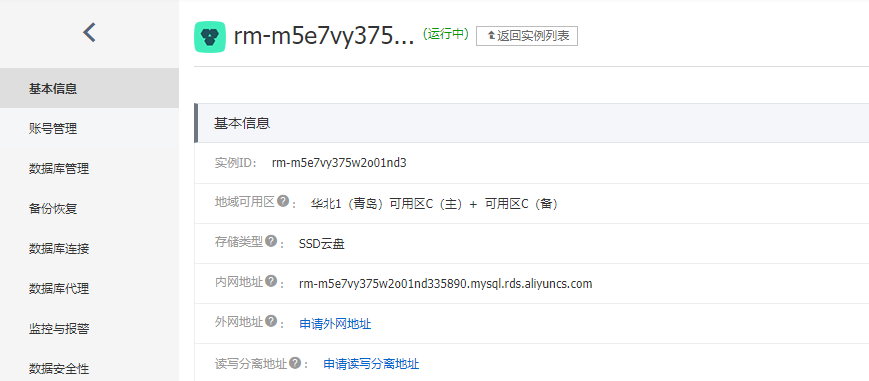
这里提供了内网和外网不同访问地址。
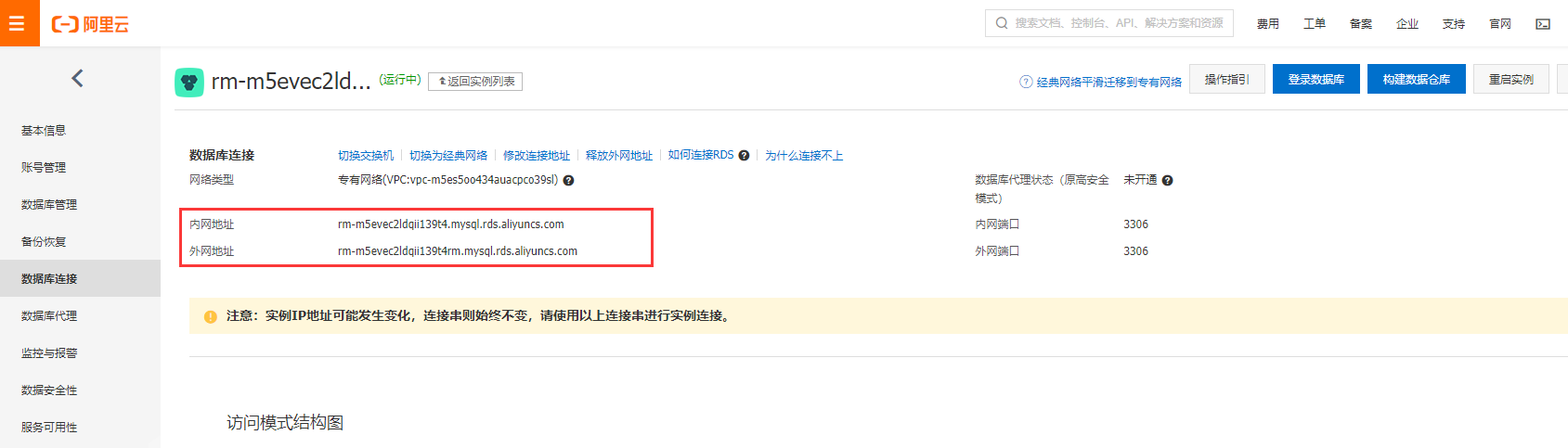
需要设定白名单, 0.0.0.0/0是允许所有主机访问, 在实际应用中, 最好要指定具体的IP。
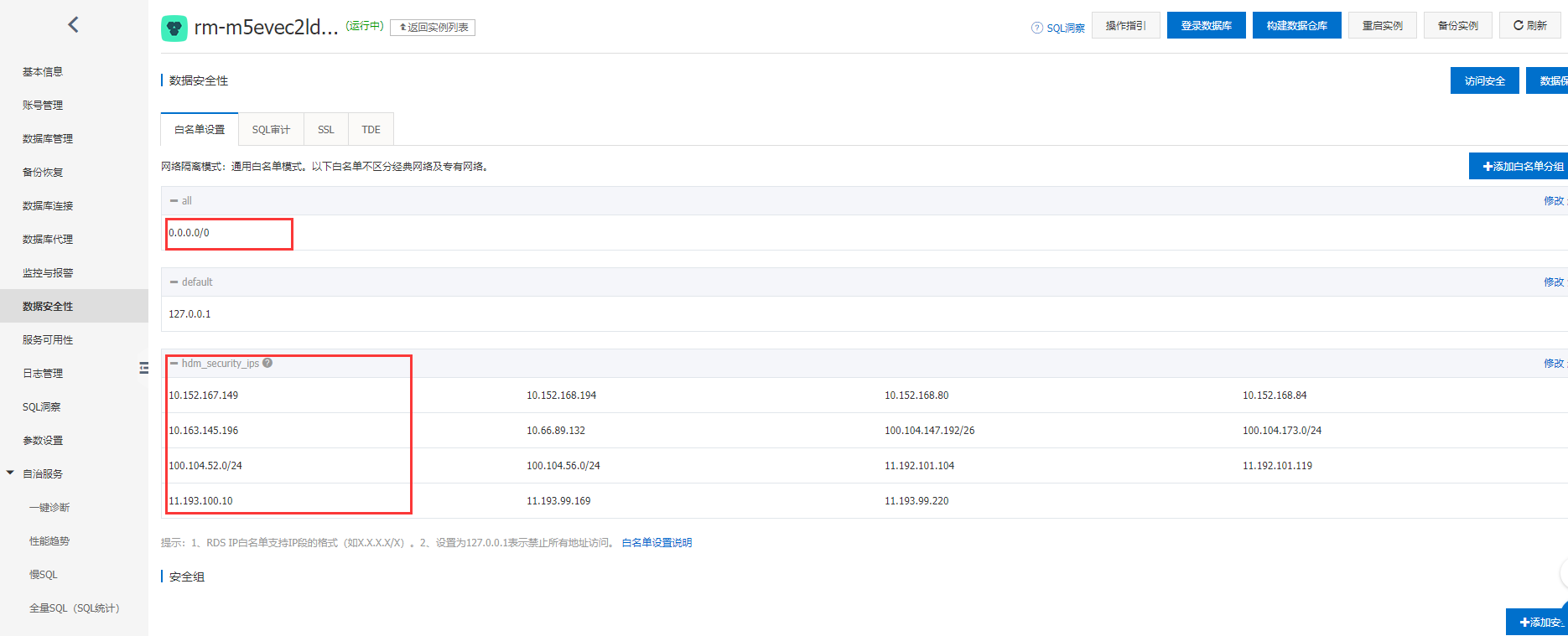
hdm_security_ips是DAS服务白名单, 自动生成。
数据库账号配置
创建访问数据库的账号密码。
服务授权标签可以开通配置权限与数据权限。
- 连接配置
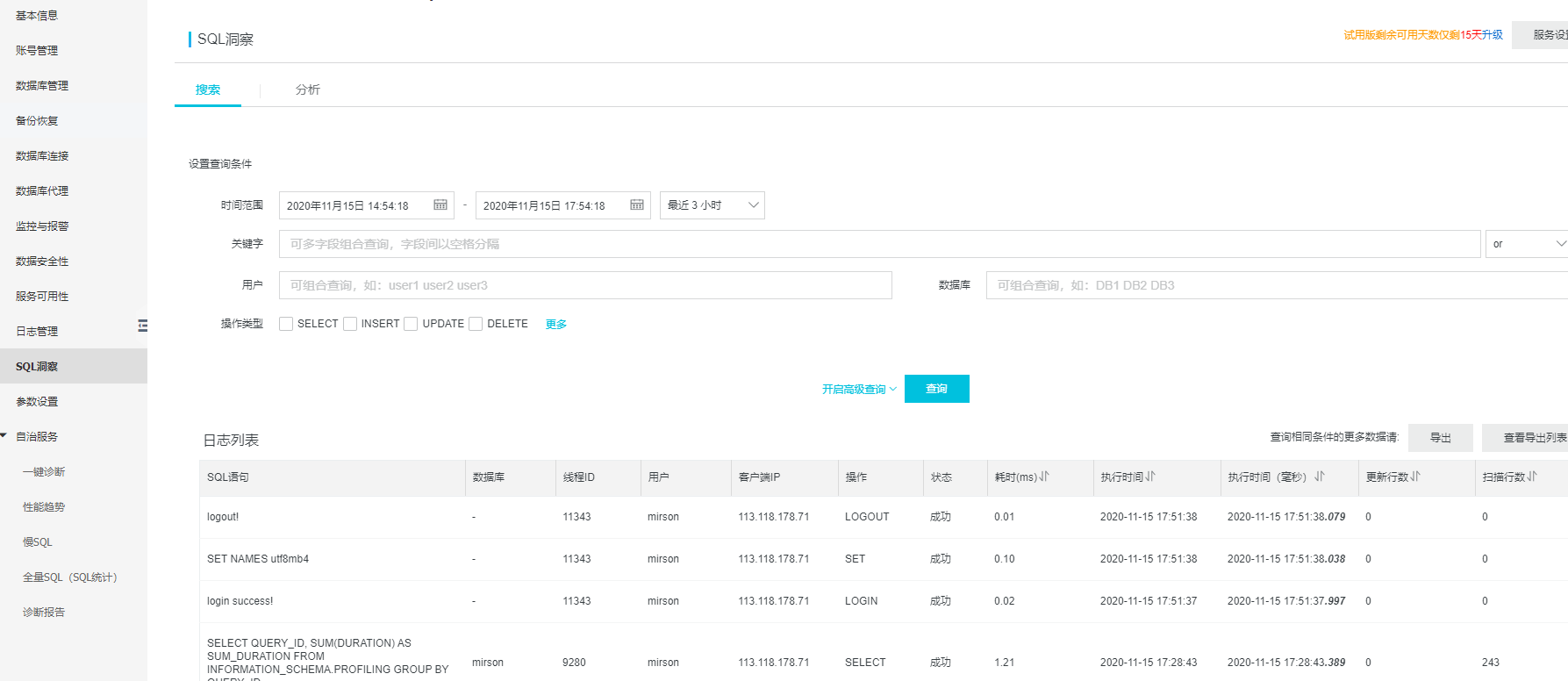
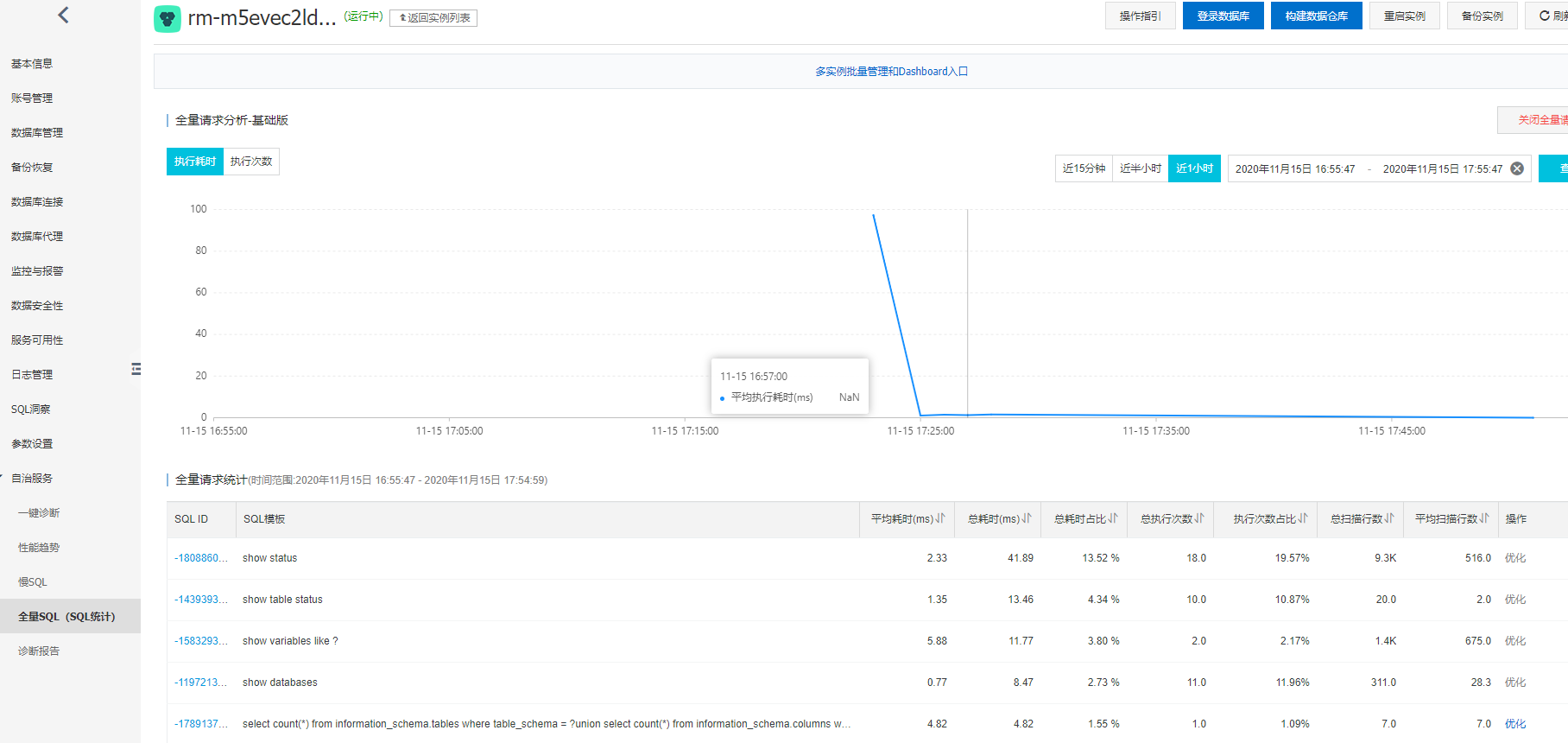
SQL洞察
连入数据库后, 做一些SQL操作, 通过SQL洞察就能看到详细的信息:
全量SQL统计
这里面会侧重性能分析, 并给出自动优化提示。
2.8 服务连接云数据库
代码
- 编写下单与查询订单的接口。
- 配置数据源连接, 指向云数据库。
- 采用JPA方式对数据进行操作。
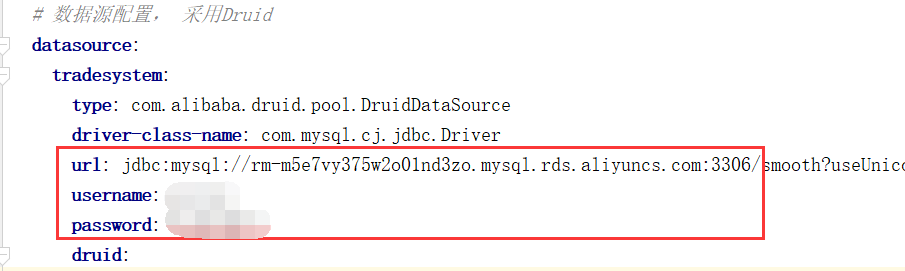
修改连接配置
修改application.yml配置文件:
服务打包
1
maven clean install
上传至云服务器
运行:
1
java -jar app-server.jar
功能验证
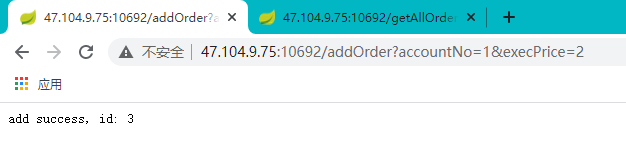
测试数据库的新增与查询功能。
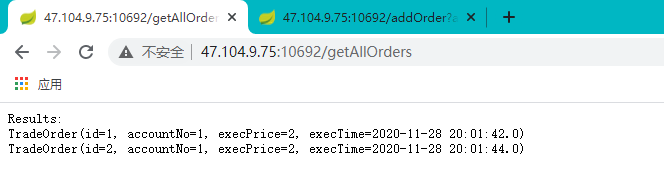
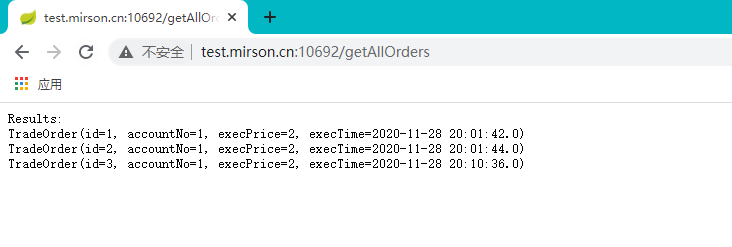
新增: http://47.104.9.75:10692/addOrder?accountNo=1&execPrice=2
查询:http://47.104.9.75:10692/getAllOrders
2.9 新一代原生数据库
新一代原生数据库 VS 云数据库
更强的性能与扩展性
云原生数据库由于原生设计, 专门为云设计的专业化存储架构, 可以支撑更大规模的数据量,关系型云原生数据库能够脱离典型的数 TB 的容量上限,达到单库数十 TB 甚至百 TB 的级别。
云原生数据库可以利用云快速地进行水平扩展,迅速调整、提升数据库的处理能力, 能够有效应对高并发场景。
更高的可用性与可靠性
云原生数据库默认就具备多副本高可用的,数据同步、读写分离等高级特性,比如Amazon Aurora云原生数据库, 就自动包含了分布在 3 个可用区、多达 6 份的数据副本。
对于多种数据模型也有很好的支持, 除了兼容关系型数据库外, 还会推出适合不同形态和查询范式的云数据库,与 NoSQL 数据库形成竞争, 比如说AWS的图数据库 Neptune,Azure Cosmos DB的NoSQL 数据库服务。
低成本与易维护性
大部分云原生数据库, 在存储上不需要预先设置大小, 会随着存储占用自动扩展;在计算上, 也有部分云数据库推出了无服务器版本,比如 亚马逊 的 Aurora Serverless,在面对间歇偶发性工作负载时,都能节省较多的成本。
阿里云PolarDB

阿里云 PolarDB 放弃了通用分布式数据库OLTP多路并发写的支持,采用一写多读的架构设计,存储与计算分离的技术架构,简化了分布式系统难以兼顾的理论模型,又能满足绝大多数OLTP的应用场景和性能要求。
PolarDB 的设计革新:
1. 通过重新设计特定的文件系统来存取 Redo log 这种特定的 WAL I/O 数据。
2. 通过高速网络和高效协议将数据库文件和 Redo log 文件放在共享存储设备上,避免了多次长路径 I/O 的重复操作,并且针对 Redolog的I/O 路径,专门设计了多副本共享存储块设备。
3. 产品架构设计
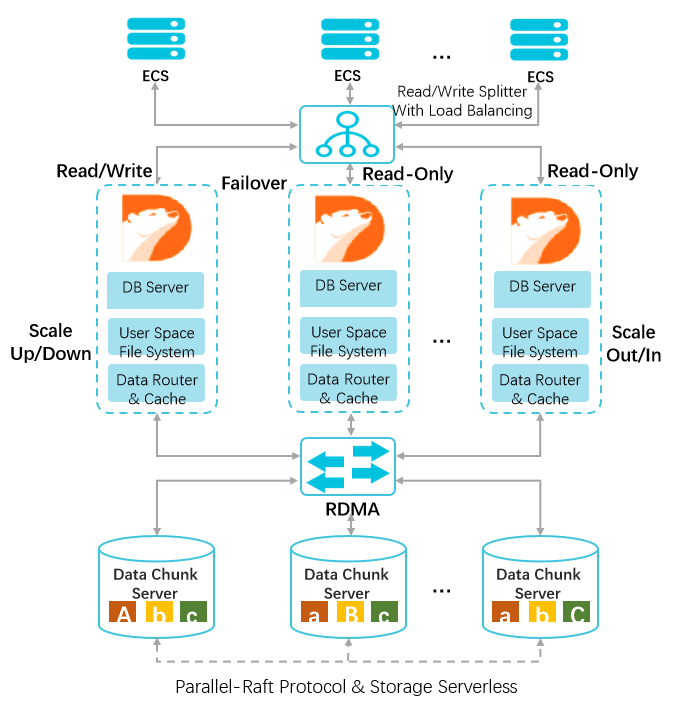
一写多读
主节点处理读写请求,只读节点仅处理读请求。一个集群版集群包含一个主节点和最多15个只读节点。
计算与存储分离
计算与存储分离的设计,计算节点仅存储元数据, 存储节点负责数据文件、Redo Log等存储。
共享分布式存储
多个计算节点共享一份数据,并非每个计算节点都存储一份数据, 降低存储成本。存储节点的数据采用多副本形式,确保数据的可靠性,并通过Parallel-Raft协议保证数据一致性。基于全新设计的分布式块存储和文件系统,存储容量可以在线平滑扩展。
POLARDB 2.0 vs POLARDB 1.0
PolarDB-X 1.0 是基于DRDS + RDS 的分布式云数据库服务, 产品的特征是采用 Share-Nothing 架构、以解决存储扩展性为出发点、提供面向用户的产品化交付能力。
PolarDB-X 2.0 主要是解决企业的各种复杂需求:
- 在功能性方面, 既要保障SQL通用性, 又要具备NoSQL的扩展性;既要高并发, 又要支持实时复杂分析。
