陌陌案例_离线与即席查询
今日内容:
- 1- 陌陌案例与Phoenix和 Hive对接
- 2- 什么是流式计算
- 3- Apache Flink的基本介绍
- 4- Apache Flink的入门案例
- 5- 基于Flink完成实时统计计算
- 6- 基于FineBI 实时看板的展示
1.陌陌案例基本介绍

如何设计这个存储方案呢?
1
2
3
4
| 数据量很庞大, 需要快速的进行检索数据, 支持进行离线处理
存储: HBase
快速进行检索数据: HBase 对接Phoenix 解决 通过 SQL 快速检索相关的数据
支持离线计算操作: HBase 对接 Hive 通过HIVE 完成离线计算处理
|
2. 陌陌案例数据源介绍
2.1 数据源介绍
每一条消息都是由以下这些字段来构成的:

2.2 模拟数据源
模拟生产数据源源不断的写入
部署陌陌数据源:
操作步骤:
- 将资料中 生产数据工具 目录下的两个文件(jar包 和 初始数据 ) 上传到 Linux的 /export/data/momo_init
1
2
3
4
| mkdir -p /export/data/momo_init
cd /export/data/momo_init
通过 rz 上传即可
|

- 执行jar包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 格式:
java -jar jar包名称 读取初始数据的路径 输出目的地路径 最大随机产生数据间隔时间(单位毫秒)
执行操作:
创建输出路径: mkdir -p /export/data/momo_data
执行操作:
cd /export/data/momo_init
java -jar MoMo_DataGen.jar MoMo_Data.xlsx /export/data/momo_data/ 3000
jar生产数据的特点:
一直不间断向 /export/data/momo_data/ 下的某一个文件中生产数据
字段与字段之间的分隔符号为 \001
|
3. 陌陌案例架构说明
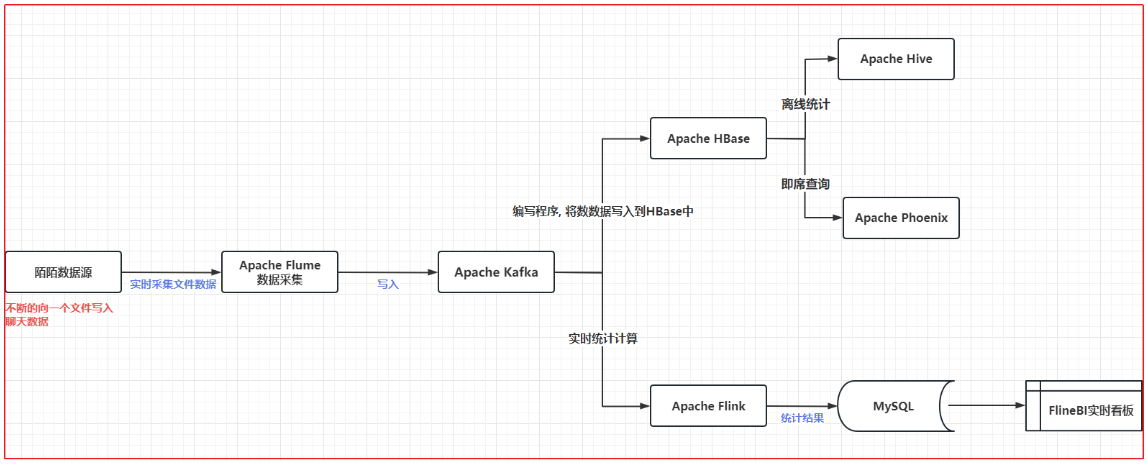
这里只是案例,实际中部门环节要用别的,比如MySQL这里可以用CK、HUDO、Doris等
4. Flume采集操作
4.1 apache flume基本介绍
Flume目前是Apache旗下的一款顶级开源项目, 最初是由cloudera公司开发的, 后期贡献给了Apache, Flume是一款专门用于数据采集的工具, 主要的目的将数据从一端传输到另一端的操作
Flume也是使用Java语言编写的, Flume一般部署在数据采集节点
在Flume中提供多种数据源的组件 和 多种目的地组件, 主要的目的是为了能够适应更多的数据采集场景
Flume老版本(Flume 0.8x)版本之前,称为Flume OG, 在0.8版本以后, 更改为Flume NG, 同时整个架构也发生变化, 整体操作也是不同的, 目前主要采用Flume NG版本, OG版本一般见不到
使用Flume核心就是学习如何配置Flume的采集脚本
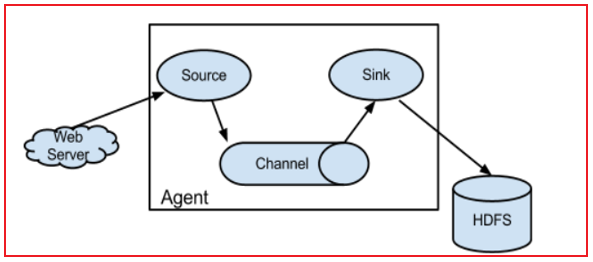
Flume的运行机制:
整个Flume启动后, 就是一个agent实例对象, 而一个Agent实例对象一般由三大组件组成:
- 1- Source 组件: 数据源 主要用于对接数据源, 从数据源中采集数据, Flume提供多种source组件
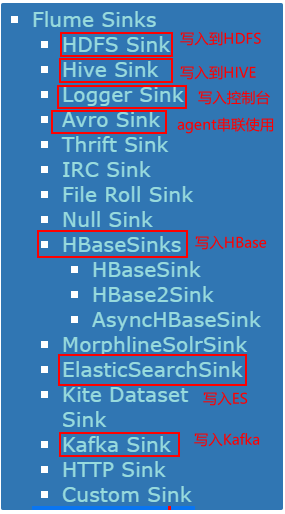
- 2- Sink组件: 下沉地(目的地) 主要用于将数据源采集过来数据通过Sink下沉具体的目的地中, Flume提供多种Sink组件
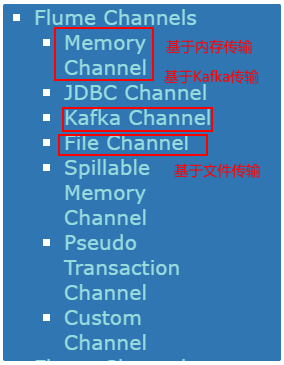
- 3- channel组件: 管道 主要是用于起到缓存的作用, 从Source将数据写入到channel, sink从channel中获取数据, 然后进行下沉操作, Flume也提供多种channel组件
在agent实例内部, 数据传递是一个个event对象方式来传输的, event对象就是数据内容, 默认只是对数据本身包裹, event除了可以保存本身数据以外, 还可以附带一些其他信息

4.2 apache flume安装
参考课件内容即可
1
| 步骤: 下载安装包 --> 上传 --> 解压(为解压后的目录配置软连接) --> 修改配置文件(仅需要改flume-env.sh 中java home地址)
|
4.3 apache flume的入门操作
4.3.1 入门案例的流程分析

因为陌陌案例是模拟生成数据,所以这里用的是netcat tcp source,监听某个端口产生的数据
4.3.2 实现入门案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| cd /export/server/flume/conf/
vim init_netcatSource_loggerSink.conf
输入 i 进入插入模式 添加以下内容:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.88.161
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = logger
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
1
2
3
4
5
6
7
| cd /export/server/flume/bin
./flume-ng agent -n a1 -c ../conf -f ../conf/init_netcatSource_loggerSink.conf -Dflume.root.logger=INFO,console
-n : 为agent起一个名字, 此名字必须和采集配置文件中定义的名称保持一致
-c : 指定Flume配置文件在那个目录下
-f : 指定采集文件的路径
-D-Dflume.root.logger=INFO,console : 打印日志行为 (固定内容)
|

1
2
3
4
| 在任意的一个节点上, 通过 telnet命令 连接node1 的 44444端口号, 然后向其发送数据, 观察node1的flume是否可以采集到数据, 如果可以采集到, 那么就说明没有任何问题, Flume整体都是正常, 入门案例结束了
操作:
telnet node1 44444
|
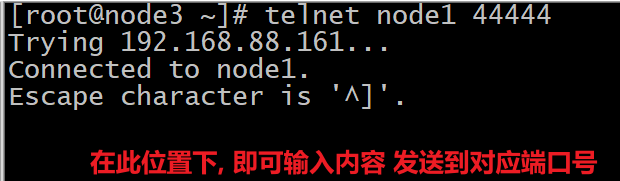
可能报出如下的错误:

1
2
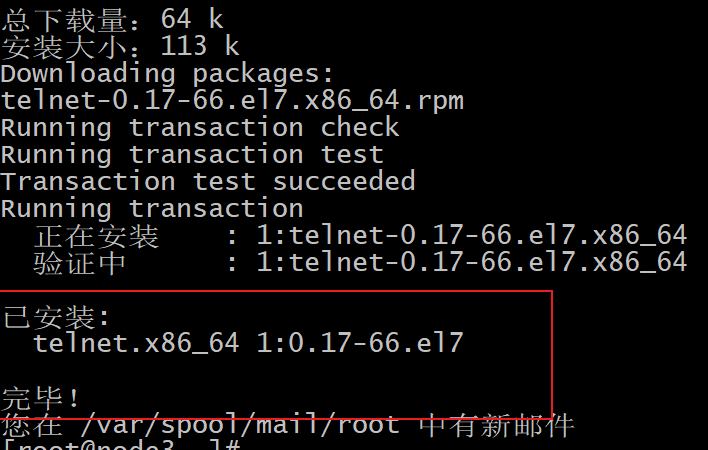
| 说明: 在此节点上, 没有这个telnet的命令, 需要安装:
yum -y install telnet
|
错误二:

1
2
3
| 原因: Flume已经关闭了, 此时对应监听端口号也会被释放, 此时这个端口号已经不存在了, 所以无法连接上 会报出拒绝连接的操作
解决方案: 先启动Flume监听, 然后连接对应的端口号即可
|
4.4 基于flume实现陌陌消息数据采集
采集需求:
1
| 监听 /export/data/momo_data/MOMO_DATA.dat 此文件, 一旦这个文件中有新的内容出现, 将对应聊天数据写入到Kafka中, 同时还支持未来的扩展需要, 要求既能监听文件, 还可以在未来监听其他文件/目录
|
操作步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| 1.1) source组件: Taildir Source
功能: 既可以采集文件 又可以采集目录
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
1.2) channel组件: Memory Channel
功能: 内存管道
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
1.3) sink组件: Kafka Sink
功能: 写入到Kafka
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| 2.1) source组件: Taildir Source
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /export/data/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /export/data/momo_data/MOMO_DATA.dat
a1.sources.r1.batchSize = 10
2.2) channel组件: Memory Channel
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 10
2.3) sink组件: Kafka Sink
a1.sinks = k1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOMO_MSG_TOPIC
a1.sinks.k1.kafka.bootstrap.servers = node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| cd /export/server/flume/conf/
vim momo_taildirSource_kafkaSink.conf
输入i 进入插入模式:
添加以下内容:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /export/data/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /export/data/momo_data/MOMO_DATA.dat
a1.sources.r1.batchSize = 10
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOMO_MSG_TOPIC
a1.sinks.k1.kafka.bootstrap.servers = node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
- 1- 在Kafka中创建一个名称为: MOMO_MSG_TOPIC 的 topic
1
2
3
4
5
| 启动Kafka集群: 先启动zookeeper, 然后启动Kafka集群
创建Topic:
cd /export/server/kafka/bin/
./kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --topic MOMO_MSG_TOPIC --partitions 6 --replication-factor 2
|
1
2
| cd /export/data/momo_data
rm -rf MOMO_DATA.dat
|
- 3- 启动Flume的实例, 准备进行数据采集工作
1
2
| cd /export/server/flume/bin/
./flume-ng agent -n a1 -c ../conf -f ../conf/momo_taildirSource_kafkaSink.conf -Dflume.root.logger=INFO,console
|
1
2
3
4
5
| 4.1 首先 先启动一个消费者 用于后续监听MOMO_MSG_TOPIC 中数据 (假设在node3启动, 任何节点均可)
cd /export/server/kafka/bin/
./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic MOMO_MSG_TOPIC
4.2 启动用于生产陌陌的聊天数据的jar包, 观察消费者, 如果消费者监听到了相关的数据, 说明Flume采集成功了...
