【系列教程】Python基础语法(十):Pandas
Pandas相关内容
中小型数据分析推荐用pandas,海量数据推荐用spark
今日内容:
- 1- pandas的中两种重要的数据结构: DataFrame(二维表格)和Series(表格的一列)
- 2- pandas的多格式的数据读写操作
- 3- dataFrame的数据CURD操作
- 4- dataFrame的数据分组的操作
- 5- 扩展:数据可视化(pyecharts)
1. pandas的基本介绍
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
- Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;当我们学会Pandas之后,再学习Spark就更加简单快速
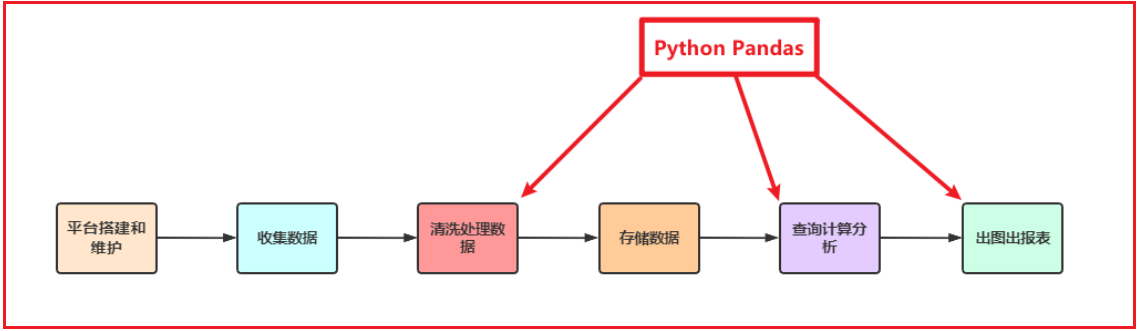
- Pandas在整个数据开发的流程中的应用场景
- 在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到excel严重卡顿,且又都是单机数据的时候,我们使用pandas
- pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用pandas
2. 安装pandas的库
打开cmd界面, 执行 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
说明:
1 | 在安装python环境的时候, 除了基于之前直接安装python解析器方案, 其实安装python还有一些其他的操作, |
3. pandas的初体验
- 1-将资料中提供的数据集导入到data目录中

- 2- 创建python脚本, 导入pandas库
1 | import pandas as pd |
- 3- 基于pandas加载数据
1 | df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk' ) |
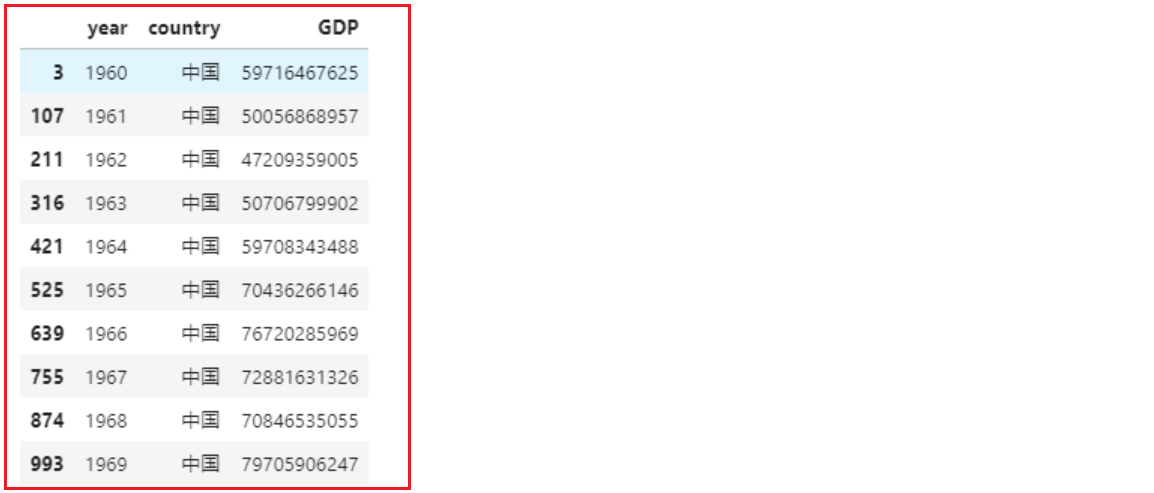
- 4- 基于pandas完成相关查询:
1 | # 查询中国的GDP |
4. pandas的数据结构
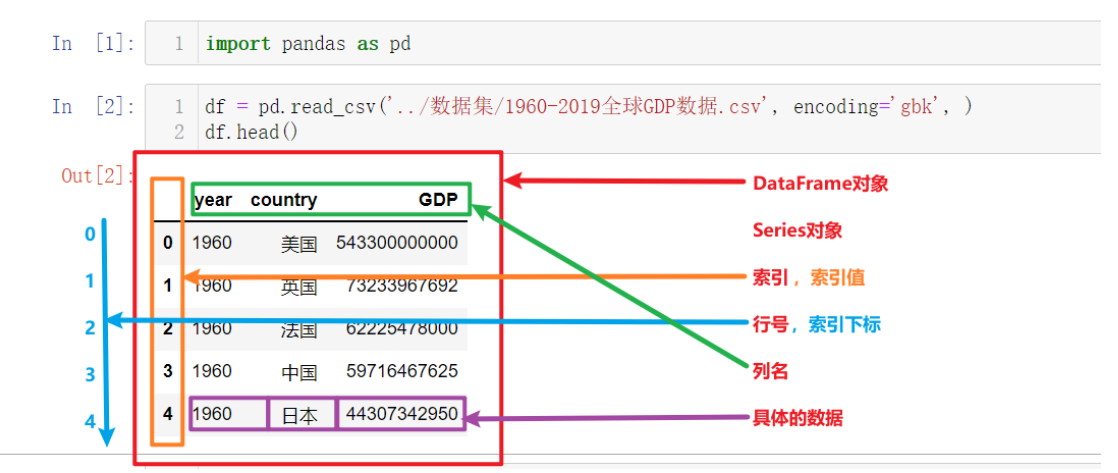
上图为上一节中读取并展示出来的数据,以此为例我们来讲解Pandas的核心概念,以及这些概念的层级关系:
- DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
- Series
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
创建Series对象
- 1- 导入pandas
1 | import pandas as pd |
