1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
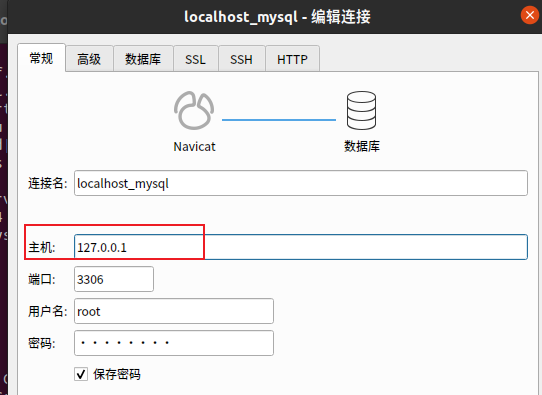
| 登录数据库:mysql -uroot -p
# 登录成功后:
显示当前时间:select now();
登出(退出)数据库:quit 或 exit 或 ctrl + d
# 数据库操作
1. 查看所有数据库:show databases;
2. 创建数据库:create database 数据库名 charset=utf8;
3. 使用数据库:use 数据库名;
4. 查看当前使用的数据库:select database();
5. 删除数据库-慎重:drop database 数据库名;
6. 查看MySQL数据库支持的表的存储引擎:show engines;
7. 修改表的存储引擎使用: alter table 表名 engine = 引擎类型(InnoDB/MyISAM);
比如: alter table students engine = 'MyISAM';
# 表结构操作
1. 查看当前数据库中所有表
show tables;
\G 可以竖着看信息
2. 创建表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) not null,
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','人妖','保密')
);
说明:
create table 表名(
字段名称 数据类型 可选的约束条件,
column1 datatype contrai,
...
);
3. 修改表-添加字段
alter table 表名 add 列名 类型 约束;
例:
alter table students add birthday datetime;
4. 修改表-修改字段类型
alter table 表名 modify 列名 类型 约束;
例:
alter table students modify birthday date not null;
说明:
* modify: 只能修改字段类型或者约束,不能修改字段名
5. 修改表-修改字段名和字段类型
alter table 表名 change 原名 新名 类型及约束;
例:
alter table students change birthday birth datetime not null;
说明:
* change: 既能对字段重命名又能修改字段类型还能修改约束
alter table goods change cate_name cate_id int not null, change brand_name brand_id int not null;
6. 修改表-删除字段
alter table 表名 drop 列名;
例:
alter table students drop birthday;
7. 查看创表SQL语句
show create table 表名;
例:
show create table students;
8. 查看创库SQL语句
show create database 数据库名;
例:
show create database mytest;
desc goods;
9.删除表
drop table 表名;
例:
drop table students;
# 表数据操作
0. 执行sql文件给areas表导入数据:
source areas.sql;
1. 查询数据
例:select * from students;
例:select id,name from students;
2. 添加数据
insert into 表名 values (...)
例:insert into students values(0, 'xx', default, default, '男');
insert into 表名 (列1,...) values(值1,...)
