【微服务从入门到入土】Zookeeper基础知识
通过之前手写RPC可以知道,注册中心选型是什么对RPC是可拔插的。
通过阅读zookeeper源码,更加深入的明白服务端应用程序,网络编程中的IO模型,线程模型,在zookeeper中的缩影和体现。
前置知识
zookeeper的网络通信架构
NIO
- zookeeper的网络通信默认基于java nio,也可以基于netty
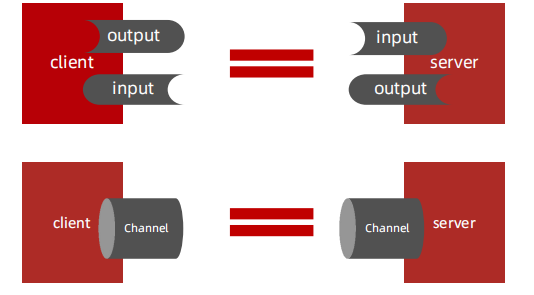
- NIO的三大核心组件:Buffer(缓冲区)、Channel(通道)、Selector(选择器/多路复用器)
Buffer(缓冲区):Buffer是一个对象,包含一些要写入或者读出的数据,体现了与原I/O的一个重要区别,在面向流的I/O中,数据读写是直接进入到Steam中,而在NIO中,所有数据都是用缓冲区处理的,读数据直接从缓冲区读,写数据直接写入到缓冲区。缓冲区的本质是一个数组,通常是一个字节数组(ByteBuffer),也可以使用其他类型,但缓冲区又不仅仅是一个数组,它还提供了对数据结构化访问以及维护读写位置等操作。

JAVA NIO模型
Channel(通道):Channel 是一个通道,管道,网络数据通过Channel读取和写入,Channel和流Stream的不同之处在于Channel是双向的,流只在一个方向上移动InputStream/OutputStream),而Channel可以用于读写同时进行,即Channel是全双工的。
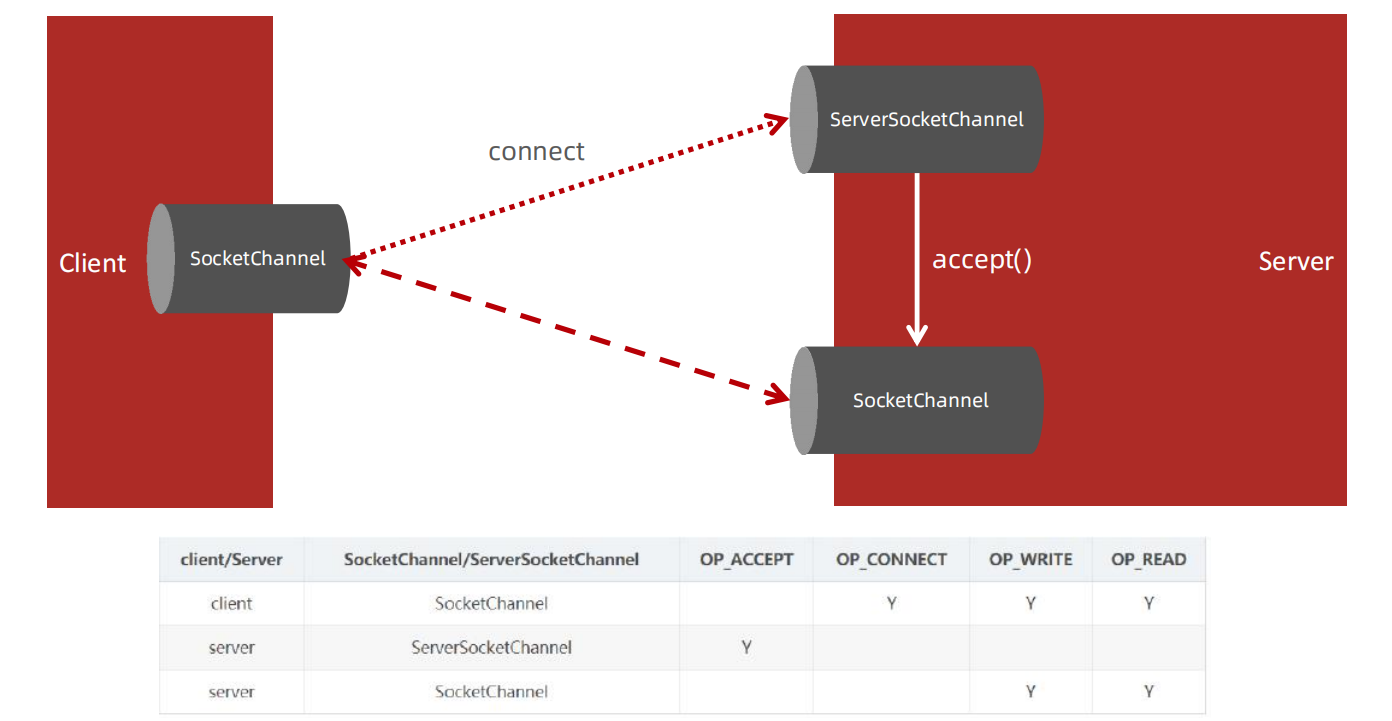
ServerSocketChannel和SocketChannel
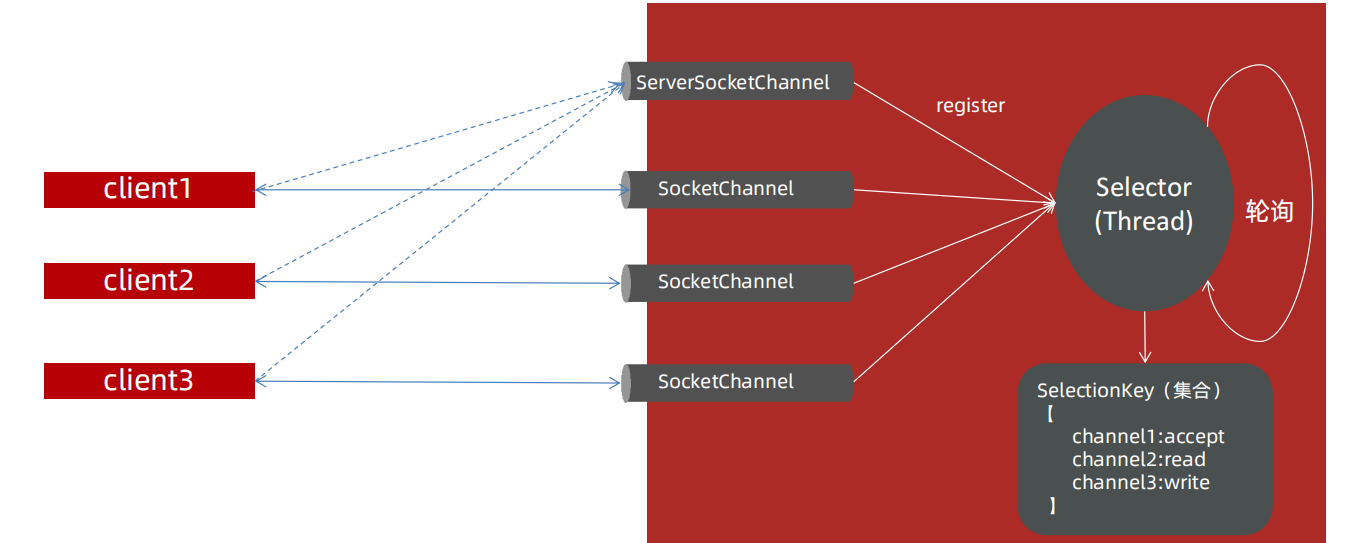
Selector
Selector(选择器/多路复用器):Selector会不断轮询注册在其上的Channel,如果某个Channel上面发生读或者写事件,即该Channel处于就绪状态,它就会被Selector轮询出来,然后通过selectedKeys可以获取就绪Channel的集合,进行后续的I/O操作。
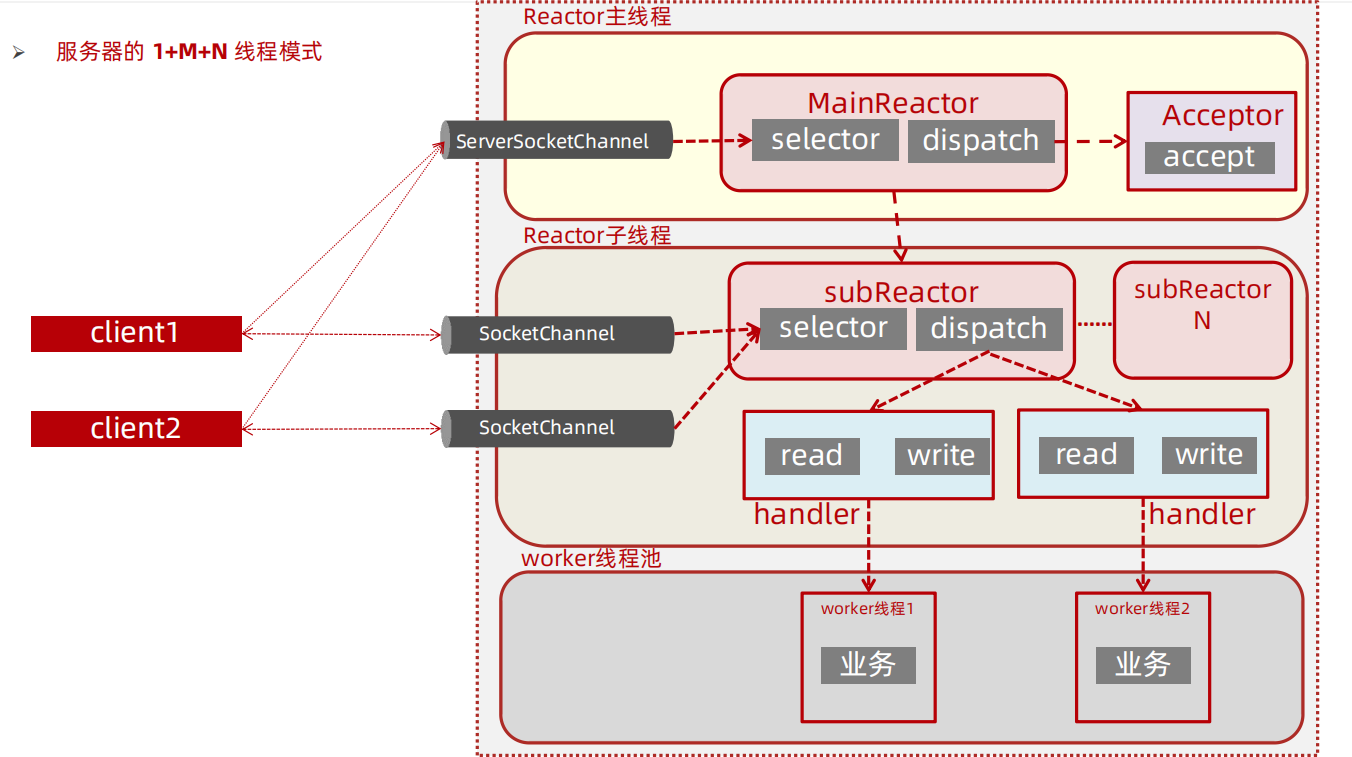
高性能服务器线程模型-主从Reactor多线程
分布式系统是什么
集中式系统
集中式系统,集中式系统中整个项目就是一个独立的应用,整个应用也就是整个项目,所有的东西都在一个应用里面。部署到一个服务器上。
布署项目时,放到一个tomcat里的。也称为单体架构
分布式系统
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据
随着公司的发展,应用的客户变多,功能也日益完善,加了很多的功能,整个项目在一个tomcat上跑,tomcat说它也很累,能不能少跑点代码,这时候 就产生了。我们可以把大项目按功能划分为很多的模块,比如说单独一个系统处理订单,一个处理用户登录,一个处理后台等等,然后每一个模块都单独在一个tomcat中跑,合起来就是一个完整的大项目,这样每一个tomcat都非常轻松。
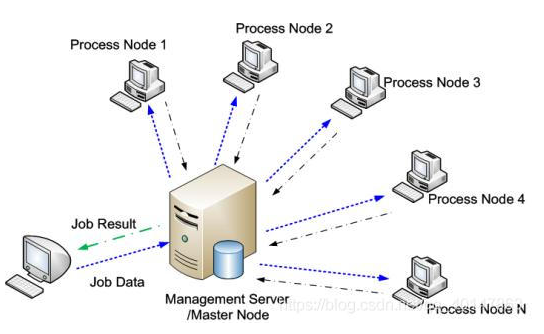
分布式系统的描述总结是:
- 多台计算机构成
- 计算机之间通过网络进行通信
- 彼此进行交互
- 共同目标 有共同的功能
zookeeper概述
zookeeper是什么
ZooKeeper从字面意思理解,【Zoo - 动物园,Keeper - 管理员】动物园中有很多种动物,这里的动物就可以比作分布式环境下多种多样的服务,而ZooKeeper做的就是管理这些服务。
Apache ZooKeeper的系统为分布式协调是构建分布式应用的高性能服务。ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。主要用来解决分布式集群中应用系统的一致性问题和数据管理问题。
ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
ZooKeeper 适用于存储和协同相关的关键数据,不适合用于大数据量存储。是一个分布式的小文件管理系统,管理分布式服务(Web Service)
ZooKeeper 的架构通过冗余服务实现高可用性(CP)。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能

在大数据中:zookeeper是大数据生态圈框架中非常重要的一员,单独使用没有意义,主要用过来管理其他框架,比如kafka依赖他。
zookeeper发展历史
ZooKeeper 最早起源于雅虎研究院的一个研究小组。当时研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个系统来进行分布式协同,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就开发了一个通用的无单点问题的分布式协调框架,这就是ZooKeeper。ZooKeeper之后在开源界被大量使用,很多著名开源项目都在使用zookeeper,例如:
- Hadoop:使用ZooKeeper 做Namenode 的高可用。
- HBase:保证集群中只有一个master,保存hbase:meta表的位置,保存集群中的RegionServer列表。
- Kafka:集群成员管理,controller 节点选举。
ZooKeeper相关特性
1.全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征;
2.可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
3.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
4.数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;
5.实时性:Zookeeper保证客户端将在一个时间间隔范围内(很短的时间间隔)获得服务器的更新信息,或者服务器失效的信息。
zookeeper应用场景
注册中心
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构。通过调用Zookeeper提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表。
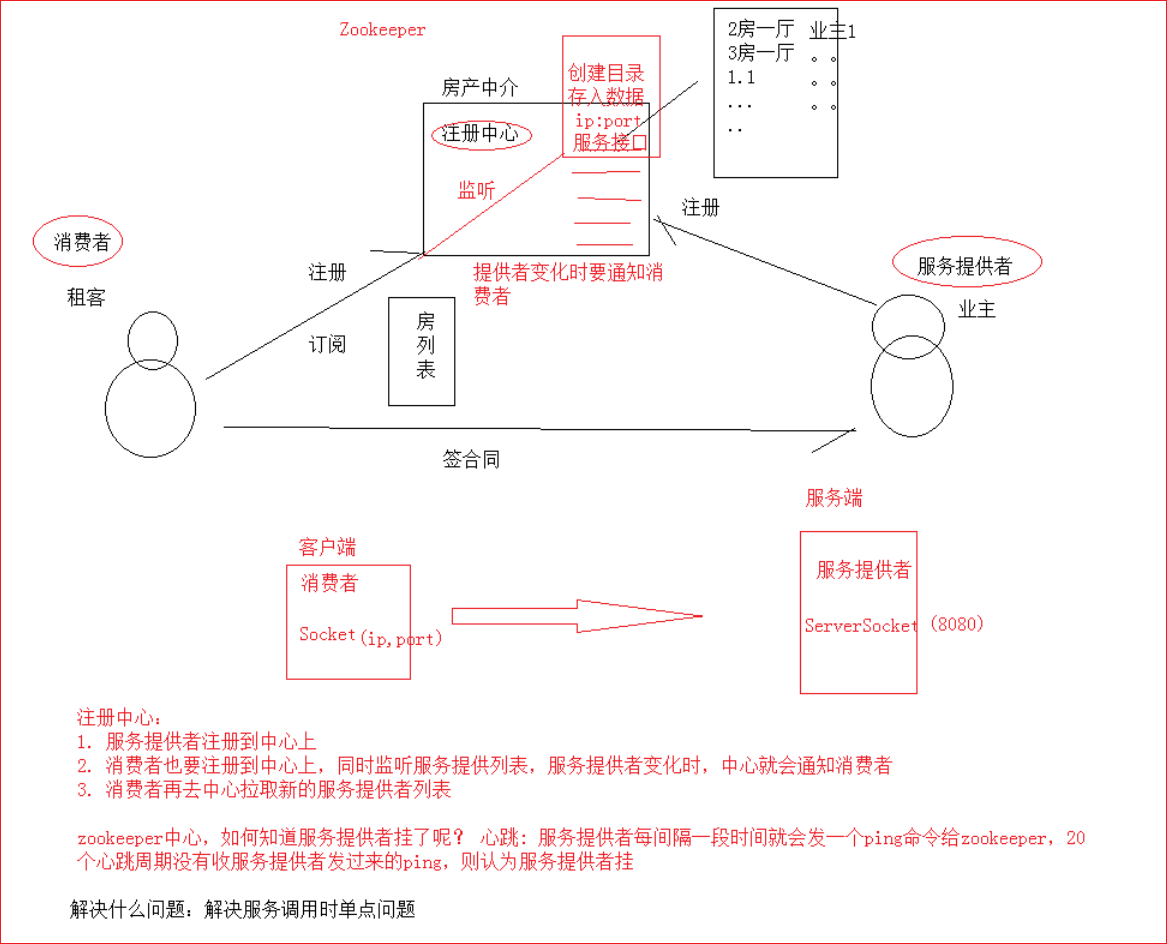
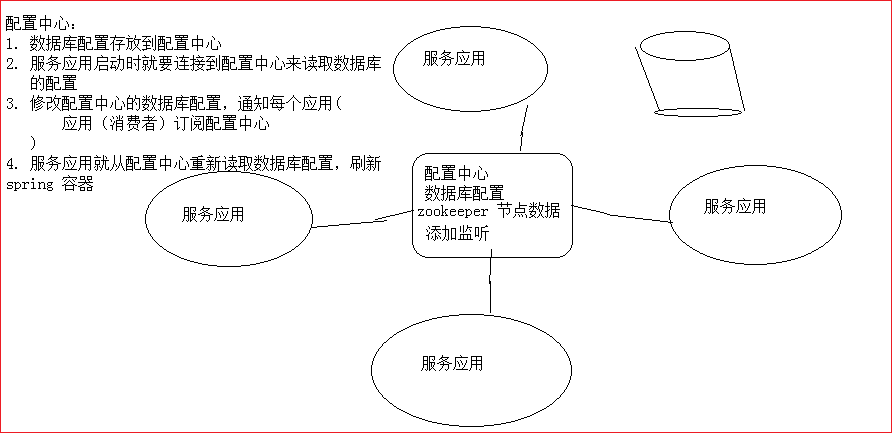
配置中心
Zookeeper本身可以看做是一个数据库,可以存储数据,但是一般是用来协调其他框架的,让其他框架可以高可用工作。所以通常存储的是配置信息
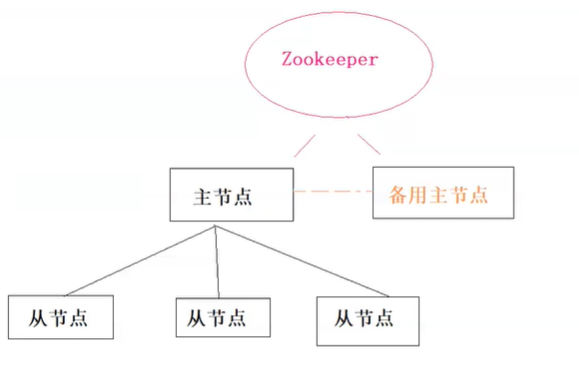
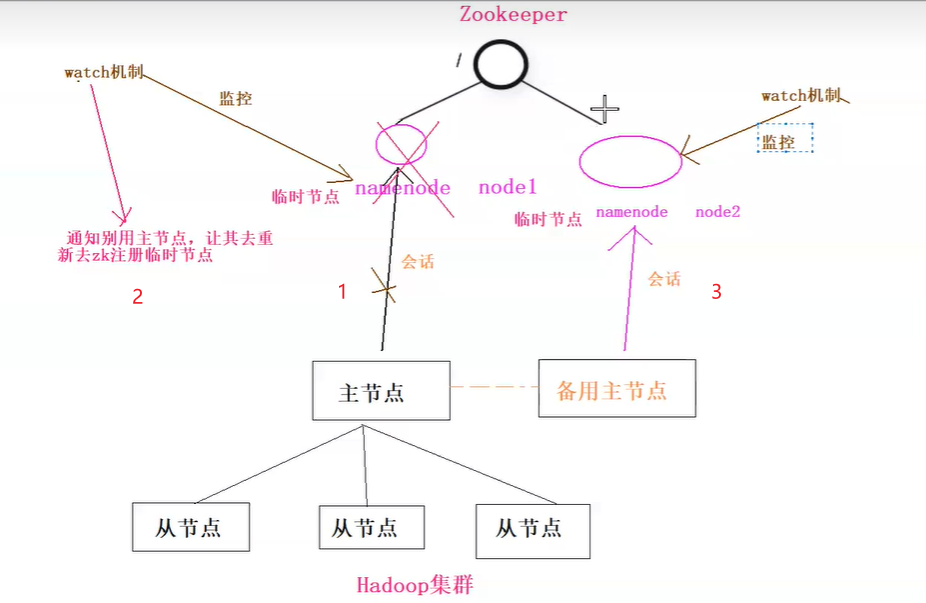
就比如大数据中Hadoop集群,有主节点,和从节点。为了集群高可用,增加备份节点。用zookeeper管理2个节点的切换,防止主节点挂掉集群不可用。(主节点挂了,无法自己切换,必须借助第三方的力量:zookeeper,告知备用节点主节点挂了)
zookeeper结合hadoop主备架构的情况:(临时节点)
zookeeper结合kafka集群数据共享的情况:(永久节点)
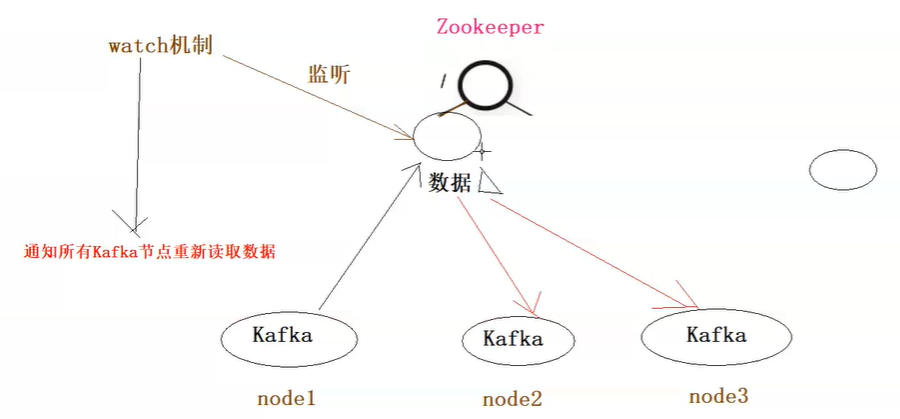
解读:其他框架,一般主从节点集群,但是主节点如果挂掉了,集群就没法工作了,所以一般有备用主节点,如果主节点挂掉了,通过zookeeper选举,从而达到其他框架的高可用。
zookeeper高可用集群和上面的架构还不太一样,zk集群(leader+follower)本身具备选举的功能。
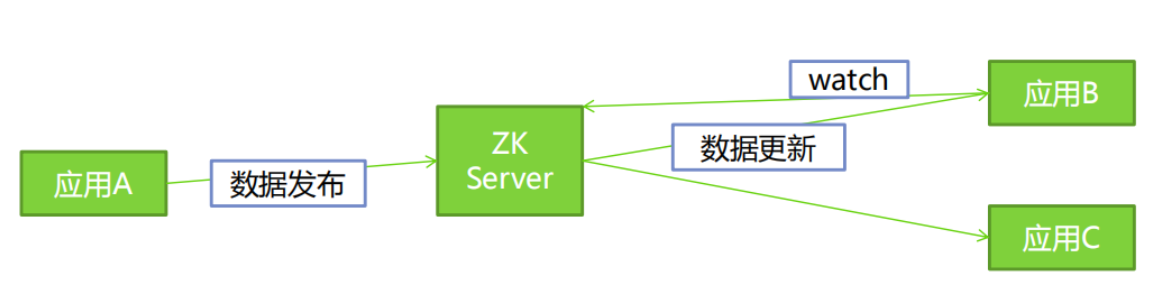
数据发布/订阅即所谓的配置中心:发布者将数据发布到ZooKeeper一系列节点上面,订阅者进行数据订阅,当数据有变化时,可以及时得到数据的变化通知,达到动态获取数据的目的。
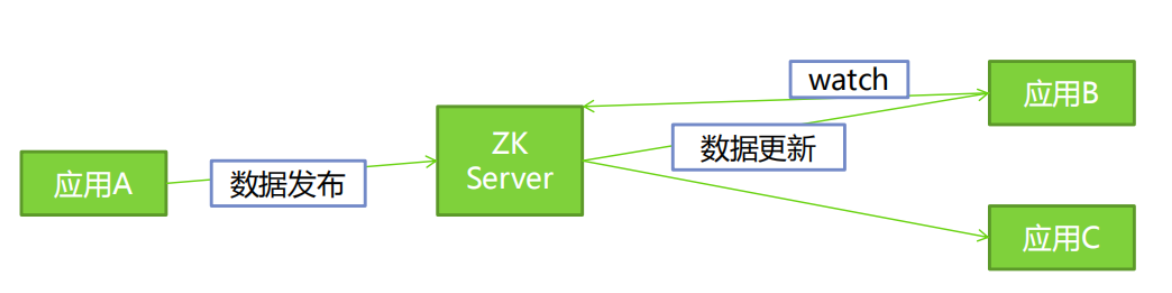
ZooKeeper采用的是推拉结合的方式。
- 1、推: 服务端会推给注册了监控节点的客户端 Wathcer 事件通知
- 2、拉: 客户端获得通知后,然后主动到服务端拉取最新的数据
分布式锁
在我们进行单机应用开发,涉及并发同步的时候,我们一般采用synchronized或者lock的方式来解决多线程间的代码问题,这时候多线程的运行都是在同一个JVM之下,没有任务问题。
但是当我们的应用试在分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。(其实就是从单机中的印证,跑到了一个服务中心的角色中去印证。)
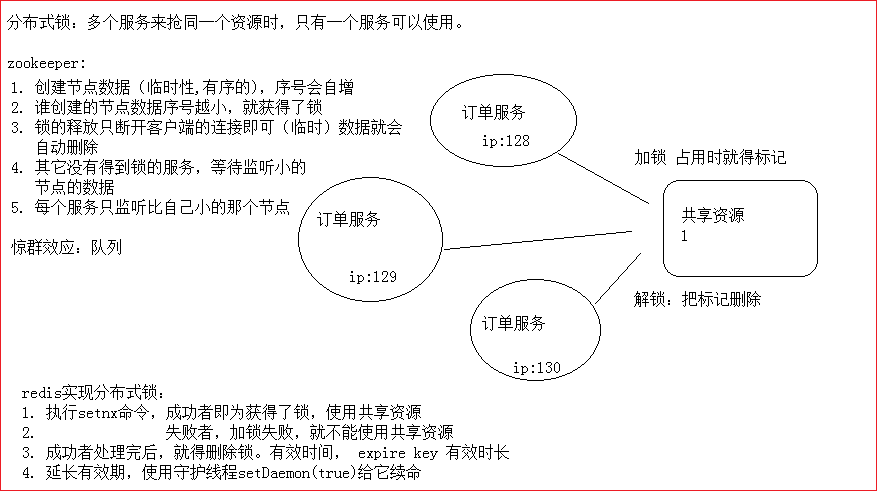
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
分布式队列
在传统的单进程编程中,我们使用队列来存储一些数据结构,用来在多线程之间共享或传递数据。分布式环境下,我们同样需要一个类似单进程队列的组件,用来实现跨进程、跨主机、跨网络的数据共享和数据传递,这就是我们的分布式队列。