- 2- 通过list列表来创建
1 | # 使用默认自增索引 |
- 3- 使用字典或元组创建series对象
1 | #使用元组 |
Series对象常用API
构造一个series对象
1 | s4 = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF']) |
- 1- series对象常用属性和方法
1 | # s对象有多少个值,int |
Series 对象的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
两个Series之间计算,索引值相同的元素之间会进行计算;索引不同的元素最终计算的结果会填充成缺失值,用NaN表示
- Series和数值型变量计算
1 | s4 * 5 |
- 索引完全相同的两个Series对象进行计算
1 | s4 |
- 索引不同的两个s对象运算
1 | s4 |
DataFrame
创建DF对象
DataFrame的创建有很多种方式
- Serires对象转换为df:上一小节中学习了
s.to_frame()以及s.reset_index() - 读取文件数据返回df:在之前的学习中我们使用了
pd.read_csv('csv格式数据文件路径')的方式获取了df对象 - 使用字典、列表、元组创建df:接下来就展示如何使用字段、列表、元组创建df
- 使用字典加列表创建df,使默认自增索引
1 | df1_data = { |
- 使用列表加元组创建df,并自定义索引
1 | df2_data = [ |
DataFrame对象常用API
- DataFrame对象常用API与Series对象几乎相同
1 | # 返回df的行数 |
DataFrame对象的运算
当DataFrame和数值进行运算时,DataFrame中的每一个元素会分别和数值进行运算,但df中的数据存在非数值类型时不能做加减法运算
两个DataFrame之间、以及df和s对象进行计算,和2个series计算一样,会根据索引的值进行对应计算:当两个对象的索引值不能对应时,不匹配的会返回NaN
- df和数值进行运算
1 | df2 * 2 # 不报错 |
- df和df进行运算
1 | # 索引完全不匹配 |
总结:在Pandas中,两个df对象如果进行加法运算,则要遵循以下原则:
① 索引相同,则相同索引行进行合并操作
② 索引不同,则也保留所有元素,但是元素值都设置为NaN
pandas的数据类型
- df或s对象中具体每一个值的数据类型有很多,如下表所示
| Pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | string |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | bool(True,False) |
| nan | 空值类型 | None |
