【微服务从入门到入土】模拟登录
我们抓取,我们采集,我们分析,我们挖掘
模拟登录基本原理
很多情况下,一些网站的页面或资源我们通常需要登录才能看到。比如说访问 GitHub 的个人设置页面,如果不登录是无法查看的;比如说 12306 买票提交订单的页面,如果不登录是无法提交订单的;比如说要发一条微博,如果不登录是无法发送的。
我们之前学习的案例都是爬取的无需登录即可访问的站点,但是诸如上面例子的情况非常非常多,那假如我们想要用爬虫来访问这些页面,比如用爬虫修改 GitHub 的个人设置,用爬虫提交购票订单,用爬虫发微博,能做到吗?
答案是可以,这里就需要用到一些模拟登录相关的技术了。
那么本节我们就先来了解一下模拟登录的一些基本原理和实现吧。
1. 网站登录验证的实现
我们要实现模拟登录,那就得首先了解网站登录验证的实现。
登录一般是需要两个内容,用户名和密码,有的网站可能是手机号和验证码,有的是微信扫码,有的是 OAuth 验证等等,但根本上来说,都是把一些可供认证的信息提交给了服务器。
比如这里我们就拿用户名和密码来说吧。用户在一个网页表单里面输入了这些内容,然后点击登录按钮的一瞬间,浏览器客户端就会向服务器发送一个登录请求,这个请求里面肯定就包含了用户名和密码信息,这时候,服务器需要处理一下这些信息,然后返回给客户端一个类似「凭证」的东西,有了这个「凭证」以后呢,客户端拿着这个「凭证」再去访问某些需要登录才能查看的页面,服务器自然就能” 放行 “了,返回对应的内容或执行对应的操作就好了。
形象点说呢,我们拿登录发微博和买票坐火车这两件事来类比。发微博就好像要坐火车,没票是没法坐火车的吧,要坐火车怎么办呢?当然是先买票了,我们拿钱去火车站买个票,有了票之后,进站口查验一下,没问题就自然能去坐火车了,这个票就是坐火车的「凭证」。那发微博也一样,我们有用户名和密码,请求下服务器,获得一个「凭证」,这就相当于买到了火车票,然后在发微博的时候拿着这个「凭证」去请求服务器,服务器校验没问题,自然就把微博发出去了。
那么问题来了,这个「凭证」到底是怎么生成和验证的呢?目前比较流行的实现方式有两种,一种是基于 Session + Cookie 的验证,一种是基于 JWT(JSON Web Token)的验证,下面我们来介绍下。
2. Session 和 Cookie
我们在第一章了解了 Session 和 Cookie 的基本概念。简而言之呢,Session 就是存在服务端的,里面保存了用户此次访问的会话信息,Cookie 则是保存在用户本地浏览器的,它会在每次用户访问网站的时候发送给服务器,Cookie 会作为 Request Headers 的一部分发送给服务器,服务器根据 Cookie 里面包含的信息判断找出其 Session 对象并做一些校验,不同的 Session 对象里面维持了不同访问用户的状态,服务器可以根据这些信息决定返回 Response 的内容。
我们以用户登录的情形来说吧,其实不同的网站对于用户的登录状态的实现是可能不同的,但是 Session 和 Cookie 一定是相互配合工作的。
下面梳理如下:
- 比如说,Cookie 里面可能只存了 Session ID 相关信息,服务器能根据 Cookie 找到对应的 Session,用户登录之后,服务器会把对应的 Session 里面标记一个字段,代表已登录状态或者其他信息(如角色、登录时间)等等,这样用户每次访问网站的时候都带着 Cookie 来访问,服务器就能找到对应的 Session,然后看一下 Session 里面的状态是登录状态,那就可以返回对应的结果或执行某些操作。
