【项目系列】执行教育数仓项目(一):数仓项目
教育项目架构和数仓建模
今日内容:
- 教育项目的架构说明 (理解)
- cloudera manager 基本介绍 (了解)
- 教育项目环境搭建 (参考搭建笔记, 搭建成功)
- 数据仓库的基本介绍(回顾) – 理解
- 维度分析的基本内容 – 理解
- 数仓建模的基本内容 – 理解
- 教育数仓分层架构 – 理解
1. 教育项目的架构说明
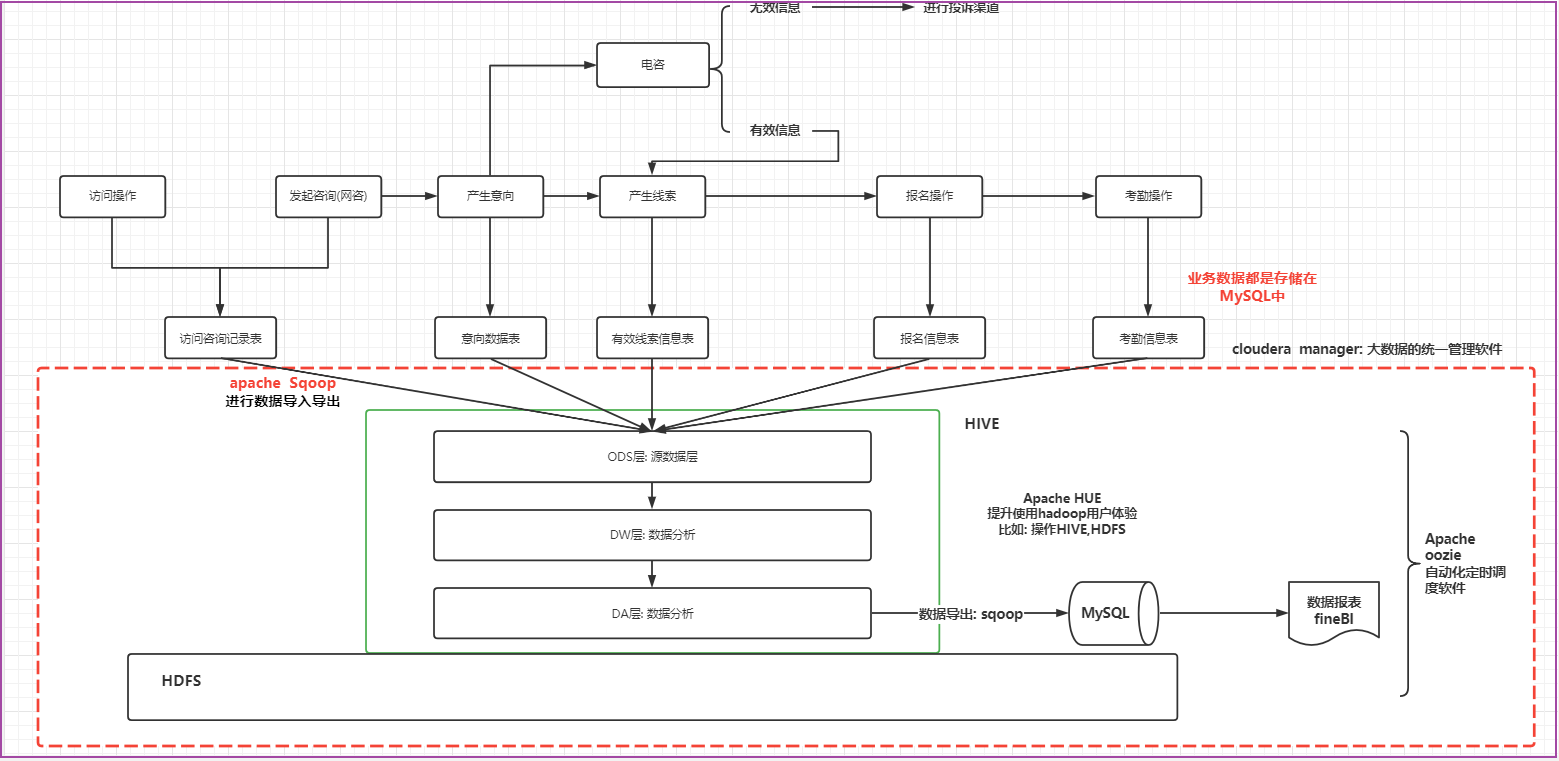
项目的架构
基于cloudera manager大数据统一管理平台, 在此平台之上构建大数据相关的软件(zookeeper,HDFS,YARN,HIVE,OOZIE,SQOOP,HUE…), 除此以外, 还使用FINEBI实现数据报表展示
各个软件相关作用
- zookeeper: 集群管理工具, 主要服务于hadoop高可用以及其他基于zookeeper管理的大数据软件
- HDFS: 主要负责最终数据的存储
- YARN: 主要提供资源的分配
- HIVE: 用于编写SQL, 进行数据分析
- oozie: 主要是用来做自动化定时调度
- sqoop: 主要是用于数据的导入导出
- HUE: 提升操作hadoop用户体验, 可以基于HUE操作HDFS, HIVE ….
- FINEBI: 由帆软公司提供的一款进行数据报表展示工具
项目架构中数据流转的流程
首先业务是存储在MySQL数据库中, 通过sqoop对MySQL的数据进行数据的导入操作, 将数据导入到HIVE的ODS层中, 对数据进行清洗转换成处理工作, 处理之后对数据进行统计分析,(hive查数据太慢了) ,将统计分析的结果基于sqoop再导出到MySQL中, 最后使用finebi实现图表展示操作, 由于分析工作是需要周期性干活, 采用ooize进行自动化的调度工作, 整个项目是基于cloudera manager进行统一监控管理
面试题
- 请介绍一下最近做了一个什么项目? 为什么要做, 以及项目的架构和数据流转流程
- 请介绍项目的架构是什么方案? 项目的架构和 数据流转的流程
- 整个项目各个软件是如何交互的? 数据流转的流程
3. 教育项目的环境搭建(废弃)
基础环境
- CentOS 7
- jdhk 1.8
- mysql 5.7
- CDH 6.2.1
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.88.165 | cdh01 | Cm、nn |
| 192.168.88.166 | cdh02 | datanode |
| 192.168.88.167 | cdh03 | datanode |
CM管理界面: 192.168.88.165:7180
安装包目录:/opt/setup/cloudera
安装目录: /usr/local/apps/cloudera
系统环境
准备3台基础虚拟机,参照Linux汇总的3台虚拟机搭建过程。
CDH下载:https://archive.cloudera.com/cdh6/6.2.1/parcels/
搭建CM本地YUM仓库
这里cdh01搭建本地YUM源作为离线安装CM的仓库,让其他主机也使用该源下载CM相关的软件
1 | 安装httpd和createrepo |
配置本地的YUM仓库
1 | cat > /etc/yum.repos.d/manager-repos.repo <<EOF |
安装CM
创建数据库
1 | create database amon DEFAULT CHARACTER SET utf8; |
1 | yum install -y cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server |
配置CM数据库
官方提供了一个脚本用于初始化 CM 数据(配置/etc/cloudera-scm-server/db.properties),执行如下命令:
1 | /opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm -h localhost scm 'root密码' |
最后提示:”All done, your SCM database is configured correctly!”代表配置成功,忽略可能的WARN信息
启动CM服务
1 | systemctl start cloudera-scm-server |
观察日志输出,当看到Started Jetty server.时表示服务已经启动成功了(大约需要等待3~5分钟左右)。
1 | tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log |
访问CM控制台
浏览器访问http://master.bigdata:7180/cmf/login或者http://192.168.122.101:7180/cmf/login,账号密码统一为admin。
4. 数据仓库的基本概念
回顾1: 什么是数据仓库
1 | 存储数据的仓库, 主要是用于存储过去既定发生的历史数据, 对这些数据进行数据分析的操作, 从而对未来提供决策支持 |
回顾2: 数据仓库最大的特点:
1 | 既不生产数据, 也不消耗数据, 数据来源于各个数据源 |
回顾3: 数据仓库的四大特征:
1 | 1) 面向于主题的: 面向于分析, 分析的内容是什么 什么就是我们的主题 |
回顾3: ETL是什么
1 | ETL: 抽取 转换 加载 |
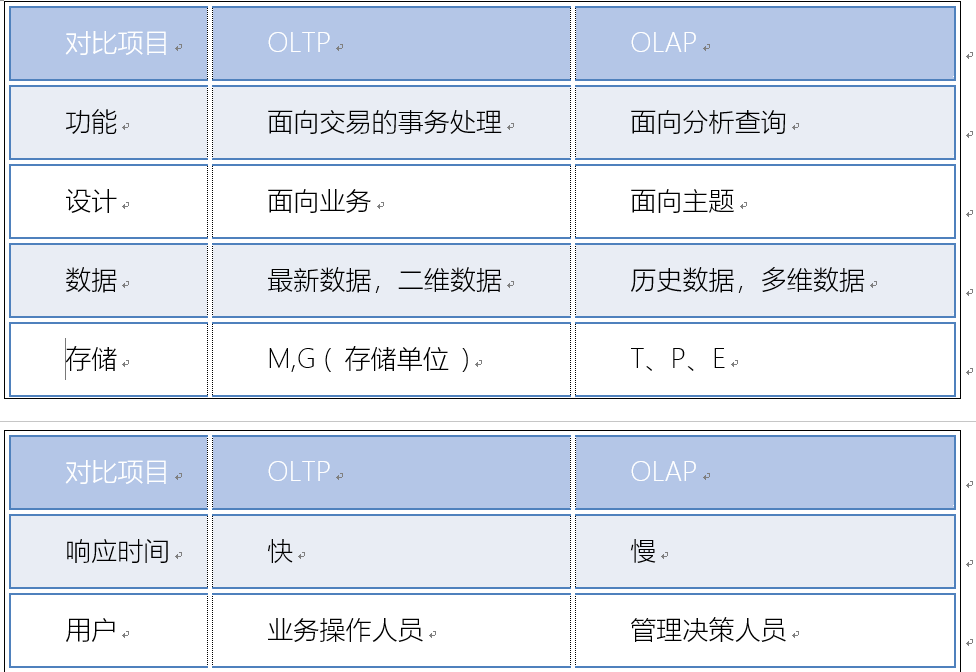
回顾四: 数据仓库和 数据库的区别
1 | 数据库(OLTP): 面向于事务(业务)的 , 主要是用于捕获数据 , 主要是存储的最近一段时间的业务数据, 交互性强 一般不允许出现数据冗余 |
数据仓库和数据集市:
1 | 数据仓库其实指的集团数据中心: 主要是将公司中所有的数据全部都聚集在一起进行相关的处理操作 (ODS层) |
5. 维度分析
维度分析: 针对某一个主题, 可以从不同的维度的进行统计分析, 从而得出各种指标的过程
- 什么是维度:
1 | 维度一般指的分析的角度, 看待一个问题的时候, 可以多个角度来看待, 而这些角度指的就是维度 |
- 什么是指标
1 | 指标指的衡量事务发展的标准, 就是度量值 |
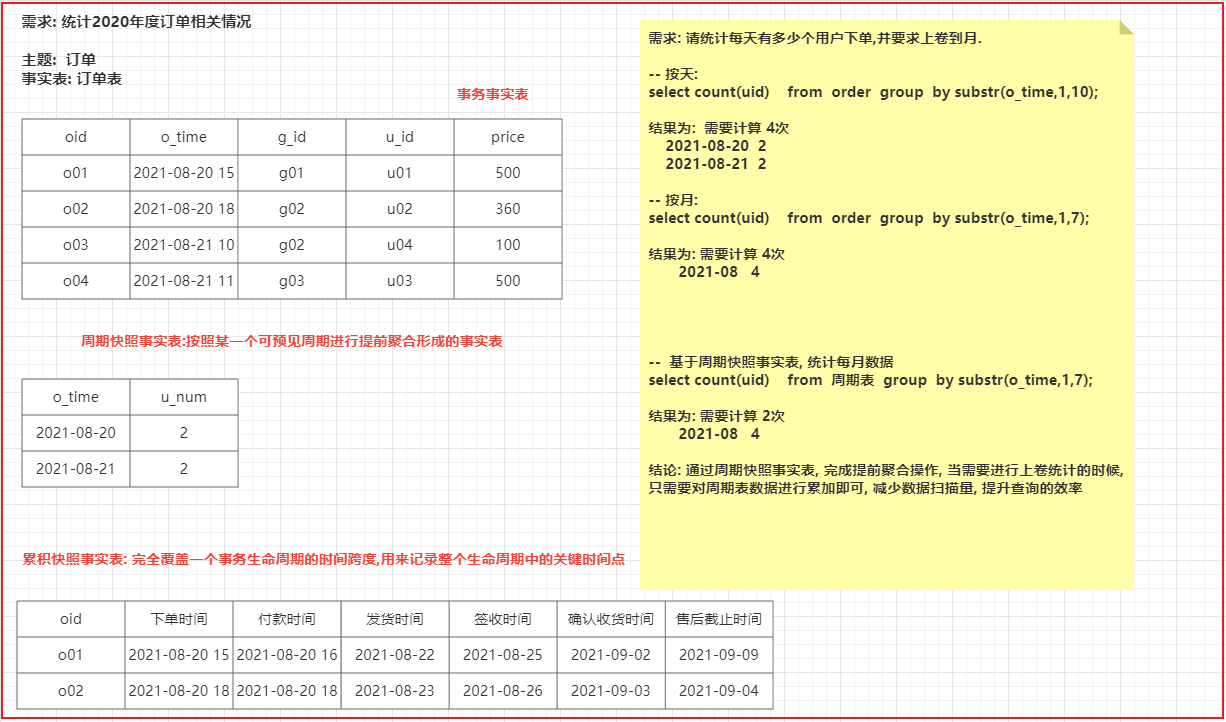
案例:
1 | 需求: 请求出在2020年度, 女性 未婚 年龄在18~25岁区间的用户每一天的订单量? |
6. 数仓建模
数仓建模指的规定如何在hive中构建表, 数仓建模中主要提供两种理论来进行数仓建模操作: 三范式建模和维度建模理论
三范式建模: 主要是存在关系型数据库建模方案上, 主要规定了比如建表的每一个表都应该有一个主键, 数据要经历的避免冗余发生等等
维度建模: 主要是存在分析性数据库建模方案上, 主要一切以分析为目标, 只要是利于分析的建模, 都是OK的, 允许出现一定的冗余, 表也可以没有主键
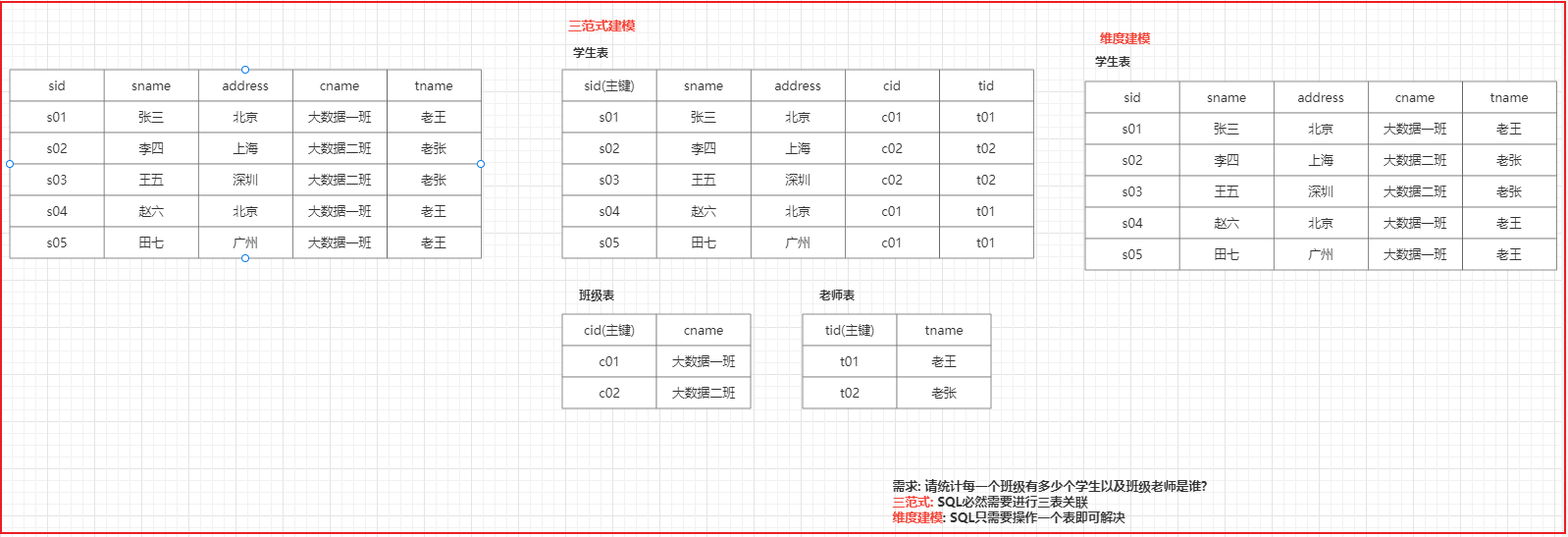
维度建模的两个核心概念:事实表和维度表。
6.1 事实表
事实表: 事实表一般指的就是分析主题所对应的表,每一条数据用于描述一个具体的事实信息, 这些表一般都是一坨主键(外键)和描述事实字段的聚集
1 | 例如: 比如说统计2020年度订单销售情况 |
事实表的分类:
1 | 1) 事务事实表: |
6.2 维度表
维度表: 指的在对事实表进行统计分析的时候, 基于某一个维度, 二这个维度信息可能其他表中, 而这些表就是维度表
1 | 维度表并不一定存在, 但是维度是一定存在: |
维度表的分类:
1 | 高基数维度表: 指的表中的数据量是比较庞大的, 而且数据也在发送的变化 |
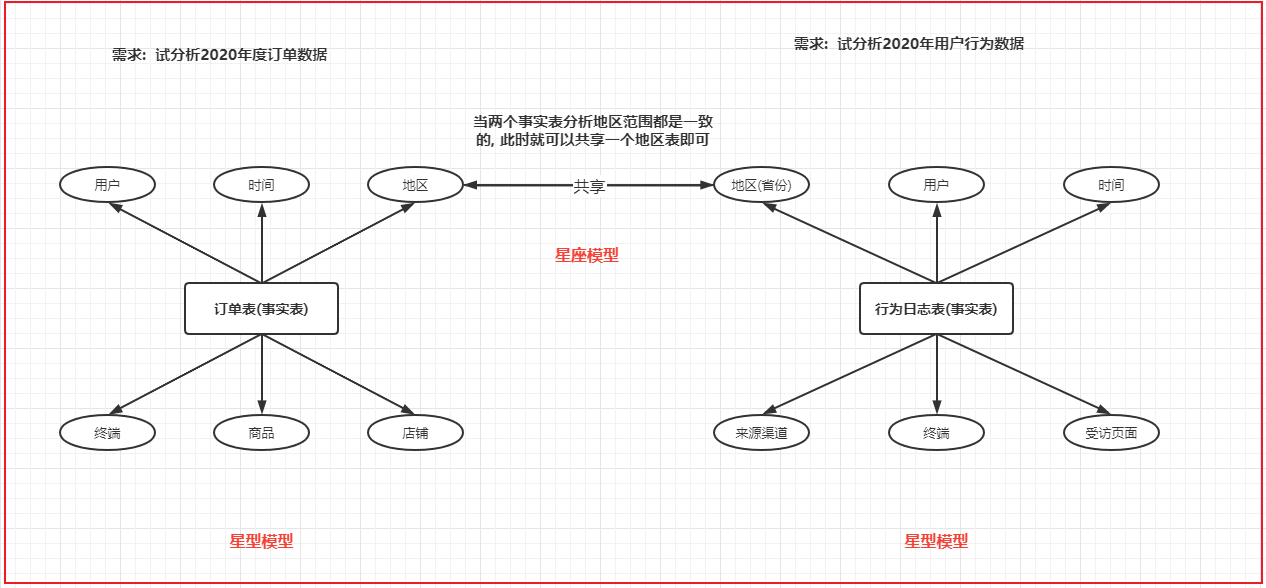
6.3 维度建模的三种模型
- 第一种: 星型模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表与维度表之间没有任何的依赖