- 企业的历史沉淀数据是一大痛点, 要以最少的成本保障数据能够顺利稳定的迁移, 并且不影响现有服务的稳定性。
- 各种应用对GIS数据的处理需求会越来越旺盛,使用开源版本GIS性能、功能无法满足,需要有一个功能强大的存储介质。
- 海量数据的运维管理, 高级DBA非常欠缺,在维护方面需要高昂的成本。
针对以上问题, POLARDB2.0应运而生,不但完全继承了1.0的架构体系,同时兼容了另外两个流行数据库Oracle与PostgreSQL。POLARDBv2.0forOracle,高度兼容Oracle;POLARDBv2.0 for PostgreSQL,完全兼容PostgreSQL。
2.10 阿里云PolarDB生产最佳实践
创建PolarDB-X 2.0实例
创建实例一定要选择专有的网络和交换机, 注意可用区要匹配正确。
创建好专有网络和交换机
配置外网
- 设置白名单

这里为便于测试,允许所有外网地址连入, 实际使用当中, 应设置为指定的IP。
- 申请外网连接地址
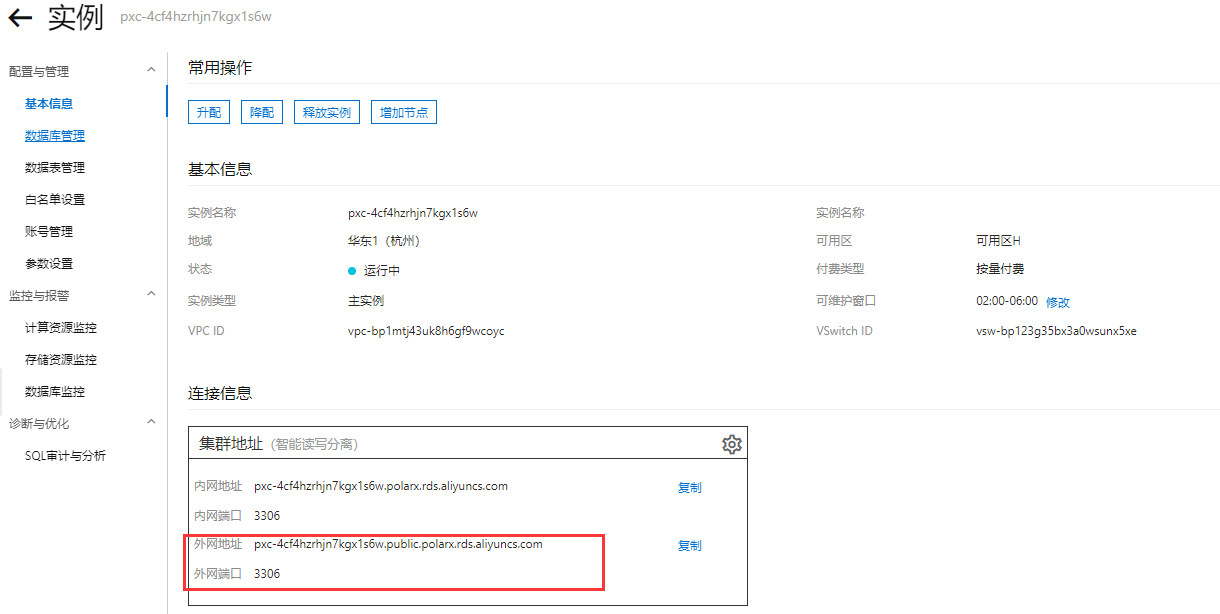
如果是内部虚拟机, 通过vpc内部网络接入, 要选择内网地址。
客户端连接
外网接入测试:
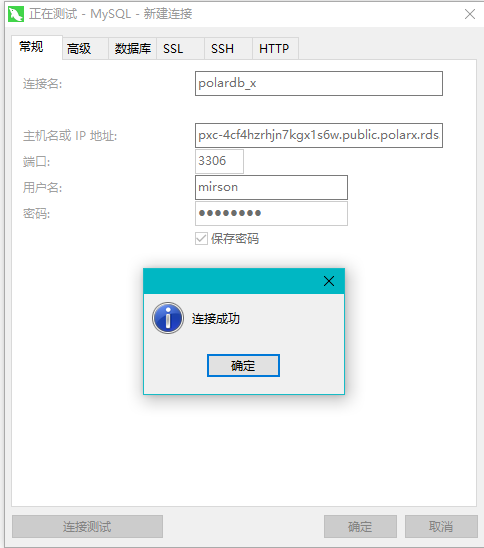
(如果不能连接出现超时, 可以尝试再添加只读实例, 还是不行的话, 可以提请工单请后台人员处理)
如果应用服务连接, 直接修改application.yml中的数据库连接配置即可。
分区的使用
根据用户标识与时间字段相结合作为拆分键,并按照一周七天进行分表:
1
2
3
4
5
6CREATE TABLE user_log (
userId INT(11) NOT NULL,
name VARCHAR(64) NOT NULL,
operation VARCHAR(128) DEFAULT NULL,
actionDate DATE DEFAULT NULL
) DBPARTITION BY HASH(userId) TBPARTITION BY WEEK(actionDate) TBPARTITIONS 7PolarDB-X将拆分键值通过拆分函数计算得到一个计算结果,然后根据这个结果将数据分拆到私有定制RDS实例上。
创建完成之后, 可以看到对应的信息:

如何配置分片数
在实际应用中, 经常会面临分库分表的场景, PolarDB-X建议单个物理分表的容量不超过500万行数据。通常可以预估1~2年内的数据增长量,用估算出的总数据量除以总的物理分库数,再除以建议的单个物理分表的最大数据量(即500万),即可得出每个物理分库上需要创建的物理分表数。
计算公式:
1
物理分库上的物理分表数=向上取整(估算的总数据量/(私有定制RDS实例数 x 8)/ 5,000,000)
示例:
假设预估一张表在2年后的总数据量约为1亿行,如果已购买了2个私有定制RDS实例,那么按照分片数公式进行如下计算:
1
物理分库上的物理分表数= CEILING(100,000,000 / ( 2 * 8 ) / 5,000,000) = CEILING(1.25) = 2
结果为2,那么需要在每个物理分库上再创建2张物理分表。
连接池配置
在实际生产当中, 官方推荐使用Druid连接池(最低要求版本1.1.11)
Druid与Spring的集成配置示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<!-- 基本属性 URL、user、password -->
<property name="url" value="jdbc:mysql://ip:port/db?autoReconnect=true&rewriteBatchedStatements=true&socketTimeout=30000&connectTimeout=3000" />
<property name="username" value="root" />
<property name="password" value="123456" />
<!-- 配置初始化大小、最小、最大 -->
<property name="maxActive" value="20" />
<property name="initialSize" value="3" />
<property name="minIdle" value="3" />
<!-- maxWait 获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- timeBetweenEvictionRunsMillis 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- minEvictableIdleTimeMillis 一个连接在池中最小空闲的时间,单位是毫秒-->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!-- 检测连接是否可用的 SQL -->
