【微服务从入门到入土】APP数据爬取
我们抓取,我们采集,我们分析,我们挖掘
app数据爬取
移动互联网发展,很多企业不在提供PC端服务,而是直接开发了app,或者在app端有更多更全的信息。
这时候怎么对app进行爬取?
大部分app是使用的协议也是HTTP、https的,app内部的页面交互背后也是有相应的后台api处理的。
在PC网页端,我们可以借助浏览器开发者工具观察请求和响应,app端怎么办?
这时候想要拦截app 的网络请求,就要用抓包工具了。比如:Charles、fiddler、mitmproxy等。通过这些工具可以拦截app请求和响应,然后构造请求模拟api,完成数据爬取。
和PC端一样,app端一般也都有加密token,如果找不到规律,即使抓到包也没办法直接构造请求完成数据爬取。这时候就需要想办法,比如直接拦截所有请求的响应内容并实时处理、使用和selenium类似工具完成“所见即所爬”、使用hook app关键防范获取数据、直接逆向app找到接口参数逻辑等等。
charles抓包工具的使用
相比 Fiddler 来说,Charles 的功能更强大,而且跨平台支持更好。所以我们选用 Charles 作为主要的移动端抓包工具,用于分析移动 App 的数据包,辅助完成 App 数据抓取工作
charles大致使用步骤
Charles运行在电脑上,运行时会在该电脑8888端口开启一个代理服务。
准备一部andriod手机或模拟器(系统最好<7.0),并且让手机或模拟器的网络和Charles所在电脑处于同一个局域网下(可以让模拟器通过虚拟网络和电脑连接,也可以让手机真机和电脑使用同一个WiFi)
设置后Charles代理和Charles CA 证书,开启SSL监听。
相关链接
下载 Charles
我们可以在官网下载最新的稳定版本。可以发现,它支持 Windows、Linux 和 Mac 三大平台。
直接点击对应的安装包下载即可,具体的安装过程这里不再赘述。
Charles 是收费软件,不过可以免费试用 30 天。如果试用期过了,其实还可以试用,不过每次试用不能超过 30 分钟,启动有 10 秒的延时,但是完整的软件功能还是可以使用的,所以还算比较友好。
证书配置
现在很多页面都在向 HTTPS 方向发展,HTTPS 通信协议应用得越来越广泛。如果一个 App 通信应用了 HTTPS 协议,那么它通信的数据都会是被加密的,常规的截包方法是无法识别请求内部的数据的。
安装完成后,如果我们想要做 HTTPS 抓包的话,那么还需要配置一下相关 SSL 证书。接下来,我们再看看各个平台下的证书配置过程。
Charles 是运行在 PC 端的,我们要抓取的是 App 端的数据,所以要在 PC 和手机端都安装证书。
Windows
如果你的 PC 是 Windows 系统,可以按照下面的操作进行证书配置。
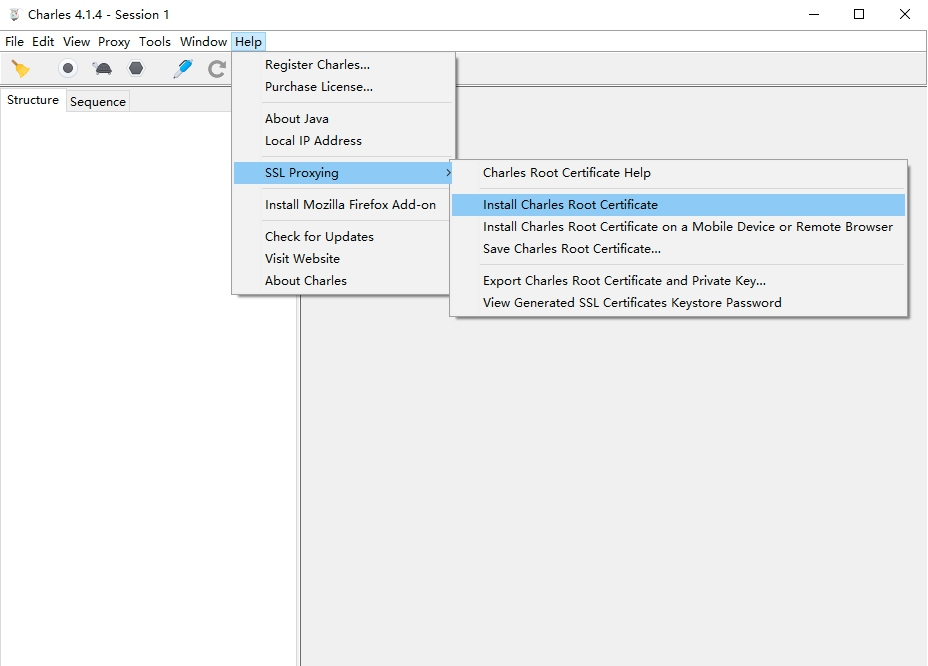