|
开始生产数据
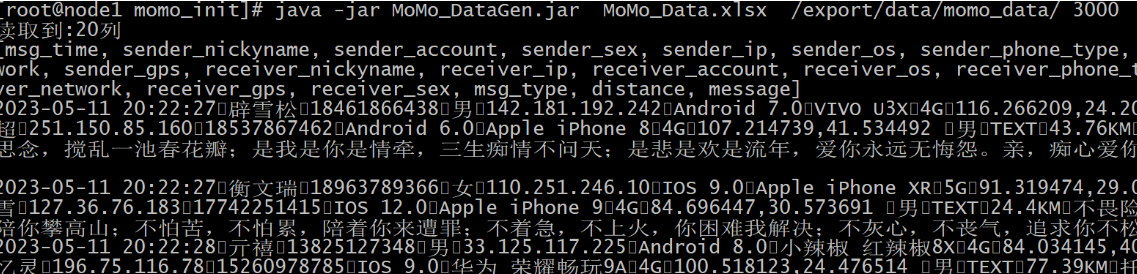
消费端: 正常监听到

5. kafka 接收消息 写入到HBase
5.1 写入到HBASE_准备工作
1
| create_namespace 'MOMO_CHAT'
|
1
2
3
4
5
6
7
8
| create 'MOMO_CHAT:MOMO_MSG',{NAME=>'C1',COMPRESSION=>'GZ'},{NUMREGIONS => 6, SPLITALGO => 'HexStringSplit'}
思考:
1- 名称空间: MOMO_CHAT
2- 列族设计: C1
3- 是否需要进行压缩: GZ 写多读少
4- 预分区设置: 基于HASH预分区 6个
5- 版本号: 仅需要保存1个版本. 因为聊天数据不存在修改 默认即可
6- TTL: 不需要考虑, 因为数据要永久保存 默认即可
|
5.2 陌陌案例中rowkey设计
回顾: rowkey的设计原则
1
2
3
4
5
6
7
8
9
| 官方原则:
1- 建议不要以自增键或者时序数据作为rowkey的前缀
2- 建议rowkey或者列的名称 长度不要过长, 建议在100个字节以内, 一般 10~30个区间
3- 使用数值类型要比String更加节省空间
4- 保证rowkey的唯一性
业务规定:
1- 相关性的数据最好放置在一起
2- 能够满足未来固定的查询需求
|
陌陌的rowkey设计
1
2
3
4
5
6
7
8
9
10
11
12
| 业务需求:
在即席查询中, 会根据发件人的账户 和 收件人的账户以及消息的时间, 查询对应消息数据
rowkey设计:
MD5HASH_发件人账户_收件人的账户_消息时间(时间戳)
说明:
MD5HASH数据(只需要八位), 通过发件人账户和收件人账户 生成MD5HASH 可以保证相关性的数据放置在一起
总长度也不会超过100个字节
时间戳可以保证rowkey的唯一性
发件人账户和收件人账户 生成的MD5HASH 可以保证相关性的在一起
发件人账户_收件人的账户_消息时间(时间戳) 可以满足固定的查询需求
|
5.3 构建一个消费者完成数据写入到HBASE操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| <repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases><enabled>true</enabled></releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
|
- 创建相关的包结构: com.itheima.momo_chat
- 代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
| package com.itheima.momo_chat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.text.SimpleDateFormat;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.Properties;
public class MomoChatConsumerToHBase {
private static Connection hConn;
private static Table table;
static{
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "node1:2181,node2:2181,node3:2181");
hConn = ConnectionFactory.createConnection(conf);
table = hConn.getTable(TableName.valueOf("MOMO_CHAT:MOMO_MSG"));
}catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);
kafkaConsumer.subscribe(Arrays.asList("MOMO_MSG_TOPIC"));
while(true){
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
String momo_msg = consumerRecord.value();
System.out.println(momo_msg);
byte[] rk = getRowkey(momo_msg);
Put put = new Put(rk);
String[] fields = momo_msg.split("\001");
put.addColumn("C1".getBytes(),"msg_time".getBytes(),fields[0].getBytes());
put.addColumn("C1".getBytes(),"sender_nickyname".getBytes(),fields[1].getBytes());
put.addColumn("C1".getBytes(),"sender_account".getBytes(),fields[2].getBytes());
put.addColumn("C1".getBytes(),"sender_sex".getBytes(),fields[3].getBytes());
put.addColumn("C1".getBytes(),"sender_ip".getBytes(),fields[4].getBytes());
put.addColumn("C1".getBytes(),"sender_os".getBytes(),fields[5].getBytes());
put.addColumn("C1".getBytes(),"sender_phone_type".getBytes(),fields[6].getBytes());
put.addColumn("C1".getBytes(),"sender_network".getBytes(),fields[7].getBytes());
put.addColumn("C1".getBytes(),"sender_gps".getBytes(),fields[8].getBytes());
put.addColumn("C1".getBytes(),"receiver_nickyname".getBytes(),fields[9].getBytes());
put.addColumn("C1".getBytes(),"receiver_ip".getBytes(),fields[10].getBytes());
put.addColumn("C1".getBytes(),"receiver_account".getBytes(),fields[11].getBytes());
put.addColumn("C1".getBytes(),"receiver_os".getBytes(),fields[12].getBytes());
put.addColumn("C1".getBytes(),"receiver_phone_type".getBytes(),fields[13].getBytes());
put.addColumn("C1".getBytes(),"receiver_network".getBytes(),fields[14].getBytes());
put.addColumn("C1".getBytes(),"receiver_gps".getBytes(),fields[15].getBytes());
put.addColumn("C1".getBytes(),"receiver_sex".getBytes(),fields[16].getBytes());
put.addColumn("C1".getBytes(),"msg_type".getBytes(),fields[17].getBytes());
put.addColumn("C1".getBytes(),"distance".getBytes(),fields[18].getBytes());
put.addColumn("C1".getBytes(),"message".getBytes(),fields[19].getBytes());
table.put(put);
}
}
}
private static byte[] getRowkey(String momo_msg) throws Exception{
String[] fields = momo_msg.split("\001");
String msg_time = fields[0];
String sender_account = fields[2];
String receiver_account = fields[11];
String md5hash = MD5Hash.getMD5AsHex((sender_account + "_" + receiver_account).getBytes()).substring(0, 8);
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long timestamp = dateFormat.parse(msg_time).getTime();
return (md5hash +"_"+sender_account +"_"+receiver_account +"_"+timestamp).getBytes();
}
}
|
5.4 测试操作
1
| zookeeper , hadoop , hbase , kafka
|
- 启动消费者代码
- 启动flume程序
- 启动陌陌数据源
- 检测 hbase的表中是否有数据
6. 陌陌案例_对接Phoenix
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
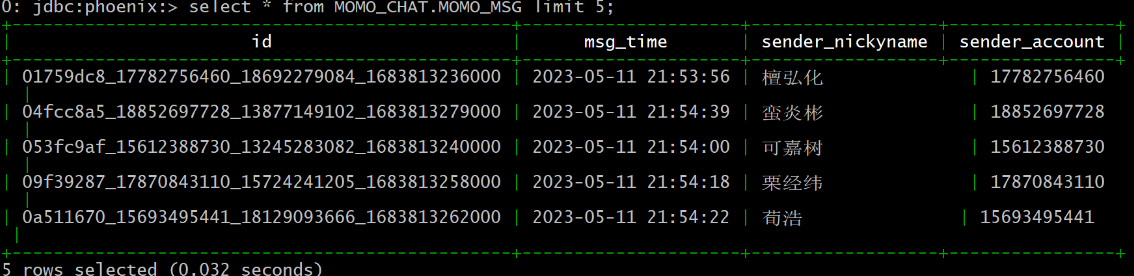
| 思考: 需要让Phoenix去读取HBase中原有的表数据? 请问如何做呢? 需要在Phoenix中构建视图, 与HBase中表进行映射
-- 创建视图:
create view MOMO_CHAT.MOMO_MSG(
"id" varchar primary key,
C1."msg_time" varchar,
C1."sender_nickyname" varchar,
C1."sender_account" varchar,
C1."sender_sex" varchar,
C1."sender_ip" varchar,
C1."sender_os" varchar,
C1."sender_phone_type" varchar,
C1."sender_network" varchar,
C1."sender_gps" varchar,
C1."receiver_nickyname" varchar,
C1."receiver_ip" varchar,
C1."receiver_account" varchar,
C1."receiver_os" varchar,
C1."receiver_phone_type" varchar,
C1."receiver_network" varchar,
C1."receiver_gps" varchar,
C1."receiver_sex" varchar,
C1."msg_type" varchar,
C1."distance" varchar,
C1."message" varchar
);
|
7. 陌陌案例_对接Hive
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| create database if not exists MOMO_CHAT;
use MOMO_CHAT;
create external table MOMO_CHAT.MOMO_MSG(
id string,
msg_time string,
sender_nickyname string,
sender_account string,
sender_sex string,
sender_ip string,
sender_os string,
sender_phone_type string,
sender_network string,
sender_gps string,
receiver_nickyname string,
receiver_ip string,
receiver_account string,
receiver_os string,
