【数据存储系列】手牵手学习UCloud
UCloud集群使用说明
1 UCloud云平台大规模服务器集群使用
学习目标:
掌握云平台的基础概念并了解UCloud云平台
学习如何使用UCloud云平台上的大规模服务器集群
1.1 前言
近几年,云平台发展异常迅速,越来越多的企业选择将业务部署在云之上,同时许多云原生服务的推出也更好的服务了企业的业务,在大数据场景中,亦是如此。不管是简单的使用云服务器,还是更深入的使用到云上Hadoop(EMR),或者结合对象存储构建存储分离的新时代架构,企业对云的依赖越来越强烈。
对于学生来说,能够掌握到云平台使用的相关技术,可以极大的提高学生在就业市场中的竞争力,对于薪资和就业的帮助是非常可观的。
同时,在学习大数据体系的过程中,有机会体验到大数据的“大”也是非常有帮助的。
目前,我们和UCloud云平台进行深入合作,在UCloud云平台上构建了大规模的服务器集群供学生使用,
学生可以去使用这些服务器集群去真正的见识到大规模服务器集群以及真正的接触到大规模的数据计算, 真正去体会大数据的”大”.
本课程即是对UCloud(后简称UC)平台中大数据集群的使用说明。
1.2 云平台介绍
1.2.1 前言
随着云计算概念的不断落地和推广, 目前云平台已经得到了非常广泛的使用.
云平台帮助用户在:
●应用落地
●服务落地
●安全保障
●性能
等方面获得比传统方式更高效, 更节省, 更稳定, 更方便的优势.
1.2.2 云平台概念
云平台也称云计算平台. 云计算, 顾名思义, 就是将计算在云上运行.
那么在这里面的3个概念
●云: 通俗的理解就是远程计算机, 并且是一组 一堆, 这些远程计算机协同工作构建出一个平台,对用户提供服务
●计算:这是一个概念很大的名词,小了说可以认为是对业务数据进行计算分析的算力,不过通俗意义上,计算是指构建业务系统的各种需求
●平台:将云(远程硬件资源)和计算(远程软件资源)组合在一起,就形成了一个平台,对用户提供各种各样的服务。
我们可以这样理解: 云平台 就是 一个云上的平台, 为用户提供各种各样的 远程服务
1.2.2.1 举个例子
现在有一个 人力外包中心, 其内部有非常多的人力资源可供客户购买使用.
那么有一个客户, 从人力资源外包公司, 花钱雇10个人干活, 发现效率不行又雇了100个一起干活, 最终活儿按时完成.
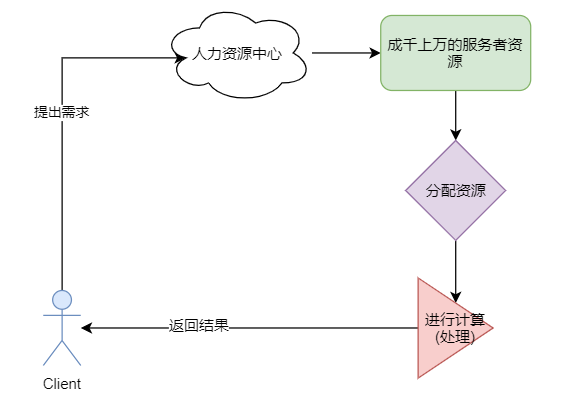
那么, 上述例子就是对云平台的一种模拟.
人力资源中心 提供的是服务, 提供的是资源, 客户只需要按量购买即可.
在例子中, 客户如果不使用人力资源中心 就需要自己招聘相应的员工, 签订劳务合同, 让自己的员工去为自己服务.
但是, 如果需求结束了, 员工又不能随意辞退, 那么这些员工就相当于资源闲置了.
而人力资源中心 就是提供了 资源 供客户使用, 按需求 按用量付费即可, 用完即停止. 对客户来说资源没有闲置.
PS: 现在很多软件人力外包, 就是这样的思路.
很多甲方公司, 不愿意招聘正式员工, 仅仅某个项目需求人手, 就从外包公司招人来做, 项目完成, 人员也就遣返回外包公司了. 甲方按人数和时间给外包公司付款.
1.2.2.2 回到计算机的世界中
云平台提供的就是 计算的资源.
那么计算的资源主要有:
●硬件资源: 主要指服务器 交换机 磁盘 GPU等硬件资源
●软件资源: 主要指 各种软件工具 如域名服务 虚拟内网 数据库软件 等.
云平台为客户提供了 一站式的解决方案.
客户可以没有任何一台服务器 同样可以搭建起来自己的业务.
业务 就运行在云平台之上.
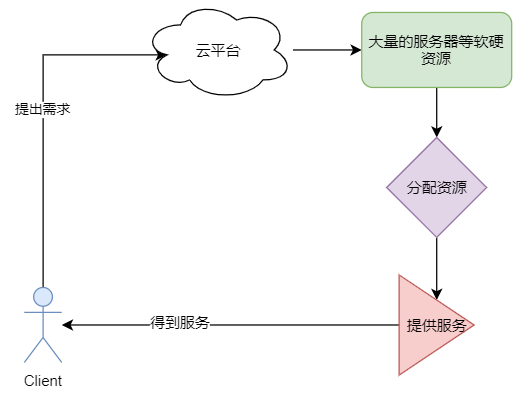
通俗的理解, 使用了云平台之后, 客户就不需要自行搭建机房了, 不需要自购服务器了.
服务器等硬件资源 从云平台购买使用即可.
并且因为云平台上的资源是很多的, 如果客户觉得资源不足, 可以追加购买. 如果觉得资源过多, 可以减少购买. 灵活方便.
毕竟, 自建机房成本很高, 并且服务器等硬件购买是一次性.
买回来发现用不到,造成资源的闲置 也是无可避免.
特别是某些业务突增的需求, 导致资源紧张, 临时加了N台服务器.
等到业务下降的时候, 这么多追加的服务器的资源就闲置了.