首先打开 Charles,点击 Help→SSL Proxying→Install Charles Root Certificate,即可进入证书的安装页面,如图 1-44 所示。
接下来,会弹出一个安装证书的页面。
点击 “安装证书” 按钮,就会打开证书导入向导。
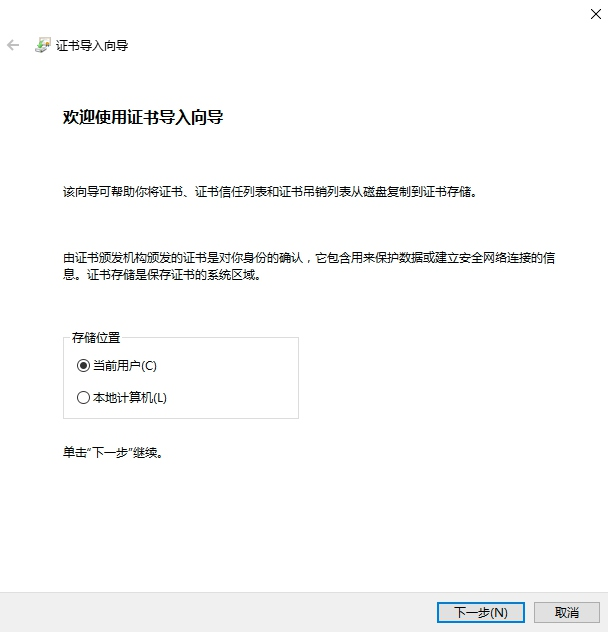
直接点击 “下一步” 按钮,此时需要选择证书的存储区域,点击第二个选项 “将所有的证书放入下列存储”,然后点击 “浏览” 按钮,从中选择证书存储位置为 “受信任的根证书颁发机构”,再点击 “确定” 按钮,然后点击 “下一步” 按钮。
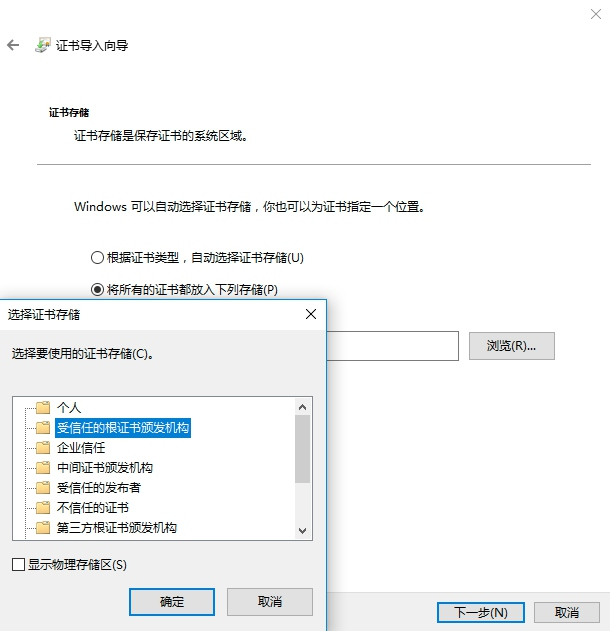
再继续点击 “下一步” 按钮完成导入。
Mac
如果你的 PC 是 Mac 系统,可以按照下面的操作进行证书配置。
同样是点击 Help→SSL Proxying→Install Charles Root Certificate,即可进入证书的安装页面。
接下来,找到 Charles 的证书并双击,将 “信任” 设置为 “始终信任” 即可。
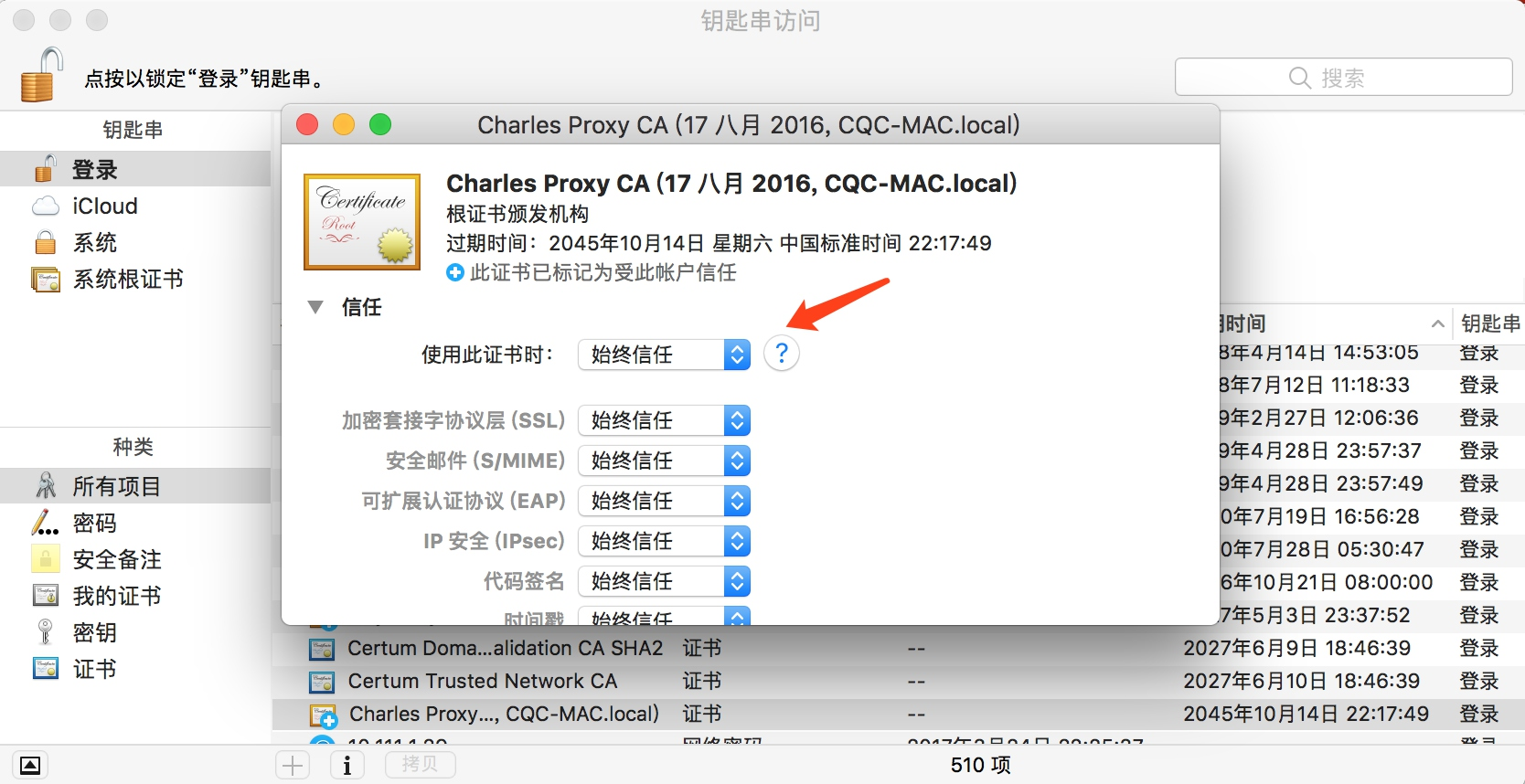
这样就成功安装了证书。
iOS
如果你的手机是 iOS 系统,可以按照下面的操作进行证书配置。
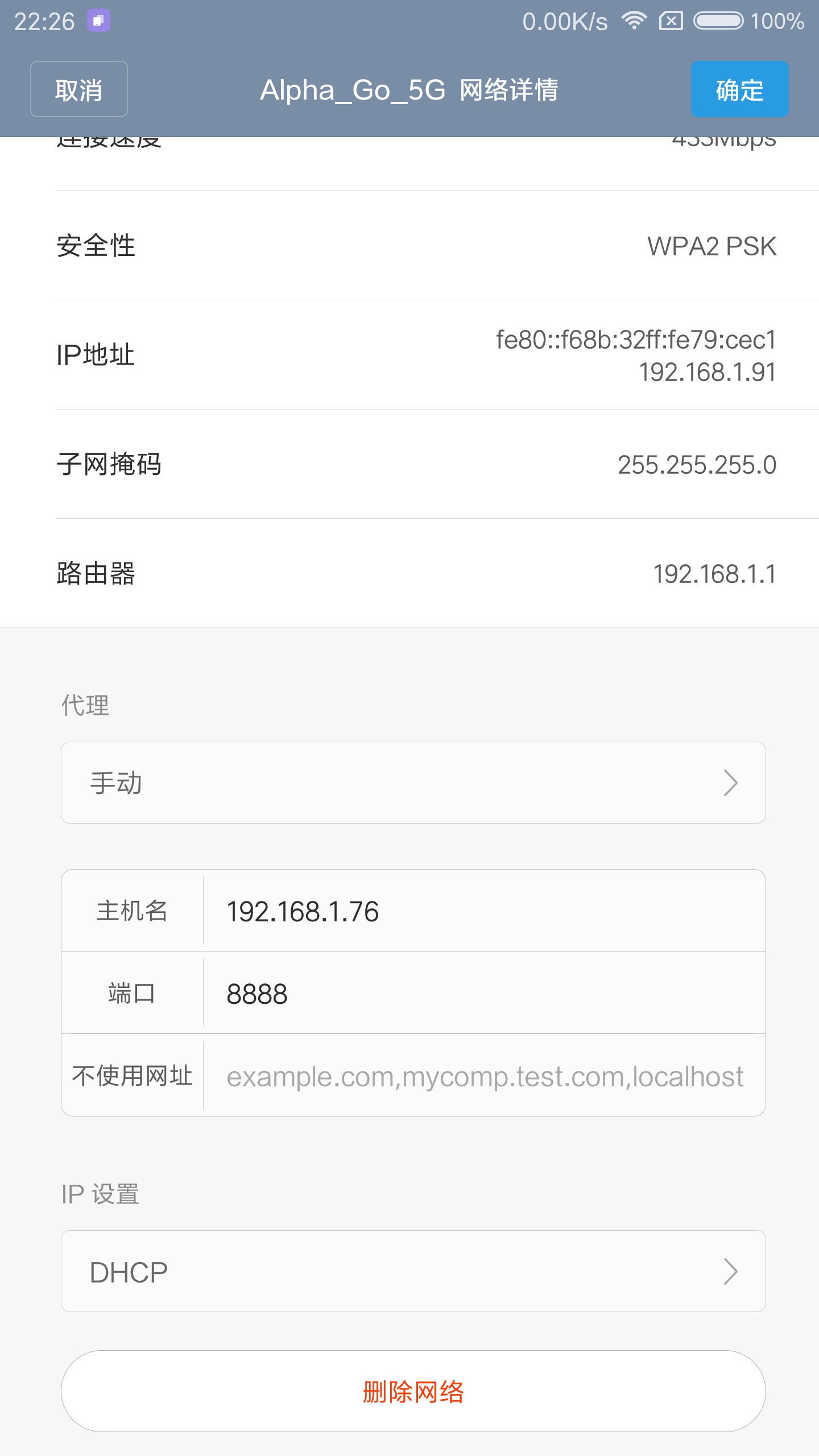
首先,查看电脑的 Charles 代理是否开启,操作是点击 Proxy→Proxy Settings,打开代理设置页面,确保当前的 HTTP 代理是开启的。这里的代理端口为 8888,也可以自行修改。
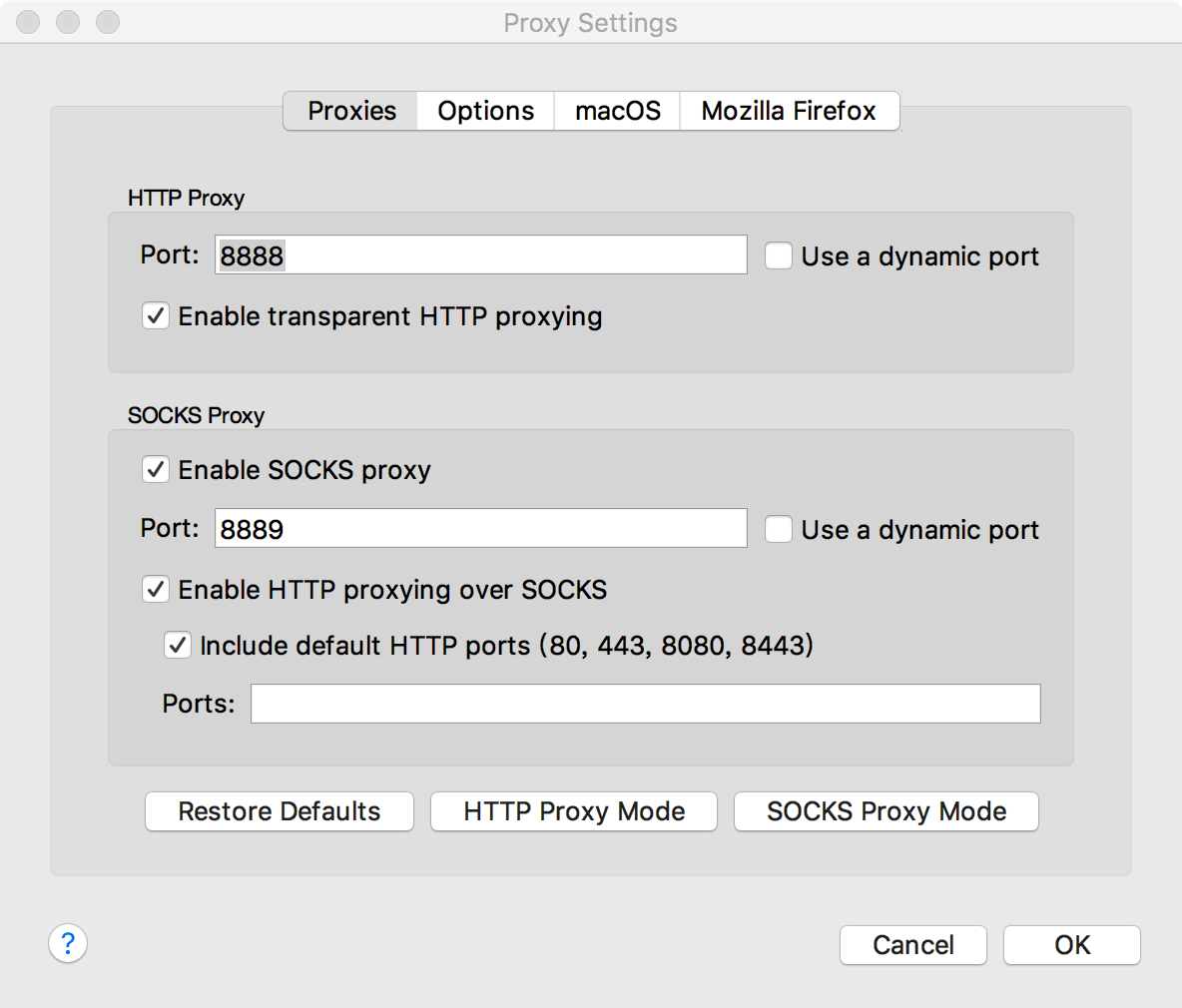
接下来,将手机和电脑连在同一个局域网下。例如,当前电脑的 IP 为 192.168.1.76,那么首先设置手机的代理为 192.168.1.76:8888。
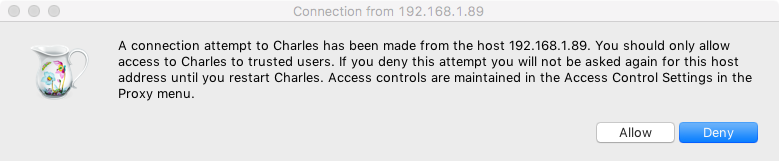
设置完毕后,电脑上会出现一个提示窗口,询问是否信任此设备。
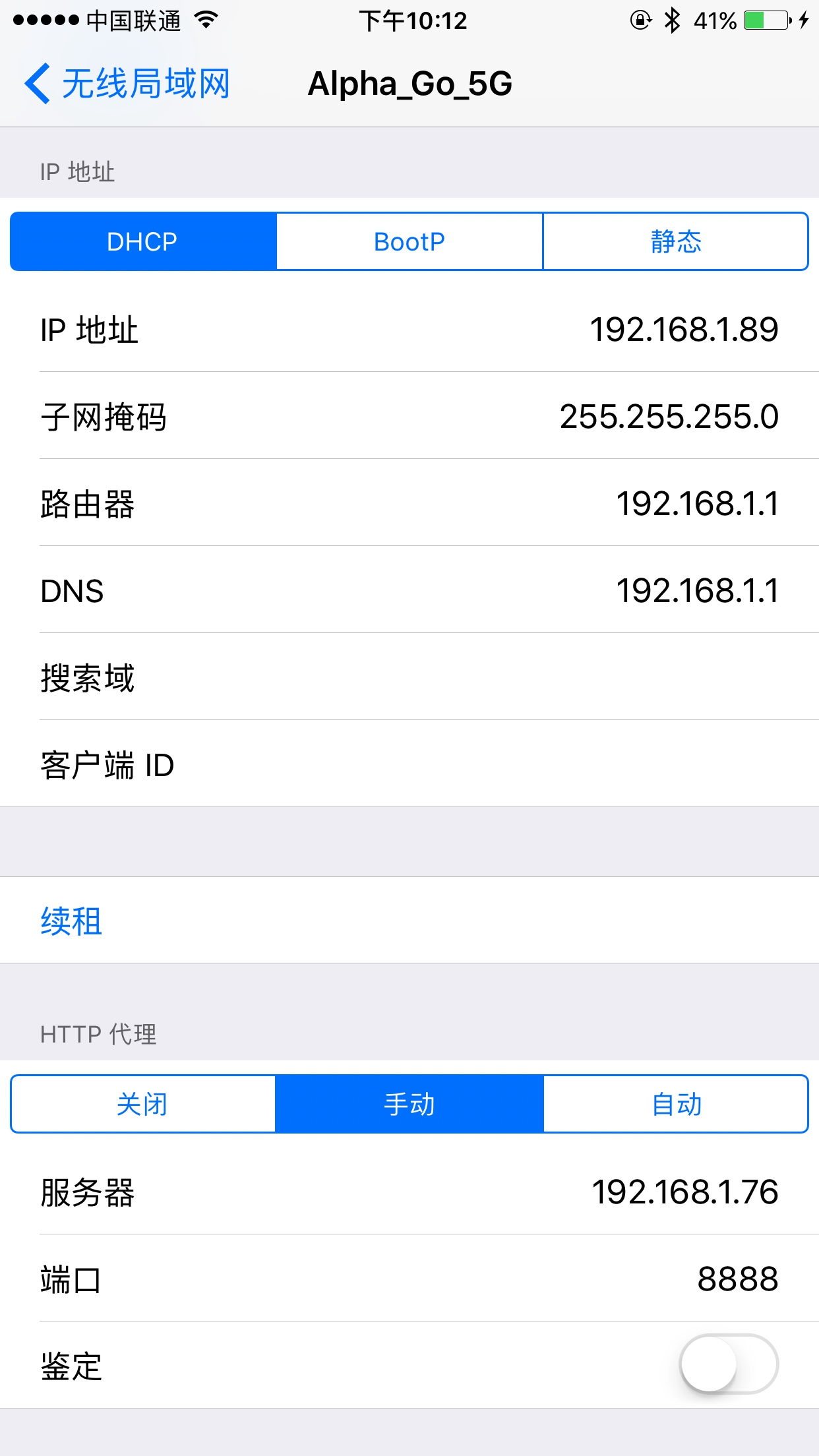
此时点击 Allow 按钮即可。这样手机就和 PC 连在同一个局域网内了,而且设置了 Charles 的代理,即 Charles 可以抓取到流经 App 的数据包了。
接下来,再安装 Charles 的 HTTPS 证书。
在电脑上打开 Help→SSL Proxying→Install Charles Root Certificate on a Mobile Device or Remote Browser。
 图 1-52 证书安装页面入口
图 1-52 证书安装页面入口
此时会看到。
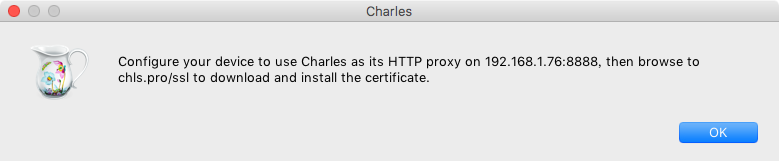