负载均衡
负载均衡是通过负载均衡算法,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力。
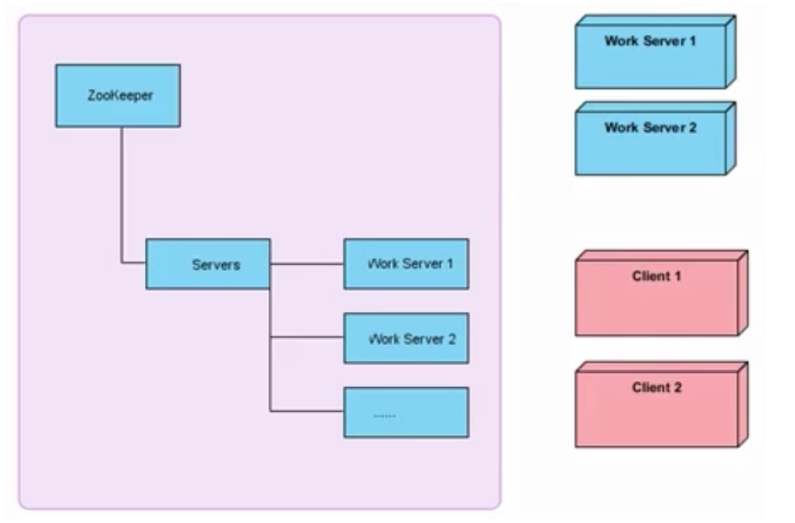
上图中左侧为ZooKeeper集群,右侧上方为工作服务器,下面为客户端。每台工作服务器在启动时都会去ZooKeeper的servers节点下注册临时节点,每台客户端在启动时都会去servers节点下取得所有可用的工作服务器列表,并通过一定的负载均衡算法计算得出一台工作服务器,并与之建立网络连接让分布式中服务被调用的次数相对就均匀。
小结:
Zookeeper: 分布式小文件存储系统,管理的是分布式中服务,树形层级目录结构
作用:
注册中心 房产中介 协调服务提供者与消费者 正常的调用
配置中心 分布式的所有应该都来中心读取配置,订阅,中心一旦修改,就会通知服务,服务就会去获取新的配置,所有应该都更新配置
分布式锁:多个应用在同一时刻只能有一个应用能访问资源。
zookeeper: 一旦获得资源,标记已使用(创建临时节点数据),被标记了则订阅。释放(删除数据),订阅者就会收到通知,竞争资源 惊群效应问题
分布式队列:使用zookeeper有序节点数据,惊群-监听上一个
负载均衡: 多个应用被调用的次数相对平均
- 随机
- 轮循
- 最小活跃数
- 一致性哈希
ZooKeeper集群
zookeeper集群机器数量不会太多,比如大厂100多台的服务器,可能只需要5台zk服务器来管理。
集群介绍
Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装。 通常由 2n+1台 servers 组成奇数。 这是因为为了保证 Leader 选举(基于 Paxos 算法的实现) 能或得到多数的支持,所以 ZooKeeper 集群的数量一般为奇数。
集群模式
ZooKeeper集群搭建有两种方式:
伪分布式集群搭建:
所谓伪分布式集群搭建ZooKeeper集群其实就是在一台机器上启动多个ZooKeeper,在启动每个ZooKeeper时分别使用不同的配置文件zoo.cfg来启动,每个配置文件使用不同的配置参数(clientPort端口号、dataDir数据目录.
在zoo.cfg中配置多个server.id,其中ip都是当前机器,而端口各不相同,启动时就是伪集群模式了。
这种模式和单机模式产生的问题是一样的。也是用在测试环境中使用。
完全分布式集群搭建:
多台机器各自配置zoo.cfg文件,将各自互相加入服务器列表,每个节点占用一台机器
架构图
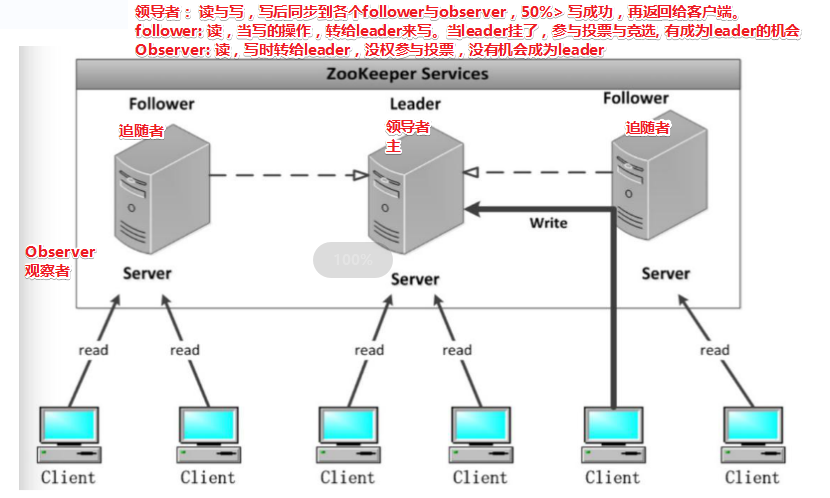
Leader:Zookeeper(领导者):
集群工作的核心
事务(ZAB>50%)请求(写操作) 的唯一调度和处理者,保证集群事务(id: zxid 16进制自增)处理的顺序性;
集群内部各个服务器的调度者。
对于 create, setData, delete 等有写操作的请求,则需要统一转发给leader 处理, leader 需要决定编号、执行操作,这个过程称为一个事务。ZAB的事务2pc, 3pc(TCC)
Follower(跟随者)
处理客户端非事务(读操作) 请求,转发事务(增删改)请求给 Leader;参与集群 Leader 选举投票 2n-1台可以做集群投票。
Observer:观察者角色
针对访问量比较大的 zookeeper 集群, 还可新增观察者角色。观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给 Leader服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
leader是甲方组长,follower是甲方正式员工,observer就是外包..(只是对职能隐喻,实际上observer很少搭建)
leader选举【面试时读】
三台服务器
在领导者选举的过程中,如果某台ZooKeeper获得了超过半数的选票,则此ZooKeeper就可以成为Leader了。
服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于
Looking(选举状态)。服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,每个Server发出一个投票由于是初始情况,1和2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时1的投票为(1, 0),2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
接受来自各个服务器的投票集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下优先检查ZXID。ZXID比较大的服务器优先作为Leader。
如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器
由于服务器2的编号大,更新自己的投票为(2, 0),然后重新投票,对于2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可,此时集群节点状态为LOOKING。
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息
服务器3启动,进行统计后,判断是否已经有过半机器接受到相同的投票信息,对于1、2、3而言,已统计出集群中已经有3台机器接受了(3, 0)的投票信息,此时投票数正好大于半数,便认为已经选出了Leader,改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。所以服务器3成为领导者,服务器1,2成为从节点。
ZXID: 即zookeeper事务id号。ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid
- 各自投自己一票
- 如果票数相同,则进入第二轮投票
- 改投zxid为大的。
- zxid相同,投myid为大的
- 统计得到的票数>50%就成为leader
5台全新集群选举
假设目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
非全新集群选举
对于运行正常的zookeeper集群,中途有机器down掉,需要重新选举时,选举过程就需要加入数据ID、服务器ID和逻辑时钟。
数据ID:数据新的version就大,数据每次更新都会更新version。
服务器ID:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值。 如果在同一次选举中,这个值是一致的。
这样选举的标准就变成:
1、逻辑时钟(投票的轮数)小的选举结果被忽略,重新投票;
2、统一逻辑时钟后,数据id(dataVersion)大的胜出;
3、数据id相同的情况下,服务器id(myid)大的胜出;
根据这个规则选出leader。
zookeeper环境搭建
单机
前提:必须安装jdk 1.8,配置jdk环境变量,步骤略
下载
下载地址:http://zookeeper.apache.org
查看zookeeper的更新历史
zookeeper下载页的地址
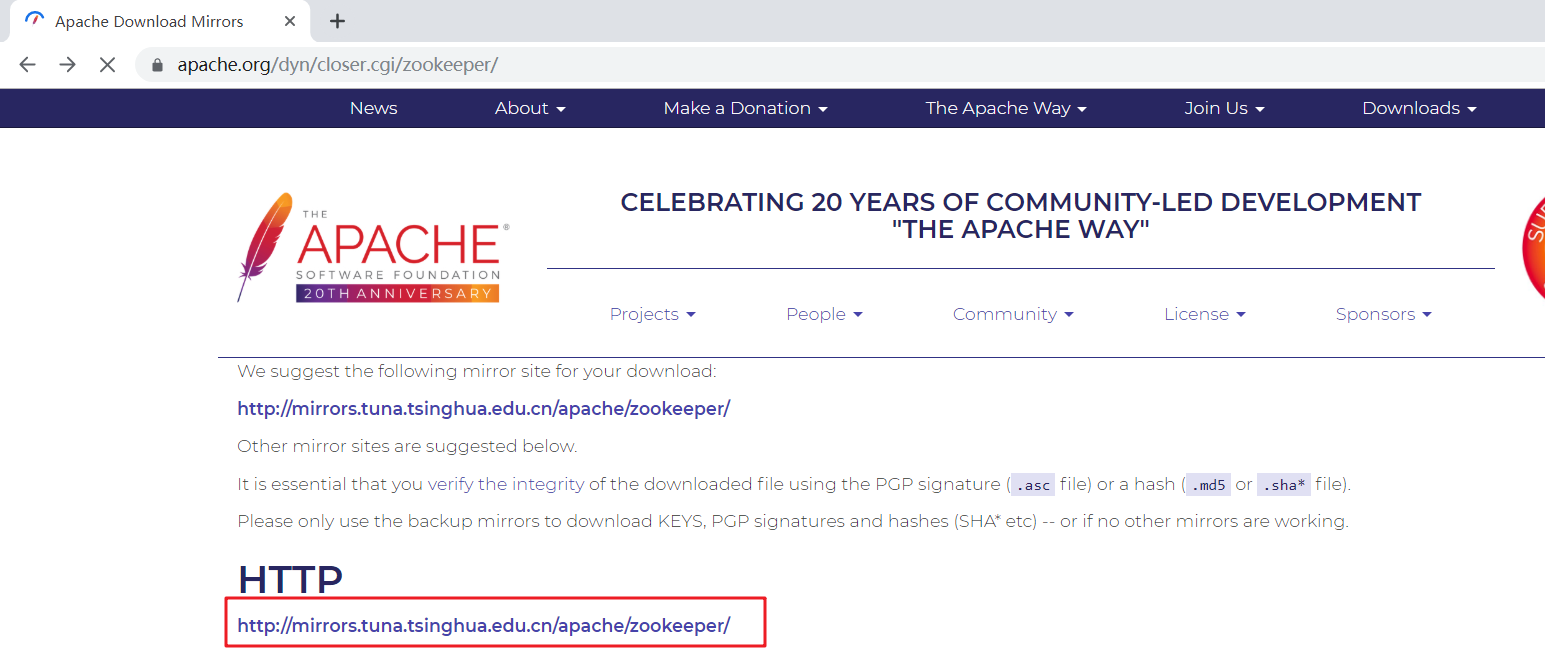
zookeeper选择下载的版本
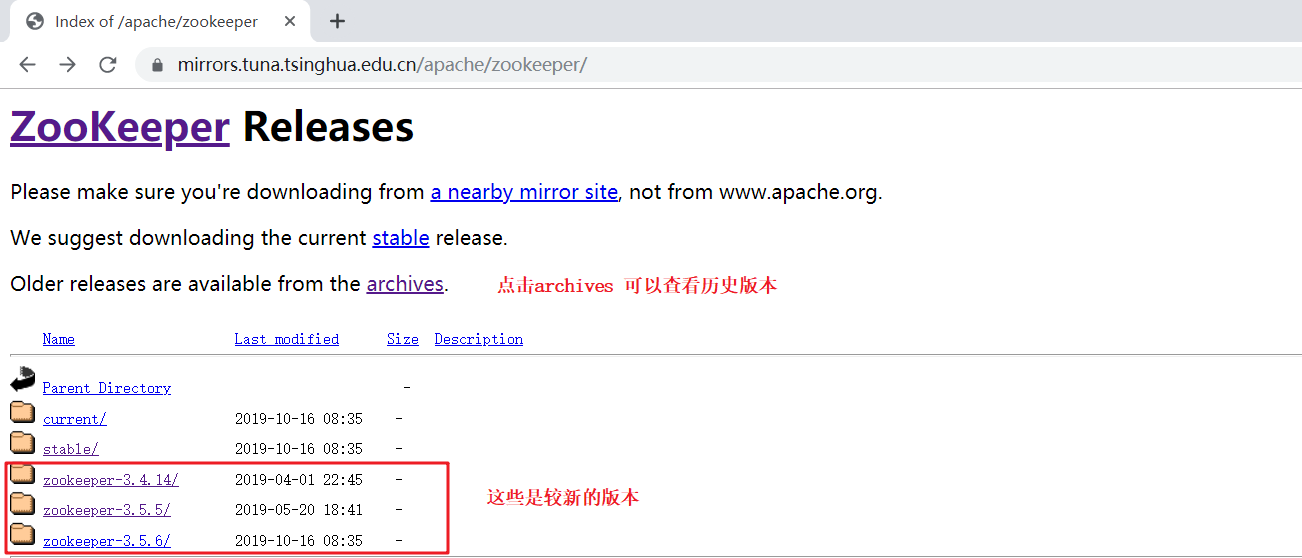
解压
【注意】:解压到没有中文路径的目录下(不要出现中文和空格)
修改配置文件
在zookeeper路径下创建一个data目录及log目录
修改配置文件
conf路径中复制一份zoo_sample.cfg,改名为 zoo.cfg
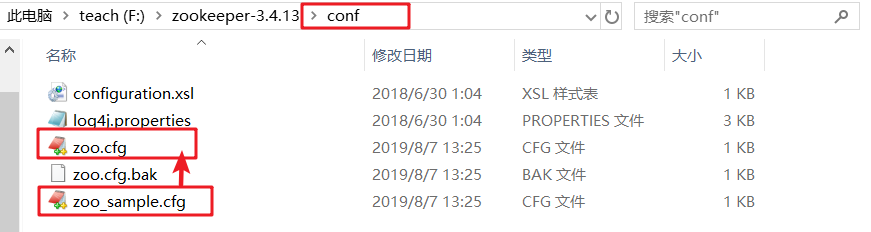
指定保存数据的目录:data目录和log存储日志
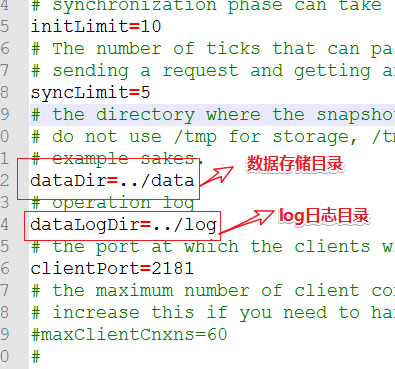
如果需要日志,可以创建log文件夹,指定dataLogDir属性
启动zookeeper
打开bin路径,双击zkServer.cmd,启动zookeeper服务
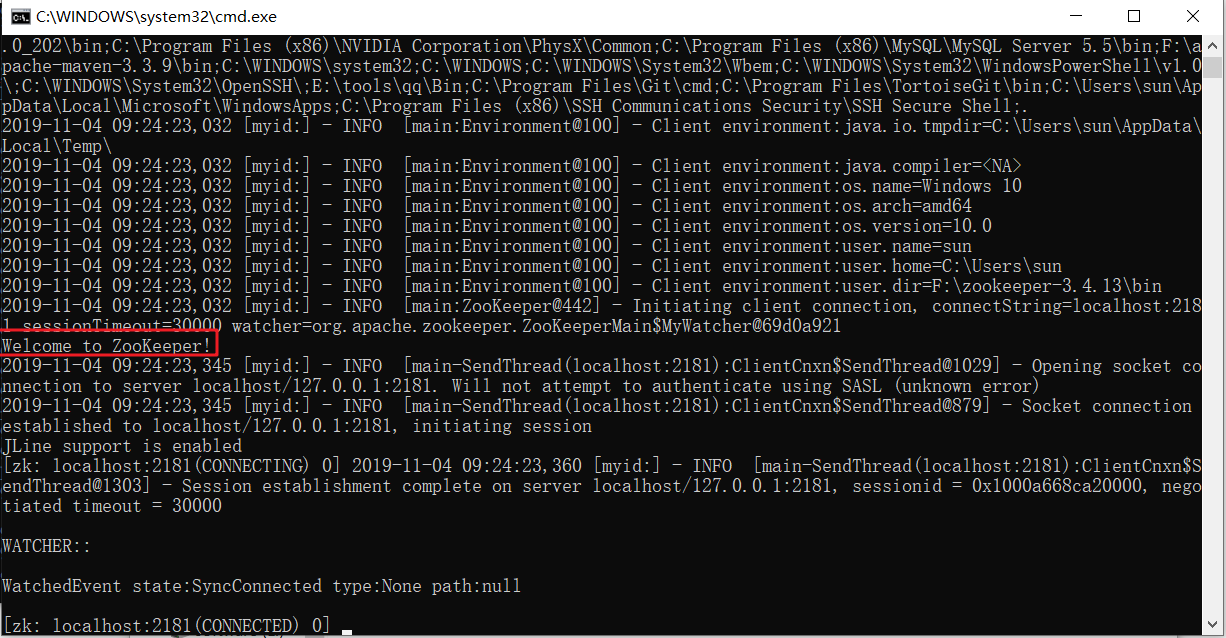
启动客户端测试
启动客户端,看到 Welcome to Zookeeper! 说明成功
【小结】
1:安装Zookeeper的前提 环境变量 jdk1.8
2:在window上安装Zookeeper 解压到没有中文没有空格的目录
创建data目录与bin同级
复制conf/zoo_simple.cfg,改名为zoo.cfg(启动时加载)
zoo.cfg -> dataDir=../data
log日志,创建log目录与bin同级
zoo.cfg -> dataLogDir=../log
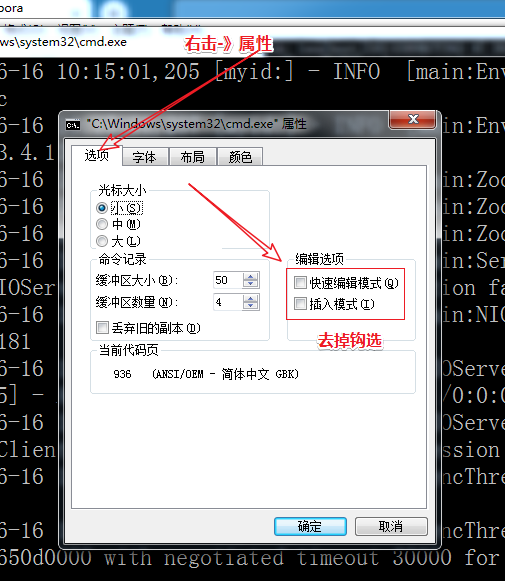
3: 【注意】:服务端 窗口不要选中任何区域(阻塞请求,客户端连不上),如果选中了则按 ESC 键
右击窗口的属性,去除编辑与插入模式钩选
集群
zookeeper只是做配置的,用来管理其他中间件的,3-5台组成集群就够用了
搭建过程
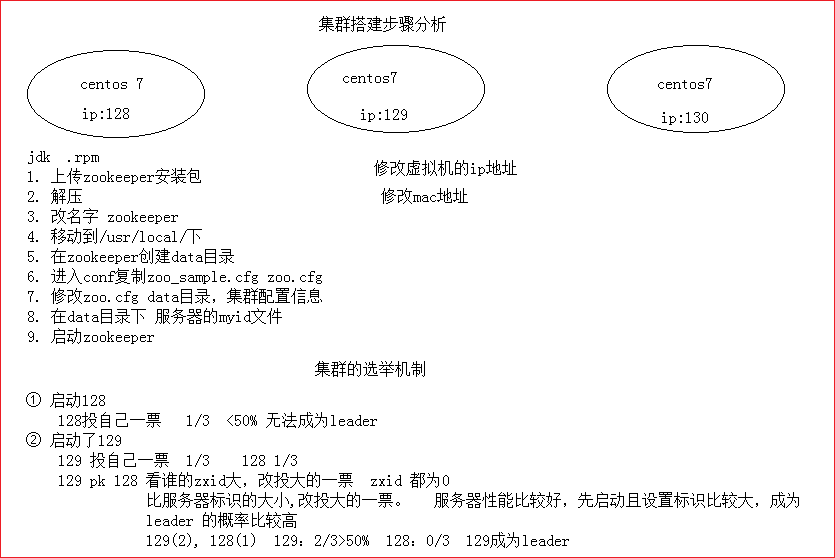
准备三台电脑(虚拟机)
安装三个linux虚拟机
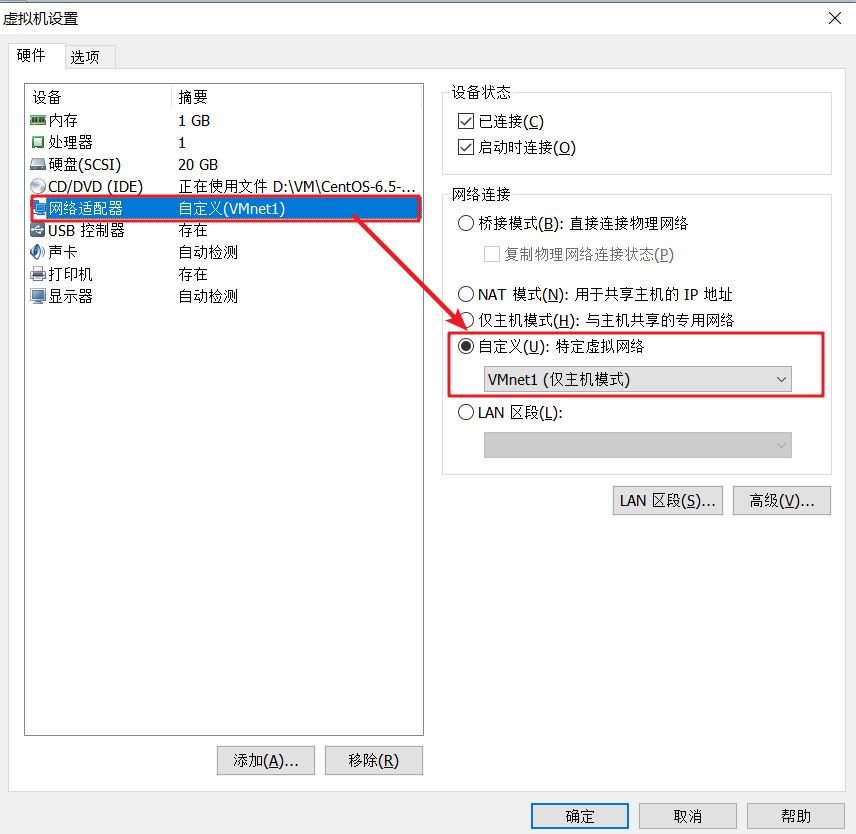
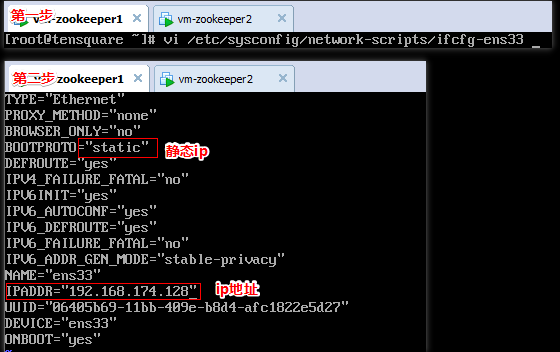
配置虚拟网卡(三台电脑配置一个虚拟网卡)(虚拟网卡ip为:192.168.174.1)
为每台虚拟机配置静态ip地址
 `
`
重启网络:service network restart
三台虚拟机分别是:192.168.174.128、192.168.174.129、192.168.174.130
关闭防火墙:
systemctl stop firewalld
service iptables stop
安装jdk
- 查看是否已经安装jdk
命令:rpm -qa|grep java

- 卸载已安装的jdk
命令:rpm -e --nodeps

上传jdk到linux
解压jdk
命令: tar -vxf jdk-8u181-linux-i586.tar.gz
- 配置环境变量
命令:cd / 退回根目录
命令:cd etc
命令:vim profile (编辑etc/profile文件,将如下配置粘贴到文件中)
1 | #set java environment |
- 重新加载profile文件,即激活profile文件
命令:source profile
上传zookeeper并解压
- 上传到虚拟机
- 解压
命令:tar -zxvf apache-zookeeper-3.5.5-bin.tar.gz /usr/local(解压)
命令:cd usr/local (进入local路径)
命令:mv apache-zookeeper-3.5.5-bin zookeeper (重命名文件夹)
配置zookeeper
- 创建data目录
命令:cd zookeeper (进入zookeeper目录)
命令:mkdir data
- 修改
conf/zoo.cfg
命令:cd conf (进入conf目录)
命令:cp zoo_sample.cfg zoo.cfg(复制zoo_sample.cfg,文件名为zoo.cfg)

命令:vim zoo.cfg (修改zoo.cfg)
内容:
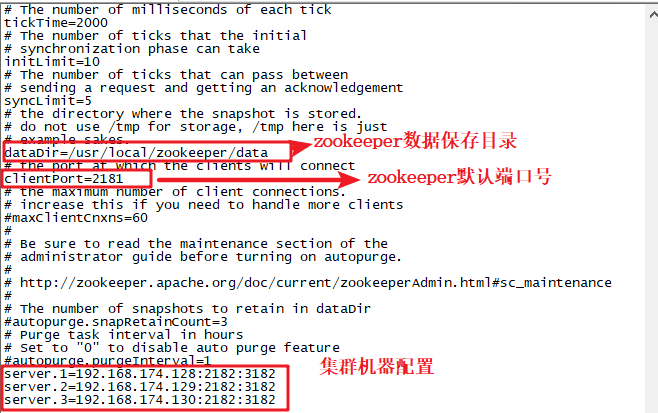
修改:
dataDir = /usr/local/zookeeper/data
添加:
server.1=192.168.174.128:2182:3182
server.2=192.168.174.129:2182:3182
server.3=192.168.174.130:2182:3182
参数详解(了解)
1 | 1)tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒 |
- 在data目录创建创建myid
命令:cd .. (退出conf目录)
命令:cd data (进入data目录)
命令:vim myid(修改myid文件,分别设置为1(128),2(129),3(130))
启动zookeeper
命令:cd .. (退出data目录)
命令:cd bin(进入bin路径)
命令: ./zkServer.sh start

查看zookeeper状态
命令:./zkServer.sh status
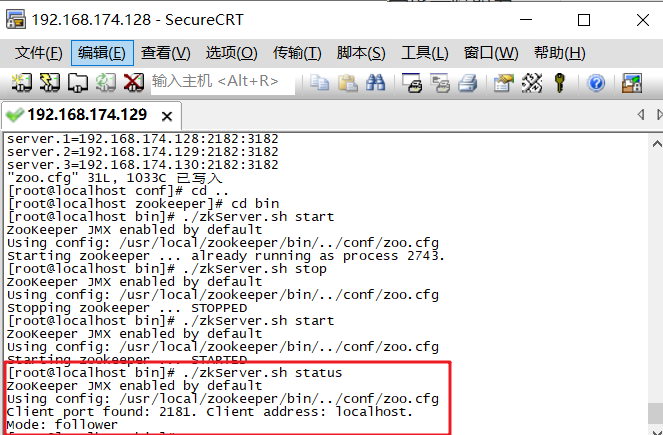
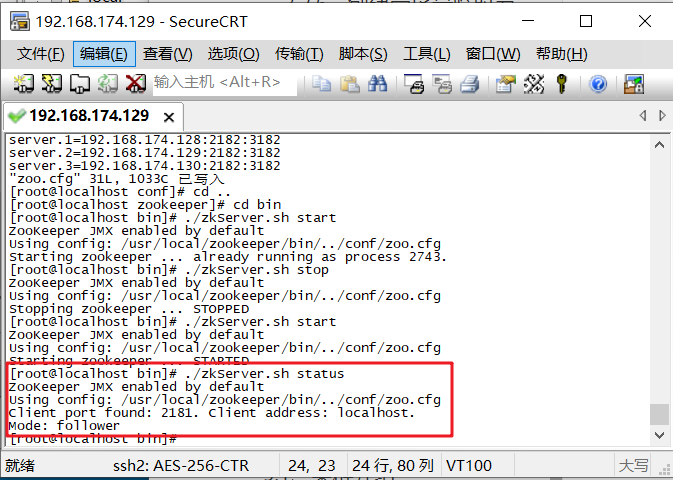
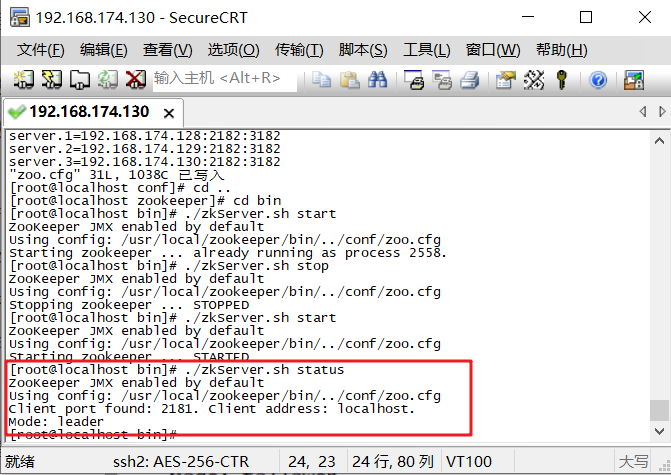
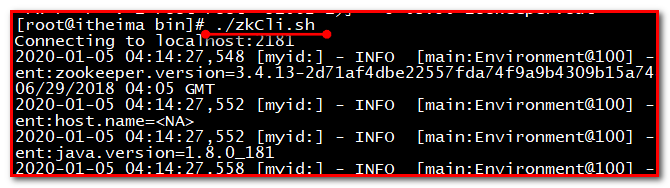
测试集(练习)
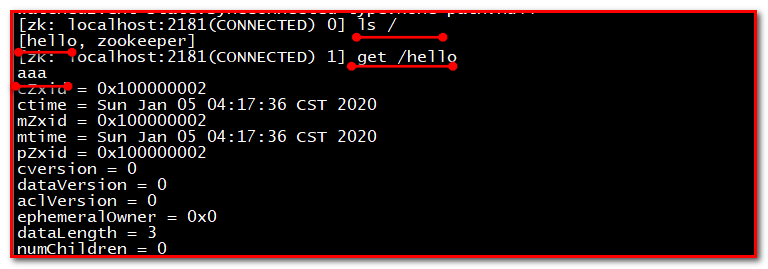
第一步:3台集群,随便挑选一个启动,执行命令./zkCli.sh
第二步:添加节点数据

第三步:找另一台机器,测试查询,可以获取hello节点的数据
也可以使用代码测试
1 |
|
测试使用任何一个IP都可以获取
测试如果有个机器宕机,(./zkServer.sh stop),会重新选取领导者。
【小结】
集群?多台相同功能服务器组成的集群
为什么?解决单点问题,高并发,高可用(故障转移)
zookeeper有哪些角色?
- leader 领导者,读写数据,同步数据到其它服务器(追随者,观察者)
- follower追随者,读,写时转给leader,同时参与投票与选举
- observer观察者。读,写时转给leader,不参与投票与选举
集群的搭建
三台虚拟机,分别修改网络与ip地址 mac地址, systemctl restart network
安装zookeeper
- 上传安装包
- 解压,重命名,移动到/usr/local
- 创建data目录, data目录下创建myid内容为server.id
- 到conf复制zoo.cfg 修改存储data目录,添加集群节点信息
启动 ./zkServer.sh start
选举机制
- 投自己一票
- 事务id log文件里 最后一行zxid 16进制
- 看myid
- 谁大改投谁
- 票数过半,票数/集群数量>50%成为leader
- 避免选不了leader 集群数量为2n+1
- 机器性能比较好的myid要调大一点
https://www.cnblogs.com/stateis0/category/1206895.html ZAB Zookeeper原子广播
2pc,3pc
zookeeper基础操作
zookeeper数据结构
ZooKeeper 的数据模型是层次模型。层次模型常见于文件系统。例如:我的电脑可以分为多个盘符(例如C、D、E等),每个盘符下可以创建多个目录,每个目录下面可以创建文件,也可以创建子目录,最终构成了一个树型结构。通过这种树型结构的目录,我们可以将文件分门别类的进行存放,方便我们后期查找。而且磁盘上的每个文件都有一个唯一的访问路径,例如:C:\Windows\itcast\hello.txt。

层次模型和key-value 模型是两种主流的数据模型。ZooKeeper 使用文件系统模型主要基于以下两点考虑:
文件系统的树形结构便于表达数据之间的层次关系。
文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace 路径url 唯一)。
ZooKeeper 的层次模型称作data tree。Datatree 的每个节点叫作znode(Zookeeper node)。不同于文件系统,每个节点都可以保存数据。每个节点都有一个版本(version)。版本从0 开始计数。
zookeeper本身是一个树形目录服务(名称空间),非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径来标识的
- 每个路径下的节点key(完整路径,名称)是唯一的,即同一级节点 key 名称是唯一的
- 每个节点中存储了节点value和对应的状态属性(多个)
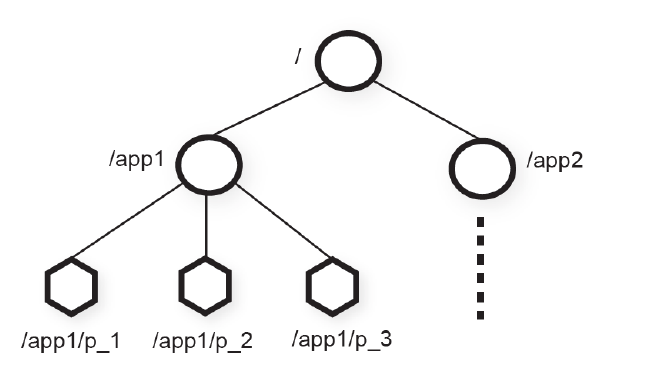
如图所示,data tree中有两个子树,用于应用1(/app1)和应用2(/app2)。
每个客户端进程pi 创建一个znode节点 p_i 在 /app1下, /app1/p_1就代表一个客户端在运行。
| 类型 | 描述 |
|---|---|
| PERSISTENT | 持久节点,默认 |
| PERSISTENT_SEQUENTIAL | 持久顺序节点,创建时zookeeper 会在路径上加上序号作为后缀,非常适合用于分布式锁、 分布式选举等场景,创建时添加 -s 参数,如图: |
| EPHEMERAL | 临时节点(不可在拥有子节点),跟连接会话绑定,临时节点会在客户端会话断开后由zk服务端自动删除。适用于心跳,服务发现等场景,创建时添加 -e 参数 |
| EPHEMERAL_SEQUENTIAL | 临时顺序节点(不可在拥有子节点),与持久顺序节点类似,不同之处在于EPHEMERAL_SEQUENTIAL是临时的,会在会话断开后删除,创建时添加 -e -s 参数 |
| CONTAINER | 容器节点,当子节点都被删除后,Container 也随即删除,创建时添加 -c 参数 |
| PERSISTENT_WITH_TTL | TTL节点,客户端断开连接后不会自动删除Znode,如果该Znode没有子Znode且在给定TTL时间内无修改,该Znode将会被删除;单位是毫秒;创建时添加 -t 参数 |
临时节点会话断开会自动删除,配合watch监控机制非常有用。主节点宕机注册临时节点会自动删除节点信息。watch监听机制监听到删除,去让备用节点创建节点信息,从而达到主备高可用。
数据模型znode结构详解
通过stat 节点可以查看节点的状态属性
zookeeper节点分类
一:一个znode可以是持久性的,也可以是临时性的
持久性znode[PERSISTENT],这个znode一旦创建不会丢失,无论是zookeeper宕机,还是client宕机。
临时性的znode[EPHEMERAL],如果zookeeper宕机了,或者client在指定的timeout时间内没有连接server,都会被认为丢失。
-e
二:znode也可以是顺序性的,每一个顺序性的znode关联一个唯一的单调递增整数。这个单调递增整数是znode名字的后缀。
持久顺序性的znode(PERSISTENT_SEQUENTIAL):znode 处理具备持久性的znode的特点之外,znode的名称具备顺序性。
-s临时顺序性的znode(EPHEMERAL_SEQUENTIAL):znode处理具备临时性的znode特点,znode的名称具备顺序性。
-s
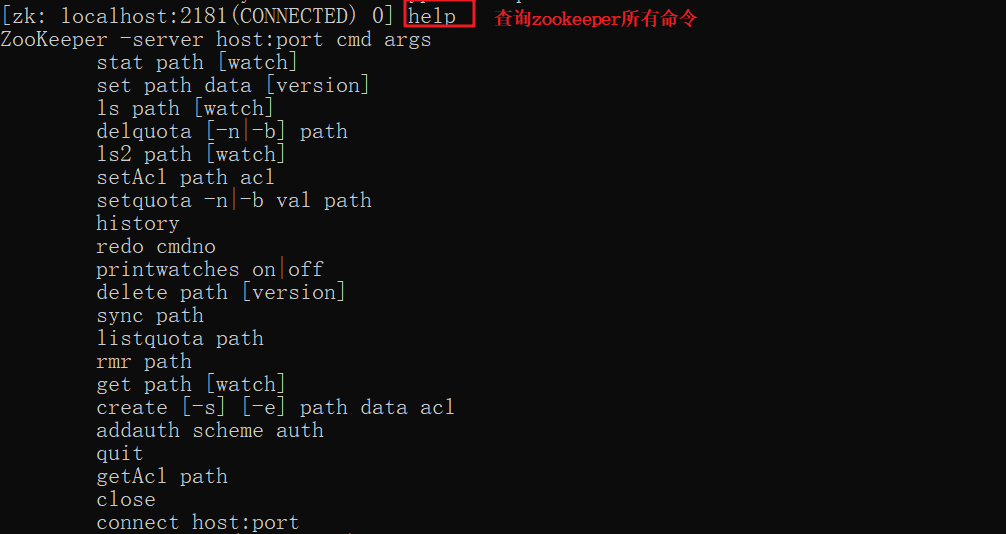
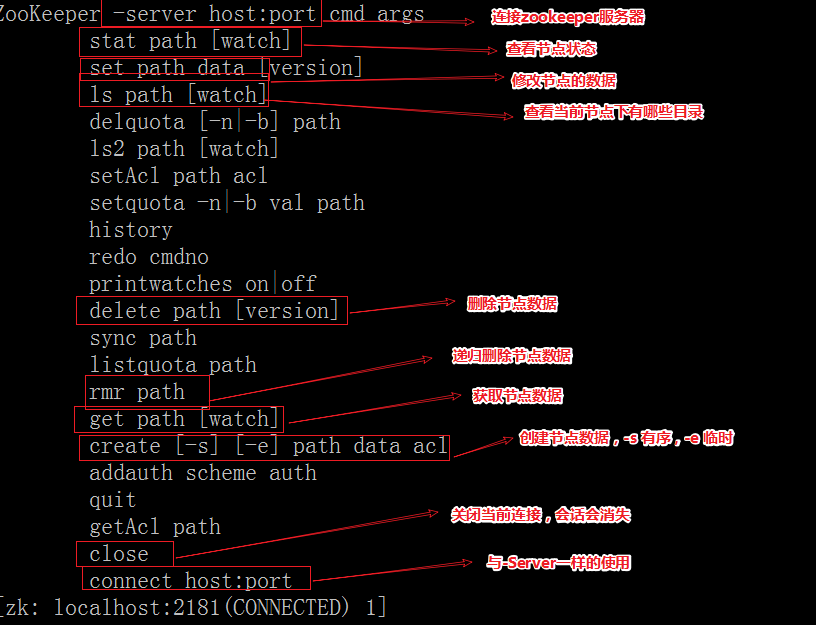
zookeeper客户端命令
更多命令:
| ls2 path [watch] | 查看Path下所有子Znode以及子Znode的属性 | |
|---|---|---|
| delete path [version] | 删除节点, 如果要删除的节点有子Znode则无法删除 | version 数据版本 |
| rmr path | 删除节点, 如果有子Znode则递归删除 | |
| setquota -n|-b val path | 修改Znode配额 | -n 设置子节点最大个数 -b 设置节点数据最大长度 |
| history | 列出历史记录 |
查询所有命令
1 | help |
查询跟路径下的节点
1 | ls /zookeeper |
查看zookeeper节点

创建普通永久节点
1 | create /app1 "helloworld" |
创建app1节点,值为helloworld

在zookeeper3.4等低版本有这种情况,使用3.7高版本就不用加双引号了
我使用 create /test 命令无法创建 test 节点,如下图:
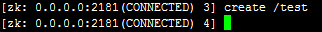
这样操作不报错,也不会创建节点,可以使用 ls / 命令去查看;
原因是需要设置节点的值,如果节点的值为空,则命令为 create /test ""
双引号不能省略;
有的时候还会报如下错误:
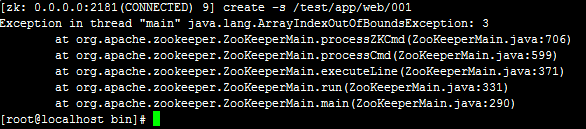
原因也是没有加节点的值,如下命令运行就可以成功创建节点了:

创建带序号永久节点
1 | create -s /hello "helloworld" |
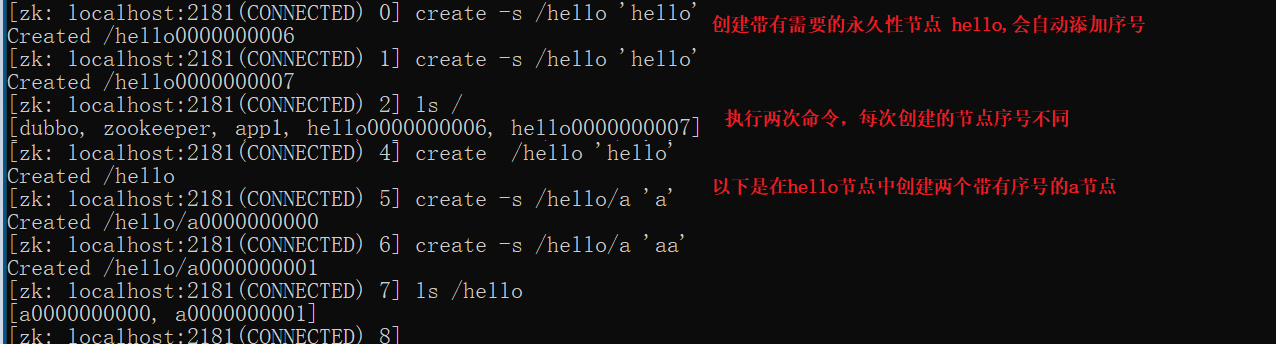
创建普通临时节点
1 | create -e /app3 'app3' |
-e:表示普通临时节点

关闭客户端,再次打开查看 app3节点消失
注意是创建这个临时节点的会话关闭,节点消失,其他客户端关闭不会影响到当前客户端创建的临时节点(想想就是,不然就乱套了)
创建带序号临时节点
1 | create -e -s /app4 'app4' |
-e:表示普通临时节点
-s:表示带序号节点

关闭客户端,再次打开查看 app4节点消失
查询节点数据
1 | get /app1 |
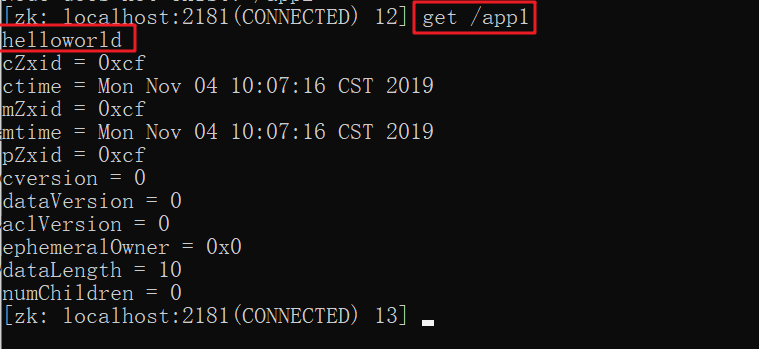
1 | 节点的状态信息,也称为stat结构体 |
修改节点数据
1 | set /app1 'hello' |
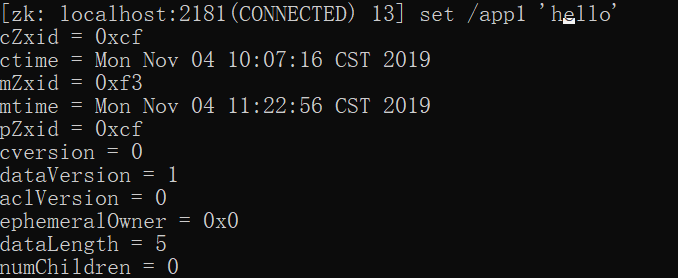
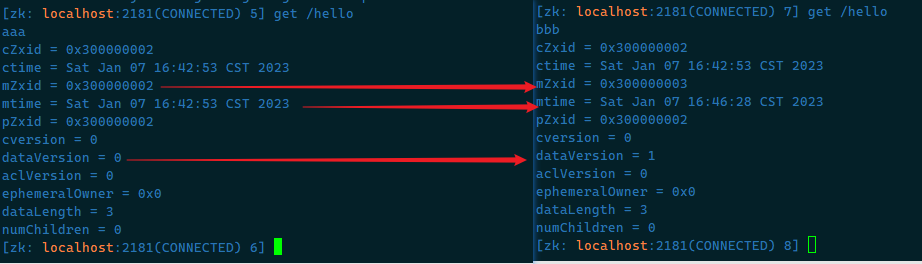
注意修改的变化:
删除节点
1 | delete /hello0000000006 |

删除节点:delete path [version] demo: delete /test/app/web
注意 delete 删除的节点下不能再有节点,否则无法删除;如果想要删除一个目录及目录下的子节点,可以使用 rmr path
递归删除节点
1 | delete /hello |