消费者还能在闲鱼让闲置游起来. 但是服务器领域…………就算也能各种二手倒腾, 在机房频繁的上架下架 也是很繁琐的. 特别是运维同学, 估计要打人……
所以,我们可以认为云平台就是一种资源的集市。 你可以从集市中去挑选你中意的资源,比如服务器资源、网络资源、存储资源等。
1.2.3 云平台的分类
云平台主要有 2大类, 分别是:
1.2.3.1 私有云平台
私有云平台, 简称私有云
顾名思义就是私人的云平台, 一般是企业自行搭建, 提供给企业内部去使用.
如, 各个业务部门 或者各个项目组作为客户, 从平台上购买资源,或者申请资源去使用,费用一般企业内部结算。
是一种提高企业内 资源利用率的手段,同时,基于云平台上提供的各种服务,也方便企业内部的开发。
但对于企业本身来说, 其硬件资源是自行组建的.(如 自建机房 自购服务器等)
1.2.3.2 公有云平台
公有云平台就是提供给大众使用的云平台.
任何人 或者任何企业 均可以在公有云平台内去 购买 申请 相应的资源.
对于公有云平台的提供商来说, 其本身的硬件资源是自行组建的(如自建机房, 自购服务器, 搭建数据中心
本次课程, 主要给大家讲解公有云平台.
1.2.4 主流公有云平台
1.2.4.1 国外公司
AWS: Amazon web service: 是亚马逊提供的一个公有云平台. 也是最早提供云平台服务的一批企业. 也是目前全球公有云的龙头标杆. 在全球市场占有率处于领先地位. 就如苹果带领手机的发展方向一样, AWS目前处于引领云平台发展方向的地位.
Azure: 微软提供的一个公有云平台. 市场占有率一般, 目前处于上升期.
GCP: Google cloud paltform: 谷歌提供的云平台, 占有率还行, 也是处于上升期.
1.2.4.2 国内公司
●阿里云: 阿里提供的云平台, 在国内市场很强势. 处于No.1地位, 在国际上占有率一般, 处于上升期.
●UCloud: UCloud云平台, 国内占有率还行, 第二梯队
●金山云、腾讯云: 金山软件公司提供的云平台,第二梯队
●京东云/时速云等等其它国内云平台…占有率低一些,第三梯队
1.2.5 云的三种服务
那么我们再来了解一下PaaS SaaS IaaS,先理解两个小案例
1.2.5.1 案例一:
前面我们简单了解到,简单的说我们可以认为云平台就是提供了云上的一堆资源,比如服务器(云上的虚拟机)的购买和使用。
对于企业开发来说,一个业务的实现在部署层面需要:
●服务器资源
●软件资源
比如要构建有一个MySQL服务,除了有服务器还需要有MySQL软件的部署。
如果仅从服务器层面来看,我们在云平台上购买云服务器,解决了服务器资源的需求。
但是MySQL还是需要我们自己部署。
那么,对于MySQL这部分我们前面提到,云提供的是计算的资源,这个资源除了硬件以外还包括软件。
那么,对于MySQL这种软件服务,其实云平台也是可以提供的。
比如,云平台可以帮你完成MySQL的部署、维护、安装、管理等一系列操作,我们只需要付费购买并使用即可。
比如:多数的云平台都提供RDS服务(关系型数据库服务),我们想要得到一个MySQL只需要在云平台上:
1挑选服务器性能(多少CPU和内存和网络等硬件能力)
2挑选软件版本等信息(如选择MySQL或者Oracle以及详细的版本等等)
3确认订单并付费购买
4购买成功后得到连接URL和账户密码等认证信息。即可连接使用
那么这一套下来,针对MySQL这种需求,硬件层面和软件层面云平台均可以帮我们解决,而我们只需要给钱,然后用就行了。
对企业来说节省了非常多的时间成本。
1.2.5.2 案例二:
一个公司的软件业务要上线,除了服务器和软件部署以外,一些其它的IT服务也要同步跟进,比如购买域名、购买HTTPS证书、做流量高防等。
我们已经由云平台解决了硬件和软件的大多数场景,那么最后的这个场景云平台是否也能帮我们解决呢?
答案是:可以的。
多数云平台都提供域名注册、HTTPS证书绑定、流量高防、服务器防火墙配置等一系列周边服务。
只需要填写信息、简单的点击几下即可在云平台上完成这些服务和已购买的软硬件服务的绑定,十分的方便快捷。
1.2.5.3 IaaS、PaaS、SaaS三种服务