它提示我们在手机上设置好 Charles 的代理(刚才已经设置好了),然后在手机浏览器中打开 chls.pro/ssl 下载证书。
在手机上打开 chls.pro/ssl 后,便会弹出证书的安装页面:
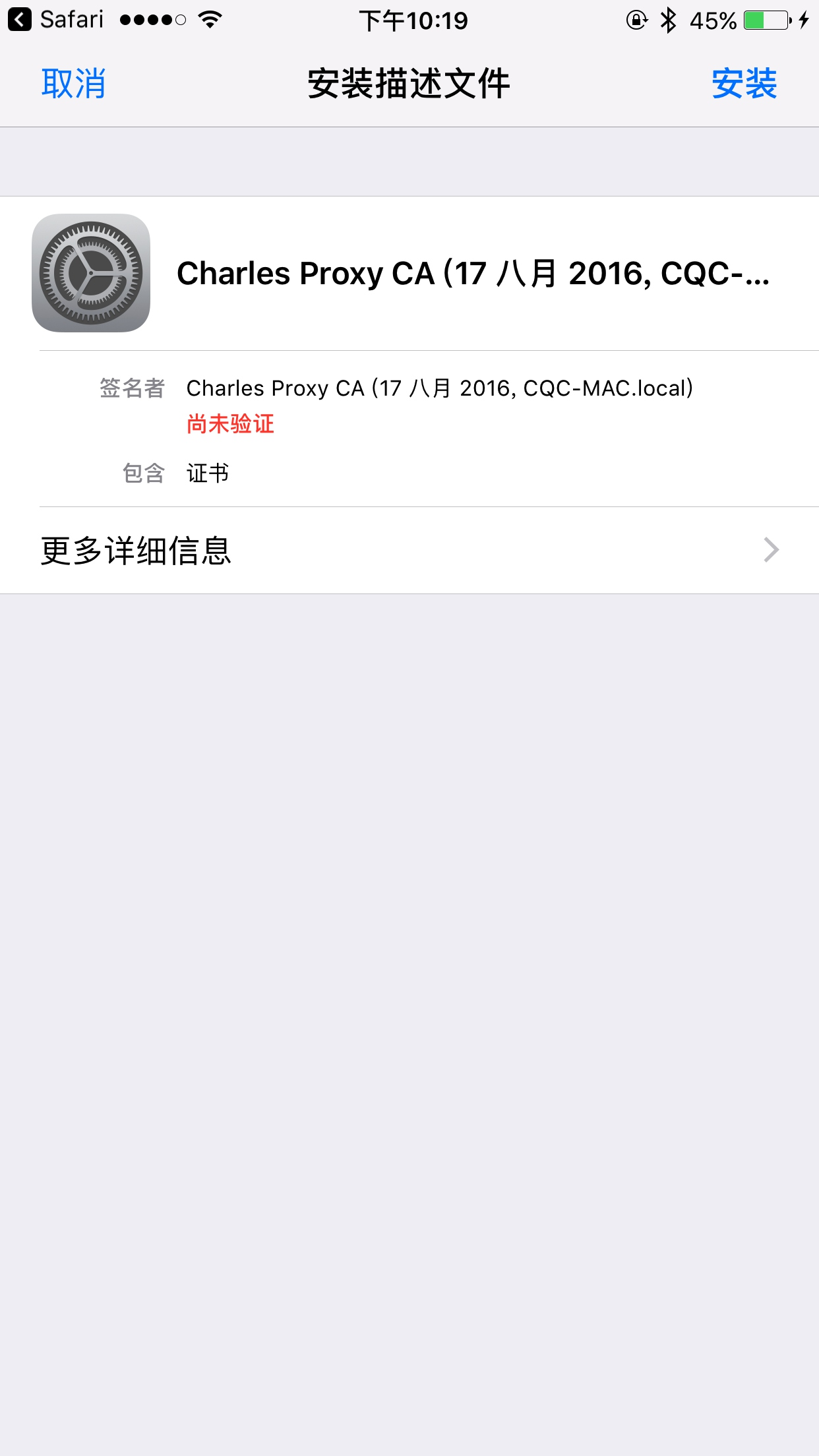
点击 “安装” 按钮,然后输入密码即可完成安装。
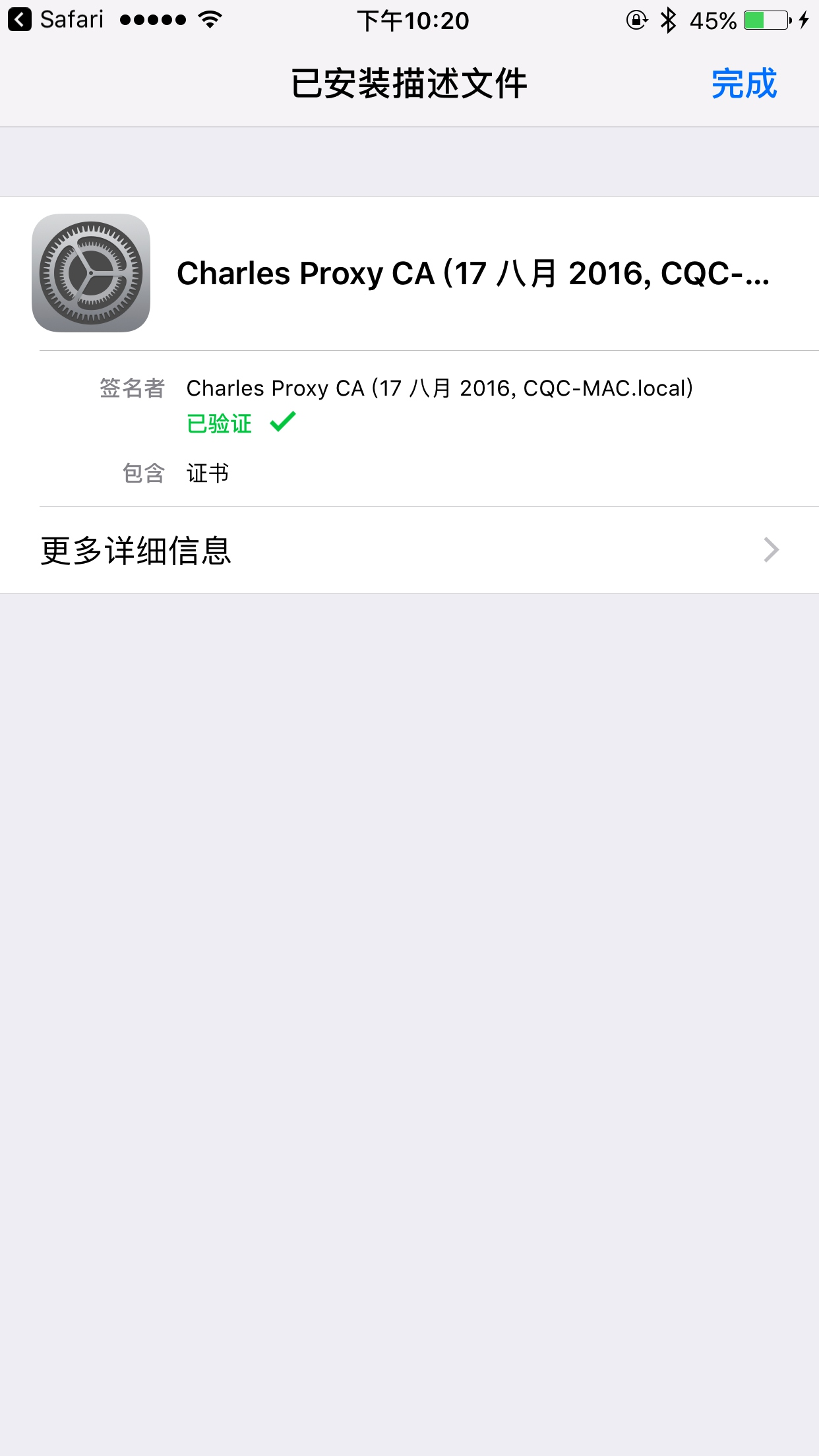
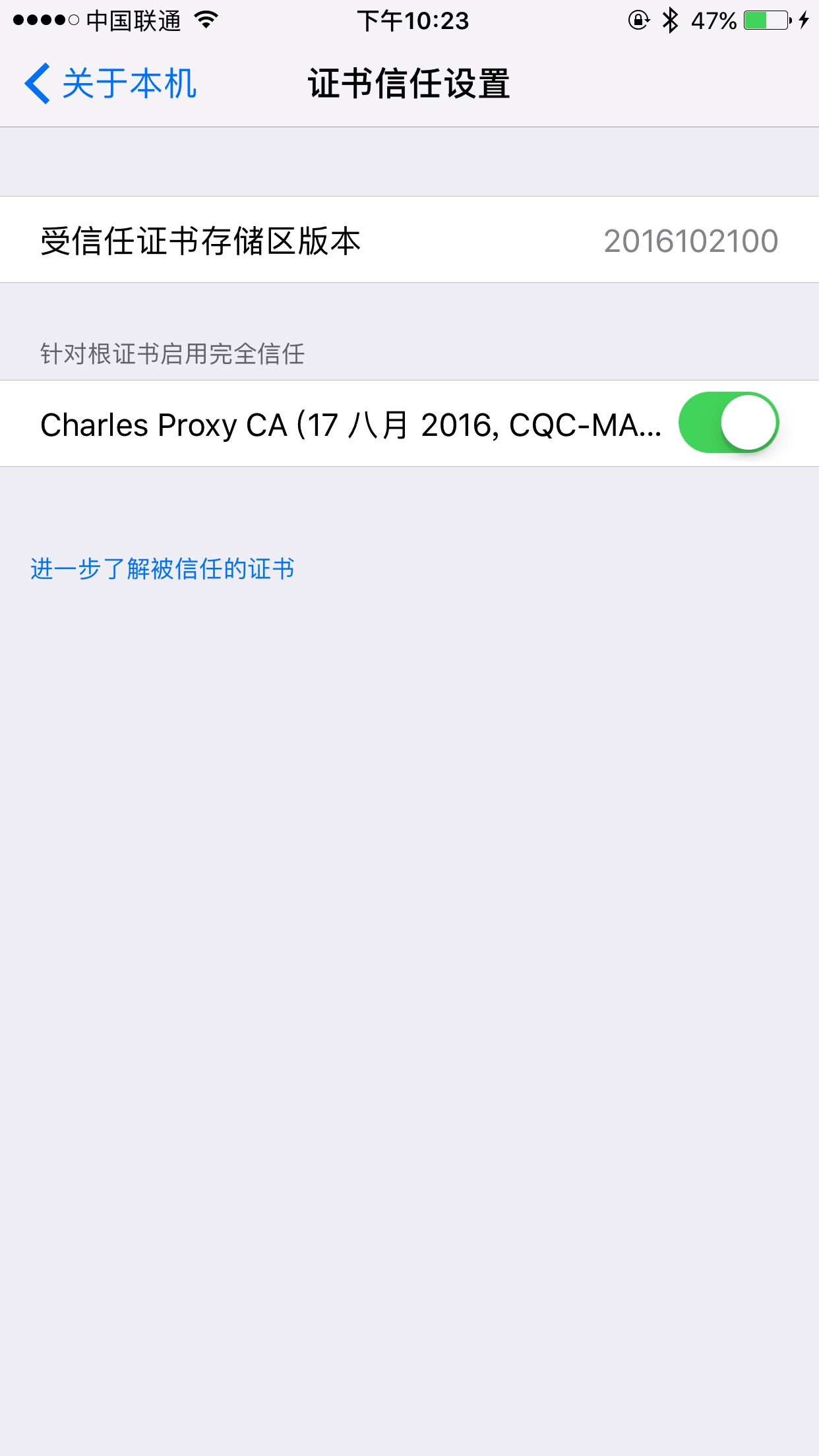
如果你的 iOS 版本是 10.3 以下的话,信任 CA 证书的流程就已经完成了。
如果你的 iOS 版本是 10.3 及以上,还需要在 “设置”→“通用”→“关于本机”→“证书信任设置” 中将证书的完全信任开关打开。
Android
如果你的手机是 Android 系统,可以按照下面的操作进行证书配置。
在 Android 系统中,同样需要设置代理为 Charles 的代理。
设置完毕后,电脑上就会出现一个提示窗口,询问是否信任此设备,如图 1-51 所示,此时直接点击 Allow 按钮即可。
接下来,像 iOS 设备那样,在手机浏览器上打开 chls.pro/ssl,这时会出现一个提示框。
我们为证书添加一个名称,然后点击 “确定” 按钮即可完成证书的安装。
抓包原理
设置手机代理为 Charles 的代理地址,这样手机访问互联网的数据包就会流经 Charles,Charles 再转发这些数据包到真实的服务器,服务器返回的数据包再由 Charles 转发回手机,Charles 就起到中间人的作用,所有流量包都可以捕捉到,因此所有 HTTP 请求和响应都可以捕获到。同时 Charles 还有权力对请求和响应进行修改。
抓包实战
抓包
初始状态界面
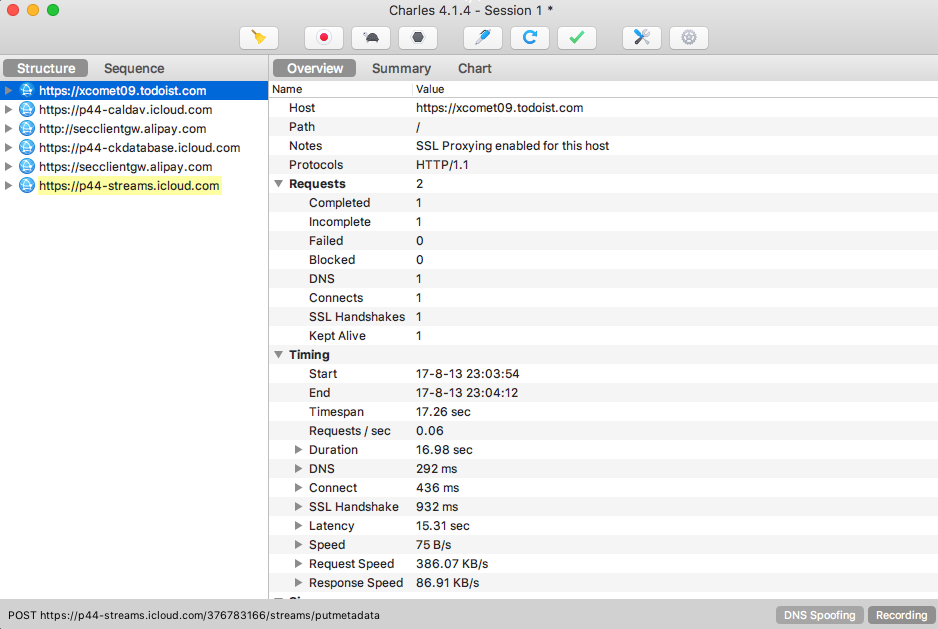
Charles 会一直监听 PC 和手机发生的网络数据包,捕获到的数据包就会显示在左侧,随着时间的推移,捕获的数据包越来越多,左侧列表的内容也会越来越多。
可以看到,图中左侧显示了 Charles 抓取到的请求站点,我们点击任意一个条目便可以查看对应请求的详细信息,其中包括 Request、Response 等内容。
接下来清空 Charles 的抓取结果,点击左侧的扫帚按钮即可清空当前捕获到的所有请求。然后点击第二个监听按钮,确保监听按钮是打开的,这表示 Charles 正在监听 App 的网络数据流。

这时打开手机京东,注意一定要提前设置好 Charles 的代理并配置好 CA 证书,否则没有效果。
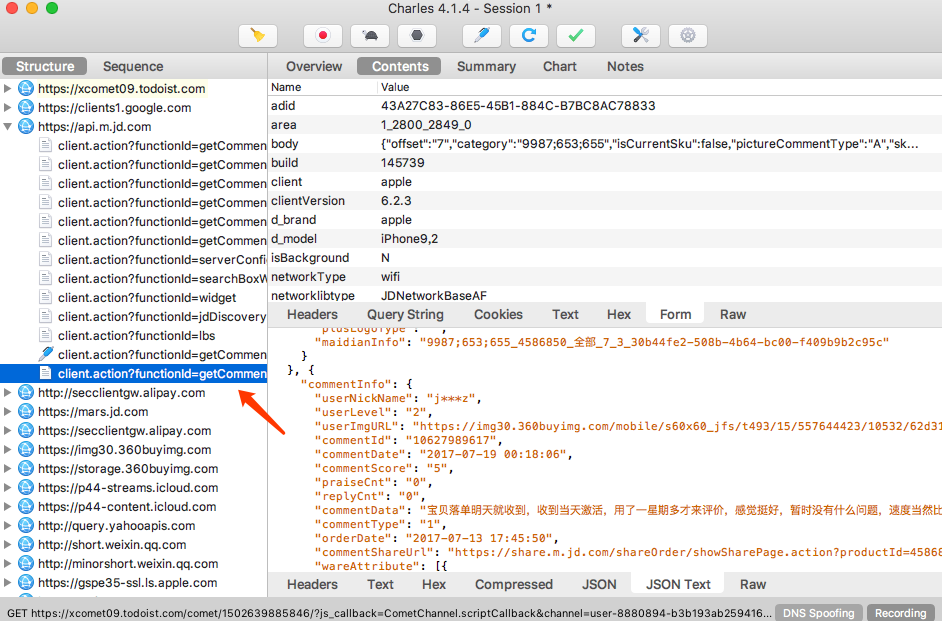
打开任意一个商品,如 iPhone,然后打开它的商品评论页面
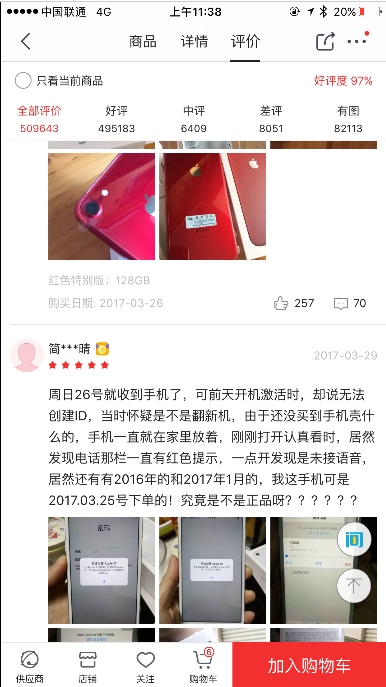