查看节点状态
1 | stat /zookeeper |
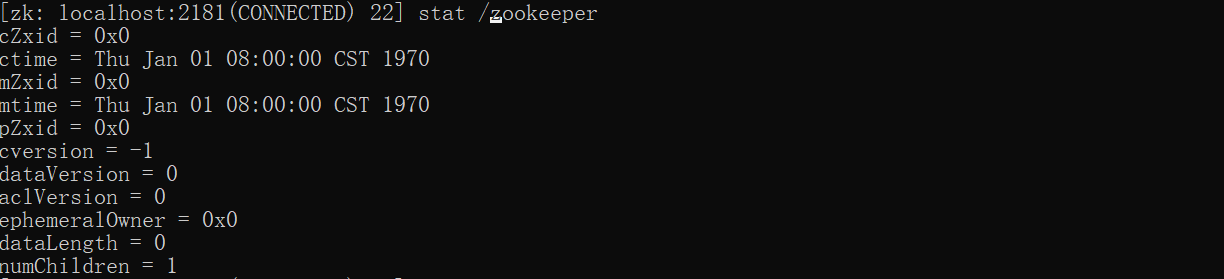
日志的可视化
这是日志的存储路径
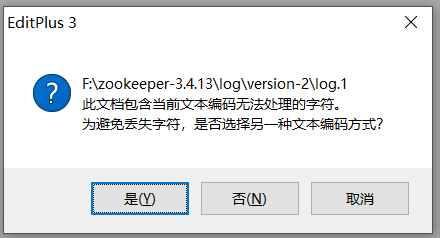
日志都是以二进制文件存储的,使用记事本打开,无意义。
为了能正常查看日志,把查看日志需要的jar包放到统一路径下
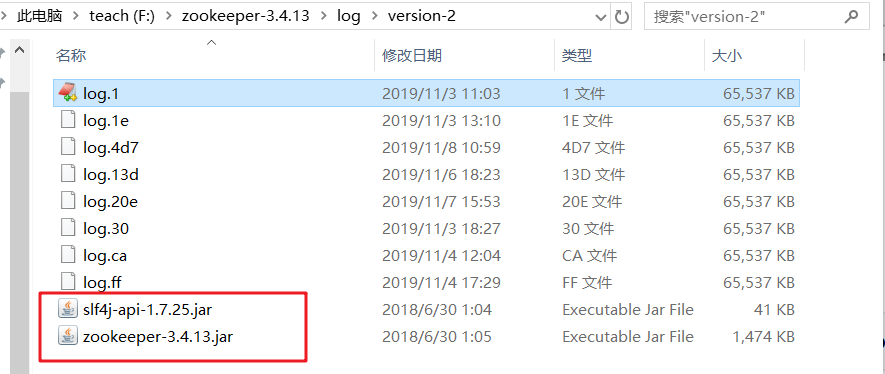
- 在当前目录下进入cmd,执行以下命令可以直接查看正常日志
1 | java -classpath ".;*" org.apache.zookeeper.server.LogFormatter log.1 |
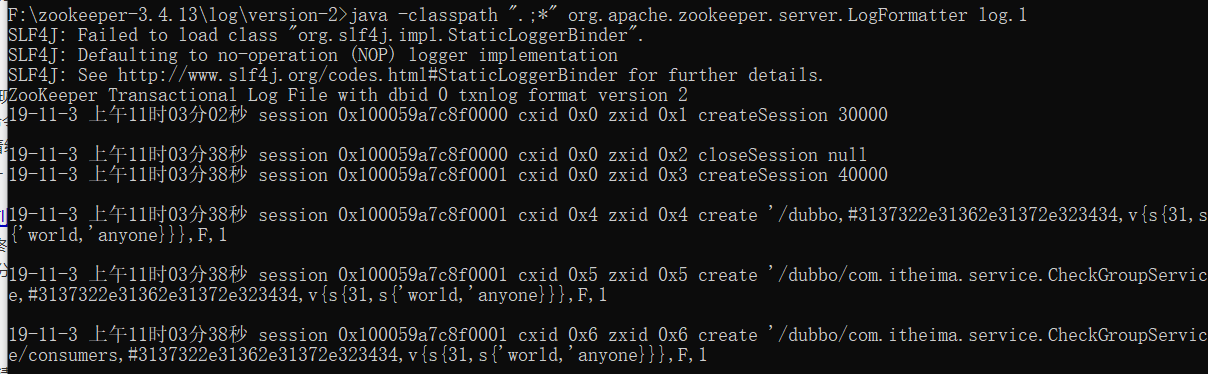
小结
数据类型: 持久,临时 -e, 有序 -s和无序
【注意】路径必须以/打头
ls 查看
help查看所有命令
create 路径 数据 -s 代表有序 -e 代临时
get 路径 查询
set 路径 新的数据
delete 路径 单一路径,没有子节点
rmr 路径 递归删除
stat 路径 查看节点状态 没有数据显示
日志 配置日志存储路径,依赖2个zookeeper-xxx.jar, sfl4-api.jar
java -classpath “.;*” org.apache.zookeeper.server.LogFormatter log.1 4
更多命令
watch机制
回顾:Zookeeper的应用场景中配置中心,其中看到watch机制
watch是什么
zookeeper作为一款成熟的分布式协调框架,订阅-发布功能是很重要的一个。所谓订阅发布功能,其实说白了就是观察者模式。观察者会订阅一些感兴趣的主题,然后这些主题一旦变化了,就会自动通知到这些观察者,使他们能够做出相应的处理。
zookeeper的订阅发布也就是watch机制,是一个轻量级的设计。因为它采用了一种推(服务端通知应用)拉(客户端获取服务端数据)结合的模式。一旦服务端感知主题变了,那么只会发送一个事件类型和节点信息给关注的客户端,而不会包括具体的变更内容,所以事件本身是轻量级的,这就是所谓的“推”部分。然后,收到变更通知的客户端需要自己去拉变更的数据,这就是“拉”部分。watche机制分为添加数据和监听节点。
总的来说可以概括Watcher为以下三个过程:客户端向服务端注册Watcher、服务端事件发生触发Watcher、客户端回调Watcher得到触发事件情况
watch机制特点
一次性触发
事件发生触发监听,一个watcher event就会被发送到设置监听的客户端,这种效果是一次性的,后续再次发生同样的事件,不会再次触发。
事件封装
ZooKeeper使用WatchedEvent对象来封装服务端事件并传递。
WatchedEvent包含了每一个事件的三个基本属性:通知状态(keeperState),事件类型(EventType)和节点路径(path)
event异步发送
watcher的通知事件从服务端发送到客户端是异步的。
先注册再触发
Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听通知给客户端。
通知状态和事件类型
同一个事件类型在不同的通知状态中代表的含义有所不同,下表列举了常见的通知状态和事件类型。
事件封装: Watcher 得到的事件是被封装过的, 包括三个内容 keeperState, eventType, path
| KeeperState | EventType | 触发条件 | 说明 |
|---|---|---|---|
| None | 连接成功 | ||
| SyncConnected | NodeCreated | Znode被创建 | 此时处于连接状态 |
| SyncConnected | NodeDeleted | Znode被删除 | 此时处于连接状态 |
| SyncConnected | NodeDataChanged | Znode数据被改变 | 此时处于连接状态 |
| SyncConnected | NodeChildChanged | Znode的子Znode数据被改变 | 此时处于连接状态 |
| Disconnected | None | 客户端和服务端断开连接 | 此时客户端和服务器处于断开连接状态 |
| Expired | None | 会话超时 | 会收到一个SessionExpiredExceptio |
| AuthFailed | None | 权限验证失败 | 会收到一个AuthFailedException |
其中连接状态事件(type=None, path=null)不需要客户端注册,客户端只要有需要直接处理就行了。
Shell 客户端设置watcher
设置节点数据变动监听:

通过另一个客户端更改节点数据:

此时设置监听的节点收到通知:

Curator(zk 客户端)
Curator(zk 客户端)在这方面做了优化,Curator引入了Cache的概念用来实现对ZooKeeper服务器端进行事件监听。Cache是Curator对事件监听的包装,其对事件的监听可以近似看做是一个本地缓存视图和远程ZooKeeper视图的对比过程。而且Curator会自动的再次监听,我们就不需要自己手动的重复监听了。
Curator中的cache共有三种
- NodeCache(监听和缓存根节点变化) 只监听单一个节点(变化 添加,修改,删除)
- PathChildrenCache(监听和缓存子节点变化) 监听这个节点下的所有子节点(变化 添加,修改,删除)
- TreeCache(监听和缓存根节点变化和子节点变化) NodeCache+ PathChildrenCache 监听当前节点及其下的所有子节点的变化
下面我们分别对三种cache详解
NodeCache
介绍:NodeCache是用来监听节点的数据变化的,当监听的节点的数据发生变化的时候就会回调对应的函数。
增加监听
1 | //创建重试策略 |
- 测试
修改节点的数据
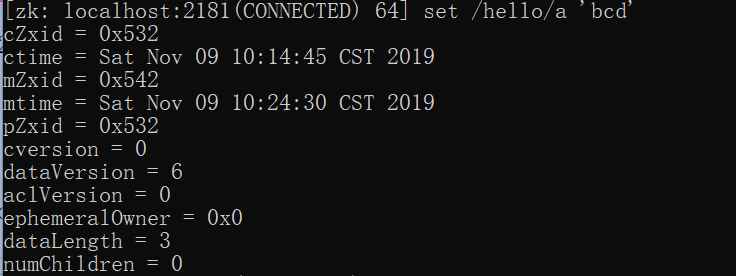
控制台显示
PathChildrenCache
PathChildrenCache是用来监听指定节点的子节点变化情况
增加监听
1 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,1); |
TreeCache
TreeCache有点像上面两种Cache的结合体,NodeCache能够监听自身节点的数据变化(或者是创建该节点),PathChildrenCache能够监听自身节点下的子节点的变化,而TreeCache既能够监听自身节点的变化、也能够监听子节点的变化。
添加监听
1 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,1); |
prettyZoo
好看的zk客户端
https://github.com/vran-dev/PrettyZoo/releases
zookeeper和java客户端
ZooKeeper常用Java API
- 原生Java API(不推荐使用)
ZooKeeper 原生Java API位于org.apache.ZooKeeper包中
ZooKeeper-3.x.x. Jar (这里有多个版本)为官方提供的 java API
Apache Curator(推荐使用)
Apache Curator是 Apache ZooKeeper的Java客户端库。
Curator项目的目标是简化ZooKeeper客户端的使用。
另外 Curator为常见的分布式协同服务提供了高质量的实现。
Apache Curator最初是Netflix研发的,后来捐献了 Apache基金会,目前是 Apache的顶级项目
- ZkClient(不推荐使用)
Github上一个开源的ZooKeeper客户端,由datameer的工程师Stefan Groschupf和Peter Voss一起开发。
zkclient-x.x.Jar也是在源生 api 基础之上进行扩展的开源 JAVA 客户端。


创建java 工程,导入依赖
导入依赖
1 | <!--zookeeper的依赖--> |
创建节点
1 | /** |
修改节点数据
1 | //创建失败策略对象 |
查询节点数据
1 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 1); |
删除节点
1 | //重试策略 |
【小结】
Curator是Appache封装操作Zookeeper的客户端, 操作zookeer数据变得更简单
使用步骤:
创建重试策略
创建客户端 ip:port sessionTimeout, connectionTimeout, retryPolicy
启动客户端 start
使用客户端对节点操作
1
2
3
4-- create forPath, creatingparent........, withMode(CreateMode.持久,临时,有序)
-- setData 修改数据
-- getData 查询数据
-- delete 删除数据, deletingChildrenIfNeeded递归删除关闭客户端, 测试临时数据时要睡眠一下
zookeeper高级应用原理
zookeeper相关高级特性
临时节点,顺序节点,Watch
- 数据发布订阅
- 负载均衡
- 集群管理
- 分布式队列
- 分布式命名服务
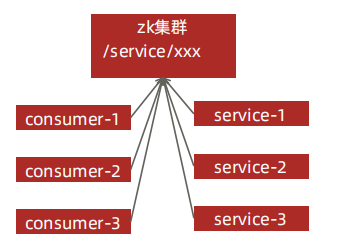
- 配置管理:指集群中的机器拥有某些配置,并且这些配置信息需要动态地改变,那么我们就可以使用发布订阅模式把配置做统一的管理,让这些机器订阅配置信息的改变,但是配置改变时这些机器得到通知并更新自己的配置
- 服务注册,服务发现:指对集群中的服务上下线做统一管理,每个工作服务器都可以作为数据的发布方,向集群注册自己的基本信息,而让某些监控服务器作为订阅方,订阅工作服务器的基本信息。当工作服务器的基本信息改变时,如服务上下线、服务器的角色或服务范围变更,那么监控服务器可以得到通知并响应这些变化
- 负载均衡:负载均衡是一种手段,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力,譬如RPC过程中的客户端负载均衡。
- 分布式队列:通过顺序节点实现分布式队列,生产者通过在某节点下创建顺序节点来存放数据,消费者通过读取顺序节点来消费数据
- 集群管理:集群监控(状态收集),集群控制,比如Kafka,Hadoop ,Solr集群等
- 分布式命名服务:zookeeper的命名服务有两个应用方向,一个是利用zookeepeer的树型分层结构,可以把系统中各种服务的名称、地址以及目录信息存放在zookeeper,需要的时候去zookeeper中读取。另一个,是利用zookeeper顺序节点的特性,制作分布式的ID生成器,分布式系统中通常需要为某一条记录创建唯一的ID,在单机环境中我们可以利用数据库的主键自增功能。但在分布式环境则无法使用,有一种方式可以使用UUID,但是它的缺陷是没有规律,很难理解。利用zookeeper顺序节点的特性,我们可以生成有顺序 的,容易理解的,同时支持分布式环境的序列号
zookeeper实现分布式锁
分布式锁,指在分布式环境下,保护跨进程、跨主机、跨网络的共享资源,实现互斥访问(不同节点间),保证一致性;在zk中,锁就是一个数据节点。
如果节点A的服务比如挂了,宕机,JVM进程都退出了。锁没有释放。zk要有对应的机制去应对。 => zk临时节点可以做到jvm进程挂了.可以删除节点。
普通实现:注册临时节点,谁注册成功谁获取锁,其他监听该节点的删除事件,一旦被删除,通知其他客户端,再次重复该流程;此为最简单的实现,但容易引发一些问题 [羊群效应:比如1个节点挂了.要通知全部节点,一只狼进入羊圈,惊了全部羊.zk服务器有压力]
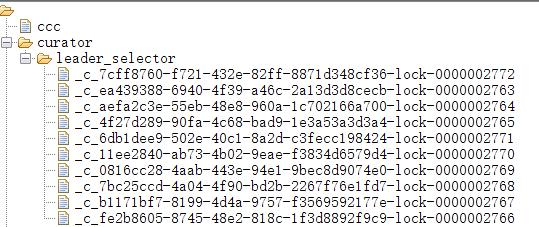
- 所有服务启动时都去zookeeper中注册一个临时顺序节点,并将基本信息写入临时节点
- 所有服务获取节点列表并判断自己的节点是否是最小的那个,谁最小谁就获取了锁
- 未获取锁的客户端添加对前一个节点删除事件的监听 => 避免了惊群效应
- 锁释放/持有锁的客户端宕机后,节点被删除
- 下一个节点的客户端收到通知,重复上述流程
可以做但是分布式锁还是推荐用redis,代码实现zk分布式锁感兴趣可以百度查一下。
读写锁
共享锁,排它锁
- 共享锁:又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放
- 排它锁:又称写锁或独占锁。如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取或更新操作,其他任务事务都不能对这个数据对象进行任何操作,直到T1释放了排他锁
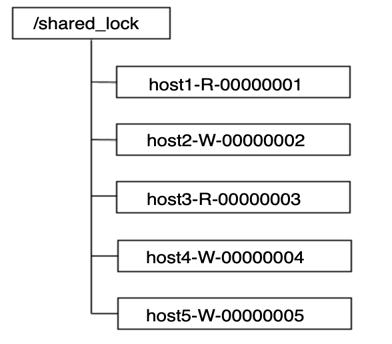
可以将临时有序节点分为读锁节点和写锁节点
- 对于读锁节点而言,其只需要关心前一个写锁节点的释放。如果前一个写锁释放了,则多个读锁节点对应的线程可以并发地读取数据
- 对于写锁节点而言,其只需要关心前一个节点的释放,而不需要关心前一个节点是写锁节点还是读锁节点。因为为了保证有序性,写操作必须要等待前面的读操作或者写操作执行完成
Curator实现

- InterProcessMutex:分布式可重入排它锁(可重入可以借助LocalMap存计数器)
- InterProcessSemaphoreMutex:分布式排它锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessReadWriteLock:分布式读写锁
Master选择
应用集群选主:一般外面的系统都是需要7*24小时向外提供服务,不能有单点故障,于是我们使用集群,采用的是Master+Slave。集群中有一台主机和多台备机,由主机向外提供服务,备机监听主机状态,一旦主机宕机,备机必需迅速接管主机继续向外提供服务。在这个过程中,从备机选出一台机作为主机的过程,就是Master选举
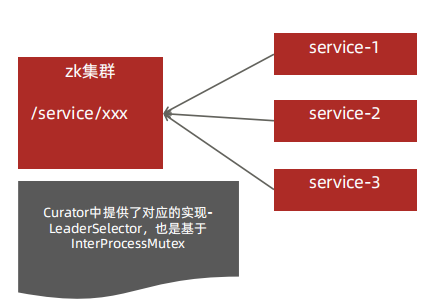
- 所有服务启动时都去zookeeper中注册一个临时顺序节点,并将基本信息写入临时节点
- 所有服务判断自己的节点是否是最小的那个,谁最小谁就是Master,其他是Slave
- Slave添加对前一个节点删除事件的监听
- Master宕机或不可用时,zookeeper会将该会话绑定的临时节点删除
- Slave接收到事件通知,重复上述流程
完成master的选择其实和zookeeper分布式锁实现原理差不多
学习源码我们想知道什么

我们将资料中 工程\dubbo 工程导入到IDEA中,上图是他们的调用关系,那么问题来了:
- 生产者向Zookeeper注册服务信息,Zookeeper把数据存哪儿了?
- 集群环境下,如果某个节点数据变更了,Zookeeper如何监听到的?
- 集群环境下各个节点的数据如何同步?
- 如果某个节点挂了,Zookeeper如何选举呢?
- ……..
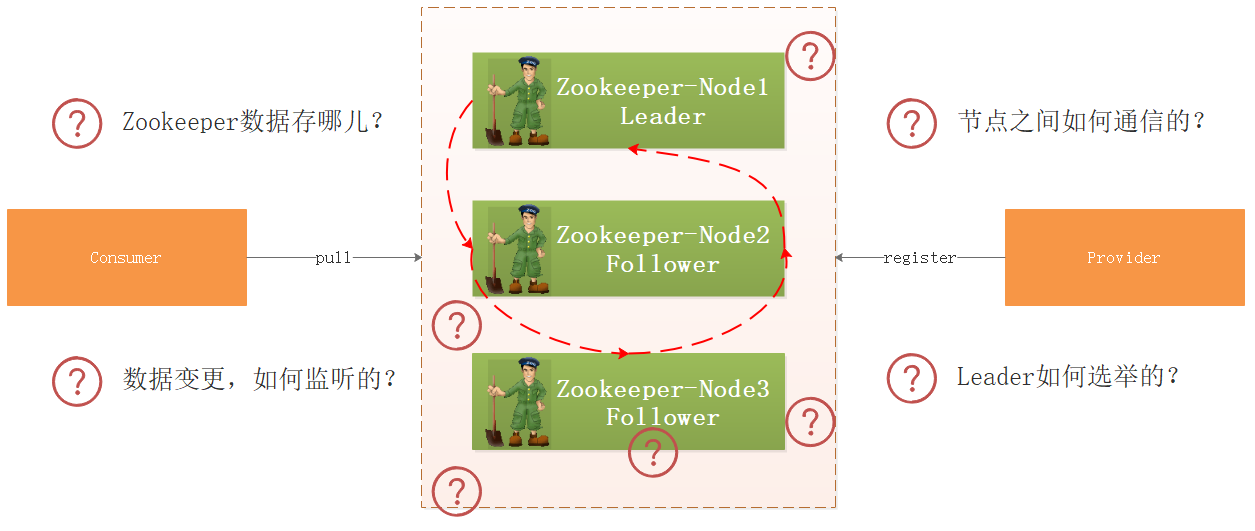
带着上面的疑问,我们开始研究Zookeeper源码。
zookeeper源码导入
Zookeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。在越来越多的分布式系。在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。
我们研究Zookeeper源码,需要将Zookeeper工程导入到IDEA中,老版的zk是通过ant进行编译的,但最新的zk(3.7)源码中已经没了build.xml ,而多了 pom.xml ,也就是说构建方式由原先的Ant变成了Maven,源码下下来后,直接编译、运行是跑不起来的,有一些配置需要调整。
工程导入
Zookeeper各个版本源码下载地址https://github.com/apache/zookeeper,我们可以在该仓库下选择不同的版本,我们选择最新版本,当前最新版本为3.7,如下图:
找到项目下载地址,我们选择 https 地址,并复制该地址,通过该地址把项目导入到 IDEA 中。
点击IDEA的 VSC>Checkout from Version Controller>GitHub ,操作如下图:
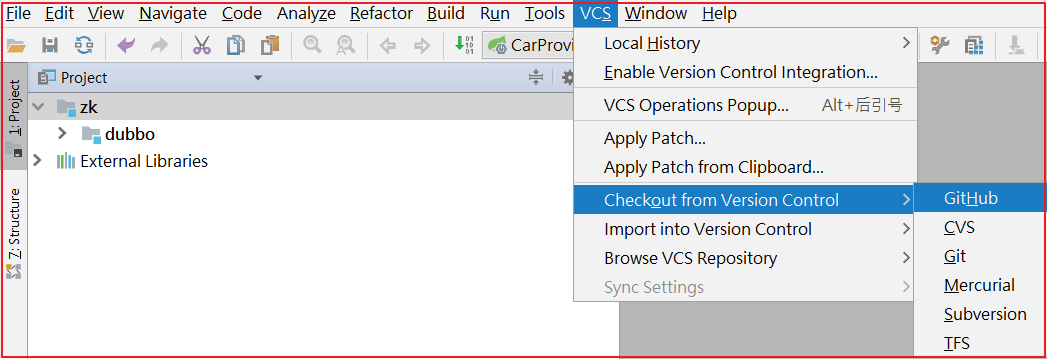
克隆项目到本地:

项目导入本地后,效果如下:

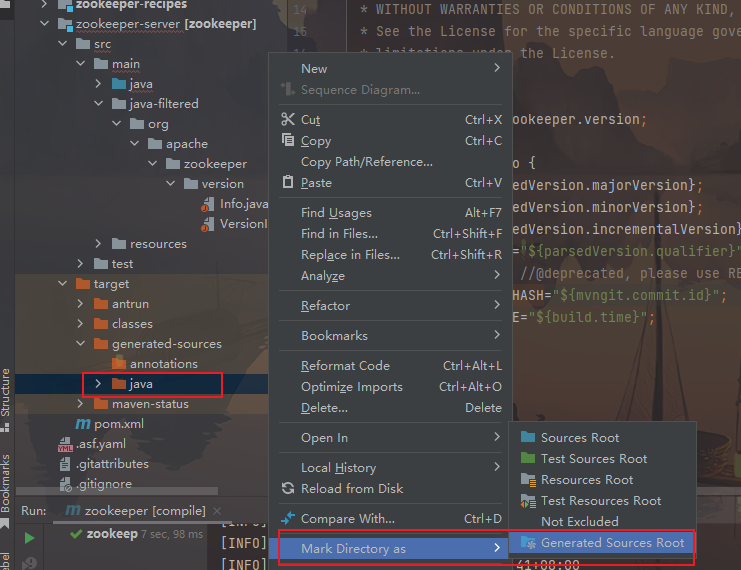
右键maven,选择compile编译zookeeper-jute工程
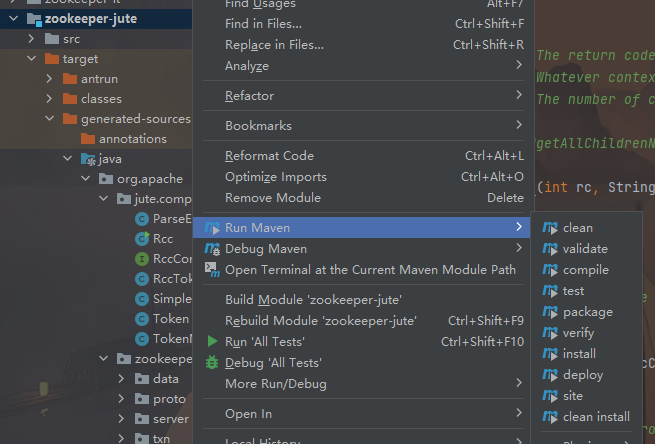
在target目录下会生成一些类,要把包标识一下
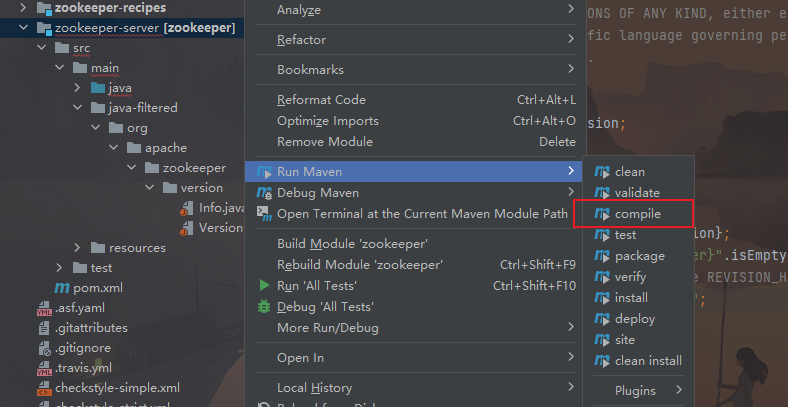
继续编译zookeeper-server工程
项目运行的时候,缺一个版本对象,这一步就是在生成org.apache.zookeeper.version.Info对象,代码如下:
1 | public interface Info { |
同样,编译后的目标要标识一下
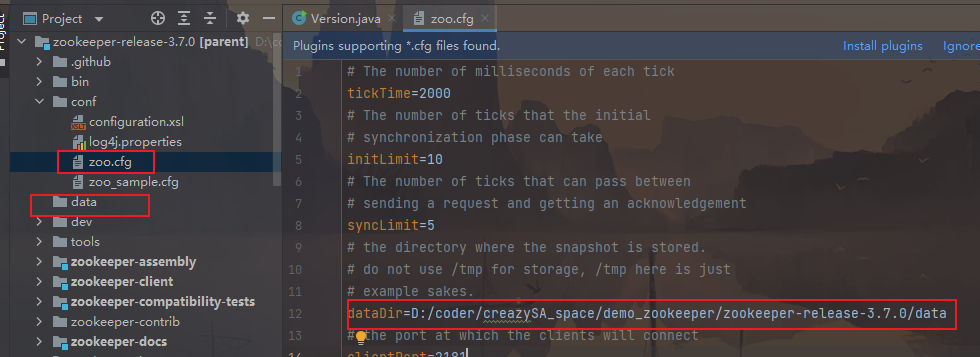
拷贝zoo.cfg并且配置data目录
Zookeeper源码错误解决
在server.cmd中的命令可以看到端倪,其实就是调用java的命令,传了入口参数等。
在 zookeeper-server 中找到org.apache.zookeeper.server.quorum.QuorumPeerMain 并启动该类,启动前做如下配置
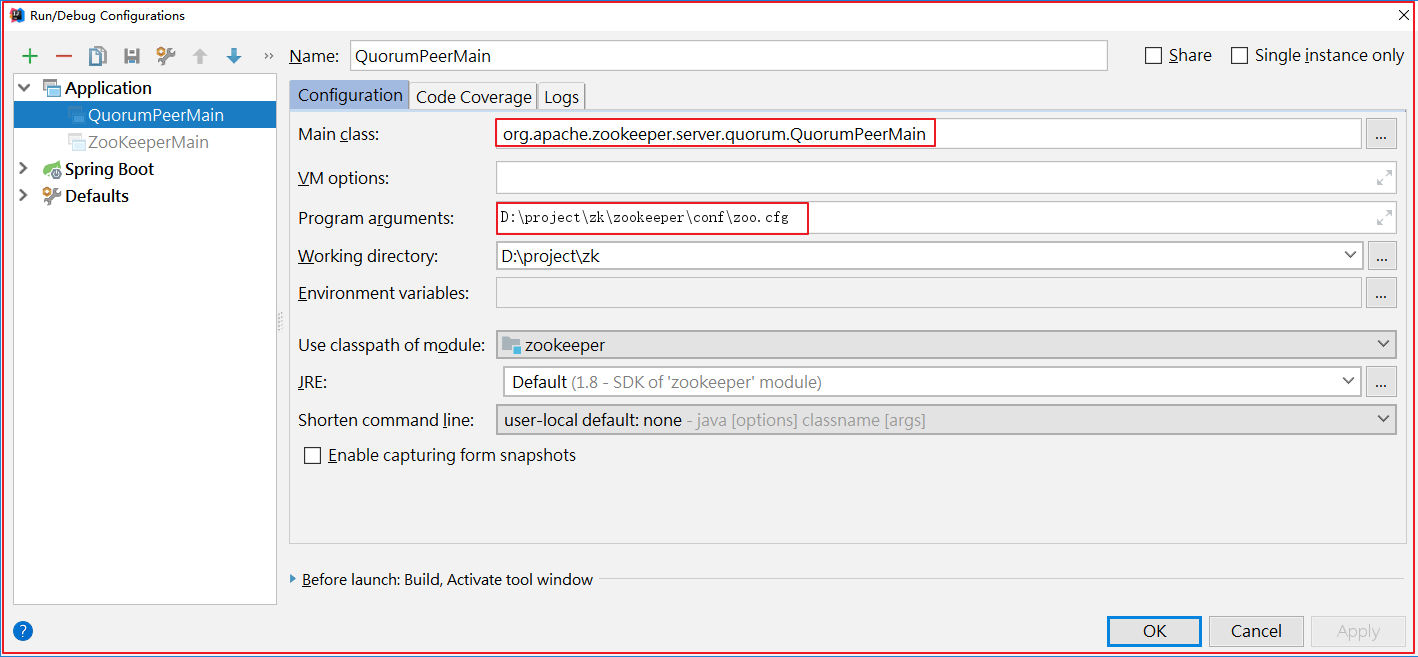
我的idea设置:
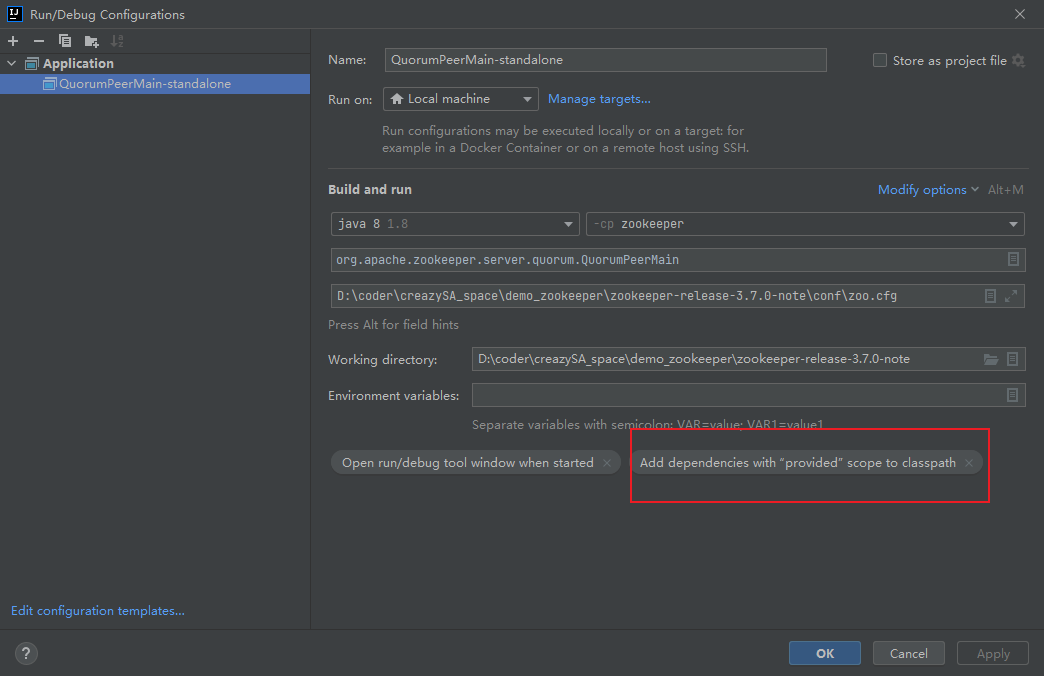
以下步骤如果通过jute编译,就不会有问题
启动的时候会会报很多错误,比如缺包、缺对象,如下几幅图:
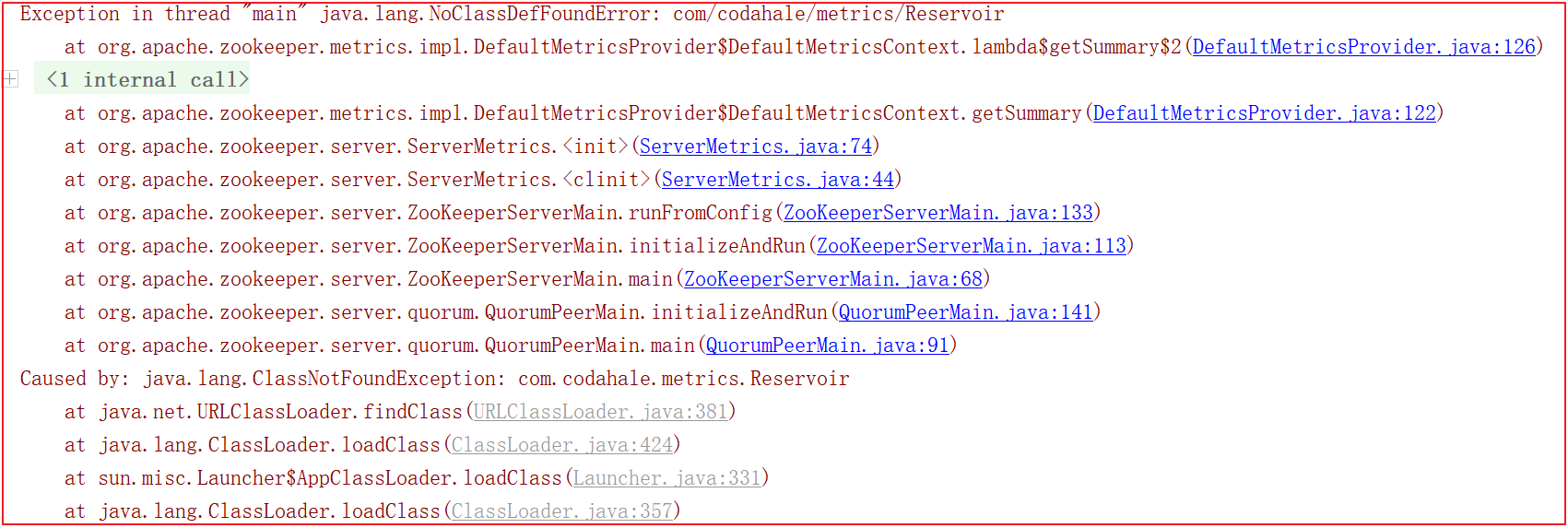

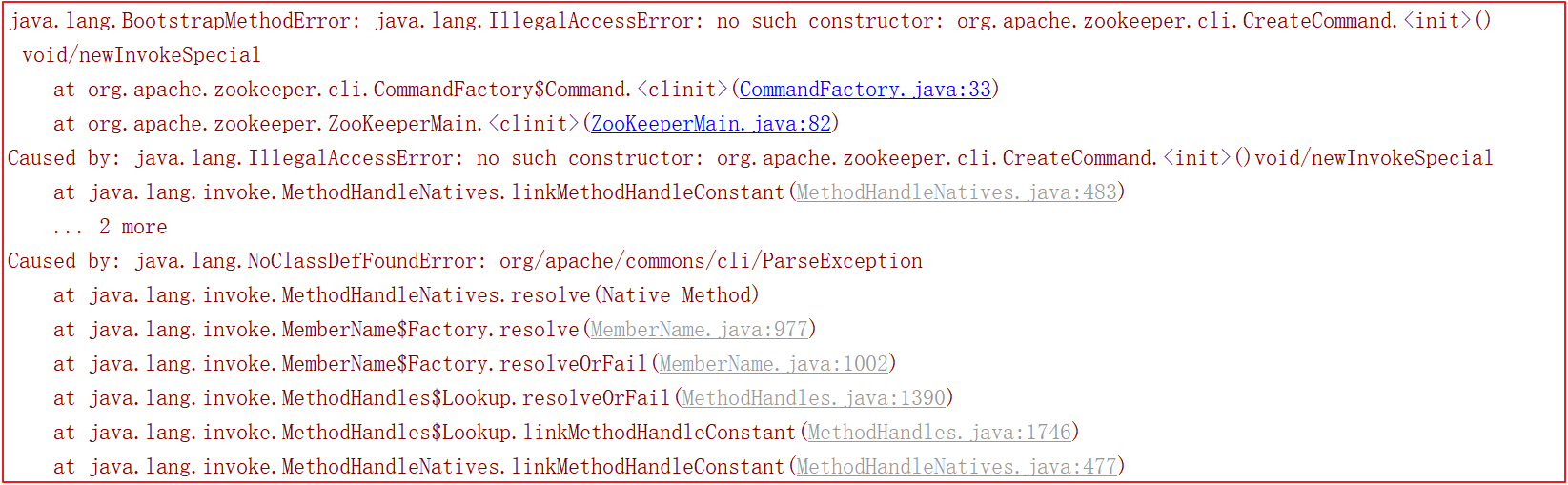
为了解决上面的错误,我们需要手动引入一些包, pom.xml 引入如下依赖:
1 | <!--引入依赖--> |
Zookeeper命令
我们要想学习Zookeeper,需要先学会使用Zookeeper,它有很多丰富的命令,借助这些命令可以深入理解Zookeeper,我们启动源码中的客户端就可以使用Zookeeper相关命令。
启动客户端 org.apache.zookeeper.ZooKeeperMain ,如下图
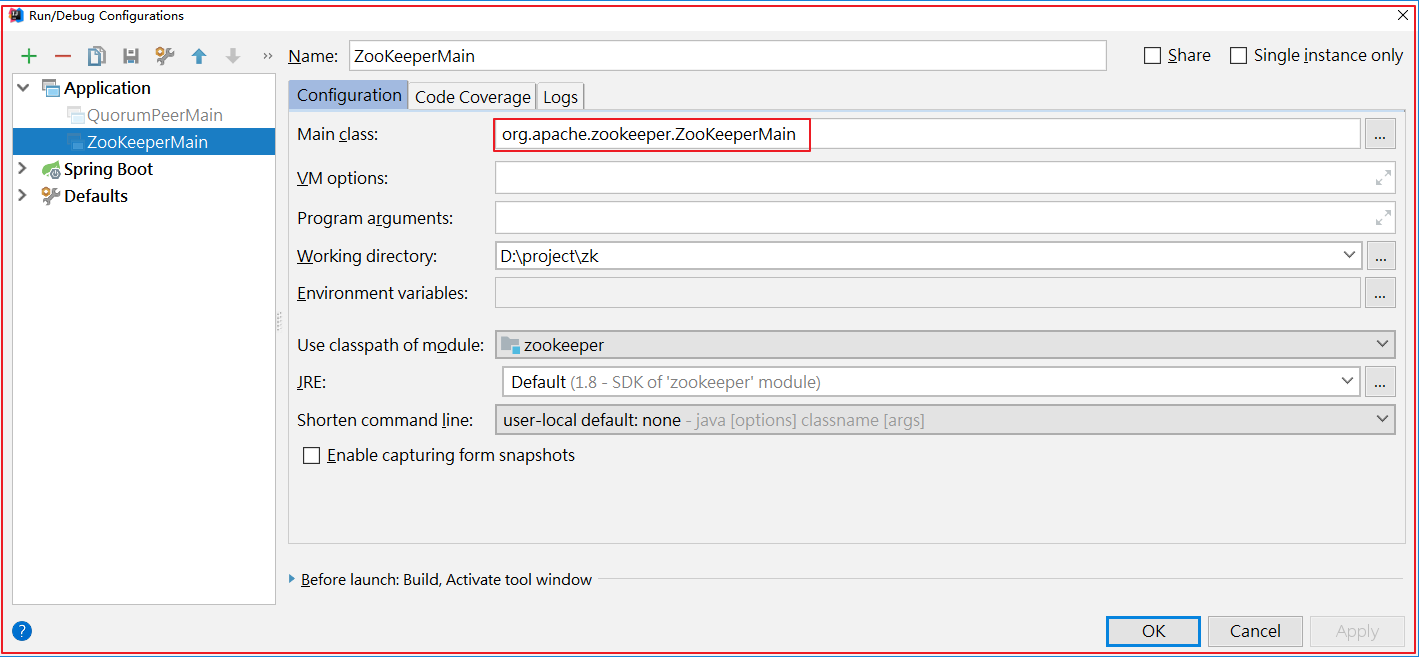
启动后,日志如下