- 可以通过下列API查看s对象或df对象中数据的类型
1 | s1.dtypes |
5. pandas多格式数据读写
常用读写文件函数清单
| 文件格式 | 读取函数 | 写入函数 |
|---|---|---|
| xlsx | pd.read_excel | df.to_excel |
| xls | pd.read_excel | df.to_excel |
| csv | pd.read_csv | df.to_csv |
| tsv | pd.read_csv | df.to_csv |
| json | pd.read_json | to_json |
| html | pd.read_html | df.to_html |
| sql | pd.read_sql | df.to_sql |
| 剪贴板 | df.read_clipboard | df.to_clipboard |
5.1 写文件
数据准备
1 | # 导包 加载数据集 |
- 以写入csv文件为例
1 | df.to_csv('./写文件.csv') # 此时应该在运行代码的相同路径下就生成了一个名为“写文件.csv”的文件 |
注意:执行df.to_csv()时,文件需要关闭才能写入,不然会报 PermissionError: [Errno 13] Permission denied: 'xxxx.csv'的异常
5.2 读文件
以读取csv文件为例
1 | df = pd.read_csv('./写文件.csv') |

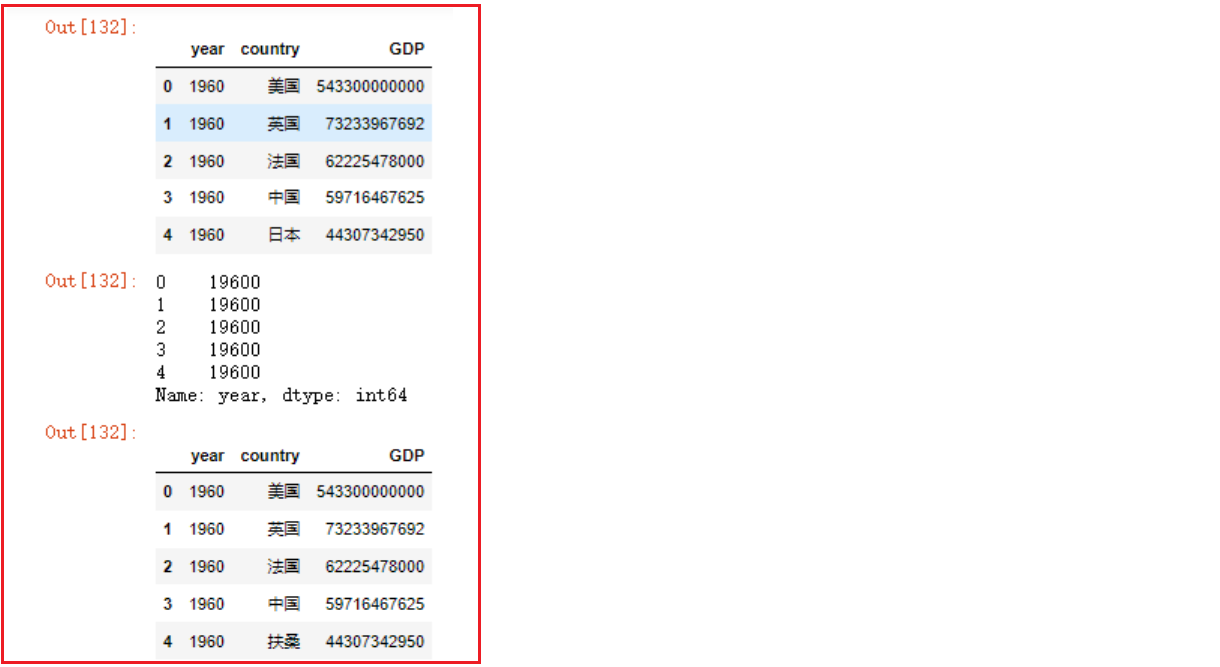
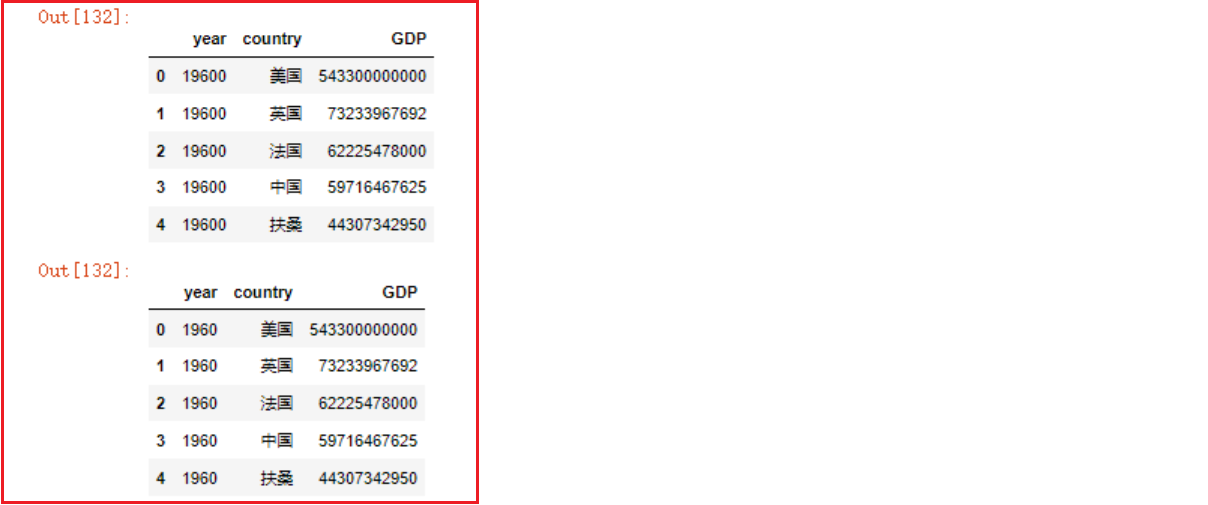
index_col 参数指定索引
1
2
3index_col参数可以在读文件的时候指定列作为返回dataframe的索引,两种用法如下:
* 通过列下标指定为索引
* 通过列名指定为索引- 通过列下标指定为索引
index_col=[列下标]
1
2df = pd.read_csv('./写文件.csv', index_col=[0])
df- 通过列名指定为索引
index_col=['列名']
1
2df = pd.read_csv('./写文件.csv', index_col=['Unnamed: 0'])
df
- 通过列下标指定为索引
parse_dates 参数指定列解析为时间日期类型
1
2
3
4
5
6parse_dates参数可以在读文件的时候解析时间日期类型的列,两种作用如下:
- 将指定的列解析为时间日期类型
- 通过列下标解析该列为时间日期类型
- 通过列名解析该列为时间日期类型
- 将df的索引解析为时间日期类型- 通过列下标解析该列为时间日期类型
parse_dates=[列下标]
1
2pd.read_csv('./写文件.csv').info()