<property name="validationQuery" value="select 'z' from dual" />
<!-- 是否开启空闲连接检查 -->
<property name="testWhileIdle" value="true" />
<!-- 是否在获取连接前检查连接状态 -->
<property name="testOnBorrow" value="false" />
<!-- 是否在归还连接时检查连接状态 -->
<property name="testOnReturn" value="false" />
<!-- 是否在固定时间关闭连接。此参数默认可以不加,但是增加此参数可以均衡后端服务节点参数 -->
<property name="phyTimeoutMillis" value="1800000" />
<!-- 是否在固定SQL使用次数之后关闭连接,此参数默认可以不加,但是增加此参数可以均衡后端服务节点参数-->
<property name="phyMaxUseCount" value="10000" />
</bean>如何平滑扩容
首先判断是否需要扩容:
- CPU 及 IOPS 指标
如果发现任何一个指标长期保持在80%以上, 并且通过优化手段也无法解决, 那么可以考虑扩容。
2. 磁盘空间
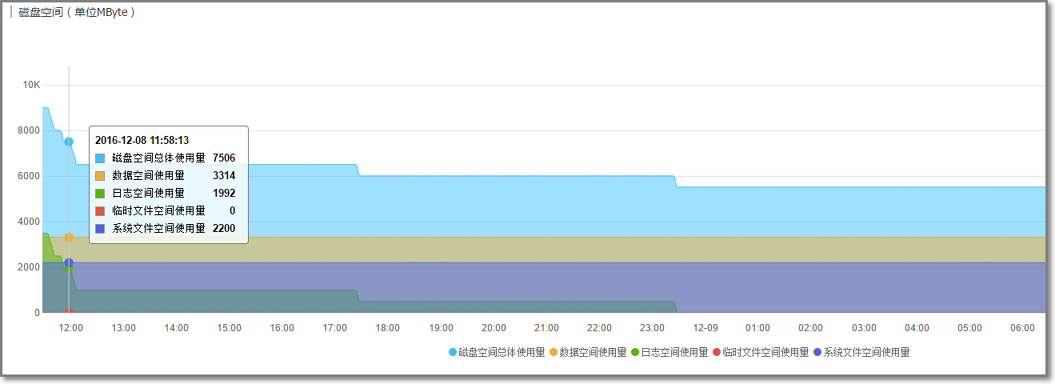
当数据空间将要或预期要超出磁盘容量时,可以通过扩容的方式将数据分散到多个 RDS。
扩容前注意事项
- 如果需要新增5个或5个以上 RDS 实例,需要事先提工单,以防平台后端迁移资源不足造成迁移不成功。
- 源 RDS 实例扩容过程中会有读压力,尽量在低负载时操作。
- 扩容期间请勿在控制台提交 DDL 任务或连接 PolarDB-X 直接执行 DDL SQL,否则会导致扩容任务失败。
- 扩容需要源库表中有主键,如果没有需要事先加好主键。
- 扩容的切换动作会将读写流量切换到新增的 RDS 上,切换过程大约持续3~5分钟,建议在停业务的情况下进行切换。
- 在执行切换前,扩容动作不会对 PolarDB-X 产生任何影响。因此在切换前都可以通过回滚来放弃本次扩容。
扩容操作步骤
扩容主要分为配置>迁移>切换>清理 四个步骤。
详情可以查阅 官方文档
3. IaaS之网络
3.1 DNS运用
3.1.1 DNS功能作用
负载均衡
DNS负载均衡, 原理是给用户返回不同的IP地址, 例如:
主机记录 记录类型 线路类型 记录值 TTL www A 默认 200.202.101.1 600 www A 默认 200.202.101.2 600 www A 默认 200.202.101.3 600 www A 默认 200.202.101.4 600 解析返回得到的 IP 地址是可以是轮询, 也可以是随机得到的 IP 地址
健康检查:
支持ping、telnet、http(s)协议实时健康检查,获取应用服务运行状态。
故障切换
支持根据健康检查结果自动或者手工进行failover切换操作,实现主备切换、自动修改故障域名的解析,对异常的地址(服务)进行故障隔离或切换。
智能DNS
支持根据不同运营商、区域进行智能DNS解析,实现用户就近访问。
阿里云DNS免费版 vs 付费版
参数项 参数值 免费版 最低TTL值 最低1秒 最低2秒 子域名级别 最高10级 最高2级 A记录负载均衡 带权重的A记录轮询,最多支持90条 带权重的A记录轮询,最多支持10条 URL转发 URL显性转发+URL隐性转发,最多支持6条 URL显性转发+URL隐性转发,最多支持2条 泛解析 √ √ 运营商线路 默认、移动、联通、电信、教育网 默认、移动、联通、电信、教育网 运营商线路细分 移动(省份)、联通(省份)、电信(省份)、教育网(省份),共135条线路 不支持 海外线路细分 亚洲、大洋洲、欧洲、北美、南美、非洲 6大洲34个国家及地区 海外 搜索引擎线路 搜索引擎、谷歌、百度、必应、有道、雅虎 谷歌、百度、必应 更多区别, 详情
3.1.2 DNS配置实践
主要步骤: 创建实例 -> 配置访问策略 -> 主域名设置CNAME解析到实例的CNAME接入域名。
创建两台虚拟机
两台虚拟机都部署相同的服务(app-server), 用于高可用的测试验证。
创建地址池
这里指向一台主节点。
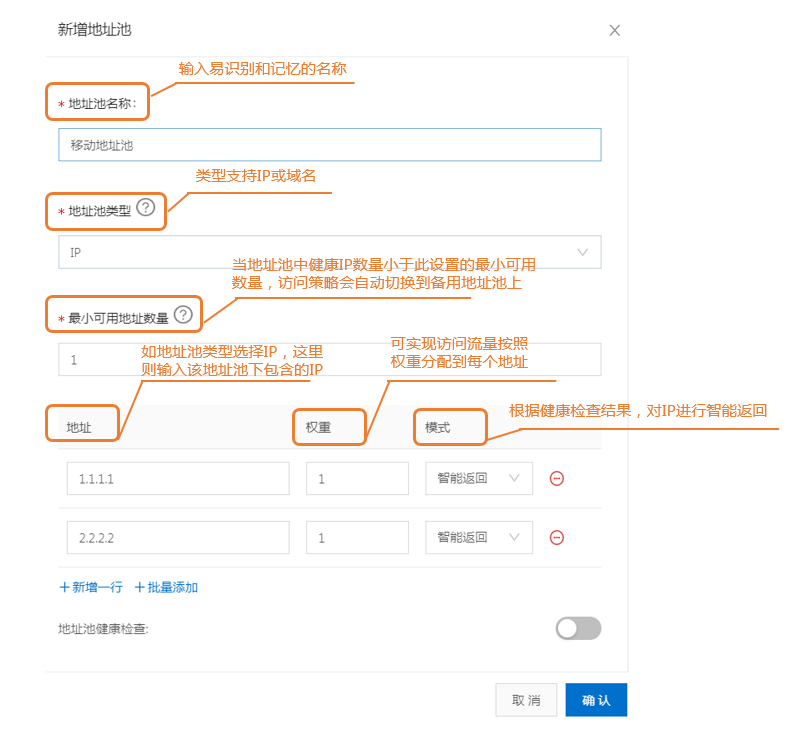
- 访问策略配置
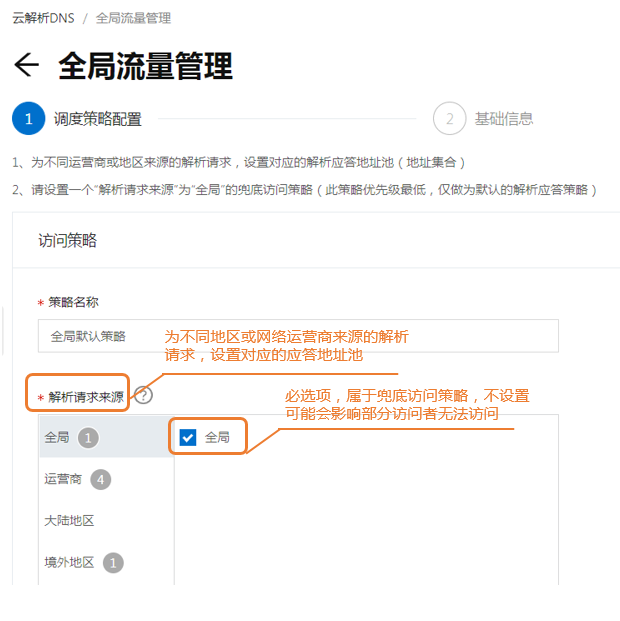
配置地址池信息, 如果出现故障, 可以自动切换至备用地址池。
备用地址池指向另外一台云服务器。
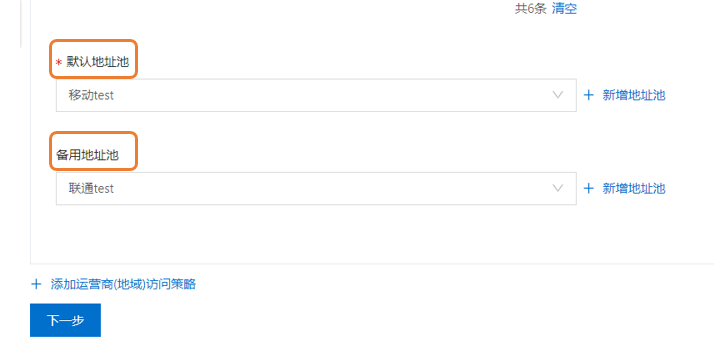
- 全局配置