1)节点列表: ls /
1 | ls / |
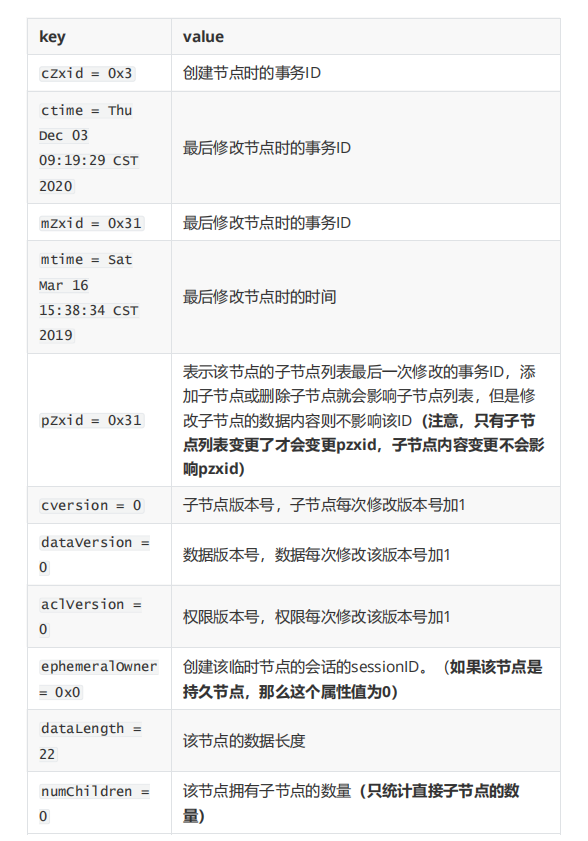
2)查看节点状态: stat /dubbo
1 | stat /dubbo |
节点信息参数说明如下:
3)创建节点: create /dubbo/code java
1 | create /dubbo/code java |
其中code表示节点,java表示节点下的内容。
4)查看节点数据: get /dubbo/code
1 | get /dubbo/code |
5)删除节点: delete /dubbo/code || deleteall /dubbo/code
删除没有子节点的节点: delete /dubbo/code
删除所有子节点: deleteall /dubbo/code
6)历史操作命令: history
1 | history |
Zookeeper分析工具
Zookeeper安装比较方便,在安装一个集群以后,查看数据却比较麻烦,下面介绍Zookeeper的数据查看工具——ZooInspector。
下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
下载压缩包后,解压后,我们需要运行 zookeeper-dev-ZooInspector.jar :

输入账号密码,就可以连接Zookeeper了,如下图:
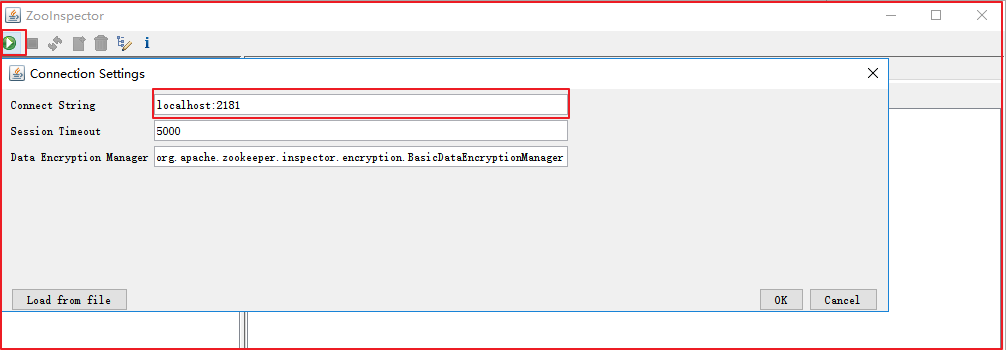
连接后,Zookeeper信息如下:
节点操作:增加节点、修改节点、删除节点
zookeeper源码深入
ZK服务启动流程源码剖析
ZooKeeper 可以以 standalone 、分布式的方式部署, standalone 模式只有一台机器作为服务器, ZooKeeper 会丧失高可用特性,分布式是使用多个器,每台机器上部署一个 ZooKeeper 服务器,即使有服务器宕机,只要少于数, ZooKeeper 集群依然可以正常对外提供服务,集群状态下 Zookeeper 是具高可用特性。
我们接下来对 ZooKeeper 以 standalone 模式启动以及集群模式做一下码分析
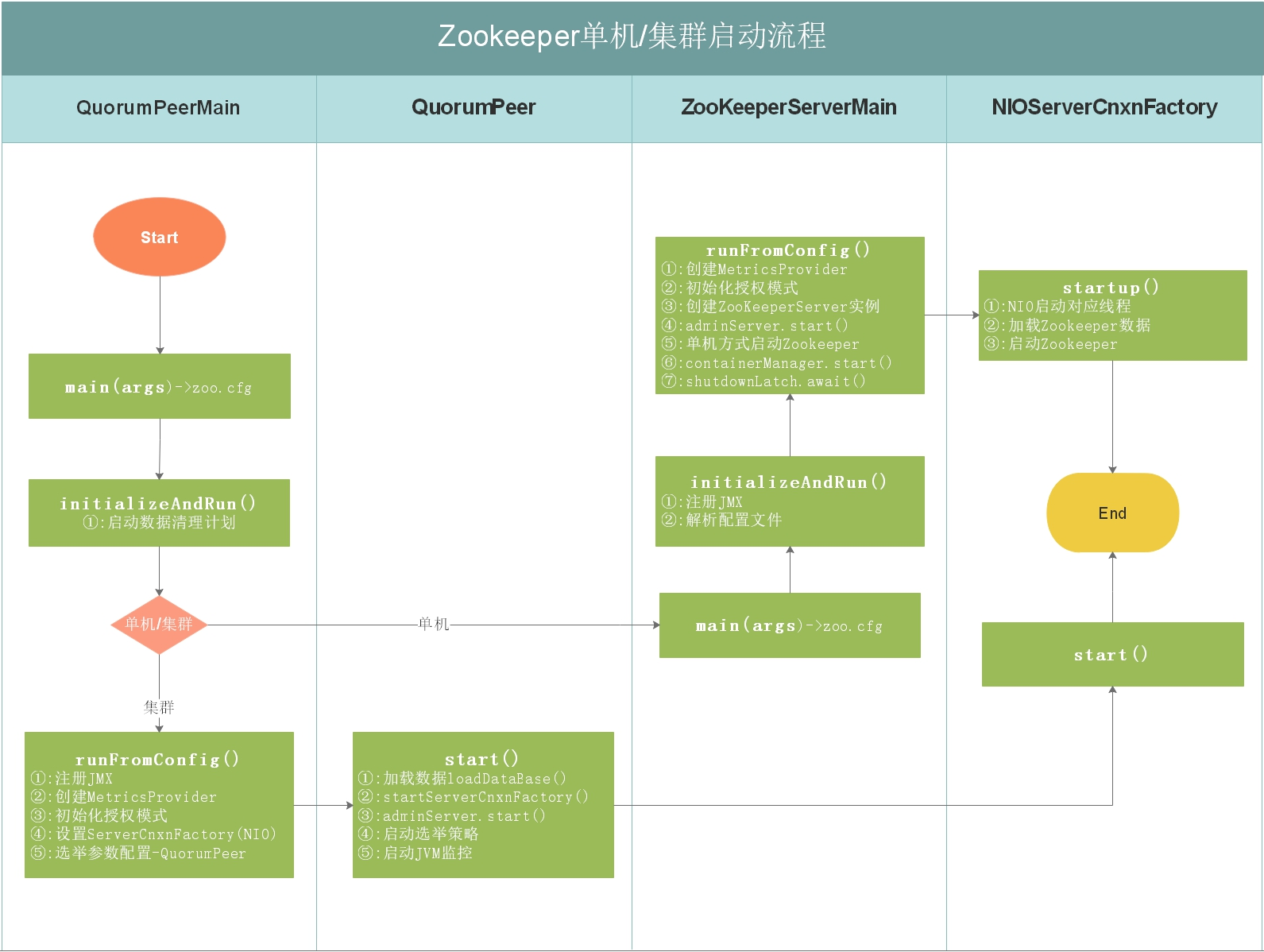
如上图,上图是 Zookeeper 单机/集群启动流程,每个细节所做的事情都在上图有说明,我们接下来按照流程图对源码进行分析
ZK启动入口分析
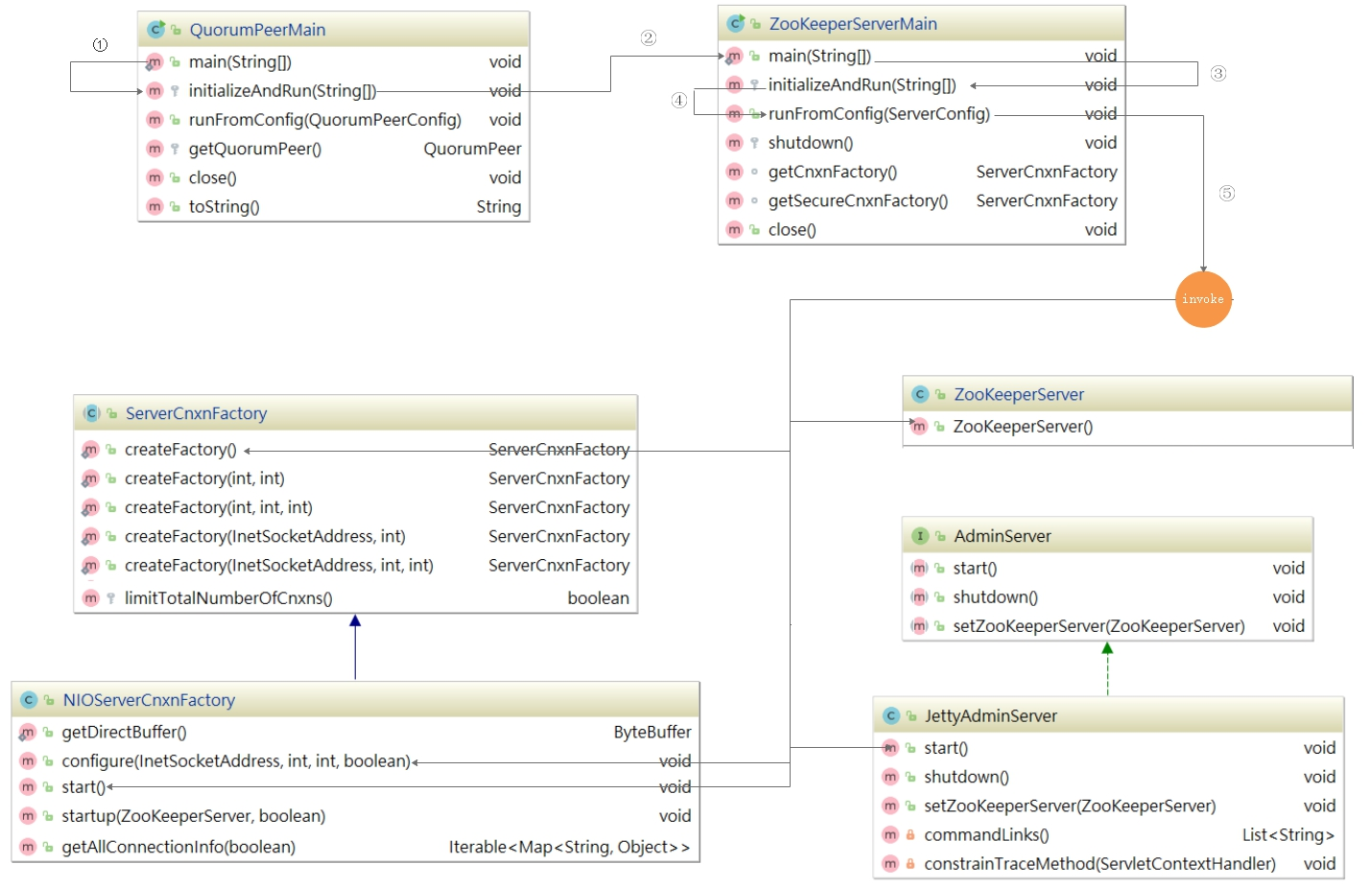
启动入口类:QuorumPeerMain
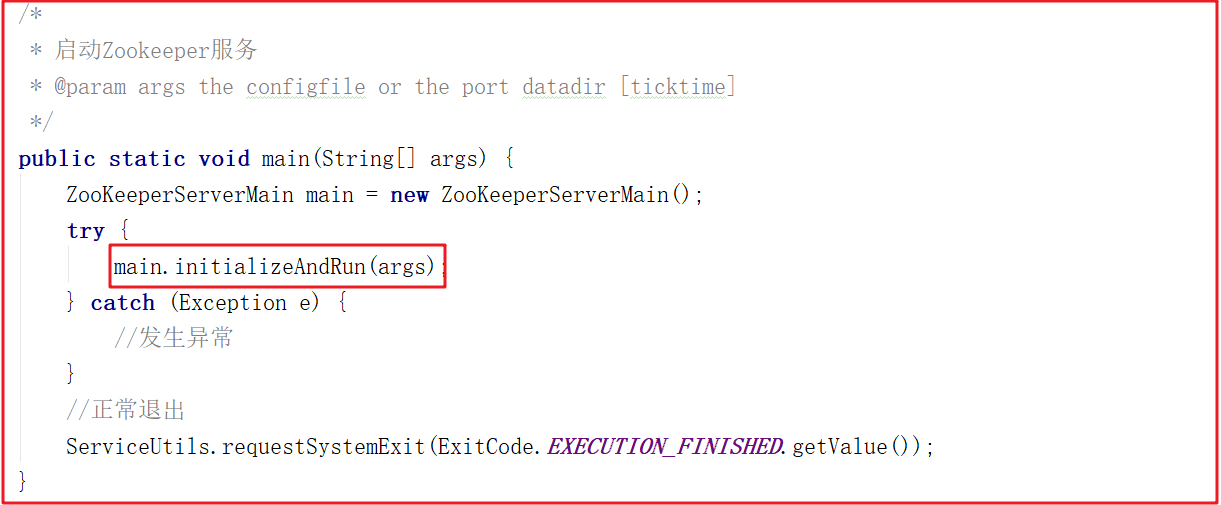
该类是 zookeeper 单机/集群的启动入口类,是用来加载配置、启QuorumPeer (选举相关)线程、创建 ServerCnxnFactory 等,我们可以把代切换到该类的主方法( main )中,从该类的主方法开始分析, main 方法代码分如下:
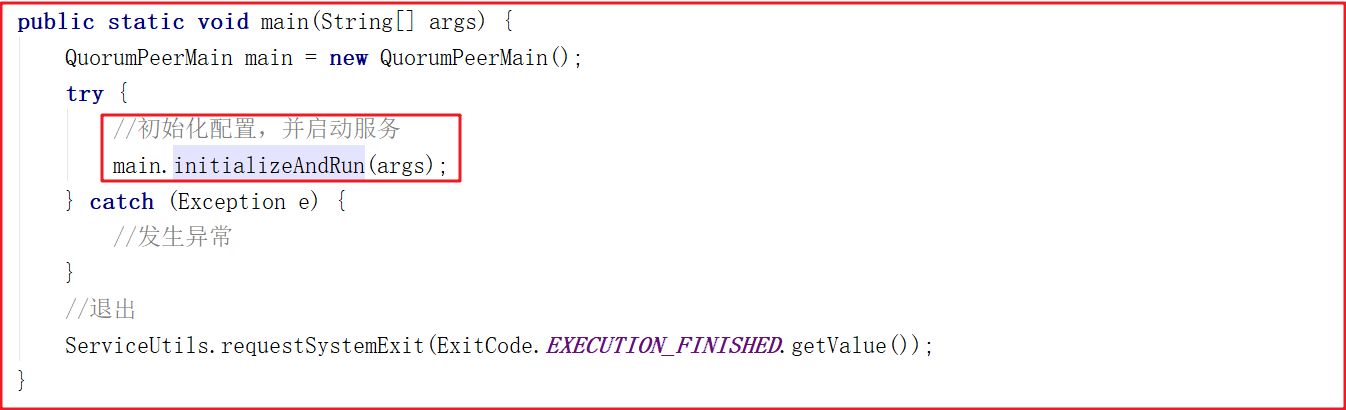
上面main方法虽然只是做了初始化配置,但调用了 initializeAndRun()方法, initializeAndRun() 方法中会根据配置来决定启动单机Zookeeper还是集群Zookeeper,源码如下:
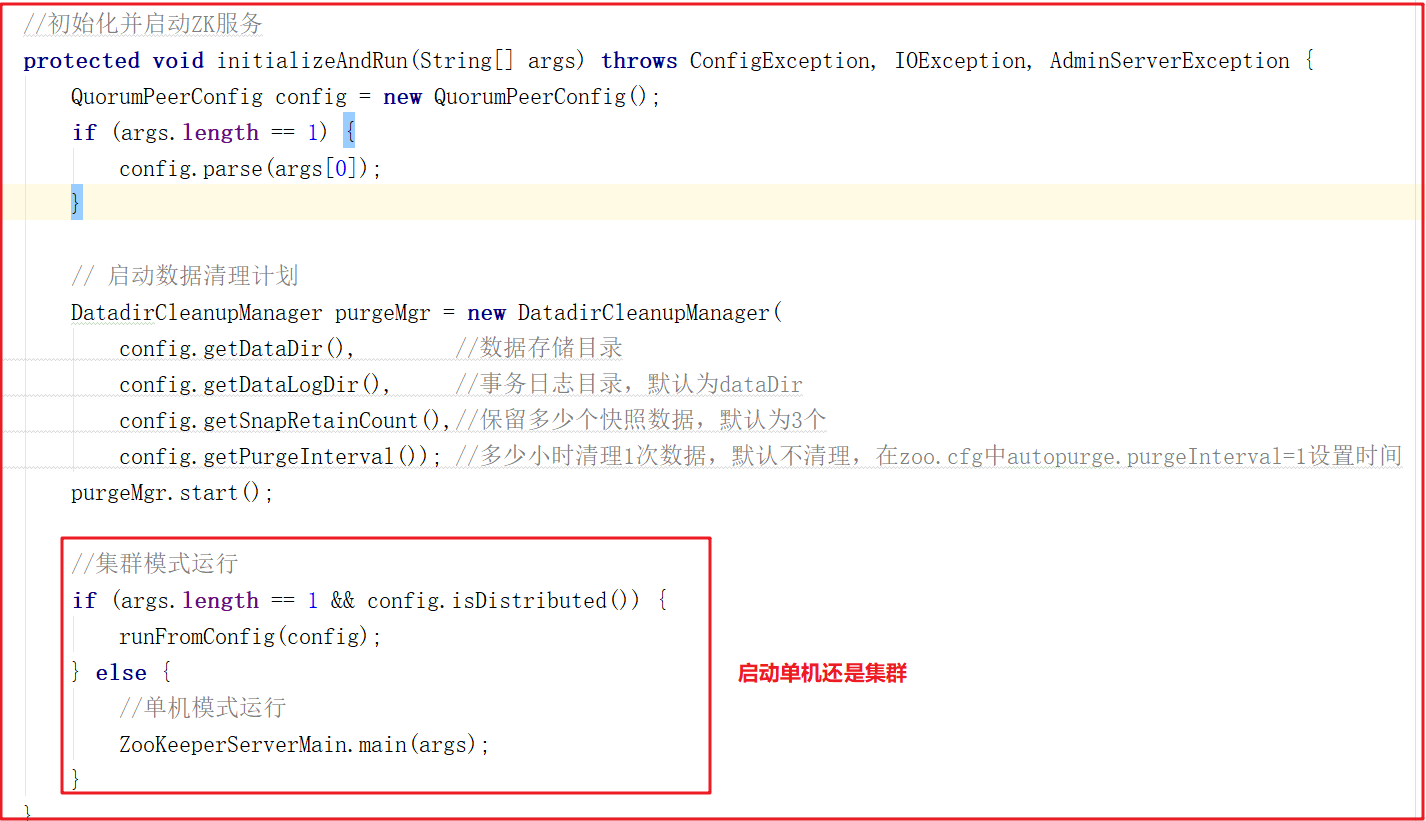
如果启动单机版,会调用 ZooKeeperServerMain.main(args); ,如果启动集群版,会调用 QuorumPeerMain.runFromConfig(config); ,我们接下来对单机版启动做源码详细剖析,集群版在后面章节中讲解选举机制时详细讲解。
单机启动流程详解
zookeeper 网络连接(涉及的类)
连接管理器工厂
客户端连接
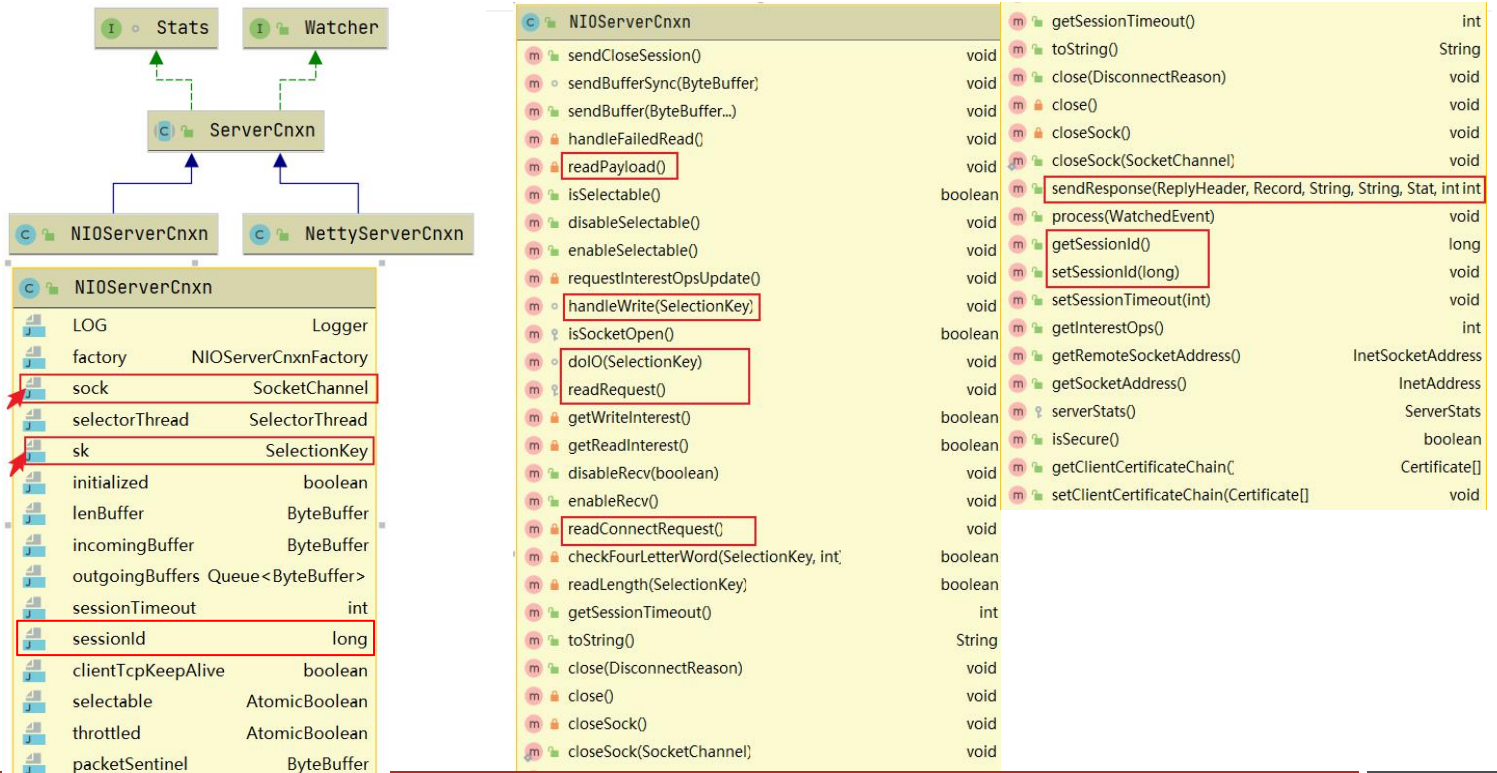
请求处理器链RequestProcessor
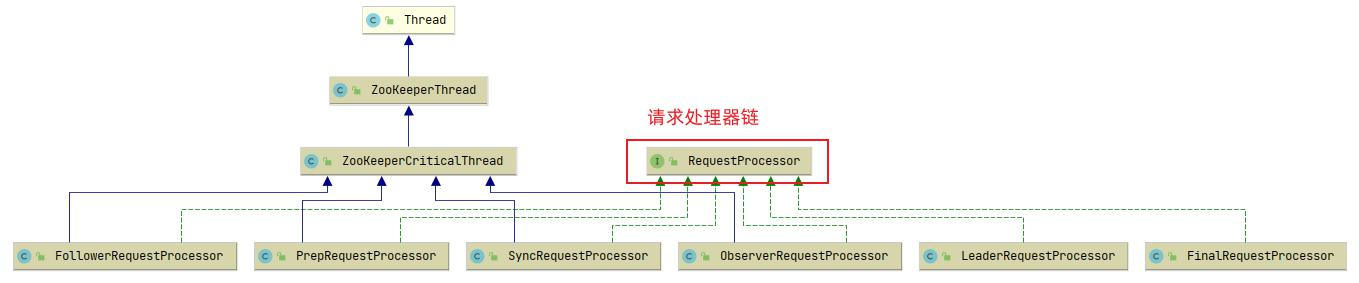