例:insert into students(name, age) values('王二小', 15);
insert into 表名 values(...),(...)...;
例:insert into students values(0, '张飞', 55, 1.75, '男'),
(0, '关羽', 58, 1.85, '男');
insert into 表名(列1,...) values(值1,...),(值1,...)...;
例:insert into students(name, height) values('刘备', 1.75),
('曹操', 1.6);
说明:
* 主键列是自动增长,但是在全列插入时需要占位,通常使用空值(0或者null或者default)
* 在全列插入时,如果字段列有默认值可以使用 default 来占位,插入后的数据就是之前设置的默认值
3. 修改数据
update 表名 set 列1=值1,列2=值2... where 条件
例:update students set age = 18, gender = '女' where id = 6;
4. 删除数据
delete from 表名 where 条件
例:delete from students where id=5;
问题:
上面的操作称之为物理删除,一旦删除就不容易恢复,我们可以使用逻辑删除的方式来解决这个问题。
alter table students add isdelete bit default 0;
update students set isdelete = 1 where id = 8;
说明:
* 逻辑删除,本质就是修改操作
# 插入查询结果
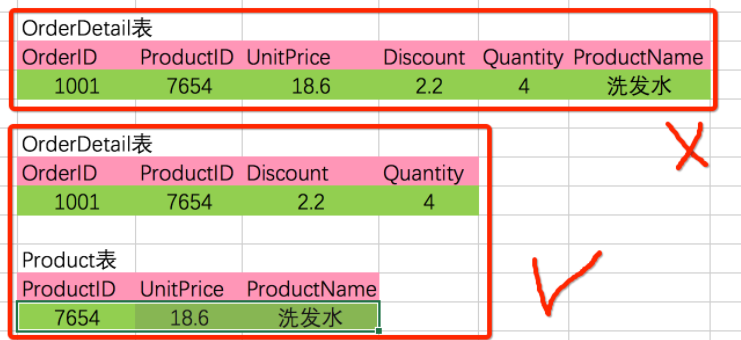
insert into .. select .. 表示: 把查询结果插入到指定表中,也就是表复制。
create table .. select 列名 .. 表示创建表并插入数据
# 关联表更新
连接更新表中数据使用: update .. join .. 语句
select * from goods inner join good_cates on goods.cate_name = good_cates.name;
update goods g inner join good_cates gc on g.cate_name=gc.name set g.cate_name=gc.id;
# 一些关键字用法
* as 关键字可以给表中字段 或者 表名起别名
* distinct 关键字可以去除重复数据行。
* 常见的比较运算符有 >,<,>=,<=,!=
* 逻辑运算符and表示多个条件同时成立则为真,or表示多个条件有一个成立则为真,not表示对条件取反
* like和%结合使用表示任意多个任意字符,like和_结合使用表示一个任意字符
* between-and限制连续性范围 in限制非连续性范围
* 判断为空使用: is null
* 判断非空使用: is not null
* 排序使用 order by 关键字
* asc 表示升序
* desc 表示降序
* 使用 limit 关键字可以限制数据显示数量,通过 limit 关键可以完成分页查询
* limit 关键字后面的第一个参数是开始行索引(默认是0,不写就是0),第二个参数是查询条数
# 聚合函数
默认忽略字段为null的记录 要想列值为null的记录也参与计算,必须使用ifnull函数对null值做替换。
* count(col): 表示求指定列的总行数
* max(col): 表示求指定列的最大值
* min(col): 表示求指定列的最小值
* sum(col): 表示求指定列的和
* avg(col): 表示求指定列的平均值
# 分组
GROUP BY 列名 [HAVING 条件表达式] [WITH ROLLUP]
说明:
* 列名: 是指按照指定字段的值进行分组。
* HAVING 条件表达式: 用来过滤分组后的数据。
* WITH ROLLUP:在所有记录的最后加上一条记录,显示select查询时聚合函数的统计和计算结果
group by + group_concat()
统计每个分组指定字段的信息集合,每个信息之间使用逗号进行分割
group by + with rollup
select gender,count(*) from students group by gender with rollup;
select gender,group_concat(age) from students group by gender with rollup;
内连接:inner join .. on .., on
左连接:left join .. on .., on
以左表为主根据条件查询右表数据,右表数据不存在使用null值填充。
右连接:right join .. on .., on
以右表为主根据条件查询左表数据,左表数据不存在使用null值填充。
自连接:
一张表模拟成左右两张表,接的表还是本身这张表,必须对表起别名
# 子查询
例1. 查询大于平均年龄的学生:
select * from students where age > (select avg(age) from students);
例2. 查询学生在班的所有班级名字:
select name from classes where id in (select cls_id from students where cls_id is not null);
例3. 查找年龄最大,身高最高的学生:
select * from students where (age, height) = (select max(age), max(height) from students);
|













 微信
微信 支付宝
支付宝