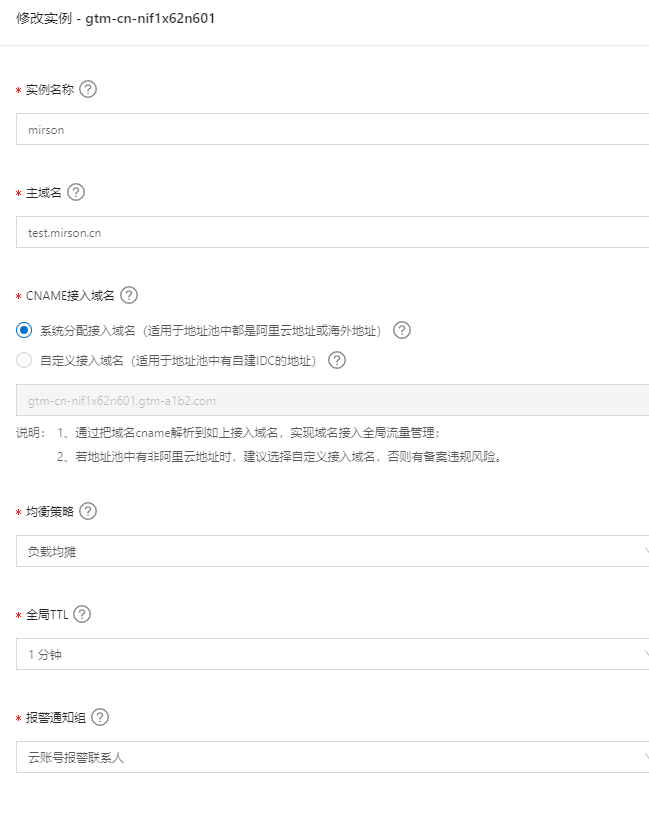
这里可以采用系统分配生成的cname域名, 主域名是用户访问应用服务使用的域名,必须填写真实主域名, 这里主域名是配置: test.mirson.cn。
- 开启健康检查
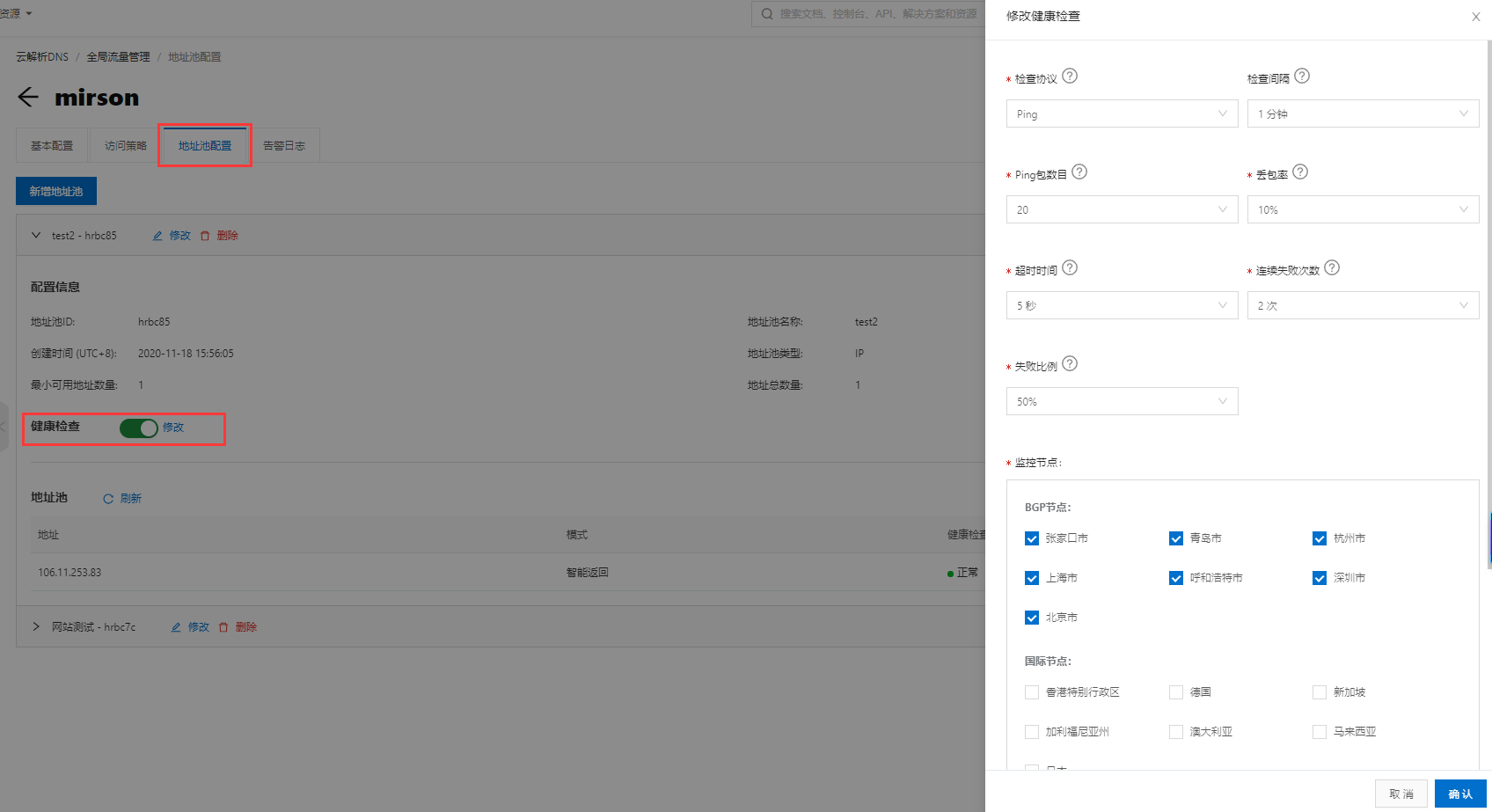
需要对地址池里的IP地址配置健康检查,以获取应用服务的可用性,从而达到根据应用服务地址可用性的状态实现自动故障隔离以及故障自动切换。
DNS解析设置
最后, 在解析设置里面, 添加记录。这里面的记录值要填写上面所设置的cname域名信息。
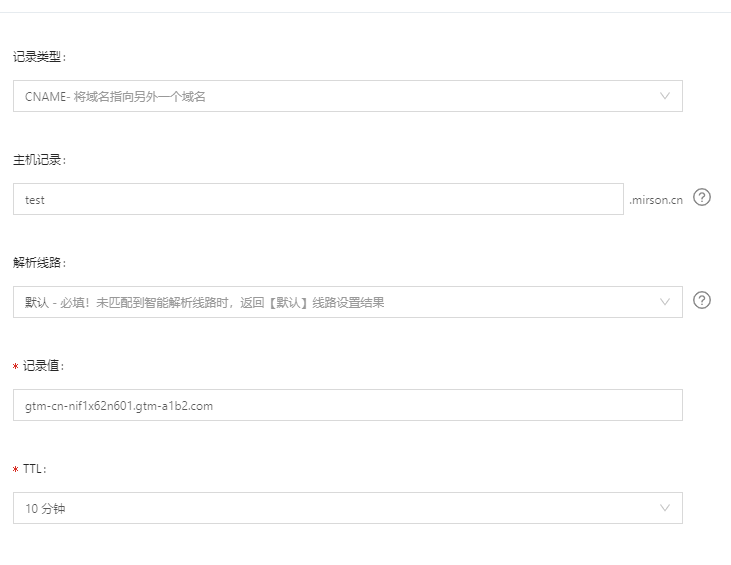
测试
通过访问test.mirson.cn会指向连接池所配置的IP信息。
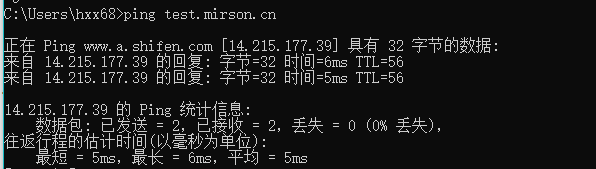
通过域名进行访问:
故障测试
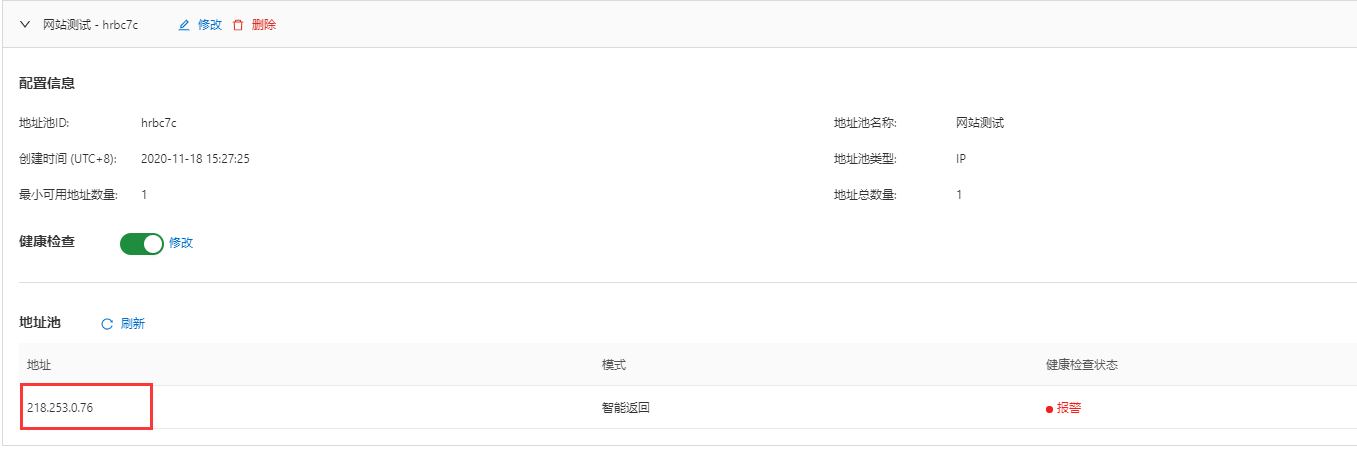
将地址池改为218.253.0.76不可用地址或停止服务, 开启健康检查后,会自动出现报警提示,并切换为备用地址池。
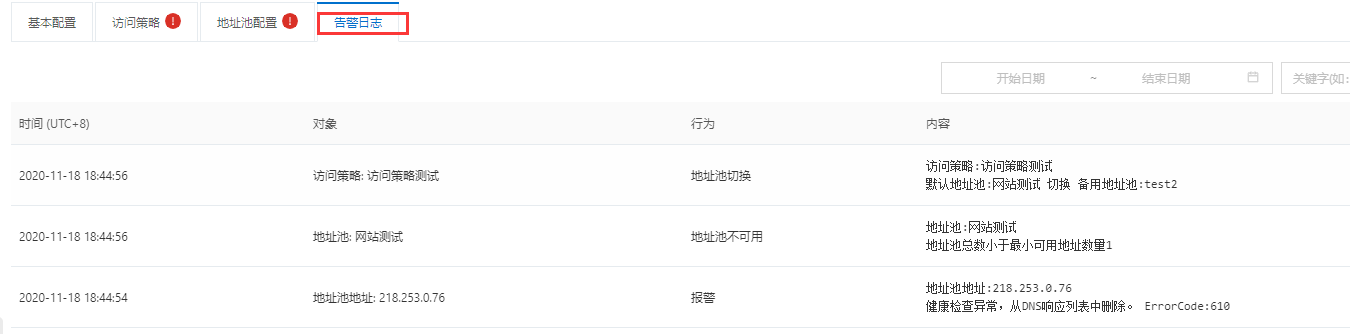
查看告警日志, 可以看到详细信息
访问服务:
3.2 DNS生产最佳实践方案
3.2.1 全球加速功能
全球加速可以为不同地域的客户端智能返回不同的加速IP,降低解析时延,如果是面向国际的服务,是需要开启此功能, 如果只是国内使用, 可以不用开启。
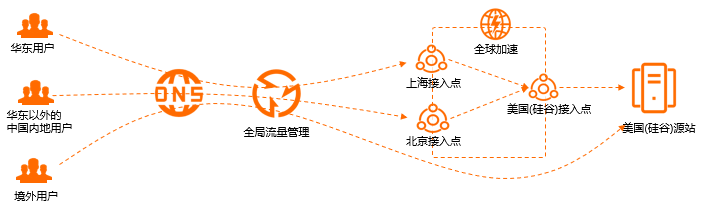
- 华东区域客户端访问Web服务会智能解析到全球加速上海加速IP。
- 华东以外的其他中国内地区域客户端访问Web服务会智能解析到全球加速北京加速IP。
- 境外区域客户端访问Web服务会直接走境外线路到美国(硅谷)源站IP。
详细操作, 查阅官方文档。
3.2.2 不同运营商的加速方案
不同运营商会有自身专有的网络, 如果跨运营商访问存在不稳定的情况, 可以开启此功能。
实现原理:
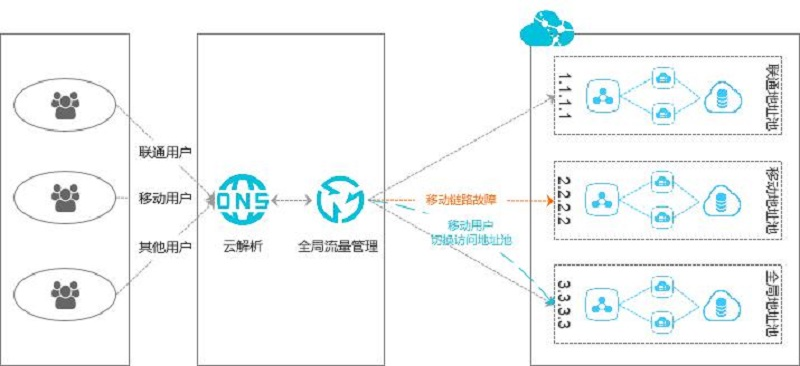
- 联通用户通过域名,访问应用服务的联通IP地址:1.1.1.1 。
- 移动用户通过域名,访问应用服务的移动IP地址:2.2.2.2 。
- 其他用户通过域名,访问应用服务的默认电信IP地址:3.3.3.3 。
详细操作, 查阅官方文档。
3.2.3 全球业务高可用方案
部署方案:
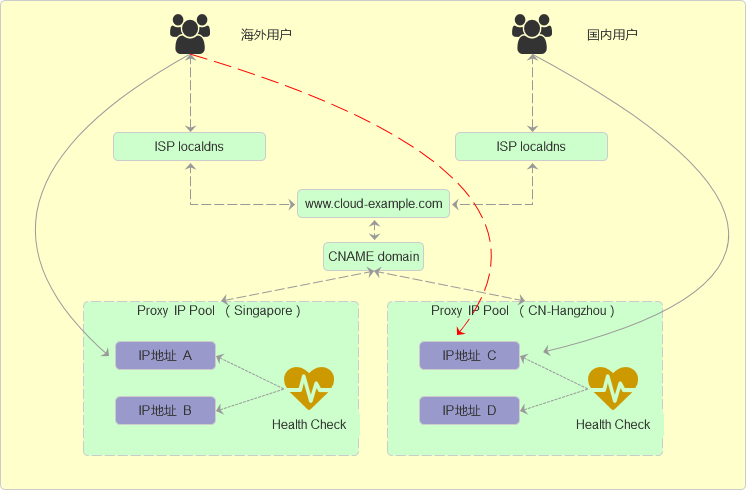
为了实现全球用户都能获得较好的访问质量,通常企业会在中国大陆和海外分别部署至少两套以上的接入服务点,后端数据服务仍然使用一套。通过DNS服务,对于不同地区的用户请求流量做智能调度,将用户访请求流量路由至不同的接入服务点。出现故障灾难时,各接入站点自建互相备份,最终实现业务的高可用。
3.2.4 跨地域负载均衡
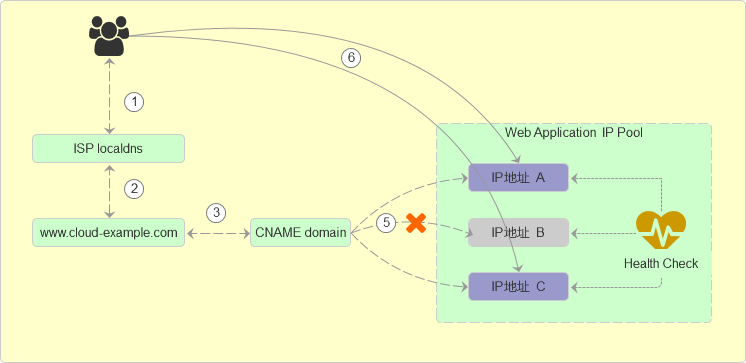
企业应用服务一般会有多个IP,且多个IP地址可能分布于不同地区。可以采用流量平均分配原则,对多个IP地址进行负载均摊,实现用户访问同一个应用服务域名时多个IP地址同时承担用户的访问请求。
实现方案:
3.3 DNS域名劫持解决方案
域名劫持
域名劫持又称DNS劫持,是指在劫持的网络范围内拦截域名解析的请求,域名劫持通常相伴的措施是封锁正常DNS的IP, 这样就可以采用虚假的IP来代替真实的IP。
常见的域名劫持问题:
- 广告劫持:用户正常页面指向到广告页面。
- 恶意劫持:域名指向IP被改变,将用户访问流量引到挂马,盗号等对用户有害页面的劫持。
- 本地DNS缓存:为了降低跨网流量及用户访问速度进行的一种劫持,导致域名解析结果不能按时更新。
HTTPDNS解决方案
HTTPDNS是仅面向移动App域名劫持解决方案,具有域名防劫持、精准调度的特性。
优势特性:
域名防劫持
域名解析请求直接发送至HTTPDNS服务器,绕过运营商Local DNS,避免域名劫持问题。
调度精准
直接获取客户端 IP ,基于客户端 IP 获得最精准的解析结果,让客户端就近接入业务节点。
实时生效
可以实现毫秒级低解析延迟的域名解析效果。
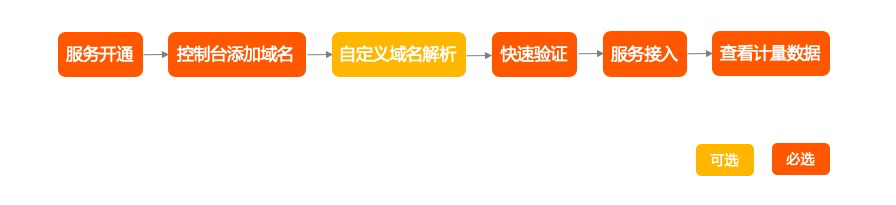
使用配置
流程:
3.4 CDN剖析
3.4.1 CDN原理
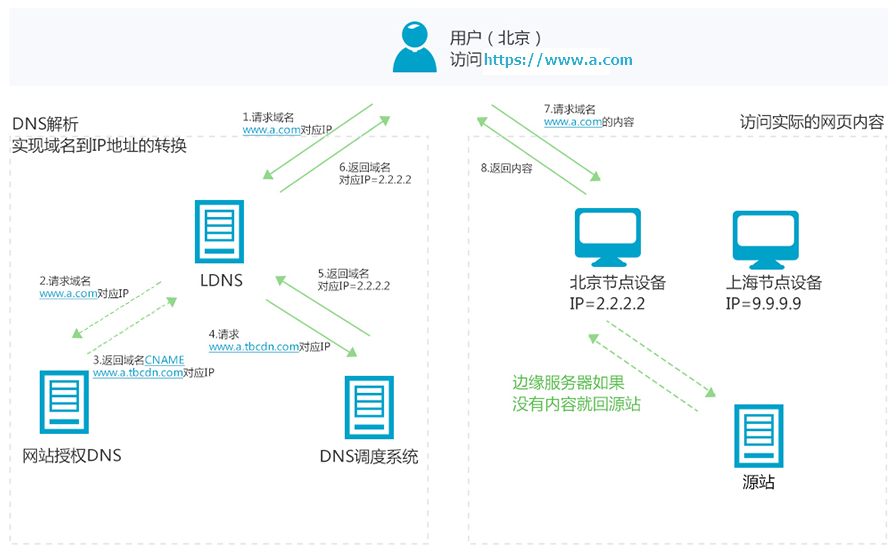
当终端用户(北京)向
www.a.com下的指定资源发起请求时,首先向LDNS(本地DNS)发起域名解析请求。LDNS检查缓存中是否有
www.a.com的IP地址记录。如果有,则直接返回给终端用户;如果没有,则向授权DNS查询。当授权DNS解析
www.a.com时,返回域名CNAMEwww.a.tbcdn.com对应IP地址。域名解析请求发送至阿里云DNS调度系统,并为请求分配最佳节点IP地址。(用户从北京访问,返回最近的北京节点信息。)
