我们抓取,我们采集,我们分析,我们挖掘
ajax数据爬取
Ajax是什么
ajax(Asynchronous JavaScript and XML),简单说就是可以让网页局部刷新的技术,异步请求。
页面的url连接没有变化,但是网页中可以有新的内容刷新。
Ajax底层代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| var xmlhttp;
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open("POST", "/ajax/", true);
xmlhttp.send();
|
其实就是创建了XMLHttpRequest对象,并且设置监听,等待请求的响应,
拿到响应后,在onreadystatechange中解析
这就是Ajax请求的原理,而我们想要抓取这些数据,需要知道这些请求到底怎么发送的,发给什么服务器,传的参数是什么。知道了这些,就可以用python模拟javascript发送操作,获取到Ajax请求的响应结果。
Ajax分析方法
我们知道拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢?
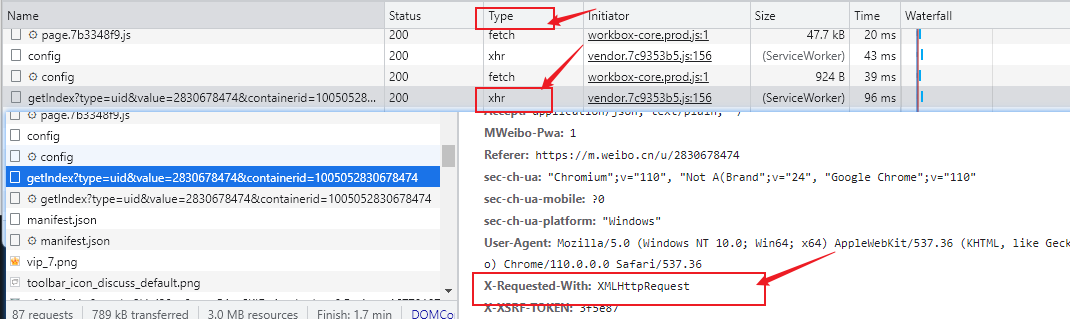
Ajax 其实有其特殊的请求类型,它叫作 xhr。在chrome开发者工具中我们可以发现一个名称以 getIndex 开头的请求,其 Type 为 xhr,这就是一个 Ajax 请求
在请求中可以看到 Request Headers 中有一个信息为 X-Requested-With:XMLHttpRequest,也表明是一个Ajax请求
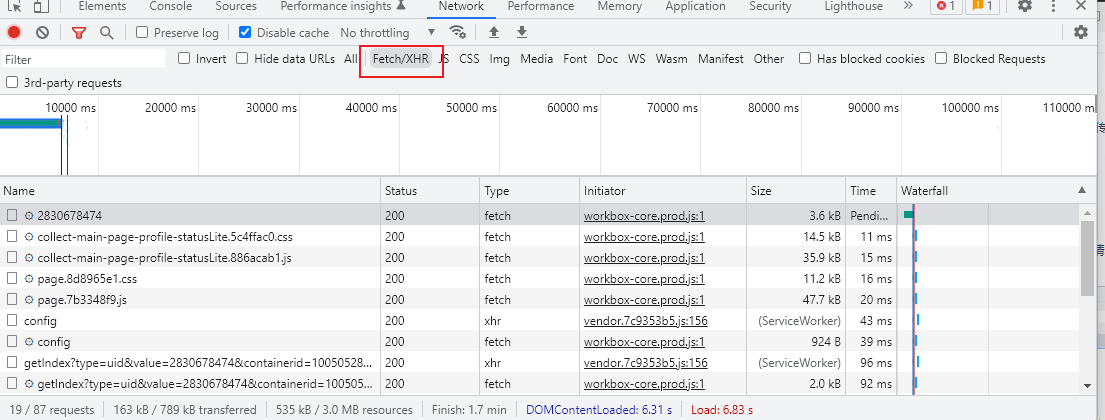
我们也可以通过点击Fetch/XHR,过滤Ajax请求
Ajax案例爬取实战
练习网站:https://spa1.scrape.center/,该示例网站的数据请求是通过Ajax完成的,内容通过JavaScript渲染的。
目标:将电影信息爬取下来,并且保存到MongoDB。
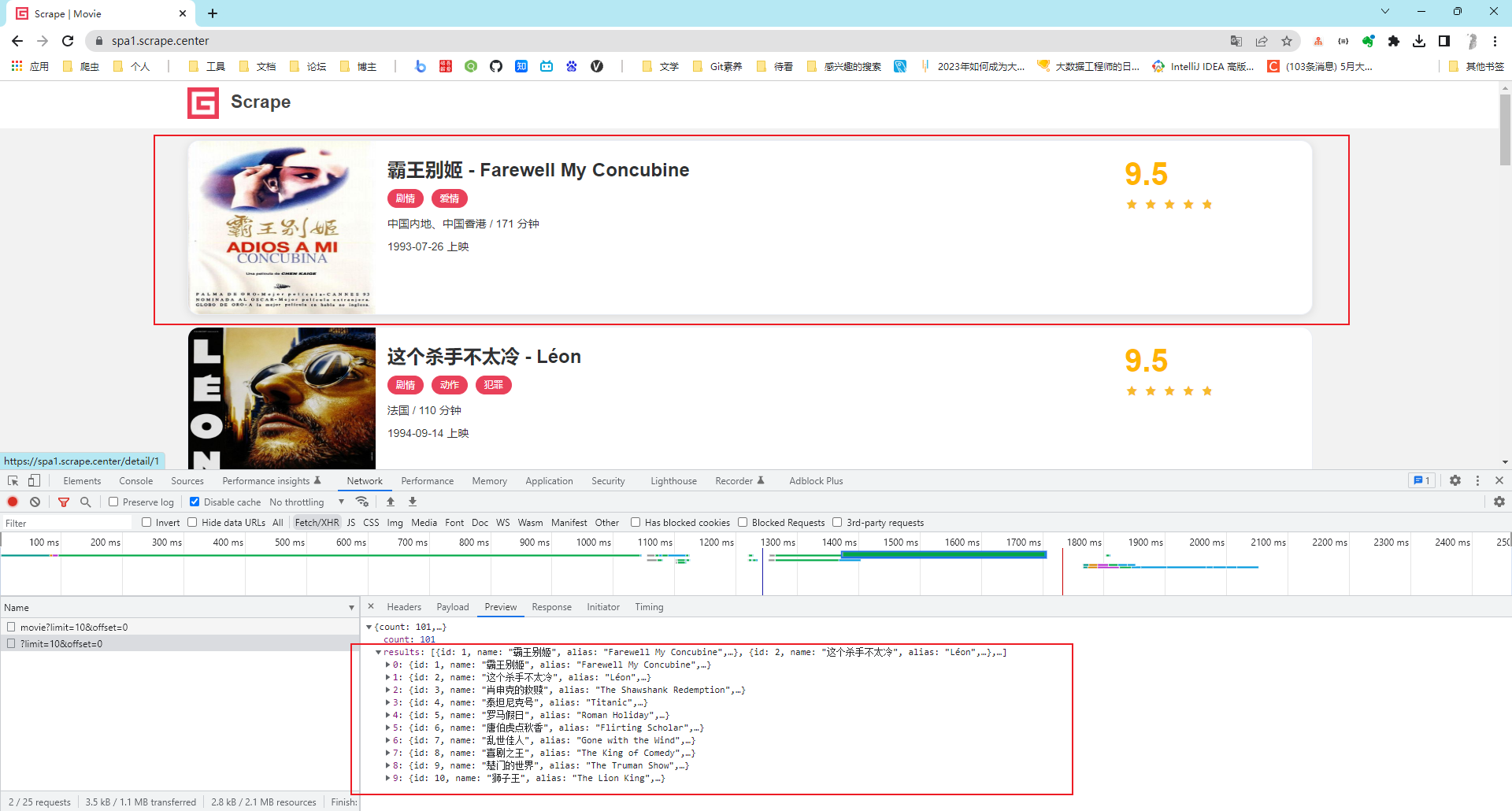
分析观察Ajax请求可以发现,渲染的请求为:https://spa1.scrape.center/api/movie/?limit=10&offset=40
其中,limit 一直为 10,这就正好对应着每页 10 条数据;offset 在依次变大,页面每加 1 页,offset 就加 10,这就代表着页面的数据偏移量。
响应的结果都是JSON数据。
我们还需要详情页的电影描述,也要记得爬取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
import logging
import requests
import pymongo
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://spa1.scrape.center/api/movie/?limit={limit}&offset={offset}'
DETAIL_URL = 'https://spa1.scrape.center/api/movie/{id}'
LIMIT = 10
TOTAL_PAGE = 10
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'movies'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movies']
collection = db['movies']
def scrape_api(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
def scrape_index(page):
url = INDEX_URL.format(limit=LIMIT, offset=LIMIT * (page - 1))
return scrape_api(url)
def scrape_detail(id):
url = DETAIL_URL.format(id=id)
return scrape_api(url)
def save_data(data):
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
def main():
for page in range(1, TOTAL_PAGE + 1):
index_data = scrape_index(page)
for item in index_data.get('results'):
id = item.get('id')
detail_data = scrape_detail(id)
logging.info('detail data %s', detail_data)
save_data(detail_data)
logging.info('data saved successfully')
if __name__ == '__main__':
main()
|
 微信
微信 支付宝
支付宝
