【微服务从入门到入土】JavaScript逆向爬虫
我们抓取,我们采集,我们分析,我们挖掘
网站加密和混淆技术
随着大数据时代的发展,各个公司的数据保护意识越来越强,大家都在想尽办法保护自家产品的数据不轻易被爬虫爬走。由于网页是提供信息和服务的重要载体,所以对网页上的信息进行保护就成了至关重要的一个环节。
网页是运行在浏览器端的,当我们浏览一个网页时,其 HTML 代码、 JavaScript 代码都会被下载到浏览器中执行。借助浏览器的开发者工具,我们可以看到网页在加载过程中所有网络请求的详细信息,也能清楚地看到网站运行的 HTML 代码和 JavaScript 代码,这些代码中就包含了网站加载的全部逻辑,如加载哪些资源、请求接口是如何构造的、页面是如何渲染的等等。正因为代码是完全透明的,所以如果我们能够把其中的执行逻辑研究出来,就可以模拟各个网络请求进行数据爬取了。
然而,事情没有想象得那么简单。随着前端技术的发展,前端代码的打包技术、混淆技术、加密技术也层出不穷,借助于这些技术,各个公司可以在前端对 JavaScript 代码采取一定的保护,比如变量名混淆、执行逻辑混淆、反调试、核心逻辑加密等,这些保护手段使得我们没法很轻易地找出 JavaScript 代码中包含的的执行逻辑。
在前几章的案例中,我们也试着爬取了各种形式的网站。其中有的网站的数据接口是没有任何验证或加密参数的,我们可以轻松模拟并爬取其中的数据;但有的网站稍显复杂,网站的接口中增加了一些加密参数,同时对 JavaScript 代码采取了上文所述的一些防护措施,当时我们没有直接尝试去破解,而是用 Selenium 等类似工具来实现模拟浏览器执行的方式来进行 “所见即所得 “的爬取。其实对于后者,我们还有另外一种解决方案,那就是直接逆向 JavaScript 代码,找出其中的加密逻辑,从而直接实现该加密逻辑来进行爬取。如果加密逻辑实在过于复杂,我们也可以找出一些关键入口,从而实现对加密逻辑的单独模拟执行和数据爬取。这些方案难度可能很大,比如关键入口很难寻找,或者加密逻辑难以模拟,可是一旦成功找到突破口,我们便可以不用借助于 Selenium 等工具进行整页数据的渲染而实现数据爬取,这样爬取效率会大幅提升。
本章我们首先会对 JavaScript 防护技术进行介绍,然后介绍一些常用的 JavaScript 逆向技巧,包括浏览器工具的使用、Hook 技术、AST 技术、特殊混淆技术的处理、WebAssembly 技术的处理。了解了这些技术,我们可以更从容地应对 JavaScript 防护技术。
1. 引入
我们在爬取网站的时候,会遇到一些情况需要分析一些接口或 URL 信息,在这个过程中,我们会遇到各种各样类似加密的情形,比如说:
- 某个网站的 URL 带有一些看不太懂的长串加密参数,要抓取就必须要懂得这些参数是怎么构造的,否则我们连完整的 URL 都构造不出来,更不用说爬取了。
- 分析某个网站的 Ajax 接口的时候,可以看到接口的一些参数也是加密的,或者 Request Headers 里面也可能带有一些加密参数,如果不知道这些参数的具体构造逻辑就没法直接用程序来模拟这些 Ajax 请求。
- 翻看网站的 JavaScript 源代码,可以发现很多压缩了或者看不太懂的字符,比如 JavaScript 文件名被编码,JavaScript 的文件内容都压缩成几行,JavaScript 变量也被修改成单个字符或者一些十六进制的字符,导致我们不好轻易根据 JavaScript 找出某些接口的加密逻辑。
这些情况呢,基本上都是网站为了保护其本身的一些数据不被轻易抓取而采取的一些措施,我们可以把它归类为两大类:
- URL/API 参数加密
- JavaScript 压缩、混淆和加密
这一节我们就来了解下这两类技术的基本原理和一些常见的示例。知己知彼,百战不殆,了解了这些技术的实现原理之后,我们才能更好地去逆向其中的逻辑,从而实现数据爬取。
2. 网站数据防护方案
当今大数据时代,数据已经变得越来越重要,网页和 App 现在是主流的数据载体,如果其数据的 API 没有设置任何保护措施,在爬虫工程师解决了一些基本的反爬如封 IP、验证码的问题之后,那么数据还是可以被轻松爬取到的。
那么,有没有可能在 URL/API 层面或 JavaScript 层面也加上一层防护呢?答案是可以。
URL/API 参数加密
网站运营者首先想到防护措施可能是对某些数据接口的参数进行加密,比如说对某些 URL 的一些参数加上校验码或者把一些 id 信息进行编码,使其变得难以阅读或构造;或者对某些 API 请求加上一些 token、sign 等签名,这样这些请求发送到服务器时,服务器会通过客户端发来的一些请求信息以及双方约定好的秘钥等来对当前的请求进行校验,如果校验通过,才返回对应数据结果。
比如说客户端和服务端约定一种接口校验逻辑,客户端在每次请求服务端接口的时候都会附带一个 sign 参数,这个 sign 参数可能是由当前时间信息、请求的 URL、请求的数据、设备的 ID、双方约定好的秘钥经过一些加密算法构造而成的,客户端会实现这个加密算法构造 sign,然后每次请求服务器的时候附带上这个参数。服务端会根据约定好的算法和请求的数据对 sign 进行校验,如果校验通过,才返回对应的数据,否则拒绝响应。
当然登录状态的校验也可以看作是此类方案,比如一个 API 的调用必须要传一个 token,这个 token 必须用户登录之后才能获取,如果请求的时候不带该 token,API 就不会返回任何数据。
倘若没有这种措施,那么基本上 URL 或者 API 接口是完全公开可以访问的,这意味着任何人都可以直接调用来获取数据,几乎是零防护的状态,这样是非常危险的,而且数据也可以被轻易地被爬虫爬取。因此对 URL/API 参数一些加密和校验是非常有必要的。
JavaScript 压缩、混淆和加密
接口加密技术看起来的确是一个不错的解决方案,但单纯依靠它并不能很好地解决问题。为什么呢?
对于网页来说,其逻辑是依赖于 JavaScript 来实现的,JavaScript 有如下特点:
- JavaScript 代码运行于客户端,也就是它必须要在用户浏览器端加载并运行。
- JavaScript 代码是公开透明的,也就是说浏览器可以直接获取到正在运行的 JavaScript 的源码。
由于这两个原因,至使 JavaScript 代码是不安全的,任何人都可以读、分析、复制、盗用,甚至篡改。
所以说,对于上述情形,客户端 JavaScript 对于某些加密的实现是很容易被找到或模拟的,了解了加密逻辑后,模拟参数的构造和请求也就是轻而易举了,所以如果 JavaScript 没有做任何层面的保护的话,接口加密技术基本上对数据起不到什么防护作用。
如果你不想让自己的数据被轻易获取,不想他人了解 JavaScript 逻辑的实现,或者想降低被不怀好意的人甚至是黑客攻击。那么就需要用到 JavaScript 压缩、混淆和加密技术了。
这里压缩、混淆和加密技术简述如下:
代码压缩:即去除 JavaScript 代码中的不必要的空格、换行等内容,使源码都压缩为几行内容,降低代码可读性,当然同时也能提高网站的加载速度。
代码混淆:使用变量替换、字符串阵列化、控制流平坦化、多态变异、僵尸函数、调试保护等手段,使代码变地难以阅读和分析,达到最终保护的目的。但这不影响代码原有功能。是理想、实用的 JavaScript 保护方案。
代码加密:可以通过某种手段将 JavaScript 代码进行加密,转成人无法阅读或者解析的代码,如借用 WebAssembly 技术,可以直接将 JavaScript 代码用 C/C++ 实现,JavaScript 调用其编译后形成的文件来执行相应的功能。
下面我们对上面的技术分别予以介绍。
3. URL/API 参数加密
现在绝大多数网站的数据一般都是通过服务器提供的 API 来获取的,网站或 App 可以请求某个数据 API 获取到对应的数据,然后再把获取的数据展示出来。但有些数据是比较宝贵或私密的,这些数据肯定是需要一定层面上的保护。所以不同 API 的实现也就对应着不同的安全防护级别,我们这里来总结下。
为了提升接口的安全性,客户端会和服务端约定一种接口校验方式,一般来说会使用到各种加密和编码算法,如 Base64、Hex 编码,MD5、AES、DES、RSA 等对称或非对称加密。
举个例子,比如说客户端和服务器双方约定一个 sign 用作接口的签名校验,其生成逻辑是客户端将 URL Path 进行 MD5 加密然后拼接上 URL 的某个参数再进行 Base64 编码,最后得到一个字符串 sign,这个 sign 会通过 Request URL 的某个参数或 Request Headers 发送给服务器。服务器接收到请求后,对 URL Path 同样进行 MD5 加密,然后拼接上 URL 的某个参数,也进行 Base64 编码也得到了一个 sign,然后比对生成的 sign 和客户端发来的 sign 是否是一致的,如果是一致的,那就返回正确的结果,否则拒绝响应。这就是一个比较简单的接口参数加密的实现。如果有人想要调用这个接口的话,必须要定义好 sign 的生成逻辑,否则是无法正常调用接口的。
当然上面的这个实现思路比较简单,这里还可以增加一些时间戳信息增加时效性判断,或增加一些非对称加密进一步提高加密的复杂程度。但不管怎样,只要客户端和服务器约定好了加密和校验逻辑,任何形式加密算法都是可以的。
这里要实现接口参数加密就需要用到一些加密算法,客户端和服务器肯定也都有对应的 SDK 实现这些加密算法,如 JavaScript 的 crypto-js,Python 的 hashlib、Crypto 等等。
但还是如上文所说,如果是网页的话,客户端实现加密逻辑如果是用 JavaScript 来实现,其源代码对用户是完全可见的,如果没有对 JavaScript 做任何保护的话,是很容易弄清楚客户端加密的流程的。
因此,我们需要对 JavaScript 利用压缩、混淆等方式来对客户端的逻辑进行一定程度上的保护。
4. JavaScript 压缩
这个非常简单,JavaScript 压缩即去除 JavaScript 代码中的不必要的空格、换行等内容或者把一些可能公用的代码进行处理实现共享,最后输出的结果都压缩为几行内容,代码可读性变得很差,同时也能提高网站加载速度。
如果仅仅是去除空格换行这样的压缩方式,其实几乎是没有任何防护作用的,因为这种压缩方式仅仅是降低了代码的直接可读性。如果我们有一些格式化工具可以轻松将 JavaScript 代码变得易读,比如利用 IDE、在线工具或 Chrome 浏览器都能还原格式化的代码。
比如这里举一个最简单的 JavaScript 压缩示例,原来的 JavaScript 代码是这样的:
1 | function echo(stringA, stringB) { |
压缩之后就变成这样子:
1 | function echo(d, c) { |
可以看到这里参数的名称都被简化了,代码中的空格也被去掉了,整个代码也被压缩成了一行,代码的整体可读性降低了。
目前主流的前端开发技术大多都会利用 Webpack、Rollup 等工具进行打包,Webpack、Rollup 会对源代码进行编译和压缩,输出几个打包好的 JavaScript 文件,其中我们可以看到输出的 JavaScript 文件名带有一些不规则字符串,同时文件内容可能只有几行内容,变量名都是一些简单字母表示。这其中就包含 JavaScript 压缩技术,比如一些公共的库输出成 bundle 文件,一些调用逻辑压缩和转义成冗长的几行代码,这些都属于 JavaScript 压缩。另外其中也包含了一些很基础的 JavaScript 混淆技术,比如把变量名、方法名替换成一些简单字符,降低代码可读性。
但整体来说,JavaScript 压缩技术只能在很小的程度上起到防护作用,要想真正提高防护效果还得依靠 JavaScript 混淆和加密技术。
5. JavaScript 混淆
JavaScript 混淆是完全是在 JavaScript 上面进行的处理,它的目的就是使得 JavaScript 变得难以阅读和分析,大大降低代码可读性,是一种很实用的 JavaScript 保护方案。
JavaScript 混淆技术主要有以下几种:
- 变量混淆:将带有含义的变量名、方法名、常量名随机变为无意义的类乱码字符串,降低代码可读性,如转成单个字符或十六进制字符串。
- 字符串混淆:将字符串阵列化集中放置、并可进行 MD5 或 Base64 加密存储,使代码中不出现明文字符串,这样可以避免使用全局搜索字符串的方式定位到入口点。
- 属性加密:针对 JavaScript 对象的属性进行加密转化,隐藏代码之间的调用关系。
- 控制流平坦化:打乱函数原有代码执行流程及函数调用关系,使代码逻变得混乱无序。
- 无用代码注入:随机在代码中插入不会被执行到的无用代码,进一步使代码看起来更加混乱。
- 调试保护:基于调试器特性,对当前运行环境进行检验,加入一些强制调试 debugger 语句,使其在调试模式下难以顺利执行 JavaScript 代码。
- 多态变异:使 JavaScript 代码每次被调用时,将代码自身即立刻自动发生变异,变化为与之前完全不同的代码,即功能完全不变,只是代码形式变异,以此杜绝代码被动态分析调试。
- 锁定域名:使 JavaScript 代码只能在指定域名下执行。
- 反格式化:如果对 JavaScript 代码进行格式化,则无法执行,导致浏览器假死。
- 特殊编码:将 JavaScript 完全编码为人不可读的代码,如表情符号、特殊表示内容等等。
总之,以上方案都是 JavaScript 混淆的实现方式,可以在不同程度上保护 JavaScript 代码。
在前端开发中,现在 JavaScript 混淆主流的实现是 javascript-obfuscator (https://github.com/javascript-obfuscator/javascript-obfuscator) 和 terser (https://github.com/terser/terser) 这两个库,其都能提供一些代码混淆功能,也都有对应的 Webpack 和 Rollup 打包工具的插件,利用它们我们可以非常方便地实现页面的混淆,最终可以输出压缩和混淆后的 JavaScript 代码,使得 JavaScript 代码可读性大大降低。
下面我们以 javascript-obfuscator 为例来介绍一些代码混淆的实现,了解了实现,那么自然我们就对混淆的机理有了更加深刻的认识。
javascript-obfuscator 的官网地址为:https://obfuscator.io/,其官方介绍内容如下:
A free and efficient obfuscator for JavaScript (including ES2017). Make your code harder to copy and prevent people from stealing your work.
它是支持 ES8 的免费、高效的 JavaScript 混淆库,它可以使得你的 JavaScript 代码经过混淆后难以被复制、盗用,混淆后的代码具有和原来的代码一模一样的功能。
怎么使用呢?首先,我们需要安装好 Node.js 12.x 版本及以上,确保可以正常使用 npm 命令,具体的安装方式可以参考:https://setup.scrape.center/nodejs。
接着新建一个文件夹,比如 js-obfuscate,然后进入该文件夹,初始化工作空间:
1 | npm init |
这里会提示我们输入一些信息,创建一个 package.json 文件,这就完成了项目初始化了。
接下来我们来安装 javascript-obfuscator 这个库:
1 | npm i -D javascript-obfuscator |
稍等片刻,即可看到本地 js-obfuscate 文件夹下生成了一个 node_modules 文件夹,里面就包含了 javascript-obfuscator 这个库,这就说明安装成功了,文件夹结构如图所示:
接下来我们就可以编写代码来实现一个混淆样例了,如新建一个 main.js 文件,内容如下:
1 | const code = ` |
在这里我们定义了两个变量,一个是 code,即需要被混淆的代码,另一个是混淆选项,是一个 Object。接下来我们引入了 javascript-obfuscator 这库,然后定义了一个方法,传入 code 和 options,来获取混淆后的代码,最后控制台输出混淆后的代码。
代码逻辑比较简单,我们来执行一下代码:
1 | node main.js |
输出结果如下:
1 | var _0x53bf = ["log"]; |
看到了吧,那么简单的两行代码,被我们混淆成了这个样子,其实这里我们就是设定了一个「控制流平坦化」的选项。整体看来,代码的可读性大大降低,也大大加大了 JavaScript 调试的难度。
好,那么我们来跟着 javascript-obfuscator 走一遍,就能具体知道 JavaScript 混淆到底有多少方法了。
注意:由于这些例子中,调用 javascript-obfuscator 进行混淆的实现是一样的,所以下文的示例只说明 code 和 options 变量的修改,完整代码请自行补全。
代码压缩
这里 javascript-obfuscator 也提供了代码压缩的功能,使用其参数 compact 即可完成 JavaScript 代码的压缩,输出为一行内容。默认是 true,如果定义为 false,则混淆后的代码会分行显示。
示例如下:
1 | const code = ` |
这里我们先把代码压缩 compact 选项设置为 false,运行结果如下:
1 | let x = "1" + 0x1; |
如果不设置 compact 或把 compact 设置为 true,结果如下:
1 | var _0x151c = ["log"]; |
可以看到单行显示的时候,对变量名进行了进一步的混淆,这里变量的命名都变成了 16 进制形式的字符串,这是因为启用了一些默认压缩和混淆配置导致的。总之我们可以看到代码的可读性相比之前大大降低了。
变量名混淆
变量名混淆可以通过在 javascript-obfuscator 中配置 identifierNamesGenerator 参数实现,我们通过这个参数可以控制变量名混淆的方式,如 hexadecimal 则会替换为 16 进制形式的字符串,在这里我们可以设定如下值:
- hexadecimal:将变量名替换为 16 进制形式的字符串,如
0xabc123。 - mangled:将变量名替换为普通的简写字符,如
a、b、c等。
该参数的值默认为 hexadecimal。
我们将该参数修改为 mangled 来试一下:
1 | const code = ` |
运行结果如下:
1 | var a = ["hello"]; |
可以看到这里的变量命名都变成了 a、b 等形式。
如果我们将 identifierNamesGenerator 修改为 hexadecimal 或者不设置,运行结果如下:
1 | var _0x4e98 = ["log", "hello"]; |
可以看到选用了 mangled,其代码体积会更小,但 hexadecimal 其可读性会更低。
另外我们还可以通过设置 identifiersPrefix 参数来控制混淆后的变量前缀,示例如下:
1 | const code = ` |
运行结果如下:
1 | var germey_0x3dea = ["log", "hello"]; |
可以看到混淆后的变量前缀加上了我们自定义的字符串 germey。
另外 renameGlobals 这个参数还可以指定是否混淆全局变量和函数名称,默认为 false。示例如下:
1 | const code = ` |
运行结果如下:
1 | var _0x4864b0 = function (_0x5763be) { |
可以看到这里我们声明了一个全局变量 这个变量也被替换了。如果后文用到了这个 $ 对象,可能就会有找不到定义的错误,因此这个参数可能导致代码执行不通。
如果我们不设置 renameGlobals 或者设置为 false,结果如下:
1 | var _0x239a = ["getElementById"]; |
可以看到,最后还是有 $ 的声明,其全局名称没有被改变。
字符串混淆
字符串混淆,即将一个字符串声明放到一个数组里面,使之无法被直接搜索到。我们可以通过控制 stringArray 参数来控制,默认为 true。
我们还可以通过 rotateStringArray 参数来控制数组化后结果的的元素顺序,默认为 true。还可以通过 stringArrayEncoding 参数来控制数组的编码形式,默认不开启编码,如果设置为 true 或 base64,则会使用 Base64 编码,如果设置为 rc4,则使用 RC4 编码。另外可以通过 stringArrayThreshold 来控制启用编码的概率,范围 0 到 1,默认 0.8。
示例如下:
1 | const code = ` |
运行结果如下:
1 | var _0x4215 = ["aGVsbG8gd29ybGQ="]; |
可以看到这里就把字符串进行了 Base64 编码,我们再也无法通过查找的方式找到字符串的位置了。
如果将 stringArray 设置为 false 的话,输出就是这样:
1 | var a = "hello\x20world"; |
字符串就仍然是明文显示的,没有被编码。
另外我们还可以使用 unicodeEscapeSequence 这个参数对字符串进行 Unicode 转码,使之更加难以辨认,示例如下:
1 | const code = ` |
运行结果如下:
1 | var _0x5c0d = ["\x68\x65\x6c\x6c\x6f\x20\x77\x6f\x72\x6c\x64"]; |