receiver_phone_type string,
receiver_network string,
receiver_gps string,
receiver_sex string,
msg_type string,
distance string,
message string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,C1:msg_time,
C1:sender_nickyname,
C1:sender_account,
C1:sender_sex,
C1:sender_ip,
C1:sender_os,
C1:sender_phone_type,
C1:sender_network,
C1:sender_gps,
C1:receiver_nickyname,
C1:receiver_ip,
C1:receiver_account,
C1:receiver_os,
C1:receiver_phone_type,
C1:receiver_network,
C1:receiver_gps,
C1:receiver_sex,
C1:msg_type,
C1:distance,
C1:message') tblproperties('hbase.table.name'='MOMO_CHAT:MOMO_MSG');
|
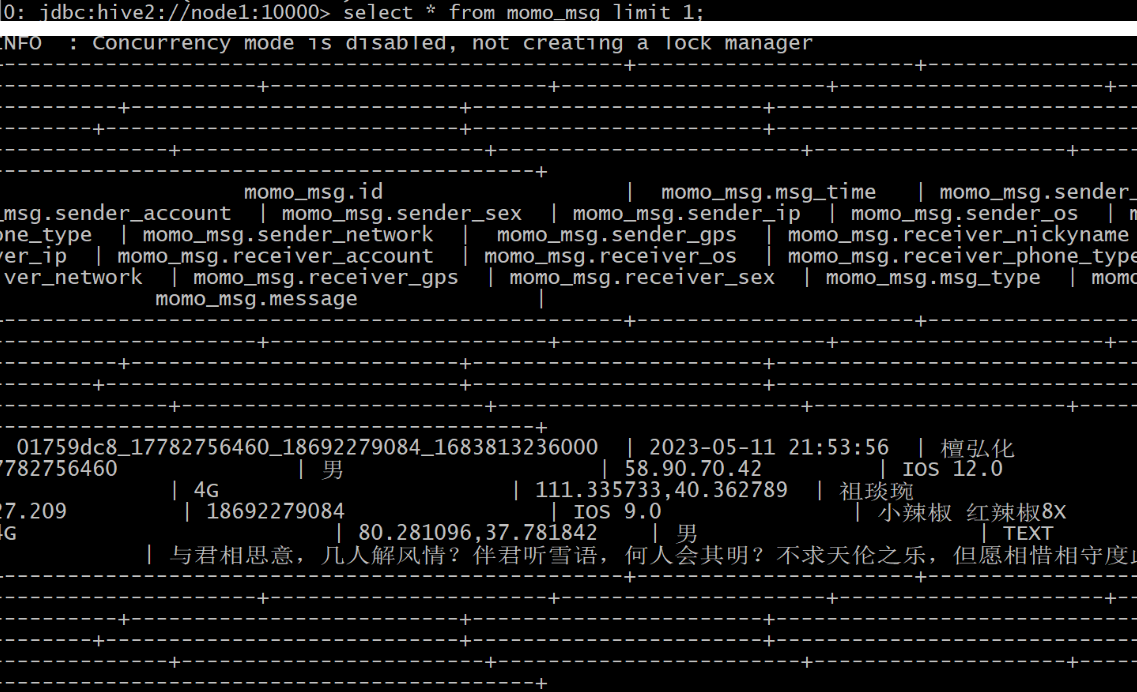
陌陌案例_实时计算
8. 什么是流式计算
总结: 数据是源源不断的在产生, 计算城市也在源源不断进行计算, 同时也在源源不断输出统计的结果
流计算和批计算的区别:
- 1- 数据时效性不同:
- 流计算: 计算实时性 延迟性低
- 批计算: 非实时 高延迟
- 2- 数据特征不同
- 流计算: 数据是动态, 无边界
- 批计算: 数据一般都是静态化, 有边界
- 3- 应用场景不同
- 流计算: 实时场景 对时效性要求比较高
- 批计算: 实时性要求不高, 无实时性要求
- 4- 运行方式不同:
- 流计算: 计算任务是持续, 不间断运行
- 批计算: 只需要在固定的某个阶段执行
9. Apache Flink的基本介绍
Apache Flink是一个既支持离线话处理, 也支持实时化处理的框架, 为了提升用户操作的便利性, 提供多种操作API:
- 1- DataSet API: 主要是用于对批量数据进行计算(离线计算)
- 2- DataSteam API: 主要用于流式计算处理(实时计算)
- 3- Table API: 主要是用于对结构化数据进行处理, 可以通过API 将数据映射为表, 支持SQL处理
10. Apache Flink的入门案例
10.1 需求说明
需求:
通过监听某一个socket网络流, 从网络流中获取相关的单词数据, 进行统计操作, 求出每个单词出现了多少次. 将实时统计的结果输出到控制台即可
10.2 案例流程分析
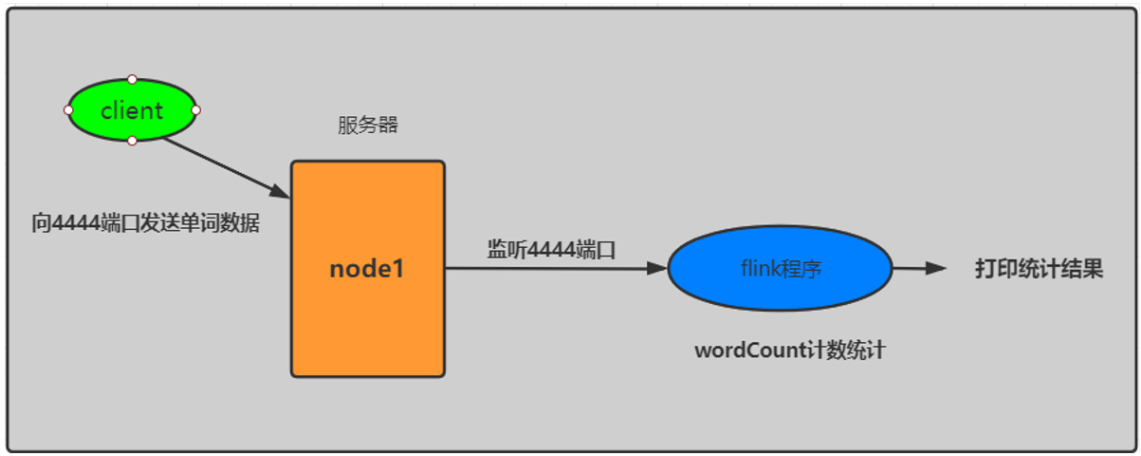
10.3 代码的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| <repositories><!--代码库-->
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases><enabled>true</enabled></releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
|
- 2- 创建包结构: com.itheima.flink
- 3- 在此包下, 创建Java类, 编写Flink代码: FlinkWordCount
1
2
3
4
5
6
7
8
9
10
| package com.itheima.flink;
// Flink的入门案例: 实时WordCount案例
public class FlinkWordCount {
public static void main(String[] args) {
}
}
|
如何编写Flink流式计算的API呢?
1
2
3
4
5
6
7
| 基本步骤:
1- 创建Flink流式计算的核心环境类对象
2- 组装Flink三大核心组件: source translation sink
2.1 在Flink的流式计算的核心环境类对象构建Source组件
2.2 在Source组件中添加相关的转换操作
2.3 在转换组件中, 添加sink组件, 完成输出
3- 启动Flink程序
|
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| package com.itheima.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
// Flink的入门案例: 实时WordCount案例
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
// 1- 创建Flink流式计算的核心环境类对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2- 组装Flink三大核心组件: source translation sink
// 2.1 在Flink的流式计算的核心环境类对象构建Source组件
DataStreamSource<String> streamSource = env.socketTextStream("node1", 4444);
// 2.2 在Source组件中添加相关的转换操作
// 2.2.1 : 将每一行数据, 拆分为一个个的单词 (给一行数据, 返回多个数据)
SingleOutputStreamOperator<String> streamOperator = streamSource.flatMap(new FlatMapFunction<String, String>() {
// flatMap方法: 参数1表示输入数据 参数2: 收集输出结果(因为多个)
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
// 执行切割操作
String[] words = line.split(" ");
// 遍历出每一个单词
for (String word : words) {
// 将每一个单词, 通过collector收集起来
collector.collect(word);
}
}
});
// 2.2.2: 将每一个单词 转换为 (单词,1) (给一个单词, 返回一个结果) 一对一的转换
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator1 = streamOperator.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 2.2.3: 根据key进行分组, 对value进行累加操作
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator2 = streamOperator1.keyBy(0).sum(1);
// 2.3 在转换组件中, 添加sink组件, 完成输出
streamOperator2.print();
// 3- 启动Flink程序
env.execute("FlinkWordCount");
}
}
|
链式写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| package com.itheima.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
// Flink的入门案例: 实时WordCount案例 (简写)
public class FlinkWordCount2 {
public static void main(String[] args) throws Exception {
// 1- 创建Flink流式计算的核心环境类对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2- 组装Flink三大核心组件: source translation sink
// 2.1 在Flink的流式计算的核心环境类对象构建Source组件
DataStreamSource<String> streamSource = env.socketTextStream("node1", 4444);
// 2.2 在Source组件中添加相关的转换操作
// 2.2.1 : 将每一行数据, 拆分为一个个的单词 (给一行数据, 返回多个数据)
// 2.2.2: 将每一个单词 转换为 (单词,1) (给一个单词, 返回一个结果) 一对一的转换
// 2.2.3: 根据key进行分组, 对value进行累加操作
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
// flatMap方法: 参数1表示输入数据 参数2: 收集输出结果(因为多个)
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 执行切割操作
String[] words = line.split(" ");
// 遍历出每一个单词
for (String word : words) {
// 将每一个单词, 通过collector收集起来
collector.collect(Tuple2.of(word,1));
}
}
}).keyBy(0).sum(1);
// 2.3 在转换组件中, 添加sink组件, 完成输出
streamOperator.print();
// 3- 启动Flink程序
env.execute("FlinkWordCount");
}
}
|
测试操作:
flume会自动打开端口号,但是flink不会,所以我们要借助nc
1
2
3
4
5
6
7
8
9
10
| 首先需要在node1开启4444端口号, 并准备写入数据:
nc -lk 4444
可能会报出: -bash: nc: 未找到命令
执行 yum -y install nc
接着开启Flink程序
最后在node1中发送单词数据, 观察Flink的输出
|
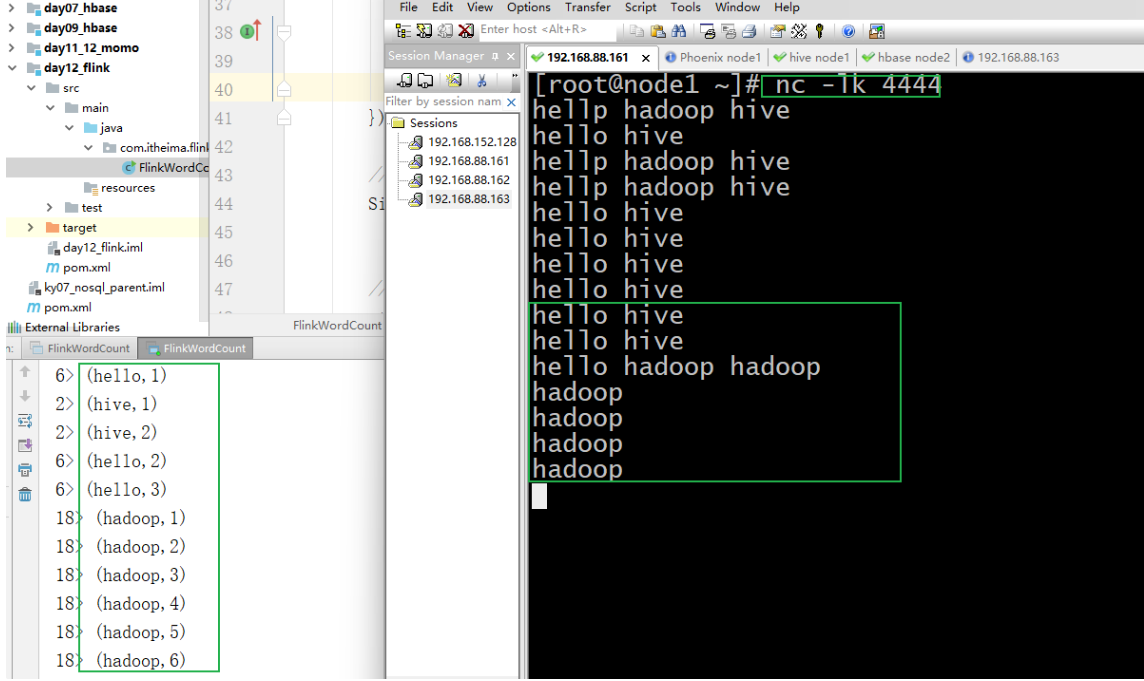
11. 基于Flink进行实时统计计算
11.1 需求说明
实时需求:
1
2
3
4
5
| 1- 实时统计消息总量
2- 实时统计 各个地区发送消息的总量
3- 实时统计 各个地区接收消息的总量
4- 实时统计 各个用户发送消息的总量
5- 实时统计 各个用户接收消息的总量
|
11.2 案例的流程
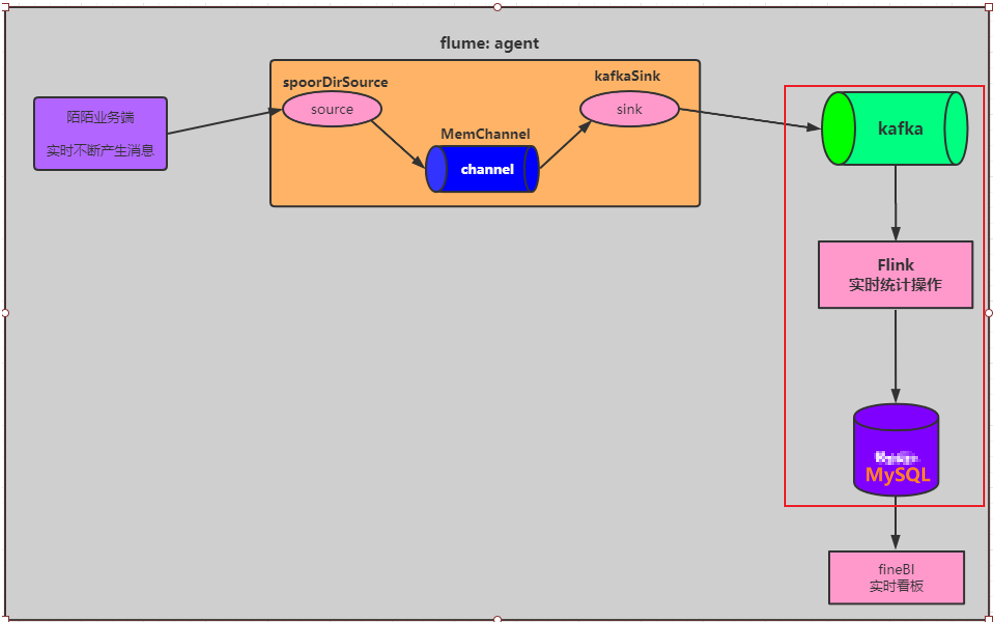
11.3 准备工作
- 1- 在项目中新增一下jar包依赖(陌陌案例项目中)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
|
- 2- 在陌陌项目中创建两个包结构:
- com.itheima.momo_chat.stream
- com.itheima.momo_chat.utils
11.4 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
| package com.itheima.momo_chat.stream;
import com.itheima.momo_chat.pojo.MoMoCountBean;
import com.itheima.momo_chat.utils.HttpClientUtils;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple1;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class MomoFlinkStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "g_02");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>("MOMO_MSG_TOPIC",new SimpleStringSchema(),props);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
SingleOutputStreamOperator<String> filterStreamOperator = source.filter(new FilterFunction<String>() {