pd.read_csv('./写文件.csv', parse_dates=[1]).info()
- 通过列名解析该列为时间日期类型
parse_dates=[列名]
1
2pd.read_csv('./写文件.csv').info()
pd.read_csv('./写文件.csv', parse_dates=['birthday']).info()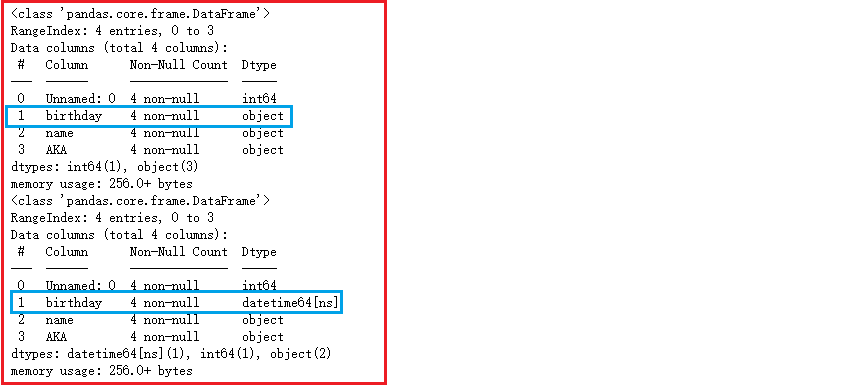
- 将df的索引解析为时间日期类型
parse_dates=True
1
2
3df = pd.read_csv('./写文件.csv', index_col=[1], parse_dates=True)
df
df.index
- 通过列下标解析该列为时间日期类型
encoding 参数 指定编码格式
常见的编码格式有:ASCII、GB2312、UTF8、GBK 等
1
pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk').head()

sep参数, 指定字段之间的分隔符号
默认的分隔符号为逗号, 当文件中的字段之间的分隔符号不是逗号的时候, 我们可以采用此参数来调整
1
pd.read_csv('../数据集/csv示例文件.csv', sep='\t', index_col=[0])

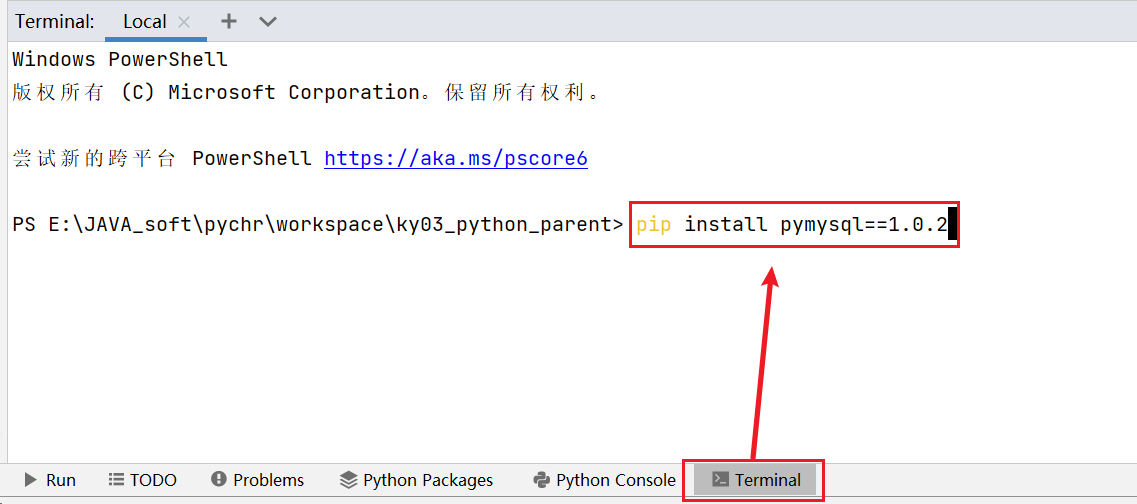
5.3 读写数据库
以MySQL数据库为例,此时默认你已经在本地安装好了MySQL数据库。如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
1 | pip install pymysql==1.0.2 |
- 准备要写入数据库的数据
1 | import pandas as pd |

- 创建数据库操作引擎对象并指定数据库
1 | # 需要安装pymysql,部分版本需要额外安装sqlalchemy |
- 将数据写入MySQL数据库
1 | # df.to_sql()方法将df数据快速写入数据库 |
此时我们就可以在本地test库的test_pdtosql表中看到写入的数据

从数据库中加载数据:
- 读取整张表, 返回dataFrame
1
2# 指定表名,传入数据库连接引擎对象
pd.read_sql('test_pdtosql', engine)- 使用SQL语句获取数据,返回dataframe
1
2# 传入sql语句,传入数据库连接引擎对象
pd.read_sql('select name,AKA from test_pdtosql', engine)
可能出现的问题:
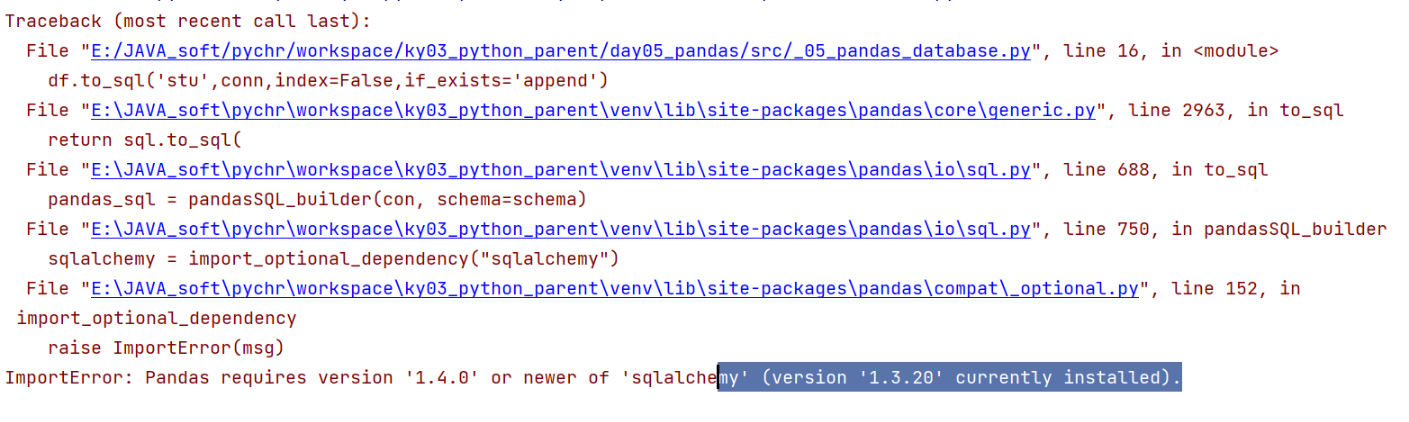
1 | 说明: |
6. dataFrame数据的增删改查操作
- 导包并加载数据:
1 | import pandas as pd |
6.1 增加列