通过上面的两个简单的案例我们可以发现,云平台从硬件到软件以及周边的一系列网络、安全等相关的服务均有提供。
一站式的帮我们解决了企业开发中的多数应用场景的需求。可谓是十分的方便。
云提供的服务如此之多,一般情况下我们对这些服务都会有一个大层面的分类,分为三大类:
●IaaS服务
●PaaS服务
●SaaS服务
IaaS
Infrastructure as a Service: 基础设施即服务, 是指把IT基础设施作为服务提供
●网络带宽
●VPC:virtual private cloud(大公有云内的小私有云,就是一个云上的私有内网)
●云上服务器(VPS:Virtual Private Server)
●弹性IP(Elastic IP、EIP)
PaaS
Platform as a Service : 平台即服务.是指将平台作为一种服务对外提供. 那么我们要学习的云平台, 就是一种PaaS服务. 其他还有如
●腾讯地图开发平台
●小程序开发平台
●云上关系型数据库(RDS)
●云上消息队列(Kafka等)
●云上Hadoop
●等
SaaS
Software as a Service: 软件即服务, 是指将软件作为一种服务对外提供.
●DNS服务
●流量高防服务
●域名托管服务
●和一切其它非云平台提供的,如:ProcessON、DrawIO、CSDN博客、邮箱服务、135编辑器、在线Office等
SaaS就是现成可用的软件(可认为是解决方案)提供给你,你只需要有网络(浏览器或其它客户端)去连接使用即可(可能付费)。
无需关心维护、管理等。
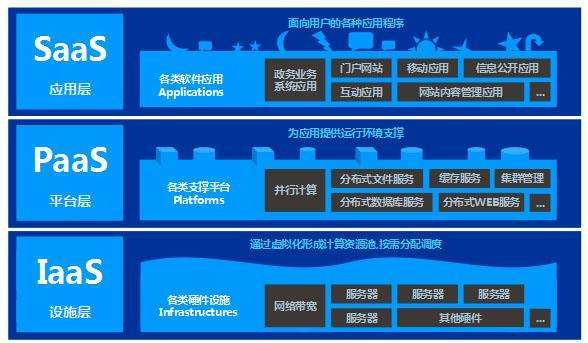
那么我们理解, 云平台本身是一个PaaS服务, 在其之上同时提供了PaaS、IaaS、SaaS三种服务
1.2.6 云平台小总结
我们可以简单认为,云平台就是:一些公司自建数据中心(机房),基于数据中心内的硬件将整体资源整合为资源池。
比如:CPU总多少个、内存总多少、带宽总多少等等。
然后,基于虚拟化技术对外售卖这些资源,如用户可以自定义购买一台服务器如2核8G等等
同时一些常见的IT相关的软件设施,这些公司也提供售卖,如云上MySQL数据库。
本质上就是由这个公司来创建好对应的MySQL服务,然后用户通过公网\云内网来连接使用。
一句话:别人电脑多,网速快,开了一堆虚拟机、划分了一堆公网带宽资源包,卖给你用(IaaS)。同时它还卖MySQL等软件(PaaS),它安装好,你用就行了,管理维护都是它的,你只负责给钱和用。同时,公司的域名、HTTPS证书、高防服务等一系列均可以在它这里购买,一站式解决方案(SaaS服务)。
这些购买、连接、管理你的资源等功能通过一个网页(云平台的网站)来供你使用(PaaS)
1.3 UCloud云平台简介
目前集群是部署在UCloud之上,所以目前我们来学习基本的UCloud概念
UCloud (优刻得科技股份有限公司)是中立、安全的云计算服务平台,坚持中立,不涉足客户业务领域。公司自主研发IaaS、PaaS、大数据流通平台、AI服务平台等一系列云计算产品,并深入了解互联网、传统企业在不同场景下的业务需求,提供公有云、混合云、私有云、专有云在内的综合性行业解决方案。
2020年1月,UCloud优刻得(股票简称:优刻得,股票代码:688158)正式登陆科创板,成为中国第一家公有云科创板上市公司,同时成为了中国A股市场首家“同股不同权” 的上市企业,开创了中国A股资本市场及公司治理的先河。
依托公司在莫斯科、圣保罗、拉各斯、雅加达等全球部署的31大高效节能绿色云计算中心,以及国内北、上、广、深、杭等11地线下服务站,UCloud在全球已有3万余家云服务消费用户,间接服务终端用户数量达到数亿人。
UCloud深耕用户需求,秉持产品快速定制、贴身应需服务的理念,推出适合行业特性的产品与服务,业务已覆盖互联网、政府、运营商、工业互联网、教育、医疗、零售、金融等在内的诸多行业。
UCloud核心团队来自腾讯、阿里、百度、盛大、华为、VMware、AWS等国内外知名互联网和IT企业,同时引进传统金融、医疗、零售、制造业等行业精英人才,目前员工总数超过1000人。
1.3.1 UCloud云平台提供的服务
UC是一个标准的公有云平台,提供了大多数云平台应有的服务