@Override
public boolean filter(String msg) throws Exception {
return msg != null && !"".equals(msg.trim()) && msg.split("\001").length == 20;
}
});
totalMsgCount(filterStreamOperator);
provinceSenderMsgCount(filterStreamOperator);
provinceReceiverMsgCount(filterStreamOperator);
userSenderMsgCount(filterStreamOperator);
userReverseMsgCount(filterStreamOperator);
env.execute("MomoFlinkStream");
}
private static void userReverseMsgCount(SingleOutputStreamOperator<String> filterStreamOperator) {
SingleOutputStreamOperator<Tuple2<String, Long>> sumStreamOperator = filterStreamOperator.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String msg) throws Exception {
String[] fields = msg.split("\001");
String receiver_nickyname = fields[9];
return Tuple2.of(receiver_nickyname, 1L);
}
}).keyBy(0).sum(1);
SingleOutputStreamOperator<MoMoCountBean> moMoCountBeanStreamOperator = sumStreamOperator.map(new MapFunction<Tuple2<String, Long>, MoMoCountBean>() {
@Override
public MoMoCountBean map(Tuple2<String, Long> res) throws Exception {
String receiver_nickyname = res.f0;
Long count = res.f1;
MoMoCountBean moMoCountBean = new MoMoCountBean();
moMoCountBean.setGroupType("5");
moMoCountBean.setMoMoUsername(receiver_nickyname);
moMoCountBean.setMoMo_MsgCount(count);
return moMoCountBean;
}
});
moMoCountBeanStreamOperator.addSink(new MysqlSink("5"));
}
private static void userSenderMsgCount(SingleOutputStreamOperator<String> filterStreamOperator) {
SingleOutputStreamOperator<Tuple2<String, Long>> sumStreamOperator = filterStreamOperator.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String msg) throws Exception {
String[] fields = msg.split("\001");
String sender_nickyname = fields[1];
return Tuple2.of(sender_nickyname, 1L);
}
}).keyBy(0).sum(1);
SingleOutputStreamOperator<MoMoCountBean> moMoCountBeanStreamOperator = sumStreamOperator.map(new MapFunction<Tuple2<String, Long>, MoMoCountBean>() {
@Override
public MoMoCountBean map(Tuple2<String, Long> res) throws Exception {
String sender_nickyname = res.f0;
Long count = res.f1;
MoMoCountBean moMoCountBean = new MoMoCountBean();
moMoCountBean.setGroupType("4");
moMoCountBean.setMoMoUsername(sender_nickyname);
moMoCountBean.setMoMo_MsgCount(count);
return moMoCountBean;
}
});
moMoCountBeanStreamOperator.addSink(new MysqlSink("4"));
}
private static void provinceReceiverMsgCount(SingleOutputStreamOperator<String> filterStreamOperator) {
SingleOutputStreamOperator<Tuple2<String, Long>> sumStreamOperator = filterStreamOperator.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String msg) throws Exception {
String[] fields = msg.split("\001");
String receiver_gps = fields[15];
String[] lngAndLat = receiver_gps.split(",");
String lat = lngAndLat[1].trim();
String lng = lngAndLat[0].trim();
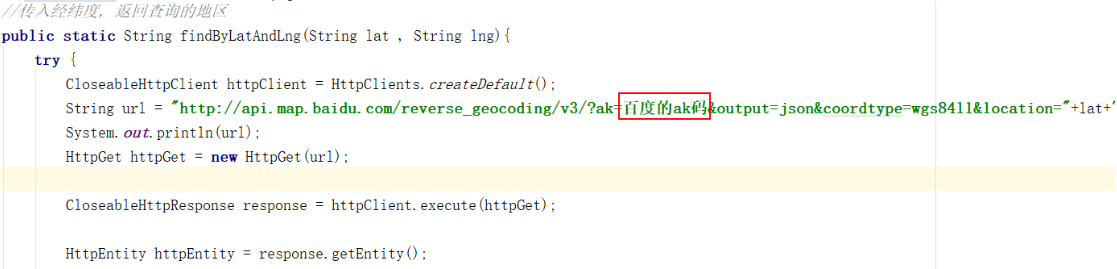
String city = HttpClientUtils.findByLatAndLng(lat, lng);
return Tuple2.of(city, 1L);
}
}).keyBy(0).sum(1);
SingleOutputStreamOperator<MoMoCountBean> moMoCountBeanStreamOperator = sumStreamOperator.map(new MapFunction<Tuple2<String, Long>, MoMoCountBean>() {
@Override
public MoMoCountBean map(Tuple2<String, Long> res) throws Exception {
String city = res.f0;
Long count = res.f1;
MoMoCountBean moMoCountBean = new MoMoCountBean();
moMoCountBean.setGroupType("3");
moMoCountBean.setMoMoProvince(city);
moMoCountBean.setMoMo_MsgCount(count);
return moMoCountBean;
}
});
moMoCountBeanStreamOperator.addSink(new MysqlSink("3"));
}
private static void provinceSenderMsgCount(SingleOutputStreamOperator<String> filterStreamOperator) {
SingleOutputStreamOperator<Tuple2<String, Long>> sumStreamOperator = filterStreamOperator.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String msg) throws Exception {
String[] fields = msg.split("\001");
String sender_gps = fields[8];
String[] lngAndLat = sender_gps.split(",");
String lat = lngAndLat[1].trim();
String lng = lngAndLat[0].trim();
String city = HttpClientUtils.findByLatAndLng(lat, lng);
return Tuple2.of(city, 1L);
}
}).keyBy(0).sum(1);
SingleOutputStreamOperator<MoMoCountBean> moMoCountBeanStreamOperator = sumStreamOperator.map(new MapFunction<Tuple2<String, Long>, MoMoCountBean>() {
@Override
public MoMoCountBean map(Tuple2<String, Long> res) throws Exception {
String city = res.f0;
Long count = res.f1;
MoMoCountBean moMoCountBean = new MoMoCountBean();
moMoCountBean.setGroupType("2");
moMoCountBean.setMoMoProvince(city);
moMoCountBean.setMoMo_MsgCount(count);
return moMoCountBean;
}
});
moMoCountBeanStreamOperator.addSink(new MysqlSink("2"));
}
private static void totalMsgCount(SingleOutputStreamOperator<String> filterStreamOperator) {
SingleOutputStreamOperator<Tuple1<Long>> MapStreamOperator = filterStreamOperator.map(new MapFunction<String, Tuple1<Long>>() {
@Override
public Tuple1<Long> map(String msg) throws Exception {
return Tuple1.of(1L);
}
});
SingleOutputStreamOperator<Tuple1<Long>> SumStreamOperator = MapStreamOperator.keyBy(0).sum(0);
SingleOutputStreamOperator<MoMoCountBean> MoMoCountBeanStreamOperator = SumStreamOperator.map(new MapFunction<Tuple1<Long>, MoMoCountBean>() {
@Override
public MoMoCountBean map(Tuple1<Long> totalCountTuple) throws Exception {
Long totalCountMsg = totalCountTuple.f0;
MoMoCountBean moMoCountBean = new MoMoCountBean();
moMoCountBean.setGroupType("1");
moMoCountBean.setMoMoTotalCount(totalCountMsg);
return moMoCountBean;
}
});
MoMoCountBeanStreamOperator.addSink(new MysqlSink("1"));
}
}
|
12. 基于FineBI实时看板展示
12.1 FineBI安装操作
直接参考资料中<<安装手册>>
注意: 默认情况下, 早期的FINE BI 是不支持实时数据源, 需要加载插件才可以被支持
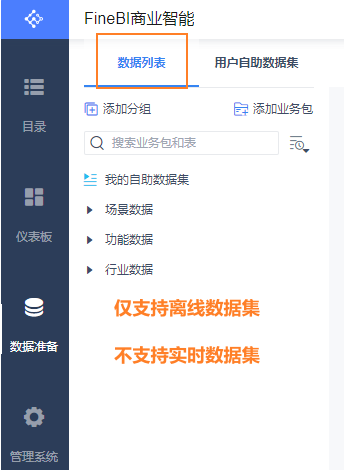
如何让当前的FINE BI 支持实时方案呢?