- 方式一: 通过直接赋值的方式添加新列
1 | # 拷贝一份df |
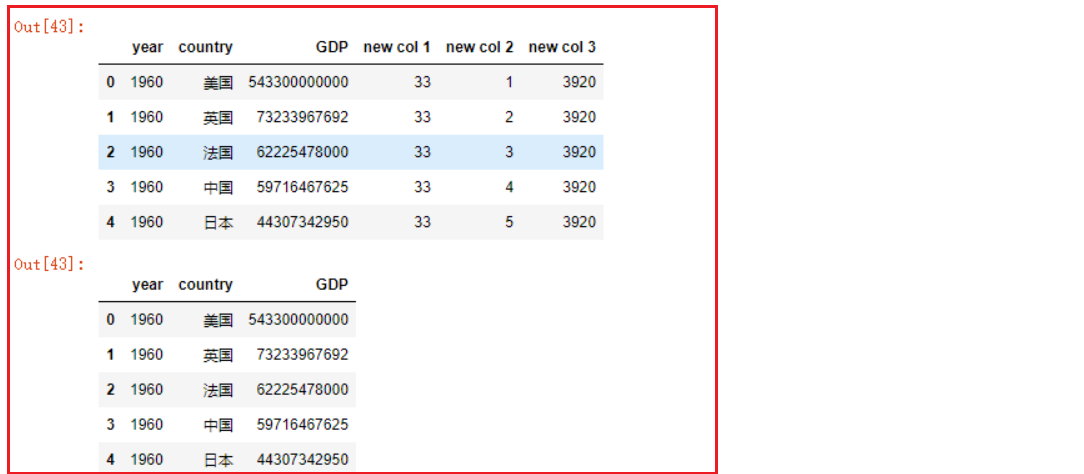
- 方式二: df.assign函数添加列
1 | # 1. 新列名=单个数据或一组数据,一组数据的数量必须和df的行数相同 |
- df.assign函数可以同时添加多列
1 | df2 |
6.2 删除与去重
- 1- df.drop删除行数据
1 | df3.drop([0]) # 默认删除行 |
- 2- df.drop删除列数据
- df.drop默认删除指定索引值的行;如果添加参数
axis=1,则删除指定列名的列
- df.drop默认删除指定索引值的行;如果添加参数
1 | df3.drop(['new col 3'], axis=1) |
- 3- 使用del删除指定的列
- 注意区别:
- del是直接永久删除原df中的列【慎重使用】
- drop是返回删除后的df或seires,原df或seires没有被修改
- 注意区别:
1 | del df3['new col 3'] |
- 4- Dataframe数据去重
1 | # 添加一部分重复的数据 |
- 5- series去重
1 | 方式一: |
6.3 修改DataFrame中的数据
- 1- df.assign替换列
1 | df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', ) |
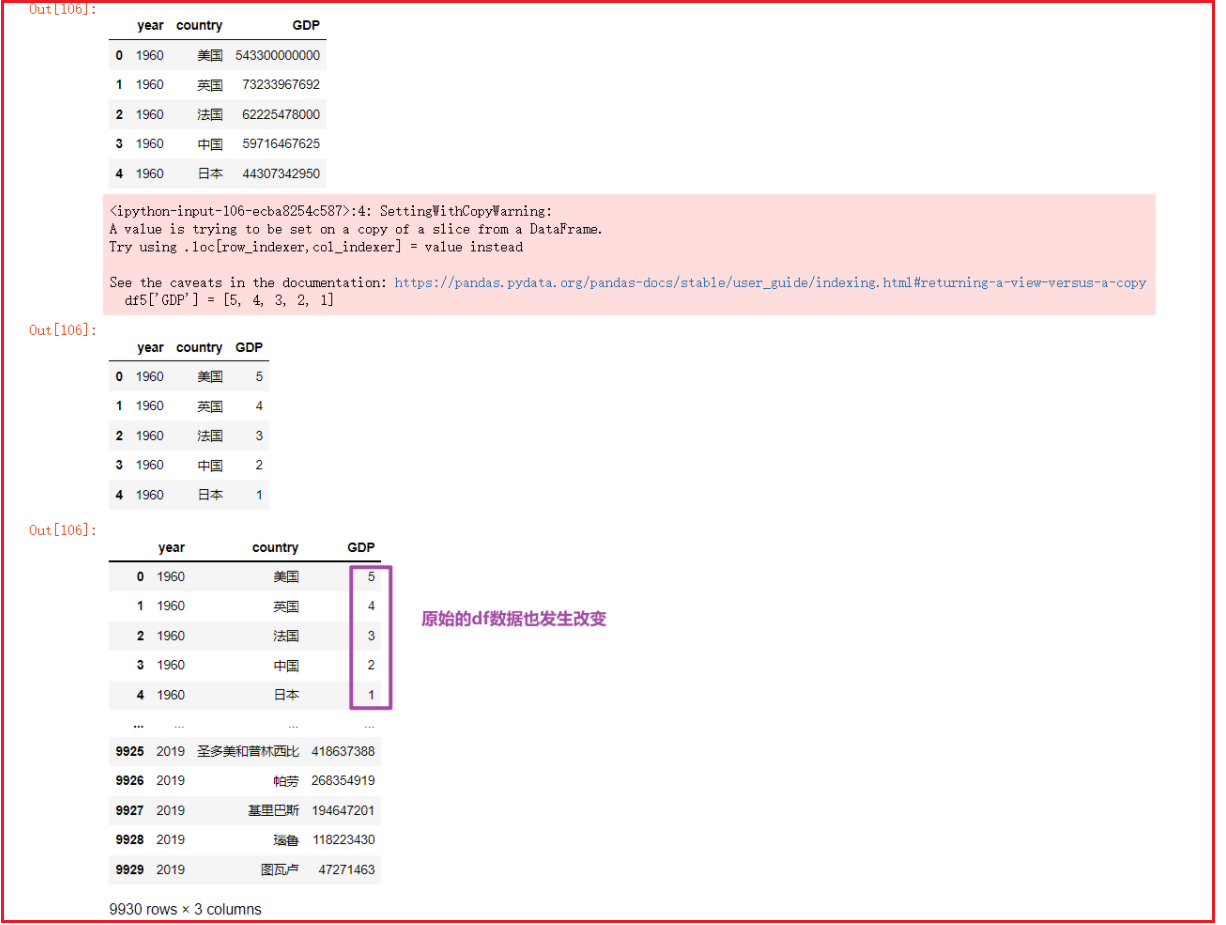
- 2- 直接对原始的DF进行赋值修改处理
- 一般不建议直接修改操作
1 | df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', ) |
- 3- replace函数替换数据
1 | # 读取数据选取前5行作为一个新的df |
6.4 查询dataFrame中的数据
1- 从前从后取多行数据
- head()
1
2
3
4
5
6
7
8# 导包
import pandas as pd
# 加载csv数据,指定gbk编码格式来读取文件,返回df
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk')
# 默认取前5行数据
df.head()
df.head(10) # 取前10行- tail()
1
2
3
4# 默认取后5行数据
df.tail()
df2 = df.tail(15) # 倒数15行
df22- 获取一列或多列数据
- 获取一列数据
df[col_name]等同于df.col_name
1
2
3df2['country']
df2.country
# 注意!如果列名字符串中间有空格的,只能使用df['country']这种形式- 获取多列数据
df[[col_name1,col_name2,...]]