不断上拉加载评论,可以看到 Charles 捕获到这个过程中京东 App 内发生的所有网络请求
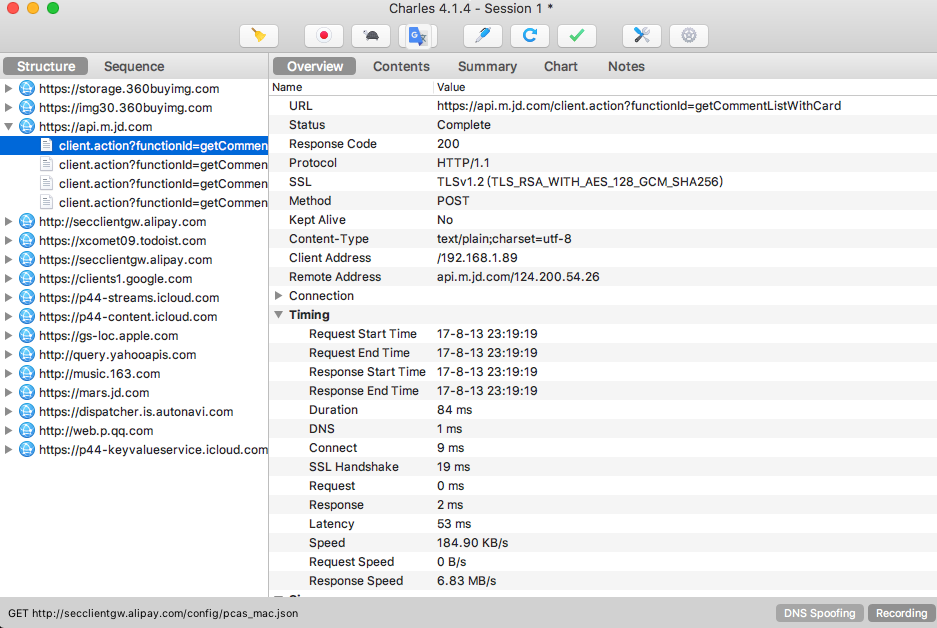
左侧列表中会出现一个 api.m.jd.com 链接,而且它在不停闪动,很可能就是当前 App 发出的获取评论数据的请求被 Charles 捕获到了。我们点击将其展开,继续上拉刷新评论。随着上拉的进行,此处又会出现一个个网络请求记录,这时新出现的数据包请求确定就是获取评论的请求。
为了验证其正确性,我们点击查看其中一个条目的详情信息。切换到 Contents 选项卡,这时我们发现一些 JSON 数据,核对一下结果,结果有 commentData 字段,其内容和我们在 App 中看到的评论内容一致
这时可以确定,此请求对应的接口就是获取商品评论的接口。这样我们就成功捕获到了在上拉刷新的过程中发生的请求和响应内容
分析
现在分析一下这个请求和响应的详细信息。首先可以回到 Overview 选项卡,上方显示了请求的接口 URL,接着是响应状态 Status Code、请求方式 Method 等
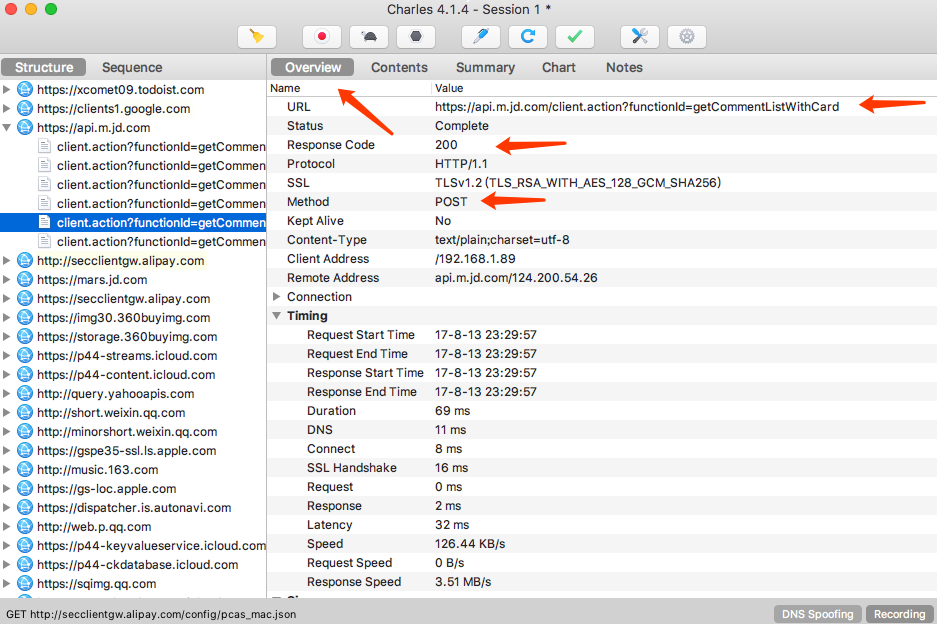
这个结果和原本在 Web 端用浏览器开发者工具内捕获到的结果形式是类似的。
接下来点击 Contents 选项卡,查看该请求和响应的详情信息。
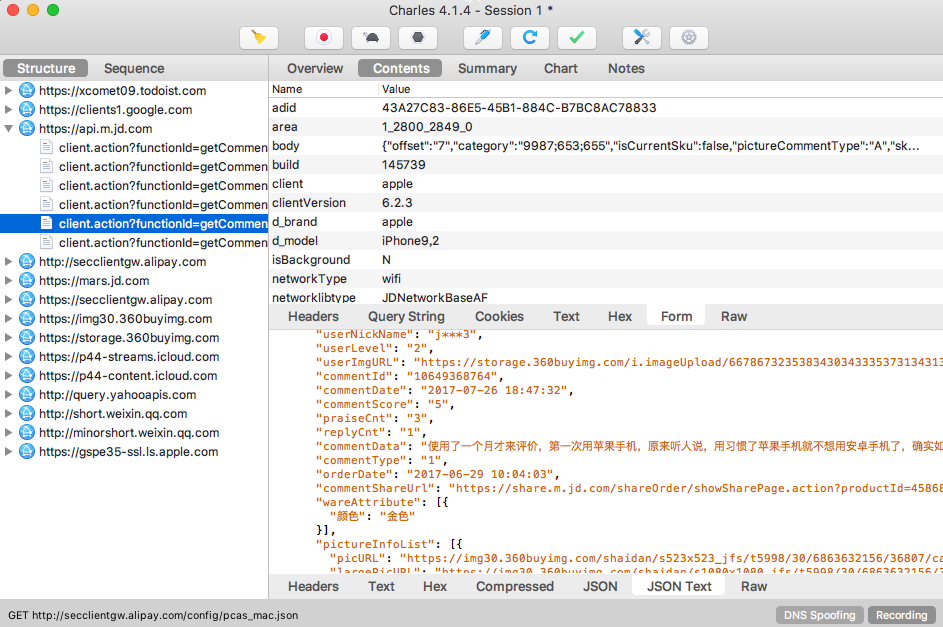
上半部分显示的是 Request 的信息,下半部分显示的是 Response 的信息。比如针对 Reqeust,我们切换到 Headers 选项卡即可看到该 Request 的 Headers 信息,针对 Response,我们切换到 JSON TEXT 选项卡即可看到该 Response 的 Body 信息,并且该内容已经被格式化
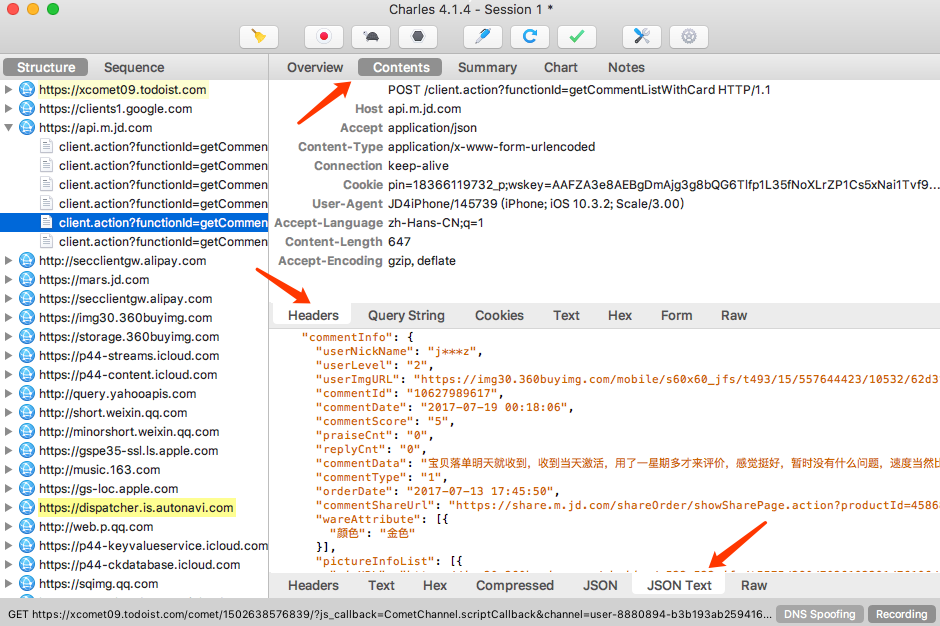
由于这个请求是 POST 请求,所以我们还需要关心的就是 POST 的表单信息,切换到 Form 选项卡即可查看
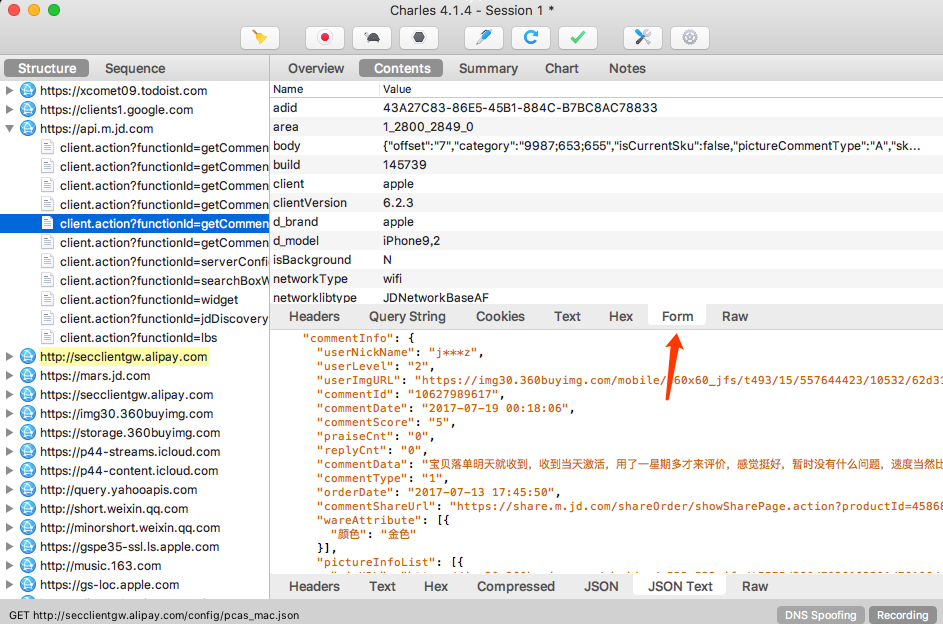
这样我们就成功抓取 App 中的评论接口的请求和响应,并且可以查看 Response 返回的 JSON 数据。
至于其他 App,我们同样可以使用这样的方式来分析。如果我们可以直接分析得到请求的 URL 和参数的规律,直接用程序模拟即可批量抓取
重发
Charles 还有一个强大功能,它可以将捕获到的请求加以修改并发送修改后的请求。点击上方的修改按钮,左侧列表就多了一个以编辑图标为开头的链接,这就代表此链接对应的请求正在被我们修改
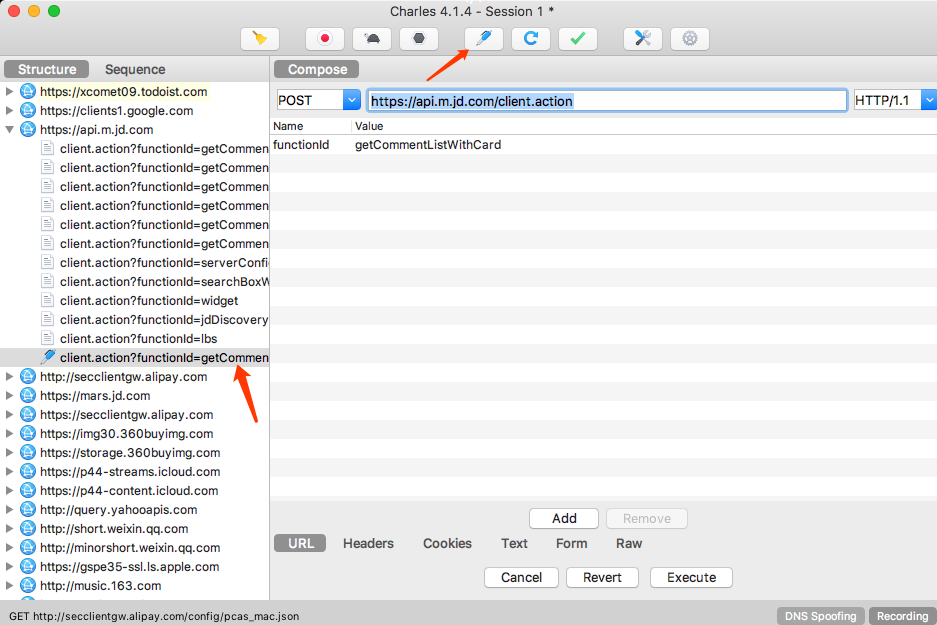
我们可以将 Form 中的某个字段移除,比如这里将 partner 字段移除,然后点击 Remove。这时我们已经对原来请求携带的 Form Data 做了修改,然后点击下方的 Execute 按钮即可执行修改后的请求