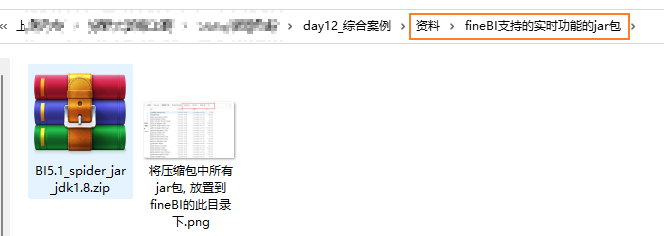
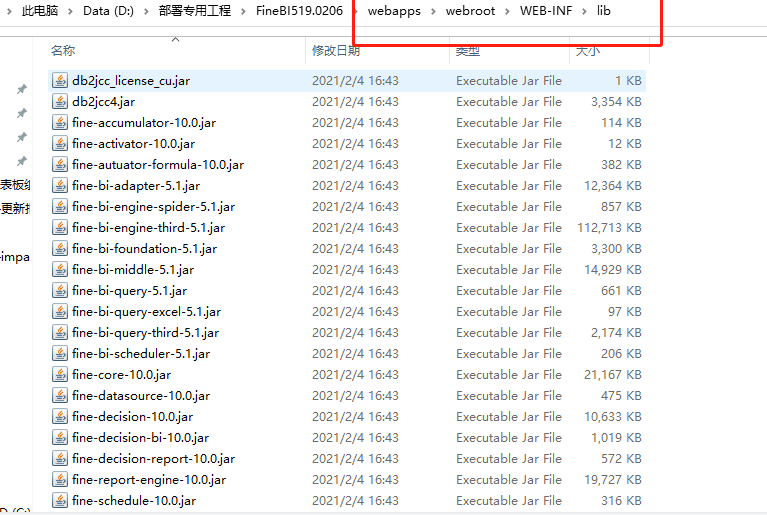
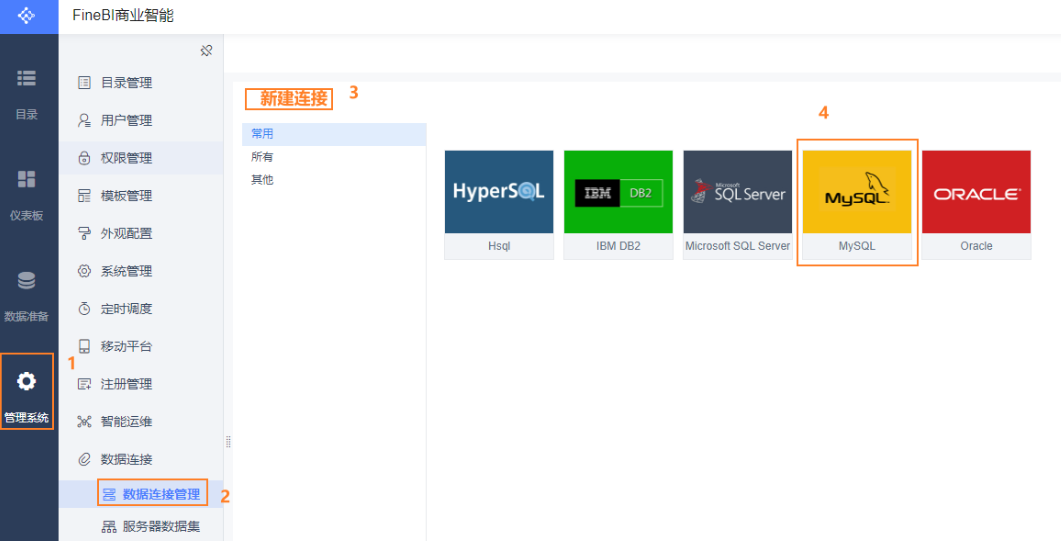
先将FINE BI 关键, 然后将 zip包中所有的jar包, 放置到 第二图中对应的目录下, 然后启动FINE BI 即可
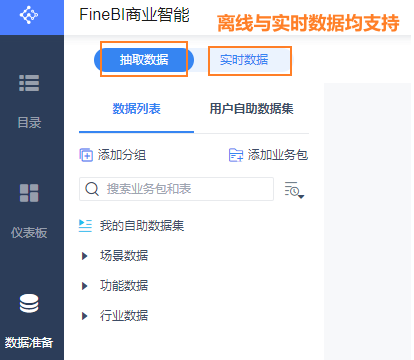
12.2 配置 FineBI 和 MySQL的数据连接
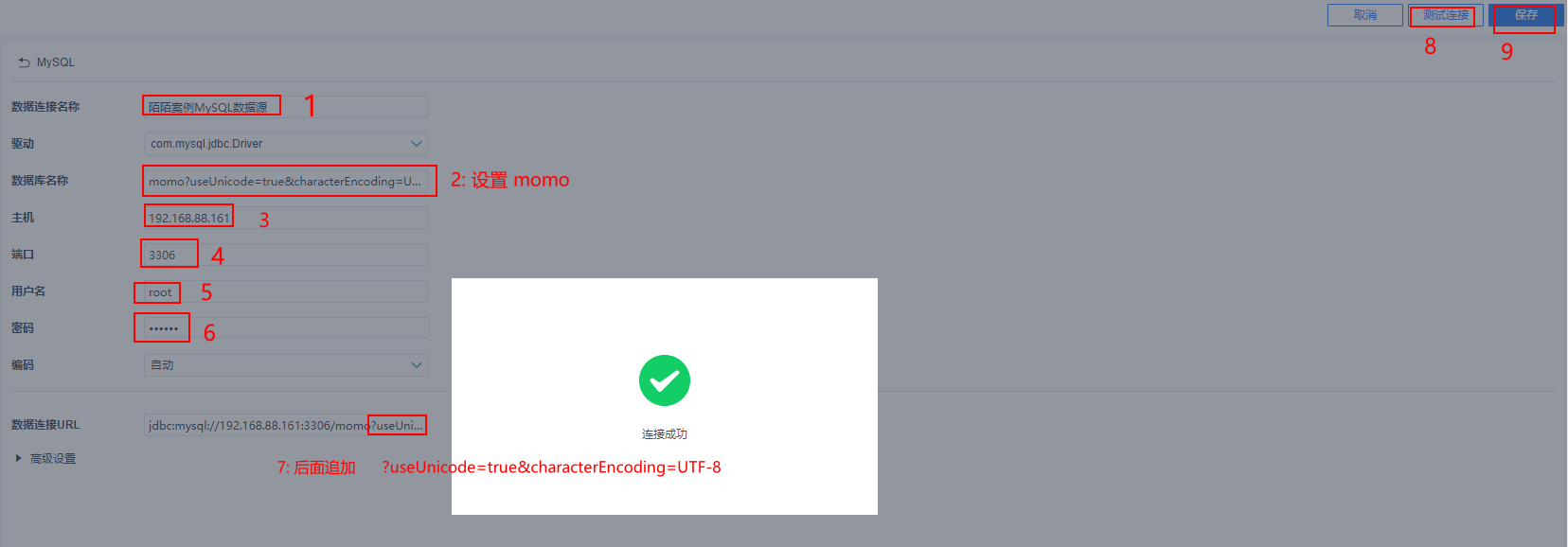
1
| ?useUnicode=true&characterEncoding=UTF-8
|
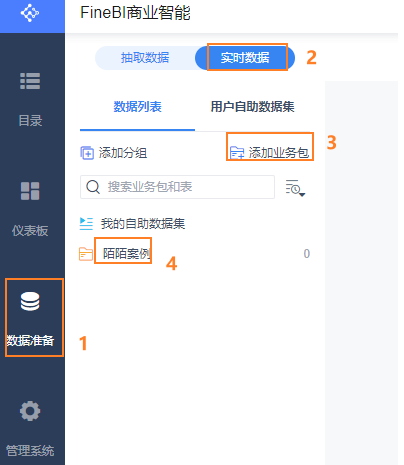
12.3 配置实时数据源
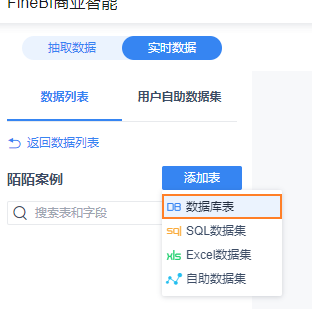
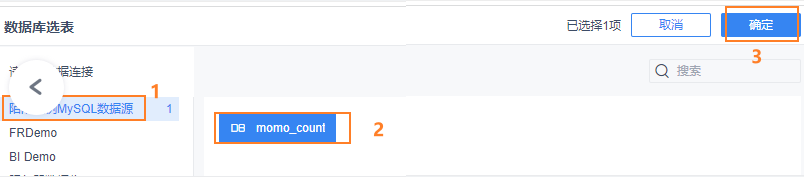