1
df2[['country', 'GDP']] # 返回新的df
- 获取一列数据
3- 索引下标切片取行
df[start:stop:step]:
df[start:stop:step]==df[起始行下标:结束行下标:步长], 遵循左包右闭原则(包含起始行,不包含结束行),步长默认为11
2
3
4df4 = df.head(10) # 取原df前10行数据作为df4,默认自增索引由0到9
df4[0:3] # 取前3行
df4[:5:2] # 取前5行,步长为2
df4[1::3] # 取第2行到最后所有行,步长为3
4- 查询函数获取子集: df.query()
df.query(判断表达式)可以依据判断表达式返回的符合条件的df子集- 与
df[布尔值向量]效果相同 - 特别注意
df.query()中传入的字符串格式
- 示例:
1
2df3.query('country=="帕劳"')
df3[df3['country']=='帕劳']
- 查询中国, 美国 日本 三国 2015年至2019年的数据
1
2df.query('country=="中国" or country=="日本" or country=="美国"').query('year in ["2015", "2016", "2017", "2018", "2019"]')
df.query('(country=="中国" or country=="日本" or country=="美国") and year in ["2015", "2016", "2017", "2018", "2019"]')
5- 排序函数
- sort_values函数: 按照指定的一列或多列的值进行排序
1
2
3
4
5
6# 按GDP列的数值由小到大进行排序
df2.sort_values(['GDP'])
# 按GDP列的数值由大到小进行排序
df2.sort_values(['GDP'], ascending=False) # 倒序, ascending默认为True
# 先对year年份进行由小到大排序,再对GDP由小到大排序
df2.sort_values(['year', 'GDP'])- rank函数:
- rank函数用法:
DataFrame.rank()或Series.rank() - rank函数返回值:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
- rank函数包含有6个参数:
- axis:设置沿着哪个轴计算排名(0或者1),默认为0按纵轴计算排名
- numeric_only:是否仅仅计算数字型的columns,默认为False
- na_option :NaN值是否参与排序及如何排序,固定参数:keep top bottom
- keep: NaN值保留原有位置
- top: NaN值全部放在前边
- bottom: NaN值全部放在最后
- ascending:设定升序排还是降序排,默认True升序
- pct:是否以排名的百分比显示排名(所有排名与最大排名的百分比),默认False
- method:排名评分的计算方式,固定值参数,常用固定值如下:
- average : 默认值,排名评分不连续;数值相同的评分一致,都为平均值
- min : 排名评分不连续;数值相同的评分一致,都为最小值
- max : 排名评分不连续;数值相同的评分一致,都为最大值
- dense : 排名评分是连续的;数值相同的评分一致
1
2
3
4
5
6df2
df2.rank()
df2.rank(axis=0)
df2.rank(numeric_only=True) # 只对数值类型的列进行统计
df2.rank(ascending=False) # 降序
df2.rank(pct=True) # 以最高分作为1,放回百分数形式的评分,pct参数默认为False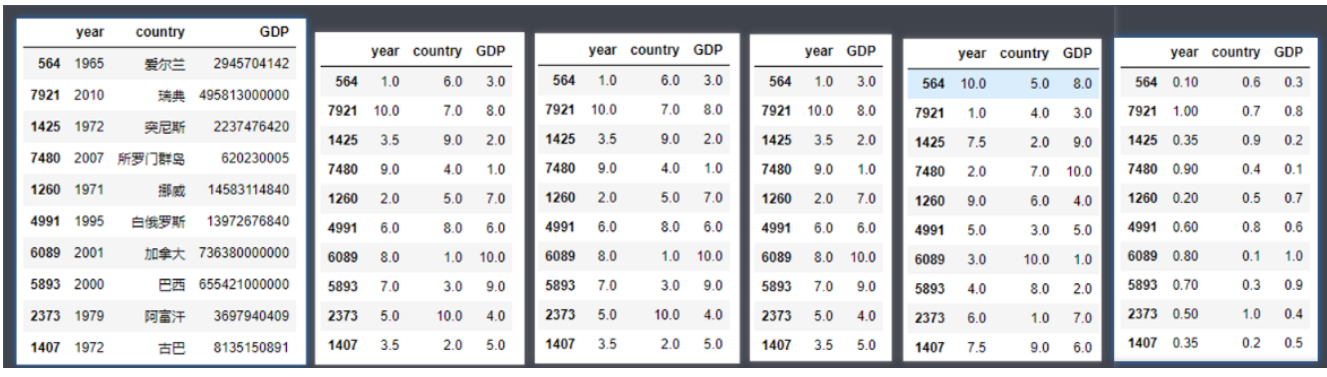
1
2
3
4df2.rank(method='average')
df2.rank(method='min')
df2.rank(method='max')
df2.rank(method='dense')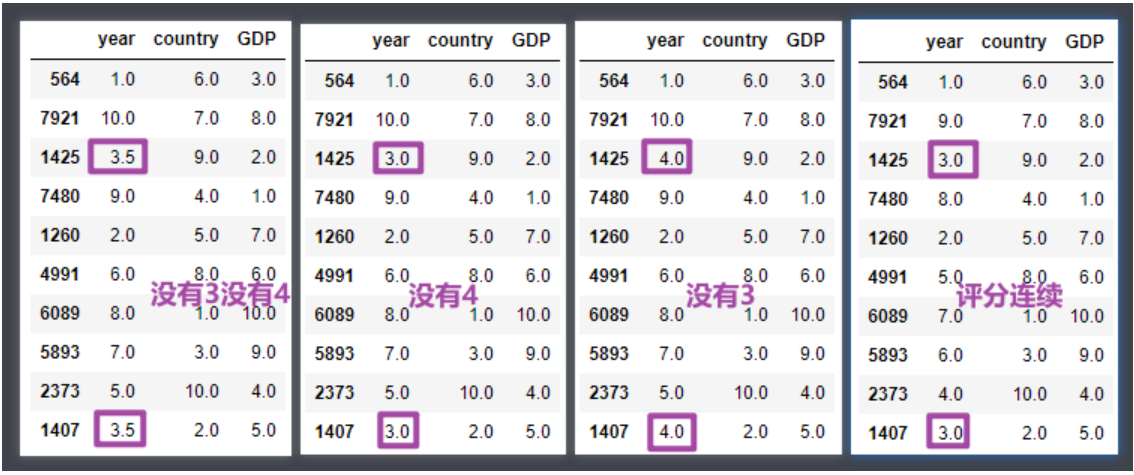
6- 聚合函数:
常用聚合函数有:
- min 最小值
- max 最大值
- mean 平均值
- sum 求和
- count 求个数
- min函数
1
2
3
4df2.min()
df2['year'].min()- max函数
1
2df2.max()
df2['year'].max()- mean 平均值
1
2
3df2.mean()
df2['year'].mean()
df2['GDP'].mean()
7. DataFrame数据分组操作
数据准备
- 加载优衣库的销售数据集,包含了不同城市优衣库门店的所有产品类别的销售记录,数据字段说明如下
- store_id 门店随机id
- city 城市
- channel 销售渠道 网购自提 门店购买
- gender_group 客户性别 男女
- age_group 客户年龄段
- wkd_ind 购买发生的时间(周末,周间)
- product 产品类别
- customer 客户数量
- revenue 销售金额
- order 订单数量
- quant 购买产品的数量
- unit_cost 成本(制作+运营)
1 | # 导包 加载数据集 |
1- df.groupby分组函数返回分组对象
【基于一列进行分组】
1 | # 基于顾客性别分组 |
【基于多列进行分组】
1 | # 基于顾客性别、不同城市分组 |
2- 分组后获取各个组内的数据
- 2.1 取出每组第一条或最后一条数据
1
2
3gs2 = df.groupby(['gender_group', 'channel'])
gs2.first() # 取出每组第一条数据
gs2.last() # 取出每组最后一条数据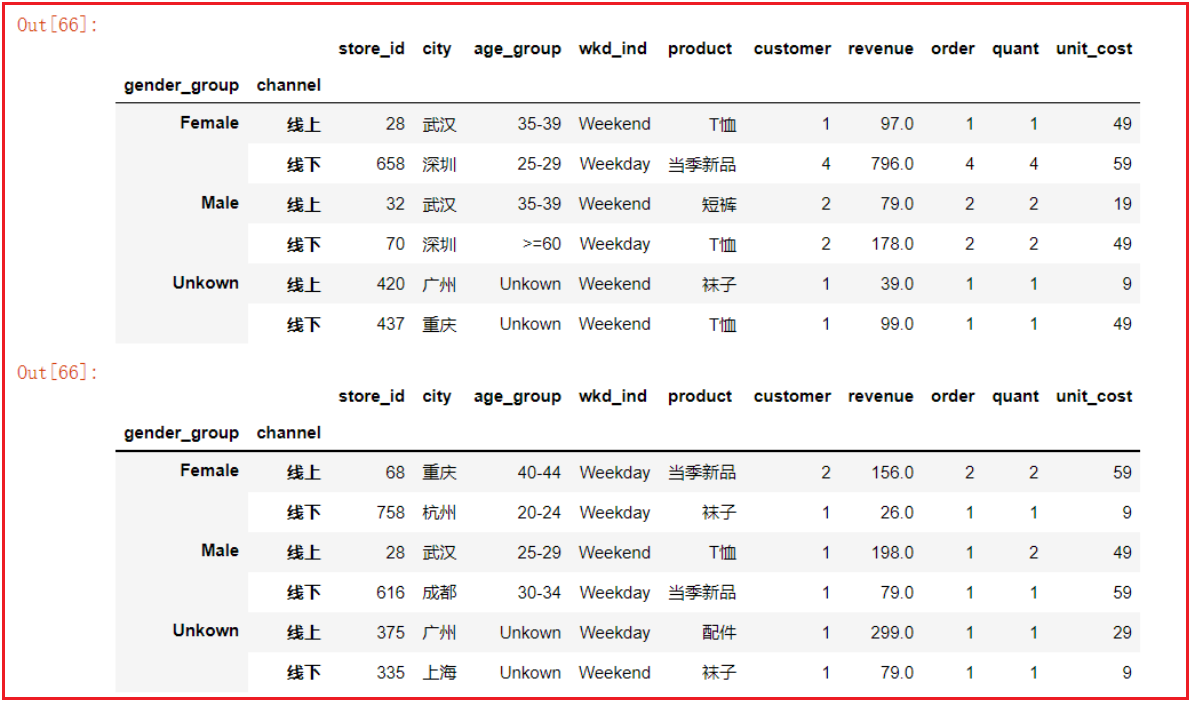
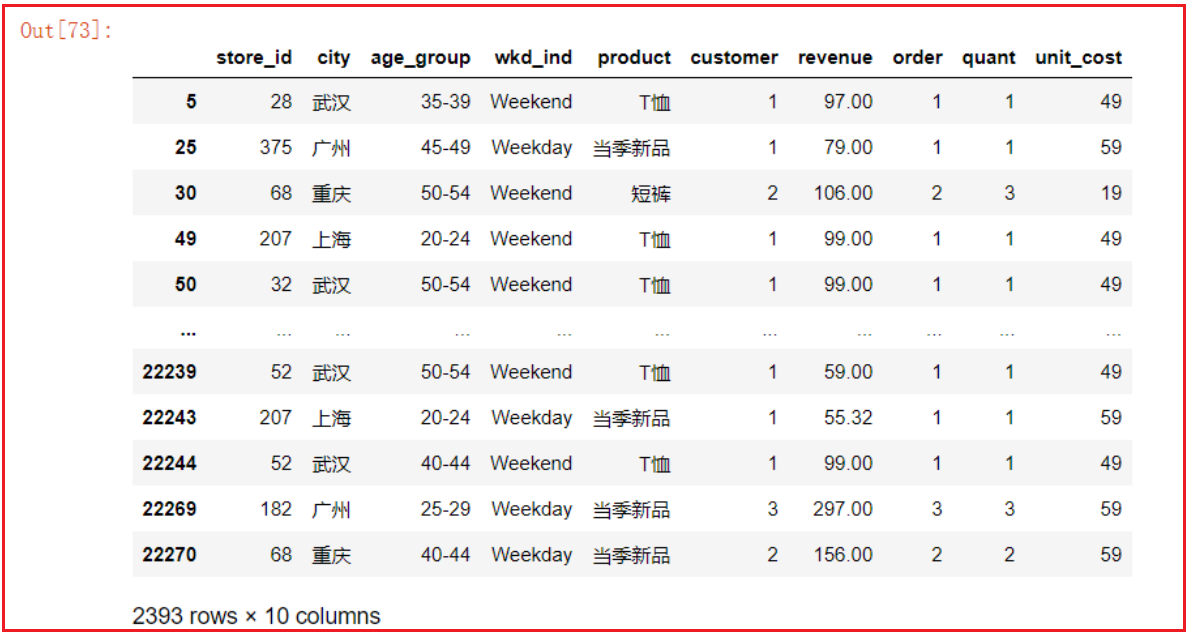
- 2.2 - 按分组依据获取其中一组
1
gs2.get_group(('Female', '线上'))
3- 分组聚合
- 格式:分组后对多列分别使用不同的聚合函数
