我们抓取,我们采集,我们分析,我们挖掘
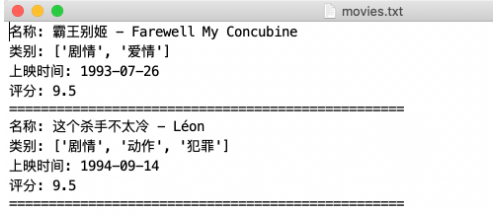
爬虫数据存储 保存为TXT 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import requestsfrom pyquery import PyQuery as pqimport reurl = 'https://ssr1.scrape.center/' html = requests.get(url).text doc = pq(html) items = doc('.el-card' ).items() file = open ('movies.txt' , 'w' , encoding='utf-8' ) for item in items: name = item.find('a > h2' ).text() file.write(f'名称: {name} \n' ) categories = [item.text() for item in item.find('.categories button span' ).items()] file.write(f'类别: {categories} \n' ) published_at = item.find('.info:contains(上映)' ).text() published_at = re.search('(\d{4}-\d{2}-\d{2})' , published_at).group(1 ) \ if published_at and re.search('\d{4}-\d{2}-\d{2}' , published_at) else None file.write(f'上映时间: {published_at} \n' ) score = item.find('p.score' ).text() file.write(f'评分: {score} \n' ) file.write(f'{"=" * 50 } \n' ) file.close()
效果:
文件打开方式
r:以只读方式打开文件,意思就是只能读取文件内容,不能写入文件内容。这是默认模式。
rb:以二进制只读方式打开一个文件,通常用于打开二进制文件,比如音频、图片、视频等等。
r+:以读写方式打开一个文件,既可以读文件又可以写文件。
rb+:以二进制读写方式打开一个文件,同样既可以读又可以写,但读取和写入的都是二进制数据。
w :以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。wb :以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件来读写。
ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件用于读写。
with as 优雅写法
在 with 控制块结束时,文件会自动关闭,所以就不需要再调用 close 方法了。
1 2 3 4 5 with open ('movies.txt' , 'w' , encoding='utf-8' ): file.write(f'名称: {name} \n' ) file.write(f'类别: {categories} \n' ) file.write(f'上映时间: {published_at} \n' ) file.write(f'评分: {score} \n' )
保存为JSON JavaScript中JSON有2种格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 {key1:value1, key2:value2, ...} ["java", "javascript", "vb", ...] 举例: [ { name: "Bob", gender: "male", birthday: "1992-10-18", }, { name: "Selina", gender: "female", birthday: "1995-10-18", }, ];
JSON可以由以上2种形式自由组合,结果清晰,是数据交换的极佳方式。
读取JSON Python 为我们提供了简单易用的 JSON 库来实现 JSON 文件的读写操作,
我们可以调用 JSON 库的 loads 方法将 JSON 文本字符串转为 JSON 对象
另外我们还可以通过 dumps 方法将 JSON 对象转为文本字符串。
例如,这里有一段 JSON 形式的字符串,它是 str 类型,我们用 Python 将其转换为可操作的数据结构,如列表或字典:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import jsonwith open ('data.json' , encoding='utf-8' ) as file: str = file.read() data = json.loads(str ) print (data) data = json.load(open ('data.json' , encoding='utf-8' )) str = ''' [{ "name": "Bob", "gender": "male", "birthday": "1992-10-18" }, { "name": "Selina", "gender": "female", "birthday": "1995-10-18" }] ''' print (type (str )) data = json.loads(str ) print (data) print (type (data)) data[0 ]['name' ] data[0 ].get('name' ) data[0 ].get('age' , 25 )
输出JSON 另外,我们还可以调用 dumps 方法将 JSON 对象转化为字符串。例如,将上例中的列表重新写入文本:
1 2 3 4 5 6 7 8 9 10 11 import jsondata = [{ 'name' : 'Bob' , 'gender' : 'male' , 'birthday' : '1992-10-18' }] with open ('data.json' , 'w' , encoding='utf-8' ) as file: file.write(json.dumps(data)) file.write(json.dumps(data, indent=2 )) file.write(json.dumps(data, indent=2 , ensure_ascii=False ))
利用 dumps 方法,我们可以将 JSON 对象转为字符串,然后再调用文件的 write 方法写入文本,结果如图所示。
写入结果如图所示。
可以发现,这样就可以输出 JSON 为中文了。