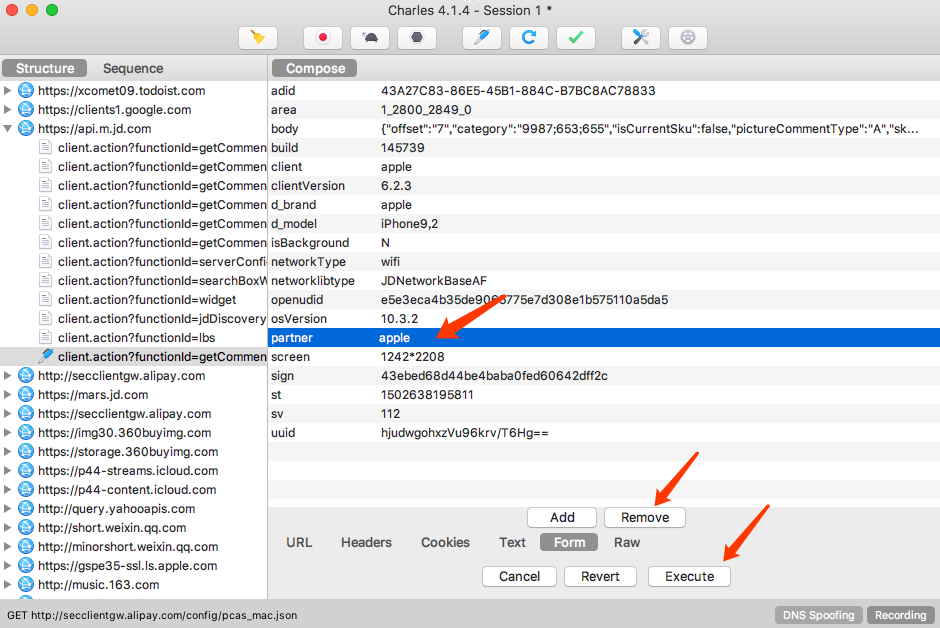
可以发现左侧列表再次出现了接口的请求结果,内容仍然不变
删除 Form 表单中的 partner 字段并没有带来什么影响,所以这个字段是无关紧要的。
有了这个功能,我们就可以方便地使用 Charles 来做调试,可以通过修改参数、接口等来测试不同请求的响应状态,就可以知道哪些参数是必要的哪些是不必要的,以及参数分别有什么规律,最后得到一个最简单的接口和参数形式以供程序模拟调用使用
以上内容便是通过 Charles 抓包分析 App 请求的过程。通过 Charles,我们成功抓取 App 中流经的网络数据包,捕获原始的数据,还可以修改原始请求和重新发起修改后的请求进行接口测试。
知道了请求和响应的具体信息,如果我们可以分析得到请求的 URL 和参数的规律,直接用程序模拟即可批量抓取,这当然最好不过了。
但是随着技术的发展,App 接口往往会带有密钥,我们并不能直接找到这些规律,那么怎么办呢?接下来,我们将了解利用 Charles 和 mitmdump 直接对接 Python 脚本实时处理抓取到的 Response 的过程。
mitmproxy抓包工具的使用
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,有类似 Fiddler、Charles 的功能,只不过它是一个控制台的形式操作。
mitmproxy 还有两个关联组件。一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它我们可以对接 Python 脚本,用 Python 实现监听后的处理。另一个是 mitmweb,它是一个 Web 程序,通过它我们可以清楚观察 mitmproxy 捕获的请求。
下面我们来了解它们的用法。
准备工作
请确保已经正确安装好了 mitmproxy,并且手机和 PC 处于同一个局域网下,同时配置好了 mitmproxy 的 CA 证书
mitmproxy 的功能
mitmproxy 有如下几项功能。
- 拦截 HTTP 和 HTTPS 请求和响应
- 保存 HTTP 会话并进行分析
- 模拟客户端发起请求,模拟服务端返回响应
- 利用反向代理将流量转发给指定的服务器
- 支持 Mac 和 Linux 上的透明代理
- 利用 Python 对 HTTP 请求和响应进行实时处理
抓包原理
和 Charles 一样,mitmproxy 运行于自己的 PC 上,mitmproxy 会在 PC 的 8080 端口运行,然后开启一个代理服务,这个服务实际上是一个 HTTP/HTTPS 的代理。