- 反映数仓发展初期最容易产生模型
- 第二种: 雪花模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表可以接着关联其他的维度表
- 反映数仓发展出现了畸形产生模型, 这种模型一旦大量出现, 对后期维护是非常繁琐, 同时如果依赖层次越多, SQL分析的难度也会加大
- 此种模型在实际生产中,建议尽量减少这种模型产生
- 第三种: 星座模型
- 特点: 有多个事实表, 那么也就意味着有了多个分析的主题, 在事实表的周围围绕了多个维度表, 多个事实表在条件符合的情况下, 可以共享维度表
- 反映数仓发展中后期最容易产生模型
6.4 缓慢渐变维
解决问题: 解决历史变更数据是否需要维护的情况
- SCD1: 直接覆盖, 不维护历史变化数据
- 主要适用于: 对错误数据处理
- SCD2:不删除、不修改已存在的数据, 当数据发生变更后, 会添加一条新的版本记录的数据, 在建表的时候, 会多加两个字段(起始时间, 截止时间), 通过这两个字段来标记每条数据的起止时间 , 一般称为拉链表
- 好处: 适用于保存多个历史版本, 方便维护实现
- 弊端: 会造成数据冗余情况, 导致磁盘占用率提升
- SCD3: 通过在增加列的方式来维护历史变化数据
- 好处: 减少数据的冗余, 适用于少量历史版本的记录以及磁盘空间不是特别充足情况
- 弊端: 无法记录更多的历史版本, 以及维护比较繁琐
1 | 面试题: |
7. 教育项目的数仓分层
回顾: 原有的基础分层
1 | ODS层: 源数据层 |
教育数仓中:
1 | ODS层: 源数据层 |
8. 数仓工具的使用
8.1 HUE相关的使用
HUE: hadoop 用户体验
出现目的: 提升使用hadoop生态圈中相关软件便利性
核心: 是将各类hadoop生态圈的软件的操作界面集成在一个软件中 (大集成者)
- 如何HUE界面呢?
用户密码:hue/hue

8.2 HUE操作OOZIE
什么是oozie:
1 | Oozie是一个用于管理Apache Hadoop作业的工作流调度程序系统。 |
什么是工作流呢?
1 | 工作流(Workflow),指“业务过程的部分或整体在计算机应用环境下的自动化”。 |
能够使用工作流完成的业务一般具有什么特点呢?
1 | 1) 整个业务流程需要周期性重复干 |
请问, 大数据的工作流程是否可以使用工作流来解决呢? 完全可以的

请问: 如何实现一个工作流呢? 已经有爱心人士将工作流软件实现了, 只需要学习如何使用这些软件配置工作流程即可
1 | 单独使用: |
oozie本质是将工作流翻译为MR程序来运行
8.3 sqoop相关的操作
sqoop是隶属于Apache旗下的, 最早是属于cloudera公司的,是一个用户进行数据的导入导出的工具, 主要是将关系型的数据库(MySQL, oracle…)导入到hadoop生态圈(HDFS,HIVE,Hbase…) , 以及将hadoop生态圈数据导出到关系型数据库中
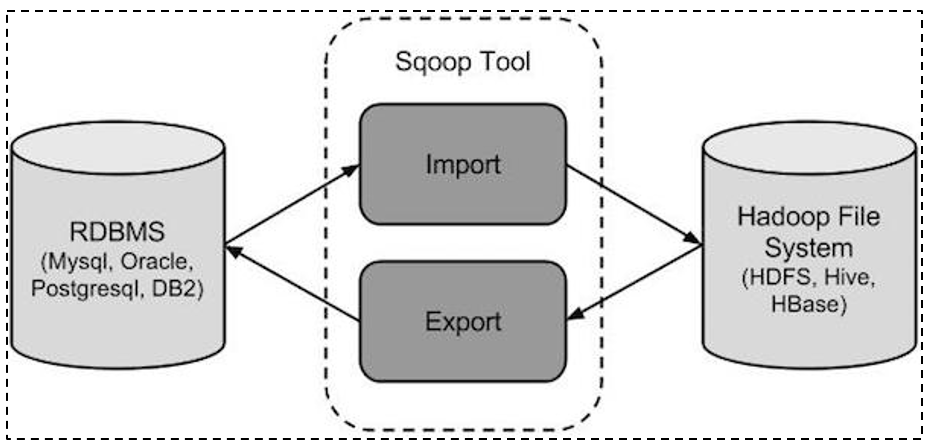
将导入或导出命令翻译成mapreduce程序来实现。
通过sqoop将数据导入到HIVE主要有二种方式: 原生API 和 hcatalog API
1 | 数据格式支持: |
目前主要采用 hcatalog的方式
8.3.1 sqoop的基本操作
- sqoop help 查看命令帮助文档
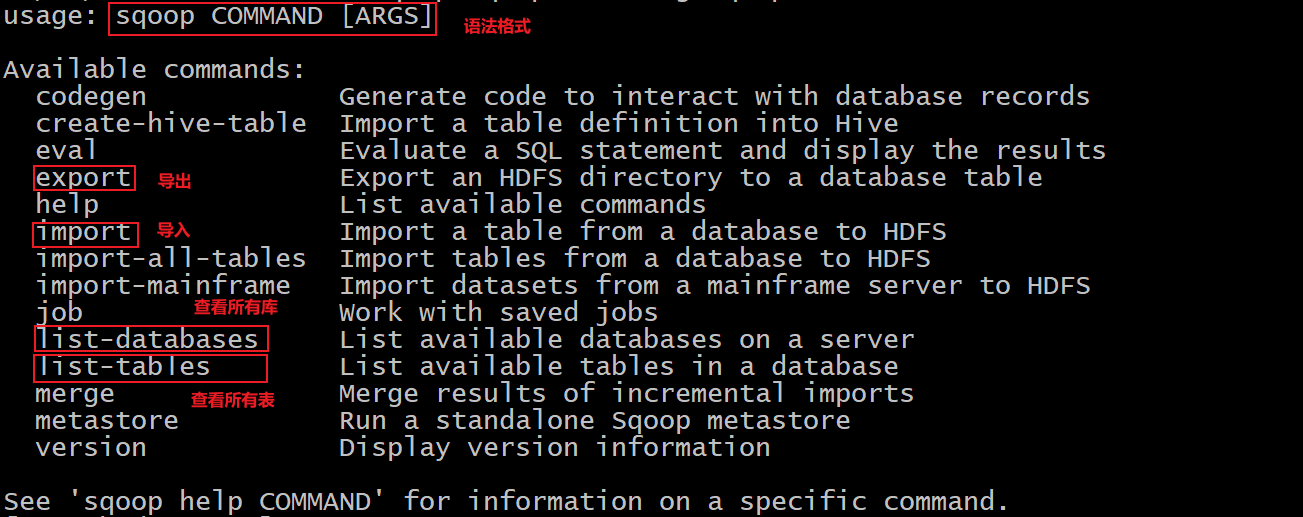
- sqoop list-databases –help 查看某一个命令帮助文档
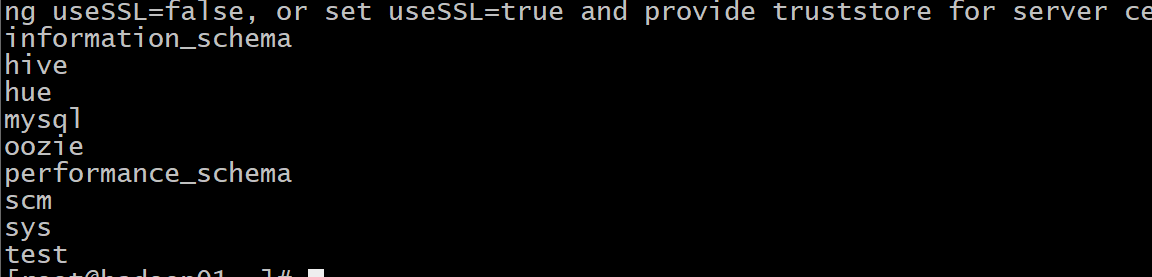
- 如何查看mysql中有那些库呢?
1 | 命令: |
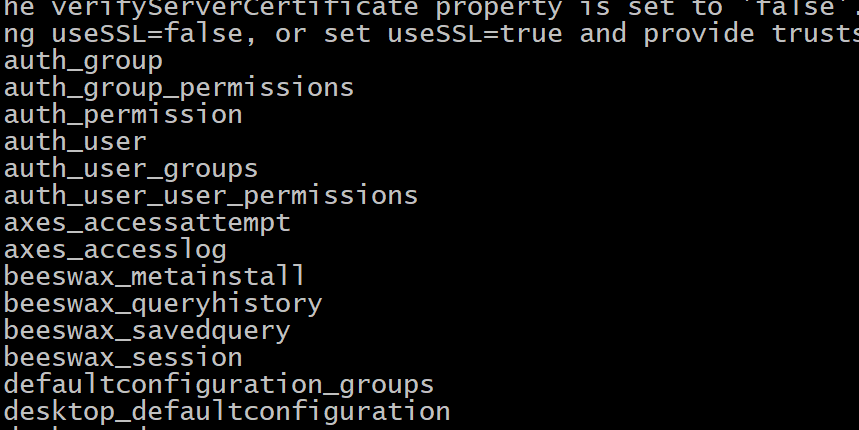
- 如何查看mysql中hue数据库下所有的表呢?
1 | 命令: |
8.3.2 sqoop的数据导入操作
- 数据准备工作 : mysql中执行
1 | create database test default character set utf8mb4 collate utf8mb4_unicode_ci; |
- 第一个: 如何将数据从mysql中导入到HDFS中 (全量)
1 | 以emp表为例: |
- 第二个: 全量导入数据到Hive中
1 | 以emp_add 表为例 |
- 第三个: 如何进行条件导入到HDFS中
1 | -- 以emp 表为例 |
- 第四个: 如何通过条件的方式导入到hive中 (后续模拟增量导入数据)
1 | -- 以 emp_add |
8.3.3 sqoop的数据导出操作
需求: 将hive中 emp_add_hive 表数据导出到MySQL中
1 | 第一步: 在mysql中创建目标表 (必须创建) |
8.3.4 sqoop相关常用参数
| 参数 | 说明 |
|---|---|
| –connect | 连接关系型数据库的URL |
| –username | 连接数据库的用户名 |
| –password | 连接数据库的密码 |
| –driver | JDBC的driver class |
| –query或–e |
将查询结果的数据导入,使用时必须伴随参–target-dir,–hcatalog-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字。 如果使用双引号包含sql,则$CONDITIONS前要加上\以完成转义:$CONDITIONS |
| –hcatalog-database | 指定HCatalog表的数据库名称。如果未指定,default则使用默认数据库名称。提供 –hcatalog-database不带选项–hcatalog-table是错误的。 |
| –hcatalog-table | 此选项的参数值为HCatalog表名。该–hcatalog-table选项的存在表示导入或导出作业是使用HCatalog表完成的,并且是HCatalog作业的必需选项。 |
| –create-hcatalog-table | 此选项指定在导入数据时是否应自动创建HCatalog表。表名将与转换为小写的数据库表名相同。 |
| –hcatalog-storage-stanza ‘stored as orc tblproperties (“orc.compress”=”SNAPPY”)’ \ | 建表时追加存储格式到建表语句中,tblproperties修改表的属性,这里设置orc的压缩格式为SNAPPY |
| -m | 指定并行处理的MapReduce任务数量。 -m不为1时,需要用split-by指定分片字段进行并行导入,尽量指定int型。 |
| –split-by id | 如果指定-split by, 必须使用$CONDITIONS关键字, 双引号的查询语句还要加\ |
| –hcatalog-partition-keys –hcatalog-partition-values | keys和values必须同时存在,相当于指定静态分区。允许将多个键和值提供为静态分区键。多个选项值之间用,(逗号)分隔。比如: –hcatalog-partition-keys year,month,day –hcatalog-partition-values 1999,12,31 |
| –null-string ‘\N’ –null-non-string ‘\N’ | 指定mysql数据为空值时用什么符号存储,null-string针对string类型的NULL值处理,–null-non-string针对非string类型的NULL值处理 |
| –hive-drop-import-delims | 设置无视字符串中的分割符(hcatalog默认开启) |
| –fields-terminated-by ‘\t’ | 设置字段分隔符 |
9. hive的索引
索引的作用: 加快查询的效率
为什么索引可以提升查询效率呢?