- 当然 Cookie 里面也可能直接存了某些凭证信息。比如说用户在发起登录请求之后,服务器校验通过,返回给客户端的 Response Headers 里面可能带有
Set-Cookie字段,里面可能就包含了类似凭证的信息,这样客户端会执行设置 Cookie 的操作,将这些信息保存到 Cookie 里面,以后再访问网页时携带这些 Cookie 信息,服务器拿着这里面的信息校验,自然也能实现登录状态检测了。
以上两种情况几乎能涵盖大部分的 Session 和 Cookie 登录验证的实现,具体的实现逻辑因服务器而异,但 Session 和 Cookie 一定是需要相互配合才能实现的。
3. JWT
Web 开发技术是一直在发展的,近几年前后端分离的趋势越来越火,很多 Web 网站都采取了前后端分离的技术来实现。而且传统的基于 Session 和 Cookie 的校验也存在一定问题,比如服务器需要维护登录用户的 Session 信息,而且分布式部署不方便,也不太适合前后端分离的项目。
所以,JWT 技术应运而生。
JWT,英文全称为 JSON Web Token,是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准。实际上就是在每次登录的时候通过一个 Token 字符串来校验登录状态。JWT 的声明一般被用来在身份提供者和服务提供者之间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的业务逻辑所必须的声明信息,所以这个 Token 也可直接被用于认证,也可传递一些额外信息。
有了 JWT,一些认证就不需要借助于 Session 和 Cookie 了,服务器也无须维护 Session 信息,减少了服务器的开销。服务器只需要有一个校验 JWT 的功能就好了,同时也可以做到分布式部署和跨语言的支持。
JWT 通常就是一个加密的字符串,它也有自己的标准,类似下面的这种格式:
1 | eyJ0eXAxIjoiMTIzNCIsImFsZzIiOiJhZG1pbiIsInR5cCI6IkpXVCIsImFsZyI6IkhTMjU2In0.eyJVc2VySWQiOjEyMywiVXNlck5hbWUiOiJhZG1pbiIsImV4cCI6MTU1MjI4Njc0Ni44Nzc0MDE4fQ.pEgdmFAy73walFonEm2zbxg46Oth3dlT02HR9iVzXa8 |
我们可以发现中间有两个用来分割的 . ,因此可以把它看成是一个三段式的加密字符串。
它由三部分构成,分别是 Header、Payload、Signature。
- Header,声明了 JWT 的签名算法,如 RSA、SHA256 等,也可能包含 JWT 编号或类型等数据,然后对整个信息进行 Base64 编码即可。
- Payload,通常用来存放一些业务需要但不敏感的信息,如 UserID 等,另外它也有很多默认是字段,如 JWT 签发者、JWT 接受者、JWT 过期时间等,Base64 编码即可。
- Signature,就是一个签名,是把 Header、Payload 的信息用秘钥 secret 加密后形成的,这个 secret 是保存在服务器端的,不能被轻易泄露。如此一来,即使一些 Payload 的信息被篡改,服务器也能通过 Signature 判断出非法请求,拒绝服务。
这三部分通过 . 组合起来就形成了 JWT 的字符串,就是用户的访问凭证。