LDNS获取DNS返回的解析IP地址。
用户获取解析IP地址。
用户向获取的IP地址发起对该资源的访问请求。
如果该IP地址对应的节点已缓存该资源,则会将数据直接返回给用户。
如果该IP地址对应的节点未缓存该资源,则节点向源站发起对该资源的请求。
可以根据缓存策略做相应配置(针对静态资源配置指定目录和文件后缀名的缓存过期时间和优先级,资源过期后,自动从CDN节点删除。)
3.4.2 缓存过期配置处理流程
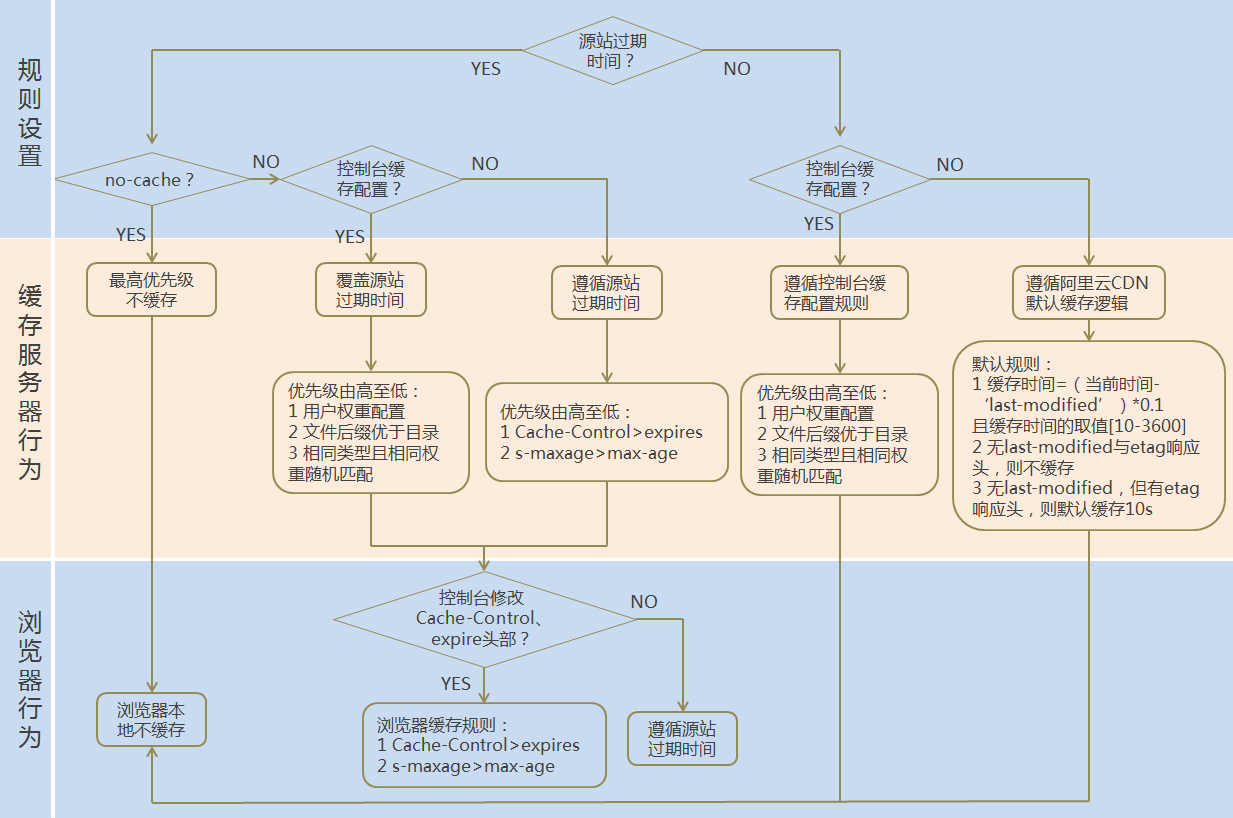
3.4.3 缓存配置规则
默认的缓存时间计算规则, 要符合3个条件:
- t =(curtime-last_modified)*0.1 【结果是时间差的10%】
- t = max(10s,t) 【最小要大于10S】
- t = min(t,3600s)【最大不能超过3600s】
缓存规则示例解析:
- 如果last-modified
为20140801 00:00:00,当前时间为20140801 00:01:00, (curtime-Last_modified)*0.1=6s,那么缓存时间为10s(因为最小值要大于10s)。 - 如果
last-modified为20140801 00:00:00,当前时间为20140802 00:00:00,(curtime-Last_modified)*0.1=8640s,那么缓存时间为3600s。 - 如果last-modified
为20140801 00:00:00,当前时间为20140801 00:10:00`,(curtime-Last_modified)*0.1=60s,那么缓存时间为60s。
3.5 CDN运用
- 验证域名所属权
域名验证设置
如果是阿里云申请的域名, 设置起来比较简单, 直接添加一条验证记录:
如果是其他第三方域名, 可以采用文件验证方式。
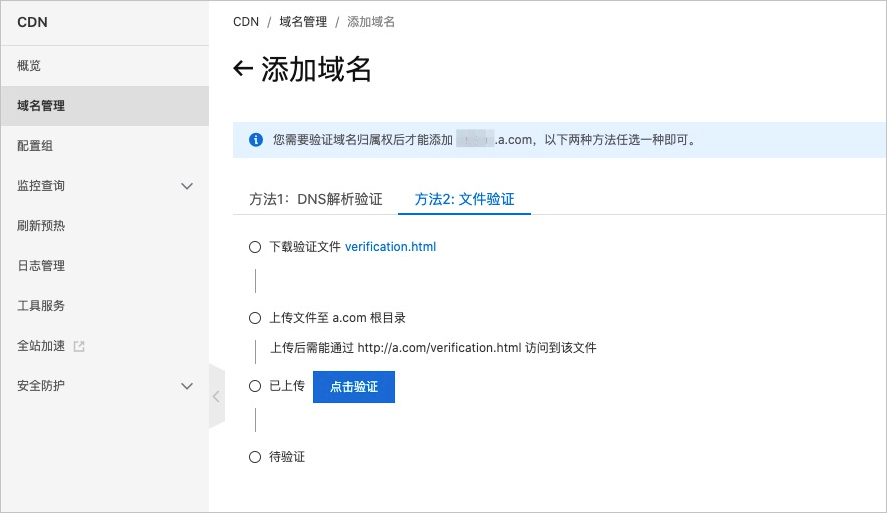
下载verification.html验证文件,上传到您的域名源站服务器的根目录。
- 添加域名
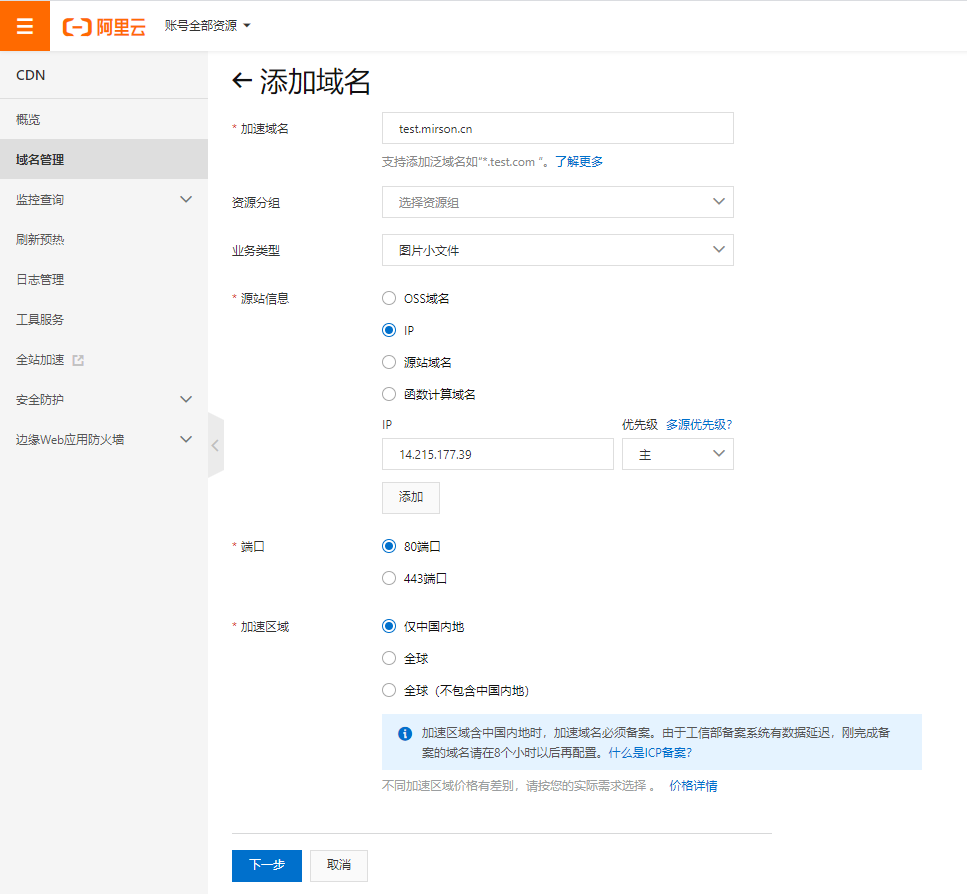
这里所填写的加速域名是需要先备案。
业务类型有五种, 根据需要选择不同配置:
图片小文件
内容多为小型的静态资源 (如小文件、图片、网页样式文件等),推荐您选择图片小文件业务类型。
大文件下载
内容为较大的文件(大于20MB的静态文件),推荐选择大文件下载业务类型。
视频点播加速
如果需要加速音频或视频文件,例如音乐、视频的点播业务场景,推荐选择此类型。
全站加速
网站或应用含有大量动静态内容混合,且较多为动态资源请求,可以使用全站加速,静态内容高速缓存,动态内容通过阿里云的最优链路算法及协议层优化快速回源获取。
安全加速
网站易遭受攻击且必须兼顾加速的业务场景,则需要使用安全加速功能,提升全站安全性。例如金融交易、电商网站等。
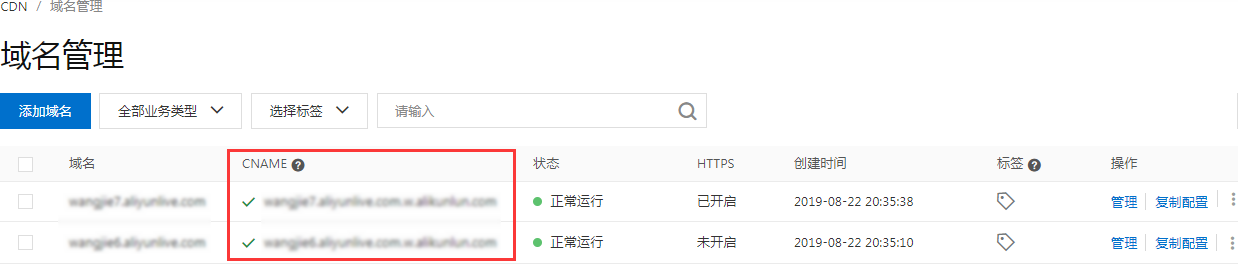
配置CNAME
阿里云的配置流程:
- 记录加速域名的CNAME地址
- 添加CNAME记录
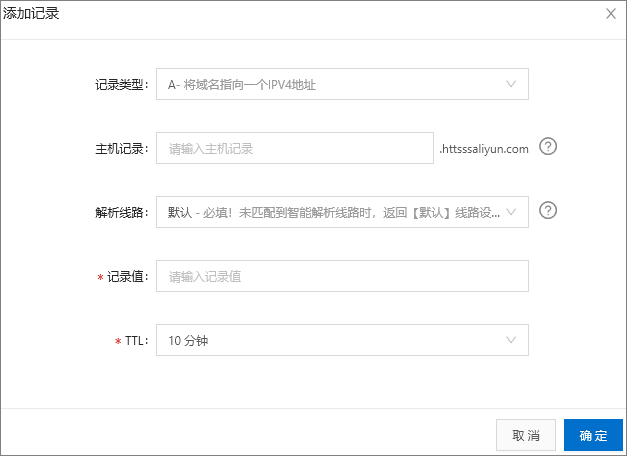
这里的记录值,填写上面的CNAME地址。
- 验证CNAME配置是否生效
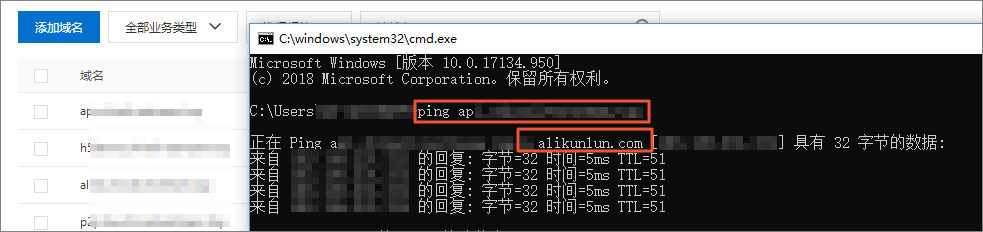
如果返回的解析结果和CDN控制台上该加速域名的CNAME值一致,则表示CDN加速已经生效。
3.6 CDN最佳实践方案
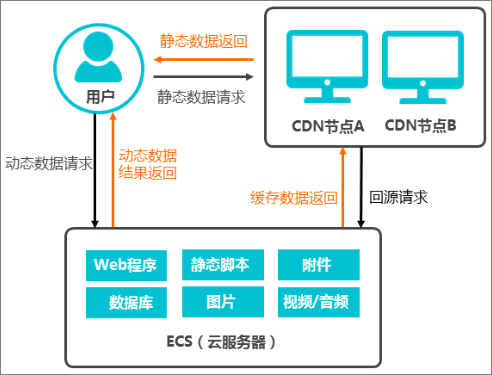
3.6.1 ECS源站加速
通过阿里云CDN实现ECS上静态资源加速, ECS上可存储的资源包括静态资源和动态资源。
访问ECS上的资源时,动态资源请求直接返回,静态资源通过CDN实现访问加速,由CDN节点返回。
操作步骤:
在CDN控制台上,添加ECS域名。
源站信息, 可以填写IP或源站域名
- 填写服务器外网IP,支持多个服务器外网IP。
- 填写源站域名,支持多个源站域名。
在CDN控制台上,获取CNAME值。
在DNS控制台上, 配置CNAME值。
通过PING命令,验证CNAME配置是否生效。
3.6.2 OSS资源加速
背景
OSS源站上存储的静态资源包括静态脚本、图片、附件等信息,当用户访问静态资源时,CDN对OSS源站上的静态资源进行加速,源站上的资源缓存到CDN的加速节点,系统自动调用离终端用户最近的CDN节点上已缓存的资源。加速OSS架构如下图所示。
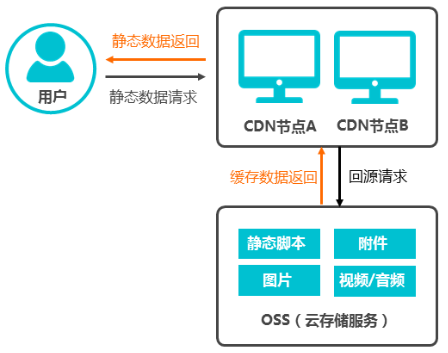
方案优势:
用户访问网站资源,全部通过CDN,降低源站压力。
使用CDN流量,单价低于OSS直接访问外网流量。
资源从距离客户端最近的CDN节点获取,减少网络传输距离,保证静态资源质量。
操作配置:
在CDN控制台上,添加OSS域名, 并记录加速域名的CNAME值。
在阿里云云解析DNS控制台上,配置加速域名的CNAME值。
通过PING命令, 验证CNAME配置是否生效。
在OSS控制台上,打开加速域名的CDN缓存自动刷新开关。
执行本操作后,如果Object有更新,OSS会自动将更新后的Object刷新到CDN的缓存节点上,从而实现文件更新后实时刷新缓存的功能。
3.6.3 CDN缓存命中率优化
背景
在实际应用中, 如果CDN缓存命中率低,则会导致源站压力大,静态资源访问效率低。
需要选择对应的优化策略,来提高CDN的缓存命中率。
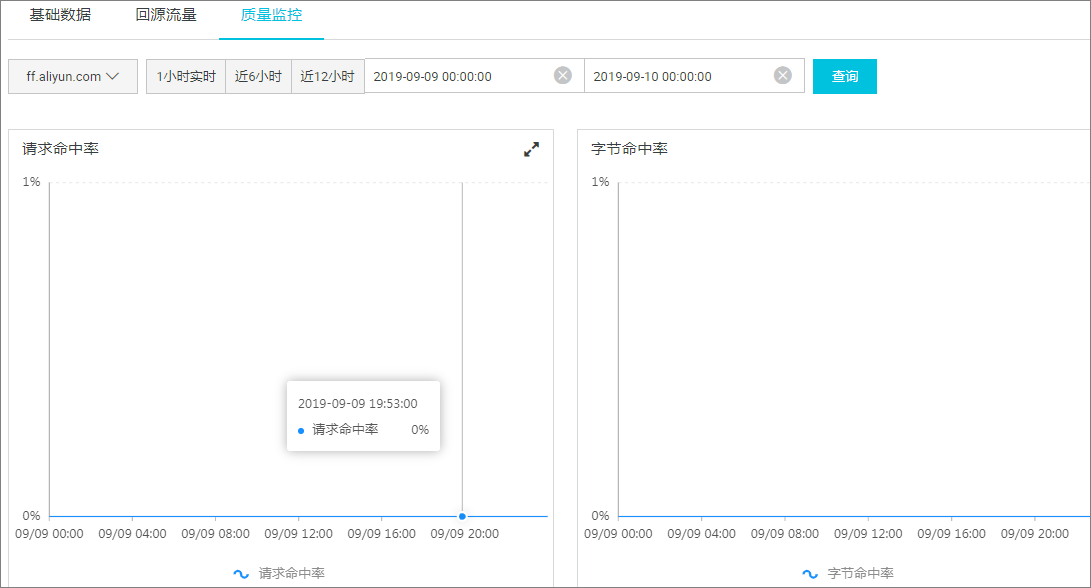
CDN缓存命中率包括:
字节缓存命中率: CDN缓存命中响应的字节数 / CDN所有请求响应的字节数。
请求缓存命中率: CDN缓存命中的请求数 / CDN所有的请求数。
字节缓存命中率越低,回源流量越大,回源流量代表了源站服务器接收到的负载压力。
查看CDN缓存命中率
CDN控制台提供的缓存命中率监控是字节缓存命中率:
优化方案
4. IaaS之高阶实践
4.1 高可用弹性伸缩实践
背景
弹性伸缩是云服务架构的重要优势,能够很好的解决高并发场景下的性能瓶颈, 同时节省运营成本。
在 IaaS 端,能够弹性伸缩的最实用的产品形态,一般是虚拟机编组。阿里云提供了弹性伸缩的功能。
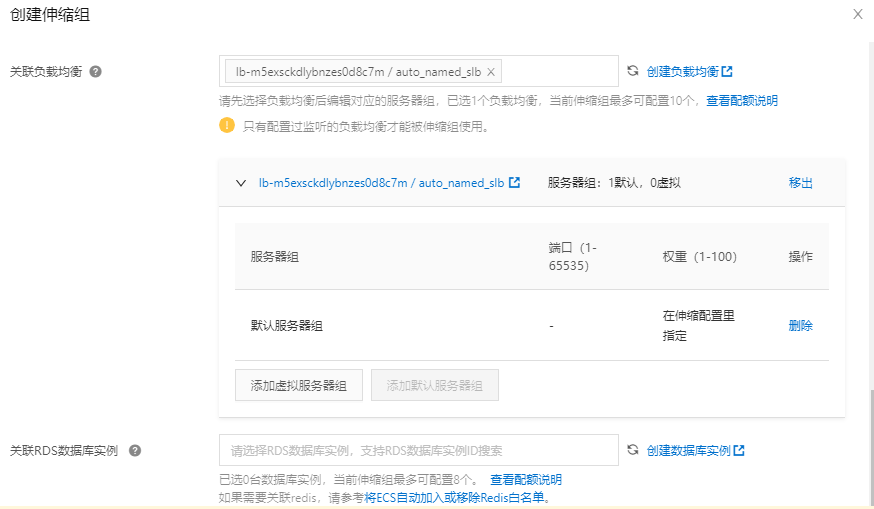
要实现弹性伸缩服务, 还需要负载均衡器作为辅助组件,它可以将流量均匀地,或者按照一定权重或规则,分发到多台虚拟机上。
创建ECS实例
实例创建完成之后, 需要绑定弹性IP
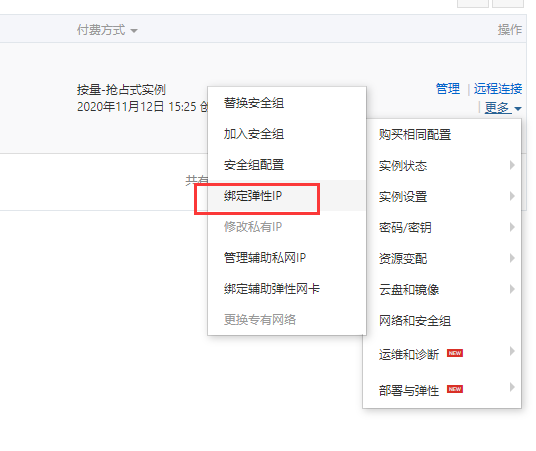
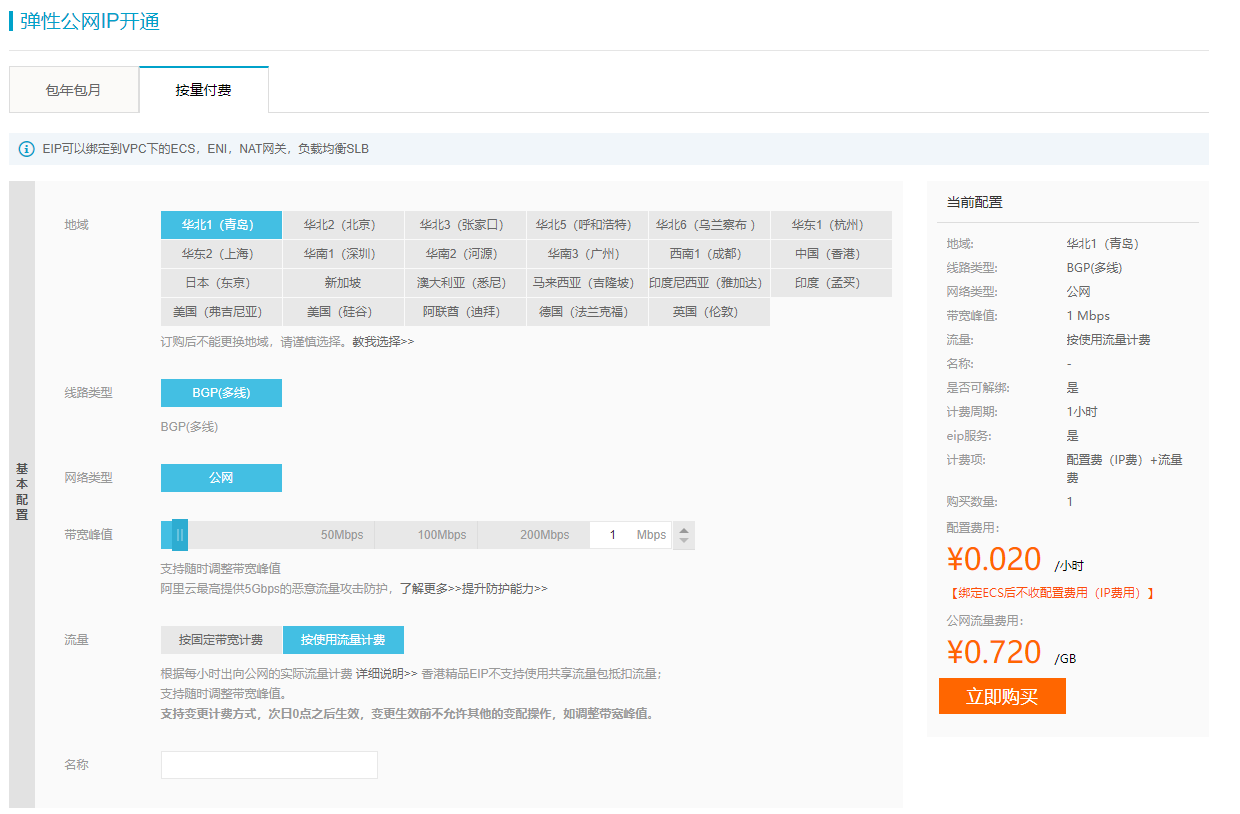
如果没有弹性公网IP, 需要付费开通:
- 创建负载均衡SLB
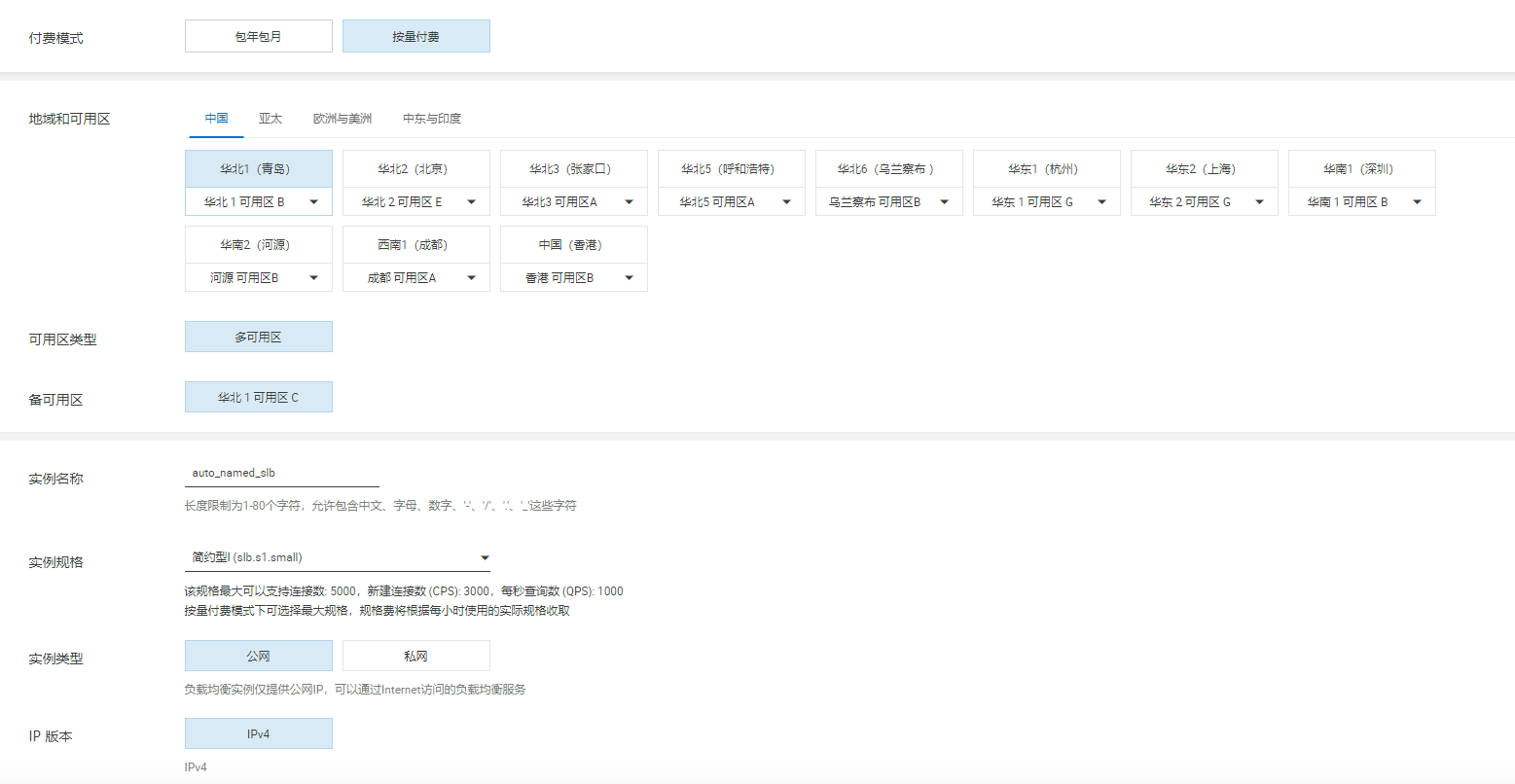
根据实际场景, 选择对应的实例规格。
在实例管理里面,选择【点我开始配置】

协议监听配置:
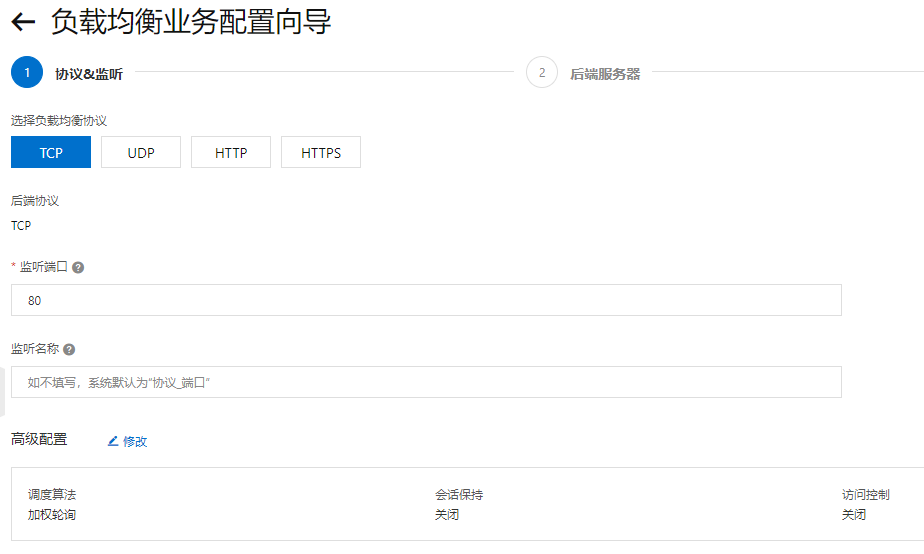
这里配置的80端口, 可以根据需要, 在高级配置里面, 设置不同的调度算法: 加权轮询 (WRR)、加权最小连接数 (WLC)、轮询 (RR)、一致性哈希 (CH)。
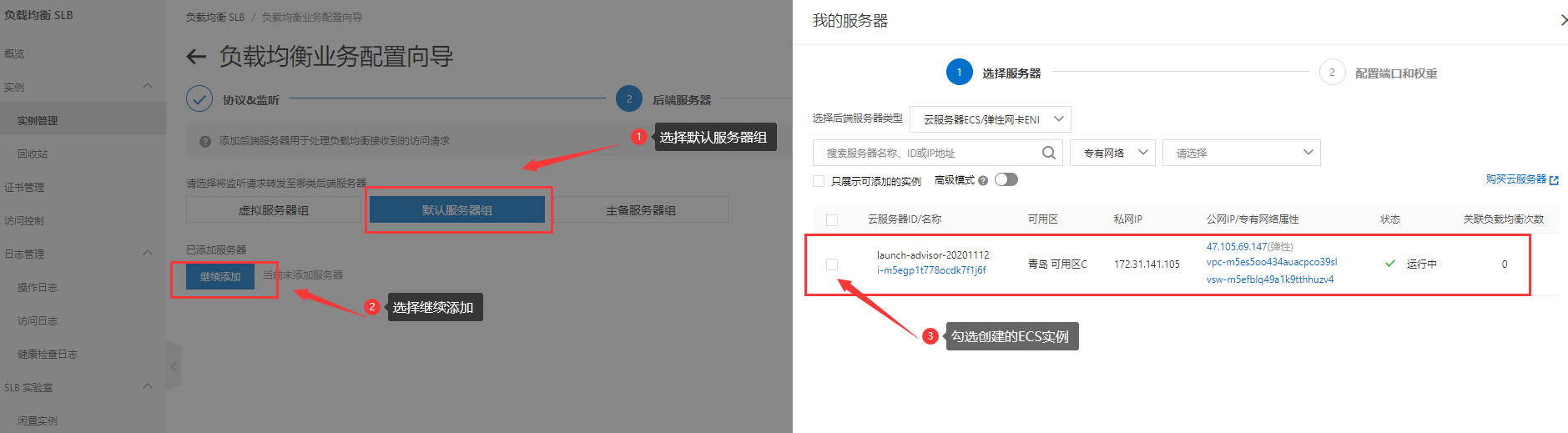
接下来, 设定ECS服务的运行端口:
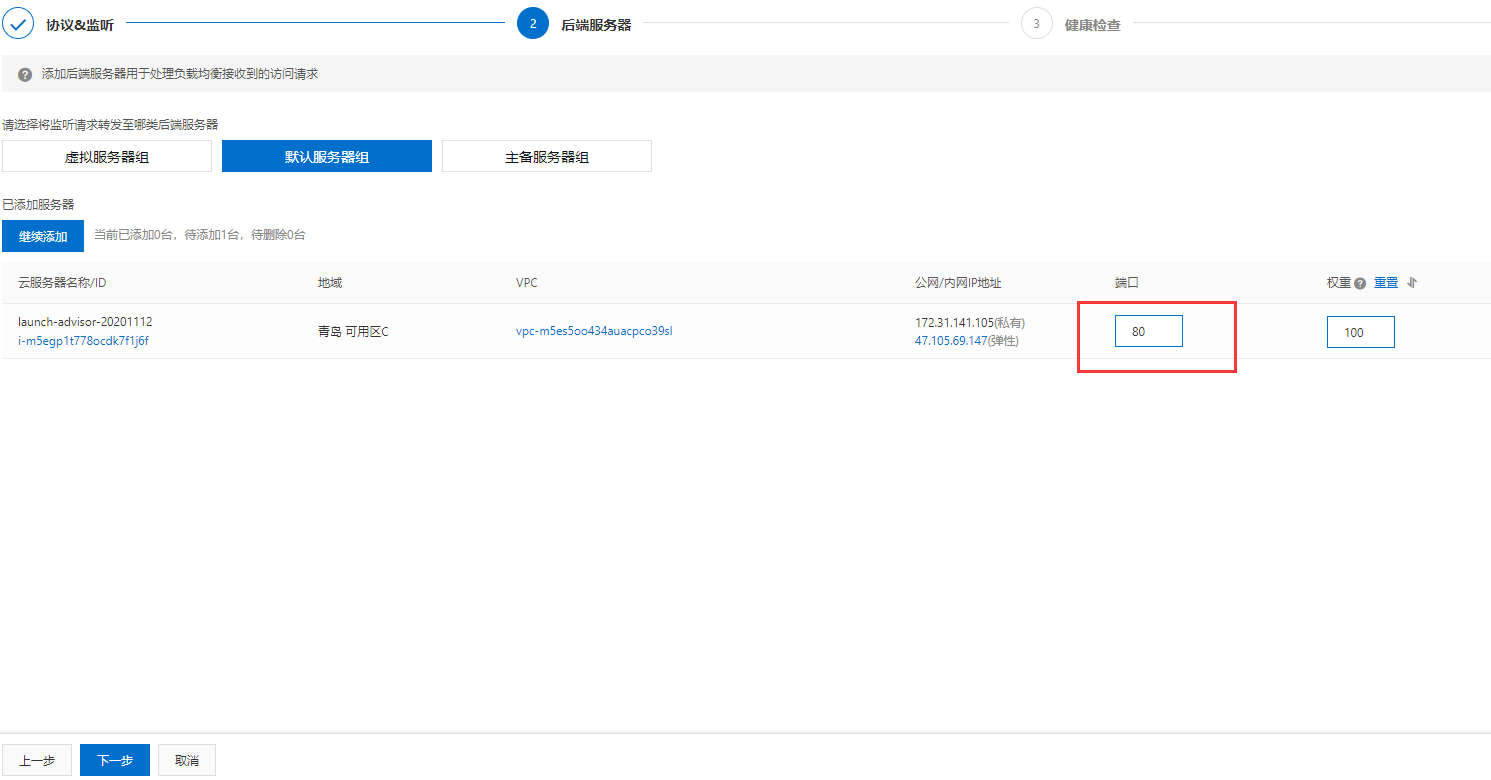
开启健康检查:
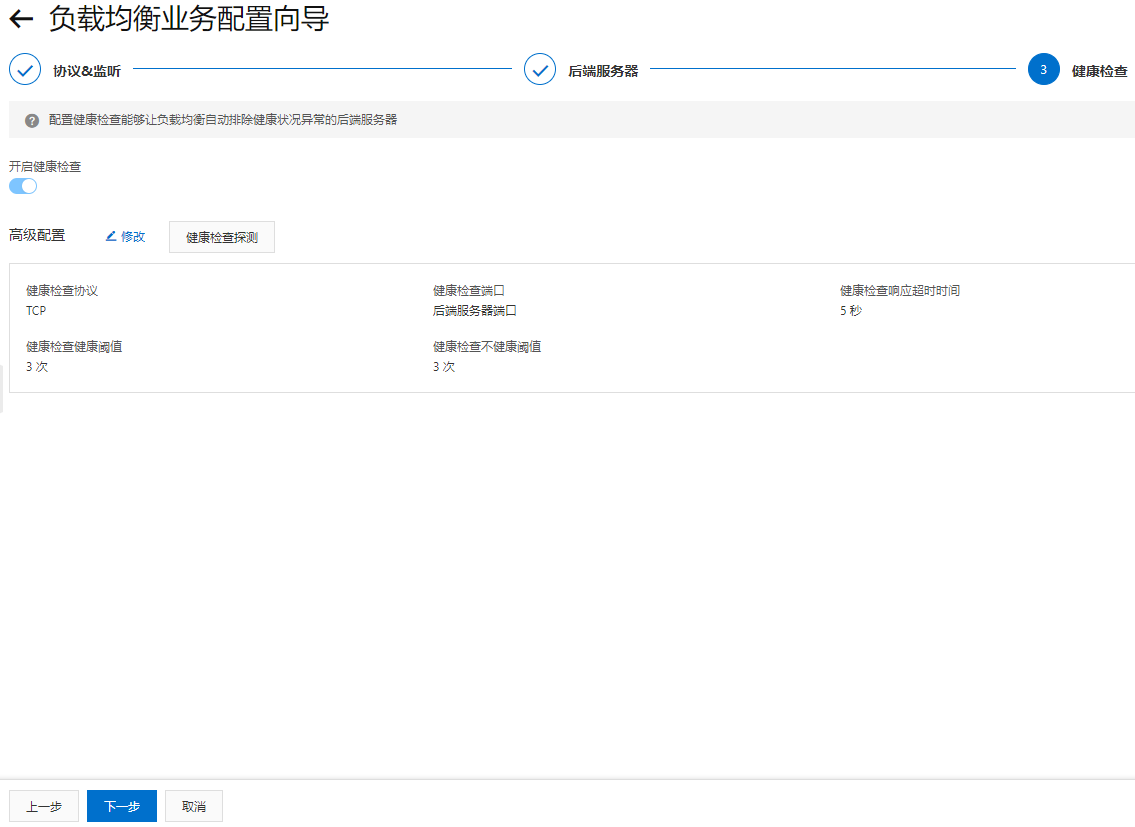
最后确认提交即可。
配置服务运行方式(服务部署方式)
编写服务接口
计算斐波那契数列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public int fibonacci(int n){
if(n==1||n==2){
flag[n]=1;
return 1;
}
else{
if(flag[n-1]!=0&&flag[n-2]!=0){
flag[n]=(flag[n-1]+flag[n-2])%10007;
return flag[n];
}
else
{
flag[n]=(fibonacci(n-2) + fibonacci(n-1))%10007;
return flag[n];
}
}
}打包上传服务
1
maven clean install
设置开机启动
创建开机脚本:
1
vi /usr/lib/systemd/system/elastic.service
添加以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17[Unit]
Description=elasticservice
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=simple
PIDFile=/run/elasticservice.pid
ExecStart=/usr/local/elasticstart.sh
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
ExecReload=
PrivateTmp=true
RemainAfterExit=yes
ExecStartPre=
[Install]
WantedBy=multi-user.target创建elasticstart.sh脚本:
1
2
nohup /usr/bin/java -jar /usr/local/app-basic.jar >/dev/null 2>&1 &设置权限:
1
chmod 777 /usr/local/elasticstart.sh
设置开机启动:
1