可以看到,这里字符串被数字化和 Unicode 化,非常难以辨认。
在很多 JavaScript 逆向的过程中,一些关键的字符串可能会作为切入点来查找加密入口。用了这种混淆之后,如果有人想通过全局搜索的方式搜索 hello 这样的字符串找加密入口,也没法搜到了。
代码自我保护
我们可以通过设置 selfDefending 参数来开启代码自我保护功能。开启之后,混淆后的 JavaScript 会以强制一行形式显示,如果我们将混淆后的代码进行格式化或者重命名,该段代码将无法执行。
示例如下:
1 | const code = ` |
运行结果如下:
1 | var _0x26da = ["log", "hello\x20world"]; |
如果我们将上述代码放到控制台,它的执行结果和之前是一模一样的,没有任何问题。
如果我们将其进行格式化,然后贴到到浏览器控制台里面,浏览器会直接卡死无法运行。这样如果有人对代码进行了格式化,就无法正常对代码进行运行和调试,从而起到了保护作用。
控制流平坦化
控制流平坦化其实就是将代码的执行逻辑混淆,使其变得复杂难读。其基本思想是将一些逻辑处理块都统一加上一个前驱逻辑块,每个逻辑块都由前驱逻辑块进行条件判断和分发,构成一个个闭环逻辑,导致整个执行逻辑十分复杂难读。
比如说这里有一段示例代码:
1 | console.log(c); |
代码逻辑一目了然,依次在控制台输出了 c、a、b 三个变量的值,但如果把这段代码进行控制流平坦化处理后,代码就会变成这样:
1 | const s = "3|1|2".split("|"); |
可以看到,混淆后的代码首先声明了一个变量 s,它的结果是一个列表,其实是 ["3", "1", "2"],然后下面通过 switch 语句对 s 中的元素进行了判断,每个 case 都加上了各自的代码逻辑。通过这样的处理,一些连续的执行逻辑就被打破了,代码被修改为一个 switch 语句,原本我们可以一眼看出的逻辑是控制台先输出 c,然后才是 a、b,但是现在我们必须要结合 switch 的判断条件和对应 case 的内容进行判断,我们很难再一眼每条语句的执行顺序了,这就大大降低了代码的可读性。
在 javascript-obfuscator 中我们通过 controlFlowFlattening 变量可以控制是否开启控制流平坦化,示例如下:
1 | const options = { |
使用控制流平坦化可以使得执行逻辑更加复杂难读,目前非常多的前端混淆都会加上这个选项。但启用控制流平坦化之后,代码的执行时间会变长,最长达 1.5 倍之多。
另外我们还能使用 controlFlowFlatteningThreshold 这个参数来控制比例,取值范围是 0 到 1,默认 0.75,如果设置为 0,那相当于 controlFlowFlattening 设置为 false,即不开启控制流扁平化 。
无用代码注入
无用代码即不会被执行的代码或对上下文没有任何影响的代码,注入之后可以对现有的 JavaScript 代码的阅读形成干扰。我们可以使用 deadCodeInjection 参数开启这个选项,默认为 false。
比如这里有一段代码:
1 | const a = function () { |
这里就声明了方法 a 和 b,然后依次进行调用,分别输出两句话。
但经过无用代码注入处理之后,代码就会变成类似这样的结果:
1 | const _0x16c18d = function () { |
可以看到,每个方法内部都增加了额外的 if else 语句,其中 if 的判断条件还是一个表达式,其结果是 true 还是 false 我们还不太一眼能看出来,比如说 _0x1f7292 这个方法,它的 if 判断条件是:
1 | "xmv2nOdfy2N".charAt(4) !== String.fromCharCode(110) |
在不等号前面其实是从字符串中取出指定位置的字符,不等号后面则调用了 fromCharCode 方法来根据 ascii 码转换得到一个字符,然后比较两个字符的结果是否是不一样的。前者经过我们推算可以知道结果是 n,但对于后者,多数情况下我们还得去查一下 ascii 码表才能知道其结果也是 n,最后两个结果是相同的,所以整个表达式的结果是 false,所以 if 后面跟的逻辑实际上就是不会被执行到的无用代码,但这些代码对我们阅读代码起到了一定的干扰作用。
因此,这种混淆方式通过混入一些特殊的判断条件并加入一些不会被执行的代码,可以对代码起到一定的混淆干扰作用。
在 javascript-obfuscator 中,我们可以通过 deadCodeInjection 参数控制无用代码的注入,配置如下:
1 | const options = { |
另外我们还可以通过设置 deadCodeInjectionThreshold 参数来控制无用代码注入的比例,取值 0 到 1,默认是 0.4。
对象键名替换
如果是一个对象,可以使用 transformObjectKeys 来对对象的键值进行替换,示例如下:
1 | const code = ` |
输出结果如下:
1 | var _0x7a5d = ["bar", "test2", "test1"]; |
可以看到,Object 的变量名被替换为了特殊的变量,使得可读性变差,这样我们就不好直接通过变量名进行搜寻了,这也可以起到一定的防护作用。
禁用控制台输出
可以使用 disableConsoleOutput 来禁用掉 console.log 输出功能,加大调试难度,示例如下:
1 | const code = ` |
运行结果如下:
1 | var _0x3a39 = [ |
此时,我们如果执行这个代码,发现是没有任何输出的,这里实际上就是将 console 的一些功能禁用了。
调试保护
我们知道,在 JavaScript 代码中如果加入 debugger 这个关键字,那么在执行到该位置的时候控制它就会进入断点调试模式。如果在代码多个位置都加入 debugger 这个关键字,或者定义某个逻辑来反复执行 debugger,那就会不断进入断点调试模式,原本的代码无法就无法顺畅地执行了。这个过程可以称为调试保护,即通过反复执行 debugger 来使得原来的代码无法顺畅执行。
其效果类似于执行了如下代码:
1 | setInterval(() => { |
如果我们把这段代码粘贴到控制台,它就会反复地执行 debugger 语句进入断点调试模式,从而干扰正常的调试流程。
在 javascript-obfuscator 中可以使用 debugProtection 来启用调试保护机制,还可以使用 debugProtectionInterval 来启用无限 Debug ,使得代码在调试过程中会不断进入断点模式,无法顺畅执行,配置如下:
1 | const options = { |
混淆后的代码会不断跳到 debugger 代码的位置,使得整个代码无法顺畅执行,对 JavaScript 代码的调试形成一定的干扰。
域名锁定
我们还可以通过控制 domainLock 来控制 JavaScript 代码只能在特定域名下运行,这样就可以降低代码被模拟或盗用的风险。
示例如下:
1 | const code = ` |
这里我们使用了 domainLock 指定了一个域名叫做 cuiqingcai.com,也就是设置了一个域名白名单,混淆后的代码结果如下:
1 | var _0x3203 = [ |
这段代码就只能在指定域名 cuiqingcai.com 下运行,不能在其他网站运行。这样的话,如果一些相关 JavaScript 代码被单独剥离出来,想在其他网站运行或者使用程序模拟运行的话,运行结果只有是失败,这样就可以有效降低被代码被模拟或盗用的风险。
特殊编码
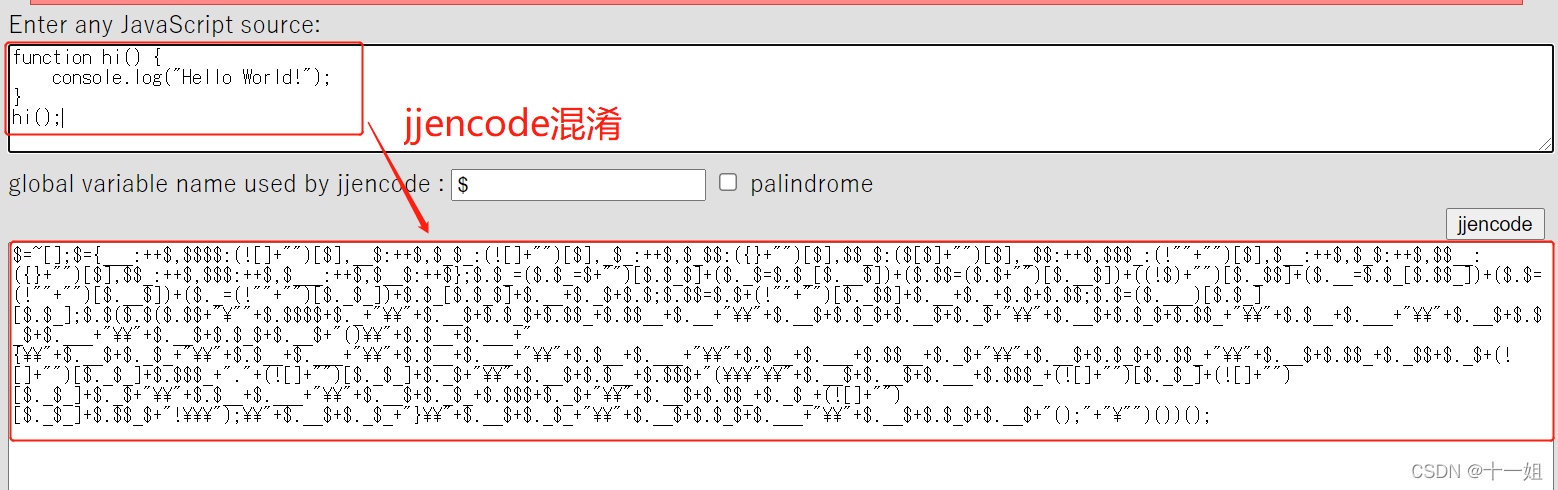
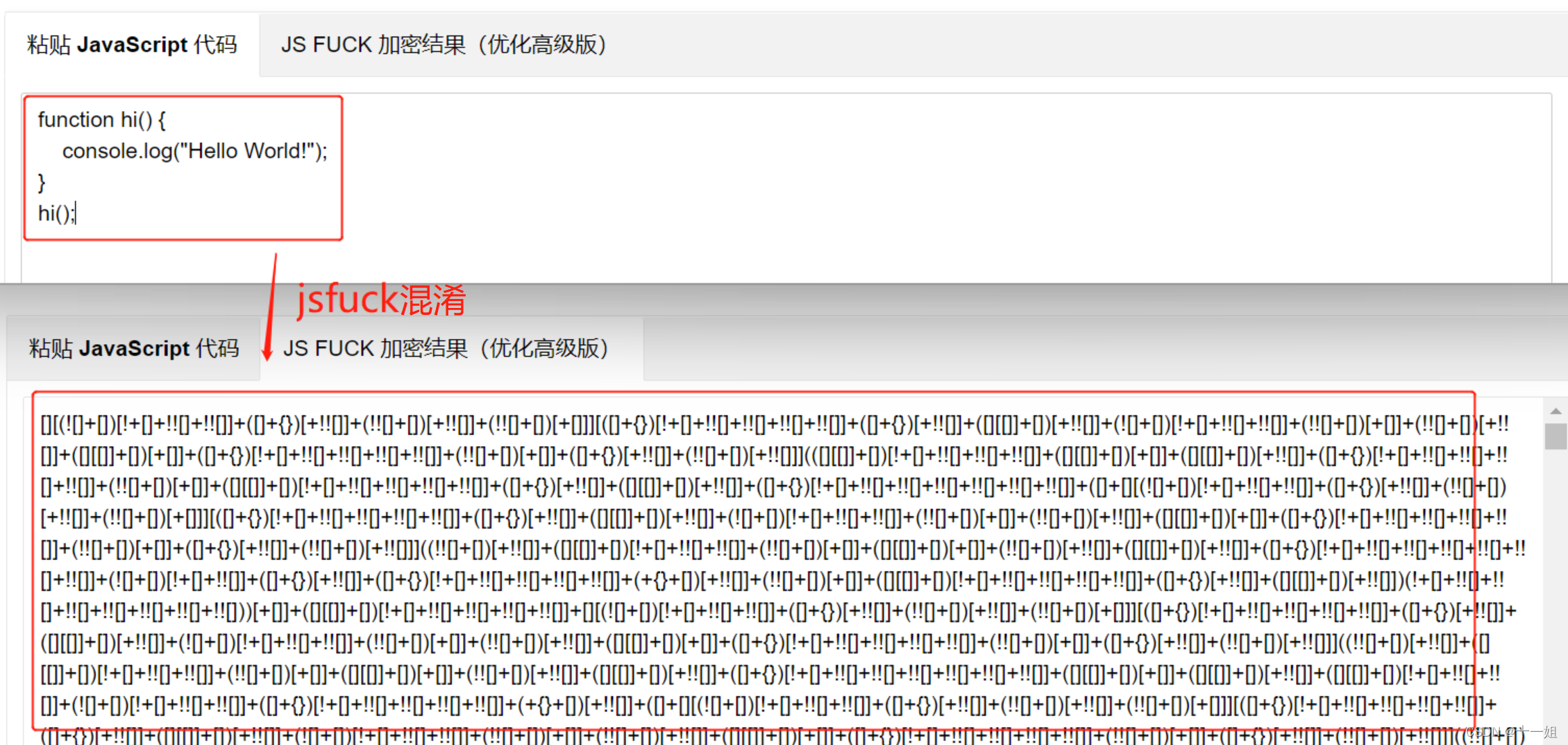
另外还有一些特殊的工具包,如使用 aaencode、jjencode、jsfuck 等工具对代码进行混淆和编码。
示例如下:
1 | var a = 1 |
jsfuck 的结果:
1 | [][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]([][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+ |
aaencode 的结果:
1 | ゚ω゚ノ= /`m´)ノ ~┻━┻ / ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] = ((゚Д゚)+'_') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) ['o'] = ((゚Д゚)+'_') [゚Θ゚];(゚o゚)=(゚Д゚) ['c']+(゚Д゚) ['o']+(゚ω゚ノ +'_')[゚Θ゚]+ ((゚ω゚ノ==3) +'_') [゚ー゚] + ((゚Д゚) +'_') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +'_') [゚Θ゚]+((゚ー゚==3) +'_') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) ['c']+((゚Д゚)+'_') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) ['o']+((゚ー゚==3) +'_') [゚Θ゚];(゚Д゚) ['_'] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +'_') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+'_') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +'_') [o^_^o -゚Θ゚]+((゚ー゚==3) +'_') [゚Θ゚]+ (゚ω゚ノ +'_') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]='\\'; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +'_')[c^_^o];(゚Д゚) [゚o゚]='\"';(゚Д゚) ['_'] ( (゚Д゚) ['_'] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((o^_^o) +(o^_^o))+ (゚Θ゚)+ (゚Д゚)[゚o゚])(゚Θ゚))((゚Θ゚)+(゚Д゚)[゚ε゚]+((゚ー゚)+(゚Θ゚))+(゚Θ゚)+(゚Д゚)[゚o゚]); |
jjencode 的结果:
1 | $=~[];$={___:++$,$$$$:(![]+"")[$],__$:++$,$_$_:(![]+"")[$],_$_:++$,$_$$:({}+"")[$],$$_$:($[$]+"")[$],_$$:++$,$$$_:(!""+"")[$],$__:++$,$_$:++$,$$__:({}+"")[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+"")[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+"")[$.__$])+((!$)+"")[$._$$]+($.__=$.$_[$.$$_])+($.$=(!""+"")[$.__$])+($._=(!""+"")[$._$_])+$.$_[$.$_$]+$.__+$._$+$.$;$.$$=$.$+(!""+"")[$._$$]+$.__+$._+$.$+$.$$;$.$=($.___)[$.$_][$.$_];$.$($.$($.$$+"\""+"\\"+$.__$+$.$$_+$.$$_+$.$_$_+"\\"+$.__$+$.$$_+$._$_+"\\"+$.$__+$.___+$.$_$_+"\\"+$.$__+$.___+"=\\"+$.$__+$.___+$.__$+"\"")())(); |
可以看到,通过这些工具,原本非常简单的代码被转化为一些几乎完全不可读的代码,但实际上运行效果还是相同的。这些混淆方式比较另类,看起来虽然没有什么头绪,但实际上找到规律是非常好还原的,其没有真正达到强力混淆的效果。
以上便是对 JavaScript 混淆方式的介绍和总结。总的来说,经过混淆的 JavaScript 代码其可读性大大降低,同时防护效果也大大增强。
6. WebAssembly
随着技术的发展,WebAssembly 逐渐流行起来。不同于 JavaScript 混淆技术, WebAssembly 其基本思路是将一些核心逻辑使用其他语言(如 C/C++ 语言)来编写,并编译成类似字节码的文件,并通过 JavaScript 调用执行,从而起到二进制级别的防护作用。
WebAssembly 是一种可以使用非 JavaScript 编程语言编写代码并且能在浏览器上运行的技术方案,比如借助于我们能将 C/C++ 利用 Emscripten 编译工具转成 wasm 格式的文件, JavaScript 可以直接调用该文件执行其中的方法。
WebAssembly 是经过编译器编译之后的字节码,可以从 C/C++ 编译而来,得到的字节码具有和 JavaScript 相同的功能,运行速度更快,体积更小,而且在语法上完全脱离 JavaScript,同时具有沙盒化的执行环境。
比如这就是一个基本的 WebAssembly 示例:
1 | WebAssembly.compile( |
这里其实是利用 WebAssembly 定义了两个方法,分别是 add 和 square,可以分别用于求和和开平方计算。那这两个方法在哪里声明的呢?其实它们被隐藏在了一个 Uint8Array 里面,仅仅查看明文代码我们确实无从知晓里面究竟定义了什么逻辑,但确实是可以执行的,我们将这段代码输入到浏览器控制台下,运行结果如下:
1 | 2 + 4 = 6 |
由此可见,通过 WebAssembly 我们可以成功将核心逻辑 “隐藏” 起来,这样某些核心逻辑就不能被轻易找出来了。
所以,很多网站越来越多使用 WebAssembly 技术来保护一些核心逻辑不被轻易被人识别或破解,可以起到更好的防护效果。
7. 总结
以上,我们就介绍了接口加密技术和 JavaScript 的压缩、混淆技术,也对 WebAssembly 技术有了初步的了解,知己知彼方能百战不殆,了解了原理,我们才能更好地去实现 JavaScript 的逆向。
本节代码:https://github.com/Python3WebSpider/JavaScriptObfuscate。
由于本节涉及一些专业名词,部分内容参考来源如下:
- GitHub - javascript-obfuscator 官方 GitHub 仓库:https://github.com/javascript-obfuscator/javascript-obfuscator
- 官网 - javascript-obfuscator 官网:https://obfuscator.io/
- 博客 - asm.js 和 Emscripten 入门教程:https://www.ruanyifeng.com/blog/2017/09/asmjs_emscripten.html
- 博客 - JavaScript 混淆安全加固:https://juejin.im/post/5cfcb9d25188257e853fa71c
浏览器调试技巧
前面一节我们了解了 JavaScript 的压缩、混淆等技术,现在越来越多的网站也已经应用了这些技术对其数据接口进行了保护,在做爬虫时如果我们遇到了这种情况,我们可能就不得不硬着头皮来去想方设法找出其中隐含的关键逻辑了,这个过程我们可以称之为 JavaScript 逆向。
既然我们要做 JavaScript 逆向,那少不了要用到浏览器的开发者工具,因为网页是在浏览器中加载的,所以多数的调试过程也是在浏览器中完成的。
工欲善其事,必先利其器。本节我们先来基于 Chrome 浏览器介绍一下浏览器开发者工具的使用。但由于开发者工具功能十分复杂,本节主要介绍对 JavaScript 逆向有一些帮助的功能,学会了这些,我们在做 JavaScript 逆向调试的过程会更加得心应手。
本节我们以一个示例网站 https://spa2.scrape.center/ 来做演示,用这个示例来介绍浏览器开发者工具各个面版的用法。
1. 面板介绍
首先我们用 Chrome 浏览器打开示例网站,页面如图所示:
接下来打开开发者工具,我们会看到类似图 xx 所示的结果。
这里可以看到多个面板标签,如 Elements、Console、Sources 等,这就是开发者工具的一个个面板,功能丰富而又强大,先对面板作下简单的介绍:
- Elements:元素面板,用于查看或修改当前网页 HTML 节点的属性、CSS 属性、监听事件等等,HTML 和 CSS 都可以即时修改和即时显示。
- Console:控制台面板,用于查看调试日志或异常信息。另外我们还可以在控制台输入 JavaScript 代码,方便调试。
- Sources:源代码面板,用于查看页面的 HTML 文件源代码、JavaScript 源代码、CSS 源代码,还可以在此面板对 JavaScript 代码进行调试,比如添加和修改 JavaScript 断点,观察 JavaScript 变量变化等。
- Network:网络面板,用于查看页面加载过程中的各个网络请求,包括请求、响应等各个详情。
- Performance:性能面板,用于记录和分析页面在运行时的所有活动,比如 CPU 占用情况,呈现页面性能分析结果,
- Memory:内存面板,用于记录和分析页面占用内存情况,如查看内存占用变化,查看 JavaScript 对象和 HTML 节点的内存分配。
- Application:应用面板,用于记录网站加载的所有资源信息,如存储、缓存、字体、图片等,同时也可以对一些资源进行修改和删除。
- Lighthouse:审核面板,用于分析网络应用和网页,收集现代性能指标并提供对开发人员最佳实践的意见。
了解了这些面板之后,我们来深入了解几个面板中对 JavaScript 调试很有帮助的功能。
2. 查看节点事件
之前我们是用 Elements 面板来审查页面的节点信息的,我们可以查看当前页面的 HTML 源代码及其在网页中对应的位置,查看某个条目的标题对应的页面源代码,如图所示。
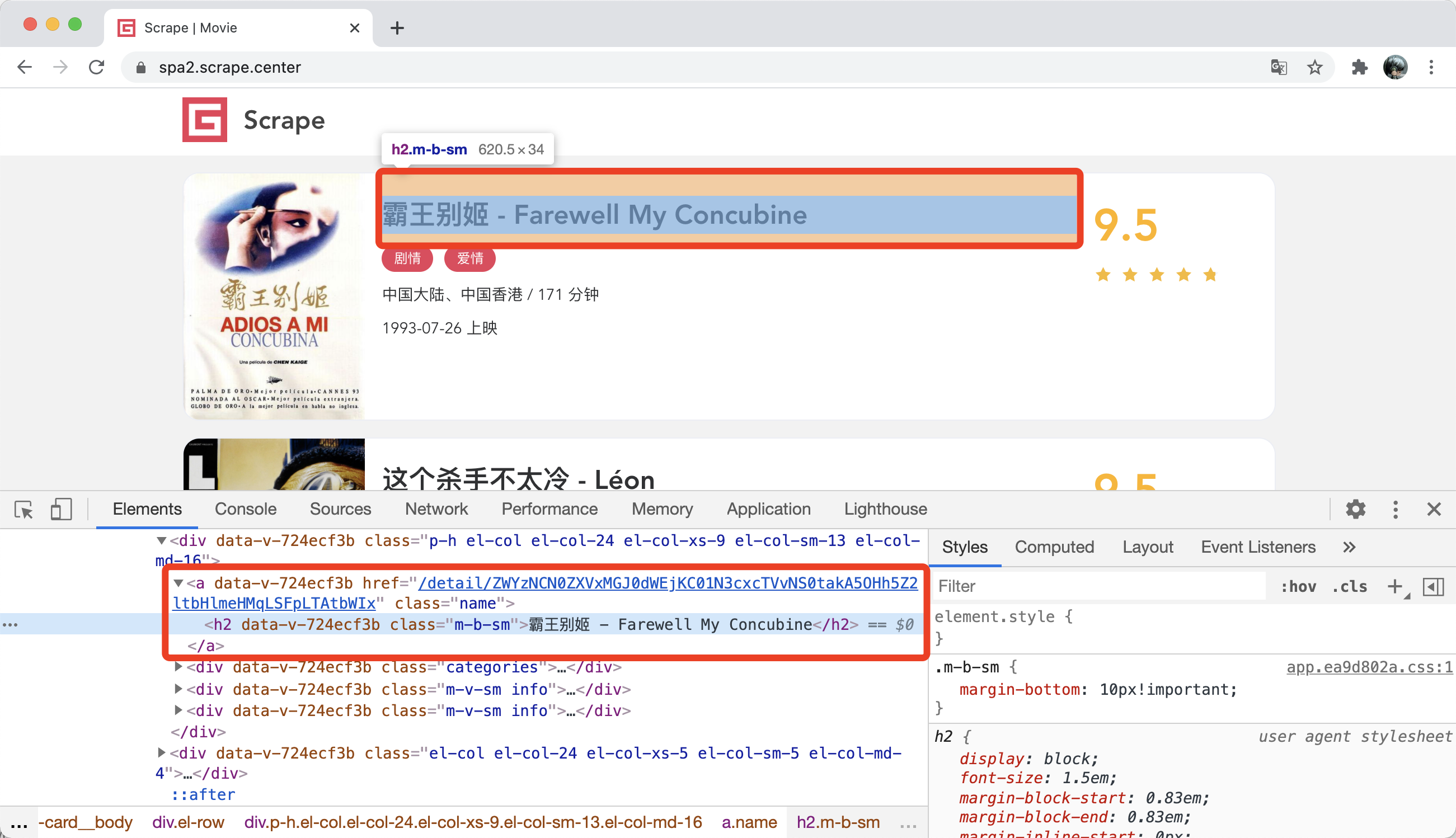
点击右侧的 Styles 选项卡,可以看到对应节点的 CSS 样式,我们可以自行在这里增删样式,实时预览效果,这对网页开发十分有帮助。
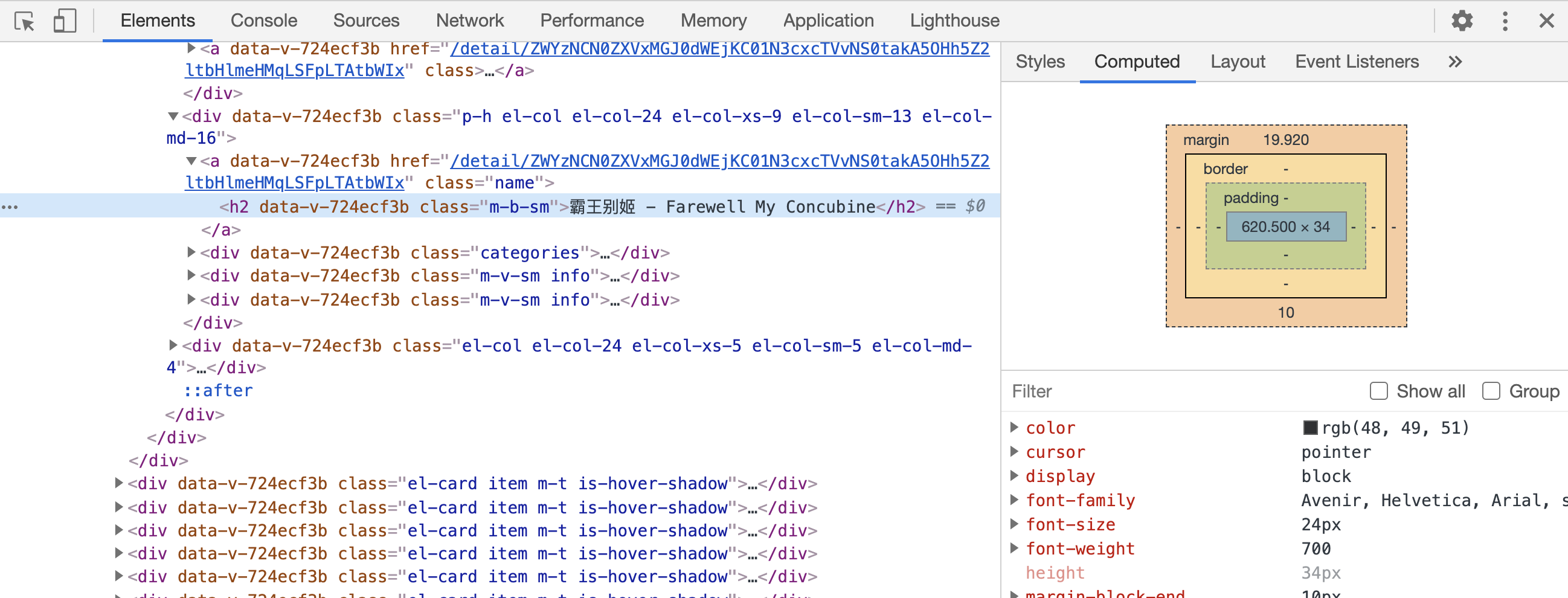
在 Computed 选项卡中还可以看到当前节点的盒子模型,比如外边距、内边距等,还可以看到当前节点最终计算出的 CSS 的样式,如图所示。
接下来切换到右侧的 Event Listeners 选项卡,这里可以显示各个节点当前已经绑定的事件,都是 JavaScript 原生支持的,下面简单列举几个事件。
change:HTML 元素改变时会触发的事件。click:用户点击 HTML 元素时会触发的事件。mouseover:用户在一个 HTML 元素上移动鼠标会触发的事件。mouseout:用户从一个 HTML 元素上移开鼠标会触发的事件。keydown:用户按下键盘按键会触发的事件。load:浏览器完成页面加载时会触发的事件。
通常,我们会给按钮绑定一个点击事件,它的处理逻辑一般是由 JavaScript 定义的,这样在我们点击按钮的时候,对应的 JavaScript 代码便会执行。比如在图 xx 中,我们选中切换到第 2 页的节点,右侧 Event Listeners 选项卡下会看到它绑定的事件。
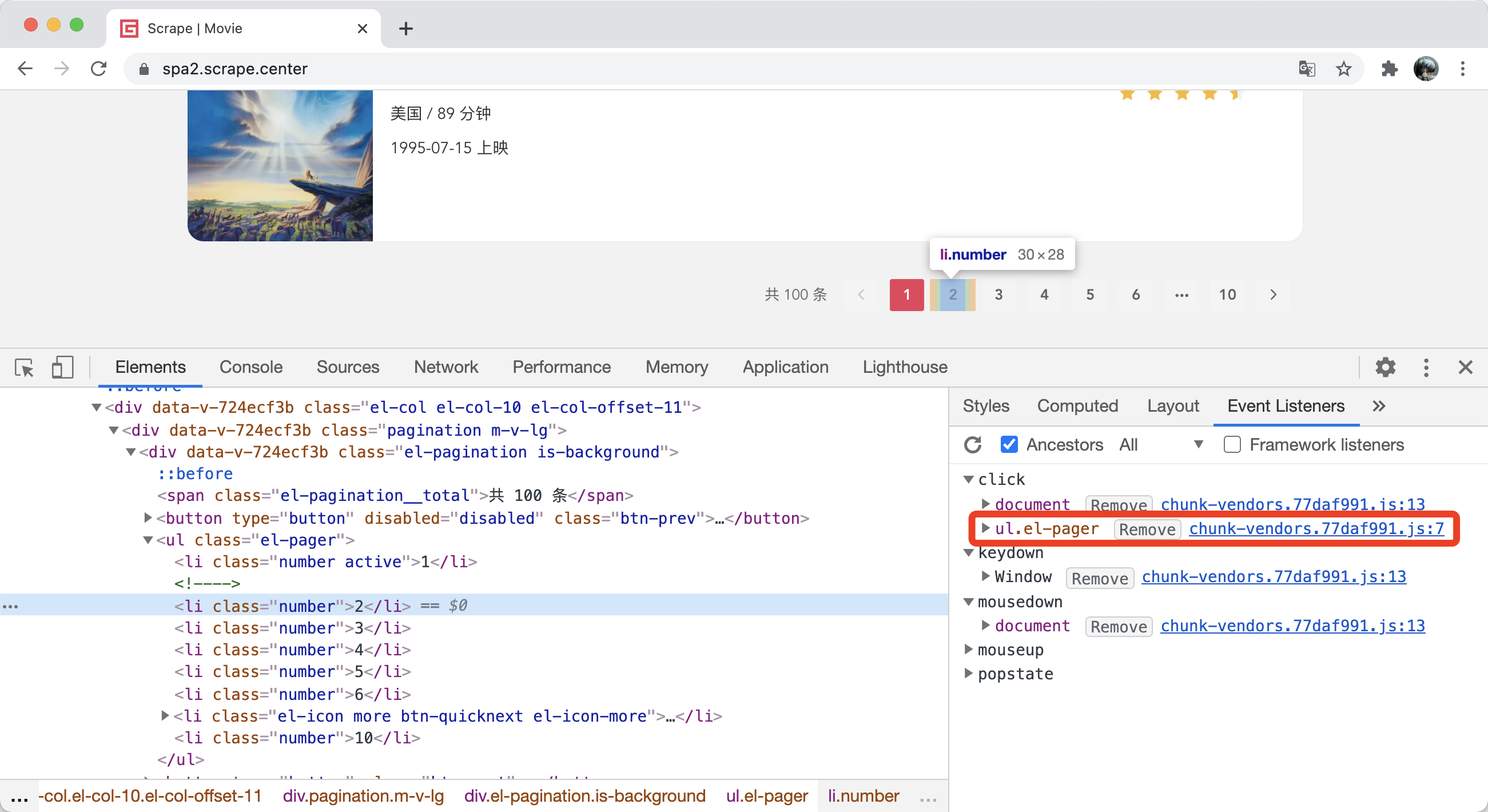
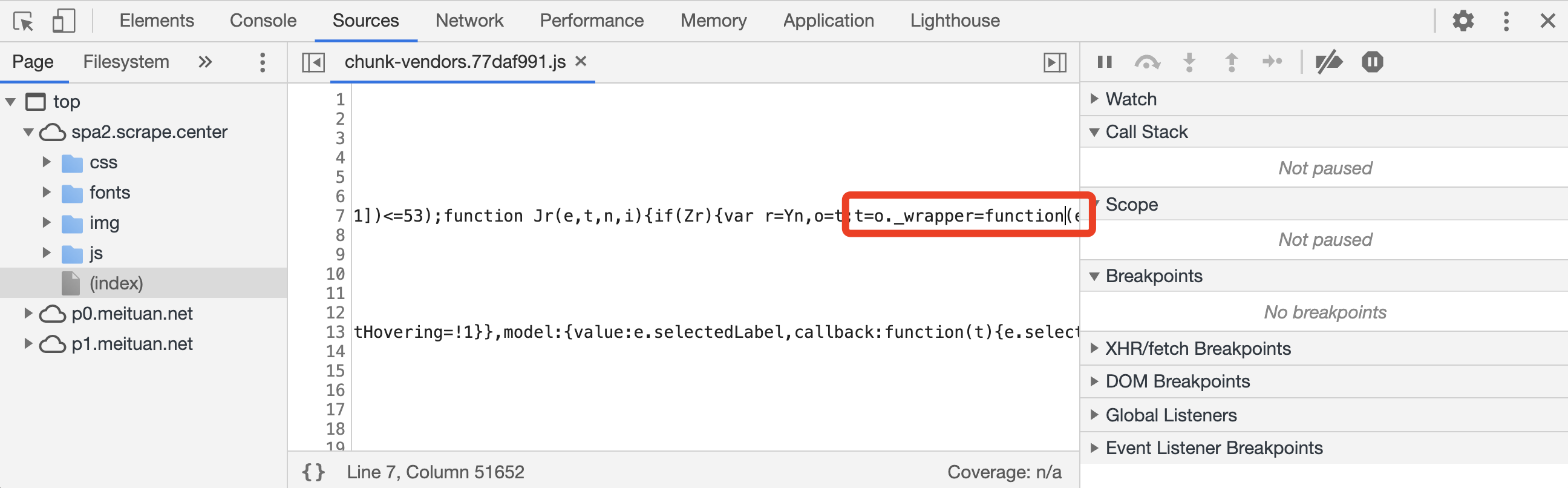
这里有对应事件的代码位置,内容为一个 JavaScript 文件名称 chunk-vendors.77daf991.js,然后紧跟一个冒号,然后再跟了一个数字 7。所以对应的事件处理函数是定义在 chunk-vendors.77daf991.js 这个文件的第 7 行。点击这个代码位置,便会自动跳转 Sources 面板,打开对应的 chunk-vendors.77daf991.js 文件并跳转到对应的位置,如图所示。
所以,利用好 Event Listeners,我们可以轻松地找到各个节点绑定事件的处理方法所在的位置,帮我们在 JavaScript 逆向过程中找到一些突破口。
3. 代码美化
刚才我们已经通过 Event Listeners 找到了对应的事件处理方法所在的位置并成功跳转到了代码所在的位置。
但是,这部分代码似乎被压缩过了,可读性很差,根本没法阅读,这时候应该怎么办呢?
不用担心,Sources 面板提供了一个便捷好用的代码美化功能。我们点击代码面板左下角的格式化按钮,代码就会变成如图所示的样子。
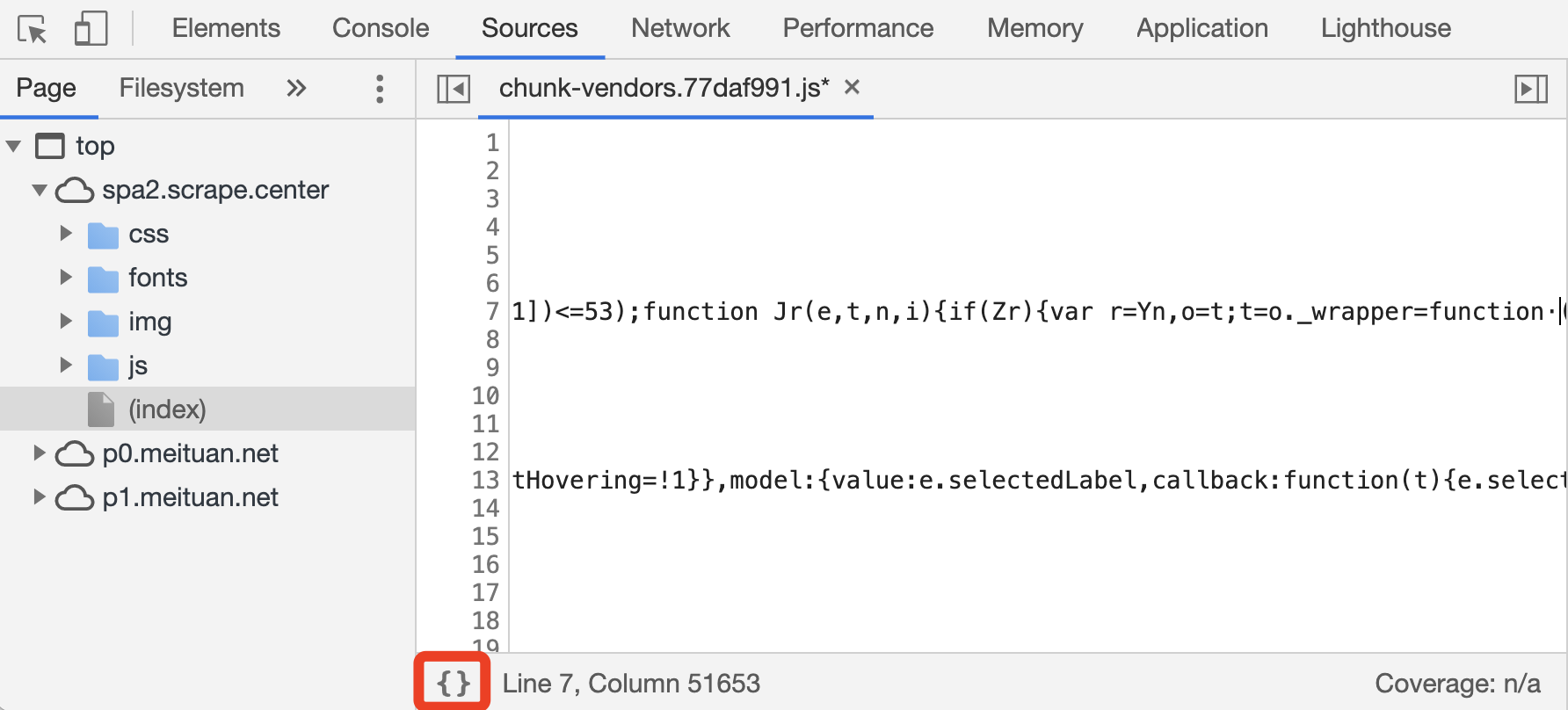
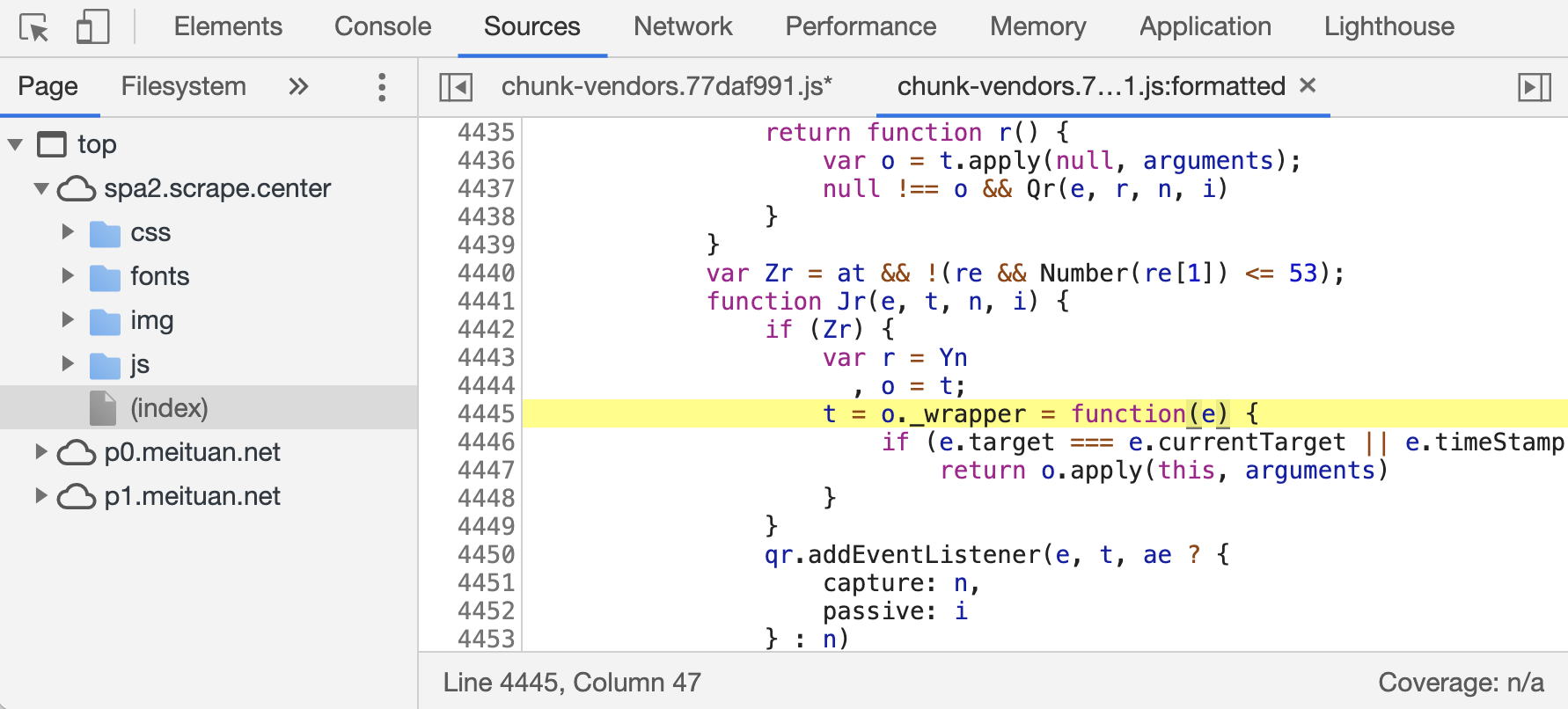
此时会新出现一个叫作 chunk-vendors.77daf991.js:formatted 的选项卡,文件名后面加了 formatted 标识,代表这是被格式化的结果。我们会发现,原来代码在第 7 行,现在自动对应到了第 4445 行,而且对应的代码位置会高亮显示,代码可读性大大增强!
