我们抓取,我们采集,我们分析,我们挖掘
异步爬虫 我们知道爬虫是 IO 密集型任务,比如如果我们使用 requests 库来爬取某个站点的话,发出一个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何事情。对于这种情况,我们有没有优化方案呢?
当然有,下面我们就来了解一下异步爬虫的基本概念和实现。
要实现异步机制的爬虫,那自然和协程脱不了关系。
协程的基本原理 案例网站:https://httpbin.org/delay/5,该站点等待5s返回响应
平时我们浏览网页的时候,绝大部分网页响应速度还是很快的,如果我们写爬虫来爬取的话,发出 Request 到收到 Response 的时间不会很长,因此我们需要等待的时间并不多。
然而像上面这个网站,一次 Request 就需要 5 秒才能得到 Response,如果我们用 requests 写爬虫来爬取的话,那每次 requests 都要等待 5 秒才能拿到结果了。
此时如果我们开了多线程或多进程来爬取的话,其爬取速度确实会成倍提升,那是否有更好的解决方案呢?
使用协程来加速的方法,此种方法对于 IO 密集型任务非常有效。如将其应用到网络爬虫中,爬取效率甚至可以成百倍地提升。
协程本质上是个单进程,它相对于多进程来说,无须线程上下文切换的开销。我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他事情,等到响应得到之后才切换回来继续处理,这样可以充分利用 CPU 和其他资源,这就是协程的优势。
从 Python 3.4 开始,Python 中加入了协程的概念,但这个版本的协程还是以生成器对象为基础。
Python 3.5 则增加了 async/await,使得协程的实现更加方便。
Python 中使用协程最常用的库莫过于 asyncio。
首先,我们需要了解下面几个概念:
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。coroutine:中文翻译叫协程,在 Python 中常指代协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。future:代表将来执行或没有执行的任务的结果,实际上和 task 没有本质区别。
另外,我们还需要了解 async/await 关键字,它是从 Python 3.5 才出现的,专门用于定义协程。其中,async 定义一个协程,await 用来挂起阻塞方法的执行。
协程初体验 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def callback (task ): print ('回调:' ,task.result()) async def execute (x ): print ('数字:' ,x) return x coroutine = execute(1 ) print ('协程:' ,coroutine)print ('11111111' )loop = asyncio.get_event_loop() task = loop.create_task(coroutine) task.add_done_callback(callback) print ('任务:' ,task)loop.run_until_complete(task) print ('任务:' ,task)print ('任务结果:' ,task.result())print ('222222222' )
多任务协程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import asyncioimport requestsimport timestart = time.time() async def request (): async with aiohttp.ClientSession() as session: res = await session.get('https://httpbin.org/delay/5' ) print (f'当前时间:{datetime.datetime.now()} , status_code = {res.status} ' ) """ tasks = [asyncio.ensure_future(request()) for _ in range(10)] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) """ if __name__ == '__main__' : loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) tasks = [loop.create_task(request()) for i in range (5 )] wait_coro = asyncio.wait(tasks) loop.run_until_complete(wait_coro) end = time.time() print ('Cost time:' , end - start)
理论来说,确实是这样的,不过有个前提,那就是服务器在同一时刻接受无限次请求都能保证正常返回结果,也就是服务器无限抗压。另外,还要忽略 IO 传输时延,确实可以做到无限 task 一起执行且在预想时间内得到结果。但由于不同服务器处理的实现机制不同,可能某些服务器并不能承受这么高的并发,因此响应速度也会减慢。
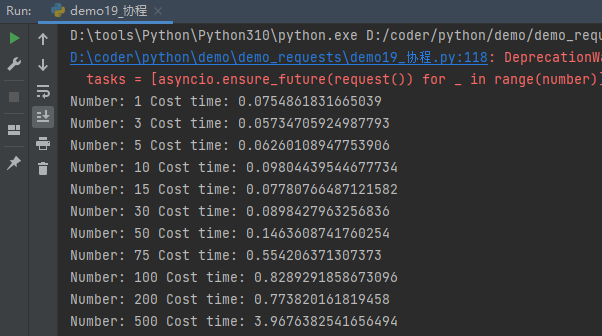
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def test (number ): start = time.time() async def get (url ): session = aiohttp.ClientSession() response = await session.get(url) await response.text() await session.close() return response async def request (): url = 'https://www.baidu.com/' await get(url) loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) tasks = [asyncio.ensure_future(request()) for _ in range (number)] loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print ('Number:' , number, 'Cost time:' , end - start) for number in [1 , 3 , 5 , 10 , 15 , 30 , 50 , 75 , 100 , 200 , 500 ]: test(number)
我们增加了并发数量,但在服务器能承受高并发的前提下,其爬取速度几乎不太受影响。
综上所述,使用了异步请求之后,我们几乎可以在相同的时间内实现成百上千倍次的网络请求,把这个运用在爬虫中,速度提升可谓是非常可观了。