保存为CSV CSV(comma-Separated Values),逗号分割值/字符串分隔值。文件以纯文本形式存储表格数据。比Excel更简洁(xls文本是电子表格,包含文本数值和格式等)
1 2 3 4 5 6 7 8 9 10 11 12 import csvwith open ('data.csv' ,'w' ) as f: fw = csv.writer(f,delimiter =' ' ) fw.writerow(['id' ,'name' ,'age' ]) fw.writerow(['1001' ,'tom' ,'18' ]) fw.writerow(['1002' ,'jerry' ,'18' ]) fw.writerows([['1003' ,'jerry2' ,'18' ],['1004' ,'jerry3' ,'18' ]])
用CSV库保存字典数据为CSV文件 一般爬虫爬取的都是结构化数据,一般用字典表示
1 2 3 4 5 6 7 8 9 10 def 字典写入 (): with open ('data.csv' , 'w' ,encoding='utf-8' ) as f: fieldnames = ['id' , 'name' , 'age' ] fw = csv.DictWriter(f, fieldnames=fieldnames) fw.writeheader() fw.writerow({'id' :'1' ,'name' :'兰陵王' ,'age' :19 }) fw.writerow({'id' :'1' ,'name' :'tom' ,'age' :19 }) fw.writerow({'id' :'1' ,'name' :'tom' ,'age' :19 }) if __name__ == '__main__' : 字典写入()
用pandas库保存字典数据为CSV文件 1 2 3 pip3 install pandas pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
保存文件:
1 2 3 4 5 6 7 8 9 import pandas as pddef pandas保存Csv (): data = [ {'id' : '1' , 'name' : '兰陵王' , 'age' : 19 }, {'id' : '2' , 'name' : '孙尚香' , 'age' : 19 }, {'id' : '3' , 'name' : '鲁班' , 'age' : 19 } ] df = pd.DataFrame(data) df.to_csv('data.csv' ,index=False )
用CSV库读取CSV文件 1 2 3 4 5 def 用CSV库读取CSV文件 (): with open ('data.csv' ,'r' ,encoding='utf-8' ) as f: fr = csv.reader(f) for row in fr: print (row)
用pandas库读取CSV文件 1 2 3 4 5 6 7 8 9 10 import pandas as pddef 用pandas库读取CSV文件 (): df = pd.read_csv('data.csv' ) print ('------将数据按默认格式输出,包括表头------' ) print (df) print ('------将数据转为list输出------' ) print (df.values.tolist()) print ('------遍历每一行------' ) for index,row in df.iterrows(): print (row.tolist())
保存到MySQL 1 2 # 安装库 pip3 install pymysql
创建一个爬虫数据库spiders
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import pymysqldef 创建表 (): db = pymysql.connect(host='localhost' ,user='root' ,password='root' ,db='spiders' ) cursor = db.cursor() sql = 'CREATE TABLE IF NOT EXISTS students(id varchar(255) not null,name varchar(255) not null,age int not null,primary key (id))' cursor.execute(sql) db.close() def 插入数据 (): db = pymysql.connect(host='localhost' , user='root' , password='root' , port=3306 , db='spiders' ) cursor = db.cursor() sql = 'insert into students(id,name,age) values(%ss,%ss,%ss)' try : cursor.execute(sql,('1' ,'孙尚香' ,18 )) db.commit() except Exception as e: print ('出错' ,e) db.rollback() db.close() def 插入JSON数据 (): db = pymysql.connect(host='localhost' , user='root' , password='root' , port=3306 , db='spiders' ) cursor = db.cursor() data = { 'id' : '2' , 'name' : 'tom' , 'age' : '20' } table = 'students' keys = ',' .join(data.keys()) values = ',' .join(['%s' * len (data)]) sql = 'insert into {table} ({keys}) values ({values})' .format (table=table,keys=keys,values=values) try : if cursor.execute(sql,tuple (data.values())): print ('插入成功' ) db.commit() except Exception as e: print ('出错' ,e) db.rollback() db.close() def 查询 (): db = pymysql.connect(host='localhost' , user='root' , password='root' , port=3306 , db='spiders' ) cursor = db.cursor() sql = 'select * from students where age > 1' try : cursor.execute(sql) print ('总数' , cursor.rowcount) print ('一条' , cursor.fetchone()) for row in cursor.fetchall(): print ('每条' ,row) except Exception as e: print ('出错' ,e) if __name__ == '__main__' : 查询()