如上图可见,UC平台中提供了非常多种类的公有云服务,包括:
●计算服务
●网络服务
●私有网络服务
●数据库服务
●存储服务
●云分发服务
●视频服务
●边缘计算服务
●数据分析服务
●人工智能服务
●物联网服务
●安全防护服务
●安全合规服务
●企业应用服务
●云通信服务
●监控与运维服务
●多云与迁移服务
●混合云服务
●账户服务
●云市场服务
等多种类型的服务体系, 基本涵盖了企业开发的方方面面的需求。
1.3.2 大数据集群使用的服务
当前,在UCloud云平台上搭建大规模数据库的集群使用的是:计算服务中的云主机(UHost)
如图所示,我们所使用的服务器集群底层为大批的云服务器,搭载CentOS7.6 Linux操作系统。
云主机使用起来和传统的物理服务器没有任何的区别,只需要拿到公网IP输入账号密码即可SSH远程登录使用。
1.4 集群架构
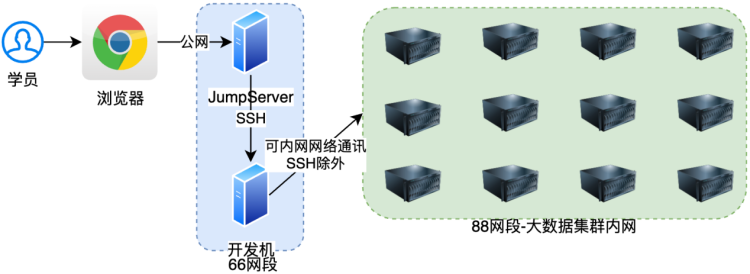
如图,集群采用了严格的权限认证管理
因为集群是公网环境,所以严格的权限认证管理是非常必要的。
学员可以通过浏览器登陆JumpServer堡垒机WEB服务,通过堡垒机登陆学员开发机
1.4.1 堡垒机
堡垒机从名字可以得知,是一个类似堡垒一样的机器。
所有的SSH登陆请求都必须从堡垒机通过。
我们想要登陆服务器,就必须通过堡垒机服务,这样极大的增强了服务器的公网安全性。
同时,堡垒机技术在企业中也是大范围使用。通过使用堡垒机服务,学员也可以体会到真实企业中的服务器管理流程,增加经验和见识。
本次集群搭建的堡垒机服务为:JumpServer,一款开源的高性能堡垒机软件。
1.4.2 开发机
开发机是学员和老师唯一能够登陆的机器
开发机是高配服务器,提供多核CPU和高内存(可以动态调整增加配置)以及大容量硬盘。
学生在登陆开发机后会拥有个人账户,可以存放学员的个人数据和程序等。
可以在开发机远程连接到大数据集群,去操作大数据集群,如:提交任务、上传下载数据、管理任务等操作。
开发机无法通过SSH登陆到大数据集群之上。
PS:当前架构和大多数企业的网络拓扑架构是相同的,学员可以学习到真实企业的开发模式增加经验和见识。
1.4.3 安全性
堡垒机和开发机均处于66网段,而大数据集群服务器均处于88网段。
两者之间网段是隔离的,无法互相SSH通讯,这样增强了安全性。
1.4.4 集群规模
试运行阶段:
●20台 4核16G 计算节点(DataNode、NodeManager)
●2台4核16GMaster节点(NameNode、ResourceManager)
●3台4核16G消息中心节点(Kafka、Pulsar、Zookeeper)
●1台4核16G(可拓展8核64G)开发机(学生登录使用)
●3台NoSQL集群(HBase\Presto\Impala\ES等)
●1台项目适配机器(适配项目上线使用)
●1台多用途机器(如JavaWEB程序\Maven仓库等)
一期正式上线:
●30台 4核16G 计算节点(DataNode、NodeManager)
●2台4核16GMaster节点(NameNode、ResourceManager)
●3台4核16G消息中心节点(Kafka、Pulsar、Zookeeper、HBase)
●1台4核16G(可拓展8核64G)开发机(学生登录使用)
●2台4核16G数据库服务机器(MySQL、Redis、HiveServer、Oracle等)
●5台4核16G NoSQL集群(HBase、Presto、Impala、ES等)
●3台项目适配机器(适配各个项目中的服务)
●3台多用途机器(如JavaWEB程序\Maven仓库等)
提供CPU核心: 200+
提供内存量: 1TB+
提供磁盘量: 1PB+
1.5 服务器登陆说明
老师和学生均只允许登陆开发机,文档也是指导如何去登陆开发机。
1.5.1 登陆堡垒机服务器
登陆地址: https://bdjump.itheima.net