所以这个登录认证流程也很简单了,用户拿着用户名密码登录,然后服务器生成 JWT 字符串返回给客户端。客户端每次请求都带着这个 JWT 就行了,服务器会自动判断其有效情况,如果有效,自然就返回对应的数据。JWT 的传输就多种多样了,可以将其放在 Request Headers 中,也可以放在 URL 里,甚至也有的网站把它放在 Cookie 里面,但总而言之,能传给服务器进行校验就好了。
好,到此为止呢,我们就已经了解了网站登录验证的实现了。
4. 模拟登录
好,那了解了网站登录验证的实现后,模拟登录自然就有思路了。
下面我们同样分两种认证方式来说明。
Session 和 Cookie
基于 Session 和 Cookie 的模拟登录,如果我们要用爬虫实现的话,其实最主要的就是把 Cookie 的信息维护好就行了,因为爬虫就相当于客户端浏览器,我们模拟好浏览器做的事情就好了。
一般怎么实现模拟登录呢?接下来我们结合之前所讲的技术总结一下。
- 第一,如果我们已经在浏览器中登录了自己的账号,要想用爬虫模拟,那么可以直接把 Cookie 复制过来交给爬虫。这是最省时省力的方式,相当于我们用浏览器手动操作登录了。我们把 Cookie 放到代码里,爬虫每次请求的时候再将其放到 Request Headers 中,完全模拟了浏览器的操作。之后服务器会通过 Cookie 校验登录状态,如果没问题,自然就可以执行某些操作或返回某些内容了。
- 第二,如果我们不想有任何手工操作,那么可以直接使用爬虫模拟登录过程。其实登录的过程多数也是一个 POST 请求。我们用爬虫提交了用户名、密码等信息给服务器,服务器返回的 Response Headers 里面可能会带有
Set-Cookie的字段,我们只需要把这些 Cookie 保存下来就行了。所以,最主要的就是把这个过程中的 Cookie 维持好。当然这里可能会遇到一些困难,比如登录过程中伴随着各种校验参数,不好直接模拟请求;网站设置 Cookie 的过程是通过 JavaScript 实现的,所以可能还得仔细分析下其中的逻辑,尤其是我们用 requests 这样的请求库进行模拟登录的时候,遇到的问题经常比较多。 - 第三,我们也可以用一些简单的方式来实现模拟登录,即实现登录过程的自动化。比如我们用 Selenium、Pyppeteer 或 Playwright 来驱动浏览器模拟执行一些操作,如填写用户名和密码、提交表单等。登录成功后,通过 Selenium 或 Pyppeteer 获取当前浏览器的 Cookie 并保存即可。这样后续就可以拿着 Cookie 的内容发起请求,同样也能实现模拟登录。
以上介绍的就是一些常用的爬虫模拟登录的方案,其目的是维护好客户端的 Cookie 信息。总之,每次请求都携带好 Cookie 信息就能实现模拟登录了。
JWT
基于 JWT 的模拟登录思路也比较清晰了,由于 JWT 的字符串就是用户访问的凭证,所以模拟登录只需要做到下面几步。
- 第一步,模拟网站登录操作的请求。比如拿着用户名和密码信息请求登录接口,获取服务器返回的结果,这个结果中通常包含 JWT 字符串的信息,将它保存即可。
- 第二步,后续的请求携带 JWT 进行访问。在 JWT 不过期的情况下,通常能正常访问和执行对应的操作。携带方式多种多样,因网站而异。
- 第三步,如果 JWT 过期了,可能需要再次进行第一步,重新获取 JWT。
当然,模拟登录的过程肯定会带有一些其他的加密参数,需要根据实际情况具体分析。
4. 账号池
如果爬虫要求爬取的数据量比较大或爬取速度比较快,而网站又有单账号并发限制或者访问状态检测等反爬虫手段,那么我们的账号可能就会无法访问或者面临封号的风险了。
这时候一般怎么办呢?