手机和 PC 在同一个局域网内,设置代理为 mitmproxy 的代理地址,这样手机在访问互联网的时候流量数据包就会流经 mitmproxy,mitmproxy 再去转发这些数据包到真实的服务器,服务器返回数据包时再由 mitmproxy 转发回手机,这样 mitmproxy 就相当于起了中间人的作用,抓取到所有 Request 和 Response,另外这个过程还可以对接 mitmdump,抓取到的 Request 和 Response 的具体内容都可以直接用 Python 来处理,比如得到 Response 之后我们可以直接进行解析,然后存入数据库,这样就完成了数据的解析和存储过程。
设置代理
首先,我们需要运行 mitmproxy,命令如下所示:
启动 mitmproxy 的命令如下:
1 | mitmproxy |
运行之后会在 8080 端口上运行一个代理服务,如图 11-12 所示:
右下角会出现当前正在监听的端口。
或者启动 mitmdump,它也会监听 8080 端口,命令如下所示:
1 | mitmdump |

将手机和 PC 连接在同一局域网下,设置代理为当前代理。首先看看 PC 的当前局域网 IP。
Windows 上的命令如下所示:
1 | ipconfig |
Linux 和 Mac 上的命令如下所示:
1 | ifconfig |
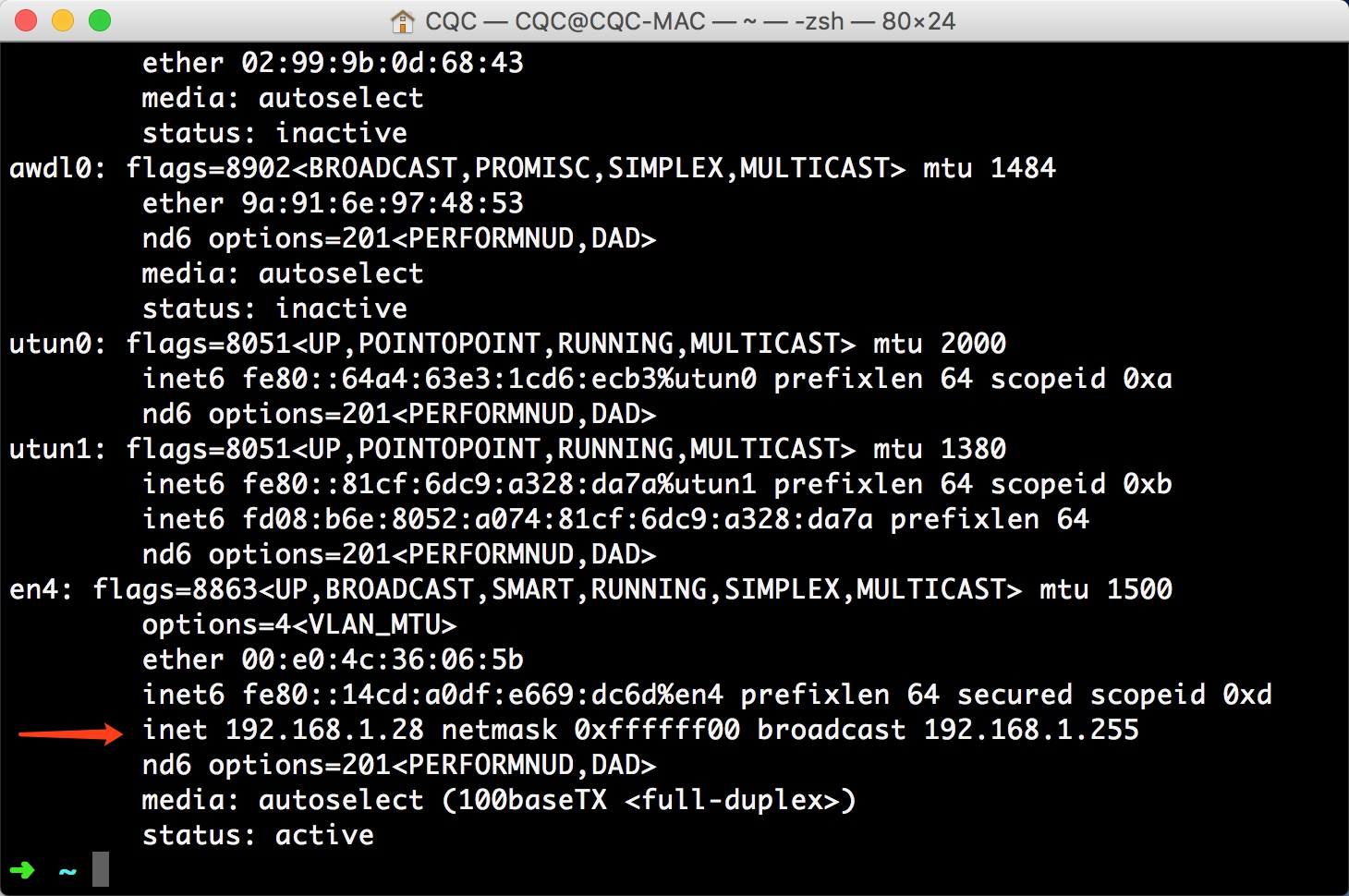
一般类似 10.*.*.* 或 172.16.*.* 或 192.168.1.* 这样的 IP 就是当前 PC 的局域网 IP,例如此图中 PC 的 IP 为 192.168.1.28,手机代理设置类似。
这样我们就配置好了 mitmproxy 的的代理。
mitmproxy 的使用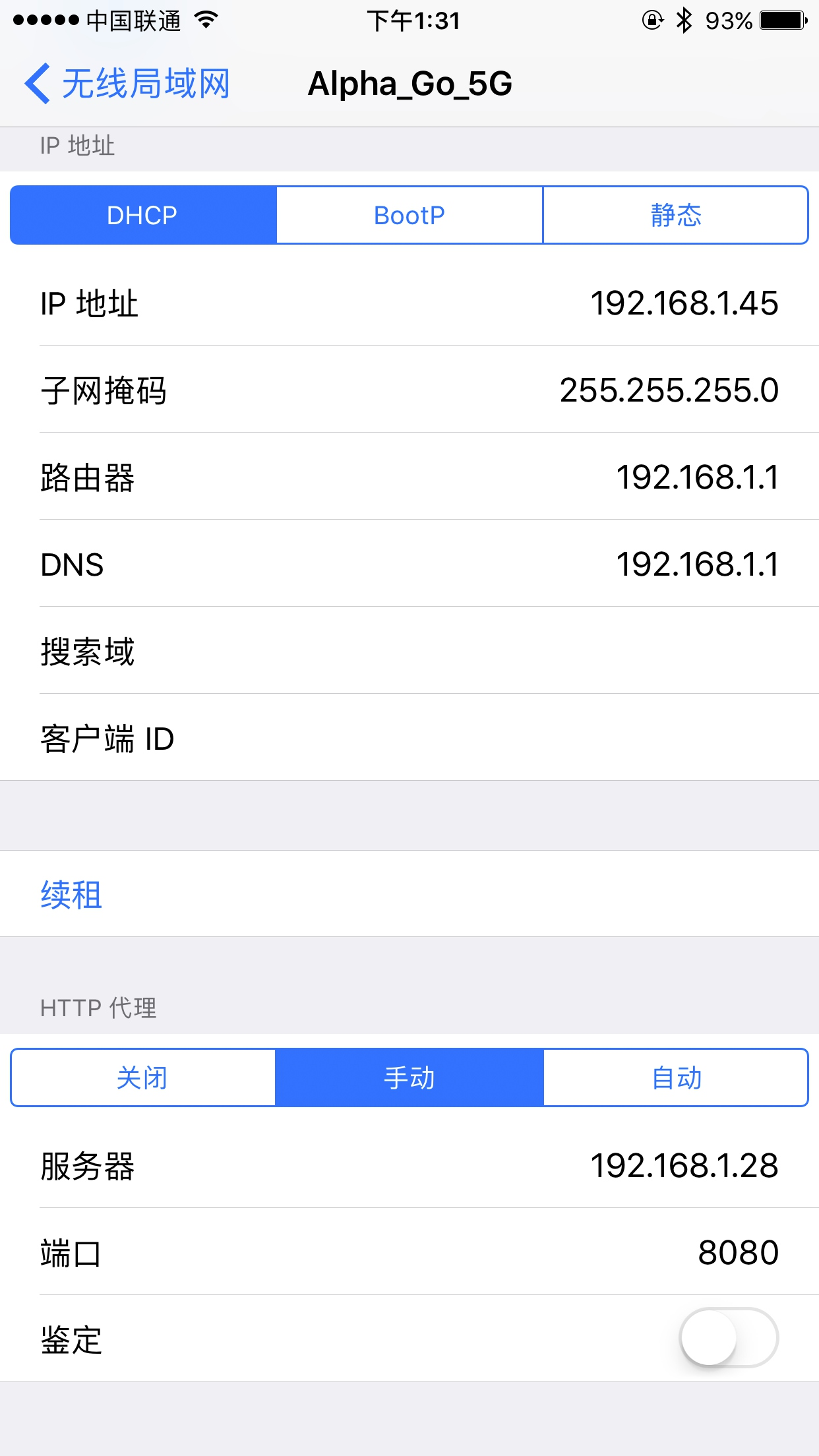 手机和 PC 处于同一个局域网内,设置了 mitmproxy 的代理,具体的配置方法可以参考第 1 章。
手机和 PC 处于同一个局域网内,设置了 mitmproxy 的代理,具体的配置方法可以参考第 1 章。
运行 mitmproxy,命令如下所示:
1 | mitmproxy |
设置成功之后,我们只需要在手机浏览器上访问任意的网页或浏览任意的 App 即可。例如在手机上打开百度,mitmproxy 页面便会呈现出手机上的所有请求。
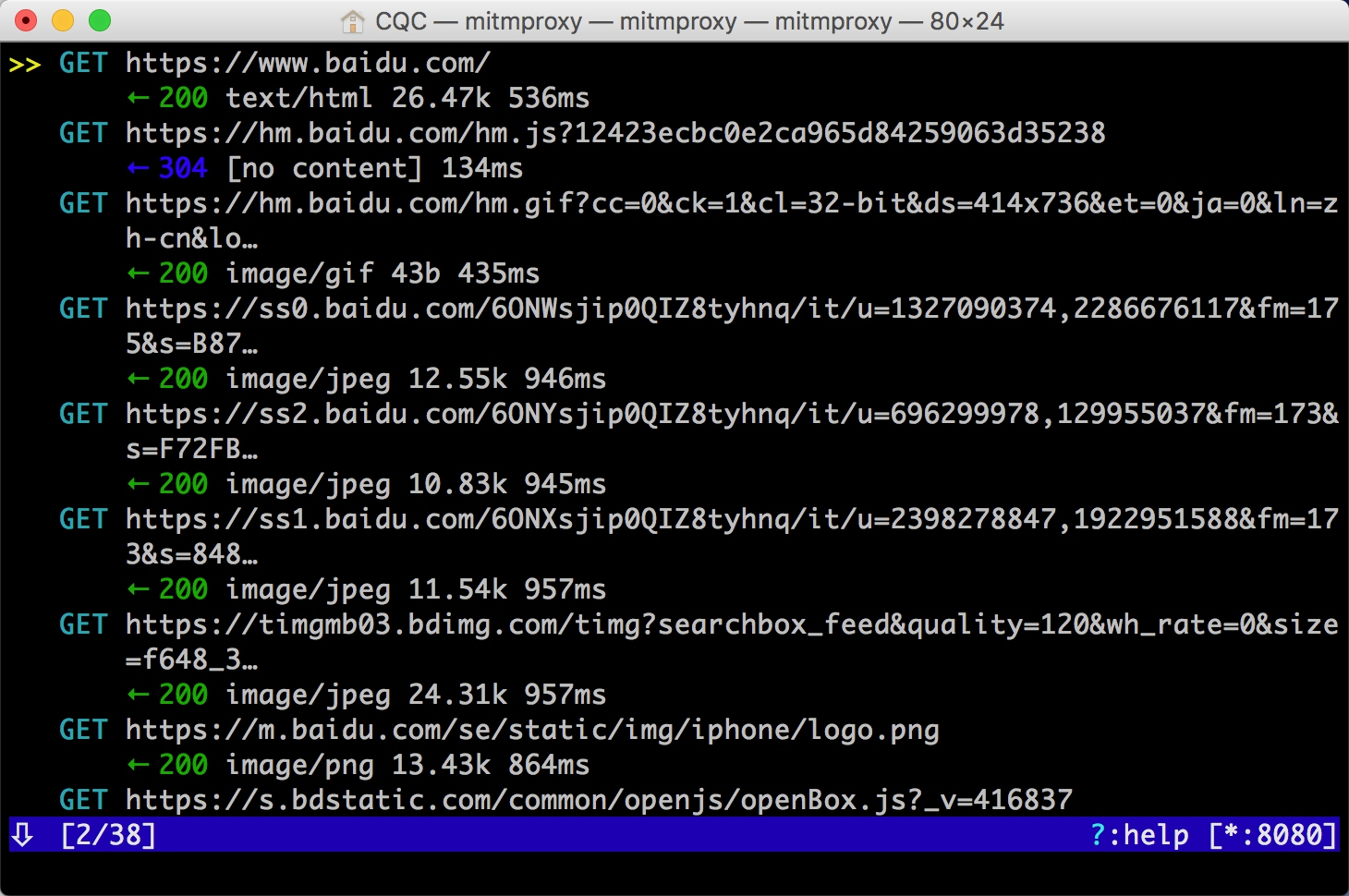
这就相当于之前我们在浏览器开发者工具监听到的浏览器请求,在这里我们借助于 mitmproxy 完成。Charles 完全也可以做到。
这里是刚才手机打开百度页面时的所有请求列表,左下角显示的 2/38 代表一共发生了 38 个请求,当前箭头所指的是第二个请求。
每个请求开头都有一个 GET 或 POST,这是各个请求的请求方式。紧接的是请求的 URL。第二行开头的数字就是请求对应的响应状态码,后面是响应内容的类型,如 text/html 代表网页文档、image/gif 代表图片。再往后是响应体的大小和响应的时间。