保存到MongoDB 爬虫一条数据可能存在因某些字段提取失败而缺失的情况,且数据可能随时调整。或者存在嵌套关系。
如果用关系型数据库,需要提前建好表,而且如果存在嵌套,要序列化才能保存,很不方便,
所以可以考虑用非关系型数据库MongoDB。
1 2 # 安装库 pip3 install pymongo
文档: https://docs.mongodb.com/manual/reference/operator/query/
crud示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 import pymongofrom bson import ObjectIdclient = pymongo.MongoClient(host='localhost' , port=27017 ) db = client.test collection = db.students def 插入单条数据 (): student = { 'id' : '20170101' , 'name' : 'Jordan' , 'age' : 20 , 'gender' : 'male' } result = collection.insert(student) print (result) def 插入多条数据 (): student1 = { 'id' : '20170101' , 'name' : 'Jordan' , 'age' : 20 , 'gender' : 'male' } student2 = { 'id' : '20170202' , 'name' : 'Mike' , 'age' : 21 , 'gender' : 'male' } result = collection.insert([student1, student2]) print (result) def 查询单条 (): result = collection.find_one({'name' : 'Mike' }) print (type (result)) print (result) collection.find({'_id' : {'$gt' : ObjectId('593278c815c2602678bb2b8d' )}}) def 查询多条 (): results = collection.find({'age' : 20 }) results = collection.find({'age' : {'$gt' : 20 }}) results = collection.find({'name' : {'$regex' : '^M.*' }}) print (results) for result in results: print (result) def 计数 (): count = collection.find().count() print (count) def 排序 (): results = collection.find().sort('name' , pymongo.ASCENDING) print ([result['name' ] for result in results]) def 偏移 (): results = collection.find().sort('name' , pymongo.ASCENDING).skip(2 ).limit(2 ) print ([result['name' ] for result in results]) def 更新 (): condition = {'name' : 'Kevin' } student = collection.find_one(condition) student['age' ] = 25 result = collection.update(condition, student) print (result) result = collection.update(condition, {'$set' : student}) condition = {'name' : 'Kevin' } student = collection.find_one(condition) student['age' ] = 26 result = collection.update_one(condition, {'$set' : student}) print (result) print (result.matched_count, result.modified_count) def 删除 (): result = collection.remove({'name' : 'Kevin' }) print (result) result = collection.delete_one({'name' : 'Kevin' }) print (result) print (result.deleted_count) result = collection.delete_many({'age' : {'$lt' : 25 }}) print (result.deleted_count)
可以用robot 3T查看
保存到redis Redis 是一个基于内存的高效的非关系型数据库,鉴于redis的便捷性和高效性我们会利用redis实现很多架构,比如维护代理池,张好吃,ADSL拨号代理池,scrapy-redis分布式架构等。
1 2 # 安装库 pip3 install redis
代码:
1 2 3 4 5 6 7 8 9 10 11 12 def 直接连接redis并设置值 (): redis = StrictRedis(host='localhost' , port=6379 , db=0 ) redis.set ('name' , 'tom' ) print (redis.get('name' )) def 连接池连接redis (): pool = ConnectionPool.from_url('redis://@localhost:6379/0' ) redis = StrictRedis(connection_pool=pool)
ElasticSearch 想查数据,就免不了搜索,而搜索离不开搜搜引擎。百度、谷歌都是非常庞大、复杂的搜索引擎,他们几乎能够索引互联网上开放的所有网页和数据。然而对于我们自己的业务数据来说,没有必要使用这么复杂的技能,如果为了便于存储和检索,想要实现自己的搜索引擎,elasticSearch就是不二之选。这是一个全文搜索引擎,可以快速存储、搜索和分析海量数据。