我们可以使用分流的方案来实现。假设某个网站设置一分钟之内检测到同一个账号访问 3 次或 3 次以上则封号,我们就可以建立一个账号池,用多个账号来随机访问或爬取数据,这样就能大幅提高爬虫的并发量,降低被封号的风险了。比如我们可以准备 100 个账号,然后 100 个账号都模拟登录,把对应的 Cookie 或 JWT 存下来,每次访问的时候随机取一个来,由于账号多,所以每个账号被取用的概率也就降下来了,这样就能避免单账号并发过大的问题,也降低封号风险。
5. 总结
本节我们首先了解了 Session + Cookie 和 JWT 模拟登录的原理,接着初步了解了两种模拟登录方式的实现思路,最后初步介绍了一下账号池的作用。
后文我们会通过几个实战案例来实现上述两种方案的模拟登录,为了更好地理解后文的实战内容,建议好好理解本节所介绍的内容。
基于Session和Cookie的模拟登录爬取实战
在上一节我们了解了网站登录验证和模拟登录的基本原理。网站登录验证主要有两种实现方式,一种是基于 Session + Cookies 的登录验证,另一种是基于 JWT 的登录验证。接下来两节,我们就通过两个实例来分别讲解这两种登录验证的分析和模拟登录流程。
本节主要介绍 Session + Cookie 模拟登录的流程。
1. 准备工作
在本节开始之前,我们需要先做好如下准备工作。
- 安装好了 requests 请求库并学会了其基本用法。
- 安装好了 Selenium 库并学会了其基本用法。
下面我们就用两个案例来分别讲解模拟登录的实现。
2. 案例介绍
本节有一个适用于 Session + Cookie 模拟登录的案例网站,网址为:https://login2.scrape.center/,访问之后,我们会看到一个登录页面,如图所示:
我们输入用户名和密码(用户名和密码都是 admin),然后点击登录。登录成功后,我们便可以看到一个和之前案例类似的电影网站,如图所示。
这个网站是基于传统的 MVC 模式开发的,因此也比较适合 Session + Cookie 的模拟登录。
3. 模拟登录
对于这个网站,我们如果要模拟登录,就需要先分析登录过程究竟发生了什么。我们打开开发者工具,重新执行登录操作,查看其登录过程中发生的请求,如图所示。
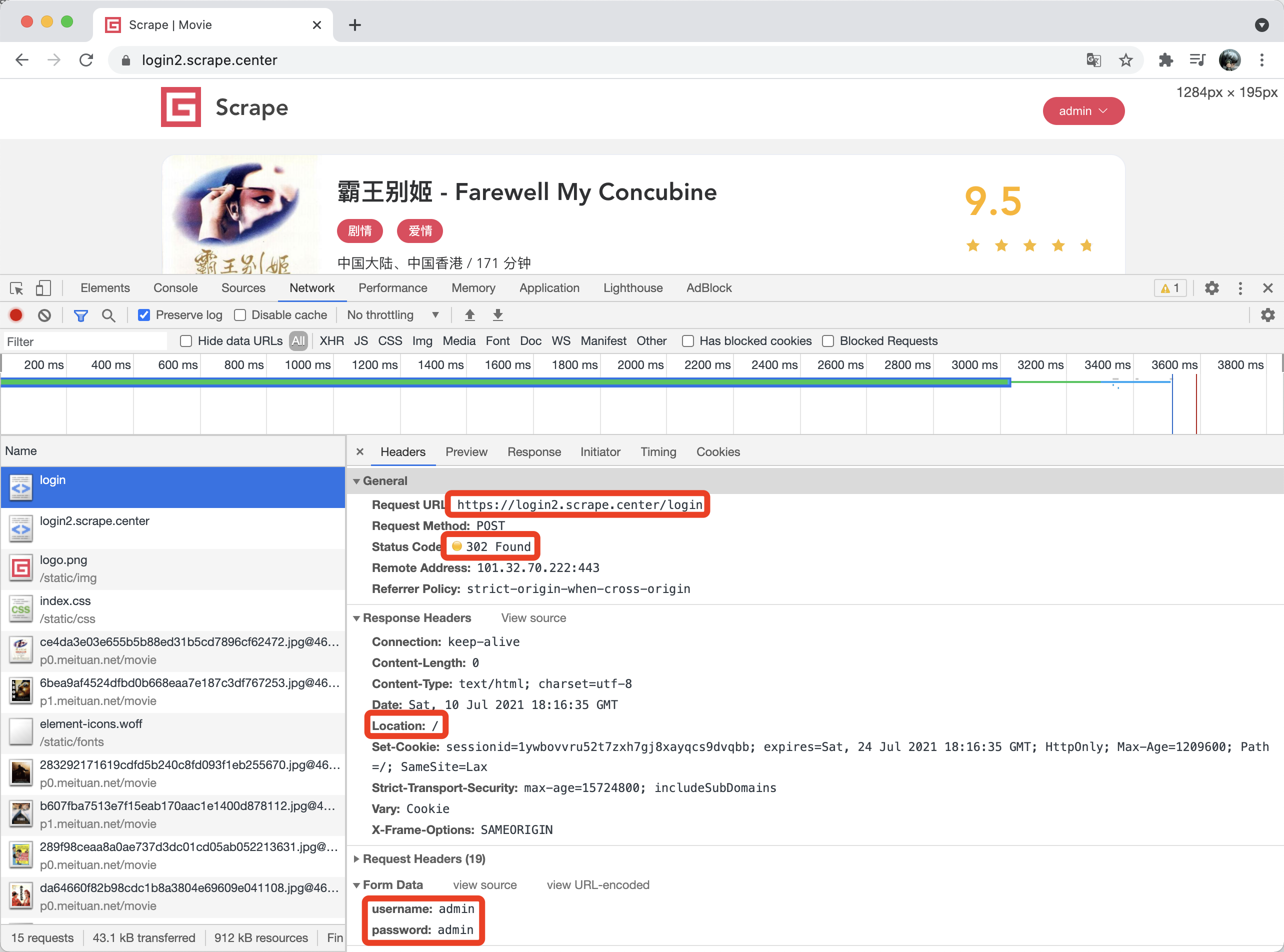
图 10-5 登录过程中发生的请求