1
2
3
4
5df.groupby(['列名1', '列名2']).agg({
'指定列1':'聚合函数名',
'指定列2':'聚合函数名',
'指定列3':'聚合函数名'
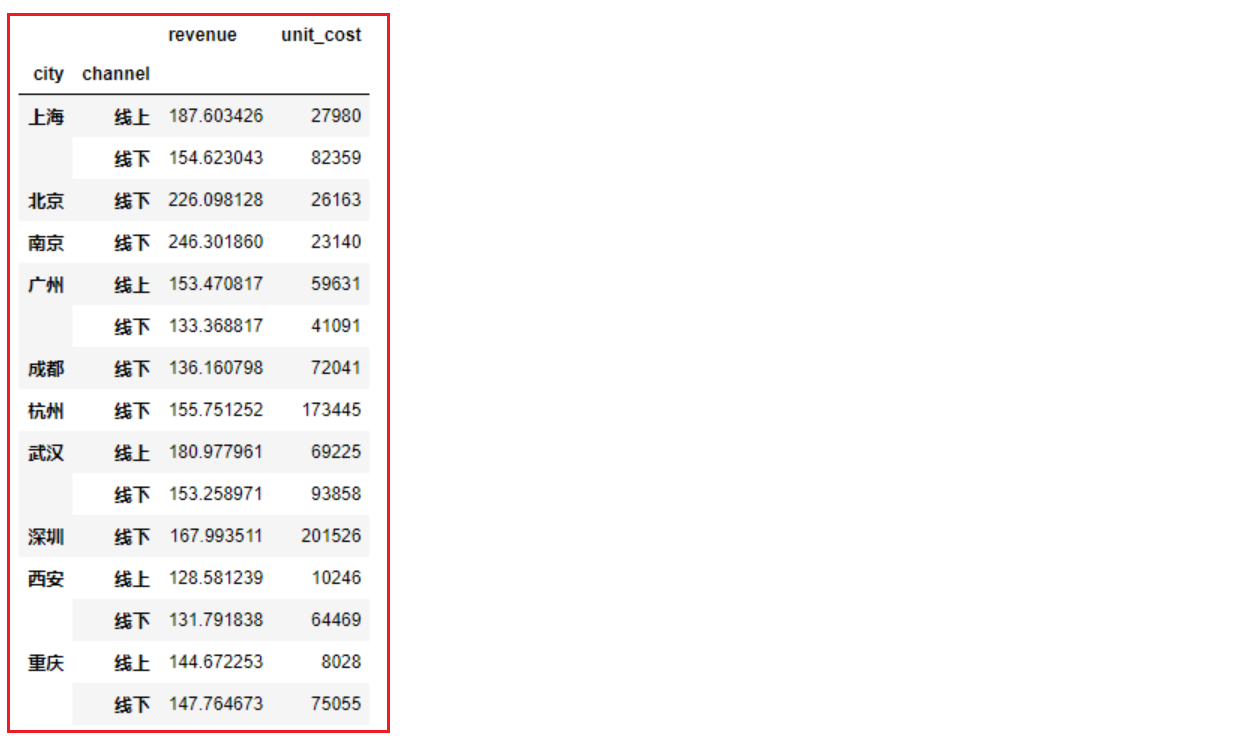
})- 按城市和线上线下划分,分别计算销售金额的平均值、成本的总和
1
2
3
4df.groupby(['city', 'channel']).agg({
'revenue':'mean',
'unit_cost':'sum'
})
分组过滤操作
- 格式:
1
2
3df.groupby(['列名1',...]).filter(
lambda x: dosomething returun True or False
)案例: 按城市分组,查询每组销售金额平均值大于200的全部数据
1
2df.groupby(['city']).filter(lambda s: s['revenue'].mean() > 200)
df.groupby(['city'])['revenue'].filter(lambda s: s.mean() > 200)
问题
python csv 转 xls 操过65535行解决
1 | import os |
- 如何将.csv批量转换为.xls / xlsx:https://superuser.com/questions/301431/how-to-batch-convert-csv-to-xls-xlsx
- https://stackoverflow.com/questions/17684610/python-convert-csv-to-xlsx
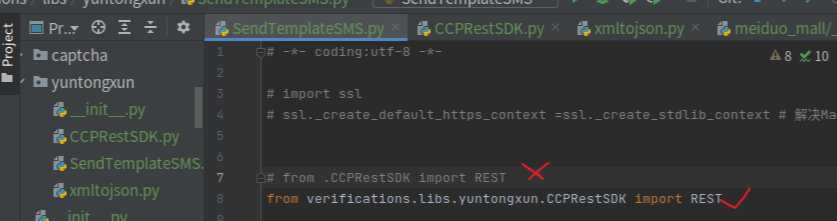
python相对路径导入bug解决
ImportError: attempted relative import with no known parent package
同级目录导入一直有问题.最后没办法,从应用顶级目录导入。就好了。。。原有不清楚
附录
- python官网: https://www.python.org/
- pycharm官网: https://www.jetbrains.com/products.html#lang=python
- 注册码: http://idea.lanyus.com/ (2019年12月18日 过期)
- pycharm激活码: http://lookdiv.com/ 钥匙: 1211268069
- jetbrains: www.medeming.com !不止激活码,还有视频教程
- python: https://pythonav.com/
- 廖雪峰python: https://www.liaoxuefeng.com/wiki/1016959663602400 !不仅python,系列教程
- 武沛齐
- 海燕博客园: https://www.cnblogs.com/haiyan123/p/8387770.html
- 编程:pep8规范
爬网实战
爬阳光电影网站的磁力链接
1 | import re |
爬网问题
 微信
微信 支付宝
支付宝