hive索引是在 分区 分桶优化基础上, 又提供一种新的优化手段, 如果分区 和分桶受限, 可以尝试使用索引的方式来优化处理
hive提供了三种索引:
- 原始索引
- row group index(行组索引)
- bloom filter index(布隆过滤索引)
7.1 hive的原始索引
结论: 此索引已经不再使用, 在hive3.0以上, 彻底不支持
1 | hive的原始索引, 可以针对表中某一列或者某几列构建索引, 构建之后, 当查询的时候使用到索引字段, 可以帮助提升一定效率 |
7.2 row group index(行组索引)

1 | 条件: |
7.3 bloom filter index(布隆过滤索引)

1 | 条件: |
注意 如果要使用hive的索引, 必须开启hive自动使用索引
1 | SET hive.optimize.index.filter=true --开启 hive的自动使用索引 |
在生产中这些索引如何选择呢?
1 | 1) 对于行组索引, 建议是常开即可 |
10. hive的相关的优化
1.1 hive的相关的函数(补充说明)
if函数:
- 作用: 用于进行逻辑判断操作
- 语法: if(条件, true返回信息,false返回信息)
- 注意: if函数支持嵌套使用
nvl函数:
- 作用: null值替换函数
- 格式: nvl(T value, T default_value)
COALESCE函数
- 作用: 非空查找函数:
- 格式: coalesce(值1,值2,值3…)
- 说明: 从第一个值开始判断, 找到第一个不为null的值, 将其返回, 如果都为null,返回null
CASE WHEN THEN 函数:
- 格式1: case 字段 when 条件 then 值1 when 条件 then 值2 .. else 值3 end
- 格式2: case when 条件 then 值1 when 条件2 then 值2 .. else 值3 end
isnull() | isnotnull() 函数
- 作用:
- isnull() 判断是否为null, 如果为null返回true, 否则返回false
- isnotnull() 判断是否不为null, 如果不为null, 返回true, 如果为null 返回false
- 作用:
1.2 hive的相关的优化
- hive的并行优化
1 | 1) 并行编译 |
- hive的小文件合并
1 | 思考: 小文件有什么影响呢? |
- 矢量化查询
1 | 说明: |
- 读取零拷贝
1 | 说明: 在hive读取数据的时候, 只需要读取跟SQL相关的列的数据即可, 不使用列, 不进行读取, 从而减少读取数据, 提升效率 |
1.3 数据倾斜的优化
思考: 什么是数据倾斜呢?
1 | 在运行过程中,有多个reduce, 每一个reduce拿到的数据不是很均匀, 导致其中某一个或者某几个reduce拿到数据量远远大于其他的reduce拿到数据量, 此时认为出现了数据倾斜问题 |
思考:数据倾斜会导致问题?
1 | 1) 执行效率下降(整个执行时间, 就看最后一个reduce结束时间) |
思考: 在执行什么SQL的时候, 会出现多个reduce的情况呢?
1 | 1) 多表join的时候 |
思考: 发生数据倾斜的情况:
1 | 1) 执行多表查询的时候 |
如何解决数据倾斜的问题呢?
1.3.1 group by 数据倾斜
解决方案:
1 | 方案一: 采用combiner的方式来解决 (在map端提前聚合) |
1.3.2 join的数据倾斜
1 | 解决方案一 : |
union all相关优化点:
1 | 配置项: |
1.3.3 如何感知有数据倾斜
方案一: 通过查看 job history历史日志(19888) 适用于MR已经执行完成了
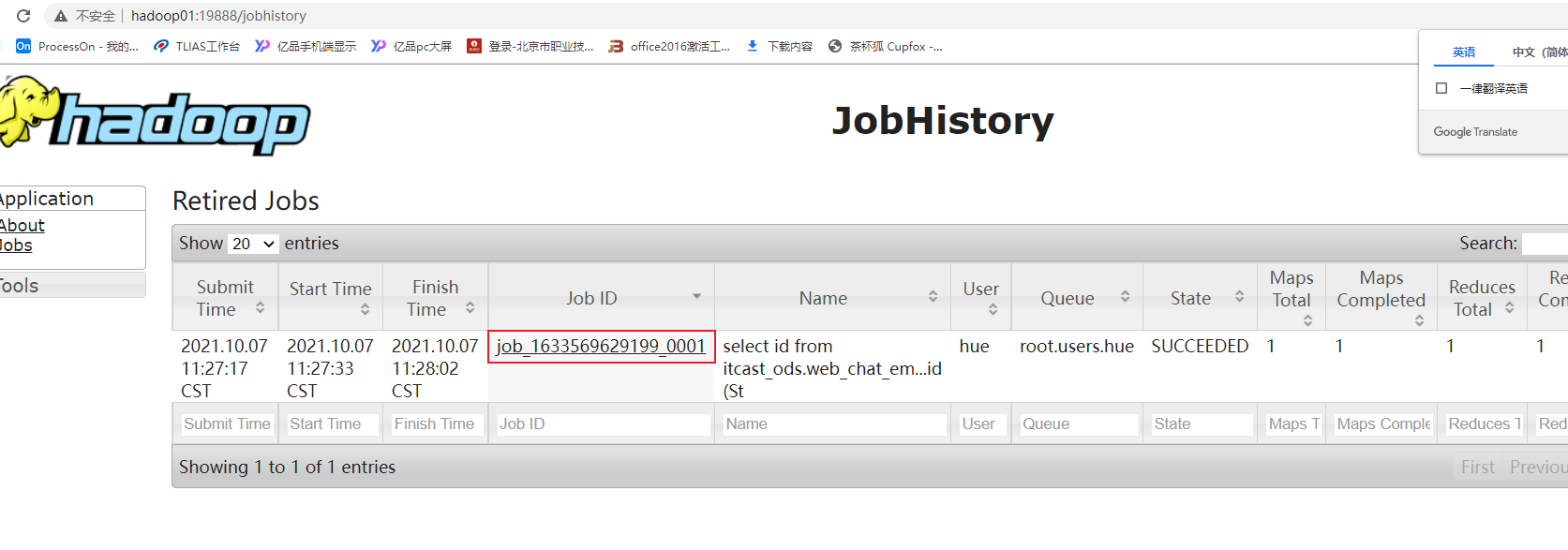
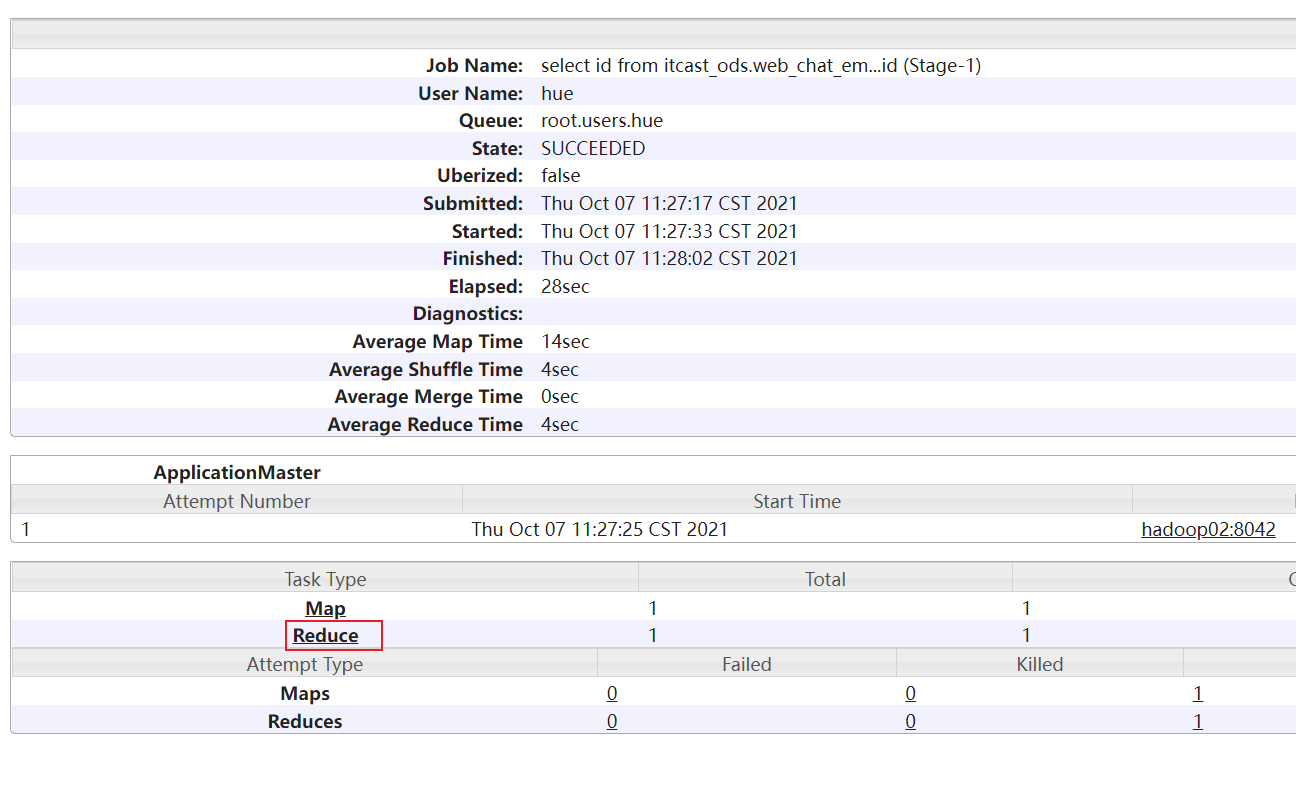
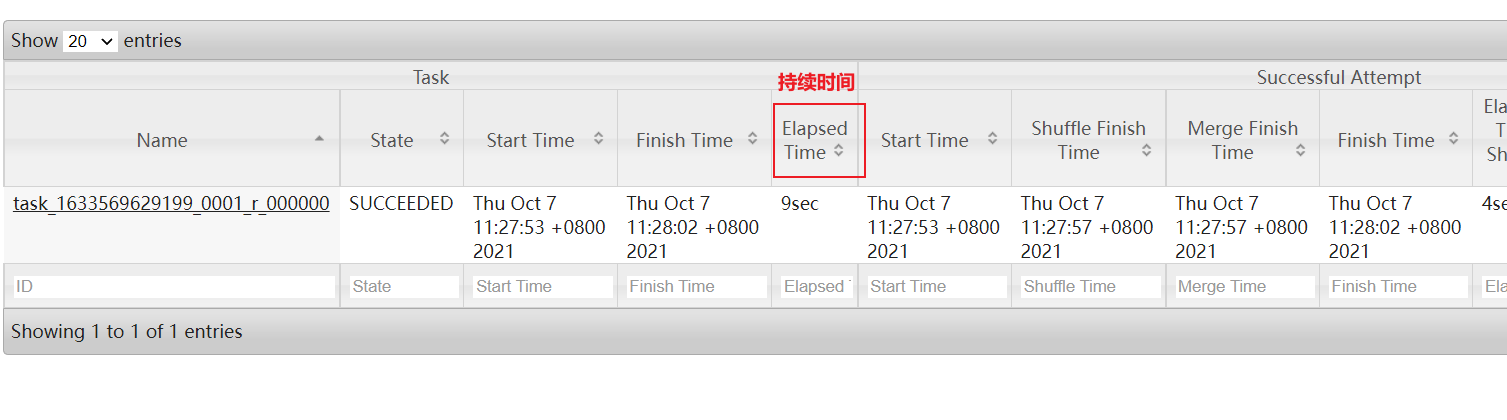
方案二: 在运行过程中如何查看是否有倾斜呢? 借助与HUE查看
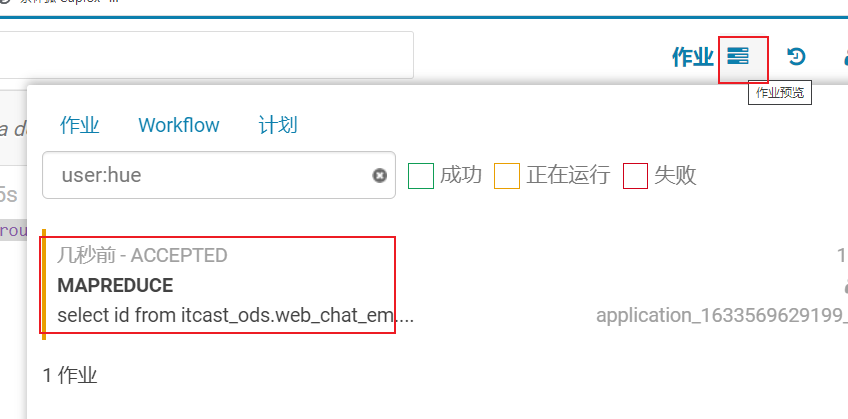
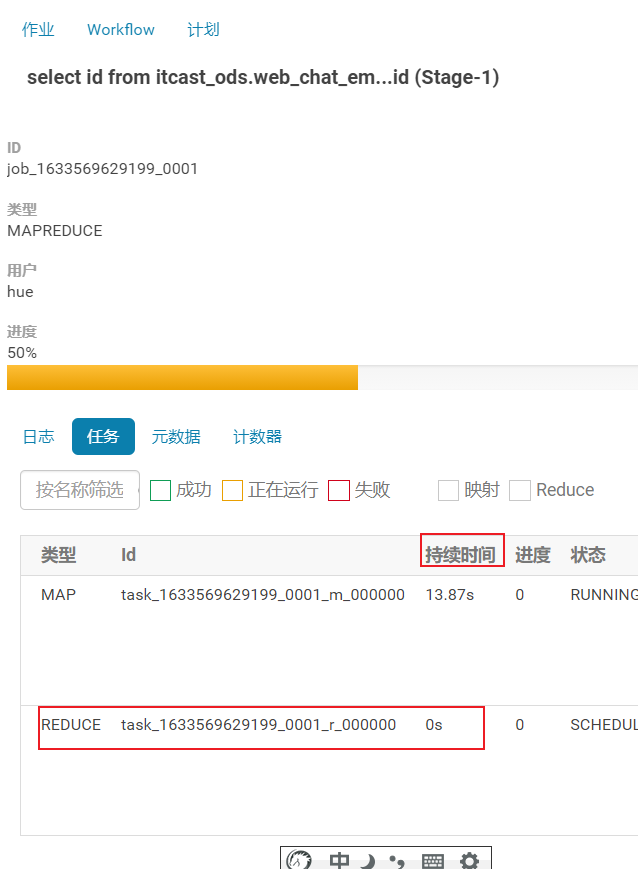
1.3.4 关联优化器(共享shuffle)
1 | 配置: |
1.4 总结说明
1 | 常开项: |
11. hive的基础优化(不需要修改)
HDFS的副本数量
默认情况HDFS的副本有 3个副本
1 | 实际生产环境中, 一般HDFS副本也是以3个 |
如何配置副本数量: 直接在CM上HDFS的配置目录下配置
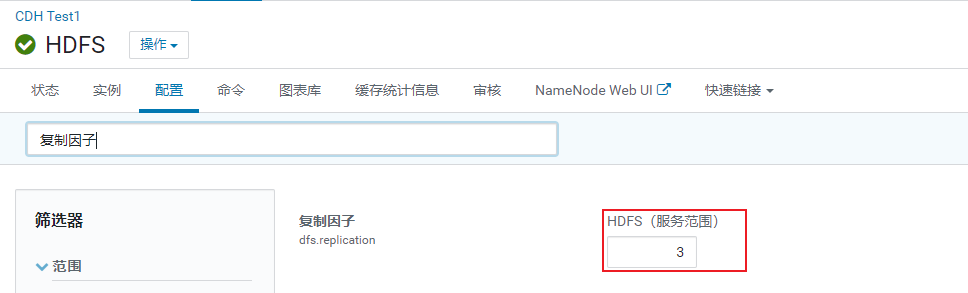
yarn的基础配置
yarn: 用于资源的分配 (资源: 内存 CPU)
1 | 其中 nodemanager 用于出内存和CPU |
- cpu的配置
1 | 注意: 每一个nodemanager 会向resourcemanager报告自己当前节点有多少核心数 |
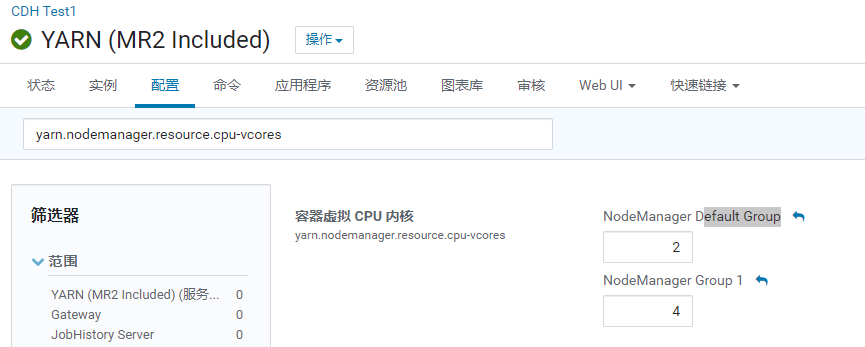
- 内存配置
1 | 注意: 每一个nodemanager 会向resourcemanager报告自己当前节点有多少内存 |
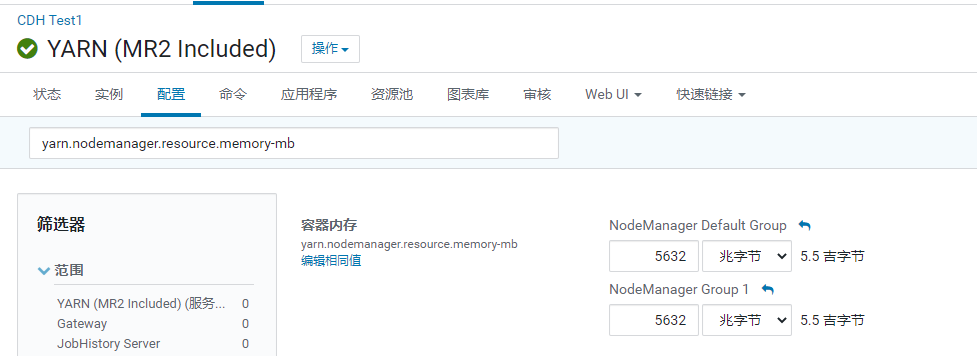
- yarn本地目录的配置