从图 10-5 中我们可以看到,在登录的瞬间,浏览器发起了一个 POST 请求,目标 URL 为 https://login2.scrape.center/login,并通过表单提交的方式像服务器提交了登录数据,其中包括 username 和 password 两个字段,返回的状态码是 302,Response Headers 的 location 字段为根页面,同时 Response Headers 还包含了 set-cookie 信息,设置了 Session ID。
由此我们可以发现,要实现模拟登录,我们只需要模拟这个请求就好了。登录完成后获取 Response 设置的 Cookie,将它保存好,后续发出请求的时候带上 Cookies 就可以正常访问了。
好,那么我们就来用代码实现一下吧!
在默认情况下,每次 requests 请求都是独立且互不干扰的,比如我们第一次调用了 post 方法模拟登录了一下,紧接着再调用 get 方法请求主页面。其实这是两个完全独立的请求,第一次请求获取的 Cookie 并不能传给第二次请求,因此常规的顺序调用是不能起到模拟登录效果的。
我们来看一段无效的代码:
1 | import requests |
这里我们先定义了几个基本的 URL 、用户名和密码,然后我们分别用 requests 请求了登录的 URL 进行模拟登录,紧接着请求了首页来获取页面内容,能正常获取数据吗?由于 requests 可以自动处理重定向,我们可以在最后把 Response 的 URL 打印出来,如果它的结果是 INDEX_URL,那么证明模拟登录成功并成功爬取到了首页的内容。如果它跳回到了登录页面,那就说明模拟登录失败。
我们通过结果来验证一下,运行结果如下:
1 | Response Status 200 |
这里可以看到,其最终的页面 URL 是登录页面的 URL。另外这里也可以通过 Response 的 text 属性来验证下页面源码,其源码内容就是登录页面的源码内容,由于内容较多,这里就不再输出比对了。
总之,这个现象说明我们并没有成功完成模拟登录,这是因为 requests 直接调用 post、get 等方法,每次请求都是一个独立的请求,都相当于是新开了一个浏览器打开这些链接,所以这两次请求对应的 Session 并不是同一个,这里我们模拟了第一个 Session 登录,并不能影响第二个 Session 的状态,因此模拟登录也就无效了。
那么怎样才能实现正确的模拟登录呢?