这个功能在调试过程中非常常用,用好这个功能会给我们的 JavaScript 调试过程带来极大的便利。
4. 断点调试
接下来介绍一个非常重要的功能 —— 断点调试。在调试代码的时候,我们可以在需要的位置上打断点,当对应事件触发时,浏览器就会自动停在断点的位置等待调试,此时我们可以选择单步调试,在面板中观察调用栈、变量值,以更好地追踪对应位置的执行逻辑。
那么断点怎么打呢?我们接着以上面的例子来说。首先单击如图所示的代码行号。
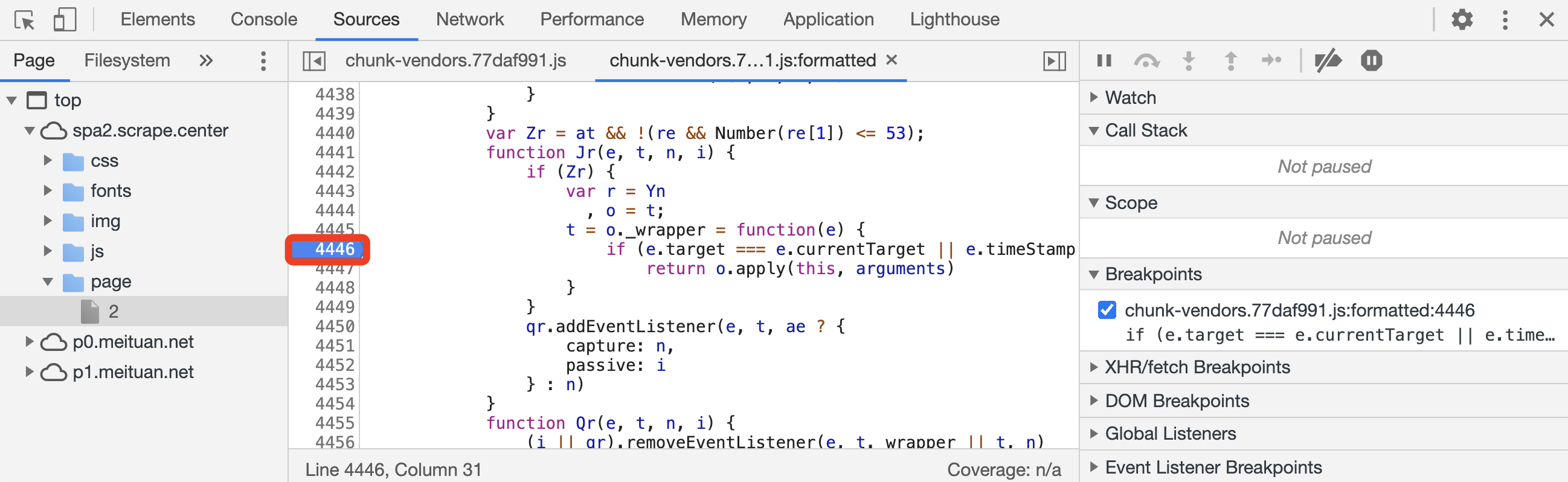
这时候行号处就出现了一个蓝色的箭头,这就证明断点已经添加好了,同时在右侧的 Breakpoints 选项卡下会出现我们添加的断点的列表。
由于我们知道这个断点是用来处理翻页按钮的点击事件的,所以可以在网页里面点击按钮试一下,比如点击第 2 页的按钮,这时候就会发现断点被触发了,如图所示。
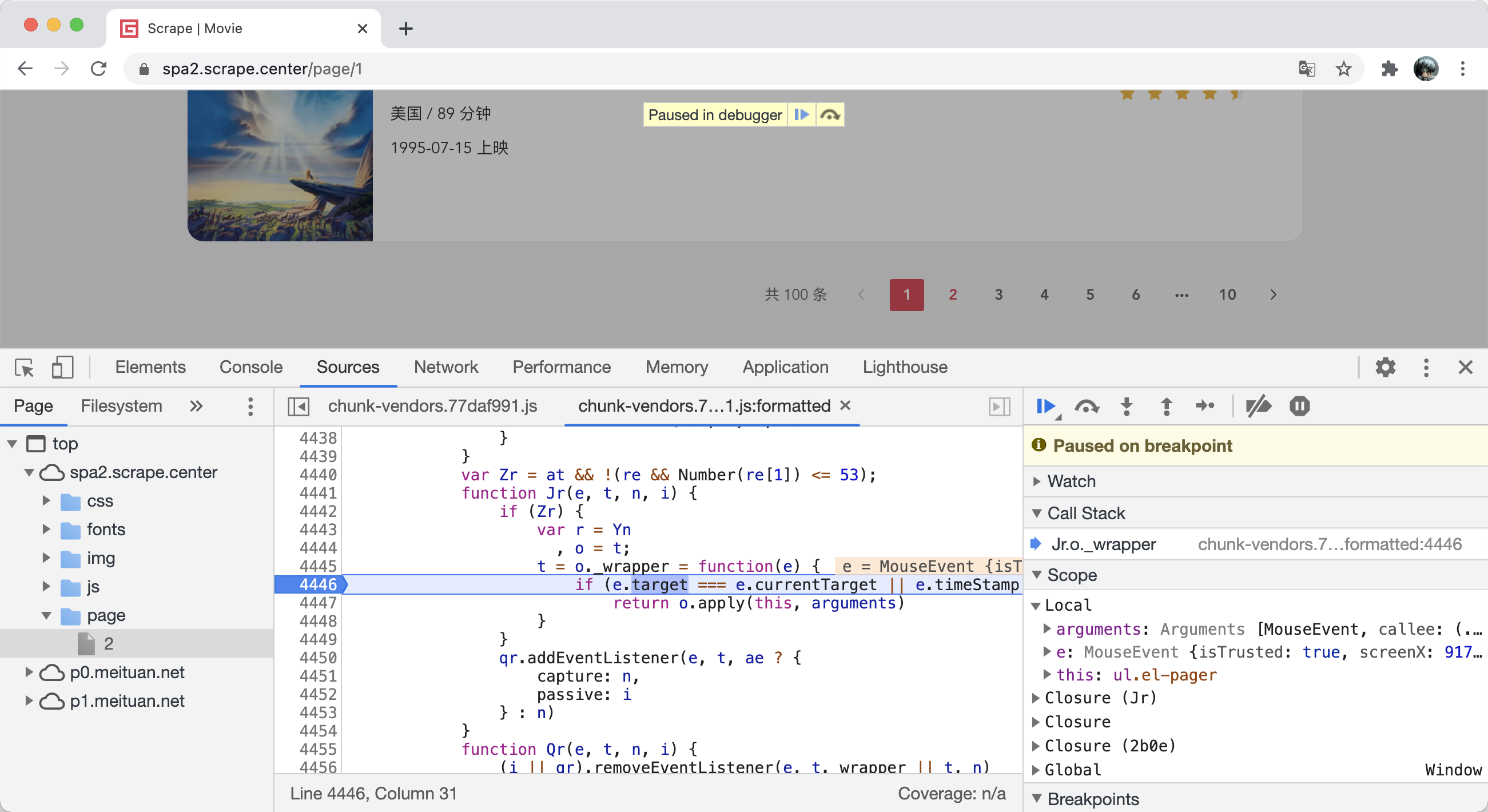
这时候我们可以看到页面中显示了一个叫作 Paused in debugger 的提示,这说明浏览器执行到刚才我们设置断点的位置处就不再继续执行了,等待我们发号施令执行调试。
此时代码停在了第 4446 行,回调参数 e 就是对应的点击事件 MouseEvent 。在右侧的 Scope 面板处,可以观察到各个变量的值,比如在 Local 域下有当前方法的局部变量,我们可以在这里看到 MouseEvent 的各个属性,如图所示。
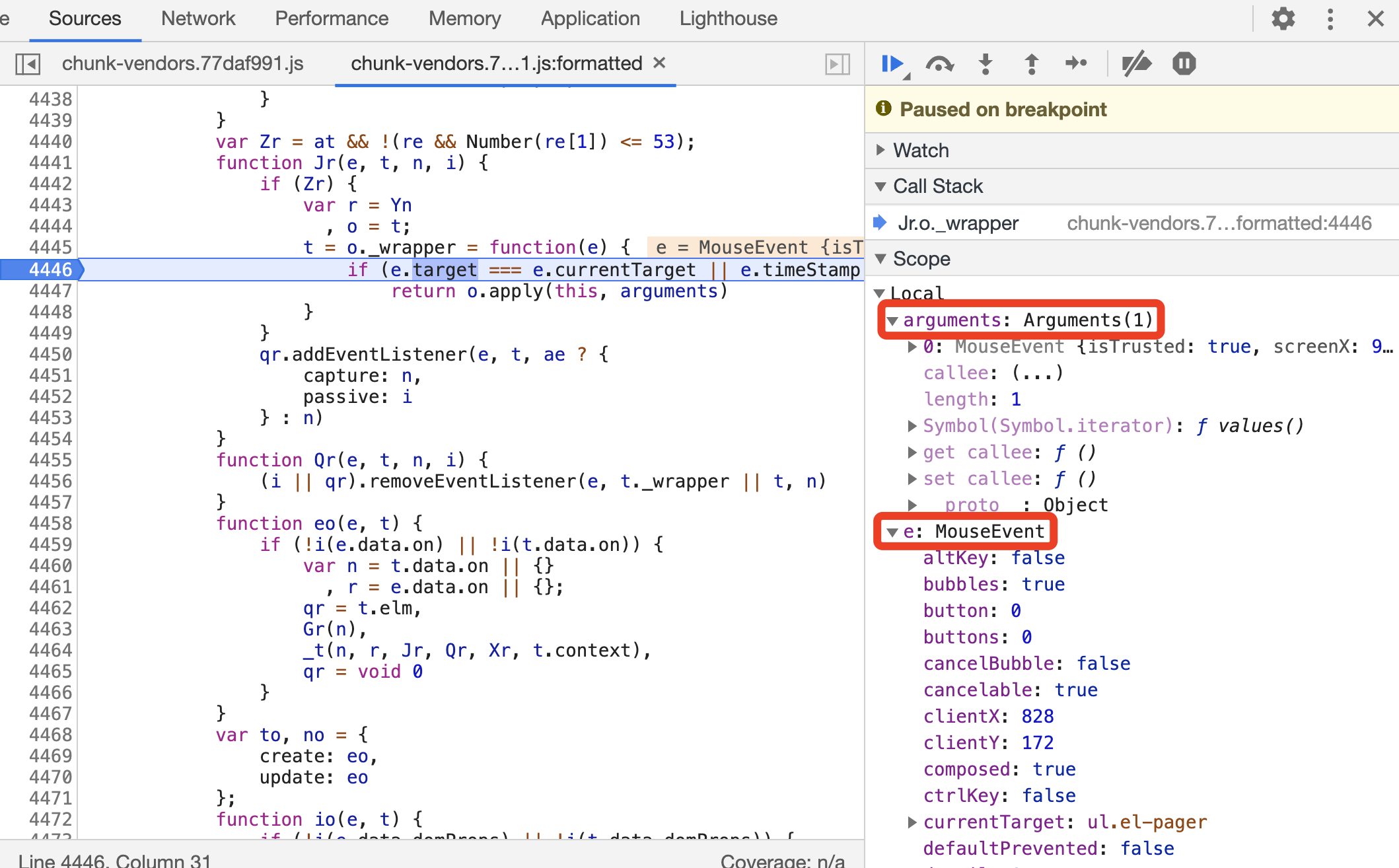
另外我们关注到有一个方法 o,它在 Jr 方法下面,所以切换到 Closure(Jr) 域可以查看它的定义及其接收的参数,如图所示。
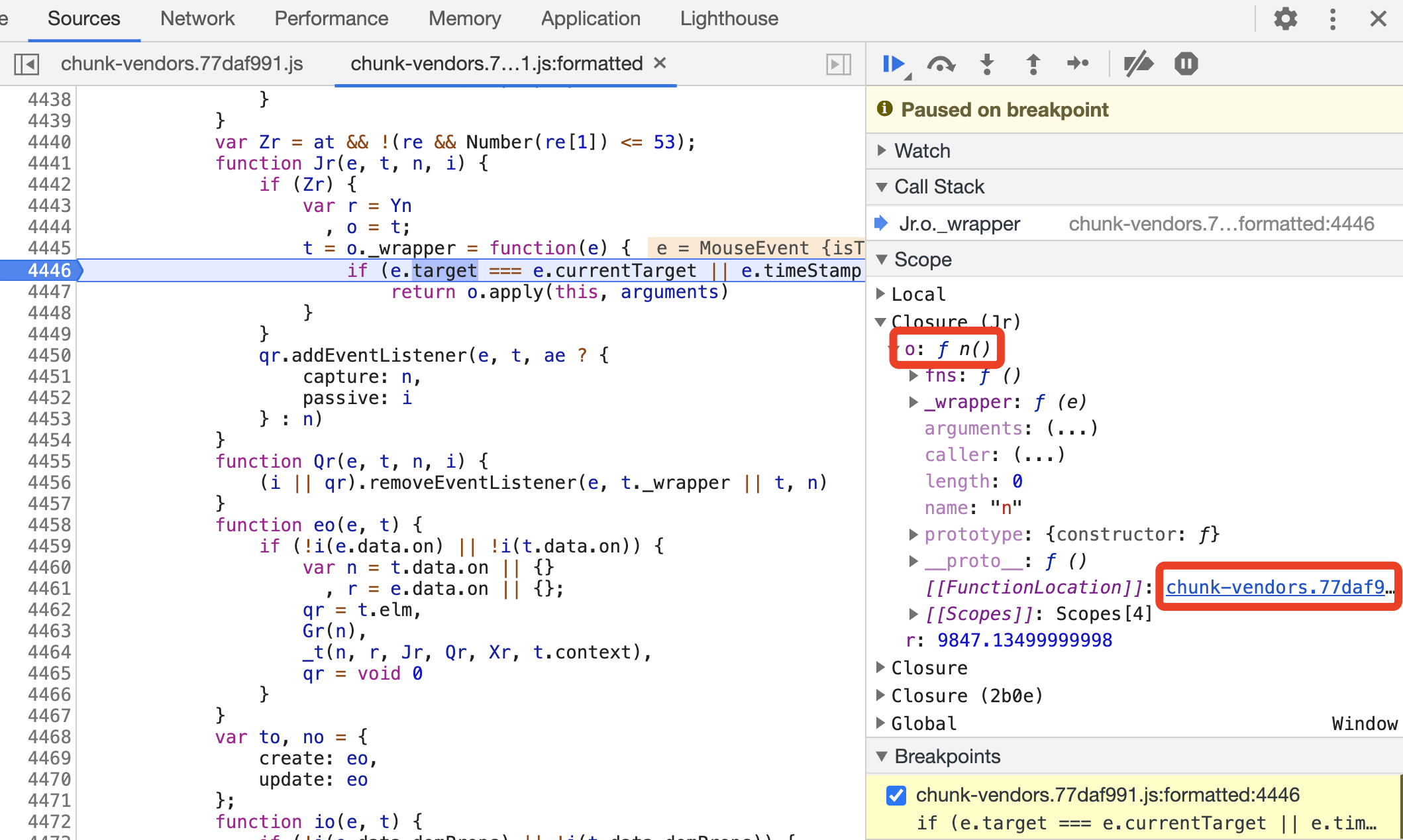
我们可以看到,FunctionLocation 又指向了方法 o ,点击之后便又可以跳到指定位置,用同样的方式进行断点调试即可。
在 Scope 面板还有多个域,这里就不再展开介绍了。总之,通过 Scope 面板,我们可以看到当前执行环境下的变量的值和方法的定义,知道当前代码究竟执行了怎样的逻辑。
接下来切换到 Watch 面板,在这里可以自行添加想要查看的变量和方法,点击右上角的 + 号按钮,我们可以任意添加想要监听的对象,如图所示。
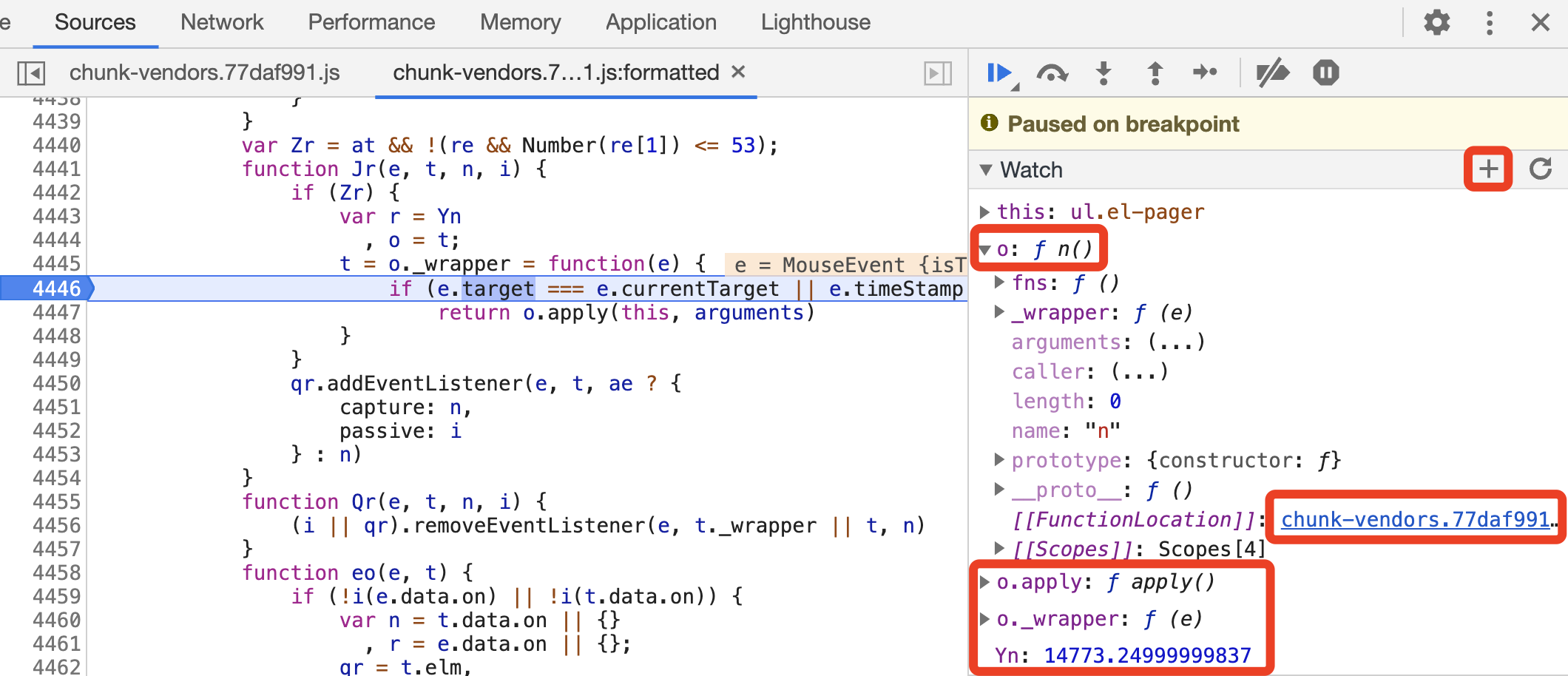
比如这里我们比较关注 o.apply 是一个怎样的方法,于是点击添加 o.apply,这里就会把对应的方法定义呈现出来,展开之后可以再点击 FunctionLocation 定位其源码位置。
我们还可以切换到 Console 面板,输入任意的 JavaScript 代码,便会执行、输出对应的结果,如图所示。
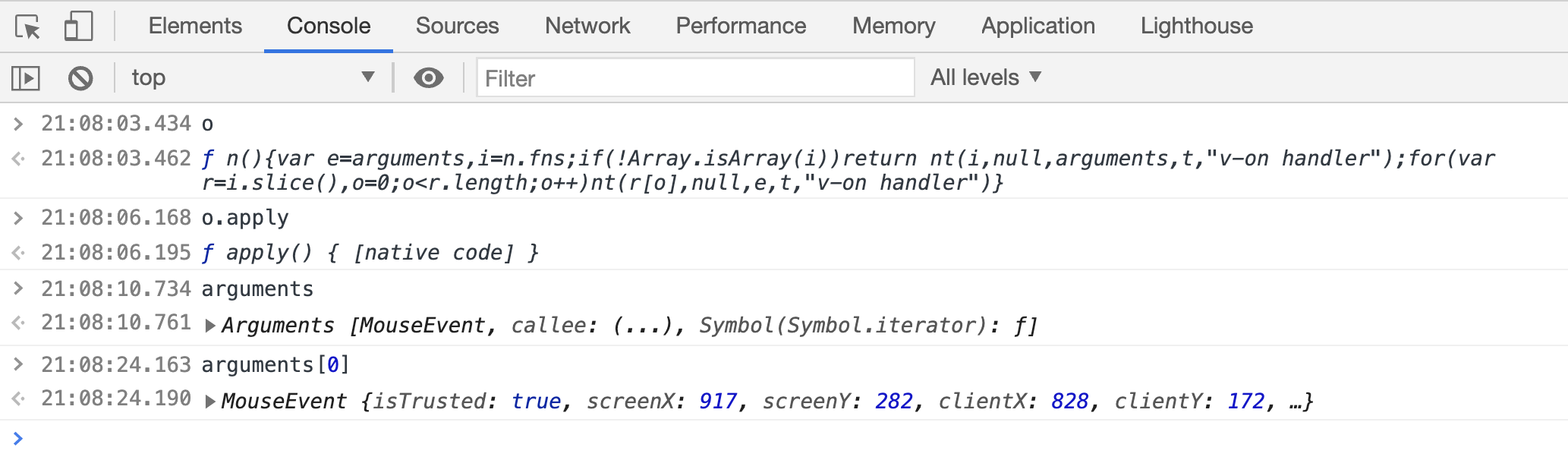
如果我们想看看变量 arguments 的第一个元素是什么,那么可以直接敲入 arguments[0],便会输出对应的结果 MouseEvent,只要在当前上下文能访问到的变量都可以直接引用并输出。
此时我们还可以选择单步调试,这里有 3 个重要的按钮,如图所示。
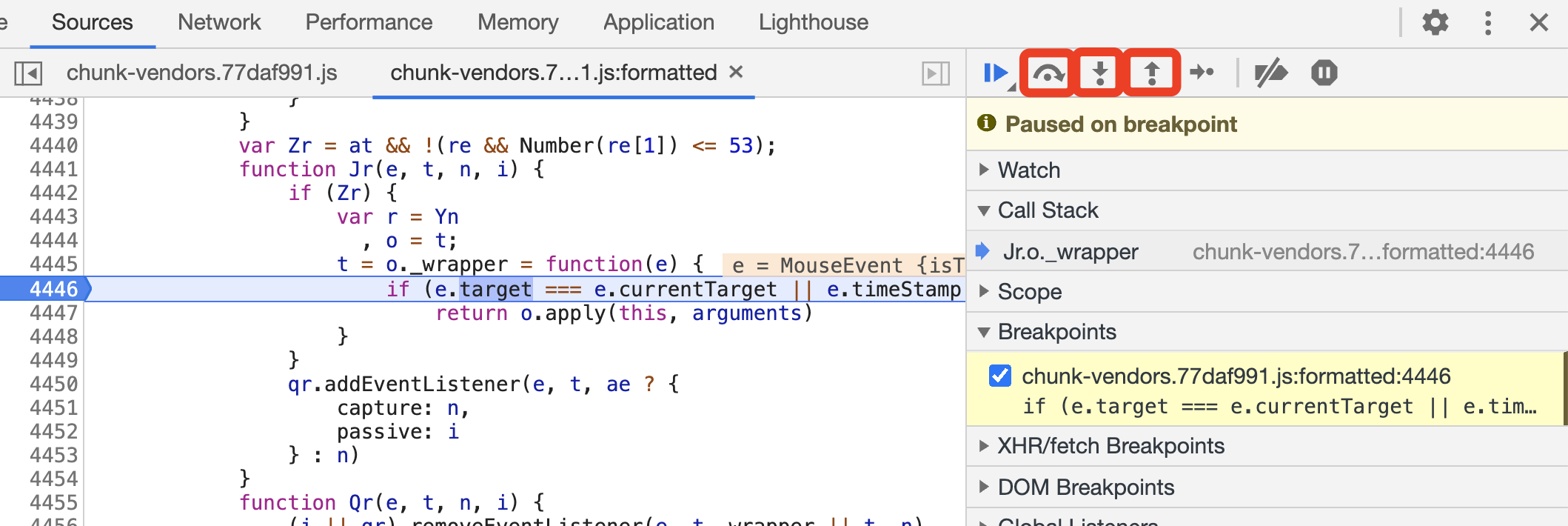
这 3 个按钮都可以做单步调试,但功能不同。
- Step Over Next Function Call:逐语句执行
- Step Into Next Function Call:进入方法内部执行
- Step Out of Current Function:跳出当前方法
用得较多的是第一个,相当于逐行调试,比如点击 Step Over Next Function Call 这个按钮,就运行到了 4447 行,高亮的位置就变成了这一行,如图所示。
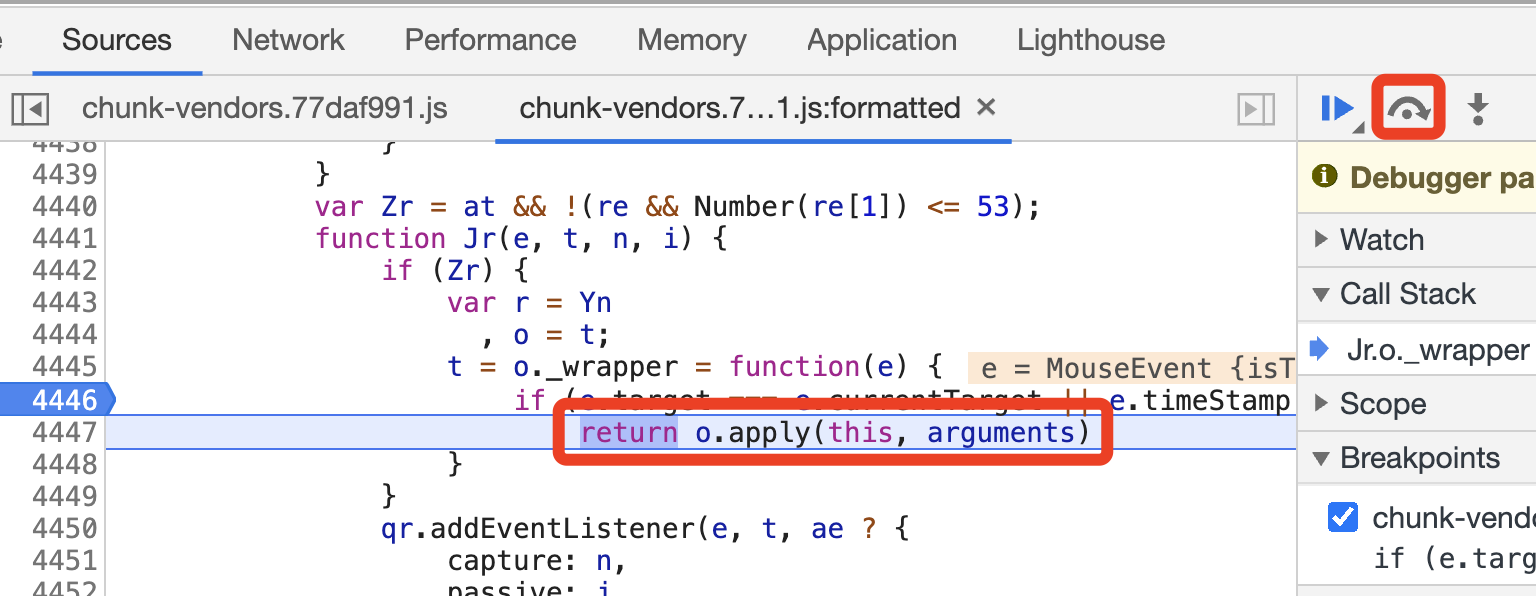
5. 观察调用栈
在调试的过程中,我们可能会跳到一个新的位置,比如点击上述 Step Over Next Function Call 几下,可能会跳到一个叫作 ct 的方法中,这时候我们也不知道发生了什么,如图所示。
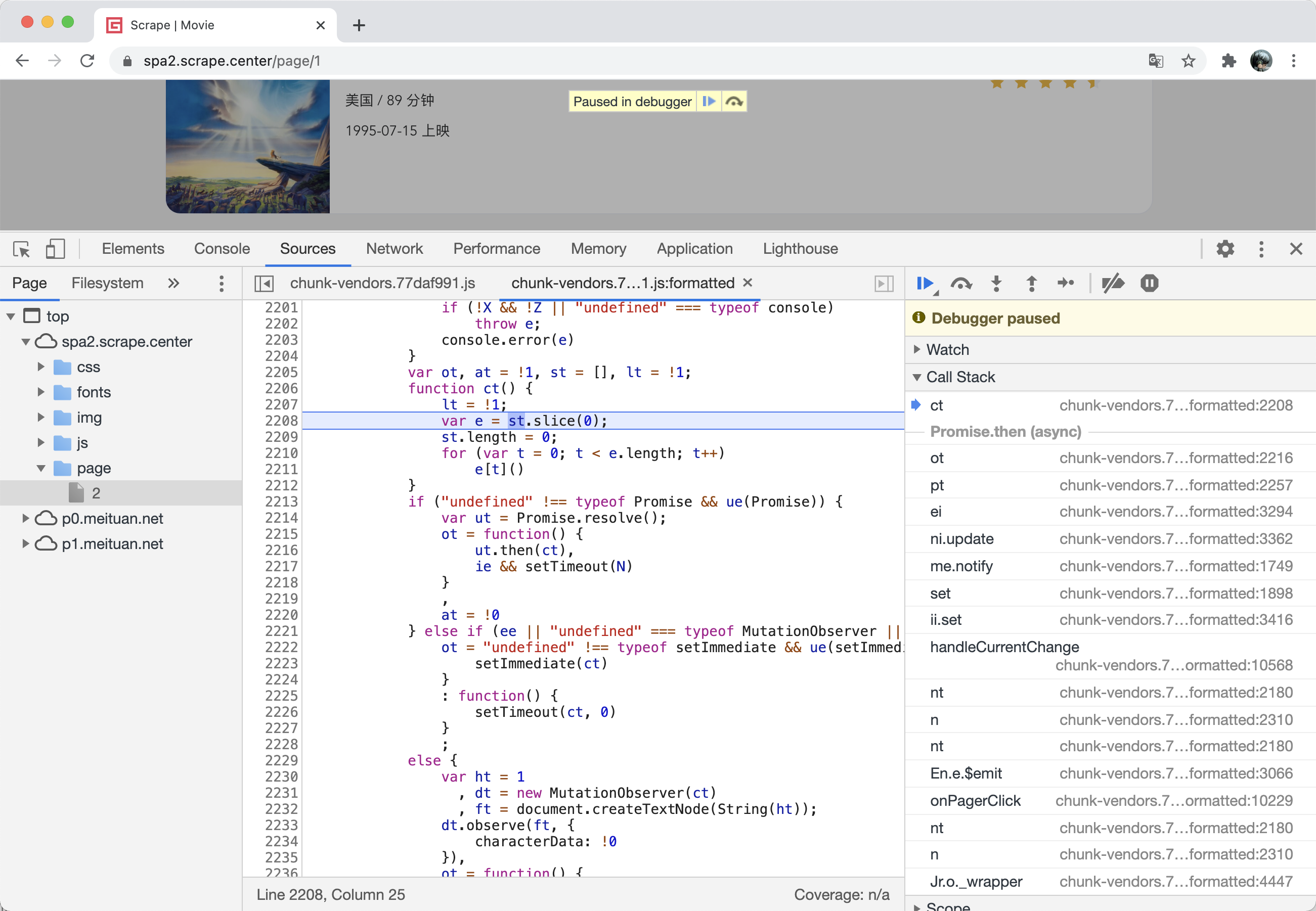
那究竟是怎么跳过来的呢?我们可以观察一下右侧的 Call Stack 面板,就可以看到全部的调用过程了。比如它的上一步是 ot 方法,再上一步是 pt 方法,点击对应的位置也可以跳转到对应的代码位置,如图所示。
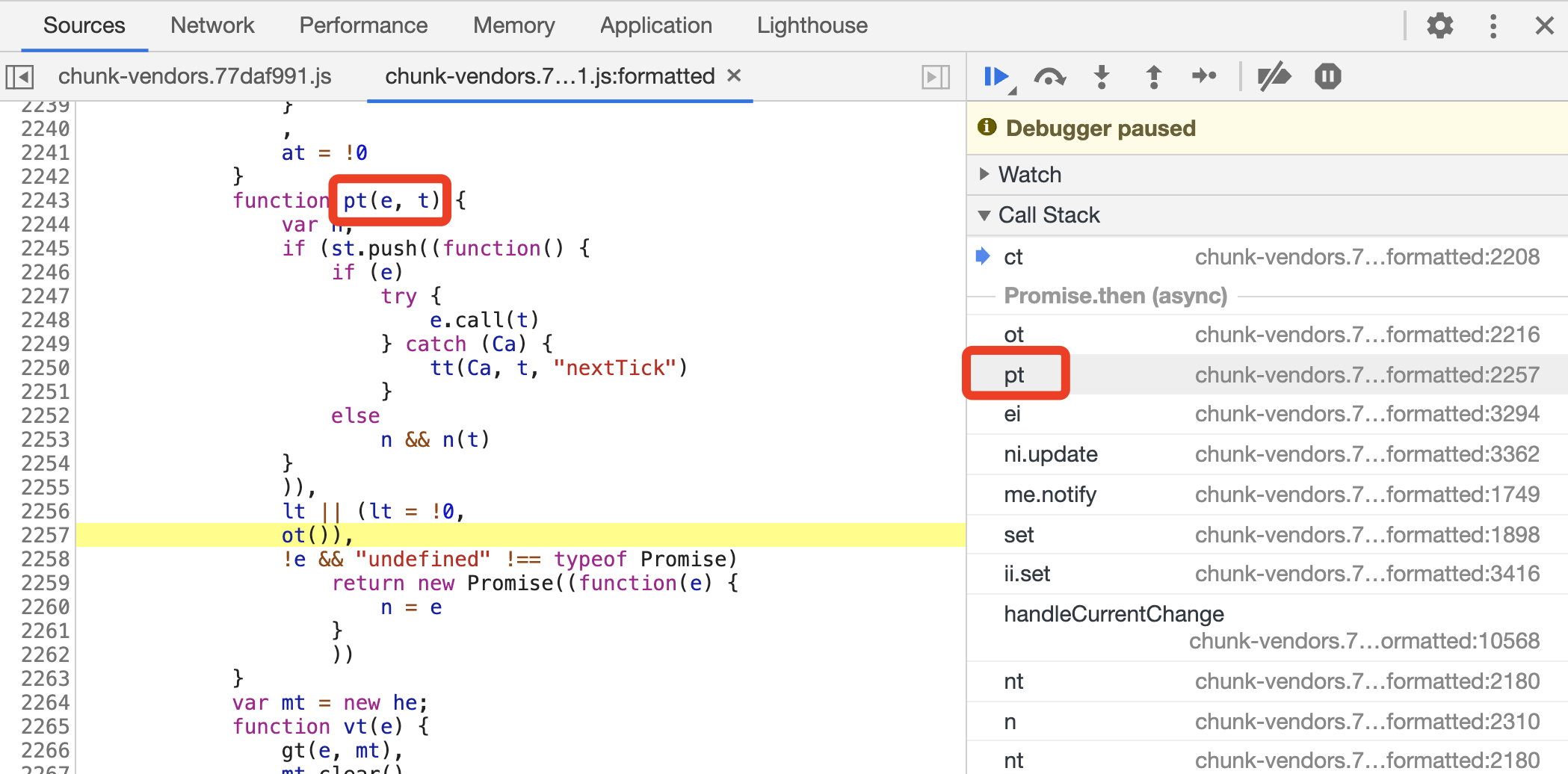
有时候调用栈是非常有用的,利用它我们可以回溯某个逻辑的执行流程,从而快速找到突破口。
6. 恢复 JavaScript 执行
在调试过程中,如果想快速跳到下一个断点或者让 JavaScript 代码运行下去,可以点击 Resume script execution 按钮,如图所示。
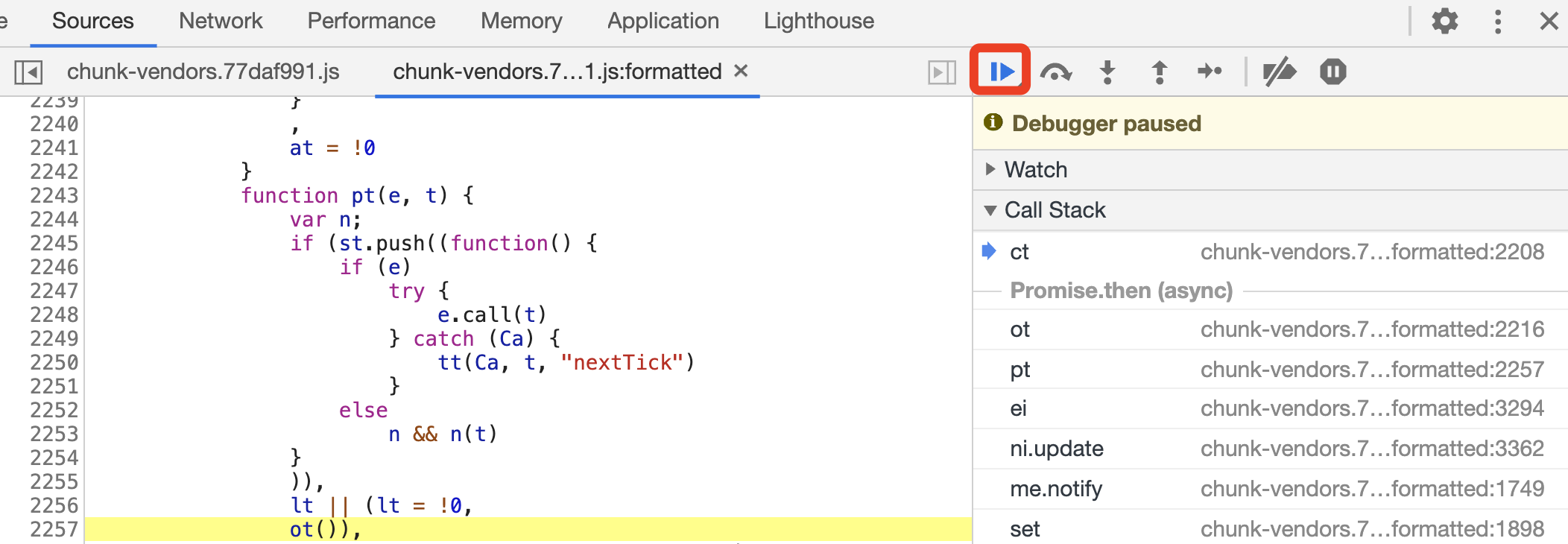
这时浏览器会直接执行到下一个断点的位置,从而避免陷入无穷无尽的调试中。
当然,如果没有其他断点了,浏览器就会恢复正常状态。比如这里我们就没有再设置其他断点了,浏览器直接运行并加载了下一页的数据,同时页面恢复正常,如图所示。
7. Ajax 断点
上面我们介绍了一些 DOM 节点的 Listener,通过 Listener 我们可以手动设置断点并进行调试。但其实针对这个例子,通过翻页的点击事件 Listener 是不太容易找到突破口的。
接下来我们再介绍一个方法 —— Ajax 断点,它可以在发生 Ajax 请求的时候触发断点。对于这个例子,我们的目标其实就是找到 Ajax 请求的那一部分逻辑,找出加密参数是怎么构造的。可以想到,通过 Ajax 断点,使页面在获取数据的时候停下来,我们就可以顺着找到构造 Ajax 请求的逻辑了。
怎么设置呢?