1 | 配置项:yarn.nodemanager.local-dirs |
MapReduce基础配置
1 | mapreduce.map.memory.mb : 在运行MR的时候, 一个mapTask需要占用多大内存 |
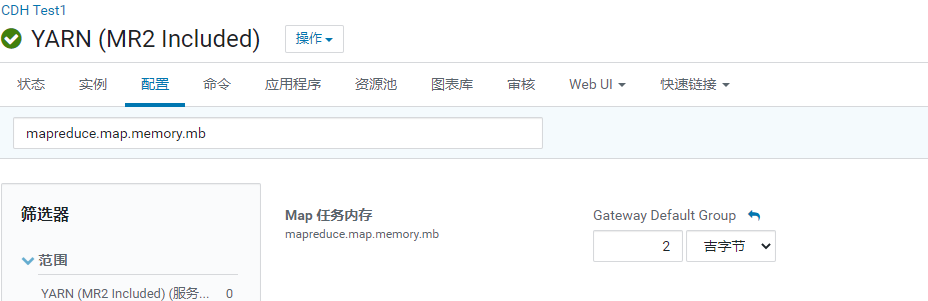
hive的基础配置
- hiveserver2的内存大小配置
1 | 配置项: HiveServer2 的 Java 堆栈大小(字节) |
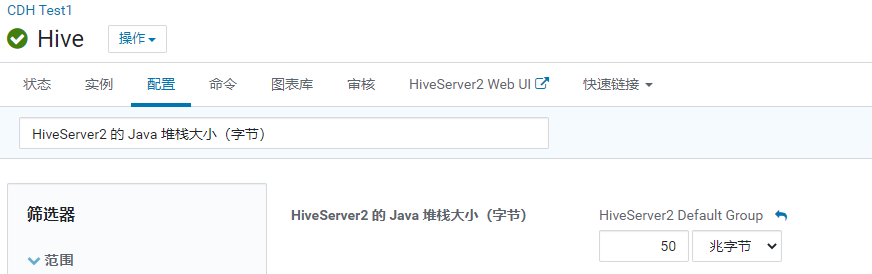
1 | 说明: 如果这个配置比较少, 在执行SQL的时候, 就会出现以下的问题: |

- 动态生成分区的线程数
1 | 配置: hive.load.dynamic.partitions.thread |
- 监听输入文件的线程数量
1 | 配置项: hive.exec.input.listing.max.threads |
hive压缩的配置
1 | map中间结果压缩配置: |
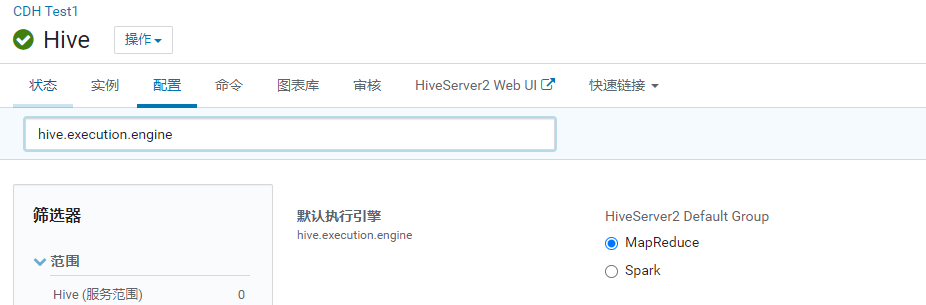
hive的执行引擎切换
1 | 配置项: hive.execution.engine |
业务看板
访问咨询主题看板_全量流程
需求分析
将调研需求转换为开发需求
1 | 如何转换呢? |
- 需求一: 统计指定时间段内,访问客户的总数量。能够下钻到小时数据。
1 | 涉及维度: |
- 需求二: 统计指定时间段内,访问客户中各区域人数热力图。能够下钻到小时数据。
1 | 涉及维度: |
需求三: 统计指定时间段内,不同地区(省、市)访问的客户中发起咨询的人数占比;
咨询率=发起咨询的人数/访问客户量;客户与网咨有说一句话的称为有效咨询。
1 | 涉及维度: |
- 需求四: 统计指定时间段内,每日客户访问量/咨询率双轴趋势图。能够下钻到小时数据。
1 | 涉及维度: |
需求五: 统计指定时间段内,1-24h之间,每个时间段的访问客户量。
横轴:1-24h,间隔为一小时,纵轴:指定时间段内同一小时内的总访问客户量。
1 | 涉及维度: |
需求六: 统计指定时间段内,不同来源渠道的访问客户量占比。能够下钻到小时数据。
占比: 各个渠道下 咨询量/访问量占比
1 | 涉及维度: |
需求七: 统计指定时间段内,不同搜索来源的访问客户量占比。能够下钻到小时数据。
占比:
各个搜索来源访问量 / 总访问量 (是要这个需求)
各个搜索来源下 咨询量 / 各个搜索来源访问量
1 | 涉及维度: |
- 需求八: 统计指定时间段内,产生访问客户量最多的页面排行榜TOPN。能够下钻到小时数据。
1 | 涉及维度: |
汇总:
1 | 涉及维度: |
业务数据准备
准备在mysql,对应实际生产中的mysql库,为数据来源。
两个表关系图:
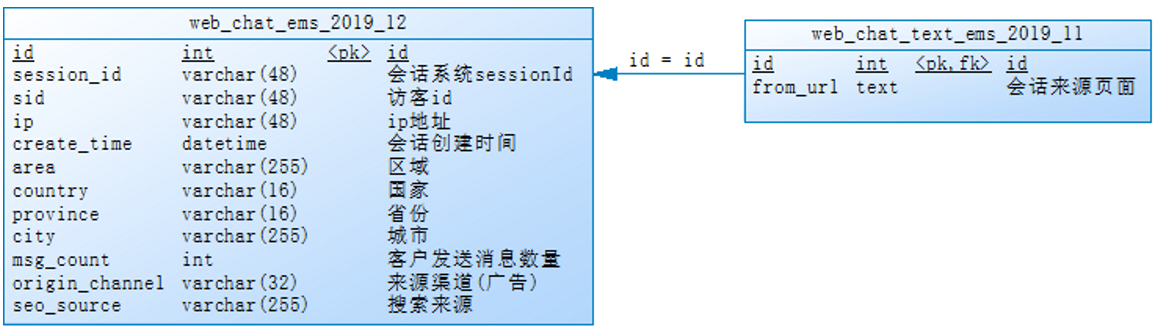
第一步: 在hadoop01的mysql中建一个数据库
1 | create database nev default character set utf8mb4 collate utf8mb4_unicode_ci; |
第二步: 将项目资料中 nev.sql 脚本数据导入到nev数据库中
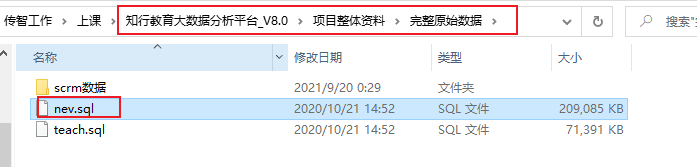
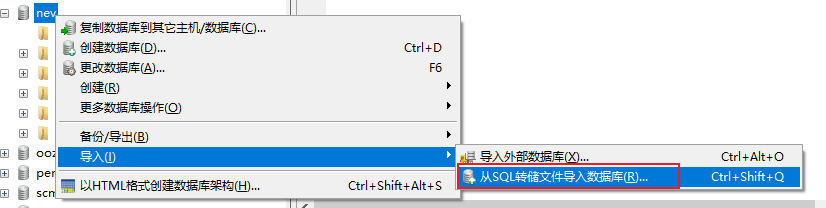
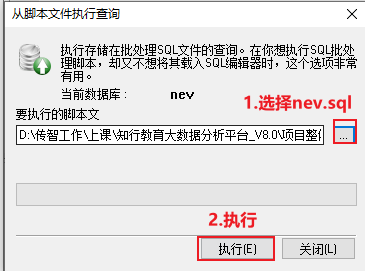
结果数据:
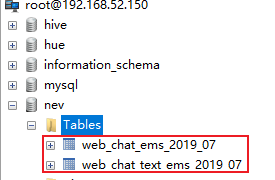
此准备工作在实际生产环境中是不存在的…
建模分析
建模: 如何在hive中构建各个层次的表
- ODS层: 源数据层
1 | 作用: 对接数据源, 一般和数据源保持相同的粒度(将数据源数据完整的拷贝到ODS层) |
- DIM层: 维度层
1 | 作用: 存储维度表数据 |
- DWD层: 明细层
1 | 作用: 1) 清洗转换 2) 少量维度退化 |
- DWM层: 中间层 (省略)
1 | 作用: 1) 维度退化操作 2) 提前聚合 |
- DWS层: 业务层
1 | 作用: 细化维度统计操作 |
不存在设置为-1,三个经验字段 time_type设置12345为时间维度的类型,group_time设置12345为产品维度的分组类型,time_str为时间的拼接,方便查看
- DA层:
1 | 作用: 对接应用, 应用需要什么数据, 从DWS层获取什么数据即可 |
建模操作
思考: 在创建表的时候, 需要考虑那些问题呢?
1 | 1) 表需要采用什么存储格式 |
数据存储格式和压缩方案
存储格式选择:
1 | 情况一: 如果数据不是来源于普通文本文件的数据, 一般存储格式选择为列式的ORC存储 |
压缩方案选择:
1 | 写多,读少: 优先考虑压缩比 建议选择 zlib gz |
最终:
ODS: orc + zlib
其他层次: orc + snappy
全量和增量
在进行数据统计分析的时候, 一般来说, 第一次统计分析都是全量统计分析 而后续的操作, 都是在结果基础上进行增量化统计操作
1 | 全量统计: 需要面对公司所有的数据进行统计分析, 数据体量一般比较大的 |
hive分区
后续的hive中构建表大部分的表都是分区表
1 | 思考: 分区表有什么作用呢? |
回顾: 内部表和外部表如何选择呢?
1 | 判断当前这份数据是否具有绝对的控制权 |
如何向分区表添加数据呢?