我们知道 Cookie 里面是保存了 Session ID 信息的,刚才也观察到了登录成功后 Response Headers 里面有 set-cookie 字段,实际上这就是让浏览器生成了 Cookie。因为 Cookies 里面包含了 Session ID 的信息,所以只要后续的请求带着这些 Cookie,服务器便能通过 Cookie 里的 Session ID 信息找到对应的 Session 了,因此,服务端对于这两次请求就会使用同一个 Session 了。因为第一次我们已经成功完成了模拟登录,所以 Session 里面就记录了用户的登录信息,在第二次访问的时候,由于是同一个 Session,服务器就能知道用户当前是登录状态,那就能够返回正确的结果而不再是跳转到登录页面了。
所以,这里的关键在于两次请求的 Cookie 的传递。这里我们可以把第一次模拟登录后的 Cookie 保存下来,在第二次请求的时候加上这个 Cookie,代码可以改写如下:
1 | import requests |
由于 requests 可以自动处理重定向,所以我们模拟登录的过程要加上 allow_redirects 参数并将其设置为 False,使其不自动处理重定向。我们将登录之后返回的 Response 赋值为 response_login,这样调用 response_login 的 cookies 就是获取了网站的 Cookie 信息了。这里 requests 自动帮我们解析了 Response Headers 的 set-cookie 字段并设置了 Cookie,所以我们不用再去手动解析 Response Headers 的内容了,直接使用 response_login 对象的 cookies 方法即可获取 Cookie。
好,接下来我们再次用 requests 的 get 方法来请求网站的 INDEX_URL。不过这里和之前不同,get 方法增加了一个参数 cookies,这就是第一次模拟登录完之后获取的 Cookie,这样第二次请求就能携带第一次模拟登录获取的 Cookie 信息了,此时网站会根据 Cookie 里面的 Session ID 信息查找到同一个 Session,校验其已经是登录状态,然后返回正确的结果。
这里我们还是输出最终的 URL,如果它是 INDEX_URL,就代表模拟登录成功并获取了有效数据,否则就代表模拟登录失败。
我们看下运行结果:
1 | Cookies <RequestsCookieJar[<Cookie sessionid=psnu8ij69f0ltecd5wasccyzc6ud41tc for login2.scrape.center/>]> |
这下没有问题了,我们发现其 URL 就是 INDEX_URL,模拟登录成功了!同时还可以进一步输出 response_index 的 text 属性看下是否获取成功。
后续用同样的方式爬取即可。但其实我们发现,这种实现方式比较烦琐,每次还需要处理 Cookie 并一次传递,有没有更简便的方法呢?
有的,我们可以直接借助于 requests 内置的 Session 对象来帮我们自动处理 Cookie,使用了 Session 对象之后,requests 会自动保存每次请求后需要设置的 Cookie ,并在下次请求时自动携带它,就相当于帮我们维持了一个 Session 对象,这样就更方便了。
所以,刚才的代码可以简化如下:
1 | import requests |
可以看到,这里我们无须再关心 Cookie 的处理和传递问题,我们声明了一个 Session 对象,然后每次调用请求的时候都直接使用 Session 对象的 post 或 get 方法就好了。
运行效果是完全一样的,结果如下:
1 | Cookies <RequestsCookieJar[<Cookie sessionid=ssngkl4i7en9vm73bb36hxif05k10k13 for login2.scrape.center/>]> |
因此,为了简化写法,这里建议直接使用 Session 对象进行请求,这样我们无须关心 Cookie 的操作了,实现起来会更加方便。