我们把之前的断点全部取消,切换到 Sources 面板下,然后展开 XHR/fetch Breakpoints,这里就可以设置 Ajax 断点,如图所示。
要设置断点,就要先观察 Ajax 请求。和之前一样,我们点击翻页按钮 2,在 Network 面板里面观察 Ajax 请求是怎样的,请求的 URL 如图所示。
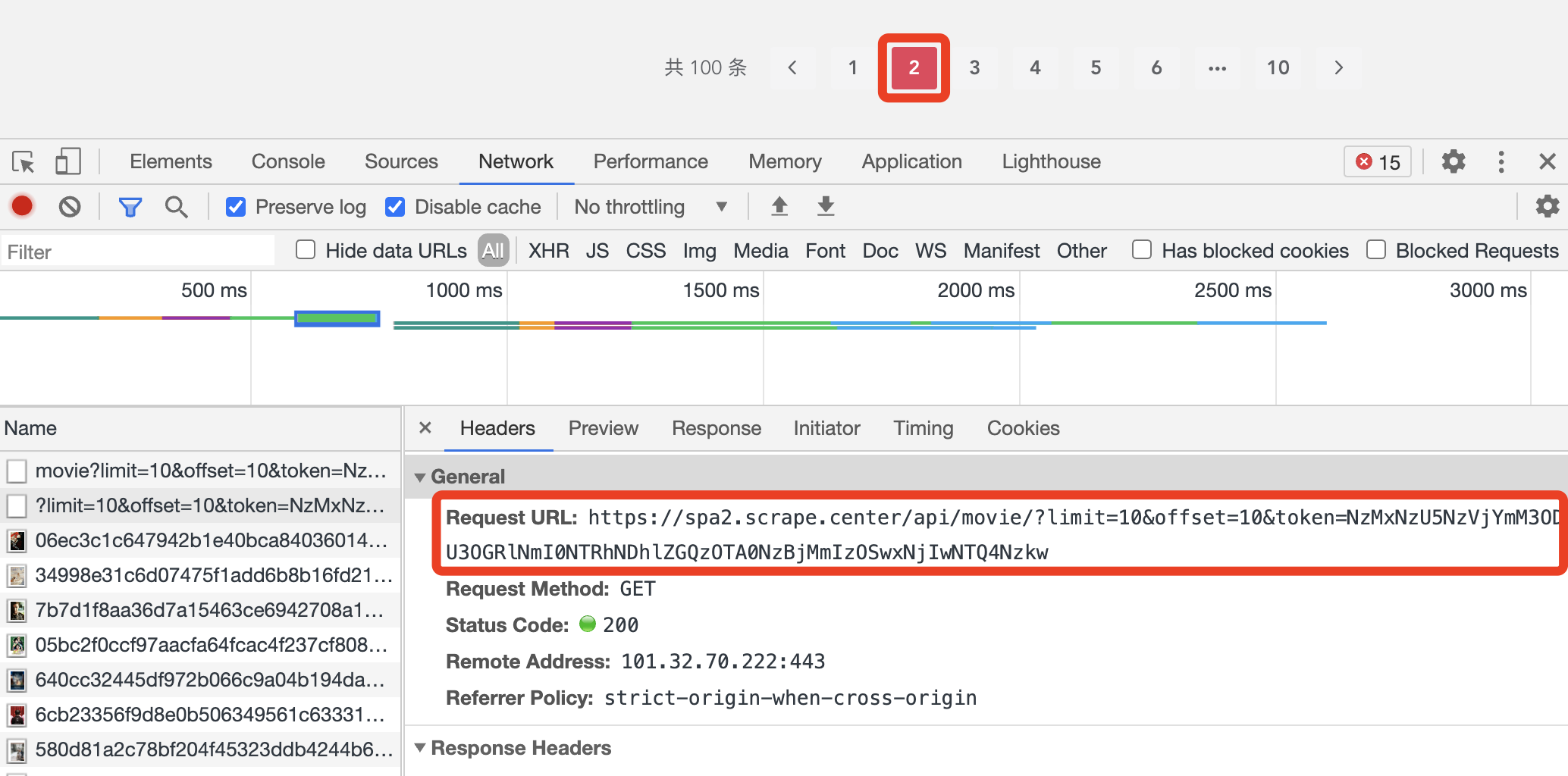
可以看到 URL 里面包含 /api/movie 这样的内容,所以我们可以在刚才的 XHR/fetch Breakpoints 面板中添加拦截规则。点击 + 号,可以看到一行 Break when URL contains: 的提示,意思是当 Ajax 请求的 URL 包含填写的内容时,会进入断点停止,这里可以填写 /api/movie,如图所示。
这时候我们再点击翻页按钮 3,触发第 3 页的 Ajax 请求。会发现点击之后页面走到断点停下来了,如图所示。
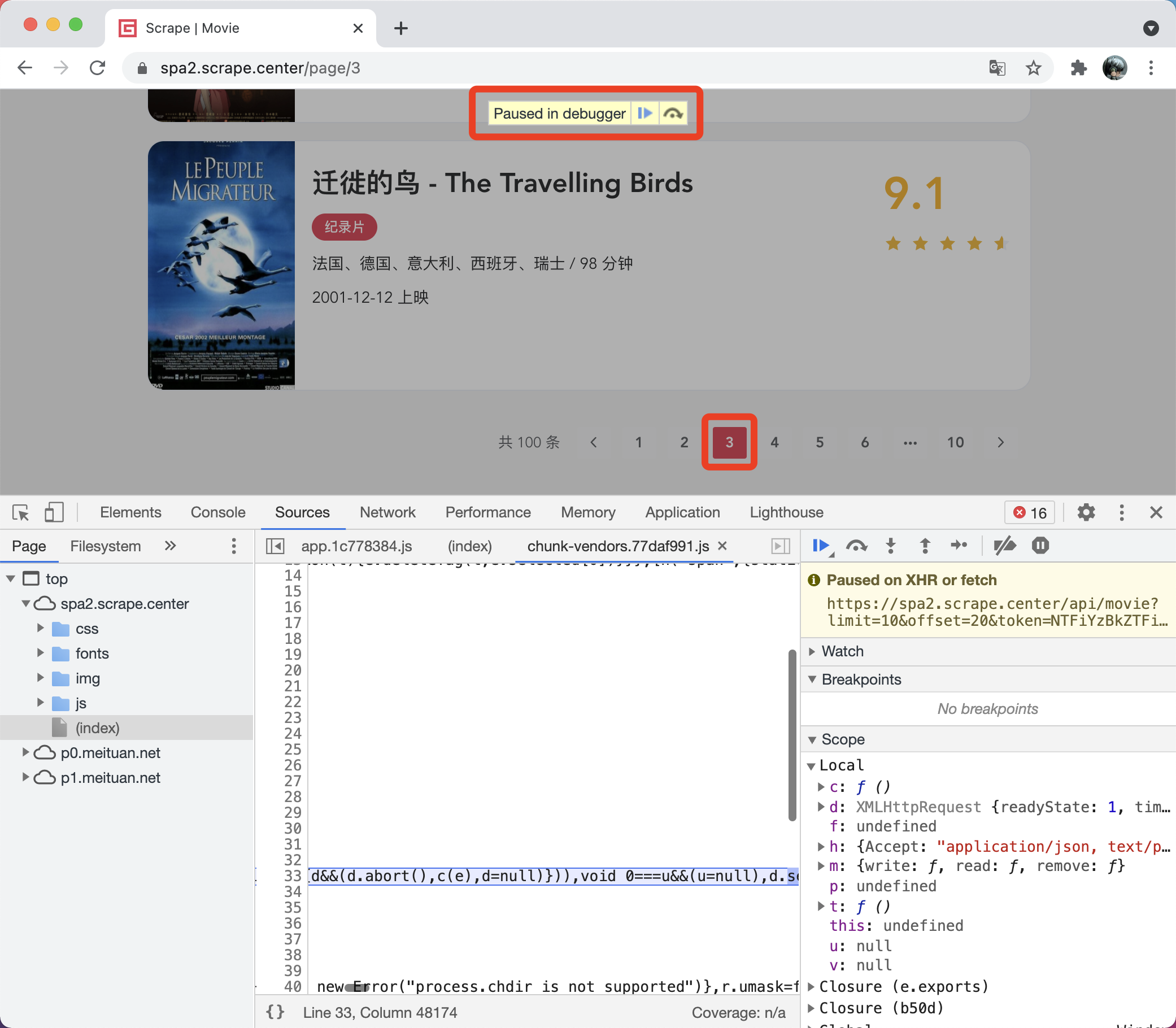
格式化代码看一下,发现它停到了 Ajax 最后发送的那个时候,即底层的 XMLHttpRequest 的 send 方法,可是似乎还是找不到 Ajax 请求是怎么构造的。前面我们讲过调用栈 Call Stack,通过调用栈是可以顺着找到前序调用逻辑的,所以顺着调用栈一层层找,也可以找到构造 Ajax 请求的逻辑,最后会找到一个叫作 onFetchData 的方法,如图所示。
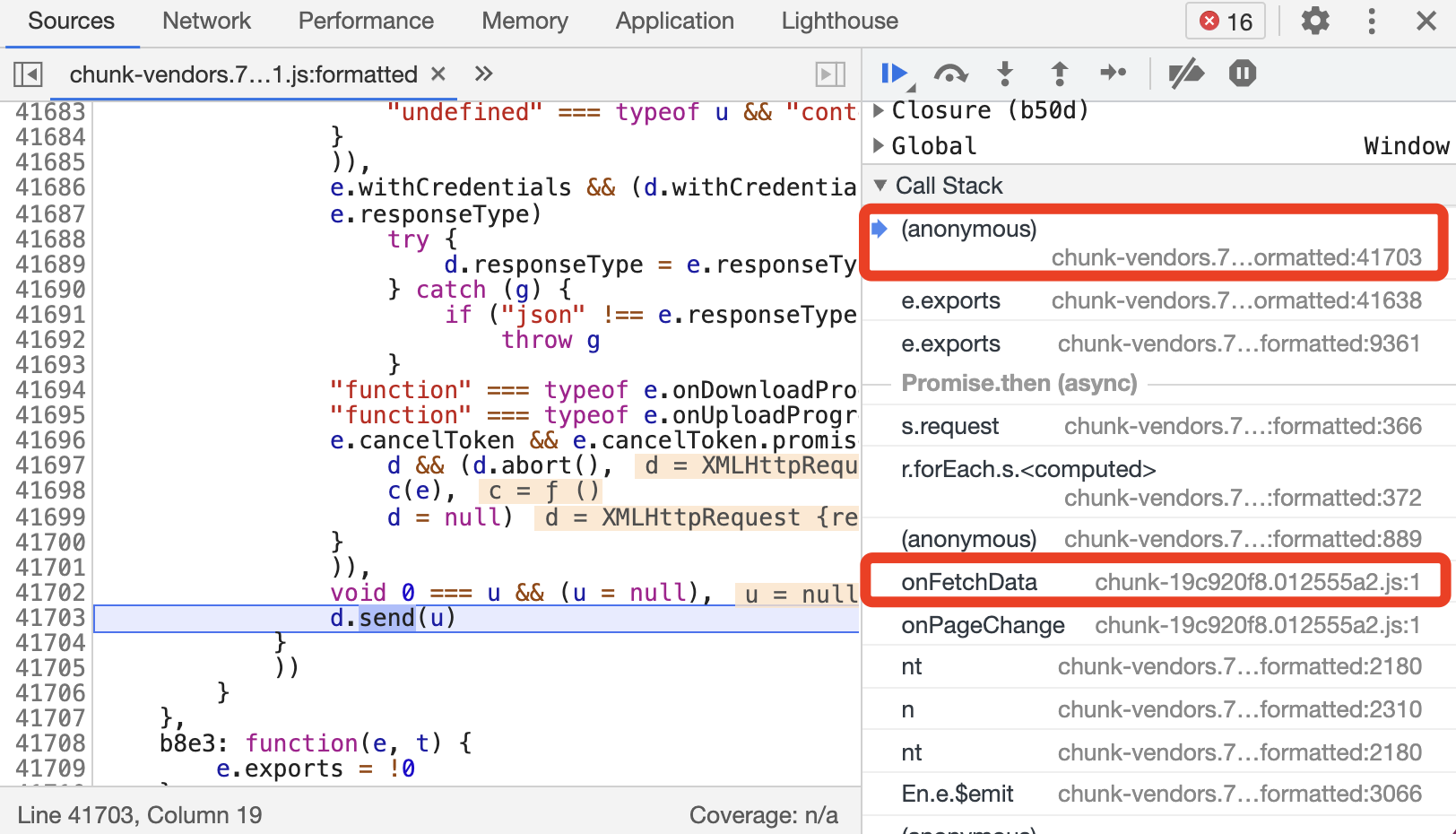
接下来切换到 onFetchData 方法并将代码格式化,可以看到如图所示的调用方法。
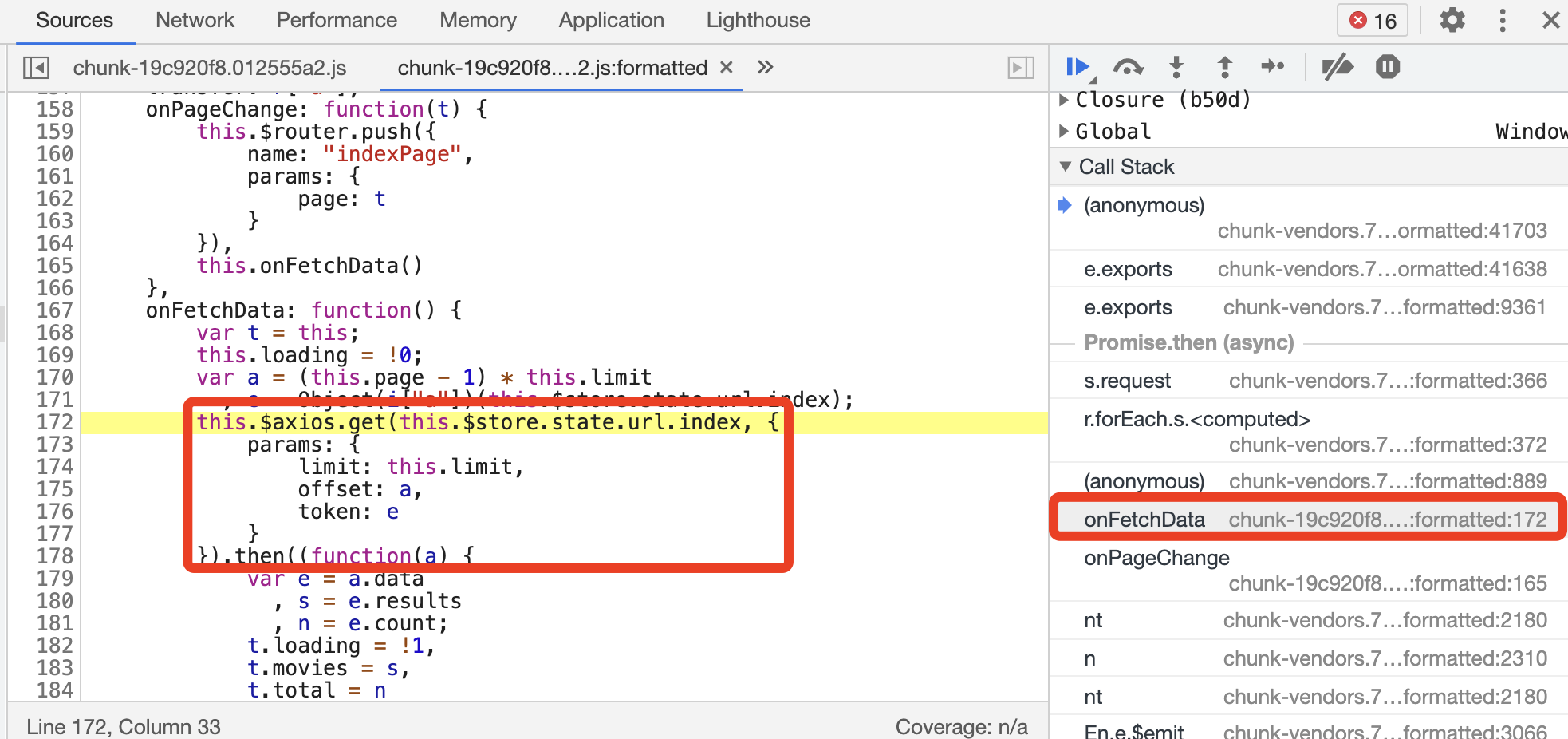
可以发现,可能使用了 axios 库发起了一个 Ajax 请求,还有 limit、offset、token 这 3 个参数,基本就能确定了,顺利找到了突破口!我们就不在此展开分析了,后文会有完整的分析实战。
因此在某些情况下,我们可以在比较容易地通过 Ajax 断点找到分析的突破口,这是一个常见的寻找 JavaScript 逆向突破口的方法。
要取消断点也很简单,只需要在 XHR/fetch Breakpoints 面板取消勾选即可,如图所示。
说实话,不太理解这里,直接从network看请求不是更方便吗
8. 改写 JavaScript 文件
我们知道,一个网页里面的 JavaScript 是从对应服务器上下载下来并在浏览器执行的。有时候,我们可能想要在调试的过程中对 JavaScript 做一些更改,比如说有以下需求:
- 发现 JavaScript 文件中包含很多阻挠调试的代码或者无效代码、干扰代码,想要将其删除。
- 调试到某处,想要加一行
console.log输出一些内容,以便观察某个变量或方法在页面加载过程中的调用情况。在某些情况下,这种方法比打断点调试更方便。 - 调试过程遇到某个局部变量或方法,想要把它赋值给
window对象以便全局可以访问或调用。 - 在调试的时候,得到的某个变量中可能包含一些关键的结果,想要加一些逻辑将这些结果转发到对应的目标服务器。
这时候我们可以试着在 Sources 面板中对 JavaScript 进行更改,但这种更改并不能长久生效,一旦刷新页面,更改就全都没有了。比如我们在 JavaScript 文件中写入一行 JavaScript 代码,然后保存,如图所示。
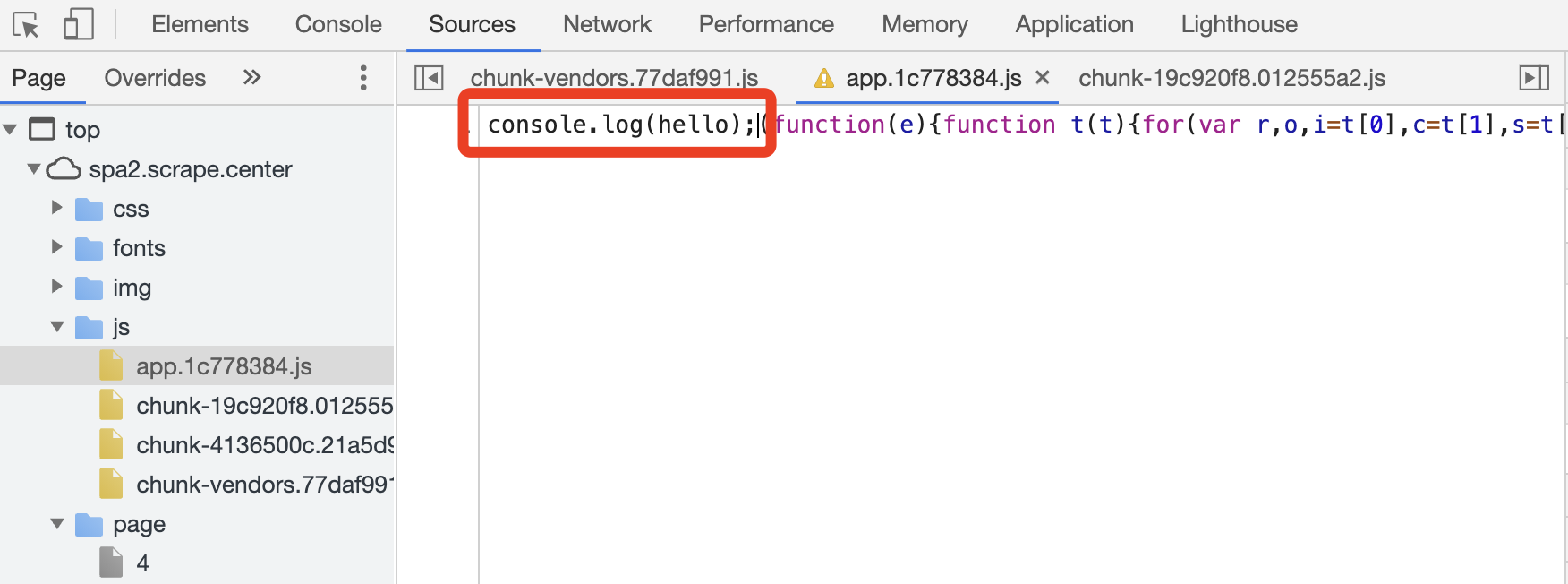
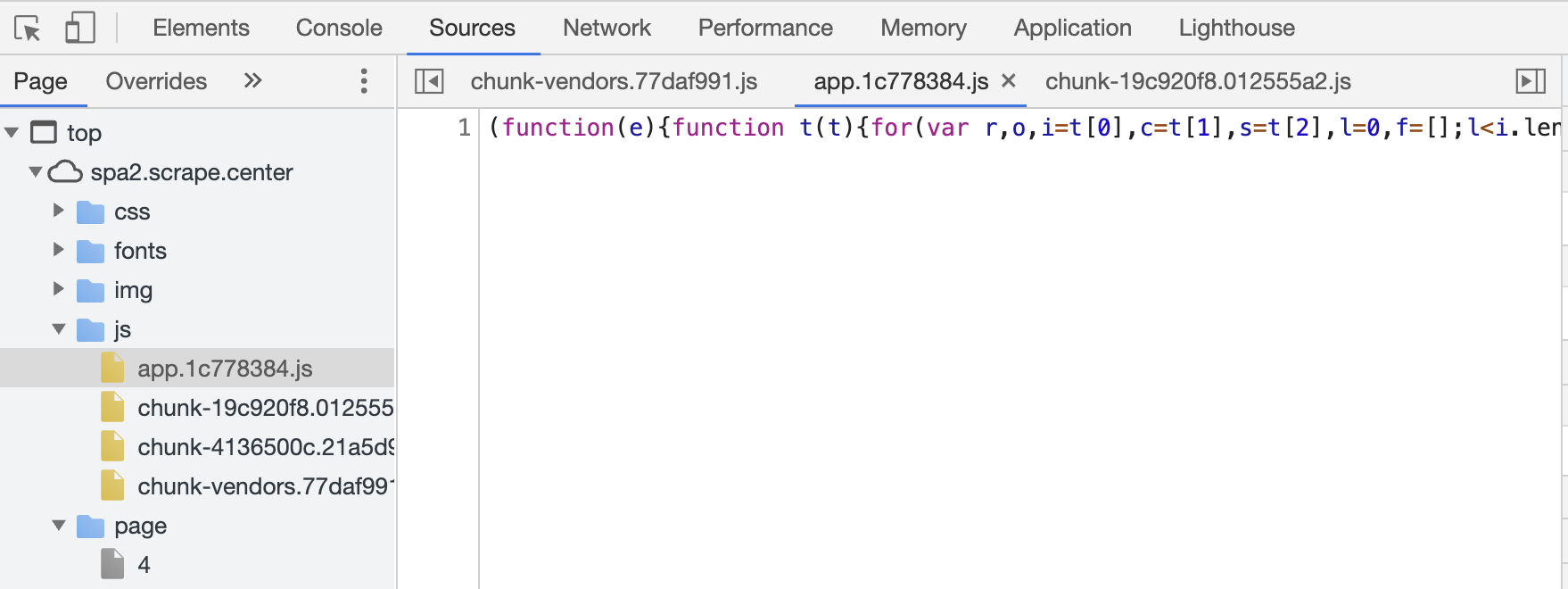
这时候可以发现 JavaScript 文件上出现了一个感叹号标志,提示我们做的更改是不会保存的。这时候重新刷新页面,再看一下更改的这个文件,如图所示。
有什么方法可以修改呢?其实有一些浏览器插件可以实现,比如 ReRes。在插件中,我们可以添加自定义的 JavaScript 文件,并配置 URL 映射规则,这样浏览器在加载某个在线 JavaScript 文件的时候就可以将内容替换成自定义的 JavaScript 文件了。另外,还有一些代理服务器也可以实现,比如 Charles、Fiddler,借助它们可以在加载 JavaScript 文件时修改对应 URL 的响应内容,以实现对 JavaScript 文件的修改。
其实浏览器的开发者工具已经原生支持这个功能了,即浏览器的 Overrides 功能,它在 Sources 面板左侧,如图所示。
我们可以在 Overrides 面板上选定一个本地的文件夹,用于保存需要更改的 JavaScript 文件,我们来实际操作一下。
首先,根据上文设置 Ajax 断点的方法,找到对应的构造 Ajax 请求的位置,根据一些网页开发知识,我们可以大体判断出 then 后面的回调方法接收的参数 a 中就包含了 Ajax 请求的结果,如图所示。
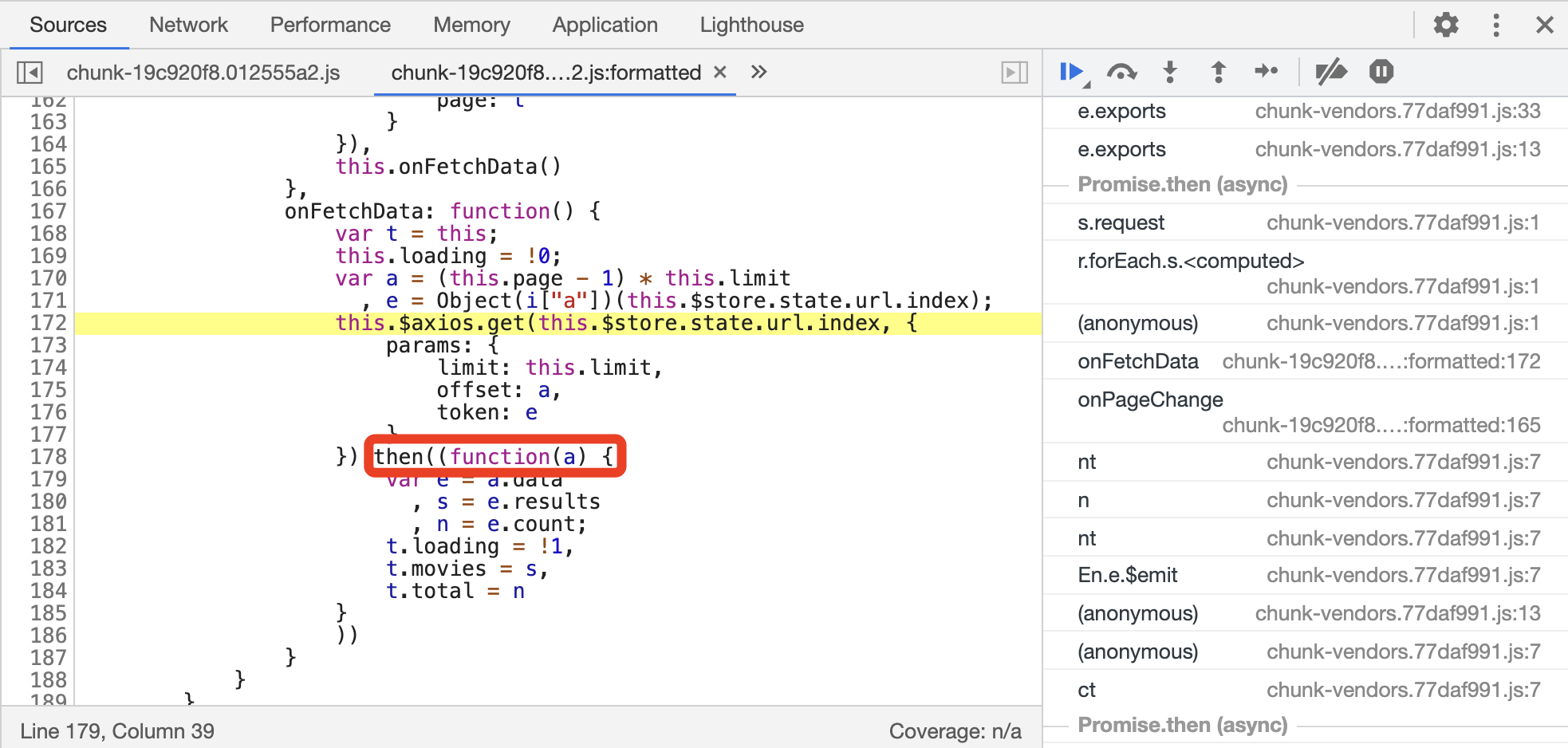
我们打算在 Ajax 请求成功获得 Response 的时候,在控制台输出 Response 的结果,也就是通过 console.log 输出变量 a。
再切回 Overrides 面板,点击 + 按钮,这时候浏览器会提示我们选择一个本地文件夹,用于存储要替换的 JavaScript 文件。这里我选定了一个我任意新建的文件夹 ChromeOverrides,注意,这时候可能会遇到如图所示的提示,如果没有问题,直接点击 “允许” 即可。

这时,在 Overrides 面板下就多了一个 ChromeOverrides 文件夹,用于存储所有我们想要更改的 JavaScript 文件,如图所示。
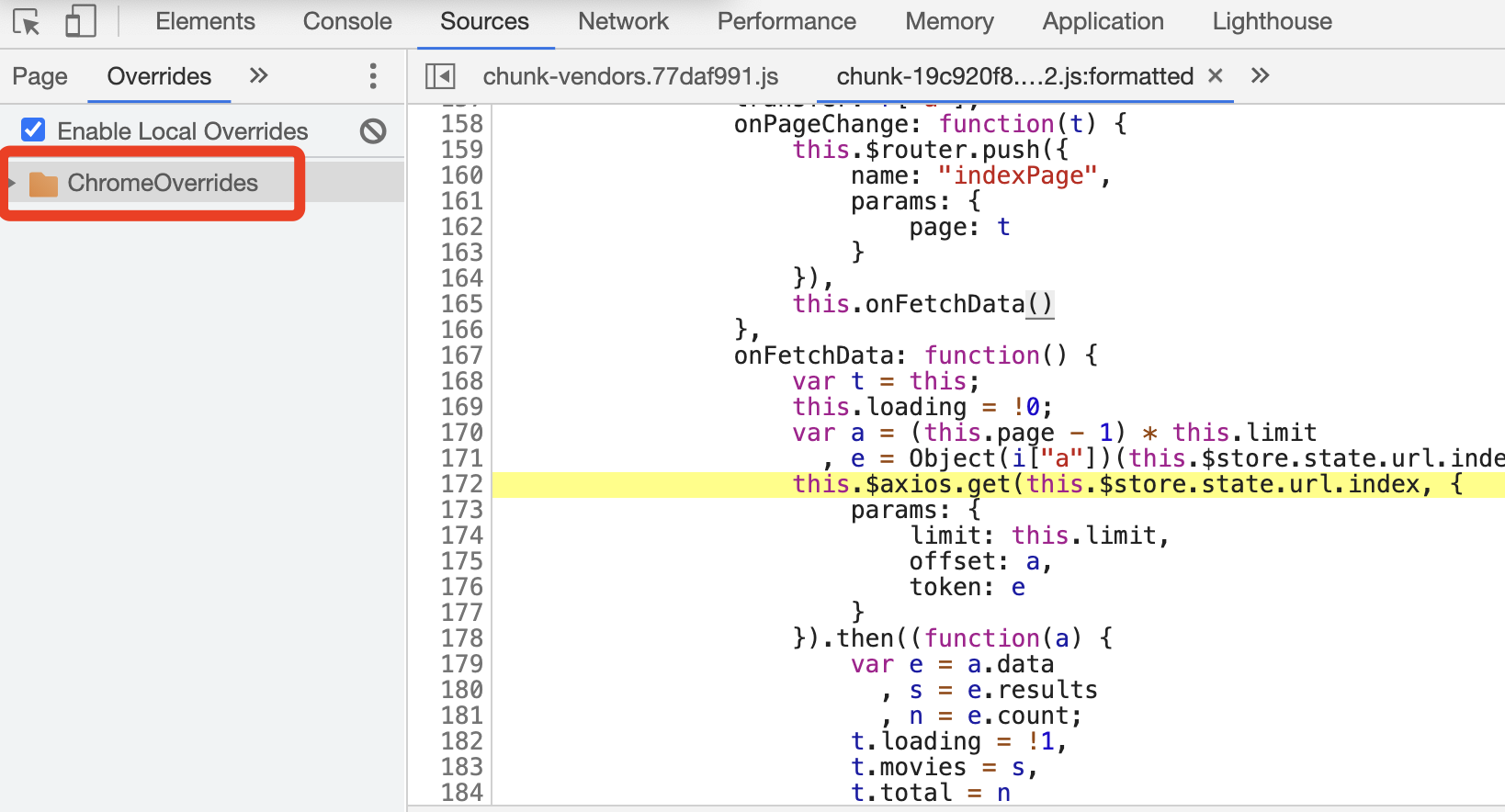
我们可以看到,现在所在的 JavaScript 选项卡是 chunk-19c920f8.012555a2.js:formatted,代码已经被格式化了。因为格式化后的代码是无法直接在浏览器中修改的,所以为了方便,我们可以将格式化后的文件复制到文本编辑器中,然后添加一行代码,修改如下:
1 | ... |
接着把修改后的内容替换到原来的 JavaScript 文件中。这里要注意,切换到 chunk-19c920f8.012555a2.js 文件才能修改,直接替换 JavaScript 文件的所有内容即可,如图所示。
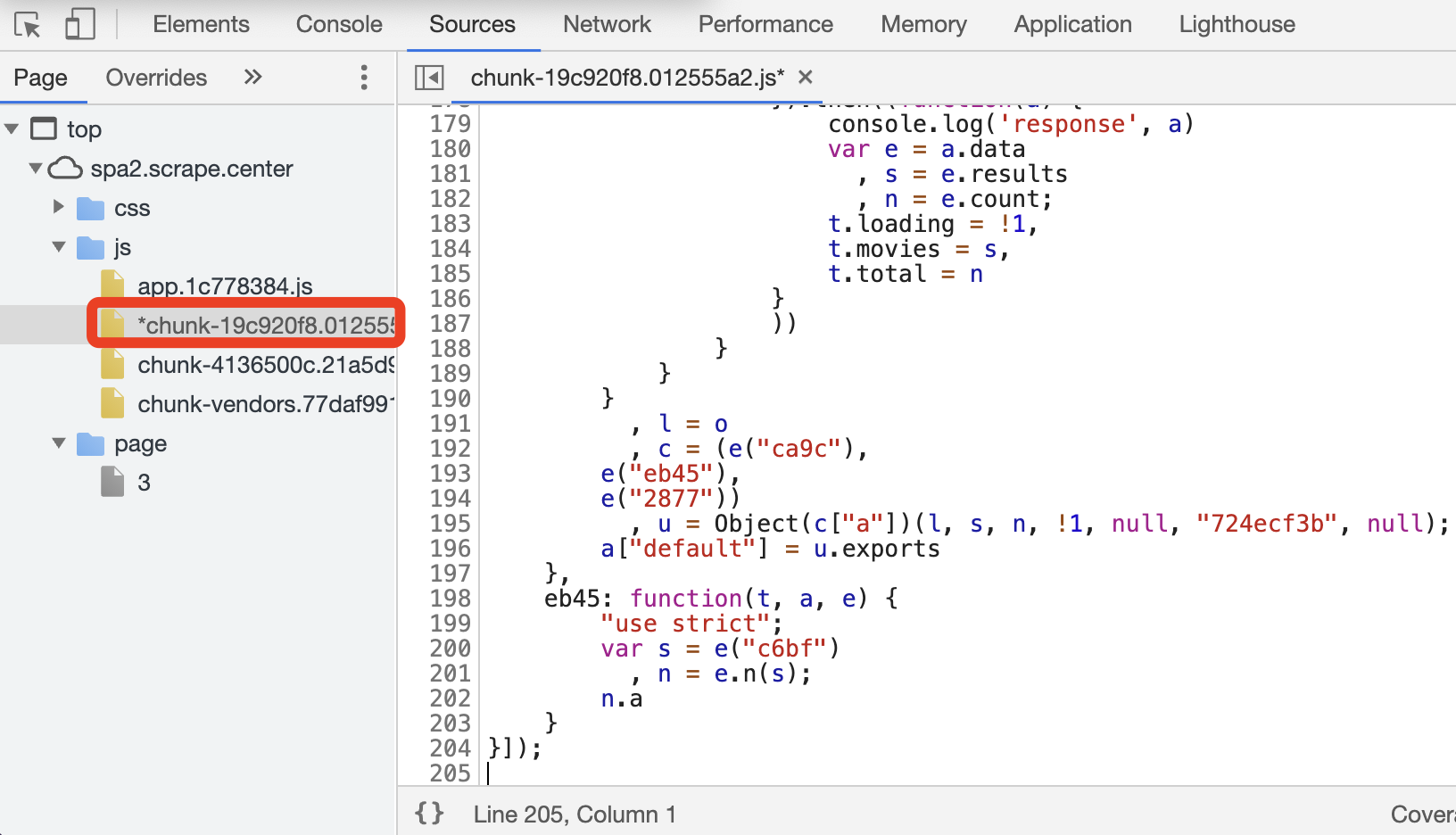
替换完毕之后保存,这时候再切换回 Overrides 面板,就可以发现成功生成了新的 JavaScript 文件,它用于替换原有的 JavaScript 文件,如图所示。
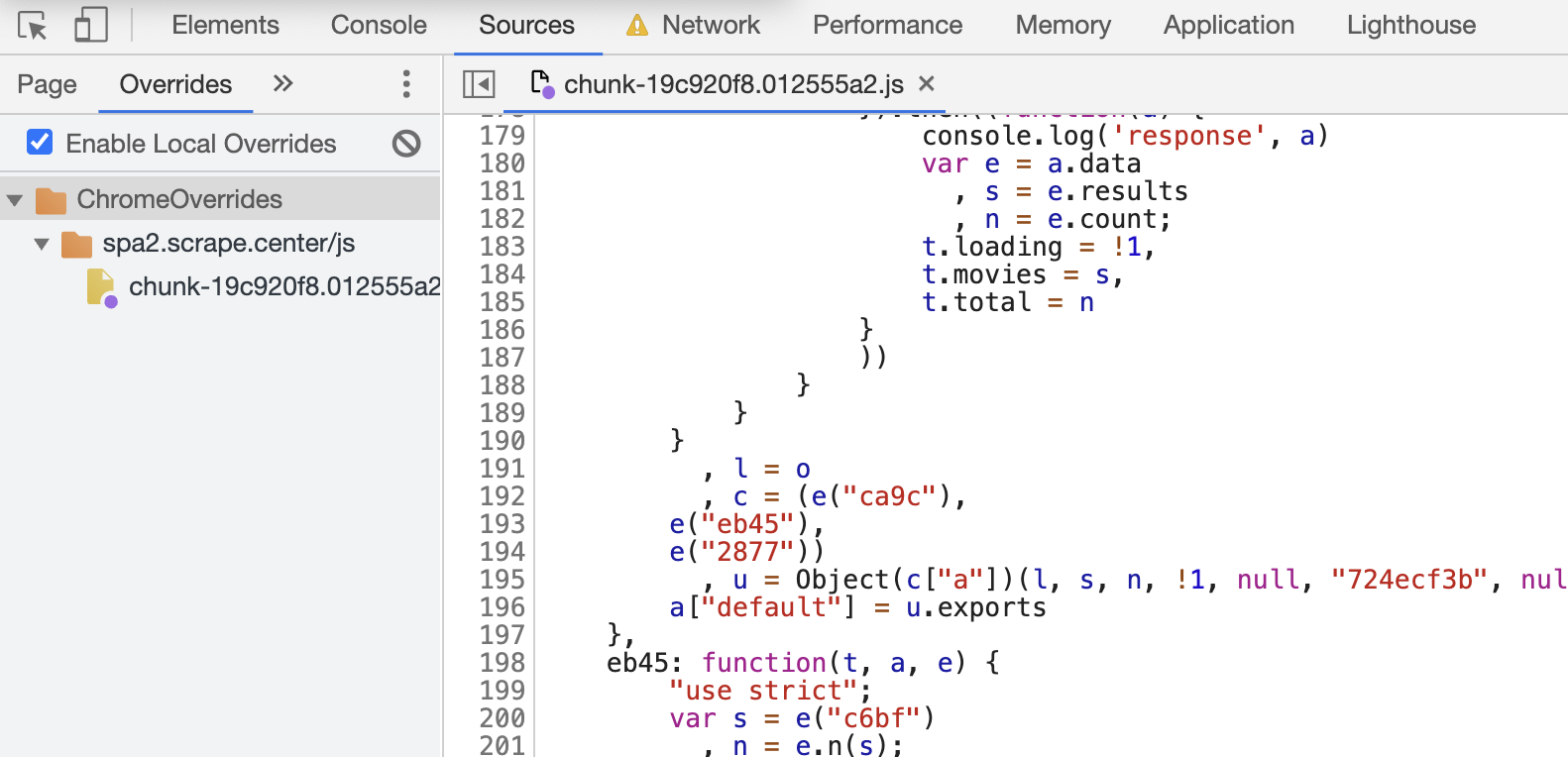
好,此时我们取消所有断点,然后刷新页面,就可以在控制台看到输出的 Reponse 结果了,如图所示。
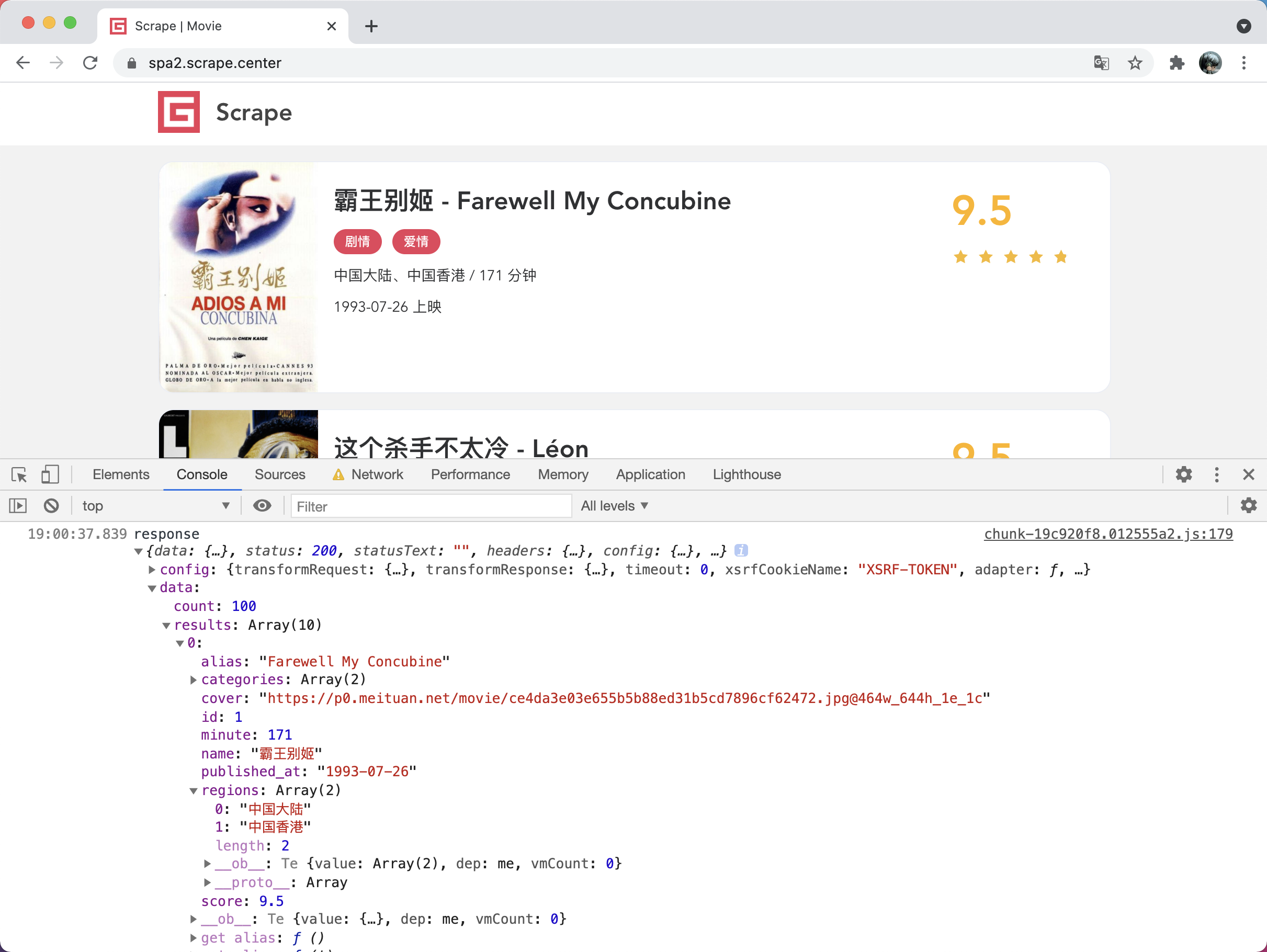
正如我们所料,我们成功将变量 a 输出,其中的 data 字段就是 Ajax 的 Response 结果,证明改写 JavaScript 成功!而且刷新页面也不会丢失了。
我们还可以增加一些 JavaScript 逻辑,比如直接将变量 a 的结果通过 API 发送到远程服务器,并通过服务器将数据保存下来,也就完成了直接拦截 Ajax 请求并保存数据的过程了。
修改 JavaScript 文件有很多用途,此方案可以为我们进行 JavaScript 的逆向带来极大的便利。
9. 总结
本节总结了一些浏览器开发者工具中对 JavaScript 逆向非常有帮助的功能,熟练掌握了这些功能会对后续 JavaScript 逆向分析打下坚实的基础,请大家好好研究。
javaScript Hook
在 JavaScript 逆向的时候,我们经常需要追踪某些方法的堆栈调用情况。但在很多情况下,一些 JavaScript 的变量或者方法名经过混淆之后是非常难以捕捉的。上一节我们介绍了一些断点调试、调用栈查看等技巧,但仅仅凭借这些技巧还不足以应对多数 JavaScript 逆向。
本节我们再来介绍一个比较常用的 JavaScript 逆向技巧 —— Hook 技术。
1. Hook 技术
Hook 技术中文又叫作钩子技术,指在程序运行的过程中,对其中的某个方法进行重写,在原先的方法前后加入我们自定义的代码。相当于在系统没有调用该函数之前,钩子程序就先捕获该消息,得到控制权,这时钩子函数既可以加工处理(改变)该函数的执行行为,也可以强制结束消息的传递。
要对 JavaScript 代码进行 Hook 操作,就需要额外在页面中执行一些自定义的有关 Hook 逻辑的代码。那么问题来了?怎样才能在浏览器中方便地执行我们所期望执行的 JavaScript 代码呢?在这里推荐一个插件,叫作 Tampermonkey。这个插件的功能非常强大,利用它我们几乎可以在网页中执行任何 JavaScript 代码,实现我们想要的功能。
下面我们就来介绍一下这个插件的使用方法,并结合一个实际案例,介绍一下这个插件在 JavaScript Hook 中的用途。
2. Tampermonkey
Tampermonkey,中文也叫作 “油猴”,它是一款浏览器插件,支持 Chrome。利用它我们可以在浏览器加载页面时自动执行某些 JavaScript 脚本。由于执行的是 JavaScript,所以我们几乎可以在网页中完成任何我们想实现的效果,如自动爬虫、自动修改页面、自动响应事件等。
其实,Tampermonkey 的用途远远不止这些,只要我们想要的功能能用 JavaScript 实现,Tampermonkey 就可以帮我们做到。比如我们可以将 Tampermonkey 应用到 JavaScript 逆向分析中,去帮助我们更方便地分析一些 JavaScript 加密和混淆代码。
3. 安装
首先我们需要安装 Tampermonkey,这里我们使用的浏览器是 Chrome。直接在 Chrome 应用商店或者在 Tampermonkey 的官网 https://www.tampermonkey.net/ 下载安装即可。
安装完成之后,在 Chrome 浏览器的右上角会出现 Tampermonkey 的图标,这就代表安装成功了,如图所示。
4. 获取脚本
Tampermonkey 运行的是 JavaScript 脚本,每个网站都能有对应的脚本运行,不同的脚本能完成不同的功能。这些脚本我们可以自定义,也可以用已经写好的很多脚本,毕竟有些轮子有了,我们就不需要再去造了。
我们可以在 https://greasyfork.org/zh-CN/scripts 找到一些非常实用的脚本,如全网视频去广告、百度云全网搜索等,大家可以体验一下。
5. 脚本编写
除了使用别人已经写好的脚本,我们也可以自己编写脚本来实现想要的功能。编写脚本难不难呢?其实就是写 JavaScript 代码,只要懂一些 JavaScript 的语法就好了。另外我们需要遵循脚本的一些写作规范,其中就包括一些参数的设置。
下面我们就简单实现一个小的脚本。首先我们可以点击 Tampermonkey 插件图标,再点击 “管理面板” 按钮,打开脚本管理页面,如图所示。
脚本管理页面如图所示。

在这里显示了我们已经有的一些 Tampermonkey 脚本,包括我们自行创建的,也包括从第三方网站下载安装的。另外这里提供了编辑、调试、删除等管理功能,在这里可以方便地对脚本进行管理。
接下来我们来创建一个新的脚本,点击左侧的 “+” 号,会显示如图所示的页面。
初始化的代码如下:
1 | // ==UserScript== |
在上面这段代码里,最前面是一些注释,它们非常有用,这部分内容叫作 UserScript Header ,我们可以在里面配置一些脚本的信息,如名称、版本、描述、生效站点等等。
下面简单介绍一下 UserScript Header 的一些参数定义。
@name:脚本的名称,就是在控制面板显示的脚本名称。@namespace:脚本的命名空间。@version:脚本的版本,主要是做版本更新时用。@author:作者。@description:脚本描述。@homepage、@homepageURL、@website、@source:作者主页,用于在 Tampermonkey 选项页面上从脚本名称点击跳转。请注意,如果@namespace标记以http://开头,此处也要一样。@icon、@iconURL、@defaulticon:低分辨率图标。@icon64、@icon64URL:64 × 64 高分辨率图标。@updateURL:检查更新的网址,需要定义@version。@downloadURL:更新下载脚本的网址,如果定义成none就不会检查更新。@supportURL:报告问题的网址。@include:生效页面,可以配置多个,但注意这里并不支持 URL Hash。例如:
1
2
3
4// @include http://www.tampermonkey.net/*
// @include http://*
// @include https://*
// @include *@match:约等于@include标签,可以配置多个。@exclude:不生效页面,可配置多个,优先级高于@include和@match。@require:附加脚本网址,相当于引入外部的脚本,这些脚本会在自定义脚本执行之前执行,比如引入一些必须的库,如 jQuery 等,这里可以支持配置多个@require参数。例如:
1
2
3// @require https://code.jquery.com/jquery-2.1.4.min.js
// @require https://code.jquery.com/jquery-2.1.3.min.js#sha256=23456...