当前呈现了所有请求和响应的概览,我们可以通过这个页面观察到所有的请求。
如果想查看某个请求的详情,我们可以敲击回车,进入请求的详情页面。
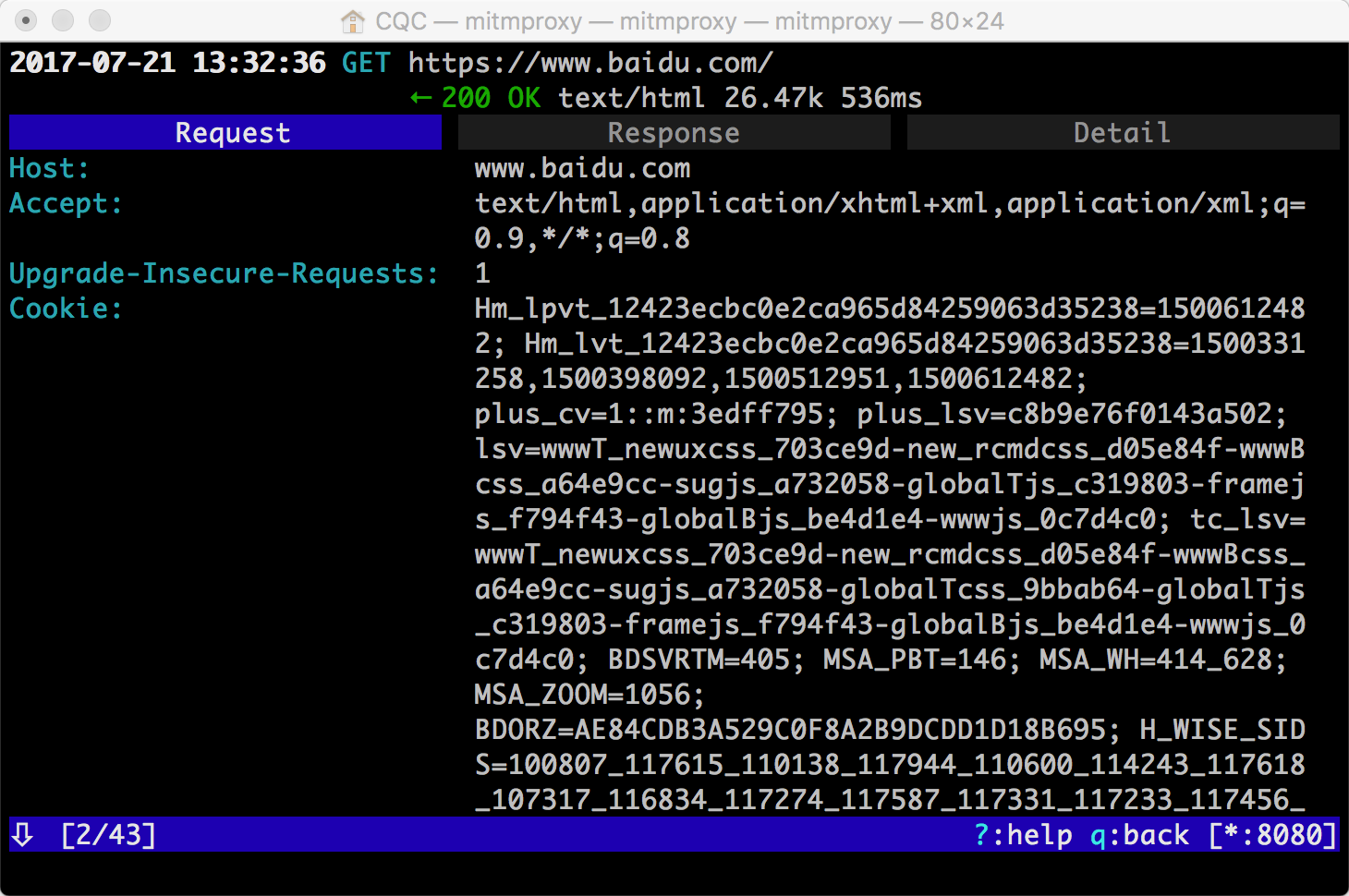
可以看到 Headers 的详细信息,如 Host、Cookies、User-Agent 等。
最上方是一个 Request、Response、Detail 的列表,当前处在 Request 这个选项上。这时我们再点击 TAB 键,即可查看这个请求对应的响应详情。
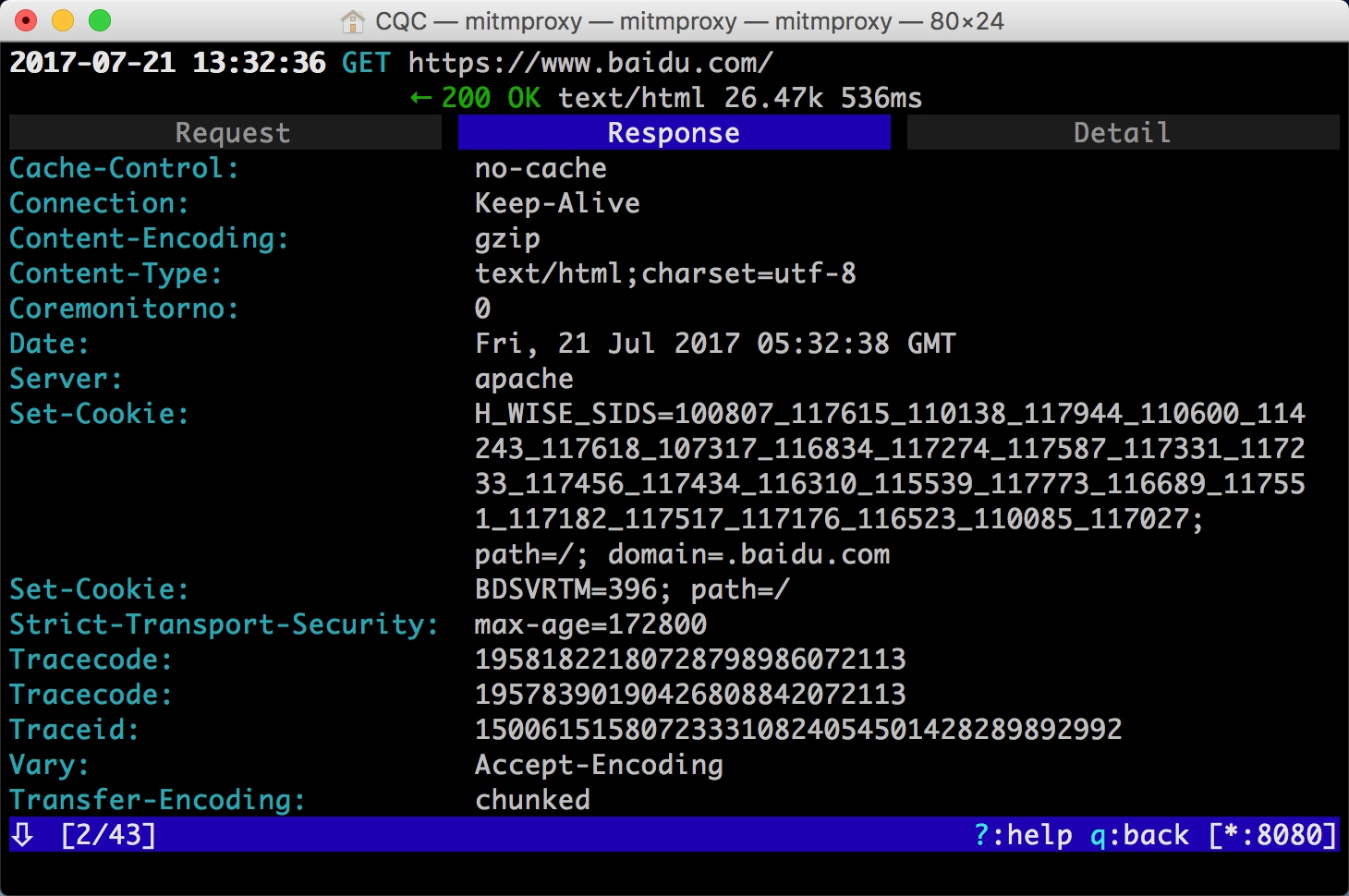
最上面是响应头的信息,下拉之后我们可以看到响应体的信息。针对当前请求,响应体就是网页的源代码。
这时再敲击 TAB 键,切换到最后一个选项卡 Detail,即可看到当前请求的详细信息,如服务器的 IP 和端口、HTTP 协议版本、客户端的 IP 和端口等。
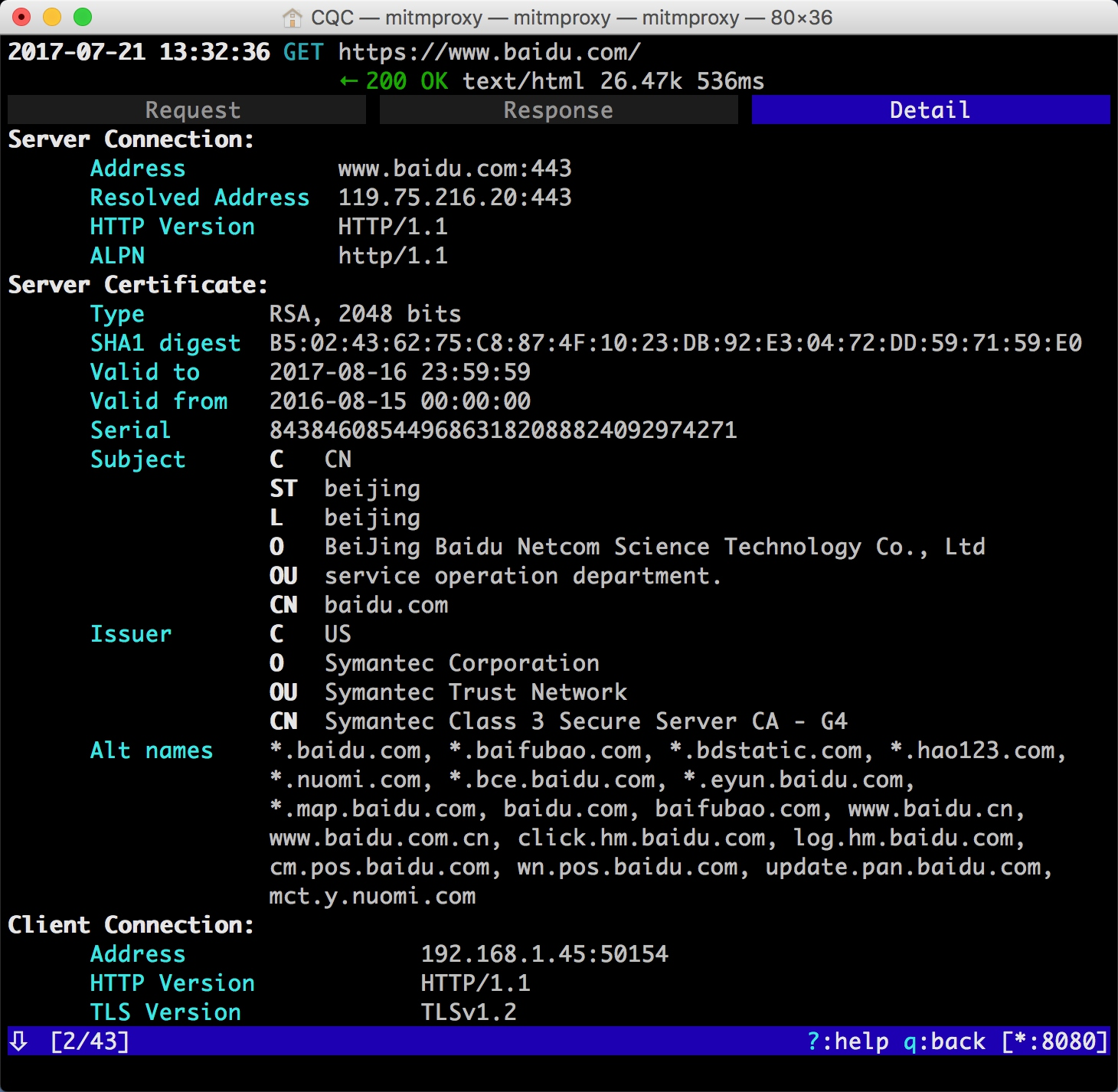
mitmproxy 还提供了命令行式的编辑功能,我们可以在此页面中重新编辑请求。敲击 e 键即可进入编辑功能,这时它会询问你要编辑哪部分内容,如 Cookies、Query、URL 等,每个选项的第一个字母会高亮显示。敲击要编辑内容名称的首字母即可进入该内容的编辑页面,如敲击 m 即可编辑请求的方式,敲击 q 即可修改 GET 请求参数 Query。
这时我们敲击 q,进入到编辑 Query 的页面。由于没有任何参数,我们可以敲击 a 来增加一行,然后就可以输入参数对应的 Key 和 Value。
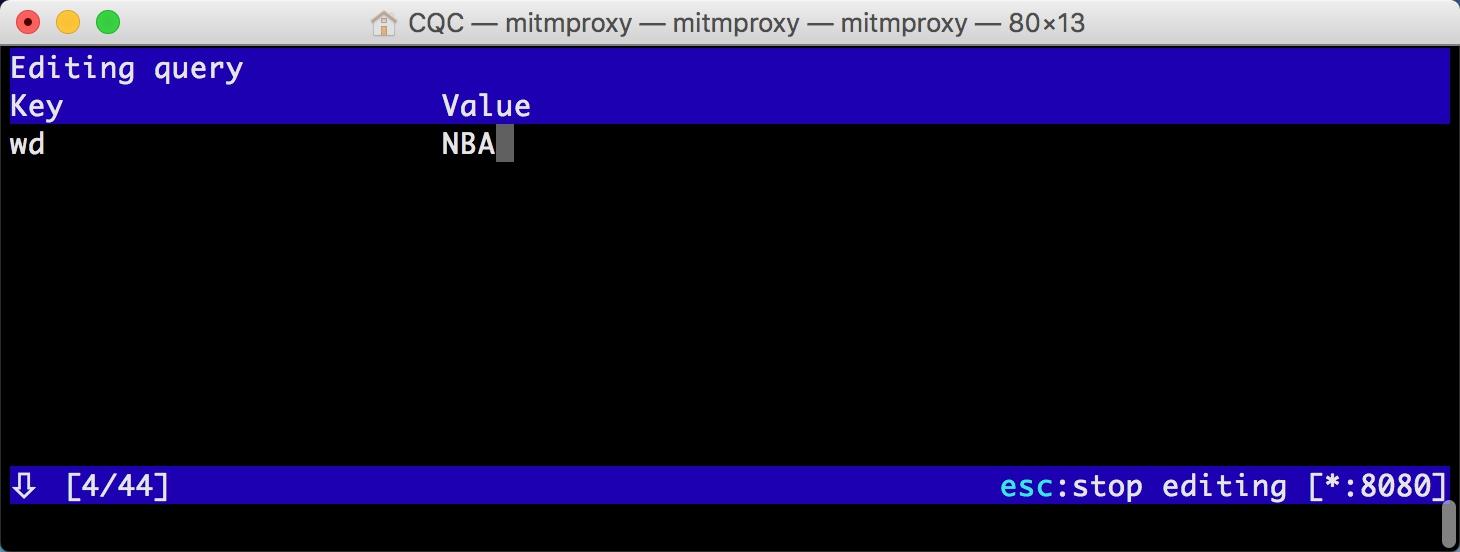
这里我们输入 Key 为 wd,Value 为 NBA。
然后再敲击 esc 键和 q 键,返回之前的页面,再敲击 e 和 p 键修改 Path。和上面一样,敲击 a 增加 Path 的内容,这时我们将 Path 修改为 s。
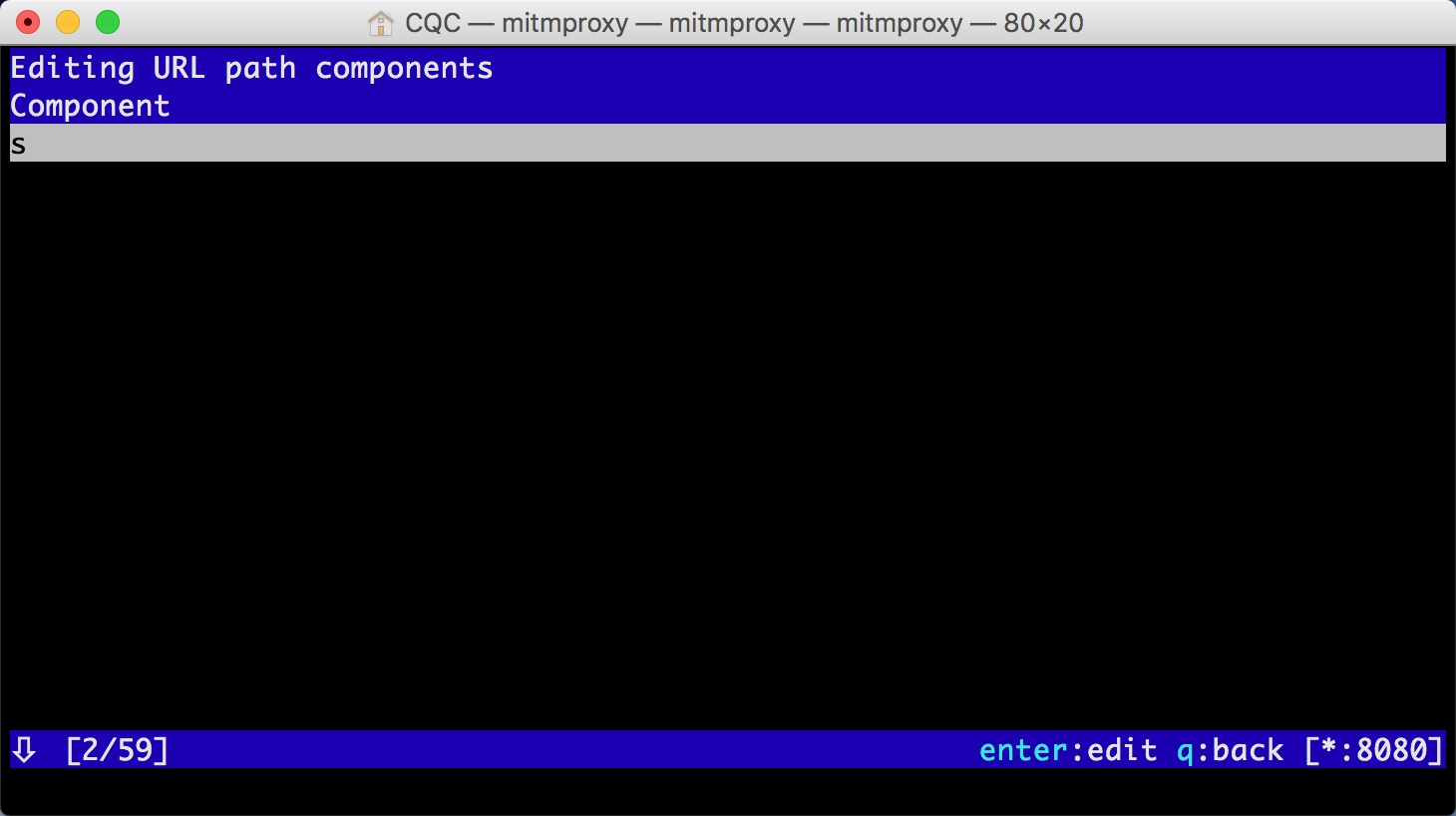
再敲击 esc 和 q 键返回,这时我们可以看到最上面的请求链接变成了 https://www.baidu.com/s?wd=NBA,访问这个页面,可以看到百度搜索 NBA 关键词的搜索结果。
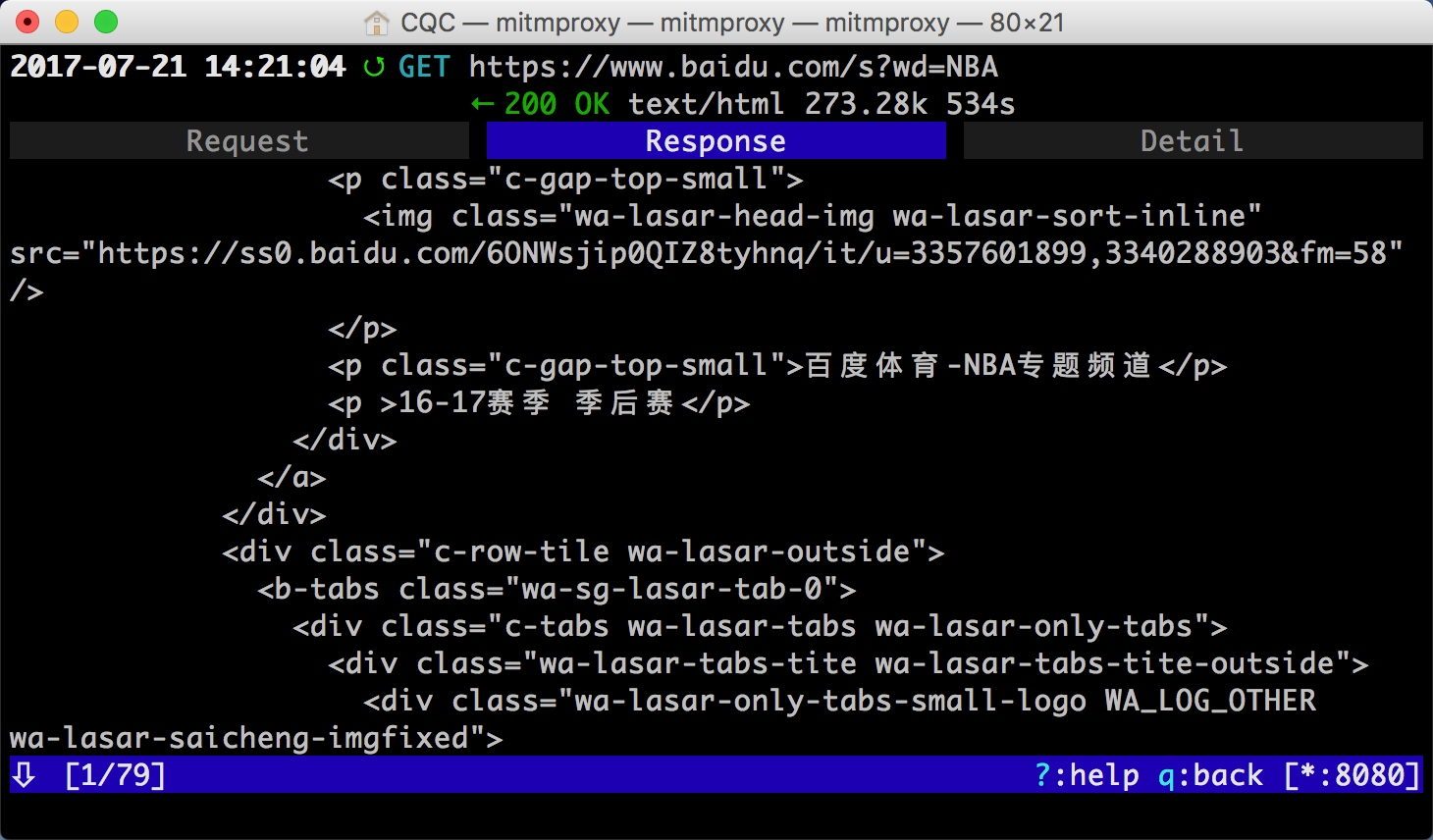
敲击 a 保存修改,敲击 r 重新发起修改后的请求,即可看到上方请求方式前面多了一个回旋箭头,这说明重新执行了修改后的请求。这时我们再观察响应体内容,即可看到搜索 NBA 的页面结果的源代码。
以上内容便是 mitmproxy 的简单用法。利用 mitmproxy,我们可以观察到手机上的所有请求,还可以对请求进行修改并重新发起。
Fiddler、Charles 也有这个功能,而且它们的图形界面操作更加方便。那么 mitmproxy 的优势何在?