这个案例整体来说比较简单,但是如果碰上复杂一点的网站,如带有验证码,带有加密参数等,直接用 requests 并不好处理模拟登录,如果登录不了,那整个页面不就都没法爬取了吗?有没有其他的方式来解决这个问题呢?当然是有的,比如说我们可以使用 Selenium 来模拟浏览器,进而实现模拟登录,然后获取模拟登录成功后的 Cookie,再把获取的 Cookie 交由 requests 等来爬取就好了。
这里我们还是以刚才的页面为例,把模拟登录这块交由 Selenium 来实现,后续的爬取交由 requests 来实现,相关的代码如下:
1 | from urllib.parse import urljoin |
这里我们使用 Selenium 先打开了 Chrome,然后跳转到了登录页面,随后模拟输入了用户名和密码,接着点击了登录按钮,我们可以发现浏览器提示登录成功,然后跳转到了主页面。
这时候,我们通过调用 get_cookies 方法便能获取当前浏览器所有的 Cookie,这就是模拟登录成功之后的 Cookie,用这些 Cookie 我们就能访问其他数据了。
接下来,我们声明了 requests 的 Session 对象,然后遍历了刚才的 Cookie 并将其设置到 Session 对象的 cookies 属性上,接着再拿着这个 Session 对象去请求 INDEX_URL,就也能够获取对应的信息而不会跳转到登录页面了。
运行结果如下:
1 | Cookies [{'domain': 'login2.scrape.center', 'expiry': 1589043753.553155, 'httpOnly': True, 'name': 'sessionid', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': 'rdag7ttjqhvazavpxjz31y0tmze81zur'}] |
可以看到,这里的模拟登录和后续的爬取也成功了。所以说,如果碰到难以模拟登录的过程,我们也可以使用 Selenium 等模拟浏览器的操作方式来实现,其目的就是获取登录后的 Cookie,有了 Cookie 之后,我们再用这些 Cookie 爬取其他页面就好了。
所以这里我们也可以发现,对于基于 Session + Cookie 验证的网站,模拟登录的核心要点就是获取 Cookie。这个 Cookie 可以被保存下来或传递给其他的程序继续使用,甚至可以将 Cookie 持久化存储或传输给其他终端来使用。
另外,为了提高 Cookie 利用率或降低封号概率,可以搭建一个账号池实现 Cookie 的随机取用。
4. 总结
以上我们通过一个示例来演示了模拟登录爬取的过程,以后遇到这种情形的时候就可以用类似的思路解决了。
本节代码:https://github.com/Python3WebSpider/ScrapeLogin2。
基于jwt的模拟登录爬取实战
目标网站:https://login3.scrape.center/login
基于jwt登录的网站,用户名和密码都是admin,输入后点击登录后才能访问到列表资源。


思路:
- 模拟登录请求,带上必要的登录信息,获取返回的JWT
- 之后发送请求时,在请求头里面加上Authorization 字段,值就是jwt对应的内容
代码实现:
1 | import requests |
这样就实现了基于jwt模拟登录以及爬取数据的梳理,以后遇到基于jwt认证的网站,也可以通过类似方式实现模拟登录
大规模账号池
想降低账号被封的风险,同时还能实现大规模爬取,自然而然的思路就是分流。
- 单位时间内所有账号的总请求量固定,每次都随机选取一个账号请求,那么账号越多,单账号访问频率就越低,被封概率就越低。
- 单位时间内单个账号请求量固定,同样是每次随机选取一个账号请求,账号越多,单位时间内总请求量越大。
利用分流的思想,在保证爬取规模的情况下,降低单个账号被封的概率,就要用到账号池了。
目标网站:https://antispider6.scrape.center/ ,访问时会自动打开登录页面,用户名密码是admin
在登录状态下多刷新几次页面,就会发现页面不再返回信息,显示403.表示账号被封了。
目标:搭建账号池,维护100个账号信息和对应cookie,保存到数据库,每次爬取随机选择一个账号的cookie。
- 获取cookie模块
- 存储cookie模块
- 检测cookie模块:定时检测cookie时效性,无效删除并模拟登录生成新的
- 调用cookie模块
 微信
微信 支付宝
支付宝