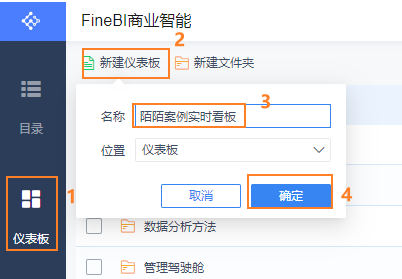
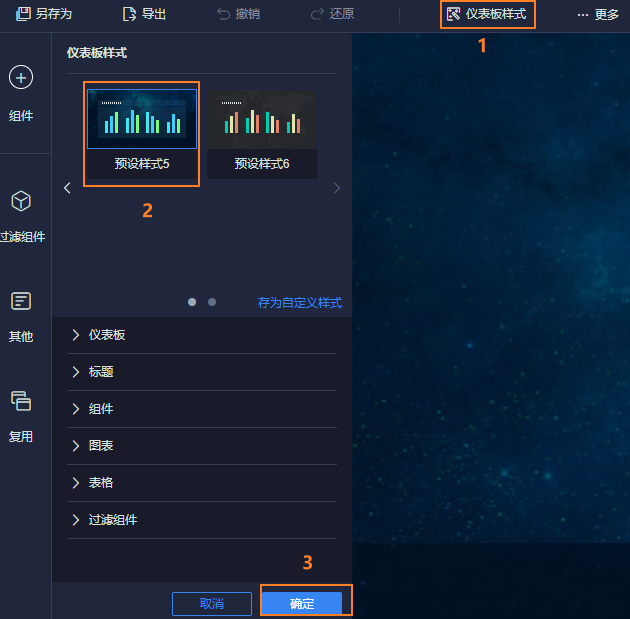
12.4 进行图表制作
12.4.1 构建一个仪表盘
12.4.2 添加标题

12.4.3 发送消息前10名的昵称
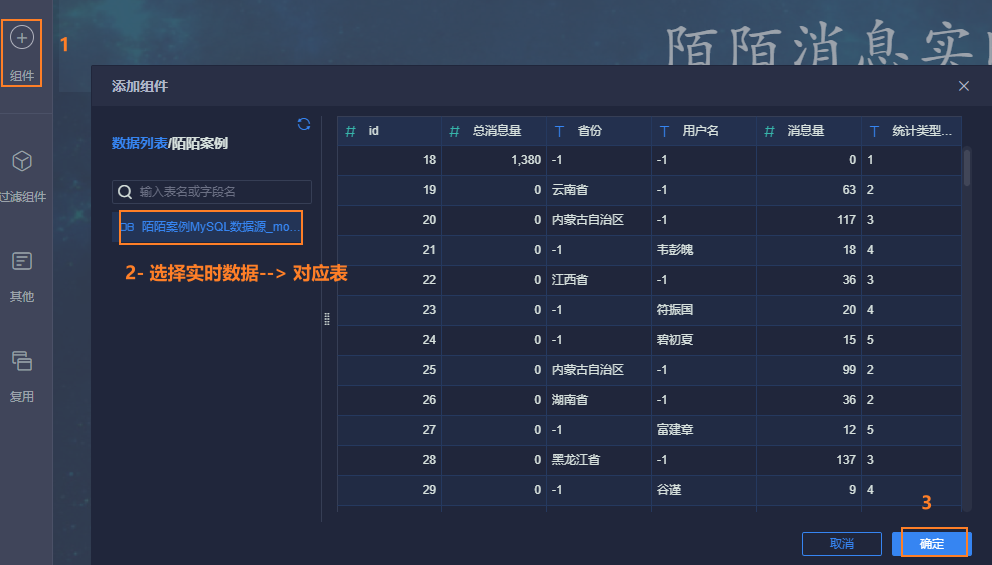
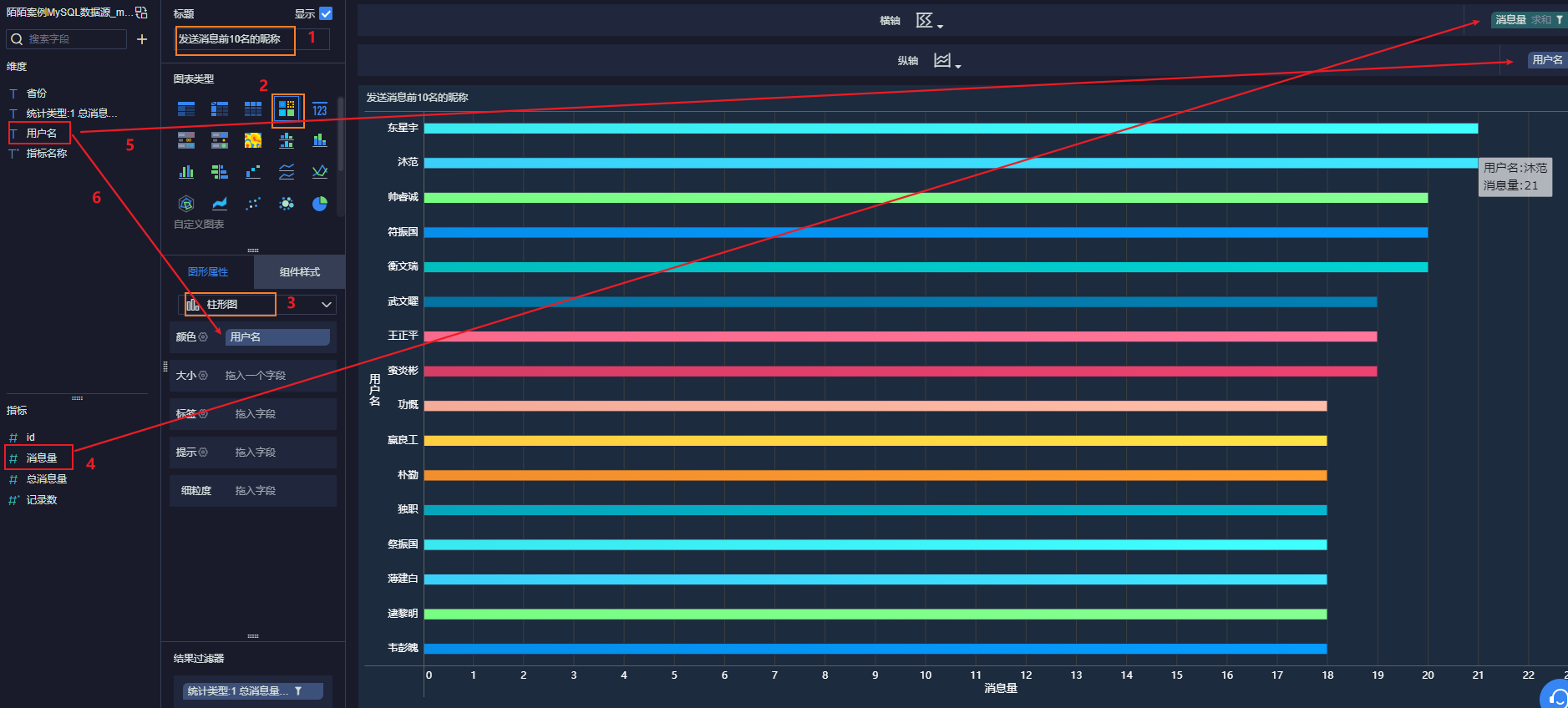

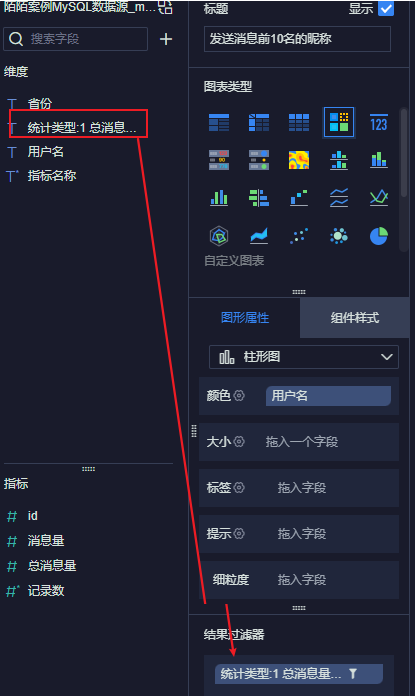
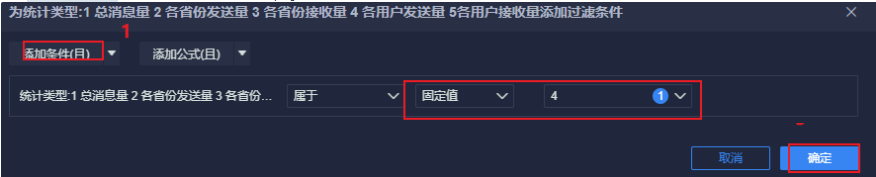
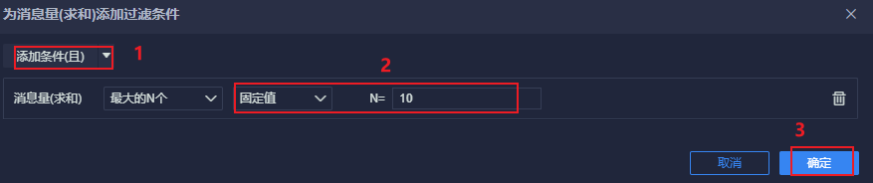

最后, 点击右上角, 添加到仪表盘
12.4.4 统计各地区接收消息前TOP10
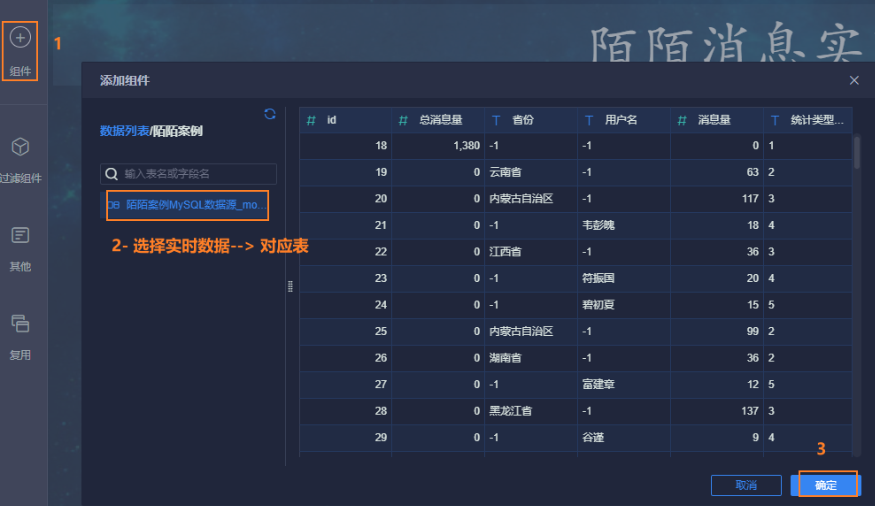
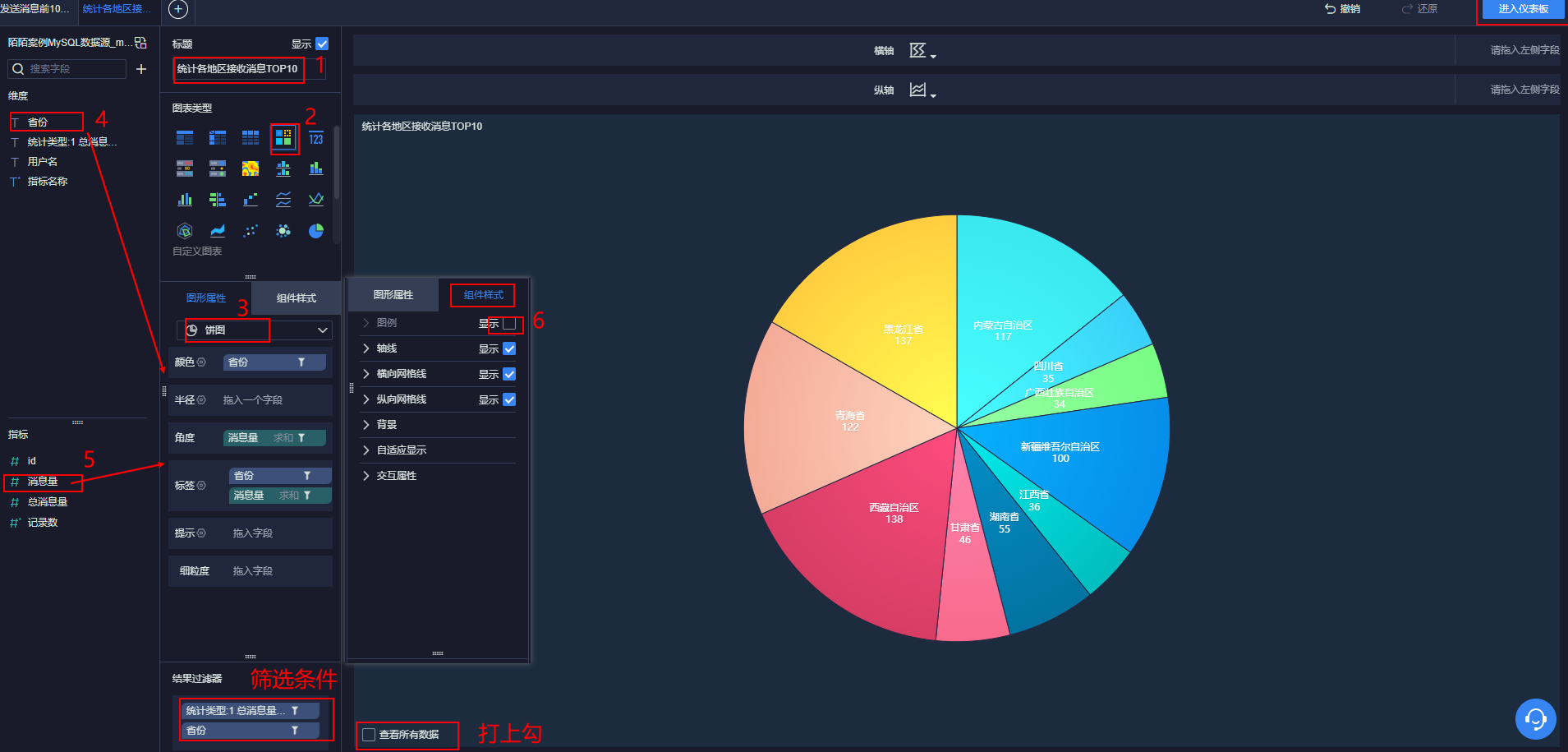
