【微服务从入门到入土】验证码识别
我们抓取,我们采集,我们分析,我们挖掘
验证码
各类网站采用了各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形,后来加入了英文字母和混淆曲线。还有一些网站使用了中文字符验证码,这使得识别愈发困难。
12306 验证码的出现使得行为验证码开始发展起来,用过 12306 的用户肯定多少为它的验证码头疼过,我们需要识别文字,点击与文字描述相符的图片,验证码完全正确,验证才能通过。随着技术的发展,现在这种交互式验证码越来越多,如滑动验证码需要将对应的滑块拖动到指定位置才能完成验证,点选验证码则需要点击正确的图形或文字才能通过验证。
验证码变得越来越复杂,爬虫的工作也变得越发艰难,有时候我们必须通过验证码的验证才可以访问页面。
本章就针对验证码的识别进行统一讲解,涉及的验证码有普通图形验证码、滑动验证码、点选验证码、手机验证码等,这些验证码识别的方式和思路各有不同,有直接使用图像处理库完成的,有的则是借助于深度学习技术完成的,有的则是借助于一些工具和平台完成的。虽然说技术各有不同,但了解这些验证码的识别方式之后,我们可以举一反三,用类似的方法识别其他类型验证码。
使用 OCR 技术识别图形验证码
我们首先来看最简单的一种验证码,即图形验证码,这种验证码最早出现,现在依然也很常见,一般由 4 位左右字母或者数字组成。
例如这个案例网站 https://captcha7.scrape.center/ 就可以看到类似的验证码,如图所示:
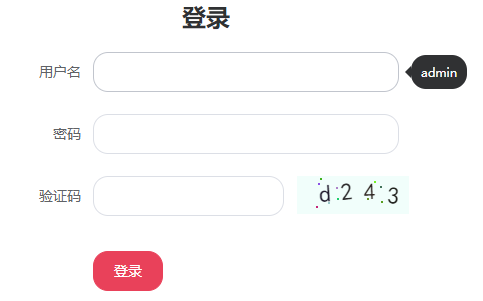
这类验证码整体上比较规整,没有过多干扰线和干扰点,且文字没有大幅度的变形和旋转。
对于这一类的验证码我们就可以使用 OCR 技术来进行识别
OCR 技术
OCR,即 Optical Character Recognition,中文翻译叫做光学字符识别。它是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。OCR 现在已经广泛应用于生产生活中,如文档识别、证件识别、字幕识别、文档检索等等。当然对于本节所述的图形验证码的识别也没有问题。
本节我们会以当前示例网站的验证码为例来讲解利用 OCR 来识别图形验证码的流程,输入上是一上图验证码的图片,输出就是验证码识别结果。
Tesserocr 技术
安装
Tesserocr 是 Python 的一个 OCR 识别库,但其实是对 Tesseract 做的一层 Python API 封装,所以它的核心是 Tesseract,所以在安装 Tesserocr 之前我们需要先安装 Tesseract,本节我们来了解下它们的安装方式。
下载:https://digi.bib.uni-mannheim.de/tesseract/ (文件名中带有 dev 的为开发版本,不带 dev 的为稳定版本)
点击安装,勾选Additional language data(download)可以识别多国语言
配置安装路径(
D:\tools\Tesseract-OCR)到环境变量PATH添加
TESSDATA_PREFIX,置为语言库安装路径(D:\tools\Tesseract-OCR\tessdata)
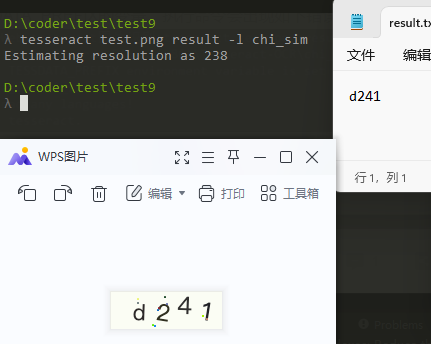
测试图片:tesseract test.png result -l chi_sim
- 从whl(https://github.com/simonflueckiger/tesserocr-windows_build/releases)下载和python版本匹配的包
- 安装镜像文件:
pip3 install D:\tesserocr-2.5.2-cp310-cp310-win_amd64.whl - 无效路径(invalid tessdata path),将语言库复制到python目录:
D:\tools\Python\Python310\tessdata
python测试代码
测试图片:
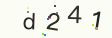
1 | import tesserocr |
安装依赖库
1 | pip3 install selenium pillow numpy retrying |
验证码处理
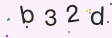
图片里面其实有一些杂乱的点,而这些点的颜色大都比文本更浅一点,因此我们可以做一些预处理,将干扰的点通过颜色来排除掉。
1 | from PIL import Image |
这个图片其实是一个三维数组,前两维 38 和 112 代表其高和宽,最后一维 4 则是每个像素点的表示向量。为什么是 4 呢,因为最后一维是一个长度为 4 的数组,分别代表 R(红色)、G(绿色)、B(蓝色)、A(透明度),即一个像素点有四个数字表示。那为什么是 RGBA 四个数字而不是 RGB 或其他呢?这是因为 image 的模式 mode 是 RGBA,即有透明通道的真彩色,我们看到第二行输出也印证了这一点。
模式 mode 定义了图像的类型和像素的位宽,一共有 9 种类型:
- 1:像素用 1 位表示,Python 中表示为 True 或 False,即二值化。
- L:像素用 8 位表示,取值 0-255,表示灰度图像,数字越小,颜色越黑。
- P:像素用 8 位表示,即调色板数据。
- RGB:像素用 3x8 位表示,即真彩色。
- RGBA:像素用 4x8 位表示,即有透明通道的真彩色。
- CMYK:像素用 4x8 位表示,即印刷四色模式。
- YCbCr:像素用 3x8 位表示,即彩色视频格式。
- I:像素用 32 位整型表示。
- F:像素用 32 位浮点型表示。
为了方便处理,我们可以将 RGBA 模式转为更简单的 L 模式,即灰度图像。
可以利用 Image 对象的 convert 方法参数传入 L,即可将图片转化为灰度图像,根据阈值筛选掉图片中的干扰点
1 | from PIL import Image |
处理的效果:

针对一些有干扰的图片,我们可以做一些去噪处理,这会提高图片识别的正确率。
OCR识别实战
1 | import time |
阈值建议重置的时候设置动态调整,有时候识别不出来。
使用 OpenCV 识别滑动验证码的缺口
上一节我们学习了利用 OCR 技术对图形验证码进行识别的方法,但随着互联网技术的发展,各种新型验证码层出不穷,最具有代表性的便是滑动验证码了。

想要用爬虫来自动化完成这一流程的话,关键步骤有:
- 识别出目标缺口的位置
- 将缺口滑动到对应位置
第二步的实现有多种方式,比如我们可以用 Selenium 等自动化工具模拟完成这个流程,验证并登录成功之后获取对应的 Cookies 或 Token 等信息再进行后续的操作,但这种方法运行效率会比较低。
另一种方法便是直接逆向验证码背后的 JavaScript 逻辑,将缺口信息直接传给 JavaScript 代码执行获取一些类似 “密钥” 的信息,再利用这些 “密钥” 进行下一步的操作。
第一步利用 OpenCV 进行基本的图像处理来实现的,主要步骤包括:
- 对验证码图片进行高斯模糊滤波处理,消除部分噪声干扰
- 对验证码图片应用边缘检测算法,通过调整相应阈值识别出滑块边缘
- 对上一步得到的各个边缘轮廓信息,通过对比面积、位置、周长等特征筛选出最可能的轮廓位置,得到缺口位置。
1 | # 安装库 |
高斯滤波
高斯滤波是用来去除图像中的一些噪声的,基本效果其实就是把一张图像变得模糊化,减少一些图像噪声干扰,从而为下一步的边缘检测做好铺垫。
OpenCV 提供了一个用于实现高斯模糊的方法,叫做 GaussianBlur,方法声明如下:
1 | def GaussianBlur(src, ksize, sigmaX, dst=None, sigmaY=None, borderType=None) |
比较重要的参数介绍如下:
- src:即需要被处理的图像。
- ksize:进行高斯滤波处理所用的高斯内核大小,它需要是一个元组,包含 x 和 y 两个维度。
- sigmaX:表示高斯核函数在 X 方向的的标准偏差。
- sigmaY:表示高斯核函数在 Y 方向的的标准偏差,若 sigmaY 为 0,就将它设为 sigmaX,如果 sigmaX 和 sigmaY 都是 0,那么 sigmaX 和 sigmaY 就通过 ksize 计算得出。
这里 ksize 和 sigmaX 是必传参数,对本节样例图片,ksize 我们可以取 (5, 5),sigmaX 可以取 0。
经过高斯滤波处理后,图像会变得模糊,效果如下:

边缘检测
由于验证码目标缺口通常具有比较明显的边缘,所以借助于一些边缘检测算法并通过调整阈值是可以找出它的位置的。目前应用比较广泛的边缘检测算法是 Canny,它是 John F. Canny 于 1986 年开发出来的一个多级边缘检测算法,效果还是不错的,OpenCV 也对此算法进行了实现,方法名称就叫做 Canny,声明如下:
1 | def Canny(image, threshold1, threshold2, edges=None, apertureSize=None, L2gradient=None) |
比较重要的参数介绍如下:
- image:即需要被处理的图像。
- threshold1、threshold2:两个阈值,分别为最小和最大判定临界点。
- apertureSize:用于查找图像渐变的 Sobel 内核的大小。
- L2gradient:指定用于查找梯度幅度的等式。
通常来说,我们只需要设定 threshold1 和 threshold2 即可,其数值大小需要视不同图像而定,比如本节样例图片可以分别取 200 和 450。
经过边缘检测算法处理后,一些比较明显的边缘信息会被保留下来,效果如下:
轮廓提取
进行边缘检测处理后,我们可以看到图像中会保留有比较明显的边缘信息,下一步我们可以用 OpenCV 将边缘轮廓提取出来,这里需要用到 findContours 方法,方法声明如下:
1 | def findContours(image, mode, method, contours=None, hierarchy=None, offset=None) |
比较重要的参数介绍如下:
- image:即需要被处理的图像。
- mode:定义轮廓的检索模式,详情见 OpenCV 的 RetrievalModes 的介绍。
- method:定义轮廓的近似方法,详情见 OpenCV 的 ContourApproximationModes 的介绍。
在这里,我们选取 mode 为 RETR_CCOMP,method 为 CHAIN_APPROX_SIMPLE,具体的选型标准可以参考 OpenCV 的文档介绍,这里不再展开讲解。
外接矩形
提取到轮廓之后,为了方便进行判定,我们可以将轮廓的外界矩形计算出来,这样方便我们根据面积、位置、周长等参数进行判定,以得出该轮廓是不是目标滑块的轮廓。
计算外接矩形使用的方法是 boundingRect,方法声明如下:
1 | def boundingRect(array) |
只有一个参数:
- array:可以是一个灰度图或者 2D 点集,这里可以传入轮廓信息。
经过轮廓信息和外接矩形判定之后,我们可以得到类似如下结果:
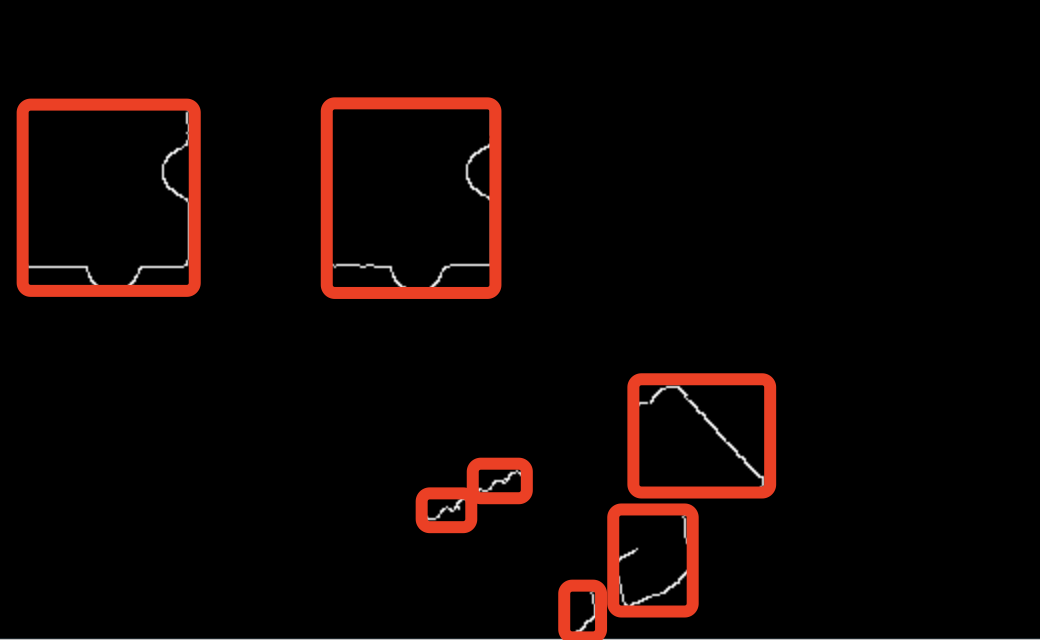
可以看到这样就能成功获取各个轮廓的外接矩形,接下来我们根据外接矩形的面积、和位置就能筛选出缺口对应的位置了。
轮廓面积
现在已经得到了各个外接矩形,但是很明显有些矩形不是我们想要的,我们可以根据面积、周长等来进行筛选,这里就需要用到计算面积的方法,叫做 contourArea,方法定义如下:
1 | def contourArea(contour, oriented=None) |
参数介绍如下:
- contour:轮廓信息。
- oriented:面向区域标识符。有默认值 False。若为 True,该函数返回一个带符号的面积值,正负取决于轮廓的方向(顺时针还是逆时针)。若为 False,表示以绝对值返回。
返回结果就是轮廓的面积。
轮廓周长
同样,周长的计算也有对应的方法,叫做 arcLength,方法定义如下:
1 | def arcLength(curve, closed) |
参数介绍如下:
- curve:轮廓信息。
- closed:表示轮廓是否封闭。
返回结果就是轮廓的周长。
以上内容介绍了一些 OpenCV 内置方法,了解了这些方法的用法,我们可以对下文的具体实现有更透彻的理解。
缺口识别
接下来我们就开始真正实现一下缺口识别算法了。
首先我们定义高斯滤波、边缘检测、轮廓提取的三个方法,实现如下:
1 | import cv2 |
三个方法介绍如下:
- get_gaussian_blur_image:传入待处理图像信息,返回高斯滤波处理后的图像,ksize 定义为
(5, 5),sigmaX 定义为 0。 - get_canny_image:传入待处理图像信息,返回边缘检测处理后的图像,threshold1 和 threshold2 分别定义为 200 和 450。
- get_contours:传入待处理图像信息,返回检测到的轮廓信息,这里 mode 设定为 RETR_CCOMP,method 设定为 CHAIN_APPROX_SIMPLE。
原始待识别验证码命名为 captcha.png,接下来我们分别调用以上方法对验证码进行处理:
1 | image_raw = cv2.imread('captcha.png') |
原始图片我们命名为 image_raw 变量,读取图片之后获取其宽高像素信息,接着调用了 get_gaussian_blur_image 方法进行高斯滤波处理,返回结果命名为 image_gaussian_blur,接着将 image_gaussian_blur 传给 get_canny_image 方法进行边缘检测处理,返回结果命名为 image_canny,接着调用 get_contours 方法得到各个边缘的轮廓信息,赋值为 contours 变量。
好,得到各个轮廓信息之后,我们便需要根据各个轮廓的外接矩形的面积、周长、位置来筛选我们想要结果了。
所以,我们需要先确定怎么来筛选,比如面积我们可以设定一个范围,周长设定一个范围,缺口位置设定一个范围,通过实际测量,我们可以得出目标缺口的外接矩形的高度大约是验证码高度的 0.25 倍,宽度大约是验证码宽度的 0.15 倍。在允许误差 20% 的情况下,根据验证码的宽高信息我们大约可以计算出面积、周长的范围,同时缺口位置(缺口左侧)也有一个最小偏移值,比如最小偏移是验证码宽度的 0.2 倍,最大偏移是验证码宽度的 0.85 倍。综合这些内容,我们可以定义三个阈值方法:
1 | def get_contour_area_threshold(image_width, image_height): |
三个方法介绍如下:
- get_contour_area_threshold:定义目标轮廓的下限和上限面积,分别为 contour_area_min 和 contour_area_max。
- get_arc_length_threshold:定义目标轮廓的下限和上限周长,分别为 arc_length_min 和 arc_length_max。
- get_offset_threshold:定义目标轮廓左侧的下限和上限偏移量,分别为 offset_min 和 offset_max。
最后我们只需要遍历各个轮廓信息,根据上述限定条件进行筛选,最后得出目标轮廓信息即可,实现如下:
1 | contour_area_min, contour_area_max = get_contour_area_threshold(image_width, image_height) |
这里我们首先调用了 get_contour_area_threshold、get_arc_length_threshold、get_offset_threshold 方法获取了轮廓的判定阈值,然后遍历了 contours 根据这些阈值进行了筛选,最终得到的外接矩形的 x 值就是目标缺口的偏移量。
同时目标缺口的外接矩形我们也调用了 rectangle 方法进行了标注,最终将其保存为 image_label.png 图像。
最终运行结果如下:
1 | offset 163 |
同时得到输出的 image_label.png 文件如下:

这样我们就成功提取出来了目标滑块的位置了,本节的问题得以解决。
注意:出于安全考虑,本书只针对于第一步 - 识别验证码缺口位置的的技术问题进行讲解,关于怎样去模拟滑动或者绕过验证码,本书不再进行介绍,可以自行搜索相关资料探索。
本节我们介绍了利用 OpenCV 来识别滑动验证码缺口的方法,其中涉及到了一些关键的图像处理和识别技术,如高斯模糊、边缘检测、轮廓提取等算法。了解了基本的图像识别技术后,我们可以举一反三,将其应用到其他类型的工作上,也会很有帮助。
使用 深度学习 识别图片验证码
我们验证了OpenCV 识别了图形验证码,深度学习不是对图像识别很准吗?那深度学习可以用在识别滑动验证码缺口位置吗?当然也是可以的
准备工作
同样地,本节还是主要侧重于完成利用深度学习模型来识别验证码缺口的过程,所以不会侧重于讲解深度学习模型的算法,另外由于整个模型实现较为复杂,本节也不会从零开始编写代码,而是倾向于把代码提前下载下来进行实操练习。
所以在最后,请提前代码下载下来,仓库地址为:https://github.com/Python3WebSpider/DeepLearningSlideCaptcha2,利用 Git 把它克隆下来:
1 | git clone https://github.com/Python3WebSpider/DeepLearningSlideCaptcha2.git |
安装必要的依赖库:
1 | pip3 install numpy torch>=1.0 torchvision matplotlib tensorflow==2.8.0 tensorboard terminaltables pillow tqdm |
推荐一个方便的日志模块:pip3 install loguru
目标检测
识别滑动验证码缺口的这个问题,其实可以归结为目标检测问题。那什么叫目标检测呢?在这里简单作下介绍。
目标检测,顾名思义,就是把我们想找的东西找出来。比如给一张「狗」的图片,如图所示:

我们想知道这只狗在哪,它的舌头在哪,找到了就把它们框选出来,这就是目标检测。
经过目标检测算法处理之后,我们期望得到的图片是这样的:

可以看到这只狗和它的舌头就被框选出来了,这就完成了一个不错的目标检测。
现在比较流行的目标检测算法有 R-CNN、Fast R-CNN、Faster R-CNN、SSD、YOLO 等,感兴趣可以了解一下,当然不太了解对本节要完成的目标也没有什么影响。
当前做目标检测的算法主要有两种方法,有一阶段式和两阶段式,英文叫做 One stage 和 Two stage,简述如下:
- Two Stage:算法首先生成一系列目标所在位置的候选框,然后再对这些框选出来的结果进行样本分类,即先找出来在哪,然后再分出来是啥,俗话说叫「看两眼」,这种算法有 R-CNN、Fast R-CNN、Faster R-CNN 等,这些算法架构相对复杂,但准确率上有优势。
- One Stage:不需要产生候选框,直接将目标定位和分类的问题转化为回归问题,俗话说叫「看一眼」,这种算法有 YOLO、SSD,这些算法虽然准确率上不及 Two stage,但架构相对简单,检测速度更快。
所以这次我们选用 One Stage 的有代表性的目标检测算法 YOLO 来实现滑动验证码缺口的识别。
YOLO,英文全称叫做 You Only Look Once,取了它们的首字母就构成了算法名,
目前 YOLO 算法最新的版本是 V5 版本,应用比较广泛的是 V3 版本,这里算法的具体流程我们就不过多介绍了,感兴趣的可以搜一下相关资料了解下,另外也可以了解下 YOLO V1-V3 版本的不同和改进之处,这里列几个参考链接:
- YOLO V3 论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
- YOLO V3 介绍:https://zhuanlan.zhihu.com/p/34997279
- YOLO V1-V3 对比介绍:https://www.cnblogs.com/makefile/p/yolov3.html
数据准备
像上一节介绍的一样,要训练深度学习模型也需要准备训练数据,数据也是分为两部分,一部分是验证码图像,另一部分是数据标注,即缺口的位置。但和上一节不一样的是,这次标注不再是单纯的验证码文本了,因为这次我们需要表示的是缺口的位置,缺口对应的是一个矩形框,要表示一个矩形框,至少需要四个数据,如左上角点的横纵坐标 x、y,矩形的宽高 w、h,所以标注数据就变成了四个数字。
所以,接下来我们就需要准备一些验证码图片和对应的四位数字的标注了,比如下图的滑动验证码:

好,那接下来我们就完成这两步吧,第一步就是收集验证码图片,第二步就是标注缺口的位置并转为我们想要的四位数字。
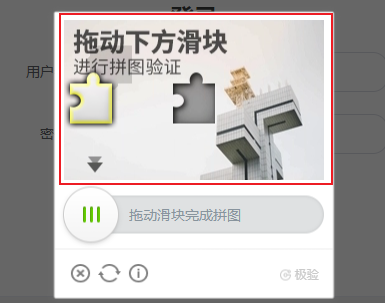
在这里我们的示例网站是 https://captcha1.scrape.center/,打开之后点击登录按钮便会弹出一个滑动验证码,如图所示:
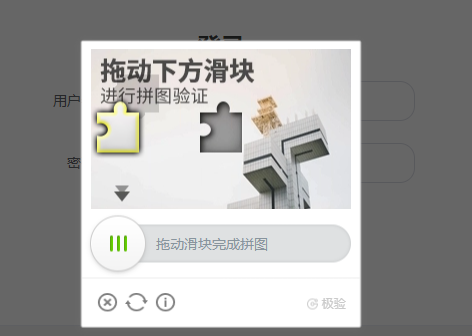
我们需要做的就是单独将滑动验证码的图像保存下来,也就是这个区域:
怎么做呢?靠手工截图肯定不太可靠,费时费力,而且不好准确定位边界,会导致存下来的图片有大有小。为了解决这个问题,我们可以简单写一个脚本来实现下自动化裁切和保存,就是仓库中的 collect.py 文件,代码如下:
1 | from selenium import webdriver |
在这里我们先定义了一个循环,循环次数为 COUNT 次,每次循环都使用 Selenium 启动一个浏览器,然后打开目标网站,模拟点击登录按钮触发验证码弹出,然后截取验证码对应的节点,再用 screenshot 方法将其保存下来。
我们将其运行:
1 | python3 collect.py |
运行完了之后我们就可以在 data/captcha/images/ 目录获得很多验证码图片了,样例如图所示:

获得验证码图片之后,我们就需要进行数据标注了,这里推荐的工具是 labelImg,GitHub 地址为 https://github.com/tzutalin/labelImg,使用 pip3 安装即可:
1 | pip3 install labelImg |
安装完成之后可以直接命令行运行:
1 | labelImg |
这样就成功启动了 labelImg:

点击 Open Dir 打开 data/captcha/images/ 目录,然后点击左下角的 Create RectBox 创建一个标注框,我们可以将缺口所在的矩形框框选出来,框选完毕之后 labelImg 就会提示保存一个名称,我们将其命名为 target,然后点击 OK,如图所示:

这时候我们可以发现其保存了一个 xml 文件,内容如下:
1 | <annotation> |
其中可以看到 size 节点里有三个节点,分别是 width、height、depth,分别代表原验证码图片的宽度、高度、通道数。另外 object 节点下的 bndbox 节点就包含了标注缺口的位置,通过观察对比可以知道 xmin、ymin 指的就是左上角的坐标,xmax、ymax 指的就是右下角的坐标。
我们可以用下面的方法简单进行下数据处理:
1 | import xmltodict |
这里我们定义了一个 parse_xml 方法,这个方法首先读取了 xml 文件,然后使用 xmltodict 库就可以将 XML 字符串转为 JSON,然后依次读取出验证码的宽高信息,缺口的位置信息,最后返回了想要的数据格式 —— 缺口左上角的坐标和宽高相对值,以元组的形式返回。
都标注完成之后,对每个 xml 文件调用此方法便可以生成想要的标注结果了。
在这里,我已经将对应的标注结果都处理好了,可以直接使用,路径为 data/captcha/labels,如图所示:

每个 txt 文件对应一张验证码图的标注结果,内容类似如下:
1 | 0 0.6153846153846154 0.275 0.16596774 0.24170968 |
第一位 0 代表标注目标的索引,由于我们只需要检测一个缺口,所以索引就是 0;第 2、3 位代表缺口的左上角的位置,比如 0.615 则代表缺口左上角的横坐标在相对验证码的 61.5% 处,乘以验证码的宽度 520,结果大约就是 320,即左上角偏移值是 320 像素;第 4、5 代表缺口的宽高相对验证码图片的占比,比如第 5 位 0.24 乘以验证码的高度 320,结果大约是 77,即缺口的高度大约为 77 像素。
好了,到此为止数据准备阶段就完成了。
训练
为了更好的训练效果,我们还需要下载一些预训练模型。预训练的意思就是已经有一个提前训练过的基础模型了,我们可以直接使用提前训练好的模型里面的权重文件,我们就不用从零开始训练了,只需要基于之前的模型进行微调就好了,这样既可以节省训练时间,又可以有比较好的效果。
YOLOV3 的训练要加载预训练模型才能有不错的训练效果,预训练模型下载命令如下:
1 | bash prepare.sh |
注意:在 Windows 下请使用 Bash 命令行工具如 Git Bash 来运行此命令。
执行这个脚本,就能下载 YOLO V3 模型的一些权重文件,包括 yolov3 和 weights 还有 darknet 的 weights,在训练之前我们需要用这些权重文件初始化 YOLO V3 模型。
接下来就可以开始训练了,执行如下脚本:
1 | bash train.sh |
注意:在 Windows 下请同样使用 Bash 命令行工具如 Git Bash 来运行此命令。
同样推荐使用 GPU 进行训练,训练过程中我们可以使用 TensorBoard 来看看 loss 和 mAP 的变化,运行 TensorBoard:
1 | tensorboard --logdir='logs' --port=6006 --host 0.0.0.0 |
注意:请确保已经正确安装了本项目的所有依赖库,其中就包括 TensorBoard,安装成功之后便可以使用 tensorboard 命令。
运行此命令后可以在 http://localhost:6006 观察到训练过程中的 loss 变化。
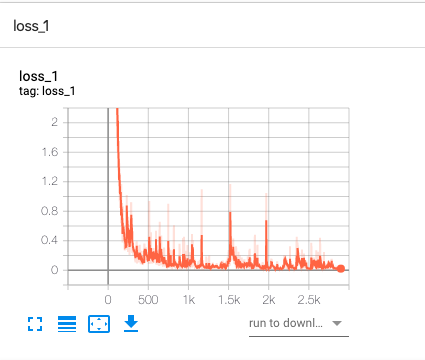
loss_1 变化类似如下:
val_mAP 变化类似如下:
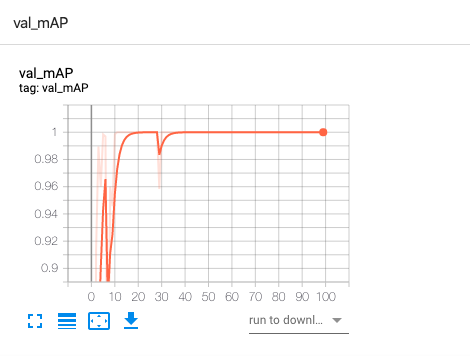
可以看到 loss 从最初的非常高下降到了很低,准确率也逐渐接近 100%。
这是训练过程中的命令行的一些输出结果:
1 | ---- [Epoch 99/100, Batch 27/29] ---- |
这里显示了训练过程中各个指标的变化情况,如 loss、recall、precision、confidence 等,分别代表训练过程的损失(越小越好)、召回率(能识别出的结果占应该识别出结果的比例,越高越好)、精确率(识别出的结果中正确的比率,越高越好)、置信度(模型有把握识别对的概率,越高越好),可以作为参考。
测试
训练完毕之后会在 checkpoints 文件夹生成 pth 文件,这就是一些模型文件,和上一节的 best_model.pkl 是一样的原理,只不过表示形式略有不同,我们可直接使用这些模型来预测生成标注结果。
要运行测试,我们可以先在测试文件夹 data/captcha/test 放入一些验证码图片:
样例验证码如下:

要运行测试,执行如下脚本:
1 | bash detect.sh |
该脚本会读取测试文件夹所有图片,并将处理后的结果输出到 data/captcha/result 文件夹,控制台输出了一些验证码的识别结果。
同时在 data/captcha/result 生成了标注的结果,样例如下:

可以看到,缺口就被准确识别出来了。
实际上,detect.sh 是执行了 detect.py 文件,在代码中有一个关键的输出结果如下:
1 | bbox = patches.Rectangle((x1 + box_w / 2, y1 + box_h / 2), box_w, box_h, linewidth=2, edgecolor=color, facecolor="none") |
这里 bbox 指的就是最终缺口的轮廓位置,同时 x1 就是指的轮廓最左侧距离整个验证码最左侧的横向偏移量,即 offset。通过这两个信息,我们就能得到缺口的关键位置了。
有了目标滑块位置之后,我们便可以进行一些模拟滑动操作从而实现通过验证码的检测了。
总结
本节主要介绍了训练深度学习模型来识别滑动验证码缺口的整体流程,最终我们成功实现了模型训练过程,并得到了一个深度学习模型文件。
利用这个模型,我们可以输入一张滑动验证码,模型便会预测出其中的缺口的位置,包括偏移量、宽度等,最后可以通过缺口的信息绘制出对应的位置。
当然本节介绍的内容也可以进一步优化:
- 当前模型的预测过程是通过命令行执行的,但在实际使用的时候可能并不太方便,可以考虑将预测过程对接 API 服务器暴露出来,比如对接 Flask、Django、FastAPI 等把预测过程实现为一个支持 POST 请求的接口,接口可以接收一张验证码图片,返回验证码的文本信息,这样会使得模型更加方便易用。
使用 打码平台 识别验证码
前面ORC、OpenCV 是识别率不高,深度学习效果不错,但是训练维护模型流程相对复杂。
更简单的:用打码平台,轻松识别各种各样的验证码、图形验证码、滑动验证码、点选验证码和逻辑推理验证码等。
平台用起来方便,给接口传图片,返回结果直接用就行。(背后是算法模型,甚至人工打码在支持)
超级鹰
从这里下载demo,https://www.chaojiying.com/api-14.html
价格体系可以看识别类型和价格:https://www.chaojiying.com/price.html
手机验证码 自动化处理
前面的基本是PC上出现图形,然后要求输入验证码,如果是要求输入手机验证码,又该怎么办?
验证码收发
通常来说,我们的自动化脚本会运行在 PC 上,比如打开一个网页,然后模拟输入手机号,然后点击获取验证码,接下来就需要输入验证码了。打开页面,输入手机号、点击获取验证码等流程我们可以非常容易地实现自动化,但是验证码被发送到手机上了,我们怎么能把它转到 PC 上呢?
为了自动化整个验证码收发的流程,这时候我们想要完成的就是 —— 当手机收到一条短信的时候,它能够自动将短信转发到某处,比如一台远程服务器上或者直接发到 PC 上,在 PC 上我们可以通过一些方法再把短信获取下来并提取验证码的内容,然后自动化填充验证码即可。
那这里关键的部分其实就是怎样完成这两个步骤:
- 如何监听手机收到了短信
- 如何将手机短信转发到想要的位置
这两个步骤缺一不可,而且都需要在手机上完成。
解决思路自然很简单了,我们以 Android 手机为例,如果有 Android 开发经验的话,其实这两个功能实现起来还是蛮简单的。
注意:这里我们仅仅简单介绍基本的思路,不会完全详细展开介绍具体的代码实现,感兴趣的话可以自行尝试。
首先如何监听手机收到了短信呢?
在 Android 开发中,整体就分为三个必要环节:
- 注册读取短信的权限:在一个 Android App 中,读取短信是需要特定的权限的,所以我们需要在 Andriod App 的 AndroidManifest.xml 中将读取短信的权限配置好,比如接收短信的权限配置如下:
1 | <uses-permission android:name="android.permission.RECEIVE_SMS"></uses-permission> |
- 注册广播事件:Android 有一个基本组件叫做 BroadcastReceiver,也就是广播接收者的意思,我们可以用它来监听来自系统的各种事件广播,比如系统电量不足的广播、系统来电的广播,当然系统收到短信的广播也就不在话下了。所以这就类似我们注册一个监听器,用来监听系统收到短信的事件。
比如这里我们可以同样在 AndroidManifest.xml 里面注册一个 BroadcastReceiver,叫做 SmsReciver:
1 | <receiver android:name=".receive.SmsReciver"> |
- 实现短信广播接收:这里就需要我们真正实现短信接收的逻辑了,这里只需要实现一个 SmsReceiver 类来继承一个 BroadcastReceiver 然后实现其 onReceive 方法即可,其中 intent 参数里面便包含了我们想要的短信息内容,实现如下:
1 | public class SmsReciver extends BroadcastReceiver { |
如此一来,我们便实现了短信的接收。
短信收到之后,发送自然也就很简单了,比如服务器提供一个 API,我们通过请求该 API 即可实现数据的发送,这个通过 Android 的一些 HTTP 请求库就可以实现,比如 OkHttp 等构造一个 HTTP 请求即可,这里就不再赘述了。
不过总的来说,整个流程下来其实还需要花费一些开发成本的,对于如此常用的功能,有没有现成的解决方案呢?自然是有的。我们可以借助于于一些开源实现,我们就没必要重复造轮子了。
这里我们就介绍一个开源软件,叫做 SmsForwarder,中文翻译过来叫做短信转发器,其 GitHub 仓库地址为:https://github.com/pppscn/SmsForwarder。
它的基本流程架构图如下:

架构图非常清晰,SmsForwarder 可以监听监听收到短信的事件,获取到短信的来源号码、接受卡槽、短信内容、接收时间等内容,然后将其通过一定的规则转发出去,支持转发到邮箱、微信群机器人、企业微信、Telegram 机器人、Webhook 等。
比如我们可以配置类似这样的规则,如图所示:

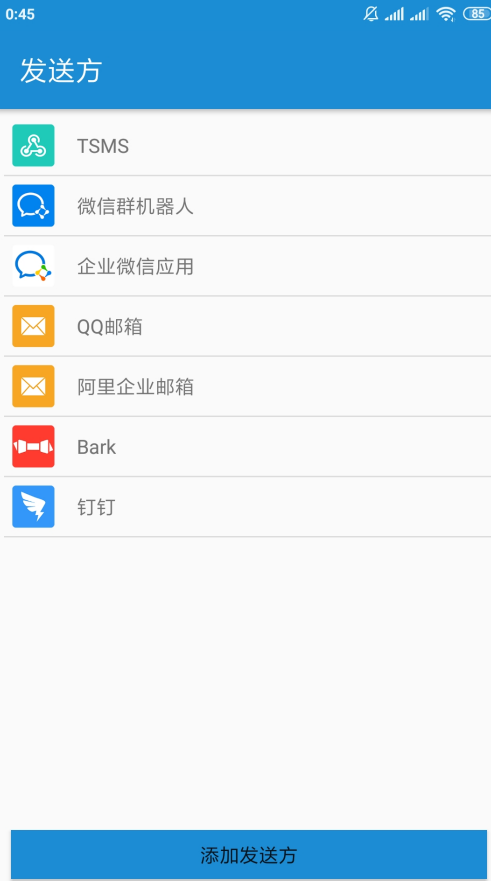
比如当手机号符合一定的规则就转发到 QQ 邮箱,比如内容包含 “报警” 就转发到阿里企业邮箱,比如内容开头是 “测试” 就发动给叫做 TSMS 的 Webhook。
其中 QQ 邮箱、阿里企业邮箱都是我们已经配置好的发送方,都属于邮箱类型,TSMS 也是一种发送方,属于 Webhook 类型,如图所示:
我们也可以点击添加发送方按钮来添加对应的发送方,比如添加邮箱的发送方,我们可以设置 SMTP 配置下发件邮箱、SMTP 服务器、SMTP 端口、授权密码等内容:
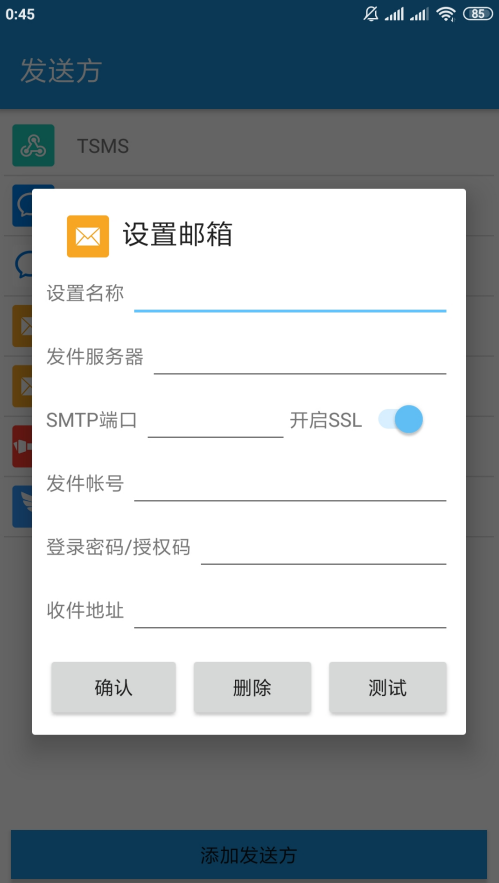
设置 Webhook 我们可以选择是 GET 还是 POST 请求,然后填入对应的 URL、密钥等内容:

设置转发规则页面如图所示:

比如这里我们可以选择匹配卡槽、匹配的字段、匹配的模式,还可以配置正则来设置匹配的值,这里就配置了尾号是 4566 的手机号来执行一定的发送操作,收到的短信会发送到钉钉这个发送方。
实战演示
比如这里我们来尝试下,这里我们用 Flask 写一个 API,实现如下:
1 | from flask import Flask, request, jsonify |
代码很简单,这里设置了一个路由,接收 POST 请求,然后读取了 Request 表单的内容,其中 content 就是短信的详情内容,然后将其打印出来。
我们将代码保存为 server.py,然后将其运行起来:
1 | python3 server.py |
运行结果输出如下:
1 | * Debug mode: on |
为了方便测试,我们可以用 Ngrok 将该服务暴露到公网:
1 | ngrok http 5000 |
注意:Ngrok 可以方便地将任何非公网的服务暴露到公网访问,并配置特定的临时二级域名,但一个域名有时长限制,所以通常仅供测试使用。试用前请先安装 Ngrok,具体可以参考 https://ngrok.com/。
运行之后,可以看到输入结果如下:
1 | Session Status online |
这里我们可以看到 Ngrok 为我们配置了一个公网地址,比如访问 https://1259539cb974.ngrok.io 即相当于访问了我们本地的 http://localhost:5000 服务,这样手机上只需要配置这个地址即可将数据发送到 PC 了。
接下来我们手机上打开 SmsForder,添加一个 Webhook 类型的发送方,配置如下:
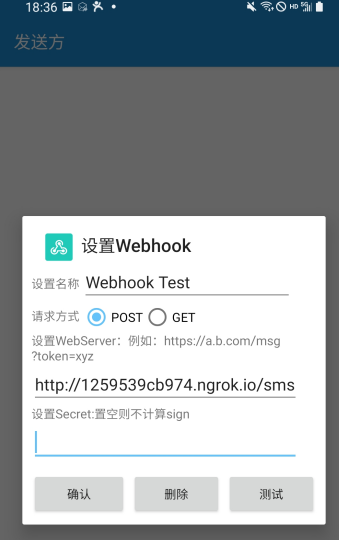
这里 Server 的地址我们就直接设置了刚才 Ngrok 提供的公网地址了,记得 URL 路径后面加上 sms。
接着我们添加一个转发规则:
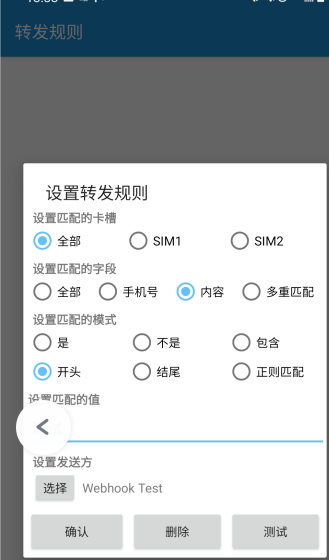
这里我们设置了内容匹配规则,比如匹配到内容开头为测试的时候,那就将短信内容转发到 Webhook 这个发送方,即发送到我们刚刚搭建的 Flask 服务器上。
OK,配置完成之后,然后我们给该手机尝试发送一个验证码,内容如下:
1 | 测试验证码593722,一分钟有效。 |
这时候就可以发现刚才的 Flask 服务器接收结果是这样的:
1 | received +8617xxxxxxxx |
可以看到刚才验证码的内容就成功由手机发送到 PC 了,接着我们便可以对此消息进行解析和处理,然后存入数据库或者消息队列即可。爬虫一端监听消息队列或者数据库改动即可将其填写并进行一些模拟登录操作了,该步骤就不再赘述了。
批量收发
当然以上只针对于一部手机的情况,如果我们有大量的手机和手机卡,我们可以实现手机的群控处理,比如统一安装短信接收软件,统一配置相同的转发规则,从而实现大量手机号验证码的接收和处理。
比如一个群控系统就是这样的:
卡池
当然还有更专业的解决方案,比如有专业的手机卡池,配合以专业的软件设备实现短信的监听。
比如如下的设备支持插 128 张 SIM 卡,就可以实现同时监听 128 个手机号的验证码,如图所示:
图片缺失!
具体的技术这里不再阐述,详细可以自行查询相关的设备供应商。
接码平台
当然如上的方案成本还是比较高的,而且这些方案其实已经不限于简单接收短信验证码了,比如手机群控系统一般都会做手机群控爬虫,而卡池也可以用来做 4G/5G 蜂窝代理,如果仅仅做短信收发是可以的,但未免有些浪费了。
如果我们不想耗费过多成本想实现短信验证码的自动化,还有一种方案就是接码平台,其基本思路是这样的:
- 平台会维护大量的手机号,并可能开放一些 API 或者提供网页供我们调用来获取手机号和查看短信的内容。
- 我们调用 API 或者爬取网页获取手机号,然后在对应的站点输入该手机号来获取验证码。
- 通过调用 API 或者爬取网页获取对应手机号短信的内容,并交由爬虫处理。
具体的操作步骤这里就不再详细阐述了,这里简单列几个接码平台:
- 番薯云:https://guanfangdiping.com/
- 云际云短信:https://yunjisms.xyz/
- 接码号:https://jiemahao.com/
- KaKa 接码:http://www.kakasms.com/
由于接码平台管控比较严格,所以可能随时不可用,请自行搜集对应的平台进行使用
 微信
微信 支付宝
支付宝