systemctl enable elastic
启动服务:
1
systemctl restart elastic
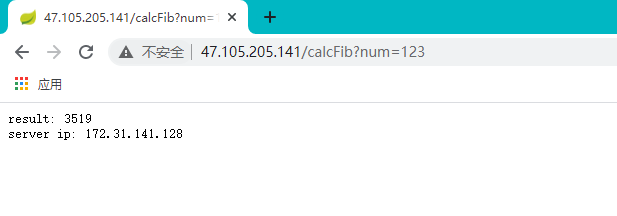
测试验证(服务部署方式)
通过接口进行访问:
配置服务运行程序(非服务部署方式)
进入ECS虚拟机, 创建配置一个Nodejs服务。
配置NodeJS环境
下载:
1
wget https://nodejs.org/dist/v10.13.0/node-v10.13.0-linux-x64.tar.xz
解压:
1
tar -xvf node-v10.13.0-linux-x64.tar.xz
创建软链接:
1
2ln -s /usr/local/node-v10.13.0-linux-x64/bin/node /usr/bin/node
ln -s /usr/local/node-v10.13.0-linux-x64/bin/npm /usr/bin/npm安装运行模块依赖
1
2
3npm install express
npm install ip
npm install os创建server.js脚本:
vi /usr/local/server.js :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const express = require('express');
const ip = require('ip');
const os = require('os');
const app = express();
//使用递归方式计算斐波那契数列
function fibo (n) {
return n > 1 ? fibo(n-1) + fibo(n-2) : 1;
}
app.get('/', function(req,res) {res.write('I am healthy'); res.end();} );
app.get('/fibo/:n', function(req, res) {
var n = parseInt(req.params['n']);
var f = fibo(n);
res.write(`Fibo(${n}) = ${f} \n`);
res.write(`Server: ${os.hostname()} , private ip: ${ip.address()} \n`);
res.end();
});
app.listen(80);运行程序
1
node server.js
设置开机启动
创建开机脚本:
1
vi /usr/lib/systemd/system/nodeapp.service
添加以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[Unit]
Description=nodeappservice
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=simple
PIDFile=/run/nodeapp.pid
ExecStart=/bin/setsid /usr/bin/node /usr/local/server.js
Restart=/bin/pkill node && /bin/setsid /usr/bin/node /usr/local/server.js
ExecStop=/bin/pkill node
ExecReload=
PrivateTmp=true
RemainAfterExit=yes
ExecStartPre=
[Install]
WantedBy=multi-user.target设置开机启动:
1
systemctl enable nodeapp
测试验证(非服务部署方式)
采用负载均衡的公网服务地址, 进行测试:
1
2
3[root@localhost siege-4.0.2]# curl http://47.104.145.210/fibo/35
Fibo(35) = 14930352
Server: iZm5egp1t778ocdk7f1j6fZ , private ip: 172.31.141.105正常能够返回主机名称和IP信息。
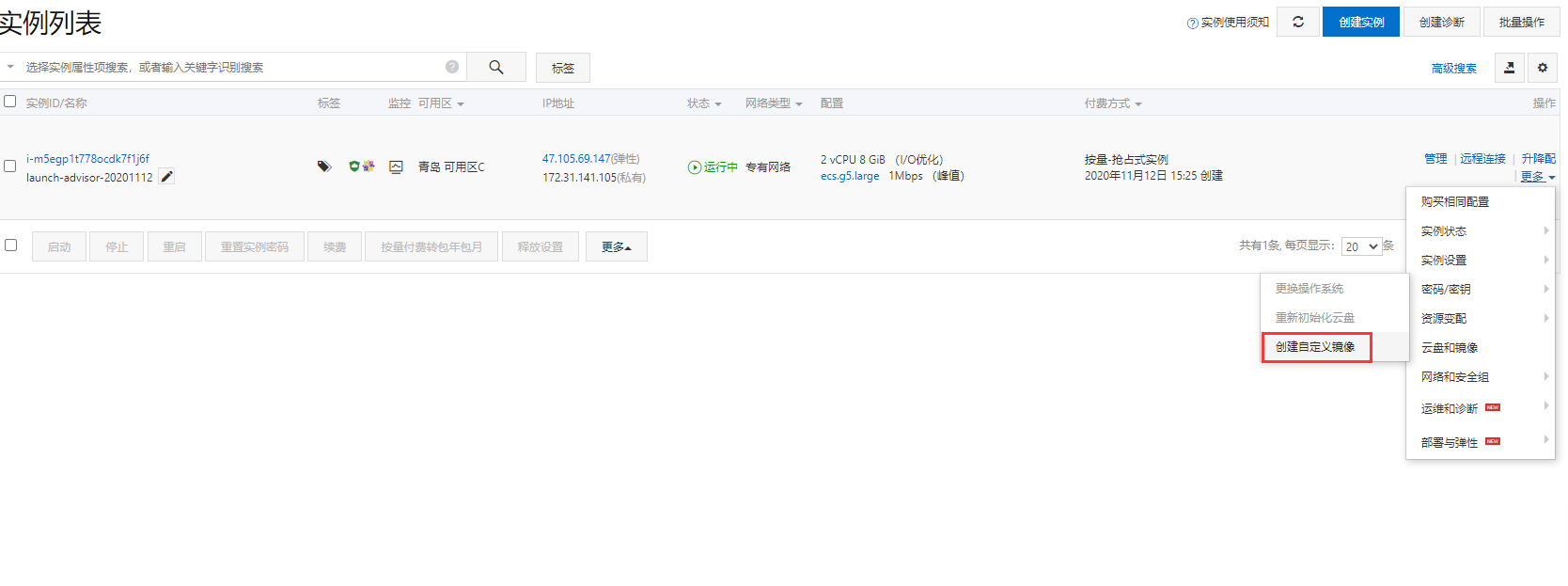
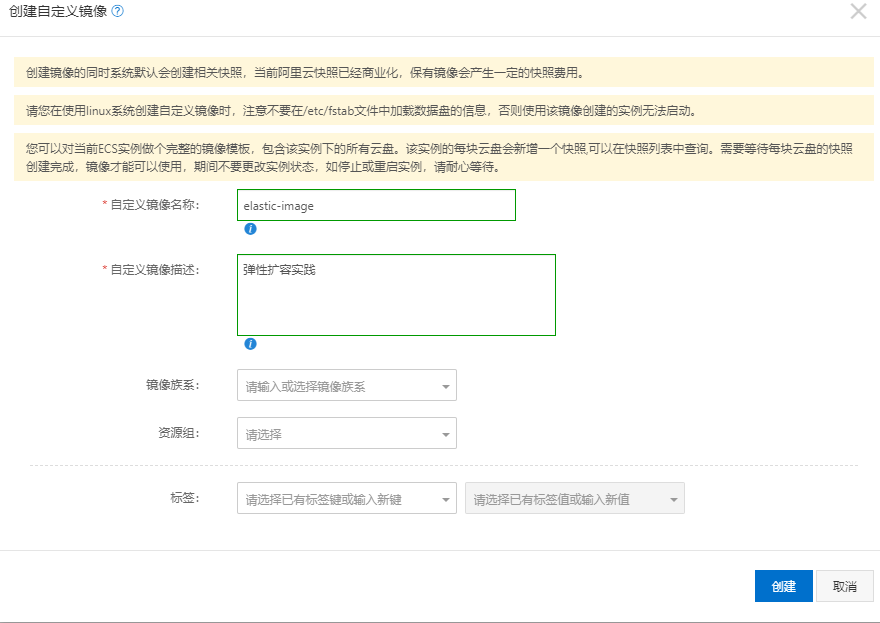
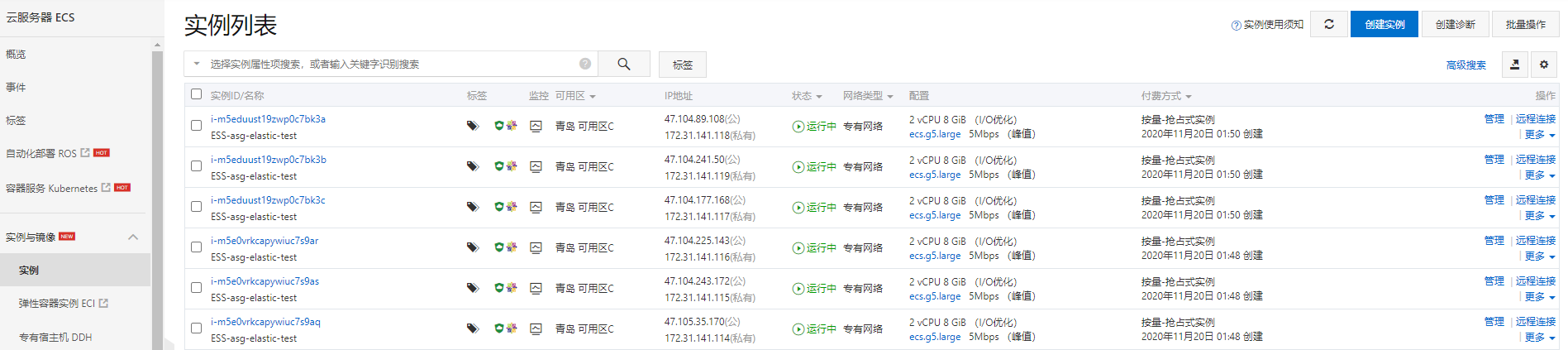
创建自定义镜像
用于弹性机器扩容使用
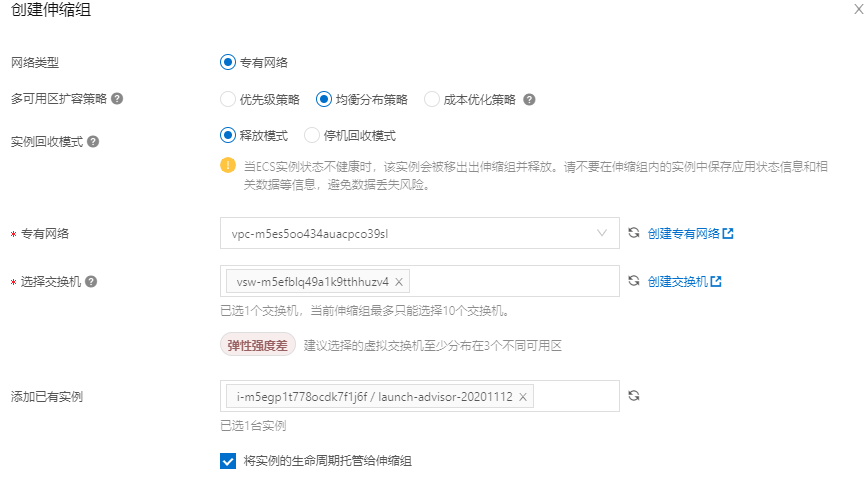
创建伸缩组
进入【部署与弹性】-【弹性伸缩】,配置信息来源, 选择【自定义伸缩配置】, 这里需要【创建伸缩配置】,在里面配置上面所自定义生成的镜像, 否则服务不能正常运行, 整个伸缩功能也就无法实现。
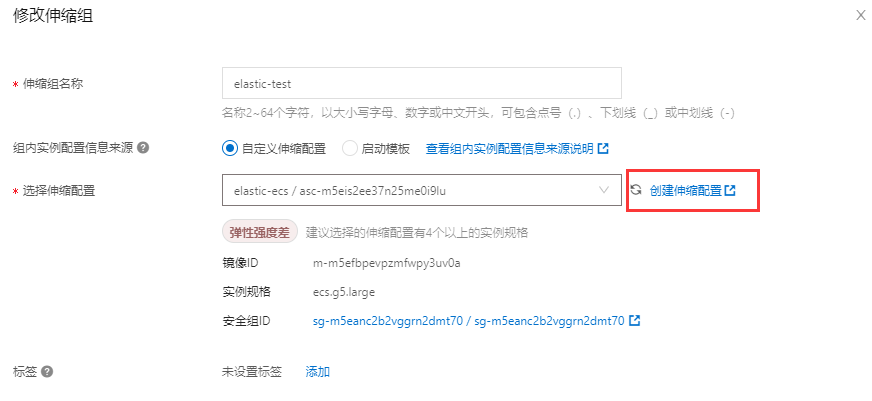