// @require https://code.jquery.com/jquery-2.1.2.min.js#md5=34567...,sha256=6789...@resource:预加载资源,可通过GM_getResourceURL和GM_getResourceText读取。@connect:允许被GM_xmlhttpRequest访问的域名,每行 1 个。@run-at:脚本注入的时刻,如页面刚加载时,某个事件发生后等。document-start:尽可能地早执行此脚本。document-body:DOM 的 body 出现时执行。document-end:DOMContentLoaded事件发生时或发生后执行。document-idle:DOMContentLoaded事件发生后执行,即 DOM 加载完成之后执行,这是默认的选项。context-menu:如果在浏览器上下文菜单(仅限桌面 Chrome 浏览器)中点击该脚本,则会注入该脚本。注意:如果使用此值,则将忽略所有@include和@exclude语句。
@grant:用于添加 GM 函数到白名单,相当于授权某些 GM 函数的使用权限。例如:
1
2
3
4
5
6// @grant GM_setValue
// @grant GM_getValue
// @grant GM_setClipboard
// @grant unsafeWindow
// @grant window.close
// @grant window.focus如果没有定义过
@grant选项,Tampermonkey 会猜测所需要的函数使用情况。@noframes:此标记使脚本在主页面上运行,但不会在 iframe 上运行。@nocompat:由于部分代码可能是为专门的浏览器所写,通过此标记,Tampermonkey 会知道脚本可以运行的浏览器。例如:
1
// @nocompat Chrome
这样就指定了脚本只在 Chrome 浏览器中运行。
除此之外,Tampermonkey 还定义了一些 API,使得我们可以方便地完成某个操作。
GM_log:将日志输出到控制台。GM_setValue:将参数内容保存到 Storage 中。GM_addValueChangeListener:为某个变量添加监听,当这个变量的值改变时,就会触发回调。GM_xmlhttpRequest:发起 Ajax 请求。GM_download:下载某个文件到磁盘。GM_setClipboard:将某个内容保存到粘贴板。
还有很多其他的 API,大家可以到 https://www.tampermonkey.net/documentation.php 查看更多的内容。
在 UserScript Header 下方是 JavaScript 函数和调用的代码,其中 'use strict' 标明代码使用 JavaScript 的严格模式。在严格模式下,可以消除 Javascript 语法的一些不合理、不严谨之处,减少一些怪异行为,如不能直接使用未声明的变量,这样可以保证代码的运行安全,同时提高编译器的效率,提高运行速度。在下方 // Your code here... 处就可以编写自己的代码了。
6. 实战分析
下面我们通过一个简单的 JavaScript 逆向案例来演示一下如何实现 JavaScript 的 Hook 操作,轻松找到某个方法执行的位置,从而快速定位逆向入口。
接下来我们来看一个简单的网站:https://login1.scrape.center/,这个网站的结构非常简单,就是一个用户名密码登录。但是不同的是,点击登录的时候,表单提交 POST 的内容并不是单纯的用户名和密码,而是一个加密后的 token。
页面如图所示。

我们输入用户名密码,都为 admin,点击登录按钮,观察一下网络请求的变化。
可以看到如下结果如图所示。
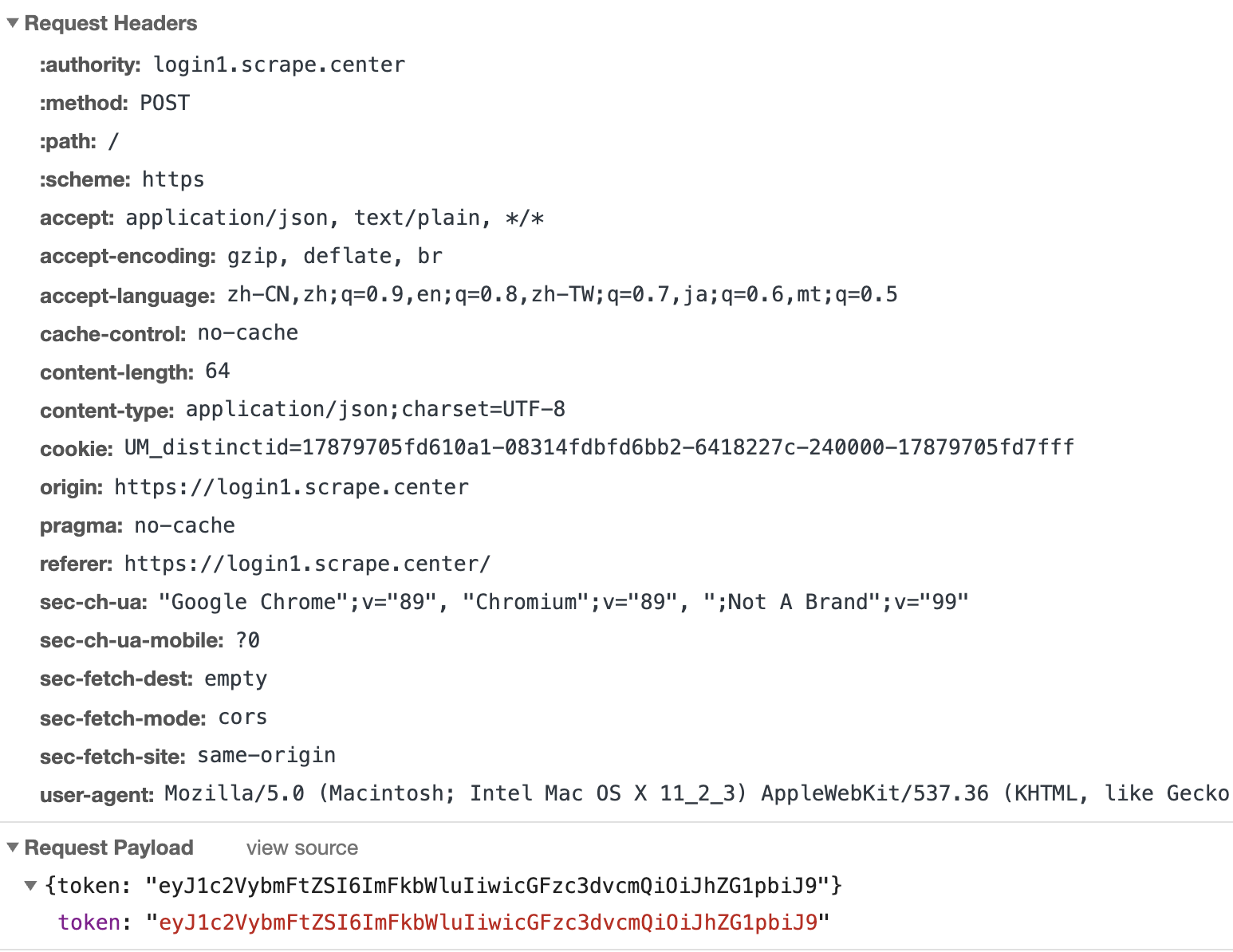
我们不需要关心 Response 的结果和状态,主要看 Request 的内容就好了。
可以看到,点击登录按钮时,发起了了一个 POST 请求,内容为:
1 | {"token":"eyJ1c2VybmFtZSI6ImFkbWluIiwicGFzc3dvcmQiOiJhZG1pbiJ9"} |
嗯,确实,没有诸如 username 和 password 的内容了,那怎么模拟登录呢?
模拟登录的前提当然就是找到当前 token 生成的逻辑了,那么问题来了,到底这个 token 和用户名、密码是什么关系呢?我们怎么来找寻其中的蛛丝马迹呢?
这里我们就可能思考了,本身输入的是用户名和密码,但提交的时候却变成了一个 token,经过观察并结合一些经验可以看出,token 的内容非常像 Base64 编码。这就代表,网站可能首先将用户名密码混为了一个新的字符串,然后经过了一次 Base64 编码,最后将其赋值为 token 来提交了。所以,初步观察我们可以得出这么多信息。
好,那就来验证一下吧!探究网站 JavaScript 代码里面是如何实现的。
首先我们看一下网站的源码,打开 Sources 面板,看起来都是 Webpack 打包之后的内容,经过了一些混淆,如图所示。
这么多混淆代码,总不能一点点扒着看吧?那么遇到这种情形,这怎么去找 token 的生成位置呢?
解决方法其实有两种,一种就是前文所讲的 Ajax 断点,另一种就是 Hook。
Ajax 断点
由于这个请求正好是一个 Ajax 请求,所以我们可以添加一个 XHR 断点监听,把 POST 的网址加到断点监听上面。在 Sources 面板右侧添加一个 XHR 断点,匹配内容就填当前域名就好了,如图所示。
这时候如果我们再次点击登录按钮,发起一次 Ajax 请求,就可以进入断点了,然后再看堆栈信息,就可以一步步找到编码的入口了。
再次点击登录按钮,页面就进入断点状态停下来了,结果如图所示。
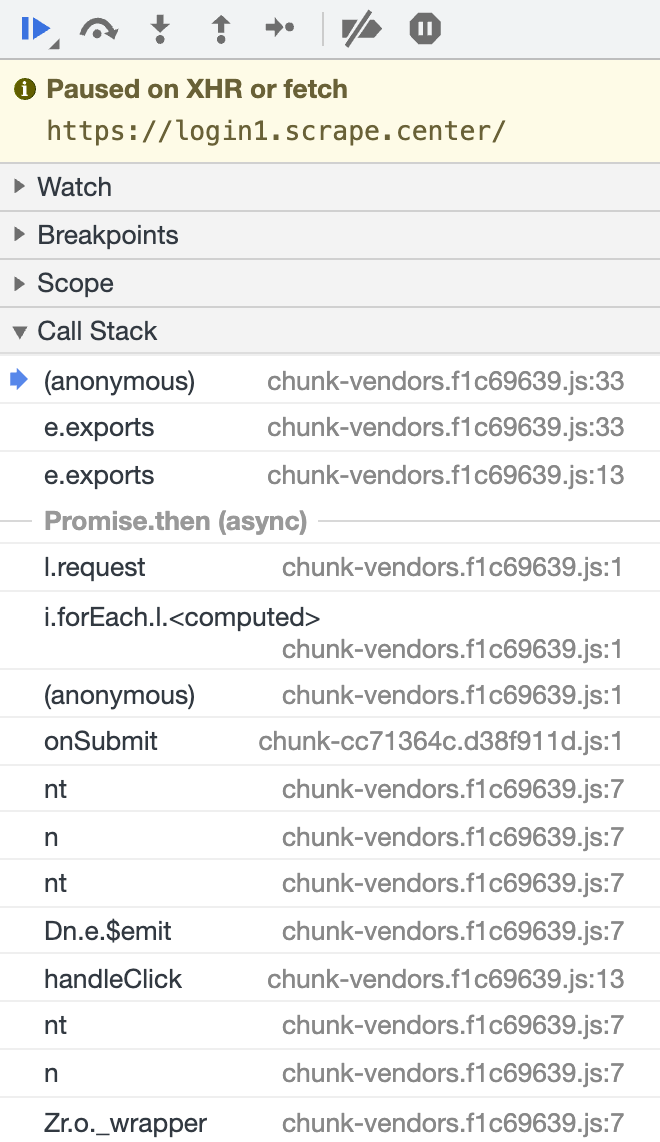
一步步找,最后可以找到入口其实是在 onSubmit 方法那里。但实际上我们观察到,这里的断点的栈顶还包括了一些类似 async Promise 等无关的内容,而我们真正想找的是用户名和密码经过处理,再进行 Base64 编码的地方,这些请求的调用实际上和我们找寻的入口没有很大的关系。
另外,如果我们想找的入口位置并不伴随这一次 Ajax 请求,这个方法就没法用了。
所以下面我们再来看另一个方法 —— Hook。
Hook Function
所以这里介绍第二种可以快速定位入口的方法,那就是使用 Tampermonkey 自定义 JavaScript,实现某个 JavaScript 方法的 Hook。Hook 哪里呢?很明显,Hook Base64 编码的位置就好了。
那么这里就涉及一个小知识点:JavaScript 里面的 Base64 编码是怎么实现的?
没错,就是 btoa 方法,在 JavaScript 中该方法用于将字符串编码成 Base64 字符串,因此我们来 Hook btoa 方法就好了。
好,这里我们新建一个 Tampermonkey 脚本,内容如下:
1 | // ==UserScript== |
首先我们定义了一些 UserScript Header,包括 @name 和 @match 等,这里比较重要的就是 @name,表示脚本名称;另外一个就是 @match,它代表脚本生效的网址。
脚本的内容如上面代码所示。我们定义了一个 hook 方法,传入 object 和 attr 参数,意思就是 Hook object 对象的 attr 参数。例如我们如果想 Hook alert 方法,那就把 object 设置为 window,把 attr 设置为字符串 alert 。这里我们想要 Hook Base64 的编码方法,而在 JavaScript 中,Based64 编码是用 btoa 方法实现的,所以这里我们就只需要 Hook window 对象的 btoa 方法就好了。
那么 Hook 是怎么实现的呢?我们来看已下,首先一句 var func = object[attr],相当于我们先把它赋值为一个变量,我们调用 func 方法就可以实现和原来相同的功能。接着,我们直接改写这个方法的定义,将 object[attr] 改写成一个新的方法,在新的方法中,通过 func.apply 方法又重新调用了原来的方法。这样我们就可以保证前后方法的执行效果是不受什么影响的,之前这个方法该干啥就还是干啥。
但是和之前不同的是,我们自定义方法之后,现在可以在 func 方法执行的前后,再加入自己的代码,如 console.log 将信息输出到控制台,debugger 进入断点等。在这个过程中,我们先临时保存下来了 func 方法,然后定义一个新的方法,接管程序控制权,在其中自定义我们想要的实现,同时在新的方法里面重新调回 func 方法,保证前后结果是不受影响的。所以,我们达到了在不影响原有方法效果的前提下,实现在方法前后自定义的功能,这就是 Hook 的过程。
最后,我们调用 hook 方法,传入 window 对象和 btoa 字符串,保存。
接下来刷新下页面,这时候我们就可以看到这个脚本在当前页面生效了,可以发现 Tempermonkey 插件面板提示了已经启用,同时在 Sources 面板下的 Page 选项卡可以观察到我们定义的 JavaScript 脚本被执行了,如图所示。
然后输入用户名、密码,点击提交,成功进入了断点模式停下来了,代码就卡在了我们自定义的 debugger 这一行代码的位置,如图所示。
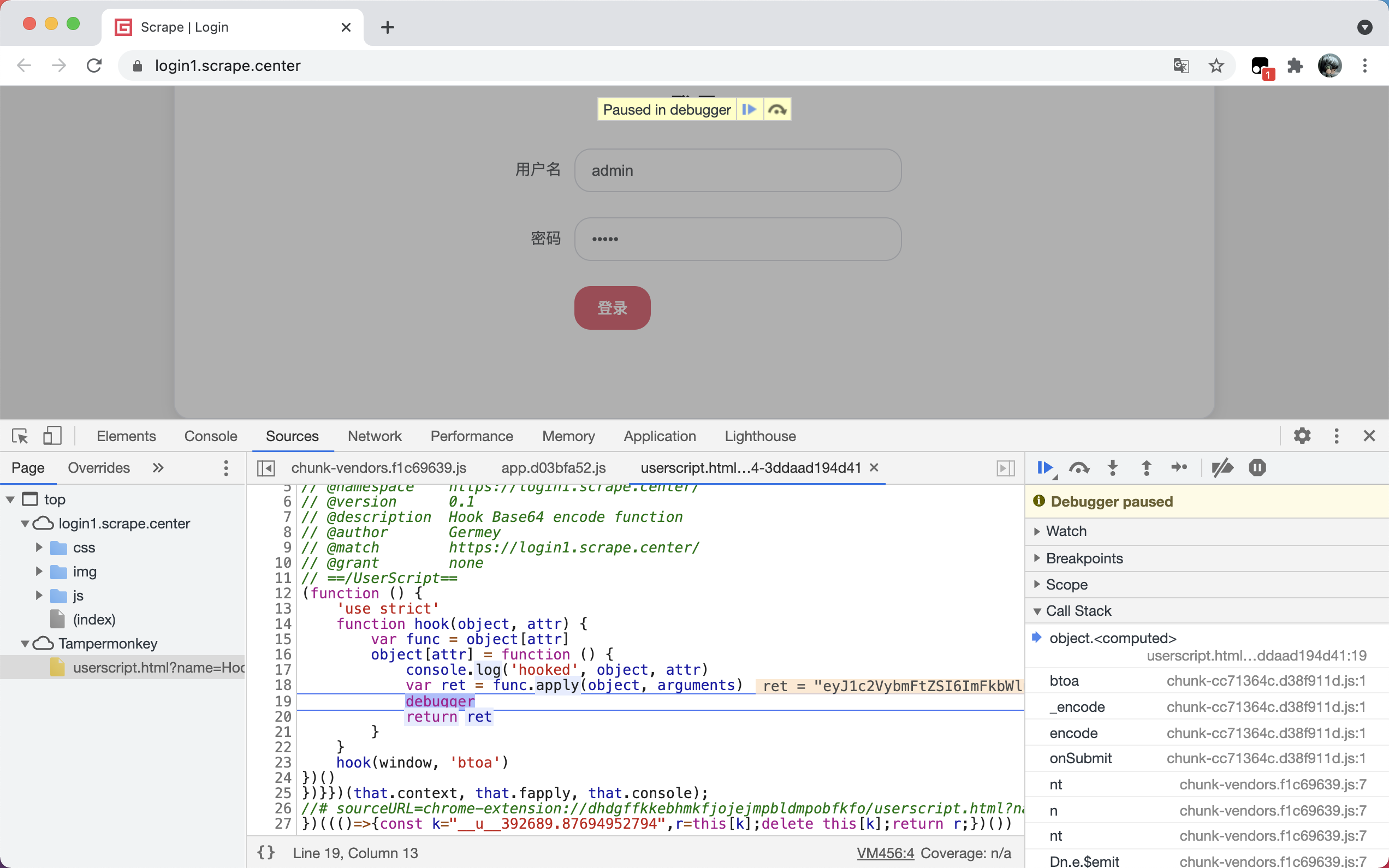
成功 Hook 住了,这说明 JavaScript 代码在执行过程中调用到了 btoa 方法。
这时看一下控制台,如图所示。

这里也输出了 window 对象和 btoa 方法,验证正确。
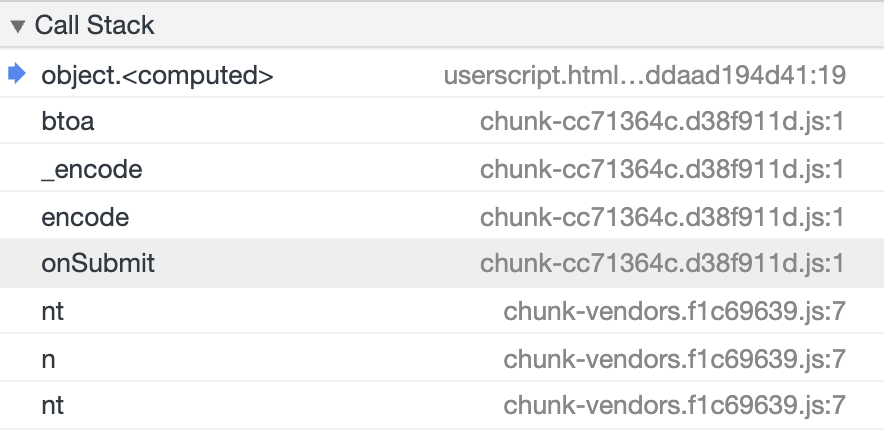
这样,我们就顺利找到了 Base64 编码操作这个路口,然后看一下堆栈信息,也已经不会出现 async、Promise 这样的调用了,很清晰地呈现了 btoa 方法逐层调用的过程,非常清晰明了,如图所示。
另外再观察下 Local 面板,看看 arguments 变量是怎样的,如图所示。
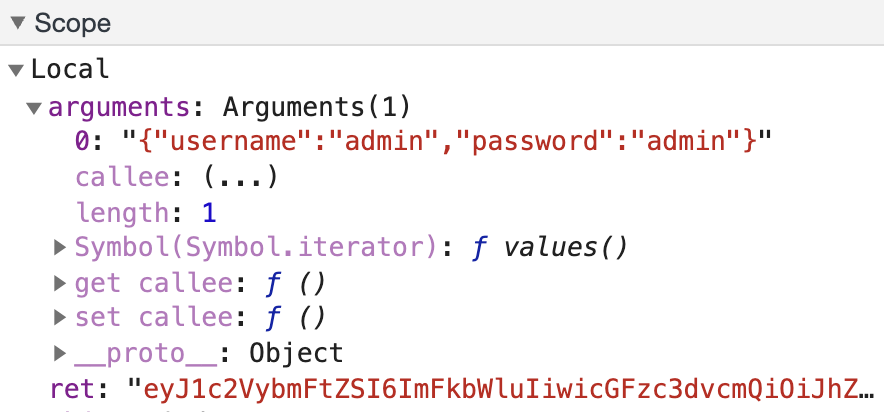
可以说一目了然了,arguments 就是指传给 btoa 方法的参数,ret 就是 btoa 方法返回的结果,可以看到 arguments 就是 username 和 password 通过 JSON 序列化之后的字符串,经过 Base64 编码之后得到的值恰好就是 Ajax 请求参数 token 的值。
结果几乎也明了了,我们还可以通过调用栈找到 onSubmit 方法的处理源码:
1 | onSubmit: function() { |
仔细看看,encode 方法其实就是调用了一下 btoa 方法,就是一个 Base64 编码的过程,答案其实已经很明了了。
当然我们还可以进一步打断点验证一下流程,比如在调用 encode 方法的一行打断点,如图所示。
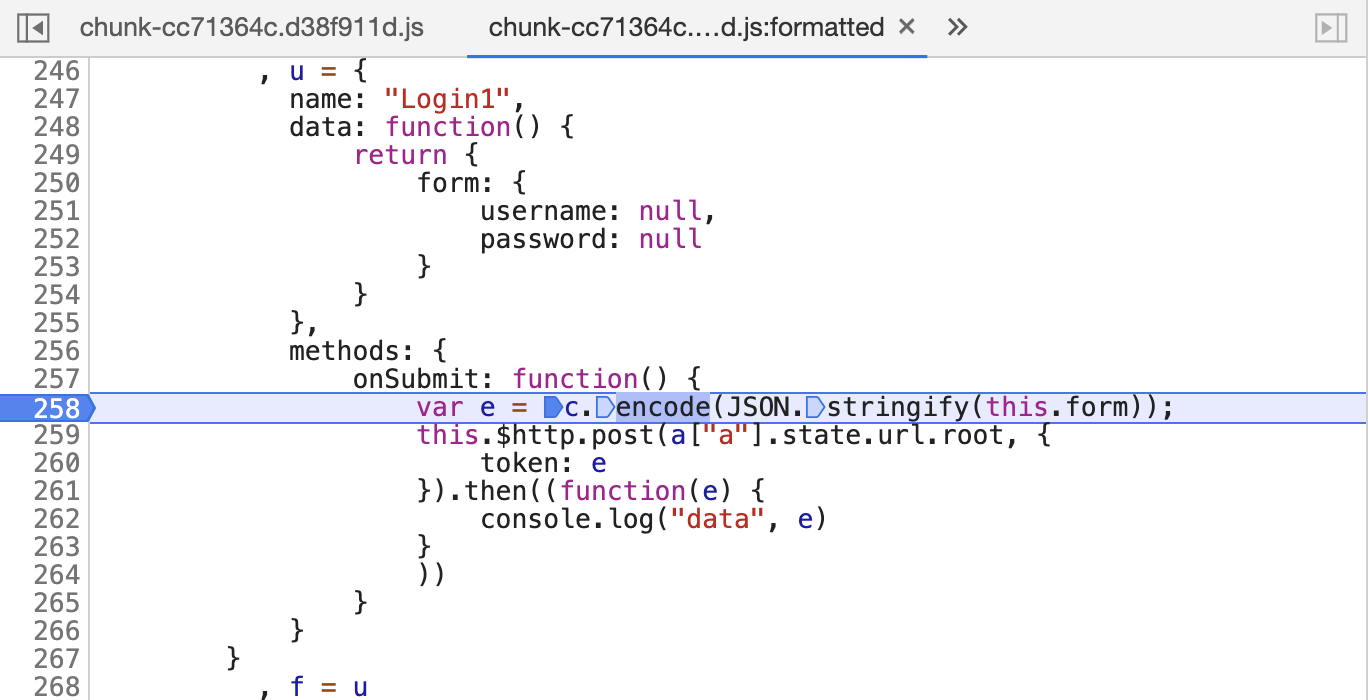
打完断点之后,可以点击 Resume 按钮恢复 JavaScript 的执行,跳过当前 Tempermonkey 定义的断点位置,如图所示。