1 | 1) 静态分区: |
动态分区的优化点: 有序动态分区
1 | 什么时候需要优化? |
建模操作
- ODS层:
1 | CREATE DATABASE IF NOT EXISTS `itcast_ods`; |
- DWD层:
1 | CREATE DATABASE IF NOT EXISTS `itcast_dwd`; |
- DWS层
1 | CREATE DATABASE IF NOT EXISTS `itcast_dws`; |
数据采集
目的: 将业务端的数据导入到ODS层对应表中
1 | 业务端数据: mysql |
导入数据的SQL语句:
1 | -- 访问咨询主表: |
执行sqoop脚本, 完成数据采集
1 | -- 访问咨询主表 |
校验数据是否导入成功:
1 | 1) 查看mysql共计有多少条数据 |
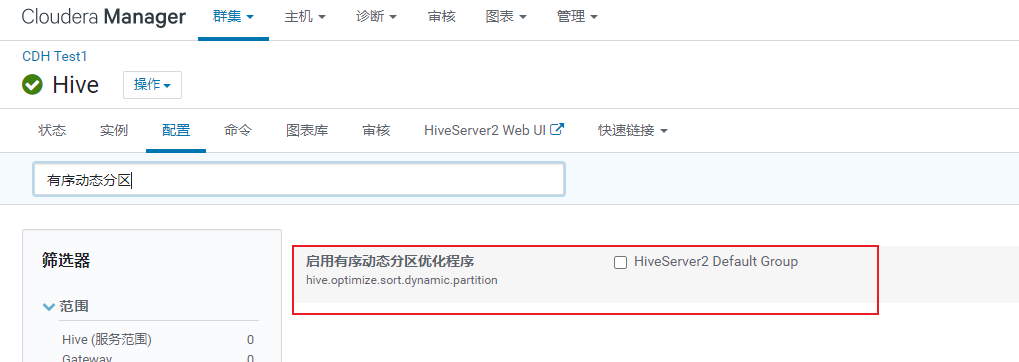
可能报出一下错误:

从cm上查看hive的hiveserver2的服务, 服务给出报出信息为:
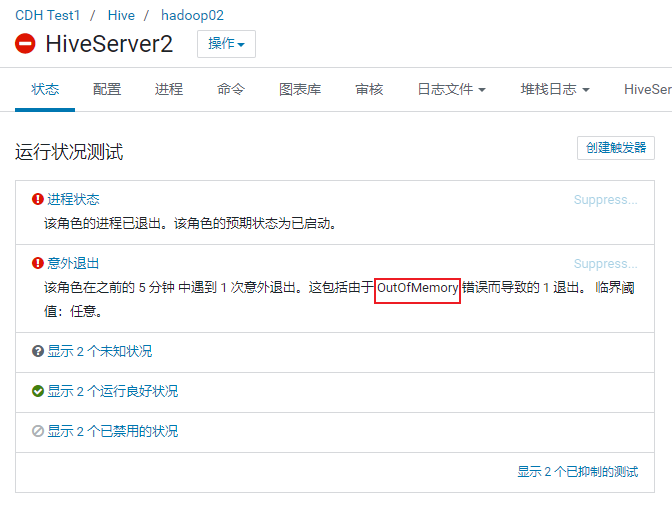
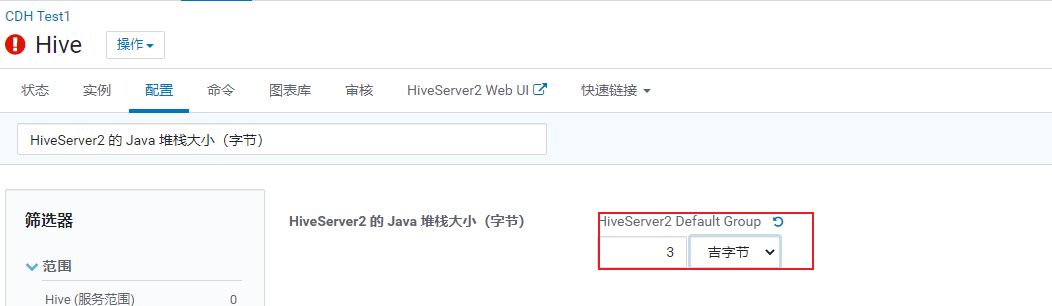
解决方案:
1 | 调整 hiveserver2的内存大小 |
数据清洗转换
目的: 将ODS层数据导入到DWD层
1 | DWD层作用: |
SQL的实现: 未完成转换操作
1 | select |
思考: 如何进行转换操作:
1 | 转换1: 将create_time 转换为 int类型的数据 (说白: 转换为时间戳) |
实现最终转换的SQL
1 | select |
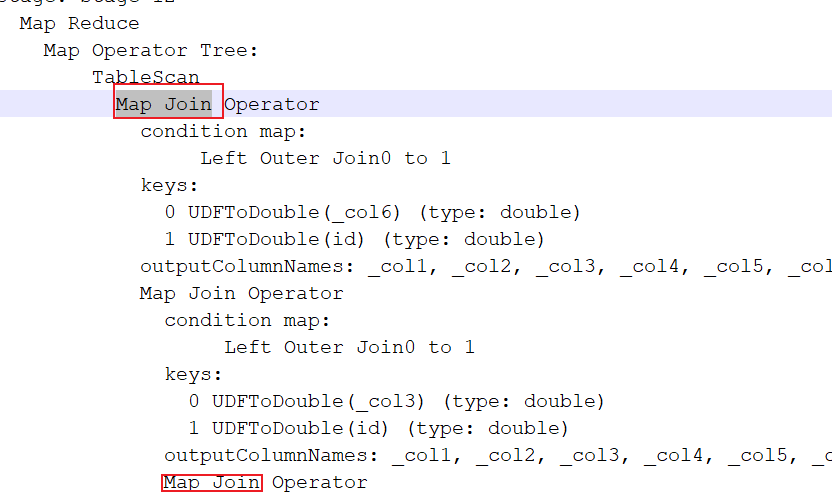
可能会出现的错误:

1 | 注意: |
解决方案:
1 | 关闭掉map join 让其采用reduce join即可 |
接下来: 将结果数据灌入到DWD层的表中
1 | --动态分区配置 |
数据分析
目的: 将DWD层数据灌入到DWS层
1 | DWS层作用: 细化维度统计操作 |
访问量
- 如何计算访问量:
1 | 访问量: |
总访问量
以时间为基准, 统计总访问量
1 | -- 统计每年的总访问量 |
受访页面
基于时间统计各个受访页面的访问量
1 | -- 统计每年各个受访页面的访问量 |
咨询量
1 | 咨询量 |
基于时间统计总咨询量
1 | -- 统计每年的总咨询量 |
基于时间,统计各个地区的咨询量
1 | -- 统计每年各个地区的咨询量 |
数据导出
目的: 从hive的DWS层将数据导出到mysql中对应目标表中
1 | 技术: |
- 第一步: 在mysql中创建目标表:
1 | create database scrm_bi default character set utf8mb4 collate utf8mb4_general_ci; |
第二步执行sqoop的数据导出
1 | -- 先导出 咨询量数据 |
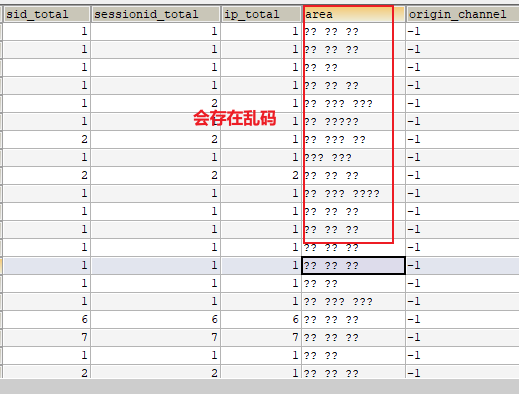
解决乱码:
完成咨询量数据导出
1 | sqoop export \ |
完成访问量数据导出
1 | sqoop export \ |