更多例子:https://blog.csdn.net/weixin_45203607/article/details/127396527
并发限制 由于aiohtt可以支持很高的并发量,如几万、几十万、上百万都是可以做到的。面对比如高的并发,目标网站很可能无法在短时间内响应,而且有瞬间将目标网站爬挂的危险,所以我们要控制一下爬取的并发量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 CONCURRENCY=5 URL = 'https://httpbin.org/delay/5' semaphore = asyncio.Semaphore(CONCURRENCY) session = None async def scrape_api (): async with semaphore: print ('爬取网站:' , URL) async with session.get(URL) as response: await asyncio.sleep(1 ) return await response.text() async def main (): global session session = aiohttp.ClientSession() scrape_index_tasks = [asyncio.ensure_future(scrape_api()) for _ in range (10000 )] await asyncio.gather(*scrape_index_tasks) if __name__ == '__main__' : loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) loop.run_until_complete(main())
异步爬取实战 目标网站:https://spa5.scrape.center/
目标:
aiohttp异步爬取全站图书数据
数据异步保存到MongoDB
1 2 # 安装库 => MongoDB异步存储 pip3 install motor
思路:
一个完善的异步爬虫应该能够充分利用资源进行全速爬取,其实现思路是维护一个动态变化的爬取队列,没产生一个task,就将其放入到爬取队列中,有专门的爬虫消费者从队列中获取task并执行,能做到在最大并发量的前提下充分利用等待时间进行额外的爬取处理。
思路整体较为繁琐,需要设计爬取队列,对调函数,消费者机制等。
此处简化实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 import asyncioimport jsonimport loggingimport aiohttpimport requestsimport pymongologging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s: %(message)s' ) INDEX_URL = 'https://spa5.scrape.center/api/book/?limit={limit}&offset={offset}' DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}' LIMIT = 18 TOTAL_PAGE = 10 CONCURRENCY = 5 semaphore = asyncio.Semaphore(CONCURRENCY) session = None MONGO_CONNECTION_STRING = 'mongodb://localhost:27017' MONGO_DB_NAME = 'books' MONGO_COLLECTION_NAME = 'books' client = pymongo.MongoClient(MONGO_CONNECTION_STRING) db = client[MONGO_DB_NAME] collection = db[MONGO_COLLECTION_NAME] async def scrape_api (url ): async with semaphore: try : logging.info('scraping %s...' , url) async with session.get(url) as response: return await response.json() except aiohttp.ClientError: logging.error('error occurred while scraping %s' , url, exc_info=True ) async def scrape_index (page ): url = INDEX_URL.format (limit=LIMIT, offset=LIMIT * (page - 1 )) return await scrape_api(url) async def scrape_detail (id url = DETAIL_URL.format (id =id ) data = await scrape_api(url) await save_data(data) async def save_data (data ): logging.info('saving data %s' ,data) if data: return await collection.update_one({ 'id' : data.get('id' ) }, { '$set' : data }, upsert=True ) async def main (): global session session = aiohttp.ClientSession() scrape_index_tasks = [asyncio.ensure_future(scrape_index(page)) for page in range (1 ,TOTAL_PAGE+1 ) ] results = await asyncio.gather(*scrape_index_tasks) logging.info('results %s' ,json.dumps(results,ensure_ascii=False ,indent=2 )) ids = [] for index_data in results: if not index_data: continue for item in index_data.get('results' ): ids.append(item.get('id' )) scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id )) for id in ids] await asyncio.wait(scrape_detail_tasks) await session.close() if __name__ == '__main__' : loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) loop.run_until_complete(main())
 微信
微信 支付宝
支付宝