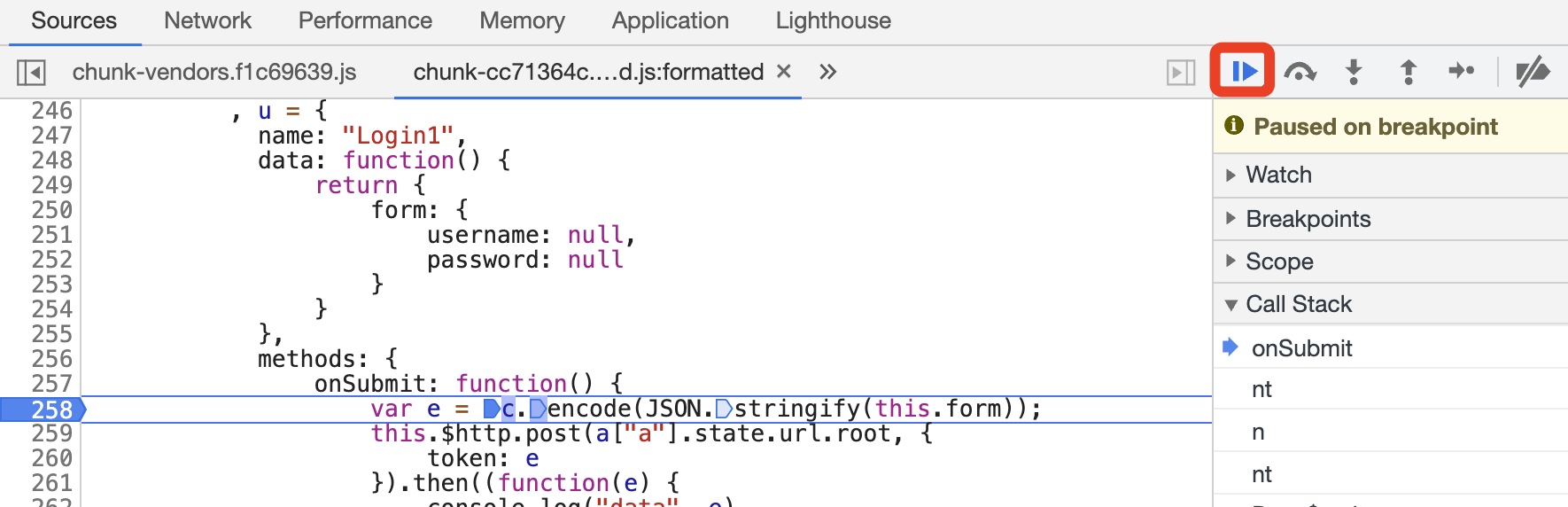
然后重新再点击登录按钮,可以看到这时候就停在了当前打断点的位置了,如图所示。
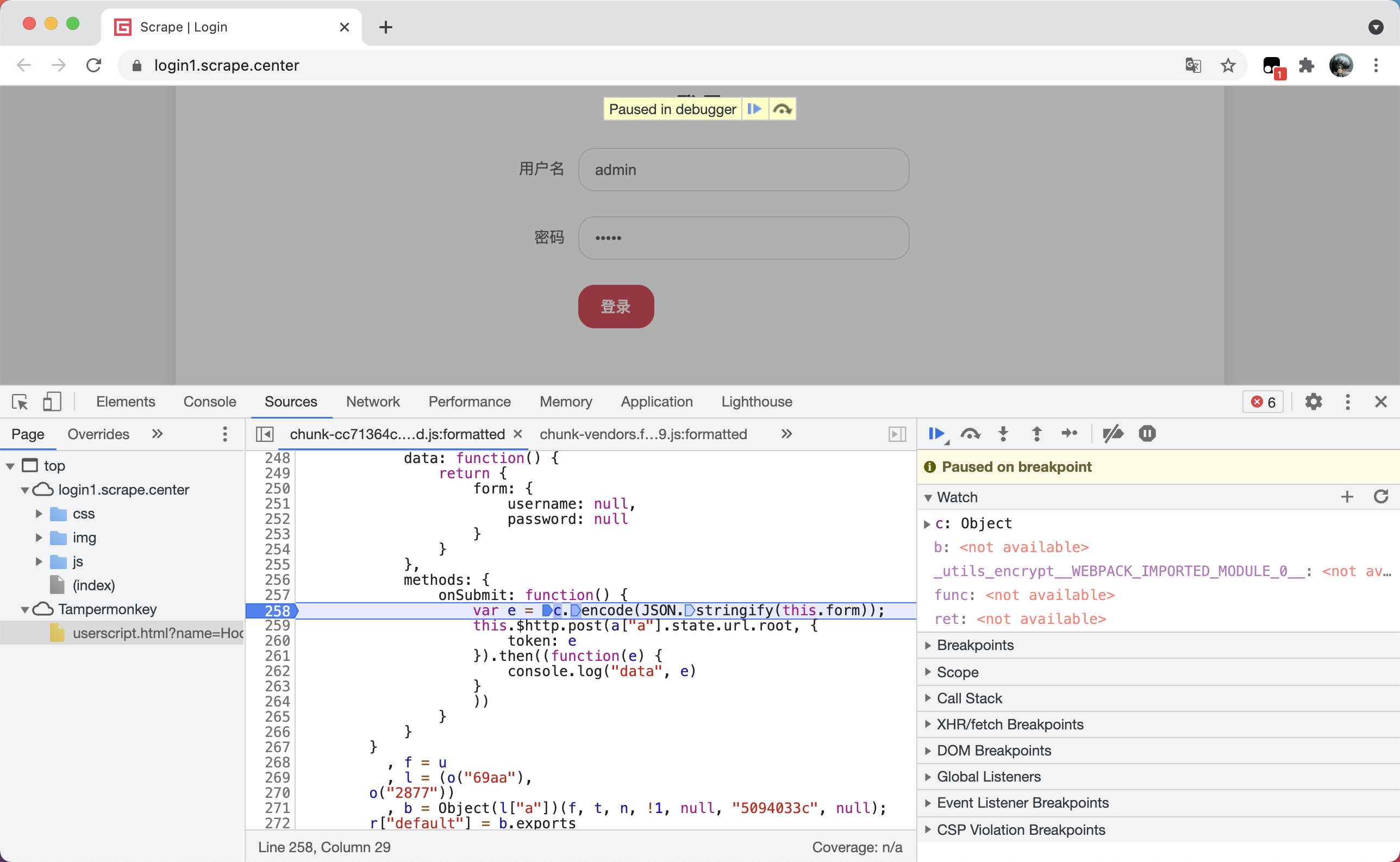
这时候可以在 Watch 面板下输入 this.form,验证此处是否为在表单中输入的用户名密码,如图所示。
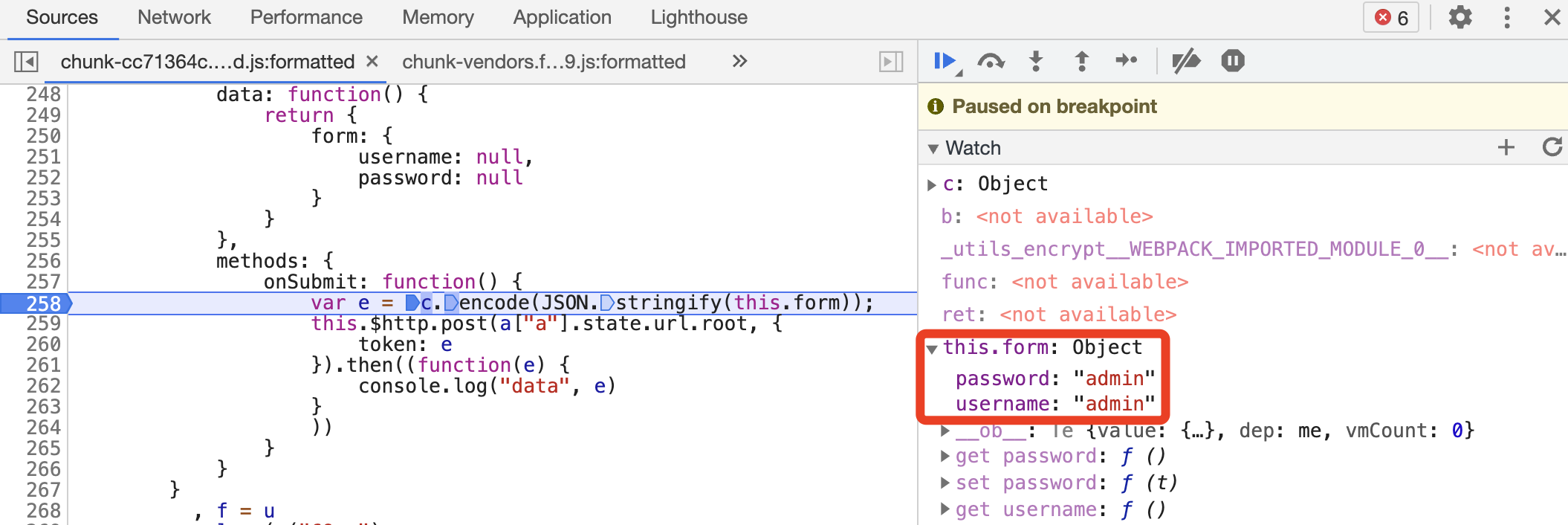
没问题,然后逐步调试。我们还可以可以观察到,下一步就跳到了我们 Hook 的位置,这说明调用了 btoa 方法,如图所示。
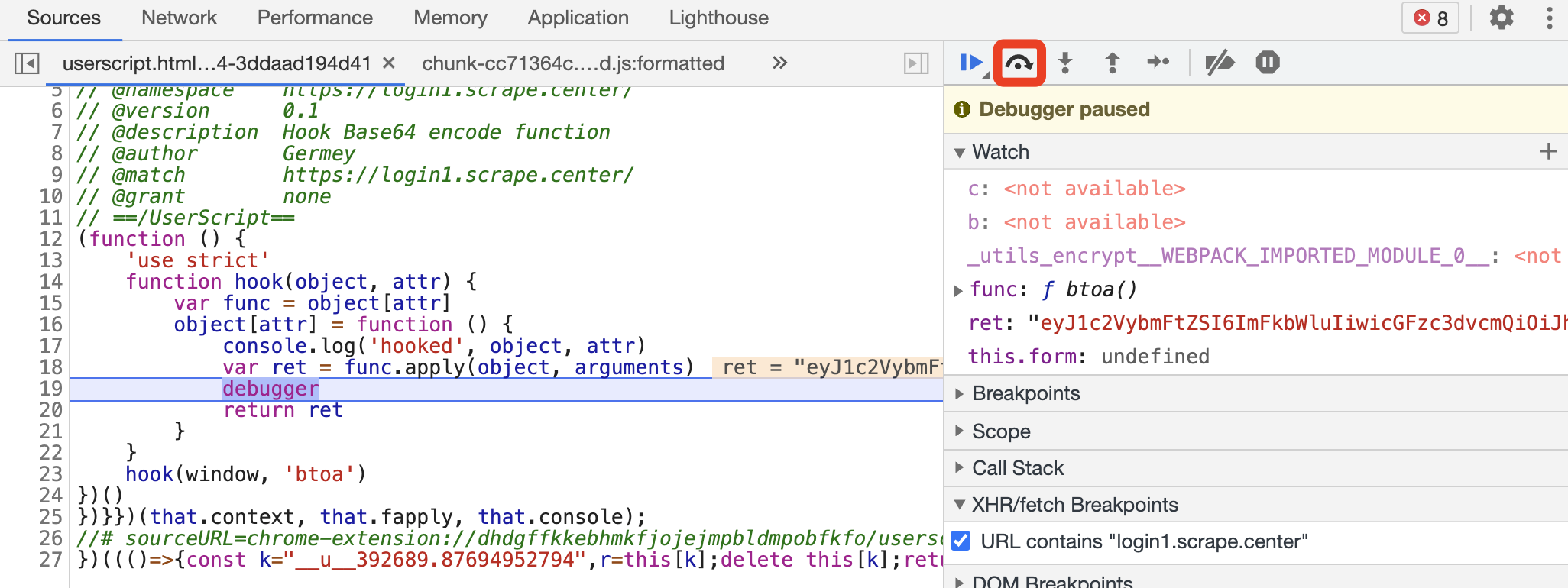
返回的结果正好就是 token 的值。
所以,验证到这里,已经非常清晰了,整体逻辑就是对登录表单的用户名和密码进行了 JSON 序列化,然后调用了 encode 也就是 btoa 方法,并赋值为了 token 发起登录的 Ajax 请求,逆向完成。
我们通过 Tampermonkey 自定义 JavaScript 脚本的方式,实现了某个方法调用的 Hook,使得我们能快速定位到加密入口的位置,非常方便。
以后如果观察出一些门道,可以多使用这种方法来尝试,如 Hook encode 方法、decode 方法、stringify 方法、log 方法、alert 方法等,简单又高效。
7. 总结
以上便是通过 Tampermonkey 实现简单 Hook 的基础操作,当然这仅仅是一个常见的基础案例,我们可以从中总结出一些 Hook 的基本门道。
由于本节涉及到一些专有名词,部分内容参考如下:
- 博客 - Hook 技术:https://www.jianshu.com/p/3382cc765b39。
- 官网 - Tampermonkey 官网:http://www.tampermonkey.net/
- 文档 - Base64 编码:https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/btoa
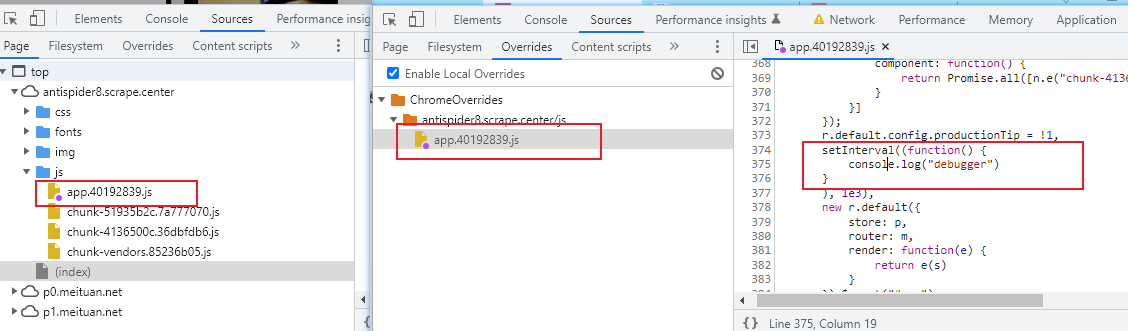
无限debugger的原理和绕过
介绍原理
有时候,网站开发者会利用debugger关键字阻挠我们正常调试。
网站:https://captcha8.scrape.center/
现象:访问没有问题,但是一旦我们打开调试模式,就会进入无线debugger循环
原理:代码中设置了setInterval,每s执行一次debugger语句
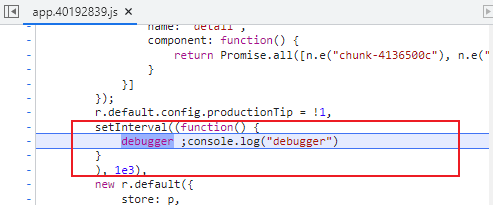
无线for循环,while循环,递归等也可以实现这种效果,原理类似。
下面介绍一下解决方案
禁用断点
第一种可以用全局禁用断点,但是禁用了,自己断点也用不了,所以这种场景下不是好的解决方案
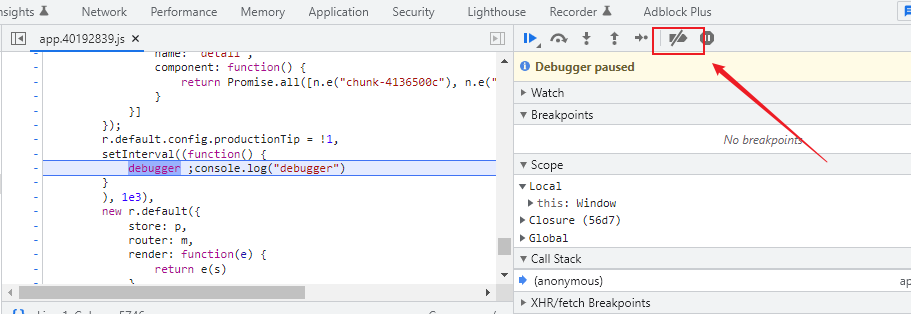
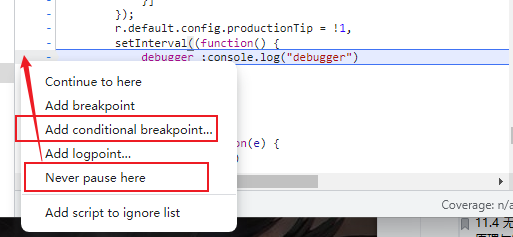
第二种可以用局部禁用断点,右键debugger所在行,选择Never pause here,就可以跳过无限循环,或者用更高级的add conditional breakpoine根据条件跳过无限循环。
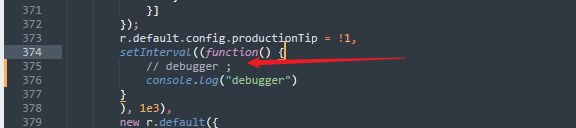
替换文件
将js文件重写掉,这样也可以避免每次刷新页面都进入debugger
创建一个目录用于保存override的js,这样也可以跳过无限循环
python模拟执行JavaScript
前面我们了解了一些 JavaScript 逆向的调试技巧,通过一些方法,我们可以找到一些突破口,进而找到关键的方法定义。
比如说,通过一些调试,我们找到了一个加密参数 token 是由某一个叫做 encrypt 方法产生的,如果里面的逻辑相对简单的话,那其实我们可以用 Python 完全重写一遍。但是现实情况往往不是这样的,一般来说,一些加密相关的方法通常会引用一些相关标准库,比如说 JavaScript 就有一个广泛使用的库,叫做 crypto-js,GitHub 仓库链接是:https://github.com/brix/crypto-js,这个库实现了很多主流的加密算法,包括对称加密、非对称加密、字符编码等等,比如对于 AES 加密,通常我们需要输入待加密文本和加密密钥,实现如下:
1 | const ciphertext = CryptoJS.AES.encrypt(message, key).toString(); |
对于这样的情况,我们其实就没法很轻易地完全重写一遍了,因为 Python 中并不一定有和 JavaScript 完全一样的类库。
那有什么解决办法吗?有的,既然 JavaScript 已经实现好了,那我用 Python 直接模拟执行这些 JavaScript 得到结果不就好了吗?
所以,本节我们就来了解下使用 Python 模拟执行 JavaScript 的解决方案。
1. 案例引入
这里我们先看一个和上文描述的情形非常相似的案例,链接是:https://spa7.scrape.center/,如图所示:
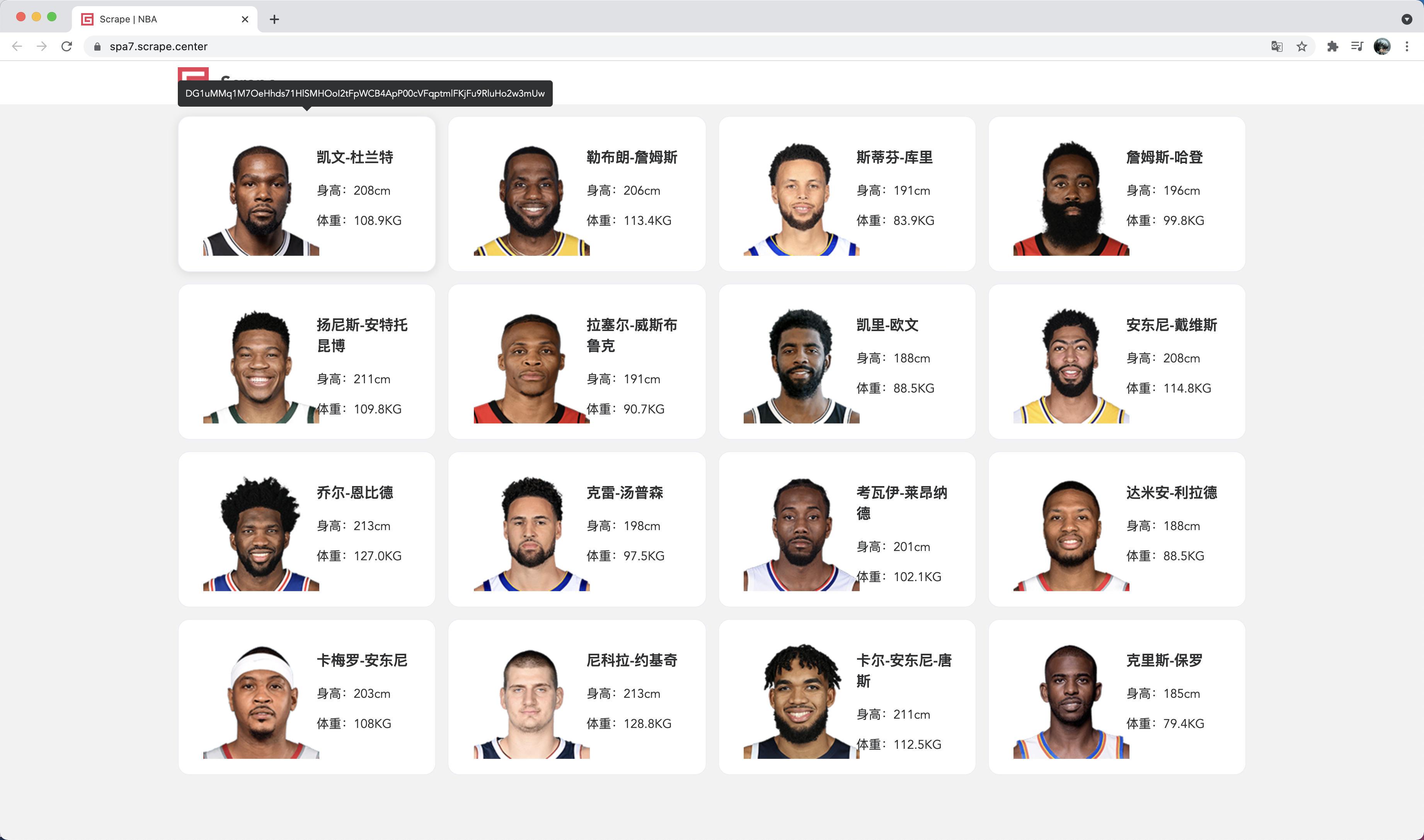
这是一个 NBA 球星网站,用卡片的形式展示了一些球星的基本信息,另外每一张卡片上其实都有一个加密字符串,这个加密字符串其实和球星的相关信息是有关联的,每个球星的 加密字符串也是不同的。
所以,这里我们要做的就是找出这个加密字符串的加密算法并用程序把加密字符串的生成过程模拟出来。
2. 准备工作
由于本节我们需要使用 Python 模拟执行 JavaScript,这里我们使用的库叫做 PyExecJS,我们使用 pip3 安装即可,命令如下:
1 | pip3 install pyexecjs |
PyExecJS 是用于执行 JavaScript 的,但执行 JavaScript 的功能需要依赖一个 JavaScript 运行环境,所以除了安装好这个库之外,我们还需要安装一个 JavaScript 运行环境,个人比较推荐的是 Node.js,所以我们还需要安装下 Node.js,可以到 https://nodejs.org/ 下载安装。更加详细的安装和配置过程可以参考:https://setup.scrape.center/pyexecjs。
PyExecJS 库在运行时会检测本地 JavaScript 运行环境来实现 JavaScript 执行,做好如上准备工作之后, 接着我们运行代码检查一下运行环境:
1 | import execjs |
运行结果类似如下:
1 | Node.js (V8) |
如果你成功安装好 PyExecJS 库和 Node.js 的话,其结果就是 Node.js (V8),当然如果你安装的是其他的 JavaScript 运行环境,结果也会有所不同。
3. 分析
接下来我们就对这个网站稍作分析,打开 Sources 面板,我们可以非常轻易地找到加密字符串的生成逻辑,如图所示:
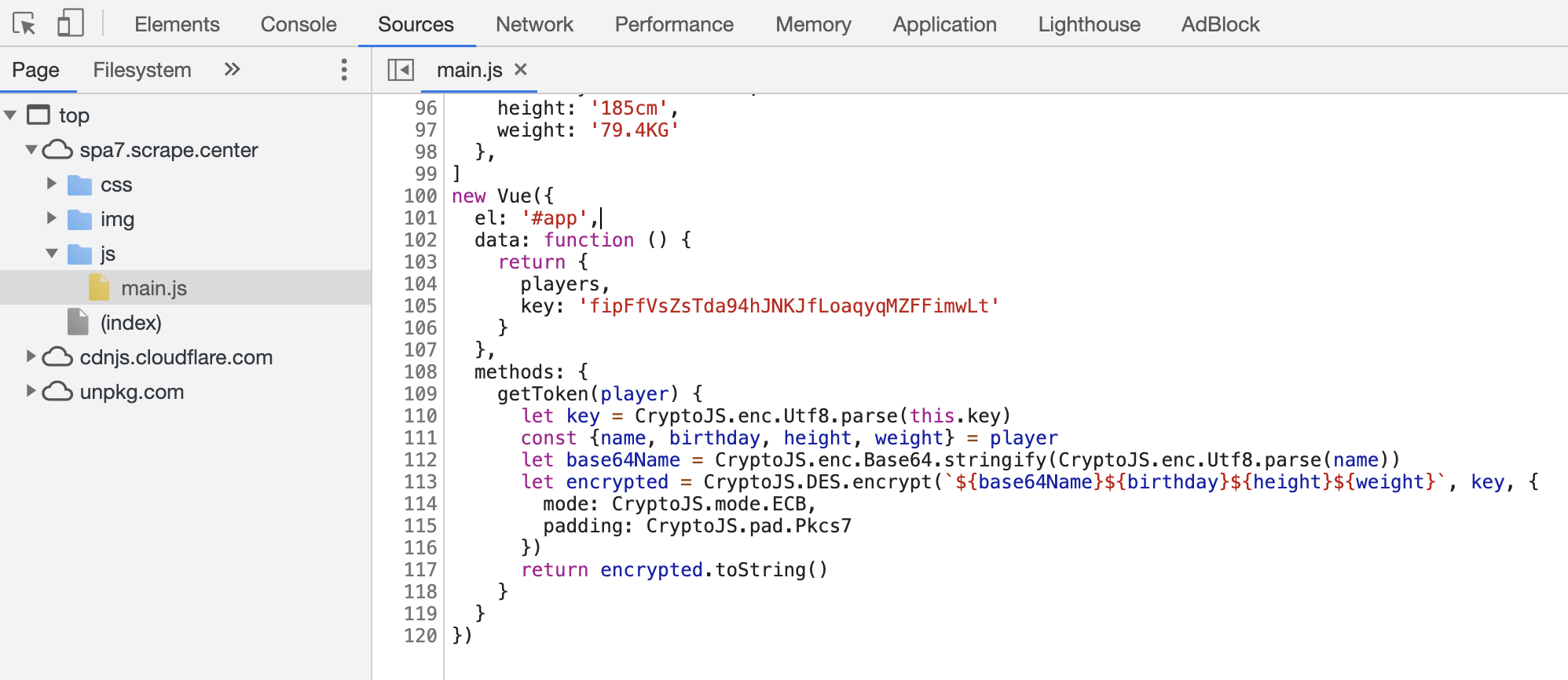
首先声明了一个球员相关的列表,如:
1 | const players = [ |
然后对于每一个球员,都把每个球员的信息调用了加密算法进行了加密,我们可以打个断点看下:
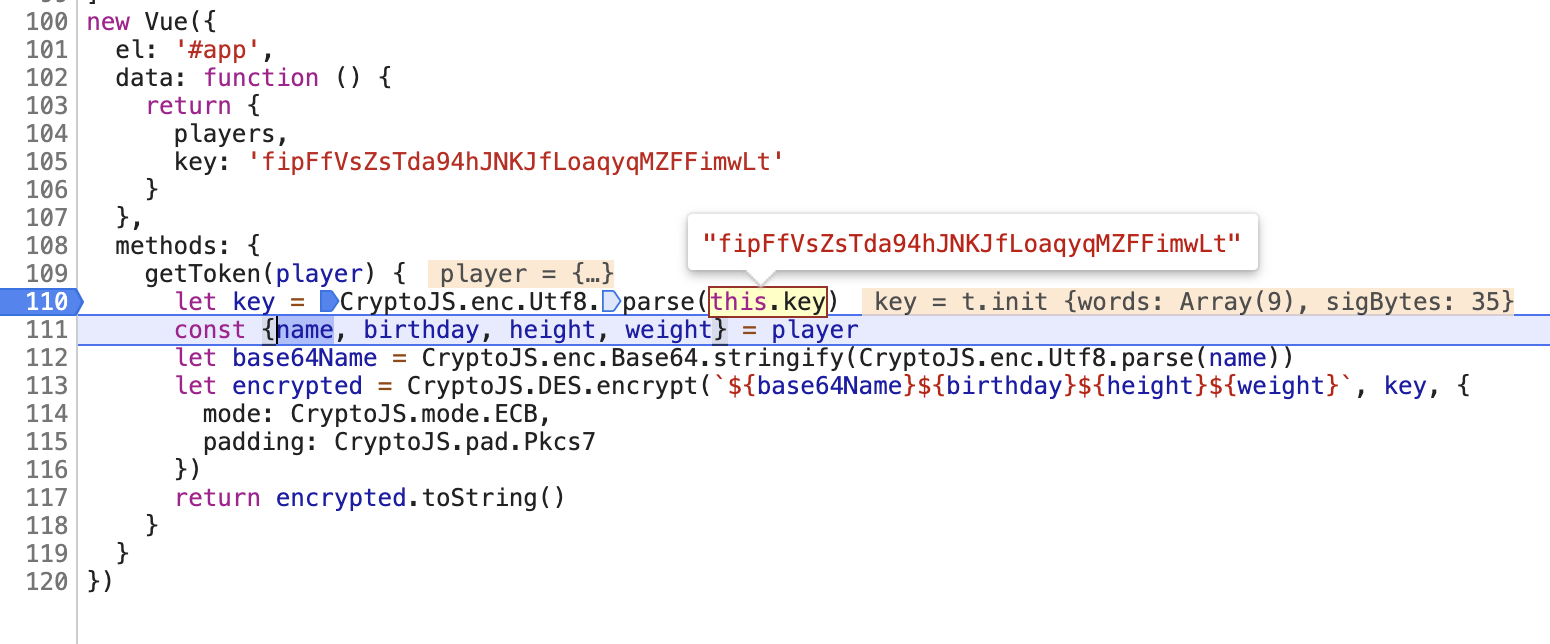
这里我们可以看到,getToken 方法的输入就是单个球员的信息,就是上述列表的一个元素对象,然后 this.key 就是一个固定的字符串。整个加密逻辑就是提取了球员的名字、生日、身高、体重,然后先 Base64 编码然后再进行 DES 加密,最后返回结果。
加密算法是怎么实现的呢?其实就是依赖了 crypto-js 库,使用了 CryptoJS 对象来实现的。
那 CryptoJS 这个对象是哪里来的呢?总不能凭空产生吧?其实这个网站就是直接引用了这个库,如图所示:
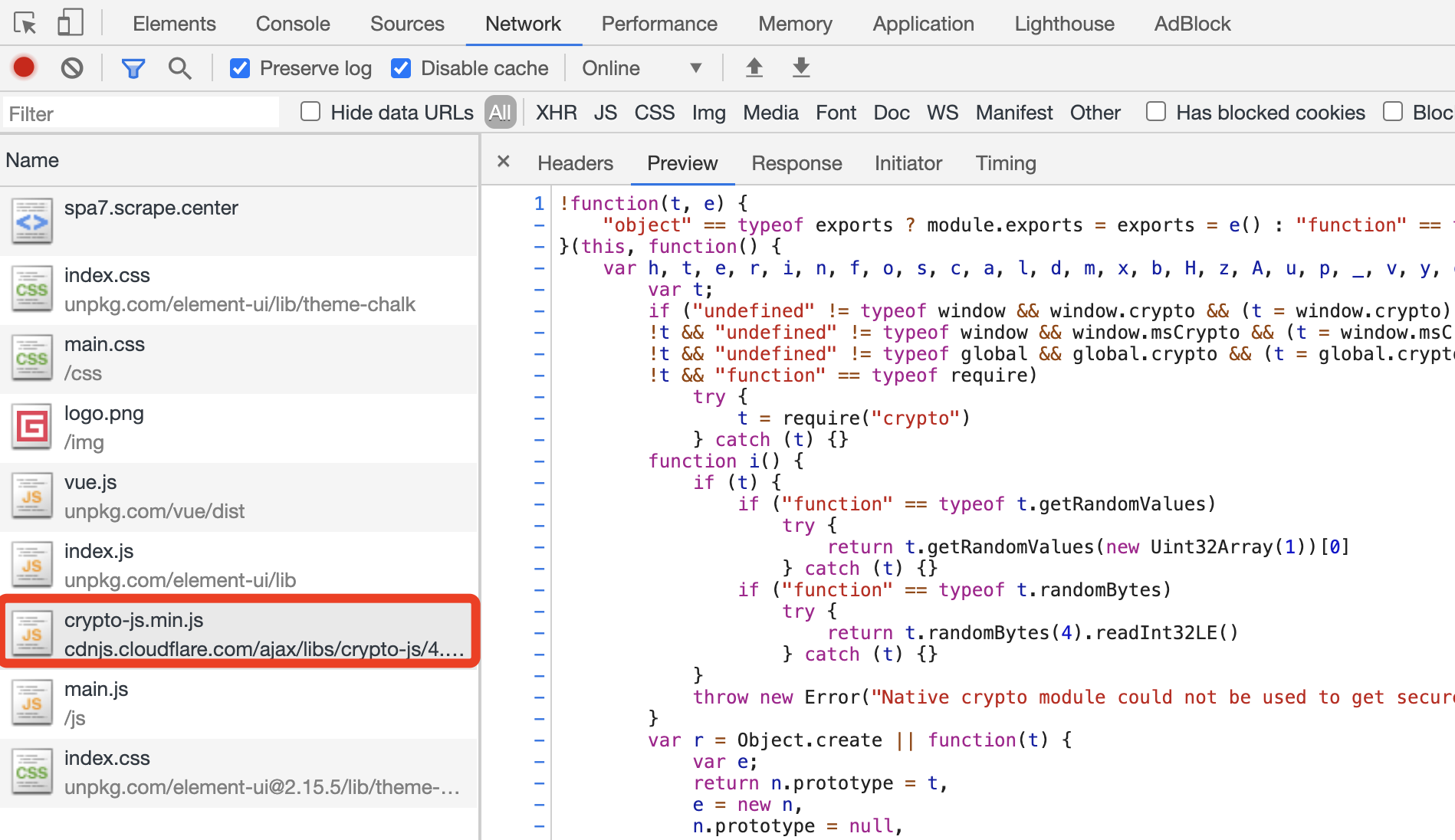
引用这个 JavaScript 文件之后,CryptoJS 就被注入到浏览器全局环境下了,因此我们就可以在别的方法里面直接使用 CryptoJS 对象里面的方法了。
4. 模拟调用
好,那既然这样,我们要怎么模拟呢?下面我们来实现下。
首先,我们要模拟的其实就是这个 getToken 方法,输入球员相关信息,得到最终的加密字符串,这里我们直接把 key 替换下,把 getToken 方法稍微改写如下:
1 | function getToken(player) { |
因为这个方法的模拟执行是需要 CryptoJS 这个对象的,如果我们直接调用这个方法肯定会报 CryptoJS 未定义的错误。
那怎么办呢?我们只需要再模拟执行下刚才看到的 crypto-js.min.js 不就好了吗?
OK,所以,我们需要模拟执行的内容就是两部分:
- 模拟运行 crypto-js.min.js 里面的 JavaScript,用于声明 CryptoJS 对象。
- 模拟运行 getToken 方法的定义,用于声明 getToken 方法。
好,接下来我们就把 crypto-js.min.js 里面的代码和上面 getToken 方法的代码复制一下,都粘贴到一个 JavaScript 文件里面,比如就叫做 crypto.js。
接下来我们就用 PyExecJS 模拟执行一下吧,代码如下:
1 | import execjs |
这里我们单独定义了一位球员的信息,赋值为 item 变量。然后使用 execjs 的 get 方法获取了 JavaScript 执行环境,赋值为 node。
接着我们调用了 node 的 compile 方法,传入了刚才定义的 crypto.js 文件的文本内容,compile 方法会返回一个 JavaScript 的上下文对象,我们赋值为 ctx。执行到这里,其实就可以理解为,ctx 对象里面就执行过了 crypto-js.min.js,CryptoJS 就声明好了,然后也执行过了 getToken 的定义,所以 getToken 方法也定义好了,相当于完成了一些初始化的工作。
接着,我们只需要定义好我们想要执行的 JavaScript 代码就好了,我们定义了一个 js 变量,其实就是模拟调用了 getToken 方法并传入了球员信息,我们打印了下 js 变量的值,内容如下:
1 | getToken({"name": "凯文-杜兰特", "image": "durant.png", "birthday": "1988-09-29", "height": "208cm", "weight": "108.9KG"}) |
其实这就是一个标准的 JavaScript 方法调用的写法而已。
接着我们调用 ctx 对象的 eval 方法并传入 js 变量,其实就是模拟执行了这句 JavaScript 代码,照理来说最终返回的就是加密字符串了。
然而,运行之后,我们可能看到这个报错:
1 | execjs._exceptions.ProgramError: ReferenceError: CryptoJS is not defined |
很奇怪,CryptoJS 未定义?我们明明执行过 crypto-js.min.js 里面的内容了呀?