zookeeper 数据库
zk要存数据,所以抽象了个ZKDatabase
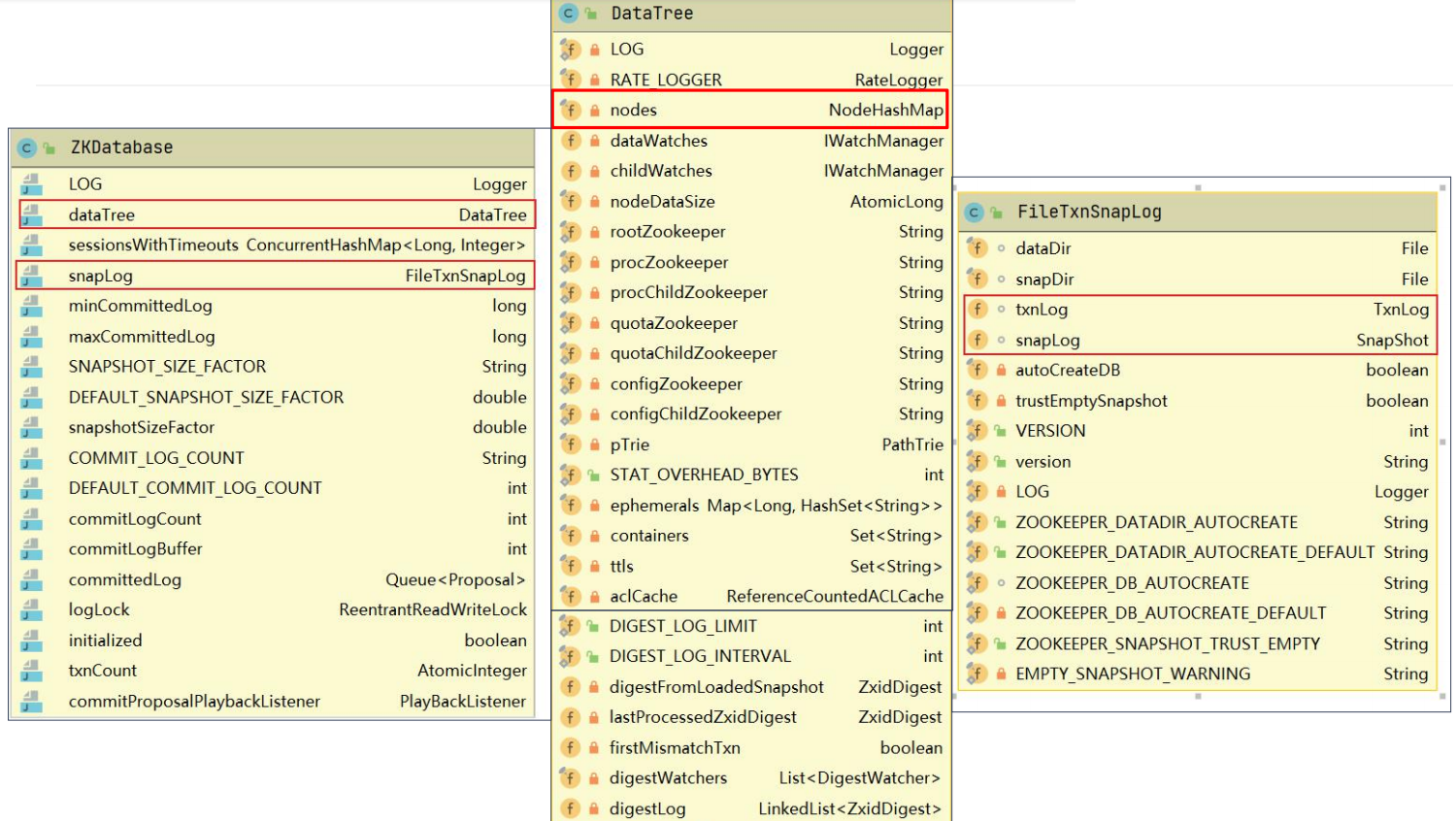
服务端对象ZookeeperServer
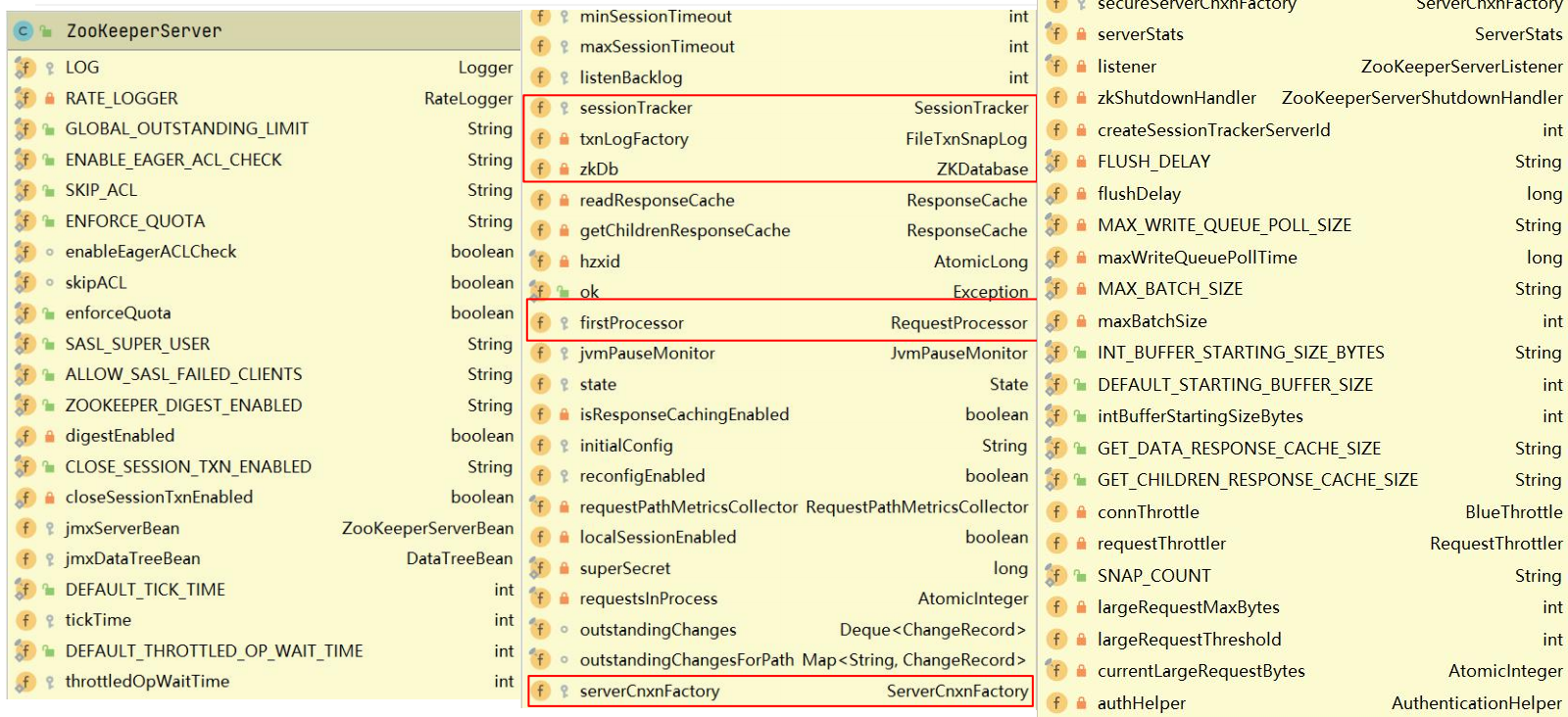
zookeeper 线程模型
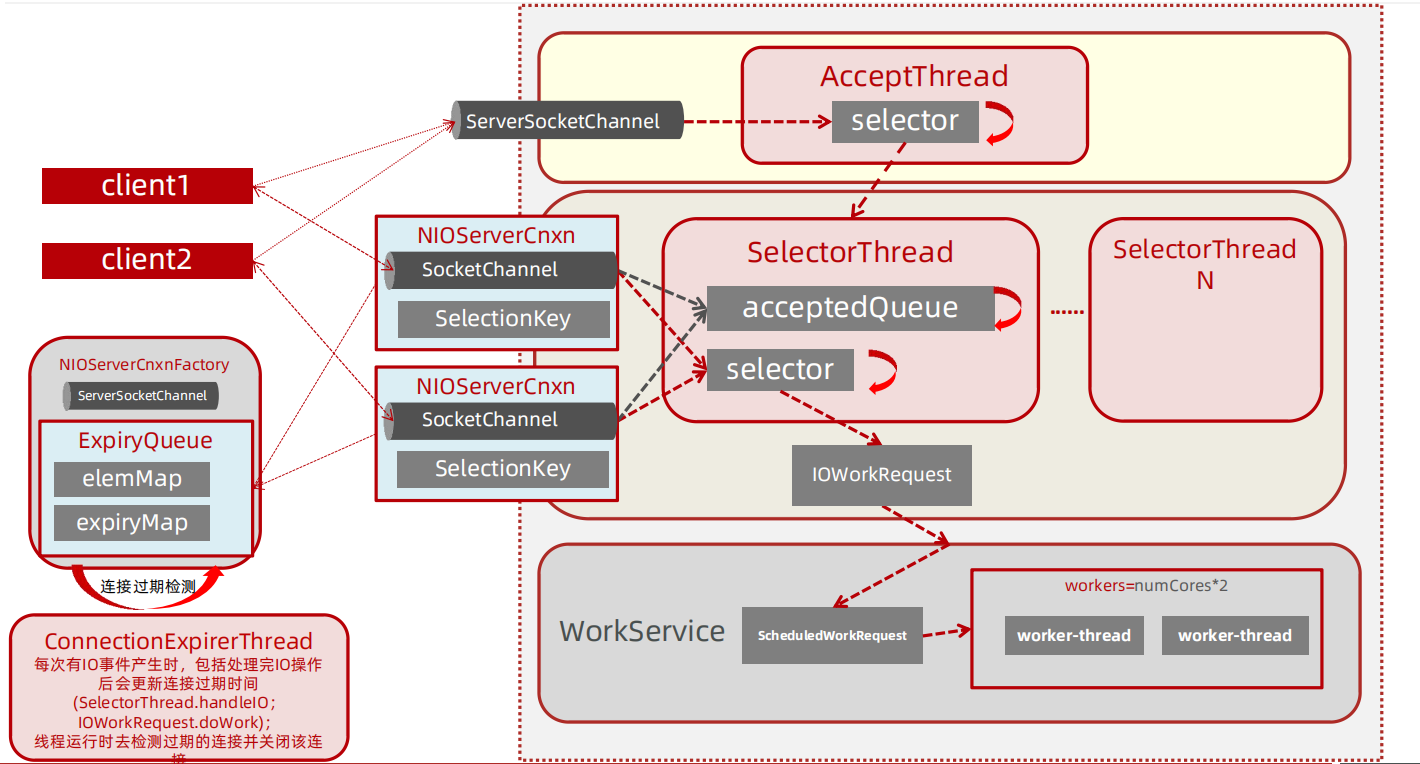
- AcceptThread:负责处理连接的建立
- SelectorThread:负责处理监听客户端连接的IO事件,检测到IO事件后封装事件信息交由worker thread 支持IO操作,线程个数为: sqrt(numCores/2),至少一个;
- ConnectionExpirerThread:负责监听连接会话是否超时
- RreRequestProcessor/SyncRequestProcessor:跟请求处理相关的处理器线程
WorkService / WorkThread:工作线程,处理具体的IO操作
1、调用WorkerService.schedule,将IOWorkRequest传入
2、将IOWorkRequest封装成ScheduledWorkRequest提交到WorkService的workers线程池中执行
3、在ScheduledWorkRequest的run方法中处理IO操作
zookeeper IO模型
zookeeper网络通信模型:
zookeeper 请求处理
zookeeper网络通信模型-请求处理流程
zookeeper Session管理
应用会话-Session
单机启动源码剖析
针对ZK单机启动源码方法调用链,我们已经提前做了一个方法调用关系图,我们讲解ZK单机启动源码,将和该图进行一一匹对,如下图:
1)单机启动入口
按照上面的源码分析,我们找到 ZooKeeperServerMain.main(args) 方法,该方法调用了 ZooKeeperServerMain 的 initializeAndRun 方法,在initializeAndRun 方法中执行初始化操作,并运行Zookeeper服务,main方法如下,debug断点启动并调试观察。
2)配置文件解析
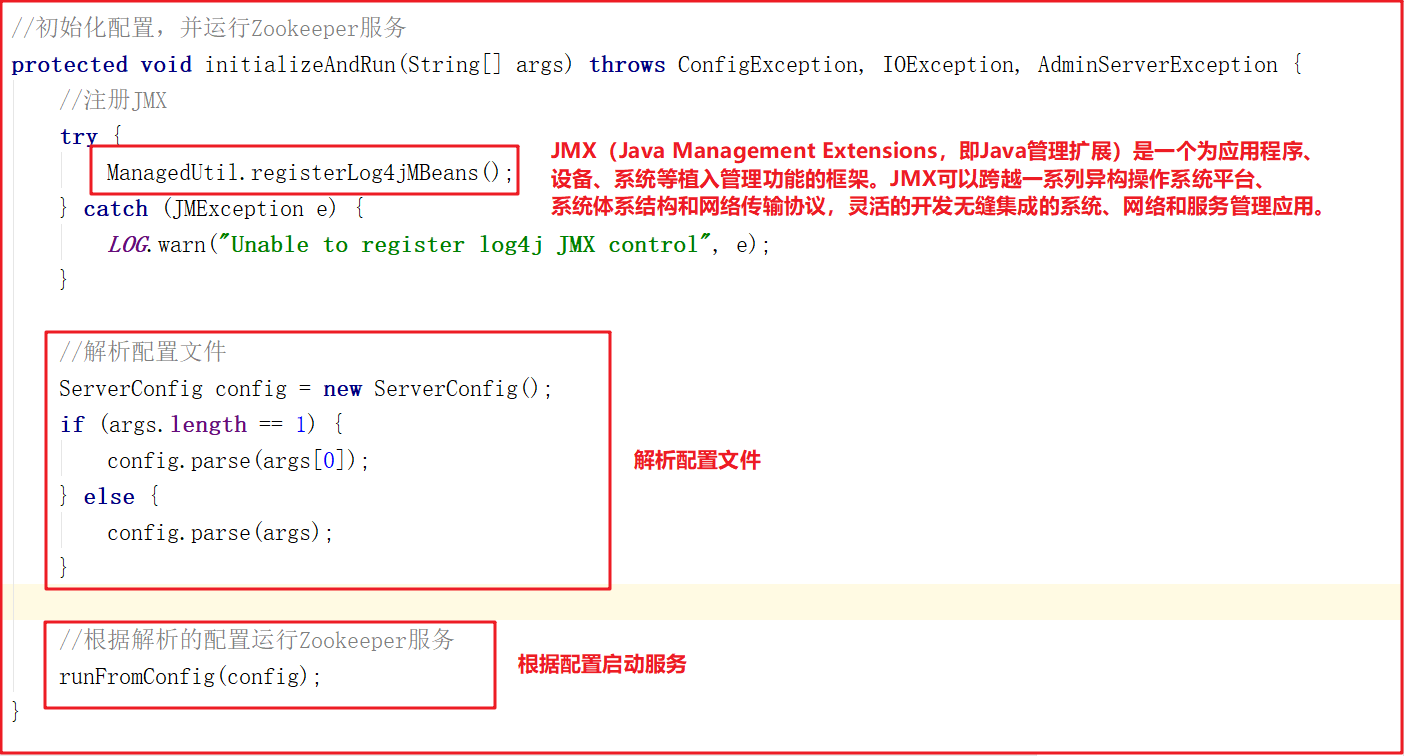
initializeAndRun() 方法会注册JMX,同时解析 zoo.cfg 配置文件,并调用 runFromConfig() 方法启动Zookeeper服务,源码如下
3)单机启动主流程
runFromConfig 方法是单机版启动的主要方法,该方法会做如下几件事:
- 1:初始化各类运行指标,比如一次提交数据最大花费多长时间、批量同步数据大小等。
- 2:初始化权限操作,例如IP权限、Digest权限。
- 3:创建事务日志操作对象,Zookeeper中每次增加节点、修改数据、删除数据都是一次事务操作,都会记录日志。
- 4:定义Jvm监控变量和常量,例如警告时间、告警阀值次数、提示阀值次数等。
- 5:创建ZookeeperServer,这里只是创建,并不在ZooKeeperServerMain类中启动。
- 6:启动Zookeeper的控制台管理对象AdminServer,该对象采用Jetty启动。
- 7:创建ServerCnxnFactory,该对象其实是Zookeeper网络通信对象,默认使用了NIOServerCnxnFactory。
- 8:在ServerCnxnFactory中启动ZookeeperServer服务。
- 9:创建并启动ContainerManager,该对象通过Timer定时执行,清理过期的容器节点和TTL节点,执行周期为分钟。
- 10:防止主线程结束,阻塞主线程。
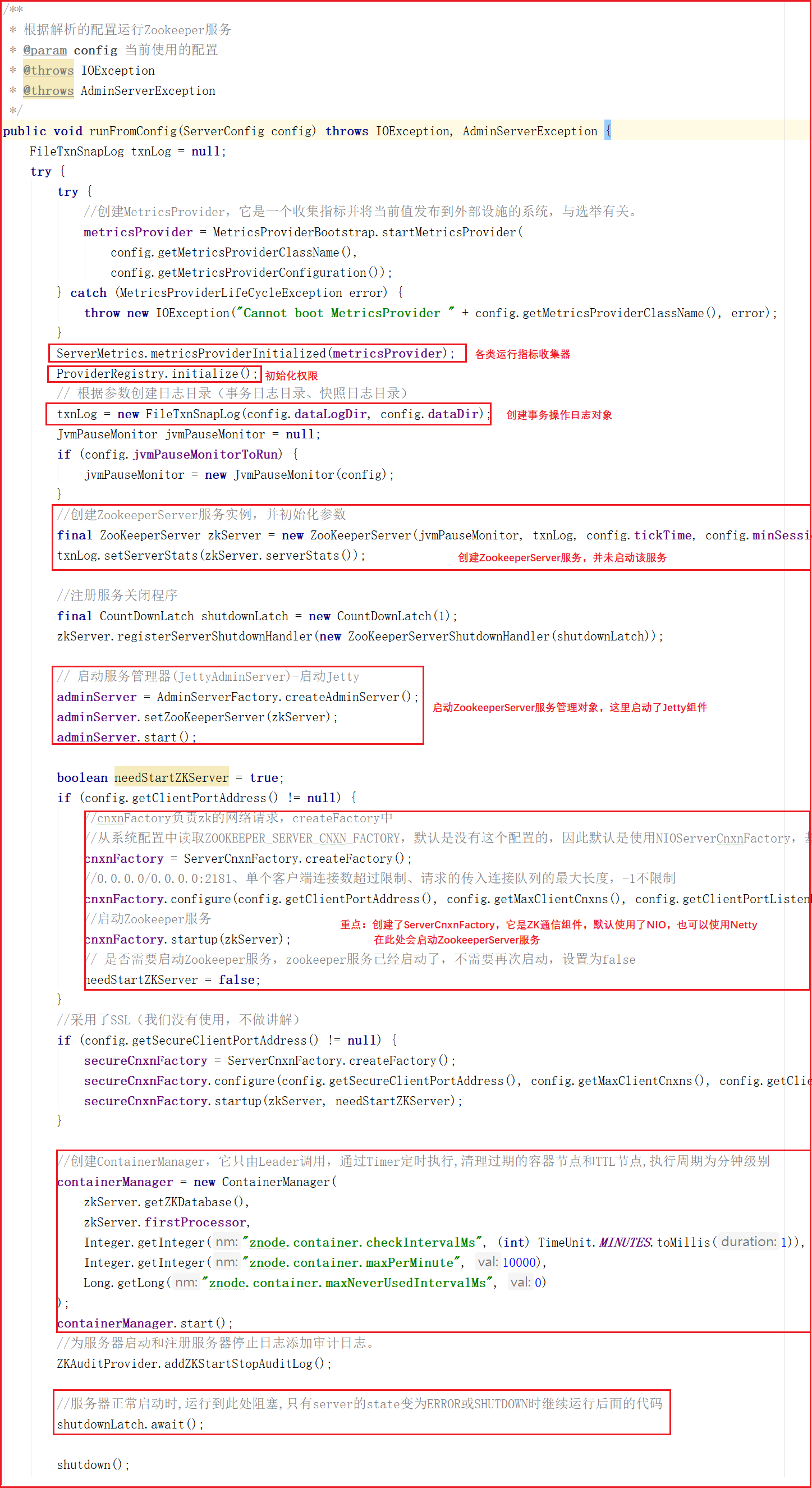
4)网络通信对象创建
上面方法在创建网络通信对象的时候调用了ServerCnxnFactory.createFactory() ,该方法其实是根据系统配置创建Zookeeper通信组件,可选的有 NIOServerCnxnFactory(默认) 和 NettyServerCnxnFactory ,关于通信对象我们会在后面进行详细讲解,该方法源码如下:
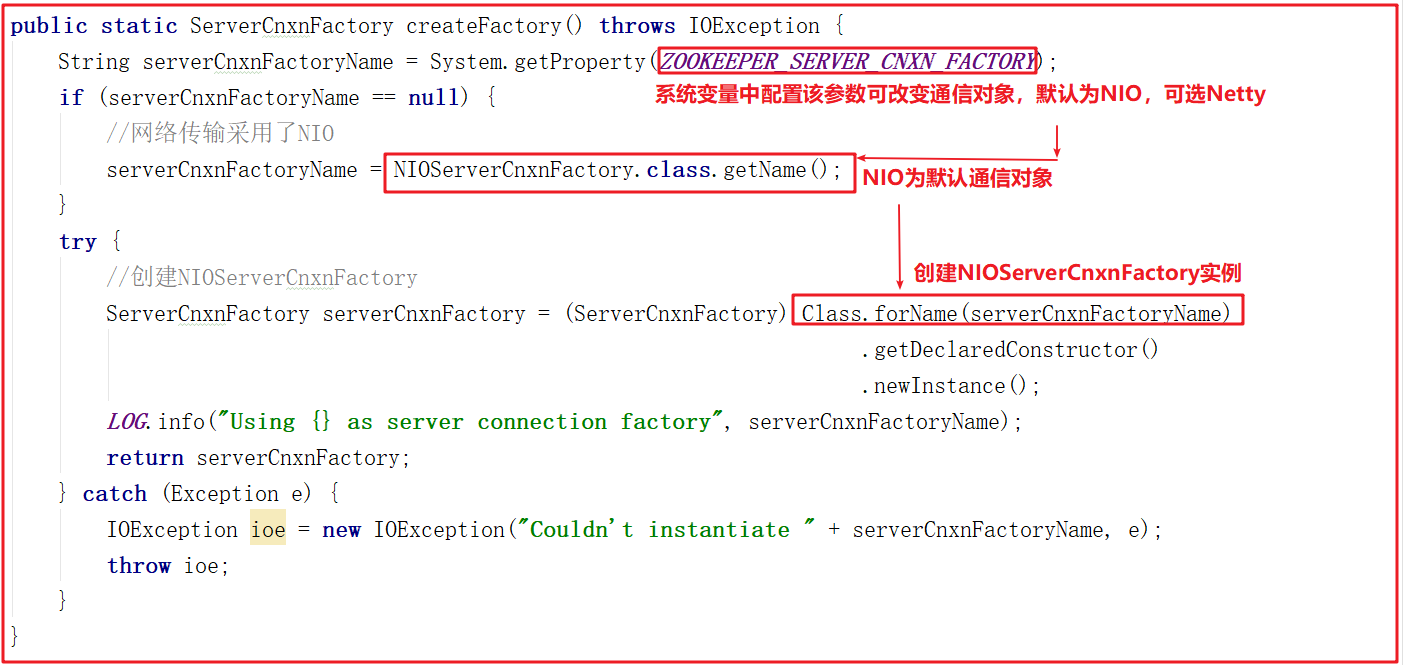
5)单机启动
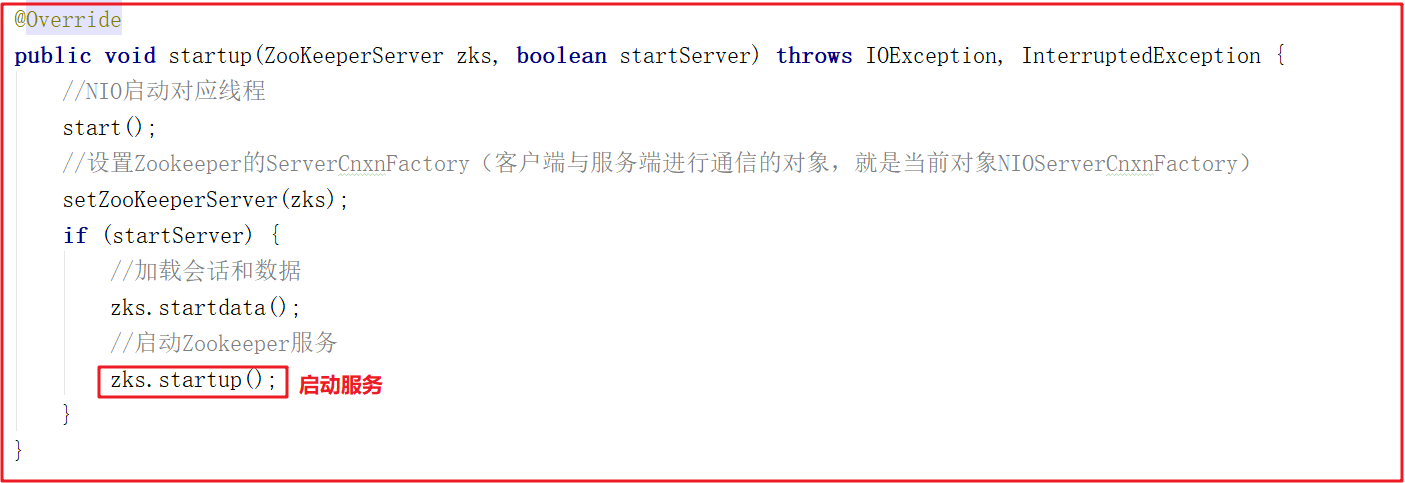
cnxnFactory.startup(zkServer); 方法其实就是启动了ZookeeperServer ,它调用 NIOServerCnxnFactory 的 startup 方法,该方法中会调用 ZookeeperServer 的 startup 方法启动服务,ZooKeeperServerMain 运行到 shutdownLatch.await(); 主线程会阻塞住,源码如下:
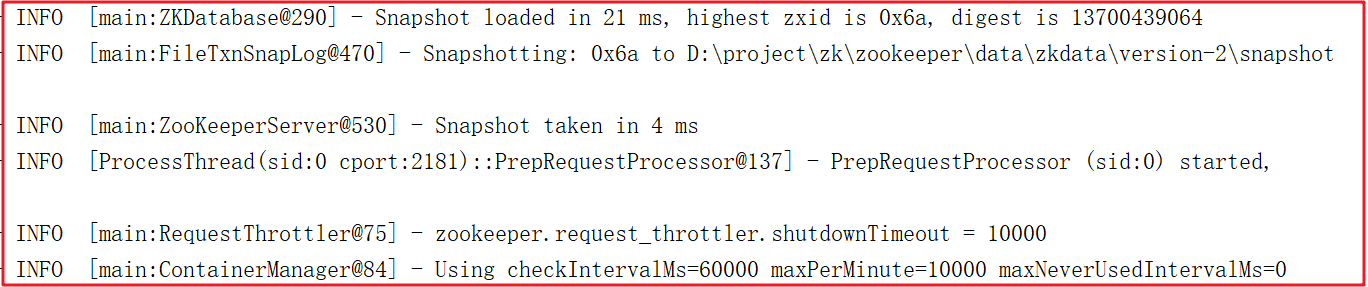
启动后日志:
ZK网络通信源码剖析
Zookeeper 作为一个服务器,自然要与客户端进行网络通信,如何高效的与客户端进行通信,让网络 IO 不成为 ZooKeeper 的瓶颈是 ZooKeeper 急需解决的问
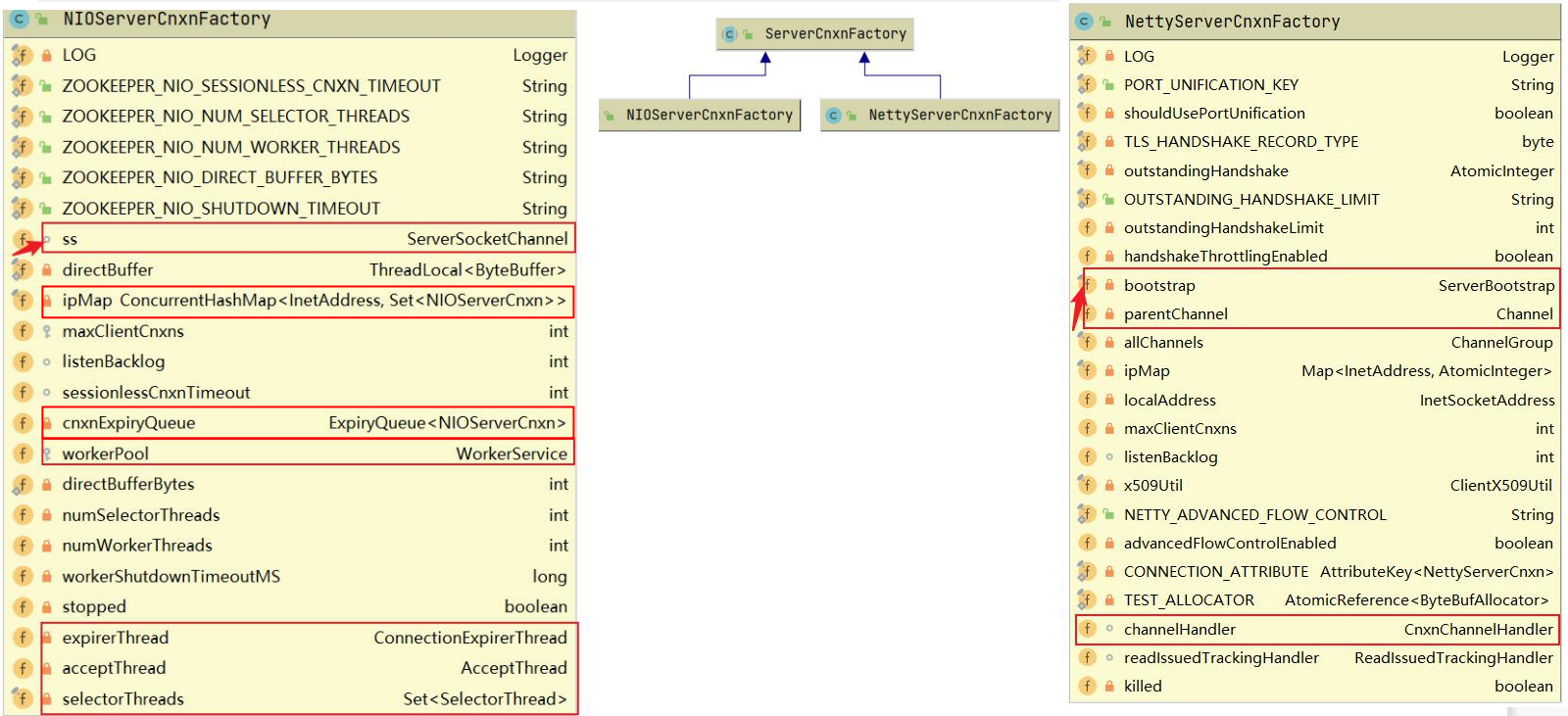
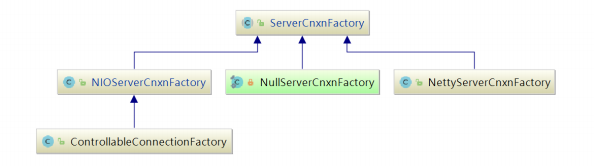
题, ZooKeeper 中使用 ServerCnxnFactory 管理与客户端的连接,其有两个实现,一个是 NIOServerCnxnFactory ,使用Java原生 NIO 实现;一个是NettyServerCnxnFactory ,使用netty实现;使用 ServerCnxn 代表一个客户端与服务端的连接。
从单机版启动中可以发现 Zookeeper 默认通信组件为NIOServerCnxnFactory ,他们和 ServerCnxnFactory 的关系如下图:
NIOServerCnxnFactory工作流程
一般使用Java NIO的思路为使用1个线程组监听 OP_ACCEPT 事件,负责处理客户端的连接;使用1个线程组监听客户端连接的 OP_READ 和 OP_WRITE 事件,处 理IO事件(netty也是这种实现方式).
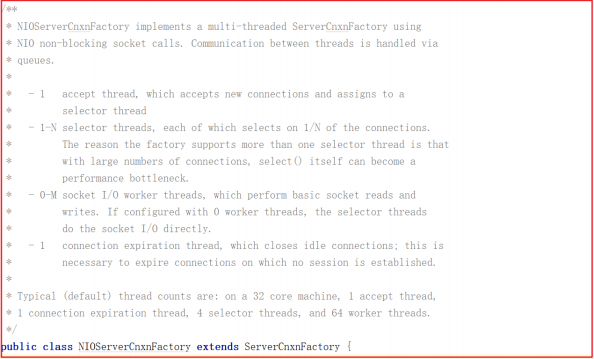
但ZooKeeper并不是如此划分线程功能的, NIOServerCnxnFactory 启动时会启动四类线程:
- 1:accept thread:该线程接收来自客户端的连接,并将其分配给selector thread(启动一个线程)。
- 2:selector thread:该线程执行select(),由于在处理大量连接时,select()会成为性能瓶颈,因此启动多个selector thread,使用系统属性zookeeper.nio.numSelectorThreads配置该类线程数,默认个数为 核 心数/2。
- 3:worker thread:该线程执行基本的套接字读写,使用系统属性zookeeper.nio.numWorkerThreads配置该类线程数,默认为核心数∗2核心数∗2.如果该类线程数为0,则另外启动一线程进行IO处理,见下文worker thread介绍。
- 4:connection expiration thread:若连接上的session已过期,则关闭该连接。
这四个线程在 NIOServerCnxnFactory 类上有说明,如下图:
ZooKeeper 中对线程需要处理的工作做了更细的拆分,解决了有大量客户端连接的情况下, selector.select() 会成为性能瓶颈,将 selector.select() 拆分出来,交由 selector thread 处理。
NIOServerCnxnFactory源码
NIOServerCnxnFactory的源码分析我们将按照上面所介绍的4个线程实现相关分析,并实现数据操作,在程序中获取指定数据。
AcceptThread剖析
为了让大家更容易理解AcceptThread,我们把它的结构和方法调用关系画了一个详细的流程图,如下图:
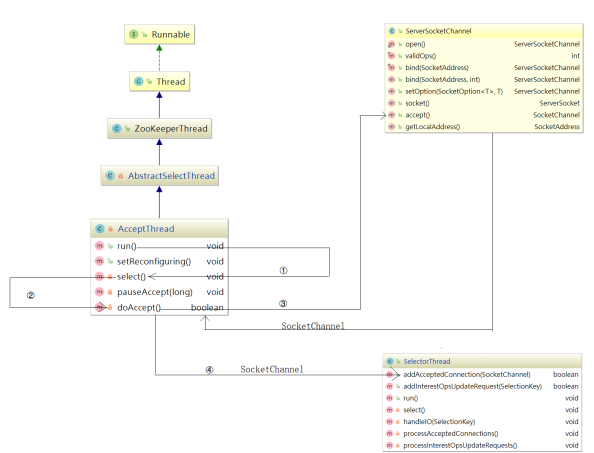
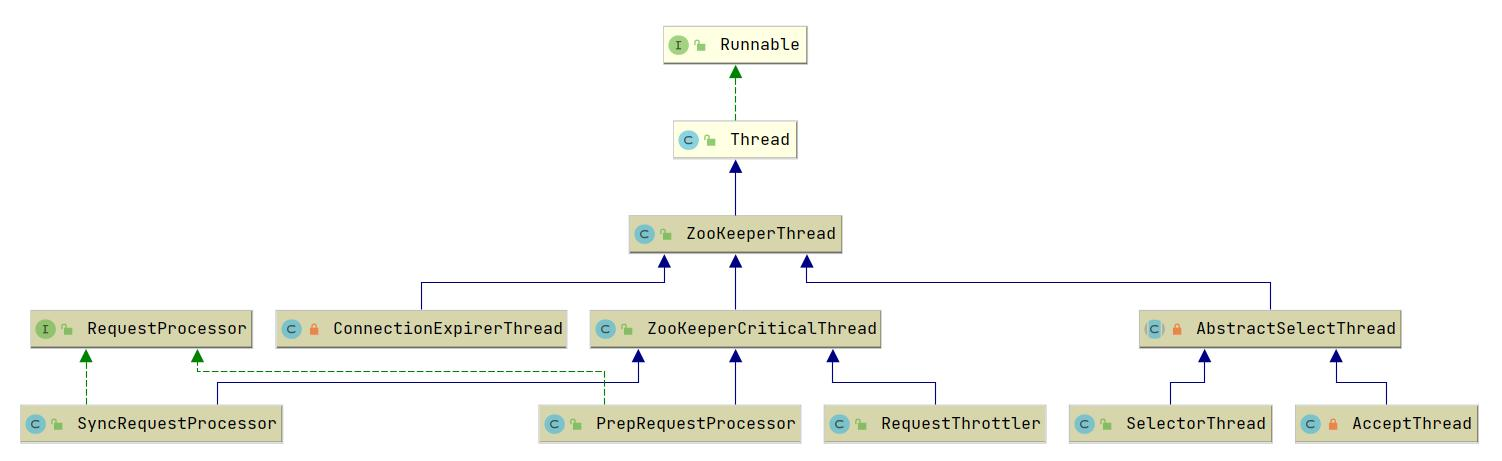
在 NIOServerCnxnFactory 类中有一个 AccpetThread 线程,为什么说它是一个线程?我们看下它的继承关系: AcceptThread > AbstractSelectThread > ZooKeeperThread > Thread,该线程接收来自客户端的连接,并将其分配给selector thread(启动一个线程)。
该线程执行流程: run 执行 selector.select() ,并调用 doAccept() 接收客户端连接,因此我们可以着重关注 doAccept() 方法,该类源码如下:
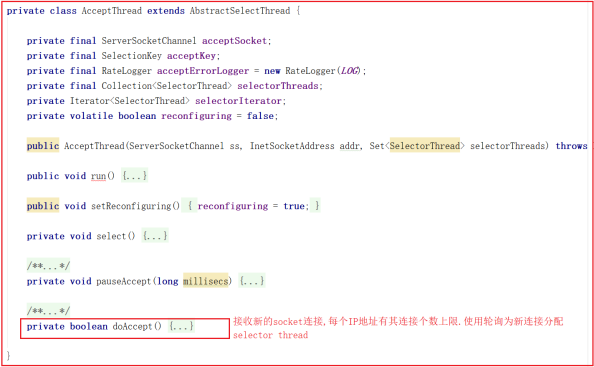
doAccept() 方法用于处理客户端链接,当客户端链接 Zookeeper 的时候,首先会调用该方法,调用该方法执行过程如下:
1:和当前服务建立链接。
2:获取远程客户端计算机地址信息。
3:判断当前链接是否超出最大限制。
4:调整为非阻塞模式。
5:轮询获取一个SelectorThread,将当前链接分配给该SelectorThread。
6:将当前请求添加到该SelectorThread的acceptedQueue中,并唤醒该SelectorThread。
doAccept() 方法源码如下:
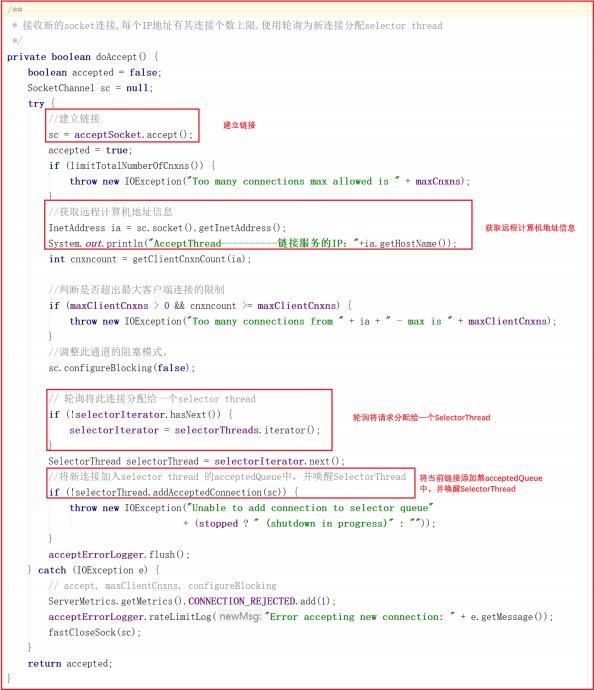
上面代码中 addAcceptedConnection 方法如下:

我们把项目中的分布式案例服务启动,可以看到如下日志打印:
1 | AcceptThread----------链接服务的IP:127.0.0.1 |
SelectorThread剖析
同样为了更容易梳理 SelectorThread ,我们也把它的结构和方法调用关系梳理成了流程图,如下图:
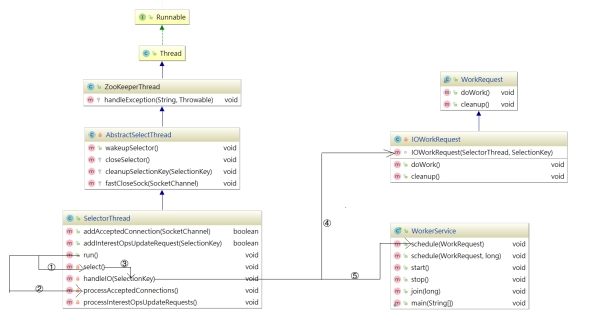
该线程的主要作用是从Socket读取数据,并封装成 workRequest ,并将workRequest 交给 workerPool 工作线程池处理,同时将acceptedQueue中未处理的链接取出,并未每个链接绑定 OP_READ 读事件,并封装对应的上下文对象 NIOServerCnxn 。 SelectorThread 的run方法如下:
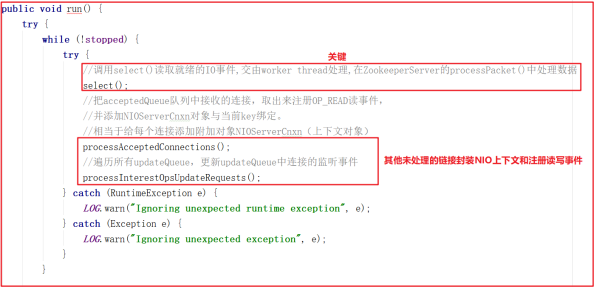
run() 方法中会调用 select() ,而 select() 中的核心调用地方是handleIO() ,我们看名字其实就知道这里是处理客户端请求的数据,但客户端请求数据并非在 SelectorThread 线程中处理,我们接着看 handleIO() 方法。
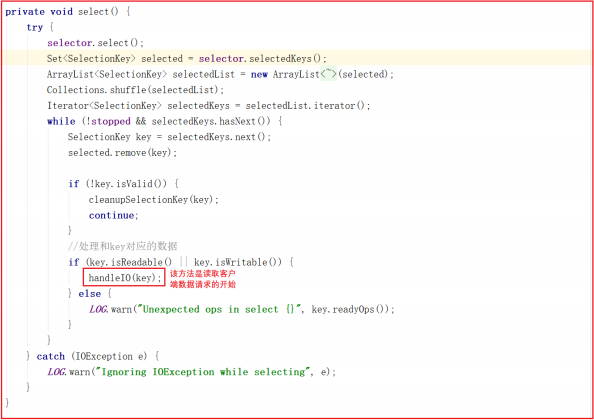
handleIO() 方法会封装当前 SelectorThread 为 IOWorkRequest ,并将IOWorkRequest 交给 workerPool 来调度,而 workerPool 调度才是读数据的开始,源码如下:
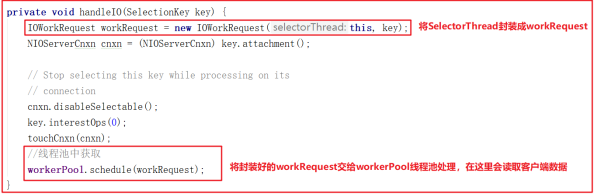
WorkerThread剖析
WorkerThread相比上面的线程而言,调用关系颇为复杂,设计到了多个对象方法调用,主要用于处理IO,但并未对数据做出处理,数据处理将有业务链对象RequestProcessor处理,调用关系图如下:

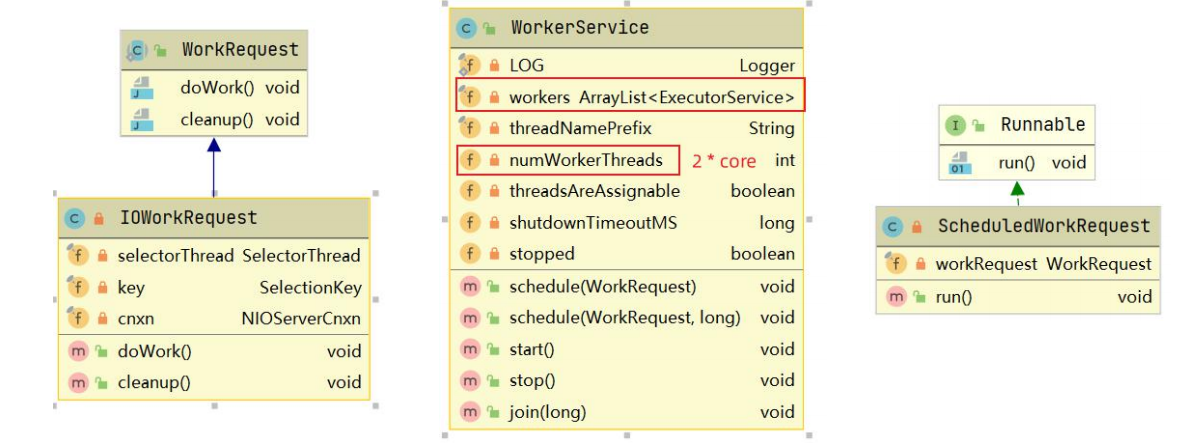
ZooKeeper 中通过 WorkerService 管理一组 worker thread 线程,前面我们在看 SelectorThread 的时候,能够看到 workerPool 的schedule方法被执行,如下图:
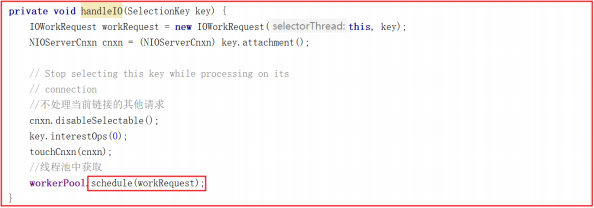
我们跟踪 workerPool.schedule(workRequest); 可以发现它调用了WorkerService.schedule(workRequest) > WorkerService.schedule(WorkRequest, long) ,该方法创建了一个新的线程 ScheduledWorkRequest ,并启动了该线程,源码如下:
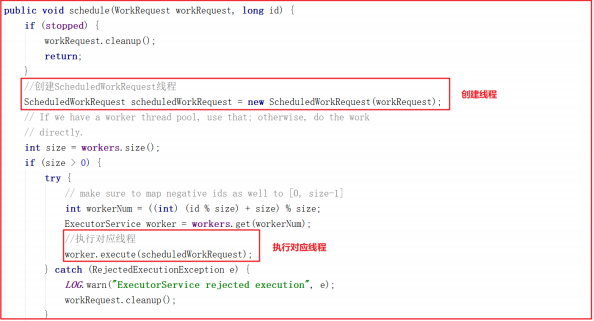
ScheduledWorkRequest 实现了 Runnable 接口,并在 run() 方法中调用了 IOWorkRequest 中的 doWork 方法,在该方法中会调用 doIO 执行IO数据处理,源码如下:
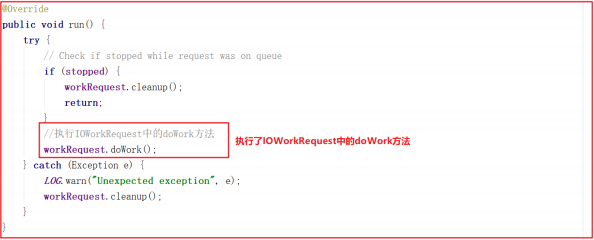
IOWorkRequest 的 doWork 源码如下:
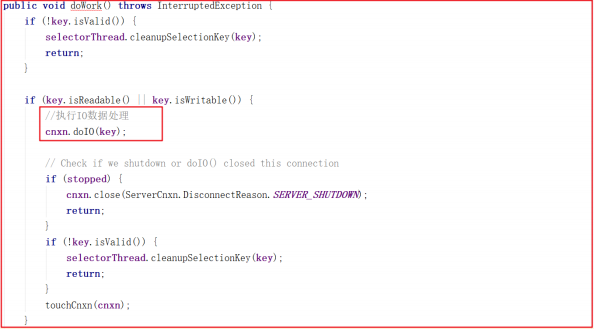
接下来的调用链路比较复杂,我们把核心步骤列出,在能直接看到数据读取的地方详细分析源码。上面方法调用链路:NIOServerCnxn.doIO()>readPayload()>readRequest() >ZookeeperServer.processPacket() ,最后一步方法是获取核心数据的地方,我们可以修改下代码读取数据:
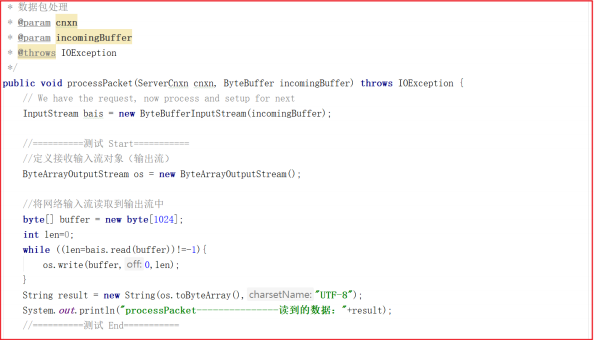
添加测试代码如下:
1 | //==========测试 Start=========== |
我们启动客户端创建一个demo节点,并添加数据为 abcdefg
1 | create /demo abcdefg |
控制台数据如下:

测试完成后,不要忘了将该测试注释掉。我们可以执行其他增删改查操作,可以输出 RequestHeader.type 查看操作类型,操作类型代码在 ZooDefs中有标识,常用的操作类型如下:
1 | int create = 1; |
ConnectionExpirerThread剖析
后台启动 ConnectionExpirerThread 清理线程清理过期的 session ,线程中无限循环,执行工作如下:
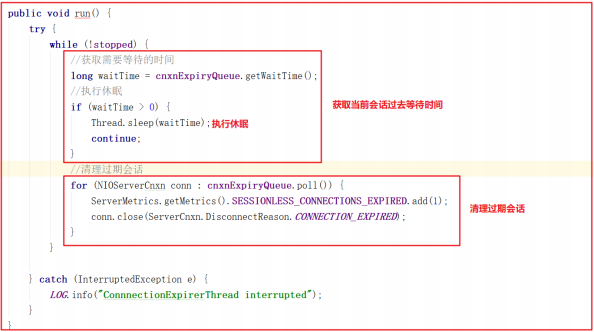
ZK通信优劣总结
Zookeeper在通信方面默认使用了NIO,并支持扩展Netty实现网络数据传输。相比传统IO,NIO在网络数据传输方面有很多明显优势:
1:传统IO在处理数据传输请求时,针对每个传输请求生成一个线程,如果IO 异常,那么线程阻塞,在IO恢复后唤醒处理线程。在同时处理大量连接时, 会实例化大量的线程对象。每个线程的实例化和回收都需要消耗资源,jvm需 要为其分配TLAB,然后初始化TLAB,最后绑定线程,线程结束时又需要回收 TLAB,这些都需要CPU资源。
2:NIO使用selector来轮询IO流,内部使用poll或者epoll,以事件驱动形 式来相应IO事件的处理。同一时间只需实例化很少的线程对象,通过对线程 的复用来提高CPU资源的使用效率。
3:CPU轮流为每个线程分配时间片的形式,间接的实现单物理核处理多线程。 当线程越多时,每个线程分配到的时间片越短,或者循环分配的周期越长, CPU很多时间都耗费在了线程的切换上。线程切换包含线程上个线程数据的同 步(TLAB同步),同步变量同步至主存,下个线程数据的加载等等,他们都是很耗费CPU资源的。
4:在同时处理大量连接,但活跃连接不多时,NIO的事件响应模式相比于传统IO有着极大的性能提升。NIO还提供了FileChannel,以zero-copy的形式传输数据,相较于传统的IO,数据不需要拷贝至用户空间,可直接由物理硬件(磁盘等)通过内核缓冲区后直接传递至网关,极大的提高了性能。
5:NIO提供了MappedByteBuffer,其将文件直接映射到内存(这里的内存指 的是虚拟内存,并不是物理内存),能极大的提高IO吞吐能力。
ZK在使用NIO通信虽然大幅提升了数据传输能力,但也存在一些代码诟病问题:
1:Zookeeper通信源码部分学习成本高,需要掌握NIO和多线程
2:多线程使用频率高,消耗资源多,但性能得到提升
3:Zookeeper数据处理调用链路复杂,多处存在内部类,代码结构不清晰,写法比较经典
RequestProcessor处理请求源码剖析
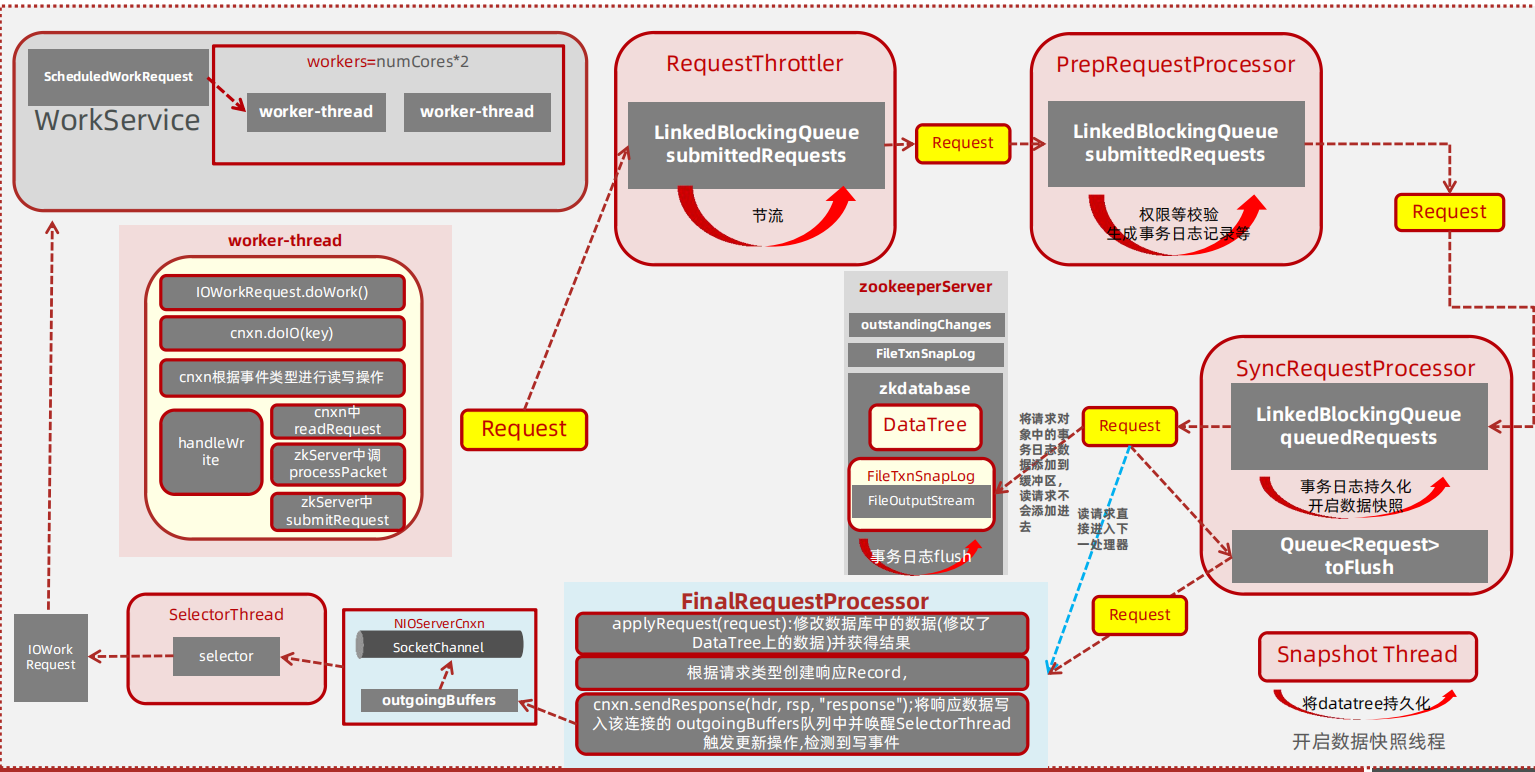
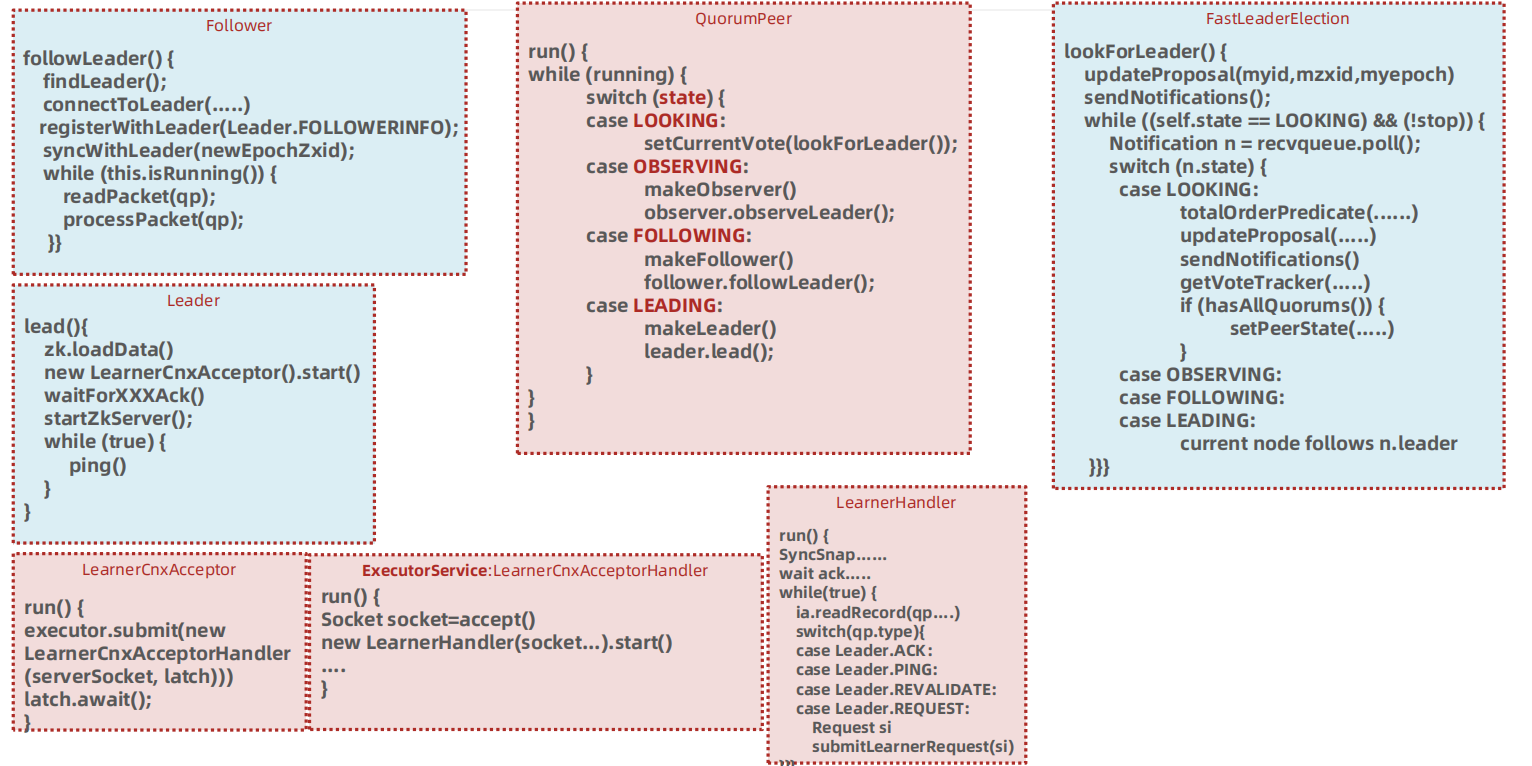
zookeeper 的业务处理流程就像工作流一样,其实就是一个单链表;在zookeeper 启动的时候,会确立各个节点的角色特性,即 leader 、 follower 和 observer ,每个角色确立后,就会初始化它的工作责任链;
RequestProcessor结构
客户端请求过来,每次执行不同事务操作的时候,Zookeeper也提供了一套业务处理流程 RequestProcessor , RequestProcessor 的处理流程如下图:
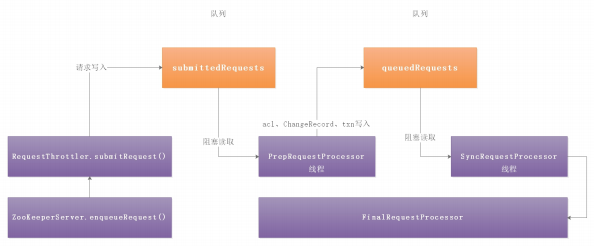
我们来看一下 RequestProcessor 初始化流程,ZooKeeperServer.setupRequestProcessors() 方法源码如下
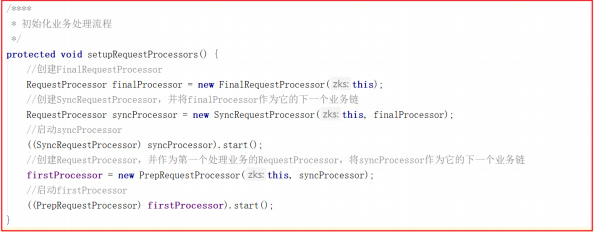
它的创建步骤:
1:创建finalProcessor。
2:创建syncProcessor,并将finalProcessor作为它的下一个业务链。
3:启动syncProcessor。
4:创建firstProcessor(PrepRequestProcessor),将syncProcessor 作为firstProcessor的下一个业务链。
5:启动firstProcessor。
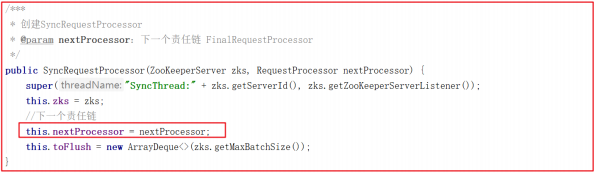
syncProcessor 创建时,将 finalProcessor 作为参数传递进来源码如下:
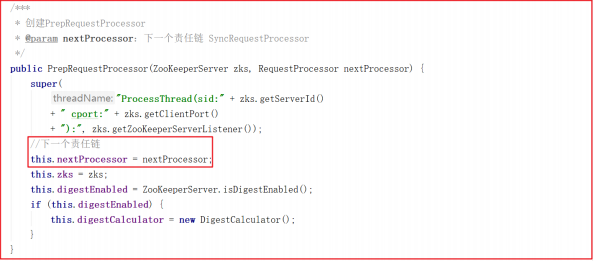
firstProcessor 创建时,将 syncProcessor 作为参数传递进来源码如下
PrepRequestProcessor/SyncRequestProcessor 关系图:
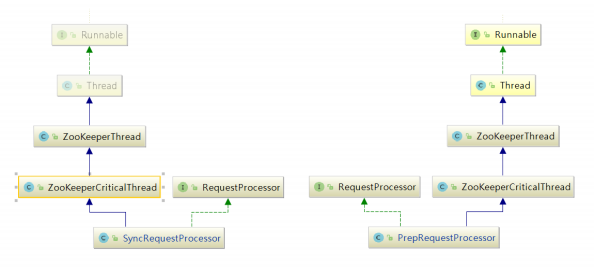
PrepRequestProcessor 和 SyncRequestProcessor 的结构一样,都是实现了 Thread 的一个线程,所以在这里初始化时便启动了这两个线程
PrepRequestProcessor剖析
PrepRequestProcessor 是请求处理器的第1个处理器,我们把之前的请求业务处理衔接起来,一步一步分析。
ZooKeeperServer.processPacket()>submitRequest()>enqueueRequest()>RequestThrottler.submitRequest() ,我们来看下RequestThrottler.submitRequest() 源码,它将当前请求添加到submittedRequests 队列中了,源码如下:
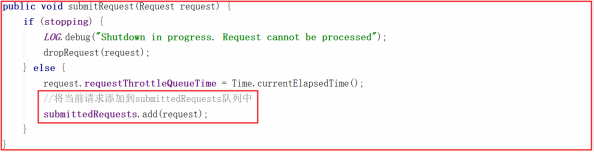
而 RequestThrottler 继承了 ZooKeeperCriticalThread > ZooKeeperThread > Thread,也就是说当前 RequestThrottler 是个线程,我们看看它的 run 方法做了什么事,源码如下:
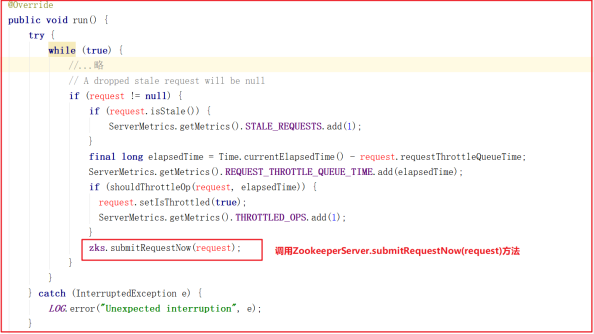
RequestThrottler 调用了 ZooKeeperServer.submitRequestNow() 方法,而该方法又调用了 firstProcessor 的方法,源码如下:
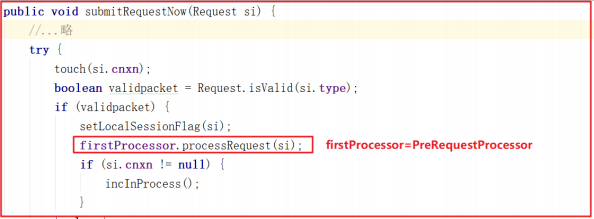
ZooKeeperServer.submitRequestNow() 方法调用了firstProcessor.processRequest() 方法,而这里的 firstProcessor 就是初始化业务处理链中的 PrepRequestProcessor ,也就是说三个RequestProecessor 中最先调用的是 PrepRequestProcessor 。
PrepRequestProcessor.processRequest() 方法将当前请求添加到了队列 submittedRequests 中,源码如下:

上面方法中并未从 submittedRequests 队列中获取请求,如何执行请求的呢,因为 PrepRequestProcessor 是一个线程,因此会在 run 中执行,我们查看 run 方法源码的时候发现它调用了 pRequest() 方法, pRequest() 方法源码如下:
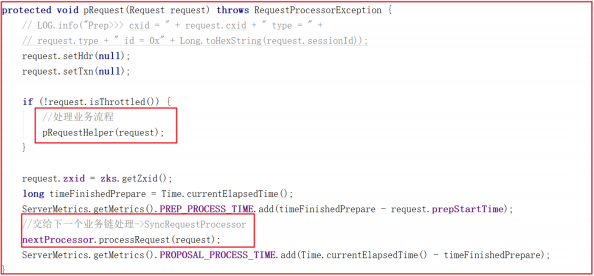
首先先执行 pRequestHelper() 方法,该方法是 PrepRequestProcessor处理核心业务流程,主要是一些过滤操作,操作完成后,会将请求交给下一个业务链,也就是 SyncRequestProcessor.processRequest() 方法处理请求。
我们来看一下 PrepRequestProcessor.pRequestHelper() 方法做了哪些事,源码如下:
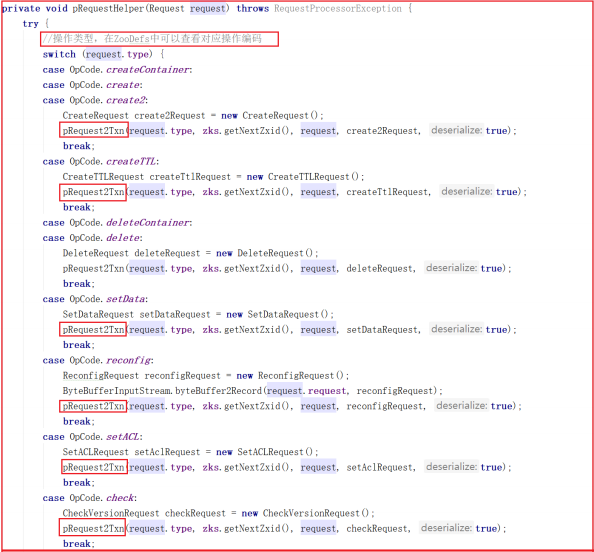
从上面源码可以看出 PrepRequestProcessor.pRequestHelper() 方法判断了客户端操作类型,但无论哪种操作类型几乎都调用了 pRequest2Txn() 方法,我们来看看源码:
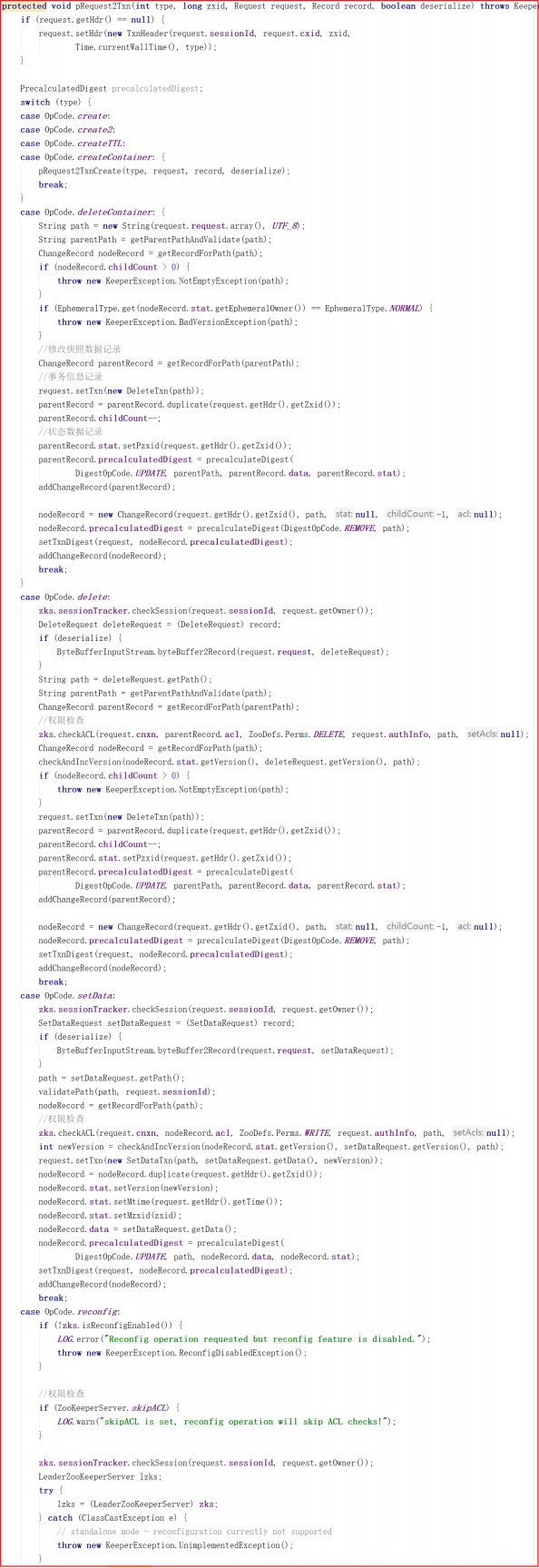
从上面代码可以看出 pRequest2Txn() 方法主要做了权限校验、快照记录、事务信息记录相关的事,还并未涉及数据处理,也就是说PrepRequestProcessor 其实是做了操作前权限校验、快照记录、事务信息记录相关的事。
我们DEBUG调试一次,看看业务处理流程是否和我们上面所分析的一致。
添加节点:
1 | create /zkdemo itheima |
DEBUG测试如下:
客户端请求先经过 ZooKeeperServer.submitRequestNow() 方法,并调用 firstProcessor.processRequest() 方法,而firstProcessor = PrepRequestProcessor ,如下图:
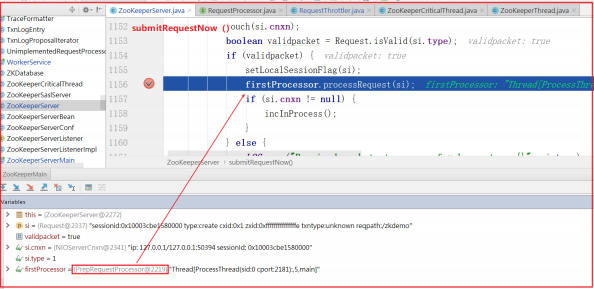
进入 PrepRequestProcessor.pRequest() 方法,执行完pRequestHelper() 方法后,开始执行下一个业务链的方法,而下一个业务链nextProcessor = SyncRequestProcessor ,如下测试图:
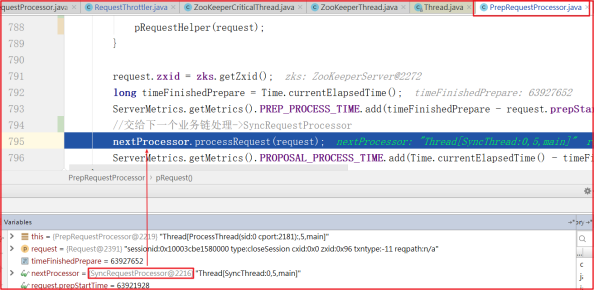
SyncRequestProcessor剖析
分析了 PrepRequestProcessor 处理器后,接着来分析SyncRequestProcessor ,该处理器主要是将请求数据高效率存入磁盘,并且请求在写入磁盘之前是不会被转发到下个处理器的。
我们先看请求被添加到队列的方法:
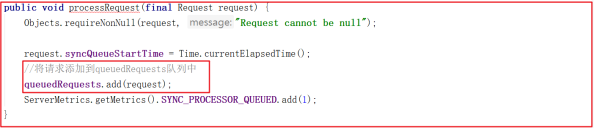
同样 SyncRequestProcessor 是一个线程,执行队列中的请求也在线程中触发,我们看它的run方法,源码如下:
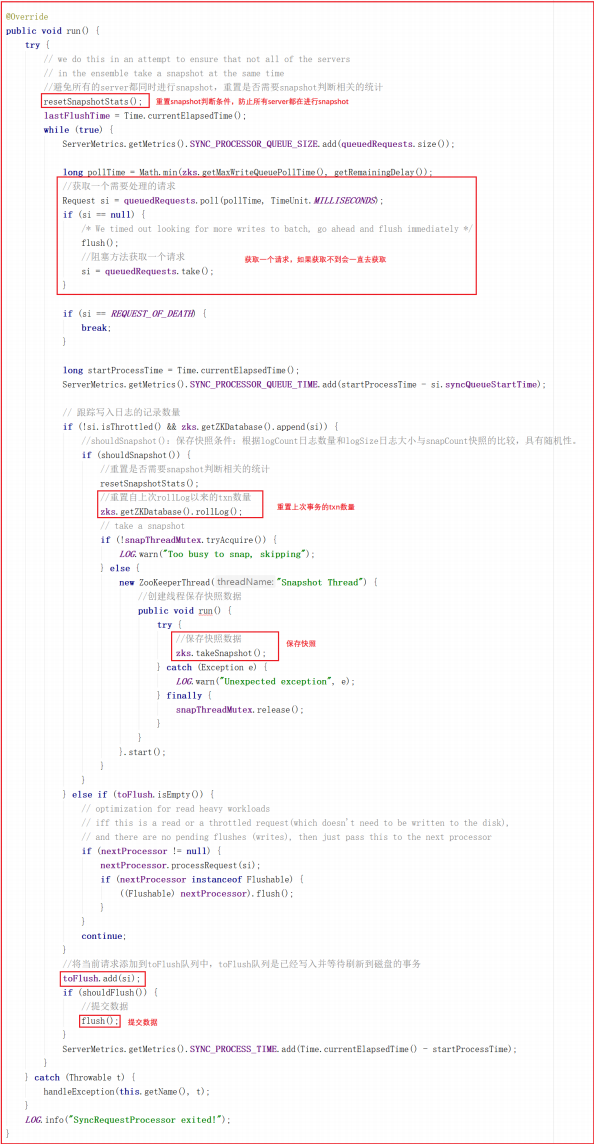
run 方法会从 queuedRequests 队列中获取一个请求,如果获取不到就会阻塞等待直到获取到一个请求对象,程序才会继续往下执行,接下来会调用Snapshot Thread 线程实现将客户端发送的数据以快照的方式写入磁盘,最终调用 flush() 方法实现数据提交, flush() 方法源码如下:
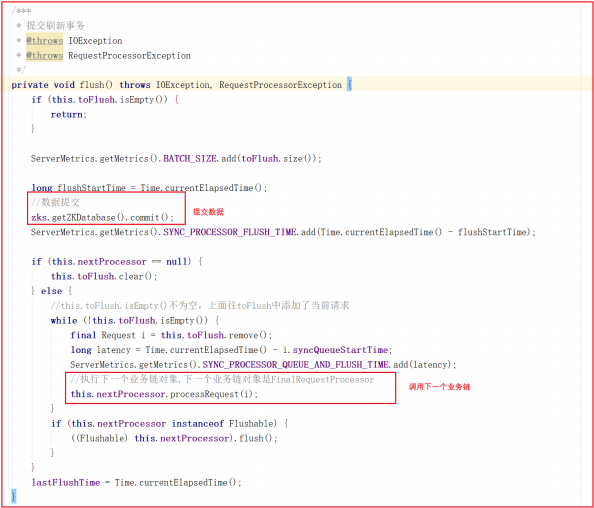
flush() 方法实现了数据提交,并且会将请求交给下一个业务链,下一个业务链为 FinalRequestProcessor 。
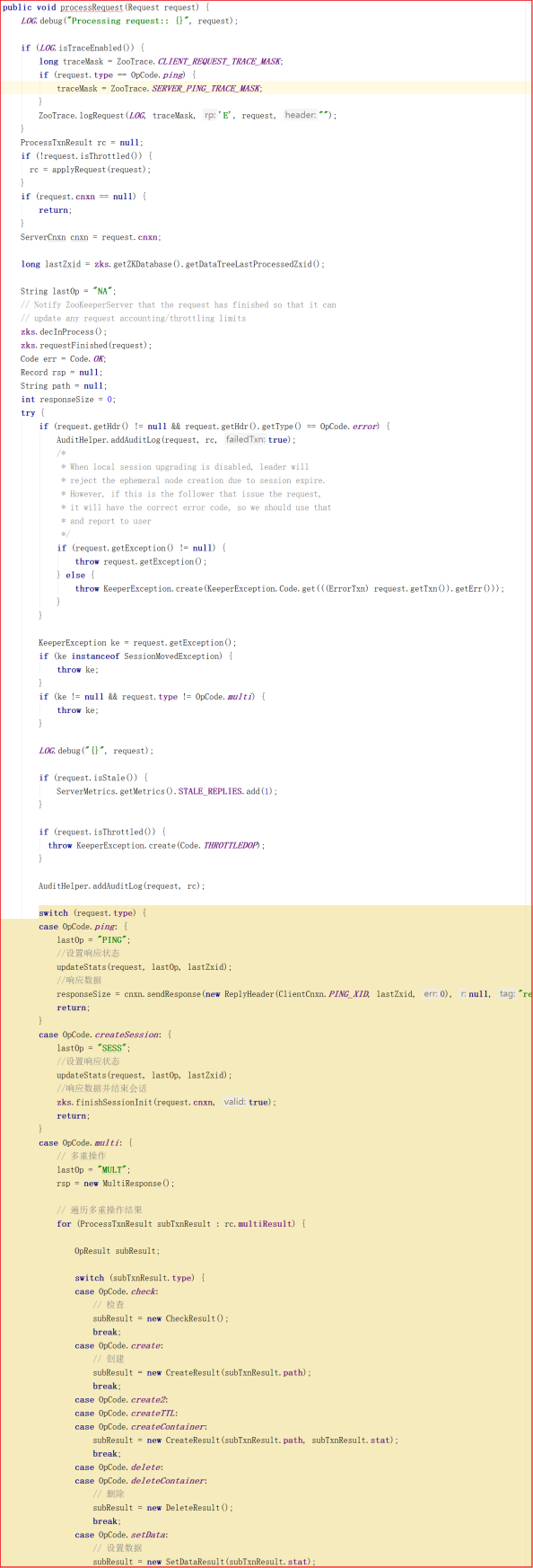
FinalRequestProcessor剖析
前面分析了 SyncReqeustProcessor ,接着分析请求处理链中最后的一个处理器 FinalRequestProcessor ,该业务处理对象主要用于返回Response。
ZK业务链处理优劣总结
Zookeeper业务链处理,思想遵循了AOP思想,但并未采用相关技术,为了提升效率,仍然大幅使用到了多线程。正因为有了业务链路处理先后顺序,使得Zookeeper业务处理流程更清晰更容易理解,但大量混入了多线程,也似的学习成本增加。
Session源码分析
客户端创建 Socket 连接后,会尝试连接,如果连接成功成功会调用到primeConnection 方法用来发送 ConnectRequest 连接请求,这里便是设置session 会话 ,关于客户端创建会话我们就不在这里做讲解了,我们直接讲解服务端 Session 会话处理流程。
服务端Session属性分析
Zookeeper服务端会话操作如下图:
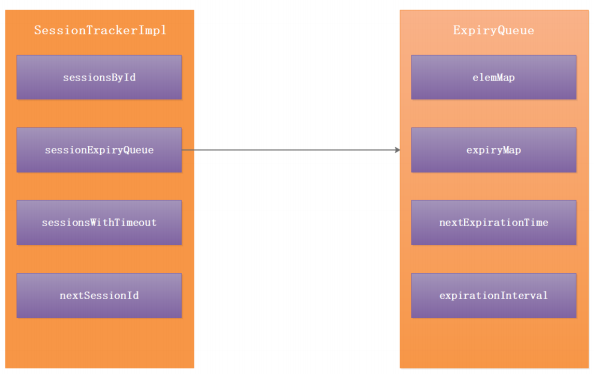
在服务端通过 SessionTrackerImpl 和 ExpiryQueue 来保存Session会话信息。
SessionTrackerImpl 有以下属性:
1 | 1:sessionsById 用来存储ConcurrentHashMap<Long, SessionImpl> {sessionId:SessionImpl} |
ExpiryQueue 失效队列有以下属性:
1 | 1:elemMap ConcurrentHashMap<E, Long> 存储的是{SessionImpl: newExpiryTime} Session实例对象,失效时间。 |
Session创建
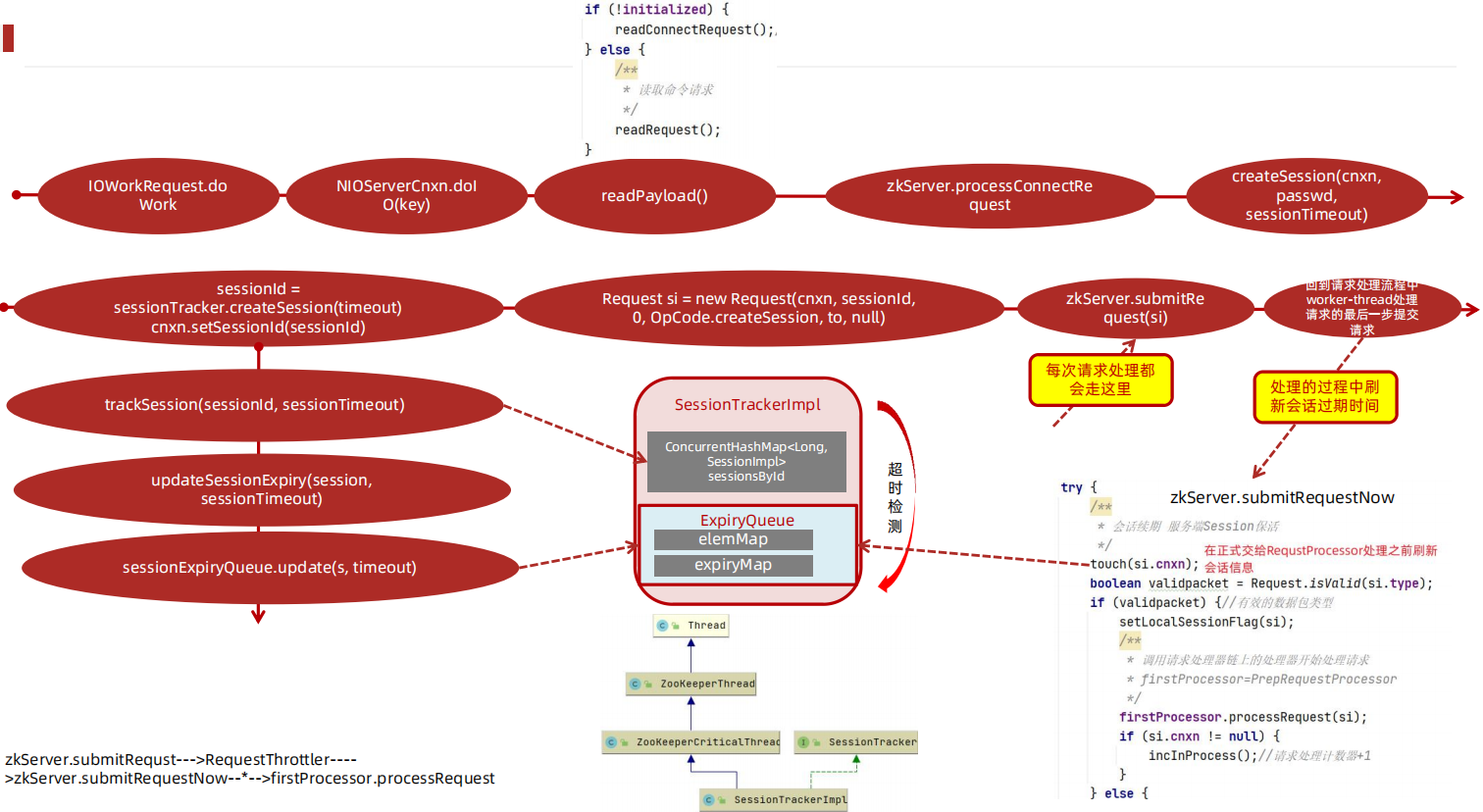
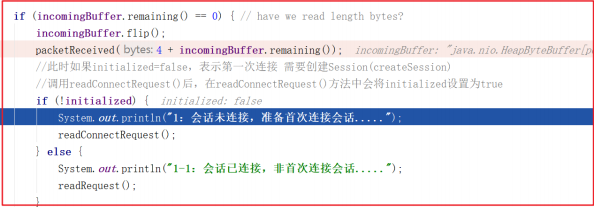
我们接着上一章的案例继续分析,假如客户端发起请求后,后端如何识别是第一次创建请求?在之前的案例源码 NIOServerCnxn.readPayload() 中有所体现, NIOServerCnxn.readPayload() 部分关键源码如下:
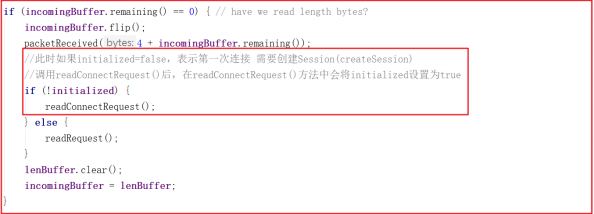
此时如果 initialized=false ,表示第一次连接 需要创建Session(createSession) ,此处调用 readConnectRequest() 后,在readConnectRequest() 方法中会将 initialized 设置为 true ,只有在处理完连接请求之后才会把 initialized 设置为 true ,才可以处理客户端其他命令。