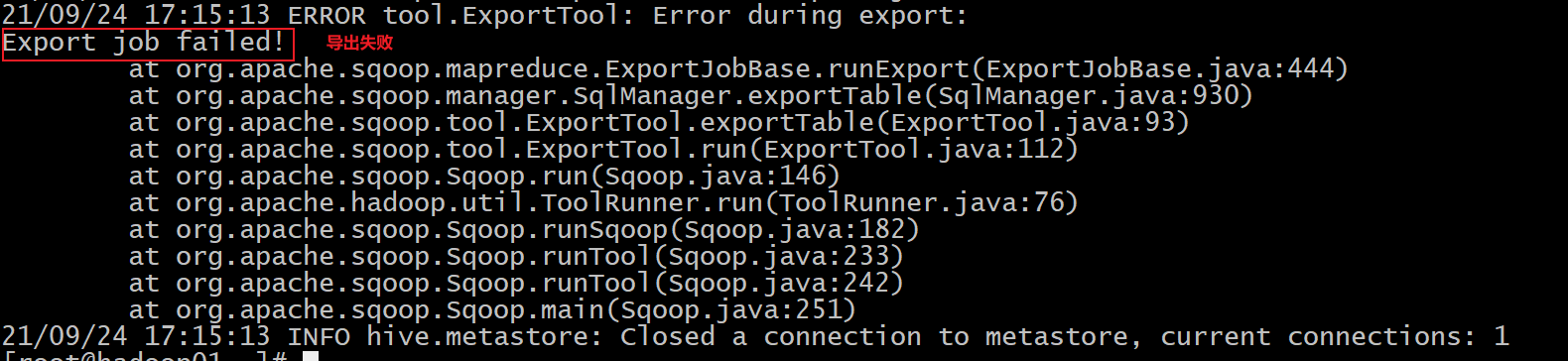
1 | 此错误是sqoop在运行导出的时候, 一旦执行MR后, 能够报出的唯一的错误: 标识导出失败 |
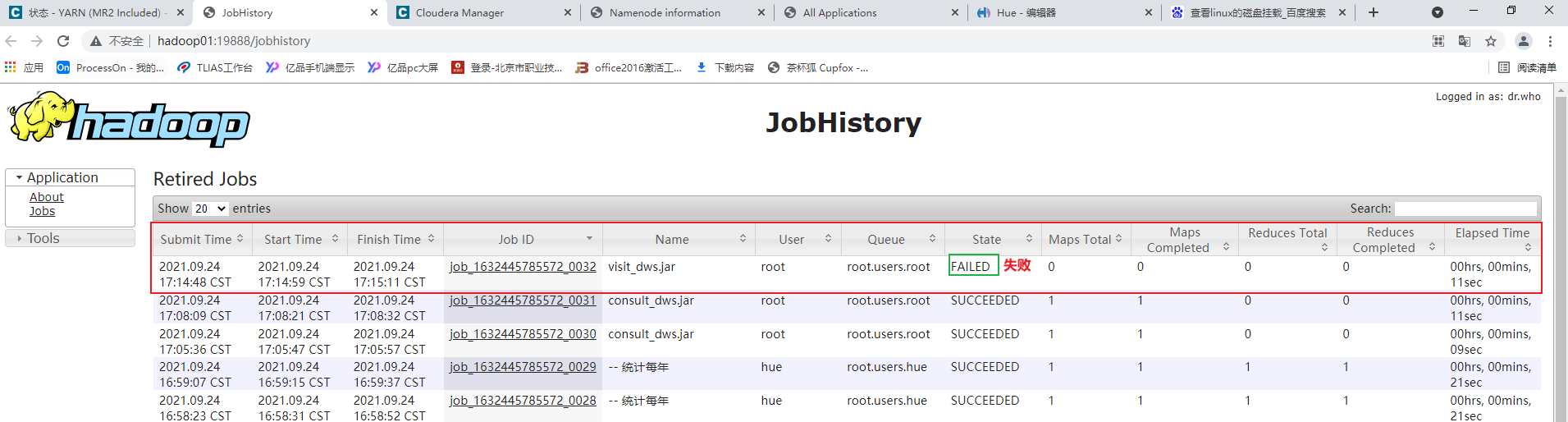
点击job id后,进入页面后点击 logs
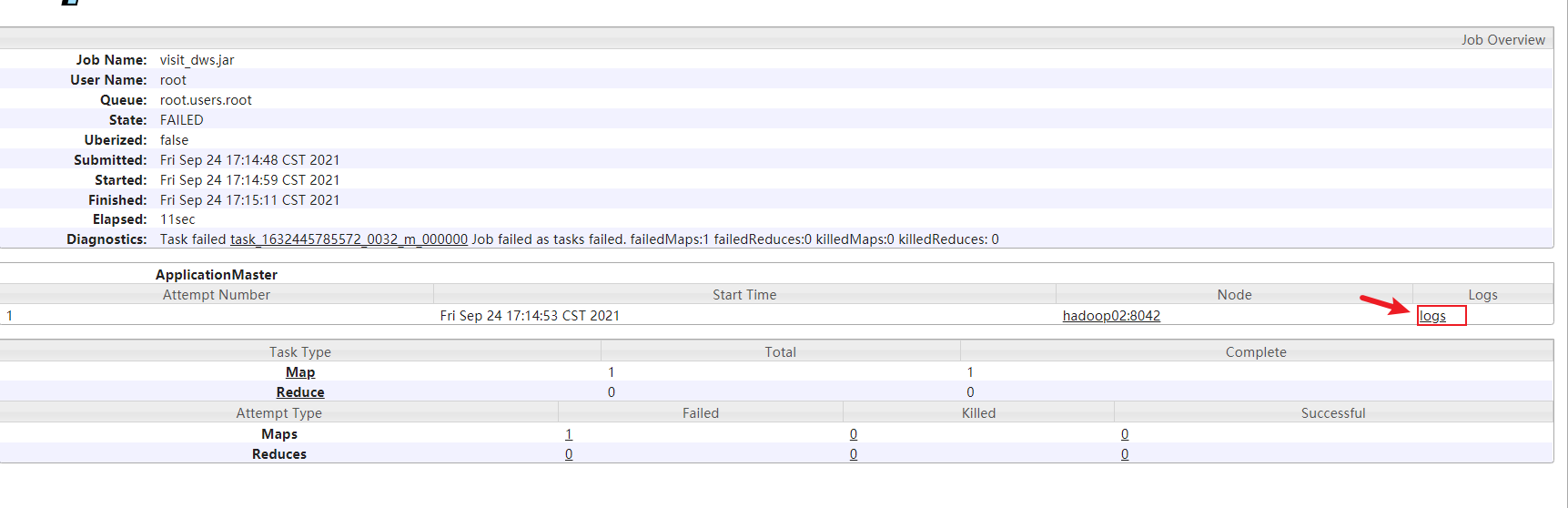
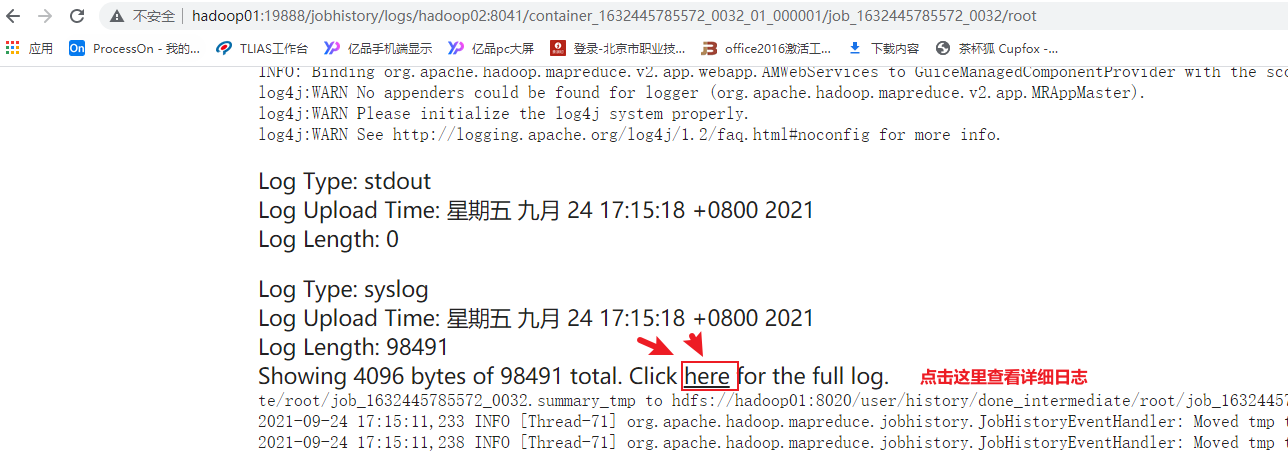
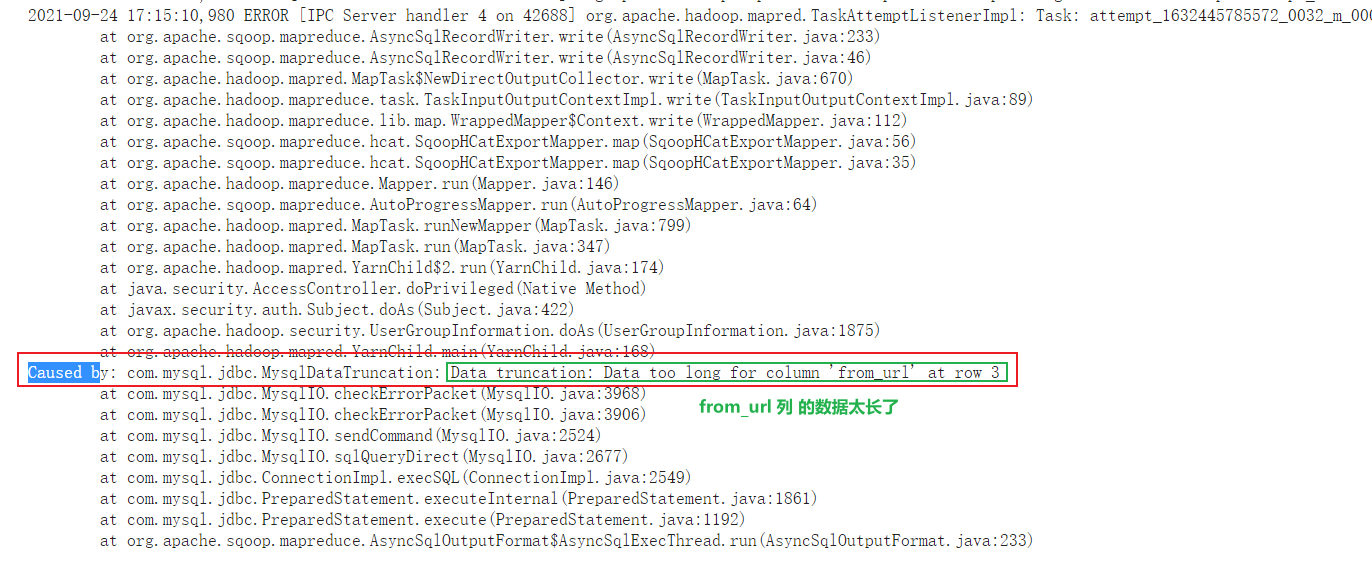
1 | 解决方案: |
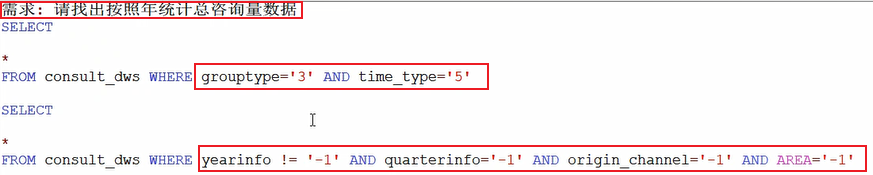
然后就可以用了,用的时候既可以发现grouptype 和 time_type 经验字段的好处
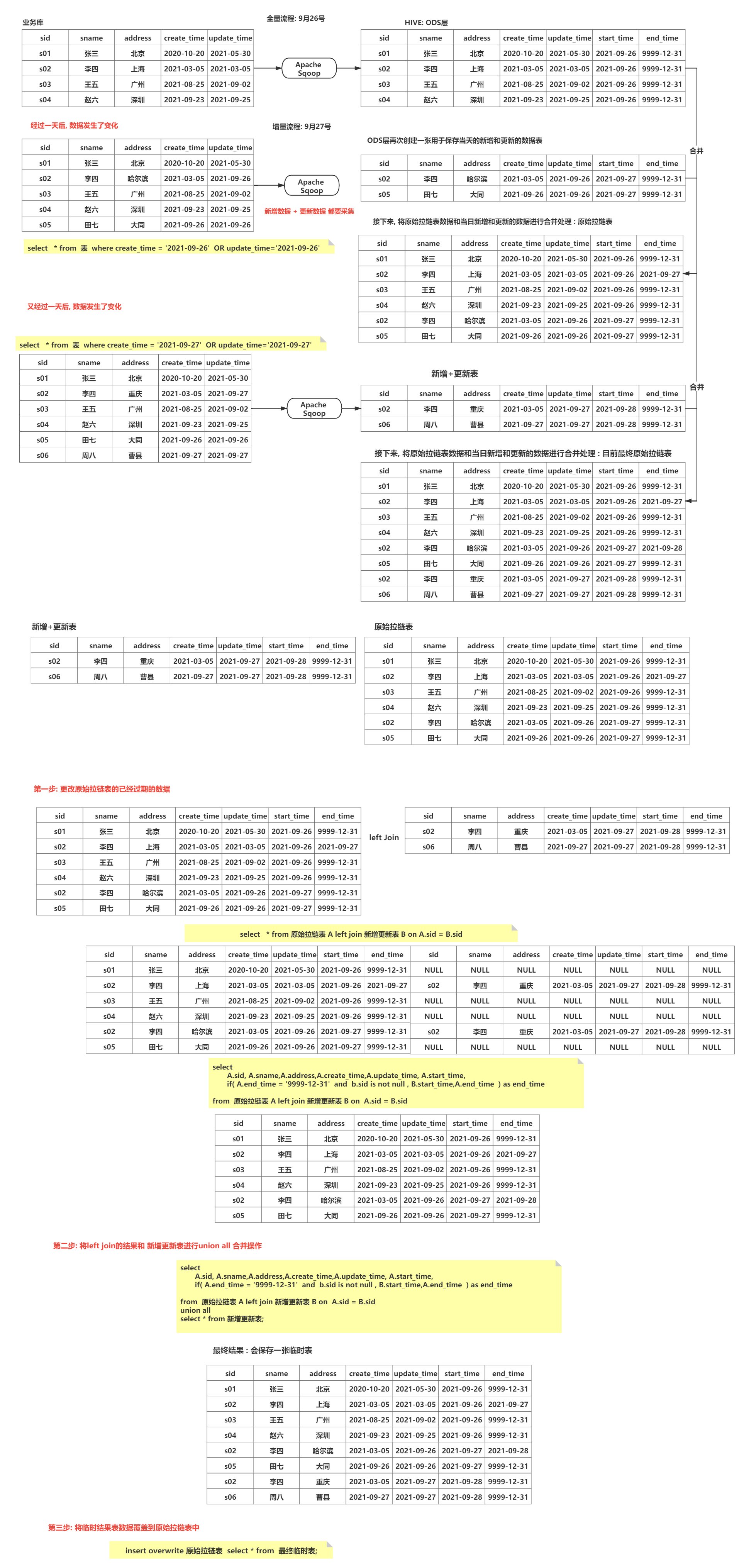
访问咨询主题看板_增量流程
业务库中模拟增量数据
实际生产中不存在这步操作,生产数据会有增量的
- 模拟上一天数据: 在mysql中执行
1 | -- 模拟访问咨询主表数据 |
增量数据采集操作
只需要采集新增的这一天的数据即可
- 思考1: 如何从表中获取新增的这一天的数据呢?
1 | -- 访问咨询的主表数据: |
- 思考2: 将增量的SQL集成到增量的sqoop脚本中
1 | -- 访问咨询主表 |
- 思考3: 此脚本为增量化的脚本操作, 随着时间的推移, 每一天都需要执行一次, 而且每次执行只需要修改日期数据即可, 请问有什么简单方案呢?
1 | 解决方案: |
思考4: 如何编写shell脚本呢?
要求: 此脚本能够实现自动获取上一天的日期数据, 并且还支持采集指定日期下数据
1 | 难度1: 如何通过shell脚本获取上一天的日期呢? |
- 编写增量数据采集的shell脚本
1 | hadoop01: 家目录 |
- 测试脚本是否可以正常执行
1 | sh edu_mode_1_collect.sh |
将shell脚本放置到ooize中,完成自动化调度操作
- 第一步骤: 配置工作流
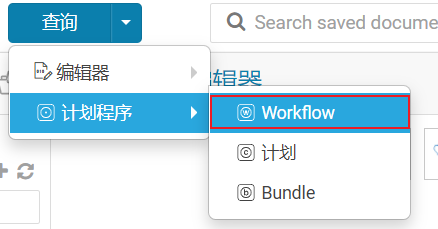
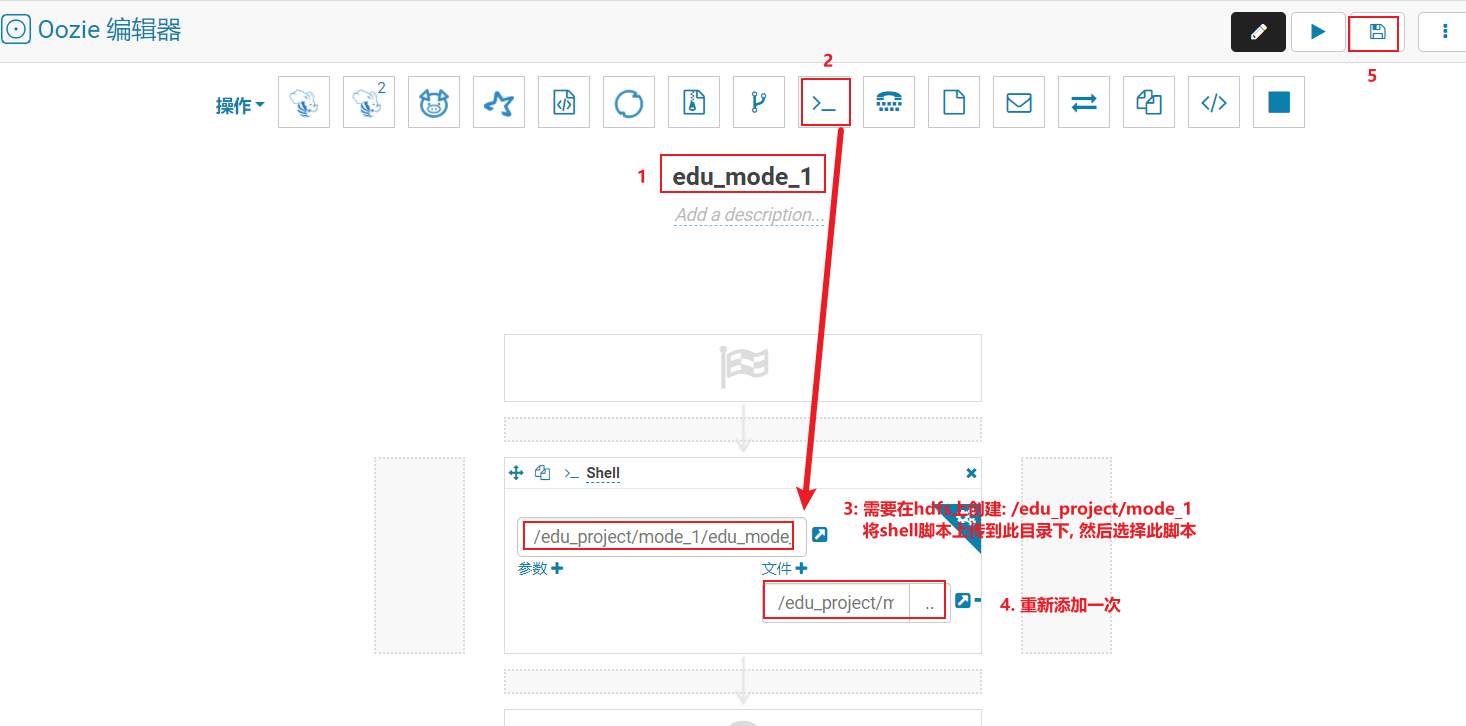
- 第二步: 配置自动化调度
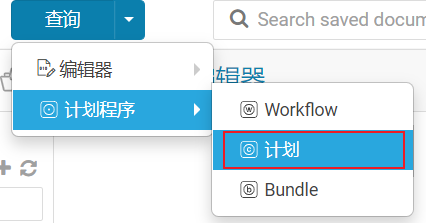
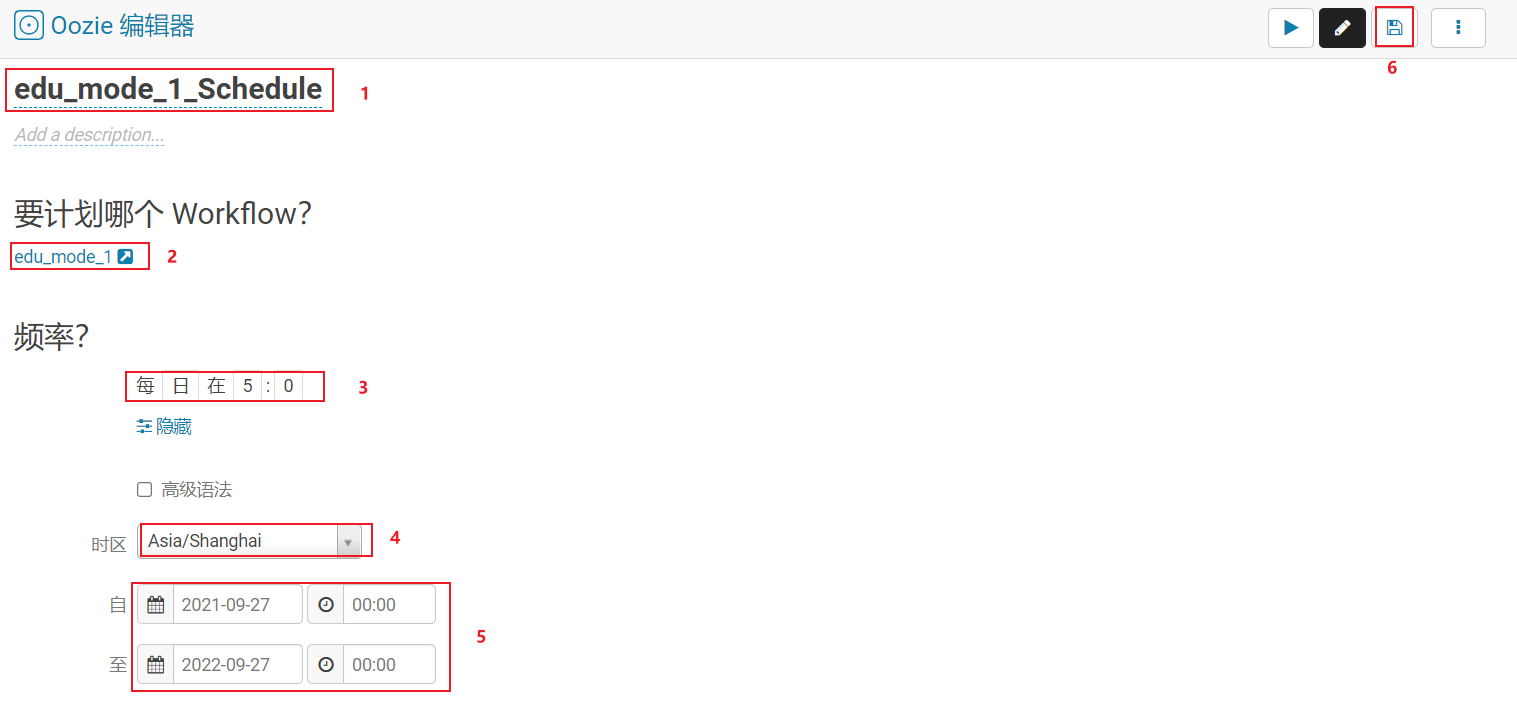
点击运行启动即可
增量数据清洗转换操作
- 原有的全量的清洗转换SQL
1 | --动态分区配置 |
- 改造后,增量的清洗转换的SQL
1 | --动态分区配置 |
- 思考: 如何在shell下执行hive的SQL
1 | 解决方案: |
- 编写shell脚本, 实现增量数据清洗转换操作
1 | hadoop01: |
将shell脚本配置到ooize中, 从而实现自动化调度
- 第一步: 配置工作流(在原有的采集工作流后续最近一个阶段即可)
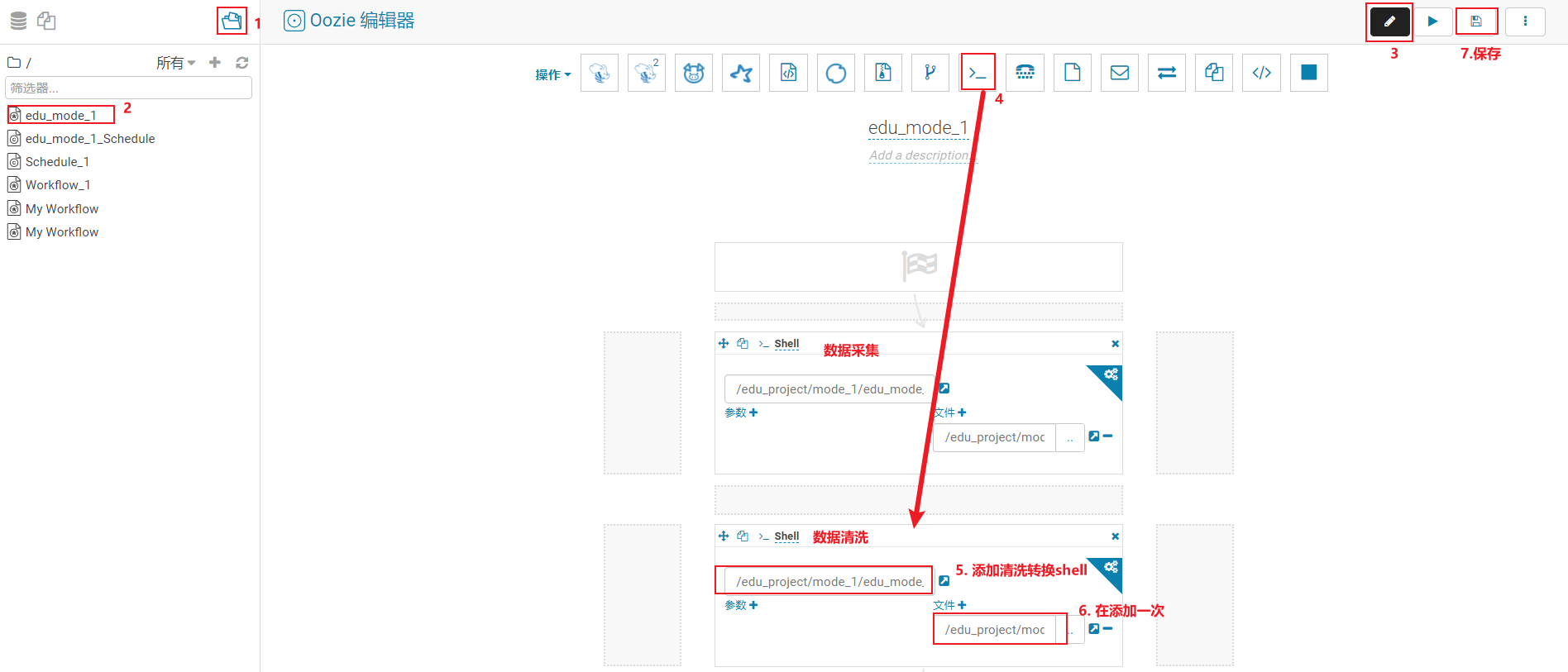
- 第二步: 配置自动化调度(可以直接省略….)