打开后输入账号密码,即可登录堡垒机服务
用户名请联系班主任,默认密码是:bigdata
首次登陆需要修改密码:



重设密码后,再次输入账号密码即可登陆。
1.5.2 绑定Google Authenticator
堡垒机强制启用了MFA认证要求
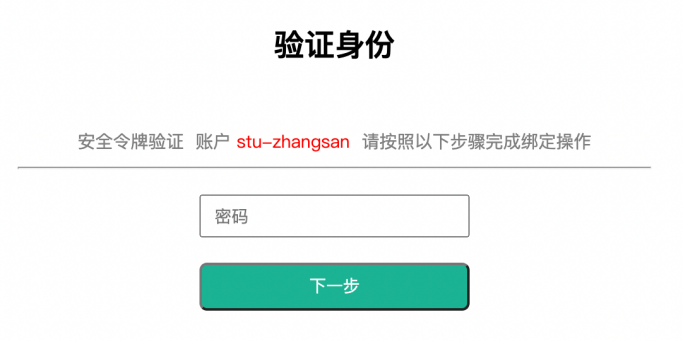
先再次输入一下账号的密码。

扫码下载Google MFA验证器应用。
下载安装后点击下一步,用APP扫码页面提示的二维码:

扫描页面提供的二维码:
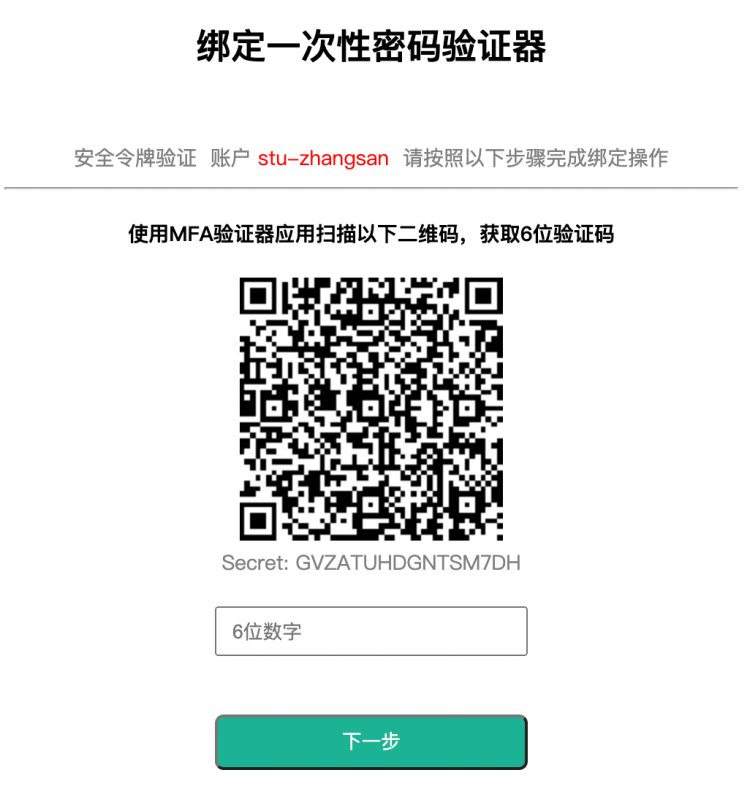
扫码后,请在输入框内输入手机提示的6位数字密码即可。

然后再次输入密码登陆,登陆后,请输入手机MFA认证器内提供的6位数字即可完成登陆。

然后补全信息,勾选我同意后提交即可。
1.5.3 通过WEB页面登陆服务器
上述内容完成后,即可看到如下页面:
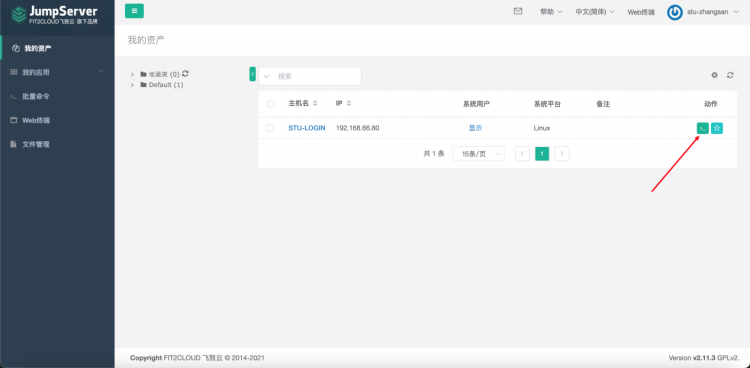
点击箭头所示按钮,即可登录服务器
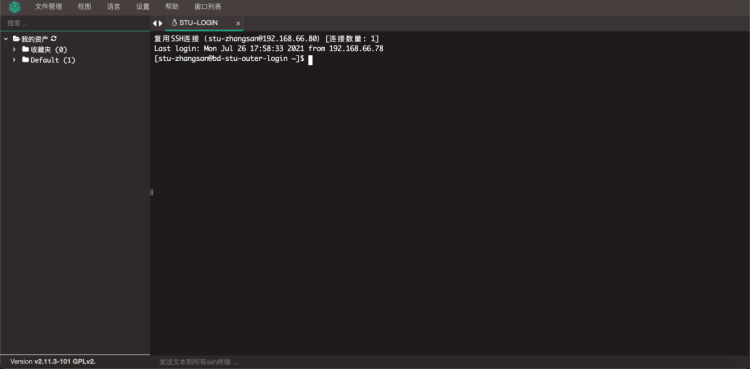
Shell页面是网页界面
系统用户和JumpServer登陆是同名用户.
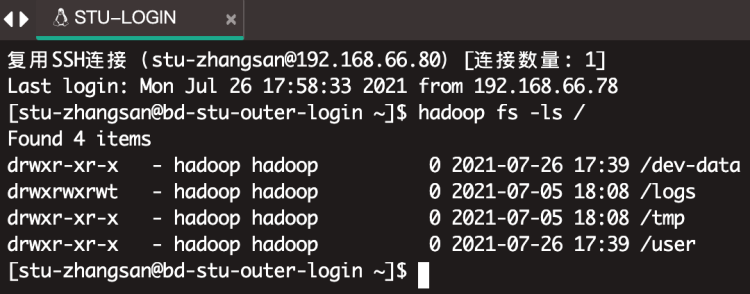
如图,测试使用Hadoop相关命令成功。
1.5.4 通过SSH命令登陆服务器
可以在命令行输入:
ssh -p 2202 用户名@bdjump.itheima.net

输入: yes
然后输入密码

打开MFA程序,输入6位认证数字:

即可登录成功

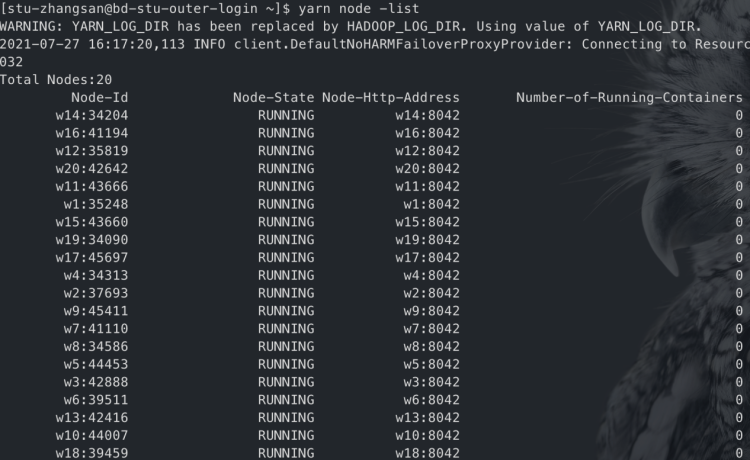
输入p查看有权限登陆的服务器:

输入ID即可登录,如输入1

登陆成功
PS: 在通过SSH命令登陆前,请先登陆堡垒机WEB网页,设置初始密码和验证MFA
1.5.4.1 将SSH登陆配置到终端模拟器中
SSH登陆每次手动敲很麻烦,可以配置到终端模拟器中,以:SecureCRT为例
添加一个新会话:
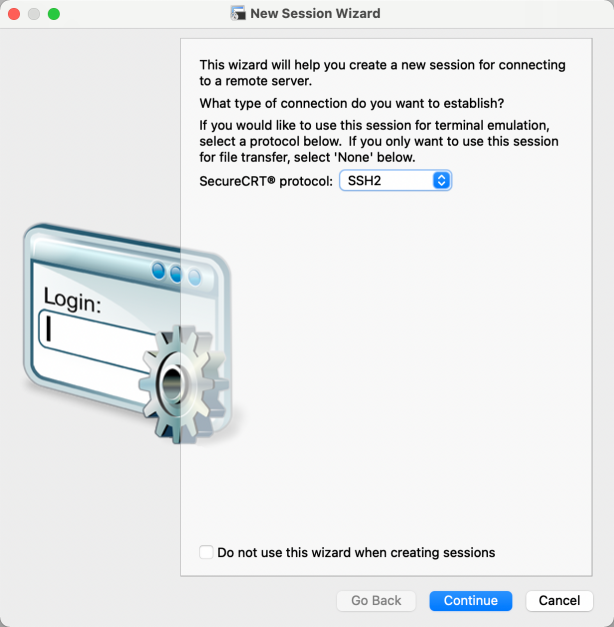
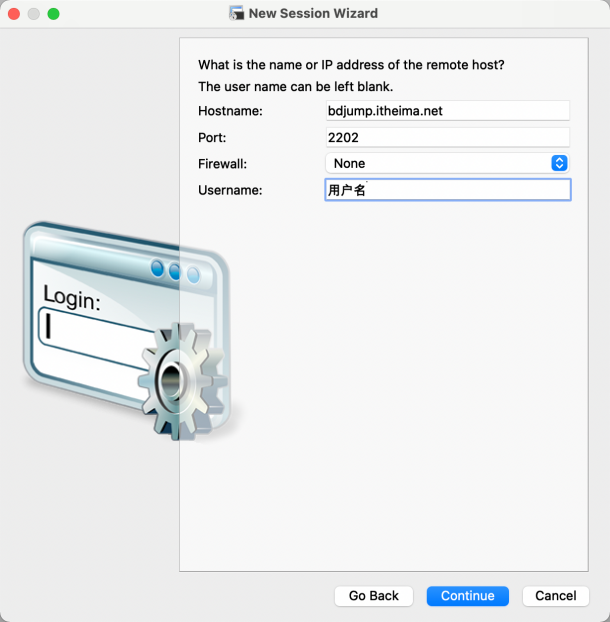
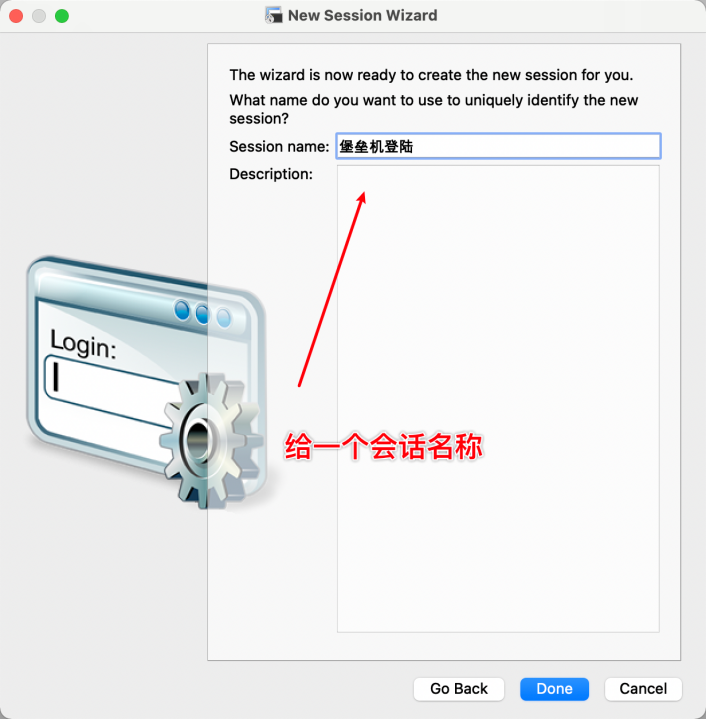
配置好后,双击会话登陆:
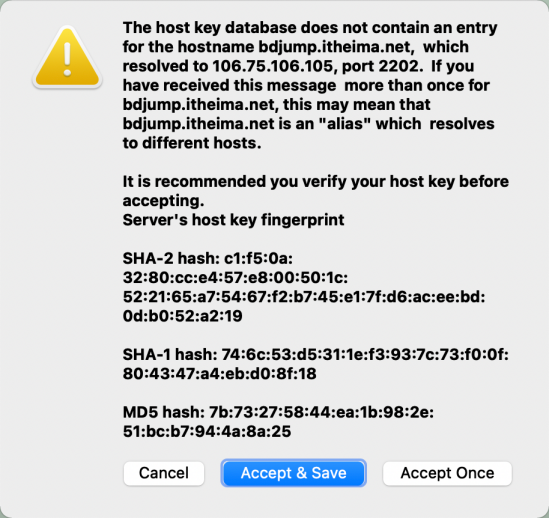
点击Accept & Save
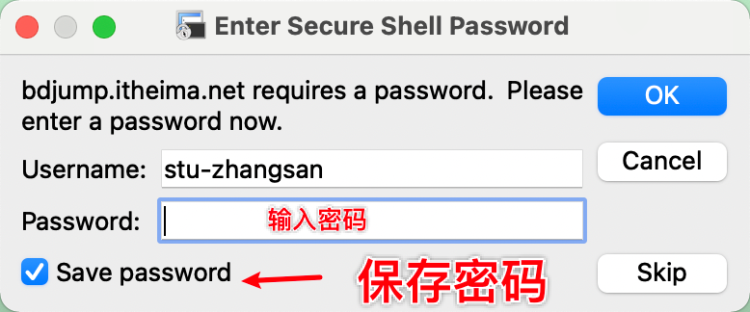
输入密码后,点击保存密码后,点击OK即可登录成功。
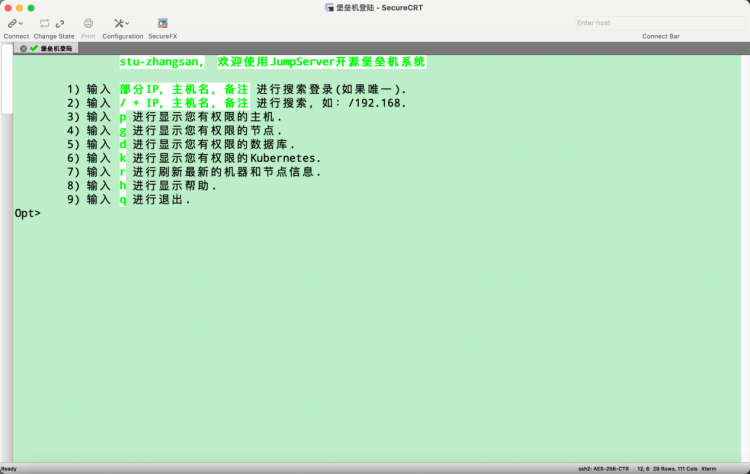
1.6 集群使用
开发机我们已经可以成功登陆了。
下面来看一下如何在开发机内操作大数据集群
下面操作以学员账户:stu-zhangsan为例
1.6.1 HDFS文件系统
学员可以在开发机执行hadoop命令来操作HDFS文件系统。
如列出文件:
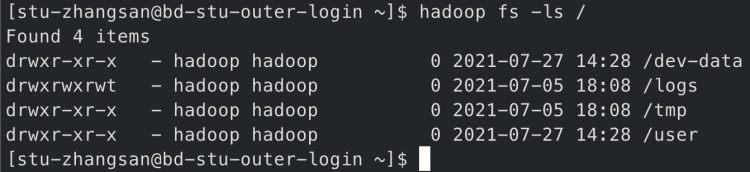
学员只有一个目录有完全的读写权限,即:/dev-data/账户名