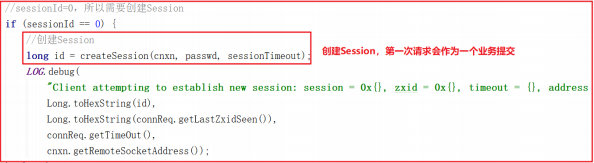
上面方法还调用了 processConnectRequest 处理连接请求, processConnectRequest 第一次从请求中获取的 sessionId=0 ,此时会把创建Session 作为一个业务,会调用 createSession() 方法,processConnectRequest 方法部分关键代码如下:
创建会话调用 createSession() ,该方法会首先创建一个sessionId,并把该sessionId作为会话ID创建一个创建session会话的请求,并将该请求交给业务链作为一个业务处理, createSession() 源码如下:
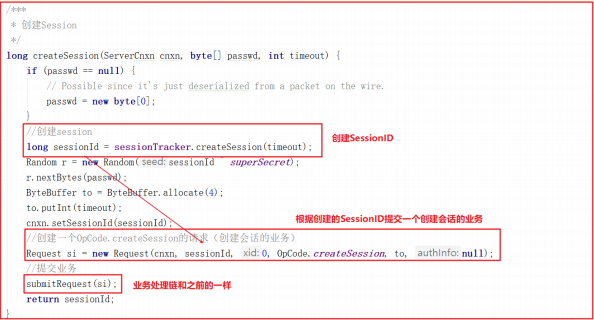
上面方法用到的 sessionTracker.createSession(timeout) 做了2个操作分别是创建sessionId和配置sessionId的跟踪信息,方法源码如下:
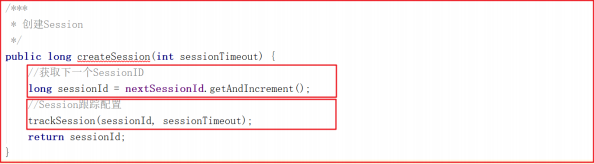
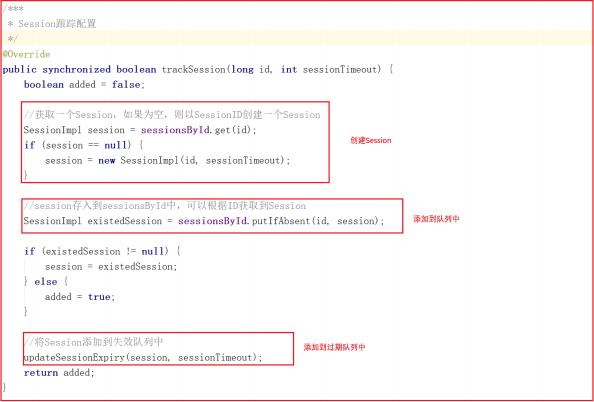
会话信息的跟踪其实就是将会话信息添加到队列中,任何地方可以根据会话ID找到会话信息, trackSession 方法实现了Session创建、Session队列存储、 Session 过期队列存储, trackSession 方法源码如下:
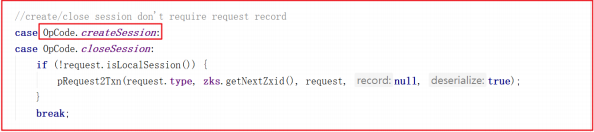
在 PrepRequestProcessor 的 run 方法中调用 pRequest2Txn ,关键代码如下:
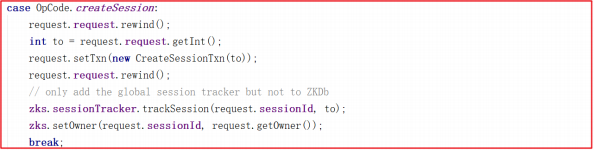
在 SyncRequestProcessor 对txn(创建session的操作)进行持久化,在FinalRequestProcessor 会对Session进行提交,其实就是把 Session 的ID和 Timeout 存到 sessionsWithTimeout 中去。
由于 FinalRequestProcessor 中调用链路太复杂,我们把调用链路写出来,大家可以按照这个顺序跟踪:
1 | 1:FinalRequestProcessor.applyRequest() 方法代码:ProcessTxnResult rc = zks.processTxn(request); |
上面调用链路中 processTxnForSessionEvents(request, hdr, request.getTxn()); 方法代码如下:
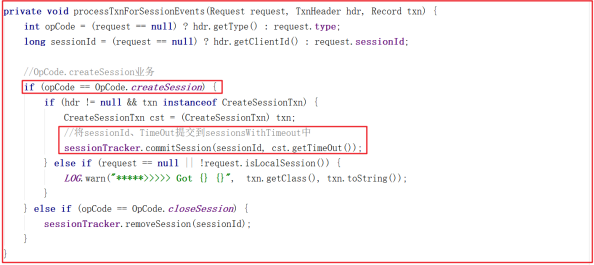
上面方法主要处理了 OpCode.createSession 并且将 sessionId、 TimeOut 提交到 sessionsWithTimeout 中,而提交到 sessionsWithTimeout的方法 SessionTrackerImpl.commitSession() 代码如下:

Session刷新
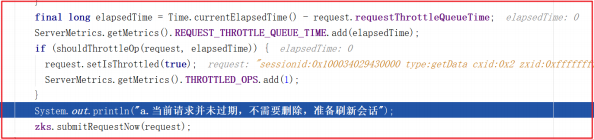
服务端无论接受什么请求命令(增删或ping等请求)都会更新Session的过期时间 。我们做增删或者ping命令的时候,都会经过 RequestThrottler , RequestThrottler 的run方法中调用 zks.submitRequestNow() ,而zks.submitRequestNow(request) 中调用了 touch(si.cnxn); ,该方法源码
如下:
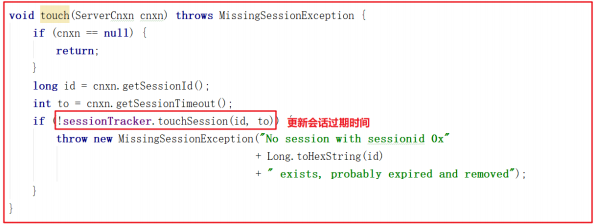
touchSession() 方法更新sessionExpiryQueue失效队列中的失效时间,源码如下:
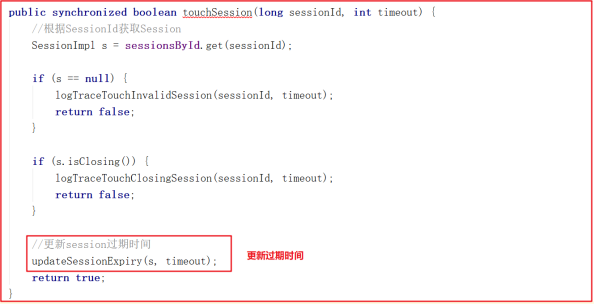
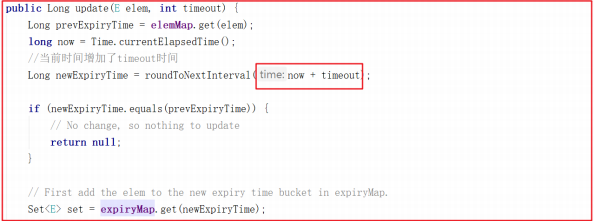
update() 方法会在当前时间的基础上增加timeout,并更新失效时间为newExpiryTime,关键源码如下:
Session过期
SessionTrackerImpl 是一个线程类,继承了ZooKeeperCriticalThread ,我们可以看它的run方法,它首先获取了下一个会话过期时间,并休眠等待会话过期时间到期,然后获取过期的客户端会话集合并循环关闭,源码如下:
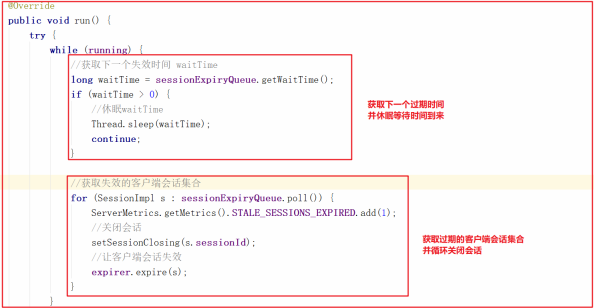
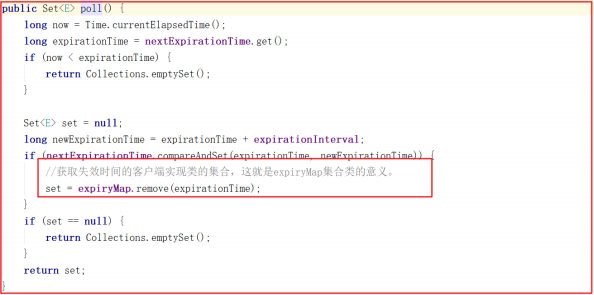
上面方法中调用了 sessionExpiryQueue.poll() ,该方法代码主要是获取过期时间对应的客户端会话集合,源码如下:
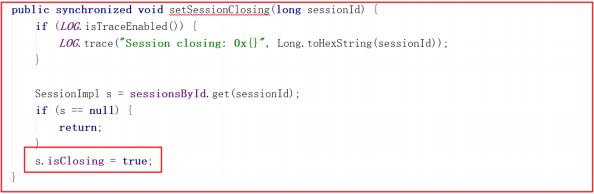
上面的 setSessionClosing() 方法其实是把Session会话的 isClosing 状态设置为了true,方法源码如下:
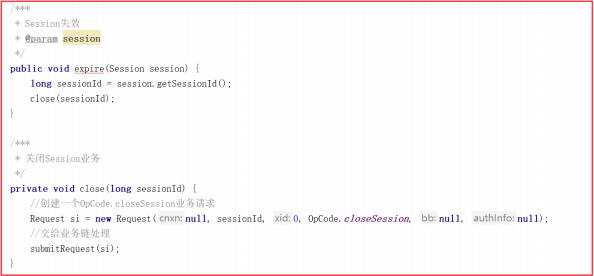
而让客户端失效的方法 expirer.expire(s); 其实也是一个业务操作,主要调用了 ZooKeeperServer.expire() 方法,而该方法获取SessionId后,又创建了一个 OpCode.closeSession 的请求,并交给业务链处理,我们查看ZooKeeperServer.expire() 方法源码如下:
在 PrepRequestProcessor.pRequest2Txn() 方法中OpCode.closeSession 操作里最后部分代理明确将会话Session的isClosing设置为了true,源码如下:
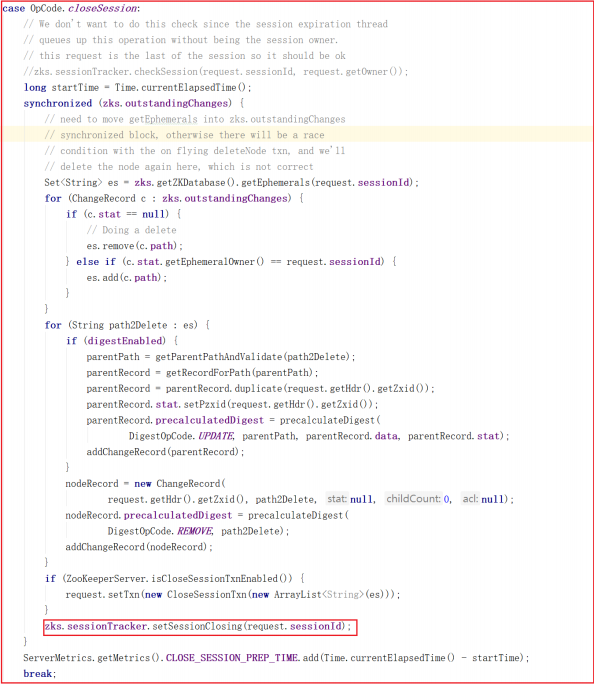
业务链处理对象 FinalRequestProcessor.processRequest() 方法调用了 ZooKeeperServer.processTxn() ,并且在 processTxn() 方法中执行了processTxnForSessionEvents ,而 processTxnForSessionEvents() 方法正好移除了会话信息,方法源码如下:
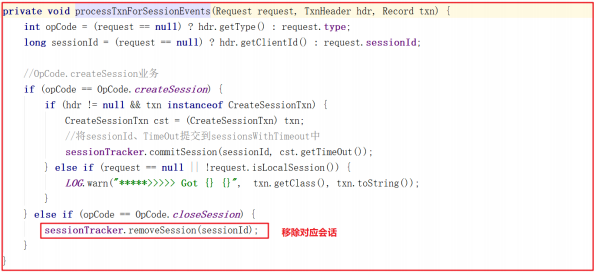
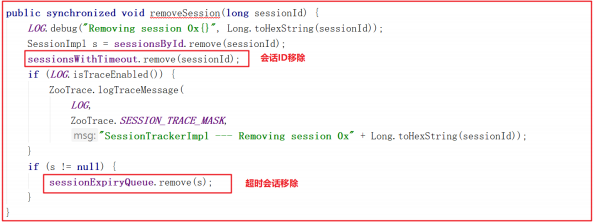
移除会话的方法 SessionTrackerImpl.removeSession() 会移除会话ID以及过期会话对象,源码如下:
Zookeeper会话测试
为了让Zookeeper的会话理解更深刻,我们对会话流程做一个测试,首先测试会话创建,再测试会话刷新。
1)会话创建测试
我们打开 NIOServerCnxn.readPayload() 方法,跟踪首次创建会话,调试情况如下:
此时会建立远程连接并创建SessionID,我们调试到NIOServerCnxn.readConnectRequest() 方法,此时建立链接,并且得到的sessionId=0。
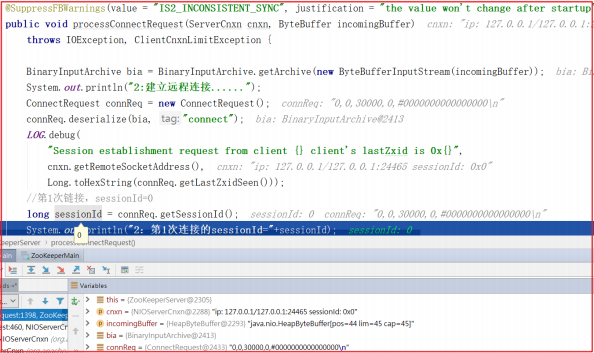
当sessionId=0时,会执行Session创建,Session创建会调用SessionTrackerImpl.createSession() 方法实现会话创建,并将会话存入跟踪队列,DEBUG测试如下:
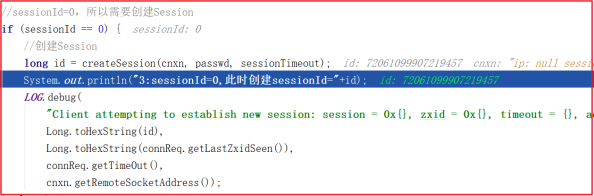
会话创建代码如下:
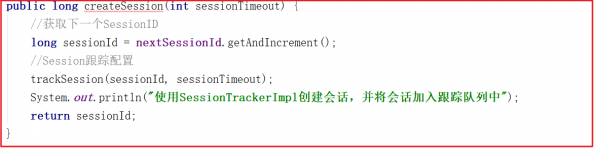
跟踪测试后,控制台输出如下信息:
1 | AcceptThread----------链接服务的IP:127.0.0.1 |
2)会话刷新测试
我们执行 get /zookeeper 指令,然后首先跟踪到RequestThrottler.run() 方法,执行如下:
执行程序到达 ZooKeeperServer.touch() ,即将开始准备刷新会话了,我们测试效果如下:
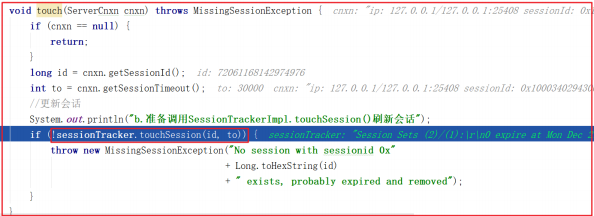
调用 SessionTrackerImpl.touchSession() 的时候会先判断会话是否为空、会话是否已经关闭,如果都没有,才执行刷新会话操作,DEBUG跟踪如下:
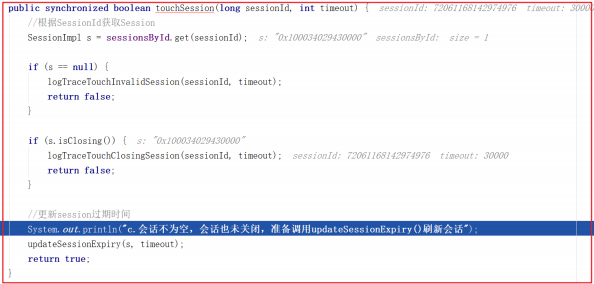
刷新会话其实就是会话时间增加,增加会话时间DEBUG跟踪如下:
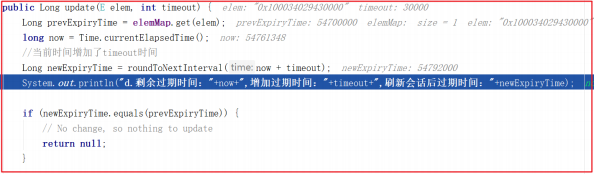
测试后效果如下:
1 | a.当前请求并未过期,不需要删除,准备刷新会话 |
集群启动流程详解
单机最大的问题就是单点故障,为了提高zookeeper的高可用.肯定是要做集群的
Zookeeper 集群启动流程
我们先搭建Zookeeper集群,再来分析选举算法
Zookeeper集群配置
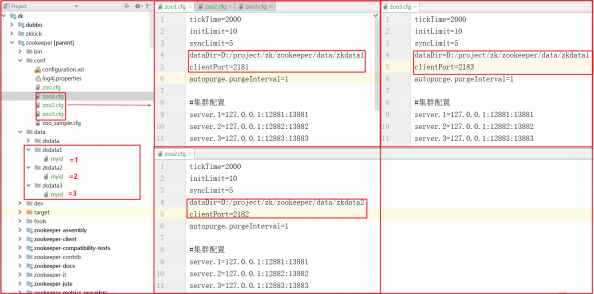
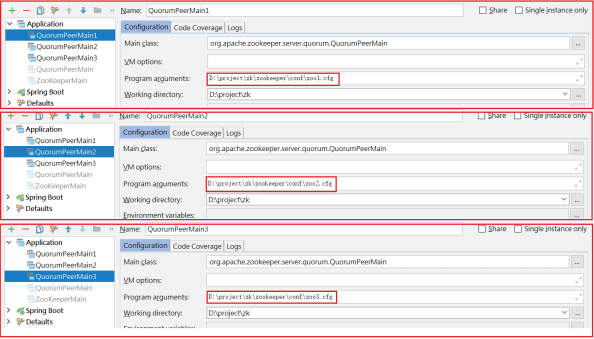
如上图:
1 | 1:创建zoo1.cfg、zoo2.cfg、zoo3.cfg |
配置3个启动类,如下图:
集群启动流程分析
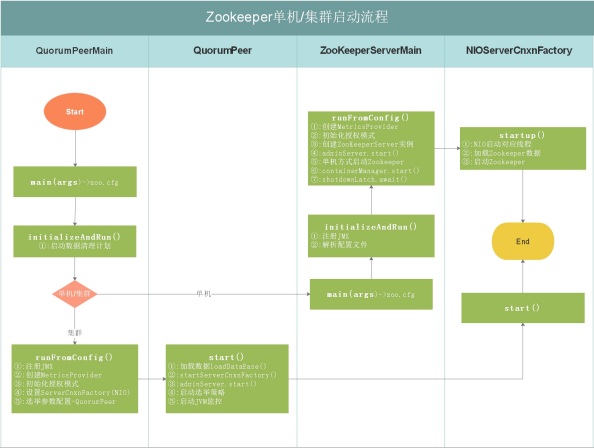
如上图,上图是Zookeeper单机/集群启动流程,每个细节所做的事情都在上图有说明,我们接下来按照流程图对源码进行分析。
程序启动,运行流程启动集群模式,如下图:
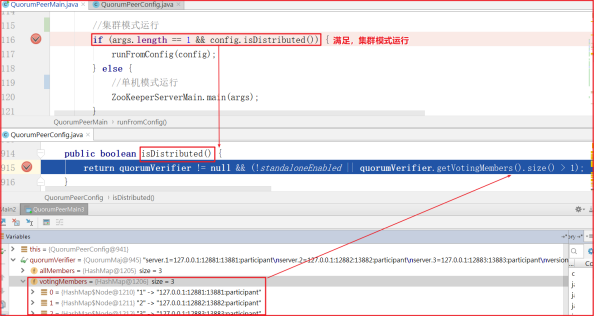
quorumPeer.start() 启动服务,如下代码:

quorumPeer.start() 方法代码如下:
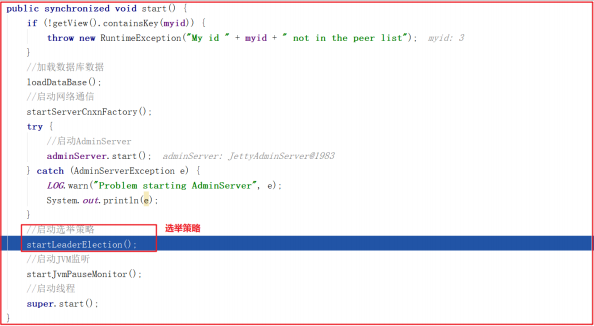
quorumPeer.start() 方法启动的主要步骤:
1:loadDataBase()加载数据。
2:startServerCnxnFactory 用来开启acceptThread、 SelectorThread和workerPool线程池。
3:开启Leader选举startLeaderElection。
4:开启JVM监控线程startJvmPauseMonitor。
5:调用父类super.start();进行Leader选举。
startLeaderElection() 开启Leader选举方法做了2件事,首先创建初始化选票选自己,接着创建选举投票方式,源码如下:
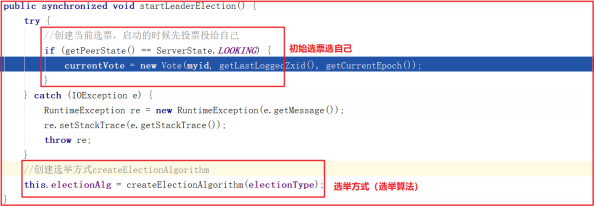
createElectionAlgorithm() 创建选举算法只有第3种,其他2种均已废弃,方法源码如下:
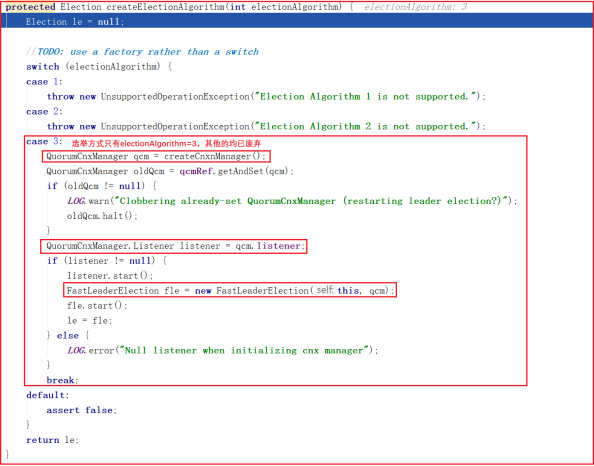
这个方法创建了以下三个对象:
- ①、创建QuorumCnxManager对象
- ②、QuorumCnxManager.Listener
- ③、FastLeaderElection
zookeeper 选举
Zookeeper选举主要依赖于FastLeaderElection算法,其他算法均已淘汰,但FastLeaderElection算法又是典型的Paxos算法,所以我们要先学习下Paxos算法,这样更有助于掌握FastLeaderElection算法。
算法模型
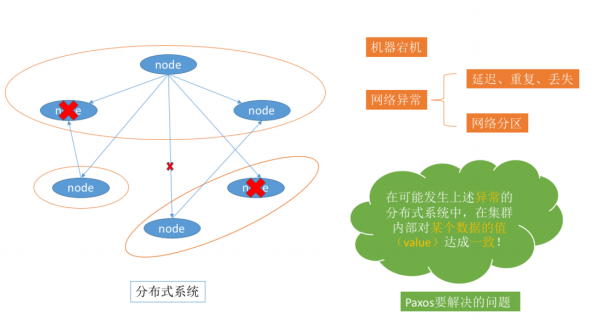
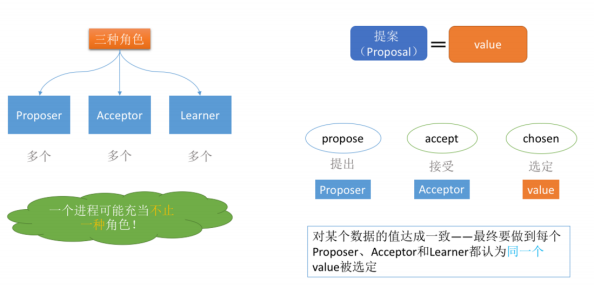
Paxos算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致,paxos是一个分布式选举算法该算法定义了三种角色
1 | ========== Paxos算法介绍 ========== |
- Proposer:提案(决议)发起者
- Acceptor:提案接收者,可同意或不同意
- Learners:虽然不同意提案,但也只能被动接收学习;或者是后来的,只能被动接受 提案遵循少数服从多数的原则,过半原则。
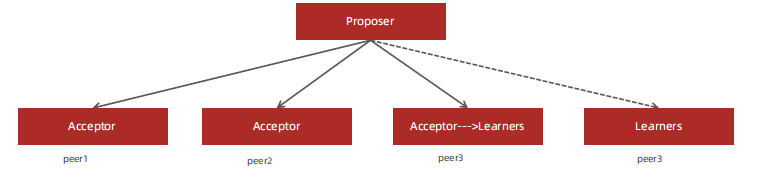
在具体的实现中,一个进程可能同时充当多种角色。比如一个进程可能既是Proposer又是Acceptor又是Learner。Proposer负责提出提案,Acceptor负责对提案作出裁决(accept与否),learner负责学习提案结果。
还有一个很重要的概念叫提案(Proposal)。最终要达成一致的value就在提案里。只要Proposer发的提案被Acceptor接受(半数以上的Acceptor同意才行),Proposer就认为该提案里的value被选定了。Acceptor告诉Learner哪个value被选定,Learner就认为那个value被选定。只要Acceptor接受了某个提案,Acceptor就认为该提案里的value被选定了。
为了避免单点故障,会有一个Acceptor集合,Proposer向Acceptor集合发送提案,Acceptor集合中的每个成员都有可能同意该提案且每个Acceptor只能批准一个提案,只有当一半以上的成员同意了一个提案,就认为该提案被选定了。
ZAB协议
ZooKeeper使用的是ZAB协议作为数据一致性的算法, ZAB(ZooKeeper Atomic Broadcast ) 全称为:原子消息广播协议。在Paxos算法基础上进行了扩展改造而来的,ZAB协议设计了支持原子广播、崩溃恢复,ZAB协议保证Leader广播的变更序列被顺序的处理。
四种状态,其中三种跟选举有关
- LOOKING:系统刚启动时或者Leader崩溃后正处于选举状态
- FOLLOWING:Follower节点所处的状态,同步leader状态,参与投票
- LEADING:Leader所处状态
- OBSERVING,观察状态,同步leader状态,不参与投票
选举时也是半数以上通过才算通过
zookeeper 集群启动及数据同步
FastLeaderElection
QuorumPeer工作流程
QuorumCnxManager:每台服务器在启动的过程中,会启动一个
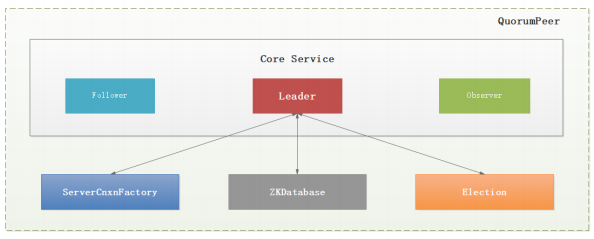
QuorumPeer ,负责各台服务器之间的底层Leader选举过程中的网络通信对应的类就是 QuorumCnxManager 。
Zookeeper 对于每个节点 QuorumPeer 的设计相当的灵活, QuorumPeer 主要包括四个组件:客户端请求接收器( ServerCnxnFactory )、数据引擎( ZKDatabase )、选举器( Election )、核心功能组件( Leader/Follower/Observer )
1 | 1:ServerCnxnFactory负责维护与客户端的连接(接收客户端的请求并发送 相应的响应);(1001行) |
QuorumPeer 工作流程比较复杂,如下图
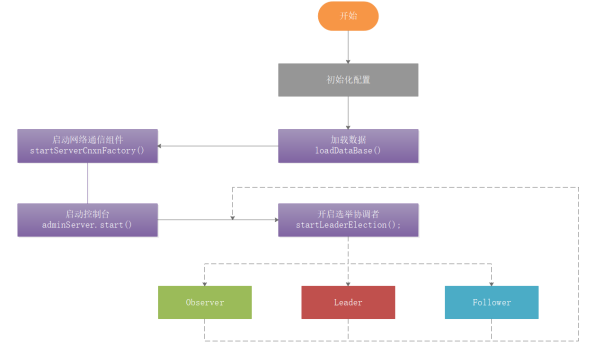
QuorumPeer工作流程:
1 | 1:初始化配置 |
QuorumCnxManager源码分析
QuorumCnxManager 内部维护了一系列的队列,用来保存接收到的、待发送的消息以及消息的发送器,除接收队列以外,其他队列都按照SID分组形成队列集合,如一个集群中除了自身还有3台机器,那么就会为这3台机器分别创建一个发送队列,互不干扰。
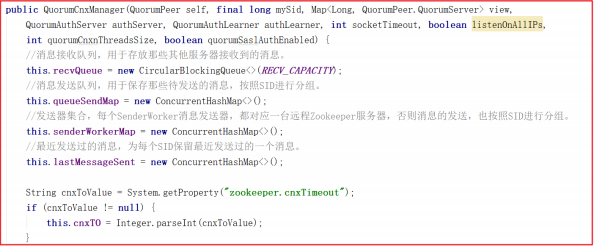
QuorumCnxManager.Listener :为了能够相互投票,Zookeeper集群中的所有机器都需要建立起网络连接。QuorumCnxManager在启动时会创建一个ServerSocket来监听Leader选举的通信端口。开启监听后,Zookeeper能够不断地接收到来自其他服务器地创建连接请求,在接收到其他服务器地TCP连接请求时,会进行处理。为了避免两台机器之间重复地创建TCP连接,Zookeeper只允许SID大的服务器主动和其他机器建立连接,否则断开连接。在接收到创建连接请求后,服务器通过对比自己和远程服务器的SID值来判断是否接收连接请求,如果当前服务器发现自己的SID更大,那么会断开当前连接,然后自己主动和远程服务器将连接(自己作为“客户端”)。一旦连接建立,就会根据远程服务器的SID来创建相应的消息发送器SendWorker和消息发送器RecvWorker,并启动。
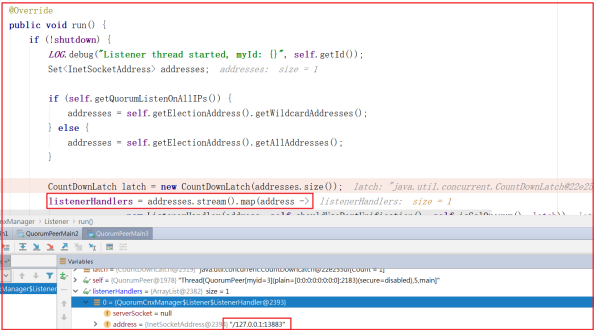
QuorumCnxManager.Listener 监听启动可以查看
QuorumCnxManager.Listener 的 run 方法,源代码如下,可以断点调试看到此时监听的正是我们所说的投票端口:
上面是监听器,各个服务之间进行通信我们需要开启 ListenerHandler 线程,在 QuorumCnxManager.Listener.ListenerHandler 的run方法中有一个方法 acceptConnections() 调用,该方法就是用于接受每次选举投票的信息,如果只有一个节点或者没有投票信息的时候,此时方法会阻塞,一旦执行选举,程序会往下执行,我们可以先启动1台服务,再启动第2台、第3台,此时会收到有客户端参与投票链接,程序会往下执行,源码如下:
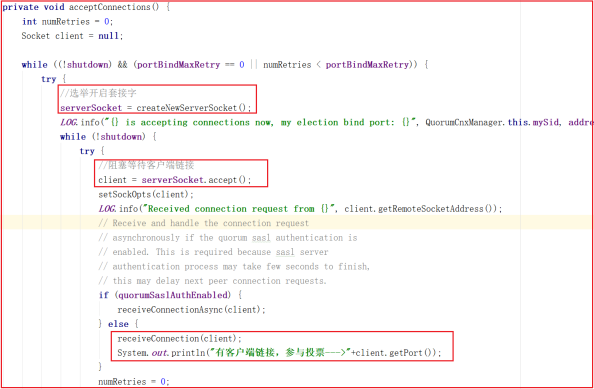
我们启动2台服务,效果如下:

上面虽然能证明投票访问了当前监听的端口,但怎么知道是哪台服务呢?我们可以沿着 receiveConnection() 源码继续研究,源码如下:
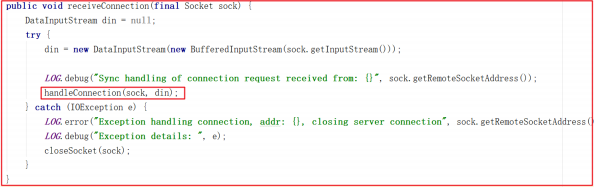
receiveConnection() 方法只是获取了数据流,并没做特殊处理,并且调用了 handleConnection() 方法,该方法源码如下:
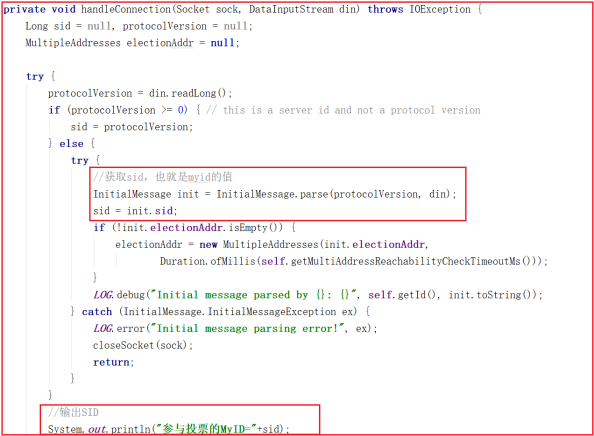
通过网络连接获取数据sid,获取sid表示是哪一台连过来的,我们可以打印输出sid,测试输出如下数据:
1 | 参与投票的MyID=2 |
FastLeaderElection算法源码分析
在 Zookeeper 集群中,主要分为三者角色,而每一个节点同时只能扮演一种角色,这三种角色分别是:
(1) Leader 接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部的数据交换(同步);
(2) Follower 直接为客户端提供服务并参与提案的投票,同时与 Leader 进行数据交换(同步);
(3) Observer 直接为客户端服务但并不参与提案的投票,同时也与 Leader进行数据交换(同步);
FastLeaderElection 选举算法是标准的 Fast Paxos 算法实现,可解决LeaderElection 选举算法收敛速度慢的问题。
创建 FastLeaderElection 只需要 new FastLeaderElection() 即可,如下代码:

创建 FastLeaderElection 会调用 starter() 方法,该方法会创建sendqueue 、 recvqueue 队列、 Messenger 对象,其中 Messenger 对象的作用非常关键,方法源码如下:
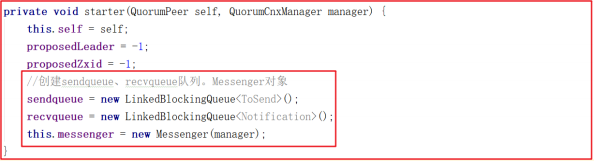
创建Messenger的时候,会创建 WorkerSender 并封装成 wsThread 线程,创建 WorkerReceiver 并封装成 wrThread 线程,看名字就很容易理解,wsThread 用于发送数据, wrThread 用于接收数据, Messenger 创建源码如下:
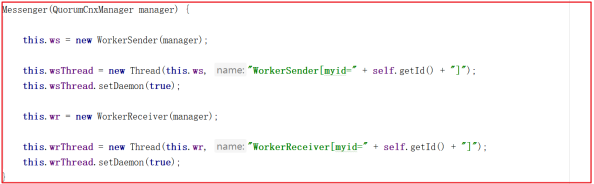
创建完 FastLeaderElection 后接着会调用它的 start() 方法启动选举算法,代码如下:
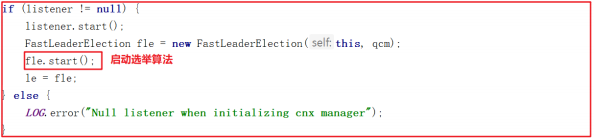
启动选举算法会调用start()方法,start()方法如下:
1 | public void start() { |
上面会执行 messager.start() ,也就是如下方法,也就意味着 wsThread 和 wrThread 线程都将启动,源码如下:
1 | void start() { |
wsThread 由 WorkerSender 封装而来,此时会调用 WorkerSender 的 run方法,run方法会调用 process() 方法,源码如下:
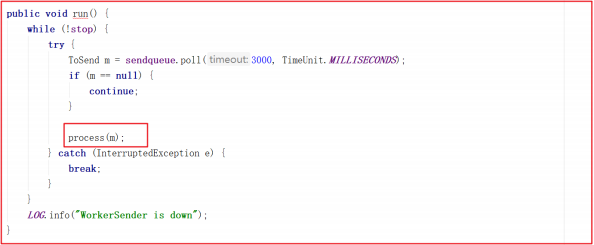
process 方法调用了 manager 的 toSend 方法,此时是把对应的sid作为了消息发送出去,这里其实是发送投票信息,源码如下:
1 | void process(ToSend m) { |
投票可以投自己,也可以投别人,如果是选票选自己,只需要把投票信息添加到 recvQueue 中即可,源码如下:
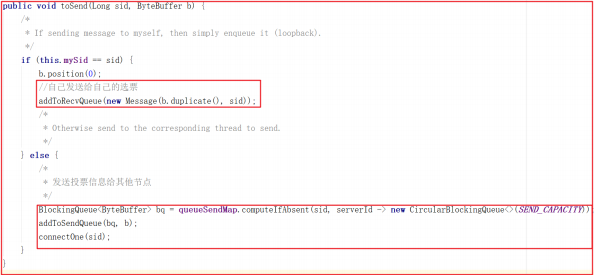
在 WorkerReceiver.run 方法中会从 recvQueue 中获取 Message ,并把发送给其他服务的投票封装到 sendqueue 队列中,交给 WorkerSender 发送处理,源码如下:
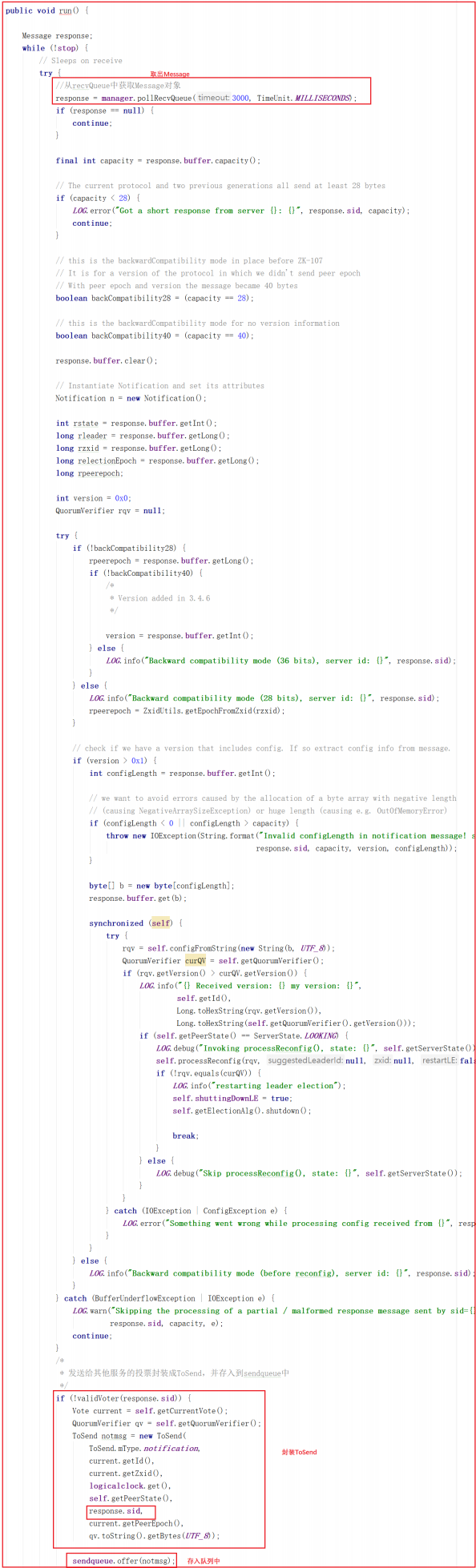
Zookeeper 选举投票剖析
选举是个很复杂的过程,要考虑很多场景,而且选举过程中有很多概念需要理解。
选举概念
1)ZK服务状态:
1 | public enum ServerState { |
2)服务角色:
1 | //Learner 是随从服务和观察者的统称 |
3)投票消息广播:
1 | public static class Notification { |
4)选票模型:
1 | public class Vote { |
5)消息发送对象:
1 | public static class ToSend { |
选举过程
QuorumPeer本身是个线程,在集群启动的时候会执行quorumPeer.start(); ,此时会调用它重写的 start() 方法,最后会调用父类的 start() 方法,所以该线程会启动执行,因此会执行它的run方法,而run方法正是选举流程的入口,我们看run方法关键源码如下:
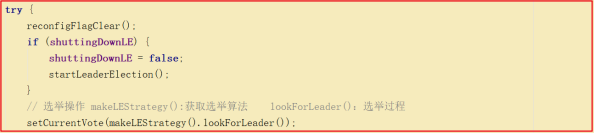
所有节点初始状态都为LOOKING,会进入到选举流程,选举流程首先要获取算法,获取算法的方法是 makeLEStrategy() ,该方法返回的是FastLeaderElection 实例,核心选举流程是FastLeaderElection 中的lookForLeader() 方法。
1 | /**** |
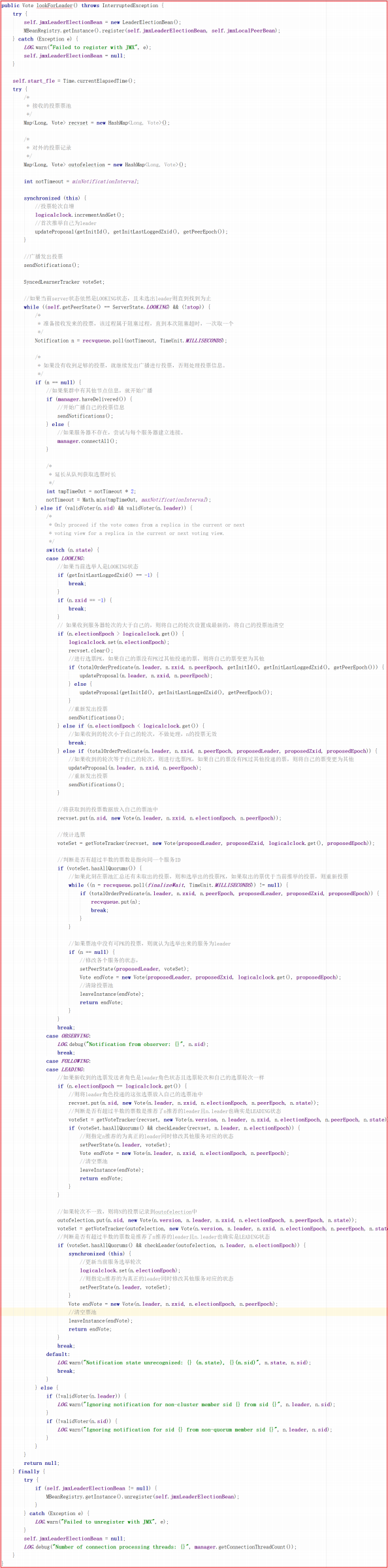
lookForLeader() 是选举过程的关键流程,源码分析如下:
上面多个地方都用到了过半数以上的方法 hasAllQuorums() 该方法用到了QuorumMaj 类,代码如下:
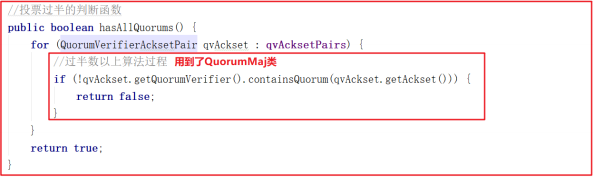
QuorumMaj 构造函数中体现了过半数以上的操作,代码如下:
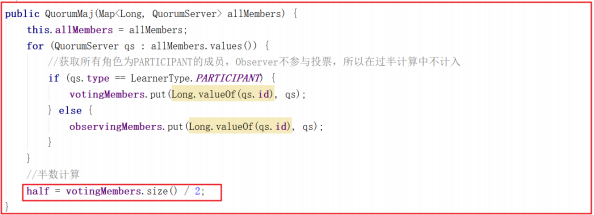
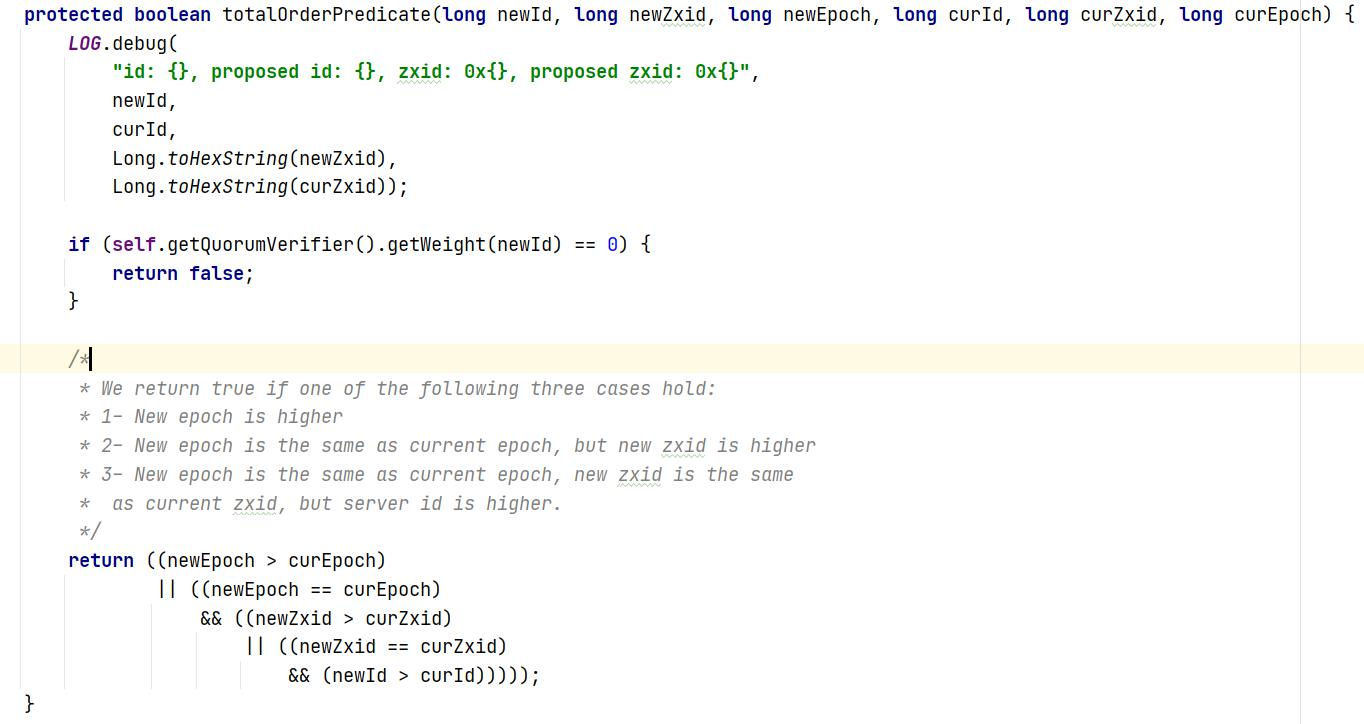
投票规则
我们来看一下选票PK的方法 totalOrderPredicate() ,该方法其实就是Leader选举规则,规则有如下三个:
1:比较 epoche(zxid高32bit),如果其他节点的epoch比自己的大,选举 epoch大的节点(理由:epoch 表示年代,epoch越大表示数据越新)代码:(newEpoch > curEpoch);
2:比较 zxid, 如果epoche相同,就比较两个节点的zxid的大小,选举 zxid大的节点(理由:zxid 表示节点所提交事务最大的id,zxid越大代表该节点的数据越完整)代码:(newEpoch == curEpoch) && (newZxid > curZxid);
3:比较 serviceId,如果 epoch和zxid都相等,就比较服务的 serverId,选举 serviceId大的节点(理由: serviceId 表示机器性 能,他是在配置zookeeper集群时确定的,所以我们配置zookeeper集群的时候可以把服务性能更高的集群的serverId设置大些,让性能好的机器担任 leader角色)代码 :(newEpoch == curEpoch) && ((newZxid == curZxid) && (newId > curId))。
源码如下:
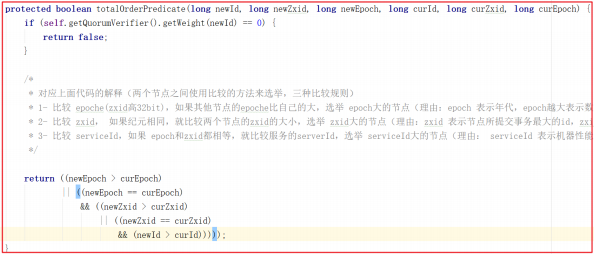
zookeeper 集群数据读写
当Client向zookeeper发出读请求时,无论是Leader还是Follower,都直接返回查询结果
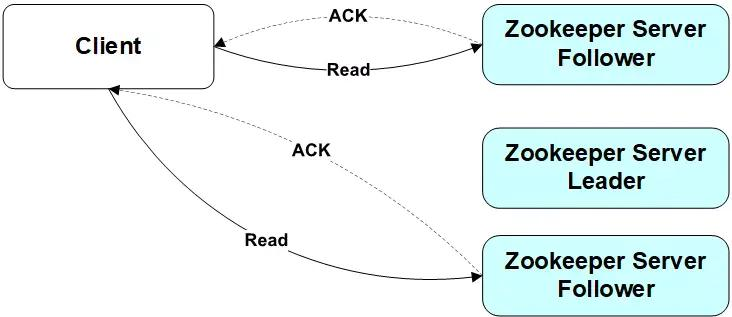
写请求-leader
Client向Leader发出写请求,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到**一半以上节点(包含自己)**返回写成功的信息之后,返回写入成功消息给client
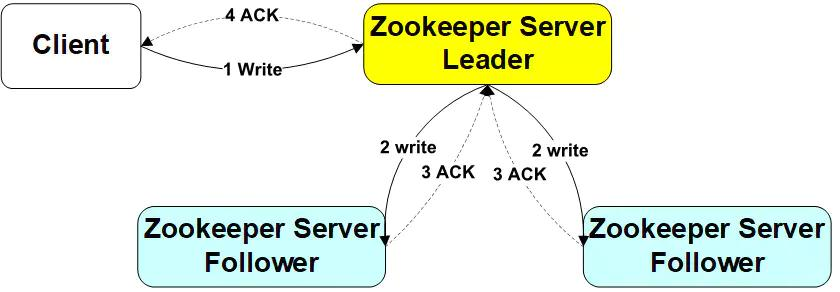
写失败的不用担心,follow会不断同步leader数据
写请求-follwer
Client向Follower发出写请求,Follower节点将请求转发给Leader,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给原来的Follower,原来的Follower返回写入成功消息给Client
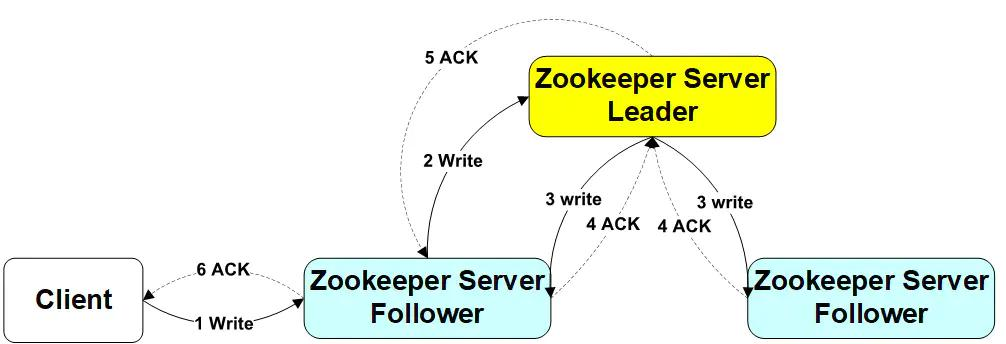
Zookeeper 集群数据同步
所有事务操作都将由leader执行,并且会把数据同步到其他节点,比如follower、observer,我们可以分析leader和follower的操作行为即可分析出数据同步流程。
Zookeeper 同步流程说明
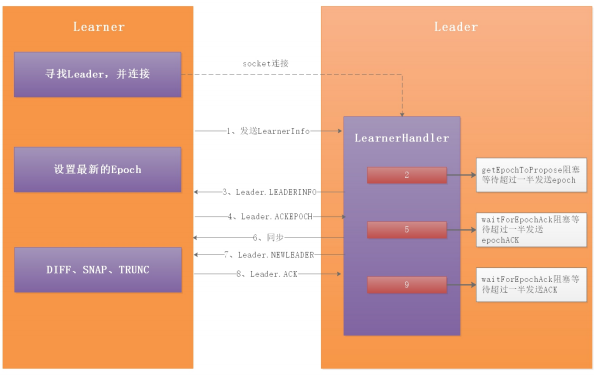
整体流程:
1 | 1:当角色确立之后,leader调用leader.lead();方法运行,创建一个接收连接的LearnerCnxAcceptor线程,在LearnerCnxAcceptor线程内部又建立一个阻塞的LearnerCnxAcceptorHandler线程等待Learner端的连接。Learner端以follower为例,follower调用 follower.followLeader();方法首先查找leader的Socket服务端,然 后建立连接。当follower建立连接后,leader端会建立一个 LearnerHandler线程相对应,用来处理follower与leader的数据包传 输。 |
我们回到 QuorumPeer.run() 方法,根据确认的不同角色执行不同操作展开分析。
Zookeeper Follower同步流程
Follower主要连接Leader实现数据同步,我们看看Follower做的事,我们仍然沿着QuorumPeer.run()展开学习,关键代码如下:
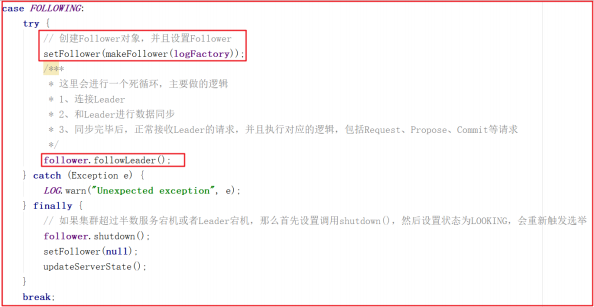
创建Follower的方法比较简单,代码如下:
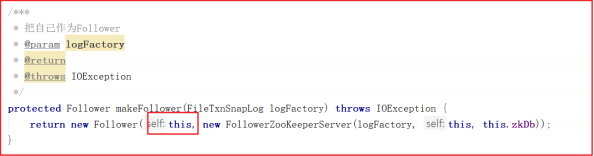
我们看一下整个Follower在数据同步中做的所有操作follower.followLeader(); ,源码如下图:
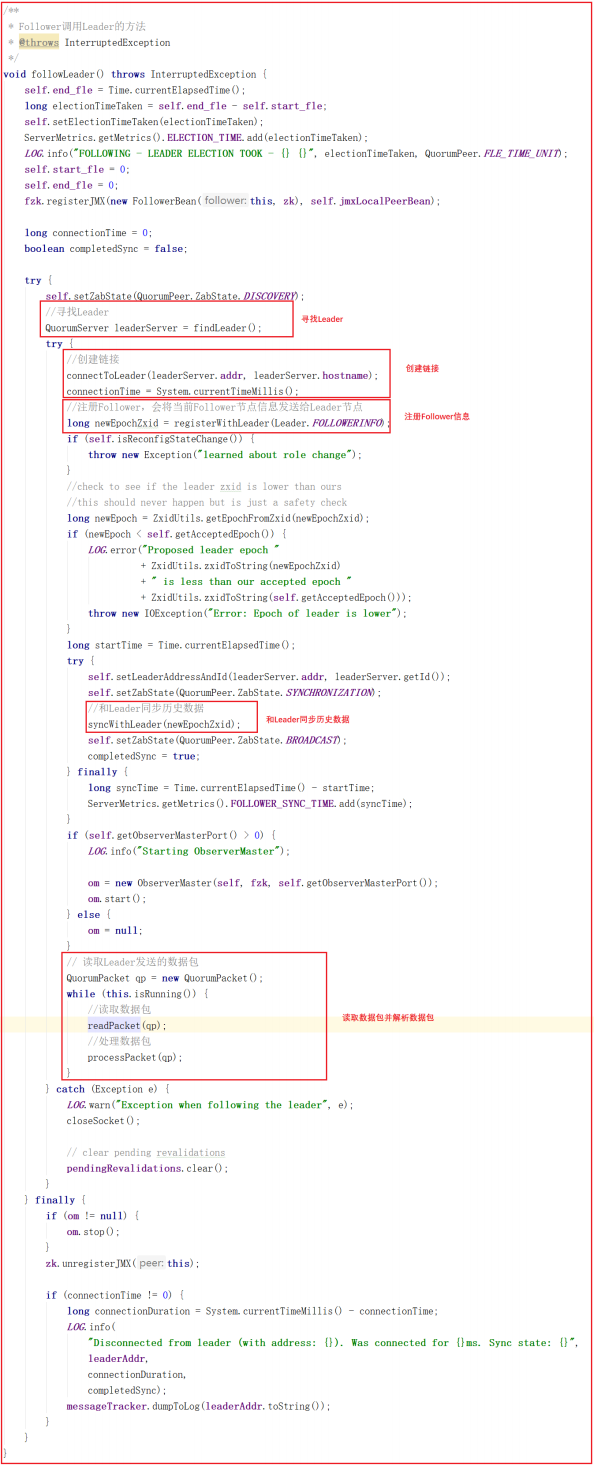
上面源码中的 follower.followLeader() 方法主要做了如下几件事:
1:寻找Leader
2:和Leader创建链接
3:向Leader注册Follower,会将当前Follower节点信息发送给Leader节 点
4:和Leader同步历史数据
5:读取Leader发送的数据包
6:同步Leader数据包
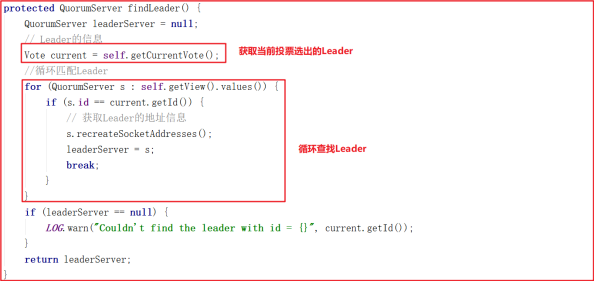
我们对 follower.followLeader() 调用的其他方法进行剖析,其中findLeader() 是寻找当前Leader节点的,源代码如下:
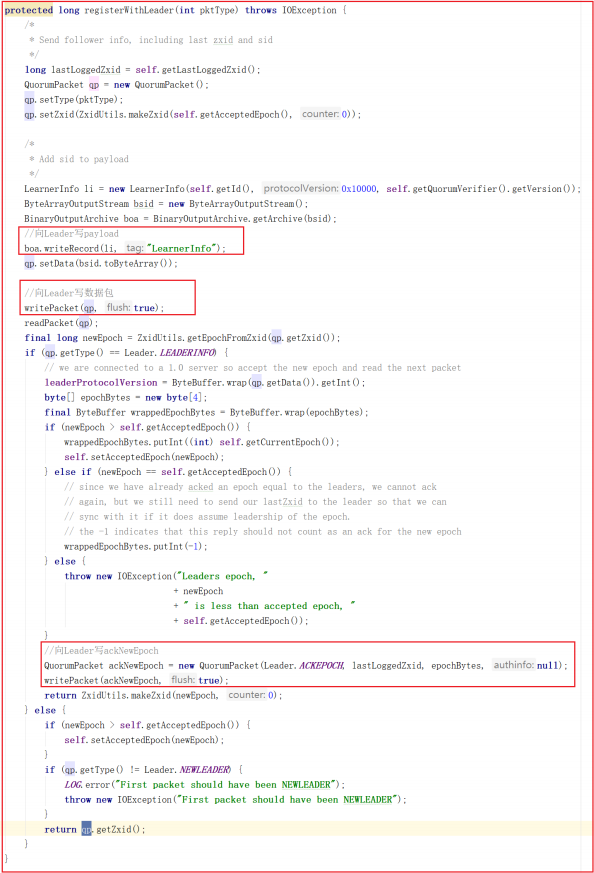
followLeader() 中调用了registerWithLeader(Leader.FOLLOWERINFO); 该方法是向Leader注册Follower,会将当前Follower节点信息发送给Leader节点,Follower节点信息发给Leader是必须的,是Leader同步数据个基础,源码如下:
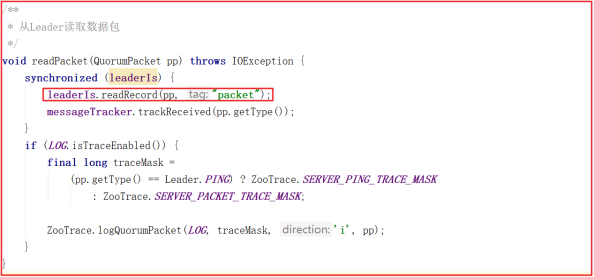
followLeader() 中最后读取数据包执行同步的方法中调用了readPacket(qp); ,这个方法就是读取Leader的数据包的封装,源码如下:
Zookeeper Leader同步流程
我们查看 QuorumPeer.run() 方法的LEADING部分,可以看到先创建了Leader对象,并设置了Leader,然后调用了 leader.lead() , leader.lead() 是执行的核心业务流程,源码如下:
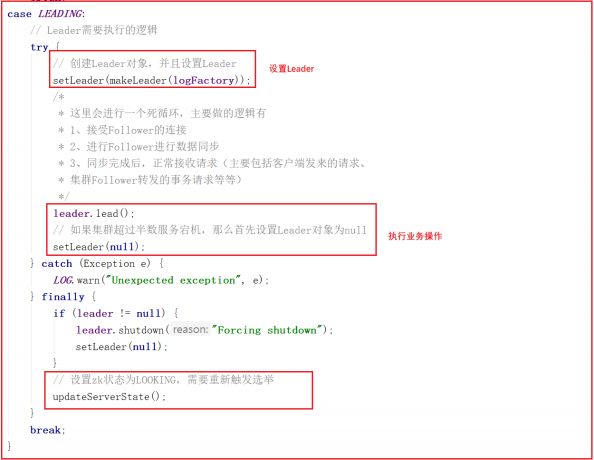
leader.lead() 方法是Leader执行的核心业务流程,源码如下:

leader.lead() 方法会执行如下几个操作:
1:从快照和事务日志中加载数据
2:创建一个线程,接收Follower/Observer的连接
3:等待超过一半的(Follower和Observer)连接,再继续往下执行程序
4:等待超过一半的(Follower和Observer)获取了新的epoch,并且返回了 Leader.ACKEPOCH,再继续往下执行程序
5:等待超过一半的(Follower和Observer)进行数据同步成功,并且返回了 Leader.ACK,再继续往下执行程序
6:数据同步完成,开启zkServer,并且同时开启请求调用链接收请求执行
7:进行一个死循环,每次休眠self.tickTime / 2,和对所有的 (Observer/Follower)发起心跳检测
8:集群中没有过半Follower在集群中,调用shutdown关闭一些对象,重新选举
lead() 方法中会创建 LearnerCnxAcceptor ,该对象是一个线程,主要用于接收followers的连接,这里加了CountDownLatch根据配置的同步的地址的数量(例如:server.2=127.0.0.1:12881:13881 配置同步的端口是12881只有一个), LearnerCnxAcceptor 的run方法源码如下:
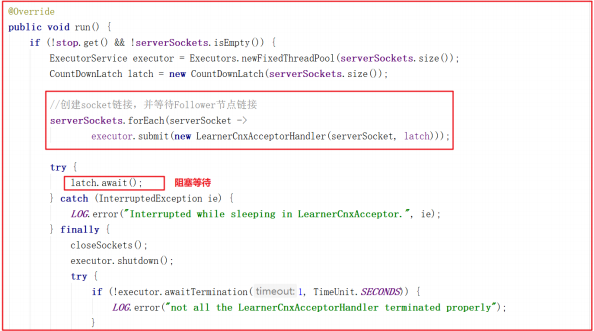
LearnerCnxAcceptor 的run方法中创建了 LearnerCnxAcceptorHandler对象,在接收到链接后,就会调用 LearnerCnxAcceptorHandler ,而LearnerCnxAcceptorHandler 是一个线程,它的run方法中调用了acceptConnections() 方法,源码如下:

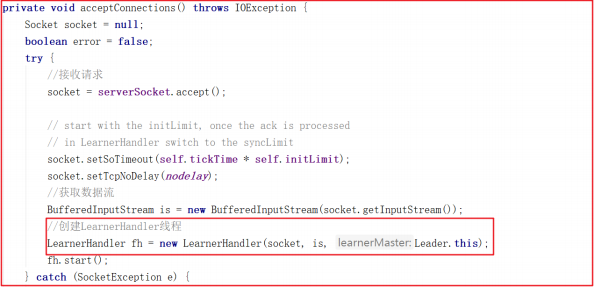
acceptConnections() 方法会在这里阻塞接收followers的连接,当有连接过来会生成一个socket对象。然后根据当前socket生成一个LearnerHandler线程 ,每个Learner者都会开启一个LearnerHandler线程,方法源码如下:
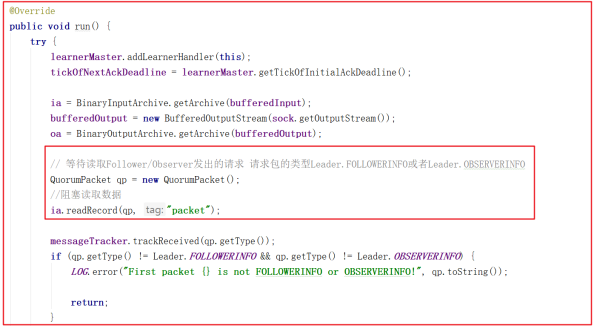
LearnerHandler.run 这里就是读取或写数据包与Learner交换数据包。如果没有数据包读取,则会阻塞当前方法 ia.readRecord(qp, “packet”); ,源码如下:
我们再回到 leader.lead() 方法,其中调用了 getEpochToPropose() 方法,该方法是判断connectingFollowers发给leader端的Epoch是否过半,如果过半则会解阻塞,不过半会一直阻塞着,直到Follower把自己的Epoch数据包发送过来并符合过半机制,源码如下
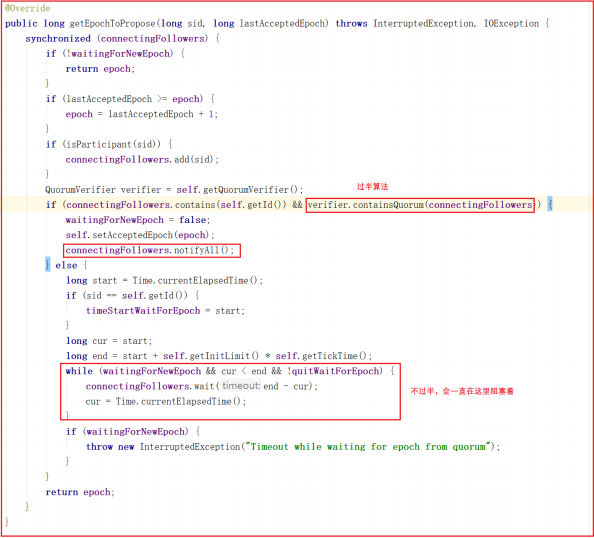
在 lead() 方法中,当发送的Epoch过半之后,把当前zxid设置到zk,并等待EpochAck,关键源码如下:
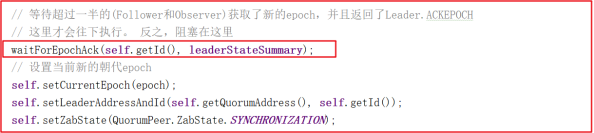
waitForEpochAck() 方法也会等待超过一半的(Follower和Observer)获取了新的epoch,并且返回了Leader.ACKEPOCH,才会解除阻塞,否则会一直阻塞。等待EpochAck解阻塞后,把得到最新的epoch更新到当前服务,设置当前leader节点的zab状态是 SYNCHRONIZATION ,方法源码如下:
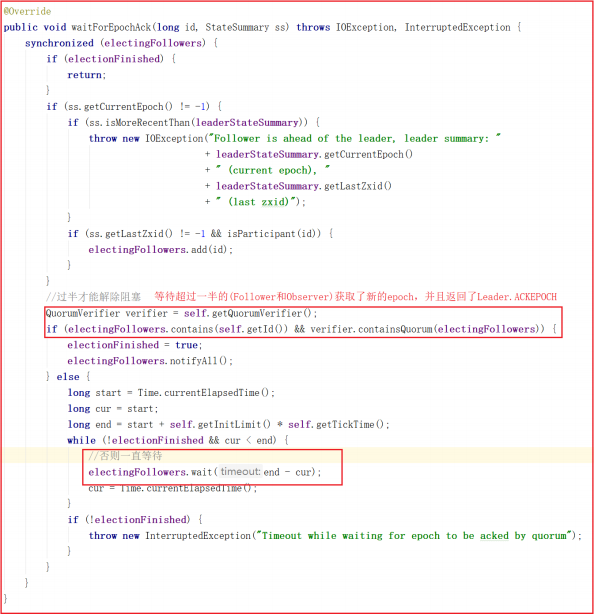
lead() 方法中还需要等待超过一半的(Follower和Observer)进行数据同步成功,并且返回了Leader.ACK,程序才会解除阻塞,如下代码:

上面所有流程都走完之后,就证明数据已经同步成功了,会执行startZkServer();
LearnerHandler数据同步操作
LearnerHandler 线程是对应于 Learner 连接 Leader 端后,建立的一个与Learner 端交换数据的线程。每一个 Learner 端都会创建一个LearnerHandler 线程。我们详细讲解 LearnerHandler.run() 方法。

readRecord 读取数据包 不断从 learner 节点读数据,如果没读到将会阻塞 readRecord 。

如果数据包类型不是Leader.FOLLOWERINFO或Leader.OBSERVERINFO将会返回,因为咱们这里本身就是Leader节点,读数据肯定是读非Leader节点数据。
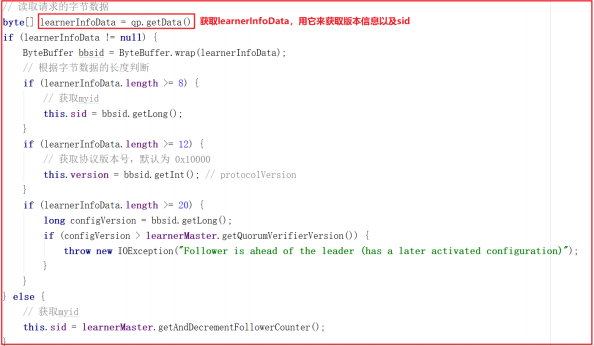
获取 learnerInfoData 来获取sid和版本信息。
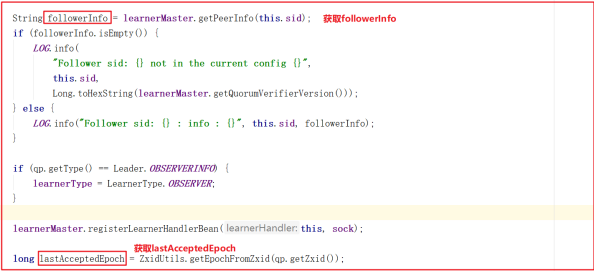
获取followerInfo和lastAcceptedEpoch,信息如下:

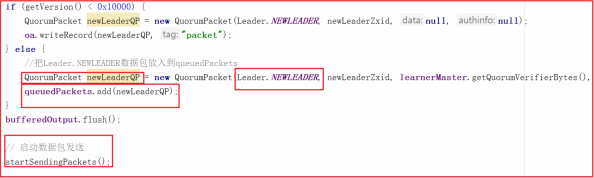
把Leader.NEWLEADER数据包放入到queuedPackets,并向其他节点发送,源码如下:
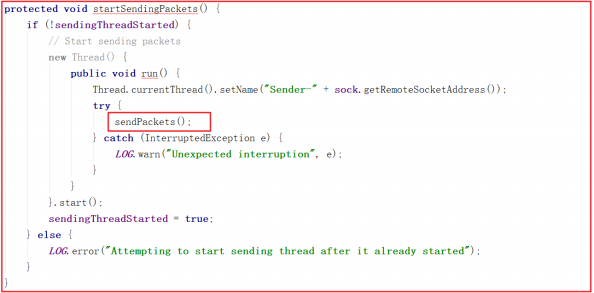
zookeeper 集群节点个数配置
为什么zookeeper节点推荐配奇数?
- 容错率:需要保证集群能够有半数进行投票
- 2台服务器,至少2台正常运行才行(2的半数为1,半数以上最少为2[至少+1]),正常运行1台服务器都不允许挂掉,但是相对于单节点服务器,2台服务器还有两个单点故障,所以直接排除了。
- 3台服务器,至少2台正常运行才行(3的半数为1.5,半数以上最少为2),正常运行可以允许1台服务器挂掉
- 4台服务器,至少3台正常运行才行(4的半数为2,半数以上最少为3),正常运行可以允许1台服务器挂掉
- 5台服务器,至少3台正常运行才行(5的半数为2.5,半数以上最少为3),正常运行可以允许2台服务器挂掉
- 防脑裂:脑裂集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的leader节 点,导致原有的集群出现多个leader节点的情况,这就是脑裂
- 3台服务器,投票选举半数为1.5,一台服务裂开,和另外两台服务器无法通行,这时候2台服务器的集群(2票大于半数1.5票),所以可以 选举出leader,而 1 台服务器的集群无法选举。
- 4台服务器,投票选举半数为2,可以分成 1,3两个集群或者2,2两个集群,对于 1,3集群,3集群可以选举;对于2,2集群,则不能选择,造成没有leader节点。
- 5台服务器,投票选举半数为2.5,可以分成1,4两个集群,或者2,3两集群,这两个集群分别都只能选举一个集群,满足zookeeper集群搭 建数目。
- 以上分析,我们从容错率以及防止脑裂两方面说明了3台服务器是搭建集群的最少数目,4台发生脑裂时会造成没有leader节点的错误
 微信
微信 支付宝
支付宝