问题其实出在 crypto-js.min.js 里面,可以看到其里面声明了一个 JavaScript 的自执行方法,如图所示:
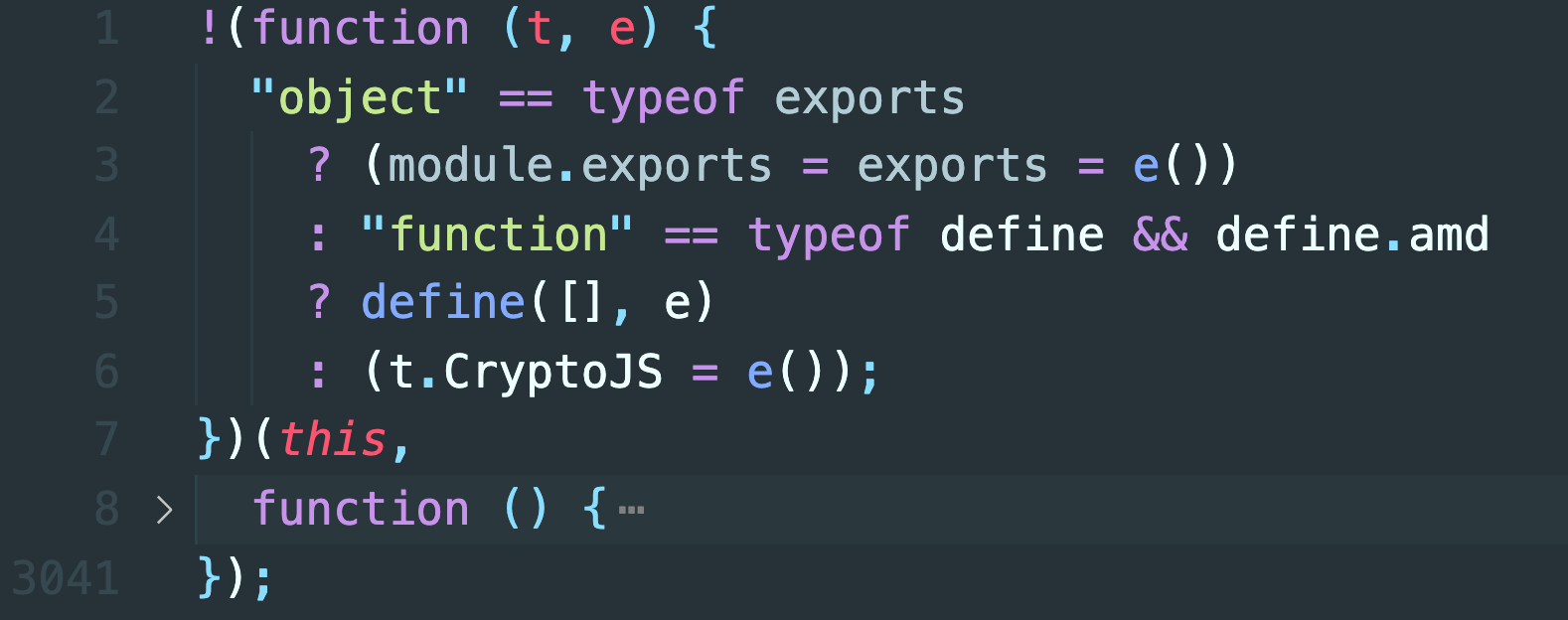
自执行方法什么意思呢?就是声明了一个方法,然后紧接着调用执行,我们可以看下这个例子:
1 | !(function (a, b) { |
这里我们先声明了一个 function,然后接收 a 和 b 两个参数,然后把内容输出出来,然后我们把这个 function 用小括号括起来,这其实就是一个方法,可以被直接调用的,怎么调用呢?后面再跟上对应的参数就好了,比如传入 1 和 2,执行结果如下:
1 | result 1 2 |
可以看到,这个自执行的方法就被执行了。
同理地,crypto-js.min.js 也符合这个格式,它接收 t 和 e 两个参数,t 就是 this,其实就是浏览器中的 window 对象,e 就是一个 function(用于定义 CryptoJS 的核心内容)。
我们再来观察下 crypto-js.min.js 开头的定义:
1 | "object" == typeof exports |
在 Node.js 中,其实 exports 就是用来将一些对象的定义进行导出的,这里 "object" == typeof exports 其实结果就是 true,所以就执行了 module.exports = exports = e() 这段代码,这样就相当于把 e() 作为整体导出了,而这个 e() 其实就对应这后面的整个 function,function 里面定义了加密相关的各个实现,其实就指代整个加密算法库。
但是在浏览器中,其结果就不一样了,浏览器环境中并没有 exports 和 define 这两个对象。所以,上述代码在浏览器中最后执行的就是 t.CryptoJS = e() 这段代码,其实这里就是把 CryptoJS 对象挂载到 this 对象上面,而 this 就是浏览器中的全局 window 对象,后面就可以直接用了。如果我们把代码放在浏览器中运行,那是没有任何问题的。
然而,我们使用的 PyExecJS 是依赖于一个 Node.js 执行环境的,所以上述代码其实执行的是 module.exports = exports = e(),这里面并没有声明 CryptoJS 对象,也没有把 CryptoJS 挂载到全局对象里面,所以后面我们再调用 CryptoJS 就自然而然出现了未定义的错误了。
那怎么办呢?其实很简单,那我们直接声明一个 CryptoJS 变量,然后手动声明一下它的初始化不就好了吗?所以我们可以把代码稍作修改,改成如下内容:
1 | var CryptoJS; |
这里我们就首先声明了一个 CryptoJS 变量,然后直接给 CryptoJS 变量赋值给 e(),这样就完成了 CryptoJS 的初始化。
这样我们再重新运行刚才的 Python 脚本,就可以得到执行结果了:
1 | gQSfeqldQIJKAZHH9TzRX/exvIwb0j73b2cjXvy6PeZ3rGW6sQsL2w== |
这样我们就成功得到加密字符串了,和示例网站上显示的是一模一样的,这样我们就成功模拟 JavaScript 的调用完成了某个加密算法的运行过程。
5. 总结
本节介绍了利用 PyExecJS 来模拟执行 JavaScript 的方法,结合一个案例来完成了整个的实现和问题排查的过程。本节内容还是比较重要的,以后我们如果需要模拟执行 JavaScript 就可以派得上用场。
本节代码;https://github.com/Python3WebSpider/ScrapeSpa7。
nodejs模拟执行JavaScript
有时候在调用过程中会发现使用python模拟执行JavaScript不太方便,而且可能出现变量未定义的问题等。有没有其他解决思路呢?
我们用python模拟执行JavaScript用的时候pyExecJs库,执行环境是Nodejs。那为什么不直接用nodejs来尝试JavaScript的执行呢?
原理是是可行的
那用nodeJs执行了加密字符串的JavaScript后,应该怎么和python对接呢?直接用node.js把加密的算法暴露成一个http服务就好了。这样python可以直接调用node.js暴露的http服务。传入球员信息,拿到加密后的信息即可。
node.js中实现http服务用express很方便:
1 | # npm i express |
浏览器模拟执行JavaScript
前面用pyexecjs和nodejs模拟执行JavaScript,在某些复杂情况下有一定的局限性
比如浏览器中找到类似这样的加密算法: const token = encrypt(a,b)
我们最终需要获取的就是token是什么,token模拟出来了,就可以用它构造请求进行爬取数据了。但是这个token由encrypt生成的,内部的逻辑可能比较复杂(关联了很多变量或对象,或混淆等),向内追踪很困难。
这时候要用python和nodejs模拟调用过程,关键步骤为:
- 下载所有依赖库
- 使用pyexecjs或nodejs加载依赖库并模拟执行encrypt方法
但是可能会有以下问题:
- 环境差异:nodejs中没有全局window对象,只有global对象,JavaScript引用到window对象的方法需要改成global对象,或者把一些浏览器中的对象用其他方法代替
- 依赖库查找:encrypt依赖的库在浏览器中是已经加载好了的,如果在其他环境中模拟执行,要完全剥离出encrypt依赖的JavaScript库需要一定的功夫,但凡少一个都可能无法运行。
对于这类复杂的情况,我们可以尝试直接用浏览器作为执行环境来辅助逆向。
1 | # 安装库 |
这里用到了palywright库
网站:https://spa2.scrape.center/
xhr/fetch 断点,监控api路径,到d.send
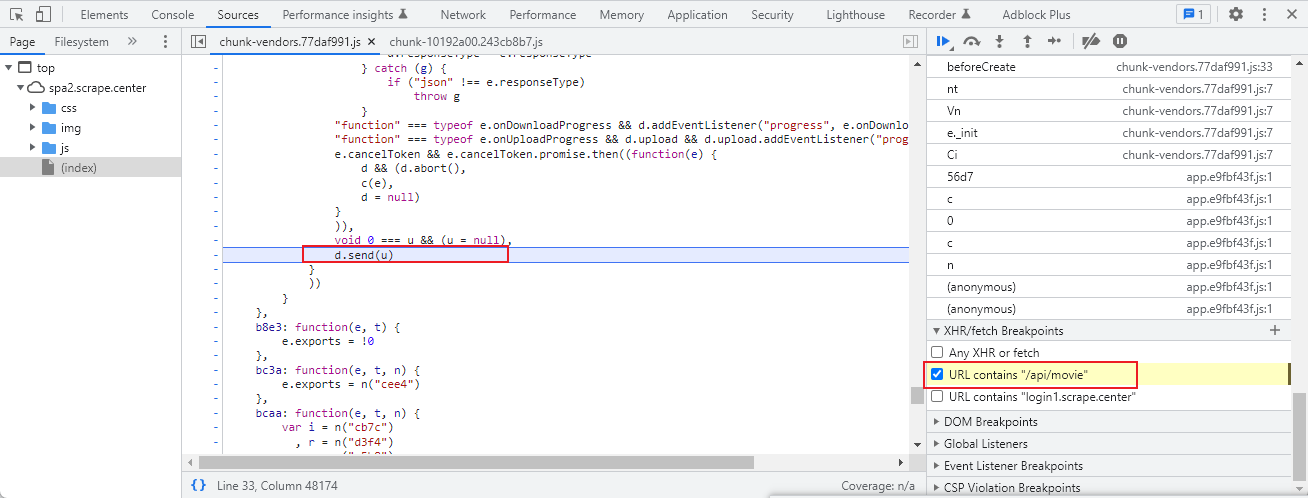
到调用方法onFetchData可以看到,token就是由Object(i["a"])生成的。
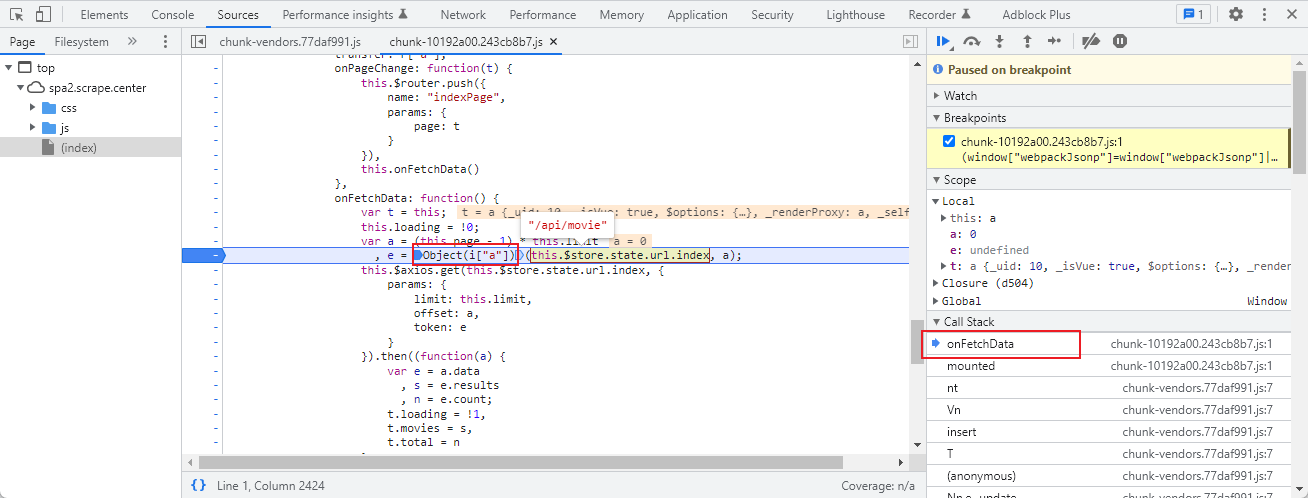
再往里跟踪这个方法函数
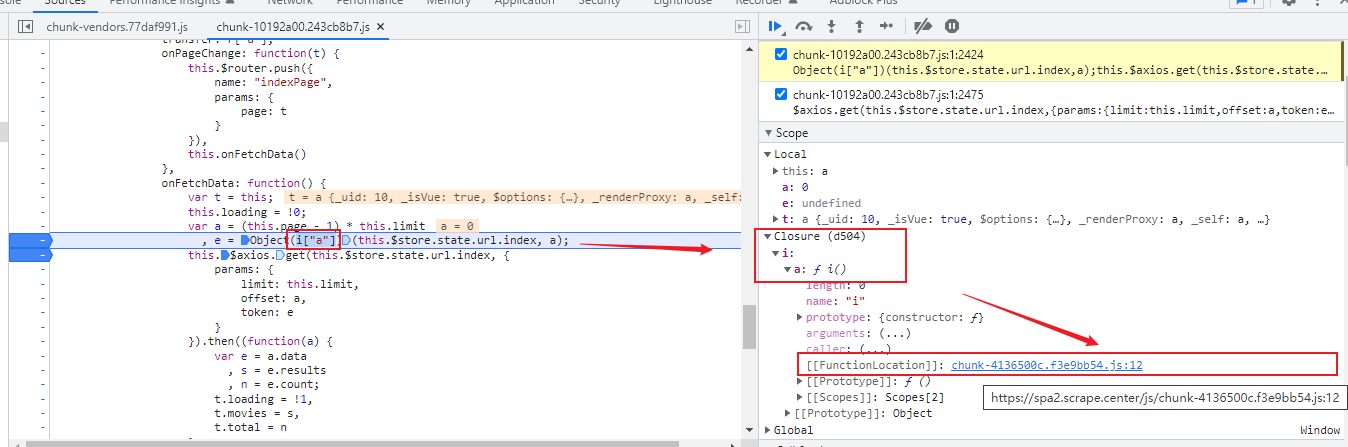
可以看到最终的加密算法

可以看到有时间,SHA1,Base64,列表等各种操作,要深入分析,需要一些时间。
现在,核心方法已经找到,参数也知道怎么构造,就是方法内部比较复杂,但我们想要的其实就是这个方法的运行结果,即最终的token。
这时候我们就会想了:
- 怎么不关心生成的逻辑,当成一个黑盒子,直接拿到方法运行结果?
- 要直接拿到结果,就需要模拟调用,怎么模拟调用呢?
- 这个方法并不是全局方法,没有办法直接调用,该怎么办呢?
有办法的:
- 模拟调用没有问题,但是在哪里调用需要想一下!浏览器已经把依赖库都加载了,直接用浏览器调用多好。
- 怎么模拟调用局部方法?很简单,将局部方法挂载到全局对象window对象上就行了
- 既然已经在浏览器中运行了,怎么修改源码挂载到全局window呢?可以用playwright的request interception机制将想要替换的任意文件进行替换即可。
AST技术
前面说了js混淆的知识,了解了字符串、变量名、对象键名、控制流平坦化等多种混淆方式,以及学习了一些调试几条,hook,断点等。但是这些方法本质是其实还是在已经混淆的代码上进行操作的,代码可能性很差。
有什么办法提高代码可读性?比如想办法欢迎字符串混淆,重新组装好,将控制流平坦化代码还原成代码控制流。
这就要用到AST技术了。
AST技术介绍
AST(Abstract Syntax Tree),中文抽象语法树,简称语法树(Syntax Tree),是源代码的抽象语法结构的树状表现形式,树上的每个节点都表示源代码中的一种结构。语法树不是某一种编程语言独有的,JavaScript、Python、Java、Golang 等几乎所有编程语言都有语法树。
小时候我们得到一个玩具,总喜欢把玩具拆解成一个一个小零件,然后按照我们自己的想法,把零件重新组装起来,一个新玩具就诞生了。而 JavaScript 就像一台精妙运作的机器,通过 AST 解析,我们也可以像童年时拆解玩具一样,深入了解 JavaScript 这台机器的各个零部件,然后重新按照我们自己的意愿来组装。
AST 的用途很广,IDE 的语法高亮、代码检查、格式化、压缩、转译等,都需要先将代码转化成 AST 再进行后续的操作,ES5 和 ES6 语法差异,为了向后兼容,在实际应用中需要进行语法的转换,也会用到 AST。AST 并不是为了逆向而生,但做逆向学会了 AST,在解混淆时可以如鱼得水。
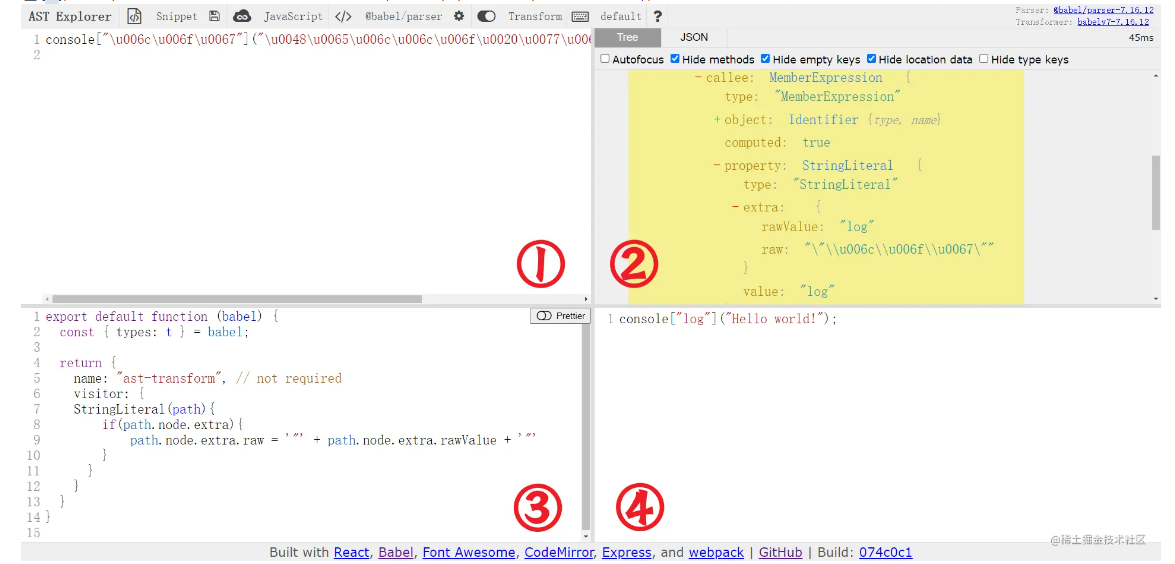
AST 有一个在线解析网站:astexplorer.net/ ,顶部可以选择语言、编译器、是否开启转化等,如下图所示,区域①是源代码,区域②是对应的 AST 语法树,区域③是转换代码,可以对语法树进行各种操作,区域④是转换后生成的新代码。图中原来的 Unicode 字符经过操作之后就变成了正常字符。
语法树没有单一的格式,选择不同的语言、不同的编译器,得到的结果也是不一样的,在 JavaScript 中,编译器有 Acorn、Espree、Esprima、Recast、Uglify-JS 等,使用最多的是 Babel,后续的学习也是以 Babel 为例。
AST 在编译中的位置
在编译原理中,编译器转换代码通常要经过三个步骤:词法分析(Lexical Analysis)、语法分析(Syntax Analysis)、代码生成(Code Generation),下图生动展示了这一过程:
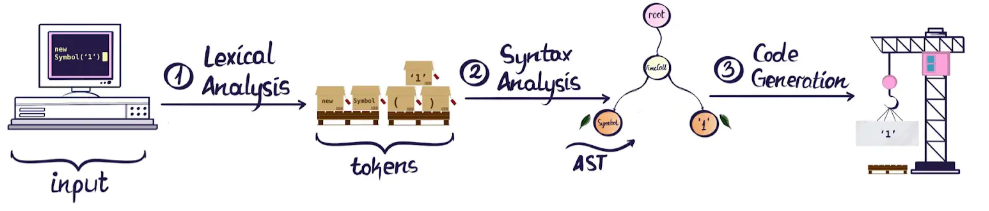
词法分析
词法分析阶段是编译过程的第一个阶段,这个阶段的任务是从左到右一个字符一个字符地读入源程序,然后根据构词规则识别单词,生成 token 符号流,比如 isPanda('🐼'),会被拆分成 isPanda,(,'🐼',) 四部分,每部分都有不同的含义,可以将词法分析过程想象为不同类型标记的列表或数组。
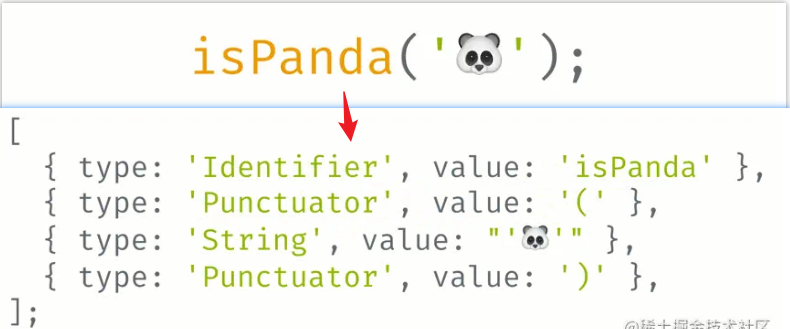
语法分析
语法分析是编译过程的一个逻辑阶段,语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,比如“程序”,“语句”,“表达式”等,前面的例子中,isPanda('🐼') 就会被分析为一条表达语句 ExpressionStatement,isPanda() 就会被分析成一个函数表达式 CallExpression,🐼 就会被分析成一个变量 Literal 等,众多语法之间的依赖、嵌套关系,就构成了一个树状结构,即 AST 语法树。

代码生成
代码生成是最后一步,将 AST 语法树转换成可执行代码即可,在转换之前,我们可以直接操作语法树,进行增删改查等操作,例如,我们可以确定变量的声明位置、更改变量的值、删除某些节点等,我们将语句 isPanda('🐼') 修改为一个布尔类型的 Literal:true,语法树就有如下变化:

在前端开发中,AST技术应用非常广泛,比如webpack打包工具的很多压缩和优化插件、Babel插件、Vue和React的手脚架工具底层都运用了AST技术,有了AST,我们可以很方便的对JavaScript代码进行转换和改写,因此还原混淆后的JavaScript代码也就不在话下了。
Babel 简介
Babel 是一个 JavaScript 编译器,也可以说是一个解析库,Babel 中文网:www.babeljs.cn/ ,Babel 英文官网:babeljs.io/ ,Babel 内置了很多分析 JavaScript 代码的方法,我们可以利用 Babel 将 JavaScript 代码转换成 AST 语法树,然后增删改查等操作之后,再转换成 JavaScript 代码。
Babel 包含的各种功能包、API、各方法可选参数等,都非常多,本文不一一列举,在实际使用过程中,应当多查询官方文档,或者参考文末给出的一些学习资料。Babel 的安装和其他 Node 包一样,需要哪个安装哪个即可,比如 npm install @babel/core @babel/parser @babel/traverse @babel/generator
在做逆向解混淆中,主要用到了 Babel 的以下几个功能包,本文也仅介绍以下几个功能包:
@babel/core:Babel 编译器本身,提供了 babel 的编译 API;@babel/parser:将 JavaScript 代码解析成 AST 语法树;@babel/traverse:遍历、修改 AST 语法树的各个节点;@babel/generator:将 AST 还原成 JavaScript 代码;@babel/types:判断、验证节点的类型、构建新 AST 节点等。
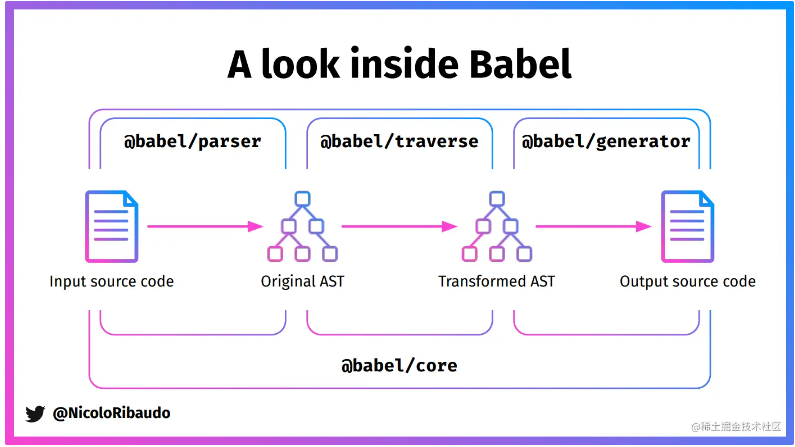
@babel/core
Babel 编译器本身,被拆分成了三个模块:@babel/parser、@babel/traverse、@babel/generator,比如以下方法的导入效果都是一样的:
1 | const parse = require("@babel/parser").parse; |
@babel/parser
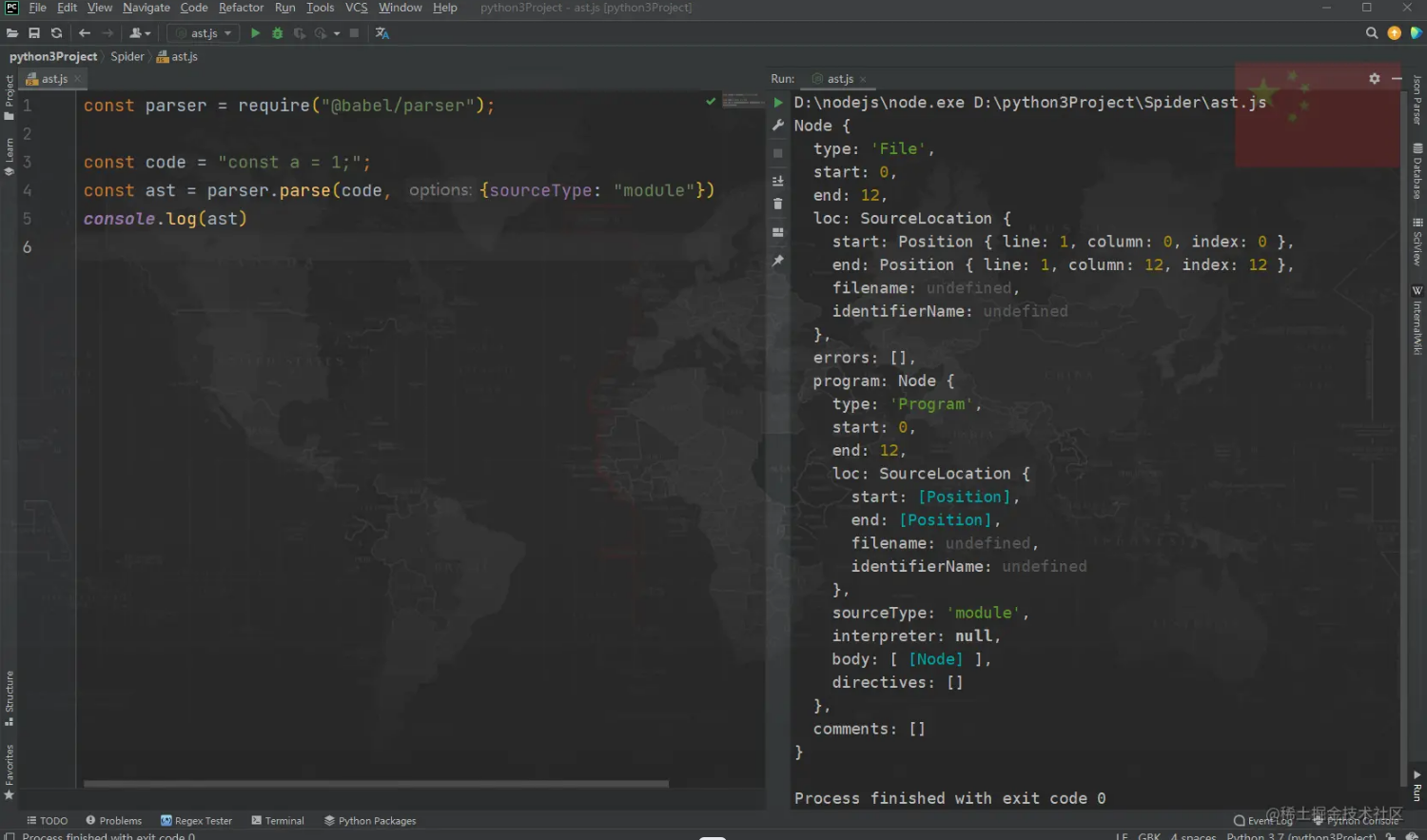
@babel/parser 可以将 JavaScript 代码解析成 AST 语法树,其中主要提供了两个方法:
parser.parse(code, [{options}]):解析一段 JavaScript 代码;parser.parseExpression(code, [{options}]):考虑到了性能问题,解析单个 JavaScript 表达式。
部分可选参数 options:
| 参数 | 描述 |
|---|---|
allowImportExportEverywhere |
默认 import 和 export 声明语句只能出现在程序的最顶层,设置为 true 则在任何地方都可以声明 |
allowReturnOutsideFunction |
默认如果在顶层中使用 return 语句会引起错误,设置为 true 就不会报错 |
sourceType |
默认为 script,当代码中含有 import 、export 等关键字时会报错,需要指定为 module |
errorRecovery |
默认如果 babel 发现一些不正常的代码就会抛出错误,设置为 true 则会在保存解析错误的同时继续解析代码,错误的记录将被保存在最终生成的 AST 的 errors 属性中,当然如果遇到严重的错误,依然会终止解析 |
举个例子看得比较清楚:
1 | const parser = require("@babel/parser"); |
{sourceType: "module"} 演示了如何添加可选参数,输出的就是 AST 语法树,这和在线网站 astexplorer.net/ 解析出来的语法树是一样的:
@babel/generator
@babel/generator 可以将 AST 还原成 JavaScript 代码,提供了一个 generate 方法:generate(ast, [{options}], code)。
部分可选参数 options:
| 参数 | 描述 |
|---|---|
auxiliaryCommentBefore |
 |
| 在输出文件内容的末尾添加注释块文字 | |
comments |
输出内容是否包含注释 |
compact |
输出内容是否不添加空格,避免格式化 |
concise |
输出内容是否减少空格使其更紧凑一些 |
minified |
是否压缩输出代码 |
retainLines |
尝试在输出代码中使用与源代码中相同的行号 |
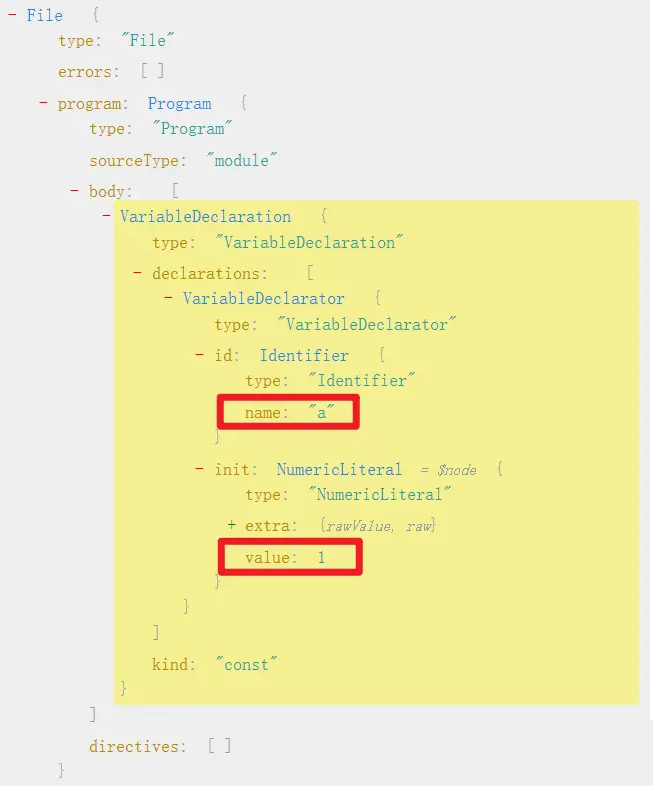
接着前面的例子,原代码是 const a = 1;,现在我们把 a 变量修改为 b,值 1 修改为 2,然后将 AST 还原生成新的 JS 代码:
1 | const parser = require("@babel/parser"); |
最终输出的是 const b=2;,变量名和值都成功更改了,由于加了压缩处理,等号左右两边的空格也没了。
代码里 {minified: true} 演示了如何添加可选参数,这里表示压缩输出代码,generate 得到的 result 得到的是一个对象,其中的 code 属性才是最终的 JS 代码。
代码里 ast.program.body[0].declarations[0].id.name 是 a 在 AST 中的位置,ast.program.body[0].declarations[0].init.value 是 1 在 AST 中的位置,如下图所示:
@babel/traverse
当代码多了,我们不可能像前面那样挨个定位并修改,对于相同类型的节点,我们可以直接遍历所有节点来进行修改,这里就用到了 @babel/traverse,它通常和 visitor 一起使用,visitor 是一个对象,这个名字是可以随意取的,visitor 里可以定义一些方法来过滤节点,这里还是用一个例子来演示:
1 | const parser = require("@babel/parser"); |
这里的原始代码定义了 abcde 五个变量,其值有数字也有字符串,我们在 AST 中可以看到对应的类型为 NumericLiteral 和 StringLiteral:
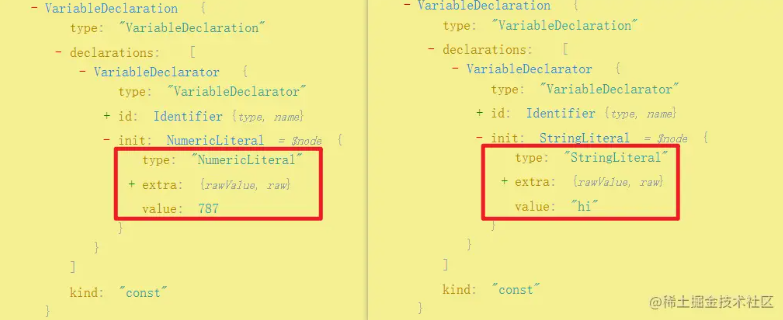
然后我们声明了一个 visitor 对象,然后定义对应类型的处理方法,traverse 接收两个参数,第一个是 AST 对象,第二个是 visitor,当 traverse 遍历所有节点,遇到节点类型为 NumericLiteral 和 StringLiteral 时,就会调用 visitor 中对应的处理方法,visitor 中的方法会接收一个当前节点的 path 对象,该对象的类型是 NodePath,该对象有非常多的属性,以下介绍几种最常用的:
| 属性 | 描述 |
|---|---|
toString() |
当前路径的源码 |
node |
当前路径的节点 |
parent |
当前路径的父级节点 |
parentPath |
当前路径的父级路径 |
type |
当前路径的类型 |