如图,文件夹权限是700,所属者是学员账户
学员可以在这个HDFS的目录内进行开发。
常用的命令:ls cp mv 等都可以使用。
注意:请勿操作其它目录,其它目录可以读,但是不允许更改一切内容。
1.6.2 YARN提交任务
学生也可以在开发机提交YARN任务到大数据集群
在开发机上学员可以执行非管理性质的YARN命令,如提交任务,查看任务,查看机器列表等:
下面以提交MR WordCount程序为例:
hadoop jar /export/server/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount -Dmapred.job.queue.name=stu /dev-data/stu-zhangsan/words.txt /dev-data/stu-zhangsan/output
注意:必须指定队列名称:stu 否则报错
submitted by user 用户名 to unknown queue: default
指定队列名称使用-Dmapred.job.queue.name=stu
语法:
hadoop jar jar路径 类名 -Dmapred.job.queue.name=stu 参数
或者
yarn jar jar路径 类名 -Dmapred.job.queue.name=stu 参数
1.6.3 提交Spark任务
/export/server/spark-3.1.2-bin-hadoop3.2/bin/spark-submit –class org.apache.spark.examples.SparkPi –master yarn –deploy-mode client –queue stu /export/server/spark-3.1.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.1.2.jar 10
注意,请勿忘记: –queue stu 指定队列为stu
1.6.5 HBase使用(部署中)
连接:
master在:nosql0
regionserver在: nosql1 nosql2 nosql3 三台服务器
每个人会有自己的一个和账户同名的NameSpace(数据库)
在开发机上,可以直接使用hbase shell直接操作hbase
1.6.6 集群服务列表
试运行阶段:
| 主机名 | 服务 | 备注 |
|---|---|---|
| m1 | NameNode | NameNode独占 |
| m2 | ResourceManager\SecondaryNamenode\HistoryServer\WebProxyServer | YARN Master和SecondaryNamenode |
| w1\w2\w3.…..\w20 | DataNode \ NodeManager | Worker节点 一期20台 |
| kz1 \ kz2 \ kz3 | Kafka \ Pulsar \ Zookeeper | 消息队列和Zookeeper |
| nosql-m1\nosql-w1\nosql-w2\nosql-w3 | HBase\Presto\Impala\ES等NoSQL | M1是主节点 W*是从节点 |
一期正式上线后新增:
| 主机名 | 服务 | 备注 |
|---|---|---|
| w21\w22\w23.…..\w30 | DataNode \ NodeManager | 拓展10台Worker |
| db1\db2 | MySQL\Oracle\Redis\HiveServer等 | 拓展2台数据库服务机器 |
| nosql1\nosql2\nosql3\nosql4\nosql5 | HBase\Presto\Impala\ES等NoSQL | 拓展5台NoSQL服务器 |
| p1\p2\p3 | 项目适配专用 | 拓展3台为项目适配用途机器 |
| o1\o2\o3 | 其它用途:如数据模拟器\JavaWEB服务等 | 拓展三台其它服务用机器 |
1.7 注意
1公共环境请注意公共秩序,请勿在开发机上运行私人程序,如有必要运行,请勿占用过多CPU资源
2请爱护环境,不要对集群进行管理操作如下架机器、删除机器、停止进程等
3请尊重他人隐私,不要尝试登陆到别人的账户上
4不可以在服务器内部上传:政治、色情、等敏感和国家明令禁止的内容,一经发现将严肃处理,如触犯法律将移交公安机关。
5不可在服务器内运行爬虫等相关程序(多数爬虫违法),一旦发现移交公安机关。
6不要在服务器内对外界发起网络攻击,一旦发现移交公安机关
7不可在服务器运行挖矿程序,一旦发现严肃处理。如有违法移交公安机关。
8以及不可以做其它危害国家安全、危害社会秩序、危害传智公司利益等相关操作,一旦发现严肃处理,如有违法移交公安机关
最终解释权由传智教育所有。
UCloud云平台大数据集群登录使用
基础IP
1 | 106.75.100.116 m1 |
如上可以写入到你们Windows电脑的hosts文件中
学生可以登录的是:stulogin机器
集群信息
大家登陆的机器是:stulogin,大家只允许登陆这一台服务器。
m1和m2是 2台master机器,运行NameNode、ResourceManager等
不允许大家SSH登录
但是可以通过网页打开如:m1:9870查看HDFS信息、m2:8088查看ResourceManager信息
可以WEB打开的网页汇总
| 地址 | 类型 | 备注 |
|---|---|---|
| http://m1:9870/dfshealth.html#tab-overview | HDFS web页面 | |
| http://m2:8088/cluster | YARN web页面 | |
| http://m2:19888/jobhistory | YARN 历史服务器 | |
| http://stulogin:18080 | Spark 历史服务器 |
登录信息
用户名:班级名-姓名拼音,如:kydsj7-wangjunkai
登录秘钥:参见附件
端口:22
IP:106.75.5.208
1 | xshell连接上去 |
HDFS使用
登录后,会进入集群对应的用户名的HOME目录内
每个人在HDFS上都有一个专属目录
路径是:/dev-data/用户名
比如我的用户名是:hz6-caoyu
我的个人HDFS路径就是:/dev-data/hz6-caoyu