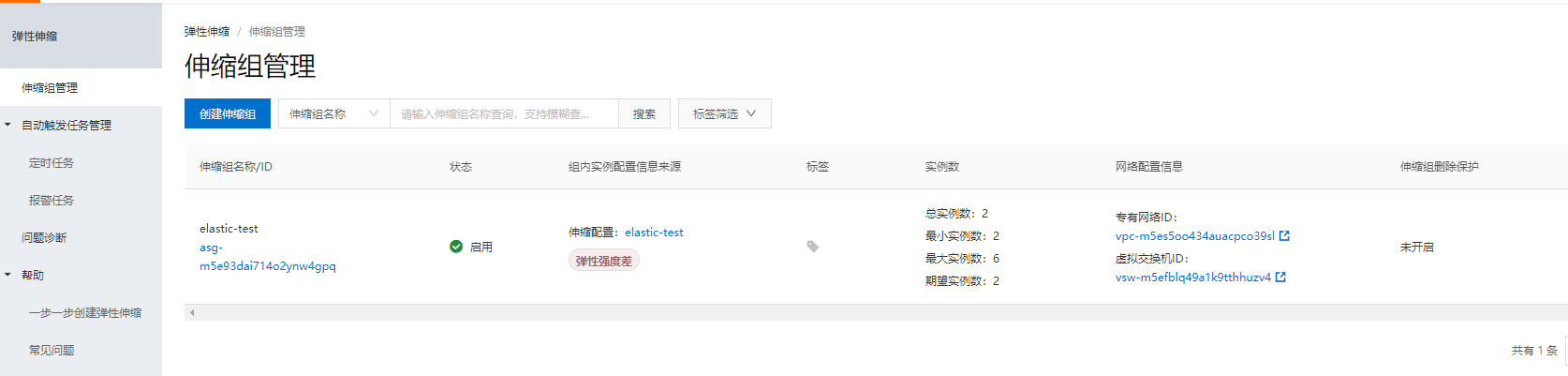
设定实例范围: 2-6台。(期望实例数, 会随着伸缩自动增长, 但不会超过最大实例数。)
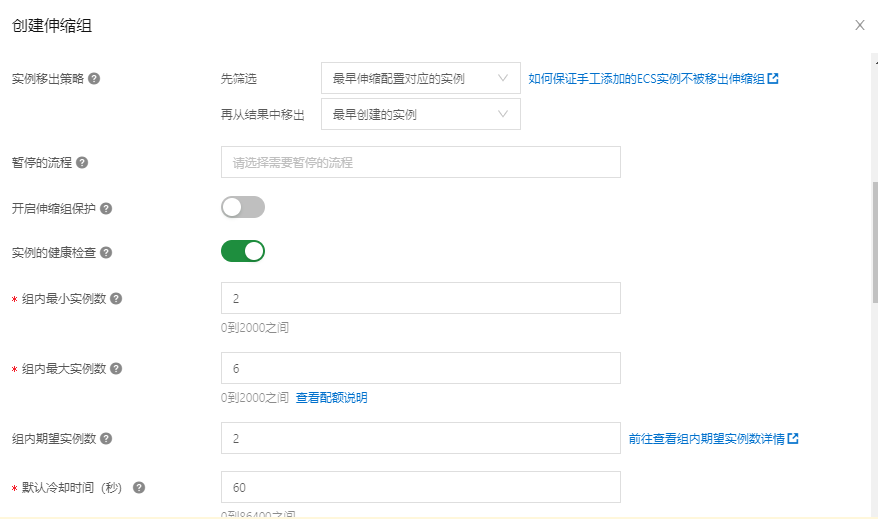
设定扩容策略为均衡分布策略,在实际应用中, 建议虚拟交换机可以划分在不同区域,以保障高可用:
创建完成:

在ECS控制台可以看到生成的实例:

在弹性伸缩后台, 可以看到实例配置信息:
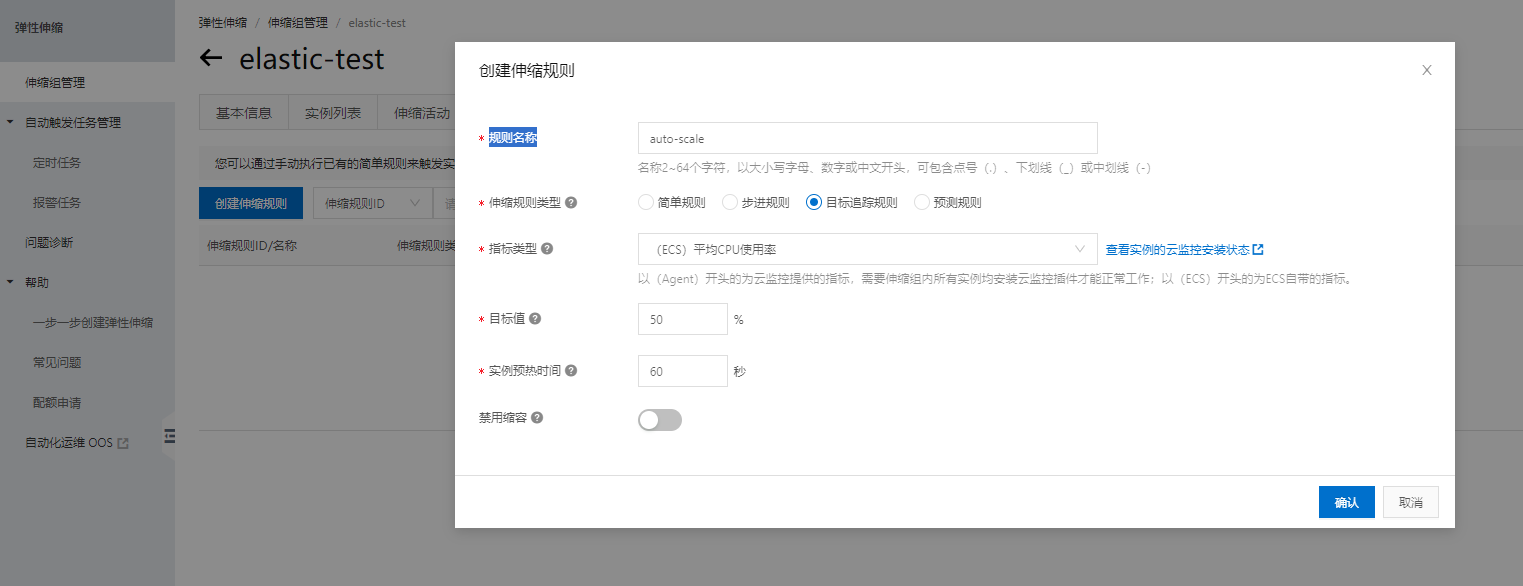
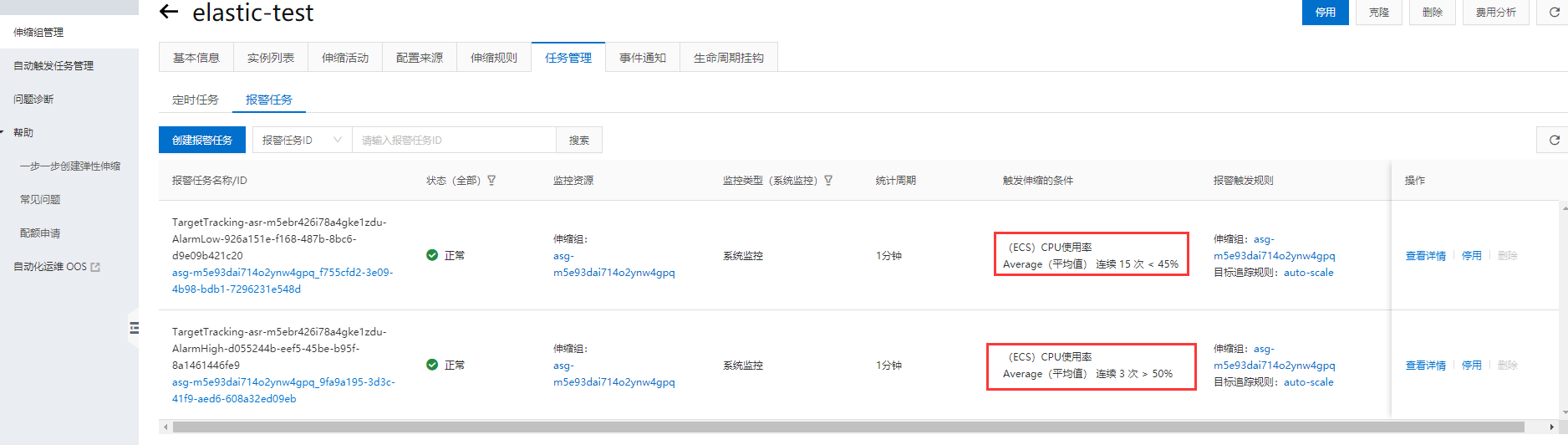
创建弹性伸缩规则
这里设定CPU使用率不能超过30%。
负载测试验证
进入负载均衡SLB,可以看到已经自动配置了初始的两台实例, 权重都设定为50:
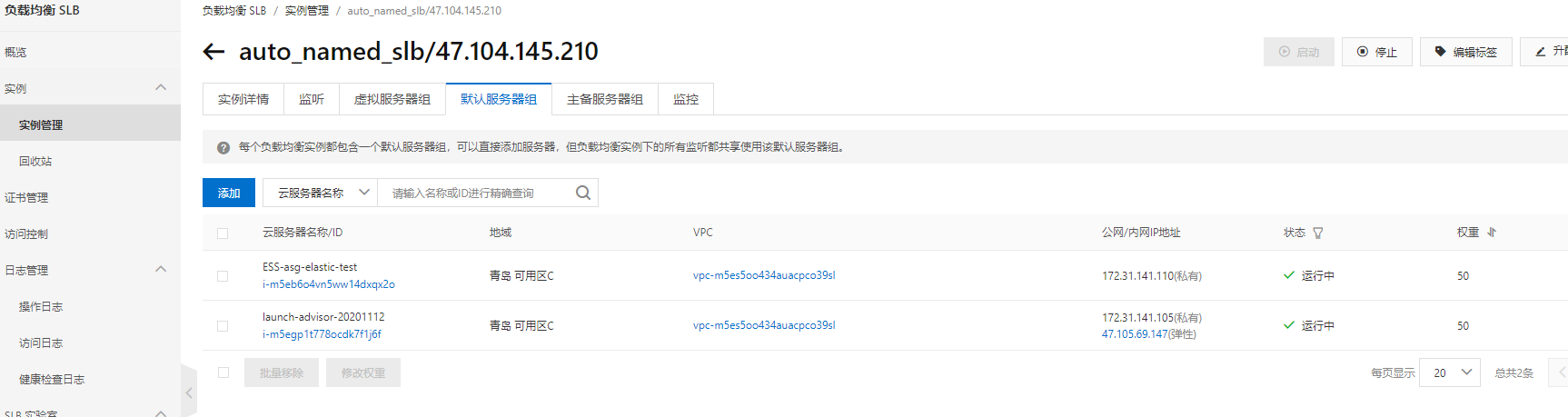
通过测试,可以看到负载均衡已经生效:
1
2
3
4
5
6
7[root@localhost siege-4.0.2]# curl http://47.104.145.210/fibo/35
Fibo(35) = 14930352
Server: iZm5ecgyf8ael3v9zrtx89Z , private ip: 172.31.141.111
[root@localhost siege-4.0.2]# curl http://47.104.145.210/fibo/35
Fibo(35) = 14930352
Server: iZm5egp1t778ocdk7f1j6fZ , private ip: 172.31.141.105安装压测组件:
下载:
1
wget http://download.joedog.org/siege/siege-4.0.2.tar.gz
解压:
1
tar -zvxf siege-4.0.2.tar.gz
安装依赖:
1
yum -y install gcc
编译安装:
1
2
3
4cd siege-4.0.2
./configure
make
make install压力测试
1
2
3
4
5
6
7
8
9
10[root@localhost siege-4.0.2]# siege -c 255 -t 10m http://47.104.145.210/calcFib?num=99
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 200 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.22 secs: 84 bytes ==> GET /fibo/99
HTTP/1.1 200 0.22 secs: 84 bytes ==> GET /fibo/99
HTTP/1.1 200 0.22 secs: 84 bytes ==> GET /fibo/99
HTTP/1.1 200 0.22 secs: 84 bytes ==> GET /fibo/99
HTTP/1.1 200 0.22 secs: 84 bytes ==> GET /fibo/99-c 是并发量,-t 是压测时间。持续数6,7分钟后, 可以看到自动伸缩生效,创建了新的实例。
这里自动伸缩是会监控一段时间再执行,所以在测试过程中需要等待一段时间, 具体规则可以查看:
4.2 无服务器计算(FaaS)
简述
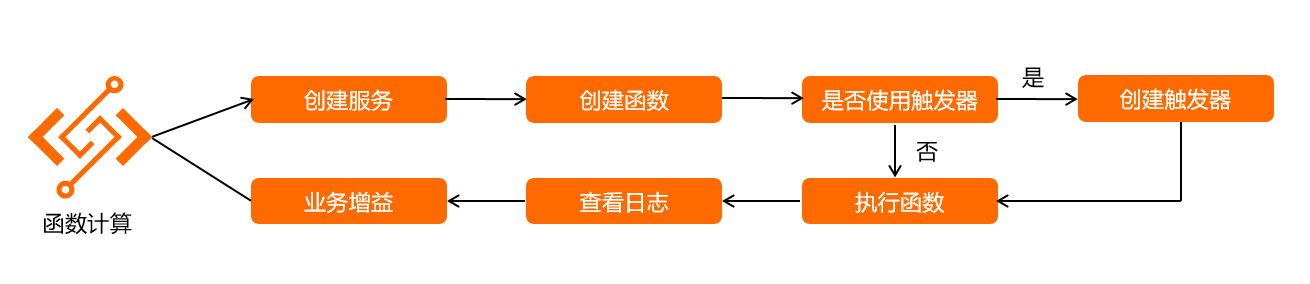
无服务器计算(Serverless Computing),实质上将计算与容器实例脱离, 可以把一个具有独立功能的函数,来作为一个单独的服务进行部署和运行, 也称为函数即服务(Function-as-a-Service,FaaS)。
使用流程
新建函数
函数创建方式选择【HTTP函数】
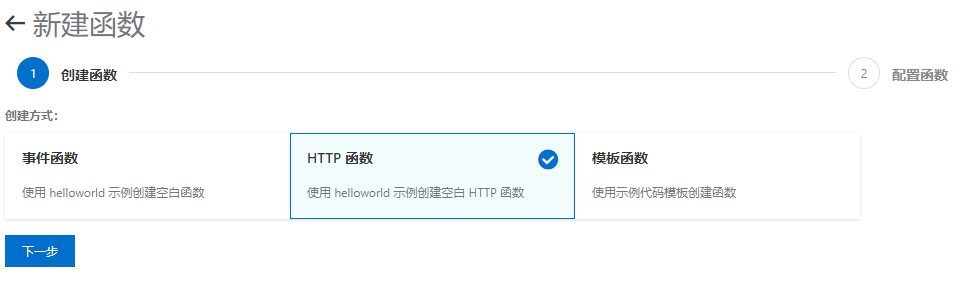
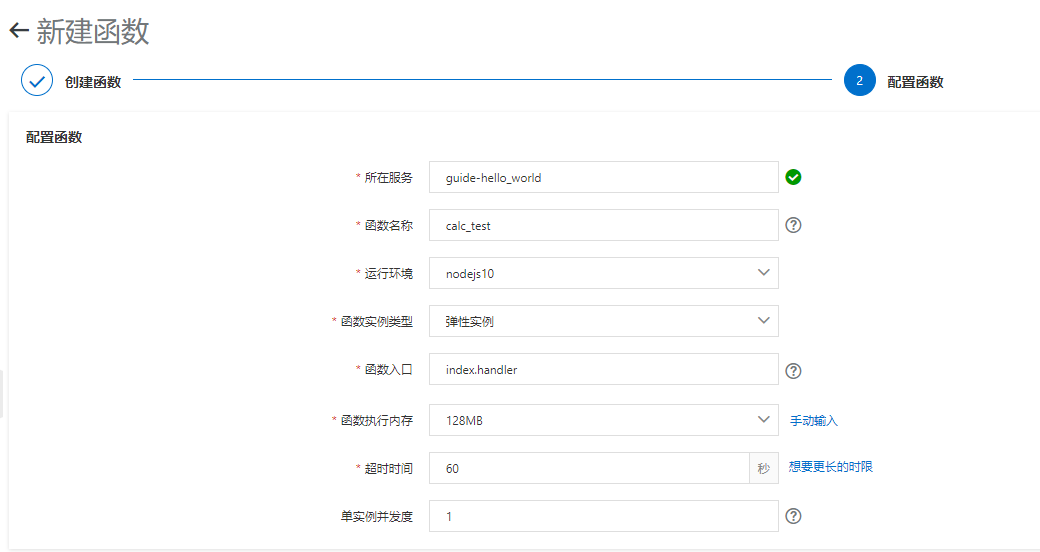
函数运行配置:
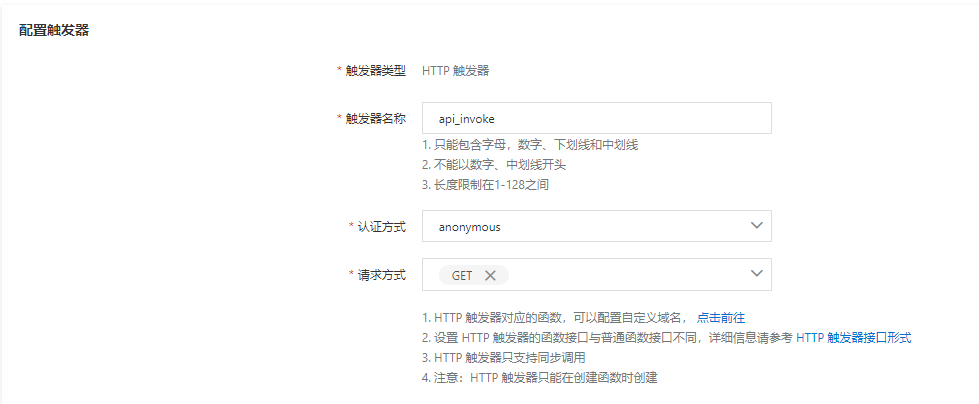
触发器配置:
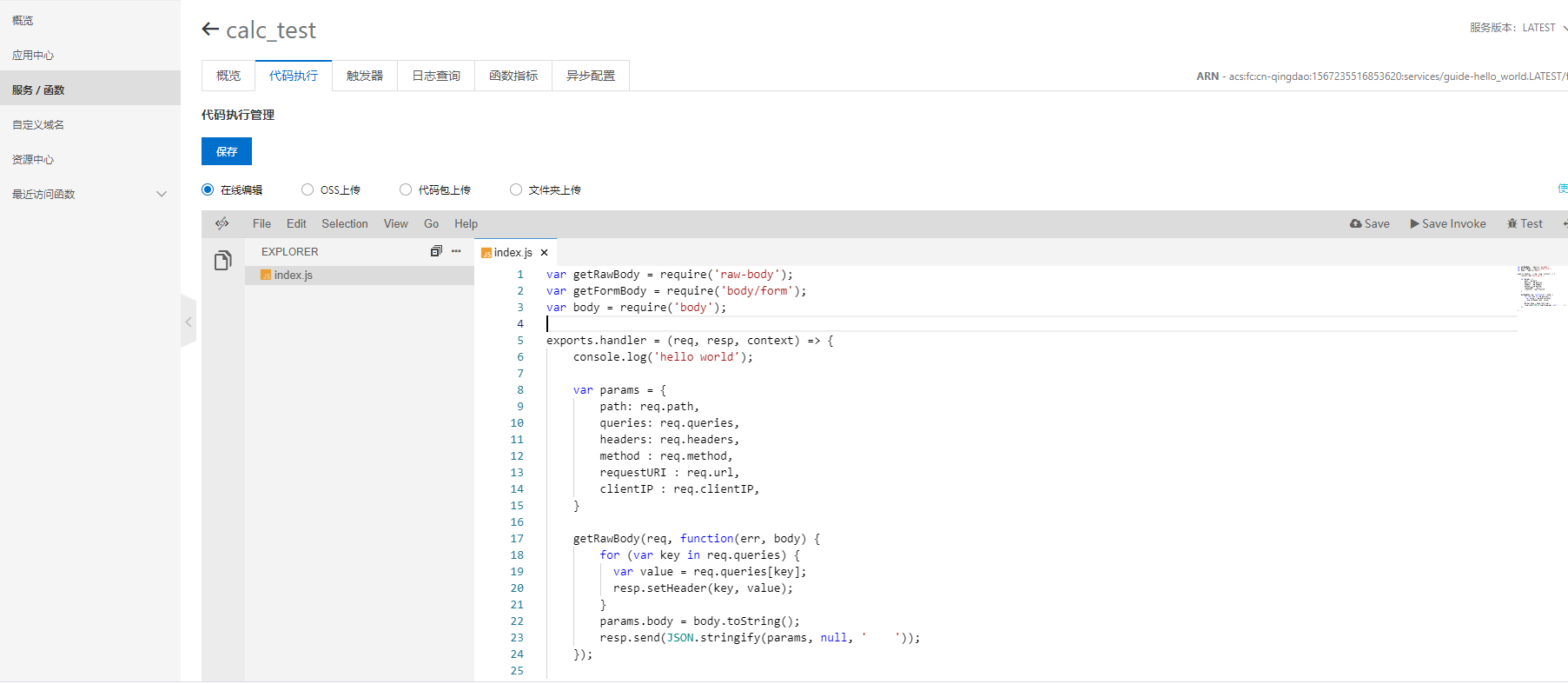
代码编辑
创建完成后, 默认会自动生成一段代码, 可以通过在线编辑器, 编写自己所需要的代码。
测试验证
通过触发器所提供的路径, 直接访问:
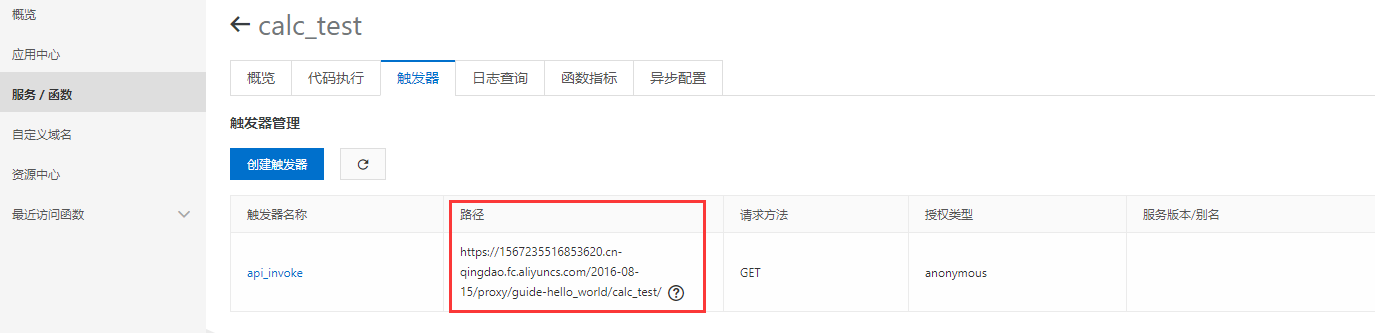
执行结果:
1 | [root@localhost ~]# curl https://1567235516853620.cn-qingdao.fc.aliyuncs.com/2016-08-15/proxy/guide-hello_world/calc_test/ |
 微信
微信 支付宝
支付宝