所以,如果我们将爬取到的数据存储到elasticsearch中,检索时会非常方便。
1 2 3 4 # 安装库 # pip3 install elasticsearch # 版本太高可能使用时会报错 # pip3 install elasticsearch==7.13.0 pip3 install elasticsearch==6.8.0 # API不一样,建议7
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from datetime import datetimefrom elasticsearch import Elasticsearches = Elasticsearch( ['http://192.168.88.130:9200' ] ) def 创建索引 (): result = es.indices.create(index='news_20230324' ,ignore=400 ) print (result) def 删除索引 (): result = es.indices.delete(index='news_20230324' ,ignore=400 ) print (result) def 插入数据 (): doc = { 'author' : '左耳' , 'text' : 'python练习es记录' , 'timestamp' : datetime.now(), } res = es.index(index="test-index" , doc_type='tweet' , id =1 , body=doc) print (res['result' ]) def 查询数据 (): res = es.get(index="test-index" , doc_type='tweet' , id =1 ) print (res['_source' ]) def 搜索数据 (): es.indices.refresh(index="test-index" ) res = es.search(index="test-index" , body={"query" : {"match_all" : {}}}) print ("查询 %d 命中:" % res['hits' ]['total' ]) for hit in res['hits' ]['hits' ]: print ("%(timestamp)s %(author)s: %(text)s" % hit["_source" ]) def 更新数据 (): doc = { 'author' : '左耳' , 'text' : 'python练习es记录-修改' , 'timestamp' : datetime.now(), } result = es.update(index="test-index" , doc_type="tweet" ,id =1 , body={"doc" :doc}) print (result) if __name__ == '__main__' : 更新数据() 查询数据()
一个比较详细的例子:https://zhuanlan.zhihu.com/p/122511360
保存到rabbitmq 在爬取数据的过程中,可能需要一些进程间的通信机制,比如:
一个进程负责构造爬取请求,另一个进程负责进程爬取请求
某个进程新建了一个爬取任务,通知另外一个负责数据爬取的进程开始爬取数据
某个数据爬取进程执行完毕,通知另外一个负责数据处理的进程开始处理数据
为了降低这些进程的耦合度,需要一个类似消息队列的中间件来存储和转发消息,实现进程间的通信。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import pikacredentials = pika.PlainCredentials("zuoer" , "zuoer" ) cparameters = pika.ConnectionParameters(host='192.168.88.130' , credentials=credentials, virtual_host='/zuoer_space' ) connection = pika.BlockingConnection(cparameters) channel = connection.channel() MAX_PRIORITY = 100 QUEUE_NAME = 'scrape' def 声明队列 (): channel.queue_declare(queue=QUEUE_NAME, arguments={'x-max-priority' : MAX_PRIORITY}, durable=True , ) def 发送消息 (data,priority=100 ): channel.basic_publish(exchange='' , routing_key=QUEUE_NAME, properties=pika.BasicProperties(priority=int (priority),delivery_mode=2 ), body=data) print ("已经发送了消息" ) if __name__ == '__main__' : while True : data = input () 发送消息(data)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import pikacredentials = pika.PlainCredentials("zuoer" , "zuoer" ) cparameters = pika.ConnectionParameters(host='192.168.88.130' , credentials=credentials, virtual_host='/zuoer_space' ) connection = pika.BlockingConnection(cparameters) channel = connection.channel() QUEUE_NAME = 'scrape' def 消费消息 (): channel.basic_consume(queue=QUEUE_NAME, auto_ack=True , on_message_callback=callback) channel.start_consuming() def callback (ch,method,properties,body ): if body: result = pickle.loads(body) print (f'消费到消息: {result} ' ) if __name__ == '__main__' : 消费消息()

 微信
微信 支付宝
支付宝