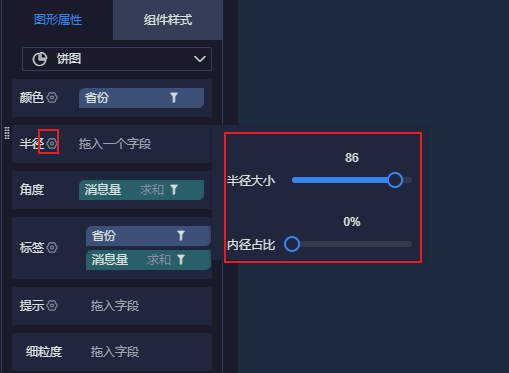
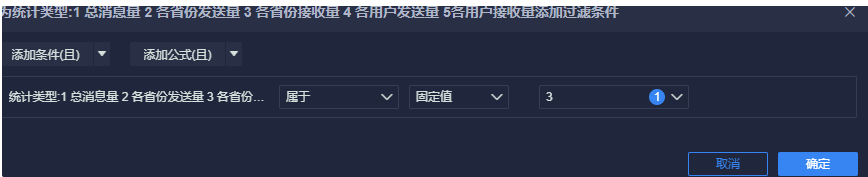
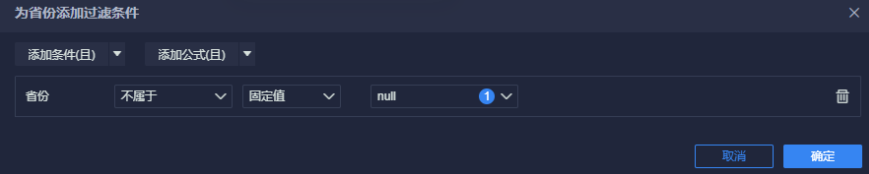
条件筛选:
添加到仪表盘
12.4.5 显示各个省份信息及其对应数量
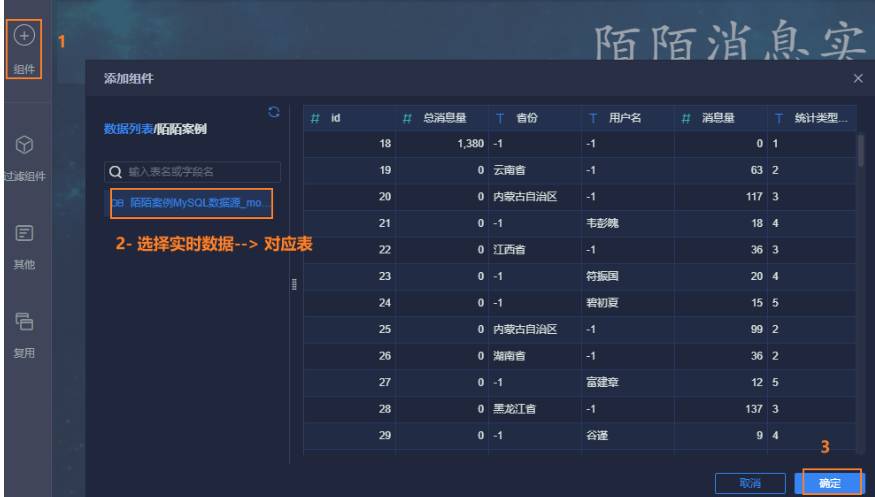
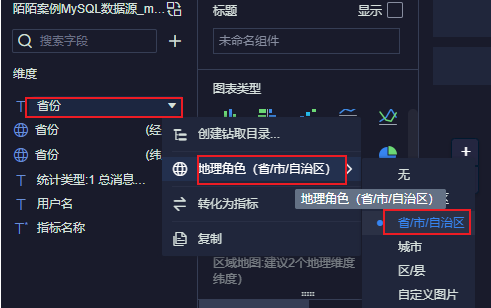

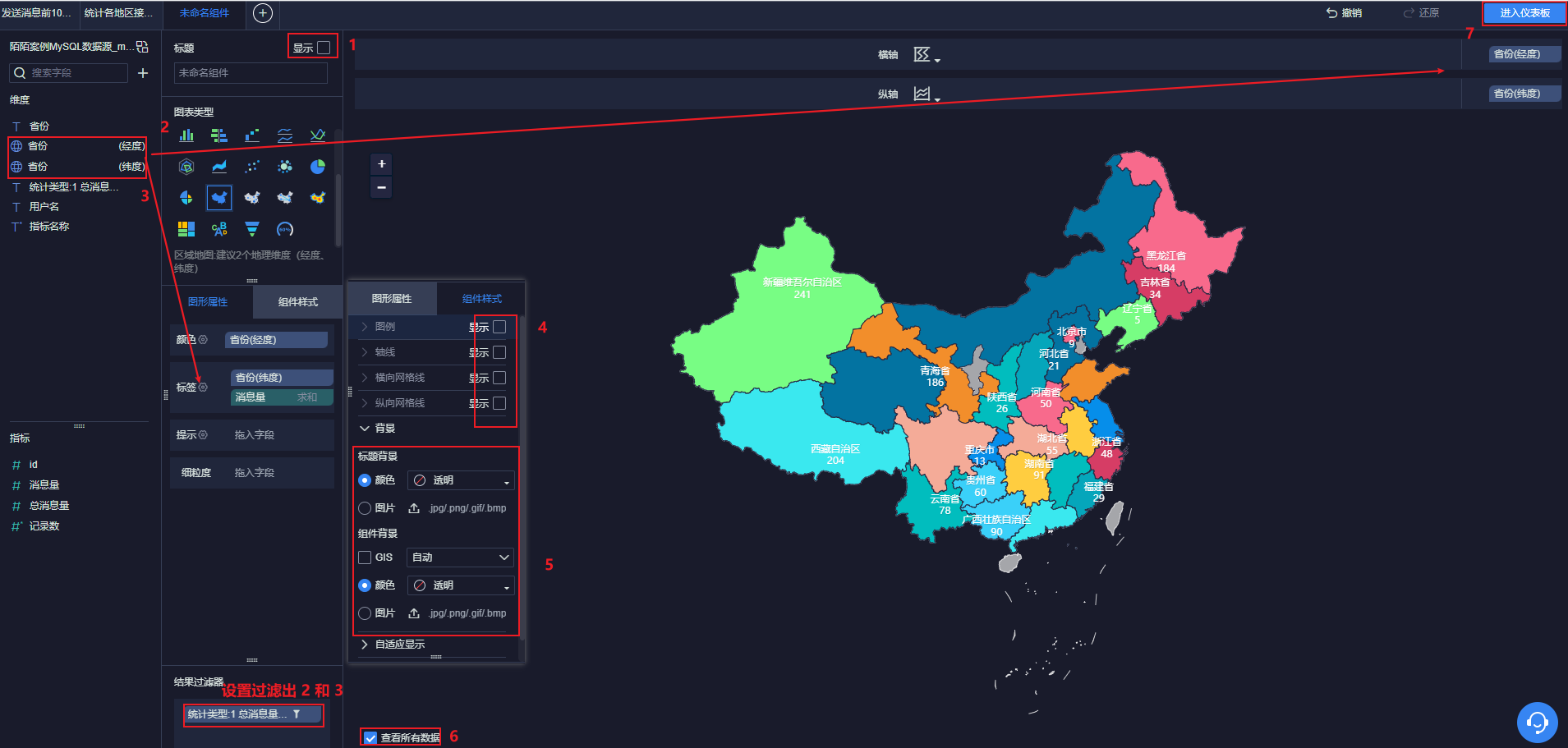
进入仪表盘:
12.4.6 显示实时消息量
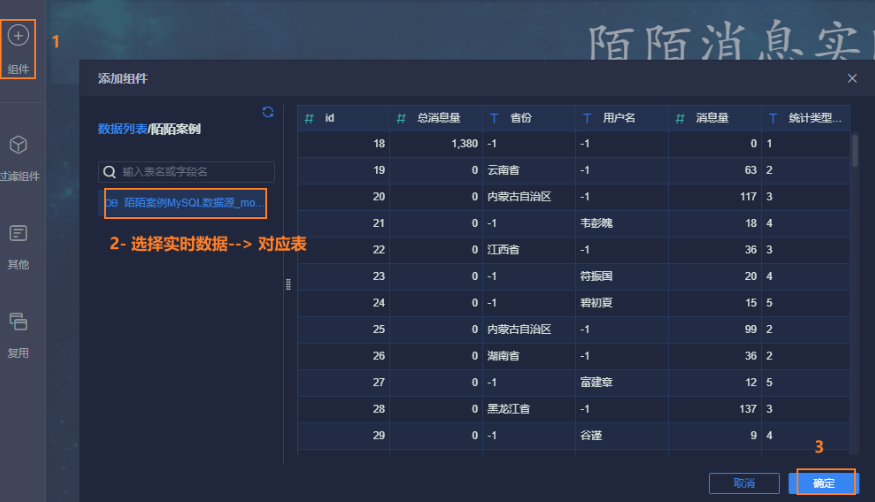
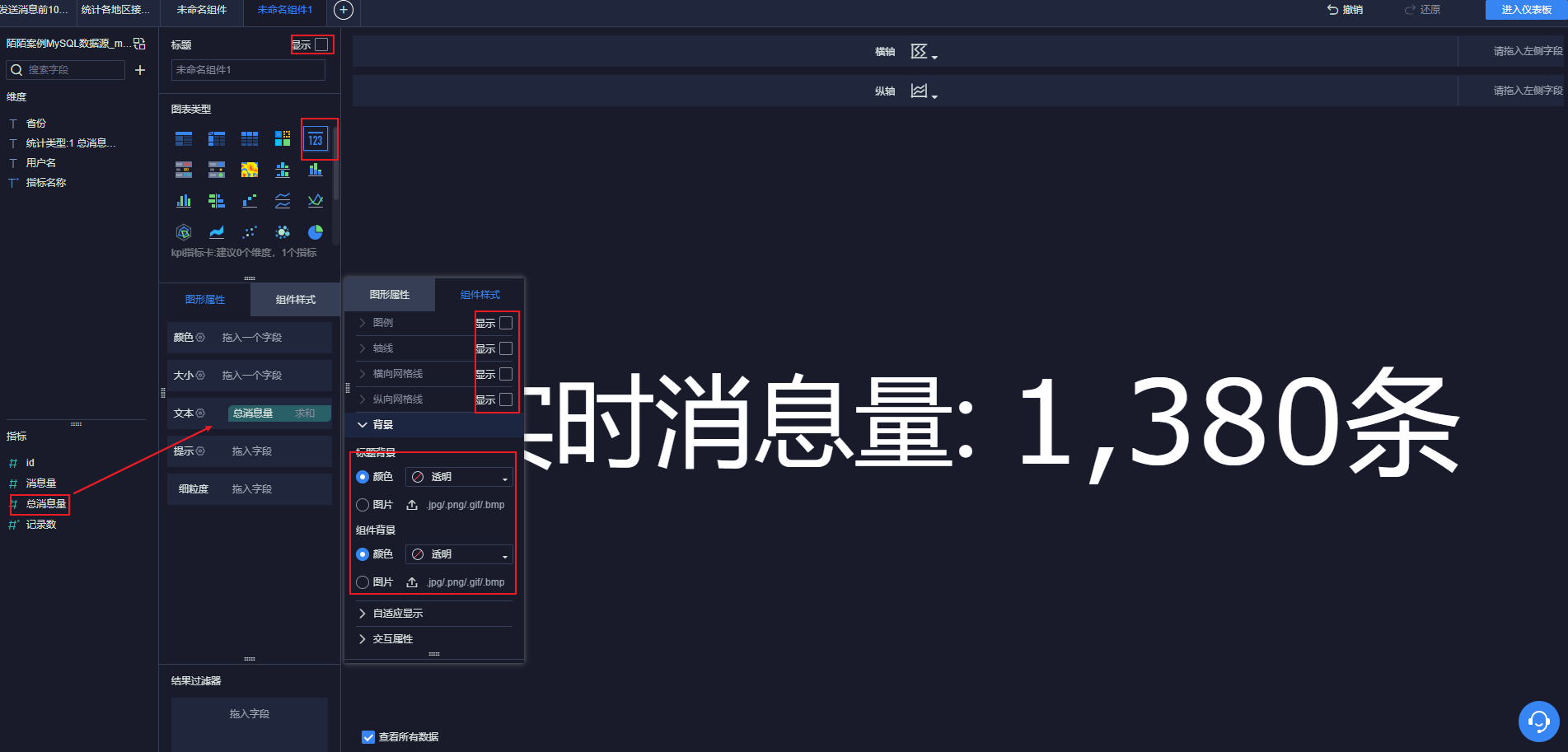
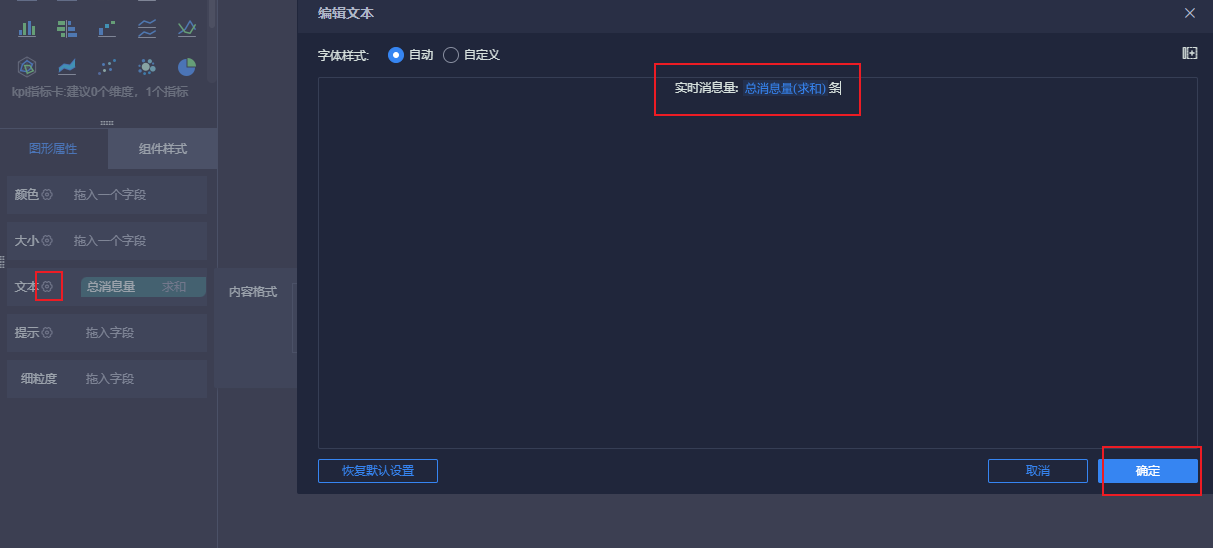
添加到仪表盘:

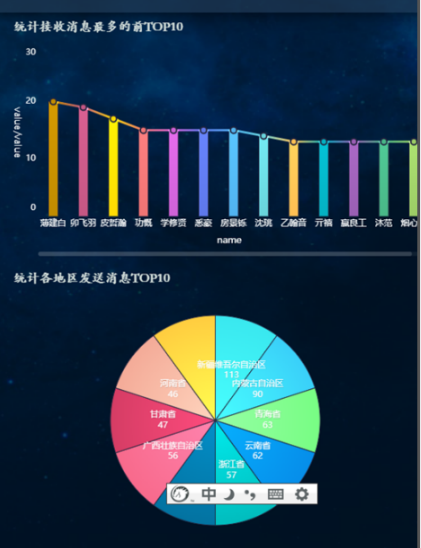
12.4.5 接收消息最多的TOP10昵称和发送消息各地区TOP10