增量数据统计分析操作
- 全量的统计SQL:
1 | -- 访问量: 5条 |
增量的SQL统计:
1 | -- 访问量: 5条 |
说明:
1 | 在统计年的时候, 只需要统计加上这一天以后这一年的数据即可, 之前年的数据是不需要统计的 |
思考: 在统计的过程中, 比如以年统计, 得到一个新的年的统计结果, 那么在DWS层表中是不是还有一个历史的结果呢? 如何解决呢
1 | 说明: |
编写shell脚本:
1 | hadoop01: |
测试shell脚本
1 | sh edu_mode_1_analyse.sh |
最后,将shell脚本配置到oozie (省略)
增量数据导出操作
说明:
1 | 在执行导出的时候, 也需要将mysql中之前的统计的当年当季度和当月的结果数据删除, 然后重新导入操作 |
编写shell脚本:
1 | hadoop01: |
将shell脚本设置到oozie中(省略)
意向用户主题看板_全量流程
需求分析
1 | 主要分析什么内容: |
- 需求一: 计期内,新增意向客户(包含自己录入的意向客户)总数。
1 | 涉及维度: |
- 需求二: 统计指定时间段内,新增的意向客户,所在城市区域人数热力图。
1 | 涉及维度: |
- 需求三: 统计指定时间段内,新增的意向客户中,意向学科人数排行榜。学科名称要关联查询出来。
1 | 涉及维度: |
- 需求四: 统计指定时间段内,新增的意向客户中,意向校区人数排行榜
1 | 涉及维度: |
- 需求五: 统计指定时间段内,新增的意向客户中,不同来源渠道的意向客户占比。
1 | 涉及维度: |
- 需求六: 统计指定时间段内,新增的意向客户中,各咨询中心产生的意向客户数占比情况。
1 | 涉及维度: |
总结:
1 | 指标: |
业务数据的准备工作
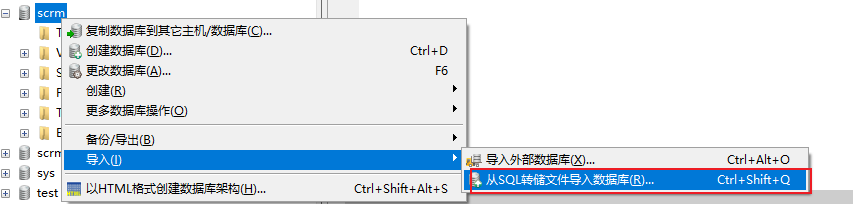
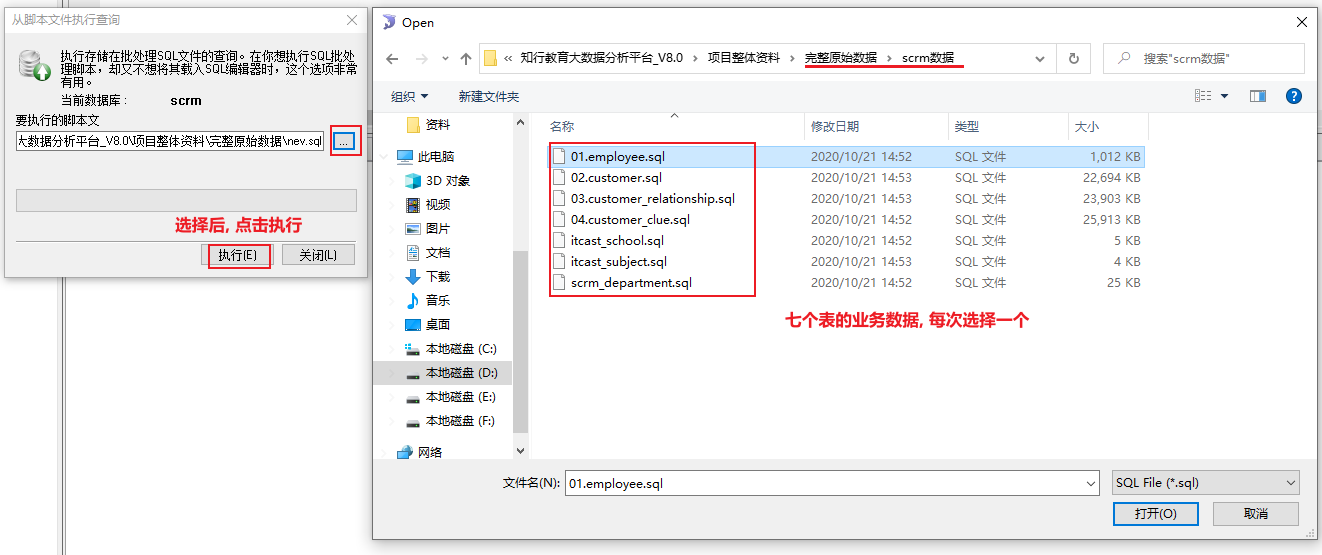
- 需要在mysql中创建一个库
1 | create database scrm default character set utf8mb4 collate utf8mb4_unicode_ci; |
- 将项目资料中, 提供的业务数据集导入到这个库中
建模分析
- ODS层: 源数据层
- 作用: 对接数据源, 一般和数据源保持相同粒度 (直白: 将数据源中拷贝到ODS层中)
- 一般放置是事实表和少量的维度表
1 | 放置事实表即可: |
- DIM层: 数据维度层
1 | 放置维度表: |
DW层: 数据仓库层
DWD层: 数据明细层
- 作用: 1) 清洗转换处理工作 2) 少量维度退化(此层不需要执行)
1
2
3
4
5
6
7
8
9
10需要清洗内容:
将标记为删除的数据进行过滤掉
需要转换内容:
1) 将create_date_time 转换为 yearinfo monthinfo dayinfo hourinfo
2) 将origin_type 转换为 origin_type_state (用于统计线上线下)
转换逻辑: origin_type的值为: NETSERVICE 或者 PRESIGNUP 认为线上 其余认为线下
3) 将clue_state 转换为 clue_state_stat (用于统计新老维度)
转换逻辑:clue_state的值为 VALID_NEW_CLUES 为新客户 其余暂定为老客户
4) 将校区和学科的 id字段, 如果为 0 或者 null 转换为 -1- 建模内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15DWD层表的构建: 必须字段(只能是事实表中字段) + 清洗的字段 + 转换的字段+ join字段
customer_relationship(意向表 ) --- 事实表
时间维度: create_date_time
线上线下: origin_type --> origin_type_stat
来源渠道: origin_type
校区维度: itcast_school_id
学科维度: itcast_subject_id
指标字段: customer_id,
关联条件的字段: creator,id
表字段的组成:
customer_id, create_date_time,origin_type,itcast_school_id,itcast_subject_id,creator,id
deleted,origin_type_stat,yearinfo monthinfo dayinfo hourinfoDWM层: 数据中间层
- 作用: 1) 提前聚合的操作( 由于有去重,导致无法实施) 2) 维度退化操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29此层后期处理的时候, 需要进行七表关联的操作
DWM层表的构建: 指标字段 + 各个表维度相关的字段
维度:
固有维度:
时间维度: 年 月 天 小时
新老维度:
线上线下
产品属性维度:
总意向量
地区(区域)维度
学科维度
校区维度
来源渠道
各咨询中心
DWM表的字段:
customer_id,
create_date_time, yearinfo monthinfo dayinfo hourinfo
deleted (意义不大)
clue_state_stat(此字段需要转换)
origin_type_stat
area,
itcast_subject_id,itcast_subject_name
itcast_school_id,itcast_school_name
origin_type
tdepart_id,tdepart_nameDWS层: 数据业务层
- 作用: 细化统计各个维度的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29DWS层表字段构成: 统计的字段 + 各个维度的字段 + 三个用于查询的字段
维度:
固有维度:
时间维度: 年 月 天 小时
新老维度:
线上线下
产品属性维度:
总意向量
地区(区域)维度
学科维度
校区维度
来源渠道
各咨询中心
DWS层表字段:
customerid_total,
yearinfo,monthinfo,dayinfo,hourinfo
clue_state_stat,
origin_type_stat,
area
itcast_subject_id,itcast_subject_name
itcast_school_id,itcast_school_name
origin_type
tdepart_id,tdepart_name
group_type
time_type
time_str
DA层: 数据应用层
- 此层不需要
分桶表优化方案:
思考: 什么是分桶表?
1 | 主要是用于分文件的, 在建表的时候, 指定按照那些字段执行分桶操作, 并可以设置需要分多少个桶, 当插入数据的时候, 执行MR的分区的操作, 将数据分散各个分区(hive分桶)中, 默认分发方案: hash 取模 |
如何构建一个分桶表呢?
1 | create table test_buck(id int, name string) |
如何向分桶表添加数据呢?
1 | 标准格式: |
分桶表有什么作用呢?
1 | 1) 进行数据采样 |

如何进行数据采样
- 采样函数: tablesample(bucket x out of y on column)
1 | 采样函数: |
如何提升查询的效率
对于单表效率的提升, 已经在前面讲过了, 这里不再讲解….
以下主要来讲解, 关于多表的效率的提升
思考: 当多表进行join的时候, 如何提升join效率呢?