mitmproxy 的强大之处体现在它的另一个工具 mitmdump,有了它我们可以直接对接 Python 对请求进行处理。下面我们来看看 mitmdump 的用法。
mitmdump实时抓包处理
mitmdump 是 mitmproxy 的命令行接口,同时还可以对接 Python 对请求进行处理,这是相比 Fiddler、Charles 等工具更加方便的地方。有了它我们可以不用手动截获和分析 HTTP 请求和响应,只需写好请求和响应的处理逻辑即可。它还可以实现数据的解析、存储等工作,这些过程都可以通过 Python 实现。
实例引入
我们可以使用命令启动 mitmproxy,并把截获的数据保存到文件中,命令如下所示:
1 | mitmdump -w outfile |
其中 outfile 的名称任意,截获的数据都会被保存到此文件中。
还可以指定一个脚本来处理截获的数据,使用 - s 参数即可:
1 | mitmdump -s script.py |
这里指定了当前处理脚本为 script.py,它需要放置在当前命令执行的目录下。
我们可以在脚本里写入如下的代码:
1 | def request(flow): |
我们定义了一个 request() 方法,参数为 flow,它其实是一个 HTTPFlow 对象,通过 request 属性即可获取到当前请求对象。然后打印输出了请求的请求头,将请求头的 User-Agent 修改成了 MitmProxy。
运行之后我们在手机端访问 http://httpbin.org/get,就可以看到有如下情况发生。
手机端的页面

PC 端控制台输出。
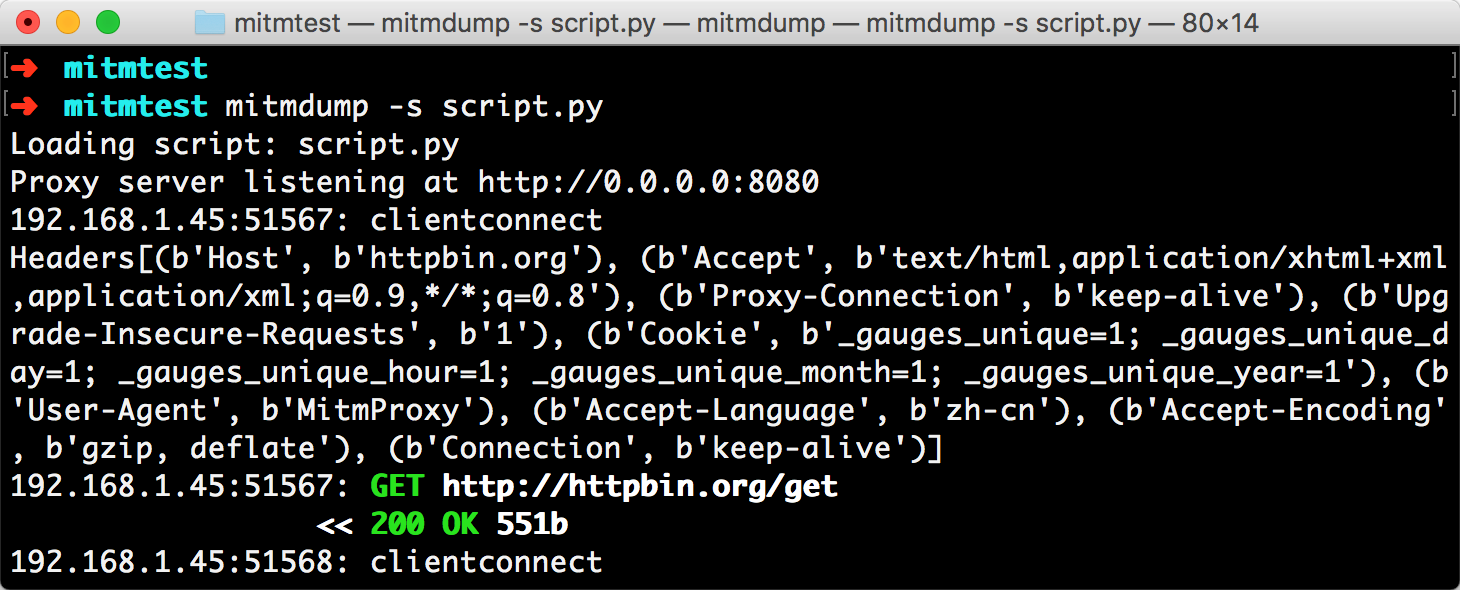
手机端返回结果的 Headers 实际上就是请求的 Headers,User-Agent 被修改成了 mitmproxy。PC 端控制台输出了修改后的 Headers 内容,其 User-Agent 的内容正是 mitmproxy。
所以,通过这三行代码我们就可以完成对请求的改写。print() 方法输出结果可以呈现在 PC 端控制台上,可以方便地进行调试。
日志输出
mitmdump 提供了专门的日志输出功能,可以设定不同级别以不同颜色输出结果。我们把脚本修改成如下内容:
1 | from mitmproxy import ctx |
这里调用了 ctx 模块,它有一个 log 功能,调用不同的输出方法就可以输出不同颜色的结果,以方便我们做调试。例如,info() 方法输出的内容是白色的,warn() 方法输出的内容是黄色的,error() 方法输出的内容是红色的。运行结果。
不同的颜色对应不同级别的输出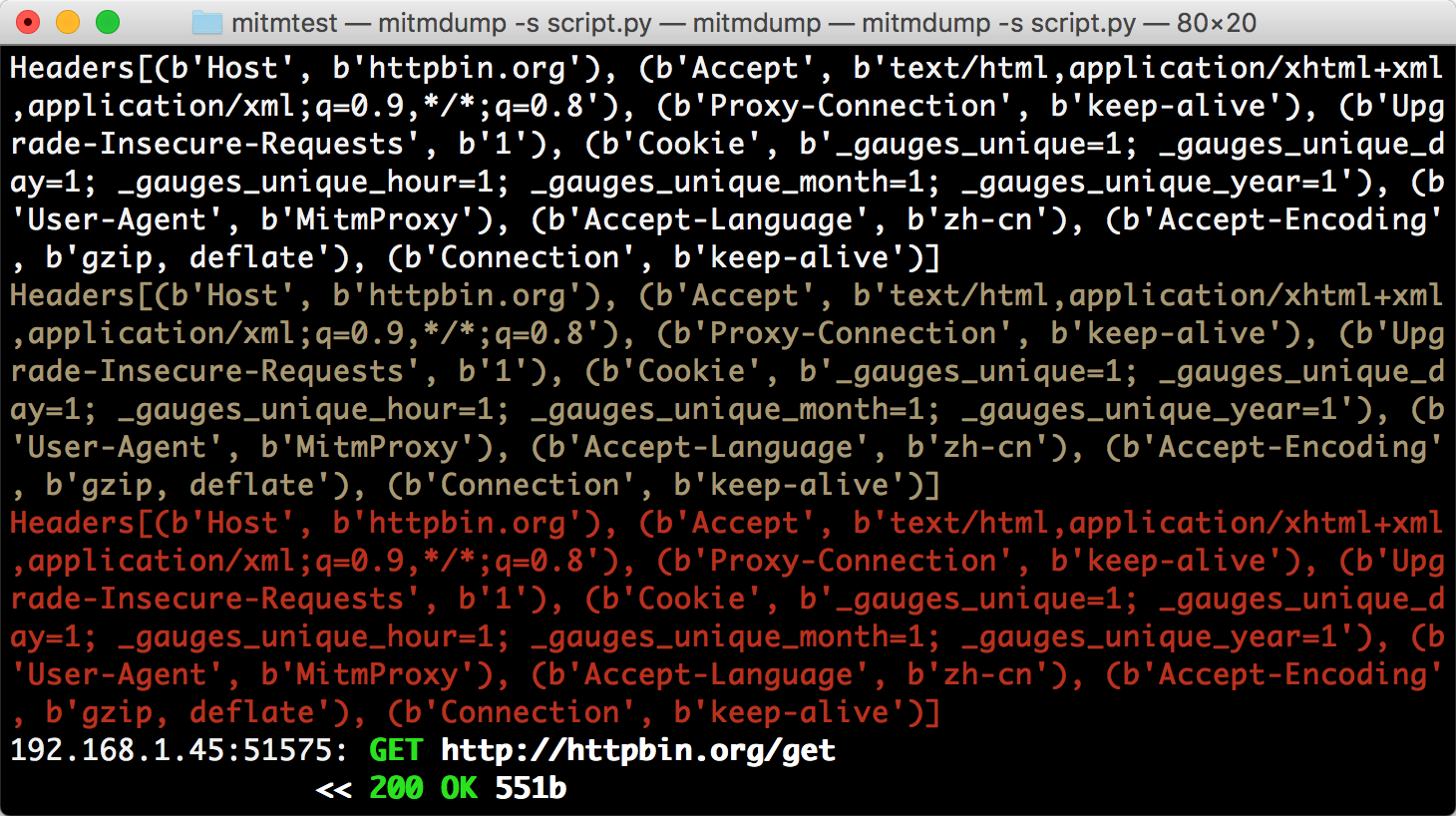 ,我们可以将不同的结果合理划分级别输出,以更直观方便地查看调试信息。
,我们可以将不同的结果合理划分级别输出,以更直观方便地查看调试信息。
Request
最开始我们实现了 request() 方法并且对 Headers 进行了修改。下面我们来看看 Request 还有哪些常用的功能。我们先用一个实例来感受一下。
1 | from mitmproxy import ctx |
我们修改脚本,然后在手机上打开百度,即可看到 PC 端控制台输出了一系列的请求,在这里我们找到第一个请求。控制台打印输出了 Request 的一些常见属性,如 URL、Headers、Cookies、Host、Method、Scheme 等。
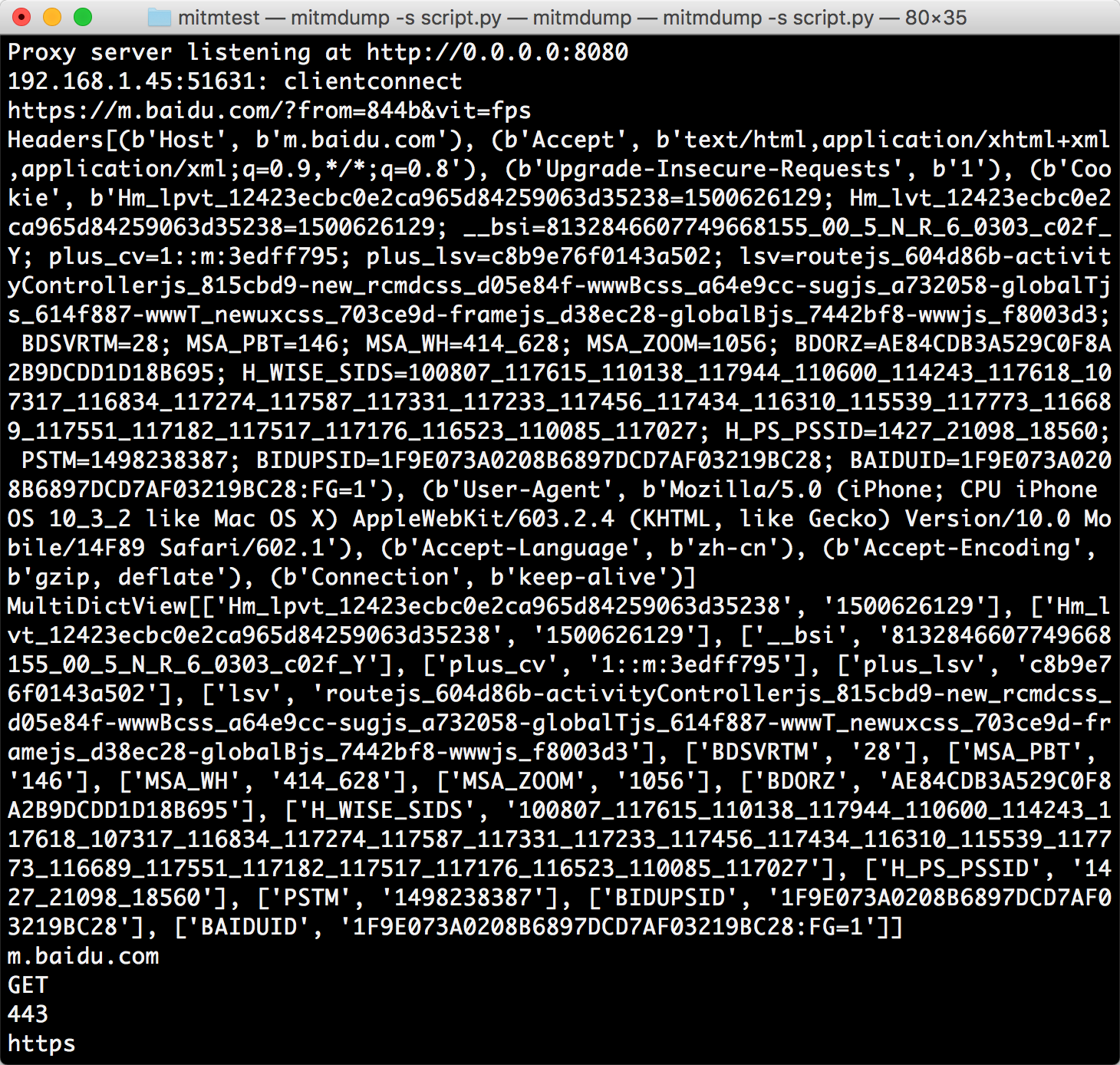
结果中分别输出了请求链接、请求头、请求 Cookies、请求 Host、请求方法、请求端口、请求协议这些内容。
同时我们还可以对任意属性进行修改,就像最初修改 Headers 一样,直接赋值即可。例如,这里将请求的 URL 修改一下,脚本修改如下所示:
1 | def request(flow): |
手机端得到如下结果。

比较有意思的是,浏览器最上方还是呈现百度的 URL,但是页面已经变成了 httpbin.org 的页面了。另外,Cookies 明显还是百度的 Cookies。我们只是用简单的脚本就成功把请求修改为其他的站点。通过这种方式修改和伪造请求就变得轻而易举。
通过这个实例我们知道,有时候 URL 虽然是正确的,但是内容并非是正确的。我们需要进一步提高自己的安全防范意识。
Request 还有很多属性,在此不再一一列举。更多属性可以参考:http://docs.mitmproxy.org/en/latest/scripting/api.html。
只要我们了解了基本用法,会很容易地获取和修改 Reqeust 的任意内容,比如可以用修改 Cookies、添加代理等方式来规避反爬。
Response
对于爬虫来说,我们更加关心的其实是响应的内容,因为 Response Body 才是爬取的结果。对于响应来说,mitmdump 也提供了对应的处理接口,就是 response() 方法。下面我们用一个实例感受一下。
1 | from mitmproxy import ctx |
将脚本修改为如上内容,然后手机访问:http://httpbin.org/get。
这里打印输出了响应的 status_code、headers、cookies、text 这几个属性,其中最主要的 text 属性就是网页的源代码。
PC 端控制台输出。
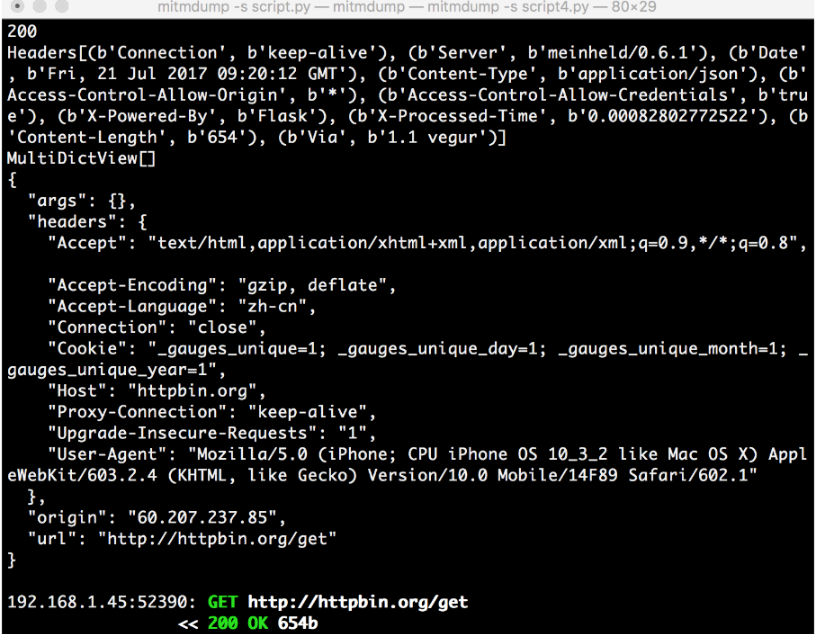
控制台输出了响应的状态码、响应头、Cookies、响应体这几部分内容。
我们可以通过 response() 方法获取每个请求的响应内容。接下来再进行响应的信息提取和存储,我们就可以成功完成爬取了。
appium的使用
airtest的使用
手机群控爬取
云手机使用
使用抓包工具还是停留在表面,某些情况下需要对app进行逆向找到核心逻辑以及数据请求究竟是怎么实现的,就涉及到app的逆向、脱壳、模拟执行so文件等技术。
 微信
微信 支付宝
支付宝