两个图, 与左侧的图形类似
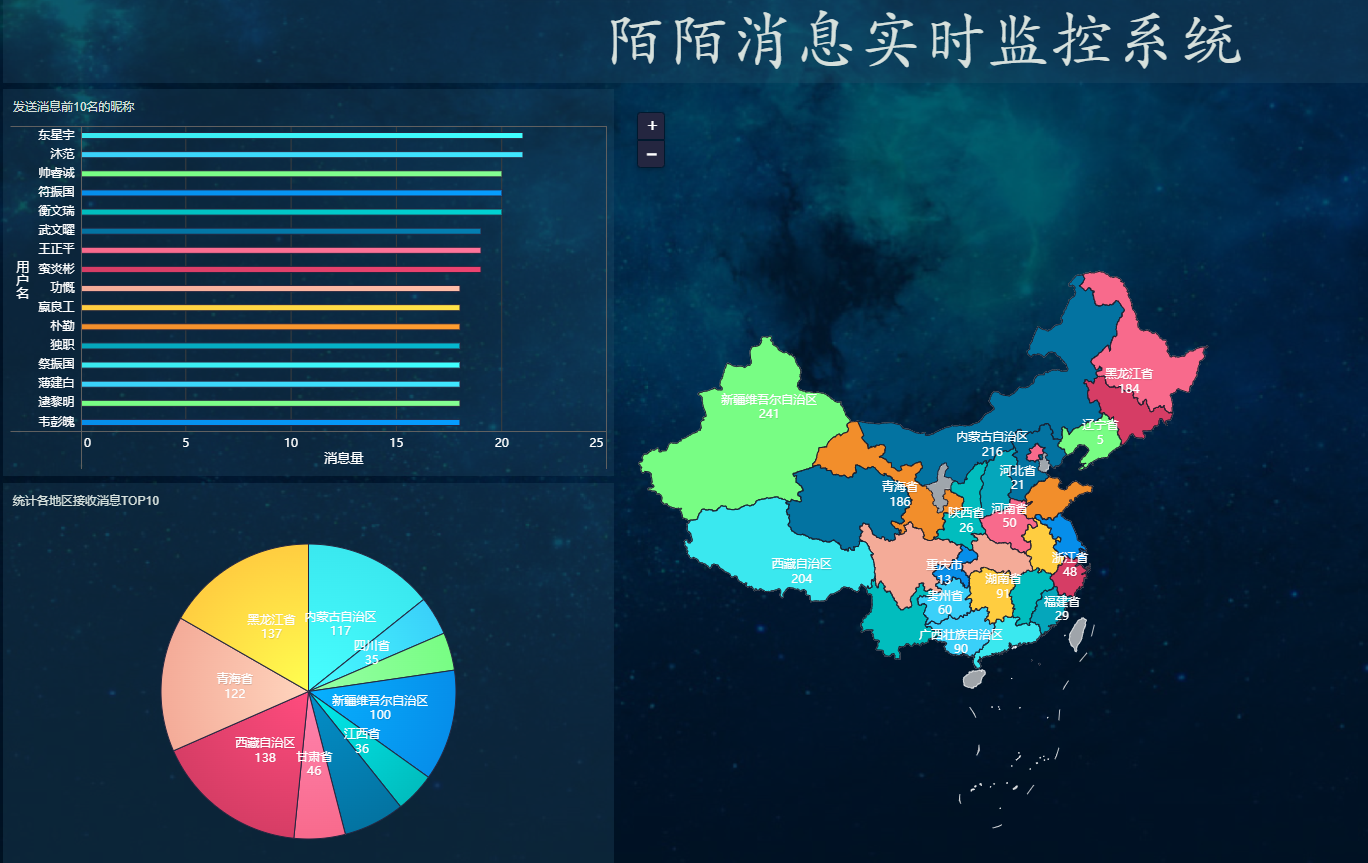
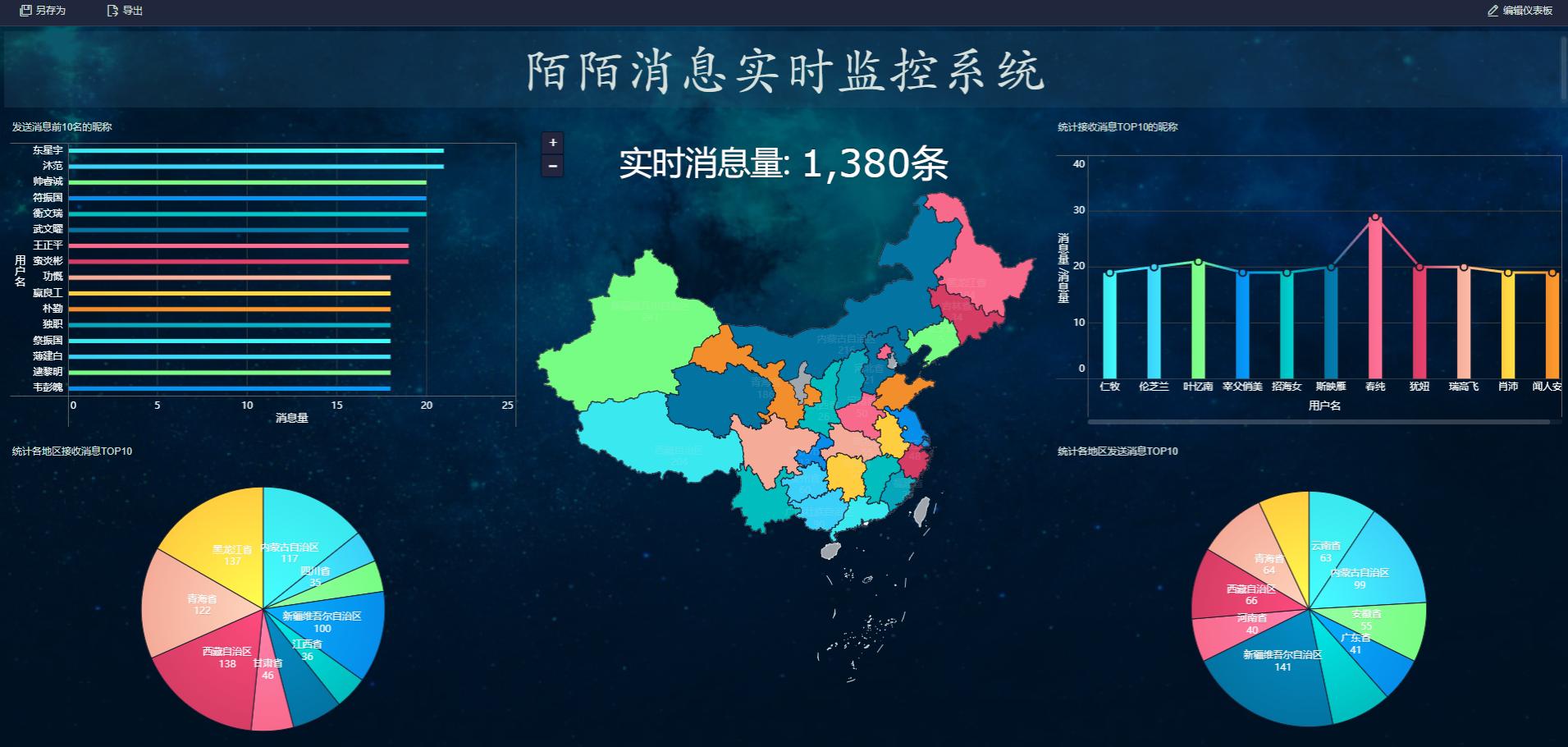
12.4.6. 最终图形:
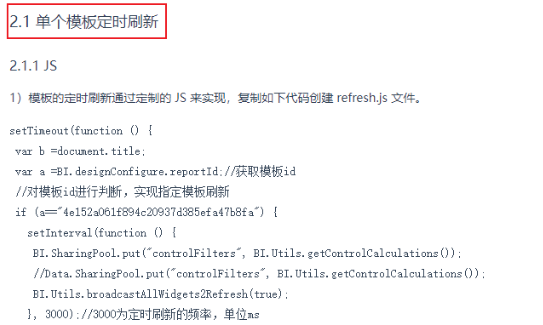
12.5 将整个图表进行定时刷新操作
修改文档: https://help.fanruan.com/finebi/edition-view-7007-10.html
主要看 2.1部分:
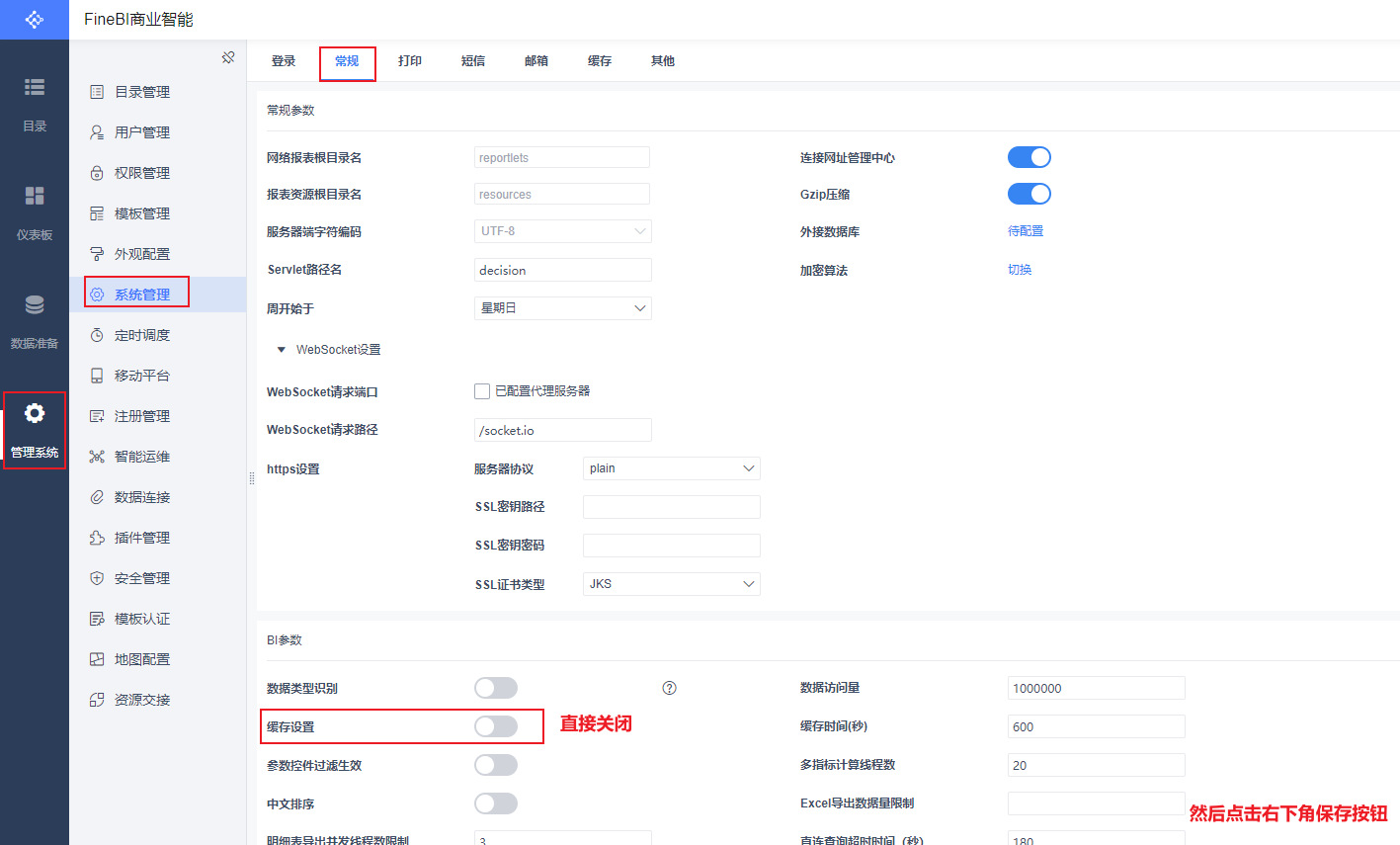
修改完成后, 还需要调整Fine BI 配置信息, 将缓存时间设置为0(默认finebi有一个缓存时间, 默认为5分钟, 如果是实时看板, 不需要有这个缓存的时间的)
验证是否每隔5s进行一次刷新操作:
通过F12 打开, 然后观察 network 网络服务, 是否为每隔5s 出现一次网络请求
或者 查看图表界面. 每隔一定时间, 就会重新加载一次
 微信
微信 支付宝
支付宝