reduce端join的流程:
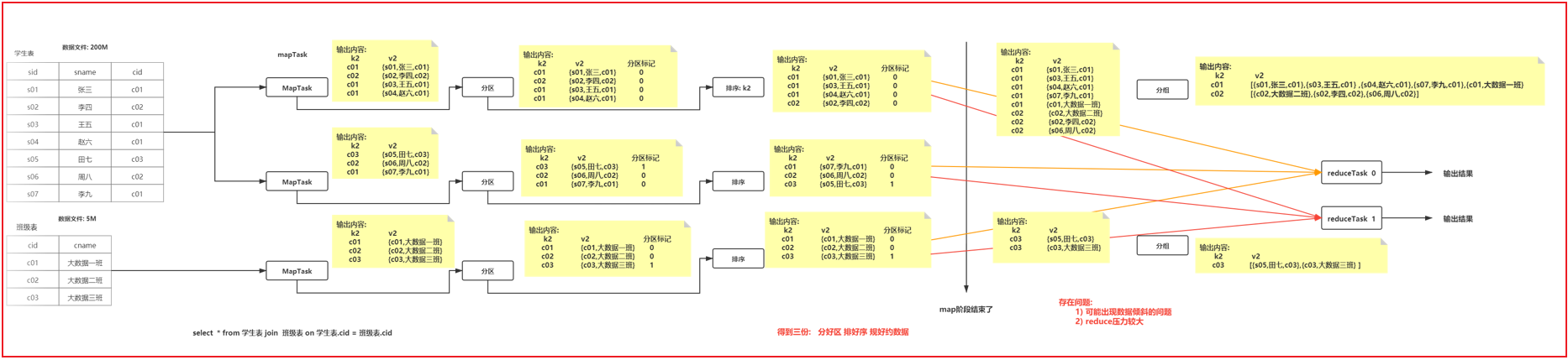
1 | 可能出现的问题: |
小表和大表:
- 采用 map join的方案
1
在进行join的时候, 将小表的数据放置到每一个读取大表的mapTask的内存中, 让mapTask每读取一次大表的数据都和内存中小表的数据进行join操作, 将join上的结果输出到reduce端即可, 从而实现在map端完成join的操作
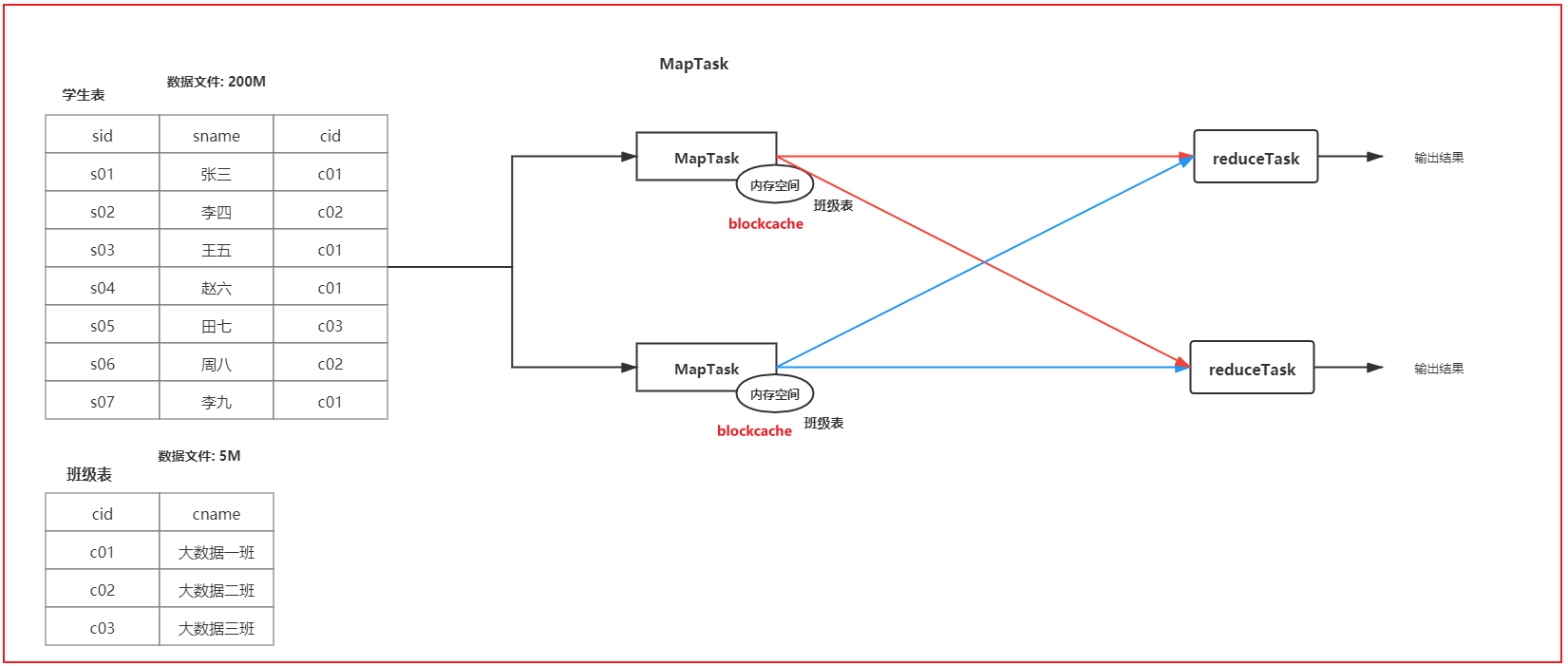
1
2
3
4
5如何开启map Join
set hive.auto.convert.join=true; -- 是否开启map Join
set hive.auto.convert.join.noconditionaltask.size=512000000; -- 设置小表最大的阈值(设置block cache 缓存大小)
map Join 不限制任何表中型表和大表:
中型表: 与小表相比 大约是小表3~10倍左右
解决方案:
- 能提前过滤就提前过滤掉(一旦提前过滤后, 会导致中型表的数据量会下降, 有可能达到小表阈值)
- 如果join的字段值有大量的null, 可以尝试添加随机数(保证各个reduce接收数据量差不多的, 减少数据倾斜问题)
- 基于分桶表的: bucket map join
1
2
3
4
5
6
7bucket map join的生效条件:
1) set hive.optimize.bucketmapjoin = true; --开启bucket map join 支持
2) 一个表的bucket数是另一个表bucket数的整数倍
3) bucket列 == join列
4) 必须是应用在map join的场景中
注意:如果表不是bucket的,则只是做普通join。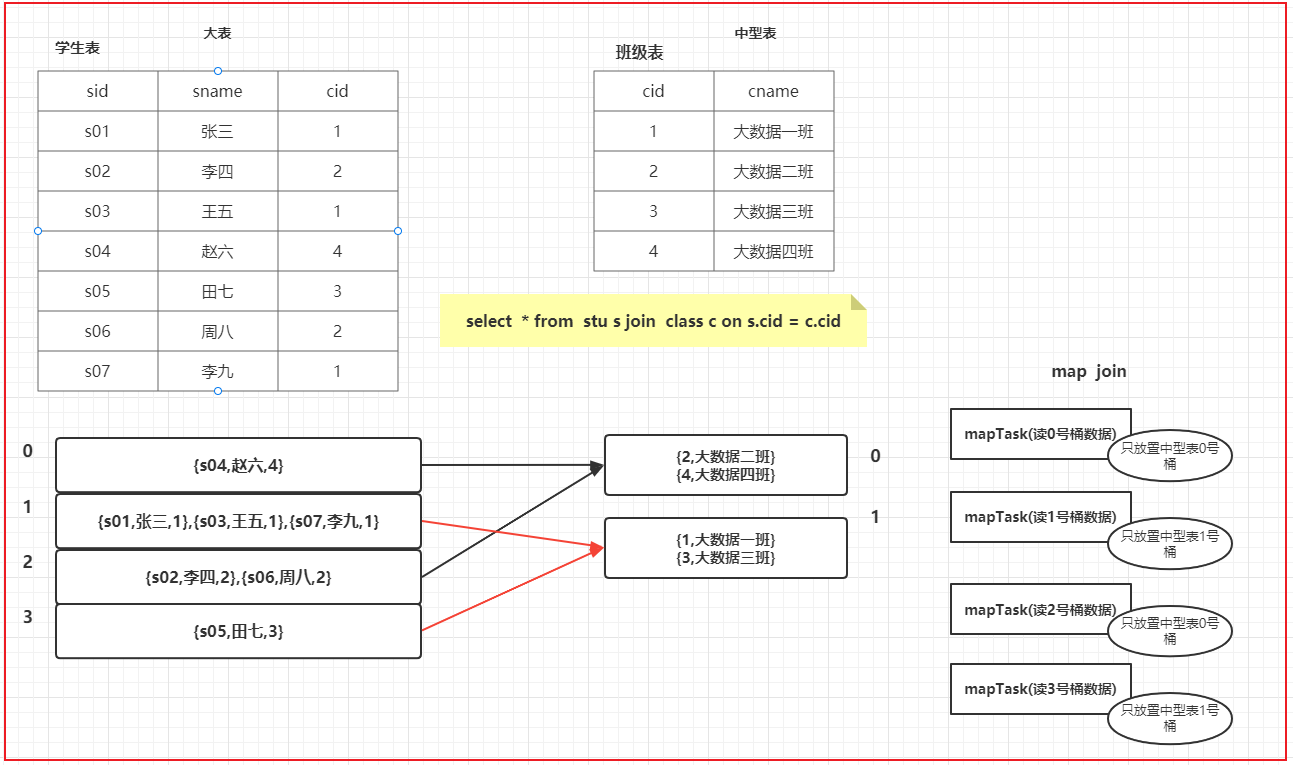
大表和大表:
解决方案:
- 能提前过滤就提前过滤掉(减少join之间的数量, 提升reduce执行效率)
- 如果join的字段值有大量的null, 可以尝试添加随机数(保证各个reduce接收数据量差不多的, 减少数据倾斜问题)
- SMB Map join (sort merge bucket map join)
1
2
3
4
5
6
7
8
9
10
11实现SMB map join的条件要求:
1) 一个表的bucket数等于另一个表bucket数(分桶数量是一致)
2) bucket列 == join列 == sort 列
3) 必须是应用在bucket map join的场景中
4) 开启相关的参数:
-- 开启SMB map join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--写入数据强制排序
set hive.enforce.sorting=true;
set hive.optimize.bucketmapjoin.sortedmerge = true; -- 开启自动尝试SMB连接
建模操作
- ODS层:
1 | set hive.exec.orc.compression.strategy=COMPRESSION; |
- DIM层:
1 | CREATE DATABASE IF NOT EXISTS itcast_dimen; |
- DWD层
1 | CREATE TABLE IF NOT EXISTS itcast_dwd.`itcast_intention_dwd` ( |
- DWM层:
1 | create database itcast_dwm; |
- DWS层:
1 | CREATE TABLE IF NOT EXISTS itcast_dws.itcast_intention_dws ( |
数据采集
指的: 将业务库中的数据一对一导入到ODS层的对应表中
1 | 业务库: mysql |
- DIM层:
1 | 客户表 |
- ODS层:
1 | -- 客户意向表 |
客户线索表
1 | -- 第一步: 创建客户线索表的临时表 |
清洗转换操作
生成DWD层数据
作用: 清洗 和 转换 以及少量的维度退化
1 | 维度退化操作: 此层不需要做 |
编写SQL:
1 | select |
将转换的SQL的结果保存到DWD层表中 (此操作, 并未执行, 而是执行后续的采样SQL)
1 | insert into table itcast_dwd.itcast_intention_dwd partition(yearinfo,monthinfo,dayinfo) |
如果希望在灌入到DWD层的时候, 对数据进行采样操作: 比如只想要第5个桶
1 | explain |
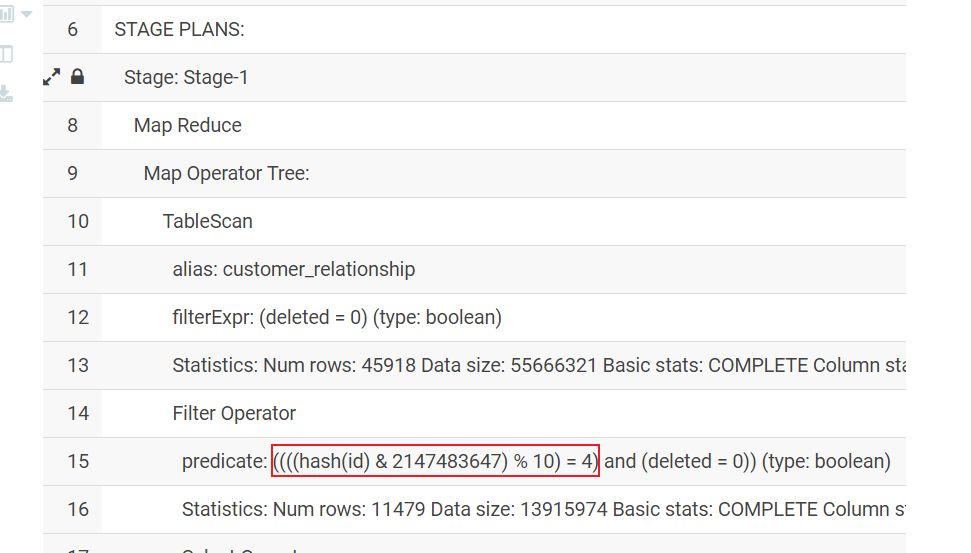
执行采样导入到DWD层
1 | --分区 |
生成DWM层数据
由于DWM层的字段是来源于事实表和所有维度表中的字段, 此时如果生成DWM层数据, 必须要先将所有的表关联在一起
1 | 所有表的表与表之间的关联条件 |
- SQL实现
1 | select |
查看这条SQL语句, 相关的优化是否执行了呢?
1 | 开启优化: |
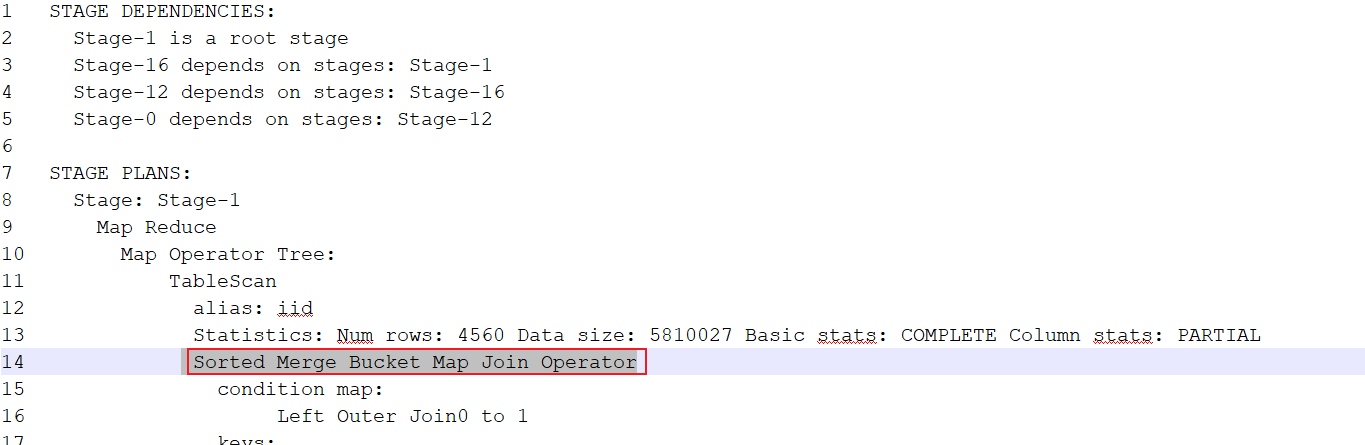
除了这个SMB 优化生效后, 其他的表的都是存在有map join的方案
最后执行SQL, 查看是否可以正常执行:
1 | 说明: |
最终: 将查询出来的数据灌入到目标表即可
1 | --分区 |
统计分析操作
目的: 生产DWS层的数据, 数据来源于DWM
1 | 指标: 意向量 |
- 统计总意向量
1 | -- 统计每年 线上线下 新老用户的总意向量 |
- 统计 咨询中心维度
1 | -- 统计每年线上线下, 新老用户产生各个咨询中心的意向量 |
数据导出操作
指的: 从DWS层将数据导出到MYSQL中
- 第一步: 在mysql中创建目标表
1 | CREATE TABLE IF NOT EXISTS scrm_bi.itcast_intention ( |
- 第二步:执行sqoop, 将数据全部到导出 MySQL中
1 | sqoop export \ |
意向用户主题看板_增量流程
数据采集(拉链表)
高清图, 查看图片目录
8. 学生出勤主题看板
2.1 需求分析
回顾:
1 | 涉及维度, 指标, 涉及表, 字段, 以及需要清洗的内容, 需要转换的内容, 如果有多个表, 表与表关联条件 |
- 需求一: 统计指定时间段内,不同班级的出勤人数。打卡时间在上课前40分钟(否则认为无效)~上课时间点之内,且未早退,则为正常上课打卡。可以下钻到具体学生的出勤数据。跨天数据直接累加。
1 | 涉及维度: |
- 需求二: 统计指定时间段内,不同班级的学生出勤率。可以下钻到具体学生的出勤数据。出勤率=出勤人数/当日在读学员人数。
1 | 涉及维度: |
- 需求三: 统计指定时间段内,不同班级的迟到人数。上课10分钟后视为迟到。可以下钻到具体学生的迟到数据。跨天数据直接累加。
1 | 涉及维度: |
- 需求四: 统计指定时间段内,不同班级的学生迟到率。上课10分钟后视为迟到。可以下钻到具体学生的迟到数据。迟到率=迟到人数/当日在读学员人数。
1 | 涉及维度: |
- 需求五: 统计指定时间段内,不同班级的请假人数。跨天数据直接累加。
1 | 涉及维度: |
- 需求六: 统计指定时间段内,不同班级的学生请假率。请假率=请假人数/当日在读学员人数。
1 | 涉及维度: |
- 需求七: 统计指定时间段内,不同班级的旷课人数。跨天数据直接累加。旷课人数=当日在读学员人数-出勤人数-请假人数。
1 | 涉及维度: |
- 需求八: 统计指定时间段内,不同班级的学生旷课率。旷课率=旷课人数/当日在读学员人数。
1 | 涉及维度: |
总结需求:
1 | 第一类: 指标: 计算 出勤人数, 出勤率, 迟到人数, 迟到率 |
2.2 业务数据准备工作
- 第一步: 在mysql中, 创建一个业务库
1 | create database teach default character set utf8mb4 collate utf8mb4_unicode_ci; |
- 第二步: 将课件中测试数据集导入到mysql的teach库中
1 | 表1: 当日在读人数表 |
2.3 建模分析
- ODS层: 源数据层
1 | 作用: 对接数据源, 一般和数据源的表保持相同粒度 |
- DIM层: 维度层
1 | 作用: 用于存储维度表的数据, 一般和数据源对表保持相同粒度 |
- DWD层: 明细层
1 | 作用: 1) 清洗转换操作 2) 少量的维度退化操作 (不需要) |
- DWM层: 中间层
1 | 作用: 维度退化 以及 提前聚合操作 |
- DWS层: 业务层
1 | 作用: 细化维度统计操作 |
2.4 建模操作
- ODS层:
1 | -- 学生打卡信息表: |
- DIM层:
1 | -- 日期课程表 |
- DWM层:
1 | -- 学生出勤状态信息表 |
- DWS层:
1 | CREATE TABLE IF NOT EXISTS itcast_dws.class_attendance_dws ( |
2.5 数据采集操作
数据: 目前存储在MySQL中
目的地: 放置hive中
技术: 采用 apache sqoop 来解决
- ODS层数据采集操作
1 | 学生打卡记录表 |
- DIM层:
1 | 当日在读人数表 |
 微信
微信 支付宝
支付宝