NameNode监控页面
可以直接在浏览器通过:http://m1:9870直接打开即可
YARN监控页面
可以直接在浏览器通过:http://m2:8088直接打开即可
YARN提交任务
学生也可以在开发机提交YARN任务到大数据集群
在开发机上学员可以执行非管理性质的YARN命令,如提交任务,查看任务,查看机器列表等:
下面以提交MR WordCount程序为例:
1 | hadoop jar /export/server/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount -Dmapred.job.queue.name=stu /dev-data/stu-zhangsan/words.txt /dev-data/stu-zhangsan/output |
注意:必须指定队列名称:stu 否则报错
submitted by user 用户名 to unknown queue: default
指定队列名称使用**-Dmapred.job.queue.name=stu**
语法:
1 | hadoop jar jar路径 类名 -Dmapred.job.queue.name=stu 参数 |
或者
1 | yarn jar jar路径 类名 -Dmapred.job.queue.name=stu 参数 |
提交Spark任务
1 | /export/server/spark/bin/spark-submit --master yarn --deploy-mode client --queue stu /export/server/spark/examples/src/main/python/pi.py 10 |
- 正常使用spark-submit提交任务即可,python、java、scala均可提交
注意,请勿忘记: –queue stu 指定队列为stu
必须指定stu队列,否则无法执行任务
Spark历史服务器
Spark历史服务器地址:
1 | http://stulogin:18080 |
Hive
可以使用DataGrip、DBeaber等软件,连接Hive的HiveServer2进行使用。
地址: stulogin:10000
账户名: 你的云平台登陆用户名
密码:bigdata
可用数据库
每个人在Hive下拥有6个个人专属数据库(别人无权操作)
假设你的用户名是:hz6_caoyu,那么你会拥有:
- hz6_caoyu
- hz6_caoyu_1
- hz6_caoyu_2
- hz6_caoyu_3
- hz6_caoyu_4
- hz6_caoyu_5
共计6个个人数据库,拥有全部权限。
1 | kydsj-chnezhijie |
请勿操作其他人的数据库
注意
- 公共环境请注意公共秩序,请勿在开发机上运行私人程序,如有必要运行,请勿占用过多CPU资源
- 请爱护环境,不要对集群进行管理操作如下架机器、删除机器、停止进程等
- 请尊重他人隐私,不要尝试登陆到别人的账户上
- 不可以在服务器内部上传:政治、色情、等敏感和国家明令禁止的内容,一经发现将严肃处理,如触犯法律将移交公安机关。
- 不可在服务器内运行爬虫等相关程序(多数爬虫违法),一旦发现移交公安机关。
- 不要在服务器内对外界发起网络攻击,一旦发现移交公安机关
- 不可在服务器运行挖矿程序,一旦发现严肃处理。如有违法移交公安机关。
- 以及不可以做其它危害国家安全、危害社会秩序、危害传智公司利益等相关操作,一旦发现严肃处理,如有违法移交公安机关
最终解释权由传智教育所有。
 微信
微信 支付宝
支付宝