PS:path 对象除了有很多属性以外,还有很多方法,比如替换节点、删除节点、插入节点、寻找父级节点、获取同级节点、添加注释、判断节点类型等,可在需要时查询相关文档或查看源码,后续介绍 @babel/types 部分将会举部分例子来演示,以后的实战文章中也会有相关实例,篇幅有限本文不再细说。
因此在上面的代码中,path.node.value 就拿到了变量的值,然后我们就可以进一步对其进行修改了。以上代码运行后,所有数字都会加上100后再乘以2,所有字符串都会被替换成 I Love JavaScript!,结果如下:
1 | const a = 3200; |
如果多个类型的节点,处理的方式都一样,那么还可以使用 | 将所有节点连接成字符串,将同一个方法应用到所有节点:
1 | const visitor = { |
visitor 对象有多种写法,以下几种写法的效果都是一样的:
1 | const visitor = { |
以上几种写法中有用到了 enter 方法,在节点的遍历过程中,进入节点(enter)与退出(exit)节点都会访问一次节点,traverse 默认在进入节点时进行节点的处理,如果要在退出节点时处理,那么在 visitor 中就必须声明 exit 方法。
@babel/types
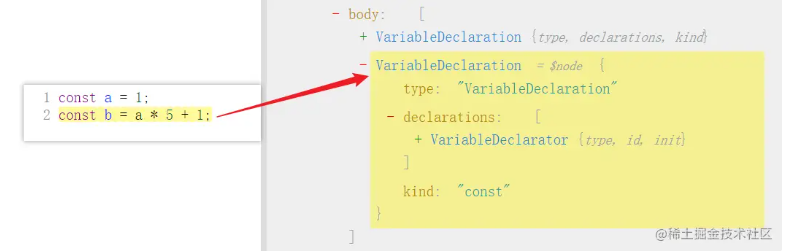
@babel/types 主要用于构建新的 AST 节点,前面的示例代码为 const a = 1;,如果想要增加内容,比如变成 const a = 1; const b = a * 5 + 1;,就可以通过 @babel/types 来实现。
首先观察一下 AST 语法树,原语句只有一个 VariableDeclaration 节点,现在增加了一个:
那么我们的思路就是在遍历节点时,遍历到 VariableDeclaration 节点,就在其后面增加一个 VariableDeclaration 节点,生成 VariableDeclaration 节点,可以使用 types.variableDeclaration() 方法,在 types 中各种方法名称和我们在 AST 中看到的是一样的,只不过首字母是小写的,所以我们不需要知道所有方法的情况下,也能大致推断其方法名,只知道这个方法还不行,还得知道传入的参数是什么,可以查文档,这里推荐直接看源码,非常清晰明了,以 Pycharm 为例,按住 Ctrl 键,再点击方法名,就进到源码里了:
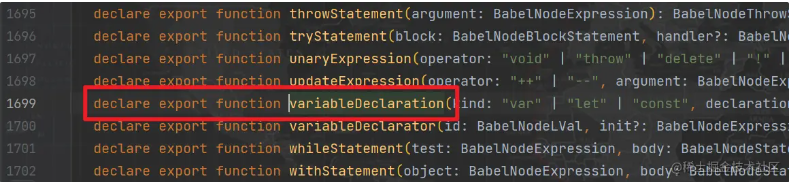
1 | function variableDeclaration(kind: "var" | "let" | "const", declarations: Array<BabelNodeVariableDeclarator>) |
可以看到需要 kind 和 declarations 两个参数,其中 declarations 是 VariableDeclarator 类型的节点组成的列表,所以我们可以先写出以下 visitor 部分的代码,其中 path.insertAfter() 是在该节点之后插入新节点的意思:
1 | const visitor = { |
接下来我们还需要进一步定义 declarator,也就是 VariableDeclarator 类型的节点,查询其源码如下:
1 | function variableDeclarator(id: BabelNodeLVal, init?: BabelNodeExpression) |
观察 AST,id 为 Identifier 对象,init 为 BinaryExpression 对象,如下图所示:
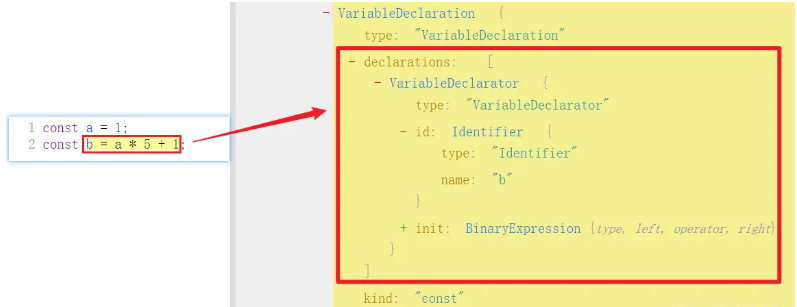
先来处理 id,可以使用 types.identifier() 方法来生成,其源码为 function identifier(name: string),name 在这里就是 b 了,此时 visitor 代码就可以这么写:
1 | const visitor = { |
然后再来看 init 该如何定义,首先仍然是看 AST 结构:
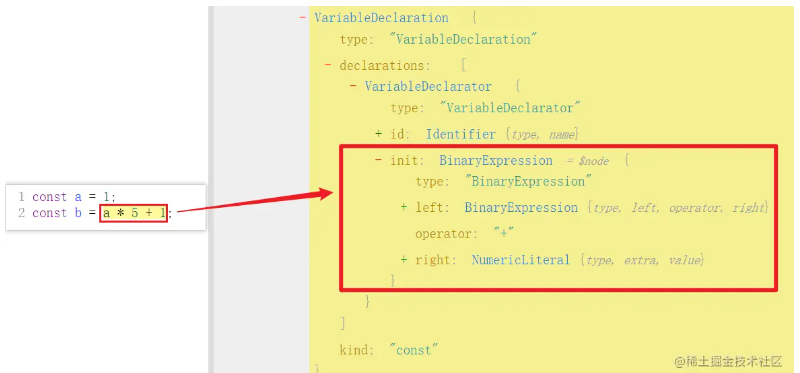
init 为 BinaryExpression 对象,left 左边是 BinaryExpression,right 右边是 NumericLiteral,可以用 types.binaryExpression() 方法来生成 init,其源码如下:
1 | function binaryExpression( |
此时 visitor 代码就可以这么写:
1 | const visitor = { |
然后继续构造 left 和 right,和前面的方法一样,观察 AST 语法树,查询对应方法应该传入的参数,层层嵌套,直到把所有的节点都构造完毕,最终的 visitor 代码应该是这样的:
1 | const visitor = { |
注意:path.insertAfter() 插入节点语句后面加了一句 path.stop(),表示插入完成后立即停止遍历当前节点和后续的子节点,添加的新节点也是 VariableDeclaration,如果不加停止语句的话,就会无限循环插入下去。
插入新节点后,再转换成 JavaScript 代码,就可以看到多了一行新代码,如下图所示:
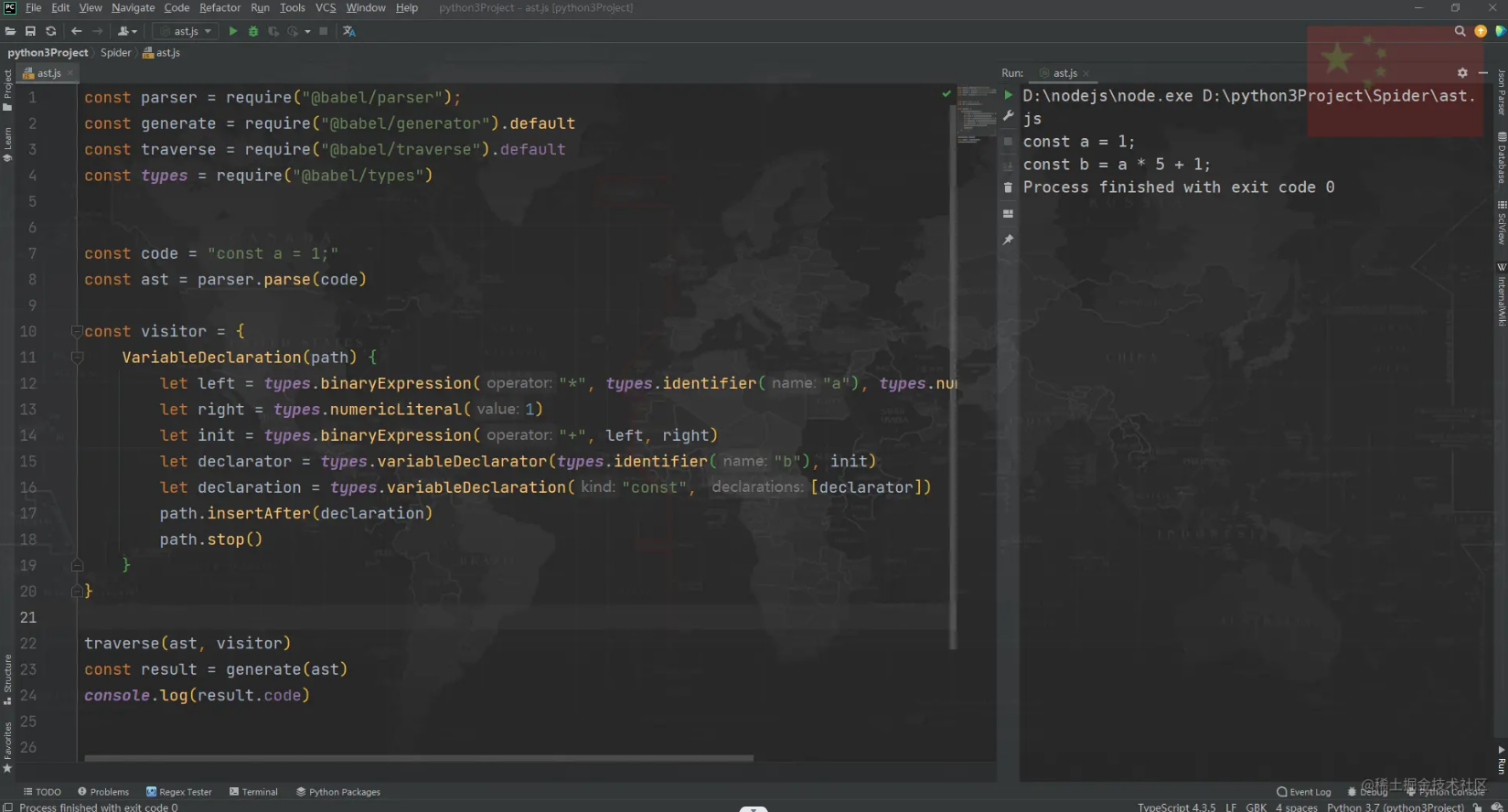
常见混淆还原
了解了 AST 和 babel 后,就可以对 JavaScript 混淆代码进行还原了,以下是部分样例,带你进一步熟悉 babel 的各种操作。
字符串还原
文章开头的图中举了个例子,正常字符被换成了 Unicode 编码:
1 | console['\u006c\u006f\u0067']('\u0048\u0065\u006c\u006c\u006f\u0020\u0077\u006f\u0072\u006c\u0064\u0021') |
观察 AST 结构:
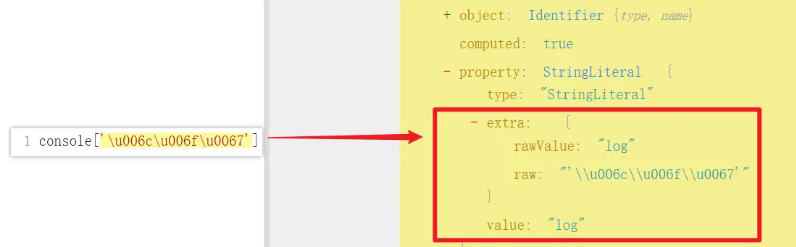
我们发现 Unicode 编码对应的是 raw,而 rawValue 和 value 都是正常的,所以我们可以将 raw 替换成 rawValue 或 value 即可,需要注意的是引号的问题,本来是 console["log"],你还原后变成了 console[log],自然会报错的,除了替换值以外,这里直接删除 extra 节点,或者删除 raw 值也是可以的,所以以下几种写法都可以还原代码:
1 | const parser = require("@babel/parser"); |
还原结果:
1 | console["log"]("Hello world!"); |
表达式还原
之前K哥写过 JSFuck 混淆的还原,其中有介绍 ![] 可表示 false,!![] 或者 !+[] 可表示 true,在一些混淆代码中,经常有这些操作,把简单的表达式复杂化,往往需要执行一下语句,才能得到真正的结果,示例代码如下:
1 | const a = !![]+!![]+!![]; |
想要执行语句,我们需要了解 path.evaluate() 方法,该方法会对 path 对象进行执行操作,自动计算出结果,返回一个对象,其中的 confident 属性表示置信度,value 表示计算结果,使用 types.valueToNode() 方法创建节点,使用 path.replaceInline() 方法将节点替换成计算结果生成的新节点,替换方法有一下几种:
replaceWith:用一个节点替换另一个节点;replaceWithMultiple:用多个节点替换另一个节点;replaceWithSourceString:将传入的源码字符串解析成对应 Node 后再替换,性能较差,不建议使用;replaceInline:用一个或多个节点替换另一个节点,相当于同时有了前两个函数的功能。
对应的 AST 处理代码如下:
1 | const parser = require("@babel/parser"); |
最终结果:
1 | const a = 3; |
删除未使用变量
有时候代码里会有一些并没有使用到的多余变量,删除这些多余变量有助于更加高效的分析代码,示例代码如下:
1 | const a = 1; |
删除多余变量,首先要了解 NodePath 中的 scope,scope 的作用主要是查找标识符的作用域、获取并修改标识符的所有引用等,删除未使用变量主要用到了 scope.getBinding() 方法,传入的值是当前节点能够引用到的标识符名称,返回的关键属性有以下几个:
identifier:标识符的 Node 对象;path:标识符的 NodePath 对象;constant:标识符是否为常量;referenced:标识符是否被引用;references:标识符被引用的次数;constantViolations:如果标识符被修改,则会存放所有修改该标识符节点的 Path 对象;referencePaths:如果标识符被引用,则会存放所有引用该标识符节点的 Path 对象。
所以我们可以通过 constantViolations、referenced、references、referencePaths 多个参数来判断变量是否可以被删除,AST 处理代码如下:
1 | const parser = require("@babel/parser"); |
处理后的代码(未使用的 b、c、e 变量已被删除):
1 | const a = 1; |
删除冗余逻辑代码
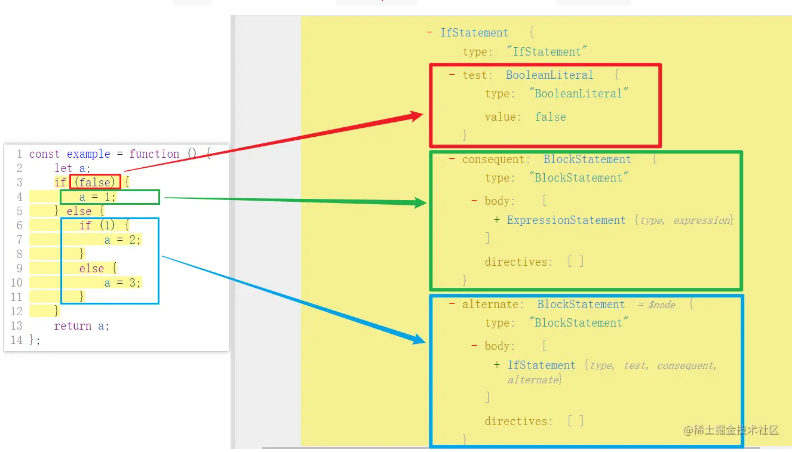
有时候为了增加逆向难度,会有很多嵌套的 if-else 语句,大量判断为假的冗余逻辑代码,同样可以利用 AST 将其删除掉,只留下判断为真的,示例代码如下:
1 | const example = function () { |
观察 AST,判断条件对应的是 test 节点,if 对应的是 consequent 节点,else 对应的是 alternate 节点,如下图所示:
AST 处理思路以及代码:
- 筛选出
BooleanLiteral和NumericLiteral节点,取其对应的值,即path.node.test.value; - 判断
value值为真,则将节点替换成consequent节点下的内容,即path.node.consequent.body; - 判断
value值为假,则替换成alternate节点下的内容,即path.node.alternate.body; - 有的 if 语句可能没有写 else,也就没有
alternate,所以这种情况下判断value值为假,则直接移除该节点,即path.remove()
1 | const parser = require("@babel/parser"); |
处理结果:
1 | const example = function () { |
switch-case 反控制流平坦化
控制流平坦化是混淆当中最常见的,通过 if-else 或者 while-switch-case 语句分解步骤,示例代码:
1 | const _0x34e16a = '3,4,0,5,1,2'['split'](','); |
AST 还原思路:
- 获取控制流原始数组,将
'3,4,0,5,1,2'['split'](',')之类的语句转化成['3','4','0','5','1','2']之类的数组,得到该数组之后,也可以选择把 split 语句对应的节点删除掉,因为最终代码里这条语句就没用了; - 遍历第一步得到的控制流数组,依次取出每个值所对应的 case 节点;
- 定义一个数组,储存每个 case 节点
consequent数组里面的内容,并删除continue语句对应的节点; - 遍历完成后,将第三步的数组替换掉整个 while 节点,也就是
WhileStatement。
不同思路,写法多样,对于如何获取控制流数组,可以有以下思路:
- 获取到
While语句节点,然后使用path.getAllPrevSiblings()方法获取其前面的所有兄弟节点,遍历每个兄弟节点,找到与switch()里面数组的变量名相同的节点,然后再取节点的值进行后续处理; - 直接取
switch()里面数组的变量名,然后使用scope.getBinding()方法获取到它绑定的节点,然后再取这个节点的值进行后续处理。
所以 AST 处理代码就有两种写法,方法一:(code.js 即为前面的示例代码,为了方便操作,这里使用 fs 从文件中读取代码)
1 | const parser = require("@babel/parser"); |
方法二:
1 | const parser = require("@babel/parser"); |
以上代码运行后,原来的 switch-case 控制流就被还原了,变成了按顺序一行一行的代码,更加简洁明了:
1 | let _0x4588f1 = 0x1; |
特殊混淆还原案例
除了基于JavaScript-obfuscator的混淆,还有其他的混淆方式,比如AAEncode,JJEncode,JSFuck
AAEncode混淆:AAEncode混淆网址,常用解决方法去除末尾(‘_’),加上toSting()
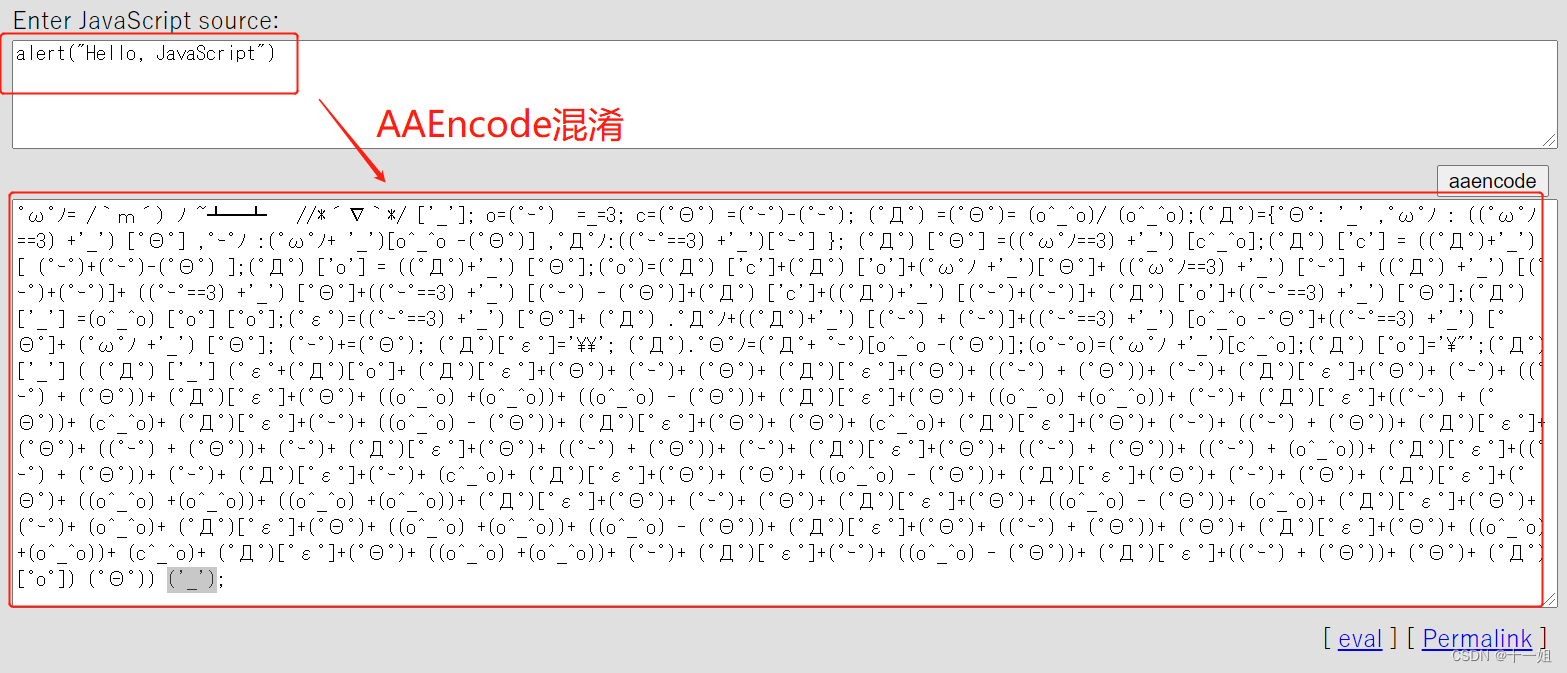
jjEncode混淆:jjEncode混淆网址,常用方法去除末尾(),加上toSting()
jsfuck混淆: jsfuck官网混淆网址,jsfuck混淆网址,常用解决方法,鼠标将光标放到最后一个括号位置,找到对称的高亮的括号,将两个括号的内容复制出来,用eval执行试试,或者直接控制台打印输出看看

webassembly案例分析和爬取实战
webassembly是一种可以使用非JavaScript编程语言编写代码并且能在浏览器上运行的技术方案。
借助Emscripten编译工具,可以将C/C++文件转成wasm格式的文件,JavaScript可以直接调用该文件执行其中方法,这样做的好处:
- 核心逻辑用c/c++实现隐藏在wasm中,逆向难度比JavaScript更大
- c/c++执行效率更高
网站:https://spa14.scrape.center/
跟踪
跟踪
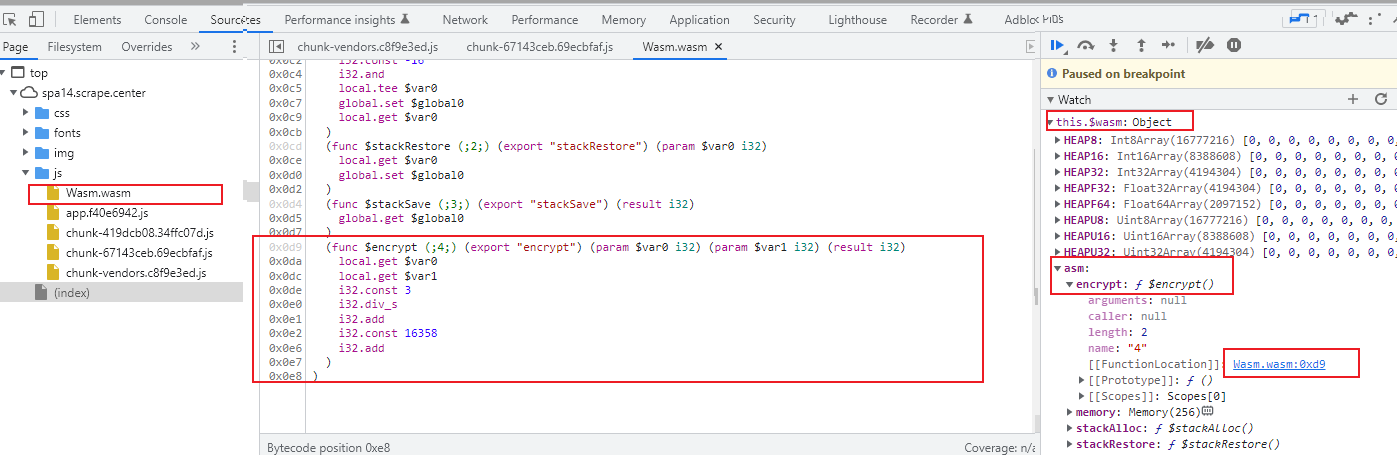
。。。跟到这里完全看不懂了。2条路:
- 将wasm文件反编译还原成c++代码(难度大)
- 通过模拟执行方式得到加密结果(拿到wasm文件,通过python模拟执行JavaScript的方式调用wasm文件,模拟调用它的encrypt方法,传入对应参数就行)
1 | # 下载wasm文件 |
JavaScript逆向总结
JavaScript可以分为3步:
- 寻找入口
- 调试分析
- 模拟执行
寻找入口
查看请求
一般来说我们先分析想要的数据到底是从哪里来的
可以看到首页有一条条数据,比如霸王别姬,这个杀手不太冷等,这些请求肯定是某个请求返回的,那究竟是哪个请求里返回的呢?
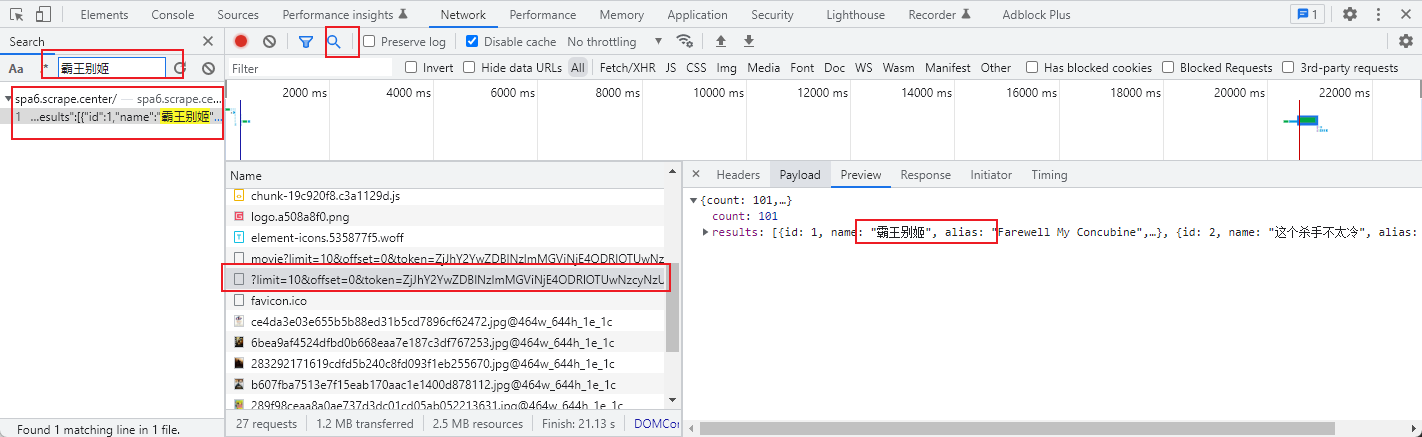
找到对应的响应就可以定位到是哪个请求发起的了。
可以看到是一个GET请求,同时有一个token参数
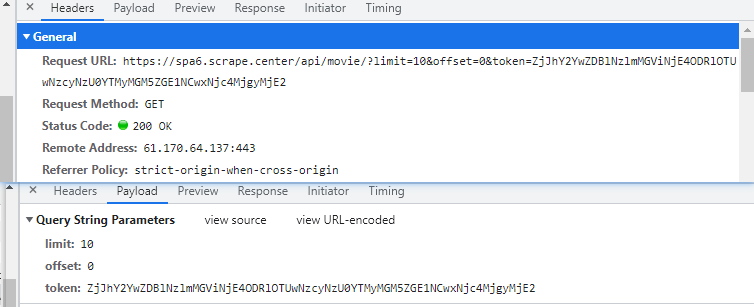
一般来说通过这种方法尝试寻找最初的突破口,
如果这个请求有带加密参数,就顺着继续找下这个参数究竟在哪里生成的。
如果这个请求对应的参数甚至没有什么加密参数,那么这个请求都可以直接模拟爬取了。
搜索参数
我们找到一个关键的加密参数token,那这又是怎么构造出来的呢?
一种简单的方式就是直接全局搜索,一般来说大多数情况下参数名就是一个普通的字符串,比如这里是token
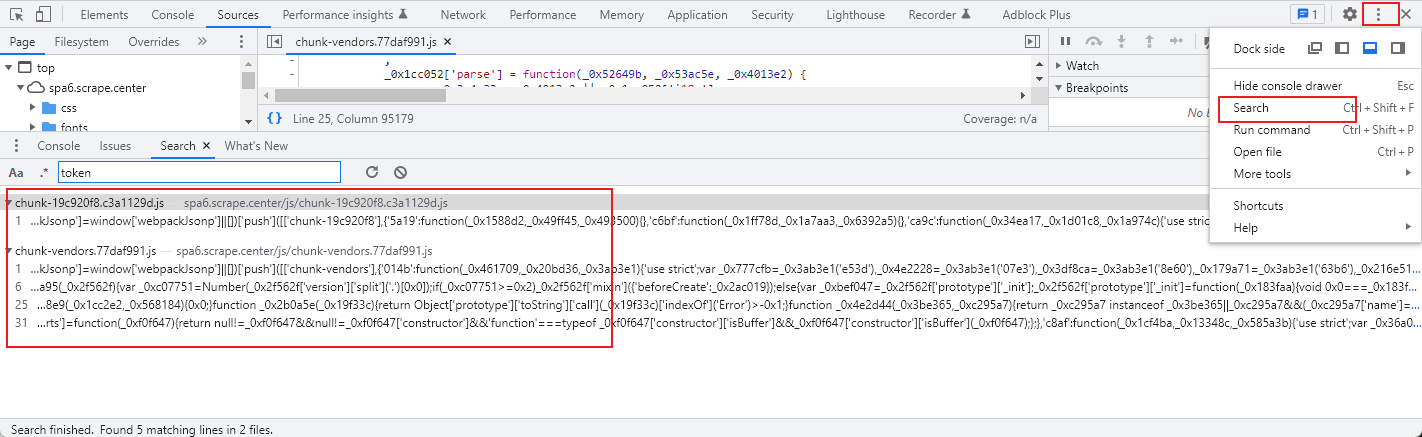
就5个结果,不多,进一步点击并定位到对应的JavaScript文件中,然后进一步分析。
分析发起调用
除了上面从源码级别直接查找参数名,还可以通过其他思路查找入口,比如定位到请求后
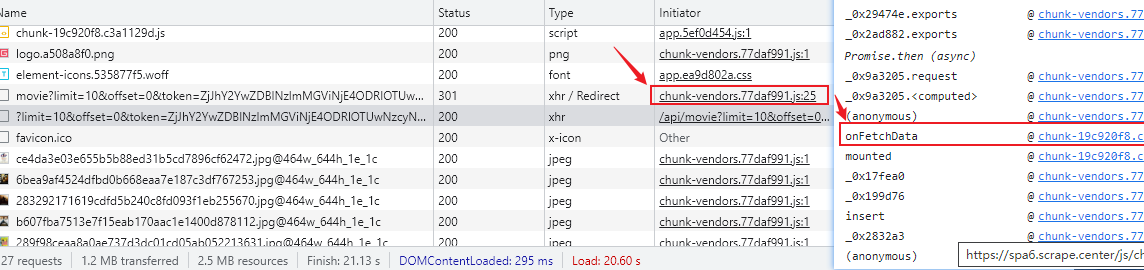
在请求上可以直接定位到send方法
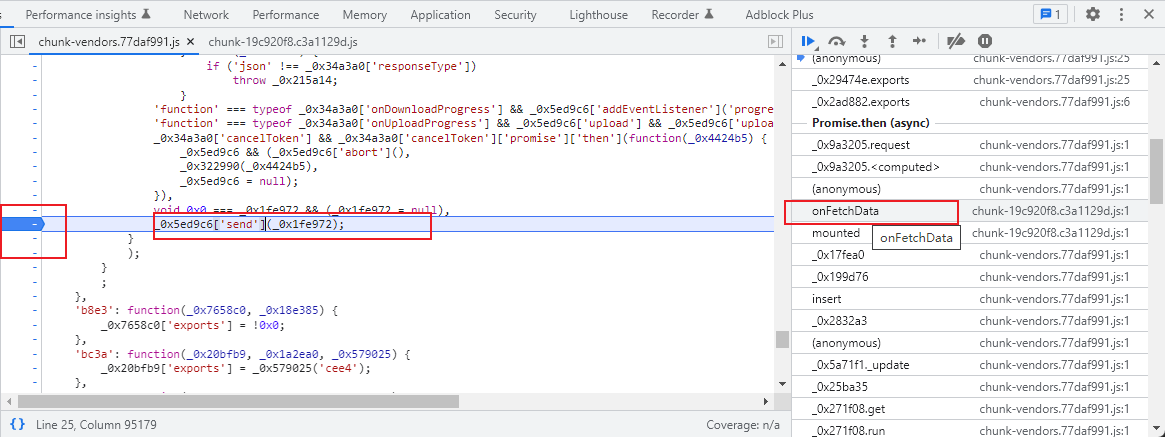
打个断点,刷新页面,就定位到token生成的地方了
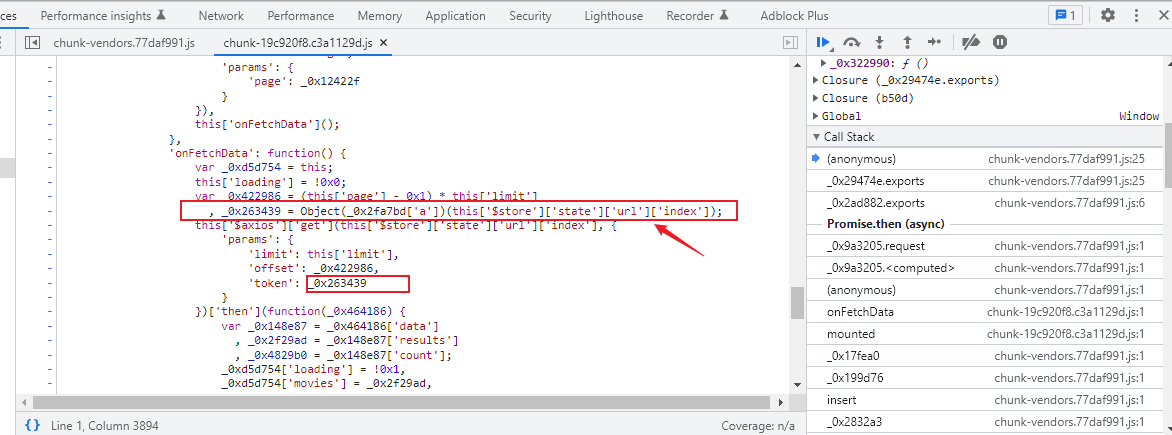
通过断点来查找入口
比如XHR断点、DOM断点、事件断点等
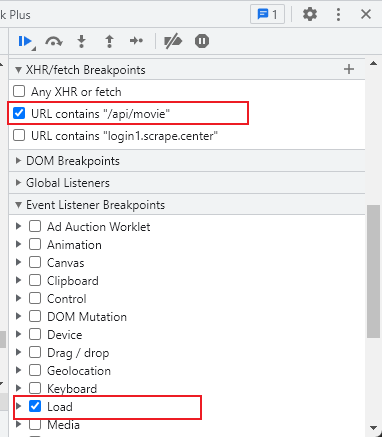
这样网页就可以在整个网页加载之后和发起Ajax请求的时候停下来,进入断点调试模式。也就是说,通过浏览器强大的断点调试功,我们也可以找到对应的入口。
通过Hook找到入口
可以对一些常用的加密和编码算法、常用的转换操作都进行一些hook,比如:Base64编码、Cookie的赋值、JSON的序列化等。
比较方便的hook方式就是通过TemporMonkey插件实现。
其他
还有很多其他方法可以找到入口,比如pyppetter、playwright内置的api实现数据拦截和过滤功能。
还有抓包工具对请求的拦截和分析,还有第三方工具或者浏览器插件服务分析等。
调试分析
找到入口后,要调试分析。通过需要做一些格式化、断点调试、反混淆等操作辅助完成整个分析流程
格式化
增加代码的可读性,一般js都是打包和压缩的
通过sources面板下的格式化按钮格式化

也有一些格式化js的网站,比如:https://beautifier.io/
断点调试
格式化后,可以进入正式调试,给想要调试的代码增加断点,在对应面板观察对应变量的值
反混淆
有时候,可能会遇到一些混淆方式,比如控制流扁平化、数组移位等,
我们无法判断真正的执行逻辑,可以尝试用AST技术对代码还原。
模拟执行
经过一系列调试后,我们可以理清其中的逻辑了,接下来就是调用执行的过程。比如
python改写或模拟执行
python简单,同时可以模拟调用执行JavaScript。如果整体加密逻辑不复杂,可以用python将加密流程完整实现一遍。
如果加密逻辑复杂, 可以尝试用python模拟调用JavaScript执行
JavaScript模拟执行+API
加密逻辑是JavaScript实现的,用python执行还是不太方便,而node.js就可以很方便执行JavaScript,然后通过express暴露成API给python使用。
浏览器模拟执行
nodejs有时候也不太方便,加密逻辑是在浏览器中运行的,所以可以直接将浏览器当成执行环境。
比如使用selenium,playwright等尝试执行一些JavaScript代码,得到加密返回结果。
方式很多种,不同情况下根据实现的难易程度选择不同的方案。
JavaScript逆向实战
 微信
微信 支付宝
支付宝

